
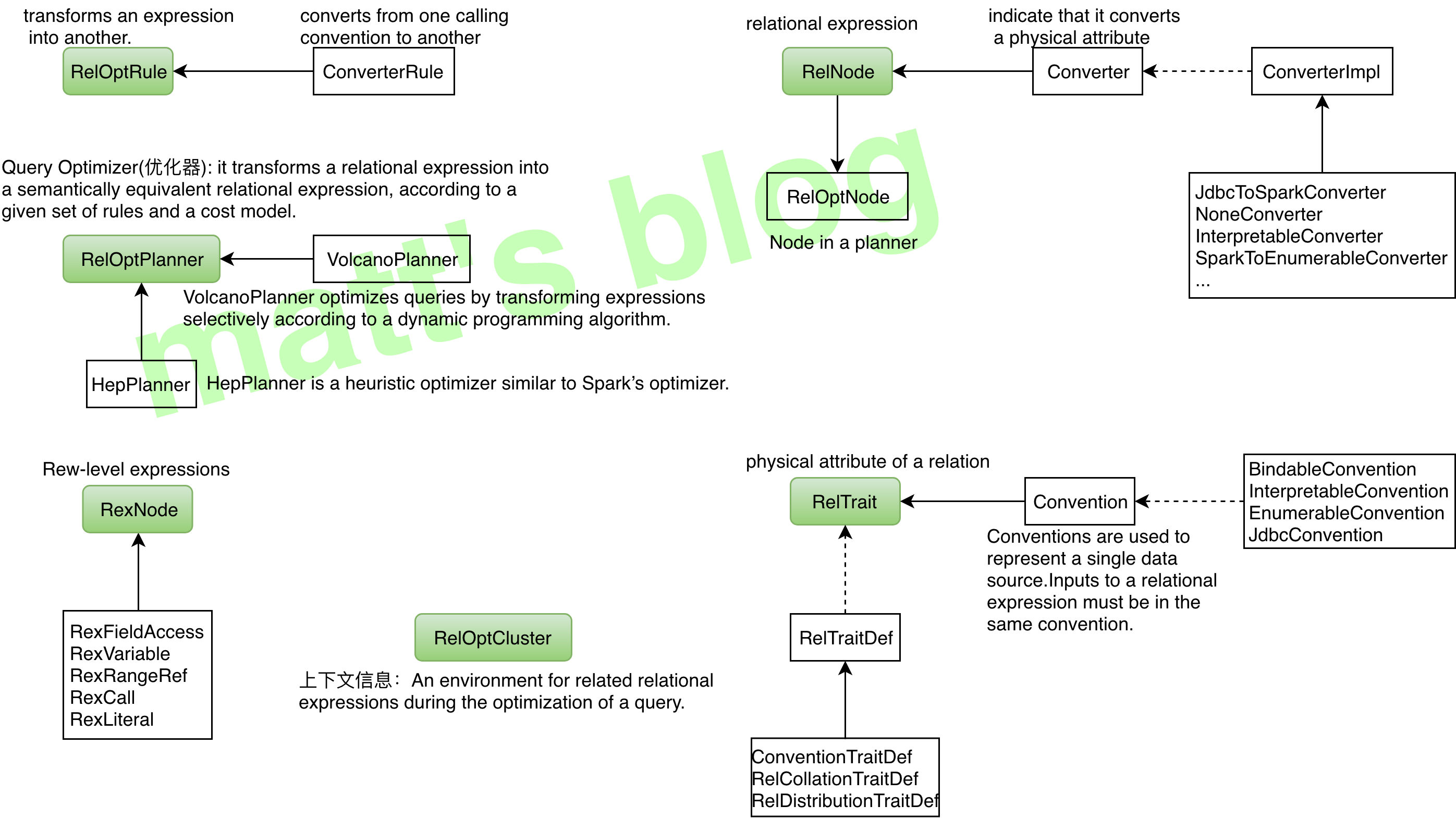
RelNode:
关系表达式, 主要有 TableScan, Project, Sort, Join 等。如果 SQL 为查询的话,所有关系达式都可以在 SqlSelect中找到, 如 where 和 having 对应的 Filter, selectList 对应 Project, orderBy、offset、fetch 对应着 Sort, From 对应着 TableScan/Join 等等, 示便 Sql 最后会生成如下 RelNode 树。

