
- 概述
- 选题背景
- 项目意义
- 可行性分析和目标群体
- 可行性分析
- 设备基础
- 行为习惯
- 竞争分析
- 目标群体
- 可行性分析
- 作品功能和产品设计
- 总体功能结构
- 具体功能模块设计
- 内容识别引擎
- 内容辅助标记模块
- 卡片模态匹配模块
- 姿态转移识别模型
- 图像叠态处理模块
- “三模式”帧态转换处理模型
- 界面设计(部分)
- 作品实现、特色和难点
- 作品实现
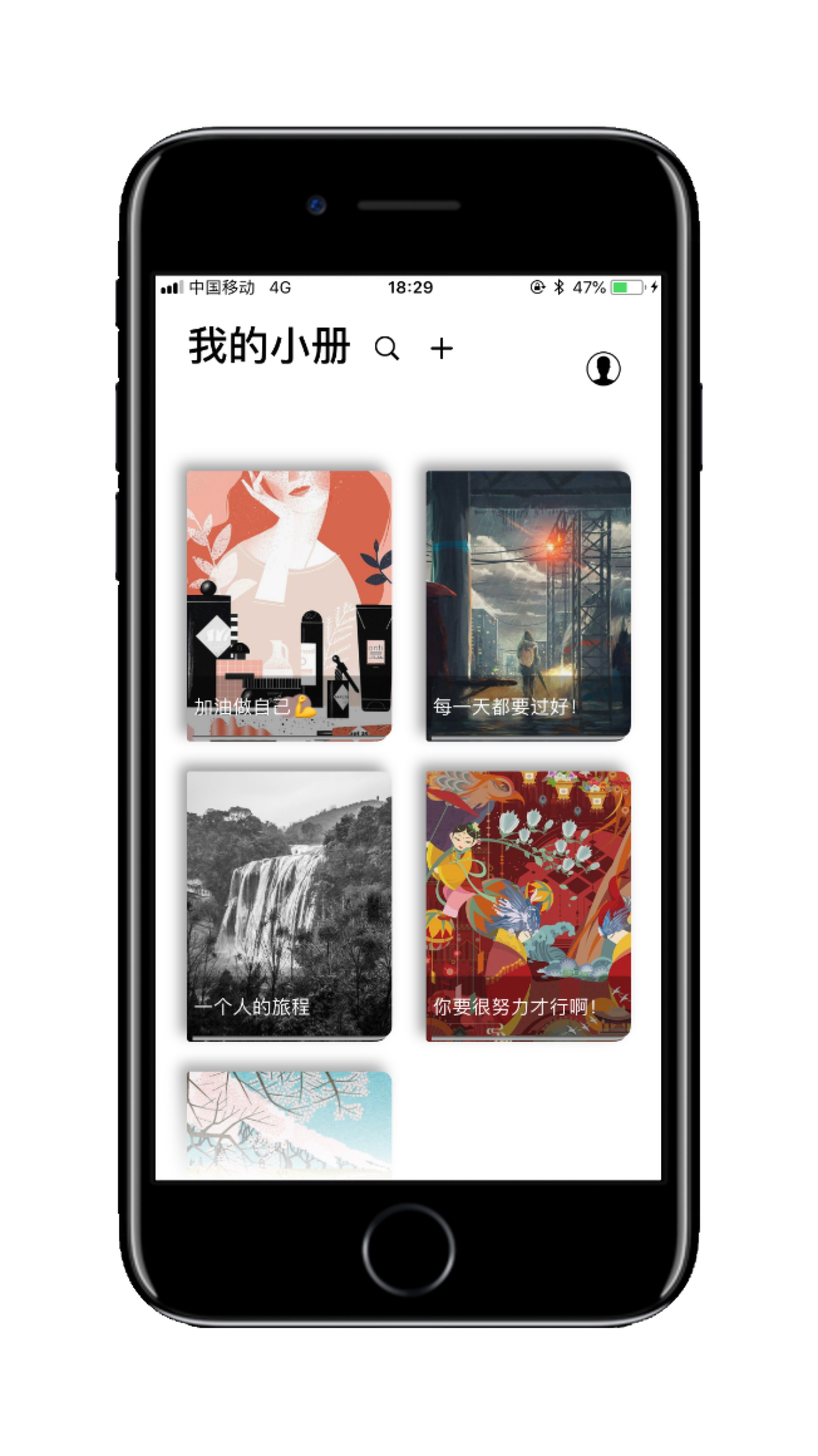
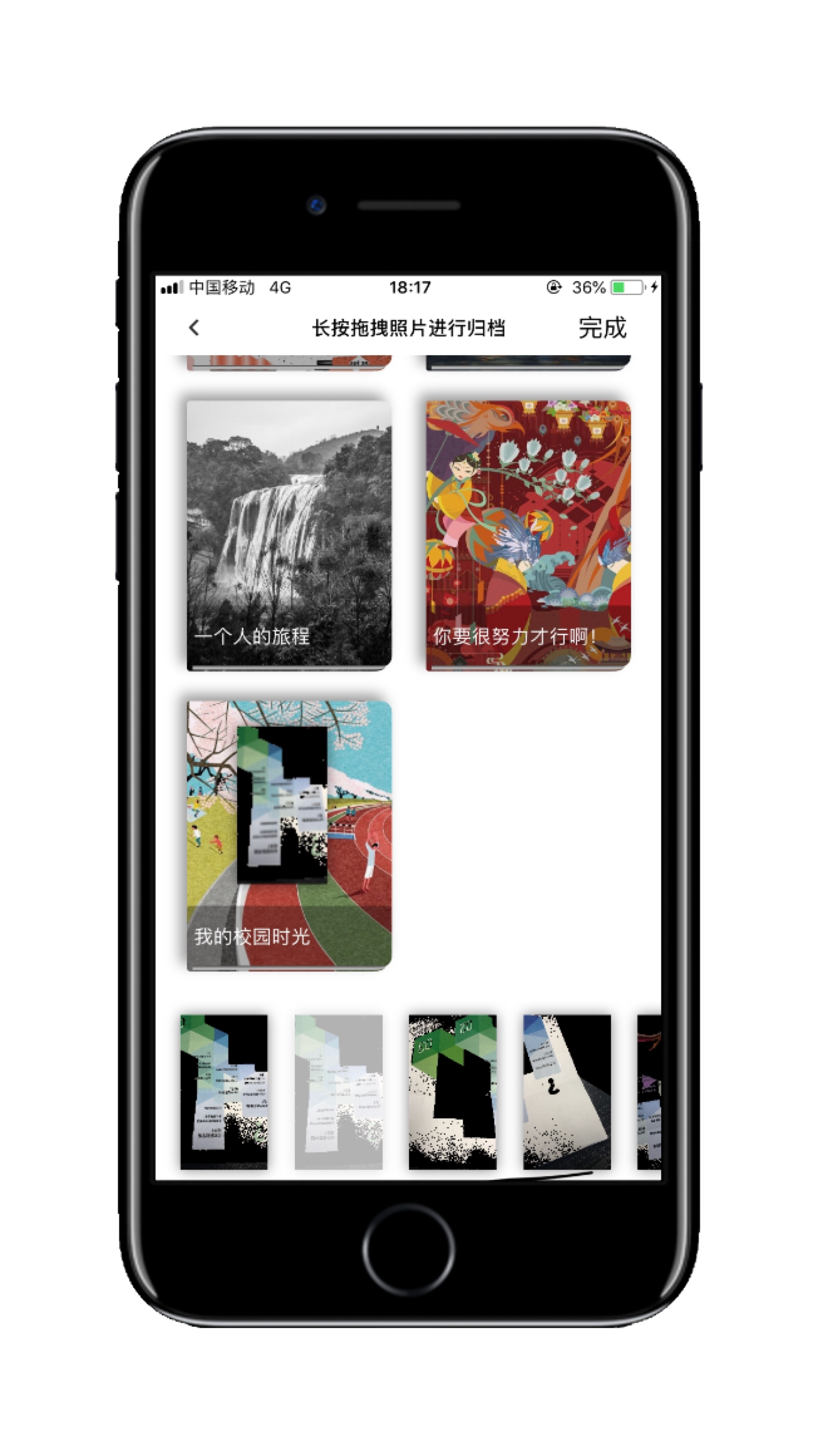
- 首页——我的小册
- 首页——我的小册——小册详情
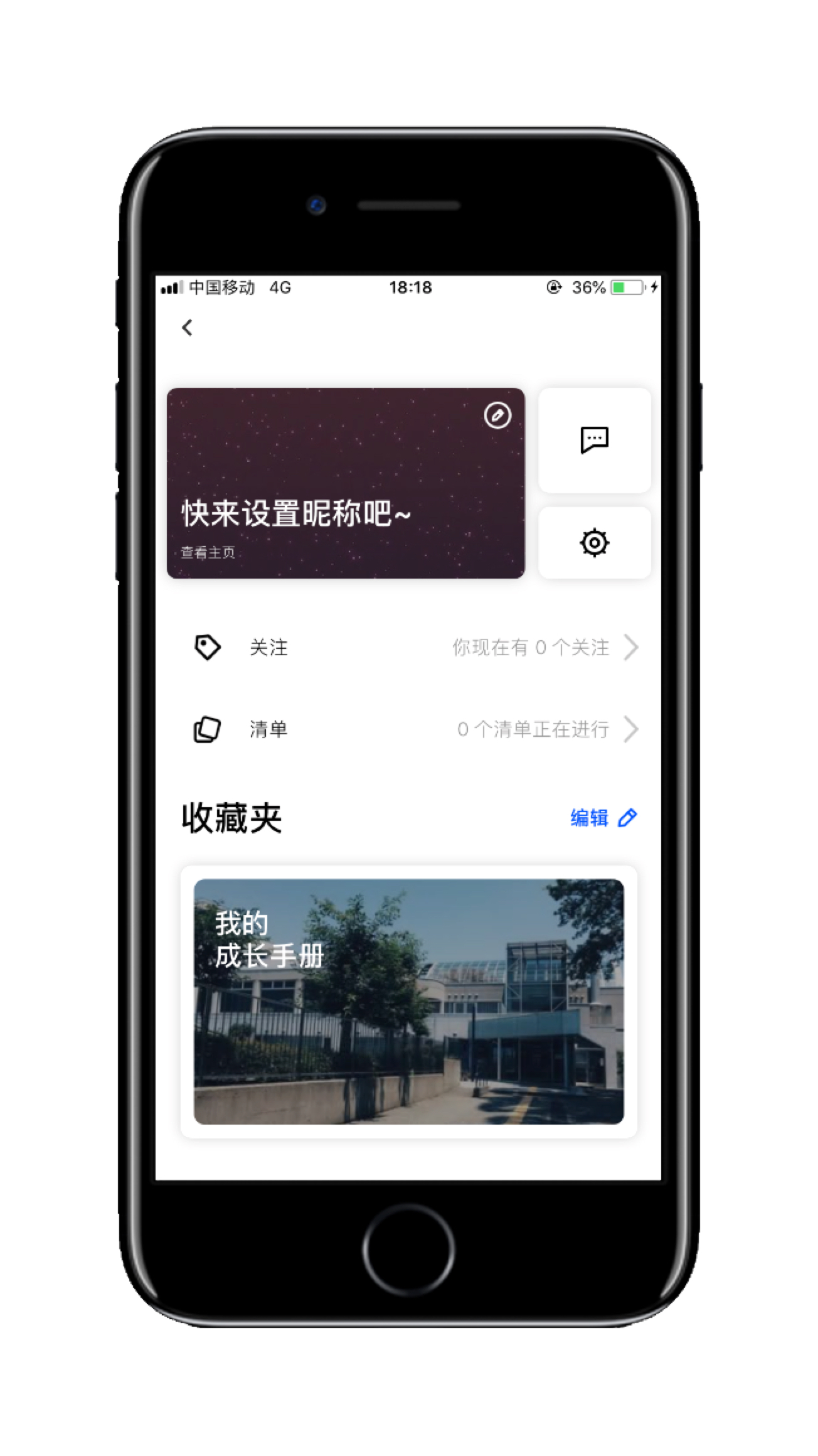
- 首页——个人中心
- 相机——进入相机
- 相机
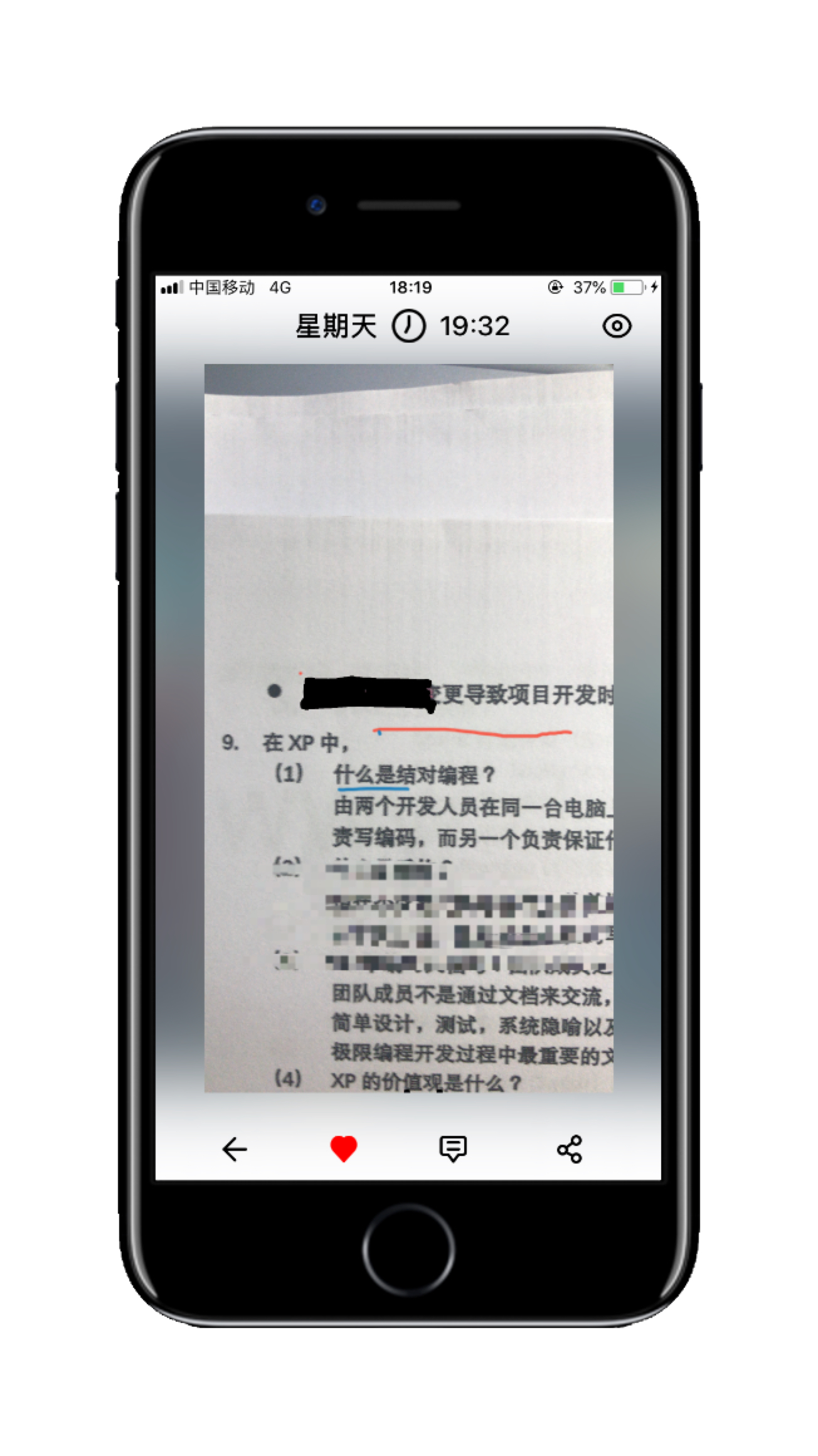
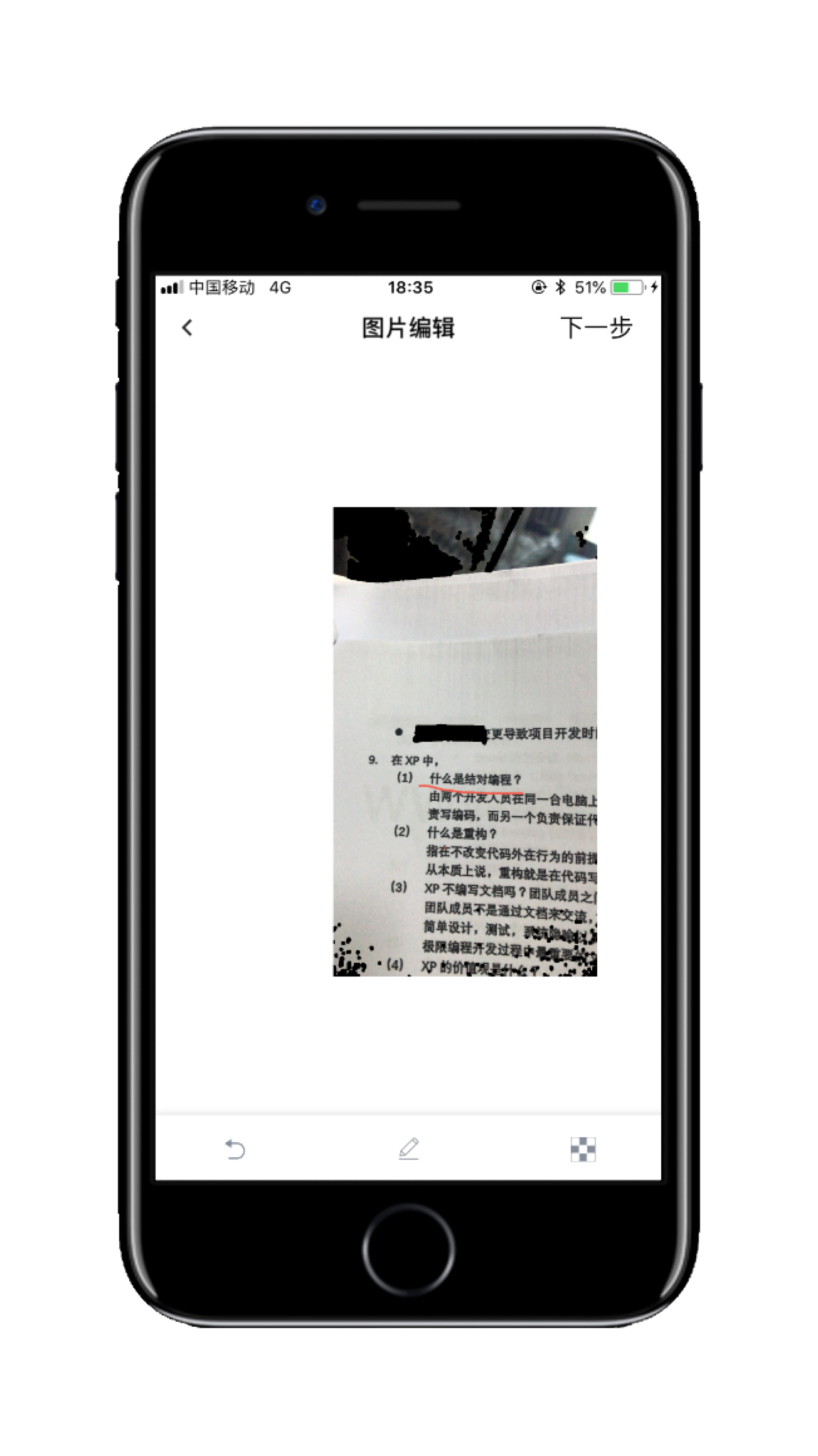
- 内容识别引擎(识别完毕)
- 内容辅助标记模块
- 内容辅助标记模块(画笔选择)
- 内容辅助标记模块(两指放大缩小)
- 卡片归档小册(长按选中小册,拖拽释放归档)
- 内容识别引擎模式
- 特色分析
- 难点和解决方案
- 首页
- 内容识别引擎:
- 作品实现
- 团队介绍和人员分工
- 其它
- 开发结束后的感想
- 不足之处和今后设想
如今人们的生活已经离不开手机,除了通讯娱乐,手机还可以帮助人们工作和学习。本产品名为“PLook”,是一款为给学生群体打造的知识分享载体,其呈现方式为移动互联网应用软件,重点利用线下学生课本知识结合PLook线上汇集打造或分享自己的知识内容。
学生时代的我们都喜欢使用荧光笔涂抹书本中的重点内容,当需要多次复习不同书本中的一部分内容时不得不带着一本一本又一本厚重的书籍;当独自一人在复习重点内容时,想要把自己梳理的一系列重点内容完整的分享给其它同学怎么办?
