2019-07-02 · 绍辉 · #分布式事务 #实践 #开源 #Seata
获取本次分享完整 PPT:下载地址
本文整理自蚂蚁金服技术专家、分布式事务 Seata 发起者之一张森(花名:绍辉)在 GIAC 全球互联网架构大会的分享。详细讲解了在分布式架构演进中,蚂蚁金服面对的跨服务、跨数据库的业务数据一致性问题以及应对措施,并分享了分布式事务 Seata 的 AT、TCC、Saga 和 XA 四种模式。
Seata:https://github.com/seata/seata

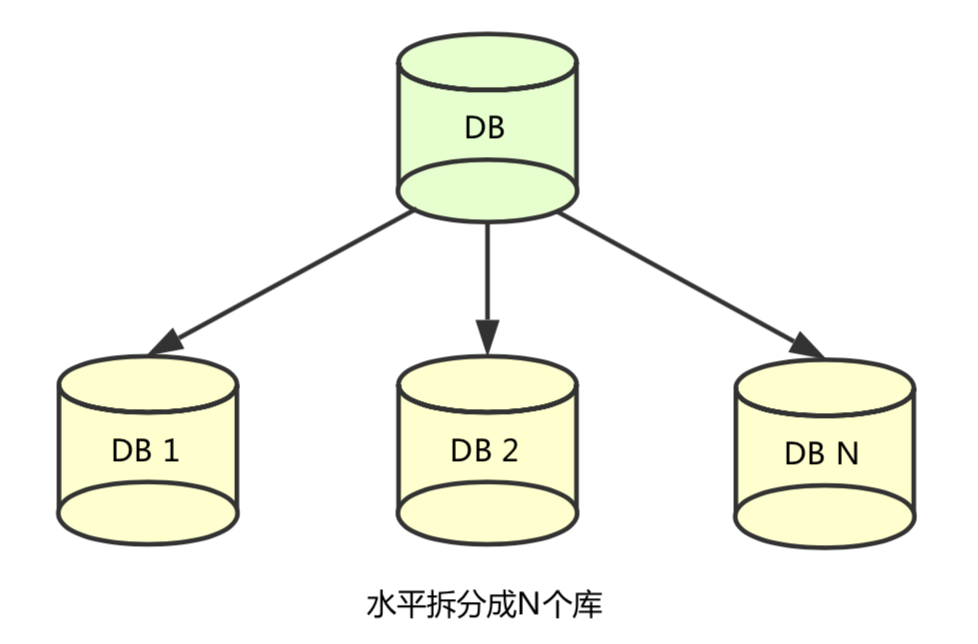
蚂蚁金服的业务数据库起初是单库单表,但随着业务数据规模的快速发展,数据量越来越大,单库单表逐渐成为瓶颈。所以我们对数据库进行了水平拆分,将原单库单表拆分成数据库分片。
如下图所示,分库分表之后,原来在一个数据库上就能完成的写操作,可能就会跨多个数据库,这就产生了跨数据库事务问题。
在业务发展初期,“一块大饼”的单业务系统架构,能满足基本的业务需求。但是随着业务的快速发展,系统的访问量和业务复杂程度都在快速增长,单系统架构逐渐成为业务发展瓶颈,解决业务系统的高耦合、可伸缩问题的需求越来越强烈。
如下图所示,蚂蚁金服按照面向服务(SOA)的架构的设计原则,将单业务系统拆分成多个业务系统,降低了各系统之间的耦合度,使不同的业务系统专注于自身业务,更有利于业务的发展和系统容量的伸缩。
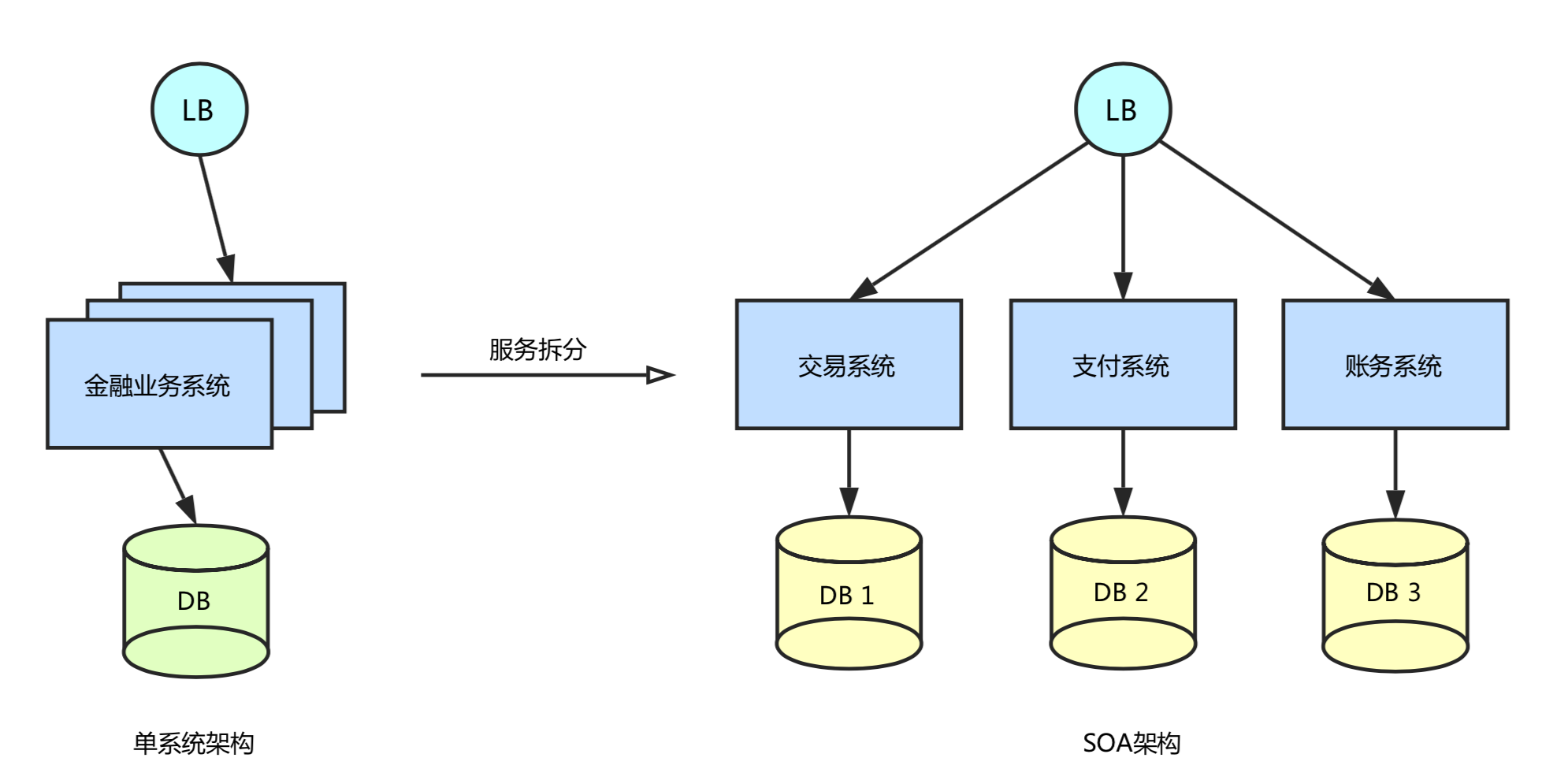
业务系统按照服务拆分之后,一个完整的业务往往需要调用多个服务,如何保证多个服务间的数据一致性成为一个难题。
在数据库水平拆分、服务垂直拆分之后,一个业务操作通常要跨多个数据库、服务才能完成。在分布式网络环境下,我们无法保障所有服务、数据库都百分百可用,一定会出现部分服务、数据库执行成功,另一部分执行失败的问题。
当出现部分业务操作成功、部分业务操作失败时,业务数据就会出现不一致。以金融业务中比较常见的“转账”场景为例:
如下图所示,在支付宝的“转账”操作中,要分别完成 4 个动作:
- 创建交易订单;
- 创建支付订单;
- A 账户扣钱;
- B 账户加钱;
而完成以上操作要分别访问 3 个服务和 4 个数据库。
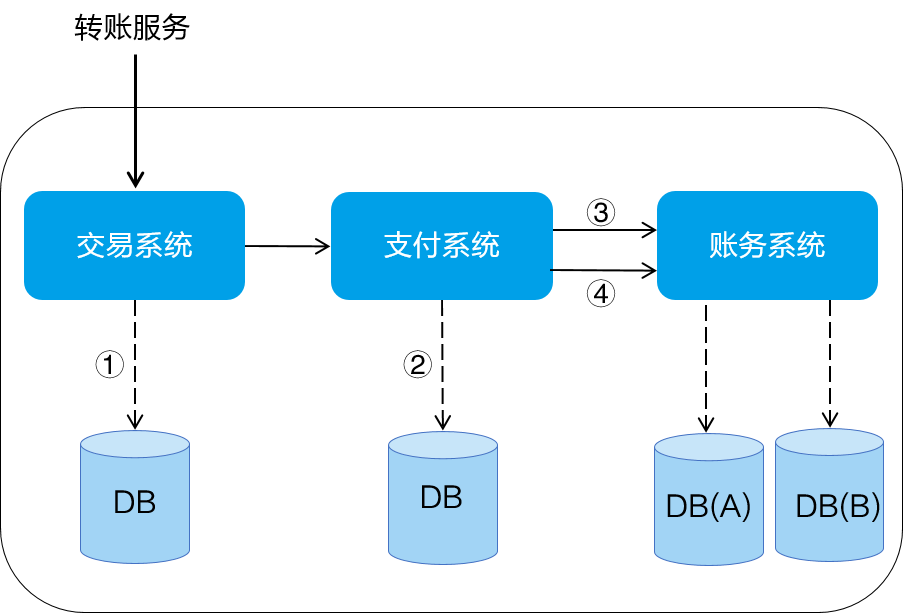
在分布式环境下,肯定会出现部分操作成功、部分操作失败的问题,比如:A 账户的钱扣了,但是 B 账户的钱没加上,这就造成了资金损失,影响资金安全。
在金融业务场景下,我们必须保证“转账”的原子性,要么所有操作全部成功,要么全部失败,不允许出现部分成功部分失败的现象。
为了解决跨数据库、跨服务的业务数据一致性问题,蚂蚁金服自主研发了分布式事务中间件。
从 2007 年开始做分布式事务并支持双十一,至今已经有 12 年。
2013 年,蚂蚁金服开始做单元化改造,分布式事务也开始支持 LDC、异地多活和高可用容灾,解决了机房故障情况下服务快速恢复的问题。
2014 年,蚂蚁金服分布式事务中间件 DTX(Distributed Transaction-eXtended)开始通过蚂蚁金融云对外输出,我们发展了一大批的外部用户。在发展外部客户的过程中,外部客户表示愿意牺牲一部分性能(无蚂蚁的业务规模)以换取接入便利性和无侵入性。所以在 2015 年,我们开始做无侵入的事务解决方案:FMT 模式和 XA 模式。
蚂蚁金服分布式事务(Distributed Transaction-eXtended,简称 DTX)链接:
https://tech.antfin.com/products/DTX
Seata(Simple Extensible Autonomous Transaction Architecture,简单可扩展自治事务框架)是 2019 年 1 月份蚂蚁金服和阿里巴巴共同开源的分布式事务解决方案。Seata 开源半年左右,目前已经有接近一万 star,社区非常活跃。我们热忱欢迎大家参与到 Seata 社区建设中,一同将 Seata 打造成开源分布式事务标杆产品。
