+ -P 3306 -u -p --ssl-ca= -e "SELECT version();"
+ ```
+
+4. Later, when configuring TiDB Cloud DM to connect via PrivateLink, you will need to return to the AWS console and approve the pending connection request from TiDB Cloud to this private endpoint.
+
+
Set up AWS PrivateLink and Private Endpoint for the MySQL source database
+ +AWS does not support direct PrivateLink access to RDS or Aurora. Therefore, you need to create a Network Load Balancer (NLB) and publish it as an endpoint service associated with your source MySQL instance. + +1. In the [Amazon EC2 console](https://console.aws.amazon.com/ec2/), create an NLB in the same subnet(s) as your RDS or Aurora writer. Configure the NLB with a TCP listener on port `3306` that forwards traffic to the database endpoint. + + For detailed instructions, see [Create a Network Load Balancer](https://docs.aws.amazon.com/elasticloadbalancing/latest/network/create-network-load-balancer.html) in AWS documentation. + +2. In the [Amazon VPC console](https://console.aws.amazon.com/vpc/), click **Endpoint Services** in the left navigation pane, and then create an endpoint service. During the setup, select the NLB created in the previous step as the backing load balancer, and enable the **Require acceptance for endpoint** option. After the endpoint service is created, copy the service name (in the `com.amazonaws.vpce-svc-xxxxxxxxxxxxxxxxx` format) for later use. + + For detailed instructions, see [Create an endpoint service](https://docs.aws.amazon.com/vpc/latest/privatelink/create-endpoint-service.html) in AWS documentation. + +3. Optional: Test connectivity from a bastion or client inside the same VPC or VNet before starting the migration: + + ```shell + mysql -h
-.mysql.database.azure.com` format.
+
+ For detailed instructions, see [Create a private endpoint via Private Link Center](https://learn.microsoft.com/en-us/azure/mysql/flexible-server/how-to-networking-private-link-portal#create-a-private-endpoint-via-private-link-center) in Azure documentation.
+
+3. Optional: Test connectivity from a bastion or client inside the same VPC or VNet before starting the migration:
+
+ ```shell
+ mysql -h -P 3306 -u -p --ssl-ca= -e "SELECT version();"
+ ```
+
+4. In the [Azure portal](https://portal.azure.com/), return to the overview page of your MySQL Flexible Server instance (not the private endpoint object), click **JSON View** for the **Essentials** section, and then copy the resource ID for later use. The resource ID is in the `/subscriptions//resourceGroups//providers/Microsoft.DBforMySQL/flexibleServers/` format. You will use this resource ID (not the private endpoint ID) to configure TiDB Cloud DM.
+
+5. Later, when configuring TiDB Cloud DM to connect via PrivateLink, you will need to return to the Azure portal and approve the pending connection request from TiDB Cloud to this private endpoint.
+
+
+
+#### VPC peering
+
+If you use AWS VPC peering or Google Cloud VPC network peering, see the following instructions to configure the network.
+
+Set up AWS VPC Peering
+Set up Azure PrivateLink and private endpoint for the MySQL source database
+ +Azure Database for MySQL - Flexible Server supports native private endpoints. You can either enable private access (VNet Integration) during MySQL instance creation or add a private endpoint later. + +To add a new private endpoint, take the following steps: + +1. In the [Azure portal](https://portal.azure.com/), search for and select **Azure Database for MySQL servers**, click your instance name, and then click **Setting** > **Networking** in the left navigation pane. +2. On the **Networking** page, scroll down to the **Private endpoints** section, click **+ Create private endpoint**, and then follow the on-screen instructions to set up the private endpoint. + + During the setup, select the virtual network and subnet that TiDB Cloud can access in the **Virtual Network** tab, and keep **Private DNS integration** enabled in the **DNS** tab. After the private endpoint is created and deployed, click **Go to resource**, click **Settings** > **DNS configuration** in the left navigation pane, and find the hostname to be used to connect with the instance in the **Customer Visible FQDNs** section. Typically, the hostname is in the `
+
Set up AWS VPC peering
If your MySQL service is in an AWS VPC, take the following steps: @@ -129,7 +274,7 @@ If your MySQL service is in an AWS VPC, take the following steps:
-
-### Enable binary logs
+### Grant required privileges for migration
+
+Before starting migration, you need to set up appropriate database users with the required privileges on both the source and target databases. These privileges enable TiDB Cloud DM to read data from MySQL, replicate changes, and write to your TiDB Cloud cluster securely. Because the migration involves both full data dumps for existing data and binlog replication for incremental changes, your migration user requires specific permissions beyond basic read access.
