diff --git a/doc/source/serve/autoscaling-guide.md b/doc/source/serve/autoscaling-guide.md
index 9f5fe95a1b8e..6aabb14246b6 100644
--- a/doc/source/serve/autoscaling-guide.md
+++ b/doc/source/serve/autoscaling-guide.md
@@ -22,29 +22,40 @@ deployments:
## Autoscaling Basic Configuration
-Instead of setting a fixed number of replicas for a deployment and manually updating it, you can configure a deployment to autoscale based on incoming traffic. The Serve autoscaler reacts to traffic spikes by monitoring queue sizes and making scaling decisions to add or remove replicas. Configure it by setting the [autoscaling_config](../serve/api/doc/ray.serve.config.AutoscalingConfig.rst) field in deployment options. The following is a quick guide on how to configure autoscaling.
+Instead of setting a fixed number of replicas for a deployment and manually updating it, you can configure a deployment to autoscale based on incoming traffic. The Serve autoscaler reacts to traffic spikes by monitoring queue sizes and making scaling decisions to add or remove replicas. Turn on autoscaling for a deployment by setting `num_replicas="auto"`. You can further configure it by tuning the [autoscaling_config](../serve/api/doc/ray.serve.config.AutoscalingConfig.rst) in deployment options.
-* **target_ongoing_requests** (replaces the deprecated `target_num_ongoing_requests_per_replica`) is the average number of ongoing requests per replica that the Serve autoscaler tries to ensure. Set this to a reasonable number (for example, 5) and adjust it based on your request processing length (the longer the requests, the smaller this number should be) as well as your latency objective (the shorter you want your latency to be, the smaller this number should be).
-* **max_ongoing_requests** (replaces the deprecated `max_concurrent_queries`) is the maximum number of ongoing requests allowed for a replica. Set this to a value ~20-50% greater than `target_ongoing_requests`. Note this parameter is not part of the autoscaling config because it's relevant to all deployments, but it's important to set it relative to the target value if you turn on autoscaling for your deployment.
-* **min_replicas** is the minimum number of replicas for the deployment. Set this to 0 if there are long periods of no traffic and some extra tail latency during upscale is acceptable. Otherwise, set this to what you think you need for low traffic.
-* **max_replicas** is the maximum number of replicas for the deployment. Set this to ~20% higher than what you think you need for peak traffic.
+The following config is what we will use in the example in the following section.
+```yaml
+- name: Model
+ num_replicas: auto
+```
-An example deployment config with autoscaling configured would be:
+Setting `num_replicas="auto"` is equivalent to the following deployment configuration.
```yaml
- name: Model
- max_ongoing_requests: 14
+ max_ongoing_requests: 5
autoscaling_config:
- target_ongoing_requests: 10
- min_replicas: 0
- max_replicas: 20
+ target_ongoing_requests: 2
+ min_replicas: 1
+ max_replicas: 100
```
+:::{note}
+You can set `num_replicas="auto"` and override its default values (shown above) by specifying `autoscaling_config`, or you can omit `num_replicas="auto"` and fully configure autoscaling yourself.
+:::
+
+Let's dive into what each of these parameters do.
+
+* **target_ongoing_requests** (replaces the deprecated `target_num_ongoing_requests_per_replica`) is the average number of ongoing requests per replica that the Serve autoscaler tries to ensure. You can adjust it based on your request processing length (the longer the requests, the smaller this number should be) as well as your latency objective (the shorter you want your latency to be, the smaller this number should be).
+* **max_ongoing_requests** (replaces the deprecated `max_concurrent_queries`) is the maximum number of ongoing requests allowed for a replica. Note this parameter is not part of the autoscaling config because it's relevant to all deployments, but it's important to set it relative to the target value if you turn on autoscaling for your deployment.
+* **min_replicas** is the minimum number of replicas for the deployment. Set this to 0 if there are long periods of no traffic and some extra tail latency during upscale is acceptable. Otherwise, set this to what you think you need for low traffic.
+* **max_replicas** is the maximum number of replicas for the deployment. Set this to ~20% higher than what you think you need for peak traffic.
These guidelines are a great starting point. If you decide to further tune your autoscaling config for your application, see [Advanced Ray Serve Autoscaling](serve-advanced-autoscaling).
(resnet-autoscaling-example)=
## Basic example
-This example is a synchronous workload that runs ResNet50. The application code and its autoscaling configuration are below. Alternatively, see the second tab for specifying the autoscaling config through a YAML file. `target_ongoing_requests = 1` because the ResNet model runs synchronously, and the goal is to keep the latencies low. Note that the deployment starts with 0 replicas.
