BiNChE
BiNChE is a tool for ontology-based chemical enrichment analysis. Based on the ChEBI chemical ontology, BiNChE enables researchers to identify overrepresented, i.e. enriched, ontological terms in their data. The tool is accessible through the ChEBI website. In addition, a stand along Java library is provided here.
Following in the footsteps of enrichment tools for the Gene Ontology, BiNChE utilizes organized chemical knowledge to allow identification of chemical classes or roles or both to help analyse small molecule omics data. Similar to use cases in genomics, chemical enrichment analysis provides higher level information and associations, e.g. to biological roles. Enrichment analysis is an essential tool for small molecule data exploration.
Entry page: http://www.ebi.ac.uk/chebi/tools/binche/
- Web Interface
- Graph Pruning Strategies
- Graphical Exploration of Results
- Use Cases
- Implementation and Core Library (API)
-
Plain: The plain or unweighted analysis requires a list of ChEBI identifiers and relies on a binomial test to define whether the provided list is enriched in certain ChEBI categories.
-
Weighted: For the weighted analysis, a list of ChEBI identifiers plus weights (decimal number) is needed. The ChEBI identifier and weight columns are tab-delimited. Examples for weights are intensity values from measurements or score values from putative molecule identification lists. This type of enrichment uses an implementation of the SaddleSum algorithm to calculate the significance of an enrichment.
-
Fragment: This is a particular case of a weighted analysis, where only a subset of the ontology is used and certain pruners are applied. As such, the input is the same as that described for the weighted analysis.
-
Plain: Plain analysis runs a bionomial test to check for the statistical significance of deviations of input related ontological terms from the background population.
-
Weighted: Weighted analysis runs a SaddleSum implementation that "approximates the distribution of sum of weights asymptotically by saddlepoint method" (see the manual). The weights indicate the importance of each term.
-
Fragment: Fragment analysis is a weighted analysis limited to the chemical classes of the ChEBI ontology (Roles are not used) and uses different pruning strategies on the resulting graph to highlight molecular entities that are enriched. "Fragments" should be understood as molecular fragments or functional groups. Data would typically come from fragmentation mass spectrometry experiments. In contrast to the weighted analysis option, terminal molecular leaves or root vertices are not removed.
The significance of the results are corrected in every case for multiple hypothesis testing using Benjamini and Hochberg's false-discovery rate (FDR). In all the types of analysis, the enrichment is calculated taking the entire selected ontology as background population.
The ChEBI chemical ontology includes three chemical branches: roles, classifications, and sub-atomic particles. BiNChE only makes use of the chemical roles and classifications. Depending on the scientific question, the branches can be used separately or in combination for an enrichment analysis.
-
ChEBI structure classification: The structure classification describes a molecular entity based on its composition and/or the connectivity between its constituent atoms.
-
ChEBI role classification: The role classification describes the role of a molecular entity within a biological context and/or its intended use by humans.
-
ChEBI structure and role classification: The structure and role classification is the union of both classifications. Note that the structure classification is significantly larger than the role classification.
The ChEBI ontology forms a directed acyclic graph. The challenge in the visualisation of enrichment results lies in the complexity and detail of the ontology graph. An informative graph should -- first and foremost -- show enriched ontological terms. To add information to that mere list of enriched terms, it is essential to map the relative position or connectivity of those terms to each other. To avoid unnecessary cluttering of the graph, pruning strategies have been added to the graph layout to remove irrelevant terms. Only terms that are not enriched are subjected to the pruning methods. In terms of code, pruners must implement the ChEBIGraphPruner interface.
-
Zero Degree Vertex Pruner: Removes vertices that have a total degree of zero.
-
Root Children Pruner: Removes the first three levels of children vertices from the root vertex of the chemical and role ontology. The removed vertices refer to less meaningful terms, such as "molecular entity", "chemical substance", or "application", and skew the overall graph layout.
-
Molecule Leaves Pruner: Removes leaves (terminal vertices) that represent discrete molecules and not a class or role.
