This tutorial focuses on utilizing USP (Unified Sequence Parallelism) in the context of the CogVideoX text-to-video model. USP combines two sequence parallelism methods such as ulysses attention and ring attention. This tutorial provides step-by-step instructions on how to apply USP to a new DiT model.
The diffusion process involves receiving Gaussian noise as input, iteratively predicting and denoising using the CogVideoX Transformer, and generating the output video. This process, typically executed on a single GPU within diffusers, is outlined in the following figure.

The Transformer's input comprises a text sequence, an image sequence, and an image rotary position embedding (RoPE). USP segments the input tensor along the sequence length dimension and assigns each segment to a GPU. Notably, the image sequence and the RoPE contains much more elements than the text sequence. Thus, two design choices emerge:
- Split the text sequence, image sequence, and RoPE; or
- Split solely the image sequence and RoPE while each GPU retains a complete text sequence.
The previous tutorial focus on the first situaion, while this tutorial will describe the second one.
As depicted in the subsequent diagram, USP harnesses multiple GPUs (2 in this instance) to execute diffusion. At the beginning of each iteration, USP segments the input image sequence and RoPE along the sequence length dimension, assigning each segment to a GPU. Additionally, the entire text seqeunce is also passed to all GPUs. As the input sequence gets partitioned, USP necessitates communication to facilitate attention computation within the transformer. Concluding the iteration, the two GPUs communicate via the all_gather primitive.
To accelerate CogVideoX inference using USP, four modifications to the original diffusion process are required.
Firstly, the xDiT environment should be initialized at the beginning of the program. This requires several function such as init_distributed_environment, initialize_model_parallel, and get_world_group provided by xDiT.
Secondly, in diffusers, the CogVideoX model is encapsulated within the CogVideoXTransformer3DModel class located at diffusers/models/transformers/cogvideox_transformer_3d.py, and it is reqired to split and merge seqeunces before and after the forward function of CogVideoXTransformer3DModel.
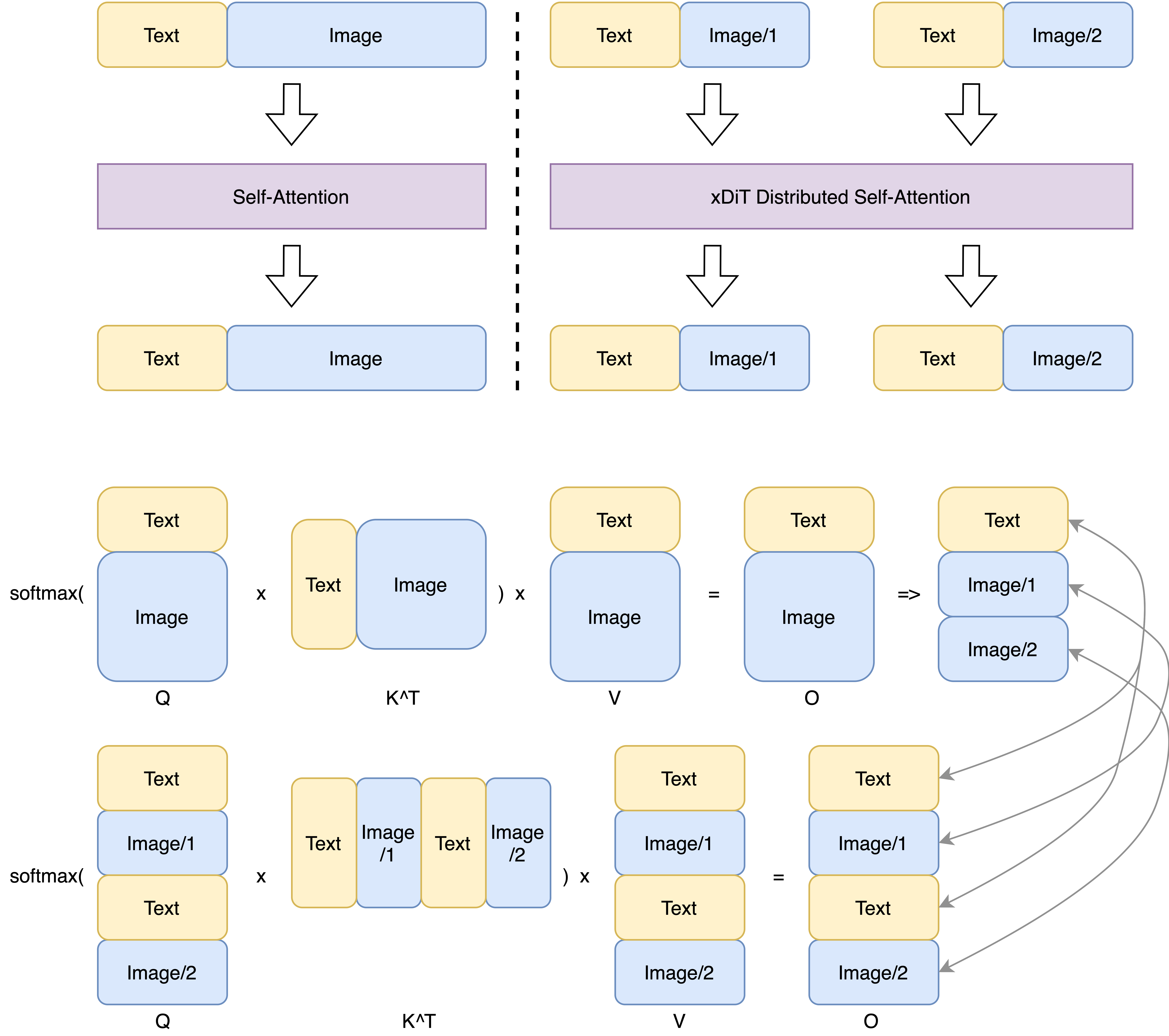
