From d3929114f0f9f4f26b47bad9c1c750f7c7b69a6a Mon Sep 17 00:00:00 2001
From: alterEgo123 <32942737+alterEgo123@users.noreply.github.com>
Date: Sat, 25 Mar 2023 13:56:41 +0100
Subject: [PATCH 001/334] [Docs] Fix typo in project.md (#3329)
---
docs/projects/project.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/docs/projects/project.md b/docs/projects/project.md
index a059718979d9..7481422458f8 100644
--- a/docs/projects/project.md
+++ b/docs/projects/project.md
@@ -7,7 +7,7 @@ MLRun **Project** is a container for all your work on a particular ML applicatio

Projects are stored in a GIT or archive and map to IDE projects (in PyCharm, VSCode, etc.), which enables versioning, collaboration, and [CI/CD](../projects/ci-integration.html).
-Projects simplify how you process data, [submit jobs](../concepts/submitting-tasks-jobs-to-functions.html), run [multi-stage workflows](../concepts/workflow-overview.html), and deploy [real-time pipelines](../serving/serving-graph.html) in continious development or production environments.
+Projects simplify how you process data, [submit jobs](../concepts/submitting-tasks-jobs-to-functions.html), run [multi-stage workflows](../concepts/workflow-overview.html), and deploy [real-time pipelines](../serving/serving-graph.html) in continuous development or production environments.

@@ -22,4 +22,4 @@ run-build-deploy
build-run-workflows-pipelines
ci-integration
../secrets
-```
\ No newline at end of file
+```
From 8900a91952fea5644c6c608cab525a123e7c1bad Mon Sep 17 00:00:00 2001
From: Eyal Danieli
Date: Sun, 26 Mar 2023 10:16:52 +0300
Subject: [PATCH 002/334] [Model Monitoring] Adjust Grafana dashboards to use
V3IO datasource instead of MLRun API (#3271)
---
.../model-monitoring-details.json | 773 +++++++++++++++
.../model-monitoring-overview.json | 927 ++++++++++++++++++
.../model-monitoring-performance.json | 593 +++++++++++
.../dashboards/model-monitoring-details.json | 531 +++++++---
.../dashboards/model-monitoring-overview.json | 360 +++----
.../model-monitoring-performance.json | 18 +-
mlrun/api/api/endpoints/grafana_proxy.py | 485 ++-------
mlrun/api/crud/model_monitoring/grafana.py | 419 ++++++++
.../model_monitoring/model_endpoint_store.py | 3 +
tests/api/api/test_grafana_proxy.py | 27 +-
10 files changed, 3367 insertions(+), 769 deletions(-)
create mode 100644 docs/monitoring/dashboards/iguazio-3.5.2-and-older/model-monitoring-details.json
create mode 100644 docs/monitoring/dashboards/iguazio-3.5.2-and-older/model-monitoring-overview.json
create mode 100644 docs/monitoring/dashboards/iguazio-3.5.2-and-older/model-monitoring-performance.json
create mode 100644 mlrun/api/crud/model_monitoring/grafana.py
diff --git a/docs/monitoring/dashboards/iguazio-3.5.2-and-older/model-monitoring-details.json b/docs/monitoring/dashboards/iguazio-3.5.2-and-older/model-monitoring-details.json
new file mode 100644
index 000000000000..5012f520a193
--- /dev/null
+++ b/docs/monitoring/dashboards/iguazio-3.5.2-and-older/model-monitoring-details.json
@@ -0,0 +1,773 @@
+{
+ "annotations": {
+ "list": [
+ {
+ "builtIn": 1,
+ "datasource": "-- Grafana --",
+ "enable": true,
+ "hide": true,
+ "iconColor": "rgba(0, 211, 255, 1)",
+ "name": "Annotations & Alerts",
+ "type": "dashboard"
+ }
+ ]
+ },
+ "editable": true,
+ "gnetId": null,
+ "graphTooltip": 0,
+ "id": 8,
+ "iteration": 1627466479152,
+ "links": [
+ {
+ "icon": "external link",
+ "includeVars": true,
+ "keepTime": true,
+ "tags": [],
+ "targetBlank": false,
+ "title": "Model Monitoring - Performance",
+ "type": "link",
+ "url": "/d/9CazA-UGz/model-monitoring-performance"
+ },
+ {
+ "icon": "dashboard",
+ "includeVars": true,
+ "keepTime": true,
+ "tags": [],
+ "targetBlank": false,
+ "title": "Model Monitoring - Overview",
+ "tooltip": "",
+ "type": "link",
+ "url": "/d/g0M4uh0Mz"
+ }
+ ],
+ "panels": [
+ {
+ "datasource": "iguazio",
+ "description": "",
+ "fieldConfig": {
+ "defaults": {
+ "custom": {
+ "align": null,
+ "displayMode": "auto",
+ "filterable": false
+ },
+ "mappings": [
+ {
+ "from": "",
+ "id": 0,
+ "text": "",
+ "to": "",
+ "type": 1
+ }
+ ],
+ "thresholds": {
+ "mode": "absolute",
+ "steps": [
+ {
+ "color": "green",
+ "value": null
+ },
+ {
+ "color": "red",
+ "value": 80
+ }
+ ]
+ }
+ },
+ "overrides": [
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "First Request"
+ },
+ "properties": [
+ {
+ "id": "unit",
+ "value": "dateTimeFromNow"
+ },
+ {
+ "id": "custom.align",
+ "value": "center"
+ }
+ ]
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "Last Request"
+ },
+ "properties": [
+ {
+ "id": "unit",
+ "value": "dateTimeFromNow"
+ },
+ {
+ "id": "custom.align",
+ "value": "center"
+ }
+ ]
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "Endpoint ID"
+ },
+ "properties": [
+ {
+ "id": "custom.align",
+ "value": "center"
+ }
+ ]
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "Model"
+ },
+ "properties": [
+ {
+ "id": "custom.align",
+ "value": "center"
+ }
+ ]
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "Function URI"
+ },
+ "properties": [
+ {
+ "id": "custom.align",
+ "value": "center"
+ }
+ ]
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "Model Class"
+ },
+ "properties": [
+ {
+ "id": "custom.align",
+ "value": "center"
+ }
+ ]
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "Predictions/s (5 minute avg)"
+ },
+ "properties": [
+ {
+ "id": "custom.align",
+ "value": "center"
+ }
+ ]
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "Average Latency (1 hour)"
+ },
+ "properties": [
+ {
+ "id": "custom.align",
+ "value": "center"
+ },
+ {
+ "id": "unit",
+ "value": "µs"
+ }
+ ]
+ }
+ ]
+ },
+ "gridPos": {
+ "h": 3,
+ "w": 24,
+ "x": 0,
+ "y": 0
+ },
+ "id": 12,
+ "options": {
+ "showHeader": true,
+ "sortBy": [
+ {
+ "desc": false,
+ "displayName": "name"
+ }
+ ]
+ },
+ "pluginVersion": "7.2.0",
+ "targets": [
+ {
+ "hide": false,
+ "rawQuery": true,
+ "refId": "A",
+ "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfilter=endpoint_id==\"$MODEL\";\nfields=endpoint_id,model,function_uri,model_class,predictions_per_second,latency_avg_1h,first_request,last_request;",
+ "type": "table"
+ }
+ ],
+ "timeFrom": null,
+ "timeShift": null,
+ "title": "",
+ "transformations": [
+ {
+ "id": "organize",
+ "options": {
+ "excludeByName": {},
+ "indexByName": {},
+ "renameByName": {
+ "endpoint_id": "Endpoint ID",
+ "first_request": "First Request",
+ "function": "Function",
+ "function_uri": "Function URI",
+ "last_request": "Last Request",
+ "latency_avg_1h": "Average Latency (1 hour)",
+ "latency_avg_1s": "Average Latency",
+ "latency_avg_5m": "Average Latency (1 hour)",
+ "model": "Model",
+ "model_class": "Model Class",
+ "predictions_per_second": "Predictions/s (5 minute avg)",
+ "predictions_per_second_count_1s": "Predictions/sec",
+ "tag": "Tag"
+ }
+ }
+ }
+ ],
+ "transparent": true,
+ "type": "table"
+ },
+ {
+ "datasource": "model-monitoring",
+ "description": "",
+ "fieldConfig": {
+ "defaults": {
+ "custom": {
+ "align": null,
+ "displayMode": "auto",
+ "filterable": false
+ },
+ "mappings": [
+ {
+ "from": "",
+ "id": 0,
+ "text": "",
+ "to": "",
+ "type": 1
+ }
+ ],
+ "thresholds": {
+ "mode": "absolute",
+ "steps": [
+ {
+ "color": "green",
+ "value": null
+ },
+ {
+ "color": "red",
+ "value": 80
+ }
+ ]
+ }
+ },
+ "overrides": [
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "tvd_sum"
+ },
+ "properties": [
+ {
+ "id": "displayName",
+ "value": "TVD (sum)"
+ },
+ {
+ "id": "custom.align",
+ "value": "center"
+ }
+ ]
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "tvd_mean"
+ },
+ "properties": [
+ {
+ "id": "displayName",
+ "value": "TVD (mean)"
+ },
+ {
+ "id": "custom.align",
+ "value": "center"
+ }
+ ]
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "hellinger_sum"
+ },
+ "properties": [
+ {
+ "id": "displayName",
+ "value": "Hellinger (sum)"
+ },
+ {
+ "id": "custom.align",
+ "value": "center"
+ }
+ ]
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "hellinger_mean"
+ },
+ "properties": [
+ {
+ "id": "displayName",
+ "value": "Hellinger (mean)"
+ },
+ {
+ "id": "custom.align",
+ "value": "center"
+ }
+ ]
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "kld_sum"
+ },
+ "properties": [
+ {
+ "id": "displayName",
+ "value": "KLD (sum)"
+ },
+ {
+ "id": "custom.align",
+ "value": "center"
+ }
+ ]
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "kld_mean"
+ },
+ "properties": [
+ {
+ "id": "displayName",
+ "value": "KLD (mean)"
+ },
+ {
+ "id": "custom.align",
+ "value": "center"
+ }
+ ]
+ }
+ ]
+ },
+ "gridPos": {
+ "h": 3,
+ "w": 24,
+ "x": 0,
+ "y": 3
+ },
+ "id": 21,
+ "options": {
+ "showHeader": true,
+ "sortBy": [
+ {
+ "desc": false,
+ "displayName": "name"
+ }
+ ]
+ },
+ "pluginVersion": "7.2.0",
+ "targets": [
+ {
+ "hide": false,
+ "rawQuery": true,
+ "refId": "A",
+ "target": "target_endpoint=overall_feature_analysis;endpoint_id=$MODEL;project=$PROJECT",
+ "type": "table"
+ }
+ ],
+ "timeFrom": null,
+ "timeShift": null,
+ "title": "Overall Drift Analysis",
+ "transformations": [
+ {
+ "id": "organize",
+ "options": {
+ "excludeByName": {},
+ "indexByName": {},
+ "renameByName": {
+ "endpoint_id": "Endpoint ID",
+ "first_request": "First Request",
+ "function": "Function",
+ "last_request": "Last Request",
+ "latency_avg_1s": "Average Latency",
+ "model": "Model",
+ "model_class": "Model Class",
+ "predictions_per_second_count_1s": "Predictions/sec",
+ "tag": "Tag"
+ }
+ }
+ }
+ ],
+ "transparent": true,
+ "type": "table"
+ },
+ {
+ "datasource": "model-monitoring",
+ "description": "Feature analysis of the latest batch",
+ "fieldConfig": {
+ "defaults": {
+ "custom": {
+ "align": "center",
+ "displayMode": "auto",
+ "filterable": false
+ },
+ "mappings": [
+ {
+ "from": "",
+ "id": 0,
+ "text": "",
+ "to": "",
+ "type": 1
+ }
+ ],
+ "thresholds": {
+ "mode": "absolute",
+ "steps": [
+ {
+ "color": "green",
+ "value": null
+ },
+ {
+ "color": "red",
+ "value": 80
+ }
+ ]
+ }
+ },
+ "overrides": [
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "Feature"
+ },
+ "properties": []
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "Actual Min"
+ },
+ "properties": []
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "Expected Min"
+ },
+ "properties": [
+ {
+ "id": "noValue",
+ "value": "N/A"
+ }
+ ]
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "Expected Mean"
+ },
+ "properties": [
+ {
+ "id": "noValue",
+ "value": "N/A"
+ }
+ ]
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "Expected Max"
+ },
+ "properties": [
+ {
+ "id": "noValue",
+ "value": "N/A"
+ }
+ ]
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "tvd"
+ },
+ "properties": [
+ {
+ "id": "displayName",
+ "value": "TVD"
+ }
+ ]
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "hellinger"
+ },
+ "properties": [
+ {
+ "id": "displayName",
+ "value": "Hellinger"
+ }
+ ]
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "kld"
+ },
+ "properties": [
+ {
+ "id": "displayName",
+ "value": "KLD"
+ }
+ ]
+ }
+ ]
+ },
+ "gridPos": {
+ "h": 7,
+ "w": 24,
+ "x": 0,
+ "y": 6
+ },
+ "id": 14,
+ "options": {
+ "showHeader": true,
+ "sortBy": [
+ {
+ "desc": false,
+ "displayName": "Feature"
+ }
+ ]
+ },
+ "pluginVersion": "7.2.0",
+ "targets": [
+ {
+ "rawQuery": true,
+ "refId": "A",
+ "target": "target_endpoint=individual_feature_analysis;endpoint_id=$MODEL;project=$PROJECT",
+ "type": "table"
+ }
+ ],
+ "timeFrom": null,
+ "timeShift": null,
+ "title": "Features Analysis",
+ "transformations": [
+ {
+ "id": "organize",
+ "options": {
+ "excludeByName": {
+ "count": true,
+ "idx": true,
+ "model": true
+ },
+ "indexByName": {
+ "actual_max": 3,
+ "actual_mean": 2,
+ "actual_min": 1,
+ "expected_max": 4,
+ "expected_mean": 5,
+ "expected_min": 6,
+ "feature_name": 0
+ },
+ "renameByName": {
+ "actual_max": "Actual Max",
+ "actual_mean": "Actual Mean",
+ "actual_min": "Actual Min",
+ "expected_max": "Expected Min",
+ "expected_mean": "Expected Mean",
+ "expected_min": "Expected Max",
+ "feature_name": "Feature"
+ }
+ }
+ }
+ ],
+ "transparent": true,
+ "type": "table"
+ },
+ {
+ "aliasColors": {},
+ "bars": false,
+ "dashLength": 10,
+ "dashes": false,
+ "datasource": "iguazio",
+ "fieldConfig": {
+ "defaults": {
+ "custom": {}
+ },
+ "overrides": []
+ },
+ "fill": 1,
+ "fillGradient": 1,
+ "gridPos": {
+ "h": 7,
+ "w": 24,
+ "x": 0,
+ "y": 13
+ },
+ "hiddenSeries": false,
+ "id": 16,
+ "legend": {
+ "alignAsTable": true,
+ "avg": false,
+ "current": true,
+ "max": false,
+ "min": false,
+ "rightSide": true,
+ "show": true,
+ "sideWidth": 250,
+ "total": false,
+ "values": true
+ },
+ "lines": true,
+ "linewidth": 1,
+ "nullPointMode": "null",
+ "options": {
+ "alertThreshold": true
+ },
+ "percentage": false,
+ "pluginVersion": "7.2.0",
+ "pointradius": 2,
+ "points": false,
+ "renderer": "flot",
+ "seriesOverrides": [],
+ "spaceLength": 10,
+ "stack": false,
+ "steppedLine": false,
+ "targets": [
+ {
+ "rawQuery": true,
+ "refId": "A",
+ "target": "backend=tsdb;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/events;\nfilter=endpoint_id=='$MODEL' AND record_type=='endpoint_features';",
+ "type": "timeserie"
+ }
+ ],
+ "thresholds": [],
+ "timeFrom": null,
+ "timeRegions": [],
+ "timeShift": null,
+ "title": "Incoming Features",
+ "tooltip": {
+ "shared": true,
+ "sort": 0,
+ "value_type": "individual"
+ },
+ "transformations": [],
+ "transparent": true,
+ "type": "graph",
+ "xaxis": {
+ "buckets": null,
+ "mode": "time",
+ "name": null,
+ "show": true,
+ "values": []
+ },
+ "yaxes": [
+ {
+ "format": "short",
+ "label": null,
+ "logBase": 1,
+ "max": null,
+ "min": null,
+ "show": true
+ },
+ {
+ "format": "short",
+ "label": null,
+ "logBase": 1,
+ "max": null,
+ "min": null,
+ "show": true
+ }
+ ],
+ "yaxis": {
+ "align": false,
+ "alignLevel": null
+ }
+ }
+ ],
+ "refresh": "1m",
+ "schemaVersion": 26,
+ "style": "dark",
+ "tags": [],
+ "templating": {
+ "list": [
+ {
+ "allValue": null,
+ "current": {},
+ "datasource": "model-monitoring",
+ "definition": "target_endpoint=list_projects",
+ "hide": 0,
+ "includeAll": false,
+ "label": "Project",
+ "multi": false,
+ "name": "PROJECT",
+ "options": [],
+ "query": "target_endpoint=list_projects",
+ "refresh": 0,
+ "regex": "",
+ "skipUrlSync": false,
+ "sort": 0,
+ "tagValuesQuery": "",
+ "tags": [],
+ "tagsQuery": "",
+ "type": "query",
+ "useTags": false
+ },
+ {
+ "allValue": null,
+ "current": {},
+ "datasource": "iguazio",
+ "definition": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=endpoint_id;",
+ "hide": 0,
+ "includeAll": false,
+ "label": "Model",
+ "multi": false,
+ "name": "MODEL",
+ "options": [],
+ "query": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=endpoint_id;",
+ "refresh": 1,
+ "regex": "",
+ "skipUrlSync": false,
+ "sort": 0,
+ "tagValuesQuery": "",
+ "tags": [],
+ "tagsQuery": "",
+ "type": "query",
+ "useTags": false
+ }
+ ]
+ },
+ "time": {
+ "from": "now-1h",
+ "to": "now"
+ },
+ "timepicker": {},
+ "timezone": "",
+ "title": "Model Monitoring - Details",
+ "uid": "AohIXhAMk",
+ "version": 3
+}
diff --git a/docs/monitoring/dashboards/iguazio-3.5.2-and-older/model-monitoring-overview.json b/docs/monitoring/dashboards/iguazio-3.5.2-and-older/model-monitoring-overview.json
new file mode 100644
index 000000000000..59fc43426d84
--- /dev/null
+++ b/docs/monitoring/dashboards/iguazio-3.5.2-and-older/model-monitoring-overview.json
@@ -0,0 +1,927 @@
+{
+ "annotations": {
+ "list": [
+ {
+ "builtIn": 1,
+ "datasource": "-- Grafana --",
+ "enable": true,
+ "hide": true,
+ "iconColor": "rgba(0, 211, 255, 1)",
+ "name": "Annotations & Alerts",
+ "type": "dashboard"
+ }
+ ]
+ },
+ "editable": true,
+ "gnetId": null,
+ "graphTooltip": 0,
+ "id": 7,
+ "iteration": 1627466285618,
+ "links": [
+ {
+ "icon": "external link",
+ "includeVars": true,
+ "keepTime": true,
+ "tags": [],
+ "title": "Model Monitoring - Performance",
+ "type": "link",
+ "url": "/d/9CazA-UGz/model-monitoring-performance"
+ },
+ {
+ "icon": "external link",
+ "includeVars": true,
+ "keepTime": true,
+ "tags": [],
+ "targetBlank": false,
+ "title": "Model Monitoring - Details",
+ "type": "link",
+ "url": "d/AohIXhAMk/model-monitoring-details"
+ }
+ ],
+ "panels": [
+ {
+ "datasource": "iguazio",
+ "fieldConfig": {
+ "defaults": {
+ "custom": {},
+ "mappings": [],
+ "thresholds": {
+ "mode": "absolute",
+ "steps": [
+ {
+ "color": "green",
+ "value": null
+ },
+ {
+ "color": "red",
+ "value": 80
+ }
+ ]
+ }
+ },
+ "overrides": []
+ },
+ "gridPos": {
+ "h": 3,
+ "w": 5,
+ "x": 0,
+ "y": 0
+ },
+ "id": 6,
+ "options": {
+ "colorMode": "value",
+ "graphMode": "none",
+ "justifyMode": "center",
+ "orientation": "auto",
+ "reduceOptions": {
+ "calcs": [
+ "mean"
+ ],
+ "fields": "",
+ "values": false
+ },
+ "textMode": "value"
+ },
+ "pluginVersion": "7.2.0",
+ "targets": [
+ {
+ "rawQuery": true,
+ "refId": "A",
+ "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=endpoint_id;",
+ "type": "table"
+ }
+ ],
+ "timeFrom": null,
+ "timeShift": null,
+ "title": "Endpoints",
+ "transformations": [
+ {
+ "id": "reduce",
+ "options": {
+ "reducers": [
+ "count"
+ ]
+ }
+ }
+ ],
+ "transparent": true,
+ "type": "stat"
+ },
+ {
+ "datasource": "iguazio",
+ "fieldConfig": {
+ "defaults": {
+ "custom": {},
+ "mappings": [],
+ "thresholds": {
+ "mode": "absolute",
+ "steps": [
+ {
+ "color": "green",
+ "value": null
+ },
+ {
+ "color": "red",
+ "value": 80
+ }
+ ]
+ }
+ },
+ "overrides": []
+ },
+ "gridPos": {
+ "h": 3,
+ "w": 5,
+ "x": 6,
+ "y": 0
+ },
+ "id": 8,
+ "options": {
+ "colorMode": "value",
+ "graphMode": "none",
+ "justifyMode": "auto",
+ "orientation": "auto",
+ "reduceOptions": {
+ "calcs": [
+ "mean"
+ ],
+ "fields": "",
+ "values": false
+ },
+ "textMode": "auto"
+ },
+ "pluginVersion": "7.2.0",
+ "targets": [
+ {
+ "hide": false,
+ "rawQuery": true,
+ "refId": "A",
+ "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=predictions_per_second;",
+ "type": "table"
+ }
+ ],
+ "timeFrom": null,
+ "timeShift": null,
+ "title": "Predictions/s (5 Minute Average)",
+ "transparent": true,
+ "type": "stat"
+ },
+ {
+ "datasource": "iguazio",
+ "fieldConfig": {
+ "defaults": {
+ "custom": {},
+ "mappings": [],
+ "thresholds": {
+ "mode": "absolute",
+ "steps": [
+ {
+ "color": "green",
+ "value": null
+ }
+ ]
+ },
+ "unit": "µs"
+ },
+ "overrides": []
+ },
+ "gridPos": {
+ "h": 3,
+ "w": 5,
+ "x": 12,
+ "y": 0
+ },
+ "id": 10,
+ "options": {
+ "colorMode": "value",
+ "graphMode": "none",
+ "justifyMode": "auto",
+ "orientation": "auto",
+ "reduceOptions": {
+ "calcs": [
+ "mean"
+ ],
+ "fields": "",
+ "values": false
+ },
+ "textMode": "auto"
+ },
+ "pluginVersion": "7.2.0",
+ "targets": [
+ {
+ "rawQuery": true,
+ "refId": "A",
+ "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=latency_avg_1h;",
+ "type": "table"
+ }
+ ],
+ "timeFrom": null,
+ "timeShift": null,
+ "title": "Average Latency (Last Hour)",
+ "transformations": [
+ {
+ "id": "reduce",
+ "options": {
+ "reducers": [
+ "mean"
+ ]
+ }
+ }
+ ],
+ "transparent": true,
+ "type": "stat"
+ },
+ {
+ "datasource": "iguazio",
+ "fieldConfig": {
+ "defaults": {
+ "custom": {},
+ "mappings": [],
+ "noValue": "0",
+ "thresholds": {
+ "mode": "absolute",
+ "steps": [
+ {
+ "color": "green",
+ "value": null
+ },
+ {
+ "color": "red",
+ "value": 80
+ }
+ ]
+ }
+ },
+ "overrides": []
+ },
+ "gridPos": {
+ "h": 3,
+ "w": 6,
+ "x": 18,
+ "y": 0
+ },
+ "id": 12,
+ "options": {
+ "colorMode": "value",
+ "graphMode": "none",
+ "justifyMode": "auto",
+ "orientation": "auto",
+ "reduceOptions": {
+ "calcs": [
+ "mean"
+ ],
+ "fields": "",
+ "values": false
+ },
+ "textMode": "auto"
+ },
+ "pluginVersion": "7.2.0",
+ "targets": [
+ {
+ "rawQuery": true,
+ "refId": "A",
+ "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=error_count;",
+ "type": "table"
+ }
+ ],
+ "timeFrom": null,
+ "timeShift": null,
+ "title": "Errors",
+ "transparent": true,
+ "type": "stat"
+ },
+ {
+ "datasource": "model-monitoring",
+ "description": "",
+ "fieldConfig": {
+ "defaults": {
+ "custom": {
+ "align": "center",
+ "displayMode": "auto",
+ "filterable": true
+ },
+ "mappings": [
+ {
+ "from": "",
+ "id": 0,
+ "text": "",
+ "to": "",
+ "type": 1
+ }
+ ],
+ "thresholds": {
+ "mode": "absolute",
+ "steps": [
+ {
+ "color": "green",
+ "value": null
+ },
+ {
+ "color": "red",
+ "value": 80
+ }
+ ]
+ }
+ },
+ "overrides": [
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "Function"
+ },
+ "properties": [
+ {
+ "id": "custom.align",
+ "value": "center"
+ }
+ ]
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "Model"
+ },
+ "properties": [
+ {
+ "id": "custom.align",
+ "value": "center"
+ }
+ ]
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "Model Class"
+ },
+ "properties": [
+ {
+ "id": "custom.align",
+ "value": "center"
+ },
+ {
+ "id": "noValue",
+ "value": "N/A"
+ }
+ ]
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "First Request"
+ },
+ "properties": [
+ {
+ "id": "unit",
+ "value": "dateTimeFromNow"
+ },
+ {
+ "id": "custom.align",
+ "value": "center"
+ },
+ {
+ "id": "noValue",
+ "value": "N/A"
+ }
+ ]
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "Last Request"
+ },
+ "properties": [
+ {
+ "id": "custom.align",
+ "value": "center"
+ },
+ {
+ "id": "unit",
+ "value": "dateTimeFromNow"
+ },
+ {
+ "id": "noValue",
+ "value": "N/A"
+ }
+ ]
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "Accuracy"
+ },
+ "properties": [
+ {
+ "id": "custom.align",
+ "value": "center"
+ },
+ {
+ "id": "noValue",
+ "value": "N/A"
+ }
+ ]
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "Error Count"
+ },
+ "properties": [
+ {
+ "id": "custom.align",
+ "value": "center"
+ },
+ {
+ "id": "noValue",
+ "value": "N/A"
+ }
+ ]
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "Drift Status"
+ },
+ "properties": [
+ {
+ "id": "custom.align",
+ "value": "center"
+ },
+ {
+ "id": "noValue",
+ "value": "N/A"
+ },
+ {
+ "id": "mappings",
+ "value": [
+ {
+ "from": "",
+ "id": 0,
+ "text": "0",
+ "to": "",
+ "type": 1,
+ "value": "NO_DRIFT"
+ },
+ {
+ "from": "",
+ "id": 1,
+ "text": "1",
+ "to": "",
+ "type": 1,
+ "value": "POSSIBLE_DRIFT"
+ },
+ {
+ "from": "",
+ "id": 2,
+ "text": "2",
+ "to": "",
+ "type": 1,
+ "value": "DRIFT_DETECTED"
+ },
+ {
+ "from": "",
+ "id": 3,
+ "text": "-1",
+ "to": "",
+ "type": 1,
+ "value": "N\\A"
+ }
+ ]
+ },
+ {
+ "id": "custom.displayMode",
+ "value": "color-background"
+ },
+ {
+ "id": "thresholds",
+ "value": {
+ "mode": "absolute",
+ "steps": [
+ {
+ "color": "rgba(255, 255, 255, 0)",
+ "value": null
+ },
+ {
+ "color": "green",
+ "value": 0
+ },
+ {
+ "color": "yellow",
+ "value": 1
+ },
+ {
+ "color": "red",
+ "value": 2
+ }
+ ]
+ }
+ }
+ ]
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "Endpoint ID"
+ },
+ "properties": [
+ {
+ "id": "links",
+ "value": [
+ {
+ "targetBlank": true,
+ "title": "",
+ "url": "/d/AohIXhAMk/model-monitoring-details?orgId=1&refresh=1m&var-PROJECT=$PROJECT&var-MODEL=${__value.text}"
+ }
+ ]
+ }
+ ]
+ }
+ ]
+ },
+ "gridPos": {
+ "h": 13,
+ "w": 24,
+ "x": 0,
+ "y": 3
+ },
+ "id": 22,
+ "options": {
+ "showHeader": true,
+ "sortBy": [
+ {
+ "desc": false,
+ "displayName": "Name"
+ }
+ ]
+ },
+ "pluginVersion": "7.2.0",
+ "targets": [
+ {
+ "hide": false,
+ "rawQuery": true,
+ "refId": "A",
+ "target": "project=$PROJECT;target_endpoint=list_endpoints",
+ "type": "table"
+ }
+ ],
+ "timeFrom": null,
+ "timeShift": null,
+ "title": "Models",
+ "transformations": [
+ {
+ "id": "organize",
+ "options": {
+ "excludeByName": {
+ "model_hash": false
+ },
+ "indexByName": {
+ "accuracy": 8,
+ "drift_status": 9,
+ "endpoint_function": 1,
+ "endpoint_id": 0,
+ "endpoint_model": 2,
+ "endpoint_model_class": 3,
+ "endpoint_tag": 4,
+ "error_count": 7,
+ "first_request": 5,
+ "last_request": 6
+ },
+ "renameByName": {
+ "accuracy": "Accuracy",
+ "drift_status": "Drift Status",
+ "endpoint_function": "Function",
+ "endpoint_id": "Endpoint ID",
+ "endpoint_model": "Model",
+ "endpoint_model_class": "Model Class",
+ "endpoint_tag": "Tag",
+ "error_count": "Error Count",
+ "first_request": "First Request",
+ "function": "Function",
+ "last_request": "Last Request",
+ "latency_avg_1s": "Average Latency",
+ "model": "Model",
+ "model_class": "Class",
+ "predictions_per_second_count_1s": "Predictions/1s",
+ "tag": "Tag"
+ }
+ }
+ }
+ ],
+ "type": "table"
+ },
+ {
+ "cards": {
+ "cardPadding": null,
+ "cardRound": null
+ },
+ "color": {
+ "cardColor": "#b4ff00",
+ "colorScale": "sqrt",
+ "colorScheme": "interpolatePlasma",
+ "exponent": 0.5,
+ "mode": "spectrum"
+ },
+ "dataFormat": "timeseries",
+ "datasource": "iguazio",
+ "fieldConfig": {
+ "defaults": {
+ "custom": {},
+ "mappings": [],
+ "thresholds": {
+ "mode": "absolute",
+ "steps": [
+ {
+ "color": "green",
+ "value": null
+ },
+ {
+ "color": "red",
+ "value": 80
+ }
+ ]
+ }
+ },
+ "overrides": []
+ },
+ "gridPos": {
+ "h": 6,
+ "w": 8,
+ "x": 0,
+ "y": 16
+ },
+ "heatmap": {},
+ "hideZeroBuckets": false,
+ "highlightCards": true,
+ "id": 18,
+ "legend": {
+ "show": false
+ },
+ "pluginVersion": "7.2.0",
+ "reverseYBuckets": false,
+ "targets": [
+ {
+ "rawQuery": true,
+ "refId": "A",
+ "target": "backend=tsdb;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/events;\nfields=predictions_per_second;",
+ "type": "timeserie"
+ }
+ ],
+ "timeFrom": null,
+ "timeShift": null,
+ "title": "Predictions/s (5 Minute Average)",
+ "tooltip": {
+ "show": true,
+ "showHistogram": false
+ },
+ "transparent": true,
+ "type": "heatmap",
+ "xAxis": {
+ "show": true
+ },
+ "xBucketNumber": null,
+ "xBucketSize": null,
+ "yAxis": {
+ "decimals": null,
+ "format": "short",
+ "logBase": 1,
+ "max": null,
+ "min": null,
+ "show": true,
+ "splitFactor": null
+ },
+ "yBucketBound": "auto",
+ "yBucketNumber": null,
+ "yBucketSize": null
+ },
+ {
+ "cards": {
+ "cardPadding": null,
+ "cardRound": null
+ },
+ "color": {
+ "cardColor": "#b4ff00",
+ "colorScale": "sqrt",
+ "colorScheme": "interpolatePlasma",
+ "exponent": 0.5,
+ "mode": "spectrum"
+ },
+ "dataFormat": "timeseries",
+ "datasource": "iguazio",
+ "fieldConfig": {
+ "defaults": {
+ "custom": {},
+ "mappings": [],
+ "thresholds": {
+ "mode": "absolute",
+ "steps": [
+ {
+ "color": "green",
+ "value": null
+ },
+ {
+ "color": "red",
+ "value": 80
+ }
+ ]
+ }
+ },
+ "overrides": [
+ {
+ "matcher": {
+ "id": "byType",
+ "options": "number"
+ },
+ "properties": [
+ {
+ "id": "unit",
+ "value": "µs"
+ }
+ ]
+ }
+ ]
+ },
+ "gridPos": {
+ "h": 6,
+ "w": 8,
+ "x": 8,
+ "y": 16
+ },
+ "heatmap": {},
+ "hideZeroBuckets": false,
+ "highlightCards": true,
+ "id": 19,
+ "legend": {
+ "show": false
+ },
+ "pluginVersion": "7.2.0",
+ "reverseYBuckets": false,
+ "targets": [
+ {
+ "rawQuery": true,
+ "refId": "A",
+ "target": "backend=tsdb;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/events;\nfields=latency_avg_1h;",
+ "type": "timeserie"
+ }
+ ],
+ "timeFrom": null,
+ "timeShift": null,
+ "title": "Average Latency (1 Hour)",
+ "tooltip": {
+ "show": true,
+ "showHistogram": false
+ },
+ "transparent": true,
+ "type": "heatmap",
+ "xAxis": {
+ "show": true
+ },
+ "xBucketNumber": null,
+ "xBucketSize": null,
+ "yAxis": {
+ "decimals": null,
+ "format": "short",
+ "logBase": 1,
+ "max": null,
+ "min": null,
+ "show": true,
+ "splitFactor": null
+ },
+ "yBucketBound": "auto",
+ "yBucketNumber": null,
+ "yBucketSize": null
+ },
+ {
+ "aliasColors": {},
+ "bars": false,
+ "dashLength": 10,
+ "dashes": false,
+ "datasource": "iguazio",
+ "fieldConfig": {
+ "defaults": {
+ "custom": {}
+ },
+ "overrides": []
+ },
+ "fill": 1,
+ "fillGradient": 0,
+ "gridPos": {
+ "h": 6,
+ "w": 8,
+ "x": 16,
+ "y": 16
+ },
+ "hiddenSeries": false,
+ "id": 20,
+ "legend": {
+ "avg": false,
+ "current": false,
+ "max": false,
+ "min": false,
+ "show": true,
+ "total": false,
+ "values": false
+ },
+ "lines": true,
+ "linewidth": 1,
+ "nullPointMode": "null",
+ "options": {
+ "alertThreshold": true
+ },
+ "percentage": false,
+ "pluginVersion": "7.2.0",
+ "pointradius": 2,
+ "points": false,
+ "renderer": "flot",
+ "seriesOverrides": [],
+ "spaceLength": 10,
+ "stack": false,
+ "steppedLine": false,
+ "targets": [
+ {
+ "refId": "A",
+ "target": "select metric",
+ "type": "timeserie"
+ }
+ ],
+ "thresholds": [],
+ "timeFrom": null,
+ "timeRegions": [],
+ "timeShift": null,
+ "title": "Errors",
+ "tooltip": {
+ "shared": true,
+ "sort": 0,
+ "value_type": "individual"
+ },
+ "transparent": true,
+ "type": "graph",
+ "xaxis": {
+ "buckets": null,
+ "mode": "time",
+ "name": null,
+ "show": true,
+ "values": []
+ },
+ "yaxes": [
+ {
+ "format": "short",
+ "label": null,
+ "logBase": 1,
+ "max": null,
+ "min": null,
+ "show": true
+ },
+ {
+ "format": "short",
+ "label": null,
+ "logBase": 1,
+ "max": null,
+ "min": null,
+ "show": true
+ }
+ ],
+ "yaxis": {
+ "align": false,
+ "alignLevel": null
+ }
+ }
+ ],
+ "refresh": "5s",
+ "schemaVersion": 26,
+ "style": "dark",
+ "tags": [],
+ "templating": {
+ "list": [
+ {
+ "allValue": null,
+ "current": {},
+ "datasource": "model-monitoring",
+ "definition": "target_endpoint=list_projects",
+ "hide": 0,
+ "includeAll": false,
+ "label": "Project",
+ "multi": false,
+ "name": "PROJECT",
+ "options": [],
+ "query": "target_endpoint=list_projects",
+ "refresh": 1,
+ "regex": "",
+ "skipUrlSync": false,
+ "sort": 0,
+ "tagValuesQuery": "",
+ "tags": [],
+ "tagsQuery": "",
+ "type": "query",
+ "useTags": false
+ }
+ ]
+ },
+ "time": {
+ "from": "now-1h",
+ "to": "now"
+ },
+ "timepicker": {},
+ "timezone": "",
+ "title": "Model Monitoring - Overview",
+ "uid": "g0M4uh0Mz",
+ "version": 2
+}
diff --git a/docs/monitoring/dashboards/iguazio-3.5.2-and-older/model-monitoring-performance.json b/docs/monitoring/dashboards/iguazio-3.5.2-and-older/model-monitoring-performance.json
new file mode 100644
index 000000000000..77adc0eb81b4
--- /dev/null
+++ b/docs/monitoring/dashboards/iguazio-3.5.2-and-older/model-monitoring-performance.json
@@ -0,0 +1,593 @@
+{
+ "annotations": {
+ "list": [
+ {
+ "builtIn": 1,
+ "datasource": "-- Grafana --",
+ "enable": true,
+ "hide": true,
+ "iconColor": "rgba(0, 211, 255, 1)",
+ "name": "Annotations & Alerts",
+ "type": "dashboard"
+ }
+ ]
+ },
+ "editable": true,
+ "gnetId": null,
+ "graphTooltip": 0,
+ "id": 9,
+ "iteration": 1627466092078,
+ "links": [
+ {
+ "asDropdown": true,
+ "icon": "external link",
+ "includeVars": true,
+ "keepTime": true,
+ "tags": [],
+ "title": "Model Monitoring - Overview",
+ "type": "link",
+ "url": "d/g0M4uh0Mz/model-monitoring-overview"
+ },
+ {
+ "icon": "external link",
+ "includeVars": true,
+ "keepTime": true,
+ "tags": [],
+ "targetBlank": false,
+ "title": "Model Monitoring - Details",
+ "type": "link",
+ "url": "d/AohIXhAMk/model-monitoring-details"
+ }
+ ],
+ "panels": [
+ {
+ "aliasColors": {},
+ "bars": false,
+ "dashLength": 10,
+ "dashes": false,
+ "datasource": "iguazio",
+ "fieldConfig": {
+ "defaults": {
+ "custom": {}
+ },
+ "overrides": []
+ },
+ "fill": 1,
+ "fillGradient": 1,
+ "gridPos": {
+ "h": 8,
+ "w": 12,
+ "x": 0,
+ "y": 0
+ },
+ "hiddenSeries": false,
+ "id": 5,
+ "legend": {
+ "alignAsTable": true,
+ "avg": false,
+ "current": true,
+ "max": false,
+ "min": false,
+ "rightSide": true,
+ "show": true,
+ "sideWidth": 250,
+ "total": false,
+ "values": true
+ },
+ "lines": true,
+ "linewidth": 1,
+ "nullPointMode": "null",
+ "options": {
+ "alertThreshold": true
+ },
+ "percentage": false,
+ "pluginVersion": "7.2.0",
+ "pointradius": 2,
+ "points": false,
+ "renderer": "flot",
+ "seriesOverrides": [],
+ "spaceLength": 10,
+ "stack": false,
+ "steppedLine": false,
+ "targets": [
+ {
+ "rawQuery": true,
+ "refId": "A",
+ "target": "backend=tsdb;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/events;\nfilter=endpoint_id=='$MODEL' AND record_type=='drift_measures';",
+ "type": "timeserie"
+ }
+ ],
+ "thresholds": [],
+ "timeFrom": null,
+ "timeRegions": [],
+ "timeShift": null,
+ "title": "Drift Measures",
+ "tooltip": {
+ "shared": true,
+ "sort": 0,
+ "value_type": "individual"
+ },
+ "transformations": [],
+ "transparent": true,
+ "type": "graph",
+ "xaxis": {
+ "buckets": null,
+ "mode": "time",
+ "name": null,
+ "show": true,
+ "values": []
+ },
+ "yaxes": [
+ {
+ "format": "short",
+ "label": null,
+ "logBase": 1,
+ "max": null,
+ "min": null,
+ "show": true
+ },
+ {
+ "format": "short",
+ "label": null,
+ "logBase": 1,
+ "max": null,
+ "min": null,
+ "show": true
+ }
+ ],
+ "yaxis": {
+ "align": false,
+ "alignLevel": null
+ }
+ },
+ {
+ "aliasColors": {},
+ "bars": false,
+ "dashLength": 10,
+ "dashes": false,
+ "datasource": "iguazio",
+ "fieldConfig": {
+ "defaults": {
+ "custom": {}
+ },
+ "overrides": []
+ },
+ "fill": 1,
+ "fillGradient": 0,
+ "gridPos": {
+ "h": 8,
+ "w": 12,
+ "x": 12,
+ "y": 0
+ },
+ "hiddenSeries": false,
+ "id": 6,
+ "legend": {
+ "avg": false,
+ "current": false,
+ "max": false,
+ "min": false,
+ "show": true,
+ "total": false,
+ "values": false
+ },
+ "lines": true,
+ "linewidth": 1,
+ "nullPointMode": "null",
+ "options": {
+ "alertThreshold": true
+ },
+ "percentage": false,
+ "pluginVersion": "7.2.0",
+ "pointradius": 2,
+ "points": false,
+ "renderer": "flot",
+ "seriesOverrides": [],
+ "spaceLength": 10,
+ "stack": false,
+ "steppedLine": false,
+ "targets": [
+ {
+ "rawQuery": true,
+ "refId": "A",
+ "target": "backend=tsdb;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/events;\nfields=latency_avg_5m,latency_avg_1h;\nfilter=endpoint_id=='$MODEL';",
+ "type": "timeserie"
+ }
+ ],
+ "thresholds": [],
+ "timeFrom": null,
+ "timeRegions": [],
+ "timeShift": null,
+ "title": "Average Latency",
+ "tooltip": {
+ "shared": true,
+ "sort": 0,
+ "value_type": "individual"
+ },
+ "transparent": true,
+ "type": "graph",
+ "xaxis": {
+ "buckets": null,
+ "mode": "time",
+ "name": null,
+ "show": true,
+ "values": []
+ },
+ "yaxes": [
+ {
+ "format": "short",
+ "label": null,
+ "logBase": 1,
+ "max": null,
+ "min": null,
+ "show": true
+ },
+ {
+ "format": "short",
+ "label": null,
+ "logBase": 1,
+ "max": null,
+ "min": null,
+ "show": true
+ }
+ ],
+ "yaxis": {
+ "align": false,
+ "alignLevel": null
+ }
+ },
+ {
+ "aliasColors": {},
+ "bars": false,
+ "dashLength": 10,
+ "dashes": false,
+ "datasource": "iguazio",
+ "fieldConfig": {
+ "defaults": {
+ "custom": {}
+ },
+ "overrides": []
+ },
+ "fill": 1,
+ "fillGradient": 0,
+ "gridPos": {
+ "h": 7,
+ "w": 12,
+ "x": 0,
+ "y": 8
+ },
+ "hiddenSeries": false,
+ "id": 2,
+ "legend": {
+ "avg": false,
+ "current": false,
+ "max": false,
+ "min": false,
+ "show": true,
+ "total": false,
+ "values": false
+ },
+ "lines": true,
+ "linewidth": 1,
+ "nullPointMode": "null",
+ "options": {
+ "alertThreshold": true
+ },
+ "percentage": false,
+ "pluginVersion": "7.2.0",
+ "pointradius": 2,
+ "points": false,
+ "renderer": "flot",
+ "seriesOverrides": [],
+ "spaceLength": 10,
+ "stack": false,
+ "steppedLine": false,
+ "targets": [
+ {
+ "rawQuery": true,
+ "refId": "A",
+ "target": "backend=tsdb;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/events;\nfields=predictions_per_second;\nfilter=endpoint_id=='$MODEL';",
+ "type": "timeserie"
+ }
+ ],
+ "thresholds": [],
+ "timeFrom": null,
+ "timeRegions": [],
+ "timeShift": null,
+ "title": "Predictions/s (5 minute average)",
+ "tooltip": {
+ "shared": true,
+ "sort": 0,
+ "value_type": "individual"
+ },
+ "transparent": true,
+ "type": "graph",
+ "xaxis": {
+ "buckets": null,
+ "mode": "time",
+ "name": null,
+ "show": true,
+ "values": []
+ },
+ "yaxes": [
+ {
+ "format": "short",
+ "label": null,
+ "logBase": 1,
+ "max": null,
+ "min": null,
+ "show": true
+ },
+ {
+ "format": "short",
+ "label": null,
+ "logBase": 1,
+ "max": null,
+ "min": null,
+ "show": true
+ }
+ ],
+ "yaxis": {
+ "align": false,
+ "alignLevel": null
+ }
+ },
+ {
+ "aliasColors": {},
+ "bars": false,
+ "dashLength": 10,
+ "dashes": false,
+ "datasource": "iguazio",
+ "fieldConfig": {
+ "defaults": {
+ "custom": {}
+ },
+ "overrides": []
+ },
+ "fill": 1,
+ "fillGradient": 0,
+ "gridPos": {
+ "h": 7,
+ "w": 12,
+ "x": 12,
+ "y": 8
+ },
+ "hiddenSeries": false,
+ "id": 7,
+ "legend": {
+ "avg": false,
+ "current": false,
+ "max": false,
+ "min": false,
+ "show": true,
+ "total": false,
+ "values": false
+ },
+ "lines": true,
+ "linewidth": 1,
+ "nullPointMode": "null",
+ "options": {
+ "alertThreshold": true
+ },
+ "percentage": false,
+ "pluginVersion": "7.2.0",
+ "pointradius": 2,
+ "points": false,
+ "renderer": "flot",
+ "seriesOverrides": [],
+ "spaceLength": 10,
+ "stack": false,
+ "steppedLine": false,
+ "targets": [
+ {
+ "rawQuery": true,
+ "refId": "A",
+ "target": "backend=tsdb;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/events;\nfields=predictions_count_5m,predictions_count_1h;\nfilter=endpoint_id=='$MODEL';",
+ "type": "timeserie"
+ }
+ ],
+ "thresholds": [],
+ "timeFrom": null,
+ "timeRegions": [],
+ "timeShift": null,
+ "title": "Predictions Count",
+ "tooltip": {
+ "shared": true,
+ "sort": 0,
+ "value_type": "individual"
+ },
+ "transparent": true,
+ "type": "graph",
+ "xaxis": {
+ "buckets": null,
+ "mode": "time",
+ "name": null,
+ "show": true,
+ "values": []
+ },
+ "yaxes": [
+ {
+ "format": "short",
+ "label": null,
+ "logBase": 1,
+ "max": null,
+ "min": null,
+ "show": true
+ },
+ {
+ "format": "short",
+ "label": null,
+ "logBase": 1,
+ "max": null,
+ "min": null,
+ "show": true
+ }
+ ],
+ "yaxis": {
+ "align": false,
+ "alignLevel": null
+ }
+ },
+ {
+ "aliasColors": {},
+ "bars": false,
+ "dashLength": 10,
+ "dashes": false,
+ "datasource": "iguazio",
+ "fieldConfig": {
+ "defaults": {
+ "custom": {}
+ },
+ "overrides": []
+ },
+ "fill": 1,
+ "fillGradient": 1,
+ "gridPos": {
+ "h": 7,
+ "w": 24,
+ "x": 0,
+ "y": 15
+ },
+ "hiddenSeries": false,
+ "id": 4,
+ "legend": {
+ "alignAsTable": true,
+ "avg": false,
+ "current": true,
+ "max": false,
+ "min": false,
+ "rightSide": true,
+ "show": true,
+ "sideWidth": 250,
+ "total": false,
+ "values": true
+ },
+ "lines": true,
+ "linewidth": 1,
+ "nullPointMode": "null",
+ "options": {
+ "alertThreshold": true
+ },
+ "percentage": false,
+ "pluginVersion": "7.2.0",
+ "pointradius": 2,
+ "points": false,
+ "renderer": "flot",
+ "seriesOverrides": [],
+ "spaceLength": 10,
+ "stack": false,
+ "steppedLine": false,
+ "targets": [
+ {
+ "rawQuery": true,
+ "refId": "A",
+ "target": "backend=tsdb; container=users; table=pipelines/$PROJECT/model-endpoints/events; filter=endpoint_id=='$MODEL' AND record_type=='custom_metrics';",
+ "type": "timeserie"
+ }
+ ],
+ "thresholds": [],
+ "timeFrom": null,
+ "timeRegions": [],
+ "timeShift": null,
+ "title": "Custom Metrics",
+ "tooltip": {
+ "shared": true,
+ "sort": 0,
+ "value_type": "individual"
+ },
+ "transformations": [],
+ "transparent": true,
+ "type": "graph",
+ "xaxis": {
+ "buckets": null,
+ "mode": "time",
+ "name": null,
+ "show": true,
+ "values": []
+ },
+ "yaxes": [
+ {
+ "format": "short",
+ "label": null,
+ "logBase": 1,
+ "max": null,
+ "min": null,
+ "show": true
+ },
+ {
+ "format": "short",
+ "label": null,
+ "logBase": 1,
+ "max": null,
+ "min": null,
+ "show": true
+ }
+ ],
+ "yaxis": {
+ "align": false,
+ "alignLevel": null
+ }
+ }
+ ],
+ "refresh": "1m",
+ "schemaVersion": 26,
+ "style": "dark",
+ "tags": [],
+ "templating": {
+ "list": [
+ {
+ "allValue": null,
+ "current": {},
+ "datasource": "model-monitoring",
+ "definition": "target_endpoint=list_projects",
+ "hide": 0,
+ "includeAll": false,
+ "label": "Project",
+ "multi": false,
+ "name": "PROJECT",
+ "options": [],
+ "query": "target_endpoint=list_projects",
+ "refresh": 1,
+ "regex": "",
+ "skipUrlSync": false,
+ "sort": 0,
+ "tagValuesQuery": "",
+ "tags": [],
+ "tagsQuery": "",
+ "type": "query",
+ "useTags": false
+ },
+ {
+ "allValue": null,
+ "current": {},
+ "datasource": "iguazio",
+ "definition": "backend=kv;container=users;table=pipelines/$PROJECT/model-endpoints/endpoints;fields=endpoint_id;",
+ "hide": 0,
+ "includeAll": false,
+ "label": "Model",
+ "multi": false,
+ "name": "MODEL",
+ "options": [],
+ "query": "backend=kv;container=users;table=pipelines/$PROJECT/model-endpoints/endpoints;fields=endpoint_id;",
+ "refresh": 0,
+ "regex": "",
+ "skipUrlSync": false,
+ "sort": 0,
+ "tagValuesQuery": "",
+ "tags": [],
+ "tagsQuery": "",
+ "type": "query",
+ "useTags": false
+ }
+ ]
+ },
+ "time": {
+ "from": "now-1h",
+ "to": "now"
+ },
+ "timepicker": {},
+ "timezone": "",
+ "title": "Model Monitoring - Performance",
+ "uid": "9CazA-UGz",
+ "version": 2
+}
diff --git a/docs/monitoring/dashboards/model-monitoring-details.json b/docs/monitoring/dashboards/model-monitoring-details.json
index 475c43464f4f..927b35e20b87 100644
--- a/docs/monitoring/dashboards/model-monitoring-details.json
+++ b/docs/monitoring/dashboards/model-monitoring-details.json
@@ -3,43 +3,50 @@
"list": [
{
"builtIn": 1,
- "datasource": "-- Grafana --",
+ "datasource": {
+ "type": "datasource",
+ "uid": "grafana"
+ },
"enable": true,
"hide": true,
"iconColor": "rgba(0, 211, 255, 1)",
"name": "Annotations & Alerts",
+ "target": {
+ "limit": 100,
+ "matchAny": false,
+ "tags": [],
+ "type": "dashboard"
+ },
"type": "dashboard"
}
]
},
"editable": true,
- "gnetId": null,
+ "fiscalYearStartMonth": 0,
"graphTooltip": 0,
- "id": 8,
- "iteration": 1627466479152,
+ "id": 18,
"links": [
{
"icon": "external link",
"includeVars": true,
"keepTime": true,
"tags": [],
- "targetBlank": true,
"title": "Model Monitoring - Performance",
"type": "link",
"url": "/d/9CazA-UGz/model-monitoring-performance"
},
{
- "icon": "dashboard",
- "includeVars": false,
+ "asDropdown": true,
+ "icon": "external link",
+ "includeVars": true,
"keepTime": true,
"tags": [],
- "targetBlank": true,
"title": "Model Monitoring - Overview",
- "tooltip": "",
"type": "link",
- "url": "/d/g0M4uh0Mz"
+ "url": "d/g0M4uh0Mz/model-monitoring-overview"
}
],
+ "liveNow": false,
"panels": [
{
"datasource": "iguazio",
@@ -47,19 +54,12 @@
"fieldConfig": {
"defaults": {
"custom": {
- "align": null,
+ "align": "auto",
"displayMode": "auto",
- "filterable": false
+ "filterable": false,
+ "inspect": false
},
- "mappings": [
- {
- "from": "",
- "id": 0,
- "text": "",
- "to": "",
- "type": 1
- }
- ],
+ "mappings": [],
"thresholds": {
"mode": "absolute",
"steps": [
@@ -191,8 +191,15 @@
"x": 0,
"y": 0
},
- "id": 12,
+ "id": 22,
"options": {
+ "footer": {
+ "fields": "",
+ "reducer": [
+ "sum"
+ ],
+ "show": false
+ },
"showHeader": true,
"sortBy": [
{
@@ -201,19 +208,17 @@
}
]
},
- "pluginVersion": "7.2.0",
+ "pluginVersion": "9.2.2",
"targets": [
{
+ "datasource": "iguazio",
"hide": false,
"rawQuery": true,
"refId": "A",
- "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfilter=endpoint_id==\"$MODEL\";\nfields=endpoint_id,model,function_uri,model_class,predictions_per_second,latency_avg_1h,first_request,last_request;",
+ "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfilter=endpoint_id==\"$MODELENDPOINT\";\nfields=endpoint_id,model,function_uri,model_class,predictions_per_second,latency_avg_1h,first_request,last_request;",
"type": "table"
}
],
- "timeFrom": null,
- "timeShift": null,
- "title": "",
"transformations": [
{
"id": "organize",
@@ -242,24 +247,17 @@
"type": "table"
},
{
- "datasource": "model-monitoring",
+ "datasource": "iguazio",
"description": "",
"fieldConfig": {
"defaults": {
"custom": {
- "align": null,
+ "align": "auto",
"displayMode": "auto",
- "filterable": false
+ "filterable": false,
+ "inspect": false
},
- "mappings": [
- {
- "from": "",
- "id": 0,
- "text": "",
- "to": "",
- "type": 1
- }
- ],
+ "mappings": [],
"thresholds": {
"mode": "absolute",
"steps": [
@@ -370,6 +368,22 @@
"value": "center"
}
]
+ },
+ {
+ "matcher": {
+ "id": "byName",
+ "options": "drift_measures"
+ },
+ "properties": [
+ {
+ "id": "custom.hidden",
+ "value": false
+ },
+ {
+ "id": "mappings",
+ "value": []
+ }
+ ]
}
]
},
@@ -379,8 +393,15 @@
"x": 0,
"y": 3
},
- "id": 21,
+ "id": 25,
"options": {
+ "footer": {
+ "fields": "",
+ "reducer": [
+ "sum"
+ ],
+ "show": false
+ },
"showHeader": true,
"sortBy": [
{
@@ -389,35 +410,39 @@
}
]
},
- "pluginVersion": "7.2.0",
+ "pluginVersion": "9.2.2",
"targets": [
{
+ "datasource": "iguazio",
"hide": false,
"rawQuery": true,
"refId": "A",
- "target": "target_endpoint=overall_feature_analysis;endpoint_id=$MODEL;project=$PROJECT",
+ "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfilter=endpoint_id==\"$MODELENDPOINT\";\nfields=drift_measures;",
"type": "table"
}
],
- "timeFrom": null,
- "timeShift": null,
"title": "Overall Drift Analysis",
"transformations": [
{
- "id": "organize",
+ "id": "extractFields",
"options": {
- "excludeByName": {},
- "indexByName": {},
- "renameByName": {
- "endpoint_id": "Endpoint ID",
- "first_request": "First Request",
- "function": "Function",
- "last_request": "Last Request",
- "latency_avg_1s": "Average Latency",
- "model": "Model",
- "model_class": "Model Class",
- "predictions_per_second_count_1s": "Predictions/sec",
- "tag": "Tag"
+ "format": "json",
+ "replace": false,
+ "source": "drift_measures"
+ }
+ },
+ {
+ "id": "filterFieldsByName",
+ "options": {
+ "include": {
+ "names": [
+ "tvd_sum",
+ "tvd_mean",
+ "hellinger_sum",
+ "hellinger_mean",
+ "kld_sum",
+ "kld_mean"
+ ]
}
}
}
@@ -426,24 +451,17 @@
"type": "table"
},
{
- "datasource": "model-monitoring",
+ "datasource": "iguazio",
"description": "Feature analysis of the latest batch",
"fieldConfig": {
"defaults": {
"custom": {
"align": "center",
"displayMode": "auto",
- "filterable": false
+ "filterable": false,
+ "inspect": false
},
- "mappings": [
- {
- "from": "",
- "id": 0,
- "text": "",
- "to": "",
- "type": 1
- }
- ],
+ "mappings": [],
"thresholds": {
"mode": "absolute",
"steps": [
@@ -459,20 +477,6 @@
}
},
"overrides": [
- {
- "matcher": {
- "id": "byName",
- "options": "Feature"
- },
- "properties": []
- },
- {
- "matcher": {
- "id": "byName",
- "options": "Actual Min"
- },
- "properties": []
- },
{
"matcher": {
"id": "byName",
@@ -553,55 +557,323 @@
"x": 0,
"y": 6
},
- "id": 14,
+ "id": 29,
"options": {
+ "footer": {
+ "fields": "",
+ "reducer": [
+ "sum"
+ ],
+ "show": false
+ },
"showHeader": true,
"sortBy": [
{
- "desc": false,
- "displayName": "Feature"
+ "desc": true,
+ "displayName": "Field"
}
]
},
- "pluginVersion": "7.2.0",
+ "pluginVersion": "9.2.2",
"targets": [
{
+ "datasource": "iguazio",
"rawQuery": true,
"refId": "A",
- "target": "target_endpoint=individual_feature_analysis;endpoint_id=$MODEL;project=$PROJECT",
+ "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfilter=endpoint_id==\"$MODELENDPOINT\";\nfields= current_stats;",
+ "type": "table"
+ },
+ {
+ "datasource": "iguazio",
+ "hide": false,
+ "refId": "B",
+ "target": "backend=kv; container=users; table=pipelines/$PROJECT/model-endpoints/endpoints; filter=endpoint_id==\"$MODELENDPOINT\"; fields= feature_stats;",
+ "type": "table"
+ },
+ {
+ "datasource": "iguazio",
+ "hide": false,
+ "refId": "C",
+ "target": "backend=kv; container=users; table=pipelines/$PROJECT/model-endpoints/endpoints; filter=endpoint_id==\"$MODELENDPOINT\"; fields= drift_measures;",
"type": "table"
}
],
- "timeFrom": null,
- "timeShift": null,
"title": "Features Analysis",
"transformations": [
+ {
+ "id": "extractFields",
+ "options": {
+ "format": "auto",
+ "replace": false,
+ "source": "current_stats"
+ }
+ },
+ {
+ "id": "extractFields",
+ "options": {
+ "format": "auto",
+ "source": "feature_stats"
+ }
+ },
+ {
+ "id": "extractFields",
+ "options": {
+ "replace": false,
+ "source": "drift_measures"
+ }
+ },
+ {
+ "id": "merge",
+ "options": {}
+ },
+ {
+ "id": "reduce",
+ "options": {
+ "includeTimeField": false,
+ "labelsToFields": false,
+ "mode": "seriesToRows",
+ "reducers": [
+ "allValues"
+ ]
+ }
+ },
+ {
+ "id": "filterByValue",
+ "options": {
+ "filters": [
+ {
+ "config": {
+ "id": "equal",
+ "options": {
+ "value": "feature_stats"
+ }
+ },
+ "fieldName": "Field"
+ },
+ {
+ "config": {
+ "id": "equal",
+ "options": {
+ "value": "current_stats"
+ }
+ },
+ "fieldName": "Field"
+ },
+ {
+ "config": {
+ "id": "equal",
+ "options": {
+ "value": "timestamp"
+ }
+ },
+ "fieldName": "Field"
+ },
+ {
+ "config": {
+ "id": "equal",
+ "options": {
+ "value": "drift_measures"
+ }
+ },
+ "fieldName": "Field"
+ },
+ {
+ "config": {
+ "id": "equal",
+ "options": {
+ "value": "kld_sum"
+ }
+ },
+ "fieldName": "Field"
+ },
+ {
+ "config": {
+ "id": "equal",
+ "options": {
+ "value": "kld_mean"
+ }
+ },
+ "fieldName": "Field"
+ },
+ {
+ "config": {
+ "id": "equal",
+ "options": {
+ "value": "tvd_mean"
+ }
+ },
+ "fieldName": "Field"
+ },
+ {
+ "config": {
+ "id": "equal",
+ "options": {
+ "value": "tvd_sum"
+ }
+ },
+ "fieldName": "Field"
+ },
+ {
+ "config": {
+ "id": "equal",
+ "options": {
+ "value": "hellinger_sum"
+ }
+ },
+ "fieldName": "Field"
+ },
+ {
+ "config": {
+ "id": "equal",
+ "options": {
+ "value": "hellinger_mean"
+ }
+ },
+ "fieldName": "Field"
+ }
+ ],
+ "match": "any",
+ "type": "exclude"
+ }
+ },
+ {
+ "id": "extractFields",
+ "options": {
+ "replace": false,
+ "source": "All values"
+ }
+ },
+ {
+ "id": "filterFieldsByName",
+ "options": {
+ "include": {
+ "names": [
+ "Field",
+ "0",
+ "1",
+ "2"
+ ]
+ }
+ }
+ },
+ {
+ "id": "extractFields",
+ "options": {
+ "replace": false,
+ "source": "0"
+ }
+ },
+ {
+ "id": "extractFields",
+ "options": {
+ "source": "1"
+ }
+ },
+ {
+ "id": "extractFields",
+ "options": {
+ "source": "2"
+ }
+ },
+ {
+ "id": "filterFieldsByName",
+ "options": {
+ "include": {
+ "names": [
+ "Field",
+ "mean 1",
+ "min 1",
+ "max 1",
+ "mean 2",
+ "min 2",
+ "tvd",
+ "hellinger",
+ "kld",
+ "max 2"
+ ]
+ }
+ }
+ },
+ {
+ "id": "renameByRegex",
+ "options": {
+ "regex": "mean 1",
+ "renamePattern": "Actual Mean"
+ }
+ },
+ {
+ "id": "renameByRegex",
+ "options": {
+ "regex": "min 1",
+ "renamePattern": "Actual Min"
+ }
+ },
+ {
+ "id": "renameByRegex",
+ "options": {
+ "regex": "max 1",
+ "renamePattern": "Actual Max"
+ }
+ },
+ {
+ "id": "renameByRegex",
+ "options": {
+ "regex": "mean 2",
+ "renamePattern": "Expected Mean"
+ }
+ },
+ {
+ "id": "renameByRegex",
+ "options": {
+ "regex": "min 2",
+ "renamePattern": "Expected Min"
+ }
+ },
+ {
+ "id": "renameByRegex",
+ "options": {
+ "regex": "max 2",
+ "renamePattern": "Expected Max"
+ }
+ },
+ {
+ "id": "renameByRegex",
+ "options": {
+ "regex": "tvd",
+ "renamePattern": "TVD"
+ }
+ },
+ {
+ "id": "renameByRegex",
+ "options": {
+ "regex": "hellinger",
+ "renamePattern": "Hellinger"
+ }
+ },
+ {
+ "id": "renameByRegex",
+ "options": {
+ "regex": "kld",
+ "renamePattern": "KLD"
+ }
+ },
{
"id": "organize",
"options": {
- "excludeByName": {
- "count": true,
- "idx": true,
- "model": true
- },
+ "excludeByName": {},
"indexByName": {
- "actual_max": 3,
- "actual_mean": 2,
- "actual_min": 1,
- "expected_max": 4,
- "expected_mean": 5,
- "expected_min": 6,
- "feature_name": 0
+ "Actual Max": 6,
+ "Actual Mean": 2,
+ "Actual Min": 4,
+ "Expected Max": 5,
+ "Expected Mean": 1,
+ "Expected Min": 3,
+ "Field": 0,
+ "Hellinger": 8,
+ "KLD": 9,
+ "TVD": 7
},
- "renameByName": {
- "actual_max": "Actual Max",
- "actual_mean": "Actual Mean",
- "actual_min": "Actual Min",
- "expected_max": "Expected Min",
- "expected_mean": "Expected Mean",
- "expected_min": "Expected Max",
- "feature_name": "Feature"
- }
+ "renameByName": {}
}
}
],
@@ -614,12 +886,6 @@
"dashLength": 10,
"dashes": false,
"datasource": "iguazio",
- "fieldConfig": {
- "defaults": {
- "custom": {}
- },
- "overrides": []
- },
"fill": 1,
"fillGradient": 1,
"gridPos": {
@@ -649,7 +915,7 @@
"alertThreshold": true
},
"percentage": false,
- "pluginVersion": "7.2.0",
+ "pluginVersion": "9.2.2",
"pointradius": 2,
"points": false,
"renderer": "flot",
@@ -659,16 +925,15 @@
"steppedLine": false,
"targets": [
{
+ "datasource": "iguazio",
"rawQuery": true,
"refId": "A",
- "target": "backend=tsdb;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/events;\nfilter=endpoint_id=='$MODEL' AND record_type=='endpoint_features';",
+ "target": "backend=tsdb;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/events;\nfilter=endpoint_id=='$MODELENDPOINT' AND record_type=='endpoint_features';",
"type": "timeserie"
}
],
"thresholds": [],
- "timeFrom": null,
"timeRegions": [],
- "timeShift": null,
"title": "Incoming Features",
"tooltip": {
"shared": true,
@@ -679,44 +944,34 @@
"transparent": true,
"type": "graph",
"xaxis": {
- "buckets": null,
"mode": "time",
- "name": null,
"show": true,
"values": []
},
"yaxes": [
{
"format": "short",
- "label": null,
"logBase": 1,
- "max": null,
- "min": null,
"show": true
},
{
"format": "short",
- "label": null,
"logBase": 1,
- "max": null,
- "min": null,
"show": true
}
],
"yaxis": {
- "align": false,
- "alignLevel": null
+ "align": false
}
}
],
"refresh": "1m",
- "schemaVersion": 26,
+ "schemaVersion": 37,
"style": "dark",
"tags": [],
"templating": {
"list": [
{
- "allValue": null,
"current": {},
"datasource": "model-monitoring",
"definition": "target_endpoint=list_projects",
@@ -727,26 +982,24 @@
"name": "PROJECT",
"options": [],
"query": "target_endpoint=list_projects",
- "refresh": 0,
+ "refresh": 1,
"regex": "",
"skipUrlSync": false,
"sort": 0,
"tagValuesQuery": "",
- "tags": [],
"tagsQuery": "",
"type": "query",
"useTags": false
},
{
- "allValue": null,
"current": {},
"datasource": "iguazio",
"definition": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=endpoint_id;",
"hide": 0,
"includeAll": false,
- "label": "Model",
+ "label": "Model Endpoint",
"multi": false,
- "name": "MODEL",
+ "name": "MODELENDPOINT",
"options": [],
"query": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=endpoint_id;",
"refresh": 1,
@@ -754,7 +1007,6 @@
"skipUrlSync": false,
"sort": 0,
"tagValuesQuery": "",
- "tags": [],
"tagsQuery": "",
"type": "query",
"useTags": false
@@ -769,5 +1021,6 @@
"timezone": "",
"title": "Model Monitoring - Details",
"uid": "AohIXhAMk",
- "version": 3
+ "version": 2,
+ "weekStart": ""
}
diff --git a/docs/monitoring/dashboards/model-monitoring-overview.json b/docs/monitoring/dashboards/model-monitoring-overview.json
index 0821a9225537..c003428d315c 100644
--- a/docs/monitoring/dashboards/model-monitoring-overview.json
+++ b/docs/monitoring/dashboards/model-monitoring-overview.json
@@ -3,20 +3,28 @@
"list": [
{
"builtIn": 1,
- "datasource": "-- Grafana --",
+ "datasource": {
+ "type": "datasource",
+ "uid": "grafana"
+ },
"enable": true,
"hide": true,
"iconColor": "rgba(0, 211, 255, 1)",
"name": "Annotations & Alerts",
+ "target": {
+ "limit": 100,
+ "matchAny": false,
+ "tags": [],
+ "type": "dashboard"
+ },
"type": "dashboard"
}
]
},
"editable": true,
- "gnetId": null,
+ "fiscalYearStartMonth": 0,
"graphTooltip": 0,
- "id": 7,
- "iteration": 1627466285618,
+ "id": 13,
"links": [
{
"icon": "external link",
@@ -28,20 +36,22 @@
"url": "/d/9CazA-UGz/model-monitoring-performance"
},
{
- "icon": "info",
+ "icon": "external link",
+ "includeVars": true,
"keepTime": true,
"tags": [],
- "title": "Model Alerts",
+ "targetBlank": false,
+ "title": "Model Monitoring - Details",
"type": "link",
- "url": "/d/q6GvXh0Gz/model-alerts"
+ "url": "d/AohIXhAMk/model-monitoring-details"
}
],
+ "liveNow": false,
"panels": [
{
"datasource": "iguazio",
"fieldConfig": {
"defaults": {
- "custom": {},
"mappings": [],
"thresholds": {
"mode": "absolute",
@@ -80,17 +90,16 @@
},
"textMode": "value"
},
- "pluginVersion": "7.2.0",
+ "pluginVersion": "9.2.2",
"targets": [
{
+"datasource": "iguazio",
"rawQuery": true,
"refId": "A",
"target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=endpoint_id;",
"type": "table"
}
],
- "timeFrom": null,
- "timeShift": null,
"title": "Endpoints",
"transformations": [
{
@@ -109,7 +118,6 @@
"datasource": "iguazio",
"fieldConfig": {
"defaults": {
- "custom": {},
"mappings": [],
"thresholds": {
"mode": "absolute",
@@ -148,9 +156,10 @@
},
"textMode": "auto"
},
- "pluginVersion": "7.2.0",
+ "pluginVersion": "9.2.2",
"targets": [
{
+"datasource": "iguazio",
"hide": false,
"rawQuery": true,
"refId": "A",
@@ -158,17 +167,14 @@
"type": "table"
}
],
- "timeFrom": null,
- "timeShift": null,
"title": "Predictions/s (5 Minute Average)",
"transparent": true,
"type": "stat"
},
{
- "datasource": "iguazio",
+ "datasource": "iguazio",
"fieldConfig": {
"defaults": {
- "custom": {},
"mappings": [],
"thresholds": {
"mode": "absolute",
@@ -204,17 +210,16 @@
},
"textMode": "auto"
},
- "pluginVersion": "7.2.0",
+ "pluginVersion": "9.2.2",
"targets": [
{
+"datasource": "iguazio",
"rawQuery": true,
"refId": "A",
"target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=latency_avg_1h;",
"type": "table"
}
],
- "timeFrom": null,
- "timeShift": null,
"title": "Average Latency (Last Hour)",
"transformations": [
{
@@ -233,7 +238,6 @@
"datasource": "iguazio",
"fieldConfig": {
"defaults": {
- "custom": {},
"mappings": [],
"noValue": "0",
"thresholds": {
@@ -266,47 +270,39 @@
"orientation": "auto",
"reduceOptions": {
"calcs": [
- "mean"
+ "sum"
],
"fields": "",
"values": false
},
"textMode": "auto"
},
- "pluginVersion": "7.2.0",
+ "pluginVersion": "9.2.2",
"targets": [
{
+"datasource": "iguazio",
"rawQuery": true,
"refId": "A",
"target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=error_count;",
"type": "table"
}
],
- "timeFrom": null,
- "timeShift": null,
"title": "Errors",
"transparent": true,
"type": "stat"
},
{
- "datasource": "model-monitoring",
+ "datasource": "iguazio",
"description": "",
"fieldConfig": {
"defaults": {
"custom": {
"align": "center",
"displayMode": "auto",
- "filterable": true
+ "filterable": true,
+ "inspect": false
},
- "mappings": [
- {
- "from": "",
- "id": 0,
- "text": "",
- "to": "",
- "type": 1
- }
- ],
+ "mappings": [],
"thresholds": {
"mode": "absolute",
"steps": [
@@ -325,7 +321,7 @@
{
"matcher": {
"id": "byName",
- "options": "Function"
+ "options": "function_uri"
},
"properties": [
{
@@ -452,36 +448,28 @@
"id": "mappings",
"value": [
{
- "from": "",
- "id": 0,
- "text": "0",
- "to": "",
- "type": 1,
- "value": "NO_DRIFT"
- },
- {
- "from": "",
- "id": 1,
- "text": "1",
- "to": "",
- "type": 1,
- "value": "POSSIBLE_DRIFT"
- },
- {
- "from": "",
- "id": 2,
- "text": "2",
- "to": "",
- "type": 1,
- "value": "DRIFT_DETECTED"
- },
- {
- "from": "",
- "id": 3,
- "text": "-1",
- "to": "",
- "type": 1,
- "value": "N\\A"
+ "options": {
+ "DRIFT_DETECTED": {
+ "color": "red",
+ "index": 3,
+ "text": "2"
+ },
+ "NO_DRIFT": {
+ "color": "green",
+ "index": 2,
+ "text": "0"
+ },
+ "N\\A": {
+ "index": 1,
+ "text": "-1"
+ },
+ "POSSIBLE_DRIFT": {
+ "color": "yellow",
+ "index": 0,
+ "text": "1"
+ }
+ },
+ "type": "value"
}
]
},
@@ -543,6 +531,13 @@
},
"id": 22,
"options": {
+ "footer": {
+ "fields": "",
+ "reducer": [
+ "sum"
+ ],
+ "show": false
+ },
"showHeader": true,
"sortBy": [
{
@@ -551,18 +546,17 @@
}
]
},
- "pluginVersion": "7.2.0",
+ "pluginVersion": "9.2.2",
"targets": [
{
+"datasource": "iguazio",
"hide": false,
"rawQuery": true,
"refId": "A",
- "target": "project=$PROJECT;target_endpoint=list_endpoints",
+ "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=endpoint_id,model,function_uri,model_class,first_request,last_request,error_count,drift_status;",
"type": "table"
}
],
- "timeFrom": null,
- "timeShift": null,
"title": "Models",
"transformations": [
{
@@ -572,16 +566,13 @@
"model_hash": false
},
"indexByName": {
- "accuracy": 8,
- "drift_status": 9,
- "endpoint_function": 1,
"endpoint_id": 0,
- "endpoint_model": 2,
- "endpoint_model_class": 3,
- "endpoint_tag": 4,
- "error_count": 7,
- "first_request": 5,
- "last_request": 6
+ "error_count": 6,
+ "first_request": 4,
+ "function_uri": 1,
+ "last_request": 5,
+ "model": 2,
+ "model_class": 3
},
"renameByName": {
"accuracy": "Accuracy",
@@ -594,6 +585,7 @@
"error_count": "Error Count",
"first_request": "First Request",
"function": "Function",
+ "function_uri": "Function",
"last_request": "Last Request",
"latency_avg_1s": "Average Latency",
"model": "Model",
@@ -607,10 +599,7 @@
"type": "table"
},
{
- "cards": {
- "cardPadding": null,
- "cardRound": null
- },
+ "cards": {},
"color": {
"cardColor": "#b4ff00",
"colorScale": "sqrt",
@@ -622,20 +611,15 @@
"datasource": "iguazio",
"fieldConfig": {
"defaults": {
- "custom": {},
- "mappings": [],
- "thresholds": {
- "mode": "absolute",
- "steps": [
- {
- "color": "green",
- "value": null
- },
- {
- "color": "red",
- "value": 80
- }
- ]
+ "custom": {
+ "hideFrom": {
+ "legend": false,
+ "tooltip": false,
+ "viz": false
+ },
+ "scaleDistribution": {
+ "type": "linear"
+ }
}
},
"overrides": []
@@ -653,18 +637,54 @@
"legend": {
"show": false
},
- "pluginVersion": "7.2.0",
+ "options": {
+ "calculate": true,
+ "calculation": {},
+ "cellGap": 2,
+ "cellValues": {},
+ "color": {
+ "exponent": 0.5,
+ "fill": "#b4ff00",
+ "mode": "scheme",
+ "reverse": false,
+ "scale": "exponential",
+ "scheme": "Plasma",
+ "steps": 128
+ },
+ "exemplars": {
+ "color": "rgba(255,0,255,0.7)"
+ },
+ "filterValues": {
+ "le": 1e-9
+ },
+ "legend": {
+ "show": false
+ },
+ "rowsFrame": {
+ "layout": "auto"
+ },
+ "showValue": "never",
+ "tooltip": {
+ "show": true,
+ "yHistogram": false
+ },
+ "yAxis": {
+ "axisPlacement": "left",
+ "reverse": false,
+ "unit": "short"
+ }
+ },
+ "pluginVersion": "9.2.2",
"reverseYBuckets": false,
"targets": [
{
+"datasource": "iguazio",
"rawQuery": true,
"refId": "A",
"target": "backend=tsdb;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/events;\nfields=predictions_per_second;",
"type": "timeserie"
}
],
- "timeFrom": null,
- "timeShift": null,
"title": "Predictions/s (5 Minute Average)",
"tooltip": {
"show": true,
@@ -675,26 +695,15 @@
"xAxis": {
"show": true
},
- "xBucketNumber": null,
- "xBucketSize": null,
"yAxis": {
- "decimals": null,
"format": "short",
"logBase": 1,
- "max": null,
- "min": null,
- "show": true,
- "splitFactor": null
+ "show": true
},
- "yBucketBound": "auto",
- "yBucketNumber": null,
- "yBucketSize": null
+ "yBucketBound": "auto"
},
{
- "cards": {
- "cardPadding": null,
- "cardRound": null
- },
+ "cards": {},
"color": {
"cardColor": "#b4ff00",
"colorScale": "sqrt",
@@ -706,36 +715,18 @@
"datasource": "iguazio",
"fieldConfig": {
"defaults": {
- "custom": {},
- "mappings": [],
- "thresholds": {
- "mode": "absolute",
- "steps": [
- {
- "color": "green",
- "value": null
- },
- {
- "color": "red",
- "value": 80
- }
- ]
- }
- },
- "overrides": [
- {
- "matcher": {
- "id": "byType",
- "options": "number"
+ "custom": {
+ "hideFrom": {
+ "legend": false,
+ "tooltip": false,
+ "viz": false
},
- "properties": [
- {
- "id": "unit",
- "value": "µs"
- }
- ]
+ "scaleDistribution": {
+ "type": "linear"
+ }
}
- ]
+ },
+ "overrides": []
},
"gridPos": {
"h": 6,
@@ -750,18 +741,54 @@
"legend": {
"show": false
},
- "pluginVersion": "7.2.0",
+ "options": {
+ "calculate": true,
+ "calculation": {},
+ "cellGap": 2,
+ "cellValues": {},
+ "color": {
+ "exponent": 0.5,
+ "fill": "#b4ff00",
+ "mode": "scheme",
+ "reverse": false,
+ "scale": "exponential",
+ "scheme": "Plasma",
+ "steps": 128
+ },
+ "exemplars": {
+ "color": "rgba(255,0,255,0.7)"
+ },
+ "filterValues": {
+ "le": 1e-9
+ },
+ "legend": {
+ "show": false
+ },
+ "rowsFrame": {
+ "layout": "auto"
+ },
+ "showValue": "never",
+ "tooltip": {
+ "show": true,
+ "yHistogram": false
+ },
+ "yAxis": {
+ "axisPlacement": "left",
+ "reverse": false,
+ "unit": "short"
+ }
+ },
+ "pluginVersion": "9.2.2",
"reverseYBuckets": false,
"targets": [
{
+"datasource": "iguazio",
"rawQuery": true,
"refId": "A",
"target": "backend=tsdb;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/events;\nfields=latency_avg_1h;",
"type": "timeserie"
}
],
- "timeFrom": null,
- "timeShift": null,
"title": "Average Latency (1 Hour)",
"tooltip": {
"show": true,
@@ -772,20 +799,12 @@
"xAxis": {
"show": true
},
- "xBucketNumber": null,
- "xBucketSize": null,
"yAxis": {
- "decimals": null,
"format": "short",
"logBase": 1,
- "max": null,
- "min": null,
- "show": true,
- "splitFactor": null
+ "show": true
},
- "yBucketBound": "auto",
- "yBucketNumber": null,
- "yBucketSize": null
+ "yBucketBound": "auto"
},
{
"aliasColors": {},
@@ -793,12 +812,6 @@
"dashLength": 10,
"dashes": false,
"datasource": "iguazio",
- "fieldConfig": {
- "defaults": {
- "custom": {}
- },
- "overrides": []
- },
"fill": 1,
"fillGradient": 0,
"gridPos": {
@@ -825,7 +838,7 @@
"alertThreshold": true
},
"percentage": false,
- "pluginVersion": "7.2.0",
+ "pluginVersion": "9.2.2",
"pointradius": 2,
"points": false,
"renderer": "flot",
@@ -835,15 +848,14 @@
"steppedLine": false,
"targets": [
{
+ "datasource": "iguazio",
"refId": "A",
"target": "select metric",
"type": "timeserie"
}
],
"thresholds": [],
- "timeFrom": null,
"timeRegions": [],
- "timeShift": null,
"title": "Errors",
"tooltip": {
"shared": true,
@@ -853,44 +865,34 @@
"transparent": true,
"type": "graph",
"xaxis": {
- "buckets": null,
"mode": "time",
- "name": null,
"show": true,
"values": []
},
"yaxes": [
{
"format": "short",
- "label": null,
"logBase": 1,
- "max": null,
- "min": null,
"show": true
},
{
"format": "short",
- "label": null,
"logBase": 1,
- "max": null,
- "min": null,
"show": true
}
],
"yaxis": {
- "align": false,
- "alignLevel": null
+ "align": false
}
}
],
"refresh": "5s",
- "schemaVersion": 26,
+ "schemaVersion": 37,
"style": "dark",
"tags": [],
"templating": {
"list": [
{
- "allValue": null,
"current": {},
"datasource": "model-monitoring",
"definition": "target_endpoint=list_projects",
@@ -906,7 +908,6 @@
"skipUrlSync": false,
"sort": 0,
"tagValuesQuery": "",
- "tags": [],
"tagsQuery": "",
"type": "query",
"useTags": false
@@ -921,5 +922,6 @@
"timezone": "",
"title": "Model Monitoring - Overview",
"uid": "g0M4uh0Mz",
- "version": 2
+ "version": 9,
+ "weekStart": ""
}
diff --git a/docs/monitoring/dashboards/model-monitoring-performance.json b/docs/monitoring/dashboards/model-monitoring-performance.json
index ab343c5055dc..8259587430fd 100644
--- a/docs/monitoring/dashboards/model-monitoring-performance.json
+++ b/docs/monitoring/dashboards/model-monitoring-performance.json
@@ -21,7 +21,7 @@
{
"asDropdown": true,
"icon": "external link",
- "includeVars": false,
+ "includeVars": true,
"keepTime": true,
"tags": [],
"title": "Model Monitoring - Overview",
@@ -34,7 +34,7 @@
"keepTime": true,
"tags": [],
"targetBlank": false,
- "title": "Model Monitoring Details",
+ "title": "Model Monitoring - Details",
"type": "link",
"url": "d/AohIXhAMk/model-monitoring-details"
}
@@ -93,7 +93,7 @@
{
"rawQuery": true,
"refId": "A",
- "target": "backend=tsdb;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/events;\nfilter=endpoint_id=='$MODEL' AND record_type=='drift_measures';",
+ "target": "backend=tsdb;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/events;\nfilter=endpoint_id=='$MODELENDPOINT' AND record_type=='drift_measures';",
"type": "timeserie"
}
],
@@ -190,7 +190,7 @@
{
"rawQuery": true,
"refId": "A",
- "target": "backend=tsdb;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/events;\nfields=latency_avg_5m,latency_avg_1h;\nfilter=endpoint_id=='$MODEL';",
+ "target": "backend=tsdb;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/events;\nfields=latency_avg_5m,latency_avg_1h;\nfilter=endpoint_id=='$MODELENDPOINT';",
"type": "timeserie"
}
],
@@ -286,7 +286,7 @@
{
"rawQuery": true,
"refId": "A",
- "target": "backend=tsdb;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/events;\nfields=predictions_per_second;\nfilter=endpoint_id=='$MODEL';",
+ "target": "backend=tsdb;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/events;\nfields=predictions_per_second;\nfilter=endpoint_id=='$MODELENDPOINT';",
"type": "timeserie"
}
],
@@ -382,7 +382,7 @@
{
"rawQuery": true,
"refId": "A",
- "target": "backend=tsdb;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/events;\nfields=predictions_count_5m,predictions_count_1h;\nfilter=endpoint_id=='$MODEL';",
+ "target": "backend=tsdb;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/events;\nfields=predictions_count_5m,predictions_count_1h;\nfilter=endpoint_id=='$MODELENDPOINT';",
"type": "timeserie"
}
],
@@ -481,7 +481,7 @@
{
"rawQuery": true,
"refId": "A",
- "target": "backend=tsdb; container=users; table=pipelines/$PROJECT/model-endpoints/events; filter=endpoint_id=='$MODEL' AND record_type=='custom_metrics';",
+ "target": "backend=tsdb; container=users; table=pipelines/$PROJECT/model-endpoints/events; filter=endpoint_id=='$MODELENDPOINT' AND record_type=='custom_metrics';",
"type": "timeserie"
}
],
@@ -564,9 +564,9 @@
"definition": "backend=kv;container=users;table=pipelines/$PROJECT/model-endpoints/endpoints;fields=endpoint_id;",
"hide": 0,
"includeAll": false,
- "label": "Model",
+ "label": "Model Endpoint",
"multi": false,
- "name": "MODEL",
+ "name": "MODELENDPOINT",
"options": [],
"query": "backend=kv;container=users;table=pipelines/$PROJECT/model-endpoints/endpoints;fields=endpoint_id;",
"refresh": 0,
diff --git a/mlrun/api/api/endpoints/grafana_proxy.py b/mlrun/api/api/endpoints/grafana_proxy.py
index eedc09c7dd87..8fbb3dfed5ef 100644
--- a/mlrun/api/api/endpoints/grafana_proxy.py
+++ b/mlrun/api/api/endpoints/grafana_proxy.py
@@ -13,33 +13,20 @@
# limitations under the License.
#
import asyncio
-import json
+import warnings
from http import HTTPStatus
-from typing import Any, Dict, List, Optional, Set, Union
+from typing import List, Union
-import numpy as np
-import pandas as pd
from fastapi import APIRouter, Depends, Request, Response
from fastapi.concurrency import run_in_threadpool
from sqlalchemy.orm import Session
import mlrun.api.crud
+import mlrun.api.crud.model_monitoring.grafana
import mlrun.api.schemas
import mlrun.api.utils.auth.verifier
from mlrun.api.api import deps
-from mlrun.api.schemas import (
- GrafanaColumn,
- GrafanaDataPoint,
- GrafanaNumberColumn,
- GrafanaTable,
- GrafanaTimeSeriesTarget,
- ProjectsFormat,
-)
-from mlrun.api.utils.singletons.project_member import get_project_member
-from mlrun.errors import MLRunBadRequestError
-from mlrun.utils import config, logger
-from mlrun.utils.model_monitoring import parse_model_endpoint_store_prefix
-from mlrun.utils.v3io_clients import get_frames_client
+from mlrun.api.schemas import GrafanaTable, GrafanaTimeSeriesTarget
router = APIRouter()
@@ -56,34 +43,10 @@ def grafana_proxy_model_endpoints_check_connection(
return Response(status_code=HTTPStatus.OK.value)
-@router.post(
- "/grafana-proxy/model-endpoints/query",
- response_model=List[Union[GrafanaTable, GrafanaTimeSeriesTarget]],
-)
-async def grafana_proxy_model_endpoints_query(
- request: Request,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
-) -> List[Union[GrafanaTable, GrafanaTimeSeriesTarget]]:
- """
- Query route for model-endpoints grafana proxy API, used for creating an interface between grafana queries and
- model-endpoints logic.
-
- This implementation requires passing target_endpoint query parameter in order to dispatch different
- model-endpoint monitoring functions.
- """
- body = await request.json()
- query_parameters = _parse_query_parameters(body)
- _validate_query_parameters(query_parameters, SUPPORTED_QUERY_FUNCTIONS)
- query_parameters = _drop_grafana_escape_chars(query_parameters)
-
- # At this point everything is validated and we can access everything that is needed without performing all previous
- # checks again.
- target_endpoint = query_parameters["target_endpoint"]
- function = NAME_TO_QUERY_FUNCTION_DICTIONARY[target_endpoint]
- if asyncio.iscoroutinefunction(function):
- return await function(body, query_parameters, auth_info)
- result = await run_in_threadpool(function, body, query_parameters, auth_info)
- return result
+NAME_TO_SEARCH_FUNCTION_DICTIONARY = {
+ "list_projects": mlrun.api.crud.model_monitoring.grafana.grafana_list_projects,
+}
+SUPPORTED_SEARCH_FUNCTIONS = set(NAME_TO_SEARCH_FUNCTION_DICTIONARY)
@router.post("/grafana-proxy/model-endpoints/search", response_model=List[str])
@@ -101,9 +64,13 @@ async def grafana_proxy_model_endpoints_search(
"""
mlrun.api.crud.ModelEndpoints().get_access_key(auth_info)
body = await request.json()
- query_parameters = _parse_search_parameters(body)
+ query_parameters = mlrun.api.crud.model_monitoring.grafana.parse_search_parameters(
+ body
+ )
- _validate_query_parameters(query_parameters, SUPPORTED_SEARCH_FUNCTIONS)
+ mlrun.api.crud.model_monitoring.grafana.validate_query_parameters(
+ query_parameters, SUPPORTED_SEARCH_FUNCTIONS
+ )
# At this point everything is validated and we can access everything that is needed without performing all previous
# checks again.
@@ -115,394 +82,56 @@ async def grafana_proxy_model_endpoints_search(
return result
-def grafana_list_projects(
- db_session: Session, auth_info: mlrun.api.schemas.AuthInfo
-) -> List[str]:
- projects_output = get_project_member().list_projects(
- db_session, format_=ProjectsFormat.name_only, leader_session=auth_info.session
- )
- return projects_output.projects
-
-
-async def grafana_list_endpoints(
- body: Dict[str, Any],
- query_parameters: Dict[str, str],
- auth_info: mlrun.api.schemas.AuthInfo,
-) -> List[GrafanaTable]:
- project = query_parameters.get("project")
-
- # Filters
- model = query_parameters.get("model", None)
- function = query_parameters.get("function", None)
- labels = query_parameters.get("labels", "")
- labels = labels.split(",") if labels else []
-
- # Metrics to include
- metrics = query_parameters.get("metrics", "")
- metrics = metrics.split(",") if metrics else []
-
- # Time range for metrics
- start = body.get("rangeRaw", {}).get("start", "now-1h")
- end = body.get("rangeRaw", {}).get("end", "now")
-
- if project:
- await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_permissions(
- project,
- mlrun.api.schemas.AuthorizationAction.read,
- auth_info,
- )
- endpoint_list = await run_in_threadpool(
- mlrun.api.crud.ModelEndpoints().list_model_endpoints,
- auth_info=auth_info,
- project=project,
- model=model,
- function=function,
- labels=labels,
- metrics=metrics,
- start=start,
- end=end,
- )
- allowed_endpoints = await mlrun.api.utils.auth.verifier.AuthVerifier().filter_project_resources_by_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.model_endpoint,
- endpoint_list.endpoints,
- lambda _endpoint: (
- _endpoint.metadata.project,
- _endpoint.metadata.uid,
- ),
- auth_info,
- )
- endpoint_list.endpoints = allowed_endpoints
-
- columns = [
- GrafanaColumn(text="endpoint_id", type="string"),
- GrafanaColumn(text="endpoint_function", type="string"),
- GrafanaColumn(text="endpoint_model", type="string"),
- GrafanaColumn(text="endpoint_model_class", type="string"),
- GrafanaColumn(text="first_request", type="time"),
- GrafanaColumn(text="last_request", type="time"),
- GrafanaColumn(text="accuracy", type="number"),
- GrafanaColumn(text="error_count", type="number"),
- GrafanaColumn(text="drift_status", type="number"),
- ]
-
- metric_columns = []
-
- found_metrics = set()
- for endpoint in endpoint_list.endpoints:
- if endpoint.status.metrics is not None:
- for key in endpoint.status.metrics.keys():
- if key not in found_metrics:
- found_metrics.add(key)
- metric_columns.append(GrafanaColumn(text=key, type="number"))
-
- columns = columns + metric_columns
- table = GrafanaTable(columns=columns)
-
- for endpoint in endpoint_list.endpoints:
- row = [
- endpoint.metadata.uid,
- endpoint.spec.function_uri,
- endpoint.spec.model,
- endpoint.spec.model_class,
- endpoint.status.first_request,
- endpoint.status.last_request,
- endpoint.status.accuracy,
- endpoint.status.error_count,
- endpoint.status.drift_status,
- ]
-
- if endpoint.status.metrics is not None and metric_columns:
- for metric_column in metric_columns:
- row.append(endpoint.status.metrics[metric_column.text])
-
- table.add_row(*row)
-
- return [table]
-
-
-async def grafana_individual_feature_analysis(
- body: Dict[str, Any],
- query_parameters: Dict[str, str],
- auth_info: mlrun.api.schemas.AuthInfo,
-):
- endpoint_id = query_parameters.get("endpoint_id")
- project = query_parameters.get("project")
- await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.model_endpoint,
- project,
- endpoint_id,
- mlrun.api.schemas.AuthorizationAction.read,
- auth_info,
- )
-
- endpoint = await run_in_threadpool(
- mlrun.api.crud.ModelEndpoints().get_model_endpoint,
- auth_info=auth_info,
- project=project,
- endpoint_id=endpoint_id,
- feature_analysis=True,
- )
-
- # Load JSON data from KV, make sure not to fail if a field is missing
- feature_stats = endpoint.status.feature_stats or {}
- current_stats = endpoint.status.current_stats or {}
- drift_measures = endpoint.status.drift_measures or {}
-
- table = GrafanaTable(
- columns=[
- GrafanaColumn(text="feature_name", type="string"),
- GrafanaColumn(text="actual_min", type="number"),
- GrafanaColumn(text="actual_mean", type="number"),
- GrafanaColumn(text="actual_max", type="number"),
- GrafanaColumn(text="expected_min", type="number"),
- GrafanaColumn(text="expected_mean", type="number"),
- GrafanaColumn(text="expected_max", type="number"),
- GrafanaColumn(text="tvd", type="number"),
- GrafanaColumn(text="hellinger", type="number"),
- GrafanaColumn(text="kld", type="number"),
- ]
- )
-
- for feature, base_stat in feature_stats.items():
- current_stat = current_stats.get(feature, {})
- drift_measure = drift_measures.get(feature, {})
-
- table.add_row(
- feature,
- current_stat.get("min"),
- current_stat.get("mean"),
- current_stat.get("max"),
- base_stat.get("min"),
- base_stat.get("mean"),
- base_stat.get("max"),
- drift_measure.get("tvd"),
- drift_measure.get("hellinger"),
- drift_measure.get("kld"),
- )
+#
+NAME_TO_QUERY_FUNCTION_DICTIONARY = {
+ "list_endpoints": mlrun.api.crud.model_monitoring.grafana.grafana_list_endpoints,
+ "individual_feature_analysis": mlrun.api.crud.model_monitoring.grafana.grafana_individual_feature_analysis,
+ "overall_feature_analysis": mlrun.api.crud.model_monitoring.grafana.grafana_overall_feature_analysis,
+ "incoming_features": mlrun.api.crud.model_monitoring.grafana.grafana_incoming_features,
+}
- return [table]
+SUPPORTED_QUERY_FUNCTIONS = set(NAME_TO_QUERY_FUNCTION_DICTIONARY.keys())
-async def grafana_overall_feature_analysis(
- body: Dict[str, Any],
- query_parameters: Dict[str, str],
- auth_info: mlrun.api.schemas.AuthInfo,
-):
- endpoint_id = query_parameters.get("endpoint_id")
- project = query_parameters.get("project")
- await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.model_endpoint,
- project,
- endpoint_id,
- mlrun.api.schemas.AuthorizationAction.read,
- auth_info,
- )
- endpoint = await run_in_threadpool(
- mlrun.api.crud.ModelEndpoints().get_model_endpoint,
- auth_info=auth_info,
- project=project,
- endpoint_id=endpoint_id,
- feature_analysis=True,
- )
+@router.post(
+ "/grafana-proxy/model-endpoints/query",
+ response_model=List[Union[GrafanaTable, GrafanaTimeSeriesTarget]],
+)
+async def grafana_proxy_model_endpoints_query(
+ request: Request,
+ auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+) -> List[Union[GrafanaTable, GrafanaTimeSeriesTarget]]:
+ """
+ Query route for model-endpoints grafana proxy API, used for creating an interface between grafana queries and
+ model-endpoints logic.
- table = GrafanaTable(
- columns=[
- GrafanaNumberColumn(text="tvd_sum"),
- GrafanaNumberColumn(text="tvd_mean"),
- GrafanaNumberColumn(text="hellinger_sum"),
- GrafanaNumberColumn(text="hellinger_mean"),
- GrafanaNumberColumn(text="kld_sum"),
- GrafanaNumberColumn(text="kld_mean"),
- ]
+ This implementation requires passing target_endpoint query parameter in order to dispatch different
+ model-endpoint monitoring functions.
+ """
+ warnings.warn(
+ "This api is deprecated in 1.3.0 and will be removed in 1.5.0. "
+ "Please update grafana model monitoring dashboards that use a different data source",
+ # TODO: remove in 1.5.0
+ FutureWarning,
)
-
- if endpoint.status.drift_measures:
- table.add_row(
- endpoint.status.drift_measures.get("tvd_sum"),
- endpoint.status.drift_measures.get("tvd_mean"),
- endpoint.status.drift_measures.get("hellinger_sum"),
- endpoint.status.drift_measures.get("hellinger_mean"),
- endpoint.status.drift_measures.get("kld_sum"),
- endpoint.status.drift_measures.get("kld_mean"),
- )
-
- return [table]
-
-
-async def grafana_incoming_features(
- body: Dict[str, Any],
- query_parameters: Dict[str, str],
- auth_info: mlrun.api.schemas.AuthInfo,
-):
- endpoint_id = query_parameters.get("endpoint_id")
- project = query_parameters.get("project")
- start = body.get("rangeRaw", {}).get("from", "now-1h")
- end = body.get("rangeRaw", {}).get("to", "now")
-
- await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.model_endpoint,
- project,
- endpoint_id,
- mlrun.api.schemas.AuthorizationAction.read,
- auth_info,
+ body = await request.json()
+ query_parameters = mlrun.api.crud.model_monitoring.grafana.parse_query_parameters(
+ body
)
-
- endpoint = await run_in_threadpool(
- mlrun.api.crud.ModelEndpoints().get_model_endpoint,
- auth_info=auth_info,
- project=project,
- endpoint_id=endpoint_id,
+ mlrun.api.crud.model_monitoring.grafana.validate_query_parameters(
+ query_parameters, SUPPORTED_QUERY_FUNCTIONS
)
-
- time_series = []
-
- feature_names = endpoint.spec.feature_names
-
- if not feature_names:
- logger.warn(
- "'feature_names' is either missing or not initialized in endpoint record",
- endpoint_id=endpoint.metadata.uid,
+ query_parameters = (
+ mlrun.api.crud.model_monitoring.grafana.drop_grafana_escape_chars(
+ query_parameters
)
- return time_series
-
- path = config.model_endpoint_monitoring.store_prefixes.default.format(
- project=project, kind=mlrun.api.schemas.ModelMonitoringStoreKinds.EVENTS
- )
- _, container, path = parse_model_endpoint_store_prefix(path)
-
- client = get_frames_client(
- token=auth_info.data_session,
- address=config.v3io_framesd,
- container=container,
- )
-
- data: pd.DataFrame = await run_in_threadpool(
- client.read,
- backend="tsdb",
- table=path,
- columns=feature_names,
- filter=f"endpoint_id=='{endpoint_id}'",
- start=start,
- end=end,
)
- data.drop(["endpoint_id"], axis=1, inplace=True, errors="ignore")
- data.index = data.index.astype(np.int64) // 10**6
-
- for feature, indexed_values in data.to_dict().items():
- target = GrafanaTimeSeriesTarget(target=feature)
- for index, value in indexed_values.items():
- data_point = GrafanaDataPoint(value=float(value), timestamp=index)
- target.add_data_point(data_point)
- time_series.append(target)
-
- return time_series
-
-
-def _parse_query_parameters(request_body: Dict[str, Any]) -> Dict[str, str]:
- """
- This function searches for the target field in Grafana's SimpleJson json. Once located, the target string is
- parsed by splitting on semi-colons (;). Each part in the resulting list is then split by an equal sign (=) to be
- read as key-value pairs.
- """
-
- # Try to get the target
- targets = request_body.get("targets", [])
-
- if len(targets) > 1:
- logger.warn(
- f"The 'targets' list contains more then one element ({len(targets)}), all targets except the first one are "
- f"ignored."
- )
-
- target_obj = targets[0] if targets else {}
- target_query = target_obj.get("target") if target_obj else ""
-
- if not target_query:
- raise MLRunBadRequestError(f"Target missing in request body:\n {request_body}")
-
- parameters = _parse_parameters(target_query)
-
- return parameters
-
-
-def _parse_search_parameters(request_body: Dict[str, Any]) -> Dict[str, str]:
- """
- This function searches for the target field in Grafana's SimpleJson json. Once located, the target string is
- parsed by splitting on semi-colons (;). Each part in the resulting list is then split by an equal sign (=) to be
- read as key-value pairs.
- """
-
- # Try to get the target
- target = request_body.get("target")
-
- if not target:
- raise MLRunBadRequestError(f"Target missing in request body:\n {request_body}")
-
- parameters = _parse_parameters(target)
-
- return parameters
-
-
-def _parse_parameters(target_query):
- parameters = {}
- for query in filter(lambda q: q, target_query.split(";")):
- query_parts = query.split("=")
- if len(query_parts) < 2:
- raise MLRunBadRequestError(
- f"Query must contain both query key and query value. Expected query_key=query_value, found {query} "
- f"instead."
- )
- parameters[query_parts[0]] = query_parts[1]
- return parameters
-
-
-def _drop_grafana_escape_chars(query_parameters: Dict[str, str]):
- query_parameters = dict(query_parameters)
- endpoint_id = query_parameters.get("endpoint_id")
- if endpoint_id is not None:
- query_parameters["endpoint_id"] = endpoint_id.replace("\\", "")
- return query_parameters
-
-
-def _validate_query_parameters(
- query_parameters: Dict[str, str], supported_endpoints: Optional[Set[str]] = None
-):
- """Validates the parameters sent via Grafana's SimpleJson query"""
- if "target_endpoint" not in query_parameters:
- raise MLRunBadRequestError(
- f"Expected 'target_endpoint' field in query, found {query_parameters} instead"
- )
-
- if (
- supported_endpoints is not None
- and query_parameters["target_endpoint"] not in supported_endpoints
- ):
- raise MLRunBadRequestError(
- f"{query_parameters['target_endpoint']} unsupported in query parameters: {query_parameters}. "
- f"Currently supports: {','.join(supported_endpoints)}"
- )
-
-
-def _json_loads_or_default(string: Optional[str], default: Any):
- if string is None:
- return default
- obj = json.loads(string)
- if not obj:
- return default
- return obj
-
-
-NAME_TO_QUERY_FUNCTION_DICTIONARY = {
- "list_endpoints": grafana_list_endpoints,
- "individual_feature_analysis": grafana_individual_feature_analysis,
- "overall_feature_analysis": grafana_overall_feature_analysis,
- "incoming_features": grafana_incoming_features,
-}
-
-NAME_TO_SEARCH_FUNCTION_DICTIONARY = {
- "list_projects": grafana_list_projects,
-}
-
-SUPPORTED_QUERY_FUNCTIONS = set(NAME_TO_QUERY_FUNCTION_DICTIONARY.keys())
-SUPPORTED_SEARCH_FUNCTIONS = set(NAME_TO_SEARCH_FUNCTION_DICTIONARY)
+ # At this point everything is validated and we can access everything that is needed without performing all previous
+ # checks again.
+ target_endpoint = query_parameters["target_endpoint"]
+ function = NAME_TO_QUERY_FUNCTION_DICTIONARY[target_endpoint]
+ if asyncio.iscoroutinefunction(function):
+ return await function(body, query_parameters, auth_info)
+ result = await run_in_threadpool(function, body, query_parameters, auth_info)
+ return result
diff --git a/mlrun/api/crud/model_monitoring/grafana.py b/mlrun/api/crud/model_monitoring/grafana.py
new file mode 100644
index 000000000000..9b95cad4db49
--- /dev/null
+++ b/mlrun/api/crud/model_monitoring/grafana.py
@@ -0,0 +1,419 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+from typing import Any, Dict, List, Optional, Set
+
+import numpy as np
+import pandas as pd
+from fastapi.concurrency import run_in_threadpool
+from sqlalchemy.orm import Session
+
+import mlrun.api.crud
+import mlrun.api.schemas
+import mlrun.api.utils.auth.verifier
+import mlrun.model_monitoring
+from mlrun.api.schemas import (
+ GrafanaColumn,
+ GrafanaDataPoint,
+ GrafanaNumberColumn,
+ GrafanaTable,
+ GrafanaTimeSeriesTarget,
+ ProjectsFormat,
+)
+from mlrun.api.utils.singletons.project_member import get_project_member
+from mlrun.errors import MLRunBadRequestError
+from mlrun.utils import config, logger
+from mlrun.utils.model_monitoring import parse_model_endpoint_store_prefix
+from mlrun.utils.v3io_clients import get_frames_client
+
+
+def grafana_list_projects(
+ db_session: Session, auth_info: mlrun.api.schemas.AuthInfo
+) -> List[str]:
+ """
+ List available project names. Will be used as a filter in each grafana dashboard.
+ :param db_session: A session that manages the current dialog with the database.
+ :param auth_info: The auth info of the request.
+
+ :return: List of available project names.
+ """
+ projects_output = get_project_member().list_projects(
+ db_session, format_=ProjectsFormat.name_only, leader_session=auth_info.session
+ )
+ return projects_output.projects
+
+
+# TODO: remove in 1.5.0 the following functions: grafana_list_endpoints, grafana_individual_feature_analysis,
+# grafana_overall_feature_analysis, grafana_income_features, parse_query_parameters, drop_grafana_escape_chars,
+
+
+async def grafana_list_endpoints(
+ body: Dict[str, Any],
+ query_parameters: Dict[str, str],
+ auth_info: mlrun.api.schemas.AuthInfo,
+) -> List[GrafanaTable]:
+ project = query_parameters.get("project")
+
+ # Filters
+ model = query_parameters.get("model", None)
+ function = query_parameters.get("function", None)
+ labels = query_parameters.get("labels", "")
+ labels = labels.split(",") if labels else []
+
+ # Metrics to include
+ metrics = query_parameters.get("metrics", "")
+ metrics = metrics.split(",") if metrics else []
+
+ # Time range for metrics
+ start = body.get("rangeRaw", {}).get("start", "now-1h")
+ end = body.get("rangeRaw", {}).get("end", "now")
+
+ if project:
+ await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_permissions(
+ project,
+ mlrun.api.schemas.AuthorizationAction.read,
+ auth_info,
+ )
+ endpoint_list = await run_in_threadpool(
+ mlrun.api.crud.ModelEndpoints().list_model_endpoints,
+ auth_info=auth_info,
+ project=project,
+ model=model,
+ function=function,
+ labels=labels,
+ metrics=metrics,
+ start=start,
+ end=end,
+ )
+ allowed_endpoints = await mlrun.api.utils.auth.verifier.AuthVerifier().filter_project_resources_by_permissions(
+ mlrun.api.schemas.AuthorizationResourceTypes.model_endpoint,
+ endpoint_list.endpoints,
+ lambda _endpoint: (
+ _endpoint.metadata.project,
+ _endpoint.metadata.uid,
+ ),
+ auth_info,
+ )
+ endpoint_list.endpoints = allowed_endpoints
+
+ columns = [
+ GrafanaColumn(text="endpoint_id", type="string"),
+ GrafanaColumn(text="endpoint_function", type="string"),
+ GrafanaColumn(text="endpoint_model", type="string"),
+ GrafanaColumn(text="endpoint_model_class", type="string"),
+ GrafanaColumn(text="first_request", type="time"),
+ GrafanaColumn(text="last_request", type="time"),
+ GrafanaColumn(text="accuracy", type="number"),
+ GrafanaColumn(text="error_count", type="number"),
+ GrafanaColumn(text="drift_status", type="number"),
+ ]
+
+ metric_columns = []
+
+ found_metrics = set()
+ for endpoint in endpoint_list.endpoints:
+ if endpoint.status.metrics is not None:
+ for key in endpoint.status.metrics.keys():
+ if key not in found_metrics:
+ found_metrics.add(key)
+ metric_columns.append(GrafanaColumn(text=key, type="number"))
+
+ columns = columns + metric_columns
+ table = GrafanaTable(columns=columns)
+
+ for endpoint in endpoint_list.endpoints:
+ row = [
+ endpoint.metadata.uid,
+ endpoint.spec.function_uri,
+ endpoint.spec.model,
+ endpoint.spec.model_class,
+ endpoint.status.first_request,
+ endpoint.status.last_request,
+ endpoint.status.accuracy,
+ endpoint.status.error_count,
+ endpoint.status.drift_status,
+ ]
+
+ if endpoint.status.metrics is not None and metric_columns:
+ for metric_column in metric_columns:
+ row.append(endpoint.status.metrics[metric_column.text])
+
+ table.add_row(*row)
+
+ return [table]
+
+
+async def grafana_individual_feature_analysis(
+ body: Dict[str, Any],
+ query_parameters: Dict[str, str],
+ auth_info: mlrun.api.schemas.AuthInfo,
+):
+ endpoint_id = query_parameters.get("endpoint_id")
+ project = query_parameters.get("project")
+ await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
+ mlrun.api.schemas.AuthorizationResourceTypes.model_endpoint,
+ project,
+ endpoint_id,
+ mlrun.api.schemas.AuthorizationAction.read,
+ auth_info,
+ )
+
+ endpoint = await run_in_threadpool(
+ mlrun.api.crud.ModelEndpoints().get_model_endpoint,
+ auth_info=auth_info,
+ project=project,
+ endpoint_id=endpoint_id,
+ feature_analysis=True,
+ )
+
+ # Load JSON data from KV, make sure not to fail if a field is missing
+ feature_stats = endpoint.status.feature_stats or {}
+ current_stats = endpoint.status.current_stats or {}
+ drift_measures = endpoint.status.drift_measures or {}
+
+ table = GrafanaTable(
+ columns=[
+ GrafanaColumn(text="feature_name", type="string"),
+ GrafanaColumn(text="actual_min", type="number"),
+ GrafanaColumn(text="actual_mean", type="number"),
+ GrafanaColumn(text="actual_max", type="number"),
+ GrafanaColumn(text="expected_min", type="number"),
+ GrafanaColumn(text="expected_mean", type="number"),
+ GrafanaColumn(text="expected_max", type="number"),
+ GrafanaColumn(text="tvd", type="number"),
+ GrafanaColumn(text="hellinger", type="number"),
+ GrafanaColumn(text="kld", type="number"),
+ ]
+ )
+
+ for feature, base_stat in feature_stats.items():
+ current_stat = current_stats.get(feature, {})
+ drift_measure = drift_measures.get(feature, {})
+
+ table.add_row(
+ feature,
+ current_stat.get("min"),
+ current_stat.get("mean"),
+ current_stat.get("max"),
+ base_stat.get("min"),
+ base_stat.get("mean"),
+ base_stat.get("max"),
+ drift_measure.get("tvd"),
+ drift_measure.get("hellinger"),
+ drift_measure.get("kld"),
+ )
+
+ return [table]
+
+
+async def grafana_overall_feature_analysis(
+ body: Dict[str, Any],
+ query_parameters: Dict[str, str],
+ auth_info: mlrun.api.schemas.AuthInfo,
+):
+ endpoint_id = query_parameters.get("endpoint_id")
+ project = query_parameters.get("project")
+ await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
+ mlrun.api.schemas.AuthorizationResourceTypes.model_endpoint,
+ project,
+ endpoint_id,
+ mlrun.api.schemas.AuthorizationAction.read,
+ auth_info,
+ )
+ endpoint = await run_in_threadpool(
+ mlrun.api.crud.ModelEndpoints().get_model_endpoint,
+ auth_info=auth_info,
+ project=project,
+ endpoint_id=endpoint_id,
+ feature_analysis=True,
+ )
+
+ table = GrafanaTable(
+ columns=[
+ GrafanaNumberColumn(text="tvd_sum"),
+ GrafanaNumberColumn(text="tvd_mean"),
+ GrafanaNumberColumn(text="hellinger_sum"),
+ GrafanaNumberColumn(text="hellinger_mean"),
+ GrafanaNumberColumn(text="kld_sum"),
+ GrafanaNumberColumn(text="kld_mean"),
+ ]
+ )
+
+ if endpoint.status.drift_measures:
+ table.add_row(
+ endpoint.status.drift_measures.get("tvd_sum"),
+ endpoint.status.drift_measures.get("tvd_mean"),
+ endpoint.status.drift_measures.get("hellinger_sum"),
+ endpoint.status.drift_measures.get("hellinger_mean"),
+ endpoint.status.drift_measures.get("kld_sum"),
+ endpoint.status.drift_measures.get("kld_mean"),
+ )
+
+ return [table]
+
+
+async def grafana_incoming_features(
+ body: Dict[str, Any],
+ query_parameters: Dict[str, str],
+ auth_info: mlrun.api.schemas.AuthInfo,
+):
+ endpoint_id = query_parameters.get("endpoint_id")
+ project = query_parameters.get("project")
+ start = body.get("rangeRaw", {}).get("from", "now-1h")
+ end = body.get("rangeRaw", {}).get("to", "now")
+
+ await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
+ mlrun.api.schemas.AuthorizationResourceTypes.model_endpoint,
+ project,
+ endpoint_id,
+ mlrun.api.schemas.AuthorizationAction.read,
+ auth_info,
+ )
+
+ endpoint = await run_in_threadpool(
+ mlrun.api.crud.ModelEndpoints().get_model_endpoint,
+ auth_info=auth_info,
+ project=project,
+ endpoint_id=endpoint_id,
+ )
+
+ time_series = []
+
+ feature_names = endpoint.spec.feature_names
+
+ if not feature_names:
+ logger.warn(
+ "'feature_names' is either missing or not initialized in endpoint record",
+ endpoint_id=endpoint.metadata.uid,
+ )
+ return time_series
+
+ path = config.model_endpoint_monitoring.store_prefixes.default.format(
+ project=project, kind=mlrun.api.schemas.ModelMonitoringStoreKinds.EVENTS
+ )
+ _, container, path = parse_model_endpoint_store_prefix(path)
+
+ client = get_frames_client(
+ token=auth_info.data_session,
+ address=config.v3io_framesd,
+ container=container,
+ )
+
+ data: pd.DataFrame = await run_in_threadpool(
+ client.read,
+ backend="tsdb",
+ table=path,
+ columns=feature_names,
+ filter=f"endpoint_id=='{endpoint_id}'",
+ start=start,
+ end=end,
+ )
+
+ data.drop(["endpoint_id"], axis=1, inplace=True, errors="ignore")
+ data.index = data.index.astype(np.int64) // 10**6
+
+ for feature, indexed_values in data.to_dict().items():
+ target = GrafanaTimeSeriesTarget(target=feature)
+ for index, value in indexed_values.items():
+ data_point = GrafanaDataPoint(value=float(value), timestamp=index)
+ target.add_data_point(data_point)
+ time_series.append(target)
+
+ return time_series
+
+
+def parse_query_parameters(request_body: Dict[str, Any]) -> Dict[str, str]:
+ """
+ This function searches for the target field in Grafana's SimpleJson json. Once located, the target string is
+ parsed by splitting on semi-colons (;). Each part in the resulting list is then split by an equal sign (=) to be
+ read as key-value pairs.
+ """
+
+ # Try to get the target
+ targets = request_body.get("targets", [])
+
+ if len(targets) > 1:
+ logger.warn(
+ f"The 'targets' list contains more then one element ({len(targets)}), all targets except the first one are "
+ f"ignored."
+ )
+
+ target_obj = targets[0] if targets else {}
+ target_query = target_obj.get("target") if target_obj else ""
+
+ if not target_query:
+ raise MLRunBadRequestError(f"Target missing in request body:\n {request_body}")
+
+ parameters = _parse_parameters(target_query)
+
+ return parameters
+
+
+def parse_search_parameters(request_body: Dict[str, Any]) -> Dict[str, str]:
+ """
+ This function searches for the target field in Grafana's SimpleJson json. Once located, the target string is
+ parsed by splitting on semi-colons (;). Each part in the resulting list is then split by an equal sign (=) to be
+ read as key-value pairs.
+ """
+
+ # Try to get the target
+ target = request_body.get("target")
+
+ if not target:
+ raise MLRunBadRequestError(f"Target missing in request body:\n {request_body}")
+
+ parameters = _parse_parameters(target)
+
+ return parameters
+
+
+def _parse_parameters(target_query):
+ parameters = {}
+ for query in filter(lambda q: q, target_query.split(";")):
+ query_parts = query.split("=")
+ if len(query_parts) < 2:
+ raise MLRunBadRequestError(
+ f"Query must contain both query key and query value. Expected query_key=query_value, found {query} "
+ f"instead."
+ )
+ parameters[query_parts[0]] = query_parts[1]
+ return parameters
+
+
+def drop_grafana_escape_chars(query_parameters: Dict[str, str]):
+ query_parameters = dict(query_parameters)
+ endpoint_id = query_parameters.get("endpoint_id")
+ if endpoint_id is not None:
+ query_parameters["endpoint_id"] = endpoint_id.replace("\\", "")
+ return query_parameters
+
+
+def validate_query_parameters(
+ query_parameters: Dict[str, str], supported_endpoints: Optional[Set[str]] = None
+):
+ """Validates the parameters sent via Grafana's SimpleJson query"""
+ if "target_endpoint" not in query_parameters:
+ raise MLRunBadRequestError(
+ f"Expected 'target_endpoint' field in query, found {query_parameters} instead"
+ )
+
+ if (
+ supported_endpoints is not None
+ and query_parameters["target_endpoint"] not in supported_endpoints
+ ):
+ raise MLRunBadRequestError(
+ f"{query_parameters['target_endpoint']} unsupported in query parameters: {query_parameters}. "
+ f"Currently supports: {','.join(supported_endpoints)}"
+ )
diff --git a/mlrun/api/crud/model_monitoring/model_endpoint_store.py b/mlrun/api/crud/model_monitoring/model_endpoint_store.py
index 54f6e30718f6..9ba43ee64c69 100644
--- a/mlrun/api/crud/model_monitoring/model_endpoint_store.py
+++ b/mlrun/api/crud/model_monitoring/model_endpoint_store.py
@@ -591,6 +591,7 @@ def flatten_model_endpoint_attributes(
label_names = endpoint.spec.label_names or []
feature_stats = endpoint.status.feature_stats or {}
current_stats = endpoint.status.current_stats or {}
+ drift_measures = endpoint.status.drift_measures or {}
children = endpoint.status.children or []
endpoint_type = endpoint.status.endpoint_type or None
children_uids = endpoint.status.children_uids or []
@@ -609,6 +610,8 @@ def flatten_model_endpoint_attributes(
"active": endpoint.spec.active or "",
"monitoring_feature_set_uri": endpoint.status.monitoring_feature_set_uri
or "",
+ "drift_status": endpoint.status.drift_status or "",
+ "drift_measures": json.dumps(drift_measures),
"monitoring_mode": endpoint.spec.monitoring_mode or "",
"state": endpoint.status.state or "",
"feature_stats": json.dumps(feature_stats),
diff --git a/tests/api/api/test_grafana_proxy.py b/tests/api/api/test_grafana_proxy.py
index 131bcc2d0452..8006d67f056e 100644
--- a/tests/api/api/test_grafana_proxy.py
+++ b/tests/api/api/test_grafana_proxy.py
@@ -31,9 +31,9 @@
import mlrun.api.crud
import mlrun.api.schemas
import mlrun.api.utils.clients.iguazio
-from mlrun.api.api.endpoints.grafana_proxy import (
- _parse_query_parameters,
- _validate_query_parameters,
+from mlrun.api.crud.model_monitoring.grafana import (
+ parse_query_parameters,
+ validate_query_parameters,
)
from mlrun.config import config
from mlrun.errors import MLRunBadRequestError
@@ -82,6 +82,7 @@ def test_grafana_proxy_model_endpoints_check_connection(
reason=_build_skip_message(),
)
def test_grafana_list_endpoints(db: Session, client: TestClient):
+
endpoints_in = [_mock_random_endpoint("active") for _ in range(5)]
# Initialize endpoint store target object
@@ -302,30 +303,30 @@ def test_grafana_overall_feature_analysis(db: Session, client: TestClient):
def test_parse_query_parameters_failure():
# No 'targets' in body
with pytest.raises(MLRunBadRequestError):
- _parse_query_parameters({})
+ parse_query_parameters({})
# No 'target' list in 'targets' dictionary
with pytest.raises(MLRunBadRequestError):
- _parse_query_parameters({"targets": []})
+ parse_query_parameters({"targets": []})
# Target query not separated by equals ('=') char
with pytest.raises(MLRunBadRequestError):
- _parse_query_parameters({"targets": [{"target": "test"}]})
+ parse_query_parameters({"targets": [{"target": "test"}]})
def test_parse_query_parameters_success():
# Target query separated by equals ('=') char
- params = _parse_query_parameters({"targets": [{"target": "test=some_test"}]})
+ params = parse_query_parameters({"targets": [{"target": "test=some_test"}]})
assert params["test"] == "some_test"
# Target query separated by equals ('=') char (multiple queries)
- params = _parse_query_parameters(
+ params = parse_query_parameters(
{"targets": [{"target": "test=some_test;another_test=some_other_test"}]}
)
assert params["test"] == "some_test"
assert params["another_test"] == "some_other_test"
- params = _parse_query_parameters(
+ params = parse_query_parameters(
{"targets": [{"target": "test=some_test;another_test=some_other_test;"}]}
)
assert params["test"] == "some_test"
@@ -335,19 +336,17 @@ def test_parse_query_parameters_success():
def test_validate_query_parameters_failure():
# No 'target_endpoint' in query parameters
with pytest.raises(MLRunBadRequestError):
- _validate_query_parameters({})
+ validate_query_parameters({})
# target_endpoint unsupported
with pytest.raises(MLRunBadRequestError):
- _validate_query_parameters(
+ validate_query_parameters(
{"target_endpoint": "unsupported_endpoint"}, {"supported_endpoint"}
)
def test_validate_query_parameters_success():
- _validate_query_parameters(
- {"target_endpoint": "list_endpoints"}, {"list_endpoints"}
- )
+ validate_query_parameters({"target_endpoint": "list_endpoints"}, {"list_endpoints"})
def _get_access_key() -> Optional[str]:
From 77359c3fce0e4701ed2e2236ff1183067673dba2 Mon Sep 17 00:00:00 2001
From: Gal Topper
Date: Sun, 26 Mar 2023 19:09:42 +0800
Subject: [PATCH 003/334] [Datastore] Fix leading zeros in time partition names
(#3325)
---
mlrun/datastore/targets.py | 4 +-
.../feature_store/test_feature_store.py | 42 +++++++++++++++++++
2 files changed, 44 insertions(+), 2 deletions(-)
diff --git a/mlrun/datastore/targets.py b/mlrun/datastore/targets.py
index 3624fe91e022..b3020c3c37c5 100644
--- a/mlrun/datastore/targets.py
+++ b/mlrun/datastore/targets.py
@@ -525,8 +525,8 @@ def write_dataframe(
("minute", "%M"),
]:
partition_cols.append(unit)
- target_df[unit] = getattr(
- pd.DatetimeIndex(target_df[timestamp_key]), unit
+ target_df[unit] = pd.DatetimeIndex(target_df[timestamp_key]).format(
+ date_format=fmt
)
if unit == time_partitioning_granularity:
break
diff --git a/tests/system/feature_store/test_feature_store.py b/tests/system/feature_store/test_feature_store.py
index da2a3ffd20ef..5778ddc17700 100644
--- a/tests/system/feature_store/test_feature_store.py
+++ b/tests/system/feature_store/test_feature_store.py
@@ -3246,6 +3246,48 @@ def test_pandas_write_parquet(self):
expected_df = pd.DataFrame({"number": [11, 22]}, index=["a", "b"])
assert read_back_df.equals(expected_df)
+ def test_pandas_write_partitioned_parquet(self):
+ prediction_set = fstore.FeatureSet(
+ name="myset",
+ entities=[fstore.Entity("id")],
+ timestamp_key="time",
+ engine="pandas",
+ )
+
+ df = pd.DataFrame(
+ {
+ "id": ["a", "b"],
+ "number": [11, 22],
+ "time": [pd.Timestamp(2022, 1, 1, 1), pd.Timestamp(2022, 1, 1, 1, 1)],
+ }
+ )
+
+ with tempfile.TemporaryDirectory() as tempdir:
+ outdir = f"{tempdir}/test_pandas_write_partitioned_parquet/"
+ prediction_set.set_targets(
+ with_defaults=False, targets=[(ParquetTarget(path=outdir))]
+ )
+
+ returned_df = fstore.ingest(prediction_set, df)
+ # check that partitions are created as expected (ML-3404)
+ read_back_df = pd.read_parquet(
+ f"{prediction_set.get_target_path()}year=2022/month=01/day=01/hour=01/"
+ )
+
+ assert read_back_df.equals(returned_df)
+
+ expected_df = pd.DataFrame(
+ {
+ "number": [11, 22],
+ "time": [
+ pd.Timestamp(2022, 1, 1, 1),
+ pd.Timestamp(2022, 1, 1, 1, 1),
+ ],
+ },
+ index=["a", "b"],
+ )
+ assert read_back_df.equals(expected_df)
+
# regression test for #2557
@pytest.mark.parametrize(
["index_columns"],
From 2fe5ab850d40c34ad0e1eaf8dc07dae8d0a62734 Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Sun, 26 Mar 2023 15:44:05 +0300
Subject: [PATCH 004/334] [CI] Security scan github action (#3331)
---
.github/actions/image-matrix-prep/action.yaml | 38 +++++
.github/workflows/build.yaml | 10 +-
.github/workflows/security_scan.yaml | 152 ++++++++++++++++++
Makefile | 41 ++++-
.../scripts/github_workflow_free_space.sh | 4 +-
go/Makefile | 4 +
6 files changed, 236 insertions(+), 13 deletions(-)
create mode 100644 .github/actions/image-matrix-prep/action.yaml
create mode 100644 .github/workflows/security_scan.yaml
diff --git a/.github/actions/image-matrix-prep/action.yaml b/.github/actions/image-matrix-prep/action.yaml
new file mode 100644
index 000000000000..247e4351875f
--- /dev/null
+++ b/.github/actions/image-matrix-prep/action.yaml
@@ -0,0 +1,38 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+name: Image Matrix Prep
+description: Prepares the matrix of images to build
+inputs:
+ skip_images:
+ description: 'Comma separated list of images to skip'
+ required: false
+ default: ''
+outputs:
+ matrix:
+ description: 'The matrix of images to build'
+ value: ${{ steps.set-matrix.outputs.matrix }}
+runs:
+ using: "composite"
+ steps:
+ - uses: actions/checkout@v3
+ - id: set-matrix
+ run: |
+ skipImages=",$INPUT_SKIP_IMAGES,"
+ matrix=$(jq --arg skipImages "$skipImages" 'map(. | select(",\(."image-name")," | inside($skipImages)|not))' ./.github/workflows/build-workflow-matrix.json)
+ echo "matrix={\"include\":$(echo $matrix)}" >> $GITHUB_OUTPUT
+ shell: bash
+ env:
+ INPUT_SKIP_IMAGES: ${{ inputs.skip_images }}
diff --git a/.github/workflows/build.yaml b/.github/workflows/build.yaml
index 864c3f659a0c..a127c7e89d73 100644
--- a/.github/workflows/build.yaml
+++ b/.github/workflows/build.yaml
@@ -51,12 +51,10 @@ jobs:
steps:
- uses: actions/checkout@v3
- id: set-matrix
- run: |
- skipImages=",$INPUT_SKIP_IMAGES,"
- matrix=$(jq --arg skipImages "$skipImages" 'map(. | select(",\(."image-name")," | inside($skipImages)|not))' ./.github/workflows/build-workflow-matrix.json)
- echo "matrix={\"include\":$(echo $matrix)}" >> $GITHUB_OUTPUT
- env:
- INPUT_SKIP_IMAGES: ${{ github.event.inputs.skip_images }}
+ uses: ./.github/actions/image-matrix-prep
+ with:
+ skip_images: ${{ github.event.inputs.skip_images }}
+
build-images:
name: Build and push image - ${{ matrix.image-name }} (Python ${{ matrix.python-version }})
runs-on: ubuntu-latest
diff --git a/.github/workflows/security_scan.yaml b/.github/workflows/security_scan.yaml
new file mode 100644
index 000000000000..642a1bdc4ca8
--- /dev/null
+++ b/.github/workflows/security_scan.yaml
@@ -0,0 +1,152 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+# Currently supported running against prebuilt images
+name: Security Scan
+
+on:
+ workflow_dispatch:
+ inputs:
+ tag:
+ description: 'MLRun image tag to scan (unstable, 1.3.0 or any other tag)'
+ required: false
+ default: 'unstable'
+ registry:
+ description: 'MLRun image registry'
+ required: false
+ default: 'ghcr.io/'
+ skip_images:
+ description: 'Comma separated list of images to skip scanning'
+ required: false
+
+ # disabling gpu images for now as scanning them takes more disk space than we can afford
+ # test images are not scanned as they are not used in production
+ default: 'test,models-gpu'
+ publish_results:
+ description: 'Whether to publish results to Github or not (default empty - no publish)'
+ required: false
+ default: ''
+ severity_threshold:
+ description: 'The minimum severity of vulnerabilities to report ("negligible", "low", "medium", "high" and "critical".)'
+ required: false
+ default: 'medium'
+ only_fixed:
+ description: 'Whether to scan only fixed vulnerabilities ("true" or "false")'
+ required: false
+ default: 'true'
+
+jobs:
+ matrix_prep:
+ name: Prepare image list
+ outputs:
+ matrix: ${{ steps.set-matrix.outputs.matrix }}
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v3
+ - id: set-matrix
+ uses: ./.github/actions/image-matrix-prep
+ with:
+ skip_images: ${{ github.event.inputs.skip_images }}
+
+ build_and_scan_docker_images:
+ name: Scan ${{ matrix.image-name }} (Python ${{ matrix.python-version }})
+ runs-on: ubuntu-latest
+ needs: matrix_prep
+ strategy:
+ fail-fast: false
+ matrix: ${{ fromJson(needs.matrix_prep.outputs.matrix) }}
+ steps:
+ - uses: actions/checkout@v3
+
+ - name: Cleanup disk
+ run: |
+ "${GITHUB_WORKSPACE}/automation/scripts/github_workflow_free_space.sh"
+
+ - name: Resolving image name
+ id: resolve_image_name
+ run: |
+ echo "image_name=$(make pull-${{ matrix.image-name }} | tail -1)" >> $GITHUB_OUTPUT
+ env:
+ MLRUN_DOCKER_REGISTRY: ${{ github.event.inputs.registry }}
+ MLRUN_VERSION: ${{ github.event.inputs.tag }}
+ MLRUN_PYTHON_VERSION: ${{ matrix.python-version }}
+
+ - name: Define output format
+ id: output-format
+
+ # this section is duplicated in the other jobs.
+ # make sure to update all when changed.
+ run: |
+ if [[ -n "${{ github.event.inputs.publish_results }}" ]]; then \
+ echo "format=sarif" >> $GITHUB_OUTPUT; \
+ echo "fail_build=false" >> $GITHUB_OUTPUT; \
+ else \
+ echo "format=table" >> $GITHUB_OUTPUT; \
+ echo "fail_build=true" >> $GITHUB_OUTPUT; \
+ fi
+
+ - name: Scan image
+ uses: anchore/scan-action@v3
+ id: scan
+ with:
+ image: ${{ steps.resolve_image_name.outputs.image_name }}
+ only-fixed: ${{ github.event.inputs.only_fixed }}
+ output-format: ${{ steps.output-format.outputs.format }}
+ fail-build: ${{ steps.output-format.outputs.fail_build }}
+ severity-cutoff: ${{ github.event.inputs.severity_threshold }}
+
+ - name: Upload scan results
+ if: github.event.inputs.publish_results != ''
+ uses: github/codeql-action/upload-sarif@v2
+ with:
+ sarif_file: ${{ steps.scan.outputs.sarif }}
+ category: ${{ matrix.image-name }}-${{ matrix.python-version }})
+
+ scan_fs:
+ name: Scan file system
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v3
+
+ - name: Define output format
+ id: output-format
+
+ # this section is duplicated in the other jobs.
+ # make sure to update all when changed.
+ run: |
+ if [[ -n "${{ github.event.inputs.publish_results }}" ]]; then \
+ echo "format=sarif" >> $GITHUB_OUTPUT; \
+ echo "fail_build=false" >> $GITHUB_OUTPUT; \
+ else \
+ echo "format=table" >> $GITHUB_OUTPUT; \
+ echo "fail_build=true" >> $GITHUB_OUTPUT; \
+ fi
+
+ - name: Scan fs
+ uses: anchore/scan-action@v3
+ id: scan
+ with:
+ path: "."
+ only-fixed: ${{ github.event.inputs.only_fixed }}
+ output-format: ${{ steps.output-format.outputs.format }}
+ fail-build: ${{ steps.output-format.outputs.fail_build }}
+ severity-cutoff: ${{ github.event.inputs.severity_threshold }}
+
+ - name: Upload scan results
+ if: github.event.inputs.publish_results != ''
+ uses: github/codeql-action/upload-sarif@v2
+ with:
+ sarif_file: ${{ steps.scan.outputs.sarif }}
+ category: "repository"
diff --git a/Makefile b/Makefile
index 9c0a97cf0598..a5f4eedb2afa 100644
--- a/Makefile
+++ b/Makefile
@@ -222,6 +222,10 @@ push-mlrun: mlrun ## Push mlrun docker image
docker push $(MLRUN_IMAGE_NAME_TAGGED)
$(MLRUN_CACHE_IMAGE_PUSH_COMMAND)
+.PHONY: pull-mlrun
+pull-mlrun: ## Pull mlrun docker image
+ docker pull $(MLRUN_IMAGE_NAME_TAGGED)
+
MLRUN_BASE_IMAGE_NAME := $(MLRUN_DOCKER_IMAGE_PREFIX)/$(MLRUN_ML_DOCKER_IMAGE_NAME_PREFIX)base
MLRUN_BASE_CACHE_IMAGE_NAME := $(MLRUN_CACHE_DOCKER_IMAGE_PREFIX)/$(MLRUN_ML_DOCKER_IMAGE_NAME_PREFIX)base
@@ -257,6 +261,9 @@ push-base: base ## Push base docker image
docker push $(MLRUN_BASE_IMAGE_NAME_TAGGED)
$(MLRUN_BASE_CACHE_IMAGE_PUSH_COMMAND)
+.PHONY: pull-base
+pull-base: ## Pull base docker image
+ docker pull $(MLRUN_BASE_IMAGE_NAME_TAGGED)
MLRUN_MODELS_IMAGE_NAME := $(MLRUN_DOCKER_IMAGE_PREFIX)/$(MLRUN_ML_DOCKER_IMAGE_NAME_PREFIX)models
MLRUN_MODELS_CACHE_IMAGE_NAME := $(MLRUN_CACHE_DOCKER_IMAGE_PREFIX)/$(MLRUN_ML_DOCKER_IMAGE_NAME_PREFIX)models
@@ -296,6 +303,10 @@ push-models: models ## Push models docker image
docker push $(MLRUN_MODELS_IMAGE_NAME_TAGGED)
$(MLRUN_MODELS_CACHE_IMAGE_PUSH_COMMAND)
+.PHONY: pull-models
+pull-models: ## Pull models docker image
+ docker pull $(MLRUN_MODELS_IMAGE_NAME_TAGGED)
+
MLRUN_MODELS_GPU_IMAGE_NAME := $(MLRUN_DOCKER_IMAGE_PREFIX)/$(MLRUN_ML_DOCKER_IMAGE_NAME_PREFIX)models-gpu
MLRUN_MODELS_GPU_CACHE_IMAGE_NAME := $(MLRUN_CACHE_DOCKER_IMAGE_PREFIX)/$(MLRUN_ML_DOCKER_IMAGE_NAME_PREFIX)models-gpu
@@ -326,6 +337,10 @@ push-models-gpu: models-gpu ## Push models gpu docker image
docker push $(MLRUN_MODELS_GPU_IMAGE_NAME_TAGGED)
$(MLRUN_MODELS_GPU_CACHE_IMAGE_PUSH_COMMAND)
+.PHONY: pull-models-gpu
+pull-models-gpu: ## Pull models gpu docker image
+ docker pull $(MLRUN_MODELS_GPU_IMAGE_NAME_TAGGED)
+
.PHONY: prebake-models-gpu
prebake-models-gpu: ## Build prebake models GPU docker image
docker build \
@@ -370,25 +385,36 @@ jupyter: update-version-file ## Build mlrun jupyter docker image
push-jupyter: jupyter ## Push mlrun jupyter docker image
docker push $(MLRUN_JUPYTER_IMAGE_NAME)
+.PHONY: pull-jupyter
+pull-jupyter: ## Pull mlrun jupyter docker image
+ docker pull $(MLRUN_JUPYTER_IMAGE_NAME)
+
.PHONY: log-collector
log-collector: update-version-file
- cd go && \
- MLRUN_VERSION=$(MLRUN_VERSION) \
+ @MLRUN_VERSION=$(MLRUN_VERSION) \
MLRUN_DOCKER_REGISTRY=$(MLRUN_DOCKER_REGISTRY) \
MLRUN_DOCKER_REPO=$(MLRUN_DOCKER_REPO) \
MLRUN_DOCKER_TAG=$(MLRUN_DOCKER_TAG) \
MLRUN_DOCKER_IMAGE_PREFIX=$(MLRUN_DOCKER_IMAGE_PREFIX) \
- make log-collector
+ make --no-print-directory -C $(shell pwd)/go log-collector
.PHONY: push-log-collector
push-log-collector: log-collector
- cd go && \
- MLRUN_VERSION=$(MLRUN_VERSION) \
+ @MLRUN_VERSION=$(MLRUN_VERSION) \
+ MLRUN_DOCKER_REGISTRY=$(MLRUN_DOCKER_REGISTRY) \
+ MLRUN_DOCKER_REPO=$(MLRUN_DOCKER_REPO) \
+ MLRUN_DOCKER_TAG=$(MLRUN_DOCKER_TAG) \
+ MLRUN_DOCKER_IMAGE_PREFIX=$(MLRUN_DOCKER_IMAGE_PREFIX) \
+ make --no-print-directory -C $(shell pwd)/go push-log-collector
+
+.PHONY: pull-log-collector
+pull-log-collector:
+ @MLRUN_VERSION=$(MLRUN_VERSION) \
MLRUN_DOCKER_REGISTRY=$(MLRUN_DOCKER_REGISTRY) \
MLRUN_DOCKER_REPO=$(MLRUN_DOCKER_REPO) \
MLRUN_DOCKER_TAG=$(MLRUN_DOCKER_TAG) \
MLRUN_DOCKER_IMAGE_PREFIX=$(MLRUN_DOCKER_IMAGE_PREFIX) \
- make push-log-collector
+ make --no-print-directory -C $(shell pwd)/go pull-log-collector
.PHONY: compile-schemas
@@ -425,6 +451,9 @@ push-api: api ## Push api docker image
docker push $(MLRUN_API_IMAGE_NAME_TAGGED)
$(MLRUN_API_CACHE_IMAGE_PUSH_COMMAND)
+.PHONY: pull-api
+pull-api: ## Pull api docker image
+ docker pull $(MLRUN_API_IMAGE_NAME_TAGGED)
MLRUN_TEST_IMAGE_NAME := $(MLRUN_DOCKER_IMAGE_PREFIX)/test
MLRUN_TEST_CACHE_IMAGE_NAME := $(MLRUN_CACHE_DOCKER_IMAGE_PREFIX)/test
diff --git a/automation/scripts/github_workflow_free_space.sh b/automation/scripts/github_workflow_free_space.sh
index d5783d86992c..afd9c3fa9e54 100755
--- a/automation/scripts/github_workflow_free_space.sh
+++ b/automation/scripts/github_workflow_free_space.sh
@@ -49,7 +49,9 @@ sudo rm --recursive --force \
"$AGENT_TOOLSDIRECTORY"
# clean unneeded docker images
-docker system prune --all --force
+if [ -z "$KEEP_DOCKER_IMAGES" ]; then
+ docker system prune --all --force
+fi
# post cleanup
print_free_space
diff --git a/go/Makefile b/go/Makefile
index 2568e58ca73e..a38e95c611e3 100644
--- a/go/Makefile
+++ b/go/Makefile
@@ -50,6 +50,10 @@ push-log-collector:
@echo Pushing log-collector image
docker push $(MLRUN_DOCKER_IMAGE_PREFIX)/log-collector:$(MLRUN_DOCKER_TAG)
+.PHONY: pull-log-collector
+pull-log-collector:
+ docker pull $(MLRUN_DOCKER_IMAGE_PREFIX)/log-collector:$(MLRUN_DOCKER_TAG)
+
.PHONY: schemas-compiler
schemas-compiler: schemas-compiler
@echo Building schemas-compiler image
From a8a47df30139de19f39721c937f1fbe4308e6c92 Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Sun, 26 Mar 2023 20:48:47 +0300
Subject: [PATCH 005/334] [Docs] Fix mlrun 1.3.0 client installation guide
(#3338)
---
docs/change-log/index.md | 15 ++++++++-------
1 file changed, 8 insertions(+), 7 deletions(-)
diff --git a/docs/change-log/index.md b/docs/change-log/index.md
index 7afb105a0a13..501b2037b57e 100644
--- a/docs/change-log/index.md
+++ b/docs/change-log/index.md
@@ -25,23 +25,24 @@ python 3.7 have the suffix: `-py37`. The correct version is automatically chosen
MLRun is pre-installed in CE Jupyter.