Seata:https://github.com/seata/seata

如下图所示,Seata 中有三大模块,分别是 TM、RM 和 TC。 其中 TM 和 RM 是作为 Seata 的客户端与业务系统集成在一起,TC 作为 Seata 的服务端独立部署。
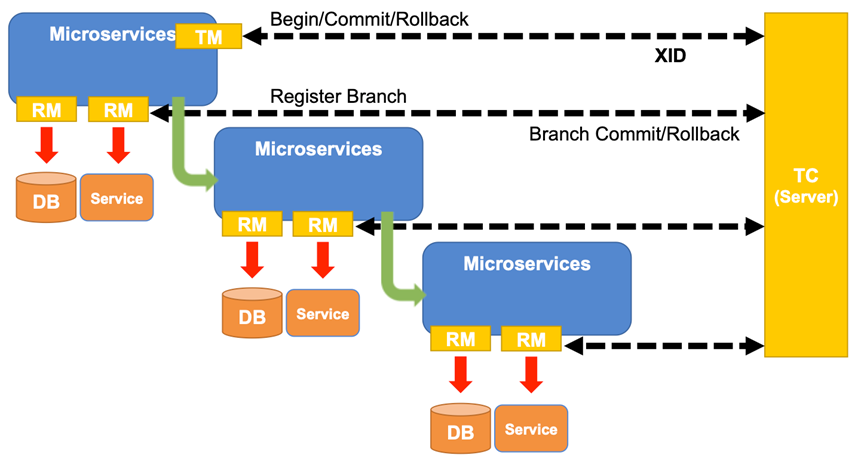
在 Seata 中,分布式事务的执行流程:
- TM 开启分布式事务(TM 向 TC 注册全局事务记录);
- 按业务场景,编排数据库、服务等事务内资源(RM 向 TC 汇报资源准备状态 );
- TM 结束分布式事务,事务一阶段结束(TM 通知 TC 提交/回滚分布式事务);
- TC 汇总事务信息,决定分布式事务是提交还是回滚;
- TC 通知所有 RM 提交/回滚 资源,事务二阶段结束。
Seata 会有 4 种分布式事务解决方案,分别是 AT 模式、TCC 模式、Saga 模式和 XA 模式。
今年 1 月份,Seata 开源了 AT 模式。AT 模式是一种无侵入的分布式事务解决方案。在 AT 模式下,用户只需关注自己的“业务 SQL”,用户的 “业务 SQL” 作为一阶段,Seata 框架会自动生成事务的二阶段提交和回滚操作。
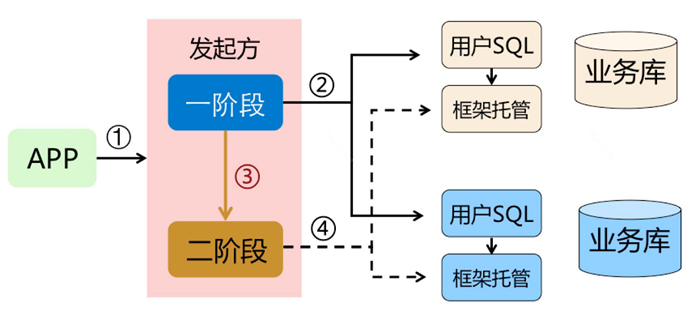
- 一阶段:
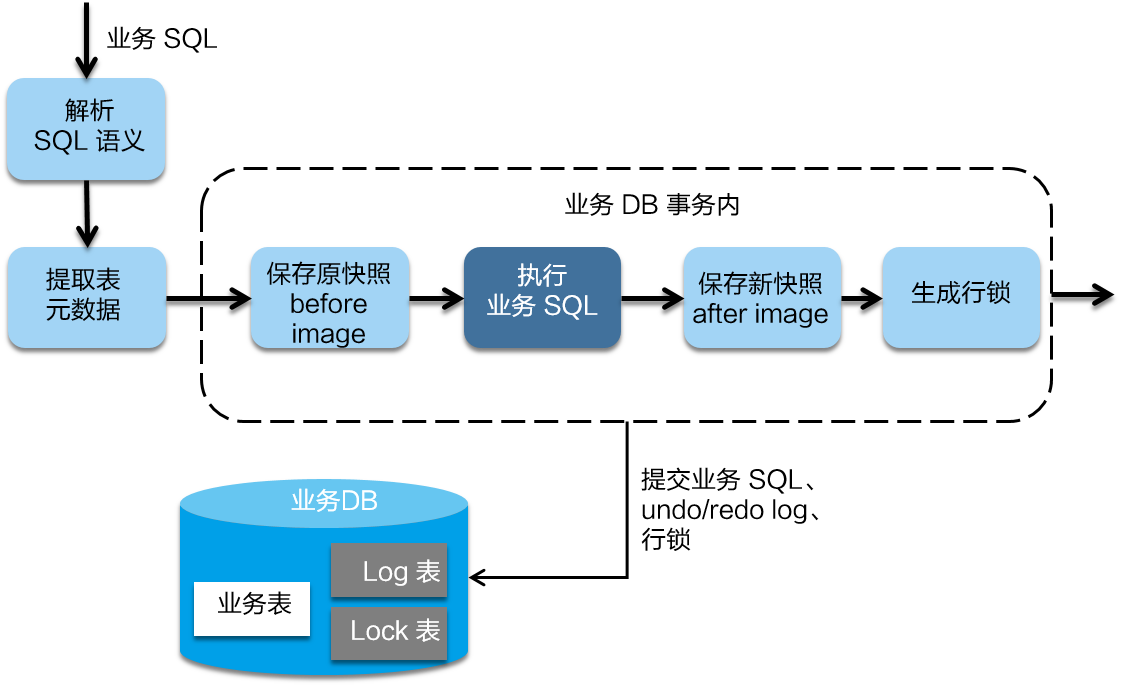
在一阶段,Seata 会拦截“业务 SQL”,首先解析 SQL 语义,找到“业务 SQL”要更新的业务数据,在业务数据被更新前,将其保存成“before image”,然后执行“业务 SQL”更新业务数据,在业务数据更新之后,再将其保存成“after image”,最后生成行锁。以上操作全部在一个数据库事务内完成,这样保证了一阶段操作的原子性。
- 二阶段提交:
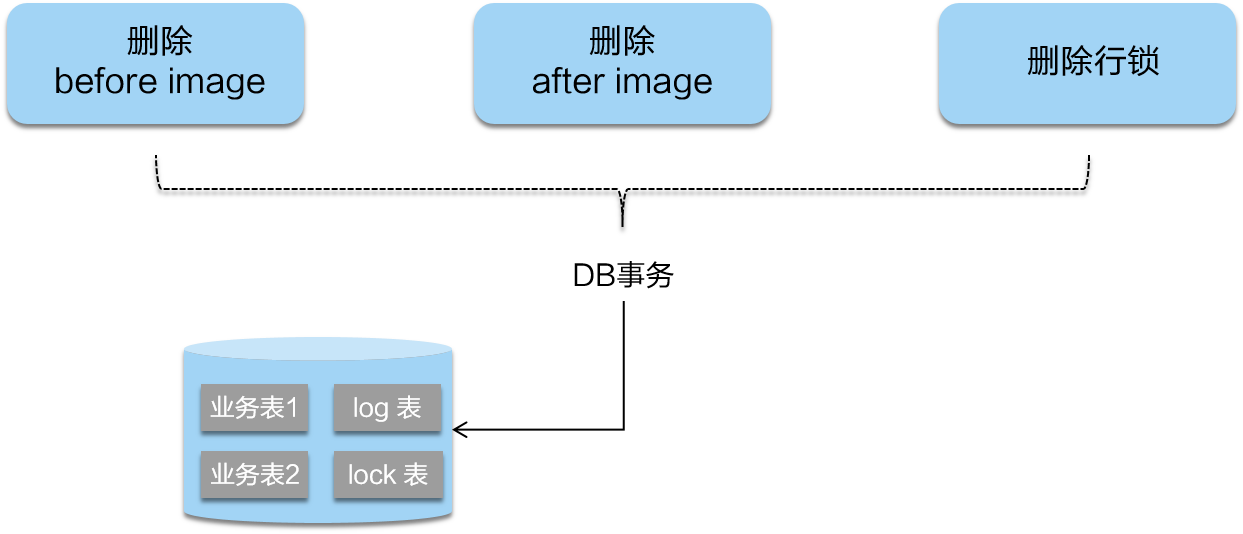
二阶段如果是提交的话,因为“业务 SQL”在一阶段已经提交至数据库, 所以 Seata 框架只需将一阶段保存的快照数据和行锁删掉,完成数据清理即可。
- 二阶段回滚:
二阶段如果是回滚的话,Seata 就需要回滚一阶段已经执行的“业务 SQL”,还原业务数据。回滚方式便是用“before image”还原业务数据;但在还原前要首先要校验脏写,对比“数据库当前业务数据”和 “after image”,如果两份数据完全一致就说明没有脏写,可以还原业务数据,如果不一致就说明有脏写,出现脏写就需要转人工处理。
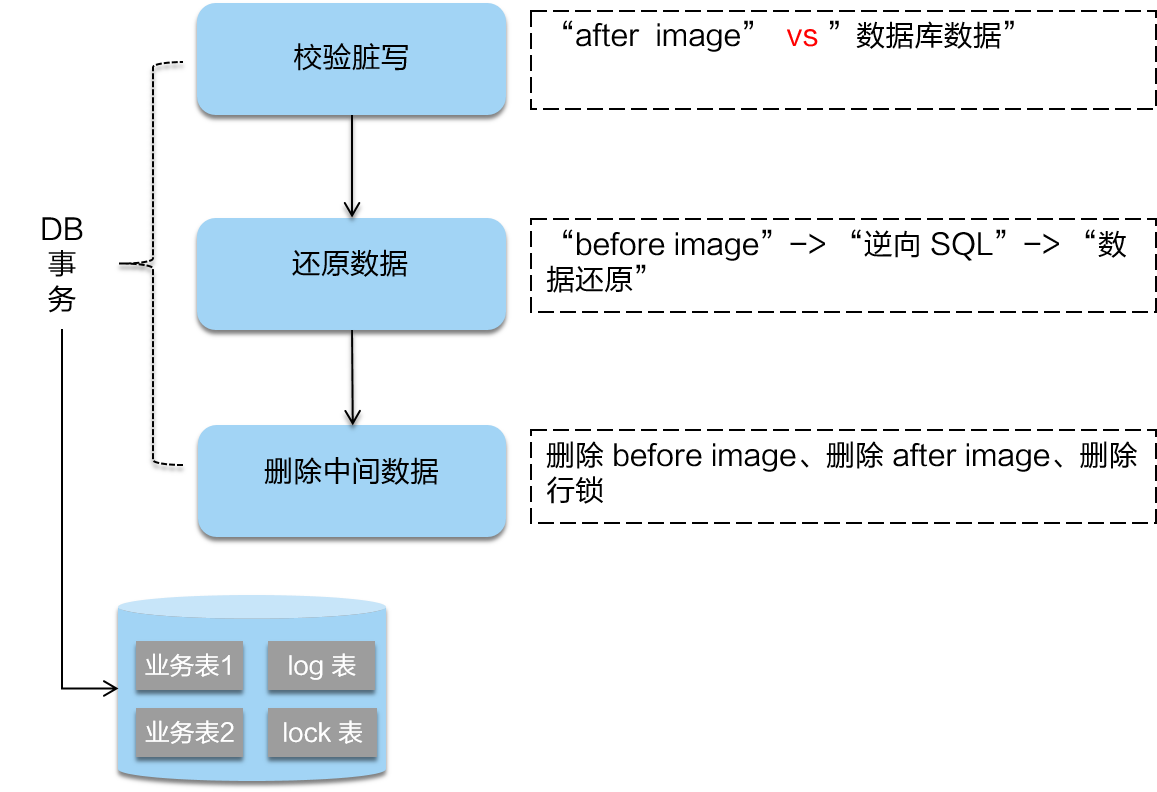
AT 模式的一阶段、二阶段提交和回滚均由 Seata 框架自动生成,用户只需编写“业务 SQL”,便能轻松接入分布式事务,AT 模式是一种对业务无任何侵入的分布式事务解决方案。
2019 年 3 月份,Seata 开源了 TCC 模式,该模式由蚂蚁金服贡献。TCC 模式需要用户根据自己的业务场景实现 Try、Confirm 和 Cancel 三个操作;事务发起方在一阶段 执行 Try 方式,在二阶段提交执行 Confirm 方法,二阶段回滚执行 Cancel 方法。
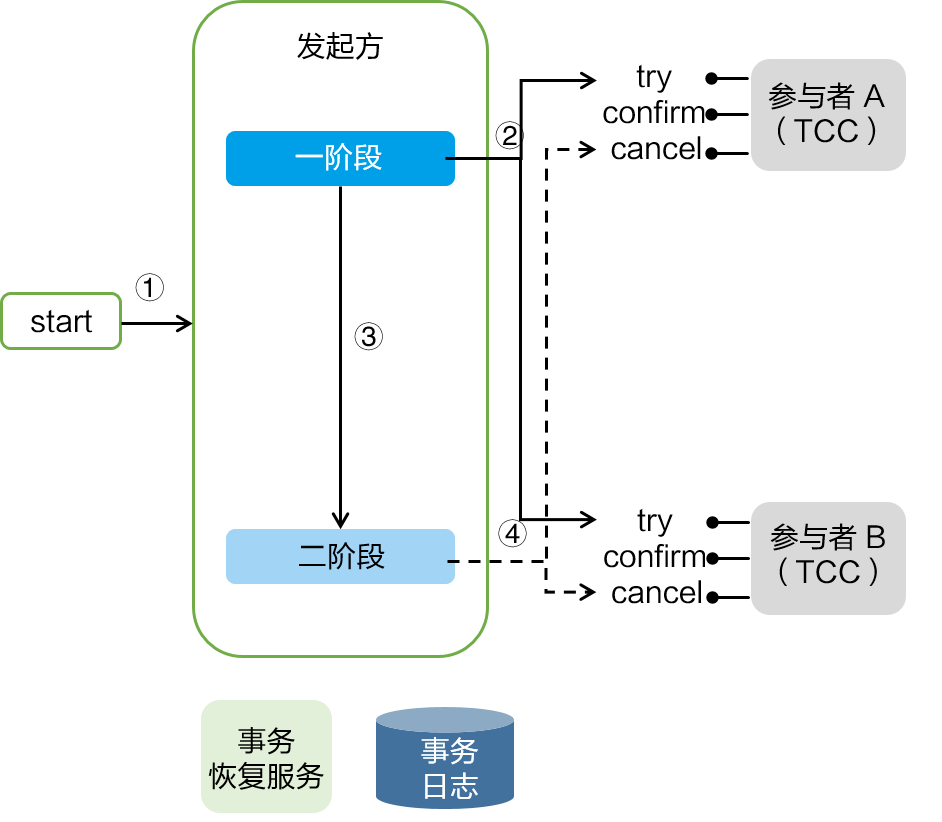
TCC 三个方法描述:
- Try:资源的检测和预留;
- Confirm:执行的业务操作提交;要求 Try 成功 Confirm 一定要能成功;
- Cancel:预留资源释放。
业务模型分 2 阶段设计:
用户接入 TCC ,最重要的是考虑如何将自己的业务模型拆成两阶段来实现。
以“扣钱”场景为例,在接入 TCC 前,对 A 账户的扣钱,只需一条更新账户余额的 SQL 便能完成;但是在接入 TCC 之后,用户就需要考虑如何将原来一步就能完成的扣钱操作,拆成两阶段,实现成三个方法,并且保证一阶段 Try 成功的话 二阶段 Confirm 一定能成功。

