아래 두 자료 참고해서 정리
InnoDB는 file-per-table 테이블스페이스에 존재하는 테이블에 대해 페이지 레벨 압축을 지원한다. 이는 Transparent Page Compression 라 불린다. 페이지 압축은 CREATE TABLE 또는 ALTER TABLE 문에 COMPRESSION attribute를 명시하여 사용할 수 있으며, Zlib과 LZ4 압축 알고리즘을 지원한다. 예를 들어, 아래와 같이 사용할 수 있다:
CREATE TABLE t1 (c1 INT) COMPRESSION="zlib";한편, ALTER TABLE ... COMPRESSION은 테이블스페이스의 압축 attribute만 업데이트한다(즉, metadata만 변경). 새 압축 알고리즘을 설정한 후에 발생하는 쓰기는 새로운 설정을 사용하지만, 기존 압축 페이지에 새 압축 알고리즘을 적용하려면 OPTIMIZE TABLE을 사용하여 테이블을 재빌드해야 한다:
ALTER TABLE t1 COMPRESSION="zlib";
OPTIMIZE TABLE t1;High level에서 봤을 때, transparent page compression은 간단한 페이지 변환이다.
Write : Page -> Transform -> Write transformed page to disk -> Punch hole
Read : Page from disk -> Transform -> Original Page
MySQL 5.7에는 여러 개의 페이지 플러싱 전용 thread가 존재한다. 이는 디스크에 페이지를 쓰기 전에 전용 background thread로 "변환"을 오프로드하여 디스크에 기록한 후, 압축과 "hole punching"을 병렬 처리하는 데 적합하다.
그리고 transparent page compression 기능을 사용하려면 운영 체제와 파일 시스템이 sparse files과 hole punching을 지원해야 한다.
Sparse file은 0이 아닌 영역에만 물리적인 디스크 공간을 할당하는 파일 유형으로써, 파일 자체가 부분적으로 비어 있는 경우 파일 시스템 공간을 보다 효율적으로 사용할 수 있음
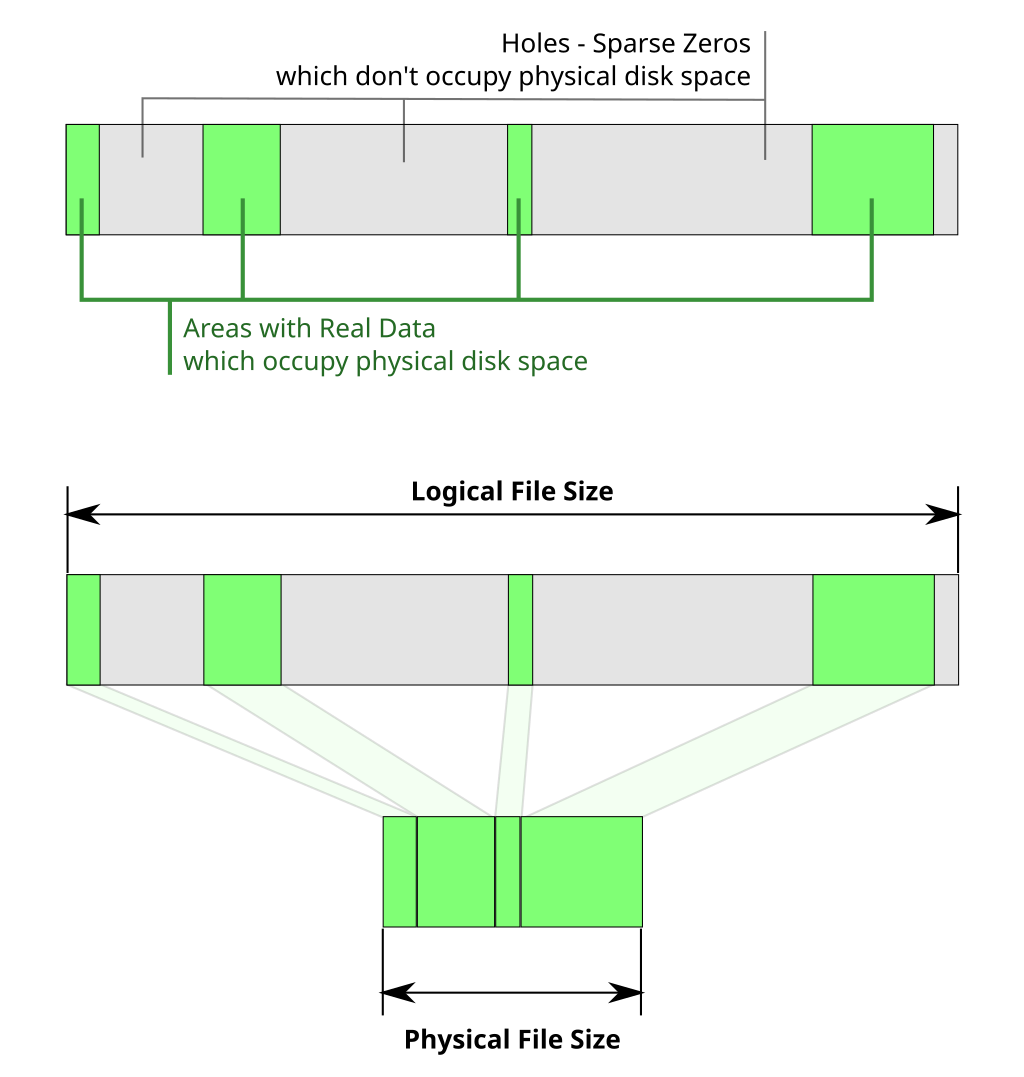
Linux 시스템에서 파일 시스템의 블록 크기는 hole punching에 사용되는 단위 크기다. 따라서, 페이지 압축은 InnoDB 페이지 크기 - 파일 시스템 블록 크기보다 작거나 같은 크기로 압축될 수 있는 경우에만 작동한다. 예를 들어, innodb_page_size가 16KB고 파일 시스템 블록 크기가 4KB인 경우, hole punching을 가능하게 하려면 페이지 데이터를 12KB 이하로 압축해야 한다.
