diff --git a/README.md b/README.md
index f9ffe25..3fb91c1 100644
--- a/README.md
+++ b/README.md
@@ -146,11 +146,11 @@ Furthermore, xDiT incorporates optimization techniques from [DiTFastAttn](https:
ComfyUI, is the most popular web-based Diffusion Model interface optimized for workflow.
It provides users with a UI platform for image generation, supporting plugins like LoRA, ControlNet, and IPAdaptor. Yet, its design for native single-GPU usage leaves it struggling with the demands of today’s large DiTs, resulting in unacceptably high latency for users like Flux.1.
-Using our commercial project **TACO-DiT**, a SaaS build on xDiT, we’ve successfully implemented a multi-GPU parallel processing workflow within ComfyUI, effectively addressing Flux.1’s performance challenges. Below is the example of using TACO-DiT to accelerate a Flux workflow with LoRA:
+Using our commercial project **TACO-DiT**, a close-sourced ComfyUI variant built with xDiT, we’ve successfully implemented a multi-GPU parallel processing workflow within ComfyUI, effectively addressing Flux.1’s performance challenges. Below is an example of using TACO-DiT to accelerate a Flux workflow with LoRA:
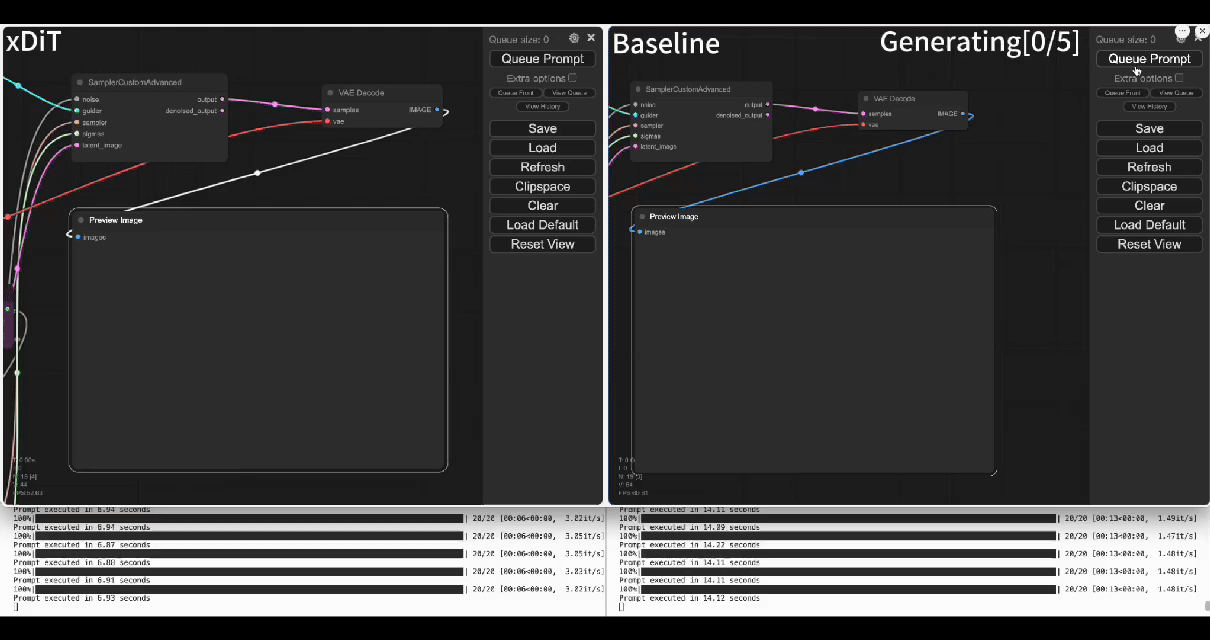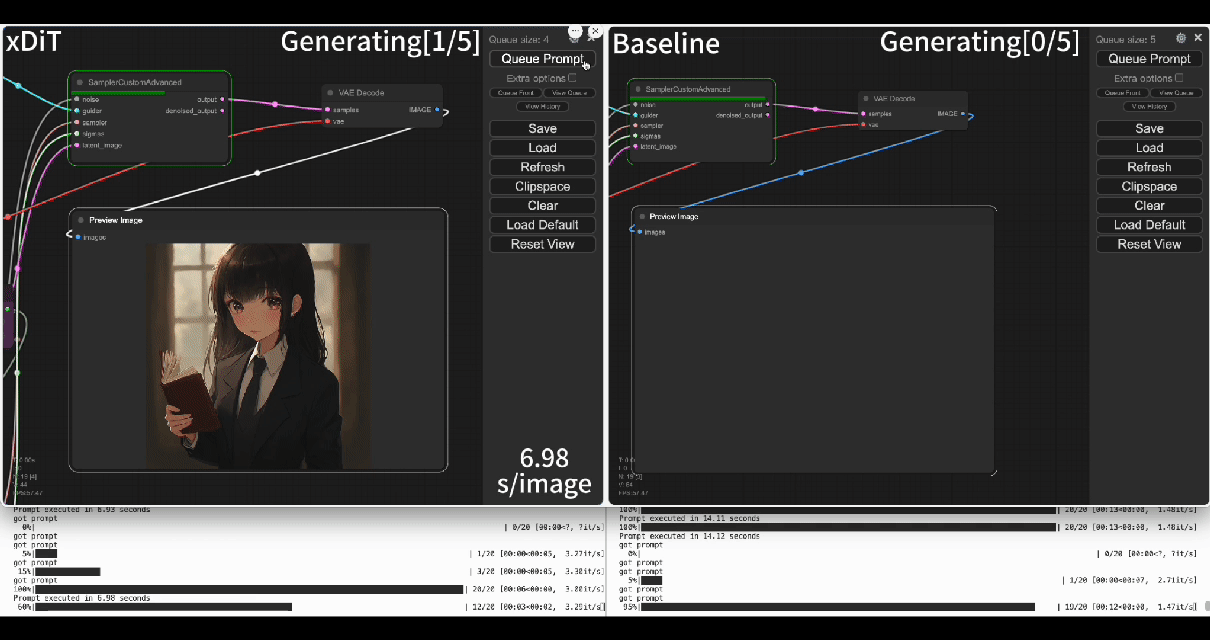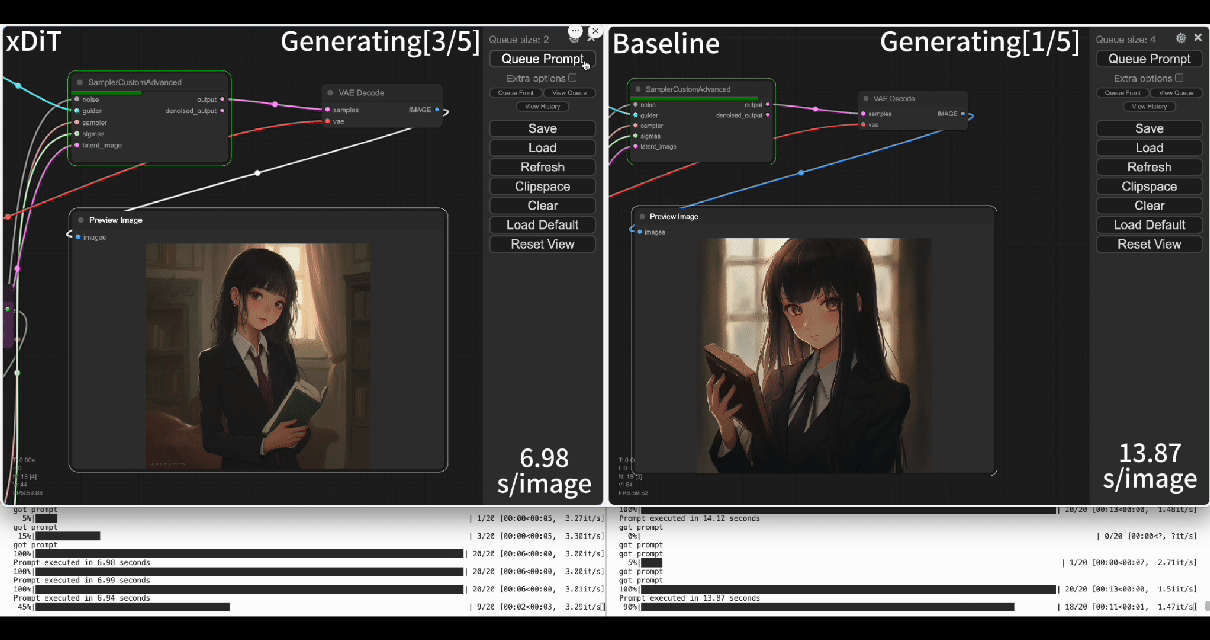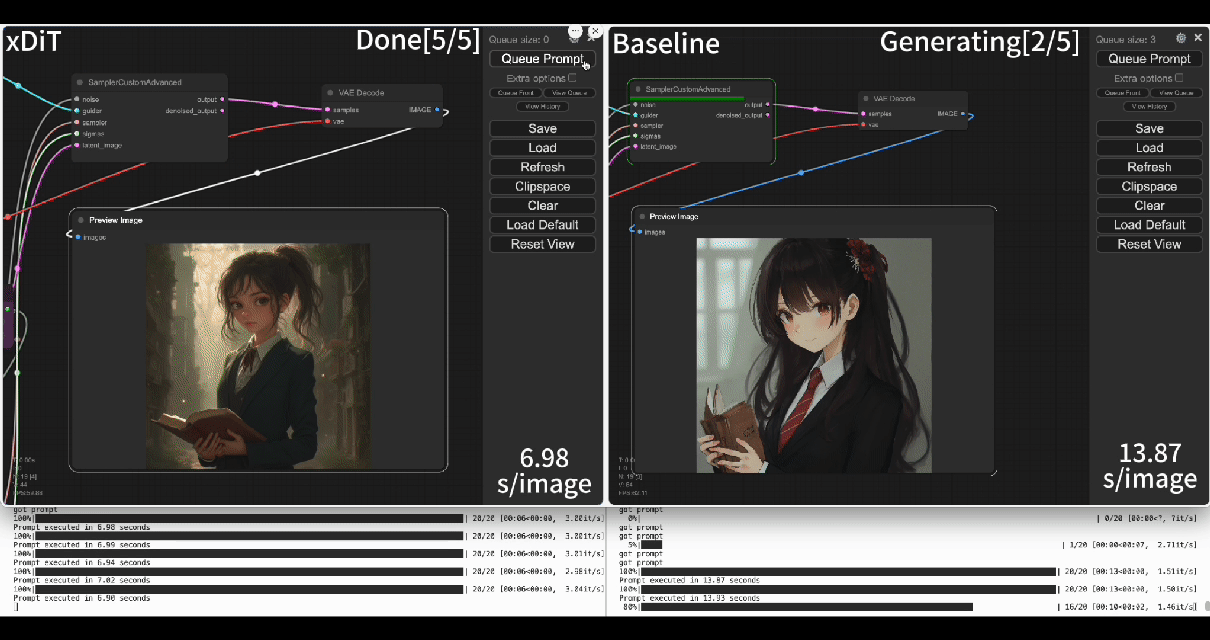
-By using TACO-DiT, you could significantly reduce your ComfyUI workflow inference latency, and boosting the throughput with Multi-GPUs. Now it is compatible with multiple Plug-ins, including Controlnet and loras.