+
+#### Grant required privileges to the migration user in the source MySQL database
+
+For testing purposes, you can use an administrative user (such as `root`) in your source MySQL database.
+
+For production workloads, it is recommended to have a dedicated user for data dump and replication in the source MySQL database, and grant only the necessary privileges:
+
+| Privilege | Scope | Purpose |
+|:----------|:------|:--------|
+| `SELECT` | Tables | Allows reading data from all tables |
+| `LOCK TABLES` | Tables | Ensures consistent snapshots during full dump |
+| `REPLICATION SLAVE` | Global | Enables binlog streaming for incremental replication |
+| `REPLICATION CLIENT` | Global | Provides access to binlog position and server status |
+
+For example, you can use the following `GRANT` statement in your source MySQL instance to grant corresponding privileges:
+
+```sql
+GRANT SELECT, LOCK TABLES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'dm_source_user'@'%';
+```
+
+#### Grant required privileges in the target TiDB Cloud cluster
-To perform incremental data migration, make sure the following requirements are met:
+For testing purposes, you can use the `root` account of your TiDB Cloud cluster.
-- Binary logs are enabled for the upstream database.
-- The binary logs are retained for at least 24 hours.
-- The binlog format for the upstream database is set to `ROW`. If not, update the format to `ROW` as follows to avoid the [format error](/tidb-cloud/tidb-cloud-dm-precheck-and-troubleshooting.md#error-message-check-whether-mysql-binlog_format-is-row):
+For production workloads, it is recommended to have a dedicated user for replication in the target TiDB Cloud cluster and grant only the necessary privileges:
- - MySQL: execute the `SET GLOBAL binlog_format=ROW;` statement. If you want to persist this change across reboots, you can execute the `SET PERSIST binlog_format=ROW;` statement.
- - Amazon Aurora MySQL or RDS for MySQL: follow the instructions in [AWS documentation](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_WorkingWithDBInstanceParamGroups.html) to create a new DB parameter group. Set the `binlog_format=row` parameter in the new DB parameter group, modify the instance to use the new DB parameter group, and then restart the instance to take effect.
+| Privilege | Scope | Purpose |
+|:----------|:------|:--------|
+| `CREATE` | Databases, Tables | Creates schema objects in the target |
+| `SELECT` | Tables | Verifies data during migration |
+| `INSERT` | Tables | Writes migrated data |
+| `UPDATE` | Tables | Modifies existing rows during incremental replication |
+| `DELETE` | Tables | Removes rows during replication or updates |
+| `ALTER` | Tables | Modifies table definitions when schema changes |
+| `DROP` | Databases, Tables | Removes objects during schema sync |
+| `INDEX` | Tables | Creates and modifies indexes |
+| `CREATE VIEW` | View | Create views used by migration |
+
+For example, you can execute the following `GRANT` statement in your target TiDB Cloud cluster to grant corresponding privileges:
+
+```sql
+GRANT CREATE, SELECT, INSERT, UPDATE, DELETE, ALTER, DROP, INDEX ON *.* TO 'dm_target_user'@'%';
+```
## Step 1: Go to the **Data Migration** page
@@ -166,38 +347,66 @@ To perform incremental data migration, make sure the following requirements are
3. On the **Data Migration** page, click **Create Migration Job** in the upper-right corner. The **Create Migration Job** page is displayed.
-## Step 2: Configure the source and target connection
+## Step 2: Configure the source and target connections
-On the **Create Migration Job** page, configure the source and target connection.
+On the **Create Migration Job** page, configure the source and target connections.
1. Enter a job name, which must start with a letter and must be less than 60 characters. Letters (A-Z, a-z), numbers (0-9), underscores (_), and hyphens (-) are acceptable.
2. Fill in the source connection profile.
- - **Data source**: the data source type.
- - **Region**: the region of the data source, which is required for cloud databases only.
- - **Connectivity method**: the connection method for the data source. Currently, you can choose public IP, VPC Peering, or Private Link according to your connection method.
