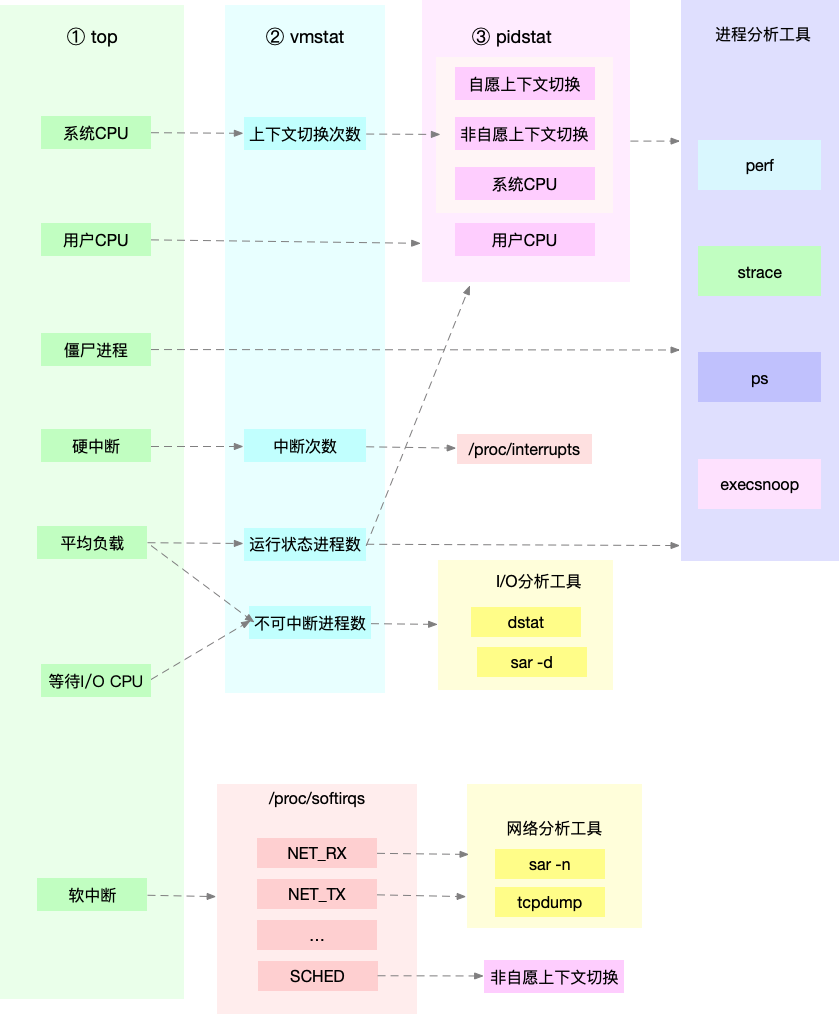
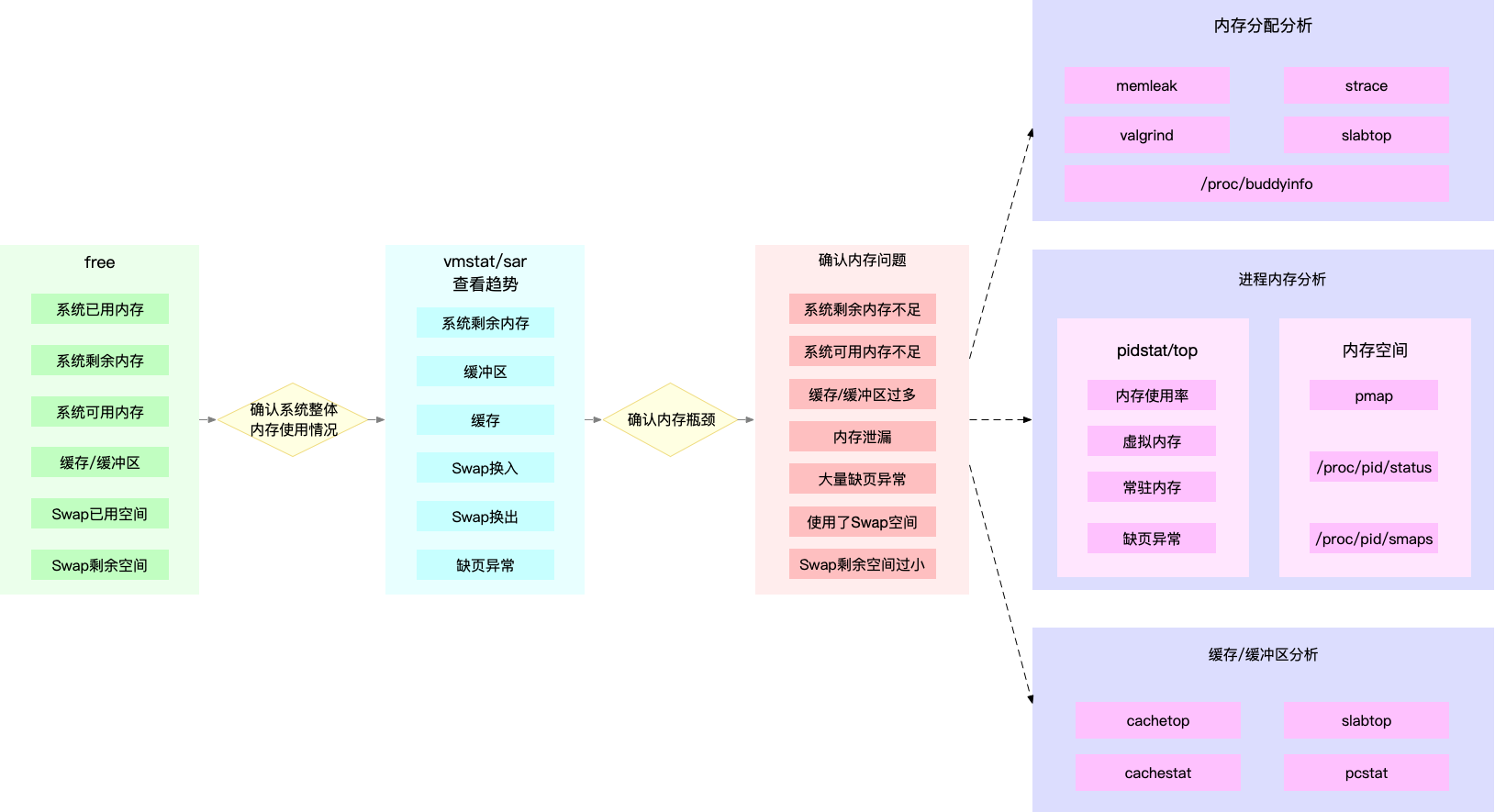
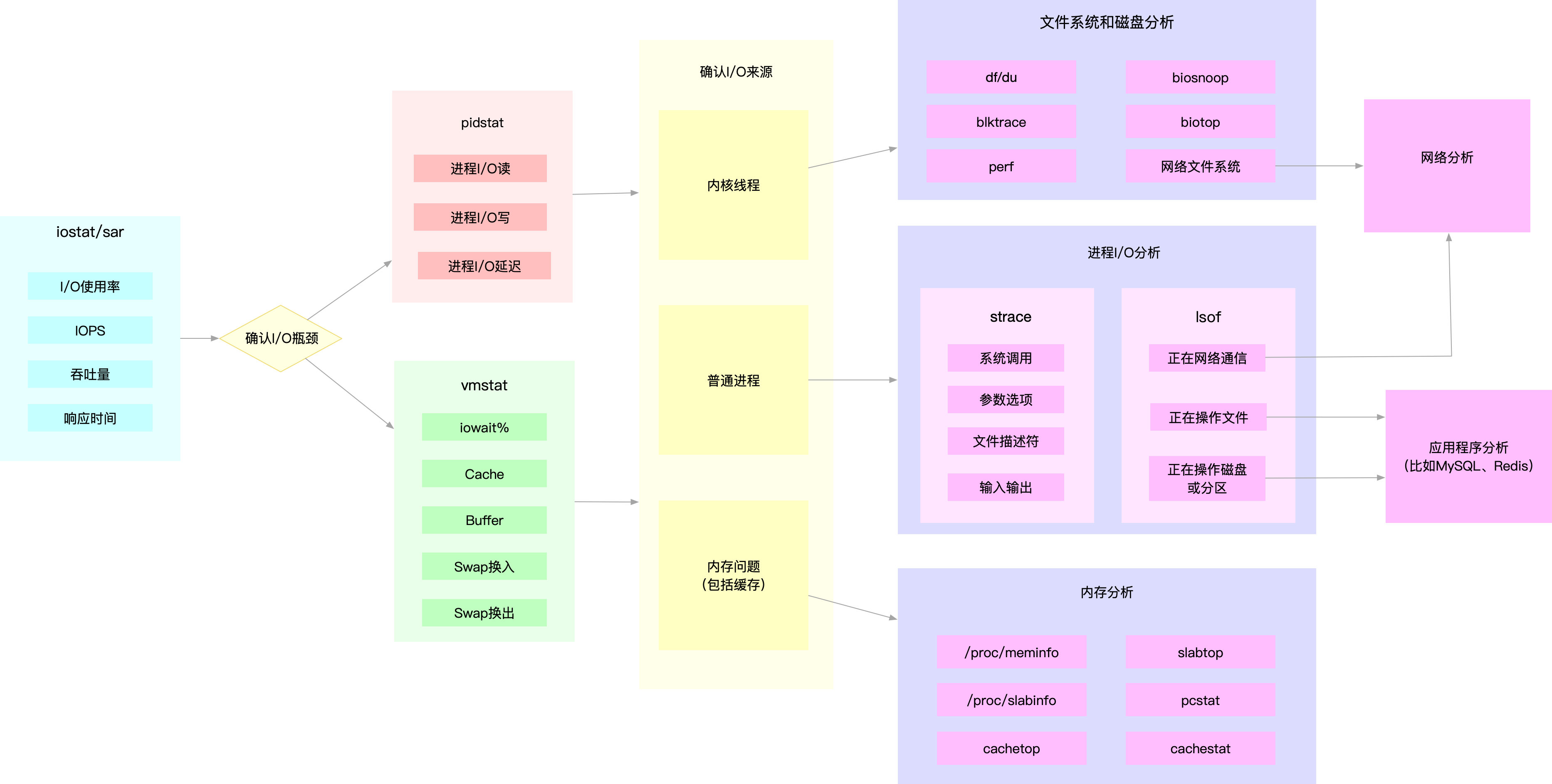
有监控的情况下,首先去看看监控大盘,看看有没有异常报警,如果初期还没有监控的情况我会按照下面步骤去看看系统层面有没有异常
1、我首先会去看看系统的平均负载,使用top或者htop命令查看,平均负载体现的是系统的一个整体情况,他应该是cpu、内存、磁盘性能的一个综合,一般是平均负载的值大于机器cpu的核数,这时候说明机器资源已经紧张了
2、平均负载高了以后,接下来就要看看具体是什么资源导致,我首先会在top中看cpu每个核的使用情况,如果占比很高,那瓶颈应该是cpu,接下来就要看看是什么进程导致的
3、如果cpu没有问题,那接下来我会去看内存,首先是用free去查看内存的是用情况,但不直接看他剩余了多少,还要结合看看cache和buffer,然后再看看具体是什么进程占用了过高的内存,我也是是用top去排序
4、内存没有问题的话就要去看磁盘了,磁盘我用iostat去查看,我遇到的磁盘问题比较少
5、还有就是带宽问题,一般会用iftop去查看流量情况,看看流量是否超过的机器给定的带宽
6、涉及到具体应用的话,就要根据具体应用的设定参数来查看,比如连接数是否查过设定值等
7、如果系统层各个指标查下来都没有发现异常,那么就要考虑外部系统了,比如数据库、缓存、存储等
8、书籍 Linux性能之巅 《Operating System Concepts》
一、什么是平均负载
正确定义:单位时间内,系统中处于可运行状态和不可中断状态的平均进程数。
错误定义:单位时间内的cpu使用率。
可运行状态的进程:正在使用cpu或者正在等待cpu的进程,即ps aux命令下STAT处于R状态的进程
不可中断状态的进程:处于内核态关键流程中的进程,且不可被打断,如等待硬件设备IO响应,ps命令D状态的进程
理想状态:每个cpu上都有一个活跃进程,即平均负载数等于cpu数
过载经验值:平均负载高于cpu数量70%的时候 例如cpu 2 负载为3.4那么要关系系统性能了
二、相关命令
cpu核数: lscpu、 grep 'model name' /proc/cpuinfo | wc -l
显示平均负载:uptime、top,显示的顺序是最近1分钟、5分钟、15分钟,从此可以看出平均负载的趋势
watch -d uptime: -d会高亮显示变化的区域
strees: 压测命令,--cpu cpu压测选项,-i io压测选项,-c 进程数压测选项,--timeout 执行时间
mpstat: 多核cpu性能分析工具,-P ALL监视所有cpu
pidstat: 进程性能分析工具,-u 显示cpu利用率
三、平均负载与cpu使用率的区别
CPU使用率:单位时间内cpu繁忙情况的统计
情况1:CPU密集型进程,CPU使用率和平均负载基本一致
情况2:IO密集型进程,平均负载升高,CPU使用率不一定升高
情况3:大量等待CPU的进程调度,平均负载升高,CPU使用率也升高
四、平均负载过高时,如何调优
工具:stress、sysstat,yum即可安装
1. CPU密集型进程case:
mpstat -P ALL 5: -P ALL表示监控所有CPU,5表示每5秒刷新一次数据,观察是否有某个cpu的%usr会很高,但iowait应很低
pidstat -u 5 1:每5秒输出一组数据,观察哪个进程%cpu很高,但是%wait很低,极有可能就是这个进程导致cpu飚高
2. IO密集型进程case:
mpstat -P ALL 5: 观察是否有某个cpu的%iowait很高,同时%usr也较高
pidstat -u 5 1:观察哪个进程%wait较高,同时%CPU也较高
iotop iostat
3. 大量进程case:
pidstat -u 5 1:观察那些%wait较高的进程是否有很多
4 htop 看负载 cpu密集型的应用,它的负载颜色是绿色偏高,iowait的操作,它的负载颜色是红色偏高等等 atop
