diff --git a/.dockerignore b/.dockerignore
new file mode 100644
index 0000000..f432270
--- /dev/null
+++ b/.dockerignore
@@ -0,0 +1,12 @@
+input
+nendo_library
+library
+processed
+separated
+polymath_library
+polymath_input
+polymath_output
+.python-version
+polymath.egg-info
+__pycache__
+models
\ No newline at end of file
diff --git a/.gitignore b/.gitignore
index e969c78..f432270 100644
--- a/.gitignore
+++ b/.gitignore
@@ -1,4 +1,12 @@
-input/
-library/
-processed/
-separated/
\ No newline at end of file
+input
+nendo_library
+library
+processed
+separated
+polymath_library
+polymath_input
+polymath_output
+.python-version
+polymath.egg-info
+__pycache__
+models
\ No newline at end of file
diff --git a/Dockerfile b/Dockerfile
index 3db1f10..ce4b3eb 100644
--- a/Dockerfile
+++ b/Dockerfile
@@ -1,14 +1,21 @@
-FROM python:3.10-bullseye
+FROM python:3.8-slim-buster
-RUN apt update
-RUN apt install -y rubberband-cli make automake gcc g++ python3-dev gfortran build-essential wget libsndfile1 ffmpeg
+RUN apt-get update \
+ && apt-get -y install rubberband-cli \
+ libasound-dev portaudio19-dev \
+ libportaudio2 libportaudiocpp0 git gcc \
+ && rm -rf /var/lib/apt/lists/*
-RUN pip install --upgrade pip
+RUN pip install git+https://github.com/CPJKU/madmom.git@0551aa8
-COPY . /polymath
WORKDIR /polymath
+COPY . .
+RUN pip install -r ./requirements.txt
-RUN pip install -r requirements.txt
-
-RUN mkdir -p input processed separated library
-
+# fixes for some dependency conflicts
+RUN pip uninstall -y soundfile
+RUN pip install soundfile
+RUN pip install soundfile==0.12.1
+RUN pip install numpy==1.22.4
+RUN pip uninstall -y essentia essentia-tensorflow
+RUN pip install essentia-tensorflow
diff --git a/README.md b/README.md
index 4d6aabb..0dbead7 100644
--- a/README.md
+++ b/README.md
@@ -1,20 +1,27 @@
-
# Polymath
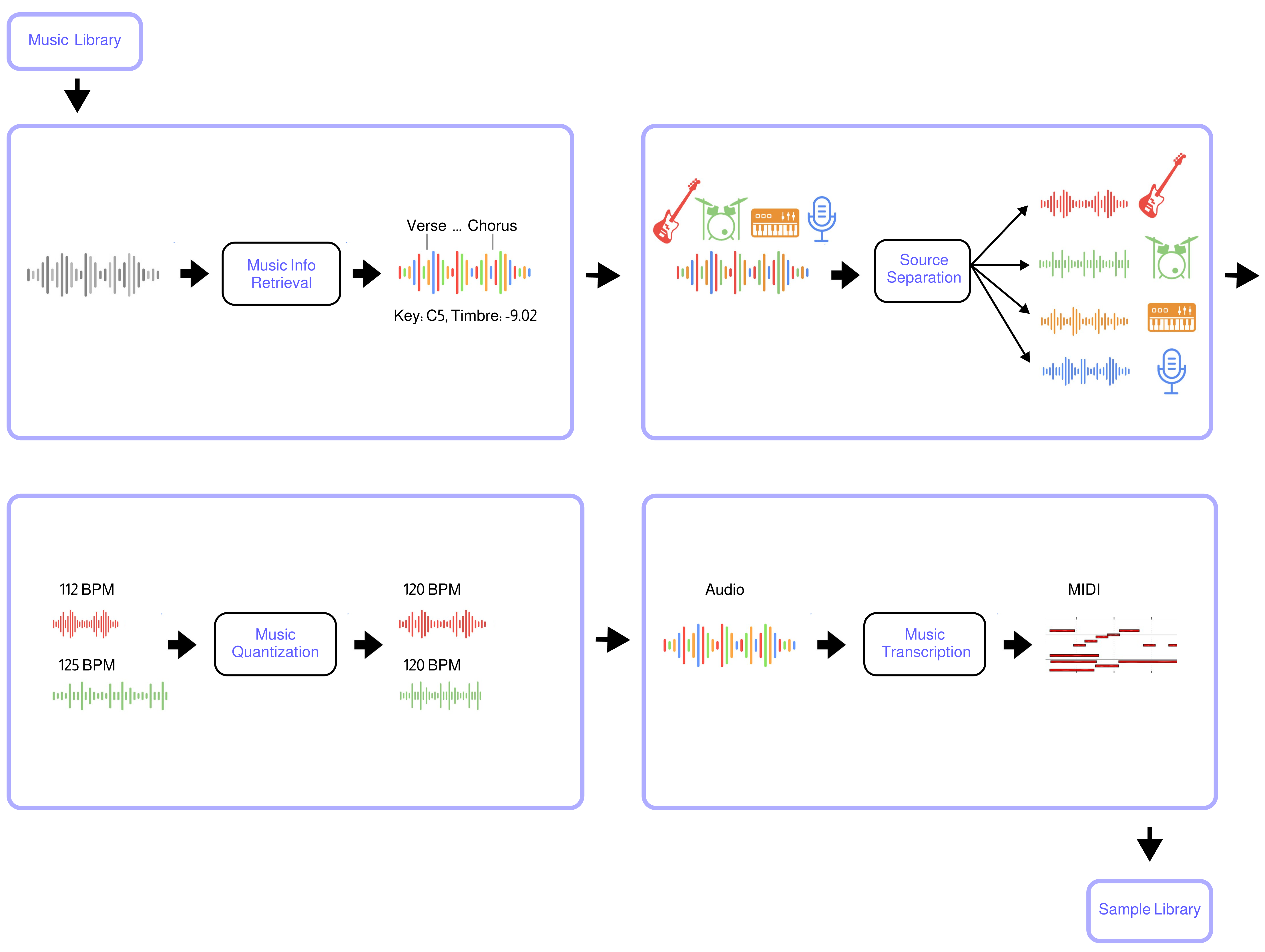
-Polymath uses machine learning to convert any music library (*e.g from Hard-Drive or YouTube*) into a music production sample-library. The tool automatically separates songs into stems (*beats, bass, etc.*), quantizes them to the same tempo and beat-grid (*e.g. 120bpm*), analyzes musical structure (*e.g. verse, chorus, etc.*), key (*e.g C4, E3, etc.*) and other infos (*timbre, loudness, etc.*), and converts audio to midi. The result is a searchable sample library that streamlines the workflow for music producers, DJs, and ML audio developers.
+Polymath uses machine learning to convert any music library (*e.g from Hard-Drive or YouTube*) into a music production sample-library. The tool automatically separates tracks into stems (_drums, bass, etc._), quantizes them to the same tempo and beat-grid (*e.g. 120bpm*), analyzes tempo, key (_e.g C4, E3, etc._) and other infos (*timbre, loudness, etc.*) and cuts loop out of them. The result is a searchable sample library that streamlines the workflow for music producers, DJs, and ML audio developers.
+
+Try it in colab:
+
+ +
-
+
-
+
## Use-cases
-Polymath makes it effortless to combine elements from different songs to create unique new compositions: Simply grab a beat from a Funkadelic track, a bassline from a Tito Puente piece, and fitting horns from a Fela Kuti song, and seamlessly integrate them into your DAW in record time. Using Polymath's search capability to discover related tracks, it is a breeze to create a polished, hour-long mash-up DJ set. For ML developers, Polymath simplifies the process of creating a large music dataset, for training generative models, etc.
