diff --git a/site/ko/federated/tutorials/building_your_own_federated_learning_algorithm.ipynb b/site/ko/federated/tutorials/building_your_own_federated_learning_algorithm.ipynb
index 88ea437e4d..83100506fa 100644
--- a/site/ko/federated/tutorials/building_your_own_federated_learning_algorithm.ipynb
+++ b/site/ko/federated/tutorials/building_your_own_federated_learning_algorithm.ipynb
@@ -39,9 +39,10 @@
"source": [
""
]
@@ -66,11 +67,7 @@
"outputs": [],
"source": [
"#@test {\"skip\": true}\n",
- "!pip install --quiet --upgrade tensorflow-federated\n",
- "!pip install --quiet --upgrade nest-asyncio\n",
- "\n",
- "import nest_asyncio\n",
- "nest_asyncio.apply()"
+ "!pip install --quiet --upgrade tensorflow-federated"
]
},
{
@@ -231,7 +228,7 @@
"id": "vLln0Q8G0Bky"
},
"source": [
- "TFF에서 이 모델을 사용하기 위해 Keras 모델을 [`tff.learning.Model`](https://www.tensorflow.org/federated/api_docs/python/tff/learning/Model)로 래핑합니다. 이를 통해 TFF 내에서 모델의 [정방향 전달](https://www.tensorflow.org/federated/api_docs/python/tff/learning/Model#forward_pass)을 수행하고 [모델 출력을 추출](https://www.tensorflow.org/federated/api_docs/python/tff/learning/Model#report_local_unfinalized_metrics)할 수 있습니다. 자세한 내용은 [이미지 분류](federated_learning_for_image_classification.ipynb) 튜토리얼을 참조하세요."
+ "TFF에서 이 모델을 사용하려면 Keras 모델을 [`tff.learning.models.VariableModel`](https://www.tensorflow.org/federated/api_docs/python/tff/learning/Model)로 래핑하세요. 이렇게 하면 TFF 내에서 모델의 [순방향 전달](https://www.tensorflow.org/federated/api_docs/python/tff/learning/Model#forward_pass)을 수행하고 [모델 출력 추출](https://www.tensorflow.org/federated/api_docs/python/tff/learning/Model#report_local_unfinalized_metrics)을 수행할 수 있습니다. 자세한 내용은 [이미지 분류](federated_learning_for_image_classification.ipynb) 튜토리얼을 참조하세요."
]
},
{
@@ -244,7 +241,7 @@
"source": [
"def model_fn():\n",
" keras_model = create_keras_model()\n",
- " return tff.learning.from_keras_model(\n",
+ " return tff.learning.models.from_keras_model(\n",
" keras_model,\n",
" input_spec=federated_train_data[0].element_spec,\n",
" loss=tf.keras.losses.SparseCategoricalCrossentropy(),\n",
@@ -257,7 +254,7 @@
"id": "pCxa44rFiere"
},
"source": [
- "여기서는 `tf.keras`를 사용하여 `tff.learning.Model`을 생성하지만 TFF는 훨씬 더 많은 일반 모델을 지원합니다. 이러한 모델에는 모델 가중치를 캡처하는 다음과 같은 관련 속성이 있습니다.\n",
+ "위에서는 `tf.keras`를 사용해 `tff.learning.models.VariableModel`을 생성했지만, TFF는 훨씬 더 일반적인 모델을 지원합니다. 이러한 모델에는 모델 가중치를 캡처하는 다음과 같은 관련 속성이 있습니다.\n",
"\n",
"- `trainable_variables`: 학습 가능한 레이어에 해당하는 텐서의 이터러블입니다.\n",
"- `non_trainable_variables`: 학습할 수 없는 레이어에 해당하는 텐서의 이터러블입니다.\n",
@@ -273,7 +270,7 @@
"source": [
"# 고유한 페더레이션 학습 알고리즘 구축하기\n",
"\n",
- "`tff.learning` API를 사용하면 Federated Averaging의 많은 변형을 생성할 수 있지만 이 프레임워크에 깔끔하게 맞지 않는 다른 페더레이션 알고리즘이 있습니다. 예를 들어 정규화, 클리핑 또는 [페더레이션 GAN 학습](https://github.com/tensorflow/federated/tree/main/tensorflow_federated/python/research/gans)과 같은 더 복잡한 알고리즘을 추가할 수도 있습니다. 아니면 [페더레이션 분석](https://ai.googleblog.com/2020/05/federated-analytics-collaborative-data.html)에 관심이 있을 수도 있습니다."
+ "`tff.learning` API를 사용하면 Federated Averaging의 많은 변형을 생성할 수 있지만, 이 프레임워크에 완전히 맞지 않는 다른 페더레이션 알고리즘도 있습니다. 예를 들어 정규화, 클리핑 또는 [페더레이션 GAN 학습](https://github.com/tensorflow/federated/tree/main/tensorflow_federated/python/research/gans)과 같은 더 복잡한 알고리즘을 추가하고 싶을 수도 있습니다. 아니면 [페더레이션 분석](https://ai.googleblog.com/2020/05/federated-analytics-collaborative-data.html)에 관심이 있을 수도 있습니다."
]
},
{
@@ -298,7 +295,7 @@
"source": [
"TFF에서는 일반적으로 페더레이션 알고리즘이 [`tff.templates.IterativeProcess`](https://www.tensorflow.org/federated/api_docs/python/tff/templates/IterativeProcess)(나머지 부분에서 `IterativeProcess`라고 함)로 나타내어집니다. 이것은 `initialize` 및 `next` 함수를 포함하는 클래스입니다. 여기서 `initialize`는 서버를 초기화하는 데 사용되며 `next`는 페더레이션 알고리즘의 한 통신 라운드를 수행합니다. FedAvg에 대한 반복 프로세스가 어떤 모습인지 그 골격을 작성해 보겠습니다.\n",
"\n",
- "먼저 `tff.learning.Model` 생성하고 훈련 가능한 가중치를 반환하는 초기화 함수가 있습니다."
+ "먼저 `tff.learning.models.VariableModel`을 간단히 생성하고 훈련 가능한 가중치를 반환하는 초기화 함수가 있습니다."
]
},
{
@@ -375,7 +372,7 @@
"source": [
"### 클라이언트 업데이트\n",
"\n",
- "`tff.learning.Model`을 사용하여 기본적으로 TensorFlow 모델을 훈련하는 것과 동일한 방식으로 클라이언트 훈련을 수행할 수 있습니다. 특히, `tf.GradientTape`를 사용하여 데이터 배치에 대한 그레디언트를 계산한 다음 `client_optimizer`를 사용하여 이러한 그레디언트를 적용할 수 있습니다. 여기에는 훈련 가능한 가중치만 관련됩니다.\n"
+ "`tff.learning.Model`을 사용해 TensorFlow 모델을 훈련할 때와 동일한 방식으로 클라이언트를 훈련할 수 있습니다. 특히 `tf.GradientTape`를 사용해 데이터 배치에 대한 그래디언트를 계산한 다음 `client_optimizer`를 사용해 이 그래디언트를 적용할 수 있습니다. 여기에서는 훈련 가능한 가중치만 사용합니다.\n"
]
},
{
@@ -472,7 +469,7 @@
"\n",
"페더레이션 코어(FC)는 `tff.learning` API의 기반 역할을 하는 하위 수준 인터페이스 집합입니다. 그러나 이러한 인터페이스는 학습에만 국한되지 않습니다. 실제로 분산 데이터에 대한 분석 및 기타 많은 계산에 사용할 수 있습니다.\n",
"\n",
- "상위 수준에서 페더레이션 코어는 간결하게 표현된 프로그램 로직을 사용하여 TensorFlow 코드를 분산 통신 연산자(예: 분산 합계 및 브로드캐스트)와 결합할 수 있는 개발 환경입니다. 목표는 시스템 구현 세부 사항(예: 지점 간 네트워크 메시지 교환 지정)을 요구하지 않고 연구자와 실무자에게 시스템의 분산 통신을 신속하게 제어할 수 있도록 하는 것입니다.\n",
+ "간단히 설명하자면, 연합 코어는 간결하게 표현된 프로그램 로직을 사용해 TensorFlow 코드와 분산 통신 연산자(예: 분산 합계 및 브로드캐스트)와 결합할 수 있는 개발 환경입니다. 연구자와 실무자가 시스템 구현 세부 사항(예: 지점 간 네트워크 메시지 교환 지정)이 없어도 시스템에서 분산 통신을 명시적으로 제어할 수 있도록 하는 것이 목표입니다.\n",
"\n",
"한 가지 요점은 TFF가 개인 정보 보호를 위해 설계되었다는 것입니다. 따라서 중앙 집중식 서버 위치에서 원치 않는 데이터 축적을 방지하기 위해 데이터가 있는 위치를 명시적으로 제어할 수 있습니다."
]
diff --git a/site/ko/guide/core/matrix_core.ipynb b/site/ko/guide/core/matrix_core.ipynb
index b766352012..72f2254200 100644
--- a/site/ko/guide/core/matrix_core.ipynb
+++ b/site/ko/guide/core/matrix_core.ipynb
@@ -209,7 +209,7 @@
"\n",
"SVD의 관점에서 ${\\mathrm{A}}$의 rank-r 근삿값은 다음 공식으로 정의합니다.\n",
"\n",
- "$${\\mathrm{A_r}} = {\\mathrm{U_r}} \\Sigma_r {\\mathrm{V_r}}^T$$\n",
+ "어디\n",
"\n",
"어디\n",
"\n",
@@ -500,17 +500,17 @@
"\n",
"여기서\n",
"\n",
- "$$c = \\large \\frac{x}{y} = \\frac{r \\times (m + n + 1)}{m \\times n}$$\n",
- "\n",
"각 RGB 근삿값은 서로 영향을 미치지 않으므로 이 수식은 색상 채널 차원과 무관합니다. 이제 원하는 압축 인자가 주어질 경우 입력 이미지를 압축하는 함수를 작성합니다.\n",
"\n",
+ "어디\n",
+ "\n",
"- $x$: ${\\mathrm{A_r}}$의 크기\n",
"- $y$: ${\\mathrm{A}}$의 크기\n",
"- $c = \\frac{x}{y}$: 압축 인자\n",
"- $r$: 근삿값의 순위\n",
"- $m$ 와 $n$: ${\\mathrm{A}}$의 행과 열 차원\n",
"\n",
- "이미지를 원하는 인자 $c$로 압축하는 데 필요한 순위 $r$를 찾기 위해 위의 수식을 다시 정렬하여 $r$를 풀이할 수 있습니다.\n",
+ "각 RGB 근삿값은 서로 영향을 미치지 않으므로 이 수식은 색상 채널 차원과 무관합니다. 이제 원하는 압축 인자가 주어질 경우 입력 이미지를 압축하는 함수를 작성합니다.\n",
"\n",
"$$r = ⌊{\\large\\frac{c \\times m \\times n}{m + n + 1}}⌋$$\n",
"\n",
diff --git a/site/ko/guide/core/optimizers_core.ipynb b/site/ko/guide/core/optimizers_core.ipynb
index 22e11899b1..54bad645cb 100644
--- a/site/ko/guide/core/optimizers_core.ipynb
+++ b/site/ko/guide/core/optimizers_core.ipynb
@@ -157,9 +157,9 @@
"\n",
"$\\frac{dL}{dx}$는 안장점이 $x = 0$이고 전역 최솟값이 $x = - \\frac{9}{8}$일 때 0 입니다. 따라서 손실 함수는 $x^\\star = - \\frac{9}{8}$일 때 최적화됩니다.\n",
"\n",
- "$$\\frac{dL}{dx} = 8x^3 + 9x^2$$\n",
+ "$\\frac{dL}{dx}$는 안장점인 $x = 0$와 전역 최소값인 $x = - \\frac{9}{8}$에서 0입니다. 따라서 손실 함수는 $x^\\star = - \\frac{9}{8}$에서 최적화됩니다.\n",
"\n",
- "$\\frac{dL}{dx}$는 안장점인 $x = 0$와 전역 최소값인 $x = - \\frac{9}{8}$에서 0입니다. 따라서 손실 함수는 $x^\\star = - \\frac{9}{8}$에서 최적화됩니다."
+ "$\\frac{dL}{dx}$ is 0 at $x = 0$, which is a saddle point and at $x = - \\frac{9}{8}$, which is the global minimum. Therefore, the loss function is optimized at $x^\\star = - \\frac{9}{8}$."
]
},
{
@@ -338,10 +338,10 @@
"\n",
"여기서,\n",
"\n",
- "$$x^{[t]} = x^{[t-1]} - \\Delta_x^{[t]}$$\n",
- "\n",
"여기서\n",
"\n",
+ "어디\n",
+ "\n",
"- $x$: 최적화하는 변수\n",
"- $\\Delta_x$: $x$에서 변경\n",
"- $lr$: 학습률\n",
diff --git a/site/ko/guide/dtensor_overview.ipynb b/site/ko/guide/dtensor_overview.ipynb
index c180fcb17d..44b39c15f6 100644
--- a/site/ko/guide/dtensor_overview.ipynb
+++ b/site/ko/guide/dtensor_overview.ipynb
@@ -167,7 +167,7 @@
"1차원 `Mesh`에서는 모든 장치가 단일 메시 차원으로 목록을 형성합니다. 다음 예제에서는 6개 장치를 사용하는 `'x'` 메시 차원에 따라 `dtensor.create_mesh`를 사용하여 메시를 생성합니다.\n",
"\n",
"\n",
- " \n"
+ " \n"
]
},
{
@@ -262,7 +262,7 @@
"동일한 텐서를 사용하고 `Layout(['unsharded', 'x'])` 레이아웃을 메시하면 6개의 장치에서 텐서의 두 번째 축이 분할될 수 있습니다.\n",
"\n",
"\n",
- "
\n"
+ " \n"
]
},
{
@@ -262,7 +262,7 @@
"동일한 텐서를 사용하고 `Layout(['unsharded', 'x'])` 레이아웃을 메시하면 6개의 장치에서 텐서의 두 번째 축이 분할될 수 있습니다.\n",
"\n",
"\n",
- " "
+ " "
]
},
{
@@ -291,7 +291,7 @@
"id": "Eyp_qOSyvieo"
},
"source": [
- "
"
+ " "
]
},
{
@@ -291,7 +291,7 @@
"id": "Eyp_qOSyvieo"
},
"source": [
- " \n"
+ " \n"
]
},
{
@@ -314,7 +314,7 @@
"동일한 `mesh_2d`의 경우 레이아웃 `Layout([\"x\", dtensor.UNSHARDED], mesh_2d)`은 2순위 `Tensor`이며, 이는 `\"y\"`에 복제되고 첫 번째 축이 메시 차원 `x`에서 분할됩니다.\n",
"\n",
"\n",
- "
\n"
+ " \n"
]
},
{
@@ -314,7 +314,7 @@
"동일한 `mesh_2d`의 경우 레이아웃 `Layout([\"x\", dtensor.UNSHARDED], mesh_2d)`은 2순위 `Tensor`이며, 이는 `\"y\"`에 복제되고 첫 번째 축이 메시 차원 `x`에서 분할됩니다.\n",
"\n",
"\n",
- " \n"
+ " \n"
]
},
{
diff --git a/site/ko/guide/profiler.md b/site/ko/guide/profiler.md
index 3084801013..2773c828fc 100644
--- a/site/ko/guide/profiler.md
+++ b/site/ko/guide/profiler.md
@@ -84,8 +84,8 @@ Profiler에는 성능 분석에 도움이 되는 다양한 도구가 있습니
- 출력: 출력 데이터를 읽는 데 소요된 시간
- 커널 시작: 호스트가 커널을 시작하는 데 소요된 시간
- 호스트 컴퓨팅 시간
- - 기기 간 통신 시간
- - 기기 내 컴퓨팅 시간
+ - 장치 간 통신 시간
+ - 장치 내 컴퓨팅 시간
- 모든 기타 시간(Python 오버헤드 포함)
2. 기기 컴퓨팅 정밀도 - 16bit 및 32bit 계산을 사용하는 기기 컴퓨팅 시간의 백분율을 보고합니다.
@@ -99,8 +99,8 @@ Profiler에는 성능 분석에 도움이 되는 다양한 도구가 있습니
- **실행 환경**: 다음을 포함하여 모델 실행 환경에 대한 높은 수준의 요약을 표시합니다.
- 사용된 호스트 수
- - 기기 유형(GPU/TPU)
- - 기기 코어 수
+ - 장치 유형(GPU/TPU)
+ - 장치 코어 수
- **다음 단계를 위한 권장 사항**: 모델이 입력 바운드될 때 보고하고, 모델의 성능 병목 현상을 찾아 해결하는 데 사용할 수 있는 도구를 권장합니다.
@@ -221,7 +221,7 @@ TensorFlow 통계 도구는 프로파일링 세션 동안 호스트 또는 기
추적 뷰어를 열면 가장 최근에 실행된 내용이 표시됩니다.
-
+
이 화면에는 다음과 같은 주요 요소가 포함되어 있습니다.
@@ -260,7 +260,7 @@ TensorFlow 통계 도구는 프로파일링 세션 동안 호스트 또는 기
이 도구는 모든 GPU 가속 커널에 대한 성능 통계 및 원래 op를 보여줍니다.
-
+
이 도구는 두 개의 창에서 정보를 표시합니다.
@@ -322,7 +322,7 @@ TensorFlow 통계 도구는 프로파일링 세션 동안 호스트 또는 기
이 섹션에는 메모리 사용량(GiB) 플롯 및 시간에 따른 조각화 비율(ms)이 표시됩니다.
-
+
X축은 프로파일링 기간의 타임라인(ms)을 나타냅니다. 왼쪽의 Y축은 메모리 사용량(GiB)을 나타내고 오른쪽의 Y축은 조각화 비율을 나타냅니다. X축의 각 시점에서 총 메모리는 스택(빨간색), 힙(주황색) 및 여유(녹색)의 세 가지 범주로 분류됩니다. 특정 타임스탬프 위로 마우스를 가져가면 아래와 같이 해당 시점의 메모리 할당/할당 해제 이벤트에 대한 세부 정보를 볼 수 있습니다.
@@ -345,7 +345,7 @@ X축은 프로파일링 기간의 타임라인(ms)을 나타냅니다. 왼쪽의
이 표에는 프로파일링 기간 동안 최대 메모리 사용량 시점에서 활성 메모리 할당량이 표시됩니다.
-
+
TensorFlow 연산마다 하나의 행이 있으며 각 행에는 다음 열이 있습니다.
@@ -365,7 +365,7 @@ TensorFlow 연산마다 하나의 행이 있으며 각 행에는 다음 열이
Pod 뷰어 도구는 모든 작업자의 학습 스텝 분석을 보여줍니다.
-
+
- 상단 창에는 스텝 번호를 선택하는 슬라이더가 있습니다.
- 아래쪽 창에는 누적 세로 막대형 차트가 표시됩니다. 이것은 분류된 스텝 시간 범주를 서로의 위에 배치한 고차원적인 보기입니다. 누적된 각 열은 고유한 작업자를 나타냅니다.