+By using TACO-DiT, you could significantly reduce your ComfyUI workflow inference latency, and boosting the throughput with Multi-GPUs. Now it is compatible with multiple Plug-ins, including ControlNet and LoRAs.
More features and details can be found in our Intro Video:
+ [[YouTube] TACO-DiT: Accelerating Your ComfyUI Generation Experience](https://www.youtube.com/watch?v=7DXnGrARqys)
@@ -158,8 +158,6 @@ More features and details can be found in our Intro Video:
The blog article is also available: [Supercharge Your AIGC Experience: Leverage xDiT for Multiple GPU Parallel in ComfyUI Flux.1 Workflow](https://medium.com/@xditproject/supercharge-your-aigc-experience-leverage-xdit-for-multiple-gpu-parallel-in-comfyui-flux-1-54b34e4bca05).
-Currently, if you need the parallel version of ComfyUI, please fill in this [application form ](https://forms.office.com/r/LjG3xJDF80) or contact [xditproject@outlook.com](mailto:xditproject@outlook.com).
-
📈 Performance
HunyuanVideo
@@ -248,7 +246,7 @@ You can easily modify the model type, model directory, and parallel options in t
bash examples/run.sh
```
-Hybriding multiple parallelism techniques togather is essential for efficiently scaling.
+Hybridizing multiple parallelism techniques together is essential for efficiently scaling.
It's important that **the product of all parallel degrees matches the number of devices**.
Note use_cfg_parallel means cfg_parallel=2. For instance, you can combine CFG, PipeFusion, and sequence parallelism with the command below to generate an image of a cute dog through hybrid parallelism.