如上图所示,
Try 方法作为一阶段准备方法,需要做资源的检查和预留。在扣钱场景下,Try 要做的事情是就是检查账户余额是否充足,预留转账资金,预留的方式就是冻结 A 账户的 转账资金。Try 方法执行之后,账号 A 余额虽然还是 100,但是其中 30 元已经被冻结了,不能被其他事务使用。
二阶段 Confirm 方法执行真正的扣钱操作。Confirm 会使用 Try 阶段冻结的资金,执行账号扣款。Confirm 方法执行之后,账号 A 在一阶段中冻结的 30 元已经被扣除,账号 A 余额变成 70 元 。
如果二阶段是回滚的话,就需要在 Cancel 方法内释放一阶段 Try 冻结的 30 元,使账号 A 的回到初始状态,100 元全部可用。
用户接入 TCC 模式,最重要的事情就是考虑如何将业务模型拆成 2 阶段,实现成 TCC 的 3 个方法,并且保证 Try 成功 Confirm 一定能成功。相对于 AT 模式,TCC 模式对业务代码有一定的侵入性,但是 TCC 模式无 AT 模式的全局行锁,TCC 性能会比 AT 模式高很多。
Saga 模式是 Seata 即将开源的长事务解决方案,将由蚂蚁金服主要贡献。在 Saga 模式下,分布式事务内有多个参与者,每一个参与者都是一个冲正补偿服务,需要用户根据业务场景实现其正向操作和逆向回滚操作。
分布式事务执行过程中,依次执行各参与者的正向操作,如果所有正向操作均执行成功,那么分布式事务提交。如果任何一个正向操作执行失败,那么分布式事务会去退回去执行前面各参与者的逆向回滚操作,回滚已提交的参与者,使分布式事务回到初始状态。
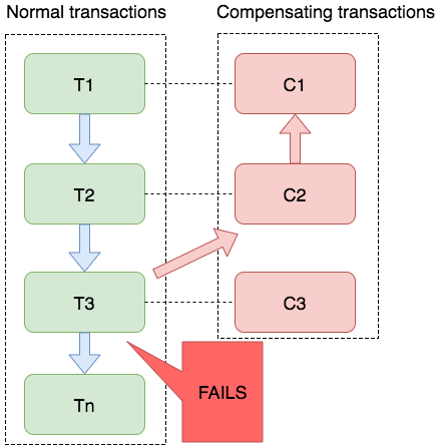
Saga 模式下分布式事务通常是由事件驱动的,各个参与者之间是异步执行的,Saga 模式是一种长事务解决方案。
XA 模式是 Seata 将会开源的另一种无侵入的分布式事务解决方案,任何实现了 XA 协议的数据库都可以作为资源参与到分布式事务中,目前主流数据库,例如 MySql、Oracle、DB2、Oceanbase 等均支持 XA 协议。