@@ -391,7 +391,7 @@ UI는 **성능 분석 요약**, **모든 입력 파이프라인 요약** 및 **
#### 성능 분석 요약
-
+
이 섹션에서는 분석 요약을 제공합니다. 프로파일에서 느린 `tf.data` 입력 파이프라인이 감지되는지 여부가 보고됩니다. 이 섹션에는 또한 입력 바운드가 가장 큰 호스트와 지연 시간이 가장 큰 가장 느린 입력 파이프라인이 표시됩니다. 그리고 가장 중요한 부분으로, 입력 파이프라인의 어느 부분이 병목인지, 이 병목을 해결할 방법을 알려줍니다. 병목 현상 정보는 반복기 유형과 해당하는 긴 이름과 함께 제공됩니다.
@@ -416,7 +416,7 @@ dataset = tf.data.Dataset.range(10).map(lambda x: x).repeat(2).batch(5)
#### 모든 입력 파이프라인 요약
-
+
이 섹션에서는 모든 호스트의 모든 입력 파이프라인에 대한 요약을 제공합니다. 일반적으로 하나의 입력 파이프라인이 있습니다. 배포 전략을 사용하는 경우, 프로그램의 `tf.data` 코드를 실행하는 하나의 호스트 입력 파이프라인과 호스트 입력 파이프라인에서 데이터를 검색하여 장치로 전송하는 여러 개의 기기 입력 파이프라인이 있습니다.
@@ -424,11 +424,11 @@ dataset = tf.data.Dataset.range(10).map(lambda x: x).repeat(2).batch(5)
#### 입력 파이프라인 그래프
-
+
이 섹션에서는 실행 시간 정보와 함께 입력 파이프라인 그래프가 표시됩니다. "호스트" 및 "입력 파이프라인"을 사용하여 보려는 호스트와 입력 파이프라인을 선택할 수 있습니다. 입력 파이프라인의 실행은 실행 시간을 기준으로 정렬되며, **Rank** 드롭다운을 사용하여 내림차순으로 정렬할 수 있습니다.
-
+
중요 경로의 노드에는 굵은 윤곽선이 있습니다. 중요 경로에서 가장 긴 자체 시간을 가진 노드인 병목 노드는 빨간색 윤곽선으로 표시됩니다. 중요하지 않은 다른 노드에는 회색 점선 윤곽선이 있습니다.
diff --git a/site/ko/lite/examples/auto_complete/overview.md b/site/ko/lite/examples/auto_complete/overview.md
index 75a066bd9d..b63c83fabe 100644
--- a/site/ko/lite/examples/auto_complete/overview.md
+++ b/site/ko/lite/examples/auto_complete/overview.md
@@ -183,6 +183,7 @@ run_inference("I'm enjoying a", quant_generate_tflite)
### 컨텍스트 창 크기
+
\n"
+ " \n"
]
},
{
diff --git a/site/ko/guide/profiler.md b/site/ko/guide/profiler.md
index 3084801013..2773c828fc 100644
--- a/site/ko/guide/profiler.md
+++ b/site/ko/guide/profiler.md
@@ -84,8 +84,8 @@ Profiler에는 성능 분석에 도움이 되는 다양한 도구가 있습니
- 출력: 출력 데이터를 읽는 데 소요된 시간
- 커널 시작: 호스트가 커널을 시작하는 데 소요된 시간
- 호스트 컴퓨팅 시간
- - 기기 간 통신 시간
- - 기기 내 컴퓨팅 시간
+ - 장치 간 통신 시간
+ - 장치 내 컴퓨팅 시간
- 모든 기타 시간(Python 오버헤드 포함)
2. 기기 컴퓨팅 정밀도 - 16bit 및 32bit 계산을 사용하는 기기 컴퓨팅 시간의 백분율을 보고합니다.
@@ -99,8 +99,8 @@ Profiler에는 성능 분석에 도움이 되는 다양한 도구가 있습니
- **실행 환경**: 다음을 포함하여 모델 실행 환경에 대한 높은 수준의 요약을 표시합니다.
- 사용된 호스트 수
- - 기기 유형(GPU/TPU)
- - 기기 코어 수
+ - 장치 유형(GPU/TPU)
+ - 장치 코어 수
- **다음 단계를 위한 권장 사항**: 모델이 입력 바운드될 때 보고하고, 모델의 성능 병목 현상을 찾아 해결하는 데 사용할 수 있는 도구를 권장합니다.
@@ -221,7 +221,7 @@ TensorFlow 통계 도구는 프로파일링 세션 동안 호스트 또는 기
추적 뷰어를 열면 가장 최근에 실행된 내용이 표시됩니다.
-
+
이 화면에는 다음과 같은 주요 요소가 포함되어 있습니다.
@@ -260,7 +260,7 @@ TensorFlow 통계 도구는 프로파일링 세션 동안 호스트 또는 기
이 도구는 모든 GPU 가속 커널에 대한 성능 통계 및 원래 op를 보여줍니다.
-
+
이 도구는 두 개의 창에서 정보를 표시합니다.
@@ -322,7 +322,7 @@ TensorFlow 통계 도구는 프로파일링 세션 동안 호스트 또는 기
이 섹션에는 메모리 사용량(GiB) 플롯 및 시간에 따른 조각화 비율(ms)이 표시됩니다.
-
+
X축은 프로파일링 기간의 타임라인(ms)을 나타냅니다. 왼쪽의 Y축은 메모리 사용량(GiB)을 나타내고 오른쪽의 Y축은 조각화 비율을 나타냅니다. X축의 각 시점에서 총 메모리는 스택(빨간색), 힙(주황색) 및 여유(녹색)의 세 가지 범주로 분류됩니다. 특정 타임스탬프 위로 마우스를 가져가면 아래와 같이 해당 시점의 메모리 할당/할당 해제 이벤트에 대한 세부 정보를 볼 수 있습니다.
@@ -345,7 +345,7 @@ X축은 프로파일링 기간의 타임라인(ms)을 나타냅니다. 왼쪽의
이 표에는 프로파일링 기간 동안 최대 메모리 사용량 시점에서 활성 메모리 할당량이 표시됩니다.
-
+
TensorFlow 연산마다 하나의 행이 있으며 각 행에는 다음 열이 있습니다.
@@ -365,7 +365,7 @@ TensorFlow 연산마다 하나의 행이 있으며 각 행에는 다음 열이
Pod 뷰어 도구는 모든 작업자의 학습 스텝 분석을 보여줍니다.
-
+
- 상단 창에는 스텝 번호를 선택하는 슬라이더가 있습니다.
- 아래쪽 창에는 누적 세로 막대형 차트가 표시됩니다. 이것은 분류된 스텝 시간 범주를 서로의 위에 배치한 고차원적인 보기입니다. 누적된 각 열은 고유한 작업자를 나타냅니다.
@@ -391,7 +391,7 @@ UI는 **성능 분석 요약**, **모든 입력 파이프라인 요약** 및 **
#### 성능 분석 요약
-
+
이 섹션에서는 분석 요약을 제공합니다. 프로파일에서 느린 `tf.data` 입력 파이프라인이 감지되는지 여부가 보고됩니다. 이 섹션에는 또한 입력 바운드가 가장 큰 호스트와 지연 시간이 가장 큰 가장 느린 입력 파이프라인이 표시됩니다. 그리고 가장 중요한 부분으로, 입력 파이프라인의 어느 부분이 병목인지, 이 병목을 해결할 방법을 알려줍니다. 병목 현상 정보는 반복기 유형과 해당하는 긴 이름과 함께 제공됩니다.
@@ -416,7 +416,7 @@ dataset = tf.data.Dataset.range(10).map(lambda x: x).repeat(2).batch(5)
#### 모든 입력 파이프라인 요약
-
+
이 섹션에서는 모든 호스트의 모든 입력 파이프라인에 대한 요약을 제공합니다. 일반적으로 하나의 입력 파이프라인이 있습니다. 배포 전략을 사용하는 경우, 프로그램의 `tf.data` 코드를 실행하는 하나의 호스트 입력 파이프라인과 호스트 입력 파이프라인에서 데이터를 검색하여 장치로 전송하는 여러 개의 기기 입력 파이프라인이 있습니다.
@@ -424,11 +424,11 @@ dataset = tf.data.Dataset.range(10).map(lambda x: x).repeat(2).batch(5)
#### 입력 파이프라인 그래프
-
+
이 섹션에서는 실행 시간 정보와 함께 입력 파이프라인 그래프가 표시됩니다. "호스트" 및 "입력 파이프라인"을 사용하여 보려는 호스트와 입력 파이프라인을 선택할 수 있습니다. 입력 파이프라인의 실행은 실행 시간을 기준으로 정렬되며, **Rank** 드롭다운을 사용하여 내림차순으로 정렬할 수 있습니다.
-
+
중요 경로의 노드에는 굵은 윤곽선이 있습니다. 중요 경로에서 가장 긴 자체 시간을 가진 노드인 병목 노드는 빨간색 윤곽선으로 표시됩니다. 중요하지 않은 다른 노드에는 회색 점선 윤곽선이 있습니다.
diff --git a/site/ko/lite/examples/auto_complete/overview.md b/site/ko/lite/examples/auto_complete/overview.md
index 75a066bd9d..b63c83fabe 100644
--- a/site/ko/lite/examples/auto_complete/overview.md
+++ b/site/ko/lite/examples/auto_complete/overview.md
@@ -183,6 +183,7 @@ run_inference("I'm enjoying a", quant_generate_tflite)
### 컨텍스트 창 크기
+
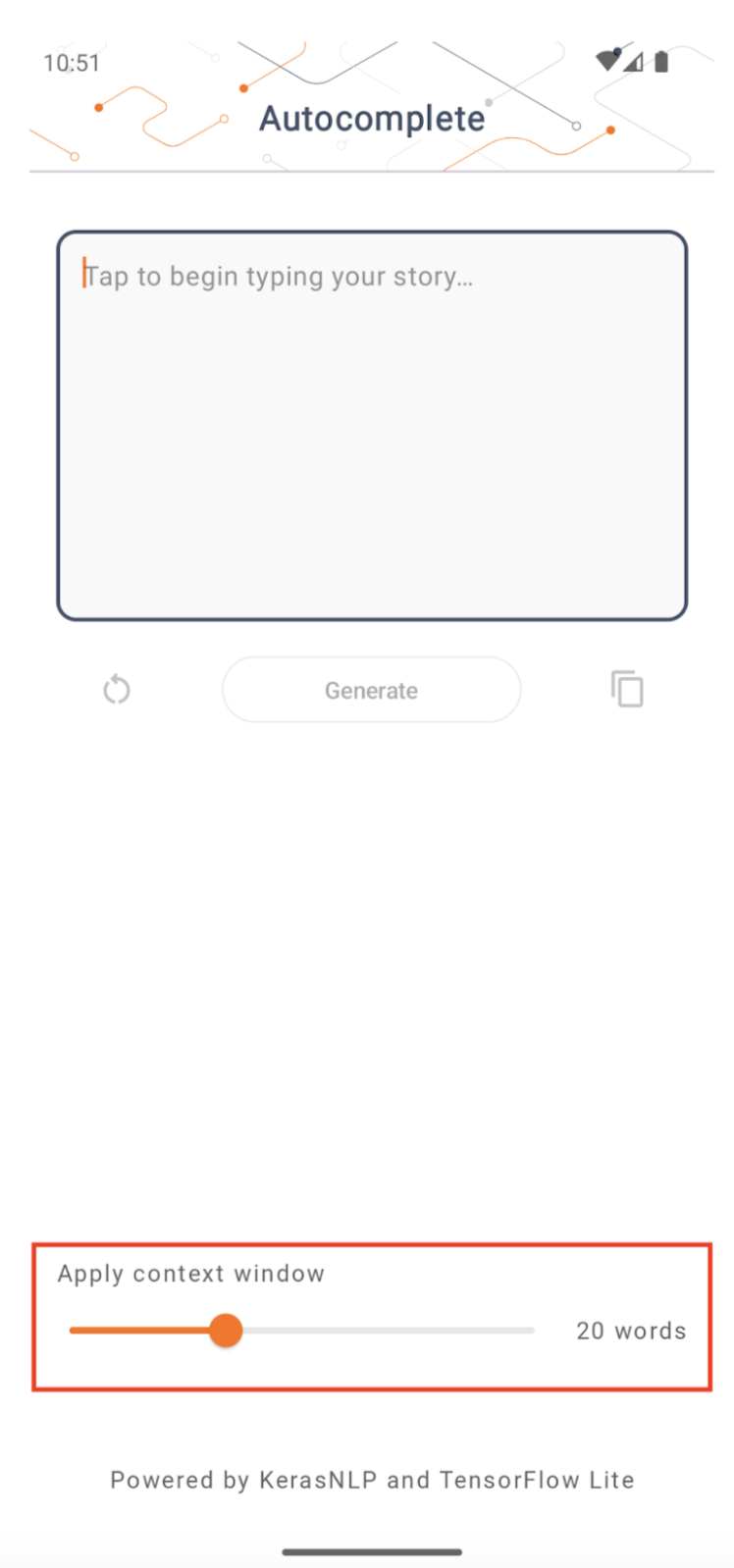 앱에는 변경 가능한 매개변수 '컨텍스트 창 크기'가 있습니다. 이는 현재 LLM이 일반적으로 모델에 '프롬프트'로 공급될 수 있는 단어/토큰의 수를 제한하는 고정된 컨텍스트 크기를 갖기 때문에 필요합니다('단어'와 '토큰'은 토큰화 방법이 다르기 때문에 이 경우 컨텍스트 크기가 반드시 동일하지는 않습니다). 이 숫자가 중요한 이유는 다음과 같습니다.
diff --git a/site/ko/lite/examples/pose_estimation/overview.md b/site/ko/lite/examples/pose_estimation/overview.md
index c54d5c775c..38c4000dae 100644
--- a/site/ko/lite/examples/pose_estimation/overview.md
+++ b/site/ko/lite/examples/pose_estimation/overview.md
@@ -113,6 +113,7 @@ TensorFlow Lite를 처음 사용하고 Android 또는 iOS로 작업하는 경우
아래에 출력의 예를 나타내었습니다.
+
앱에는 변경 가능한 매개변수 '컨텍스트 창 크기'가 있습니다. 이는 현재 LLM이 일반적으로 모델에 '프롬프트'로 공급될 수 있는 단어/토큰의 수를 제한하는 고정된 컨텍스트 크기를 갖기 때문에 필요합니다('단어'와 '토큰'은 토큰화 방법이 다르기 때문에 이 경우 컨텍스트 크기가 반드시 동일하지는 않습니다). 이 숫자가 중요한 이유는 다음과 같습니다.
diff --git a/site/ko/lite/examples/pose_estimation/overview.md b/site/ko/lite/examples/pose_estimation/overview.md
index c54d5c775c..38c4000dae 100644
--- a/site/ko/lite/examples/pose_estimation/overview.md
+++ b/site/ko/lite/examples/pose_estimation/overview.md
@@ -113,6 +113,7 @@ TensorFlow Lite를 처음 사용하고 Android 또는 iOS로 작업하는 경우
아래에 출력의 예를 나타내었습니다.
