Kubecost leverages Thanos to enable durable storage for three different purposes:
- Centralize metric data for a global multi-cluster view into Kubernetes costs via a Prometheus sidecar
- Allow for unlimited data retention
- Backup Kubecost ETL data
Note: This feature requires an Enterprise license.
To enable Thanos, follow these steps:
This step creates the object-store.yaml file that contains your durable storage target (e.g. GCS, S3, etc.) configuration and access credentials. The details of this file are documented thoroughly in Thanos documentation.
We have guides for using cloud-native storage for the largest cloud providers. Other providers can be similarly configured.
Use the appropriate guide for your cloud provider:
Create a secret with the yaml file generated in the previous step:
kubectl create secret generic kubecost-thanos -n kubecost --from-file=./object-store.yamlEach cluster needs to be labelled with a unique Cluster ID, this is done in two places.
values-clusterName.yaml
kubecostProductConfigs:
clusterName: kubecostProductConfigs_clusterName
prometheus:
server:
global:
external_labels:
cluster_id: kubecostProductConfigs_clusterNameThe Thanos subchart includes thanos-bucket, thanos-query, thanos-store, thanos-compact, and service discovery for thanos-sidecar. These components are recommended when deploying Thanos on the primary cluster.
These values can be adjusted under the thanos block in values-thanos.yaml - Available options are here: thanos/values.yaml
helm upgrade kubecost kubecost/cost-analyzer \
--install \
--namespace kubecost \
-f https://raw.githubusercontent.com/kubecost/cost-analyzer-helm-chart/master/cost-analyzer/values-thanos.yaml \
-f values-clusterName.yamlNote: The
thanos-storecontainer is configured to request 2.5GB memory, this may be reduced for smaller deployments.thanos-storeis only used on the primary Kubecost cluster.
To verify installation, check to see all pods are in a READY state. View pod logs for more detail and see common troubleshooting steps below.
Thanos sends data to the bucket every 2 hours. Once 2 hours has passed, logs should indicate if data has been sent successfully or not.
You can monitor the logs with:
kubectl logs --namespace kubecost -l app=prometheus -l component=server --prefix=true --container thanos-sidecar --tail=-1 | grep uploadedShould return results like this:
[pod/kubecost-prometheus-server-xxx/thanos-sidecar] level=debug ts=2022-06-09T13:00:10.084904136Z caller=objstore.go:206 msg="uploaded file" from=/data/thanos/upload/BUCKETID/chunks/000001 dst=BUCKETID/chunks/000001 bucket="tracing: kc-thanos-store"
As an aside, you can validate the prometheus metrics are all configured with correct cluster names with:
kubectl logs --namespace kubecost -l app=prometheus -l component=server --prefix=true --container thanos-sidecar --tail=-1 | grep external_labelsTo troubleshoot the IAM Role Attached to the serviceaccount, you can create a pod using the same service account used by the thanos-sidecar (default is kubecost-prometheus-server):
s3-pod.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: s3-pod
name: s3-pod
spec:
serviceAccountName: kubecost-prometheus-server
containers:
- image: amazon/aws-cli
name: my-aws-cli
command: ['sleep', '500']kubectl apply -f s3-pod.yaml
kubectl exec -i -t s3-pod -- aws s3 ls s3://kc-thanos-storeThis should return a list of objects (or at least not give a permission error).
If a cluster is not successfully writing data to the bucket, we recommend reviewing thanos-sidecar logs with the following command:
kubectl logs kubecost-prometheus-server-<your-pod-id> -n kubecost -c thanos-sidecarLogs in the following format are evidence of a successful bucket write:
level=debug ts=2019-12-20T20:38:32.288251067Z caller=objstore.go:91 msg="uploaded file" from=/data/thanos/upload/BUCKET-ID/meta.json dst=debug/metas/BUCKET-ID.json bucket=kc-thanos
If thanos-query can't connect to both the sidecar and the store, you may want to directly specify the store gRPC service address instead of using DNS discovery (the default). You can quickly test if this is the issue by running
kubectl edit deployment kubecost-thanos-query -n kubecost
and adding
--store=kubecost-thanos-store-grpc.kubecost:10901
to the container args. This will cause a query restart and you can visit /stores again to see if the store has been added.
