Benchmarks were run to compare HaloDB against RocksDB and KyotoCabinet. KyotoCabinet was chosen as we were using it in production. RockDB was chosen as it is a well known storage engine with good documentation and a large community. HaloDB and KyotoCabinet supports only a subset of RocksDB's features, therefore the comparison is not exactly fair to RocksDB.
All benchmarks were run on bare-metal box with the following specifications:
- 2 x Xeon E5-2680 2.50GHz (HT enabled, 24 cores, 48 threads)
- 128 GB of RAM.
- 1 Samsung PM863 960 GB SSD with XFS file system.
- RHEL 6 with kernel 2.6.32.
Key size was 8 bytes and value size 1024 bytes. Tests created a db with 500 million records with total size of approximately 500GB. Since this is significantly bigger than the available memory it will ensure that the workload will be IO bound, which is what HaloDB was primarily designed for.
Benchmark tool can be found here
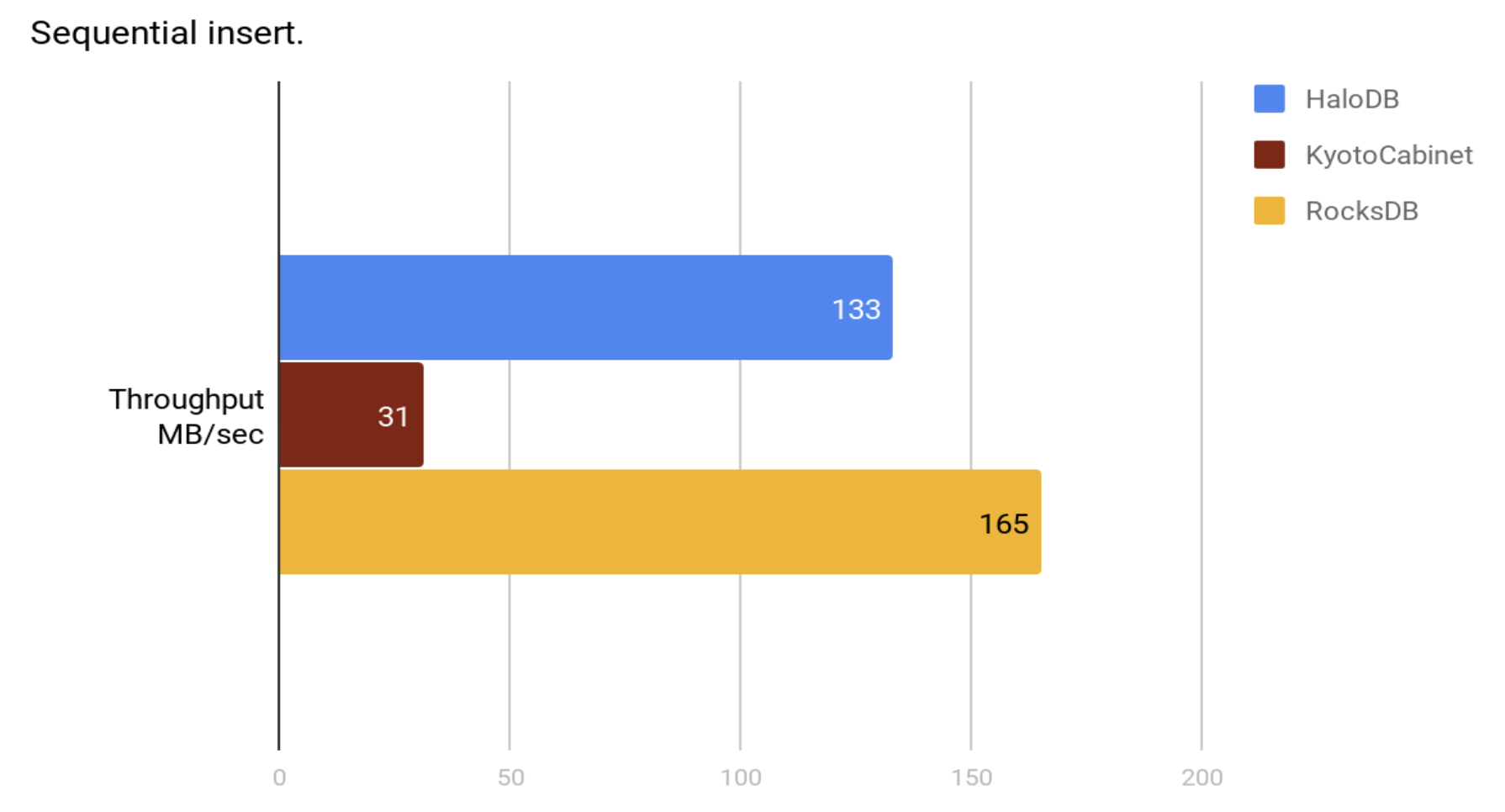
Create a new db by inserting 500 million records in sorted key order.
DB size at the end of the test run.
| Storage Engine | GB |
|---|---|
| HaloDB | 503 |
| KyotoCabinet | 609 |
| RocksDB | 487 |
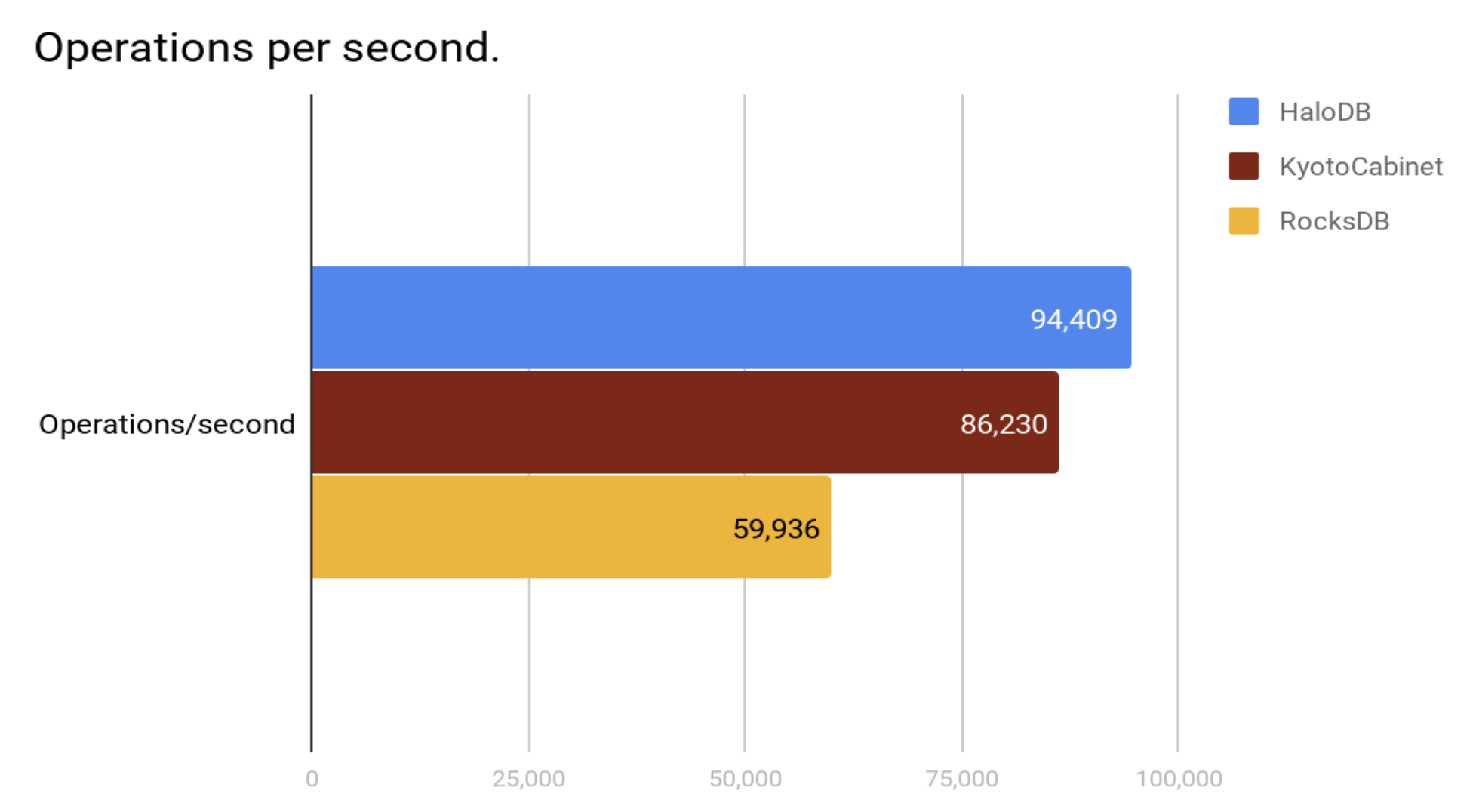
Measure random read performance with 32 threads doing 640 million reads in total. Read ahead was disabled for this test.