+
 ## 성능 벤치마크
diff --git a/site/ko/lite/examples/segmentation/overview.md b/site/ko/lite/examples/segmentation/overview.md
index fe1f1d89fd..e6fb602a5f 100644
--- a/site/ko/lite/examples/segmentation/overview.md
+++ b/site/ko/lite/examples/segmentation/overview.md
@@ -57,9 +57,8 @@ Android 또는 iOS 이외의 플랫폼을 사용 중이거나 Deeplab v3
-
-
## 성능 벤치마크
diff --git a/site/ko/lite/examples/segmentation/overview.md b/site/ko/lite/examples/segmentation/overview.md
index fe1f1d89fd..e6fb602a5f 100644
--- a/site/ko/lite/examples/segmentation/overview.md
+++ b/site/ko/lite/examples/segmentation/overview.md
@@ -57,9 +57,8 @@ Android 또는 iOS 이외의 플랫폼을 사용 중이거나 Deeplab v3
-
- 2.7Mb |
+ Deeplab v3 |
+ 2.7 Mb |
Pixel 3(Android 10) |
16ms |
37ms * |
diff --git a/site/ko/lite/examples/text_classification/overview.md b/site/ko/lite/examples/text_classification/overview.md
index fe61bd8191..abc5e715cc 100644
--- a/site/ko/lite/examples/text_classification/overview.md
+++ b/site/ko/lite/examples/text_classification/overview.md
@@ -51,7 +51,7 @@ Android이외의 플랫폼을 사용 중이거나 TensorFlow Lite API에 이미
| 텍스트 분류 |
- 0.6Mb |
+ 0.6 Mb |
Pixel 3(Android 10) |
0.05ms * |
diff --git a/site/ko/lite/models/bert_qa/overview.md b/site/ko/lite/models/bert_qa/overview.md
index 085ed3c723..7ea10f71b0 100644
--- a/site/ko/lite/models/bert_qa/overview.md
+++ b/site/ko/lite/models/bert_qa/overview.md
@@ -46,7 +46,7 @@ Android/iOS 이외의 플랫폼을 사용 중이거나 [TensorFlow Lite API](htt
| Mobile Bert |
- 100.5Mb |
+ 100.5 Mb |
Pixel 3(Android 10) |
123ms * |
diff --git a/site/ko/lite/models/modify/model_maker/image_classification.ipynb b/site/ko/lite/models/modify/model_maker/image_classification.ipynb
index 748c18fe0f..edff8c026e 100644
--- a/site/ko/lite/models/modify/model_maker/image_classification.ipynb
+++ b/site/ko/lite/models/modify/model_maker/image_classification.ipynb
@@ -166,7 +166,7 @@
"source": [
"`image_path`를 자신의 이미지 폴더로 바꿀 수 있습니다. colab에 데이터를 업로드하는 경우, 아래 이미지에 빨간색 사각형으로 표시된 왼쪽 사이드 바에서 Upload 버튼을 찾을 수 있습니다. zip 파일을 업로드하고 압축을 풉니다. 루트 파일 경로는 현재 경로입니다.\n",
"\n",
- "  "
+ " "
]
},
{
diff --git a/site/ko/lite/models/modify/model_maker/object_detection.ipynb b/site/ko/lite/models/modify/model_maker/object_detection.ipynb
index b955dba076..3495d75e02 100644
--- a/site/ko/lite/models/modify/model_maker/object_detection.ipynb
+++ b/site/ko/lite/models/modify/model_maker/object_detection.ipynb
@@ -81,7 +81,7 @@
"
"
+ " "
]
},
{
diff --git a/site/ko/lite/models/modify/model_maker/object_detection.ipynb b/site/ko/lite/models/modify/model_maker/object_detection.ipynb
index b955dba076..3495d75e02 100644
--- a/site/ko/lite/models/modify/model_maker/object_detection.ipynb
+++ b/site/ko/lite/models/modify/model_maker/object_detection.ipynb
@@ -81,7 +81,7 @@
"
\n",
"\n",
"\n",
- " \n"
+ " \n"
]
},
{
diff --git a/site/ko/lite/models/modify/model_maker/text_classification.ipynb b/site/ko/lite/models/modify/model_maker/text_classification.ipynb
index 53f4f05590..19a56a4d7f 100644
--- a/site/ko/lite/models/modify/model_maker/text_classification.ipynb
+++ b/site/ko/lite/models/modify/model_maker/text_classification.ipynb
@@ -170,7 +170,7 @@
"\n",
"다음은 훈련 데이터세트의 처음 5줄입니다. label=0은 부정적, label=1은 긍정적을 의미합니다.\n",
"\n",
- "문장 | label | | |\n",
+ "문장 | 상표 | | |\n",
"--- | --- | --- | --- | ---\n",
"hide new secretions from the parental units | 0 | | |\n",
"contains no wit , only labored gags | 0 | | |\n",
@@ -178,7 +178,7 @@
"remains utterly satisfied to remain the same throughout | 0 | | |\n",
"on the worst revenge-of-the-nerds clichés the filmmakers could dredge up | 0 | | |\n",
"\n",
- "문장 | label | | | --- | --- | --- | --- | --- hide new secretions from the parental units | 0 | | | contains no wit , only labored gags | 0 | | | that loves its characters and communicates something rather beautiful about human nature | 1 | | | remains utterly satisfied to remain the same throughout | 0 | | | on the worst revenge-of-the-nerds clichés the filmmakers could dredge up | 0 | | |\n"
+ "다음으로 데이터세트를 Pandas 데이터 프레임에 로드하고 현재 레이블 이름(`0` 및 `1`)을 좀 더 사람이 읽을 수 있는 이름(`negative` 및 `positive`)으로 변경하여 모델 훈련에 사용합니다.\n"
]
},
{
diff --git a/site/ko/model_optimization/guide/clustering/clustering_example.ipynb b/site/ko/model_optimization/guide/clustering/clustering_example.ipynb
index 031670c4b3..42959aa2a3 100644
--- a/site/ko/model_optimization/guide/clustering/clustering_example.ipynb
+++ b/site/ko/model_optimization/guide/clustering/clustering_example.ipynb
@@ -48,8 +48,7 @@
"source": [
""
diff --git a/site/ko/probability/examples/A_Tour_of_TensorFlow_Probability.ipynb b/site/ko/probability/examples/A_Tour_of_TensorFlow_Probability.ipynb
index ad78c647a9..a1c184d143 100644
--- a/site/ko/probability/examples/A_Tour_of_TensorFlow_Probability.ipynb
+++ b/site/ko/probability/examples/A_Tour_of_TensorFlow_Probability.ipynb
@@ -1001,7 +1001,7 @@
"각 bijector는 최소 3가지 메서드를 구현합니다.\n",
"\n",
"- `forward`\n",
- "- `inverse`\n",
+ "- `inverse` , 그리고\n",
"- (적어도) `forward_log_det_jacobian` 및 `inverse_log_det_jacobian` 중 하나.\n",
"\n",
"위의 성분을 사용하여 분포를 변환하고 결과에서 샘플 및 log_probs를 얻을 수 있습니다.\n",
diff --git a/site/ko/probability/examples/Distributed_Inference_with_JAX.ipynb b/site/ko/probability/examples/Distributed_Inference_with_JAX.ipynb
index ea96fd110c..5773605399 100644
--- a/site/ko/probability/examples/Distributed_Inference_with_JAX.ipynb
+++ b/site/ko/probability/examples/Distributed_Inference_with_JAX.ipynb
@@ -43,8 +43,7 @@
"\n",
""
@@ -996,7 +995,7 @@
"id": "wUeySkfVuqI-"
},
"source": [
- "MNIST 분류를 위해 다음 베이지안 로지스틱 회귀 모델을 사용합니다: $$ \\begin{align*} w &\\sim \\mathcal{N}(0, 1) \\ b &\\sim \\mathcal{N}(0, 1) \\ y_i | w, b, x_i &\\sim \\textrm{Categorical}(w^T x_i + b) \\end{align*} $$"
+ "MNIST 분류를 위해 다음 베이지안 로지스틱 회귀 모델을 사용합니다: $$ \\begin{align*} w &\\sim \\mathcal{N}(0, 1) \\ b &\\sim \\mathcal{N}(0, 1) \\ y_i | w, b, x_i &\\sim \\textrm{Categorical}(w^T x_i + b) \\end{align*} $$"
]
},
{
@@ -1557,7 +1556,7 @@
"id": "H8hKi0Aw-KVT"
},
"source": [
- "간단한 확률적 행렬 인수 분해 모델을 사용하여 $W$에 대한 생성 모델을 정의할 수 있습니다. 잠재 $N \\times D$ 사용자 행렬 $U$ 및 잠재 $M \\times D$ 영화 행렬 $V$를 추정합니다. 이 행렬을 곱하면 시청 행렬 $W$에 대한 베르누이 로짓을 생성합니다. 또한 사용자 및 영화, $u$ and $v$에 대한 편향 벡터를 포함하겠습니다. $$ \\begin{align*} U &\\sim \\mathcal{N}(0, 1) \\quad u \\sim \\mathcal{N}(0, 1)\\ V &\\sim \\mathcal{N}(0, 1) \\quad v \\sim \\mathcal{N}(0, 1)\\ W_{ij} &\\sim \\textrm{Bernoulli}\\left(\\sigma\\left(\\left(UV^T\\right)_{ij} + u_i + v_j\\right)\\right) \\end{align*} $$"
+ "간단한 확률적 행렬 인수 분해 모델을 사용하여 $W$에 대한 생성 모델을 정의할 수 있습니다. 잠재 $N \\times D$ 사용자 행렬 $U$ 및 잠재 $M \\times D$ 영화 행렬 $V$를 추정합니다. 이 행렬을 곱하면 시청 행렬 $W$에 대한 베르누이 로짓을 생성합니다. 또한 사용자 및 영화, $u$ and $v$에 대한 편향 벡터를 포함하겠습니다. $$ \\begin{align*} U &\\sim \\mathcal{N}(0, 1) \\quad u \\sim \\mathcal{N}(0, 1)\\ V &\\sim \\mathcal{N}(0, 1) \\quad v \\sim \\mathcal{N}(0, 1)\\ W_{ij} &\\sim \\textrm{Bernoulli}\\left(\\sigma\\left(\\left(UV^T\\right)_{ij} + u_i + v_j\\right)\\right) \\end{align*} $$"
]
},
{
diff --git a/site/ko/probability/examples/Gaussian_Process_Regression_In_TFP.ipynb b/site/ko/probability/examples/Gaussian_Process_Regression_In_TFP.ipynb
index 9d86cc99e8..4da3283082 100644
--- a/site/ko/probability/examples/Gaussian_Process_Regression_In_TFP.ipynb
+++ b/site/ko/probability/examples/Gaussian_Process_Regression_In_TFP.ipynb
@@ -64,57 +64,7 @@
"id": "n4-qQf7qZLVI"
},
"source": [
- "## 배경 설명\n",
- "\n",
- "$\\mathcal{X}$를 임의의 집합으로 둡니다. *가우시안 프로세스*(GP)는 $\\mathcal{X}$로 인덱싱한 확률 함수 모음으로, ${X_1, \\ldots, X_n} \\subset \\mathcal{X}$가 유한 부분 집합이면 한계 밀도 $p(X_1 = x_1, \\ldots, X_n = x_n)$는 다변량 가우시안입니다. 모든 가우시안 분포는 첫 번째와 두 번째 중심 모멘트(평균 및 공분산)로 완전히 지정되며 GP도 예외는 아닙니다. 평균 함수 $\\mu : \\mathcal{X} \\to \\mathbb{R}$ 및 공분산 함수 $k : \\mathcal{X} \\times \\mathcal{X} \\to \\mathbb{R}$로 GP를 완전히 지정할 수 있습니다. GP의 표현 능력의 대부분은 선택한 공분산 함수로 캡슐화됩니다. 다양한 이유로 공분산 함수를 *커널 함수*라고도 합니다. 대칭 양정치면 됩니다([Rasmussen & Williams의 4장](http://www.gaussianprocess.org/gpml/chapters/RW4.pdf) 참조). 아래에서는 ExponentiatedQuadratic 공분산 커널을 사용합니다. 형태는 다음과 같습니다.\n",
- "\n",
- "$$ k(x, x') := \\sigma^2 \\exp \\left( \\frac{|x - x'|^2}{\\lambda^2} \\right) $$\n",
- "\n",
- "여기서 $\\sigma^2$는 '진폭'이고 $\\lambda$는 *길이 척도* 입니다. 커널 매개변수는 최대 가능성 최적화 절차를 통해 선택할 수 있습니다.\n",
- "\n",
- "GP의 전체 샘플은 전체 공간 $\\mathcal{X}$에 대한 실수값 함수로 구성되며 실제로는 실현하기가 비현실적입니다. 종종 샘플을 관찰할 점집합을 선택하고 이들 지점에서 함수값을 추출합니다. 이는 적절한 유한 차원 다변량 가우시안에서 샘플링하여 달성됩니다.\n",
- "\n",
- "위의 정의에 따르면 모든 유한 차원 다변량 가우시안 분포도 가우시안 프로세스입니다. 일반적으로 GP를 참조할 때 인덱스 세트가 일부 $\\mathbb{R}^n$라는 것은 암시적이며 여기에서도 실제로 이러한 가정을 사용할 것입니다.\n",
- "\n",
- "머신러닝에서 가우시안 프로세스의 일반적인 적용은 가우시안 프로세스 회귀입니다. 이 아이디어는 유한수의 지점 ${x_1, \\ldots x_N}.$에서 함수의 노이즈가 있는 관측치 ${y_1, \\ldots, y_N}$를 고려하여 알려지지 않은 함수를 추정하는 것입니다. 다음의 생성 과정을 생각해봅니다.\n",
- "\n",
- "$$ \\begin{align} f \\sim : & \\textsf{GaussianProcess}\\left( \\text{mean_fn}=\\mu(x), \\text{covariance_fn}=k(x, x')\\right) \\ y_i \\sim : & \\textsf{Normal}\\left( \\text{loc}=f(x_i), \\text{scale}=\\sigma\\right), i = 1, \\ldots, N \\end{align} $$\n",
- "\n",
- "위에서 언급했듯이 샘플링된 함수는 무한수의 지점에서 값이 필요하므로 계산이 불가능합니다. 대신 다변량 가우시안의 유한 샘플을 고려합니다.\n",
- "\n",
- "$$ \\begin{gather} \\begin{bmatrix} f(x_1) \\ \\vdots \\ f(x_N) \\end{bmatrix} \\sim \\textsf{MultivariateNormal} \\left( : \\text{loc}= \\begin{bmatrix} \\mu(x_1) \\ \\vdots \\ \\mu(x_N) \\end{bmatrix} :,: \\text{scale}= \\begin{bmatrix} k(x_1, x_1) & \\cdots & k(x_1, x_N) \\ \\vdots & \\ddots & \\vdots \\ k(x_N, x_1) & \\cdots & k(x_N, x_N) \\ \\end{bmatrix}^{1/2} : \\right) \\end{gather} \\ y_i \\sim \\textsf{Normal} \\left( \\text{loc}=f(x_i), \\text{scale}=\\sigma \\right) $$\n",
- "\n",
- "공분산 행렬의 지수 $\\frac{1}{2}$에 유의하세요. 이는 콜레스키(Cholesky) 분해를 나타냅니다. MVN은 위치 스케일 패밀리 분포이므로 콜레스키 계산이 필요합니다. 불행히도 콜레스키 분해는 $O(N^3)$ 시간과 $O(N^2)$ 공간을 차지하기 때문에 계산 비용이 많이 듭니다. GP 문헌의 대부분은 이 겉보기에 무해한 작은 지수를 다루는 데 초점을 맞추고 있습니다.\n",
- "\n",
- "사전 확률 평균 함수를 상수(종종 0)로 사용하는 것이 일반적입니다. 일부 표기법도 편리합니다. 샘플링된 함수값의 유한 벡터에 대해 $\\mathbf{f}$를 종종 작성합니다. $k$를 입력 쌍에 적용한 결과 공분산 행렬에는 여러 가지 흥미로운 표기법이 사용됩니다. [(Quiñonero-Candela, 2005)](http://www.jmlr.org/papers/volume6/quinonero-candela05a/quinonero-candela05a.pdf)에 이어 행렬의 구성 요소가 특정 입력 지점에서 함수값의 공분산이라는 점에 주목합니다. 따라서 공분산 행렬을 $K_{AB}$로 표시할 수 있습니다. 여기서 $A$ 및 $B$는 주어진 행렬 차원에 따른 함수값 모음의 일부 지표입니다.\n",
- "\n",
- "예를 들어, 잠재 함수값 $\\mathbf{f}$가 포함된 관측 데이터 $(\\mathbf{x}, \\mathbf{y})$가 주어지면 다음과 같이 작성할 수 있습니다.\n",
- "\n",
- "$$ K_{\\mathbf{f},\\mathbf{f}} = \\begin{bmatrix} k(x_1, x_1) & \\cdots & k(x_1, x_N) \\ \\vdots & \\ddots & \\vdots \\ k(x_N, x_1) & \\cdots & k(x_N, x_N) \\ \\end{bmatrix} $$\n",
- "\n",
- "이와 유사하게, 다음과 같이 입력 집합을 혼합할 수 있습니다.\n",
- "\n",
- "$$ K_{\\mathbf{f},} = \\begin{bmatrix} k(x_1, x^_1) & \\cdots & k(x_1, x^_T) \\ \\vdots & \\ddots & \\vdots \\ k(x_N, x^_1) & \\cdots & k(x_N, x^*_T) \\ \\end{bmatrix} $$\n",
- "\n",
- "$N$ 훈련 입력과 $T$ 테스트 입력이 있다고 가정합니다. 위의 생성 프로세스는 다음과 같이 간결하게 작성될 수 있습니다.\n",
- "\n",
- "$$ \\begin{align} \\mathbf{f} \\sim : & \\textsf{MultivariateNormal} \\left( \\text{loc}=\\mathbf{0}, \\text{scale}=K_{\\mathbf{f},\\mathbf{f}}^{1/2} \\right) \\ y_i \\sim : & \\textsf{Normal} \\left( \\text{loc}=f_i, \\text{scale}=\\sigma \\right), i = 1, \\ldots, N \\end{align} $$\n",
- "\n",
- "첫 번째 줄의 샘플링 연산은 *위의 GP 추출 표기법에서와 같이 전체 함수가 아닌* 다변량 가우시안에서 유한한 $N$ 함수값 집합을 생성합니다. 두 번째 줄은 고정된 관측 노이즈 $\\sigma^2$를 사용하여 다양한 함수값을 중심으로 하는 *일변량* 가우시안에서 $N$ 추출 모음을 설명합니다.\n",
- "\n",
- "위의 생성 모델을 사용하면 사후 확률 추론 문제를 고려할 수 있습니다. 이렇게 하면 위의 프로세스에서 관찰된 노이즈가 있는 데이터를 조건으로 새로운 테스트 포인트 집합에서 함수값에 대한 사후 확률 분포가 생성됩니다.\n",
- "\n",
- "위의 표기법을 사용하면 다음과 같이 해당 입력 및 훈련 데이터를 조건으로 미래의 관찰(노이즈가 있는)에 대한 사후 확률 예측 분포를 다음과 같이 간결하게 작성할 수 있습니다(자세한 내용은 [Rasmussen & Williams](http://www.gaussianprocess.org/gpml/)의 §2.2 참조).\n",
- "\n",
- "$$ \\mathbf{y}^* \\mid \\mathbf{x}^, \\mathbf{x}, \\mathbf{y} \\sim \\textsf{Normal} \\left( \\text{loc}=\\mathbf{\\mu}^, \\text{scale}=(\\Sigma^*)^{1/2} \\right), $$\n",
- "\n",
- "여기서\n",
- "\n",
- "$$ \\mathbf{\\mu}^* = K_{*,\\mathbf{f}}\\left(K_{\\mathbf{f},\\mathbf{f}} + \\sigma^2 I \\right)^{-1} \\mathbf{y} $$\n",
- "\n",
- "및\n",
- "\n",
- "$$ \\Sigma^* = K_{,} - K_{,\\mathbf{f}} \\left(K_{\\mathbf{f},\\mathbf{f}} + \\sigma^2 I \\right)^{-1} K_{\\mathbf{f},} $$"
+ "$$ \\begin{align} \\mathbf{f} \\sim : & \\textsf{MultivariateNormal} \\left( \\text{loc}=\\mathbf{0}, \\text{scale}=K_{\\mathbf{f},\\mathbf{f}}^{1/2} \\right) \\ y_i \\sim : & \\textsf{Normal} \\left( \\text{loc}=f_i, \\text{scale}=\\sigma \\right), i = 1, \\ldots, N \\end{align} $$"
]
},
{
diff --git a/site/ko/probability/examples/HLM_TFP_R_Stan.ipynb b/site/ko/probability/examples/HLM_TFP_R_Stan.ipynb
index f5f9818f65..63b4659df2 100644
--- a/site/ko/probability/examples/HLM_TFP_R_Stan.ipynb
+++ b/site/ko/probability/examples/HLM_TFP_R_Stan.ipynb
@@ -120,9 +120,7 @@
"id": "fAD8am2a4TaY"
},
"source": [
- "다음 생성 모델을 가정합니다.\n",
- "\n",
- "$$\\begin{align*} \\text{for } & c=1\\ldots \\text{NumCounties}:\\ & \\beta_c \\sim \\text{Normal}\\left(\\text{loc}=0, \\text{scale}=\\sigma_C \\right) \\ \\text{for } & i=1\\ldots \\text{NumSamples}:\\ &\\eta_i = \\underbrace{\\omega_0 + \\omega_1 \\text{Floor}i}\\text{fixed effects} + \\underbrace{\\beta_{ \\text{County}i} \\log( \\text{UraniumPPM}{\\text{County}i}))}\\text{random effects} \\ &\\log(\\text{Radon}_i) \\sim \\text{Normal}(\\text{loc}=\\eta_i , \\text{scale}=\\sigma_N) \\end{align*}$$\n"
+ "$$\\begin{align*} \\text{for } & c=1\\ldots \\text{NumCounties}:\\ & \\beta_c \\sim \\text{Normal}\\left(\\text{loc}=0, \\text{scale}=\\sigma_C \\right) \\ \\text{for } & i=1\\ldots \\text{NumSamples}:\\ &\\eta_i = \\underbrace{\\omega_0 + \\omega_1 \\text{Floor}i}\\text{fixed effects} + \\underbrace{\\beta_{ \\text{County}i} \\log( \\text{UraniumPPM}{\\text{County}i}))}\\text{random effects} \\ &\\log(\\text{Radon}_i) \\sim \\text{Normal}(\\text{loc}=\\eta_i , \\text{scale}=\\sigma_N) \\end{align*}$$\n"
]
},
{
@@ -1625,13 +1623,7 @@
"id": "h7Xr0X4Qbe9C"
},
"source": [
- "선형 혼합 효과 회귀 모델에 피팅하기 위해 기대값 최대화 알고리즘(SAEM)의 확률적 근사 버전을 사용합니다. 기본적인 개념은 예상되는 결합 로그-밀도를 근사하기 위해 사후 샘플을 사용하는 것입니다(E-단계). 그런 다음 이 계산을 최대화하는 매개변수를 찾습니다(M-단계). 좀 더 구체적으로, 고정 소수점 반복은 다음과 같이 주어집니다.\n",
- "\n",
- "$$\\begin{align*} \\text{E}[ \\log p(x, Z | \\theta) | \\theta_0] &\\approx \\frac{1}{M} \\sum_{m=1}^M \\log p(x, z_m | \\theta), \\quad Z_m\\sim p(Z | x, \\theta_0) && \\text{E-step}\\ &=: Q_M(\\theta, \\theta_0) \\ \\theta_0 &= \\theta_0 - \\eta \\left.\\nabla_\\theta Q_M(\\theta, \\theta_0)\\right|_{\\theta=\\theta_0} && \\text{M-step} \\end{align*}$$\n",
- "\n",
- "여기서 $x$는 증거를 나타내고, $Z$는 주변화해야 하는 일부 잠재 변수를 나타내며, $\\theta,\\theta_0$은 가능한 매개변수화를 나타냅니다.\n",
- "\n",
- "더 자세한 설명은 [Bernard Delyon, Marc Lavielle, Eric, Moulines(Ann. Statist., 1999)의 *EM 알고리즘의 확률적 근사 버전의 수렴*](https://projecteuclid.org/euclid.aos/1018031103)을 참조하세요."
+ "$$\\begin{align*} \\text{E}[ \\log p(x, Z | \\theta) | \\theta_0] &\\approx \\frac{1}{M} \\sum_{m=1}^M \\log p(x, z_m | \\theta), \\quad Z_m\\sim p(Z | x, \\theta_0) && \\text{E-step}\\ &=: Q_M(\\theta, \\theta_0) \\ \\theta_0 &= \\theta_0 - \\eta \\left.\\nabla_\\theta Q_M(\\theta, \\theta_0)\\right|_{\\theta=\\theta_0} && \\text{M-step} \\end{align*}$$"
]
},
{
@@ -2183,7 +2175,7 @@
"id": "qt8a50GYSqbe"
},
"source": [
- "$$\\begin{align*} \\text{for } & c=1\\ldots \\text{NumCounties}:\\ & \\beta_c \\sim \\text{MultivariateNormal}\\left(\\text{loc}=\\left[ \\begin{array}{c} 0 \\ 0 \\end{array}\\right] , \\text{scale}=\\left[\\begin{array}{cc} \\sigma_{11} & 0 \\ \\sigma_{12} & \\sigma_{22} \\end{array}\\right] \\right) \\ \\text{for } & i=1\\ldots \\text{NumSamples}:\\ & c_i := \\text{County}i \\ &\\eta_i = \\underbrace{\\omega_0 + \\omega_1\\text{Floor}i \\vphantom{\\log( \\text{CountyUraniumPPM}{c_i}))}}{\\text{fixed effects}} + \\underbrace{\\beta_{c_i,0} + \\beta_{c_i,1}\\log( \\text{CountyUraniumPPM}{c_i}))}{\\text{random effects}} \\ &\\log(\\text{Radon}_i) \\sim \\text{Normal}(\\text{loc}=\\eta_i , \\text{scale}=\\sigma) \\end{align*}$$\n"
+ "$$\\begin{align*} \\text{for } & c=1\\ldots \\text{NumCounties}:\\ & \\beta_c \\sim \\text{MultivariateNormal}\\left(\\text{loc}=\\left[ \\begin{array}{c} 0 \\ 0 \\end{array}\\right] , \\text{scale}=\\left[\\begin{array}{cc} \\sigma_{11} & 0 \\ \\sigma_{12} & \\sigma_{22} \\end{array}\\right] \\right) \\ \\text{for } & i=1\\ldots \\text{NumSamples}:\\ & c_i := \\text{County}i \\ &\\eta_i = \\underbrace{\\omega_0 + \\omega_1\\text{Floor}i \\vphantom{\\log( \\text{CountyUraniumPPM}{c_i}))}}{\\text{fixed effects}} + \\underbrace{\\beta_{c_i,0} + \\beta_{c_i,1}\\log( \\text{CountyUraniumPPM}{c_i}))}{\\text{random effects}} \\ &\\log(\\text{Radon}_i) \\sim \\text{Normal}(\\text{loc}=\\eta_i , \\text{scale}=\\sigma) \\end{align*}$$\n"
]
},
{
diff --git a/site/ko/probability/examples/Linear_Mixed_Effects_Model_Variational_Inference.ipynb b/site/ko/probability/examples/Linear_Mixed_Effects_Model_Variational_Inference.ipynb
index ee9afcf0fc..8843a283bf 100644
--- a/site/ko/probability/examples/Linear_Mixed_Effects_Model_Variational_Inference.ipynb
+++ b/site/ko/probability/examples/Linear_Mixed_Effects_Model_Variational_Inference.ipynb
@@ -139,9 +139,7 @@
"id": "H-B38entvltq"
},
"source": [
- "생성 프로세스로서 일반화된 선형 혼합 효과 모델(GLMM)은 다음과 같은 특징이 있습니다.\n",
- "\n",
- "$$ \\begin{align} \\text{for } & r = 1\\ldots R: \\hspace{2.45cm}\\text{# for each random-effect group}\\ &\\begin{aligned} \\text{for } &c = 1\\ldots |C_r|: \\hspace{1.3cm}\\text{# for each category (\"level\") of group $r$}\\ &\\begin{aligned} \\beta_{rc} &\\sim \\text{MultivariateNormal}(\\text{loc}=0_{D_r}, \\text{scale}=\\Sigma_r^{1/2}) \\end{aligned} \\end{aligned}\\ \\text{for } & i = 1 \\ldots N: \\hspace{2.45cm}\\text{# for each sample}\\ &\\begin{aligned} &\\eta_i = \\underbrace{\\vphantom{\\sum_{r=1}^R}x_i^\\top\\omega}\\text{fixed-effects} + \\underbrace{\\sum{r=1}^R z_{r,i}^\\top \\beta_{r,C_r(i) }}\\text{random-effects} \\ &Y_i|x_i,\\omega,{z{r,i} , \\beta_r}_{r=1}^R \\sim \\text{Distribution}(\\text{mean}= g^{-1}(\\eta_i)) \\end{aligned} \\end{align} $$"
+ "$$ \\begin{align} \\text{for } & r = 1\\ldots R: \\hspace{2.45cm}\\text{# for each random-effect group}\\ &\\begin{aligned} \\text{for } &c = 1\\ldots |C_r|: \\hspace{1.3cm}\\text{# for each category (\"level\") of group $r$}\\ &\\begin{aligned} \\beta_{rc} &\\sim \\text{MultivariateNormal}(\\text{loc}=0_{D_r}, \\text{scale}=\\Sigma_r^{1/2}) \\end{aligned} \\end{aligned}\\ \\text{for } & i = 1 \\ldots N: \\hspace{2.45cm}\\text{# for each sample}\\ &\\begin{aligned} &\\eta_i = \\underbrace{\\vphantom{\\sum_{r=1}^R}x_i^\\top\\omega}\\text{fixed-effects} + \\underbrace{\\sum{r=1}^R z_{r,i}^\\top \\beta_{r,C_r(i) }}\\text{random-effects} \\ &Y_i|x_i,\\omega,{z{r,i} , \\beta_r}_{r=1}^R \\sim \\text{Distribution}(\\text{mean}= g^{-1}(\\eta_i)) \\end{aligned} \\end{align} $$"
]
},
{
@@ -150,8 +148,6 @@
"id": "3gZmFJXAHwfy"
},
"source": [
- "여기서\n",
- "\n",
"$$ \\begin{align} R &= \\text{number of random-effect groups}\\ |C_r| &= \\text{number of categories for group $r$}\\ N &= \\text{number of training samples}\\ x_i,\\omega &\\in \\mathbb{R}^{D_0}\\ D_0 &= \\text{number of fixed-effects}\\ C_r(i) &= \\text{category (under group $r$) of the $i$th sample}\\ z_{r,i} &\\in \\mathbb{R}^{D_r}\\ D_r &= \\text{number of random-effects associated with group $r$}\\ \\Sigma_{r} &\\in {S\\in\\mathbb{R}^{D_r \\times D_r} : S \\succ 0 }\\ \\eta_i\\mapsto g^{-1}(\\eta_i) &= \\mu_i, \\text{inverse link function}\\ \\text{Distribution} &=\\text{some distribution parameterizable solely by its mean} \\end{align} $$"
]
},
@@ -501,18 +497,7 @@
"id": "8MqU1SefgRy5"
},
"source": [
- "지리에 관한 내용을 포함하여 모델을 좀 더 정교하게 만드는 것이 아마도 더 좋을 것입니다. 라돈은 땅에 존재할 수 있는 우라늄의 붕괴 사슬의 일부이므로 지리를 설명하는 것이 중요합니다.\n",
- "\n",
- "$$ \\mathbb{E}[\\log(\\text{radon}_j)] = c + \\text{floor_effect}_j + \\text{county_effect}_j $$\n",
- "\n",
- "다시 하면, 의사 코드에서 다음과 같습니다.\n",
- "\n",
- "```\n",
- "def estimate_log_radon(floor, county):\n",
- " return intercept + floor_effect[floor] + county_effect[county]\n",
- "```\n",
- "\n",
- "카운티별 가중치를 제외하고는 이전과 동일합니다."
+ "$$ \\mathbb{E}[\\log(\\text{radon}_j)] = c + \\text{floor_effect}_j + \\text{county_effect}_j $$"
]
},
{
@@ -564,22 +549,7 @@
"id": "VxtwlODcdJZe"
},
"source": [
- "이 모델을 맞춤 조정하면 `county_effect` 벡터는 훈련 샘플이 거의 없는 카운티에 대한 결과를 기억하게 될 것입니다. 아마도 과대적합이 발생하여 일반화가 불량할 수 있습니다.\n",
- "\n",
- "GLMM은 위의 두 GLM에 대해 적절한 타협점을 제공합니다. 다음과 같이 맞춤 조정하는 것을 고려할 수 있습니다.\n",
- "\n",
- "$$ \\log(\\text{radon}_j) \\sim c + \\text{floor_effect}_j + \\mathcal{N}(\\text{county_effect}_j, \\text{county_scale}) $$\n",
- "\n",
- "이 모델은 첫 번째 모델과 같지만, 가능성이 정규 분포가 되도록 고정했으며 단일 변수 `county_scale`을 통해 모든 카운티에서 분산을 공유합니다. 의사 코드는 다음과 같습니다.\n",
- "\n",
- "```\n",
- "def estimate_log_radon(floor, county):\n",
- " county_mean = county_effect[county]\n",
- " random_effect = np.random.normal() * county_scale + county_mean\n",
- " return intercept + floor_effect[floor] + random_effect\n",
- "```\n",
- "\n",
- "관측된 데이터로 `county_scale`, `county_mean` 및 `random_effect`에 대한 결합 분포를 추론합니다. 글로벌 `county_scale`을 사용하면 카운티 간에 통계적 강도를 공유할 수 있습니다. 관측치가 많은 경우 관측치가 거의 없는 카운티 분산에 도움이 됩니다. 또한 더 많은 데이터를 수집하면 이 모델은 scale 변수가 풀링하지 않는 모델로 수렴됩니다. 이 데이터세트를 사용하더라도 두 모델 중 하나를 사용하여 관측치가 가장 많은 카운티에 대한 유사한 결론에 도달하게 됩니다."
+ "$$ \\log(\\text{radon}_j) \\sim c + \\text{floor_effect}_j + \\mathcal{N}(\\text{county_effect}_j, \\text{county_scale}) $$"
]
},
{
diff --git a/site/ko/probability/examples/Linear_Mixed_Effects_Models.ipynb b/site/ko/probability/examples/Linear_Mixed_Effects_Models.ipynb
index 1e49b55372..8834a7925e 100644
--- a/site/ko/probability/examples/Linear_Mixed_Effects_Models.ipynb
+++ b/site/ko/probability/examples/Linear_Mixed_Effects_Models.ipynb
@@ -493,9 +493,11 @@
"\n",
"이를 캡처하기 위해 $N\\times D$ 특성 $\\mathbf{X}$ 및 $N$ 레이블 $\\mathbf{y}$의 데이터세트에 대해 선형 회귀가 모델을 가정한다는 점을 기억하세요.\n",
"\n",
- "```\n",
- "$$ \\begin{equation*} \\mathbf{y} = \\mathbf{X}\\beta + \\alpha + \\epsilon, \\end{equation*} $$\n",
- "```\n",
+ "$$\n",
+ "\\begin{equation*}\n",
+ "\\mathbf{y} = \\mathbf{X}\\beta + \\alpha + \\epsilon,\n",
+ "\\end{equation*}\n",
+ "$$\n",
"\n",
"여기에 기울기 벡터 $\\beta\\in\\mathbb{R}^D$, 절편 $\\alpha\\in\\mathbb{R}$와 무작위 노이즈 $\\epsilon\\sim\\text{Normal}(\\mathbf{0}, \\mathbf{I})$가 있습니다. $\\beta$와 $\\alpha$는 '고정 효과'라고 합니다. 이들은 데이터 포인트 $(x, y)$ 전체에 걸쳐 일정하게 유지되는 효과입니다. 등가식의 가능성 공식은 $\\mathbf{y} \\sim \\text{Normal}(\\mathbf{X}\\beta + \\alpha, \\mathbf{I})$입니다. 이 가능성은 데이터에 맞춤 조정된 $\\beta$와 $\\alpha$의 포인트 추정치를 찾기 위해 추론하는 동안 최대화됩니다.\n",
"\n",
diff --git a/site/ko/probability/examples/Optimizers_in_TensorFlow_Probability.ipynb b/site/ko/probability/examples/Optimizers_in_TensorFlow_Probability.ipynb
index f598bc9f64..b785cb3fbf 100644
--- a/site/ko/probability/examples/Optimizers_in_TensorFlow_Probability.ipynb
+++ b/site/ko/probability/examples/Optimizers_in_TensorFlow_Probability.ipynb
@@ -42,14 +42,10 @@
"# TensorFlow Probability에서 옵티마이저\n",
"\n",
""
]
},
@@ -633,20 +629,7 @@
"id": "xVAO1lit8zzK"
},
"source": [
- "### 단일 함수, 복수 시작 지점\n",
- "\n",
- "Himmelblau 함수는 최적화 테스트 케이스입니다. 함수는 다음과 같이 주어집니다.\n",
- "\n",
- "$$f(x, y) = (x^2 + y - 11)^2 + (x + y^2 - 7)^2$$\n",
- "\n",
- "함수는 다음 위치에서 4개의 minima를 가집니다.\n",
- "\n",
- "- (3, 2),\n",
- "- (-2.805118, 3.131312),\n",
- "- (-3.779310, -3.283186),\n",
- "- (3.584428, -1.848126).\n",
- "\n",
- "이러한 모든 minima는 적절한 시작 지점으로부터 도달할 수 있습니다.\n"
+ "$$f(x, y) = (x^2 + y - 11)^2 + (x + y^2 - 7)^2$$\n"
]
},
{
diff --git a/site/ko/probability/examples/TFP_Release_Notebook_0_11_0.ipynb b/site/ko/probability/examples/TFP_Release_Notebook_0_11_0.ipynb
index e257965d57..42046dc79f 100644
--- a/site/ko/probability/examples/TFP_Release_Notebook_0_11_0.ipynb
+++ b/site/ko/probability/examples/TFP_Release_Notebook_0_11_0.ipynb
@@ -1328,7 +1328,7 @@
"name": "stdout",
"output_type": "stream",
"text": [
- "WARNING:tensorflow:Note that RandomUniformInt inside pfor op may not give same output as inside a sequential loop.\n"
+ "WARNING:tensorflow:Note that RandomStandardNormal inside pfor op may not give same output as inside a sequential loop.\n"
]
},
{
@@ -1342,14 +1342,11 @@
"name": "stdout",
"output_type": "stream",
"text": [
- "(, ) \n",
- " ((3,) sample)\n"
+ "(, ) \n",
+ " ((1,) sample)\n",
+ "WARNING:tensorflow:Note that RandomUniformInt inside pfor op may not give same output as inside a sequential loop.\n"
]
},
{
@@ -1370,7 +1367,14 @@
"name": "stderr",
"output_type": "stream",
"text": [
- "WARNING:tensorflow:Note that RandomStandardNormal inside pfor op may not give same output as inside a sequential loop.\n"
+ "(, ) \n",
+ " ((3,) sample)\n"
]
},
{
diff --git a/site/ko/probability/examples/TFP_Release_Notebook_0_12_1.ipynb b/site/ko/probability/examples/TFP_Release_Notebook_0_12_1.ipynb
index f379a554dc..8f73a694d6 100644
--- a/site/ko/probability/examples/TFP_Release_Notebook_0_12_1.ipynb
+++ b/site/ko/probability/examples/TFP_Release_Notebook_0_12_1.ipynb
@@ -45,8 +45,7 @@
"\n",
""
diff --git a/site/ko/probability/examples/TFP_Release_Notebook_0_13_0.ipynb b/site/ko/probability/examples/TFP_Release_Notebook_0_13_0.ipynb
index fa0c4913bb..7a051c05a2 100644
--- a/site/ko/probability/examples/TFP_Release_Notebook_0_13_0.ipynb
+++ b/site/ko/probability/examples/TFP_Release_Notebook_0_13_0.ipynb
@@ -45,8 +45,7 @@
"\n",
""
diff --git a/site/ko/probability/examples/TensorFlow_Probability_Case_Study_Covariance_Estimation.ipynb b/site/ko/probability/examples/TensorFlow_Probability_Case_Study_Covariance_Estimation.ipynb
index 764df20c0c..0e9fc2baaf 100644
--- a/site/ko/probability/examples/TensorFlow_Probability_Case_Study_Covariance_Estimation.ipynb
+++ b/site/ko/probability/examples/TensorFlow_Probability_Case_Study_Covariance_Estimation.ipynb
@@ -226,7 +226,7 @@
"source": [
"### 일부 합성 관측 생성\n",
"\n",
- "**TensorFlow 확률은 데이터의 초기 차원이 샘플 인덱스를 나타내며 데이터의 최종 차원이 여러분의 샘플의 차원수를 나타낸다는 규칙을 사용합니다.**\n",
+ "TensorFlow 확률은 데이터의 초기 차원이 샘플 인덱스를 나타내며 데이터의 최종 차원이 여러분의 샘플의 차원수를 나타낸다는 규칙을 사용합니다.\n",
"\n",
"여기에서 우리는 각각 길이 2의 벡터인 샘플 100개가 필요합니다. 우리는 형상이 (100,2)인 배열 `my_data`를 생성합니다. `my_data[i, :]`는 $i$번째 샘플이며 길이 2의 벡터입니다.\n",
"\n",
diff --git a/site/ko/quantum/tutorials/quantum_reinforcement_learning.ipynb b/site/ko/quantum/tutorials/quantum_reinforcement_learning.ipynb
index daf8ef7bdd..367fbcbbc6 100644
--- a/site/ko/quantum/tutorials/quantum_reinforcement_learning.ipynb
+++ b/site/ko/quantum/tutorials/quantum_reinforcement_learning.ipynb
@@ -223,7 +223,7 @@
"PQC에서 입력 벡터를 인코딩하는 일반적인 방법은 단일 큐비트 회전을 사용하는 것입니다. 여기서 회전 각도는 이 입력 벡터의 구성 요소에 의해 제어됩니다. [표현력이 높은 모델](https://arxiv.org/abs/2008.08605)을 얻기 위해 이러한 단일 큐비트 인코딩을 PQC에서 한 번만 수행하는 것이 아닌 여러 번의 \"[재업로드](https://quantum-journal.org/papers/q-2020-02-06-226/)\"로 변이 게이트 사이에 삽입하여 수행합니다. 이러한 PQC의 레이아웃은 다음과 같습니다.\n",
"\n",
