diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/DataX-write.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/DataX-write.md
deleted file mode 100644
index e1369c3c6..000000000
--- a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/DataX-write.md
+++ /dev/null
@@ -1,212 +0,0 @@
-# Writing Data to MatrixOne Using DataX
-
-## Overview
-
-This article explains using the DataX tool to write data to offline MatrixOne databases.
-
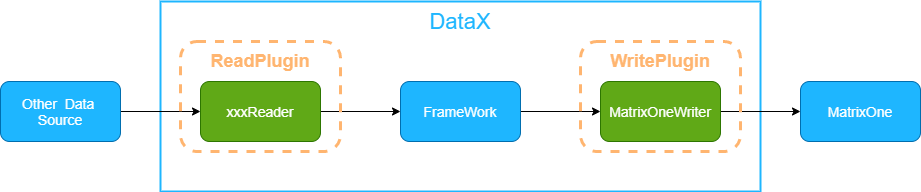
-DataX is an open-source heterogeneous data source offline synchronization tool developed by Alibaba. It provides stable and efficient data synchronization functions to achieve efficient data synchronization between various heterogeneous data sources.
-
-DataX divides the synchronization of different data sources into two main components: **Reader (read data source)** and **Writer (write to the target data source)**. The DataX framework theoretically supports data synchronization work for any data source type.
-
-MatrixOne is highly compatible with MySQL 8.0. However, since the MySQL Writer plugin with DataX is adapted to the MySQL 5.1 JDBC driver, the community has separately modified the MatrixOneWriter plugin based on the MySQL 8.0 driver to improve compatibility. The MatrixOneWriter plugin implements the functionality of writing data to the target table in the MatrixOne database. In the underlying implementation, MatrixOneWriter connects to the remote MatrixOne database via JDBC and executes the corresponding `insert into ...` SQL statements to write data to MatrixOne. It also supports batch commits for performance optimization.
-
-MatrixOneWriter uses DataX to retrieve generated protocol data from the Reader and generates the corresponding `insert into ...` statements based on your configured `writeMode`. In the event of primary key or uniqueness index conflicts, conflicting rows are excluded, and writing continues. For performance optimization, we use the `PreparedStatement + Batch` method and set the `rewriteBatchedStatements=true` option to buffer data to the thread context buffer. The write request is triggered only when the data volume in the buffer reaches the specified threshold.
-
-
-
-!!! note
- To execute the entire task, you must have permission to execute `insert into ...`. Whether other permissions are required depends on the `preSql` and `postSql` in your task configuration.
-
-MatrixOneWriter mainly aims at ETL development engineers who use MatrixOneWriter to import data from data warehouses into MatrixOne. At the same time, MatrixOneWriter can also serve as a data migration tool for users such as DBAs.
-
-## Before you start
-
-Before using DataX to write data to MatrixOne, you need to complete the installation of the following software:
-
-- Install [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html).
-- Install [Python 3.8 (or newer)](https://www.python.org/downloads/).
-- Download the [DataX](https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz) installation package and unzip it.
-- Download [matrixonewriter.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/Computing-Engine/datax-write/matrixonewriter.zip) and unzip it to the `plugin/writer/` directory in the root directory of your DataX project.
-- Install the [MySQL Client](https://dev.mysql.com/downloads/mysql).
-- [Install and start MatrixOne](../../../Get-Started/install-standalone-matrixone.md).
-
-## Steps
-
-### Create a MatrixOne Table
-
-Connect to MatrixOne using the MySQL Client and create a test table in MatrixOne:
-
-```sql
-CREATE DATABASE mo_demo;
-USE mo_demo;
-CREATE TABLE m_user(
- M_ID INT NOT NULL,
- M_NAME CHAR(25) NOT NULL
-);
-```
-
-### Configure the Data Source
-
-In this example, we use data generated **in memory** as the data source:
-
-```json
-"reader": {
- "name": "streamreader",
- "parameter": {
- "column" : [ # You can write multiple columns
- {
- "value": 20210106, # Represents the value of this column
- "type": "long" # Represents the type of this column
- },
- {
- "value": "matrixone",
- "type": "string"
- }
- ],
- "sliceRecordCount": 1000 # Indicates how many times to print
- }
-}
-```
-
-### Write the Job Configuration File
-
-Use the following command to view the configuration template:
-
-```shell
-python datax.py -r {YOUR_READER} -w matrixonewriter
-```
-
-Write the job configuration file `stream2matrixone.json`:
-
-```json
-{
- "job": {
- "setting": {
- "speed": {
- "channel": 1
- }
- },
- "content": [
- {
- "reader": {
- "name": "streamreader",
- "parameter": {
- "column" : [
- {
- "value": 20210106,
- "type": "long"
- },
- {
- "value": "matrixone",
- "type": "string"
- }
- ],
- "sliceRecordCount": 1000
- }
- },
- "writer": {
- "name": "matrixonewriter",
- "parameter": {
- "writeMode": "insert",
- "username": "root",
- "password": "111",
- "column": [
- "M_ID",
- "M_NAME"
- ],
- "preSql": [
- "delete from m_user"
- ],
- "connection": [
- {
- "jdbcUrl": "jdbc:mysql://127.0.0.1:6001/mo_demo",
- "table": [
- "m_user"
- ]
- }
- ]
- }
- }
- }
- ]
- }
-}
-```
-
-### Start DataX
-
-Execute the following command to start DataX:
-
-```shell
-$ cd {YOUR_DATAX_DIR_BIN}
-$ python datax.py stream2matrixone.json
-```
-
-### View the Results
-
-Connect to MatrixOne using the MySQL Client and use `select` to query the inserted results. The 1000 records in memory have been successfully written to MatrixOne.
-
-```sql
-mysql> select * from m_user limit 5;
-+----------+-----------+
-| m_id | m_name |
-+----------+-----------+
-| 20210106 | matrixone |
-| 20210106 | matrixone |
-| 20210106 | matrixone |
-| 20210106 | matrixone |
-| 20210106 | matrixone |
-+----------+-----------+
-5 rows in set (0.01 sec)
-
-mysql> select count(*) from m_user limit 5;
-+----------+
-| count(*) |
-+----------+
-| 1000 |
-+----------+
-1 row in set (0.00 sec)
-```
-
-## Parameter Descriptions
-
-Here are some commonly used parameters for MatrixOneWriter:
-
-| Parameter Name | Parameter Description | Mandatory | Default Value |
-| --- | --- | --- | --- |
-| **jdbcUrl** | JDBC connection information for the target database. DataX will append some attributes to the provided `jdbcUrl` during runtime, such as `yearIsDateType=false&zeroDateTimeBehavior=CONVERT_TO_NULL&rewriteBatchedStatements=true&tinyInt1isBit=false&serverTimezone=Asia/Shanghai`. | Yes | None |
-| **username** | Username for the target database. | Yes | None |
-| **password** | Password for the target database. | Yes | None |
-| **table** | Name of the target table. Supports writing to one or more tables. If configuring multiple tables, make sure their structures are consistent. | Yes | None |
-| **column** | Fields in the target table that must be written with data, separated by commas. For example: `"column": ["id","name","age"]`. To write all columns, you can use `*`, for example: `"column": ["*"]`. | Yes | None |
-| **preSql** | Standard SQL statements to be executed before writing data to the target table. | No | None |
-| **postSql** | Standard SQL statements to be executed after writing data to the target table. | No | None |
-| **writeMode** | Controls the SQL statements used when writing data to the target table. You can choose `insert` or `update`. | `insert` or `update` | `insert` |
-| **batchSize** | Size of records for batch submission. This can significantly reduce network interactions between DataX and MatrixOne, improving overall throughput. However, setting it too large may cause DataX to run out of memory. | No | 1024 |
-
-## Type Conversion
-
-MatrixOneWriter supports most MatrixOne data types, but a few types still need to be supported, so you need to pay special attention to your data types.
-
-Here is a list of type conversions that MatrixOneWriter performs for MatrixOne data types:
-
-| DataX Internal Type | MatrixOne Data Type |
-| ------------------- | ------------------- |
-| Long | int, tinyint, smallint, bigint |
-| Double | float, double, decimal |
-| String | varchar, char, text |
-| Date | date, datetime, timestamp, time |
-| Boolean | bool |
-| Bytes | blob |
-
-## Additional References
-
-- MatrixOne is compatible with the MySQL protocol. MatrixOneWriter is a modified version of the MySQL Writer with adjustments for JDBC driver versions. You can still use the MySQL Writer to write to MatrixOne.
-
-- To add the MatrixOne Writer in DataX, you need to download [matrixonewriter.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/Computing-Engine/datax-write/matrixonewriter.zip) and unzip it into the `plugin/writer/` directory in the root directory of your DataX project.
-
-## Ask and Questions
-
-**Q: During runtime, I encountered the error "Configuration information error, the configuration file you provided /{YOUR_MATRIXONE_WRITER_PATH}/plugin.json does not exist." What should I do?**
-
-A: DataX attempts to find the plugin.json file by searching for similar folders when it starts. If the matrixonewriter.zip file also exists in the same directory, DataX will try to find it in `.../datax/plugin/writer/matrixonewriter.zip/plugin.json`. In the MacOS environment, DataX will also attempt to see it in `.../datax/plugin/writer/.DS_Store/plugin.json`. In this case, you need to delete these extra files or folders.
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink.md
deleted file mode 100644
index 77b791158..000000000
--- a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink.md
+++ /dev/null
@@ -1,806 +0,0 @@
-# Writing Real-Time Data to MatrixOne Using Flink
-
-## Overview
-
-Apache Flink is a powerful framework and distributed processing engine focusing on stateful computation. It is suitable for processing both unbounded and bounded data streams efficiently. Flink can operate efficiently in various common cluster environments and performs calculations at memory speed. It supports processing data of any scale.
-
-### Scenarios
-
-* Event-Driven Applications
-
- Event-driven applications typically have states and extract data from one or more event streams. They trigger computations, update states, or perform other external actions based on incoming events. Typical event-driven applications include anti-fraud systems, anomaly detection, rule-based alert systems, and business process monitoring.
-
-* Data Analytics Applications
-
- The primary goal of data analytics tasks is to extract valuable information and metrics from raw data. Flink supports streaming and batch analytics applications, making it suitable for various scenarios such as telecom network quality monitoring, product updates, and experiment evaluation analysis in mobile applications, real-time ad-hoc analysis in the consumer technology space, and large-scale graph analysis.
-
-* Data Pipeline Applications
-
- Extract, transform, load (ETL) is a standard method for transferring data between different storage systems. Data pipelines and ETL jobs are similar in that they can perform data transformation and enrichment and move data from one storage system to another. The difference is that data pipelines run in a continuous streaming mode rather than being triggered periodically. Typical data pipeline applications include real-time query index building in e-commerce and continuous ETL.
-
-This document will introduce two examples. One involves using the Flink computing engine to write real-time data to MatrixOne, and the other uses the Flink computing engine to write streaming data to the MatrixOne database.
-
-## Before you start
-
-### Hardware Environment
-
-The hardware requirements for this practice are as follows:
-
-| Server Name | Server IP | Installed Software | Operating System |
-| node1 | 192.168.146.10 | MatrixOne | Debian11.1 x86 |
-| node2 | 192.168.146.12 | kafka | Centos7.9 |
-| node3 | 192.168.146.11 | IDEA,MYSQL | win10 |
-
-### Software Environment
-
-This practice requires the installation and deployment of the following software environments:
-
-- Install and start MatrixOne by following the steps in [Install standalone MatrixOne](../../../Get-Started/install-standalone-matrixone.md).
-- Download and install [IntelliJ IDEA version 2022.2.1 or higher](https://www.jetbrains.com/idea/download/).
-- Download and install [Kafka 2.13 - 3.5.0](https://archive.apache.org/dist/kafka/3.5.0/kafka_2.13-3.5.0.tgz).
-- Download and install [Flink 1.17.0](https://archive.apache.org/dist/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz).
-- Download and install the [MySQL Client 8.0.33](https://downloads.mysql.com/archives/get/p/23/file/mysql-server_8.0.33-1ubuntu23.04_amd64.deb-bundle.tar).
-
-## Example 1: Migrating Data from MySQL to MatrixOne
-
-### Step 1: Initialize the Project
-
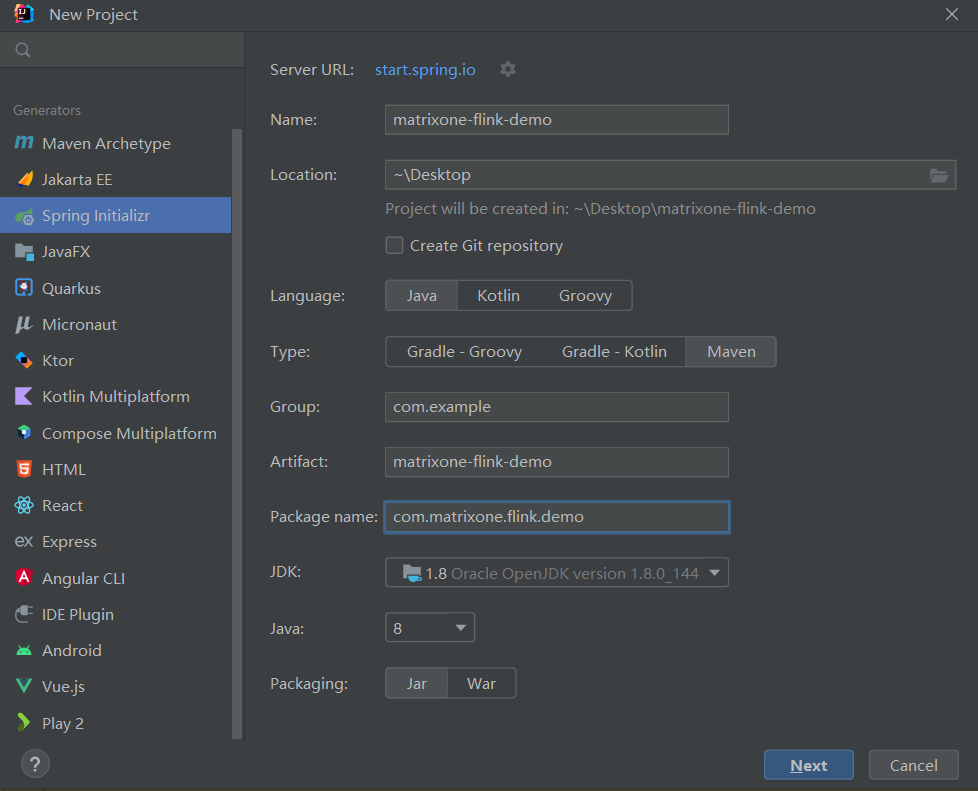
-1. Start IDEA, click **File > New > Project**, select **Spring Initializer**, and fill in the following configuration parameters:
-
- - **Name**:matrixone-flink-demo
- - **Location**:~\Desktop
- - **Language**:Java
- - **Type**:Maven
- - **Group**:com.example
- - **Artifact**:matrixone-flink-demo
- - **Package name**:com.matrixone.flink.demo
- - **JDK** 1.8
-
- 
-
-2. Add project dependencies and edit the content of `pom.xml` in the project root directory as follows:
-
-```xml
-
-
- 4.0.0
-
- com.matrixone.flink
- matrixone-flink-demo
- 1.0-SNAPSHOT
-
-
- 2.12
- 1.8
- 1.17.0
- compile
-
-
-
-
-
-
- org.apache.flink
- flink-connector-hive_2.12
- ${flink.version}
-
-
-
- org.apache.flink
- flink-java
- ${flink.version}
-
-
-
- org.apache.flink
- flink-streaming-java
- ${flink.version}
-
-
-
- org.apache.flink
- flink-clients
- ${flink.version}
-
-
-
- org.apache.flink
- flink-table-api-java-bridge
- ${flink.version}
-
-
-
- org.apache.flink
- flink-table-planner_2.12
- ${flink.version}
-
-
-
-
- org.apache.flink
- flink-connector-jdbc
- 1.15.4
-
-
- mysql
- mysql-connector-java
- 8.0.33
-
-
-
-
- org.apache.kafka
- kafka_2.13
- 3.5.0
-
-
- org.apache.flink
- flink-connector-kafka
- 3.0.0-1.17
-
-
-
-
- com.alibaba.fastjson2
- fastjson2
- 2.0.34
-
-
-
-
-
-
-
-
-
-
- org.apache.maven.plugins
- maven-compiler-plugin
- 3.8.0
-
- ${java.version}
- ${java.version}
- UTF-8
-
-
-
- maven-assembly-plugin
- 2.6
-
-
- jar-with-dependencies
-
-
-
-
- make-assembly
- package
-
- single
-
-
-
-
-
-
-
-
-
-```
-
-### Step 2: Read MatrixOne Data
-
-After connecting to MatrixOne using the MySQL client, create the necessary database and data tables for the demonstration.
-
-1. Create a database, tables and import data in MatrixOne:
-
- ```SQL
- CREATE DATABASE test;
- USE test;
- CREATE TABLE `person` (`id` INT DEFAULT NULL, `name` VARCHAR(255) DEFAULT NULL, `birthday` DATE DEFAULT NULL);
- INSERT INTO test.person (id, name, birthday) VALUES(1, 'zhangsan', '2023-07-09'),(2, 'lisi', '2023-07-08'),(3, 'wangwu', '2023-07-12');
- ```
-
-2. In IDEA, create the `MoRead.java` class to read MatrixOne data using Flink:
-
- ```java
- package com.matrixone.flink.demo;
-
- import org.apache.flink.api.common.functions.MapFunction;
- import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
- import org.apache.flink.api.java.ExecutionEnvironment;
- import org.apache.flink.api.java.operators.DataSource;
- import org.apache.flink.api.java.operators.MapOperator;
- import org.apache.flink.api.java.typeutils.RowTypeInfo;
- import org.apache.flink.connector.jdbc.JdbcInputFormat;
- import org.apache.flink.types.Row;
-
- import java.text.SimpleDateFormat;
-
- /**
- * @author MatrixOne
- * @description
- */
- public class MoRead {
-
- private static String srcHost = "192.168.146.10";
- private static Integer srcPort = 6001;
- private static String srcUserName = "root";
- private static String srcPassword = "111";
- private static String srcDataBase = "test";
-
- public static void main(String[] args) throws Exception {
-
- ExecutionEnvironment environment = ExecutionEnvironment.getExecutionEnvironment();
- // Set parallelism
- environment.setParallelism(1);
- SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
-
- // Set query field type
- RowTypeInfo rowTypeInfo = new RowTypeInfo(
- new BasicTypeInfo[]{
- BasicTypeInfo.INT_TYPE_INFO,
- BasicTypeInfo.STRING_TYPE_INFO,
- BasicTypeInfo.DATE_TYPE_INFO
- },
- new String[]{
- "id",
- "name",
- "birthday"
- }
- );
-
- DataSource dataSource = environment.createInput(JdbcInputFormat.buildJdbcInputFormat()
- .setDrivername("com.mysql.cj.jdbc.Driver")
- .setDBUrl("jdbc:mysql://" + srcHost + ":" + srcPort + "/" + srcDataBase)
- .setUsername(srcUserName)
- .setPassword(srcPassword)
- .setQuery("select * from person")
- .setRowTypeInfo(rowTypeInfo)
- .finish());
-
- // Convert Wed Jul 12 00:00:00 CST 2023 date format to 2023-07-12
- MapOperator mapOperator = dataSource.map((MapFunction) row -> {
- row.setField("birthday", sdf.format(row.getField("birthday")));
- return row;
- });
-
- mapOperator.print();
- }
- }
- ```
-
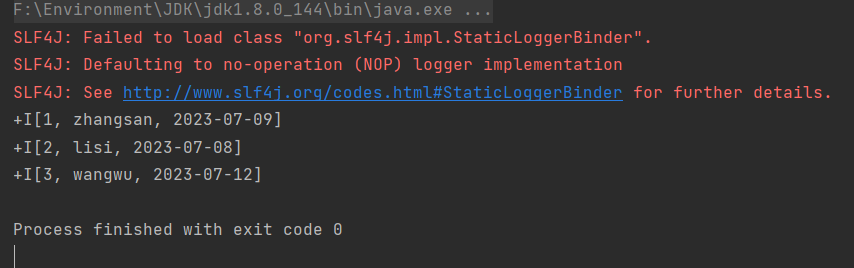
-3. Run `MoRead.Main()` in IDEA, the result is as below:
-
- 
-
-### Step 3: Write MySQL Data to MatrixOne
-
-Now, you can begin migrating MySQL data to MatrixOne using Flink.
-
-1. Prepare MySQL data: On node3, use the MySQL client to connect to the local MySQL instance. Create the necessary database, tables, and insert data:
-
- ```sql
- mysql -h127.0.0.1 -P3306 -uroot -proot
- mysql> CREATE DATABASE motest;
- mysql> USE motest;
- mysql> CREATE TABLE `person` (`id` int DEFAULT NULL, `name` varchar(255) DEFAULT NULL, `birthday` date DEFAULT NULL);
- mysql> INSERT INTO motest.person (id, name, birthday) VALUES(2, 'lisi', '2023-07-09'),(3, 'wangwu', '2023-07-13'),(4, 'zhaoliu', '2023-08-08');
- ```
-
-2. Clear MatrixOne table data:
-
- On node3, use the MySQL client to connect to the local MatrixOne instance. Since this example continues to use the `test` database from the previous MatrixOne data reading example, you need to clear the data from the `person` table first.
-
- ```sql
- -- On node3, use the MySQL client to connect to the local MatrixOne
- mysql -h192.168.146.10 -P6001 -uroot -p111
- mysql> TRUNCATE TABLE test.person;
- ```
-
-3. Write code in IDEA:
-
- Create the `Person.java` and `Mysql2Mo.java` classes to use Flink to read MySQL data. Refer to the following example for the `Mysql2Mo.java` class code:
-
-```java
-package com.matrixone.flink.demo.entity;
-
-
-import java.util.Date;
-
-public class Person {
-
- private int id;
- private String name;
- private Date birthday;
-
- public int getId() {
- return id;
- }
-
- public void setId(int id) {
- this.id = id;
- }
-
- public String getName() {
- return name;
- }
-
- public void setName(String name) {
- this.name = name;
- }
-
- public Date getBirthday() {
- return birthday;
- }
-
- public void setBirthday(Date birthday) {
- this.birthday = birthday;
- }
-}
-```
-
-```java
-package com.matrixone.flink.demo;
-
-import com.matrixone.flink.demo.entity.Person;
-import org.apache.flink.api.common.functions.MapFunction;
-import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
-import org.apache.flink.api.java.typeutils.RowTypeInfo;
-import org.apache.flink.connector.jdbc.*;
-import org.apache.flink.streaming.api.datastream.DataStreamSink;
-import org.apache.flink.streaming.api.datastream.DataStreamSource;
-import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
-import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
-import org.apache.flink.types.Row;
-
-import java.sql.Date;
-
-/**
- * @author MatrixOne
- * @description
- */
-public class Mysql2Mo {
-
- private static String srcHost = "127.0.0.1";
- private static Integer srcPort = 3306;
- private static String srcUserName = "root";
- private static String srcPassword = "root";
- private static String srcDataBase = "motest";
-
- private static String destHost = "192.168.146.10";
- private static Integer destPort = 6001;
- private static String destUserName = "root";
- private static String destPassword = "111";
- private static String destDataBase = "test";
- private static String destTable = "person";
-
-
- public static void main(String[] args) throws Exception {
-
- StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
- //Set parallelism
- environment.setParallelism(1);
- //Set query field type
- RowTypeInfo rowTypeInfo = new RowTypeInfo(
- new BasicTypeInfo[]{
- BasicTypeInfo.INT_TYPE_INFO,
- BasicTypeInfo.STRING_TYPE_INFO,
- BasicTypeInfo.DATE_TYPE_INFO
- },
- new String[]{
- "id",
- "name",
- "birthday"
- }
- );
-
- // add srouce
- DataStreamSource dataSource = environment.createInput(JdbcInputFormat.buildJdbcInputFormat()
- .setDrivername("com.mysql.cj.jdbc.Driver")
- .setDBUrl("jdbc:mysql://" + srcHost + ":" + srcPort + "/" + srcDataBase)
- .setUsername(srcUserName)
- .setPassword(srcPassword)
- .setQuery("select * from person")
- .setRowTypeInfo(rowTypeInfo)
- .finish());
-
- //run ETL
- SingleOutputStreamOperator mapOperator = dataSource.map((MapFunction) row -> {
- Person person = new Person();
- person.setId((Integer) row.getField("id"));
- person.setName((String) row.getField("name"));
- person.setBirthday((java.util.Date)row.getField("birthday"));
- return person;
- });
-
- //set matrixone sink information
- mapOperator.addSink(
- JdbcSink.sink(
- "insert into " + destTable + " values(?,?,?)",
- (ps, t) -> {
- ps.setInt(1, t.getId());
- ps.setString(2, t.getName());
- ps.setDate(3, new Date(t.getBirthday().getTime()));
- },
- new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
- .withDriverName("com.mysql.cj.jdbc.Driver")
- .withUrl("jdbc:mysql://" + destHost + ":" + destPort + "/" + destDataBase)
- .withUsername(destUserName)
- .withPassword(destPassword)
- .build()
- )
- );
-
- environment.execute();
- }
-
-}
-```
-
-### Step 4: View the Execution Results
-
-Execute the following SQL in MatrixOne to view the execution results:
-
-```sql
-mysql> select * from test.person;
-+------+---------+------------+
-| id | name | birthday |
-+------+---------+------------+
-| 2 | lisi | 2023-07-09 |
-| 3 | wangwu | 2023-07-13 |
-| 4 | zhaoliu | 2023-08-08 |
-+------+---------+------------+
-3 rows in set (0.01 sec)
-```
-
-## Example 2: Importing Kafka data to MatrixOne
-
-### Step 1: Start the Kafka Service
-
-Kafka cluster coordination and metadata management can be achieved using KRaft or ZooKeeper. Here, we will use Kafka version 3.5.0, eliminating the need for a standalone ZooKeeper software and utilizing Kafka's built-in **KRaft** for metadata management. Follow the steps below to configure the settings. The configuration file can be found in the Kafka software's root directory under `config/kraft/server.properties`.
-
-The configuration file is as follows:
-
-```properties
-# Licensed to the Apache Software Foundation (ASF) under one or more
-# contributor license agreements. See the NOTICE file distributed with
-# this work for additional information regarding copyright ownership.
-# The ASF licenses this file to You under the Apache License, Version 2.0
-# (the "License"); you may not use this file except in compliance with
-# the License. You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-#
-# This configuration file is intended for use in KRaft mode, where
-# Apache ZooKeeper is not present. See config/kraft/README.md for details.