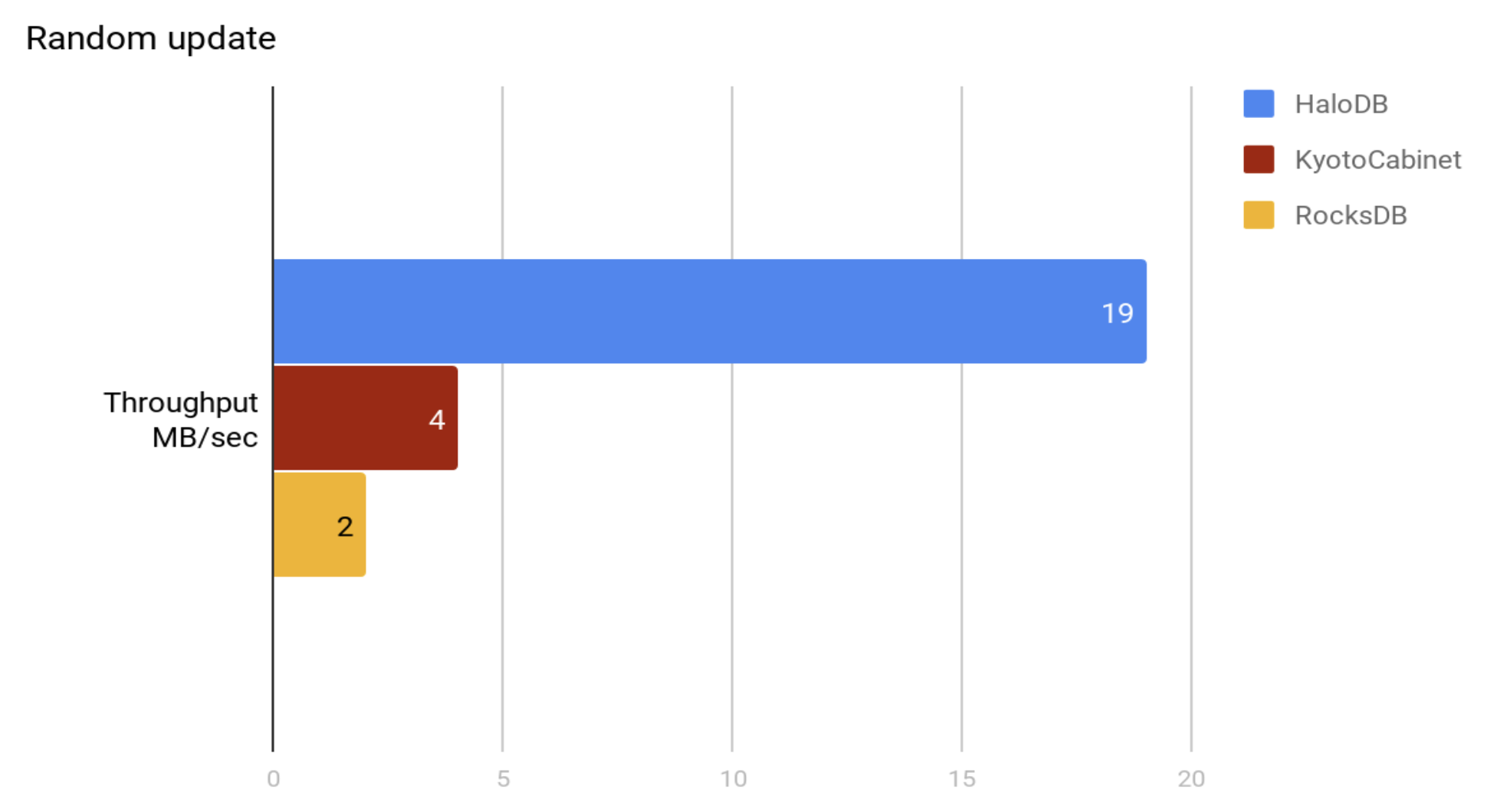
Perform 500 million updates to randomly selected records.