Thirdly, in diffusers, the attention computation is managed by the CogVideoXAttnProcessor2_0 class in diffusers/models/attention_processor.py. As shown at the top of the following figure, we need to replace the attention computation into the USP version provided by xDiT to achieve parallel computation. The bottom of the figure indicates that, the results obtained from both versions of attention computation are consistent.
Finally, as each GPU own a distict sequence segment, the patch embedding layer in diffusers/models/embeddings.py need to be adapted.
The initialization routine is the same as the previous tutorial.
The forward function of CogVideoXTransformer3DModel orchestrates the inference process for a single step iteration, outlined below:
class CogVideoXTransformer3DModel(ModelMixin, ConfigMixin, PeftAdapterMixin):
...
def forward(
self,
hidden_states: torch.Tensor,
encoder_hidden_states: torch.Tensor,
timestep: Union[int, float, torch.LongTensor],
timestep_cond: Optional[torch.Tensor] = None,
ofs: Optional[Union[int, float, torch.LongTensor]] = None,
image_rotary_emb: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
attention_kwargs: Optional[Dict[str, Any]] = None,
return_dict: bool = True,
)To parallelize the inference process, we utilize parallelize_transformer on pipe. Within this function, a new_forward function is introduced with identical input and output parameters as the original function. The new_forward function performs the following steps:
- Splits the image sequence, and the RoPE based on the sequence length dimension, allocating each batch to a GPU.
- Executes the original forward process on all GPUs.
- Merges the predicted noise using all_gather.
The code snippet below demonstrates the utilization of @functools.wraps to decorate the new_forward function, ensuring that essential details such as the function name, docstring, and argument list are inherited from original_forward. As forward is a method of a class object, the __get__ function is employed to set transformer as the initial argument for new_forward, subsequently assigning new_forward to transformer.forward.
def parallelize_transformer(pipe: DiffusionPipeline):
transformer = pipe.transformer
original_forward = transformer.forward
# definition of the new forward
@functools.wraps(transformer.__class__.forward)
def new_forward(...)