"\n",
- "
\n"
+ " \n"
]
},
{
diff --git a/site/ko/lite/models/modify/model_maker/text_classification.ipynb b/site/ko/lite/models/modify/model_maker/text_classification.ipynb
index 53f4f05590..19a56a4d7f 100644
--- a/site/ko/lite/models/modify/model_maker/text_classification.ipynb
+++ b/site/ko/lite/models/modify/model_maker/text_classification.ipynb
@@ -170,7 +170,7 @@
"\n",
"다음은 훈련 데이터세트의 처음 5줄입니다. label=0은 부정적, label=1은 긍정적을 의미합니다.\n",
"\n",
- "문장 | label | | |\n",
+ "문장 | 상표 | | |\n",
"--- | --- | --- | --- | ---\n",
"hide new secretions from the parental units | 0 | | |\n",
"contains no wit , only labored gags | 0 | | |\n",
@@ -178,7 +178,7 @@
"remains utterly satisfied to remain the same throughout | 0 | | |\n",
"on the worst revenge-of-the-nerds clichés the filmmakers could dredge up | 0 | | |\n",
"\n",
- "문장 | label | | | --- | --- | --- | --- | --- hide new secretions from the parental units | 0 | | | contains no wit , only labored gags | 0 | | | that loves its characters and communicates something rather beautiful about human nature | 1 | | | remains utterly satisfied to remain the same throughout | 0 | | | on the worst revenge-of-the-nerds clichés the filmmakers could dredge up | 0 | | |\n"
+ "다음으로 데이터세트를 Pandas 데이터 프레임에 로드하고 현재 레이블 이름(`0` 및 `1`)을 좀 더 사람이 읽을 수 있는 이름(`negative` 및 `positive`)으로 변경하여 모델 훈련에 사용합니다.\n"
]
},
{
diff --git a/site/ko/model_optimization/guide/clustering/clustering_example.ipynb b/site/ko/model_optimization/guide/clustering/clustering_example.ipynb
index 031670c4b3..42959aa2a3 100644
--- a/site/ko/model_optimization/guide/clustering/clustering_example.ipynb
+++ b/site/ko/model_optimization/guide/clustering/clustering_example.ipynb
@@ -48,8 +48,7 @@
"source": [
""
diff --git a/site/ko/probability/examples/A_Tour_of_TensorFlow_Probability.ipynb b/site/ko/probability/examples/A_Tour_of_TensorFlow_Probability.ipynb
index ad78c647a9..a1c184d143 100644
--- a/site/ko/probability/examples/A_Tour_of_TensorFlow_Probability.ipynb
+++ b/site/ko/probability/examples/A_Tour_of_TensorFlow_Probability.ipynb
@@ -1001,7 +1001,7 @@
"각 bijector는 최소 3가지 메서드를 구현합니다.\n",
"\n",
"- `forward`\n",
- "- `inverse`\n",
+ "- `inverse` , 그리고\n",
"- (적어도) `forward_log_det_jacobian` 및 `inverse_log_det_jacobian` 중 하나.\n",
"\n",
"위의 성분을 사용하여 분포를 변환하고 결과에서 샘플 및 log_probs를 얻을 수 있습니다.\n",
diff --git a/site/ko/probability/examples/Distributed_Inference_with_JAX.ipynb b/site/ko/probability/examples/Distributed_Inference_with_JAX.ipynb
index ea96fd110c..5773605399 100644
--- a/site/ko/probability/examples/Distributed_Inference_with_JAX.ipynb
+++ b/site/ko/probability/examples/Distributed_Inference_with_JAX.ipynb
@@ -43,8 +43,7 @@
"\n",
""
@@ -996,7 +995,7 @@
"id": "wUeySkfVuqI-"
},
"source": [
- "MNIST 분류를 위해 다음 베이지안 로지스틱 회귀 모델을 사용합니다: $$ \\begin{align*} w &\\sim \\mathcal{N}(0, 1) \\ b &\\sim \\mathcal{N}(0, 1) \\ y_i | w, b, x_i &\\sim \\textrm{Categorical}(w^T x_i + b) \\end{align*} $$"
+ "MNIST 분류를 위해 다음 베이지안 로지스틱 회귀 모델을 사용합니다: $$ \\begin{align*} w &\\sim \\mathcal{N}(0, 1) \\ b &\\sim \\mathcal{N}(0, 1) \\ y_i | w, b, x_i &\\sim \\textrm{Categorical}(w^T x_i + b) \\end{align*} $$"
]
},
{
@@ -1557,7 +1556,7 @@
"id": "H8hKi0Aw-KVT"
},
"source": [
- "간단한 확률적 행렬 인수 분해 모델을 사용하여 $W$에 대한 생성 모델을 정의할 수 있습니다. 잠재 $N \\times D$ 사용자 행렬 $U$ 및 잠재 $M \\times D$ 영화 행렬 $V$를 추정합니다. 이 행렬을 곱하면 시청 행렬 $W$에 대한 베르누이 로짓을 생성합니다. 또한 사용자 및 영화, $u$ and $v$에 대한 편향 벡터를 포함하겠습니다. $$ \\begin{align*} U &\\sim \\mathcal{N}(0, 1) \\quad u \\sim \\mathcal{N}(0, 1)\\ V &\\sim \\mathcal{N}(0, 1) \\quad v \\sim \\mathcal{N}(0, 1)\\ W_{ij} &\\sim \\textrm{Bernoulli}\\left(\\sigma\\left(\\left(UV^T\\right)_{ij} + u_i + v_j\\right)\\right) \\end{align*} $$"
+ "간단한 확률적 행렬 인수 분해 모델을 사용하여 $W$에 대한 생성 모델을 정의할 수 있습니다. 잠재 $N \\times D$ 사용자 행렬 $U$ 및 잠재 $M \\times D$ 영화 행렬 $V$를 추정합니다. 이 행렬을 곱하면 시청 행렬 $W$에 대한 베르누이 로짓을 생성합니다. 또한 사용자 및 영화, $u$ and $v$에 대한 편향 벡터를 포함하겠습니다. $$ \\begin{align*} U &\\sim \\mathcal{N}(0, 1) \\quad u \\sim \\mathcal{N}(0, 1)\\ V &\\sim \\mathcal{N}(0, 1) \\quad v \\sim \\mathcal{N}(0, 1)\\ W_{ij} &\\sim \\textrm{Bernoulli}\\left(\\sigma\\left(\\left(UV^T\\right)_{ij} + u_i + v_j\\right)\\right) \\end{align*} $$"
]
},
{
diff --git a/site/ko/probability/examples/Gaussian_Process_Regression_In_TFP.ipynb b/site/ko/probability/examples/Gaussian_Process_Regression_In_TFP.ipynb
index 9d86cc99e8..4da3283082 100644
--- a/site/ko/probability/examples/Gaussian_Process_Regression_In_TFP.ipynb
+++ b/site/ko/probability/examples/Gaussian_Process_Regression_In_TFP.ipynb
@@ -64,57 +64,7 @@
"id": "n4-qQf7qZLVI"
},
"source": [
- "## 배경 설명\n",
- "\n",
- "$\\mathcal{X}$를 임의의 집합으로 둡니다. *가우시안 프로세스*(GP)는 $\\mathcal{X}$로 인덱싱한 확률 함수 모음으로, ${X_1, \\ldots, X_n} \\subset \\mathcal{X}$가 유한 부분 집합이면 한계 밀도 $p(X_1 = x_1, \\ldots, X_n = x_n)$는 다변량 가우시안입니다. 모든 가우시안 분포는 첫 번째와 두 번째 중심 모멘트(평균 및 공분산)로 완전히 지정되며 GP도 예외는 아닙니다. 평균 함수 $\\mu : \\mathcal{X} \\to \\mathbb{R}$ 및 공분산 함수 $k : \\mathcal{X} \\times \\mathcal{X} \\to \\mathbb{R}$로 GP를 완전히 지정할 수 있습니다. GP의 표현 능력의 대부분은 선택한 공분산 함수로 캡슐화됩니다. 다양한 이유로 공분산 함수를 *커널 함수*라고도 합니다. 대칭 양정치면 됩니다([Rasmussen & Williams의 4장](http://www.gaussianprocess.org/gpml/chapters/RW4.pdf) 참조). 아래에서는 ExponentiatedQuadratic 공분산 커널을 사용합니다. 형태는 다음과 같습니다.\n",
- "\n",
- "$$ k(x, x') := \\sigma^2 \\exp \\left( \\frac{|x - x'|^2}{\\lambda^2} \\right) $$\n",
- "\n",
- "여기서 $\\sigma^2$는 '진폭'이고 $\\lambda$는 *길이 척도* 입니다. 커널 매개변수는 최대 가능성 최적화 절차를 통해 선택할 수 있습니다.\n",
- "\n",
- "GP의 전체 샘플은 전체 공간 $\\mathcal{X}$에 대한 실수값 함수로 구성되며 실제로는 실현하기가 비현실적입니다. 종종 샘플을 관찰할 점집합을 선택하고 이들 지점에서 함수값을 추출합니다. 이는 적절한 유한 차원 다변량 가우시안에서 샘플링하여 달성됩니다.\n",
- "\n",
- "위의 정의에 따르면 모든 유한 차원 다변량 가우시안 분포도 가우시안 프로세스입니다. 일반적으로 GP를 참조할 때 인덱스 세트가 일부 $\\mathbb{R}^n$라는 것은 암시적이며 여기에서도 실제로 이러한 가정을 사용할 것입니다.\n",
- "\n",
- "머신러닝에서 가우시안 프로세스의 일반적인 적용은 가우시안 프로세스 회귀입니다. 이 아이디어는 유한수의 지점 ${x_1, \\ldots x_N}.$에서 함수의 노이즈가 있는 관측치 ${y_1, \\ldots, y_N}$를 고려하여 알려지지 않은 함수를 추정하는 것입니다. 다음의 생성 과정을 생각해봅니다.\n",
- "\n",
- "$$ \\begin{align} f \\sim : & \\textsf{GaussianProcess}\\left( \\text{mean_fn}=\\mu(x), \\text{covariance_fn}=k(x, x')\\right) \\ y_i \\sim : & \\textsf{Normal}\\left( \\text{loc}=f(x_i), \\text{scale}=\\sigma\\right), i = 1, \\ldots, N \\end{align} $$\n",
- "\n",
- "위에서 언급했듯이 샘플링된 함수는 무한수의 지점에서 값이 필요하므로 계산이 불가능합니다. 대신 다변량 가우시안의 유한 샘플을 고려합니다.\n",
- "\n",
- "$$ \\begin{gather} \\begin{bmatrix} f(x_1) \\ \\vdots \\ f(x_N) \\end{bmatrix} \\sim \\textsf{MultivariateNormal} \\left( : \\text{loc}= \\begin{bmatrix} \\mu(x_1) \\ \\vdots \\ \\mu(x_N) \\end{bmatrix} :,: \\text{scale}= \\begin{bmatrix} k(x_1, x_1) & \\cdots & k(x_1, x_N) \\ \\vdots & \\ddots & \\vdots \\ k(x_N, x_1) & \\cdots & k(x_N, x_N) \\ \\end{bmatrix}^{1/2} : \\right) \\end{gather} \\ y_i \\sim \\textsf{Normal} \\left( \\text{loc}=f(x_i), \\text{scale}=\\sigma \\right) $$\n",
- "\n",
- "공분산 행렬의 지수 $\\frac{1}{2}$에 유의하세요. 이는 콜레스키(Cholesky) 분해를 나타냅니다. MVN은 위치 스케일 패밀리 분포이므로 콜레스키 계산이 필요합니다. 불행히도 콜레스키 분해는 $O(N^3)$ 시간과 $O(N^2)$ 공간을 차지하기 때문에 계산 비용이 많이 듭니다. GP 문헌의 대부분은 이 겉보기에 무해한 작은 지수를 다루는 데 초점을 맞추고 있습니다.\n",
- "\n",
- "사전 확률 평균 함수를 상수(종종 0)로 사용하는 것이 일반적입니다. 일부 표기법도 편리합니다. 샘플링된 함수값의 유한 벡터에 대해 $\\mathbf{f}$를 종종 작성합니다. $k$를 입력 쌍에 적용한 결과 공분산 행렬에는 여러 가지 흥미로운 표기법이 사용됩니다. [(Quiñonero-Candela, 2005)](http://www.jmlr.org/papers/volume6/quinonero-candela05a/quinonero-candela05a.pdf)에 이어 행렬의 구성 요소가 특정 입력 지점에서 함수값의 공분산이라는 점에 주목합니다. 따라서 공분산 행렬을 $K_{AB}$로 표시할 수 있습니다. 여기서 $A$ 및 $B$는 주어진 행렬 차원에 따른 함수값 모음의 일부 지표입니다.\n",
- "\n",
- "예를 들어, 잠재 함수값 $\\mathbf{f}$가 포함된 관측 데이터 $(\\mathbf{x}, \\mathbf{y})$가 주어지면 다음과 같이 작성할 수 있습니다.\n",
- "\n",
- "$$ K_{\\mathbf{f},\\mathbf{f}} = \\begin{bmatrix} k(x_1, x_1) & \\cdots & k(x_1, x_N) \\ \\vdots & \\ddots & \\vdots \\ k(x_N, x_1) & \\cdots & k(x_N, x_N) \\ \\end{bmatrix} $$\n",
- "\n",
- "이와 유사하게, 다음과 같이 입력 집합을 혼합할 수 있습니다.\n",
- "\n",
- "$$ K_{\\mathbf{f},} = \\begin{bmatrix} k(x_1, x^_1) & \\cdots & k(x_1, x^_T) \\ \\vdots & \\ddots & \\vdots \\ k(x_N, x^_1) & \\cdots & k(x_N, x^*_T) \\ \\end{bmatrix} $$\n",
- "\n",
- "$N$ 훈련 입력과 $T$ 테스트 입력이 있다고 가정합니다. 위의 생성 프로세스는 다음과 같이 간결하게 작성될 수 있습니다.\n",
- "\n",
- "$$ \\begin{align} \\mathbf{f} \\sim : & \\textsf{MultivariateNormal} \\left( \\text{loc}=\\mathbf{0}, \\text{scale}=K_{\\mathbf{f},\\mathbf{f}}^{1/2} \\right) \\ y_i \\sim : & \\textsf{Normal} \\left( \\text{loc}=f_i, \\text{scale}=\\sigma \\right), i = 1, \\ldots, N \\end{align} $$\n",
- "\n",
- "첫 번째 줄의 샘플링 연산은 *위의 GP 추출 표기법에서와 같이 전체 함수가 아닌* 다변량 가우시안에서 유한한 $N$ 함수값 집합을 생성합니다. 두 번째 줄은 고정된 관측 노이즈 $\\sigma^2$를 사용하여 다양한 함수값을 중심으로 하는 *일변량* 가우시안에서 $N$ 추출 모음을 설명합니다.\n",
- "\n",
- "위의 생성 모델을 사용하면 사후 확률 추론 문제를 고려할 수 있습니다. 이렇게 하면 위의 프로세스에서 관찰된 노이즈가 있는 데이터를 조건으로 새로운 테스트 포인트 집합에서 함수값에 대한 사후 확률 분포가 생성됩니다.\n",
- "\n",
- "위의 표기법을 사용하면 다음과 같이 해당 입력 및 훈련 데이터를 조건으로 미래의 관찰(노이즈가 있는)에 대한 사후 확률 예측 분포를 다음과 같이 간결하게 작성할 수 있습니다(자세한 내용은 [Rasmussen & Williams](http://www.gaussianprocess.org/gpml/)의 §2.2 참조).\n",
- "\n",
- "$$ \\mathbf{y}^* \\mid \\mathbf{x}^, \\mathbf{x}, \\mathbf{y} \\sim \\textsf{Normal} \\left( \\text{loc}=\\mathbf{\\mu}^, \\text{scale}=(\\Sigma^*)^{1/2} \\right), $$\n",
- "\n",
- "여기서\n",
- "\n",
- "$$ \\mathbf{\\mu}^* = K_{*,\\mathbf{f}}\\left(K_{\\mathbf{f},\\mathbf{f}} + \\sigma^2 I \\right)^{-1} \\mathbf{y} $$\n",
- "\n",
- "및\n",
- "\n",
- "$$ \\Sigma^* = K_{,} - K_{,\\mathbf{f}} \\left(K_{\\mathbf{f},\\mathbf{f}} + \\sigma^2 I \\right)^{-1} K_{\\mathbf{f},} $$"
+ "$$ \\begin{align} \\mathbf{f} \\sim : & \\textsf{MultivariateNormal} \\left( \\text{loc}=\\mathbf{0}, \\text{scale}=K_{\\mathbf{f},\\mathbf{f}}^{1/2} \\right) \\ y_i \\sim : & \\textsf{Normal} \\left( \\text{loc}=f_i, \\text{scale}=\\sigma \\right), i = 1, \\ldots, N \\end{align} $$"
]
},
{
diff --git a/site/ko/probability/examples/HLM_TFP_R_Stan.ipynb b/site/ko/probability/examples/HLM_TFP_R_Stan.ipynb
index f5f9818f65..63b4659df2 100644
--- a/site/ko/probability/examples/HLM_TFP_R_Stan.ipynb
+++ b/site/ko/probability/examples/HLM_TFP_R_Stan.ipynb
@@ -120,9 +120,7 @@
"id": "fAD8am2a4TaY"
},
"source": [
- "다음 생성 모델을 가정합니다.\n",
- "\n",
- "$$\\begin{align*} \\text{for } & c=1\\ldots \\text{NumCounties}:\\ & \\beta_c \\sim \\text{Normal}\\left(\\text{loc}=0, \\text{scale}=\\sigma_C \\right) \\ \\text{for } & i=1\\ldots \\text{NumSamples}:\\ &\\eta_i = \\underbrace{\\omega_0 + \\omega_1 \\text{Floor}i}\\text{fixed effects} + \\underbrace{\\beta_{ \\text{County}i} \\log( \\text{UraniumPPM}{\\text{County}i}))}\\text{random effects} \\ &\\log(\\text{Radon}_i) \\sim \\text{Normal}(\\text{loc}=\\eta_i , \\text{scale}=\\sigma_N) \\end{align*}$$\n"
+ "$$\\begin{align*} \\text{for } & c=1\\ldots \\text{NumCounties}:\\ & \\beta_c \\sim \\text{Normal}\\left(\\text{loc}=0, \\text{scale}=\\sigma_C \\right) \\ \\text{for } & i=1\\ldots \\text{NumSamples}:\\ &\\eta_i = \\underbrace{\\omega_0 + \\omega_1 \\text{Floor}i}\\text{fixed effects} + \\underbrace{\\beta_{ \\text{County}i} \\log( \\text{UraniumPPM}{\\text{County}i}))}\\text{random effects} \\ &\\log(\\text{Radon}_i) \\sim \\text{Normal}(\\text{loc}=\\eta_i , \\text{scale}=\\sigma_N) \\end{align*}$$\n"
]
},
{
@@ -1625,13 +1623,7 @@
"id": "h7Xr0X4Qbe9C"
},
"source": [
- "선형 혼합 효과 회귀 모델에 피팅하기 위해 기대값 최대화 알고리즘(SAEM)의 확률적 근사 버전을 사용합니다. 기본적인 개념은 예상되는 결합 로그-밀도를 근사하기 위해 사후 샘플을 사용하는 것입니다(E-단계). 그런 다음 이 계산을 최대화하는 매개변수를 찾습니다(M-단계). 좀 더 구체적으로, 고정 소수점 반복은 다음과 같이 주어집니다.\n",
- "\n",
- "$$\\begin{align*} \\text{E}[ \\log p(x, Z | \\theta) | \\theta_0] &\\approx \\frac{1}{M} \\sum_{m=1}^M \\log p(x, z_m | \\theta), \\quad Z_m\\sim p(Z | x, \\theta_0) && \\text{E-step}\\ &=: Q_M(\\theta, \\theta_0) \\ \\theta_0 &= \\theta_0 - \\eta \\left.\\nabla_\\theta Q_M(\\theta, \\theta_0)\\right|_{\\theta=\\theta_0} && \\text{M-step} \\end{align*}$$\n",
- "\n",
- "여기서 $x$는 증거를 나타내고, $Z$는 주변화해야 하는 일부 잠재 변수를 나타내며, $\\theta,\\theta_0$은 가능한 매개변수화를 나타냅니다.\n",
- "\n",
- "더 자세한 설명은 [Bernard Delyon, Marc Lavielle, Eric, Moulines(Ann. Statist., 1999)의 *EM 알고리즘의 확률적 근사 버전의 수렴*](https://projecteuclid.org/euclid.aos/1018031103)을 참조하세요."