Hole punching에서 ls -l로 보여지는 파일 크기는 블록 디바이스의 실제 할당 크기가 아닌 논리적 파일 크기를 표시한다. 이는 sparse file의 일반적인 이슈며, 논리적 크기와 실제 할당 크기는 INNODB_SYS_TABLESPACES의 information schema 테이블에 쿼리를 수행하여 얻을 수 있다.
다음과 같은 추가적인 열이 information schema 뷰에 추가되었다: FS_BLOCK_SIZE, FILE_SIZE, ALLOCATED_SIZE 및 COMPRESSION
FS_BLOCK_SIZE: 파일 시스템 블록 크기FILE_SIZE: 파일의 논리적 크기이며, ls -l로 볼 수 있음ALLOCATED_SIZE: 파일 시스템의 블록 디바이스에 실제로 할당된 크기COMPRESSION: 현재 압축 알고리즘 설정(있는 경우)
앞서 언급했듯이,
COMPRESSION값은 현재 테이블스페이스의 설정이며 현재 테이블스페이스에 있는 모든 페이지가 해당 형식을 갖는 것을 보장하지는 않는다.
다음은 간단한 예시다:
mysql> select * from information_schema.INNODB_SYS_TABLESPACES WHERE name like 'linkdb%';
+-------+------------------------+------+-------------+----------------------+-----------+---------------+------------+---------------+-------------+----------------+-------------+
| SPACE | NAME | FLAG | FILE_FORMAT | ROW_FORMAT | PAGE_SIZE | ZIP_PAGE_SIZE | SPACE_TYPE | FS_BLOCK_SIZE | FILE_SIZE | ALLOCATED_SIZE | COMPRESSION |
+-------+------------------------+------+-------------+----------------------+-----------+---------------+------------+---------------+-------------+----------------+-------------+
| 23 | linkdb/linktable#P#p0 | 0 | Antelope | Compact or Redundant | 16384 | 0 | Single | 512 | 4861198336 | 2376154112 | LZ4 |mysql> select name, ((file_size-allocated_size)*100)/file_size as compressed_pct from information_schema.INNODB_SYS_TABLESPACES WHERE name like 'linkdb%';
+------------------------+----------------+
| name | compressed_pct |
+------------------------+----------------+
| linkdb/linktable#P#p0 | 51.1323 |
| linkdb/linktable#P#p1 | 51.1794 |
| linkdb/linktable#P#p2 | 51.5254 |
| linkdb/linktable#P#p3 | 50.9341 |
| linkdb/linktable#P#p4 | 51.6542 |
| linkdb/linktable#P#p5 | 51.2027 |
| linkdb/linktable#P#p6 | 51.3837 |
| linkdb/linktable#P#p7 | 51.6309 |
| linkdb/linktable#P#p8 | 51.8193 |
| linkdb/linktable#P#p9 | 50.6776 |
| linkdb/linktable#P#p10 | 51.2959 |
| linkdb/linktable#P#p11 | 51.7169 |
| linkdb/linktable#P#p12 | 51.0571 |
| linkdb/linktable#P#p13 | 51.4743 |
| linkdb/linktable#P#p14 | 51.4895 |
| linkdb/linktable#P#p15 | 51.2749 |
| linkdb/counttable | 50.1664 |
| linkdb/nodetable | 31.2724 |
+------------------------+----------------+
18 rows in set (0.00 sec)블록을 파일 시스템의 free list로 다시 내보내는 hole punching으로 인해 파일 시스템에서 fragmentation이 일어날 수 있다. 여기에는 두 가지 파급 효과가 있다:
- Sequential 스캔이 실제로는 Random I/O로 끝날 수 있다. 이는 특히 HDD의 경우 문제가 된다.
- FS free list 관리 오버 헤드가 증가할 수 있다.