5 top和ps或者lsof来分析
6 ps-axjf 查看是否存在状态为D+状态的进程
五 相关笔记
http://www.brendangregg.com/blog/2017-08-08/linux-load-averages.html
http://note.youdao.com/noteshare?id=7f3c0445f1828c8cd2094de4b59a331b
iostat
https://www.cnblogs.com/ftl1012/p/iostat.html
https://www.jellythink.com/archives/438
https://www.zybuluo.com/Gugoole/note/1354842
* 上下文切换是什么?
上下文切换是对任务当前运行状态的暂存和恢复
* CPU为什么要进行上下文切换?
当多个进程竞争CPU的时候,CPU为了保证每个进程能公平被调度运行,采取了处理任务时间分片的机制,轮流处理多个进程,由于CPU处理速度非常快,在人类的感官上认为是并行处理,实际是"伪"并行,同一时间只有一个任务在运行处理。
* 上下文切换主要消耗什么资源,为什么说上下文切换次数过多不可取?
根据 Tsuna 的测试报告,每次上下文切换都需要几十纳秒到到微秒的CPU时间,这些时间对CPU来说,就好比人类对1分钟或10分钟的感觉概念。在分秒必争的计算机处理环境下,浪费太多时间在切换上,只能会降低真正处理任务的时间,表象上导致延时、排队、卡顿现象发生。
* 上下文切换的过程
(1)记录当前任务的上下文(即寄存器和计算器等所有的状态);(2)找到新任务的上下文并加载; (3)切换到新任务的程序计算器位置,恢复其任务。
* 上下文切换分几种?
进程上下文切换、线程上下文切换、中断上下文切换
* 什么情况下会触发上下文切换?
系统调用、进程状态转换(运行、就绪、阻塞)、时间片耗尽、系统资源不足、sleep、优先级调度、硬件中断等
* 线程上下文切换和进程上下文切换的最大区别?