不想因为几个重点知识点而带上一本厚厚的书?不想把自己努力梳理出来的重点知识束之高阁?很想跟同学们打造一本属于自己的知识小册?我们来了!PLook打造了独特的内容识别引擎,不管你是使用了荧光笔还是中性笔进行重点内容区域的涂抹和绘制,PLook都能够较好的识别,帮助你快速记录重点知识!
市面上任何一种荧光笔(主要是红和蓝)都可以透过PLook来将课本中的划线部分传送到手机中显示,如此一来不管学生身处何地,都可以使用手机来复习书上的重点,对于碎片时间的利用率会更高。通过PLook自研的内容识别引擎,能够较好的减轻初高中的同学们能够在日常的学习生活中对重点知识记录和记忆的负担,并且我们还了打造一个完整知识分享平台,同学们能够把自己收集起来的重点知识内容进行归档保存,汇集成册,分享给自己的好友,也可以浏览到好友目前正在收集的知识小册内容,从而达到流量闭环,缩减同学们进行知识交流所耗费的精力。
PLook自研的内容识别引擎结合了Core ML、Visio、OpenCV三大成熟框架,站在巨人的肩膀上,重新调整,能够对初高中同学们的日常知识内容识别率达60%,当然我们开发团队也在持续不断的努力攻关当中。

- 本产品面向的对象为初高中同学,据团队同学调研,我国大部分初高中学生都携带了智能手机,家长们也都比较开明,但是还是会有部分家长十分抵制自己的孩子携带智能手机;
- 一小部分初高中学校已经明令禁止学生携带智能手机进入校园,以上两点都对本产品推广具备一定量的挑战;
- 但很大一部分的家长和初高中学校并没有进行禁止学生们携带智能手机,或者准备禁止携带的态度存在;
- PLook这个产品的本意就是给初高中同学们减轻学习压力,利用课间、放学回家路上等等一些零碎的时间去完善自己的重点知识,协助同学们牢记重点知识。
