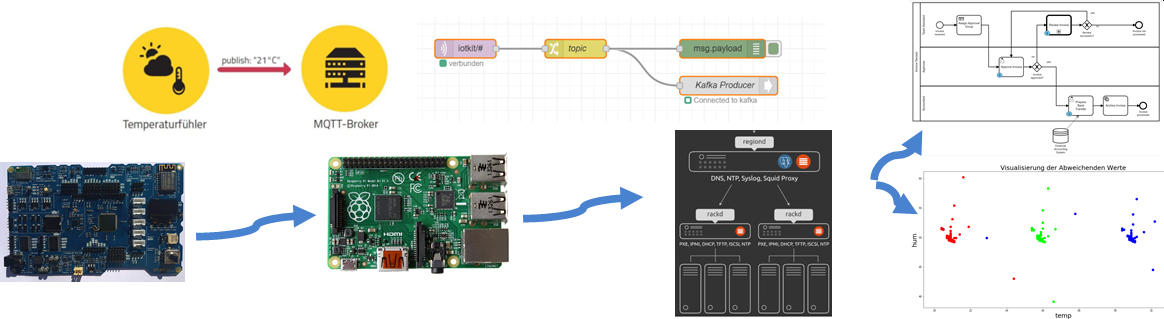
Bei dieser Fast Data Pipeline werden
- Sensordaten (Temperatur) von einen IoT Gerät erhoben und
- weitergerreicht (Publish) an einem Raspberry Pi (Edge) mit MQTT Broker
- der Low-Code Service Node-RED holt diese Daten (Subscribe)
- wandelt diese nach HTTP (REST) für die Prozess Workflow Engine (BPMN) und
- reicht sie an ein Hochverfügbares Messaging System (Kafka) weiter für Verarbeitungen wie Maschine Learning.
Dabei kommen folgende Technologien/Produkte zum Einsatz:
- Iot: M5Stack Core2 - Beispiel
- Cloud: lernMAAS oder eine lokale Umgebung z.B. die vom ModTec Kurs
- Kubernetes als Container Umgebung
- Node-RED (Triage und Protokollwandler)
- Hochverfügbarkeits Messaging mittels Kafka
- die Camunda Prozess (BPMN) Engine für Geschäftsprozesse Workflows
- Juypter Notebook für die Verarbeitung der Daten mittels Machine Learning.
Auf den Raspberry Pi (Edge) wird verzichtet, weil dort die gleiche Umgebung wie in der Cloud läuft (Linux/Kubernetes).

In der einfachsten Variante, werden mit dem obigen Beispiel die Temperatur der MCU und die Batterieladung in % übermittelt.
Je nach vorhandenen Sensoren (z.B. Unit Env III) und Aktoren (z.B. Servo) kann das Programm auch erweitert werden.
Variante a) lernMAAS mit ModTec Umgebung
In einer lernMAAS Umgebung ist eine VM mit Namen modtec-XX (XX = Hostanteil für VPN) zu erstellen und auf dem lokalen Notebook kann die
Umgebung vom ModTec Kurs verwendet werden.
Bei beiden Umgebungen sind alle benötigten Services wie Camunda, Node-RED, Kafka etc. bereits gestartet.
Evtl. muss der BPMN Prozess noch veröffentlicht werden.
Variante b) Cloud und Cloud-init
Erstellen Sie einen Account für die AWS oder Azure Cloud.
Erstellen Sie eine neue Virtuelle Maschine mit min. 2 CPUs, 4 GB RAM und 32 GB HD. Als Betriebsystem nehmen Sie Ubuntu ab der Version 20.04.
Im Feld custom data o.ä. füllen Sie folgende Cloud-init Konfiguration ein:
#cloud-config
users:
- name: ubuntu
sudo: ALL=(ALL) NOPASSWD:ALL
groups: users, admin
shell: /bin/bash
lock_passwd: false
plain_text_passwd: 'insecure'
ssh_authorized_keys:
- ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDUHol1mBvP5Nwe3Bzbpq4GsHTSw96phXLZ27aPiRdrzhnQ2jMu4kSgv9xFsnpZgBsQa84EhdJQMZz8EOeuhvYuJtmhAVzAvNjjRak+bpxLPdWlox1pLJTuhcIqfTTSfBYJYB68VRAXJ29ocQB7qn7aDj6Cuw3s9IyXoaKhyb4n7I8yI3r0U30NAcMjyvV3LYOXx/JQbX+PjVsJMzp2NlrC7snz8gcSKxUtL/eF0g+WnC75iuhBbKbNPr7QP/ItHaAh9Tv5a3myBLNZQ56SgnSCgmS0EUVeMNsO8XaaKr2H2x5592IIoz7YRyL4wlOmj35bQocwdahdOCFI7nT9fr6f insecure@lerncloud
# login ssh and console with password
ssh_pwauth: true
disable_root: false
packages:
- jq
- shellinabox
runcmd:
- curl -sfL https://raw.githubusercontent.com/mc-b/lerncloud/main/services/nfsshare.sh | bash -
- curl -sfL https://raw.githubusercontent.com/mc-b/lerncloud/main/services/vpn.sh | bash -
- curl -sfL https://raw.githubusercontent.com/mc-b/lerncloud/main/services/microk8s.sh | bash -
- curl -sfL https://raw.githubusercontent.com/mc-b/lerncloud/main/services/microk8saddons.sh | bash -
- sudo su - ubuntu -c "curl -sfL https://raw.githubusercontent.com/mc-b/lerncloud/main/services/repository.sh | bash -s https://github.com/mc-b/duk"
- sudo su - ubuntu -c "curl -sfL https://raw.githubusercontent.com/mc-b/lerncloud/main/services/knative.sh | bash -"
- sudo su - ubuntu -c "curl -sfL https://raw.githubusercontent.com/mc-b/modtec/master/scripts/jupyter-notebook.sh | bash -"
- curl -sfL https://raw.githubusercontent.com/mc-b/lerncloud/main/services/k8stools.sh | bash -
- microk8s kubectl apply -f https://raw.githubusercontent.com/mc-b/duk/master/iot/mosquitto.yaml
Nach erfolgreicher Installation sind folgende Services verfügbar:
- mosquitto auf Port 31883 (nur MQTT Broker ohne UI)
- Jupyter mit Machine Learning Notebooks auf http://[ip vm]:32188/tree/work/mlg
- Kubernetes Dashboard auf https://[ip vm]:8443
ACHTUNG: das ist eine Lernumgebung, werden die Ports gegen das gesamte Internet geöffnet ist die VM ungeschützt im Internet. Ports nur für eigene IP-Adresse (Router) öffnen.
Hinweis: Statt die VM über das Cloud UI zu Erstellen, kann auch das CLI der Cloud Anbieter verwendet werden. Dazu erstellt man eine Datei cloud-init.cfg und fügt obigen Inhalt in die Datei. Die weiteren Befehle stehen hier.
Veröffentlichung des BPMN Prozesses
Die Pipeline braucht einen vorbereitenden BPMN Prozess. Diesen können Sie über das Juypter Notebook http://[ip vm]:32088/notebooks/Microservices-BPMN-microk8s.ipynb veröffentlichen.