+ "$$\\begin{align*} \\text{E}[ \\log p(x, Z | \\theta) | \\theta_0] &\\approx \\frac{1}{M} \\sum_{m=1}^M \\log p(x, z_m | \\theta), \\quad Z_m\\sim p(Z | x, \\theta_0) && \\text{E-step}\\ &=: Q_M(\\theta, \\theta_0) \\ \\theta_0 &= \\theta_0 - \\eta \\left.\\nabla_\\theta Q_M(\\theta, \\theta_0)\\right|_{\\theta=\\theta_0} && \\text{M-step} \\end{align*}$$"
]
},
{
@@ -2183,7 +2175,7 @@
"id": "qt8a50GYSqbe"
},
"source": [
- "$$\\begin{align*} \\text{for } & c=1\\ldots \\text{NumCounties}:\\ & \\beta_c \\sim \\text{MultivariateNormal}\\left(\\text{loc}=\\left[ \\begin{array}{c} 0 \\ 0 \\end{array}\\right] , \\text{scale}=\\left[\\begin{array}{cc} \\sigma_{11} & 0 \\ \\sigma_{12} & \\sigma_{22} \\end{array}\\right] \\right) \\ \\text{for } & i=1\\ldots \\text{NumSamples}:\\ & c_i := \\text{County}i \\ &\\eta_i = \\underbrace{\\omega_0 + \\omega_1\\text{Floor}i \\vphantom{\\log( \\text{CountyUraniumPPM}{c_i}))}}{\\text{fixed effects}} + \\underbrace{\\beta_{c_i,0} + \\beta_{c_i,1}\\log( \\text{CountyUraniumPPM}{c_i}))}{\\text{random effects}} \\ &\\log(\\text{Radon}_i) \\sim \\text{Normal}(\\text{loc}=\\eta_i , \\text{scale}=\\sigma) \\end{align*}$$\n"
+ "$$\\begin{align*} \\text{for } & c=1\\ldots \\text{NumCounties}:\\ & \\beta_c \\sim \\text{MultivariateNormal}\\left(\\text{loc}=\\left[ \\begin{array}{c} 0 \\ 0 \\end{array}\\right] , \\text{scale}=\\left[\\begin{array}{cc} \\sigma_{11} & 0 \\ \\sigma_{12} & \\sigma_{22} \\end{array}\\right] \\right) \\ \\text{for } & i=1\\ldots \\text{NumSamples}:\\ & c_i := \\text{County}i \\ &\\eta_i = \\underbrace{\\omega_0 + \\omega_1\\text{Floor}i \\vphantom{\\log( \\text{CountyUraniumPPM}{c_i}))}}{\\text{fixed effects}} + \\underbrace{\\beta_{c_i,0} + \\beta_{c_i,1}\\log( \\text{CountyUraniumPPM}{c_i}))}{\\text{random effects}} \\ &\\log(\\text{Radon}_i) \\sim \\text{Normal}(\\text{loc}=\\eta_i , \\text{scale}=\\sigma) \\end{align*}$$\n"
]
},
{
diff --git a/site/ko/probability/examples/Linear_Mixed_Effects_Model_Variational_Inference.ipynb b/site/ko/probability/examples/Linear_Mixed_Effects_Model_Variational_Inference.ipynb
index ee9afcf0fc..8843a283bf 100644
--- a/site/ko/probability/examples/Linear_Mixed_Effects_Model_Variational_Inference.ipynb
+++ b/site/ko/probability/examples/Linear_Mixed_Effects_Model_Variational_Inference.ipynb
@@ -139,9 +139,7 @@
"id": "H-B38entvltq"
},
"source": [
- "생성 프로세스로서 일반화된 선형 혼합 효과 모델(GLMM)은 다음과 같은 특징이 있습니다.\n",
- "\n",
- "$$ \\begin{align} \\text{for } & r = 1\\ldots R: \\hspace{2.45cm}\\text{# for each random-effect group}\\ &\\begin{aligned} \\text{for } &c = 1\\ldots |C_r|: \\hspace{1.3cm}\\text{# for each category (\"level\") of group $r$}\\ &\\begin{aligned} \\beta_{rc} &\\sim \\text{MultivariateNormal}(\\text{loc}=0_{D_r}, \\text{scale}=\\Sigma_r^{1/2}) \\end{aligned} \\end{aligned}\\ \\text{for } & i = 1 \\ldots N: \\hspace{2.45cm}\\text{# for each sample}\\ &\\begin{aligned} &\\eta_i = \\underbrace{\\vphantom{\\sum_{r=1}^R}x_i^\\top\\omega}\\text{fixed-effects} + \\underbrace{\\sum{r=1}^R z_{r,i}^\\top \\beta_{r,C_r(i) }}\\text{random-effects} \\ &Y_i|x_i,\\omega,{z{r,i} , \\beta_r}_{r=1}^R \\sim \\text{Distribution}(\\text{mean}= g^{-1}(\\eta_i)) \\end{aligned} \\end{align} $$"
+ "$$ \\begin{align} \\text{for } & r = 1\\ldots R: \\hspace{2.45cm}\\text{# for each random-effect group}\\ &\\begin{aligned} \\text{for } &c = 1\\ldots |C_r|: \\hspace{1.3cm}\\text{# for each category (\"level\") of group $r$}\\ &\\begin{aligned} \\beta_{rc} &\\sim \\text{MultivariateNormal}(\\text{loc}=0_{D_r}, \\text{scale}=\\Sigma_r^{1/2}) \\end{aligned} \\end{aligned}\\ \\text{for } & i = 1 \\ldots N: \\hspace{2.45cm}\\text{# for each sample}\\ &\\begin{aligned} &\\eta_i = \\underbrace{\\vphantom{\\sum_{r=1}^R}x_i^\\top\\omega}\\text{fixed-effects} + \\underbrace{\\sum{r=1}^R z_{r,i}^\\top \\beta_{r,C_r(i) }}\\text{random-effects} \\ &Y_i|x_i,\\omega,{z{r,i} , \\beta_r}_{r=1}^R \\sim \\text{Distribution}(\\text{mean}= g^{-1}(\\eta_i)) \\end{aligned} \\end{align} $$"
]
},
{
@@ -150,8 +148,6 @@
"id": "3gZmFJXAHwfy"
},
"source": [
- "여기서\n",
- "\n",
"$$ \\begin{align} R &= \\text{number of random-effect groups}\\ |C_r| &= \\text{number of categories for group $r$}\\ N &= \\text{number of training samples}\\ x_i,\\omega &\\in \\mathbb{R}^{D_0}\\ D_0 &= \\text{number of fixed-effects}\\ C_r(i) &= \\text{category (under group $r$) of the $i$th sample}\\ z_{r,i} &\\in \\mathbb{R}^{D_r}\\ D_r &= \\text{number of random-effects associated with group $r$}\\ \\Sigma_{r} &\\in {S\\in\\mathbb{R}^{D_r \\times D_r} : S \\succ 0 }\\ \\eta_i\\mapsto g^{-1}(\\eta_i) &= \\mu_i, \\text{inverse link function}\\ \\text{Distribution} &=\\text{some distribution parameterizable solely by its mean} \\end{align} $$"
]
},
@@ -501,18 +497,7 @@
"id": "8MqU1SefgRy5"
},
"source": [
- "지리에 관한 내용을 포함하여 모델을 좀 더 정교하게 만드는 것이 아마도 더 좋을 것입니다. 라돈은 땅에 존재할 수 있는 우라늄의 붕괴 사슬의 일부이므로 지리를 설명하는 것이 중요합니다.\n",
- "\n",
- "$$ \\mathbb{E}[\\log(\\text{radon}_j)] = c + \\text{floor_effect}_j + \\text{county_effect}_j $$\n",
- "\n",
- "다시 하면, 의사 코드에서 다음과 같습니다.\n",
- "\n",
- "```\n",
- "def estimate_log_radon(floor, county):\n",
- " return intercept + floor_effect[floor] + county_effect[county]\n",
- "```\n",
- "\n",
- "카운티별 가중치를 제외하고는 이전과 동일합니다."
+ "$$ \\mathbb{E}[\\log(\\text{radon}_j)] = c + \\text{floor_effect}_j + \\text{county_effect}_j $$"
]
},
{
@@ -564,22 +549,7 @@
"id": "VxtwlODcdJZe"
},
"source": [
- "이 모델을 맞춤 조정하면 `county_effect` 벡터는 훈련 샘플이 거의 없는 카운티에 대한 결과를 기억하게 될 것입니다. 아마도 과대적합이 발생하여 일반화가 불량할 수 있습니다.\n",
- "\n",
- "GLMM은 위의 두 GLM에 대해 적절한 타협점을 제공합니다. 다음과 같이 맞춤 조정하는 것을 고려할 수 있습니다.\n",
- "\n",
- "$$ \\log(\\text{radon}_j) \\sim c + \\text{floor_effect}_j + \\mathcal{N}(\\text{county_effect}_j, \\text{county_scale}) $$\n",
- "\n",
- "이 모델은 첫 번째 모델과 같지만, 가능성이 정규 분포가 되도록 고정했으며 단일 변수 `county_scale`을 통해 모든 카운티에서 분산을 공유합니다. 의사 코드는 다음과 같습니다.\n",
- "\n",
- "```\n",
- "def estimate_log_radon(floor, county):\n",
- " county_mean = county_effect[county]\n",
- " random_effect = np.random.normal() * county_scale + county_mean\n",
- " return intercept + floor_effect[floor] + random_effect\n",
- "```\n",
- "\n",
- "관측된 데이터로 `county_scale`, `county_mean` 및 `random_effect`에 대한 결합 분포를 추론합니다. 글로벌 `county_scale`을 사용하면 카운티 간에 통계적 강도를 공유할 수 있습니다. 관측치가 많은 경우 관측치가 거의 없는 카운티 분산에 도움이 됩니다. 또한 더 많은 데이터를 수집하면 이 모델은 scale 변수가 풀링하지 않는 모델로 수렴됩니다. 이 데이터세트를 사용하더라도 두 모델 중 하나를 사용하여 관측치가 가장 많은 카운티에 대한 유사한 결론에 도달하게 됩니다."
+ "$$ \\log(\\text{radon}_j) \\sim c + \\text{floor_effect}_j + \\mathcal{N}(\\text{county_effect}_j, \\text{county_scale}) $$"
]
},
{
diff --git a/site/ko/probability/examples/Linear_Mixed_Effects_Models.ipynb b/site/ko/probability/examples/Linear_Mixed_Effects_Models.ipynb
index 1e49b55372..8834a7925e 100644
--- a/site/ko/probability/examples/Linear_Mixed_Effects_Models.ipynb
+++ b/site/ko/probability/examples/Linear_Mixed_Effects_Models.ipynb
@@ -493,9 +493,11 @@
"\n",
"이를 캡처하기 위해 $N\\times D$ 특성 $\\mathbf{X}$ 및 $N$ 레이블 $\\mathbf{y}$의 데이터세트에 대해 선형 회귀가 모델을 가정한다는 점을 기억하세요.\n",
"\n",
- "```\n",
- "$$ \\begin{equation*} \\mathbf{y} = \\mathbf{X}\\beta + \\alpha + \\epsilon, \\end{equation*} $$\n",
- "```\n",
+ "$$\n",
+ "\\begin{equation*}\n",
+ "\\mathbf{y} = \\mathbf{X}\\beta + \\alpha + \\epsilon,\n",
+ "\\end{equation*}\n",
+ "$$\n",
"\n",
"여기에 기울기 벡터 $\\beta\\in\\mathbb{R}^D$, 절편 $\\alpha\\in\\mathbb{R}$와 무작위 노이즈 $\\epsilon\\sim\\text{Normal}(\\mathbf{0}, \\mathbf{I})$가 있습니다. $\\beta$와 $\\alpha$는 '고정 효과'라고 합니다. 이들은 데이터 포인트 $(x, y)$ 전체에 걸쳐 일정하게 유지되는 효과입니다. 등가식의 가능성 공식은 $\\mathbf{y} \\sim \\text{Normal}(\\mathbf{X}\\beta + \\alpha, \\mathbf{I})$입니다. 이 가능성은 데이터에 맞춤 조정된 $\\beta$와 $\\alpha$의 포인트 추정치를 찾기 위해 추론하는 동안 최대화됩니다.\n",
"\n",
diff --git a/site/ko/probability/examples/Optimizers_in_TensorFlow_Probability.ipynb b/site/ko/probability/examples/Optimizers_in_TensorFlow_Probability.ipynb
index f598bc9f64..b785cb3fbf 100644
--- a/site/ko/probability/examples/Optimizers_in_TensorFlow_Probability.ipynb
+++ b/site/ko/probability/examples/Optimizers_in_TensorFlow_Probability.ipynb
@@ -42,14 +42,10 @@
"# TensorFlow Probability에서 옵티마이저\n",
"\n",
""
]
},
@@ -633,20 +629,7 @@
"id": "xVAO1lit8zzK"
},
"source": [
- "### 단일 함수, 복수 시작 지점\n",
- "\n",
- "Himmelblau 함수는 최적화 테스트 케이스입니다. 함수는 다음과 같이 주어집니다.\n",
- "\n",
- "$$f(x, y) = (x^2 + y - 11)^2 + (x + y^2 - 7)^2$$\n",
- "\n",
- "함수는 다음 위치에서 4개의 minima를 가집니다.\n",
- "\n",
- "- (3, 2),\n",
- "- (-2.805118, 3.131312),\n",
- "- (-3.779310, -3.283186),\n",
- "- (3.584428, -1.848126).\n",
- "\n",
- "이러한 모든 minima는 적절한 시작 지점으로부터 도달할 수 있습니다.\n"
+ "$$f(x, y) = (x^2 + y - 11)^2 + (x + y^2 - 7)^2$$\n"
]
},
{
diff --git a/site/ko/probability/examples/TFP_Release_Notebook_0_11_0.ipynb b/site/ko/probability/examples/TFP_Release_Notebook_0_11_0.ipynb
index e257965d57..42046dc79f 100644
--- a/site/ko/probability/examples/TFP_Release_Notebook_0_11_0.ipynb
+++ b/site/ko/probability/examples/TFP_Release_Notebook_0_11_0.ipynb
@@ -1328,7 +1328,7 @@
"name": "stdout",
"output_type": "stream",
"text": [
- "WARNING:tensorflow:Note that RandomUniformInt inside pfor op may not give same output as inside a sequential loop.\n"
+ "WARNING:tensorflow:Note that RandomStandardNormal inside pfor op may not give same output as inside a sequential loop.\n"
]
},
{
@@ -1342,14 +1342,11 @@
"name": "stdout",
"output_type": "stream",
"text": [
- "(, ) \n",
- " ((3,) sample)\n"
+ "(, ) \n",
+ " ((1,) sample)\n",
+ "WARNING:tensorflow:Note that RandomUniformInt inside pfor op may not give same output as inside a sequential loop.\n"
]
},
{
@@ -1370,7 +1367,14 @@
"name": "stderr",
"output_type": "stream",
"text": [
- "WARNING:tensorflow:Note that RandomStandardNormal inside pfor op may not give same output as inside a sequential loop.\n"
+ "(, ) \n",
+ " ((3,) sample)\n"
]
},
{
diff --git a/site/ko/probability/examples/TFP_Release_Notebook_0_12_1.ipynb b/site/ko/probability/examples/TFP_Release_Notebook_0_12_1.ipynb
index f379a554dc..8f73a694d6 100644
--- a/site/ko/probability/examples/TFP_Release_Notebook_0_12_1.ipynb
+++ b/site/ko/probability/examples/TFP_Release_Notebook_0_12_1.ipynb
@@ -45,8 +45,7 @@
"\n",
""
diff --git a/site/ko/probability/examples/TFP_Release_Notebook_0_13_0.ipynb b/site/ko/probability/examples/TFP_Release_Notebook_0_13_0.ipynb
index fa0c4913bb..7a051c05a2 100644
--- a/site/ko/probability/examples/TFP_Release_Notebook_0_13_0.ipynb
+++ b/site/ko/probability/examples/TFP_Release_Notebook_0_13_0.ipynb
@@ -45,8 +45,7 @@
"\n",
""
diff --git a/site/ko/probability/examples/TensorFlow_Probability_Case_Study_Covariance_Estimation.ipynb b/site/ko/probability/examples/TensorFlow_Probability_Case_Study_Covariance_Estimation.ipynb
index 764df20c0c..0e9fc2baaf 100644
--- a/site/ko/probability/examples/TensorFlow_Probability_Case_Study_Covariance_Estimation.ipynb
+++ b/site/ko/probability/examples/TensorFlow_Probability_Case_Study_Covariance_Estimation.ipynb
@@ -226,7 +226,7 @@
"source": [
"### 일부 합성 관측 생성\n",
"\n",
- "**TensorFlow 확률은 데이터의 초기 차원이 샘플 인덱스를 나타내며 데이터의 최종 차원이 여러분의 샘플의 차원수를 나타낸다는 규칙을 사용합니다.**\n",
+ "TensorFlow 확률은 데이터의 초기 차원이 샘플 인덱스를 나타내며 데이터의 최종 차원이 여러분의 샘플의 차원수를 나타낸다는 규칙을 사용합니다.\n",
"\n",
"여기에서 우리는 각각 길이 2의 벡터인 샘플 100개가 필요합니다. 우리는 형상이 (100,2)인 배열 `my_data`를 생성합니다. `my_data[i, :]`는 $i$번째 샘플이며 길이 2의 벡터입니다.\n",
"\n",
diff --git a/site/ko/quantum/tutorials/quantum_reinforcement_learning.ipynb b/site/ko/quantum/tutorials/quantum_reinforcement_learning.ipynb
index daf8ef7bdd..367fbcbbc6 100644
--- a/site/ko/quantum/tutorials/quantum_reinforcement_learning.ipynb
+++ b/site/ko/quantum/tutorials/quantum_reinforcement_learning.ipynb
@@ -223,7 +223,7 @@
"PQC에서 입력 벡터를 인코딩하는 일반적인 방법은 단일 큐비트 회전을 사용하는 것입니다. 여기서 회전 각도는 이 입력 벡터의 구성 요소에 의해 제어됩니다. [표현력이 높은 모델](https://arxiv.org/abs/2008.08605)을 얻기 위해 이러한 단일 큐비트 인코딩을 PQC에서 한 번만 수행하는 것이 아닌 여러 번의 \"[재업로드](https://quantum-journal.org/papers/q-2020-02-06-226/)\"로 변이 게이트 사이에 삽입하여 수행합니다. 이러한 PQC의 레이아웃은 다음과 같습니다.\n",
"\n",
"\n",
- " "
+ " "
]
},
{
@@ -947,7 +947,7 @@
"id": "i0iA0nubwpUX"
},
"source": [
- "
"
+ " "
]
},
{
@@ -947,7 +947,7 @@
"id": "i0iA0nubwpUX"
},
"source": [
- " "
+ " "
]
},
{
diff --git a/site/ko/tensorboard/image_summaries.ipynb b/site/ko/tensorboard/image_summaries.ipynb
index 3b5f3d886d..a3dbd980c8 100644
--- a/site/ko/tensorboard/image_summaries.ipynb
+++ b/site/ko/tensorboard/image_summaries.ipynb
@@ -69,6 +69,65 @@
"## 설정"
]
},
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "metadata": {
+ "id": "3U5gdCw_nSG3"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "TensorFlow 2.x selected.\n"
+ ]
+ }
+ ],
+ "source": [
+ "try:\n",
+ " # %tensorflow_version only exists in Colab.\n",
+ " %tensorflow_version 2.x\n",
+ "except Exception:\n",
+ " pass\n",
+ "\n",
+ "# Load the TensorBoard notebook extension.\n",
+ "%load_ext tensorboard"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "metadata": {
+ "id": "1qIKtOBrqc9Y"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "TensorFlow version: 2.2\n"
+ ]
+ }
+ ],
+ "source": [
+ "from datetime import datetime\n",
+ "import io\n",
+ "import itertools\n",
+ "from packaging import version\n",
+ "\n",
+ "import tensorflow as tf\n",
+ "from tensorflow import keras\n",
+ "\n",
+ "import matplotlib.pyplot as plt\n",
+ "import numpy as np\n",
+ "import sklearn.metrics\n",
+ "\n",
+ "print(\"TensorFlow version: \", tf.__version__)\n",
+ "assert version.parse(tf.__version__).release[0] >= 2, \\\n",
+ " \"This notebook requires TensorFlow 2.0 or above.\""
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {
diff --git a/site/ko/tfx/tutorials/tfx/cloud-ai-platform-pipelines.md b/site/ko/tfx/tutorials/tfx/cloud-ai-platform-pipelines.md
index 5ea3a4a92c..ed5f4219b1 100644
--- a/site/ko/tfx/tutorials/tfx/cloud-ai-platform-pipelines.md
+++ b/site/ko/tfx/tutorials/tfx/cloud-ai-platform-pipelines.md
@@ -41,7 +41,7 @@ https://pixabay.com/photos/new-york-cab-cabs-taxi-urban-city-2087998/ -->