- - **Hostname or IP address** (for public IP and VPC Peering): the hostname or IP address of the data source.
- - **Service Name** (for Private Link): the endpoint service name.
- - **Port**: the port of the data source.
- - **Username**: the username of the data source.
- - **Password**: the password of the username.
- - **SSL/TLS**: if you enable SSL/TLS, you need to upload the certificates of the data source, including any of the following:
- - only the CA certificate
- - the client certificate and client key
- - the CA certificate, client certificate and client key
+ - **Data source**: the data source type.
+ - **Connectivity method**: select a connection method for your data source based on your security requirements and cloud provider:
+ - **Public IP**: available for all cloud providers (recommended for testing and proof-of-concept migrations).
+ - **Private Link**: available for AWS and Azure only (recommended for production workloads requiring private connectivity).
+ - **VPC Peering**: available for AWS and Google Cloud only (recommended for production workloads needing low-latency, intra-region connections with non-overlapping VPC/VNet CIDRs).
+ - Based on the selected **Connectivity method**, do the following:
+ - If **Public IP** or **VPC Peering** is selected, fill in the **Hostname or IP address** field with the hostname or IP address of the data source.
+ - If **Private Link** is selected, fill in the following information:
+ - **Endpoint Service Name** (available if **Data source** is from AWS): enter the VPC endpoint service name (format: `com.amazonaws.vpce-svc-xxxxxxxxxxxxxxxxx`) that you created for your RDS or Aurora instance.
+ - **Private Endpoint Resource ID** (available if **Data source** is from Azure): enter the resource ID of your MySQL Flexible Server instance (format: `/subscriptions//resourceGroups/Set up Google Cloud VPC Network Peering
+Set up Google Cloud VPC network peering
If your MySQL service is in a Google Cloud VPC, take the following steps: @@ -143,16 +288,52 @@ If your MySQL service is in a Google Cloud VPC, take the following steps:
+
3. Fill in the target connection profile.
- - **Username**: enter the username of the target cluster in TiDB Cloud.
- - **Password**: enter the password of the TiDB Cloud username.
+ - **User Name**: enter the username of the target cluster in TiDB Cloud.
+ - **Password**: enter the password of the TiDB Cloud username.
4. Click **Validate Connection and Next** to validate the information you have entered.
5. Take action according to the message you see:
- - If you use Public IP or VPC Peering, you need to add the Data Migration service's IP addresses to the IP Access List of your source database and firewall (if any).
- - If you use AWS Private Link, you are prompted to accept the endpoint request. Go to the [AWS VPC console](https://us-west-2.console.aws.amazon.com/vpc/home), and click **Endpoint services** to accept the endpoint request.
+ - If you use **Public IP** or **VPC Peering** as the connectivity method, you need to add the Data Migration service's IP addresses to the IP Access List of your source database and firewall (if any).
+ - If you use **Private Link** as the connectivity method, you are prompted to accept the endpoint request:
+ - For AWS: go to the [AWS VPC console](https://us-west-2.console.aws.amazon.com/vpc/home), click **Endpoint services**, and accept the endpoint request from TiDB Cloud.
+ - For Azure: go to the [Azure portal](https://portal.azure.com), search for your MySQL Flexible Server by name, click **Setting** > **Networking** in the left navigation pane, locate the **Private endpoint** section on the right side, and then approve the pending connection request from TiDB Cloud.
## Step 3: Choose migration job type
@@ -209,20 +418,18 @@ To migrate data to TiDB Cloud once and for all, choose both **Existing data migr
You can use **physical mode** or **logical mode** to migrate **existing data** and **incremental data**.
-- The default mode is **logical mode**. This mode exports data from upstream databases as SQL statements, and then executes them on TiDB. In this mode, the target tables before migration can be either empty or non-empty. But the performance is slower than physical mode.
-
-- For large datasets, it is recommended to use **physical mode**. This mode exports data from upstream databases and encodes it as KV pairs, writing directly to TiKV to achieve faster performance. This mode requires the target tables to be empty before migration. For the specification of 16 RCUs (Replication Capacity Units), the performance is about 2.5 times faster than logical mode. The performance of other specifications can increase by 20% to 50% compared with logical mode. Note that the performance data is for reference only and might vary in different scenarios.