If it has, you'll want to use these addresses instead of DNS more permanently by setting .Values.thanos.query.stores in values-thanos.yaml
...
thanos:
store:
enabled: true
grpcSeriesMaxConcurrency: 20
blockSyncConcurrency: 20
extraEnv:
- name: GOGC
value: "100"
resources:
requests:
memory: "2.5Gi"
query:
enabled: true
timeout: 3m
# Maximum number of queries processed concurrently by query node.
maxConcurrent: 8
# Maximum number of select requests made concurrently per a query.
maxConcurrentSelect: 2
resources:
requests:
memory: "2.5Gi"
autoDownsampling: false
extraEnv:
- name: GOGC
value: "100"
stores:
- "kubecost-thanos-store-grpc.kubecost:10901"
A common error is as follows, which means you do not have the correct access to the supplied bucket:
[email protected] does not have storage.objects.list access to thanos-bucket., forbidden"
Assuming pods are running, use port forwarding to connect to the thanos-query-http endpoint:
kubectl port-forward svc/kubecost-thanos-query-http 8080:10902 --namespace kubecostThen navigate to http://localhost:8080 in your browser. This page should look very similar to the Prometheus console.
If you navigate to the Stores using the top navigation bar, you should be able to see the status of both the thanos-store and thanos-sidecar which accompanied prometheus server:
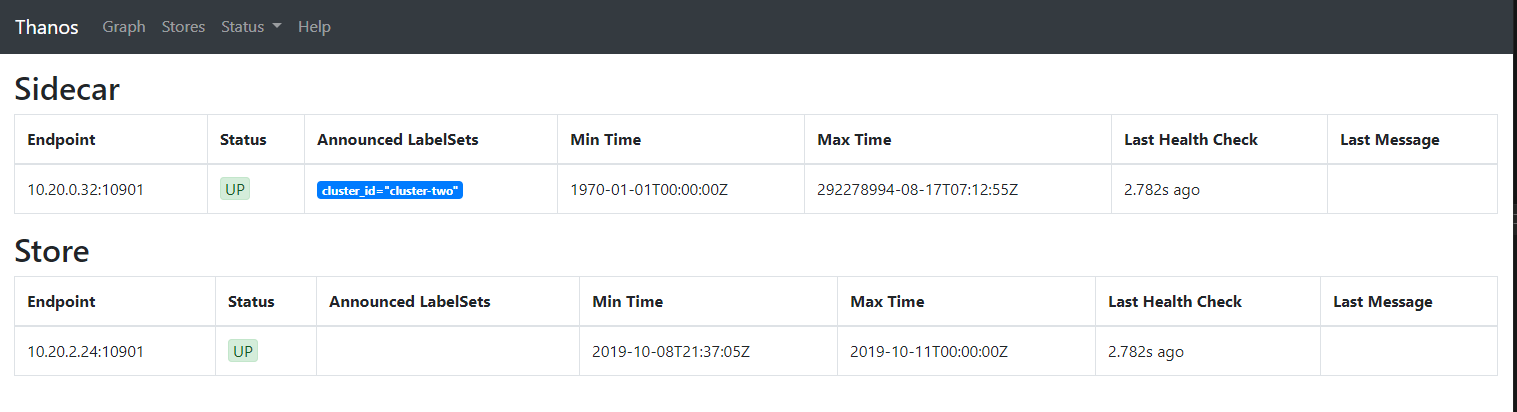
Also note that the sidecar should identify with the unique cluster_id provided in your values.yaml in the previous step. Default value is cluster-one.
The default retention period for when data is moved into the object storage is currently 2h - This configuration is based on Thanos suggested values. By default, it will be 2 hours before data is written to the provided bucket.
Instead of waiting 2h to ensure that thanos was configured correctly, the default log level for the thanos workloads is debug (it's very light logging even on debug). You can get logs for the thanos-sidecar, which is part of the prometheus-server pod, and thanos-store. The logs should give you a clear indication of whether or not there was a problem consuming the secret and what the issue is. For more on Thanos architecture, view this resource.
Please let us know if you run into any issues, we are here to help.
Slack community - check out #support for any help you may need & drop your introduction in the #general channel
Email: [email protected]
Edit this doc on GitHub