A music streaming company, Sparkify, has decided that it is time to introduce more automation and monitoring to their data warehouse ETL pipelines and come to the conclusion that the best tool to achieve this is Apache Airflow.
The source data resides in S3 and needs to be processed in Sparkify's data warehouse in Amazon Redshift. The source datasets consist of JSON logs that tell about user activity in the application and JSON metadata about the songs the users listen to.

airflow-data-pipeline
│ README.md # Project description
│ docker-compose.yml # Airflow containers description
│ requirements.txt # Python dependencies
| dag.png # Pipeline DAG image
│
└───airflow # Airflow home
| |
│ └───dags # Jupyter notebooks
│ | │ s3_to_redshift_dag.py # DAG definition
| | |
| └───plugins
│ │
| └───helpers
| | | sql_queries.py # All sql queries needed
| |
| └───operators
| | | data_quality.py # DataQualityOperator
| | | load_dimension.py # LoadDimensionOperator
| | | load_fact.py # LoadFactOperator
| | | stage_redshift.py # StageToRedshiftOperator
- Install Python3
- Install Docker Compose
- AWS account and Redshift cluster
Instead of installing docker and we can also install Ubuntu WSL on Windows and install airflow in that. Please refer link for more information.
git clone https://github.com/sudip-padhye/Data-Pipeline-Orchestration-using-Airflow.git
cd airflow-data-pipeline
Everything is configured in the docker-compose.yml file. If you are satisfied with the default configurations you can just start the containers.
docker-compose up
Go to http://localhost:8080
Username: user
Password: password
-
Click on the Admin tab and select Connections.
-
Under Connections, select Create.
-
On the create connection page, enter the following values:
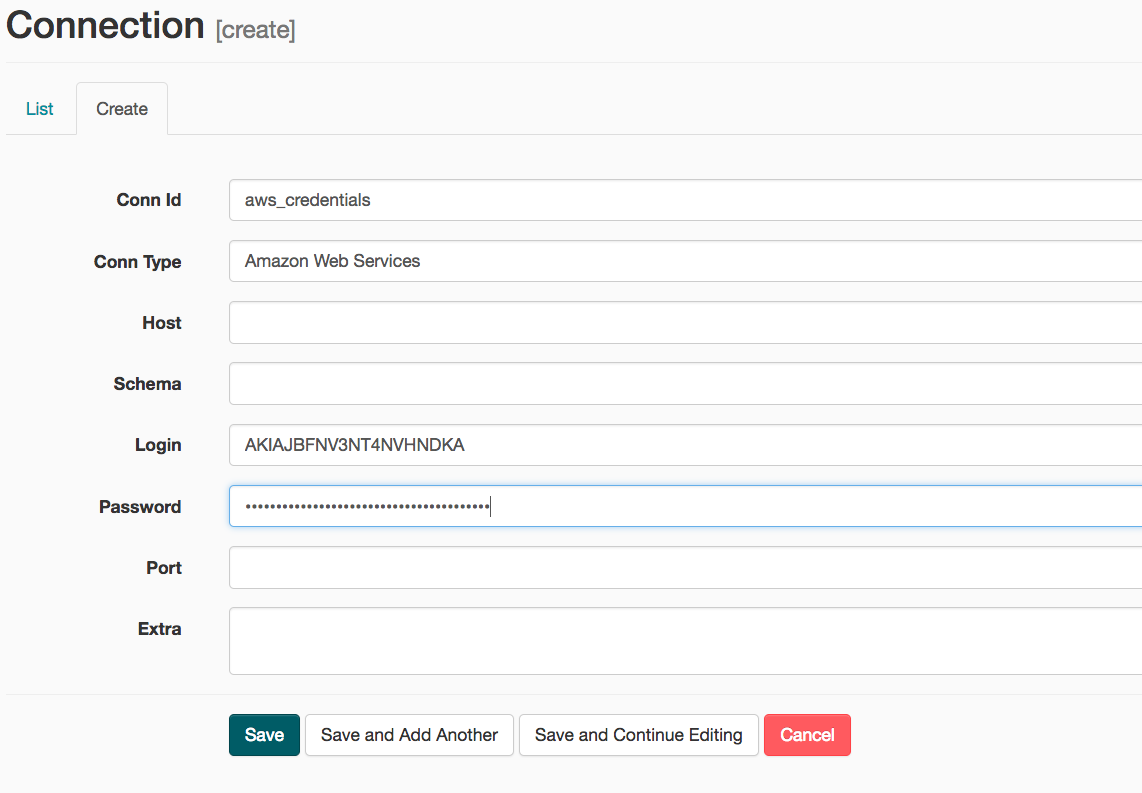
- Conn Id: Enter aws_credentials.
- Conn Type: Enter Amazon Web Services.
- Login: Enter your Access key ID from the IAM User credentials.
- Password: Enter your Secret access key from the IAM User credentials.
Once you've entered these values, select Save and Add Another.
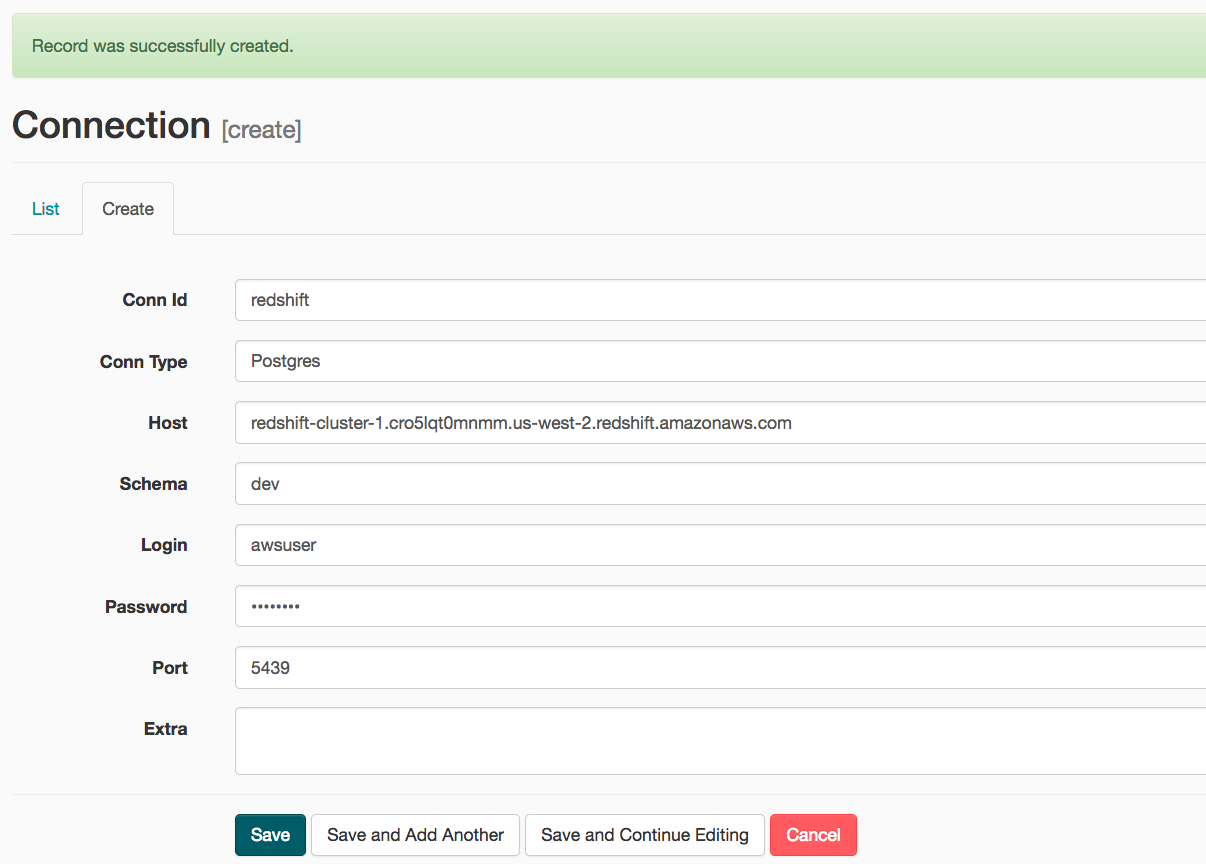
- On the next create connection page, enter the following values:
- Conn Id: Enter redshift.
- Conn Type: Enter Postgres.
- Host: Enter the endpoint of your Redshift cluster, excluding the port at the end.
- Schema: Enter dev. This is the Redshift database you want to connect to.
- Login: Enter awsuser.
- Password: Enter the password you created when launching your Redshift cluster.
- Port: Enter 5439.
Once you've entered these values, select Save.
We will create custom operators to perform tasks such as staging the data, filling the data warehouse and running checks. The tasks will need to be linked together to achieve a coherent and sensible data flow within the pipeline.
The log data is located at s3://udacity-dend/log_data and the song data is located in s3://udacity-dend/song_data.
- There are three major components of the project:
- Dag template with all imports and task templates.
- Operators folder with operator templates.
- Helper class with SQL transformations.
-
Add
default parametersto the Dag template as follows:- Dag does not have dependencies on past runs
- On failure, tasks are retried 3 times
- Retries happen every 5 minutes
- Catchup is turned off
- Do not email on retry
-
There are four operators:
- Stage operator
- Loads JSON and CSV files from S3 to Amazon Redshift
- Creates and runs a
SQL COPYstatement based on the parameters provided - Parameters should specify where in S3 file resides and the target table
- Parameters should distinguish between JSON and CSV files
- Contain a templated field that allows it to load timestamped files from S3 based on the execution time and run backfills
- Fact and Dimension Operators
- Use SQL helper class to run data transformations
- Take as input a SQL statement and target database to run query against
- Define a target table that will contain results of the transformation
- Dimension loads are often done with truncate-insert pattern where target table is emptied before the load
- Fact tables are usually so massive that they should only allow append type functionality
- Data Quality Operator
- Run checks on the data
- Receives one or more SQL based test cases along with the expected results and executes the tests
- Test result and expected results are checked and if there is no match, operator should raise an exception and the task should retry and fail eventually
Run /opt/airflow.start.sh to start the Airflow server. Access the Airflow UI by clicking Access Airflow button. Note that Airflow can take up to 10 minutes to create the connection due to the size of the files in S3.
Start the DAG by switching it state from OFF to ON.
Refresh the page and click on the s3_to_redshift_dag to view the current state.
The whole pipeline should take around 10 minutes to complete.