线程是调度的基本单位,进程是资源拥有的基本单位,同属一个进程的线程,发生上下文切换,只切换线程的私有数据,共享数据不变,因此速度非常快。进程间的上下文切换是从用户态到内核态的切换,性能消耗比较大
* 中断上下文切换,如何理解?
为了快速响应硬件的事件(如USB接入),中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而打断其它进程执行时,需要进行上下文切换。中断事件过多,会无谓的消耗CPU资源,导致进程处理时间延长。
* 有哪些减少上下文切换的技术用例?
数据库连接池(复用连接)、合理设置应用的最大进程,线程数、直接内存访问DMA、零拷贝技术
过多上下文切换会缩短进程运行时间
vmstat 1 1:分析内存使用情况、cpu上下文切换和中断的次数。cs每秒上下文切换的次数,in每秒中断的次数,r运行或等待cpu的进程数,b中断睡眠状态的进程数。
pidstat -w 5:查看每个进程详细情况。cswch(每秒自愿)上下文切换次数,如系统资源不足导致,nvcswch每秒非自愿上下文切换次数,如cpu时间片用完或高优先级线程
案例分析:
sysbench:多线程的基准测试工具,模拟context switch
终端1:sysbench --threads=10 --max-time=300 threads run
终端2:vmstat 1:sys列占用84%说明主要被内核占用,ur占用16%;r就绪队列8;in中断处理1w,cs切换139w==>等待进程过多,频繁上下文切换,内核cpu占用率升高
终端3:pidstat -w -u 1:sysbench的cpu占用100%(-wt发现子线程切换过多),其他进程导致上下文切换 pidstat -wt 1
watch -d cat /proc/interupts :查看另一个指标中断次数,在/proc/interupts中读取,发现重调度中断res变化速度最快
总结:cswch过多说明资源IO问题,nvcswch过多说明调度争抢cpu过多,中断次数变多说明cpu被中断程序调用
用户空间节拍率( USER_HZ)是一个固定设置
[root@dbayang ~]# grep 'CONFIG_HZ=' /boot/config-$(uname -r)
CONFIG_HZ=1000
1. CPU使用率怎么计算的?
前面讲过CPU使用率是单位时间内CPU使用情况的统计,如果我们只关注系统的CPU和任务统计信息,可以通过/proc/stat来统计,但是反应的是开机时间以来平均CPU使用率,没有意义
CPU使用率常见的重要指标有:
user(us)
用户态CPU的时间,注意不包括nice时间
nice(ni)
低优先级用户态CPU时间
system(sys)
内核态CPU时间
idle(id)
空闲时间,不包括等待I/O的时间(iowait)
iowait(wa)
等待I/O的CPU时间
irq(hi)
硬中断的CPU时间
softirq(si)
处理软中断的CPU时间
CPU 使用率,就是除了空闲时间外的其他时间占总 CPU 时间的百分比
CPU使用率 = 1 - (空闲时间)/ (总CPU时间)
但是实时CPU使用率都是通过以下公式计算的:
CPU使用率高 = 1 - 【空闲时间(new)- 空闲时间(old)】/【总CPU时间(new)- 总CPU时间(old)】
2. 如何查看CPU使用率
top 显示了系统总体的 CPU 和内存使用情况,以及各个进程的资源使用情况
Ps 则只显示了每个进程的资源使用情况
mpstat -P ALL
3. CPU使用率过高怎么办?
方法一:Perf top,它能够实时显示占用 CPU 时钟最多的函数或者指令,因此可以查找热点函数
方法二:perf record 和 perf report。可用于离线分析
4 工具查看
1: 对于pidstat,vmstat,top无法定位到问题的时候。
2: 可以选择perf record -g 记录。perf record -ag -- sleep 2
3: 用perf report查看是否可以定位到问题。
4: 用pstree | grep [xx],这样定位到具体的调用方法里。
5: 用grep [xx] -r [项目文件],找到具体代码位置。
6: 查找源码,定位到具体位置,修改。
https://github.com/brendangregg/perf-tools
R:运行 Running或Runnable的缩写 表示进程在CPU的就绪队列中,正在运行或正在等待运行
I:空闲 Idle的缩写,用在不可中断睡眠的内核线程上。空闲线程不会导致平均负载升高,D状态的会导致平均负载升高
D:不可中断睡眠 Disk Sleep的缩写 表示进程正在跟硬件交互,并且交互过程中不允许被其他进程或中断打断
S:可中断睡眠 Interruptible Sleep的缩写 表示进程因为等待某个事件而被系统挂起。当进程等待的事件发生时,它会被唤醒并进入R状态
Z:僵尸 Zombie缩写 进程已经结束,但父进程还没有回收它的资源(如进程的描述符、PID等)
T:暂停 Stopped或Traced的缩写,表示进程处于暂停或者跟踪状态
1、进程的多种状态,D (Disk Sleep) 状态的进程,会导致平均负载升高
2、僵尸进程:
(1)父子进程的运行是异步的过程,父进程需要知道子进程是何时关闭的
(2)子进程需要父进程来收尸,但父进程没有安装SIGCHLD信号处理函数调用wait或waitpid()等待子进程结束,或是子进程执行太快,父进程还没来得及处理子进程状态
(3)父进程退出后,init进程会自动接手子进程,进行清理
(4)僵尸进程已经放弃了几乎所有内存空间,没有任何可执行代码,也不能被调度,仅仅在进程列表中保留一个位置,记载该进程的退出状态等信息供其他进程收集
(5)大量的僵尸进程会用尽 PID 进程号,导致新进程不能创建
3、会话和进程组