-#
-
-############################# Server Basics #############################
-
-# The role of this server. Setting this puts us in KRaft mode
-process.roles=broker,controller
-
-# The node id associated with this instance's roles
-node.id=1
-
-# The connect string for the controller quorum
-controller.quorum.voters=1@192.168.146.12:9093
-
-############################# Socket Server Settings #############################
-
-# The address the socket server listens on.
-# Combined nodes (i.e. those with `process.roles=broker,controller`) must list the controller listener here at a minimum.
-# If the broker listener is not defined, the default listener will use a host name that is equal to the value of java.net.InetAddress.getCanonicalHostName(),
-# with PLAINTEXT listener name, and port 9092.
-# FORMAT:
-# listeners = listener_name://host_name:port
-# EXAMPLE:
-# listeners = PLAINTEXT://your.host.name:9092
-#listeners=PLAINTEXT://:9092,CONTROLLER://:9093
-listeners=PLAINTEXT://192.168.146.12:9092,CONTROLLER://192.168.146.12:9093
-
-# Name of listener used for communication between brokers.
-inter.broker.listener.name=PLAINTEXT
-
-# Listener name, hostname and port the broker will advertise to clients.
-# If not set, it uses the value for "listeners".
-#advertised.listeners=PLAINTEXT://localhost:9092
-
-# A comma-separated list of the names of the listeners used by the controller.
-# If no explicit mapping set in `listener.security.protocol.map`, default will be using PLAINTEXT protocol
-# This is required if running in KRaft mode.
-controller.listener.names=CONTROLLER
-
-# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
-listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
-
-# The number of threads that the server uses for receiving requests from the network and sending responses to the network
-num.network.threads=3
-
-# The number of threads that the server uses for processing requests, which may include disk I/O
-num.io.threads=8
-
-# The send buffer (SO_SNDBUF) used by the socket server
-socket.send.buffer.bytes=102400
-
-# The receive buffer (SO_RCVBUF) used by the socket server
-socket.receive.buffer.bytes=102400
-
-# The maximum size of a request that the socket server will accept (protection against OOM)
-socket.request.max.bytes=104857600
-
-
-############################# Log Basics #############################
-
-# A comma separated list of directories under which to store log files
-log.dirs=/home/software/kafka_2.13-3.5.0/kraft-combined-logs
-
-# The default number of log partitions per topic. More partitions allow greater
-# parallelism for consumption, but this will also result in more files across
-# the brokers.
-num.partitions=1
-
-# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
-# This value is recommended to be increased for installations with data dirs located in RAID array.
-num.recovery.threads.per.data.dir=1
-
-############################# Internal Topic Settings #############################
-# The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"
-# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
-offsets.topic.replication.factor=1
-transaction.state.log.replication.factor=1
-transaction.state.log.min.isr=1
-
-############################# Log Flush Policy #############################
-
-# Messages are immediately written to the filesystem but by default we only fsync() to sync
-# the OS cache lazily. The following configurations control the flush of data to disk.
-# There are a few important trade-offs here:
-# 1. Durability: Unflushed data may be lost if you are not using replication.
-# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
-# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
-# The settings below allow one to configure the flush policy to flush data after a period of time or
-# every N messages (or both). This can be done globally and overridden on a per-topic basis.
-
-# The number of messages to accept before forcing a flush of data to disk
-#log.flush.interval.messages=10000
-
-# The maximum amount of time a message can sit in a log before we force a flush
-#log.flush.interval.ms=1000
-
-############################# Log Retention Policy #############################
-
-# The following configurations control the disposal of log segments. The policy can
-# be set to delete segments after a period of time, or after a given size has accumulated.
-# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
-# from the end of the log.
-
-# The minimum age of a log file to be eligible for deletion due to age
-log.retention.hours=72
-
-# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
-# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
-#log.retention.bytes=1073741824
-
-# The maximum size of a log segment file. When this size is reached a new log segment will be created.
-log.segment.bytes=1073741824
-
-# The interval at which log segments are checked to see if they can be deleted according
-# to the retention policies
-log.retention.check.interval.ms=300000
-```
-
-After the file configuration is completed, execute the following command to start the Kafka service:
-
-```shell
-#Generate cluster ID
-$ KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
-#Set log directory format
-$ bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties
-#Start Kafka service
-$ bin/kafka-server-start.sh config/kraft/server.properties
-```
-
-### Step 2: Create a Kafka Topic
-
-To enable Flink to read data from and write data to MatrixOne, we first need to create a Kafka topic named "matrixone." In the command below, use the `--bootstrap-server` parameter to specify the Kafka service's listening address as `192.168.146.12:9092`:
-
-```shell
-$ bin/kafka-topics.sh --create --topic matrixone --bootstrap-server 192.168.146.12:9092
-```
-
-### Step 3: Read MatrixOne Data
-
-After connecting to the MatrixOne database, perform the following steps to create the necessary database and tables:
-
-1. Create a database, and tables and import data in MatrixOne:
-
- ```sql
- CREATE TABLE `users` (
- `id` INT DEFAULT NULL,
- `name` VARCHAR(255) DEFAULT NULL,
- `age` INT DEFAULT NULL
- )
- ```
-
-2. Write code in the IDEA integrated development environment:
-
- In IDEA, create two classes: `User.java` and `Kafka2Mo.java`. These classes read from Kafka and write data to the MatrixOne database using Flink.
-
-```java
-package com.matrixone.flink.demo.entity;
-
-public class User {
-
- private int id;
- private String name;
- private int age;
-
- public int getId() {
- return id;
- }
-
- public void setId(int id) {
- this.id = id;
- }
-
- public String getName() {
- return name;
- }
-
- public void setName(String name) {
- this.name = name;
- }
-
- public int getAge() {
- return age;
- }
-
- public void setAge(int age) {
- this.age = age;
- }
-}
-```
-
-```java
-package com.matrixone.flink.demo;
-
-import com.alibaba.fastjson2.JSON;
-import com.matrixone.flink.demo.entity.User;
-import org.apache.flink.api.common.eventtime.WatermarkStrategy;
-import org.apache.flink.api.common.serialization.AbstractDeserializationSchema;
-import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
-import org.apache.flink.connector.jdbc.JdbcSink;
-import org.apache.flink.connector.jdbc.JdbcStatementBuilder;
-import org.apache.flink.connector.jdbc.internal.options.JdbcConnectorOptions;
-import org.apache.flink.connector.kafka.source.KafkaSource;
-import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
-import org.apache.flink.streaming.api.datastream.DataStreamSource;
-import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
-import org.apache.kafka.clients.consumer.OffsetResetStrategy;
-
-import java.nio.charset.StandardCharsets;
-
-/**
- * @author MatrixOne
- * @desc
- */
-public class Kafka2Mo {
-
- private static String srcServer = "192.168.146.12:9092";
- private static String srcTopic = "matrixone";
- private static String consumerGroup = "matrixone_group";
-
- private static String destHost = "192.168.146.10";
- private static Integer destPort = 6001;
- private static String destUserName = "root";
- private static String destPassword = "111";
- private static String destDataBase = "test";
- private static String destTable = "person";
-
- public static void main(String[] args) throws Exception {
-
- //Initialize environment
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- //Set parallelism
- env.setParallelism(1);
-
- //Set kafka source information
- KafkaSource source = KafkaSource.builder()
- //Kafka service
- .setBootstrapServers(srcServer)
- //Message topic
- .setTopics(srcTopic)
- //Consumer group
- .setGroupId(consumerGroup)
- //Offset When no offset is submitted, consumption starts from the beginning.
- .setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.LATEST))
- //Customized parsing message content
- .setValueOnlyDeserializer(new AbstractDeserializationSchema() {
- @Override
- public User deserialize(byte[] message) {
- return JSON.parseObject(new String(message, StandardCharsets.UTF_8), User.class);
- }
- })
- .build();
- DataStreamSource kafkaSource = env.fromSource(source, WatermarkStrategy.noWatermarks(), "kafka_maxtixone");
- //kafkaSource.print();
-
- //set matrixone sink information
- kafkaSource.addSink(JdbcSink.sink(
- "insert into users (id,name,age) values(?,?,?)",
- (JdbcStatementBuilder) (preparedStatement, user) -> {
- preparedStatement.setInt(1, user.getId());
- preparedStatement.setString(2, user.getName());
- preparedStatement.setInt(3, user.getAge());
- },
- JdbcExecutionOptions.builder()
- //default value is 5000
- .withBatchSize(1000)
- //default value is 0
- .withBatchIntervalMs(200)
- //Maximum attempts
- .withMaxRetries(5)
- .build(),
- JdbcConnectorOptions.builder()
- .setDBUrl("jdbc:mysql://"+destHost+":"+destPort+"/"+destDataBase)
- .setUsername(destUserName)
- .setPassword(destPassword)
- .setDriverName("com.mysql.cj.jdbc.Driver")
- .setTableName(destTable)
- .build()
- ));
- env.execute();
- }
-}
-```
-
-After writing the code, you can run the Flink task by selecting the `Kafka2Mo.java` file in IDEA and executing `Kafka2Mo.Main()`.
-
-### Step 4: Generate data
-
-You can add data to Kafka's "matrixone" topic using the command-line producer tools provided by Kafka. In the following command, use the `--topic` parameter to specify the topic to add to and the `--bootstrap-server` parameter to determine the listening address of the Kafka service.
-
-```shell
-bin/kafka-console-producer.sh --topic matrixone --bootstrap-server 192.168.146.12:9092
-```
-
-After executing the above command, you will wait for the message content to be entered on the console. Enter the message values (values) directly, with each line representing one message (separated by newline characters), as follows:
-
-```shell
-{"id": 10, "name": "xiaowang", "age": 22}
-{"id": 20, "name": "xiaozhang", "age": 24}
-{"id": 30, "name": "xiaogao", "age": 18}
-{"id": 40, "name": "xiaowu", "age": 20}
-{"id": 50, "name": "xiaoli", "age": 42}
-```
-
-
-
-### Step 5: View execution results
-
-Execute the following SQL query results in MatrixOne:
-
-```sql
-mysql> select * from test.users;
-+------+-----------+------+
-| id | name | age |
-+------+-----------+------+
-| 10 | xiaowang | 22 |
-| 20 | xiaozhang | 24 |
-| 30 | xiaogao | 18 |
-| 40 | xiaowu | 20 |
-| 50 | xiaoli | 42 |
-+------+-----------+------+
-5 rows in set (0.01 sec)
-```
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-kafka-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-kafka-matrixone.md
new file mode 100644
index 000000000..f5618e9be
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-kafka-matrixone.md
@@ -0,0 +1,359 @@
+# Write Kafka data to MatrixOne using Flink
+
+This chapter describes how to write Kafka data to MatrixOne using Flink.
+
+## Pre-preparation
+
+This practice requires the installation and deployment of the following software environments:
+
+- Complete [standalone MatrixOne deployment](https://docs.matrixorigin.cn/1.2.2/MatrixOne/Get-Started/install-standalone-matrixone/).
+- Download and install [lntelliJ IDEA (2022.2.1 or later version)](https://www.jetbrains.com/idea/download/).
+- Select the [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html) version to download and install depending on your system environment.
+- Download and install [Kafka](https://archive.apache.org/dist/kafka/3.5.0/kafka_2.13-3.5.0.tgz).
+- Download and install [Flink](https://archive.apache.org/dist/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz) with a minimum supported version of 1.11.
+- Download and install the [MySQL Client](https://dev.mysql.com/downloads/mysql).
+
+## Operational steps
+
+### Step one: Start the Kafka service
+
+Kafka cluster coordination and metadata management can be achieved through KRaft or ZooKeeper. Here, instead of relying on standalone ZooKeeper software, we'll use Kafka's own **KRaft** for metadata management. Follow these steps to configure the configuration file, which is located in `config/kraft/server.properties` in the root of the Kafka software.
+
+The configuration file reads as follows:
+
+```properties
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+#
+# This configuration file is intended for use in KRaft mode, where
+# Apache ZooKeeper is not present. See config/kraft/README.md for details.
+#
+
+############################# Server Basics #############################
+
+# The role of this server. Setting this puts us in KRaft mode
+process.roles=broker,controller
+
+# The node id associated with this instance's roles
+node.id=1
+
+# The connect string for the controller quorum
+controller.quorum.voters=1@xx.xx.xx.xx:9093
+
+############################# Socket Server Settings #############################
+
+# The address the socket server listens on.
+# Combined nodes (i.e. those with `process.roles=broker,controller`) must list the controller listener here at a minimum.
+# If the broker listener is not defined, the default listener will use a host name that is equal to the value of java.net.InetAddress.getCanonicalHostName(),
+# with PLAINTEXT listener name, and port 9092.
+# FORMAT:
+# listeners = listener_name://host_name:port
+# EXAMPLE:
+# listeners = PLAINTEXT://your.host.name:9092
+#listeners=PLAINTEXT://:9092,CONTROLLER://:9093 listeners=PLAINTEXT://xx.xx.xx.xx:9092,CONTROLLER://xx.xx.xx.xx:9093
+
+# Name of listener used for communication between brokers.
+inter.broker.listener.name=PLAINTEXT
+
+# Listener name, hostname and port the broker will advertise to clients.
+# If not set, it uses the value for "listeners".
+#advertised.listeners=PLAINTEXT://localhost:9092
+
+# A comma-separated list of the names of the listeners used by the controller.
+# If no explicit mapping set in `listener.security.protocol.map`, default will be using PLAINTEXT protocol
+# This is required if running in KRaft mode.
+controller.listener.names=CONTROLLER
+
+# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
+listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
+
+# The number of threads that the server uses for receiving requests from the network and sending responses to the network
+num.network.threads=3
+
+# The number of threads that the server uses for processing requests, which may include disk I/O
+num.io.threads=8
+
+# The send buffer (SO_SNDBUF) used by the socket server
+socket.send.buffer.bytes=102400
+
+# The receive buffer (SO_RCVBUF) used by the socket server
+socket.receive.buffer.bytes=102400
+
+# The maximum size of a request that the socket server will accept (protection against OOM)
+socket.request.max.bytes=104857600
+
+
+############################# Log Basics #############################
+
+# A comma separated list of directories under which to store log files
+log.dirs=/home/software/kafka_2.13-3.5.0/kraft-combined-logs
+
+# The default number of log partitions per topic. More partitions allow greater
+# parallelism for consumption, but this will also result in more files across
+# the brokers.
+num.partitions=1
+
+# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
+# This value is recommended to be increased for installations with data dirs located in RAID array.
+num.recovery.threads.per.data.dir=1
+
+############################# Internal Topic Settings #############################
+# The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"
+# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
+offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1
+
+############################# Log Flush Policy #############################
+
+# Messages are immediately written to the filesystem but by default we only fsync() to sync
+# the OS cache lazily. The following configurations control the flush of data to disk.
+# There are a few important trade-offs here:
+# 1. Durability: Unflushed data may be lost if you are not using replication.
+# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
+# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
+# The settings below allow one to configure the flush policy to flush data after a period of time or
+# every N messages (or both). This can be done globally and overridden on a per-topic basis.
+
+# The number of messages to accept before forcing a flush of data to disk
+#log.flush.interval.messages=10000
+
+# The maximum amount of time a message can sit in a log before we force a flush
+#log.flush.interval.ms=1000
+
+############################# Log Retention Policy #############################
+
+# The following configurations control the disposal of log segments. The policy can
+# be set to delete segments after a period of time, or after a given size has accumulated.
+# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
+# from the end of the log.
+
+# The minimum age of a log file to be eligible for deletion due to age
+log.retention.hours=72
+
+# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
+# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
+#log.retention.bytes=1073741824
+
+# The maximum size of a log segment file. When this size is reached a new log segment will be created.
+log.segment.bytes=1073741824
+
+# The interval at which log segments are checked to see if they can be deleted according
+# to the retention policies
+log.retention.check.interval.ms=300000
+```
+
+When the file configuration is complete, start the Kafka service by executing the following command:
+
+```shell
+#Generate cluster ID
+$ KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)" #Set log directory format
+$ bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties #Start Kafka service
+$ bin/kafka-server-start.sh config/kraft/server.properties
+```
+
+### Step two: Create a Kafka theme
+
+In order for Flink to read data from and write to MatrixOne, we need to first create a Kafka theme called "matrixone." Specify the listening address of the Kafka service as `xx.xx.xx.xx:9092` using the `--bootstrap-server` parameter in the following command:
+
+```shell
+$ bin/kafka-topics.sh --create --topic matrixone --bootstrap-server xx.xx.xx.xx:9092
+```
+
+### Step Three: Read MatrixOne Data
+
+After connecting to the MatrixOne database, you need to do the following to create the required databases and data tables:
+
+1. Create databases and data tables in MatrixOne and import data:
+
+ ```sql
+ CREATE TABLE `users` (
+ `id` INT DEFAULT NULL,
+ `name` VARCHAR(255) DEFAULT NULL,
+ `age` INT DEFAULT NULL
+ )
+ ```
+
+2. Write code in the IDEA integrated development environment:
+
+ In IDEA, create two classes: `User.java` and `Kafka2Mo.java`. These classes are used to read data from Kafka using Flink and write the data to the MatrixOne database.
+
+```java
+
+package com.matrixone.flink.demo.entity;
+
+public class User {
+
+ private int id;
+ private String name;
+ private int age;
+
+ public int getId() {
+ return id;
+ }
+
+ public void setId(int id) {
+ this.id = id;
+ }
+
+ public String getName() {
+ return name;
+ }
+
+ public void setName(String name) {
+ this.name = name;
+ }
+
+ public int getAge() {
+ return age;
+ }
+
+ public void setAge(int age) {
+ this.age = age;
+ }
+}
+```
+
+```java
+package com.matrixone.flink.demo;
+
+import com.alibaba.fastjson2.JSON;
+import com.matrixone.flink.demo.entity.User;
+import org.apache.flink.api.common.eventtime.WatermarkStrategy;
+import org.apache.flink.api.common.serialization.AbstractDeserializationSchema;
+import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
+import org.apache.flink.connector.jdbc.JdbcSink;
+import org.apache.flink.connector.jdbc.JdbcStatementBuilder;
+import org.apache.flink.connector.jdbc.internal.options.JdbcConnectorOptions;
+import org.apache.flink.connector.kafka.source.KafkaSource;
+import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
+import org.apache.flink.streaming.api.datastream.DataStreamSource;
+import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
+import org.apache.kafka.clients.consumer.OffsetResetStrategy;
+
+import java.nio.charset.StandardCharsets;
+
+/**
+ * @author MatrixOne
+ * @desc
+ */
+public class Kafka2Mo {
+
+ private static String srcServer = "xx.xx.xx.xx:9092";
+ private static String srcTopic = "matrixone";
+ private static String consumerGroup = "matrixone_group";
+
+ private static String destHost = "xx.xx.xx.xx";
+ private static Integer destPort = 6001;
+ private static String destUserName = "root";
+ private static String destPassword = "111";
+ private static String destDataBase = "test";
+ private static String destTable = "person";
+
+ public static void main(String[] args) throws Exception {
+
+ // Initialize the environment
+ StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
+ // Set parallelism
+ env.setParallelism(1);
+
+ // Set kafka source information
+ KafkaSource source = KafkaSource.builder()
+ //Kafka service
+ .setBootstrapServers(srcServer)
+ // message subject
+ .setTopics(srcTopic)
+ // consumption group
+ .setGroupId(consumerGroup)
+ // offset Consume from the beginning when no offset is submitted
+ .setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.LATEST))
+ // custom parse message content
+ .setValueOnlyDeserializer(new AbstractDeserializationSchema() {
+ @Override
+ public User deserialize(byte[] message) {
+ return JSON.parseObject(new String(message, StandardCharsets.UTF_8), User.class);
+ }
+ })
+ .build();
+ DataStreamSource kafkaSource = env.fromSource(source, WatermarkStrategy.noWatermarks(), "kafka_maxtixone");
+ //kafkaSource.print();
+
+ // Set matrixone sink information
+ kafkaSource.addSink(JdbcSink.sink()
+ "insert into users (id,name,age) values(?,?,?)",
+ (JdbcStatementBuilder) (preparedStatement, user) -> {
+ preparedStatement.setInt(1, user.getId());
+ preparedStatement.setString(2, user.getName());
+ preparedStatement.setInt(3, user.getAge());
+ },
+ JdbcExecutionOptions.builder()
+ //Default value 5000
+ .withBatchSize(1000)
+ //Default value is 0
+ .withBatchIntervalMs(200)
+ // Maximum number of attempts
+ .withMaxRetries(5)
+ .build(),
+ JdbcConnectorOptions.builder()
+ .setDBUrl("jdbc:mysql://"+destHost+":"+destPort+"/"+destDataBase)
+ .setUsername(destUserName)
+ .setPassword(destPassword)
+ .setDriverName("com.mysql.cj.jdbc.Driver")
+ .setTableName(destTable)
+ .build()
+ ));
+ env.execute();
+ }
+}
+```
+
+Once the code is written, you can run the Flink task, which is to select the `Kafka2Mo.java` file in IDEA and execute `Kafka2Mo.Main()`.
+
+### Step Four: Generating Data
+
+Using the command-line producer tools provided by Kafka, you can add data to Kafka's "matrixone" theme. In the following command, use the `--topic` parameter to specify the topic to add to, and the `--bootstrap-server` parameter to specify the listening address of the Kafka service.
+
+```shell
+bin/kafka-console-producer.sh --topic matrixone --bootstrap-server xx.xx.xx.xx:9092
+```
+
+After executing the above command, you will wait on the console to enter the message content. Simply enter the message value (value) directly, one message per line (separated by a newline character), as follows:
+
+```shell
+{"id": 10, "name": "xiaowang", "age": 22}
+{"id": 20, "name": "xiaozhang", "age": 24}
+{"id": 30, "name": "xiaogao", "age": 18}
+{"id": 40, "name": "xiaowu", "age": 20}
+{"id": 50, "name": "xiaoli", "age": 42}
+```
+
+
+
+### Step Five: View Implementation Results
+
+Execute the following SQL query results in MatrixOne:
+
+```sql
+mysql> select * from test.users;
++------+-----------+------+
+| id | name | age |
++------+-----------+------+
+| 10 | xiaowang | 22 |
+| 20 | xiaozhang | 24 |
+| 30 | xiaogao | 18 |
+| 40 | xiaowu | 20 |
+| 50 | xiaoli | 42 |
++------+-----------+------+
+5 rows in set (0.01 sec)
+```
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-mongo-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-mongo-matrixone.md
new file mode 100644
index 000000000..27d9b16c6
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-mongo-matrixone.md
@@ -0,0 +1,155 @@
+# Write MongoDB data to MatrixOne using Flink
+
+This chapter describes how to write MongoDB data to MatrixOne using Flink.
+
+## Pre-preparation
+
+This practice requires the installation and deployment of the following software environments:
+
+- Complete [standalone MatrixOne deployment](https://docs.matrixorigin.cn/1.2.2/MatrixOne/Get-Started/install-standalone-matrixone/).
+- Download and install [lntelliJ IDEA (2022.2.1 or later version)](https://www.jetbrains.com/idea/download/).
+- Select the [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html) version to download and install depending on your system environment.
+- Download and install [Flink](https://archive.apache.org/dist/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz) with a minimum supported version of 1.11.
+- Download and install [MongoDB](https://www.mongodb.com/).
+- Download and install [MySQL](https://downloads.mysql.com/archives/get/p/23/file/mysql-server_8.0.33-1ubuntu23.04_amd64.deb-bundle.tar), the recommended version is 8.0.33.
+
+## Operational steps
+
+### Turn on Mongodb replica set mode
+
+Shutdown command:
+
+```bash
+mongod -f /opt/software/mongodb/conf/config.conf --shutdown
+```
+
+Add the following parameters to /opt/software/mongodb/conf/config.conf
+
+```shell
+replication:
+replSetName: rs0 #replication set name
+```
+
+Restart mangod
+
+```bash
+mongod -f /opt/software/mongodb/conf/config.conf
+```
+
+Then go into mongo and execute `rs.initiate()` then `rs.status()`
+
+```shell
+> rs.initiate()
+{
+"info2" : "no configuration specified. Using a default configuration for the set",
+"me" : "xx.xx.xx.xx:27017",
+"ok" : 1
+}
+rs0:SECONDARY> rs.status()
+```
+
+See the following information indicating that the replication set started successfully
+
+```bash
+"members" : [
+{
+"_id" : 0,
+"name" : "xx.xx.xx.xx:27017",
+"health" : 1,
+"state" : 1,
+"stateStr" : "PRIMARY",
+"uptime" : 77,
+"optime" : {
+"ts" : Timestamp(1665998544, 1),
+"t" : NumberLong(1)
+},
+"optimeDate" : ISODate("2022-10-17T09:22:24Z"),
+"syncingTo" : "",
+"syncSourceHost" : "",
+"syncSourceId" : -1,
+"infoMessage" : "could not find member to sync from",
+"electionTime" : Timestamp(1665998504, 2),
+"electionDate" : ISODate("2022-10-17T09:21:44Z"),
+"configVersion" : 1,
+"self" : true,
+"lastHeartbeatMessage" : ""
+}
+],
+"ok" : 1,
+
+rs0:PRIMARY> show dbs
+admin 0.000GB
+config 0.000GB
+local 0.000GB
+test 0.000GB
+```
+
+### Create source table (mongodb) in flinkcdc sql interface
+
+Execute in the lib directory in the flink directory and download the cdcjar package for mongodb
+
+```bash
+wget
+```
+
+Build a mapping table for the data source mongodb, the column names must also be identical
+
+```sql
+CREATE TABLE products (
+ _id STRING,#There must be this column, and it must also be the primary key, because mongodb automatically generates an id for each row of data
+ `name` STRING,
+ age INT,
+ PRIMARY KEY(_id) NOT ENFORCED
+) WITH (
+ 'connector' = 'mongodb-cdc',
+ 'hosts' = 'xx.xx.xx.xx:27017',
+ 'username' = 'root',
+ 'password' = '',
+ 'database' = 'test',
+ 'collection' = 'test'
+);
+```
+
+Once established you can execute `select * from` products; check if the connection is successful
+
+### Create sink table in flinkcdc sql interface (MatrixOne)
+
+Create a mapping table for matrixone with the same structure and no columns with ids
+
+```sql
+CREATE TABLE cdc_matrixone (
+ `name` STRING,
+ age INT,
+ PRIMARY KEY (`name`) NOT ENFORCED
+)WITH (
+'connector' = 'jdbc',
+'url' = 'jdbc:mysql://xx.xx.xx.xx:6001/test',
+'driver' = 'com.mysql.cj.jdbc.Driver',
+'username' = 'root',
+'password' = '111',
+'table-name' = 'mongodbtest'
+);
+```
+
+### Turn on the cdc synchronization task
+
+Once the sync task is turned on here, mongodb additions and deletions can be synchronized
+
+```sql
+INSERT INTO cdc_matrixone SELECT `name`,age FROM products;
+
+#insert
+rs0:PRIMARY> db.test.insert({"name" : "ddd", "age" : 90})
+WriteResult({ "nInserted" : 1 })
+rs0:PRIMARY> db.test.find()
+{ "_id" : ObjectId("6347e3c6229d6017c82bf03d"), "name" : "aaa", "age" : 20 }
+{ "_id" : ObjectId("6347e64a229d6017c82bf03e"), "name" : "bbb", "age" : 18 }
+{ "_id" : ObjectId("6347e652229d6017c82bf03f"), "name" : "ccc", "age" : 28 }
+{ "_id" : ObjectId("634d248f10e21b45c73b1a36"), "name" : "ddd", "age" : 90 }
+#update
+rs0:PRIMARY> db.test.update({'name':'ddd'},{$set:{'age':'99'}})
+WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
+#delete
+rs0:PRIMARY> db.test.remove({'name':'ddd'})
+WriteResult({ "nRemoved" : 1 })
+```
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-mysql-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-mysql-matrixone.md
new file mode 100644
index 000000000..be51aab3b
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-mysql-matrixone.md
@@ -0,0 +1,431 @@
+# Writing MySQL data to MatrixOne using Flink
+
+This chapter describes how to write MySQL data to MatrixOne using Flink.