RexNode:
行表达式, 如 RexLiteral(常量), RexCall(函数), RexInputRef (输入引用) 等,举个例子:
SELECT LOCATION as LOCATION,MERGE2(VALUE2) as VALUE2
FROM transaction
WHERE REPORTTIME >=1594887720000 AND REPORTTIME <=1594891320000 AND APPID = 'base-center-outlet-api' AND GROUP2 IN ('DubboService','URL') AND METRICKEY IN ('$$TOTAL') GROUP BY LOCATIONRexCall
<=($1, 1595496539000)RexInputRef
$1RexLiteral
1595496539000:BIGINTSqlNode:
SELECT `LOCATION` AS `LOCATION`
FROM `HEARTBEAT`
WHERE `REPORTTIME` >= 1595507940000 AND `REPORTTIME` <= 1595511540000 AND `APPID` = 'ZTO_TP_TitansDemo'
GROUP BY `LOCATION`
sql:
SELECT deptno, count(*) AS c, sum(sal) AS s
FROM emp
GROUP BY deptno
HAVING count(*) > 10sql -> sqlNode:
LogicalFilter(condition=[>($1, 10)])
LogicalAggregate(group=[{7}], C=[COUNT()], S=[SUM($5)])
LogicalTableScan(table=[[scott, EMP]])
如上,节点树中的最后节点为LogicalTableScan,假设我们不参与(LogicalTableScan)Calcite的查询过程,即不做SQL解析,不做优化,只要把它接入进来,实际Calcite是可以工作的,无非就是可能会有扫全表、数据全部加载到内存里等问题,所以实际中我们可能会参与全部(Translatable)或部分工作(FilterableTable),覆盖Calcite的一些执行计划或过滤条件,让它能更高效的工作。
1、ScannableTable
这种方式基本不会用,原因是查询数据库的时候没有任何条件限制,默认会先把全部数据拉到内存,然后再根据filter条件在内存中过滤。
使用方式:实现
Enumerable scan(DataContext root);,该函数返回Enumerable对象,通过该对象可以一行行的获取这个Table的全部数据。
2、FilterableTable
初级用法,我们能拿到filter条件,即能再查询底层DB时进行一部分的数据过滤,一般开始介入calcite可以用这种方式(translatable方式学习成本较高)。
使用方式:实现
Enumerable scan(DataContext root, List filters )。如果当前类型的“表”能够支持我们自己写代码优化这个过滤器,那么执行完自定义优化器,可以把该过滤条件从集合中移除,否则,就让calcite来过滤,简言之就是,如果我们不处理
List filters,Calcite也会根据自己的规则在内存中过滤,无非就是对于查询引擎来说查的数据多了,但如果我们可以写查询引擎支持的过滤器(比如写一些hbase、es的filter),这样在查的时候引擎本身就能先过滤掉多余数据,更加优化。提示,即使走了我们的查询过滤条件,可以再让calcite帮我们过滤一次,比较灵活。
3、TranslatableTable
高阶用法,有些查询用上面的方式都支持不了或支持的不好,比如join、聚合、或对于select的字段筛选等,需要用这种方式来支持,好处是可以支持更全的功能,代价是所有的解析都要自己写,“承上启下”,上面解析sql的各个部件,下面要根据不同的DB(esmysqldrudi..)来写不同的语法查询。
当使用ScannableTable的时候,我们只需要实现函数
Enumerable scan(DataContext root);,该函数返回Enumerable对象,通过该对象可以一行行的获取这个Table的全部数据(也就意味着每次的查询都是扫描这个表的数据,我们干涉不了任何执行过程);当使用FilterableTable的时候,我们需要实现函数Enumerable scan(DataContext root, List filters );参数中多了filters数组,这个数据包含了针对这个表的过滤条件,这样我们根据过滤条件只返回过滤之后的行,减少上层进行其它运算的数据集;当使用TranslatableTable的时候,我们需要实现RelNode toRel( RelOptTable.ToRelContext context, RelOptTable relOptTable);,该函数可以让我们根据上下文自己定义表扫描的物理执行计划,至于为什么不在返回一个Enumerable对象了,因为上面两种其实使用的是默认的执行计划,转换成EnumerableTableAccessRel算子,通过TranslatableTable我们可以实现自定义的算子,以及执行一些其他的rule,Kylin就是使用这个类型的Table实现查询。
大概就是自定义一系列的 Rule,通过 TranslatableTable#toRel 方法创建一个自定义的 OLAPTableScan,通过 OLAPTableScan 将这些规则注册到 calcite 中,calcite 执行这些自定义 Rule,将原始的 RelNode 转换成优化过的 RelNode:
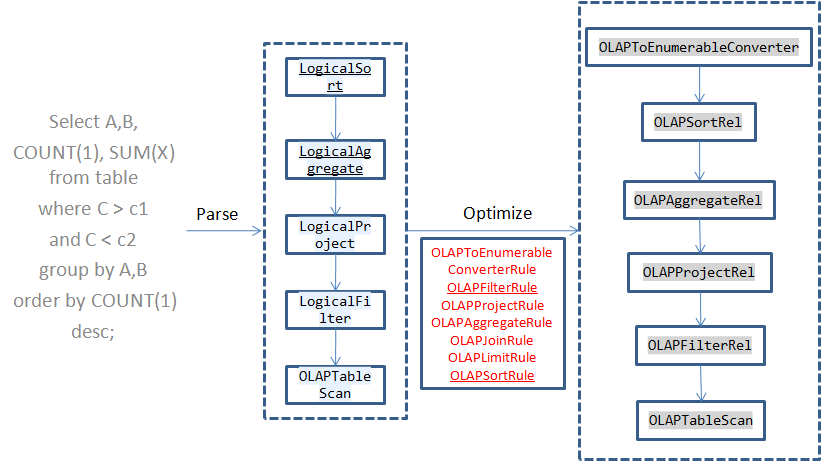
OLAPContext、SQLDigest
// TODO
基于规则优化(RBO):HepPlanner
基于成本优化(CBO):VolcanoPlanner
优化规则:谓词下推、常量折叠、列裁剪
// TODO
需要做如下几步:
- 编写 model.json
- 自定义 SchemaFactory
- 自定义 Schema(像一个“没有存储层的databse”一样,Calcite不会去了解任何文件格式)
- 自定义Table
- 自定义 Enumerator
demo url: https://github.com/objcoding/calcite-demo