2. Google Cloud 이용 약관에 동의합니다.
-
"
+ " "
]
},
{
diff --git a/site/ko/tensorboard/image_summaries.ipynb b/site/ko/tensorboard/image_summaries.ipynb
index 3b5f3d886d..a3dbd980c8 100644
--- a/site/ko/tensorboard/image_summaries.ipynb
+++ b/site/ko/tensorboard/image_summaries.ipynb
@@ -69,6 +69,65 @@
"## 설정"
]
},
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "metadata": {
+ "id": "3U5gdCw_nSG3"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "TensorFlow 2.x selected.\n"
+ ]
+ }
+ ],
+ "source": [
+ "try:\n",
+ " # %tensorflow_version only exists in Colab.\n",
+ " %tensorflow_version 2.x\n",
+ "except Exception:\n",
+ " pass\n",
+ "\n",
+ "# Load the TensorBoard notebook extension.\n",
+ "%load_ext tensorboard"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "metadata": {
+ "id": "1qIKtOBrqc9Y"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "TensorFlow version: 2.2\n"
+ ]
+ }
+ ],
+ "source": [
+ "from datetime import datetime\n",
+ "import io\n",
+ "import itertools\n",
+ "from packaging import version\n",
+ "\n",
+ "import tensorflow as tf\n",
+ "from tensorflow import keras\n",
+ "\n",
+ "import matplotlib.pyplot as plt\n",
+ "import numpy as np\n",
+ "import sklearn.metrics\n",
+ "\n",
+ "print(\"TensorFlow version: \", tf.__version__)\n",
+ "assert version.parse(tf.__version__).release[0] >= 2, \\\n",
+ " \"This notebook requires TensorFlow 2.0 or above.\""
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {
diff --git a/site/ko/tfx/tutorials/tfx/cloud-ai-platform-pipelines.md b/site/ko/tfx/tutorials/tfx/cloud-ai-platform-pipelines.md
index 5ea3a4a92c..ed5f4219b1 100644
--- a/site/ko/tfx/tutorials/tfx/cloud-ai-platform-pipelines.md
+++ b/site/ko/tfx/tutorials/tfx/cloud-ai-platform-pipelines.md
@@ -41,7 +41,7 @@ https://pixabay.com/photos/new-york-cab-cabs-taxi-urban-city-2087998/ -->
2. Google Cloud 이용 약관에 동의합니다.
-  +
3. 무료 평가판 계정으로 시작하려면 [**무료로 사용하기**](https://console.cloud.google.com/freetrial)(또는 [**무료로 시작하기**](https://console.cloud.google.com/freetrial))를 클릭하세요.
@@ -75,15 +75,15 @@ https://pixabay.com/photos/new-york-cab-cabs-taxi-urban-city-2087998/ -->
2. **+ New Instance(+ 새 인스턴스)**를 클릭하여 새 클러스터를 만듭니다.
-
+
3. 무료 평가판 계정으로 시작하려면 [**무료로 사용하기**](https://console.cloud.google.com/freetrial)(또는 [**무료로 시작하기**](https://console.cloud.google.com/freetrial))를 클릭하세요.
@@ -75,15 +75,15 @@ https://pixabay.com/photos/new-york-cab-cabs-taxi-urban-city-2087998/ -->
2. **+ New Instance(+ 새 인스턴스)**를 클릭하여 새 클러스터를 만듭니다.
-  +
3. **Kubeflow Pipelines(Kubeflow 파이프라인)** 개요 페이지에서 **Configure(구성)**을 클릭합니다.
-
+
3. **Kubeflow Pipelines(Kubeflow 파이프라인)** 개요 페이지에서 **Configure(구성)**을 클릭합니다.
-  +
4. "활성화"를 클릭하여 Kubernetes Engine API를 활성화합니다.
-
+
4. "활성화"를 클릭하여 Kubernetes Engine API를 활성화합니다.
-  +
+  참고: 계속 진행하기 전에 Kubernetes Engine API를 사용할 수 있게 준비되는 동안 몇 분 정도 기다려야 할 수 있습니다.
@@ -93,7 +93,7 @@ https://pixabay.com/photos/new-york-cab-cabs-taxi-urban-city-2087998/ -->
2. **중요** *다음 Cloud API에 대한 액세스 허용* 상자를 선택 표시합니다. (이 클러스터가 프로젝트의 다른 부분에 액세스하는 데 필요합니다. 이 단계를 놓치면 나중에 수정하기가 약간 까다롭습니다.)
-
참고: 계속 진행하기 전에 Kubernetes Engine API를 사용할 수 있게 준비되는 동안 몇 분 정도 기다려야 할 수 있습니다.
@@ -93,7 +93,7 @@ https://pixabay.com/photos/new-york-cab-cabs-taxi-urban-city-2087998/ -->
2. **중요** *다음 Cloud API에 대한 액세스 허용* 상자를 선택 표시합니다. (이 클러스터가 프로젝트의 다른 부분에 액세스하는 데 필요합니다. 이 단계를 놓치면 나중에 수정하기가 약간 까다롭습니다.)
-  +
3. **새 클러스터 만들기**를 클릭하고 클러스터가 생성될 때까지 몇 분 정도 기다립니다. 이 작업은 몇 분 정도 걸립니다. 완료되면 다음과 같은 메시지가 표시됩니다.
@@ -113,7 +113,7 @@ https://pixabay.com/photos/new-york-cab-cabs-taxi-urban-city-2087998/ -->
3. TensorFlow Enterprise 2.7(또는 그 이상)이 설치된 **새 노트북**을 생성합니다.
-
+
+
3. **새 클러스터 만들기**를 클릭하고 클러스터가 생성될 때까지 몇 분 정도 기다립니다. 이 작업은 몇 분 정도 걸립니다. 완료되면 다음과 같은 메시지가 표시됩니다.
@@ -113,7 +113,7 @@ https://pixabay.com/photos/new-york-cab-cabs-taxi-urban-city-2087998/ -->
3. TensorFlow Enterprise 2.7(또는 그 이상)이 설치된 **새 노트북**을 생성합니다.
-
+  새 노트북 -> TensorFlow Enterprise 2.7 -> Without GPU
@@ -125,7 +125,7 @@ https://pixabay.com/photos/new-york-cab-cabs-taxi-urban-city-2087998/ -->
2. 무료 등급을 유지해야 하는 경우 **머신 구성**에서 vCPU가 1개 또는 2개인 구성을 선택할 수 있습니다.
-
+
3. 새 노트북이 생성될 때까지 기다린 후 **Notebooks API 사용 설정**을 클릭합니다.
@@ -139,15 +139,15 @@ https://pixabay.com/photos/new-york-cab-cabs-taxi-urban-city-2087998/ -->
2. 이 튜토리얼에서 사용중인 클러스터 라인에서 **Open Pipelines Dashboard를** 클릭합니다.
-
+
3. **시작하기** 페이지에서 **Google Cloud에서 Cloud AI Platform 노트북 열기**를 클릭합니다.
-
+
4. 이 튜토리얼에서 사용 중인 노트북 인스턴스를 선택하고 **계속**을 선택한 후 **확인**을 선택합니다.
-
새 노트북 -> TensorFlow Enterprise 2.7 -> Without GPU
@@ -125,7 +125,7 @@ https://pixabay.com/photos/new-york-cab-cabs-taxi-urban-city-2087998/ -->
2. 무료 등급을 유지해야 하는 경우 **머신 구성**에서 vCPU가 1개 또는 2개인 구성을 선택할 수 있습니다.
-
+
3. 새 노트북이 생성될 때까지 기다린 후 **Notebooks API 사용 설정**을 클릭합니다.
@@ -139,15 +139,15 @@ https://pixabay.com/photos/new-york-cab-cabs-taxi-urban-city-2087998/ -->
2. 이 튜토리얼에서 사용중인 클러스터 라인에서 **Open Pipelines Dashboard를** 클릭합니다.
-
+
3. **시작하기** 페이지에서 **Google Cloud에서 Cloud AI Platform 노트북 열기**를 클릭합니다.
-
+
4. 이 튜토리얼에서 사용 중인 노트북 인스턴스를 선택하고 **계속**을 선택한 후 **확인**을 선택합니다.
-  +
## 5. 노트북에서 계속 작업
diff --git a/site/ko/tfx/tutorials/tfx/penguin_simple.ipynb b/site/ko/tfx/tutorials/tfx/penguin_simple.ipynb
index 0621655b2e..2dc157cb11 100644
--- a/site/ko/tfx/tutorials/tfx/penguin_simple.ipynb
+++ b/site/ko/tfx/tutorials/tfx/penguin_simple.ipynb
@@ -52,11 +52,9 @@
"\n",
""
]
},
diff --git a/site/ko/tfx/tutorials/tfx/penguin_tfma.ipynb b/site/ko/tfx/tutorials/tfx/penguin_tfma.ipynb
index 4b7d125756..aefa0337c8 100644
--- a/site/ko/tfx/tutorials/tfx/penguin_tfma.ipynb
+++ b/site/ko/tfx/tutorials/tfx/penguin_tfma.ipynb
@@ -18,17 +18,17 @@
},
"outputs": [],
"source": [
- "#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n",
- "# you may not use this file except in compliance with the License.\n",
- "# You may obtain a copy of the License at\n",
+ "# Apache License, 버전 2.0(\"라이선스\")에 따라서만 라이선스가 허여되며, \n",
+ "# 라이선스를 준수하는 경우에 한해 이 파일을 사용할 수 있습니다. \n",
+ "# 라이선스 사본은 다음에서 받을 수 있습니다.\n",
"#\n",
- "# https://www.apache.org/licenses/LICENSE-2.0\n",
+ "# http://www.apache.org/licenses/LICENSE-2.0\n",
"#\n",
- "# Unless required by applicable law or agreed to in writing, software\n",
- "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
- "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
- "# See the License for the specific language governing permissions and\n",
- "# limitations under the License."
+ "# 이 코드는 묵시적 보증이나 소유권, \n",
+ "# 특정 목적에의 적합성 또는 비침해성을 포함하되 그에 한정하지 않고\n",
+ "# 어떠한 종류의 명시적 또는 묵시적 보증도 없이 있는 그대로 제공됩니다.\n",
+ "# 라이선스에 따른 허가 및 제한에 적용되는 특정 언어는\n",
+ "# License를 참조하십시오. "
]
},
{
diff --git a/site/ko/tfx/tutorials/transform/census.ipynb b/site/ko/tfx/tutorials/transform/census.ipynb
index 5f18255fa0..0316c2bbcb 100644
--- a/site/ko/tfx/tutorials/transform/census.ipynb
+++ b/site/ko/tfx/tutorials/transform/census.ipynb
@@ -7,12 +7,10 @@
},
"source": [
""
]
},
@@ -62,7 +60,7 @@
"TensorFlow Transform은 훈련 데이터세트에 대한 전체 전달이 필요한 특성 생성을 포함하여 TensorFlow에 대한 입력 데이터를 전처리하기 위한 라이브러리입니다. 예를 들어 TensorFlow Transform을 사용하여 다음을 수행할 수 있습니다.\n",
"\n",
"- 평균과 표준 편차를 이용하여 입력값 정규화\n",
- "- 모든 입력 값에 대해 어휘를 생성하여 문자열을 정수로 변환\n",
+ "- 모든 입력값에 대해 어휘를 생성하여 문자열을 정수로 변환\n",
"- 관찰된 데이터 분포를 기반으로 부동 소수점을 버킷에 할당하여 정수로 변환\n",
"\n",
"TensorFlow는 단일 예제 또는 예제 배치에 대한 조작을 기본적으로 지원합니다. `tf.Transform`은 이러한 기능을 확장하여 전체 훈련 데이터세트에 대한 전체 전달을 지원합니다.\n",
@@ -84,7 +82,7 @@
"\n",
"핵심 포인트: 모델러 및 개발자로서 이 데이터가 어떻게 사용되는지, 그리고 모델의 예측이 초래할 수 있는 잠재적인 이점과 피해에 대해 생각해보세요. 이와 같은 모델은 사회적 편견과 불균형을 강화시킬 수 있습니다. 기능이 해결하려는 문제와 관련이 있습니까? 아니면 편견을 유발합니까? 자세한 내용은 ML 공정성에 대해 읽어보세요.\n",
"\n",
- "참고: TensorFlow 모델 분석은 모델이 사회적 편견과 격차를 강화할 수 있는 방법을 이해하는 것을 포함하여 모델이 데이터의 다양한 세그먼트에 대해 예측을 얼마나 잘 수행하는지 이해하기 위한 강력한 도구입니다."
+ "참고: TensorFlow 모델 분석은 모델이 사회적 바이어스와 격차를 강화할 수 있는 방법을 이해하는 것을 포함하여 모델이 데이터의 다양한 세그먼트에 대해 예측을 얼마나 잘 수행하는지 이해하기 위한 강력한 도구입니다."
]
},
{
@@ -660,7 +658,7 @@
"result = pass_this | 'name this step' >> to_this_call\n",
"```\n",
"\n",
- "
+
## 5. 노트북에서 계속 작업
diff --git a/site/ko/tfx/tutorials/tfx/penguin_simple.ipynb b/site/ko/tfx/tutorials/tfx/penguin_simple.ipynb
index 0621655b2e..2dc157cb11 100644
--- a/site/ko/tfx/tutorials/tfx/penguin_simple.ipynb
+++ b/site/ko/tfx/tutorials/tfx/penguin_simple.ipynb
@@ -52,11 +52,9 @@
"\n",
""
]
},
diff --git a/site/ko/tfx/tutorials/tfx/penguin_tfma.ipynb b/site/ko/tfx/tutorials/tfx/penguin_tfma.ipynb
index 4b7d125756..aefa0337c8 100644
--- a/site/ko/tfx/tutorials/tfx/penguin_tfma.ipynb
+++ b/site/ko/tfx/tutorials/tfx/penguin_tfma.ipynb
@@ -18,17 +18,17 @@
},
"outputs": [],
"source": [
- "#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n",
- "# you may not use this file except in compliance with the License.\n",
- "# You may obtain a copy of the License at\n",
+ "# Apache License, 버전 2.0(\"라이선스\")에 따라서만 라이선스가 허여되며, \n",
+ "# 라이선스를 준수하는 경우에 한해 이 파일을 사용할 수 있습니다. \n",
+ "# 라이선스 사본은 다음에서 받을 수 있습니다.\n",
"#\n",
- "# https://www.apache.org/licenses/LICENSE-2.0\n",
+ "# http://www.apache.org/licenses/LICENSE-2.0\n",
"#\n",
- "# Unless required by applicable law or agreed to in writing, software\n",
- "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
- "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
- "# See the License for the specific language governing permissions and\n",
- "# limitations under the License."