+- The default mode is **logical mode**. This mode exports data from MySQL source databases as SQL statements and then executes them on TiDB. In this mode, the target tables before migration can be either empty or non-empty. But the performance is slower than physical mode.
-Physical mode is available for TiDB clusters deployed on AWS and Google Cloud.
+- For large datasets, it is recommended to use **physical mode**. This mode exports data from MySQL source databases and encodes it as KV pairs, writing directly to TiKV to achieve faster performance. This mode requires the target tables to be empty before migration. For the specification of 16 RCUs (Replication Capacity Units), the performance is about 2.5 times faster than logical mode. The performance of other specifications can increase by 20% to 50% compared with logical mode. Note that the performance data is for reference only and might vary in different scenarios.
> **Note:**
>
> - When you use physical mode, you cannot create a second migration job or import task for the TiDB cluster before the existing data migration is completed.
> - When you use physical mode and the migration job has started, do **NOT** enable PITR (Point-in-time Recovery) or have any changefeed on the cluster. Otherwise, the migration job will be stuck. If you need to enable PITR or have any changefeed, use logical mode instead to migrate data.
-Physical mode exports the upstream data as fast as possible, so [different specifications](/tidb-cloud/tidb-cloud-billing-dm.md#specifications-for-data-migration) have different performance impacts on QPS and TPS of the upstream database during data export. The following table shows the performance regression of each specification.
+Physical mode exports the MySQL source data as fast as possible, so [different specifications](/tidb-cloud/tidb-cloud-billing-dm.md#specifications-for-data-migration) have different performance impacts on QPS and TPS of the MySQL source database during data export. The following table shows the performance regression of each specification.
-| Migration specification | Maximum export speed | Performance regression of the upstream database |
+| Migration specification | Maximum export speed | Performance regression of the MySQL source database |
|---------|-------------|--------|
| 2 RCUs | 80.84 MiB/s | 15.6% |
| 4 RCUs | 214.2 MiB/s | 20.0% |
@@ -246,22 +453,8 @@ For detailed instructions about incremental data migration, see [Migrate Only In
1. On the **Choose Objects to Migrate** page, select the objects to be migrated. You can click **All** to select all objects, or click **Customize** and then click the checkbox next to the object name to select the object.
- If you click **All**, the migration job will migrate the existing data from the whole source database instance to TiDB Cloud and migrate ongoing changes after the full migration. Note that it happens only if you have selected the **Existing data migration** and **Incremental data migration** checkboxes in the previous step.