+
+## Pre-preparation
+
+This practice requires the installation and deployment of the following software environments:
+
+- Complete [standalone MatrixOne deployment](https://docs.matrixorigin.cn/1.2.2/MatrixOne/Get-Started/install-standalone-matrixone/).
+- Download and install [lntelliJ IDEA (2022.2.1 or later version)](https://www.jetbrains.com/idea/download/).
+- Select the [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html) version to download and install depending on your system environment.
+- Download and install [Flink](https://archive.apache.org/dist/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz) with a minimum supported version of 1.11.
+- Download and install [MySQL](https://downloads.mysql.com/archives/get/p/23/file/mysql-server_8.0.33-1ubuntu23.04_amd64.deb-bundle.tar), the recommended version is 8.0.33.
+
+## Operational steps
+
+### Step one: Initialize the project
+
+1. Open IDEA, click **File > New > Project**, select **Spring Initializer**, and fill in the following configuration parameters:
+
+ - **Name**:matrixone-flink-demo
+ - **Location**:~\Desktop
+ - **Language**:Java
+ - **Type**:Maven
+ - **Group**:com.example
+ - **Artifact**:matrixone-flink-demo
+ - **Package name**:com.matrixone.flink.demo
+ - **JDK** 1.8
+
+ An example configuration is shown in the following figure:
+
+
+
+
+
+2. Add project dependencies, edit the `pom.xml` file in the root of your project, and add the following to the file:
+
+```xml
+
+
+ 4.0.0
+
+ com.matrixone.flink
+ matrixone-flink-demo
+ 1.0-SNAPSHOT
+
+
+ 2.12
+ 1.8
+ 1.17.0
+ compile
+
+
+
+
+
+
+ org.apache.flink
+ flink-connector-hive_2.12
+ ${flink.version}
+
+
+
+ org.apache.flink
+ flink-java
+ ${flink.version}
+
+
+
+ org.apache.flink
+ flink-streaming-java
+ ${flink.version}
+
+
+
+ org.apache.flink
+ flink-clients
+ ${flink.version}
+
+
+
+ org.apache.flink
+ flink-table-api-java-bridge
+ ${flink.version}
+
+
+
+ org.apache.flink
+ flink-table-planner_2.12
+ ${flink.version}
+
+
+
+
+ org.apache.flink
+ flink-connector-jdbc
+ 1.15.4
+
+
+ mysql
+ mysql-connector-java
+ 8.0.33
+
+
+
+
+ org.apache.kafka
+ kafka_2.13
+ 3.5.0
+
+
+ org.apache.flink
+ flink-connector-kafka
+ 3.0.0-1.17
+
+
+
+
+ com.alibaba.fastjson2
+ fastjson2
+ 2.0.34
+
+
+
+
+
+
+
+
+
+
+ org.apache.maven.plugins
+ maven-compiler-plugin
+ 3.8.0
+
+ ${java.version}
+ ${java.version}
+ UTF-8
+
+
+
+ maven-assembly-plugin
+ 2.6
+
+
+ jar-with-dependencies
+
+
+
+
+ make-assembly
+ package
+
+ single
+
+
+
+
+
+
+
+
+
+```
+
+### Step Two: Read MatrixOne Data
+
+After connecting to MatrixOne using a MySQL client, create the database you need for the demo, as well as the data tables.
+
+1. Create databases, data tables, and import data in MatrixOne:
+
+ ```SQL
+ CREATE DATABASE test;
+ USE test;
+ CREATE TABLE `person` (`id` INT DEFAULT NULL, `name` VARCHAR(255) DEFAULT NULL, `birthday` DATE DEFAULT NULL);
+ INSERT INTO test.person (id, name, birthday) VALUES(1, 'zhangsan', '2023-07-09'),(2, 'lisi', '2023-07-08'),(3, 'wangwu', '2023-07-12');
+ ```
+
+2. Create a `MoRead.java` class in IDEA to read MatrixOne data using Flink:
+
+ ```java
+ package com.matrixone.flink.demo;
+
+ import org.apache.flink.api.common.functions.MapFunction;
+ import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
+ import org.apache.flink.api.java.ExecutionEnvironment;
+ import org.apache.flink.api.java.operators.DataSource;
+ import org.apache.flink.api.java.operators.MapOperator;
+ import org.apache.flink.api.java.typeutils.RowTypeInfo;
+ import org.apache.flink.connector.jdbc.JdbcInputFormat;
+ import org.apache.flink.types.Row;
+
+ import java.text.SimpleDateFormat;
+
+ /**
+ * @author MatrixOne
+ * @description
+ */
+ public class MoRead {
+ private static String srcHost = "xx.xx.xx.xx";
+ private static Integer srcPort = 6001;
+ private static String srcUserName = "root";
+ private static String srcPassword = "111";
+ private static String srcDataBase = "test";
+
+ public static void main(String[] args) throws Exception {
+
+ ExecutionEnvironment environment = ExecutionEnvironment.getExecutionEnvironment();
+ // Set parallelism
+ environment.setParallelism(1);
+ SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
+
+ // Set the field type of the query
+ RowTypeInfo rowTypeInfo = new RowTypeInfo(
+ new BasicTypeInfo[]{
+ BasicTypeInfo.INT_TYPE_INFO,
+ BasicTypeInfo.STRING_TYPE_INFO,
+ BasicTypeInfo.DATE_TYPE_INFO
+ },
+ new String[]{
+ "id",
+ "name",
+ "birthday"
+ }
+ );
+
+ DataSource dataSource = environment.createInput(JdbcInputFormat.buildJdbcInputFormat()
+ .setDrivername("com.mysql.cj.jdbc.Driver")
+ .setDBUrl("jdbc:mysql://" + srcHost + ":" + srcPort + "/" + srcDataBase)
+ .setUsername(srcUserName)
+ .setPassword(srcPassword)
+ .setQuery("select * from person")
+ .setRowTypeInfo(rowTypeInfo)
+ .finish());
+
+ // Convert Wed Jul 12 00:00:00 CST 2023 date format to 2023-07-12
+ MapOperator mapOperator = dataSource.map((MapFunction) row -> {
+ row.setField("birthday", sdf.format(row.getField("birthday")));
+ return row;
+ });
+
+ mapOperator.print();
+ }
+ }
+ ```
+
+3. Run `MoRead.Main()` in IDEA with the following result:
+
+ 
+
+### Step Three: Write MySQL Data to MatrixOne
+
+You can now start migrating MySQL data to MatrixOne using Flink.
+
+1. Prepare MySQL data: On node3, connect to your local Mysql using the Mysql client, create the required database, data table, and insert the data:
+
+ ```sql
+ mysql -h127.0.0.1 -P3306 -uroot -proot
+ mysql> CREATE DATABASE motest;
+ mysql> USE motest;
+ mysql> CREATE TABLE `person` (`id` int DEFAULT NULL, `name` varchar(255) DEFAULT NULL, `birthday` date DEFAULT NULL);
+ mysql> INSERT INTO motest.person (id, name, birthday) VALUES(2, 'lisi', '2023-07-09'),(3, 'wangwu', '2023-07-13'),(4, 'zhaoliu', '2023-08-08');
+ ```
+
+2. Empty MatrixOne table data:
+
+ On node3, connect node1's MatrixOne using a MySQL client. Since this example continues to use the `test` database from the example that read the MatrixOne data earlier, we need to first empty the data from the `person` table.
+
+ ```sql
+ -- on node3, connect node1's MatrixOne
+ mysql -hxx.xx.xx.xx -P6001 -uroot -p111
+ mysql> TRUNCATE TABLE test.person using the Mysql client;
+ ```
+
+3. Write code in IDEA:
+
+ Create `Person.java` and `Mysql2Mo.java` classes, use Flink to read MySQL data, perform simple ETL operations (convert Row to Person object), and finally write the data to MatrixOne.
+
+```java
+package com.matrixone.flink.demo.entity;
+
+
+import java.util.Date;
+
+public class Person {
+
+ private int id;
+ private String name;
+ private Date birthday;
+
+ public int getId() {
+ return id;
+ }
+
+ public void setId(int id) {
+ this.id = id;
+ }
+
+ public String getName() {
+ return name;
+ }
+
+ public void setName(String name) {
+ this.name = name;
+ }
+
+ public Date getBirthday() {
+ return birthday;
+ }
+
+ public void setBirthday(Date birthday) {
+ this.birthday = birthday;
+ }
+}
+```
+
+```java
+package com.matrixone.flink.demo;
+
+import com.matrixone.flink.demo.entity.Person;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
+import org.apache.flink.api.java.typeutils.RowTypeInfo;
+import org.apache.flink.connector.jdbc.*;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.DataStreamSource;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
+import org.apache.flink.types.Row;
+
+import java.sql.Date;
+
+/**
+ * @author MatrixOne
+ * @description
+ */
+public class Mysql2Mo {
+
+ private static String srcHost = "127.0.0.1";
+ private static Integer srcPort = 3306;
+ private static String srcUserName = "root";
+ private static String srcPassword = "root";
+ private static String srcDataBase = "motest";
+
+ private static String destHost = "xx.xx.xx.xx";
+ private static Integer destPort = 6001;
+ private static String destUserName = "root";
+ private static String destPassword = "111";
+ private static String destDataBase = "test";
+ private static String destTable = "person";
+
+
+ public static void main(String[] args) throws Exception {
+
+ StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
+ // Set parallelism
+ environment.setParallelism(1);
+ // Set the field type of the query
+ RowTypeInfo rowTypeInfo = new RowTypeInfo(
+ new BasicTypeInfo[]{
+ BasicTypeInfo.INT_TYPE_INFO,
+ BasicTypeInfo.STRING_TYPE_INFO,
+ BasicTypeInfo.DATE_TYPE_INFO
+ },
+ new String[]{
+ "id",
+ "name",
+ "birthday"
+ }
+ );
+
+ // Add srouce
+ DataStreamSource dataSource = environment.createInput(JdbcInputFormat.buildJdbcInputFormat()
+ .setDrivername("com.mysql.cj.jdbc.Driver")
+ .setDBUrl("jdbc:mysql://" + srcHost + ":" + srcPort + "/" + srcDataBase)
+ .setUsername(srcUserName)
+ .setPassword(srcPassword)
+ .setQuery("select * from person")
+ .setRowTypeInfo(rowTypeInfo)
+ .finish());
+
+ // Conduct ETL
+ SingleOutputStreamOperator mapOperator = dataSource.map((MapFunction) row -> {
+ Person person = new Person();
+ person.setId((Integer) row.getField("id"));
+ person.setName((String) row.getField("name"));
+ person.setBirthday((java.util.Date)row.getField("birthday"));
+ return person;
+ });
+
+ // Set matrixone sink information
+ mapOperator.addSink(
+ JdbcSink.sink(
+ "insert into " + destTable + " values(?,?,?)",
+ (ps, t) -> {
+ ps.setInt(1, t.getId());
+ ps.setString(2, t.getName());
+ ps.setDate(3, new Date(t.getBirthday().getTime()));
+ },
+ new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
+ .withDriverName("com.mysql.cj.jdbc.Driver")
+ .withUrl("jdbc:mysql://" + destHost + ":" + destPort + "/" + destDataBase)
+ .withUsername(destUserName)
+ .withPassword(destPassword)
+ .build()
+ )
+ );
+
+ environment.execute();
+ }
+
+}
+```
+
+### Step Four: View Implementation Results
+
+Execute the following SQL query results in MatrixOne:
+
+```sql
+mysql> select * from test.person;
++------+---------+------------+
+| id | name | birthday |
++------+---------+------------+
+| 2 | lisi | 2023-07-09 |
+| 3 | wangwu | 2023-07-13 |
+| 4 | zhaoliu | 2023-08-08 |
++------+---------+------------+
+3 rows in set (0.01 sec)
+```
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-oracle-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-oracle-matrixone.md
new file mode 100644
index 000000000..fe5db3981
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-oracle-matrixone.md
@@ -0,0 +1,142 @@
+# Write Oracle data to MatrixOne using Flink
+
+This chapter describes how to write Oracle data to MatrixOne using Flink.
+
+## Pre-preparation
+
+This practice requires the installation and deployment of the following software environments:
+
+- Complete [standalone MatrixOne deployment](https://docs.matrixorigin.cn/1.2.2/MatrixOne/Get-Started/install-standalone-matrixone/).
+- Download and install [lntelliJ IDEA (2022.2.1 or later version)](https://www.jetbrains.com/idea/download/).
+- Select the [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html) version to download and install depending on your system environment.
+- Download and install [Flink](https://archive.apache.org/dist/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz) with a minimum supported version of 1.11.
+- Finished [installing Oracle 19c](https://www.oracle.com/database/technologies/oracle-database-software-downloads.html).
+- Download and install [MySQL](https://downloads.mysql.com/archives/get/p/23/file/mysql-server_8.0.33-1ubuntu23.04_amd64.deb-bundle.tar), the recommended version is 8.0.33.
+
+## Operational steps
+
+### Create a table in Oracle and insert data
+
+```sql
+create table flinkcdc_empt
+(
+ EMPNO NUMBER not null primary key,
+ ENAME VARCHAR2(10),
+ JOB VARCHAR2(9),
+ MGR NUMBER(4),
+ HIREDATE DATE,
+ SAL NUMBER(7, 2),
+ COMM NUMBER(7, 2),
+ DEPTNO NUMBER(2)
+)
+--Modify the FLINKCDC_EMPT table to support incremental logging
+ALTER TABLE scott.FLINKCDC_EMPT ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
+--Insert test data:
+INSERT INTO SCOTT.FLINKCDC_EMPT (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO) VALUES(1, 'TURNER', 'SALESMAN', 7698, TIMESTAMP '2022-10-31 16:21:11.000000', 1500, 0, 30);
+INSERT INTO SCOTT.FLINKCDC_EMPT (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO) VALUES(2, 'TURNER', 'SALESMAN', 7698, TIMESTAMP '2022-10-31 16:21:11.000000', 1500, 0, 30);
+INSERT INTO SCOTT.FLINKCDC_EMPT (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO) VALUES(3, 'TURNER', 'SALESMAN', 7698, TIMESTAMP '2022-10-31 16:21:11.000000', 1500, 0, 30);
+INSERT INTO SCOTT.FLINKCDC_EMPT (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO) VALUES(4, 'TURNER', 'SALESMAN', 7698, TIMESTAMP '2022-10-31 16:21:11.000000', 1500, 0, 30);
+INSERT INTO SCOTT.FLINKCDC_EMPT (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO) VALUES(5, 'TURNER', 'SALESMAN', 7698, TIMESTAMP '2022-10-31 16:21:11.000000', 1500, 0, 30);
+INSERT INTO SCOTT.FLINKCDC_EMPT (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO) VALUES(6, 'TURNER', 'SALESMAN', 7698, TIMESTAMP '2022-10-31 16:21:11.000000', 1500, 0, 30);
+INSERT INTO SCOTT.FLINKCDC_EMPT (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO) VALUES(5989, 'TURNER', 'SALESMAN', 7698, TIMESTAMP '2022-10-31 16:21:11.000000', 1500, 0, 30);
+```
+
+### Creating a Target Table in MatrixOne
+
+```SQL
+create database test;
+use test;
+CREATE TABLE `oracle_empt` (
+ `empno` bigint NOT NULL COMMENT "",
+ `ename` varchar(10) NULL COMMENT "",
+ `job` varchar(9) NULL COMMENT "",
+ `mgr` int NULL COMMENT "",
+ `hiredate` datetime NULL COMMENT "",
+ `sal` decimal(7, 2) NULL COMMENT "",
+ `comm` decimal(7, 2) NULL COMMENT "",
+ `deptno` int NULL COMMENT ""
+);
+```
+
+### Copy the jar package
+
+Copy `flink-sql-connector-oracle-cdc-2.2.1.jar`, `flink-connector-jdbc_2.11-1.13.6.jar`, `mysql-connector-j-8.0.31.jar` to `flink-1.13.6/lib/`.
+
+If flink is already started, you need to restart flink and load the effective jar package.
+
+### Switch to the flink directory and start the cluster
+
+```bash
+./bin/start-cluster.sh
+```
+
+### Start Flink SQL CLI
+
+```bash
+./bin/sql-client.sh
+```
+
+### Turn on checkpoint
+
+```bash
+SET execution.checkpointing.interval = 3s;
+```
+
+### Create source/sink table with flink ddl
+
+```sql
+-- Create source table (oracle)
+CREATE TABLE `oracle_source` (
+ EMPNO bigint NOT NULL,
+ ENAME VARCHAR(10),
+ JOB VARCHAR(9),
+ MGR int,
+ HIREDATE timestamp,
+ SAL decimal(7,2),
+ COMM decimal(7,2),
+ DEPTNO int,
+ PRIMARY KEY(EMPNO) NOT ENFORCED
+) WITH (
+ 'connector' = 'oracle-cdc',
+ 'hostname' = 'xx.xx.xx.xx',
+ 'port' = '1521',
+ 'username' = 'scott',
+ 'password' = 'tiger',
+ 'database-name' = 'ORCLCDB',
+ 'schema-name' = 'SCOTT',
+ 'table-name' = 'FLINKCDC_EMPT',
+ 'debezium.database.tablename.case.insensitive'='false',
+ 'debezium.log.mining.strategy'='online_catalog'
+ );
+-- Creating a sink table (mo)
+CREATE TABLE IF NOT EXISTS `oracle_sink` (
+ EMPNO bigint NOT NULL,
+ ENAME VARCHAR(10),
+ JOB VARCHAR(9),
+ MGR int,
+ HIREDATE timestamp,
+ SAL decimal(7,2),
+ COMM decimal(7,2),
+ DEPTNO int,
+ PRIMARY KEY(EMPNO) NOT ENFORCED
+) with (
+'connector' = 'jdbc',
+ 'url' = 'jdbc:mysql://ip:6001/test',
+ 'driver' = 'com.mysql.cj.jdbc.Driver',
+ 'username' = 'root',
+ 'password' = '111',
+ 'table-name' = 'oracle_empt'
+);
+-- Read and insert the source table data into the sink table.
+insert into `oracle_sink` select * from `oracle_source`;
+```
+
+### Query correspondence table data in MatrixOne
+
+```sql
+select * from oracle_empt;
+```
+
+
+
+
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-overview.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-overview.md
new file mode 100644
index 000000000..b75e56338
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-overview.md
@@ -0,0 +1,17 @@
+# Overview
+
+Apache Flink is a powerful framework and distributed processing engine focused on performing stateful computations for handling borderless and bounded data streams. Flink operates efficiently in a variety of common cluster environments and performs computations at memory speeds, supporting the processing of data of any size.
+
+## Application scenarios
+
+* Event Driven Applications
+
+ Event-driven applications typically have state, and they extract data from one or more event streams to trigger calculations, state updates, or other external actions based on arriving events. Typical event-driven applications include anti-fraud systems, anomaly detection, rule-based alarm systems, and business process monitoring.
+
+* Data analysis applications
+
+ The main objective of the data analysis task is to extract valuable information and indicators from raw data. Flink supports streaming and batch analysis applications for scenarios such as telecom network quality monitoring, product updates and experimental evaluation analysis in mobile applications, real-time data impromptu analysis in consumer technology, and large-scale graph analysis.
+
+* Data Pipeline Applications
+
+ Extract-Transform-Load (ETL) is a common method of data conversion and migration between different storage systems. There are similarities between data pipelines and ETL jobs, both of which can transform and enrich data and then move it from one storage system to another. The difference is that the data pipeline operates in a continuous stream mode rather than a periodic trigger. Typical data pipeline applications include real-time query index building and continuous ETL in e-commerce.
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-postgresql-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-postgresql-matrixone.md
new file mode 100644
index 000000000..9cca9fd36
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-postgresql-matrixone.md
@@ -0,0 +1,221 @@
+# Write PostgreSQL data to MatrixOne using Flink
+
+This chapter describes how to write PostgreSQL data to MatrixOne using Flink.
+
+## Pre-preparation
+
+This practice requires the installation and deployment of the following software environments:
+
+- Complete [standalone MatrixOne deployment](https://docs.matrixorigin.cn/1.2.2/MatrixOne/Get-Started/install-standalone-matrixone/).
+- Download and install [lntelliJ IDEA (2022.2.1 or later version)](https://www.jetbrains.com/idea/download/).
+- Select the [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html) version to download and install depending on your system environment.
+- Install [PostgreSQL](https://www.postgresql.org/download/).
+- Download and install [Flink](https://archive.apache.org/dist/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz) with a minimum supported version of 1.11.
+- Download and install [MySQL](https://downloads.mysql.com/archives/get/p/23/file/mysql-server_8.0.33-1ubuntu23.04_amd64.deb-bundle.tar), the recommended version is 8.0.33.
+
+## Operational steps
+
+### Download Flink CDC connector
+
+```bash
+wget https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-postgres-cdc/2.1.1/flink-sql-connector-postgres-cdc-2.1.1.jar
+```
+
+### Copy the jar package
+
+Copy the `Flink CDC connector` and the corresponding Jar packages for `flink-connector-jdbc_2.12-1.13.6.jar` and `mysql-connector-j-8.0.33.jar` to `flink-1.13.6/lib/` If flink is already started, restart flink and load the valid jar package.
+
+### Postgresql Turn on cdc configuration
+
+1. postgresql.conf Configuration
+
+ ```conf
+ #change the maximum number of wal send processes (default is 10), which is the same value as the solts setting above
+ max_wal_senders = 10 # max number of walsender processes #break replication connections that have been inactive for more than the specified number of milliseconds, you can set it appropriately a little larger (default 60s)
+ wal_sender_timeout = 180s # in milliseconds; 0 disables #change the maximum number of solts (default is 10), flink-cdc defaults to one table
+ max_replication_slots = 10 # max number of replication slots #specify as logical
+ wal_level = logical # minimal, replica, or logical
+ ```
+
+2. pg_hba.conf
+
+ ```conf
+ #IPv4 local connections:
+ host all all 0.0.0.0/0 password
+ host replication all 0.0.0.0/0 password
+ ```
+
+### Create table in postgresql and insert data
+
+```sql
+create table student
+(
+ stu_id integer not null unique,
+ stu_name varchar(50),
+ stu_age integer,
+ stu_bth date
+);
+
+INSERT into student VALUES (1,"lisa",12,'2022-10-12');
+INSERT into student VALUES (2,"tom",23,'2021-11-10');
+INSERT into student VALUES (3,"jenny",11,'2024-02-19');
+INSERT into student VALUES (4,"henry",12,'2022-04-22');
+```
+
+### Building tables in MatrixOne
+
+```sql
+create table student
+(
+ stu_id integer not null unique,
+ stu_name varchar(50),
+ stu_age integer,
+ stu_bth date
+);
+```
+
+### Start cluster
+
+Switch to the flink directory and execute the following command:
+
+```bash
+./bin/start-cluster.sh
+```
+
+### Start Flink SQL CLI
+
+```bash
+./bin/sql-client.sh
+```
+
+### Turn on checkpoint
+
+Set up checkpoint every 3 seconds
+
+```sql
+SET execution.checkpointing.interval = 3s;
+```
+
+### Create source table with flink ddl
+
+```sql
+CREATE TABLE pgsql_bog (
+ stu_id int not null,
+ stu_name varchar(50),
+ stu_age int,
+ stu_bth date,
+ primary key (stu_id) not enforced
+) WITH (
+ 'connector' = 'postgres-cdc',
+ 'hostname' = 'xx.xx.xx.xx',
+ 'port' = '5432',
+ 'username' = 'postgres',
+ 'password' = '123456',
+ 'database-name' = 'postgres',
+ 'schema-name' = 'public',
+ 'table-name' = 'student',
+ 'decoding.plugin.name' = 'pgoutput' ,
+ 'debezium.snapshot.mode' = 'initial'
+ ) ;
+```
+
+If it's table sql, pgoutput is the standard logical decode output plugin in PostgreSQL 10+. It needs to be set up. Without adding: `'decoding.plugin.name' = 'pgoutput'`, an error is reported: `org.postgresql.util.PSQLException: ERROR: could not access file "decoderbufs": No such file or directory`.
+
+### Create sink table
+
+```sql
+CREATE TABLE test_pg (
+ stu_id int not null,
+ stu_name varchar(50),
+ stu_age int,
+ stu_bth date,
+ primary key (stu_id) not enforced
+) WITH (
+'connector' = 'jdbc',
+'url' = 'jdbc:mysql://xx.xx.xx.xx:6001/postgre',
+'driver' = 'com.mysql.cj.jdbc.Driver',
+'username' = 'root',
+'password' = '111',
+'table-name' = 'student'
+);
+```
+
+### Importing PostgreSQL data into MatrixOne
+
+```sql
+insert into test_pg select * from pgsql_bog;
+```
+
+Query the corresponding table data in MatrixOne;
+
+```sql
+mysql> select * from student;
++--------+----------+---------+------------+
+| stu_id | stu_name | stu_age | stu_bth |
++--------+----------+---------+------------+
+| 1 | lisa | 12 | 2022-10-12 |
+| 2 | tom | 23 | 2021-11-10 |
+| 3 | jenny | 11 | 2024-02-19 |
+| 4 | henry | 12 | 2022-04-22 |
++--------+----------+---------+------------+
+4 rows in set (0.00 sec)
+```
+
+Data can be found to have been imported
+
+### Adding data to postgrsql
+
+```sql
+insert into public.student values (51, '58', 39, '2020-01-03');
+```
+
+Query the corresponding table data in MatrixOne;
+
+```sql
+mysql> select * from student;
++--------+----------+---------+------------+
+| stu_id | stu_name | stu_age | stu_bth |
++--------+----------+---------+------------+
+| 1 | lisa | 12 | 2022-10-12 |
+| 2 | tom | 23 | 2021-11-10 |
+| 3 | jenny | 11 | 2024-02-19 |
+| 4 | henry | 12 | 2022-04-22 |
+| 51 | 58 | 39 | 2020-01-03 |
++--------+----------+---------+------------+
+5 rows in set (0.01 sec)
+```
+
+You can find that the data has been synchronized to the MatrixOne correspondence table.