- 初高中学生几乎都会在自己的课本上使用各种颜色的荧光笔涂抹课本上的重点内容,以提醒自己,方便复习;
- 初高中学生已经接受了使用互联网产品(App)的文化,并且也乐于分享自己的成就、乐于分享自己的所见所闻;
这可以说是目前互联网+教育仅存不多的蓝海之一了,市场上保有量非常高的教育类产品基本上都是“解题”、“刷题”、“搜题”、“网课”等等内容,基本上都是站在了引导性学习的一面,但是还没有一个产品是站在学生的角度,让学生自发的组建自己的知识集,利用学生的零散时间去回顾自己的所做下的重点知识,没有一个比较好的方式去汇集、去分享自己的课本中的知识内容。
PLook主要面向的人群为初高中学生,目标人群较为明确,受众群体基数庞大,特别适合在学生过程中需要大量学习资料、整理大量学习资料的同学们。
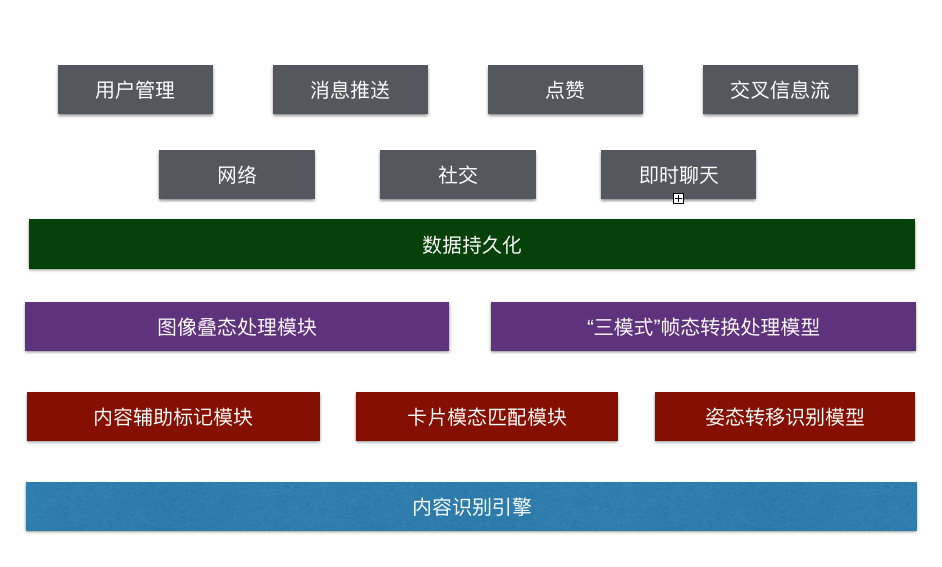
我们使用 OpenCV 作为图像识别及处理核心,结合 Core ML 和 Visio 框架管理相关模型和输出内容模型,在三者的相互协作下打造出了PLook独特的内容识别引擎。
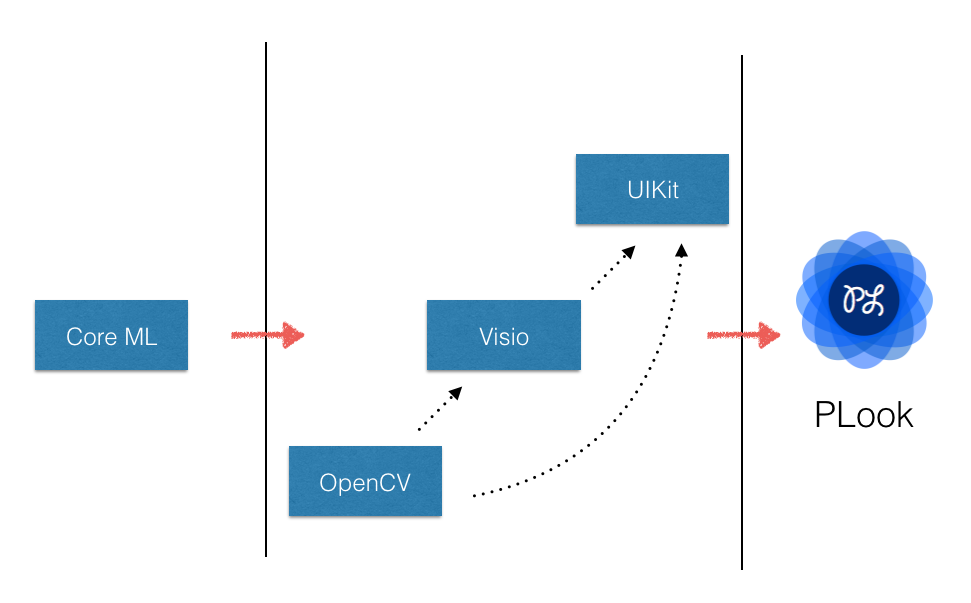
引擎支持红色荧光笔、蓝色荧光笔、OCR扫描识别三大主要功能,因时间因素引擎只完成了红色荧光笔和蓝色荧光笔两种识别模式。红色荧光笔起名为—— “遮罩模式”,蓝色荧光笔起名为—— “切割模式”,这两个模式互不干扰,红色无法识别蓝色,蓝色无法识别红色,但是可以在PLook自带独特的相机模块中连续拍摄不同模式下的照片。
PLook的内容识别引擎能够较好的处理用户所拍摄照片中核心识别对象因为所处环境的光线明暗、杂物干扰、主体差异等问题干扰,从而较为完整的输出用户想要识别的核心内容。并且用户还可以进行选择是否将识别出的内容转文字,目前PLook的内容识别引擎支持英文和中文两种文字的识别。