-
- SSL/TLS configuration options
+ + - **Option 1: Server authentication only** + - If your MySQL server is configured for server authentication only, upload only the **CA Certificate**. + - In this option, the MySQL server presents its certificate to prove its identity, and TiDB Cloud verifies the server certificate against the CA. + - The CA certificate protects against man-in-the-middle attacks and is required if the MySQL server is started with `require_secure_transport = ON`. + - **Option 2: Client certificate authentication** + - If your MySQL server is configured for client certificate authentication, upload **Client Certificate** and **Client private key**. + - In this option, TiDB Cloud presents its certificate to the MySQL server for authentication, but TiDB Cloud does not verify the MySQL server's certificate. + - This option is typically used when the MySQL server is configured with options such as `REQUIRE SUBJECT '...'` or `REQUIRE ISSUER '...'` without `REQUIRE X509`, allowing it to check specific attributes of the client certificate without full CA validation of that client certificate. + - This option is often used when the MySQL server accepts client certificates in self-signed or custom PKI environments. Note that this configuration is vulnerable to man-in-the-middle attacks and is not recommended for production environments unless other network-level controls guarantee server authenticity. + - **Option 3: Mutual TLS (mTLS) - highest security** + - If your MySQL server is configured for mutual TLS (mTLS) authentication, upload **CA Certificate**, **Client Certificate**, and **Client private key**. + - In this option, the MySQL server verifies TiDB Cloud's identity using the client certificate, and TiDB Cloud verifies MySQL server's identity using the CA certificate. + - This option is required when the MySQL server has `REQUIRE X509` or `REQUIRE SSL` configured for the migration user. + - This option is used when the MySQL server requires client certificates for authentication. + - You can get the certificates from the following sources: + - Download from your cloud provider (see [TLS certificate links](#end-to-end-encryption-over-tlsssl)). + - Use your organization's internal CA certificates. + - Self-signed certificates (for development/testing only). + +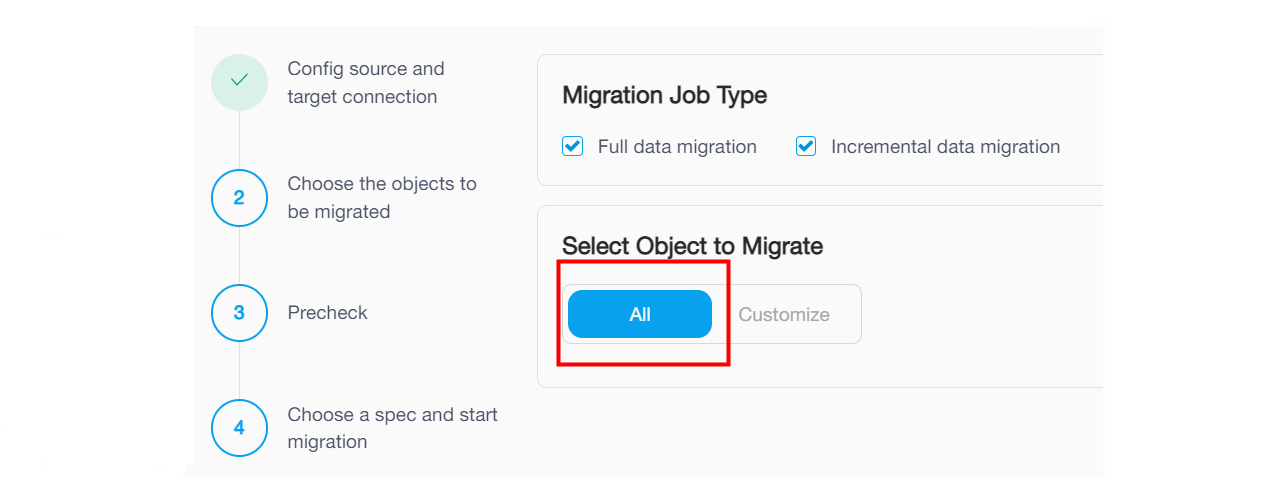 -
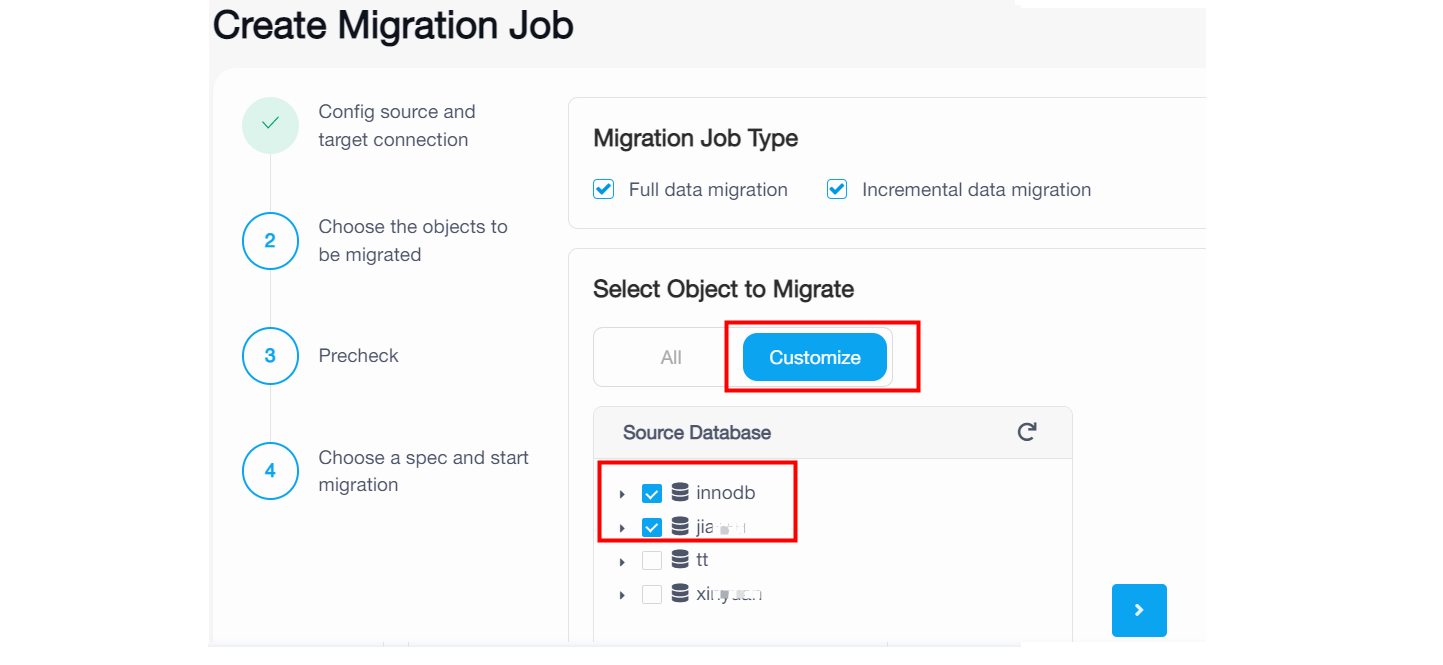
- If you click **Customize** and select some databases, the migration job will migrate the existing data and migrate ongoing changes of the selected databases to TiDB Cloud. Note that it happens only if you have selected the **Existing data migration** and **Incremental data migration** checkboxes in the previous step.