+
+To delete data:
+
+```sql
+delete from public.student where stu_id=1;
+```
+
+If something goes wrong,
+
+```sql
+cannot delete from table "student" because it does not have a replica identity and publishes deletes
+```
+
+then execute
+
+```sql
+alter table public.student replica identity full;
+```
+
+Query the corresponding table data in MatrixOne;
+
+```sql
+mysql> select * from student;
++--------+----------+---------+------------+
+| stu_id | stu_name | stu_age | stu_bth |
++--------+----------+---------+------------+
+| 2 | tom | 23 | 2021-11-10 |
+| 3 | jenny | 11 | 2024-02-19 |
+| 4 | henry | 12 | 2022-04-22 |
+| 51 | 58 | 39 | 2020-01-03 |
++--------+----------+---------+------------+
+4 rows in set (0.00 sec)
+```
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-sqlserver-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-sqlserver-matrixone.md
new file mode 100644
index 000000000..3758338aa
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-sqlserver-matrixone.md
@@ -0,0 +1,262 @@
+# Write SQL Server data to MatrixOne using Flink
+
+This chapter describes how to write SQL Server data to MatrixOne using Flink.
+
+## Pre-preparation
+
+This practice requires the installation and deployment of the following software environments:
+
+- Complete [standalone MatrixOne deployment](https://docs.matrixorigin.cn/1.2.2/MatrixOne/Get-Started/install-standalone-matrixone/).
+- Download and install [lntelliJ IDEA (2022.2.1 or later version)](https://www.jetbrains.com/idea/download/).
+- Select the [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html) version to download and install depending on your system environment.
+- Download and install [Flink](https://archive.apache.org/dist/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz) with a minimum supported version of 1.11.
+- Completed [SQL Server 2022](https://www.microsoft.com/en-us/sql-server/sql-server-downloads).
+- Download and install [MySQL](https://downloads.mysql.com/archives/get/p/23/file/mysql-server_8.0.33-1ubuntu23.04_amd64.deb-bundle.tar), the recommended version is 8.0.33.
+
+## Operational steps
+
+### Create libraries, tables, and insert data in SQL Server
+
+```sql
+create database sstomo;
+use sstomo;
+create table sqlserver_data (
+ id INT PRIMARY KEY,
+ name NVARCHAR(100),
+ age INT,
+ entrytime DATE,
+ gender NVARCHAR(2)
+);
+
+insert into sqlserver_data (id, name, age, entrytime, gender)
+values (1, 'Lisa', 25, '2010-10-12', '0'),
+ (2, 'Liming', 26, '2013-10-12', '0'),
+ (3, 'asdfa', 27, '2022-10-12', '0'),
+ (4, 'aerg', 28, '2005-10-12', '0'),
+ (5, 'asga', 29, '2015-10-12', '1'),
+ (6, 'sgeq', 30, '2010-10-12', '1');
+```
+
+### SQL Server Configuration CDC
+
+1. Verify that the current user has sysadmin privileges turned on Queries for the current user permissions. The CDC (Change Data Capture) feature must be enabled for the database to be a member of the sysadmin fixed server role. query the sa user for sysadmin by the following command
+
+ ```sql exec sp_helpsrvrolemember 'sysadmin';```
+
+
+
+
+
+2. Queries if the current database has CDC (Change Data Capture Capability) enabled
+
+
+
+
+
+ Remarks: 0: means not enabled; 1: means enabled
+
+ If not, execute the following sql open:
+
+ ```sql
+ use sstomo; exec sys.sp_cdc_enable_db;
+ ```
+
+3. Query whether the table has CDC (Change Data Capture) enabled
+
+ ```sql
+ select name,is_tracked_by_cdc from sys.tables where name = 'sqlserver_data';
+ ```
+
+
+
+
+
+ Remarks: 0: means not enabled; 1: means enabled If not, execute the following sql to turn it on:
+
+ ```sql
+ use sstomo;
+ exec sys.sp_cdc_enable_table
+ @source_schema = 'dbo',
+ @source_name = 'sqlserver_data',
+ @role_name = NULL,
+ @supports_net_changes = 0;
+ ```
+
+4. Table sqlserver_data Start CDC (Change Data Capture) Feature Configuration Completed
+
+ Looking at the system tables under the database, you will see more cdc-related data tables, where cdc.dbo_sqlserver_flink_CT is the record of all DML operations that record the source tables, each corresponding to an instance table.
+
+
+
+
+
+5. Verify that the CDC agent starts properly
+
+ Execute the following command to see if the CDC agent is on:
+
+ ```sql
+ exec master.dbo.xp_servicecontrol N'QUERYSTATE', N'SQLSERVERAGENT';
+ ```
+
+ If the status is `Stopped`, you need to turn on the CDC agent.
+
+
+
+
+
+ Open the CDC agent in a Windows environment: On the machine where the SqlServer database is installed, open Microsoft Sql Server Managememt Studio, right-click the following image location (SQL Server agent), and click Open, as shown below:
+
+
+
+
+
+ Once on, query the agent status again to confirm that the status has changed to running
+
+
+
+
+
+ At this point, the table sqlserver_data starts the CDC (Change Data Capture) function all complete.
+
+### Creating target libraries and tables in MatrixOne
+
+```sql
+create database sstomo;
+use sstomo;
+CREATE TABLE sqlserver_data (
+ id int NOT NULL,
+ name varchar(100) DEFAULT NULL,
+ age int DEFAULT NULL,
+ entrytime date DEFAULT NULL,
+ gender char(1) DEFAULT NULL,
+ PRIMARY KEY (id)
+);
+```
+
+### Start flink
+
+1. Copy the cdc jar package
+
+ Copy `link-sql-connector-sqlserver-cdc-2.3.0.jar`, `flink-connector-jdbc_2.12-1.13.6.jar`, `mysql-connector-j-8.0.33.jar` to the lib directory of flink.
+
+2. Start flink
+
+ Switch to the flink directory and start the cluster
+
+ ```bash
+ ./bin/start-cluster.sh
+ ```
+
+ Start Flink SQL CLIENT
+
+ ```bash
+ ./bin/sql-client.sh
+ ```
+
+3. Turn on checkpoint
+
+ ```bash
+ SET execution.checkpointing.interval = 3s;
+ ```
+
+### Create source/sink table with flink ddl
+
+```sql
+-- Create source table
+CREATE TABLE sqlserver_source (
+id INT,
+name varchar(50),
+age INT,
+entrytime date,
+gender varchar(100),
+PRIMARY KEY (`id`) not enforced
+) WITH(
+'connector' = 'sqlserver-cdc',
+'hostname' = 'xx.xx.xx.xx',
+'port' = '1433',
+'username' = 'sa',
+'password' = '123456',
+'database-name' = 'sstomo',
+'schema-name' = 'dbo',
+'table-name' = 'sqlserver_data');
+
+-- Creating a sink table
+CREATE TABLE sqlserver_sink (
+id INT,
+name varchar(100),
+age INT,
+entrytime date,
+gender varchar(10),
+PRIMARY KEY (`id`) not enforced
+) WITH(
+'connector' = 'jdbc',
+'url' = 'jdbc:mysql://xx.xx.xx.xx:6001/sstomo',
+'driver' = 'com.mysql.cj.jdbc.Driver',
+'username' = 'root',
+'password' = '111',
+'table-name' = 'sqlserver_data'
+);
+
+-- Read and insert the source table data into the sink table.
+Insert into sqlserver_sink select * from sqlserver_source;
+```
+
+### Query correspondence table data in MatrixOne
+
+```sql
+use sstomo;
+select * from sqlserver_data;
+```
+
+
+
+
+
+### Inserting data to SQL Server
+
+Insert 3 pieces of data into the SqlServer table sqlserver_data:
+
+```sql
+insert into sstomo.dbo.sqlserver_data (id, name, age, entrytime, gender)
+values (7, 'Liss12a', 25, '2010-10-12', '0'),
+ (8, '12233s', 26, '2013-10-12', '0'),
+ (9, 'sgeq1', 304, '2010-10-12', '1');
+```
+
+Query corresponding table data in MatrixOne:
+
+```sql
+select * from sstomo.sqlserver_data;
+```
+
+
+
+
+
+### Deleting incremental data in SQL Server
+
+Delete two rows with ids 3 and 4 in SQL Server:
+
+```sql
+delete from sstomo.dbo.sqlserver_data where id in(3,4);
+```
+
+Query table data in mo, these two rows have been deleted synchronously:
+
+
+
+
+
+### Adding new data to SQL Server
+
+Update two rows of data in a SqlServer table:
+
+```sql
+update sstomo.dbo.sqlserver_data set age = 18 where id in(1,2);
+```
+
+Query table data in MatrixOne, the two rows have been updated in sync:
+
+
+
+
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-tidb-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-tidb-matrixone.md
new file mode 100644
index 000000000..fa1fe0418
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-tidb-matrixone.md
@@ -0,0 +1,157 @@
+# Write TiDB data to MatrixOne using Flink
+
+This chapter describes how to write TiDB data to MatrixOne using Flink.
+
+## Pre-preparation
+
+This practice requires the installation and deployment of the following software environments:
+
+- Complete [standalone MatrixOne deployment](https://docs.matrixorigin.cn/1.2.2/MatrixOne/Get-Started/install-standalone-matrixone/).
+- Download and install [lntelliJ IDEA (2022.2.1 or later version)](https://www.jetbrains.com/idea/download/).
+- Select the [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html) version to download and install depending on your system environment.
+- TiDB standalone deployment completed.
+- Download and install [Flink](https://archive.apache.org/dist/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz) with a minimum supported version of 1.11.
+- Download and install [MySQL](https://downloads.mysql.com/archives/get/p/23/file/mysql-server_8.0.33-1ubuntu23.04_amd64.deb-bundle.tar), the recommended version is 8.0.33.
+- Download [Flink CDC connector](https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-tidb-cdc/2.2.1/flink-sql-connector-tidb-cdc-2.2.1.jar)
+
+## Operational steps
+
+### Copy the jar package
+
+Copy the `Flink CDC connector` and the corresponding Jar packages for `flink-connector-jdbc_2.12-1.13.6.jar` and `mysql-connector-j-8.0.33.jar` to `flink-1.13.6/lib/`.
+
+If flink is already started, you need to restart flink and load the effective jar package.
+
+### Create a table in TiDB and insert data
+
+```sql
+create table EMPQ_cdc
+(
+ empno bigint not null,
+ ename VARCHAR(10),
+ job VARCHAR(9),
+ mgr int,
+ hiredate DATE,
+ sal decimal(7,2),
+ comm decimal(7,2),
+ deptno int(2),
+ primary key (empno)
+)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
+
+INSERT into empq VALUES (1,"张三","sale",1,'2024-01-01',1000,NULL,1);
+INSERT into empq VALUES (2,"李四","develo,"2,'2024-03-05',5000,NULL,2);
+INSERT into empq VALUES (3,"王五","hr",3,'2024-03-18',2000,NULL,2);
+INSERT into empq VALUES (4,"赵六","pm",4,'2024-03-11',2000,NULL,3);
+```
+
+### Creating a Target Table in MatrixOne
+
+```sql
+create table EMPQ
+(
+ empno bigint not null,
+ ename VARCHAR(10),
+ job VARCHAR(9),
+ mgr int,
+ hiredate DATE,
+ sal decimal(7,2),
+ comm decimal(7,2),
+ deptno int(2),
+ primary key (empno)
+);
+```
+
+### Switch to the flink directory and start the cluster
+
+```bash
+./bin/start-cluster.sh
+```
+
+### Start Flink SQL CLI
+
+```bash
+./bin/sql-client.sh
+```
+
+### Turn on checkpoint
+
+```sql
+SET execution.checkpointing.interval = 3s;
+```
+
+### Create source and sink tables using flink ddl
+
+The build table statement is in smt/result/flink-create.all.sql.
+
+```sql
+-- Creating Test Libraries
+CREATE DATABASE IF NOT EXISTS `default_catalog`.`test`;
+
+-- Create source table
+CREATE TABLE IF NOT EXISTS `default_catalog`.`test`.`EMPQ_src` (
+`empno` BIGINT NOT NULL,
+`ename` STRING NULL,
+`job` STRING NULL,
+`mgr` INT NULL,
+`hiredate` DATE NULL,
+`sal` DECIMAL(7, 2) NULL,
+`comm` DECIMAL(7, 2) NULL,
+`deptno` INT NULL,
+PRIMARY KEY(`empno`) NOT ENFORCED
+) with (
+ 'connector' = 'tidb-cdc',
+ 'database-name' = 'test',
+ 'table-name' = 'EMPQ_cdc',
+ 'pd-addresses' = 'xx.xx.xx.xx:2379'
+);
+
+-- Creating a sink table
+CREATE TABLE IF NOT EXISTS `default_catalog`.`test`.`EMPQ_sink` (
+`empno` BIGINT NOT NULL,
+`ename` STRING NULL,
+`job` STRING NULL,
+`mgr` INT NULL,
+`hiredate` DATE NULL,
+`sal` DECIMAL(7, 2) NULL,
+`comm` DECIMAL(7, 2) NULL,
+`deptno` INT NULL,
+PRIMARY KEY(`empno`) NOT ENFORCED
+) with (
+'connector' = 'jdbc',
+'url' = 'jdbc:mysql://xx.xx.xx.xx:6001/test',
+'driver' = 'com.mysql.cj.jdbc.Driver',
+'username' = 'root',
+'password' = '111',
+'table-name' = 'empq'
+);
+```
+
+### Importing TiDB data into MatrixOne
+
+```sql
+INSERT INTO `default_catalog`.`test`.`EMPQ_sink` SELECT * FROM `default_catalog`.`test`.`EMPQ_src`;
+```
+
+### Query correspondence table data in Matrixone
+
+```sql
+select * from EMPQ;
+```
+
+
+
+
+
+Data can be found to have been imported
+
+### Delete a piece of data in TiDB
+
+```sql
+delete from EMPQ_cdc where empno=1;
+```
+
+
+
+
+
+Query table data in MatrixOne, this row has been deleted synchronously.
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark.md
deleted file mode 100644
index 87a3a026b..000000000
--- a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark.md
+++ /dev/null
@@ -1,460 +0,0 @@
-# Writing Data to MatrixOne Using Spark
-
-## Overview
-
-Apache Spark is a distributed computing engine designed to process large-scale data efficiently. It employs distributed parallel computing to distribute tasks like data splitting, computation, and merging across multiple machines, thereby achieving efficient data processing and analysis.
-
-### Scenarios
-
-- Large-Scale Data Processing and Analysis
-
- Spark can handle massive volumes of data, improving processing efficiency through parallel computing tasks. It is widely used in data processing and analysis in various sectors like finance, telecommunications, healthcare, and more.
-
-- Stream Data Processing
-
- Spark Streaming allows real-time data stream processing, transforming it into batch-processing data for analysis and storage. This is particularly valuable in real-time data analysis scenarios like online advertising and network security.
-
-- Machine Learning
-
- Spark provides a machine learning library (MLlib) supporting various machine learning algorithms and model training for applications such as recommendation systems and image recognition.
-
-- Graph Computing
-
- Spark's graph computing library (GraphX) supports various graph computing algorithms, making it suitable for graph analysis scenarios like social network analysis and recommendation systems.
-
-This document introduces two examples of using the Spark computing engine to write bulk data into MatrixOne. One example covers migrating data from MySQL to MatrixOne, and the other involves writing Hive data into MatrixOne.
-
-## Before you start
-
-### Hardware Environment
-
-The hardware requirements for this practice are as follows:
-
-| Server Name | Server IP | Installed Software | Operating System |
-| ----------- | -------------- | ------------------------ | ----------------- |
-| node1 | 192.168.146.10 | MatrixOne | Debian11.1 x86 |
-| node3 | 192.168.146.11 | IDEA, MYSQL, Hadoop, Hive | Windows 10 |
-
-### Software Environment
-
-This practice requires the installation and deployment of the following software environments:
-
-- Install and start MatrixOne by following the steps in [Install standalone MatrixOne](../../../Get-Started/install-standalone-matrixone.md).
-- Download and install [IntelliJ IDEA version 2022.2.1 or higher](https://www.jetbrains.com/idea/download/).
-- Download and install [JDK 8+](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html).
-- If you need to import data from Hive, you need to install [Hadoop](http://archive.apache.org/dist/hadoop/core/hadoop-3.1.4/) and [Hive](https://dlcdn.apache.org/hive/hive-3.1.3/).
-- Download and install the [MySQL Client 8.0.33](https://downloads.mysql.com/archives/get/p/23/file/mysql-server_8.0.33-1ubuntu23.04_amd64.deb-bundle.tar).
-
-## Example 1: Migrating Data from MySQL to MatrixOne
-
-### Step 1: Initialize the Project
-
-1. Start IDEA, click **File > New > Project**, select **Spring Initializer**, and fill in the following configuration parameters:
-
- - **Name**:mo-spark-demo
- - **Location**:~\Desktop
- - **Language**:Java
- - **Type**:Maven
- - **Group**:com.example
- - **Artiface**:matrixone-spark-demo
- - **Package name**:com.matrixone.demo
- - **JDK** 1.8
-
- 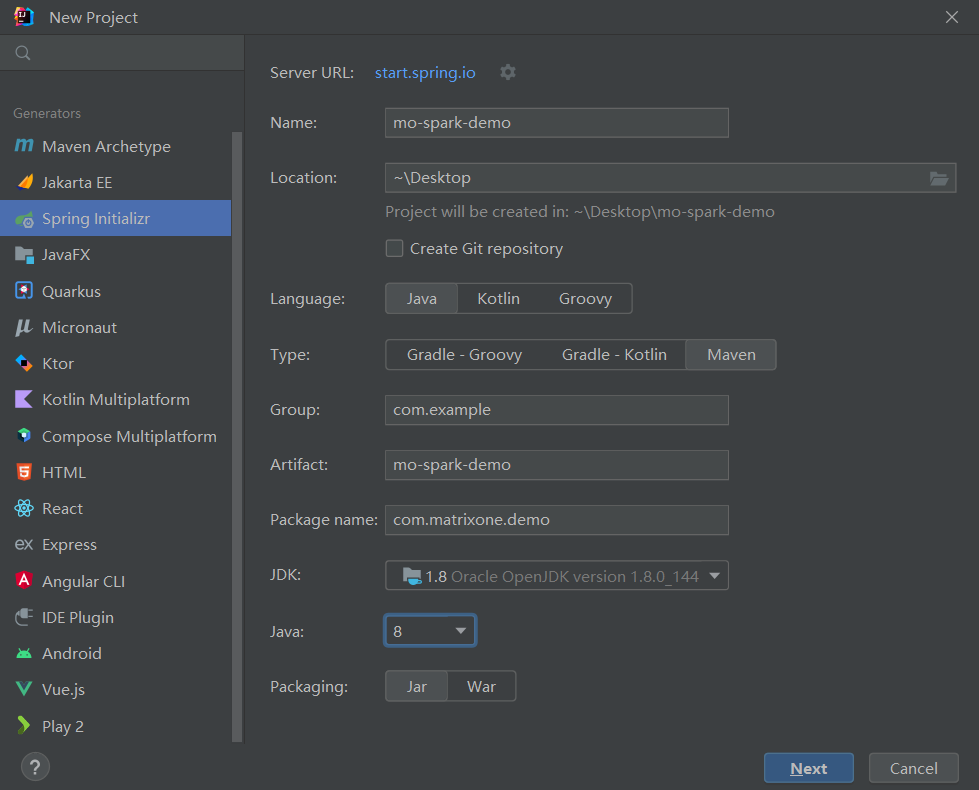
-
-2. Add project dependencies and edit the content of `pom.xml` in the project root directory as follows:
-
-```xml
-
-
- 4.0.0
-
- com.example.mo
- mo-spark-demo
- 1.0-SNAPSHOT
-
-
- 8
- 8
- 3.2.1
-
-
-
-
- org.apache.spark
- spark-sql_2.12
- ${spark.version}
-
-
-
- org.apache.spark
- spark-hive_2.12
- ${spark.version}
-
-
- org.apache.spark
- spark-catalyst_2.12
- ${spark.version}
-
-
- org.apache.spark
- spark-core_2.12
- ${spark.version}
-
-
- org.codehaus.jackson
- jackson-core-asl
- 1.9.13
-
-
- org.codehaus.jackson
- jackson-mapper-asl
- 1.9.13
-
-
-
-
- mysql
- mysql-connector-java
- 8.0.16
-
-
-
-
-
-```
-
-### Step 2: Read MatrixOne Data
-
-After connecting to MatrixOne using the MySQL client, create the necessary database and data tables for the demonstration.
-
-1. Create a database, tables and import data in MatrixOne:
-
- ```sql
- CREATE DATABASE test;
- USE test;
- CREATE TABLE `person` (`id` INT DEFAULT NULL, `name` VARCHAR(255) DEFAULT NULL, `birthday` DATE DEFAULT NULL);
- INSERT INTO test.person (id, name, birthday) VALUES(1, 'zhangsan', '2023-07-09'),(2, 'lisi', '2023-07-08'),(3, 'wangwu', '2023-07-12');
- ```
-
-2. In IDEA, create the `MoRead.java` class to read MatrixOne data using Spark:
-
- ```java
- package com.matrixone.spark;
-
- import org.apache.spark.sql.Dataset;
- import org.apache.spark.sql.Row;
- import org.apache.spark.sql.SQLContext;
- import org.apache.spark.sql.SparkSession;
-
- import java.util.Properties;
-
- /**
- * @auther MatrixOne
- * @desc read the MatrixOne data
- */
- public class MoRead {
-
- // parameters
- private static String master = "local[2]";
- private static String appName = "mo_spark_demo";
-
- private static String srcHost = "192.168.146.10";
- private static Integer srcPort = 6001;
- private static String srcUserName = "root";
- private static String srcPassword = "111";
- private static String srcDataBase = "test";
- private static String srcTable = "person";
-
- public static void main(String[] args) {
- SparkSession sparkSession = SparkSession.builder().appName(appName).master(master).getOrCreate();
- SQLContext sqlContext = new SQLContext(sparkSession);
- Properties properties = new Properties();
- properties.put("user", srcUserName);
- properties.put("password", srcPassword);
- Dataset dataset = sqlContext.read()
- .jdbc("jdbc:mysql://" + srcHost + ":" + srcPort + "/" + srcDataBase,srcTable, properties);
- dataset.show();
- }
-
- }
- ```
-
-3. Run `MoRead.Main()` in IDEA, the result is as below:
-
- 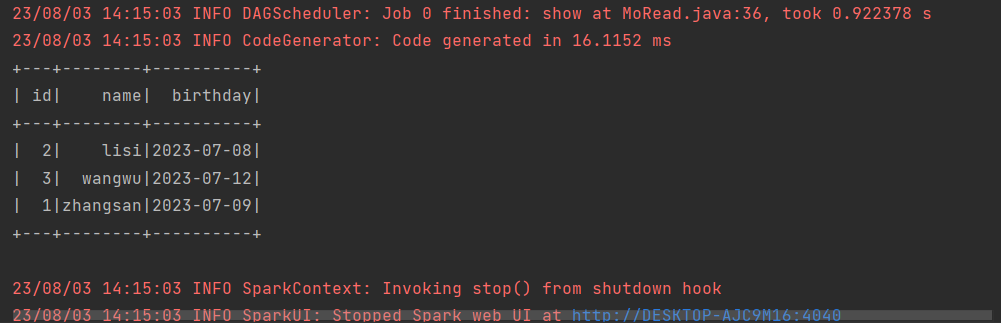
-
-### Step 3: Write MySQL Data to MatrixOne
-
-Now, you can begin migrating MySQL data to MatrixOne using Spark.
-
-1. Prepare MySQL data: On node3, use the MySQL client to connect to the local MySQL instance. Create the necessary database, tables, and insert data:
-
- ```sql
- mysql -h127.0.0.1 -P3306 -uroot -proot
- mysql> CREATE DATABASE test;
- mysql> USE test;
- mysql> CREATE TABLE `person` (`id` int DEFAULT NULL, `name` varchar(255) DEFAULT NULL, `birthday` date DEFAULT NULL);
- mysql> INSERT INTO test.person (id, name, birthday) VALUES(2, 'lisi', '2023-07-09'),(3, 'wangwu', '2023-07-13'),(4, 'zhaoliu', '2023-08-08');
- ```
-
-2. Clear MatrixOne table data:
-
- On node3, use the MySQL client to connect to the local MatrixOne instance. Since this example continues to use the `test` database from the previous MatrixOne data reading example, you need to clear the data from the `person` table first.
-
- ```sql
- -- On node3, use the MySQL client to connect to the local MatrixOne
- mysql -h192.168.146.10 -P6001 -uroot -p111
- mysql> TRUNCATE TABLE test.person;
- ```
-
-3. Write code in IDEA:
-
- Create the `Person.java` and `Mysql2Mo.java` classes to use Spark to read MySQL data. Refer to the following example for the `Mysql2Mo.java` class code:
-
-```java
-// Import necessary libraries
-import org.apache.spark.api.java.function.MapFunction;
-import org.apache.spark.sql.*;
-
-public class Mysql2Mo {
-
- // Define parameters
- private static String master = "local[2]";
- private static String appName = "app_spark_demo";
-
- private static String srcHost = "127.0.0.1";
- private static Integer srcPort = 3306;
- private static String srcUserName = "root";
- private static String srcPassword = "root";
- private static String srcDataBase = "motest";
- private static String srcTable = "person";
-
- private static String destHost = "192.168.146.10";
- private static Integer destPort = 6001;
- private static String destUserName = "root";
- private static String destPassword = "111";
- private static String destDataBase = "test";
- private static String destTable = "person";
-
- public static void main(String[] args) throws SQLException {
- SparkSession sparkSession = SparkSession.builder().appName(appName).master(master).getOrCreate();
- SQLContext sqlContext = new SQLContext(sparkSession);
- Properties connectionProperties = new Properties();
- connectionProperties.put("user", srcUserName);
- connectionProperties.put("password", srcPassword);
- connectionProperties.put("driver", "com.mysql.cj.jdbc.Driver");
-
- // Define the JDBC URL
- String url = "jdbc:mysql://" + srcHost + ":" + srcPort + "/" + srcDataBase + "?characterEncoding=utf-8&autoReconnect=true&zeroDateTimeBehavior=convertToNull&useSSL=false&serverTimezone=Asia/Shanghai";
-
- // Read table contents using Spark JDBC
- System.out.println("Reading data from the 'person' table in the database");
- Dataset rowDataset = sqlContext.read().jdbc(url, srcTable, connectionProperties).select("*");
-
- // Apply transformations to the data (filter records where id > 2 and add 'spark_' prefix to 'name' field)
- Dataset dataset = rowDataset.filter("id > 2")
- .map((MapFunction) row -> RowFactory.create(row.getInt(0), "spark_" + row.getString(1), row.getDate(2)), RowEncoder.apply(rowDataset.schema()));
-
- // Specify connection properties for writing the data
- Properties properties = new Properties();
- properties.put("user", destUserName);
- properties.put("password", destPassword);
- dataset.write()
- .mode(SaveMode.Append)
- .jdbc("jdbc:mysql://" + destHost + ":" + destPort + "/" + destDataBase, destTable, properties);
- }
-}
-```
-
-In the above code, a simple ETL operation is performed (filtering data where id > 2 and adding the prefix "spark_" to the 'name' field) and the processed data is written to the MatrixOne database.
