-
Notifications
You must be signed in to change notification settings - Fork 3
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
* fix typos * add buttons for google colab everywhere * update readme, separate out FAQ * add privacy disclosure statement * do not install using uv * update docs notebook * explicit install of libopenblas * explicit install of libopenblas * explicit install of libopenblas * try to get scipy installed using uv * use ubuntu 24.04 * go back to pip * try with scipy only * try with a few others * use hatchling * wording changes, install all requirements * fix offending spacy version * run all tests * include faq in documentation, fix link
- Loading branch information
Showing
14 changed files
with
445 additions
and
194 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,104 @@ | ||
| # FAQ | ||
|
|
||
| ## Compatibility problems solving | ||
|
|
||
| Some ammico components require `tensorflow` (e.g. Emotion detector), some `pytorch` (e.g. Summary detector). Sometimes there are compatibility problems between these two frameworks. To avoid these problems on your machines, you can prepare proper environment before installing the package (you need conda on your machine): | ||
|
|
||
| ### 1. First, install tensorflow (https://www.tensorflow.org/install/pip) | ||
| - create a new environment with python and activate it | ||
|
|
||
| ```conda create -n ammico_env python=3.10``` | ||
|
|
||
| ```conda activate ammico_env``` | ||
| - install cudatoolkit from conda-forge | ||
|
|
||
| ``` conda install -c conda-forge cudatoolkit=11.8.0``` | ||
| - install nvidia-cudnn-cu11 from pip | ||
|
|
||
| ```python -m pip install nvidia-cudnn-cu11==8.6.0.163``` | ||
| - add script that runs when conda environment `ammico_env` is activated to put the right libraries on your LD_LIBRARY_PATH | ||
|
|
||
| ``` | ||
| mkdir -p $CONDA_PREFIX/etc/conda/activate.d | ||
| echo 'CUDNN_PATH=$(dirname $(python -c "import nvidia.cudnn;print(nvidia.cudnn.__file__)"))' >> $CONDA_PREFIX/etc/conda/activate.d/env_vars.sh | ||
| echo 'export LD_LIBRARY_PATH=$CUDNN_PATH/lib:$CONDA_PREFIX/lib/:$LD_LIBRARY_PATH' >> $CONDA_PREFIX/etc/conda/activate.d/env_vars.sh | ||
| source $CONDA_PREFIX/etc/conda/activate.d/env_vars.sh | ||
| ``` | ||
| - deactivate and re-activate conda environment to call script above | ||
| ```conda deactivate``` | ||
| ```conda activate ammico_env ``` | ||
| - install tensorflow | ||
| ```python -m pip install tensorflow==2.12.1``` | ||
| ### 2. Second, install pytorch | ||
| - install pytorch for same cuda version as above | ||
| ```python -m pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118``` | ||
| ### 3. After we prepared right environment we can install the ```ammico``` package | ||
| - ```python -m pip install ammico``` | ||
| It is done. | ||
| ### Micromamba | ||
| If you are using micromamba you can prepare environment with just one command: | ||
| ```micromamba create --no-channel-priority -c nvidia -c pytorch -c conda-forge -n ammico_env "python=3.10" pytorch torchvision torchaudio pytorch-cuda "tensorflow-gpu<=2.12.3" "numpy<=1.23.4"``` | ||
| ### Windows | ||
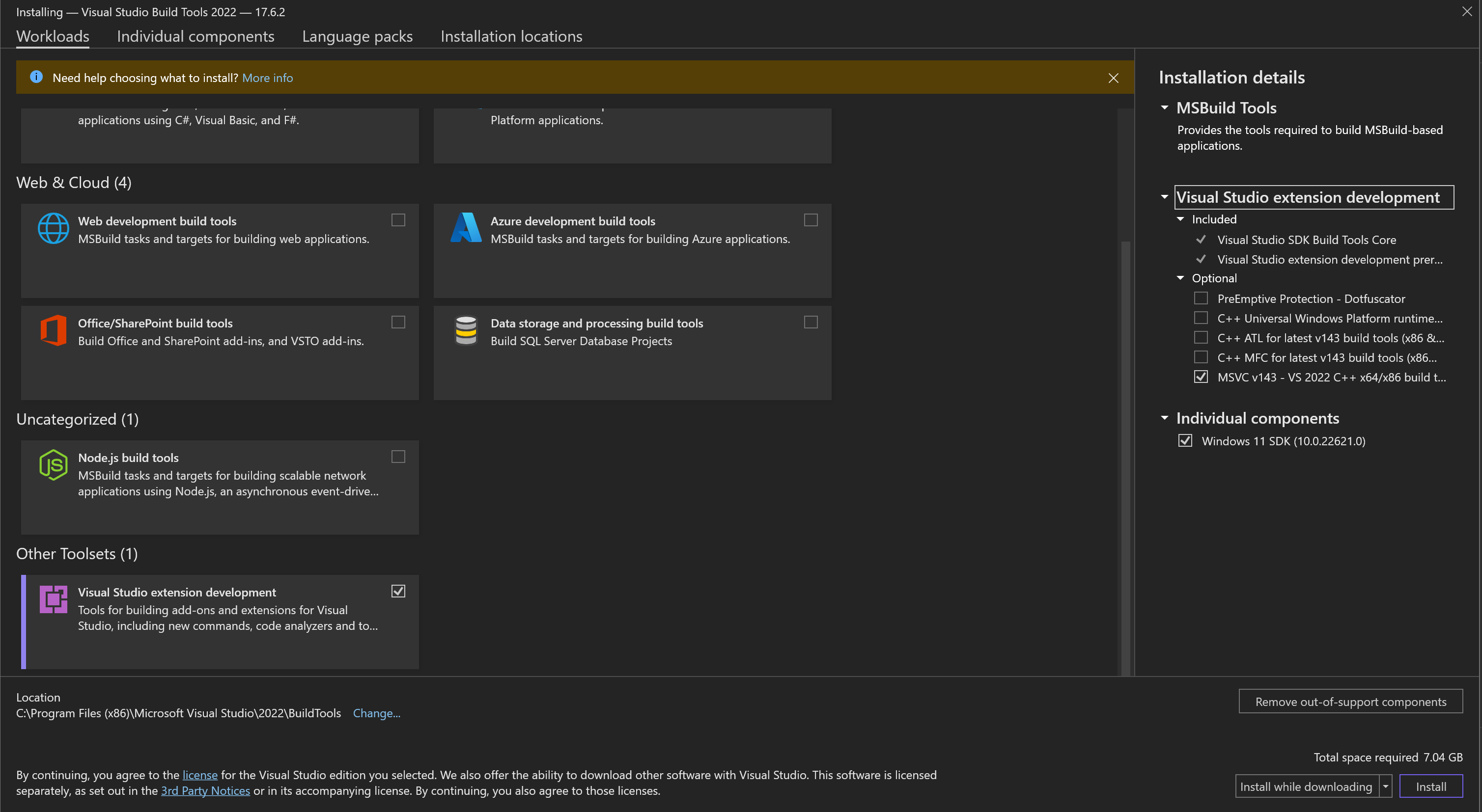
| To make pycocotools work on Windows OS you may need to install `vs_BuildTools.exe` from https://visualstudio.microsoft.com/visual-cpp-build-tools/ and choose following elements: | ||
| - `Visual Studio extension development` | ||
| - `MSVC v143 - VS 2022 C++ x64/x86 build tools` | ||
| - `Windows 11 SDK` for Windows 11 (or `Windows 10 SDK` for Windows 10) | ||
| Be careful, it requires around 7 GB of disk space. | ||
|  | ||
| ## What happens to the images that are sent to google Cloud Vision? | ||
| You have to accept the privacy statement of ammico to run this type of analyis. | ||
| According to the [google Vision API](https://cloud.google.com/vision/docs/data-usage), the images that are uploaded and analysed are not stored and not shared with third parties: | ||
| > We won't make the content that you send available to the public. We won't share the content with any third party. The content is only used by Google as necessary to provide the Vision API service. Vision API complies with the Cloud Data Processing Addendum. | ||