-
-
-
- If you click **Customize** and select some databases, the migration job will migrate the existing data and migrate ongoing changes of the selected databases to TiDB Cloud. Note that it happens only if you have selected the **Existing data migration** and **Incremental data migration** checkboxes in the previous step.
-
-  -
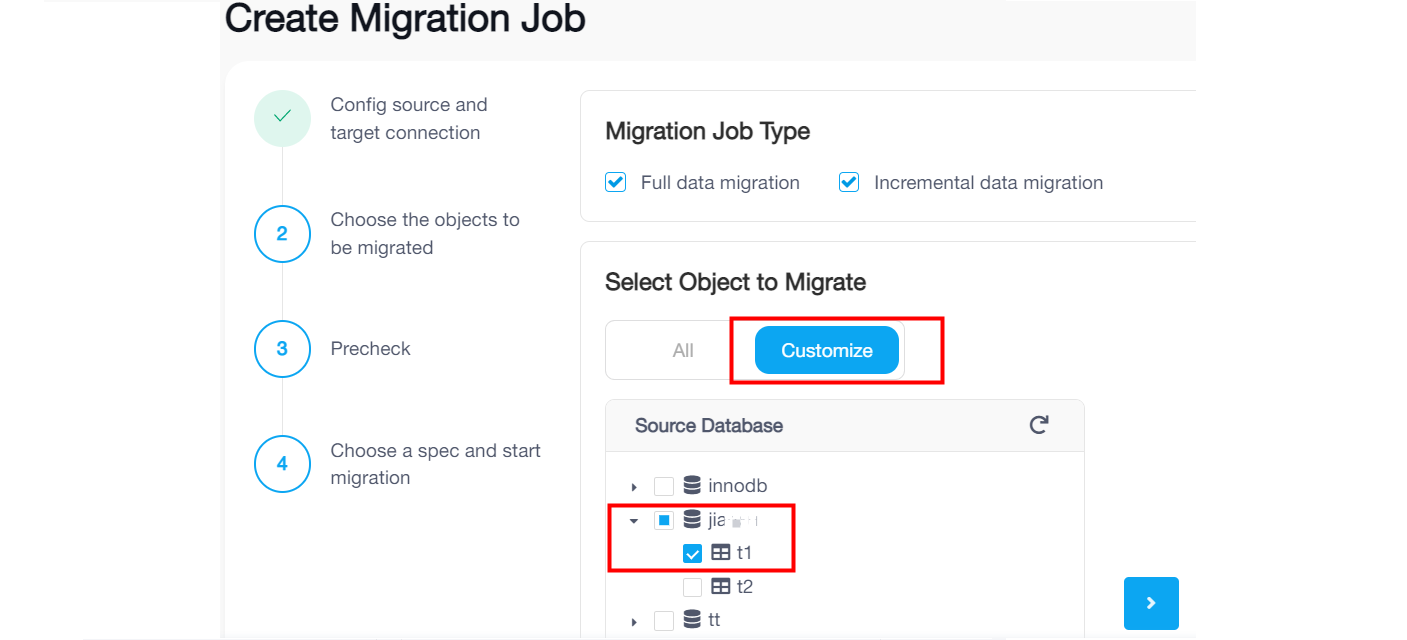
- - If you click **Customize** and select some tables under a dataset name, the migration job only will migrate the existing data and migrate ongoing changes of the selected tables. Tables created afterwards in the same database will not be migrated.