-
-### Step 4: View the Execution Results
-
-Execute the following SQL in MatrixOne to view the execution results:
-
-```sql
-select * from test.person;
-+------+---------------+------------+
-| id | name | birthday |
-+------+---------------+------------+
-| 3 | spark_wangwu | 2023-07-12 |
-| 4 | spark_zhaoliu | 2023-08-07 |
-+------+---------------+------------+
-2 rows in set (0.01 sec)
-```
-
-## Example 2: Importing Hive Data into MatrixOne
-
-### Step 1: Initialize the Project
-
-1. Launch IDEA and click **File > New > Project**. Select **Spring Initializer** and fill in the following configuration parameters:
-
- - **Name**: mo-spark-demo
- - **Location**: ~\Desktop
- - **Language**: Java
- - **Type**: Maven
- - **Group**: com.example
- - **Artifact**: matrixone-spark-demo
- - **Package name**: com.matrixone.demo
- - **JDK**: 1.8
-
- 
-
-2. Add project dependencies. Edit the contents of the `pom.xml` file in the project's root directory as follows:
-
-```xml
-
-
- 4.0.0
-
- com.example.mo
- mo-spark-demo
- 1.0-SNAPSHOT
-
-
- 8
- 8
- 3.2.1
-
-
-
-
- org.apache.spark
- spark-sql_2.12
- ${spark.version}
-
-
-
- org.apache.spark
- spark-hive_2.12
- ${spark.version}
-
-
- org.apache.spark
- spark-catalyst_2.12
- ${spark.version}
-
-
- org.apache.spark
- spark-core_2.12
- ${spark.version}
-
-
- org.codehaus.jackson
- jackson-core-asl
- 1.9.13
-
-
- org.codehaus.jackson
- jackson-mapper-asl
- 1.9.13
-
-
-
-
- mysql
- mysql-connector-java
- 8.0.16
-
-
-
-
-
-```
-
-### Step 2: Prepare Hive Data
-
-Execute the following commands in a terminal window to create a Hive database, data table, and insert data:
-
-```sql
-hive
-hive> create database motest;
-hive> CREATE TABLE `users`(
- `id` int,
- `name` varchar(255),
- `age` int);
-hive> INSERT INTO motest.users (id, name, age) VALUES(1, 'zhangsan', 12),(2, 'lisi', 17),(3, 'wangwu', 19);
-```
-
-### Step 3: Create MatrixOne Data Table
-
-Connect to the local MatrixOne using the MySQL client on node3. Continue using the previously created "test" database and create a new data table called "users."
-
-```sql
-CREATE TABLE `users` (
-`id` INT DEFAULT NULL,
-`name` VARCHAR(255) DEFAULT NULL,
-`age` INT DEFAULT NULL
-)
-```
-
-### Step 4: Copy Configuration Files
-
-Copy the following three configuration files from the Hadoop root directory, "etc/hadoop/core-site.xml" and "hdfs-site.xml," and from the Hive root directory, "conf/hive-site.xml," to the "resource" directory of your project.
-
-
-
-### Step 5: Write Code
-
-In IntelliJ IDEA, create a class named "Hive2Mo.java" to read data from Hive using Spark and write it to MatrixOne.
-
-```java
-package com.matrixone.spark;
-
-import org.apache.spark.sql.*;
-
-import java.sql.SQLException;
-import java.util.Properties;
-
-public class Hive2Mo {
-
- // Parameters
- private static String master = "local[2]";
- private static String appName = "app_spark_demo";
-
- private static String destHost = "192.168.146.10";
- private static Integer destPort = 6001;
- private static String destUserName = "root";
- private static String destPassword = "111";
- private static String destDataBase = "test";
- private static String destTable = "users";
-
- public static void main(String[] args) throws SQLException {
- SparkSession sparkSession = SparkSession.builder()
- .appName(appName)
- .master(master)
- .enableHiveSupport()
- .getOrCreate();
-
- System.out.println("Reading data from the Hive table");
- Dataset rowDataset = sparkSession.sql("select * from motest.users");
- Properties properties = new Properties();
- properties.put("user", destUserName);
- properties.put("password", destPassword);
- rowDataset.write()
- .mode(SaveMode.Append)
- .jdbc("jdbc:mysql://" + destHost + ":" + destPort + "/" + destDataBase, destTable, properties);
- }
-}
-```
-
-### Step 6: View the Execution Result
-
-Execute the following SQL in MatrixOne to view the execution result.
-
-```sql
-mysql> select * from test.users;
-+------+----------+------+
-| id | name | age |
-+------+----------+------+
-| 1 | zhangsan | 12 |
-| 2 | lisi | 17 |
-| 3 | wangwu | 19 |
-+------+----------+------+
-3 rows in set (0.00 sec)
-```
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-doris-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-doris-matrixone.md
new file mode 100644
index 000000000..400e538fb
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-doris-matrixone.md
@@ -0,0 +1,307 @@
+# Migrating data from Doris to MatrixOne with Spark
+
+In this chapter, we will cover the implementation of Doris bulk data writing to MatrixOne using the Spark calculation engine.
+
+## Pre-preparation
+
+This practice requires the installation and deployment of the following software environments:
+
+- Finished [installing and starting](https://docs.matrixorigin.cn/1.2.2/MatrixOne/Get-Started/install-standalone-matrixone/) MatrixOne.
+- Download and install [Doris](https://doris.apache.org/zh-CN/docs/dev/get-starting/quick-start/).
+- Download and install [IntelliJ IDEA version 2022.2.1 and above](https://www.jetbrains.com/idea/download/).
+- Download and install [JDK 8+](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html).
+- Download and install [MySQL Client 8.0.33](https://downloads.mysql.com/archives/get/p/23/file/mysql-server_8.0.33-1ubuntu23.04_amd64.deb-bundle.tar).
+
+## Operational steps
+
+### Step one: Prepare data in Doris
+
+```sql
+create database test;
+
+use test;
+
+CREATE TABLE IF NOT EXISTS example_tbl
+(
+ user_id BIGINT NOT NULL COMMENT "用户id",
+ date DATE NOT NULL COMMENT "数据灌入日期时间",
+ city VARCHAR(20) COMMENT "用户所在城市",
+ age SMALLINT COMMENT "用户年龄",
+ sex TINYINT COMMENT "用户性别"
+)
+DUPLICATE KEY(user_id, date)
+DISTRIBUTED BY HASH(user_id) BUCKETS 1
+PROPERTIES (
+ "replication_num"="1"
+);
+
+insert into example_tbl values
+(10000,'2017-10-01','北京',20,0),
+(10000,'2017-10-01','北京',20,0),
+(10001,'2017-10-01','北京',30,1),
+(10002,'2017-10-02','上海',20,1),
+(10003,'2017-10-02','广州',32,0),
+(10004,'2017-10-01','深圳',35,0),
+(10004,'2017-10-03','深圳',35,0);
+```
+
+### Step Two: Prepare Library Tables in MatrixOne
+
+```sql
+create database sparkdemo;
+use sparkdemo;
+
+CREATE TABLE IF NOT EXISTS example_tbl
+(
+ user_id BIGINT NOT NULL COMMENT "用户id",
+ date DATE NOT NULL COMMENT "数据灌入日期时间",
+ city VARCHAR(20) COMMENT "用户所在城市",
+ age SMALLINT COMMENT "用户年龄",
+ sex TINYINT COMMENT "用户性别"
+);
+```
+
+### Step Three: Initialize the Project
+
+Start IDEA and create a new Maven project, add the project dependencies, and the pom.xml file is as follows:
+
+```xml
+
+
+ 4.0.0
+
+ com.example.mo
+ mo-spark-demo
+ 1.0-SNAPSHOT
+
+
+ 8
+ 8
+ 3.2.1
+ 8
+
+
+
+
+ org.apache.doris
+ spark-doris-connector-3.1_2.12
+ 1.2.0
+
+
+
+ org.apache.spark
+ spark-sql_2.12
+ ${spark.version}
+
+
+
+ org.apache.spark
+ spark-hive_2.12
+ ${spark.version}
+
+
+ org.apache.spark
+ spark-catalyst_2.12
+ ${spark.version}
+
+
+ org.apache.spark
+ spark-core_2.12
+ ${spark.version}
+
+
+ org.codehaus.jackson
+ jackson-core-asl
+ 1.9.13
+
+
+ org.codehaus.jackson
+ jackson-mapper-asl
+ 1.9.13
+
+
+
+
+ mysql
+ mysql-connector-java
+ 8.0.30
+
+
+
+
+
+
+ org.apache.maven.plugins
+ maven-compiler-plugin
+ 3.8.0
+
+ ${java.version}
+ ${java.version}
+ UTF-8
+
+
+
+
+ org.scala-tools
+ maven-scala-plugin
+
+ 2.12.16
+
+ 2.15.1
+
+
+ compile-scala
+
+ add-source
+ compile
+
+
+
+
+ -dependencyfile
+ ${project.build.directory}/.scala_dependencies
+
+
+
+
+
+
+
+ maven-assembly-plugin
+
+
+ jar-with-dependencies
+
+
+
+
+ make-assembly
+ package
+
+ single
+
+
+
+
+
+
+
+
+```
+
+### Step Four: Write Doris data to MatrixOne
+
+1. Writing code
+
+ Create a Doris2Mo.java class that reads Doris data through Spark and writes it to MatrixOne:
+
+ ```java
+ package org.example;
+
+ import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; import org.apache.spark.sql.SaveMode; import org.apache.spark.sql.SparkSession;
+
+ import java.sql.SQLException;
+
+ /\** * @auther MatrixOne * @desc \*/ public class Doris2Mo { public static void main(String\[] args) throws SQLException { SparkSession spark = SparkSession .builder() .appName("Spark Doris to MatixOne") .master("local") .getOrCreate();
+
+ Dataset df = spark.read().format("doris").option("doris.table.identifier", "test.example_tbl")
+ .option("doris.fenodes", "192.168.110.11:8030")
+ .option("user", "root")
+ .option("password", "root")
+ .load();
+
+ // JDBC properties for MySQL
+ java.util.Properties mysqlProperties = new java.util.Properties();
+ mysqlProperties.setProperty("user", "root");
+ mysqlProperties.setProperty("password", "111");
+ mysqlProperties.setProperty("driver", "com.mysql.cj.jdbc.Driver");
+
+ // MySQL JDBC URL
+ String mysqlUrl = "jdbc:mysql://xx.xx.xx.xx:6001/sparkdemo";
+
+ // Write to MySQL
+ df.write()
+ .mode(SaveMode.Append)
+ .jdbc(mysqlUrl, "example_tbl", mysqlProperties);
+ }
+
+ }
+ ```
+
+2. View execution results
+
+ Execute the following SQL query results in MatrixOne:
+
+ ```sql
+ mysql> select * from sparkdemo.example_tbl;
+ +---------+------------+--------+------+------+
+ | user_id | date | city | age | sex |
+ +---------+------------+--------+------+------+
+ | 10000 | 2017-10-01 | 北京 | 20 | 0 |
+ | 10000 | 2017-10-01 | 北京 | 20 | 0 |
+ | 10001 | 2017-10-01 | 北京 | 30 | 1 |
+ | 10002 | 2017-10-02 | 上海 | 20 | 1 |
+ | 10003 | 2017-10-02 | 广州 | 32 | 0 |
+ | 10004 | 2017-10-01 | 深圳 | 35 | 0 |
+ | 10004 | 2017-10-03 | 深圳 | 35 | 0 |
+ +---------+------------+--------+------+------+
+ 7 rows in set (0.01 sec)
+ ```
+
+3. Execute in Spark
+
+ - Add Dependencies
+
+ Package the code written in step 2 through Maven: `mo-spark-demo-1.0-SNAPSHOT-jar-with-dependencies.jar`. Place the above Jar package under the Spark installation directory jars.
+
+ - Start Spark
+
+ Once the dependency is added, start Spark, where I start using Spark Standalone mode
+
+ ```bash
+ ./sbin/start-all.sh
+ ```
+
+ When the startup is complete, use the jps command to query if the startup was successful, and the master and worker processes start successfully
+
+ ```bash
+ [root@node02 jars]# jps
+ 5990 Worker
+ 8093 Jps
+ 5870 Master
+ ```
+
+ - Executing procedures
+
+ Go to the Spark installation directory and execute the following command
+
+ ```bash
+ [root@node02 spark-3.2.4-bin-hadoop3.2]# bin/spark-submit --class org.example.Doris2Mo --master spark://192.168.110.247:7077 ./jars/mo-spark-demo-1.0-SNAPSHOT-jar-with-dependencies.jar
+
+ //class:Indicates the main class to be executed
+ //master:Patterns of Spark Program Operation
+ //mo-spark-demo-1.0-SNAPSHOT-jar-with-dependencies.jar:Running program jar package
+ ```
+
+ The output of the following results indicates a successful write:
+
+ ```bash
+ 24/04/30 10:24:53 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 1261 bytes result sent to driver
+ 24/04/30 10:24:53 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 1493 ms on node02 (executor driver) (1/1)
+ 24/04/30 10:24:53 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
+ 24/04/30 10:24:53 INFO DAGScheduler: ResultStage 0 (jdbc at Doris2Mo.java:40) finished in 1.748 s
+ 24/04/30 10:24:53 INFO DAGScheduler: Job 0 is finished. Cancelling potential speculative or zombie tasks for this job
+ 24/04/30 10:24:53 INFO TaskSchedulerImpl: Killing all running tasks in stage 0: Stage finished
+ 24/04/30 10:24:53 INFO DAGScheduler: Job 0 finished: jdbc at Doris2Mo.java:40, took 1.848481 s
+ 24/04/30 10:24:53 INFO SparkContext: Invoking stop() from shutdown hook
+ 24/04/30 10:24:53 INFO SparkUI: Stopped Spark web UI at http://node02:4040
+ 24/04/30 10:24:53 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
+ 24/04/30 10:24:53 INFO MemoryStore: MemoryStore cleared
+ 24/04/30 10:24:53 INFO BlockManager: BlockManager stopped
+ 24/04/30 10:24:53 INFO BlockManagerMaster: BlockManagerMaster stopped
+ 24/04/30 10:24:53 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
+ 24/04/30 10:24:53 INFO SparkContext: Successfully stopped SparkContext
+ 24/04/30 10:24:53 INFO ShutdownHookManager: Shutdown hook called
+ ```
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-hive-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-hive-matrixone.md
new file mode 100644
index 000000000..fdb175b26
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-hive-matrixone.md
@@ -0,0 +1,206 @@
+# Import Hive data into MatrixOne using Spark
+
+In this chapter, we will cover the implementation of Hive bulk data writing to MatrixOne using the Spark calculation engine.
+
+## Pre-preparation
+
+This practice requires the installation and deployment of the following software environments:
+
+- Finished [installing and starting](https://docs.matrixorigin.cn/1.2.2/MatrixOne/Get-Started/install-standalone-matrixone/) MatrixOne.
+- Download and install [IntelliJ IDEA version 2022.2.1 and above](https://www.jetbrains.com/idea/download/).
+- Download and install [JDK 8+](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html).
+- Importing data from Hive requires installing [Hadoop](http://archive.apache.org/dist/hadoop/core/hadoop-3.1.4/) and [Hive](https://dlcdn.apache.org/hive/hive-3.1.3/).
+- Download and install [MySQL Client 8.0.33](https://downloads.mysql.com/archives/get/p/23/file/mysql-server_8.0.33-1ubuntu23.04_amd64.deb-bundle.tar).
+
+## Operational steps
+
+### Step one: Initialize the project
+
+1. Launch IDEA, click **File > New > Project**, select **Spring Initializer**, and fill in the following configuration parameters:
+
+ - **Name**:mo-spark-demo
+ - **Location**:~\Desktop
+ - **Language**:Java
+ - **Type**:Maven
+ - **Group**:com.example
+ - **Artiface**:matrixone-spark-demo
+ - **Package name**:com.matrixone.demo
+ - **JDK** 1.8
+
+
+
+
+
+2. Add a project dependency and edit the contents of `pom.xml` in the project root as follows:
+
+```xml
+
+
+
+ 4.0.0
+
+ com.example.mo
+ mo-spark-demo
+ 1.0-SNAPSHOT
+
+
+ 8
+ 8
+ 3.2.1
+
+
+
+
+ org.apache.spark
+ spark-sql_2.12
+ ${spark.version}
+
+
+
+ org.apache.spark
+ spark-hive_2.12
+ ${spark.version}
+
+
+ org.apache.spark
+ spark-catalyst_2.12
+ ${spark.version}
+
+
+ org.apache.spark
+ spark-core_2.12
+ ${spark.version}
+
+
+ org.codehaus.jackson
+ jackson-core-asl
+ 1.9.13
+
+
+ org.codehaus.jackson
+ jackson-mapper-asl
+ 1.9.13
+
+
+
+
+ mysql
+ mysql-connector-java
+ 8.0.16
+
+
+
+
+
+```
+
+### Step Two: Prepare Hive Data
+
+Create a Hive database, data table, and insert data by executing the following command in a terminal window:
+
+```sql
+hive
+hive> create database motest;
+hive> CREATE TABLE `users`(
+ `id` int,
+ `name` varchar(255),
+ `age` int);
+hive> INSERT INTO motest.users (id, name, age) VALUES(1, 'zhangsan', 12),(2, 'lisi', 17),(3, 'wangwu', 19);
+```
+
+### Step Three: Create a MatrixOne data table
+
+On node3, connect to node1's MatrixOne using a MySQL client. Then continue with the "test" database you created earlier and create a new data table "users".
+
+```sql
+CREATE TABLE `users` (
+`id` INT DEFAULT NULL,
+`name` VARCHAR(255) DEFAULT NULL,
+`age` INT DEFAULT NULL
+)
+```
+
+### Step four: Copy the configuration file
+
+Copy the three configuration files "etc/hadoop/core-site.xml" and "hdfs-site.xml" in the Hadoop root and "conf/hive-site.xml" in the Hive root to the "resource" directory of your project.
+
+
+
+
+
+### Step five: Write the code
+
+Create a class called "Hive2Mo.java" in IntelliJ IDEA to use Spark to read data from Hive and write data to MatrixOne.
+
+```java
+package com.matrixone.spark;
+
+import org.apache.spark.sql.*;
+
+import java.sql.SQLException;
+import java.util.Properties;
+
+/**
+ * @auther MatrixOne
+ * @date 2022/2/9 10:02
+ * @desc
+ *
+ * 1.在 hive 和 matrixone 中分别创建相应的表
+ * 2.将 core-site.xml hdfs-site.xml 和 hive-site.xml 拷贝到 resources 目录下
+ * 3.需要设置域名映射
+ */
+public class Hive2Mo {
+
+ // parameters
+ private static String master = "local[2]";
+ private static String appName = "app_spark_demo";
+
+ private static String destHost = "xx.xx.xx.xx";
+ private static Integer destPort = 6001;
+ private static String destUserName = "root";
+ private static String destPassword = "111";
+ private static String destDataBase = "test";
+ private static String destTable = "users";
+
+
+ public static void main(String[] args) throws SQLException {
+ SparkSession sparkSession = SparkSession.builder()
+ .appName(appName)
+ .master(master)
+ .enableHiveSupport()
+ .getOrCreate();
+
+ //SparkJdbc to read table contents
+ System.out.println("Read table contents of person in hive");
+ // Read all data in the table
+ Dataset rowDataset = sparkSession.sql("select * from motest.users");
+ // Show data
+ //rowDataset.show();
+ Properties properties = new Properties();
+ properties.put("user", destUserName);
+ properties.put("password", destPassword);;
+ rowDataset.write()
+ .mode(SaveMode.Append)
+ .jdbc("jdbc:mysql://" + destHost + ":" + destPort + "/" + destDataBase,destTable, properties);
+ }
+
+}
+```
+
+### Step Six: View Implementation Results
+
+Execute the following SQL in MatrixOne to view the execution results:
+
+```sql
+mysql> select * from test.users;
++------+----------+------+
+| id | name | age |
++------+----------+------+
+| 1 | zhangsan | 12 |
+| 2 | lisi | 17 |
+| 3 | wangwu | 19 |
++------+----------+------+
+3 rows in set (0.00 sec)
+```
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-mysql-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-mysql-matrixone.md
new file mode 100644
index 000000000..e718e6bbc
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-mysql-matrixone.md
@@ -0,0 +1,267 @@
+# Migrating data from MySQL to MatrixOne using Spark
+
+In this chapter, we will cover the implementation of MySQL bulk data writing to MatrixOne using the Spark compute engine.
+
+## Pre-preparation
+
+This practice requires the installation and deployment of the following software environments:
+
+- Finished [installing and starting](https://docs.matrixorigin.cn/1.2.2/MatrixOne/Get-Started/install-standalone-matrixone/) MatrixOne.
+- Download and install [IntelliJ IDEA version 2022.2.1 and above](https://www.jetbrains.com/idea/download/).
+- Download and install [JDK 8+](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html).
+- Download and install [MySQL](https://downloads.mysql.com/archives/get/p/23/file/mysql-server_8.0.33-1ubuntu23.04_amd64.deb-bundle.tar).
+
+## Operational steps
+
+### Step one: Initialize the project
+
+1. Launch IDEA, click **File > New > Project**, select **Spring Initializer**, and fill in the following configuration parameters:
+
+ - **Name**:mo-spark-demo
+ - **Location**:~\Desktop
+ - **Language**:Java
+ - **Type**:Maven
+ - **Group**:com.example
+ - **Artiface**:matrixone-spark-demo
+ - **Package name**:com.matrixone.demo
+ - **JDK** 1.8
+
+
+
+
+
+2. Add a project dependency and edit the contents of `pom.xml` in the project root as follows:
+
+```xml
+
+
+ 4.0.0
+
+ com.example.mo
+ mo-spark-demo
+ 1.0-SNAPSHOT
+
+
+ 8
+ 8
+ 3.2.1
+
+
+
+
+ org.apache.spark
+ spark-sql_2.12
+ ${spark.version}
+
+
+
+ org.apache.spark
+ spark-hive_2.12
+ ${spark.version}
+
+
+ org.apache.spark
+ spark-catalyst_2.12
+ ${spark.version}
+
+
+ org.apache.spark
+ spark-core_2.12
+ ${spark.version}
+
+
+ org.codehaus.jackson
+ jackson-core-asl
+ 1.9.13
+
+
+ org.codehaus.jackson
+ jackson-mapper-asl
+ 1.9.13
+
+
+
+
+ mysql
+ mysql-connector-java
+ 8.0.16
+
+
+
+
+
+```
+
+### Step Two: Read MatrixOne Data
+
+After connecting to MatrixOne using a MySQL client, create the database you need for the demo, as well as the data tables.
+
+1. Create databases, data tables, and import data in MatrixOne:
+
+ ```sql
+ CREATE DATABASE test;
+ USE test;
+ CREATE TABLE `person` (`id` INT DEFAULT NULL, `name` VARCHAR(255) DEFAULT NULL, `birthday` DATE DEFAULT NULL);
+ INSERT INTO test.person (id, name, birthday) VALUES(1, 'zhangsan', '2023-07-09'),(2, 'lisi', '2023-07-08'),(3, 'wangwu', '2023-07-12');
+ ```
+
+2. Create a `MoRead.java` class in IDEA to read MatrixOne data using Spark:
+
+ ```java
+ package com.matrixone.spark;
+
+ import org.apache.spark.sql.Dataset;
+ import org.apache.spark.sql.Row;
+ import org.apache.spark.sql.SQLContext;
+ import org.apache.spark.sql.SparkSession;
+
+ import java.util.Properties;
+
+ /**
+ * @auther MatrixOne
+ * @desc 读取 MatrixOne 数据
+ */
+ public class MoRead {
+
+ // parameters
+ private static String master = "local[2]";
+ private static String appName = "mo_spark_demo";
+
+ private static String srcHost = "xx.xx.xx.xx";
+ private static Integer srcPort = 6001;
+ private static String srcUserName = "root";
+ private static String srcPassword = "111";
+ private static String srcDataBase = "test";
+ private static String srcTable = "person";
+
+ public static void main(String[] args) {
+ SparkSession sparkSession = SparkSession.builder().appName(appName).master(master).getOrCreate();
+ SQLContext sqlContext = new SQLContext(sparkSession);
+ Properties properties = new Properties();
+ properties.put("user", srcUserName);
+ properties.put("password", srcPassword);
+ Dataset dataset = sqlContext.read()
+ .jdbc("jdbc:mysql://" + srcHost + ":" + srcPort + "/" + srcDataBase,srcTable, properties);
+ dataset.show();
+ }
+
+ }
+ ```
+
+3. Run `MoRead.Main()` in IDEA with the following result:
+
+ 
+
+### Step Three: Write MySQL Data to MatrixOne
+
+You can now start migrating MySQL data to MatrixOne using Spark.
+
+1. Prepare MySQL data: On node3, connect to your local Mysql using the Mysql client, create the required database, data table, and insert the data:
+
+ ```sql
+ mysql -h127.0.0.1 -P3306 -uroot -proot
+ mysql> CREATE DATABASE motest;
+ mysql> USE motest;
+ mysql> CREATE TABLE `person` (`id` int DEFAULT NULL, `name` varchar(255) DEFAULT NULL, `birthday` date DEFAULT NULL);
+ mysql> INSERT INTO motest.person (id, name, birthday) VALUES(2, 'lisi', '2023-07-09'),(3, 'wangwu', '2023-07-13'),(4, 'zhaoliu', '2023-08-08');
+ ```
+
+2. Empty MatrixOne table data:
+
+ On node3, connect to the local MatrixOne using a MySQL client. Since this example continues to use the `test` database from the example that read the MatrixOne data earlier, we need to first empty the data from the `person` table.