-
High P-Value Branch Pruner: Removes branches from the graph components that contain only vertices with a p-value greater than 0.05.
-
Linear Branch Collapser Pruner: Collapses linear branches within the graph to hide connecting vertices that are not involved in branching. Consequently, these vertices have an in- and out-degree of one.
To use pruners, they need to be combined through pruning strategies. Pruning strategies implement the [PruningStrategy] (https://github.com/pcm32/BiNChE/blob/develop/src/main/java/net/sourceforge/metware/binche/graph/PrunningStrategy.java) interface. Given that the different pruners exert changes on the graph on each application, subsequent applications of them on the graph can further reduce its elements. Pruning strategies apply pruners at three stages: initial, loop, and final, which are executed in that order. For each of these stages, pruners need to be assigned (a pruner can be assigned to more than one phase). The initial and final phases only involve the application of pruners a single time, while the loop phase iterates the application of the pruners set until the graph converges. Currently, the implemented strategies are:
-
Empty Pruning Strategy: No pruning applied.
-
Fragment Enrichment Pruning Strategy: Applies the High P-Value Branch Pruner (with a cut-off at 0.05) and the Linear Branch Collapser Pruner, both in the initial and loop phases.
-
Plain Enrichment Pruning Strategy: For the pre-loop phase this strategy applies the High Value Branch Pruner (0.05), the Linear Branch Collapser Pruner, and the Root Children Pruner (3 levels, without repetition). During the loop phase, this strategy applies the Molecule Leaves Pruner, the High P-Value Branch Pruner (0.05), the Linear Branch Collapser Pruner, and the Zero Degree Vertex Pruner. No pruners are applied in the final phase post-loop.
-