XA 协议有一系列的指令,分别对应一阶段和二阶段操作。“xa start”和 “xa end”用于开启和结束XA 事务;“xa prepare” 用于预提交 XA 事务,对应一阶段准备;“xa commit”和“xa rollback”用于提交、回滚 XA 事务,对应二阶段提交和回滚。
在 XA 模式下,每一个 XA 事务都是一个事务参与者。分布式事务开启之后,首先在一阶段执行“xa start”、“业务 SQL”、“xa end”和 “xa prepare” 完成 XA 事务的执行和预提交;二阶段如果提交的话就执行 “xa commit”,如果是回滚则执行“xa rollback”。这样便能保证所有 XA 事务都提交或者都回滚。
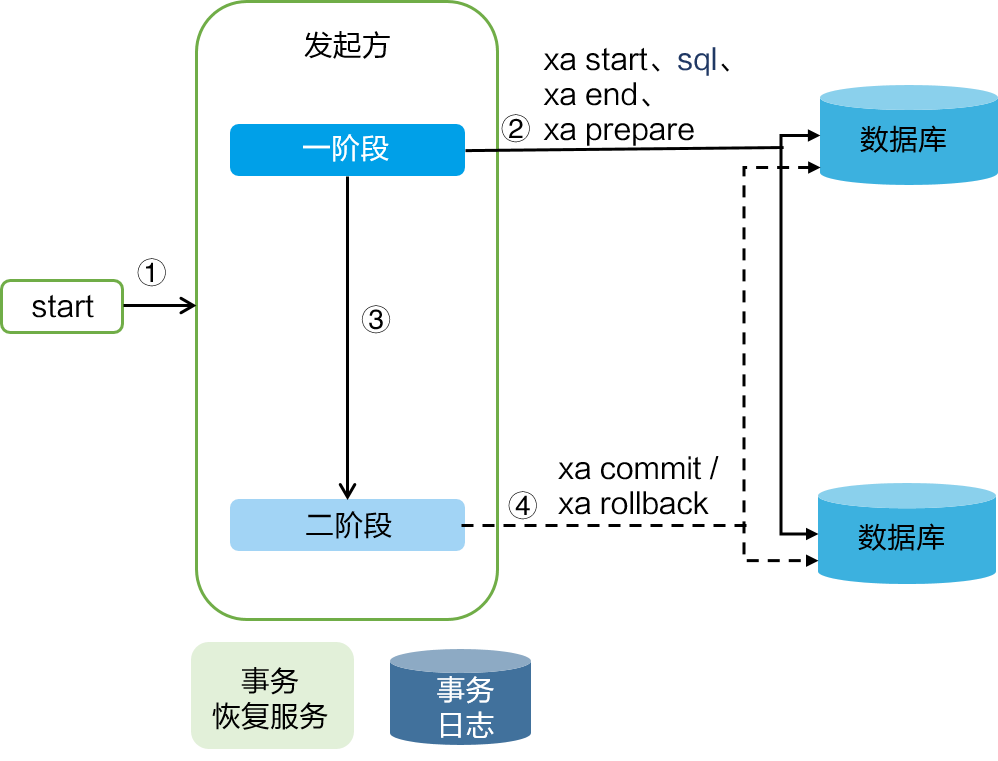
XA 模式下,用户只需关注自己的“业务 SQL”,Seata 框架会自动生成一阶段、二阶段操作;XA 模式的实现如下:
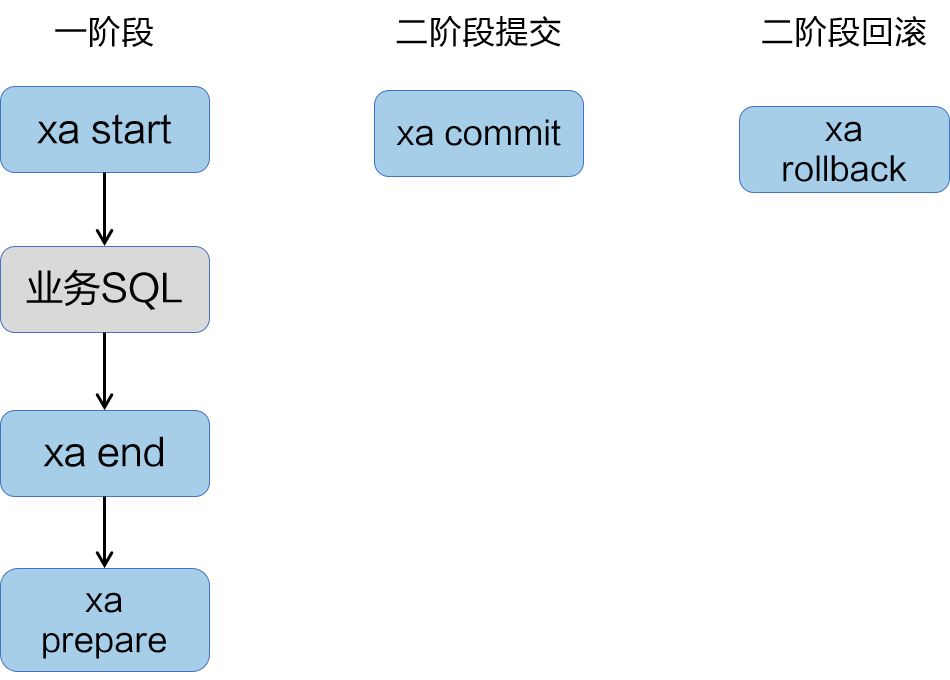
- 一阶段:
在 XA 模式的一阶段,Seata 会拦截“业务 SQL”,在“业务 SQL”之前开启 XA 事务(“xa start”),然后执行“业务 SQL”,结束 XA 事务“xa end”,最后预提交 XA 事务(“xa prepare”),这样便完成 “业务 SQL”的准备操作。
- 二阶段提交:
执行“xa commit”指令,提交 XA 事务,此时“业务 SQL”才算真正的提交至数据库。
- 二阶段回滚:
执行“xa rollback”指令,回滚 XA 事务,完成“业务 SQL”回滚,释放数据库锁资源。
XA 模式下,用户只需关注“业务 SQL”,Seata 会自动生成一阶段、二阶段提交和二阶段回滚操作。XA 模式和 AT 模式一样是一种对业务无侵入性的解决方案;但与 AT 模式不同的是,XA 模式将快照数据和行锁等通过 XA 指令委托给了数据库来完成,这样 XA 模式实现更加轻量化。