+
+ ```sql
+ -- On node3, connect to MatrixOne on node1 using the Mysql client
+ mysql -hxx.xx.xx.xx -P6001 -uroot -p111
+ mysql> TRUNCATE TABLE test.person;
+ ```
+
+3. Write code in IDEA:
+
+ Create `Person.java` and `Mysql2Mo.java` classes to read MySQL data using Spark. The `Mysql2Mo.java` class code can be referenced in the following example:
+
+```java
+package com.matrixone.spark;
+
+import org.apache.spark.api.java.function.MapFunction;
+import org.apache.spark.sql.*;
+
+import java.sql.SQLException;
+import java.util.Properties;
+
+/**
+ * @auther MatrixOne
+ * @desc
+ */
+public class Mysql2Mo {
+
+ // parameters
+ private static String master = "local[2]";
+ private static String appName = "app_spark_demo";
+
+ private static String srcHost = "127.0.0.1";
+ private static Integer srcPort = 3306;
+ private static String srcUserName = "root";
+ private static String srcPassword = "root";
+ private static String srcDataBase = "motest";
+ private static String srcTable = "person";
+
+ private static String destHost = "xx.xx.xx.xx";
+ private static Integer destPort = 6001;
+ private static String destUserName = "root";
+ private static String destPassword = "111";
+ private static String destDataBase = "test";
+ private static String destTable = "person";
+
+
+ public static void main(String[] args) throws SQLException {
+ SparkSession sparkSession = SparkSession.builder().appName(appName).master(master).getOrCreate();
+ SQLContext sqlContext = new SQLContext(sparkSession);
+ Properties connectionProperties = new Properties();
+ connectionProperties.put("user", srcUserName);
+ connectionProperties.put("password", srcPassword);
+ connectionProperties.put("driver","com.mysql.cj.jdbc.Driver");
+
+ //jdbc.url=jdbc:mysql://127.0.0.1:3306/database
+ String url = "jdbc:mysql://" + srcHost + ":" + srcPort + "/" + srcDataBase + "?characterEncoding=utf-8&autoReconnect=true&zeroDateTimeBehavior=convertToNull&useSSL=false&serverTimezone=Asia/Shanghai";
+
+ //SparkJdbc to read table contents
+ System.out.println("Read table contents of person in database");
+ // Read all data in the table
+ Dataset rowDataset = sqlContext.read().jdbc(url,srcTable,connectionProperties).select("*");
+ // Show data
+ //rowDataset.show();
+ // Filter data with id > 2 and add spark_ prefix to name field
+ Dataset dataset = rowDataset.filter("id > 2")
+ .map((MapFunction) row -> RowFactory.create(row.getInt(0), "spark_" + row.getString(1), row.getDate(2)), RowEncoder.apply(rowDataset.schema()));
+ // Show data
+ //dataset.show();
+ Properties properties = new Properties();
+ properties.put("user", destUserName);
+ properties.put("password", destPassword);;
+ dataset.write()
+ .mode(SaveMode.Append)
+ .jdbc("jdbc:mysql://" + destHost + ":" + destPort + "/" + destDataBase,destTable, properties);
+ }
+
+}
+```
+
+In the above code, a simple ETL operation (filtering data with id > 2 and adding the prefix "spark\_" to the name field) is performed and the processed data is written to the MatrixOne database.
+
+### Step Four: View Implementation Results
+
+Execute the following SQL in MatrixOne to view the execution results:
+
+```sql
+select * from test.person;
++------+---------------+------------+
+| id | name | birthday |
++------+---------------+------------+
+| 3 | spark_wangwu | 2023-07-12 |
+| 4 | spark_zhaoliu | 2023-08-07 |
++------+---------------+------------+
+2 rows in set (0.01 sec)
+```
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-overview.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-overview.md
new file mode 100644
index 000000000..603cd3dc8
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-overview.md
@@ -0,0 +1,21 @@
+# Overview
+
+Apache Spark is a distributed computing engine designed to efficiently handle large-scale data. It uses distributed parallel computing to spread the tasks of data splitting,computing and merging over multiple computers,thus realizing efficient data processing and analysis.
+
+## Application scenarios
+
+- Large-scale data processing and analysis
+
+ Spark is capable of handling huge amounts of data, increasing processing efficiency through parallel computing tasks. It is widely used in data processing and analysis in finance, telecommunications, medical and other fields.
+
+- stream data processing
+
+ Spark Streaming allows real-time processing of data streams into batch data for analysis and storage. This is useful in real-time data analysis scenarios such as online advertising, network security, etc.
+
+- Machine learning
+
+ Spark provides a machine learning library (MLlib) that supports multiple machine learning algorithms and model training for machine learning applications such as recommendation systems, image recognition, and more.
+
+- Figure calculation
+
+ Spark's Graph Calculation Library (GraphX) supports multiple graph calculation algorithms for graph analysis scenarios such as social network analysis, recommendation systems, and more.
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/seatunnel-write.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/seatunnel-write.md
deleted file mode 100644
index 58d154363..000000000
--- a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/seatunnel-write.md
+++ /dev/null
@@ -1,131 +0,0 @@
-# Writing Data to MatrixOne Using SeaTunnel
-
-## Overview
-
-[SeaTunnel](https://seatunnel.apache.org/) is a distributed, high-performance, and highly scalable data integration platform that focuses on synchronizing and transforming massive data, including offline and real-time data. MatrixOne supports using SeaTunnel to synchronize data from other databases and can efficiently handle hundreds of billions of records.
-
-This document will explain how to use SeaTunnel to write data to MatrixOne.
-
-## Before you start
-
-Before using SeaTunnel to write data to MatrixOne, make sure to complete the following preparations:
-
-- Install and start MatrixOne by following the steps in [Install standalone MatrixOne](../../../Get-Started/install-standalone-matrixone.md).
-
-- Install SeaTunnel Version 2.3.3 by downloading it from [here](https://www.apache.org/dyn/closer.lua/seatunnel/2.3.3/apache-seatunnel-2.3.3-bin.tar.gz). After installation, you can define the installation path of SeaTunnel using a shell command:
-
-```shell
-export SEATNUNNEL_HOME="/root/seatunnel"
-```
-
-## Steps
-
-### Create Test Data
-
-1. Create a MySQL database named `test1` and create a table named `test_table` within it. Store this in a file named `mysql.sql` under the root directory. Here's the MySQL DDL statement:
-
- ```sql
- create database test1;
- use test1;
- CREATE TABLE `test_table` (
- `name` varchar(255) DEFAULT NULL,
- `age` int(11) DEFAULT NULL
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- ```
-
-2. Use the [mo_ctl](https://docs.matrixorigin.cn/1.2.0/MatrixOne/Maintain/mo_ctl/) tool to import the MySQL DDL statements into MatrixOne directly. Execute the following command:
-
- ```shell
- mo_ctl sql /root/mysql.sql
- ```
-
-### Install the Connectors Plugin
-
-This document will explain how to use SeaTunnel's `connector-jdbc` connection plugin to connect to MatrixOne.
-
-1. In the `${SEATNUNNEL_HOME}/config/plugin_config` file of SeaTunnel, add the following content:
-
- ```shell
- --connectors-v2--
- connector-jdbc
- --end--
- ```
-
-2. SeaTunnel binary package version 2.3.3 does not provide connector dependencies by default. You need to install the connectors when using SeaTunnel for the first time by running the following command:
-
- ```shell
- sh bin/install-plugin.sh 2.3.3
- ```
-
- __Note:__ This document uses the SeaTunnel engine to write data to MatrixOne without relying on Flink or Spark.
-
-## Define the Task Configuration File
-
-In this document, we use the `test_table` table in the MySQL database as the data source, and we write data directly to the `test_table` table in the MatrixOne database without data processing.
-
-Due to data compatibility issues, you need to configure the task configuration file `${SEATNUNNEL_HOME}/config/v2.batch.config.template`, which defines how SeaTunnel handles data input, processing, and output logic after it starts.
-
-Edit the configuration file with the following content:
-
-```shell
-env {
- execution.parallelism = 2
- job.mode = "BATCH"
-}
-
-source {
- Jdbc {
- url = "jdbc:mysql://192.168.110.40:3306/test"
- driver = "com.mysql.cj.jdbc.Driver"
- connection_check_timeout_sec = 100
- user = "root"
- password = "123456"
- query = "select * from test_table"
- }
-}
-
-transform {
-
-}
-
-sink {
- jdbc {
- url = "jdbc:mysql://192.168.110.248:6001/test"
- driver = "com.mysql.cj.jdbc.Driver"
- user = "root"
- password = "111"
- query = "insert into test_table(name,age) values(?,?)"
- }
-}
-```
-
-### Install Database Dependencies
-
-Download [mysql-connector-java-8.0.33.jar](https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-j-8.0.33.zip) and copy the file to the `${SEATNUNNEL_HOME}/plugins/jdbc/lib/` directory.
-
-### Run the SeaTunnel Application
-
-Execute the following command to start the SeaTunnel application:
-
-```shell
-./bin/seatunnel.sh --config ./config/v2.batch.config.template -e local
-```
-
-### View the Results
-
-After SeaTunnel finishes running, it will display statistics similar to the following, summarizing the time taken for this write operation, the total number of data read, the total number of writes, and the total number of write failures:
-
-```shell
-***********************************************
- Job Statistic Information
-***********************************************
-Start Time : 2023-08-07 16:45:02
-End Time : 2023-08-07 16:45:05
-Total Time(s) : 3
-Total Read Count : 5000000
-Total Write Count : 5000000
-Total Failed Count : 0
-***********************************************
-```
-
-You have successfully synchronized data from a MySQL database into the MatrixOne database.
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-clickhouse-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-clickhouse-matrixone.md
new file mode 100644
index 000000000..e2513bd03
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-clickhouse-matrixone.md
@@ -0,0 +1,230 @@
+# Write ClickHouse data to MatrixOne using DataX
+
+This article describes how to write ClickHouse data offline to a MatrixOne database using the DataX tool.
+
+## Prepare before you start
+
+Before you can start writing data to MatrixOne using DataX, you need to complete the installation of the following software:
+
+- Finished [installing and starting](../../../Get-Started/install-standalone-matrixone.md) MatrixOne.
+- Install [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html).
+- Install [Python 3.8 (or plus)](https://www.python.org/downloads/).
+- Download the [DataX](https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz) installation package and unzip it.
+- Completed [ClickHouse](https://packages.clickhouse.com/tgz/stable/) installation deployment
+- Download [matrixonewriter.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/Computing-Engine/datax-write/matrixonewriter.zip) and extract it to the `plugin/writer/` directory in the root of your DataX project.
+- Install the MySQL Client.
+
+## Steps
+
+### Log in to the clickhouse database to create test data
+
+```sql
+create database source_ck_database;
+use source_ck_database;
+
+create table if not exists student(
+`id` Int64 COMMENT '学生 id',
+`name` String COMMENT '学生姓名',
+`birthday` String COMMENT '学生出生日期',
+`class` Int64 COMMENT '学生班级编号',
+`grade` Int64 COMMENT '学生年级编号',
+`score` decimal(18,0) COMMENT '学生成绩'
+) engine = MergeTree
+order by id;
+```
+
+### Importing data using datax
+
+#### Using clickhousereader
+
+Note: Datax cannot synchronize table structures, so you need to create the table MatrixOne build statement in MatrixOne in advance:
+
+```sql
+CREATE TABLE datax_db.`datax_ckreader_ck_student` (
+ `id` bigint(20) NULL COMMENT "",
+ `name` varchar(100) NULL COMMENT "",
+ `birthday` varchar(100) NULL COMMENT "",
+ `class` bigint(20) NULL COMMENT "",
+ `grade` bigint(20) NULL COMMENT "",
+ `score` decimal(18, 0) NULL COMMENT ""
+);
+
+CREATE TABLE datax_db.`datax_rdbmsreader_ck_student` (
+ `id` bigint(20) NULL COMMENT "",
+ `name` varchar(100) NULL COMMENT "",
+ `birthday` varchar(100) NULL COMMENT "",
+ `class` bigint(20) NULL COMMENT "",
+ `grade` bigint(20) NULL COMMENT "",
+ `score` decimal(18, 0) NULL COMMENT ""
+);
+```
+
+Upload clikchousereader to the $DATAX\_HOME/plugin/reader directory Unzip the installation package:
+
+```bash
+[root@root ~]$ unzip clickhousereader.zip
+```
+
+Move the archive to the /opt/ directory:
+
+```bash
+[root@root ~] mv clickhousereader.zip /opt/
+ ```
+
+Writing a task json file
+
+```bash
+[root@root ~] vim $DATAX_HOME/job/ck2sr.json
+```
+
+```json
+{
+ "job": {
+ "setting": {
+ "speed": {
+"channel": "1"
+ }
+ },
+ "content": [
+ {
+ "reader": {
+ "name": "clickhousereader",
+ "parameter": {
+ "username": "default",
+ "password": "123456",
+ "column": [
+ "*"
+ ],
+ "splitPK": "id",
+ "connection": [
+ {
+ "table": [
+ "student"
+ ],
+ "jdbcUrl": [
+ "jdbc:clickhouse://xx.xx.xx.xx:8123/source_ck_database"
+ ]
+ }
+ ]
+ }
+ },
+ "writer": {
+ "name": "matrixonewriter",
+ "parameter": {
+ "column": [
+ "*"
+ ],
+ "connection": [
+ {
+ "jdbcUrl": "jdbc:mysql://xx.xx.xx.xx:6001/datax_db",
+ "table": [
+ "datax_ckreader_ck_student"
+ ]
+ }
+ ],
+ "password": "111",
+ "username": "root",
+ "writeMode": "insert"
+ }
+ }
+ }
+ ]
+ }
+}
+```
+
+Perform import tasks
+
+```bash
+[root@root ~] cd $DATAX_HOME/bin
+[root@root ~] ./python datax.py ../jobs/ck2sr.json
+```
+
+#### Importing with Rdbmsreader
+
+Upload the ClickHouse JDBC driver to the $DATAX\_HOME/plugin/reader/rdbmsreader/libs/ directory
+
+Modify the configuration file
+
+```bash
+[root@root ~] vim $DATAX_HOME/plugin/reader/rdbmsreader/plugin.json
+```
+
+```json
+{
+ "name": "rdbmsreader",
+ "class": "com.alibaba.datax.plugin.reader.rdbmsreader.RdbmsReader",
+ "description": "useScene: prod. mechanism: Jdbc connection using the database, execute select sql, retrieve data from the ResultSet. warn: The more you know about the database, the less problems you encounter.",
+ "developer": "alibaba",
+ "drivers":["dm.jdbc.driver.DmDriver", "com.sybase.jdbc3.jdbc.SybDriver", "com.edb.Driver", "org.apache.hive.jdbc.HiveDriver","com.clickhouse.jdbc.ClickHouseDriver"]
+}
+```
+
+Writing a json task file
+
+```bash
+[root@root ~] vim $DATAX_HOME/job/ckrdbms2sr.json
+```
+
+```json
+{
+ "job": {
+ "setting": {
+ "speed": {
+ "byte": 1048576
+ }
+ },
+ "content": [
+ {
+ "reader": {
+ "name": "rdbmsreader",
+ "parameter": {
+ "username": "default",
+ "password": "123456",
+ "column": [
+ "*"
+ ],
+ "splitPK": "id",
+ "connection": [
+ {
+ "table": [
+ "student"
+ ],
+ "jdbcUrl": [
+ "jdbc:clickhouse://xx.xx.xx.xx:8123/source_ck_database"
+ ]
+ }
+ ]
+ }
+ },
+ "writer": {
+ "name": "matrixonewriter",
+ "parameter": {
+ "column": [
+ "*"
+ ],
+ "connection": [
+ {
+ "jdbcUrl": "jdbc:mysql://xx.xx.xx.xx:6001/datax_db",
+ "table": [
+ "datax_rdbmsreader_ck_student"
+ ]
+ }
+ ],
+ "password": "111",
+ "username": "root",
+ "writeMode": "insert"
+ }
+ }
+ }
+ ]
+ }
+}
+```
+
+Perform the import task
+
+```bash
+[root@root ~] cd $DATAX_HOME/bin
+[root@root ~] ./python datax.py ../jobs/ckrdbms2sr.json
+```
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-doris-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-doris-matrixone.md
new file mode 100644
index 000000000..7c2aad58f
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-doris-matrixone.md
@@ -0,0 +1,145 @@
+# Write Doris data to MatrixOne using DataX
+
+This article describes how to write Doris data offline to a MatrixOne database using the DataX tool.
+
+## Prepare before you start
+
+Before you can start writing data to MatrixOne using DataX, you need to complete the installation of the following software:
+
+- Finished [installing and starting](../../../Get-Started/install-standalone-matrixone.md) MatrixOne.
+- Install [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html).
+- Install [Python 3.8 (or plus)](https://www.python.org/downloads/).
+- Download the [DataX](https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz) installation package and unzip it.
+- Download and install [Doris](https://doris.apache.org/zh-CN/docs/dev/get-starting/quick-start/).
+- Download [matrixonewriter.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/Computing-Engine/datax-write/matrixonewriter.zip) and extract it to the `plugin/writer/` directory in the root of your DataX project.
+- Install the MySQL Client.
+
+## Steps
+
+### Creating Test Data in Doris
+
+```sql
+create database test;
+
+use test;
+
+CREATE TABLE IF NOT EXISTS example_tbl
+(
+ user_id BIGINT NOT NULL COMMENT "用户id",
+ date DATE NOT NULL COMMENT "数据灌入日期时间",
+ city VARCHAR(20) COMMENT "用户所在城市",
+ age SMALLINT COMMENT "用户年龄",
+ sex TINYINT COMMENT "用户性别"
+)
+DUPLICATE KEY(user_id, date)
+DISTRIBUTED BY HASH(user_id) BUCKETS 1
+PROPERTIES (
+ "replication_num"="1"
+);
+
+insert into example_tbl values
+(10000,'2017-10-01','北京',20,0),
+(10000,'2017-10-01','北京',20,0),
+(10001,'2017-10-01','北京',30,1),
+(10002,'2017-10-02','上海',20,1),
+(10003,'2017-10-02','广州',32,0),
+(10004,'2017-10-01','深圳',35,0),
+(10004,'2017-10-03','深圳',35,0);
+
+```
+
+### Creating a Target Library Table in MatrixOne
+
+```sql
+create database sparkdemo;
+use sparkdemo;
+
+CREATE TABLE IF NOT EXISTS example_tbl
+(
+ user_id BIGINT NOT NULL COMMENT "用户id",
+ date DATE NOT NULL COMMENT "数据灌入日期时间",
+ city VARCHAR(20) COMMENT "用户所在城市",
+ age SMALLINT COMMENT "用户年龄",
+ sex TINYINT COMMENT "用户性别"
+);
+```
+
+### Edit the json template file for datax
+
+Go to the datax/job path and fill in the following at doris2mo.json
+
+```json
+{
+ "job": {
+ "setting": {
+ "speed": {
+ "channel": 8
+ }
+ },
+ "content": [
+ {
+ "reader": {
+ "name": "mysqlreader",
+ "parameter": {
+ "username": "root",
+ "password": "root",
+ "splitPk": "user_id",
+ "column": [
+ '*'
+ ],
+ "connection": [
+ {
+ "table": [
+ "example_tbl"
+ ],
+ "jdbcUrl": [
+ "jdbc:mysql://xx.xx.xx.xx:9030/test"
+ ]
+ }
+ ],
+ "fetchSize": 1024
+ }
+ },
+ "writer": {
+ "name": "matrixonewriter",
+ "parameter": {
+ "writeMode": "insert",
+ "username": "root",
+ "password": "111",
+ "column": [
+ '*'
+ ],
+ "connection": [
+ {
+ "jdbcUrl": "jdbc:mysql://xx.xx.xx.xx:6001/sparkdemo",
+ "table": [
+ "example_tbl"
+ ]
+ }
+ ]
+ }
+ }
+ }
+ ]
+ }
+}
+```
+
+### Start the datax job
+
+```bash
+python bin/datax.py job/doris2mo.json
+```
+
+The following results are displayed:
+
+```bash
+2024-04-28 15:47:38.222 [job-0] INFO JobContainer -
+任务启动时刻 : 2024-04-28 15:47:26
+任务结束时刻 : 2024-04-28 15:47:38
+任务总计耗时 : 11s
+任务平均流量 : 12B/s
+记录写入速度 : 0rec/s
+读出记录总数 : 7
+读写失败总数 : 0
+```
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-elasticsearch-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-elasticsearch-matrixone.md
new file mode 100644
index 000000000..cc9012eaa
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-elasticsearch-matrixone.md
@@ -0,0 +1,194 @@
+# Write ElasticSearch data to MatrixOne using DataX
+
+This article describes how to write ElasticSearch data offline to a MatrixOne database using the DataX tool.
+
+## Prepare before you start
+
+Before you can start writing data to MatrixOne using DataX, you need to complete the installation of the following software:
+
+- Finished [installing and starting](../../../Get-Started/install-standalone-matrixone.md) MatrixOne.
+- Install [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html).
+- Install [Python 3.8 (or plus)](https://www.python.org/downloads/).
+- Download the [DataX](https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz) installation package and unzip it.
+- Download and install [ElasticSearch](https://www.elastic.co/cn/downloads/elasticsearch).
+- Download [matrixonewriter.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/Computing-Engine/datax-write/matrixonewriter.zip) and extract it to the `plugin/writer/` directory in the root of your DataX project.
+- Download [elasticsearchreader.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/datax_es_mo/elasticsearchreader.zip) and extract it to the datax/plugin/reader directory.
+- Install the MySQL Client.
+
+## Steps
+
+### Import data into ElasticSearch
+
+#### Create Index
+
+Create an index with the name person (username and password in ElasticSearch after the -u parameter below, which can be modified or deleted as needed for local testing):
+
+```bash
+curl -X PUT "" -u elastic:elastic
+```
+
+Output the following message to indicate successful creation:
+
+```bash
+{"acknowledged":true,"shards_acknowledged":true,"index":"person"}
+```
+
+#### Add a field to the index person
+
+```bash
+curl -X PUT "127.0.0.1:9200/person/_mapping" -H 'Content-Type: application/json' -u elastic:elastic -d'{ "properties": { "id": { "type": "integer" }, "name": { "type": "text" }, "birthday": {"type": "date"} }}'
+```
+
+Output the following message to indicate successful setup:
+
+```bash
+{"acknowledged":true}
+```
+
+#### Adding data to an ElasticSearch index
+
+Add three pieces of data via the curl command:
+
+```bash
+curl -X POST '127.0.0.1:9200/person/_bulk' -H 'Content-Type: application/json' -u elastic:elastic -d '{"index":{"_index":"person","_type":"_doc","_id":1}}{"id": 1,"name": "MatrixOne","birthday": "1992-08-08"}{"index":{"_index":"person","_type":"_doc","_id":2}}{"id": 2,"name": "MO","birthday": "1993-08-08"}{"index":{"_index":"person","_type":"_doc","_id":3}}{"id": 3,"name": "墨墨","birthday": "1994-08-08"}
+```
+
+Output the following message to indicate successful execution:
+
+```bash
+{"took":5,"errors":false,"items":[{"index":{"_index":"person","_type":"_doc","_id":"1","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":0,"_primary_term":1,"status":201}},{"index":{"_index":"person","_type":"_doc","_id":"2","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":1,"_primary_term":1,"status":201}},{"index":{"_index":"person","_type":"_doc","_id":"3","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":2,"_primary_term":1,"status":201}}]}
+```
+
+### Building tables in MatrixOne
+
+```sql
+create database mo;
+CREATE TABLE mo.`person` (
+`id` INT DEFAULT NULL,
+`name` VARCHAR(255) DEFAULT NULL,
+`birthday` DATE DEFAULT NULL
+);
+```
+
+### Writing Migration Files
+
+Go to the datax/job path and write the job file `es2mo.json`:
+
+```json
+{
+ "job":{
+ "setting":{
+ "speed":{
+ "channel":1
+ },
+ "errorLimit":{
+ "record":0,
+ "percentage":0.02
+ }
+ },
+ "content":[
+ {
+ "reader":{
+ "name":"elasticsearchreader",
+ "parameter":{
+ "endpoint":"http://127.0.0.1:9200",
+ "accessId":"elastic",
+ "accessKey":"elastic",
+ "index":"person",
+ "type":"_doc",
+ "headers":{
+
+ },
+ "scroll":"3m",
+ "search":[
+ {
+ "query":{
+ "match_all":{
+
+ }
+ }
+ }
+ ],
+ "table":{
+ "filter":"",
+ "nameCase":"UPPERCASE",
+ "column":[
+ {
+ "name":"id",
+ "type":"integer"
+ },
+ {
+ "name":"name",
+ "type":"text"
+ },
+ {
+ "name":"birthday",
+ "type":"date"
+ }
+ ]
+ }
+ }
+ },
+ "writer":{
+ "name":"matrixonewriter",
+ "parameter":{
+ "username":"root",
+ "password":"111",
+ "column":[
+ "id",
+ "name",
+ "birthday"
+ ],
+ "connection":[
+ {
+ "table":[
+ "person"
+ ],
+ "jdbcUrl":"jdbc:mysql://127.0.0.1:6001/mo"
+ }
+ ]
+ }
+ }
+ }
+ ]
+ }
+}
+```
+
+### Perform migration tasks
+
+Enter the datax installation directory and execute the following command to start the migration job:
+
+```bash
+cd datax
+python bin/datax.py job/es2mo.json
+```
+
+After the job is executed, the output is as follows:
+
+```bash
+2023-11-28 15:55:45.642 [job-0] INFO StandAloneJobContainerCommunicator - Total 3 records, 67 bytes | Speed 6B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.456s | Percentage 100.00%2023-11-28 15:55:45.644 [job-0] INFO JobContainer -
+任务启动时刻 : 2023-11-28 15:55:31
+任务结束时刻 : 2023-11-28 15:55:45
+任务总计耗时 : 14s
+任务平均流量 : 6B/s
+记录写入速度 : 0rec/s
+读出记录总数 : 3
+读写失败总数 : 0
+```
+
+### View post-migration data in MatrixOne
+
+View the results in the target table in the MatrixOne database to confirm that the migration is complete:
+
+```sql
+mysql> select * from mo.person;
++------+-----------+------------+
+| id | name | birthday |
++------+-----------+------------+
+| 1 | MatrixOne | 1992-08-08 |
+| 2 | MO | 1993-08-08 |
+| 3 | 墨墨 | 1994-08-08 |
++------+-----------+------------+
+3 rows in set (0.00 sec)
+```
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-influxdb-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-influxdb-matrixone.md
new file mode 100644
index 000000000..fae37d8b6
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-influxdb-matrixone.md
@@ -0,0 +1,150 @@
+# Write InfluxDB data to MatrixOne using DataX
+
+This article describes how to write InfluxDB data offline to a MatrixOne database using the DataX tool.
+
+## Prepare before you start
+
+Before you can start writing data to MatrixOne using DataX, you need to complete the installation of the following software:
+
+- Finished [installing and starting](../../../Get-Started/install-standalone-matrixone.md) MatrixOne.
