Spark random forest issues #19
Comments
|
Apologies for the slow reply! I've been bogged down with QA for the next Spark release. I wrote the code for one-hot encoding + running RFs and computing AUC. Let me know if you run into issues using it: [https://gist.github.com/jkbradley/1e3cc0b3116f2f615b3f] |
|
Fantastic, thanks Joseph! I'll take a look asap and re-run the benchmarks with the new code. I'll let you know if I have more questions along the way... |
|
@jkbradley
I can verify I get AUC 71.4 instead of 62.5 Any comments on 3 and especially on 4 above? |
{kind=link}
|
I'm glad 1 & 2 worked out! For 3, I should have been more specific. Tungsten makes improvements on DataFrames, so it should improve the performance of simple ML Pipeline operations like feature transformation and prediction. However, to get the same benefits for model training, we'll need to rewrite the algorithms to use DataFrames and not RDDs. Future work... For 4: Are you able to examine the tree structure? I'm wondering if the limit on MLlib tree depth is the difference. What happens when you set a max depth for the other libraries? I'll try to look into it more too. |
|
Thanks again for 1 & 2. For 3: Yes, that was my guess too. One more question: I re-run the logistic regression https://github.com/szilard/benchm-ml/blob/master/1-linear/5-spark.txt with 1.5.0 as well and got same training time as with 1.4.0. While my guess was that RF will be the same, I thought LR uses the DF as underlying and it will be faster with Tungsten. No? |
|
For 4: I'm not sure if it's max_depth, for example H2O does not have similar behavior (with same max_depth = 20). To make further testing simple I zipped the 0.1M and 1M train and test datasets after being 1-hot encoded and exported to parquet format with your code and you can get it all in 1 from here: https://s3.amazonaws.com/benchm-ml--spark2/spark-0.1m%2B1m-1hot-parquet.tgz As for the training/AUC part I made some little changes and my code is here: https://github.com/szilard/benchm-ml/blob/master/z-other-tools/5xb-spark-trainpred.txt that is file names (in current dir) and to match the "absolute minimal benchmark". So with these I get: as I mentioned above. I think now it would be easier for you to take a look. There should be a higher increase in AUC from n=0.1M to 1M. |
No, unfortunately. It's using a different optimizer (OWLQN) for some models, but it's still using the RDD API. I'll take a look at the AUC issue. |
|
Thanks for answer to 3 and thanks for looking into 4 :) |
|
I didn't find anything obvious yet for issue 4, but there are still some items I want to investigate. (I haven't yet scanned the sklearn implementation carefully for comparison.) In the meantime, would you be able to update the blog post to include the soft predictions? It'd be nice now that it's easily available in Spark 1.5. Thanks! |
|
Thanks @jkbradley for working on this. I already updated the github README a few days ago and I'll update the http://datascience.la post as well soon. |
|
Hi there. It's been a few months and I'm curious if any progress has been made here? Is there a JIRA on the apache page tracking the work in Spark for this? Thanks |
|
@ehiggs thanks for asking, though I defer this to @jkbradley and Team |
|
I made an issue on the Apache Jira here. |
|
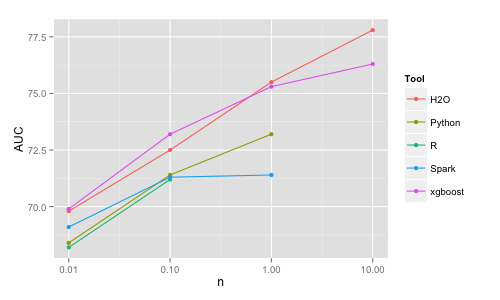
Great, thanks. The memory and speed are one issue, but there is also the issue of accuracy, see point numbered as 4 earlier in this thread. In short the AUC does not increase from 100K records to 1M as it does for all other tools: It can be an implementation bug or an "architecture bug" (by using some approximation that does not work well). I'm curious if anyone is using RF in production for large datasets and if they are really validating the results by comparing the accuracy to other tools. |
|
I rewrote the RF code to use the pipeline/spark.ml API: It is slower than before (despite Tungsten/new data.frame API), 100 trees 20 deep: more details here: https://github.com/szilard/benchm-ml/tree/master/z-other-tools#how-to-benchmark-your-tool-of-choice-with-minimal-work In addition Spark RF is still less accurate than piers. Also, it still shows the weird learning curve: So basically issues 3 & 4 above did not change for the better. |
{kind=link}
|
Progress seems to be taking places here. Thanks to @smurching. |
|
@szilard @jkbradley I am able to reproduce AUC gain on spark 1.4 using @jkbradley code shared over gist(https://gist.github.com/jkbradley/1e3cc0b3116f2f615b3f#file-benchm-ml-spark-L6) at the start of this thread.
Area Under ROC without using soft predictions: 0.5102859778512581 Please provide any insights what could be the issue here. |
|
@riya2216 the only insight I can give after doing all these benchmarks is forget Spark for machine learning, it's slow, inaccurate, buggy and uses tons of RAM. There is no reason to waste your time using clearly inferior products. Just use e.g. h2o. |
|
@szilard Thanks for all of your work in putting this together and noticing these issues with Spark ML's Random Forest implementation. I have a couple of quick questions, please pardon my ignorance if you've answered these elsewhere:
Thanks! |
|
Have you tried increasing the maxBins parameter? Could be due to the binning approximation that Spark uses. |
|
@137alpha No, I gave up on Spark for ML long time ago. There are way better tools for machine learning than Spark MLlib (e.g. h2o), just use those. |
This is to collaborate on some issues with Spark RF also addressed by @jkbradley in comments to this post http://datascience.la/benchmarking-random-forest-implementations/ (see comments by Joseph Bradley). cc: @mengxr
Please see “Absolute Minimal Benchmark” for random forests https://github.com/szilard/benchm-ml/tree/master/z-other-tools and let's use the 1M row training set and the test set linked in from there.
@jkbradley says: One-hot encoder: Spark 1.4 includes this, plus a lot more feature transformers. Preprocessing should become ever-easier, especially using DataFrames (Spark 1.3+).
Yes, indeed. Can you please provide code that reads in the original dataset (pre- 1-hot encoding) and does the 1-hot encoding in Spark. Also, if random forest 1.4 API can use data frames, I guess we should use that for the training. Can you please provide code for that too.
@jkbradley says: AUC/accuracy: The AUC issue appears to be caused by MLlib tree ensembles aggregating votes, rather than class probabilities, as you suggested. I re-ran your test using class probabilities (which can be aggregated by hand), and then got the same AUC as other libraries. We’re planning on including this fix in Spark 1.5 (and thanks for providing some evidence of its importance!).
Fantastic. Can you please share code that does that already? I would be happy to check it out.
The text was updated successfully, but these errors were encountered: