Code for the Genetics in Medicine article entitled Targeted genetic analysis in a large cohort of familial and sporadic cases of aneurysm or dissection of the thoracic aorta to define the frequency of causative genetic variants and phenotypic risk factors associated with a genetic aetiology of thoracic aortic aneurysm/dissection (TAAD).
git clone https://github.com/superDross/TAAD_analysis
pip3 install -r TAAD_analysis/requirements.txt
PYTHONPATH=$PYTHONPATH:/full/path/to/TAAD_analysis
# ensure input_files and output directories exist before execution
python3 TAAD_analysisAn input_files directory should exist within the TAAD_analysis directory and contain the most damaging data (most damaging variant per patient) and all variants data (all variants identified in each patient). The structure of the input files directory should be as below:
input_files/
│
├── UK_Depth/
│ ├── depth_vs_taadx/
│ └── depth_vs_taadz/
├── Yale_Depth/
│ ├── depth_vs_taadx/
│ └── depth_vs_taadz/
│
├── UK_All_Variants_Data.csv
├── UK_Most_Damaging_Data.csv
├── UK_Phenotype_Data.csv
├── Yale_All_Variants_Data.csv
├── Yale_Most_Damaging_Data.csv
├── Yale_Phenotype_Data.csv
└── Yale_Survival_Data_Clean.csv
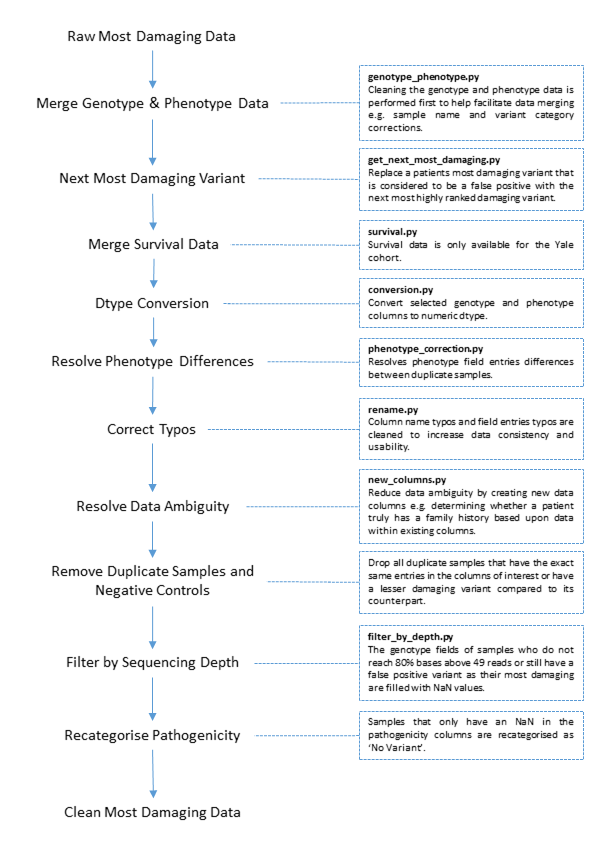
The most damaging data is cleaned and combined and ultimately used to produce all the plots, tables and most of the data mentioned in the paper. The all variants data primary use is for helping to select the next most damaging variant. Each major step in the most damaging data cleaning process, and the sub-package (if any) used to achieve said step, are detailed below: