{kind=link}
{kind=link}
{kind=link}
{kind=link}
.png){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Mr K. is a very methodical fellow, but unfortunately today, Mr. K is in a rush he must go directly to work but he only has 25L in his car's tank. What is the probability that he will be able to go to work and return home without running out of gas.
Luckily Mr K. has monitored how much his car consume every single day on his daily commute. This data is available on the consumption.csv on this folder.
One of the most important steps when modeling it to be clear and conscious about your premises. Even for such a simple problem as this one we have a lot of premises that can pass totally unnoticed if we do not explicit them.
The first premise we are making is that we can achieve the desired precision by modeling the consumption using just one simple model. In our case will be a normal distribution model. In reality almost everything somehow affects the car consumption: the traffic, the weather, the car age, tire age, the driver skill, driver mood, gas price, Mid East politics etc... In our case we will simplify, without further tests, the model to a Normal Distribution (two variables, mean and standard deviation).
Given that we do not know the real mean and the real standard deviation we will need to estimate these values; this is called "a posteriori" estimation. In the field of "a posteriori" estimation, when we maximize the likelihood of a database to a normal distribution we call "Maximum Likelihood Estimation", which is a special case os "Maximum a Posteriori Estimation" (MAP).
Our fist task, off course, is to make a very simple plot of the consumption on the "Home-Work" commute.
#R
> consumption <- read.csv("consumption.csv")
> homeWork <- consumption[consumption$type == 1,]
> png(filename="homeWork.plot.png")
> plot(homeWork$day, homeWork$consumption)
> dev.off()

Well, it is not hard to see that we do not have clear relationship between the day and the consumption, but maybe we can understand the data better looking to its histogram.
#R
> png(filename="homeWork.hist.png")
> hist(homeWork$consumption)
> dev.off()
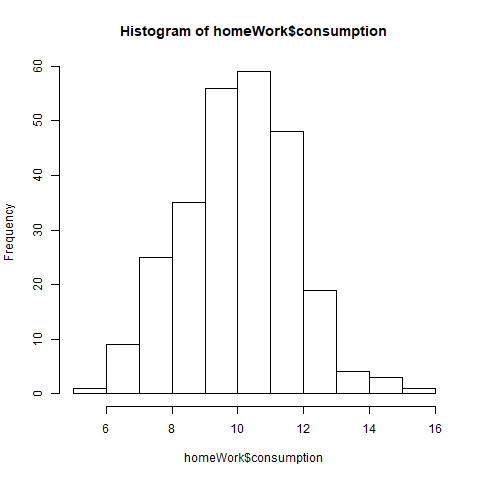
hum... The resemblance with a normal distribution is almost perfect. Which is wonderful for us, because allows us to model the consumption using a simple normal distribution.
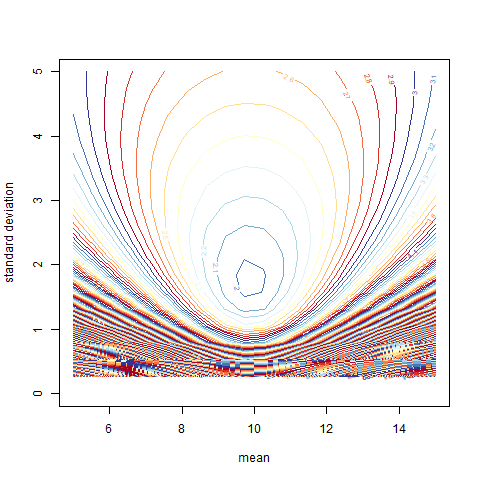
The graph below show the Normal Likelihood of the home-work data. We can see that the maximum is converging around mean = 10 and standard deviation (sd) = 2.
#R
#plotMLE is our custom function (code is below)
> plotMLE(homeWork$consumption, x=c(5,15),y=c(0,5), levels = 2000)

We can ask R to give us the exact value using a numerical optimization algorithm.
#R
> optim(c(12,4), normal.lik.muvar, y=homeWork$consumption, method="BFGS")
#Result
$par
[1] 10.01983 1.70105
$value
[1] 1.950178
$counts
function gradient
23 19
$convergence
[1] 0
$message
NULL
So R is telling us that the optimal (as we defined, more on how we defined this below) parameters are: mean = 10, sd = 1.70. And just to confirm let us plot dashed lines to see if the results are consistent.
> png(filename="homeWork.likelihood.withlines.png")
> plotMLE(homeWork$consumption, x=c(5,15),y=c(0,5), levels = 2000)
> abline(h=1.70105, lty=2)
> abline(v=10.01983, lty=2)
> dev.off()

OK. First step done. We now have a model to Mr. K. home work consumption.
Normal Distribution
μ (mean): 10
σ (standard deviation): 1.70
We can even see how out model is compared to the real histogram. And one can easily see that we have a vary good model.

Let us follow the same steps on the Work-Home commute.

Now, plotting the MLE:
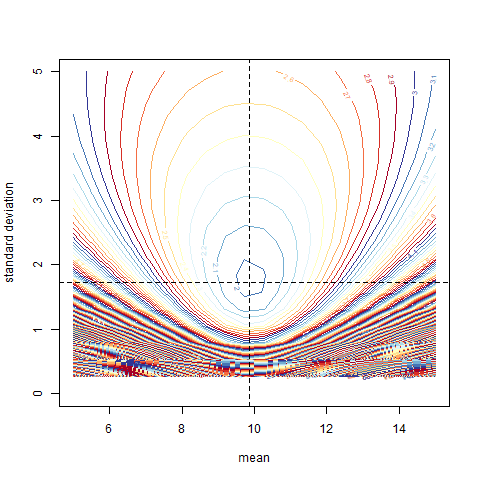
The actual optimal value is:
> optim(c(12,4),normal.lik.muvar,y=workHome$consumption,method="BFGS")
$par
[1] 9.879261 1.727495
$value
[1] 1.96561
$counts
function gradient
24 18
$convergence
[1] 0
$message
NULL
Well, now with these two model we can analyze Mr. K. daily consumption, that is, obviously, home to work plus work to home consumption.
D = HW + WH
We know that when summing two normal distributed random variables both the mean and the standard deviation can be calculated by its sum.
mean(D) = mean(HW) + mean(WH)
sd(D) = sd(HW) + sd(WH)
Before continuing let us test the theory. First we will aggregate the consumption per day.


As we can see, both mean and standard deviation are compliant with the theory and we still have the normal distribution as a good model.
Now we are ready to answer the question. What is the probability of Mr. K. running out of gas if he has 25L in his tank.
What we need to do know is draw the line corresponding 25L, and calculate the area under our normal distribution PDF from minus infinity until 25L. Which is the same as the CDF at 25 using out mean and standard deviation.
> pnorm(25, mean = 19.899697, sd = 2.421108)
[1] 0.9824238
This give us the probability of Mr. K. being able to go to work and return home. We actually want the inverse of that. We must do:
> pnorm(25, mean = 19.899697, sd = 2.421108, lower.tail = FALSE)
[1] 0.01757619
So we can, finally!, say that there is a 1.75% chance of Mr. K running out of gas returning home.
Maximum Likelihood Estimation
Geometric Interpretation of Covariance Matrix