| > For online (immediate response) operations (`BatchAnnotateImages` and `BatchAnnotateFiles`), the image data is processed in memory and not persisted to disk. | ||
| For asynchronous offline batch operations (`AsyncBatchAnnotateImages` and `AsyncBatchAnnotateFiles`), we must store that image for a short period of time in order to perform the analysis and return the results to you. The stored image is typically deleted right after the processing is done, with a failsafe Time to live (TTL) of a few hours. | ||
| Google also temporarily logs some metadata about your Vision API requests (such as the time the request was received and the size of the request) to improve our service and combat abuse. | ||
| ## What happens to the text that is sent to google Translate? | ||
| You have to accept the privacy statement of ammico to run this type of analyis. | ||
| According to [google Translate](https://cloud.google.com/translate/data-usage), the data is not stored after processing and not made available to third parties: | ||
| > We will not make the content of the text that you send available to the public. We will not share the content with any third party. The content of the text is only used by Google as necessary to provide the Cloud Translation API service. Cloud Translation API complies with the Cloud Data Processing Addendum. | ||
| > When you send text to Cloud Translation API, text is held briefly in-memory in order to perform the translation and return the results to you. | ||
| ## What happens if I don't have internet access - can I still use ammico? | ||
| Some features of ammico require internet access; a general answer to this question is not possible, some services require an internet connection, others can be used offline: | ||
| - Text extraction: To extract text from images, and translate the text, the data needs to be processed by google Cloud Vision and google Translate, which run in the cloud. Without internet access, text extraction and translation is not possible. | ||
| - Image summary and query: After an initial download of the models, the `summary` module does not require an internet connection. | ||
| - Facial expressions: After an initial download of the models, the `faces` module does not require an internet connection. | ||
| - Multimodal search: After an initial download of the models, the `multimodal_search` module does not require an internet connection. | ||
| - Color analysis: The `color` module does not require an internet connection. | ||
| ## Why don't I get probabilistic assessments of age, gender and race when running the Emotion Detector? | ||
| Due to well documented biases in the detection of minorities with computer vision tools, and to the ethical implications of such detection, these parts of the tool are not directly made available to users. To access these capabilities, users must first agree with a ethical disclosure statement that reads: | ||
| "DeepFace and RetinaFace provide wrappers to trained models in face recognition and emotion detection. Age, gender and race/ethnicity models were trained on the backbone of VGG-Face with transfer learning. | ||
| ETHICAL DISCLOSURE STATEMENT: | ||
| The Emotion Detector uses DeepFace and RetinaFace to probabilistically assess the gender, age and race of the detected faces. Such assessments may not reflect how the individuals identify. Additionally, the classification is carried out in simplistic categories and contains only the most basic classes (for example, “male” and “female” for gender, and seven non-overlapping categories for ethnicity). To access these probabilistic assessments, you must therefore agree with the following statement: “I understand the ethical and privacy implications such assessments have for the interpretation of the results and that this analysis may result in personal and possibly sensitive data, and I wish to proceed.” | ||
| This disclosure statement is included as a separate line of code early in the flow of the Emotion Detector. Once the user has agreed with the statement, further data analyses will also include these assessments. |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Oops, something went wrong.