Here ulysses_degree * pipefusion_parallel_degree * cfg_degree(use_cfg_parallel) == number of devices == 8.
@@ -306,7 +304,7 @@ The (xDiT) highlights the methods first propose
The communication and memory costs associated with the aforementioned intra-image parallelism, except for the CFG and DP (they are inter-image parallel), in DiTs are detailed in the table below. (* denotes that communication can be overlapped with computation.)
-As we can see, PipeFusion and Sequence Parallel achieve lowest communication cost on different scales and hardware configurations, making them suitable foundational components for a hybrid approach.
+As we can see, PipeFusion and Sequence Parallel achieve the lowest communication cost on different scales and hardware configurations, making them suitable foundational components for a hybrid approach.
𝒑: Number of pixels;\
𝒉𝒔: Model hidden size;\
@@ -367,7 +365,7 @@ For usage instructions, refer to the [example/run.sh](./examples/run.sh). Simply
DiTFastAttn
-xDiT also provides DiTFastAttn for single GPU acceleration. It can reduce computation cost of attention layer by leveraging redundancies between different steps of the Diffusion Model.
+xDiT also provides DiTFastAttn for single GPU acceleration. It can reduce the computation cost of attention layers by leveraging redundancies between different steps of the Diffusion Model.
[DiTFastAttn: Attention Compression for Diffusion Transformer Models](./docs/methods/ditfastattn.md)