+
+Polymath makes it effortless to combine elements from different tracks to create unique new compositions: Simply grab a beat from a Funkadelic track, a bassline from a Tito Puente piece, and fitting horns from a Fela Kuti song, and seamlessly integrate them into your DAW in record time. Using Polymath's search capability to discover related tracks, it is a breeze to create a polished, hour-long mash-up DJ set. For ML developers, Polymath simplifies the process of creating a large music dataset, for training generative models, etc.
## How does it work?
-- Music Source Separation is performed with the [Demucs](https://github.com/facebookresearch/demucs) neural network
-- Music Structure Segmentation/Labeling is performed with the [sf_segmenter](https://github.com/wayne391/sf_segmenter) neural network
-- Music Pitch Tracking and Key Detection are performed with [Crepe](https://github.com/marl/crepe) neural network
-- Music to MIDI transcription is performed with [Basic Pitch](https://github.com/spotify/basic-pitch) neural network
-- Music Quantization and Alignment are performed with [pyrubberband](https://github.com/bmcfee/pyrubberband)
-- Music Info retrieval and processing is performed with [librosa](https://github.com/librosa/librosa)
+
+- Import tracks from youtube or directly from your google drive
+- Process selected (or all) tracks with a configurable selection of nendo plugins:
+ - Apply the [classification plugin](https://github.com/okio-ai/nendo-plugin-classify-core) to compute _volume_, _tempo_ (bpm), _key_, _intensity_, _frequency_, and _loudness_ for each track
+ - Apply the [stemification plugin](https://github.com/okio-ai/nendo-plugin-stemify-demucs) to separate each track into four source signals: _vocals_, _drum_, _bass_, and _other_
+ - Apply the [quantization plugin](https://github.com/okio-ai/nendo-plugin-quantize-core) to quantize each track to a specified target _bpm_
+ - Apply the [loopification plugin](https://github.com/okio-ai/nendo-plugin-loopify) to automatically detect and extract loops from each sample
+- Export the results of the processing with informative file names to your google drive in _wav_, _mp3_ or _ogg_ format.
## Community
@@ -22,23 +29,31 @@ Join the Polymath Community on [Discord](https://discord.gg/gaZMZKzScj)
## Requirements
-You need to have the following software installed on your system:
+**Polymath requires Python version 3.8, 3.9 or 3.10.**
+
+> It is recommended to use a [virtual environment](https://docs.python.org/3/library/venv.html), in order to avoid dependency conflicts. You can use your favorite virtual environment management system, like [conda](https://docs.conda.io/en/latest/), [poetry](https://python-poetry.org/), or [pyenv](https://github.com/pyenv/pyenv) for example.
+
+Furthermore, the following software packages need to be installed in your system:
-- ``ffmpeg``
+- **Ubuntu**: `sudo apt-get install ffmpeg libsndfile1 libportaudio2 rubberband-cli libmpg123-dev`
+- **Mac OS**: `brew install ffmpeg libsndfile portaudio rubberband mpg123`
+- **Windows**
+
+ > Windows support is currently under development. For the time being, we highly recommend using [Windows Subsystem for Linux](https://learn.microsoft.com/en-us/windows/wsl/install) and then following the linux instructions.
## Installation
-You need python version `>=3.7` and `<=3.10`. From your terminal run:
+You need python version `>=3.8` and `<=3.10`. From your terminal run:
+
```bash
+pip install git+https://github.com/CPJKU/madmom.git@0551aa8
git clone https://github.com/samim23/polymath
cd polymath
pip install -r requirements.txt
+pip uninstall -y essentia essentia-tensorflow && pip install essentia-tensorflow
```
-If you run into an issue with basic-pitch while trying to run Polymath, run this command after your installation:
-```bash
-pip install git+https://github.com/spotify/basic-pitch.git
-```
+The last line is a fix that's needed to avoid a dependency conflict among the plugins.
## GPU support
@@ -54,114 +69,119 @@ docker build -t polymath ./
In order to exchange input and output files between your hosts system and the polymath docker container, you need to create the following four directories:
-- `./input`
-- `./library`
-- `./processed`
-- `./separated`
+- `./polymath_input`
+- `./polymath_library`
+- `./polymath_output`
+- `./models`
+
+E.g. run `mkdir -p ./polymath_input ./polymath_library ./polymath_output ./models`.
-Now put any files you want to process with polymath into the `input` folder.
+Now put any files you want to process with polymath into the `polymath_input` folder.
Then you can run polymath through docker by using the `docker run` command and pass any arguments that you would originally pass to the python command, e.g. if you are in a linux OS call:
```bash
docker run \
- -v "$(pwd)"/processed:/polymath/processed \
- -v "$(pwd)"/separated:/polymath/separated \
- -v "$(pwd)"/library:/polymath/library \
- -v "$(pwd)"/input:/polymath/input \
- polymath python /polymath/polymath.py -a ./input/song1.wav
+ -v "$(pwd)"/models:/polymath/models \
+ -v "$(pwd)"/polymath_input:/polymath/polymath_input \
+ -v "$(pwd)"/polymath_library:/polymath/polymath_library \
+ -v "$(pwd)"/polymath_output:/polymath/polymath_output \
+ polymath \
+ python polymath.py -i ./polymath_input/song1.wav -p -e
```
## Run Polymath
-### 1. Add songs to the Polymath Library
+To print the help for the python command line arguments:
+
+```bash
+python polymath.py -h
+```
+
+### 1. Add tracks to the Polymath Library
##### Add YouTube video to library (auto-download)
+
```bash
-python polymath.py -a n6DAqMFe97E
+python polymath.py -i n6DAqMFe97E
```
+
##### Add audio file (wav or mp3)
+
```bash
-python polymath.py -a /path/to/audiolib/song.wav
+python polymath.py -i /path/to/audiolib/song.wav
```
+
##### Add multiple files at once
-```bash
-python polymath.py -a n6DAqMFe97E,eaPzCHEQExs,RijB8wnJCN0
-python polymath.py -a /path/to/audiolib/song1.wav,/path/to/audiolib/song2.wav
-python polymath.py -a /path/to/audiolib/
-```
-Songs are automatically analyzed once which takes some time. Once in the database, they can be access rapidly. The database is stored in the folder "/library/database.p". To reset everything, simply delete it.
-### 2. Quantize songs in the Polymath Library
-##### Quantize a specific songs in the library to tempo 120 BPM (-q = database audio file ID, -t = tempo in BPM)
-```bash
-python polymath.py -q n6DAqMFe97E -t 120
-```
-##### Quantize all songs in the library to tempo 120 BPM
```bash
-python polymath.py -q all -t 120
+python polymath.py -i n6DAqMFe97E,eaPzCHEQExs,RijB8wnJCN0
+python polymath.py -i /path/to/audiolib/song1.wav,/path/to/audiolib/song2.wav
+python polymath.py -i /path/to/audiolib/
+# you can even mix imports:
+python polymath.py -i /path/to/audiolib/,n6DAqMFe97E,/path/to/song2.wav
```
-##### Quantize a specific songs in the library to the tempo of the song (-k)
-```bash
-python polymath.py -q n6DAqMFe97E -k
-```
-Songs are automatically quantized to the same tempo and beat-grid and saved to the folder “/processed”.
-### 3. Search for similar songs in the Polymath Library
-##### Search for 10 similar songs based on a specific songs in the library (-s = database audio file ID, -sa = results amount)
+Once in the database, they can be searched through, processed and exported. The database is stored by default in the folder "./polymath_library". To change the library folder use the `--library_path` console argument. To reset everything, simply delete that directory.