new_forward = new_forward.__get__(transformer)
transformer.forward = new_forward
parallelize_transformer(pipe)In the input parameters, hidden_state, and image_rotary_emb represent the image sequence, and the RoPE, which are added to hidden_state respectively. These two tensors require splitting. The shapes of the two tensors are outlined in the table below. Note that, encoder_hidden_states represents the text sequence and does not need to be split.
hidden_state(batch_size, temporal_length, channels, height, width)image_rotary_emb(batch_size, rope_temporal_length, rope_height, rope_width, hidden_state)
In CogVideoX, rope_height and rope_width are half of height and width respectively. xDiT provides helper functions for USP, offering functionalities such as get_sequence_parallel_rank() and get_sequence_parallel_world_size() to access the number of GPUs and their respective ranks. The get_sp_group() function facilitates USP, incorporating an all_gather() operation to merge sequences after forward. When partitioning the text sequence by the text_length dimension and the image sequence and RoPE by the height dimension, the new forward function can be defined as follows:
@functools.wraps(transformer.__class__.forward)
def new_forward(
self,
hidden_states: torch.Tensor,
encoder_hidden_states: Optional[torch.Tensor] = None,
timestep: torch.LongTensor = None,
timestep_cond: Optional[torch.Tensor] = None,
ofs: Optional[Union[int, float, torch.LongTensor]] = None,
image_rotary_emb: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
**kwargs,
):
rope_h, rope_w = hidden_states.shape[-2] // 2, hidden_states.shape[-1] // 2
# Step 1: split tensors
hidden_states = torch.chunk(hidden_states, get_sequence_parallel_world_size(), dim=-2)[get_sequence_parallel_rank()]
if image_rotary_emb is not None:
freqs_cos, freqs_sin = image_rotary_emb
dim_thw = freqs_cos.shape[-1]
freqs_cos = freqs_cos.reshape(-1, rope_h, rope_w, dim_thw)
freqs_cos = torch.chunk(freqs_cos, get_sequence_parallel_world_size(), dim=-3)[get_sequence_parallel_rank()]
freqs_cos = freqs_cos.reshape(-1, dim_thw)
freqs_sin = freqs_sin.reshape(-1, rope_h, rope_w, dim_thw)
freqs_sin = torch.chunk(freqs_sin, get_sequence_parallel_world_size(), dim=-3)[get_sequence_parallel_rank()]
freqs_sin = freqs_sin.reshape(-1, dim_thw)
image_rotary_emb = (freqs_cos, freqs_sin)
# Step 2: perform the original forward
output = original_forward(
hidden_states,
encoder_hidden_states,
timestep=timestep,
timestep_cond=timestep_cond,
ofs=ofs,
image_rotary_emb=image_rotary_emb,
**kwargs,
)
return_dict = not isinstance(output, tuple)
sample = output[0]
# Step 3: merge the output from two GPUs
sample = get_sp_group().all_gather(sample, dim=-2)
if return_dict:
return output.__class__(sample, *output[1:])
return (sample, *output[1:])Within CogVideoXAttnProcessor2_0, the __call__ function concatenates the text and image sequences into a unified sequence. Subsequently, the function extracts Q, K, and V from this sequence and conducts the attention computation.
In our scenario, each GPU possesses an entire text sequence along with a portion of the image sequence. When the GPU concatenates these two sequences and derives Q, K, and V from the combined result, a direct usage of these values in USP isn't feasible due to the text sequence appearing multiple times. Fortunately, xFuserLongContextAttention() in xDiT accommodates this configuration. The function's signature is outlined below:
class xFuserLongContextAttention(LongContextAttention):
def forward(
self, attn,
query: Tensor,
key: Tensor,
value: Tensor,
*,
joint_tensor_query=None,
joint_tensor_key=None,
joint_tensor_value=None,
...
joint_strategy="none",
)Within this function, query, key, and value correspond to Q, K, and V derived from the image sequence segment, while joint_tensor_query, joint_tensor_key, and joint_tensor_value correspond to Q, K, and V derived from the entire text sequence. The joint_strategy parameter takes values of either "front" or "rear", indicating whether the text is concatenated to the front or rear of the image sequence, respectively.