-To install on a **Python 3.9** client, run:
+To install on a **Python 3.9** environment, run:
```
./align_mlrun.sh
```
-To install on a **Python 3.7** client, run:
+To install on a **Python 3.7** environment (and optionally upgrade to python 3.9), run:
1. Configure the Jupyter service with the env variable`JUPYTER_PREFER_ENV_PATH=false`.
2. Within the Jupyter service, open a terminal and update conda and pip to have an up to date pip resolver.
-```$CONDA_HOME/bin/conda install -y conda=23.1.0
- $CONDA_HOME/bin/conda install -y pip
```
-3. If you are going to work with python 3.9, create a new conda env and activate it:
+$CONDA_HOME/bin/conda install -y conda=23.1.0
+$CONDA_HOME/bin/conda install -y pip
```
- conda create -n python39 python=3.9 ipykernel -y
- conda activate python39
+3. If you wish to upgrade to python 3.9, create a new conda env and activate it:
+```
+conda create -n python39 python=3.9 ipykernel -y
+conda activate python39
```
4. Install mlrun:
```
From c284bb0430e604c6f386f02a173fa4092b33244e Mon Sep 17 00:00:00 2001
From: Eyal Danieli
Date: Mon, 27 Mar 2023 11:56:38 +0300
Subject: [PATCH 006/334] [Model Monitoring] Support SQL store target for model
endpoints (#2685)
---
.../model-monitoring-details.json | 56 +-
.../model-monitoring-overview.json | 241 ++---
.../model-monitoring-performance.json | 8 +-
.../dashboards/model-monitoring-details.json | 104 ++-
.../dashboards/model-monitoring-overview.json | 109 ++-
.../model-monitoring-performance.json | 146 +--
mlrun/api/api/endpoints/functions.py | 6 +-
mlrun/api/api/endpoints/grafana_proxy.py | 50 +-
mlrun/api/api/endpoints/model_endpoints.py | 70 +-
mlrun/api/crud/__init__.py | 32 +-
mlrun/api/crud/model_monitoring/__init__.py | 4 +-
mlrun/api/crud/model_monitoring/grafana.py | 42 +-
.../model_monitoring/model_endpoint_store.py | 850 ------------------
.../crud/model_monitoring/model_endpoints.py | 366 ++++++--
mlrun/api/db/sqldb/models/models_mysql.py | 95 +-
mlrun/api/db/sqldb/models/models_sqlite.py | 73 +-
mlrun/api/db/sqldb/session.py | 45 +-
mlrun/api/schemas/__init__.py | 2 -
mlrun/api/schemas/model_endpoints.py | 230 ++++-
mlrun/config.py | 3 +-
mlrun/db/base.py | 6 +-
mlrun/db/filedb.py | 6 +-
mlrun/db/httpdb.py | 86 +-
mlrun/db/sqldb.py | 6 +-
mlrun/model_monitoring/__init__.py | 42 +
mlrun/model_monitoring/common.py | 112 +++
mlrun/model_monitoring/constants.py | 40 +-
mlrun/model_monitoring/helpers.py | 9 +-
mlrun/model_monitoring/model_endpoint.py | 141 +++
.../model_monitoring_batch.py | 403 +++++----
mlrun/model_monitoring/stores/__init__.py | 106 +++
.../stores/kv_model_endpoint_store.py | 441 +++++++++
.../stores/model_endpoint_store.py | 147 +++
.../stores/models/__init__.py | 23 +
mlrun/model_monitoring/stores/models/base.py | 18 +
mlrun/model_monitoring/stores/models/mysql.py | 100 +++
.../model_monitoring/stores/models/sqlite.py | 98 ++
.../stores/sql_model_endpoint_store.py | 375 ++++++++
.../model_monitoring/stream_processing_fs.py | 259 +++---
mlrun/projects/project.py | 27 +-
mlrun/serving/routers.py | 51 +-
mlrun/serving/v2_serving.py | 18 +-
mlrun/utils/db.py | 52 ++
mlrun/utils/model_monitoring.py | 165 ++--
tests/api/api/test_grafana_proxy.py | 29 +-
tests/api/api/test_model_endpoints.py | 218 ++++-
tests/api/conftest.py | 2 +-
tests/api/db/conftest.py | 2 +-
tests/api/test_initial_data.py | 5 +-
tests/common_fixtures.py | 2 +-
tests/rundb/test_dbs.py | 2 +-
.../model_monitoring/test_model_monitoring.py | 66 +-
52 files changed, 3423 insertions(+), 2166 deletions(-)
delete mode 100644 mlrun/api/crud/model_monitoring/model_endpoint_store.py
create mode 100644 mlrun/model_monitoring/__init__.py
create mode 100644 mlrun/model_monitoring/common.py
create mode 100644 mlrun/model_monitoring/model_endpoint.py
create mode 100644 mlrun/model_monitoring/stores/__init__.py
create mode 100644 mlrun/model_monitoring/stores/kv_model_endpoint_store.py
create mode 100644 mlrun/model_monitoring/stores/model_endpoint_store.py
create mode 100644 mlrun/model_monitoring/stores/models/__init__.py
create mode 100644 mlrun/model_monitoring/stores/models/base.py
create mode 100644 mlrun/model_monitoring/stores/models/mysql.py
create mode 100644 mlrun/model_monitoring/stores/models/sqlite.py
create mode 100644 mlrun/model_monitoring/stores/sql_model_endpoint_store.py
create mode 100644 mlrun/utils/db.py
diff --git a/docs/monitoring/dashboards/iguazio-3.5.2-and-older/model-monitoring-details.json b/docs/monitoring/dashboards/iguazio-3.5.2-and-older/model-monitoring-details.json
index 5012f520a193..d5d8a440e38b 100644
--- a/docs/monitoring/dashboards/iguazio-3.5.2-and-older/model-monitoring-details.json
+++ b/docs/monitoring/dashboards/iguazio-3.5.2-and-older/model-monitoring-details.json
@@ -15,8 +15,8 @@
"editable": true,
"gnetId": null,
"graphTooltip": 0,
- "id": 8,
- "iteration": 1627466479152,
+ "id": 45,
+ "iteration": 1679739783082,
"links": [
{
"icon": "external link",
@@ -42,7 +42,7 @@
],
"panels": [
{
- "datasource": "iguazio",
+ "datasource": "model-monitoring",
"description": "",
"fieldConfig": {
"defaults": {
@@ -88,6 +88,10 @@
{
"id": "custom.align",
"value": "center"
+ },
+ {
+ "id": "custom.width",
+ "value": null
}
]
},
@@ -194,12 +198,7 @@
"id": 12,
"options": {
"showHeader": true,
- "sortBy": [
- {
- "desc": false,
- "displayName": "name"
- }
- ]
+ "sortBy": []
},
"pluginVersion": "7.2.0",
"targets": [
@@ -207,7 +206,7 @@
"hide": false,
"rawQuery": true,
"refId": "A",
- "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfilter=endpoint_id==\"$MODEL\";\nfields=endpoint_id,model,function_uri,model_class,predictions_per_second,latency_avg_1h,first_request,last_request;",
+ "target": "project=$PROJECT;target_endpoint=list_endpoints",
"type": "table"
}
],
@@ -218,10 +217,31 @@
{
"id": "organize",
"options": {
- "excludeByName": {},
- "indexByName": {},
+ "excludeByName": {
+ "accuracy": true,
+ "drift_status": true,
+ "endpoint_function": false,
+ "endpoint_model": false,
+ "error_count": true
+ },
+ "indexByName": {
+ "accuracy": 4,
+ "drift_status": 6,
+ "endpoint_function": 2,
+ "endpoint_id": 0,
+ "endpoint_model": 1,
+ "endpoint_model_class": 10,
+ "error_count": 5,
+ "first_request": 9,
+ "last_request": 3,
+ "latency_avg_1h": 8,
+ "predictions_per_second": 7
+ },
"renameByName": {
+ "endpoint_function": "Function URI",
"endpoint_id": "Endpoint ID",
+ "endpoint_model": "Model",
+ "endpoint_model_class": "Model Class",
"first_request": "First Request",
"function": "Function",
"function_uri": "Function URI",
@@ -709,15 +729,13 @@
}
}
],
- "refresh": "1m",
+ "refresh": "30s",
"schemaVersion": 26,
"style": "dark",
"tags": [],
"templating": {
"list": [
{
- "allValue": null,
- "current": {},
"datasource": "model-monitoring",
"definition": "target_endpoint=list_projects",
"hide": 0,
@@ -727,7 +745,7 @@
"name": "PROJECT",
"options": [],
"query": "target_endpoint=list_projects",
- "refresh": 0,
+ "refresh": 1,
"regex": "",
"skipUrlSync": false,
"sort": 0,
@@ -741,14 +759,14 @@
"allValue": null,
"current": {},
"datasource": "iguazio",
- "definition": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=endpoint_id;",
+ "definition": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=uid;",
"hide": 0,
"includeAll": false,
"label": "Model",
"multi": false,
"name": "MODEL",
"options": [],
- "query": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=endpoint_id;",
+ "query": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=uid;",
"refresh": 1,
"regex": "",
"skipUrlSync": false,
@@ -770,4 +788,4 @@
"title": "Model Monitoring - Details",
"uid": "AohIXhAMk",
"version": 3
-}
+}
\ No newline at end of file
diff --git a/docs/monitoring/dashboards/iguazio-3.5.2-and-older/model-monitoring-overview.json b/docs/monitoring/dashboards/iguazio-3.5.2-and-older/model-monitoring-overview.json
index 59fc43426d84..bb979bb18468 100644
--- a/docs/monitoring/dashboards/iguazio-3.5.2-and-older/model-monitoring-overview.json
+++ b/docs/monitoring/dashboards/iguazio-3.5.2-and-older/model-monitoring-overview.json
@@ -15,8 +15,8 @@
"editable": true,
"gnetId": null,
"graphTooltip": 0,
- "id": 7,
- "iteration": 1627466285618,
+ "id": 37,
+ "iteration": 1679742399589,
"links": [
{
"icon": "external link",
@@ -27,7 +27,7 @@
"type": "link",
"url": "/d/9CazA-UGz/model-monitoring-performance"
},
- {
+ {
"icon": "external link",
"includeVars": true,
"keepTime": true,
@@ -87,7 +87,7 @@
{
"rawQuery": true,
"refId": "A",
- "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=endpoint_id;",
+ "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=uid;",
"type": "table"
}
],
@@ -108,7 +108,7 @@
"type": "stat"
},
{
- "datasource": "iguazio",
+ "datasource": "model-monitoring",
"fieldConfig": {
"defaults": {
"custom": {},
@@ -156,18 +156,39 @@
"hide": false,
"rawQuery": true,
"refId": "A",
- "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=predictions_per_second;",
+ "target": "project=$PROJECT;target_endpoint=list_endpoints",
"type": "table"
}
],
"timeFrom": null,
"timeShift": null,
"title": "Predictions/s (5 Minute Average)",
+ "transformations": [
+ {
+ "id": "organize",
+ "options": {
+ "excludeByName": {
+ "accuracy": true,
+ "drift_status": true,
+ "endpoint_function": true,
+ "endpoint_id": true,
+ "endpoint_model": true,
+ "endpoint_model_class": true,
+ "error_count": true,
+ "first_request": true,
+ "last_request": true,
+ "latency_avg_1h": true
+ },
+ "indexByName": {},
+ "renameByName": {}
+ }
+ }
+ ],
"transparent": true,
"type": "stat"
},
{
- "datasource": "iguazio",
+ "datasource": "model-monitoring",
"fieldConfig": {
"defaults": {
"custom": {},
@@ -191,7 +212,7 @@
"x": 12,
"y": 0
},
- "id": 10,
+ "id": 25,
"options": {
"colorMode": "value",
"graphMode": "none",
@@ -209,9 +230,10 @@
"pluginVersion": "7.2.0",
"targets": [
{
+ "hide": false,
"rawQuery": true,
"refId": "A",
- "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=latency_avg_1h;",
+ "target": "project=$PROJECT;target_endpoint=list_endpoints",
"type": "table"
}
],
@@ -220,11 +242,25 @@
"title": "Average Latency (Last Hour)",
"transformations": [
{
- "id": "reduce",
+ "id": "organize",
"options": {
- "reducers": [
- "mean"
- ]
+ "excludeByName": {
+ "accuracy": true,
+ "drift_status": true,
+ "endpoint_function": true,
+ "endpoint_id": true,
+ "endpoint_model": true,
+ "endpoint_model_class": true,
+ "error_count": true,
+ "first_request": true,
+ "last_request": true,
+ "latency_avg_1h": false,
+ "predictions_per_second": true
+ },
+ "indexByName": {},
+ "renameByName": {
+ "latency_avg_1h": "Average Latency (Last Hour)"
+ }
}
}
],
@@ -291,7 +327,7 @@
"type": "stat"
},
{
- "datasource": "model-monitoring",
+ "datasource": "iguazio",
"description": "",
"fieldConfig": {
"defaults": {
@@ -324,46 +360,6 @@
}
},
"overrides": [
- {
- "matcher": {
- "id": "byName",
- "options": "Function"
- },
- "properties": [
- {
- "id": "custom.align",
- "value": "center"
- }
- ]
- },
- {
- "matcher": {
- "id": "byName",
- "options": "Model"
- },
- "properties": [
- {
- "id": "custom.align",
- "value": "center"
- }
- ]
- },
- {
- "matcher": {
- "id": "byName",
- "options": "Model Class"
- },
- "properties": [
- {
- "id": "custom.align",
- "value": "center"
- },
- {
- "id": "noValue",
- "value": "N/A"
- }
- ]
- },
{
"matcher": {
"id": "byName",
@@ -377,10 +373,6 @@
{
"id": "custom.align",
"value": "center"
- },
- {
- "id": "noValue",
- "value": "N/A"
}
]
},
@@ -390,49 +382,30 @@
"options": "Last Request"
},
"properties": [
- {
- "id": "custom.align",
- "value": "center"
- },
{
"id": "unit",
"value": "dateTimeFromNow"
},
- {
- "id": "noValue",
- "value": "N/A"
- }
- ]
- },
- {
- "matcher": {
- "id": "byName",
- "options": "Accuracy"
- },
- "properties": [
{
"id": "custom.align",
"value": "center"
- },
- {
- "id": "noValue",
- "value": "N/A"
}
]
},
{
"matcher": {
"id": "byName",
- "options": "Error Count"
+ "options": "Endpoint ID"
},
"properties": [
{
- "id": "custom.align",
- "value": "center"
- },
- {
- "id": "noValue",
- "value": "N/A"
+ "id": "links",
+ "value": [
+ {
+ "title": "Endpoint ID Details",
+ "url": "/d/AohIXhAMk/model-monitoring-details?orgId=1&refresh=1m&var-PROJECT=$PROJECT&var-MODEL=${__value.text}"
+ }
+ ]
}
]
},
@@ -442,14 +415,6 @@
"options": "Drift Status"
},
"properties": [
- {
- "id": "custom.align",
- "value": "center"
- },
- {
- "id": "noValue",
- "value": "N/A"
- },
{
"id": "mappings",
"value": [
@@ -476,60 +441,6 @@
"to": "",
"type": 1,
"value": "DRIFT_DETECTED"
- },
- {
- "from": "",
- "id": 3,
- "text": "-1",
- "to": "",
- "type": 1,
- "value": "N\\A"
- }
- ]
- },
- {
- "id": "custom.displayMode",
- "value": "color-background"
- },
- {
- "id": "thresholds",
- "value": {
- "mode": "absolute",
- "steps": [
- {
- "color": "rgba(255, 255, 255, 0)",
- "value": null
- },
- {
- "color": "green",
- "value": 0
- },
- {
- "color": "yellow",
- "value": 1
- },
- {
- "color": "red",
- "value": 2
- }
- ]
- }
- }
- ]
- },
- {
- "matcher": {
- "id": "byName",
- "options": "Endpoint ID"
- },
- "properties": [
- {
- "id": "links",
- "value": [
- {
- "targetBlank": true,
- "title": "",
- "url": "/d/AohIXhAMk/model-monitoring-details?orgId=1&refresh=1m&var-PROJECT=$PROJECT&var-MODEL=${__value.text}"
}
]
}
@@ -543,7 +454,7 @@
"x": 0,
"y": 3
},
- "id": 22,
+ "id": 24,
"options": {
"showHeader": true,
"sortBy": [
@@ -559,7 +470,7 @@
"hide": false,
"rawQuery": true,
"refId": "A",
- "target": "project=$PROJECT;target_endpoint=list_endpoints",
+ "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=uid,function_uri,model,model_class,first_request,last_request,error_count,drift_status",
"type": "table"
}
],
@@ -574,34 +485,32 @@
"model_hash": false
},
"indexByName": {
- "accuracy": 8,
- "drift_status": 9,
- "endpoint_function": 1,
- "endpoint_id": 0,
- "endpoint_model": 2,
- "endpoint_model_class": 3,
- "endpoint_tag": 4,
- "error_count": 7,
- "first_request": 5,
- "last_request": 6
+ "drift_status": 7,
+ "error_count": 6,
+ "first_request": 4,
+ "function_uri": 1,
+ "last_request": 5,
+ "model": 2,
+ "model_class": 3,
+ "uid": 0
},
"renameByName": {
- "accuracy": "Accuracy",
"drift_status": "Drift Status",
"endpoint_function": "Function",
- "endpoint_id": "Endpoint ID",
"endpoint_model": "Model",
"endpoint_model_class": "Model Class",
"endpoint_tag": "Tag",
"error_count": "Error Count",
"first_request": "First Request",
"function": "Function",
+ "function_uri": "Function",
"last_request": "Last Request",
"latency_avg_1s": "Average Latency",
"model": "Model",
"model_class": "Class",
"predictions_per_second_count_1s": "Predictions/1s",
- "tag": "Tag"
+ "tag": "Tag",
+ "uid": "Endpoint ID"
}
}
}
@@ -885,7 +794,7 @@
}
}
],
- "refresh": "5s",
+ "refresh": "30s",
"schemaVersion": 26,
"style": "dark",
"tags": [],
@@ -916,12 +825,12 @@
]
},
"time": {
- "from": "now-1h",
+ "from": "now-3h",
"to": "now"
},
"timepicker": {},
"timezone": "",
"title": "Model Monitoring - Overview",
"uid": "g0M4uh0Mz",
- "version": 2
-}
+ "version": 13
+}
\ No newline at end of file
diff --git a/docs/monitoring/dashboards/iguazio-3.5.2-and-older/model-monitoring-performance.json b/docs/monitoring/dashboards/iguazio-3.5.2-and-older/model-monitoring-performance.json
index 77adc0eb81b4..14bb34e8d319 100644
--- a/docs/monitoring/dashboards/iguazio-3.5.2-and-older/model-monitoring-performance.json
+++ b/docs/monitoring/dashboards/iguazio-3.5.2-and-older/model-monitoring-performance.json
@@ -529,7 +529,7 @@
}
}
],
- "refresh": "1m",
+ "refresh": "30s",
"schemaVersion": 26,
"style": "dark",
"tags": [],
@@ -561,14 +561,14 @@
"allValue": null,
"current": {},
"datasource": "iguazio",
- "definition": "backend=kv;container=users;table=pipelines/$PROJECT/model-endpoints/endpoints;fields=endpoint_id;",
+ "definition": "backend=kv;container=users;table=pipelines/$PROJECT/model-endpoints/endpoints;fields=uid;",
"hide": 0,
"includeAll": false,
"label": "Model",
"multi": false,
"name": "MODEL",
"options": [],
- "query": "backend=kv;container=users;table=pipelines/$PROJECT/model-endpoints/endpoints;fields=endpoint_id;",
+ "query": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=uid;",
"refresh": 0,
"regex": "",
"skipUrlSync": false,
@@ -590,4 +590,4 @@
"title": "Model Monitoring - Performance",
"uid": "9CazA-UGz",
"version": 2
-}
+}
\ No newline at end of file
diff --git a/docs/monitoring/dashboards/model-monitoring-details.json b/docs/monitoring/dashboards/model-monitoring-details.json
index 927b35e20b87..ce53ed00ac31 100644
--- a/docs/monitoring/dashboards/model-monitoring-details.json
+++ b/docs/monitoring/dashboards/model-monitoring-details.json
@@ -24,7 +24,7 @@
"editable": true,
"fiscalYearStartMonth": 0,
"graphTooltip": 0,
- "id": 18,
+ "id": 33,
"links": [
{
"icon": "external link",
@@ -49,7 +49,10 @@
"liveNow": false,
"panels": [
{
- "datasource": "iguazio",
+ "datasource": {
+ "type": "grafana-simple-json-datasource",
+ "uid": "PiBy-ta4z"
+ },
"description": "",
"fieldConfig": {
"defaults": {
@@ -64,8 +67,7 @@
"mode": "absolute",
"steps": [
{
- "color": "green",
- "value": null
+ "color": "green"
},
{
"color": "red",
@@ -211,19 +213,40 @@
"pluginVersion": "9.2.2",
"targets": [
{
- "datasource": "iguazio",
+ "datasource": {
+ "type": "grafana-simple-json-datasource",
+ "uid": "PiBy-ta4z"
+ },
"hide": false,
"rawQuery": true,
"refId": "A",
- "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfilter=endpoint_id==\"$MODELENDPOINT\";\nfields=endpoint_id,model,function_uri,model_class,predictions_per_second,latency_avg_1h,first_request,last_request;",
+ "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfilter=uid==\"$MODELENDPOINT\";\nfields=uid,model,function_uri,model_class,first_request,metrics,last_request;",
"type": "table"
}
],
"transformations": [
+ {
+ "id": "extractFields",
+ "options": {
+ "source": "metrics"
+ }
+ },
+ {
+ "id": "extractFields",
+ "options": {
+ "source": "generic"
+ }
+ },
{
"id": "organize",
"options": {
- "excludeByName": {},
+ "excludeByName": {
+ "generic": true,
+ "latency_avg_5m": true,
+ "metrics": true,
+ "predictions_count_1h": true,
+ "predictions_count_5m": true
+ },
"indexByName": {},
"renameByName": {
"endpoint_id": "Endpoint ID",
@@ -233,12 +256,14 @@
"last_request": "Last Request",
"latency_avg_1h": "Average Latency (1 hour)",
"latency_avg_1s": "Average Latency",
- "latency_avg_5m": "Average Latency (1 hour)",
+ "latency_avg_5m": "",
+ "metrics": "",
"model": "Model",
"model_class": "Model Class",
"predictions_per_second": "Predictions/s (5 minute avg)",
"predictions_per_second_count_1s": "Predictions/sec",
- "tag": "Tag"
+ "tag": "Tag",
+ "uid": "Endpoint ID"
}
}
}
@@ -247,7 +272,10 @@
"type": "table"
},
{
- "datasource": "iguazio",
+ "datasource": {
+ "type": "grafana-simple-json-datasource",
+ "uid": "PiBy-ta4z"
+ },
"description": "",
"fieldConfig": {
"defaults": {
@@ -262,8 +290,7 @@
"mode": "absolute",
"steps": [
{
- "color": "green",
- "value": null
+ "color": "green"
},
{
"color": "red",
@@ -417,7 +444,7 @@
"hide": false,
"rawQuery": true,
"refId": "A",
- "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfilter=endpoint_id==\"$MODELENDPOINT\";\nfields=drift_measures;",
+ "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfilter=uid==\"$MODELENDPOINT\";\nfields=drift_measures;",
"type": "table"
}
],
@@ -466,8 +493,7 @@
"mode": "absolute",
"steps": [
{
- "color": "green",
- "value": null
+ "color": "green"
},
{
"color": "red",
@@ -570,7 +596,7 @@
"sortBy": [
{
"desc": true,
- "displayName": "Field"
+ "displayName": "current_stats"
}
]
},
@@ -580,21 +606,21 @@
"datasource": "iguazio",
"rawQuery": true,
"refId": "A",
- "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfilter=endpoint_id==\"$MODELENDPOINT\";\nfields= current_stats;",
+ "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfilter=uid==\"$MODELENDPOINT\";\nfields= current_stats;",
"type": "table"
},
{
"datasource": "iguazio",
"hide": false,
"refId": "B",
- "target": "backend=kv; container=users; table=pipelines/$PROJECT/model-endpoints/endpoints; filter=endpoint_id==\"$MODELENDPOINT\"; fields= feature_stats;",
+ "target": "backend=kv; container=users; table=pipelines/$PROJECT/model-endpoints/endpoints; filter=uid==\"$MODELENDPOINT\"; fields= feature_stats;",
"type": "table"
},
{
"datasource": "iguazio",
"hide": false,
"refId": "C",
- "target": "backend=kv; container=users; table=pipelines/$PROJECT/model-endpoints/endpoints; filter=endpoint_id==\"$MODELENDPOINT\"; fields= drift_measures;",
+ "target": "backend=kv; container=users; table=pipelines/$PROJECT/model-endpoints/endpoints; filter=uid==\"$MODELENDPOINT\"; fields= drift_measures;",
"type": "table"
}
],
@@ -763,9 +789,35 @@
"source": "0"
}
},
+ {
+ "id": "filterByValue",
+ "options": {
+ "filters": [
+ {
+ "config": {
+ "id": "isNull",
+ "options": {}
+ },
+ "fieldName": "1"
+ },
+ {
+ "config": {
+ "id": "greater",
+ "options": {
+ "value": 0
+ }
+ },
+ "fieldName": "2"
+ }
+ ],
+ "match": "any",
+ "type": "exclude"
+ }
+ },
{
"id": "extractFields",
"options": {
+ "format": "json",
"source": "1"
}
},
@@ -786,10 +838,10 @@
"max 1",
"mean 2",
"min 2",
+ "max 2",
"tvd",
"hellinger",
- "kld",
- "max 2"
+ "kld"
]
}
}
@@ -965,7 +1017,7 @@
}
}
],
- "refresh": "1m",
+ "refresh": "30s",
"schemaVersion": 37,
"style": "dark",
"tags": [],
@@ -994,14 +1046,14 @@
{
"current": {},
"datasource": "iguazio",
- "definition": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=endpoint_id;",
+ "definition": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=uid;",
"hide": 0,
"includeAll": false,
"label": "Model Endpoint",
"multi": false,
"name": "MODELENDPOINT",
"options": [],
- "query": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=endpoint_id;",
+ "query": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=uid;",
"refresh": 1,
"regex": "",
"skipUrlSync": false,
@@ -1021,6 +1073,6 @@
"timezone": "",
"title": "Model Monitoring - Details",
"uid": "AohIXhAMk",
- "version": 2,
+ "version": 9,
"weekStart": ""
-}
+}
\ No newline at end of file
diff --git a/docs/monitoring/dashboards/model-monitoring-overview.json b/docs/monitoring/dashboards/model-monitoring-overview.json
index c003428d315c..7f3829118aee 100644
--- a/docs/monitoring/dashboards/model-monitoring-overview.json
+++ b/docs/monitoring/dashboards/model-monitoring-overview.json
@@ -24,7 +24,7 @@
"editable": true,
"fiscalYearStartMonth": 0,
"graphTooltip": 0,
- "id": 13,
+ "id": 31,
"links": [
{
"icon": "external link",
@@ -93,10 +93,10 @@
"pluginVersion": "9.2.2",
"targets": [
{
-"datasource": "iguazio",
+ "datasource": "iguazio",
"rawQuery": true,
"refId": "A",
- "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=endpoint_id;",
+ "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=uid;",
"type": "table"
}
],
@@ -159,20 +159,51 @@
"pluginVersion": "9.2.2",
"targets": [
{
-"datasource": "iguazio",
+ "datasource": "iguazio",
"hide": false,
"rawQuery": true,
"refId": "A",
- "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=predictions_per_second;",
+ "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=metrics;",
"type": "table"
}
],
"title": "Predictions/s (5 Minute Average)",
+ "transformations": [
+ {
+ "id": "extractFields",
+ "options": {
+ "source": "metrics"
+ }
+ },
+ {
+ "id": "extractFields",
+ "options": {
+ "source": "generic"
+ }
+ },
+ {
+ "id": "organize",
+ "options": {
+ "excludeByName": {
+ "generic": true,
+ "latency_avg_1h": true,
+ "latency_avg_5m": true,
+ "metrics": true,
+ "predictions_count_1h": true,
+ "predictions_count_5m": true
+ },
+ "indexByName": {},
+ "renameByName": {
+ "predictions_per_second": "Predictions/s (5 Minute Average)"
+ }
+ }
+ }
+ ],
"transparent": true,
"type": "stat"
},
{
- "datasource": "iguazio",
+ "datasource": "iguazio",
"fieldConfig": {
"defaults": {
"mappings": [],
@@ -192,10 +223,10 @@
"gridPos": {
"h": 3,
"w": 5,
- "x": 12,
+ "x": 11,
"y": 0
},
- "id": 10,
+ "id": 23,
"options": {
"colorMode": "value",
"graphMode": "none",
@@ -213,21 +244,45 @@
"pluginVersion": "9.2.2",
"targets": [
{
-"datasource": "iguazio",
+ "datasource": "iguazio",
+ "hide": false,
"rawQuery": true,
"refId": "A",
- "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=latency_avg_1h;",
+ "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=metrics;",
"type": "table"
}
],
"title": "Average Latency (Last Hour)",
"transformations": [
{
- "id": "reduce",
+ "id": "extractFields",
"options": {
- "reducers": [
- "mean"
- ]
+ "source": "metrics"
+ }
+ },
+ {
+ "id": "extractFields",
+ "options": {
+ "source": "generic"
+ }
+ },
+ {
+ "id": "organize",
+ "options": {
+ "excludeByName": {
+ "generic": true,
+ "latency_avg_1h": false,
+ "latency_avg_5m": true,
+ "metrics": true,
+ "predictions_count_1h": true,
+ "predictions_count_5m": true,
+ "predictions_per_second": true
+ },
+ "indexByName": {},
+ "renameByName": {
+ "latency_avg_1h": "Average Latency (Last Hour)",
+ "predictions_per_second": "Predictions/s (5 Minute Average)"
+ }
}
}
],
@@ -280,7 +335,7 @@
"pluginVersion": "9.2.2",
"targets": [
{
-"datasource": "iguazio",
+ "datasource": "iguazio",
"rawQuery": true,
"refId": "A",
"target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=error_count;",
@@ -549,11 +604,11 @@
"pluginVersion": "9.2.2",
"targets": [
{
-"datasource": "iguazio",
+ "datasource": "iguazio",
"hide": false,
"rawQuery": true,
"refId": "A",
- "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=endpoint_id,model,function_uri,model_class,first_request,last_request,error_count,drift_status;",
+ "target": "backend=kv;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/endpoints;\nfields=uid,model,function_uri,model_class,first_request,last_request,error_count,drift_status;",
"type": "table"
}
],
@@ -566,13 +621,14 @@
"model_hash": false
},
"indexByName": {
- "endpoint_id": 0,
+ "drift_status": 7,
"error_count": 6,
"first_request": 4,
"function_uri": 1,
"last_request": 5,
"model": 2,
- "model_class": 3
+ "model_class": 3,
+ "uid": 0
},
"renameByName": {
"accuracy": "Accuracy",
@@ -591,7 +647,8 @@
"model": "Model",
"model_class": "Class",
"predictions_per_second_count_1s": "Predictions/1s",
- "tag": "Tag"
+ "tag": "Tag",
+ "uid": "Endpoint ID"
}
}
}
@@ -678,7 +735,7 @@
"reverseYBuckets": false,
"targets": [
{
-"datasource": "iguazio",
+ "datasource": "iguazio",
"rawQuery": true,
"refId": "A",
"target": "backend=tsdb;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/events;\nfields=predictions_per_second;",
@@ -782,7 +839,7 @@
"reverseYBuckets": false,
"targets": [
{
-"datasource": "iguazio",
+ "datasource": "iguazio",
"rawQuery": true,
"refId": "A",
"target": "backend=tsdb;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/events;\nfields=latency_avg_1h;",
@@ -848,7 +905,7 @@
"steppedLine": false,
"targets": [
{
- "datasource": "iguazio",
+ "datasource": "iguazio",
"refId": "A",
"target": "select metric",
"type": "timeserie"
@@ -886,7 +943,7 @@
}
}
],
- "refresh": "5s",
+ "refresh": "30s",
"schemaVersion": 37,
"style": "dark",
"tags": [],
@@ -922,6 +979,6 @@
"timezone": "",
"title": "Model Monitoring - Overview",
"uid": "g0M4uh0Mz",
- "version": 9,
+ "version": 2,
"weekStart": ""
-}
+}
\ No newline at end of file
diff --git a/docs/monitoring/dashboards/model-monitoring-performance.json b/docs/monitoring/dashboards/model-monitoring-performance.json
index 8259587430fd..1956e3fcafc9 100644
--- a/docs/monitoring/dashboards/model-monitoring-performance.json
+++ b/docs/monitoring/dashboards/model-monitoring-performance.json
@@ -3,20 +3,28 @@
"list": [
{
"builtIn": 1,
- "datasource": "-- Grafana --",
+ "datasource": {
+ "type": "datasource",
+ "uid": "grafana"
+ },
"enable": true,
"hide": true,
"iconColor": "rgba(0, 211, 255, 1)",
"name": "Annotations & Alerts",
+ "target": {
+ "limit": 100,
+ "matchAny": false,
+ "tags": [],
+ "type": "dashboard"
+ },
"type": "dashboard"
}
]
},
"editable": true,
- "gnetId": null,
+ "fiscalYearStartMonth": 0,
"graphTooltip": 0,
- "id": 9,
- "iteration": 1627466092078,
+ "id": 32,
"links": [
{
"asDropdown": true,
@@ -39,6 +47,7 @@
"url": "d/AohIXhAMk/model-monitoring-details"
}
],
+ "liveNow": false,
"panels": [
{
"aliasColors": {},
@@ -46,12 +55,6 @@
"dashLength": 10,
"dashes": false,
"datasource": "iguazio",
- "fieldConfig": {
- "defaults": {
- "custom": {}
- },
- "overrides": []
- },
"fill": 1,
"fillGradient": 1,
"gridPos": {
@@ -81,7 +84,7 @@
"alertThreshold": true
},
"percentage": false,
- "pluginVersion": "7.2.0",
+ "pluginVersion": "9.2.2",
"pointradius": 2,
"points": false,
"renderer": "flot",
@@ -91,6 +94,7 @@
"steppedLine": false,
"targets": [
{
+ "datasource": "iguazio",
"rawQuery": true,
"refId": "A",
"target": "backend=tsdb;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/events;\nfilter=endpoint_id=='$MODELENDPOINT' AND record_type=='drift_measures';",
@@ -98,9 +102,7 @@
}
],
"thresholds": [],
- "timeFrom": null,
"timeRegions": [],
- "timeShift": null,
"title": "Drift Measures",
"tooltip": {
"shared": true,
@@ -111,33 +113,24 @@
"transparent": true,
"type": "graph",
"xaxis": {
- "buckets": null,
"mode": "time",
- "name": null,
"show": true,
"values": []
},
"yaxes": [
{
"format": "short",
- "label": null,
"logBase": 1,
- "max": null,
- "min": null,
"show": true
},
{
"format": "short",
- "label": null,
"logBase": 1,
- "max": null,
- "min": null,
"show": true
}
],
"yaxis": {
- "align": false,
- "alignLevel": null
+ "align": false
}
},
{
@@ -146,12 +139,6 @@
"dashLength": 10,
"dashes": false,
"datasource": "iguazio",
- "fieldConfig": {
- "defaults": {
- "custom": {}
- },
- "overrides": []
- },
"fill": 1,
"fillGradient": 0,
"gridPos": {
@@ -178,7 +165,7 @@
"alertThreshold": true
},
"percentage": false,
- "pluginVersion": "7.2.0",
+ "pluginVersion": "9.2.2",
"pointradius": 2,
"points": false,
"renderer": "flot",
@@ -188,6 +175,7 @@
"steppedLine": false,
"targets": [
{
+ "datasource": "iguazio",
"rawQuery": true,
"refId": "A",
"target": "backend=tsdb;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/events;\nfields=latency_avg_5m,latency_avg_1h;\nfilter=endpoint_id=='$MODELENDPOINT';",
@@ -195,9 +183,7 @@
}
],
"thresholds": [],
- "timeFrom": null,
"timeRegions": [],
- "timeShift": null,
"title": "Average Latency",
"tooltip": {
"shared": true,
@@ -207,33 +193,24 @@
"transparent": true,
"type": "graph",
"xaxis": {
- "buckets": null,
"mode": "time",
- "name": null,
"show": true,
"values": []
},
"yaxes": [
{
"format": "short",
- "label": null,
"logBase": 1,
- "max": null,
- "min": null,
"show": true
},
{
"format": "short",
- "label": null,
"logBase": 1,
- "max": null,
- "min": null,
"show": true
}
],
"yaxis": {
- "align": false,
- "alignLevel": null
+ "align": false
}
},
{
@@ -242,12 +219,6 @@
"dashLength": 10,
"dashes": false,
"datasource": "iguazio",
- "fieldConfig": {
- "defaults": {
- "custom": {}
- },
- "overrides": []
- },
"fill": 1,
"fillGradient": 0,
"gridPos": {
@@ -274,7 +245,7 @@
"alertThreshold": true
},
"percentage": false,
- "pluginVersion": "7.2.0",
+ "pluginVersion": "9.2.2",
"pointradius": 2,
"points": false,
"renderer": "flot",
@@ -284,6 +255,7 @@
"steppedLine": false,
"targets": [
{
+ "datasource": "iguazio",
"rawQuery": true,
"refId": "A",
"target": "backend=tsdb;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/events;\nfields=predictions_per_second;\nfilter=endpoint_id=='$MODELENDPOINT';",
@@ -291,9 +263,7 @@
}
],
"thresholds": [],
- "timeFrom": null,
"timeRegions": [],
- "timeShift": null,
"title": "Predictions/s (5 minute average)",
"tooltip": {
"shared": true,
@@ -303,33 +273,24 @@
"transparent": true,
"type": "graph",
"xaxis": {
- "buckets": null,
"mode": "time",
- "name": null,
"show": true,
"values": []
},
"yaxes": [
{
"format": "short",
- "label": null,
"logBase": 1,
- "max": null,
- "min": null,
"show": true
},
{
"format": "short",
- "label": null,
"logBase": 1,
- "max": null,
- "min": null,
"show": true
}
],
"yaxis": {
- "align": false,
- "alignLevel": null
+ "align": false
}
},
{
@@ -338,12 +299,6 @@
"dashLength": 10,
"dashes": false,
"datasource": "iguazio",
- "fieldConfig": {
- "defaults": {
- "custom": {}
- },
- "overrides": []
- },
"fill": 1,
"fillGradient": 0,
"gridPos": {
@@ -370,7 +325,7 @@
"alertThreshold": true
},
"percentage": false,
- "pluginVersion": "7.2.0",
+ "pluginVersion": "9.2.2",
"pointradius": 2,
"points": false,
"renderer": "flot",
@@ -380,6 +335,7 @@
"steppedLine": false,
"targets": [
{
+ "datasource": "iguazio",
"rawQuery": true,
"refId": "A",
"target": "backend=tsdb;\ncontainer=users;\ntable=pipelines/$PROJECT/model-endpoints/events;\nfields=predictions_count_5m,predictions_count_1h;\nfilter=endpoint_id=='$MODELENDPOINT';",
@@ -387,9 +343,7 @@
}
],
"thresholds": [],
- "timeFrom": null,
"timeRegions": [],
- "timeShift": null,
"title": "Predictions Count",
"tooltip": {
"shared": true,
@@ -399,33 +353,24 @@
"transparent": true,
"type": "graph",
"xaxis": {
- "buckets": null,
"mode": "time",
- "name": null,
"show": true,
"values": []
},
"yaxes": [
{
"format": "short",
- "label": null,
"logBase": 1,
- "max": null,
- "min": null,
"show": true
},
{
"format": "short",
- "label": null,
"logBase": 1,
- "max": null,
- "min": null,
"show": true
}
],
"yaxis": {
- "align": false,
- "alignLevel": null
+ "align": false
}
},
{
@@ -434,12 +379,6 @@
"dashLength": 10,
"dashes": false,
"datasource": "iguazio",
- "fieldConfig": {
- "defaults": {
- "custom": {}
- },
- "overrides": []
- },
"fill": 1,
"fillGradient": 1,
"gridPos": {
@@ -469,7 +408,7 @@
"alertThreshold": true
},
"percentage": false,
- "pluginVersion": "7.2.0",
+ "pluginVersion": "9.2.2",
"pointradius": 2,
"points": false,
"renderer": "flot",
@@ -479,6 +418,7 @@
"steppedLine": false,
"targets": [
{
+ "datasource": "iguazio",
"rawQuery": true,
"refId": "A",
"target": "backend=tsdb; container=users; table=pipelines/$PROJECT/model-endpoints/events; filter=endpoint_id=='$MODELENDPOINT' AND record_type=='custom_metrics';",
@@ -486,9 +426,7 @@
}
],
"thresholds": [],
- "timeFrom": null,
"timeRegions": [],
- "timeShift": null,
"title": "Custom Metrics",
"tooltip": {
"shared": true,
@@ -499,44 +437,34 @@
"transparent": true,
"type": "graph",
"xaxis": {
- "buckets": null,
"mode": "time",
- "name": null,
"show": true,
"values": []
},
"yaxes": [
{
"format": "short",
- "label": null,
"logBase": 1,
- "max": null,
- "min": null,
"show": true
},
{
"format": "short",
- "label": null,
"logBase": 1,
- "max": null,
- "min": null,
"show": true
}
],
"yaxis": {
- "align": false,
- "alignLevel": null
+ "align": false
}
}
],
- "refresh": "1m",
- "schemaVersion": 26,
+ "refresh": "30s",
+ "schemaVersion": 37,
"style": "dark",
"tags": [],
"templating": {
"list": [
{
- "allValue": null,
"current": {},
"datasource": "model-monitoring",
"definition": "target_endpoint=list_projects",
@@ -552,29 +480,26 @@
"skipUrlSync": false,
"sort": 0,
"tagValuesQuery": "",
- "tags": [],
"tagsQuery": "",
"type": "query",
"useTags": false
},
{
- "allValue": null,
"current": {},
"datasource": "iguazio",
- "definition": "backend=kv;container=users;table=pipelines/$PROJECT/model-endpoints/endpoints;fields=endpoint_id;",
+ "definition": "backend=kv;container=users;table=pipelines/$PROJECT/model-endpoints/endpoints;fields=uid;",
"hide": 0,
"includeAll": false,
"label": "Model Endpoint",
"multi": false,
"name": "MODELENDPOINT",
"options": [],
- "query": "backend=kv;container=users;table=pipelines/$PROJECT/model-endpoints/endpoints;fields=endpoint_id;",
- "refresh": 0,
+ "query": "backend=kv;container=users;table=pipelines/$PROJECT/model-endpoints/endpoints;fields=uid;",
+ "refresh": 1,
"regex": "",
"skipUrlSync": false,
"sort": 0,
"tagValuesQuery": "",
- "tags": [],
"tagsQuery": "",
"type": "query",
"useTags": false
@@ -589,5 +514,6 @@
"timezone": "",
"title": "Model Monitoring - Performance",
"uid": "9CazA-UGz",
- "version": 2
-}
+ "version": 2,
+ "weekStart": ""
+}
\ No newline at end of file
diff --git a/mlrun/api/api/endpoints/functions.py b/mlrun/api/api/endpoints/functions.py
index 51fd608ad170..53a84d99b7cb 100644
--- a/mlrun/api/api/endpoints/functions.py
+++ b/mlrun/api/api/endpoints/functions.py
@@ -40,6 +40,7 @@
import mlrun.api.utils.background_tasks
import mlrun.api.utils.clients.chief
import mlrun.api.utils.singletons.project_member
+import mlrun.model_monitoring.constants
from mlrun.api.api import deps
from mlrun.api.api.utils import get_run_db_instance, log_and_raise, log_path
from mlrun.api.crud.secrets import Secrets, SecretsClientType
@@ -635,8 +636,9 @@ def _build_function(
model_monitoring_access_key = _process_model_monitoring_secret(
db_session,
fn.metadata.project,
- "MODEL_MONITORING_ACCESS_KEY",
+ mlrun.model_monitoring.constants.ProjectSecretKeys.ACCESS_KEY,
)
+
# initialize model monitoring stream
_create_model_monitoring_stream(project=fn.metadata.project)
@@ -656,10 +658,10 @@ def _build_function(
# deploy both model monitoring stream and model monitoring batch job
mlrun.api.crud.ModelEndpoints().deploy_monitoring_functions(
project=fn.metadata.project,
- model_monitoring_access_key=model_monitoring_access_key,
db_session=db_session,
auth_info=auth_info,
tracking_policy=fn.spec.tracking_policy,
+ model_monitoring_access_key=model_monitoring_access_key,
)
except Exception as exc:
logger.warning(
diff --git a/mlrun/api/api/endpoints/grafana_proxy.py b/mlrun/api/api/endpoints/grafana_proxy.py
index 8fbb3dfed5ef..7780a19c5424 100644
--- a/mlrun/api/api/endpoints/grafana_proxy.py
+++ b/mlrun/api/api/endpoints/grafana_proxy.py
@@ -25,11 +25,25 @@
import mlrun.api.crud.model_monitoring.grafana
import mlrun.api.schemas
import mlrun.api.utils.auth.verifier
+import mlrun.model_monitoring
from mlrun.api.api import deps
from mlrun.api.schemas import GrafanaTable, GrafanaTimeSeriesTarget
router = APIRouter()
+NAME_TO_SEARCH_FUNCTION_DICTIONARY = {
+ "list_projects": mlrun.api.crud.model_monitoring.grafana.grafana_list_projects,
+}
+NAME_TO_QUERY_FUNCTION_DICTIONARY = {
+ "list_endpoints": mlrun.api.crud.model_monitoring.grafana.grafana_list_endpoints,
+ "individual_feature_analysis": mlrun.api.crud.model_monitoring.grafana.grafana_individual_feature_analysis,
+ "overall_feature_analysis": mlrun.api.crud.model_monitoring.grafana.grafana_overall_feature_analysis,
+ "incoming_features": mlrun.api.crud.model_monitoring.grafana.grafana_incoming_features,
+}
+
+SUPPORTED_QUERY_FUNCTIONS = set(NAME_TO_QUERY_FUNCTION_DICTIONARY.keys())
+SUPPORTED_SEARCH_FUNCTIONS = set(NAME_TO_SEARCH_FUNCTION_DICTIONARY)
+
@router.get("/grafana-proxy/model-endpoints", status_code=HTTPStatus.OK.value)
def grafana_proxy_model_endpoints_check_connection(
@@ -43,12 +57,6 @@ def grafana_proxy_model_endpoints_check_connection(
return Response(status_code=HTTPStatus.OK.value)
-NAME_TO_SEARCH_FUNCTION_DICTIONARY = {
- "list_projects": mlrun.api.crud.model_monitoring.grafana.grafana_list_projects,
-}
-SUPPORTED_SEARCH_FUNCTIONS = set(NAME_TO_SEARCH_FUNCTION_DICTIONARY)
-
-
@router.post("/grafana-proxy/model-endpoints/search", response_model=List[str])
async def grafana_proxy_model_endpoints_search(
request: Request,
@@ -61,13 +69,18 @@ async def grafana_proxy_model_endpoints_search(
This implementation requires passing target_endpoint query parameter in order to dispatch different
model-endpoint monitoring functions.
+
+ :param request: An api request with the required target and parameters.
+ :param auth_info: The auth info of the request.
+ :param db_session: A session that manages the current dialog with the database.
+
+ :return: List of results. e.g. list of available project names.
"""
mlrun.api.crud.ModelEndpoints().get_access_key(auth_info)
body = await request.json()
query_parameters = mlrun.api.crud.model_monitoring.grafana.parse_search_parameters(
body
)
-
mlrun.api.crud.model_monitoring.grafana.validate_query_parameters(
query_parameters, SUPPORTED_SEARCH_FUNCTIONS
)
@@ -76,23 +89,16 @@ async def grafana_proxy_model_endpoints_search(
# checks again.
target_endpoint = query_parameters["target_endpoint"]
function = NAME_TO_SEARCH_FUNCTION_DICTIONARY[target_endpoint]
+
if asyncio.iscoroutinefunction(function):
- return await function(db_session, auth_info)
- result = await run_in_threadpool(function, db_session, auth_info)
+ result = await function(db_session, auth_info, query_parameters)
+ else:
+ result = await run_in_threadpool(
+ function, db_session, auth_info, query_parameters
+ )
return result
-#
-NAME_TO_QUERY_FUNCTION_DICTIONARY = {
- "list_endpoints": mlrun.api.crud.model_monitoring.grafana.grafana_list_endpoints,
- "individual_feature_analysis": mlrun.api.crud.model_monitoring.grafana.grafana_individual_feature_analysis,
- "overall_feature_analysis": mlrun.api.crud.model_monitoring.grafana.grafana_overall_feature_analysis,
- "incoming_features": mlrun.api.crud.model_monitoring.grafana.grafana_incoming_features,
-}
-
-SUPPORTED_QUERY_FUNCTIONS = set(NAME_TO_QUERY_FUNCTION_DICTIONARY.keys())
-
-
@router.post(
"/grafana-proxy/model-endpoints/query",
response_model=List[Union[GrafanaTable, GrafanaTimeSeriesTarget]],
@@ -108,12 +114,14 @@ async def grafana_proxy_model_endpoints_query(
This implementation requires passing target_endpoint query parameter in order to dispatch different
model-endpoint monitoring functions.
"""
+
warnings.warn(
- "This api is deprecated in 1.3.0 and will be removed in 1.5.0. "
+ "This api is deprecated in 1.3.1 and will be removed in 1.5.0. "
"Please update grafana model monitoring dashboards that use a different data source",
# TODO: remove in 1.5.0
FutureWarning,
)
+
body = await request.json()
query_parameters = mlrun.api.crud.model_monitoring.grafana.parse_query_parameters(
body
diff --git a/mlrun/api/api/endpoints/model_endpoints.py b/mlrun/api/api/endpoints/model_endpoints.py
index 4171e8e91744..6d9282615de1 100644
--- a/mlrun/api/api/endpoints/model_endpoints.py
+++ b/mlrun/api/api/endpoints/model_endpoints.py
@@ -33,7 +33,7 @@
@router.put(
"/projects/{project}/model-endpoints/{endpoint_id}",
- status_code=HTTPStatus.NO_CONTENT.value,
+ response_model=mlrun.api.schemas.ModelEndpoint,
)
async def create_or_patch(
project: str,
@@ -43,9 +43,9 @@ async def create_or_patch(
mlrun.api.api.deps.authenticate_request
),
db_session: Session = Depends(mlrun.api.api.deps.get_db_session),
-):
+) -> mlrun.api.schemas.ModelEndpoint:
"""
- Either create or updates the record of a given ModelEndpoint object.
+ Either create or update the record of a given `ModelEndpoint` object.
Leaving here for backwards compatibility.
"""
@@ -76,7 +76,7 @@ async def create_or_patch(
)
# Since the endpoint records are created automatically, at point of serving function deployment, we need to use
# V3IO_ACCESS_KEY here
- await run_in_threadpool(
+ return await run_in_threadpool(
mlrun.api.crud.ModelEndpoints().create_or_patch,
db_session=db_session,
access_key=os.environ.get("V3IO_ACCESS_KEY"),
@@ -99,7 +99,7 @@ async def create_model_endpoint(
db_session: Session = Depends(mlrun.api.api.deps.get_db_session),
) -> mlrun.api.schemas.ModelEndpoint:
"""
- Create a DB record of a given ModelEndpoint object.
+ Create a DB record of a given `ModelEndpoint` object.
:param project: The name of the project.
:param endpoint_id: The unique id of the model endpoint.
@@ -111,6 +111,7 @@ async def create_model_endpoint(
:return: A Model endpoint object.
"""
+
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
resource_type=mlrun.api.schemas.AuthorizationResourceTypes.model_endpoint,
project_name=project,
@@ -149,14 +150,13 @@ async def patch_model_endpoint(
),
) -> mlrun.api.schemas.ModelEndpoint:
"""
- Update a DB record of a given ModelEndpoint object.
+ Update a DB record of a given `ModelEndpoint` object.
:param project: The name of the project.
:param endpoint_id: The unique id of the model endpoint.
:param attributes: Attributes that will be updated. The input is provided in a json structure that will be
converted into a dictionary before applying the patch process. Note that the keys of
- dictionary should exist in the DB target. More details about the model endpoint available
- attributes can be found under :py:class:`~mlrun.api.schemas.ModelEndpoint`.
+ the dictionary should exist in the DB target.
example::
@@ -245,7 +245,7 @@ async def list_model_endpoints(
labels or top level. By default, when no filters are applied, all available endpoints for the given project will be
listed.
- If uids are passed: will return ModelEndpointList of endpoints with uid in uids
+ If uids are passed: will return `ModelEndpointList` of endpoints with uid in uids
Labels can be used to filter on the existence of a label:
api/projects/{project}/model-endpoints/?label=mylabel
@@ -264,11 +264,11 @@ async def list_model_endpoints(
:param model: The name of the model to filter by.
:param function: The name of the function to filter by.
:param labels: A list of labels to filter by. Label filters work by either filtering a specific value of a label
- (i.e. list("key==value")) or by looking for the existence of a given key (i.e. "key").
- :param metrics: A list of metrics to return for each endpoint. There are pre-defined metrics for model endpoints
- such as predictions_per_second and latency_avg_5m but also custom metrics defined by the user.
- Please note that these metrics are stored in the time series DB and the results will be appeared
- under model_endpoint.spec.metrics of each endpoint.
+ (i.e. list("key=value")) or by looking for the existence of a given key (i.e. "key").
+ :param metrics: A list of real-time metrics to return for each endpoint. There are pre-defined real-time metrics
+ for model endpoints such as predictions_per_second and latency_avg_5m but also custom metrics
+ defined by the user. Please note that these metrics are stored in the time series DB and the
+ results will be appeared under model_endpoint.spec.metrics of each endpoint.
:param start: The start time of the metrics. Can be represented by a string containing an RFC 3339
time, a Unix timestamp in milliseconds, a relative time (`'now'` or `'now-[0-9]+[mhd]'`, where
`m` = minutes, `h` = hours, and `'d'` = days), or 0 for the earliest time.
@@ -276,9 +276,9 @@ async def list_model_endpoints(
time, a Unix timestamp in milliseconds, a relative time (`'now'` or `'now-[0-9]+[mhd]'`, where
`m` = minutes, `h` = hours, and `'d'` = days), or 0 for the earliest time.
:param top_level: If True will return only routers and endpoint that are NOT children of any router.
- :param uids: Will return ModelEndpointList of endpoints with uid in uids.
+ :param uids: Will return `ModelEndpointList` of endpoints with uid in uids.
- :return: An object of ModelEndpointList which is literally a list of model endpoints along with some metadata. To
+ :return: An object of `ModelEndpointList` which is literally a list of model endpoints along with some metadata. To
get a standard list of model endpoints use ModelEndpointList.endpoints.
"""
@@ -333,23 +333,27 @@ async def get_model_endpoint(
"""Get a single model endpoint object. You can apply different time series metrics that will be added to the
result.
- :param project: The name of the project.
- :param endpoint_id: The unique id of the model endpoint.
- :param start: The start time of the metrics. Can be represented by a string containing an RFC 3339
- time, a Unix timestamp in milliseconds, a relative time (`'now'` or `'now-[0-9]+[mhd]'`,
- where `m` = minutes, `h` = hours, and `'d'` = days), or 0 for the earliest time.
- :param end: The end time of the metrics. Can be represented by a string containing an RFC 3339
- time, a Unix timestamp in milliseconds, a relative time (`'now'` or `'now-[0-9]+[mhd]'`,
- where `m` = minutes, `h` = hours, and `'d'` = days), or 0 for the earliest time.
- :param metrics: A list of metrics to return for the model endpoint. There are pre-defined metrics for model
- endpoints such as predictions_per_second and latency_avg_5m but also custom metrics
- defined by the user. Please note that these metrics are stored in the time series DB and
- the results will be appeared under model_endpoint.spec.metrics.
- :param feature_analysis: When True, the base feature statistics and current feature statistics will be added to
- the output of the resulting object.
- :param auth_info: The auth info of the request.
-
- :return: A ModelEndpoint object.
+
+ :param project: The name of the project
+ :param endpoint_id: The unique id of the model endpoint.
+ :param start: The start time of the metrics. Can be represented by a string containing an
+ RFC 3339 time, a Unix timestamp in milliseconds, a relative time (`'now'` or
+ `'now-[0-9]+[mhd]'`, where `m` = minutes, `h` = hours, and `'d'` = days), or
+ 0 for the earliest time.
+ :param end: The end time of the metrics. Can be represented by a string containing an
+ RFC 3339 time, a Unix timestamp in milliseconds, a relative time (`'now'` or
+ `'now-[0-9]+[mhd]'`, where `m` = minutes, `h` = hours, and `'d'` = days), or
+ 0 for the earliest time.
+ :param metrics: A list of real-time metrics to return for the model endpoint. There are
+ pre-defined real-time metrics for model endpoints such as predictions_per_second
+ and latency_avg_5m but also custom metrics defined by the user. Please note that
+ these metrics are stored in the time series DB and the results will be
+ appeared under model_endpoint.spec.metrics.
+ :param feature_analysis: When True, the base feature statistics and current feature statistics will
+ be added to the output of the resulting object.
+ :param auth_info: The auth info of the request
+
+ :return: A `ModelEndpoint` object.
"""
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
mlrun.api.schemas.AuthorizationResourceTypes.model_endpoint,
diff --git a/mlrun/api/crud/__init__.py b/mlrun/api/crud/__init__.py
index 0fdd2c760de5..0a71f167b2a4 100644
--- a/mlrun/api/crud/__init__.py
+++ b/mlrun/api/crud/__init__.py
@@ -12,18 +12,20 @@
# See the License for the specific language governing permissions and
# limitations under the License.
#
-from .artifacts import Artifacts # noqa: F401
-from .client_spec import ClientSpec # noqa: F401
-from .clusterization_spec import ClusterizationSpec # noqa: F401
-from .feature_store import FeatureStore # noqa: F401
-from .functions import Functions # noqa: F401
-from .logs import Logs # noqa: F401
-from .marketplace import Marketplace # noqa: F401
-from .model_monitoring import ModelEndpoints, ModelEndpointStoreType # noqa: F401
-from .notifications import Notifications # noqa: F401
-from .pipelines import Pipelines # noqa: F401
-from .projects import Projects # noqa: F401
-from .runs import Runs # noqa: F401
-from .runtime_resources import RuntimeResources # noqa: F401
-from .secrets import Secrets, SecretsClientType # noqa: F401
-from .tags import Tags # noqa: F401
+# flake8: noqa: F401 - this is until we take care of the F401 violations with respect to __all__ & sphinx
+
+from .artifacts import Artifacts
+from .client_spec import ClientSpec
+from .clusterization_spec import ClusterizationSpec
+from .feature_store import FeatureStore
+from .functions import Functions
+from .logs import Logs
+from .marketplace import Marketplace
+from .model_monitoring import ModelEndpoints
+from .notifications import Notifications
+from .pipelines import Pipelines
+from .projects import Projects
+from .runs import Runs
+from .runtime_resources import RuntimeResources
+from .secrets import Secrets, SecretsClientType
+from .tags import Tags
diff --git a/mlrun/api/crud/model_monitoring/__init__.py b/mlrun/api/crud/model_monitoring/__init__.py
index 62b0bf17478b..11c0e215715a 100644
--- a/mlrun/api/crud/model_monitoring/__init__.py
+++ b/mlrun/api/crud/model_monitoring/__init__.py
@@ -12,6 +12,6 @@
# See the License for the specific language governing permissions and
# limitations under the License.
#
+# flake8: noqa: F401 - this is until we take care of the F401 violations with respect to __all__ & sphinx
-from .model_endpoint_store import ModelEndpointStoreType # noqa: F401
-from .model_endpoints import ModelEndpoints # noqa: F401
+from .model_endpoints import ModelEndpoints
diff --git a/mlrun/api/crud/model_monitoring/grafana.py b/mlrun/api/crud/model_monitoring/grafana.py
index 9b95cad4db49..7bc527aec970 100644
--- a/mlrun/api/crud/model_monitoring/grafana.py
+++ b/mlrun/api/crud/model_monitoring/grafana.py
@@ -40,15 +40,21 @@
def grafana_list_projects(
- db_session: Session, auth_info: mlrun.api.schemas.AuthInfo
+ db_session: Session,
+ auth_info: mlrun.api.schemas.AuthInfo,
+ query_parameters: Dict[str, str],
) -> List[str]:
"""
List available project names. Will be used as a filter in each grafana dashboard.
+
:param db_session: A session that manages the current dialog with the database.
:param auth_info: The auth info of the request.
+ :param query_parameters: Dictionary of query parameters attached to the request. Note that this parameter is
+ required by the API even though it is not being used in this function.
:return: List of available project names.
"""
+
projects_output = get_project_member().list_projects(
db_session, format_=ProjectsFormat.name_only, leader_session=auth_info.session
)
@@ -118,21 +124,11 @@ async def grafana_list_endpoints(
GrafanaColumn(text="accuracy", type="number"),
GrafanaColumn(text="error_count", type="number"),
GrafanaColumn(text="drift_status", type="number"),
+ GrafanaColumn(text="predictions_per_second", type="number"),
+ GrafanaColumn(text="latency_avg_1h", type="number"),
]
- metric_columns = []
-
- found_metrics = set()
- for endpoint in endpoint_list.endpoints:
- if endpoint.status.metrics is not None:
- for key in endpoint.status.metrics.keys():
- if key not in found_metrics:
- found_metrics.add(key)
- metric_columns.append(GrafanaColumn(text=key, type="number"))
-
- columns = columns + metric_columns
table = GrafanaTable(columns=columns)
-
for endpoint in endpoint_list.endpoints:
row = [
endpoint.metadata.uid,
@@ -141,14 +137,26 @@ async def grafana_list_endpoints(
endpoint.spec.model_class,
endpoint.status.first_request,
endpoint.status.last_request,
- endpoint.status.accuracy,
+ "N/A", # Leaving here for backwards compatibility
endpoint.status.error_count,
endpoint.status.drift_status,
]
- if endpoint.status.metrics is not None and metric_columns:
- for metric_column in metric_columns:
- row.append(endpoint.status.metrics[metric_column.text])
+ if (
+ endpoint.status.metrics
+ and mlrun.model_monitoring.EventKeyMetrics.GENERIC
+ in endpoint.status.metrics
+ ):
+ row.extend(
+ [
+ endpoint.status.metrics[
+ mlrun.model_monitoring.EventKeyMetrics.GENERIC
+ ][mlrun.model_monitoring.EventLiveStats.PREDICTIONS_PER_SECOND],
+ endpoint.status.metrics[
+ mlrun.model_monitoring.EventKeyMetrics.GENERIC
+ ][mlrun.model_monitoring.EventLiveStats.LATENCY_AVG_1H],
+ ]
+ )
table.add_row(*row)
diff --git a/mlrun/api/crud/model_monitoring/model_endpoint_store.py b/mlrun/api/crud/model_monitoring/model_endpoint_store.py
deleted file mode 100644
index 9ba43ee64c69..000000000000
--- a/mlrun/api/crud/model_monitoring/model_endpoint_store.py
+++ /dev/null
@@ -1,850 +0,0 @@
-# Copyright 2018 Iguazio
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-#
-
-import enum
-import json
-import typing
-from abc import ABC, abstractmethod
-
-import v3io.dataplane
-import v3io_frames
-
-import mlrun
-import mlrun.api.schemas
-import mlrun.model_monitoring.constants as model_monitoring_constants
-import mlrun.utils.model_monitoring
-import mlrun.utils.v3io_clients
-from mlrun.utils import logger
-
-
-class _ModelEndpointStore(ABC):
- """
- An abstract class to handle the model endpoint in the DB target.
- """
-
- def __init__(self, project: str):
- """
- Initialize a new model endpoint target.
-
- :param project: The name of the project.
- """
- self.project = project
-
- @abstractmethod
- def write_model_endpoint(self, endpoint: mlrun.api.schemas.ModelEndpoint):
- """
- Create a new endpoint record in the DB table.
-
- :param endpoint: ModelEndpoint object that will be written into the DB.
- """
- pass
-
- @abstractmethod
- def update_model_endpoint(self, endpoint_id: str, attributes: dict):
- """
- Update a model endpoint record with a given attributes.
-
- :param endpoint_id: The unique id of the model endpoint.
- :param attributes: Dictionary of attributes that will be used for update the model endpoint. Note that the keys
- of the attributes dictionary should exist in the KV table.
-
- """
- pass
-
- @abstractmethod
- def delete_model_endpoint(self, endpoint_id: str):
- """
- Deletes the record of a given model endpoint id.
-
- :param endpoint_id: The unique id of the model endpoint.
- """
- pass
-
- @abstractmethod
- def delete_model_endpoints_resources(
- self, endpoints: mlrun.api.schemas.model_endpoints.ModelEndpointList
- ):
- """
- Delete all model endpoints resources.
-
- :param endpoints: An object of ModelEndpointList which is literally a list of model endpoints along with some
- metadata. To get a standard list of model endpoints use ModelEndpointList.endpoints.
- """
- pass
-
- @abstractmethod
- def get_model_endpoint(
- self,
- metrics: typing.List[str] = None,
- start: str = "now-1h",
- end: str = "now",
- feature_analysis: bool = False,
- endpoint_id: str = None,
- ) -> mlrun.api.schemas.ModelEndpoint:
- """
- Get a single model endpoint object. You can apply different time series metrics that will be added to the
- result.
-
- :param endpoint_id: The unique id of the model endpoint.
- :param start: The start time of the metrics. Can be represented by a string containing an RFC 3339
- time, a Unix timestamp in milliseconds, a relative time (`'now'` or
- `'now-[0-9]+[mhd]'`, where `m` = minutes, `h` = hours, and `'d'` = days), or 0 for the
- earliest time.
- :param end: The end time of the metrics. Can be represented by a string containing an RFC 3339
- time, a Unix timestamp in milliseconds, a relative time (`'now'` or
- `'now-[0-9]+[mhd]'`, where `m` = minutes, `h` = hours, and `'d'` = days), or 0 for the
- earliest time.
- :param metrics: A list of metrics to return for the model endpoint. There are pre-defined metrics for
- model endpoints such as predictions_per_second and latency_avg_5m but also custom
- metrics defined by the user. Please note that these metrics are stored in the time
- series DB and the results will be appeared under model_endpoint.spec.metrics.
- :param feature_analysis: When True, the base feature statistics and current feature statistics will be added to
- the output of the resulting object.
-
- :return: A ModelEndpoint object.
- """
- pass
-
- @abstractmethod
- def list_model_endpoints(
- self, model: str, function: str, labels: typing.List, top_level: bool
- ):
- """
- Returns a list of endpoint unique ids, supports filtering by model, function,
- labels or top level. By default, when no filters are applied, all available endpoint ids for the given project
- will be listed.
-
- :param model: The name of the model to filter by.
- :param function: The name of the function to filter by.
- :param labels: A list of labels to filter by. Label filters work by either filtering a specific value
- of a label (i.e. list("key==value")) or by looking for the existence of a given
- key (i.e. "key").
- :param top_level: If True will return only routers and endpoint that are NOT children of any router.
-
- :return: List of model endpoints unique ids.
- """
- pass
-
-
-class _ModelEndpointKVStore(_ModelEndpointStore):
- """
- Handles the DB operations when the DB target is from type KV. For the KV operations, we use an instance of V3IO
- client and usually the KV table can be found under v3io:///users/pipelines/project-name/model-endpoints/endpoints/.
- """
-
- def __init__(self, access_key: str, project: str):
- super().__init__(project=project)
- # Initialize a V3IO client instance
- self.access_key = access_key
- self.client = mlrun.utils.v3io_clients.get_v3io_client(
- endpoint=mlrun.mlconf.v3io_api, access_key=self.access_key
- )
- # Get the KV table path and container
- self.path, self.container = self._get_path_and_container()
-
- def write_model_endpoint(self, endpoint: mlrun.api.schemas.ModelEndpoint):
- """
- Create a new endpoint record in the KV table.
-
- :param endpoint: ModelEndpoint object that will be written into the DB.
- """
-
- # Flatten the model endpoint structure in order to write it into the DB table.
- # More details about the model endpoint available attributes can be found under
- # :py:class:`~mlrun.api.schemas.ModelEndpoint`.`
- attributes = self.flatten_model_endpoint_attributes(endpoint)
-
- # Create or update the model endpoint record
- self.client.kv.put(
- container=self.container,
- table_path=self.path,
- key=endpoint.metadata.uid,
- attributes=attributes,
- )
-
- def update_model_endpoint(self, endpoint_id: str, attributes: dict):
- """
- Update a model endpoint record with a given attributes.
-
- :param endpoint_id: The unique id of the model endpoint.
- :param attributes: Dictionary of attributes that will be used for update the model endpoint. Note that the keys
- of the attributes dictionary should exist in the KV table. More details about the model
- endpoint available attributes can be found under
- :py:class:`~mlrun.api.schemas.ModelEndpoint`.
-
- """
-
- self.client.kv.update(
- container=self.container,
- table_path=self.path,
- key=endpoint_id,
- attributes=attributes,
- )
-
- logger.info("Model endpoint table updated", endpoint_id=endpoint_id)
-
- def delete_model_endpoint(
- self,
- endpoint_id: str,
- ):
- """
- Deletes the KV record of a given model endpoint id.
-
- :param endpoint_id: The unique id of the model endpoint.
- """
-
- self.client.kv.delete(
- container=self.container,
- table_path=self.path,
- key=endpoint_id,
- )
-
- logger.info("Model endpoint table cleared", endpoint_id=endpoint_id)
-
- def get_model_endpoint(
- self,
- endpoint_id: str = None,
- start: str = "now-1h",
- end: str = "now",
- metrics: typing.List[str] = None,
- feature_analysis: bool = False,
- ) -> mlrun.api.schemas.ModelEndpoint:
- """
- Get a single model endpoint object. You can apply different time series metrics that will be added to the
- result.
-
- :param endpoint_id: The unique id of the model endpoint.
- :param start: The start time of the metrics. Can be represented by a string containing an RFC 3339
- time, a Unix timestamp in milliseconds, a relative time (`'now'` or
- `'now-[0-9]+[mhd]'`, where `m` = minutes, `h` = hours, and `'d'` = days), or 0 for the
- earliest time.
- :param end: The end time of the metrics. Can be represented by a string containing an RFC 3339
- time, a Unix timestamp in milliseconds, a relative time (`'now'` or
- `'now-[0-9]+[mhd]'`, where `m` = minutes, `h` = hours, and `'d'` = days), or 0 for the
- earliest time.
- :param metrics: A list of metrics to return for the model endpoint. There are pre-defined metrics for
- model endpoints such as predictions_per_second and latency_avg_5m but also custom
- metrics defined by the user. Please note that these metrics are stored in the time
- series DB and the results will be appeared under model_endpoint.spec.metrics.
- :param feature_analysis: When True, the base feature statistics and current feature statistics will be added to
- the output of the resulting object.
-
- :return: A ModelEndpoint object.
- """
- logger.info(
- "Getting model endpoint record from kv",
- endpoint_id=endpoint_id,
- )
-
- # Getting the raw data from the KV table
- endpoint = self.client.kv.get(
- container=self.container,
- table_path=self.path,
- key=endpoint_id,
- raise_for_status=v3io.dataplane.RaiseForStatus.never,
- access_key=self.access_key,
- )
- endpoint = endpoint.output.item
-
- if not endpoint:
- raise mlrun.errors.MLRunNotFoundError(f"Endpoint {endpoint_id} not found")
-
- # Generate a model endpoint object from the model endpoint KV record
- endpoint_obj = self._convert_into_model_endpoint_object(
- endpoint, start, end, metrics, feature_analysis
- )
-
- return endpoint_obj
-
- def _convert_into_model_endpoint_object(
- self, endpoint, start, end, metrics, feature_analysis
- ):
- """
- Create a ModelEndpoint object according to a provided endpoint record from the DB.
-
- :param endpoint: KV record of model endpoint which need to be converted into a valid ModelEndpoint
- object.
- :param start: The start time of the metrics. Can be represented by a string containing an RFC 3339
- time, a Unix timestamp in milliseconds, a relative time (`'now'` or
- `'now-[0-9]+[mhd]'`, where `m` = minutes, `h` = hours, and `'d'` = days), or 0 for the
- earliest time.
- :param end: The end time of the metrics. Can be represented by a string containing an RFC 3339
- time, a Unix timestamp in milliseconds, a relative time (`'now'` or
- `'now-[0-9]+[mhd]'`, where `m` = minutes, `h` = hours, and `'d'` = days), or 0 for the
- earliest time.
- :param metrics: A list of metrics to return for the model endpoint. There are pre-defined metrics for
- model endpoints such as predictions_per_second and latency_avg_5m but also custom
- metrics defined by the user. Please note that these metrics are stored in the time
- series DB and the results will be appeared under model_endpoint.spec.metrics.
- :param feature_analysis: When True, the base feature statistics and current feature statistics will be added to
- the output of the resulting object.
-
- :return: A ModelEndpoint object.
- """
-
- # Parse JSON values into a dictionary
- feature_names = self._json_loads_if_not_none(endpoint.get("feature_names"))
- label_names = self._json_loads_if_not_none(endpoint.get("label_names"))
- feature_stats = self._json_loads_if_not_none(endpoint.get("feature_stats"))
- current_stats = self._json_loads_if_not_none(endpoint.get("current_stats"))
- children = self._json_loads_if_not_none(endpoint.get("children"))
- monitor_configuration = self._json_loads_if_not_none(
- endpoint.get("monitor_configuration")
- )
- endpoint_type = self._json_loads_if_not_none(endpoint.get("endpoint_type"))
- children_uids = self._json_loads_if_not_none(endpoint.get("children_uids"))
- labels = self._json_loads_if_not_none(endpoint.get("labels"))
-
- # Convert into model endpoint object
- endpoint_obj = mlrun.api.schemas.ModelEndpoint(
- metadata=mlrun.api.schemas.ModelEndpointMetadata(
- project=endpoint.get("project"),
- labels=labels,
- uid=endpoint.get("endpoint_id"),
- ),
- spec=mlrun.api.schemas.ModelEndpointSpec(
- function_uri=endpoint.get("function_uri"),
- model=endpoint.get("model"),
- model_class=endpoint.get("model_class"),
- model_uri=endpoint.get("model_uri"),
- feature_names=feature_names or None,
- label_names=label_names or None,
- stream_path=endpoint.get("stream_path"),
- algorithm=endpoint.get("algorithm"),
- monitor_configuration=monitor_configuration or None,
- active=endpoint.get("active"),
- monitoring_mode=endpoint.get("monitoring_mode"),
- ),
- status=mlrun.api.schemas.ModelEndpointStatus(
- state=endpoint.get("state") or None,
- feature_stats=feature_stats or None,
- current_stats=current_stats or None,
- children=children or None,
- first_request=endpoint.get("first_request"),
- last_request=endpoint.get("last_request"),
- accuracy=endpoint.get("accuracy"),
- error_count=endpoint.get("error_count"),
- drift_status=endpoint.get("drift_status"),
- endpoint_type=endpoint_type or None,
- children_uids=children_uids or None,
- monitoring_feature_set_uri=endpoint.get("monitoring_feature_set_uri")
- or None,
- ),
- )
-
- # If feature analysis was applied, add feature stats and current stats to the model endpoint result
- if feature_analysis and feature_names:
- endpoint_features = self.get_endpoint_features(
- feature_names=feature_names,
- feature_stats=feature_stats,
- current_stats=current_stats,
- )
- if endpoint_features:
- endpoint_obj.status.features = endpoint_features
- # Add the latest drift measures results (calculated by the model monitoring batch)
- drift_measures = self._json_loads_if_not_none(
- endpoint.get("drift_measures")
- )
- endpoint_obj.status.drift_measures = drift_measures
-
- # If time metrics were provided, retrieve the results from the time series DB
- if metrics:
- endpoint_metrics = self.get_endpoint_metrics(
- endpoint_id=endpoint_obj.metadata.uid,
- start=start,
- end=end,
- metrics=metrics,
- )
- if endpoint_metrics:
- endpoint_obj.status.metrics = endpoint_metrics
-
- return endpoint_obj
-
- def _get_path_and_container(self):
- """Getting path and container based on the model monitoring configurations"""
- path = mlrun.mlconf.model_endpoint_monitoring.store_prefixes.default.format(
- project=self.project,
- kind=mlrun.api.schemas.ModelMonitoringStoreKinds.ENDPOINTS,
- )
- (
- _,
- container,
- path,
- ) = mlrun.utils.model_monitoring.parse_model_endpoint_store_prefix(path)
- return path, container
-
- def list_model_endpoints(
- self, model: str, function: str, labels: typing.List, top_level: bool
- ):
- """
- Returns a list of endpoint unique ids, supports filtering by model, function,
- labels or top level. By default, when no filters are applied, all available endpoint ids for the given project
- will be listed.
-
- :param model: The name of the model to filter by.
- :param function: The name of the function to filter by.
- :param labels: A list of labels to filter by. Label filters work by either filtering a specific value
- of a label (i.e. list("key==value")) or by looking for the existence of a given
- key (i.e. "key").
- :param top_level: If True will return only routers and endpoint that are NOT children of any router.
-
- :return: List of model endpoints unique ids.
- """
-
- # Retrieve the raw data from the KV table and get the endpoint ids
- cursor = self.client.kv.new_cursor(
- container=self.container,
- table_path=self.path,
- filter_expression=self.build_kv_cursor_filter_expression(
- self.project,
- function,
- model,
- labels,
- top_level,
- ),
- attribute_names=["endpoint_id"],
- raise_for_status=v3io.dataplane.RaiseForStatus.never,
- )
- try:
- items = cursor.all()
- except Exception:
- return []
-
- # Create a list of model endpoints unique ids
- uids = [item["endpoint_id"] for item in items]
-
- return uids
-
- def delete_model_endpoints_resources(
- self, endpoints: mlrun.api.schemas.model_endpoints.ModelEndpointList
- ):
- """
- Delete all model endpoints resources in both KV and the time series DB.
-
- :param endpoints: An object of ModelEndpointList which is literally a list of model endpoints along with some
- metadata. To get a standard list of model endpoints use ModelEndpointList.endpoints.
- """
-
- # Delete model endpoint record from KV table
- for endpoint in endpoints.endpoints:
- self.delete_model_endpoint(
- endpoint.metadata.uid,
- )
-
- # Delete remain records in the KV
- all_records = self.client.kv.new_cursor(
- container=self.container,
- table_path=self.path,
- raise_for_status=v3io.dataplane.RaiseForStatus.never,
- ).all()
-
- all_records = [r["__name"] for r in all_records]
-
- # Cleanup KV
- for record in all_records:
- self.client.kv.delete(
- container=self.container,
- table_path=self.path,
- key=record,
- raise_for_status=v3io.dataplane.RaiseForStatus.never,
- )
-
- # Cleanup TSDB
- frames = mlrun.utils.v3io_clients.get_frames_client(
- token=self.access_key,
- address=mlrun.mlconf.v3io_framesd,
- container=self.container,
- )
-
- # Generate the required tsdb paths
- tsdb_path, filtered_path = self._generate_tsdb_paths()
-
- # Delete time series DB resources
- try:
- frames.delete(
- backend=model_monitoring_constants.StoreTarget.TSDB,
- table=filtered_path,
- if_missing=v3io_frames.frames_pb2.IGNORE,
- )
- except v3io_frames.errors.CreateError:
- # Frames might raise an exception if schema file does not exist.
- pass
-
- # Final cleanup of tsdb path
- tsdb_path.replace("://u", ":///u")
- store, _ = mlrun.store_manager.get_or_create_store(tsdb_path)
- store.rm(tsdb_path, recursive=True)
-
- def _generate_tsdb_paths(self) -> typing.Tuple[str, str]:
- """Generate a short path to the TSDB resources and a filtered path for the frames object
-
- :return: A tuple of:
- [0] = Short path to the TSDB resources
- [1] = Filtered path to TSDB events without schema and container
- """
- # Full path for the time series DB events
- full_path = (
- mlrun.mlconf.model_endpoint_monitoring.store_prefixes.default.format(
- project=self.project,
- kind=mlrun.api.schemas.ModelMonitoringStoreKinds.EVENTS,
- )
- )
-
- # Generate the main directory with the TSDB resources
- tsdb_path = mlrun.utils.model_monitoring.parse_model_endpoint_project_prefix(
- full_path, self.project
- )
-
- # Generate filtered path without schema and container as required by the frames object
- (
- _,
- _,
- filtered_path,
- ) = mlrun.utils.model_monitoring.parse_model_endpoint_store_prefix(full_path)
- return tsdb_path, filtered_path
-
- @staticmethod
- def build_kv_cursor_filter_expression(
- project: str,
- function: str = None,
- model: str = None,
- labels: typing.List[str] = None,
- top_level: bool = False,
- ) -> str:
- """
- Convert the provided filters into a valid filter expression. The expected filter expression includes different
- conditions, divided by ' AND '.
-
- :param project: The name of the project.
- :param model: The name of the model to filter by.
- :param function: The name of the function to filter by.
- :param labels: A list of labels to filter by. Label filters work by either filtering a specific value of
- a label (i.e. list("key==value")) or by looking for the existence of a given
- key (i.e. "key").
- :param top_level: If True will return only routers and endpoint that are NOT children of any router.
-
- :return: A valid filter expression as a string.
- """
-
- if not project:
- raise mlrun.errors.MLRunInvalidArgumentError("project can't be empty")
-
- # Add project filter
- filter_expression = [f"project=='{project}'"]
-
- # Add function and model filters
- if function:
- filter_expression.append(f"function=='{function}'")
- if model:
- filter_expression.append(f"model=='{model}'")
-
- # Add labels filters
- if labels:
- for label in labels:
-
- if not label.startswith("_"):
- label = f"_{label}"
-
- if "=" in label:
- lbl, value = list(map(lambda x: x.strip(), label.split("=")))
- filter_expression.append(f"{lbl}=='{value}'")
- else:
- filter_expression.append(f"exists({label})")
-
- # Apply top_level filter (remove endpoints that considered a child of a router)
- if top_level:
- filter_expression.append(
- f"(endpoint_type=='{str(mlrun.utils.model_monitoring.EndpointType.NODE_EP.value)}' "
- f"OR endpoint_type=='{str(mlrun.utils.model_monitoring.EndpointType.ROUTER.value)}')"
- )
-
- return " AND ".join(filter_expression)
-
- @staticmethod
- def flatten_model_endpoint_attributes(
- endpoint: mlrun.api.schemas.ModelEndpoint,
- ) -> typing.Dict:
- """
- Retrieving flatten structure of the model endpoint object.
-
- :param endpoint: ModelEndpoint object that will be used for getting the attributes.
-
- :return: A flat dictionary of attributes.
- """
-
- # Prepare the data for the attributes dictionary
- labels = endpoint.metadata.labels or {}
- searchable_labels = {f"_{k}": v for k, v in labels.items()}
- feature_names = endpoint.spec.feature_names or []
- label_names = endpoint.spec.label_names or []
- feature_stats = endpoint.status.feature_stats or {}
- current_stats = endpoint.status.current_stats or {}
- drift_measures = endpoint.status.drift_measures or {}
- children = endpoint.status.children or []
- endpoint_type = endpoint.status.endpoint_type or None
- children_uids = endpoint.status.children_uids or []
-
- # Fill the data. Note that because it is a flat dictionary, we use json.dumps() for encoding hierarchies
- # such as current_stats or label_names
- attributes = {
- "endpoint_id": endpoint.metadata.uid,
- "project": endpoint.metadata.project,
- "function_uri": endpoint.spec.function_uri,
- "model": endpoint.spec.model,
- "model_class": endpoint.spec.model_class or "",
- "labels": json.dumps(labels),
- "model_uri": endpoint.spec.model_uri or "",
- "stream_path": endpoint.spec.stream_path or "",
- "active": endpoint.spec.active or "",
- "monitoring_feature_set_uri": endpoint.status.monitoring_feature_set_uri
- or "",
- "drift_status": endpoint.status.drift_status or "",
- "drift_measures": json.dumps(drift_measures),
- "monitoring_mode": endpoint.spec.monitoring_mode or "",
- "state": endpoint.status.state or "",
- "feature_stats": json.dumps(feature_stats),
- "current_stats": json.dumps(current_stats),
- "feature_names": json.dumps(feature_names),
- "children": json.dumps(children),
- "label_names": json.dumps(label_names),
- "endpoint_type": json.dumps(endpoint_type),
- "children_uids": json.dumps(children_uids),
- **searchable_labels,
- }
- return attributes
-
- @staticmethod
- def _json_loads_if_not_none(field: typing.Any) -> typing.Any:
- return json.loads(field) if field is not None else None
-
- @staticmethod
- def get_endpoint_features(
- feature_names: typing.List[str],
- feature_stats: dict = None,
- current_stats: dict = None,
- ) -> typing.List[mlrun.api.schemas.Features]:
- """
- Getting a new list of features that exist in feature_names along with their expected (feature_stats) and
- actual (current_stats) stats. The expected stats were calculated during the creation of the model endpoint,
- usually based on the data from the Model Artifact. The actual stats are based on the results from the latest
- model monitoring batch job.
-
- param feature_names: List of feature names.
- param feature_stats: Dictionary of feature stats that were stored during the creation of the model endpoint
- object.
- param current_stats: Dictionary of the latest stats that were stored during the last run of the model monitoring
- batch job.
-
- return: List of feature objects. Each feature has a name, weight, expected values, and actual values. More info
- can be found under mlrun.api.schemas.Features.
- """
-
- # Initialize feature and current stats dictionaries
- safe_feature_stats = feature_stats or {}
- safe_current_stats = current_stats or {}
-
- # Create feature object and add it to a general features list
- features = []
- for name in feature_names:
- if feature_stats is not None and name not in feature_stats:
- logger.warn("Feature missing from 'feature_stats'", name=name)
- if current_stats is not None and name not in current_stats:
- logger.warn("Feature missing from 'current_stats'", name=name)
- f = mlrun.api.schemas.Features.new(
- name, safe_feature_stats.get(name), safe_current_stats.get(name)
- )
- features.append(f)
- return features
-
- def get_endpoint_metrics(
- self,
- endpoint_id: str,
- metrics: typing.List[str],
- start: str = "now-1h",
- end: str = "now",
- ) -> typing.Dict[str, mlrun.api.schemas.Metric]:
- """
- Getting metrics from the time series DB. There are pre-defined metrics for model endpoints such as
- predictions_per_second and latency_avg_5m but also custom metrics defined by the user.
-
- :param endpoint_id: The unique id of the model endpoint.
- :param metrics: A list of metrics to return for the model endpoint.
- :param start: The start time of the metrics. Can be represented by a string containing an RFC 3339
- time, a Unix timestamp in milliseconds, a relative time (`'now'` or
- `'now-[0-9]+[mhd]'`, where `m` = minutes, `h` = hours, and `'d'` = days), or 0 for the
- earliest time.
- :param end: The end time of the metrics. Can be represented by a string containing an RFC 3339
- time, a Unix timestamp in milliseconds, a relative time (`'now'` or
- `'now-[0-9]+[mhd]'`, where `m` = minutes, `h` = hours, and `'d'` = days), or 0 for the
- earliest time.
-
- :return: A dictionary of metrics in which the key is a metric name and the value is a Metric object that also
- includes the relevant timestamp. More details about the Metric object can be found under
- mlrun.api.schemas.Metric.
- """
-
- if not metrics:
- raise mlrun.errors.MLRunInvalidArgumentError(
- "Metric names must be provided"
- )
-
- # Initialize metrics mapping dictionary
- metrics_mapping = {}
-
- # Getting the path for the time series DB
- events_path = (
- mlrun.mlconf.model_endpoint_monitoring.store_prefixes.default.format(
- project=self.project,
- kind=mlrun.api.schemas.ModelMonitoringStoreKinds.EVENTS,
- )
- )
- (
- _,
- _,
- events_path,
- ) = mlrun.utils.model_monitoring.parse_model_endpoint_store_prefix(events_path)
-
- # Retrieve the raw data from the time series DB based on the provided metrics and time ranges
- frames_client = mlrun.utils.v3io_clients.get_frames_client(
- token=self.access_key,
- address=mlrun.mlconf.v3io_framesd,
- container=self.container,
- )
-
- try:
- data = frames_client.read(
- backend=model_monitoring_constants.StoreTarget.TSDB,
- table=events_path,
- columns=["endpoint_id", *metrics],
- filter=f"endpoint_id=='{endpoint_id}'",
- start=start,
- end=end,
- )
-
- # Fill the metrics mapping dictionary with the metric name and values
- data_dict = data.to_dict()
- for metric in metrics:
- metric_data = data_dict.get(metric)
- if metric_data is None:
- continue
-
- values = [
- (str(timestamp), value) for timestamp, value in metric_data.items()
- ]
- metrics_mapping[metric] = mlrun.api.schemas.Metric(
- name=metric, values=values
- )
- except v3io_frames.errors.ReadError:
- logger.warn("Failed to read tsdb", endpoint=endpoint_id)
- return metrics_mapping
-
-
-class _ModelEndpointSQLStore(_ModelEndpointStore):
- def write_model_endpoint(self, endpoint, update=True):
- raise NotImplementedError
-
- def update_model_endpoint(self, endpoint_id, attributes):
- raise NotImplementedError
-
- def delete_model_endpoint(self, endpoint_id):
- raise NotImplementedError
-
- def delete_model_endpoints_resources(
- self, endpoints: mlrun.api.schemas.model_endpoints.ModelEndpointList
- ):
- raise NotImplementedError
-
- def get_model_endpoint(
- self,
- metrics: typing.List[str] = None,
- start: str = "now-1h",
- end: str = "now",
- feature_analysis: bool = False,
- endpoint_id: str = None,
- ):
- raise NotImplementedError
-
- def list_model_endpoints(
- self, model: str, function: str, labels: typing.List, top_level: bool
- ):
- raise NotImplementedError
-
-
-class ModelEndpointStoreType(enum.Enum):
- """Enum class to handle the different store type values for saving a model endpoint record."""
-
- kv = "kv"
- sql = "sql"
-
- def to_endpoint_target(
- self, project: str, access_key: str = None
- ) -> _ModelEndpointStore:
- """
- Return a ModelEndpointStore object based on the provided enum value.
-
- :param project: The name of the project.
- :param access_key: Access key with permission to the DB table. Note that if access key is None and the
- endpoint target is from type KV then the access key will be retrieved from the environment
- variable.
-
- :return: ModelEndpointStore object.
-
- """
-
- if self.value == ModelEndpointStoreType.kv.value:
-
- # Get V3IO access key from env
- access_key = (
- mlrun.mlconf.get_v3io_access_key() if access_key is None else access_key
- )
-
- return _ModelEndpointKVStore(project=project, access_key=access_key)
-
- # Assuming SQL store target if store type is not KV.
- # Update these lines once there are more than two store target types.
- return _ModelEndpointSQLStore(project=project)
-
- @classmethod
- def _missing_(cls, value: typing.Any):
- """A lookup function to handle an invalid value.
- :param value: Provided enum (invalid) value.
- """
- valid_values = list(cls.__members__.keys())
- raise mlrun.errors.MLRunInvalidArgumentError(
- "%r is not a valid %s, please choose a valid value: %s."
- % (value, cls.__name__, valid_values)
- )
-
-
-def get_model_endpoint_target(
- project: str, access_key: str = None
-) -> _ModelEndpointStore:
- """
- Getting the DB target type based on mlrun.config.model_endpoint_monitoring.store_type.
-
- :param project: The name of the project.
- :param access_key: Access key with permission to the DB table.
-
- :return: ModelEndpointStore object. Using this object, the user can apply different operations on the
- model endpoint record such as write, update, get and delete.
- """
-
- # Get store type value from ModelEndpointStoreType enum class
- model_endpoint_store_type = ModelEndpointStoreType(
- mlrun.mlconf.model_endpoint_monitoring.store_type
- )
-
- # Convert into model endpoint store target object
- return model_endpoint_store_type.to_endpoint_target(project, access_key)
diff --git a/mlrun/api/crud/model_monitoring/model_endpoints.py b/mlrun/api/crud/model_monitoring/model_endpoints.py
index 4b3b5365aab3..d6d792b961c4 100644
--- a/mlrun/api/crud/model_monitoring/model_endpoints.py
+++ b/mlrun/api/crud/model_monitoring/model_endpoints.py
@@ -12,10 +12,10 @@
# See the License for the specific language governing permissions and
# limitations under the License.
#
-
-
+import json
import os
import typing
+import warnings
import sqlalchemy.orm
@@ -35,10 +35,9 @@
import mlrun.utils.helpers
import mlrun.utils.model_monitoring
import mlrun.utils.v3io_clients
+from mlrun.model_monitoring.stores import get_model_endpoint_store
from mlrun.utils import logger
-from .model_endpoint_store import get_model_endpoint_target
-
class ModelEndpoints:
"""Provide different methods for handling model endpoints such as listing, writing and deleting"""
@@ -50,9 +49,14 @@ def create_or_patch(
model_endpoint: mlrun.api.schemas.ModelEndpoint,
auth_info: mlrun.api.schemas.AuthInfo = mlrun.api.schemas.AuthInfo(),
) -> mlrun.api.schemas.ModelEndpoint:
- # TODO: deprecated, remove in 1.5.0.
+ # TODO: deprecated in 1.3.0, remove in 1.5.0.
+ warnings.warn(
+ "This is deprecated in 1.3.0, and will be removed in 1.5.0."
+ "Please use create_model_endpoint() for create or patch_model_endpoint() for update",
+ FutureWarning,
+ )
"""
- Either create or updates the record of a given ModelEndpoint object.
+ Either create or updates the record of a given `ModelEndpoint` object.
Leaving here for backwards compatibility, remove in 1.5.0.
:param db_session: A session that manages the current dialog with the database
@@ -60,7 +64,7 @@ def create_or_patch(
:param model_endpoint: Model endpoint object to update
:param auth_info: The auth info of the request
- :return: Model endpoint object.
+ :return: `ModelEndpoint` object.
"""
return self.create_model_endpoint(
@@ -74,12 +78,12 @@ def create_model_endpoint(
) -> mlrun.api.schemas.ModelEndpoint:
"""
Creates model endpoint record in DB. The DB target type is defined under
- mlrun.config.model_endpoint_monitoring.store_type (KV by default).
+ `mlrun.config.model_endpoint_monitoring.store_type` (V3IO-NOSQL by default).
:param db_session: A session that manages the current dialog with the database.
:param model_endpoint: Model endpoint object to update.
- :return: Model endpoint object.
+ :return: `ModelEndpoint` object.
"""
if model_endpoint.spec.model_uri or model_endpoint.status.feature_stats:
@@ -107,23 +111,22 @@ def create_model_endpoint(
if not model_endpoint.status.feature_stats and hasattr(
model_obj, "feature_stats"
):
- model_endpoint.status.feature_stats = model_obj.feature_stats
-
+ model_endpoint.status.feature_stats = model_obj.spec.feature_stats
# Get labels from model object if not found in model endpoint object
- if not model_endpoint.spec.label_names and hasattr(model_obj, "outputs"):
+ if not model_endpoint.spec.label_names and model_obj.spec.outputs:
model_label_names = [
- self._clean_feature_name(f.name) for f in model_obj.outputs
+ self._clean_feature_name(f.name) for f in model_obj.spec.outputs
]
model_endpoint.spec.label_names = model_label_names
# Get algorithm from model object if not found in model endpoint object
- if not model_endpoint.spec.algorithm and hasattr(model_obj, "algorithm"):
- model_endpoint.spec.algorithm = model_obj.algorithm
+ if not model_endpoint.spec.algorithm and model_obj.spec.algorithm:
+ model_endpoint.spec.algorithm = model_obj.spec.algorithm
# Create monitoring feature set if monitoring found in model endpoint object
if (
model_endpoint.spec.monitoring_mode
- == mlrun.api.schemas.ModelMonitoringMode.enabled.value
+ == mlrun.model_monitoring.ModelMonitoringMode.enabled.value
):
monitoring_feature_set = self.create_monitoring_feature_set(
model_endpoint, model_obj, db_session, run_db
@@ -158,10 +161,10 @@ def create_model_endpoint(
logger.info("Creating model endpoint", endpoint_id=model_endpoint.metadata.uid)
# Write the new model endpoint
- model_endpoint_target = get_model_endpoint_target(
+ model_endpoint_store = get_model_endpoint_store(
project=model_endpoint.metadata.project,
)
- model_endpoint_target.write_model_endpoint(endpoint=model_endpoint)
+ model_endpoint_store.write_model_endpoint(endpoint=model_endpoint.flat_dict())
logger.info("Model endpoint created", endpoint_id=model_endpoint.metadata.uid)
@@ -207,17 +210,17 @@ def create_monitoring_feature_set(
}
# Add features to the feature set according to the model object
- if model_obj.inputs.values():
- for feature in model_obj.inputs.values():
+ if model_obj.spec.inputs:
+ for feature in model_obj.spec.inputs:
feature_set.add_feature(
mlrun.feature_store.Feature(
name=feature.name, value_type=feature.value_type
)
)
# Check if features can be found within the feature vector
- elif model_obj.feature_vector:
+ elif model_obj.spec.feature_vector:
_, name, _, tag, _ = mlrun.utils.helpers.parse_artifact_uri(
- model_obj.feature_vector
+ model_obj.spec.feature_vector
)
fv = run_db.get_feature_vector(
name=name, project=model_endpoint.metadata.project, tag=tag
@@ -261,7 +264,7 @@ def create_monitoring_feature_set(
@staticmethod
def _validate_length_features_and_labels(model_endpoint):
"""
- Validate that the length of feature_stats is equal to the length of feature_names and label_names
+ Validate that the length of feature_stats is equal to the length of `feature_names` and `label_names`
:param model_endpoint: An object representing the model endpoint.
"""
@@ -288,8 +291,8 @@ def _adjust_feature_names_and_stats(
self, model_endpoint
) -> typing.Tuple[typing.Dict, typing.List]:
"""
- Create a clean matching version of feature names for both feature_stats and feature_names. Please note that
- label names exist only in feature_stats and label_names.
+ Create a clean matching version of feature names for both `feature_stats` and `feature_names`. Please note that
+ label names exist only in `feature_stats` and `label_names`.
:param model_endpoint: An object representing the model endpoint.
:return: A tuple of:
@@ -312,8 +315,8 @@ def _adjust_feature_names_and_stats(
clean_feature_names.append(clean_name)
return clean_feature_stats, clean_feature_names
- @staticmethod
def patch_model_endpoint(
+ self,
project: str,
endpoint_id: str,
attributes: dict,
@@ -324,24 +327,30 @@ def patch_model_endpoint(
:param project: The name of the project.
:param endpoint_id: The unique id of the model endpoint.
:param attributes: Dictionary of attributes that will be used for update the model endpoint. Note that the keys
- of the attributes dictionary should exist in the KV table. More details about the model
+ of the attributes dictionary should exist in the DB table. More details about the model
endpoint available attributes can be found under
:py:class:`~mlrun.api.schemas.ModelEndpoint`.
- :return: A patched ModelEndpoint object.
+ :return: A patched `ModelEndpoint` object.
"""
- model_endpoint_target = get_model_endpoint_target(
+ # Generate a model endpoint store object and apply the update process
+ model_endpoint_store = get_model_endpoint_store(
project=project,
)
- model_endpoint_target.update_model_endpoint(
+ model_endpoint_store.update_model_endpoint(
endpoint_id=endpoint_id, attributes=attributes
)
- return model_endpoint_target.get_model_endpoint(
- endpoint_id=endpoint_id, start="now-1h", end="now"
+ logger.info("Model endpoint table updated", endpoint_id=endpoint_id)
+
+ # Get the patched model endpoint record
+ model_endpoint_record = model_endpoint_store.get_model_endpoint(
+ endpoint_id=endpoint_id,
)
+ return self._convert_into_model_endpoint_object(endpoint=model_endpoint_record)
+
@staticmethod
def delete_model_endpoint(
project: str,
@@ -353,13 +362,15 @@ def delete_model_endpoint(
:param project: The name of the project.
:param endpoint_id: The id of the endpoint.
"""
- model_endpoint_target = get_model_endpoint_target(
+ model_endpoint_store = get_model_endpoint_store(
project=project,
)
- model_endpoint_target.delete_model_endpoint(endpoint_id=endpoint_id)
+ model_endpoint_store.delete_model_endpoint(endpoint_id=endpoint_id)
+
+ logger.info("Model endpoint table cleared", endpoint_id=endpoint_id)
- @staticmethod
def get_model_endpoint(
+ self,
auth_info: mlrun.api.schemas.AuthInfo,
project: str,
endpoint_id: str,
@@ -371,40 +382,61 @@ def get_model_endpoint(
"""Get a single model endpoint object. You can apply different time series metrics that will be added to the
result.
- :param auth_info: The auth info of the request
- :param project: The name of the project
- :param endpoint_id: The unique id of the model endpoint.
- :param metrics: A list of metrics to return for the model endpoint. There are pre-defined metrics for
- model endpoints such as predictions_per_second and latency_avg_5m but also custom
- metrics defined by the user. Please note that these metrics are stored in the time
- series DB and the results will be appeared under model_endpoint.spec.metrics.
- :param start: The start time of the metrics. Can be represented by a string containing an RFC 3339
- time, a Unix timestamp in milliseconds, a relative time (`'now'` or
- `'now-[0-9]+[mhd]'`, where `m` = minutes, `h` = hours, and `'d'` =
- days), or 0 for the earliest time.
- :param end: The end time of the metrics. Can be represented by a string containing an RFC 3339
- time, a Unix timestamp in milliseconds, a relative time (`'now'` or
- `'now-[0-9]+[mhd]'`, where `m` = minutes, `h` = hours, and `'d'` =
- days), or 0 for the earliest time.
- :param feature_analysis: When True, the base feature statistics and current feature statistics will be added to
- the output of the resulting object.
-
- :return: A ModelEndpoint object.
+ :param auth_info: The auth info of the request
+ :param project: The name of the project
+ :param endpoint_id: The unique id of the model endpoint.
+ :param metrics: A list of metrics to return for the model endpoint. There are pre-defined
+ metrics for model endpoints such as predictions_per_second and
+ latency_avg_5m but also custom metrics defined by the user. Please note that
+ these metrics are stored in the time series DB and the results will be
+ appeared under `model_endpoint.spec.metrics`.
+ :param start: The start time of the metrics. Can be represented by a string containing an
+ RFC 3339 time, a Unix timestamp in milliseconds, a relative time (`'now'` or
+ `'now-[0-9]+[mhd]'`, where `m` = minutes, `h` = hours, and `'d'` = days), or
+ 0 for the earliest time.
+ :param end: The end time of the metrics. Can be represented by a string containing an
+ RFC 3339 time, a Unix timestamp in milliseconds, a relative time (`'now'` or
+ `'now-[0-9]+[mhd]'`, where `m` = minutes, `h` = hours, and `'d'` = days), or
+ 0 for the earliest time.
+ :param feature_analysis: When True, the base feature statistics and current feature statistics will
+ be added to the output of the resulting object.
+
+ :return: A `ModelEndpoint` object.
"""
- model_endpoint_target = get_model_endpoint_target(
+ logger.info(
+ "Getting model endpoint record from DB",
+ endpoint_id=endpoint_id,
+ )
+
+ # Generate a model endpoint store object and get the model endpoint record as a dictionary
+ model_endpoint_store = get_model_endpoint_store(
project=project, access_key=auth_info.data_session
)
- return model_endpoint_target.get_model_endpoint(
+
+ model_endpoint_record = model_endpoint_store.get_model_endpoint(
endpoint_id=endpoint_id,
- metrics=metrics,
- start=start,
- end=end,
- feature_analysis=feature_analysis,
)
- @staticmethod
+ # Convert to `ModelEndpoint` object
+ model_endpoint_object = self._convert_into_model_endpoint_object(
+ endpoint=model_endpoint_record, feature_analysis=feature_analysis
+ )
+
+ # If time metrics were provided, retrieve the results from the time series DB
+ if metrics:
+ self._add_real_time_metrics(
+ model_endpoint_store=model_endpoint_store,
+ model_endpoint_object=model_endpoint_object,
+ metrics=metrics,
+ start=start,
+ end=end,
+ )
+
+ return model_endpoint_object
+
def list_model_endpoints(
+ self,
auth_info: mlrun.api.schemas.AuthInfo,
project: str,
model: str = None,
@@ -415,10 +447,11 @@ def list_model_endpoints(
end: str = "now",
top_level: bool = False,
uids: typing.List[str] = None,
- ) -> mlrun.api.schemas.model_endpoints.ModelEndpointList:
+ ) -> mlrun.api.schemas.ModelEndpointList:
"""
- Returns a list of ModelEndpointState objects. Each object represents the current state of a model endpoint.
- This functions supports filtering by the following parameters:
+ Returns a list of `ModelEndpoint` objects, wrapped in `ModelEndpointList` object. Each `ModelEndpoint`
+ object represents the current state of a model endpoint. This functions supports filtering by the following
+ parameters:
1) model
2) function
3) labels
@@ -435,22 +468,22 @@ def list_model_endpoints(
:param model: The name of the model to filter by.
:param function: The name of the function to filter by.
:param labels: A list of labels to filter by. Label filters work by either filtering a specific value of a
- label (i.e. list("key==value")) or by looking for the existence of a given key (i.e. "key").
+ label (i.e. list("key=value")) or by looking for the existence of a given key (i.e. "key").
:param metrics: A list of metrics to return for each endpoint. There are pre-defined metrics for model
- endpoints such as predictions_per_second and latency_avg_5m but also custom metrics defined
- by the user. Please note that these metrics are stored in the time series DB and the results
- will be appeared under model_endpoint.spec.metrics of each endpoint.
+ endpoints such as `predictions_per_second` and `latency_avg_5m` but also custom metrics
+ defined by the user. Please note that these metrics are stored in the time series DB and the
+ results will be appeared under model_endpoint.spec.metrics of each endpoint.
:param start: The start time of the metrics. Can be represented by a string containing an RFC 3339 time,
a Unix timestamp in milliseconds, a relative time (`'now'` or `'now-[0-9]+[mhd]'`, where `m`
= minutes, `h` = hours, and `'d'` = days), or 0 for the earliest time.
:param end: The end time of the metrics. Can be represented by a string containing an RFC 3339 time,
a Unix timestamp in milliseconds, a relative time (`'now'` or `'now-[0-9]+[mhd]'`, where `m`
= minutes, `h` = hours, and `'d'` = days), or 0 for the earliest time.
- :param top_level: If True will return only routers and endpoint that are NOT children of any router.
- :param uids: Will return ModelEndpointList of endpoints with uid in uids.
+ :param top_level: If True, return only routers and endpoints that are NOT children of any router.
+ :param uids: List of model endpoint unique ids to include in the result.
- :return: An object of ModelEndpointList which is literally a list of model endpoints along with some metadata.
- To get a standard list of model endpoints use ModelEndpointList.endpoints.
+ :return: An object of `ModelEndpointList` which is literally a list of model endpoints along with some metadata.
+ To get a standard list of model endpoints use `ModelEndpointList.endpoints`.
"""
logger.info(
@@ -466,33 +499,175 @@ def list_model_endpoints(
uids=uids,
)
- endpoint_target = get_model_endpoint_target(
- access_key=auth_info.data_session, project=project
- )
-
# Initialize an empty model endpoints list
endpoint_list = mlrun.api.schemas.model_endpoints.ModelEndpointList(
endpoints=[]
)
- # If list of model endpoint ids was not provided, retrieve it from the DB
- if uids is None:
- uids = endpoint_target.list_model_endpoints(
- function=function, model=model, labels=labels, top_level=top_level
- )
+ # Generate a model endpoint store object and get a list of model endpoint dictionaries
+ endpoint_store = get_model_endpoint_store(
+ access_key=auth_info.data_session, project=project
+ )
- # Add each relevant model endpoint to the model endpoints list
- for endpoint_id in uids:
- endpoint = endpoint_target.get_model_endpoint(
- metrics=metrics,
- endpoint_id=endpoint_id,
- start=start,
- end=end,
+ endpoint_dictionary_list = endpoint_store.list_model_endpoints(
+ function=function,
+ model=model,
+ labels=labels,
+ top_level=top_level,
+ uids=uids,
+ )
+
+ for endpoint_dict in endpoint_dictionary_list:
+
+ # Convert to `ModelEndpoint` object
+ endpoint_obj = self._convert_into_model_endpoint_object(
+ endpoint=endpoint_dict
)
- endpoint_list.endpoints.append(endpoint)
+
+ # If time metrics were provided, retrieve the results from the time series DB
+ if metrics:
+ self._add_real_time_metrics(
+ model_endpoint_store=endpoint_store,
+ model_endpoint_object=endpoint_obj,
+ metrics=metrics,
+ start=start,
+ end=end,
+ )
+
+ # Add the `ModelEndpoint` object into the model endpoints list
+ endpoint_list.endpoints.append(endpoint_obj)
return endpoint_list
+ @staticmethod
+ def _add_real_time_metrics(
+ model_endpoint_store: mlrun.model_monitoring.stores.ModelEndpointStore,
+ model_endpoint_object: mlrun.api.schemas.ModelEndpoint,
+ metrics: typing.List[str] = None,
+ start: str = "now-1h",
+ end: str = "now",
+ ) -> mlrun.api.schemas.ModelEndpoint:
+ """Add real time metrics from the time series DB to a provided `ModelEndpoint` object. The real time metrics
+ will be stored under `ModelEndpoint.status.metrics.real_time`
+
+ :param model_endpoint_store: `ModelEndpointStore` object that will be used for communicating with the database
+ and querying the required metrics.
+ :param model_endpoint_object: `ModelEndpoint` object that will be filled with the relevant
+ real time metrics.
+ :param metrics: A list of metrics to return for each endpoint. There are pre-defined metrics for
+ model endpoints such as `predictions_per_second` and `latency_avg_5m` but also
+ custom metrics defined by the user. Please note that these metrics are stored in
+ the time series DB and the results will be appeared under
+ model_endpoint.spec.metrics of each endpoint.
+ :param start: The start time of the metrics. Can be represented by a string containing an RFC
+ 3339 time, a Unix timestamp in milliseconds, a relative time (`'now'` or
+ `'now-[0-9]+[mhd]'`, where `m`= minutes, `h` = hours, and `'d'` = days), or 0
+ for the earliest time.
+ :param end: The end time of the metrics. Can be represented by a string containing an RFC
+ 3339 time, a Unix timestamp in milliseconds, a relative time (`'now'` or
+ `'now-[0-9]+[mhd]'`, where `m`= minutes, `h` = hours, and `'d'` = days), or 0
+ for the earliest time.
+
+ """
+ if model_endpoint_object.status.metrics is None:
+ model_endpoint_object.status.metrics = {}
+
+ endpoint_metrics = model_endpoint_store.get_endpoint_real_time_metrics(
+ endpoint_id=model_endpoint_object.metadata.uid,
+ start=start,
+ end=end,
+ metrics=metrics,
+ )
+ if endpoint_metrics:
+ model_endpoint_object.status.metrics[
+ model_monitoring_constants.EventKeyMetrics.REAL_TIME
+ ] = endpoint_metrics
+ return model_endpoint_object
+
+ def _convert_into_model_endpoint_object(
+ self, endpoint: typing.Dict[str, typing.Any], feature_analysis: bool = False
+ ) -> mlrun.api.schemas.ModelEndpoint:
+ """
+ Create a `ModelEndpoint` object according to a provided model endpoint dictionary.
+
+ :param endpoint: Dictinoary that represents a DB record of a model endpoint which need to be converted
+ into a valid `ModelEndpoint` object.
+ :param feature_analysis: When True, the base feature statistics and current feature statistics will be added to
+ the output of the resulting object.
+
+ :return: A `ModelEndpoint` object.
+ """
+
+ # Convert into `ModelEndpoint` object
+ endpoint_obj = mlrun.api.schemas.ModelEndpoint().from_flat_dict(endpoint)
+
+ # If feature analysis was applied, add feature stats and current stats to the model endpoint result
+ if feature_analysis and endpoint_obj.spec.feature_names:
+
+ endpoint_features = self.get_endpoint_features(
+ feature_names=endpoint_obj.spec.feature_names,
+ feature_stats=endpoint_obj.status.feature_stats,
+ current_stats=endpoint_obj.status.current_stats,
+ )
+ if endpoint_features:
+ endpoint_obj.status.features = endpoint_features
+ # Add the latest drift measures results (calculated by the model monitoring batch)
+ drift_measures = self._json_loads_if_not_none(
+ endpoint.get(
+ model_monitoring_constants.EventFieldType.DRIFT_MEASURES
+ )
+ )
+ endpoint_obj.status.drift_measures = drift_measures
+
+ return endpoint_obj
+
+ @staticmethod
+ def get_endpoint_features(
+ feature_names: typing.List[str],
+ feature_stats: dict = None,
+ current_stats: dict = None,
+ ) -> typing.List[mlrun.api.schemas.Features]:
+ """
+ Getting a new list of features that exist in feature_names along with their expected (feature_stats) and
+ actual (current_stats) stats. The expected stats were calculated during the creation of the model endpoint,
+ usually based on the data from the Model Artifact. The actual stats are based on the results from the latest
+ model monitoring batch job.
+
+ param feature_names: List of feature names.
+ param feature_stats: Dictionary of feature stats that were stored during the creation of the model endpoint
+ object.
+ param current_stats: Dictionary of the latest stats that were stored during the last run of the model monitoring
+ batch job.
+
+ return: List of feature objects. Each feature has a name, weight, expected values, and actual values. More info
+ can be found under `mlrun.api.schemas.Features`.
+ """
+
+ # Initialize feature and current stats dictionaries
+ safe_feature_stats = feature_stats or {}
+ safe_current_stats = current_stats or {}
+
+ # Create feature object and add it to a general features list
+ features = []
+ for name in feature_names:
+ if feature_stats is not None and name not in feature_stats:
+ logger.warn("Feature missing from 'feature_stats'", name=name)
+ if current_stats is not None and name not in current_stats:
+ logger.warn("Feature missing from 'current_stats'", name=name)
+ f = mlrun.api.schemas.Features.new(
+ name, safe_feature_stats.get(name), safe_current_stats.get(name)
+ )
+ features.append(f)
+ return features
+
+ @staticmethod
+ def _json_loads_if_not_none(field: typing.Any) -> typing.Any:
+ return (
+ json.loads(field)
+ if field and field != "null" and field is not None
+ else None
+ )
+
def deploy_monitoring_functions(
self,
project: str,
@@ -539,7 +714,8 @@ def verify_project_has_no_model_endpoints(self, project_name: str):
f"Project {project_name} can not be deleted since related resources found: model endpoints"
)
- def delete_model_endpoints_resources(self, project_name: str):
+ @staticmethod
+ def delete_model_endpoints_resources(project_name: str):
"""
Delete all model endpoints resources.
@@ -554,12 +730,14 @@ def delete_model_endpoints_resources(self, project_name: str):
if not mlrun.mlconf.igz_version or not mlrun.mlconf.v3io_api:
return
- endpoints = self.list_model_endpoints(auth_info, project_name)
-
- endpoint_target = get_model_endpoint_target(
+ # Generate a model endpoint store object and get a list of model endpoint dictionaries
+ endpoint_store = get_model_endpoint_store(
access_key=auth_info.data_session, project=project_name
)
- endpoint_target.delete_model_endpoints_resources(endpoints)
+ endpoints = endpoint_store.list_model_endpoints()
+
+ # Delete model endpoints resources from databases using the model endpoint store object
+ endpoint_store.delete_model_endpoints_resources(endpoints)
@staticmethod
def deploy_model_monitoring_stream_processing(
diff --git a/mlrun/api/db/sqldb/models/models_mysql.py b/mlrun/api/db/sqldb/models/models_mysql.py
index f7fad72eea6b..344c449764ce 100644
--- a/mlrun/api/db/sqldb/models/models_mysql.py
+++ b/mlrun/api/db/sqldb/models/models_mysql.py
@@ -30,8 +30,9 @@
UniqueConstraint,
)
from sqlalchemy.ext.declarative import declarative_base
-from sqlalchemy.orm import class_mapper, relationship
+from sqlalchemy.orm import relationship
+import mlrun.utils.db
from mlrun.api import schemas
from mlrun.api.utils.db.sql_collation import SQLCollationUtil
@@ -40,42 +41,8 @@
run_time_fmt = "%Y-%m-%dT%H:%M:%S.%fZ"
-class BaseModel:
- def to_dict(self, exclude=None):
- """
- NOTE - this function (currently) does not handle serializing relationships
- """
- exclude = exclude or []
- mapper = class_mapper(self.__class__)
- columns = [column.key for column in mapper.columns if column.key not in exclude]
- get_key_value = (
- lambda c: (c, getattr(self, c).isoformat())
- if isinstance(getattr(self, c), datetime)
- else (c, getattr(self, c))
- )
- return dict(map(get_key_value, columns))
-
-
-class HasStruct(BaseModel):
- @property
- def struct(self):
- return pickle.loads(self.body)
-
- @struct.setter
- def struct(self, value):
- self.body = pickle.dumps(value)
-
- def to_dict(self, exclude=None):
- """
- NOTE - this function (currently) does not handle serializing relationships
- """
- exclude = exclude or []
- exclude.append("body")
- return super().to_dict(exclude)
-
-
def make_label(table):
- class Label(Base, BaseModel):
+ class Label(Base, mlrun.utils.db.BaseModel):
__tablename__ = f"{table}_labels"
__table_args__ = (
UniqueConstraint("name", "parent", name=f"_{table}_labels_uc"),
@@ -90,7 +57,7 @@ class Label(Base, BaseModel):
def make_tag(table):
- class Tag(Base, BaseModel):
+ class Tag(Base, mlrun.utils.db.BaseModel):
__tablename__ = f"{table}_tags"
__table_args__ = (
UniqueConstraint("project", "name", "obj_id", name=f"_{table}_tags_uc"),
@@ -107,7 +74,7 @@ class Tag(Base, BaseModel):
# TODO: don't want to refactor everything in one PR so splitting this function to 2 versions - eventually only this one
# should be used
def make_tag_v2(table):
- class Tag(Base, BaseModel):
+ class Tag(Base, mlrun.utils.db.BaseModel):
__tablename__ = f"{table}_tags"
__table_args__ = (
UniqueConstraint("project", "name", "obj_name", name=f"_{table}_tags_uc"),
@@ -126,7 +93,7 @@ class Tag(Base, BaseModel):
with warnings.catch_warnings():
warnings.simplefilter("ignore")
- class Artifact(Base, HasStruct):
+ class Artifact(Base, mlrun.utils.db.HasStruct):
__tablename__ = "artifacts"
__table_args__ = (
UniqueConstraint("uid", "project", "key", name="_artifacts_uc"),
@@ -149,7 +116,7 @@ class Artifact(Base, HasStruct):
def get_identifier_string(self) -> str:
return f"{self.project}/{self.key}/{self.uid}"
- class Function(Base, HasStruct):
+ class Function(Base, mlrun.utils.db.HasStruct):
__tablename__ = "functions"
__table_args__ = (
UniqueConstraint("name", "project", "uid", name="_functions_uc"),
@@ -172,19 +139,7 @@ class Function(Base, HasStruct):
def get_identifier_string(self) -> str:
return f"{self.project}/{self.name}/{self.uid}"
- class Log(Base, BaseModel):
- __tablename__ = "logs"
-
- id = Column(Integer, primary_key=True)
- uid = Column(String(255, collation=SQLCollationUtil.collation()))
- project = Column(String(255, collation=SQLCollationUtil.collation()))
- # TODO: change to JSON, see mlrun/api/schemas/function.py::FunctionState for reasoning
- body = Column(sqlalchemy.dialects.mysql.MEDIUMBLOB)
-
- def get_identifier_string(self) -> str:
- return f"{self.project}/{self.uid}"
-
- class Notification(Base, BaseModel):
+ class Notification(Base, mlrun.utils.db.BaseModel):
__tablename__ = "notifications"
__table_args__ = (UniqueConstraint("name", "run", name="_notifications_uc"),)
@@ -224,7 +179,19 @@ class Notification(Base, BaseModel):
String(255, collation=SQLCollationUtil.collation()), nullable=False
)
- class Run(Base, HasStruct):
+ class Log(Base, mlrun.utils.db.BaseModel):
+ __tablename__ = "logs"
+
+ id = Column(Integer, primary_key=True)
+ uid = Column(String(255, collation=SQLCollationUtil.collation()))
+ project = Column(String(255, collation=SQLCollationUtil.collation()))
+ # TODO: change to JSON, see mlrun/api/schemas/function.py::FunctionState for reasoning
+ body = Column(sqlalchemy.dialects.mysql.MEDIUMBLOB)
+
+ def get_identifier_string(self) -> str:
+ return f"{self.project}/{self.uid}"
+
+ class Run(Base, mlrun.utils.db.HasStruct):
__tablename__ = "runs"
__table_args__ = (
UniqueConstraint("uid", "project", "iteration", name="_runs_uc"),
@@ -260,7 +227,7 @@ class Run(Base, HasStruct):
def get_identifier_string(self) -> str:
return f"{self.project}/{self.uid}/{self.iteration}"
- class BackgroundTask(Base, BaseModel):
+ class BackgroundTask(Base, mlrun.utils.db.BaseModel):
__tablename__ = "background_tasks"
__table_args__ = (
UniqueConstraint("name", "project", name="_background_tasks_uc"),
@@ -284,7 +251,7 @@ class BackgroundTask(Base, BaseModel):
state = Column(String(255, collation=SQLCollationUtil.collation()))
timeout = Column(Integer)
- class Schedule(Base, BaseModel):
+ class Schedule(Base, mlrun.utils.db.BaseModel):
__tablename__ = "schedules_v2"
__table_args__ = (UniqueConstraint("project", "name", name="_schedules_v2_uc"),)
@@ -336,14 +303,14 @@ def cron_trigger(self, trigger: schemas.ScheduleCronTrigger):
Column("user_id", Integer, ForeignKey("users.id")),
)
- class User(Base, BaseModel):
+ class User(Base, mlrun.utils.db.BaseModel):
__tablename__ = "users"
__table_args__ = (UniqueConstraint("name", name="_users_uc"),)
id = Column(Integer, primary_key=True)
name = Column(String(255, collation=SQLCollationUtil.collation()))
- class Project(Base, BaseModel):
+ class Project(Base, mlrun.utils.db.BaseModel):
__tablename__ = "projects"
# For now since we use project name a lot
__table_args__ = (UniqueConstraint("name", name="_projects_uc"),)
@@ -379,7 +346,7 @@ def full_object(self):
def full_object(self, value):
self._full_object = pickle.dumps(value)
- class Feature(Base, BaseModel):
+ class Feature(Base, mlrun.utils.db.BaseModel):
__tablename__ = "features"
id = Column(Integer, primary_key=True)
feature_set_id = Column(Integer, ForeignKey("feature_sets.id"))
@@ -393,7 +360,7 @@ class Feature(Base, BaseModel):
def get_identifier_string(self) -> str:
return f"{self.project}/{self.name}"
- class Entity(Base, BaseModel):
+ class Entity(Base, mlrun.utils.db.BaseModel):
__tablename__ = "entities"
id = Column(Integer, primary_key=True)
feature_set_id = Column(Integer, ForeignKey("feature_sets.id"))
@@ -407,7 +374,7 @@ class Entity(Base, BaseModel):
def get_identifier_string(self) -> str:
return f"{self.project}/{self.name}"
- class FeatureSet(Base, BaseModel):
+ class FeatureSet(Base, mlrun.utils.db.BaseModel):
__tablename__ = "feature_sets"
__table_args__ = (
UniqueConstraint("name", "project", "uid", name="_feature_set_uc"),
@@ -451,7 +418,7 @@ def full_object(self, value):
# TODO - convert to pickle, to avoid issues with non-json serializable fields such as datetime
self._full_object = json.dumps(value, default=str)
- class FeatureVector(Base, BaseModel):
+ class FeatureVector(Base, mlrun.utils.db.BaseModel):
__tablename__ = "feature_vectors"
__table_args__ = (
UniqueConstraint("name", "project", "uid", name="_feature_vectors_uc"),
@@ -492,7 +459,7 @@ def full_object(self, value):
# TODO - convert to pickle, to avoid issues with non-json serializable fields such as datetime
self._full_object = json.dumps(value, default=str)
- class MarketplaceSource(Base, BaseModel):
+ class MarketplaceSource(Base, mlrun.utils.db.BaseModel):
__tablename__ = "marketplace_sources"
__table_args__ = (UniqueConstraint("name", name="_marketplace_sources_uc"),)
@@ -523,7 +490,7 @@ def full_object(self, value):
# TODO - convert to pickle, to avoid issues with non-json serializable fields such as datetime
self._full_object = json.dumps(value, default=str)
- class DataVersion(Base, BaseModel):
+ class DataVersion(Base, mlrun.utils.db.BaseModel):
__tablename__ = "data_versions"
__table_args__ = (UniqueConstraint("version", name="_versions_uc"),)
diff --git a/mlrun/api/db/sqldb/models/models_sqlite.py b/mlrun/api/db/sqldb/models/models_sqlite.py
index 597983fbe997..387cd58f56bb 100644
--- a/mlrun/api/db/sqldb/models/models_sqlite.py
+++ b/mlrun/api/db/sqldb/models/models_sqlite.py
@@ -31,8 +31,9 @@
UniqueConstraint,
)
from sqlalchemy.ext.declarative import declarative_base
-from sqlalchemy.orm import class_mapper, relationship
+from sqlalchemy.orm import relationship
+import mlrun.utils.db
from mlrun.api import schemas
from mlrun.api.utils.db.sql_collation import SQLCollationUtil
@@ -41,42 +42,8 @@
run_time_fmt = "%Y-%m-%dT%H:%M:%S.%fZ"
-class BaseModel:
- def to_dict(self, exclude=None):
- """
- NOTE - this function (currently) does not handle serializing relationships
- """
- exclude = exclude or []
- mapper = class_mapper(self.__class__)
- columns = [column.key for column in mapper.columns if column.key not in exclude]
- get_key_value = (
- lambda c: (c, getattr(self, c).isoformat())
- if isinstance(getattr(self, c), datetime)
- else (c, getattr(self, c))
- )
- return dict(map(get_key_value, columns))
-
-
-class HasStruct(BaseModel):
- @property
- def struct(self):
- return pickle.loads(self.body)
-
- @struct.setter
- def struct(self, value):
- self.body = pickle.dumps(value)
-
- def to_dict(self, exclude=None):
- """
- NOTE - this function (currently) does not handle serializing relationships
- """
- exclude = exclude or []
- exclude.append("body")
- return super().to_dict(exclude)
-
-
def make_label(table):
- class Label(Base, BaseModel):
+ class Label(Base, mlrun.utils.db.BaseModel):
__tablename__ = f"{table}_labels"
__table_args__ = (
UniqueConstraint("name", "parent", name=f"_{table}_labels_uc"),
@@ -91,7 +58,7 @@ class Label(Base, BaseModel):
def make_tag(table):
- class Tag(Base, BaseModel):
+ class Tag(Base, mlrun.utils.db.BaseModel):
__tablename__ = f"{table}_tags"
__table_args__ = (
UniqueConstraint("project", "name", "obj_id", name=f"_{table}_tags_uc"),
@@ -108,7 +75,7 @@ class Tag(Base, BaseModel):
# TODO: don't want to refactor everything in one PR so splitting this function to 2 versions - eventually only this one
# should be used
def make_tag_v2(table):
- class Tag(Base, BaseModel):
+ class Tag(Base, mlrun.utils.db.BaseModel):
__tablename__ = f"{table}_tags"
__table_args__ = (
UniqueConstraint("project", "name", "obj_name", name=f"_{table}_tags_uc"),
@@ -130,7 +97,7 @@ class Tag(Base, BaseModel):
with warnings.catch_warnings():
warnings.simplefilter("ignore")
- class Artifact(Base, HasStruct):
+ class Artifact(Base, mlrun.utils.db.HasStruct):
__tablename__ = "artifacts"
__table_args__ = (
UniqueConstraint("uid", "project", "key", name="_artifacts_uc"),
@@ -151,7 +118,7 @@ class Artifact(Base, HasStruct):
def get_identifier_string(self) -> str:
return f"{self.project}/{self.key}/{self.uid}"
- class Function(Base, HasStruct):
+ class Function(Base, mlrun.utils.db.HasStruct):
__tablename__ = "functions"
__table_args__ = (
UniqueConstraint("name", "project", "uid", name="_functions_uc"),
@@ -172,7 +139,7 @@ class Function(Base, HasStruct):
def get_identifier_string(self) -> str:
return f"{self.project}/{self.name}/{self.uid}"
- class Log(Base, BaseModel):
+ class Log(Base, mlrun.utils.db.BaseModel):
__tablename__ = "logs"
id = Column(Integer, primary_key=True)
@@ -184,7 +151,7 @@ class Log(Base, BaseModel):
def get_identifier_string(self) -> str:
return f"{self.project}/{self.uid}"
- class Notification(Base, BaseModel):
+ class Notification(Base, mlrun.utils.db.BaseModel):
__tablename__ = "notifications"
__table_args__ = (UniqueConstraint("name", "run", name="_notifications_uc"),)
@@ -218,7 +185,7 @@ class Notification(Base, BaseModel):
String(255, collation=SQLCollationUtil.collation()), nullable=False
)
- class Run(Base, HasStruct):
+ class Run(Base, mlrun.utils.db.HasStruct):
__tablename__ = "runs"
__table_args__ = (
UniqueConstraint("uid", "project", "iteration", name="_runs_uc"),
@@ -250,7 +217,7 @@ class Run(Base, HasStruct):
def get_identifier_string(self) -> str:
return f"{self.project}/{self.uid}/{self.iteration}"
- class BackgroundTask(Base, BaseModel):
+ class BackgroundTask(Base, mlrun.utils.db.BaseModel):
__tablename__ = "background_tasks"
__table_args__ = (
UniqueConstraint("name", "project", name="_background_tasks_uc"),
@@ -268,7 +235,7 @@ class BackgroundTask(Base, BaseModel):
state = Column(String(255, collation=SQLCollationUtil.collation()))
timeout = Column(Integer)
- class Schedule(Base, BaseModel):
+ class Schedule(Base, mlrun.utils.db.BaseModel):
__tablename__ = "schedules_v2"
__table_args__ = (UniqueConstraint("project", "name", name="_schedules_v2_uc"),)
@@ -320,14 +287,14 @@ def cron_trigger(self, trigger: schemas.ScheduleCronTrigger):
Column("user_id", Integer, ForeignKey("users.id")),
)
- class User(Base, BaseModel):
+ class User(Base, mlrun.utils.db.BaseModel):
__tablename__ = "users"
__table_args__ = (UniqueConstraint("name", name="_users_uc"),)
id = Column(Integer, primary_key=True)
name = Column(String(255, collation=SQLCollationUtil.collation()))
- class Project(Base, BaseModel):
+ class Project(Base, mlrun.utils.db.BaseModel):
__tablename__ = "projects"
# For now since we use project name a lot
__table_args__ = (UniqueConstraint("name", name="_projects_uc"),)
@@ -361,7 +328,7 @@ def full_object(self):
def full_object(self, value):
self._full_object = pickle.dumps(value)
- class Feature(Base, BaseModel):
+ class Feature(Base, mlrun.utils.db.BaseModel):
__tablename__ = "features"
id = Column(Integer, primary_key=True)
feature_set_id = Column(Integer, ForeignKey("feature_sets.id"))
@@ -375,7 +342,7 @@ class Feature(Base, BaseModel):
def get_identifier_string(self) -> str:
return f"{self.project}/{self.name}"
- class Entity(Base, BaseModel):
+ class Entity(Base, mlrun.utils.db.BaseModel):
__tablename__ = "entities"
id = Column(Integer, primary_key=True)
feature_set_id = Column(Integer, ForeignKey("feature_sets.id"))
@@ -389,7 +356,7 @@ class Entity(Base, BaseModel):
def get_identifier_string(self) -> str:
return f"{self.project}/{self.name}"
- class FeatureSet(Base, BaseModel):
+ class FeatureSet(Base, mlrun.utils.db.BaseModel):
__tablename__ = "feature_sets"
__table_args__ = (
UniqueConstraint("name", "project", "uid", name="_feature_set_uc"),
@@ -425,7 +392,7 @@ def full_object(self):
def full_object(self, value):
self._full_object = json.dumps(value, default=str)
- class FeatureVector(Base, BaseModel):
+ class FeatureVector(Base, mlrun.utils.db.BaseModel):
__tablename__ = "feature_vectors"
__table_args__ = (
UniqueConstraint("name", "project", "uid", name="_feature_vectors_uc"),
@@ -458,7 +425,7 @@ def full_object(self):
def full_object(self, value):
self._full_object = json.dumps(value, default=str)
- class MarketplaceSource(Base, BaseModel):
+ class MarketplaceSource(Base, mlrun.utils.db.BaseModel):
__tablename__ = "marketplace_sources"
__table_args__ = (UniqueConstraint("name", name="_marketplace_sources_uc"),)
@@ -482,7 +449,7 @@ def full_object(self):
def full_object(self, value):
self._full_object = json.dumps(value, default=str)
- class DataVersion(Base, BaseModel):
+ class DataVersion(Base, mlrun.utils.db.BaseModel):
__tablename__ = "data_versions"
__table_args__ = (UniqueConstraint("version", name="_versions_uc"),)
diff --git a/mlrun/api/db/sqldb/session.py b/mlrun/api/db/sqldb/session.py
index 197d2af30429..34b3475e3e61 100644
--- a/mlrun/api/db/sqldb/session.py
+++ b/mlrun/api/db/sqldb/session.py
@@ -12,6 +12,9 @@
# See the License for the specific language governing permissions and
# limitations under the License.
#
+
+import typing
+
from sqlalchemy import create_engine
from sqlalchemy.engine import Engine
from sqlalchemy.orm import Session
@@ -19,35 +22,38 @@
from mlrun.config import config
-engine: Engine = None
-_session_maker: SessionMaker = None
+# TODO: wrap the following functions in a singleton class
+_engines: typing.Dict[str, Engine] = {}
+_session_makers: typing.Dict[str, SessionMaker] = {}
# doing lazy load to allow tests to initialize the engine
-def get_engine() -> Engine:
- global engine
- if engine is None:
- _init_engine()
- return engine
+def get_engine(dsn=None) -> Engine:
+ global _engines
+ dsn = dsn or config.httpdb.dsn
+ if dsn not in _engines:
+ _init_engine(dsn=dsn)
+ return _engines[dsn]
-def create_session() -> Session:
- session_maker = _get_session_maker()
+def create_session(dsn=None) -> Session:
+ session_maker = _get_session_maker(dsn=dsn)
return session_maker()
# doing lazy load to allow tests to initialize the engine
-def _get_session_maker() -> SessionMaker:
- global _session_maker
- if _session_maker is None:
- _init_session_maker()
- return _session_maker
+def _get_session_maker(dsn) -> SessionMaker:
+ global _session_makers
+ dsn = dsn or config.httpdb.dsn
+ if dsn not in _session_makers:
+ _init_session_maker(dsn=dsn)
+ return _session_makers[dsn]
# TODO: we accept the dsn here to enable tests to override it, the "right" thing will be that config will be easily
# overridable by tests (today when you import the config it is already being initialized.. should be lazy load)
def _init_engine(dsn=None):
- global engine
+ global _engines
dsn = dsn or config.httpdb.dsn
kwargs = {}
if "mysql" in dsn:
@@ -62,9 +68,10 @@ def _init_engine(dsn=None):
"max_overflow": max_overflow,
}
engine = create_engine(dsn, **kwargs)
- _init_session_maker()
+ _engines[dsn] = engine
+ _init_session_maker(dsn=dsn)
-def _init_session_maker():
- global _session_maker
- _session_maker = SessionMaker(bind=get_engine())
+def _init_session_maker(dsn):
+ global _session_makers
+ _session_makers[dsn] = SessionMaker(bind=get_engine(dsn=dsn))
diff --git a/mlrun/api/schemas/__init__.py b/mlrun/api/schemas/__init__.py
index a2f91cd26645..cd7fa547c14d 100644
--- a/mlrun/api/schemas/__init__.py
+++ b/mlrun/api/schemas/__init__.py
@@ -100,13 +100,11 @@
GrafanaStringColumn,
GrafanaTable,
GrafanaTimeSeriesTarget,
- Metric,
ModelEndpoint,
ModelEndpointList,
ModelEndpointMetadata,
ModelEndpointSpec,
ModelEndpointStatus,
- ModelMonitoringMode,
ModelMonitoringStoreKinds,
)
from .notification import NotificationSeverity, NotificationStatus
diff --git a/mlrun/api/schemas/model_endpoints.py b/mlrun/api/schemas/model_endpoints.py
index 0ae5aee397f0..4cbe6aa00a61 100644
--- a/mlrun/api/schemas/model_endpoints.py
+++ b/mlrun/api/schemas/model_endpoints.py
@@ -12,52 +12,86 @@
# See the License for the specific language governing permissions and
# limitations under the License.
#
+
+import json
+import typing
from typing import Any, Dict, List, Optional, Tuple, Union
from pydantic import BaseModel, Field
from pydantic.main import Extra
-import mlrun.api.utils.helpers
+import mlrun.model_monitoring
from mlrun.api.schemas.object import ObjectKind, ObjectSpec, ObjectStatus
-from mlrun.utils.model_monitoring import EndpointType, create_model_endpoint_id
class ModelMonitoringStoreKinds:
+ # TODO: do changes in examples & demos In 1.5.0 remove
ENDPOINTS = "endpoints"
EVENTS = "events"
class ModelEndpointMetadata(BaseModel):
- project: Optional[str]
+ project: Optional[str] = ""
labels: Optional[dict] = {}
- uid: Optional[str]
+ uid: Optional[str] = ""
class Config:
extra = Extra.allow
-
-class ModelMonitoringMode(mlrun.api.utils.helpers.StrEnum):
- enabled = "enabled"
- disabled = "disabled"
+ @classmethod
+ def from_flat_dict(cls, endpoint_dict: dict, json_parse_values: typing.List = None):
+ """Create a `ModelEndpointMetadata` object from an endpoint dictionary
+
+ :param endpoint_dict: Model endpoint dictionary.
+ :param json_parse_values: List of dictionary keys with a JSON string value that will be parsed into a
+ dictionary using json.loads().
+ """
+ new_object = cls()
+ if json_parse_values is None:
+ json_parse_values = [mlrun.model_monitoring.EventFieldType.LABELS]
+
+ return _mapping_attributes(
+ base_model=new_object,
+ flattened_dictionary=endpoint_dict,
+ json_parse_values=json_parse_values,
+ )
class ModelEndpointSpec(ObjectSpec):
- function_uri: Optional[str] # /:
- model: Optional[str] # :
- model_class: Optional[str]
- model_uri: Optional[str]
- feature_names: Optional[List[str]]
- label_names: Optional[List[str]]
- stream_path: Optional[str]
- algorithm: Optional[str]
+ function_uri: Optional[str] = "" # /:
+ model: Optional[str] = "" # :
+ model_class: Optional[str] = ""
+ model_uri: Optional[str] = ""
+ feature_names: Optional[List[str]] = []
+ label_names: Optional[List[str]] = []
+ stream_path: Optional[str] = ""
+ algorithm: Optional[str] = ""
monitor_configuration: Optional[dict] = {}
- active: Optional[bool]
- monitoring_mode: Optional[str] = ModelMonitoringMode.disabled
-
+ active: Optional[bool] = True
+ monitoring_mode: Optional[
+ mlrun.model_monitoring.ModelMonitoringMode
+ ] = mlrun.model_monitoring.ModelMonitoringMode.disabled.value
-class Metric(BaseModel):
- name: str
- values: List[Tuple[str, float]]
+ @classmethod
+ def from_flat_dict(cls, endpoint_dict: dict, json_parse_values: typing.List = None):
+ """Create a `ModelEndpointSpec` object from an endpoint dictionary
+
+ :param endpoint_dict: Model endpoint dictionary.
+ :param json_parse_values: List of dictionary keys with a JSON string value that will be parsed into a
+ dictionary using json.loads().
+ """
+ new_object = cls()
+ if json_parse_values is None:
+ json_parse_values = [
+ mlrun.model_monitoring.EventFieldType.FEATURE_NAMES,
+ mlrun.model_monitoring.EventFieldType.LABEL_NAMES,
+ mlrun.model_monitoring.EventFieldType.MONITOR_CONFIGURATION,
+ ]
+ return _mapping_attributes(
+ base_model=new_object,
+ flattened_dictionary=endpoint_dict,
+ json_parse_values=json_parse_values,
+ )
class Histogram(BaseModel):
@@ -108,28 +142,60 @@ def new(
class ModelEndpointStatus(ObjectStatus):
feature_stats: Optional[dict] = {}
current_stats: Optional[dict] = {}
- first_request: Optional[str]
- last_request: Optional[str]
- accuracy: Optional[float]
- error_count: Optional[int]
- drift_status: Optional[str]
+ first_request: Optional[str] = ""
+ last_request: Optional[str] = ""
+ error_count: Optional[int] = 0
+ drift_status: Optional[str] = ""
drift_measures: Optional[dict] = {}
- metrics: Optional[Dict[str, Metric]]
- features: Optional[List[Features]]
- children: Optional[List[str]]
- children_uids: Optional[List[str]]
- endpoint_type: Optional[EndpointType]
- monitoring_feature_set_uri: Optional[str]
+ metrics: Optional[Dict[str, Dict[str, Any]]] = {
+ mlrun.model_monitoring.EventKeyMetrics.GENERIC: {
+ mlrun.model_monitoring.EventLiveStats.LATENCY_AVG_1H: 0,
+ mlrun.model_monitoring.EventLiveStats.PREDICTIONS_PER_SECOND: 0,
+ }
+ }
+ features: Optional[List[Features]] = []
+ children: Optional[List[str]] = []
+ children_uids: Optional[List[str]] = []
+ endpoint_type: Optional[
+ mlrun.model_monitoring.EndpointType
+ ] = mlrun.model_monitoring.EndpointType.NODE_EP.value
+ monitoring_feature_set_uri: Optional[str] = ""
+ state: Optional[str] = ""
class Config:
extra = Extra.allow
+ @classmethod
+ def from_flat_dict(cls, endpoint_dict: dict, json_parse_values: typing.List = None):
+ """Create a `ModelEndpointStatus` object from an endpoint dictionary
+
+ :param endpoint_dict: Model endpoint dictionary.
+ :param json_parse_values: List of dictionary keys with a JSON string value that will be parsed into a
+ dictionary using json.loads().
+ """
+ new_object = cls()
+ if json_parse_values is None:
+ json_parse_values = [
+ mlrun.model_monitoring.EventFieldType.FEATURE_STATS,
+ mlrun.model_monitoring.EventFieldType.CURRENT_STATS,
+ mlrun.model_monitoring.EventFieldType.DRIFT_MEASURES,
+ mlrun.model_monitoring.EventFieldType.METRICS,
+ mlrun.model_monitoring.EventFieldType.CHILDREN,
+ mlrun.model_monitoring.EventFieldType.CHILDREN_UIDS,
+ mlrun.model_monitoring.EventFieldType.ENDPOINT_TYPE,
+ ]
+ return _mapping_attributes(
+ base_model=new_object,
+ flattened_dictionary=endpoint_dict,
+ json_parse_values=json_parse_values,
+ )
+
class ModelEndpoint(BaseModel):
kind: ObjectKind = Field(ObjectKind.model_endpoint, const=True)
- metadata: ModelEndpointMetadata
- spec: ModelEndpointSpec
- status: ModelEndpointStatus
+ metadata: ModelEndpointMetadata = ModelEndpointMetadata()
+ spec: ModelEndpointSpec = ModelEndpointSpec()
+ status: ModelEndpointStatus = ModelEndpointStatus()
class Config:
extra = Extra.allow
@@ -137,15 +203,66 @@ class Config:
def __init__(self, **data: Any):
super().__init__(**data)
if self.metadata.uid is None:
- uid = create_model_endpoint_id(
+ uid = mlrun.model_monitoring.create_model_endpoint_uid(
function_uri=self.spec.function_uri,
versioned_model=self.spec.model,
)
self.metadata.uid = str(uid)
+ def flat_dict(self):
+ """Generate a flattened `ModelEndpoint` dictionary. The flattened dictionary result is important for storing
+ the model endpoint object in the database.
+
+ :return: Flattened `ModelEndpoint` dictionary.
+ """
+ # Convert the ModelEndpoint object into a dictionary using BaseModel dict() function
+ # In addition, remove the BaseModel kind as it is not required by the DB schema
+ model_endpoint_dictionary = self.dict(exclude={"kind"})
+
+ # Initialize a flattened dictionary that will be filled with the model endpoint dictionary attributes
+ flatten_dict = {}
+ for k_object in model_endpoint_dictionary:
+ for key in model_endpoint_dictionary[k_object]:
+ # If the value is not from type str or bool (e.g. dict), convert it into a JSON string
+ # for matching the database required format
+ if not isinstance(
+ model_endpoint_dictionary[k_object][key], (str, bool)
+ ):
+ flatten_dict[key] = json.dumps(
+ model_endpoint_dictionary[k_object][key]
+ )
+ else:
+ flatten_dict[key] = model_endpoint_dictionary[k_object][key]
+
+ if mlrun.model_monitoring.EventFieldType.METRICS not in flatten_dict:
+ # Initialize metrics dictionary
+ flatten_dict[mlrun.model_monitoring.EventFieldType.METRICS] = {
+ mlrun.model_monitoring.EventKeyMetrics.GENERIC: {
+ mlrun.model_monitoring.EventLiveStats.LATENCY_AVG_1H: 0,
+ mlrun.model_monitoring.EventLiveStats.PREDICTIONS_PER_SECOND: 0,
+ }
+ }
+ # Remove the features from the dictionary as this field will be filled only within the feature analysis process
+ flatten_dict.pop(mlrun.model_monitoring.EventFieldType.FEATURES, None)
+ return flatten_dict
+
+ @classmethod
+ def from_flat_dict(cls, endpoint_dict: dict):
+ """Create a `ModelEndpoint` object from an endpoint flattened dictionary. Because the provided dictionary
+ is flattened, we pass it as is to the subclasses without splitting the keys into spec, metadata, and status.
+
+ :param endpoint_dict: Model endpoint dictionary.
+ """
+
+ return cls(
+ metadata=ModelEndpointMetadata.from_flat_dict(endpoint_dict=endpoint_dict),
+ spec=ModelEndpointSpec.from_flat_dict(endpoint_dict=endpoint_dict),
+ status=ModelEndpointStatus.from_flat_dict(endpoint_dict=endpoint_dict),
+ )
+
class ModelEndpointList(BaseModel):
- endpoints: List[ModelEndpoint]
+ endpoints: List[ModelEndpoint] = []
class GrafanaColumn(BaseModel):
@@ -183,3 +300,40 @@ class GrafanaTimeSeriesTarget(BaseModel):
def add_data_point(self, data_point: GrafanaDataPoint):
self.datapoints.append((data_point.value, data_point.timestamp))
+
+
+def _mapping_attributes(
+ base_model: BaseModel,
+ flattened_dictionary: dict,
+ json_parse_values: typing.List = None,
+):
+ """Generate a `BaseModel` object with the provided dictionary attributes.
+
+ :param base_model: `BaseModel` object (e.g. `ModelEndpointMetadata`).
+ :param flattened_dictionary: Flattened dictionary that contains the model endpoint attributes.
+ :param json_parse_values: List of dictionary keys with a JSON string value that will be parsed into a
+ dictionary using json.loads().
+ """
+ # Get the fields of the provided base model object. These fields will be used to filter to relevent keys
+ # from the flattened dictionary.
+ wanted_keys = base_model.__fields__.keys()
+
+ # Generate a filtered flattened dictionary that will be parsed into the BaseModel object
+ dict_to_parse = {}
+ for field_key in wanted_keys:
+ if field_key in flattened_dictionary:
+ if field_key in json_parse_values:
+ # Parse the JSON value into a valid dictionary
+ dict_to_parse[field_key] = _json_loads_if_not_none(
+ flattened_dictionary[field_key]
+ )
+ else:
+ dict_to_parse[field_key] = flattened_dictionary[field_key]
+
+ return base_model.parse_obj(dict_to_parse)
+
+
+def _json_loads_if_not_none(field: Any) -> Any:
+ return (
+ json.loads(field) if field and field != "null" and field is not None else None
+ )
diff --git a/mlrun/config.py b/mlrun/config.py
index c289eaea0b0d..601bcc5336e3 100644
--- a/mlrun/config.py
+++ b/mlrun/config.py
@@ -383,7 +383,8 @@
"batch_processing_function_branch": "master",
"parquet_batching_max_events": 10000,
# See mlrun.api.schemas.ModelEndpointStoreType for available options
- "store_type": "kv",
+ "store_type": "v3io-nosql",
+ "endpoint_store_connection": "",
},
"secret_stores": {
"vault": {
diff --git a/mlrun/db/base.py b/mlrun/db/base.py
index 28c6c4ed4596..f98ca974056c 100644
--- a/mlrun/db/base.py
+++ b/mlrun/db/base.py
@@ -17,8 +17,8 @@
from abc import ABC, abstractmethod
from typing import List, Optional, Union
+import mlrun.model_monitoring.model_endpoint
from mlrun.api import schemas
-from mlrun.api.schemas import ModelEndpoint
class RunDBError(Exception):
@@ -480,7 +480,9 @@ def create_model_endpoint(
self,
project: str,
endpoint_id: str,
- model_endpoint: ModelEndpoint,
+ model_endpoint: Union[
+ mlrun.model_monitoring.model_endpoint.ModelEndpoint, dict
+ ],
):
pass
diff --git a/mlrun/db/filedb.py b/mlrun/db/filedb.py
index d96a1cdf26be..3dd7a1ebe581 100644
--- a/mlrun/db/filedb.py
+++ b/mlrun/db/filedb.py
@@ -23,9 +23,9 @@
import mlrun.api.schemas
import mlrun.errors
+import mlrun.model_monitoring.model_endpoint
from ..api import schemas
-from ..api.schemas import ModelEndpoint
from ..config import config
from ..datastore import store_manager
from ..lists import ArtifactList, RunList
@@ -781,7 +781,9 @@ def create_model_endpoint(
self,
project: str,
endpoint_id: str,
- model_endpoint: ModelEndpoint,
+ model_endpoint: Union[
+ mlrun.model_monitoring.model_endpoint.ModelEndpoint, dict
+ ],
):
raise NotImplementedError()
diff --git a/mlrun/db/httpdb.py b/mlrun/db/httpdb.py
index ccf97dfd9a38..29b009b4e568 100644
--- a/mlrun/db/httpdb.py
+++ b/mlrun/db/httpdb.py
@@ -27,11 +27,11 @@
import semver
import mlrun
+import mlrun.model_monitoring.model_endpoint
import mlrun.projects
from mlrun.api import schemas
from mlrun.errors import MLRunInvalidArgumentError, err_to_str
-from ..api.schemas import ModelEndpoint
from ..artifacts import Artifact
from ..config import config
from ..feature_store import FeatureSet, FeatureVector
@@ -2532,7 +2532,9 @@ def create_model_endpoint(
self,
project: str,
endpoint_id: str,
- model_endpoint: ModelEndpoint,
+ model_endpoint: Union[
+ mlrun.model_monitoring.model_endpoint.ModelEndpoint, dict
+ ],
):
"""
Creates a DB record with the given model_endpoint record.
@@ -2542,11 +2544,16 @@ def create_model_endpoint(
:param model_endpoint: An object representing the model endpoint.
"""
+ if isinstance(
+ model_endpoint, mlrun.model_monitoring.model_endpoint.ModelEndpoint
+ ):
+ model_endpoint = model_endpoint.to_dict()
+
path = f"projects/{project}/model-endpoints/{endpoint_id}"
self.api_call(
method="POST",
path=path,
- body=model_endpoint.json(),
+ body=dict_to_json(model_endpoint),
)
def delete_model_endpoint(
@@ -2555,7 +2562,7 @@ def delete_model_endpoint(
endpoint_id: str,
):
"""
- Deletes the KV record of a given model endpoint, project and endpoint_id are used for lookup
+ Deletes the DB record of a given model endpoint, project and endpoint_id are used for lookup
:param project: The name of the project
:param endpoint_id: The id of the endpoint
@@ -2578,7 +2585,7 @@ def list_model_endpoints(
metrics: Optional[List[str]] = None,
top_level: bool = False,
uids: Optional[List[str]] = None,
- ) -> schemas.ModelEndpointList:
+ ) -> List[mlrun.model_monitoring.model_endpoint.ModelEndpoint]:
"""
Returns a list of ModelEndpointState objects. Each object represents the current state of a model endpoint.
This functions supports filtering by the following parameters:
@@ -2594,8 +2601,8 @@ def list_model_endpoints(
:param project: The name of the project
:param model: The name of the model to filter by
:param function: The name of the function to filter by
- :param labels: A list of labels to filter by. Label filters work by either filtering a specific value of a label
- (i.e. list("key==value")) or by looking for the existence of a given key (i.e. "key")
+ :param labels: A list of labels to filter by. Label filters work by either filtering a specific value of a
+ label (i.e. list("key=value")) or by looking for the existence of a given key (i.e. "key")
:param metrics: A list of metrics to return for each endpoint, read more in 'TimeMetric'
:param start: The start time of the metrics. Can be represented by a string containing an RFC 3339
time, a Unix timestamp in milliseconds, a relative time (`'now'` or
@@ -2606,10 +2613,14 @@ def list_model_endpoints(
`'now-[0-9]+[mhd]'`, where `m` = minutes, `h` = hours, and `'d'` =
days), or 0 for the earliest time.
:param top_level: if true will return only routers and endpoint that are NOT children of any router
- :param uids: if passed will return ModelEndpointList of endpoints with uid in uids
+ :param uids: if passed will return `ModelEndpointList` of endpoints with uid in uids
"""
path = f"projects/{project}/model-endpoints"
+
+ if labels and isinstance(labels, dict):
+ labels = [f"{key}={value}" for key, value in labels.items()]
+
response = self.api_call(
method="GET",
path=path,
@@ -2624,7 +2635,15 @@ def list_model_endpoints(
"uid": uids,
},
)
- return schemas.ModelEndpointList(**response.json())
+
+ # Generate a list of a model endpoint dictionaries
+ model_endpoints = response.json()["endpoints"]
+ if model_endpoints:
+ return [
+ mlrun.model_monitoring.model_endpoint.ModelEndpoint.from_dict(obj)
+ for obj in model_endpoints
+ ]
+ return []
def get_model_endpoint(
self,
@@ -2634,21 +2653,29 @@ def get_model_endpoint(
end: Optional[str] = None,
metrics: Optional[List[str]] = None,
feature_analysis: bool = False,
- ) -> schemas.ModelEndpoint:
- """
- Returns a ModelEndpoint object with additional metrics and feature related data.
-
- :param project: The name of the project
- :param endpoint_id: The id of the model endpoint
- :param metrics: A list of metrics to return for each endpoint, read more in 'TimeMetric'
- :param start: The start time of the metrics. Can be represented by a string containing an RFC 3339
- time, a Unix timestamp in milliseconds, a relative time (`'now'` or `'now-[0-9]+[mhd]'`,
- where `m` = minutes, `h` = hours, and `'d'` = days), or 0 for the earliest time.
- :param end: The end time of the metrics. Can be represented by a string containing an RFC 3339
- time, a Unix timestamp in milliseconds, a relative time (`'now'` or `'now-[0-9]+[mhd]'`,
- where `m` = minutes, `h` = hours, and `'d'` = days), or 0 for the earliest time.
- :param feature_analysis: When True, the base feature statistics and current feature statistics will be added to
- the output of the resulting object
+ ) -> mlrun.model_monitoring.model_endpoint.ModelEndpoint:
+ """
+ Returns a single `ModelEndpoint` object with additional metrics and feature related data.
+
+ :param project: The name of the project
+ :param endpoint_id: The unique id of the model endpoint.
+ :param start: The start time of the metrics. Can be represented by a string containing an
+ RFC 3339 time, a Unix timestamp in milliseconds, a relative time (`'now'` or
+ `'now-[0-9]+[mhd]'`, where `m` = minutes, `h` = hours, and `'d'` = days), or
+ 0 for the earliest time.
+ :param end: The end time of the metrics. Can be represented by a string containing an
+ RFC 3339 time, a Unix timestamp in milliseconds, a relative time (`'now'` or
+ `'now-[0-9]+[mhd]'`, where `m` = minutes, `h` = hours, and `'d'` = days), or
+ 0 for the earliest time.
+ :param metrics: A list of metrics to return for the model endpoint. There are pre-defined
+ metrics for model endpoints such as predictions_per_second and
+ latency_avg_5m but also custom metrics defined by the user. Please note that
+ these metrics are stored in the time series DB and the results will be
+ appeared under model_endpoint.spec.metrics.
+ :param feature_analysis: When True, the base feature statistics and current feature statistics will
+ be added to the output of the resulting object.
+
+ :return: A `ModelEndpoint` object.
"""
path = f"projects/{project}/model-endpoints/{endpoint_id}"
@@ -2662,7 +2689,10 @@ def get_model_endpoint(
"feature_analysis": feature_analysis,
},
)
- return schemas.ModelEndpoint(**response.json())
+
+ return mlrun.model_monitoring.model_endpoint.ModelEndpoint.from_dict(
+ response.json()
+ )
def patch_model_endpoint(
self,
@@ -2676,9 +2706,9 @@ def patch_model_endpoint(
:param project: The name of the project.
:param endpoint_id: The id of the endpoint.
:param attributes: Dictionary of attributes that will be used for update the model endpoint. The keys
- of this dictionary should exist in the target table. The values should be
- from type string or from a valid numerical type such as int or float. More details
- about the model endpoint available attributes can be found under
+ of this dictionary should exist in the target table. Note that the values should be
+ from type string or from a valid numerical type such as int or float.
+ More details about the model endpoint available attributes can be found under
:py:class:`~mlrun.api.schemas.ModelEndpoint`.
Example::
diff --git a/mlrun/db/sqldb.py b/mlrun/db/sqldb.py
index 7b6249442a78..028480dddea8 100644
--- a/mlrun/db/sqldb.py
+++ b/mlrun/db/sqldb.py
@@ -16,6 +16,7 @@
from typing import List, Optional, Union
import mlrun.api.schemas
+import mlrun.model_monitoring.model_endpoint
from mlrun.api.db.base import DBError
from mlrun.api.db.sqldb.db import SQLDB as SQLAPIDB
from mlrun.api.db.sqldb.session import create_session
@@ -29,7 +30,6 @@
# will be httpdb to that same api service) we have this class which is kind of a proxy between the RunDB interface to
# the api service's DB interface
from ..api import schemas
-from ..api.schemas import ModelEndpoint
from .base import RunDBError, RunDBInterface
@@ -775,7 +775,9 @@ def create_model_endpoint(
self,
project: str,
endpoint_id: str,
- model_endpoint: ModelEndpoint,
+ model_endpoint: Union[
+ mlrun.model_monitoring.model_endpoint.ModelEndpoint, dict
+ ],
):
raise NotImplementedError()
diff --git a/mlrun/model_monitoring/__init__.py b/mlrun/model_monitoring/__init__.py
new file mode 100644
index 000000000000..b8f9b449ef7e
--- /dev/null
+++ b/mlrun/model_monitoring/__init__.py
@@ -0,0 +1,42 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+# flake8: noqa - this is until we take care of the F401 violations with respect to __all__ & sphinx
+# for backwards compatibility
+
+__all__ = [
+ "ModelEndpoint",
+ "ModelMonitoringMode",
+ "EndpointType",
+ "create_model_endpoint_uid",
+ "EventFieldType",
+ "EventLiveStats",
+ "EventKeyMetrics",
+ "TimeSeriesTarget",
+ "ModelEndpointTarget",
+ "ProjectSecretKeys",
+ "ModelMonitoringStoreKinds",
+]
+
+from .common import EndpointType, ModelMonitoringMode, create_model_endpoint_uid
+from .constants import (
+ EventFieldType,
+ EventKeyMetrics,
+ EventLiveStats,
+ ModelEndpointTarget,
+ ModelMonitoringStoreKinds,
+ ProjectSecretKeys,
+ TimeSeriesTarget,
+)
+from .model_endpoint import ModelEndpoint
diff --git a/mlrun/model_monitoring/common.py b/mlrun/model_monitoring/common.py
new file mode 100644
index 000000000000..c20114473ee5
--- /dev/null
+++ b/mlrun/model_monitoring/common.py
@@ -0,0 +1,112 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+import enum
+import hashlib
+from dataclasses import dataclass
+from typing import Optional
+
+import mlrun.utils
+
+
+class ModelMonitoringMode(str, enum.Enum):
+ enabled = "enabled"
+ disabled = "disabled"
+
+
+class EndpointType(enum.IntEnum):
+ NODE_EP = 1 # end point that is not a child of a router
+ ROUTER = 2 # endpoint that is router
+ LEAF_EP = 3 # end point that is a child of a router
+
+
+def create_model_endpoint_uid(function_uri: str, versioned_model: str):
+ function_uri = FunctionURI.from_string(function_uri)
+ versioned_model = VersionedModel.from_string(versioned_model)
+
+ if (
+ not function_uri.project
+ or not function_uri.function
+ or not versioned_model.model
+ ):
+ raise ValueError("Both function_uri and versioned_model have to be initialized")
+
+ uid = EndpointUID(
+ function_uri.project,
+ function_uri.function,
+ function_uri.tag,
+ function_uri.hash_key,
+ versioned_model.model,
+ versioned_model.version,
+ )
+
+ return uid
+
+
+@dataclass
+class FunctionURI:
+ project: str
+ function: str
+ tag: Optional[str] = None
+ hash_key: Optional[str] = None
+
+ @classmethod
+ def from_string(cls, function_uri):
+ project, uri, tag, hash_key = mlrun.utils.parse_versioned_object_uri(
+ function_uri
+ )
+ return cls(
+ project=project,
+ function=uri,
+ tag=tag or None,
+ hash_key=hash_key or None,
+ )
+
+
+@dataclass
+class VersionedModel:
+ model: str
+ version: Optional[str]
+
+ @classmethod
+ def from_string(cls, model):
+ try:
+ model, version = model.split(":")
+ except ValueError:
+ model, version = model, None
+
+ return cls(model, version)
+
+
+@dataclass
+class EndpointUID:
+ project: str
+ function: str
+ function_tag: str
+ function_hash_key: str
+ model: str
+ model_version: str
+ uid: Optional[str] = None
+
+ def __post_init__(self):
+ function_ref = (
+ f"{self.function}_{self.function_tag or self.function_hash_key or 'N/A'}"
+ )
+ versioned_model = f"{self.model}_{self.model_version or 'N/A'}"
+ unique_string = f"{self.project}_{function_ref}_{versioned_model}"
+ self.uid = hashlib.sha1(unique_string.encode("utf-8")).hexdigest()
+
+ def __str__(self):
+ return self.uid
diff --git a/mlrun/model_monitoring/constants.py b/mlrun/model_monitoring/constants.py
index bf3c616f36d9..c6824e571253 100644
--- a/mlrun/model_monitoring/constants.py
+++ b/mlrun/model_monitoring/constants.py
@@ -14,12 +14,16 @@
#
class EventFieldType:
FUNCTION_URI = "function_uri"
+ FUNCTION = "function"
+ MODEL_URI = "model_uri"
MODEL = "model"
VERSION = "version"
VERSIONED_MODEL = "versioned_model"
MODEL_CLASS = "model_class"
TIMESTAMP = "timestamp"
ENDPOINT_ID = "endpoint_id"
+ UID = "uid"
+ ENDPOINT_TYPE = "endpoint_type"
REQUEST_ID = "request_id"
RECORD_TYPE = "record_type"
FEATURES = "features"
@@ -27,7 +31,6 @@ class EventFieldType:
NAMED_FEATURES = "named_features"
LABELS = "labels"
LATENCY = "latency"
- UNPACKED_LABELS = "unpacked_labels"
LABEL_COLUMNS = "label_columns"
LABEL_NAMES = "label_names"
PREDICTION = "prediction"
@@ -47,6 +50,22 @@ class EventFieldType:
MINUTES = "minutes"
HOURS = "hours"
DAYS = "days"
+ MODEL_ENDPOINTS = "model_endpoints"
+ STATE = "state"
+ PROJECT = "project"
+ STREAM_PATH = "stream_path"
+ ACTIVE = "active"
+ MONITORING_MODE = "monitoring_mode"
+ FEATURE_STATS = "feature_stats"
+ CURRENT_STATS = "current_stats"
+ CHILDREN = "children"
+ CHILDREN_UIDS = "children_uids"
+ DRIFT_MEASURES = "drift_measures"
+ DRIFT_STATUS = "drift_status"
+ MONITOR_CONFIGURATION = "monitor_configuration"
+ FEATURE_SET_URI = "monitoring_feature_set_uri"
+ ALGORITHM = "algorithm"
+ ACCURACY = "accuracy"
class EventLiveStats:
@@ -61,7 +80,24 @@ class EventKeyMetrics:
BASE_METRICS = "base_metrics"
CUSTOM_METRICS = "custom_metrics"
ENDPOINT_FEATURES = "endpoint_features"
+ GENERIC = "generic"
+ REAL_TIME = "real_time"
-class StoreTarget:
+class TimeSeriesTarget:
TSDB = "tsdb"
+
+
+class ModelEndpointTarget:
+ V3IO_NOSQL = "v3io-nosql"
+ SQL = "sql"
+
+
+class ProjectSecretKeys:
+ ENDPOINT_STORE_CONNECTION = "MODEL_MONITORING_ENDPOINT_STORE_CONNECTION"
+ ACCESS_KEY = "MODEL_MONITORING_ACCESS_KEY"
+
+
+class ModelMonitoringStoreKinds:
+ ENDPOINTS = "endpoints"
+ EVENTS = "events"
diff --git a/mlrun/model_monitoring/helpers.py b/mlrun/model_monitoring/helpers.py
index d35ecd28ebed..22f0450a2856 100644
--- a/mlrun/model_monitoring/helpers.py
+++ b/mlrun/model_monitoring/helpers.py
@@ -22,6 +22,7 @@
import mlrun.api.utils.singletons.db
import mlrun.config
import mlrun.feature_store as fstore
+import mlrun.model_monitoring.constants as model_monitoring_constants
import mlrun.model_monitoring.stream_processing_fs
import mlrun.runtimes
import mlrun.utils.helpers
@@ -85,11 +86,11 @@ def initial_model_monitoring_stream_processing_function(
# Set model monitoring access key for managing permissions
function.set_env_from_secret(
- "MODEL_MONITORING_ACCESS_KEY",
+ model_monitoring_constants.ProjectSecretKeys.ACCESS_KEY,
mlrun.api.utils.singletons.k8s.get_k8s().get_project_secret_name(project),
mlrun.api.crud.secrets.Secrets().generate_client_project_secret_key(
mlrun.api.crud.secrets.SecretsClientType.model_monitoring,
- "MODEL_MONITORING_ACCESS_KEY",
+ model_monitoring_constants.ProjectSecretKeys.ACCESS_KEY,
),
)
@@ -139,11 +140,11 @@ def get_model_monitoring_batch_function(
# Set model monitoring access key for managing permissions
function.set_env_from_secret(
- "MODEL_MONITORING_ACCESS_KEY",
+ model_monitoring_constants.ProjectSecretKeys.ACCESS_KEY,
mlrun.api.utils.singletons.k8s.get_k8s().get_project_secret_name(project),
mlrun.api.crud.secrets.Secrets().generate_client_project_secret_key(
mlrun.api.crud.secrets.SecretsClientType.model_monitoring,
- "MODEL_MONITORING_ACCESS_KEY",
+ model_monitoring_constants.ProjectSecretKeys.ACCESS_KEY,
),
)
diff --git a/mlrun/model_monitoring/model_endpoint.py b/mlrun/model_monitoring/model_endpoint.py
new file mode 100644
index 000000000000..3ad8d094fa8d
--- /dev/null
+++ b/mlrun/model_monitoring/model_endpoint.py
@@ -0,0 +1,141 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+from typing import Any, Dict, List, Optional
+
+import mlrun.model
+
+from .common import EndpointType, ModelMonitoringMode
+from .constants import EventKeyMetrics, EventLiveStats
+
+
+class ModelEndpointSpec(mlrun.model.ModelObj):
+ def __init__(
+ self,
+ function_uri: Optional[str] = "",
+ model: Optional[str] = "",
+ model_class: Optional[str] = "",
+ model_uri: Optional[str] = "",
+ feature_names: Optional[List[str]] = None,
+ label_names: Optional[List[str]] = None,
+ stream_path: Optional[str] = "",
+ algorithm: Optional[str] = "",
+ monitor_configuration: Optional[dict] = None,
+ active: Optional[bool] = True,
+ monitoring_mode: Optional[ModelMonitoringMode] = ModelMonitoringMode.disabled,
+ ):
+ self.function_uri = function_uri # /:
+ self.model = model # :
+ self.model_class = model_class
+ self.model_uri = model_uri
+ self.feature_names = feature_names or []
+ self.label_names = label_names or []
+ self.stream_path = stream_path
+ self.algorithm = algorithm
+ self.monitor_configuration = monitor_configuration or {}
+ self.active = active
+ self.monitoring_mode = monitoring_mode
+
+
+class ModelEndpointStatus(mlrun.model.ModelObj):
+ def __init__(
+ self,
+ feature_stats: Optional[dict] = None,
+ current_stats: Optional[dict] = None,
+ first_request: Optional[str] = "",
+ last_request: Optional[str] = "",
+ error_count: Optional[int] = 0,
+ drift_status: Optional[str] = "",
+ drift_measures: Optional[dict] = None,
+ metrics: Optional[Dict[str, Dict[str, Any]]] = None,
+ features: Optional[List[Dict[str, Any]]] = None,
+ children: Optional[List[str]] = None,
+ children_uids: Optional[List[str]] = None,
+ endpoint_type: Optional[EndpointType] = EndpointType.NODE_EP.value,
+ monitoring_feature_set_uri: Optional[str] = "",
+ state: Optional[str] = "",
+ ):
+ self.feature_stats = feature_stats or {}
+ self.current_stats = current_stats or {}
+ self.first_request = first_request
+ self.last_request = last_request
+ self.error_count = error_count
+ self.drift_status = drift_status
+ self.drift_measures = drift_measures or {}
+ self.features = features or []
+ self.children = children or []
+ self.children_uids = children_uids or []
+ self.endpoint_type = endpoint_type
+ self.monitoring_feature_set_uri = monitoring_feature_set_uri
+ if metrics is None:
+ self.metrics = {
+ EventKeyMetrics.GENERIC: {
+ EventLiveStats.LATENCY_AVG_1H: 0,
+ EventLiveStats.PREDICTIONS_PER_SECOND: 0,
+ }
+ }
+ self.state = state
+
+
+class ModelEndpoint(mlrun.model.ModelObj):
+ kind = "model-endpoint"
+ _dict_fields = ["kind", "metadata", "spec", "status"]
+
+ def __init__(self):
+ self._status: ModelEndpointStatus = ModelEndpointStatus()
+ self._spec: ModelEndpointSpec = ModelEndpointSpec()
+ self._metadata: mlrun.model.VersionedObjMetadata = (
+ mlrun.model.VersionedObjMetadata()
+ )
+
+ @property
+ def status(self) -> ModelEndpointStatus:
+ return self._status
+
+ @status.setter
+ def status(self, status):
+ self._status = self._verify_dict(status, "status", ModelEndpointStatus)
+
+ @property
+ def spec(self) -> ModelEndpointSpec:
+ return self._spec
+
+ @spec.setter
+ def spec(self, spec):
+ self._spec = self._verify_dict(spec, "spec", ModelEndpointSpec)
+
+ @property
+ def metadata(self) -> mlrun.model.VersionedObjMetadata:
+ return self._metadata
+
+ @metadata.setter
+ def metadata(self, metadata):
+ self._metadata = self._verify_dict(
+ metadata, "metadata", mlrun.model.VersionedObjMetadata
+ )
+
+ @classmethod
+ def from_flat_dict(cls, struct=None, fields=None, deprecated_fields: dict = None):
+ new_obj = cls()
+ new_obj._metadata = mlrun.model.VersionedObjMetadata().from_dict(
+ struct=struct, fields=fields, deprecated_fields=deprecated_fields
+ )
+ new_obj._status = ModelEndpointStatus().from_dict(
+ struct=struct, fields=fields, deprecated_fields=deprecated_fields
+ )
+ new_obj._spec = ModelEndpointSpec().from_dict(
+ struct=struct, fields=fields, deprecated_fields=deprecated_fields
+ )
+ return new_obj
diff --git a/mlrun/model_monitoring/model_monitoring_batch.py b/mlrun/model_monitoring/model_monitoring_batch.py
index b8ad312af65e..2d3abf2a1977 100644
--- a/mlrun/model_monitoring/model_monitoring_batch.py
+++ b/mlrun/model_monitoring/model_monitoring_batch.py
@@ -31,11 +31,12 @@
import mlrun.api.schemas
import mlrun.data_types.infer
import mlrun.feature_store as fstore
+import mlrun.model_monitoring
+import mlrun.model_monitoring.stores
import mlrun.run
import mlrun.utils.helpers
import mlrun.utils.model_monitoring
import mlrun.utils.v3io_clients
-from mlrun.model_monitoring.constants import EventFieldType
from mlrun.utils import logger
@@ -461,6 +462,7 @@ def calculate_inputs_statistics(
:returns: The calculated statistics of the inputs data.
"""
+
# Use `DFDataInfer` to calculate the statistics over the inputs:
inputs_statistics = mlrun.data_types.infer.DFDataInfer.get_stats(
df=inputs,
@@ -567,7 +569,10 @@ def __init__(
)
# Get a runtime database
- self.db = mlrun.get_run_db()
+ # self.db = mlrun.get_run_db()
+ self.db = mlrun.model_monitoring.stores.get_model_endpoint_store(
+ project=project
+ )
# Get the frames clients based on the v3io configuration
# it will be used later for writing the results into the tsdb
@@ -584,7 +589,9 @@ def __init__(
self.exception = None
# Get the batch interval range
- self.batch_dict = context.parameters[EventFieldType.BATCH_INTERVALS_DICT]
+ self.batch_dict = context.parameters[
+ mlrun.model_monitoring.EventFieldType.BATCH_INTERVALS_DICT
+ ]
# TODO: This will be removed in 1.2.0 once the job params can be parsed with different types
# Convert batch dict string into a dictionary
@@ -614,231 +621,245 @@ def run(self):
"""
# Get model endpoints (each deployed project has at least 1 serving model):
try:
- endpoints = self.db.list_model_endpoints(self.project)
+ endpoints = self.db.list_model_endpoints()
except Exception as e:
logger.error("Failed to list endpoints", exc=e)
return
- active_endpoints = set()
- for endpoint in endpoints.endpoints:
+ for endpoint in endpoints:
if (
- endpoint.spec.active
- and endpoint.spec.monitoring_mode
- == mlrun.api.schemas.ModelMonitoringMode.enabled.value
+ endpoint[mlrun.model_monitoring.EventFieldType.ACTIVE]
+ and endpoint[mlrun.model_monitoring.EventFieldType.MONITORING_MODE]
+ == mlrun.model_monitoring.ModelMonitoringMode.enabled.value
):
- active_endpoints.add(endpoint.metadata.uid)
-
- # perform drift analysis for each model endpoint
- for endpoint_id in active_endpoints:
- try:
-
- # Get model endpoint object:
- endpoint = self.db.get_model_endpoint(
- project=self.project, endpoint_id=endpoint_id
- )
-
# Skip router endpoint:
if (
- endpoint.status.endpoint_type
- == mlrun.utils.model_monitoring.EndpointType.ROUTER
+ endpoint[mlrun.model_monitoring.EventFieldType.ENDPOINT_TYPE]
+ == mlrun.model_monitoring.EndpointType.ROUTER
):
- # endpoint.status.feature_stats is None
- logger.info(f"{endpoint_id} is router skipping")
+ # Router endpoint has no feature stats
+ logger.info(
+ f"{endpoint[mlrun.model_monitoring.EventFieldType.UID]} is router skipping"
+ )
continue
+ self.update_drift_metrics(endpoint=endpoint)
- # convert feature set into dataframe and get the latest dataset
- (
- _,
- serving_function_name,
- _,
- _,
- ) = mlrun.utils.helpers.parse_versioned_object_uri(
- endpoint.spec.function_uri
- )
+ def update_drift_metrics(self, endpoint: dict):
+ try:
- model_name = endpoint.spec.model.replace(":", "-")
+ # Convert feature set into dataframe and get the latest dataset
+ (
+ _,
+ serving_function_name,
+ _,
+ _,
+ ) = mlrun.utils.helpers.parse_versioned_object_uri(
+ endpoint[mlrun.model_monitoring.EventFieldType.FUNCTION_URI]
+ )
- m_fs = fstore.get_feature_set(
- f"store://feature-sets/{self.project}/monitoring-{serving_function_name}-{model_name}"
- )
+ model_name = endpoint[mlrun.model_monitoring.EventFieldType.MODEL].replace(
+ ":", "-"
+ )
+
+ m_fs = fstore.get_feature_set(
+ f"store://feature-sets/{self.project}/monitoring-{serving_function_name}-{model_name}"
+ )
- # Getting batch interval start time and end time
- start_time, end_time = self.get_interval_range()
+ # Getting batch interval start time and end time
+ start_time, end_time = self.get_interval_range()
- try:
- df = m_fs.to_dataframe(
- start_time=start_time,
- end_time=end_time,
- time_column="timestamp",
- )
+ try:
+ df = m_fs.to_dataframe(
+ start_time=start_time,
+ end_time=end_time,
+ time_column="timestamp",
+ )
- if len(df) == 0:
- logger.warn(
- "Not enough model events since the beginning of the batch interval",
- parquet_target=m_fs.status.targets[0].path,
- endpoint=endpoint_id,
- min_rqeuired_events=mlrun.mlconf.model_endpoint_monitoring.parquet_batching_max_events,
- start_time=str(
- datetime.datetime.now() - datetime.timedelta(hours=1)
- ),
- end_time=str(datetime.datetime.now()),
- )
- continue
-
- # TODO: The below warn will be removed once the state of the Feature Store target is updated
- # as expected. In that case, the existence of the file will be checked before trying to get
- # the offline data from the feature set.
- # Continue if not enough events provided since the deployment of the model endpoint
- except FileNotFoundError:
+ if len(df) == 0:
logger.warn(
- "Parquet not found, probably due to not enough model events",
+ "Not enough model events since the beginning of the batch interval",
parquet_target=m_fs.status.targets[0].path,
- endpoint=endpoint_id,
+ endpoint=endpoint[mlrun.model_monitoring.EventFieldType.UID],
min_rqeuired_events=mlrun.mlconf.model_endpoint_monitoring.parquet_batching_max_events,
+ start_time=str(
+ datetime.datetime.now() - datetime.timedelta(hours=1)
+ ),
+ end_time=str(datetime.datetime.now()),
)
- continue
-
- # Get feature names from monitoring feature set
- feature_names = [
- feature_name["name"]
- for feature_name in m_fs.spec.features.to_dict()
- ]
-
- # Create DataFrame based on the input features
- stats_columns = [
- "timestamp",
- *feature_names,
- ]
-
- # Add label names if provided
- if endpoint.spec.label_names:
- stats_columns.extend(endpoint.spec.label_names)
-
- named_features_df = df[stats_columns].copy()
-
- # Infer feature set stats and schema
- fstore.api._infer_from_static_df(
- named_features_df,
- m_fs,
- options=mlrun.data_types.infer.InferOptions.all_stats(),
+ return
+
+ # TODO: The below warn will be removed once the state of the Feature Store target is updated
+ # as expected. In that case, the existence of the file will be checked before trying to get
+ # the offline data from the feature set.
+ # Continue if not enough events provided since the deployment of the model endpoint
+ except FileNotFoundError:
+ logger.warn(
+ "Parquet not found, probably due to not enough model events",
+ parquet_target=m_fs.status.targets[0].path,
+ endpoint=endpoint[mlrun.model_monitoring.EventFieldType.UID],
+ min_rqeuired_events=mlrun.mlconf.model_endpoint_monitoring.parquet_batching_max_events,
)
+ return
- # Save feature set to apply changes
- m_fs.save()
+ # Get feature names from monitoring feature set
+ feature_names = [
+ feature_name["name"] for feature_name in m_fs.spec.features.to_dict()
+ ]
+ # Create DataFrame based on the input features
+ stats_columns = [
+ "timestamp",
+ *feature_names,
+ ]
+ # Add label names if provided
+ if endpoint[mlrun.model_monitoring.EventFieldType.LABEL_NAMES]:
+ labels = endpoint[mlrun.model_monitoring.EventFieldType.LABEL_NAMES]
+ if isinstance(labels, str):
+ labels = json.loads(labels)
+ stats_columns.extend(labels)
+
+ named_features_df = df[stats_columns].copy()
+
+ # Infer feature set stats and schema
+ fstore.api._infer_from_static_df(
+ named_features_df,
+ m_fs,
+ options=mlrun.data_types.infer.InferOptions.all_stats(),
+ )
- # Get the timestamp of the latest request:
- timestamp = df["timestamp"].iloc[-1]
+ # Save feature set to apply changes
+ m_fs.save()
- # Get the current stats:
- current_stats = calculate_inputs_statistics(
- sample_set_statistics=endpoint.status.feature_stats,
- inputs=named_features_df,
- )
+ # Get the timestamp of the latest request:
+ timestamp = df["timestamp"].iloc[-1]
- # Compute the drift based on the histogram of the current stats and the histogram of the original
- # feature stats that can be found in the model endpoint object:
- drift_result = self.virtual_drift.compute_drift_from_histograms(
- feature_stats=endpoint.status.feature_stats,
- current_stats=current_stats,
- )
- logger.info("Drift result", drift_result=drift_result)
+ # Get the feature stats from the model endpoint for reference data
+ feature_stats = json.loads(
+ endpoint[mlrun.model_monitoring.EventFieldType.FEATURE_STATS]
+ )
- # Get drift thresholds from the model configuration:
- monitor_configuration = endpoint.spec.monitor_configuration or {}
- possible_drift = monitor_configuration.get(
- "possible_drift", self.default_possible_drift_threshold
- )
- drift_detected = monitor_configuration.get(
- "drift_detected", self.default_drift_detected_threshold
- )
+ # Get the current stats:
+ current_stats = calculate_inputs_statistics(
+ sample_set_statistics=feature_stats,
+ inputs=named_features_df,
+ )
- # Check for possible drift based on the results of the statistical metrics defined above:
- drift_status, drift_measure = self.virtual_drift.check_for_drift(
- metrics_results_dictionary=drift_result,
- possible_drift_threshold=possible_drift,
- drift_detected_threshold=drift_detected,
+ # Compute the drift based on the histogram of the current stats and the histogram of the original
+ # feature stats that can be found in the model endpoint object:
+ drift_result = self.virtual_drift.compute_drift_from_histograms(
+ feature_stats=feature_stats,
+ current_stats=current_stats,
+ )
+ logger.info("Drift result", drift_result=drift_result)
+
+ # Get drift thresholds from the model configuration:
+ monitor_configuration = (
+ json.loads(
+ endpoint[
+ mlrun.model_monitoring.EventFieldType.MONITOR_CONFIGURATION
+ ]
)
- logger.info(
- "Drift status",
- endpoint_id=endpoint_id,
- drift_status=drift_status.value,
- drift_measure=drift_measure,
+ or {}
+ )
+ possible_drift = monitor_configuration.get(
+ "possible_drift", self.default_possible_drift_threshold
+ )
+ drift_detected = monitor_configuration.get(
+ "drift_detected", self.default_drift_detected_threshold
+ )
+
+ # Check for possible drift based on the results of the statistical metrics defined above:
+ drift_status, drift_measure = self.virtual_drift.check_for_drift(
+ metrics_results_dictionary=drift_result,
+ possible_drift_threshold=possible_drift,
+ drift_detected_threshold=drift_detected,
+ )
+ logger.info(
+ "Drift status",
+ endpoint_id=endpoint[mlrun.model_monitoring.EventFieldType.UID],
+ drift_status=drift_status.value,
+ drift_measure=drift_measure,
+ )
+
+ # If drift was detected, add the results to the input stream
+ if (
+ drift_status == DriftStatus.POSSIBLE_DRIFT
+ or drift_status == DriftStatus.DRIFT_DETECTED
+ ):
+ self.v3io.stream.put_records(
+ container=self.stream_container,
+ stream_path=self.stream_path,
+ records=[
+ {
+ "data": json.dumps(
+ {
+ "endpoint_id": endpoint[
+ mlrun.model_monitoring.EventFieldType.UID
+ ],
+ "drift_status": drift_status.value,
+ "drift_measure": drift_measure,
+ "drift_per_feature": {**drift_result},
+ }
+ )
+ }
+ ],
)
- # If drift was detected, add the results to the input stream
- if (
- drift_status == DriftStatus.POSSIBLE_DRIFT
- or drift_status == DriftStatus.DRIFT_DETECTED
- ):
- self.v3io.stream.put_records(
- container=self.stream_container,
- stream_path=self.stream_path,
- records=[
- {
- "data": json.dumps(
- {
- "endpoint_id": endpoint_id,
- "drift_status": drift_status.value,
- "drift_measure": drift_measure,
- "drift_per_feature": {**drift_result},
- }
- )
- }
- ],
- )
+ attributes = {
+ "current_stats": json.dumps(current_stats),
+ "drift_measures": json.dumps(drift_result),
+ "drift_status": drift_status.value,
+ }
- attributes = {
- "current_stats": json.dumps(current_stats),
- "drift_measures": json.dumps(drift_result),
- "drift_status": drift_status.value,
- }
+ self.db.update_model_endpoint(
+ endpoint_id=endpoint[mlrun.model_monitoring.EventFieldType.UID],
+ attributes=attributes,
+ )
- self.db.patch_model_endpoint(
- project=self.project,
- endpoint_id=endpoint_id,
- attributes=attributes,
- )
+ # Update the results in tsdb:
+ tsdb_drift_measures = {
+ "endpoint_id": endpoint[mlrun.model_monitoring.EventFieldType.UID],
+ "timestamp": pd.to_datetime(
+ timestamp,
+ format=mlrun.model_monitoring.EventFieldType.TIME_FORMAT,
+ ),
+ "record_type": "drift_measures",
+ "tvd_mean": drift_result["tvd_mean"],
+ "kld_mean": drift_result["kld_mean"],
+ "hellinger_mean": drift_result["hellinger_mean"],
+ }
- # Update the results in tsdb:
- tsdb_drift_measures = {
- "endpoint_id": endpoint_id,
- "timestamp": pd.to_datetime(
- timestamp,
- format=EventFieldType.TIME_FORMAT,
- ),
- "record_type": "drift_measures",
- "tvd_mean": drift_result["tvd_mean"],
- "kld_mean": drift_result["kld_mean"],
- "hellinger_mean": drift_result["hellinger_mean"],
- }
-
- try:
- self.frames.write(
- backend="tsdb",
- table=self.tsdb_path,
- dfs=pd.DataFrame.from_dict([tsdb_drift_measures]),
- index_cols=["timestamp", "endpoint_id", "record_type"],
- )
- except v3io_frames.errors.Error as err:
- logger.warn(
- "Could not write drift measures to TSDB",
- err=err,
- tsdb_path=self.tsdb_path,
- endpoint=endpoint_id,
- )
+ try:
+ self.frames.write(
+ backend="tsdb",
+ table=self.tsdb_path,
+ dfs=pd.DataFrame.from_dict([tsdb_drift_measures]),
+ index_cols=["timestamp", "endpoint_id", "record_type"],
+ )
+ except v3io_frames.errors.Error as err:
+ logger.warn(
+ "Could not write drift measures to TSDB",
+ err=err,
+ tsdb_path=self.tsdb_path,
+ endpoint=endpoint[mlrun.model_monitoring.EventFieldType.UID],
+ )
- logger.info("Done updating drift measures", endpoint_id=endpoint_id)
+ logger.info(
+ "Done updating drift measures",
+ endpoint_id=endpoint[mlrun.model_monitoring.EventFieldType.UID],
+ )
- except Exception as e:
- logger.error(f"Exception for endpoint {endpoint_id}")
- self.exception = e
+ except Exception as e:
+ logger.error(
+ f"Exception for endpoint {endpoint[mlrun.model_monitoring.EventFieldType.UID]}"
+ )
+ self.exception = e
def get_interval_range(self) -> Tuple[datetime.datetime, datetime.datetime]:
"""Getting batch interval time range"""
minutes, hours, days = (
- self.batch_dict[EventFieldType.MINUTES],
- self.batch_dict[EventFieldType.HOURS],
- self.batch_dict[EventFieldType.DAYS],
+ self.batch_dict[mlrun.model_monitoring.EventFieldType.MINUTES],
+ self.batch_dict[mlrun.model_monitoring.EventFieldType.HOURS],
+ self.batch_dict[mlrun.model_monitoring.EventFieldType.DAYS],
)
start_time = datetime.datetime.now() - datetime.timedelta(
minutes=minutes, hours=hours, days=days
@@ -863,7 +884,9 @@ def handler(context: mlrun.run.MLClientCtx):
batch_processor = BatchProcessor(
context=context,
project=context.project,
- model_monitoring_access_key=os.environ.get("MODEL_MONITORING_ACCESS_KEY"),
+ model_monitoring_access_key=os.environ.get(
+ mlrun.model_monitoring.ProjectSecretKeys.ACCESS_KEY
+ ),
v3io_access_key=os.environ.get("V3IO_ACCESS_KEY"),
)
batch_processor.post_init()
diff --git a/mlrun/model_monitoring/stores/__init__.py b/mlrun/model_monitoring/stores/__init__.py
new file mode 100644
index 000000000000..b36430ebc676
--- /dev/null
+++ b/mlrun/model_monitoring/stores/__init__.py
@@ -0,0 +1,106 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# flake8: noqa - this is until we take care of the F401 violations with respect to __all__ & sphinx
+
+import enum
+import typing
+
+import mlrun
+
+from .model_endpoint_store import ModelEndpointStore
+
+
+class ModelEndpointStoreType(enum.Enum):
+ """Enum class to handle the different store type values for saving a model endpoint record."""
+
+ v3io_nosql = "v3io-nosql"
+ SQL = "sql"
+
+ def to_endpoint_store(
+ self,
+ project: str,
+ access_key: str = None,
+ endpoint_store_connection: str = None,
+ ) -> ModelEndpointStore:
+ """
+ Return a ModelEndpointStore object based on the provided enum value.
+
+ :param project: The name of the project.
+ :param access_key: Access key with permission to the DB table. Note that if access key is None
+ and the endpoint target is from type KV then the access key will be
+ retrieved from the environment variable.
+ :param endpoint_store_connection: A valid connection string for model endpoint target. Contains several
+ key-value pairs that required for the database connection.
+ e.g. A root user with password 1234, tries to connect a schema called
+ mlrun within a local MySQL DB instance:
+ 'mysql+pymysql://root:1234@localhost:3306/mlrun'.
+
+ :return: `ModelEndpointStore` object.
+
+ """
+
+ if self.value == ModelEndpointStoreType.v3io_nosql.value:
+
+ from .kv_model_endpoint_store import KVModelEndpointStore
+
+ # Get V3IO access key from env
+ access_key = access_key or mlrun.mlconf.get_v3io_access_key()
+
+ return KVModelEndpointStore(project=project, access_key=access_key)
+
+ # Assuming SQL store target if store type is not KV.
+ # Update these lines once there are more than two store target types.
+ from mlrun.utils.model_monitoring import get_connection_string
+
+ sql_connection_string = endpoint_store_connection or get_connection_string(
+ project=project
+ )
+ from .sql_model_endpoint_store import SQLModelEndpointStore
+
+ return SQLModelEndpointStore(
+ project=project, sql_connection_string=sql_connection_string
+ )
+
+ @classmethod
+ def _missing_(cls, value: typing.Any):
+ """A lookup function to handle an invalid value.
+ :param value: Provided enum (invalid) value.
+ """
+ valid_values = list(cls.__members__.keys())
+ raise mlrun.errors.MLRunInvalidArgumentError(
+ f"{value} is not a valid endpoint store, please choose a valid value: %{valid_values}."
+ )
+
+
+def get_model_endpoint_store(
+ project: str, access_key: str = None
+) -> ModelEndpointStore:
+ """
+ Getting the DB target type based on mlrun.config.model_endpoint_monitoring.store_type.
+
+ :param project: The name of the project.
+ :param access_key: Access key with permission to the DB table.
+
+ :return: `ModelEndpointStore` object. Using this object, the user can apply different operations on the
+ model endpoint record such as write, update, get and delete.
+ """
+
+ # Get store type value from ModelEndpointStoreType enum class
+ model_endpoint_store_type = ModelEndpointStoreType(
+ mlrun.mlconf.model_endpoint_monitoring.store_type
+ )
+
+ # Convert into model endpoint store target object
+ return model_endpoint_store_type.to_endpoint_store(project, access_key)
diff --git a/mlrun/model_monitoring/stores/kv_model_endpoint_store.py b/mlrun/model_monitoring/stores/kv_model_endpoint_store.py
new file mode 100644
index 000000000000..1d5bed5acbda
--- /dev/null
+++ b/mlrun/model_monitoring/stores/kv_model_endpoint_store.py
@@ -0,0 +1,441 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+import os
+import typing
+
+import v3io.dataplane
+import v3io_frames
+
+import mlrun
+import mlrun.model_monitoring.constants as model_monitoring_constants
+import mlrun.utils.model_monitoring
+import mlrun.utils.v3io_clients
+from mlrun.utils import logger
+
+from .model_endpoint_store import ModelEndpointStore
+
+
+class KVModelEndpointStore(ModelEndpointStore):
+ """
+ Handles the DB operations when the DB target is from type KV. For the KV operations, we use an instance of V3IO
+ client and usually the KV table can be found under v3io:///users/pipelines/project-name/model-endpoints/endpoints/.
+ """
+
+ def __init__(self, project: str, access_key: str):
+ super().__init__(project=project)
+ # Initialize a V3IO client instance
+ self.access_key = access_key or os.environ.get("V3IO_ACCESS_KEY")
+ self.client = mlrun.utils.v3io_clients.get_v3io_client(
+ endpoint=mlrun.mlconf.v3io_api, access_key=self.access_key
+ )
+ # Get the KV table path and container
+ self.path, self.container = self._get_path_and_container()
+
+ def write_model_endpoint(self, endpoint: typing.Dict[str, typing.Any]):
+ """
+ Create a new endpoint record in the KV table.
+
+ :param endpoint: model endpoint dictionary that will be written into the DB.
+ """
+
+ self.client.kv.put(
+ container=self.container,
+ table_path=self.path,
+ key=endpoint[model_monitoring_constants.EventFieldType.UID],
+ attributes=endpoint,
+ )
+
+ def update_model_endpoint(
+ self, endpoint_id: str, attributes: typing.Dict[str, typing.Any]
+ ):
+ """
+ Update a model endpoint record with a given attributes.
+
+ :param endpoint_id: The unique id of the model endpoint.
+ :param attributes: Dictionary of attributes that will be used for update the model endpoint. Note that the keys
+ of the attributes dictionary should exist in the KV table.
+
+ """
+
+ self.client.kv.update(
+ container=self.container,
+ table_path=self.path,
+ key=endpoint_id,
+ attributes=attributes,
+ )
+
+ def delete_model_endpoint(
+ self,
+ endpoint_id: str,
+ ):
+ """
+ Deletes the KV record of a given model endpoint id.
+
+ :param endpoint_id: The unique id of the model endpoint.
+ """
+
+ self.client.kv.delete(
+ container=self.container,
+ table_path=self.path,
+ key=endpoint_id,
+ )
+
+ def get_model_endpoint(
+ self,
+ endpoint_id: str,
+ ) -> typing.Dict[str, typing.Any]:
+ """
+ Get a single model endpoint record.
+
+ :param endpoint_id: The unique id of the model endpoint.
+
+ :return: A model endpoint record as a dictionary.
+
+ :raise MLRunNotFoundError: If the endpoint was not found.
+ """
+
+ # Getting the raw data from the KV table
+ endpoint = self.client.kv.get(
+ container=self.container,
+ table_path=self.path,
+ key=endpoint_id,
+ raise_for_status=v3io.dataplane.RaiseForStatus.never,
+ access_key=self.access_key,
+ )
+ endpoint = endpoint.output.item
+
+ if not endpoint:
+ raise mlrun.errors.MLRunNotFoundError(f"Endpoint {endpoint_id} not found")
+
+ # For backwards compatability: replace null values for `error_count` and `metrics`
+ mlrun.utils.model_monitoring.validate_errors_and_metrics(endpoint=endpoint)
+
+ return endpoint
+
+ def _get_path_and_container(self):
+ """Getting path and container based on the model monitoring configurations"""
+ path = mlrun.mlconf.model_endpoint_monitoring.store_prefixes.default.format(
+ project=self.project,
+ kind=model_monitoring_constants.ModelMonitoringStoreKinds.ENDPOINTS,
+ )
+ (
+ _,
+ container,
+ path,
+ ) = mlrun.utils.model_monitoring.parse_model_endpoint_store_prefix(path)
+ return path, container
+
+ def list_model_endpoints(
+ self,
+ model: str = None,
+ function: str = None,
+ labels: typing.List[str] = None,
+ top_level: bool = None,
+ uids: typing.List = None,
+ ) -> typing.List[typing.Dict[str, typing.Any]]:
+ """
+ Returns a list of model endpoint dictionaries, supports filtering by model, function, labels or top level.
+ By default, when no filters are applied, all available model endpoints for the given project will
+ be listed.
+
+ :param model: The name of the model to filter by.
+ :param function: The name of the function to filter by.
+ :param labels: A list of labels to filter by. Label filters work by either filtering a specific value
+ of a label (i.e. list("key=value")) or by looking for the existence of a given
+ key (i.e. "key").
+ :param top_level: If True will return only routers and endpoint that are NOT children of any router.
+ :param uids: List of model endpoint unique ids to include in the result.
+
+
+ :return: A list of model endpoint dictionaries.
+ """
+
+ # # Initialize an empty model endpoints list
+ endpoint_list = []
+
+ # Retrieve the raw data from the KV table and get the endpoint ids
+ try:
+
+ cursor = self.client.kv.new_cursor(
+ container=self.container,
+ table_path=self.path,
+ filter_expression=self._build_kv_cursor_filter_expression(
+ self.project,
+ function,
+ model,
+ labels,
+ top_level,
+ ),
+ raise_for_status=v3io.dataplane.RaiseForStatus.never,
+ )
+ items = cursor.all()
+
+ except Exception as exc:
+ logger.warning("Failed retrieving raw data from kv table", exc=exc)
+ return endpoint_list
+
+ # Create a list of model endpoints unique ids
+ if uids is None:
+ uids = []
+ for item in items:
+ if model_monitoring_constants.EventFieldType.UID not in item:
+ # This is kept for backwards compatibility - in old versions the key column named endpoint_id
+ uids.append(
+ item[model_monitoring_constants.EventFieldType.ENDPOINT_ID]
+ )
+ else:
+ uids.append(item[model_monitoring_constants.EventFieldType.UID])
+
+ # Add each relevant model endpoint to the model endpoints list
+ for endpoint_id in uids:
+ endpoint = self.get_model_endpoint(
+ endpoint_id=endpoint_id,
+ )
+ endpoint_list.append(endpoint)
+
+ return endpoint_list
+
+ def delete_model_endpoints_resources(
+ self, endpoints: typing.List[typing.Dict[str, typing.Any]]
+ ):
+ """
+ Delete all model endpoints resources in both KV and the time series DB.
+
+ :param endpoints: A list of model endpoints flattened dictionaries.
+ """
+
+ # Delete model endpoint record from KV table
+ for endpoint_dict in endpoints:
+ self.delete_model_endpoint(
+ endpoint_dict[model_monitoring_constants.EventFieldType.UID],
+ )
+
+ # Delete remain records in the KV
+ all_records = self.client.kv.new_cursor(
+ container=self.container,
+ table_path=self.path,
+ raise_for_status=v3io.dataplane.RaiseForStatus.never,
+ ).all()
+
+ all_records = [r["__name"] for r in all_records]
+
+ # Cleanup KV
+ for record in all_records:
+ self.client.kv.delete(
+ container=self.container,
+ table_path=self.path,
+ key=record,
+ raise_for_status=v3io.dataplane.RaiseForStatus.never,
+ )
+
+ # Cleanup TSDB
+ frames = mlrun.utils.v3io_clients.get_frames_client(
+ token=self.access_key,
+ address=mlrun.mlconf.v3io_framesd,
+ container=self.container,
+ )
+
+ # Generate the required tsdb paths
+ tsdb_path, filtered_path = self._generate_tsdb_paths()
+
+ # Delete time series DB resources
+ try:
+ frames.delete(
+ backend=model_monitoring_constants.TimeSeriesTarget.TSDB,
+ table=filtered_path,
+ )
+ except (v3io_frames.errors.DeleteError, v3io_frames.errors.CreateError) as e:
+ # Frames might raise an exception if schema file does not exist.
+ logger.warning("Failed to delete TSDB schema file:", err=e)
+ pass
+
+ # Final cleanup of tsdb path
+ tsdb_path.replace("://u", ":///u")
+ store, _ = mlrun.store_manager.get_or_create_store(tsdb_path)
+ store.rm(tsdb_path, recursive=True)
+
+ def get_endpoint_real_time_metrics(
+ self,
+ endpoint_id: str,
+ metrics: typing.List[str],
+ start: str = "now-1h",
+ end: str = "now",
+ access_key: str = None,
+ ) -> typing.Dict[str, typing.List[typing.Tuple[str, float]]]:
+ """
+ Getting metrics from the time series DB. There are pre-defined metrics for model endpoints such as
+ `predictions_per_second` and `latency_avg_5m` but also custom metrics defined by the user.
+
+ :param endpoint_id: The unique id of the model endpoint.
+ :param metrics: A list of real-time metrics to return for the model endpoint.
+ :param start: The start time of the metrics. Can be represented by a string containing an RFC 3339
+ time, a Unix timestamp in milliseconds, a relative time (`'now'` or
+ `'now-[0-9]+[mhd]'`, where `m` = minutes, `h` = hours, and `'d'` = days), or 0 for the
+ earliest time.
+ :param end: The end time of the metrics. Can be represented by a string containing an RFC 3339
+ time, a Unix timestamp in milliseconds, a relative time (`'now'` or
+ `'now-[0-9]+[mhd]'`, where `m` = minutes, `h` = hours, and `'d'` = days), or 0 for the
+ earliest time.
+ :param access_key: V3IO access key that will be used for generating Frames client object. If not
+ provided, the access key will be retrieved from the environment variables.
+
+ :return: A dictionary of metrics in which the key is a metric name and the value is a list of tuples that
+ includes timestamps and the values.
+ """
+
+ # Initialize access key
+ access_key = access_key or mlrun.mlconf.get_v3io_access_key()
+
+ if not metrics:
+ raise mlrun.errors.MLRunInvalidArgumentError(
+ "Metric names must be provided"
+ )
+
+ # Initialize metrics mapping dictionary
+ metrics_mapping = {}
+
+ # Getting the path for the time series DB
+ events_path = (
+ mlrun.mlconf.model_endpoint_monitoring.store_prefixes.default.format(
+ project=self.project,
+ kind=model_monitoring_constants.ModelMonitoringStoreKinds.EVENTS,
+ )
+ )
+ (
+ _,
+ container,
+ events_path,
+ ) = mlrun.utils.model_monitoring.parse_model_endpoint_store_prefix(events_path)
+
+ # Retrieve the raw data from the time series DB based on the provided metrics and time ranges
+ frames_client = mlrun.utils.v3io_clients.get_frames_client(
+ token=access_key,
+ address=mlrun.mlconf.v3io_framesd,
+ container=container,
+ )
+
+ try:
+ data = frames_client.read(
+ backend=model_monitoring_constants.TimeSeriesTarget.TSDB,
+ table=events_path,
+ columns=["endpoint_id", *metrics],
+ filter=f"endpoint_id=='{endpoint_id}'",
+ start=start,
+ end=end,
+ )
+
+ # Fill the metrics mapping dictionary with the metric name and values
+ data_dict = data.to_dict()
+ for metric in metrics:
+ metric_data = data_dict.get(metric)
+ if metric_data is None:
+ continue
+
+ values = [
+ (str(timestamp), value) for timestamp, value in metric_data.items()
+ ]
+ metrics_mapping[metric] = values
+
+ except v3io_frames.errors.ReadError:
+ logger.warn("Failed to read tsdb", endpoint=endpoint_id)
+
+ return metrics_mapping
+
+ def _generate_tsdb_paths(self) -> typing.Tuple[str, str]:
+ """Generate a short path to the TSDB resources and a filtered path for the frames object
+ :return: A tuple of:
+ [0] = Short path to the TSDB resources
+ [1] = Filtered path to TSDB events without schema and container
+ """
+ # Full path for the time series DB events
+ full_path = (
+ mlrun.mlconf.model_endpoint_monitoring.store_prefixes.default.format(
+ project=self.project,
+ kind=model_monitoring_constants.ModelMonitoringStoreKinds.EVENTS,
+ )
+ )
+
+ # Generate the main directory with the TSDB resources
+ tsdb_path = mlrun.utils.model_monitoring.parse_model_endpoint_project_prefix(
+ full_path, self.project
+ )
+
+ # Generate filtered path without schema and container as required by the frames object
+ (
+ _,
+ _,
+ filtered_path,
+ ) = mlrun.utils.model_monitoring.parse_model_endpoint_store_prefix(full_path)
+ return tsdb_path, filtered_path
+
+ @staticmethod
+ def _build_kv_cursor_filter_expression(
+ project: str,
+ function: str = None,
+ model: str = None,
+ labels: typing.List[str] = None,
+ top_level: bool = False,
+ ) -> str:
+ """
+ Convert the provided filters into a valid filter expression. The expected filter expression includes different
+ conditions, divided by ' AND '.
+
+ :param project: The name of the project.
+ :param model: The name of the model to filter by.
+ :param function: The name of the function to filter by.
+ :param labels: A list of labels to filter by. Label filters work by either filtering a specific value of
+ a label (i.e. list("key=value")) or by looking for the existence of a given
+ key (i.e. "key").
+ :param top_level: If True will return only routers and endpoint that are NOT children of any router.
+
+ :return: A valid filter expression as a string.
+
+ :raise MLRunInvalidArgumentError: If project value is None.
+ """
+
+ if not project:
+ raise mlrun.errors.MLRunInvalidArgumentError("project can't be empty")
+
+ # Add project filter
+ filter_expression = [f"project=='{project}'"]
+
+ # Add function and model filters
+ if function:
+ filter_expression.append(f"function=='{function}'")
+ if model:
+ filter_expression.append(f"model=='{model}'")
+
+ # Add labels filters
+ if labels:
+
+ for label in labels:
+ if not label.startswith("_"):
+ label = f"_{label}"
+
+ if "=" in label:
+ lbl, value = list(map(lambda x: x.strip(), label.split("=")))
+ filter_expression.append(f"{lbl}=='{value}'")
+ else:
+ filter_expression.append(f"exists({label})")
+
+ # Apply top_level filter (remove endpoints that considered a child of a router)
+ if top_level:
+ filter_expression.append(
+ f"(endpoint_type=='{str(mlrun.model_monitoring.EndpointType.NODE_EP.value)}' "
+ f"OR endpoint_type=='{str(mlrun.model_monitoring.EndpointType.ROUTER.value)}')"
+ )
+
+ return " AND ".join(filter_expression)
diff --git a/mlrun/model_monitoring/stores/model_endpoint_store.py b/mlrun/model_monitoring/stores/model_endpoint_store.py
new file mode 100644
index 000000000000..6aaa51081328
--- /dev/null
+++ b/mlrun/model_monitoring/stores/model_endpoint_store.py
@@ -0,0 +1,147 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+import typing
+from abc import ABC, abstractmethod
+
+
+class ModelEndpointStore(ABC):
+ """
+ An abstract class to handle the model endpoint in the DB target.
+ """
+
+ def __init__(self, project: str):
+ """
+ Initialize a new model endpoint target.
+
+ :param project: The name of the project.
+ """
+ self.project = project
+
+ @abstractmethod
+ def write_model_endpoint(self, endpoint: typing.Dict[str, typing.Any]):
+ """
+ Create a new endpoint record in the DB table.
+
+ :param endpoint: model endpoint dictionary that will be written into the DB.
+ """
+ pass
+
+ @abstractmethod
+ def update_model_endpoint(
+ self, endpoint_id: str, attributes: typing.Dict[str, typing.Any]
+ ):
+ """
+ Update a model endpoint record with a given attributes.
+
+ :param endpoint_id: The unique id of the model endpoint.
+ :param attributes: Dictionary of attributes that will be used for update the model endpoint. Note that the keys
+ of the attributes dictionary should exist in the DB table.
+
+ """
+ pass
+
+ @abstractmethod
+ def delete_model_endpoint(self, endpoint_id: str):
+ """
+ Deletes the record of a given model endpoint id.
+
+ :param endpoint_id: The unique id of the model endpoint.
+ """
+ pass
+
+ @abstractmethod
+ def delete_model_endpoints_resources(
+ self, endpoints: typing.List[typing.Dict[str, typing.Any]]
+ ):
+ """
+ Delete all model endpoints resources.
+
+ :param endpoints: A list of model endpoints flattened dictionaries.
+
+ """
+ pass
+
+ @abstractmethod
+ def get_model_endpoint(
+ self,
+ endpoint_id: str,
+ ) -> typing.Dict[str, typing.Any]:
+ """
+ Get a single model endpoint record.
+
+ :param endpoint_id: The unique id of the model endpoint.
+
+ :return: A model endpoint record as a dictionary.
+ """
+ pass
+
+ @abstractmethod
+ def list_model_endpoints(
+ self,
+ model: str = None,
+ function: str = None,
+ labels: typing.List[str] = None,
+ top_level: bool = None,
+ uids: typing.List = None,
+ ) -> typing.List[typing.Dict[str, typing.Any]]:
+ """
+ Returns a list of model endpoint dictionaries, supports filtering by model, function, labels or top level.
+ By default, when no filters are applied, all available model endpoints for the given project will
+ be listed.
+
+ :param model: The name of the model to filter by.
+ :param function: The name of the function to filter by.
+ :param labels: A list of labels to filter by. Label filters work by either filtering a specific value
+ of a label (i.e. list("key=value")) or by looking for the existence of a given
+ key (i.e. "key").
+ :param top_level: If True will return only routers and endpoint that are NOT children of any router.
+ :param uids: List of model endpoint unique ids to include in the result.
+
+ :return: A list of model endpoint dictionaries.
+ """
+ pass
+
+ @abstractmethod
+ def get_endpoint_real_time_metrics(
+ self,
+ endpoint_id: str,
+ metrics: typing.List[str],
+ start: str = "now-1h",
+ end: str = "now",
+ access_key: str = None,
+ ) -> typing.Dict[str, typing.List[typing.Tuple[str, float]]]:
+ """
+ Getting metrics from the time series DB. There are pre-defined metrics for model endpoints such as
+ `predictions_per_second` and `latency_avg_5m` but also custom metrics defined by the user.
+
+ :param endpoint_id: The unique id of the model endpoint.
+ :param metrics: A list of real-time metrics to return for the model endpoint.
+ :param start: The start time of the metrics. Can be represented by a string containing an RFC 3339
+ time, a Unix timestamp in milliseconds, a relative time (`'now'` or
+ `'now-[0-9]+[mhd]'`, where `m` = minutes, `h` = hours, and `'d'` = days), or 0 for the
+ earliest time.
+ :param end: The end time of the metrics. Can be represented by a string containing an RFC 3339
+ time, a Unix timestamp in milliseconds, a relative time (`'now'` or
+ `'now-[0-9]+[mhd]'`, where `m` = minutes, `h` = hours, and `'d'` = days), or 0 for the
+ earliest time.
+ :param access_key: V3IO access key that will be used for generating Frames client object. If not
+ provided, the access key will be retrieved from the environment variables.
+
+ :return: A dictionary of metrics in which the key is a metric name and the value is a list of tuples that
+ includes timestamps and the values.
+ """
+
+ pass
diff --git a/mlrun/model_monitoring/stores/models/__init__.py b/mlrun/model_monitoring/stores/models/__init__.py
new file mode 100644
index 000000000000..4329738e5bbb
--- /dev/null
+++ b/mlrun/model_monitoring/stores/models/__init__.py
@@ -0,0 +1,23 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+
+def get_ModelEndpointsTable(connection_string: str = None):
+ """Return ModelEndpointsTable based on the provided connection string"""
+ if "mysql:" in connection_string:
+ from .mysql import ModelEndpointsTable
+ else:
+ from .sqlite import ModelEndpointsTable
+ return ModelEndpointsTable
diff --git a/mlrun/model_monitoring/stores/models/base.py b/mlrun/model_monitoring/stores/models/base.py
new file mode 100644
index 000000000000..ad3a65122cbc
--- /dev/null
+++ b/mlrun/model_monitoring/stores/models/base.py
@@ -0,0 +1,18 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+from sqlalchemy.ext.declarative import declarative_base
+
+Base = declarative_base()
diff --git a/mlrun/model_monitoring/stores/models/mysql.py b/mlrun/model_monitoring/stores/models/mysql.py
new file mode 100644
index 000000000000..69f3faf43b62
--- /dev/null
+++ b/mlrun/model_monitoring/stores/models/mysql.py
@@ -0,0 +1,100 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+
+import sqlalchemy.dialects
+from sqlalchemy import Boolean, Column, Integer, String, Text
+
+import mlrun.model_monitoring.constants as model_monitoring_constants
+from mlrun.utils.db import BaseModel
+
+from .base import Base
+
+
+class ModelEndpointsTable(Base, BaseModel):
+ __tablename__ = model_monitoring_constants.EventFieldType.MODEL_ENDPOINTS
+
+ uid = Column(
+ model_monitoring_constants.EventFieldType.UID,
+ String(40),
+ primary_key=True,
+ )
+ state = Column(model_monitoring_constants.EventFieldType.STATE, String(10))
+ project = Column(model_monitoring_constants.EventFieldType.PROJECT, String(40))
+ function_uri = Column(
+ model_monitoring_constants.EventFieldType.FUNCTION_URI,
+ String(255),
+ )
+ model = Column(model_monitoring_constants.EventFieldType.MODEL, String(255))
+ model_class = Column(
+ model_monitoring_constants.EventFieldType.MODEL_CLASS,
+ String(255),
+ )
+ labels = Column(model_monitoring_constants.EventFieldType.LABELS, Text)
+ model_uri = Column(model_monitoring_constants.EventFieldType.MODEL_URI, String(255))
+ stream_path = Column(model_monitoring_constants.EventFieldType.STREAM_PATH, Text)
+ algorithm = Column(
+ model_monitoring_constants.EventFieldType.ALGORITHM,
+ String(255),
+ )
+ active = Column(model_monitoring_constants.EventFieldType.ACTIVE, Boolean)
+ monitoring_mode = Column(
+ model_monitoring_constants.EventFieldType.MONITORING_MODE,
+ String(10),
+ )
+ feature_stats = Column(
+ model_monitoring_constants.EventFieldType.FEATURE_STATS, Text
+ )
+ current_stats = Column(
+ model_monitoring_constants.EventFieldType.CURRENT_STATS, Text
+ )
+ feature_names = Column(
+ model_monitoring_constants.EventFieldType.FEATURE_NAMES, Text
+ )
+ children = Column(model_monitoring_constants.EventFieldType.CHILDREN, Text)
+ label_names = Column(model_monitoring_constants.EventFieldType.LABEL_NAMES, Text)
+
+ endpoint_type = Column(
+ model_monitoring_constants.EventFieldType.ENDPOINT_TYPE,
+ String(10),
+ )
+ children_uids = Column(
+ model_monitoring_constants.EventFieldType.CHILDREN_UIDS, Text
+ )
+ drift_measures = Column(
+ model_monitoring_constants.EventFieldType.DRIFT_MEASURES, Text
+ )
+ drift_status = Column(
+ model_monitoring_constants.EventFieldType.DRIFT_STATUS,
+ String(40),
+ )
+ monitor_configuration = Column(
+ model_monitoring_constants.EventFieldType.MONITOR_CONFIGURATION,
+ Text,
+ )
+ monitoring_feature_set_uri = Column(
+ model_monitoring_constants.EventFieldType.FEATURE_SET_URI,
+ String(255),
+ )
+ first_request = Column(
+ model_monitoring_constants.EventFieldType.FIRST_REQUEST,
+ sqlalchemy.dialects.mysql.TIMESTAMP(fsp=3),
+ )
+ last_request = Column(
+ model_monitoring_constants.EventFieldType.LAST_REQUEST,
+ sqlalchemy.dialects.mysql.TIMESTAMP(fsp=3),
+ )
+ error_count = Column(model_monitoring_constants.EventFieldType.ERROR_COUNT, Integer)
+ metrics = Column(model_monitoring_constants.EventFieldType.METRICS, Text)
diff --git a/mlrun/model_monitoring/stores/models/sqlite.py b/mlrun/model_monitoring/stores/models/sqlite.py
new file mode 100644
index 000000000000..9e2ce9f05a23
--- /dev/null
+++ b/mlrun/model_monitoring/stores/models/sqlite.py
@@ -0,0 +1,98 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+
+from sqlalchemy import TIMESTAMP, Boolean, Column, Integer, String, Text
+
+import mlrun.model_monitoring.constants as model_monitoring_constants
+from mlrun.utils.db import BaseModel
+
+from .base import Base
+
+
+class ModelEndpointsTable(Base, BaseModel):
+ __tablename__ = model_monitoring_constants.EventFieldType.MODEL_ENDPOINTS
+
+ uid = Column(
+ model_monitoring_constants.EventFieldType.UID,
+ String(40),
+ primary_key=True,
+ )
+ state = Column(model_monitoring_constants.EventFieldType.STATE, String(10))
+ project = Column(model_monitoring_constants.EventFieldType.PROJECT, String(40))
+ function_uri = Column(
+ model_monitoring_constants.EventFieldType.FUNCTION_URI,
+ String(255),
+ )
+ model = Column(model_monitoring_constants.EventFieldType.MODEL, String(255))
+ model_class = Column(
+ model_monitoring_constants.EventFieldType.MODEL_CLASS,
+ String(255),
+ )
+ labels = Column(model_monitoring_constants.EventFieldType.LABELS, Text)
+ model_uri = Column(model_monitoring_constants.EventFieldType.MODEL_URI, String(255))
+ stream_path = Column(model_monitoring_constants.EventFieldType.STREAM_PATH, Text)
+ algorithm = Column(
+ model_monitoring_constants.EventFieldType.ALGORITHM,
+ String(255),
+ )
+ active = Column(model_monitoring_constants.EventFieldType.ACTIVE, Boolean)
+ monitoring_mode = Column(
+ model_monitoring_constants.EventFieldType.MONITORING_MODE,
+ String(10),
+ )
+ feature_stats = Column(
+ model_monitoring_constants.EventFieldType.FEATURE_STATS, Text
+ )
+ current_stats = Column(
+ model_monitoring_constants.EventFieldType.CURRENT_STATS, Text
+ )
+ feature_names = Column(
+ model_monitoring_constants.EventFieldType.FEATURE_NAMES, Text
+ )
+ children = Column(model_monitoring_constants.EventFieldType.CHILDREN, Text)
+ label_names = Column(model_monitoring_constants.EventFieldType.LABEL_NAMES, Text)
+ endpoint_type = Column(
+ model_monitoring_constants.EventFieldType.ENDPOINT_TYPE,
+ String(10),
+ )
+ children_uids = Column(
+ model_monitoring_constants.EventFieldType.CHILDREN_UIDS, Text
+ )
+ drift_measures = Column(
+ model_monitoring_constants.EventFieldType.DRIFT_MEASURES, Text
+ )
+ drift_status = Column(
+ model_monitoring_constants.EventFieldType.DRIFT_STATUS,
+ String(40),
+ )
+ monitor_configuration = Column(
+ model_monitoring_constants.EventFieldType.MONITOR_CONFIGURATION,
+ Text,
+ )
+ monitoring_feature_set_uri = Column(
+ model_monitoring_constants.EventFieldType.FEATURE_SET_URI,
+ String(255),
+ )
+ first_request = Column(
+ model_monitoring_constants.EventFieldType.FIRST_REQUEST,
+ TIMESTAMP,
+ )
+ last_request = Column(
+ model_monitoring_constants.EventFieldType.LAST_REQUEST,
+ TIMESTAMP,
+ )
+ error_count = Column(model_monitoring_constants.EventFieldType.ERROR_COUNT, Integer)
+ metrics = Column(model_monitoring_constants.EventFieldType.METRICS, Text)
diff --git a/mlrun/model_monitoring/stores/sql_model_endpoint_store.py b/mlrun/model_monitoring/stores/sql_model_endpoint_store.py
new file mode 100644
index 000000000000..5fc5198791d7
--- /dev/null
+++ b/mlrun/model_monitoring/stores/sql_model_endpoint_store.py
@@ -0,0 +1,375 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+import json
+import typing
+from datetime import datetime, timezone
+
+import pandas as pd
+import sqlalchemy as db
+
+import mlrun
+import mlrun.model_monitoring.constants as model_monitoring_constants
+import mlrun.model_monitoring.model_endpoint
+import mlrun.utils.model_monitoring
+import mlrun.utils.v3io_clients
+from mlrun.api.db.sqldb.session import create_session, get_engine
+from mlrun.utils import logger
+
+from .model_endpoint_store import ModelEndpointStore
+from .models import get_ModelEndpointsTable
+from .models.base import Base
+
+
+class SQLModelEndpointStore(ModelEndpointStore):
+
+ """
+ Handles the DB operations when the DB target is from type SQL. For the SQL operations, we use SQLAlchemy, a Python
+ SQL toolkit that handles the communication with the database. When using SQL for storing the model endpoints
+ record, the user needs to provide a valid connection string for the database.
+ """
+
+ _engine = None
+
+ def __init__(
+ self,
+ project: str,
+ sql_connection_string: str = None,
+ ):
+ """
+ Initialize SQL store target object.
+
+ :param project: The name of the project.
+ :param sql_connection_string: Valid connection string or a path to SQL database with model endpoints table.
+ """
+
+ super().__init__(project=project)
+
+ self.sql_connection_string = (
+ sql_connection_string
+ or mlrun.utils.model_monitoring.get_connection_string(project=self.project)
+ )
+
+ self.table_name = model_monitoring_constants.EventFieldType.MODEL_ENDPOINTS
+
+ self._engine = get_engine(dsn=self.sql_connection_string)
+ self.ModelEndpointsTable = get_ModelEndpointsTable(
+ connection_string=self.sql_connection_string
+ )
+ # Create table if not exist. The `metadata` contains the `ModelEndpointsTable`
+ if not self._engine.has_table(self.table_name):
+ Base.metadata.create_all(bind=self._engine)
+ self.model_endpoints_table = self.ModelEndpointsTable.__table__
+
+ def write_model_endpoint(self, endpoint: typing.Dict[str, typing.Any]):
+ """
+ Create a new endpoint record in the SQL table. This method also creates the model endpoints table within the
+ SQL database if not exist.
+
+ :param endpoint: model endpoint dictionary that will be written into the DB.
+ """
+
+ with self._engine.connect() as connection:
+
+ # Adjust timestamps fields
+ endpoint[
+ model_monitoring_constants.EventFieldType.FIRST_REQUEST
+ ] = datetime.now(timezone.utc)
+ endpoint[
+ model_monitoring_constants.EventFieldType.LAST_REQUEST
+ ] = datetime.now(timezone.utc)
+
+ # Convert the result into a pandas Dataframe and write it into the database
+ endpoint_df = pd.DataFrame([endpoint])
+
+ endpoint_df.to_sql(
+ self.table_name, con=connection, index=False, if_exists="append"
+ )
+
+ def update_model_endpoint(
+ self, endpoint_id: str, attributes: typing.Dict[str, typing.Any]
+ ):
+ """
+ Update a model endpoint record with a given attributes.
+
+ :param endpoint_id: The unique id of the model endpoint.
+ :param attributes: Dictionary of attributes that will be used for update the model endpoint. Note that the keys
+ of the attributes dictionary should exist in the SQL table.
+
+ """
+
+ # Update the model endpoint record using sqlalchemy ORM
+ with create_session(dsn=self.sql_connection_string) as session:
+
+ # Remove endpoint id (foreign key) from the update query
+ attributes.pop(model_monitoring_constants.EventFieldType.ENDPOINT_ID, None)
+
+ # Generate and commit the update session query
+ session.query(self.ModelEndpointsTable).filter(
+ self.ModelEndpointsTable.uid == endpoint_id
+ ).update(attributes)
+ session.commit()
+
+ def delete_model_endpoint(self, endpoint_id: str):
+ """
+ Deletes the SQL record of a given model endpoint id.
+
+ :param endpoint_id: The unique id of the model endpoint.
+ """
+
+ # Delete the model endpoint record using sqlalchemy ORM
+ with create_session(dsn=self.sql_connection_string) as session:
+
+ # Generate and commit the delete query
+ session.query(self.ModelEndpointsTable).filter_by(uid=endpoint_id).delete()
+ session.commit()
+
+ def get_model_endpoint(
+ self,
+ endpoint_id: str,
+ ) -> typing.Dict[str, typing.Any]:
+ """
+ Get a single model endpoint record.
+
+ :param endpoint_id: The unique id of the model endpoint.
+
+ :return: A model endpoint record as a dictionary.
+
+ :raise MLRunNotFoundError: If the model endpoints table was not found or the model endpoint id was not found.
+ """
+
+ # Get the model endpoint record using sqlalchemy ORM
+ with create_session(dsn=self.sql_connection_string) as session:
+
+ # Generate the get query
+ endpoint_record = (
+ session.query(self.ModelEndpointsTable)
+ .filter_by(uid=endpoint_id)
+ .one_or_none()
+ )
+
+ if not endpoint_record:
+ raise mlrun.errors.MLRunNotFoundError(f"Endpoint {endpoint_id} not found")
+
+ # Convert the database values and the table columns into a python dictionary
+ return endpoint_record.to_dict()
+
+ def list_model_endpoints(
+ self,
+ model: str = None,
+ function: str = None,
+ labels: typing.List[str] = None,
+ top_level: bool = None,
+ uids: typing.List = None,
+ ) -> typing.List[typing.Dict[str, typing.Any]]:
+ """
+ Returns a list of model endpoint dictionaries, supports filtering by model, function, labels or top level.
+ By default, when no filters are applied, all available model endpoints for the given project will
+ be listed.
+
+ :param model: The name of the model to filter by.
+ :param function: The name of the function to filter by.
+ :param labels: A list of labels to filter by. Label filters work by either filtering a specific value
+ of a label (i.e. list("key=value")) or by looking for the existence of a given
+ key (i.e. "key").
+ :param top_level: If True will return only routers and endpoint that are NOT children of any router.
+ :param uids: List of model endpoint unique ids to include in the result.
+
+ :return: A list of model endpoint dictionaries.
+ """
+
+ # Generate an empty model endpoints that will be filled afterwards with model endpoint dictionaries
+ endpoint_list = []
+
+ # Get the model endpoints records using sqlalchemy ORM
+ with create_session(dsn=self.sql_connection_string) as session:
+
+ # Generate the list query
+ query = session.query(self.ModelEndpointsTable).filter_by(
+ project=self.project
+ )
+
+ # Apply filters
+ if model:
+ query = self._filter_values(
+ query=query,
+ model_endpoints_table=self.model_endpoints_table,
+ key_filter=model_monitoring_constants.EventFieldType.MODEL,
+ filtered_values=[model],
+ )
+ if function:
+ query = self._filter_values(
+ query=query,
+ model_endpoints_table=self.model_endpoints_table,
+ key_filter=model_monitoring_constants.EventFieldType.FUNCTION,
+ filtered_values=[function],
+ )
+ if uids:
+ query = self._filter_values(
+ query=query,
+ model_endpoints_table=self.model_endpoints_table,
+ key_filter=model_monitoring_constants.EventFieldType.UID,
+ filtered_values=uids,
+ combined=False,
+ )
+ if top_level:
+ node_ep = str(mlrun.model_monitoring.EndpointType.NODE_EP.value)
+ router_ep = str(mlrun.model_monitoring.EndpointType.ROUTER.value)
+ endpoint_types = [node_ep, router_ep]
+ query = self._filter_values(
+ query=query,
+ model_endpoints_table=self.model_endpoints_table,
+ key_filter=model_monitoring_constants.EventFieldType.ENDPOINT_TYPE,
+ filtered_values=endpoint_types,
+ combined=False,
+ )
+ # Convert the results from the DB into a ModelEndpoint object and append it to the model endpoints list
+ for endpoint_record in query.all():
+ endpoint_dict = endpoint_record.to_dict()
+
+ # Filter labels
+ if labels and not self._validate_labels(
+ endpoint_dict=endpoint_dict, labels=labels
+ ):
+ continue
+
+ endpoint_list.append(endpoint_dict)
+
+ return endpoint_list
+
+ @staticmethod
+ def _filter_values(
+ query: db.orm.query.Query,
+ model_endpoints_table: db.Table,
+ key_filter: str,
+ filtered_values: typing.List,
+ combined=True,
+ ) -> db.orm.query.Query:
+ """Filtering the SQL query object according to the provided filters.
+
+ :param query: SQLAlchemy ORM query object. Includes the SELECT statements generated by the ORM
+ for getting the model endpoint data from the SQL table.
+ :param model_endpoints_table: SQLAlchemy table object that represents the model endpoints table.
+ :param key_filter: Key column to filter by.
+ :param filtered_values: List of values to filter the query the result.
+ :param combined: If true, then apply AND operator on the filtered values list. Otherwise, apply OR
+ operator.
+
+ return: SQLAlchemy ORM query object that represents the updated query with the provided
+ filters.
+ """
+
+ if combined and len(filtered_values) > 1:
+ raise mlrun.errors.MLRunInvalidArgumentError(
+ "Can't apply combined policy with multiple values"
+ )
+
+ if not combined:
+ return query.filter(
+ model_endpoints_table.c[key_filter].in_(filtered_values)
+ )
+
+ # Generating a tuple with the relevant filters
+ filter_query = []
+ for _filter in filtered_values:
+ filter_query.append(model_endpoints_table.c[key_filter] == _filter)
+
+ # Apply AND operator on the SQL query object with the filters tuple
+ return query.filter(db.and_(*filter_query))
+
+ @staticmethod
+ def _validate_labels(
+ endpoint_dict: dict,
+ labels: typing.List,
+ ) -> bool:
+ """Validate that the model endpoint dictionary has the provided labels. There are 2 possible cases:
+ 1 - Labels were provided as a list of key-values pairs (e.g. ['label_1=value_1', 'label_2=value_2']): Validate
+ that each pair exist in the endpoint dictionary.
+ 2 - Labels were provided as a list of key labels (e.g. ['label_1', 'label_2']): Validate that each key exist in
+ the endpoint labels dictionary.
+
+ :param endpoint_dict: Dictionary of the model endpoint records.
+ :param labels: List of dictionary of required labels.
+
+ :return: True if the labels exist in the endpoint labels dictionary, otherwise False.
+ """
+
+ # Convert endpoint labels into dictionary
+ endpoint_labels = json.loads(
+ endpoint_dict.get(model_monitoring_constants.EventFieldType.LABELS)
+ )
+
+ for label in labels:
+ # Case 1 - label is a key=value pair
+ if "=" in label:
+ lbl, value = list(map(lambda x: x.strip(), label.split("=")))
+ if lbl not in endpoint_labels or str(endpoint_labels[lbl]) != value:
+ return False
+ # Case 2 - label is just a key
+ else:
+ if label not in endpoint_labels:
+ return False
+
+ return True
+
+ def delete_model_endpoints_resources(
+ self, endpoints: typing.List[typing.Dict[str, typing.Any]]
+ ):
+ """
+ Delete all model endpoints resources in both SQL and the time series DB.
+
+ :param endpoints: A list of model endpoints flattened dictionaries.
+ """
+
+ for endpoint_dict in endpoints:
+ # Delete model endpoint record from SQL table
+ self.delete_model_endpoint(
+ endpoint_dict[model_monitoring_constants.EventFieldType.UID],
+ )
+
+ def get_endpoint_real_time_metrics(
+ self,
+ endpoint_id: str,
+ metrics: typing.List[str],
+ start: str = "now-1h",
+ end: str = "now",
+ access_key: str = None,
+ ) -> typing.Dict[str, typing.List[typing.Tuple[str, float]]]:
+ """
+ Getting metrics from the time series DB. There are pre-defined metrics for model endpoints such as
+ `predictions_per_second` and `latency_avg_5m` but also custom metrics defined by the user.
+
+ :param endpoint_id: The unique id of the model endpoint.
+ :param metrics: A list of real-time metrics to return for the model endpoint.
+ :param start: The start time of the metrics. Can be represented by a string containing an RFC 3339
+ time, a Unix timestamp in milliseconds, a relative time (`'now'` or
+ `'now-[0-9]+[mhd]'`, where `m` = minutes, `h` = hours, and `'d'` = days), or 0 for the
+ earliest time.
+ :param end: The end time of the metrics. Can be represented by a string containing an RFC 3339
+ time, a Unix timestamp in milliseconds, a relative time (`'now'` or
+ `'now-[0-9]+[mhd]'`, where `m` = minutes, `h` = hours, and `'d'` = days), or 0 for the
+ earliest time.
+ :param access_key: V3IO access key that will be used for generating Frames client object. If not
+ provided, the access key will be retrieved from the environment variables.
+
+ :return: A dictionary of metrics in which the key is a metric name and the value is a list of tuples that
+ includes timestamps and the values.
+ """
+ # # TODO : Implement this method once Perometheus is supported
+ logger.warning(
+ "Real time metrics service using Prometheus will be implemented in 1.4.0"
+ )
+
+ return {}
diff --git a/mlrun/model_monitoring/stream_processing_fs.py b/mlrun/model_monitoring/stream_processing_fs.py
index ff2c2a0f854e..46209659d4bc 100644
--- a/mlrun/model_monitoring/stream_processing_fs.py
+++ b/mlrun/model_monitoring/stream_processing_fs.py
@@ -19,23 +19,23 @@
import typing
import pandas as pd
-
-# Constants
import storey
-import v3io
-import v3io.dataplane
+import mlrun
import mlrun.config
import mlrun.datastore.targets
import mlrun.feature_store.steps
import mlrun.utils
import mlrun.utils.model_monitoring
import mlrun.utils.v3io_clients
-from mlrun.model_monitoring.constants import (
+from mlrun.model_monitoring import (
EventFieldType,
EventKeyMetrics,
EventLiveStats,
+ ModelEndpointTarget,
+ ProjectSecretKeys,
)
+from mlrun.model_monitoring.stores import get_model_endpoint_store
from mlrun.utils import logger
@@ -75,12 +75,15 @@ def __init__(
self.v3io_access_key = v3io_access_key or os.environ.get("V3IO_ACCESS_KEY")
self.model_monitoring_access_key = (
model_monitoring_access_key
- or os.environ.get("MODEL_MONITORING_ACCESS_KEY")
+ or os.environ.get(ProjectSecretKeys.ACCESS_KEY)
or self.v3io_access_key
)
self.storage_options = dict(
v3io_access_key=self.model_monitoring_access_key, v3io_api=self.v3io_api
)
+ self.model_endpoint_store_target = (
+ mlrun.mlconf.model_endpoint_monitoring.store_type
+ )
template = mlrun.mlconf.model_endpoint_monitoring.store_prefixes.default
@@ -127,12 +130,14 @@ def apply_monitoring_serving_graph(self, fn):
of different operations that are executed on the events from the model server. Each event has
metadata (function_uri, timestamp, class, etc.) but also inputs and predictions from the model server.
Throughout the serving graph, the results are written to 3 different databases:
- 1. KV (steps 7-9): Stores metadata and stats about the average latency and the amount of predictions over time
- per endpoint. for example the amount of predictions of endpoint x in the last 5 min. This data is used by
- the monitoring dashboards in grafana. Please note that the KV table, which can be found under
- v3io:///users/pipelines/project-name/model-endpoints/endpoints/ also contains data on the model endpoint
- from other processes, such as current_stats that is being calculated by the monitoring batch job
- process.
+ 1. KV/SQL (steps 7-9): Stores metadata and stats about the average latency and the amount of predictions over
+ time per endpoint. for example the amount of predictions of endpoint x in the last 5 min. This data is used
+ by the monitoring dashboards in grafana. The model endpoints table also contains data on the model endpoint
+ from other processes, such as current_stats that is being calculated by the monitoring batch job
+ process. If the target is from type KV, then the model endpoints table can be found under
+ v3io:///users/pipelines/project-name/model-endpoints/endpoints/. If the target is SQL, then the table
+ is stored within the database that was defined in the provided connection string and can be found
+ under mlrun.mlconf.model_endpoint_monitoring.endpoint_store_connection.
2. TSDB (steps 12-18): Stores live data of different key metric dictionaries in tsdb target. Results can be
found under v3io:///users/pipelines/project-name/model-endpoints/events/. At the moment, this part supports
3 different key metric dictionaries: base_metrics (average latency and predictions over time),
@@ -151,9 +156,6 @@ def apply_monitoring_serving_graph(self, fn):
def apply_process_endpoint_event():
graph.add_step(
"ProcessEndpointEvent",
- kv_container=self.kv_container,
- kv_path=self.kv_path,
- v3io_access_key=self.v3io_access_key,
full_event=True,
project=self.project,
)
@@ -182,10 +184,8 @@ def apply_map_feature_names():
graph.add_step(
"MapFeatureNames",
name="MapFeatureNames",
- kv_container=self.kv_container,
- kv_path=self.kv_path,
- access_key=self.v3io_access_key,
infer_columns_from_data=True,
+ project=self.project,
after="flatten_events",
)
@@ -244,41 +244,45 @@ def apply_storey_sample_window():
apply_storey_sample_window()
- # Steps 7-9 - KV branch
- # Step 7 - Filter relevant keys from the event before writing the data into KV
- def apply_process_before_kv():
- graph.add_step("ProcessBeforeKV", name="ProcessBeforeKV", after="sample")
+ # Steps 7-9 - KV/SQL branch
+ # Step 7 - Filter relevant keys from the event before writing the data into the database table
+ def apply_process_before_endpoint_update():
+ graph.add_step(
+ "ProcessBeforeEndpointUpdate",
+ name="ProcessBeforeEndpointUpdate",
+ after="sample",
+ )
- apply_process_before_kv()
+ apply_process_before_endpoint_update()
- # Step 8 - Write the filtered event to KV table. At this point, the serving graph updates the stats
+ # Step 8 - Write the filtered event to KV/SQL table. At this point, the serving graph updates the stats
# about average latency and the amount of predictions over time
- def apply_write_to_kv():
+ def apply_update_endpoint():
graph.add_step(
- "WriteToKV",
- name="WriteToKV",
- after="ProcessBeforeKV",
- container=self.kv_container,
- table=self.kv_path,
- v3io_access_key=self.v3io_access_key,
+ "UpdateEndpoint",
+ name="UpdateEndpoint",
+ after="ProcessBeforeEndpointUpdate",
+ project=self.project,
+ model_endpoint_store_target=self.model_endpoint_store_target,
)
- apply_write_to_kv()
+ apply_update_endpoint()
- # Step 9 - Apply infer_schema on the KB table for generating schema file
+ # Step 9 (only for KV target) - Apply infer_schema on the model endpoints table for generating schema file
# which will be used by Grafana monitoring dashboards
def apply_infer_schema():
graph.add_step(
"InferSchema",
name="InferSchema",
- after="WriteToKV",
+ after="UpdateEndpoint",
v3io_access_key=self.v3io_access_key,
v3io_framesd=self.v3io_framesd,
container=self.kv_container,
table=self.kv_path,
)
- apply_infer_schema()
+ if self.model_endpoint_store_target == ModelEndpointTarget.V3IO_NOSQL:
+ apply_infer_schema()
# Steps 11-18 - TSDB branch
# Step 11 - Before writing data to TSDB, create dictionary of 2-3 dictionaries that contains
@@ -384,14 +388,14 @@ def apply_parquet_target():
apply_parquet_target()
-class ProcessBeforeKV(mlrun.feature_store.steps.MapClass):
+class ProcessBeforeEndpointUpdate(mlrun.feature_store.steps.MapClass):
def __init__(self, **kwargs):
"""
- Filter relevant keys from the event before writing the data to KV table (in WriteToKV step). Note that in KV
- we only keep metadata (function_uri, model_class, etc.) and stats about the average latency and the number
- of predictions (per 5min and 1hour).
+ Filter relevant keys from the event before writing the data to database table (in EndpointUpdate step).
+ Note that in the endpoint table we only keep metadata (function_uri, model_class, etc.) and stats about the
+ average latency and the number of predictions (per 5min and 1hour).
- :returns: A filtered event as a dictionary which will be written to KV table in the next step.
+ :returns: A filtered event as a dictionary which will be written to the endpoint table in the next step.
"""
super().__init__(**kwargs)
@@ -408,26 +412,31 @@ def do(self, event):
EventFieldType.FUNCTION_URI,
EventFieldType.MODEL,
EventFieldType.MODEL_CLASS,
- EventFieldType.TIMESTAMP,
EventFieldType.ENDPOINT_ID,
EventFieldType.LABELS,
- EventFieldType.UNPACKED_LABELS,
+ EventFieldType.FIRST_REQUEST,
+ EventFieldType.LAST_REQUEST,
+ EventFieldType.ERROR_COUNT,
+ ]
+ }
+
+ # Add generic metrics statistics
+ generic_metrics = {
+ k: event[k]
+ for k in [
EventLiveStats.LATENCY_AVG_5M,
EventLiveStats.LATENCY_AVG_1H,
EventLiveStats.PREDICTIONS_PER_SECOND,
EventLiveStats.PREDICTIONS_COUNT_5M,
EventLiveStats.PREDICTIONS_COUNT_1H,
- EventFieldType.FIRST_REQUEST,
- EventFieldType.LAST_REQUEST,
- EventFieldType.ERROR_COUNT,
]
}
- # Unpack labels dictionary
- e = {
- **e.pop(EventFieldType.UNPACKED_LABELS, {}),
- **e,
- }
- # Write labels to kv as json string to be presentable later
+
+ e[EventFieldType.METRICS] = json.dumps(
+ {EventKeyMetrics.GENERIC: generic_metrics}
+ )
+
+ # Write labels as json string as required by the DB format
e[EventFieldType.LABELS] = json.dumps(e[EventFieldType.LABELS])
return e
@@ -523,7 +532,6 @@ def do(self, event):
logger.info("ProcessBeforeParquet1", event=event)
# Remove the following keys from the event
for key in [
- EventFieldType.UNPACKED_LABELS,
EventFieldType.FEATURES,
EventFieldType.NAMED_FEATURES,
]:
@@ -549,32 +557,23 @@ def do(self, event):
class ProcessEndpointEvent(mlrun.feature_store.steps.MapClass):
def __init__(
self,
- kv_container: str,
- kv_path: str,
- v3io_access_key: str,
+ project: str,
**kwargs,
):
"""
Process event or batch of events as part of the first step of the monitoring serving graph. It includes
- Adding important details to the event such as endpoint_id, handling errors coming from the stream, Validation
+ Adding important details to the event such as endpoint_id, handling errors coming from the stream, validation
of event data such as inputs and outputs, and splitting model event into sub-events.
- :param kv_container: Name of the container that will be used to retrieve the endpoint id. For model
- endpoints it is usually 'users'.
- :param kv_path: KV table path that will be used to retrieve the endpoint id. For model endpoints
- it is usually pipelines/project-name/model-endpoints/endpoints/
- :param v3io_access_key: Access key with permission to read from a KV table.
- :param project: Project name.
-
+ :param project: Project name.
:returns: A Storey event object which is the basic unit of data in Storey. Note that the next steps of
the monitoring serving graph are based on Storey operations.
"""
super().__init__(**kwargs)
- self.kv_container: str = kv_container
- self.kv_path: str = kv_path
- self.v3io_access_key: str = v3io_access_key
+
+ self.project: str = project
# First and last requests timestamps (value) of each endpoint (key)
self.first_request: typing.Dict[str, str] = dict()
@@ -602,7 +601,7 @@ def do(self, full_event):
version = event.get(EventFieldType.VERSION)
versioned_model = f"{model}:{version}" if version else f"{model}:latest"
- endpoint_id = mlrun.utils.model_monitoring.create_model_endpoint_id(
+ endpoint_id = mlrun.model_monitoring.create_model_endpoint_uid(
function_uri=function_uri,
versioned_model=versioned_model,
)
@@ -679,11 +678,6 @@ def do(self, full_event):
):
return None
- # Get labels from event (if exist)
- unpacked_labels = {
- f"_{k}": v for k, v in event.get(EventFieldType.LABELS, {}).items()
- }
-
# Adjust timestamp format
timestamp = datetime.datetime.strptime(timestamp[:-6], "%Y-%m-%d %H:%M:%S.%f")
@@ -722,7 +716,6 @@ def do(self, full_event):
EventFieldType.ENTITIES: event.get("request", {}).get(
EventFieldType.ENTITIES, {}
),
- EventFieldType.UNPACKED_LABELS: unpacked_labels,
}
)
@@ -751,8 +744,8 @@ def _validate_last_request_timestamp(self, endpoint_id: str, timestamp: str):
f"{self.last_request[endpoint_id]} - write to TSDB will be rejected"
)
+ @staticmethod
def is_list_of_numerics(
- self,
field: typing.List[typing.Union[int, float, dict, list]],
dict_path: typing.List[str],
):
@@ -767,12 +760,12 @@ def resume_state(self, endpoint_id):
# Make sure process is resumable, if process fails for any reason, be able to pick things up close to where we
# left them
if endpoint_id not in self.endpoints:
+
logger.info("Trying to resume state", endpoint_id=endpoint_id)
+
endpoint_record = get_endpoint_record(
- kv_container=self.kv_container,
- kv_path=self.kv_path,
+ project=self.project,
endpoint_id=endpoint_id,
- access_key=self.v3io_access_key,
)
# If model endpoint found, get first_request, last_request and error_count values
@@ -857,9 +850,7 @@ def do(self, event):
class MapFeatureNames(mlrun.feature_store.steps.MapClass):
def __init__(
self,
- kv_container: str,
- kv_path: str,
- access_key: str,
+ project: str,
infer_columns_from_data: bool = False,
**kwargs,
):
@@ -867,11 +858,7 @@ def __init__(
Validating feature names and label columns and map each feature to its value. In the end of this step,
the event should have key-value pairs of (feature name: feature value).
- :param kv_container: Name of the container that will be used to retrieve the endpoint id. For model
- endpoints it is usually 'users'.
- :param kv_path: KV table path that will be used to retrieve the endpoint id. For model endpoints
- it is usually pipelines/project-name/model-endpoints/endpoints/
- :param v3io_access_key: Access key with permission to read from a KV table.
+ :param project: Project name.
:param infer_columns_from_data: If true and features or labels names were not found, then try to
retrieve them from data that was stored in the previous events of
the current process. This data can be found under self.feature_names and
@@ -882,10 +869,9 @@ def __init__(
feature names and values (as well as the prediction results).
"""
super().__init__(**kwargs)
- self.kv_container = kv_container
- self.kv_path = kv_path
- self.access_key = access_key
+
self._infer_columns_from_data = infer_columns_from_data
+ self.project = project
# Dictionaries that will be used in case features names
# and labels columns were not found in the current event
@@ -914,10 +900,8 @@ def do(self, event: typing.Dict):
# Get feature names and label columns
if endpoint_id not in self.feature_names:
endpoint_record = get_endpoint_record(
- kv_container=self.kv_container,
- kv_path=self.kv_path,
+ project=self.project,
endpoint_id=endpoint_id,
- access_key=self.access_key,
)
feature_names = endpoint_record.get(EventFieldType.FEATURE_NAMES)
feature_names = json.loads(feature_names) if feature_names else None
@@ -940,15 +924,12 @@ def do(self, event: typing.Dict):
]
# Update the endpoint record with the generated features
- mlrun.utils.v3io_clients.get_v3io_client().kv.update(
- container=self.kv_container,
- table_path=self.kv_path,
- access_key=self.access_key,
- key=event[EventFieldType.ENDPOINT_ID],
+ update_endpoint_record(
+ project=self.project,
+ endpoint_id=endpoint_id,
attributes={
EventFieldType.FEATURE_NAMES: json.dumps(feature_names)
},
- raise_for_status=v3io.dataplane.RaiseForStatus.always,
)
# Similar process with label columns
@@ -963,15 +944,11 @@ def do(self, event: typing.Dict):
label_columns = [
f"p{i}" for i, _ in enumerate(event[EventFieldType.PREDICTION])
]
- mlrun.utils.v3io_clients.get_v3io_client().kv.update(
- container=self.kv_container,
- table_path=self.kv_path,
- access_key=self.access_key,
- key=event[EventFieldType.ENDPOINT_ID],
- attributes={
- EventFieldType.LABEL_COLUMNS: json.dumps(label_columns)
- },
- raise_for_status=v3io.dataplane.RaiseForStatus.always,
+
+ update_endpoint_record(
+ project=self.project,
+ endpoint_id=endpoint_id,
+ attributes={EventFieldType.LABEL_NAMES: json.dumps(label_columns)},
)
self.label_columns[endpoint_id] = label_columns
@@ -1033,33 +1010,24 @@ def _map_dictionary_values(
event[mapping_dictionary][name] = value
-class WriteToKV(mlrun.feature_store.steps.MapClass):
- def __init__(self, container: str, table: str, v3io_access_key: str, **kwargs):
+class UpdateEndpoint(mlrun.feature_store.steps.MapClass):
+ def __init__(self, project: str, model_endpoint_store_target: str, **kwargs):
"""
- Writes the event to KV table. Note that the event at this point includes metadata and stats about the
- average latency and the amount of predictions over time. This data will be used in the monitoring dashboards
+ Update the model endpoint record in the DB. Note that the event at this point includes metadata and stats about
+ the average latency and the amount of predictions over time. This data will be used in the monitoring dashboards
such as "Model Monitoring - Performance" which can be found in Grafana.
- :param kv_container: Name of the container that will be used to retrieve the endpoint id. For model
- endpoints it is usually 'users'.
- :param table: KV table path that will be used to retrieve the endpoint id. For model endpoints
- it is usually pipelines/project-name/model-endpoints/endpoints/.
- :param v3io_access_key: Access key with permission to read from a KV table.
-
:returns: Event as a dictionary (without any changes) for the next step (InferSchema).
"""
super().__init__(**kwargs)
- self.container = container
- self.table = table
- self.v3io_access_key = v3io_access_key
+ self.project = project
+ self.model_endpoint_store_target = model_endpoint_store_target
def do(self, event: typing.Dict):
- mlrun.utils.v3io_clients.get_v3io_client().kv.update(
- container=self.container,
- table_path=self.table,
- key=event[EventFieldType.ENDPOINT_ID],
+ update_endpoint_record(
+ project=self.project,
+ endpoint_id=event.pop(EventFieldType.ENDPOINT_ID),
attributes=event,
- access_key=self.v3io_access_key,
)
return event
@@ -1093,6 +1061,7 @@ def __init__(
self.keys = set()
def do(self, event: typing.Dict):
+
key_set = set(event.keys())
if not key_set.issubset(self.keys):
self.keys.update(key_set)
@@ -1102,30 +1071,26 @@ def do(self, event: typing.Dict):
container=self.container,
address=self.v3io_framesd,
).execute(backend="kv", table=self.table, command="infer_schema")
+
return event
-def get_endpoint_record(
- kv_container: str, kv_path: str, endpoint_id: str, access_key: str
-) -> typing.Optional[dict]:
- logger.info(
- "Grabbing endpoint data",
- container=kv_container,
- table_path=kv_path,
- key=endpoint_id,
+def update_endpoint_record(
+ project: str,
+ endpoint_id: str,
+ attributes: dict,
+):
+ model_endpoint_store = get_model_endpoint_store(
+ project=project,
)
- try:
- endpoint_record = (
- mlrun.utils.v3io_clients.get_v3io_client()
- .kv.get(
- container=kv_container,
- table_path=kv_path,
- key=endpoint_id,
- access_key=access_key,
- raise_for_status=v3io.dataplane.RaiseForStatus.always,
- )
- .output.item
- )
- return endpoint_record
- except Exception:
- return None
+
+ model_endpoint_store.update_model_endpoint(
+ endpoint_id=endpoint_id, attributes=attributes
+ )
+
+
+def get_endpoint_record(project: str, endpoint_id: str):
+ model_endpoint_store = get_model_endpoint_store(
+ project=project,
+ )
+ return model_endpoint_store.get_model_endpoint(endpoint_id=endpoint_id)
diff --git a/mlrun/projects/project.py b/mlrun/projects/project.py
index fac672ea52a7..17519ec5e3dd 100644
--- a/mlrun/projects/project.py
+++ b/mlrun/projects/project.py
@@ -36,6 +36,7 @@
import mlrun.api.schemas
import mlrun.db
import mlrun.errors
+import mlrun.model_monitoring.constants as model_monitoring_constants
import mlrun.utils.regex
from mlrun.runtimes import RuntimeKinds
@@ -57,7 +58,6 @@
)
from ..utils.clones import clone_git, clone_tgz, clone_zip, get_repo_url
from ..utils.helpers import ensure_git_branch, resolve_git_reference_from_source
-from ..utils.model_monitoring import set_project_model_monitoring_credentials
from ..utils.notifications import CustomNotificationPusher, NotificationTypes
from .operations import (
BuildStatus,
@@ -2139,15 +2139,30 @@ def export(self, filepath=None, include_files: str = None):
mlrun.get_dataitem(filepath).upload(tmp_path)
remove(tmp_path)
- def set_model_monitoring_credentials(self, access_key: str):
+ def set_model_monitoring_credentials(
+ self, access_key: str = None, endpoint_store_connection: str = None
+ ):
"""Set the credentials that will be used by the project's model monitoring
infrastructure functions.
- The supplied credentials must have data access
- :param access_key: Model Monitoring access key for managing user permissions.
+ :param access_key: Model Monitoring access key for managing user permissions
+ :param endpoint_store_connection: Endpoint store connection string
"""
- set_project_model_monitoring_credentials(
- access_key=access_key, project=self.metadata.name
+
+ secrets_dict = {}
+ if access_key:
+ secrets_dict[
+ model_monitoring_constants.ProjectSecretKeys.ACCESS_KEY
+ ] = access_key
+
+ if endpoint_store_connection:
+ secrets_dict[
+ model_monitoring_constants.ProjectSecretKeys.ENDPOINT_STORE_CONNECTION
+ ] = endpoint_store_connection
+
+ self.set_secrets(
+ secrets=secrets_dict,
+ provider=mlrun.api.schemas.SecretProviderName.kubernetes,
)
def run_function(
diff --git a/mlrun/serving/routers.py b/mlrun/serving/routers.py
index 1685387b0062..70f2cb29a5cb 100644
--- a/mlrun/serving/routers.py
+++ b/mlrun/serving/routers.py
@@ -24,6 +24,7 @@
import numpy as np
import mlrun
+import mlrun.model_monitoring
import mlrun.utils.model_monitoring
from mlrun.utils import logger, now_date, parse_versioned_object_uri
@@ -32,10 +33,8 @@
ModelEndpointMetadata,
ModelEndpointSpec,
ModelEndpointStatus,
- ModelMonitoringMode,
)
from ..config import config
-from ..utils.model_monitoring import EndpointType
from .server import GraphServer
from .utils import RouterToDict, _extract_input_data, _update_result_body
from .v2_serving import _ModelLogPusher
@@ -1043,7 +1042,7 @@ def _init_endpoint_record(
versioned_model_name = f"{voting_ensemble.name}:latest"
# Generating model endpoint ID based on function uri and model version
- endpoint_uid = mlrun.utils.model_monitoring.create_model_endpoint_id(
+ endpoint_uid = mlrun.model_monitoring.create_model_endpoint_uid(
function_uri=graph_server.function_uri, versioned_model=versioned_model_name
).uid
@@ -1061,33 +1060,33 @@ def _init_endpoint_record(
if hasattr(c, "endpoint_uid"):
children_uids.append(c.endpoint_uid)
- model_endpoint = ModelEndpoint(
- metadata=ModelEndpointMetadata(project=project, uid=endpoint_uid),
- spec=ModelEndpointSpec(
- function_uri=graph_server.function_uri,
- model=versioned_model_name,
- model_class=voting_ensemble.__class__.__name__,
- stream_path=config.model_endpoint_monitoring.store_prefixes.default.format(
- project=project, kind="stream"
- ),
- active=True,
- monitoring_mode=ModelMonitoringMode.enabled
- if voting_ensemble.context.server.track_models
- else ModelMonitoringMode.disabled,
+ model_endpoint = ModelEndpoint(
+ metadata=ModelEndpointMetadata(project=project, uid=endpoint_uid),
+ spec=ModelEndpointSpec(
+ function_uri=graph_server.function_uri,
+ model=versioned_model_name,
+ model_class=voting_ensemble.__class__.__name__,
+ stream_path=config.model_endpoint_monitoring.store_prefixes.default.format(
+ project=project, kind="stream"
),
- status=ModelEndpointStatus(
- children=list(voting_ensemble.routes.keys()),
- endpoint_type=EndpointType.ROUTER,
- children_uids=children_uids,
- ),
- )
+ active=True,
+ monitoring_mode=mlrun.model_monitoring.ModelMonitoringMode.enabled
+ if voting_ensemble.context.server.track_models
+ else mlrun.model_monitoring.ModelMonitoringMode.disabled,
+ ),
+ status=ModelEndpointStatus(
+ children=list(voting_ensemble.routes.keys()),
+ endpoint_type=mlrun.model_monitoring.EndpointType.ROUTER,
+ children_uids=children_uids,
+ ),
+ )
db = mlrun.get_run_db()
db.create_model_endpoint(
project=project,
endpoint_id=model_endpoint.metadata.uid,
- model_endpoint=model_endpoint,
+ model_endpoint=model_endpoint.dict(),
)
# Update model endpoint children type
@@ -1095,11 +1094,13 @@ def _init_endpoint_record(
current_endpoint = db.get_model_endpoint(
project=project, endpoint_id=model_endpoint
)
- current_endpoint.status.endpoint_type = EndpointType.LEAF_EP
+ current_endpoint.status.endpoint_type = (
+ mlrun.model_monitoring.EndpointType.LEAF_EP
+ )
db.create_model_endpoint(
project=project,
endpoint_id=model_endpoint,
- model_endpoint=current_endpoint,
+ model_endpoint=current_endpoint.dict(),
)
except Exception as exc:
diff --git a/mlrun/serving/v2_serving.py b/mlrun/serving/v2_serving.py
index 14e79a336ef0..0b8675f794a3 100644
--- a/mlrun/serving/v2_serving.py
+++ b/mlrun/serving/v2_serving.py
@@ -17,17 +17,16 @@
from typing import Dict, Union
import mlrun
+import mlrun.model_monitoring
from mlrun.api.schemas import (
ModelEndpoint,
ModelEndpointMetadata,
ModelEndpointSpec,
ModelEndpointStatus,
- ModelMonitoringMode,
)
from mlrun.artifacts import ModelArtifact # noqa: F401
from mlrun.config import config
from mlrun.utils import logger, now_date, parse_versioned_object_uri
-from mlrun.utils.model_monitoring import EndpointType
from .server import GraphServer
from .utils import StepToDict, _extract_input_data, _update_result_body
@@ -487,7 +486,7 @@ def _init_endpoint_record(
versioned_model_name = f"{model.name}:latest"
# Generating model endpoint ID based on function uri and model version
- uid = mlrun.utils.model_monitoring.create_model_endpoint_id(
+ uid = mlrun.model_monitoring.create_model_endpoint_uid(
function_uri=graph_server.function_uri, versioned_model=versioned_model_name
).uid
@@ -512,18 +511,21 @@ def _init_endpoint_record(
project=project, kind="stream"
),
active=True,
- monitoring_mode=ModelMonitoringMode.enabled
+ monitoring_mode=mlrun.model_monitoring.ModelMonitoringMode.enabled
if model.context.server.track_models
- else ModelMonitoringMode.disabled,
+ else mlrun.model_monitoring.ModelMonitoringMode.disabled,
+ ),
+ status=ModelEndpointStatus(
+ endpoint_type=mlrun.model_monitoring.EndpointType.NODE_EP
),
- status=ModelEndpointStatus(endpoint_type=EndpointType.NODE_EP),
)
db = mlrun.get_run_db()
+
db.create_model_endpoint(
project=project,
- endpoint_id=model_endpoint.metadata.uid,
- model_endpoint=model_endpoint,
+ endpoint_id=uid,
+ model_endpoint=model_endpoint.dict(),
)
except Exception as e:
diff --git a/mlrun/utils/db.py b/mlrun/utils/db.py
new file mode 100644
index 000000000000..e66940e99825
--- /dev/null
+++ b/mlrun/utils/db.py
@@ -0,0 +1,52 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+import pickle
+from datetime import datetime
+
+from sqlalchemy.orm import class_mapper
+
+
+class BaseModel:
+ def to_dict(self, exclude=None):
+ """
+ NOTE - this function (currently) does not handle serializing relationships
+ """
+ exclude = exclude or []
+ mapper = class_mapper(self.__class__)
+ columns = [column.key for column in mapper.columns if column.key not in exclude]
+ get_key_value = (
+ lambda c: (c, getattr(self, c).isoformat())
+ if isinstance(getattr(self, c), datetime)
+ else (c, getattr(self, c))
+ )
+ return dict(map(get_key_value, columns))
+
+
+class HasStruct(BaseModel):
+ @property
+ def struct(self):
+ return pickle.loads(self.body)
+
+ @struct.setter
+ def struct(self, value):
+ self.body = pickle.dumps(value)
+
+ def to_dict(self, exclude=None):
+ """
+ NOTE - this function (currently) does not handle serializing relationships
+ """
+ exclude = exclude or []
+ exclude.append("body")
+ return super().to_dict(exclude)
diff --git a/mlrun/utils/model_monitoring.py b/mlrun/utils/model_monitoring.py
index 361f938b2b0f..999e92541241 100644
--- a/mlrun/utils/model_monitoring.py
+++ b/mlrun/utils/model_monitoring.py
@@ -13,97 +13,16 @@
# limitations under the License.
#
-import enum
-import hashlib
-from dataclasses import dataclass
-from typing import Optional, Union
+import json
+import warnings
+from typing import Union
import mlrun
import mlrun.model
import mlrun.model_monitoring.constants as model_monitoring_constants
import mlrun.platforms.iguazio
-import mlrun.utils
from mlrun.api.schemas.schedule import ScheduleCronTrigger
-
-
-@dataclass
-class FunctionURI:
- project: str
- function: str
- tag: Optional[str] = None
- hash_key: Optional[str] = None
-
- @classmethod
- def from_string(cls, function_uri):
- project, uri, tag, hash_key = mlrun.utils.parse_versioned_object_uri(
- function_uri
- )
- return cls(
- project=project,
- function=uri,
- tag=tag or None,
- hash_key=hash_key or None,
- )
-
-
-@dataclass
-class VersionedModel:
- model: str
- version: Optional[str]
-
- @classmethod
- def from_string(cls, model):
- try:
- model, version = model.split(":")
- except ValueError:
- model, version = model, None
-
- return cls(model, version)
-
-
-@dataclass
-class EndpointUID:
- project: str
- function: str
- function_tag: str
- function_hash_key: str
- model: str
- model_version: str
- uid: Optional[str] = None
-
- def __post_init__(self):
- function_ref = (
- f"{self.function}_{self.function_tag or self.function_hash_key or 'N/A'}"
- )
- versioned_model = f"{self.model}_{self.model_version or 'N/A'}"
- unique_string = f"{self.project}_{function_ref}_{versioned_model}"
- self.uid = hashlib.sha1(unique_string.encode("utf-8")).hexdigest()
-
- def __str__(self):
- return self.uid
-
-
-def create_model_endpoint_id(function_uri: str, versioned_model: str):
- function_uri = FunctionURI.from_string(function_uri)
- versioned_model = VersionedModel.from_string(versioned_model)
-
- if (
- not function_uri.project
- or not function_uri.function
- or not versioned_model.model
- ):
- raise ValueError("Both function_uri and versioned_model have to be initialized")
-
- uid = EndpointUID(
- function_uri.project,
- function_uri.function,
- function_uri.tag,
- function_uri.hash_key,
- versioned_model.model,
- versioned_model.version,
- )
-
- return uid
+from mlrun.config import is_running_as_api
def parse_model_endpoint_project_prefix(path: str, project_name: str):
@@ -116,29 +35,20 @@ def parse_model_endpoint_store_prefix(store_prefix: str):
return endpoint, container, path
-def set_project_model_monitoring_credentials(
- access_key: str, project: Optional[str] = None
-):
+def set_project_model_monitoring_credentials(access_key: str, project: str = None):
"""Set the credentials that will be used by the project's model monitoring
infrastructure functions.
The supplied credentials must have data access
-
:param access_key: Model Monitoring access key for managing user permissions.
:param project: The name of the model monitoring project.
"""
mlrun.get_run_db().create_project_secrets(
project=project or mlrun.mlconf.default_project,
provider=mlrun.api.schemas.SecretProviderName.kubernetes,
- secrets={"MODEL_MONITORING_ACCESS_KEY": access_key},
+ secrets={model_monitoring_constants.ProjectSecretKeys.ACCESS_KEY: access_key},
)
-class EndpointType(enum.IntEnum):
- NODE_EP = 1 # end point that is not a child of a router
- ROUTER = 2 # endpoint that is router
- LEAF_EP = 3 # end point that is a child of a router
-
-
class TrackingPolicy(mlrun.model.ModelObj):
"""
Modified model monitoring configurations. By using TrackingPolicy, the user can apply his model monitoring
@@ -215,3 +125,66 @@ def to_dict(self, fields=None, exclude=None):
model_monitoring_constants.EventFieldType.DEFAULT_BATCH_INTERVALS
] = self.default_batch_intervals.dict()
return struct
+
+
+def get_connection_string(project: str = None):
+ """Get endpoint store connection string from the project secret.
+ If wasn't set, take it from the system configurations"""
+ if is_running_as_api():
+ # Running on API server side
+ import mlrun.api.crud.secrets
+ import mlrun.api.schemas
+
+ return (
+ mlrun.api.crud.secrets.Secrets().get_project_secret(
+ project=project,
+ provider=mlrun.api.schemas.secret.SecretProviderName.kubernetes,
+ allow_secrets_from_k8s=True,
+ secret_key=model_monitoring_constants.ProjectSecretKeys.ENDPOINT_STORE_CONNECTION,
+ )
+ or mlrun.mlconf.model_endpoint_monitoring.endpoint_store_connection
+ )
+ else:
+ # Running on stream server side
+ import mlrun
+
+ return (
+ mlrun.get_secret_or_env(
+ model_monitoring_constants.ProjectSecretKeys.ENDPOINT_STORE_CONNECTION
+ )
+ or mlrun.mlconf.model_endpoint_monitoring.endpoint_store_connection
+ )
+
+
+def validate_errors_and_metrics(endpoint: dict):
+ """
+ Replace default null values for `error_count` and `metrics` for users that logged a model endpoint before 1.3.0
+
+ Leaving here for backwards compatibility which related to the model endpoint schema
+
+ :param endpoint: An endpoint flattened dictionary.
+ """
+ warnings.warn(
+ "This will be deprecated in 1.3.0, and will be removed in 1.5.0",
+ # TODO: In 1.3.0 do changes in examples & demos In 1.5.0 remove
+ FutureWarning,
+ )
+
+ # Validate default value for `error_count`
+ if endpoint[model_monitoring_constants.EventFieldType.ERROR_COUNT] == "null":
+ endpoint[model_monitoring_constants.EventFieldType.ERROR_COUNT] = "0"
+
+ # Validate default value for `metrics`
+ # For backwards compatibility reasons, we validate that the model endpoint includes the `metrics` key
+ if (
+ model_monitoring_constants.EventFieldType.METRICS in endpoint
+ and endpoint[model_monitoring_constants.EventFieldType.METRICS] == "null"
+ ):
+ endpoint[model_monitoring_constants.EventFieldType.METRICS] = json.dumps(
+ {
+ model_monitoring_constants.EventKeyMetrics.GENERIC: {
+ model_monitoring_constants.EventLiveStats.LATENCY_AVG_1H: 0,
+ model_monitoring_constants.EventLiveStats.PREDICTIONS_PER_SECOND: 0,
+ }
+ }
+ )
diff --git a/tests/api/api/test_grafana_proxy.py b/tests/api/api/test_grafana_proxy.py
index 8006d67f056e..f1c6ed0621d7 100644
--- a/tests/api/api/test_grafana_proxy.py
+++ b/tests/api/api/test_grafana_proxy.py
@@ -31,6 +31,8 @@
import mlrun.api.crud
import mlrun.api.schemas
import mlrun.api.utils.clients.iguazio
+import mlrun.model_monitoring.constants as model_monitoring_constants
+import mlrun.model_monitoring.stores
from mlrun.api.crud.model_monitoring.grafana import (
parse_query_parameters,
validate_query_parameters,
@@ -86,14 +88,13 @@ def test_grafana_list_endpoints(db: Session, client: TestClient):
endpoints_in = [_mock_random_endpoint("active") for _ in range(5)]
# Initialize endpoint store target object
- endpoint_target = (
- mlrun.api.crud.model_monitoring.model_endpoint_store._ModelEndpointKVStore(
- project=TEST_PROJECT, access_key=_get_access_key()
- )
+ store_type_object = mlrun.model_monitoring.stores.ModelEndpointStoreType(value="kv")
+ endpoint_store = store_type_object.to_endpoint_store(
+ project=TEST_PROJECT, access_key=_get_access_key()
)
for endpoint in endpoints_in:
- endpoint_target.write_model_endpoint(endpoint)
+ endpoint_store.write_model_endpoint(endpoint.flat_dict())
response = client.post(
url="grafana-proxy/model-endpoints/query",
@@ -358,13 +359,13 @@ def cleanup_endpoints(db: Session, client: TestClient):
if not _is_env_params_dont_exist():
kv_path = config.model_endpoint_monitoring.store_prefixes.default.format(
project=TEST_PROJECT,
- kind=mlrun.api.schemas.ModelMonitoringStoreKinds.ENDPOINTS,
+ kind=model_monitoring_constants.ModelMonitoringStoreKinds.ENDPOINTS,
)
_, kv_container, kv_path = parse_model_endpoint_store_prefix(kv_path)
tsdb_path = config.model_endpoint_monitoring.store_prefixes.default.format(
project=TEST_PROJECT,
- kind=mlrun.api.schemas.ModelMonitoringStoreKinds.EVENTS,
+ kind=model_monitoring_constants.ModelMonitoringStoreKinds.EVENTS,
)
_, tsdb_container, tsdb_path = parse_model_endpoint_store_prefix(tsdb_path)
@@ -413,7 +414,8 @@ def cleanup_endpoints(db: Session, client: TestClient):
)
def test_grafana_incoming_features(db: Session, client: TestClient):
path = config.model_endpoint_monitoring.store_prefixes.default.format(
- project=TEST_PROJECT, kind=mlrun.api.schemas.ModelMonitoringStoreKinds.EVENTS
+ project=TEST_PROJECT,
+ kind=model_monitoring_constants.ModelMonitoringStoreKinds.EVENTS,
)
_, container, path = parse_model_endpoint_store_prefix(path)
@@ -431,14 +433,15 @@ def test_grafana_incoming_features(db: Session, client: TestClient):
e.spec.feature_names = ["f0", "f1", "f2", "f3"]
# Initialize endpoint store target object
- endpoint_target = (
- mlrun.api.crud.model_monitoring.model_endpoint_store._ModelEndpointKVStore(
- project=TEST_PROJECT, access_key=_get_access_key()
- )
+ store_type_object = mlrun.model_monitoring.stores.ModelEndpointStoreType(
+ value="v3io-nosql"
+ )
+ endpoint_store = store_type_object.to_endpoint_store(
+ project=TEST_PROJECT, access_key=_get_access_key()
)
for endpoint in endpoints:
- endpoint_target.write_model_endpoint(endpoint)
+ endpoint_store.write_model_endpoint(endpoint.flat_dict())
total = 0
diff --git a/tests/api/api/test_model_endpoints.py b/tests/api/api/test_model_endpoints.py
index 1b6ab99644f2..4d0e3e657b09 100644
--- a/tests/api/api/test_model_endpoints.py
+++ b/tests/api/api/test_model_endpoints.py
@@ -14,52 +14,59 @@
#
import os
import string
+import typing
from random import choice, randint
from typing import Optional
+import deepdiff
import pytest
import mlrun.api.crud
import mlrun.api.schemas
-from mlrun.api.schemas import (
- ModelEndpoint,
- ModelEndpointMetadata,
- ModelEndpointSpec,
- ModelEndpointStatus,
-)
from mlrun.errors import MLRunBadRequestError, MLRunInvalidArgumentError
+from mlrun.model_monitoring import ModelMonitoringStoreKinds
+from mlrun.model_monitoring.stores import ( # noqa: F401
+ ModelEndpointStore,
+ ModelEndpointStoreType,
+)
TEST_PROJECT = "test_model_endpoints"
-
+ENDPOINT_STORE_CONNECTION = "sqlite:///test.db"
# Set a default v3io access key env variable
V3IO_ACCESS_KEY = "1111-2222-3333-4444"
os.environ["V3IO_ACCESS_KEY"] = V3IO_ACCESS_KEY
+# Bound a typing variable for ModelEndpointStore
+KVmodelType = typing.TypeVar("KVmodelType", bound="ModelEndpointStore")
+
def test_build_kv_cursor_filter_expression():
"""Validate that the filter expression format converter for the KV cursor works as expected."""
# Initialize endpoint store target object
- endpoint_target = (
- mlrun.api.crud.model_monitoring.model_endpoint_store._ModelEndpointKVStore(
- project=TEST_PROJECT, access_key=V3IO_ACCESS_KEY
- )
+ store_type_object = mlrun.model_monitoring.stores.ModelEndpointStoreType(
+ value="v3io-nosql"
+ )
+
+ endpoint_store: KVmodelType = store_type_object.to_endpoint_store(
+ project=TEST_PROJECT, access_key=V3IO_ACCESS_KEY
)
+
with pytest.raises(MLRunInvalidArgumentError):
- endpoint_target.build_kv_cursor_filter_expression("")
+ endpoint_store._build_kv_cursor_filter_expression("")
- filter_expression = endpoint_target.build_kv_cursor_filter_expression(
+ filter_expression = endpoint_store._build_kv_cursor_filter_expression(
project=TEST_PROJECT
)
assert filter_expression == f"project=='{TEST_PROJECT}'"
- filter_expression = endpoint_target.build_kv_cursor_filter_expression(
+ filter_expression = endpoint_store._build_kv_cursor_filter_expression(
project=TEST_PROJECT, function="test_function", model="test_model"
)
expected = f"project=='{TEST_PROJECT}' AND function=='test_function' AND model=='test_model'"
assert filter_expression == expected
- filter_expression = endpoint_target.build_kv_cursor_filter_expression(
+ filter_expression = endpoint_store._build_kv_cursor_filter_expression(
project=TEST_PROJECT, labels=["lbl1", "lbl2"]
)
assert (
@@ -67,7 +74,7 @@ def test_build_kv_cursor_filter_expression():
== f"project=='{TEST_PROJECT}' AND exists(_lbl1) AND exists(_lbl2)"
)
- filter_expression = endpoint_target.build_kv_cursor_filter_expression(
+ filter_expression = endpoint_store._build_kv_cursor_filter_expression(
project=TEST_PROJECT, labels=["lbl1=1", "lbl2=2"]
)
assert (
@@ -222,14 +229,9 @@ def test_get_endpoint_features_function():
}
feature_names = list(stats.keys())
- # Initialize endpoint store target object
- endpoint_target = (
- mlrun.api.crud.model_monitoring.model_endpoint_store._ModelEndpointKVStore(
- project=TEST_PROJECT, access_key=V3IO_ACCESS_KEY
- )
+ features = mlrun.api.crud.ModelEndpoints.get_endpoint_features(
+ feature_names, stats, stats
)
-
- features = endpoint_target.get_endpoint_features(feature_names, stats, stats)
assert len(features) == 4
# Commented out asserts should be re-enabled once buckets/counts length mismatch bug is fixed
for feature in features:
@@ -242,7 +244,9 @@ def test_get_endpoint_features_function():
assert feature.actual.histogram is not None
# assert len(feature.actual.histogram.buckets) == len(feature.actual.histogram.counts)
- features = endpoint_target.get_endpoint_features(feature_names, stats, None)
+ features = mlrun.api.crud.ModelEndpoints.get_endpoint_features(
+ feature_names, stats, None
+ )
assert len(features) == 4
for feature in features:
assert feature.expected is not None
@@ -251,7 +255,9 @@ def test_get_endpoint_features_function():
assert feature.expected.histogram is not None
# assert len(feature.expected.histogram.buckets) == len(feature.expected.histogram.counts)
- features = endpoint_target.get_endpoint_features(feature_names, None, stats)
+ features = mlrun.api.crud.ModelEndpoints.get_endpoint_features(
+ feature_names, None, stats
+ )
assert len(features) == 4
for feature in features:
assert feature.expected is None
@@ -260,28 +266,31 @@ def test_get_endpoint_features_function():
assert feature.actual.histogram is not None
# assert len(feature.actual.histogram.buckets) == len(feature.actual.histogram.counts)
- features = endpoint_target.get_endpoint_features(feature_names[1:], None, stats)
+ features = mlrun.api.crud.ModelEndpoints.get_endpoint_features(
+ feature_names[1:], None, stats
+ )
assert len(features) == 3
def test_generating_tsdb_paths():
- """Validate that the TSDB paths for the _ModelEndpointKVStore object are created as expected. These paths are
+ """Validate that the TSDB paths for the KVModelEndpointStore object are created as expected. These paths are
usually important when the user call the delete project API and as a result the TSDB resources should be deleted"""
# Initialize endpoint store target object
- endpoint_target = (
- mlrun.api.crud.model_monitoring.model_endpoint_store._ModelEndpointKVStore(
- project=TEST_PROJECT, access_key=V3IO_ACCESS_KEY
- )
+ store_type_object = mlrun.model_monitoring.stores.ModelEndpointStoreType(
+ value="v3io-nosql"
+ )
+ endpoint_store: KVmodelType = store_type_object.to_endpoint_store(
+ project=TEST_PROJECT, access_key=V3IO_ACCESS_KEY
)
# Generating the required tsdb paths
- tsdb_path, filtered_path = endpoint_target._generate_tsdb_paths()
+ tsdb_path, filtered_path = endpoint_store._generate_tsdb_paths()
# Validate the expected results based on the full path to the TSDB events directory
full_path = mlrun.mlconf.model_endpoint_monitoring.store_prefixes.default.format(
project=TEST_PROJECT,
- kind=mlrun.api.schemas.ModelMonitoringStoreKinds.EVENTS,
+ kind=ModelMonitoringStoreKinds.EVENTS,
)
# TSDB short path that should point to the main directory
@@ -295,16 +304,149 @@ def _get_auth_info() -> mlrun.api.schemas.AuthInfo:
return mlrun.api.schemas.AuthInfo(data_session=os.environ.get("V3IO_ACCESS_KEY"))
-def _mock_random_endpoint(state: Optional[str] = None) -> ModelEndpoint:
+def _mock_random_endpoint(
+ state: Optional[str] = None,
+) -> mlrun.api.schemas.ModelEndpoint:
def random_labels():
return {f"{choice(string.ascii_letters)}": randint(0, 100) for _ in range(1, 5)}
- return ModelEndpoint(
- metadata=ModelEndpointMetadata(project=TEST_PROJECT, labels=random_labels()),
- spec=ModelEndpointSpec(
+ return mlrun.api.schemas.ModelEndpoint(
+ metadata=mlrun.api.schemas.ModelEndpointMetadata(
+ project=TEST_PROJECT, labels=random_labels()
+ ),
+ spec=mlrun.api.schemas.ModelEndpointSpec(
function_uri=f"test/function_{randint(0, 100)}:v{randint(0, 100)}",
model=f"model_{randint(0, 100)}:v{randint(0, 100)}",
model_class="classifier",
),
- status=ModelEndpointStatus(state=state),
+ status=mlrun.api.schemas.ModelEndpointStatus(state=state),
+ )
+
+
+def test_sql_target_list_model_endpoints():
+ """Testing list model endpoint using SQLModelEndpointStore object. In the following test
+ we create two model endpoints and list these endpoints. In addition, this test validates the
+ filter optional operation within the list model endpoints API. At the end of this test, we validate
+ that the model endpoints are deleted from the DB.
+ """
+
+ # Generate model endpoint target
+ store_type_object = mlrun.model_monitoring.stores.ModelEndpointStoreType(
+ value="sql"
+ )
+ endpoint_store = store_type_object.to_endpoint_store(
+ project=TEST_PROJECT, endpoint_store_connection=ENDPOINT_STORE_CONNECTION
+ )
+
+ # First, validate that there are no model endpoints records at the moment
+ list_of_endpoints = endpoint_store.list_model_endpoints()
+ endpoint_store.delete_model_endpoints_resources(endpoints=list_of_endpoints)
+
+ list_of_endpoints = endpoint_store.list_model_endpoints()
+ assert len(list_of_endpoints) == 0
+
+ # Generate and write the 1st model endpoint into the DB table
+ mock_endpoint_1 = _mock_random_endpoint()
+ endpoint_store.write_model_endpoint(endpoint=mock_endpoint_1.flat_dict())
+
+ # Validate that there is a single model endpoint
+ list_of_endpoints = endpoint_store.list_model_endpoints()
+ assert len(list_of_endpoints) == 1
+
+ # Generate and write the 2nd model endpoint into the DB table
+ mock_endpoint_2 = _mock_random_endpoint()
+ mock_endpoint_2.spec.model = "test_model"
+ mock_endpoint_2.metadata.uid = "12345"
+ endpoint_store.write_model_endpoint(endpoint=mock_endpoint_2.flat_dict())
+
+ # Validate that there are exactly two model endpoints within the DB
+ list_of_endpoints = endpoint_store.list_model_endpoints()
+ assert len(list_of_endpoints) == 2
+
+ # List only the model endpoint that has the model test_model
+ filtered_list_of_endpoints = endpoint_store.list_model_endpoints(model="test_model")
+ assert len(filtered_list_of_endpoints) == 1
+
+ # Clean model endpoints from DB
+ endpoint_store.delete_model_endpoints_resources(endpoints=list_of_endpoints)
+ list_of_endpoints = endpoint_store.list_model_endpoints()
+ assert (len(list_of_endpoints)) == 0
+
+
+def test_sql_target_patch_endpoint():
+ """Testing the update of a model endpoint using SQLModelEndpointStore object. In the following
+ test we update attributes within the model endpoint spec and status and then validate that there
+ attributes were actually updated.
+ """
+
+ # Generate model endpoint target
+ store_type_object = mlrun.model_monitoring.stores.ModelEndpointStoreType(
+ value="sql"
+ )
+ endpoint_store = store_type_object.to_endpoint_store(
+ project=TEST_PROJECT, endpoint_store_connection=ENDPOINT_STORE_CONNECTION
)
+
+ # First, validate that there are no model endpoints records at the moment
+ list_of_endpoints = endpoint_store.list_model_endpoints()
+ if len(list_of_endpoints) > 0:
+ # Delete old model endpoints records
+ endpoint_store.delete_model_endpoints_resources(endpoints=list_of_endpoints)
+ list_of_endpoints = endpoint_store.list_model_endpoints()
+ assert len(list_of_endpoints) == 0
+
+ # Generate and write the model endpoint into the DB table
+ mock_endpoint = _mock_random_endpoint()
+ mock_endpoint.metadata.uid = "1234"
+ endpoint_store.write_model_endpoint(mock_endpoint.flat_dict())
+
+ # Generate dictionary of attributes and update the model endpoint
+ updated_attributes = {"model": "test_model", "error_count": 2}
+ endpoint_store.update_model_endpoint(
+ endpoint_id=mock_endpoint.metadata.uid, attributes=updated_attributes
+ )
+
+ # Validate that these attributes were actually updated
+ endpoint = endpoint_store.get_model_endpoint(endpoint_id=mock_endpoint.metadata.uid)
+
+ # Convert to model endpoint object
+ endpoint = mlrun.api.crud.ModelEndpoints()._convert_into_model_endpoint_object(
+ endpoint=endpoint
+ )
+ assert endpoint.spec.model == "test_model"
+ assert endpoint.status.error_count == 2
+
+ # Clear model endpoint from DB
+ endpoint_store.delete_model_endpoint(endpoint_id=mock_endpoint.metadata.uid)
+
+ # Drop model endpoints test table from DB
+ list_of_endpoints = endpoint_store.list_model_endpoints()
+ endpoint_store.delete_model_endpoints_resources(endpoints=list_of_endpoints)
+
+
+def test_validate_model_endpoints_schema():
+ # Validate that both model endpoint basemodel schema and model endpoint ModelObj schema have similar keys
+ model_endpoint_basemodel = mlrun.api.schemas.ModelEndpoint()
+ model_endpoint_modelobj = mlrun.model_monitoring.ModelEndpoint()
+
+ # Compare status
+ base_model_status = model_endpoint_basemodel.status.__dict__
+ model_object_status = model_endpoint_modelobj.status.__dict__
+ assert (
+ deepdiff.DeepDiff(
+ base_model_status,
+ model_object_status,
+ ignore_order=True,
+ )
+ ) == {}
+
+ # Compare spec
+ base_model_status = model_endpoint_basemodel.status.__dict__
+ model_object_status = model_endpoint_modelobj.status.__dict__
+ assert (
+ deepdiff.DeepDiff(
+ base_model_status,
+ model_object_status,
+ ignore_order=True,
+ )
+ ) == {}
diff --git a/tests/api/conftest.py b/tests/api/conftest.py
index fcf0e3b32786..a42cadbe1e3b 100644
--- a/tests/api/conftest.py
+++ b/tests/api/conftest.py
@@ -51,7 +51,7 @@ def db() -> Generator:
# TODO: make it simpler - doesn't make sense to call 3 different functions to initialize the db
# we need to force re-init the engine cause otherwise it is cached between tests
- _init_engine(config.httpdb.dsn)
+ _init_engine(dsn=config.httpdb.dsn)
# forcing from scratch because we created an empty file for the db
init_data(from_scratch=True)
diff --git a/tests/api/db/conftest.py b/tests/api/db/conftest.py
index 9acc393a1c71..1b3a1248aa1b 100644
--- a/tests/api/db/conftest.py
+++ b/tests/api/db/conftest.py
@@ -74,7 +74,7 @@ def data_migration_db(request) -> Generator:
if request.param == "sqldb":
dsn = "sqlite:///:memory:?check_same_thread=false"
config.httpdb.dsn = dsn
- _init_engine()
+ _init_engine(dsn=dsn)
# memory sqldb remove it self when all session closed, this session will keep it up during all test
db_session = create_session()
diff --git a/tests/api/test_initial_data.py b/tests/api/test_initial_data.py
index 72884da5352c..5d8dd8ae9da1 100644
--- a/tests/api/test_initial_data.py
+++ b/tests/api/test_initial_data.py
@@ -135,10 +135,9 @@ def _initialize_db_without_migrations() -> typing.Tuple[
]:
dsn = "sqlite:///:memory:?check_same_thread=false"
mlrun.mlconf.httpdb.dsn = dsn
- mlrun.api.db.sqldb.session._init_engine(dsn)
-
+ mlrun.api.db.sqldb.session._init_engine(dsn=dsn)
mlrun.api.utils.singletons.db.initialize_db()
- db_session = mlrun.api.db.sqldb.session.create_session()
+ db_session = mlrun.api.db.sqldb.session.create_session(dsn=dsn)
db = mlrun.api.db.sqldb.db.SQLDB(dsn)
db.initialize(db_session)
mlrun.api.db.init_db.init_db(db_session)
diff --git a/tests/common_fixtures.py b/tests/common_fixtures.py
index ef0b4808182e..4bba994edde4 100644
--- a/tests/common_fixtures.py
+++ b/tests/common_fixtures.py
@@ -116,7 +116,7 @@ def db():
db_session = None
try:
config.httpdb.dsn = dsn
- _init_engine(dsn)
+ _init_engine(dsn=dsn)
init_data()
initialize_db()
db_session = create_session()
diff --git a/tests/rundb/test_dbs.py b/tests/rundb/test_dbs.py
index da37918e26ae..3b6d9b4bd236 100644
--- a/tests/rundb/test_dbs.py
+++ b/tests/rundb/test_dbs.py
@@ -42,7 +42,7 @@ def db(request):
db_file = f"{path}/mlrun.db"
dsn = f"sqlite:///{db_file}?check_same_thread=false"
config.httpdb.dsn = dsn
- _init_engine(dsn)
+ _init_engine(dsn=dsn)
init_data()
initialize_db()
db_session = create_session()
diff --git a/tests/system/model_monitoring/test_model_monitoring.py b/tests/system/model_monitoring/test_model_monitoring.py
index 23348f4b750d..17fe2151f342 100644
--- a/tests/system/model_monitoring/test_model_monitoring.py
+++ b/tests/system/model_monitoring/test_model_monitoring.py
@@ -41,8 +41,8 @@
)
from mlrun.errors import MLRunNotFoundError
from mlrun.model import BaseMetadata
+from mlrun.model_monitoring import EndpointType, ModelMonitoringMode
from mlrun.runtimes import BaseRuntime
-from mlrun.utils.model_monitoring import EndpointType
from mlrun.utils.v3io_clients import get_frames_client
from tests.system.base import TestMLRunSystem
@@ -62,7 +62,7 @@ def test_clear_endpoint(self):
db = mlrun.get_run_db()
db.create_model_endpoint(
- endpoint.metadata.project, endpoint.metadata.uid, endpoint
+ endpoint.metadata.project, endpoint.metadata.uid, endpoint.dict()
)
endpoint_response = db.get_model_endpoint(
@@ -88,14 +88,14 @@ def test_store_endpoint_update_existing(self):
db.create_model_endpoint(
project=endpoint.metadata.project,
endpoint_id=endpoint.metadata.uid,
- model_endpoint=endpoint,
+ model_endpoint=endpoint.dict(),
)
endpoint_before_update = db.get_model_endpoint(
project=endpoint.metadata.project, endpoint_id=endpoint.metadata.uid
)
- assert endpoint_before_update.status.state is None
+ assert endpoint_before_update.status.state == "null"
updated_state = "testing...testing...1 2 1 2"
drift_status = "DRIFT_DETECTED"
@@ -133,7 +133,7 @@ def test_store_endpoint_update_existing(self):
def test_list_endpoints_on_empty_project(self):
endpoints_out = mlrun.get_run_db().list_model_endpoints(self.project_name)
- assert len(endpoints_out.endpoints) == 0
+ assert len(endpoints_out) == 0
def test_list_endpoints(self):
db = mlrun.get_run_db()
@@ -145,13 +145,13 @@ def test_list_endpoints(self):
for endpoint in endpoints_in:
db.create_model_endpoint(
- endpoint.metadata.project, endpoint.metadata.uid, endpoint
+ endpoint.metadata.project, endpoint.metadata.uid, endpoint.dict()
)
endpoints_out = db.list_model_endpoints(self.project_name)
in_endpoint_ids = set(map(lambda e: e.metadata.uid, endpoints_in))
- out_endpoint_ids = set(map(lambda e: e.metadata.uid, endpoints_out.endpoints))
+ out_endpoint_ids = set(map(lambda e: e.metadata.uid, endpoints_out))
endpoints_intersect = in_endpoint_ids.intersection(out_endpoint_ids)
assert len(endpoints_intersect) == number_of_endpoints
@@ -176,32 +176,33 @@ def test_list_endpoints_filter(self):
db.create_model_endpoint(
endpoint_details.metadata.project,
endpoint_details.metadata.uid,
- endpoint_details,
+ endpoint_details.dict(),
)
filter_model = db.list_model_endpoints(self.project_name, model="filterme")
- assert len(filter_model.endpoints) == 1
-
- filter_labels = db.list_model_endpoints(
- self.project_name, labels=["filtermex=1"]
- )
- assert len(filter_labels.endpoints) == 4
-
- filter_labels = db.list_model_endpoints(
- self.project_name, labels=["filtermex=1", "filtermey=2"]
- )
- assert len(filter_labels.endpoints) == 4
-
- filter_labels = db.list_model_endpoints(
- self.project_name, labels=["filtermey=2"]
- )
- assert len(filter_labels.endpoints) == 4
-
- @staticmethod
- def _get_auth_info() -> mlrun.api.schemas.AuthInfo:
- return mlrun.api.schemas.AuthInfo(
- data_session=os.environ.get("V3IO_ACCESS_KEY")
- )
+ assert len(filter_model) == 1
+
+ # TODO: Uncomment the following assertions once the KV labels filters is fixed.
+ # Following the implementation of supporting SQL store for model endpoints records, this table
+ # has static schema. That means, in order to keep the schema logic for both SQL and KV,
+ # it is not possible to add new label columns dynamically to the KV table. Therefore, the label filtering
+ # process for the KV should be updated accordingly.
+ #
+
+ # filter_labels = db.list_model_endpoints(
+ # self.project_name, labels=["filtermex=1"]
+ # )
+ # assert len(filter_labels) == 4
+ #
+ # filter_labels = db.list_model_endpoints(
+ # self.project_name, labels=["filtermex=1", "filtermey=2"]
+ # )
+ # assert len(filter_labels) == 4
+ #
+ # filter_labels = db.list_model_endpoints(
+ # self.project_name, labels=["filtermey=2"]
+ # )
+ # assert len(filter_labels) == 4
def _mock_random_endpoint(self, state: Optional[str] = None) -> ModelEndpoint:
def random_labels():
@@ -434,10 +435,7 @@ def test_model_monitoring_with_regression(self):
# Validate monitoring mode
model_endpoint = endpoints_list.endpoints[0]
- assert (
- model_endpoint.spec.monitoring_mode
- == mlrun.api.schemas.ModelMonitoringMode.enabled.value
- )
+ assert model_endpoint.spec.monitoring_mode == ModelMonitoringMode.enabled.value
# Validate tracking policy
batch_job = db.get_schedule(
From 9aa8441e7c2aea1d47600edbbe1d4aa531c593ff Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Mon, 27 Mar 2023 12:29:29 +0300
Subject: [PATCH 007/334] [Makefile] Fix compile schemas dockerized dir volume
(#3346)
---
go/Makefile | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/go/Makefile b/go/Makefile
index a38e95c611e3..f805f7783744 100644
--- a/go/Makefile
+++ b/go/Makefile
@@ -77,7 +77,7 @@ compile-schemas-local: cleanup compile-schemas-go compile-schemas-python
compile-schemas-dockerized: schemas-compiler
@echo Compiling schemas in docker container
docker run \
- -v $(shell dirname $(PWD)):/app \
+ -v $(shell dirname $(CURDIR)):/app \
$(MLRUN_DOCKER_IMAGE_PREFIX)/schemas-compiler:latest \
make compile-schemas-local
From bd943f3497644ed023503e8afcc44ad8a272f6c8 Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Mon, 27 Mar 2023 14:50:21 +0300
Subject: [PATCH 008/334] [API] Reflect correct message wen waiting for chief
(#3336)
---
mlrun/api/api/deps.py | 15 +-----------
mlrun/api/schemas/constants.py | 13 ++++++++++
tests/api/test_api_states.py | 45 ++++++++++++++++++++--------------
3 files changed, 41 insertions(+), 32 deletions(-)
diff --git a/mlrun/api/api/deps.py b/mlrun/api/api/deps.py
index 5d31f297ef5f..0375f3913956 100644
--- a/mlrun/api/api/deps.py
+++ b/mlrun/api/api/deps.py
@@ -70,20 +70,7 @@ def verify_api_state(request: Request):
"memory-reports",
]
if not any(enabled_endpoint in path for enabled_endpoint in enabled_endpoints):
- message = (
- "API is waiting for migrations to be triggered. Send POST request to /api/operations/migrations to"
- " trigger it"
- )
- if (
- mlrun.mlconf.httpdb.state
- == mlrun.api.schemas.APIStates.migrations_in_progress
- ):
- message = "Migrations are in progress"
- elif (
- mlrun.mlconf.httpdb.state
- == mlrun.api.schemas.APIStates.migrations_failed
- ):
- message = "Migrations failed, API can't be started"
+ message = mlrun.api.schemas.APIStates.description(mlrun.mlconf.httpdb.state)
raise mlrun.errors.MLRunPreconditionFailedError(message)
diff --git a/mlrun/api/schemas/constants.py b/mlrun/api/schemas/constants.py
index 31d3897dfb46..dafb4e7ed6af 100644
--- a/mlrun/api/schemas/constants.py
+++ b/mlrun/api/schemas/constants.py
@@ -170,6 +170,19 @@ class APIStates:
def terminal_states():
return [APIStates.online, APIStates.offline]
+ @staticmethod
+ def description(state: str):
+ return {
+ APIStates.online: "API is online",
+ APIStates.waiting_for_migrations: "API is waiting for migrations to be triggered. "
+ "Send POST request to /api/operations/migrations to trigger it",
+ APIStates.migrations_in_progress: "Migrations are in progress",
+ APIStates.migrations_failed: "Migrations failed, API can't be started",
+ APIStates.migrations_completed: "Migrations completed, API is waiting to become online",
+ APIStates.offline: "API is offline",
+ APIStates.waiting_for_chief: "API is waiting for chief to be ready",
+ }.get(state, f"Unknown API state '{state}'")
+
class ClusterizationRole:
chief = "chief"
diff --git a/tests/api/test_api_states.py b/tests/api/test_api_states.py
index e7d11a8909ff..91ae63222b0a 100644
--- a/tests/api/test_api_states.py
+++ b/tests/api/test_api_states.py
@@ -16,6 +16,7 @@
import unittest.mock
import fastapi.testclient
+import pytest
import sqlalchemy.orm
import mlrun.api.initial_data
@@ -38,28 +39,36 @@ def test_offline_state(
assert "API is in offline state" in response.text
-def test_migrations_states(
- db: sqlalchemy.orm.Session, client: fastapi.testclient.TestClient
+@pytest.mark.parametrize(
+ "state",
+ [
+ mlrun.api.schemas.APIStates.waiting_for_migrations,
+ mlrun.api.schemas.APIStates.migrations_in_progress,
+ mlrun.api.schemas.APIStates.migrations_failed,
+ mlrun.api.schemas.APIStates.waiting_for_chief,
+ ],
+)
+def test_api_states(
+ db: sqlalchemy.orm.Session,
+ client: fastapi.testclient.TestClient,
+ state,
) -> None:
- expected_message_map = {
- mlrun.api.schemas.APIStates.waiting_for_migrations: "API is waiting for migrations to be triggered",
- mlrun.api.schemas.APIStates.migrations_in_progress: "Migrations are in progress",
- mlrun.api.schemas.APIStates.migrations_failed: "Migrations failed",
- }
- for state, expected_message in expected_message_map.items():
- mlrun.mlconf.httpdb.state = state
- response = client.get("healthz")
- assert response.status_code == http.HTTPStatus.OK.value
+ mlrun.mlconf.httpdb.state = state
+ response = client.get("healthz")
+ assert response.status_code == http.HTTPStatus.OK.value
- response = client.get("projects/some-project/background-tasks/some-task")
- assert response.status_code == http.HTTPStatus.NOT_FOUND.value
+ response = client.get("projects/some-project/background-tasks/some-task")
+ assert response.status_code == http.HTTPStatus.NOT_FOUND.value
- response = client.get("client-spec")
- assert response.status_code == http.HTTPStatus.OK.value
+ response = client.get("client-spec")
+ assert response.status_code == http.HTTPStatus.OK.value
- response = client.get("projects")
- assert response.status_code == http.HTTPStatus.PRECONDITION_FAILED.value
- assert expected_message in response.text
+ response = client.get("projects")
+ expected_message = mlrun.api.schemas.APIStates.description(state)
+ assert response.status_code == http.HTTPStatus.PRECONDITION_FAILED.value
+ assert (
+ expected_message in response.text
+ ), f"Expected message: {expected_message}, actual: {response.text}"
def test_init_data_migration_required_recognition(monkeypatch) -> None:
From 9268392d578b14807b3dcb644c864fce6ad8c308 Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Mon, 27 Mar 2023 23:01:14 +0300
Subject: [PATCH 009/334] [CI] Trigger CI on pull request against `feature/`
branches (#3345) (#3348)
---
.github/workflows/ci.yaml | 1 +
1 file changed, 1 insertion(+)
diff --git a/.github/workflows/ci.yaml b/.github/workflows/ci.yaml
index af89c68a2ce2..9116e4e5523f 100644
--- a/.github/workflows/ci.yaml
+++ b/.github/workflows/ci.yaml
@@ -19,6 +19,7 @@ on:
branches:
- development
- '[0-9]+.[0-9]+.x'
+ - 'feature/**'
# Run CI also on push to backport release branches - we sometimes push code there by cherry-picking, meaning it
# doesn't go through CI (no PR)
From a190884860ca247f0dbe773b03d6d71be270ee2c Mon Sep 17 00:00:00 2001
From: jist <95856749+george0st@users.noreply.github.com>
Date: Mon, 27 Mar 2023 23:33:31 +0200
Subject: [PATCH 010/334] [Docs] Fix SQLSource documentation anr remove
ToDataFrame from targets table (#3330)
---
docs/data-prep/ingest-data-fs.md | 2 +-
docs/serving/available-steps.md | 1 -
mlrun/datastore/sources.py | 2 +-
3 files changed, 2 insertions(+), 3 deletions(-)
diff --git a/docs/data-prep/ingest-data-fs.md b/docs/data-prep/ingest-data-fs.md
index d8ef7895ac38..bcea5a7c080f 100644
--- a/docs/data-prep/ingest-data-fs.md
+++ b/docs/data-prep/ingest-data-fs.md
@@ -174,7 +174,7 @@ either, pass the `db_uri` or overwrite the `MLRUN_SQL__URL` env var, in this for
`mysql+pymysql://:@:/`, for example:
```
-source = SqlDBSource(table_name='my_table',
+source = SQLSource(table_name='my_table',
db_path="mysql+pymysql://abc:abc@localhost:3306/my_db",
key_field='key',
time_fields=['timestamp'], )
diff --git a/docs/serving/available-steps.md b/docs/serving/available-steps.md
index 511e65680c22..fef9cb380ef8 100644
--- a/docs/serving/available-steps.md
+++ b/docs/serving/available-steps.md
@@ -84,7 +84,6 @@ The following table lists the available data-transformation steps. The next tabl
| mlrun.datastore.SqlTarget | Persists the data in SQL table to its associated storage by key. | Y | N | Y |
| [mlrun.datastore.ParquetTarget](https://storey.readthedocs.io/en/latest/api.html#storey.targets.ParquetTarget) | The Parquet target storage driver, used to materialize feature set/vector data into parquet files. | Y | Y | Y |
| [mlrun.datastore.StreamTarget](https://storey.readthedocs.io/en/latest/api.html#storey.targets.StreamTarget) | Writes all incoming events into a V3IO stream. | Y | N | N |
-| [storey.transformations.ToDataFrame](https://storey.readthedocs.io/en/latest/api.html#storey.transformations.ToDataFrame) | Create pandas data frame from events. Can appear in the middle of the flow. | Y | N | N |
## Models
| Class name | Description |
diff --git a/mlrun/datastore/sources.py b/mlrun/datastore/sources.py
index be9bb0237df8..1dfb182cb445 100644
--- a/mlrun/datastore/sources.py
+++ b/mlrun/datastore/sources.py
@@ -885,7 +885,7 @@ def __init__(
Reads SqlDB as input source for a flow.
example::
db_path = "mysql+pymysql://:@:/"
- source = SqlDBSource(
+ source = SQLSource(
collection_name='source_name', db_path=self.db, key_field='key'
)
:param name: source name
From d52d3c6cab004f5349b97b2559bb2ebe014316e3 Mon Sep 17 00:00:00 2001
From: Tom Tankilevitch <59158507+Tankilevitch@users.noreply.github.com>
Date: Tue, 28 Mar 2023 10:22:16 +0300
Subject: [PATCH 011/334] [DB] Remove FileDB (#2867)
---
.gitignore | 3 +
Makefile | 2 -
mlrun/api/db/filedb/db.py | 543 -----------
mlrun/api/db/session.py | 14 +-
mlrun/api/utils/singletons/db.py | 22 +-
mlrun/config.py | 9 +
mlrun/db/__init__.py | 10 +-
mlrun/db/filedb.py | 892 ------------------
mlrun/db/nopdb.py | 463 +++++++++
mlrun/db/sqldb.py | 50 +-
tests/api/db/conftest.py | 101 +-
tests/api/db/test_artifacts.py | 63 --
tests/api/db/test_background_tasks.py | 16 -
tests/api/db/test_feature_sets.py | 15 -
tests/api/db/test_functions.py | 44 -
tests/api/db/test_projects.py | 41 -
tests/api/db/test_runs.py | 45 -
tests/artifacts/test_artifacts.py | 34 -
tests/artifacts/test_model.py | 92 --
tests/common_fixtures.py | 118 ++-
tests/feature-store/test_infer.py | 39 +-
tests/feature-store/test_steps.py | 4 +-
tests/frameworks/lgbm/test_lgbm.py | 6 +-
tests/frameworks/test_ml_frameworks.py | 76 +-
.../sdk_api/artifacts/test_artifacts.py | 40 +
tests/integration/sdk_api/base.py | 2 +-
.../sdk_api/httpdb/runs}/__init__.py | 2 +-
.../httpdb/{ => runs}/assets/big-run.json | 0
.../sdk_api/httpdb/runs/test_dask.py | 56 ++
.../sdk_api/httpdb/{ => runs}/test_runs.py | 22 +
.../sdk_api/projects/test_project.py | 36 +
tests/integration/sdk_api/run/test_main.py | 450 +++++++++
tests/notebooks.yml | 20 -
tests/projects/test_local_pipeline.py | 4 +-
tests/projects/test_project.py | 13 +-
tests/run/test_handler_decorator.py | 20 +-
tests/run/test_hyper.py | 2 +-
tests/run/test_main.py | 446 ---------
tests/run/test_run.py | 56 +-
tests/rundb/test_dbs.py | 7 +-
tests/rundb/test_filedb.py | 91 --
tests/rundb/test_nopdb.py | 44 +
tests/runtimes/test_logging_and_parsing.py | 2 +-
tests/serving/test_serving.py | 2 +-
tests/test_code_to_func.py | 22 +-
tests/test_datastores.py | 2 +-
tests/test_notebooks.py | 77 --
47 files changed, 1420 insertions(+), 2698 deletions(-)
delete mode 100644 mlrun/api/db/filedb/db.py
delete mode 100644 mlrun/db/filedb.py
create mode 100644 mlrun/db/nopdb.py
delete mode 100644 tests/artifacts/test_model.py
rename {mlrun/api/db/filedb => tests/integration/sdk_api/httpdb/runs}/__init__.py (94%)
rename tests/integration/sdk_api/httpdb/{ => runs}/assets/big-run.json (100%)
create mode 100644 tests/integration/sdk_api/httpdb/runs/test_dask.py
rename tests/integration/sdk_api/httpdb/{ => runs}/test_runs.py (87%)
create mode 100644 tests/integration/sdk_api/run/test_main.py
delete mode 100644 tests/notebooks.yml
delete mode 100644 tests/run/test_main.py
delete mode 100644 tests/rundb/test_filedb.py
create mode 100644 tests/rundb/test_nopdb.py
delete mode 100644 tests/test_notebooks.py
diff --git a/.gitignore b/.gitignore
index d51b023d0e7d..580a9cd33ba3 100644
--- a/.gitignore
+++ b/.gitignore
@@ -21,6 +21,9 @@ mlrun.egg-info/
model.txt
result*.html
tests/test_results/
+tests/temp*
+tests/*.pkl
+tests/project.yaml
*venv*
mlrun/utils/version/version.json
mlrun/api/migrations_sqlite/mlrun.db
diff --git a/Makefile b/Makefile
index a5f4eedb2afa..ac10315e1886 100644
--- a/Makefile
+++ b/Makefile
@@ -527,7 +527,6 @@ test: clean ## Run mlrun tests
--durations=100 \
--ignore=tests/integration \
--ignore=tests/system \
- --ignore=tests/test_notebooks.py \
--ignore=tests/rundb/test_httpdb.py \
-rf \
tests
@@ -551,7 +550,6 @@ test-integration: clean ## Run mlrun integration tests
--durations=100 \
-rf \
tests/integration \
- tests/test_notebooks.py \
tests/rundb/test_httpdb.py
.PHONY: test-migrations-dockerized
diff --git a/mlrun/api/db/filedb/db.py b/mlrun/api/db/filedb/db.py
deleted file mode 100644
index 5fb3ac254d60..000000000000
--- a/mlrun/api/db/filedb/db.py
+++ /dev/null
@@ -1,543 +0,0 @@
-# Copyright 2018 Iguazio
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-#
-import datetime
-from typing import Any, Dict, List, Optional, Tuple, Union
-
-from mlrun.api import schemas
-from mlrun.api.db.base import DBError, DBInterface
-from mlrun.db.base import RunDBError
-from mlrun.db.filedb import FileRunDB
-
-
-class FileDB(DBInterface):
- def __init__(self, dirpath="", format=".yaml"):
- self.db = FileRunDB(dirpath, format)
-
- def initialize(self, session):
- self.db.connect()
-
- def store_log(
- self,
- session,
- uid,
- project="",
- body=None,
- append=False,
- ):
- return self._transform_run_db_error(
- self.db.store_log, uid, project, body, append
- )
-
- def get_log(self, session, uid, project="", offset=0, size=0):
- return self._transform_run_db_error(self.db.get_log, uid, project, offset, size)
-
- def store_run(
- self,
- session,
- struct,
- uid,
- project="",
- iter=0,
- ):
- return self._transform_run_db_error(
- self.db.store_run, struct, uid, project, iter
- )
-
- def update_run(self, session, updates: dict, uid, project="", iter=0):
- return self._transform_run_db_error(
- self.db.update_run, updates, uid, project, iter
- )
-
- def list_distinct_runs_uids(
- self,
- session,
- project: str = None,
- requested_logs_modes: List[bool] = None,
- only_uids: bool = False,
- last_update_time_from: datetime.datetime = None,
- states: List[str] = None,
- ):
- raise NotImplementedError()
-
- def update_runs_requested_logs(
- self, session, uids: List[str], requested_logs: bool = True
- ):
- raise NotImplementedError()
-
- def read_run(self, session, uid, project="", iter=0):
- return self._transform_run_db_error(self.db.read_run, uid, project, iter)
-
- def list_runs(
- self,
- session,
- name="",
- uid: Optional[Union[str, List[str]]] = None,
- project="",
- labels=None,
- states=None,
- sort=True,
- last=0,
- iter=False,
- start_time_from=None,
- start_time_to=None,
- last_update_time_from=None,
- last_update_time_to=None,
- partition_by: schemas.RunPartitionByField = None,
- rows_per_partition: int = 1,
- partition_sort_by: schemas.SortField = None,
- partition_order: schemas.OrderType = schemas.OrderType.desc,
- max_partitions: int = 0,
- requested_logs: bool = None,
- return_as_run_structs: bool = True,
- with_notifications: bool = False,
- ):
- return self._transform_run_db_error(
- self.db.list_runs,
- name,
- uid,
- project,
- labels,
- states[0] if states else "",
- sort,
- last,
- iter,
- start_time_from,
- start_time_to,
- last_update_time_from,
- last_update_time_to,
- partition_by,
- rows_per_partition,
- partition_sort_by,
- partition_order,
- max_partitions,
- requested_logs,
- return_as_run_structs,
- with_notifications,
- )
-
- def del_run(self, session, uid, project="", iter=0):
- return self._transform_run_db_error(self.db.del_run, uid, project, iter)
-
- def del_runs(self, session, name="", project="", labels=None, state="", days_ago=0):
- return self._transform_run_db_error(
- self.db.del_runs, name, project, labels, state, days_ago
- )
-
- def overwrite_artifacts_with_tag(
- self,
- session,
- project: str,
- tag: str,
- identifiers: List[schemas.ArtifactIdentifier],
- ):
- raise NotImplementedError()
-
- def append_tag_to_artifacts(
- self,
- session,
- project: str,
- tag: str,
- identifiers: List[schemas.ArtifactIdentifier],
- ):
- raise NotImplementedError()
-
- def delete_tag_from_artifacts(
- self,
- session,
- project: str,
- tag: str,
- identifiers: List[schemas.ArtifactIdentifier],
- ):
- raise NotImplementedError()
-
- def store_artifact(
- self,
- session,
- key,
- artifact,
- uid,
- iter=None,
- tag="",
- project="",
- ):
- return self._transform_run_db_error(
- self.db.store_artifact, key, artifact, uid, iter, tag, project
- )
-
- def read_artifact(self, session, key, tag="", iter=None, project=""):
- return self._transform_run_db_error(
- self.db.read_artifact, key, tag, iter, project
- )
-
- def list_artifacts(
- self,
- session,
- name="",
- project="",
- tag="",
- labels=None,
- since=None,
- until=None,
- kind=None,
- category: schemas.ArtifactCategories = None,
- iter: int = None,
- best_iteration: bool = False,
- as_records: bool = False,
- use_tag_as_uid: bool = None,
- ):
- return self._transform_run_db_error(
- self.db.list_artifacts, name, project, tag, labels, since, until
- )
-
- def del_artifact(self, session, key, tag="", project=""):
- return self._transform_run_db_error(self.db.del_artifact, key, tag, project)
-
- def del_artifacts(self, session, name="", project="", tag="", labels=None):
- return self._transform_run_db_error(
- self.db.del_artifacts, name, project, tag, labels
- )
-
- def store_function(
- self,
- session,
- function,
- name,
- project="",
- tag="",
- versioned=False,
- ) -> str:
- return self._transform_run_db_error(
- self.db.store_function, function, name, project, tag, versioned
- )
-
- def get_function(self, session, name, project="", tag="", hash_key=""):
- return self._transform_run_db_error(
- self.db.get_function, name, project, tag, hash_key
- )
-
- def delete_function(self, session, project: str, name: str):
- raise NotImplementedError()
-
- def list_functions(
- self, session, name=None, project="", tag="", labels=None, hash_key=None
- ):
- return self._transform_run_db_error(
- self.db.list_functions, name, project, tag, labels
- )
-
- def store_schedule(self, session, data):
- return self._transform_run_db_error(self.db.store_schedule, data)
-
- def generate_projects_summaries(
- self, session, projects: List[str]
- ) -> List[schemas.ProjectSummary]:
- raise NotImplementedError()
-
- def delete_project_related_resources(self, session, name: str):
- raise NotImplementedError()
-
- def verify_project_has_no_related_resources(self, session, name: str):
- raise NotImplementedError()
-
- def is_project_exists(self, session, name: str):
- raise NotImplementedError()
-
- def list_projects(
- self,
- session,
- owner: str = None,
- format_: schemas.ProjectsFormat = schemas.ProjectsFormat.full,
- labels: List[str] = None,
- state: schemas.ProjectState = None,
- names: Optional[List[str]] = None,
- ) -> schemas.ProjectsOutput:
- return self._transform_run_db_error(
- self.db.list_projects, owner, format_, labels, state
- )
-
- async def get_project_resources_counters(
- self,
- ) -> Tuple[
- Dict[str, int],
- Dict[str, int],
- Dict[str, int],
- Dict[str, int],
- Dict[str, int],
- Dict[str, int],
- ]:
- raise NotImplementedError()
-
- def store_project(self, session, name: str, project: schemas.Project):
- raise NotImplementedError()
-
- def patch_project(
- self,
- session,
- name: str,
- project: dict,
- patch_mode: schemas.PatchMode = schemas.PatchMode.replace,
- ):
- raise NotImplementedError()
-
- def create_project(self, session, project: schemas.Project):
- raise NotImplementedError()
-
- def get_project(
- self, session, name: str = None, project_id: int = None
- ) -> schemas.Project:
- raise NotImplementedError()
-
- def delete_project(
- self,
- session,
- name: str,
- deletion_strategy: schemas.DeletionStrategy = schemas.DeletionStrategy.default(),
- ):
- raise NotImplementedError()
-
- def create_feature_set(
- self,
- session,
- project,
- feature_set: schemas.FeatureSet,
- versioned=True,
- ) -> str:
- raise NotImplementedError()
-
- def store_feature_set(
- self,
- session,
- project,
- name,
- feature_set: schemas.FeatureSet,
- tag=None,
- uid=None,
- versioned=True,
- always_overwrite=False,
- ) -> str:
- raise NotImplementedError()
-
- def get_feature_set(
- self, session, project: str, name: str, tag: str = None, uid: str = None
- ) -> schemas.FeatureSet:
- raise NotImplementedError()
-
- def list_features(
- self,
- session,
- project: str,
- name: str = None,
- tag: str = None,
- entities: List[str] = None,
- labels: List[str] = None,
- ) -> schemas.FeaturesOutput:
- raise NotImplementedError()
-
- def list_entities(
- self,
- session,
- project: str,
- name: str = None,
- tag: str = None,
- labels: List[str] = None,
- ) -> schemas.EntitiesOutput:
- pass
-
- def list_feature_sets(
- self,
- session,
- project: str,
- name: str = None,
- tag: str = None,
- state: str = None,
- entities: List[str] = None,
- features: List[str] = None,
- labels: List[str] = None,
- partition_by: schemas.FeatureStorePartitionByField = None,
- rows_per_partition: int = 1,
- partition_sort_by: schemas.SortField = None,
- partition_order: schemas.OrderType = schemas.OrderType.desc,
- ) -> schemas.FeatureSetsOutput:
- raise NotImplementedError()
-
- def list_feature_sets_tags(
- self,
- session,
- project: str,
- ):
- raise NotImplementedError()
-
- def patch_feature_set(
- self,
- session,
- project,
- name,
- feature_set_patch: dict,
- tag=None,
- uid=None,
- patch_mode: schemas.PatchMode = schemas.PatchMode.replace,
- ) -> str:
- raise NotImplementedError()
-
- def delete_feature_set(self, session, project, name, tag=None, uid=None):
- raise NotImplementedError()
-
- def create_feature_vector(
- self,
- session,
- project,
- feature_vector: schemas.FeatureVector,
- versioned=True,
- ) -> str:
- raise NotImplementedError()
-
- def get_feature_vector(
- self, session, project: str, name: str, tag: str = None, uid: str = None
- ) -> schemas.FeatureVector:
- raise NotImplementedError()
-
- def list_feature_vectors(
- self,
- session,
- project: str,
- name: str = None,
- tag: str = None,
- state: str = None,
- labels: List[str] = None,
- partition_by: schemas.FeatureStorePartitionByField = None,
- rows_per_partition: int = 1,
- partition_sort_by: schemas.SortField = None,
- partition_order: schemas.OrderType = schemas.OrderType.desc,
- ) -> schemas.FeatureVectorsOutput:
- raise NotImplementedError()
-
- def list_feature_vectors_tags(
- self,
- session,
- project: str,
- ):
- raise NotImplementedError()
-
- def store_feature_vector(
- self,
- session,
- project,
- name,
- feature_vector: schemas.FeatureVector,
- tag=None,
- uid=None,
- versioned=True,
- always_overwrite=False,
- ) -> str:
- raise NotImplementedError()
-
- def patch_feature_vector(
- self,
- session,
- project,
- name,
- feature_vector_update: dict,
- tag=None,
- uid=None,
- patch_mode: schemas.PatchMode = schemas.PatchMode.replace,
- ) -> str:
- raise NotImplementedError()
-
- def delete_feature_vector(self, session, project, name, tag=None, uid=None):
- raise NotImplementedError()
-
- def list_artifact_tags(
- self, session, project, category: Union[str, schemas.ArtifactCategories] = None
- ):
- return self._transform_run_db_error(
- self.db.list_artifact_tags, project, category
- )
-
- def create_schedule(
- self,
- session,
- project: str,
- name: str,
- kind: schemas.ScheduleKinds,
- scheduled_object: Any,
- cron_trigger: schemas.ScheduleCronTrigger,
- concurrency_limit: int,
- labels: Dict = None,
- next_run_time: datetime.datetime = None,
- ):
- raise NotImplementedError()
-
- def update_schedule(
- self,
- session,
- project: str,
- name: str,
- scheduled_object: Any = None,
- cron_trigger: schemas.ScheduleCronTrigger = None,
- labels: Dict = None,
- last_run_uri: str = None,
- concurrency_limit: int = None,
- next_run_time: datetime.datetime = None,
- ):
- raise NotImplementedError()
-
- def list_schedules(
- self,
- session,
- project: str = None,
- name: str = None,
- labels: str = None,
- kind: schemas.ScheduleKinds = None,
- ) -> List[schemas.ScheduleRecord]:
- raise NotImplementedError()
-
- def get_schedule(self, session, project: str, name: str) -> schemas.ScheduleRecord:
- raise NotImplementedError()
-
- def delete_schedule(self, session, project: str, name: str):
- raise NotImplementedError()
-
- def delete_schedules(self, session, project: str):
- raise NotImplementedError()
-
- @staticmethod
- def _transform_run_db_error(func, *args, **kwargs):
- try:
- return func(*args, **kwargs)
- except RunDBError as exc:
- raise DBError(exc.args)
-
- def store_run_notifications(
- self, session, notification_objects, run_uid: str, project: str
- ):
- raise NotImplementedError()
-
- def list_run_notifications(
- self,
- session,
- run_uid: str,
- project: str = "",
- ):
- raise NotImplementedError()
-
- def delete_run_notifications(
- self,
- session,
- name: str = None,
- run_uid: str = None,
- project: str = None,
- commit: bool = True,
- ):
- raise NotImplementedError()
diff --git a/mlrun/api/db/session.py b/mlrun/api/db/session.py
index 3db0e9b7fcf3..ef62d84d849f 100644
--- a/mlrun/api/db/session.py
+++ b/mlrun/api/db/session.py
@@ -15,22 +15,14 @@
from sqlalchemy.orm import Session
from mlrun.api.db.sqldb.session import create_session as sqldb_create_session
-from mlrun.config import config
-def create_session(db_type=None) -> Session:
- db_type = db_type or config.httpdb.db_type
- if db_type == "filedb":
- return None
- else:
- return sqldb_create_session()
+def create_session() -> Session:
+ return sqldb_create_session()
def close_session(db_session):
-
- # will be None when it's filedb session
- if db_session is not None:
- db_session.close()
+ db_session.close()
def run_function_with_new_db_session(func):
diff --git a/mlrun/api/utils/singletons/db.py b/mlrun/api/utils/singletons/db.py
index c7b3cbe0d908..d31d7df73008 100644
--- a/mlrun/api/utils/singletons/db.py
+++ b/mlrun/api/utils/singletons/db.py
@@ -13,7 +13,6 @@
# limitations under the License.
#
from mlrun.api.db.base import DBInterface
-from mlrun.api.db.filedb.db import FileDB
from mlrun.api.db.sqldb.db import SQLDB
from mlrun.api.db.sqldb.session import create_session
from mlrun.config import config
@@ -33,16 +32,11 @@ def initialize_db(override_db=None):
if override_db:
db = override_db
return
- if config.httpdb.db_type == "filedb":
- logger.info("Creating file db")
- db = FileDB(config.httpdb.dirpath)
- db.initialize(None)
- else:
- logger.info("Creating sql db")
- db = SQLDB(config.httpdb.dsn)
- db_session = None
- try:
- db_session = create_session()
- db.initialize(db_session)
- finally:
- db_session.close()
+ logger.info("Creating sql db")
+ db = SQLDB(config.httpdb.dsn)
+ db_session = None
+ try:
+ db_session = create_session()
+ db.initialize(db_session)
+ finally:
+ db_session.close()
diff --git a/mlrun/config.py b/mlrun/config.py
index 601bcc5336e3..1867c6ab3484 100644
--- a/mlrun/config.py
+++ b/mlrun/config.py
@@ -372,6 +372,15 @@
},
"v3io_api": "",
"v3io_framesd": "",
+ # If running from sdk and MLRUN_DBPATH is not set, the db will fallback to a nop db which will not preform any
+ # run db operations.
+ "nop_db": {
+ # if set to true, will raise an error for trying to use run db functionality
+ # if set to false, will use a nop db which will not preform any run db operations
+ "raise_error": False,
+ # if set to true, will log a warning for trying to use run db functionality while in nop db mode
+ "verbose": True,
+ },
},
"model_endpoint_monitoring": {
"serving_stream_args": {"shard_count": 1, "retention_period_hours": 24},
diff --git a/mlrun/db/__init__.py b/mlrun/db/__init__.py
index 3692ac49cdf9..63cadc04c5c5 100644
--- a/mlrun/db/__init__.py
+++ b/mlrun/db/__init__.py
@@ -18,7 +18,7 @@
from ..platforms import add_or_refresh_credentials
from ..utils import logger
from .base import RunDBError, RunDBInterface # noqa
-from .filedb import FileRunDB
+from .nopdb import NopDB
from .sqldb import SQLDB
@@ -69,12 +69,14 @@ def get_run_db(url="", secrets=None, force_reconnect=False):
kwargs = {}
if "://" not in str(url) or scheme in ["file", "s3", "v3io", "v3ios"]:
logger.warning(
- "Could not detect path to API server, Using Deprecated client interface"
+ "Could not detect path to API server, not connected to API server!"
)
logger.warning(
- "Please make sure your env variable MLRUN_DBPATH is configured correctly to point to the API server!"
+ "MLRUN_DBPATH is not set. Set this environment variable to the URL of the API server"
+ " in order to connect"
)
- cls = FileRunDB
+ cls = NopDB
+
elif scheme in ("http", "https"):
# import here to avoid circular imports
from .httpdb import HTTPRunDB
diff --git a/mlrun/db/filedb.py b/mlrun/db/filedb.py
deleted file mode 100644
index 3dd7a1ebe581..000000000000
--- a/mlrun/db/filedb.py
+++ /dev/null
@@ -1,892 +0,0 @@
-# Copyright 2018 Iguazio
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import json
-import pathlib
-from datetime import datetime, timedelta, timezone
-from os import listdir, makedirs, path, remove, scandir
-from typing import List, Optional, Union
-
-import yaml
-from dateutil.parser import parse as parse_time
-
-import mlrun.api.schemas
-import mlrun.errors
-import mlrun.model_monitoring.model_endpoint
-
-from ..api import schemas
-from ..config import config
-from ..datastore import store_manager
-from ..lists import ArtifactList, RunList
-from ..utils import (
- dict_to_json,
- dict_to_yaml,
- fill_function_hash,
- generate_object_uri,
- get_in,
- logger,
- match_labels,
- match_times,
- match_value,
- match_value_options,
- update_in,
-)
-from .base import RunDBError, RunDBInterface
-
-run_logs = "runs"
-artifacts_dir = "artifacts"
-functions_dir = "functions"
-schedules_dir = "schedules"
-
-
-# TODO: remove fileDB, doesn't needs to be used anymore
-class FileRunDB(RunDBInterface):
- kind = "file"
-
- def __init__(self, dirpath="", format=".yaml"):
- self.format = format
- self.dirpath = dirpath
- self._datastore = None
- self._subpath = None
- self._secrets = None
- makedirs(self.schedules_dir, exist_ok=True)
-
- def connect(self, secrets=None):
- self._secrets = secrets
- return self
-
- def _connect(self, secrets=None):
- sm = store_manager.set(secrets or self._secrets)
- self._datastore, self._subpath = sm.get_or_create_store(self.dirpath)
- return self
-
- @property
- def datastore(self):
- if not self._datastore:
- self._connect()
- return self._datastore
-
- def store_log(self, uid, project="", body=None, append=False):
- filepath = self._filepath(run_logs, project, uid, "") + ".log"
- makedirs(path.dirname(filepath), exist_ok=True)
- mode = "ab" if append else "wb"
- with open(filepath, mode) as fp:
- fp.write(body)
- fp.close()
-
- def get_log(self, uid, project="", offset=0, size=0):
- filepath = self._filepath(run_logs, project, uid, "") + ".log"
- if pathlib.Path(filepath).is_file():
- with open(filepath, "rb") as fp:
- if offset:
- fp.seek(offset)
- if not size:
- size = 2**18
- return "", fp.read(size)
- return "", None
-
- def _run_path(self, uid, iter):
- if iter:
- return f"{uid}-{iter}"
- return uid
-
- def store_run(self, struct, uid, project="", iter=0):
- data = self._dumps(struct)
- filepath = (
- self._filepath(run_logs, project, self._run_path(uid, iter), "")
- + self.format
- )
- self.datastore.put(filepath, data)
-
- def update_run(self, updates: dict, uid, project="", iter=0):
- run = self.read_run(uid, project, iter=iter)
- if run and updates:
- for key, val in updates.items():
- update_in(run, key, val)
- self.store_run(run, uid, project, iter=iter)
-
- def abort_run(self, uid, project="", iter=0):
- raise NotImplementedError()
-
- def read_run(self, uid, project="", iter=0):
- filepath = (
- self._filepath(run_logs, project, self._run_path(uid, iter), "")
- + self.format
- )
- if not pathlib.Path(filepath).is_file():
- raise mlrun.errors.MLRunNotFoundError(uid)
- data = self.datastore.get(filepath)
- return self._loads(data)
-
- def list_runs(
- self,
- name="",
- uid: Optional[Union[str, List[str]]] = None,
- project="",
- labels=None,
- state="",
- sort=True,
- last=1000,
- iter=False,
- start_time_from: datetime = None,
- start_time_to: datetime = None,
- last_update_time_from: datetime = None,
- last_update_time_to: datetime = None,
- partition_by: Union[schemas.RunPartitionByField, str] = None,
- rows_per_partition: int = 1,
- partition_sort_by: Union[schemas.SortField, str] = None,
- partition_order: Union[schemas.OrderType, str] = schemas.OrderType.desc,
- max_partitions: int = 0,
- with_notifications: bool = False,
- ):
- if partition_by is not None:
- raise mlrun.errors.MLRunInvalidArgumentError(
- "Runs partitioning not supported"
- )
- if uid and isinstance(uid, list):
- raise mlrun.errors.MLRunInvalidArgumentError(
- "Runs list with multiple uids not supported"
- )
-
- labels = [] if labels is None else labels
- filepath = self._filepath(run_logs, project)
- results = RunList()
- if isinstance(labels, str):
- labels = labels.split(",")
- for run, _ in self._load_list(filepath, "*"):
- if (
- match_value(name, run, "metadata.name")
- and match_labels(get_in(run, "metadata.labels", {}), labels)
- and match_value_options(state, run, "status.state")
- and match_value(uid, run, "metadata.uid")
- and match_times(
- start_time_from,
- start_time_to,
- run,
- "status.start_time",
- )
- and match_times(
- last_update_time_from,
- last_update_time_to,
- run,
- "status.last_update",
- )
- and (iter or get_in(run, "metadata.iteration", 0) == 0)
- ):
- results.append(run)
-
- if sort or last:
- results.sort(
- key=lambda i: get_in(i, ["status", "start_time"], ""), reverse=True
- )
- if last and len(results) > last:
- return RunList(results[:last])
- return results
-
- def del_run(self, uid, project="", iter=0):
- filepath = (
- self._filepath(run_logs, project, self._run_path(uid, iter), "")
- + self.format
- )
- self._safe_del(filepath)
-
- def del_runs(self, name="", project="", labels=None, state="", days_ago=0):
-
- labels = [] if labels is None else labels
- if not any([name, state, days_ago, labels]):
- raise RunDBError(
- "filter is too wide, select name and/or state and/or days_ago"
- )
-
- filepath = self._filepath(run_logs, project)
- if isinstance(labels, str):
- labels = labels.split(",")
-
- if days_ago:
- days_ago = datetime.now() - timedelta(days=days_ago)
-
- def date_before(run):
- d = get_in(run, "status.start_time", "")
- if not d:
- return False
- return parse_time(d) < days_ago
-
- for run, p in self._load_list(filepath, "*"):
- if (
- match_value(name, run, "metadata.name")
- and match_labels(get_in(run, "metadata.labels", {}), labels)
- and match_value(state, run, "status.state")
- and (not days_ago or date_before(run))
- ):
- self._safe_del(p)
-
- def store_artifact(self, key, artifact, uid, iter=None, tag="", project=""):
- if "updated" not in artifact:
- artifact["updated"] = datetime.now(timezone.utc).isoformat()
- data = self._dumps(artifact)
- if iter:
- key = f"{iter}-{key}"
- filepath = self._filepath(artifacts_dir, project, key, uid) + self.format
- self.datastore.put(filepath, data)
- filepath = (
- self._filepath(artifacts_dir, project, key, tag or "latest") + self.format
- )
- self.datastore.put(filepath, data)
-
- def read_artifact(self, key, tag="", iter=None, project=""):
- tag = tag or "latest"
- if iter:
- key = f"{iter}-{key}"
- filepath = self._filepath(artifacts_dir, project, key, tag) + self.format
-
- if not pathlib.Path(filepath).is_file():
- raise RunDBError(key)
- data = self.datastore.get(filepath)
- return self._loads(data)
-
- def list_artifacts(
- self,
- name="",
- project="",
- tag="",
- labels=None,
- since=None,
- until=None,
- iter: int = None,
- best_iteration: bool = False,
- kind: str = None,
- category: Union[str, schemas.ArtifactCategories] = None,
- ):
- if iter or kind or category:
- raise NotImplementedError(
- "iter/kind/category parameters are not supported for filedb implementation"
- )
-
- labels = [] if labels is None else labels
- tag = tag or "latest"
- name = name or ""
- logger.info(f"reading artifacts in {project} name/mask: {name} tag: {tag} ...")
- filepath = self._filepath(artifacts_dir, project, tag=tag)
- results = ArtifactList()
- results.tag = tag
- if isinstance(labels, str):
- labels = labels.split(",")
- if tag == "*":
- mask = "**/*" + name
- if name:
- mask += "*"
- else:
- mask = "**/*"
-
- time_pred = make_time_pred(since, until)
- for artifact, p in self._load_list(filepath, mask):
- if (name == "" or name in get_in(artifact, "key", "")) and match_labels(
- get_in(artifact, "labels", {}), labels
- ):
- if not time_pred(artifact):
- continue
- if "artifacts/latest" in p:
- artifact["tree"] = "latest"
- results.append(artifact)
-
- return results
-
- def del_artifact(self, key, tag="", project=""):
- tag = tag or "latest"
- filepath = self._filepath(artifacts_dir, project, key, tag) + self.format
- self._safe_del(filepath)
-
- def del_artifacts(self, name="", project="", tag="", labels=None):
- labels = [] if labels is None else labels
- tag = tag or "latest"
- filepath = self._filepath(artifacts_dir, project, tag=tag)
-
- if isinstance(labels, str):
- labels = labels.split(",")
- if tag == "*":
- mask = "**/*" + name
- if name:
- mask += "*"
- else:
- mask = "**/*"
-
- for artifact, p in self._load_list(filepath, mask):
- if (name == "" or name == get_in(artifact, "key", "")) and match_labels(
- get_in(artifact, "labels", {}), labels
- ):
-
- self._safe_del(p)
-
- def store_function(self, function, name, project="", tag="", versioned=False):
- tag = tag or get_in(function, "metadata.tag") or "latest"
- hash_key = fill_function_hash(function, tag)
- update_in(function, "metadata.updated", datetime.now(timezone.utc))
- update_in(function, "metadata.tag", "")
- data = self._dumps(function)
- filepath = (
- path.join(
- self.dirpath,
- functions_dir,
- project or config.default_project,
- name,
- tag,
- )
- + self.format
- )
- self.datastore.put(filepath, data)
- if versioned:
-
- # the "hash_key" version should not include the status
- function["status"] = None
-
- # versioned means we want this function to be queryable by its hash key so save another file that the
- # hash key is the file name
- filepath = (
- path.join(
- self.dirpath,
- functions_dir,
- project or config.default_project,
- name,
- hash_key,
- )
- + self.format
- )
- data = self._dumps(function)
- self.datastore.put(filepath, data)
- return hash_key
-
- def get_function(self, name, project="", tag="", hash_key=""):
- tag = tag or "latest"
- file_name = hash_key or tag
- filepath = (
- path.join(
- self.dirpath,
- functions_dir,
- project or config.default_project,
- name,
- file_name,
- )
- + self.format
- )
- if not pathlib.Path(filepath).is_file():
- function_uri = generate_object_uri(project, name, tag, hash_key)
- raise mlrun.errors.MLRunNotFoundError(f"Function not found {function_uri}")
- data = self.datastore.get(filepath)
- parsed_data = self._loads(data)
-
- # tag should be filled only when queried by tag
- parsed_data["metadata"]["tag"] = "" if hash_key else tag
- return parsed_data
-
- def delete_function(self, name: str, project: str = ""):
- raise NotImplementedError()
-
- def list_functions(self, name=None, project="", tag="", labels=None):
- labels = labels or []
- logger.info(f"reading functions in {project} name/mask: {name} tag: {tag} ...")
- filepath = path.join(
- self.dirpath,
- functions_dir,
- project or config.default_project,
- )
- filepath += "/"
-
- # function name -> tag name -> function dict
- functions_with_tag_filename = {}
- # function name -> hash key -> function dict
- functions_with_hash_key_filename = {}
- # function name -> hash keys set
- function_with_tag_hash_keys = {}
- if isinstance(labels, str):
- labels = labels.split(",")
- mask = "**/*"
- if name:
- filepath = f"{filepath}{name}/"
- mask = "*"
- for func, fullname in self._load_list(filepath, mask):
- if match_labels(get_in(func, "metadata.labels", {}), labels):
- file_name, _ = path.splitext(path.basename(fullname))
- function_name = path.basename(path.dirname(fullname))
- target_dict = functions_with_tag_filename
-
- tag_name = file_name
- # Heuristic - if tag length is bigger than 20 it's probably a hash key
- if len(tag_name) > 20: # hash vs tags
- tag_name = ""
- target_dict = functions_with_hash_key_filename
- else:
- function_with_tag_hash_keys.setdefault(function_name, set()).add(
- func["metadata"]["hash"]
- )
- update_in(func, "metadata.tag", tag_name)
- target_dict.setdefault(function_name, {})[file_name] = func
-
- # clean duplicated function e.g. function that was saved both in a hash key filename and tag filename
- for (
- function_name,
- hash_keys_to_function_dict_map,
- ) in functions_with_hash_key_filename.items():
- function_hash_keys_to_remove = []
- for (
- function_hash_key,
- function_dict,
- ) in hash_keys_to_function_dict_map.items():
- if function_hash_key in function_with_tag_hash_keys.get(
- function_name, set()
- ):
- function_hash_keys_to_remove.append(function_hash_key)
-
- for function_hash_key in function_hash_keys_to_remove:
- del hash_keys_to_function_dict_map[function_hash_key]
-
- results = []
- for functions_map in [
- functions_with_hash_key_filename,
- functions_with_tag_filename,
- ]:
- for function_name, filename_to_function_map in functions_map.items():
- results.extend(filename_to_function_map.values())
-
- return results
-
- def _filepath(self, table, project, key="", tag=""):
- if tag == "*":
- tag = ""
- if tag:
- key = "/" + key
- project = project or config.default_project
- return path.join(self.dirpath, table, project, tag + key)
-
- def list_projects(
- self,
- owner: str = None,
- format_: mlrun.api.schemas.ProjectsFormat = mlrun.api.schemas.ProjectsFormat.full,
- labels: List[str] = None,
- state: mlrun.api.schemas.ProjectState = None,
- names: Optional[List[str]] = None,
- ) -> mlrun.api.schemas.ProjectsOutput:
- if (
- owner
- or format_ == mlrun.api.schemas.ProjectsFormat.full
- or labels
- or state
- or names
- ):
- raise NotImplementedError()
- run_dir = path.join(self.dirpath, run_logs)
- if not path.isdir(run_dir):
- return mlrun.api.schemas.ProjectsOutput(projects=[])
- project_names = [
- d for d in listdir(run_dir) if path.isdir(path.join(run_dir, d))
- ]
- return mlrun.api.schemas.ProjectsOutput(projects=project_names)
-
- def tag_objects(
- self,
- project: str,
- tag_name: str,
- tag_objects: schemas.TagObjects,
- replace: bool = False,
- ):
- raise NotImplementedError()
-
- def delete_objects_tag(
- self, project: str, tag_name: str, tag_objects: schemas.TagObjects
- ):
- raise NotImplementedError()
-
- def tag_artifacts(
- self,
- artifacts,
- project: str,
- tag_name: str,
- replace: bool = False,
- ):
- raise NotImplementedError()
-
- def delete_artifacts_tags(
- self,
- artifacts,
- project: str,
- tag_name: str,
- ):
- raise NotImplementedError()
-
- def get_project(self, name: str) -> mlrun.api.schemas.Project:
- # returns None if project not found, mainly for tests, until we remove fileDB
- return None
-
- def delete_project(
- self,
- name: str,
- deletion_strategy: mlrun.api.schemas.DeletionStrategy = mlrun.api.schemas.DeletionStrategy.default(),
- ):
- raise NotImplementedError()
-
- def store_project(
- self,
- name: str,
- project: mlrun.api.schemas.Project,
- ) -> mlrun.api.schemas.Project:
- raise NotImplementedError()
-
- def patch_project(
- self,
- name: str,
- project: dict,
- patch_mode: mlrun.api.schemas.PatchMode = mlrun.api.schemas.PatchMode.replace,
- ) -> mlrun.api.schemas.Project:
- raise NotImplementedError()
-
- def create_project(
- self,
- project: mlrun.api.schemas.Project,
- ) -> mlrun.api.schemas.Project:
- raise NotImplementedError()
-
- @property
- def schedules_dir(self):
- return path.join(self.dirpath, schedules_dir)
-
- def store_schedule(self, data):
- sched_id = 1 + sum(1 for _ in scandir(self.schedules_dir))
- fname = path.join(self.schedules_dir, f"{sched_id}{self.format}")
- with open(fname, "w") as out:
- out.write(self._dumps(data))
-
- def list_schedules(self):
- pattern = f"*{self.format}"
- for p in pathlib.Path(self.schedules_dir).glob(pattern):
- with p.open() as fp:
- yield self._loads(fp.read())
-
- return []
-
- _encodings = {
- ".yaml": ("to_yaml", dict_to_yaml),
- ".json": ("to_json", dict_to_json),
- }
-
- def _dumps(self, obj):
- meth_name, enc_fn = self._encodings.get(self.format, (None, None))
- if meth_name is None:
- raise ValueError(f"unsupported format - {self.format}")
-
- meth = getattr(obj, meth_name, None)
- if meth:
- return meth()
-
- return enc_fn(obj)
-
- def _loads(self, data):
- if self.format == ".yaml":
- return yaml.load(data, Loader=yaml.FullLoader)
- else:
- return json.loads(data)
-
- def _load_list(self, dirpath, mask):
- for p in pathlib.Path(dirpath).glob(mask + self.format):
- if p.is_file():
- if ".ipynb_checkpoints" in p.parts:
- continue
- data = self._loads(p.read_text())
- if data:
- yield data, str(p)
-
- def _safe_del(self, filepath):
- if path.isfile(filepath):
- remove(filepath)
- else:
- raise RunDBError(f"run file is not found or valid ({filepath})")
-
- def create_feature_set(self, feature_set, project="", versioned=True):
- raise NotImplementedError()
-
- def get_feature_set(
- self, name: str, project: str = "", tag: str = None, uid: str = None
- ):
- raise NotImplementedError()
-
- def list_features(
- self,
- project: str,
- name: str = None,
- tag: str = None,
- entities: List[str] = None,
- labels: List[str] = None,
- ):
- raise NotImplementedError()
-
- def list_entities(
- self,
- project: str,
- name: str = None,
- tag: str = None,
- labels: List[str] = None,
- ):
- raise NotImplementedError()
-
- def list_feature_sets(
- self,
- project: str = "",
- name: str = None,
- tag: str = None,
- state: str = None,
- entities: List[str] = None,
- features: List[str] = None,
- labels: List[str] = None,
- partition_by: str = None,
- rows_per_partition: int = 1,
- partition_sort_by: str = None,
- partition_order: str = "desc",
- ):
- raise NotImplementedError()
-
- def store_feature_set(
- self, feature_set, name=None, project="", tag=None, uid=None, versioned=True
- ):
- raise NotImplementedError()
-
- def patch_feature_set(
- self,
- name,
- feature_set,
- project="",
- tag=None,
- uid=None,
- patch_mode="replace",
- ):
- raise NotImplementedError()
-
- def delete_feature_set(self, name, project="", tag=None, uid=None):
- raise NotImplementedError()
-
- def create_feature_vector(self, feature_vector, project="", versioned=True) -> dict:
- raise NotImplementedError()
-
- def get_feature_vector(
- self, name: str, project: str = "", tag: str = None, uid: str = None
- ) -> dict:
- raise NotImplementedError()
-
- def list_feature_vectors(
- self,
- project: str = "",
- name: str = None,
- tag: str = None,
- state: str = None,
- labels: List[str] = None,
- partition_by: str = None,
- rows_per_partition: int = 1,
- partition_sort_by: str = None,
- partition_order: str = "desc",
- ) -> List[dict]:
- raise NotImplementedError()
-
- def store_feature_vector(
- self,
- feature_vector,
- name=None,
- project="",
- tag=None,
- uid=None,
- versioned=True,
- ):
- raise NotImplementedError()
-
- def patch_feature_vector(
- self,
- name,
- feature_vector_update: dict,
- project="",
- tag=None,
- uid=None,
- patch_mode="replace",
- ):
- raise NotImplementedError()
-
- def delete_feature_vector(self, name, project="", tag=None, uid=None):
- raise NotImplementedError()
-
- def list_pipelines(
- self,
- project: str,
- namespace: str = None,
- sort_by: str = "",
- page_token: str = "",
- filter_: str = "",
- format_: Union[
- str, mlrun.api.schemas.PipelinesFormat
- ] = mlrun.api.schemas.PipelinesFormat.metadata_only,
- page_size: int = None,
- ) -> mlrun.api.schemas.PipelinesOutput:
- raise NotImplementedError()
-
- def create_project_secrets(
- self,
- project: str,
- provider: str = mlrun.api.schemas.SecretProviderName.kubernetes.value,
- secrets: dict = None,
- ):
- raise NotImplementedError()
-
- def list_project_secrets(
- self,
- project: str,
- token: str,
- provider: str = mlrun.api.schemas.SecretProviderName.kubernetes.value,
- secrets: List[str] = None,
- ) -> mlrun.api.schemas.SecretsData:
- raise NotImplementedError()
-
- def list_project_secret_keys(
- self,
- project: str,
- provider: str = mlrun.api.schemas.SecretProviderName.kubernetes,
- token: str = None,
- ) -> mlrun.api.schemas.SecretKeysData:
- raise NotImplementedError()
-
- def delete_project_secrets(
- self,
- project: str,
- provider: str = mlrun.api.schemas.SecretProviderName.kubernetes.value,
- secrets: List[str] = None,
- ):
- raise NotImplementedError()
-
- def create_user_secrets(
- self,
- user: str,
- provider: str = mlrun.api.schemas.secret.SecretProviderName.vault.value,
- secrets: dict = None,
- ):
- raise NotImplementedError()
-
- def list_artifact_tags(self, project=None, category=None):
- raise NotImplementedError()
-
- def create_model_endpoint(
- self,
- project: str,
- endpoint_id: str,
- model_endpoint: Union[
- mlrun.model_monitoring.model_endpoint.ModelEndpoint, dict
- ],
- ):
- raise NotImplementedError()
-
- def delete_model_endpoint(
- self,
- project: str,
- endpoint_id: str,
- ):
- raise NotImplementedError()
-
- def list_model_endpoints(
- self,
- project: str,
- model: Optional[str] = None,
- function: Optional[str] = None,
- labels: List[str] = None,
- start: str = "now-1h",
- end: str = "now",
- metrics: Optional[List[str]] = None,
- ):
- raise NotImplementedError()
-
- def get_model_endpoint(
- self,
- project: str,
- endpoint_id: str,
- start: Optional[str] = None,
- end: Optional[str] = None,
- metrics: Optional[List[str]] = None,
- features: bool = False,
- ):
- raise NotImplementedError()
-
- def patch_model_endpoint(
- self,
- project: str,
- endpoint_id: str,
- attributes: dict,
- ):
- raise NotImplementedError()
-
- def create_marketplace_source(
- self, source: Union[dict, schemas.IndexedMarketplaceSource]
- ):
- raise NotImplementedError()
-
- def store_marketplace_source(
- self, source_name: str, source: Union[dict, schemas.IndexedMarketplaceSource]
- ):
- raise NotImplementedError()
-
- def list_marketplace_sources(self):
- raise NotImplementedError()
-
- def get_marketplace_source(self, source_name: str):
- raise NotImplementedError()
-
- def delete_marketplace_source(self, source_name: str):
- raise NotImplementedError()
-
- def get_marketplace_catalog(
- self,
- source_name: str,
- version: str = None,
- tag: str = None,
- force_refresh: bool = False,
- ):
- raise NotImplementedError()
-
- def get_marketplace_item(
- self,
- source_name: str,
- item_name: str,
- version: str = None,
- tag: str = "latest",
- force_refresh: bool = False,
- ):
- raise NotImplementedError()
-
- def verify_authorization(
- self,
- authorization_verification_input: mlrun.api.schemas.AuthorizationVerificationInput,
- ):
- raise NotImplementedError()
-
-
-def make_time_pred(since, until):
- if not (since or until):
- return lambda artifact: True
-
- since = since or datetime.min
- until = until or datetime.max
-
- if since.tzinfo is None:
- since = since.replace(tzinfo=timezone.utc)
- if until.tzinfo is None:
- until = until.replace(tzinfo=timezone.utc)
-
- def pred(artifact):
- val = artifact.get("updated")
- if not val:
- return True
- t = parse_time(val).replace(tzinfo=timezone.utc)
- return since <= t <= until
-
- return pred
diff --git a/mlrun/db/nopdb.py b/mlrun/db/nopdb.py
new file mode 100644
index 000000000000..8d92590d99b9
--- /dev/null
+++ b/mlrun/db/nopdb.py
@@ -0,0 +1,463 @@
+# Copyright 2022 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import datetime
+from typing import List, Optional, Union
+
+import mlrun.errors
+
+from ..api import schemas
+from ..api.schemas import ModelEndpoint
+from ..config import config
+from ..utils import logger
+from .base import RunDBInterface
+
+
+class NopDB(RunDBInterface):
+ def __init__(self, url=None, *args, **kwargs):
+ self.url = url
+
+ def __getattribute__(self, attr):
+ def nop(*args, **kwargs):
+ env_var_message = (
+ "MLRUN_DBPATH is not set. Set this environment variable to the URL of the API "
+ "server in order to connect"
+ )
+ if config.httpdb.nop_db.raise_error:
+ raise mlrun.errors.MLRunBadRequestError(env_var_message)
+
+ if config.httpdb.nop_db.verbose:
+ logger.warning(
+ "Could not detect path to API server, not connected to API server!"
+ )
+ logger.warning(env_var_message)
+
+ return
+
+ if attr == "connect":
+ return super().__getattribute__(attr)
+ else:
+ nop()
+ return super().__getattribute__(attr)
+
+ def connect(self, secrets=None):
+ pass
+
+ def store_log(self, uid, project="", body=None, append=False):
+ pass
+
+ def get_log(self, uid, project="", offset=0, size=0):
+ pass
+
+ def store_run(self, struct, uid, project="", iter=0):
+ pass
+
+ def update_run(self, updates: dict, uid, project="", iter=0):
+ pass
+
+ def abort_run(self, uid, project="", iter=0):
+ pass
+
+ def read_run(self, uid, project="", iter=0):
+ pass
+
+ def list_runs(
+ self,
+ name="",
+ uid: Optional[Union[str, List[str]]] = None,
+ project="",
+ labels=None,
+ state="",
+ sort=True,
+ last=0,
+ iter=False,
+ start_time_from: datetime.datetime = None,
+ start_time_to: datetime.datetime = None,
+ last_update_time_from: datetime.datetime = None,
+ last_update_time_to: datetime.datetime = None,
+ partition_by: Union[schemas.RunPartitionByField, str] = None,
+ rows_per_partition: int = 1,
+ partition_sort_by: Union[schemas.SortField, str] = None,
+ partition_order: Union[schemas.OrderType, str] = schemas.OrderType.desc,
+ max_partitions: int = 0,
+ ):
+ pass
+
+ def del_run(self, uid, project="", iter=0):
+ pass
+
+ def del_runs(self, name="", project="", labels=None, state="", days_ago=0):
+ pass
+
+ def store_artifact(self, key, artifact, uid, iter=None, tag="", project=""):
+ pass
+
+ def read_artifact(self, key, tag="", iter=None, project=""):
+ pass
+
+ def list_artifacts(
+ self,
+ name="",
+ project="",
+ tag="",
+ labels=None,
+ since=None,
+ until=None,
+ iter: int = None,
+ best_iteration: bool = False,
+ kind: str = None,
+ category: Union[str, schemas.ArtifactCategories] = None,
+ ):
+ pass
+
+ def del_artifact(self, key, tag="", project=""):
+ pass
+
+ def del_artifacts(self, name="", project="", tag="", labels=None):
+ pass
+
+ def store_function(self, function, name, project="", tag="", versioned=False):
+ pass
+
+ def get_function(self, name, project="", tag="", hash_key=""):
+ pass
+
+ def delete_function(self, name: str, project: str = ""):
+ pass
+
+ def list_functions(self, name=None, project="", tag="", labels=None):
+ pass
+
+ def tag_objects(
+ self,
+ project: str,
+ tag_name: str,
+ tag_objects: schemas.TagObjects,
+ replace: bool = False,
+ ):
+ pass
+
+ def delete_objects_tag(
+ self, project: str, tag_name: str, tag_objects: schemas.TagObjects
+ ):
+ pass
+
+ def tag_artifacts(
+ self, artifacts, project: str, tag_name: str, replace: bool = False
+ ):
+ pass
+
+ def delete_artifacts_tags(self, artifacts, project: str, tag_name: str):
+ pass
+
+ def delete_project(
+ self,
+ name: str,
+ deletion_strategy: schemas.DeletionStrategy = schemas.DeletionStrategy.default(),
+ ):
+ pass
+
+ def store_project(self, name: str, project: schemas.Project) -> schemas.Project:
+ pass
+
+ def patch_project(
+ self,
+ name: str,
+ project: dict,
+ patch_mode: schemas.PatchMode = schemas.PatchMode.replace,
+ ) -> schemas.Project:
+ pass
+
+ def create_project(self, project: schemas.Project) -> schemas.Project:
+ pass
+
+ def list_projects(
+ self,
+ owner: str = None,
+ format_: schemas.ProjectsFormat = schemas.ProjectsFormat.full,
+ labels: List[str] = None,
+ state: schemas.ProjectState = None,
+ ) -> schemas.ProjectsOutput:
+ pass
+
+ def get_project(self, name: str) -> schemas.Project:
+ pass
+
+ def list_artifact_tags(
+ self, project=None, category: Union[str, schemas.ArtifactCategories] = None
+ ):
+ pass
+
+ def create_feature_set(
+ self, feature_set: Union[dict, schemas.FeatureSet], project="", versioned=True
+ ) -> dict:
+ pass
+
+ def get_feature_set(
+ self, name: str, project: str = "", tag: str = None, uid: str = None
+ ) -> dict:
+ pass
+
+ def list_features(
+ self,
+ project: str,
+ name: str = None,
+ tag: str = None,
+ entities: List[str] = None,
+ labels: List[str] = None,
+ ) -> schemas.FeaturesOutput:
+ pass
+
+ def list_entities(
+ self, project: str, name: str = None, tag: str = None, labels: List[str] = None
+ ) -> schemas.EntitiesOutput:
+ pass
+
+ def list_feature_sets(
+ self,
+ project: str = "",
+ name: str = None,
+ tag: str = None,
+ state: str = None,
+ entities: List[str] = None,
+ features: List[str] = None,
+ labels: List[str] = None,
+ partition_by: Union[schemas.FeatureStorePartitionByField, str] = None,
+ rows_per_partition: int = 1,
+ partition_sort_by: Union[schemas.SortField, str] = None,
+ partition_order: Union[schemas.OrderType, str] = schemas.OrderType.desc,
+ ) -> List[dict]:
+ pass
+
+ def store_feature_set(
+ self,
+ feature_set: Union[dict, schemas.FeatureSet],
+ name=None,
+ project="",
+ tag=None,
+ uid=None,
+ versioned=True,
+ ):
+ pass
+
+ def patch_feature_set(
+ self,
+ name,
+ feature_set: dict,
+ project="",
+ tag=None,
+ uid=None,
+ patch_mode: Union[str, schemas.PatchMode] = schemas.PatchMode.replace,
+ ):
+ pass
+
+ def delete_feature_set(self, name, project="", tag=None, uid=None):
+ pass
+
+ def create_feature_vector(
+ self,
+ feature_vector: Union[dict, schemas.FeatureVector],
+ project="",
+ versioned=True,
+ ) -> dict:
+ pass
+
+ def get_feature_vector(
+ self, name: str, project: str = "", tag: str = None, uid: str = None
+ ) -> dict:
+ pass
+
+ def list_feature_vectors(
+ self,
+ project: str = "",
+ name: str = None,
+ tag: str = None,
+ state: str = None,
+ labels: List[str] = None,
+ partition_by: Union[schemas.FeatureStorePartitionByField, str] = None,
+ rows_per_partition: int = 1,
+ partition_sort_by: Union[schemas.SortField, str] = None,
+ partition_order: Union[schemas.OrderType, str] = schemas.OrderType.desc,
+ ) -> List[dict]:
+ pass
+
+ def store_feature_vector(
+ self,
+ feature_vector: Union[dict, schemas.FeatureVector],
+ name=None,
+ project="",
+ tag=None,
+ uid=None,
+ versioned=True,
+ ):
+ pass
+
+ def patch_feature_vector(
+ self,
+ name,
+ feature_vector_update: dict,
+ project="",
+ tag=None,
+ uid=None,
+ patch_mode: Union[str, schemas.PatchMode] = schemas.PatchMode.replace,
+ ):
+ pass
+
+ def delete_feature_vector(self, name, project="", tag=None, uid=None):
+ pass
+
+ def list_pipelines(
+ self,
+ project: str,
+ namespace: str = None,
+ sort_by: str = "",
+ page_token: str = "",
+ filter_: str = "",
+ format_: Union[
+ str, schemas.PipelinesFormat
+ ] = schemas.PipelinesFormat.metadata_only,
+ page_size: int = None,
+ ) -> schemas.PipelinesOutput:
+ pass
+
+ def create_project_secrets(
+ self,
+ project: str,
+ provider: Union[
+ str, schemas.SecretProviderName
+ ] = schemas.SecretProviderName.kubernetes,
+ secrets: dict = None,
+ ):
+ pass
+
+ def list_project_secrets(
+ self,
+ project: str,
+ token: str,
+ provider: Union[
+ str, schemas.SecretProviderName
+ ] = schemas.SecretProviderName.kubernetes,
+ secrets: List[str] = None,
+ ) -> schemas.SecretsData:
+ pass
+
+ def list_project_secret_keys(
+ self,
+ project: str,
+ provider: Union[
+ str, schemas.SecretProviderName
+ ] = schemas.SecretProviderName.kubernetes,
+ token: str = None,
+ ) -> schemas.SecretKeysData:
+ pass
+
+ def delete_project_secrets(
+ self,
+ project: str,
+ provider: Union[
+ str, schemas.SecretProviderName
+ ] = schemas.SecretProviderName.kubernetes,
+ secrets: List[str] = None,
+ ):
+ pass
+
+ def create_user_secrets(
+ self,
+ user: str,
+ provider: Union[
+ str, schemas.SecretProviderName
+ ] = schemas.SecretProviderName.vault,
+ secrets: dict = None,
+ ):
+ pass
+
+ def create_model_endpoint(
+ self, project: str, endpoint_id: str, model_endpoint: ModelEndpoint
+ ):
+ pass
+
+ def delete_model_endpoint(self, project: str, endpoint_id: str):
+ pass
+
+ def list_model_endpoints(
+ self,
+ project: str,
+ model: Optional[str] = None,
+ function: Optional[str] = None,
+ labels: List[str] = None,
+ start: str = "now-1h",
+ end: str = "now",
+ metrics: Optional[List[str]] = None,
+ ):
+ pass
+
+ def get_model_endpoint(
+ self,
+ project: str,
+ endpoint_id: str,
+ start: Optional[str] = None,
+ end: Optional[str] = None,
+ metrics: Optional[List[str]] = None,
+ features: bool = False,
+ ):
+ pass
+
+ def patch_model_endpoint(self, project: str, endpoint_id: str, attributes: dict):
+ pass
+
+ def create_marketplace_source(
+ self, source: Union[dict, schemas.IndexedMarketplaceSource]
+ ):
+ pass
+
+ def store_marketplace_source(
+ self, source_name: str, source: Union[dict, schemas.IndexedMarketplaceSource]
+ ):
+ pass
+
+ def list_marketplace_sources(self):
+ pass
+
+ def get_marketplace_source(self, source_name: str):
+ pass
+
+ def delete_marketplace_source(self, source_name: str):
+ pass
+
+ def get_marketplace_catalog(
+ self,
+ source_name: str,
+ channel: str = None,
+ version: str = None,
+ tag: str = None,
+ force_refresh: bool = False,
+ ):
+ pass
+
+ def get_marketplace_item(
+ self,
+ source_name: str,
+ item_name: str,
+ channel: str = "development",
+ version: str = None,
+ tag: str = "latest",
+ force_refresh: bool = False,
+ ):
+ pass
+
+ def verify_authorization(
+ self, authorization_verification_input: schemas.AuthorizationVerificationInput
+ ):
+ pass
diff --git a/mlrun/db/sqldb.py b/mlrun/db/sqldb.py
index 028480dddea8..19135f9cfe75 100644
--- a/mlrun/db/sqldb.py
+++ b/mlrun/db/sqldb.py
@@ -396,7 +396,17 @@ def store_project(
name: str,
project: mlrun.api.schemas.Project,
) -> mlrun.api.schemas.Project:
- raise NotImplementedError()
+ import mlrun.api.crud
+
+ if isinstance(project, dict):
+ project = mlrun.api.schemas.Project(**project)
+
+ return self._transform_db_error(
+ mlrun.api.crud.Projects().store_project,
+ self.session,
+ name=name,
+ project=project,
+ )
def patch_project(
self,
@@ -404,20 +414,41 @@ def patch_project(
project: dict,
patch_mode: mlrun.api.schemas.PatchMode = mlrun.api.schemas.PatchMode.replace,
) -> mlrun.api.schemas.Project:
- raise NotImplementedError()
+ import mlrun.api.crud
+
+ return self._transform_db_error(
+ mlrun.api.crud.Projects().patch_project,
+ self.session,
+ name=name,
+ project=project,
+ patch_mode=patch_mode,
+ )
def create_project(
self,
project: mlrun.api.schemas.Project,
) -> mlrun.api.schemas.Project:
- raise NotImplementedError()
+ import mlrun.api.crud
+
+ return self._transform_db_error(
+ mlrun.api.crud.Projects().create_project,
+ self.session,
+ project=project,
+ )
def delete_project(
self,
name: str,
deletion_strategy: mlrun.api.schemas.DeletionStrategy = mlrun.api.schemas.DeletionStrategy.default(),
):
- raise NotImplementedError()
+ import mlrun.api.crud
+
+ return self._transform_db_error(
+ mlrun.api.crud.Projects().delete_project,
+ self.session,
+ name=name,
+ deletion_strategy=deletion_strategy,
+ )
def get_project(
self, name: str = None, project_id: int = None
@@ -437,7 +468,16 @@ def list_projects(
labels: List[str] = None,
state: mlrun.api.schemas.ProjectState = None,
) -> mlrun.api.schemas.ProjectsOutput:
- raise NotImplementedError()
+ import mlrun.api.crud
+
+ return self._transform_db_error(
+ mlrun.api.crud.Projects().list_projects,
+ self.session,
+ owner=owner,
+ format_=format_,
+ labels=labels,
+ state=state,
+ )
@staticmethod
def _transform_db_error(func, *args, **kwargs):
diff --git a/tests/api/db/conftest.py b/tests/api/db/conftest.py
index 1b3a1248aa1b..88d0dfa636a6 100644
--- a/tests/api/db/conftest.py
+++ b/tests/api/db/conftest.py
@@ -12,12 +12,10 @@
# See the License for the specific language governing permissions and
# limitations under the License.
#
-import shutil
from typing import Generator
import pytest
-from mlrun.api.db.filedb.db import FileDB
from mlrun.api.db.session import close_session, create_session
from mlrun.api.db.sqldb.db import SQLDB
from mlrun.api.db.sqldb.session import _init_engine
@@ -26,83 +24,50 @@
from mlrun.api.utils.singletons.project_member import initialize_project_member
from mlrun.config import config
-dbs = [
- "sqldb",
- "filedb",
-]
-
-@pytest.fixture(params=dbs)
-def db(request) -> Generator:
- if request.param == "sqldb":
- dsn = "sqlite:///:memory:?check_same_thread=false"
- config.httpdb.dsn = dsn
- _init_engine()
-
- # memory sqldb remove it self when all session closed, this session will keep it up during all test
- db_session = create_session()
- try:
- init_data()
- db = SQLDB(dsn)
- db.initialize(db_session)
- initialize_db(db)
- initialize_project_member()
- yield db
- finally:
- close_session(db_session)
- elif request.param == "filedb":
- db = FileDB(config.httpdb.dirpath)
- db_session = create_session(request.param)
- try:
- db.initialize(db_session)
-
- yield db
- finally:
- shutil.rmtree(config.httpdb.dirpath, ignore_errors=True, onerror=None)
- close_session(db_session)
- else:
- raise Exception("Unknown db type")
+@pytest.fixture()
+def db() -> Generator:
+ dsn = "sqlite:///:memory:?check_same_thread=false"
+ config.httpdb.dsn = dsn
+ _init_engine()
+ # memory sqldb remove it self when all session closed, this session will keep it up during all test
+ db_session = create_session()
+ try:
+ init_data()
+ db = SQLDB(dsn)
+ db.initialize(db_session)
+ initialize_db(db)
+ initialize_project_member()
+ yield db
+ finally:
+ close_session(db_session)
@pytest.fixture()
-def data_migration_db(request) -> Generator:
+def data_migration_db() -> Generator:
# Data migrations performed before the API goes up, therefore there's no project member yet
# that's the only difference between this fixture and the db fixture. because of the parameterization it was hard to
# share code between them, we anyway going to remove filedb soon, then there won't be params, and we could re-use
# code
# TODO: fix duplication
- if request.param == "sqldb":
- dsn = "sqlite:///:memory:?check_same_thread=false"
- config.httpdb.dsn = dsn
- _init_engine(dsn=dsn)
-
- # memory sqldb remove it self when all session closed, this session will keep it up during all test
- db_session = create_session()
- try:
- init_data()
- db = SQLDB(dsn)
- db.initialize(db_session)
- initialize_db(db)
- yield db
- finally:
- close_session(db_session)
- elif request.param == "filedb":
- db = FileDB(config.httpdb.dirpath)
- db_session = create_session(request.param)
- try:
- db.initialize(db_session)
-
- yield db
- finally:
- shutil.rmtree(config.httpdb.dirpath, ignore_errors=True, onerror=None)
- close_session(db_session)
- else:
- raise Exception("Unknown db type")
+ dsn = "sqlite:///:memory:?check_same_thread=false"
+ config.httpdb.dsn = dsn
+ _init_engine(dsn=dsn)
+ # memory sqldb remove it self when all session closed, this session will keep it up during all test
+ db_session = create_session()
+ try:
+ init_data()
+ db = SQLDB(dsn)
+ db.initialize(db_session)
+ initialize_db(db)
+ yield db
+ finally:
+ close_session(db_session)
-@pytest.fixture(params=dbs)
-def db_session(request) -> Generator:
- db_session = create_session(request.param)
+@pytest.fixture()
+def db_session() -> Generator:
+ db_session = create_session()
try:
yield db_session
finally:
diff --git a/tests/api/db/test_artifacts.py b/tests/api/db/test_artifacts.py
index 133c64eaffea..8d3b47f1847b 100644
--- a/tests/api/db/test_artifacts.py
+++ b/tests/api/db/test_artifacts.py
@@ -26,13 +26,8 @@
from mlrun.artifacts.dataset import DatasetArtifact
from mlrun.artifacts.model import ModelArtifact
from mlrun.artifacts.plots import ChartArtifact, PlotArtifact
-from tests.api.db.conftest import dbs
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_list_artifact_name_filter(db: DBInterface, db_session: Session):
artifact_name_1 = "artifact_name_1"
artifact_name_2 = "artifact_name_2"
@@ -67,10 +62,6 @@ def test_list_artifact_name_filter(db: DBInterface, db_session: Session):
assert len(artifacts) == 2
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_list_artifact_iter_parameter(db: DBInterface, db_session: Session):
artifact_name_1 = "artifact_name_1"
artifact_name_2 = "artifact_name_2"
@@ -105,10 +96,6 @@ def test_list_artifact_iter_parameter(db: DBInterface, db_session: Session):
assert len(artifacts) == 1
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_list_artifact_kind_filter(db: DBInterface, db_session: Session):
artifact_name_1 = "artifact_name_1"
artifact_kind_1 = ChartArtifact.kind
@@ -142,10 +129,6 @@ def test_list_artifact_kind_filter(db: DBInterface, db_session: Session):
assert artifacts[0]["metadata"]["name"] == artifact_name_2
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_list_artifact_category_filter(db: DBInterface, db_session: Session):
artifact_name_1 = "artifact_name_1"
artifact_kind_1 = ChartArtifact.kind
@@ -204,10 +187,6 @@ def test_list_artifact_category_filter(db: DBInterface, db_session: Session):
assert artifacts[1]["metadata"]["name"] == artifact_name_2
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_store_artifact_tagging(db: DBInterface, db_session: Session):
artifact_1_key = "artifact_key_1"
artifact_1_body = _generate_artifact(artifact_1_key)
@@ -238,10 +217,6 @@ def test_store_artifact_tagging(db: DBInterface, db_session: Session):
assert len(artifacts) == 1
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_store_artifact_restoring_multiple_tags(db: DBInterface, db_session: Session):
artifact_key = "artifact_key_1"
artifact_1_uid = "artifact_uid_1"
@@ -295,10 +270,6 @@ def test_store_artifact_restoring_multiple_tags(db: DBInterface, db_session: Ses
assert artifact["metadata"]["tag"] == artifact_2_tag
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_read_artifact_tag_resolution(db: DBInterface, db_session: Session):
"""
We had a bug in which when we got a tag filter for read/list artifact, we were transforming this tag to list of
@@ -341,10 +312,6 @@ def test_read_artifact_tag_resolution(db: DBInterface, db_session: Session):
assert len(artifacts) == 1
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_delete_artifacts_tag_filter(db: DBInterface, db_session: Session):
artifact_1_key = "artifact_key_1"
artifact_2_key = "artifact_key_2"
@@ -379,10 +346,6 @@ def test_delete_artifacts_tag_filter(db: DBInterface, db_session: Session):
assert len(artifacts) == 0
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_delete_artifact_tag_filter(db: DBInterface, db_session: Session):
project = "artifact_project"
artifact_1_key = "artifact_key_1"
@@ -460,10 +423,6 @@ def test_delete_artifact_tag_filter(db: DBInterface, db_session: Session):
assert len(tags) == 0
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_list_artifacts_exact_name_match(db: DBInterface, db_session: Session):
artifact_1_key = "pre_artifact_key_suffix"
artifact_2_key = "pre-artifact-key-suffix"
@@ -547,9 +506,6 @@ def _generate_artifact_with_iterations(
)
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_list_artifacts_best_iter_with_tagged_iteration(
db: DBInterface, db_session: Session
):
@@ -611,10 +567,6 @@ def test_list_artifacts_best_iter_with_tagged_iteration(
)
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_list_artifacts_best_iter(db: DBInterface, db_session: Session):
artifact_1_key = "artifact-1"
artifact_1_uid = "uid-1"
@@ -690,9 +642,6 @@ def test_list_artifacts_best_iter(db: DBInterface, db_session: Session):
)
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_list_artifacts_best_iteration(db: DBInterface, db_session: Session):
artifact_key = "artifact-1"
artifact_1_uid = "uid-1"
@@ -748,12 +697,6 @@ def test_list_artifacts_best_iteration(db: DBInterface, db_session: Session):
assert set(expected_uids) == set(uids)
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "data_migration_db,db_session",
- [(dbs[0], dbs[0])],
- indirect=["data_migration_db", "db_session"],
-)
def test_data_migration_fix_legacy_datasets_large_previews(
data_migration_db: DBInterface,
db_session: Session,
@@ -845,12 +788,6 @@ def test_data_migration_fix_legacy_datasets_large_previews(
)
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "data_migration_db,db_session",
- [(dbs[0], dbs[0])],
- indirect=["data_migration_db", "db_session"],
-)
def test_data_migration_fix_datasets_large_previews(
data_migration_db: DBInterface,
db_session: Session,
diff --git a/tests/api/db/test_background_tasks.py b/tests/api/db/test_background_tasks.py
index 5ae1dbc909b7..ea199b50b4fa 100644
--- a/tests/api/db/test_background_tasks.py
+++ b/tests/api/db/test_background_tasks.py
@@ -21,12 +21,8 @@
import mlrun.errors
from mlrun.api import schemas
from mlrun.api.db.base import DBInterface
-from tests.api.db.conftest import dbs
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_store_project_background_task(db: DBInterface, db_session: Session):
project = "test-project"
db.store_background_task(db_session, "test", timeout=600, project=project)
@@ -35,9 +31,6 @@ def test_store_project_background_task(db: DBInterface, db_session: Session):
assert background_task.status.state == "running"
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_get_project_background_task_with_timeout_exceeded(
db: DBInterface, db_session: Session
):
@@ -50,9 +43,6 @@ def test_get_project_background_task_with_timeout_exceeded(
assert background_task.status.state == "failed"
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_get_project_background_task_doesnt_exists(
db: DBInterface, db_session: Session
):
@@ -61,9 +51,6 @@ def test_get_project_background_task_doesnt_exists(
db.get_background_task(db_session, "test", project=project)
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_store_project_background_task_after_status_updated(
db: DBInterface, db_session: Session
):
@@ -100,9 +87,6 @@ def test_store_project_background_task_after_status_updated(
)
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_get_project_background_task_with_disabled_timeout(
db: DBInterface, db_session: Session
):
diff --git a/tests/api/db/test_feature_sets.py b/tests/api/db/test_feature_sets.py
index f36d75776489..5b595f0b52d6 100644
--- a/tests/api/db/test_feature_sets.py
+++ b/tests/api/db/test_feature_sets.py
@@ -21,7 +21,6 @@
from mlrun import errors
from mlrun.api import schemas
from mlrun.api.db.base import DBInterface
-from tests.api.db.conftest import dbs
def _create_feature_set(name):
@@ -59,10 +58,6 @@ def _create_feature_set(name):
}
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_create_feature_set(db: DBInterface, db_session: Session):
name = "dummy"
feature_set = _create_feature_set(name)
@@ -82,10 +77,6 @@ def test_create_feature_set(db: DBInterface, db_session: Session):
assert len(features_res.features) == 1
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_handle_feature_set_with_datetime_fields(db: DBInterface, db_session: Session):
# Simulate a situation where a feature-set client-side object is created with datetime fields, and then stored to
# DB. This may happen in API calls which utilize client-side objects (such as ingest). See ML-3552.
@@ -99,9 +90,6 @@ def test_handle_feature_set_with_datetime_fields(db: DBInterface, db_session: Se
mlrun.utils.helpers.fill_object_hash(fs_server_object.dict(), "uid")
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_update_feature_set_labels(db: DBInterface, db_session: Session):
name = "dummy"
feature_set = _create_feature_set(name)
@@ -159,9 +147,6 @@ def test_update_feature_set_labels(db: DBInterface, db_session: Session):
assert updated_feature_set.metadata.labels == feature_set.metadata.labels
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_update_feature_set_by_uid(db: DBInterface, db_session: Session):
name = "mock_feature_set"
feature_set = _create_feature_set(name)
diff --git a/tests/api/db/test_functions.py b/tests/api/db/test_functions.py
index 93877664c00b..235b796bff1f 100644
--- a/tests/api/db/test_functions.py
+++ b/tests/api/db/test_functions.py
@@ -18,12 +18,8 @@
import mlrun.errors
from mlrun.api.db.base import DBInterface
from mlrun.api.db.sqldb.models import Function
-from tests.api.db.conftest import dbs
-@pytest.mark.parametrize(
- "db,db_session", [(db, db) for db in dbs], indirect=["db", "db_session"]
-)
def test_store_function_default_to_latest(db: DBInterface, db_session: Session):
function_1 = _generate_function()
function_hash_key = db.store_function(
@@ -43,9 +39,6 @@ def test_store_function_default_to_latest(db: DBInterface, db_session: Session):
assert function_queried_without_tag_hash == function_queried_without_tag_hash
-@pytest.mark.parametrize(
- "db,db_session", [(db, db) for db in dbs], indirect=["db", "db_session"]
-)
def test_store_function_versioned(db: DBInterface, db_session: Session):
function_1 = _generate_function()
function_hash_key = db.store_function(
@@ -84,9 +77,6 @@ def test_store_function_versioned(db: DBInterface, db_session: Session):
assert tagged_count == 1
-@pytest.mark.parametrize(
- "db,db_session", [(db, db) for db in dbs], indirect=["db", "db_session"]
-)
def test_store_function_not_versioned(db: DBInterface, db_session: Session):
function_1 = _generate_function()
function_hash_key = db.store_function(
@@ -110,9 +100,6 @@ def test_store_function_not_versioned(db: DBInterface, db_session: Session):
assert len(functions) == 1
-@pytest.mark.parametrize(
- "db,db_session", [(db, db) for db in dbs], indirect=["db", "db_session"]
-)
def test_get_function_by_hash_key(db: DBInterface, db_session: Session):
function_1 = _generate_function()
function_hash_key = db.store_function(
@@ -134,9 +121,6 @@ def test_get_function_by_hash_key(db: DBInterface, db_session: Session):
assert function_queried_with_hash_key["metadata"]["tag"] == ""
-@pytest.mark.parametrize(
- "db,db_session", [(db, db) for db in dbs], indirect=["db", "db_session"]
-)
def test_get_function_by_tag(db: DBInterface, db_session: Session):
function_1 = _generate_function()
function_hash_key = db.store_function(
@@ -149,9 +133,6 @@ def test_get_function_by_tag(db: DBInterface, db_session: Session):
assert function_hash_key == function_not_queried_by_tag_hash
-@pytest.mark.parametrize(
- "db,db_session", [(db, db) for db in dbs], indirect=["db", "db_session"]
-)
def test_get_function_not_found(db: DBInterface, db_session: Session):
function_1 = _generate_function()
db.store_function(
@@ -167,9 +148,6 @@ def test_get_function_not_found(db: DBInterface, db_session: Session):
)
-@pytest.mark.parametrize(
- "db,db_session", [(db, db) for db in dbs], indirect=["db", "db_session"]
-)
def test_list_functions_no_tags(db: DBInterface, db_session: Session):
function_1 = {"bla": "blabla", "status": {"bla": "blabla"}}
function_2 = {"bla2": "blabla", "status": {"bla": "blabla"}}
@@ -195,9 +173,6 @@ def test_list_functions_no_tags(db: DBInterface, db_session: Session):
assert function["status"] is None
-@pytest.mark.parametrize(
- "db,db_session", [(db, db) for db in dbs], indirect=["db", "db_session"]
-)
def test_list_functions_by_tag(db: DBInterface, db_session: Session):
tag = "function_name_1"
@@ -213,10 +188,6 @@ def test_list_functions_by_tag(db: DBInterface, db_session: Session):
assert len(names) == 0
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_list_functions_with_non_existent_tag(db: DBInterface, db_session: Session):
names = ["some_name", "some_name2", "some_name3"]
for name in names:
@@ -226,9 +197,6 @@ def test_list_functions_with_non_existent_tag(db: DBInterface, db_session: Sessi
assert len(functions) == 0
-@pytest.mark.parametrize(
- "db,db_session", [(db, db) for db in dbs], indirect=["db", "db_session"]
-)
def test_list_functions_filtering_unversioned_untagged(
db: DBInterface, db_session: Session
):
@@ -257,10 +225,6 @@ def test_list_functions_filtering_unversioned_untagged(
assert functions[0]["metadata"]["hash"] == tagged_function_hash_key
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_delete_function(db: DBInterface, db_session: Session):
labels = {
"name": "value",
@@ -316,10 +280,6 @@ def test_delete_function(db: DBInterface, db_session: Session):
assert number_of_labels == 0
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
@pytest.mark.parametrize("use_hash_key", [True, False])
def test_list_functions_multiple_tags(
db: DBInterface, db_session: Session, use_hash_key: bool
@@ -349,10 +309,6 @@ def test_list_functions_multiple_tags(
assert len(tags) == 0
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_list_function_with_tag_and_uid(db: DBInterface, db_session: Session):
tag_name = "some_tag"
function_1 = _generate_function(tag=tag_name)
diff --git a/tests/api/db/test_projects.py b/tests/api/db/test_projects.py
index be4b977ecf03..cc05323450c5 100644
--- a/tests/api/db/test_projects.py
+++ b/tests/api/db/test_projects.py
@@ -26,13 +26,8 @@
import mlrun.errors
from mlrun.api.db.base import DBInterface
from mlrun.api.db.sqldb.models import Project
-from tests.api.db.conftest import dbs
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_get_project(
db: DBInterface,
db_session: sqlalchemy.orm.Session,
@@ -65,10 +60,6 @@ def test_get_project(
)
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_get_project_with_pre_060_record(
db: DBInterface,
db_session: sqlalchemy.orm.Session,
@@ -91,10 +82,6 @@ def test_get_project_with_pre_060_record(
assert updated_record.full_object is not None
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_data_migration_enrich_project_state(
db: DBInterface,
db_session: sqlalchemy.orm.Session,
@@ -126,10 +113,6 @@ def _generate_and_insert_pre_060_record(
db_session.commit()
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_list_project(
db: DBInterface,
db_session: sqlalchemy.orm.Session,
@@ -170,10 +153,6 @@ def test_list_project(
)
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_list_project_names_filter(
db: DBInterface,
db_session: sqlalchemy.orm.Session,
@@ -212,10 +191,6 @@ def test_list_project_names_filter(
assert projects_output.projects == []
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_create_project(
db: DBInterface,
db_session: sqlalchemy.orm.Session,
@@ -228,10 +203,6 @@ def test_create_project(
_assert_project(db, db_session, project)
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_store_project_creation(
db: DBInterface,
db_session: sqlalchemy.orm.Session,
@@ -245,10 +216,6 @@ def test_store_project_creation(
_assert_project(db, db_session, project)
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_store_project_update(
db: DBInterface,
db_session: sqlalchemy.orm.Session,
@@ -274,10 +241,6 @@ def test_store_project_update(
assert project_output.metadata.created != project.metadata.created
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_patch_project(
db: DBInterface,
db_session: sqlalchemy.orm.Session,
@@ -318,10 +281,6 @@ def test_patch_project(
)
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_delete_project(
db: DBInterface,
db_session: sqlalchemy.orm.Session,
diff --git a/tests/api/db/test_runs.py b/tests/api/db/test_runs.py
index fe19706cf29f..7539b40686f4 100644
--- a/tests/api/db/test_runs.py
+++ b/tests/api/db/test_runs.py
@@ -20,13 +20,8 @@
import mlrun.api.db.sqldb.helpers
import mlrun.api.initial_data
from mlrun.api.db.base import DBInterface
-from tests.api.db.conftest import dbs
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_list_runs_name_filter(db: DBInterface, db_session: Session):
project = "project"
run_name_1 = "run_name_1"
@@ -57,10 +52,6 @@ def test_list_runs_name_filter(db: DBInterface, db_session: Session):
assert len(runs) == 2
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_list_distinct_runs_uids(db: DBInterface, db_session: Session):
project_name = "project"
uid = "run-uid"
@@ -108,10 +99,6 @@ def test_list_distinct_runs_uids(db: DBInterface, db_session: Session):
assert type(distinct_runs[0]) == dict
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_list_runs_state_filter(db: DBInterface, db_session: Session):
project = "project"
run_uid_running = "run-running"
@@ -148,10 +135,6 @@ def test_list_runs_state_filter(db: DBInterface, db_session: Session):
assert runs[0]["metadata"]["uid"] == run_uid_completed
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_store_run_overriding_start_time(db: DBInterface, db_session: Session):
# First store - fills the start_time
project, name, uid, iteration, run = _create_new_run(db, db_session)
@@ -178,10 +161,6 @@ def test_store_run_overriding_start_time(db: DBInterface, db_session: Session):
assert runs[0].struct["status"]["start_time"] == run["status"]["start_time"]
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_data_migration_align_runs_table(db: DBInterface, db_session: Session):
time_before_creation = datetime.now(tz=timezone.utc)
# Create runs
@@ -214,10 +193,6 @@ def test_data_migration_align_runs_table(db: DBInterface, db_session: Session):
_ensure_run_after_align_runs_migration(db, run, time_before_creation)
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_data_migration_align_runs_table_with_empty_run_body(
db: DBInterface, db_session: Session
):
@@ -244,10 +219,6 @@ def test_data_migration_align_runs_table_with_empty_run_body(
_ensure_run_after_align_runs_migration(db, run)
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_store_run_success(db: DBInterface, db_session: Session):
project, name, uid, iteration, run = _create_new_run(db, db_session)
@@ -272,10 +243,6 @@ def test_store_run_success(db: DBInterface, db_session: Session):
)
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_update_runs_requested_logs(db: DBInterface, db_session: Session):
project, name, uid, iteration, run = _create_new_run(db, db_session)
@@ -294,10 +261,6 @@ def test_update_runs_requested_logs(db: DBInterface, db_session: Session):
assert runs_after[0].updated > run_updated_time
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_update_run_success(db: DBInterface, db_session: Session):
project, name, uid, iteration, run = _create_new_run(db, db_session)
@@ -315,10 +278,6 @@ def test_update_run_success(db: DBInterface, db_session: Session):
assert run["spec"]["another-new-field"] == "value"
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_store_and_update_run_update_name_failure(db: DBInterface, db_session: Session):
project, name, uid, iteration, run = _create_new_run(db, db_session)
@@ -348,10 +307,6 @@ def test_store_and_update_run_update_name_failure(db: DBInterface, db_session: S
)
-# running only on sqldb cause filedb is not really a thing anymore, will be removed soon
-@pytest.mark.parametrize(
- "db,db_session", [(dbs[0], dbs[0])], indirect=["db", "db_session"]
-)
def test_list_runs_limited_unsorted_failure(db: DBInterface, db_session: Session):
with pytest.raises(
mlrun.errors.MLRunInvalidArgumentError,
diff --git a/tests/artifacts/test_artifacts.py b/tests/artifacts/test_artifacts.py
index eed506afedd7..2ec434b8ba91 100644
--- a/tests/artifacts/test_artifacts.py
+++ b/tests/artifacts/test_artifacts.py
@@ -468,40 +468,6 @@ def test_resolve_body_hash_path(
assert expected_target_path == target_path
-def test_export_import():
- project = mlrun.new_project("log-mod", save=False)
- target_project = mlrun.new_project("log-mod2", save=False)
- for mode in [False, True]:
- mlrun.mlconf.artifacts.generate_target_path_from_artifact_hash = mode
-
- model = project.log_model(
- "mymod",
- body=b"123",
- model_file="model.pkl",
- extra_data={"kk": b"456"},
- artifact_path=results_dir,
- )
-
- for suffix in ["yaml", "json", "zip"]:
- # export the artifact to a file
- model.export(f"{results_dir}/a.{suffix}")
-
- # import and log the artifact to the new project
- artifact = target_project.import_artifact(
- f"{results_dir}/a.{suffix}", f"mod-{suffix}", artifact_path=results_dir
- )
- assert artifact.kind == "model"
- assert artifact.metadata.key == f"mod-{suffix}"
- assert artifact.metadata.project == "log-mod2"
- temp_path, model_spec, extra_dataitems = mlrun.artifacts.get_model(
- artifact.uri
- )
- with open(temp_path, "rb") as fp:
- data = fp.read()
- assert data == b"123"
- assert extra_dataitems["kk"].get() == b"456"
-
-
def test_inline_body():
project = mlrun.new_project("inline", save=False)
diff --git a/tests/artifacts/test_model.py b/tests/artifacts/test_model.py
deleted file mode 100644
index cef8a1133540..000000000000
--- a/tests/artifacts/test_model.py
+++ /dev/null
@@ -1,92 +0,0 @@
-# Copyright 2018 Iguazio
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-#
-import pathlib
-
-import pandas as pd
-
-import mlrun
-from mlrun.artifacts.model import ModelArtifact, get_model, update_model
-from mlrun.features import Feature
-from tests.conftest import results
-
-results_dir = f"{results}/artifacts/"
-
-raw_data = {
- "first_name": ["Jason", "Molly", "Tina", "Jake", "Amy"],
- "last_name": ["Miller", "Jacobson", "Ali", "Milner", "Cooze"],
- "age": [42, 52, 36, 24, 73],
- "testScore": [25, 94, 57, 62, 70],
-}
-
-expected_inputs = [
- {"name": "last_name", "value_type": "str"},
- {"name": "first_name", "value_type": "str"},
- {"name": "age", "value_type": "int"},
-]
-expected_outputs = [{"name": "testScore", "value_type": "int"}]
-
-
-def test_infer():
- model = ModelArtifact("my-model")
- df = pd.DataFrame(raw_data, columns=["last_name", "first_name", "age", "testScore"])
- model.infer_from_df(df, ["testScore"])
- assert model.inputs.to_dict() == expected_inputs, "unexpected model inputs"
- assert model.outputs.to_dict() == expected_outputs, "unexpected model outputs"
- assert list(model.feature_stats.keys()) == [
- "last_name",
- "first_name",
- "age",
- "testScore",
- ], "wrong stat keys"
-
-
-def test_model_update():
- path = pathlib.Path(__file__).absolute().parent
- model = ModelArtifact(
- "my-model", model_dir=str(path / "assets"), model_file="model.pkl"
- )
-
- target_path = results_dir + "model/"
-
- project = mlrun.new_project("test-proj", save=False)
- artifact = project.log_artifact(model, upload=True, artifact_path=target_path)
-
- artifact_uri = f"store://artifacts/{artifact.project}/{artifact.db_key}"
- updated_model_spec = update_model(
- artifact_uri,
- parameters={"a": 1},
- metrics={"b": 2},
- inputs=[Feature(name="f1")],
- outputs=[Feature(name="f2")],
- feature_vector="vec",
- feature_weights=[1, 2],
- key_prefix="test-",
- labels={"lbl": "tst"},
- write_spec_copy=False,
- )
- print(updated_model_spec.to_yaml())
-
- model_path, model, extra_dataitems = get_model(artifact_uri)
-
- assert model_path.endswith(f"model/{model.model_file}"), "illegal model path"
- assert model.parameters == {"a": 1}, "wrong parameters"
- assert model.metrics == {"test-b": 2}, "wrong metrics"
-
- assert model.inputs[0].name == "f1", "wrong inputs"
- assert model.outputs[0].name == "f2", "wrong outputs"
-
- assert model.feature_vector == "vec", "wrong feature_vector"
- assert model.feature_weights == [1, 2], "wrong feature_weights"
- assert model.labels == {"lbl": "tst"}, "wrong labels"
diff --git a/tests/common_fixtures.py b/tests/common_fixtures.py
index 4bba994edde4..cf8e2495467f 100644
--- a/tests/common_fixtures.py
+++ b/tests/common_fixtures.py
@@ -35,6 +35,7 @@
import mlrun.datastore
import mlrun.db
import mlrun.k8s_utils
+import mlrun.projects.project
import mlrun.utils
import mlrun.utils.singleton
from mlrun.api.db.sqldb.db import SQLDB
@@ -42,6 +43,7 @@
from mlrun.api.initial_data import init_data
from mlrun.api.utils.singletons.db import initialize_db
from mlrun.config import config
+from mlrun.lists import ArtifactList
from mlrun.runtimes import BaseRuntime
from mlrun.runtimes.function import NuclioStatus
from mlrun.runtimes.utils import global_context
@@ -80,6 +82,9 @@ def config_test_base():
mlrun.datastore.store_manager._db = None
mlrun.datastore.store_manager._stores = {}
+ # no need to raise error when using nop_db
+ mlrun.mlconf.httpdb.nop_db.raise_error = False
+
# remove the is_running_as_api cache, so it won't pass between tests
mlrun.config._is_running_as_api = None
# remove singletons in case they were changed (we don't want changes to pass between tests)
@@ -122,14 +127,21 @@ def db():
db_session = create_session()
db = SQLDB(dsn)
db.initialize(db_session)
+ config.dbpath = dsn
finally:
if db_session is not None:
db_session.close()
mlrun.api.utils.singletons.db.initialize_db(db)
+ mlrun.api.utils.singletons.logs_dir.initialize_logs_dir()
mlrun.api.utils.singletons.project_member.initialize_project_member()
return db
+@pytest.fixture
+def ensure_default_project() -> mlrun.projects.project.MlrunProject:
+ return mlrun.get_or_create_project("default")
+
+
@pytest.fixture()
def db_session() -> Generator:
db_session = None
@@ -190,21 +202,51 @@ class RunDBMock:
def __init__(self):
self.kind = "http"
self._pipeline = None
- self._function = None
- self._artifact = None
+ self._functions = {}
+ self._artifacts = {}
+ self._project_name = None
self._runs = {}
def reset(self):
- self._function = None
+ self._functions = {}
self._pipeline = None
self._project_name = None
self._project = None
- self._artifact = None
+ self._artifacts = {}
# Expected to return a hash-key
def store_function(self, function, name, project="", tag=None, versioned=False):
- self._function = function
- return "1234-1234-1234-1234"
+ hash_key = mlrun.utils.fill_function_hash(function, tag)
+ self._functions[name] = function
+ return hash_key
+
+ def store_artifact(self, key, artifact, uid, iter=None, tag="", project=""):
+ self._artifacts[key] = artifact
+ return artifact
+
+ def read_artifact(self, key, tag=None, iter=None, project=""):
+ return self._artifacts.get(key, None)
+
+ def list_artifacts(
+ self,
+ name="",
+ project="",
+ tag="",
+ labels=None,
+ since=None,
+ until=None,
+ kind=None,
+ category=None,
+ iter: int = None,
+ best_iteration: bool = False,
+ as_records: bool = False,
+ use_tag_as_uid: bool = None,
+ ):
+ def filter_artifact(artifact):
+ if artifact["metadata"].get("tag", None) == tag:
+ return True
+
+ return ArtifactList(filter(filter_artifact, self._artifacts.values()))
def store_run(self, struct, uid, project="", iter=0):
self._runs[uid] = {
@@ -216,20 +258,10 @@ def store_run(self, struct, uid, project="", iter=0):
def read_run(self, uid, project, iter=0):
return self._runs.get(uid, {})
- def store_artifact(self, key, artifact, uid, iter=None, tag="", project=""):
- self._artifact = artifact
-
- def read_artifact(self, key, tag=None, iter=None, project=""):
- return self._artifact
-
- def get_function(self, function, project, tag):
- return {
- "name": function,
- "metadata": "bla",
- "uid": "1234-1234-1234-1234",
- "project": project,
- "tag": tag,
- }
+ def get_function(self, function, project, tag, hash_key=None):
+ if function not in self._functions:
+ raise mlrun.errors.MLRunNotFoundError("Function not found")
+ return self._functions[function]
def submit_job(self, runspec, schedule=None):
return {"status": {"status_text": "just a status"}}
@@ -266,16 +298,17 @@ def remote_builder(
skip_deployed=False,
builder_env=None,
):
- self._function = func.to_dict()
+ function = func.to_dict()
status = NuclioStatus(
state="ready",
nuclio_name="test-nuclio-name",
)
+ self._functions[function["metadata"]["name"]] = function
return {
"data": {
"status": status.to_dict(),
- "metadata": self._function.get("metadata"),
- "spec": self._function.get("spec"),
+ "metadata": function.get("metadata"),
+ "spec": function.get("spec"),
}
}
@@ -293,8 +326,10 @@ def update_run(self, updates: dict, uid, project="", iter=0):
for key, value in updates.items():
update_in(self._runs[uid]["struct"], key, value)
- def assert_no_mount_or_creds_configured(self):
- env_list = self._function["spec"]["env"]
+ def assert_no_mount_or_creds_configured(self, function_name=None):
+ function = self._get_function_internal(function_name)
+
+ env_list = function["spec"]["env"]
env_params = [item["name"] for item in env_list]
for env_variable in [
"V3IO_USERNAME",
@@ -304,15 +339,16 @@ def assert_no_mount_or_creds_configured(self):
]:
assert env_variable not in env_params
- volume_mounts = self._function["spec"]["volume_mounts"]
- volumes = self._function["spec"]["volumes"]
+ volume_mounts = function["spec"]["volume_mounts"]
+ volumes = function["spec"]["volumes"]
assert len(volumes) == 0
assert len(volume_mounts) == 0
def assert_v3io_mount_or_creds_configured(
- self, v3io_user, v3io_access_key, cred_only=False
+ self, v3io_user, v3io_access_key, cred_only=False, function_name=None
):
- env_list = self._function["spec"]["env"]
+ function = self._get_function_internal(function_name)
+ env_list = function["spec"]["env"]
env_dict = {item["name"]: item["value"] for item in env_list}
expected_env = {
"V3IO_USERNAME": v3io_user,
@@ -323,8 +359,8 @@ def assert_v3io_mount_or_creds_configured(
result.pop("dictionary_item_removed")
assert result == {}
- volume_mounts = self._function["spec"]["volume_mounts"]
- volumes = self._function["spec"]["volumes"]
+ volume_mounts = function["spec"]["volume_mounts"]
+ volumes = function["spec"]["volumes"]
if cred_only:
assert len(volumes) == 0
@@ -348,8 +384,8 @@ def assert_v3io_mount_or_creds_configured(
assert deepdiff.DeepDiff(volumes, expected_volumes) == {}
assert deepdiff.DeepDiff(volume_mounts, expected_mounts) == {}
- def assert_pvc_mount_configured(self, pvc_params):
- function_spec = self._function["spec"]
+ def assert_pvc_mount_configured(self, pvc_params, function_name=None):
+ function_spec = self._get_function_internal(function_name)["spec"]
expected_volumes = [
{
@@ -367,8 +403,9 @@ def assert_pvc_mount_configured(self, pvc_params):
assert deepdiff.DeepDiff(function_spec["volumes"], expected_volumes) == {}
assert deepdiff.DeepDiff(function_spec["volume_mounts"], expected_mounts) == {}
- def assert_s3_mount_configured(self, s3_params):
- env_list = self._function["spec"]["env"]
+ def assert_s3_mount_configured(self, s3_params, function_name=None):
+ function = self._get_function_internal(function_name)
+ env_list = function["spec"]["env"]
param_names = ["AWS_ACCESS_KEY_ID", "AWS_SECRET_ACCESS_KEY"]
secret_name = s3_params.get("secret_name")
non_anonymous = s3_params.get("non_anonymous")
@@ -393,8 +430,9 @@ def assert_s3_mount_configured(self, s3_params):
expected_envs["S3_NON_ANONYMOUS"] = "true"
assert expected_envs == env_dict
- def assert_env_variables(self, expected_env_dict):
- env_list = self._function["spec"]["env"]
+ def assert_env_variables(self, expected_env_dict, function_name=None):
+ function = self._get_function_internal(function_name)
+ env_list = function["spec"]["env"]
env_dict = {item["name"]: item["value"] for item in env_list}
for key, value in expected_env_dict.items():
@@ -406,6 +444,12 @@ def verify_authorization(
):
pass
+ def _get_function_internal(self, function_name: str = None):
+ if function_name:
+ return self._functions[function_name]
+
+ return list(self._functions.values())[0]
+
@pytest.fixture()
def rundb_mock() -> RunDBMock:
diff --git a/tests/feature-store/test_infer.py b/tests/feature-store/test_infer.py
index b7c2cd1e564c..e60d2e6a73d8 100644
--- a/tests/feature-store/test_infer.py
+++ b/tests/feature-store/test_infer.py
@@ -107,7 +107,7 @@ def test_target_no_time_column():
)
-def test_check_permissions():
+def test_check_permissions(rundb_mock, monkeypatch):
data = pd.DataFrame(
{
"time_stamp": [
@@ -121,54 +121,37 @@ def test_check_permissions():
)
data_set1 = fstore.FeatureSet("fs1", entities=[Entity("string")])
- mlrun.db.FileRunDB.verify_authorization = unittest.mock.Mock(
- side_effect=mlrun.errors.MLRunAccessDeniedError("")
+ monkeypatch.setattr(
+ rundb_mock,
+ "verify_authorization",
+ unittest.mock.Mock(side_effect=mlrun.errors.MLRunAccessDeniedError("")),
)
- try:
+ with pytest.raises(mlrun.errors.MLRunAccessDeniedError):
fstore.preview(
data_set1,
data,
entity_columns=[Entity("string")],
timestamp_key="time_stamp",
)
- assert False
- except mlrun.errors.MLRunAccessDeniedError:
- pass
-
- try:
+ with pytest.raises(mlrun.errors.MLRunAccessDeniedError):
fstore.ingest(data_set1, data, infer_options=fstore.InferOptions.default())
- assert False
- except mlrun.errors.MLRunAccessDeniedError:
- pass
features = ["fs1.*"]
feature_vector = fstore.FeatureVector("test", features)
- try:
+ with pytest.raises(mlrun.errors.MLRunAccessDeniedError):
fstore.get_offline_features(
feature_vector, entity_timestamp_column="time_stamp"
)
- assert False
- except mlrun.errors.MLRunAccessDeniedError:
- pass
- try:
+ with pytest.raises(mlrun.errors.MLRunAccessDeniedError):
fstore.get_online_feature_service(feature_vector)
- assert False
- except mlrun.errors.MLRunAccessDeniedError:
- pass
- try:
+ with pytest.raises(mlrun.errors.MLRunAccessDeniedError):
fstore.deploy_ingestion_service(featureset=data_set1)
- assert False
- except mlrun.errors.MLRunAccessDeniedError:
- pass
- try:
+ with pytest.raises(mlrun.errors.MLRunAccessDeniedError):
data_set1.purge_targets()
- assert False
- except mlrun.errors.MLRunAccessDeniedError:
- pass
def test_check_timestamp_key_is_entity():
diff --git a/tests/feature-store/test_steps.py b/tests/feature-store/test_steps.py
index 0d92511c6fa0..6aae92c5ac19 100644
--- a/tests/feature-store/test_steps.py
+++ b/tests/feature-store/test_steps.py
@@ -43,7 +43,7 @@ def extract_meta(event):
return event
-def test_set_event_meta():
+def test_set_event_meta(rundb_mock):
function = mlrun.new_function("test1", kind="serving")
flow = function.set_topology("flow")
flow.to(SetEventMetadata(id_path="myid", key_path="mykey")).to(
@@ -60,7 +60,7 @@ def test_set_event_meta():
}
-def test_set_event_random_id():
+def test_set_event_random_id(rundb_mock):
function = mlrun.new_function("test2", kind="serving")
flow = function.set_topology("flow")
flow.to(SetEventMetadata(random_id=True)).to(
diff --git a/tests/frameworks/lgbm/test_lgbm.py b/tests/frameworks/lgbm/test_lgbm.py
index e8d6c4f43c5c..cbf19e12fa7e 100644
--- a/tests/frameworks/lgbm/test_lgbm.py
+++ b/tests/frameworks/lgbm/test_lgbm.py
@@ -34,7 +34,7 @@
@pytest.mark.parametrize("algorithm_functionality", ALGORITHM_FUNCTIONALITIES)
-def test_training_api_training(algorithm_functionality: str):
+def test_training_api_training(rundb_mock, algorithm_functionality: str):
# Run training:
train_run = mlrun.new_function().run(
artifact_path="./temp",
@@ -53,7 +53,7 @@ def test_training_api_training(algorithm_functionality: str):
@pytest.mark.parametrize("algorithm_functionality", ALGORITHM_FUNCTIONALITIES)
-def test_sklearn_api_training(algorithm_functionality: str):
+def test_sklearn_api_training(rundb_mock, algorithm_functionality: str):
# Run training:
train_run = mlrun.new_function().run(
artifact_path="./temp",
@@ -81,7 +81,7 @@ def test_sklearn_api_training(algorithm_functionality: str):
@pytest.mark.parametrize("algorithm_functionality", ALGORITHM_FUNCTIONALITIES)
-def test_sklearn_api_evaluation(algorithm_functionality: str):
+def test_sklearn_api_evaluation(rundb_mock, algorithm_functionality: str):
# Run training:
train_run = mlrun.new_function().run(
artifact_path="./temp2",
diff --git a/tests/frameworks/test_ml_frameworks.py b/tests/frameworks/test_ml_frameworks.py
index 108a04ff286a..134a780ac71b 100644
--- a/tests/frameworks/test_ml_frameworks.py
+++ b/tests/frameworks/test_ml_frameworks.py
@@ -13,6 +13,7 @@
# limitations under the License.
#
import json
+import typing
from typing import Dict, List, Tuple
import pytest
@@ -33,7 +34,7 @@ class FrameworkKeys:
SKLEARN = "sklearn"
-FRAMEWORKS = { # type: Dict[str, Tuple[MLFunctions, ArtifactsLibrary, MetricsLibrary]]
+FRAMEWORKS = {
FrameworkKeys.XGBOOST: (
XGBoostFunctions,
XGBoostArtifactsLibrary,
@@ -44,36 +45,47 @@ class FrameworkKeys:
SKLearnArtifactsLibrary,
MetricsLibrary,
),
-}
-FRAMEWORKS_KEYS = [ # type: List[str]
+} # type: Dict[str, Tuple[MLFunctions, ArtifactsLibrary, MetricsLibrary]]
+FRAMEWORKS_KEYS = [
FrameworkKeys.XGBOOST,
FrameworkKeys.SKLEARN,
-]
-ALGORITHM_FUNCTIONALITIES = [ # type: List[str]
+] # type: List[str]
+ALGORITHM_FUNCTIONALITIES = [
algorithm_functionality.value
for algorithm_functionality in AlgorithmFunctionality
if "Unknown" not in algorithm_functionality.value
-]
+] # type: List[str]
+FRAMEWORKS_ALGORITHM_FUNCTIONALITIES = [
+ (framework, algorithm_functionality)
+ for framework in FRAMEWORKS_KEYS
+ for algorithm_functionality in ALGORITHM_FUNCTIONALITIES
+ if (
+ framework is not FrameworkKeys.XGBOOST
+ or algorithm_functionality
+ != AlgorithmFunctionality.MULTI_OUTPUT_MULTICLASS_CLASSIFICATION.value
+ )
+] # type: List[Tuple[str, str]]
+
+def framework_algorithm_functionality_pair_ids(
+ framework_algorithm_functionality_pair: typing.Tuple[str, str]
+) -> str:
+ framework, algorithm_functionality = framework_algorithm_functionality_pair
+ return f"{framework}-{algorithm_functionality}"
-@pytest.mark.parametrize("framework", FRAMEWORKS_KEYS)
-@pytest.mark.parametrize("algorithm_functionality", ALGORITHM_FUNCTIONALITIES)
-def test_training(framework: str, algorithm_functionality: str):
+
+@pytest.mark.parametrize(
+ "framework_algorithm_functionality_pair",
+ FRAMEWORKS_ALGORITHM_FUNCTIONALITIES,
+ ids=framework_algorithm_functionality_pair_ids,
+)
+def test_training(framework_algorithm_functionality_pair: typing.Tuple[str, str]):
+ framework, algorithm_functionality = framework_algorithm_functionality_pair
# Unpack the framework classes:
(functions, artifacts_library, metrics_library) = FRAMEWORKS[
framework
] # type: MLFunctions, ArtifactsLibrary, MetricsLibrary
- # Skips:
- if (
- functions is XGBoostFunctions
- and algorithm_functionality
- == AlgorithmFunctionality.MULTI_OUTPUT_MULTICLASS_CLASSIFICATION.value
- ):
- pytest.skip(
- "multiclass multi output classification are not supported in 'xgboost'."
- )
-
# Run training:
train_run = mlrun.new_function().run(
artifact_path="./temp",
@@ -100,24 +112,21 @@ def test_training(framework: str, algorithm_functionality: str):
assert len(train_run.status.results) == len(expected_results)
-@pytest.mark.parametrize("framework", FRAMEWORKS_KEYS)
-@pytest.mark.parametrize("algorithm_functionality", ALGORITHM_FUNCTIONALITIES)
-def test_evaluation(framework: str, algorithm_functionality: str):
+@pytest.mark.parametrize(
+ "framework_algorithm_functionality_pair",
+ FRAMEWORKS_ALGORITHM_FUNCTIONALITIES,
+ ids=framework_algorithm_functionality_pair_ids,
+)
+def test_evaluation(
+ rundb_mock,
+ framework_algorithm_functionality_pair: typing.Tuple[str, str],
+):
+ framework, algorithm_functionality = framework_algorithm_functionality_pair
# Unpack the framework classes:
(functions, artifacts_library, metrics_library) = FRAMEWORKS[
framework
] # type: MLFunctions, ArtifactsLibrary, MetricsLibrary
- # Skips:
- if (
- functions is XGBoostFunctions
- and algorithm_functionality
- == AlgorithmFunctionality.MULTI_OUTPUT_MULTICLASS_CLASSIFICATION.value
- ):
- pytest.skip(
- "multiclass multi output classification are not supported in 'xgboost'."
- )
-
# Run training:
train_run = mlrun.new_function().run(
artifact_path="./temp2",
@@ -147,7 +156,8 @@ def test_evaluation(framework: str, algorithm_functionality: str):
expected_artifacts = [
plan
for plan in artifacts_library.get_plans(model=dummy_model, y=dummy_y)
- if not ( # Count only pre and post prediction artifacts (evaluation artifacts).
+ if not (
+ # Count only pre and post prediction artifacts (evaluation artifacts).
plan.is_ready(stage=MLPlanStages.POST_FIT, is_probabilities=False)
or plan.is_ready(stage=MLPlanStages.PRE_FIT, is_probabilities=False)
)
diff --git a/tests/integration/sdk_api/artifacts/test_artifacts.py b/tests/integration/sdk_api/artifacts/test_artifacts.py
index 66529f6567a2..0fcc68a9f996 100644
--- a/tests/integration/sdk_api/artifacts/test_artifacts.py
+++ b/tests/integration/sdk_api/artifacts/test_artifacts.py
@@ -12,11 +12,16 @@
# See the License for the specific language governing permissions and
# limitations under the License.
#
+import pathlib
+
import pandas
import mlrun
import mlrun.artifacts
import tests.integration.sdk_api.base
+from tests import conftest
+
+results_dir = (pathlib.Path(conftest.results) / "artifacts").absolute()
class TestArtifacts(tests.integration.sdk_api.base.TestMLRunIntegration):
@@ -71,3 +76,38 @@ def test_list_artifacts_filter_by_kind(self):
project=prj, category=mlrun.api.schemas.ArtifactCategories.dataset
)
assert len(artifacts) == 1, "bad number of dataset artifacts"
+
+ def test_export_import(self):
+ project = mlrun.new_project("log-mod")
+ target_project = mlrun.new_project("log-mod2")
+ for mode in [False, True]:
+ mlrun.mlconf.artifacts.generate_target_path_from_artifact_hash = mode
+
+ model = project.log_model(
+ "mymod",
+ body=b"123",
+ model_file="model.pkl",
+ extra_data={"kk": b"456"},
+ artifact_path=results_dir,
+ )
+
+ for suffix in ["yaml", "json", "zip"]:
+ # export the artifact to a file
+ model.export(f"{results_dir}/a.{suffix}")
+
+ # import and log the artifact to the new project
+ artifact = target_project.import_artifact(
+ f"{results_dir}/a.{suffix}",
+ f"mod-{suffix}",
+ artifact_path=results_dir,
+ )
+ assert artifact.kind == "model"
+ assert artifact.metadata.key == f"mod-{suffix}"
+ assert artifact.metadata.project == "log-mod2"
+ temp_path, model_spec, extra_dataitems = mlrun.artifacts.get_model(
+ artifact.uri
+ )
+ with open(temp_path, "rb") as fp:
+ data = fp.read()
+ assert data == b"123"
+ assert extra_dataitems["kk"].get() == b"456"
diff --git a/tests/integration/sdk_api/base.py b/tests/integration/sdk_api/base.py
index 5e7b3ee8ced4..a8e9e5e0d241 100644
--- a/tests/integration/sdk_api/base.py
+++ b/tests/integration/sdk_api/base.py
@@ -215,7 +215,7 @@ def _extend_current_env(env):
@staticmethod
def _check_api_is_healthy(url):
health_url = f"{url}/{HTTPRunDB.get_api_path_prefix()}/healthz"
- timeout = 30
+ timeout = 90
if not tests.conftest.wait_for_server(health_url, timeout):
raise RuntimeError(f"API did not start after {timeout} sec")
diff --git a/mlrun/api/db/filedb/__init__.py b/tests/integration/sdk_api/httpdb/runs/__init__.py
similarity index 94%
rename from mlrun/api/db/filedb/__init__.py
rename to tests/integration/sdk_api/httpdb/runs/__init__.py
index b3085be1eb56..245d0063f465 100644
--- a/mlrun/api/db/filedb/__init__.py
+++ b/tests/integration/sdk_api/httpdb/runs/__init__.py
@@ -1,4 +1,4 @@
-# Copyright 2018 Iguazio
+# Copyright 2023 MLRun Authors
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
diff --git a/tests/integration/sdk_api/httpdb/assets/big-run.json b/tests/integration/sdk_api/httpdb/runs/assets/big-run.json
similarity index 100%
rename from tests/integration/sdk_api/httpdb/assets/big-run.json
rename to tests/integration/sdk_api/httpdb/runs/assets/big-run.json
diff --git a/tests/integration/sdk_api/httpdb/runs/test_dask.py b/tests/integration/sdk_api/httpdb/runs/test_dask.py
new file mode 100644
index 000000000000..cb716258d004
--- /dev/null
+++ b/tests/integration/sdk_api/httpdb/runs/test_dask.py
@@ -0,0 +1,56 @@
+# Copyright 2023 MLRun Authors
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+import pytest
+
+import mlrun
+import tests.conftest
+import tests.integration.sdk_api.base
+
+has_dask = False
+try:
+ import dask # noqa
+
+ has_dask = True
+except ImportError:
+ pass
+
+
+def inc(x):
+ return x + 2
+
+
+def my_func(context, p1=1, p2="a-string"):
+ print(f"Run: {context.name} (uid={context.uid})")
+ print(f"Params: p1={p1}, p2={p2}\n")
+
+ x = context.dask_client.submit(inc, p1)
+
+ context.log_result("accuracy", x.result())
+ context.log_metric("loss", 7)
+ context.log_artifact("chart", body="abc")
+ return f"tst-me-{context.iteration}"
+
+
+@pytest.mark.skipif(not has_dask, reason="missing dask")
+class TestDask(tests.integration.sdk_api.base.TestMLRunIntegration):
+ def test_dask_local(self, ensure_default_project):
+ spec = tests.conftest.tag_test(
+ mlrun.new_task(params={"p1": 3, "p2": "vv"}), "test_dask_local"
+ )
+ function = mlrun.new_function(kind="dask")
+ function.spec.remote = False
+ run = function.run(spec, handler=my_func)
+ tests.conftest.verify_state(run)
diff --git a/tests/integration/sdk_api/httpdb/test_runs.py b/tests/integration/sdk_api/httpdb/runs/test_runs.py
similarity index 87%
rename from tests/integration/sdk_api/httpdb/test_runs.py
rename to tests/integration/sdk_api/httpdb/runs/test_runs.py
index a02653d62941..75b985ef18b7 100644
--- a/tests/integration/sdk_api/httpdb/test_runs.py
+++ b/tests/integration/sdk_api/httpdb/runs/test_runs.py
@@ -20,6 +20,7 @@
import mlrun
import mlrun.api.schemas
import tests.integration.sdk_api.base
+from tests.conftest import examples_path
class TestRuns(tests.integration.sdk_api.base.TestMLRunIntegration):
@@ -172,6 +173,27 @@ def test_list_runs(self):
assert run["metadata"]["uid"] in uid_list
uid_list.remove(run["metadata"]["uid"])
+ def test_job_file(self, ensure_default_project):
+ filename = f"{examples_path}/training.py"
+ fn = mlrun.code_to_function(filename=filename, kind="job")
+ assert fn.kind == "job", "kind not set, test failed"
+ assert fn.spec.build.functionSourceCode, "code not embedded"
+ assert fn.spec.build.origin_filename == filename, "did not record filename"
+ assert type(fn.metadata.labels) == dict, "metadata labels were not set"
+ run = fn.run(workdir=str(examples_path), local=True)
+
+ project, uri, tag, hash_key = mlrun.utils.parse_versioned_object_uri(
+ run.spec.function
+ )
+ local_fn = mlrun.get_run_db().get_function(
+ uri, project, tag=tag, hash_key=hash_key
+ )
+ assert local_fn["spec"]["command"] == filename, "wrong command path"
+ assert (
+ local_fn["spec"]["build"]["functionSourceCode"]
+ == fn.spec.build.functionSourceCode
+ ), "code was not copied to local function"
+
def _list_and_assert_objects(expected_number_of_runs: int, **kwargs):
runs = mlrun.get_run_db().list_runs(**kwargs)
diff --git a/tests/integration/sdk_api/projects/test_project.py b/tests/integration/sdk_api/projects/test_project.py
index 7d42b8dad200..93f962536a3f 100644
--- a/tests/integration/sdk_api/projects/test_project.py
+++ b/tests/integration/sdk_api/projects/test_project.py
@@ -42,6 +42,26 @@ def test_create_project_failure_already_exists(self):
in str(exc.value)
)
+ def test_sync_functions(self):
+ project_name = "project-name"
+ project = mlrun.new_project(project_name)
+ project.set_function("hub://describe", "describe")
+ project_function_object = project.spec._function_objects
+ project_file_path = pathlib.Path(tests.conftest.results) / "project.yaml"
+ project.export(str(project_file_path))
+ imported_project = mlrun.load_project("./", str(project_file_path))
+ assert imported_project.spec._function_objects == {}
+ imported_project.sync_functions()
+ _assert_project_function_objects(imported_project, project_function_object)
+
+ fn = project.get_function("describe")
+ assert fn.metadata.name == "describe", "func did not return"
+
+ # test that functions can be fetched from the DB (w/o set_function)
+ mlrun.import_function("hub://sklearn_classifier", new_name="train").save()
+ fn = project.get_function("train")
+ assert fn.metadata.name == "train", "train func did not return"
+
def test_overwrite_project(self):
project_name = "some-project"
@@ -238,3 +258,19 @@ def _assert_projects(expected_project, project):
)
assert expected_project.spec.desired_state == project.spec.desired_state
assert expected_project.spec.desired_state == project.status.state
+
+
+def _assert_project_function_objects(project, expected_function_objects):
+ project_function_objects = project.spec._function_objects
+ assert len(project_function_objects) == len(expected_function_objects)
+ for function_name, function_object in expected_function_objects.items():
+ assert function_name in project_function_objects
+ assert (
+ deepdiff.DeepDiff(
+ project_function_objects[function_name].to_dict(),
+ function_object.to_dict(),
+ ignore_order=True,
+ exclude_paths=["root['spec']['build']['code_origin']"],
+ )
+ == {}
+ )
diff --git a/tests/integration/sdk_api/run/test_main.py b/tests/integration/sdk_api/run/test_main.py
new file mode 100644
index 000000000000..3b02a0bd3150
--- /dev/null
+++ b/tests/integration/sdk_api/run/test_main.py
@@ -0,0 +1,450 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import datetime
+import os
+import pathlib
+import sys
+import traceback
+from base64 import b64encode
+from subprocess import PIPE, run
+from sys import executable, stderr
+
+import pytest
+
+import mlrun
+import tests.integration.sdk_api.base
+from tests.conftest import examples_path, out_path, tests_root_directory
+
+code = """
+import mlrun, sys
+if __name__ == "__main__":
+ context = mlrun.get_or_create_ctx("test1")
+ context.log_result("my_args", sys.argv)
+ context.commit(completed=True)
+"""
+
+nonpy_code = """
+echo "abc123" $1
+"""
+
+
+class TestMain(tests.integration.sdk_api.base.TestMLRunIntegration):
+
+ assets_path = (
+ pathlib.Path(__file__).absolute().parent.parent.parent.parent / "run" / "assets"
+ )
+
+ def custom_setup(self):
+ # ensure default project exists
+ mlrun.get_or_create_project("default")
+
+ def test_main_run_basic(self):
+ out = self._exec_run(
+ f"{examples_path}/training.py",
+ self._compose_param_list(dict(p1=5, p2='"aaa"')),
+ "test_main_run_basic",
+ )
+ print(out)
+ assert out.find("state: completed") != -1, out
+
+ def test_main_run_wait_for_completion(self):
+ """
+ Test that the run command waits for the run to complete before returning
+ (mainly sanity as this is expected when running local function)
+ """
+ path = str(self.assets_path / "sleep.py")
+ time_to_sleep = 10
+ start_time = datetime.datetime.now()
+ out = self._exec_run(
+ path,
+ self._compose_param_list(dict(time_to_sleep=time_to_sleep))
+ + ["--handler", "handler"],
+ "test_main_run_wait_for_completion",
+ )
+ end_time = datetime.datetime.now()
+ print(out)
+ assert out.find("state: completed") != -1, out
+ assert (
+ end_time - start_time
+ ).seconds >= time_to_sleep, "run did not wait for completion"
+
+ def test_main_run_hyper(self):
+ out = self._exec_run(
+ f"{examples_path}/training.py",
+ self._compose_param_list(dict(p2=[4, 5, 6]), "-x"),
+ "test_main_run_hyper",
+ )
+ print(out)
+ assert out.find("state: completed") != -1, out
+ assert out.find("iterations:") != -1, out
+
+ def test_main_run_args(self):
+ out = self._exec_run(
+ f"{tests_root_directory}/no_ctx.py -x " + "{p2}",
+ ["--uid", "123457"] + self._compose_param_list(dict(p1=5, p2="aaa")),
+ "test_main_run_args",
+ )
+ print(out)
+ assert out.find("state: completed") != -1, out
+ db = mlrun.get_run_db()
+ state, log = db.get_log("123457")
+ print(log)
+ assert str(log).find(", -x, aaa") != -1, "params not detected in argv"
+
+ def test_main_run_args_with_url_placeholder_missing_env(self):
+ args = [
+ "--name",
+ "test_main_run_args_with_url_placeholder_missing_env",
+ "--dump",
+ "*",
+ "--arg1",
+ "value1",
+ "--arg2",
+ "value2",
+ ]
+ out = self._exec_main(
+ "run",
+ args,
+ raise_on_error=False,
+ )
+ out_stdout = out.stdout.decode("utf-8")
+ print(out)
+ assert (
+ out_stdout.find(
+ "command/url '*' placeholder is not allowed when code is not from env"
+ )
+ != -1
+ ), out
+
+ def test_main_run_args_with_url_placeholder_from_env(self):
+ os.environ["MLRUN_EXEC_CODE"] = b64encode(code.encode("utf-8")).decode("utf-8")
+ args = [
+ "--name",
+ "test_main_run_args_with_url_placeholder_from_env",
+ "--uid",
+ "123456789",
+ "--from-env",
+ "--dump",
+ "*",
+ "--arg1",
+ "value1",
+ "--arg2",
+ "value2",
+ ]
+ self._exec_main(
+ "run",
+ args,
+ raise_on_error=True,
+ )
+ db = mlrun.get_run_db()
+ _run = db.read_run("123456789")
+ print(_run)
+ assert _run["status"]["results"]["my_args"] == [
+ "main.py",
+ "--arg1",
+ "value1",
+ "--arg2",
+ "value2",
+ ]
+ assert _run["status"]["state"] == "completed"
+
+ args = [
+ "--name",
+ "test_main_run_args_with_url_placeholder_with_origin_file",
+ "--uid",
+ "987654321",
+ "--from-env",
+ "--dump",
+ "*",
+ "--origin-file",
+ "my_file.py",
+ "--arg3",
+ "value3",
+ ]
+ self._exec_main(
+ "run",
+ args,
+ raise_on_error=True,
+ )
+ db = mlrun.get_run_db()
+ _run = db.read_run("987654321")
+ print(_run)
+ assert _run["status"]["results"]["my_args"] == [
+ "my_file.py",
+ "--arg3",
+ "value3",
+ ]
+ assert _run["status"]["state"] == "completed"
+
+ def test_main_with_url_placeholder(self):
+ os.environ["MLRUN_EXEC_CODE"] = b64encode(code.encode("utf-8")).decode("utf-8")
+ args = [
+ "--name",
+ "test_main_with_url_placeholder",
+ "--uid",
+ "123456789",
+ "--from-env",
+ "*",
+ ]
+ self._exec_main(
+ "run",
+ args,
+ raise_on_error=True,
+ )
+ db = mlrun.get_run_db()
+ _run = db.read_run("123456789")
+ print(_run)
+ assert _run["status"]["results"]["my_args"] == ["main.py"]
+ assert _run["status"]["state"] == "completed"
+
+ @pytest.mark.parametrize(
+ "op,args,raise_on_error,expected_output",
+ [
+ # bad flag before command
+ [
+ "run",
+ [
+ "--bad-flag",
+ "--name",
+ "test_main_run_basic",
+ "--dump",
+ f"{examples_path}/training.py",
+ ],
+ False,
+ "Error: Invalid value for '[URL]': URL (--bad-flag) cannot start with '-', "
+ "ensure the command options are typed correctly. Preferably use '--' to separate options and "
+ "arguments e.g. 'mlrun run --option1 --option2 -- [URL] [--arg1|arg1] [--arg2|arg2]'",
+ ],
+ # bad flag with no command
+ [
+ "run",
+ ["--name", "test_main_run_basic", "--bad-flag"],
+ False,
+ "Error: Invalid value for '[URL]': URL (--bad-flag) cannot start with '-', "
+ "ensure the command options are typed correctly. Preferably use '--' to separate options and "
+ "arguments e.g. 'mlrun run --option1 --option2 -- [URL] [--arg1|arg1] [--arg2|arg2]'",
+ ],
+ # bad flag after -- separator
+ [
+ "run",
+ ["--name", "test_main_run_basic", "--", "-notaflag"],
+ False,
+ "Error: Invalid value for '[URL]': URL (-notaflag) cannot start with '-', "
+ "ensure the command options are typed correctly. Preferably use '--' to separate options and "
+ "arguments e.g. 'mlrun run --option1 --option2 -- [URL] [--arg1|arg1] [--arg2|arg2]'",
+ ],
+ # correct command with -- separator
+ [
+ "run",
+ [
+ "--name",
+ "test_main_run_basic",
+ "--",
+ f"{examples_path}/training.py",
+ "--some-arg",
+ ],
+ True,
+ "status=completed",
+ ],
+ ],
+ )
+ def test_main_run_args_validation(self, op, args, raise_on_error, expected_output):
+ out = self._exec_main(
+ op,
+ args,
+ raise_on_error=raise_on_error,
+ )
+ if not raise_on_error:
+ out = out.stderr.decode("utf-8")
+
+ assert out.find(expected_output) != -1, out
+
+ def test_main_run_args_from_env(self):
+ os.environ["MLRUN_EXEC_CODE"] = b64encode(code.encode("utf-8")).decode("utf-8")
+ os.environ["MLRUN_EXEC_CONFIG"] = (
+ '{"spec":{"parameters":{"x": "bbb"}},'
+ '"metadata":{"uid":"123459", "name":"tst", "labels": {"kind": "job"}}}'
+ )
+
+ out = self._exec_run(
+ "'main.py -x {x}'",
+ ["--from-env"],
+ "test_main_run_args_from_env",
+ )
+ db = mlrun.get_run_db()
+ run_object = db.read_run("123459")
+ print(out)
+ assert run_object["status"]["state"] == "completed", out
+ assert run_object["status"]["results"]["my_args"] == [
+ "main.py",
+ "-x",
+ "bbb",
+ ], "params not detected in argv"
+
+ @pytest.mark.skipif(sys.platform == "win32", reason="skip on windows")
+ def test_main_run_nonpy_from_env(self):
+ os.environ["MLRUN_EXEC_CODE"] = b64encode(nonpy_code.encode("utf-8")).decode(
+ "utf-8"
+ )
+ os.environ[
+ "MLRUN_EXEC_CONFIG"
+ ] = '{"spec":{},"metadata":{"uid":"123411", "name":"tst", "labels": {"kind": "job"}}}'
+
+ # --kfp flag will force the logs to print (for the assert)
+ out = self._exec_run(
+ "bash {codefile} xx",
+ ["--from-env", "--mode", "pass", "--kfp"],
+ "test_main_run_nonpy_from_env",
+ )
+ db = mlrun.get_run_db()
+ run_object = db.read_run("123411")
+ assert run_object["status"]["state"] == "completed", out
+ state, log = db.get_log("123411")
+ print(state, log)
+ assert str(log).find("abc123 xx") != -1, "incorrect output"
+
+ def test_main_run_pass(self):
+ out = self._exec_run(
+ "python -c print(56)",
+ ["--mode", "pass", "--uid", "123458"],
+ "test_main_run_pass",
+ )
+ print(out)
+ assert out.find("state: completed") != -1, out
+ db = mlrun.get_run_db()
+ state, log = db.get_log("123458")
+ assert str(log).find("56") != -1, "incorrect output"
+
+ def test_main_run_pass_args(self):
+ out = self._exec_run(
+ "'python -c print({x})'",
+ ["--mode", "pass", "--uid", "123451", "-p", "x=33"],
+ "test_main_run_pass",
+ )
+ print(out)
+ assert out.find("state: completed") != -1, out
+ db = mlrun.get_run_db()
+ state, log = db.get_log("123451")
+ print(log)
+ assert str(log).find("33") != -1, "incorrect output"
+
+ def test_main_run_archive(self):
+ args = f"--source {examples_path}/archive.zip --handler handler -p p1=1"
+ out = self._exec_run("./myfunc.py", args.split(), "test_main_run_archive")
+ assert out.find("state: completed") != -1, out
+
+ def test_main_local_source(self):
+ args = f"--source {examples_path} --handler my_func"
+ with pytest.raises(Exception) as e:
+ self._exec_run("./handler.py", args.split(), "test_main_local_source")
+ assert (
+ "source must be a compressed (tar.gz / zip) file, a git repo, a file path or in the project's context (.)"
+ in str(e.value)
+ )
+
+ def test_main_run_archive_subdir(self):
+ runtime = '{"spec":{"pythonpath":"./subdir"}}'
+ args = f"--source {examples_path}/archive.zip -r {runtime}"
+ out = self._exec_run(
+ "./subdir/func2.py", args.split(), "test_main_run_archive_subdir"
+ )
+ print(out)
+ assert out.find("state: completed") != -1, out
+
+ def test_main_local_project(self):
+ mlrun.get_or_create_project("testproject")
+ project_path = str(self.assets_path)
+ args = "-f simple -p x=2 --dump"
+ out = self._exec_main("run", args.split(), cwd=project_path)
+ assert out.find("state: completed") != -1, out
+ assert out.find("y: 4") != -1, out # y = x * 2
+
+ def test_main_local_flag(self):
+ fn = mlrun.code_to_function(
+ filename=f"{examples_path}/handler.py", kind="job", handler="my_func"
+ )
+ yaml_path = f"{out_path}/myfunc.yaml"
+ fn.export(yaml_path)
+ args = f"-f {yaml_path} --local"
+ out = self._exec_run("", args.split(), "test_main_local_flag")
+ print(out)
+ assert out.find("state: completed") != -1, out
+
+ def test_main_run_class(self):
+ function_path = str(self.assets_path / "handler.py")
+
+ out = self._exec_run(
+ function_path,
+ self._compose_param_list(dict(x=8)) + ["--handler", "mycls::mtd"],
+ "test_main_run_class",
+ )
+ assert out.find("state: completed") != -1, out
+ assert out.find("rx: 8") != -1, out
+
+ def test_run_from_module(self):
+ args = [
+ "--name",
+ "test1",
+ "--dump",
+ "--handler",
+ "json.dumps",
+ "-p",
+ "obj=[6,7]",
+ ]
+ out = self._exec_main("run", args)
+ assert out.find("state: completed") != -1, out
+ assert out.find("return: '[6, 7]'") != -1, out
+
+ def test_main_env_file(self):
+ # test run with env vars loaded from a .env file
+ function_path = str(self.assets_path / "handler.py")
+ envfile = str(self.assets_path / "envfile")
+
+ out = self._exec_run(
+ function_path,
+ ["--handler", "env_file_test", "--env-file", envfile],
+ "test_main_env_file",
+ )
+ assert out.find("state: completed") != -1, out
+ assert out.find("ENV_ARG1: '123'") != -1, out
+ assert out.find("kfp_ttl: 12345") != -1, out
+
+ @staticmethod
+ def _exec_main(op, args, cwd=examples_path, raise_on_error=True):
+ cmd = [executable, "-m", "mlrun", op]
+ if args:
+ cmd += args
+ out = run(cmd, stdout=PIPE, stderr=PIPE, cwd=cwd)
+ if out.returncode != 0:
+ print(out.stderr.decode("utf-8"), file=stderr)
+ print(out.stdout.decode("utf-8"), file=stderr)
+ print(traceback.format_exc())
+ if raise_on_error:
+ raise Exception(out.stderr.decode("utf-8"))
+ else:
+ # return out so that we can check the error message on stdout and stderr
+ return out
+
+ return out.stdout.decode("utf-8")
+
+ def _exec_run(self, cmd, args, test, raise_on_error=True):
+ args = args + ["--name", test, "--dump", cmd]
+ return self._exec_main("run", args, raise_on_error=raise_on_error)
+
+ @staticmethod
+ def _compose_param_list(params: dict, flag="-p"):
+ composed_params = []
+ for k, v in params.items():
+ composed_params += [flag, f"{k}={v}"]
+ return composed_params
diff --git a/tests/notebooks.yml b/tests/notebooks.yml
deleted file mode 100644
index 3887daddbc63..000000000000
--- a/tests/notebooks.yml
+++ /dev/null
@@ -1,20 +0,0 @@
-# Copyright 2018 Iguazio
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-#
-- nb: mlrun_db.ipynb
-- nb: mlrun_basics.ipynb
- env:
- MLRUN_DBPATH: /tmp/mlrun-db
- pip:
- - matplotlib
diff --git a/tests/projects/test_local_pipeline.py b/tests/projects/test_local_pipeline.py
index 669cb6a0675f..ea98e60d7547 100644
--- a/tests/projects/test_local_pipeline.py
+++ b/tests/projects/test_local_pipeline.py
@@ -34,7 +34,7 @@ def _set_functions(self):
# kind="job"
)
- def test_set_artifact(self):
+ def test_set_artifact(self, rundb_mock):
self.project = mlrun.new_project("test-sa", save=False)
self.project.set_artifact(
"data1", mlrun.artifacts.Artifact(target_path=self.data_url)
@@ -51,7 +51,7 @@ def test_set_artifact(self):
artifacts = self.project.list_artifacts(tag="x")
assert len(artifacts) == 1
- def test_import_artifacts(self):
+ def test_import_artifacts(self, rundb_mock):
results_path = str(pathlib.Path(tests.conftest.results) / "project")
project = mlrun.new_project(
"test-sa2", context=str(self.assets_path), save=False
diff --git a/tests/projects/test_project.py b/tests/projects/test_project.py
index af903fde1041..2cf2156c3649 100644
--- a/tests/projects/test_project.py
+++ b/tests/projects/test_project.py
@@ -45,7 +45,7 @@ def assets_path():
return pathlib.Path(__file__).absolute().parent / "assets"
-def test_sync_functions():
+def test_sync_functions(rundb_mock):
project_name = "project-name"
project = mlrun.new_project(project_name, save=False)
project.set_function("hub://describe", "describe")
@@ -358,12 +358,11 @@ def test_load_project_and_sync_functions(
assert len(function_names) == expected_num_of_funcs
for func in function_names:
fn = project.get_function(func)
- assert fn.metadata.name == mlrun.utils.helpers.normalize_name(
- func
- ), "func did not return"
+ normalized_name = mlrun.utils.helpers.normalize_name(func)
+ assert fn.metadata.name == normalized_name, "func did not return"
- if save:
- assert rundb_mock._function is not None
+ if save:
+ assert normalized_name in rundb_mock._functions
def _assert_project_function_objects(project, expected_function_objects):
@@ -407,7 +406,7 @@ def test_set_func_requirements():
]
-def test_set_function_underscore_name():
+def test_set_function_underscore_name(rundb_mock):
project = mlrun.projects.MlrunProject(
"project", default_requirements=["pandas>1, <3"]
)
diff --git a/tests/run/test_handler_decorator.py b/tests/run/test_handler_decorator.py
index 00a8f3a56a84..5f5aa056a8dc 100644
--- a/tests/run/test_handler_decorator.py
+++ b/tests/run/test_handler_decorator.py
@@ -144,7 +144,7 @@ def test_log_dataset_without_mlrun():
assert isinstance(my_list, list)
-def test_log_dataset_with_mlrun():
+def test_log_dataset_with_mlrun(rundb_mock):
"""
Run the `log_dataset` function with MLRun to see the wrapper is logging the returned values as datasets artifacts.
"""
@@ -454,7 +454,7 @@ def test_log_as_default_artifact_types_without_mlrun():
assert isinstance(my_imputer, SimpleImputer)
-def test_log_as_default_artifact_types_with_mlrun():
+def test_log_as_default_artifact_types_with_mlrun(rundb_mock):
"""
Run the `log_as_default_artifact_types` function with MLRun to see the wrapper is logging the returned values
as the correct default artifact types as the artifact types are not provided to the decorator.
@@ -518,7 +518,7 @@ def test_log_with_none_values_without_mlrun():
@pytest.mark.parametrize("is_none_result", [True, False])
@pytest.mark.parametrize("is_none_no_type", [True, False])
def test_log_with_none_values_with_mlrun(
- is_none_dataset: bool, is_none_result: bool, is_none_no_type: bool
+ rundb_mock, is_none_dataset: bool, is_none_result: bool, is_none_no_type: bool
):
"""
Run the `log_with_none_values` function with MLRun to see the wrapper is logging and ignoring the returned values
@@ -574,7 +574,7 @@ def test_log_from_function_and_wrapper_without_mlrun():
assert isinstance(my_result, str)
-def test_log_from_function_and_wrapper_with_mlrun():
+def test_log_from_function_and_wrapper_with_mlrun(rundb_mock):
"""
Run the `log_from_function_and_wrapper` function with MLRun to see the wrapper is logging the returned values
among the other values logged via the context manually inside the function.
@@ -634,7 +634,7 @@ def test_parse_inputs_from_type_hints_without_mlrun():
assert result == [[2], [3], [4]]
-def test_parse_inputs_from_type_hints_with_mlrun():
+def test_parse_inputs_from_type_hints_with_mlrun(rundb_mock):
"""
Run the `parse_inputs_from_type_hints` function with MLRun to see the wrapper is parsing the given inputs
(`DataItem`s) to the written type hints.
@@ -708,7 +708,7 @@ def test_parse_inputs_from_wrapper_using_types_without_mlrun():
assert result == [[2], [3], [4]]
-def test_parse_inputs_from_wrapper_using_types_with_mlrun():
+def test_parse_inputs_from_wrapper_using_types_with_mlrun(rundb_mock):
"""
Run the `parse_inputs_from_wrapper_using_types` function with MLRun to see the wrapper is parsing the given inputs
(`DataItem`s) to the written configuration provided to the wrapper.
@@ -786,7 +786,7 @@ def test_parse_inputs_from_wrapper_using_strings_without_mlrun():
assert result == 402
-def test_parse_inputs_from_wrapper_using_strings_with_mlrun():
+def test_parse_inputs_from_wrapper_using_strings_with_mlrun(rundb_mock):
"""
Run the `parse_inputs_from_wrapper_using_strings` function with MLRun to see the wrapper is parsing the given inputs
(`DataItem`s) to the written configuration provided to the wrapper.
@@ -836,7 +836,7 @@ def raise_error_while_logging():
return np.ones(shape=(7, 7, 7))
-def test_raise_error_while_logging_with_mlrun():
+def test_raise_error_while_logging_with_mlrun(db):
"""
Run the `raise_error_while_logging` function with MLRun to see the wrapper is raising the relevant error.
"""
@@ -860,7 +860,7 @@ def test_raise_error_while_logging_with_mlrun():
artifact_path.cleanup()
-def test_raise_error_while_parsing_with_mlrun():
+def test_raise_error_while_parsing_with_mlrun(db):
"""
Run the `parse_inputs_from_wrapper_using_types` function with MLRun and send it wrong types to see the wrapper is
raising the relevant exception.
@@ -978,7 +978,7 @@ def test_class_methods_without_mlrun():
temp_dir.cleanup()
-def test_class_methods_with_mlrun():
+def test_class_methods_with_mlrun(rundb_mock):
"""
Run the `log_dataset` function with MLRun to see the wrapper is logging the returned values as datasets artifacts.
"""
diff --git a/tests/run/test_hyper.py b/tests/run/test_hyper.py
index 71ccbe0b9d17..07b8e8944d8b 100644
--- a/tests/run/test_hyper.py
+++ b/tests/run/test_hyper.py
@@ -188,7 +188,7 @@ def hyper_func2(context, p1=1):
context.log_dataset("df2", df=df)
-def test_hyper_get_artifact():
+def test_hyper_get_artifact(rundb_mock):
fn = mlrun.new_function("test_hyper_get_artifact")
run = mlrun.run_function(
fn,
diff --git a/tests/run/test_main.py b/tests/run/test_main.py
deleted file mode 100644
index e9870e85da88..000000000000
--- a/tests/run/test_main.py
+++ /dev/null
@@ -1,446 +0,0 @@
-# Copyright 2018 Iguazio
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-import datetime
-import os
-import pathlib
-import sys
-import traceback
-from base64 import b64encode
-from subprocess import PIPE, run
-from sys import executable, stderr
-
-import pytest
-
-import mlrun
-from tests.conftest import examples_path, out_path, tests_root_directory
-
-
-def exec_main(op, args, cwd=examples_path, raise_on_error=True):
- cmd = [executable, "-m", "mlrun", op]
- if args:
- cmd += args
- out = run(cmd, stdout=PIPE, stderr=PIPE, cwd=cwd)
- if out.returncode != 0:
- print(out.stderr.decode("utf-8"), file=stderr)
- print(out.stdout.decode("utf-8"), file=stderr)
- print(traceback.format_exc())
- if raise_on_error:
- raise Exception(out.stderr.decode("utf-8"))
- else:
- # return out so that we can check the error message on stdout and stderr
- return out
-
- return out.stdout.decode("utf-8")
-
-
-def exec_run(cmd, args, test, raise_on_error=True):
- args = args + ["--name", test, "--dump", cmd]
- return exec_main("run", args, raise_on_error=raise_on_error)
-
-
-def compose_param_list(params: dict, flag="-p"):
- composed_params = []
- for k, v in params.items():
- composed_params += [flag, f"{k}={v}"]
- return composed_params
-
-
-def test_main_run_basic():
- out = exec_run(
- f"{examples_path}/training.py",
- compose_param_list(dict(p1=5, p2='"aaa"')),
- "test_main_run_basic",
- )
- print(out)
- assert out.find("state: completed") != -1, out
-
-
-def test_main_run_wait_for_completion():
- """
- Test that the run command waits for the run to complete before returning
- (mainly sanity as this is expected when running local function)
- """
- path = str(pathlib.Path(__file__).absolute().parent / "assets" / "sleep.py")
- time_to_sleep = 10
- start_time = datetime.datetime.now()
- out = exec_run(
- path,
- compose_param_list(dict(time_to_sleep=time_to_sleep))
- + ["--handler", "handler"],
- "test_main_run_wait_for_completion",
- )
- end_time = datetime.datetime.now()
- print(out)
- assert out.find("state: completed") != -1, out
- assert (
- end_time - start_time
- ).seconds >= time_to_sleep, "run did not wait for completion"
-
-
-def test_main_run_hyper():
- out = exec_run(
- f"{examples_path}/training.py",
- compose_param_list(dict(p2=[4, 5, 6]), "-x"),
- "test_main_run_hyper",
- )
- print(out)
- assert out.find("state: completed") != -1, out
- assert out.find("iterations:") != -1, out
-
-
-def test_main_run_args():
- out = exec_run(
- f"{tests_root_directory}/no_ctx.py -x " + "{p2}",
- ["--uid", "123457"] + compose_param_list(dict(p1=5, p2="aaa")),
- "test_main_run_args",
- )
- print(out)
- assert out.find("state: completed") != -1, out
- db = mlrun.get_run_db()
- state, log = db.get_log("123457")
- print(log)
- assert str(log).find(", -x, aaa") != -1, "params not detected in argv"
-
-
-def test_main_run_args_with_url_placeholder_missing_env():
- args = [
- "--name",
- "test_main_run_args_with_url_placeholder_missing_env",
- "--dump",
- "*",
- "--arg1",
- "value1",
- "--arg2",
- "value2",
- ]
- out = exec_main(
- "run",
- args,
- raise_on_error=False,
- )
- out_stdout = out.stdout.decode("utf-8")
- print(out)
- assert (
- out_stdout.find(
- "command/url '*' placeholder is not allowed when code is not from env"
- )
- != -1
- ), out
-
-
-def test_main_run_args_with_url_placeholder_from_env():
- os.environ["MLRUN_EXEC_CODE"] = b64encode(code.encode("utf-8")).decode("utf-8")
- args = [
- "--name",
- "test_main_run_args_with_url_placeholder_from_env",
- "--uid",
- "123456789",
- "--from-env",
- "--dump",
- "*",
- "--arg1",
- "value1",
- "--arg2",
- "value2",
- ]
- exec_main(
- "run",
- args,
- raise_on_error=True,
- )
- db = mlrun.get_run_db()
- _run = db.read_run("123456789")
- print(_run)
- assert _run["status"]["results"]["my_args"] == [
- "main.py",
- "--arg1",
- "value1",
- "--arg2",
- "value2",
- ]
- assert _run["status"]["state"] == "completed"
-
- args = [
- "--name",
- "test_main_run_args_with_url_placeholder_with_origin_file",
- "--uid",
- "987654321",
- "--from-env",
- "--dump",
- "*",
- "--origin-file",
- "my_file.py",
- "--arg3",
- "value3",
- ]
- exec_main(
- "run",
- args,
- raise_on_error=True,
- )
- db = mlrun.get_run_db()
- _run = db.read_run("987654321")
- print(_run)
- assert _run["status"]["results"]["my_args"] == ["my_file.py", "--arg3", "value3"]
- assert _run["status"]["state"] == "completed"
-
-
-def test_main_with_url_placeholder():
- os.environ["MLRUN_EXEC_CODE"] = b64encode(code.encode("utf-8")).decode("utf-8")
- args = [
- "--name",
- "test_main_with_url_placeholder",
- "--uid",
- "123456789",
- "--from-env",
- "*",
- ]
- exec_main(
- "run",
- args,
- raise_on_error=True,
- )
- db = mlrun.get_run_db()
- _run = db.read_run("123456789")
- print(_run)
- assert _run["status"]["results"]["my_args"] == ["main.py"]
- assert _run["status"]["state"] == "completed"
-
-
-@pytest.mark.parametrize(
- "op,args,raise_on_error,expected_output",
- [
- # bad flag before command
- [
- "run",
- [
- "--bad-flag",
- "--name",
- "test_main_run_basic",
- "--dump",
- f"{examples_path}/training.py",
- ],
- False,
- "Error: Invalid value for '[URL]': URL (--bad-flag) cannot start with '-', "
- "ensure the command options are typed correctly. Preferably use '--' to separate options and "
- "arguments e.g. 'mlrun run --option1 --option2 -- [URL] [--arg1|arg1] [--arg2|arg2]'",
- ],
- # bad flag with no command
- [
- "run",
- ["--name", "test_main_run_basic", "--bad-flag"],
- False,
- "Error: Invalid value for '[URL]': URL (--bad-flag) cannot start with '-', "
- "ensure the command options are typed correctly. Preferably use '--' to separate options and "
- "arguments e.g. 'mlrun run --option1 --option2 -- [URL] [--arg1|arg1] [--arg2|arg2]'",
- ],
- # bad flag after -- separator
- [
- "run",
- ["--name", "test_main_run_basic", "--", "-notaflag"],
- False,
- "Error: Invalid value for '[URL]': URL (-notaflag) cannot start with '-', "
- "ensure the command options are typed correctly. Preferably use '--' to separate options and "
- "arguments e.g. 'mlrun run --option1 --option2 -- [URL] [--arg1|arg1] [--arg2|arg2]'",
- ],
- # correct command with -- separator
- [
- "run",
- [
- "--name",
- "test_main_run_basic",
- "--",
- f"{examples_path}/training.py",
- "--some-arg",
- ],
- True,
- "status=completed",
- ],
- ],
-)
-def test_main_run_args_validation(op, args, raise_on_error, expected_output):
- out = exec_main(
- op,
- args,
- raise_on_error=raise_on_error,
- )
- if not raise_on_error:
- out = out.stderr.decode("utf-8")
-
- assert out.find(expected_output) != -1, out
-
-
-code = """
-import mlrun, sys
-if __name__ == "__main__":
- context = mlrun.get_or_create_ctx("test1")
- context.log_result("my_args", sys.argv)
- context.commit(completed=True)
-"""
-
-
-def test_main_run_args_from_env():
- os.environ["MLRUN_EXEC_CODE"] = b64encode(code.encode("utf-8")).decode("utf-8")
- os.environ["MLRUN_EXEC_CONFIG"] = (
- '{"spec":{"parameters":{"x": "bbb"}},'
- '"metadata":{"uid":"123459", "name":"tst", "labels": {"kind": "job"}}}'
- )
-
- out = exec_run(
- "'main.py -x {x}'",
- ["--from-env"],
- "test_main_run_args_from_env",
- )
- db = mlrun.get_run_db()
- run = db.read_run("123459")
- print(out)
- assert run["status"]["state"] == "completed", out
- assert run["status"]["results"]["my_args"] == [
- "main.py",
- "-x",
- "bbb",
- ], "params not detected in argv"
-
-
-nonpy_code = """
-echo "abc123" $1
-"""
-
-
-@pytest.mark.skipif(sys.platform == "win32", reason="skip on windows")
-def test_main_run_nonpy_from_env():
- os.environ["MLRUN_EXEC_CODE"] = b64encode(nonpy_code.encode("utf-8")).decode(
- "utf-8"
- )
- os.environ[
- "MLRUN_EXEC_CONFIG"
- ] = '{"spec":{},"metadata":{"uid":"123411", "name":"tst", "labels": {"kind": "job"}}}'
-
- # --kfp flag will force the logs to print (for the assert)
- out = exec_run(
- "bash {codefile} xx",
- ["--from-env", "--mode", "pass", "--kfp"],
- "test_main_run_nonpy_from_env",
- )
- db = mlrun.get_run_db()
- run = db.read_run("123411")
- assert run["status"]["state"] == "completed", out
- state, log = db.get_log("123411")
- print(state, log)
- assert str(log).find("abc123 xx") != -1, "incorrect output"
-
-
-def test_main_run_pass():
- out = exec_run(
- "python -c print(56)",
- ["--mode", "pass", "--uid", "123458"],
- "test_main_run_pass",
- )
- print(out)
- assert out.find("state: completed") != -1, out
- db = mlrun.get_run_db()
- state, log = db.get_log("123458")
- assert str(log).find("56") != -1, "incorrect output"
-
-
-def test_main_run_pass_args():
- out = exec_run(
- "'python -c print({x})'",
- ["--mode", "pass", "--uid", "123451", "-p", "x=33"],
- "test_main_run_pass",
- )
- print(out)
- assert out.find("state: completed") != -1, out
- db = mlrun.get_run_db()
- state, log = db.get_log("123451")
- print(log)
- assert str(log).find("33") != -1, "incorrect output"
-
-
-def test_main_run_archive():
- args = f"--source {examples_path}/archive.zip --handler handler -p p1=1"
- out = exec_run("./myfunc.py", args.split(), "test_main_run_archive")
- assert out.find("state: completed") != -1, out
-
-
-def test_main_local_source():
- args = f"--source {examples_path} --handler my_func"
- with pytest.raises(Exception) as e:
- exec_run("./handler.py", args.split(), "test_main_local_source")
- assert (
- "source must be a compressed (tar.gz / zip) file, a git repo, a file path or in the project's context (.)"
- in str(e.value)
- )
-
-
-def test_main_run_archive_subdir():
- runtime = '{"spec":{"pythonpath":"./subdir"}}'
- args = f"--source {examples_path}/archive.zip -r {runtime}"
- out = exec_run("./subdir/func2.py", args.split(), "test_main_run_archive_subdir")
- print(out)
- assert out.find("state: completed") != -1, out
-
-
-def test_main_local_project():
- project_path = str(pathlib.Path(__file__).parent / "assets")
- args = "-f simple -p x=2 --dump"
- out = exec_main("run", args.split(), cwd=project_path)
- assert out.find("state: completed") != -1, out
- assert out.find("y: 4") != -1, out # y = x * 2
-
-
-def test_main_local_flag():
- fn = mlrun.code_to_function(
- filename=f"{examples_path}/handler.py", kind="job", handler="my_func"
- )
- yaml_path = f"{out_path}/myfunc.yaml"
- fn.export(yaml_path)
- args = f"-f {yaml_path} --local"
- out = exec_run("", args.split(), "test_main_local_flag")
- print(out)
- assert out.find("state: completed") != -1, out
-
-
-def test_main_run_class():
- function_path = str(pathlib.Path(__file__).parent / "assets" / "handler.py")
-
- out = exec_run(
- function_path,
- compose_param_list(dict(x=8)) + ["--handler", "mycls::mtd"],
- "test_main_run_class",
- )
- assert out.find("state: completed") != -1, out
- assert out.find("rx: 8") != -1, out
-
-
-def test_run_from_module():
- args = ["--name", "test1", "--dump", "--handler", "json.dumps", "-p", "obj=[6,7]"]
- out = exec_main("run", args)
- assert out.find("state: completed") != -1, out
- assert out.find("return: '[6, 7]'") != -1, out
-
-
-def test_main_env_file():
- # test run with env vars loaded from a .env file
- function_path = str(pathlib.Path(__file__).parent / "assets" / "handler.py")
- envfile = str(pathlib.Path(__file__).parent / "assets" / "envfile")
-
- out = exec_run(
- function_path,
- ["--handler", "env_file_test", "--env-file", envfile],
- "test_main_env_file",
- )
- assert out.find("state: completed") != -1, out
- assert out.find("ENV_ARG1: '123'") != -1, out
- assert out.find("kfp_ttl: 12345") != -1, out
diff --git a/tests/run/test_run.py b/tests/run/test_run.py
index b1df0ea2ff96..b38ae1b7a88e 100644
--- a/tests/run/test_run.py
+++ b/tests/run/test_run.py
@@ -11,15 +11,18 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
+import contextlib
import datetime
+import io
import pathlib
+import sys
from unittest.mock import MagicMock, Mock
import pytest
import mlrun
import mlrun.errors
-from mlrun import MLClientCtx, get_run_db, new_function, new_task
+from mlrun import MLClientCtx, new_function, new_task
from tests.conftest import (
examples_path,
has_secrets,
@@ -43,7 +46,18 @@
assets_path = str(pathlib.Path(__file__).parent / "assets")
-def test_noparams():
+@contextlib.contextmanager
+def captured_output():
+ new_out, new_err = io.StringIO(), io.StringIO()
+ old_out, old_err = sys.stdout, sys.stderr
+ try:
+ sys.stdout, sys.stderr = new_out, new_err
+ yield sys.stdout, sys.stderr
+ finally:
+ sys.stdout, sys.stderr = old_out, old_err
+
+
+def test_noparams(db):
# Since we're executing the function without inputs, it will try to use the input name as the file path
result = new_function().run(
params={"input_name": str(input_file_path)}, handler=my_func
@@ -121,7 +135,7 @@ def test_local_runtime():
verify_state(result)
-def test_local_runtime_failure_before_executing_the_function_code():
+def test_local_runtime_failure_before_executing_the_function_code(db):
function = new_function(command=f"{assets_path}/fail.py")
with pytest.raises(mlrun.runtimes.utils.RunError) as exc:
function.run(local=True, handler="handler")
@@ -188,20 +202,20 @@ def test_is_watchable(rundb_mock, kind, watch, expected_watch_count):
assert mlrun.RunObject.logs.call_count == expected_watch_count
-def test_local_args():
+@pytest.mark.asyncio
+async def test_local_args(db, db_session):
spec = tag_test(base_spec, "test_local_no_context")
spec.spec.parameters = {"xyz": "789"}
- result = new_function(
- command=f"{tests_root_directory}/no_ctx.py --xyz {{xyz}}"
- ).run(spec)
+
+ function = new_function(command=f"{tests_root_directory}/no_ctx.py --xyz {{xyz}}")
+ with captured_output() as (out, err):
+ result = function.run(spec)
+
+ output = out.getvalue().strip()
+
verify_state(result)
- db = get_run_db()
- state, log = db.get_log(result.metadata.uid)
- log = str(log)
- print(state)
- print(log)
- assert log.find(", --xyz, 789") != -1, "params not detected in argv"
+ assert output.find(", --xyz, 789") != -1, "params not detected in argv"
def test_local_context(rundb_mock):
@@ -372,15 +386,15 @@ def test_run_from_module():
def test_args_integrity():
spec = tag_test(base_spec, "test_local_no_context")
spec.spec.parameters = {"xyz": "789"}
- result = new_function(
+ function = new_function(
command=f"{tests_root_directory}/no_ctx.py",
args=["It's", "a", "nice", "day!"],
- ).run(spec)
+ )
+
+ with captured_output() as (out, err):
+ result = function.run(spec)
+
+ output = out.getvalue().strip()
verify_state(result)
- db = get_run_db()
- state, log = db.get_log(result.metadata.uid)
- log = str(log)
- print(state)
- print(log)
- assert log.find("It's, a, nice, day!") != -1, "params not detected in argv"
+ assert output.find("It's, a, nice, day!") != -1, "params not detected in argv"
diff --git a/tests/rundb/test_dbs.py b/tests/rundb/test_dbs.py
index 3b6d9b4bd236..1a8d7542f002 100644
--- a/tests/rundb/test_dbs.py
+++ b/tests/rundb/test_dbs.py
@@ -23,13 +23,12 @@
from mlrun.api.initial_data import init_data
from mlrun.api.utils.singletons.db import initialize_db
from mlrun.config import config
-from mlrun.db import SQLDB, FileRunDB, sqldb
+from mlrun.db import SQLDB, sqldb
from mlrun.db.base import RunDBInterface
from tests.conftest import new_run, run_now
dbs = [
"sql",
- "file",
# TODO: 'httpdb',
]
@@ -47,8 +46,6 @@ def db(request):
initialize_db()
db_session = create_session()
db = SQLDB(dsn, session=db_session)
- elif request.param == "file":
- db = FileRunDB(path)
else:
assert False, f"unknown db type - {request.param}"
@@ -139,8 +136,6 @@ def test_artifacts(db: RunDBInterface):
def test_list_runs(db: RunDBInterface):
- if isinstance(db, FileRunDB):
- pytest.skip("FIXME")
uid = "u183"
run = new_run("s1", {"l1": "v1", "l2": "v2"}, uid, x=1)
count = 5
diff --git a/tests/rundb/test_filedb.py b/tests/rundb/test_filedb.py
deleted file mode 100644
index 523df8f51a47..000000000000
--- a/tests/rundb/test_filedb.py
+++ /dev/null
@@ -1,91 +0,0 @@
-# Copyright 2018 Iguazio
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-from datetime import datetime, timedelta, timezone
-from tempfile import mkdtemp
-
-import pytest
-
-from mlrun.db import FileRunDB
-
-
-@pytest.fixture
-def db():
- path = mkdtemp(prefix="mlrun-test")
- db = FileRunDB(dirpath=path)
- db.connect()
- return db
-
-
-def test_save_get_function(db: FileRunDB):
- func, name, proj = {"x": 1, "y": 2}, "f1", "p2"
- db.store_function(func, name, proj)
- db_func = db.get_function(name, proj)
-
- # db methods enriches metadata
- del db_func["metadata"]
- del func["metadata"]
- assert db_func == func, "wrong func"
-
-
-def test_list_functions(db: FileRunDB):
- proj = "p4"
- count = 5
- for i in range(count):
- name = f"func{i}"
- func = {"fid": i}
- db.store_function(func, name, proj)
- db.store_function({}, "f2", "p7")
-
- out = db.list_functions("", proj)
- assert len(out) == count, "bad list"
-
-
-def test_schedules(db: FileRunDB):
- count = 7
- for i in range(count):
- data = {"i": i}
- db.store_schedule(data)
-
- scheds = list(db.list_schedules())
- assert count == len(scheds), "wrong number of schedules"
- assert set(range(count)) == set(s["i"] for s in scheds), "bad scheds"
-
-
-def test_list_artifact_date(db: FileRunDB):
- print("dirpath: ", db.dirpath)
- t1 = datetime(2020, 2, 16, tzinfo=timezone.utc)
- t2 = t1 - timedelta(days=7)
- t3 = t2 - timedelta(days=7)
- prj = "p7"
-
- db.store_artifact("k1", {"updated": t1.isoformat()}, "u1", project=prj)
- db.store_artifact("k2", {"updated": t2.isoformat()}, "u2", project=prj)
- db.store_artifact("k3", {"updated": t3.isoformat()}, "u3", project=prj)
-
- # FIXME: We get double what we expect since latest is an alias
- arts = db.list_artifacts(project=prj, since=t3, tag="*")
- assert 6 == len(arts), "since t3"
-
- arts = db.list_artifacts(project=prj, since=t2, tag="*")
- assert 4 == len(arts), "since t2"
-
- arts = db.list_artifacts(project=prj, since=t1 + timedelta(days=1), tag="*")
- assert not arts, "since t1+"
-
- arts = db.list_artifacts(project=prj, until=t2, tag="*")
- assert 4 == len(arts), "until t2"
-
- arts = db.list_artifacts(project=prj, since=t2, until=t2, tag="*")
- assert 2 == len(arts), "since/until t2"
diff --git a/tests/rundb/test_nopdb.py b/tests/rundb/test_nopdb.py
new file mode 100644
index 000000000000..c8dc848e52b0
--- /dev/null
+++ b/tests/rundb/test_nopdb.py
@@ -0,0 +1,44 @@
+# Copyright 2022 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import pytest
+
+import mlrun
+
+
+def test_nopdb():
+ # by default we use a nopdb with raise_error = False
+ assert mlrun.mlconf.httpdb.nop_db.raise_error is False
+
+ rundb = mlrun.get_run_db()
+ assert isinstance(rundb, mlrun.db.NopDB)
+
+ # not expected to fail as it in the white list
+ rundb.connect()
+
+ # not expected to fail
+ rundb.read_run("123")
+
+ # set raise_error to True
+ mlrun.mlconf.httpdb.nop_db.raise_error = True
+
+ assert mlrun.mlconf.httpdb.nop_db.raise_error is True
+
+ # not expected to fail as it in the white list
+ rundb.connect()
+
+ # expected to fail
+ with pytest.raises(mlrun.errors.MLRunBadRequestError):
+ rundb.read_run("123")
diff --git a/tests/runtimes/test_logging_and_parsing.py b/tests/runtimes/test_logging_and_parsing.py
index ee2e6ec172d7..8624d6d2f321 100644
--- a/tests/runtimes/test_logging_and_parsing.py
+++ b/tests/runtimes/test_logging_and_parsing.py
@@ -69,7 +69,7 @@ def parse_inputs(my_array, my_df, my_dict: dict, my_list, my_object, my_int, my_
return [my_str] * my_int
-def test_parse_inputs_from_mlrun_function():
+def test_parse_inputs_from_mlrun_function(rundb_mock):
"""
Run the `parse_inputs_from_mlrun_function` function with MLRun to see the wrapper is parsing the given inputs
(`DataItem`s) to the written configuration provided to the wrapper.
diff --git a/tests/serving/test_serving.py b/tests/serving/test_serving.py
index 114988eb30e7..5d4ee6e0ed7a 100644
--- a/tests/serving/test_serving.py
+++ b/tests/serving/test_serving.py
@@ -499,7 +499,7 @@ def test_v2_explain():
assert data["outputs"]["explained"] == 5, f"wrong explain response {resp.body}"
-def test_v2_get_modelmeta():
+def test_v2_get_modelmeta(rundb_mock):
project = mlrun.new_project("tstsrv", save=False)
fn = mlrun.new_function("tst", kind="serving")
model_uri = _log_model(project)
diff --git a/tests/test_code_to_func.py b/tests/test_code_to_func.py
index 6e111ad38b87..3cb3b7bbd6f6 100644
--- a/tests/test_code_to_func.py
+++ b/tests/test_code_to_func.py
@@ -14,9 +14,9 @@
from os import path
-from mlrun import code_to_function, get_run_db, new_model_server
+from mlrun import code_to_function, new_model_server
from mlrun.runtimes.function import compile_function_config
-from mlrun.utils import get_in, parse_versioned_object_uri
+from mlrun.utils import get_in
from tests.conftest import examples_path, results, tests_root_directory
@@ -48,24 +48,6 @@ def test_nuclio_nb_serving():
assert fn.spec.build.origin_filename == filename, "did not record filename"
-def test_job_file():
- filename = f"{examples_path}/training.py"
- fn = code_to_function(filename=filename, kind="job")
- assert fn.kind == "job", "kind not set, test failed"
- assert fn.spec.build.functionSourceCode, "code not embedded"
- assert fn.spec.build.origin_filename == filename, "did not record filename"
- assert type(fn.metadata.labels) == dict, "metadata labels were not set"
- run = fn.run(workdir=str(examples_path), local=True)
-
- project, uri, tag, hash_key = parse_versioned_object_uri(run.spec.function)
- local_fn = get_run_db().get_function(uri, project, tag=tag, hash_key=hash_key)
- assert local_fn["spec"]["command"] == filename, "wrong command path"
- assert (
- local_fn["spec"]["build"]["functionSourceCode"]
- == fn.spec.build.functionSourceCode
- ), "code was not copied to local function"
-
-
def test_job_file_noembed():
name = f"{examples_path}/training.py"
fn = code_to_function(filename=name, kind="job", embed_code=False)
diff --git a/tests/test_datastores.py b/tests/test_datastores.py
index 8f714f504dff..acd5b564cb76 100644
--- a/tests/test_datastores.py
+++ b/tests/test_datastores.py
@@ -52,7 +52,7 @@ def test_in_memory():
), "failed to log in mem artifact"
-def test_file():
+def test_file(rundb_mock):
with TemporaryDirectory() as tmpdir:
print(tmpdir)
diff --git a/tests/test_notebooks.py b/tests/test_notebooks.py
deleted file mode 100644
index d0eaefe2c1e6..000000000000
--- a/tests/test_notebooks.py
+++ /dev/null
@@ -1,77 +0,0 @@
-# Copyright 2018 Iguazio
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-
-from collections import ChainMap
-from os import environ
-from pathlib import Path
-from subprocess import run
-
-import pytest
-import yaml
-
-here = Path(__file__).absolute().parent
-root = here.parent
-# Need to be in root for docker context
-tmp_dockerfile = Path(root / "Dockerfile.mlrun-test-nb")
-with (here / "Dockerfile.test-nb").open() as fp:
- dockerfile_template = fp.read()
-docker_tag = "mlrun/test-notebook"
-
-
-def iter_notebooks():
- cfg_file = here / "notebooks.yml"
- with cfg_file.open() as fp:
- configs = yaml.safe_load(fp)
-
- for config in configs:
- if "env" not in config:
- config["env"] = {}
- yield pytest.param(config, id=config["nb"])
-
-
-def args_from_env(env):
- env = ChainMap(env, environ)
- args, cmd = [], []
- for name in env:
- if not name.startswith("MLRUN_"):
- continue
- value = env[name]
- args.append(f"ARG {name}")
- cmd.extend(["--build-arg", f"{name}={value}"])
-
- args = "\n".join(args)
- return args, cmd
-
-
-@pytest.mark.parametrize("notebook", iter_notebooks())
-def test_notebook(notebook):
- path = f'./examples/{notebook["nb"]}'
- args, args_cmd = args_from_env(notebook["env"])
- deps = []
- for dep in notebook.get("pip", []):
- deps.append(f"RUN python -m pip install {dep}")
- pip = "\n".join(deps)
-
- code = dockerfile_template.format(notebook=path, args=args, pip=pip)
- with tmp_dockerfile.open("w") as out:
- out.write(code)
-
- cmd = (
- ["docker", "build", "--file", str(tmp_dockerfile), "--tag", docker_tag]
- + args_cmd
- + ["."]
- )
- out = run(cmd, cwd=root)
- assert out.returncode == 0, f"Failed building {out.stdout} {out.stderr}"
From fc64e9982ef7bb7a114e3f058a4b013c167d9c09 Mon Sep 17 00:00:00 2001
From: yevgenykhazan <119507401+yevgenykhazan@users.noreply.github.com>
Date: Tue, 28 Mar 2023 13:56:17 +0300
Subject: [PATCH 012/334] [Docs] Fix CE upgrade and slack notification command
(#3351)
---
docs/concepts/workflow-overview.md | 3 +--
docs/install/kubernetes.md | 8 +++++---
2 files changed, 6 insertions(+), 5 deletions(-)
diff --git a/docs/concepts/workflow-overview.md b/docs/concepts/workflow-overview.md
index accb7b7e75c0..18bd41a06375 100644
--- a/docs/concepts/workflow-overview.md
+++ b/docs/concepts/workflow-overview.md
@@ -173,8 +173,7 @@ Instead of waiting for completion, you can set up a notification in Slack with a
Use one of:
```
-# If you want to get slack notification after the run with the results summary, use
-# project.notifiers.slack(webhook="https://")
+project.notifiers.add_notification(notification_type="slack",params={"webhook":""})
```
or in a Jupyter notebook with the` %env` magic command:
```
diff --git a/docs/install/kubernetes.md b/docs/install/kubernetes.md
index 8c994b299ba9..d61eb2dc19c9 100644
--- a/docs/install/kubernetes.md
+++ b/docs/install/kubernetes.md
@@ -289,8 +289,10 @@ In order to upgrade to the latest version of the chart, first make sure you have
helm repo update
```
-Then upgrade the chart:
+Then try to upgrade the chart:
```bash
-helm upgrade --install --reuse-values mlrun-ce mlrun-ce/mlrun-ce
-```
\ No newline at end of file
+helm upgrade --install --reuse-values mlrun-ce —namespace mlrun mlrun-ce/mlrun-ce
+```
+
+If it fails, you should reinstall the chart
\ No newline at end of file
From ee62334e8e0df66757cccb915dc733f904b48aa4 Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Tue, 28 Mar 2023 16:08:01 +0300
Subject: [PATCH 013/334] [Runtimes] Fix workdir and source target dir (#3334)
---
mlrun/builder.py | 19 +++++++------
mlrun/runtimes/base.py | 5 ++++
mlrun/runtimes/daskjob.py | 2 ++
mlrun/runtimes/function.py | 2 ++
mlrun/runtimes/kubejob.py | 35 +++++++++++++++---------
mlrun/runtimes/local.py | 40 +---------------------------
mlrun/runtimes/mpijob/abstract.py | 2 ++
mlrun/runtimes/mpijob/v1.py | 2 ++
mlrun/runtimes/pod.py | 2 ++
mlrun/runtimes/remotesparkjob.py | 2 ++
mlrun/runtimes/serving.py | 2 ++
mlrun/runtimes/sparkjob/abstract.py | 19 ++++++++-----
mlrun/runtimes/sparkjob/spark3job.py | 2 ++
tests/api/runtimes/test_spark.py | 2 +-
tests/runtimes/test_run.py | 1 +
tests/test_builder.py | 11 ++++----
16 files changed, 76 insertions(+), 72 deletions(-)
diff --git a/mlrun/builder.py b/mlrun/builder.py
index c11e41947f8f..c5d38fbf3e95 100644
--- a/mlrun/builder.py
+++ b/mlrun/builder.py
@@ -55,7 +55,6 @@ def make_dockerfile(
dock += f"ARG {build_arg_key}={build_arg_value}\n"
if source:
- dock += f"RUN mkdir -p {workdir}\n"
dock += f"WORKDIR {workdir}\n"
# 'ADD' command does not extract zip files - add extraction stage to the dockerfile
if source.endswith(".zip"):
@@ -398,14 +397,18 @@ def build_image(
enriched_group_id = runtime.spec.security_context.run_as_group
if source_to_copy and (
- not runtime.spec.workdir or not path.isabs(runtime.spec.workdir)
+ not runtime.spec.clone_target_dir
+ or not os.path.isabs(runtime.spec.clone_target_dir)
):
- # the user may give a relative workdir to the source where the code is located
- # add the relative workdir to the target source copy path
+ # use a temp dir for permissions and set it as the workdir
tmpdir = tempfile.mkdtemp()
- relative_workdir = runtime.spec.workdir or ""
- _, _, relative_workdir = relative_workdir.partition("./")
- runtime.spec.workdir = path.join(tmpdir, "mlrun", relative_workdir)
+ relative_workdir = runtime.spec.clone_target_dir or ""
+ if relative_workdir.startswith("./"):
+ # TODO: use 'removeprefix' when we drop python 3.7 support
+ # relative_workdir.removeprefix("./")
+ relative_workdir = relative_workdir[2:]
+
+ runtime.spec.clone_target_dir = path.join(tmpdir, "mlrun", relative_workdir)
dock = make_dockerfile(
base_image,
@@ -415,7 +418,7 @@ def build_image(
extra=extra,
user_unix_id=user_unix_id,
enriched_group_id=enriched_group_id,
- workdir=runtime.spec.workdir,
+ workdir=runtime.spec.clone_target_dir,
)
kpod = make_kaniko_pod(
diff --git a/mlrun/runtimes/base.py b/mlrun/runtimes/base.py
index d0ac3777aea9..fba3e3cede98 100644
--- a/mlrun/runtimes/base.py
+++ b/mlrun/runtimes/base.py
@@ -93,6 +93,7 @@
"pythonpath",
"disable_auto_mount",
"allow_empty_resources",
+ "clone_target_dir",
]
@@ -133,6 +134,7 @@ def __init__(
default_handler=None,
pythonpath=None,
disable_auto_mount=False,
+ clone_target_dir=None,
):
self.command = command or ""
@@ -151,6 +153,9 @@ def __init__(
self.entry_points = entry_points or {}
self.disable_auto_mount = disable_auto_mount
self.allow_empty_resources = None
+ # the build.source is cloned/extracted to the specified clone_target_dir
+ # if a relative path is specified, it will be enriched with a temp dir path
+ self.clone_target_dir = clone_target_dir or ""
@property
def build(self) -> ImageBuilder:
diff --git a/mlrun/runtimes/daskjob.py b/mlrun/runtimes/daskjob.py
index b04b32897cf8..ed3fe30466d2 100644
--- a/mlrun/runtimes/daskjob.py
+++ b/mlrun/runtimes/daskjob.py
@@ -106,6 +106,7 @@ def __init__(
tolerations=None,
preemption_mode=None,
security_context=None,
+ clone_target_dir=None,
):
super().__init__(
@@ -135,6 +136,7 @@ def __init__(
tolerations=tolerations,
preemption_mode=preemption_mode,
security_context=security_context,
+ clone_target_dir=clone_target_dir,
)
self.args = args
diff --git a/mlrun/runtimes/function.py b/mlrun/runtimes/function.py
index 03fbaff5a480..33d096c1c6b8 100644
--- a/mlrun/runtimes/function.py
+++ b/mlrun/runtimes/function.py
@@ -183,6 +183,7 @@ def __init__(
security_context=None,
service_type=None,
add_templated_ingress_host_mode=None,
+ clone_target_dir=None,
):
super().__init__(
@@ -212,6 +213,7 @@ def __init__(
tolerations=tolerations,
preemption_mode=preemption_mode,
security_context=security_context,
+ clone_target_dir=clone_target_dir,
)
self.base_spec = base_spec or {}
diff --git a/mlrun/runtimes/kubejob.py b/mlrun/runtimes/kubejob.py
index 745004ab4791..f0ad9b78f06b 100644
--- a/mlrun/runtimes/kubejob.py
+++ b/mlrun/runtimes/kubejob.py
@@ -58,16 +58,17 @@ def is_deployed(self):
return False
def with_source_archive(
- self, source, workdir=None, handler=None, pull_at_runtime=True
+ self, source, workdir=None, handler=None, pull_at_runtime=True, target_dir=None
):
"""load the code from git/tar/zip archive at runtime or build
- :param source: valid path to git, zip, or tar file, e.g.
- git://github.com/mlrun/something.git
- http://some/url/file.zip
- :param handler: default function handler
- :param workdir: working dir relative to the archive root or absolute (e.g. './subdir')
+ :param source: valid path to git, zip, or tar file, e.g.
+ git://github.com/mlrun/something.git
+ http://some/url/file.zip
+ :param handler: default function handler
+ :param workdir: working dir relative to the archive root or absolute (e.g. './subdir')
:param pull_at_runtime: load the archive into the container at job runtime vs on build/deploy
+ :param target_dir: target dir on runtime pod or repo clone / archive extraction
"""
if source.endswith(".zip") and not pull_at_runtime:
logger.warn(
@@ -79,6 +80,9 @@ def with_source_archive(
self.spec.default_handler = handler
if workdir:
self.spec.workdir = workdir
+ if target_dir:
+ self.spec.clone_target_dir = target_dir
+
self.spec.build.load_source_on_run = pull_at_runtime
if (
self.spec.build.base_image
@@ -86,7 +90,7 @@ def with_source_archive(
and pull_at_runtime
and not self.spec.image
):
- # if we load source from repo and dont need a full build use the base_image as the image
+ # if we load source from repo and don't need a full build use the base_image as the image
self.spec.image = self.spec.build.base_image
elif not pull_at_runtime:
# clear the image so build will not be skipped
@@ -223,7 +227,8 @@ def deploy(
self.spec.build.base_image = self.spec.build.base_image or get_in(
data, "data.spec.build.base_image"
)
- self.spec.workdir = get_in(data, "data.spec.workdir")
+ # get the clone target dir in case it was enriched due to loading source
+ self.spec.clone_target_dir = get_in(data, "data.spec.clone_target_dir")
ready = data.get("ready", False)
if not ready:
logger.info(
@@ -348,11 +353,17 @@ def _run(self, runobj: RunObject, execution):
workdir = self.spec.workdir
if workdir:
if self.spec.build.source and self.spec.build.load_source_on_run:
- # workdir will be set AFTER the clone
+ # workdir will be set AFTER the clone which is done in the pre-run of local runtime
workdir = None
- elif not workdir.startswith("/"):
- # relative path mapped to real path in the job pod
- workdir = os.path.join("/mlrun", workdir)
+ elif not os.path.isabs(workdir):
+ # workdir is a relative path from the source root to where the code is located
+ # add the clone_target_dir (where to source was copied), if not specified assume the workdir is complete
+ if self.spec.clone_target_dir:
+ if workdir.startswith("./"):
+ # TODO: use 'removeprefix' when we drop python 3.7 support
+ # workdir.removeprefix("./")
+ workdir = workdir[2:]
+ workdir = os.path.join(self.spec.clone_target_dir, workdir)
pod_spec = func_to_pod(
self.full_image_path(
diff --git a/mlrun/runtimes/local.py b/mlrun/runtimes/local.py
index 2ea733f039d1..8d0ecb5b6d81 100644
--- a/mlrun/runtimes/local.py
+++ b/mlrun/runtimes/local.py
@@ -39,7 +39,7 @@
from ..model import RunObject
from ..utils import get_handler_extended, get_in, logger, set_paths
from ..utils.clones import extract_source
-from .base import BaseRuntime, FunctionSpec, spec_fields
+from .base import BaseRuntime
from .kubejob import KubejobRuntime
from .remotesparkjob import RemoteSparkRuntime
from .utils import RunError, global_context, log_std
@@ -170,48 +170,10 @@ def _run(self, runobj: RunObject, execution: MLClientCtx):
return context.to_dict()
-class LocalFunctionSpec(FunctionSpec):
- _dict_fields = spec_fields + ["clone_target_dir"]
-
- def __init__(
- self,
- command=None,
- args=None,
- mode=None,
- default_handler=None,
- pythonpath=None,
- entry_points=None,
- description=None,
- workdir=None,
- build=None,
- clone_target_dir=None,
- ):
- super().__init__(
- command=command,
- args=args,
- mode=mode,
- build=build,
- entry_points=entry_points,
- description=description,
- workdir=workdir,
- default_handler=default_handler,
- pythonpath=pythonpath,
- )
- self.clone_target_dir = clone_target_dir
-
-
class LocalRuntime(BaseRuntime, ParallelRunner):
kind = "local"
_is_remote = False
- @property
- def spec(self) -> LocalFunctionSpec:
- return self._spec
-
- @spec.setter
- def spec(self, spec):
- self._spec = self._verify_dict(spec, "spec", LocalFunctionSpec)
-
def to_job(self, image=""):
struct = self.to_dict()
obj = KubejobRuntime.from_dict(struct)
diff --git a/mlrun/runtimes/mpijob/abstract.py b/mlrun/runtimes/mpijob/abstract.py
index ec54df540e41..d6ef2dc573d5 100644
--- a/mlrun/runtimes/mpijob/abstract.py
+++ b/mlrun/runtimes/mpijob/abstract.py
@@ -60,6 +60,7 @@ def __init__(
tolerations=None,
preemption_mode=None,
security_context=None,
+ clone_target_dir=None,
):
super().__init__(
command=command,
@@ -88,6 +89,7 @@ def __init__(
tolerations=tolerations,
preemption_mode=preemption_mode,
security_context=security_context,
+ clone_target_dir=clone_target_dir,
)
self.mpi_args = mpi_args or [
"-x",
diff --git a/mlrun/runtimes/mpijob/v1.py b/mlrun/runtimes/mpijob/v1.py
index 52115e05c378..e867b4a8859c 100644
--- a/mlrun/runtimes/mpijob/v1.py
+++ b/mlrun/runtimes/mpijob/v1.py
@@ -62,6 +62,7 @@ def __init__(
tolerations=None,
preemption_mode=None,
security_context=None,
+ clone_target_dir=None,
):
super().__init__(
command=command,
@@ -91,6 +92,7 @@ def __init__(
tolerations=tolerations,
preemption_mode=preemption_mode,
security_context=security_context,
+ clone_target_dir=clone_target_dir,
)
self.clean_pod_policy = clean_pod_policy or MPIJobV1CleanPodPolicies.default()
diff --git a/mlrun/runtimes/pod.py b/mlrun/runtimes/pod.py
index 97cde8af0f10..0bc603646eec 100644
--- a/mlrun/runtimes/pod.py
+++ b/mlrun/runtimes/pod.py
@@ -135,6 +135,7 @@ def __init__(
tolerations=None,
preemption_mode=None,
security_context=None,
+ clone_target_dir=None,
):
super().__init__(
command=command,
@@ -148,6 +149,7 @@ def __init__(
default_handler=default_handler,
pythonpath=pythonpath,
disable_auto_mount=disable_auto_mount,
+ clone_target_dir=clone_target_dir,
)
self._volumes = {}
self._volume_mounts = {}
diff --git a/mlrun/runtimes/remotesparkjob.py b/mlrun/runtimes/remotesparkjob.py
index 46731f0c47d3..c262b6059f72 100644
--- a/mlrun/runtimes/remotesparkjob.py
+++ b/mlrun/runtimes/remotesparkjob.py
@@ -58,6 +58,7 @@ def __init__(
tolerations=None,
preemption_mode=None,
security_context=None,
+ clone_target_dir=None,
):
super().__init__(
command=command,
@@ -86,6 +87,7 @@ def __init__(
tolerations=tolerations,
preemption_mode=preemption_mode,
security_context=security_context,
+ clone_target_dir=clone_target_dir,
)
self.provider = provider
diff --git a/mlrun/runtimes/serving.py b/mlrun/runtimes/serving.py
index 15b4e09ed724..f8bb5ffa282d 100644
--- a/mlrun/runtimes/serving.py
+++ b/mlrun/runtimes/serving.py
@@ -143,6 +143,7 @@ def __init__(
security_context=None,
service_type=None,
add_templated_ingress_host_mode=None,
+ clone_target_dir=None,
):
super().__init__(
@@ -182,6 +183,7 @@ def __init__(
security_context=security_context,
service_type=service_type,
add_templated_ingress_host_mode=add_templated_ingress_host_mode,
+ clone_target_dir=clone_target_dir,
)
self.models = models or {}
diff --git a/mlrun/runtimes/sparkjob/abstract.py b/mlrun/runtimes/sparkjob/abstract.py
index 4aeca02bcf13..923003dc8b3b 100644
--- a/mlrun/runtimes/sparkjob/abstract.py
+++ b/mlrun/runtimes/sparkjob/abstract.py
@@ -143,6 +143,7 @@ def __init__(
tolerations=None,
preemption_mode=None,
security_context=None,
+ clone_target_dir=None,
):
super().__init__(
@@ -172,6 +173,7 @@ def __init__(
tolerations=tolerations,
preemption_mode=preemption_mode,
security_context=security_context,
+ clone_target_dir=clone_target_dir,
)
self._driver_resources = self.enrich_resources_with_default_pod_resources(
@@ -801,23 +803,26 @@ def with_restart_policy(
)
def with_source_archive(
- self, source, workdir=None, handler=None, pull_at_runtime=True
+ self, source, workdir=None, handler=None, pull_at_runtime=True, target_dir=None
):
"""load the code from git/tar/zip archive at runtime or build
- :param source: valid path to git, zip, or tar file, e.g.
- git://github.com/mlrun/something.git
- http://some/url/file.zip
- :param handler: default function handler
- :param workdir: working dir relative to the archive root or absolute (e.g. './subdir')
+ :param source: valid path to git, zip, or tar file, e.g.