在该模块中我们充分发挥了iOS操作系统的优越性,基于Quartz 2D框架开发了一套独特的内容辅助标记模块。整体使用了Core Graphic进行绘制,并且进行了一定量的性能调优,在一定量程度上缓解了传统方法直接重载使用drawRect:方法进行绘制导致的内存暴涨,同时也避免了直接生产寄宿图,渲染快速,使用了硬件加速,并且高效使用内存。因为避免了创建一个寄宿图形,所以无论有用户进行绘制的图像有多大,都不会占用太多的内存,不会被图层边界剪裁掉也不会出现像素化。
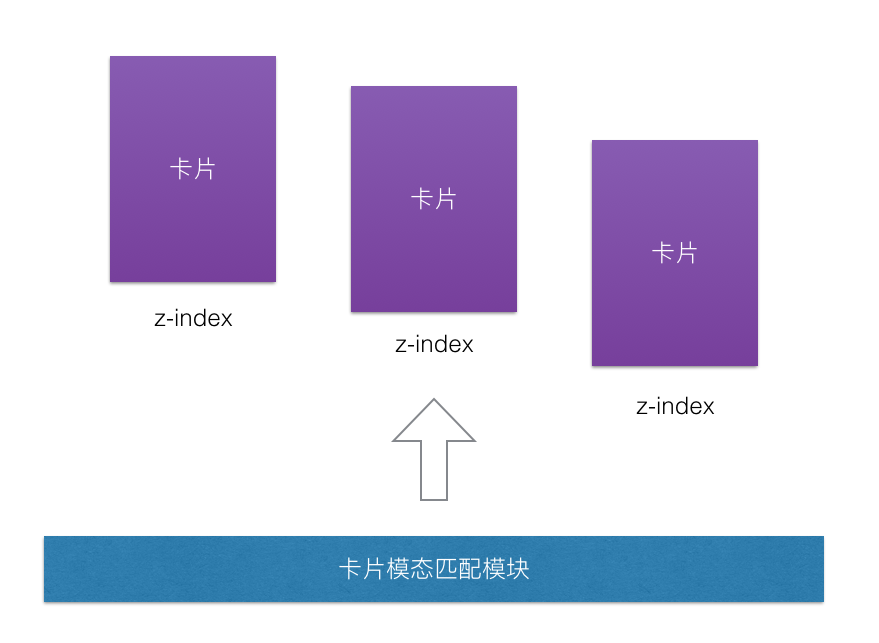
PLook的灵魂基本上就在用户所拍摄一张张的卡片,所以卡片在某种程度上就成为了决定用户留存的关键因素。卡片模态匹配主要呈现在PLook的内容识别引擎把用户的关键内容识别出来后以及在内容辅助标记模块中处理完后的关键阶段发挥作用,在该阶段中,卡片模态匹配模块需要精准定位对应模态的z-index参数,并根据该参数开放模态匹配模式,根据事件传递响应链的层级关系映射到对应z-index参数对应的卡片上,从而达到完整的匹配闭环。
我们根据PLook的业务操作逻辑开发了一套姿态转移识别模型,在该模型中能够较为精准的识别出用户姿态的变化,从而让PLook做出提前的判断,预先加载业务资源,提前load上对应的资源文件,稍微用一些空间上的资源浪费来换取时间是的资源减少,较大的拓展iPhone设备的硬件资源能力。
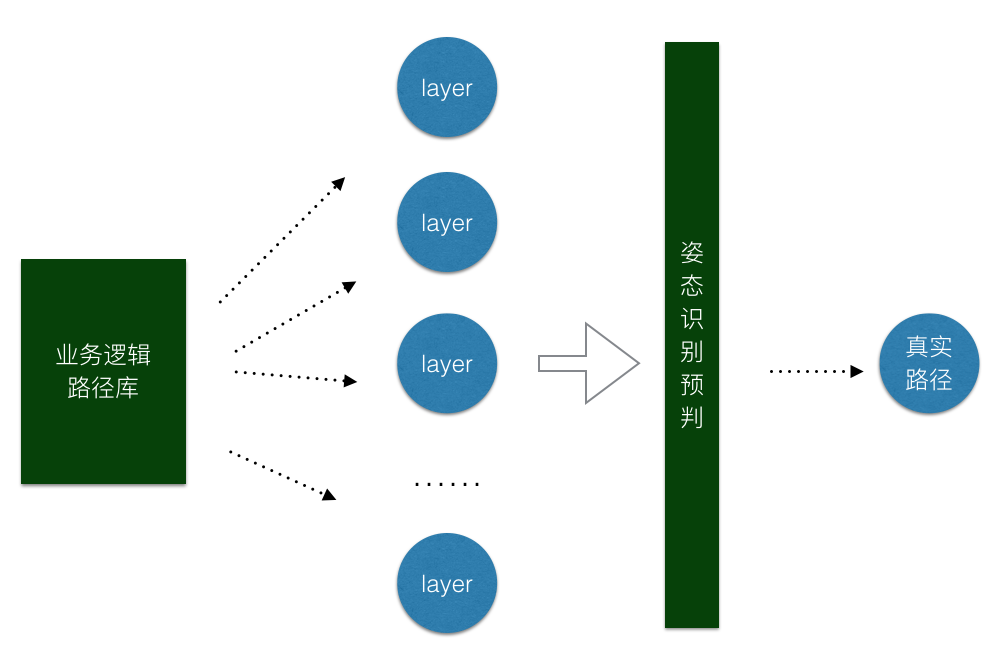
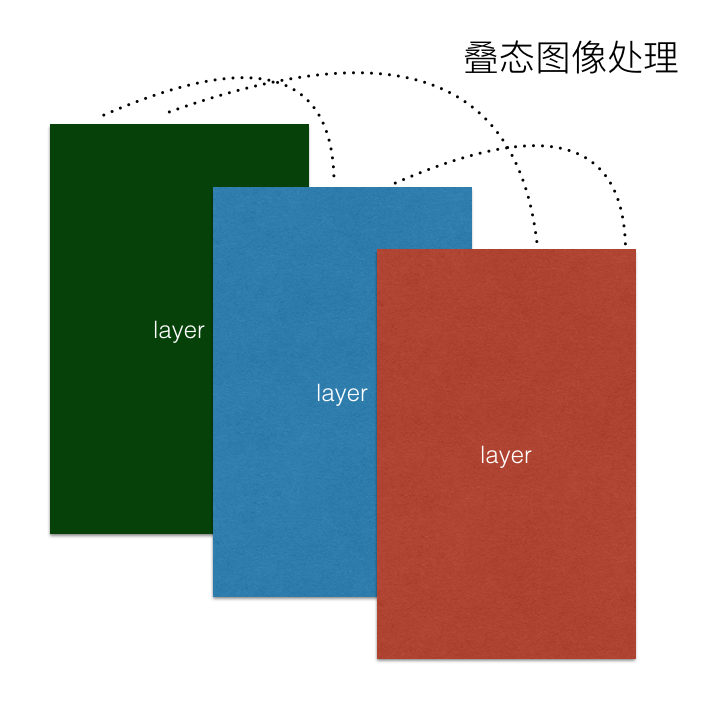
PLook经过一系列模块生成的最终卡片实际上三态图像的叠态状态,三态图像中各自都具备各自需要渲染的图像内容,而如何处理好三态图像的叠加渲染流程就是“图像叠态处理模块”要解决的核心问题,再加上我们要将引入3D-Touch技术,配合该技术能够让用户直达一重态渲染的原始图像,提升用户体验的同时也能充分的发挥出该模块的核心功能。