4、实操
(1)查看了僵尸进程 查看僵尸进程的命令 ps -e -o stat,ppid,pid,cmd | egrep '^[Zz]' 或 ps -ef | grep "defunct",停止父进程后,僵尸进程会被回收
现象:
①iowait太高,导致平均负载升高,并且达到了系统CPU的个数
②僵尸进程不断增多
分析过程:
1.先分析iowait升高的原因
一般iowait升高,可能的原因是i/o问题
①用dstat 命令同时查看cpu和i/o对比情况(如 dstat 1 10 间隔1秒输出10组数据),通过结果可以发现iowait升高时,磁盘读请求(read)升高
所以推断iowait升高是磁盘读导致
②定位磁盘读的进程,使用top命令查看处于不可中断状态(D)的进程PID
③查看对应进程的磁盘读写情况,使用pidstat命令,加上-d参数,可以看到i/o使用情况(如 pidstat -d -p <pid> 1 3),发现处于不可中断状态的进程都没有进行磁盘读写
④继续使用pidstat命令,但是去掉进程号,查看所有进程的i/o情况(pidstat -d 1 20),可以定位到进行磁盘读写的进程。我们知道进程访问磁盘,需要使用系统调用,
下面的重点就是找到该进程的系统调用
⑤使用strace查看进程的系统调用 strace -p <pid>
发现报了 strace:attach :ptrace(PTRACE_SIZE,6028):Operation not peritted,说没有权限,我是使用的root权限,所以这个时候就要查看进程的状态是否正常
⑥ps aux | grep <pid> 发现进程处于Z状态,已经变成了僵尸进程,所以不能进行系统调用分析了
⑦既然top和pidstat都不能找出问题,使用基于事件记录的动态追踪工具
这里看top 就可以看到了 s 栏出现很多z 状态的进程 task 里 z 数目很多 其实先 top 看进程 然后 pidstat -d 查看进程使用资源使用情况
然后 找到 读写很大的进程 strace 跟踪 或者 ps aux | grep pid 查看进程状态 如果是z 那么要找到父进程 pstree - pid
什么是软中断?
硬中断是硬件产生的,比如键盘、鼠标的输入,硬盘的写入读取、网卡有数据了;软中断是软件产生的,比如程序内的定时器、[文中提到的RCU锁]。
网卡的处理实际是有硬中断和软中断的。
问题:有没有碰到过因为软中断出现的性能问题?
通过vmstat 检测到系统的软中断每秒有100W+次.
分析
1.检测是哪个线程占用了cpu: top -H -p XX 1 / pidstat -wut -p XX 1
2.在进程中打印各线程号. 找到是哪个线程.[ 此过程也可以省略 但可以快速定位线程]
3.第一步应该可以判断出来中断数过高. 再使用 cat /proc/softirqs 查看是哪种类型的中断数过高. cat /proc/interrupts 硬中断
NET_RX 表示网络接收中断,而 NET_TX 表示网络发送中断。
步骤
top 看到 负载和cpu 都不高 但是主要的cpu 都在 si(软中断上) 性能慢
watch -d cat /proc/softirqs 查看是哪种类型的中断数过高 TIMER(定时中断)、NET_RX(网络接收)、SCHED(内核调度)、RCU(RCU 锁)
看到 NET_RX 发生变化 就用 sar 工具 网络报告
# -n DEV 表示显示网络收发的报告,间隔 1 秒输出一组数据
$ sar -n DEV 1
15:03:46 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
15:03:47 eth0 12607.00 6304.00 664.86 358.11 0.00 0.00 0.00 0.01
15:03:47 docker0 6302.00 12604.00 270.79 664.66 0.00 0.00 0.00 0.00
15:03:47 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
15:03:47 veth9f6bbcd 6302.00 12604.00 356.95 664.66 0.00 0.00 0.00 0.05
第二列:IFACE 表示网卡。第三、四列:rxpck/s 和 txpck/s 分别表示每秒接收、发送的网络帧数,也就是 PPS。第五、六列:rxkB/s 和 txkB/s 分别表示每秒接收、发送的千字节数,也就是 BPS。
从中看到 eth0 接收数据比较大 但是发送比较少 说明接收中断了
然后 抓包 tcpdump
# -i eth0 只抓取 eth0 网卡,-n 不解析协议名和主机名
# tcp port 80 表示只抓取 tcp 协议并且端口号为 80 的网络帧
$ tcpdump -i eth0 -n tcp port 80
15:11:32.678966 IP 192.168.0.2.18238 > 192.168.0.30.80: Flags [S], seq 458303614, win 512, length 0
看到是 Flags [S] 就证明是SYN 包 接收中断了
其他
找网络相关的错误,可以有几种方式。
1. 找系统类的错误, dmesg | tail
2. 直接的网络错误 sar -n ETCP 1 或者 sar -n EDEV 1
3.查看网络状态, netstat -s 或者 watch -d netstat -s
4.网络状态的统计 ss -ant | awk '{++s[$1]} END {for(k in s) print k,s[k]}'
pidstat 中, %wait 表示进程等待 CPU 的时间百分比。此时进程是运行状态。
top 中 ,iowait% 则表示等待 I/O 的 CPU 时间百分比。此时进程处于不可中断睡眠态。