+
+### 2. Quantize tracks in the Polymath Library
+
+##### Find a specific song in the library and quantize it to tempo 120 BPM (-f = find ID in library, -q = quantize to tempo in BPM)
+
```bash
-python polymath.py -s n6DAqMFe97E -sa 10
+python polymath.py -f n6DAqMFe97E -q 120
```
-##### Search for similar songs based on a specific songs in the library and quantize all of them to tempo 120 BPM
+
+##### Quantize all tracks in the library to tempo 120 BPM
+
```bash
-python polymath.py -s n6DAqMFe97E -sa 10 -q all -t 120
+python polymath.py -q 120
```
-##### Include BPM as search criteria (-st)
+
+### 3. Search for specific tracks in the Polymath Library
+
+##### Find tracks with specific search keys in the library and export them
+
```bash
-python polymath.py -s n6DAqMFe97E -sa 10 -q all -t 120 -st -k
+python polymath.py -f n6DAqMFe97E,my_song.mp3 -e
```
-Similar songs are automatically found and optionally quantized and saved to the folder "/processed". This makes it easy to create for example an hour long mix of songs that perfectly match one after the other.
-### 4. Convert Audio to MIDI
-##### Convert all processed audio files and stems to MIDI (-m)
+The default export directory is `./polymath_output`. To specify a different directory, use the `-o /path/to/my/output/dir` flag.
+
+##### Find tracks in specific BPM range as search criteria (-bmin and -bmax) and also export loops (-fl)
+
```bash
-python polymath.py -a n6DAqMFe97E -q all -t 120 -m
+python polymath.py -bmin 80 -bmax 100 -fl -e
```
-Generated Midi Files are currently always 120BPM and need to be time adjusted in your DAW. This will be resolved [soon](https://github.com/spotify/basic-pitch/issues/40). The current Audio2Midi model gives mixed results with drums/percussion. This will be resolved with additional audio2midi model options in the future.
-
## Audio Features
### Extracted Stems
-The Demucs Neural Net has settings that can be adjusted in the python file
+
+Stems are extracted with the [nendo stemify plugin](https://github.com/okio-ai/nendo_plugin_stemify_demucs/). Extracted stem types are:
+
```bash
- bass
- drum
-- guitare
-- other
-- piano
- vocals
+- other
```
+
### Extracted Features
-The audio feature extractors have settings that can be adjusted in the python file
+
+Music Information Retrieval features are computed using the [nendo classify plugin](https://github.com/okio-ai/nendo_plugin_classify_core/). Extracted features are:
+
```bash
- tempo
- duration
-- timbre
-- timbre_frames
-- pitch
-- pitch_frames
- intensity
-- intensity_frames
-- volume
- avg_volume
- loudness
-- beats
-- segments_boundaries
-- segments_labels
-- frequency_frames
- frequency
- key
```
## License
+
Polymath is released under the MIT license as found in the [LICENSE](https://github.com/samim23/polymath/blob/main/LICENSE) file.
+
+As for [nendo core](https://github.com/okio-ai/nendo) and the [plugins used in polymath](#how-does-it-work), see their respective repositories for information about their license.
\ No newline at end of file
diff --git a/__init__.py b/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/docs/images/polymath.png b/docs/images/polymath.png
new file mode 100644
index 0000000..e9c9d8a
Binary files /dev/null and b/docs/images/polymath.png differ
diff --git a/polymath.py b/polymath.py
index 99921ec..a18bcb1 100755
--- a/polymath.py
+++ b/polymath.py
@@ -1,742 +1,510 @@
#!/usr/bin/env python
+# ruff: noqa: T201
+"""Polymath.py - Playing with your music library.
+Polymath uses machine learning to convert any music library
+(e.g from Hard-Drive or YouTube) into a music production sample-library.
+"""
-import os
-import sys
-import pickle
import argparse
-import subprocess
-import fnmatch
-import hashlib
-import shutil
-from math import log2, pow
+import os
+import random
+import string
+import tempfile
-from numba import cuda
-import numpy as np
import librosa
-import crepe
-import soundfile as sf
-import pyrubberband as pyrb
+from nendo import Nendo, NendoConfig, NendoTrack
from yt_dlp import YoutubeDL
-from sf_segmenter.segmenter import Segmenter
-import tensorflow as tf
-from basic_pitch import ICASSP_2022_MODEL_PATH
-from basic_pitch.inference import predict_and_save
-from basic_pitch.inference import predict
-
-##########################################
-################ POLYMATH ################
-############## by samim.io ###############
-##########################################
-
-class Video:
- def __init__(self,name,video,audio):
- self.id = ""
- self.url = ""
- self.name = name
- self.video = video
- self.audio = audio
- self.video_features = []
- self.audio_features = []
-
-### Library
-
-LIBRARY_FILENAME = "library/database.p"
-basic_pitch_model = ""
-
-def write_library(videos):
- with open(LIBRARY_FILENAME, "wb") as lib:
- pickle.dump(videos, lib)
-
-
-def read_library():
- try:
- with open(LIBRARY_FILENAME, "rb") as lib:
- return pickle.load(lib)
- except:
- print("No Database file found:", LIBRARY_FILENAME)
- return []
-
-
-################## VIDEO PROCESSING ##################
-
-def audio_extract(vidobj,file):
- print("audio_extract",file)
- command = "ffmpeg -hide_banner -loglevel panic -i "+file+" -ab 160k -ac 2 -ar 44100 -vn -y " + vidobj.audio
- subprocess.call(command,shell=True)
- return vidobj.audio
-
-def video_download(vidobj,url):
- print("video_download",url)
- ydl_opts = {
- 'outtmpl': 'library/%(id)s',
- 'format': 'bestvideo[ext=mp4]+bestaudio[ext=m4a]/bestvideo+bestaudio/best--merge-output-format mp4',
- }
- with YoutubeDL(ydl_opts) as ydl:
- ydl.download(url)
-
- with ydl: result = ydl.extract_info(url, download=True)
-
- if 'entries' in result: video = result['entries'][0] # Can be a playlist or a list of videos
- else: video = result # Just a video
-
- filename = f"library/{video['id']}.{video['ext']}"
- print("video_download: filename",filename,"extension",video['ext'])
- vidobj.id = video['id']
- vidobj.name = video['title']
- vidobj.video = filename
- vidobj.url = url
- return vidobj
-
-def video_process(vids,videos):
- for vid in vids:
- print('------ process video',vid)
- # check if id already in db
- download_vid = True
- for video in videos:
- if video.id == vid:
- print("already in db",vid)
- download_vid = False
- break
-
- # analyse videos and save to disk
- if download_vid:
- video = Video(vid,vid,f"library/{vid}.wav")
- video = video_download(video,f"https://www.youtube.com/watch?v={vid}")
- audio_extract(video,video.video)
- videos.append(video)
- print("NAME",video.name,"VIDEO",video.video,"AUDIO",video.audio)
- write_library(videos)
- print("video_process DONE",len(videos))
- return videos
-
-################## AUDIO PROCESSING ##################
-
-def audio_directory_process(vids, videos):
- filesToProcess = []
- for vid in vids:
- path = vid
- pattern = "*.mp3"
- for filename in fnmatch.filter(os.listdir(path), pattern):
- filepath = os.path.join(path, filename)
- print(filepath)
- if os.path.isfile(filepath):
- filesToProcess.append(filepath)
-
- print('Found', len(filesToProcess), 'wav or mp3 files')
- if len(filesToProcess) > 0:
- videos = audio_process(filesToProcess, videos)
- return videos
-
-def audio_process(vids, videos):
- for vid in vids:
- print('------ process audio',vid)
- # extract file name
- audioname = vid.split("/")[-1]
- audioname, _ = audioname.split(".")