+ git://github.com/mlrun/something.git
+ http://some/url/file.zip
+ :param handler: default function handler
+ :param workdir: working dir relative to the archive root or absolute (e.g. './subdir')
:param pull_at_runtime: not supported for spark runtime, must be False
+ :param target_dir: target dir on runtime pod for repo clone / archive extraction
"""
if pull_at_runtime:
raise mlrun.errors.MLRunInvalidArgumentError(
"pull_at_runtime is not supported for spark runtime, use pull_at_runtime=False"
)
- super().with_source_archive(source, workdir, handler, pull_at_runtime)
+ super().with_source_archive(
+ source, workdir, handler, pull_at_runtime, target_dir
+ )
def get_pods(self, name=None, namespace=None, driver=False):
k8s = self._get_k8s()
diff --git a/mlrun/runtimes/sparkjob/spark3job.py b/mlrun/runtimes/sparkjob/spark3job.py
index 0f9e9c5a6588..9ddb538a6887 100644
--- a/mlrun/runtimes/sparkjob/spark3job.py
+++ b/mlrun/runtimes/sparkjob/spark3job.py
@@ -100,6 +100,7 @@ def __init__(
driver_cores=None,
executor_cores=None,
security_context=None,
+ clone_target_dir=None,
):
super().__init__(
@@ -129,6 +130,7 @@ def __init__(
tolerations=tolerations,
preemption_mode=preemption_mode,
security_context=security_context,
+ clone_target_dir=clone_target_dir,
)
self.driver_resources = driver_resources or {}
diff --git a/tests/api/runtimes/test_spark.py b/tests/api/runtimes/test_spark.py
index 0fac7386c1d8..0d7e4176b68e 100644
--- a/tests/api/runtimes/test_spark.py
+++ b/tests/api/runtimes/test_spark.py
@@ -650,7 +650,7 @@ def test_get_offline_features(
},
"outputs": [],
"output_path": "v3io:///mypath",
- "function": "None/my-vector-merger@e67bf7add40a6bafa25e19a1b80f3d4cc3789eff",
+ "function": "None/my-vector-merger@a15d3e85a5326af937459528b28426ae7759e640",
"secret_sources": [],
"data_stores": [],
"handler": "merge_handler",
diff --git a/tests/runtimes/test_run.py b/tests/runtimes/test_run.py
index 86693594cb88..b336d9709532 100644
--- a/tests/runtimes/test_run.py
+++ b/tests/runtimes/test_run.py
@@ -50,6 +50,7 @@ def _get_runtime():
"priority_class_name": "",
"tolerations": None,
"security_context": None,
+ "clone_target_dir": "",
},
"verbose": False,
}
diff --git a/tests/test_builder.py b/tests/test_builder.py
index 324e9390217c..ccc49835ac6b 100644
--- a/tests/test_builder.py
+++ b/tests/test_builder.py
@@ -811,15 +811,16 @@ def test_kaniko_pod_spec_user_service_account_enrichment(monkeypatch):
@pytest.mark.parametrize(
- "workdir,expected_workdir",
+ "clone_target_dir,expected_workdir",
[
(None, r"WORKDIR .*\/tmp.*\/mlrun"),
("", r"WORKDIR .*\/tmp.*\/mlrun"),
("./path/to/code", r"WORKDIR .*\/tmp.*\/mlrun\/path\/to\/code"),
+ ("rel_path", r"WORKDIR .*\/tmp.*\/mlrun\/rel_path"),
("/some/workdir", r"WORKDIR \/some\/workdir"),
],
)
-def test_builder_workdir(monkeypatch, workdir, expected_workdir):
+def test_builder_workdir(monkeypatch, clone_target_dir, expected_workdir):
_patch_k8s_helper(monkeypatch)
mlrun.builder.make_kaniko_pod = unittest.mock.MagicMock()
docker_registry = "default.docker.registry/default-repository"
@@ -832,8 +833,8 @@ def test_builder_workdir(monkeypatch, workdir, expected_workdir):
image="mlrun/mlrun",
kind="job",
)
- if workdir is not None:
- function.spec.workdir = workdir
+ if clone_target_dir is not None:
+ function.spec.clone_target_dir = clone_target_dir
function.spec.build.source = "some-source.tgz"
mlrun.builder.build_runtime(
mlrun.api.schemas.AuthInfo(),
@@ -842,7 +843,7 @@ def test_builder_workdir(monkeypatch, workdir, expected_workdir):
dockerfile = mlrun.builder.make_kaniko_pod.call_args[1]["dockertext"]
dockerfile_lines = dockerfile.splitlines()
expected_workdir_re = re.compile(expected_workdir)
- assert expected_workdir_re.match(dockerfile_lines[2])
+ assert expected_workdir_re.match(dockerfile_lines[1])
def _get_target_image_from_create_pod_mock():
From 21fb1756be8278a1a46d18fb44f4e5797c0da6c0 Mon Sep 17 00:00:00 2001
From: yevgenykhazan <119507401+yevgenykhazan@users.noreply.github.com>
Date: Tue, 28 Mar 2023 21:03:53 +0300
Subject: [PATCH 014/334] [Docs] Jobs and workflows (#3353)
---
docs/install/kubernetes.md | 17 ++++++++++++++++-
1 file changed, 16 insertions(+), 1 deletion(-)
diff --git a/docs/install/kubernetes.md b/docs/install/kubernetes.md
index d61eb2dc19c9..c5c68909d590 100644
--- a/docs/install/kubernetes.md
+++ b/docs/install/kubernetes.md
@@ -295,4 +295,19 @@ Then try to upgrade the chart:
helm upgrade --install --reuse-values mlrun-ce —namespace mlrun mlrun-ce/mlrun-ce
```
-If it fails, you should reinstall the chart
\ No newline at end of file
+If it fails, you should reinstall the chart:
+
+1. remove current mlrun-ce
+```bash
+mkdir ~/tmp
+helm get values -n mlrun mlrun-ce > ~/tmp/mlrun-ce-values.yaml
+helm uninstall mlrun-ce
+```
+2. reinstall mlrun-ce, reuse values
+```bash
+helm install -n mlrun --values ~/tmp/mlrun-ce-values.yaml mlrun-ce mlrun-ce/mlrun-ce --devel
+```
+
+```{admonition} Note
+If your values have fixed mlrun service versions (e..g: mlrun:1.2.1) then you might want to remove it from the values file to allow newer chart defaults to kick in
+```
\ No newline at end of file
From b18699215deb6954292e0f42a0a8766e7e09f5ed Mon Sep 17 00:00:00 2001
From: jillnogold <88145832+jillnogold@users.noreply.github.com>
Date: Tue, 28 Mar 2023 21:04:44 +0300
Subject: [PATCH 015/334] [Docs] Add stament about which CE/Enterprise version
gets installed (#3347)
---
docs/install/aws-install.md | 4 ++++
docs/install/kubernetes.md | 6 +++++-
2 files changed, 9 insertions(+), 1 deletion(-)
diff --git a/docs/install/aws-install.md b/docs/install/aws-install.md
index c92095b0864f..58d2c7a73f52 100644
--- a/docs/install/aws-install.md
+++ b/docs/install/aws-install.md
@@ -3,6 +3,10 @@
For AWS users, the easiest way to install MLRun is to use a native AWS deployment. This option deploys MLRun on an AWS EKS service using a CloudFormation stack.
+```{admonition} Note
+These instructions install the community edition, which currently includes MLRun 1.2.1. See the [release documentation](https://docs.mlrun.org/en/v1.2.1/index.html).
+```
+
## Prerequisites
1. An AWS account with permissions that include the ability to:
diff --git a/docs/install/kubernetes.md b/docs/install/kubernetes.md
index c5c68909d590..3b06cebac62d 100644
--- a/docs/install/kubernetes.md
+++ b/docs/install/kubernetes.md
@@ -1,6 +1,10 @@
(install-on-kubernetes)=
# Install MLRun on Kubernetes
+```{admonition} Note
+These instructions install the community edition, which currently includes MLRun 1.2.1. See the [release documentation](https://docs.mlrun.org/en/v1.2.1/index.html).
+```
+
**In this section**
- [Prerequisites](#prerequisites)
- [Community Edition Flavors](#community-edition-flavors)
@@ -28,7 +32,7 @@ instructions](https://kubernetes.io/docs/tasks/tools/install-kubectl/) for more
- RAM: A minimum of 8Gi is required for running all the initial MLRun components. The amount of RAM required for running MLRun jobs depends on the job's requirements.
``` {admonition} Note
-The MLRun Community Edition resources are configured initially with the default cluster/namespace resources limits. You can modify the resources from outside if needed.
+The MLRun Community Edition resources are configured initially with the default cluster/namespace resource limits. You can modify the resources from outside if needed.
```
## Community Edition flavors
From 7360738a334a285b60ff30ff9098a775392827a8 Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Tue, 28 Mar 2023 21:05:06 +0300
Subject: [PATCH 016/334] [API] Fail `healthz` requests when offline / waiting
for chief (#3344)
---
mlrun/api/api/endpoints/healthz.py | 18 +++++++++++++-----
mlrun/errors.py | 5 +++++
tests/api/api/test_healthz.py | 22 ++++++++--------------
tests/api/test_api_states.py | 2 +-
4 files changed, 27 insertions(+), 20 deletions(-)
diff --git a/mlrun/api/api/endpoints/healthz.py b/mlrun/api/api/endpoints/healthz.py
index d1cb2a1f73c6..2053075f5a45 100644
--- a/mlrun/api/api/endpoints/healthz.py
+++ b/mlrun/api/api/endpoints/healthz.py
@@ -12,20 +12,28 @@
# See the License for the specific language governing permissions and
# limitations under the License.
#
+import http
+
from fastapi import APIRouter
-import mlrun.api.crud
import mlrun.api.schemas
+from mlrun.config import config as mlconfig
router = APIRouter()
@router.get(
"/healthz",
- response_model=mlrun.api.schemas.ClientSpec,
+ status_code=http.HTTPStatus.OK.value,
)
def health():
- # TODO: From 0.7.0 client uses the /client-spec endpoint,
- # when this is the oldest relevant client, remove this logic from the healthz endpoint
- return mlrun.api.crud.ClientSpec().get_client_spec()
+ # offline is the initial state
+ # waiting for chief is set for workers waiting for chief to be ready and then clusterize against it
+ if mlconfig.httpdb.state in [
+ mlrun.api.schemas.APIStates.offline,
+ mlrun.api.schemas.APIStates.waiting_for_chief,
+ ]:
+ raise mlrun.errors.MLRunServiceUnavailableError()
+
+ return {"status": "ok"}
diff --git a/mlrun/errors.py b/mlrun/errors.py
index e5ea58635424..c224720213f0 100644
--- a/mlrun/errors.py
+++ b/mlrun/errors.py
@@ -179,6 +179,10 @@ class MLRunInternalServerError(MLRunHTTPStatusError):
error_status_code = HTTPStatus.INTERNAL_SERVER_ERROR.value
+class MLRunServiceUnavailableError(MLRunHTTPStatusError):
+ error_status_code = HTTPStatus.SERVICE_UNAVAILABLE.value
+
+
class MLRunRuntimeError(MLRunHTTPStatusError, RuntimeError):
error_status_code = HTTPStatus.INTERNAL_SERVER_ERROR.value
@@ -213,4 +217,5 @@ def __init__(
HTTPStatus.CONFLICT.value: MLRunConflictError,
HTTPStatus.PRECONDITION_FAILED.value: MLRunPreconditionFailedError,
HTTPStatus.INTERNAL_SERVER_ERROR.value: MLRunInternalServerError,
+ HTTPStatus.SERVICE_UNAVAILABLE.value: MLRunServiceUnavailableError,
}
diff --git a/tests/api/api/test_healthz.py b/tests/api/api/test_healthz.py
index f8dcc34ed0e2..ce8f5eac72cb 100644
--- a/tests/api/api/test_healthz.py
+++ b/tests/api/api/test_healthz.py
@@ -17,25 +17,19 @@
import fastapi.testclient
import sqlalchemy.orm
-import mlrun
-import mlrun.api.crud
import mlrun.api.schemas
-import mlrun.api.utils.clients.iguazio
-import mlrun.errors
-import mlrun.runtimes
+import mlrun.config
def test_health(
db: sqlalchemy.orm.Session, client: fastapi.testclient.TestClient
) -> None:
- overridden_ui_projects_prefix = "some-prefix"
- mlrun.mlconf.ui.projects_prefix = overridden_ui_projects_prefix
- nuclio_version = "x.x.x"
- mlrun.mlconf.nuclio_version = nuclio_version
+
+ # sanity
response = client.get("healthz")
assert response.status_code == http.HTTPStatus.OK.value
- response_body = response.json()
- for key in ["scrape_metrics", "hub_url"]:
- assert response_body[key] is None
- assert response_body["ui_projects_prefix"] == overridden_ui_projects_prefix
- assert response_body["nuclio_version"] == nuclio_version
+
+ # fail
+ mlrun.config.config.httpdb.state = mlrun.api.schemas.APIStates.offline
+ response = client.get("healthz")
+ assert response.status_code == http.HTTPStatus.SERVICE_UNAVAILABLE.value
diff --git a/tests/api/test_api_states.py b/tests/api/test_api_states.py
index 91ae63222b0a..b37a589657c5 100644
--- a/tests/api/test_api_states.py
+++ b/tests/api/test_api_states.py
@@ -32,7 +32,7 @@ def test_offline_state(
) -> None:
mlrun.mlconf.httpdb.state = mlrun.api.schemas.APIStates.offline
response = client.get("healthz")
- assert response.status_code == http.HTTPStatus.OK.value
+ assert response.status_code == http.HTTPStatus.SERVICE_UNAVAILABLE.value
response = client.get("projects")
assert response.status_code == http.HTTPStatus.PRECONDITION_FAILED.value
From ff181dabdc3fda8b867ac1a1ea876241e061a7f2 Mon Sep 17 00:00:00 2001
From: jist <95856749+george0st@users.noreply.github.com>
Date: Tue, 28 Mar 2023 21:51:28 +0200
Subject: [PATCH 017/334] [Extras] Add avro for kafka (#3193)
---
dependencies.py | 6 +++++-
extras-requirements.txt | 1 +
2 files changed, 6 insertions(+), 1 deletion(-)
diff --git a/dependencies.py b/dependencies.py
index 1d4239022c7b..e3d4e2f42714 100644
--- a/dependencies.py
+++ b/dependencies.py
@@ -71,7 +71,11 @@ def extra_requirements() -> typing.Dict[str, typing.List[str]]:
],
"google-cloud-storage": ["gcsfs~=2021.8.1"],
"google-cloud-bigquery": ["google-cloud-bigquery[pandas, bqstorage]~=3.2"],
- "kafka": ["kafka-python~=2.0"],
+ "kafka": [
+ "kafka-python~=2.0",
+ # because confluent kafka supports avro format by default
+ "avro~=1.11",
+ ],
"redis": ["redis~=4.3"],
}
diff --git a/extras-requirements.txt b/extras-requirements.txt
index a9f6d5e13b0f..b1ca7d9d6d20 100644
--- a/extras-requirements.txt
+++ b/extras-requirements.txt
@@ -31,5 +31,6 @@ plotly~=5.4, <5.12.0
# required by frames (because it upgrades protobuf from 3.x to 4.x, breaking binary compatibility)
google-cloud-bigquery[pandas, bqstorage]~=3.2
kafka-python~=2.0
+avro~=1.11
redis~=4.3
graphviz~=0.20.0
From bba309c879c7e903b6c9ab7277e95052fc59bd43 Mon Sep 17 00:00:00 2001
From: Gal Topper
Date: Wed, 29 Mar 2023 15:07:47 +0800
Subject: [PATCH 018/334] [Serving] Fix initialization of graph steps in error
flow (#3337)
[ML-3654](https://jira.iguazeng.com/browse/ML-3654)
---
mlrun/serving/states.py | 5 ++++-
1 file changed, 4 insertions(+), 1 deletion(-)
diff --git a/mlrun/serving/states.py b/mlrun/serving/states.py
index 2cef1a6f00b8..b6d20076056f 100644
--- a/mlrun/serving/states.py
+++ b/mlrun/serving/states.py
@@ -954,7 +954,10 @@ def _build_async_flow(self):
def process_step(state, step, root):
if not state._is_local_function(self.context) or state._visited:
return
- for item in state.next or []:
+ next_steps = state.next or []
+ if state.on_error:
+ next_steps.append(state.on_error)
+ for item in next_steps:
next_state = root[item]
if next_state.async_object:
next_step = step.to(next_state.async_object)
From f498afca78cd77581cec5fec56b3c17d8675c36f Mon Sep 17 00:00:00 2001
From: Eyal Danieli
Date: Wed, 29 Mar 2023 11:03:53 +0300
Subject: [PATCH 019/334] [Model Monitoring] Fix monitoring feature set target
(#3357)
---
mlrun/api/crud/model_monitoring/model_endpoints.py | 3 ++-
1 file changed, 2 insertions(+), 1 deletion(-)
diff --git a/mlrun/api/crud/model_monitoring/model_endpoints.py b/mlrun/api/crud/model_monitoring/model_endpoints.py
index d6d792b961c4..8eaba5cc1ed8 100644
--- a/mlrun/api/crud/model_monitoring/model_endpoints.py
+++ b/mlrun/api/crud/model_monitoring/model_endpoints.py
@@ -244,11 +244,12 @@ def create_monitoring_feature_set(
)
parquet_target = mlrun.datastore.targets.ParquetTarget("parquet", parquet_path)
driver = mlrun.datastore.targets.get_target_driver(parquet_target, feature_set)
- driver.update_resource_status("created")
+
feature_set.set_targets(
[mlrun.datastore.targets.ParquetTarget(path=parquet_path)],
with_defaults=False,
)
+ driver.update_resource_status("created")
# Save the new feature set
feature_set._override_run_db(db_session)
From 96edbed3416b8026300f9934b41d2fde568b816e Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Wed, 29 Mar 2023 11:59:40 +0300
Subject: [PATCH 020/334] [Test] Fix API states healthz status code (#3358)
---
tests/api/test_api_states.py | 16 ++++++++++------
1 file changed, 10 insertions(+), 6 deletions(-)
diff --git a/tests/api/test_api_states.py b/tests/api/test_api_states.py
index b37a589657c5..d1a75ed9d6cb 100644
--- a/tests/api/test_api_states.py
+++ b/tests/api/test_api_states.py
@@ -40,22 +40,26 @@ def test_offline_state(
@pytest.mark.parametrize(
- "state",
+ "state, expected_healthz_status_code",
[
- mlrun.api.schemas.APIStates.waiting_for_migrations,
- mlrun.api.schemas.APIStates.migrations_in_progress,
- mlrun.api.schemas.APIStates.migrations_failed,
- mlrun.api.schemas.APIStates.waiting_for_chief,
+ (mlrun.api.schemas.APIStates.waiting_for_migrations, http.HTTPStatus.OK.value),
+ (mlrun.api.schemas.APIStates.migrations_in_progress, http.HTTPStatus.OK.value),
+ (mlrun.api.schemas.APIStates.migrations_failed, http.HTTPStatus.OK.value),
+ (
+ mlrun.api.schemas.APIStates.waiting_for_chief,
+ http.HTTPStatus.SERVICE_UNAVAILABLE.value,
+ ),
],
)
def test_api_states(
db: sqlalchemy.orm.Session,
client: fastapi.testclient.TestClient,
state,
+ expected_healthz_status_code,
) -> None:
mlrun.mlconf.httpdb.state = state
response = client.get("healthz")
- assert response.status_code == http.HTTPStatus.OK.value
+ assert response.status_code == expected_healthz_status_code
response = client.get("projects/some-project/background-tasks/some-task")
assert response.status_code == http.HTTPStatus.NOT_FOUND.value
From ba82e6d55fe9489ddea9993385521193dc728649 Mon Sep 17 00:00:00 2001
From: Eyal Danieli
Date: Wed, 29 Mar 2023 12:20:46 +0300
Subject: [PATCH 021/334] [Model Monitoring] Update system tests and fix
endpoint_type in batch job (#3350)
---
.../model_monitoring_batch.py | 3 +-
mlrun/serving/routers.py | 2 +-
tests/api/api/test_model_endpoints.py | 2 +-
.../model_monitoring/test_model_monitoring.py | 34 +++++++++----------
4 files changed, 20 insertions(+), 21 deletions(-)
diff --git a/mlrun/model_monitoring/model_monitoring_batch.py b/mlrun/model_monitoring/model_monitoring_batch.py
index 2d3abf2a1977..92da5d3fec13 100644
--- a/mlrun/model_monitoring/model_monitoring_batch.py
+++ b/mlrun/model_monitoring/model_monitoring_batch.py
@@ -634,7 +634,7 @@ def run(self):
):
# Skip router endpoint:
if (
- endpoint[mlrun.model_monitoring.EventFieldType.ENDPOINT_TYPE]
+ int(endpoint[mlrun.model_monitoring.EventFieldType.ENDPOINT_TYPE])
== mlrun.model_monitoring.EndpointType.ROUTER
):
# Router endpoint has no feature stats
@@ -646,7 +646,6 @@ def run(self):
def update_drift_metrics(self, endpoint: dict):
try:
-
# Convert feature set into dataframe and get the latest dataset
(
_,
diff --git a/mlrun/serving/routers.py b/mlrun/serving/routers.py
index 70f2cb29a5cb..e7343f6686b7 100644
--- a/mlrun/serving/routers.py
+++ b/mlrun/serving/routers.py
@@ -1100,7 +1100,7 @@ def _init_endpoint_record(
db.create_model_endpoint(
project=project,
endpoint_id=model_endpoint,
- model_endpoint=current_endpoint.dict(),
+ model_endpoint=current_endpoint,
)
except Exception as exc:
diff --git a/tests/api/api/test_model_endpoints.py b/tests/api/api/test_model_endpoints.py
index 4d0e3e657b09..a42206046c35 100644
--- a/tests/api/api/test_model_endpoints.py
+++ b/tests/api/api/test_model_endpoints.py
@@ -312,7 +312,7 @@ def random_labels():
return mlrun.api.schemas.ModelEndpoint(
metadata=mlrun.api.schemas.ModelEndpointMetadata(
- project=TEST_PROJECT, labels=random_labels()
+ project=TEST_PROJECT, labels=random_labels(), uid=str(randint(1000, 5000))
),
spec=mlrun.api.schemas.ModelEndpointSpec(
function_uri=f"test/function_{randint(0, 100)}:v{randint(0, 100)}",
diff --git a/tests/system/model_monitoring/test_model_monitoring.py b/tests/system/model_monitoring/test_model_monitoring.py
index 17fe2151f342..b8ec44a72337 100644
--- a/tests/system/model_monitoring/test_model_monitoring.py
+++ b/tests/system/model_monitoring/test_model_monitoring.py
@@ -212,7 +212,9 @@ def random_labels():
return ModelEndpoint(
metadata=ModelEndpointMetadata(
- project=self.project_name, labels=random_labels()
+ project=self.project_name,
+ labels=random_labels(),
+ uid=str(randint(1000, 5000)),
),
spec=ModelEndpointSpec(
function_uri=f"test/function_{randint(0, 100)}:v{randint(0, 100)}",
@@ -295,15 +297,15 @@ def test_basic_model_monitoring(self):
endpoints_list = mlrun.get_run_db().list_model_endpoints(
self.project_name, metrics=["predictions_per_second"]
)
- assert len(endpoints_list.endpoints) == 1
+ assert len(endpoints_list) == 1
- endpoint = endpoints_list.endpoints[0]
+ endpoint = endpoints_list[0]
assert len(endpoint.status.metrics) > 0
- predictions_per_second = endpoint.status.metrics["predictions_per_second"]
- assert predictions_per_second.name == "predictions_per_second"
-
- total = sum((m[1] for m in predictions_per_second.values))
+ predictions_per_second = endpoint.status.metrics["real_time"][
+ "predictions_per_second"
+ ]
+ total = sum((m[1] for m in predictions_per_second))
assert total > 0
@@ -431,10 +433,10 @@ def test_model_monitoring_with_regression(self):
# Validate a single endpoint
endpoints_list = mlrun.get_run_db().list_model_endpoints(self.project_name)
- assert len(endpoints_list.endpoints) == 1
+ assert len(endpoints_list) == 1
# Validate monitoring mode
- model_endpoint = endpoints_list.endpoints[0]
+ model_endpoint = endpoints_list[0]
assert model_endpoint.spec.monitoring_mode == ModelMonitoringMode.enabled.value
# Validate tracking policy
@@ -612,25 +614,23 @@ def test_model_monitoring_voting_ensemble(self):
self.project_name, top_level=True
)
- assert len(top_level_endpoints.endpoints) == 1
- assert (
- top_level_endpoints.endpoints[0].status.endpoint_type == EndpointType.ROUTER
- )
+ assert len(top_level_endpoints) == 1
+ assert top_level_endpoints[0].status.endpoint_type == EndpointType.ROUTER
- children_list = top_level_endpoints.endpoints[0].status.children_uids
+ children_list = top_level_endpoints[0].status.children_uids
assert len(children_list) == len(model_names)
endpoints_children_list = mlrun.get_run_db().list_model_endpoints(
self.project_name, uids=children_list
)
- assert len(endpoints_children_list.endpoints) == len(model_names)
- for child in endpoints_children_list.endpoints:
+ assert len(endpoints_children_list) == len(model_names)
+ for child in endpoints_children_list:
assert child.status.endpoint_type == EndpointType.LEAF_EP
# list model endpoints and perform analysis for each endpoint
endpoints_list = mlrun.get_run_db().list_model_endpoints(self.project_name)
- for endpoint in endpoints_list.endpoints:
+ for endpoint in endpoints_list:
# Validate that the model endpoint record has been updated through the stream process
assert endpoint.status.first_request != endpoint.status.last_request
data = client.read(
From b948c1dba5fb85f58ddfbdcb7fac4fad0654eaa8 Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Wed, 29 Mar 2023 18:27:55 +0300
Subject: [PATCH 022/334] [Spark] Fix resolving code path (#3356)
---
mlrun/runtimes/kubejob.py | 42 ++++++++++++++++++-----------
mlrun/runtimes/local.py | 12 ++++-----
mlrun/runtimes/sparkjob/abstract.py | 6 +++--
tests/api/runtimes/test_kubejob.py | 27 +++++++++++++++++++
4 files changed, 64 insertions(+), 23 deletions(-)
diff --git a/mlrun/runtimes/kubejob.py b/mlrun/runtimes/kubejob.py
index f0ad9b78f06b..defc13b81db6 100644
--- a/mlrun/runtimes/kubejob.py
+++ b/mlrun/runtimes/kubejob.py
@@ -66,7 +66,7 @@ def with_source_archive(
git://github.com/mlrun/something.git
http://some/url/file.zip
:param handler: default function handler
- :param workdir: working dir relative to the archive root or absolute (e.g. './subdir')
+ :param workdir: working dir relative to the archive root (e.g. './subdir') or absolute to the image root
:param pull_at_runtime: load the archive into the container at job runtime vs on build/deploy
:param target_dir: target dir on runtime pod or repo clone / archive extraction
"""
@@ -350,20 +350,7 @@ def _run(self, runobj: RunObject, execution):
new_meta = self._get_meta(runobj)
self._add_secrets_to_spec_before_running(runobj)
- workdir = self.spec.workdir
- if workdir:
- if self.spec.build.source and self.spec.build.load_source_on_run:
- # workdir will be set AFTER the clone which is done in the pre-run of local runtime
- workdir = None
- elif not os.path.isabs(workdir):
- # workdir is a relative path from the source root to where the code is located
- # add the clone_target_dir (where to source was copied), if not specified assume the workdir is complete
- if self.spec.clone_target_dir:
- if workdir.startswith("./"):
- # TODO: use 'removeprefix' when we drop python 3.7 support
- # workdir.removeprefix("./")
- workdir = workdir[2:]
- workdir = os.path.join(self.spec.clone_target_dir, workdir)
+ workdir = self._resolve_workdir()
pod_spec = func_to_pod(
self.full_image_path(
@@ -397,6 +384,31 @@ def _run(self, runobj: RunObject, execution):
return None
+ def _resolve_workdir(self):
+ """
+ The workdir is relative to the source root, if the source is not loaded on run then the workdir
+ is relative to the clone target dir (where the source was copied to).
+ Otherwise, if the source is loaded on run, the workdir is resolved on the run as well.
+ If the workdir is absolute, keep it as is.
+ """
+ workdir = self.spec.workdir
+ if self.spec.build.source and self.spec.build.load_source_on_run:
+ # workdir will be set AFTER the clone which is done in the pre-run of local runtime
+ return None
+
+ if workdir and os.path.isabs(workdir):
+ return workdir
+
+ if self.spec.clone_target_dir:
+ workdir = workdir or ""
+ if workdir.startswith("./"):
+ # TODO: use 'removeprefix' when we drop python 3.7 support
+ # workdir.removeprefix("./")
+ workdir = workdir[2:]
+ return os.path.join(self.spec.clone_target_dir, workdir)
+
+ return workdir
+
def func_to_pod(image, runtime, extra_env, command, args, workdir):
container = client.V1Container(
diff --git a/mlrun/runtimes/local.py b/mlrun/runtimes/local.py
index 8d0ecb5b6d81..e402afa96d19 100644
--- a/mlrun/runtimes/local.py
+++ b/mlrun/runtimes/local.py
@@ -184,12 +184,12 @@ def to_job(self, image=""):
def with_source_archive(self, source, workdir=None, handler=None, target_dir=None):
"""load the code from git/tar/zip archive at runtime or build
- :param source: valid path to git, zip, or tar file, e.g.
- git://github.com/mlrun/something.git
- http://some/url/file.zip
- :param handler: default function handler
- :param workdir: working dir relative to the archive root or absolute (e.g. './subdir')
- :param target_dir: local target dir for repo clone (by default its /code)
+ :param source: valid path to git, zip, or tar file, e.g.
+ git://github.com/mlrun/something.git
+ http://some/url/file.zip
+ :param handler: default function handler
+ :param workdir: working dir relative to the archive root (e.g. './subdir') or absolute
+ :param target_dir: local target dir for repo clone (by default its /code)
"""
self.spec.build.source = source
self.spec.build.load_source_on_run = True
diff --git a/mlrun/runtimes/sparkjob/abstract.py b/mlrun/runtimes/sparkjob/abstract.py
index 923003dc8b3b..fa6234e777ee 100644
--- a/mlrun/runtimes/sparkjob/abstract.py
+++ b/mlrun/runtimes/sparkjob/abstract.py
@@ -570,8 +570,10 @@ def _run(self, runobj: RunObject, execution: MLClientCtx):
if self.spec.command:
if "://" not in self.spec.command:
+ workdir = self._resolve_workdir()
self.spec.command = "local://" + os.path.join(
- self.spec.workdir or "", self.spec.command
+ workdir or "",
+ self.spec.command,
)
update_in(job, "spec.mainApplicationFile", self.spec.command)
@@ -811,7 +813,7 @@ def with_source_archive(
git://github.com/mlrun/something.git
http://some/url/file.zip
:param handler: default function handler
- :param workdir: working dir relative to the archive root or absolute (e.g. './subdir')
+ :param workdir: working dir relative to the archive root (e.g. './subdir') or absolute to the image root
:param pull_at_runtime: not supported for spark runtime, must be False
:param target_dir: target dir on runtime pod for repo clone / archive extraction
"""
diff --git a/tests/api/runtimes/test_kubejob.py b/tests/api/runtimes/test_kubejob.py
index 7a4356e05305..57dee7e00450 100644
--- a/tests/api/runtimes/test_kubejob.py
+++ b/tests/api/runtimes/test_kubejob.py
@@ -741,6 +741,33 @@ def test_deploy_upgrade_pip(
not in dockerfile
)
+ @pytest.mark.parametrize(
+ "workdir, source, pull_at_runtime, target_dir, expected_workdir",
+ [
+ ("", "git://bla", True, None, None),
+ ("", "git://bla", False, None, None),
+ ("", "git://bla", False, "/a/b/c", "/a/b/c/"),
+ ("subdir", "git://bla", False, "/a/b/c", "/a/b/c/subdir"),
+ ("./subdir", "git://bla", False, "/a/b/c", "/a/b/c/subdir"),
+ ("./subdir", "git://bla", True, "/a/b/c", None),
+ ("/abs/subdir", "git://bla", False, "/a/b/c", "/abs/subdir"),
+ ("/abs/subdir", "git://bla", False, None, "/abs/subdir"),
+ ],
+ )
+ def test_resolve_workdir(
+ self, workdir, source, pull_at_runtime, target_dir, expected_workdir
+ ):
+ runtime = self._generate_runtime()
+ runtime.with_source_archive(
+ source, workdir, pull_at_runtime=pull_at_runtime, target_dir=target_dir
+ )
+
+ # mock the build
+ runtime.spec.image = "some/image"
+ self.execute_function(runtime)
+ pod = self._get_pod_creation_args()
+ assert pod.spec.containers[0].working_dir == expected_workdir
+
@staticmethod
def _assert_build_commands(expected_commands, runtime):
assert (
From f37f20ae228231d96e1a161371115000facb2aa4 Mon Sep 17 00:00:00 2001
From: Yoni Shelach <92271540+yonishelach@users.noreply.github.com>
Date: Thu, 30 Mar 2023 12:58:53 +0300
Subject: [PATCH 023/334] [API] Add marketplace `get_asset` endpoint (#3339)
---
mlrun/api/api/endpoints/marketplace.py | 57 +++++++++++++++++
mlrun/api/crud/marketplace.py | 50 ++++++++++++++-
mlrun/api/schemas/marketplace.py | 2 +-
mlrun/db/httpdb.py | 29 +++++++++
.../functions/channel/catalog.json | 3 +
.../dev_function/latest/static/my_html.html | 6 ++
tests/api/api/marketplace/test_marketplace.py | 63 ++++++++++++++++++-
7 files changed, 206 insertions(+), 4 deletions(-)
create mode 100644 tests/api/api/marketplace/functions/channel/dev_function/latest/static/my_html.html
diff --git a/mlrun/api/api/endpoints/marketplace.py b/mlrun/api/api/endpoints/marketplace.py
index 3118dd597537..6978f0669fe4 100644
--- a/mlrun/api/api/endpoints/marketplace.py
+++ b/mlrun/api/api/endpoints/marketplace.py
@@ -251,3 +251,60 @@ async def get_object(
if not ctype:
ctype = "application/octet-stream"
return Response(content=object_data, media_type=ctype)
+
+
+@router.get("/marketplace/sources/{source_name}/items/{item_name}/assets/{asset_name}")
+async def get_asset(
+ source_name: str,
+ item_name: str,
+ asset_name: str,
+ tag: Optional[str] = Query("latest"),
+ version: Optional[str] = Query(None),
+ db_session: Session = Depends(mlrun.api.api.deps.get_db_session),
+ auth_info: mlrun.api.schemas.AuthInfo = Depends(
+ mlrun.api.api.deps.authenticate_request
+ ),
+):
+ """
+ Retrieve asset from a specific item in specific marketplace source.
+
+ :param source_name: marketplace source name
+ :param item_name: the name of the item
+ :param asset_name: the name of the asset to retrieve
+ :param tag: tag of item - latest or version number
+ :param version: item version
+ :param db_session: a session that manages the current dialog with the database
+ :param auth_info: the auth info of the request
+
+ :return: fastapi response with the asset in content
+ """
+ source = await run_in_threadpool(
+ get_db().get_marketplace_source, db_session, source_name
+ )
+
+ await mlrun.api.utils.auth.verifier.AuthVerifier().query_global_resource_permissions(
+ mlrun.api.schemas.AuthorizationResourceTypes.marketplace_source,
+ AuthorizationAction.read,
+ auth_info,
+ )
+ # Getting the relevant item which hold the asset information
+ item = await run_in_threadpool(
+ mlrun.api.crud.Marketplace().get_item,
+ source.source,
+ item_name,
+ version,
+ tag,
+ )
+
+ # Getting the asset from the item
+ asset, url = await run_in_threadpool(
+ mlrun.api.crud.Marketplace().get_asset,
+ source.source,
+ item,
+ asset_name,
+ )
+
+ ctype, _ = mimetypes.guess_type(url)
+ if not ctype:
+ ctype = "application/octet-stream"
+ return Response(content=asset, media_type=ctype)
diff --git a/mlrun/api/crud/marketplace.py b/mlrun/api/crud/marketplace.py
index d521f667ccd7..56621ab2c2d6 100644
--- a/mlrun/api/crud/marketplace.py
+++ b/mlrun/api/crud/marketplace.py
@@ -13,7 +13,7 @@
# limitations under the License.
#
import json
-from typing import Any, Dict, List, Optional
+from typing import Any, Dict, List, Optional, Tuple
import mlrun.errors
import mlrun.utils.singleton
@@ -121,6 +121,27 @@ def _get_source_credentials(self, source_name):
return source_secrets
+ @staticmethod
+ def _get_asset_full_path(
+ source: MarketplaceSource, item: MarketplaceItem, asset: str
+ ):
+ """
+ Combining the item path with the asset path.
+
+ :param source: Marketplace source object.
+ :param item: The relevant item to get the asset from.
+ :param asset: The asset name
+ :return: Full path to the asset, relative to the item directory.
+ """
+ asset_path = item.spec.assets.get(asset, None)
+ if not asset_path:
+ raise mlrun.errors.MLRunNotFoundError(
+ f"Asset={asset} not found. "
+ f"item={item.metadata.name}, version={item.metadata.version}, tag={item.metadata.tag}"
+ )
+ item_path = item.metadata.get_relative_path()
+ return source.get_full_uri(item_path + asset_path)
+
@staticmethod
def _transform_catalog_dict_to_schema(
source: MarketplaceSource, catalog_dict: Dict[str, Any]
@@ -139,11 +160,14 @@ def _transform_catalog_dict_to_schema(
for version_tag, version_dict in object_dict.items():
object_details_dict = version_dict.copy()
spec_dict = object_details_dict.pop("spec", {})
+ assets = object_details_dict.pop("assets", {})
metadata = MarketplaceItemMetadata(
tag=version_tag, **object_details_dict
)
item_uri = source.get_full_uri(metadata.get_relative_path())
- spec = MarketplaceItemSpec(item_uri=item_uri, **spec_dict)
+ spec = MarketplaceItemSpec(
+ item_uri=item_uri, assets=assets, **spec_dict
+ )
item = MarketplaceItem(
metadata=metadata,
spec=spec,
@@ -262,3 +286,25 @@ def get_item_object_using_source_credentials(self, source: MarketplaceSource, ur
else:
catalog_data = mlrun.run.get_object(url=url, secrets=credentials)
return catalog_data
+
+ def get_asset(
+ self,
+ source: MarketplaceSource,
+ item: MarketplaceItem,
+ asset_name: str,
+ ) -> Tuple[bytes, str]:
+ """
+ Retrieve asset object from marketplace source.
+
+ :param source: marketplace source
+ :param item: marketplace item which contains the assets
+ :param asset_name: asset name, like source, example, etc.
+
+ :return: tuple of asset as bytes and url of asset
+ """
+ credentials = self._get_source_credentials(source.metadata.name)
+ asset_path = self._get_asset_full_path(source, item, asset_name)
+ return (
+ mlrun.run.get_object(url=asset_path, secrets=credentials),
+ asset_path,
+ )
diff --git a/mlrun/api/schemas/marketplace.py b/mlrun/api/schemas/marketplace.py
index fda43d3deff7..c2ad9420e246 100644
--- a/mlrun/api/schemas/marketplace.py
+++ b/mlrun/api/schemas/marketplace.py
@@ -122,6 +122,7 @@ def get_relative_path(self) -> str:
class MarketplaceItemSpec(ObjectSpec):
item_uri: str
+ assets: Dict[str, str] = {}
class MarketplaceItem(BaseModel):
@@ -129,7 +130,6 @@ class MarketplaceItem(BaseModel):
metadata: MarketplaceItemMetadata
spec: MarketplaceItemSpec
status: ObjectStatus
- assets: Dict[str, str] = {}
class MarketplaceCatalog(BaseModel):
diff --git a/mlrun/db/httpdb.py b/mlrun/db/httpdb.py
index 29b009b4e568..0ca5cd57c077 100644
--- a/mlrun/db/httpdb.py
+++ b/mlrun/db/httpdb.py
@@ -2906,6 +2906,35 @@ def get_marketplace_item(
response = self.api_call(method="GET", path=path, params=params)
return schemas.MarketplaceItem(**response.json())
+ def get_marketplace_asset(
+ self,
+ source_name: str,
+ item_name: str,
+ asset_name: str,
+ version: str = None,
+ tag: str = "latest",
+ ):
+ """
+ Get marketplace asset from item.
+
+ :param source_name: Name of source.
+ :param item_name: Name of the item which holds the asset.
+ :param asset_name: Name of the asset to retrieve.
+ :param version: Get a specific version of the item. Default is ``None``.
+ :param tag: Get a specific version of the item identified by tag. Default is ``latest``.
+
+ :return: http response with the asset in the content attribute
+ """
+ path = (
+ f"marketplace/sources/{source_name}/items/{item_name}/assets/{asset_name}",
+ )
+ params = {
+ "version": version,
+ "tag": tag,
+ }
+ response = self.api_call(method="GET", path=path, params=params)
+ return response
+
def verify_authorization(
self, authorization_verification_input: schemas.AuthorizationVerificationInput
):
diff --git a/tests/api/api/marketplace/functions/channel/catalog.json b/tests/api/api/marketplace/functions/channel/catalog.json
index 0407fc5acae5..18b99bcd6e9b 100644
--- a/tests/api/api/marketplace/functions/channel/catalog.json
+++ b/tests/api/api/marketplace/functions/channel/catalog.json
@@ -27,6 +27,9 @@
"pandas_profiling"
]
},
+ "assets": {
+ "html_asset": "static/my_html.html"
+ },
"url": "",
"version": "0.0.1"
}
diff --git a/tests/api/api/marketplace/functions/channel/dev_function/latest/static/my_html.html b/tests/api/api/marketplace/functions/channel/dev_function/latest/static/my_html.html
new file mode 100644
index 000000000000..2a53fedf8ac0
--- /dev/null
+++ b/tests/api/api/marketplace/functions/channel/dev_function/latest/static/my_html.html
@@ -0,0 +1,6 @@
+
+
+
+Example HTML File
+
+
diff --git a/tests/api/api/marketplace/test_marketplace.py b/tests/api/api/marketplace/test_marketplace.py
index eb8bb76917aa..90fd7f5be02c 100644
--- a/tests/api/api/marketplace/test_marketplace.py
+++ b/tests/api/api/marketplace/test_marketplace.py
@@ -12,11 +12,13 @@
# See the License for the specific language governing permissions and
# limitations under the License.
#
+import http
import pathlib
import random
from http import HTTPStatus
import deepdiff
+import pytest
import yaml
from fastapi.testclient import TestClient
from sqlalchemy.orm import Session
@@ -255,7 +257,6 @@ def test_marketplace_default_source(
) -> None:
# This test validates that the default source is valid is its catalog and objects can be retrieved.
manager = mlrun.api.crud.Marketplace()
-
source_object = mlrun.api.schemas.MarketplaceSource.generate_default_source()
catalog = manager.get_source_catalog(source_object)
assert len(catalog.catalog) > 0
@@ -304,3 +305,63 @@ def test_marketplace_catalog_apis(
function_modified_name = item["metadata"]["name"].replace("_", "-")
assert yaml_function_name == function_modified_name
+
+
+def test_marketplace_get_asset_from_default_source(
+ db: Session, client: TestClient, k8s_secrets_mock: tests.api.conftest.K8sSecretsMock
+) -> None:
+ possible_assets = [
+ ("docs", "text/html; charset=utf-8"),
+ ("source", "text/x-python; charset=utf-8"),
+ ("example", "application/octet-stream"),
+ ("function", "application/octet-stream"),
+ ]
+ sources = client.get("marketplace/sources").json()
+ source_name = sources[0]["source"]["metadata"]["name"]
+ catalog = client.get(f"marketplace/sources/{source_name}/items").json()
+ for _ in range(10):
+ item = random.choice(catalog["catalog"])
+ asset_name, expected_content_type = random.choice(possible_assets)
+ response = client.get(
+ f"marketplace/sources/{source_name}/items/{item['metadata']['name']}/assets/{asset_name}"
+ )
+ assert response.status_code == http.HTTPStatus.OK.value
+ assert response.headers["content-type"] == expected_content_type
+
+
+def test_marketplace_get_asset(
+ k8s_secrets_mock: tests.api.conftest.K8sSecretsMock,
+) -> None:
+ manager = mlrun.api.crud.Marketplace()
+
+ # Adding marketplace source with credentials:
+ credentials = {"secret": "value"}
+
+ source_dict = _generate_source_dict(1, "source", credentials)
+ expected_credentials = {
+ mlrun.api.crud.Marketplace()._generate_credentials_secret_key(
+ "source", "secret"
+ ): credentials["secret"]
+ }
+ source_object = mlrun.api.schemas.MarketplaceSource(**source_dict["source"])
+ manager.add_source(source_object)
+ k8s_secrets_mock.assert_project_secrets(
+ config.marketplace.k8s_secrets_project_name, expected_credentials
+ )
+ # getting asset:
+ catalog = manager.get_source_catalog(source_object)
+ item = catalog.catalog[0]
+ # verifying item contain the asset:
+ assert item.spec.assets.get("html_asset", "") == "static/my_html.html"
+
+ asset_object, url = manager.get_asset(source_object, item, "html_asset")
+ relative_asset_path = "functions/channel/dev_function/latest/static/my_html.html"
+ asset_path = pathlib.Path(__file__).absolute().parent / relative_asset_path
+ with open(asset_path, "r") as f:
+ expected_content = f.read()
+ # Validating content and url:
+ assert expected_content == asset_object.decode("utf-8") and url == str(asset_path)
+
+ # Verify not-found assets are handled properly
+ with pytest.raises(mlrun.errors.MLRunNotFoundError):
+ manager.get_asset(source_object, item, "not-found")
From 780e2f143916b91a2720b0aeaef8084daee9b253 Mon Sep 17 00:00:00 2001
From: davesh0812 <85231462+davesh0812@users.noreply.github.com>
Date: Thu, 30 Mar 2023 18:37:04 +0300
Subject: [PATCH 024/334] [Requirements] Bump pyarrow upper limitation & Fix
system test to use ParquetDatasetV2 (#3321)
---
requirements.txt | 4 ++--
tests/system/feature_store/test_feature_store.py | 9 +++++++--
tests/test_requirements.py | 2 +-
3 files changed, 10 insertions(+), 5 deletions(-)
diff --git a/requirements.txt b/requirements.txt
index 9b1f0ec99f8e..87650c476d29 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -28,8 +28,8 @@ numpy>=1.16.5, <1.23.0
pandas~=1.2, <1.5.0
# used as a the engine for parquet files by pandas
# >=10 to resolve https://issues.apache.org/jira/browse/ARROW-16838 bug that is triggered by ingest (ML-3299)
-# < 11 since starting from 11 ParquetDataset is deprecated and ParquetDatasetV2 is used instead
-pyarrow>=10,<11
+# <12 to prevent bugs due to major upgrading
+pyarrow>=10.0, <12
pyyaml~=5.1
requests~=2.22
# in sqlalchemy>=2.0 there is breaking changes (such as in Table class autoload argument is removed)
diff --git a/tests/system/feature_store/test_feature_store.py b/tests/system/feature_store/test_feature_store.py
index 5778ddc17700..0b5de34a38a5 100644
--- a/tests/system/feature_store/test_feature_store.py
+++ b/tests/system/feature_store/test_feature_store.py
@@ -26,6 +26,7 @@
import fsspec
import numpy as np
import pandas as pd
+import pyarrow
import pyarrow.parquet as pq
import pytest
import requests
@@ -853,13 +854,17 @@ def test_ingest_partitioned_by_key_and_time(
assert resp1 == resp2
+ major_pyarrow_version = int(pyarrow.__version__.split(".")[0])
file_system = fsspec.filesystem("v3io")
path = measurements.get_target_path("parquet")
dataset = pq.ParquetDataset(
- path,
+ path if major_pyarrow_version < 11 else path[len("v3io://") :],
filesystem=file_system,
)
- partitions = [key for key, _ in dataset.pieces[0].partition_keys]
+ if major_pyarrow_version < 11:
+ partitions = [key for key, _ in dataset.pieces[0].partition_keys]
+ else:
+ partitions = dataset.partitioning.schema.names
if key_bucketing_number is None:
expected_partitions = []
diff --git a/tests/test_requirements.py b/tests/test_requirements.py
index 65c083433182..961b85f67bf3 100644
--- a/tests/test_requirements.py
+++ b/tests/test_requirements.py
@@ -125,7 +125,7 @@ def test_requirement_specifiers_convention():
"alembic": {"~=1.4,<1.6.0"},
"boto3": {"~=1.9, <1.17.107"},
"dask-ml": {"~=1.4,<1.9.0"},
- "pyarrow": {">=10,<11"},
+ "pyarrow": {">=10.0, <12"},
"nbclassic": {">=0.2.8"},
"protobuf": {">=3.13, <3.20"},
"pandas": {"~=1.2, <1.5.0"},
From 69bf2bfc0d717be29785081ca4a92a39eccd3286 Mon Sep 17 00:00:00 2001
From: Gal Topper
Date: Sun, 2 Apr 2023 05:17:07 +0800
Subject: [PATCH 025/334] [Tests] Fix parameter in tests (#3363)
---
tests/system/feature_store/test_spark_engine.py | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/tests/system/feature_store/test_spark_engine.py b/tests/system/feature_store/test_spark_engine.py
index ebe347483f5a..b01b836f8459 100644
--- a/tests/system/feature_store/test_spark_engine.py
+++ b/tests/system/feature_store/test_spark_engine.py
@@ -357,7 +357,7 @@ def test_ingest_to_redis(self):
measurements,
source,
spark_context=self.spark_service,
- run_config=fstore.RunConfig(False),
+ run_config=fstore.RunConfig(local=False),
overwrite=True,
)
# read the dataframe from the redis back
@@ -405,7 +405,7 @@ def test_ingest_to_redis_numeric_index(self):
measurements,
source,
spark_context=self.spark_service,
- run_config=fstore.RunConfig(False),
+ run_config=fstore.RunConfig(local=False),
overwrite=True,
)
# read the dataframe from the redis back
From 8ddeb385f09c8be10ad5e4a7d9748ef3fe6d5ee3 Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Sun, 2 Apr 2023 09:22:40 +0300
Subject: [PATCH 026/334] [Tests] System test prepare purge DB (#3366)
---
.github/workflows/system-tests-enterprise.yml | 3 +
automation/system_test/prepare.py | 104 +++++++++++++++++-
2 files changed, 106 insertions(+), 1 deletion(-)
diff --git a/.github/workflows/system-tests-enterprise.yml b/.github/workflows/system-tests-enterprise.yml
index 25de189cb53f..dd7ecfe6606b 100644
--- a/.github/workflows/system-tests-enterprise.yml
+++ b/.github/workflows/system-tests-enterprise.yml
@@ -208,6 +208,9 @@ jobs:
"${{ secrets.LATEST_SYSTEM_TEST_SPARK_SERVICE }}" \
"${{ secrets.LATEST_SYSTEM_TEST_PASSWORD }}" \
"${{ secrets.LATEST_SYSTEM_TEST_SLACK_WEBHOOK_URL }}" \
+ "${{ secrets.LATEST_SYSTEM_TEST_MYSQL_USER }}" \
+ "${{ secrets.LATEST_SYSTEM_TEST_MYSQL_PASSWORD }}" \
+ --purge-db \
--mlrun-commit "${{ steps.computed_params.outputs.mlrun_hash }}" \
--override-image-registry "${{ steps.computed_params.outputs.mlrun_docker_registry }}" \
--override-image-repo ${{ steps.computed_params.outputs.mlrun_docker_repo }} \
diff --git a/automation/system_test/prepare.py b/automation/system_test/prepare.py
index c2db2d62d42e..4cf599382743 100644
--- a/automation/system_test/prepare.py
+++ b/automation/system_test/prepare.py
@@ -42,6 +42,7 @@ class Constants:
mlrun_code_path = workdir / "mlrun"
provctl_path = workdir / "provctl"
system_tests_env_yaml = pathlib.Path("tests") / "system" / "env.yml"
+ namespace = "default-tenant"
git_url = "https://github.com/mlrun/mlrun.git"
@@ -69,6 +70,9 @@ def __init__(
spark_service: str = None,
password: str = None,
slack_webhook_url: str = None,
+ mysql_user: str = None,
+ mysql_password: str = None,
+ purge_db: bool = False,
debug: bool = False,
):
self._logger = logger
@@ -91,6 +95,9 @@ def __init__(
self._provctl_download_s3_access_key = provctl_download_s3_access_key
self._provctl_download_s3_key_id = provctl_download_s3_key_id
self._iguazio_version = iguazio_version
+ self._mysql_user = mysql_user
+ self._mysql_password = mysql_password
+ self._purge_db = purge_db
self._env_config = {
"MLRUN_DBPATH": mlrun_dbpath,
@@ -136,6 +143,9 @@ def run(self):
self._patch_mlrun()
+ if self._purge_db:
+ self._purge_mlrun_db()
+
def clean_up_remote_workdir(self):
self._logger.info(
"Cleaning up remote workdir", workdir=str(self.Constants.workdir)
@@ -334,7 +344,10 @@ def _override_mlrun_api_env(self):
"apiVersion": "v1",
"data": data,
"kind": "ConfigMap",
- "metadata": {"name": "mlrun-override-env", "namespace": "default-tenant"},
+ "metadata": {
+ "name": "mlrun-override-env",
+ "namespace": self.Constants.namespace,
+ },
}
manifest_file_name = "override_mlrun_registry.yml"
self._run_command(
@@ -503,6 +516,86 @@ def _resolve_iguazio_version(self):
"Resolved iguazio version", iguazio_version=self._iguazio_version
)
+ def _purge_mlrun_db(self):
+ """
+ Purge mlrun db - exec into mlrun-db pod, delete the database and restart mlrun pods
+ """
+ self._delete_mlrun_db()
+ self._rollout_restart_mlrun()
+ self._wait_for_mlrun_to_be_ready()
+
+ def _delete_mlrun_db(self):
+ self._logger.info("Deleting mlrun db")
+
+ get_mlrun_db_pod_name_cmd = self._get_pod_name_command(
+ labels={
+ "app.kubernetes.io/component": "db",
+ "app.kubernetes.io/instance": "mlrun",
+ },
+ )
+
+ password = ""
+ if self._mysql_password:
+ password = f"-p {self._mysql_password} "
+
+ drop_db_cmd = f"mysql --socket=/run/mysqld/mysql.sock -u {self._mysql_user} {password}-e 'DROP DATABASE mlrun;'"
+ self._run_kubectl_command(
+ args=[
+ "exec",
+ "-n",
+ self.Constants.namespace,
+ "-it",
+ f"$({get_mlrun_db_pod_name_cmd})",
+ "--",
+ drop_db_cmd,
+ ],
+ verbose=False,
+ )
+
+ def _get_pod_name_command(self, labels, namespace=None):
+ namespace = namespace or self.Constants.namespace
+ labels_selector = ",".join([f"{k}={v}" for k, v in labels.items()])
+ return "kubectl get pods -n {namespace} -l {labels_selector} | tail -n 1 | awk '{{print $1}}'".format(
+ namespace=namespace, labels_selector=labels_selector
+ )
+
+ def _rollout_restart_mlrun(self):
+ self._logger.info("Restarting mlrun")
+ self._run_kubectl_command(
+ args=[
+ "rollout",
+ "restart",
+ "deployment",
+ "-n",
+ self.Constants.namespace,
+ "mlrun-api-chief",
+ "mlrun-api-worker",
+ "mlrun-db",
+ ]
+ )
+
+ def _wait_for_mlrun_to_be_ready(self):
+ self._logger.info("Waiting for mlrun to be ready")
+ self._run_kubectl_command(
+ args=[
+ "wait",
+ "--for=condition=available",
+ "--timeout=300s",
+ "deployment",
+ "-n",
+ self.Constants.namespace,
+ "mlrun-api-chief",
+ "mlrun-db",
+ ]
+ )
+
+ def _run_kubectl_command(self, args, verbose=True):
+ self._run_command(
+ command="kubectl",
+ args=args,
+ verbose=verbose,
+ )
+
@click.group()
def main():
@@ -552,6 +645,9 @@ def main():
@click.argument("spark-service", type=str, required=True)
@click.argument("password", type=str, default=None, required=False)
@click.argument("slack-webhook-url", type=str, default=None, required=False)
+@click.argument("mysql-user", type=str, default=None, required=False)
+@click.argument("mysql-password", type=str, default=None, required=False)
+@click.option("--purge-db", "-pdb", is_flag=True, help="Purge mlrun db")
@click.option(
"--debug",
"-d",
@@ -581,6 +677,9 @@ def run(
spark_service: str,
password: str,
slack_webhook_url: str,
+ mysql_user: str,
+ mysql_password: str,
+ purge_db: bool,
debug: bool,
):
system_test_preparer = SystemTestPreparer(
@@ -606,6 +705,9 @@ def run(
spark_service,
password,
slack_webhook_url,
+ mysql_user,
+ mysql_password,
+ purge_db,
debug,
)
try:
From 9c0be5bb4319c3af17199482b7df37dfa801acd1 Mon Sep 17 00:00:00 2001
From: davesh0812 <85231462+davesh0812@users.noreply.github.com>
Date: Sun, 2 Apr 2023 11:53:26 +0300
Subject: [PATCH 027/334] [Features] Fixing issue when value_type is
`ValueType` instance (#3368)
---
mlrun/features.py | 11 ++++++-----
1 file changed, 6 insertions(+), 5 deletions(-)
diff --git a/mlrun/features.py b/mlrun/features.py
index ba7eb5584a0e..60615cde1163 100644
--- a/mlrun/features.py
+++ b/mlrun/features.py
@@ -105,11 +105,12 @@ def __init__(
:param labels: a set of key/value labels (tags)
"""
self.name = name or ""
- self.value_type = (
- python_type_to_value_type(value_type)
- if value_type is not None
- else ValueType.STRING
- )
+ if isinstance(value_type, ValueType):
+ self.value_type = value_type
+ elif value_type is not None:
+ self.value_type = python_type_to_value_type(value_type)
+ else:
+ self.value_type = ValueType.STRING
self.dims = dims
self.description = description
self.default = default
From cdd9387aeab343292592e4b5d8062aad697bb7d4 Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Sun, 2 Apr 2023 13:47:53 +0300
Subject: [PATCH 028/334] [Project] Fix cleanup of downloaded artifact zip on
import (#3323)
---
mlrun/datastore/base.py | 11 +++++-
mlrun/projects/project.py | 7 ++--
.../sdk_api/artifacts/test_artifacts.py | 34 +++++++++++++++++++
3 files changed, 49 insertions(+), 3 deletions(-)
diff --git a/mlrun/datastore/base.py b/mlrun/datastore/base.py
index c0f5f51186ed..830e7abe66fc 100644
--- a/mlrun/datastore/base.py
+++ b/mlrun/datastore/base.py
@@ -383,7 +383,7 @@ def listdir(self):
return self._store.listdir(self._path)
def local(self):
- """get the local path of the file, download to tmp first if its a remote object"""
+ """get the local path of the file, download to tmp first if it's a remote object"""
if self.kind == "file":
return self._path
if self._local_path:
@@ -397,6 +397,15 @@ def local(self):
self.download(self._local_path)
return self._local_path
+ def remove_local(self):
+ """remove the local file if it exists and was downloaded from a remote object"""
+ if self.kind == "file":
+ return
+
+ if self._local_path:
+ remove(self._local_path)
+ self._local_path = ""
+
def as_df(
self,
columns=None,
diff --git a/mlrun/projects/project.py b/mlrun/projects/project.py
index 17519ec5e3dd..242a0a074739 100644
--- a/mlrun/projects/project.py
+++ b/mlrun/projects/project.py
@@ -1469,12 +1469,15 @@ def get_artifact(spec):
with open(f"{temp_dir}/_body", "rb") as fp:
artifact.spec._body = fp.read()
artifact.target_path = ""
+
+ # if the dataitem is not a file, it means we downloaded it from a remote source to a temp file,
+ # so we need to remove it after we're done with it
+ dataitem.remove_local()
+
return self.log_artifact(
artifact, local_path=temp_dir, artifact_path=artifact_path
)
- if dataitem.kind != "file":
- remove(item_file)
else:
raise ValueError("unsupported file suffix, use .yaml, .json, or .zip")
diff --git a/tests/integration/sdk_api/artifacts/test_artifacts.py b/tests/integration/sdk_api/artifacts/test_artifacts.py
index 0fcc68a9f996..3d83860e2016 100644
--- a/tests/integration/sdk_api/artifacts/test_artifacts.py
+++ b/tests/integration/sdk_api/artifacts/test_artifacts.py
@@ -12,7 +12,10 @@
# See the License for the specific language governing permissions and
# limitations under the License.
#
+import os
import pathlib
+import shutil
+import unittest.mock
import pandas
@@ -111,3 +114,34 @@ def test_export_import(self):
data = fp.read()
assert data == b"123"
assert extra_dataitems["kk"].get() == b"456"
+
+ def test_import_remote_zip(self):
+ project = mlrun.new_project("log-mod")
+ target_project = mlrun.new_project("log-mod2")
+ model = project.log_model(
+ "mymod",
+ body=b"123",
+ model_file="model.pkl",
+ extra_data={"kk": b"456"},
+ artifact_path=results_dir,
+ )
+
+ artifact_url = f"{results_dir}/a.zip"
+ model.export(artifact_url)
+
+ # mock downloading the artifact from s3 by copying it locally to a temp path
+ mlrun.datastore.base.DataStore.download = unittest.mock.MagicMock(
+ side_effect=shutil.copyfile
+ )
+ artifact = target_project.import_artifact(
+ f"s3://ֿ{results_dir}/a.zip",
+ "mod-zip",
+ artifact_path=results_dir,
+ )
+
+ temp_local_path = mlrun.datastore.base.DataStore.download.call_args[0][1]
+ assert artifact.metadata.project == "log-mod2"
+ # verify that the original artifact was not deleted
+ assert os.path.exists(artifact_url)
+ # verify that the temp path was deleted after the import
+ assert not os.path.exists(temp_local_path)
From 41e6625c8fa4f1d896e1452163c6e6775c7d24fb Mon Sep 17 00:00:00 2001
From: jist <95856749+george0st@users.noreply.github.com>
Date: Sun, 2 Apr 2023 19:43:32 +0200
Subject: [PATCH 029/334] [Docs] Repair reference (#3371)
---
docs/change-log/index.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/change-log/index.md b/docs/change-log/index.md
index 501b2037b57e..6844a6606531 100644
--- a/docs/change-log/index.md
+++ b/docs/change-log/index.md
@@ -68,7 +68,7 @@ conda activate python39
#### Logging data
| ID | Description |
| --- | ----------------------------------------------------------------- |
-| ML-2845 | Logging data using `hints`. You can now pass data into MLRun and log it using log hints, instead of the decorator. This is the initial change in MLRun to simplify wrapping usable code into MLRun without having to modify it. Future releases will continue this paradigm shift. See [more details](../cheat-sheet.html#track-returning-values-using-returns-new-in-v1-3-0). |
+| ML-2845 | Logging data using `hints`. You can now pass data into MLRun and log it using log hints, instead of the decorator. This is the initial change in MLRun to simplify wrapping usable code into MLRun without having to modify it. Future releases will continue this paradigm shift. See [more details](../cheat-sheet.html#track-returning-values-using-hints-and-returns). |
#### Projects
From bf07df6eb0aa986da5e1ce805a87b58e02239433 Mon Sep 17 00:00:00 2001
From: Gal Topper
Date: Mon, 3 Apr 2023 01:44:05 +0800
Subject: [PATCH 030/334] [Runtimes] Avoid hang on large stderr output in
`run_exec` (#3364)
---
mlrun/runtimes/local.py | 43 ++++++++++++++++++-------
tests/runtimes/assets/verbose_stderr.py | 22 +++++++++++++
tests/runtimes/test_local.py | 30 +++++++++++++++++
3 files changed, 83 insertions(+), 12 deletions(-)
create mode 100644 tests/runtimes/assets/verbose_stderr.py
create mode 100644 tests/runtimes/test_local.py
diff --git a/mlrun/runtimes/local.py b/mlrun/runtimes/local.py
index e402afa96d19..a4dd402744ae 100644
--- a/mlrun/runtimes/local.py
+++ b/mlrun/runtimes/local.py
@@ -14,11 +14,13 @@
import importlib.util as imputil
import inspect
+import io
import json
import os
import socket
import sys
import tempfile
+import threading
import traceback
from contextlib import redirect_stdout
from copy import copy
@@ -358,21 +360,38 @@ def load_module(file_name, handler, context):
def run_exec(cmd, args, env=None, cwd=None):
if args:
cmd += args
- out = ""
if env and "SYSTEMROOT" in os.environ:
env["SYSTEMROOT"] = os.environ["SYSTEMROOT"]
print("running:", cmd)
- process = Popen(cmd, stdout=PIPE, stderr=PIPE, env=os.environ, cwd=cwd)
- while True:
- nextline = process.stdout.readline()
- if not nextline and process.poll() is not None:
- break
- print(nextline.decode("utf-8"), end="")
- sys.stdout.flush()
- out += nextline.decode("utf-8")
- code = process.poll()
-
- err = process.stderr.read().decode("utf-8") if code != 0 else ""
+ process = Popen(
+ cmd, stdout=PIPE, stderr=PIPE, env=os.environ, cwd=cwd, universal_newlines=True
+ )
+
+ def read_stderr(stderr):
+ while True:
+ nextline = process.stderr.readline()
+ if not nextline:
+ break
+ stderr.write(nextline)
+
+ # ML-3710. We must read stderr in a separate thread to drain the stderr pipe so that the spawned process won't
+ # hang if it tries to write more to stderr than the buffer size (default of approx 8kb).
+ with io.StringIO() as stderr:
+ stderr_consumer_thread = threading.Thread(target=read_stderr, args=[stderr])
+ stderr_consumer_thread.start()
+
+ with io.StringIO() as stdout:
+ while True:
+ nextline = process.stdout.readline()
+ if not nextline:
+ break
+ print(nextline, end="")
+ sys.stdout.flush()
+ stdout.write(nextline)
+ out = stdout.getvalue()
+
+ stderr_consumer_thread.join()
+ err = stderr.getvalue()
return out, err
diff --git a/tests/runtimes/assets/verbose_stderr.py b/tests/runtimes/assets/verbose_stderr.py
new file mode 100644
index 000000000000..46d58a43bad5
--- /dev/null
+++ b/tests/runtimes/assets/verbose_stderr.py
@@ -0,0 +1,22 @@
+# Copyright 2023 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+
+print("some output")
+
+for i in range(10000):
+ print("123456789", file=sys.stderr)
+
+sys.exit(1)
diff --git a/tests/runtimes/test_local.py b/tests/runtimes/test_local.py
new file mode 100644
index 000000000000..f4460d4e1bca
--- /dev/null
+++ b/tests/runtimes/test_local.py
@@ -0,0 +1,30 @@
+# Copyright 2023 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import pathlib
+
+from mlrun.runtimes.local import run_exec
+
+
+def test_run_exec_basic():
+ out, err = run_exec(["echo"], ["hello"])
+ assert out == "hello\n"
+ assert err == ""
+
+
+# ML-3710
+def test_run_exec_verbose_stderr():
+ script_path = str(pathlib.Path(__file__).parent / "assets" / "verbose_stderr.py")
+ out, err = run_exec(["python"], [script_path])
+ assert out == "some output\n"
+ assert len(err) == 100000
From 688e48ef64d62146b6f990aee9f206a310328899 Mon Sep 17 00:00:00 2001
From: daniels290813 <78727943+daniels290813@users.noreply.github.com>
Date: Mon, 3 Apr 2023 12:31:51 +0300
Subject: [PATCH 031/334] [CI] Publish tutorials tarball asset on releases
(#3369)
---
.github/workflows/release.yaml | 18 ++++++++++++++++++
1 file changed, 18 insertions(+)
diff --git a/.github/workflows/release.yaml b/.github/workflows/release.yaml
index eb083528e49a..b644a9e389d7 100644
--- a/.github/workflows/release.yaml
+++ b/.github/workflows/release.yaml
@@ -157,3 +157,21 @@ jobs:
allowUpdates: true
prerelease: ${{ github.event.inputs.pre_release }}
body: ${{ steps.resolve-release-notes.outputs.body }}
+
+
+ update-tutorials:
+ name: Bundle tutorials
+ needs: create-releases
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v3
+ - name: Create tutorials tar
+ run: |
+ tar -cvf mlrun-tutorials.tar docs/tutorial
+ - name: Add tutorials tar to release
+ uses: ncipollo/release-action@v1
+ with:
+ allowUpdates: true
+ tag: v${{ github.event.inputs.version }}
+ token: ${{ secrets.RELEASE_GITHUB_ACCESS_TOKEN }}
+ artifacts: mlrun-tutorials.tar
From 7d7382710e448b4a25d1590b95cd3a2943691bd4 Mon Sep 17 00:00:00 2001
From: Gal Topper
Date: Mon, 3 Apr 2023 21:38:54 +0800
Subject: [PATCH 032/334] [Tests] Remove excessive logs in serving tests
(#3376)
---
tests/serving/test_async_flow.py | 3 ---
tests/serving/test_flow.py | 11 +----------
tests/serving/test_serving.py | 5 +----
3 files changed, 2 insertions(+), 17 deletions(-)
diff --git a/tests/serving/test_async_flow.py b/tests/serving/test_async_flow.py
index 66f0b748f9da..8054aecee96a 100644
--- a/tests/serving/test_async_flow.py
+++ b/tests/serving/test_async_flow.py
@@ -74,7 +74,6 @@ def test_async_nested():
graph.add_step(name="final", class_name="Echo", after="ensemble").respond()
- logger.info(graph.to_yaml())
server = function.to_mock_server()
# plot the graph for test & debug
@@ -96,7 +95,6 @@ def test_on_error():
).respond().full_event = True
function.verbose = True
server = function.to_mock_server()
- logger.info(graph.to_yaml())
# plot the graph for test & debug
graph.plot(f"{results}/serving/on_error.png")
@@ -118,7 +116,6 @@ def test_push_error():
server.error_stream = "dummy:///nothing"
# Force an error inside push_error itself
server._error_stream_object = _DummyStreamRaiser()
- logger.info(graph.to_yaml())
server.test(body=[])
server.wait_for_completion()
diff --git a/tests/serving/test_flow.py b/tests/serving/test_flow.py
index 94a65196eac0..10129df61e18 100644
--- a/tests/serving/test_flow.py
+++ b/tests/serving/test_flow.py
@@ -19,7 +19,6 @@
import mlrun
from mlrun.serving import GraphContext, V2ModelServer
from mlrun.serving.states import TaskStep
-from mlrun.utils import logger
from .demo_states import * # noqa
@@ -70,7 +69,6 @@ def test_basic_flow():
server = fn.to_mock_server()
# graph.plot("flow.png")
- print("\nFlow1:\n", graph.to_yaml())
resp = server.test(body=[])
assert resp == ["s1", "s2", "s3"], "flow1 result is incorrect"
@@ -82,7 +80,6 @@ def test_basic_flow():
graph.add_step(name="s3", class_name="Chain", after="s2")
server = fn.to_mock_server()
- logger.info(f"flow: {graph.to_yaml()}")
resp = server.test(body=[])
assert resp == ["s1", "s2", "s3"], "flow2 result is incorrect"
@@ -92,7 +89,6 @@ def test_basic_flow():
graph.add_step(name="s2", class_name="Chain", after="s1", before="s3")
server = fn.to_mock_server()
- logger.info(f"flow: {graph.to_yaml()}")
resp = server.test(body=[])
assert resp == ["s1", "s2", "s3"], "flow3 result is incorrect"
assert server.context.project == "x", "context.project was not set"
@@ -122,7 +118,7 @@ def test_handler_with_context():
)
server = fn.to_mock_server()
resp = server.test(body=5)
- # expext 5 * 2 * 2 * 2 = 40
+ # expect 5 * 2 * 2 * 2 = 40
assert resp == 40, f"got unexpected result {resp}"
@@ -147,7 +143,6 @@ def test_on_error():
graph.add_step(name="catch", class_name="EchoError").full_event = True
server = fn.to_mock_server()
- logger.info(f"flow: {graph.to_yaml()}")
resp = server.test(body=[])
assert resp["error"] and resp["origin_state"] == "raiser", "error wasnt caught"
@@ -205,7 +200,6 @@ def test_add_model():
graph = fn.set_topology("flow", engine="sync")
graph.to("Echo", "e1").to("*", "router").to("Echo", "e2")
fn.add_model("m1", class_name="ModelTestingClass", model_path=".")
- print(graph.to_yaml())
assert "m1" in graph["router"].routes, "model was not added to router"
@@ -214,7 +208,6 @@ def test_add_model():
graph = fn.set_topology("flow", engine="sync")
graph.to("Echo", "e1").to("*", "r1").to("Echo", "e2").to("*", "r2")
fn.add_model("m1", class_name="ModelTestingClass", model_path=".", router_step="r2")
- print(graph.to_yaml())
assert "m1" in graph["r2"].routes, "model was not added to proper router"
@@ -273,7 +266,6 @@ def test_path_control_routers():
"*", name="r1", input_path="x", result_path="y"
).to(name="s3", class_name="Echo").respond()
function.add_model("m1", class_name="ModelClass", model_path=".")
- logger.info(graph.to_yaml())
server = function.to_mock_server()
resp = server.test("/v2/models/m1/infer", body={"x": {"inputs": [5]}})
@@ -292,7 +284,6 @@ def test_path_control_routers():
).to(name="s3", class_name="Echo").respond()
function.add_model("m1", class_name="ModelClassList", model_path=".", multiplier=10)
function.add_model("m2", class_name="ModelClassList", model_path=".", multiplier=20)
- logger.info(graph.to_yaml())
server = function.to_mock_server()
resp = server.test("/v2/models/infer", body={"x": {"inputs": [[5]]}})
diff --git a/tests/serving/test_serving.py b/tests/serving/test_serving.py
index 5d4ee6e0ed7a..a71a7ff7c078 100644
--- a/tests/serving/test_serving.py
+++ b/tests/serving/test_serving.py
@@ -239,7 +239,6 @@ def test_ensemble_get_models():
)
graph.routes = generate_test_routes("EnsembleModelTestingClass")
server = fn.to_mock_server()
- logger.info(f"flow: {graph.to_yaml()}")
resp = server.test("/v2/models/")
# expected: {"models": ["m1", "m2", "m3:v1", "m3:v2", "VotingEnsemble"],
# "weights": None}
@@ -256,7 +255,6 @@ def test_ensemble_get_metadata_of_models():
)
graph.routes = generate_test_routes("EnsembleModelTestingClass")
server = fn.to_mock_server()
- logger.info(f"flow: {graph.to_yaml()}")
resp = server.test("/v2/models/m1")
expected = {"name": "m1", "version": "", "inputs": [], "outputs": []}
assert resp == expected, f"wrong get models response {resp}"
@@ -588,12 +586,11 @@ def test_v2_mock():
def test_function():
fn = mlrun.new_function("tests", kind="serving")
- graph = fn.set_topology("router")
+ fn.set_topology("router")
fn.add_model("my", ".", class_name=ModelTestingClass(multiplier=100))
fn.set_tracking("dummy://") # track using the _DummyStream
server = fn.to_mock_server()
- logger.info(f"flow: {graph.to_yaml()}")
resp = server.test("/v2/models/my/infer", testdata)
# expected: source (5) * multiplier (100)
assert resp["outputs"] == 5 * 100, f"wrong data response {resp}"
From 549d9994ec882154c14afb6d726cc54d629cf692 Mon Sep 17 00:00:00 2001
From: Gal Topper
Date: Tue, 4 Apr 2023 01:38:12 +0800
Subject: [PATCH 033/334] [Serving] Fix 200x logging in CI (and potentially
elsewhere) (#3377)
---
mlrun/serving/server.py | 5 ++---
1 file changed, 2 insertions(+), 3 deletions(-)
diff --git a/mlrun/serving/server.py b/mlrun/serving/server.py
index 1bd6e048881b..b5280638fbfe 100644
--- a/mlrun/serving/server.py
+++ b/mlrun/serving/server.py
@@ -18,7 +18,6 @@
import json
import os
import socket
-import sys
import traceback
import uuid
from typing import Optional, Union
@@ -32,7 +31,7 @@
from ..datastore.store_resources import ResourceCache
from ..errors import MLRunInvalidArgumentError
from ..model import ModelObj
-from ..utils import create_logger, get_caller_globals, parse_versioned_object_uri
+from ..utils import get_caller_globals, parse_versioned_object_uri
from .states import RootFlowStep, RouterStep, get_function, graph_root_setter
from .utils import event_id_key, event_path_key
@@ -445,7 +444,7 @@ def __init__(self, level="info", logger=None, server=None, nuclio_context=None):
self.Response = nuclio_context.Response
self.worker_id = nuclio_context.worker_id
elif not logger:
- self.logger = create_logger(level, "human", "flow", sys.stdout)
+ self.logger = mlrun.utils.helpers.logger
self._server = server
self.current_function = None
From 92b5cc1a35d401fed954a726304f66cccdcf08f0 Mon Sep 17 00:00:00 2001
From: alxtkr77 <3098237+alxtkr77@users.noreply.github.com>
Date: Tue, 4 Apr 2023 00:26:49 +0300
Subject: [PATCH 034/334] [Spark] Support more than 2 keys in spark online
target ingestion engine (#3322)
---
mlrun/datastore/targets.py | 81 ++++++++++++-------
.../system/feature_store/test_spark_engine.py | 60 ++++++++++++++
2 files changed, 112 insertions(+), 29 deletions(-)
diff --git a/mlrun/datastore/targets.py b/mlrun/datastore/targets.py
index b3020c3c37c5..d3eb45427dfc 100644
--- a/mlrun/datastore/targets.py
+++ b/mlrun/datastore/targets.py
@@ -23,6 +23,7 @@
import pandas as pd
import sqlalchemy
+from storey.utils import hash_list, stringify_key
import mlrun
import mlrun.utils.helpers
@@ -1050,24 +1051,11 @@ def add_writer_step(
**self.attributes,
)
+ def prepare_spark_df(self, df, key_columns):
+ raise NotImplementedError()
+
def get_spark_options(self, key_column=None, timestamp_key=None, overwrite=True):
- spark_options = {
- "path": store_path_to_spark(self.get_target_path()),
- "format": "io.iguaz.v3io.spark.sql.kv",
- }
- if isinstance(key_column, list) and len(key_column) >= 1:
- if len(key_column) > 2:
- raise mlrun.errors.MLRunInvalidArgumentError(
- f"Spark supports maximun of 2 keys and {key_column} are provided"
- )
- spark_options["key"] = key_column[0]
- if len(key_column) > 1:
- spark_options["sorting-key"] = key_column[1]
- else:
- spark_options["key"] = key_column
- if not overwrite:
- spark_options["columnUpdate"] = True
- return spark_options
+ raise NotImplementedError()
def get_dask_options(self):
return {"format": "csv"}
@@ -1075,15 +1063,6 @@ def get_dask_options(self):
def as_df(self, columns=None, df_module=None, **kwargs):
raise NotImplementedError()
- def prepare_spark_df(self, df, key_columns):
- import pyspark.sql.functions as funcs
-
- for col_name, col_type in df.dtypes:
- if col_type.startswith("decimal("):
- # V3IO does not support this level of precision
- df = df.withColumn(col_name, funcs.col(col_name).cast("double"))
- return df
-
def write_dataframe(
self, df, key_column=None, timestamp_key=None, chunk_id=0, **kwargs
):
@@ -1127,6 +1106,41 @@ def get_table_object(self):
flush_interval_secs=mlrun.mlconf.feature_store.flush_interval,
)
+ def get_spark_options(self, key_column=None, timestamp_key=None, overwrite=True):
+ spark_options = {
+ "path": store_path_to_spark(self.get_target_path()),
+ "format": "io.iguaz.v3io.spark.sql.kv",
+ }
+ if isinstance(key_column, list) and len(key_column) >= 1:
+ spark_options["key"] = key_column[0]
+ if len(key_column) > 2:
+ spark_options["sorting-key"] = "_spark_object_sorting_key"
+ if len(key_column) == 2:
+ spark_options["sorting-key"] = key_column[1]
+ else:
+ spark_options["key"] = key_column
+ if not overwrite:
+ spark_options["columnUpdate"] = True
+ return spark_options
+
+ def prepare_spark_df(self, df, key_columns):
+ from pyspark.sql.functions import col, udf
+ from pyspark.sql.types import StringType
+
+ for col_name, col_type in df.dtypes:
+ if col_type.startswith("decimal("):
+ # V3IO does not support this level of precision
+ df = df.withColumn(col_name, col(col_name).cast("double"))
+ if len(key_columns) > 2:
+ hash_and_concat_udf = udf(
+ lambda *x: hash_list([str(i) for i in x]), StringType()
+ )
+ return df.withColumn(
+ "_spark_object_sorting_key",
+ hash_and_concat_udf(*[col(c) for c in key_columns[1:]]),
+ )
+ return df
+
class RedisNoSqlTarget(NoSqlBaseTarget):
kind = TargetTypes.redisnosql
@@ -1186,11 +1200,20 @@ def get_target_path_with_credentials(self):
return endpoint
def prepare_spark_df(self, df, key_columns):
- from pyspark.sql.functions import udf
+ from pyspark.sql.functions import col, udf
from pyspark.sql.types import StringType
- udf1 = udf(lambda x: str(x) + "}:static", StringType())
- return df.withColumn("_spark_object_name", udf1(key_columns[0]))
+ if len(key_columns) > 1:
+ hash_and_concat_udf = udf(
+ lambda *x: stringify_key([str(i) for i in x]) + "}:static", StringType()
+ )
+ return df.withColumn(
+ "_spark_object_name",
+ hash_and_concat_udf(*[col(c) for c in key_columns]),
+ )
+ else:
+ udf1 = udf(lambda x: str(x) + "}:static", StringType())
+ return df.withColumn("_spark_object_name", udf1(key_columns[0]))
class StreamTarget(BaseStoreTarget):
diff --git a/tests/system/feature_store/test_spark_engine.py b/tests/system/feature_store/test_spark_engine.py
index b01b836f8459..b2488bf85997 100644
--- a/tests/system/feature_store/test_spark_engine.py
+++ b/tests/system/feature_store/test_spark_engine.py
@@ -384,6 +384,66 @@ def test_ingest_to_redis(self):
}
]
+ @pytest.mark.parametrize(
+ "target_kind",
+ ["Redis", "v3io"] if mlrun.mlconf.redis.url is not None else ["v3io"],
+ )
+ def test_ingest_multiple_entities(self, target_kind):
+ key1 = "patient_id"
+ key2 = "bad"
+ key3 = "department"
+ name = "measurements_spark"
+
+ measurements = fstore.FeatureSet(
+ name,
+ entities=[fstore.Entity(key1), fstore.Entity(key2), fstore.Entity(key3)],
+ timestamp_key="timestamp",
+ engine="spark",
+ )
+ source = ParquetSource("myparquet", path=self.get_remote_pq_source_path())
+ if target_kind == "Redis":
+ targets = [RedisNoSqlTarget()]
+ else:
+ targets = [NoSqlTarget()]
+ measurements.set_targets(targets, with_defaults=False)
+
+ fstore.ingest(
+ measurements,
+ source,
+ spark_context=self.spark_service,
+ run_config=fstore.RunConfig(False),
+ overwrite=True,
+ )
+ # read the dataframe
+ vector = fstore.FeatureVector("myvector", features=[f"{name}.*"])
+ with fstore.get_online_feature_service(vector) as svc:
+ resp = svc.get(
+ [
+ {
+ "patient_id": "305-90-1613",
+ "bad": 95,
+ "department": "01e9fe31-76de-45f0-9aed-0f94cc97bca0",
+ }
+ ]
+ )
+ assert resp == [
+ {
+ "room": 2,
+ "hr": 220.0,
+ "hr_is_error": False,
+ "rr": 25,
+ "rr_is_error": False,
+ "spo2": 99,
+ "spo2_is_error": False,
+ "movements": 4.614601941071927,
+ "movements_is_error": False,
+ "turn_count": 0.3582583538239813,
+ "turn_count_is_error": False,
+ "is_in_bed": 1,
+ "is_in_bed_is_error": False,
+ }
+ ]
+
@pytest.mark.skipif(
not mlrun.mlconf.redis.url,
reason="mlrun.mlconf.redis.url is not set, skipping until testing against real redis",
From c540f320544278ee82de59561b0909c4bd190503 Mon Sep 17 00:00:00 2001
From: tomerm-iguazio <125267619+tomerm-iguazio@users.noreply.github.com>
Date: Tue, 4 Apr 2023 10:04:43 +0300
Subject: [PATCH 035/334] [Datastore] Fix `MapValues` spark implementation to
account for change of type (#3313)
---
mlrun/feature_store/steps.py | 123 ++++++++++++++++--
tests/feature-store/test_steps.py | 83 ++++++++++++
.../system/feature_store/test_spark_engine.py | 97 ++++++++++++--
3 files changed, 277 insertions(+), 26 deletions(-)
diff --git a/mlrun/feature_store/steps.py b/mlrun/feature_store/steps.py
index 4262caf6c7a3..3d9a47c84c1b 100644
--- a/mlrun/feature_store/steps.py
+++ b/mlrun/feature_store/steps.py
@@ -12,6 +12,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
#
+import math
import re
import uuid
import warnings
@@ -55,7 +56,7 @@ def do(self, event):
engine = get_engine(event)
self.do = self._engine_to_do_method.get(engine, None)
if self.do is None:
- raise mlrun.errors.InvalidArgummentError(
+ raise mlrun.errors.MLRunInvalidArgumentError(
f"Unrecognized engine: {engine}. Available engines are: pandas, spark and storey"
)
@@ -136,7 +137,7 @@ class MapValues(StepToDict, MLRunStep):
def __init__(
self,
- mapping: Dict[str, Dict[str, Any]],
+ mapping: Dict[str, Dict[Union[str, int, bool], Any]],
with_original_features: bool = False,
suffix: str = "mapped",
**kwargs,
@@ -226,34 +227,130 @@ def _do_pandas(self, event):
def _do_spark(self, event):
from itertools import chain
- from pyspark.sql.functions import col, create_map, lit, when
+ from pyspark.sql.functions import col, create_map, isnan, isnull, lit, when
+ from pyspark.sql.types import DecimalType, DoubleType, FloatType
+ from pyspark.sql.utils import AnalysisException
+ df = event
+ source_column_names = df.columns
for column, column_map in self.mapping.items():
new_column_name = self._get_feature_name(column)
- if "ranges" not in column_map:
+ if not self.get_ranges_key() in column_map:
+ if column not in source_column_names:
+ continue
mapping_expr = create_map([lit(x) for x in chain(*column_map.items())])
- event = event.withColumn(
- new_column_name, mapping_expr.getItem(col(column))
- )
+ try:
+ df = df.withColumn(
+ new_column_name,
+ when(
+ col(column).isin(list(column_map.keys())),
+ mapping_expr.getItem(col(column)),
+ ).otherwise(col(column)),
+ )
+ # if failed to use otherwise it is probably because the new column has different type
+ # then the original column.
+ # we will try to replace the values without using 'otherwise'.
+ except AnalysisException:
+ df = df.withColumn(
+ new_column_name, mapping_expr.getItem(col(column))
+ )
+ col_type = df.schema[column].dataType
+ new_col_type = df.schema[new_column_name].dataType
+ # in order to avoid exception at isna on non-decimal/float columns -
+ # we need to check their types before filtering.
+ if isinstance(col_type, (FloatType, DoubleType, DecimalType)):
+ column_filter = (~isnull(col(column))) & (~isnan(col(column)))
+ else:
+ column_filter = ~isnull(col(column))
+ if isinstance(new_col_type, (FloatType, DoubleType, DecimalType)):
+ new_column_filter = isnull(col(new_column_name)) | isnan(
+ col(new_column_name)
+ )
+ else:
+ # we need to check that every value replaced if we changed column type - except None or NaN.
+ new_column_filter = isnull(col(new_column_name))
+ mapping_to_null = [
+ k
+ for k, v in column_map.items()
+ if v is None
+ or (
+ isinstance(v, (float, np.float64, np.float32, np.float16))
+ and math.isnan(v)
+ )
+ ]
+ turned_to_none_values = df.filter(
+ column_filter & new_column_filter
+ ).filter(~col(column).isin(mapping_to_null))
+
+ if len(turned_to_none_values.head(1)) > 0:
+ raise mlrun.errors.MLRunInvalidArgumentError(
+ f"MapValues - mapping that changes column type must change all values accordingly,"
+ f" which is not the case for column '{column}'"
+ )
else:
for val, val_range in column_map["ranges"].items():
min_val = val_range[0] if val_range[0] != "-inf" else -np.inf
max_val = val_range[1] if val_range[1] != "inf" else np.inf
otherwise = ""
- if new_column_name in event.columns:
- otherwise = event[new_column_name]
- event = event.withColumn(
+ if new_column_name in df.columns:
+ otherwise = df[new_column_name]
+ df = df.withColumn(
new_column_name,
when(
- (event[column] < max_val) & (event[column] >= min_val),
+ (df[column] < max_val) & (df[column] >= min_val),
lit(val),
).otherwise(otherwise),
)
if not self.with_original_features:
- event = event.select(*self.mapping.keys())
+ df = df.select(*self.mapping.keys())
- return event
+ return df
+
+ @classmethod
+ def validate_args(cls, feature_set, **kwargs):
+ mapping = kwargs.get("mapping", [])
+ for column, column_map in mapping.items():
+ if not cls.get_ranges_key() in column_map:
+ types = set(
+ type(val)
+ for val in column_map.values()
+ if type(val) is not None
+ and not (
+ isinstance(val, (float, np.float64, np.float32, np.float16))
+ and math.isnan(val)
+ )
+ )
+ else:
+ if len(column_map) > 1:
+ raise mlrun.errors.MLRunInvalidArgumentError(
+ f"MapValues - mapping values of the same column can not combine ranges and "
+ f"single replacement, which is the case for column '{column}'"
+ )
+ ranges_dict = column_map[cls.get_ranges_key()]
+ types = set()
+ for ranges_mapping_values in ranges_dict.values():
+ range_types = set(
+ type(val)
+ for val in ranges_mapping_values
+ if type(val) is not None
+ and val != "-inf"
+ and val != "inf"
+ and not (
+ isinstance(val, (float, np.float64, np.float32, np.float16))
+ and math.isnan(val)
+ )
+ )
+ types = types.union(range_types)
+ if len(types) > 1:
+ raise mlrun.errors.MLRunInvalidArgumentError(
+ f"MapValues - mapping values of the same column must be in the"
+ f" same type, which was not the case for Column '{column}'"
+ )
+
+ @staticmethod
+ def get_ranges_key():
+ return "ranges"
class Imputer(StepToDict, MLRunStep):
diff --git a/tests/feature-store/test_steps.py b/tests/feature-store/test_steps.py
index 6aae92c5ac19..258981478e5d 100644
--- a/tests/feature-store/test_steps.py
+++ b/tests/feature-store/test_steps.py
@@ -458,6 +458,89 @@ def test_pandas_step_data_extractor(
)
+@pytest.mark.parametrize(
+ "mapping",
+ [
+ {"age": {"ranges": {"one": [0, 30], "two": ["a", "inf"]}}},
+ {"names": {"A": 1, "B": False}},
+ ],
+)
+def test_mapvalues_mixed_types_validator(rundb_mock, mapping):
+ data, _ = get_data()
+ data_to_ingest = data.copy()
+ # Define the corresponding FeatureSet
+ data_set_pandas = fstore.FeatureSet(
+ "fs-new",
+ entities=[fstore.Entity("id")],
+ description="feature set",
+ engine="pandas",
+ )
+ # Pre-processing grpah steps
+ data_set_pandas.graph.to(
+ MapValues(
+ mapping=mapping,
+ with_original_features=True,
+ )
+ )
+ data_set_pandas._run_db = rundb_mock
+
+ data_set_pandas.reload = unittest.mock.Mock()
+ data_set_pandas.save = unittest.mock.Mock()
+ data_set_pandas.purge_targets = unittest.mock.Mock()
+ # Create a temp directory:
+ output_path = tempfile.TemporaryDirectory()
+
+ with pytest.raises(
+ mlrun.errors.MLRunInvalidArgumentError,
+ match=f"^MapValues - mapping values of the same column must be in the same type, which was not the case for"
+ f" Column '{list(mapping.keys())[0]}'$",
+ ):
+ fstore.ingest(
+ data_set_pandas,
+ data_to_ingest,
+ targets=[ParquetTarget(path=f"{output_path.name}/temp.parquet")],
+ )
+
+
+def test_mapvalues_combined_mapping_validator(rundb_mock):
+ data, _ = get_data()
+ data_to_ingest = data.copy()
+ # Define the corresponding FeatureSet
+ data_set_pandas = fstore.FeatureSet(
+ "fs-new",
+ entities=[fstore.Entity("id")],
+ description="feature set",
+ engine="pandas",
+ )
+ # Pre-processing grpah steps
+ data_set_pandas.graph.to(
+ MapValues(
+ mapping={
+ "age": {"ranges": {"one": [0, 30], "two": ["a", "inf"]}, 4: "kid"}
+ },
+ with_original_features=True,
+ )
+ )
+ data_set_pandas._run_db = rundb_mock
+
+ data_set_pandas.reload = unittest.mock.Mock()
+ data_set_pandas.save = unittest.mock.Mock()
+ data_set_pandas.purge_targets = unittest.mock.Mock()
+ # Create a temp directory:
+ output_path = tempfile.TemporaryDirectory()
+
+ with pytest.raises(
+ mlrun.errors.MLRunInvalidArgumentError,
+ match="^MapValues - mapping values of the same column can not combine ranges and single "
+ "replacement, which is the case for column 'age'$",
+ ):
+ fstore.ingest(
+ data_set_pandas,
+ data_to_ingest,
+ targets=[ParquetTarget(path=f"{output_path.name}/temp.parquet")],
+ )
+
+
@pytest.mark.parametrize("set_index_before", [True, False, 0])
@pytest.mark.parametrize("entities", [["id"], ["id", "name"]])
def test_pandas_step_data_validator(rundb_mock, entities, set_index_before):
diff --git a/tests/system/feature_store/test_spark_engine.py b/tests/system/feature_store/test_spark_engine.py
index b2488bf85997..1dfd381f9b25 100644
--- a/tests/system/feature_store/test_spark_engine.py
+++ b/tests/system/feature_store/test_spark_engine.py
@@ -171,22 +171,22 @@ def read_parquet_and_assert(out_path_spark, out_path_storey):
)
@staticmethod
- def read_csv_and_assert(csv_path_spark, csv_path_storey):
- read_back_df_spark = None
+ def read_csv(csv_path: str) -> pd.DataFrame:
file_system = fsspec.filesystem("v3io")
- for file_entry in file_system.ls(csv_path_spark):
+ for file_entry in file_system.ls(csv_path):
filepath = file_entry["name"]
if not filepath.endswith("/_SUCCESS"):
- read_back_df_spark = pd.read_csv(f"v3io://{filepath}")
- break
- assert read_back_df_spark is not None
+ return pd.read_csv(f"v3io://{filepath}")
+ raise AssertionError(f"No files found in {csv_path}")
- read_back_df_storey = None
- for file_entry in file_system.ls(csv_path_storey):
- filepath = file_entry["name"]
- read_back_df_storey = pd.read_csv(f"v3io://{filepath}")
- break
- assert read_back_df_storey is not None
+ @staticmethod
+ def read_csv_and_assert(csv_path_spark, csv_path_storey):
+ read_back_df_spark = TestFeatureStoreSparkEngine.read_csv(
+ csv_path=csv_path_spark
+ )
+ read_back_df_storey = TestFeatureStoreSparkEngine.read_csv(
+ csv_path=csv_path_storey
+ )
read_back_df_storey = read_back_df_storey.dropna(axis=1, how="all")
read_back_df_spark = read_back_df_spark.dropna(axis=1, how="all")
@@ -1427,7 +1427,7 @@ def test_ingest_with_steps_onehot(self):
self.read_csv_and_assert(csv_path_spark, csv_path_storey)
@pytest.mark.parametrize("with_original_features", [True, False])
- def test_ingest_with_steps_mapval(self, with_original_features):
+ def test_ingest_with_steps_mapvalues(self, with_original_features):
key = "patient_id"
csv_path_spark = "v3io:///bigdata/test_ingest_to_csv_spark"
csv_path_storey = "v3io:///bigdata/test_ingest_to_csv_storey.csv"
@@ -1482,6 +1482,77 @@ def test_ingest_with_steps_mapval(self, with_original_features):
csv_path_storey = measurements.get_target_path(name="csv")
self.read_csv_and_assert(csv_path_spark, csv_path_storey)
+ def test_mapvalues_with_partial_mapping(self):
+ # checks partial mapping -> only part of the values in field are replaced.
+ key = "patient_id"
+ csv_path_spark = "v3io:///bigdata/test_mapvalues_with_partial_mapping"
+ original_df = pd.read_parquet(self.get_remote_pq_source_path())
+ measurements = fstore.FeatureSet(
+ "measurements_spark",
+ entities=[fstore.Entity(key)],
+ timestamp_key="timestamp",
+ engine="spark",
+ )
+ measurements.graph.to(
+ MapValues(
+ mapping={
+ "bad": {17: -1},
+ },
+ with_original_features=True,
+ )
+ )
+ source = ParquetSource("myparquet", path=self.get_remote_pq_source_path())
+ targets = [CSVTarget(name="csv", path=csv_path_spark)]
+ fstore.ingest(
+ measurements,
+ source,
+ targets,
+ spark_context=self.spark_service,
+ run_config=fstore.RunConfig(local=False),
+ )
+ csv_path_spark = measurements.get_target_path(name="csv")
+ df = self.read_csv(csv_path=csv_path_spark)
+ assert not df.empty
+ assert not df["bad_mapped"].isna().any()
+ assert not df["bad_mapped"].isnull().any()
+ assert not (df["bad_mapped"] == 17).any()
+ # Note that there are no occurrences of -1 in the "bad" field of the original DataFrame.
+ assert len(df[df["bad_mapped"] == -1]) == len(
+ original_df[original_df["bad"] == 17]
+ )
+
+ def test_mapvalues_with_mixed_types(self):
+ key = "patient_id"
+ csv_path_spark = "v3io:///bigdata/test_mapvalues_with_mixed_types"
+ measurements = fstore.FeatureSet(
+ "measurements_spark",
+ entities=[fstore.Entity(key)],
+ timestamp_key="timestamp",
+ engine="spark",
+ )
+ measurements.graph.to(
+ MapValues(
+ mapping={
+ "hr_is_error": {True: "1"},
+ },
+ with_original_features=True,
+ )
+ )
+ source = ParquetSource("myparquet", path=self.get_remote_pq_source_path())
+ targets = [CSVTarget(name="csv", path=csv_path_spark)]
+ with pytest.raises(
+ mlrun.runtimes.utils.RunError,
+ match="^MapValues - mapping that changes column type must change all values accordingly,"
+ " which is not the case for column 'hr_is_error'$",
+ ):
+ fstore.ingest(
+ measurements,
+ source,
+ targets,
+ spark_context=self.spark_service,
+ run_config=fstore.RunConfig(local=False),
+ )
+
@pytest.mark.parametrize("timestamp_col", [None, "timestamp"])
def test_ingest_with_steps_extractor(self, timestamp_col):
key = "patient_id"
From 422940611b719d5efb7788e4bc1c7e2fa31d39b1 Mon Sep 17 00:00:00 2001
From: Gal Topper
Date: Tue, 4 Apr 2023 15:59:29 +0800
Subject: [PATCH 036/334] [Utils] Fix multiple logs (#3381)
---
mlrun/utils/logger.py | 20 ++++++++++----------
tests/utils/logger/test_logger.py | 14 ++++++++++++++
2 files changed, 24 insertions(+), 10 deletions(-)
diff --git a/mlrun/utils/logger.py b/mlrun/utils/logger.py
index 266968da8ca9..b5606b8c6e1c 100644
--- a/mlrun/utils/logger.py
+++ b/mlrun/utils/logger.py
@@ -59,7 +59,6 @@ def __init__(self, level, name="mlrun", propagate=True):
self._logger.propagate = propagate
self._logger.setLevel(level)
self._bound_variables = {}
- self._handlers = {}
for log_level_func in [
self.exception,
@@ -76,14 +75,14 @@ def set_handler(
):
# check if there's a handler by this name
- if handler_name in self._handlers:
- # log that we're removing it
- self.info("Replacing logger output", handler_name=handler_name)
-
- self._logger.removeHandler(self._handlers[handler_name])
+ for handler in self._logger.handlers:
+ if handler.name == handler_name:
+ self._logger.removeHandler(handler)
+ break
# create a stream handler from the file
stream_handler = logging.StreamHandler(file)
+ stream_handler.name = handler_name
# set the formatter
stream_handler.setFormatter(formatter)
@@ -91,9 +90,6 @@ def set_handler(
# add the handler to the logger
self._logger.addHandler(stream_handler)
- # save as the named output
- self._handlers[handler_name] = stream_handler
-
@property
def level(self):
return self._logger.level
@@ -102,7 +98,11 @@ def set_logger_level(self, level: Union[str, int]):
self._logger.setLevel(level)
def replace_handler_stream(self, handler_name: str, file: IO[str]):
- self._handlers[handler_name].stream = file
+ for handler in self._logger.handlers:
+ if handler.name == handler_name:
+ handler.stream = file
+ return
+ raise ValueError(f"Logger does not have a handler named '{handler_name}'")
def debug(self, message, *args, **kw_args):
self._update_bound_vars_and_log(logging.DEBUG, message, *args, **kw_args)
diff --git a/tests/utils/logger/test_logger.py b/tests/utils/logger/test_logger.py
index b7e45906c0a1..33a935662e47 100644
--- a/tests/utils/logger/test_logger.py
+++ b/tests/utils/logger/test_logger.py
@@ -92,3 +92,17 @@ def test_exception_with_stack(make_stream_logger):
test_logger.exception("This is just a test")
assert str(err) in stream.getvalue()
assert "This is just a test" in stream.getvalue()
+
+
+# Regression test for duplicate logs bug fixed in PR #3381
+def test_redundant_logger_creation():
+ stream = StringIO()
+ logger1 = create_logger("debug", name="test-logger", stream=stream)
+ logger2 = create_logger("debug", name="test-logger", stream=stream)
+ logger3 = create_logger("debug", name="test-logger", stream=stream)
+ logger1.info("1")
+ assert stream.getvalue().count("[info] 1\n") == 1
+ logger2.info("2")
+ assert stream.getvalue().count("[info] 2\n") == 1
+ logger3.info("3")
+ assert stream.getvalue().count("[info] 3\n") == 1
From f3f41f7bd902ad446879fb6f7fe763158ef2764d Mon Sep 17 00:00:00 2001
From: Tom Tankilevitch <59158507+Tankilevitch@users.noreply.github.com>
Date: Tue, 4 Apr 2023 14:40:28 +0300
Subject: [PATCH 037/334] [Builder] Fix commands and requirements order when
creating kaniko Dockerfile (#3375)
---
mlrun/builder.py | 41 +++++++++++++++++-------------
mlrun/runtimes/kubejob.py | 4 +--
tests/api/runtimes/test_kubejob.py | 15 +++++++++++
3 files changed, 40 insertions(+), 20 deletions(-)
diff --git a/mlrun/builder.py b/mlrun/builder.py
index c5d38fbf3e95..0eb6e1c7c5d3 100644
--- a/mlrun/builder.py
+++ b/mlrun/builder.py
@@ -35,14 +35,14 @@
def make_dockerfile(
- base_image,
- commands=None,
- source=None,
- requirements=None,
- workdir="/mlrun",
- extra="",
- user_unix_id=None,
- enriched_group_id=None,
+ base_image: str,
+ commands: list = None,
+ source: str = None,
+ requirements: str = None,
+ workdir: str = "/mlrun",
+ extra: str = "",
+ user_unix_id: int = None,
+ enriched_group_id: int = None,
):
dock = f"FROM {base_image}\n"
@@ -76,10 +76,10 @@ def make_dockerfile(
dock += f"RUN chown -R {user_unix_id}:{enriched_group_id} {workdir}\n"
dock += f"ENV PYTHONPATH {workdir}\n"
- if requirements:
- dock += f"RUN python -m pip install -r {requirements}\n"
if commands:
dock += "".join([f"RUN {command}\n" for command in commands])
+ if requirements:
+ dock += f"RUN python -m pip install -r {requirements}\n"
if extra:
dock += extra
logger.debug("Resolved dockerfile", dockfile_contents=dock)
@@ -193,19 +193,23 @@ def make_kaniko_pod(
commands = []
env = {}
if dockertext:
- commands.append("echo ${DOCKERFILE} | base64 -d > /empty/Dockerfile")
+ # set and encode docker content to the DOCKERFILE environment variable in the kaniko pod
env["DOCKERFILE"] = b64encode(dockertext.encode("utf-8")).decode("utf-8")
+ # dump dockerfile content and decode to Dockerfile destination
+ commands.append("echo ${DOCKERFILE} | base64 -d > /empty/Dockerfile")
if inline_code:
name = inline_path or "main.py"
- commands.append("echo ${CODE} | base64 -d > /empty/" + name)
env["CODE"] = b64encode(inline_code.encode("utf-8")).decode("utf-8")
+ commands.append("echo ${CODE} | base64 -d > /empty/" + name)
if requirements:
- commands.append(
- "echo ${REQUIREMENTS} | base64 -d > /empty/requirements.txt"
- )
+ # set and encode requirements to the REQUIREMENTS environment variable in the kaniko pod
env["REQUIREMENTS"] = b64encode(
"\n".join(requirements).encode("utf-8")
).decode("utf-8")
+ # dump requirement content and decode to the requirement.txt destination
+ commands.append(
+ "echo ${REQUIREMENTS} | base64 -d > /empty/requirements.txt"
+ )
kpod.append_init_container(
config.httpdb.builder.kaniko_init_container_image,
@@ -295,7 +299,6 @@ def build_image(
image_target,
commands=None,
source="",
- mounter="v3io",
base_image=None,
requirements=None,
inline_code=None,
@@ -318,7 +321,10 @@ def build_image(
image_target, secret_name = _resolve_image_target_and_registry_secret(
image_target, registry, secret_name
)
-
+ # TODO: currently requirements are not being passed to that method, this is due to the ImageBuilder class not having
+ # requirements attribute in it, remove this comment when requirements attribute is being added to the class and
+ # passed to the `build_image` method. Also `with_requirements` will have to be changed to set them to the
+ # requirements attribute instead of transforming it right to commands
if isinstance(requirements, list):
requirements_list = requirements
requirements_path = "requirements.txt"
@@ -583,7 +589,6 @@ def build_runtime(
base_image=enriched_base_image,
commands=build.commands,
namespace=namespace,
- # inline_code=inline,
source=build.source,
secret_name=build.secret,
interactive=interactive,
diff --git a/mlrun/runtimes/kubejob.py b/mlrun/runtimes/kubejob.py
index defc13b81db6..f3626452ad14 100644
--- a/mlrun/runtimes/kubejob.py
+++ b/mlrun/runtimes/kubejob.py
@@ -141,12 +141,12 @@ def build_config(
# (requirements are added to the commands parameter)
if (requirements or commands) and overwrite:
self.spec.build.commands = None
+ if commands:
+ self.with_commands(commands, overwrite=False, verify_base_image=False)
if requirements:
self.with_requirements(
requirements, overwrite=False, verify_base_image=False
)
- if commands:
- self.with_commands(commands, overwrite=False, verify_base_image=False)
if extra:
self.spec.build.extra = extra
if secret is not None:
diff --git a/tests/api/runtimes/test_kubejob.py b/tests/api/runtimes/test_kubejob.py
index 57dee7e00450..edb44d0bb7d7 100644
--- a/tests/api/runtimes/test_kubejob.py
+++ b/tests/api/runtimes/test_kubejob.py
@@ -690,6 +690,21 @@ def test_build_config(self, db: Session, client: TestClient):
== {}
)
+ def test_build_config_commands_and_requirements_order(
+ self, db: Session, client: TestClient
+ ):
+ runtime = self._generate_runtime()
+ runtime.build_config(commands=["apt-get update"], requirements=["scikit-learn"])
+ expected_commands = ["apt-get update", "python -m pip install scikit-learn"]
+ assert (
+ deepdiff.DeepDiff(
+ expected_commands,
+ runtime.spec.build.commands,
+ ignore_order=False,
+ )
+ == {}
+ )
+
def test_build_config_with_images(self, db: Session, client: TestClient):
runtime = self._generate_runtime()
runtime.build_config(base_image="mlrun/mlrun", image="target/mlrun")
From a832c9e891879013f08b11c6f0cbd64ff1330806 Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Wed, 5 Apr 2023 15:02:53 +0300
Subject: [PATCH 038/334] [Requirements] ARM64 requirements over conda env
(#3386)
---
Makefile | 4 ++++
conda-arm64-requirements.txt | 4 ++++
dev-requirements.txt | 2 +-
tests/test_requirements.py | 5 +++++
4 files changed, 14 insertions(+), 1 deletion(-)
create mode 100644 conda-arm64-requirements.txt
diff --git a/Makefile b/Makefile
index ac10315e1886..3175198893eb 100644
--- a/Makefile
+++ b/Makefile
@@ -108,6 +108,10 @@ install-requirements: ## Install all requirements needed for development
-r dockerfiles/mlrun-api/requirements.txt \
-r docs/requirements.txt
+.PHONY: install-conda-requirements
+install-conda-requirements: install-requirements ## Install all requirements needed for development with specific conda packages for arm64
+ conda install --yes --file conda-arm64-requirements.txt
+
.PHONY: install-complete-requirements
install-complete-requirements: ## Install all requirements needed for development and testing
python -m pip install --upgrade $(MLRUN_PIP_NO_CACHE_FLAG) pip~=$(MLRUN_PIP_VERSION)
diff --git a/conda-arm64-requirements.txt b/conda-arm64-requirements.txt
new file mode 100644
index 000000000000..00aeb2548f5f
--- /dev/null
+++ b/conda-arm64-requirements.txt
@@ -0,0 +1,4 @@
+# with moving to arm64 for the new M1/M2 macs some packages are not yet compatible via pip and require
+# conda which supports different architecture environments on the same machine
+protobuf>=3.13, <3.20
+lightgbm>=3.0
diff --git a/dev-requirements.txt b/dev-requirements.txt
index 46645ab0afaa..7adb9f2868c2 100644
--- a/dev-requirements.txt
+++ b/dev-requirements.txt
@@ -17,6 +17,6 @@ avro~=1.11
# needed for mlutils tests
scikit-learn~=1.0
# needed for frameworks tests
-lightgbm~=3.0
+lightgbm~=3.0; platform_machine != 'arm64'
xgboost~=1.1
sqlalchemy_utils~=0.39.0
diff --git a/tests/test_requirements.py b/tests/test_requirements.py
index 961b85f67bf3..485b7e57f6fa 100644
--- a/tests/test_requirements.py
+++ b/tests/test_requirements.py
@@ -139,6 +139,8 @@ def test_requirement_specifiers_convention():
"plotly": {"~=5.4, <5.12.0"},
# used in tests
"aioresponses": {"~=0.7"},
+ # conda requirements since conda does not support ~= operator
+ "lightgbm": {">=3.0"},
}
for (
@@ -169,6 +171,9 @@ def test_requirement_specifiers_inconsistencies():
# The empty specifier is from tests/runtimes/assets/requirements.txt which is there specifically to test the
# scenario of requirements without version specifiers
"python-dotenv": {"", "~=0.17.0"},
+ # conda requirements since conda does not support ~= operator and
+ # since platform condition is not required for docker
+ "lightgbm": {"~=3.0", "~=3.0; platform_machine != 'arm64'", ">=3.0"},
}
for (
From 7e3c2bbc0eb8b767da74aa3adf8cfcda9bdf924a Mon Sep 17 00:00:00 2001
From: Tom Tankilevitch <59158507+Tankilevitch@users.noreply.github.com>
Date: Mon, 10 Apr 2023 07:32:08 +0300
Subject: [PATCH 039/334] [Runtime] Introduce `requirements` attribute in the
build spec to provide full separation between commands and requirements
(#3385)
---
mlrun/builder.py | 38 +++++++------
mlrun/model.py | 2 +
mlrun/runtimes/base.py | 48 +++++++----------
mlrun/runtimes/function.py | 22 ++++++++
mlrun/runtimes/kubejob.py | 8 +--
tests/api/runtimes/test_kubejob.py | 43 ++++++++++-----
tests/api/runtimes/test_nuclio.py | 59 +++++++++++++++++++++
tests/api/runtimes/test_spark.py | 14 ++++-
tests/projects/test_project.py | 14 ++---
tests/runtimes/test_base.py | 39 ++++++++++----
tests/runtimes/test_run.py | 2 +-
tests/test_builder.py | 85 +++++++++++-------------------
12 files changed, 234 insertions(+), 140 deletions(-)
diff --git a/mlrun/builder.py b/mlrun/builder.py
index 0eb6e1c7c5d3..93a70d8823f9 100644
--- a/mlrun/builder.py
+++ b/mlrun/builder.py
@@ -38,7 +38,7 @@ def make_dockerfile(
base_image: str,
commands: list = None,
source: str = None,
- requirements: str = None,
+ requirements_path: str = None,
workdir: str = "/mlrun",
extra: str = "",
user_unix_id: int = None,
@@ -78,8 +78,11 @@ def make_dockerfile(
dock += f"ENV PYTHONPATH {workdir}\n"
if commands:
dock += "".join([f"RUN {command}\n" for command in commands])
- if requirements:
- dock += f"RUN python -m pip install -r {requirements}\n"
+ if requirements_path:
+ dock += (
+ f"RUN echo 'Installing {requirements_path}...'; cat {requirements_path}\n"
+ )
+ dock += f"RUN python -m pip install -r {requirements_path}\n"
if extra:
dock += extra
logger.debug("Resolved dockerfile", dockfile_contents=dock)
@@ -95,6 +98,7 @@ def make_kaniko_pod(
inline_code=None,
inline_path=None,
requirements=None,
+ requirements_path=None,
secret_name=None,
name="",
verbose=False,
@@ -208,7 +212,7 @@ def make_kaniko_pod(
).decode("utf-8")
# dump requirement content and decode to the requirement.txt destination
commands.append(
- "echo ${REQUIREMENTS} | base64 -d > /empty/requirements.txt"
+ "echo ${REQUIREMENTS}" + " | " + f"base64 -d > {requirements_path}"
)
kpod.append_init_container(
@@ -321,18 +325,12 @@ def build_image(
image_target, secret_name = _resolve_image_target_and_registry_secret(
image_target, registry, secret_name
)
- # TODO: currently requirements are not being passed to that method, this is due to the ImageBuilder class not having
- # requirements attribute in it, remove this comment when requirements attribute is being added to the class and
- # passed to the `build_image` method. Also `with_requirements` will have to be changed to set them to the
- # requirements attribute instead of transforming it right to commands
- if isinstance(requirements, list):
+ if requirements and isinstance(requirements, list):
requirements_list = requirements
- requirements_path = "requirements.txt"
- if source:
- raise ValueError("requirements list only works with inline code")
+ requirements_path = "/empty/requirements.txt"
else:
requirements_list = None
- requirements_path = requirements
+ requirements_path = requirements or ""
commands = commands or []
if with_mlrun:
@@ -347,7 +345,7 @@ def build_image(
if mlrun_command:
commands.append(mlrun_command)
- if not inline_code and not source and not commands:
+ if not inline_code and not source and not commands and not requirements:
logger.info("skipping build, nothing to add")
return "skipped"
@@ -420,7 +418,7 @@ def build_image(
base_image,
commands,
source=source_to_copy,
- requirements=requirements_path,
+ requirements_path=requirements_path,
extra=extra,
user_unix_id=user_unix_id,
enriched_group_id=enriched_group_id,
@@ -435,6 +433,7 @@ def build_image(
inline_code=inline_code,
inline_path=inline_path,
requirements=requirements_list,
+ requirements_path=requirements_path,
secret_name=secret_name,
name=name,
verbose=verbose,
@@ -544,7 +543,13 @@ def build_runtime(
# if the base is one of mlrun images - no need to install mlrun
if any([image in build.base_image for image in mlrun_images]):
with_mlrun = False
- if not build.source and not build.commands and not build.extra and not with_mlrun:
+ if (
+ not build.source
+ and not build.commands
+ and not build.requirements
+ and not build.extra
+ and not with_mlrun
+ ):
if not runtime.spec.image:
if build.base_image:
runtime.spec.image = build.base_image
@@ -588,6 +593,7 @@ def build_runtime(
image_target=build.image,
base_image=enriched_base_image,
commands=build.commands,
+ requirements=build.requirements,
namespace=namespace,
source=build.source,
secret_name=build.secret,
diff --git a/mlrun/model.py b/mlrun/model.py
index 3ec204b20b97..7838d507407d 100644
--- a/mlrun/model.py
+++ b/mlrun/model.py
@@ -338,6 +338,7 @@ def __init__(
origin_filename=None,
with_mlrun=None,
auto_build=None,
+ requirements: list = None,
):
self.functionSourceCode = functionSourceCode #: functionSourceCode
self.codeEntryType = "" #: codeEntryType
@@ -355,6 +356,7 @@ def __init__(
self.with_mlrun = with_mlrun #: with_mlrun
self.auto_build = auto_build #: auto_build
self.build_pod = None
+ self.requirements = requirements or [] #: pip requirements
@property
def source(self):
diff --git a/mlrun/runtimes/base.py b/mlrun/runtimes/base.py
index fba3e3cede98..b2b66bc223a6 100644
--- a/mlrun/runtimes/base.py
+++ b/mlrun/runtimes/base.py
@@ -15,7 +15,6 @@
import getpass
import http
import os.path
-import shlex
import traceback
import typing
import uuid
@@ -1277,15 +1276,19 @@ def with_requirements(
:param verify_base_image: verify that the base image is configured
:return: function object
"""
- encoded_requirements = self._encode_requirements(requirements)
- commands = self.spec.build.commands or [] if not overwrite else []
- new_command = f"python -m pip install {encoded_requirements}"
- # make sure we dont append the same line twice
- if new_command not in commands:
- commands.append(new_command)
- self.spec.build.commands = commands
+ resolved_requirements = self._resolve_requirements(requirements)
+ requirements = self.spec.build.requirements or [] if not overwrite else []
+
+ # make sure we don't append the same line twice
+ for requirement in resolved_requirements:
+ if requirement not in requirements:
+ requirements.append(requirement)
+
+ self.spec.build.requirements = requirements
+
if verify_base_image:
self.verify_base_image()
+
return self
def with_commands(
@@ -1453,15 +1456,16 @@ def doc(self):
line += f", default={p['default']}"
print(" " + line)
- def _encode_requirements(self, requirements_to_encode):
-
+ @staticmethod
+ def _resolve_requirements(requirements_to_resolve: typing.Union[str, list]) -> list:
# if a string, read the file then encode
- if isinstance(requirements_to_encode, str):
- with open(requirements_to_encode, "r") as fp:
- requirements_to_encode = fp.read().splitlines()
+ if isinstance(requirements_to_resolve, str):
+ with open(requirements_to_resolve, "r") as fp:
+ requirements_to_resolve = fp.read().splitlines()
requirements = []
- for requirement in requirements_to_encode:
+ for requirement in requirements_to_resolve:
+ # clean redundant leading and trailing whitespaces
requirement = requirement.strip()
# ignore empty lines
@@ -1474,21 +1478,9 @@ def _encode_requirements(self, requirements_to_encode):
if len(inline_comment) > 1:
requirement = inline_comment[0].strip()
- # -r / --requirement are flags and should not be escaped
- # we allow such flags (could be passed within the requirements.txt file) and do not
- # try to open the file and include its content since it might be a remote file
- # given on the base image.
- for req_flag in ["-r", "--requirement"]:
- if requirement.startswith(req_flag):
- requirement = requirement[len(req_flag) :].strip()
- requirements.append(req_flag)
- break
-
- # wrap in single quote to ensure that the requirement is treated as a single string
- # quote the requirement to avoid issues with special characters, double quotes, etc.
- requirements.append(shlex.quote(requirement))
+ requirements.append(requirement)
- return " ".join(requirements)
+ return requirements
def _validate_output_path(self, run):
if is_local(run.spec.output_path):
diff --git a/mlrun/runtimes/function.py b/mlrun/runtimes/function.py
index 33d096c1c6b8..0be66a3a786a 100644
--- a/mlrun/runtimes/function.py
+++ b/mlrun/runtimes/function.py
@@ -14,6 +14,7 @@
import asyncio
import json
+import shlex
import typing
import warnings
from base64 import b64encode
@@ -1389,6 +1390,27 @@ def compile_function_config(
config=function.spec.config,
)
nuclio_spec.cmd = function.spec.build.commands or []
+
+ if function.spec.build.requirements:
+ resolved_requirements = []
+ # wrap in single quote to ensure that the requirement is treated as a single string
+ # quote the requirement to avoid issues with special characters, double quotes, etc.
+ for requirement in function.spec.build.requirements:
+ # -r / --requirement are flags and should not be escaped
+ # we allow such flags (could be passed within the requirements.txt file) and do not
+ # try to open the file and include its content since it might be a remote file
+ # given on the base image.
+ for req_flag in ["-r", "--requirement"]:
+ if requirement.startswith(req_flag):
+ requirement = requirement[len(req_flag) :].strip()
+ resolved_requirements.append(req_flag)
+ break
+
+ resolved_requirements.append(shlex.quote(requirement))
+
+ encoded_requirements = " ".join(resolved_requirements)
+ nuclio_spec.cmd.append(f"python -m pip install {encoded_requirements}")
+
project = function.metadata.project or "default"
tag = function.metadata.tag
handler = function.spec.function_handler
diff --git a/mlrun/runtimes/kubejob.py b/mlrun/runtimes/kubejob.py
index f3626452ad14..3d3f98f81a67 100644
--- a/mlrun/runtimes/kubejob.py
+++ b/mlrun/runtimes/kubejob.py
@@ -137,15 +137,11 @@ def build_config(
self.spec.build.image = image
if base_image:
self.spec.build.base_image = base_image
- # if overwrite and requirements or commands passed, clear the existing commands
- # (requirements are added to the commands parameter)
- if (requirements or commands) and overwrite:
- self.spec.build.commands = None
if commands:
- self.with_commands(commands, overwrite=False, verify_base_image=False)
+ self.with_commands(commands, overwrite=overwrite, verify_base_image=False)
if requirements:
self.with_requirements(
- requirements, overwrite=False, verify_base_image=False
+ requirements, overwrite=overwrite, verify_base_image=False
)
if extra:
self.spec.build.extra = extra
diff --git a/tests/api/runtimes/test_kubejob.py b/tests/api/runtimes/test_kubejob.py
index edb44d0bb7d7..0d72e054259a 100644
--- a/tests/api/runtimes/test_kubejob.py
+++ b/tests/api/runtimes/test_kubejob.py
@@ -554,13 +554,11 @@ def test_with_image_pull_configuration(self, db: Session, client: TestClient):
def test_with_requirements(self, db: Session, client: TestClient):
runtime = self._generate_runtime()
runtime.with_requirements(self.requirements_file)
- expected_commands = [
- "python -m pip install faker python-dotenv 'chardet>=3.0.2, <4.0'"
- ]
+ expected_requirements = ["faker", "python-dotenv", "chardet>=3.0.2, <4.0"]
assert (
deepdiff.DeepDiff(
- expected_commands,
- runtime.spec.build.commands,
+ expected_requirements,
+ runtime.spec.build.requirements,
ignore_order=True,
)
== {}
@@ -665,21 +663,18 @@ def test_build_config(self, db: Session, client: TestClient):
)
runtime.build_config(requirements=["pandas", "numpy"])
- expected_commands = [
- "python -m pip install scikit-learn",
- "python -m pip install pandas numpy",
+ expected_requirements = [
+ "pandas",
+ "numpy",
]
- print(runtime.spec.build.commands)
assert (
deepdiff.DeepDiff(
- expected_commands,
- runtime.spec.build.commands,
+ expected_requirements,
+ runtime.spec.build.requirements,
ignore_order=False,
)
== {}
)
-
- runtime.build_config(requirements=["scikit-learn"], overwrite=True)
expected_commands = ["python -m pip install scikit-learn"]
assert (
deepdiff.DeepDiff(
@@ -690,12 +685,24 @@ def test_build_config(self, db: Session, client: TestClient):
== {}
)
+ runtime.build_config(requirements=["scikit-learn"], overwrite=True)
+ expected_requirements = ["scikit-learn"]
+ assert (
+ deepdiff.DeepDiff(
+ expected_requirements,
+ runtime.spec.build.requirements,
+ ignore_order=True,
+ )
+ == {}
+ )
+
def test_build_config_commands_and_requirements_order(
self, db: Session, client: TestClient
):
runtime = self._generate_runtime()
runtime.build_config(commands=["apt-get update"], requirements=["scikit-learn"])
- expected_commands = ["apt-get update", "python -m pip install scikit-learn"]
+ expected_commands = ["apt-get update"]
+ expected_requirements = ["scikit-learn"]
assert (
deepdiff.DeepDiff(
expected_commands,
@@ -704,6 +711,14 @@ def test_build_config_commands_and_requirements_order(
)
== {}
)
+ assert (
+ deepdiff.DeepDiff(
+ expected_requirements,
+ runtime.spec.build.requirements,
+ ignore_order=False,
+ )
+ == {}
+ )
def test_build_config_with_images(self, db: Session, client: TestClient):
runtime = self._generate_runtime()
diff --git a/tests/api/runtimes/test_nuclio.py b/tests/api/runtimes/test_nuclio.py
index c02fd3e9cbe2..acf2a872d05c 100644
--- a/tests/api/runtimes/test_nuclio.py
+++ b/tests/api/runtimes/test_nuclio.py
@@ -156,6 +156,7 @@ def _assert_deploy_called_basic_config(
expected_build_base_image=None,
expected_nuclio_runtime=None,
expected_env=None,
+ expected_build_commands=None,
):
if expected_labels is None:
expected_labels = {}
@@ -221,6 +222,13 @@ def _assert_deploy_called_basic_config(
if expected_nuclio_runtime:
assert deploy_config["spec"]["runtime"] == expected_nuclio_runtime
+
+ if expected_build_commands:
+ assert (
+ deploy_config["spec"]["build"]["commands"]
+ == expected_build_commands
+ )
+
return deploy_configs
def _assert_triggers(self, http_trigger=None, v3io_trigger=None):
@@ -611,6 +619,57 @@ def test_deploy_without_image_and_build_base_image(
self._assert_deploy_called_basic_config(expected_class=self.class_name)
+ @pytest.mark.parametrize(
+ "requirements,expected_commands",
+ [
+ (["pandas", "numpy"], ["python -m pip install pandas numpy"]),
+ (
+ ["-r requirements.txt", "numpy"],
+ ["python -m pip install -r requirements.txt numpy"],
+ ),
+ (["pandas>=1.0.0, <2"], ["python -m pip install 'pandas>=1.0.0, <2'"]),
+ (["pandas>=1.0.0,<2"], ["python -m pip install 'pandas>=1.0.0,<2'"]),
+ (
+ ["-r somewhere/requirements.txt"],
+ ["python -m pip install -r somewhere/requirements.txt"],
+ ),
+ (
+ ["something @ git+https://somewhere.com/a/b.git@v0.0.0#egg=something"],
+ [
+ "python -m pip install 'something @ git+https://somewhere.com/a/b.git@v0.0.0#egg=something'"
+ ],
+ ),
+ ],
+ )
+ def test_deploy_function_with_requirements(
+ self,
+ requirements: list,
+ expected_commands: list,
+ db: Session,
+ client: TestClient,
+ ):
+ function = self._generate_runtime(self.runtime_kind)
+ function.with_requirements(requirements)
+ self.execute_function(function)
+ self._assert_deploy_called_basic_config(
+ expected_class=self.class_name, expected_build_commands=expected_commands
+ )
+
+ def test_deploy_function_with_commands_and_requirements(
+ self, db: Session, client: TestClient
+ ):
+ function = self._generate_runtime(self.runtime_kind)
+ function.with_commands(["python -m pip install scikit-learn"])
+ function.with_requirements(["pandas", "numpy"])
+ self.execute_function(function)
+ expected_commands = [
+ "python -m pip install scikit-learn",
+ "python -m pip install pandas numpy",
+ ]
+ self._assert_deploy_called_basic_config(
+ expected_class=self.class_name, expected_build_commands=expected_commands
+ )
+
def test_deploy_function_with_labels(self, db: Session, client: TestClient):
labels = {
"key": "value",
diff --git a/tests/api/runtimes/test_spark.py b/tests/api/runtimes/test_spark.py
index 0d7e4176b68e..7d532abc7d80 100644
--- a/tests/api/runtimes/test_spark.py
+++ b/tests/api/runtimes/test_spark.py
@@ -630,7 +630,7 @@ def test_get_offline_features(
target=ParquetTarget(),
)
runspec = resp.run.spec.to_dict()
- assert runspec == {
+ expected_runspec = {
"parameters": {
"vector_uri": "store://feature-vectors/default/my-vector",
"target": {
@@ -650,11 +650,21 @@ def test_get_offline_features(
},
"outputs": [],
"output_path": "v3io:///mypath",
- "function": "None/my-vector-merger@a15d3e85a5326af937459528b28426ae7759e640",
"secret_sources": [],
+ "function": "None/my-vector-merger@3d197a096f5466a35961fc9fb6c6cdbc9d7266d2",
"data_stores": [],
"handler": "merge_handler",
}
+ assert (
+ deepdiff.DeepDiff(
+ runspec,
+ expected_runspec,
+ # excluding function attribute as it contains hash of the object, excluding this path because any change
+ # in the structure of the run will require to update the function hash
+ exclude_paths="function",
+ )
+ == {}
+ )
self.name = "my-vector-merger"
self.project = "default"
diff --git a/tests/projects/test_project.py b/tests/projects/test_project.py
index 2cf2156c3649..7cae71d77f4e 100644
--- a/tests/projects/test_project.py
+++ b/tests/projects/test_project.py
@@ -381,7 +381,7 @@ def _assert_project_function_objects(project, expected_function_objects):
)
-def test_set_func_requirements():
+def test_set_function_requirements():
project = mlrun.projects.project.MlrunProject.from_dict(
{
"metadata": {
@@ -393,16 +393,16 @@ def test_set_func_requirements():
}
)
project.set_function("hub://describe", "desc1", requirements=["x"])
- assert project.get_function("desc1", enrich=True).spec.build.commands == [
- "python -m pip install x",
- "python -m pip install 'pandas>1, <3'",
+ assert project.get_function("desc1", enrich=True).spec.build.requirements == [
+ "x",
+ "pandas>1, <3",
]
fn = mlrun.import_function("hub://describe")
project.set_function(fn, "desc2", requirements=["y"])
- assert project.get_function("desc2", enrich=True).spec.build.commands == [
- "python -m pip install y",
- "python -m pip install 'pandas>1, <3'",
+ assert project.get_function("desc2", enrich=True).spec.build.requirements == [
+ "y",
+ "pandas>1, <3",
]
diff --git a/tests/runtimes/test_base.py b/tests/runtimes/test_base.py
index 6a770b00f123..1042c1d4f5b5 100644
--- a/tests/runtimes/test_base.py
+++ b/tests/runtimes/test_base.py
@@ -82,30 +82,47 @@ def test_auto_mount_v3io(self, cred_only, rundb_mock):
"requirements,encoded_requirements",
[
# strip spaces
- (["pandas==1.0.0", "numpy==1.0.0 "], "pandas==1.0.0 numpy==1.0.0"),
+ (["pandas==1.0.0", "numpy==1.0.0 "], ["pandas==1.0.0", "numpy==1.0.0"]),
# handle ranges
- (["pandas>=1.0.0, <2"], "'pandas>=1.0.0, <2'"),
- (["pandas>=1.0.0,<2"], "'pandas>=1.0.0,<2'"),
+ (["pandas>=1.0.0, <2"], ["pandas>=1.0.0, <2"]),
+ (["pandas>=1.0.0,<2"], ["pandas>=1.0.0,<2"]),
# handle flags
- (["-r somewhere/requirements.txt"], "-r somewhere/requirements.txt"),
+ (["-r somewhere/requirements.txt"], ["-r somewhere/requirements.txt"]),
# handle flags and specific
# handle escaping within specific
(
["-r somewhere/requirements.txt", "pandas>=1.0.0, <2"],
- "-r somewhere/requirements.txt 'pandas>=1.0.0, <2'",
+ ["-r somewhere/requirements.txt", "pandas>=1.0.0, <2"],
),
# handle from git
(
["something @ git+https://somewhere.com/a/b.git@v0.0.0#egg=something"],
- "'something @ git+https://somewhere.com/a/b.git@v0.0.0#egg=something'",
+ ["something @ git+https://somewhere.com/a/b.git@v0.0.0#egg=something"],
),
# handle comments
- (["# dont care", "faker"], "faker"),
- (["faker # inline dontcare"], "faker"),
- (["faker #inline dontcare2"], "faker"),
+ (["# dont care", "faker"], ["faker"]),
+ (["faker # inline dontcare"], ["faker"]),
+ (["faker #inline dontcare2"], ["faker"]),
+ (
+ [
+ "numpy==1.0.0 ",
+ "pandas>=1.0.0, <2",
+ "# dont care",
+ "pandas2>=1.0.0,<2 # just an inline comment",
+ "-r somewhere/requirements.txt",
+ "something @ git+https://somewhere.com/a/b.git@v0.0.0#egg=something",
+ ],
+ [
+ "numpy==1.0.0",
+ "pandas>=1.0.0, <2",
+ "pandas2>=1.0.0,<2",
+ "-r somewhere/requirements.txt",
+ "something @ git+https://somewhere.com/a/b.git@v0.0.0#egg=something",
+ ],
+ ),
],
)
- def test_encode_requirements(self, requirements, encoded_requirements):
+ def test_resolve_requirements(self, requirements, encoded_requirements):
for requirements_as_file in [True, False]:
if requirements_as_file:
@@ -118,7 +135,7 @@ def test_encode_requirements(self, requirements, encoded_requirements):
f.write(requirement + "\n")
requirements = temp_file.name
- encoded = self._generate_runtime()._encode_requirements(requirements)
+ encoded = self._generate_runtime()._resolve_requirements(requirements)
assert (
encoded == encoded_requirements
), f"Failed to encode {requirements} as file {requirements_as_file}"
diff --git a/tests/runtimes/test_run.py b/tests/runtimes/test_run.py
index b336d9709532..91cd1a458b87 100644
--- a/tests/runtimes/test_run.py
+++ b/tests/runtimes/test_run.py
@@ -44,7 +44,7 @@ def _get_runtime():
"volume_mounts": [],
"env": [],
"description": "",
- "build": {"commands": []},
+ "build": {"commands": [], "requirements": []},
"affinity": None,
"disable_auto_mount": False,
"priority_class_name": "",
diff --git a/tests/test_builder.py b/tests/test_builder.py
index ccc49835ac6b..d828b8d04a8e 100644
--- a/tests/test_builder.py
+++ b/tests/test_builder.py
@@ -83,7 +83,20 @@ def test_build_config_preserve_order():
assert function.spec.build.commands == commands
-def test_build_runtime_insecure_registries(monkeypatch):
+@pytest.mark.parametrize(
+ "pull_mode,push_mode,secret,flags_expected",
+ [
+ ("auto", "auto", "", True),
+ ("auto", "auto", "some-secret-name", False),
+ ("enabled", "enabled", "some-secret-name", True),
+ ("enabled", "enabled", "", True),
+ ("disabled", "disabled", "some-secret-name", False),
+ ("disabled", "disabled", "", False),
+ ],
+)
+def test_build_runtime_insecure_registries(
+ monkeypatch, pull_mode, push_mode, secret, flags_expected
+):
_patch_k8s_helper(monkeypatch)
mlrun.mlconf.httpdb.builder.docker_registry = "registry.hub.docker.com/username"
function = mlrun.new_function(
@@ -96,62 +109,24 @@ def test_build_runtime_insecure_registries(monkeypatch):
)
insecure_flags = {"--insecure", "--insecure-pull"}
- for case in [
- {
- "pull_mode": "auto",
- "push_mode": "auto",
- "secret": "",
- "flags_expected": True,
- },
- {
- "pull_mode": "auto",
- "push_mode": "auto",
- "secret": "some-secret-name",
- "flags_expected": False,
- },
- {
- "pull_mode": "enabled",
- "push_mode": "enabled",
- "secret": "some-secret-name",
- "flags_expected": True,
- },
- {
- "pull_mode": "enabled",
- "push_mode": "enabled",
- "secret": "",
- "flags_expected": True,
- },
- {
- "pull_mode": "disabled",
- "push_mode": "disabled",
- "secret": "some-secret-name",
- "flags_expected": False,
- },
- {
- "pull_mode": "disabled",
- "push_mode": "disabled",
- "secret": "",
- "flags_expected": False,
- },
- ]:
- mlrun.mlconf.httpdb.builder.insecure_pull_registry_mode = case["pull_mode"]
- mlrun.mlconf.httpdb.builder.insecure_push_registry_mode = case["push_mode"]
- mlrun.mlconf.httpdb.builder.docker_registry_secret = case["secret"]
- mlrun.builder.build_runtime(
- mlrun.api.schemas.AuthInfo(),
- function,
- )
- assert (
- insecure_flags.issubset(
- set(
- mlrun.builder.get_k8s_helper()
- .create_pod.call_args[0][0]
- .pod.spec.containers[0]
- .args
- )
+ mlrun.mlconf.httpdb.builder.insecure_pull_registry_mode = pull_mode
+ mlrun.mlconf.httpdb.builder.insecure_push_registry_mode = push_mode
+ mlrun.mlconf.httpdb.builder.docker_registry_secret = secret
+ mlrun.builder.build_runtime(
+ mlrun.api.schemas.AuthInfo(),
+ function,
+ )
+ assert (
+ insecure_flags.issubset(
+ set(
+ mlrun.builder.get_k8s_helper()
+ .create_pod.call_args[0][0]
+ .pod.spec.containers[0]
+ .args
)
- == case["flags_expected"]
)
+ == flags_expected
+ )
def test_build_runtime_target_image(monkeypatch):
From 5481f5b28f8146cfe715f168ad3e52ab026041d1 Mon Sep 17 00:00:00 2001
From: Tom Tankilevitch <59158507+Tankilevitch@users.noreply.github.com>
Date: Tue, 11 Apr 2023 17:05:02 +0300
Subject: [PATCH 040/334] [CI] Support multi branch system tests (#3393)
---
.github/workflows/system-tests-enterprise.yml | 89 +++++++++++++++----
automation/system_test/prepare.py | 39 ++++----
2 files changed, 89 insertions(+), 39 deletions(-)
diff --git a/.github/workflows/system-tests-enterprise.yml b/.github/workflows/system-tests-enterprise.yml
index dd7ecfe6606b..bc1c4a983263 100644
--- a/.github/workflows/system-tests-enterprise.yml
+++ b/.github/workflows/system-tests-enterprise.yml
@@ -43,9 +43,9 @@ on:
description: 'Override the configured target system iguazio version (leave empty to resolve automatically)'
required: false
test_code_from_action:
- description: 'Take tested code from action REF rather than upstream (default: true). If running on personal fork you will want to set to false in order to pull images from mlrun ghcr (note that test code will be taken from the action REF anyways)'
+ description: 'Take tested code from action from upstream rather than ref (default: false). If running on personal fork you will want to set to false in order to pull images from mlrun ghcr (note that test code will be taken from the action REF anyways)'
required: true
- default: 'true'
+ default: 'false'
ui_code_from_action:
description: 'Take ui code from action branch in mlrun/ui (default: false - take from upstream)'
required: true
@@ -107,6 +107,57 @@ jobs:
steps:
- uses: actions/checkout@v3
+ - name: Copy state branch file from remote
+ run: |
+ sshpass -p "${{ secrets.LATEST_SYSTEM_TEST_DATA_CLUSTER_SSH_PASSWORD }}" scp -o StrictHostKeyChecking=no ${{ secrets.LATEST_SYSTEM_TEST_DATA_CLUSTER_SSH_USERNAME }}@${{ secrets.LATEST_SYSTEM_TEST_DATA_CLUSTER_IP }}:/tmp/system-tests-branches-list.txt system-tests-branches-list.txt
+
+ - name: Resolve Branch To Run System Tests
+ id: current-branch
+ # we store a file named /tmp/system-tests-branches-list.txt which contains a list of branches to run system tests
+ # on the branches are separated with commas, so each run we pop the first branch in the list and append it to the
+ # end of the list.
+ # This mechanism allows us to run on multiple branches without the need to modify the file or secrets each time
+ # a new branch is added or removed
+ run: |
+ # Read branches from local file
+ branches=$(cat system-tests-branches-list.txt)
+ echo "branches found in system-tests-branches-list.txt: $branches"
+
+ # Split branches into an array
+ IFS=',' read -ra branches_array <<< "$branches"
+
+ # Get the first branch in the list to work on
+ first_branch="${branches_array[0]}"
+ echo "working on $first_branch"
+
+ # Remove the first branch from the list
+ branches_array=("${branches_array[@]:1}")
+
+ # Add the first branch at the end of the list
+ branches_array+=("$first_branch")
+
+ # Join branches back into a string
+ branches=$(printf ",%s" "${branches_array[@]}")
+ branches=${branches:1}
+
+ # Output the new list of branches
+ echo "$branches"
+
+ # Write new branches order to a local file
+ echo "$branches" | cat > system-tests-branches-list.txt
+
+ # Set output
+ echo "name=$(echo $first_branch)" >> $GITHUB_OUTPUT
+
+ - name: Override remote file from local resolved branch list
+ run: |
+ # Override the remote file with the new list of branches
+ sshpass -p "${{ secrets.LATEST_SYSTEM_TEST_DATA_CLUSTER_SSH_PASSWORD }}" scp -o StrictHostKeyChecking=no system-tests-branches-list.txt ${{ secrets.LATEST_SYSTEM_TEST_DATA_CLUSTER_SSH_USERNAME }}@${{ secrets.LATEST_SYSTEM_TEST_DATA_CLUSTER_IP }}:/tmp/
+ # checking out to base branch and not the target(resolved) branch, to be able to run the changed preparation code
+ # before merging the changes to upstream.
+ - name: Checkout base branch
+ uses: actions/checkout@v3
+
- name: Set up python
uses: actions/setup-python@v4
with:
@@ -116,13 +167,10 @@ jobs:
run: pip install -r automation/requirements.txt && pip install -e .
- name: Install curl and jq
run: sudo apt-get install curl jq
- - name: Extract git branch
- id: git_info
- run: |
- echo "branch=$(echo ${GITHUB_REF#refs/heads/})" >> $GITHUB_OUTPUT
- name: Extract git hash from action mlrun version
- # by default when running as part of the CI this param doesn't get enriched meaning it will be empty.
- # we want the mlrun_hash to be set from the $GITHUB_SHA when running in CI
+ # because it is being run mainly on CI and the code is of the development but can be run against multiple branches
+ # the default is false so it will use the code of the chosen branch
+ # TODO: remove - might not be relevant anymore due to multi branch system tests
if: ${{ github.event.inputs.test_code_from_action != 'false' }}
id: git_action_info
run: |
@@ -133,7 +181,7 @@ jobs:
run: |
echo "ui_hash=$( \
cd /tmp && \
- git clone --single-branch --branch ${{ steps.git_info.outputs.branch }} https://github.com/mlrun/ui.git mlrun-ui 2> /dev/null && \
+ git clone --single-branch --branch ${{ steps.current-branch.outputs.name }} https://github.com/mlrun/ui.git mlrun-ui 2> /dev/null && \
cd mlrun-ui && \
git rev-parse --short=8 HEAD && \
cd .. && \
@@ -143,29 +191,35 @@ jobs:
run: |
echo "mlrun_hash=$( \
cd /tmp && \
- git clone --single-branch --branch development https://github.com/mlrun/mlrun.git mlrun-upstream 2> /dev/null && \
+ git clone --single-branch --branch ${{ steps.current-branch.outputs.name }} https://github.com/mlrun/mlrun.git mlrun-upstream 2> /dev/null && \
cd mlrun-upstream && \
git rev-parse --short=8 HEAD && \
cd .. && \
rm -rf mlrun-upstream)" >> $GITHUB_OUTPUT
echo "ui_hash=$( \
cd /tmp && \
- git clone --single-branch --branch development https://github.com/mlrun/ui.git mlrun-ui 2> /dev/null && \
+ git clone --single-branch --branch ${{ steps.current-branch.outputs.name }} https://github.com/mlrun/ui.git mlrun-ui 2> /dev/null && \
cd mlrun-ui && \
git rev-parse --short=8 HEAD && \
cd .. && \
rm -rf mlrun-ui)" >> $GITHUB_OUTPUT
- echo "unstable_version_prefix=$(cat automation/version/unstable_version_prefix)" >> $GITHUB_OUTPUT
+ echo "unstable_version_prefix=$( \
+ cd /tmp && \
+ git clone --single-branch --branch ${{ steps.current-branch.outputs.name }} https://github.com/mlrun/mlrun.git mlrun-upstream 2> /dev/null && \
+ cd mlrun-upstream && \
+ cat automation/version/unstable_version_prefix && \
+ cd .. && \
+ rm -rf mlrun-upstream)" >> $GITHUB_OUTPUT
- name: Set computed versions params
id: computed_params
run: |
action_mlrun_hash=${{ steps.git_action_info.outputs.mlrun_hash }} && \
upstream_mlrun_hash=${{ steps.git_upstream_info.outputs.mlrun_hash }} && \
- export mlrun_hash=${action_mlrun_hash:-`echo $upstream_mlrun_hash`}
+ export mlrun_hash=${upstream_mlrun_hash:-`echo $action_mlrun_hash`}
echo "mlrun_hash=$(echo $mlrun_hash)" >> $GITHUB_OUTPUT
action_mlrun_ui_hash=${{ steps.git_action_ui_info.outputs.ui_hash }} && \
upstream_mlrun_ui_hash=${{ steps.git_upstream_info.outputs.ui_hash }} && \
- export ui_hash=${action_mlrun_ui_hash:-`echo $upstream_mlrun_ui_hash`}
+ export ui_hash=${upstream_mlrun_ui_hash:-`echo $action_mlrun_ui_hash`}
echo "ui_hash=$(echo $ui_hash)" >> $GITHUB_OUTPUT
echo "mlrun_version=$(echo ${{ steps.git_upstream_info.outputs.unstable_version_prefix }}+$mlrun_hash)" >> $GITHUB_OUTPUT
echo "mlrun_docker_tag=$(echo ${{ steps.git_upstream_info.outputs.unstable_version_prefix }}-$mlrun_hash)" >> $GITHUB_OUTPUT
@@ -220,6 +274,7 @@ jobs:
outputs:
mlrunVersion: ${{ steps.computed_params.outputs.mlrun_version }}
+ mlrunBranch: ${{ steps.current-branch.outputs.name }}
mlrunSystemTestsCleanResources: ${{ steps.computed_params.outputs.mlrun_system_tests_clean_resources }}
run-system-tests-enterprise-ci:
@@ -237,8 +292,12 @@ jobs:
matrix:
test_component: [api,runtimes,projects,model_monitoring,examples,backwards_compatibility,feature_store]
steps:
- # checking out to the commit hash that the preparation step executed on
- uses: actions/checkout@v3
+ # checking out to the resolved branch to run system tests on, as now we run the actual tests, we don't want to run
+ # the system tests of the branch that triggered the system tests as it might be in a different version
+ # than the mlrun version we deployed on the previous job (can have features that the resolved branch doesn't have)
+ with:
+ ref: ${{ needs.prepare-system-tests-enterprise-ci.outputs.mlrunBranch }}
- name: Set up python
uses: actions/setup-python@v4
with:
diff --git a/automation/system_test/prepare.py b/automation/system_test/prepare.py
index 4cf599382743..fc06b71ad5b0 100644
--- a/automation/system_test/prepare.py
+++ b/automation/system_test/prepare.py
@@ -141,11 +141,14 @@ def run(self):
self._override_mlrun_api_env()
- self._patch_mlrun()
-
+ # purge of the database needs to be executed before patching mlrun so that the mlrun migrations
+ # that run as part of the patch would succeed even if we move from a newer version to an older one
+ # e.g from development branch which is (1.4.0) and has a newer alembic revision than 1.3.x which is (1.3.1)
if self._purge_db:
self._purge_mlrun_db()
+ self._patch_mlrun()
+
def clean_up_remote_workdir(self):
self._logger.info(
"Cleaning up remote workdir", workdir=str(self.Constants.workdir)
@@ -486,6 +489,9 @@ def _patch_mlrun(self):
self._data_cluster_ssh_password,
"patch",
"appservice",
+ # we force because by default provctl doesn't allow downgrading between version but due to system tests
+ # running on multiple branches this might occur.
+ "--force",
"mlrun",
mlrun_archive,
],
@@ -518,11 +524,10 @@ def _resolve_iguazio_version(self):
def _purge_mlrun_db(self):
"""
- Purge mlrun db - exec into mlrun-db pod, delete the database and restart mlrun pods
+ Purge mlrun db - exec into mlrun-db pod, delete the database and scale down mlrun pods
"""
self._delete_mlrun_db()
- self._rollout_restart_mlrun()
- self._wait_for_mlrun_to_be_ready()
+ self._scale_down_mlrun_deployments()
def _delete_mlrun_db(self):
self._logger.info("Deleting mlrun db")
@@ -559,33 +564,19 @@ def _get_pod_name_command(self, labels, namespace=None):
namespace=namespace, labels_selector=labels_selector
)
- def _rollout_restart_mlrun(self):
- self._logger.info("Restarting mlrun")
+ def _scale_down_mlrun_deployments(self):
+ # scaling down to avoid automatically deployments restarts and failures
+ self._logger.info("scaling down mlrun deployments")
self._run_kubectl_command(
args=[
- "rollout",
- "restart",
+ "scale",
"deployment",
"-n",
self.Constants.namespace,
"mlrun-api-chief",
"mlrun-api-worker",
"mlrun-db",
- ]
- )
-
- def _wait_for_mlrun_to_be_ready(self):
- self._logger.info("Waiting for mlrun to be ready")
- self._run_kubectl_command(
- args=[
- "wait",
- "--for=condition=available",
- "--timeout=300s",
- "deployment",
- "-n",
- self.Constants.namespace,
- "mlrun-api-chief",
- "mlrun-db",
+ "--replicas=0",
]
)
From 9cea482c0b58ba31a30655270503f9bde9d7c1b5 Mon Sep 17 00:00:00 2001
From: Tom Tankilevitch <59158507+Tankilevitch@users.noreply.github.com>
Date: Thu, 13 Apr 2023 11:44:22 +0300
Subject: [PATCH 041/334] [Runtimes] Adjust `require_build` logic to include
new requirements attribute (#3396)
---
mlrun/runtimes/base.py | 6 ++++--
mlrun/runtimes/kubejob.py | 8 +++++++-
2 files changed, 11 insertions(+), 3 deletions(-)
diff --git a/mlrun/runtimes/base.py b/mlrun/runtimes/base.py
index b2b66bc223a6..bed99d0abf64 100644
--- a/mlrun/runtimes/base.py
+++ b/mlrun/runtimes/base.py
@@ -1330,8 +1330,10 @@ def clean_build_params(self):
def verify_base_image(self):
build = self.spec.build
- require_build = build.commands or (
- build.source and not build.load_source_on_run
+ require_build = (
+ build.commands
+ or build.requirements
+ or (build.source and not build.load_source_on_run)
)
image = self.spec.image
# we allow users to not set an image, in that case we'll use the default
diff --git a/mlrun/runtimes/kubejob.py b/mlrun/runtimes/kubejob.py
index 3d3f98f81a67..349c031ed0c5 100644
--- a/mlrun/runtimes/kubejob.py
+++ b/mlrun/runtimes/kubejob.py
@@ -194,7 +194,13 @@ def deploy(
or "/mlrun/" in build.base_image
)
- if not build.source and not build.commands and not build.extra and with_mlrun:
+ if (
+ not build.source
+ and not build.commands
+ and not build.requirements
+ and not build.extra
+ and with_mlrun
+ ):
logger.info(
"running build to add mlrun package, set "
"with_mlrun=False to skip if its already in the image"
From d6dbd34b259710fbd29ab95f0ac5026a1deb4128 Mon Sep 17 00:00:00 2001
From: Adam
Date: Thu, 13 Apr 2023 11:56:13 +0300
Subject: [PATCH 042/334] [System Tests] Fix Run Notifications System Test
(#3397)
---
tests/system/runtimes/test_notifications.py | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/tests/system/runtimes/test_notifications.py b/tests/system/runtimes/test_notifications.py
index 120181a85f12..9b2435ed4059 100644
--- a/tests/system/runtimes/test_notifications.py
+++ b/tests/system/runtimes/test_notifications.py
@@ -31,8 +31,8 @@ def _assert_notifications():
with_notifications=True,
)
assert len(runs) == 1
- assert len(runs[0]["spec"]["notifications"]) == 2
- for notification in runs[0]["spec"]["notifications"]:
+ assert len(runs[0]["status"]["notifications"]) == 2
+ for notification in runs[0]["status"]["notifications"]:
if notification["name"] == error_notification.name:
assert notification["status"] == "error"
elif notification["name"] == success_notification.name:
From 7aae8e9794d8445012298ede748690540421f1e0 Mon Sep 17 00:00:00 2001
From: GiladShapira94 <100074049+GiladShapira94@users.noreply.github.com>
Date: Thu, 13 Apr 2023 12:16:05 +0300
Subject: [PATCH 043/334] [CLI] Add notifications to project (#2934)
---
mlrun/__main__.py | 62 +++++++++++++++++++++++++++++++---
mlrun/projects/pipelines.py | 5 +--
tests/assets/notification.json | 1 +
tests/test_cli.py | 36 ++++++++++++++++++++
4 files changed, 98 insertions(+), 6 deletions(-)
create mode 100644 tests/assets/notification.json
create mode 100644 tests/test_cli.py
diff --git a/mlrun/__main__.py b/mlrun/__main__.py
index fded06f63325..67d1ebfc9f99 100644
--- a/mlrun/__main__.py
+++ b/mlrun/__main__.py
@@ -29,6 +29,7 @@
import click
import dotenv
import pandas as pd
+import simplejson
import yaml
from tabulate import tabulate
@@ -1052,6 +1053,15 @@ def logs(uid, project, offset, db, watch):
is_flag=True,
help="Store the project secrets as k8s secrets",
)
+@click.option(
+ "--notifications",
+ "--notification",
+ "-nt",
+ multiple=True,
+ help="To have a notification for the run set notification file "
+ "destination define: file=notification.json or a "
+ 'dictionary configuration e.g \'{"slack":{"webhook":""}}\'',
+)
def project(
context,
name,
@@ -1077,6 +1087,7 @@ def project(
timeout,
ensure_project,
schedule,
+ notifications,
overwrite_schedule,
save_secrets,
save,
@@ -1152,6 +1163,8 @@ def project(
"token": proj.get_param("GIT_TOKEN"),
},
)
+ if notifications:
+ load_notification(notifications, proj)
try:
proj.run(
name=run,
@@ -1169,11 +1182,9 @@ def project(
timeout=timeout,
overwrite=overwrite_schedule,
)
-
- except Exception as exc:
+ except Exception as err:
print(traceback.format_exc())
- message = f"failed to run pipeline, {err_to_str(exc)}"
- proj.notifiers.push(message, "error")
+ send_workflow_error_notification(run, proj, err)
exit(1)
elif sync:
@@ -1450,5 +1461,48 @@ def func_url_to_runtime(func_url, ensure_project: bool = False):
return runtime
+def load_notification(notifications: str, project: mlrun.projects.MlrunProject):
+ """
+ A dictionary or json file containing notification dictionaries can be used by the user to set notifications.
+ Each notification is stored in a tuple called notifications.
+ The code then goes through each value in the notifications tuple and check
+ if the notification starts with "file=", such as "file=notification.json," in those cases it loads the
+ notification.json file and uses add_notification_to_project to add the notifications from the file to
+ the project. If not, it adds the notification dictionary to the project.
+ :param notifications: Notifications file or a dictionary to be added to the project
+ :param project: The object to which the notifications will be added
+ :return:
+ """
+ for notification in notifications:
+ if notification.startswith("file="):
+ file_path = notification.split("=")[-1]
+ notification = open(file_path, "r")
+ notification = simplejson.load(notification)
+ else:
+ notification = simplejson.loads(notification)
+ add_notification_to_project(notification, project)
+
+
+def add_notification_to_project(
+ notification: str, project: mlrun.projects.MlrunProject
+):
+ for notification_type, notification_params in notification.items():
+ project.notifiers.add_notification(
+ notification_type=notification_type, params=notification_params
+ )
+
+
+def send_workflow_error_notification(
+ run_id: str, project: mlrun.projects.MlrunProject, error: KeyError
+):
+ message = (
+ f":x: Failed to run scheduled workflow {run_id} in Project {project.name} !\n"
+ f"error: ```{err_to_str(error)}```"
+ )
+ project.notifiers.push(
+ message=message, severity=mlrun.api.schemas.NotificationSeverity.ERROR
+ )
+
+
if __name__ == "__main__":
main()
diff --git a/mlrun/projects/pipelines.py b/mlrun/projects/pipelines.py
index 8d426bcbdf2e..9dfa9214c9eb 100644
--- a/mlrun/projects/pipelines.py
+++ b/mlrun/projects/pipelines.py
@@ -705,7 +705,7 @@ def run(
trace = traceback.format_exc()
logger.error(trace)
project.notifiers.push(
- f"Workflow {workflow_id} run failed!, error: {e}\n{trace}", "error"
+ f":x: Workflow {workflow_id} run failed!, error: {e}\n{trace}", "error"
)
state = mlrun.run.RunStatuses.failed
mlrun.run.wait_for_runs_completion(pipeline_context.runs_map.values())
@@ -874,7 +874,8 @@ def run(
trace = traceback.format_exc()
logger.error(trace)
project.notifiers.push(
- f"Workflow {workflow_name} run failed!, error: {e}\n{trace}", "error"
+ f":x: Workflow {workflow_name} run failed!, error: {e}\n{trace}",
+ "error",
)
state = mlrun.run.RunStatuses.failed
return _PipelineRunStatus(
diff --git a/tests/assets/notification.json b/tests/assets/notification.json
new file mode 100644
index 000000000000..c30eb56b99dd
--- /dev/null
+++ b/tests/assets/notification.json
@@ -0,0 +1 @@
+{"slack": {"webhook": "123456"},"ipython" : {"webhook": "1234"}}
diff --git a/tests/test_cli.py b/tests/test_cli.py
new file mode 100644
index 000000000000..e9600623b925
--- /dev/null
+++ b/tests/test_cli.py
@@ -0,0 +1,36 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import pathlib
+
+import mlrun.projects
+from mlrun.__main__ import load_notification
+
+
+def test_add_notification_to_cli_from_file():
+ input_file_path = str(pathlib.Path(__file__).parent / "assets/notification.json")
+ notifications = (f"file={input_file_path}",)
+ project = mlrun.projects.MlrunProject(name="test")
+ load_notification(notifications, project)
+
+ assert project._notifiers._notifications["slack"].params.get("webhook") == "123456"
+ assert project._notifiers._notifications["ipython"].params.get("webhook") == "1234"
+
+
+def test_add_notification_to_cli_from_dict():
+ notifications = ('{"slack":{"webhook":"123456"}}', '{"ipython":{"webhook":"1234"}}')
+ project = mlrun.projects.MlrunProject(name="test")
+ load_notification(notifications, project)
+
+ assert project._notifiers._notifications["slack"].params.get("webhook") == "123456"
+ assert project._notifiers._notifications["ipython"].params.get("webhook") == "1234"
From e6a004976eadeeeef9609968f131fee06e70da02 Mon Sep 17 00:00:00 2001
From: Gal Topper
Date: Thu, 13 Apr 2023 16:44:15 +0800
Subject: [PATCH 044/334] [Spark] Fix unexpected spark job failure
[https://jira.iguazeng.com/browse/ML-3738](ML-3738)
Fixes a regression in 1.3.1-rc1 caused by #3364.