等待 CPU 的进程已经在 CPU 的就绪队列中,处于运行状态;而等待 I/O 的进程则处于不可中断状态。
一 内存分配
1、调用c标准库的都是用户空间的调用,用户空间的内存分配都是基于buddy算法(伙伴算法),并不涉及slab
2、brk()方式之所以会产生内存碎片,是由于brk分配的内存是推_edata指针,从堆的低地址向高地址推进。这种情况下,如果高地址的内存不释放,低地址的内存是得不到释放的
3、mmap()方式分配的内存,是在堆与栈之间的空闲区域分配虚拟内存,直接拿到的是内存地址,可以直接操作内存的释放
上述的都是在用户空间发生的行为,只有在内核空间,内核调用kmalloc去分配内存的时候,才会涉及到slab
二 其他人遇到的内存问题
1 redis对内存比较敏感,曾经就因为配置项是默认值,在内存用完后,所有的set操作都直接返回错误,导致线上系统故障。(redis在备份时会新开一个进程,实际使用内存量会翻番。)后来会定期检查redis 的info memory 看内存使用情况。
2 使用top和ps查询系统中大量占用内存的进程,使用cat /proc/[pid]/status和pmap -x pid查看某个进程使用内存的情况和动态变化。
三 命宁
top free
四 buffer/cache
cache是针对文件系统的缓存 ,而buffers是对磁盘数据的缓存,是直接跟硬件那一层相关的,那一般来说,cache会比buffers的数量大了很多。
理论上,一个文件读首先到Block Buffer, 然后到Page Cache。有了文件系统才有了Page Cache.对于文件,Page Cache指向Block Buffer,对于非文件
则是Block Buffer。这样就如文件实验的结果,文件操作,只影响Page Cache,Raw操作,则只影响Buffer. 比如一此VM虚拟机,则会越过File System,只接操作 Disk, 常说的Direct IO(直接io)
五 磁盘和文件的区别
磁盘是一个块设备,可以划分为不同的分区;在分区之上再创建文件系统,挂载到某个目录,之后才可以在这个目录中读写文件。
其实 Linux 中“一切皆文件”,而文章中提到的“文件”是普通文件,磁盘是块设备文件,这些大家可以执行 "ls -l <路径>" 查看它们的区别(输出的含义如果不懂请 man ls 查询)。
在读写普通文件时,会经过文件系统,由文件系统负责与磁盘交互;而读写磁盘或者分区时,就会跳过文件系统,也就是所谓的“裸I/O“。这两种读写方式所使用的缓存是不同的,也就是文中所讲的 Cache 和 Buffer 区别。
shell 脚本 取内存占用top10的进程 但是有重复计算的情况 RSS 表示常驻内存,把进程用到的共享内存也算了进去。所以,直接累加会导致共享内存被重复计算
for i in $( ls /proc/ |grep "^[0-9]"|awk '$0 >100') ;do cmd="";[ -f /proc/$i/cmdline ] && cmd=`cat /proc/$i/cmdline`;[ "$cmd"X = ""X ] && cmd=$i;awk -v i="$cmd" '/Rss:/{a=a+$2}END{printf("%s:%d\n",i,a)}' /proc/$i/smaps 2>/dev/null; done | sort -t: -k2nr | head -10
内存统计 使用grep查找Pss指标后,再用awk计算累加值
$ grep Pss /proc/[1-9]*/smaps | awk '{total+=$2}; END {printf "%d kB\n", total }'
391266 kB
smem|awk '{total+=$7};END{printf "%d kb/n",total}'
前面提到,Swap 说白了就是把一块磁盘空间或者一个本地文件(以下讲解以磁盘为例),当成内存来使用。它包括换出和换入两个过程。
swap应该是针对以前内存小的一种优化吧,不过现在内存没那么昂贵之后,所以就没那么大的必要开启了
numa感觉是对系统资源做的隔离分区,不过目前虚拟化和docker这么流行。而且node与node之间访问更耗时,针对大程序不一定启到了优化作用,针对小程序,也没有太大必要。所以numa也没必要开启。
你可以设置 /proc/sys/vm/min_free_kbytes,来调整系统定期回收内存的阈值(也就是页低阈值),还可以设置 /proc/sys/vm/swappiness,来调整文件页和匿名页的回收倾向。
你可以设置 /proc/sys/vm/zone_reclaim_mode ,来调整 NUMA 本地内存的回收策略。
当 Swap 变高时,你可以用 sar、/proc/zoneinfo、/proc/pid/status 等方法,查看系统和进程的内存使用情况,进而找出 Swap 升高的根源和受影响的进程。
禁止 Swap,现在服务器的内存足够大,所以除非有必要,禁用 Swap 就可以了。随着云计算的普及,大部分云平台中的虚拟机都默认禁止 Swap。
用smem --sort swap命令可以直接将进程按照swap使用量排序显示
sar -h --human -r -S 1 5
1 相关文档 主要是cachestat cachetop 工具
https://github.com/iovisor/bcc/issues/462
https://www.jianshu.com/p/997e0a6d8e09
# 升级系统
yum update -y
# 安装ELRepo
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
rpm -Uvh https://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm
# 安装新内核
yum remove -y kernel-headers kernel-tools kernel-tools-libs
yum --enablerepo="elrepo-kernel" install -y kernel-ml kernel-ml-devel kernel-ml-headers kernel-ml-tools kernel-ml-tools-libs kernel-ml-tools-libs-devel
# 更新Grub后重启
grub2-mkconfig -o /boot/grub2/grub.cfg
grub2-set-default 0
reboot
# 重启后确认内核版本已升级为4.20.0-1.el7.elrepo.x86_64
uname -r
# 安装bcc-tools
yum install -y bcc-tools
# 配置PATH路径
export PATH=$PATH:/usr/share/bcc/tools
# 验证安装成功
cachestat
其他 人经历
我的系统centos7.3更新了之后内核是5.0.5版本的,升完之后一直提示缺少库文件,我的做法是
rpm -qa |grep kerner,先查找系统内核版本,网上查找相应的匹配kerner-devel包,及时没有相同版本也不要紧,比如5.0.5-1的版本就是我系统的版本网上找了没有这个版本对应的kerner-devel包但是不知道为什么升级了会安装这个版本,我系统升级前centos7.3,升级后7.6。我就下载了5.0.5-3并安装,然后版本的,找到对应的包版本,rpm -ql 包版本,做个软连接就OK。至此bcc已经安装完成。做为一个linux运维我都装了2天,可想而知大家。此方法亲测centos7.3
在这里 http://mirror.rc.usf.edu/compute_lock/elrepo/kernel/el7/x86_64/RPMS/找一个 4.1-4.20 的内核版本安装就好了,5.0 的会有 bug https://github.com/iovisor/bcc/issues/2329
bcc-tools install(centos6.9) 已尝试可以顺利安装
https://blog.csdn.net/luckgl/article/details/88355074
查看 文件系统容量
$ df -h /dev/sda1
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 29G 3.1G 26G 11% /
统计索引节点 df -i df -h显示还有很多空间,可就是无法创建文件了。
$ df -i /dev/sda1
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/sda1 3870720 157460 3713260 5% /
查看页面cache 大小
$ cat /proc/meminfo | grep -E "SReclaimable|Cached"
Cached: 748316 kB
SwapCached: 0 kB
SReclaimable: 179508 kB
# 按下c按照缓存大小排序,按下a按照活跃对象数排序
$ slabtop
io 问题分析
先是top看%iowait到升高,再看pidstat是哪个进程在操作磁盘(kB_ccwr)写次数,再strace看进程的调用栈。
1.用iostat看磁盘的await(响应时间),utils(使用率), aqu-sz (等待队列),iops,bandwidth (iostat -d -x 1)
2.用smartctl看磁盘的health status
3.用iotop/pidstat找出持续读写的进程做优化(pidstat -d 1)
4.看进程是否写文件 strace -p 12280 2>&1 | grep write
5.其他命宁
strace -fp pid 跟踪所有线程。
pidstat -wut 1 既可以看上下文切换 又可以看cpu使用统计 还可以看各线程.
strace -p 3387 -f 2>&1 | grep write 可以追逐子线程
可以用pstree -p 查看Python的进程树,然后strace -p 线程号,不过本例中线程消失非常快,需要写个脚本才行 比如:Python进程号是13205 strace -p `pstree -p 13205 | tail -n 1 | awk -F '(' '{print $NF}' | awk -F ')' '{print $1}'
其他
1.用top查看指标,发现 [系统] 有i/o瓶颈 或者 cpu瓶颈.
2.使用iostat辅助看下磁盘i/o读写速度和大小等指标.
3.用pidstat判断是哪个 [进程] 导致的. 既可以看进程各线程的cpu中断数,也可以看磁盘io数.
4.用strace追踪进程及各线程的 [系统调用].(以前经常到这里就知道了是操作的什么文件)
5.继续用lsof查看该进程打开的 [文件] .linux下一切皆文件,则可以查看的东西就很多很多了.连进程保持的socket等信息也一目了然.
6.本例因为用到了容器,所以用到了nsenter进入容器的网络命名空间,查看对应的socket信息.
7.根据第4.5步获取的信息,找源码或看系统配置.确定问题,做出调整.然后收工.
其他人遇到问题
数据写es,运行一段时间后,发现写入很慢,查io时发现,读的io很高,写的io很少,很奇怪只写数据还没查询,读的io使用率基本接近100%。
用iotop定位到es一些写的线程,将线程id转成16进制,用jstack打印出es的堆栈信息,查出16进制的线程号的堆栈。发现原来是es会跟据doc id查数据,然后选择更新或新插入。es数据量大时,会占用了很多读的io.