-
- # generate a unique ID based on file path and name
- hash_object = hashlib.sha256(vid.encode())
- audioid = hash_object.hexdigest()
- audioid = f"{audioname}_{audioid}"
-
- # check if id already in db
- process_audio = True
- for video in videos:
- if video.id == audioid:
- print("already in db",vid)
- process_audio = False
- break
-
- # check if is mp3 and convert it to wav
- if vid.endswith(".mp3"):
- # convert mp3 to wav and save it
- print('converting mp3 to wav:', vid)
- y, sr = librosa.load(path=vid, sr=None, mono=False)
- path = os.path.join(os.getcwd(), 'library', audioid+'.wav')
- # resample to 44100k if required
- if sr != 44100:
- print('converting audio file to 44100:', vid)
- y = librosa.resample(y, orig_sr=sr, target_sr=44100)
- sf.write(path, np.ravel(y), 44100)
- vid = path
-
- # check if is wav and copy it to local folder
- elif vid.endswith(".wav"):
- path1 = vid
- path2 = os.path.join(os.getcwd(), 'library', audioid+'.wav')
- y, sr = librosa.load(path=vid, sr=None, mono=False)
- if sr != 44100:
- print('converting audio file to 44100:', vid)
- y = librosa.resample(y, orig_sr=sr, target_sr=44100)
- sf.write(path2, y, 44100)
- else:
- shutil.copy2(path1, path2)
- vid = path2
-
- # analyse videos and save to disk
- if process_audio:
- video = Video(audioname,'',vid)
- video.id = audioid
- video.url = vid
- videos.append(video)
- write_library(videos)
- print("Finished procesing files:",len(videos))
-
- return videos
-
-################## AUDIO FEATURES ##################
-
-def root_mean_square(data):
- return float(np.sqrt(np.mean(np.square(data))))
-
-def loudness_of(data):
- return root_mean_square(data)
-
-def normalized(list):
- """Given an audio buffer, return it with the loudest value scaled to 1.0"""
- return list.astype(np.float32) / float(np.amax(np.abs(list)))
-neg80point8db = 0.00009120108393559096
-bit_depth = 16
-default_silence_threshold = (neg80point8db * (2 ** (bit_depth - 1))) * 4
-def start_of(list, threshold=default_silence_threshold, samples_before=1):
- if int(threshold) != threshold:
- threshold = threshold * float(2 ** (bit_depth - 1))
- index = np.argmax(np.absolute(list) > threshold)
- if index > (samples_before - 1):
- return index - samples_before
- else:
- return 0
-
-def end_of(list, threshold=default_silence_threshold, samples_after=1):
- if int(threshold) != threshold:
- threshold = threshold * float(2 ** (bit_depth - 1))
- rev_index = np.argmax(
- np.flipud(np.absolute(list)) > threshold
- )
- if rev_index > (samples_after - 1):
- return len(list) - (rev_index - samples_after)
- else:
- return len(list)
+def import_youtube(nendo, yt_id):
+ """Import the audio from the given youtube ID into the library.
+
+ Args:
+ nendo (Nendo): The nendo instance to use.
+ yt_id (str): ID of the youtube video.
+
+ Returns:
+ NendoTrack: The imported track.
+ """
+ # check if id already in db
+ db_tracks = nendo.library.find_tracks(value=yt_id)
+ if len(db_tracks) > 0:
+ print(f"Track with youtube id {yt_id} already exists in library. Skipping.")
+ return None
+
+ # analyse videos and save to disk
+ url = f"https://www.youtube.com/watch?v={yt_id}"
+ with tempfile.TemporaryDirectory() as temp_dir:
+ ydl_opts = {
+ "quiet": True,
+ "outtmpl": temp_dir + "/%(id)s.%(ext)s",
+ "format": "bestaudio/best",
+ "postprocessors": [
+ {
+ "key": "FFmpegExtractAudio",
+ "preferredcodec": "vorbis",
+ "preferredquality": "192",
+ },
+ ],
+ }
+ with YoutubeDL(ydl_opts) as ydl:
+ result = ydl.extract_info(url, download=True)
+ video = result["entries"][0] if "entries" in result else result
+ return nendo.library.add_track(
+ file_path=f"{temp_dir}/{video['id']}.ogg",
+ meta={
+ "original_info": video["id"],
+ },
+ )
-def trim_data(
- data,
- start_threshold=default_silence_threshold,
- end_threshold=default_silence_threshold
+def input_tracks(nendo, input_string):
+ """Import a list of tracks from youtube and local FS.
+
+ Args:
+ nendo (Nendo): The Nendo instance to use.
+ input_string (str): Comma-separated list of items to import into the
+ polymath library.
+ """
+ input_items = input_string.split(",")
+ for item in input_items:
+ if os.path.isdir(item):
+ nendo.add_tracks(path=item)
+ elif os.path.isfile(item):
+ nendo.add_track(file_path=item)
+ else:
+ import_youtube(nendo, item)
+ print(f"Added {item}")
+
+def process_tracks(
+ nendo,
+ tracks,
+ analyze,
+ stemify,
+ quantize,
+ quantize_to_bpm,
+ loopify,
+ n_loops,
+ beats_per_loop,
):
- start = start_of(data, start_threshold)
- end = end_of(data, end_threshold)
-
- return data[start:end]
-
-def load_and_trim(file):
- y, rate = librosa.load(file, mono=True)
- y = normalized(y)
- trimmed = trim_data(y)
- return trimmed, rate
-
-def get_loudness(file):
- loudness = -1
- try:
- audio, rate = load_and_trim(file)
- loudness = loudness_of(audio)
- except Exception as e:
- sys.stderr.write(f"Failed to run on {file}: {e}\n")
- return loudness
-
-def get_volume(file):
- volume = -1
- avg_volume = -1
- try:
- audio, rate = load_and_trim(file)
- volume = librosa.feature.rms(y=audio)[0]
- avg_volume = np.mean(volume)
- loudness = loudness_of(audio)
- except Exception as e:
- sys.stderr.write(f"Failed to get Volume and Loudness on {file}: {e}\n")
- return volume, avg_volume, loudness
-
-def get_key(freq):
- A4 = 440
- C0 = A4*pow(2, -4.75)
- name = ["C", "C#", "D", "D#", "E", "F", "F#", "G", "G#", "A", "A#", "B"]
- h = round(12*log2(freq/C0))
- octave = h // 12
- n = h % 12
- return name[n] + str(octave)
-
-def get_average_pitch(pitch):
- pitches = []
- confidences_thresh = 0.8
- i = 0
- while i < len(pitch):
- if(pitch[i][2] > confidences_thresh):
- pitches.append(pitch[i][1])
- i += 1
- if len(pitches) > 0:
- average_frequency = np.array(pitches).mean()
- average_key = get_key(average_frequency)
- else:
- average_frequency = 0
- average_key = "A0"
- return average_frequency,average_key
-
-def get_intensity(y, sr, beats):
- # Beat-synchronous Loudness - Intensity
- CQT = librosa.cqt(y, sr=sr, fmin=librosa.note_to_hz('A1'))
- freqs = librosa.cqt_frequencies(CQT.shape[0], fmin=librosa.note_to_hz('A1'))
- perceptual_CQT = librosa.perceptual_weighting(CQT**2, freqs, ref=np.max)
- CQT_sync = librosa.util.sync(perceptual_CQT, beats, aggregate=np.median)
- return CQT_sync
-
-def get_pitch(y_harmonic, sr, beats):
- # Chromagram
- C = librosa.feature.chroma_cqt(y=y_harmonic, sr=sr)
- # Beat-synchronous Chroma - Pitch
- C_sync = librosa.util.sync(C, beats, aggregate=np.median)
- return C_sync
-
-def get_timbre(y, sr, beats):
- # Mel spectogram
- S = librosa.feature.melspectrogram(y, sr=sr, n_mels=128)
- log_S = librosa.power_to_db(S, ref=np.max)
- # MFCC - Timbre
- mfcc = librosa.feature.mfcc(S=log_S, n_mfcc=13)
- delta_mfcc = librosa.feature.delta(mfcc)
- delta2_mfcc = librosa.feature.delta(mfcc, order=2)
- M = np.vstack([mfcc, delta_mfcc, delta2_mfcc])
- # Beat-synchronous MFCC - Timbre
- M_sync = librosa.util.sync(M, beats)
- return M_sync
-
-def get_segments(audio_file):
- segmenter = Segmenter()
- boundaries, labs = segmenter.proc_audio(audio_file)
- return boundaries,labs
-
-def get_pitch_dnn(audio_file):
- # DNN Pitch Detection
- pitch = []
- audio, sr = librosa.load(audio_file)
- time, frequency, confidence, activation = crepe.predict(audio, sr, model_capacity="tiny", viterbi=True, center=True, step_size=10, verbose=1) # tiny|small|medium|large|full
- i = 0
- while i < len(time):
- pitch.append([time[i],frequency[i],confidence[i]])
- i += 1
- return pitch
-
-def stemsplit(destination, demucsmodel):
- subprocess.run(["demucs", destination, "-n", demucsmodel]) # '--mp3'
-
-def extractMIDI(audio_paths, output_dir):
- print('- Extract Midi')
- save_midi = True
- sonify_midi = False
- save_model_outputs = False
- save_notes = False
-
- predict_and_save(audio_path_list=audio_paths,
- output_directory=output_dir,
- save_midi=save_midi,
- sonify_midi=sonify_midi,
- save_model_outputs=save_model_outputs,
- save_notes=save_notes)
-
-
-def quantizeAudio(vid, bpm=120, keepOriginalBpm = False, pitchShiftFirst = False, extractMidi = False):
- print("Quantize Audio: Target BPM", bpm,
- "-- id:",vid.id,
- "bpm:",round(vid.audio_features["tempo"],2),
- "frequency:",round(vid.audio_features['frequency'],2),
- "key:",vid.audio_features['key'],
- "timbre:",round(vid.audio_features['timbre'],2),
- "name:",vid.name,
- 'keepOriginalBpm:', keepOriginalBpm
+ """Process the given list of NendoTracks using Nendo plugins.