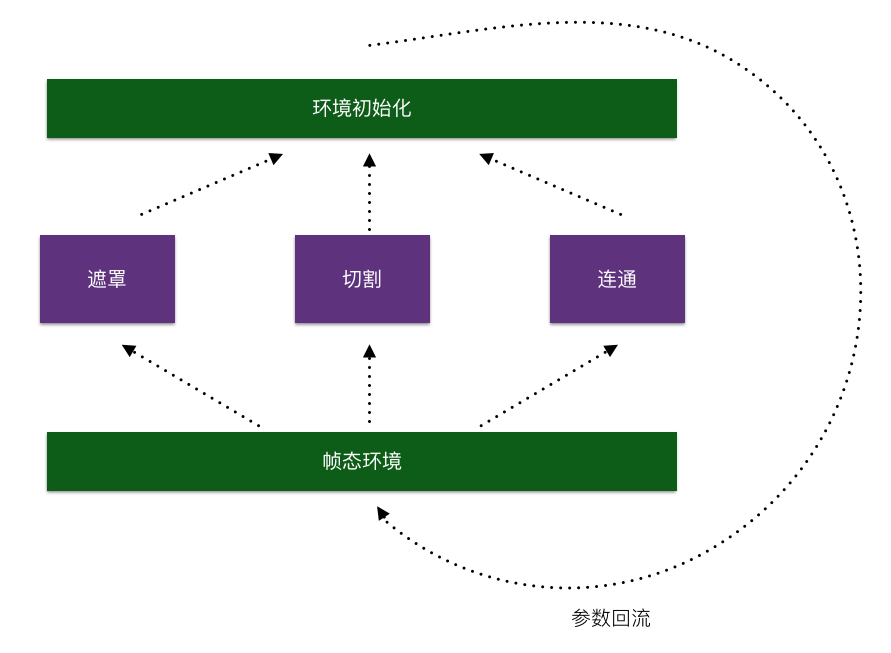
PLook中预制了三种帧态处理模式,分别为“遮罩”、“切割”、“连通”三种模式。三种帧态都依赖于同一环境,对环境要求较为苛刻,需要对同一环境下的单一帧态进行环境隔离和清洗,稍一不慎就会导致共用内存区域泄露,该模型能够较好的转换在同一环境下的不同帧态所要求的初始化环境,能够保证每次切换帧态时环境的完整性和独立性。






- 蓝色荧光笔——“切割模式”:

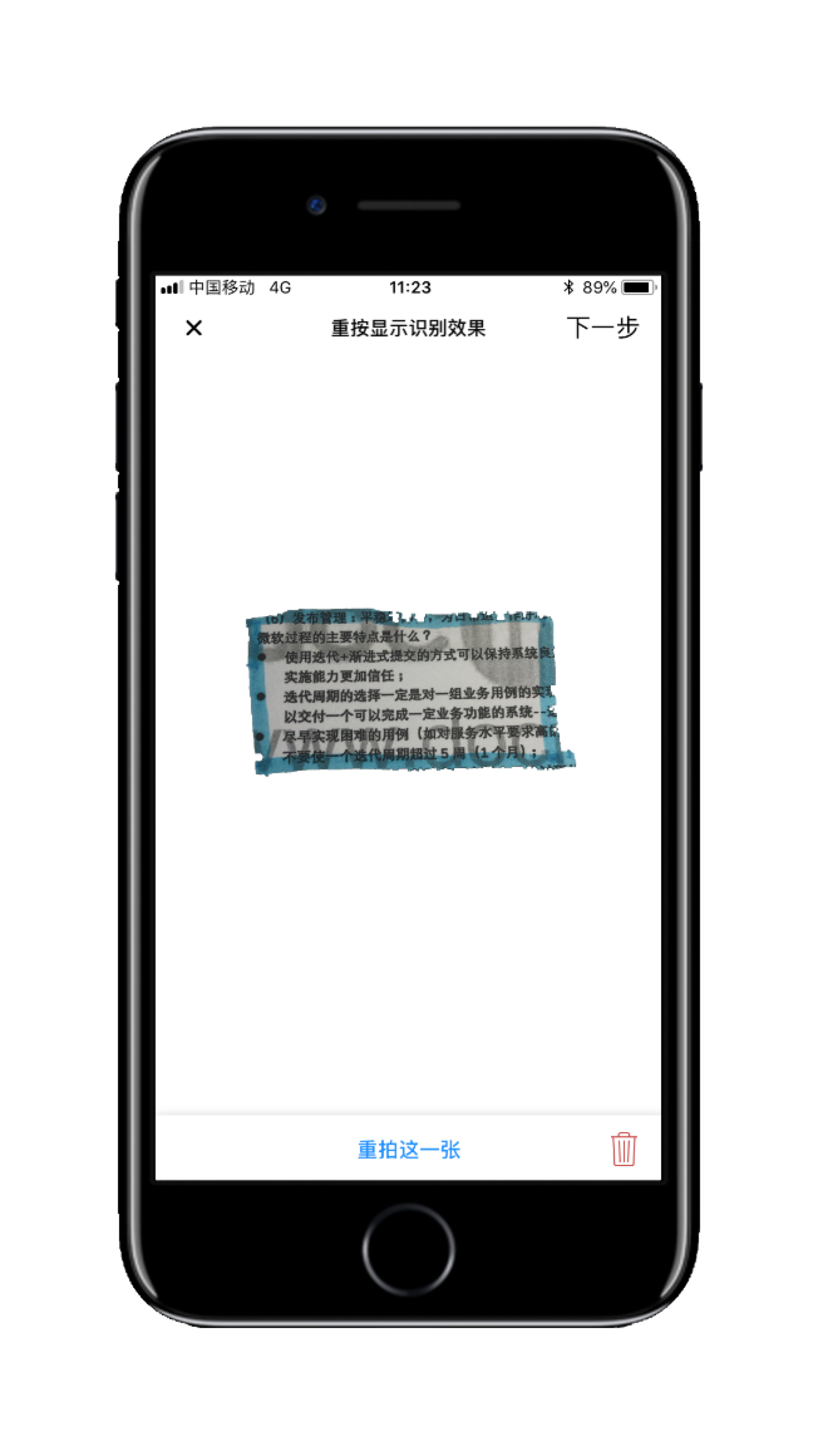
- 红色荧光笔——“遮罩模式”:


PLook除了基础框架外达到了核心模块的100%自研,存在一定的技术壁垒,能够较好的解决初高中学生使用零散时间温习重点知识的需求,并且我们会持续完善PLook的内容识别引擎,使其支持多种颜色荧光笔的识别和提升现有颜色荧光笔识别的准确度。
开发团队来来回回修改了好几次核心业务操作流程,大大缩短了面向的目标人群使用产品的多余时间。从时间诉求上看,PLook并没有花费学生们多余的时间,学生们在使用PLook的过程中,排除一些必须操作几乎都是自动化流程,一张卡片从拍摄到归档,最短只需要不到10秒的时间;从精力上看,学生们只需要确定好自己要手机知识内容,掏出手机,打开PLook,上滑开启相机,拍摄,归档,这一系列流程下来,非常的顺滑,一气呵成。
在使用PLook制作制作卡片的过程中,我们十分推荐用户一旦发现PLook内置的内容识别引擎做出的识别效果只要有一些稍微的不满意,在条件允许的情况下最好直接丢弃或者重拍,因为这样会让你手中的PLook越用越聪明,越用越符合学生们各自的习惯。