---
mlrun/runtimes/local.py | 5 +++++
.../assets/verbose_stderr_return_code_0.py | 22 +++++++++++++++++++
...err.py => verbose_stderr_return_code_1.py} | 0
tests/runtimes/test_local.py | 14 +++++++++---
4 files changed, 38 insertions(+), 3 deletions(-)
create mode 100644 tests/runtimes/assets/verbose_stderr_return_code_0.py
rename tests/runtimes/assets/{verbose_stderr.py => verbose_stderr_return_code_1.py} (100%)
diff --git a/mlrun/runtimes/local.py b/mlrun/runtimes/local.py
index a4dd402744ae..18cc7982e74a 100644
--- a/mlrun/runtimes/local.py
+++ b/mlrun/runtimes/local.py
@@ -392,6 +392,11 @@ def read_stderr(stderr):
stderr_consumer_thread.join()
err = stderr.getvalue()
+
+ # if we return anything for err, the caller will assume that the process failed
+ code = process.poll()
+ err = "" if code == 0 else err
+
return out, err
diff --git a/tests/runtimes/assets/verbose_stderr_return_code_0.py b/tests/runtimes/assets/verbose_stderr_return_code_0.py
new file mode 100644
index 000000000000..2d88e2b40ab9
--- /dev/null
+++ b/tests/runtimes/assets/verbose_stderr_return_code_0.py
@@ -0,0 +1,22 @@
+# Copyright 2023 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+
+print("some output")
+
+for i in range(10000):
+ print("123456789", file=sys.stderr)
+
+sys.exit(0)
diff --git a/tests/runtimes/assets/verbose_stderr.py b/tests/runtimes/assets/verbose_stderr_return_code_1.py
similarity index 100%
rename from tests/runtimes/assets/verbose_stderr.py
rename to tests/runtimes/assets/verbose_stderr_return_code_1.py
diff --git a/tests/runtimes/test_local.py b/tests/runtimes/test_local.py
index f4460d4e1bca..902ea21fda39 100644
--- a/tests/runtimes/test_local.py
+++ b/tests/runtimes/test_local.py
@@ -13,6 +13,8 @@
# limitations under the License.
import pathlib
+import pytest
+
from mlrun.runtimes.local import run_exec
@@ -23,8 +25,14 @@ def test_run_exec_basic():
# ML-3710
-def test_run_exec_verbose_stderr():
- script_path = str(pathlib.Path(__file__).parent / "assets" / "verbose_stderr.py")
+@pytest.mark.parametrize("return_code", [0, 1])
+def test_run_exec_verbose_stderr(return_code):
+ script_path = str(
+ pathlib.Path(__file__).parent
+ / "assets"
+ / f"verbose_stderr_return_code_{return_code}.py"
+ )
out, err = run_exec(["python"], [script_path])
assert out == "some output\n"
- assert len(err) == 100000
+ expected_err_length = 100000 if return_code else 0
+ assert len(err) == expected_err_length
From 8c9d84470938bad62b2398df2b188f98d08d6424 Mon Sep 17 00:00:00 2001
From: davesh0812 <85231462+davesh0812@users.noreply.github.com>
Date: Thu, 13 Apr 2023 15:39:07 +0300
Subject: [PATCH 045/334] [Serving] Fix process executer in ParallelRun
(#3400)
---
mlrun/serving/routers.py | 21 ++++++++++-----------
1 file changed, 10 insertions(+), 11 deletions(-)
diff --git a/mlrun/serving/routers.py b/mlrun/serving/routers.py
index e7343f6686b7..0b68ab019567 100644
--- a/mlrun/serving/routers.py
+++ b/mlrun/serving/routers.py
@@ -401,12 +401,14 @@ def _init_pool(
step._parent = None
if step._object:
step._object.context = None
+ if hasattr(step._object, "_kwargs"):
+ step._object._kwargs["graph_step"] = None
routes[key] = step
executor_class = concurrent.futures.ProcessPoolExecutor
self._pool = executor_class(
max_workers=len(self.routes),
initializer=ParallelRun.init_pool,
- initargs=(server, routes, id(self)),
+ initargs=(server, routes),
)
elif self.executor_type == ParallelRunnerModes.thread:
executor_class = concurrent.futures.ThreadPoolExecutor
@@ -421,7 +423,7 @@ def _shutdown_pool(self):
if self._pool is not None:
if self.executor_type == ParallelRunnerModes.process:
global local_routes
- local_routes.pop(id(self))
+ del local_routes
self._pool.shutdown()
self._pool = None
@@ -445,7 +447,7 @@ def _parallel_run(self, event: dict):
for route in self.routes.keys():
if self.executor_type == ParallelRunnerModes.process:
future = executor.submit(
- ParallelRun._wrap_step, route, id(self), copy.copy(event)
+ ParallelRun._wrap_step, route, copy.copy(event)
)
elif self.executor_type == ParallelRunnerModes.thread:
step = self.routes[route]
@@ -469,25 +471,22 @@ def _parallel_run(self, event: dict):
return results
@staticmethod
- def init_pool(server_spec, routes, object_id):
+ def init_pool(server_spec, routes):
server = mlrun.serving.GraphServer.from_dict(server_spec)
server.init_states(None, None)
global local_routes
- if object_id in local_routes:
- return
for route in routes.values():
route.context = server.context
if route._object:
route._object.context = server.context
- local_routes[object_id] = routes
+ local_routes = routes
@staticmethod
- def _wrap_step(route, object_id, event):
+ def _wrap_step(route, event):
global local_routes
- routes = local_routes.get(object_id, None).copy()
- if routes is None:
+ if local_routes is None:
return None, None
- return route, routes[route].run(event)
+ return route, local_routes[route].run(event)
@staticmethod
def _wrap_method(route, handler, event):
From 973c0df2152a02808981305efa0e85e2df775a08 Mon Sep 17 00:00:00 2001
From: Yael Genish <62285310+yaelgen@users.noreply.github.com>
Date: Thu, 13 Apr 2023 16:59:34 +0300
Subject: [PATCH 046/334] [Tests] Fix pipeline system tests (#3389)
---
docs/tutorial/src/workflow.py | 2 +-
mlrun/feature_store/common.py | 2 +-
mlrun/projects/operations.py | 4 ++--
mlrun/projects/project.py | 6 +++---
mlrun/run.py | 4 ++--
mlrun/runtimes/serving.py | 2 +-
tests/api/api/test_utils.py | 2 +-
tests/projects/test_project.py | 2 +-
tests/system/demos/churn/test_churn.py | 10 +++++-----
tests/system/demos/horovod/test_horovod.py | 2 +-
tests/system/demos/sklearn/test_sklearn.py | 6 +++---
tests/system/model_monitoring/test_model_monitoring.py | 10 +++++-----
tests/system/projects/assets/kflow.py | 4 ++--
tests/system/projects/assets/newflow.py | 6 +++---
tests/system/projects/test_project.py | 6 +++---
15 files changed, 34 insertions(+), 34 deletions(-)
diff --git a/docs/tutorial/src/workflow.py b/docs/tutorial/src/workflow.py
index 3fadf9b20068..033051140119 100644
--- a/docs/tutorial/src/workflow.py
+++ b/docs/tutorial/src/workflow.py
@@ -16,7 +16,7 @@ def pipeline(model_name="cancer-classifier"):
# Train a model using the auto_trainer hub function
train = mlrun.run_function(
- "hub://auto_trainer",
+ "hub://auto-trainer",
inputs={"dataset": ingest.outputs["dataset"]},
params={
"model_class": "sklearn.ensemble.RandomForestClassifier",
diff --git a/mlrun/feature_store/common.py b/mlrun/feature_store/common.py
index 8198e217f6bc..a3b4bb886ac0 100644
--- a/mlrun/feature_store/common.py
+++ b/mlrun/feature_store/common.py
@@ -218,7 +218,7 @@ def __init__(
config = RunConfig("mycode.py", image="mlrun/mlrun", requirements=["spacy"])
# config for using function object
- function = mlrun.import_function("hub://some_function")
+ function = mlrun.import_function("hub://some-function")
config = RunConfig(function)
:param function: this can be function uri or function object or path to function code (.py/.ipynb)
diff --git a/mlrun/projects/operations.py b/mlrun/projects/operations.py
index e77d2f11571f..7bbfce59ce1e 100644
--- a/mlrun/projects/operations.py
+++ b/mlrun/projects/operations.py
@@ -92,7 +92,7 @@ def run_function(
LABELS = "is_error"
MODEL_CLASS = "sklearn.ensemble.RandomForestClassifier"
DATA_PATH = "s3://bigdata/data.parquet"
- function = mlrun.import_function("hub://auto_trainer")
+ function = mlrun.import_function("hub://auto-trainer")
run1 = run_function(function, params={"label_columns": LABELS, "model_class": MODEL_CLASS},
inputs={"dataset": DATA_PATH})
@@ -101,7 +101,7 @@ def run_function(
# create a project with two functions (local and from marketplace)
project = mlrun.new_project(project_name, "./proj)
project.set_function("mycode.py", "myfunc", image="mlrun/mlrun")
- project.set_function("hub://auto_trainer", "train")
+ project.set_function("hub://auto-trainer", "train")
# run functions (refer to them by name)
run1 = run_function("myfunc", params={"x": 7})
diff --git a/mlrun/projects/project.py b/mlrun/projects/project.py
index 242a0a074739..044f246018ee 100644
--- a/mlrun/projects/project.py
+++ b/mlrun/projects/project.py
@@ -117,7 +117,7 @@ def new_project(
# create a project with local and marketplace functions, a workflow, and an artifact
project = mlrun.new_project("myproj", "./", init_git=True, description="my new project")
project.set_function('prep_data.py', 'prep-data', image='mlrun/mlrun', handler='prep_data')
- project.set_function('hub://auto_trainer', 'train')
+ project.set_function('hub://auto-trainer', 'train')
project.set_artifact('data', Artifact(target_path=data_url))
project.set_workflow('main', "./myflow.py")
project.save()
@@ -1525,7 +1525,7 @@ def set_function(
object (s3://, v3io://, ..)
MLRun DB e.g. db://project/func:ver
- functions hub/market: e.g. hub://auto_trainer:master
+ functions hub/market: e.g. hub://auto-trainer:master
examples::
@@ -2198,7 +2198,7 @@ def run_function(
# create a project with two functions (local and from marketplace)
project = mlrun.new_project(project_name, "./proj")
project.set_function("mycode.py", "myfunc", image="mlrun/mlrun")
- project.set_function("hub://auto_trainer", "train")
+ project.set_function("hub://auto-trainer", "train")
# run functions (refer to them by name)
run1 = project.run_function("myfunc", params={"x": 7})
diff --git a/mlrun/run.py b/mlrun/run.py
index 06873a5f8a39..f93561f2742a 100644
--- a/mlrun/run.py
+++ b/mlrun/run.py
@@ -236,7 +236,7 @@ def function_to_module(code="", workdir=None, secrets=None, silent=False):
mod.my_job(context, p1=1, p2='x')
print(context.to_yaml())
- fn = mlrun.import_function('hub://open_archive')
+ fn = mlrun.import_function('hub://open-archive')
mod = mlrun.function_to_module(fn)
data = mlrun.run.get_dataitem("https://fpsignals-public.s3.amazonaws.com/catsndogs.tar.gz")
context = mlrun.get_or_create_ctx('myfunc')
@@ -458,7 +458,7 @@ def import_function(url="", secrets=None, db="", project=None, new_name=None):
examples::
- function = mlrun.import_function("hub://auto_trainer")
+ function = mlrun.import_function("hub://auto-trainer")
function = mlrun.import_function("./func.yaml")
function = mlrun.import_function("https://raw.githubusercontent.com/org/repo/func.yaml")
diff --git a/mlrun/runtimes/serving.py b/mlrun/runtimes/serving.py
index f8bb5ffa282d..5e96cfbdec55 100644
--- a/mlrun/runtimes/serving.py
+++ b/mlrun/runtimes/serving.py
@@ -319,7 +319,7 @@ def set_tracking(
example::
# initialize a new serving function
- serving_fn = mlrun.import_function("hub://v2_model_server", new_name="serving")
+ serving_fn = mlrun.import_function("hub://v2-model-server", new_name="serving")
# apply model monitoring and set monitoring batch job to run every 3 hours
tracking_policy = {'default_batch_intervals':"0 */3 * * *"}
serving_fn.set_tracking(tracking_policy=tracking_policy)
diff --git a/tests/api/api/test_utils.py b/tests/api/api/test_utils.py
index 00aa22c98c29..8eb1846bf4c5 100644
--- a/tests/api/api/test_utils.py
+++ b/tests/api/api/test_utils.py
@@ -1181,7 +1181,7 @@ def test_generate_function_and_task_from_submit_run_body_imported_function_proje
_mock_import_function(monkeypatch)
submit_job_body = {
"task": {
- "spec": {"function": "hub://gen_class_data"},
+ "spec": {"function": "hub://gen-class-data"},
"metadata": {"name": task_name, "project": PROJECT},
},
"function": {"spec": {"resources": {"limits": {}, "requests": {}}}},
diff --git a/tests/projects/test_project.py b/tests/projects/test_project.py
index 7cae71d77f4e..ef70b65f38ae 100644
--- a/tests/projects/test_project.py
+++ b/tests/projects/test_project.py
@@ -61,7 +61,7 @@ def test_sync_functions(rundb_mock):
assert fn.metadata.name == "describe", "func did not return"
# test that functions can be fetched from the DB (w/o set_function)
- mlrun.import_function("hub://auto_trainer", new_name="train").save()
+ mlrun.import_function("hub://auto-trainer", new_name="train").save()
fn = project.get_function("train")
assert fn.metadata.name == "train", "train func did not return"
diff --git a/tests/system/demos/churn/test_churn.py b/tests/system/demos/churn/test_churn.py
index 06df66360295..9bfba810abc2 100644
--- a/tests/system/demos/churn/test_churn.py
+++ b/tests/system/demos/churn/test_churn.py
@@ -59,11 +59,11 @@ def create_demo_project(self) -> mlrun.projects.MlrunProject:
self._logger.debug("Setting project functions")
demo_project.set_function(clean_data_function)
demo_project.set_function("hub://describe", "describe")
- demo_project.set_function("hub://xgb_trainer", "classify")
- demo_project.set_function("hub://xgb_test", "xgbtest")
- demo_project.set_function("hub://coxph_trainer", "survive")
- demo_project.set_function("hub://coxph_test", "coxtest")
- demo_project.set_function("hub://churn_server", "server")
+ demo_project.set_function("hub://xgb-trainer", "classify")
+ demo_project.set_function("hub://xgb-test", "xgbtest")
+ demo_project.set_function("hub://coxph-trainer", "survive")
+ demo_project.set_function("hub://coxph-test", "coxtest")
+ demo_project.set_function("hub://churn-server", "server")
self._logger.debug("Setting project workflow")
demo_project.set_workflow(
diff --git a/tests/system/demos/horovod/test_horovod.py b/tests/system/demos/horovod/test_horovod.py
index 785a6ac17663..c19669d239b6 100644
--- a/tests/system/demos/horovod/test_horovod.py
+++ b/tests/system/demos/horovod/test_horovod.py
@@ -73,7 +73,7 @@ def create_demo_project(self) -> mlrun.projects.MlrunProject:
trainer.spec.service_type = "NodePort"
demo_project.set_function(trainer)
- demo_project.set_function("hub://tf2_serving", "serving")
+ demo_project.set_function("hub://tf2-serving", "serving")
demo_project.log_artifact(
"images",
diff --git a/tests/system/demos/sklearn/test_sklearn.py b/tests/system/demos/sklearn/test_sklearn.py
index 1909a2101e3e..a71292b47163 100644
--- a/tests/system/demos/sklearn/test_sklearn.py
+++ b/tests/system/demos/sklearn/test_sklearn.py
@@ -52,9 +52,9 @@ def create_demo_project(self) -> mlrun.projects.MlrunProject:
self._logger.debug("Setting project functions")
demo_project.set_function(iris_generator_function)
demo_project.set_function("hub://describe", "describe")
- demo_project.set_function("hub://auto_trainer", "auto_trainer")
- demo_project.set_function("hub://model_server", "serving")
- demo_project.set_function("hub://model_server_tester", "live_tester")
+ demo_project.set_function("hub://auto-trainer", "auto-trainer")
+ demo_project.set_function("hub://model-server", "serving")
+ demo_project.set_function("hub://model-server-tester", "live-tester")
self._logger.debug("Setting project workflow")
demo_project.set_workflow(
diff --git a/tests/system/model_monitoring/test_model_monitoring.py b/tests/system/model_monitoring/test_model_monitoring.py
index b8ec44a72337..16b9d1be63fc 100644
--- a/tests/system/model_monitoring/test_model_monitoring.py
+++ b/tests/system/model_monitoring/test_model_monitoring.py
@@ -256,7 +256,7 @@ def test_basic_model_monitoring(self):
# Import the serving function from the function hub
serving_fn = mlrun.import_function(
- "hub://v2_model_server", project=self.project_name
+ "hub://v2-model-server", project=self.project_name
).apply(mlrun.auto_mount())
# enable model monitoring
serving_fn.set_tracking()
@@ -369,7 +369,7 @@ def test_model_monitoring_with_regression(self):
)
# Train the model using the auto trainer from the marketplace
- train = mlrun.import_function("hub://auto_trainer", new_name="train")
+ train = mlrun.import_function("hub://auto-trainer", new_name="train")
train.deploy()
model_class = "sklearn.linear_model.LinearRegression"
model_name = "diabetes_model"
@@ -399,7 +399,7 @@ def test_model_monitoring_with_regression(self):
# Set the serving topology to simple model routing
# with data enrichment and imputing from the feature vector
- serving_fn = mlrun.import_function("hub://v2_model_server", new_name="serving")
+ serving_fn = mlrun.import_function("hub://v2-model-server", new_name="serving")
serving_fn.set_topology(
"router",
mlrun.serving.routers.EnrichmentModelRouter(
@@ -512,7 +512,7 @@ def test_model_monitoring_voting_ensemble(self):
# Import the serving function from the function hub
serving_fn = mlrun.import_function(
- "hub://v2_model_server", project=self.project_name
+ "hub://v2-model-server", project=self.project_name
).apply(mlrun.auto_mount())
serving_fn.set_topology(
@@ -530,7 +530,7 @@ def test_model_monitoring_voting_ensemble(self):
}
# Import the auto trainer function from the marketplace (hub://)
- train = mlrun.import_function("hub://auto_trainer")
+ train = mlrun.import_function("hub://auto-trainer")
for name, pkg in model_names.items():
diff --git a/tests/system/projects/assets/kflow.py b/tests/system/projects/assets/kflow.py
index 87ef60c9083b..522f6926aa38 100644
--- a/tests/system/projects/assets/kflow.py
+++ b/tests/system/projects/assets/kflow.py
@@ -42,7 +42,7 @@ def kfpipeline(model_class=default_pkg_class, build=0):
# train the model using a library (hub://) function and the generated data
# no need to define handler in this step because the train function is the default handler
- train = funcs["auto_trainer"].as_step(
+ train = funcs["auto-trainer"].as_step(
name="train",
inputs={"dataset": prep_data.outputs["cleaned_data"]},
params={
@@ -53,7 +53,7 @@ def kfpipeline(model_class=default_pkg_class, build=0):
)
# test the model using a library (hub://) function and the generated model
- funcs["auto_trainer"].as_step(
+ funcs["auto-trainer"].as_step(
name="test",
handler="evaluate",
params={"label_columns": "label", "model": train.outputs["model"]},
diff --git a/tests/system/projects/assets/newflow.py b/tests/system/projects/assets/newflow.py
index 6e0e9a96ec08..67b1dc69b70f 100644
--- a/tests/system/projects/assets/newflow.py
+++ b/tests/system/projects/assets/newflow.py
@@ -52,7 +52,7 @@ def newpipe():
# train with hyper-paremeters
train = run_function(
- "auto_trainer",
+ "auto-trainer",
name="train",
params={"label_columns": LABELS, "train_test_split_size": 0.10},
hyperparams={
@@ -70,7 +70,7 @@ def newpipe():
# test and visualize our model
run_function(
- "auto_trainer",
+ "auto-trainer",
name="test",
handler="evaluate",
params={"label_columns": LABELS, "model": train.outputs["model"]},
@@ -87,7 +87,7 @@ def newpipe():
# test out new model server (via REST API calls), use imported function
run_function(
- "hub://v2_model_tester",
+ "hub://v2-model-tester",
name="model-tester",
params={"addr": deploy.outputs["endpoint"], "model": f"{DATASET}:v1"},
inputs={"table": train.outputs["test_set"]},
diff --git a/tests/system/projects/test_project.py b/tests/system/projects/test_project.py
index 881bb20bbd07..c457c55ae537 100644
--- a/tests/system/projects/test_project.py
+++ b/tests/system/projects/test_project.py
@@ -45,7 +45,7 @@ def exec_project(args):
@dsl.pipeline(name="test pipeline", description="test")
def pipe_test():
# train the model using a library (hub://) function and the generated data
- funcs["auto_trainer"].as_step(
+ funcs["auto-trainer"].as_step(
name="train",
inputs={"dataset": data_url},
params={"model_class": model_class, "label_columns": "label"},
@@ -86,8 +86,8 @@ def _create_project(self, project_name, with_repo=False, overwrite=False):
with_repo=with_repo,
)
proj.set_function("hub://describe")
- proj.set_function("hub://auto_trainer", "auto_trainer")
- proj.set_function("hub://v2_model_server", "serving")
+ proj.set_function("hub://auto-trainer", "auto-trainer")
+ proj.set_function("hub://v2-model-server", "serving")
proj.set_artifact("data", Artifact(target_path=data_url))
proj.spec.params = {"label_columns": "label"}
arg = EntrypointParam(
From 0fb7cccd4c64683be6a48569bd55ec4327d4631a Mon Sep 17 00:00:00 2001
From: Tom Tankilevitch <59158507+Tankilevitch@users.noreply.github.com>
Date: Thu, 13 Apr 2023 17:22:55 +0300
Subject: [PATCH 047/334] [CI] Add branch information to the slack message in
system tests (#3401)
---
.github/workflows/system-tests-enterprise.yml | 4 +++-
automation/system_test/prepare.py | 5 +++++
tests/system/conftest.py | 5 +++++
3 files changed, 13 insertions(+), 1 deletion(-)
diff --git a/.github/workflows/system-tests-enterprise.yml b/.github/workflows/system-tests-enterprise.yml
index bc1c4a983263..89241a697b4f 100644
--- a/.github/workflows/system-tests-enterprise.yml
+++ b/.github/workflows/system-tests-enterprise.yml
@@ -318,10 +318,12 @@ jobs:
"${{ secrets.LATEST_SYSTEM_TEST_ACCESS_KEY }}" \
"${{ secrets.LATEST_SYSTEM_TEST_SPARK_SERVICE }}" \
"${{ secrets.LATEST_SYSTEM_TEST_PASSWORD }}" \
- "${{ secrets.LATEST_SYSTEM_TEST_SLACK_WEBHOOK_URL }}"
+ "${{ secrets.LATEST_SYSTEM_TEST_SLACK_WEBHOOK_URL }}" \
+ "${{ needs.prepare-system-tests-enterprise-ci.outputs.mlrunBranch }}"
- name: Run System Tests
run: |
MLRUN_SYSTEM_TESTS_CLEAN_RESOURCES="${{ needs.prepare-system-tests-enterprise-ci.outputs.mlrunSystemTestsCleanResources }}" \
MLRUN_VERSION="${{ needs.prepare-system-tests-enterprise-ci.outputs.mlrunVersion }}" \
MLRUN_SYSTEM_TESTS_COMPONENT="${{ matrix.test_component }}" \
+ MLRUN_SYSTEM_TESTS_BRANCH="${{ needs.prepare-system-tests-enterprise-ci.outputs.mlrunBranch }}" \
make test-system-dockerized
diff --git a/automation/system_test/prepare.py b/automation/system_test/prepare.py
index fc06b71ad5b0..1c3550699b16 100644
--- a/automation/system_test/prepare.py
+++ b/automation/system_test/prepare.py
@@ -74,6 +74,7 @@ def __init__(
mysql_password: str = None,
purge_db: bool = False,
debug: bool = False,
+ branch: str = None,
):
self._logger = logger
self._debug = debug
@@ -107,6 +108,7 @@ def __init__(
"V3IO_ACCESS_KEY": access_key,
"MLRUN_SYSTEM_TESTS_DEFAULT_SPARK_SERVICE": spark_service,
"MLRUN_SYSTEM_TESTS_SLACK_WEBHOOK_URL": slack_webhook_url,
+ "MLRUN_SYSTEM_TESTS_BRANCH": branch,
}
if password:
self._env_config["V3IO_PASSWORD"] = password
@@ -723,6 +725,7 @@ def run(
is_flag=True,
help="Don't run the ci only show the commands that will be run",
)
+@click.argument("branch", type=str, default=None, required=False)
def env(
mlrun_dbpath: str,
webapi_direct_url: str,
@@ -733,6 +736,7 @@ def env(
password: str,
slack_webhook_url: str,
debug: bool,
+ branch: str,
):
system_test_preparer = SystemTestPreparer(
mlrun_dbpath=mlrun_dbpath,
@@ -744,6 +748,7 @@ def env(
password=password,
debug=debug,
slack_webhook_url=slack_webhook_url,
+ branch=branch,
)
try:
system_test_preparer.prepare_local_env()
diff --git a/tests/system/conftest.py b/tests/system/conftest.py
index fe7435fb9bc3..929944e03fa3 100644
--- a/tests/system/conftest.py
+++ b/tests/system/conftest.py
@@ -64,9 +64,14 @@ def post_report_session_finish_to_slack(
session: Session, exitstatus: ExitCode, slack_webhook_url
):
mlrun_version = os.getenv("MLRUN_VERSION", "")
+ mlrun_current_branch = os.getenv("MLRUN_SYSTEM_TESTS_BRANCH", "")
mlrun_system_tests_component = os.getenv("MLRUN_SYSTEM_TESTS_COMPONENT", "")
total_executed_tests = session.testscollected
total_failed_tests = session.testsfailed
+ text = ""
+ if mlrun_current_branch:
+ text += f"[{mlrun_current_branch}] "
+
if exitstatus == ExitCode.OK:
text = f"All {total_executed_tests} tests passed successfully"
else:
From 241cc6ee9ebe284d922f421979aab9438ccef82e Mon Sep 17 00:00:00 2001
From: Tom Tankilevitch <59158507+Tankilevitch@users.noreply.github.com>
Date: Sun, 16 Apr 2023 10:04:37 +0300
Subject: [PATCH 048/334] [MLRun] Fix use of json instead of simplejson (#3405)
---
mlrun/__main__.py | 5 ++---
1 file changed, 2 insertions(+), 3 deletions(-)
diff --git a/mlrun/__main__.py b/mlrun/__main__.py
index 67d1ebfc9f99..13bbfc6360fe 100644
--- a/mlrun/__main__.py
+++ b/mlrun/__main__.py
@@ -29,7 +29,6 @@
import click
import dotenv
import pandas as pd
-import simplejson
import yaml
from tabulate import tabulate
@@ -1477,9 +1476,9 @@ def load_notification(notifications: str, project: mlrun.projects.MlrunProject):
if notification.startswith("file="):
file_path = notification.split("=")[-1]
notification = open(file_path, "r")
- notification = simplejson.load(notification)
+ notification = json.load(notification)
else:
- notification = simplejson.loads(notification)
+ notification = json.loads(notification)
add_notification_to_project(notification, project)
From 64553567dcc3d56fb36a5fbb1d24ce9340b1d2a8 Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Sun, 16 Apr 2023 13:17:37 +0300
Subject: [PATCH 049/334] [API] Reduce spammy logs (#3408)
---
mlrun/api/main.py | 3 +++
mlrun/utils/notifications/notification_pusher.py | 3 +++
2 files changed, 6 insertions(+)
diff --git a/mlrun/api/main.py b/mlrun/api/main.py
index d9332cd2e492..12805ae2b3ae 100644
--- a/mlrun/api/main.py
+++ b/mlrun/api/main.py
@@ -580,6 +580,9 @@ def _push_terminal_run_notifications(db: mlrun.api.db.base.DBInterface, db_sessi
with_notifications=True,
)
+ if not len(runs):
+ return
+
# Unmasking the run parameters from secrets before handing them over to the notification handler
# as importing the `Secrets` crud in the notification handler will cause a circular import
unmasked_runs = [
diff --git a/mlrun/utils/notifications/notification_pusher.py b/mlrun/utils/notifications/notification_pusher.py
index b0becaddbd6b..36f1892ec225 100644
--- a/mlrun/utils/notifications/notification_pusher.py
+++ b/mlrun/utils/notifications/notification_pusher.py
@@ -63,6 +63,9 @@ def push(
wait for all notifications to be pushed before returning.
"""
+ if not len(self._notification_data):
+ return
+
async def _push():
tasks = []
for notification_data in self._notification_data:
From 99179dd20f497e017b72cbfef95b49bead92e2e6 Mon Sep 17 00:00:00 2001
From: Tom Tankilevitch <59158507+Tankilevitch@users.noreply.github.com>
Date: Sun, 16 Apr 2023 18:25:34 +0300
Subject: [PATCH 050/334] [CI] Add datanode docker images removal command and
skip DB deletion if DB instance is not available (#3404)
---
.github/workflows/system-tests-enterprise.yml | 1 +
automation/system_test/cleanup.py | 28 +++++++++++++++++++
automation/system_test/prepare.py | 7 +++--
tests/system/conftest.py | 4 +--
4 files changed, 36 insertions(+), 4 deletions(-)
diff --git a/.github/workflows/system-tests-enterprise.yml b/.github/workflows/system-tests-enterprise.yml
index 89241a697b4f..38c96ace06bf 100644
--- a/.github/workflows/system-tests-enterprise.yml
+++ b/.github/workflows/system-tests-enterprise.yml
@@ -102,6 +102,7 @@ jobs:
name: Prepare System Tests Enterprise
runs-on: ubuntu-latest
+ needs: [system-test-cleanup]
# let's not run this on every fork, change to your fork when developing
if: github.repository == 'mlrun/mlrun' || github.event_name == 'workflow_dispatch'
diff --git a/automation/system_test/cleanup.py b/automation/system_test/cleanup.py
index eec04d0b0ddb..bbcda2be2389 100644
--- a/automation/system_test/cleanup.py
+++ b/automation/system_test/cleanup.py
@@ -38,6 +38,13 @@ def main():
def docker_images(registry_url: str, registry_container_name: str, images: str):
images = images.split(",")
loop = asyncio.get_event_loop()
+ try:
+ click.echo("Removing images from datanode docker")
+ _remove_image_from_datanode_docker()
+ except Exception as exc:
+ click.echo(
+ f"Unable to remove images from datanode docker: {exc}, continuing anyway"
+ )
try:
_run_registry_garbage_collection(registry_container_name)
except Exception as exc:
@@ -81,6 +88,27 @@ async def _collect_image_tags(
return tags
+def _remove_image_from_datanode_docker():
+ """Remove image from datanode docker"""
+ subprocess.run(
+ [
+ "docker",
+ "images",
+ "--format",
+ "'{{.Repository }}:{{.Tag}}'",
+ "|",
+ "grep",
+ "mlrun",
+ "|",
+ "xargs",
+ "--no-run-if-empty",
+ "docker",
+ "rmi",
+ "-f",
+ ]
+ )
+
+
async def _delete_image_tags(
registry: str, tags: typing.Dict[str, typing.List[str]]
) -> None:
diff --git a/automation/system_test/prepare.py b/automation/system_test/prepare.py
index 1c3550699b16..6e9702b28ea2 100644
--- a/automation/system_test/prepare.py
+++ b/automation/system_test/prepare.py
@@ -534,12 +534,15 @@ def _purge_mlrun_db(self):
def _delete_mlrun_db(self):
self._logger.info("Deleting mlrun db")
- get_mlrun_db_pod_name_cmd = self._get_pod_name_command(
+ mlrun_db_pod_name_cmd = self._get_pod_name_command(
labels={
"app.kubernetes.io/component": "db",
"app.kubernetes.io/instance": "mlrun",
},
)
+ if not mlrun_db_pod_name_cmd:
+ self._logger.info("No mlrun db pod found")
+ return
password = ""
if self._mysql_password:
@@ -552,7 +555,7 @@ def _delete_mlrun_db(self):
"-n",
self.Constants.namespace,
"-it",
- f"$({get_mlrun_db_pod_name_cmd})",
+ f"$({mlrun_db_pod_name_cmd})",
"--",
drop_db_cmd,
],
diff --git a/tests/system/conftest.py b/tests/system/conftest.py
index 929944e03fa3..76f22b35739f 100644
--- a/tests/system/conftest.py
+++ b/tests/system/conftest.py
@@ -73,9 +73,9 @@ def post_report_session_finish_to_slack(
text += f"[{mlrun_current_branch}] "
if exitstatus == ExitCode.OK:
- text = f"All {total_executed_tests} tests passed successfully"
+ text += f"All {total_executed_tests} tests passed successfully"
else:
- text = f"{total_failed_tests} out of {total_executed_tests} tests failed"
+ text += f"{total_failed_tests} out of {total_executed_tests} tests failed"
test_session_info = ""
if mlrun_system_tests_component:
From ee33b3f7e045ea904b320e8021aab0c80ffa1733 Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Sun, 16 Apr 2023 18:31:00 +0300
Subject: [PATCH 051/334] [Builder] Fix pushing to ECR (#3407)
---
mlrun/builder.py | 23 ++++++++++++++++++++---
tests/test_builder.py | 29 +++++++++++++++++++++++------
2 files changed, 43 insertions(+), 9 deletions(-)
diff --git a/mlrun/builder.py b/mlrun/builder.py
index 93a70d8823f9..68370b7ffa1b 100644
--- a/mlrun/builder.py
+++ b/mlrun/builder.py
@@ -229,7 +229,21 @@ def make_kaniko_pod(
if end == -1:
end = len(dest)
repo = dest[dest.find("/") + 1 : end]
- configure_kaniko_ecr_init_container(kpod, registry, repo)
+
+ # if no secret is given, assume ec2 instance has attached role which provides read/write access to ECR
+ assume_instance_role = not config.httpdb.builder.docker_registry_secret
+ configure_kaniko_ecr_init_container(kpod, registry, repo, assume_instance_role)
+
+ # project secret might conflict with the attached instance role
+ # ensure "AWS_ACCESS_KEY_ID", "AWS_SECRET_ACCESS_KEY" have no values or else kaniko will fail
+ # due to credentials conflict / lack of permission on given credentials
+ if assume_instance_role:
+ kpod.pod.spec.containers[0].env.extend(
+ [
+ client.V1EnvVar(name="AWS_ACCESS_KEY_ID", value=""),
+ client.V1EnvVar(name="AWS_SECRET_ACCESS_KEY", value=""),
+ ]
+ )
# mount regular docker config secret
elif secret_name:
@@ -239,7 +253,9 @@ def make_kaniko_pod(
return kpod
-def configure_kaniko_ecr_init_container(kpod, registry, repo):
+def configure_kaniko_ecr_init_container(
+ kpod, registry, repo, assume_instance_role=True
+):
region = registry.split(".")[3]
# fail silently in order to ignore "repository already exists" errors
@@ -250,12 +266,13 @@ def configure_kaniko_ecr_init_container(kpod, registry, repo):
)
init_container_env = {}
- if not config.httpdb.builder.docker_registry_secret:
+ if assume_instance_role:
# assume instance role has permissions to register and store a container image
# https://github.com/GoogleContainerTools/kaniko#pushing-to-amazon-ecr
# we only need this in the kaniko container
kpod.env.append(client.V1EnvVar(name="AWS_SDK_LOAD_CONFIG", value="true"))
+
else:
aws_credentials_file_env_key = "AWS_SHARED_CREDENTIALS_FILE"
aws_credentials_file_env_value = "/tmp/credentials"
diff --git a/tests/test_builder.py b/tests/test_builder.py
index d828b8d04a8e..7c2bb0878077 100644
--- a/tests/test_builder.py
+++ b/tests/test_builder.py
@@ -447,13 +447,17 @@ def test_build_runtime_ecr_with_ec2_iam_policy(monkeypatch):
mlrun.mlconf.httpdb.builder.docker_registry = (
"aws_account_id.dkr.ecr.region.amazonaws.com"
)
- function = mlrun.new_function(
- "some-function",
- "some-project",
- "some-tag",
- image="mlrun/mlrun",
+ project = mlrun.new_project("some-project")
+ project.set_secrets(
+ secrets={
+ "AWS_ACCESS_KEY_ID": "test-a",
+ "AWS_SECRET_ACCESS_KEY": "test-b",
+ }
+ )
+ function = project.set_function(
+ "hub://describe",
+ name="some-function",
kind="job",
- requirements=["some-package"],
)
mlrun.builder.build_runtime(
mlrun.api.schemas.AuthInfo(),
@@ -463,6 +467,19 @@ def test_build_runtime_ecr_with_ec2_iam_policy(monkeypatch):
assert {"name": "AWS_SDK_LOAD_CONFIG", "value": "true", "value_from": None} in [
env.to_dict() for env in pod_spec.containers[0].env
]
+
+ # ensure both envvars are set without values so they wont interfere with the iam policy
+ for env_name in ["AWS_ACCESS_KEY_ID", "AWS_SECRET_ACCESS_KEY"]:
+ assert {"name": env_name, "value": "", "value_from": None} in [
+ env.to_dict() for env in pod_spec.containers[0].env
+ ]
+
+ # 1 for the AWS_SDK_LOAD_CONFIG=true
+ # 2 for the AWS_ACCESS_KEY_ID="" and AWS_SECRET_ACCESS_KEY=""
+ # 1 for the project secret
+ # == 4
+ assert len(pod_spec.containers[0].env) == 4, "expected 4 env items"
+
assert len(pod_spec.init_containers) == 2
for init_container in pod_spec.init_containers:
if init_container.name == "create-repos":
From 156821f958a02df70efeb9bd052bbbe6e9c100c6 Mon Sep 17 00:00:00 2001
From: alxtkr77 <3098237+alxtkr77@users.noreply.github.com>
Date: Mon, 17 Apr 2023 13:16:19 +0300
Subject: [PATCH 052/334] [Spark] Fix UDF - remove dependencies (#3403)
---
mlrun/datastore/spark_udf.py | 37 +++++++++++
mlrun/datastore/targets.py | 64 +++++++++++--------
.../system/feature_store/test_spark_engine.py | 2 +-
3 files changed, 75 insertions(+), 28 deletions(-)
create mode 100644 mlrun/datastore/spark_udf.py
diff --git a/mlrun/datastore/spark_udf.py b/mlrun/datastore/spark_udf.py
new file mode 100644
index 000000000000..8d0a796210e2
--- /dev/null
+++ b/mlrun/datastore/spark_udf.py
@@ -0,0 +1,37 @@
+# Copyright 2023 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import hashlib
+
+from pyspark.sql.functions import udf
+from pyspark.sql.types import StringType
+
+
+def _hash_list(*list_to_hash):
+ list_to_hash = [str(element) for element in list_to_hash]
+ str_concatted = "".join(list_to_hash)
+ sha1 = hashlib.sha1()
+ sha1.update(str_concatted.encode("utf8"))
+ return sha1.hexdigest()
+
+
+def _redis_stringify_key(key_list):
+ if len(key_list) >= 2:
+ return str(key_list[0]) + "." + _hash_list(key_list[1:]) + "}:static"
+ if len(key_list) == 2:
+ return str(key_list[0]) + "." + str(key_list[1]) + "}:static"
+ return str(key_list[0]) + "}:static"
+
+
+hash_and_concat_v3io_udf = udf(_hash_list, StringType())
+hash_and_concat_redis_udf = udf(_redis_stringify_key, StringType())
diff --git a/mlrun/datastore/targets.py b/mlrun/datastore/targets.py
index d3eb45427dfc..28376f7c251a 100644
--- a/mlrun/datastore/targets.py
+++ b/mlrun/datastore/targets.py
@@ -15,6 +15,7 @@
import datetime
import os
import random
+import sys
import time
from collections import Counter
from copy import copy
@@ -23,7 +24,6 @@
import pandas as pd
import sqlalchemy
-from storey.utils import hash_list, stringify_key
import mlrun
import mlrun.utils.helpers
@@ -1114,7 +1114,7 @@ def get_spark_options(self, key_column=None, timestamp_key=None, overwrite=True)
if isinstance(key_column, list) and len(key_column) >= 1:
spark_options["key"] = key_column[0]
if len(key_column) > 2:
- spark_options["sorting-key"] = "_spark_object_sorting_key"
+ spark_options["sorting-key"] = "_spark_object_name"
if len(key_column) == 2:
spark_options["sorting-key"] = key_column[1]
else:
@@ -1124,21 +1124,28 @@ def get_spark_options(self, key_column=None, timestamp_key=None, overwrite=True)
return spark_options
def prepare_spark_df(self, df, key_columns):
- from pyspark.sql.functions import col, udf
- from pyspark.sql.types import StringType
+ from pyspark.sql.functions import col
- for col_name, col_type in df.dtypes:
- if col_type.startswith("decimal("):
- # V3IO does not support this level of precision
- df = df.withColumn(col_name, col(col_name).cast("double"))
- if len(key_columns) > 2:
- hash_and_concat_udf = udf(
- lambda *x: hash_list([str(i) for i in x]), StringType()
- )
- return df.withColumn(
- "_spark_object_sorting_key",
- hash_and_concat_udf(*[col(c) for c in key_columns[1:]]),
- )
+ spark_udf_directory = os.path.dirname(os.path.abspath(__file__))
+ sys.path.append(spark_udf_directory)
+ try:
+ import spark_udf
+
+ df.rdd.context.addFile(spark_udf.__file__)
+
+ for col_name, col_type in df.dtypes:
+ if col_type.startswith("decimal("):
+ # V3IO does not support this level of precision
+ df = df.withColumn(col_name, col(col_name).cast("double"))
+ if len(key_columns) > 2:
+ return df.withColumn(
+ "_spark_object_name",
+ spark_udf.hash_and_concat_v3io_udf(
+ *[col(c) for c in key_columns[1:]]
+ ),
+ )
+ finally:
+ sys.path.remove(spark_udf_directory)
return df
@@ -1200,20 +1207,23 @@ def get_target_path_with_credentials(self):
return endpoint
def prepare_spark_df(self, df, key_columns):
- from pyspark.sql.functions import col, udf
- from pyspark.sql.types import StringType
+ from pyspark.sql.functions import col
- if len(key_columns) > 1:
- hash_and_concat_udf = udf(
- lambda *x: stringify_key([str(i) for i in x]) + "}:static", StringType()
- )
- return df.withColumn(
+ spark_udf_directory = os.path.dirname(os.path.abspath(__file__))
+ sys.path.append(spark_udf_directory)
+ try:
+ import spark_udf
+
+ df.rdd.context.addFile(spark_udf.__file__)
+
+ df = df.withColumn(
"_spark_object_name",
- hash_and_concat_udf(*[col(c) for c in key_columns]),
+ spark_udf.hash_and_concat_redis_udf(*[col(c) for c in key_columns]),
)
- else:
- udf1 = udf(lambda x: str(x) + "}:static", StringType())
- return df.withColumn("_spark_object_name", udf1(key_columns[0]))
+ finally:
+ sys.path.remove(spark_udf_directory)
+
+ return df
class StreamTarget(BaseStoreTarget):
diff --git a/tests/system/feature_store/test_spark_engine.py b/tests/system/feature_store/test_spark_engine.py
index 1dfd381f9b25..a66f5a5cb73a 100644
--- a/tests/system/feature_store/test_spark_engine.py
+++ b/tests/system/feature_store/test_spark_engine.py
@@ -386,7 +386,7 @@ def test_ingest_to_redis(self):
@pytest.mark.parametrize(
"target_kind",
- ["Redis", "v3io"] if mlrun.mlconf.redis.url is not None else ["v3io"],
+ ["Redis", "v3io"] if mlrun.mlconf.redis.url else ["v3io"],
)
def test_ingest_multiple_entities(self, target_kind):
key1 = "patient_id"
From 031fe7bf1d21ece9b67cdf93251ab8c6a202150f Mon Sep 17 00:00:00 2001
From: Assaf Ben-Amitai
Date: Tue, 18 Apr 2023 08:38:45 +0300
Subject: [PATCH 053/334] [Requirements] Bump storey to v1.3.17 (#3415)
---
requirements.txt | 2 +-
tests/test_requirements.py | 2 +-
2 files changed, 2 insertions(+), 2 deletions(-)
diff --git a/requirements.txt b/requirements.txt
index 87650c476d29..c06e99a2751a 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -53,7 +53,7 @@ humanfriendly~=8.2
fastapi~=0.92.0
fsspec~=2021.8.1
v3iofs~=0.1.15
-storey~=1.3.15
+storey~=1.3.17
deepdiff~=5.0
pymysql~=1.0
inflection~=0.5.0
diff --git a/tests/test_requirements.py b/tests/test_requirements.py
index 485b7e57f6fa..62f30907374e 100644
--- a/tests/test_requirements.py
+++ b/tests/test_requirements.py
@@ -95,7 +95,7 @@ def test_requirement_specifiers_convention():
"kfp": {"~=1.8.0, <1.8.14"},
"botocore": {">=1.20.106,<1.20.107"},
"aiobotocore": {"~=1.4.0"},
- "storey": {"~=1.3.15"},
+ "storey": {"~=1.3.17"},
"bokeh": {"~=2.4, >=2.4.2"},
"typing-extensions": {">=3.10.0,<5"},
"sphinx": {"~=4.3.0"},
From 4c68d22f79e07ecc8f976c26d72bec842a3b0227 Mon Sep 17 00:00:00 2001
From: Tom Tankilevitch <59158507+Tankilevitch@users.noreply.github.com>
Date: Tue, 18 Apr 2023 15:27:00 +0300
Subject: [PATCH 054/334] [CI] Set API log level in integration tests to
`DEBUG` (#3417)
---
Makefile | 1 +
tests/integration/sdk_api/base.py | 3 +--
2 files changed, 2 insertions(+), 2 deletions(-)
diff --git a/Makefile b/Makefile
index 3175198893eb..5c7a9c048182 100644
--- a/Makefile
+++ b/Makefile
@@ -642,6 +642,7 @@ run-api: api ## Run mlrun api (dockerized)
--publish 8080 \
--add-host host.docker.internal:host-gateway \
--env MLRUN_HTTPDB__DSN=$(MLRUN_HTTPDB__DSN) \
+ --env MLRUN_LOG_LEVEL=$(MLRUN_LOG_LEVEL) \
$(MLRUN_API_IMAGE_NAME_TAGGED)
.PHONY: run-test-db
diff --git a/tests/integration/sdk_api/base.py b/tests/integration/sdk_api/base.py
index a8e9e5e0d241..4a826d6ea42a 100644
--- a/tests/integration/sdk_api/base.py
+++ b/tests/integration/sdk_api/base.py
@@ -142,8 +142,7 @@ def _run_api(self):
{
"MLRUN_VERSION": "0.0.0+unstable",
"MLRUN_HTTPDB__DSN": self.db_dsn,
- # integration tests run in docker, and do no support sidecars for log collection
- "MLRUN__LOG_COLLECTOR__MODE": "legacy",
+ "MLRUN_LOG_LEVEL": "DEBUG",
}
),
cwd=TestMLRunIntegration.root_path,
From 69a4ea46e82edc34665569577ca07f701ddd3fff Mon Sep 17 00:00:00 2001
From: davesh0812 <85231462+davesh0812@users.noreply.github.com>
Date: Tue, 18 Apr 2023 17:38:04 +0300
Subject: [PATCH 055/334] [Tests] Fix spark system tests (#3418)
---
tests/system/feature_store/test_spark_engine.py | 5 +++--
1 file changed, 3 insertions(+), 2 deletions(-)
diff --git a/tests/system/feature_store/test_spark_engine.py b/tests/system/feature_store/test_spark_engine.py
index a66f5a5cb73a..8f35c81ee767 100644
--- a/tests/system/feature_store/test_spark_engine.py
+++ b/tests/system/feature_store/test_spark_engine.py
@@ -92,8 +92,9 @@ def get_remote_pq_target_path(self, without_prefix=False, clean_up=True):
path += "/bigdata/" + self.pq_target
if clean_up:
fsys = fsspec.filesystem(v3iofs.fs.V3ioFS.protocol)
- for f in fsys.listdir(path):
- fsys._rm(f["name"])
+ if fsys.isdir(path):
+ for f in fsys.listdir(path):
+ fsys._rm(f["name"])
return path
@classmethod
From 90391e0d91ca0d40da4db425e29d096a54b8715f Mon Sep 17 00:00:00 2001
From: Tom Tankilevitch <59158507+Tankilevitch@users.noreply.github.com>
Date: Wed, 19 Apr 2023 10:07:24 +0300
Subject: [PATCH 056/334] [DataStore] Enrich `V3ioDriver` with
`mlconf.v3io_api` (#3414)
---
mlrun/config.py | 3 ++
mlrun/datastore/store_resources.py | 2 +-
mlrun/datastore/targets.py | 4 +-
mlrun/platforms/iguazio.py | 2 +
mlrun/serving/states.py | 2 +-
tests/test_config.py | 63 ++++++++++++++++++++++++++++++
6 files changed, 72 insertions(+), 4 deletions(-)
diff --git a/mlrun/config.py b/mlrun/config.py
index 1867c6ab3484..8f1820c2c3f8 100644
--- a/mlrun/config.py
+++ b/mlrun/config.py
@@ -1059,15 +1059,18 @@ def read_env(env=None, prefix=env_prefix):
cfg[path[0]] = value
env_dbpath = env.get("MLRUN_DBPATH", "")
+ # expected format: https://mlrun-api.tenant.default-tenant.app.some-system.some-namespace.com
is_remote_mlrun = (
env_dbpath.startswith("https://mlrun-api.") and "tenant." in env_dbpath
)
+
# It's already a standard to set this env var to configure the v3io api, so we're supporting it (instead
# of MLRUN_V3IO_API), in remote usage this can be auto detected from the DBPATH
v3io_api = env.get("V3IO_API")
if v3io_api:
config["v3io_api"] = v3io_api
elif is_remote_mlrun:
+ # in remote mlrun we can't use http, so we'll use https
config["v3io_api"] = env_dbpath.replace("https://mlrun-api.", "https://webapi.")
# It's already a standard to set this env var to configure the v3io framesd, so we're supporting it (instead
diff --git a/mlrun/datastore/store_resources.py b/mlrun/datastore/store_resources.py
index d85aae13ae8b..d6ffe47f5394 100644
--- a/mlrun/datastore/store_resources.py
+++ b/mlrun/datastore/store_resources.py
@@ -81,7 +81,7 @@ def get_table(self, uri):
endpoint, uri = parse_path(uri)
self._tabels[uri] = Table(
uri,
- V3ioDriver(webapi=endpoint),
+ V3ioDriver(webapi=endpoint or mlrun.mlconf.v3io_api),
flush_interval_secs=mlrun.mlconf.feature_store.flush_interval,
)
return self._tabels[uri]
diff --git a/mlrun/datastore/targets.py b/mlrun/datastore/targets.py
index 28376f7c251a..95169487e1cc 100644
--- a/mlrun/datastore/targets.py
+++ b/mlrun/datastore/targets.py
@@ -1102,7 +1102,7 @@ def get_table_object(self):
endpoint, uri = parse_path(self.get_target_path())
return Table(
uri,
- V3ioDriver(webapi=endpoint),
+ V3ioDriver(webapi=endpoint or mlrun.mlconf.v3io_api),
flush_interval_secs=mlrun.mlconf.feature_store.flush_interval,
)
@@ -1257,7 +1257,7 @@ def add_writer_step(
graph_shape="cylinder",
class_name="storey.StreamTarget",
columns=column_list,
- storage=V3ioDriver(webapi=endpoint),
+ storage=V3ioDriver(webapi=endpoint or mlrun.mlconf.v3io_api),
stream_path=uri,
**self.attributes,
)
diff --git a/mlrun/platforms/iguazio.py b/mlrun/platforms/iguazio.py
index c16d2698e96f..f3c52fea83fa 100644
--- a/mlrun/platforms/iguazio.py
+++ b/mlrun/platforms/iguazio.py
@@ -650,6 +650,8 @@ def parse_path(url, suffix="/"):
)
endpoint = f"{prefix}://{parsed_url.netloc}"
else:
+ # no netloc is mainly when using v3io (v3io:///) and expecting the url to be resolved automatically from env or
+ # config
endpoint = None
return endpoint, parsed_url.path.strip("/") + suffix
diff --git a/mlrun/serving/states.py b/mlrun/serving/states.py
index b6d20076056f..6e63564d2845 100644
--- a/mlrun/serving/states.py
+++ b/mlrun/serving/states.py
@@ -1358,7 +1358,7 @@ def _init_async_objects(context, steps):
endpoint, stream_path = parse_path(step.path)
stream_path = stream_path.strip("/")
step._async_object = storey.StreamTarget(
- storey.V3ioDriver(endpoint),
+ storey.V3ioDriver(endpoint or config.v3io_api),
stream_path,
context=context,
**options,
diff --git a/tests/test_config.py b/tests/test_config.py
index f68b945eee2a..8bc9288321e2 100644
--- a/tests/test_config.py
+++ b/tests/test_config.py
@@ -12,6 +12,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
+import unittest.mock
from contextlib import contextmanager
from os import environ
from tempfile import NamedTemporaryFile
@@ -100,6 +101,68 @@ def test_file(config):
assert config.namespace == ns, "not populated from file"
+@pytest.mark.parametrize(
+ "mlrun_dbpath,v3io_api,v3io_framesd,expected_v3io_api,expected_v3io_framesd",
+ (
+ (
+ "http://mlrun-api:8080",
+ "",
+ "",
+ "http://v3io-webapi:8081",
+ "http://framesd:8080",
+ ),
+ (
+ "http://mlrun-api:8080",
+ "http://v3io-webapi:8081",
+ "",
+ "http://v3io-webapi:8081",
+ "http://framesd:8080",
+ ),
+ (
+ "https://mlrun-api.default-tenant.app.somedev.cluster.amzn.com",
+ "",
+ "",
+ "https://webapi.default-tenant.app.somedev.cluster.amzn.com",
+ "https://framesd.default-tenant.app.somedev.cluster.amzn.com",
+ ),
+ (
+ "https://mlrun-api.default-tenant.app.somedev.cluster.amzn.com",
+ "https://webapi.default-tenant.app.somedev.cluster.amzn.com",
+ "",
+ "https://webapi.default-tenant.app.somedev.cluster.amzn.com",
+ "https://framesd.default-tenant.app.somedev.cluster.amzn.com",
+ ),
+ (
+ "https://mlrun-api.default-tenant.app.somedev.cluster.amzn.com",
+ "",
+ "https://framesd.default-tenant.app.somedev.cluster.amzn.com",
+ "https://webapi.default-tenant.app.somedev.cluster.amzn.com",
+ "https://framesd.default-tenant.app.somedev.cluster.amzn.com",
+ ),
+ ),
+)
+def test_v3io_api_and_framesd_enrichment_from_dbpath(
+ config,
+ mlrun_dbpath,
+ v3io_api,
+ v3io_framesd,
+ expected_v3io_api,
+ expected_v3io_framesd,
+ monkeypatch,
+):
+ with unittest.mock.patch.object(mlrun.db, "get_run_db", return_value=None):
+ env = {
+ "MLRUN_DBPATH": mlrun_dbpath,
+ "V3IO_API": v3io_api,
+ "V3IO_FRAMESD": v3io_framesd,
+ }
+ with patch_env(env):
+ mlconf.config.reload()
+
+ assert config.v3io_api == expected_v3io_api
+ assert config.v3io_framesd == expected_v3io_framesd
+
+
def test_env(config):
ns = "orange"
with patch_env({namespace_env_key: ns}):
From 114dd09da86efe9b1e113476434bff24683b371b Mon Sep 17 00:00:00 2001
From: alxtkr77 <3098237+alxtkr77@users.noreply.github.com>
Date: Sat, 22 Apr 2023 22:17:15 +0300
Subject: [PATCH 057/334] [Spark] Fix Redis key generation for single entity
(#3425)
---
mlrun/datastore/spark_udf.py | 13 ++++++++-----
1 file changed, 8 insertions(+), 5 deletions(-)
diff --git a/mlrun/datastore/spark_udf.py b/mlrun/datastore/spark_udf.py
index 8d0a796210e2..c067b64fa8dc 100644
--- a/mlrun/datastore/spark_udf.py
+++ b/mlrun/datastore/spark_udf.py
@@ -26,11 +26,14 @@ def _hash_list(*list_to_hash):
def _redis_stringify_key(key_list):
- if len(key_list) >= 2:
- return str(key_list[0]) + "." + _hash_list(key_list[1:]) + "}:static"
- if len(key_list) == 2:
- return str(key_list[0]) + "." + str(key_list[1]) + "}:static"
- return str(key_list[0]) + "}:static"
+ try:
+ if len(key_list) >= 2:
+ return str(key_list[0]) + "." + _hash_list(key_list[1:]) + "}:static"
+ if len(key_list) == 2:
+ return str(key_list[0]) + "." + str(key_list[1]) + "}:static"
+ return str(key_list[0]) + "}:static"
+ except TypeError:
+ return str(key_list) + "}:static"
hash_and_concat_v3io_udf = udf(_hash_list, StringType())
From d8adcfd26555ad9eab507f87d13a78f32d124bf7 Mon Sep 17 00:00:00 2001
From: davesh0812 <85231462+davesh0812@users.noreply.github.com>
Date: Sun, 23 Apr 2023 21:22:00 +0300
Subject: [PATCH 058/334] [Feature Set] Fix ingest to raise error when user did
not provide targets and called set_targets with_default=False (#3420)
---
mlrun/feature_store/api.py | 9 +++++++++
mlrun/feature_store/feature_set.py | 4 ++++
2 files changed, 13 insertions(+)
diff --git a/mlrun/feature_store/api.py b/mlrun/feature_store/api.py
index f3427e886c8d..22b85e1829cd 100644
--- a/mlrun/feature_store/api.py
+++ b/mlrun/feature_store/api.py
@@ -410,6 +410,15 @@ def ingest(
raise mlrun.errors.MLRunInvalidArgumentError(
"feature set and source must be specified"
)
+ if (
+ not mlrun_context
+ and not targets
+ and not (featureset.spec.targets or featureset.spec.with_default_targets)
+ ):
+ raise mlrun.errors.MLRunInvalidArgumentError(
+ f"No targets provided to feature set {featureset.metadata.name} ingest, aborting.\n"
+ "(preview can be used as an alternative to local ingest when targets are not needed)"
+ )
if featureset is not None:
featureset.validate_steps(namespace=namespace)
diff --git a/mlrun/feature_store/feature_set.py b/mlrun/feature_store/feature_set.py
index e19eaecd30c1..ca21917c36f1 100644
--- a/mlrun/feature_store/feature_set.py
+++ b/mlrun/feature_store/feature_set.py
@@ -131,6 +131,7 @@ def __init__(
self.engine = engine
self.output_path = output_path or mlconf.artifact_path
self.passthrough = passthrough
+ self.with_default_targets = True
@property
def entities(self) -> List[Entity]:
@@ -473,7 +474,10 @@ def set_targets(
)
targets = targets or []
if with_defaults:
+ self.spec.with_default_targets = True
targets.extend(get_default_targets())
+ else:
+ self.spec.with_default_targets = False
validate_target_list(targets=targets)
From 998a50c510207bf9557ca0aae9764725b712df17 Mon Sep 17 00:00:00 2001
From: Gal Topper
Date: Mon, 24 Apr 2023 06:20:39 +0800
Subject: [PATCH 059/334] Support running most spark system tests locally with
`run_local` flag (#3419)
---
mlrun/data_types/spark.py | 11 +-
mlrun/feature_store/api.py | 29 +-
mlrun/run.py | 1 +
mlrun/utils/helpers.py | 2 +-
tests/system/feature_store/expected_stats.py | 52 +-
.../system/feature_store/test_spark_engine.py | 478 ++++++++++++------
6 files changed, 374 insertions(+), 199 deletions(-)
diff --git a/mlrun/data_types/spark.py b/mlrun/data_types/spark.py
index 2e6ef44eef53..9da70288e054 100644
--- a/mlrun/data_types/spark.py
+++ b/mlrun/data_types/spark.py
@@ -16,6 +16,8 @@
from os import environ
import numpy as np
+import pytz
+from pyspark.sql.functions import to_utc_timestamp
from pyspark.sql.types import BooleanType, DoubleType, TimestampType
from mlrun.utils import logger
@@ -143,6 +145,9 @@ def get_df_stats_spark(df, options, num_bins=20, sample_size=None):
is_timestamp = isinstance(field.dataType, TimestampType)
is_boolean = isinstance(field.dataType, BooleanType)
if is_timestamp:
+ df_after_type_casts = df_after_type_casts.withColumn(
+ field.name, to_utc_timestamp(df_after_type_casts[field.name], "UTC")
+ )
timestamp_columns.add(field.name)
if is_boolean:
boolean_columns.add(field.name)
@@ -210,11 +215,13 @@ def get_df_stats_spark(df, options, num_bins=20, sample_size=None):
if col in timestamp_columns:
for stat, val in stats.items():
if stat == "mean" or stat in original_type_stats:
- stats[stat] = datetime.fromtimestamp(val).isoformat()
+ stats[stat] = datetime.fromtimestamp(val, tz=pytz.UTC).isoformat()
elif stat == "hist":
values = stats[stat][1]
for i in range(len(values)):
- values[i] = datetime.fromtimestamp(values[i]).isoformat()
+ values[i] = datetime.fromtimestamp(
+ values[i], tz=pytz.UTC
+ ).isoformat()
# for boolean values, keep mean and histogram values numeric (0 to 1 representation)
if col in boolean_columns:
for stat, val in stats.items():
diff --git a/mlrun/feature_store/api.py b/mlrun/feature_store/api.py
index 22b85e1829cd..47439477dd0f 100644
--- a/mlrun/feature_store/api.py
+++ b/mlrun/feature_store/api.py
@@ -12,9 +12,12 @@
# See the License for the specific language governing permissions and
# limitations under the License.
import copy
+import importlib.util
+import pathlib
+import sys
import warnings
from datetime import datetime
-from typing import List, Optional, Union
+from typing import Any, Dict, List, Optional, Union
from urllib.parse import urlparse
import pandas as pd
@@ -327,6 +330,21 @@ def _rename_source_dataframe_columns(df):
return df
+def _get_namespace(run_config: RunConfig) -> Dict[str, Any]:
+ # if running locally, we need to import the file dynamically to get its namespace
+ if run_config and run_config.local and run_config.function:
+ filename = run_config.function.spec.filename
+ if filename:
+ module_name = pathlib.Path(filename).name.rsplit(".", maxsplit=1)[0]
+ spec = importlib.util.spec_from_file_location(module_name, filename)
+ module = importlib.util.module_from_spec(spec)
+ sys.modules[module_name] = module
+ spec.loader.exec_module(module)
+ return vars(__import__(module_name))
+ else:
+ return get_caller_globals()
+
+
def ingest(
featureset: Union[FeatureSet, str] = None,
source=None,
@@ -501,7 +519,8 @@ def ingest(
featureset.spec.source = source
featureset.spec.validate_no_processing_for_passthrough()
- namespace = namespace or get_caller_globals()
+ if not namespace:
+ namespace = _get_namespace(run_config)
targets_to_ingest = targets or featureset.spec.targets or get_default_targets()
targets_to_ingest = copy.deepcopy(targets_to_ingest)
@@ -846,7 +865,11 @@ def _ingest_with_spark(
f"{featureset.metadata.project}-{featureset.metadata.name}"
)
- spark = pyspark.sql.SparkSession.builder.appName(session_name).getOrCreate()
+ spark = (
+ pyspark.sql.SparkSession.builder.appName(session_name)
+ .config("spark.sql.session.timeZone", "UTC")
+ .getOrCreate()
+ )
created_spark_context = True
timestamp_key = featureset.spec.timestamp_key
diff --git a/mlrun/run.py b/mlrun/run.py
index f93561f2742a..8f4be7b79011 100644
--- a/mlrun/run.py
+++ b/mlrun/run.py
@@ -793,6 +793,7 @@ def add_name(origin, name=""):
def update_common(fn, spec):
fn.spec.image = image or get_in(spec, "spec.image", "")
+ fn.spec.filename = filename or get_in(spec, "spec.filename", "")
fn.spec.build.base_image = get_in(spec, "spec.build.baseImage")
fn.spec.build.commands = get_in(spec, "spec.build.commands")
fn.spec.build.secret = get_in(spec, "spec.build.secret")
diff --git a/mlrun/utils/helpers.py b/mlrun/utils/helpers.py
index 7d8dfe40196c..7b6aaa34401a 100644
--- a/mlrun/utils/helpers.py
+++ b/mlrun/utils/helpers.py
@@ -1000,7 +1000,7 @@ def create_class(pkg_class: str):
return class_
-def create_function(pkg_func: list):
+def create_function(pkg_func: str):
"""Create a function from a package.module.function string
:param pkg_func: full function location,
diff --git a/tests/system/feature_store/expected_stats.py b/tests/system/feature_store/expected_stats.py
index e1194ae931c1..8af9ba7d8800 100644
--- a/tests/system/feature_store/expected_stats.py
+++ b/tests/system/feature_store/expected_stats.py
@@ -50,7 +50,7 @@
"rr_is_error": 0.015789473684210527,
"spo2": 98.77894736842106,
"spo2_is_error": 0.015789473684210527,
- "timestamp": "2020-12-01T17:28:31.695824",
+ "timestamp": "2020-12-01T17:28:31.695824+00:00",
"turn_count": 1.3398340922970073,
"turn_count_is_error": 0.015789473684210527,
},
@@ -88,7 +88,7 @@
"rr_is_error": False,
"spo2": 85.0,
"spo2_is_error": False,
- "timestamp": "2020-12-01T17:24:15.906352",
+ "timestamp": "2020-12-01T17:24:15.906352+00:00",
"turn_count": 0.0,
"turn_count_is_error": False,
},
@@ -107,7 +107,7 @@
"rr_is_error": False,
"spo2": 99.0,
"spo2_is_error": False,
- "timestamp": "2020-12-01T17:26:15.906352",
+ "timestamp": "2020-12-01T17:26:15.906352+00:00",
"turn_count": 0.0,
"turn_count_is_error": False,
},
@@ -126,7 +126,7 @@
"rr_is_error": False,
"spo2": 99.0,
"spo2_is_error": False,
- "timestamp": "2020-12-01T17:28:15.906352",
+ "timestamp": "2020-12-01T17:28:15.906352+00:00",
"turn_count": 1.1724099011618052,
"turn_count_is_error": False,
},
@@ -145,7 +145,7 @@
"rr_is_error": False,
"spo2": 99.0,
"spo2_is_error": False,
- "timestamp": "2020-12-01T17:31:15.906352",
+ "timestamp": "2020-12-01T17:31:15.906352+00:00",
"turn_count": 2.951729964062169,
"turn_count_is_error": False,
},
@@ -164,7 +164,7 @@
"rr_is_error": True,
"spo2": 99.0,
"spo2_is_error": True,
- "timestamp": "2020-12-01T17:33:15.906352",
+ "timestamp": "2020-12-01T17:33:15.906352+00:00",
"turn_count": 3.0,
"turn_count_is_error": True,
},
@@ -474,26 +474,26 @@
"timestamp": [
[20, 0, 20, 0, 20, 0, 20, 0, 20, 0, 0, 20, 0, 20, 0, 20, 0, 20, 0, 10],
[
- "2020-12-01T17:24:15.910000",
- "2020-12-01T17:24:42.910000",
- "2020-12-01T17:25:09.910000",
- "2020-12-01T17:25:36.910000",
- "2020-12-01T17:26:03.910000",
- "2020-12-01T17:26:30.910000",
- "2020-12-01T17:26:57.910000",
- "2020-12-01T17:27:24.910000",
- "2020-12-01T17:27:51.910000",
- "2020-12-01T17:28:18.910000",
- "2020-12-01T17:28:45.910000",
- "2020-12-01T17:29:12.910000",
- "2020-12-01T17:29:39.910000",
- "2020-12-01T17:30:06.910000",
- "2020-12-01T17:30:33.910000",
- "2020-12-01T17:31:00.910000",
- "2020-12-01T17:31:27.910000",
- "2020-12-01T17:31:54.910000",
- "2020-12-01T17:32:21.910000",
- "2020-12-01T17:32:48.910000",
+ "2020-12-01T17:24:15.910000+00:00",
+ "2020-12-01T17:24:42.910000+00:00",
+ "2020-12-01T17:25:09.910000+00:00",
+ "2020-12-01T17:25:36.910000+00:00",
+ "2020-12-01T17:26:03.910000+00:00",
+ "2020-12-01T17:26:30.910000+00:00",
+ "2020-12-01T17:26:57.910000+00:00",
+ "2020-12-01T17:27:24.910000+00:00",
+ "2020-12-01T17:27:51.910000+00:00",
+ "2020-12-01T17:28:18.910000+00:00",
+ "2020-12-01T17:28:45.910000+00:00",
+ "2020-12-01T17:29:12.910000+00:00",
+ "2020-12-01T17:29:39.910000+00:00",
+ "2020-12-01T17:30:06.910000+00:00",
+ "2020-12-01T17:30:33.910000+00:00",
+ "2020-12-01T17:31:00.910000+00:00",
+ "2020-12-01T17:31:27.910000+00:00",
+ "2020-12-01T17:31:54.910000+00:00",
+ "2020-12-01T17:32:21.910000+00:00",
+ "2020-12-01T17:32:48.910000+00:00",
],
],
"turn_count": [
diff --git a/tests/system/feature_store/test_spark_engine.py b/tests/system/feature_store/test_spark_engine.py
index 8f35c81ee767..81f1505d2991 100644
--- a/tests/system/feature_store/test_spark_engine.py
+++ b/tests/system/feature_store/test_spark_engine.py
@@ -15,11 +15,13 @@
import os
import pathlib
import sys
+import tempfile
import uuid
from datetime import datetime
import fsspec
import pandas as pd
+import pyspark.sql.utils
import pytest
import v3iofs
from pandas._testing import assert_frame_equal
@@ -53,11 +55,26 @@
# Marked as enterprise because of v3io mount and remote spark
@pytest.mark.enterprise
class TestFeatureStoreSparkEngine(TestMLRunSystem):
+ """
+ This suite tests feature store functionality with the remote spark runtime (spark service). It does not test spark
+ operator. Make sure that, in env.yml, MLRUN_SYSTEM_TESTS_DEFAULT_SPARK_SERVICE is set to the name of a spark service
+ that exists on the remote system, or alternative set spark_service (below) to that name.
+
+ To run the tests against code other than mlrun/mlrun@development, set test_branch below.
+
+ After any tests have already run at least once, you may want to set spark_image_deployed=True (below) to avoid
+ rebuilding the image on subsequent runs, as it takes several minutes.
+
+ It is also possible to run most tests in this suite locally if you have pyspark installed. To run locally, set
+ run_local=True. This can be very useful for debugging.
+ """
+
project_name = "fs-system-spark-engine"
spark_service = ""
pq_source = "testdata.parquet"
pq_target = "testdata_target"
csv_source = "testdata.csv"
+ run_local = False
spark_image_deployed = (
False # Set to True if you want to avoid the image building phase
)
@@ -66,7 +83,10 @@ class TestFeatureStoreSparkEngine(TestMLRunSystem):
@classmethod
def _init_env_from_file(cls):
env = cls._get_env_from_file()
- cls.spark_service = env["MLRUN_SYSTEM_TESTS_DEFAULT_SPARK_SERVICE"]
+ if cls.run_local:
+ cls.spark_service = None
+ else:
+ cls.spark_service = env["MLRUN_SYSTEM_TESTS_DEFAULT_SPARK_SERVICE"]
@classmethod
def get_local_pq_source_path(cls):
@@ -80,23 +100,18 @@ def get_remote_pq_source_path(cls, without_prefix=False):
path += "/bigdata/" + cls.pq_source
return path
- def _print_full_df(self, df: pd.DataFrame, df_name: str, passthrough: str) -> None:
+ @classmethod
+ def get_pq_source_path(cls):
+ if cls.run_local:
+ return cls.get_local_pq_source_path()
+ else:
+ return cls.get_remote_pq_source_path()
+
+ def _print_full_df(self, df: pd.DataFrame, df_name: str, passthrough: bool) -> None:
with pd.option_context("display.max_rows", None, "display.max_columns", None):
self._logger.info(f"{df_name}-passthrough_{passthrough}:")
self._logger.info(df)
- def get_remote_pq_target_path(self, without_prefix=False, clean_up=True):
- path = "v3io://"
- if without_prefix:
- path = ""
- path += "/bigdata/" + self.pq_target
- if clean_up:
- fsys = fsspec.filesystem(v3iofs.fs.V3ioFS.protocol)
- if fsys.isdir(path):
- for f in fsys.listdir(path):
- fsys._rm(f["name"])
- return path
-
@classmethod
def get_local_csv_source_path(cls):
return os.path.relpath(str(cls.get_assets_path() / cls.csv_source))
@@ -109,14 +124,26 @@ def get_remote_csv_source_path(cls, without_prefix=False):
path += "/bigdata/" + cls.csv_source
return path
+ @classmethod
+ def get_csv_source_path(cls):
+ if cls.run_local:
+ return cls.get_local_csv_source_path()
+ else:
+ return cls.get_remote_csv_source_path()
+
@classmethod
def custom_setup_class(cls):
+ cls._init_env_from_file()
+
+ if not cls.run_local:
+ cls._setup_remote_run()
+
+ @classmethod
+ def _setup_remote_run(cls):
from mlrun import get_run_db
from mlrun.run import new_function
from mlrun.runtimes import RemoteSparkRuntime
- cls._init_env_from_file()
-
store, _ = store_manager.get_or_create_store(cls.get_remote_pq_source_path())
store.upload(
cls.get_remote_pq_source_path(without_prefix=True),
@@ -144,20 +171,24 @@ def custom_setup_class(cls):
cls.spark_image_deployed = True
@staticmethod
- def read_parquet_and_assert(out_path_spark, out_path_storey):
+ def is_path_spark_metadata(path):
+ return path.endswith("/_SUCCESS") or path.endswith(".crc")
+
+ @classmethod
+ def read_parquet_and_assert(cls, out_path_spark, out_path_storey):
read_back_df_spark = None
- file_system = fsspec.filesystem("v3io")
+ file_system = fsspec.filesystem("file" if cls.run_local else "v3io")
for file_entry in file_system.ls(out_path_spark):
- filepath = file_entry["name"]
- if not filepath.endswith("/_SUCCESS"):
- read_back_df_spark = pd.read_parquet(f"v3io://{filepath}")
+ filepath = file_entry if cls.run_local else f'v3io://{file_entry["name"]}'
+ if not cls.is_path_spark_metadata(filepath):
+ read_back_df_spark = pd.read_parquet(filepath)
break
assert read_back_df_spark is not None
read_back_df_storey = None
for file_entry in file_system.ls(out_path_storey):
- filepath = file_entry["name"]
- read_back_df_storey = pd.read_parquet(f"v3io://{filepath}")
+ filepath = file_entry if cls.run_local else f'v3io://{file_entry["name"]}'
+ read_back_df_storey = pd.read_parquet(filepath)
break
assert read_back_df_storey is not None
@@ -167,17 +198,25 @@ def read_parquet_and_assert(out_path_spark, out_path_storey):
# spark does not support indexes, so we need to reset the storey result to match it
read_back_df_storey.reset_index(inplace=True)
- assert read_back_df_spark.sort_index(axis=1).equals(
- read_back_df_storey.sort_index(axis=1)
+ pd.testing.assert_frame_equal(
+ read_back_df_spark,
+ read_back_df_storey,
+ check_categorical=False,
+ check_like=True,
)
- @staticmethod
- def read_csv(csv_path: str) -> pd.DataFrame:
- file_system = fsspec.filesystem("v3io")
- for file_entry in file_system.ls(csv_path):
- filepath = file_entry["name"]
- if not filepath.endswith("/_SUCCESS"):
- return pd.read_csv(f"v3io://{filepath}")
+ @classmethod
+ def read_csv(cls, csv_path: str) -> pd.DataFrame:
+ file_system = fsspec.filesystem("file" if cls.run_local else "v3io")
+ if file_system.isdir(csv_path):
+ for file_entry in file_system.ls(csv_path):
+ filepath = (
+ file_entry if cls.run_local else f'v3io://{file_entry["name"]}'
+ )
+ if not cls.is_path_spark_metadata(filepath):
+ return pd.read_csv(filepath)
+ else:
+ return pd.read_csv(csv_path)
raise AssertionError(f"No files found in {csv_path}")
@staticmethod
@@ -192,9 +231,54 @@ def read_csv_and_assert(csv_path_spark, csv_path_storey):
read_back_df_storey = read_back_df_storey.dropna(axis=1, how="all")
read_back_df_spark = read_back_df_spark.dropna(axis=1, how="all")
- assert read_back_df_spark.sort_index(axis=1).equals(
- read_back_df_storey.sort_index(axis=1)
- )
+ pd.testing.assert_frame_equal(
+ read_back_df_storey,
+ read_back_df_spark,
+ check_categorical=False,
+ check_like=True,
+ )
+
+ def setup_method(self, method):
+ super().setup_method(method)
+ if self.run_local:
+ self._tmpdir = tempfile.TemporaryDirectory()
+
+ def teardown_method(self, method):
+ super().teardown_method(method)
+ if self.run_local:
+ self._tmpdir.cleanup()
+
+ def output_dir(self, url=True):
+ if self.run_local:
+ prefix = "file://" if url else ""
+ base_dir = f"{prefix}{self._tmpdir.name}"
+ else:
+ base_dir = f"v3io:///projects/{self.project_name}"
+ result = f"{base_dir}/spark-tests-output"
+ if self.run_local:
+ os.makedirs(result, exist_ok=True)
+ return result
+
+ @staticmethod
+ def test_name():
+ return (
+ os.environ.get("PYTEST_CURRENT_TEST")
+ .split(":")[-1]
+ .split(" ")[0]
+ .replace("[", "__")
+ .replace("]", "")
+ )
+
+ def test_output_subdir_path(self, url=True):
+ return f"{self.output_dir(url=url)}/{self.test_name()}"
+
+ def set_targets(self, feature_set, also_in_remote=False):
+ dir_name = self.test_name()
+ if self.run_local or also_in_remote:
+ target_path = f"{self.output_dir()}/{dir_name}"
+ feature_set.set_targets(
+ [ParquetTarget(path=target_path)], with_defaults=False
+ )
def test_basic_remote_spark_ingest(self):
key = "patient_id"
@@ -204,13 +288,14 @@ def test_basic_remote_spark_ingest(self):
timestamp_key="timestamp",
engine="spark",
)
- source = ParquetSource("myparquet", path=self.get_remote_pq_source_path())
+ source = ParquetSource("myparquet", path=self.get_pq_source_path())
+ self.set_targets(measurements)
fstore.ingest(
measurements,
source,
return_df=True,
spark_context=self.spark_service,
- run_config=fstore.RunConfig(local=False),
+ run_config=fstore.RunConfig(local=self.run_local),
)
assert measurements.status.targets[0].run_id is not None
@@ -233,7 +318,7 @@ def test_basic_remote_spark_ingest_csv(self):
measurements.graph.to(name="rename_column", handler="rename_column")
source = CSVSource(
"mycsv",
- path=self.get_remote_csv_source_path(),
+ path=self.get_csv_source_path(),
)
filename = str(
pathlib.Path(sys.modules[self.__module__].__file__).absolute().parent
@@ -241,8 +326,9 @@ def test_basic_remote_spark_ingest_csv(self):
)
func = code_to_function("func", kind="remote-spark", filename=filename)
run_config = fstore.RunConfig(
- local=False, function=func, handler="ingest_handler"
+ local=self.run_local, function=func, handler="ingest_handler"
)
+ self.set_targets(measurements)
fstore.ingest(
measurements,
source,
@@ -278,13 +364,14 @@ def test_error_flow(self):
df,
return_df=True,
spark_context=self.spark_service,
- run_config=fstore.RunConfig(local=False),
+ run_config=fstore.RunConfig(local=self.run_local),
)
def test_ingest_to_csv(self):
key = "patient_id"
- csv_path_spark = "v3io:///bigdata/test_ingest_to_csv_spark"
- csv_path_storey = "v3io:///bigdata/test_ingest_to_csv_storey.csv"
+ base_path = self.test_output_subdir_path()
+ csv_path_spark = f"{base_path}_spark"
+ csv_path_storey = f"{base_path}_storey.csv"
measurements = fstore.FeatureSet(
"measurements_spark",
@@ -292,14 +379,14 @@ def test_ingest_to_csv(self):
timestamp_key="timestamp",
engine="spark",
)
- source = ParquetSource("myparquet", path=self.get_remote_pq_source_path())
+ source = ParquetSource("myparquet", path=self.get_pq_source_path())
targets = [CSVTarget(name="csv", path=csv_path_spark)]
fstore.ingest(
measurements,
source,
targets,
spark_context=self.spark_service,
- run_config=fstore.RunConfig(local=False),
+ run_config=fstore.RunConfig(local=self.run_local),
)
csv_path_spark = measurements.get_target_path(name="csv")
@@ -308,7 +395,7 @@ def test_ingest_to_csv(self):
entities=[fstore.Entity(key)],
timestamp_key="timestamp",
)
- source = ParquetSource("myparquet", path=self.get_remote_pq_source_path())
+ source = ParquetSource("myparquet", path=self.get_pq_source_path())
targets = [CSVTarget(name="csv", path=csv_path_storey)]
fstore.ingest(
measurements,
@@ -318,19 +405,17 @@ def test_ingest_to_csv(self):
csv_path_storey = measurements.get_target_path(name="csv")
read_back_df_spark = None
- file_system = fsspec.filesystem("v3io")
+ file_system = fsspec.filesystem("file" if self.run_local else "v3io")
for file_entry in file_system.ls(csv_path_spark):
- filepath = file_entry["name"]
- if not filepath.endswith("/_SUCCESS"):
- read_back_df_spark = pd.read_csv(f"v3io://{filepath}")
+ filepath = file_entry if self.run_local else f'v3io://{file_entry["name"]}'
+ if not self.is_path_spark_metadata(filepath):
+ read_back_df_spark = pd.read_csv(filepath)
break
assert read_back_df_spark is not None
- read_back_df_storey = None
- for file_entry in file_system.ls(csv_path_storey):
- filepath = file_entry["name"]
- read_back_df_storey = pd.read_csv(f"v3io://{filepath}")
- break
+ filepath = csv_path_storey if self.run_local else f"v3io://{csv_path_storey}"
+ read_back_df_storey = pd.read_csv(filepath)
+
assert read_back_df_storey is not None
assert read_back_df_spark.sort_index(axis=1).equals(
@@ -351,14 +436,14 @@ def test_ingest_to_redis(self):
timestamp_key="timestamp",
engine="spark",
)
- source = ParquetSource("myparquet", path=self.get_remote_pq_source_path())
+ source = ParquetSource("myparquet", path=self.get_pq_source_path())
targets = [RedisNoSqlTarget()]
measurements.set_targets(targets, with_defaults=False)
fstore.ingest(
measurements,
source,
spark_context=self.spark_service,
- run_config=fstore.RunConfig(local=False),
+ run_config=fstore.RunConfig(local=self.run_local),
overwrite=True,
)
# read the dataframe from the redis back
@@ -385,6 +470,10 @@ def test_ingest_to_redis(self):
}
]
+ @pytest.mark.skipif(
+ run_local,
+ reason="We don't normally have redis or v3io jars when running locally",
+ )
@pytest.mark.parametrize(
"target_kind",
["Redis", "v3io"] if mlrun.mlconf.redis.url else ["v3io"],
@@ -401,7 +490,7 @@ def test_ingest_multiple_entities(self, target_kind):
timestamp_key="timestamp",
engine="spark",
)
- source = ParquetSource("myparquet", path=self.get_remote_pq_source_path())
+ source = ParquetSource("myparquet", path=self.get_pq_source_path())
if target_kind == "Redis":
targets = [RedisNoSqlTarget()]
else:
@@ -412,7 +501,7 @@ def test_ingest_multiple_entities(self, target_kind):
measurements,
source,
spark_context=self.spark_service,
- run_config=fstore.RunConfig(False),
+ run_config=fstore.RunConfig(local=self.run_local),
overwrite=True,
)
# read the dataframe
@@ -459,14 +548,14 @@ def test_ingest_to_redis_numeric_index(self):
timestamp_key="timestamp",
engine="spark",
)
- source = ParquetSource("myparquet", path=self.get_remote_pq_source_path())
+ source = ParquetSource("myparquet", path=self.get_pq_source_path())
targets = [RedisNoSqlTarget()]
measurements.set_targets(targets, with_defaults=False)
fstore.ingest(
measurements,
source,
spark_context=self.spark_service,
- run_config=fstore.RunConfig(local=False),
+ run_config=fstore.RunConfig(local=self.run_local),
overwrite=True,
)
# read the dataframe from the redis back
@@ -494,14 +583,17 @@ def test_ingest_to_redis_numeric_index(self):
]
# tests that data is filtered by time in scheduled jobs
+ @pytest.mark.skipif(run_local, reason="Local scheduling is not supported")
@pytest.mark.parametrize("partitioned", [True, False])
def test_schedule_on_filtered_by_time(self, partitioned):
name = f"sched-time-{str(partitioned)}"
now = datetime.now()
- path = "v3io:///bigdata/bla.parquet"
- fsys = fsspec.filesystem(v3iofs.fs.V3ioFS.protocol)
+ path = f"{self.output_dir()}/bla.parquet"
+ fsys = fsspec.filesystem(
+ "file" if self.run_local else v3iofs.fs.V3ioFS.protocol
+ )
pd.DataFrame(
{
"time": [
@@ -531,7 +623,7 @@ def test_schedule_on_filtered_by_time(self, partitioned):
NoSqlTarget(),
ParquetTarget(
name="tar1",
- path="v3io:///bigdata/fs1/",
+ path=f"{self.output_dir()}/fs1/",
partitioned=True,
partition_cols=["time"],
),
@@ -539,7 +631,7 @@ def test_schedule_on_filtered_by_time(self, partitioned):
else:
targets = [
ParquetTarget(
- name="tar2", path="v3io:///bigdata/fs2/", partitioned=False
+ name="tar2", path=f"{self.output_dir()}/fs2/", partitioned=False
),
NoSqlTarget(),
]
@@ -547,7 +639,7 @@ def test_schedule_on_filtered_by_time(self, partitioned):
fstore.ingest(
feature_set,
source,
- run_config=fstore.RunConfig(local=False),
+ run_config=fstore.RunConfig(local=self.run_local),
targets=targets,
spark_context=self.spark_service,
)
@@ -577,7 +669,7 @@ def test_schedule_on_filtered_by_time(self, partitioned):
fstore.ingest(
feature_set,
source,
- run_config=fstore.RunConfig(local=False),
+ run_config=fstore.RunConfig(local=self.run_local),
targets=targets,
spark_context=self.spark_service,
)
@@ -623,8 +715,10 @@ def test_aggregations(self):
}
)
- path = "v3io:///bigdata/test_aggregations.parquet"
- fsys = fsspec.filesystem(v3iofs.fs.V3ioFS.protocol)
+ path = f"{self.output_dir(url=False)}/test_aggregations.parquet"
+ fsys = fsspec.filesystem(
+ "file" if self.run_local else v3iofs.fs.V3ioFS.protocol
+ )
df.to_parquet(path=path, filesystem=fsys)
source = ParquetSource("myparquet", path=path)
@@ -716,12 +810,12 @@ def test_aggregations(self):
windows="1h",
period="10m",
)
-
+ self.set_targets(data_set)
fstore.ingest(
data_set,
source,
spark_context=self.spark_service,
- run_config=fstore.RunConfig(local=False),
+ run_config=fstore.RunConfig(local=self.run_local),
)
features = [
@@ -892,8 +986,12 @@ def test_aggregations_emit_every_event(self):
}
)
- path = "v3io:///bigdata/test_aggregations_emit_every_event.parquet"
- fsys = fsspec.filesystem(v3iofs.fs.V3ioFS.protocol)
+ path = (
+ f"{self.output_dir(url=False)}/test_aggregations_emit_every_event.parquet"
+ )
+ fsys = fsspec.filesystem(
+ "file" if self.run_local else v3iofs.fs.V3ioFS.protocol
+ )
df.to_parquet(path=path, filesystem=fsys)
source = ParquetSource("myparquet", path=path)
@@ -913,12 +1011,12 @@ def test_aggregations_emit_every_event(self):
period="10m",
emit_policy=EmitEveryEvent(),
)
-
+ self.set_targets(data_set)
fstore.ingest(
data_set,
source,
spark_context=self.spark_service,
- run_config=fstore.RunConfig(local=False),
+ run_config=fstore.RunConfig(local=self.run_local),
)
print(f"Results:\n{data_set.to_dataframe().sort_values('time').to_string()}\n")
@@ -978,8 +1076,11 @@ def test_aggregations_emit_every_event(self):
def test_mix_of_partitioned_and_nonpartitioned_targets(self):
name = "test_mix_of_partitioned_and_nonpartitioned_targets"
- path = "v3io:///bigdata/bla.parquet"
- fsys = fsspec.filesystem(v3iofs.fs.V3ioFS.protocol)
+ path = f"{self.output_dir(url=False)}/bla.parquet"
+ url = f"{self.output_dir()}/bla.parquet"
+ fsys = fsspec.filesystem(
+ "file" if self.run_local else v3iofs.fs.V3ioFS.protocol
+ )
pd.DataFrame(
{
"time": [
@@ -993,7 +1094,7 @@ def test_mix_of_partitioned_and_nonpartitioned_targets(self):
source = ParquetSource(
"myparquet",
- path=path,
+ path=url,
)
feature_set = fstore.FeatureSet(
@@ -1003,8 +1104,8 @@ def test_mix_of_partitioned_and_nonpartitioned_targets(self):
engine="spark",
)
- partitioned_output_path = "v3io:///bigdata/partitioned/"
- nonpartitioned_output_path = "v3io:///bigdata/nonpartitioned/"
+ partitioned_output_path = f"{self.output_dir()}/partitioned/"
+ nonpartitioned_output_path = f"{self.output_dir()}/nonpartitioned/"
targets = [
ParquetTarget(
name="tar1",
@@ -1019,7 +1120,7 @@ def test_mix_of_partitioned_and_nonpartitioned_targets(self):
fstore.ingest(
feature_set,
source,
- run_config=fstore.RunConfig(local=False),
+ run_config=fstore.RunConfig(local=self.run_local),
targets=targets,
spark_context=self.spark_service,
)
@@ -1040,8 +1141,10 @@ def test_mix_of_partitioned_and_nonpartitioned_targets(self):
def test_write_empty_dataframe_overwrite_false(self):
name = "test_write_empty_dataframe_overwrite_false"
- path = "v3io:///bigdata/test_write_empty_dataframe_overwrite_false.parquet"
- fsys = fsspec.filesystem(v3iofs.fs.V3ioFS.protocol)
+ path = f"{self.output_dir(url=False)}/test_write_empty_dataframe_overwrite_false.parquet"
+ fsys = fsspec.filesystem(
+ "file" if self.run_local else v3iofs.fs.V3ioFS.protocol
+ )
empty_df = pd.DataFrame(
{
"time": [
@@ -1067,14 +1170,14 @@ def test_write_empty_dataframe_overwrite_false(self):
target = ParquetTarget(
name="pq",
- path="v3io:///bigdata/test_write_empty_dataframe_overwrite_false/",
+ path=f"{self.output_dir()}/{self.test_name()}/",
partitioned=False,
)
fstore.ingest(
feature_set,
source,
- run_config=fstore.RunConfig(local=False),
+ run_config=fstore.RunConfig(local=self.run_local),
targets=[
target,
],
@@ -1089,8 +1192,12 @@ def test_write_empty_dataframe_overwrite_false(self):
def test_write_dataframe_overwrite_false(self):
name = "test_write_dataframe_overwrite_false"
- path = "v3io:///bigdata/test_write_dataframe_overwrite_false.parquet"
- fsys = fsspec.filesystem(v3iofs.fs.V3ioFS.protocol)
+ path = (
+ f"{self.output_dir(url=False)}/test_write_dataframe_overwrite_false.parquet"
+ )
+ fsys = fsspec.filesystem(
+ "file" if self.run_local else v3iofs.fs.V3ioFS.protocol
+ )
df = pd.DataFrame(
{
"time": [
@@ -1116,14 +1223,14 @@ def test_write_dataframe_overwrite_false(self):
target = ParquetTarget(
name="pq",
- path="v3io:///bigdata/test_write_dataframe_overwrite_false/",
+ path=f"{self.output_dir()}/{self.test_name()}/",
partitioned=False,
)
fstore.ingest(
feature_set,
source,
- run_config=fstore.RunConfig(local=False),
+ run_config=fstore.RunConfig(local=self.run_local),
targets=[
target,
],
@@ -1142,24 +1249,26 @@ def test_write_dataframe_overwrite_false(self):
"should_succeed, is_parquet, is_partitioned, target_path",
[
# spark - csv - fail for single file
- (True, False, None, "v3io:///bigdata/dif-eng/csv"),
- (False, False, None, "v3io:///bigdata/dif-eng/file.csv"),
+ (True, False, None, "dif-eng/csv"),
+ (False, False, None, "dif-eng/file.csv"),
# spark - parquet - fail for single file
- (True, True, True, "v3io:///bigdata/dif-eng/pq"),
- (False, True, True, "v3io:///bigdata/dif-eng/file.pq"),
- (True, True, False, "v3io:///bigdata/dif-eng/pq"),
- (False, True, False, "v3io:///bigdata/dif-eng/file.pq"),
+ (True, True, True, "dif-eng/pq"),
+ (False, True, True, "dif-eng/file.pq"),
+ (True, True, False, "dif-eng/pq"),
+ (False, True, False, "dif-eng/file.pq"),
],
)
def test_different_paths_for_ingest_on_spark_engines(
self, should_succeed, is_parquet, is_partitioned, target_path
):
+ target_path = f"{self.output_dir()}/{target_path}"
+
fset = FeatureSet("fsname", entities=[Entity("ticker")], engine="spark")
- source = (
- "v3io:///bigdata/test_different_paths_for_ingest_on_spark_engines.parquet"
+ source = f"{self.output_dir(url=False)}/test_different_paths_for_ingest_on_spark_engines.parquet"
+ fsys = fsspec.filesystem(
+ "file" if self.run_local else v3iofs.fs.V3ioFS.protocol
)
- fsys = fsspec.filesystem(v3iofs.fs.V3ioFS.protocol)
stocks.to_parquet(path=source, filesystem=fsys)
source = ParquetSource(
"myparquet",
@@ -1175,7 +1284,7 @@ def test_different_paths_for_ingest_on_spark_engines(
if should_succeed:
fstore.ingest(
fset,
- run_config=fstore.RunConfig(local=False),
+ run_config=fstore.RunConfig(local=self.run_local),
spark_context=self.spark_service,
source=source,
targets=[target],
@@ -1200,13 +1309,17 @@ def test_error_is_properly_propagated(self):
engine="spark",
)
source = ParquetSource("myparquet", path="wrong-path.pq")
- with pytest.raises(mlrun.runtimes.utils.RunError):
+ with pytest.raises(
+ pyspark.sql.utils.AnalysisException
+ if self.run_local
+ else mlrun.runtimes.utils.RunError
+ ):
fstore.ingest(
measurements,
source,
return_df=True,
spark_context=self.spark_service,
- run_config=fstore.RunConfig(local=False),
+ run_config=fstore.RunConfig(local=self.run_local),
)
# ML-3092
@@ -1219,12 +1332,13 @@ def test_get_offline_features_with_filter_and_indexes(self, timestamp_key):
timestamp_key=timestamp_key,
engine="spark",
)
- source = ParquetSource("myparquet", path=self.get_remote_pq_source_path())
+ source = ParquetSource("myparquet", path=self.get_pq_source_path())
+ self.set_targets(measurements)
fstore.ingest(
measurements,
source,
spark_context=self.spark_service,
- run_config=fstore.RunConfig(local=False),
+ run_config=fstore.RunConfig(local=self.run_local),
)
assert measurements.status.targets[0].run_id is not None
fv_name = "measurements-fv"
@@ -1238,13 +1352,15 @@ def test_get_offline_features_with_filter_and_indexes(self, timestamp_key):
)
my_fv.spec.with_indexes = True
my_fv.save()
- target = ParquetTarget("mytarget", path=self.get_remote_pq_target_path())
+ target = ParquetTarget(
+ "mytarget", path=f"{self.output_dir()}-get_offline_features"
+ )
resp = fstore.get_offline_features(
fv_name,
target=target,
query="bad>6 and bad<8",
engine="spark",
- run_config=fstore.RunConfig(local=False, kind="remote-spark"),
+ run_config=fstore.RunConfig(local=self.run_local),
spark_service=self.spark_service,
)
resp_df = resp.to_dataframe()
@@ -1280,17 +1396,19 @@ def test_get_offline_features_with_spark_engine(self, passthrough, target_type):
engine="spark",
passthrough=passthrough,
)
- source = ParquetSource("myparquet", path=self.get_remote_pq_source_path())
+ source = ParquetSource("myparquet", path=self.get_pq_source_path())
+ self.set_targets(measurements)
fstore.ingest(
measurements,
source,
spark_context=self.spark_service,
- run_config=fstore.RunConfig(local=False),
+ run_config=fstore.RunConfig(local=self.run_local),
)
- assert measurements.status.targets[0].run_id is not None
+ if not self.run_local:
+ assert measurements.status.targets[0].run_id is not None
# assert that online target exist (nosql) and offline target does not (parquet)
- if passthrough:
+ if passthrough and not self.run_local:
assert len(measurements.status.targets) == 1
assert isinstance(measurements.status.targets["nosql"], DataTarget)
@@ -1306,13 +1424,13 @@ def test_get_offline_features_with_spark_engine(self, passthrough, target_type):
my_fv.save()
target = target_type(
"mytarget",
- path="v3io:///bigdata/test_get_offline_features_with_spark_engine_testdata_target/",
+ path=f"{self.output_dir()}-get_offline_features",
)
resp = fstore.get_offline_features(
fv_name,
target=target,
query="bad>6 and bad<8",
- run_config=fstore.RunConfig(local=False, kind="remote-spark"),
+ run_config=fstore.RunConfig(local=self.run_local),
engine="spark",
spark_service=self.spark_service,
)
@@ -1331,8 +1449,9 @@ def test_get_offline_features_with_spark_engine(self, passthrough, target_type):
def test_ingest_with_steps_drop_features(self):
key = "patient_id"
- csv_path_spark = "v3io:///bigdata/test_ingest_to_csv_spark"
- csv_path_storey = "v3io:///bigdata/test_ingest_to_csv_storey.csv"
+ base_path = self.test_output_subdir_path()
+ csv_path_spark = f"{base_path}_spark"
+ csv_path_storey = f"{base_path}_storey.csv"
measurements = fstore.FeatureSet(
"measurements_spark",
@@ -1341,14 +1460,14 @@ def test_ingest_with_steps_drop_features(self):
engine="spark",
)
measurements.graph.to(DropFeatures(features=["bad"]))
- source = ParquetSource("myparquet", path=self.get_remote_pq_source_path())
+ source = ParquetSource("myparquet", path=self.get_pq_source_path())
targets = [CSVTarget(name="csv", path=csv_path_spark)]
fstore.ingest(
measurements,
source,
targets,
spark_context=self.spark_service,
- run_config=fstore.RunConfig(local=False),
+ run_config=fstore.RunConfig(local=self.run_local),
)
csv_path_spark = measurements.get_target_path(name="csv")
@@ -1358,7 +1477,7 @@ def test_ingest_with_steps_drop_features(self):
timestamp_key="timestamp",
)
measurements.graph.to(DropFeatures(features=["bad"]))
- source = ParquetSource("myparquet", path=self.get_remote_pq_source_path())
+ source = ParquetSource("myparquet", path=self.get_pq_source_path())
targets = [CSVTarget(name="csv", path=csv_path_storey)]
fstore.ingest(
measurements,
@@ -1375,7 +1494,7 @@ def test_ingest_with_steps_drop_features(self):
engine="spark",
)
measurements.graph.to(DropFeatures(features=[key]))
- source = ParquetSource("myparquet", path=self.get_remote_pq_source_path())
+ source = ParquetSource("myparquet", path=self.get_pq_source_path())
key_as_set = {key}
with pytest.raises(
mlrun.errors.MLRunInvalidArgumentError,
@@ -1385,13 +1504,14 @@ def test_ingest_with_steps_drop_features(self):
measurements,
source,
spark_context=self.spark_service,
- run_config=fstore.RunConfig(local=False),
+ run_config=fstore.RunConfig(local=self.run_local),
)
def test_ingest_with_steps_onehot(self):
key = "patient_id"
- csv_path_spark = "v3io:///bigdata/test_ingest_to_csv_spark"
- csv_path_storey = "v3io:///bigdata/test_ingest_to_csv_storey.csv"
+ base_path = self.test_output_subdir_path()
+ csv_path_spark = f"{base_path}_spark"
+ csv_path_storey = f"{base_path}_storey.csv"
measurements = fstore.FeatureSet(
"measurements_spark",
@@ -1400,14 +1520,14 @@ def test_ingest_with_steps_onehot(self):
engine="spark",
)
measurements.graph.to(OneHotEncoder(mapping={"is_in_bed": [0, 1]}))
- source = ParquetSource("myparquet", path=self.get_remote_pq_source_path())
+ source = ParquetSource("myparquet", path=self.get_pq_source_path())
targets = [CSVTarget(name="csv", path=csv_path_spark)]
fstore.ingest(
measurements,
source,
targets,
spark_context=self.spark_service,
- run_config=fstore.RunConfig(local=False),
+ run_config=fstore.RunConfig(local=self.run_local),
)
csv_path_spark = measurements.get_target_path(name="csv")
@@ -1417,7 +1537,7 @@ def test_ingest_with_steps_onehot(self):
timestamp_key="timestamp",
)
measurements.graph.to(OneHotEncoder(mapping={"is_in_bed": [0, 1]}))
- source = ParquetSource("myparquet", path=self.get_remote_pq_source_path())
+ source = ParquetSource("myparquet", path=self.get_pq_source_path())
targets = [CSVTarget(name="csv", path=csv_path_storey)]
fstore.ingest(
measurements,
@@ -1430,8 +1550,9 @@ def test_ingest_with_steps_onehot(self):
@pytest.mark.parametrize("with_original_features", [True, False])
def test_ingest_with_steps_mapvalues(self, with_original_features):
key = "patient_id"
- csv_path_spark = "v3io:///bigdata/test_ingest_to_csv_spark"
- csv_path_storey = "v3io:///bigdata/test_ingest_to_csv_storey.csv"
+ base_path = self.test_output_subdir_path()
+ csv_path_spark = f"{base_path}_spark"
+ csv_path_storey = f"{base_path}_storey.csv"
measurements = fstore.FeatureSet(
"measurements_spark",
@@ -1448,14 +1569,14 @@ def test_ingest_with_steps_mapvalues(self, with_original_features):
with_original_features=with_original_features,
)
)
- source = ParquetSource("myparquet", path=self.get_remote_pq_source_path())
+ source = ParquetSource("myparquet", path=self.get_pq_source_path())
targets = [CSVTarget(name="csv", path=csv_path_spark)]
fstore.ingest(
measurements,
source,
targets,
spark_context=self.spark_service,
- run_config=fstore.RunConfig(local=False),
+ run_config=fstore.RunConfig(local=self.run_local),
)
csv_path_spark = measurements.get_target_path(name="csv")
@@ -1473,7 +1594,7 @@ def test_ingest_with_steps_mapvalues(self, with_original_features):
with_original_features=with_original_features,
)
)
- source = ParquetSource("myparquet", path=self.get_remote_pq_source_path())
+ source = ParquetSource("myparquet", path=self.get_pq_source_path())
targets = [CSVTarget(name="csv", path=csv_path_storey)]
fstore.ingest(
measurements,
@@ -1486,8 +1607,8 @@ def test_ingest_with_steps_mapvalues(self, with_original_features):
def test_mapvalues_with_partial_mapping(self):
# checks partial mapping -> only part of the values in field are replaced.
key = "patient_id"
- csv_path_spark = "v3io:///bigdata/test_mapvalues_with_partial_mapping"
- original_df = pd.read_parquet(self.get_remote_pq_source_path())
+ csv_path_spark = self.test_output_subdir_path()
+ original_df = pd.read_parquet(self.get_pq_source_path())
measurements = fstore.FeatureSet(
"measurements_spark",
entities=[fstore.Entity(key)],
@@ -1502,14 +1623,14 @@ def test_mapvalues_with_partial_mapping(self):
with_original_features=True,
)
)
- source = ParquetSource("myparquet", path=self.get_remote_pq_source_path())
+ source = ParquetSource("myparquet", path=self.get_pq_source_path())
targets = [CSVTarget(name="csv", path=csv_path_spark)]
fstore.ingest(
measurements,
source,
targets,
spark_context=self.spark_service,
- run_config=fstore.RunConfig(local=False),
+ run_config=fstore.RunConfig(local=self.run_local),
)
csv_path_spark = measurements.get_target_path(name="csv")
df = self.read_csv(csv_path=csv_path_spark)
@@ -1524,7 +1645,7 @@ def test_mapvalues_with_partial_mapping(self):
def test_mapvalues_with_mixed_types(self):
key = "patient_id"
- csv_path_spark = "v3io:///bigdata/test_mapvalues_with_mixed_types"
+ csv_path_spark = self.test_output_subdir_path()
measurements = fstore.FeatureSet(
"measurements_spark",
entities=[fstore.Entity(key)],
@@ -1539,7 +1660,7 @@ def test_mapvalues_with_mixed_types(self):
with_original_features=True,
)
)
- source = ParquetSource("myparquet", path=self.get_remote_pq_source_path())
+ source = ParquetSource("myparquet", path=self.get_pq_source_path())
targets = [CSVTarget(name="csv", path=csv_path_spark)]
with pytest.raises(
mlrun.runtimes.utils.RunError,
@@ -1551,14 +1672,15 @@ def test_mapvalues_with_mixed_types(self):
source,
targets,
spark_context=self.spark_service,
- run_config=fstore.RunConfig(local=False),
+ run_config=fstore.RunConfig(local=self.run_local),
)
@pytest.mark.parametrize("timestamp_col", [None, "timestamp"])
def test_ingest_with_steps_extractor(self, timestamp_col):
key = "patient_id"
- out_path_spark = "v3io:///bigdata/test_ingest_with_steps_extractor_spark"
- out_path_storey = "v3io:///bigdata/test_ingest_with_steps_extractor_storey"
+ base_path = self.test_output_subdir_path()
+ out_path_spark = f"{base_path}_spark"
+ out_path_storey = f"{base_path}_storey"
measurements = fstore.FeatureSet(
"measurements_spark",
@@ -1572,14 +1694,14 @@ def test_ingest_with_steps_extractor(self, timestamp_col):
timestamp_col=timestamp_col,
)
)
- source = ParquetSource("myparquet", path=self.get_remote_pq_source_path())
+ source = ParquetSource("myparquet", path=self.get_pq_source_path())
targets = [ParquetTarget(path=out_path_spark)]
fstore.ingest(
measurements,
source,
targets,
spark_context=self.spark_service,
- run_config=fstore.RunConfig(local=False),
+ run_config=fstore.RunConfig(local=self.run_local),
)
out_path_spark = measurements.get_target_path()
@@ -1594,7 +1716,7 @@ def test_ingest_with_steps_extractor(self, timestamp_col):
timestamp_col=timestamp_col,
)
)
- source = ParquetSource("myparquet", path=self.get_remote_pq_source_path())
+ source = ParquetSource("myparquet", path=self.get_pq_source_path())
targets = [ParquetTarget(path=out_path_storey)]
fstore.ingest(
measurements,
@@ -1751,7 +1873,7 @@ def test_relation_join(self, join_type, with_indexes):
"managers",
entities=[managers_set_entity],
)
- managers_set.set_targets(targets=["parquet"], with_defaults=False)
+ self.set_targets(managers_set, also_in_remote=True)
fstore.ingest(managers_set, managers)
classes_set_entity = fstore.Entity("c_id")
@@ -1759,7 +1881,7 @@ def test_relation_join(self, join_type, with_indexes):
"classes",
entities=[classes_set_entity],
)
- managers_set.set_targets(targets=["parquet"], with_defaults=False)
+ self.set_targets(classes_set, also_in_remote=True)
fstore.ingest(classes_set, classes)
departments_set_entity = fstore.Entity("d_id")
@@ -1768,7 +1890,7 @@ def test_relation_join(self, join_type, with_indexes):
entities=[departments_set_entity],
relations={"manager_id": managers_set_entity},
)
- departments_set.set_targets(targets=["parquet"], with_defaults=False)
+ self.set_targets(departments_set, also_in_remote=True)
fstore.ingest(departments_set, departments)
employees_set_entity = fstore.Entity("id")
@@ -1777,7 +1899,7 @@ def test_relation_join(self, join_type, with_indexes):
entities=[employees_set_entity],
relations={"department_id": departments_set_entity},
)
- employees_set.set_targets(targets=["parquet"], with_defaults=False)
+ self.set_targets(employees_set, also_in_remote=True)
fstore.ingest(employees_set, employees_with_department)
mini_employees_set = fstore.FeatureSet(
@@ -1788,7 +1910,7 @@ def test_relation_join(self, join_type, with_indexes):
"class_id": classes_set_entity,
},
)
- mini_employees_set.set_targets(targets=["parquet"], with_defaults=False)
+ self.set_targets(mini_employees_set, also_in_remote=True)
fstore.ingest(mini_employees_set, employees_with_class)
features = ["employees.name"]
@@ -1798,12 +1920,14 @@ def test_relation_join(self, join_type, with_indexes):
)
vector.save()
- target = ParquetTarget("mytarget", path=self.get_remote_pq_target_path())
+ target = ParquetTarget(
+ "mytarget", path=f"{self.output_dir()}-get_offline_features"
+ )
resp = fstore.get_offline_features(
vector,
target=target,
with_indexes=with_indexes,
- run_config=fstore.RunConfig(local=False, kind="remote-spark"),
+ run_config=fstore.RunConfig(local=self.run_local),
engine="spark",
spark_service=self.spark_service,
join_type=join_type,
@@ -1826,12 +1950,14 @@ def test_relation_join(self, join_type, with_indexes):
)
vector.save()
- target = ParquetTarget("mytarget", path=self.get_remote_pq_target_path())
+ target = ParquetTarget(
+ "mytarget", path=f"{self.output_dir()}-get_offline_features"
+ )
resp_1 = fstore.get_offline_features(
vector,
target=target,
with_indexes=with_indexes,
- run_config=fstore.RunConfig(local=False, kind="remote-spark"),
+ run_config=fstore.RunConfig(local=self.run_local),
engine="spark",
spark_service=self.spark_service,
join_type=join_type,
@@ -1850,12 +1976,14 @@ def test_relation_join(self, join_type, with_indexes):
)
vector.save()
- target = ParquetTarget("mytarget", path=self.get_remote_pq_target_path())
+ target = ParquetTarget(
+ "mytarget", path=f"{self.output_dir()}-get_offline_features"
+ )
resp_2 = fstore.get_offline_features(
vector,
target=target,
with_indexes=with_indexes,
- run_config=fstore.RunConfig(local=False, kind="remote-spark"),
+ run_config=fstore.RunConfig(local=self.run_local),
engine="spark",
spark_service=self.spark_service,
join_type=join_type,
@@ -1870,12 +1998,14 @@ def test_relation_join(self, join_type, with_indexes):
)
vector.save()
- target = ParquetTarget("mytarget", path=self.get_remote_pq_target_path())
+ target = ParquetTarget(
+ "mytarget", path=f"{self.output_dir()}-get_offline_features"
+ )
resp_3 = fstore.get_offline_features(
vector,
target=target,
with_indexes=with_indexes,
- run_config=fstore.RunConfig(local=False, kind="remote-spark"),
+ run_config=fstore.RunConfig(local=self.run_local),
engine="spark",
spark_service=self.spark_service,
join_type=join_type,
@@ -1895,12 +2025,14 @@ def test_relation_join(self, join_type, with_indexes):
)
vector.save()
- target = ParquetTarget("mytarget", path=self.get_remote_pq_target_path())
+ target = ParquetTarget(
+ "mytarget", path=f"{self.output_dir()}-get_offline_features"
+ )
resp_4 = fstore.get_offline_features(
vector,
target=target,
with_indexes=with_indexes,
- run_config=fstore.RunConfig(local=False, kind="remote-spark"),
+ run_config=fstore.RunConfig(local=self.run_local),
engine="spark",
spark_service=self.spark_service,
join_type=join_type,
@@ -1957,7 +2089,7 @@ def test_relation_asof_join(self, with_indexes):
departments_set = fstore.FeatureSet(
"departments", entities=[departments_set_entity], timestamp_key="time"
)
- departments_set.set_targets(targets=["parquet"], with_defaults=False)
+ self.set_targets(departments_set, also_in_remote=True)
fstore.ingest(departments_set, departments)
employees_set_entity = fstore.Entity("id")
@@ -1967,7 +2099,7 @@ def test_relation_asof_join(self, with_indexes):
relations={"department_id": departments_set_entity},
timestamp_key="time",
)
- employees_set.set_targets(targets=["parquet"], with_defaults=False)
+ self.set_targets(employees_set, also_in_remote=True)
fstore.ingest(employees_set, employees_with_department)
features = ["employees.name as n", "departments.name as n2"]
@@ -1976,12 +2108,14 @@ def test_relation_asof_join(self, with_indexes):
"employees-vec", features, description="Employees feature vector"
)
vector.save()
- target = ParquetTarget("mytarget", path=self.get_remote_pq_target_path())
+ target = ParquetTarget(
+ "mytarget", path=f"{self.output_dir()}-get_offline_features"
+ )
resp_1 = fstore.get_offline_features(
vector,
target=target,
with_indexes=with_indexes,
- run_config=fstore.RunConfig(local=False, kind="remote-spark"),
+ run_config=fstore.RunConfig(local=self.run_local),
engine="spark",
spark_service=self.spark_service,
order_by=["n"],
@@ -2016,20 +2150,28 @@ def test_as_of_join_result(self):
}
)
- left_path = "v3io:///bigdata/asof_join/df_left.parquet"
- right_path = "v3io:///bigdata/asof_join/df_right.parquet"
+ base_path = self.test_output_subdir_path(url=False)
+ left_path = f"{base_path}/df_left.parquet"
+ right_path = f"{base_path}/df_right.parquet"
- fsys = fsspec.filesystem(v3iofs.fs.V3ioFS.protocol)
+ fsys = fsspec.filesystem(
+ "file" if self.run_local else v3iofs.fs.V3ioFS.protocol
+ )
+ fsys.makedirs(base_path, exist_ok=True)
df_left.to_parquet(path=left_path, filesystem=fsys)
df_right.to_parquet(path=right_path, filesystem=fsys)
fset1 = fstore.FeatureSet("fs1-as-of", entities=["ent"], timestamp_key="ts")
- fset1.set_targets(["parquet"], with_defaults=False)
+ self.set_targets(fset1, also_in_remote=True)
fset2 = fstore.FeatureSet("fs2-as-of", entities=["ent"], timestamp_key="ts")
- fset2.set_targets(["parquet"], with_defaults=False)
+ self.set_targets(fset2, also_in_remote=True)
+
+ base_url = self.test_output_subdir_path()
+ left_url = f"{base_url}/df_left.parquet"
+ right_url = f"{base_url}/df_right.parquet"
- source_left = ParquetSource("pq1", path=left_path)
- source_right = ParquetSource("pq2", path=right_path)
+ source_left = ParquetSource("pq1", path=left_url)
+ source_right = ParquetSource("pq2", path=right_url)
fstore.ingest(fset1, source_left)
fstore.ingest(fset2, source_right)
@@ -2052,11 +2194,13 @@ def test_as_of_join_result(self):
vec_for_spark = fstore.FeatureVector(
"vec1-spark", ["fs1-as-of.*", "fs2-as-of.*"]
)
- target = ParquetTarget("mytarget", path=self.get_remote_pq_target_path())
+ target = ParquetTarget(
+ "mytarget", path=f"{self.output_dir()}-get_offline_features"
+ )
resp = fstore.get_offline_features(
vec_for_spark,
engine="spark",
- run_config=fstore.RunConfig(local=False, kind="remote-spark"),
+ run_config=fstore.RunConfig(local=self.run_local),
spark_service=self.spark_service,
target=target,
)
From 7a308ddc313df3647541dc39d582d77b608c80ec Mon Sep 17 00:00:00 2001
From: davesh0812 <85231462+davesh0812@users.noreply.github.com>
Date: Mon, 24 Apr 2023 13:50:38 +0300
Subject: [PATCH 060/334] [Serving] Graph/Step custom error-handler - fix bug
and provide cleaner api (#3390)
---
mlrun/serving/__init__.py | 3 +-
mlrun/serving/states.py | 172 ++++++++++++++++++++++++++-----
tests/serving/test_async_flow.py | 18 ++--
tests/serving/test_flow.py | 8 +-
4 files changed, 166 insertions(+), 35 deletions(-)
diff --git a/mlrun/serving/__init__.py b/mlrun/serving/__init__.py
index 5a9f14f22f7d..24f02af98f21 100644
--- a/mlrun/serving/__init__.py
+++ b/mlrun/serving/__init__.py
@@ -21,10 +21,11 @@
"TaskStep",
"RouterStep",
"QueueStep",
+ "ErrorStep",
]
from .routers import ModelRouter, VotingEnsemble # noqa
from .server import GraphContext, GraphServer, create_graph_server # noqa
-from .states import QueueStep, RouterStep, TaskStep # noqa
+from .states import ErrorStep, QueueStep, RouterStep, TaskStep # noqa
from .v1_serving import MLModelServer, new_v1_model_server # noqa
from .v2_serving import V2ModelServer # noqa
diff --git a/mlrun/serving/states.py b/mlrun/serving/states.py
index 6e63564d2845..28b765802c48 100644
--- a/mlrun/serving/states.py
+++ b/mlrun/serving/states.py
@@ -12,7 +12,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-__all__ = ["TaskStep", "RouterStep", "RootFlowStep"]
+__all__ = ["TaskStep", "RouterStep", "RootFlowStep", "ErrorStep"]
import os
import pathlib
@@ -49,6 +49,7 @@ class StepKinds:
queue = "queue"
choice = "choice"
root = "root"
+ error_step = "error_step"
_task_step_fields = [
@@ -134,11 +135,82 @@ def after_step(self, *after, append=True):
self.after.append(name)
return self
- def error_handler(self, step_name: str = None):
- """set error handler step (on failure/raise of this step)"""
- if not step_name:
- raise MLRunInvalidArgumentError("Must specify step_name")
- self.on_error = step_name
+ def error_handler(
+ self,
+ name: str = None,
+ class_name=None,
+ handler=None,
+ before=None,
+ function=None,
+ full_event: bool = None,
+ input_path: str = None,
+ result_path: str = None,
+ **class_args,
+ ):
+ """set error handler on a step or the entire graph (to be executed on failure/raise)
+
+ When setting the error_handler on the graph object, the graph completes after the error handler execution.
+
+ example:
+ in the below example, an 'error_catcher' step is set as the error_handler of the 'raise' step:
+ in case of error/raise in 'raise' step, the handle_error will be run. after that,
+ the 'echo' step will be run.
+ graph = function.set_topology('flow', engine='async')
+ graph.to(name='raise', handler='raising_step')\
+ .error_handler(name='error_catcher', handler='handle_error', full_event=True, before='echo')
+ graph.add_step(name="echo", handler='echo', after="raise").respond()
+
+ :param name: unique name (and path) for the error handler step, default is class name
+ :param class_name: class name or step object to build the step from
+ the error handler step is derived from task step (ie no router/queue functionally)
+ :param handler: class/function handler to invoke on run/event
+ :param before: string or list of next step(s) names that will run after this step.
+ the `before` param must not specify upstream steps as it will cause a loop.
+ if `before` is not specified, the graph will complete after the error handler execution.
+ :param function: function this step should run in
+ :param full_event: this step accepts the full event (not just the body)
+ :param input_path: selects the key/path in the event to use as input to the step
+ this requires that the event body will behave like a dict, for example:
+ event: {"data": {"a": 5, "b": 7}}, input_path="data.b" means the step will
+ receive 7 as input
+ :param result_path: selects the key/path in the event to write the results to
+ this requires that the event body will behave like a dict, for example:
+ event: {"x": 5} , result_path="y" means the output of the step will be written
+ to event["y"] resulting in {"x": 5, "y": }
+ :param class_args: class init arguments
+
+ """
+ if not (class_name or handler):
+ raise MLRunInvalidArgumentError("class_name or handler must be provided")
+ if isinstance(self, RootFlowStep) and before:
+ raise MLRunInvalidArgumentError(
+ "`before` arg can't be specified for graph error handler"
+ )
+
+ name = get_name(name, class_name)
+ step = ErrorStep(
+ class_name,
+ class_args,
+ handler,
+ name=name,
+ function=function,
+ full_event=full_event,
+ input_path=input_path,
+ result_path=result_path,
+ )
+ self.on_error = name
+ before = [before] if isinstance(before, str) else before
+ step.before = before or []
+ step.base_step = self.name
+ if hasattr(self, "_parent") and self._parent:
+ # when self is a step
+ step = self._parent._steps.update(name, step)
+ step.set_parent(self._parent)
+ else:
+ # when self is the graph
+ step = self._steps.update(name, step)
+ step.set_parent(self)
+
return self
def init_object(self, context, namespace, mode="sync", reset=False, **extra_kwargs):
@@ -186,10 +258,11 @@ def _log_error(self, event, err, **kwargs):
def _call_error_handler(self, event, err, **kwargs):
"""call the error handler if exist"""
- if self._on_error_handler:
- event.error = err_to_str(err)
- event.origin_state = self.fullname
- return self._on_error_handler(event)
+ if not event.error:
+ event.error = {}
+ event.error[self.name] = err_to_str(err)
+ event.origin_state = self.fullname
+ return self._on_error_handler(event)
def path_to_step(self, path: str):
"""return step object from step relative/fullname"""
@@ -327,6 +400,7 @@ def init_object(self, context, namespace, mode="sync", reset=False, **extra_kwar
args = signature(self._handler).parameters
if args and "context" in list(args.keys()):
self._inject_context = True
+ self._set_error_handler()
return
self._class_object, self.class_name = self.get_step_class_object(
@@ -464,14 +538,23 @@ def run(self, event, *args, **kwargs):
)
event.body = _update_result_body(self.result_path, event.body, result)
except Exception as exc:
- self._log_error(event, exc)
- handled = self._call_error_handler(event, exc)
- if not handled:
+ if self._on_error_handler:
+ self._log_error(event, exc)
+ result = self._call_error_handler(event, exc)
+ event.body = _update_result_body(self.result_path, event.body, result)
+ else:
raise exc
- event.terminated = True
return event
+class ErrorStep(TaskStep):
+ """error execution step, runs a class or handler"""
+
+ kind = "error_step"
+ _dict_fields = _task_step_fields + ["before", "base_step"]
+ _default_class = ""
+
+
class RouterStep(TaskStep):
"""router step, implement routing logic for running child routes"""
@@ -824,6 +907,7 @@ def __iter__(self):
def init_object(self, context, namespace, mode="sync", reset=False, **extra_kwargs):
"""initialize graph objects and classes"""
self.context = context
+ self._insert_all_error_handlers()
self.check_and_process_graph()
for step in self._steps.values():
@@ -866,7 +950,11 @@ def has_loop(step, previous):
responders = []
for step in self._steps.values():
- if hasattr(step, "responder") and step.responder:
+ if (
+ hasattr(step, "responder")
+ and step.responder
+ and step.kind != "error_step"
+ ):
responders.append(step.name)
if step.on_error and step.on_error in start_steps:
start_steps.remove(step.on_error)
@@ -954,10 +1042,7 @@ def _build_async_flow(self):
def process_step(state, step, root):
if not state._is_local_function(self.context) or state._visited:
return
- next_steps = state.next or []
- if state.on_error:
- next_steps.append(state.on_error)
- for item in next_steps:
+ for item in state.next or []:
next_state = root[item]
if next_state.async_object:
next_step = step.to(next_state.async_object)
@@ -982,6 +1067,10 @@ def process_step(state, step, root):
# never set a step as its own error handler
if step != error_step:
step.async_object.set_recovery_step(error_step.async_object)
+ for next_step in error_step.next or []:
+ next_state = self[next_step]
+ if next_state.async_object and error_step.async_object:
+ error_step.async_object.to(next_state.async_object)
self._controller = source.run()
@@ -1062,15 +1151,22 @@ def run(self, event, *args, **kwargs):
try:
event = next_obj.run(event, *args, **kwargs)
except Exception as exc:
- self._log_error(event, exc, failed_step=next_obj.name)
- handled = self._call_error_handler(event, exc)
- if not handled:
+ if self._on_error_handler:
+ self._log_error(event, exc, failed_step=next_obj.name)
+ event.body = self._call_error_handler(event, exc)
+ event.terminated = True
+ return event
+ else:
raise exc
- event.terminated = True
- return event
if hasattr(event, "terminated") and event.terminated:
return event
+ if (
+ hasattr(event, "error")
+ and isinstance(event.error, dict)
+ and next_obj.name in event.error
+ ):
+ next_obj = self._steps[next_obj.on_error]
next = next_obj.next
if next and len(next) > 1:
raise GraphError(
@@ -1106,6 +1202,33 @@ def plot(self, filename=None, format=None, source=None, targets=None, **kw):
**kw,
)
+ def _insert_all_error_handlers(self):
+ """
+ insert all error steps to the graph
+ run after deployment
+ """
+ for name, step in self._steps.items():
+ if step.kind == "error_step":
+ self._insert_error_step(name, step)
+
+ def _insert_error_step(self, name, step):
+ """
+ insert error step to the graph
+ run after deployment
+ """
+ if not step.before and not any(
+ [step.name in other_step.after for other_step in self._steps.values()]
+ ):
+ step.responder = True
+ return
+
+ for step_name in step.before:
+ if step_name not in self._steps.keys():
+ raise MLRunInvalidArgumentError(
+ f"cant set before, there is no step named {step_name}"
+ )
+ self[step_name].after_step(name)
+
class RootFlowStep(FlowStep):
"""root flow step"""
@@ -1119,6 +1242,7 @@ class RootFlowStep(FlowStep):
"router": RouterStep,
"flow": FlowStep,
"queue": QueueStep,
+ "error_step": ErrorStep,
}
diff --git a/tests/serving/test_async_flow.py b/tests/serving/test_async_flow.py
index 8054aecee96a..09761fbfb017 100644
--- a/tests/serving/test_async_flow.py
+++ b/tests/serving/test_async_flow.py
@@ -88,11 +88,10 @@ def test_on_error():
function = mlrun.new_function("tests", kind="serving")
graph = function.set_topology("flow", engine="async")
chain = graph.to("Chain", name="s1")
- chain.to("Raiser").error_handler("catch").to("Chain", name="s3")
+ chain.to("Raiser").error_handler(
+ name="catch", class_name="EchoError", full_event=True
+ ).to("Chain", name="s3")
- graph.add_step(
- name="catch", class_name="EchoError", after=""
- ).respond().full_event = True
function.verbose = True
server = function.to_mock_server()
@@ -100,9 +99,14 @@ def test_on_error():
graph.plot(f"{results}/serving/on_error.png")
resp = server.test(body=[])
server.wait_for_completion()
- assert (
- resp["error"] and resp["origin_state"] == "Raiser"
- ), f"error wasnt caught, resp={resp}"
+ if isinstance(resp, dict):
+ assert (
+ resp["error"] and resp["origin_state"] == "Raiser"
+ ), f"error wasn't caught, resp={resp}"
+ else:
+ assert (
+ resp.error and resp.origin_state == "Raiser"
+ ), f"error wasn't caught, resp={resp}"
def test_push_error():
diff --git a/tests/serving/test_flow.py b/tests/serving/test_flow.py
index 10129df61e18..3caa895d87db 100644
--- a/tests/serving/test_flow.py
+++ b/tests/serving/test_flow.py
@@ -137,14 +137,16 @@ def test_on_error():
graph = fn.set_topology("flow", engine="sync")
graph.add_step(name="s1", class_name="Chain")
graph.add_step(name="raiser", class_name="Raiser", after="$prev").error_handler(
- "catch"
+ name="catch", class_name="EchoError", full_event=True
)
graph.add_step(name="s3", class_name="Chain", after="$prev")
- graph.add_step(name="catch", class_name="EchoError").full_event = True
server = fn.to_mock_server()
resp = server.test(body=[])
- assert resp["error"] and resp["origin_state"] == "raiser", "error wasnt caught"
+ if isinstance(resp, dict):
+ assert resp["error"] and resp["origin_state"] == "raiser", "error wasn't caught"
+ else:
+ assert resp.error and resp.origin_state == "raiser", "error wasn't caught"
def return_type(event):
From 6eef0f72d241636392904f4f4aa77b99da7ba53a Mon Sep 17 00:00:00 2001
From: Gal Topper
Date: Mon, 24 Apr 2023 20:59:25 +0800
Subject: [PATCH 061/334] [Spark] Allow ingesting to a local path (#3432)
---
mlrun/feature_store/api.py | 9 ---------
tests/system/feature_store/test_spark_engine.py | 2 +-
2 files changed, 1 insertion(+), 10 deletions(-)
diff --git a/mlrun/feature_store/api.py b/mlrun/feature_store/api.py
index 47439477dd0f..c1853b3f9a33 100644
--- a/mlrun/feature_store/api.py
+++ b/mlrun/feature_store/api.py
@@ -18,7 +18,6 @@
import warnings
from datetime import datetime
from typing import Any, Dict, List, Optional, Union
-from urllib.parse import urlparse
import pandas as pd
@@ -900,14 +899,6 @@ def _ingest_with_spark(
target.set_resource(featureset)
if featureset.spec.passthrough and target.is_offline:
continue
- if target.path and urlparse(target.path).scheme == "":
- if mlrun_context:
- mlrun_context.logger.error(
- "Paths for spark ingest must contain schema, i.e v3io, s3, az"
- )
- raise mlrun.errors.MLRunInvalidArgumentError(
- "Paths for spark ingest must contain schema, i.e v3io, s3, az"
- )
spark_options = target.get_spark_options(
key_columns, timestamp_key, overwrite
)
diff --git a/tests/system/feature_store/test_spark_engine.py b/tests/system/feature_store/test_spark_engine.py
index 81f1505d2991..dace813172bd 100644
--- a/tests/system/feature_store/test_spark_engine.py
+++ b/tests/system/feature_store/test_spark_engine.py
@@ -275,7 +275,7 @@ def test_output_subdir_path(self, url=True):
def set_targets(self, feature_set, also_in_remote=False):
dir_name = self.test_name()
if self.run_local or also_in_remote:
- target_path = f"{self.output_dir()}/{dir_name}"
+ target_path = f"{self.output_dir(url=False)}/{dir_name}"
feature_set.set_targets(
[ParquetTarget(path=target_path)], with_defaults=False
)
From ad06081aa559ac606379709fabc7dd5b6b7f3d92 Mon Sep 17 00:00:00 2001
From: Tom Tankilevitch <59158507+Tankilevitch@users.noreply.github.com>
Date: Mon, 24 Apr 2023 18:32:03 +0300
Subject: [PATCH 062/334] [CI] Add freeing up disk space and add more logs to
go integration tests (#3434)
---
.github/workflows/ci.yaml | 20 ++++++++++++++++++++
1 file changed, 20 insertions(+)
diff --git a/.github/workflows/ci.yaml b/.github/workflows/ci.yaml
index 9116e4e5523f..640fc1d29f63 100644
--- a/.github/workflows/ci.yaml
+++ b/.github/workflows/ci.yaml
@@ -30,6 +30,9 @@ on:
- master
- '[0-9]+.[0-9]+.x'
+env:
+ NAMESPACE: mlrun-integ-test
+
jobs:
lint:
name: Lint code (Python ${{ matrix.python-version }})
@@ -128,6 +131,10 @@ jobs:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
+ # since github-actions gives us 14G only, and fills it up with some garbage
+ - name: Freeing up disk space
+ run: |
+ "${GITHUB_WORKSPACE}/automation/scripts/github_workflow_free_space.sh"
- uses: manusa/actions-setup-minikube@v2.7.2
with:
minikube version: "v1.28.0"
@@ -141,6 +148,19 @@ jobs:
- name: Run GO tests
run: |
make test-go-integration-dockerized
+ - name: Output some logs in case of failure
+ if: ${{ failure() }}
+ # add set -x to print commands before executing to make logs reading easier
+ run: |
+ set -x
+ minikube ip
+ minikube logs
+ minikube kubectl -- --namespace ${NAMESPACE} get events
+ minikube kubectl -- --namespace ${NAMESPACE} logs -l app.kubernetes.io/component=api,app.kubernetes.io/name=mlrun --tail=-1
+ minikube kubectl -- --namespace ${NAMESPACE} get pods
+ minikube kubectl -- --namespace ${NAMESPACE} get pods -o yaml
+ minikube kubectl -- --namespace ${NAMESPACE} describe pods
+ set +x
migrations-tests:
name: Run Dockerized Migrations Tests
From cb08ab98ea0bfcb91a23b672fada2f5425f82ff0 Mon Sep 17 00:00:00 2001
From: Assaf Ben-Amitai
Date: Tue, 25 Apr 2023 10:43:13 +0300
Subject: [PATCH 063/334] [Requirments] bump storey to v1.3.18 (#3436)
---
requirements.txt | 2 +-
tests/test_requirements.py | 2 +-
2 files changed, 2 insertions(+), 2 deletions(-)
diff --git a/requirements.txt b/requirements.txt
index c06e99a2751a..f02ffedf59f3 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -53,7 +53,7 @@ humanfriendly~=8.2
fastapi~=0.92.0
fsspec~=2021.8.1
v3iofs~=0.1.15
-storey~=1.3.17
+storey~=1.3.18
deepdiff~=5.0
pymysql~=1.0
inflection~=0.5.0
diff --git a/tests/test_requirements.py b/tests/test_requirements.py
index 62f30907374e..a3ee595a057d 100644
--- a/tests/test_requirements.py
+++ b/tests/test_requirements.py
@@ -95,7 +95,7 @@ def test_requirement_specifiers_convention():
"kfp": {"~=1.8.0, <1.8.14"},
"botocore": {">=1.20.106,<1.20.107"},
"aiobotocore": {"~=1.4.0"},
- "storey": {"~=1.3.17"},
+ "storey": {"~=1.3.18"},
"bokeh": {"~=2.4, >=2.4.2"},
"typing-extensions": {">=3.10.0,<5"},
"sphinx": {"~=4.3.0"},
From f760105dd81b8903cdd218cadcae06b256e3d958 Mon Sep 17 00:00:00 2001
From: davesh0812 <85231462+davesh0812@users.noreply.github.com>
Date: Tue, 25 Apr 2023 10:55:47 +0300
Subject: [PATCH 064/334] [Tests] Fix tests to use preview if ingest is done
with no targets and with_default_targets=False
---
tests/system/feature_store/test_feature_store.py | 11 +++++------
1 file changed, 5 insertions(+), 6 deletions(-)
diff --git a/tests/system/feature_store/test_feature_store.py b/tests/system/feature_store/test_feature_store.py
index 0b5de34a38a5..af71566de6d8 100644
--- a/tests/system/feature_store/test_feature_store.py
+++ b/tests/system/feature_store/test_feature_store.py
@@ -2384,8 +2384,9 @@ def test_join_with_table(self):
attributes=["aug"],
inner_join=True,
)
- df = fstore.ingest(
- fset, df, targets=[], infer_options=fstore.InferOptions.default()
+ df = fstore.preview(
+ fset,
+ df,
)
assert df.to_dict() == {
"foreignkey1": {"mykey1": "AB", "mykey2": "DE"},
@@ -2428,7 +2429,7 @@ def test_directional_graph(self):
attributes=["aug"],
inner_join=True,
)
- df = fstore.ingest(fset, df, targets=[])
+ df = fstore.preview(fset, df)
assert df.to_dict() == {
"foreignkey1": {
"mykey1_1": "AB",
@@ -2748,9 +2749,7 @@ def test_map_with_state_with_table(self):
group_by_key=True,
_fn="map_with_state_test_function",
)
- df = fstore.ingest(
- fset, df, targets=[], infer_options=fstore.InferOptions.default()
- )
+ df = fstore.preview(fset, df)
assert df.to_dict() == {
"name": {"a": "a", "b": "b"},
"sum": {"a": 16, "b": 26},
From 11fee9f04e66041b9883f73dbdc61be0b4c6498b Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Thu, 27 Apr 2023 10:25:00 +0300
Subject: [PATCH 065/334] [API] Add version to healthz endpoint (#3445)
---
mlrun/api/api/endpoints/healthz.py | 7 ++++++-
1 file changed, 6 insertions(+), 1 deletion(-)
diff --git a/mlrun/api/api/endpoints/healthz.py b/mlrun/api/api/endpoints/healthz.py
index 2053075f5a45..d17280ce8757 100644
--- a/mlrun/api/api/endpoints/healthz.py
+++ b/mlrun/api/api/endpoints/healthz.py
@@ -36,4 +36,9 @@ def health():
]:
raise mlrun.errors.MLRunServiceUnavailableError()
- return {"status": "ok"}
+ return {
+ # for old `align_mlrun.sh` scripts expecting `version` in the response
+ # TODO: remove on mlrun >= 1.6.0
+ "version": mlconfig.version,
+ "status": "ok",
+ }
From 83ddd680a2f5a3fc49ed6be891d004c5b0213309 Mon Sep 17 00:00:00 2001
From: Tom Tankilevitch <59158507+Tankilevitch@users.noreply.github.com>
Date: Thu, 27 Apr 2023 12:26:14 +0300
Subject: [PATCH 066/334] [CI] Pass GitHub token to `env.yaml` of enterprise
system tests for tests relying on private repos (#3447)
---
.github/workflows/system-tests-enterprise.yml | 1 +
automation/system_test/prepare.py | 6 ++++++
2 files changed, 7 insertions(+)
diff --git a/.github/workflows/system-tests-enterprise.yml b/.github/workflows/system-tests-enterprise.yml
index 38c96ace06bf..0549710c7ea9 100644
--- a/.github/workflows/system-tests-enterprise.yml
+++ b/.github/workflows/system-tests-enterprise.yml
@@ -321,6 +321,7 @@ jobs:
"${{ secrets.LATEST_SYSTEM_TEST_PASSWORD }}" \
"${{ secrets.LATEST_SYSTEM_TEST_SLACK_WEBHOOK_URL }}" \
"${{ needs.prepare-system-tests-enterprise-ci.outputs.mlrunBranch }}"
+ "${{ secrets.SYSTEM_TEST_GITHUB_ACCESS_TOKEN }}" \
- name: Run System Tests
run: |
MLRUN_SYSTEM_TESTS_CLEAN_RESOURCES="${{ needs.prepare-system-tests-enterprise-ci.outputs.mlrunSystemTestsCleanResources }}" \
diff --git a/automation/system_test/prepare.py b/automation/system_test/prepare.py
index 6e9702b28ea2..58b3225bfab3 100644
--- a/automation/system_test/prepare.py
+++ b/automation/system_test/prepare.py
@@ -109,6 +109,9 @@ def __init__(
"MLRUN_SYSTEM_TESTS_DEFAULT_SPARK_SERVICE": spark_service,
"MLRUN_SYSTEM_TESTS_SLACK_WEBHOOK_URL": slack_webhook_url,
"MLRUN_SYSTEM_TESTS_BRANCH": branch,
+ # Setting to MLRUN_SYSTEM_TESTS_GIT_TOKEN instead of GIT_TOKEN, to not affect tests which doesn't need it
+ # (e.g. tests which use public repos, therefor doesn't need that access token)
+ "MLRUN_SYSTEM_TESTS_GIT_TOKEN": github_access_token,
}
if password:
self._env_config["V3IO_PASSWORD"] = password
@@ -729,6 +732,7 @@ def run(
help="Don't run the ci only show the commands that will be run",
)
@click.argument("branch", type=str, default=None, required=False)
+@click.argument("github-access-token", type=str, default=None, required=False)
def env(
mlrun_dbpath: str,
webapi_direct_url: str,
@@ -740,6 +744,7 @@ def env(
slack_webhook_url: str,
debug: bool,
branch: str,
+ github_access_token: str,
):
system_test_preparer = SystemTestPreparer(
mlrun_dbpath=mlrun_dbpath,
@@ -752,6 +757,7 @@ def env(
debug=debug,
slack_webhook_url=slack_webhook_url,
branch=branch,
+ github_access_token=github_access_token,
)
try:
system_test_preparer.prepare_local_env()
From b3f081f0d208ae572e9d22b84bef2d9c54a9c256 Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Thu, 27 Apr 2023 13:42:37 +0300
Subject: [PATCH 067/334] [Docs] Installation on ARM64 machines (#3443)
---
CONTRIBUTING.md | 42 ++++++++++++++++++++++++++++++++++++++++++
1 file changed, 42 insertions(+)
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index e94d21dd3ff8..90951e5d0cff 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -2,6 +2,8 @@
## Creating a development environment
+If you are working with an ARM64 machine, please see [Developing with ARM64 machines](#developing-with-arm64-machines).
+
We recommend using [pyenv](https://github.com/pyenv/pyenv#installation) to manage your python versions.
Once you have pyenv installed, you can create a new environment by running:
@@ -40,6 +42,46 @@ make install-requirements
pip install -e '.[complete]'
```
+## Developing with ARM64 machines
+
+Some mlrun dependencies are not yet available for ARM64 machines via pypi, so we need to work with conda to get the packages compiled for ARM64 platform.
+Install Anaconda from [here](https://docs.anaconda.com/free/anaconda/install/index.html) and then follow the steps below:
+
+Fork, clone and cd into the MLRun repository directory
+```shell script
+git clone git@github.com:/mlrun.git
+cd mlrun
+```
+
+Create a conda environment and activate it
+```shell script
+conda create -n mlrun python=3.9
+conda activate mlrun
+```
+
+Then, install the dependencies
+```shell script
+make install-conda-requirements
+```
+
+Run some unit tests to make sure everything works:
+```shell script
+python -m pytest ./tests/projects
+```
+
+If you encounter any error with 'charset_normalizer' for example:
+```shell script
+AttributeError: partially initialized module 'charset_normalizer' has no attribute 'md__mypyc' (most likely due to a circular import)
+```
+Run:
+```shell script
+pip install --force-reinstall charset-normalizer
+```
+Finally, install mlrun
+```shell script
+pip install -e '.[complete]'
+```
+
## Formatting
We use [black](https://github.com/psf/black) as our formatter.
From 3553014ed1420c8f44486804116ef314ddce2718 Mon Sep 17 00:00:00 2001
From: Gal Topper
Date: Thu, 27 Apr 2023 19:26:47 +0800
Subject: [PATCH 068/334] [Tests] Fix spark system tests (#3448)
---
tests/system/feature_store/test_spark_engine.py | 14 ++++++++------
1 file changed, 8 insertions(+), 6 deletions(-)
diff --git a/tests/system/feature_store/test_spark_engine.py b/tests/system/feature_store/test_spark_engine.py
index dace813172bd..6c992ec9d6d1 100644
--- a/tests/system/feature_store/test_spark_engine.py
+++ b/tests/system/feature_store/test_spark_engine.py
@@ -21,7 +21,6 @@
import fsspec
import pandas as pd
-import pyspark.sql.utils
import pytest
import v3iofs
from pandas._testing import assert_frame_equal
@@ -1301,6 +1300,13 @@ def test_different_paths_for_ingest_on_spark_engines(
fstore.ingest(fset, source=source, targets=[target])
def test_error_is_properly_propagated(self):
+ if self.run_local:
+ import pyspark.sql.utils
+
+ expected_error = pyspark.sql.utils.AnalysisException
+ else:
+ expected_error = mlrun.runtimes.utils.RunError
+
key = "patient_id"
measurements = fstore.FeatureSet(
"measurements",
@@ -1309,11 +1315,7 @@ def test_error_is_properly_propagated(self):
engine="spark",
)
source = ParquetSource("myparquet", path="wrong-path.pq")
- with pytest.raises(
- pyspark.sql.utils.AnalysisException
- if self.run_local
- else mlrun.runtimes.utils.RunError
- ):
+ with pytest.raises(expected_error):
fstore.ingest(
measurements,
source,
From 2a415c7741bc92a42607a46ce95422c1707d2844 Mon Sep 17 00:00:00 2001
From: GiladShapira94 <100074049+GiladShapira94@users.noreply.github.com>
Date: Fri, 28 Apr 2023 11:44:50 +0300
Subject: [PATCH 069/334] [Projects] Fix forwarding project subpath value to
schedule workflow (#3365)
---
mlrun/projects/pipelines.py | 4 ++++
tests/system/projects/test_project.py | 14 ++++++++++++++
2 files changed, 18 insertions(+)
diff --git a/mlrun/projects/pipelines.py b/mlrun/projects/pipelines.py
index 9dfa9214c9eb..ed8faadc1ec2 100644
--- a/mlrun/projects/pipelines.py
+++ b/mlrun/projects/pipelines.py
@@ -755,6 +755,7 @@ def _prepare_load_and_run_function(
artifact_path: str,
workflow_handler: str,
namespace: str,
+ subpath: str,
) -> typing.Tuple[mlrun.runtimes.RemoteRuntime, "mlrun.RunObject"]:
"""
Helper function for creating the runspec of the load and run function.
@@ -767,6 +768,7 @@ def _prepare_load_and_run_function(
:param artifact_path: path to store artifacts
:param workflow_handler: workflow function handler (for running workflow function directly)
:param namespace: kubernetes namespace if other than default
+ :param subpath: project subpath (within the archive)
:return:
"""
# Creating the load project and workflow running function:
@@ -792,6 +794,7 @@ def _prepare_load_and_run_function(
"engine": workflow_spec.engine,
"local": workflow_spec.run_local,
"schedule": workflow_spec.schedule,
+ "subpath": subpath,
},
handler="mlrun.projects.load_and_run",
),
@@ -840,6 +843,7 @@ def run(
artifact_path=artifact_path,
workflow_handler=workflow_handler,
namespace=namespace,
+ subpath=project.spec.subpath,
)
# The returned engine for this runner is the engine of the workflow.
diff --git a/tests/system/projects/test_project.py b/tests/system/projects/test_project.py
index c457c55ae537..132ff8ab860c 100644
--- a/tests/system/projects/test_project.py
+++ b/tests/system/projects/test_project.py
@@ -818,3 +818,17 @@ def test_remote_workflow_source(self):
def _assert_scheduled(self, project_name, schedule_str):
schedule = self._run_db.get_schedule(project_name, "main")
assert schedule.scheduled_object["schedule"] == schedule_str
+
+ def test_remote_workflow_source_with_subpath(self):
+ # Test running remote workflow when the project files are store in a relative path (the subpath)
+ project_source = "git://github.com/mlrun/system-tests.git#main"
+ project_context = "./test_subpath_remote"
+ project_name = "test-remote-workflow-source-with-subpath"
+ self.custom_project_names_to_delete.append(project_name)
+ project = mlrun.load_project(
+ context=project_context,
+ url=project_source,
+ subpath="./test_remote_workflow_subpath",
+ name=project_name,
+ )
+ project.run("main", arguments={"x": 1}, engine="remote:kfp", watch=True)
From 77932647e6ecc857ccb93d1142978f78f5c53507 Mon Sep 17 00:00:00 2001
From: GiladShapira94 <100074049+GiladShapira94@users.noreply.github.com>
Date: Fri, 28 Apr 2023 11:45:41 +0300
Subject: [PATCH 070/334] [DataStore] Allow import item from authenticated
endpoint (#3352)
---
mlrun/datastore/base.py | 20 +++++++++++++-
tests/system/datastore/test_http.py | 41 +++++++++++++++++++++++++++++
2 files changed, 60 insertions(+), 1 deletion(-)
create mode 100644 tests/system/datastore/test_http.py
diff --git a/mlrun/datastore/base.py b/mlrun/datastore/base.py
index 830e7abe66fc..a2be7d1ba10c 100644
--- a/mlrun/datastore/base.py
+++ b/mlrun/datastore/base.py
@@ -523,7 +523,12 @@ def http_upload(url, file_path, headers=None, auth=None):
class HttpStore(DataStore):
def __init__(self, parent, schema, name, endpoint="", secrets: dict = None):
super().__init__(parent, name, schema, endpoint, secrets)
+ self._https_auth_token = None
+ self._schema = schema
self.auth = None
+ self._headers = {}
+ self._enrich_https_token()
+ self._validate_https_token()
def get_filesystem(self, silent=True):
"""return fsspec file system object, if supported"""
@@ -541,9 +546,22 @@ def put(self, key, data, append=False):
raise ValueError("unimplemented")
def get(self, key, size=None, offset=0):
- data = http_get(self.url + self._join(key), None, self.auth)
+ data = http_get(self.url + self._join(key), self._headers, self.auth)
if offset:
data = data[offset:]
if size:
data = data[:size]
return data
+
+ def _enrich_https_token(self):
+ token = self._get_secret_or_env("HTTPS_AUTH_TOKEN")
+ if token:
+ self._https_auth_token = token
+ self._headers.setdefault("Authorization", f"token {token}")
+
+ def _validate_https_token(self):
+ if self._https_auth_token and self._schema in ["http"]:
+ logger.warn(
+ f"A AUTH TOKEN should not be provided while using {self._schema} "
+ f"schema as it is not secure and is not recommended."
+ )
diff --git a/tests/system/datastore/test_http.py b/tests/system/datastore/test_http.py
new file mode 100644
index 000000000000..69a9291adf7e
--- /dev/null
+++ b/tests/system/datastore/test_http.py
@@ -0,0 +1,41 @@
+# Copyright 2022 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+
+import mlrun.datastore
+from tests.system.base import TestMLRunSystem
+
+
+class TestHttpDataStore(TestMLRunSystem):
+ def test_https_auth_token_with_env(self):
+ mlrun.mlconf.hub_url = (
+ "https://raw.githubusercontent.com/mlrun/private-system-tests/"
+ )
+ os.environ["HTTPS_AUTH_TOKEN"] = os.environ["MLRUN_SYSTEM_TESTS_GIT_TOKEN"]
+ func = mlrun.import_function(
+ "hub://support_private_hub_repo/func:main",
+ secrets=None,
+ )
+ assert func.metadata.name == "func"
+
+ def test_https_auth_token_with_secrets_flag(self):
+ mlrun.mlconf.hub_url = (
+ "https://raw.githubusercontent.com/mlrun/private-system-tests/"
+ )
+ secrets = {"HTTPS_AUTH_TOKEN": os.environ["MLRUN_SYSTEM_TESTS_GIT_TOKEN"]}
+ func = mlrun.import_function(
+ "hub://support_private_hub_repo/func:main", secrets=secrets
+ )
+ assert func.metadata.name == "func"
From 2b4dc9728c853849a7ee05835149d1712f45de4c Mon Sep 17 00:00:00 2001
From: Tom Tankilevitch <59158507+Tankilevitch@users.noreply.github.com>
Date: Sat, 29 Apr 2023 11:38:51 +0300
Subject: [PATCH 071/334] [CI] Fix backslash missing in passing params (#3454)
---
.github/workflows/system-tests-enterprise.yml | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/.github/workflows/system-tests-enterprise.yml b/.github/workflows/system-tests-enterprise.yml
index 0549710c7ea9..fec56b1b9124 100644
--- a/.github/workflows/system-tests-enterprise.yml
+++ b/.github/workflows/system-tests-enterprise.yml
@@ -320,8 +320,8 @@ jobs:
"${{ secrets.LATEST_SYSTEM_TEST_SPARK_SERVICE }}" \
"${{ secrets.LATEST_SYSTEM_TEST_PASSWORD }}" \
"${{ secrets.LATEST_SYSTEM_TEST_SLACK_WEBHOOK_URL }}" \
- "${{ needs.prepare-system-tests-enterprise-ci.outputs.mlrunBranch }}"
- "${{ secrets.SYSTEM_TEST_GITHUB_ACCESS_TOKEN }}" \
+ "${{ needs.prepare-system-tests-enterprise-ci.outputs.mlrunBranch }}" \
+ "${{ secrets.SYSTEM_TEST_GITHUB_ACCESS_TOKEN }}"
- name: Run System Tests
run: |
MLRUN_SYSTEM_TESTS_CLEAN_RESOURCES="${{ needs.prepare-system-tests-enterprise-ci.outputs.mlrunSystemTestsCleanResources }}" \
From 7937ad3a579190b6482688c414a12959f806a1d6 Mon Sep 17 00:00:00 2001
From: Tom Tankilevitch <59158507+Tankilevitch@users.noreply.github.com>
Date: Sat, 29 Apr 2023 22:52:32 +0300
Subject: [PATCH 072/334] [Tests] Add tests failure handling for serving graphs
(#3456)
---
tests/serving/test_remote.py | 43 ++++++++++++++++++++++++++----------
1 file changed, 31 insertions(+), 12 deletions(-)
diff --git a/tests/serving/test_remote.py b/tests/serving/test_remote.py
index 06ffdd89681f..e8e8b804402b 100644
--- a/tests/serving/test_remote.py
+++ b/tests/serving/test_remote.py
@@ -70,18 +70,25 @@ def test_remote_step(httpserver, engine):
{"post": "ok"}
)
url = httpserver.url_for("/")
-
for params, request, expected in tests_map:
- print(f"test params: {params}")
+ print(f"test params: {params}, request: {request}, expected: {expected}")
server = _new_server(url, engine, **params)
- resp = server.test(**request)
- server.wait_for_completion()
+ try:
+ resp = server.test(**request)
+ except Exception as e:
+ raise e
+ finally:
+ server.wait_for_completion()
assert resp == expected
# test with url generated with expression (from the event)
server = _new_server(None, engine, method="GET", url_expression="event['myurl']")
- resp = server.test(body={"myurl": httpserver.url_for("/foo")})
- server.wait_for_completion()
+ try:
+ resp = server.test(body={"myurl": httpserver.url_for("/foo")})
+ except Exception as e:
+ raise e
+ finally:
+ server.wait_for_completion()
assert resp == {"foo": "ok"}
@@ -106,8 +113,12 @@ def test_remote_step_bad_status_code(httpserver, engine):
for params, request, expected in tests_map:
print(f"test params: {params}")
server = _new_server(url, engine, **params)
- resp = server.test(**request)
- server.wait_for_completion()
+ try:
+ resp = server.test(**request)
+ except Exception as e:
+ raise e
+ finally:
+ server.wait_for_completion()
assert resp == expected
# test with url generated with expression (from the event)
@@ -136,8 +147,12 @@ def test_remote_class(httpserver, engine):
).to(name="s3", handler="echo").respond()
server = function.to_mock_server()
- resp = server.test(body={"req": {"x": 5}})
- server.wait_for_completion()
+ try:
+ resp = server.test(body={"req": {"x": 5}})
+ except Exception as e:
+ raise e
+ finally:
+ server.wait_for_completion()
assert resp == {"req": {"x": 5}, "resp": {"cat": "ok"}}
@@ -225,8 +240,12 @@ def test_remote_advance(httpserver, engine):
).to(name="s3", handler="echo").respond()
server = function.to_mock_server()
- resp = server.test(body={"req": {"url": "/dog", "data": {"x": 5}}})
- server.wait_for_completion()
+ try:
+ resp = server.test(body={"req": {"url": "/dog", "data": {"x": 5}}})
+ except Exception as e:
+ raise e
+ finally:
+ server.wait_for_completion()
assert resp == {"req": {"url": "/dog", "data": {"x": 5}}, "resp": {"post": "ok"}}
From 3d194d516f102390dcbe893054abd27f8b8000fc Mon Sep 17 00:00:00 2001
From: Assaf Ben-Amitai
Date: Sun, 30 Apr 2023 09:54:34 +0300
Subject: [PATCH 073/334] [Tests] Fix test_deploy_function_with_error_handler
(#3450)
---
tests/system/runtimes/test_nuclio.py | 5 +----
1 file changed, 1 insertion(+), 4 deletions(-)
diff --git a/tests/system/runtimes/test_nuclio.py b/tests/system/runtimes/test_nuclio.py
index a8127dea6fec..9d5eae7eba16 100644
--- a/tests/system/runtimes/test_nuclio.py
+++ b/tests/system/runtimes/test_nuclio.py
@@ -48,11 +48,8 @@ def test_deploy_function_with_error_handler(self):
)
graph = function.set_topology("flow", engine="async")
-
graph.to(name="step1", handler="inc")
- graph.add_step(name="catcher", handler="catcher", full_event=True, after="")
-
- graph.error_handler("catcher")
+ graph.error_handler("catcher", handler="catcher", full_event=True)
self._logger.debug("Deploying nuclio function")
deployment = function.deploy()
From b395f51f5ff08deeb3a9ab10b7bf9be009abd3e9 Mon Sep 17 00:00:00 2001
From: Eyal Danieli
Date: Sun, 30 Apr 2023 10:12:11 +0300
Subject: [PATCH 074/334] [Model Monitoring] Support HTTP/Kafka stream and add
monitoring file target function (#3355)
---
mlrun/api/api/endpoints/functions.py | 38 ++-
mlrun/api/api/endpoints/grafana_proxy.py | 3 +-
.../crud/model_monitoring/model_endpoints.py | 64 +++-
mlrun/config.py | 71 +++++
mlrun/datastore/__init__.py | 11 +-
mlrun/datastore/sources.py | 3 +
mlrun/datastore/utils.py | 30 +-
mlrun/model_monitoring/__init__.py | 2 +
mlrun/model_monitoring/constants.py | 11 +
mlrun/model_monitoring/helpers.py | 148 +++++++---
.../model_monitoring_batch.py | 275 +++++++++---------
.../model_monitoring/stream_processing_fs.py | 220 +++++++-------
mlrun/platforms/iguazio.py | 31 ++
mlrun/projects/project.py | 15 +-
mlrun/serving/server.py | 29 +-
mlrun/utils/model_monitoring.py | 55 +++-
tests/api/api/test_functions.py | 1 +
tests/model_monitoring/test_target_path.py | 73 +++++
.../model_monitoring/test_model_monitoring.py | 102 +++++++
19 files changed, 866 insertions(+), 316 deletions(-)
create mode 100644 tests/model_monitoring/test_target_path.py
diff --git a/mlrun/api/api/endpoints/functions.py b/mlrun/api/api/endpoints/functions.py
index 53a84d99b7cb..7a9b003fafcf 100644
--- a/mlrun/api/api/endpoints/functions.py
+++ b/mlrun/api/api/endpoints/functions.py
@@ -631,26 +631,33 @@ def _build_function(
try:
if fn.spec.track_models:
logger.info("Tracking enabled, initializing model monitoring")
- _init_serving_function_stream_args(fn=fn)
- # get model monitoring access key
- model_monitoring_access_key = _process_model_monitoring_secret(
- db_session,
- fn.metadata.project,
- mlrun.model_monitoring.constants.ProjectSecretKeys.ACCESS_KEY,
- )
- # initialize model monitoring stream
- _create_model_monitoring_stream(project=fn.metadata.project)
+ # Generating model monitoring access key
+ model_monitoring_access_key = None
+ if not mlrun.mlconf.is_ce_mode():
+ model_monitoring_access_key = _process_model_monitoring_secret(
+ db_session,
+ fn.metadata.project,
+ mlrun.model_monitoring.constants.ProjectSecretKeys.ACCESS_KEY,
+ )
+ if mlrun.utils.model_monitoring.get_stream_path(
+ project=fn.metadata.project
+ ).startswith("v3io://"):
+ # Initialize model monitoring V3IO stream
+ _create_model_monitoring_stream(
+ project=fn.metadata.project,
+ function=fn,
+ )
if fn.spec.tracking_policy:
- # convert to `TrackingPolicy` object as `fn.spec.tracking_policy` is provided as a dict
+ # Convert to `TrackingPolicy` object as `fn.spec.tracking_policy` is provided as a dict
fn.spec.tracking_policy = (
mlrun.utils.model_monitoring.TrackingPolicy.from_dict(
fn.spec.tracking_policy
)
)
else:
- # initialize tracking policy with default values
+ # Initialize tracking policy with default values
fn.spec.tracking_policy = (
mlrun.utils.model_monitoring.TrackingPolicy()
)
@@ -812,9 +819,12 @@ async def _get_function_status(data, auth_info: mlrun.api.schemas.AuthInfo):
)
-def _create_model_monitoring_stream(project: str):
- stream_path = config.model_endpoint_monitoring.store_prefixes.default.format(
- project=project, kind="stream"
+def _create_model_monitoring_stream(project: str, function):
+
+ _init_serving_function_stream_args(fn=function)
+
+ stream_path = mlrun.mlconf.get_model_monitoring_file_target_path(
+ project=project, kind="events"
)
_, container, stream_path = parse_model_endpoint_store_prefix(stream_path)
diff --git a/mlrun/api/api/endpoints/grafana_proxy.py b/mlrun/api/api/endpoints/grafana_proxy.py
index 7780a19c5424..19dea291bb5f 100644
--- a/mlrun/api/api/endpoints/grafana_proxy.py
+++ b/mlrun/api/api/endpoints/grafana_proxy.py
@@ -76,7 +76,8 @@ async def grafana_proxy_model_endpoints_search(
:return: List of results. e.g. list of available project names.