+
+ Args:
+ nendo (Nendo): The Nendo instance to use.
+ tracks (List[NendoTrack]): List of tracks to process.
+ analyze (bool): Flag determining whether to analyze as part of processing.
+ stemify (bool): Flag determining whether to stemify as part of processing.
+ quantize (bool): Flag determining whether to quantize as part of processing.
+ quantize_to_bpm (int): Target bpm for quantization.
+ loopify (bool): Flag determining whether to loopify as part of processing.
+ n_loops (int): Number of loops to extract.
+ beats_per_loop (int): Beats per loop to extract.
+ """
+ n = 0
+ for track in tracks:
+ original_title = track.meta["title"]
+ print(f"Processing track {1}/{len(tracks)}: {original_title}")
+ duration = round(librosa.get_duration(y=track.signal, sr=track.sr), 3)
+ if (analyze is True and (
+ len(
+ track.get_plugin_data(
+ plugin_name="nendo_plugin_classify_core",
+ ),
+ ) == 0 or nendo.config.replace_plugin_data is True)
+ ):
+ print("Analyzing...")
+ track.process("nendo_plugin_classify_core")
+ # analysis_data = track.get_plugin_data(
+ # plugin_name="nendo_plugin_classify_core",
+ # )
+ stems = track
+ if (stemify is True and
+ track.track_type != "stem" and
+ "has_stems" not in track.resource.meta):
+ print("Stemifying...")
+ stems = track.process("nendo_plugin_stemify_demucs")
+ track.set_meta({"has_stems": True })
+ for stem in stems:
+ stem_type = stem.get_meta("stem_type")
+ stem.meta = dict(track.meta)
+ stem.set_meta(
+ {
+ "title": f"{original_title} - {stem_type} stem",
+ "stem_type": stem_type,
+ "duration": duration,
+ },
+ )
+ quantized = stems
+ if quantize is True:
+ print("Quantizing...")
+ quantized = stems.process(
+ "nendo_plugin_quantize_core",
+ bpm=quantize_to_bpm,
+ )
+ if type(quantized) == NendoTrack: # is a single track
+ if not quantized.has_related_track(track_id=track.id, direction="from"):
+ quantized.relate_to_track(
+ track_id=track.id,
+ relationship_type="quantized",
+ )
+ quantized.meta = dict(track.meta)
+ duration = round(librosa.get_duration(y=quantized.signal, sr=quantized.sr), 3)
+ quantized.set_meta(
+ {
+ "title": f"{original_title} - ({quantize_to_bpm} bpm)",
+ "duration": duration,
+ },
+ )
+ else: # is a collection
+ for j, qt in enumerate(quantized):
+ if not qt.has_related_track(track_id=track.id, direction="from"):
+ qt.relate_to_track(
+ track_id=track.id,
+ relationship_type="quantized",
+ )
+ qt.meta = dict(track.meta)
+ duration = round(librosa.get_duration(y=qt.signal, sr=qt.sr), 3)
+ if stems[j].track_type == "stem":
+ qt.set_meta(
+ {
+ "title": (
+ f"{original_title} - "
+ f"{stems[j].meta['stem_type']} "
+ f"({quantize_to_bpm} bpm)"
+ ),
+ "stem_type": stems[j].meta["stem_type"],
+ "duration": duration,
+ },
+ )
+ else:
+ qt.set_meta(
+ {
+ "title": f"{original_title} ({quantize_to_bpm} bpm)",
+ "duration": duration,
+ },
+ )
+ loopified = quantized
+ if loopify is True:
+ print("Loopifying...")
+ loopified = []
+ if type(quantized) == NendoTrack:
+ quantized = [quantized]
+ for qt in quantized:
+ qt_loops = qt.process(
+ "nendo_plugin_loopify",
+ n_loops=n_loops,
+ beats_per_loop=beats_per_loop,
+ )
+ loopified += qt_loops
+ num_loop = 1
+ for lp in qt_loops:
+ if not lp.has_related_track(track_id=track.id, direction="from"):
+ lp.relate_to_track(
+ track_id=track.id,
+ relationship_type="loop",
+ )
+ stem_type = qt.meta["stem_type"] if qt.has_meta("stem_type") else ""
+ qt_info = (
+ f" ({quantize_to_bpm} bpm)"
+ if qt.track_type == "quantized"
+ else ""
+ )
+ lp.meta = dict(track.meta)
+ duration = round(librosa.get_duration(y=lp.signal, sr=lp.sr), 3)
+ lp.set_meta(
+ {
+ "title": f"{original_title} - {stem_type} loop {num_loop} {qt_info}",
+ "duration": duration,
+ },
+ )
+ num_loop += 1
+ n = n+1
+ print(f"Track {n}/{len(tracks)} Done.\n")
+ print("Processing completed. "
+ f"The library now contains {len(nendo.library)} tracks.")
+
+def export_tracks(nendo, tracks, output_folder, export_format):
+ """Export the given tracks to the given output folder in the given format.
+
+ Args:
+ nendo (Nendo): The Nendo instance to use.
+ tracks (List[NendoTrack]): List of track to export.
+ output_folder (str): Output path.
+ export_format (str): Output format.