SELECT LOCATION as LOCATION,MERGE2(VALUE2) as VALUE2
FROM transaction
WHERE REPORTTIME >=1594887720000 AND REPORTTIME <=1594891320000 AND APPID = 'base-center-outlet-api' AND GROUP2 IN ('DubboService','URL') AND METRICKEY IN ('$$TOTAL') GROUP BY LOCATION一条 sql 在 zcat 中的流转:

- 通过 filter 方法对 sql 的 RexNode 进行解析:appId、startAt/endAt、sqlConditions;
- 通过 doInit 方法对解析出来的值进行加工处理:按分钟聚合还是按消息聚合、跨天查询、根据条件获取 ReportIndex。
根据初始化获取的 ReportIndex 循环读取数据,每读取一条数据就按照表结构进行封装。
1、优化 Enumerable 创建
2、优化 calcite 连接的创建
3、增加 Bindable 缓存
在 EnumerableRel(RelNode,我们可以通过 TranslatableTable自定义 FilterRel、JoinRel、AggregateRel)的每个算子的 implement 方法中会将一些算子(Group、join、sort、function)要实现的算法写成 Linq4j 的表达式,然后通过这些 Linq4j 表达式生成 Java Class。(通过 JavaRowFormat 格式化)
calcite 会将 sql 生成的 linq4j 表达式生成可执行的 Java 代码( Bindable 类): org.apache.calcite.adapter.enumerable.EnumerableInterpretable#getBindable
Calcite 会调用 Janino 编译器动态编译这个 java 类,并且实例化这个类的一个对象,然后将其封装到 CalciteSignature 对象中。
调用 executorQuery 查询方法并创建 CalciteResultSet 的时候会调用 Bindable 对象的 bind 方法,这个方法返回一个Eumerable对象:
org.apache.calcite.avatica.AvaticaResultSet#execute

org.apache.calcite.jdbc.CalcitePrepare.CalciteSignature#enumerable

将 Enumerable 赋值给 CalciteResultSet 的 cursor 成员变量。
在执行真正的数据库查询时,获得实际的 CalciteResultSet,最终会调用:
org.apache.calcite.avatica.AvaticaResultSet#next