Weighted Enrichment Pruning Strategy In the initial phase, this strategy applies the Molecule Leaves Pruner, the Root Children Pruner (4 levels, no repetition), and the High P-Value Branch Pruner(0.05). No pruners are applied in the loop phase. In the final phase, the Linear Branch Collapser and Zero Degree Vertex Pruners are applied.
Once the enrichment analysis result is presented to the user through the UI, the user can explore the result interactively through the CytoscapeWeb interface provided.
-
Highlighting and tooltip : hovering over a node highlights it and shows a tooltip with relevant data.
-
Select node : clicking on a node selects it, changing the highlight to blue.
-
Descendants : Given a node of interest, all its descendants can be selected through a contextual menu when clicking on the node.
-
Direct neighbours : all the connected nodes (parents and children, one degree), can be selected through a contextual menu.
-
Change layout : for the visible nodes, the layout can be changed through the menu.
Resulting in the following arrangement for those nodes:
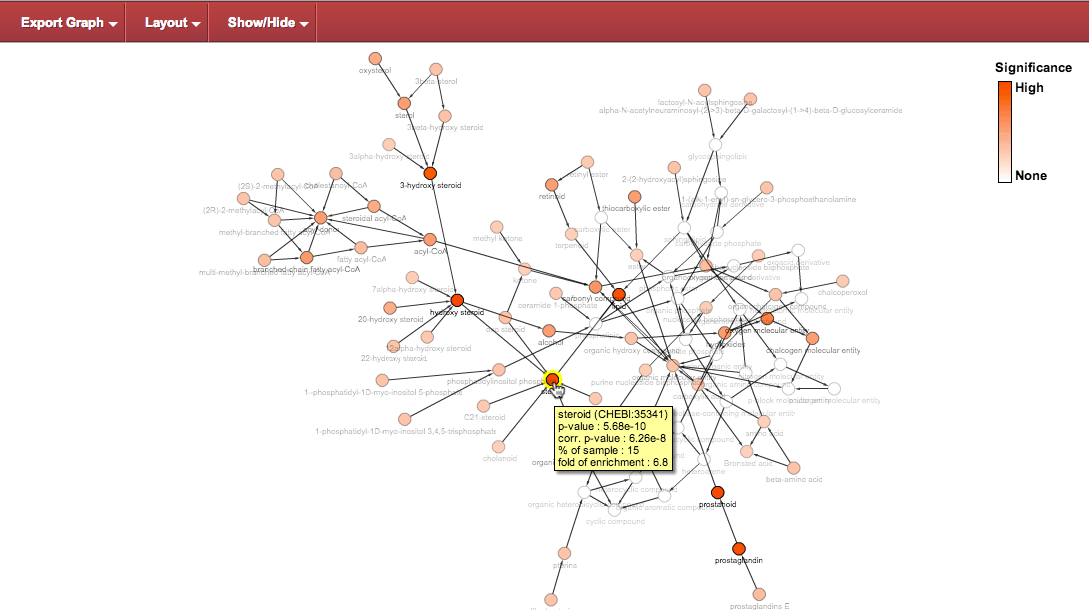
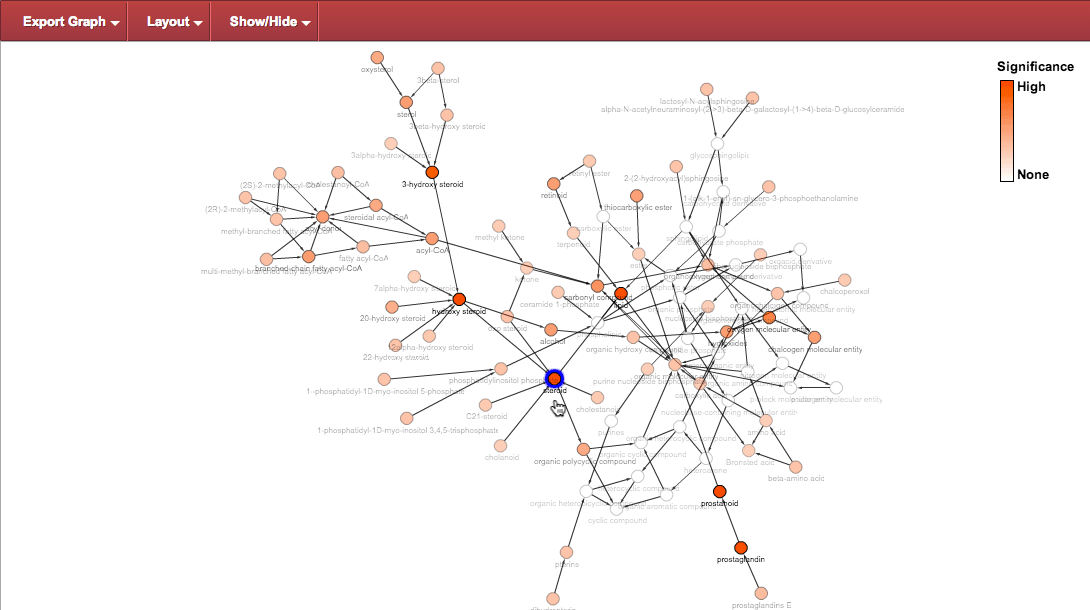
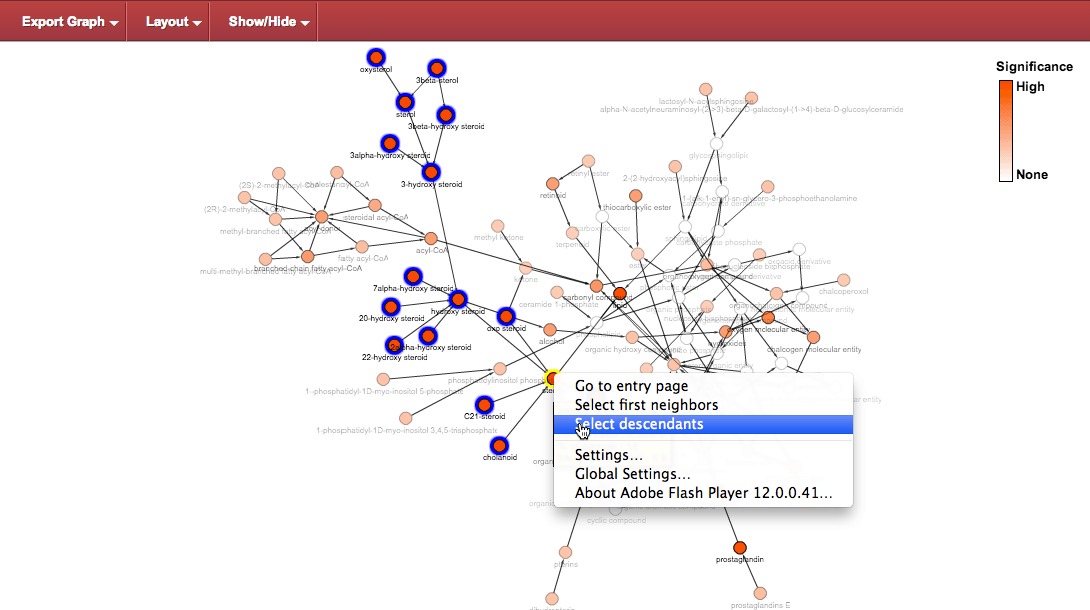
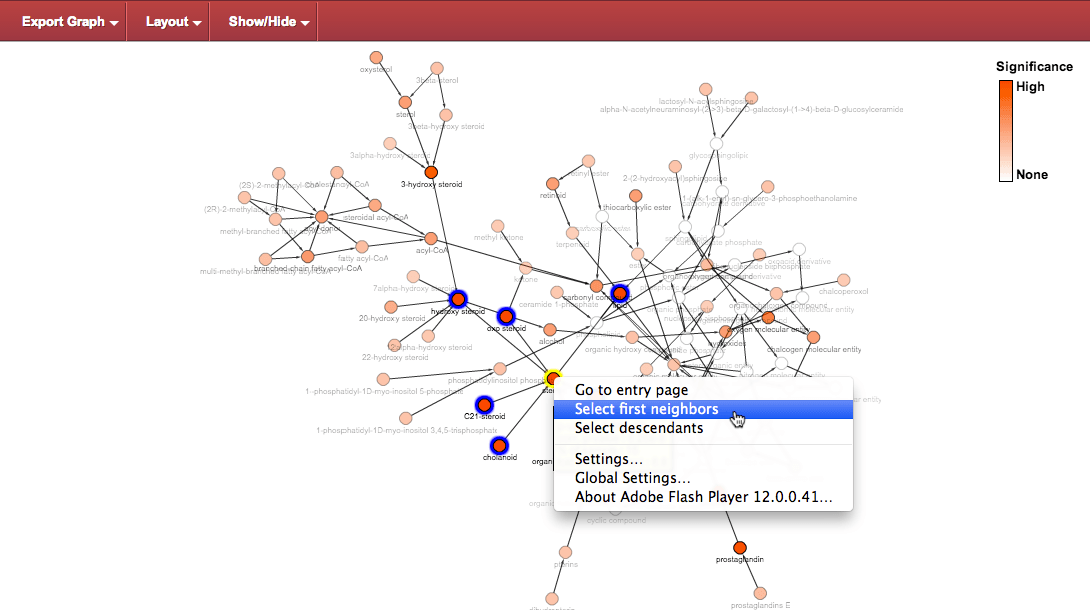
 Resulting in the following arrangement for those nodes:
Resulting in the following arrangement for those nodes:
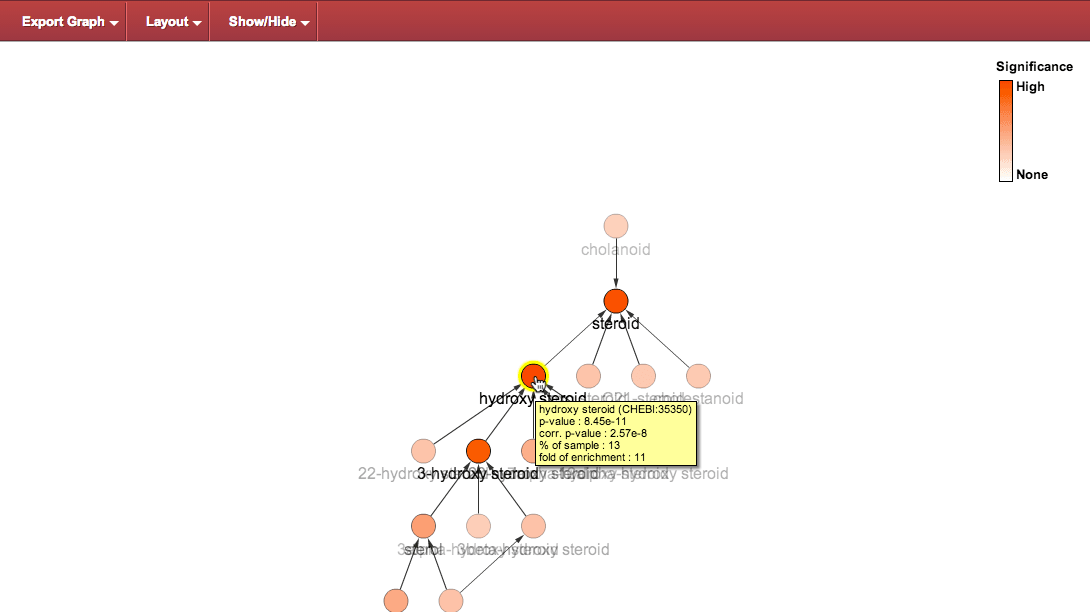
###Decluttering results:
These steps allow you to declutter the graph, to focus on regions of interest.
-
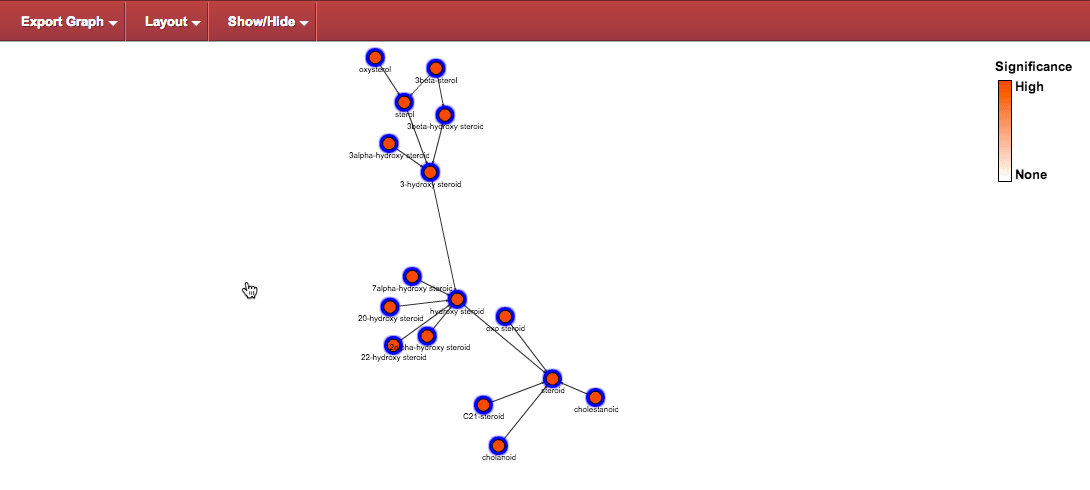
Hide non-selected nodes : Once a set of nodes have been selected, the complement of nodes can be hidden by using the menu:
This command produces the following view:
-
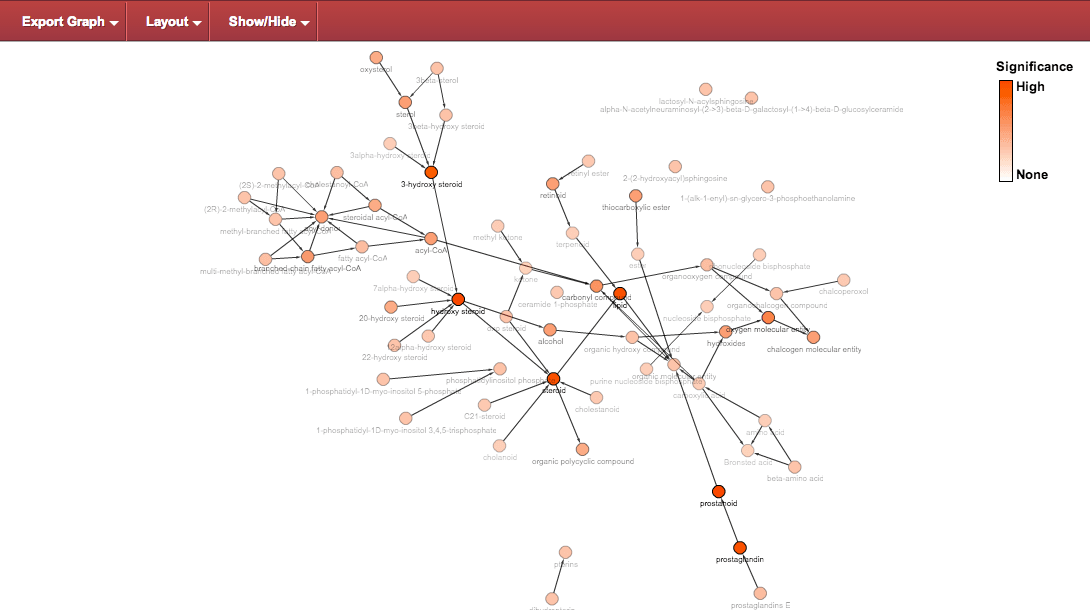
Hide non-significant nodes : hides nodes with p-value > 0.05 through the menu:
This command produces the following view:
-
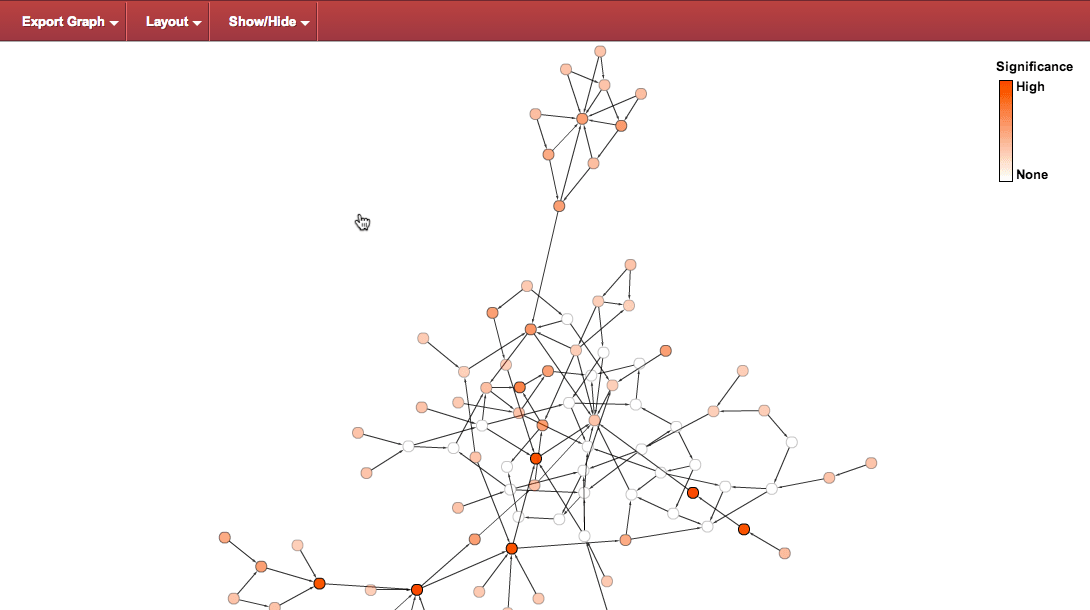
Hide node's labels : reduces the clutter by hiding the labels of the nodes using the menu option:
This command produces the following view:
 This command produces the following view:
This command produces the following view:
 This command produces the following view:
This command produces the following view:
 This command produces the following view:
This command produces the following view:
In general, any list of small molecules, produced via a computational pipeline, experimental technique or any other method, is suitable for the analysis through BiNChE. Examples of these could be a list of small molecules that are relevant within a set of biological assays; metabolites that are consumed or produced by a set of enzymes of interest; a set of metabolites that are known to be part of the metabolism of an organism but that are absent in other organisms of interest; a set of small molecules that where defined as relevant in a metabolomics study; etc.