+ """
+ if os.path.exists(output_folder) is False:
+ os.mkdir(output_folder)
+
+ print(f"Exporting {len(tracks)} tracks")
+ for found_track in tracks:
+ bpm = ""
+ bpm_pd = found_track.get_plugin_data(
+ key="tempo",
)
-
- # load audio file
- y, sr = librosa.load(vid.audio, sr=None)
-
- # Keep Original Song BPM
- if keepOriginalBpm:
- bpm = float(vid.audio_features['tempo'])
- print('Keep original audio file BPM:', vid.audio_features['tempo'])
- # Pitch Shift audio file to desired BPM first
- elif pitchShiftFirst: # WORK IN PROGRESS
- print('Pitch Shifting audio to desired BPM', bpm)
- # Desired tempo in bpm
- original_tempo = vid.audio_features['tempo']
- speed_factor = bpm / original_tempo
- # Resample the audio to adjust the sample rate accordingly
- sr_stretched = int(sr / speed_factor)
- y = librosa.resample(y=y, orig_sr=sr, target_sr=sr_stretched) #, res_type='linear'
- y = librosa.resample(y, orig_sr=sr, target_sr=44100)
-
- # extract beat
- y_harmonic, y_percussive = librosa.effects.hpss(y)
- tempo, beats = librosa.beat.beat_track(sr=sr, onset_envelope=librosa.onset.onset_strength(y=y_percussive, sr=sr), trim=False)
- beat_frames = librosa.frames_to_samples(beats)
-
- # generate metronome
- fixed_beat_times = []
- for i in range(len(beat_frames)):
- fixed_beat_times.append(i * 120 / bpm)
- fixed_beat_frames = librosa.time_to_samples(fixed_beat_times)
-
- # construct time map
- time_map = []
- for i in range(len(beat_frames)):
- new_member = (beat_frames[i], fixed_beat_frames[i])
- time_map.append(new_member)
-
- # add ending to time map
- original_length = len(y+1)
- orig_end_diff = original_length - time_map[i][0]
- new_ending = int(round(time_map[i][1] + orig_end_diff * (tempo / bpm)))
- new_member = (original_length, new_ending)
- time_map.append(new_member)
-
- # time strech audio
- print('- Quantize Audio: source')
- strechedaudio = pyrb.timemap_stretch(y, sr, time_map)
-
- path_suffix = (
- f"Key {vid.audio_features['key']} - "
- f"Freq {round(vid.audio_features['frequency'], 2)} - "
- f"Timbre {round(vid.audio_features['timbre'], 2)} - "
- f"BPM Original {int(vid.audio_features['tempo'])} - "
- f"BPM {bpm}"
+ if not isinstance(bpm_pd, list) and len(bpm_pd) != 0:
+ bpm = f"_{int(float(bpm_pd))}bpm"
+ stem = (
+ f"_{found_track.get_meta('stem_type')}" if
+ found_track.has_meta("stem_type") else
+ ""
+ )
+ track_type = (
+ f"_{found_track.track_type}" if
+ found_track.track_type != "track" else
+ ""
+ )
+ alphabet = string.ascii_lowercase + string.digits
+ rnd = "".join(random.choices(alphabet, k=6)) # noqa: S311
+ file_path = (
+ f"{output_folder}/{found_track.meta['title']}"
+ f"{stem}{track_type}{bpm}"
+ f"_{rnd}.{export_format}"
+ )
+ exported_path = nendo.library.export_track(
+ track_id=found_track.id,
+ file_path=file_path,
+ )
+ print(f"Exported track {exported_path}")
+
+def parse_args() -> argparse.Namespace: # noqa: D103
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "-i",
+ "--input",
+ type=str,
+ required=False,
+ help=("Comma-separated list of tracks to add to the polymath library."
+ "Tracks can be either youtube IDs, file paths or directories."
+ ),
)
- path_prefix = (
- f"{vid.id} - {vid.name}"
+ parser.add_argument(
+ "-p",
+ "--process",
+ required=False,
+ action="store_true",
+ help=(
+ "Flag that enables all processing steps "
+ "(use -q aswell to specify target bpm)."
+ ),
+ )
+ parser.add_argument(
+ "-a",
+ "--analyze",
+ required=False,
+ action="store_true",
+ help="Flag to enable running the analysis plugin.",
+ )
+ parser.add_argument(
+ "-s",
+ "--stemify",
+ required=False,
+ action="store_true",
+ help="Flag to enable running the stemify plugin.",
+ )
+ parser.add_argument(
+ "-q",
+ "--quantize",
+ required=False,
+ type=int,
+ help="Quantize tracks to given bpm (default is 120).",
+ )
+ parser.add_argument(
+ "-l",
+ "--loopify",
+ required=False,
+ action="store_true",
+ help="Flag to enable running the loopify plugin.",
+ )
+ parser.add_argument(
+ "-ln",
+ "--loop_num",
+ type=int,
+ default=1,
+ help="Number of loops to extract (requires -l, default is 1).",
+ )
+ parser.add_argument(
+ "-lb",
+ "--loop_beats",
+ type=int,
+ default=8,
+ help="Number of beats per loop (requires -l, default is 8).",
+ )
+ parser.add_argument(
+ "-f",
+ "--find",
+ required=False,
+ type=str,
+ help=(
+ "Find specific tracks to apply polymath. "
+ "Omit to work with all tracks."
+ ),
+ )
+ parser.add_argument(
+ "-bmin",
+ "--bpm_min",
+ required=False,
+ type=int,
+ help="Find tracks with a minimum bpm provided by this paramter.",
+ )
+ parser.add_argument(
+ "-bmax",
+ "--bpm_max",
+ required=False,
+ type=int,
+ help="Find tracks with a maximum bpm provided by this paramter.",
+ )
+ parser.add_argument(
+ "-fs",
+ "--find_stems",
+ required=False,
+ action="store_true",
+ help="Flag to enable finding stems.",
+ )
+ parser.add_argument(
+ "-st",
+ "--stem_type",
+ choices=["any", "vocals", "drums", "bass", "other"],
+ default="any",
+ help="Flag to enable searching for stems.",
+ )
+ parser.add_argument(
+ "-fl",
+ "--find_loops",
+ required=False,
+ action="store_true",
+ help="Flag to enable finding loops.",
+ )
+ parser.add_argument(
+ "-e",
+ "--export",
+ required=False,
+ action="store_true",
+ help="Flag to enable exporting of tracks.",
+ )
+ parser.add_argument(
+ "-o",
+ "--output_path",
+ type=str,
+ default="polymath_output",
+ help="Output path for file export.",
+ )
+ parser.add_argument(
+ "-of",
+ "--output_format",
+ choices=["wav", "mp3", "ogg"],
+ default="wav",
+ help="Output path for file export.",
+ )
+ parser.add_argument(
+ "-lp",
+ "--library_path",
+ default="polymath_library",
+ type=str,
+ help="Path to the polymath library directory.",
+ )
+ return parser.parse_args()
+
+
+def main(): # noqa: D103
+ args = parse_args()
+
+ nendo = Nendo(
+ config=NendoConfig(
+ log_level="error",
+ library_path=args.library_path,
+ skip_duplicate=True,
+ plugins=[
+ "nendo_plugin_classify_core",
+ "nendo_plugin_quantize_core",
+ "nendo_plugin_stemify_demucs",
+ "nendo_plugin_loopify",
+ ],
+ ),
)
- audiofilepaths = []
- # save audio to disk
- path = os.path.join(os.getcwd(), 'processed', path_prefix + " - " + path_suffix +'.wav')
- sf.write(path, strechedaudio, sr)
- audiofilepaths.append(path)
-
- # process stems
- stems = ['bass', 'drums', 'guitar', 'other', 'piano', 'vocals']
- for stem in stems:
- path = os.path.join(os.getcwd(), 'separated', 'htdemucs_6s', vid.id, stem +'.wav')
- print(f"- Quantize Audio: {stem}")
- y, sr = librosa.load(path, sr=None)
- strechedaudio = pyrb.timemap_stretch(y, sr, time_map)
- # save stems to disk
- path = os.path.join(os.getcwd(), 'processed', path_prefix + " - Stem " + stem + " - " + path_suffix +'.wav')
- sf.write(path, strechedaudio, sr)
- audiofilepaths.append(path)
-
- # metronome click (optinal)
- click = False
- if click:
- clicks_audio = librosa.clicks(times=fixed_beat_times, sr=sr)
- print(len(clicks_audio), len(strechedaudio))
- clicks_audio = clicks_audio[:len(strechedaudio)]
- path = os.path.join(os.getcwd(), 'processed', vid.id + '- click.wav')
- sf.write(path, clicks_audio, sr)