后面写es就不传id,让es自动生成。解决了问题。
1 top 命宁看到 系统等待时间超过60% 说明存在io 等待
$ top
top - 12:02:15 up 6 days, 8:05, 1 user, load average: 0.66, 0.72, 0.59
Tasks: 137 total, 1 running, 81 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.7 us, 1.3 sy, 0.0 ni, 35.9 id, 62.1 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 0.3 us, 0.7 sy, 0.0 ni, 84.7 id, 14.3 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 8169300 total, 7238472 free, 546132 used, 384696 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 7316952 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
27458 999 20 0 833852 57968 13176 S 1.7 0.7 0:12.40 mysqld
2 iostat 命宁看到 读32M每秒 而且io使用率达到了97% 磁盘 sda 的读取确实碰到了性能瓶颈。
$ iostat -d -x 1
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
sda 273.00 0.00 32568.00 0.00 0.00 0.00 0.00 0.00 7.90 0.00 1.16 119.30 0.00 3.56 97.20
3 pidstat 命宁看到 mysql的进程 符合上面的分析 每秒大概32m的读数据,说明是mysql 的问题
# -d选项表示展示进程的I/O情况
$ pidstat -d 1
12:04:11 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
12:04:12 999 27458 32640.00 0.00 0.00 0 mysqld
12:04:12 0 27617 4.00 4.00 0.00 3 python
12:04:12 0 27864 0.00 4.00 0.00 0 systemd-journal
4 strace /lsof 查看进程打开的文件
$ strace -f -p 27458
[pid 28014] read(38, "934EiwT363aak7VtqF1mHGa4LL4Dhbks"..., 131072) = 131072
[pid 28014] read(38, "hSs7KBDepBqA6m4ce6i6iUfFTeG9Ot9z"..., 20480) = 20480
[pid 28014] read(38, "NRhRjCSsLLBjTfdqiBRLvN9K6FRfqqLm"..., 131072) = 131072
lsof -p 27458
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
mysqld 27458 999 38u REG 8,1 512440000 2601895 /var/lib/mysql/test/products.MYD
5 然后上面的已经说明了 mysql 一直在打开 那个文件 在用 show full processlist; 查看响应时间慢的sql 然后看sql 执行计划和表结构和索引情况
mysql> show full processlist;
+----+------+-----------------+------+---------+------+--------------+-----------------------------------------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+------+-----------------+------+---------+------+--------------+-----------------------------------------------------+
| 27 | root | localhost | test | Query | 0 | init | show full processlist |
| 28 | root | 127.0.0.1:42262 | test | Query | 1 | Sending data | select * from products where productName='geektime' |
+----+------+-----------------+------+---------+------+--------------+-----------------------------------------------------+
2 rows in set (0.00 sec)
首先打开系统配置设置
vim /etc/sysconfig/iptables
添加端口开启
-A INPUT -m state --state NEW -m tcp -p tcp --dport 端口号 -j ACCEPT
例如
-A INPUT -s 203.100.87.24/32 -p tcp -m tcp --dport 9184 -j ACCEPT
重启服务
service iptables restart
查看端口号开启情况
/sbin/iptables -L -n
netstat -anp|grep xx
5 为什么top显示 iowait比较高,但是使用iostat却发现io的使用率并不高那? iowait不代表磁盘I/O存在瓶颈,只是代表CPU上I/O操作的时间占用的百分比。假如这时候没有其他进程在运行,那么很小的I/O就会导致iowait升高
%iowait 表示在一个采样周期内有百分之几的时间属于以下情况:CPU空闲、并且有仍未完成的I/O请求。
对 %iowait 常见的误解有两个:
一是误以为 %iowait 表示CPU不能工作的时间,
二是误以为 %iowait 表示I/O有瓶颈。
首先 %iowait 升高并不能证明等待I/O的进程数量增多了,也不能证明等待I/O的总时间增加了。
例如,在CPU繁忙期间发生的I/O,无论IO是多还是少,%iowait都不会变;当CPU繁忙程度下降时,有一部分IO落入CPU空闲时间段内,导致%iowait升高。
再比如,IO的并发度低,%iowait就高;IO的并发度高,%iowait可能就比较低。
可见%iowait是一个非常模糊的指标,如果看到 %iowait 升高,还需检查I/O量有没有明显增加,avserv/avwait/avque等指标有没有明显增大,应用有没有感觉变慢,如果都没有,就没什么好担心的
应用层,负责向用户提供一组应用程序,比如 HTTP、FTP、DNS 等。
传输层,负责端到端的通信,比如 TCP、UDP 等。
网络层,负责网络包的封装、寻址和路由,比如 IP、ICMP 等。
网络接口层,负责网络包在物理网络中的传输,比如 MAC 寻址、错误侦测以及通过网卡传输网络帧等。
在进行网络传输时,数据包就会按照协议栈,对上一层发来的数据进行逐层处理;然后封装上该层的协议头,再发送给下一层。
tcpdump 和 Wireshark 就是最常用的网络抓包和分析工具,更是分析网络性能必不可少的利器
wireshark的使用推荐阅读林沛满的《Wireshark网络分析就这么简单》和《Wireshark网络分析的艺术》
捕获访问本机3306端口的报文
tcpdump -A -XX -s0 -nn tcp dst port 3306 and dst host 172.16.5.15
抓取哪个端口上的某个操作
tcpdump -i any -s0 -A -nn tcp dst port 3306 and dst host 172.16.5.12 | grep -i -E
sudo tcpdump -i any -A dst port 20880
'SELECT|INSERT|CREATE|DROP|DELETE'
tcpdump -i eth0 -s 0 -l -w - port 8188|strings|more
实时抓取端口号8000的GET包,然后写入GET.log
tcpdump -i eth0 '((port 8000) and (tcp[(tcp[12]>>2):4]=0x47455420))' -nnAl -w /tmp/GET.log
使用dstat -d命令,会看到如下的东西:
-dsk/total -
read writ
103k 211k
0 11k
在上面可以清晰看到,存储的IO吞吐量是每秒钟读取103kb的数据,每秒写入211kb的数据,像这个存储IO吞吐量基本上都不
算多的,因为普通的机械硬盘都可以做到每秒钟上百MB的读写数据量。
使用命令:dstat -r,可以看到如下的信息
--io/total read writ
0.25 31.9
0 253
0 39.0
他的这个意思就是读IOPS和写IOPS分别是多少,也就是说随机磁盘读取每秒钟多少次,随机磁盘写入每秒钟执行多少次,大
概就是这个意思,一般来说,随机磁盘读写每秒在两三百次都是可以承受的。
接着我们可以使用dstat -n命令,可以看到如下的信息:
-net/total recv send
16k 17k
这个说的就是每秒钟网卡接收到流量有多少kb,每秒钟通过网卡发送出去的流量有多少kb,通常来说,如果你的机器使用的
是千兆网卡,那么每秒钟网卡的总流量也就在100MB左右,甚至更低一些