在PLook的首页设计中,我们开发团队迭代了十几次,从最初的Peek到现在最新的PLook,一边是内容识别引擎的升级一边是首页的迭代,这两块重担在比赛要求时间这么紧的情况下压力十分巨大。我们都知道,一个App最重要的地方就在首页,因为首页是用户对这个App第一印象最直接的判断,好不好用、想不想用,很可能就在这短短的十几秒中,就在这个App的两三个页面滑滑看看,点点这点点那。
所以我们开发团队阅读了一些关于心理学的书,比如《认知心理学基础》、《行为心理学》等等资料,并且仔细攻关拿下最终的首页的定稿——拟物化书本设计。这不是简单意义上的UI出几张图就能应付得过去挑剔用户的视觉感官体验的,开发团队最后在PLook的代码中把首页的“拟物化书本设计”进行了二次封装,跟随外部设备尺寸变化而进行拟物化书本设计的扩缩,较为充分的把拟物化书本的设计进行了2D平面上的延伸。如下所示:
内容识别引擎是我们开发团队重点攻关和技术沉淀,并且花费了大量时间的基础模块,其中最大的难点就在几大框架的协同合作上,尤其是OpenCV的识别模式嫁接,数据流的导向和在上下流层级的格式转换是一块非常难啃的硬骨头,多次把开发团队的小伙伴搞得十分的郁闷和无奈。一直在截止提交作品的前一天晚上,开发团队的小伙伴都一直还在接着对内容识别模块进行调优。
大家好!我们是PJYF!PJ和YF都来自北京信息科技大学计算机学院,软件工程专业,大三。
PJ是一个阳光积极的小伙子,从大一入学开始就被学长带入iOS开发中,整个大一不但要熟悉大学生活,还要马不停蹄的跟进课程的学习,所以留给自己喜欢的iOS开发中时间并不多,直到暑假才能静下心来好好的梳理一遍iOS开发中需要掌握的知识内容。这一路走来也磕磕碰碰的掌握了一些iOS开发的要点,也算是踏入了iOS开发的大门。PJ主要负责PLook的开发、测试、部署和。
YF是原本也非常的喜欢计算机,但是在接下来的计算机专业学习过程中,YF发现其实自己还是喜欢画画,遂萌生往设计方向发展,形成了一套自己设计语言,并持续的输出自己的设计思想。YF主要负责PLook的调研、设计和产品。