-
- if extractMidi:
- output_dir = os.path.join(os.getcwd(), 'processed')
- extractMIDI(audiofilepaths, output_dir)
-
-
-def get_audio_features(file,file_id,extractMidi = False):
- print("------------------------------ get_audio_features:",file_id,"------------------------------")
- print('1/8 segementation')
- segments_boundaries,segments_labels = get_segments(file)
-
- print('2/8 pitch tracking')
- frequency_frames = get_pitch_dnn(file)
- average_frequency,average_key = get_average_pitch(frequency_frames)
-
- print('3/8 load sample')
- y, sr = librosa.load(file, sr=None)
- song_duration = librosa.get_duration(y=y, sr=sr)
-
- print('4/8 sample separation')
- y_harmonic, y_percussive = librosa.effects.hpss(y)
-
- print('5/8 beat tracking')
- tempo, beats = librosa.beat.beat_track(sr=sr, onset_envelope=librosa.onset.onset_strength(y=y_percussive, sr=sr), trim=False)
-
- print('6/8 feature extraction')
- CQT_sync = get_intensity(y, sr, beats)
- C_sync = get_pitch(y_harmonic, sr, beats)
- M_sync = get_timbre(y, sr, beats)
- volume, avg_volume, loudness = get_volume(file)
-
- print('7/8 feature aggregation')
- intensity_frames = np.matrix(CQT_sync).getT()
- pitch_frames = np.matrix(C_sync).getT()
- timbre_frames = np.matrix(M_sync).getT()
-
- if cuda.is_available():
- print('Cleaning up GPU memory')
- device = cuda.get_current_device()
- device.reset()
-
- print('8/8 split stems')
- stemsplit(file, 'htdemucs_6s')
-
- if extractMidi:
- audiofilepaths = []
- stems = ['bass', 'drums', 'guitar', 'other', 'piano', 'vocals']
- for stem in stems:
- path = os.path.join(os.getcwd(), 'separated', 'htdemucs_6s', file_id, stem +'.wav')
- audiofilepaths.append(path)
- output_dir = os.path.join(os.getcwd(), 'separated', 'htdemucs_6s', file_id)
- extractMIDI(audiofilepaths, output_dir)
-
- audio_features = {
- "id":file_id,
- "tempo":tempo,
- "duration":song_duration,
- "timbre":np.mean(timbre_frames),
- "timbre_frames":timbre_frames,
- "pitch":np.mean(pitch_frames),
- "pitch_frames":pitch_frames,
- "intensity":np.mean(intensity_frames),
- "intensity_frames":intensity_frames,
- "volume": volume,
- "avg_volume": avg_volume,
- "loudness": loudness,
- "beats":librosa.frames_to_time(beats, sr=sr),
- "segments_boundaries":segments_boundaries,
- "segments_labels":segments_labels,
- "frequency_frames":frequency_frames,
- "frequency":average_frequency,
- "key":average_key
- }
- return audio_features
-
-################## SEARCH NEAREST AUDIO ##################
-
-previous_list = []
-
-def get_nearest(query,videos,querybpm, searchforbpm):
- global previous_list
- # print("Search: query:", query.name, '- Incl. BPM in search:', searchforbpm)
- nearest = {}
- smallest = 1000000000
- smallestBPM = 1000000000
- smallestTimbre = 1000000000
- smallestIntensity = 1000000000
- for vid in videos:
- if vid.id != query.id:
- comp_bpm = abs(querybpm - vid.audio_features['tempo'])
- comp_timbre = abs(query.audio_features["timbre"] - vid.audio_features['timbre'])
- comp_intensity = abs(query.audio_features["intensity"] - vid.audio_features['intensity'])
- #comp = abs(query.audio_features["pitch"] - vid.audio_features['pitch'])
- comp = abs(query.audio_features["frequency"] - vid.audio_features['frequency'])
-
- if searchforbpm:
- if vid.id not in previous_list and comp < smallest and comp_bpm < smallestBPM:# and comp_timbre < smallestTimbre:
- smallest = comp
- smallestBPM = comp_bpm
- smallestTimbre = comp_timbre
- nearest = vid
- else:
- if vid.id not in previous_list and comp < smallest:
- smallest = comp
- smallestBPM = comp_bpm
- smallestTimbre = comp_timbre
- nearest = vid
- #print("--- result",i['file'],i['average_frequency'],i['average_key'],"diff",comp)
- # print(nearest)
- previous_list.append(nearest.id)
-
- if len(previous_list) >= len(videos)-1:
- previous_list.pop(0)
- # print("getNearestPitch: previous_list, pop first")
- # print("get_nearest",nearest.id)
- return nearest
-
-def getNearest(k, array):
- k = k / 10 # HACK
- return min(enumerate(array), key=lambda x: abs(x[1]-k))
-
-
-################## MAIN ##################
-
-def main():
- print("---------------------------------------------------------------------------- ")
- print("--------------------------------- POLYMATH --------------------------------- ")
- print("---------------------------------------------------------------------------- ")
- # Load DB
- videos = read_library()
-
- for directory in ("processed", "library", "separated", "separated/htdemucs_6s"):
- os.makedirs(directory, exist_ok=True)
-
- # Parse command line input
- parser = argparse.ArgumentParser(description='polymath')
- parser.add_argument('-a', '--add', help='youtube id', required=False)
- parser.add_argument('-r', '--remove', help='youtube id', required=False)
- parser.add_argument('-v', '--videos', help='video db length', required=False)
- parser.add_argument('-t', '--tempo', help='quantize audio tempo in BPM', required=False, type=float)
- parser.add_argument('-q', '--quantize', help='quantize: id or "all"', required=False)
- parser.add_argument('-k', '--quantizekeepbpm', help='quantize to the BPM of the original audio file"', required=False, action="store_true", default=False)
- parser.add_argument('-s', '--search', help='search for musically similar audio files, given a database id"', required=False)
- parser.add_argument('-sa', '--searchamount', help='amount of results the search returns"', required=False, type=int)
- parser.add_argument('-st', '--searchbpm', help='include BPM of audio files as similiarty search criteria"', required=False, action="store_true", default=False)
- parser.add_argument('-m', '--midi', help='extract midi from audio files"', required=False, action="store_true", default=False)
-
- args = parser.parse_args()
-
- # List of videos to use
- if args.videos is not None:
- finalvids = []
- vids = args.videos.split(",")
- print("process selected videos only:",vids)
- for vid in vids:
- v = [x for x in videos if x.id == vid][0]
- finalvids.append(v)
- videos = finalvids
-
- # List of videos to delete
- if args.remove is not None:
- print("remove video:",args.remove)
- for vid in videos:
- if vid.id == args.remove:
- videos.remove(vid)
- break
- write_library(videos)
-
- # List of videos to download
- newvids = []
- if args.add is not None:
- print("add video:",args.add,"to videos:",len(videos))
- vids = args.add.split(",")
- if "/" in args.add and not (args.add.endswith(".wav") or args.add.endswith(".mp3")):
- print('add directory with wav or mp3 files')
- videos = audio_directory_process(vids,videos)
- elif ".wav" in args.add or ".mp3" in args.add:
- print('add wav or mp3 file')
- videos = audio_process(vids,videos)
+ if args.input:
+ input_tracks(nendo, args.input)
+
+ if (
+ args.process or
+ args.analyze or
+ args.stemify or
+ (args.quantize is not None) or
+ args.loopify
+ ):
+ # apply search
+ tracks = []
+ if args.find is None:
+ tracks = nendo.filter_tracks(track_type="track")
else:
- videos = video_process(vids,videos)
- newvids = vids
-
- # List of audio to quantize
- vidargs = []
- if args.quantize is not None:
- vidargs = args.quantize.split(",")
