My yolo model does not work well on object detection in live video stream. Even if it has achieved great performance when training. #2787
-
|
My dear friends, I urgently need your help on Yolo. Please help. I need to use the Yolo model to detect dumbbells in the hands of exercisers. I randomly divided 8000 labelled data into training set and validation set according to the ratio of 7:3. My model performed well after training for 30 epochs. This model can achieve 95% accuracy and 92% recall rate. But when I deployed the model on the server, I found that his performance was not good. He often detects the exerciser's clothes as dumbbells or fails to detect dumbbells. Why does my model perform well in the validation set, but it does not work properly? I have done the following measures to improve my model, but the effect is not good:
Is it because the lower video bit rate causes poor video quality, which makes the model unable to detect dumbbells? Can the performance be improved if the video stream is denoised or the image quality is improved, and then the model is used for detection? At present, I hope that the effect of the model can be greatly improved. What should I do? |

Beta Was this translation helpful? Give feedback.
Replies: 3 comments
-
|
@CharliePip your training pipeline probably suffers from both problems below, as randomly dividing video frames between train and val sets will produce artificially high mAP and poor generalization in the real world.
Here are our main suggestions: 👋 Hello! Thanks for asking about improving training results. Most of the time good results can be obtained with no changes to the models or training settings, provided your dataset is sufficiently large and well labelled. If at first you don't get good results, there are steps you might be able to take to improve, but we always recommend users first train with all default settings before considering any changes. This helps establish a performance baseline and spot areas for improvement. If you have questions about your training results we recommend you provide the maximum amount of information possible if you expect a helpful response, including results plots (train losses, val losses, P, R, mAP), PR curve, confusion matrix, training mosaics, test results and dataset statistics images such as labels.png. All of these are located in your We've put together a full guide for users looking to get the best results on their YOLOv5 trainings below. Dataset
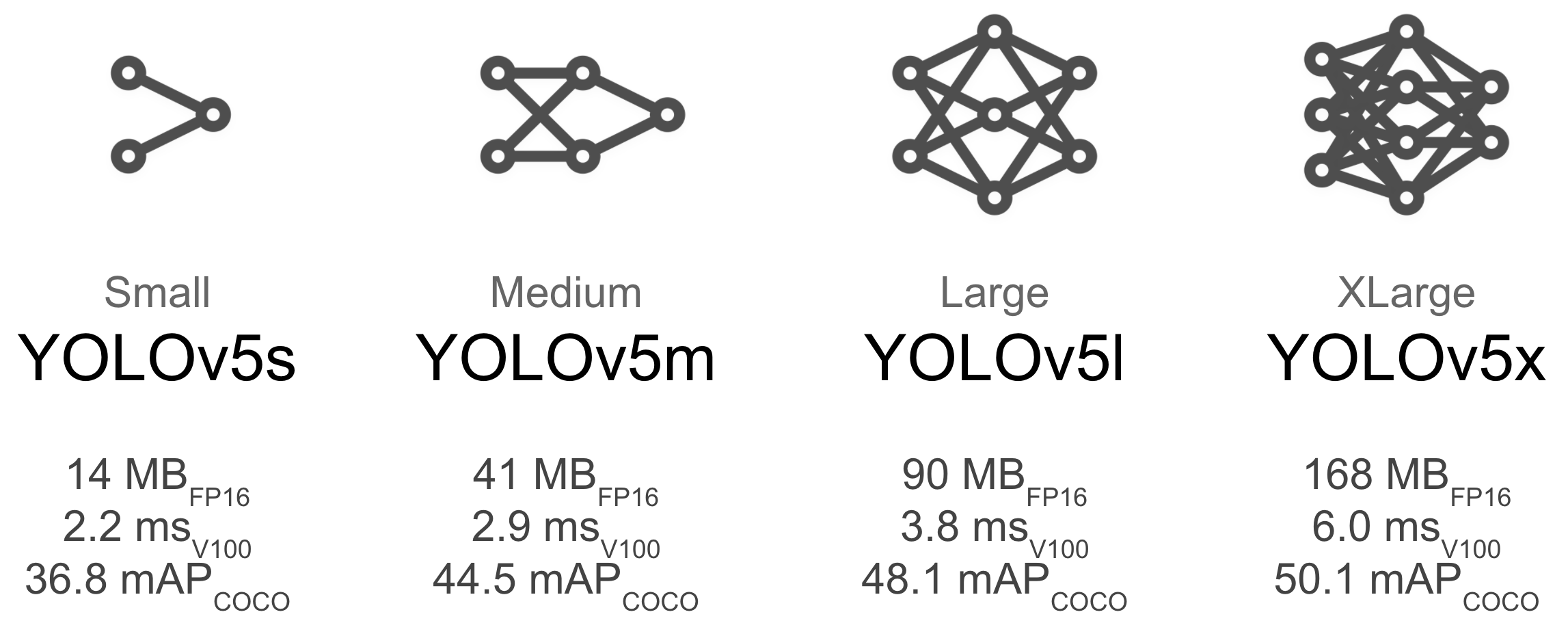
Model SelectionLarger models like YOLOv5x will produce better results in nearly all cases, but have more parameters and are slower to run. For mobile applications we recommend YOLOv5s/m, for cloud or desktop applications we recommend YOLOv5l/x. See our README table for a full comparison of all models. To start training from pretrained weights simply pass the name of the model to the python train.py --data custom.yaml --weights yolov5s.pt
yolov5m.pt
yolov5l.pt
yolov5x.pt
Training SettingsBefore modifying anything, first train with default settings to establish a performance baseline. A full list of train.py settings can be found in the train.py argparser.
Further ReadingIf you'd like to know more a good place to start is Karpathy's 'Recipe for Training Neural Networks', which has great ideas for training that apply broadly across all ML domains: |


Beta Was this translation helpful? Give feedback.
-
|
I still feel as though YOLO is a failed CNN |
Beta Was this translation helpful? Give feedback.
-
|
I have classifed 5 classes with each 1000 images or more and have labels 100s per 5-7 states per class with annotations (boring to commit to) and trained using your v8, however, the limitations of your hub app prevents me from securing a solid detection for my 26 total classes, it think everything is either nothing or something else entirely and has a bounding box of one class constantly sitting in my camera viewing window on my phone, despite any accuracy from the epochs, this CNN can only successfully detect images using images it has already trained on, anything else, and it has no clue, its not smart at all, I could teach a dog more tricks. |
Beta Was this translation helpful? Give feedback.
@CharliePip your training pipeline probably suffers from both problems below, as randomly dividing video frames between train and val sets will produce artificially high mAP and poor generalization in the real world.
Here are our main suggestions:
👋 Hello! Thanks for asking about improving training results. Most of the time good results can be obtained with no changes to the models or training settings, provided your dataset is sufficiently large and well labelled. If at first you don't get good results, there are steps you might be able to take to improve, but we always recommend users first train with all default settings before considering any changes. This helps establish a performan…