+- Install [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html).
+- Install [Python 3.8 (or plus)](https://www.python.org/downloads/).
+- Download the [DataX](https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz) installation package and unzip it.
+- Download and install [InfluxDB](https://www.influxdata.com/products/influxdb/).
+- Download [matrixonewriter.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/Computing-Engine/datax-write/matrixonewriter.zip) and extract it to the `plugin/writer/` directory in the root of your DataX project.
+- Download [influxdbreader](https://github.com/wowiscrazy/InfluxDBReader-DataX) to the datax/plugin/reader path.
+- Install the MySQL Client.
+
+## Steps
+
+### Creating test data in influxdb
+
+Log in with your default account
+
+```bash
+influx -host 'localhost' -port '8086'
+```
+
+```sql
+--Creating and using databases
+create database testDb;
+use testDb;
+--insert data
+insert air_condition_outdoor,home_id=0000000000000,sensor_id=0000000000034 temperature=0.0000000000000000,humidity=80.0000000000000000,battery_voltage=3.2000000000000002 1514764800000000000
+insert air_condition_outdoor,home_id=0000000000001,sensor_id=0000000000093 temperature=0.0000000000000000,humidity=80.0000000000000000,battery_voltage=3.2000000000000002 1514764800000000000
+insert air_condition_outdoor,home_id=0000000000003,sensor_id=0000000000197 temperature=0.0000000000000000,humidity=80.0000000000000000,battery_voltage=3.2000000000000002 1514764800000000000
+insert air_condition_outdoor,home_id=0000000000003,sensor_id=0000000000198 temperature=0.0000000000000000,humidity=80.0000000000000000,battery_voltage=3.2000000000000002 1514764800000000000
+insert air_condition_outdoor,home_id=0000000000003,sensor_id=0000000000199 temperature=0.0000000000000000,humidity=80.0000000000000000,battery_voltage=3.2000000000000002 1514764800000000000
+insert air_condition_outdoor,home_id=0000000000003,sensor_id=0000000000200 temperature=0.0000000000000000,humidity=80.0000000000000000,battery_voltage=3.2000000000000002 1514764800000000000
+insert air_condition_outdoor,home_id=0000000000003,sensor_id=0000000000201 temperature=0.0000000000000000,humidity=80.0000000000000000,battery_voltage=3.2000000000000002 1514764800000000000
+insert air_condition_outdoor,home_id=0000000000003,sensor_id=0000000000202 temperature=0.0000000000000000,humidity=80.0000000000000000,battery_voltage=3.2000000000000002 1514764800000000000
+insert air_condition_outdoor,home_id=0000000000003,sensor_id=0000000000203 temperature=0.0000000000000000,humidity=80.0000000000000000,battery_voltage=3.2000000000000002 1514764800000000000
+insert air_condition_outdoor,home_id=0000000000003,sensor_id=0000000000204 temperature=0.0000000000000000,humidity=80.0000000000000000,battery_voltage=3.2000000000000002 1514764800000000000
+```
+
+### Create a test account
+
+```sql
+create user "test" with password '123456' with all privileges;
+grant all privileges on testDb to test;
+show grants for test;
+```
+
+### Turn on database authentication
+
+```bash
+vim /etc/influxdb/influxdb.conf
+```
+
+
+
+
+
+### Restart influxdb
+
+```bash
+systemctl restart influxdb
+```
+
+### Test Authentication Login
+
+```bash
+influx -host 'localhost' -port '8086' -username 'test' -password '123456'
+```
+
+### Creating a Target Table in MatrixOne
+
+```sql
+mysql> create database test;
+mysql> use test;
+mysql> create table air_condition_outdoor(
+time datetime,
+battery_voltage float,
+home_id char(15),
+humidity int,
+sensor_id char(15),
+temperature int
+);
+```
+
+### Edit the json template file for datax
+
+Go to the datax/job path and fill in the following at influxdb2mo.json
+
+```json
+{
+ "job": {
+ "setting": {
+ "speed": {
+ "channel": 1
+ }
+ },
+ "content": [
+ {
+ "reader": {
+ "name": "influxdbreader",
+ "parameter": {
+ "dbType": "InfluxDB",
+ "address": "http://xx.xx.xx.xx:8086",
+ "username": "test",
+ "password": "123456",
+ "database": "testDb",
+ "querySql": "select * from air_condition_outdoor limit 20",
+ }
+ },
+ "writer": {
+ "name": "matrixonewriter",
+ "parameter": {
+ "username": "root",
+ "password": "111",
+ "writeMode": "insert",
+ "connection": [
+ {
+ "jdbcUrl": "jdbc:mysql://xx.xx.xx.xx:6001/test",
+ "table": ["air_condition_outdoor"]
+ }
+ ],
+ "column": ["*"],
+ }
+ }
+ }
+ ]
+ }
+}
+```
+
+### Start the datax job
+
+Seeing results similar to the following indicates successful import
+
+```bash
+#python bin/datax.py job/influxdb2mo.json
+2024-04-28 13:51:19.665 [job-0] INFO JobContainer -
+任务启动时刻 : 2024-04-28 13:51:08
+任务结束时刻 : 2024-04-28 13:51:19
+任务总计耗时 : 10s
+任务平均流量 : 2B/s
+记录写入速度 : 0rec/s
+读出记录总数 : 20
+读写失败总数 : 0
+```
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-mongodb-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-mongodb-matrixone.md
new file mode 100644
index 000000000..d43f794a4
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-mongodb-matrixone.md
@@ -0,0 +1,121 @@
+# Write MongoDB data to MatrixOne using DataX
+
+This article describes how to write MongoDB data offline to a MatrixOne database using the DataX tool.
+
+## Prepare before you start
+
+Before you can start writing data to MatrixOne using DataX, you need to complete the installation of the following software:
+
+- Finished [installing and starting](../../../Get-Started/install-standalone-matrixone.md) MatrixOne.
+- Install [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html).
+- Install [Python 3.8 (or plus)](https://www.python.org/downloads/).
+- Download the [DataX](https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz) installation package and unzip it.
+- Download and install [MongoDB](https://www.mongodb.com/).
+- Download [matrixonewriter.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/Computing-Engine/datax-write/matrixonewriter.zip) and extract it to the `plugin/writer/` directory in the root of your DataX project.
+- Install the MySQL Client.
+
+## Steps
+
+### Creating MongoDB Test Data
+
+Create database test or test if test does not exist
+
+```sql
+>create database test;
+>use test
+#Viewing the current database
+>db
+test
+#Create collection db.createCollection("collection name")
+>db. createCollection('test')
+#Insert document data db.collection name.insert(document content)
+>db.test. insert({"name" : " aaa ", "age" : 20})
+>db.test. insert({"name" : " bbb ", "age" : 18})
+>db.test. insert({"name" : " ccc ", "age" : 28})
+#View Data
+>db.test.find()
+{ "_id" : ObjectId("6347e3c6229d6017c82bf03d"), "name" : "aaa", "age" : 20 }
+{ "_id" : ObjectId("6347e64a229d6017c82bf03e"), "name" : "bbb", "age" : 18 }
+{ "_id" : ObjectId("6347e652229d6017c82bf03f"), "name" : "ccc", "age" : 28 }
+```
+
+### Creating a Target Table in MatrixOne
+
+```sql
+mysql> create database test;
+mysql> use test;
+mysql> CREATE TABLE `mongodbtest` (
+ `name` varchar(30) NOT NULL COMMENT "",
+ `age` int(11) NOT NULL COMMENT ""
+);
+```
+
+### Edit the json template file for datax
+
+Go to the datax/job path, create a new file `mongo2matrixone.json` and fill in the following:
+
+```json
+{
+ "job": {
+ "setting": {
+ "speed": {
+ "channel": 1
+ }
+ },
+ "content": [
+ {
+ "reader": {
+ "name": "mongodbreader",
+ "parameter": {
+ "address": [
+ "xx.xx.xx.xx:27017"
+ ],
+ "userName": "root",
+ "userPassword": "",
+ "dbName": "test",
+ "collectionName": "test",
+ "column": [
+ {
+ "name": "name",
+ "type": "string"
+ },
+ {
+ "name": "age",
+ "type": "int"
+ }
+ ]
+ }
+ },
+ "writer": {
+ "name": "matrixonewriter",
+ "parameter": {
+ "username": "root",
+ "password": "111",
+ "column": ["*"],
+ "connection": [
+ {
+ "table": ["mongodbtest"],
+ "jdbcUrl": "jdbc:mysql://127.0.0.1:6001/test"
+ }
+ ]
+ }
+ }
+ }
+ ]
+ }
+}
+```
+
+### Start the datax job
+
+```bash
+python bin/datax.py job/mongo2matrixone.json
+2024-04-28 13:51:19.665 [job-0] INFO JobContainer -
+任务启动时刻 : 2024-04-28 13:51:08
+任务结束时刻 : 2024-04-28 13:51:19
+任务总计耗时 : 10s
+任务平均流量 : 2B/s
+记录写入速度 : 0rec/s
+读出记录总数 : 3
+读写失败总数 : 0
+```
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-mysql-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-mysql-matrixone.md
new file mode 100644
index 000000000..900ff0f5d
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-mysql-matrixone.md
@@ -0,0 +1,132 @@
+# Writing MySQL data to MatrixOne using DataX
+
+This article describes how to write MySQL data offline to a MatrixOne database using the DataX tool.
+
+## Prepare before you start
+
+Before you can start writing data to MatrixOne using DataX, you need to complete the installation of the following software:
+
+- Complete [standalone MatrixOne deployment](https://docs.matrixorigin.cn/1.2.2/MatrixOne/Get-Started/install-standalone-matrixone/).
+- Install [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html).
+- Install [Python 3.8 (or plus)](https://www.python.org/downloads/).
+- Download the [DataX](https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz) installation package and unzip it.
+- Download [matrixonewriter.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/Computing-Engine/datax-write/matrixonewriter.zip) and extract it to the `plugin/writer/` directory in the root of your DataX project.
+- Download and install [MySQL](https://downloads.mysql.com/archives/get/p/23/file/mysql-server_8.0.33-1ubuntu23.04_amd64.deb-bundle.tar).
+
+## Steps
+
+### Create table and insert data in mysql
+
+```sql
+CREATE TABLE `mysql_datax` (
+ `id` bigint(20) NOT NULL,
+ `name` varchar(100) DEFAULT NULL,
+ `salary` decimal(10,0) DEFAULT NULL,
+ `age` int(11) DEFAULT NULL,
+ `entrytime` date DEFAULT NULL,
+ `gender` char(1) DEFAULT NULL,
+ PRIMARY KEY (`id`)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
+
+--Insert sample data
+insert into mysql_datax valus
+(1,"lisa",15660,30,'2022-10-12',0),
+(2,"tom",15060,24,'2021-11-10',1),
+(3,"jenny",15000,28,'2024-02-19',0),
+(4,"henry",12660,24,'2022-04-22',1);
+```
+
+### Create target library table in Matrixone
+
+Since DataX can only synchronize data, not table structure, we need to manually create the table in the target database (Matrixone) before we can perform the task.
+
+```sql
+CREATE TABLE `mysql_datax` (
+ `id` bigint(20) NOT NULL,
+ `name` varchar(100) DEFAULT NULL,
+ `salary` decimal(10,0) DEFAULT NULL,
+ `age` int(11) DEFAULT NULL,
+ `entrytime` date DEFAULT NULL,
+ `gender` char(1) DEFAULT NULL,
+ PRIMARY KEY (`id`)
+);
+```
+
+### Creating a Job Profile
+
+The task configuration file in DataX is in json format and the built-in task configuration template can be viewed by the following command:
+
+```bash
+python datax.py -r mysqlreader -w matrixonewriter
+```
+
+Go to the datax/job path and, according to the template, write the job file `mysql2mo.json`:
+
+```json
+{
+ "job": {
+ "content": [
+ {
+ "reader": {
+ "name": "mysqlreader",
+ "parameter": {
+ "column": ["*"],
+ "connection": [
+ {
+ "jdbcUrl": ["jdbc:mysql://xx.xx.xx.xx:3306/test"],
+ "table": ["mysql_datax"]
+ }
+ ],
+ "password": "root",
+ "username": "root",
+ "where": ""
+ }
+ },
+ "writer": {
+ "name": "matrixonewriter",
+ "parameter": {
+ "column": ["*"],
+ "connection": [
+ {
+ "jdbcUrl": "jdbc:mysql://xx.xx.xx.xx:6001/test",
+ "table": ["mysql_datax"]
+ }
+ ],
+ "password": "111",
+ "preSql": [],
+ "session": [],
+ "username": "root",
+ "writeMode": "insert" --目前仅支持replace,update 或 insert 方式
+ }
+ }
+ }
+ ],
+ "setting": {
+ "speed": {
+ "channel": "1"
+ }
+ }
+ }
+}
+```
+
+### Start the datax job
+
+```bash
+python /opt/module/datax/bin/datax.py /opt/module/datax/job/mysql2mo.json
+```
+
+### View data in a MatrixOne table
+
+```sql
+mysql> select * from mysql_datax;
++------+-------+--------+------+------------+--------+
+| id | name | salary | age | entrytime | gender |
++------+-------+--------+------+------------+--------+
+| 1 | lisa | 15660 | 30 | 2022-10-12 | 0 |
+| 2 | tom | 15060 | 24 | 2021-11-10 | 1 |
+| 3 | jenny | 15000 | 28 | 2024-02-19 | 0 |
+| 4 | henry | 12660 | 24 | 2022-04-22 | 1 |
++------+-------+--------+------+------------+--------+
+4 rows in set (0.00 sec)
+```
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-oracle-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-oracle-matrixone.md
new file mode 100644
index 000000000..56a1893c6
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-oracle-matrixone.md
@@ -0,0 +1,149 @@
+# Write data to MatrixOne using DataX
+
+This article describes how to write Oracle data offline to a MatrixOne database using the DataX tool.
+
+## Prepare before you start
+
+Before you can start writing data to MatrixOne using DataX, you need to complete the installation of the following software:
+
+- Complete [standalone MatrixOne deployment](https://docs.matrixorigin.cn/1.2.2/MatrixOne/Get-Started/install-standalone-matrixone/).
+- Install [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html).
+- Install [Python 3.8 (or plus)](https://www.python.org/downloads/).
+- Download the [DataX](https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz) installation package and unzip it.
+- Download [matrixonewriter.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/Computing-Engine/datax-write/matrixonewriter.zip) and extract it to the `plugin/writer/` directory in the root of your DataX project.
+- Install [Oracle 19c](https://www.oracle.com/database/technologies/oracle-database-software-downloads.html).
+- Install the MySQL Client.
+
+## Operational steps
+
+### scott users using Oracle
+
+This time you are using the user scott in Oracle to create the table (or other users, of course), and in Oracle 19c the scott user needs to be created manually and can be unlocked by command using the sqlplus tool.
+
+```sql
+sqlplus / as sysdba
+create user scott identified by tiger;
+grant dba to scott;
+```
+
+This can then be accessed via the scott user login:
+
+```sql
+sqlplus scott/tiger
+```
+
+### Creating Oracle Test Data
+
+To create the employees\_oracle table in Oracle:
+
+```sql
+create table employees_oracle(
+ id number(5),
+ name varchar(20)
+);
+--Insert sample data:
+insert into employees_oracle values(1,'zhangsan');
+insert into employees_oracle values(2,'lisi');
+insert into employees_oracle values(3,'wangwu');
+insert into employees_oracle values(4,'oracle');
+-- In sqlplus, transactions are not committed by default without exiting, so you need to commit the transaction manually after inserting the data (or perform the insertion with a tool such as DBeaver)
+COMMIT;
+```
+
+### Creating a MatrixOne Test Sheet
+
+Since DataX can only synchronize data, not table structure, we need to manually create the table in the target database (MatrixOne) before we can perform the task.
+
+```sql
+CREATE TABLE `oracle_datax` (
+ `id` bigint(20) NOT NULL,
+ `name` varchar(100) DEFAULT NULL,
+ PRIMARY KEY (`id`)
+) ;
+```
+
+### Creating a Job Profile
+
+The task configuration file in DataX is in json format and the built-in task configuration template can be viewed by the following command:
+
+```python
+python datax.py -r oraclereader -w matrixonewriter
+```
+
+Go to the datax/job path and write the job file oracle2mo.json according to the template
+
+```json
+{
+ "job": {
+ "setting": {
+ "speed": {
+ "channel": 8
+ }
+ },
+ "content": [
+ {
+ "reader": {
+ "name": "oraclereader",
+ "parameter": {
+ "username": "scott",
+ "password": "tiger",
+ "column": [
+ '*'
+ ],
+ "connection": [
+ {
+ "table": [
+ "employees_oracle"
+ ],
+ "jdbcUrl": [
+ "jdbc:oracle:thin:@xx.xx.xx.xx:1521:ORCLCDB"
+ ]
+ }
+ ]
+ }
+ },
+ "writer": {
+ "name": "matrixonewriter",
+ "parameter": {
+ "writeMode": "insert",
+ "username": "root",
+ "password": "111",
+ "column": [
+ '*'
+ ],
+ "connection": [
+ {
+ "jdbcUrl": "jdbc:mysql://xx.xx.xx.xx:6001/test",
+ "table": [
+ "oracle_datax"
+ ]
+ }
+ ]
+ }
+ }
+ }
+ ]
+ }
+}
+```
+
+### Starting a datax job
+
+```bash
+python /opt/module/datax/bin/datax.py /opt/module/datax/job/oracle2mo.json
+```
+
+### Viewing Data in MatrixOne Tables
+
+```sql
+mysql> select * from oracle_datax;
++------+----------+
+| id | name |
++------+----------+
+| 1 | zhangsan |
+| 2 | lisi |
+| 3 | wangwu |
+| 4 | oracle |
++------+----------+
+4 rows in set (0.00 sec)
+```
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-overview.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-overview.md
new file mode 100644
index 000000000..de37d74d0
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-overview.md
@@ -0,0 +1,18 @@
+# Write data to MatrixOne using DataX
+
+## Overview
+
+DataX is an Ali open source offline synchronization tool for heterogeneous data sources that provides stable and efficient data synchronization for efficient data synchronization between heterogeneous data sources.
+
+DataX divides synchronization of different data sources into two main components: **Reader** and **Writer**. The DataX framework theoretically supports data synchronization efforts for any data source type.
+
+MatrixOne is highly compatible with MySQL 8.0, but since DataX's included MySQL Writer plug-in adapts to the JDBC driver of MySQL 5.1, the community has separately revamped the MySQL 8.0-driven MatrixOneWriter plug-in to improve compatibility. The MatrixOneWriter plugin implements the ability to write data to the MatrixOne database target table. In the underlying implementation, the MatrixOneWriter connects to a remote MatrixOne database via JDBC and executes the corresponding `insert into ...` SQL statement to write data to MatrixOne, while supporting bulk commits.
+
+MatrixOneWriter leverages the DataX framework to get the generated protocol data from Reader and generates the appropriate `insert into...` statement based on the `writeMode` you configured. When a primary key or unique index conflict is encountered, conflicting rows are excluded and writes continue. For performance optimization reasons, we took the `PreparedStatement + Batch` approach and set the `rewriteBatchedStatements=true` option to buffer the data into the thread context's buffer. A write request is triggered only when the amount of data in the buffer reaches a predetermined threshold.
+
+
+
+!!! note
+ You need to have at least `insert into ...` permissions to execute the entire task. Whether you need additional permissions depends on your `preSql` and `postSql` in the task configuration.
+
+MatrixOneWriter is primarily intended for ETL development engineers who use MatrixOneWriter to import data from a data warehouse into MatrixOne. At the same time, MatrixOneWriter can also serve users such as DBAs as a data migration tool.
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-postgresql-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-postgresql-matrixone.md
new file mode 100644
index 000000000..aa2e64e1e
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-postgresql-matrixone.md
@@ -0,0 +1,206 @@
+# Write data to MatrixOne using DataX
+
+This article describes how to write PostgreSQL data offline to a MatrixOne database using the DataX tool.
+
+## Prepare before you start
+
+Before you can start writing data to MatrixOne using DataX, you need to complete the installation of the following software:
+
+- Complete [standalone MatrixOne deployment](https://docs.matrixorigin.cn/1.2.2/MatrixOne/Get-Started/install-standalone-matrixone/).
+- Install [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html).
+- Install [Python 3.8 (or plus)](https://www.python.org/downloads/).
+- Download the [DataX](https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz) installation package and unzip it.
+- Download [matrixonewriter.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/Computing-Engine/datax-write/matrixonewriter.zip) and extract it to the `plugin/writer/` directory in the root of your DataX project.
+- Install [PostgreSQL](https://www.postgresql.org/download/).
+- Install the MySQL Client.
+
+## Operational steps
+
+### Creating test data in postgresql
+
+```sql
+create table public.student
+(
+ stu_id integer not null unique,
+ stu_name varchar(50),
+ stu_age integer,
+ stu_bth date,
+ stu_tel varchar(20),
+ stu_address varchar(100)
+);
+
+insert into public.student (stu_id, stu_name, stu_age, stu_bth, stu_tel, stu_address)
+values (1, '89', 37, '2020-04-08', '13774736413', '8c5ab4290b7b503a616428aa018810f7'),
+ (2, '32', 99, '2021-03-29', '15144066883', '6362da2f9dec9f4ed4b9cb746d614f8b'),
+ (3, '19', 47, '2022-08-12', '18467326153', '3872f24472ac73f756093e7035469519'),
+ (4, '64', 52, '2020-05-23', '17420017216', '70ae7aa670faeb46552aad7a1e9c0962'),
+ (5, '4', 92, '2021-07-26', '17176145462', 'e1a98b2e907d0c485278b9f4ccc8b2e2'),
+ (6, '64', 32, '2021-02-15', '17781344827', '46ee127c3093d94626ba6ef8cd0692ba'),
+ (7, '3', 81, '2021-05-30', '18884764747', '0d1933c53c9a4346d3f6c858dca790fd'),
+ (8, '20', 53, '2022-05-09', '18270755716', '0b58cad62f9ecded847a3c5528bfeb32'),
+ (9, '35', 80, '2022-02-06', '15947563604', 'a31547f9dc4e47ce78cee591072286a5'),
+ (10, '2', 4, '2021-12-27', '17125567735', '527f56f97b043e07f841a71a77fb65e1'),
+ (11, '93', 99, '2020-09-21', '17227442051', '6cd20735456bf7fc0de181f219df1f05'),
+ (12, '85', 92, '2021-06-18', '17552708612', 'ec0f8ea9c8c9a1ffba168b71381c844a'),
+ (13, '4', 85, '2022-06-23', '18600681601', 'f12086a2ac3c78524273b62387142dbb'),
+ (14, '57', 62, '2022-09-05', '15445191147', '8e4a867c3fdda49da4094f0928ff6d9c'),
+ (15, '60', 14, '2020-01-13', '15341861644', 'cb2dea86155dfbe899459679548d5c4d'),
+ (16, '38', 4, '2021-06-24', '17881144821', 'f8013e50862a69cb6b008559565bd8a9'),
+ (17, '38', 48, '2022-01-10', '17779696343', 'c3a6b5fbeb4859c0ffc0797e36f1fd83'),
+ (18, '22', 26, '2020-10-15', '13391701987', '395782c95547d269e252091715aa5c88'),
+ (19, '73', 15, '2022-05-29', '13759716790', '808ef7710cdc6175d23b0a73543470d9'),
+ (20, '42', 41, '2020-10-17', '18172716366', 'ba1f364fb884e8c4a50b0fde920a1ae8'),
+ (21, '56', 83, '2020-03-07', '15513537478', '870ad362c8c7590a71886243fcafd0d0'),
+ (22, '55', 66, '2021-10-29', '17344805585', '31691a27ae3e848194c07ef1d58e54e8'),
+ (23, '90', 36, '2020-10-04', '15687526785', '8f8b8026eda6058d08dc74b382e0bd4d'),
+ (24, '16', 35, '2020-02-02', '17162730436', '3d16fcff6ef498fd405390f5829be16f'),
+ (25, '71', 99, '2020-06-25', '17669694580', '0998093bfa7a4ec2f7e118cd90c7bf27'),
+ (26, '25', 81, '2022-01-30', '15443178508', '5457d230659f7355e2171561a8eaad1f'),
+ (27, '84', 9, '2020-03-04', '17068873272', '17757d8bf2d3b2fa34d70bb063c44c4a'),
+ (28, '78', 15, '2020-05-29', '17284471816', 'a8e671065639ac5ca655a88ee2d3818f'),
+ (29, '50', 34, '2022-05-20', '18317827143', '0851e6701cadb06352ee780a27669b3b'),
+ (30, '90', 20, '2022-02-02', '15262333350', 'f22142e561721084763533c61ff6af36'),
+ (31, '7', 30, '2021-04-21', '17225107071', '276c949aec2059caafefb2dee1a5eb11'),
+ (32, '80', 15, '2022-05-11', '15627026685', '2e2bcaedc089af94472cb6190003c207'),
+ (33, '79', 17, '2020-01-16', '17042154756', 'ebf9433c31a13a92f937d5e45c71fc1b'),
+ (34, '93', 30, '2021-05-01', '17686515037', 'b7f94776c0ccb835cc9dc652f9f2ae3f'),
+ (35, '32', 46, '2020-06-15', '15143715218', '1aa0ce5454f6cfeff32037a277e1cbbb'),
+ (36, '21', 41, '2020-07-07', '13573552861', '1cfabf362081bea99ce05d3564442a6a'),
+ (37, '38', 87, '2022-01-27', '17474570881', '579e80b0a04bfe379f6657fad9abe051'),
+ (38, '95', 61, '2022-07-12', '13559275228', 'e3036ce9936e482dc48834dfd4efbc42'),
+ (39, '77', 55, '2021-01-27', '15592080796', '088ef31273124964d62f815a6ccebb33'),
+ (40, '24', 51, '2020-12-28', '17146346717', '6cc3197ab62ae06ba673a102c1c4f28e'),
+ (41, '48', 93, '2022-05-12', '15030604962', '3295c7b1c22587d076e02ed310805027'),
+ (42, '64', 57, '2022-02-07', '17130181503', 'e8b134c2af77f5c273c60d723554f5a8'),
+ (43, '97', 2, '2021-01-05', '17496292202', 'fbfbdf19d463020dbde0378d50daf715'),
+ (44, '10', 92, '2021-08-17', '15112084250', '2c9b3419ff84ba43d7285be362221824'),
+ (45, '99', 55, '2020-09-26', '17148657962', 'e46e3c6af186e95ff354ad08683984bc'),
+ (46, '24', 27, '2020-10-09', '17456279238', '397d0eff64bfb47c8211a3723e873b9a'),
+ (47, '80', 40, '2020-02-09', '15881886181', 'ef2c50d70a12dfb034c43d61e38ddd9f'),
+ (48, '80', 65, '2021-06-17', '15159743156', 'c6f826d3f22c63c89c2dc1c226172e56'),
+ (49, '92', 73, '2022-01-16', '18614514771', '657af9e596c2dc8b6eb8a1cda4630a5d'),
+ (50, '46', 1, '2022-04-10', '17347722479', '603b4bb6d8c94aa47064b79557347597');
+```
+
+### Creating a Target Table in MatrixOne
+
+```sql
+CREATE TABLE `student` (
+ `stu_id` int(11) NOT NULL COMMENT "",
+ `stu_name` varchar(50) NULL COMMENT "",
+ `stu_age` int(11) NULL COMMENT "",
+ `stu_bth` date NULL COMMENT "",
+ `stu_tel` varchar(11) NULL COMMENT "",
+ `stu_address` varchar(100) NULL COMMENT "",
+ primary key(stu_id)
+ );
+```
+
+### Creating a Job Profile
+
+Go to the datax/job path, create the file `pgsql2matrixone.json` and enter the following:
+
+```json
+{
+ "job": {
+ "setting": {
+ "speed": {
+ "channel": 3,
+ "byte": 1048576
+ },
+ "errorLimit": {
+ "record": 0,
+ "percentage": 0.02
+ }
+ },
+ "content": [
+ {
+ "reader": {
+ "name": "postgresqlreader",
+ "parameter": {
+ "connection": [
+ {
+ "jdbcUrl": [
+ "jdbc:postgresql://xx.xx.xx.xx:5432/postgres"
+ ],
+ "table": [
+ "public.student"
+ ],
+
+ }
+ ],
+ "password": "123456",
+ "username": "postgres",
+ "column": [
+ "stu_id",
+ "stu_name",
+ "stu_age",
+ "stu_bth",
+ "stu_tel",
+ "stu_address"
+ ]
+ }
+ },
+ "writer": {
+ "name": "matrixonewriter",
+ "parameter": {
+ "column": [
+ "stu_id",
+ "stu_name",
+ "stu_age",
+ "stu_bth",
+ "stu_tel",
+ "stu_address"
+ ],
+ "connection": [
+ {
+ "jdbcUrl": "jdbc:mysql://xx.xx.xx.xx:6001/postgre",
+ "table": [
+ "student"
+ ]
+ }
+ ],
+ "username": "root",
+ "password": "111",
+ "writeMode": "insert"
+ }
+ }
+ }
+ ]
+ }
+}
+```
+
+If Error "The most likely cause of the error for this task, as intelligently analyzed by DataX, is: com.alibaba.datax.common.exception.DataXException: Code: \[Framework-03], Description: The DataX engine is misconfigured, a problem usually caused by a DataX installation error, please contact your operations to resolve it. - The bps value for a single channel cannot be empty or non-positive when there is a total bps speed limit", then you need to add it in json
+
+```json
+"core": {
+ "transport": {
+ "channel": {
+ "class": "com.alibaba.datax.core.transport.channel.memory.MemoryChannel",
+ "speed": {
+ "byte": 2000000,
+ "record": -1
+ }
+ }
+ }
+ }
+```
+
+### Start the datax job
+
+```bash
+python ./bin/datax.py ./job/pgsql2mo.json #in the datax directory
+```
+
+When the task is complete, print the overall operation:
+
+
+
+
+
+### View data in a MatrixOne table
+
+
+
+
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-sqlserver-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-sqlserver-matrixone.md
new file mode 100644
index 000000000..976489264
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-sqlserver-matrixone.md
@@ -0,0 +1,119 @@
+# Write data to MatrixOne using DataX
+
+This article describes how to write SQL Server data offline to a MatrixOne database using the DataX tool.