- # print("Quantize:", vidargs)
- if vidargs[0] == 'all' and len(newvids) != 0:
- vidargs = newvids
-
- # MIDI
- extractmidi = bool(args.midi)
- if extractmidi:
- global basic_pitch_model
- basic_pitch_model = tf.saved_model.load(str(ICASSP_2022_MODEL_PATH))
-
- # Tempo
- tempo = int(args.tempo or 120)
-
- # Quanize: Keep bpm of original audio file
- keepOriginalBpm = bool(args.quantizekeepbpm)
-
- # WIP: Quanize: Pitch shift before quanize
- pitchShiftFirst = False
- # if args.quantizepitchshift:
- # pitchShiftFirst = True
-
- # Analyse to DB
- print(f"------------------------------ Files in DB: {len(videos)} ------------------------------")
- dump_db = False
- # get/detect audio metadata
- for vid in videos:
- feature_file = f"library/{vid.id}.a"
- # load features from disk
- if os.path.isfile(feature_file):
- with open(feature_file, "rb") as f:
- audio_features = pickle.load(f)
- # extract features
+ for search_value in args.find.split(","):
+ tracks = tracks + nendo.filter_tracks(
+ search_meta={"": search_value},
+ track_type="track",
+ )
+
+ if args.process:
+ process_tracks(
+ nendo = nendo,
+ tracks = tracks,
+ analyze = True,
+ stemify = True,
+ quantize = True,
+ quantize_to_bpm = args.quantize or 120,
+ loopify = True,
+ n_loops = args.loop_num,
+ beats_per_loop = args.loop_beats,
+ )
else:
- # Is audio file from disk
- if len(vid.id) > 12:
- print('is audio', vid.id, vid.name, vid.url)
- file = vid.url
- # if is mp3 file
- if vid.url[-3:] == "mp3":
- file = os.path.join(os.getcwd(), 'library', vid.id + '.wav')
- # Is audio file extracted from downloaded video
- else:
- file = os.path.join(os.getcwd(), 'library', vid.id + '.wav')
-
- # Audio feature extraction
- audio_features = get_audio_features(file=file,file_id=vid.id, extractMidi=extractmidi)
-
- # Save to disk
- with open(feature_file, "wb") as f:
- pickle.dump(audio_features, f)
-
- # assign features to video
- vid.audio_features = audio_features
- print(
- vid.id,
- "tempo", round(audio_features["tempo"], 2),
- "duration", round(audio_features["duration"], 2),
- "timbre", round(audio_features["timbre"], 2),
- "pitch", round(audio_features["pitch"], 2),
- "intensity", round(audio_features["intensity"], 2),
- "segments", len(audio_features["segments_boundaries"]),
- "frequency", round(audio_features["frequency"], 2),
- "key", audio_features["key"],
- "name", vid.name,
+ process_tracks(
+ nendo = nendo,
+ tracks = tracks,
+ analyze = args.analyze,
+ stemify = args.stemify,
+ quantize = args.quantize is not None,
+ quantize_to_bpm = args.quantize if args.quantize is not None else 120,
+ loopify = args.loopify,
+ n_loops = args.loop_num,
+ beats_per_loop = args.loop_beats,
+ )
+
+ if args.export and args.output_path is not None:
+ if args.find is not None:
+ search_values = args.find.split(",")
+ search_meta = { f"arg{i}": search_values[i] for i in range(len(search_values)) }
+ track_type = ["track"]
+ if args.find_stems is True:
+ track_type.append("stem")
+ if args.find_loops is True:
+ track_type.append("loop")
+ if args.find is None:
+ track_type.append("quantized")
+ filters = {}
+ if args.bpm_min is not None or args.bpm_max is not None:
+ track_type.append("quantized")
+ bpm_min = args.bpm_min or 0
+ bpm_max = args.bpm_max or 999
+ filters.update({"tempo": (float(bpm_min), float(bpm_max))})
+
+ found_tracks = nendo.filter_tracks(
+ filters=filters if len(filters) > 0 else None,
+ track_type=track_type,
+ search_meta=search_meta if args.find is not None else None,
+ )
+ found_tracks = [
+ ft for ft in found_tracks if (
+ not ft.has_meta("stem_type") or
+ (args.find_stems is True and
+ (args.stem_type == "any" or
+ ft.get_meta("stem_type") == args.stem_type)))
+ ]
+ export_tracks(
+ nendo=nendo,
+ tracks=found_tracks,
+ output_folder=args.output_path,
+ export_format=args.output_format,
)
- #dump_db = True
- if dump_db:
- write_library(videos)
-
- print("--------------------------------------------------------------------------")
-
- # Quantize audio
- if args.search is None:
- for vidarg in vidargs:
- for idx, vid in enumerate(videos):
- if vid.id == vidarg:
- quantizeAudio(videos[idx], bpm=tempo, keepOriginalBpm = keepOriginalBpm, pitchShiftFirst = pitchShiftFirst, extractMidi = extractmidi)
- break
- if vidarg == 'all' and len(newvids) == 0:
- quantizeAudio(videos[idx], bpm=tempo, keepOriginalBpm = keepOriginalBpm, pitchShiftFirst = pitchShiftFirst, extractMidi = extractmidi)
-
- # Search
- searchamount = int(args.searchamount or 20)
- searchforbpm = bool(args.searchbpm)
- if args.search is not None:
- for vid in videos:
- if vid.id == args.search:
- query = vid
- print(
- 'Audio files related to:', query.id,
- "- Key:", query.audio_features['key'],
- "- Tempo:", int(query.audio_features['tempo']),
- ' - ', query.name,
- )
- if args.quantize is not None:
- quantizeAudio(query, bpm=tempo, keepOriginalBpm = keepOriginalBpm, pitchShiftFirst = pitchShiftFirst, extractMidi = extractmidi)
- i = 0
- while i < searchamount:
- nearest = get_nearest(query, videos, tempo, searchforbpm)
- query = nearest
- print(
- "- Relate:", query.id,
- "- Key:", query.audio_features['key'],
- "- Tempo:", int(query.audio_features['tempo']),
- ' - ', query.name,
- )
- if args.quantize is not None:
- quantizeAudio(query, bpm=tempo, keepOriginalBpm = keepOriginalBpm, pitchShiftFirst = pitchShiftFirst, extractMidi = extractmidi)
- i += 1
- break
if __name__ == "__main__":
main()
diff --git a/requirements.txt b/requirements.txt
index c447f84..09430ed 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -1,14 +1,8 @@
-crepe==0.0.13
-librosa==0.9.2
-numpy>=1.20
-pyrubberband==0.3.0
-sf_segmenter==0.0.2
-soundfile==0.11.0
-yt_dlp==2023.02.17
-demucs==4.0.0
-basic-pitch==0.2.0
-matplotlib
-tensorflow==2.9; sys_platform == 'windows' or platform_machine != 'arm64'
-tensorflow-macos; sys_platform == 'darwin' and platform_machine == 'arm64'
-tensorflow-metal; sys_platform == 'darwin' and platform_machine == 'arm64'
-
+nendo==0.2.1
+nendo_plugin_classify_core==0.2.6
+nendo_plugin_quantize_core==0.2.6
+nendo_plugin_stemify_demucs==0.1.2
+nendo_plugin_loopify==0.1.6
+tensorflow
+git+https://github.com/CPJKU/madmom.git@0551aa8
+yt_dlp>=2023.12.30
diff --git a/run_docker.sh b/run_docker.sh
new file mode 100755
index 0000000..533e44f
--- /dev/null
+++ b/run_docker.sh
@@ -0,0 +1,5 @@
+#!/bin/bash
+
+
+mkdir -p processed separated library input
+sudo docker run -v "$(pwd)"/processed:/polymath/processed -v "$(pwd)"/separated:/polymath/separated -v"$(pwd)"/library:/polymath/library -v "$(pwd)"/input:/polymath/input polymath python /polymath/polymath.py "$@"
\ No newline at end of file
diff --git a/setup.py b/setup.py
new file mode 100644
index 0000000..192cd1d
--- /dev/null
+++ b/setup.py
@@ -0,0 +1,16 @@
+from setuptools import setup
+
+setup(
+ name='polymath',
+ version='0.1.0',
+ packages=['.'],
+ install_requires=[
+ "nendo>=0.1.2",
+ "nendo_plugin_classify_core>=0.2.3",
+ "nendo_plugin_quantize_core>=0.1.2",
+ "nendo_plugin_stemify_demucs>=0.1.0",
+ "nendo_plugin_loopify>=0.1.1",
+ "yt_dlp>=2023.11.16",
+ "tensorflow",
+ ],
+)