以下是根据 SQL 动态生成的 linq4j 表达式:
public static class Record2_0 implements java.io.Serializable {
public Object f0;
public boolean f1;
public Record2_0() {}
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (!(o instanceof Record2_0)) {
return false;
}
return java.util.Objects.equals(this.f0, ((Record2_0) o).f0) && this.f1 == ((Record2_0) o).f1;
}
public int hashCode() {
int h = 0;
h = org.apache.calcite.runtime.Utilities.hash(h, this.f0);
h = org.apache.calcite.runtime.Utilities.hash(h, this.f1);
return h;
}
public int compareTo(Record2_0 that) {
int c;
c = org.apache.calcite.runtime.Utilities.compare(this.f1, that.f1);
if (c != 0) {
return c;
}
return 0;
}
public String toString() {
return "{f0=" + this.f0 + ", f1=" + this.f1 + "}";
}
}
public org.apache.calcite.linq4j.Enumerable bind(final org.apache.calcite.DataContext root) {
final org.apache.calcite.rel.RelNode v1stashed = (org.apache.calcite.rel.RelNode) root.get("v1stashed");
final org.apache.calcite.interpreter.Interpreter interpreter = new org.apache.calcite.interpreter.Interpreter(
root,
v1stashed);
java.util.List accumulatorAdders = new java.util.LinkedList();
accumulatorAdders.add(new org.apache.calcite.linq4j.function.Function2() {
public Record2_0 apply(Record2_0 acc, Object[] in) {
final Object inp9_ = in[9];
if (inp9_ != null) {
acc.f1 = true;
acc.f0 = com.zto.zcat.store.api.query.Merge2Fun.add(acc.f0, inp9_);
}
return acc;
}
public Record2_0 apply(Object acc, Object in) {
return apply(
(Record2_0) acc,
(Object[]) in);
}
}
);
org.apache.calcite.adapter.enumerable.AggregateLambdaFactory lambdaFactory = new org.apache.calcite.adapter.enumerable.BasicAggregateLambdaFactory(
new org.apache.calcite.linq4j.function.Function0() {
public Object apply() {
Object a0s0;
boolean a0s1;
a0s1 = false;
a0s0 = com.zto.zcat.store.api.query.Merge2Fun.init();
Record2_0 record0;
record0 = new Record2_0();
record0.f0 = a0s0;
record0.f1 = a0s1;
return record0;
}
}
,
accumulatorAdders);
return org.apache.calcite.linq4j.Linq4j.singletonEnumerable(interpreter.aggregate(lambdaFactory.accumulatorInitializer().apply(), lambdaFactory.accumulatorAdder(), lambdaFactory.singleGroupResultSelector(new org.apache.calcite.linq4j.function.Function1() {
public Object apply(Record2_0 acc) {
return acc.f1 ? com.zto.zcat.store.api.query.Merge2Fun.result(acc.f0) : (Object) null;
}
public Object apply(Object acc) {
return apply(
(Record2_0) acc);
}
}
)));
}
public Class getElementType() {
return java.lang.Object.class;
}总结执行顺序:
1、executeQuery 方法:
1.1 根据算子 linq4j 表达式子生成 Bindable 执行对象,如果有设置缓存,则会将对像存储到缓存中;
1.2 生成 CalciteResultSet 时会调用 Bindable#bind 方法返回一个 Enumerable 对象;
2、getData 方法:
2.1 调用 ResultSet#next 方法最终会嗲用 Enumerable#moveNext
一图理解 Bindable 在 calcite 中的作用:

发现 Bindable 缓存会持续增加,说明 Bindable 类内容不一致:

也说明了 calcite 会根据不同的 SQL 动态生成 linq4j 表达式。
- 动态管理url,心跳检查请求剔除
- zcat-admin 对查询进行缓存