"""
- mlrun.api.crud.ModelEndpoints().get_access_key(auth_info)
+ if not mlrun.mlconf.is_ce_mode():
+ mlrun.api.crud.ModelEndpoints().get_access_key(auth_info)
body = await request.json()
query_parameters = mlrun.api.crud.model_monitoring.grafana.parse_search_parameters(
body
diff --git a/mlrun/api/crud/model_monitoring/model_endpoints.py b/mlrun/api/crud/model_monitoring/model_endpoints.py
index 8eaba5cc1ed8..e50d85954776 100644
--- a/mlrun/api/crud/model_monitoring/model_endpoints.py
+++ b/mlrun/api/crud/model_monitoring/model_endpoints.py
@@ -170,8 +170,8 @@ def create_model_endpoint(
return model_endpoint
- @staticmethod
def create_monitoring_feature_set(
+ self,
model_endpoint: mlrun.api.schemas.ModelEndpoint,
model_obj: mlrun.artifacts.ModelArtifact,
db_session: sqlalchemy.orm.Session,
@@ -198,15 +198,15 @@ def create_monitoring_feature_set(
feature_set = mlrun.feature_store.FeatureSet(
f"monitoring-{serving_function_name}-{model_name}",
- entities=["endpoint_id"],
- timestamp_key="timestamp",
+ entities=[model_monitoring_constants.EventFieldType.ENDPOINT_ID],
+ timestamp_key=model_monitoring_constants.EventFieldType.TIMESTAMP,
description=f"Monitoring feature set for endpoint: {model_endpoint.spec.model}",
)
feature_set.metadata.project = model_endpoint.metadata.project
feature_set.metadata.labels = {
- "endpoint_id": model_endpoint.metadata.uid,
- "model_class": model_endpoint.spec.model_class,
+ model_monitoring_constants.EventFieldType.ENDPOINT_ID: model_endpoint.metadata.uid,
+ model_monitoring_constants.EventFieldType.MODEL_CLASS: model_endpoint.spec.model_class,
}
# Add features to the feature set according to the model object
@@ -239,10 +239,15 @@ def create_monitoring_feature_set(
# Define parquet target for this feature set
parquet_path = (
- f"v3io:///projects/{model_endpoint.metadata.project}"
- f"/model-endpoints/parquet/key={model_endpoint.metadata.uid}"
+ self._get_monitoring_parquet_path(
+ db_session=db_session, project=model_endpoint.metadata.project
+ )
+ + f"/key={model_endpoint.metadata.uid}"
+ )
+
+ parquet_target = mlrun.datastore.targets.ParquetTarget(
+ model_monitoring_constants.FileTargetKind.PARQUET, parquet_path
)
- parquet_target = mlrun.datastore.targets.ParquetTarget("parquet", parquet_path)
driver = mlrun.datastore.targets.get_target_driver(parquet_target, feature_set)
feature_set.set_targets(
@@ -262,6 +267,35 @@ def create_monitoring_feature_set(
return feature_set
+ @staticmethod
+ def _get_monitoring_parquet_path(
+ db_session: sqlalchemy.orm.Session, project: str
+ ) -> str:
+ """Getting model monitoring parquet target for the current project. The parquet target path is based on the
+ project artifact path. If project artifact path is not defined, the parquet target path will be based on MLRun
+ artifact path.
+
+ :param db_session: A session that manages the current dialog with the database. Will be used in this function
+ to get the project record from DB.
+ :param project: Project name.
+
+ :return: Monitoring parquet target path.
+ """
+
+ # Get the artifact path from the project record that was stored in the DB
+ project_obj = mlrun.api.crud.projects.Projects().get_project(
+ session=db_session, name=project
+ )
+ artifact_path = project_obj.spec.artifact_path
+ # Generate monitoring parquet path value
+ parquet_path = mlrun.mlconf.get_model_monitoring_file_target_path(
+ project=project,
+ kind=model_monitoring_constants.FileTargetKind.PARQUET,
+ target="offline",
+ artifact_path=artifact_path,
+ )
+ return parquet_path
+
@staticmethod
def _validate_length_features_and_labels(model_endpoint):
"""
@@ -366,6 +400,7 @@ def delete_model_endpoint(
model_endpoint_store = get_model_endpoint_store(
project=project,
)
+
model_endpoint_store.delete_model_endpoint(endpoint_id=endpoint_id)
logger.info("Model endpoint table cleared", endpoint_id=endpoint_id)
@@ -740,8 +775,8 @@ def delete_model_endpoints_resources(project_name: str):
# Delete model endpoints resources from databases using the model endpoint store object
endpoint_store.delete_model_endpoints_resources(endpoints)
- @staticmethod
def deploy_model_monitoring_stream_processing(
+ self,
project: str,
model_monitoring_access_key: str,
db_session: sqlalchemy.orm.Session,
@@ -782,8 +817,17 @@ def deploy_model_monitoring_stream_processing(
"Deploying model monitoring stream processing function", project=project
)
+ # Get parquet target value for model monitoring stream function
+ parquet_target = self._get_monitoring_parquet_path(
+ db_session=db_session, project=project
+ )
+
fn = mlrun.model_monitoring.helpers.initial_model_monitoring_stream_processing_function(
- project, model_monitoring_access_key, db_session, tracking_policy
+ project=project,
+ model_monitoring_access_key=model_monitoring_access_key,
+ tracking_policy=tracking_policy,
+ auth_info=auth_info,
+ parquet_target=parquet_target,
)
mlrun.api.api.endpoints.functions._build_function(
diff --git a/mlrun/config.py b/mlrun/config.py
index 8f1820c2c3f8..a32f49394e39 100644
--- a/mlrun/config.py
+++ b/mlrun/config.py
@@ -385,10 +385,19 @@
"model_endpoint_monitoring": {
"serving_stream_args": {"shard_count": 1, "retention_period_hours": 24},
"drift_thresholds": {"default": {"possible_drift": 0.5, "drift_detected": 0.7}},
+ # Store prefixes are used to handle model monitoring storing policies based on project and kind, such as events,
+ # stream, and endpoints.
"store_prefixes": {
"default": "v3io:///users/pipelines/{project}/model-endpoints/{kind}",
"user_space": "v3io:///projects/{project}/model-endpoints/{kind}",
+ "stream": "",
},
+ # Offline storage path can be either relative or a full path. This path is used for general offline data
+ # storage such as the parquet file which is generated from the monitoring stream function for the drift analysis
+ "offline_storage_path": "model-endpoints/{kind}",
+ # Default http path that points to the monitoring stream nuclio function. Will be used as a stream path
+ # when the user is working in CE environment and has not provided any stream path.
+ "default_http_sink": "http://nuclio-{project}-model-monitoring-stream.mlrun.svc.cluster.local:8080",
"batch_processing_function_branch": "master",
"parquet_batching_max_events": 10000,
# See mlrun.api.schemas.ModelEndpointStoreType for available options
@@ -937,6 +946,68 @@ def get_v3io_access_key(self):
# Get v3io access key from the environment
return os.environ.get("V3IO_ACCESS_KEY")
+ def get_model_monitoring_file_target_path(
+ self,
+ project: str = "",
+ kind: str = "",
+ target: str = "online",
+ artifact_path: str = None,
+ ) -> str:
+ """Get the full path from the configuration based on the provided project and kind.
+
+ :param project: Project name.
+ :param kind: Kind of target path (e.g. events, log_stream, endpoints, etc.)
+ :param target: Can be either online or offline. If the target is online, then we try to get a specific
+ path for the provided kind. If it doesn't exist, use the default path.
+ If the target path is offline and the offline path is already a full path in the
+ configuration, then the result will be that path as-is. If the offline path is a
+ relative path, then the result will be based on the project artifact path and the offline
+ relative path. If project artifact path wasn't provided, then we use MLRun artifact
+ path instead.
+ :param artifact_path: Optional artifact path that will be used as a relative path. If not provided, the
+ relative artifact path will be taken from the global MLRun artifact path.
+
+ :return: Full configured path for the provided kind.
+ """
+
+ if target != "offline":
+ store_prefix_dict = (
+ mlrun.mlconf.model_endpoint_monitoring.store_prefixes.to_dict()
+ )
+ if store_prefix_dict.get(kind):
+ # Target exist in store prefix and has a valid string value
+ return store_prefix_dict[kind].format(project=project)
+ return mlrun.mlconf.model_endpoint_monitoring.store_prefixes.default.format(
+ project=project, kind=kind
+ )
+
+ # Get the current offline path from the configuration
+ file_path = mlrun.mlconf.model_endpoint_monitoring.offline_storage_path.format(
+ project=project, kind=kind
+ )
+
+ # Absolute path
+ if any(value in file_path for value in ["://", ":///"]) or os.path.isabs(
+ file_path
+ ):
+ return file_path
+
+ # Relative path
+ else:
+ artifact_path = artifact_path or config.artifact_path
+ if artifact_path[-1] != "/":
+ artifact_path += "/"
+
+ return mlrun.utils.helpers.fill_artifact_path_template(
+ artifact_path=artifact_path + file_path, project=project
+ )
+
+ def is_ce_mode(self) -> bool:
+ # True if the setup is in CE environment
+ return isinstance(mlrun.mlconf.ce, mlrun.config.Config) and any(
+ ver in mlrun.mlconf.ce.mode for ver in ["lite", "full"]
+ )
+
# Global configuration
config = Config.from_dict(default_config)
diff --git a/mlrun/datastore/__init__.py b/mlrun/datastore/__init__.py
index 9833fa1495aa..ac39cf1844a8 100644
--- a/mlrun/datastore/__init__.py
+++ b/mlrun/datastore/__init__.py
@@ -33,7 +33,12 @@
import mlrun.datastore.wasbfs
-from ..platforms.iguazio import KafkaOutputStream, OutputStream, parse_path
+from ..platforms.iguazio import (
+ HTTPOutputStream,
+ KafkaOutputStream,
+ OutputStream,
+ parse_path,
+)
from ..utils import logger
from .base import DataItem
from .datastore import StoreManager, in_memory_store, uri_to_ipython
@@ -69,7 +74,7 @@ def get_in_memory_items():
def get_stream_pusher(stream_path: str, **kwargs):
- """get a stream pusher object from URL, currently only support v3io stream
+ """get a stream pusher object from URL.
common kwargs::
@@ -87,6 +92,8 @@ def get_stream_pusher(stream_path: str, **kwargs):
return KafkaOutputStream(
topic, bootstrap_servers, kwargs.get("kafka_producer_options")
)
+ elif stream_path.startswith("http://") or stream_path.startswith("https://"):
+ return HTTPOutputStream(stream_path=stream_path)
elif "://" not in stream_path:
return OutputStream(stream_path, **kwargs)
elif stream_path.startswith("v3io"):
diff --git a/mlrun/datastore/sources.py b/mlrun/datastore/sources.py
index 1dfb182cb445..5700b6bb4f98 100644
--- a/mlrun/datastore/sources.py
+++ b/mlrun/datastore/sources.py
@@ -727,6 +727,9 @@ def add_nuclio_trigger(self, function):
class HttpSource(OnlineSource):
kind = "http"
+ def __init__(self, path: str = None):
+ super().__init__(path=path)
+
def add_nuclio_trigger(self, function):
trigger_args = self.attributes.get("trigger_args")
if trigger_args:
diff --git a/mlrun/datastore/utils.py b/mlrun/datastore/utils.py
index 9fd7be42fc0e..c1b0ed0f2bee 100644
--- a/mlrun/datastore/utils.py
+++ b/mlrun/datastore/utils.py
@@ -12,7 +12,8 @@
# See the License for the specific language governing permissions and
# limitations under the License.
#
-from urllib.parse import urlparse
+import typing
+from urllib.parse import parse_qs, urlparse
def store_path_to_spark(path):
@@ -36,11 +37,32 @@ def store_path_to_spark(path):
return path
-def parse_kafka_url(url, bootstrap_servers=None):
+def parse_kafka_url(
+ url: str, bootstrap_servers: typing.List = None
+) -> typing.Tuple[str, typing.List]:
+ """Generating Kafka topic and adjusting a list of bootstrap servers.
+
+ :param url: URL path to parse using urllib.parse.urlparse.
+ :param bootstrap_servers: List of bootstrap servers for the kafka brokers.
+
+ :return: A tuple of:
+ [0] = Kafka topic value
+ [1] = List of bootstrap servers
+ """
bootstrap_servers = bootstrap_servers or []
+
+ # Parse the provided URL into six components according to the general structure of a URL
url = urlparse(url)
+
+ # Add the network location to the bootstrap servers list
if url.netloc:
bootstrap_servers = [url.netloc] + bootstrap_servers
- topic = url.path
- topic = topic.lstrip("/")
+
+ # Get the topic value from the parsed url
+ query_dict = parse_qs(url.query)
+ if "topic" in query_dict:
+ topic = query_dict["topic"][0]
+ else:
+ topic = url.path
+ topic = topic.lstrip("/")
return topic, bootstrap_servers
diff --git a/mlrun/model_monitoring/__init__.py b/mlrun/model_monitoring/__init__.py
index b8f9b449ef7e..80d3f7dacd3b 100644
--- a/mlrun/model_monitoring/__init__.py
+++ b/mlrun/model_monitoring/__init__.py
@@ -25,6 +25,7 @@
"EventKeyMetrics",
"TimeSeriesTarget",
"ModelEndpointTarget",
+ "FileTargetKind",
"ProjectSecretKeys",
"ModelMonitoringStoreKinds",
]
@@ -34,6 +35,7 @@
EventFieldType,
EventKeyMetrics,
EventLiveStats,
+ FileTargetKind,
ModelEndpointTarget,
ModelMonitoringStoreKinds,
ProjectSecretKeys,
diff --git a/mlrun/model_monitoring/constants.py b/mlrun/model_monitoring/constants.py
index c6824e571253..ef201d78e13a 100644
--- a/mlrun/model_monitoring/constants.py
+++ b/mlrun/model_monitoring/constants.py
@@ -96,8 +96,19 @@ class ModelEndpointTarget:
class ProjectSecretKeys:
ENDPOINT_STORE_CONNECTION = "MODEL_MONITORING_ENDPOINT_STORE_CONNECTION"
ACCESS_KEY = "MODEL_MONITORING_ACCESS_KEY"
+ KAFKA_BOOTSTRAP_SERVERS = "KAFKA_BOOTSTRAP_SERVERS"
+ STREAM_PATH = "STREAM_PATH"
class ModelMonitoringStoreKinds:
ENDPOINTS = "endpoints"
EVENTS = "events"
+
+
+class FileTargetKind:
+ ENDPOINTS = "endpoints"
+ EVENTS = "events"
+ STREAM = "stream"
+ PARQUET = "parquet"
+ LOG_STREAM = "log_stream"
+ DEFAULT_HTTP_SINK = "default_http_sink"
diff --git a/mlrun/model_monitoring/helpers.py b/mlrun/model_monitoring/helpers.py
index 22f0450a2856..165d5d58ccf6 100644
--- a/mlrun/model_monitoring/helpers.py
+++ b/mlrun/model_monitoring/helpers.py
@@ -13,19 +13,25 @@
# limitations under the License.
#
import pathlib
+import typing
import sqlalchemy.orm
+from fastapi import Depends
import mlrun
import mlrun.api.api.utils
import mlrun.api.crud.secrets
+import mlrun.api.schemas
import mlrun.api.utils.singletons.db
+import mlrun.api.utils.singletons.k8s
import mlrun.config
import mlrun.feature_store as fstore
import mlrun.model_monitoring.constants as model_monitoring_constants
import mlrun.model_monitoring.stream_processing_fs
import mlrun.runtimes
import mlrun.utils.helpers
+import mlrun.utils.model_monitoring
+from mlrun.api.api import deps
_CURRENT_FILE_PATH = pathlib.Path(__file__)
_STREAM_PROCESSING_FUNCTION_PATH = _CURRENT_FILE_PATH.parent / "stream_processing_fs.py"
@@ -37,16 +43,20 @@
def initial_model_monitoring_stream_processing_function(
project: str,
model_monitoring_access_key: str,
- db_session: sqlalchemy.orm.Session,
tracking_policy: mlrun.utils.model_monitoring.TrackingPolicy,
+ auth_info: mlrun.api.schemas.AuthInfo,
+ parquet_target: str,
):
"""
Initialize model monitoring stream processing function.
- :param project: project name.
- :param model_monitoring_access_key: access key to apply the model monitoring process.
- :param db_session: A session that manages the current dialog with the database.
+ :param project: Project name.
+ :param model_monitoring_access_key: Access key to apply the model monitoring process. Please note that in CE
+ deployments this parameter will be None.
:param tracking_policy: Model monitoring configurations.
+ :param auth_info: The auth info of the request.
+ :parquet_target: Path to model monitoring parquet file that will be generated by the monitoring
+ stream nuclio function.
:return: A function object from a mlrun runtime class
@@ -55,12 +65,11 @@ def initial_model_monitoring_stream_processing_function(
# Initialize Stream Processor object
stream_processor = mlrun.model_monitoring.stream_processing_fs.EventStreamProcessor(
project=project,
- model_monitoring_access_key=model_monitoring_access_key,
parquet_batching_max_events=mlrun.mlconf.model_endpoint_monitoring.parquet_batching_max_events,
+ parquet_target=parquet_target,
+ model_monitoring_access_key=model_monitoring_access_key,
)
- http_source = mlrun.datastore.sources.HttpSource()
-
# Create a new serving function for the streaming process
function = mlrun.code_to_function(
name="model-monitoring-stream",
@@ -76,32 +85,19 @@ def initial_model_monitoring_stream_processing_function(
# Set the project to the serving function
function.metadata.project = project
- # Add v3io stream trigger
- stream_path = mlrun.mlconf.model_endpoint_monitoring.store_prefixes.default.format(
- project=project, kind="stream"
- )
- function.add_v3io_stream_trigger(
- stream_path=stream_path, name="monitoring_stream_trigger"
- )
-
- # Set model monitoring access key for managing permissions
- function.set_env_from_secret(
- model_monitoring_constants.ProjectSecretKeys.ACCESS_KEY,
- mlrun.api.utils.singletons.k8s.get_k8s().get_project_secret_name(project),
- mlrun.api.crud.secrets.Secrets().generate_client_project_secret_key(
- mlrun.api.crud.secrets.SecretsClientType.model_monitoring,
- model_monitoring_constants.ProjectSecretKeys.ACCESS_KEY,
- ),
+ # Add stream triggers
+ function = _apply_stream_trigger(
+ project=project,
+ function=function,
+ model_monitoring_access_key=model_monitoring_access_key,
+ auth_info=auth_info,
)
+ # Apply feature store run configurations on the serving function
run_config = fstore.RunConfig(function=function, local=False)
function.spec.parameters = run_config.parameters
- func = http_source.add_nuclio_trigger(function)
- func.metadata.credentials.access_key = model_monitoring_access_key
- func.apply(mlrun.v3io_cred())
-
- return func
+ return function
def get_model_monitoring_batch_function(
@@ -115,7 +111,8 @@ def get_model_monitoring_batch_function(
Initialize model monitoring batch function.
:param project: project name.
- :param model_monitoring_access_key: access key to apply the model monitoring process.
+ :param model_monitoring_access_key: access key to apply the model monitoring process. Please note that in CE
+ deployments this parameter will be None.
:param db_session: A session that manages the current dialog with the database.
:param auth_info: The auth info of the request.
:param tracking_policy: Model monitoring configurations.
@@ -138,6 +135,94 @@ def get_model_monitoring_batch_function(
# Set the project to the job function
function.metadata.project = project
+ if not mlrun.mlconf.is_ce_mode():
+ function = _apply_access_key_and_mount_function(
+ project=project,
+ function=function,
+ model_monitoring_access_key=model_monitoring_access_key,
+ auth_info=auth_info,
+ )
+
+ # Enrich runtime with the required configurations
+ mlrun.api.api.utils.apply_enrichment_and_validation_on_function(function, auth_info)
+
+ return function
+
+
+def _apply_stream_trigger(
+ project: str,
+ function: mlrun.runtimes.ServingRuntime,
+ model_monitoring_access_key: str = None,
+ auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+) -> mlrun.runtimes.ServingRuntime:
+ """Adding stream source for the nuclio serving function. By default, the function has HTTP stream trigger along
+ with another supported stream source that can be either Kafka or V3IO, depends on the stream path schema that is
+ defined under mlrun.mlconf.model_endpoint_monitoring.store_prefixes. Note that if no valid stream path has been
+ provided then the function will have a single HTTP stream source.
+
+ :param project: Project name.
+ :param function: The serving function object that will be applied with the stream trigger.
+ :param model_monitoring_access_key: Access key to apply the model monitoring stream function when the stream is
+ schema is V3IO.
+ :param auth_info: The auth info of the request.
+
+ :return: ServingRuntime object with stream trigger.
+ """
+
+ # Get the stream path from the configuration
+ # stream_path = mlrun.mlconf.get_file_target_path(project=project, kind="stream", target="stream")
+ stream_path = mlrun.utils.model_monitoring.get_stream_path(project=project)
+
+ if stream_path.startswith("kafka://"):
+
+ topic, brokers = mlrun.datastore.utils.parse_kafka_url(url=stream_path)
+ # Generate Kafka stream source
+ stream_source = mlrun.datastore.sources.KafkaSource(
+ brokers=brokers,
+ topics=[topic],
+ )
+ function = stream_source.add_nuclio_trigger(function)
+
+ if not mlrun.mlconf.is_ce_mode():
+ function = _apply_access_key_and_mount_function(
+ project=project,
+ function=function,
+ model_monitoring_access_key=model_monitoring_access_key,
+ auth_info=auth_info,
+ )
+ if stream_path.startswith("v3io://"):
+ # Generate V3IO stream trigger
+ function.add_v3io_stream_trigger(
+ stream_path=stream_path, name="monitoring_stream_trigger"
+ )
+ # Add the default HTTP source
+ http_source = mlrun.datastore.sources.HttpSource()
+ function = http_source.add_nuclio_trigger(function)
+
+ return function
+
+
+def _apply_access_key_and_mount_function(
+ project: str,
+ function: typing.Union[
+ mlrun.runtimes.KubejobRuntime, mlrun.runtimes.ServingRuntime
+ ],
+ model_monitoring_access_key: str,
+ auth_info: mlrun.api.schemas.AuthInfo,
+) -> typing.Union[mlrun.runtimes.KubejobRuntime, mlrun.runtimes.ServingRuntime]:
+ """Applying model monitoring access key on the provided function when using V3IO path. In addition, this method
+ mount the V3IO path for the provided function to configure the access to the system files.
+
+ :param project: Project name.
+ :param function: Model monitoring function object that will be filled with the access key and
+ the access to the system files.
+ :param model_monitoring_access_key: Access key to apply the model monitoring stream function when the stream is
+ schema is V3IO.
+ :param auth_info: The auth info of the request.
+
+ :return: function runtime object with access key and access to system files.
+ """
+
# Set model monitoring access key for managing permissions
function.set_env_from_secret(
model_monitoring_constants.ProjectSecretKeys.ACCESS_KEY,
@@ -147,11 +232,8 @@ def get_model_monitoring_batch_function(
model_monitoring_constants.ProjectSecretKeys.ACCESS_KEY,
),
)
-
- function.apply(mlrun.mount_v3io())
-
- # Needs to be a member of the project and have access to project data path
function.metadata.credentials.access_key = model_monitoring_access_key
+ function.apply(mlrun.mount_v3io())
# Ensure that the auth env vars are set
mlrun.api.api.utils.ensure_function_has_auth_set(function, auth_info)
diff --git a/mlrun/model_monitoring/model_monitoring_batch.py b/mlrun/model_monitoring/model_monitoring_batch.py
index 92da5d3fec13..ce07bab90f12 100644
--- a/mlrun/model_monitoring/model_monitoring_batch.py
+++ b/mlrun/model_monitoring/model_monitoring_batch.py
@@ -495,8 +495,6 @@ def __init__(
self,
context: mlrun.run.MLClientCtx,
project: str,
- model_monitoring_access_key: str,
- v3io_access_key: str,
):
"""
@@ -504,60 +502,16 @@ def __init__(
:param context: An MLRun context.
:param project: Project name.
- :param model_monitoring_access_key: Access key to apply the model monitoring process.
- :param v3io_access_key: Token key for v3io.
"""
self.context = context
self.project = project
- self.v3io_access_key = v3io_access_key
- self.model_monitoring_access_key = (
- model_monitoring_access_key or v3io_access_key
- )
-
# Initialize virtual drift object
self.virtual_drift = VirtualDrift(inf_capping=10)
- # Define the required paths for the project objects.
- # Note that the kv table, tsdb, and the input stream paths are located at the default location
- # while the parquet path is located at the user-space location
- template = mlrun.mlconf.model_endpoint_monitoring.store_prefixes.default
- kv_path = template.format(project=self.project, kind="endpoints")
- (
- _,
- self.kv_container,
- self.kv_path,
- ) = mlrun.utils.model_monitoring.parse_model_endpoint_store_prefix(kv_path)
- tsdb_path = template.format(project=project, kind="events")
- (
- _,
- self.tsdb_container,
- self.tsdb_path,
- ) = mlrun.utils.model_monitoring.parse_model_endpoint_store_prefix(tsdb_path)
- stream_path = template.format(project=self.project, kind="log_stream")
- (
- _,
- self.stream_container,
- self.stream_path,
- ) = mlrun.utils.model_monitoring.parse_model_endpoint_store_prefix(stream_path)
- self.parquet_path = (
- mlrun.mlconf.model_endpoint_monitoring.store_prefixes.user_space.format(
- project=project, kind="parquet"
- )
- )
-
logger.info(
"Initializing BatchProcessor",
project=project,
- model_monitoring_access_key_initalized=bool(model_monitoring_access_key),
- v3io_access_key_initialized=bool(v3io_access_key),
- parquet_path=self.parquet_path,
- kv_container=self.kv_container,
- kv_path=self.kv_path,
- tsdb_container=self.tsdb_container,
- tsdb_path=self.tsdb_path,
- stream_container=self.stream_container,
- stream_path=self.stream_path,
)
# Get drift thresholds from the model monitoring configuration
@@ -569,21 +523,15 @@ def __init__(
)
# Get a runtime database
- # self.db = mlrun.get_run_db()
+
self.db = mlrun.model_monitoring.stores.get_model_endpoint_store(
project=project
)
- # Get the frames clients based on the v3io configuration
- # it will be used later for writing the results into the tsdb
- self.v3io = mlrun.utils.v3io_clients.get_v3io_client(
- access_key=self.v3io_access_key
- )
- self.frames = mlrun.utils.v3io_clients.get_frames_client(
- address=mlrun.mlconf.v3io_framesd,
- container=self.tsdb_container,
- token=self.v3io_access_key,
- )
+ if not mlrun.mlconf.is_ce_mode():
+ # TODO: Once there is a time series DB alternative in a non-CE deployment, we need to update this if
+ # statement to be applied only for V3IO TSDB
+ self._initialize_v3io_configurations()
# If an error occurs, it will be raised using the following argument
self.exception = None
@@ -593,27 +541,68 @@ def __init__(
mlrun.model_monitoring.EventFieldType.BATCH_INTERVALS_DICT
]
- # TODO: This will be removed in 1.2.0 once the job params can be parsed with different types
+ # TODO: This will be removed in 1.5.0 once the job params can be parsed with different types
# Convert batch dict string into a dictionary
if isinstance(self.batch_dict, str):
self._parse_batch_dict_str()
+ def _initialize_v3io_configurations(self):
+ self.v3io_access_key = os.environ.get("V3IO_ACCESS_KEY")
+ self.model_monitoring_access_key = (
+ os.environ.get("MODEL_MONITORING_ACCESS_KEY") or self.v3io_access_key
+ )
+
+ # Define the required paths for the project objects
+ tsdb_path = mlrun.mlconf.get_model_monitoring_file_target_path(
+ project=self.project, kind=mlrun.model_monitoring.FileTargetKind.EVENTS
+ )
+ (
+ _,
+ self.tsdb_container,
+ self.tsdb_path,
+ ) = mlrun.utils.model_monitoring.parse_model_endpoint_store_prefix(tsdb_path)
+ # stream_path = template.format(project=self.project, kind="log_stream")
+ stream_path = mlrun.mlconf.get_model_monitoring_file_target_path(
+ project=self.project,
+ kind=mlrun.model_monitoring.FileTargetKind.LOG_STREAM,
+ )
+ (
+ _,
+ self.stream_container,
+ self.stream_path,
+ ) = mlrun.utils.model_monitoring.parse_model_endpoint_store_prefix(stream_path)
+
+ # Get the frames clients based on the v3io configuration
+ # it will be used later for writing the results into the tsdb
+ self.v3io = mlrun.utils.v3io_clients.get_v3io_client(
+ access_key=self.v3io_access_key
+ )
+ self.frames = mlrun.utils.v3io_clients.get_frames_client(
+ address=mlrun.mlconf.v3io_framesd,
+ container=self.tsdb_container,
+ token=self.v3io_access_key,
+ )
+
def post_init(self):
"""
Preprocess of the batch processing.
"""
- # create v3io stream based on the input stream
- response = self.v3io.create_stream(
- container=self.stream_container,
- path=self.stream_path,
- shard_count=1,
- raise_for_status=v3io.dataplane.RaiseForStatus.never,
- access_key=self.v3io_access_key,
- )
+ if not mlrun.mlconf.is_ce_mode():
+ # Create v3io stream based on the input stream
+ response = self.v3io.create_stream(
+ container=self.stream_container,
+ path=self.stream_path,
+ shard_count=1,
+ raise_for_status=v3io.dataplane.RaiseForStatus.never,
+ access_key=self.v3io_access_key,
+ )
- if not (response.status_code == 400 and "ResourceInUse" in str(response.body)):
- response.raise_for_status([409, 204, 403])
+ if not (
+ response.status_code == 400 and "ResourceInUse" in str(response.body)
+ ):
+ response.raise_for_status([409, 204, 403])
+ pass
def run(self):
"""
@@ -665,13 +654,13 @@ def update_drift_metrics(self, endpoint: dict):
)
# Getting batch interval start time and end time
- start_time, end_time = self.get_interval_range()
+ start_time, end_time = self._get_interval_range()
try:
df = m_fs.to_dataframe(
start_time=start_time,
end_time=end_time,
- time_column="timestamp",
+ time_column=mlrun.model_monitoring.EventFieldType.TIMESTAMP,
)
if len(df) == 0:
@@ -704,18 +693,19 @@ def update_drift_metrics(self, endpoint: dict):
feature_names = [
feature_name["name"] for feature_name in m_fs.spec.features.to_dict()
]
+
# Create DataFrame based on the input features
stats_columns = [
- "timestamp",
+ mlrun.model_monitoring.EventFieldType.TIMESTAMP,
*feature_names,
]
+
# Add label names if provided
if endpoint[mlrun.model_monitoring.EventFieldType.LABEL_NAMES]:
labels = endpoint[mlrun.model_monitoring.EventFieldType.LABEL_NAMES]
if isinstance(labels, str):
labels = json.loads(labels)
stats_columns.extend(labels)
-
named_features_df = df[stats_columns].copy()
# Infer feature set stats and schema
@@ -729,7 +719,7 @@ def update_drift_metrics(self, endpoint: dict):
m_fs.save()
# Get the timestamp of the latest request:
- timestamp = df["timestamp"].iloc[-1]
+ timestamp = df[mlrun.model_monitoring.EventFieldType.TIMESTAMP].iloc[-1]
# Get the feature stats from the model endpoint for reference data
feature_stats = json.loads(
@@ -779,30 +769,6 @@ def update_drift_metrics(self, endpoint: dict):
drift_measure=drift_measure,
)
- # If drift was detected, add the results to the input stream
- if (
- drift_status == DriftStatus.POSSIBLE_DRIFT
- or drift_status == DriftStatus.DRIFT_DETECTED
- ):
- self.v3io.stream.put_records(
- container=self.stream_container,
- stream_path=self.stream_path,
- records=[
- {
- "data": json.dumps(
- {
- "endpoint_id": endpoint[
- mlrun.model_monitoring.EventFieldType.UID
- ],
- "drift_status": drift_status.value,
- "drift_measure": drift_measure,
- "drift_per_feature": {**drift_result},
- }
- )
- }
- ],
- )
-
attributes = {
"current_stats": json.dumps(current_stats),
"drift_measures": json.dumps(drift_result),
@@ -814,46 +780,27 @@ def update_drift_metrics(self, endpoint: dict):
attributes=attributes,
)
- # Update the results in tsdb:
- tsdb_drift_measures = {
- "endpoint_id": endpoint[mlrun.model_monitoring.EventFieldType.UID],
- "timestamp": pd.to_datetime(
- timestamp,
- format=mlrun.model_monitoring.EventFieldType.TIME_FORMAT,
- ),
- "record_type": "drift_measures",
- "tvd_mean": drift_result["tvd_mean"],
- "kld_mean": drift_result["kld_mean"],
- "hellinger_mean": drift_result["hellinger_mean"],
- }
-
- try:
- self.frames.write(
- backend="tsdb",
- table=self.tsdb_path,
- dfs=pd.DataFrame.from_dict([tsdb_drift_measures]),
- index_cols=["timestamp", "endpoint_id", "record_type"],
+ if not mlrun.mlconf.is_ce_mode():
+ # Update drift results in TSDB
+ self._update_drift_in_input_stream(
+ endpoint_id=endpoint[mlrun.model_monitoring.EventFieldType.UID],
+ drift_status=drift_status,
+ drift_measure=drift_measure,
+ drift_result=drift_result,
+ timestamp=timestamp,
)
- except v3io_frames.errors.Error as err:
- logger.warn(
- "Could not write drift measures to TSDB",
- err=err,
- tsdb_path=self.tsdb_path,
- endpoint=endpoint[mlrun.model_monitoring.EventFieldType.UID],
+ logger.info(
+ "Done updating drift measures",
+ endpoint_id=endpoint[mlrun.model_monitoring.EventFieldType.UID],
)
- logger.info(
- "Done updating drift measures",
- endpoint_id=endpoint[mlrun.model_monitoring.EventFieldType.UID],
- )
-
except Exception as e:
logger.error(
f"Exception for endpoint {endpoint[mlrun.model_monitoring.EventFieldType.UID]}"
)
self.exception = e
- def get_interval_range(self) -> Tuple[datetime.datetime, datetime.datetime]:
+ def _get_interval_range(self) -> Tuple[datetime.datetime, datetime.datetime]:
"""Getting batch interval time range"""
minutes, hours, days = (
self.batch_dict[mlrun.model_monitoring.EventFieldType.MINUTES],
@@ -878,15 +825,79 @@ def _parse_batch_dict_str(self):
pair_list = pair.split(":")
self.batch_dict[pair_list[0]] = float(pair_list[1])
+ def _update_drift_in_input_stream(
+ self,
+ endpoint_id: str,
+ drift_status: DriftStatus,
+ drift_measure: float,
+ drift_result: Dict[str, Dict[str, Any]],
+ timestamp: pd._libs.tslibs.timestamps.Timestamp,
+ ):
+ """Update drift results in input stream.
+
+ :param endpoint_id: The unique id of the model endpoint.
+ :param drift_status: Drift status result. Possible values can be found under DriftStatus enum class.
+ :param drift_measure: The drift result (float) based on the mean of the Total Variance Distance and the
+ Hellinger distance.
+ :param drift_result: A dictionary that includes the drift results for each feature.
+ :param timestamp: Pandas Timestamp value.
+
+ """
+
+ if (
+ drift_status == DriftStatus.POSSIBLE_DRIFT
+ or drift_status == DriftStatus.DRIFT_DETECTED
+ ):
+ self.v3io.stream.put_records(
+ container=self.stream_container,
+ stream_path=self.stream_path,
+ records=[
+ {
+ "data": json.dumps(
+ {
+ "endpoint_id": endpoint_id,
+ "drift_status": drift_status.value,
+ "drift_measure": drift_measure,
+ "drift_per_feature": {**drift_result},
+ }
+ )
+ }
+ ],
+ )
+
+ # Update the results in tsdb:
+ tsdb_drift_measures = {
+ "endpoint_id": endpoint_id,
+ "timestamp": pd.to_datetime(
+ timestamp,
+ format=mlrun.model_monitoring.EventFieldType.TIME_FORMAT,
+ ),
+ "record_type": "drift_measures",
+ "tvd_mean": drift_result["tvd_mean"],
+ "kld_mean": drift_result["kld_mean"],
+ "hellinger_mean": drift_result["hellinger_mean"],
+ }
+
+ try:
+ self.frames.write(
+ backend="tsdb",
+ table=self.tsdb_path,
+ dfs=pd.DataFrame.from_dict([tsdb_drift_measures]),
+ index_cols=["timestamp", "endpoint_id", "record_type"],
+ )
+ except v3io_frames.errors.Error as err:
+ logger.warn(
+ "Could not write drift measures to TSDB",
+ err=err,
+ tsdb_path=self.tsdb_path,
+ endpoint=endpoint_id,
+ )
+
def handler(context: mlrun.run.MLClientCtx):
batch_processor = BatchProcessor(
context=context,
project=context.project,
- model_monitoring_access_key=os.environ.get(
- mlrun.model_monitoring.ProjectSecretKeys.ACCESS_KEY
- ),
- v3io_access_key=os.environ.get("V3IO_ACCESS_KEY"),
)
batch_processor.post_init()
batch_processor.run()
diff --git a/mlrun/model_monitoring/stream_processing_fs.py b/mlrun/model_monitoring/stream_processing_fs.py
index 46209659d4bc..13b265900aa1 100644
--- a/mlrun/model_monitoring/stream_processing_fs.py
+++ b/mlrun/model_monitoring/stream_processing_fs.py
@@ -32,6 +32,7 @@
EventFieldType,
EventKeyMetrics,
EventLiveStats,
+ FileTargetKind,
ModelEndpointTarget,
ProjectSecretKeys,
)
@@ -45,30 +46,54 @@ def __init__(
self,
project: str,
parquet_batching_max_events: int,
+ parquet_target: str,
sample_window: int = 10,
- tsdb_batching_max_events: int = 10,
- tsdb_batching_timeout_secs: int = 60 * 5, # Default 5 minutes
parquet_batching_timeout_secs: int = 30 * 60, # Default 30 minutes
aggregate_count_windows: typing.Optional[typing.List[str]] = None,
aggregate_count_period: str = "30s",
aggregate_avg_windows: typing.Optional[typing.List[str]] = None,
aggregate_avg_period: str = "30s",
- v3io_access_key: typing.Optional[str] = None,
- v3io_framesd: typing.Optional[str] = None,
- v3io_api: typing.Optional[str] = None,
model_monitoring_access_key: str = None,
):
+ # General configurations, mainly used for the storey steps in the future serving graph
self.project = project
self.sample_window = sample_window
- self.tsdb_batching_max_events = tsdb_batching_max_events
- self.tsdb_batching_timeout_secs = tsdb_batching_timeout_secs
- self.parquet_batching_max_events = parquet_batching_max_events
- self.parquet_batching_timeout_secs = parquet_batching_timeout_secs
self.aggregate_count_windows = aggregate_count_windows or ["5m", "1h"]
self.aggregate_count_period = aggregate_count_period
self.aggregate_avg_windows = aggregate_avg_windows or ["5m", "1h"]
self.aggregate_avg_period = aggregate_avg_period
+ # Parquet path and configurations
+ self.parquet_path = parquet_target
+ self.parquet_batching_max_events = parquet_batching_max_events
+ self.parquet_batching_timeout_secs = parquet_batching_timeout_secs
+
+ self.model_endpoint_store_target = (
+ mlrun.mlconf.model_endpoint_monitoring.store_type
+ )
+
+ logger.info(
+ "Initializing model monitoring event stream processor",
+ parquet_path=self.parquet_path,
+ parquet_batching_max_events=self.parquet_batching_max_events,
+ )
+
+ self.storage_options = None
+ if not mlrun.mlconf.is_ce_mode():
+ self._initialize_v3io_configurations(
+ model_monitoring_access_key=model_monitoring_access_key
+ )
+
+ def _initialize_v3io_configurations(
+ self,
+ tsdb_batching_max_events: int = 10,
+ tsdb_batching_timeout_secs: int = 60 * 5, # Default 5 minutes
+ v3io_access_key: typing.Optional[str] = None,
+ v3io_framesd: typing.Optional[str] = None,
+ v3io_api: typing.Optional[str] = None,
+ model_monitoring_access_key: str = None,
+ ):
+ # Get the V3IO configurations
self.v3io_framesd = v3io_framesd or mlrun.mlconf.v3io_framesd
self.v3io_api = v3io_api or mlrun.mlconf.v3io_api
@@ -81,48 +106,30 @@ def __init__(
self.storage_options = dict(
v3io_access_key=self.model_monitoring_access_key, v3io_api=self.v3io_api
)
- self.model_endpoint_store_target = (
- mlrun.mlconf.model_endpoint_monitoring.store_type
- )
- template = mlrun.mlconf.model_endpoint_monitoring.store_prefixes.default
-
- kv_path = template.format(project=project, kind="endpoints")
+ # KV path
+ kv_path = mlrun.mlconf.get_model_monitoring_file_target_path(
+ project=self.project, kind=FileTargetKind.ENDPOINTS
+ )
(
_,
self.kv_container,
self.kv_path,
) = mlrun.utils.model_monitoring.parse_model_endpoint_store_prefix(kv_path)
- tsdb_path = template.format(project=project, kind="events")
+ # TSDB path and configurations
+ tsdb_path = mlrun.mlconf.get_model_monitoring_file_target_path(
+ project=self.project, kind=FileTargetKind.EVENTS
+ )
(
_,
self.tsdb_container,
self.tsdb_path,
) = mlrun.utils.model_monitoring.parse_model_endpoint_store_prefix(tsdb_path)
- self.tsdb_path = f"{self.tsdb_container}/{self.tsdb_path}"
-
- self.parquet_path = (
- mlrun.mlconf.model_endpoint_monitoring.store_prefixes.user_space.format(
- project=project, kind="parquet"
- )
- )
- logger.info(
- "Initializing model monitoring event stream processor",
- parquet_batching_max_events=self.parquet_batching_max_events,
- v3io_access_key=self.v3io_access_key,
- model_monitoring_access_key=self.model_monitoring_access_key,
- default_store_prefix=mlrun.mlconf.model_endpoint_monitoring.store_prefixes.default,
- user_space_store_prefix=mlrun.mlconf.model_endpoint_monitoring.store_prefixes.user_space,
- v3io_api=self.v3io_api,
- v3io_framesd=self.v3io_framesd,
- kv_container=self.kv_container,
- kv_path=self.kv_path,
- tsdb_container=self.tsdb_container,
- tsdb_path=self.tsdb_path,
- parquet_path=self.parquet_path,
- )
+ self.tsdb_path = f"{self.tsdb_container}/{self.tsdb_path}"
+ self.tsdb_batching_max_events = tsdb_batching_max_events
+ self.tsdb_batching_timeout_secs = tsdb_batching_timeout_secs
def apply_monitoring_serving_graph(self, fn):
"""
@@ -144,8 +151,9 @@ def apply_monitoring_serving_graph(self, fn):
endpoint_features (Prediction and feature names and values), and custom_metrics (user-defined metrics).
This data is also being used by the monitoring dashboards in grafana.
3. Parquet (steps 19-20): This Parquet file includes the required data for the model monitoring batch job
- that run every hour by default. The parquet target can be found under
- v3io:///projects/{project}/model-endpoints/.
+ that run every hour by default. If defined, the parquet target path can be found under
+ mlrun.mlconf.model_endpoint_monitoring.offline. Otherwise, the default parquet path is under
+ mlrun.mlconf.model_endpoint_monitoring.user_space.
:param fn: A serving function.
"""
@@ -209,7 +217,6 @@ def apply_storey_aggregations():
after="MapFeatureNames",
step_name="Aggregates",
table=".",
- v3io_access_key=self.v3io_access_key,
)
# Step 5.2 - Calculate average latency time for each window (5 min and 1 hour by default)
graph.add_step(
@@ -226,7 +233,6 @@ def apply_storey_aggregations():
name=EventFieldType.LATENCY,
after=EventFieldType.PREDICTIONS,
table=".",
- v3io_access_key=self.v3io_access_key,
)
apply_storey_aggregations()
@@ -239,7 +245,6 @@ def apply_storey_sample_window():
after=EventFieldType.LATENCY,
window_size=self.sample_window,
key=EventFieldType.ENDPOINT_ID,
- v3io_access_key=self.v3io_access_key,
)
apply_storey_sample_window()
@@ -275,7 +280,6 @@ def apply_infer_schema():
"InferSchema",
name="InferSchema",
after="UpdateEndpoint",
- v3io_access_key=self.v3io_access_key,
v3io_framesd=self.v3io_framesd,
container=self.kv_container,
table=self.kv_path,
@@ -284,76 +288,78 @@ def apply_infer_schema():
if self.model_endpoint_store_target == ModelEndpointTarget.V3IO_NOSQL:
apply_infer_schema()
- # Steps 11-18 - TSDB branch
- # Step 11 - Before writing data to TSDB, create dictionary of 2-3 dictionaries that contains
- # stats and details about the events
- def apply_process_before_tsdb():
- graph.add_step(
- "ProcessBeforeTSDB", name="ProcessBeforeTSDB", after="sample"
- )
+ # Steps 11-18 - TSDB branch (not supported in CE environment at the moment)
- apply_process_before_tsdb()
+ if not mlrun.mlconf.is_ce_mode():
+ # Step 11 - Before writing data to TSDB, create dictionary of 2-3 dictionaries that contains
+ # stats and details about the events
+ def apply_process_before_tsdb():
+ graph.add_step(
+ "ProcessBeforeTSDB", name="ProcessBeforeTSDB", after="sample"
+ )
- # Steps 12-18: - Unpacked keys from each dictionary and write to TSDB target
- def apply_filter_and_unpacked_keys(name, keys):
- graph.add_step(
- "FilterAndUnpackKeys",
- name=name,
- after="ProcessBeforeTSDB",
- keys=[keys],
- )
+ apply_process_before_tsdb()
- def apply_tsdb_target(name, after):
- graph.add_step(
- "storey.TSDBTarget",
- name=name,
- after=after,
- path=self.tsdb_path,
- rate="10/m",
- time_col=EventFieldType.TIMESTAMP,
- container=self.tsdb_container,
- access_key=self.v3io_access_key,
- v3io_frames=self.v3io_framesd,
- infer_columns_from_data=True,
- index_cols=[
- EventFieldType.ENDPOINT_ID,
- EventFieldType.RECORD_TYPE,
- ],
- max_events=self.tsdb_batching_max_events,
- flush_after_seconds=self.tsdb_batching_timeout_secs,
- key=EventFieldType.ENDPOINT_ID,
- )
+ # Steps 12-18: - Unpacked keys from each dictionary and write to TSDB target
+ def apply_filter_and_unpacked_keys(name, keys):
+ graph.add_step(
+ "FilterAndUnpackKeys",
+ name=name,
+ after="ProcessBeforeTSDB",
+ keys=[keys],
+ )
- # Steps 12-13 - unpacked base_metrics dictionary
- apply_filter_and_unpacked_keys(
- name="FilterAndUnpackKeys1",
- keys=EventKeyMetrics.BASE_METRICS,
- )
- apply_tsdb_target(name="tsdb1", after="FilterAndUnpackKeys1")
+ def apply_tsdb_target(name, after):
+ graph.add_step(
+ "storey.TSDBTarget",
+ name=name,
+ after=after,
+ path=self.tsdb_path,
+ rate="10/m",
+ time_col=EventFieldType.TIMESTAMP,
+ container=self.tsdb_container,
+ access_key=self.v3io_access_key,
+ v3io_frames=self.v3io_framesd,
+ infer_columns_from_data=True,
+ index_cols=[
+ EventFieldType.ENDPOINT_ID,
+ EventFieldType.RECORD_TYPE,
+ ],
+ max_events=self.tsdb_batching_max_events,
+ flush_after_seconds=self.tsdb_batching_timeout_secs,
+ key=EventFieldType.ENDPOINT_ID,
+ )
- # Steps 14-15 - unpacked endpoint_features dictionary
- apply_filter_and_unpacked_keys(
- name="FilterAndUnpackKeys2",
- keys=EventKeyMetrics.ENDPOINT_FEATURES,
- )
- apply_tsdb_target(name="tsdb2", after="FilterAndUnpackKeys2")
+ # Steps 12-13 - unpacked base_metrics dictionary
+ apply_filter_and_unpacked_keys(
+ name="FilterAndUnpackKeys1",
+ keys=EventKeyMetrics.BASE_METRICS,
+ )
+ apply_tsdb_target(name="tsdb1", after="FilterAndUnpackKeys1")
- # Steps 16-18 - unpacked custom_metrics dictionary. In addition, use storey.Filter remove none values
- apply_filter_and_unpacked_keys(
- name="FilterAndUnpackKeys3",
- keys=EventKeyMetrics.CUSTOM_METRICS,
- )
+ # Steps 14-15 - unpacked endpoint_features dictionary
+ apply_filter_and_unpacked_keys(
+ name="FilterAndUnpackKeys2",
+ keys=EventKeyMetrics.ENDPOINT_FEATURES,
+ )
+ apply_tsdb_target(name="tsdb2", after="FilterAndUnpackKeys2")
- def apply_storey_filter():
- graph.add_step(
- "storey.Filter",
- "FilterNotNone",
- after="FilterAndUnpackKeys3",
- _fn="(event is not None)",
+ # Steps 16-18 - unpacked custom_metrics dictionary. In addition, use storey.Filter remove none values
+ apply_filter_and_unpacked_keys(
+ name="FilterAndUnpackKeys3",
+ keys=EventKeyMetrics.CUSTOM_METRICS,
)
- apply_storey_filter()
- apply_tsdb_target(name="tsdb3", after="FilterNotNone")
+ def apply_storey_filter():
+ graph.add_step(
+ "storey.Filter",
+ "FilterNotNone",
+ after="FilterAndUnpackKeys3",
+ _fn="(event is not None)",
+ )
+
+ apply_storey_filter()
+ apply_tsdb_target(name="tsdb3", after="FilterNotNone")
# Steps 19-20 - Parquet branch
# Step 19 - Filter and validate different keys before writing the data to Parquet target
@@ -762,7 +768,6 @@ def resume_state(self, endpoint_id):
if endpoint_id not in self.endpoints:
logger.info("Trying to resume state", endpoint_id=endpoint_id)
-
endpoint_record = get_endpoint_record(
project=self.project,
endpoint_id=endpoint_id,
@@ -1035,7 +1040,6 @@ def do(self, event: typing.Dict):
class InferSchema(mlrun.feature_store.steps.MapClass):
def __init__(
self,
- v3io_access_key: str,
v3io_framesd: str,
container: str,
table: str,
@@ -1055,7 +1059,6 @@ def __init__(
"""
super().__init__(**kwargs)
self.container = container
- self.v3io_access_key = v3io_access_key
self.v3io_framesd = v3io_framesd
self.table = table
self.keys = set()
@@ -1067,7 +1070,6 @@ def do(self, event: typing.Dict):
self.keys.update(key_set)
# Apply infer_schema on the kv table for generating the schema file
mlrun.utils.v3io_clients.get_frames_client(
- token=self.v3io_access_key,
container=self.container,
address=self.v3io_framesd,
).execute(backend="kv", table=self.table, command="infer_schema")
diff --git a/mlrun/platforms/iguazio.py b/mlrun/platforms/iguazio.py
index f3c52fea83fa..2194819fe66f 100644
--- a/mlrun/platforms/iguazio.py
+++ b/mlrun/platforms/iguazio.py
@@ -403,6 +403,37 @@ def dump_record(rec):
)
+class HTTPOutputStream:
+ """HTTP output source that usually used for CE mode and debugging process"""
+
+ def __init__(self, stream_path: str):
+ self._stream_path = stream_path
+
+ def push(self, data):
+ def dump_record(rec):
+ if isinstance(rec, bytes):
+ return rec
+
+ if not isinstance(rec, str):
+ rec = dict_to_json(rec)
+
+ return rec.encode("UTF-8")
+
+ if not isinstance(data, list):
+ data = [data]
+
+ for record in data:
+
+ # Convert the new record to the required format
+ serialized_record = dump_record(record)
+ response = requests.post(self._stream_path, data=serialized_record)
+ if not response:
+ raise mlrun.errors.MLRunInvalidArgumentError(
+ f"API call failed push a new record through {self._stream_path}"
+ f"status {response.status_code}: {response.reason}"
+ )
+
+
class KafkaOutputStream:
def __init__(
self,
diff --git a/mlrun/projects/project.py b/mlrun/projects/project.py
index 044f246018ee..130ac691d290 100644
--- a/mlrun/projects/project.py
+++ b/mlrun/projects/project.py
@@ -2143,13 +2143,17 @@ def export(self, filepath=None, include_files: str = None):
remove(tmp_path)
def set_model_monitoring_credentials(
- self, access_key: str = None, endpoint_store_connection: str = None
+ self,
+ access_key: str = None,
+ endpoint_store_connection: str = None,
+ stream_path: str = None,
):
"""Set the credentials that will be used by the project's model monitoring
infrastructure functions.
:param access_key: Model Monitoring access key for managing user permissions
:param endpoint_store_connection: Endpoint store connection string
+ :param stream_path: Path to the model monitoring stream
"""
secrets_dict = {}
@@ -2163,6 +2167,15 @@ def set_model_monitoring_credentials(
model_monitoring_constants.ProjectSecretKeys.ENDPOINT_STORE_CONNECTION
] = endpoint_store_connection
+ if stream_path:
+ if stream_path.startswith("kafka://") and "?topic" in stream_path:
+ raise mlrun.errors.MLRunInvalidArgumentError(
+ "Custom kafka topic is not allowed"
+ )
+ secrets_dict[
+ model_monitoring_constants.ProjectSecretKeys.STREAM_PATH
+ ] = stream_path
+
self.set_secrets(
secrets=secrets_dict,
provider=mlrun.api.schemas.SecretProviderName.kubernetes,
diff --git a/mlrun/serving/server.py b/mlrun/serving/server.py
index b5280638fbfe..49b64dbfb36b 100644
--- a/mlrun/serving/server.py
+++ b/mlrun/serving/server.py
@@ -23,8 +23,10 @@
from typing import Optional, Union
import mlrun
+import mlrun.utils.model_monitoring
from mlrun.config import config
from mlrun.errors import err_to_str
+from mlrun.model_monitoring import FileTargetKind
from mlrun.secrets import SecretsStore
from ..datastore import get_stream_pusher
@@ -37,32 +39,41 @@
class _StreamContext:
- def __init__(self, enabled, parameters, function_uri):
+ """Handles the stream context for the events stream process. Includes the configuration for the output stream
+ that will be used for pushing the events from the nuclio model serving function"""
+
+ def __init__(self, enabled: bool, parameters: dict, function_uri: str):
+
+ """
+ Initialize _StreamContext object.
+ :param enabled: A boolean indication for applying the stream context
+ :param parameters: Dictionary of optional parameters, such as `log_stream` and `stream_args`. Note that these
+ parameters might be relevant to the output source such as `kafka_bootstrap_servers` if
+ the output source is from type Kafka.
+ :param function_uri: Full value of the function uri, usually it's /
+ """
+
self.enabled = False
self.hostname = socket.gethostname()
self.function_uri = function_uri
self.output_stream = None
self.stream_uri = None
+ log_stream = parameters.get(FileTargetKind.LOG_STREAM, "")
- log_stream = parameters.get("log_stream", "")
- stream_uri = config.model_endpoint_monitoring.store_prefixes.default
-
- if ((enabled and stream_uri) or log_stream) and function_uri:
+ if (enabled or log_stream) and function_uri:
self.enabled = True
-
project, _, _, _ = parse_versioned_object_uri(
function_uri, config.default_project
)
- stream_uri = stream_uri.format(project=project, kind="stream")
+ stream_uri = mlrun.utils.model_monitoring.get_stream_path(project=project)
if log_stream:
+ # Update the stream path to the log stream value
stream_uri = log_stream.format(project=project)
stream_args = parameters.get("stream_args", {})
- self.stream_uri = stream_uri
-
self.output_stream = get_stream_pusher(stream_uri, **stream_args)
diff --git a/mlrun/utils/model_monitoring.py b/mlrun/utils/model_monitoring.py
index 999e92541241..5b121d6dd721 100644
--- a/mlrun/utils/model_monitoring.py
+++ b/mlrun/utils/model_monitoring.py
@@ -156,6 +156,55 @@ def get_connection_string(project: str = None):
)
+def get_stream_path(project: str = None):
+ # TODO: This function (as well as other methods in this file) includes both client and server side code. We will
+ # need to refactor and adjust this file in the future.
+ """Get stream path from the project secret. If wasn't set, take it from the system configurations"""
+
+ if is_running_as_api():
+
+ # Running on API server side
+ import mlrun.api.crud.secrets
+ import mlrun.api.schemas
+
+ stream_uri = mlrun.api.crud.secrets.Secrets().get_project_secret(
+ project=project,
+ provider=mlrun.api.schemas.secret.SecretProviderName.kubernetes,
+ allow_secrets_from_k8s=True,
+ secret_key=model_monitoring_constants.ProjectSecretKeys.STREAM_PATH,
+ ) or mlrun.mlconf.get_model_monitoring_file_target_path(
+ project=project,
+ kind=model_monitoring_constants.FileTargetKind.STREAM,
+ target="online",
+ )
+
+ else:
+
+ import mlrun
+
+ stream_uri = mlrun.get_secret_or_env(
+ model_monitoring_constants.ProjectSecretKeys.STREAM_PATH
+ ) or mlrun.mlconf.get_model_monitoring_file_target_path(
+ project=project,
+ kind=model_monitoring_constants.FileTargetKind.STREAM,
+ target="online",
+ )
+
+ if stream_uri.startswith("kafka://"):
+ if "?topic" in stream_uri:
+ raise mlrun.errors.MLRunInvalidArgumentError(
+ "Custom kafka topic is not allowed"
+ )
+ # Add topic to stream kafka uri
+ stream_uri += f"?topic=monitoring_stream_{project}"
+
+ elif stream_uri.startswith("v3io://") and mlrun.mlconf.is_ce_mode():
+ # V3IO is not supported in CE mode, generating a default http stream path
+ stream_uri = mlrun.mlconf.model_endpoint_monitoring.default_http_sink
+
+ return stream_uri
+
+
def validate_errors_and_metrics(endpoint: dict):
"""
Replace default null values for `error_count` and `metrics` for users that logged a model endpoint before 1.3.0
@@ -171,7 +220,11 @@ def validate_errors_and_metrics(endpoint: dict):
)
# Validate default value for `error_count`
- if endpoint[model_monitoring_constants.EventFieldType.ERROR_COUNT] == "null":
+ # For backwards compatibility reasons, we validate that the model endpoint includes the `error_count` key
+ if (
+ model_monitoring_constants.EventFieldType.ERROR_COUNT in endpoint
+ and endpoint[model_monitoring_constants.EventFieldType.ERROR_COUNT] == "null"
+ ):
endpoint[model_monitoring_constants.EventFieldType.ERROR_COUNT] = "0"
# Validate default value for `metrics`
diff --git a/tests/api/api/test_functions.py b/tests/api/api/test_functions.py
index 1d65ae7c9fab..9cc0266b7c3a 100644
--- a/tests/api/api/test_functions.py
+++ b/tests/api/api/test_functions.py
@@ -296,6 +296,7 @@ def test_tracking_on_serving(
],
mlrun.api.crud: ["ModelEndpoints"],
nuclio.deploy: ["deploy_config"],
+ mlrun.utils.model_monitoring: ["get_stream_path"],
}
for package in functions_to_monkeypatch:
diff --git a/tests/model_monitoring/test_target_path.py b/tests/model_monitoring/test_target_path.py
new file mode 100644
index 000000000000..097afc9d57bc
--- /dev/null
+++ b/tests/model_monitoring/test_target_path.py
@@ -0,0 +1,73 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import os
+from unittest import mock
+
+import mlrun.config
+import mlrun.utils.model_monitoring
+
+TEST_PROJECT = "test-model-endpoints"
+
+
+@mock.patch.dict(os.environ, {"MLRUN_ARTIFACT_PATH": "s3://some-bucket/"}, clear=True)
+def test_get_file_target_path():
+
+ # offline target with relative path
+ offline_parquet_relative = mlrun.mlconf.get_model_monitoring_file_target_path(
+ project=TEST_PROJECT,
+ kind="parquet",
+ target="offline",
+ artifact_path=os.environ["MLRUN_ARTIFACT_PATH"],
+ )
+ assert (
+ offline_parquet_relative
+ == os.environ["MLRUN_ARTIFACT_PATH"] + "model-endpoints/parquet"
+ )
+
+ # online target
+ online_target = mlrun.mlconf.get_model_monitoring_file_target_path(
+ project=TEST_PROJECT, kind="some_kind", target="online"
+ )
+ assert (
+ online_target
+ == f"v3io:///users/pipelines/{TEST_PROJECT}/model-endpoints/some_kind"
+ )
+
+ # offline target with absolute path
+ mlrun.mlconf.model_endpoint_monitoring.offline_storage_path = (
+ "schema://projects/test-path"
+ )
+ offline_parquet_abs = mlrun.mlconf.get_model_monitoring_file_target_path(
+ project=TEST_PROJECT, kind="parquet", target="offline"
+ )
+ assert (
+ offline_parquet_abs + f"/{TEST_PROJECT}/parquet"
+ == f"schema://projects/test-path/{TEST_PROJECT}/parquet"
+ )
+
+
+def test_get_stream_path():
+ # default stream path
+ stream_path = mlrun.utils.model_monitoring.get_stream_path(project=TEST_PROJECT)
+ assert (
+ stream_path == f"v3io:///users/pipelines/{TEST_PROJECT}/model-endpoints/stream"
+ )
+
+ # kafka stream path from env
+ os.environ["STREAM_PATH"] = "kafka://some_kafka_bootstrap_servers:8080"
+ stream_path = mlrun.utils.model_monitoring.get_stream_path(project=TEST_PROJECT)
+ assert (
+ stream_path
+ == f"kafka://some_kafka_bootstrap_servers:8080?topic=monitoring_stream_{TEST_PROJECT}"
+ )
diff --git a/tests/system/model_monitoring/test_model_monitoring.py b/tests/system/model_monitoring/test_model_monitoring.py
index 16b9d1be63fc..a927f304f5ca 100644
--- a/tests/system/model_monitoring/test_model_monitoring.py
+++ b/tests/system/model_monitoring/test_model_monitoring.py
@@ -693,3 +693,105 @@ def _check_monitoring_building_state(self, base_runtime):
# Check if model monitoring stream function is ready
stat = mlrun.get_run_db().get_builder_status(base_runtime)
assert base_runtime.status.state == "ready", stat
+
+
+@TestMLRunSystem.skip_test_if_env_not_configured
+@pytest.mark.enterprise
+class TestModelMonitoringKafka(TestMLRunSystem):
+ """Deploy a basic iris model configured with kafka stream"""
+
+ brokers = (
+ os.environ["MLRUN_SYSTEM_TESTS_KAFKA_BROKERS"]
+ if "MLRUN_SYSTEM_TESTS_KAFKA_BROKERS" in os.environ
+ and os.environ["MLRUN_SYSTEM_TESTS_KAFKA_BROKERS"]
+ else None
+ )
+ project_name = "pr-kafka-model-monitoring"
+
+ @pytest.mark.timeout(300)
+ @pytest.mark.skipif(
+ not brokers, reason="MLRUN_SYSTEM_TESTS_KAFKA_BROKERS not defined"
+ )
+ def test_model_monitoring_with_kafka_stream(self):
+ project = mlrun.get_run_db().get_project(self.project_name)
+
+ iris = load_iris()
+ train_set = pd.DataFrame(
+ iris["data"],
+ columns=[
+ "sepal_length_cm",
+ "sepal_width_cm",
+ "petal_length_cm",
+ "petal_width_cm",
+ ],
+ )
+
+ # Import the serving function from the function hub
+ serving_fn = mlrun.import_function(
+ "hub://v2_model_server", project=self.project_name
+ ).apply(mlrun.auto_mount())
+
+ model_name = "sklearn_RandomForestClassifier"
+
+ # Upload the model through the projects API so that it is available to the serving function
+ project.log_model(
+ model_name,
+ model_dir=os.path.relpath(self.assets_path),
+ model_file="model.pkl",
+ training_set=train_set,
+ artifact_path=f"v3io:///projects/{project.metadata.name}",
+ )
+ # Add the model to the serving function's routing spec
+ serving_fn.add_model(
+ model_name,
+ model_path=project.get_artifact_uri(
+ key=model_name, category="model", tag="latest"
+ ),
+ )
+
+ project.set_model_monitoring_credentials(stream_path=f"kafka://{self.brokers}")
+
+ # enable model monitoring
+ serving_fn.set_tracking()
+ # Deploy the function
+ serving_fn.deploy()
+
+ monitoring_stream_fn = project.get_function("model-monitoring-stream")
+
+ function_config = monitoring_stream_fn.spec.config
+
+ # Validate kakfa stream trigger configurations
+ assert function_config["spec.triggers.kafka"]
+ assert (
+ function_config["spec.triggers.kafka"]["attributes"]["topics"][0]
+ == f"monitoring_stream_{self.project_name}"
+ )
+ assert (
+ function_config["spec.triggers.kafka"]["attributes"]["brokers"][0]
+ == self.brokers
+ )
+
+ import kafka
+
+ # Validate that the topic exist as expected
+ consumer = kafka.KafkaConsumer(bootstrap_servers=[self.brokers])
+ topics = consumer.topics()
+ assert f"monitoring_stream_{self.project_name}" in topics
+
+ # Simulating Requests
+ iris_data = iris["data"].tolist()
+
+ for i in range(100):
+ data_point = choice(iris_data)
+ serving_fn.invoke(
+ f"v2/models/{model_name}/infer", json.dumps({"inputs": [data_point]})
+ )
+ sleep(uniform(0.02, 0.03))
+
+ # Validate that the model endpoint metrics were updated as indication for the sanity of the flow
+ model_endpoint = mlrun.get_run_db().list_model_endpoints(
+ project=self.project_name
+ )[0]
+
+ assert model_endpoint.status.metrics["generic"]["latency_avg_5m"] > 0
+ assert model_endpoint.status.metrics["generic"]["predictions_count_5m"] > 0
From 8d9b7e5ac0364ceb88bcd98acb394a67f908fea3 Mon Sep 17 00:00:00 2001
From: TomerShor <90552140+TomerShor@users.noreply.github.com>
Date: Sun, 30 Apr 2023 13:32:44 +0300
Subject: [PATCH 075/334] [Runtimes] Remove option to deploy Nuclio function
straight from client (#3453)
---
mlrun/runtimes/function.py | 87 ++++++++++++-----------------------
tests/serving/test_serving.py | 28 +++++++++++
2 files changed, 58 insertions(+), 57 deletions(-)
diff --git a/mlrun/runtimes/function.py b/mlrun/runtimes/function.py
index 0be66a3a786a..d3c7d8bfd4a6 100644
--- a/mlrun/runtimes/function.py
+++ b/mlrun/runtimes/function.py
@@ -569,66 +569,39 @@ def deploy(
if tag:
self.metadata.tag = tag
- save_record = False
- if not dashboard:
- # Attempt auto-mounting, before sending to remote build
- self.try_auto_mount_based_on_config()
- self._fill_credentials()
- db = self._get_db()
- logger.info("Starting remote function deploy")
- data = db.remote_builder(self, False, builder_env=builder_env)
- self.status = data["data"].get("status")
- self._update_credentials_from_remote_build(data["data"])
-
- # when a function is deployed, we wait for it to be ready by default
- # this also means that the function object will be updated with the function status
- self._wait_for_function_deployment(db, verbose=verbose)
-
- # NOTE: on older mlrun versions & nuclio versions, function are exposed via NodePort
- # now, functions can be not exposed (using service type ClusterIP) and hence
- # for BC we first try to populate the external invocation url, and then
- # if not exists, take the internal invocation url
- if self.status.external_invocation_urls:
- self.spec.command = f"http://{self.status.external_invocation_urls[0]}"
- save_record = True
- elif self.status.internal_invocation_urls:
- self.spec.command = f"http://{self.status.internal_invocation_urls[0]}"
- save_record = True
- elif self.status.address:
- self.spec.command = f"http://{self.status.address}"
- save_record = True
-
- else:
-
+ if dashboard:
warnings.warn(
- "'dashboard' is deprecated in 1.3.0, and will be removed in 1.5.0, "
- "Keep 'dashboard' value empty to allow auto-detection by MLRun API.",
- # TODO: Remove in 1.5.0
- FutureWarning,
+ "'dashboard' parameter is no longer supported on client side, "
+ "it is being configured through the MLRun API.",
)
- self.save(versioned=False)
- self._ensure_run_db()
- internal_invocation_urls, external_invocation_urls = deploy_nuclio_function(
- self,
- dashboard=dashboard,
- watch=True,
- auth_info=auth_info,
- )
- self.status.internal_invocation_urls = internal_invocation_urls
- self.status.external_invocation_urls = external_invocation_urls
-
- # save the (first) function external invocation url
- # this is made for backwards compatability because the user, at this point, may
- # work remotely and need the external invocation url on the spec.command
- # TODO: when using `ClusterIP`, this block might not fulfilled
- # as long as function doesnt have ingresses
- if self.status.external_invocation_urls:
- address = self.status.external_invocation_urls[0]
- self.spec.command = f"http://{address}"
- self.status.state = "ready"
- self.status.address = address
- save_record = True
+ save_record = False
+ # Attempt auto-mounting, before sending to remote build
+ self.try_auto_mount_based_on_config()
+ self._fill_credentials()
+ db = self._get_db()
+ logger.info("Starting remote function deploy")
+ data = db.remote_builder(self, False, builder_env=builder_env)
+ self.status = data["data"].get("status")
+ self._update_credentials_from_remote_build(data["data"])
+
+ # when a function is deployed, we wait for it to be ready by default
+ # this also means that the function object will be updated with the function status
+ self._wait_for_function_deployment(db, verbose=verbose)
+
+ # NOTE: on older mlrun versions & nuclio versions, function are exposed via NodePort
+ # now, functions can be not exposed (using service type ClusterIP) and hence
+ # for BC we first try to populate the external invocation url, and then
+ # if not exists, take the internal invocation url
+ if self.status.external_invocation_urls:
+ self.spec.command = f"http://{self.status.external_invocation_urls[0]}"
+ save_record = True
+ elif self.status.internal_invocation_urls:
+ self.spec.command = f"http://{self.status.internal_invocation_urls[0]}"
+ save_record = True
+ elif self.status.address:
+ self.spec.command = f"http://{self.status.address}"
+ save_record = True
logger.info(
"successfully deployed function",
diff --git a/tests/serving/test_serving.py b/tests/serving/test_serving.py
index a71a7ff7c078..3adbffe963ff 100644
--- a/tests/serving/test_serving.py
+++ b/tests/serving/test_serving.py
@@ -16,6 +16,7 @@
import os
import pathlib
import time
+import unittest.mock
import pandas as pd
import pytest
@@ -711,3 +712,30 @@ def test_mock_invoke():
# return config valued
mlrun.mlconf.mock_nuclio_deployment = mock_nuclio_config
+
+
+def test_deploy_with_dashboard_argument():
+ fn = mlrun.new_function("tests", kind="serving")
+ fn.add_model("my", ".", class_name=ModelTestingClass(multiplier=100))
+ db_instance = fn._get_db()
+ db_instance.remote_builder = unittest.mock.Mock(
+ return_value={
+ "data": {
+ "metadata": {
+ "name": "test",
+ },
+ "status": {
+ "state": "ready",
+ "external_invocation_urls": ["http://test-url.com"],
+ },
+ },
+ },
+ )
+ db_instance.get_builder_status = unittest.mock.Mock(
+ return_value=(None, None),
+ )
+
+ mlrun.deploy_function(fn, dashboard="bad-address")
+
+ # test that the remote builder was called even with dashboard argument
+ assert db_instance.remote_builder.call_count == 1
From c55501fe7964aa80221a7ad54a4b2af2b344c0c3 Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Sun, 30 Apr 2023 18:21:55 +0300
Subject: [PATCH 076/334] [Project] Fix running pipelines with local code
(#3460)
---
mlrun/model.py | 4 +--
mlrun/projects/pipelines.py | 8 +++++-
mlrun/projects/project.py | 12 ++++++---
tests/integration/sdk_api/run/test_main.py | 4 +--
.../projects/assets/handler_workflow.py | 22 ++++++++++++++++
tests/system/projects/test_project.py | 26 +++++++++++++++++++
6 files changed, 67 insertions(+), 9 deletions(-)
create mode 100644 tests/system/projects/assets/handler_workflow.py
diff --git a/mlrun/model.py b/mlrun/model.py
index 7838d507407d..98ce4379b84e 100644
--- a/mlrun/model.py
+++ b/mlrun/model.py
@@ -371,8 +371,8 @@ def source(self, source):
or source in [".", "./"]
):
raise mlrun.errors.MLRunInvalidArgumentError(
- "source must be a compressed (tar.gz / zip) file, a git repo, "
- "a file path or in the project's context (.)"
+ f"source ({source}) must be a compressed (tar.gz / zip) file, a git repo, "
+ f"a file path or in the project's context (.)"
)
self._source = source
diff --git a/mlrun/projects/pipelines.py b/mlrun/projects/pipelines.py
index ed8faadc1ec2..76516ea024aa 100644
--- a/mlrun/projects/pipelines.py
+++ b/mlrun/projects/pipelines.py
@@ -116,7 +116,13 @@ def get_source_file(self, context=""):
self._tmp_path = workflow_path = workflow_fh.name
else:
workflow_path = self.path or ""
- if context and not workflow_path.startswith("/"):
+ if (
+ context
+ and not workflow_path.startswith("/")
+ # since the user may provide a path the includes the context,
+ # we need to make sure we don't add it twice
+ and not workflow_path.startswith(context)
+ ):
workflow_path = os.path.join(context, workflow_path)
return workflow_path
diff --git a/mlrun/projects/project.py b/mlrun/projects/project.py
index 130ac691d290..e1a1565047b9 100644
--- a/mlrun/projects/project.py
+++ b/mlrun/projects/project.py
@@ -585,8 +585,6 @@ def source(self) -> str:
if url:
self._source = url
- if self._source in [".", "./"]:
- return path.abspath(self.context)
return self._source
@source.setter
@@ -1044,8 +1042,14 @@ def set_workflow(
if not workflow_path:
raise ValueError("valid workflow_path must be specified")
if embed:
- if self.spec.context and not workflow_path.startswith("/"):
- workflow_path = path.join(self.spec.context, workflow_path)
+ if (
+ self.context
+ and not workflow_path.startswith("/")
+ # since the user may provide a path the includes the context,
+ # we need to make sure we don't add it twice
+ and not workflow_path.startswith(self.context)
+ ):
+ workflow_path = path.join(self.context, workflow_path)
with open(workflow_path, "r") as fp:
txt = fp.read()
workflow = {"name": name, "code": txt}
diff --git a/tests/integration/sdk_api/run/test_main.py b/tests/integration/sdk_api/run/test_main.py
index 3b02a0bd3150..50917128f811 100644
--- a/tests/integration/sdk_api/run/test_main.py
+++ b/tests/integration/sdk_api/run/test_main.py
@@ -349,8 +349,8 @@ def test_main_local_source(self):
with pytest.raises(Exception) as e:
self._exec_run("./handler.py", args.split(), "test_main_local_source")
assert (
- "source must be a compressed (tar.gz / zip) file, a git repo, a file path or in the project's context (.)"
- in str(e.value)
+ f"source ({examples_path}) must be a compressed (tar.gz / zip) file, "
+ f"a git repo, a file path or in the project's context (.)" in str(e.value)
)
def test_main_run_archive_subdir(self):
diff --git a/tests/system/projects/assets/handler_workflow.py b/tests/system/projects/assets/handler_workflow.py
new file mode 100644
index 000000000000..0464d2c5b10d
--- /dev/null
+++ b/tests/system/projects/assets/handler_workflow.py
@@ -0,0 +1,22 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+from kfp import dsl
+
+funcs = {}
+
+
+@dsl.pipeline(name="Demo training pipeline", description="Tests simple handler")
+def job_pipeline():
+ funcs["my-func"].as_step()
diff --git a/tests/system/projects/test_project.py b/tests/system/projects/test_project.py
index 132ff8ab860c..4f9688ee88ce 100644
--- a/tests/system/projects/test_project.py
+++ b/tests/system/projects/test_project.py
@@ -511,6 +511,32 @@ def test_remote_from_archive(self):
assert run.state == mlrun.run.RunStatuses.succeeded, "pipeline failed"
assert run.run_id, "workflow's run id failed to fetch"
+ def test_kfp_from_local_code(self):
+ name = "kfp-from-local-code"
+ self.custom_project_names_to_delete.append(name)
+ project = mlrun.get_or_create_project(name, user_project=True, context="./")
+
+ handler_fn = project.set_function(
+ func="./assets/handler.py",
+ handler="my_func",
+ name="my-func",
+ kind="job",
+ image="mlrun/mlrun",
+ )
+ project.build_function(handler_fn)
+
+ project.set_workflow(
+ "main", "./assets/handler_workflow.py", handler="job_pipeline"
+ )
+ project.save()
+
+ run = project.run(
+ "main",
+ watch=True,
+ )
+ assert run.state == mlrun.run.RunStatuses.succeeded, "pipeline failed"
+ assert run.run_id, "workflow's run id failed to fetch"
+
def test_local_cli(self):
# load project from git
name = "lclclipipe"
From bd82117fd43744ae38a9aa1a73072628f32df199 Mon Sep 17 00:00:00 2001
From: Tom Tankilevitch <59158507+Tankilevitch@users.noreply.github.com>
Date: Mon, 1 May 2023 01:05:27 +0300
Subject: [PATCH 077/334] [Serving] Fix passing MLRun event headers with
underscore in RemoteStep (#3457)
---
.importlinter | 32 ++++++++++++++++++++++++++++++++
Makefile | 9 +++++++--
dev-requirements.txt | 1 +
mlrun/common/__init__.py | 14 ++++++++++++++
mlrun/serving/server.py | 23 ++++++++++++++++++-----
mlrun/serving/utils.py | 10 ++++++++--
6 files changed, 80 insertions(+), 9 deletions(-)
create mode 100644 .importlinter
create mode 100644 mlrun/common/__init__.py
diff --git a/.importlinter b/.importlinter
new file mode 100644
index 000000000000..275a80e20e35
--- /dev/null
+++ b/.importlinter
@@ -0,0 +1,32 @@
+[importlinter]
+root_package=mlrun
+include_external_packages=True
+
+
+[importlinter:contract:1]
+name=common modules shouldn't import other mlrun utilities
+type=forbidden
+source_modules=
+ mlrun.common
+
+forbidden_modules=
+ mlrun.api
+ mlrun.artifacts
+ mlrun.data_types
+ mlrun.datastore
+ mlrun.db
+ mlrun.feature_store
+ mlrun.frameworks
+ mlrun.mlutils
+ mlrun.model_monitoring
+ mlrun.platforms
+ mlrun.projects
+ mlrun.runtimes
+ mlrun.serving
+ mlrun.utils
+ mlrun.builder
+ mlrun.config
+ mlrun.errors
+ mlrun.lists
+ mlrun.model
+ mlrun.run
diff --git a/Makefile b/Makefile
index 5c7a9c048182..ae530f708189 100644
--- a/Makefile
+++ b/Makefile
@@ -533,7 +533,7 @@ test: clean ## Run mlrun tests
--ignore=tests/system \
--ignore=tests/rundb/test_httpdb.py \
-rf \
- tests
+ tests/serving/test_remote.py::test_remote_step
.PHONY: test-integration-dockerized
@@ -682,8 +682,13 @@ fmt: ## Format the code (using black and isort)
python -m black .
python -m isort .
+.PHONY: lint-imports
+lint-imports: ## making sure imports dependencies are aligned
+ @echo "Running import linter"
+ lint-imports
+
.PHONY: lint
-lint: flake8 fmt-check ## Run lint on the code
+lint: flake8 fmt-check lint-imports ## Run lint on the code
.PHONY: fmt-check
fmt-check: ## Format and check the code (using black)
diff --git a/dev-requirements.txt b/dev-requirements.txt
index 7adb9f2868c2..b2a80acdff47 100644
--- a/dev-requirements.txt
+++ b/dev-requirements.txt
@@ -20,3 +20,4 @@ scikit-learn~=1.0
lightgbm~=3.0; platform_machine != 'arm64'
xgboost~=1.1
sqlalchemy_utils~=0.39.0
+import-linter~=1.8
\ No newline at end of file
diff --git a/mlrun/common/__init__.py b/mlrun/common/__init__.py
new file mode 100644
index 000000000000..b3085be1eb56
--- /dev/null
+++ b/mlrun/common/__init__.py
@@ -0,0 +1,14 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
diff --git a/mlrun/serving/server.py b/mlrun/serving/server.py
index 49b64dbfb36b..98d376eec195 100644
--- a/mlrun/serving/server.py
+++ b/mlrun/serving/server.py
@@ -35,7 +35,12 @@
from ..model import ModelObj
from ..utils import get_caller_globals, parse_versioned_object_uri
from .states import RootFlowStep, RouterStep, get_function, graph_root_setter
-from .utils import event_id_key, event_path_key
+from .utils import (
+ event_id_key,
+ event_path_key,
+ legacy_event_id_key,
+ legacy_event_path_key,
+)
class _StreamContext:
@@ -251,10 +256,18 @@ def run(self, event, context=None, get_body=False, extra_args=None):
context = context or server_context
event.content_type = event.content_type or self.default_content_type or ""
if event.headers:
- if event_id_key in event.headers:
- event.id = event.headers.get(event_id_key)
- if event_path_key in event.headers:
- event.path = event.headers.get(event_path_key)
+ # TODO: remove old event id and path keys in 1.6.0
+ if event_id_key in event.headers or legacy_event_id_key in event.headers:
+ event.id = event.headers.get(event_id_key) or event.headers.get(
+ legacy_event_id_key
+ )
+ if (
+ event_path_key in event.headers
+ or legacy_event_path_key in event.headers
+ ):
+ event.path = event.headers.get(event_path_key) or event.headers.get(
+ legacy_event_path_key
+ )
if isinstance(event.body, (str, bytes)) and (
not event.content_type or event.content_type in ["json", "application/json"]
diff --git a/mlrun/serving/utils.py b/mlrun/serving/utils.py
index 6f4917f79fca..ee8b9034f91f 100644
--- a/mlrun/serving/utils.py
+++ b/mlrun/serving/utils.py
@@ -16,8 +16,14 @@
from mlrun.utils import get_in, update_in
-event_id_key = "MLRUN_EVENT_ID"
-event_path_key = "MLRUN_EVENT_PATH"
+# headers keys with underscore are getting ignored by werkzeug https://github.com/pallets/werkzeug/pull/2622
+# to avoid conflicts with WGSI which converts all header keys to uppercase with underscores.
+# more info https://github.com/benoitc/gunicorn/issues/2799, this comment can be removed once old keys are removed
+event_id_key = "MLRUN-EVENT-ID"
+event_path_key = "MLRUN-EVENT-PATH"
+# TODO: remove these keys in 1.6.0
+legacy_event_id_key = "MLRUN_EVENT_ID"
+legacy_event_path_key = "MLRUN_EVENT_PATH"
def _extract_input_data(input_path, body):
From a39ef9cd88b0636c134823708e1c0cfd842e78c8 Mon Sep 17 00:00:00 2001
From: Eyal Danieli
Date: Mon, 1 May 2023 01:52:00 +0300
Subject: [PATCH 078/334] [Model Monitoring] Fix: Convert error_count value to
integer in the monitoring stream graph (#3452)
---
.../model_monitoring/stream_processing_fs.py | 2 +-
.../model_monitoring/test_model_monitoring.py | 20 ++++++++++++++++---
2 files changed, 18 insertions(+), 4 deletions(-)
diff --git a/mlrun/model_monitoring/stream_processing_fs.py b/mlrun/model_monitoring/stream_processing_fs.py
index 13b265900aa1..9accb4a6c11b 100644
--- a/mlrun/model_monitoring/stream_processing_fs.py
+++ b/mlrun/model_monitoring/stream_processing_fs.py
@@ -788,7 +788,7 @@ def resume_state(self, endpoint_id):
error_count = endpoint_record.get(EventFieldType.ERROR_COUNT)
if error_count:
- self.error_count[endpoint_id] = error_count
+ self.error_count[endpoint_id] = int(error_count)
# add endpoint to endpoints set
self.endpoints.add(endpoint_id)
diff --git a/tests/system/model_monitoring/test_model_monitoring.py b/tests/system/model_monitoring/test_model_monitoring.py
index a927f304f5ca..d19d2b86756c 100644
--- a/tests/system/model_monitoring/test_model_monitoring.py
+++ b/tests/system/model_monitoring/test_model_monitoring.py
@@ -238,6 +238,7 @@ def test_basic_model_monitoring(self):
# Main validations:
# 1 - a single model endpoint is created
# 2 - stream metrics are recorded as expected under the model endpoint
+ # 3 - invalid records are considered in the aggregated error count value
simulation_time = 90 # 90 seconds
# Deploy Model Servers
@@ -282,9 +283,19 @@ def test_basic_model_monitoring(self):
# Deploy the function
serving_fn.deploy()
- # Simulating Requests
- iris_data = iris["data"].tolist()
+ # Simulating invalid requests
+ invalid_input = ["n", "s", "o", "-"]
+ for _ in range(10):
+ try:
+ serving_fn.invoke(
+ f"v2/models/{model_name}/infer",
+ json.dumps({"inputs": [invalid_input]}),
+ )
+ except RuntimeError:
+ pass
+ # Simulating valid requests
+ iris_data = iris["data"].tolist()
t_end = monotonic() + simulation_time
while monotonic() < t_end:
data_point = choice(iris_data)
@@ -293,7 +304,7 @@ def test_basic_model_monitoring(self):
)
sleep(uniform(0.2, 1.1))
- # test metrics
+ # Test metrics
endpoints_list = mlrun.get_run_db().list_model_endpoints(
self.project_name, metrics=["predictions_per_second"]
)
@@ -308,6 +319,9 @@ def test_basic_model_monitoring(self):
total = sum((m[1] for m in predictions_per_second))
assert total > 0
+ # Validate error count value
+ assert endpoint.status.error_count == 10
+
@TestMLRunSystem.skip_test_if_env_not_configured
@pytest.mark.enterprise
From 7b035ba3aa469d30420f72750fa776404785d2ef Mon Sep 17 00:00:00 2001
From: Eyal Danieli
Date: Mon, 1 May 2023 01:57:48 +0300
Subject: [PATCH 079/334] [Model Monitoring] Fix list_model_endpoints
docstrings (#3459)
---
mlrun/db/httpdb.py | 8 +++++---
1 file changed, 5 insertions(+), 3 deletions(-)
diff --git a/mlrun/db/httpdb.py b/mlrun/db/httpdb.py
index 0ca5cd57c077..7b35f7d75f4b 100644
--- a/mlrun/db/httpdb.py
+++ b/mlrun/db/httpdb.py
@@ -2587,11 +2587,13 @@ def list_model_endpoints(
uids: Optional[List[str]] = None,
) -> List[mlrun.model_monitoring.model_endpoint.ModelEndpoint]:
"""
- Returns a list of ModelEndpointState objects. Each object represents the current state of a model endpoint.
- This functions supports filtering by the following parameters:
+ Returns a list of `ModelEndpoint` objects. Each `ModelEndpoint` object represents the current state of a
+ model endpoint. This functions supports filtering by the following parameters:
1) model
2) function
3) labels
+ 4) top level
+ 5) uids
By default, when no filters are applied, all available endpoints for the given project will be listed.
In addition, this functions provides a facade for listing endpoint related metrics. This facade is time-based
@@ -2613,7 +2615,7 @@ def list_model_endpoints(
`'now-[0-9]+[mhd]'`, where `m` = minutes, `h` = hours, and `'d'` =
days), or 0 for the earliest time.
:param top_level: if true will return only routers and endpoint that are NOT children of any router
- :param uids: if passed will return `ModelEndpointList` of endpoints with uid in uids
+ :param uids: if passed will return a list `ModelEndpoint` object with uid in uids
"""
path = f"projects/{project}/model-endpoints"
From 1253670a882640dcb54a4ffe9162c49c920b66a5 Mon Sep 17 00:00:00 2001
From: Eyal Danieli
Date: Tue, 2 May 2023 11:50:19 +0300
Subject: [PATCH 080/334] [Model Monitoring] Fix Grafana datasource name in
details dashboard (#3464)
---
.../dashboards/model-monitoring-details.json | 15 +++------------
1 file changed, 3 insertions(+), 12 deletions(-)
diff --git a/docs/monitoring/dashboards/model-monitoring-details.json b/docs/monitoring/dashboards/model-monitoring-details.json
index ce53ed00ac31..4868e67c83d6 100644
--- a/docs/monitoring/dashboards/model-monitoring-details.json
+++ b/docs/monitoring/dashboards/model-monitoring-details.json
@@ -49,10 +49,7 @@
"liveNow": false,
"panels": [
{
- "datasource": {
- "type": "grafana-simple-json-datasource",
- "uid": "PiBy-ta4z"
- },
+ "datasource": "iguazio",
"description": "",
"fieldConfig": {
"defaults": {
@@ -213,10 +210,7 @@
"pluginVersion": "9.2.2",
"targets": [
{
- "datasource": {
- "type": "grafana-simple-json-datasource",
- "uid": "PiBy-ta4z"
- },
+ "datasource": "iguazio",
"hide": false,
"rawQuery": true,
"refId": "A",
@@ -272,10 +266,7 @@
"type": "table"
},
{
- "datasource": {
- "type": "grafana-simple-json-datasource",
- "uid": "PiBy-ta4z"
- },
+ "datasource": "iguazio",
"description": "",
"fieldConfig": {
"defaults": {
From f64bdd8286cc863e933f41baf6aab61c86bf58b3 Mon Sep 17 00:00:00 2001
From: Gal Topper
Date: Tue, 2 May 2023 20:54:55 +0800
Subject: [PATCH 081/334] [Datastore] Improve `BigQuerySource` documentation to
cover credentials (#3466)
---
docs/store/datastore.md | 7 ++++---
mlrun/datastore/sources.py | 5 +++++
2 files changed, 9 insertions(+), 3 deletions(-)
diff --git a/docs/store/datastore.md b/docs/store/datastore.md
index 3e091c198be3..7798901c0094 100644
--- a/docs/store/datastore.md
+++ b/docs/store/datastore.md
@@ -112,6 +112,7 @@ authentication methods that use the `fsspec` mechanism.
### Google cloud storage
* `GOOGLE_APPLICATION_CREDENTIALS` — path to the application credentials to use (in the form of a JSON file). This can
be used if this file is located in a location on shared storage, accessible to pods executing MLRun jobs.
-* `GCP_CREDENTIALS` — when the credentials file cannot be mounted to the pod, this environment variable may contain
-the contents of this file. If configured in the function pod, MLRun dumps its contents to a temporary file
-and points `GOOGLE_APPLICATION_CREDENTIALS` at it.
\ No newline at end of file
+* `GCP_CREDENTIALS` — when the credentials file cannot be mounted to the pod, this secret or environment variable
+may contain the contents of this file. If configured in the function pod, MLRun dumps its contents to a temporary file
+and points `GOOGLE_APPLICATION_CREDENTIALS` at it. An exception is `BigQuerySource`, which passes `GCP_CREDENTIALS`'s
+contents directly to the query engine.
\ No newline at end of file
diff --git a/mlrun/datastore/sources.py b/mlrun/datastore/sources.py
index 5700b6bb4f98..daa7141f7852 100644
--- a/mlrun/datastore/sources.py
+++ b/mlrun/datastore/sources.py
@@ -323,8 +323,13 @@ class BigQuerySource(BaseSourceDriver):
"""
Reads Google BigQuery query results as input source for a flow.
+ For authentication, set the GCP_CREDENTIALS project secret to the credentials json string.
+
example::
+ # set the credentials
+ project.set_secrets({"GCP_CREDENTIALS": gcp_credentials_json})
+
# use sql query
query_string = "SELECT * FROM `the-psf.pypi.downloads20210328` LIMIT 5000"
source = BigQuerySource("bq1", query=query_string,
From ce49dc9f88d1837183c7365913b5f4d3d7081124 Mon Sep 17 00:00:00 2001
From: Gal Topper
Date: Tue, 2 May 2023 22:22:09 +0800
Subject: [PATCH 082/334] [Requirements] Bump storey to 1.3.19 (#3467)
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
With a related documentation update – see [ML-3782](https://jira.iguazeng.com/browse/ML-3782).
---
docs/data-prep/ingest-data-fs.md | 2 ++
requirements.txt | 2 +-
tests/test_requirements.py | 2 +-
3 files changed, 4 insertions(+), 2 deletions(-)
diff --git a/docs/data-prep/ingest-data-fs.md b/docs/data-prep/ingest-data-fs.md
index bcea5a7c080f..87a04210db21 100644
--- a/docs/data-prep/ingest-data-fs.md
+++ b/docs/data-prep/ingest-data-fs.md
@@ -16,6 +16,8 @@ When targets are not specified, data is stored in the configured default targets
```{admonition} Limitations
- Do not name columns starting with either `_` or `aggr_`. They are reserved for internal use. See
also general limitations in [Attribute name restrictions](https://www.iguazio.com/docs/latest-release/data-layer/objects/attributes/#attribute-names).
+- Do not name columns to match the regex pattern `.*_[a-z]+_[0-9]+[smhd]$`, where [a-z]+ is an aggregation name,
+one of: count, sum, sqr, max, min, first, last, avg, stdvar, stddev. E.g. x_count_1h.
- When using the pandas engine, do not use spaces (` `) or periods (`.`) in the column names. These cause errors in the ingestion.
```
diff --git a/requirements.txt b/requirements.txt
index f02ffedf59f3..aa869b7653ac 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -53,7 +53,7 @@ humanfriendly~=8.2
fastapi~=0.92.0
fsspec~=2021.8.1
v3iofs~=0.1.15
-storey~=1.3.18
+storey~=1.3.19
deepdiff~=5.0
pymysql~=1.0
inflection~=0.5.0
diff --git a/tests/test_requirements.py b/tests/test_requirements.py
index a3ee595a057d..9eb3e7bc5570 100644
--- a/tests/test_requirements.py
+++ b/tests/test_requirements.py
@@ -95,7 +95,7 @@ def test_requirement_specifiers_convention():
"kfp": {"~=1.8.0, <1.8.14"},
"botocore": {">=1.20.106,<1.20.107"},
"aiobotocore": {"~=1.4.0"},
- "storey": {"~=1.3.18"},
+ "storey": {"~=1.3.19"},
"bokeh": {"~=2.4, >=2.4.2"},
"typing-extensions": {">=3.10.0,<5"},
"sphinx": {"~=4.3.0"},
From be5137653d11602a252135c6be8856302aad9393 Mon Sep 17 00:00:00 2001
From: Gal Topper
Date: Wed, 3 May 2023 15:41:00 +0800
Subject: [PATCH 083/334] [Feature Store] Fix `BigQuerySource` support for
passthrough+`chunksize` (#3449)
---
mlrun/datastore/sources.py | 44 +++++----
mlrun/feature_store/api.py | 9 +-
mlrun/feature_store/feature_set.py | 6 +-
mlrun/feature_store/ingestion.py | 19 ++--
.../feature_store/test_google_big_query.py | 89 +++++++------------
5 files changed, 76 insertions(+), 91 deletions(-)
diff --git a/mlrun/datastore/sources.py b/mlrun/datastore/sources.py
index daa7141f7852..6b02907094f3 100644
--- a/mlrun/datastore/sources.py
+++ b/mlrun/datastore/sources.py
@@ -62,6 +62,11 @@ def _get_store(self):
def to_step(self, key_field=None, time_field=None, context=None):
import storey
+ if not self.support_storey:
+ raise mlrun.errors.MLRunRuntimeError(
+ f"{type(self).__name__} does not support storey engine"
+ )
+
return storey.SyncEmitSource(context=context)
def get_table_object(self):
@@ -381,6 +386,15 @@ def __init__(
raise mlrun.errors.MLRunInvalidArgumentError(
"cannot specify both table and query args"
)
+ # Otherwise, the client library does not fully respect the limit
+ if (
+ max_results_for_table
+ and chunksize
+ and max_results_for_table % chunksize != 0
+ ):
+ raise mlrun.errors.MLRunInvalidArgumentError(
+ "max_results_for_table must be a multiple of chunksize"
+ )
attrs = {
"query": query,
"table": table,
@@ -400,7 +414,6 @@ def __init__(
start_time=start_time,
end_time=end_time,
)
- self._rows_iterator = None
def _get_credentials_string(self):
gcp_project = self.attributes.get("gcp_project", None)
@@ -443,35 +456,28 @@ def schema_to_dtypes(schema):
if query:
query_job = bqclient.query(query)
- self._rows_iterator = query_job.result(page_size=chunksize)
- dtypes = schema_to_dtypes(self._rows_iterator.schema)
- if chunksize:
- # passing bqstorage_client greatly improves performance
- return self._rows_iterator.to_dataframe_iterable(
- bqstorage_client=BigQueryReadClient(), dtypes=dtypes
- )
- else:
- return self._rows_iterator.to_dataframe(dtypes=dtypes)
+ rows_iterator = query_job.result(page_size=chunksize)
elif table:
table = self.attributes.get("table")
max_results = self.attributes.get("max_results")
- rows = bqclient.list_rows(
+ rows_iterator = bqclient.list_rows(
table, page_size=chunksize, max_results=max_results
)
- dtypes = schema_to_dtypes(rows.schema)
- if chunksize:
- # passing bqstorage_client greatly improves performance
- return rows.to_dataframe_iterable(
- bqstorage_client=BigQueryReadClient(), dtypes=dtypes
- )
- else:
- return rows.to_dataframe(dtypes=dtypes)
else:
raise mlrun.errors.MLRunInvalidArgumentError(
"table or query args must be specified"
)
+ dtypes = schema_to_dtypes(rows_iterator.schema)
+ if chunksize:
+ # passing bqstorage_client greatly improves performance
+ return rows_iterator.to_dataframe_iterable(
+ bqstorage_client=BigQueryReadClient(), dtypes=dtypes
+ )
+ else:
+ return rows_iterator.to_dataframe(dtypes=dtypes)
+
def is_iterator(self):
return bool(self.attributes.get("chunksize"))
diff --git a/mlrun/feature_store/api.py b/mlrun/feature_store/api.py
index c1853b3f9a33..5f01b8c59f71 100644
--- a/mlrun/feature_store/api.py
+++ b/mlrun/feature_store/api.py
@@ -508,10 +508,11 @@ def ingest(
f"Source.end_time is {str(source.end_time)}"
)
- if mlrun_context:
- mlrun_context.logger.info(
- f"starting ingestion task to {featureset.uri}.{filter_time_string}"
- )
+ if mlrun_context:
+ mlrun_context.logger.info(
+ f"starting ingestion task to {featureset.uri}.{filter_time_string}"
+ )
+
return_df = False
if featureset.spec.passthrough:
diff --git a/mlrun/feature_store/feature_set.py b/mlrun/feature_store/feature_set.py
index ca21917c36f1..eccc1848ef75 100644
--- a/mlrun/feature_store/feature_set.py
+++ b/mlrun/feature_store/feature_set.py
@@ -930,7 +930,11 @@ def to_dataframe(
raise mlrun.errors.MLRunNotFoundError(
"passthrough feature set {self.metadata.name} with no source"
)
- return self.spec.source.to_dataframe()
+ df = self.spec.source.to_dataframe()
+ # to_dataframe() can sometimes return an iterator of dataframes instead of one dataframe
+ if not isinstance(df, pd.DataFrame):
+ df = pd.concat(df)
+ return df
target = get_offline_target(self, name=target_name)
if not target:
diff --git a/mlrun/feature_store/ingestion.py b/mlrun/feature_store/ingestion.py
index d2649c395103..d07b1691ac75 100644
--- a/mlrun/feature_store/ingestion.py
+++ b/mlrun/feature_store/ingestion.py
@@ -89,7 +89,7 @@ def init_featureset_graph(
key_fields = entity_columns if entity_columns else None
sizes = [0] * len(targets)
- data_result = None
+ result_dfs = []
total_rows = 0
targets = [get_target_driver(target, featureset) for target in targets]
if featureset.spec.passthrough:
@@ -100,11 +100,11 @@ def init_featureset_graph(
# set the entities to be the indexes of the df
event.body = entities_to_index(featureset, event.body)
- data = server.run(event, get_body=True)
- if data is not None:
+ df = server.run(event, get_body=True)
+ if df is not None:
for i, target in enumerate(targets):
size = target.write_dataframe(
- data,
+ df,
key_column=key_fields,
timestamp_key=featureset.spec.timestamp_key,
chunk_id=chunk_id,
@@ -112,21 +112,18 @@ def init_featureset_graph(
if size:
sizes[i] += size
chunk_id += 1
- if data_result is None:
- # in case of multiple chunks only return the first chunk (last may be too small)
- data_result = data
- total_rows += data.shape[0]
+ result_dfs.append(df)
+ total_rows += df.shape[0]
if rows_limit and total_rows >= rows_limit:
break
- # todo: fire termination event if iterator
-
for i, target in enumerate(targets):
target_status = target.update_resource_status("ready", size=sizes[i])
if verbose:
logger.info(f"wrote target: {target_status}")
- return data_result
+ result_df = pd.concat(result_dfs)
+ return result_df.head(rows_limit)
def featureset_initializer(server):
diff --git a/tests/system/feature_store/test_google_big_query.py b/tests/system/feature_store/test_google_big_query.py
index f955b7553991..9f269abd52a9 100644
--- a/tests/system/feature_store/test_google_big_query.py
+++ b/tests/system/feature_store/test_google_big_query.py
@@ -30,7 +30,7 @@
)
-def _resolve_google_credentials_json_path() -> typing.Optional[pathlib.Path]:
+def resolve_google_credentials_json_path() -> typing.Optional[pathlib.Path]:
default_path = pathlib.Path(CREDENTIALS_JSON_DEFAULT_PATH)
if os.getenv(CREDENTIALS_ENV):
return pathlib.Path(os.getenv(CREDENTIALS_ENV))
@@ -39,71 +39,26 @@ def _resolve_google_credentials_json_path() -> typing.Optional[pathlib.Path]:
return None
-def _are_google_credentials_not_set() -> bool:
- # credentials_path = _resolve_google_credentials_json_path()
- # return not credentials_path
-
- # Once issues with installation of packages - 'google-cloud-bigquery' and 'six' - will be fixed
- # uncomment the above and let the tests run.
- return True
+def are_google_credentials_not_set() -> bool:
+ credentials_path = resolve_google_credentials_json_path()
+ return not credentials_path
# Marked as enterprise because of v3io mount and pipelines
@TestMLRunSystem.skip_test_if_env_not_configured
@pytest.mark.skipif(
- _are_google_credentials_not_set(),
+ are_google_credentials_not_set(),
reason=f"Environment variable {CREDENTIALS_ENV} is not defined, and credentials file not in default path"
f" {CREDENTIALS_JSON_DEFAULT_PATH}, skipping...",
)
@pytest.mark.enterprise
class TestFeatureStoreGoogleBigQuery(TestMLRunSystem):
project_name = "fs-system-test-google-big-query"
+ max_results = 100
- def test_big_query_source_query(self):
- max_results = 100
- query_string = f"select *\nfrom `bigquery-public-data.chicago_taxi_trips.taxi_trips`\nlimit {max_results}"
- source = BigQuerySource(
- "BigQuerySource",
- query=query_string,
- materialization_dataset="chicago_taxi_trips",
- )
- self._test_big_query_source("query", source, max_results)
-
- def test_big_query_source_query_with_chunk_size(self):
- max_results = 100
- query_string = f"select *\nfrom `bigquery-public-data.chicago_taxi_trips.taxi_trips`\nlimit {max_results * 2}"
- source = BigQuerySource(
- "BigQuerySource",
- query=query_string,
- materialization_dataset="chicago_taxi_trips",
- chunksize=max_results,
- )
- self._test_big_query_source("query_c", source, max_results)
-
- def test_big_query_source_table(self):
- max_results = 100
- source = BigQuerySource(
- "BigQuerySource",
- table="bigquery-public-data.chicago_taxi_trips.taxi_trips",
- max_results_for_table=max_results,
- materialization_dataset="chicago_taxi_trips",
- )
- self._test_big_query_source("table", source, max_results)
-
- def test_big_query_source_table_with_chunk_size(self):
- max_results = 100
- source = BigQuerySource(
- "BigQuerySource",
- table="bigquery-public-data.chicago_taxi_trips.taxi_trips",
- max_results_for_table=max_results * 2,
- materialization_dataset="chicago_taxi_trips",
- chunksize=max_results,
- )
- self._test_big_query_source("table_c", source, max_results)
-
- @staticmethod
- def _test_big_query_source(name: str, source: BigQuerySource, max_results: int):
- credentials_path = _resolve_google_credentials_json_path()
+ @classmethod
+ def ingest_and_assert(cls, name: str, source: BigQuerySource):
+ credentials_path = resolve_google_credentials_json_path()
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = str(credentials_path)
targets = [
@@ -120,8 +75,30 @@ def _test_big_query_source(name: str, source: BigQuerySource, max_results: int):
timestamp_key="trip_start_timestamp",
engine="pandas",
)
- ingest_df = fstore.ingest(feature_set, source, targets, return_df=False)
+ ingest_df = fstore.ingest(feature_set, source, targets)
assert ingest_df is not None
- assert len(ingest_df) == max_results
+ assert len(ingest_df) == cls.max_results
assert ingest_df.dtypes["pickup_latitude"] == "float64"
assert ingest_df.dtypes["trip_seconds"] == pd.Int64Dtype()
+
+ @pytest.mark.parametrize("chunksize", [None, 30])
+ def test_big_query_source_query(self, chunksize):
+ query_string = f"select *\nfrom `bigquery-public-data.chicago_taxi_trips.taxi_trips`\nlimit {self.max_results}"
+ source = BigQuerySource(
+ "BigQuerySource",
+ query=query_string,
+ materialization_dataset="chicago_taxi_trips",
+ chunksize=chunksize,
+ )
+ self.ingest_and_assert("query", source)
+
+ @pytest.mark.parametrize("chunksize", [None, 50])
+ def test_big_query_source_table(self, chunksize):
+ source = BigQuerySource(
+ "BigQuerySource",
+ table="bigquery-public-data.chicago_taxi_trips.taxi_trips",
+ max_results_for_table=self.max_results,
+ materialization_dataset="chicago_taxi_trips",
+ chunksize=chunksize,
+ )
+ self.ingest_and_assert("table_c", source)
From 060e92b3ffc2fe06f24a0357f635d8dc7a90caf3 Mon Sep 17 00:00:00 2001
From: Tom Tankilevitch <59158507+Tankilevitch@users.noreply.github.com>
Date: Wed, 3 May 2023 12:29:42 +0300
Subject: [PATCH 084/334] [CI] Fix Makefile dockerized tests (#3471)
---
Makefile | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/Makefile b/Makefile
index ae530f708189..d4fba02c9345 100644
--- a/Makefile
+++ b/Makefile
@@ -533,7 +533,7 @@ test: clean ## Run mlrun tests
--ignore=tests/system \
--ignore=tests/rundb/test_httpdb.py \
-rf \
- tests/serving/test_remote.py::test_remote_step
+ tests
.PHONY: test-integration-dockerized
From ec9e0f3194f3aef3eb108e0d18199fd3090aa407 Mon Sep 17 00:00:00 2001
From: Yael Genish <62285310+yaelgen@users.noreply.github.com>
Date: Wed, 3 May 2023 23:20:13 +0300
Subject: [PATCH 085/334] [Marketplace] Replace term from marketplace to hub
(#3409)
---
docs/conf.py | 2 +-
mlrun/api/api/api.py | 6 +-
.../api/endpoints/{marketplace.py => hub.py} | 110 +++++++---------
mlrun/api/crud/__init__.py | 2 +-
mlrun/api/crud/{marketplace.py => hub.py} | 80 ++++++------
mlrun/api/crud/secrets.py | 2 +-
mlrun/api/db/base.py | 16 +--
mlrun/api/db/sqldb/db.py | 122 ++++++++----------
mlrun/api/db/sqldb/models/models_mysql.py | 6 +-
mlrun/api/db/sqldb/models/models_sqlite.py | 6 +-
mlrun/api/initial_data.py | 24 ++--
.../28383af526f3_market_place_to_hub.py | 40 ++++++
.../4acd9430b093_market_place_to_hub.py | 77 +++++++++++
mlrun/api/schemas/__init__.py | 16 +--
mlrun/api/schemas/auth.py | 6 +-
mlrun/api/schemas/{marketplace.py => hub.py} | 68 +++++-----
mlrun/api/schemas/object.py | 6 +-
mlrun/config.py | 4 +-
mlrun/db/base.py | 18 ++-
mlrun/db/httpdb.py | 114 ++++++++--------
mlrun/db/nopdb.py | 18 ++-
mlrun/db/sqldb.py | 18 ++-
mlrun/projects/operations.py | 2 +-
mlrun/projects/project.py | 4 +-
.../api/api/{marketplace => hub}/__init__.py | 0
.../functions/channel/catalog.json | 0
.../dev_function/latest/static/my_html.html | 0
.../test_marketplace.py => hub/test_hub.py} | 90 ++++++-------
tests/api/api/test_projects.py | 4 +-
tests/integration/sdk_api/hub/__init__.py | 14 ++
.../test_marketplace.py => hub/test_hub.py} | 34 ++---
.../demos/churn/assets/data_clean_function.py | 2 +-
.../model_monitoring/test_model_monitoring.py | 6 +-
33 files changed, 494 insertions(+), 423 deletions(-)
rename mlrun/api/api/endpoints/{marketplace.py => hub.py} (67%)
rename mlrun/api/crud/{marketplace.py => hub.py} (82%)
create mode 100644 mlrun/api/migrations_mysql/versions/28383af526f3_market_place_to_hub.py
create mode 100644 mlrun/api/migrations_sqlite/versions/4acd9430b093_market_place_to_hub.py
rename mlrun/api/schemas/{marketplace.py => hub.py} (59%)
rename tests/api/api/{marketplace => hub}/__init__.py (100%)
rename tests/api/api/{marketplace => hub}/functions/channel/catalog.json (100%)
rename tests/api/api/{marketplace => hub}/functions/channel/dev_function/latest/static/my_html.html (100%)
rename tests/api/api/{marketplace/test_marketplace.py => hub/test_hub.py} (80%)
create mode 100644 tests/integration/sdk_api/hub/__init__.py
rename tests/integration/sdk_api/{marketplace/test_marketplace.py => hub/test_hub.py} (67%)
diff --git a/docs/conf.py b/docs/conf.py
index 8809c559195b..c6825418c6da 100644
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -64,7 +64,7 @@ def current_version():
]
# redirect paths due to filename changes
-redirects = {"runtimes/load-from-marketplace": "load-from-hub.html"}
+redirects = {"runtimes/load-from-hub": "load-from-hub.html"}
# Add any paths that contain templates here, relative to this directory.
templates_path = [
diff --git a/mlrun/api/api/api.py b/mlrun/api/api/api.py
index 8d1966499f38..3d9ae2eebd85 100644
--- a/mlrun/api/api/api.py
+++ b/mlrun/api/api/api.py
@@ -28,9 +28,9 @@
functions,
grafana_proxy,
healthz,
+ hub,
internal,
logs,
- marketplace,
model_endpoints,
operations,
pipelines,
@@ -125,8 +125,8 @@
api_router.include_router(grafana_proxy.router, tags=["grafana", "model-endpoints"])
api_router.include_router(model_endpoints.router, tags=["model-endpoints"])
api_router.include_router(
- marketplace.router,
- tags=["marketplace"],
+ hub.router,
+ tags=["hub"],
dependencies=[Depends(mlrun.api.api.deps.authenticate_request)],
)
api_router.include_router(
diff --git a/mlrun/api/api/endpoints/marketplace.py b/mlrun/api/api/endpoints/hub.py
similarity index 67%
rename from mlrun/api/api/endpoints/marketplace.py
rename to mlrun/api/api/endpoints/hub.py
index 6978f0669fe4..b2ec74ddc11d 100644
--- a/mlrun/api/api/endpoints/marketplace.py
+++ b/mlrun/api/api/endpoints/hub.py
@@ -26,45 +26,41 @@
import mlrun.api.crud
import mlrun.api.utils.auth.verifier
from mlrun.api.schemas import AuthorizationAction
-from mlrun.api.schemas.marketplace import (
- IndexedMarketplaceSource,
- MarketplaceCatalog,
- MarketplaceItem,
-)
+from mlrun.api.schemas.hub import HubCatalog, HubItem, IndexedHubSource
from mlrun.api.utils.singletons.db import get_db
router = APIRouter()
@router.post(
- path="/marketplace/sources",
+ path="/hub/sources",
status_code=HTTPStatus.CREATED.value,
- response_model=IndexedMarketplaceSource,
+ response_model=IndexedHubSource,
)
async def create_source(
- source: IndexedMarketplaceSource,
+ source: IndexedHubSource,
db_session: Session = Depends(mlrun.api.api.deps.get_db_session),
auth_info: mlrun.api.schemas.AuthInfo = Depends(
mlrun.api.api.deps.authenticate_request
),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_global_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.marketplace_source,
+ mlrun.api.schemas.AuthorizationResourceTypes.hub_source,
AuthorizationAction.create,
auth_info,
)
- await run_in_threadpool(get_db().create_marketplace_source, db_session, source)
+ await run_in_threadpool(get_db().create_hub_source, db_session, source)
# Handle credentials if they exist
- await run_in_threadpool(mlrun.api.crud.Marketplace().add_source, source.source)
+ await run_in_threadpool(mlrun.api.crud.Hub().add_source, source.source)
return await run_in_threadpool(
- get_db().get_marketplace_source, db_session, source.source.metadata.name
+ get_db().get_hub_source, db_session, source.source.metadata.name
)
@router.get(
- path="/marketplace/sources",
- response_model=List[IndexedMarketplaceSource],
+ path="/hub/sources",
+ response_model=List[IndexedHubSource],
)
async def list_sources(
db_session: Session = Depends(mlrun.api.api.deps.get_db_session),
@@ -73,16 +69,16 @@ async def list_sources(
),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_global_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.marketplace_source,
+ mlrun.api.schemas.AuthorizationResourceTypes.hub_source,
AuthorizationAction.read,
auth_info,
)
- return await run_in_threadpool(get_db().list_marketplace_sources, db_session)
+ return await run_in_threadpool(get_db().list_hub_sources, db_session)
@router.delete(
- path="/marketplace/sources/{source_name}",
+ path="/hub/sources/{source_name}",
status_code=HTTPStatus.NO_CONTENT.value,
)
async def delete_source(
@@ -93,18 +89,18 @@ async def delete_source(
),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_global_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.marketplace_source,
+ mlrun.api.schemas.AuthorizationResourceTypes.hub_source,
AuthorizationAction.delete,
auth_info,
)
- await run_in_threadpool(get_db().delete_marketplace_source, db_session, source_name)
- await run_in_threadpool(mlrun.api.crud.Marketplace().remove_source, source_name)
+ await run_in_threadpool(get_db().delete_hub_source, db_session, source_name)
+ await run_in_threadpool(mlrun.api.crud.Hub().remove_source, source_name)
@router.get(
- path="/marketplace/sources/{source_name}",
- response_model=IndexedMarketplaceSource,
+ path="/hub/sources/{source_name}",
+ response_model=IndexedHubSource,
)
async def get_source(
source_name: str,
@@ -113,49 +109,43 @@ async def get_source(
mlrun.api.api.deps.authenticate_request
),
):
- marketplace_source = await run_in_threadpool(
- get_db().get_marketplace_source, db_session, source_name
+ hub_source = await run_in_threadpool(
+ get_db().get_hub_source, db_session, source_name
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_global_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.marketplace_source,
+ mlrun.api.schemas.AuthorizationResourceTypes.hub_source,
AuthorizationAction.read,
auth_info,
)
- return marketplace_source
+ return hub_source
-@router.put(
- path="/marketplace/sources/{source_name}", response_model=IndexedMarketplaceSource
-)
+@router.put(path="/hub/sources/{source_name}", response_model=IndexedHubSource)
async def store_source(
source_name: str,
- source: IndexedMarketplaceSource,
+ source: IndexedHubSource,
db_session: Session = Depends(mlrun.api.api.deps.get_db_session),
auth_info: mlrun.api.schemas.AuthInfo = Depends(
mlrun.api.api.deps.authenticate_request
),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_global_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.marketplace_source,
+ mlrun.api.schemas.AuthorizationResourceTypes.hub_source,
AuthorizationAction.store,
auth_info,
)
- await run_in_threadpool(
- get_db().store_marketplace_source, db_session, source_name, source
- )
+ await run_in_threadpool(get_db().store_hub_source, db_session, source_name, source)
# Handle credentials if they exist
- await run_in_threadpool(mlrun.api.crud.Marketplace().add_source, source.source)
+ await run_in_threadpool(mlrun.api.crud.Hub().add_source, source.source)
- return await run_in_threadpool(
- get_db().get_marketplace_source, db_session, source_name
- )
+ return await run_in_threadpool(get_db().get_hub_source, db_session, source_name)
@router.get(
- path="/marketplace/sources/{source_name}/items",
- response_model=MarketplaceCatalog,
+ path="/hub/sources/{source_name}/items",
+ response_model=HubCatalog,
)
async def get_catalog(
source_name: str,
@@ -168,16 +158,16 @@ async def get_catalog(
),
):
ordered_source = await run_in_threadpool(
- get_db().get_marketplace_source, db_session, source_name
+ get_db().get_hub_source, db_session, source_name
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_global_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.marketplace_source,
+ mlrun.api.schemas.AuthorizationResourceTypes.hub_source,
AuthorizationAction.read,
auth_info,
)
return await run_in_threadpool(
- mlrun.api.crud.Marketplace().get_source_catalog,
+ mlrun.api.crud.Hub().get_source_catalog,
ordered_source.source,
version,
tag,
@@ -186,8 +176,8 @@ async def get_catalog(
@router.get(
- "/marketplace/sources/{source_name}/items/{item_name}",
- response_model=MarketplaceItem,
+ "/hub/sources/{source_name}/items/{item_name}",
+ response_model=HubItem,
)
async def get_item(
source_name: str,
@@ -201,16 +191,16 @@ async def get_item(
),
):
ordered_source = await run_in_threadpool(
- get_db().get_marketplace_source, db_session, source_name
+ get_db().get_hub_source, db_session, source_name
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_global_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.marketplace_source,
+ mlrun.api.schemas.AuthorizationResourceTypes.hub_source,
AuthorizationAction.read,
auth_info,
)
return await run_in_threadpool(
- mlrun.api.crud.Marketplace().get_item,
+ mlrun.api.crud.Hub().get_item,
ordered_source.source,
item_name,
version,
@@ -220,7 +210,7 @@ async def get_item(
@router.get(
- "/marketplace/sources/{source_name}/item-object",
+ "/hub/sources/{source_name}/item-object",
)
async def get_object(
source_name: str,
@@ -231,15 +221,15 @@ async def get_object(
),
):
ordered_source = await run_in_threadpool(
- get_db().get_marketplace_source, db_session, source_name
+ get_db().get_hub_source, db_session, source_name
)
object_data = await run_in_threadpool(
- mlrun.api.crud.Marketplace().get_item_object_using_source_credentials,
+ mlrun.api.crud.Hub().get_item_object_using_source_credentials,
ordered_source.source,
url,
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_global_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.marketplace_source,
+ mlrun.api.schemas.AuthorizationResourceTypes.hub_source,
AuthorizationAction.read,
auth_info,
)
@@ -253,7 +243,7 @@ async def get_object(
return Response(content=object_data, media_type=ctype)
-@router.get("/marketplace/sources/{source_name}/items/{item_name}/assets/{asset_name}")
+@router.get("/hub/sources/{source_name}/items/{item_name}/assets/{asset_name}")
async def get_asset(
source_name: str,
item_name: str,
@@ -266,9 +256,9 @@ async def get_asset(
),
):
"""
- Retrieve asset from a specific item in specific marketplace source.
+ Retrieve asset from a specific item in specific hub source.
- :param source_name: marketplace source name
+ :param source_name: hub source name
:param item_name: the name of the item
:param asset_name: the name of the asset to retrieve
:param tag: tag of item - latest or version number
@@ -278,18 +268,16 @@ async def get_asset(
:return: fastapi response with the asset in content
"""
- source = await run_in_threadpool(
- get_db().get_marketplace_source, db_session, source_name
- )
+ source = await run_in_threadpool(get_db().get_hub_source, db_session, source_name)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_global_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.marketplace_source,
+ mlrun.api.schemas.AuthorizationResourceTypes.hub_source,
AuthorizationAction.read,
auth_info,
)
# Getting the relevant item which hold the asset information
item = await run_in_threadpool(
- mlrun.api.crud.Marketplace().get_item,
+ mlrun.api.crud.Hub().get_item,
source.source,
item_name,
version,
@@ -298,7 +286,7 @@ async def get_asset(
# Getting the asset from the item
asset, url = await run_in_threadpool(
- mlrun.api.crud.Marketplace().get_asset,
+ mlrun.api.crud.Hub().get_asset,
source.source,
item,
asset_name,
diff --git a/mlrun/api/crud/__init__.py b/mlrun/api/crud/__init__.py
index 0a71f167b2a4..00126c862c57 100644
--- a/mlrun/api/crud/__init__.py
+++ b/mlrun/api/crud/__init__.py
@@ -19,8 +19,8 @@
from .clusterization_spec import ClusterizationSpec
from .feature_store import FeatureStore
from .functions import Functions
+from .hub import Hub
from .logs import Logs
-from .marketplace import Marketplace
from .model_monitoring import ModelEndpoints
from .notifications import Notifications
from .pipelines import Pipelines
diff --git a/mlrun/api/crud/marketplace.py b/mlrun/api/crud/hub.py
similarity index 82%
rename from mlrun/api/crud/marketplace.py
rename to mlrun/api/crud/hub.py
index 56621ab2c2d6..0060a6c02f32 100644
--- a/mlrun/api/crud/marketplace.py
+++ b/mlrun/api/crud/hub.py
@@ -17,12 +17,12 @@
import mlrun.errors
import mlrun.utils.singleton
-from mlrun.api.schemas.marketplace import (
- MarketplaceCatalog,
- MarketplaceItem,
- MarketplaceItemMetadata,
- MarketplaceItemSpec,
- MarketplaceSource,
+from mlrun.api.schemas.hub import (
+ HubCatalog,
+ HubItem,
+ HubItemMetadata,
+ HubItemSpec,
+ HubSource,
ObjectStatus,
)
from mlrun.api.utils.singletons.k8s import get_k8s
@@ -36,9 +36,9 @@
secret_name_separator = "-__-"
-class Marketplace(metaclass=mlrun.utils.singleton.Singleton):
+class Hub(metaclass=mlrun.utils.singleton.Singleton):
def __init__(self):
- self._internal_project_name = config.marketplace.k8s_secrets_project_name
+ self._internal_project_name = config.hub.k8s_secrets_project_name
self._catalogs = {}
@staticmethod
@@ -52,10 +52,10 @@ def _in_k8s():
def _generate_credentials_secret_key(source, key=""):
full_key = source + secret_name_separator + key
return Secrets().generate_client_project_secret_key(
- SecretsClientType.marketplace, full_key
+ SecretsClientType.hub, full_key
)
- def add_source(self, source: MarketplaceSource):
+ def add_source(self, source: HubSource):
source_name = source.metadata.name
credentials = source.spec.credentials
if credentials:
@@ -83,7 +83,7 @@ def remove_source(self, source_name):
def _store_source_credentials(self, source_name, credentials: dict):
if not self._in_k8s():
raise mlrun.errors.MLRunInvalidArgumentError(
- "MLRun is not configured with k8s, marketplace source credentials cannot be stored securely"
+ "MLRun is not configured with k8s, hub source credentials cannot be stored securely"
)
adjusted_credentials = {
@@ -122,13 +122,11 @@ def _get_source_credentials(self, source_name):
return source_secrets
@staticmethod
- def _get_asset_full_path(
- source: MarketplaceSource, item: MarketplaceItem, asset: str
- ):
+ def _get_asset_full_path(source: HubSource, item: HubItem, asset: str):
"""
Combining the item path with the asset path.
- :param source: Marketplace source object.
+ :param source: Hub source object.
:param item: The relevant item to get the asset from.
:param asset: The asset name
:return: Full path to the asset, relative to the item directory.
@@ -144,31 +142,27 @@ def _get_asset_full_path(
@staticmethod
def _transform_catalog_dict_to_schema(
- source: MarketplaceSource, catalog_dict: Dict[str, Any]
- ) -> MarketplaceCatalog:
+ source: HubSource, catalog_dict: Dict[str, Any]
+ ) -> HubCatalog:
"""
- Transforms catalog dictionary to MarketplaceCatalog schema
- :param source: Marketplace source object.
+ Transforms catalog dictionary to HubCatalog schema
+ :param source: Hub source object.
:param catalog_dict: raw catalog dict, top level keys are item names,
second level keys are version tags ("latest, "1.1.0", ...) and
bottom level keys include spec as a dict and all the rest is considered as metadata.
:return: catalog object
"""
- catalog = MarketplaceCatalog(catalog=[], channel=source.spec.channel)
+ catalog = HubCatalog(catalog=[], channel=source.spec.channel)
# Loop over objects, then over object versions.
for object_name, object_dict in catalog_dict.items():
for version_tag, version_dict in object_dict.items():
object_details_dict = version_dict.copy()
spec_dict = object_details_dict.pop("spec", {})
assets = object_details_dict.pop("assets", {})
- metadata = MarketplaceItemMetadata(
- tag=version_tag, **object_details_dict
- )
+ metadata = HubItemMetadata(tag=version_tag, **object_details_dict)
item_uri = source.get_full_uri(metadata.get_relative_path())
- spec = MarketplaceItemSpec(
- item_uri=item_uri, assets=assets, **spec_dict
- )
- item = MarketplaceItem(
+ spec = HubItemSpec(item_uri=item_uri, assets=assets, **spec_dict)
+ item = HubItem(
metadata=metadata,
spec=spec,
status=ObjectStatus(),
@@ -179,16 +173,16 @@ def _transform_catalog_dict_to_schema(
def get_source_catalog(
self,
- source: MarketplaceSource,
+ source: HubSource,
version: Optional[str] = None,
tag: Optional[str] = None,
force_refresh: bool = False,
- ) -> MarketplaceCatalog:
+ ) -> HubCatalog:
"""
Getting the catalog object by source.
If version and/or tag are given, the catalog will be filtered accordingly.
- :param source: Marketplace source object.
+ :param source: Hub source object.
:param version: version of items to filter by
:param tag: tag of items to filter by
:param force_refresh: if True, the catalog will be loaded from source always,
@@ -206,7 +200,7 @@ def get_source_catalog(
else:
catalog = self._catalogs[source_name]
- result_catalog = MarketplaceCatalog(catalog=[], channel=source.spec.channel)
+ result_catalog = HubCatalog(catalog=[], channel=source.spec.channel)
for item in catalog.catalog:
# Because tag and version are optionals,
# we filter the catalog by one of them with priority to tag
@@ -219,23 +213,23 @@ def get_source_catalog(
def get_item(
self,
- source: MarketplaceSource,
+ source: HubSource,
item_name: str,
version: Optional[str] = None,
tag: Optional[str] = None,
force_refresh: bool = False,
- ) -> MarketplaceItem:
+ ) -> HubItem:
"""
Retrieve item from source. The item is filtered by tag and version.
- :param source: Marketplace source object
+ :param source: Hub source object
:param item_name: name of the item to retrieve
:param version: version of the item
:param tag: tag of the item
:param force_refresh: if True, the catalog will be loaded from source always,
otherwise will be pulled from db (if loaded before)
- :return: marketplace item object
+ :return: hub item object
:raise if the number of collected items from catalog is not exactly one.
"""
@@ -256,9 +250,9 @@ def get_item(
@staticmethod
def _get_catalog_items_filtered_by_name(
- catalog: List[MarketplaceItem],
+ catalog: List[HubItem],
item_name: str,
- ) -> List[MarketplaceItem]:
+ ) -> List[HubItem]:
"""
Retrieve items from catalog filtered by name
@@ -269,7 +263,7 @@ def _get_catalog_items_filtered_by_name(
"""
return [item for item in catalog if item.metadata.name == item_name]
- def get_item_object_using_source_credentials(self, source: MarketplaceSource, url):
+ def get_item_object_using_source_credentials(self, source: HubSource, url):
credentials = self._get_source_credentials(source.metadata.name)
if not url.startswith(source.spec.path):
@@ -289,15 +283,15 @@ def get_item_object_using_source_credentials(self, source: MarketplaceSource, ur
def get_asset(
self,
- source: MarketplaceSource,
- item: MarketplaceItem,
+ source: HubSource,
+ item: HubItem,
asset_name: str,
) -> Tuple[bytes, str]:
"""
- Retrieve asset object from marketplace source.
+ Retrieve asset object from hub source.
- :param source: marketplace source
- :param item: marketplace item which contains the assets
+ :param source: hub source
+ :param item: hub item which contains the assets
:param asset_name: asset name, like source, example, etc.
:return: tuple of asset as bytes and url of asset
diff --git a/mlrun/api/crud/secrets.py b/mlrun/api/crud/secrets.py
index ddcea5ef9025..619fcfb67a47 100644
--- a/mlrun/api/crud/secrets.py
+++ b/mlrun/api/crud/secrets.py
@@ -30,7 +30,7 @@ class SecretsClientType(str, enum.Enum):
schedules = "schedules"
model_monitoring = "model-monitoring"
service_accounts = "service-accounts"
- marketplace = "marketplace"
+ hub = "hub"
notifications = "notifications"
diff --git a/mlrun/api/db/base.py b/mlrun/api/db/base.py
index 3d8d726098d1..3d522e506bc7 100644
--- a/mlrun/api/db/base.py
+++ b/mlrun/api/db/base.py
@@ -543,25 +543,19 @@ def list_artifact_tags(
):
return []
- def create_marketplace_source(
- self, session, ordered_source: schemas.IndexedMarketplaceSource
- ):
+ def create_hub_source(self, session, ordered_source: schemas.IndexedHubSource):
pass
- def store_marketplace_source(
- self, session, name, ordered_source: schemas.IndexedMarketplaceSource
- ):
+ def store_hub_source(self, session, name, ordered_source: schemas.IndexedHubSource):
pass
- def list_marketplace_sources(
- self, session
- ) -> List[schemas.IndexedMarketplaceSource]:
+ def list_hub_sources(self, session) -> List[schemas.IndexedHubSource]:
pass
- def delete_marketplace_source(self, session, name):
+ def delete_hub_source(self, session, name):
pass
- def get_marketplace_source(self, session, name) -> schemas.IndexedMarketplaceSource:
+ def get_hub_source(self, session, name) -> schemas.IndexedHubSource:
pass
def store_background_task(
diff --git a/mlrun/api/db/sqldb/db.py b/mlrun/api/db/sqldb/db.py
index e8a916c1bee3..263eca4a1e19 100644
--- a/mlrun/api/db/sqldb/db.py
+++ b/mlrun/api/db/sqldb/db.py
@@ -53,8 +53,8 @@
FeatureSet,
FeatureVector,
Function,
+ HubSource,
Log,
- MarketplaceSource,
Notification,
Project,
Run,
@@ -3258,11 +3258,9 @@ def _move_and_reorder_table_items(
else:
start, end = move_to, move_from - 1
- query = session.query(MarketplaceSource).filter(
- MarketplaceSource.index >= start
- )
+ query = session.query(HubSource).filter(HubSource.index >= start)
if end:
- query = query.filter(MarketplaceSource.index <= end)
+ query = query.filter(HubSource.index <= end)
for source_record in query:
source_record.index = source_record.index + modifier
@@ -3277,54 +3275,54 @@ def _move_and_reorder_table_items(
session.commit()
@staticmethod
- def _transform_marketplace_source_record_to_schema(
- marketplace_source_record: MarketplaceSource,
- ) -> schemas.IndexedMarketplaceSource:
- source_full_dict = marketplace_source_record.full_object
- marketplace_source = schemas.MarketplaceSource(**source_full_dict)
- return schemas.IndexedMarketplaceSource(
- index=marketplace_source_record.index, source=marketplace_source
+ def _transform_hub_source_record_to_schema(
+ hub_source_record: HubSource,
+ ) -> schemas.IndexedHubSource:
+ source_full_dict = hub_source_record.full_object
+ hub_source = schemas.HubSource(**source_full_dict)
+ return schemas.IndexedHubSource(
+ index=hub_source_record.index, source=hub_source
)
@staticmethod
- def _transform_marketplace_source_schema_to_record(
- marketplace_source_schema: schemas.IndexedMarketplaceSource,
- current_object: MarketplaceSource = None,
+ def _transform_hub_source_schema_to_record(
+ hub_source_schema: schemas.IndexedHubSource,
+ current_object: HubSource = None,
):
now = datetime.now(timezone.utc)
if current_object:
- if current_object.name != marketplace_source_schema.source.metadata.name:
+ if current_object.name != hub_source_schema.source.metadata.name:
raise mlrun.errors.MLRunInternalServerError(
"Attempt to update object while replacing its name"
)
created_timestamp = current_object.created
else:
- created_timestamp = marketplace_source_schema.source.metadata.created or now
- updated_timestamp = marketplace_source_schema.source.metadata.updated or now
+ created_timestamp = hub_source_schema.source.metadata.created or now
+ updated_timestamp = hub_source_schema.source.metadata.updated or now
- marketplace_source_record = MarketplaceSource(
+ hub_source_record = HubSource(
id=current_object.id if current_object else None,
- name=marketplace_source_schema.source.metadata.name,
- index=marketplace_source_schema.index,
+ name=hub_source_schema.source.metadata.name,
+ index=hub_source_schema.index,
created=created_timestamp,
updated=updated_timestamp,
)
- full_object = marketplace_source_schema.source.dict()
+ full_object = hub_source_schema.source.dict()
full_object["metadata"]["created"] = str(created_timestamp)
full_object["metadata"]["updated"] = str(updated_timestamp)
- # Make sure we don't keep any credentials in the DB. These are handled in the marketplace crud object.
+ # Make sure we don't keep any credentials in the DB. These are handled in the hub crud object.
full_object["spec"].pop("credentials", None)
- marketplace_source_record.full_object = full_object
- return marketplace_source_record
+ hub_source_record.full_object = full_object
+ return hub_source_record
@staticmethod
- def _validate_and_adjust_marketplace_order(session, order):
- max_order = session.query(func.max(MarketplaceSource.index)).scalar()
+ def _validate_and_adjust_hub_order(session, order):
+ max_order = session.query(func.max(HubSource.index)).scalar()
if not max_order or max_order < 0:
max_order = 0
- if order == schemas.marketplace.last_source_index:
+ if order == schemas.hub.last_source_index:
order = max_order + 1
if order > max_order + 1:
@@ -3334,62 +3332,52 @@ def _validate_and_adjust_marketplace_order(session, order):
if order < 1:
raise mlrun.errors.MLRunInvalidArgumentError(
"Order of inserted source must be greater than 0 or "
- + f"{schemas.marketplace.last_source_index} (for last). order = {order}"
+ + f"{schemas.hub.last_source_index} (for last). order = {order}"
)
return order
- def create_marketplace_source(
- self, session, ordered_source: schemas.IndexedMarketplaceSource
- ):
+ def create_hub_source(self, session, ordered_source: schemas.IndexedHubSource):
logger.debug(
- "Creating marketplace source in DB",
+ "Creating hub source in DB",
index=ordered_source.index,
name=ordered_source.source.metadata.name,
)
- order = self._validate_and_adjust_marketplace_order(
- session, ordered_source.index
- )
+ order = self._validate_and_adjust_hub_order(session, ordered_source.index)
name = ordered_source.source.metadata.name
- source_record = self._query(session, MarketplaceSource, name=name).one_or_none()
+ source_record = self._query(session, HubSource, name=name).one_or_none()
if source_record:
raise mlrun.errors.MLRunConflictError(
- f"Marketplace source name already exists. name = {name}"
+ f"Hub source name already exists. name = {name}"
)
- source_record = self._transform_marketplace_source_schema_to_record(
- ordered_source
- )
+ source_record = self._transform_hub_source_schema_to_record(ordered_source)
self._move_and_reorder_table_items(
session, source_record, move_to=order, move_from=None
)
@retry_on_conflict
- def store_marketplace_source(
+ def store_hub_source(
self,
session,
name,
- ordered_source: schemas.IndexedMarketplaceSource,
+ ordered_source: schemas.IndexedHubSource,
):
- logger.debug(
- "Storing marketplace source in DB", index=ordered_source.index, name=name
- )
+ logger.debug("Storing hub source in DB", index=ordered_source.index, name=name)
if name != ordered_source.source.metadata.name:
raise mlrun.errors.MLRunInvalidArgumentError(
"Conflict between resource name and metadata.name in the stored object"
)
- order = self._validate_and_adjust_marketplace_order(
- session, ordered_source.index
- )
+ order = self._validate_and_adjust_hub_order(session, ordered_source.index)
- source_record = self._query(session, MarketplaceSource, name=name).one_or_none()
+ source_record = self._query(session, HubSource, name=name).one_or_none()
current_order = source_record.index if source_record else None
- if current_order == schemas.marketplace.last_source_index:
+ if current_order == schemas.hub.last_source_index:
raise mlrun.errors.MLRunInvalidArgumentError(
- "Attempting to modify the global marketplace source."
+ "Attempting to modify the global hub source."
)
- source_record = self._transform_marketplace_source_schema_to_record(
+ source_record = self._transform_hub_source_schema_to_record(
ordered_source, source_record
)
@@ -3397,15 +3385,11 @@ def store_marketplace_source(
session, source_record, move_to=order, move_from=current_order
)
- def list_marketplace_sources(
- self, session
- ) -> List[schemas.IndexedMarketplaceSource]:
+ def list_hub_sources(self, session) -> List[schemas.IndexedHubSource]:
results = []
- query = self._query(session, MarketplaceSource).order_by(
- MarketplaceSource.index.desc()
- )
+ query = self._query(session, HubSource).order_by(HubSource.index.desc())
for record in query:
- ordered_source = self._transform_marketplace_source_record_to_schema(record)
+ ordered_source = self._transform_hub_source_record_to_schema(record)
# Need this to make the list return such that the default source is last in the response.
if ordered_source.index != schemas.last_source_index:
results.insert(0, ordered_source)
@@ -3413,31 +3397,31 @@ def list_marketplace_sources(
results.append(ordered_source)
return results
- def delete_marketplace_source(self, session, name):
- logger.debug("Deleting marketplace source from DB", name=name)
+ def delete_hub_source(self, session, name):
+ logger.debug("Deleting hub source from DB", name=name)
- source_record = self._query(session, MarketplaceSource, name=name).one_or_none()
+ source_record = self._query(session, HubSource, name=name).one_or_none()
if not source_record:
return
current_order = source_record.index
- if current_order == schemas.marketplace.last_source_index:
+ if current_order == schemas.hub.last_source_index:
raise mlrun.errors.MLRunInvalidArgumentError(
- "Attempting to delete the global marketplace source."
+ "Attempting to delete the global hub source."
)
self._move_and_reorder_table_items(
session, source_record, move_to=None, move_from=current_order
)
- def get_marketplace_source(self, session, name) -> schemas.IndexedMarketplaceSource:
- source_record = self._query(session, MarketplaceSource, name=name).one_or_none()
+ def get_hub_source(self, session, name) -> schemas.IndexedHubSource:
+ source_record = self._query(session, HubSource, name=name).one_or_none()
if not source_record:
raise mlrun.errors.MLRunNotFoundError(
- f"Marketplace source not found. name = {name}"
+ f"Hub source not found. name = {name}"
)
- return self._transform_marketplace_source_record_to_schema(source_record)
+ return self._transform_hub_source_record_to_schema(source_record)
def get_current_data_version(
self, session, raise_on_not_found=True
diff --git a/mlrun/api/db/sqldb/models/models_mysql.py b/mlrun/api/db/sqldb/models/models_mysql.py
index 344c449764ce..bc06b6b9c552 100644
--- a/mlrun/api/db/sqldb/models/models_mysql.py
+++ b/mlrun/api/db/sqldb/models/models_mysql.py
@@ -459,9 +459,9 @@ def full_object(self, value):
# TODO - convert to pickle, to avoid issues with non-json serializable fields such as datetime
self._full_object = json.dumps(value, default=str)
- class MarketplaceSource(Base, mlrun.utils.db.BaseModel):
- __tablename__ = "marketplace_sources"
- __table_args__ = (UniqueConstraint("name", name="_marketplace_sources_uc"),)
+ class HubSource(Base, mlrun.utils.db.BaseModel):
+ __tablename__ = "hub_sources"
+ __table_args__ = (UniqueConstraint("name", name="_hub_sources_uc"),)
id = Column(Integer, primary_key=True)
name = Column(String(255, collation=SQLCollationUtil.collation()))
diff --git a/mlrun/api/db/sqldb/models/models_sqlite.py b/mlrun/api/db/sqldb/models/models_sqlite.py
index 387cd58f56bb..ab7c576a89ae 100644
--- a/mlrun/api/db/sqldb/models/models_sqlite.py
+++ b/mlrun/api/db/sqldb/models/models_sqlite.py
@@ -425,9 +425,9 @@ def full_object(self):
def full_object(self, value):
self._full_object = json.dumps(value, default=str)
- class MarketplaceSource(Base, mlrun.utils.db.BaseModel):
- __tablename__ = "marketplace_sources"
- __table_args__ = (UniqueConstraint("name", name="_marketplace_sources_uc"),)
+ class HubSource(Base, mlrun.utils.db.BaseModel):
+ __tablename__ = "hub_sources"
+ __table_args__ = (UniqueConstraint("name", name="_hub_sources_uc"),)
id = Column(Integer, primary_key=True)
name = Column(String(255, collation=SQLCollationUtil.collation()))
diff --git a/mlrun/api/initial_data.py b/mlrun/api/initial_data.py
index 1282e6efc434..76c89e343edc 100644
--- a/mlrun/api/initial_data.py
+++ b/mlrun/api/initial_data.py
@@ -218,7 +218,7 @@ def _perform_data_migrations(db_session: sqlalchemy.orm.Session):
def _add_initial_data(db_session: sqlalchemy.orm.Session):
# FileDB is not really a thing anymore, so using SQLDB directly
db = mlrun.api.db.sqldb.db.SQLDB("")
- _add_default_marketplace_source_if_needed(db, db_session)
+ _add_default_hub_source_if_needed(db, db_session)
_add_data_version(db, db_session)
@@ -494,32 +494,32 @@ def _enrich_project_state(
db.store_project(db_session, project.metadata.name, project)
-def _add_default_marketplace_source_if_needed(
+def _add_default_hub_source_if_needed(
db: mlrun.api.db.sqldb.db.SQLDB, db_session: sqlalchemy.orm.Session
):
try:
- hub_marketplace_source = db.get_marketplace_source(
- db_session, config.marketplace.default_source.name
+ hub_marketplace_source = db.get_hub_source(
+ db_session, config.hub.default_source.name
)
except mlrun.errors.MLRunNotFoundError:
hub_marketplace_source = None
if not hub_marketplace_source:
- hub_source = mlrun.api.schemas.MarketplaceSource.generate_default_source()
- # hub_source will be None if the configuration has marketplace.default_source.create=False
+ hub_source = mlrun.api.schemas.HubSource.generate_default_source()
+ # hub_source will be None if the configuration has hub.default_source.create=False
if hub_source:
- logger.info("Adding default marketplace source")
- # Not using db.store_marketplace_source() since it doesn't allow changing the default marketplace source.
- hub_record = db._transform_marketplace_source_schema_to_record(
- mlrun.api.schemas.IndexedMarketplaceSource(
- index=mlrun.api.schemas.marketplace.last_source_index,
+ logger.info("Adding default hub source")
+ # Not using db.store_marketplace_source() since it doesn't allow changing the default hub source.
+ hub_record = db._transform_hub_source_schema_to_record(
+ mlrun.api.schemas.IndexedHubSource(
+ index=mlrun.api.schemas.hub.last_source_index,
source=hub_source,
)
)
db_session.add(hub_record)
db_session.commit()
else:
- logger.info("Not adding default marketplace source, per configuration")
+ logger.info("Not adding default hub source, per configuration")
return
diff --git a/mlrun/api/migrations_mysql/versions/28383af526f3_market_place_to_hub.py b/mlrun/api/migrations_mysql/versions/28383af526f3_market_place_to_hub.py
new file mode 100644
index 000000000000..8edf1db6f7aa
--- /dev/null
+++ b/mlrun/api/migrations_mysql/versions/28383af526f3_market_place_to_hub.py
@@ -0,0 +1,40 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+"""market_place_to_hub
+
+Revision ID: 28383af526f3
+Revises: c905d15bd91d
+Create Date: 2023-04-24 11:06:36.177314
+
+"""
+from alembic import op
+
+# revision identifiers, used by Alembic.
+revision = "28383af526f3"
+down_revision = "c905d15bd91d"
+branch_labels = None
+depends_on = None
+
+
+def upgrade():
+ # ### commands auto generated by Alembic - please adjust! ###
+ op.rename_table("marketplace_sources", "hub_sources")
+ # ### end Alembic commands ###
+
+
+def downgrade():
+ # ### commands auto generated by Alembic - please adjust! ###
+ op.rename_table("hub_sources", "marketplace_sources")
+ # ### end Alembic commands ###
diff --git a/mlrun/api/migrations_sqlite/versions/4acd9430b093_market_place_to_hub.py b/mlrun/api/migrations_sqlite/versions/4acd9430b093_market_place_to_hub.py
new file mode 100644
index 000000000000..553dbad93b9a
--- /dev/null
+++ b/mlrun/api/migrations_sqlite/versions/4acd9430b093_market_place_to_hub.py
@@ -0,0 +1,77 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+"""market_place_to_hub
+
+Revision ID: 4acd9430b093
+Revises: 959ae00528ad
+Create Date: 2023-04-26 22:41:59.726305
+
+"""
+import sqlalchemy as sa
+from alembic import op
+
+from mlrun.api.utils.db.sql_collation import SQLCollationUtil
+
+# revision identifiers, used by Alembic.
+revision = "4acd9430b093"
+down_revision = "959ae00528ad"
+branch_labels = None
+depends_on = None
+
+
+def upgrade():
+ # ### commands auto generated by Alembic - please adjust! ###
+ rename_hub_marketplace_table("marketplace_sources", "hub_sources")
+ # ### end Alembic commands ###
+
+
+def downgrade():
+ pass
+ # ### commands auto generated by Alembic - please adjust! ###
+ rename_hub_marketplace_table("hub_sources", "marketplace_sources")
+ # ### end Alembic commands ###
+
+
+def rename_hub_marketplace_table(current_name, new_name):
+ op.create_table(
+ new_name,
+ sa.Column("id", sa.Integer(), nullable=False),
+ sa.Column(
+ "name",
+ sa.String(255, collation=SQLCollationUtil.collation()),
+ nullable=True,
+ ),
+ sa.Column("index", sa.Integer(), nullable=True),
+ sa.Column("created", sa.TIMESTAMP(), nullable=True),
+ sa.Column("updated", sa.TIMESTAMP(), nullable=True),
+ sa.Column("object", sa.JSON(), nullable=True),
+ sa.PrimaryKeyConstraint("id"),
+ sa.UniqueConstraint("name", name=f"_{new_name}_uc"),
+ )
+ hub_sources = sa.sql.table(
+ new_name,
+ sa.Column("name", sa.String(255), nullable=True),
+ sa.Column("object", sa.JSON, nullable=True),
+ sa.Column("index", sa.Integer, nullable=True),
+ sa.Column("created", sa.TIMESTAMP, nullable=True),
+ sa.Column("updated", sa.TIMESTAMP, nullable=True),
+ )
+ connection = op.get_bind()
+ select_previous_table_data_query = connection.execute(
+ f"SELECT * FROM {current_name}"
+ )
+ previous_table_data = select_previous_table_data_query.fetchall()
+ op.bulk_insert(hub_sources, previous_table_data)
+ op.drop_table(current_name)
diff --git a/mlrun/api/schemas/__init__.py b/mlrun/api/schemas/__init__.py
index cd7fa547c14d..dbe176f90db7 100644
--- a/mlrun/api/schemas/__init__.py
+++ b/mlrun/api/schemas/__init__.py
@@ -80,16 +80,16 @@
)
from .function import FunctionState, PreemptionModes, SecurityContextEnrichmentModes
from .http import HTTPSessionRetryMode
-from .k8s import NodeSelectorOperator, Resources, ResourceSpec
-from .marketplace import (
- IndexedMarketplaceSource,
- MarketplaceCatalog,
- MarketplaceItem,
- MarketplaceObjectMetadata,
- MarketplaceSource,
- MarketplaceSourceSpec,
+from .hub import (
+ HubCatalog,
+ HubItem,
+ HubObjectMetadata,
+ HubSource,
+ HubSourceSpec,
+ IndexedHubSource,
last_source_index,
)
+from .k8s import NodeSelectorOperator, Resources, ResourceSpec
from .memory_reports import MostCommonObjectTypesReport, ObjectTypeReport
from .model_endpoints import (
Features,
diff --git a/mlrun/api/schemas/auth.py b/mlrun/api/schemas/auth.py
index e6968525779b..8e4bdde29e10 100644
--- a/mlrun/api/schemas/auth.py
+++ b/mlrun/api/schemas/auth.py
@@ -56,7 +56,7 @@ class AuthorizationResourceTypes(mlrun.api.utils.helpers.StrEnum):
run = "run"
model_endpoint = "model-endpoint"
pipeline = "pipeline"
- marketplace_source = "marketplace-source"
+ hub_source = "hub-source"
def to_resource_string(
self,
@@ -85,8 +85,8 @@ def to_resource_string(
AuthorizationResourceTypes.runtime_resource: "/projects/{project_name}/runtime-resources",
AuthorizationResourceTypes.model_endpoint: "/projects/{project_name}/model-endpoints/{resource_name}",
AuthorizationResourceTypes.pipeline: "/projects/{project_name}/pipelines/{resource_name}",
- # Marketplace sources are not project-scoped, and auth is globally on the sources endpoint.
- AuthorizationResourceTypes.marketplace_source: "/marketplace/sources",
+ # Hub sources are not project-scoped, and auth is globally on the sources endpoint.
+ AuthorizationResourceTypes.hub_source: "/hub/sources",
}[self].format(project_name=project_name, resource_name=resource_name)
diff --git a/mlrun/api/schemas/marketplace.py b/mlrun/api/schemas/hub.py
similarity index 59%
rename from mlrun/api/schemas/marketplace.py
rename to mlrun/api/schemas/hub.py
index c2ad9420e246..b1ad7ba589be 100644
--- a/mlrun/api/schemas/marketplace.py
+++ b/mlrun/api/schemas/hub.py
@@ -25,7 +25,7 @@
# Defining a different base class (not ObjectMetadata), as there's no project, and it differs enough to
# justify a new class
-class MarketplaceObjectMetadata(BaseModel):
+class HubObjectMetadata(BaseModel):
name: str
description: str = ""
labels: Optional[dict] = {}
@@ -37,24 +37,22 @@ class Config:
# Currently only functions are supported. Will add more in the future.
-class MarketplaceSourceType(mlrun.api.utils.helpers.StrEnum):
+class HubSourceType(mlrun.api.utils.helpers.StrEnum):
functions = "functions"
# Sources-related objects
-class MarketplaceSourceSpec(ObjectSpec):
+class HubSourceSpec(ObjectSpec):
path: str # URL to base directory, should include schema (s3://, etc...)
channel: str
credentials: Optional[dict] = {}
- object_type: MarketplaceSourceType = Field(
- MarketplaceSourceType.functions, const=True
- )
+ object_type: HubSourceType = Field(HubSourceType.functions, const=True)
-class MarketplaceSource(BaseModel):
- kind: ObjectKind = Field(ObjectKind.marketplace_source, const=True)
- metadata: MarketplaceObjectMetadata
- spec: MarketplaceSourceSpec
+class HubSource(BaseModel):
+ kind: ObjectKind = Field(ObjectKind.hub_source, const=True)
+ metadata: HubObjectMetadata
+ spec: HubSourceSpec
status: Optional[ObjectStatus] = ObjectStatus(state="created")
def get_full_uri(self, relative_path):
@@ -66,28 +64,26 @@ def get_full_uri(self, relative_path):
)
def get_catalog_uri(self):
- return self.get_full_uri(config.marketplace.catalog_filename)
+ return self.get_full_uri(config.hub.catalog_filename)
@classmethod
def generate_default_source(cls):
- if not config.marketplace.default_source.create:
+ if not config.hub.default_source.create:
return None
now = datetime.now(timezone.utc)
- hub_metadata = MarketplaceObjectMetadata(
- name=config.marketplace.default_source.name,
- description=config.marketplace.default_source.description,
+ hub_metadata = HubObjectMetadata(
+ name=config.hub.default_source.name,
+ description=config.hub.default_source.description,
created=now,
updated=now,
)
return cls(
metadata=hub_metadata,
- spec=MarketplaceSourceSpec(
- path=config.marketplace.default_source.url,
- channel=config.marketplace.default_source.channel,
- object_type=MarketplaceSourceType(
- config.marketplace.default_source.object_type
- ),
+ spec=HubSourceSpec(
+ path=config.hub.default_source.url,
+ channel=config.hub.default_source.channel,
+ object_type=HubSourceType(config.hub.default_source.object_type),
),
status=ObjectStatus(state="created"),
)
@@ -96,43 +92,43 @@ def generate_default_source(cls):
last_source_index = -1
-class IndexedMarketplaceSource(BaseModel):
+class IndexedHubSource(BaseModel):
index: int = last_source_index # Default last. Otherwise, must be > 0
- source: MarketplaceSource
+ source: HubSource
# Item-related objects
-class MarketplaceItemMetadata(MarketplaceObjectMetadata):
- source: MarketplaceSourceType = Field(MarketplaceSourceType.functions, const=True)
+class HubItemMetadata(HubObjectMetadata):
+ source: HubSourceType = Field(HubSourceType.functions, const=True)
version: str
tag: Optional[str]
def get_relative_path(self) -> str:
- if self.source == MarketplaceSourceType.functions:
- # This is needed since the marketplace deployment script modifies the paths to use _ instead of -.