在参加比赛开发PLook的这段时间里,中途还得兼顾这期末考试,给团队的同学都增加了不少压力,在加上PLook的核心模块——内容识别引擎的最终识别效果实际上只能达到60%左右,性能优化问题一直困扰着开发团队,虽然说可以让用户在日常使用PLook的过程中对其进行持续的调教,但是需要的时间过长,按照PLook的内容识别引擎目前的情况来看,如果只是依靠用户自身的调教,要把准确度提升到90%的稳定输出状态,需要有效样本至少是一千张,转换到日常使用情况上来看,每天拍至少十张卡片的用户也需要一直持续的拍100天,成本还是很大,引擎部分我们开发团队还是会继续努力优化,突破难点。
在这一段时间中,我们逐渐的对技术充满了敬畏之心,曾经一些我们看起来实在是很高深的技术点在我们的不懈努力下也都慢慢的完善了出来,也感受到了自身的知识水平和技术实力的局限性,导致一些功能的实现上走了不少弯路。
我们开发团队认为,PLook最值得称赞的地方也是它最危险的地方,如果不能很好处理内容识别引擎的上下流层级的对接关系和提升识别准确度,势必会流失大量用户,甚至还会直接导致PLook的消失。因此下一步我们的做法将把内容识别引擎上云,在云端进行处理,虽然把内容识别引擎挂载在云端,从整体的使用感受上用户会觉得速度上慢一些,但是依托云服务强大的硬件能力,PLook做出的内容识别准确度会更高。
很遗憾,这个项目没进决赛,可以说是非常非常遗憾了,看到名单后心都凉了,因为付出的汗水很多很多了。总结了一下,其实问题就出在视频上,视频在这,因为最后几天搞得我十分的烦躁,所以做视频的时候心里想着这么付出了这么多汗水应该是稳了,视频就没怎么好好做,直接录屏然后配点音就完了(这视频做的完全不是我原本水准),完全没有当时大一做“大学+”时的那种感觉,总之就是很遗憾了吧,不管怎么说,我都没有处理好很多细节,以为扣了很多细节其它事情就不管了,因为当时做“大学+”的时候,决赛去答辩时慌得不行,因为根本没有任何亮点,就是做的平台,但是不管是从文档还是视频上看,都做的比现在好太多了,有可能就是那种“老子有技术,天下不怕”的感觉吧,哈哈哈哈。