Die MQTT Messages sollen nun an Apache Kafka weitergeleitet werden. Das hat den Vorteil, dass wir diese
- in andere Formate, z.B. von Binär nach JSON, umwandeln können
- sie Persistieren können
- ein Eventlog erhalten
- etc.
Um Apache Kafka anzusprechen brauchen wir ein paar zusätzliche Plugins.
Diese können in Node-RED mittels Pulldownmenu rechts -> Palette verwalten, Tab Installieren hinzugefügt werden. Es handelt es sich um die Plugins:
- node-red-contrib-kafka-node-latest - mindestens Version 0.2
- node-red-contrib-kafka-manager - letzte Version
Dadurch erhalten wird neu Nodes für die Integration mit Apache Kafka.
- In Node-RED
mqttInput Node auf Flow 1 platzieren, mit Mosquitto Server verbinden, als Topiciotkit/#und bei Outputa Stringeintragen.debugOutput Node auf Flow 1 platzieren und mit Input Node verbinden - damit können wir die MQTT Messages kontrollierenchangeNode auf Flow 1 platzieren und als RegelÄndernWertmsg.topicvoniotkit/alertinbroker_message, weitere Regel hinzufügen und gleich verfahren füriotkit/sensornachbroker_message.- Kafka Producer auf Flow 1 platzieren und mit Kafka Server (kafka:9092) verbinden
- Alle Nodes wie oben in der Grafik verbinden und veröffentlichen (deploy).
- Kubernetes
- Neben Kafka wurden drei Microservices,
iot-kafka-alert(Weiterleitung iotkit/alert Topic an Camunda),iot-kafka-consumer(Schreiben der Sensordaten nach /data/ml-data.csv) undiot-kafka-pipe(Umwandeln der Sensordaten ins JSON Format), gestartet. - Das Ergebnis kann mittels
kubectl logs deployment/iot-....angeschaut werden.
- Neben Kafka wurden drei Microservices,
kubectl logs deployment/iot-kafka-alert
kubectl logs deployment/iot-kafka-consumer
kubectl logs deployment/iot-kafka-pipe
- In Camunda BPMN Workflow Engine https://localhost:30443/camunda (URL kann abweichen, je nach Umgebung) einloggen mittels User/Password
demo/demo. Bei jedem Alarm welcher vom Board (Hall Sensor) mittels Magneten ausgelöst wird, sollte ein neuer Rechnungsprozess gestartet werden.
Topics auslesen, lesen und schreiben auf Topics in Kafka Container, siehe Projekt duk.
Der Flow zum importieren und anpassen, siehe Node-RED-Kafka.json.

Ein Jupyter Notebook ist eine Open-Source-Webanwendung, mit der Sie wiederholende Abläufe erstellen können. Die Live-Code, Gleichungen, Visualisierungen und Text enthalten können.
Verwendungsmöglichkeiten:
- Datenbereinigung und -transformation
- numerische Simulation
- statistische Modellierung
- Datenvisualisierung
- maschinelles Lernen und vieles mehr.
Jupyter Notebooks laufen lokal, ein einem Container oder in der Cloud.
Maschinelles Lernen ist ein Oberbegriff für die «künstliche» Generierung von Wissen aus Erfahrung. Ein künstliches System lernt aus Beispielen und kann diese nach Beendigung der Lernphase verallgemeinern. Das heisst, es werden nicht einfach die Beispiele auswendig gelernt, sondern es «erkennt» Muster und Gesetzmässigkeiten in den Lerndaten.
Das Juypter Notebook MLTempHumSensor demonstriert Predictive Maintenance anhand von Demodaten.
Sollen die Live Daten des IoTKitV3 ausgewertet werden, ist der Code unter "Gegenprüfung mit Testdaten" wie folgt zu ändern:
test = pd.read_csv('ml-data.csv', header=None, names=['sensor', 'temp', 'hum', 'class'] )
Wird das Beispiel jetzt nochmals von vorne durchgespielt (Kernel -> Restart & Run All), erfolgt ein Vergleich mit den Live Daten des M5Stack Core2.