+ "# 이 코드는 묵시적 보증이나 소유권, \n",
+ "# 특정 목적에의 적합성 또는 비침해성을 포함하되 그에 한정하지 않고\n",
+ "# 어떠한 종류의 명시적 또는 묵시적 보증도 없이 있는 그대로 제공됩니다.\n",
+ "# 라이선스에 따른 허가 및 제한에 적용되는 특정 언어는\n",
+ "# License를 참조하십시오. "
]
},
{
diff --git a/site/ko/tfx/tutorials/transform/census.ipynb b/site/ko/tfx/tutorials/transform/census.ipynb
index 5f18255fa0..0316c2bbcb 100644
--- a/site/ko/tfx/tutorials/transform/census.ipynb
+++ b/site/ko/tfx/tutorials/transform/census.ipynb
@@ -7,12 +7,10 @@
},
"source": [
""
]
},
@@ -62,7 +60,7 @@
"TensorFlow Transform은 훈련 데이터세트에 대한 전체 전달이 필요한 특성 생성을 포함하여 TensorFlow에 대한 입력 데이터를 전처리하기 위한 라이브러리입니다. 예를 들어 TensorFlow Transform을 사용하여 다음을 수행할 수 있습니다.\n",
"\n",
"- 평균과 표준 편차를 이용하여 입력값 정규화\n",
- "- 모든 입력 값에 대해 어휘를 생성하여 문자열을 정수로 변환\n",
+ "- 모든 입력값에 대해 어휘를 생성하여 문자열을 정수로 변환\n",
"- 관찰된 데이터 분포를 기반으로 부동 소수점을 버킷에 할당하여 정수로 변환\n",
"\n",
"TensorFlow는 단일 예제 또는 예제 배치에 대한 조작을 기본적으로 지원합니다. `tf.Transform`은 이러한 기능을 확장하여 전체 훈련 데이터세트에 대한 전체 전달을 지원합니다.\n",
@@ -84,7 +82,7 @@
"\n",
"핵심 포인트: 모델러 및 개발자로서 이 데이터가 어떻게 사용되는지, 그리고 모델의 예측이 초래할 수 있는 잠재적인 이점과 피해에 대해 생각해보세요. 이와 같은 모델은 사회적 편견과 불균형을 강화시킬 수 있습니다. 기능이 해결하려는 문제와 관련이 있습니까? 아니면 편견을 유발합니까? 자세한 내용은 ML 공정성에 대해 읽어보세요.\n",
"\n",
- "참고: TensorFlow 모델 분석은 모델이 사회적 편견과 격차를 강화할 수 있는 방법을 이해하는 것을 포함하여 모델이 데이터의 다양한 세그먼트에 대해 예측을 얼마나 잘 수행하는지 이해하기 위한 강력한 도구입니다."
+ "참고: TensorFlow 모델 분석은 모델이 사회적 바이어스와 격차를 강화할 수 있는 방법을 이해하는 것을 포함하여 모델이 데이터의 다양한 세그먼트에 대해 예측을 얼마나 잘 수행하는지 이해하기 위한 강력한 도구입니다."
]
},
{
@@ -660,7 +658,7 @@
"result = pass_this | 'name this step' >> to_this_call\n",
"```\n",
"\n",
- "to_this_call 메서드는 pass_this라는 개체를 호출 및 전달하고 이 연산을 스택 추적에서 name this step이라고 합니다. to_this_call에 대한 호출의 결과는 result에서 반환됩니다. 다음과 같이 함께 연결된 파이프라인의 단계를 종종 볼 수 있습니다.\n",
+ "`to_this_call` 메서드는 `pass_this`라는 개체를 호출 및 전달하고 이 연산을 스택 추적에서 name this step이라고 합니다. `to_this_call`에 대한 호출의 결과는 `result`에서 반환됩니다. 다음과 같이 함께 연결된 파이프라인의 단계를 종종 볼 수 있습니다.\n",
"\n",
"```\n",
"result = apache_beam.Pipeline() | 'first step' >> do_this_first() | 'second step' >> do_this_last()\n",
@@ -888,7 +886,7 @@
"source": [
"##전처리된 데이터를 사용하여 tf.keras로 모델 훈련하기\n",
"\n",
- "훈련과 제공 모두에 동일한 코드를 사용하여 왜곡을 방지하는 데 `tf.Transform`이 어떻게 이용되는지 보여주기 위해 모델을 훈련할 것입니다. 모델을 훈련하고 훈련된 모델을 프로덕션에 적합하게 준비하려면 입력 함수를 생성해야 합니다. 훈련 입력 함수와 제공 입력 함수의 주된 차이점은 훈련 데이터에는 레이블이 포함되고 프로덕션 데이터에는 포함되지 않는다는 것입니다. 인수와 반환도 약간 다릅니다."
+ "훈련과 적용 모두에 동일한 코드를 사용하여 왜곡을 방지하는 데 `tf.Transform`이 어떻게 이용되는지 보여주기 위해 모델을 훈련할 것입니다. 모델을 훈련하고 훈련된 모델을 운영에 적합하게 준비하려면 입력 함수를 생성해야 합니다. 훈련 입력 함수와 적용 입력 함수의 주된 차이점은 훈련 데이터에는 레이블이 포함되고 운영 데이터에는 포함되지 않는다는 것입니다. 인수와 반환도 약간 다릅니다."
]
},
{
@@ -1235,7 +1233,7 @@
"\n",
"새 데이터에서 작업하려면 `tft_beam.WriteTransformFn`에 의해 저장된 `preprocessing_fn`의 최종 버전을 로드해야 합니다.\n",
"\n",
- "`TFTransformOutput.transform_features_layer` 메서드는 출력 디렉터리에서 `preprocessing_fn` 저장 모델을 로드합니다."
+ "`TFTransformOutput.transform_features_layer` 메서드는 출력 디렉터리에서 `preprocessing_fn` SavedModel을 로드합니다."
]
},
{
@@ -1530,7 +1528,7 @@
"id": "BWhighof3AK8"
},
"source": [
- "모델을 저장된 모델로 내보냅니다."
+ "모델을 SavedModel로 내보냅니다."
]
},
{
@@ -1583,7 +1581,7 @@
"id": "ICqetCnSjwp1"
},
"source": [
- "##우리가 수행한 작업. 이 예제에서는 `tf.Transform`을 사용하여 인구 조사 데이터의 데이터세트를 사전 처리하고 정리 및 변환된 데이터로 모델을 훈련했습니다. 또한 추론을 수행하기 위해 프로덕션 환경에 훈련된 모델을 배포할 때 사용할 수 있는 입력 함수를 만들었습니다. 훈련과 추론 모두에 동일한 코드를 사용함으로써 데이터 왜곡 문제를 피할 수 있습니다. 그 과정에서 데이터 정리에 필요한 변환을 수행하기 위해 Apache Beam 변환을 생성하는 방법을 배웠습니다. 또한 이 변환 데이터를 이용해 `tf.keras`로 모델을 훈련하는 방법도 보았습니다. 이것은 TensorFlow Transform으로 수행할 수 있는 작업의 일부일 뿐입니다! tf.Transform을 더욱 자세히 살펴보고 이것으로 무엇을 할 수 있는지 알아보기 바랍니다."
+ "##우리가 수행한 작업. 이 예제에서는 `tf.Transform`을 사용하여 인구 조사 데이터의 데이터세트를 전처리하고 정리 및 변환된 데이터로 모델을 훈련했습니다. 또한 추론을 수행하기 위해 운영 환경에 훈련된 모델을 배포할 때 사용할 수 있는 입력 함수를 만들었습니다. 훈련과 추론 모두에 동일한 코드를 사용함으로써 데이터 기울이기 문제를 피할 수 있습니다. 그 과정에서 데이터 정리에 필요한 변환을 수행하기 위해 Apache Beam 변환을 생성하는 방법을 배웠습니다. 또한 이 변환 데이터를 이용해 `tf.keras`로 모델을 훈련하는 방법도 보았습니다. 이것은 TensorFlow Transform으로 수행할 수 있는 작업의 일부일 뿐입니다! `tf.Transform`을 더욱 자세히 살펴보고 이것으로 무엇을 할 수 있는지 알아보기 바랍니다."
]
},
{
diff --git a/site/ko/tfx/tutorials/transform/data_preprocessing_with_cloud.md b/site/ko/tfx/tutorials/transform/data_preprocessing_with_cloud.md
index d1e8bef394..c8d0483023 100644
--- a/site/ko/tfx/tutorials/transform/data_preprocessing_with_cloud.md
+++ b/site/ko/tfx/tutorials/transform/data_preprocessing_with_cloud.md
@@ -24,7 +24,7 @@
-이 튜토리얼을 실행하는 비용을 추정하려면 하루 종일 모든 리소스를 사용한다고 가정하고 미리 구성된 [가격 계산기](/products/calculator/#id=fad4d8-dd68-45b8-954e-5a56a5d148){: .external }를 사용하세요.
+이 튜토리얼을 실행하는 비용을 추정하려면 하루 종일 모든 리소스를 사용한다고 가정하고 미리 구성된 [가격 계산기](/products/calculator/#id=fad4d8-dd68-45b8-954e-5a56a5d){: .external }를 사용하세요.
## 시작하기 전에
@@ -42,7 +42,7 @@
다음 Jupyter 노트북은 구현 예제를 보여줍니다.
-- [Notebook 1](https://github.com/GoogleCloudPlatform/training-data-analyst/blob/master/blogs/babyweight_tft/babyweight_tft_keras_01.ipynb){: .external }은 데이터 전처리에 대한 내용을 다룹니다. 자세한 내용은 나중에 [Apache Beam 파이프라인 구현하기](#implement-the-apache-beam-pipeline) 섹션에서 제공됩니다.
+- [Notebook 1](https://github.com/GoogleCloudPlatform/training-data-analyst/blob/master/blogs/babyweight_tft/babyweight_tft_keras_.ipynb){: .external }은 데이터 전처리에 대한 내용을 다룹니다. 자세한 내용은 나중에 [Apache Beam 파이프라인 구현하기](#implement-the-apache-beam-pipeline) 섹션에서 제공됩니다.
- [Notebook 2](https://github.com/GoogleCloudPlatform/training-data-analyst/blob/master/blogs/babyweight_tft/babyweight_tft_keras_02.ipynb){: .external }는 모델 훈련에 대한 내용을 다룹니다. 자세한 내용은 나중에 [TensorFlow 모델 구현하기](#implement-the-tensorflow-model) 섹션에서 제공됩니다.
다음 섹션에서는 이러한 노트북을 복제하고 노트북을 실행하여 구현 예제가 작동하는 방식을 알아봅니다.
@@ -372,8 +372,7 @@ def preprocess_fn(input_features):
tfidf |
텍스트 특성 |
-
-x의 용어를 해당 용어 빈도 * 역 문서 빈도에 매핑 |
+ x의 용어를 해당 용어 빈도 * 역 문서 빈도에 매핑 |
compute_and_apply_vocabulary |
diff --git a/site/ko/tutorials/distribute/dtensor_ml_tutorial.ipynb b/site/ko/tutorials/distribute/dtensor_ml_tutorial.ipynb
index 7adbabc566..502ebb3f9f 100644
--- a/site/ko/tutorials/distribute/dtensor_ml_tutorial.ipynb
+++ b/site/ko/tutorials/distribute/dtensor_ml_tutorial.ipynb
@@ -384,7 +384,7 @@
"id": "udFGAO-NrZw6"
},
"source": [
- " \n"
+ " \n"
]
},
{
@@ -766,7 +766,7 @@
"- 단일 모델 복제본 내의 2개 장치는 복제된 훈련 데이터를 수신합니다.\n",
"\n",
"\n",
- "
\n"
+ " \n"
]
},
{
@@ -766,7 +766,7 @@
"- 단일 모델 복제본 내의 2개 장치는 복제된 훈련 데이터를 수신합니다.\n",
"\n",
"\n",
- " \n"
+ " \n"
]
},
{
diff --git a/site/ko/tutorials/generative/cyclegan.ipynb b/site/ko/tutorials/generative/cyclegan.ipynb
index cd0ce2df88..7280c29ae2 100644
--- a/site/ko/tutorials/generative/cyclegan.ipynb
+++ b/site/ko/tutorials/generative/cyclegan.ipynb
@@ -511,9 +511,9 @@
"\n",
"\n",
"\n",
- "$$backward\\ cycle\\ consistency\\ loss: Y -> F(Y) -> G(F(Y)) \\sim \\hat{Y}$$\n",
+ "\n",
"\n",
- ""
+ ""
]
},
{
diff --git a/site/ko/tutorials/generative/deepdream.ipynb b/site/ko/tutorials/generative/deepdream.ipynb
index 353a56e176..cbef5e1e4c 100644
--- a/site/ko/tutorials/generative/deepdream.ipynb
+++ b/site/ko/tutorials/generative/deepdream.ipynb
@@ -50,8 +50,7 @@
"
\n"
+ " \n"
]
},
{
diff --git a/site/ko/tutorials/generative/cyclegan.ipynb b/site/ko/tutorials/generative/cyclegan.ipynb
index cd0ce2df88..7280c29ae2 100644
--- a/site/ko/tutorials/generative/cyclegan.ipynb
+++ b/site/ko/tutorials/generative/cyclegan.ipynb
@@ -511,9 +511,9 @@
"\n",
"\n",
"\n",
- "$$backward\\ cycle\\ consistency\\ loss: Y -> F(Y) -> G(F(Y)) \\sim \\hat{Y}$$\n",
+ "\n",
"\n",
- ""
+ ""
]
},
{
diff --git a/site/ko/tutorials/generative/deepdream.ipynb b/site/ko/tutorials/generative/deepdream.ipynb
index 353a56e176..cbef5e1e4c 100644
--- a/site/ko/tutorials/generative/deepdream.ipynb
+++ b/site/ko/tutorials/generative/deepdream.ipynb
@@ -50,8 +50,7 @@
"  TensorFlow.org에서 보기 TensorFlow.org에서 보기 | \n",
"  Google Colab에서 실행 Google Colab에서 실행 | \n",
"  GitHub에서 소그 보기 GitHub에서 소그 보기 | \n",
- "  노트북 다운로드하기\n",
- " 노트북 다운로드하기\n",
- " | \n",
+ " 노트북 다운로드하기 | \n",
""
]
},
diff --git a/site/ko/tutorials/generative/style_transfer.ipynb b/site/ko/tutorials/generative/style_transfer.ipynb
index b7313a32ad..326562baa2 100644
--- a/site/ko/tutorials/generative/style_transfer.ipynb
+++ b/site/ko/tutorials/generative/style_transfer.ipynb
@@ -98,7 +98,7 @@
"이제 Kandinsky가 이 스타일로만 이 개의 그림을 그리기로 결정했다면 어떤 모습이 될까요? 이렇지 않을까요?\n",
"\n",
"\n",
- " "
+ " "
]
},
{
diff --git a/site/ko/tutorials/images/data_augmentation.ipynb b/site/ko/tutorials/images/data_augmentation.ipynb
index ad6ee5e477..e06ca45f87 100644
--- a/site/ko/tutorials/images/data_augmentation.ipynb
+++ b/site/ko/tutorials/images/data_augmentation.ipynb
@@ -1239,7 +1239,7 @@
"#### 옵션 2: `tf.random.Generator` 사용\n",
"\n",
"- 초기 `seed` 값으로 `tf.random.Generator` 객체를 생성합니다. 동일한 생성기 객체에서 `make_seeds` 함수를 호출하면 항상 새롭고 고유한 `seed` 값이 반환됩니다.\n",
- "- 1) `make_seeds` 함수를 호출하고 2) 새로 생성된 `seed` 값을 무작위 변환을 위한 `augment` 함수에 전달하는 래퍼 함수를 정의합니다.\n",
+ "- 다음을 수행하는 래퍼 함수를 정의합니다 1) `make_seeds` 함수를 호출하고 2) 새로 생성된 `seed` 값을 무작위 변환을 위한 `augment` 함수에 전달하는 래퍼 함수를 정의합니다.\n",
"\n",
"참고: `tf.random.Generator` 객체는 `tf.Variable`에 RNG 상태를 저장합니다. 즉, [체크포인트](../../guide/checkpoint.ipynb)로 저장하거나 [SavedModel](../../guide/saved_model.ipynb)에 저장할 수 있습니다. 자세한 내용은 [난수 생성](../../guide/random_numbers.ipynb)을 참조하세요."
]
diff --git a/site/ko/tutorials/load_data/images.ipynb b/site/ko/tutorials/load_data/images.ipynb
index 858a2d67e6..215ac21436 100644
--- a/site/ko/tutorials/load_data/images.ipynb
+++ b/site/ko/tutorials/load_data/images.ipynb
@@ -47,8 +47,7 @@
},
"source": [
"
"
+ " "
]
},
{
diff --git a/site/ko/tutorials/images/data_augmentation.ipynb b/site/ko/tutorials/images/data_augmentation.ipynb
index ad6ee5e477..e06ca45f87 100644
--- a/site/ko/tutorials/images/data_augmentation.ipynb
+++ b/site/ko/tutorials/images/data_augmentation.ipynb
@@ -1239,7 +1239,7 @@
"#### 옵션 2: `tf.random.Generator` 사용\n",
"\n",
"- 초기 `seed` 값으로 `tf.random.Generator` 객체를 생성합니다. 동일한 생성기 객체에서 `make_seeds` 함수를 호출하면 항상 새롭고 고유한 `seed` 값이 반환됩니다.\n",
- "- 1) `make_seeds` 함수를 호출하고 2) 새로 생성된 `seed` 값을 무작위 변환을 위한 `augment` 함수에 전달하는 래퍼 함수를 정의합니다.\n",
+ "- 다음을 수행하는 래퍼 함수를 정의합니다 1) `make_seeds` 함수를 호출하고 2) 새로 생성된 `seed` 값을 무작위 변환을 위한 `augment` 함수에 전달하는 래퍼 함수를 정의합니다.\n",
"\n",
"참고: `tf.random.Generator` 객체는 `tf.Variable`에 RNG 상태를 저장합니다. 즉, [체크포인트](../../guide/checkpoint.ipynb)로 저장하거나 [SavedModel](../../guide/saved_model.ipynb)에 저장할 수 있습니다. 자세한 내용은 [난수 생성](../../guide/random_numbers.ipynb)을 참조하세요."
]
diff --git a/site/ko/tutorials/load_data/images.ipynb b/site/ko/tutorials/load_data/images.ipynb
index 858a2d67e6..215ac21436 100644
--- a/site/ko/tutorials/load_data/images.ipynb
+++ b/site/ko/tutorials/load_data/images.ipynb
@@ -47,8 +47,7 @@
},
"source": [
"