+This example is a synchronous workload that runs ResNet50. The application code and its autoscaling configuration are below. Alternatively, see the second tab for specifying the autoscaling config through a YAML file.
::::{tab-set}
@@ -64,12 +75,7 @@ applications:
import_path: resnet:app
deployments:
- name: Model
- max_ongoing_requests: 5
- autoscaling_config:
- target_ongoing_requests: 1
- min_replicas: 0
- initial_replicas: 0
- max_replicas: 200
+ num_replicas: auto
```
:::
@@ -84,13 +90,13 @@ The results of the load test are as follows:
| | | |
| -------- | --- | ------- |
| Replicas | 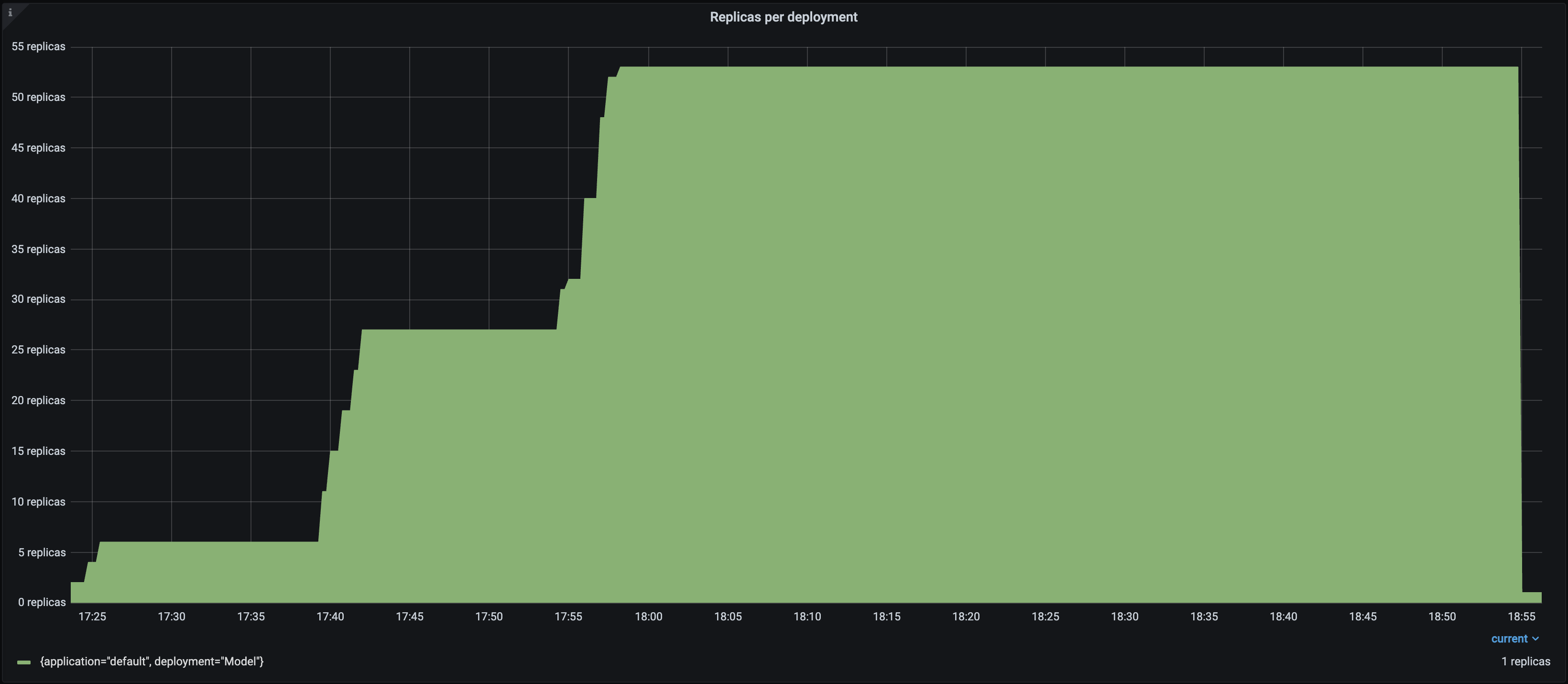 |
-| QPS |
|
-| QPS |  |
-| P50 Latency |
|
-| P50 Latency |  |
+| QPS |
|
+| QPS | 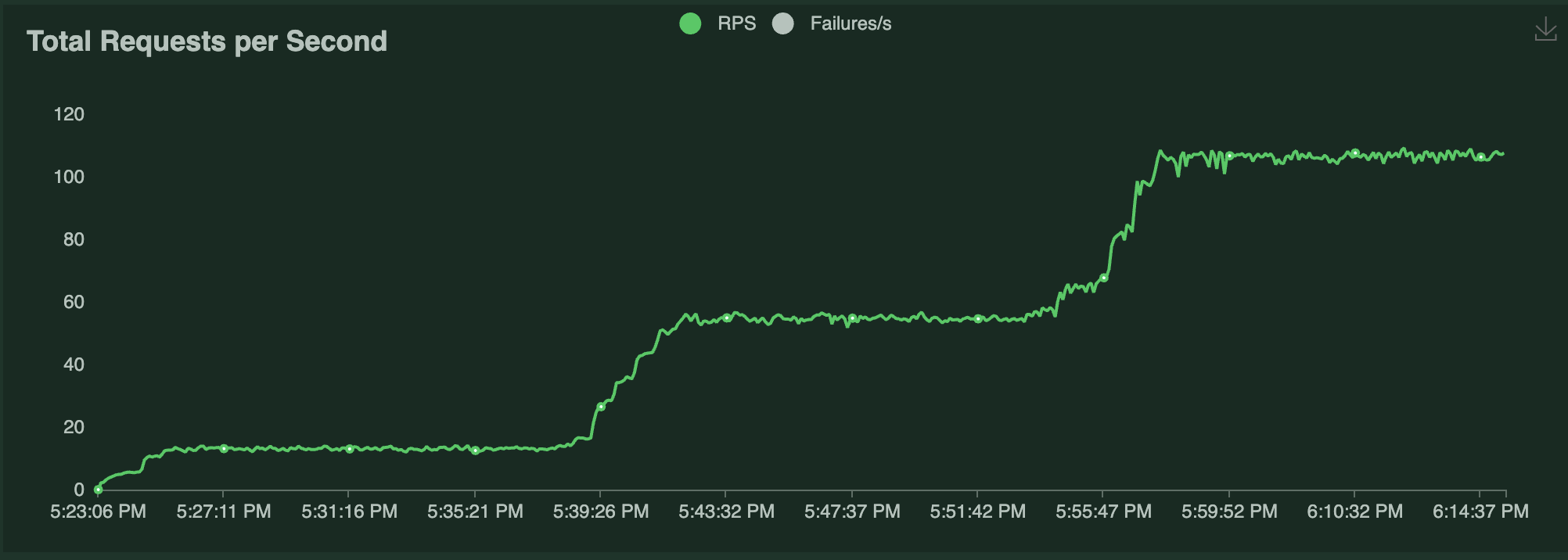 |
+| P50 Latency |
|
+| P50 Latency | 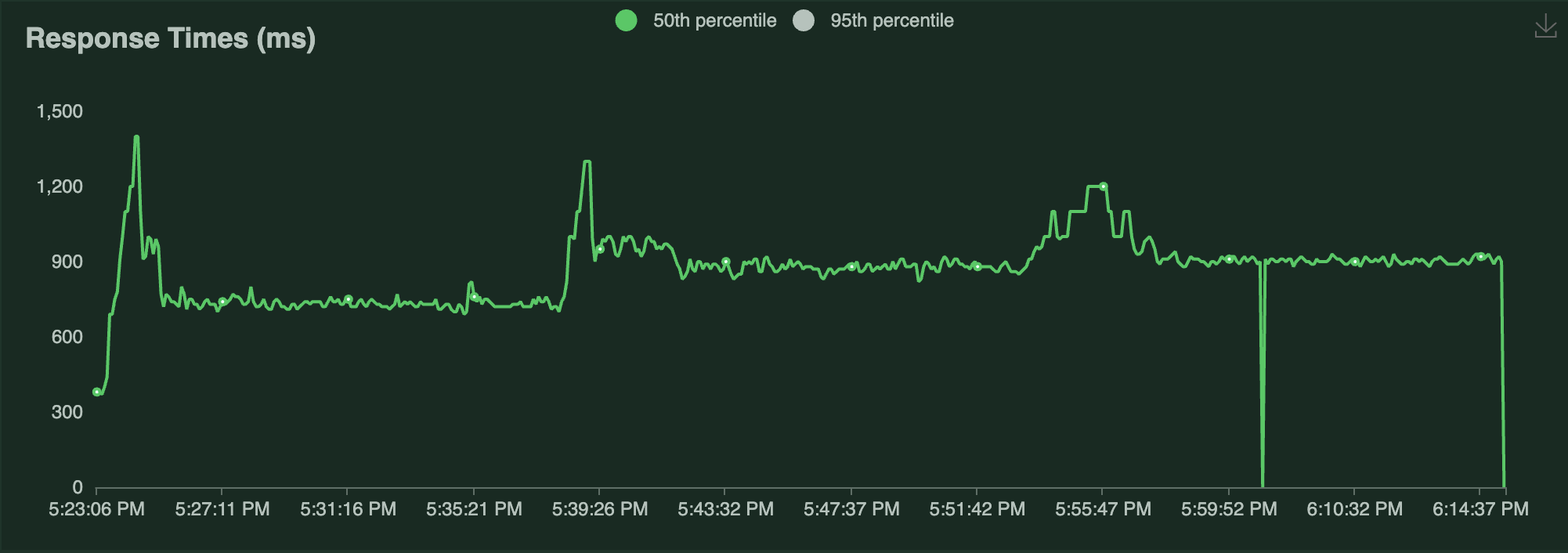 |
Notice the following:
-- Each Locust user constantly sends a single request and waits for a response. As a result, the number of autoscaled replicas closely matches the number of Locust users over time as Serve attempts to satisfy the `target_ongoing_requests=1` setting.
+- Each Locust user constantly sends a single request and waits for a response. As a result, the number of autoscaled replicas is roughly half the number of Locust users over time as Serve attempts to satisfy the `target_ongoing_requests=2` setting.
- The throughput of the system increases with the number of users and replicas.
-- The latency briefly spikes when traffic increases, but otherwise stays relatively steady. The biggest latency spike happens at the beginning of the test, because the deployment starts with 0 replicas.
+- The latency briefly spikes when traffic increases, but otherwise stays relatively steady.
## Ray Serve Autoscaler vs Ray Autoscaler
diff --git a/doc/source/serve/configure-serve-deployment.md b/doc/source/serve/configure-serve-deployment.md
index c29779215f7d..316d80107032 100644
--- a/doc/source/serve/configure-serve-deployment.md
+++ b/doc/source/serve/configure-serve-deployment.md
@@ -13,10 +13,10 @@ Use this guide to learn the essentials of configuring deployments:
You can also refer to the [API reference](../serve/api/doc/ray.serve.deployment_decorator.rst) for the `@serve.deployment` decorator.
- `name` - Name uniquely identifying this deployment within the application. If not provided, the name of the class or function is used.
-- `num_replicas` - Number of replicas to run that handle requests to this deployment. Defaults to 1.
+- `num_replicas` - Controls the number of replicas to run that handle requests to this deployment. This can be a positive integer, in which case the number of replicas stays constant, or `auto`, in which case the number of replicas will autoscale with a default configuration (see [Ray Serve Autoscaling](serve-autoscaling) for more). Defaults to 1.
- `ray_actor_options` - Options to pass to the Ray Actor decorator, such as resource requirements. Valid options are: `accelerator_type`, `memory`, `num_cpus`, `num_gpus`, `object_store_memory`, `resources`, and `runtime_env` For more details - [Resource management in Serve](serve-cpus-gpus)
- `max_ongoing_requests` (replaces the deprecated `max_concurrent_queries`) - Maximum number of queries that are sent to a replica of this deployment without receiving a response. Defaults to 100 (the default will change to 5 in an upcoming release). This may be an important parameter to configure for [performance tuning](serve-perf-tuning).
-- `autoscaling_config` - Parameters to configure autoscaling behavior. If this is set, you can't set `num_replicas`. For more details on configurable parameters for autoscaling, see [Ray Serve Autoscaling](serve-autoscaling).
+- `autoscaling_config` - Parameters to configure autoscaling behavior. If this is set, you can't set `num_replicas` to a number. For more details on configurable parameters for autoscaling, see [Ray Serve Autoscaling](serve-autoscaling).
- `user_config` - Config to pass to the reconfigure method of the deployment. This can be updated dynamically without restarting the replicas of the deployment. The user_config must be fully JSON-serializable. For more details, see [Serve User Config](serve-user-config).
- `health_check_period_s` - Duration between health check calls for the replica. Defaults to 10s. The health check is by default a no-op Actor call to the replica, but you can define your own health check using the "check_health" method in your deployment that raises an exception when unhealthy.
- `health_check_timeout_s` - Duration in seconds, that replicas wait for a health check method to return before considering it as failed. Defaults to 30s.
diff --git a/doc/source/serve/doc_code/resnet50_example.py b/doc/source/serve/doc_code/resnet50_example.py
index 7bba7e1392e1..303edb8a30c8 100644
--- a/doc/source/serve/doc_code/resnet50_example.py
+++ b/doc/source/serve/doc_code/resnet50_example.py
@@ -14,13 +14,7 @@
@serve.deployment(
ray_actor_options={"num_cpus": 1},
- max_ongoing_requests=5,
- autoscaling_config={
- "target_ongoing_requests": 1,
- "min_replicas": 0,
- "initial_replicas": 0,
- "max_replicas": 200,
- },
+ num_replicas="auto",
)
class Model:
def __init__(self):
|
Notice the following:
-- Each Locust user constantly sends a single request and waits for a response. As a result, the number of autoscaled replicas closely matches the number of Locust users over time as Serve attempts to satisfy the `target_ongoing_requests=1` setting.
+- Each Locust user constantly sends a single request and waits for a response. As a result, the number of autoscaled replicas is roughly half the number of Locust users over time as Serve attempts to satisfy the `target_ongoing_requests=2` setting.
- The throughput of the system increases with the number of users and replicas.
-- The latency briefly spikes when traffic increases, but otherwise stays relatively steady. The biggest latency spike happens at the beginning of the test, because the deployment starts with 0 replicas.
+- The latency briefly spikes when traffic increases, but otherwise stays relatively steady.
## Ray Serve Autoscaler vs Ray Autoscaler
diff --git a/doc/source/serve/configure-serve-deployment.md b/doc/source/serve/configure-serve-deployment.md
index c29779215f7d..316d80107032 100644
--- a/doc/source/serve/configure-serve-deployment.md
+++ b/doc/source/serve/configure-serve-deployment.md
@@ -13,10 +13,10 @@ Use this guide to learn the essentials of configuring deployments:
You can also refer to the [API reference](../serve/api/doc/ray.serve.deployment_decorator.rst) for the `@serve.deployment` decorator.
- `name` - Name uniquely identifying this deployment within the application. If not provided, the name of the class or function is used.
-- `num_replicas` - Number of replicas to run that handle requests to this deployment. Defaults to 1.
+- `num_replicas` - Controls the number of replicas to run that handle requests to this deployment. This can be a positive integer, in which case the number of replicas stays constant, or `auto`, in which case the number of replicas will autoscale with a default configuration (see [Ray Serve Autoscaling](serve-autoscaling) for more). Defaults to 1.
- `ray_actor_options` - Options to pass to the Ray Actor decorator, such as resource requirements. Valid options are: `accelerator_type`, `memory`, `num_cpus`, `num_gpus`, `object_store_memory`, `resources`, and `runtime_env` For more details - [Resource management in Serve](serve-cpus-gpus)
- `max_ongoing_requests` (replaces the deprecated `max_concurrent_queries`) - Maximum number of queries that are sent to a replica of this deployment without receiving a response. Defaults to 100 (the default will change to 5 in an upcoming release). This may be an important parameter to configure for [performance tuning](serve-perf-tuning).
-- `autoscaling_config` - Parameters to configure autoscaling behavior. If this is set, you can't set `num_replicas`. For more details on configurable parameters for autoscaling, see [Ray Serve Autoscaling](serve-autoscaling).
+- `autoscaling_config` - Parameters to configure autoscaling behavior. If this is set, you can't set `num_replicas` to a number. For more details on configurable parameters for autoscaling, see [Ray Serve Autoscaling](serve-autoscaling).
- `user_config` - Config to pass to the reconfigure method of the deployment. This can be updated dynamically without restarting the replicas of the deployment. The user_config must be fully JSON-serializable. For more details, see [Serve User Config](serve-user-config).
- `health_check_period_s` - Duration between health check calls for the replica. Defaults to 10s. The health check is by default a no-op Actor call to the replica, but you can define your own health check using the "check_health" method in your deployment that raises an exception when unhealthy.
- `health_check_timeout_s` - Duration in seconds, that replicas wait for a health check method to return before considering it as failed. Defaults to 30s.
diff --git a/doc/source/serve/doc_code/resnet50_example.py b/doc/source/serve/doc_code/resnet50_example.py
index 7bba7e1392e1..303edb8a30c8 100644
--- a/doc/source/serve/doc_code/resnet50_example.py
+++ b/doc/source/serve/doc_code/resnet50_example.py
@@ -14,13 +14,7 @@
@serve.deployment(
ray_actor_options={"num_cpus": 1},
- max_ongoing_requests=5,
- autoscaling_config={
- "target_ongoing_requests": 1,
- "min_replicas": 0,
- "initial_replicas": 0,
- "max_replicas": 200,
- },
+ num_replicas="auto",
)
class Model:
def __init__(self):