+
+## Prepare before you start
+
+Before you can start writing data to MatrixOne using DataX, you need to complete the installation of the following software:
+
+- Complete [standalone MatrixOne deployment](https://docs.matrixorigin.cn/1.2.2/MatrixOne/Get-Started/install-standalone-matrixone/).
+- Install [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html).
+- Install [Python 3.8 (or plus)](https://www.python.org/downloads/).
+- Download the [DataX](https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz) installation package and unzip it.
+- Download [matrixonewriter.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/Computing-Engine/datax-write/matrixonewriter.zip) and extract it to the `plugin/writer/` directory in the root of your DataX project.
+- Completed [SQL Server 2022](https://www.microsoft.com/en-us/sql-server/sql-server-downloads).
+- Install the MySQL Client.
+
+## Operational steps
+
+### Create sql server test data
+
+```sql
+CREATE TABLE test.dbo.test2 (
+ id int NULL,
+ age int NULL,
+ name varchar(50) null
+);
+
+INSERT INTO test.dbo.test2
+(id, age, name)
+VALUES(1, 1, N'shdfhg '),
+(4, 4, N' dhdhdf '),
+(2, 2, N' ndgnh '),
+(3, 3, N' dgh '),
+(5, 5, N' dfghnd '),
+(6, 6, N' dete ');
+```
+
+### Creating a Target Table in MatrixOne
+
+Since DataX can only synchronize data, not table structure, we need to manually create the table in the target database (MatrixOne) before we can perform the task.
+
+```sql
+CREATE TABLE test.test_2 (
+ id int not NULL,
+ age int NULL,
+ name varchar(50) null
+);
+```
+
+### Creating a Job Profile
+
+The task configuration file in DataX is in json format and the built-in task configuration template can be viewed by the following command:
+
+```bash
+python datax.py -r sqlserverreader -w matrixonewriter
+```
+
+Go to the datax/job path and, according to the template, write the job file `sqlserver2mo.json`:
+
+```json
+{
+ "job": {
+ "content": [
+ {
+ "reader": {
+ "name": "sqlserverreader",
+ "parameter": {
+ "column": ["id","age","name"],
+ "connection": [
+ {
+ "jdbcUrl": ["jdbc:sqlserver://xx.xx.xx.xx:1433;databaseName=test"],
+ "table": ["dbo.test2"]
+ }
+ ],
+ "password": "123456",
+ "username": "sa"
+ }
+ },
+ "writer": {
+ "name": "matrixonewriter",
+ "parameter": {
+ "column": ["id","age","name"],
+ "connection": [
+ {
+ "jdbcUrl": "jdbc:mysql://xx.xx.xx:6001/test",
+ "table": ["test_2"]
+ }
+ ],
+ "password": "111",
+ "username": "root",
+ "writeMode": "insert"
+ }
+ }
+ }
+ ],
+ "setting": {
+ "speed": {
+ "channel": "1"
+ }
+ }
+ }
+}
+```
+
+### Starting a datax job
+
+```bash
+python datax.py sqlserver2mo.json
+```
+
+### Viewing data in the mo table
+
+```sql
+select * from test_2;
+```
+
+
+
+
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-tidb-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-tidb-matrixone.md
new file mode 100644
index 000000000..594cd6a07
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-tidb-matrixone.md
@@ -0,0 +1,132 @@
+# Write data to MatrixOne using DataX
+
+This article describes how to write TiDB data offline to a MatrixOne database using the DataX tool.
+
+## Prepare before you start
+
+Before you can start writing data to MatrixOne using DataX, you need to complete the installation of the following software:
+
+- Complete [standalone MatrixOne deployment](https://docs.matrixorigin.cn/1.2.2/MatrixOne/Get-Started/install-standalone-matrixone/).
+- Install [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html).
+- Install [Python 3.8 (or plus)](https://www.python.org/downloads/).
+- Download the [DataX](https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz) installation package and unzip it.
+- Download [matrixonewriter.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/Computing-Engine/datax-write/matrixonewriter.zip) and extract it to the `plugin/writer/` directory in the root of your DataX project.
+- TiDB standalone deployment completed.
+- Install the MySQL Client.
+
+## Operational steps
+
+### Creating Test Data in TiDB
+
+```sql
+CREATE TABLE `tidb_dx` (
+ `id` bigint(20) NOT NULL,
+ `name` varchar(100) DEFAULT NULL,
+ `salary` decimal(10,0) DEFAULT NULL,
+ `age` int(11) DEFAULT NULL,
+ `entrytime` date DEFAULT NULL,
+ `gender` char(1) DEFAULT NULL,
+ PRIMARY KEY (`id`)
+);
+
+insert into testdx2tidb values
+(1,"lisa",15660,30,'2022-10-12',0),
+(2,"tom",15060,24,'2021-11-10',1),
+(3,"jenny",15000,28,'2024-02-19',0),
+(4,"henry",12660,24,'2022-04-22',1);
+```
+
+### Creating a Target Table in MatrixOne
+
+Since DataX can only synchronize data, not table structure, we need to manually create the table in the target database (MatrixOne) before we can perform the task.
+
+```sql
+CREATE TABLE `testdx2tidb` (
+ `id` bigint(20) NOT NULL COMMENT "",
+ `name` varchar(100) NULL COMMENT "",
+ `salary` decimal(10, 0) NULL COMMENT "",
+ `age` int(11) NULL COMMENT "",
+ `entrytime` date NULL COMMENT "",
+ `gender` varchar(1) NULL COMMENT "",
+ PRIMARY KEY (`id`)
+);
+```
+
+### Configure the json file
+
+tidb can be read directly using mysqlreader. in the job directory of datax. Edit the configuration file `tidb2mo.json`:
+
+```json
+{
+ "job": {
+ "setting": {
+ "speed": {
+ "channel": 1
+ },
+ "errorLimit": {
+ "record": 0,
+ "percentage": 0
+ }
+ },
+ "content": [
+ {
+ "reader": {
+ "name": "mysqlreader",
+ "parameter": {
+ "username": "root",
+ "password": "root",
+ "column": [ "*" ],
+ "splitPk": "id",
+ "connection": [
+ {
+ "table": [ "tidb_dx" ],
+ "jdbcUrl": [
+ "jdbc:mysql://xx.xx.xx.xx:4000/test"
+ ]
+ }
+ ]
+ }
+ },
+ "writer": {
+ "name": "matrixonewriter",
+ "parameter": {
+ "column": ["*"],
+ "connection": [
+ {
+ "jdbcUrl": "jdbc:mysql://xx.xx.xx.xx:6001/test",
+ "table": ["testdx2tidb"]
+ }
+ ],
+ "password": "111",
+ "username": "root",
+ "writeMode": "insert"
+ }
+ }
+ }
+ ]
+ }
+}
+```
+
+### Carrying out tasks
+
+```bash
+python bin/datax.py job/tidb2mo.json
+```
+
+### View target table data in MatrixOne
+
+```sql
+mysql> select * from testdx2tidb;
++------+-------+--------+------+------------+--------+
+| id | name | salary | age | entrytime | gender |
++------+-------+--------+------+------------+--------+
+| 1 | lisa | 15660 | 30 | 2022-10-12 | 0 |
+| 2 | tom | 15060 | 24 | 2021-11-10 | 1 |
+| 3 | jenny | 15000 | 28 | 2024-02-19 | 0 |
+| 4 | henry | 12660 | 24 | 2022-04-22 | 1 |
++------+-------+--------+------+------------+--------+
+4 rows in set (0.01 sec)
+```
+
+Data import succeeded.
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Etl/Seatunnel/seatunnel-mysql-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/Seatunnel/seatunnel-mysql-matrixone.md
new file mode 100644
index 000000000..9640e7b4c
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/Seatunnel/seatunnel-mysql-matrixone.md
@@ -0,0 +1,125 @@
+# Writing MySQL data to MatrixOne using SeaTunnel
+
+This chapter describes how to write MySQL data to MatrixOne using SeaTunnel.
+
+## Prepare before you start
+
+- Finished [installing and starting](../../../Get-Started/install-standalone-matrixone.md) MatrixOne.
+
+- Finished [installing SeaTunnel Version 2.3.3](https://www.apache.org/dyn/closer.lua/seatunnel/2.3.3/apache-seatunnel-2.3.3-bin.tar.gz). Once installed, the installation path for SeaTunnel can be defined from the shell command line:
+
+```shell
+export SEATNUNNEL_HOME="/root/seatunnel"
+```
+
+- Download and install [MySQL](https://downloads.mysql.com/archives/get/p/23/file/mysql-server_8.0.33-1ubuntu23.04_amd64.deb-bundle.tar).
+
+- Download [mysql-connector-java-8.0.33.jar](https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-j-8.0.33.zip) and copy the file to the `${SEATNUNNEL_HOME}/plugins/jdbc/lib/` directory.
+
+## Operational steps
+
+### Create Test Data
+
+1. Create a MySQL database named `test1` and create a table named `test_table` in it, stored in `mysql.sql` under root. Here is the DDL statement for MySQL:
+
+ ```sql
+ create database test1;
+ use test1;
+ CREATE TABLE `test_table` (
+ `name` varchar(255) DEFAULT NULL,
+ `age` int(11) DEFAULT NULL
+ ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
+ ```
+
+2. Use the [mo\_ctl](https://docs.matrixorigin.cn/1.2.2/MatrixOne/Maintain/mo_ctl/) tool to import MySQL's DDL statements directly into MatrixOne. Execute the following command:
+
+ ```shell
+ mo_ctl sql /root/mysql.sql
+ ```
+
+### Install the Connectors plug-in
+
+Connect to MatrixOne using SeaTunnel's `connector-jdbc` connection plug-in.
+
+1. In SeaTunnel's `${SEATNUNNEL_HOME}/config/plugin_config` file, add the following:
+
+ ```shell
+ --connectors-v2--
+ connector-jdbc
+ --end--
+ ```
+
+2. The SeaTunnel binary package for version 2.3.3 does not provide connector dependencies by default. You need to install the connector by executing the following command the first time you use SeaTunnel:
+
+ ```shell
+ sh bin/install-plugin.sh 2.3.3
+ ```
+
+ __Note:__ This document uses the SeaTunnel engine to write data to MatrixOne without relying on Flink or Spark.
+
+### Define Task Profile
+
+In this document, we use the `test_table` table of the MySQL database as the data source and write the data directly to the `test_table` table of the MatrixOne database without data processing.
+
+Well, due to data compatibility issues, you need to configure the task configuration file `${SEATNUNNEL_HOME}/config/v2.batch.config.template`, which defines how and how data is entered, processed, and exported after SeaTunnel is started.
+
+Edit the configuration file as follows:
+
+```shell
+env {
+ execution.parallelism = 2
+ job.mode = "BATCH"
+}
+
+source {
+ Jdbc {
+ url = "jdbc:mysql://xx.xx.xx.xx:3306/test"
+ driver = "com.mysql.cj.jdbc.Driver"
+ connection_check_timeout_sec = 100
+ user = "root"
+ password = "123456"
+ query = "select * from test_table"
+ }
+}
+
+transform {
+
+}
+
+sink {
+ jdbc {
+ url = "jdbc:mysql://xx.xx.xx.xx:6001/test"
+ driver = "com.mysql.cj.jdbc.Driver"
+ user = "root"
+ password = "111"
+ query = "insert into test_table(name,age) values(?,?)"
+ }
+}
+```
+
+### Run the SeaTunnel app
+
+Launch the SeaTunnel app by executing the following command:
+
+```shell
+./bin/seatunnel.sh --config ./config/v2.batch.config.template -e local
+```
+
+### View run results
+
+At the end of the SeaTunnel run, statistics similar to the following are displayed summarizing the time taken for this write, the total number of read data, the total number of writes, and the total number of write failures:
+
+```shell
+***********************************************
+ Job Statistic Information
+***********************************************
+Start Time : 2023-08-07 16:45:02
+End Time : 2023-08-07 16:45:05
+Total Time(s) : 3
+Total Read Count : 5000000
+Total Write Count : 5000000
+Total Failed Count : 0
+***********************************************
+```
+
+You have successfully synchronously written data from the MySQL database to the MatrixOne database.
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Etl/Seatunnel/seatunnel-oracle-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/Seatunnel/seatunnel-oracle-matrixone.md
new file mode 100644
index 000000000..a20119ca4
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/Seatunnel/seatunnel-oracle-matrixone.md
@@ -0,0 +1,163 @@
+# Write data to MatrixOne using SeaTunnel
+
+This document describes how to write Oracle data to MatrixOne using SeaTunnel.
+
+## Prepare before you start
+
+- Finished [installing and starting](../../../Get-Started/install-standalone-matrixone.md) MatrixOne.
+
+- Finished [installing Oracle 19c](https://www.oracle.com/database/technologies/oracle-database-software-downloads.html).
+
+- Finished [installing SeaTunnel Version 2.3.3](https://www.apache.org/dyn/closer.lua/seatunnel/2.3.3/apache-seatunnel-2.3.3-bin.tar.gz). Once installed, the installation path for SeaTunnel can be defined from the shell command line:
+
+```shell
+export SEATNUNNEL_HOME="/root/seatunnel"
+```
+
+- Install the MySQL Client.
+
+- Download ojdbc8-23.3.0.23.09.jar and copy the file to the ${SEATNUNNEL\_HOME}/plugins/jdbc/lib/ directory.
+
+## Operational steps
+
+### Create test data with scott user in Oracle
+
+This time you are using the user scott in Oracle to create the table (or other users, of course), and in Oracle 19c the scott user needs to be created manually and can be unlocked by command using the sqlplus tool.
+
+- Access to the database
+
+```sql
+sqlplus / as sysdba
+```
+
+- Create a scott user and specify a password
+
+```sql
+create user scott identified by tiger;
+```
+
+- To facilitate testing, we grant the scott dba role:
+
+```sql
+grant dba to scott;
+```
+
+- Subsequent access is available via the scott user login:
+
+```sql
+sqlplus scott/tiger
+```
+
+- Creating Test Data in Oracle
+
+```sql
+create table employees_oracle(
+id number(5),
+name varchar(20)
+);
+
+insert into employees_oracle values(1,'zhangsan');
+insert into employees_oracle values(2,'lisi');
+insert into employees_oracle values(3,'wangwu');
+insert into employees_oracle values(4,'oracle');
+COMMIT;
+--View table data:
+select * from employees_oracle;
+```
+
+### Build tables in advance in MatrixOne
+
+Since SeaTunnel can only synchronize data, not table structure, we need to manually create the table in the target database (mo) before we can perform the task.
+
+```sql
+CREATE TABLE `oracle_datax` (
+ `id` bigint(20) NOT NULL,
+ `name` varchar(100) DEFAULT NULL,
+ PRIMARY KEY (`id`)
+) ;
+```
+
+### Install the Connectors plug-in
+
+Next, explain how to connect to MatrixOne using SeaTunnel's `connector-jdbc` connection plug-in.
+
+1. In SeaTunnel's `${SEATNUNNEL_HOME}/config/plugin_config` file, add the following:
+
+ ```conf
+ --connectors-v2--
+ connector-jdbc
+ --end--
+ ```
+
+2. The SeaTunnel binary package for version 2.3.3 does not provide connector dependencies by default. You need to install the connector by executing the following command the first time you use SeaTunnel:
+
+ ```shell
+ sh bin/install-plugin.sh 2.3.3
+ ```
+
+ __Note:__ This document uses the SeaTunnel engine to write data to MatrixOne without relying on Flink or Spark.
+
+### Define Task Profile
+
+In this section, we use the `employees_oracle` table of the Oracle database as the data source and write the data directly to the `oracle_datax` table of the MatrixOne database without data processing.
+
+Well, due to data compatibility issues, you need to configure the task configuration file `${SEATNUNNEL_HOME}/config/v2.batch.config.template`, which defines how and how data is entered, processed, and exported after SeaTunnel is started.
+
+Edit the configuration file as follows:
+
+```conf
+env {
+ # You can set SeaTunnel environment configuration here
+ execution.parallelism = 10
+ job.mode = "BATCH"
+ #execution.checkpoint.interval = 10000
+ #execution.checkpoint.data-uri = "hdfs://localhost:9000/checkpoint"
+}
+
+source {
+ Jdbc {
+ url = "jdbc:oracle:thin:@xx.xx.xx.xx:1521:ORCLCDB"
+ driver = "oracle.jdbc.OracleDriver"
+ user = "scott"
+ password = "tiger"
+ query = "select * from employees_oracle"
+ }
+}
+
+sink {
+ Jdbc {
+ url = "jdbc:mysql://xx.xx.xx.xx:6001/test"
+ driver = "com.mysql.cj.jdbc.Driver"
+ user = "root"
+ password = "111"
+ query = "insert into oracle_datax values(?,?)"
+ }
+}
+```
+
+### Run the SeaTunnel app
+
+Launch the SeaTunnel app by executing the following command:
+
+```shell
+./bin/seatunnel.sh --config ./config/v2.batch.config.template -e local
+```
+
+### View run results
+
+At the end of the SeaTunnel run, statistics similar to the following are displayed summarizing the time taken for this write, the total number of read data, the total number of writes, and the total number of write failures:
+
+```shell
+***********************************************
+ Job Statistic Information
+***********************************************
+Start Time : 2023-08-07 16:45:02
+End Time : 2023-08-07 16:45:05
+Total Time(s) : 3
+Total Read Count : 4
+Total Write Count : 4
+Total Failed Count : 0
+***********************************************
+```
+
+You have successfully synchronously written data from the Oracle database to the MatrixOne database.
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Etl/Seatunnel/seatunnel-overview.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/Seatunnel/seatunnel-overview.md
new file mode 100644
index 000000000..0789323cd
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/Seatunnel/seatunnel-overview.md
@@ -0,0 +1,17 @@
+# Overview
+
+[SeaTunnel](https://seatunnel.apache.org/) is a distributed, high-performance, easily scalable data integration platform focused on synchronizing and transforming massive amounts of data, both offline and in real time. MatrixOne supports the use of SeaTunnel to synchronize data from other databases, processing tens of billions of pieces of data stably and efficiently.
+
+## Application scenarios
+
+Apache SeaTunnel is a versatile distributed data integration platform for a variety of application scenarios, including:
+
+- Massive data synchronization: SeaTunnel handles the task of synchronizing large-scale data, enabling stable and efficient synchronization of tens of billions of data per day.
+
+- Data Integration: It helps users integrate data from multiple data sources into a unified storage system for subsequent data analysis and processing.
+
+- Real-time streaming: SeaTunnel supports the processing of real-time data streams for scenarios requiring real-time data synchronization and conversion.
+
+- Offline batch processing: In addition to real-time processing, SeaTunnel also supports offline batch processing for regular data synchronization and analysis tasks.
+
+- ETL processing: SeaTunnel can be used for data extraction, transformation and load (ETL) operations to help organizations transform and load data from the source to the target system.
\ No newline at end of file
diff --git a/mkdocs.yml b/mkdocs.yml
index 32bc58a19..ea40f82bd 100644
--- a/mkdocs.yml
+++ b/mkdocs.yml
@@ -176,18 +176,44 @@ nav:
- Rag Application demo: MatrixOne/Tutorial/rag-demo.md
- Picture(Text)-to-Picture Search Application demo: MatrixOne/Tutorial/search-picture-demo.md
- Ecological Tools:
+ - Message Queue Tools:
+ - Connecting MatrixOne with Kafka : MatrixOne/Develop/Ecological-Tools/Message-Queue/Kafka.md
- BI Tools:
- Visualizing MatrixOne Data with FineBI: MatrixOne/Develop/Ecological-Tools/BI-Connection/FineBI-connection.md
- Visualizing MatrixOne Reports with Yonghong BI: MatrixOne/Develop/Ecological-Tools/BI-Connection/yonghong-connection.md
- Visual Monitoring of MatrixOne with Superset: MatrixOne/Develop/Ecological-Tools/BI-Connection/Superset-connection.md
- ETL Tools:
- - Writing Data to MatrixOne Using SeaTunnel: MatrixOne/Develop/Ecological-Tools/Computing-Engine/seatunnel-write.md
- - Writing Data to MatrixOne Using DataX: MatrixOne/Develop/Ecological-Tools/Computing-Engine/DataX-write.md
+ - Write Data to MatrixOne using SeaTunnel:
+ - Overview: MatrixOne/Develop/Ecological-Tools/Etl/Seatunnel/seatunnel-overview.md
+ - Writing Data from MySQL to MatrixOne: MatrixOne/Develop/Ecological-Tools/Etl/Seatunnel/seatunnel-mysql-matrixone.md
+ - Writing Data from Oracle to MatrixOne: MatrixOne/Develop/Ecological-Tools/Etl/Seatunnel/seatunnel-oracle-matrixone.md
+ - Using DataX to write data to MatrixOne:
+ - Overview: MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-overview.md
+ - Writing Data from MySQL to MatrixOne: MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-mysql-matrixone.md
+ - Writing Data from Oracle to MatrixOne: MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-oracle-matrixone.md
+ - Writing Data from PostgreSQL to MatrixOne: MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-postgresql-matrixone.md
+ - Writing Data from SQL Server to MatrixOne: MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-sqlserver-matrixone.md
+ - Writing Data from MongoDB to MatrixOne: MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-mongodb-matrixone.md
+ - Writing Data from TiDB to MatrixOne: MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-tidb-matrixone.md
+ - Writing Data from ClickHouse to MatrixOne: MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-clickhouse-matrixone.md
+ - Writing Data from Doris to MatrixOne: MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-doris-matrixone.md
+ - Writing Data from InfluxDB to MatrixOne: MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-influxdb-matrixone.md
+ - Writing Data from Elasticsearch to MatrixOne: MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-elasticsearch-matrixone.md
- Computing Engine:
- - Writing Batch data to MatrixOne Using Spark: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark.md
- - Writing Real-Time Data to MatrixOne Using Flink: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink.md
- - Scheduling Tools:
- - Connecting MatrixOne with DolphinScheduler: MatrixOne/Develop/Ecological-Tools/Scheduling-Tools/dolphinScheduler.md
+ - Using Spark to Write Batch Data to MatrixOne:
+ - Overview: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-overview.md
+ - Writing Data from MySQL to MatrixOne: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-mysql-matrixone.md
+ - Writing Data from Hive to MatrixOne: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-hive-matrixone.md
+ - Writing Data from Doris to MatrixOne: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-doris-matrixone.md
+ - Using Flink to Write Real-Time Data to MatrixOne:
+ - Overview: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-overview.md
+ - Writing Data from MySQL to MatrixOne: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-mysql-matrixone.md
+ - Writing Data from Oracle to MatrixOne: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-oracle-matrixone.md
+ - Writing Data from SQL Server to MatrixOne: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-sqlserver-matrixone.md
+ - Writing Data from PostgreSQL to MatrixOne: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-postgresql-matrixone.md
+ - Writing Data from MongoDB to MatrixOne: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-mongo-matrixone.md
+ - Writing Data from TiDB to MatrixOne: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-tidb-matrixone.md
+ - Writing Data from Kafka to MatrixOne: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-kafka-matrixone.md
- Deploying:
- Plan MatrixOne Cluster Topology:
- Cluster Topology Planning Overview: MatrixOne/Deploy/deployment-topology/topology-overview.md
 +
+  +
+ +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+ +
+ +
+ +
+ +
+ +
+ +
+  +
+ +
+ +
+ +
+ +
+