Weighted analysis provides a bird eye view of a list of compounds that have associated weights, e.g. from network analysis or metabolomics. The example below comes from an effort to build tissue specific metabolic pathways. Here, weighted enrichment analysis highlights the presence of "isoquinolinol" (CHEBI:24923) in the target tissue. Subsequent reasoning about the presence of isoquinolinols in that tissue helps to validate and refine the methods used.
CHEBI:17079 0.7665
CHEBI:46816 0.7465
CHEBI:28658 0.7465
CHEBI:28611 0.7465
CHEBI:28594 0.6915
CHEBI:17048 0.6915
CHEBI:7852 0.60575
CHEBI:164200 0.2342
CHEBI:8489 0.25321
CHEBI:9630 0.2543
CHEBI:59477 0.2335
CHEBI:9495 0.2433
CHEBI:3540 0.509
Plain analysis can be used to analyse metabolite identification lists from MetFrag. Running MetFrag with default settings results in a list of 15 putative identifications of the fragmentation spectrum. The identifiers can be used as input for BiNChE after identifier conversion (e.g. using the ChEBI plug-in in KNIME). Amongst others, plain analysis shows significant enrichment in the term flavonoids. This suggests that the spectrum represents a compound with a C15 or C16 skeleton.
CHEBI:78023
CHEBI:78026
CHEBI:78029
CHEBI:15649
CHEBI:34707
CHEBI:8908
CHEBI:52047
CHEBI:27587
CHEBI:28103
CHEBI:17846
CHEBI:27725
CHEBI:18131
CHEBI:16035
CHEBI:3237
CHEBI:15413
Source code for the core library can be found here. Javadocs for the core API can be found here. An example of usage would be:
Preferences binchePrefs = Preferences.userNodeForPackage(BiNChe.class);
try {
if (binchePrefs.keys().length == 0) {
// loads the ChEBI Ontology file from ChEBI and process it for BiNChE
// if this hasn't been done already.
new OfficialChEBIOboLoader();
}
} catch (Exception e) {
LOGGER.error("Problems loading preferences", e);
return;
}
String ontologyFile = binchePrefs.get(BiNChEOntologyPrefs.RoleAndStructOntology.name(), null);
// the input path points to a file where the list of ChEBI IDs (one per line, CHEBI:03432) are stored.
String elementsForEnrichFile = inputPath;
LOGGER.log(Level.INFO, "Setting default parameters ...");
BingoParameters bingoParameters = getDefaultParameters(ontologyFile);
BiNChe binche = new BiNChe();
binche.setParameters(bingoParameters);
LOGGER.log(Level.INFO, "Reading input file ...");
try {
binche.loadDesiredElementsForEnrichmentFromFile(elementsForEnrichFile);
} catch (IOException e) {
LOGGER.log(ERROR, "Error reading file: " + e.getMessage());
System.exit(1);
}
// enrichment analysis execution.
binche.execute();
// object to receive and process results
ChebiGraph chebiGraph =
new ChebiGraph(binche.getEnrichedNodes(), binche.getOntology(), binche.getInputNodes());
// the ChebiGraph can be traversed, for instance, to make a table of enrichment.
LOGGER.log(Level.INFO, "Writing out graph ...");
SvgWriter writer = new SvgWriter();
// the graph can be written to svg.
writer.writeSvg(chebiGraph.getVisualisationServer(), outputPath);
http://cytoscapeweb.cytoscape.org/ https://github.com/pcm32/BiNChE