DB size at the end of the test run.
| Storage Engine | GB |
|---|---|
| HaloDB | 556 |
| KyotoCabinet | 609 |
| RocksDB | 504 |
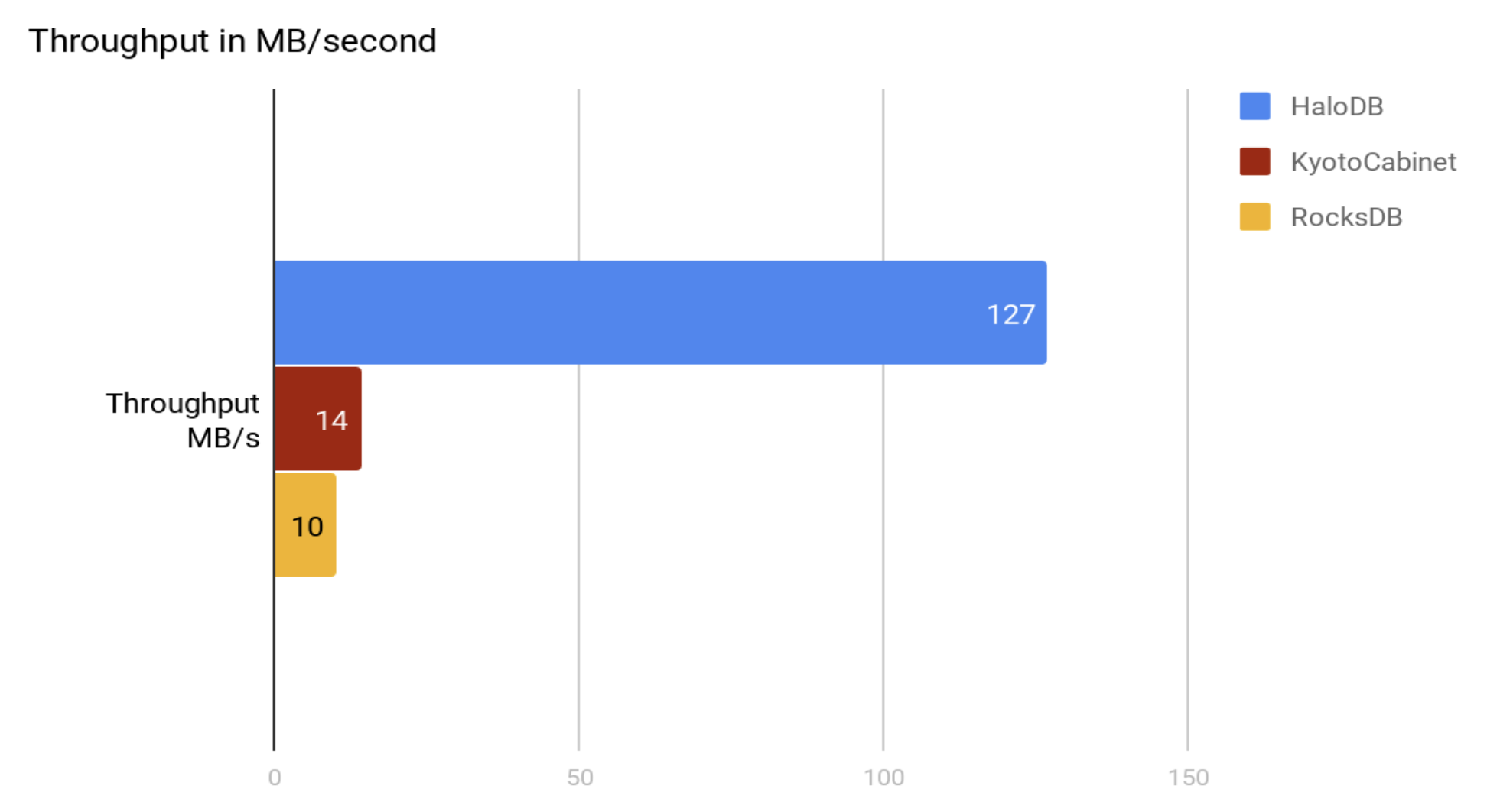
Insert 500 million records into an empty db in random order.
32 threads doing a total of 640 million random reads and one thread doing random updates as fast as possible.