也算是给了自己不小的一个教训吧,不管以后要做什么,每一步都要稳扎稳打,不要因为某一块做的好了,就放弃了另外一块,刚好其实评委能够看到的就只有文档和视频,尤其是视频,这是抓住评委第一印象的东西,但是我在这狠狠的摔了,突然想起来去年年末帮一个同学就做了一个视频,然后就靠着这个视频进了决赛,当时我也只负责做视频,参加比赛的作品是一个VR家居展示,其实我觉得这玩意就是在 Scene 中拖出来了几个墙和地,添加上纹理,再把柜子啊床啊都拖上去,再给这些 Sprite 添加上点击事件,点了就换 model,最后再添加几个 button 去选择去哪个房间,没了。任何人只要学了 Unity 都能做的出来,不,应该说是拖的出来。当时这个同学托我做了初赛视频,反正我也只负责视频,就这么做了,其实我到现在想起来都觉得很不可思议,这玩意怎么就拿了银奖。
最初是去年上半年的一次课堂中,我看到了一个 app 的宣传视频,我觉得做的东西非常神奇,视频找不到了,找到了个链接,当时就想着一定要把它做出来,去年下半年的时候就磕磕碰碰的做出了核心 demo ,也是因为这个比赛的原因才让我重新完善了它,意外的是,没想到 PLook 能进复赛,把我原本凉了的心重新燃了起来,现在也没想到经过自己的一番努力,PLook 居然没进决赛哈哈哈,又把我给浇灭了。但是在继续开发 PLook 的这段时间中,也有让我成长了不少的地方。在此把该项目开源出来,供大家参考学习,如果你有好的想法,我非常希望大家能够和我一同沟通,当然,如果你能够利用上我已有的功能模块,集合到自己的项目当中,并且还上架了,恭喜你!一定要告知我!我会多多给你宣传的!
GitHub地址:https://github.com/windstormeye/Peek