-
-
-
- - If you click **Customize** and select some tables under a dataset name, the migration job only will migrate the existing data and migrate ongoing changes of the selected tables. Tables created afterwards in the same database will not be migrated.
-
-  -
-
+ - If you click **Customize** and select some tables under a dataset name, the migration job will only migrate the existing data and migrate ongoing changes of the selected tables. Tables created afterwards in the same database will not be migrated.
2. Click **Next**.
@@ -299,7 +492,7 @@ If you encounter any problems during the migration, see [Migration errors and so
TiDB Cloud supports scaling up or down a migration job specification to meet your performance and cost requirements in different scenarios.
-Different migration specifications have different performances. Your performance requirements might vary at different stages as well. For example, during the existing data migration, you want the performance to be as fast as possible, so you choose a migration job with a large specification, such as 8 RCU. Once the existing data migration is completed, the incremental migration does not require such a high performance, so you can scale down the job specification, for example, from 8 RCU to 2 RUC, to save cost.
+Different migration specifications have different performances. Your performance requirements might vary at different stages as well. For example, during the existing data migration, you want the performance to be as fast as possible, so you choose a migration job with a large specification, such as 8 RCU. Once the existing data migration is completed, the incremental migration does not require such a high performance, so you can scale down the job specification, for example, from 8 RCU to 2 RCU, to save cost.
When scaling a migration job specification, note the following:
@@ -311,7 +504,7 @@ When scaling a migration job specification, note the following:
- You can only scale a migration job specification when the job is in the **Running** or **Paused** status.
- TiDB Cloud does not support scaling a migration job specification during the existing data export stage.
- Scaling a migration job specification will restart the job. If a source table of the job does not have a primary key, duplicate data might be inserted.
-- During scaling, do not purge the binary log of the source database or increase `expire_logs_days` of the upstream database temporarily. Otherwise, the job might fail because it cannot get the continuous binary log position.
+- During scaling, do not purge the binary log of the source database or increase `expire_logs_days` of the MySQL source database temporarily. Otherwise, the job might fail because it cannot get the continuous binary log position.
### Scaling procedure
-
-
+ - If you click **Customize** and select some tables under a dataset name, the migration job will only migrate the existing data and migrate ongoing changes of the selected tables. Tables created afterwards in the same database will not be migrated.
2. Click **Next**.
@@ -299,7 +492,7 @@ If you encounter any problems during the migration, see [Migration errors and so
TiDB Cloud supports scaling up or down a migration job specification to meet your performance and cost requirements in different scenarios.
-Different migration specifications have different performances. Your performance requirements might vary at different stages as well. For example, during the existing data migration, you want the performance to be as fast as possible, so you choose a migration job with a large specification, such as 8 RCU. Once the existing data migration is completed, the incremental migration does not require such a high performance, so you can scale down the job specification, for example, from 8 RCU to 2 RUC, to save cost.
+Different migration specifications have different performances. Your performance requirements might vary at different stages as well. For example, during the existing data migration, you want the performance to be as fast as possible, so you choose a migration job with a large specification, such as 8 RCU. Once the existing data migration is completed, the incremental migration does not require such a high performance, so you can scale down the job specification, for example, from 8 RCU to 2 RCU, to save cost.
When scaling a migration job specification, note the following:
@@ -311,7 +504,7 @@ When scaling a migration job specification, note the following:
- You can only scale a migration job specification when the job is in the **Running** or **Paused** status.
- TiDB Cloud does not support scaling a migration job specification during the existing data export stage.
- Scaling a migration job specification will restart the job. If a source table of the job does not have a primary key, duplicate data might be inserted.
-- During scaling, do not purge the binary log of the source database or increase `expire_logs_days` of the upstream database temporarily. Otherwise, the job might fail because it cannot get the continuous binary log position.
+- During scaling, do not purge the binary log of the source database or increase `expire_logs_days` of the MySQL source database temporarily. Otherwise, the job might fail because it cannot get the continuous binary log position.
### Scaling procedure