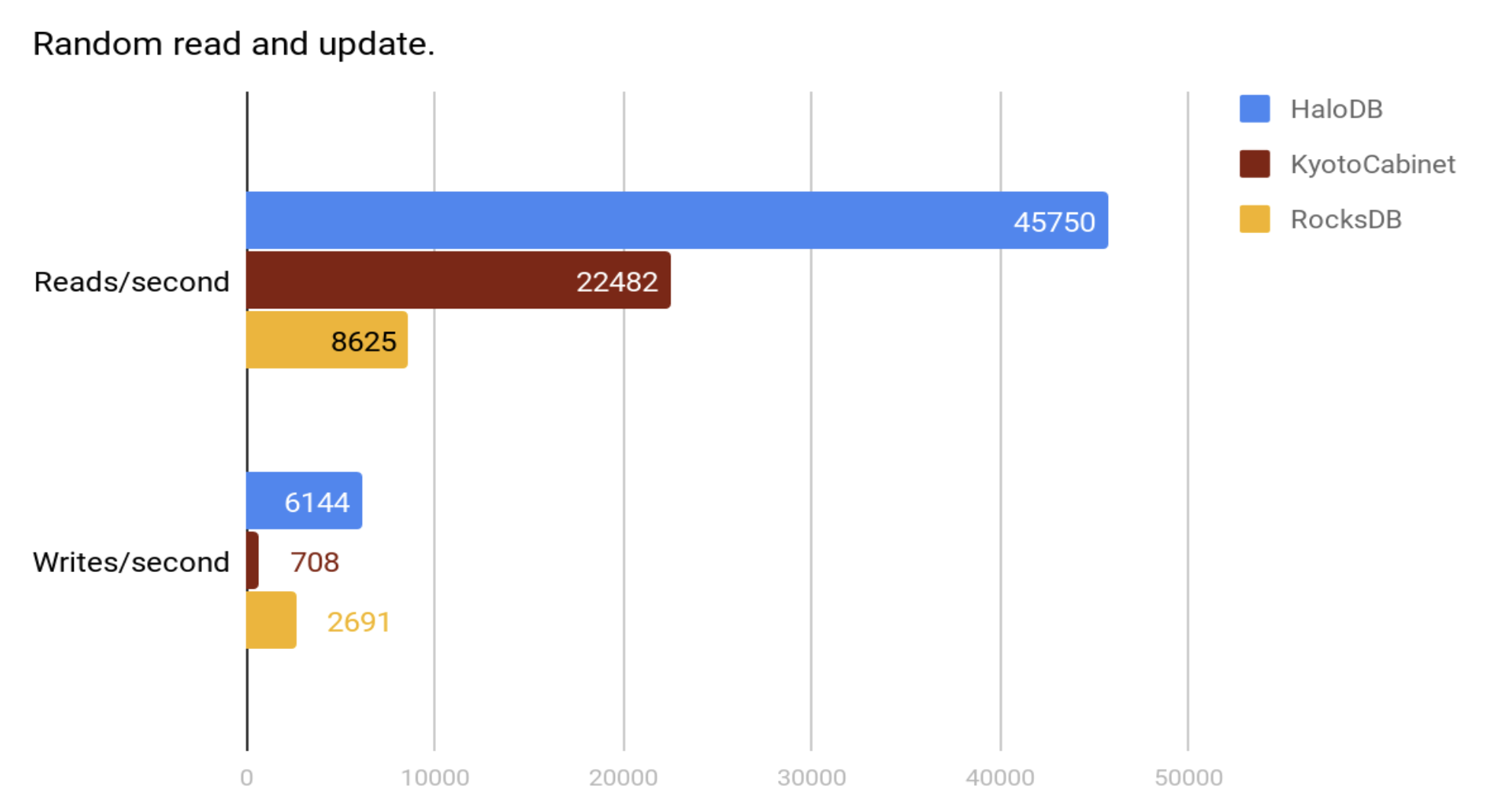
HaloDB doesn't claim to be always better than RocksDB or KyotoCabinet. HaloDB was written for a specific type of workload, and therefore had the advantage of optimizing for that workload; the trade-offs that HaloDB makes might make it sub-optimal for other workloads (best to run benchmarks to verify). HaloDB also offers only a small subset of features compared to other storage engines like RocksDB.
All writes to HaloDB are sequential writes to append-only log files. HaloDB uses a background compaction job to clean up stale data. The threshold at which a file is compacted can be tuned and this determines HaloDB's write amplification and space amplification. A compaction threshold of 50% gives a write amplification of only 2, this coupled with the fact that we do only sequential writes are the primary reasons for HaloDB’s high write throughput. Additionally, the only meta-data that HaloDB need to modify during writes are those of the index in memory. The trade-off here is that HaloDB will occupy more space on disk.
To lookup the value for a key its corresponding metadata is first read from the in-memory index and then the value is read from disk. Therefore each lookup request requires at most a single read from disk, giving us a read amplification of 1, and is primarily responsible for HaloDB’s low read latencies. The trade-off here is that we need to store all the keys and their associated metadata in memory. HaloDB also need to scan all the keys during startup to build the in-memory index. This, depending on the number of keys, might take a few minutes.
HaloDB avoids doing in-place updates and doesn't need record level locks. A type of MVCC is inherent in the design of all log-structured storage systems. This also helps with performance even under high read and write throughput.
HaloDB also doesn't support range scans and therefore doesn't pay the cost associated with storing data in a format suitable for efficient range scans.