蚂蚁金服从 2007 年开始研发和应用分布式事务中间件,用 TCC 模式解决各类金融场景的数据一致性问题,后续又演进出 FMT(AT)、XA、Saga 等模式,各种模式分别适用于各类业务场景。我们决定将蚂蚁金服多年的技术积累开源出来,与社区共享蚂蚁金服的科技成果。
蚂蚁金服内部的分布式事务产品,在实现原理和使用方式上,与 Seata 类似,不同的是,为了支持双十一,对性能进行了极致优化,为了支持金融系统的高可用容灾,借助蚂蚁金服三地五中心架构实现了分布式事务服务的高可用容灾;接下来主要介绍蚂蚁金服在性能优化和高可用容灾方面的实践经验。
通常,一个 TM 会产生一笔主事务日志,一个 RM 会产生一条分支事务日志,每个分布式事务由一个 TM 和若干 RM 组成,一个分布式事务总共会有 1+N 条事务日志(N 为 RM 个数)。
在默认情况下,分布式事务执行过程中客户端将事务日志发送给服务端,服务端再将事务日志存储至数据库中,一条事务日志的存储链路会有 2 次 TCP ,分别是“客户端到服务端”和“服务端到数据库”, 我们称这种模式为异库模式。
在异库模式下,分布式事务存储事务日志总共需要 2*(1+N) 次左右的 TCP 通信。在 RM 数量较少的业务场景下,分布式事务性能还能接收,但有些业务场景下 RM 数量较多,此时事务内 TCP 数量也会增多,分布式事务性能急剧下降。
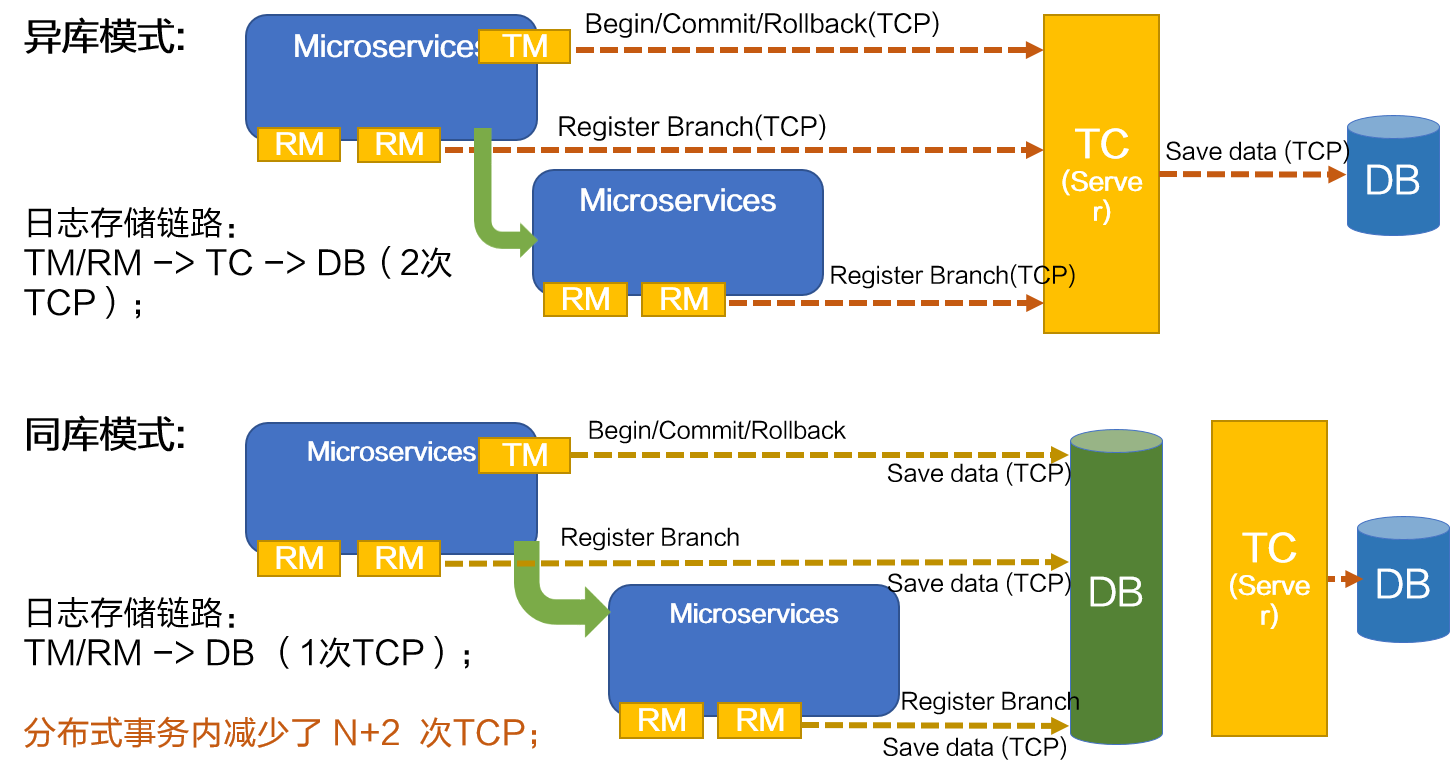
在事务执行过程中,客户端和服务端进行通信的目的是为了存储事务日志。如果客户端在存储事务日志时,绕过服务端直接将事务日志写入数据库(如上图“同库模式”所示),那么一笔事务日志的存储链路就由原来的 2 次 TCP 变成只需访问一次数据库便可,每条事务日志的存储减少了一次 TCP 通信,整个分布式事务就减少了 N+2 次 TCP 请求,分布式事务的性能大幅提升。我们将客户端直接将事务日志存储至数据库的模式称为同库模式。