To incorporate USP, we introduce a novel class, xDiTCogVideoAttentionProcessor. The primary distinction in its __call__ function, as opposed to the original method, lies in the attention computation step, as illustrated below:
def __init__(self):
...
+ self.hybrid_seq_parallel_attn = xFuserLongContextAttention()
def __call__(...):
...
- hidden_states = F.scaled_dot_product_attention(
- query, key, value, dropout_p=0.0, is_causal=False
- )
- hidden_states = hidden_states.transpose(1, 2).reshape(
- batch_size, -1, attn.heads * head_dim
- )
+ # split the text and image part of the combined sequence
+ encoder_query = query[:, :, :text_seq_length, :]
+ query = query[:, :, text_seq_length:, :]
+ encoder_key = key[:, :, :text_seq_length, :]
+ key = key[:, :, text_seq_length:, :]
+ encoder_value = value[:, :, :text_seq_length, :]
+ value = value[:, :, text_seq_length:, :]
+ query = query.transpose(1, 2)
+ key = key.transpose(1, 2)
+ value = value.transpose(1, 2)
+ encoder_query = encoder_query.transpose(1, 2)
+ encoder_key = encoder_key.transpose(1, 2)
+ encoder_value = encoder_value.transpose(1, 2)
+
+ # pass the `Q`, `K`, and `V` of the image and text sequence
+ hidden_states = self.hybrid_seq_parallel_attn(
+ None, query, key, value, dropout_p=0.0, causal=False,
+ joint_tensor_query=encoder_query,
+ joint_tensor_key=encoder_key,
+ joint_tensor_value=encoder_value,
+ joint_strategy="front",
+ )
+ hidden_states = hidden_states.reshape(
+ batch_size, -1, attn.heads * head_dim
+ )Lastly, to incorporate our xDiTCogVideoAttentionProcessor into the forward operation instead of the original CogVideoXAttnProcessor2_0, we iterate through each transformer block and update its attention processor. Prior to output = original_forward..., we include the following line to ensure that each attention block utilizes our processor:
for block in transformer.transformer_blocks:
block.attn1.processor = xDiTCogVideoAttentionProcessor()As in previous tutorial, we need to modify the original patch_embed layer. The new forward function performs the following steps:
- Merge the text and image sequence by the
all_gatheroperation to ensure every GPU obtains the complete text and image sequences; - Apply the original
transformer.patch_embedoperation to the entire sequence on each GPU; and - Segment the text and image sequences identically to before.
However, since the image sequence is partitioned but the text sequence is not. we only merge and segment the image sequence at the first and third step.
original_patch_embed_forward = transformer.patch_embed.forward
@functools.wraps(transformer.patch_embed.__class__.forward)
def new_patch_embed(
self, text_embeds: torch.Tensor, image_embeds: torch.Tensor
):
# Step 1: merge the text and image sequence
image_embeds = get_sp_group().all_gather(image_embeds.contiguous(), dim=-2)
batch, embed_height, embed_width = image_embeds.shape[0], image_embeds.shape[-2] // 2, image_embeds.shape[-1] // 2
text_len = text_embeds.shape[-2]
# Step 2: apply the original patch_embed
output = original_patch_embed_forward(text_embeds, image_embeds)
# Step 3: segment the text and image sequences
text_embeds = output[:,:text_len,:]
image_embeds = output[:,text_len:,:].reshape(batch, -1, embed_height, embed_width, output.shape[-1])
image_embeds = torch.chunk(image_embeds, get_sequence_parallel_world_size(),dim=-3)[get_sequence_parallel_rank()]
image_embeds = image_embeds.reshape(batch, -1, image_embeds.shape[-1])
return torch.cat([text_embeds, image_embeds], dim=1)
new_patch_embed = new_patch_embed.__get__(transformer.patch_embed)
transformer.patch_embed.forward = new_patch_embedA complete example script can be found in adding_model_usp_text_replica.py.