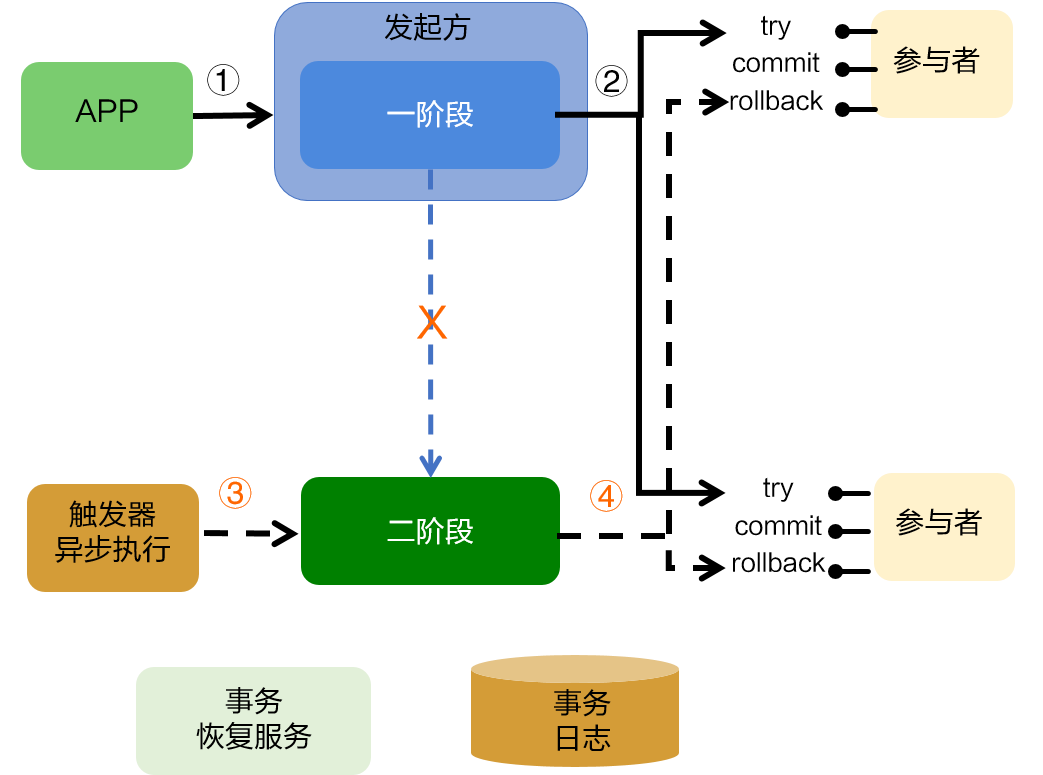
通常情况下,分布式事务发起方会依次执行一阶段和二阶段方法,然后结束分布式事务,返回结果。如果让分布式事务发起方执行完一阶段之后马上结束并返回结果,二阶段交由独立的线程或者进程异步执行,这样分布式事务的二阶段会晚几秒钟或者若干分钟执行,但事务的最终结果不会有任何改变。
二阶段异步执行之后,分布式事务的最终结果不会有任何影响,但是事务发起方要执行的内容减少一半(一阶段和二阶段都执行变成只执行一阶段),直观的用户感受是分布式事务的性能提升了 50%。
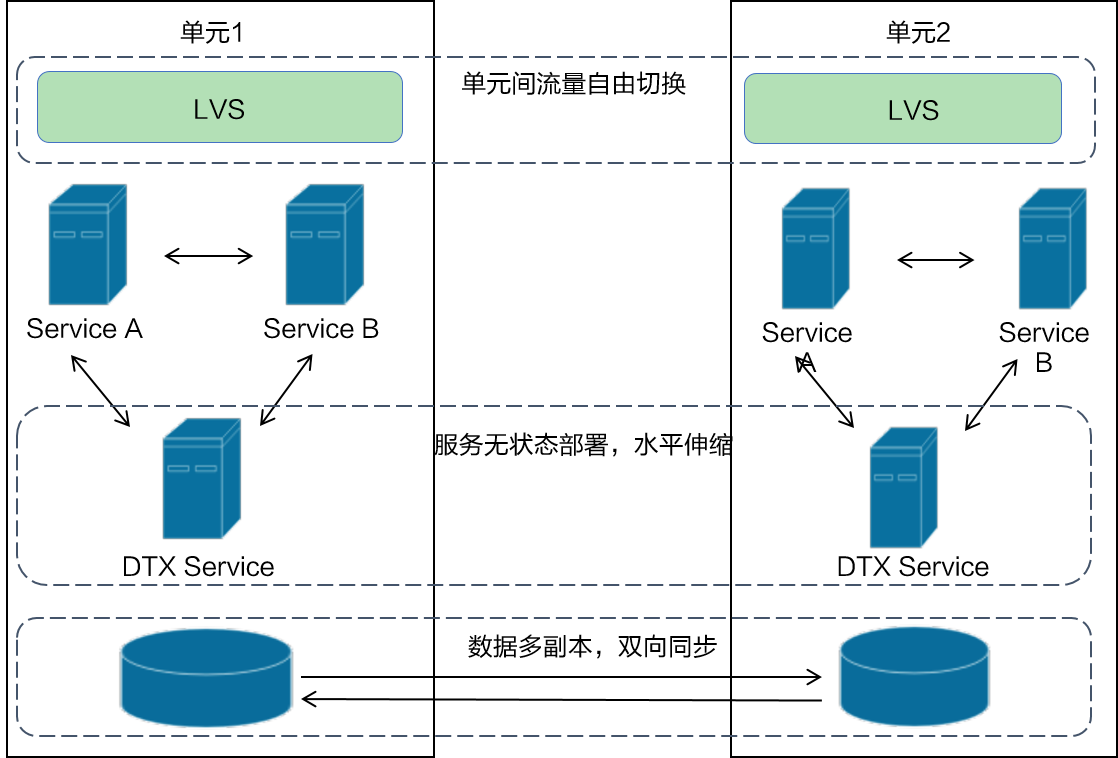
为了保障金融系统的高可用,分布式事务服务必须达到 99.99% 的可用率。分布式事务使用了蚂蚁金服的三地五中心架构部署,在每个机房都独立部署分布式事务服务,分布式事务服务是无状态的,而底层数据库副本在各机房间也是双向同步,这样业务流量从一个机房切到另外一个机房,分布式事务服务不会对业务有任何影响,从而保证了分布式事务服务的高可用。
在分布式架构演进中,蚂蚁金服对数据库进了水平拆分,对服务面向功能进行了服务化拆分,从而出现了跨服务、跨数据库的业务数据一致性挑战。
2007 年,蚂蚁金服自主研发分布式事务中间件经历 12 年的严苛业务锤炼。2019 年,将多年的技术积累分享给开源分布式事务 Seata,并持续投入社区共建。目前 Seata 提供了 AT、TCC、Saga 和 XA 四种模式,每一种模式分别有各自的应用场景,丰富的解决方案帮助用户解决给了各类场景的数据一致性问题。
最后一部分,分享了蚂蚁金服具体的实践。为了支持双十一的高性能需求,对分布式事务进行了极致的性能优化,例如同库模式、二阶段异步执行。为了使金融服务的可用性达到 99.99%,蚂蚁金服分布式事务采用三地五中心架构,异地多活的部署模式保障了分布式事务服务的高可用。