+ if self.source == HubSourceType.functions:
+ # This is needed since the hub deployment script modifies the paths to use _ instead of -.
modified_name = self.name.replace("-", "_")
# Prefer using the tag if exists. Otherwise, use version.
version = self.tag or self.version
return f"{modified_name}/{version}/"
else:
raise mlrun.errors.MLRunInvalidArgumentError(
- f"Bad source for marketplace item - {self.source}"
+ f"Bad source for hub item - {self.source}"
)
-class MarketplaceItemSpec(ObjectSpec):
+class HubItemSpec(ObjectSpec):
item_uri: str
assets: Dict[str, str] = {}
-class MarketplaceItem(BaseModel):
- kind: ObjectKind = Field(ObjectKind.marketplace_item, const=True)
- metadata: MarketplaceItemMetadata
- spec: MarketplaceItemSpec
+class HubItem(BaseModel):
+ kind: ObjectKind = Field(ObjectKind.hub_item, const=True)
+ metadata: HubItemMetadata
+ spec: HubItemSpec
status: ObjectStatus
-class MarketplaceCatalog(BaseModel):
- kind: ObjectKind = Field(ObjectKind.marketplace_catalog, const=True)
+class HubCatalog(BaseModel):
+ kind: ObjectKind = Field(ObjectKind.hub_catalog, const=True)
channel: str
- catalog: List[MarketplaceItem]
+ catalog: List[HubItem]
diff --git a/mlrun/api/schemas/object.py b/mlrun/api/schemas/object.py
index e5f34746a7d6..8ec6a738efb1 100644
--- a/mlrun/api/schemas/object.py
+++ b/mlrun/api/schemas/object.py
@@ -75,6 +75,6 @@ class ObjectKind(mlrun.api.utils.helpers.StrEnum):
background_task = "BackgroundTask"
feature_vector = "FeatureVector"
model_endpoint = "model-endpoint"
- marketplace_source = "MarketplaceSource"
- marketplace_item = "MarketplaceItem"
- marketplace_catalog = "MarketplaceCatalog"
+ hub_source = "HubSource"
+ hub_item = "HubItem"
+ hub_catalog = "HubCatalog"
diff --git a/mlrun/config.py b/mlrun/config.py
index a32f49394e39..9630b2f8e383 100644
--- a/mlrun/config.py
+++ b/mlrun/config.py
@@ -446,8 +446,8 @@
"projects_prefix": "projects", # The UI link prefix for projects
"url": "", # remote/external mlrun UI url (for hyperlinks)
},
- "marketplace": {
- "k8s_secrets_project_name": "-marketplace-secrets",
+ "hub": {
+ "k8s_secrets_project_name": "-hub-secrets",
"catalog_filename": "catalog.json",
"default_source": {
# Set false to avoid creating a global source (for example in a dark site)
diff --git a/mlrun/db/base.py b/mlrun/db/base.py
index f98ca974056c..e794506e7aaf 100644
--- a/mlrun/db/base.py
+++ b/mlrun/db/base.py
@@ -529,31 +529,29 @@ def patch_model_endpoint(
pass
@abstractmethod
- def create_marketplace_source(
- self, source: Union[dict, schemas.IndexedMarketplaceSource]
- ):
+ def create_hub_source(self, source: Union[dict, schemas.IndexedHubSource]):
pass
@abstractmethod
- def store_marketplace_source(
- self, source_name: str, source: Union[dict, schemas.IndexedMarketplaceSource]
+ def store_hub_source(
+ self, source_name: str, source: Union[dict, schemas.IndexedHubSource]
):
pass
@abstractmethod
- def list_marketplace_sources(self):
+ def list_hub_sources(self):
pass
@abstractmethod
- def get_marketplace_source(self, source_name: str):
+ def get_hub_source(self, source_name: str):
pass
@abstractmethod
- def delete_marketplace_source(self, source_name: str):
+ def delete_hub_source(self, source_name: str):
pass
@abstractmethod
- def get_marketplace_catalog(
+ def get_hub_catalog(
self,
source_name: str,
version: str = None,
@@ -563,7 +561,7 @@ def get_marketplace_catalog(
pass
@abstractmethod
- def get_marketplace_item(
+ def get_hub_item(
self,
source_name: str,
item_name: str,
diff --git a/mlrun/db/httpdb.py b/mlrun/db/httpdb.py
index 7b35f7d75f4b..c34b044a3d23 100644
--- a/mlrun/db/httpdb.py
+++ b/mlrun/db/httpdb.py
@@ -2739,18 +2739,16 @@ def patch_model_endpoint(
params=attributes,
)
- def create_marketplace_source(
- self, source: Union[dict, schemas.IndexedMarketplaceSource]
- ):
+ def create_hub_source(self, source: Union[dict, schemas.IndexedHubSource]):
"""
- Add a new marketplace source.
+ Add a new hub source.
- MLRun maintains an ordered list of marketplace sources (“sources”) Each source has
+ MLRun maintains an ordered list of hub sources (“sources”) Each source has
its details registered and its order within the list. When creating a new source, the special order ``-1``
can be used to mark this source as last in the list. However, once the source is in the MLRun list,
its order will always be ``>0``.
- The global marketplace source always exists in the list, and is always the last source
+ The global hub source always exists in the list, and is always the last source
(``order = -1``). It cannot be modified nor can it be moved to another order in the list.
The source object may contain credentials which are needed to access the datastore where the source is stored.
@@ -2762,46 +2760,46 @@ def create_marketplace_source(
import mlrun.api.schemas
# Add a private source as the last one (will be #1 in the list)
- private_source = mlrun.api.schemas.IndexedMarketplaceSource(
+ private_source = mlrun.api.schemas.IndexedHubeSource(
order=-1,
- source=mlrun.api.schemas.MarketplaceSource(
- metadata=mlrun.api.schemas.MarketplaceObjectMetadata(name="priv", description="a private source"),
- spec=mlrun.api.schemas.MarketplaceSourceSpec(path="/local/path/to/source", channel="development")
+ source=mlrun.api.schemas.HubSource(
+ metadata=mlrun.api.schemas.HubObjectMetadata(name="priv", description="a private source"),
+ spec=mlrun.api.schemas.HubSourceSpec(path="/local/path/to/source", channel="development")
)
)
- db.create_marketplace_source(private_source)
+ db.create_hub_source(private_source)
# Add another source as 1st in the list - will push previous one to be #2
- another_source = mlrun.api.schemas.IndexedMarketplaceSource(
+ another_source = mlrun.api.schemas.IndexedHubSource(
order=1,
- source=mlrun.api.schemas.MarketplaceSource(
- metadata=mlrun.api.schemas.MarketplaceObjectMetadata(name="priv-2", description="another source"),
- spec=mlrun.api.schemas.MarketplaceSourceSpec(
+ source=mlrun.api.schemas.HubSource(
+ metadata=mlrun.api.schemas.HubObjectMetadata(name="priv-2", description="another source"),
+ spec=mlrun.api.schemas.HubSourceSpec(
path="/local/path/to/source/2",
channel="development",
credentials={...}
)
)
)
- db.create_marketplace_source(another_source)
+ db.create_hub_source(another_source)
:param source: The source and its order, of type
- :py:class:`~mlrun.api.schemas.marketplace.IndexedMarketplaceSource`, or in dictionary form.
+ :py:class:`~mlrun.api.schemas.hub.IndexedHubSource`, or in dictionary form.
:returns: The source object as inserted into the database, with credentials stripped.
"""
- path = "marketplace/sources"
- if isinstance(source, schemas.IndexedMarketplaceSource):
+ path = "hub/sources"
+ if isinstance(source, schemas.IndexedHubSource):
source = source.dict()
response = self.api_call(method="POST", path=path, json=source)
- return schemas.IndexedMarketplaceSource(**response.json())
+ return schemas.IndexedHubSource(**response.json())
- def store_marketplace_source(
- self, source_name: str, source: Union[dict, schemas.IndexedMarketplaceSource]
+ def store_hub_source(
+ self, source_name: str, source: Union[dict, schemas.IndexedHubSource]
):
"""
- Create or replace a marketplace source.
+ Create or replace a hub source.
For an example of the source format and explanation of the source order logic,
- please see :py:func:`~create_marketplace_source`. This method can be used to modify the source itself or its
+ please see :py:func:`~create_hub_source`. This method can be used to modify the source itself or its
order in the list of sources.
:param source_name: Name of the source object to modify/create. It must match the ``source.metadata.name``
@@ -2809,47 +2807,47 @@ def store_marketplace_source(
:param source: Source object to store in the database.
:returns: The source object as stored in the DB.
"""
- path = f"marketplace/sources/{source_name}"
- if isinstance(source, schemas.IndexedMarketplaceSource):
+ path = f"hub/sources/{source_name}"
+ if isinstance(source, schemas.IndexedHubSource):
source = source.dict()
response = self.api_call(method="PUT", path=path, json=source)
- return schemas.IndexedMarketplaceSource(**response.json())
+ return schemas.IndexedHubSource(**response.json())
- def list_marketplace_sources(self):
+ def list_hub_sources(self):
"""
- List marketplace sources in the MLRun DB.
+ List hub sources in the MLRun DB.
"""
- path = "marketplace/sources"
+ path = "hub/sources"
response = self.api_call(method="GET", path=path).json()
results = []
for item in response:
- results.append(schemas.IndexedMarketplaceSource(**item))
+ results.append(schemas.IndexedHubSource(**item))
return results
- def get_marketplace_source(self, source_name: str):
+ def get_hub_source(self, source_name: str):
"""
- Retrieve a marketplace source from the DB.
+ Retrieve a hub source from the DB.
- :param source_name: Name of the marketplace source to retrieve.
+ :param source_name: Name of the hub source to retrieve.
"""
- path = f"marketplace/sources/{source_name}"
+ path = f"hub/sources/{source_name}"
response = self.api_call(method="GET", path=path)
- return schemas.IndexedMarketplaceSource(**response.json())
+ return schemas.IndexedHubSource(**response.json())
- def delete_marketplace_source(self, source_name: str):
+ def delete_hub_source(self, source_name: str):
"""
- Delete a marketplace source from the DB.
+ Delete a hub source from the DB.
The source will be deleted from the list, and any following sources will be promoted - for example, if the
1st source is deleted, the 2nd source will become #1 in the list.
- The global marketplace source cannot be deleted.
+ The global hub source cannot be deleted.
- :param source_name: Name of the marketplace source to delete.
+ :param source_name: Name of the hub source to delete.
"""
- path = f"marketplace/sources/{source_name}"
+ path = f"hub/sources/{source_name}"
self.api_call(method="DELETE", path=path)
- def get_marketplace_catalog(
+ def get_hub_catalog(
self,
source_name: str,
version: str = None,
@@ -2857,29 +2855,29 @@ def get_marketplace_catalog(
force_refresh: bool = False,
):
"""
- Retrieve the item catalog for a specified marketplace source.
+ Retrieve the item catalog for a specified hub source.
The list of items can be filtered according to various filters, using item's metadata to filter.
:param source_name: Name of the source.
:param version: Filter items according to their version.
:param tag: Filter items based on tag.
- :param force_refresh: Make the server fetch the catalog from the actual marketplace source,
+ :param force_refresh: Make the server fetch the catalog from the actual hub source,
rather than rely on cached information which may exist from previous get requests. For example,
if the source was re-built,
this will make the server get the updated information. Default is ``False``.
- :returns: :py:class:`~mlrun.api.schemas.marketplace.MarketplaceCatalog` object, which is essentially a list
- of :py:class:`~mlrun.api.schemas.marketplace.MarketplaceItem` entries.
+ :returns: :py:class:`~mlrun.api.schemas.hub.HubCatalog` object, which is essentially a list
+ of :py:class:`~mlrun.api.schemas.hub.HubItem` entries.
"""
- path = (f"marketplace/sources/{source_name}/items",)
+ path = (f"hub/sources/{source_name}/items",)
params = {
"version": version,
"tag": tag,
"force-refresh": force_refresh,
}
response = self.api_call(method="GET", path=path, params=params)
- return schemas.MarketplaceCatalog(**response.json())
+ return schemas.HubCatalog(**response.json())
- def get_marketplace_item(
+ def get_hub_item(
self,
source_name: str,
item_name: str,
@@ -2888,27 +2886,27 @@ def get_marketplace_item(
force_refresh: bool = False,
):
"""
- Retrieve a specific marketplace item.
+ Retrieve a specific hub item.
:param source_name: Name of source.
:param item_name: Name of the item to retrieve, as it appears in the catalog.
:param version: Get a specific version of the item. Default is ``None``.
:param tag: Get a specific version of the item identified by tag. Default is ``latest``.
- :param force_refresh: Make the server fetch the information from the actual marketplace
+ :param force_refresh: Make the server fetch the information from the actual hub
source, rather than
rely on cached information. Default is ``False``.
- :returns: :py:class:`~mlrun.api.schemas.marketplace.MarketplaceItem`.
+ :returns: :py:class:`~mlrun.api.schemas.hub.HubItem`.
"""
- path = (f"marketplace/sources/{source_name}/items/{item_name}",)
+ path = (f"hub/sources/{source_name}/items/{item_name}",)
params = {
"version": version,
"tag": tag,
"force-refresh": force_refresh,
}
response = self.api_call(method="GET", path=path, params=params)
- return schemas.MarketplaceItem(**response.json())
+ return schemas.HubItem(**response.json())
- def get_marketplace_asset(
+ def get_hub_asset(
self,
source_name: str,
item_name: str,
@@ -2917,7 +2915,7 @@ def get_marketplace_asset(
tag: str = "latest",
):
"""
- Get marketplace asset from item.
+ Get hub asset from item.
:param source_name: Name of source.
:param item_name: Name of the item which holds the asset.
@@ -2927,9 +2925,7 @@ def get_marketplace_asset(
:return: http response with the asset in the content attribute
"""
- path = (
- f"marketplace/sources/{source_name}/items/{item_name}/assets/{asset_name}",
- )
+ path = (f"hub/sources/{source_name}/items/{item_name}/assets/{asset_name}",)
params = {
"version": version,
"tag": tag,
diff --git a/mlrun/db/nopdb.py b/mlrun/db/nopdb.py
index 8d92590d99b9..0f7a232086da 100644
--- a/mlrun/db/nopdb.py
+++ b/mlrun/db/nopdb.py
@@ -417,26 +417,24 @@ def get_model_endpoint(
def patch_model_endpoint(self, project: str, endpoint_id: str, attributes: dict):
pass
- def create_marketplace_source(
- self, source: Union[dict, schemas.IndexedMarketplaceSource]
- ):
+ def create_hub_source(self, source: Union[dict, schemas.IndexedHubSource]):
pass
- def store_marketplace_source(
- self, source_name: str, source: Union[dict, schemas.IndexedMarketplaceSource]
+ def store_hub_source(
+ self, source_name: str, source: Union[dict, schemas.IndexedHubSource]
):
pass
- def list_marketplace_sources(self):
+ def list_hub_sources(self):
pass
- def get_marketplace_source(self, source_name: str):
+ def get_hub_source(self, source_name: str):
pass
- def delete_marketplace_source(self, source_name: str):
+ def delete_hub_source(self, source_name: str):
pass
- def get_marketplace_catalog(
+ def get_hub_catalog(
self,
source_name: str,
channel: str = None,
@@ -446,7 +444,7 @@ def get_marketplace_catalog(
):
pass
- def get_marketplace_item(
+ def get_hub_item(
self,
source_name: str,
item_name: str,
diff --git a/mlrun/db/sqldb.py b/mlrun/db/sqldb.py
index 19135f9cfe75..2a5e97957b12 100644
--- a/mlrun/db/sqldb.py
+++ b/mlrun/db/sqldb.py
@@ -859,26 +859,24 @@ def patch_model_endpoint(
):
raise NotImplementedError()
- def create_marketplace_source(
- self, source: Union[dict, schemas.IndexedMarketplaceSource]
- ):
+ def create_hub_source(self, source: Union[dict, schemas.IndexedHubSource]):
raise NotImplementedError()
- def store_marketplace_source(
- self, source_name: str, source: Union[dict, schemas.IndexedMarketplaceSource]
+ def store_hub_source(
+ self, source_name: str, source: Union[dict, schemas.IndexedHubSource]
):
raise NotImplementedError()
- def list_marketplace_sources(self):
+ def list_hub_sources(self):
raise NotImplementedError()
- def get_marketplace_source(self, source_name: str):
+ def get_hub_source(self, source_name: str):
raise NotImplementedError()
- def delete_marketplace_source(self, source_name: str):
+ def delete_hub_source(self, source_name: str):
raise NotImplementedError()
- def get_marketplace_catalog(
+ def get_hub_catalog(
self,
source_name: str,
version: str = None,
@@ -887,7 +885,7 @@ def get_marketplace_catalog(
):
raise NotImplementedError()
- def get_marketplace_item(
+ def get_hub_item(
self,
source_name: str,
item_name: str,
diff --git a/mlrun/projects/operations.py b/mlrun/projects/operations.py
index 7bbfce59ce1e..b9aeb9945319 100644
--- a/mlrun/projects/operations.py
+++ b/mlrun/projects/operations.py
@@ -98,7 +98,7 @@ def run_function(
example (use with project)::
- # create a project with two functions (local and from marketplace)
+ # create a project with two functions (local and from hub)
project = mlrun.new_project(project_name, "./proj)
project.set_function("mycode.py", "myfunc", image="mlrun/mlrun")
project.set_function("hub://auto-trainer", "train")
diff --git a/mlrun/projects/project.py b/mlrun/projects/project.py
index e1a1565047b9..95073d408c69 100644
--- a/mlrun/projects/project.py
+++ b/mlrun/projects/project.py
@@ -114,7 +114,7 @@ def new_project(
example::
- # create a project with local and marketplace functions, a workflow, and an artifact
+ # create a project with local and hub functions, a workflow, and an artifact
project = mlrun.new_project("myproj", "./", init_git=True, description="my new project")
project.set_function('prep_data.py', 'prep-data', image='mlrun/mlrun', handler='prep_data')
project.set_function('hub://auto-trainer', 'train')
@@ -2212,7 +2212,7 @@ def run_function(
example (use with project)::
- # create a project with two functions (local and from marketplace)
+ # create a project with two functions (local and from hub)
project = mlrun.new_project(project_name, "./proj")
project.set_function("mycode.py", "myfunc", image="mlrun/mlrun")
project.set_function("hub://auto-trainer", "train")
diff --git a/tests/api/api/marketplace/__init__.py b/tests/api/api/hub/__init__.py
similarity index 100%
rename from tests/api/api/marketplace/__init__.py
rename to tests/api/api/hub/__init__.py
diff --git a/tests/api/api/marketplace/functions/channel/catalog.json b/tests/api/api/hub/functions/channel/catalog.json
similarity index 100%
rename from tests/api/api/marketplace/functions/channel/catalog.json
rename to tests/api/api/hub/functions/channel/catalog.json
diff --git a/tests/api/api/marketplace/functions/channel/dev_function/latest/static/my_html.html b/tests/api/api/hub/functions/channel/dev_function/latest/static/my_html.html
similarity index 100%
rename from tests/api/api/marketplace/functions/channel/dev_function/latest/static/my_html.html
rename to tests/api/api/hub/functions/channel/dev_function/latest/static/my_html.html
diff --git a/tests/api/api/marketplace/test_marketplace.py b/tests/api/api/hub/test_hub.py
similarity index 80%
rename from tests/api/api/marketplace/test_marketplace.py
rename to tests/api/api/hub/test_hub.py
index 90fd7f5be02c..46a7617ef8ab 100644
--- a/tests/api/api/marketplace/test_marketplace.py
+++ b/tests/api/api/hub/test_hub.py
@@ -35,7 +35,7 @@ def _generate_source_dict(index, name, credentials=None):
return {
"index": index,
"source": {
- "kind": "MarketplaceSource",
+ "kind": "HubSource",
"metadata": {"name": name, "description": "A test", "labels": None},
"spec": {
"path": path,
@@ -53,7 +53,7 @@ def _assert_sources_in_correct_order(client, expected_order, exclude_paths=None)
"root['metadata']['created']",
"root['spec']['object_type']",
]
- response = client.get("marketplace/sources")
+ response = client.get("hub/sources")
assert response.status_code == HTTPStatus.OK.value
json_response = response.json()
# Default source is not in the expected data
@@ -70,29 +70,29 @@ def _assert_sources_in_correct_order(client, expected_order, exclude_paths=None)
)
-def test_marketplace_source_apis(
+def test_hub_source_apis(
db: Session,
client: TestClient,
k8s_secrets_mock: tests.api.conftest.K8sSecretsMock,
) -> None:
# Make sure the default source is there.
- response = client.get("marketplace/sources")
+ response = client.get("hub/sources")
assert response.status_code == HTTPStatus.OK.value
json_response = response.json()
assert (
len(json_response) == 1
and json_response[0]["index"] == -1
and json_response[0]["source"]["metadata"]["name"]
- == config.marketplace.default_source.name
+ == config.hub.default_source.name
)
source_1 = _generate_source_dict(1, "source_1")
- response = client.post("marketplace/sources", json=source_1)
+ response = client.post("hub/sources", json=source_1)
assert response.status_code == HTTPStatus.CREATED.value
# Modify existing source with a new field
source_1["source"]["metadata"]["something_new"] = 42
- response = client.put("marketplace/sources/source_1", json=source_1)
+ response = client.put("hub/sources/source_1", json=source_1)
assert response.status_code == HTTPStatus.OK.value
exclude_paths = [
"root['metadata']['updated']",
@@ -108,12 +108,12 @@ def test_marketplace_source_apis(
# Insert in 1st place, pushing source_1 to be #2
source_2 = _generate_source_dict(1, "source_2")
- response = client.put("marketplace/sources/source_2", json=source_2)
+ response = client.put("hub/sources/source_2", json=source_2)
assert response.status_code == HTTPStatus.OK.value
# Insert last, making it #3
source_3 = _generate_source_dict(-1, "source_3")
- response = client.post("marketplace/sources", json=source_3)
+ response = client.post("hub/sources", json=source_3)
assert response.status_code == HTTPStatus.CREATED.value
expected_response = {
@@ -125,7 +125,7 @@ def test_marketplace_source_apis(
# Change order for existing source (3->1)
source_3["index"] = 1
- response = client.put("marketplace/sources/source_3", json=source_3)
+ response = client.put("hub/sources/source_3", json=source_3)
assert response.status_code == HTTPStatus.OK.value
expected_response = {
1: source_3,
@@ -134,7 +134,7 @@ def test_marketplace_source_apis(
}
_assert_sources_in_correct_order(client, expected_response)
- response = client.delete("marketplace/sources/source_2")
+ response = client.delete("hub/sources/source_2")
assert response.status_code == HTTPStatus.NO_CONTENT.value
expected_response = {
@@ -145,27 +145,25 @@ def test_marketplace_source_apis(
# Negative tests
# Try to delete the default source.
- response = client.delete(
- f"marketplace/sources/{config.marketplace.default_source.name}"
- )
+ response = client.delete(f"hub/sources/{config.hub.default_source.name}")
assert response.status_code == HTTPStatus.BAD_REQUEST.value
# Try to store an object with invalid order
source_2["index"] = 42
- response = client.post("marketplace/sources", json=source_2)
+ response = client.post("hub/sources", json=source_2)
assert response.status_code == HTTPStatus.BAD_REQUEST.value
-def test_marketplace_credentials_removed_from_db(
+def test_hub_credentials_removed_from_db(
db: Session, client: TestClient, k8s_secrets_mock: tests.api.conftest.K8sSecretsMock
) -> None:
# Validate that a source with credentials is stored (and retrieved back) without them, while the creds
# are stored in the k8s secret.
credentials = {"secret1": "value1", "another-secret": "42"}
source_1 = _generate_source_dict(-1, "source_1", credentials)
- response = client.post("marketplace/sources", json=source_1)
+ response = client.post("hub/sources", json=source_1)
assert response.status_code == HTTPStatus.CREATED.value
- response = client.get("marketplace/sources/source_1")
+ response = client.get("hub/sources/source_1")
assert response.status_code == HTTPStatus.OK.value
object_dict = response.json()
@@ -183,20 +181,18 @@ def test_marketplace_credentials_removed_from_db(
== {}
)
expected_credentials = {
- mlrun.api.crud.Marketplace()._generate_credentials_secret_key(
- "source_1", key
- ): value
+ mlrun.api.crud.Hub()._generate_credentials_secret_key("source_1", key): value
for key, value in credentials.items()
}
k8s_secrets_mock.assert_project_secrets(
- config.marketplace.k8s_secrets_project_name, expected_credentials
+ config.hub.k8s_secrets_project_name, expected_credentials
)
-def test_marketplace_source_manager(
+def test_hub_source_manager(
k8s_secrets_mock: tests.api.conftest.K8sSecretsMock,
) -> None:
- manager = mlrun.api.crud.Marketplace()
+ manager = mlrun.api.crud.Hub()
credentials = {"secret1": "value1", "secret2": "value2"}
expected_credentials = {}
@@ -204,28 +200,26 @@ def test_marketplace_source_manager(
source_dict = _generate_source_dict(i, f"source_{i}", credentials)
expected_credentials.update(
{
- mlrun.api.crud.Marketplace()._generate_credentials_secret_key(
+ mlrun.api.crud.Hub()._generate_credentials_secret_key(
f"source_{i}", key
): value
for key, value in credentials.items()
}
)
- source_object = mlrun.api.schemas.MarketplaceSource(**source_dict["source"])
+ source_object = mlrun.api.schemas.HubSource(**source_dict["source"])
manager.add_source(source_object)
k8s_secrets_mock.assert_project_secrets(
- config.marketplace.k8s_secrets_project_name, expected_credentials
+ config.hub.k8s_secrets_project_name, expected_credentials
)
manager.remove_source("source_1")
for key in credentials:
expected_credentials.pop(
- mlrun.api.crud.Marketplace()._generate_credentials_secret_key(
- "source_1", key
- )
+ mlrun.api.crud.Hub()._generate_credentials_secret_key("source_1", key)
)
k8s_secrets_mock.assert_project_secrets(
- config.marketplace.k8s_secrets_project_name, expected_credentials
+ config.hub.k8s_secrets_project_name, expected_credentials
)
# Test catalog retrieval, with various filters
@@ -252,12 +246,12 @@ def test_marketplace_source_manager(
assert item.metadata.name == "prod_function" and item.metadata.version == "1.0.0"
-def test_marketplace_default_source(
+def test_hub_default_source(
k8s_secrets_mock: tests.api.conftest.K8sSecretsMock,
) -> None:
# This test validates that the default source is valid is its catalog and objects can be retrieved.
- manager = mlrun.api.crud.Marketplace()
- source_object = mlrun.api.schemas.MarketplaceSource.generate_default_source()
+ manager = mlrun.api.crud.Hub()
+ source_object = mlrun.api.schemas.HubSource.generate_default_source()
catalog = manager.get_source_catalog(source_object)
assert len(catalog.catalog) > 0
print(f"Retrieved function catalog. Has {len(catalog.catalog)} functions in it.")
@@ -282,19 +276,19 @@ def test_marketplace_default_source(
assert yaml_function_name == function_modified_name
-def test_marketplace_catalog_apis(
+def test_hub_catalog_apis(
db: Session, client: TestClient, k8s_secrets_mock: tests.api.conftest.K8sSecretsMock
) -> None:
# Get the global hub source-name
- sources = client.get("marketplace/sources").json()
+ sources = client.get("hub/sources").json()
source_name = sources[0]["source"]["metadata"]["name"]
- catalog = client.get(f"marketplace/sources/{source_name}/items").json()
+ catalog = client.get(f"hub/sources/{source_name}/items").json()
item = random.choice(catalog["catalog"])
url = item["spec"]["item_uri"] + "src/function.yaml"
function_yaml = client.get(
- f"marketplace/sources/{source_name}/item-object", params={"url": url}
+ f"hub/sources/{source_name}/item-object", params={"url": url}
)
function_dict = yaml.safe_load(function_yaml.content)
@@ -307,7 +301,7 @@ def test_marketplace_catalog_apis(
assert yaml_function_name == function_modified_name
-def test_marketplace_get_asset_from_default_source(
+def test_hub_get_asset_from_default_source(
db: Session, client: TestClient, k8s_secrets_mock: tests.api.conftest.K8sSecretsMock
) -> None:
possible_assets = [
@@ -316,37 +310,37 @@ def test_marketplace_get_asset_from_default_source(
("example", "application/octet-stream"),
("function", "application/octet-stream"),
]
- sources = client.get("marketplace/sources").json()
+ sources = client.get("hub/sources").json()
source_name = sources[0]["source"]["metadata"]["name"]
- catalog = client.get(f"marketplace/sources/{source_name}/items").json()
+ catalog = client.get(f"hub/sources/{source_name}/items").json()
for _ in range(10):
item = random.choice(catalog["catalog"])
asset_name, expected_content_type = random.choice(possible_assets)
response = client.get(
- f"marketplace/sources/{source_name}/items/{item['metadata']['name']}/assets/{asset_name}"
+ f"hub/sources/{source_name}/items/{item['metadata']['name']}/assets/{asset_name}"
)
assert response.status_code == http.HTTPStatus.OK.value
assert response.headers["content-type"] == expected_content_type
-def test_marketplace_get_asset(
+def test_hub_get_asset(
k8s_secrets_mock: tests.api.conftest.K8sSecretsMock,
) -> None:
- manager = mlrun.api.crud.Marketplace()
+ manager = mlrun.api.crud.Hub()
- # Adding marketplace source with credentials:
+ # Adding hub source with credentials:
credentials = {"secret": "value"}
source_dict = _generate_source_dict(1, "source", credentials)
expected_credentials = {
- mlrun.api.crud.Marketplace()._generate_credentials_secret_key(
+ mlrun.api.crud.Hub()._generate_credentials_secret_key(
"source", "secret"
): credentials["secret"]
}
- source_object = mlrun.api.schemas.MarketplaceSource(**source_dict["source"])
+ source_object = mlrun.api.schemas.HubSource(**source_dict["source"])
manager.add_source(source_object)
k8s_secrets_mock.assert_project_secrets(
- config.marketplace.k8s_secrets_project_name, expected_credentials
+ config.hub.k8s_secrets_project_name, expected_credentials
)
# getting asset:
catalog = manager.get_source_catalog(source_object)
diff --git a/tests/api/api/test_projects.py b/tests/api/api/test_projects.py
index f3960ce218fd..0959abf13533 100644
--- a/tests/api/api/test_projects.py
+++ b/tests/api/api/test_projects.py
@@ -1163,7 +1163,7 @@ def _assert_db_resources_in_project(
for cls in _classes:
# User support is not really implemented or in use
# Run tags support is not really implemented or in use
- # Marketplace sources is not a project-level table, and hence is not relevant here.
+ # Hub sources is not a project-level table, and hence is not relevant here.
# Version is not a project-level table, and hence is not relevant here.
# Features and Entities are not directly linked to project since they are sub-entity of feature-sets
# Logs are saved as files, the DB table is not really in use
@@ -1171,7 +1171,7 @@ def _assert_db_resources_in_project(
if (
cls.__name__ == "User"
or cls.__tablename__ == "runs_tags"
- or cls.__tablename__ == "marketplace_sources"
+ or cls.__tablename__ == "hub_sources"
or cls.__tablename__ == "data_versions"
or cls.__name__ == "Feature"
or cls.__name__ == "Entity"
diff --git a/tests/integration/sdk_api/hub/__init__.py b/tests/integration/sdk_api/hub/__init__.py
new file mode 100644
index 000000000000..b3085be1eb56
--- /dev/null
+++ b/tests/integration/sdk_api/hub/__init__.py
@@ -0,0 +1,14 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
diff --git a/tests/integration/sdk_api/marketplace/test_marketplace.py b/tests/integration/sdk_api/hub/test_hub.py
similarity index 67%
rename from tests/integration/sdk_api/marketplace/test_marketplace.py
rename to tests/integration/sdk_api/hub/test_hub.py
index a39f60618071..cf2aa79b453d 100644
--- a/tests/integration/sdk_api/marketplace/test_marketplace.py
+++ b/tests/integration/sdk_api/hub/test_hub.py
@@ -18,10 +18,10 @@
import tests.integration.sdk_api.base
-class TestMarketplace(tests.integration.sdk_api.base.TestMLRunIntegration):
+class TestHub(tests.integration.sdk_api.base.TestMLRunIntegration):
@staticmethod
def _assert_source_lists_match(expected_response):
- response = mlrun.get_run_db().list_marketplace_sources()
+ response = mlrun.get_run_db().list_hub_sources()
exclude_paths = [
"root['source']['metadata']['updated']",
@@ -37,50 +37,50 @@ def _assert_source_lists_match(expected_response):
== {}
)
- def test_marketplace(self):
+ def test_hub(self):
db = mlrun.get_run_db()
- default_source = mlrun.api.schemas.IndexedMarketplaceSource(
+ default_source = mlrun.api.schemas.IndexedHubSource(
index=-1,
- source=mlrun.api.schemas.MarketplaceSource.generate_default_source(),
+ source=mlrun.api.schemas.HubSource.generate_default_source(),
)
self._assert_source_lists_match([default_source])
- new_source = mlrun.api.schemas.IndexedMarketplaceSource(
- source=mlrun.api.schemas.MarketplaceSource(
- metadata=mlrun.api.schemas.MarketplaceObjectMetadata(
+ new_source = mlrun.api.schemas.IndexedHubSource(
+ source=mlrun.api.schemas.HubSource(
+ metadata=mlrun.api.schemas.HubObjectMetadata(
name="source-1", description="a private source"
),
- spec=mlrun.api.schemas.MarketplaceSourceSpec(
+ spec=mlrun.api.schemas.HubSourceSpec(
path="/local/path/to/source", channel="development"
),
)
)
- db.create_marketplace_source(new_source)
+ db.create_hub_source(new_source)
new_source.index = 1
self._assert_source_lists_match([new_source, default_source])
- new_source_2 = mlrun.api.schemas.IndexedMarketplaceSource(
+ new_source_2 = mlrun.api.schemas.IndexedHubSource(
index=1,
- source=mlrun.api.schemas.MarketplaceSource(
- metadata=mlrun.api.schemas.MarketplaceObjectMetadata(
+ source=mlrun.api.schemas.HubSource(
+ metadata=mlrun.api.schemas.HubObjectMetadata(
name="source-2", description="2nd private source"
),
- spec=mlrun.api.schemas.MarketplaceSourceSpec(
+ spec=mlrun.api.schemas.HubSourceSpec(
path="/local/path/to/source", channel="prod"
),
),
)
- db.create_marketplace_source(new_source_2)
+ db.create_hub_source(new_source_2)
new_source.index = 2
self._assert_source_lists_match([new_source_2, new_source, default_source])
new_source.index = 1
- db.store_marketplace_source(new_source.source.metadata.name, new_source)
+ db.store_hub_source(new_source.source.metadata.name, new_source)
new_source_2.index = 2
self._assert_source_lists_match([new_source, new_source_2, default_source])
- db.delete_marketplace_source("source-1")
+ db.delete_hub_source("source-1")
new_source_2.index = 1
self._assert_source_lists_match([new_source_2, default_source])
diff --git a/tests/system/demos/churn/assets/data_clean_function.py b/tests/system/demos/churn/assets/data_clean_function.py
index f32b631b7be2..45cc2da4920b 100644
--- a/tests/system/demos/churn/assets/data_clean_function.py
+++ b/tests/system/demos/churn/assets/data_clean_function.py
@@ -63,7 +63,7 @@ def data_clean(
TODO:
* parallelize where possible
* more abstraction (more parameters, chain sklearn transformers)
- * convert to marketplace function
+ * convert to hub function
:param context: the function execution context
:param src: an artifact or file path
diff --git a/tests/system/model_monitoring/test_model_monitoring.py b/tests/system/model_monitoring/test_model_monitoring.py
index d19d2b86756c..f2617e9f4a22 100644
--- a/tests/system/model_monitoring/test_model_monitoring.py
+++ b/tests/system/model_monitoring/test_model_monitoring.py
@@ -382,7 +382,7 @@ def test_model_monitoring_with_regression(self):
fv, target=mlrun.datastore.targets.ParquetTarget()
)
- # Train the model using the auto trainer from the marketplace
+ # Train the model using the auto trainer from the hub
train = mlrun.import_function("hub://auto-trainer", new_name="train")
train.deploy()
model_class = "sklearn.linear_model.LinearRegression"
@@ -460,7 +460,7 @@ def test_model_monitoring_with_regression(self):
assert batch_job.cron_trigger.hour == "*/3"
# TODO: uncomment the following assertion once the auto trainer function
- # from mlrun marketplace is upgraded to 1.0.8
+ # from mlrun hub is upgraded to 1.0.8
# assert len(model_obj.spec.feature_stats) == len(
# model_endpoint.spec.feature_names
# ) + len(model_endpoint.spec.label_names)
@@ -543,7 +543,7 @@ def test_model_monitoring_voting_ensemble(self):
"sklearn_AdaBoostClassifier": "sklearn.ensemble.AdaBoostClassifier",
}
- # Import the auto trainer function from the marketplace (hub://)
+ # Import the auto trainer function from the hub (hub://)
train = mlrun.import_function("hub://auto-trainer")
for name, pkg in model_names.items():
From f1d4a543d117cc87b09ebc733b3e4bd3d7e4ceb5 Mon Sep 17 00:00:00 2001
From: daniels290813 <78727943+daniels290813@users.noreply.github.com>
Date: Thu, 4 May 2023 09:51:32 +0300
Subject: [PATCH 086/334] [Docs] Fix tutorials sklearn bump version (#3437)
---
docs/tutorial/01-mlrun-basics.ipynb | 4 ++--
docs/tutorial/02-model-training.ipynb | 2 +-
2 files changed, 3 insertions(+), 3 deletions(-)
diff --git a/docs/tutorial/01-mlrun-basics.ipynb b/docs/tutorial/01-mlrun-basics.ipynb
index ea9d70280a20..2e7eea0ac08d 100644
--- a/docs/tutorial/01-mlrun-basics.ipynb
+++ b/docs/tutorial/01-mlrun-basics.ipynb
@@ -67,7 +67,7 @@
"\n",
"**Before you start, make sure the MLRun client package is installed and configured properly:**\n",
"\n",
- "This notebook uses sklearn. If it is not installed in your environment run `!pip install scikit-learn~=1.0`."
+ "This notebook uses sklearn. If it is not installed in your environment run `!pip install scikit-learn~=1.2`."
]
},
{
@@ -82,7 +82,7 @@
"outputs": [],
"source": [
"# Install MLRun and sklearn, run this only once (restart the notebook after the install !!!)\n",
- "%pip install mlrun scikit-learn~=1.0"
+ "%pip install mlrun scikit-learn~=1.2"
]
},
{
diff --git a/docs/tutorial/02-model-training.ipynb b/docs/tutorial/02-model-training.ipynb
index d9facb1a94e9..86042167d28a 100644
--- a/docs/tutorial/02-model-training.ipynb
+++ b/docs/tutorial/02-model-training.ipynb
@@ -21,7 +21,7 @@
"\n",
"## MLRun installation and configuration\n",
"\n",
- "Before running this notebook make sure `mlrun` and `sklearn` packages are installed (`pip install mlrun scikit-learn~=1.0`) and that you have configured the access to the MLRun service. "
+ "Before running this notebook make sure `mlrun` and `sklearn` packages are installed (`pip install mlrun scikit-learn~=1.2`) and that you have configured the access to the MLRun service. "
]
},
{
From 1695e6595496c0f525a31f6583450f77e279fbaa Mon Sep 17 00:00:00 2001
From: Adam
Date: Thu, 4 May 2023 10:54:58 +0300
Subject: [PATCH 087/334] MLRun CE Deployer Script (#3435)
* ce deployer
* ce deployer
* Fixes
* oops
* zips
* Many changes
* oops
* copyright
* upgrade
* message
* ordered
* lint
* cr
* copyright
* nicer helpers
* better flag desc
---------
Co-authored-by: quaark
---
automation/common/__init__.py | 13 +
automation/common/helpers.py | 71 ++++
automation/deployment/__init__.py | 13 +
automation/deployment/ce.py | 292 ++++++++++++++
automation/deployment/deployer.py | 605 ++++++++++++++++++++++++++++++
automation/system_test/prepare.py | 44 +--
6 files changed, 996 insertions(+), 42 deletions(-)
create mode 100644 automation/common/__init__.py
create mode 100644 automation/common/helpers.py
create mode 100644 automation/deployment/__init__.py
create mode 100644 automation/deployment/ce.py
create mode 100644 automation/deployment/deployer.py
diff --git a/automation/common/__init__.py b/automation/common/__init__.py
new file mode 100644
index 000000000000..7f557697af77
--- /dev/null
+++ b/automation/common/__init__.py
@@ -0,0 +1,13 @@
+# Copyright 2023 MLRun Authors
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
diff --git a/automation/common/helpers.py b/automation/common/helpers.py
new file mode 100644
index 000000000000..126272f245de
--- /dev/null
+++ b/automation/common/helpers.py
@@ -0,0 +1,71 @@
+# Copyright 2023 MLRun Authors
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import subprocess
+import sys
+import typing
+
+
+def run_command(
+ command: str,
+ args: list = None,
+ workdir: str = None,
+ stdin: str = None,
+ live: bool = True,
+ log_file_handler: typing.IO[str] = None,
+) -> (str, str, int):
+ if workdir:
+ command = f"cd {workdir}; " + command
+ if args:
+ command += " " + " ".join(args)
+
+ process = subprocess.Popen(
+ command,
+ stdout=subprocess.PIPE,
+ stderr=subprocess.PIPE,
+ stdin=subprocess.PIPE,
+ shell=True,
+ )
+
+ if stdin:
+ process.stdin.write(bytes(stdin, "ascii"))
+ process.stdin.close()
+
+ stdout = _handle_command_stdout(process.stdout, log_file_handler, live)
+ stderr = process.stderr.read()
+ exit_status = process.wait()
+
+ return stdout, stderr, exit_status
+
+
+def _handle_command_stdout(
+ stdout_stream: typing.IO[bytes],
+ log_file_handler: typing.IO[str] = None,
+ live: bool = True,
+) -> str:
+ def _write_to_log_file(text: bytes):
+ if log_file_handler:
+ log_file_handler.write(text.decode(sys.stdout.encoding))
+
+ stdout = ""
+ if live:
+ for line in iter(stdout_stream.readline, b""):
+ stdout += str(line)
+ sys.stdout.write(line.decode(sys.stdout.encoding))
+ _write_to_log_file(line)
+ else:
+ stdout = stdout_stream.read()
+ _write_to_log_file(stdout)
+
+ return stdout
diff --git a/automation/deployment/__init__.py b/automation/deployment/__init__.py
new file mode 100644
index 000000000000..7f557697af77
--- /dev/null
+++ b/automation/deployment/__init__.py
@@ -0,0 +1,13 @@
+# Copyright 2023 MLRun Authors
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
diff --git a/automation/deployment/ce.py b/automation/deployment/ce.py
new file mode 100644
index 000000000000..0314d9ab06e0
--- /dev/null
+++ b/automation/deployment/ce.py
@@ -0,0 +1,292 @@
+# Copyright 2023 MLRun Authors
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import typing
+
+import click
+
+from automation.deployment.deployer import CommunityEditionDeployer
+
+common_options = [
+ click.option(
+ "-v",
+ "--verbose",
+ is_flag=True,
+ help="Enable debug logging",
+ ),
+ click.option(
+ "-f",
+ "--log-file",
+ help="Path to log file. If not specified, will log only to stdout",
+ ),
+]
+
+common_deployment_options = [
+ click.option(
+ "-n",
+ "--namespace",
+ default="mlrun",
+ help="Namespace to install the platform in. Defaults to 'mlrun'",
+ ),
+ click.option(
+ "--registry-secret-name",
+ help="Name of the secret containing the credentials for the container registry to use for storing images",
+ ),
+ click.option(
+ "--sqlite",
+ help="Path to sqlite file to use as the mlrun database. If not supplied, will use MySQL deployment",
+ ),
+]
+
+
+def add_options(options):
+ def _add_options(func):
+ for option in reversed(options):
+ func = option(func)
+ return func
+
+ return _add_options
+
+
+def order_click_options(func):
+ func.__click_params__ = list(
+ reversed(sorted(func.__click_params__, key=lambda option: option.name))
+ )
+ return func
+
+
+@click.group(help="MLRun Community Edition Deployment CLI Tool")
+def cli():
+ pass
+
+
+@cli.command(help="Deploy (or upgrade) MLRun Community Edition")
+@order_click_options
+@click.option(
+ "-mv",
+ "--mlrun-version",
+ help="Version of mlrun to install. If not specified, will install the latest version",
+)
+@click.option(
+ "-cv",
+ "--chart-version",
+ help="Version of the mlrun chart to install. If not specified, will install the latest version",
+)
+@click.option(
+ "--registry-url",
+ help="URL of the container registry to use for storing images",
+ required=True,
+)
+@click.option(
+ "--registry-username",
+ help="Username of the container registry to use for storing images",
+)
+@click.option(
+ "--registry-password",
+ help="Password of the container registry to use for storing images",
+)
+@click.option(
+ "--override-mlrun-api-image",
+ help="Override the mlrun-api image. Format: :",
+)
+@click.option(
+ "--override-mlrun-ui-image",
+ help="Override the mlrun-ui image. Format: :",
+)
+@click.option(
+ "--override-jupyter-image",
+ help="Override the jupyter image. Format: :",
+)
+@click.option(
+ "--disable-pipelines",
+ is_flag=True,
+ help="Disable the installation of Kubeflow Pipelines",
+)
+@click.option(
+ "--disable-prometheus-stack",
+ is_flag=True,
+ help="Disable the installation of the Prometheus stack",
+)
+@click.option(
+ "--disable-spark-operator",
+ is_flag=True,
+ help="Disable the installation of the Spark operator",
+)
+@click.option(
+ "--devel",
+ is_flag=True,
+ help="Get the latest RC version of the mlrun chart. (Only works if --chart-version is not specified)",
+)
+@click.option(
+ "-m",
+ "--minikube",
+ is_flag=True,
+ help="Install the mlrun chart in local minikube",
+)
+@click.option(
+ "--set",
+ "set_",
+ help="Set custom values for the mlrun chart. Format: =",
+ multiple=True,
+)
+@click.option(
+ "--upgrade",
+ is_flag=True,
+ help="Upgrade the existing mlrun installation",
+)
+@add_options(common_options)
+@add_options(common_deployment_options)
+def deploy(
+ verbose: bool = False,
+ log_file: str = None,
+ namespace: str = "mlrun",
+ mlrun_version: str = None,
+ chart_version: str = None,
+ registry_url: str = None,
+ registry_secret_name: str = None,
+ registry_username: str = None,
+ registry_password: str = None,
+ override_mlrun_api_image: str = None,
+ override_mlrun_ui_image: str = None,
+ override_jupyter_image: str = None,
+ disable_pipelines: bool = False,
+ disable_prometheus_stack: bool = False,
+ disable_spark_operator: bool = False,
+ sqlite: str = None,
+ devel: bool = False,
+ minikube: bool = False,
+ upgrade: bool = False,
+ set_: typing.List[str] = None,
+):
+ deployer = CommunityEditionDeployer(
+ namespace=namespace,
+ log_level="debug" if verbose else "info",
+ log_file=log_file,
+ )
+ deployer.deploy(
+ registry_url=registry_url,
+ registry_username=registry_username,
+ registry_password=registry_password,
+ registry_secret_name=registry_secret_name,
+ mlrun_version=mlrun_version,
+ chart_version=chart_version,
+ override_mlrun_api_image=override_mlrun_api_image,
+ override_mlrun_ui_image=override_mlrun_ui_image,
+ override_jupyter_image=override_jupyter_image,
+ disable_pipelines=disable_pipelines,
+ disable_prometheus_stack=disable_prometheus_stack,
+ disable_spark_operator=disable_spark_operator,
+ devel=devel,
+ minikube=minikube,
+ sqlite=sqlite,
+ upgrade=upgrade,
+ custom_values=set_,
+ )
+
+
+@cli.command(help="Uninstall MLRun Community Edition Deployment")
+@order_click_options
+@click.option(
+ "--skip-uninstall",
+ is_flag=True,
+ help="Skip uninstalling the Helm chart. Useful if already uninstalled and you want to perform cleanup only",
+)
+@click.option(
+ "--skip-cleanup-registry-secret",
+ is_flag=True,
+ help="Skip deleting the registry secret created during installation",
+)
+@click.option(
+ "--cleanup-volumes",
+ is_flag=True,
+ help="Delete the PVCs created during installation. WARNING: This will result in data loss!",
+)
+@click.option(
+ "--cleanup-namespace",
+ is_flag=True,
+ help="Delete the namespace created during installation. This overrides the other cleanup options. "
+ "WARNING: This will result in data loss!",
+)
+@add_options(common_options)
+@add_options(common_deployment_options)
+def delete(
+ verbose: bool = False,
+ log_file: str = None,
+ namespace: str = "mlrun",
+ registry_secret_name: str = None,
+ skip_uninstall: bool = False,
+ skip_cleanup_registry_secret: bool = False,
+ cleanup_volumes: bool = False,
+ cleanup_namespace: bool = False,
+ sqlite: str = None,
+):
+ deployer = CommunityEditionDeployer(
+ namespace=namespace,
+ log_level="debug" if verbose else "info",
+ log_file=log_file,
+ )
+ deployer.delete(
+ skip_uninstall=skip_uninstall,
+ sqlite=sqlite,
+ cleanup_registry_secret=not skip_cleanup_registry_secret,
+ cleanup_volumes=cleanup_volumes,
+ cleanup_namespace=cleanup_namespace,
+ registry_secret_name=registry_secret_name,
+ )
+
+
+@cli.command(
+ help="Patch MLRun Community Edition Deployment images to minikube. "
+ "Useful if overriding images and running in minikube"
+)
+@order_click_options
+@click.option(
+ "--mlrun-api-image",
+ help="Override the mlrun-api image. Format: :",
+)
+@click.option(
+ "--mlrun-ui-image",
+ help="Override the mlrun-ui image. Format: :",
+)
+@click.option(
+ "--jupyter-image",
+ help="Override the jupyter image. Format: :",
+)
+@add_options(common_options)
+def patch_minikube_images(
+ verbose: bool = False,
+ log_file: str = None,
+ mlrun_api_image: str = None,
+ mlrun_ui_image: str = None,
+ jupyter_image: str = None,
+):
+ deployer = CommunityEditionDeployer(
+ namespace="",
+ log_level="debug" if verbose else "info",
+ log_file=log_file,
+ )
+ deployer.patch_minikube_images(
+ mlrun_api_image=mlrun_api_image,
+ mlrun_ui_image=mlrun_ui_image,
+ jupyter_image=jupyter_image,
+ )
+
+
+if __name__ == "__main__":
+ try:
+ cli()
+ except Exception as exc:
+ print("Unexpected error:", exc)
+ sys.exit(1)
diff --git a/automation/deployment/deployer.py b/automation/deployment/deployer.py
new file mode 100644
index 000000000000..6a901152b8e9
--- /dev/null
+++ b/automation/deployment/deployer.py
@@ -0,0 +1,605 @@
+# Copyright 2023 MLRun Authors
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import os.path
+import platform
+import typing
+
+import requests
+
+import automation.common.helpers
+import mlrun.utils
+
+
+class Constants:
+ helm_repo_name = "mlrun-ce"
+ helm_release_name = "mlrun-ce"
+ helm_chart_name = f"{helm_repo_name}/{helm_release_name}"
+ helm_repo_url = "https://mlrun.github.io/ce"
+ default_registry_secret_name = "registry-credentials"
+ mlrun_image_values = ["mlrun.api", "mlrun.ui", "jupyterNotebook"]
+ disableable_deployments = ["pipelines", "kube-prometheus-stack", "spark-operator"]
+
+
+class CommunityEditionDeployer:
+ """
+ Deployer for MLRun Community Edition (CE) stack.
+ """
+
+ def __init__(
+ self,
+ namespace: str,
+ log_level: str = "info",
+ log_file: str = None,
+ ) -> None:
+ self._debug = log_level == "debug"
+ self._log_file_handler = None
+ self._logger = mlrun.utils.create_logger(level=log_level, name="automation")
+ if log_file:
+ self._log_file_handler = open(log_file, "w")
+ self._logger.set_handler(
+ "file", self._log_file_handler, mlrun.utils.HumanReadableFormatter()
+ )
+ self._namespace = namespace
+
+ def deploy(
+ self,
+ registry_url: str,
+ registry_username: str = None,
+ registry_password: str = None,
+ registry_secret_name: str = None,
+ chart_version: str = None,
+ mlrun_version: str = None,
+ override_mlrun_api_image: str = None,
+ override_mlrun_ui_image: str = None,
+ override_jupyter_image: str = None,
+ disable_pipelines: bool = False,
+ disable_prometheus_stack: bool = False,
+ disable_spark_operator: bool = False,
+ devel: bool = False,
+ minikube: bool = False,
+ sqlite: str = None,
+ upgrade: bool = False,
+ custom_values: typing.List[str] = None,
+ ) -> None:
+ """
+ Deploy MLRun CE stack.
+ :param registry_url: URL of the container registry to use for storing images
+ :param registry_username: Username for the container registry (not required if registry_secret_name is provided)
+ :param registry_password: Password for the container registry (not required if registry_secret_name is provided)
+ :param registry_secret_name: Name of the secret containing the credentials for the container registry
+ :param chart_version: Version of the helm chart to deploy (defaults to the latest stable version)
+ :param mlrun_version: Version of MLRun to deploy (defaults to the latest stable version)
+ :param override_mlrun_api_image: Override the default MLRun API image
+ :param override_mlrun_ui_image: Override the default MLRun UI image
+ :param override_jupyter_image: Override the default Jupyter image
+ :param disable_pipelines: Disable the deployment of the pipelines component
+ :param disable_prometheus_stack: Disable the deployment of the Prometheus stack component
+ :param disable_spark_operator: Disable the deployment of the Spark operator component
+ :param devel: Deploy the development version of the helm chart
+ :param minikube: Deploy the helm chart with minikube configuration
+ :param sqlite: Path to sqlite file to use as the mlrun database. If not supplied, will use MySQL deployment
+ :param upgrade: Upgrade an existing MLRun CE deployment
+ :param custom_values: List of custom values to pass to the helm chart
+ """
+ self._prepare_prerequisites(
+ registry_url, registry_username, registry_password, registry_secret_name
+ )
+ helm_arguments = self._generate_helm_install_arguments(
+ registry_url,
+ registry_secret_name,
+ chart_version,
+ mlrun_version,
+ override_mlrun_api_image,
+ override_mlrun_ui_image,
+ override_jupyter_image,
+ disable_pipelines,
+ disable_prometheus_stack,
+ disable_spark_operator,
+ devel,
+ minikube,
+ sqlite,
+ upgrade,
+ custom_values,
+ )
+
+ self._logger.info(
+ "Installing helm chart with arguments", helm_arguments=helm_arguments
+ )
+ automation.common.helpers.run_command("helm", helm_arguments)
+
+ self._teardown()
+
+ def delete(
+ self,
+ skip_uninstall: bool = False,
+ sqlite: str = None,
+ cleanup_registry_secret: bool = True,
+ cleanup_volumes: bool = False,
+ cleanup_namespace: bool = False,
+ registry_secret_name: str = Constants.default_registry_secret_name,
+ ) -> None:
+ """
+ Delete MLRun CE stack.
+ :param skip_uninstall: Skip the uninstallation of the helm chart
+ :param sqlite: Path to sqlite file to delete (if needed).
+ :param cleanup_registry_secret: Delete the registry secret
+ :param cleanup_volumes: Delete the MLRun volumes
+ :param cleanup_namespace: Delete the entire namespace
+ :param registry_secret_name: Name of the registry secret to delete
+ """
+ if cleanup_namespace:
+ self._logger.warning(
+ "Cleaning up entire namespace", namespace=self._namespace
+ )
+ automation.common.helpers.run_command(
+ "kubectl", ["delete", "namespace", self._namespace]
+ )
+ return
+
+ if not skip_uninstall:
+ self._logger.info(
+ "Cleaning up helm release", release=Constants.helm_release_name
+ )
+ automation.common.helpers.run_command(
+ "helm",
+ [
+ "--namespace",
+ self._namespace,
+ "uninstall",
+ Constants.helm_release_name,
+ ],
+ )
+
+ if cleanup_volumes:
+ self._logger.warning("Cleaning up mlrun volumes")
+ automation.common.helpers.run_command(
+ "kubectl",
+ [
+ "--namespace",
+ self._namespace,
+ "delete",
+ "pvc",
+ "-l",
+ f"app.kubernetes.io/name={Constants.helm_release_name}",
+ ],
+ )
+
+ if cleanup_registry_secret:
+ self._logger.warning(
+ "Cleaning up registry secret",
+ secret_name=registry_secret_name,
+ )
+ automation.common.helpers.run_command(
+ "kubectl",
+ [
+ "--namespace",
+ self._namespace,
+ "delete",
+ "secret",
+ registry_secret_name,
+ ],
+ )
+
+ if sqlite:
+ os.remove(sqlite)
+
+ self._teardown()
+
+ def patch_minikube_images(
+ self,
+ mlrun_api_image: str = None,
+ mlrun_ui_image: str = None,
+ jupyter_image: str = None,
+ ) -> None:
+ """
+ Patch the MLRun CE stack images in minikube.
+ :param mlrun_api_image: MLRun API image to use
+ :param mlrun_ui_image: MLRun UI image to use
+ :param jupyter_image: Jupyter image to use
+ """
+ for image in [mlrun_api_image, mlrun_ui_image, jupyter_image]:
+ if image:
+ automation.common.helpers.run_command("minikube", ["load", image])
+
+ self._teardown()
+
+ def _teardown(self):
+ """
+ Teardown the CLI tool.
+ Close the log file handler if exists.
+ """
+ if self._log_file_handler:
+ self._log_file_handler.close()
+
+ def _prepare_prerequisites(
+ self,
+ registry_url: str,
+ registry_username: str = None,
+ registry_password: str = None,
+ registry_secret_name: str = None,
+ ) -> None:
+ """
+ Prepare the prerequisites for the MLRun CE stack deployment.
+ Creates namespace, adds helm repository, creates registry secret if needed.
+ :param registry_url: URL of the registry to use
+ :param registry_username: Username of the registry to use (not required if registry_secret_name is provided)
+ :param registry_password: Password of the registry to use (not required if registry_secret_name is provided)
+ :param registry_secret_name: Name of the registry secret to use
+ """
+ self._logger.info("Preparing prerequisites")
+ self._validate_registry_url(registry_url)
+
+ self._logger.info("Creating namespace", namespace=self._namespace)
+ automation.common.helpers.run_command(
+ "kubectl", ["create", "namespace", self._namespace]
+ )
+
+ self._logger.debug("Adding helm repo")
+ automation.common.helpers.run_command(
+ "helm", ["repo", "add", Constants.helm_repo_name, Constants.helm_repo_url]
+ )
+
+ self._logger.debug("Updating helm repo")
+ automation.common.helpers.run_command("helm", ["repo", "update"])
+
+ if registry_username and registry_password:
+ self._create_registry_credentials_secret(
+ registry_url, registry_username, registry_password
+ )
+ elif registry_secret_name:
+ self._logger.warning(
+ "Using existing registry secret", secret_name=registry_secret_name
+ )
+ else:
+ raise ValueError(
+ "Either registry credentials or registry secret name must be provided"
+ )
+
+ def _generate_helm_install_arguments(
+ self,
+ registry_url: str = None,
+ registry_secret_name: str = None,
+ chart_version: str = None,
+ mlrun_version: str = None,
+ override_mlrun_api_image: str = None,
+ override_mlrun_ui_image: str = None,
+ override_jupyter_image: str = None,
+ disable_pipelines: bool = False,
+ disable_prometheus_stack: bool = False,
+ disable_spark_operator: bool = False,
+ devel: bool = False,
+ minikube: bool = False,
+ sqlite: str = None,
+ upgrade: bool = False,
+ custom_values: typing.List[str] = None,
+ ) -> typing.List[str]:
+ """
+ Generate the helm install arguments.
+ :param registry_url: URL of the registry to use
+ :param registry_secret_name: Name of the registry secret to use
+ :param chart_version: Version of the chart to use
+ :param mlrun_version: Version of MLRun to use
+ :param override_mlrun_api_image: Override MLRun API image to use
+ :param override_mlrun_ui_image: Override MLRun UI image to use
+ :param override_jupyter_image: Override Jupyter image to use
+ :param disable_pipelines: Disable pipelines
+ :param disable_prometheus_stack: Disable Prometheus stack
+ :param disable_spark_operator: Disable Spark operator
+ :param devel: Use development chart
+ :param minikube: Use minikube
+ :param sqlite: Path to sqlite file to use as the mlrun database. If not supplied, will use MySQL deployment
+ :param upgrade: Upgrade an existing MLRun CE deployment
+ :param custom_values: List of custom values to use
+ :return: List of helm install arguments
+ """
+ helm_arguments = [
+ "--namespace",
+ self._namespace,
+ "upgrade",
+ "--install",
+ Constants.helm_release_name,
+ "--wait",
+ "--timeout",
+ "960s",
+ ]
+
+ if self._debug:
+ helm_arguments.append("--debug")
+
+ if upgrade:
+ helm_arguments.append("--reuse-values")
+
+ for helm_key, helm_value in self._generate_helm_values(
+ registry_url,
+ registry_secret_name,
+ mlrun_version,
+ override_mlrun_api_image,
+ override_mlrun_ui_image,
+ override_jupyter_image,
+ disable_pipelines,
+ disable_prometheus_stack,
+ disable_spark_operator,
+ minikube,
+ ).items():
+ helm_arguments.extend(
+ [
+ "--set",
+ f"{helm_key}={helm_value}",
+ ]
+ )
+
+ for value in custom_values:
+ helm_arguments.extend(
+ [
+ "--set",
+ value,
+ ]
+ )
+
+ if sqlite:
+ dir_path = os.path.dirname(sqlite)
+ helm_arguments.extend(
+ [
+ "--set",
+ 'mlrun.httpDB.dbType="sqlite"',
+ "--set",
+ f'mlrun.httpDB.dirPath="{dir_path}"',
+ "--set",
+ f'mlrun.httpDB.dsn="sqlite:///{sqlite}?check_same_thread=false"',
+ "--set",
+ 'mlrun.httpDB.oldDsn=""',
+ ]
+ )
+
+ helm_arguments.append(Constants.helm_chart_name)
+
+ if chart_version:
+ self._logger.warning(
+ "Installing specific chart version", chart_version=chart_version
+ )
+ helm_arguments.extend(
+ [
+ "--version",
+ chart_version,
+ ]
+ )
+
+ if devel:
+ self._logger.warning("Installing development chart version")
+ helm_arguments.append("--devel")
+
+ return helm_arguments
+
+ def _generate_helm_values(
+ self,
+ registry_url: str,
+ registry_secret_name: str = None,
+ mlrun_version: str = None,
+ override_mlrun_api_image: str = None,
+ override_mlrun_ui_image: str = None,
+ override_jupyter_image: str = None,
+ disable_pipelines: bool = False,
+ disable_prometheus_stack: bool = False,
+ disable_spark_operator: bool = False,
+ minikube: bool = False,
+ ) -> typing.Dict[str, str]:
+ """
+ Generate the helm values.
+ :param registry_url: URL of the registry to use
+ :param registry_secret_name: Name of the registry secret to use
+ :param mlrun_version: Version of MLRun to use
+ :param override_mlrun_api_image: Override MLRun API image to use
+ :param override_mlrun_ui_image: Override MLRun UI image to use
+ :param override_jupyter_image: Override Jupyter image to use
+ :param disable_pipelines: Disable pipelines
+ :param disable_prometheus_stack: Disable Prometheus stack
+ :param disable_spark_operator: Disable Spark operator
+ :param minikube: Use minikube
+ :return: Dictionary of helm values
+ """
+
+ helm_values = {
+ "global.registry.url": registry_url,
+ "global.registry.secretName": registry_secret_name
+ or Constants.default_registry_secret_name,
+ "global.externalHostAddress": self._get_minikube_ip()
+ if minikube
+ else self._get_host_ip(),
+ }
+
+ if mlrun_version:
+ self._set_mlrun_version_in_helm_values(helm_values, mlrun_version)
+
+ for value, overriden_image in zip(
+ Constants.mlrun_image_values,
+ [
+ override_mlrun_api_image,
+ override_mlrun_ui_image,
+ override_jupyter_image,
+ ],
+ ):
+ if overriden_image:
+ self._override_image_in_helm_values(helm_values, value, overriden_image)
+
+ for deployment, disabled in zip(
+ Constants.disableable_deployments,
+ [
+ disable_pipelines,
+ disable_prometheus_stack,
+ disable_spark_operator,
+ ],
+ ):
+ if disabled:
+ self._disable_deployment_in_helm_values(helm_values, deployment)
+
+ # TODO: We need to fix the pipelines metadata grpc server to work on arm
+ if self._check_platform_architecture() == "arm":
+ self._logger.warning(
+ "Kubeflow Pipelines is not supported on ARM architecture. Disabling KFP installation."
+ )
+ self._disable_deployment_in_helm_values(helm_values, "pipelines")
+
+ self._logger.debug(
+ "Generated helm values",
+ helm_values=helm_values,
+ )
+
+ return helm_values
+
+ def _create_registry_credentials_secret(
+ self,
+ registry_url: str,
+ registry_username: str,
+ registry_password: str,
+ registry_secret_name: str = None,
+ ) -> None:
+ """
+ Create a registry credentials secret.
+ :param registry_url: URL of the registry to use
+ :param registry_username: Username of the registry to use
+ :param registry_password: Password of the registry to use
+ :param registry_secret_name: Name of the registry secret to use
+ """
+ registry_secret_name = (
+ registry_secret_name or Constants.default_registry_secret_name
+ )
+ self._logger.debug(
+ "Creating registry credentials secret",
+ secret_name=registry_secret_name,
+ )
+ automation.common.helpers.run_command(
+ "kubectl",
+ [
+ "--namespace",
+ self._namespace,
+ "create",
+ "secret",
+ "docker-registry",
+ registry_secret_name,
+ f"--docker-server={registry_url}",
+ f"--docker-username={registry_username}",
+ f"--docker-password={registry_password}",
+ ],
+ )
+
+ @staticmethod
+ def _check_platform_architecture() -> str:
+ """
+ Check the platform architecture. If running on macOS, check if Rosetta is enabled.
+ Used for kubeflow pipelines which is not supported on ARM architecture (specifically the metadata grpc server).
+ :return: Platform architecture
+ """
+ if platform.system() == "Darwin":
+ translated, _, exit_status = automation.common.helpers.run_command(
+ "sysctl",
+ ["-n", "sysctl.proc_translated"],
+ live=False,
+ )
+ is_rosetta = translated.strip() == b"1" and exit_status == 0
+
+ if is_rosetta:
+ return "arm"
+
+ return platform.processor()
+
+ def _get_host_ip(self) -> str:
+ """
+ Get the host machine IP.
+ :return: Host IP
+ """
+ if platform.system() == "Darwin":
+ return automation.common.helpers.run_command(
+ "ipconfig", ["getifaddr", "en0"], live=False
+ )[0].strip()
+ elif platform.system() == "Linux":
+ return (
+ automation.common.helpers.run_command("hostname", ["-I"], live=False)[0]
+ .split()[0]
+ .strip()
+ )
+ else:
+ raise NotImplementedError(
+ f"Platform {platform.system()} is not supported for this action"
+ )
+
+ @staticmethod
+ def _get_minikube_ip() -> str:
+ """
+ Get the minikube IP.
+ :return: Minikube IP
+ """
+ return automation.common.helpers.run_command("minikube", ["ip"], live=False)[
+ 0
+ ].strip()
+
+ def _validate_registry_url(self, registry_url):
+ """
+ Validate the registry url. Send simple GET request to the registry url.
+ :param registry_url: URL of the registry to use
+ """
+ if not registry_url:
+ raise ValueError("Registry url is required")
+ try:
+ response = requests.get(registry_url)
+ response.raise_for_status()
+ except Exception as exc:
+ self._logger.error("Failed to validate registry url", exc=exc)
+ raise exc
+
+ def _set_mlrun_version_in_helm_values(
+ self, helm_values: typing.Dict[str, str], mlrun_version: str
+ ) -> None:
+ """
+ Set the mlrun version in all the image tags in the helm values.
+ :param helm_values: Helm values to update
+ :param mlrun_version: MLRun version to use
+ """
+ self._logger.warning(
+ "Installing specific mlrun version", mlrun_version=mlrun_version
+ )
+ for image in Constants.mlrun_image_values:
+ helm_values[f"{image}.image.tag"] = mlrun_version
+
+ def _override_image_in_helm_values(
+ self,
+ helm_values: typing.Dict[str, str],
+ image_helm_value: str,
+ overriden_image: str,
+ ) -> None:
+ """
+ Override an image in the helm values.
+ :param helm_values: Helm values to update
+ :param image_helm_value: Helm value of the image to override
+ :param overriden_image: Image with which to override
+ """
+ (
+ overriden_image_repo,
+ overriden_image_tag,
+ ) = overriden_image.split(":")
+ self._logger.warning(
+ "Overriding image", image=image_helm_value, overriden_image=overriden_image
+ )
+ helm_values[f"{image_helm_value}.image.repository"] = overriden_image_repo
+ helm_values[f"{image_helm_value}.image.tag"] = overriden_image_tag
+
+ def _disable_deployment_in_helm_values(
+ self, helm_values: typing.Dict[str, str], deployment: str
+ ) -> None:
+ """
+ Disable a deployment in the helm values.
+ :param helm_values: Helm values to update
+ :param deployment: Deployment to disable
+ """
+ self._logger.warning("Disabling deployment", deployment=deployment)
+ helm_values[f"{deployment}.enabled"] = "false"
diff --git a/automation/system_test/prepare.py b/automation/system_test/prepare.py
index 58b3225bfab3..b246c53d5ad4 100644
--- a/automation/system_test/prepare.py
+++ b/automation/system_test/prepare.py
@@ -16,8 +16,6 @@
import datetime
import logging
import pathlib
-import subprocess
-import sys
import tempfile
import time
import urllib.parse
@@ -27,6 +25,7 @@
import paramiko
import yaml
+import automation.common.helpers
import mlrun.utils
logger = mlrun.utils.create_logger(level="debug", name="automation")
@@ -191,7 +190,7 @@ def _run_command(
return ""
try:
if local:
- stdout, stderr, exit_status = self._run_command_locally(
+ stdout, stderr, exit_status = automation.common.helpers.run_command(
command, args, workdir, stdin, live
)
else:
@@ -274,45 +273,6 @@ def _run_command_remotely(
return stdout, stderr, exit_status
- @staticmethod
- def _run_command_locally(
- command: str,
- args: list = None,
- workdir: str = None,
- stdin: str = None,
- live: bool = True,
- ) -> (str, str, int):
- stdout, stderr, exit_status = "", "", 0
- if workdir:
- command = f"cd {workdir}; " + command
- if args:
- command += " " + " ".join(args)
-
- process = subprocess.Popen(
- command,
- stdout=subprocess.PIPE,
- stderr=subprocess.PIPE,
- stdin=subprocess.PIPE,
- shell=True,
- )
-
- if stdin:
- process.stdin.write(bytes(stdin, "ascii"))
- process.stdin.close()
-
- if live:
- for line in iter(process.stdout.readline, b""):
- stdout += str(line)
- sys.stdout.write(line.decode(sys.stdout.encoding))
- else:
- stdout = process.stdout.read()
-
- stderr = process.stderr.read()
-
- exit_status = process.wait()
-
- return stdout, stderr, exit_status
-
def _prepare_env_remote(self):
self._run_command(
"mkdir",
From 5912aa144b1b63b7058b3274d4ed33871baa0745 Mon Sep 17 00:00:00 2001
From: Adam
Date: Thu, 4 May 2023 17:43:33 +0300
Subject: [PATCH 088/334] [Automation] Refactor CE Deployer Script (#3474)
---
automation/deployment/README.md | 102 ++++++++++++++++++++++++++++++
automation/deployment/deployer.py | 29 ++++-----
automation/system_test/prepare.py | 5 +-
3 files changed, 119 insertions(+), 17 deletions(-)
create mode 100644 automation/deployment/README.md
diff --git a/automation/deployment/README.md b/automation/deployment/README.md
new file mode 100644
index 000000000000..46ebe8f4db2b
--- /dev/null
+++ b/automation/deployment/README.md
@@ -0,0 +1,102 @@
+# MLRun Community Edition Deployer
+
+CLI tool for deploying MLRun Community Edition.
+The CLI supports 3 commands:
+- `deploy`: Deploys (or upgrades) an MLRun Community Edition Stack.
+- `delete`: Uninstalls the CE and cleans up dangling resources.
+- `patch-minikube-images`: If using custom images and running from Minikube, this command will patch the images to the Minikube env.
+
+## Command Usage:
+
+### Deploy:
+To deploy the CE the minimum needed is the registry url and registry credentials. You can run:
+```
+$ python automation/deployment/ce.py deploy \
+ --registry-url \
+ --registry-username \
+ --registry-password
+```
+This will deploy the CE with the default configuration.
+
+Instead of passing the registry credentials as command line arguments, you can create a secret in the cluster and pass the secret name:
+```
+$ python automation/deployment/ce.py deploy \
+ --registry-url \
+ --registry-secret-name
+```
+
+#### Extra Configurations:
+
+You can override the mlrun version and chart version by using the flags `--mlrun-version` and `--chart-version` respectively.
+
+To disable the components that are installed by default, you can use the following flags:
+- `--disable-pipelines`: Disable the installation of Kubeflow Pipelines.
+- `--disable-prometheus-stack`: Disable the installation of the Prometheus stack.
+- `--disable-spark-operator`: Disable the installation of the Spark operator.
+
+To override the images used by the CE, you can use the following flags:
+- `--override-jupyter-image`: Override the jupyter image. Format: `:`
+- `--override-mlrun-api-image`: Override the mlrun-api image. Format: `:`
+- `--override-mlrun-ui-image`: Override the mlrun-ui image. Format: `:`
+
+To run mlrun with sqlite instead of MySQL, you can use the `--sqlite` flag. The value should be the path to the sqlite file to use.
+
+To set custom values for the mlrun chart, you can use the `--set` flag. The format is `=`. For example:
+```
+$ python automation/deployment/ce.py deploy \
+ --registry-url \
+ --registry-username \
+ --registry-password \
+ --set mlrun.db.persistence.size="1Gi" \
+ --set mlrun.api.persistence.size="1Gi"
+```
+
+To install the CE in a different namespace, you can use the `--namespace` flag.
+
+To install the CE in minikube, you can use the `--minikube` flag.
+
+
+### Upgrade
+To upgrade the CE, you can use the same command as deploy with the flag `--upgrade`.
+The CLI will detect that the CE is already installed and will perform an upgrade. The flag will instruct helm to reuse values from the previous deployment.
+
+### Delete:
+To simply uninstall the CE deployment, you can run:
+```
+$ python automation/deployment/ce.py delete
+```
+
+To delete the CE deployment and clean up remaining volumes, you can run:
+```
+$ python automation/deployment/ce.py delete --cleanup-volumes
+```
+
+To cleanup the entire namespace, you can run:
+```
+$ python automation/deployment/ce.py delete --cleanup-namespace
+```
+
+If you already uninstalled, and only want to run cleanup, you can use the `--skip-uninstall` flag.
+
+
+### Patch Minikube Images:
+Patch MLRun Community Edition Deployment images to minikube. Useful if overriding images and running in minikube.
+If you have some custom images, before deploying the CE, run:
+```
+$ python automation/deployment/ce.py patch-minikube-images \
+ --mlrun-api-image \
+ --mlrun-ui-image \
+ --jupyter-image
+```
+
+Then you can deploy the CE with:
+```
+$ python automation/deployment/ce.py deploy \
+ --registry-url \
+ --registry-username \
+ --registry-password \
+ --minikube \
+ --override-mlrun-api-image \
+ --override-mlrun-ui-image \
+ --override-jupyter-image
+```
diff --git a/automation/deployment/deployer.py b/automation/deployment/deployer.py
index 6a901152b8e9..62bfafaeac15 100644
--- a/automation/deployment/deployer.py
+++ b/automation/deployment/deployer.py
@@ -330,6 +330,7 @@ def _generate_helm_install_arguments(
disable_pipelines,
disable_prometheus_stack,
disable_spark_operator,
+ sqlite,
minikube,
).items():
helm_arguments.extend(
@@ -347,21 +348,6 @@ def _generate_helm_install_arguments(
]
)
- if sqlite:
- dir_path = os.path.dirname(sqlite)
- helm_arguments.extend(
- [
- "--set",
- 'mlrun.httpDB.dbType="sqlite"',
- "--set",
- f'mlrun.httpDB.dirPath="{dir_path}"',
- "--set",
- f'mlrun.httpDB.dsn="sqlite:///{sqlite}?check_same_thread=false"',
- "--set",
- 'mlrun.httpDB.oldDsn=""',
- ]
- )
-
helm_arguments.append(Constants.helm_chart_name)
if chart_version:
@@ -392,6 +378,7 @@ def _generate_helm_values(
disable_pipelines: bool = False,
disable_prometheus_stack: bool = False,
disable_spark_operator: bool = False,
+ sqlite: str = None,
minikube: bool = False,
) -> typing.Dict[str, str]:
"""
@@ -405,6 +392,7 @@ def _generate_helm_values(
:param disable_pipelines: Disable pipelines
:param disable_prometheus_stack: Disable Prometheus stack
:param disable_spark_operator: Disable Spark operator
+ :param sqlite: Path to sqlite file to use as the mlrun database. If not supplied, will use MySQL deployment
:param minikube: Use minikube
:return: Dictionary of helm values
"""
@@ -443,6 +431,17 @@ def _generate_helm_values(
if disabled:
self._disable_deployment_in_helm_values(helm_values, deployment)
+ if sqlite:
+ dir_path = os.path.dirname(sqlite)
+ helm_values.update(
+ {
+ "mlrun.httpDB.dbType": "sqlite",
+ "mlrun.httpDB.dirPath": {dir_path},
+ "mlrun.httpDB.dsn": f"sqlite:///{sqlite}?check_same_thread=false",
+ "mlrun.httpDB.oldDsn": "",
+ }
+ )
+
# TODO: We need to fix the pipelines metadata grpc server to work on arm
if self._check_platform_architecture() == "arm":
self._logger.warning(
diff --git a/automation/system_test/prepare.py b/automation/system_test/prepare.py
index b246c53d5ad4..d579c65ae1d3 100644
--- a/automation/system_test/prepare.py
+++ b/automation/system_test/prepare.py
@@ -25,9 +25,10 @@
import paramiko
import yaml
-import automation.common.helpers
import mlrun.utils
+from ..common.helpers import run_command
+
logger = mlrun.utils.create_logger(level="debug", name="automation")
logging.getLogger("paramiko").setLevel(logging.DEBUG)
@@ -190,7 +191,7 @@ def _run_command(
return ""
try:
if local:
- stdout, stderr, exit_status = automation.common.helpers.run_command(
+ stdout, stderr, exit_status = run_command(
command, args, workdir, stdin, live
)
else:
From 74cf6327fbb23ab3a2061386d513e382069b1c61 Mon Sep 17 00:00:00 2001
From: gilad-shaham <62057752+gilad-shaham@users.noreply.github.com>
Date: Sat, 6 May 2023 18:50:02 +0100
Subject: [PATCH 089/334] [Docs] Minor fixes (#3475)
---
docs/feature-store/training-serving.md | 2 +-
docs/index.md | 5 +++--
docs/runtimes/create-and-use-functions.ipynb | 11 ++++++++---
docs/runtimes/functions-architecture.md | 2 +-
docs/runtimes/load-from-hub.md | 2 +-
docs/secrets.md | 18 ++++++++++--------
docs/training/built-in-training-function.ipynb | 2 +-
docs/tutorial/01-mlrun-basics.ipynb | 4 ++--
docs/tutorial/05-model-monitoring.ipynb | 2 +-
docs/tutorial/07-batch-infer.ipynb | 4 ++--
.../tutorial/colab/01-mlrun-basics-colab.ipynb | 4 ++--
11 files changed, 32 insertions(+), 24 deletions(-)
diff --git a/docs/feature-store/training-serving.md b/docs/feature-store/training-serving.md
index 909c0a451e62..c438aca4fe81 100644
--- a/docs/feature-store/training-serving.md
+++ b/docs/feature-store/training-serving.md
@@ -31,7 +31,7 @@ You define a serving model class and the computational graph required to run you
To embed the online feature service in your model server, just create the feature vector service once when the model initializes, and then use it to retrieve the feature vectors of incoming keys.
-You can import ready-made classes and functions from the MLRun [Function Hub](https://www.mlrun.org/marketplace/) or write your own.
+You can import ready-made classes and functions from the MLRun [Function Hub](https://www.mlrun.org/hub/) or write your own.
As example of a scikit-learn based model server:
diff --git a/docs/index.md b/docs/index.md
index 65196f958f96..c32bc4a12aac 100644
--- a/docs/index.md
+++ b/docs/index.md
@@ -1,4 +1,4 @@
-(architecture)=
+(using-mlrun)=
# Using MLRun
```{div} full-width
@@ -127,7 +127,8 @@ MLRun rapidly deploys and manages production-grade real-time or batch applicatio
Observability is built into the different MLRun objects (data, functions, jobs, models, pipelines, etc.), eliminating the need for complex integrations and code instrumentation. With MLRun, you can observe the application/model resource usage and model behavior (drift, performance, etc.), define custom app metrics, and trigger alerts or retraining jobs.
{bdg-link-primary-line}`more... <./monitoring/index.html>`
-`````{div} full-width{octicon}`mortar-board` **Docs:**
+`````{div} full-width
+{octicon}`mortar-board` **Docs:**
{bdg-link-info}`Model monitoring overview <./monitoring/model-monitoring-deployment.html>`
, {octicon}`code-square` **Tutorials:**
{bdg-link-primary}`Model monitoring & drift detection <./tutorial/05-model-monitoring.html>`
diff --git a/docs/runtimes/create-and-use-functions.ipynb b/docs/runtimes/create-and-use-functions.ipynb
index 87f1d1567ae2..21159277bc2d 100644
--- a/docs/runtimes/create-and-use-functions.ipynb
+++ b/docs/runtimes/create-and-use-functions.ipynb
@@ -381,7 +381,7 @@
"id": "8a65c196",
"metadata": {},
"source": [
- "Functions can also be imported from the [**MLRun Function Hub**](https://www.mlrun.org/marketplace): simply import using the name of the function and the `hub://` prefix:\n",
+ "Functions can also be imported from the [**MLRun Function Hub**](https://www.mlrun.org/hub): simply import using the name of the function and the `hub://` prefix:\n",
"``` {admonition} Note\n",
"By default, the `hub://` prefix points to the official Function Hub. You can, however, also substitute your own repo to create your own hub.\n",
"```"
@@ -532,7 +532,7 @@
],
"metadata": {
"kernelspec": {
- "display_name": "Python 3 (ipykernel)",
+ "display_name": "Python 3",
"language": "python",
"name": "python3"
},
@@ -546,7 +546,12 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.7.7"
+ "version": "3.10.6 (main, Nov 14 2022, 16:10:14) [GCC 11.3.0]"
+ },
+ "vscode": {
+ "interpreter": {
+ "hash": "916dbcbb3f70747c44a77c7bcd40155683ae19c65e1c03b4aa3499c5328201f1"
+ }
}
},
"nbformat": 4,
diff --git a/docs/runtimes/functions-architecture.md b/docs/runtimes/functions-architecture.md
index dc71ece53a01..2af97ba3a594 100644
--- a/docs/runtimes/functions-architecture.md
+++ b/docs/runtimes/functions-architecture.md
@@ -7,7 +7,7 @@ MLRun supports:
- Iterative tasks for automatic and distributed execution of many tasks with variable parameters (hyperparams). See [Hyperparam and iterative jobs](../hyper-params.html).
- Horizontal scaling of functions across multiple containers. See [Distributed and Parallel Jobs](./distributed.html).
-MLRun has an open [public Function Hub](https://www.mlrun.org/marketplace/functions/) that stores many pre-developed functions for
+MLRun has an open [public Function Hub](https://www.mlrun.org/hub/functions/) that stores many pre-developed functions for
use in your projects.

diff --git a/docs/runtimes/load-from-hub.md b/docs/runtimes/load-from-hub.md
index 4499efdb2ad6..450493109770 100644
--- a/docs/runtimes/load-from-hub.md
+++ b/docs/runtimes/load-from-hub.md
@@ -22,7 +22,7 @@ Functions can be easily imported into your project and therefore help you to spe
## Searching for functions
-The Function Hub is located [here](https://www.mlrun.org/marketplace/).
+The Function Hub is located [here](https://www.mlrun.org/hub/).
You can search and filter the categories and kinds to find a function that meets your needs.

diff --git a/docs/secrets.md b/docs/secrets.md
index 715218c79689..080519dac9b6 100644
--- a/docs/secrets.md
+++ b/docs/secrets.md
@@ -10,11 +10,11 @@ and how much exposure they create for your secrets.
**In this section**
- [Overview](#overview)
- [MLRun-managed secrets](#mlrun-managed-secrets)
- - [Using tasks with secrets](#using-tasks-with-secrets)
+ - [Using tasks with secrets](#using-tasks-with-secrets)
- [Secret providers](#secret-providers)
- - [Kubernetes project secrets](#kubernetes-project-secrets)
- - [Azure Vault](#azure-vault)
- - [Demo/Development secret providers](#demo-development-secret-providers)
+ - [Kubernetes project secrets](#kubernetes-project-secrets)
+ - [Azure Vault](#azure-vault)
+ - [Demo/Development secret providers](#demo-development-secret-providers)
- [Externally managed secrets](#externally-managed-secrets)
- [Mapping secrets to environment](#mapping-secrets-to-environment)
- [Mapping secrets as files](#mapping-secrets-as-files)
@@ -317,9 +317,11 @@ MLRun provides facilities to map k8s secrets that were created externally to job
the spec of the runtime that is created should be modified by mounting secrets to it - either as files or as
environment variables containing specific keys from the secret.
+In the following examples, assume a k8s secret called `my-secret` was created in the same k8s namespace where MLRun is running, with two
+keys in it - `secret1` and `secret2`.
+
### Mapping secrets to environment
-Let's assume a k8s secret called `my-secret` was created in the same k8s namespace where MLRun is running, with two
-keys in it - `secret1` and `secret2`. The following example adds these two secret keys as environment variables
+ The following example adds these two secret keys as environment variables
to an MLRun job:
```{code-block} python
@@ -359,9 +361,9 @@ function:
```python
# Mount all keys in the secret as files under /mnt/secrets
-function.mount_secret("my-secret", "/mnt/secrets/")
+function.apply(mlrun.platforms.mount_secret("my-secret", "/mnt/secrets/"))
```
-This creates two files in the function pod, called `/mnt/secrets/secret1` and `/mnt/secrets/secret2`. Reading these
+In our example, the two keys in `my-secret` are created as two files in the function pod, called `/mnt/secrets/secret1` and `/mnt/secrets/secret2`. Reading these
files provide the values. It is possible to limit the keys mounted to the function - see the documentation
of {py:func}`~mlrun.platforms.mount_secret` for more details.
diff --git a/docs/training/built-in-training-function.ipynb b/docs/training/built-in-training-function.ipynb
index 1816ed6bb397..5e795fd4fa5e 100644
--- a/docs/training/built-in-training-function.ipynb
+++ b/docs/training/built-in-training-function.ipynb
@@ -14,7 +14,7 @@
"id": "0e900797",
"metadata": {},
"source": [
- "The MLRun [Function Hub](https://www.mlrun.org/marketplace/) includes, among other things, training functions. The most commonly used function for training is [`auto_trainer`](https://github.com/mlrun/functions/tree/development/auto_trainer), which includes the following handlers:\n",
+ "The MLRun [Function Hub](https://www.mlrun.org/hub/) includes, among other things, training functions. The most commonly used function for training is [`auto_trainer`](https://github.com/mlrun/functions/tree/development/auto_trainer), which includes the following handlers:\n",
"\n",
"- [Train](#train)\n",
"- [Evaluate](#evaluate)"
diff --git a/docs/tutorial/01-mlrun-basics.ipynb b/docs/tutorial/01-mlrun-basics.ipynb
index 2e7eea0ac08d..deb74ae82220 100644
--- a/docs/tutorial/01-mlrun-basics.ipynb
+++ b/docs/tutorial/01-mlrun-basics.ipynb
@@ -878,7 +878,7 @@
"\n",
"## Train a model using an MLRun built-in Function Hub\n",
"\n",
- "MLRun provides a [**Function Hub**](https://www.mlrun.org/marketplace/) that hosts a set of pre-implemented and\n",
+ "MLRun provides a [**Function Hub**](https://www.mlrun.org/hub/) that hosts a set of pre-implemented and\n",
"validated ML, DL, and data processing functions.\n",
"\n",
"You can import the `auto-trainer` hub function that can: train an ML model using a variety of ML frameworks; generate\n",
@@ -910,7 +910,7 @@
},
"source": [
"\n",
- "See the `auto_trainer` function usage instructions in [the Function Hub](https://www.mlrun.org/marketplace/functions/master/auto_trainer/) or by typing `trainer.doc()`\n",
+ "See the `auto_trainer` function usage instructions in [the Function Hub](https://www.mlrun.org/hub/functions/master/auto_trainer/) or by typing `trainer.doc()`\n",
"\n",
"**Run the function on the cluster (if there is)**"
]
diff --git a/docs/tutorial/05-model-monitoring.ipynb b/docs/tutorial/05-model-monitoring.ipynb
index 22a293136fa9..1444506c4472 100644
--- a/docs/tutorial/05-model-monitoring.ipynb
+++ b/docs/tutorial/05-model-monitoring.ipynb
@@ -171,7 +171,7 @@
"\n",
"## Import and deploy the serving function\n",
"\n",
- "Import the [model server](https://github.com/mlrun/functions/tree/master/v2_model_server) function from the [MLRun Function Hub](https://www.mlrun.org/marketplace/). Additionally, mount the filesytem, add the model that was logged via experiment tracking, and enable drift detection.\n",
+ "Import the [model server](https://github.com/mlrun/functions/tree/master/v2_model_server) function from the [MLRun Function Hub](https://www.mlrun.org/hub/). Additionally, mount the filesytem, add the model that was logged via experiment tracking, and enable drift detection.\n",
"\n",
"The core line here is `serving_fn.set_tracking()` that creates the required infrastructure behind the scenes to perform drift detection. See the [Model monitoring overview](https://docs.mlrun.org/en/latest/monitoring/model-monitoring-deployment.html) for more info on what is deployed."
]
diff --git a/docs/tutorial/07-batch-infer.ipynb b/docs/tutorial/07-batch-infer.ipynb
index f121a1e42561..44eb251327d0 100644
--- a/docs/tutorial/07-batch-infer.ipynb
+++ b/docs/tutorial/07-batch-infer.ipynb
@@ -7,7 +7,7 @@
"source": [
"# Batch inference and drift detection\n",
"\n",
- "This tutorial leverages a function from the [MLRun Function Hub](https://www.mlrun.org/marketplace/) to perform [batch inference](https://www.mlrun.org/marketplace/functions/master/batch_inference/) using a logged model and a new prediction dataset. The function also calculates data drift by comparing the new prediction dataset with the original training set.\n",
+ "This tutorial leverages a function from the [MLRun Function Hub](https://www.mlrun.org/hub/) to perform [batch inference](https://www.mlrun.org/hub/functions/master/batch_inference/) using a logged model and a new prediction dataset. The function also calculates data drift by comparing the new prediction dataset with the original training set.\n",
"\n",
"Make sure you have reviewed the basics in MLRun [**Quick Start Tutorial**](../01-mlrun-basics.html)."
]
@@ -607,7 +607,7 @@
"\n",
"## Import and run the batch inference function\n",
"\n",
- "Next, import the [batch inference](https://www.mlrun.org/marketplace/functions/master/batch_inference/) function from the [MLRun Function Hub](https://www.mlrun.org/marketplace/):"
+ "Next, import the [batch inference](https://www.mlrun.org/hub/functions/master/batch_inference/) function from the [MLRun Function Hub](https://www.mlrun.org/hub/):"
]
},
{
diff --git a/docs/tutorial/colab/01-mlrun-basics-colab.ipynb b/docs/tutorial/colab/01-mlrun-basics-colab.ipynb
index 925d12d0fbda..c5a9e950d9f7 100644
--- a/docs/tutorial/colab/01-mlrun-basics-colab.ipynb
+++ b/docs/tutorial/colab/01-mlrun-basics-colab.ipynb
@@ -922,7 +922,7 @@
"\n",
"## Train a model using an MLRun built-in function \n",
"\n",
- "MLRun provides a [**public Function Hub**](https://www.mlrun.org/marketplace/) which hosts a set of pre-implemented and\n",
+ "MLRun provides a [**public Function Hub**](https://www.mlrun.org/hub/) which hosts a set of pre-implemented and\n",
"validated ML, DL, and data processing functions.\n",
"\n",
"You can import the `auto-trainer` hub function which can train an ML model using variety of ML frameworks, generate\n",
@@ -954,7 +954,7 @@
},
"source": [
"\n",
- "> See the `auto_trainer` function usage instructions in [the Function Hub](https://www.mlrun.org/marketplace/functions/master/auto_trainer/) or by typing `trainer.doc()`\n",
+ "> See the `auto_trainer` function usage instructions in [the Function Hub](https://www.mlrun.org/hub/functions/master/auto_trainer/) or by typing `trainer.doc()`\n",
"\n",
"**Run the function on the cluster (if exist):**"
]
From 11cf287e85a672f803e92e81cc12dbd6cddbdb06 Mon Sep 17 00:00:00 2001
From: Eyal Danieli
Date: Sun, 7 May 2023 11:00:19 +0300
Subject: [PATCH 090/334] [Model Monitoring] Validate access key in Grafana
only in non-CE deployment (#3476)
---
mlrun/api/api/endpoints/grafana_proxy.py | 3 ++-
1 file changed, 2 insertions(+), 1 deletion(-)
diff --git a/mlrun/api/api/endpoints/grafana_proxy.py b/mlrun/api/api/endpoints/grafana_proxy.py
index 19dea291bb5f..eab4a5be6f9a 100644
--- a/mlrun/api/api/endpoints/grafana_proxy.py
+++ b/mlrun/api/api/endpoints/grafana_proxy.py
@@ -53,7 +53,8 @@ def grafana_proxy_model_endpoints_check_connection(
Root of grafana proxy for the model-endpoints API, used for validating the model-endpoints data source
connectivity.
"""
- mlrun.api.crud.ModelEndpoints().get_access_key(auth_info)
+ if not mlrun.mlconf.is_ce_mode():
+ mlrun.api.crud.ModelEndpoints().get_access_key(auth_info)
return Response(status_code=HTTPStatus.OK.value)
From 0ed889f9e98fb9370a3315c576a08afdd729ae3a Mon Sep 17 00:00:00 2001
From: TomerShor <90552140+TomerShor@users.noreply.github.com>
Date: Sun, 7 May 2023 11:40:59 +0300
Subject: [PATCH 091/334] [Schemas] Move API Pydantic schemas to common (#3461)
---
Makefile | 2 +-
docs/api/mlrun.db.rst | 2 +-
docs/feature-store/using-spark-engine.md | 2 +-
mlrun/__main__.py | 2 +-
mlrun/api/api/deps.py | 18 +-
mlrun/api/api/endpoints/artifacts.py | 48 +--
mlrun/api/api/endpoints/auth.py | 6 +-
mlrun/api/api/endpoints/background_tasks.py | 20 +-
mlrun/api/api/endpoints/client_spec.py | 8 +-
.../api/api/endpoints/clusterization_spec.py | 8 +-
mlrun/api/api/endpoints/feature_store.py | 220 ++++++------
mlrun/api/api/endpoints/files.py | 26 +-
mlrun/api/api/endpoints/frontend_spec.py | 26 +-
mlrun/api/api/endpoints/functions.py | 94 ++---
mlrun/api/api/endpoints/grafana_proxy.py | 24 +-
mlrun/api/api/endpoints/healthz.py | 6 +-
mlrun/api/api/endpoints/hub.py | 120 ++++---
.../api/endpoints/internal/memory_reports.py | 10 +-
mlrun/api/api/endpoints/logs.py | 14 +-
mlrun/api/api/endpoints/model_endpoints.py | 62 ++--
mlrun/api/api/endpoints/operations.py | 20 +-
mlrun/api/api/endpoints/pipelines.py | 54 +--
mlrun/api/api/endpoints/projects.py | 68 ++--
mlrun/api/api/endpoints/runs.py | 50 +--
mlrun/api/api/endpoints/runtime_resources.py | 48 +--
mlrun/api/api/endpoints/schedules.py | 67 ++--
mlrun/api/api/endpoints/secrets.py | 55 +--
mlrun/api/api/endpoints/submit.py | 22 +-
mlrun/api/api/endpoints/tags.py | 34 +-
mlrun/api/api/utils.py | 79 +++--
mlrun/api/crud/artifacts.py | 18 +-
mlrun/api/crud/client_spec.py | 4 +-
mlrun/api/crud/clusterization_spec.py | 4 +-
mlrun/api/crud/feature_store.py | 92 ++---
mlrun/api/crud/functions.py | 4 +-
mlrun/api/crud/hub.py | 72 ++--
mlrun/api/crud/logs.py | 8 +-
mlrun/api/crud/model_monitoring/grafana.py | 126 +++----
.../crud/model_monitoring/model_endpoints.py | 62 ++--
mlrun/api/crud/pipelines.py | 24 +-
mlrun/api/crud/projects.py | 40 +--
mlrun/api/crud/runs.py | 8 +-
mlrun/api/crud/runtime_resources.py | 24 +-
mlrun/api/crud/secrets.py | 67 ++--
mlrun/api/crud/tags.py | 8 +-
mlrun/api/db/base.py | 108 +++---
mlrun/api/db/sqldb/db.py | 243 +++++++------
mlrun/api/db/sqldb/models/models_mysql.py | 18 +-
mlrun/api/db/sqldb/models/models_sqlite.py | 18 +-
mlrun/api/initial_data.py | 20 +-
mlrun/api/main.py | 36 +-
mlrun/api/middlewares.py | 8 +-
mlrun/api/schemas/__init__.py | 307 ++++++++--------
mlrun/api/utils/auth/providers/base.py | 12 +-
mlrun/api/utils/auth/providers/nop.py | 11 +-
mlrun/api/utils/auth/providers/opa.py | 32 +-
mlrun/api/utils/auth/verifier.py | 68 ++--
mlrun/api/utils/background_tasks.py | 46 +--
mlrun/api/utils/clients/chief.py | 8 +-
mlrun/api/utils/clients/iguazio.py | 66 ++--
mlrun/api/utils/clients/nuclio.py | 44 +--
mlrun/api/utils/clients/protocols/grpc.py | 2 +-
mlrun/api/utils/helpers.py | 14 +-
mlrun/api/utils/projects/follower.py | 64 ++--
mlrun/api/utils/projects/leader.py | 68 ++--
mlrun/api/utils/projects/member.py | 52 +--
mlrun/api/utils/projects/remotes/follower.py | 24 +-
mlrun/api/utils/projects/remotes/leader.py | 18 +-
.../utils/projects/remotes/nop_follower.py | 36 +-
.../api/utils/projects/remotes/nop_leader.py | 31 +-
mlrun/api/utils/scheduler.py | 96 ++---
mlrun/artifacts/dataset.py | 3 +-
mlrun/builder.py | 20 +-
.../model_monitoring.py} | 100 ++++++
mlrun/common/schemas/__init__.py | 152 ++++++++
mlrun/{api => common}/schemas/artifact.py | 25 +-
mlrun/{api => common}/schemas/auth.py | 8 +-
.../schemas/background_task.py | 4 +-
mlrun/{api => common}/schemas/client_spec.py | 0
.../schemas/clusterization_spec.py | 4 +-
mlrun/{api => common}/schemas/constants.py | 14 +-
.../{api => common}/schemas/feature_store.py | 0
.../{api => common}/schemas/frontend_spec.py | 10 +-
mlrun/{api => common}/schemas/function.py | 8 +-
mlrun/{api => common}/schemas/http.py | 4 +-
mlrun/{api => common}/schemas/hub.py | 6 +-
mlrun/{api => common}/schemas/k8s.py | 4 +-
.../{api => common}/schemas/memory_reports.py | 0
.../schemas/model_endpoints.py | 54 +--
mlrun/{api => common}/schemas/notification.py | 6 +-
mlrun/{api => common}/schemas/object.py | 4 +-
mlrun/{api => common}/schemas/pipeline.py | 4 +-
mlrun/{api => common}/schemas/project.py | 8 +-
.../schemas/runtime_resource.py | 4 +-
mlrun/{api => common}/schemas/schedule.py | 8 +-
mlrun/{api => common}/schemas/secret.py | 4 +-
mlrun/{api => common}/schemas/tag.py | 0
mlrun/common/types.py | 25 ++
mlrun/config.py | 8 +-
mlrun/datastore/store_resources.py | 4 +-
mlrun/datastore/targets.py | 4 +-
mlrun/db/base.py | 136 +++++---
mlrun/db/httpdb.py | 329 ++++++++++--------
mlrun/db/nopdb.py | 132 ++++---
mlrun/db/sqldb.py | 112 +++---
mlrun/feature_store/api.py | 10 +-
mlrun/feature_store/common.py | 28 +-
mlrun/feature_store/feature_set.py | 6 +-
mlrun/feature_store/feature_vector.py | 2 +-
mlrun/k8s_utils.py | 18 +-
mlrun/model_monitoring/__init__.py | 7 +-
mlrun/model_monitoring/common.py | 112 ------
mlrun/model_monitoring/helpers.py | 12 +-
mlrun/model_monitoring/model_endpoint.py | 9 +-
.../model_monitoring_batch.py | 82 +++--
.../stores/kv_model_endpoint_store.py | 6 +-
mlrun/model_monitoring/stores/models/mysql.py | 2 +-
.../model_monitoring/stores/models/sqlite.py | 2 +-
.../stores/sql_model_endpoint_store.py | 2 +-
.../model_monitoring/stream_processing_fs.py | 5 +-
mlrun/projects/operations.py | 2 +-
mlrun/projects/pipelines.py | 10 +-
mlrun/projects/project.py | 24 +-
mlrun/run.py | 12 +-
mlrun/runtimes/base.py | 113 +++---
mlrun/runtimes/daskjob.py | 58 +--
mlrun/runtimes/function.py | 4 +-
mlrun/runtimes/kubejob.py | 4 +-
mlrun/runtimes/package/context_handler.py | 2 +-
mlrun/runtimes/pod.py | 8 +-
mlrun/runtimes/serving.py | 4 +-
mlrun/runtimes/sparkjob/spark3job.py | 16 +-
mlrun/serving/routers.py | 29 +-
mlrun/serving/server.py | 2 +-
mlrun/serving/v2_serving.py | 25 +-
mlrun/utils/helpers.py | 23 ++
mlrun/utils/model_monitoring.py | 14 +-
.../utils/notifications/notification/base.py | 10 +-
.../notifications/notification/console.py | 6 +-
mlrun/utils/notifications/notification/git.py | 6 +-
.../notifications/notification/ipython.py | 6 +-
.../utils/notifications/notification/slack.py | 10 +-
.../notifications/notification_pusher.py | 19 +-
tests/api/api/feature_store/base.py | 4 +-
.../api/feature_store/test_feature_vectors.py | 10 +-
tests/api/api/framework/test_middlewares.py | 10 +-
tests/api/api/hub/test_hub.py | 8 +-
tests/api/api/test_artifacts.py | 14 +-
tests/api/api/test_auth.py | 9 +-
tests/api/api/test_background_tasks.py | 43 ++-
tests/api/api/test_client_spec.py | 24 +-
tests/api/api/test_frontend_spec.py | 40 +--
tests/api/api/test_functions.py | 39 ++-
tests/api/api/test_grafana_proxy.py | 6 +-
tests/api/api/test_healthz.py | 4 +-
tests/api/api/test_model_endpoints.py | 22 +-
tests/api/api/test_operations.py | 39 ++-
tests/api/api/test_pipelines.py | 42 +--
tests/api/api/test_projects.py | 156 +++++----
tests/api/api/test_runs.py | 32 +-
tests/api/api/test_runtime_resources.py | 64 ++--
tests/api/api/test_schedules.py | 8 +-
tests/api/api/test_secrets.py | 9 +-
tests/api/api/test_submit.py | 10 +-
tests/api/api/test_tags.py | 60 ++--
tests/api/api/test_utils.py | 66 ++--
tests/api/api/utils.py | 22 +-
tests/api/conftest.py | 12 +-
tests/api/crud/test_secrets.py | 70 ++--
tests/api/db/test_artifacts.py | 18 +-
tests/api/db/test_background_tasks.py | 36 +-
tests/api/db/test_feature_sets.py | 10 +-
tests/api/db/test_projects.py | 44 +--
tests/api/runtime_handlers/base.py | 20 +-
tests/api/runtime_handlers/test_daskjob.py | 6 +-
tests/api/runtime_handlers/test_kubejob.py | 8 +-
tests/api/runtime_handlers/test_mpijob.py | 6 +-
tests/api/runtime_handlers/test_sparkjob.py | 6 +-
tests/api/runtimes/base.py | 134 ++++---
tests/api/runtimes/test_dask.py | 8 +-
tests/api/runtimes/test_kubejob.py | 4 +-
tests/api/runtimes/test_nuclio.py | 22 +-
tests/api/runtimes/test_spark.py | 2 +-
tests/api/test_api_states.py | 24 +-
tests/api/test_initial_data.py | 10 +-
tests/api/utils/auth/providers/test_opa.py | 28 +-
tests/api/utils/clients/test_chief.py | 44 ++-
tests/api/utils/clients/test_iguazio.py | 38 +-
tests/api/utils/clients/test_log_collector.py | 4 +-
tests/api/utils/clients/test_nuclio.py | 22 +-
.../utils/projects/test_follower_member.py | 60 ++--
.../api/utils/projects/test_leader_member.py | 112 +++---
tests/api/utils/test_scheduler.py | 218 ++++++------
tests/common_fixtures.py | 2 +-
.../sdk_api/artifacts/test_artifacts.py | 2 +-
tests/integration/sdk_api/base.py | 2 +-
.../sdk_api/httpdb/runs/test_runs.py | 36 +-
.../sdk_api/httpdb/test_exception_handling.py | 6 +-
tests/integration/sdk_api/hub/test_hub.py | 20 +-
.../sdk_api/projects/test_project.py | 2 +-
tests/projects/test_remote_pipeline.py | 2 +-
tests/rundb/test_httpdb.py | 11 +-
tests/rundb/test_sqldb.py | 22 +-
tests/system/api/test_secrets.py | 4 +-
tests/system/base.py | 4 +-
.../model_monitoring/test_model_monitoring.py | 6 +-
tests/test_builder.py | 42 +--
tests/test_config.py | 2 +-
tests/test_model.py | 4 +-
tests/utils/test_deprecation.py | 52 +++
tests/utils/test_vault.py | 2 +-
211 files changed, 3869 insertions(+), 3199 deletions(-)
rename mlrun/{model_monitoring/constants.py => common/model_monitoring.py} (58%)
create mode 100644 mlrun/common/schemas/__init__.py
rename mlrun/{api => common}/schemas/artifact.py (64%)
rename mlrun/{api => common}/schemas/auth.py (95%)
rename mlrun/{api => common}/schemas/background_task.py (94%)
rename mlrun/{api => common}/schemas/client_spec.py (100%)
rename mlrun/{api => common}/schemas/clusterization_spec.py (87%)
rename mlrun/{api => common}/schemas/constants.py (94%)
rename mlrun/{api => common}/schemas/feature_store.py (100%)
rename mlrun/{api => common}/schemas/frontend_spec.py (88%)
rename mlrun/{api => common}/schemas/function.py (93%)
rename mlrun/{api => common}/schemas/http.py (87%)
rename mlrun/{api => common}/schemas/hub.py (96%)
rename mlrun/{api => common}/schemas/k8s.py (93%)
rename mlrun/{api => common}/schemas/memory_reports.py (100%)
rename mlrun/{api => common}/schemas/model_endpoints.py (83%)
rename mlrun/{api => common}/schemas/notification.py (83%)
rename mlrun/{api => common}/schemas/object.py (95%)
rename mlrun/{api => common}/schemas/pipeline.py (92%)
rename mlrun/{api => common}/schemas/project.py (94%)
rename mlrun/{api => common}/schemas/runtime_resource.py (93%)
rename mlrun/{api => common}/schemas/schedule.py (95%)
rename mlrun/{api => common}/schemas/secret.py (93%)
rename mlrun/{api => common}/schemas/tag.py (100%)
create mode 100644 mlrun/common/types.py
delete mode 100644 mlrun/model_monitoring/common.py
diff --git a/Makefile b/Makefile
index d4fba02c9345..f2d99997458a 100644
--- a/Makefile
+++ b/Makefile
@@ -688,7 +688,7 @@ lint-imports: ## making sure imports dependencies are aligned
lint-imports
.PHONY: lint
-lint: flake8 fmt-check lint-imports ## Run lint on the code
+lint: flake8 fmt-check ## Run lint on the code
.PHONY: fmt-check
fmt-check: ## Format and check the code (using black)
diff --git a/docs/api/mlrun.db.rst b/docs/api/mlrun.db.rst
index 32524a250d3a..2247fc752a4e 100644
--- a/docs/api/mlrun.db.rst
+++ b/docs/api/mlrun.db.rst
@@ -6,7 +6,7 @@ mlrun.db
:show-inheritance:
:undoc-members:
-.. autoclass:: mlrun.api.schemas.secret::SecretProviderName
+.. autoclass:: mlrun.common.schemas.secret::SecretProviderName
:members:
:show-inheritance:
:undoc-members:
diff --git a/docs/feature-store/using-spark-engine.md b/docs/feature-store/using-spark-engine.md
index ae19d51b4593..f27d8b8ba0b3 100644
--- a/docs/feature-store/using-spark-engine.md
+++ b/docs/feature-store/using-spark-engine.md
@@ -208,7 +208,7 @@ One-time setup:
secrets = {'s3_access_key': AWS_ACCESS_KEY, 's3_secret_key': AWS_SECRET_KEY}
mlrun.get_run_db().create_project_secrets(
project = "uhuh-proj",
- provider=mlrun.api.schemas.SecretProviderName.kubernetes,
+ provider=mlrun.common.schemas.SecretProviderName.kubernetes,
secrets=secrets
)
```
diff --git a/mlrun/__main__.py b/mlrun/__main__.py
index 13bbfc6360fe..824c6629b178 100644
--- a/mlrun/__main__.py
+++ b/mlrun/__main__.py
@@ -1499,7 +1499,7 @@ def send_workflow_error_notification(
f"error: ```{err_to_str(error)}```"
)
project.notifiers.push(
- message=message, severity=mlrun.api.schemas.NotificationSeverity.ERROR
+ message=message, severity=mlrun.common.schemas.NotificationSeverity.ERROR
)
diff --git a/mlrun/api/api/deps.py b/mlrun/api/api/deps.py
index 0375f3913956..50eda225ba26 100644
--- a/mlrun/api/api/deps.py
+++ b/mlrun/api/api/deps.py
@@ -20,9 +20,9 @@
import mlrun
import mlrun.api.db.session
-import mlrun.api.schemas
import mlrun.api.utils.auth.verifier
import mlrun.api.utils.clients.iguazio
+import mlrun.common.schemas
def get_db_session() -> typing.Generator[Session, None, None]:
@@ -35,7 +35,7 @@ def get_db_session() -> typing.Generator[Session, None, None]:
mlrun.api.db.session.close_session(db_session)
-async def authenticate_request(request: Request) -> mlrun.api.schemas.AuthInfo:
+async def authenticate_request(request: Request) -> mlrun.common.schemas.AuthInfo:
return await mlrun.api.utils.auth.verifier.AuthVerifier().authenticate_request(
request
)
@@ -46,7 +46,7 @@ def verify_api_state(request: Request):
request.scope
)
path = path_with_query_string.split("?")[0]
- if mlrun.mlconf.httpdb.state == mlrun.api.schemas.APIStates.offline:
+ if mlrun.mlconf.httpdb.state == mlrun.common.schemas.APIStates.offline:
enabled_endpoints = [
# we want to stay healthy
"healthz",
@@ -56,10 +56,10 @@ def verify_api_state(request: Request):
if not any(enabled_endpoint in path for enabled_endpoint in enabled_endpoints):
raise mlrun.errors.MLRunPreconditionFailedError("API is in offline state")
if mlrun.mlconf.httpdb.state in [
- mlrun.api.schemas.APIStates.waiting_for_migrations,
- mlrun.api.schemas.APIStates.migrations_in_progress,
- mlrun.api.schemas.APIStates.migrations_failed,
- mlrun.api.schemas.APIStates.waiting_for_chief,
+ mlrun.common.schemas.APIStates.waiting_for_migrations,
+ mlrun.common.schemas.APIStates.migrations_in_progress,
+ mlrun.common.schemas.APIStates.migrations_failed,
+ mlrun.common.schemas.APIStates.waiting_for_chief,
]:
enabled_endpoints = [
"healthz",
@@ -70,7 +70,9 @@ def verify_api_state(request: Request):
"memory-reports",
]
if not any(enabled_endpoint in path for enabled_endpoint in enabled_endpoints):
- message = mlrun.api.schemas.APIStates.description(mlrun.mlconf.httpdb.state)
+ message = mlrun.common.schemas.APIStates.description(
+ mlrun.mlconf.httpdb.state
+ )
raise mlrun.errors.MLRunPreconditionFailedError(message)
diff --git a/mlrun/api/api/endpoints/artifacts.py b/mlrun/api/api/endpoints/artifacts.py
index f8a29ef53c65..ee43f16f8b15 100644
--- a/mlrun/api/api/endpoints/artifacts.py
+++ b/mlrun/api/api/endpoints/artifacts.py
@@ -22,10 +22,10 @@
import mlrun.api.crud
import mlrun.api.utils.auth.verifier
import mlrun.api.utils.singletons.project_member
-from mlrun.api import schemas
+import mlrun.common.schemas
from mlrun.api.api import deps
from mlrun.api.api.utils import log_and_raise
-from mlrun.api.schemas.artifact import ArtifactsFormat
+from mlrun.common.schemas.artifact import ArtifactsFormat
from mlrun.config import config
from mlrun.utils import is_legacy_artifact, logger
@@ -42,7 +42,7 @@ async def store_artifact(
key: str,
tag: str = "",
iter: int = 0,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await run_in_threadpool(
@@ -52,10 +52,10 @@ async def store_artifact(
auth_info=auth_info,
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.artifact,
+ mlrun.common.schemas.AuthorizationResourceTypes.artifact,
project,
key,
- mlrun.api.schemas.AuthorizationAction.store,
+ mlrun.common.schemas.AuthorizationAction.store,
auth_info,
)
@@ -82,13 +82,13 @@ async def store_artifact(
@router.get("/projects/{project}/artifact-tags")
async def list_artifact_tags(
project: str,
- category: schemas.ArtifactCategories = None,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ category: mlrun.common.schemas.ArtifactCategories = None,
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_permissions(
project,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
tag_tuples = await run_in_threadpool(
@@ -96,7 +96,7 @@ async def list_artifact_tags(
)
artifact_key_to_tag = {tag_tuple[1]: tag_tuple[2] for tag_tuple in tag_tuples}
allowed_artifact_keys = await mlrun.api.utils.auth.verifier.AuthVerifier().filter_project_resources_by_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.artifact,
+ mlrun.common.schemas.AuthorizationResourceTypes.artifact,
list(artifact_key_to_tag.keys()),
lambda artifact_key: (
project,
@@ -125,7 +125,7 @@ async def get_artifact(
tag: str = "latest",
iter: int = 0,
format_: ArtifactsFormat = Query(ArtifactsFormat.full, alias="format"),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
data = await run_in_threadpool(
@@ -138,10 +138,10 @@ async def get_artifact(
format_,
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.artifact,
+ mlrun.common.schemas.AuthorizationResourceTypes.artifact,
project,
key,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
return {
@@ -157,14 +157,14 @@ async def delete_artifact(
uid: str,
key: str,
tag: str = "",
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.artifact,
+ mlrun.common.schemas.AuthorizationResourceTypes.artifact,
project,
key,
- mlrun.api.schemas.AuthorizationAction.delete,
+ mlrun.common.schemas.AuthorizationAction.delete,
auth_info,
)
await run_in_threadpool(
@@ -181,19 +181,19 @@ async def list_artifacts(
name: str = None,
tag: str = None,
kind: str = None,
- category: schemas.ArtifactCategories = None,
+ category: mlrun.common.schemas.ArtifactCategories = None,
labels: List[str] = Query([], alias="label"),
iter: int = Query(None, ge=0),
best_iteration: bool = Query(False, alias="best-iteration"),
format_: ArtifactsFormat = Query(ArtifactsFormat.full, alias="format"),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
if project is None:
project = config.default_project
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_permissions(
project,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
@@ -212,7 +212,7 @@ async def list_artifacts(
)
artifacts = await mlrun.api.utils.auth.verifier.AuthVerifier().filter_project_resources_by_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.artifact,
+ mlrun.common.schemas.AuthorizationResourceTypes.artifact,
artifacts,
_artifact_project_and_resource_name_extractor,
auth_info,
@@ -229,7 +229,7 @@ async def delete_artifacts_legacy(
name: str = "",
tag: str = "",
labels: List[str] = Query([], alias="label"),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
return await _delete_artifacts(
@@ -248,7 +248,7 @@ async def delete_artifacts(
name: str = "",
tag: str = "",
labels: List[str] = Query([], alias="label"),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
return await _delete_artifacts(
@@ -266,7 +266,7 @@ async def _delete_artifacts(
name: str = None,
tag: str = None,
labels: List[str] = None,
- auth_info: mlrun.api.schemas.AuthInfo = None,
+ auth_info: mlrun.common.schemas.AuthInfo = None,
db_session: Session = None,
):
artifacts = await run_in_threadpool(
@@ -278,10 +278,10 @@ async def _delete_artifacts(
labels,
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resources_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.artifact,
+ mlrun.common.schemas.AuthorizationResourceTypes.artifact,
artifacts,
_artifact_project_and_resource_name_extractor,
- mlrun.api.schemas.AuthorizationAction.delete,
+ mlrun.common.schemas.AuthorizationAction.delete,
auth_info,
)
await run_in_threadpool(
diff --git a/mlrun/api/api/endpoints/auth.py b/mlrun/api/api/endpoints/auth.py
index 4d3fd2b2938a..58b8b6ff3574 100644
--- a/mlrun/api/api/endpoints/auth.py
+++ b/mlrun/api/api/endpoints/auth.py
@@ -15,16 +15,16 @@
import fastapi
import mlrun.api.api.deps
-import mlrun.api.schemas
import mlrun.api.utils.auth.verifier
+import mlrun.common.schemas
router = fastapi.APIRouter()
@router.post("/authorization/verifications")
async def verify_authorization(
- authorization_verification_input: mlrun.api.schemas.AuthorizationVerificationInput,
- auth_info: mlrun.api.schemas.AuthInfo = fastapi.Depends(
+ authorization_verification_input: mlrun.common.schemas.AuthorizationVerificationInput,
+ auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
):
diff --git a/mlrun/api/api/endpoints/background_tasks.py b/mlrun/api/api/endpoints/background_tasks.py
index 4586e09878d5..26c80e183716 100644
--- a/mlrun/api/api/endpoints/background_tasks.py
+++ b/mlrun/api/api/endpoints/background_tasks.py
@@ -18,10 +18,10 @@
from fastapi.concurrency import run_in_threadpool
import mlrun.api.api.deps
-import mlrun.api.schemas
import mlrun.api.utils.auth.verifier
import mlrun.api.utils.background_tasks
import mlrun.api.utils.clients.chief
+import mlrun.common.schemas
from mlrun.utils import logger
router = fastapi.APIRouter()
@@ -29,12 +29,12 @@
@router.get(
"/projects/{project}/background-tasks/{name}",
- response_model=mlrun.api.schemas.BackgroundTask,
+ response_model=mlrun.common.schemas.BackgroundTask,
)
async def get_project_background_task(
project: str,
name: str,
- auth_info: mlrun.api.schemas.AuthInfo = fastapi.Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
db_session: sqlalchemy.orm.Session = fastapi.Depends(
@@ -44,10 +44,10 @@ async def get_project_background_task(
# Since there's no not-found option on get_project_background_task - we authorize before getting (unlike other
# get endpoint)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.project_background_task,
+ mlrun.common.schemas.AuthorizationResourceTypes.project_background_task,
project,
name,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
return await run_in_threadpool(
@@ -60,12 +60,12 @@ async def get_project_background_task(
@router.get(
"/background-tasks/{name}",
- response_model=mlrun.api.schemas.BackgroundTask,
+ response_model=mlrun.common.schemas.BackgroundTask,
)
async def get_internal_background_task(
name: str,
request: fastapi.Request,
- auth_info: mlrun.api.schemas.AuthInfo = fastapi.Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
):
@@ -76,14 +76,14 @@ async def get_internal_background_task(
igz_version = mlrun.mlconf.get_parsed_igz_version()
if igz_version and igz_version >= semver.VersionInfo.parse("3.7.0-b1"):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.background_task,
+ mlrun.common.schemas.AuthorizationResourceTypes.background_task,
name,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
if (
mlrun.mlconf.httpdb.clusterization.role
- != mlrun.api.schemas.ClusterizationRole.chief
+ != mlrun.common.schemas.ClusterizationRole.chief
):
logger.info(
"Requesting internal background task, re-routing to chief",
diff --git a/mlrun/api/api/endpoints/client_spec.py b/mlrun/api/api/endpoints/client_spec.py
index 788276eb90c7..3fd477fbf4d2 100644
--- a/mlrun/api/api/endpoints/client_spec.py
+++ b/mlrun/api/api/endpoints/client_spec.py
@@ -17,21 +17,21 @@
from fastapi import APIRouter, Header
import mlrun.api.crud
-import mlrun.api.schemas
+import mlrun.common.schemas
router = APIRouter()
@router.get(
"/client-spec",
- response_model=mlrun.api.schemas.ClientSpec,
+ response_model=mlrun.common.schemas.ClientSpec,
)
def get_client_spec(
client_version: typing.Optional[str] = Header(
- None, alias=mlrun.api.schemas.HeaderNames.client_version
+ None, alias=mlrun.common.schemas.HeaderNames.client_version
),
client_python_version: typing.Optional[str] = Header(
- None, alias=mlrun.api.schemas.HeaderNames.python_version
+ None, alias=mlrun.common.schemas.HeaderNames.python_version
),
):
return mlrun.api.crud.ClientSpec().get_client_spec(
diff --git a/mlrun/api/api/endpoints/clusterization_spec.py b/mlrun/api/api/endpoints/clusterization_spec.py
index fc14e755a501..005e490ac461 100644
--- a/mlrun/api/api/endpoints/clusterization_spec.py
+++ b/mlrun/api/api/endpoints/clusterization_spec.py
@@ -15,17 +15,19 @@
import fastapi
import mlrun.api.crud
-import mlrun.api.schemas
import mlrun.api.utils.clients.chief
+import mlrun.common.schemas
router = fastapi.APIRouter()
-@router.get("/clusterization-spec", response_model=mlrun.api.schemas.ClusterizationSpec)
+@router.get(
+ "/clusterization-spec", response_model=mlrun.common.schemas.ClusterizationSpec
+)
async def clusterization_spec():
if (
mlrun.mlconf.httpdb.clusterization.role
- != mlrun.api.schemas.ClusterizationRole.chief
+ != mlrun.common.schemas.ClusterizationRole.chief
):
chief_client = mlrun.api.utils.clients.chief.Client()
return await chief_client.get_clusterization_spec()
diff --git a/mlrun/api/api/endpoints/feature_store.py b/mlrun/api/api/endpoints/feature_store.py
index 127af270ba2e..f274a0eea61b 100644
--- a/mlrun/api/api/endpoints/feature_store.py
+++ b/mlrun/api/api/endpoints/feature_store.py
@@ -13,6 +13,7 @@
# limitations under the License.
#
import asyncio
+import typing
from http import HTTPStatus
from typing import List, Optional
@@ -23,10 +24,10 @@
import mlrun.api.crud
import mlrun.api.utils.auth.verifier
import mlrun.api.utils.singletons.project_member
+import mlrun.common.schemas
import mlrun.errors
import mlrun.feature_store
from mlrun import v3io_cred
-from mlrun.api import schemas
from mlrun.api.api import deps
from mlrun.api.api.utils import log_and_raise, parse_reference
from mlrun.data_types import InferOptions
@@ -37,12 +38,14 @@
router = APIRouter()
-@router.post("/projects/{project}/feature-sets", response_model=schemas.FeatureSet)
+@router.post(
+ "/projects/{project}/feature-sets", response_model=mlrun.common.schemas.FeatureSet
+)
async def create_feature_set(
project: str,
- feature_set: schemas.FeatureSet,
+ feature_set: mlrun.common.schemas.FeatureSet,
versioned: bool = True,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await run_in_threadpool(
@@ -52,10 +55,10 @@ async def create_feature_set(
auth_info=auth_info,
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.feature_set,
+ mlrun.common.schemas.AuthorizationResourceTypes.feature_set,
project,
feature_set.metadata.name,
- mlrun.api.schemas.AuthorizationAction.create,
+ mlrun.common.schemas.AuthorizationAction.create,
auth_info,
)
feature_set_uid = await run_in_threadpool(
@@ -78,15 +81,15 @@ async def create_feature_set(
@router.put(
"/projects/{project}/feature-sets/{name}/references/{reference}",
- response_model=schemas.FeatureSet,
+ response_model=mlrun.common.schemas.FeatureSet,
)
async def store_feature_set(
project: str,
name: str,
reference: str,
- feature_set: schemas.FeatureSet,
+ feature_set: mlrun.common.schemas.FeatureSet,
versioned: bool = True,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await run_in_threadpool(
@@ -96,10 +99,10 @@ async def store_feature_set(
auth_info=auth_info,
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.feature_set,
+ mlrun.common.schemas.AuthorizationResourceTypes.feature_set,
project,
name,
- mlrun.api.schemas.AuthorizationAction.store,
+ mlrun.common.schemas.AuthorizationAction.store,
auth_info,
)
tag, uid = parse_reference(reference)
@@ -129,17 +132,18 @@ async def patch_feature_set(
name: str,
feature_set_update: dict,
reference: str,
- patch_mode: schemas.PatchMode = Header(
- schemas.PatchMode.replace, alias=schemas.HeaderNames.patch_mode
+ patch_mode: mlrun.common.schemas.PatchMode = Header(
+ mlrun.common.schemas.PatchMode.replace,
+ alias=mlrun.common.schemas.HeaderNames.patch_mode,
),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.feature_set,
+ mlrun.common.schemas.AuthorizationResourceTypes.feature_set,
project,
name,
- mlrun.api.schemas.AuthorizationAction.update,
+ mlrun.common.schemas.AuthorizationAction.update,
auth_info,
)
tag, uid = parse_reference(reference)
@@ -158,13 +162,13 @@ async def patch_feature_set(
@router.get(
"/projects/{project}/feature-sets/{name}/references/{reference}",
- response_model=schemas.FeatureSet,
+ response_model=mlrun.common.schemas.FeatureSet,
)
async def get_feature_set(
project: str,
name: str,
reference: str,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
tag, uid = parse_reference(reference)
@@ -177,10 +181,10 @@ async def get_feature_set(
uid,
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.feature_set,
+ mlrun.common.schemas.AuthorizationResourceTypes.feature_set,
project,
name,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
return feature_set
@@ -192,14 +196,14 @@ async def delete_feature_set(
project: str,
name: str,
reference: str = None,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.feature_set,
+ mlrun.common.schemas.AuthorizationResourceTypes.feature_set,
project,
name,
- mlrun.api.schemas.AuthorizationAction.delete,
+ mlrun.common.schemas.AuthorizationAction.delete,
auth_info,
)
tag = uid = None
@@ -217,7 +221,8 @@ async def delete_feature_set(
@router.get(
- "/projects/{project}/feature-sets", response_model=schemas.FeatureSetsOutput
+ "/projects/{project}/feature-sets",
+ response_model=mlrun.common.schemas.FeatureSetsOutput,
)
async def list_feature_sets(
project: str,
@@ -227,20 +232,22 @@ async def list_feature_sets(
entities: List[str] = Query(None, alias="entity"),
features: List[str] = Query(None, alias="feature"),
labels: List[str] = Query(None, alias="label"),
- partition_by: schemas.FeatureStorePartitionByField = Query(
+ partition_by: mlrun.common.schemas.FeatureStorePartitionByField = Query(
None, alias="partition-by"
),
rows_per_partition: int = Query(1, alias="rows-per-partition", gt=0),
- partition_sort_by: schemas.SortField = Query(None, alias="partition-sort-by"),
- partition_order: schemas.OrderType = Query(
- schemas.OrderType.desc, alias="partition-order"
+ partition_sort_by: mlrun.common.schemas.SortField = Query(
+ None, alias="partition-sort-by"
),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ partition_order: mlrun.common.schemas.OrderType = Query(
+ mlrun.common.schemas.OrderType.desc, alias="partition-order"
+ ),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_permissions(
project,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
feature_sets = await run_in_threadpool(
@@ -259,7 +266,7 @@ async def list_feature_sets(
partition_order,
)
feature_sets = await mlrun.api.utils.auth.verifier.AuthVerifier().filter_project_resources_by_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.feature_set,
+ mlrun.common.schemas.AuthorizationResourceTypes.feature_set,
feature_sets.feature_sets,
lambda feature_set: (
feature_set.metadata.project,
@@ -267,17 +274,17 @@ async def list_feature_sets(
),
auth_info,
)
- return mlrun.api.schemas.FeatureSetsOutput(feature_sets=feature_sets)
+ return mlrun.common.schemas.FeatureSetsOutput(feature_sets=feature_sets)
@router.get(
"/projects/{project}/feature-sets/{name}/tags",
- response_model=schemas.FeatureSetsTagsOutput,
+ response_model=mlrun.common.schemas.FeatureSetsTagsOutput,
)
async def list_feature_sets_tags(
project: str,
name: str,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
if name != "*":
@@ -286,7 +293,7 @@ async def list_feature_sets_tags(
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_permissions(
project,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
tag_tuples = await run_in_threadpool(
@@ -298,7 +305,7 @@ async def list_feature_sets_tags(
auth_verifier = mlrun.api.utils.auth.verifier.AuthVerifier()
allowed_feature_set_names = (
await auth_verifier.filter_project_resources_by_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.feature_set,
+ mlrun.common.schemas.AuthorizationResourceTypes.feature_set,
list(feature_set_name_to_tag.keys()),
lambda feature_set_name: (
project,
@@ -312,7 +319,7 @@ async def list_feature_sets_tags(
for tag_tuple in tag_tuples
if tag_tuple[1] in allowed_feature_set_names
}
- return mlrun.api.schemas.FeatureSetsTagsOutput(tags=list(tags))
+ return mlrun.common.schemas.FeatureSetsTagsOutput(tags=list(tags))
def _has_v3io_path(data_source, data_targets, feature_set):
@@ -342,7 +349,7 @@ def _has_v3io_path(data_source, data_targets, feature_set):
@router.post(
"/projects/{project}/feature-sets/{name}/references/{reference}/ingest",
- response_model=schemas.FeatureSetIngestOutput,
+ response_model=mlrun.common.schemas.FeatureSetIngestOutput,
status_code=HTTPStatus.ACCEPTED.value,
)
async def ingest_feature_set(
@@ -350,10 +357,10 @@ async def ingest_feature_set(
name: str,
reference: str,
ingest_parameters: Optional[
- schemas.FeatureSetIngestInput
- ] = schemas.FeatureSetIngestInput(),
+ mlrun.common.schemas.FeatureSetIngestInput
+ ] = mlrun.common.schemas.FeatureSetIngestInput(),
username: str = Header(None, alias="x-remote-user"),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
"""
@@ -361,17 +368,17 @@ async def ingest_feature_set(
that already being happen on client side
"""
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.feature_set,
+ mlrun.common.schemas.AuthorizationResourceTypes.feature_set,
project,
name,
- mlrun.api.schemas.AuthorizationAction.update,
+ mlrun.common.schemas.AuthorizationAction.update,
auth_info,
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.run,
+ mlrun.common.schemas.AuthorizationResourceTypes.run,
project,
"",
- mlrun.api.schemas.AuthorizationAction.create,
+ mlrun.common.schemas.AuthorizationAction.create,
auth_info,
)
data_source = data_targets = None
@@ -379,10 +386,10 @@ async def ingest_feature_set(
data_source = DataSource.from_dict(ingest_parameters.source.dict())
if data_source.schedule:
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.schedule,
+ mlrun.common.schemas.AuthorizationResourceTypes.schedule,
project,
"",
- mlrun.api.schemas.AuthorizationAction.create,
+ mlrun.common.schemas.AuthorizationAction.create,
auth_info,
)
tag, uid = parse_reference(reference)
@@ -398,10 +405,10 @@ async def ingest_feature_set(
if feature_set.spec.function and feature_set.spec.function.function_object:
function = feature_set.spec.function.function_object
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.function,
+ mlrun.common.schemas.AuthorizationResourceTypes.function,
function.metadata.project,
function.metadata.name,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
# Need to override the default rundb since we're in the server.
@@ -447,25 +454,27 @@ async def ingest_feature_set(
run_config=run_config,
)
# ingest may modify the feature-set contents, so returning the updated feature-set.
- result_feature_set = schemas.FeatureSet(**feature_set.to_dict())
- return schemas.FeatureSetIngestOutput(
+ result_feature_set = mlrun.common.schemas.FeatureSet(**feature_set.to_dict())
+ return mlrun.common.schemas.FeatureSetIngestOutput(
feature_set=result_feature_set, run_object=run_params.to_dict()
)
-@router.get("/projects/{project}/features", response_model=schemas.FeaturesOutput)
+@router.get(
+ "/projects/{project}/features", response_model=mlrun.common.schemas.FeaturesOutput
+)
async def list_features(
project: str,
name: str = None,
tag: str = None,
entities: List[str] = Query(None, alias="entity"),
labels: List[str] = Query(None, alias="label"),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_permissions(
project,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
features = await run_in_threadpool(
@@ -478,7 +487,7 @@ async def list_features(
labels,
)
features = await mlrun.api.utils.auth.verifier.AuthVerifier().filter_project_resources_by_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.feature,
+ mlrun.common.schemas.AuthorizationResourceTypes.feature,
features.features,
lambda feature_list_output: (
feature_list_output.feature_set_digest.metadata.project,
@@ -486,21 +495,25 @@ async def list_features(
),
auth_info,
)
- return mlrun.api.schemas.FeaturesOutput(features=features)
+ return mlrun.common.schemas.FeaturesOutput(features=features)
-@router.get("/projects/{project}/entities", response_model=schemas.EntitiesOutput)
+@router.get(
+ "/projects/{project}/entities", response_model=mlrun.common.schemas.EntitiesOutput
+)
async def list_entities(
project: str,
name: str = None,
tag: str = None,
labels: List[str] = Query(None, alias="label"),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: typing.Union[
+ mlrun.common.schemas.AuthInfo, mlrun.common.schemas.AuthInfo
+ ] = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_permissions(
project,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
entities = await run_in_threadpool(
@@ -512,7 +525,7 @@ async def list_entities(
labels,
)
entities = await mlrun.api.utils.auth.verifier.AuthVerifier().filter_project_resources_by_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.entity,
+ mlrun.common.schemas.AuthorizationResourceTypes.entity,
entities.entities,
lambda entity_list_output: (
entity_list_output.feature_set_digest.metadata.project,
@@ -520,17 +533,20 @@ async def list_entities(
),
auth_info,
)
- return mlrun.api.schemas.EntitiesOutput(entities=entities)
+ return mlrun.common.schemas.EntitiesOutput(entities=entities)
@router.post(
- "/projects/{project}/feature-vectors", response_model=schemas.FeatureVector
+ "/projects/{project}/feature-vectors",
+ response_model=mlrun.common.schemas.FeatureVector,
)
async def create_feature_vector(
project: str,
- feature_vector: schemas.FeatureVector,
+ feature_vector: mlrun.common.schemas.FeatureVector,
versioned: bool = True,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: typing.Union[
+ mlrun.common.schemas.AuthInfo, mlrun.common.schemas.AuthInfo
+ ] = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await run_in_threadpool(
@@ -540,10 +556,10 @@ async def create_feature_vector(
auth_info=auth_info,
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.feature_vector,
+ mlrun.common.schemas.AuthorizationResourceTypes.feature_vector,
project,
feature_vector.metadata.name,
- mlrun.api.schemas.AuthorizationAction.create,
+ mlrun.common.schemas.AuthorizationAction.create,
auth_info,
)
await _verify_feature_vector_features_permissions(
@@ -569,13 +585,13 @@ async def create_feature_vector(
@router.get(
"/projects/{project}/feature-vectors/{name}/references/{reference}",
- response_model=schemas.FeatureVector,
+ response_model=mlrun.common.schemas.FeatureVector,
)
async def get_feature_vector(
project: str,
name: str,
reference: str,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
tag, uid = parse_reference(reference)
@@ -588,10 +604,10 @@ async def get_feature_vector(
uid,
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.feature_vector,
+ mlrun.common.schemas.AuthorizationResourceTypes.feature_vector,
project,
name,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
await _verify_feature_vector_features_permissions(
@@ -601,7 +617,8 @@ async def get_feature_vector(
@router.get(
- "/projects/{project}/feature-vectors", response_model=schemas.FeatureVectorsOutput
+ "/projects/{project}/feature-vectors",
+ response_model=mlrun.common.schemas.FeatureVectorsOutput,
)
async def list_feature_vectors(
project: str,
@@ -609,20 +626,22 @@ async def list_feature_vectors(
state: str = None,
tag: str = None,
labels: List[str] = Query(None, alias="label"),
- partition_by: schemas.FeatureStorePartitionByField = Query(
+ partition_by: mlrun.common.schemas.FeatureStorePartitionByField = Query(
None, alias="partition-by"
),
rows_per_partition: int = Query(1, alias="rows-per-partition", gt=0),
- partition_sort_by: schemas.SortField = Query(None, alias="partition-sort-by"),
- partition_order: schemas.OrderType = Query(
- schemas.OrderType.desc, alias="partition-order"
+ partition_sort_by: mlrun.common.schemas.SortField = Query(
+ None, alias="partition-sort-by"
+ ),
+ partition_order: mlrun.common.schemas.OrderType = Query(
+ mlrun.common.schemas.OrderType.desc, alias="partition-order"
),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_permissions(
project,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
feature_vectors = await run_in_threadpool(
@@ -639,7 +658,7 @@ async def list_feature_vectors(
partition_order,
)
feature_vectors = await mlrun.api.utils.auth.verifier.AuthVerifier().filter_project_resources_by_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.feature_vector,
+ mlrun.common.schemas.AuthorizationResourceTypes.feature_vector,
feature_vectors.feature_vectors,
lambda feature_vector: (
feature_vector.metadata.project,
@@ -653,17 +672,17 @@ async def list_feature_vectors(
for fv in feature_vectors
]
)
- return mlrun.api.schemas.FeatureVectorsOutput(feature_vectors=feature_vectors)
+ return mlrun.common.schemas.FeatureVectorsOutput(feature_vectors=feature_vectors)
@router.get(
"/projects/{project}/feature-vectors/{name}/tags",
- response_model=schemas.FeatureVectorsTagsOutput,
+ response_model=mlrun.common.schemas.FeatureVectorsTagsOutput,
)
async def list_feature_vectors_tags(
project: str,
name: str,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
if name != "*":
@@ -672,7 +691,7 @@ async def list_feature_vectors_tags(
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_permissions(
project,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
tag_tuples = await run_in_threadpool(
@@ -686,7 +705,7 @@ async def list_feature_vectors_tags(
auth_verifier = mlrun.api.utils.auth.verifier.AuthVerifier()
allowed_feature_vector_names = (
await auth_verifier.filter_project_resources_by_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.feature_vector,
+ mlrun.common.schemas.AuthorizationResourceTypes.feature_vector,
list(feature_vector_name_to_tag.keys()),
lambda feature_vector_name: (
project,
@@ -700,20 +719,20 @@ async def list_feature_vectors_tags(
for tag_tuple in tag_tuples
if tag_tuple[1] in allowed_feature_vector_names
}
- return mlrun.api.schemas.FeatureVectorsTagsOutput(tags=list(tags))
+ return mlrun.common.schemas.FeatureVectorsTagsOutput(tags=list(tags))
@router.put(
"/projects/{project}/feature-vectors/{name}/references/{reference}",
- response_model=schemas.FeatureVector,
+ response_model=mlrun.common.schemas.FeatureVector,
)
async def store_feature_vector(
project: str,
name: str,
reference: str,
- feature_vector: schemas.FeatureVector,
+ feature_vector: mlrun.common.schemas.FeatureVector,
versioned: bool = True,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await run_in_threadpool(
@@ -723,10 +742,10 @@ async def store_feature_vector(
auth_info=auth_info,
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.feature_vector,
+ mlrun.common.schemas.AuthorizationResourceTypes.feature_vector,
project,
name,
- mlrun.api.schemas.AuthorizationAction.update,
+ mlrun.common.schemas.AuthorizationAction.update,
auth_info,
)
await _verify_feature_vector_features_permissions(
@@ -760,17 +779,18 @@ async def patch_feature_vector(
name: str,
feature_vector_patch: dict,
reference: str,
- patch_mode: schemas.PatchMode = Header(
- schemas.PatchMode.replace, alias=schemas.HeaderNames.patch_mode
+ patch_mode: mlrun.common.schemas.PatchMode = Header(
+ mlrun.common.schemas.PatchMode.replace,
+ alias=mlrun.common.schemas.HeaderNames.patch_mode,
),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.feature_vector,
+ mlrun.common.schemas.AuthorizationResourceTypes.feature_vector,
project,
name,
- mlrun.api.schemas.AuthorizationAction.update,
+ mlrun.common.schemas.AuthorizationAction.update,
auth_info,
)
await _verify_feature_vector_features_permissions(
@@ -796,14 +816,14 @@ async def delete_feature_vector(
project: str,
name: str,
reference: str = None,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.feature_vector,
+ mlrun.common.schemas.AuthorizationResourceTypes.feature_vector,
project,
name,
- mlrun.api.schemas.AuthorizationAction.delete,
+ mlrun.common.schemas.AuthorizationAction.delete,
auth_info,
)
tag = uid = None
@@ -821,7 +841,7 @@ async def delete_feature_vector(
async def _verify_feature_vector_features_permissions(
- auth_info: mlrun.api.schemas.AuthInfo, project: str, feature_vector: dict
+ auth_info: mlrun.common.schemas.AuthInfo, project: str, feature_vector: dict
):
features = []
if feature_vector.get("spec", {}).get("features"):
@@ -840,12 +860,12 @@ async def _verify_feature_vector_features_permissions(
for name in names:
feature_set_project_name_tuples.append((_project, name))
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resources_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.feature_set,
+ mlrun.common.schemas.AuthorizationResourceTypes.feature_set,
feature_set_project_name_tuples,
lambda feature_set_project_name_tuple: (
feature_set_project_name_tuple[0],
feature_set_project_name_tuple[1],
),
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
diff --git a/mlrun/api/api/endpoints/files.py b/mlrun/api/api/endpoints/files.py
index e2777d4d7d9c..4a52d76a6964 100644
--- a/mlrun/api/api/endpoints/files.py
+++ b/mlrun/api/api/endpoints/files.py
@@ -20,8 +20,8 @@
import mlrun.api.api.deps
import mlrun.api.crud.secrets
-import mlrun.api.schemas
import mlrun.api.utils.auth.verifier
+import mlrun.common.schemas
from mlrun.api.api.utils import get_obj_path, get_secrets, log_and_raise
from mlrun.datastore import store_manager
from mlrun.errors import err_to_str
@@ -37,7 +37,7 @@ def get_files(
user: str = "",
size: int = 0,
offset: int = 0,
- auth_info: mlrun.api.schemas.AuthInfo = fastapi.Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
):
@@ -53,13 +53,13 @@ async def get_files_with_project_secrets(
size: int = 0,
offset: int = 0,
use_secrets: bool = fastapi.Query(True, alias="use-secrets"),
- auth_info: mlrun.api.schemas.AuthInfo = fastapi.Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_permissions(
project,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
@@ -76,7 +76,7 @@ async def get_files_with_project_secrets(
def get_filestat(
schema: str = "",
path: str = "",
- auth_info: mlrun.api.schemas.AuthInfo = fastapi.Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
user: str = "",
@@ -89,7 +89,7 @@ async def get_filestat_with_project_secrets(
project: str,
schema: str = "",
path: str = "",
- auth_info: mlrun.api.schemas.AuthInfo = fastapi.Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
user: str = "",
@@ -97,7 +97,7 @@ async def get_filestat_with_project_secrets(
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_permissions(
project,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
@@ -116,7 +116,7 @@ def _get_files(
user: str,
size: int,
offset: int,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
secrets: dict = None,
):
_, filename = objpath.split(objpath)
@@ -162,7 +162,7 @@ def _get_filestat(
schema: str,
path: str,
user: str,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
secrets: dict = None,
):
_, filename = path.split(path)
@@ -197,16 +197,16 @@ def _get_filestat(
async def _verify_and_get_project_secrets(project, auth_info):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.secret,
+ mlrun.common.schemas.AuthorizationResourceTypes.secret,
project,
- mlrun.api.schemas.SecretProviderName.kubernetes,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.SecretProviderName.kubernetes,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
secrets_data = await run_in_threadpool(
mlrun.api.crud.Secrets().list_project_secrets,
project,
- mlrun.api.schemas.SecretProviderName.kubernetes,
+ mlrun.common.schemas.SecretProviderName.kubernetes,
allow_secrets_from_k8s=True,
)
return secrets_data.secrets or {}
diff --git a/mlrun/api/api/endpoints/frontend_spec.py b/mlrun/api/api/endpoints/frontend_spec.py
index d180d302920f..d2c7069cac85 100644
--- a/mlrun/api/api/endpoints/frontend_spec.py
+++ b/mlrun/api/api/endpoints/frontend_spec.py
@@ -18,9 +18,9 @@
import semver
import mlrun.api.api.deps
-import mlrun.api.schemas
import mlrun.api.utils.clients.iguazio
import mlrun.builder
+import mlrun.common.schemas
import mlrun.runtimes
import mlrun.runtimes.utils
import mlrun.utils.helpers
@@ -33,10 +33,10 @@
@router.get(
"/frontend-spec",
- response_model=mlrun.api.schemas.FrontendSpec,
+ response_model=mlrun.common.schemas.FrontendSpec,
)
def get_frontend_spec(
- auth_info: mlrun.api.schemas.AuthInfo = fastapi.Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
# In Iguazio 3.0 auth is turned off, but for this endpoint specifically the session is a must, so getting it from
@@ -66,7 +66,7 @@ def get_frontend_spec(
function_target_image_name_prefix_template = (
config.httpdb.builder.function_target_image_name_prefix_template
)
- return mlrun.api.schemas.FrontendSpec(
+ return mlrun.common.schemas.FrontendSpec(
jobs_dashboard_url=jobs_dashboard_url,
abortable_function_kinds=mlrun.runtimes.RuntimeKinds.abortable_runtimes(),
feature_flags=feature_flags,
@@ -102,25 +102,25 @@ def _resolve_jobs_dashboard_url(session: str) -> typing.Optional[str]:
return None
-def _resolve_feature_flags() -> mlrun.api.schemas.FeatureFlags:
- project_membership = mlrun.api.schemas.ProjectMembershipFeatureFlag.disabled
+def _resolve_feature_flags() -> mlrun.common.schemas.FeatureFlags:
+ project_membership = mlrun.common.schemas.ProjectMembershipFeatureFlag.disabled
if mlrun.mlconf.httpdb.authorization.mode == "opa":
- project_membership = mlrun.api.schemas.ProjectMembershipFeatureFlag.enabled
- authentication = mlrun.api.schemas.AuthenticationFeatureFlag(
+ project_membership = mlrun.common.schemas.ProjectMembershipFeatureFlag.enabled
+ authentication = mlrun.common.schemas.AuthenticationFeatureFlag(
mlrun.mlconf.httpdb.authentication.mode
)
- nuclio_streams = mlrun.api.schemas.NuclioStreamsFeatureFlag.disabled
+ nuclio_streams = mlrun.common.schemas.NuclioStreamsFeatureFlag.disabled
if mlrun.mlconf.get_parsed_igz_version() and semver.VersionInfo.parse(
mlrun.runtimes.utils.resolve_nuclio_version()
) >= semver.VersionInfo.parse("1.7.8"):
- nuclio_streams = mlrun.api.schemas.NuclioStreamsFeatureFlag.enabled
+ nuclio_streams = mlrun.common.schemas.NuclioStreamsFeatureFlag.enabled
- preemption_nodes = mlrun.api.schemas.PreemptionNodesFeatureFlag.disabled
+ preemption_nodes = mlrun.common.schemas.PreemptionNodesFeatureFlag.disabled
if mlrun.mlconf.is_preemption_nodes_configured():
- preemption_nodes = mlrun.api.schemas.PreemptionNodesFeatureFlag.enabled
+ preemption_nodes = mlrun.common.schemas.PreemptionNodesFeatureFlag.enabled
- return mlrun.api.schemas.FeatureFlags(
+ return mlrun.common.schemas.FeatureFlags(
project_membership=project_membership,
authentication=authentication,
nuclio_streams=nuclio_streams,
diff --git a/mlrun/api/api/endpoints/functions.py b/mlrun/api/api/endpoints/functions.py
index 7a9b003fafcf..d2cf0cc5418f 100644
--- a/mlrun/api/api/endpoints/functions.py
+++ b/mlrun/api/api/endpoints/functions.py
@@ -35,16 +35,15 @@
import mlrun.api.crud
import mlrun.api.db.session
-import mlrun.api.schemas
import mlrun.api.utils.auth.verifier
import mlrun.api.utils.background_tasks
import mlrun.api.utils.clients.chief
import mlrun.api.utils.singletons.project_member
-import mlrun.model_monitoring.constants
+import mlrun.common.model_monitoring
+import mlrun.common.schemas
from mlrun.api.api import deps
from mlrun.api.api.utils import get_run_db_instance, log_and_raise, log_path
from mlrun.api.crud.secrets import Secrets, SecretsClientType
-from mlrun.api.schemas import SecretProviderName, SecretsData
from mlrun.api.utils.singletons.k8s import get_k8s
from mlrun.builder import build_runtime
from mlrun.config import config
@@ -66,7 +65,7 @@ async def store_function(
name: str,
tag: str = "",
versioned: bool = False,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await run_in_threadpool(
@@ -76,10 +75,10 @@ async def store_function(
auth_info=auth_info,
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.function,
+ mlrun.common.schemas.AuthorizationResourceTypes.function,
project,
name,
- mlrun.api.schemas.AuthorizationAction.store,
+ mlrun.common.schemas.AuthorizationAction.store,
auth_info,
)
data = None
@@ -110,7 +109,7 @@ async def get_function(
name: str,
tag: str = "",
hash_key="",
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
func = await run_in_threadpool(
@@ -122,10 +121,10 @@ async def get_function(
hash_key,
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.function,
+ mlrun.common.schemas.AuthorizationResourceTypes.function,
project,
name,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
return {
@@ -139,14 +138,14 @@ async def get_function(
async def delete_function(
project: str,
name: str,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.function,
+ mlrun.common.schemas.AuthorizationResourceTypes.function,
project,
name,
- mlrun.api.schemas.AuthorizationAction.delete,
+ mlrun.common.schemas.AuthorizationAction.delete,
auth_info,
)
await run_in_threadpool(
@@ -162,14 +161,14 @@ async def list_functions(
tag: str = None,
labels: List[str] = Query([], alias="label"),
hash_key: str = None,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
if project is None:
project = config.default_project
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_permissions(
project,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
functions = await run_in_threadpool(
@@ -182,7 +181,7 @@ async def list_functions(
hash_key=hash_key,
)
functions = await mlrun.api.utils.auth.verifier.AuthVerifier().filter_project_resources_by_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.function,
+ mlrun.common.schemas.AuthorizationResourceTypes.function,
functions,
lambda function: (
function.get("metadata", {}).get("project", mlrun.mlconf.default_project),
@@ -199,13 +198,13 @@ async def list_functions(
@router.post("/build/function/")
async def build_function(
request: Request,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
client_version: Optional[str] = Header(
- None, alias=mlrun.api.schemas.HeaderNames.client_version
+ None, alias=mlrun.common.schemas.HeaderNames.client_version
),
client_python_version: Optional[str] = Header(
- None, alias=mlrun.api.schemas.HeaderNames.python_version
+ None, alias=mlrun.common.schemas.HeaderNames.python_version
),
):
data = None
@@ -225,10 +224,10 @@ async def build_function(
auth_info=auth_info,
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.function,
+ mlrun.common.schemas.AuthorizationResourceTypes.function,
project,
function_name,
- mlrun.api.schemas.AuthorizationAction.update,
+ mlrun.common.schemas.AuthorizationAction.update,
auth_info,
)
@@ -240,7 +239,7 @@ async def build_function(
).get("track_models", False):
if (
mlrun.mlconf.httpdb.clusterization.role
- != mlrun.api.schemas.ClusterizationRole.chief
+ != mlrun.common.schemas.ClusterizationRole.chief
):
logger.info(
"Requesting to deploy serving function with track models, re-routing to chief",
@@ -275,18 +274,18 @@ async def build_function(
}
-@router.post("/start/function", response_model=mlrun.api.schemas.BackgroundTask)
-@router.post("/start/function/", response_model=mlrun.api.schemas.BackgroundTask)
+@router.post("/start/function", response_model=mlrun.common.schemas.BackgroundTask)
+@router.post("/start/function/", response_model=mlrun.common.schemas.BackgroundTask)
async def start_function(
request: Request,
background_tasks: BackgroundTasks,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
client_version: Optional[str] = Header(
- None, alias=mlrun.api.schemas.HeaderNames.client_version
+ None, alias=mlrun.common.schemas.HeaderNames.client_version
),
client_python_version: Optional[str] = Header(
- None, alias=mlrun.api.schemas.HeaderNames.python_version
+ None, alias=mlrun.common.schemas.HeaderNames.python_version
),
):
# TODO: ensure project here !!! for background task
@@ -300,10 +299,10 @@ async def start_function(
function = await run_in_threadpool(_parse_start_function_body, db_session, data)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.function,
+ mlrun.common.schemas.AuthorizationResourceTypes.function,
function.metadata.project,
function.metadata.name,
- mlrun.api.schemas.AuthorizationAction.update,
+ mlrun.common.schemas.AuthorizationAction.update,
auth_info,
)
background_timeout = mlrun.mlconf.background_tasks.default_timeouts.runtimes.dask
@@ -329,7 +328,7 @@ async def start_function(
@router.post("/status/function/")
async def function_status(
request: Request,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
):
data = None
try:
@@ -353,16 +352,16 @@ async def build_status(
logs: bool = True,
last_log_timestamp: float = 0.0,
verbose: bool = False,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.function,
+ mlrun.common.schemas.AuthorizationResourceTypes.function,
project or mlrun.mlconf.default_project,
name,
# store since with the current mechanism we update the status (and store the function) in the DB when a client
# query for the status
- mlrun.api.schemas.AuthorizationAction.store,
+ mlrun.common.schemas.AuthorizationAction.store,
auth_info,
)
fn = await run_in_threadpool(
@@ -418,7 +417,7 @@ def _handle_job_deploy_status(
image = get_in(fn, "spec.build.image", "")
out = b""
if not pod:
- if state == mlrun.api.schemas.FunctionState.ready:
+ if state == mlrun.common.schemas.FunctionState.ready:
# when the function has been built we set the created image into the `spec.image` for reference see at the
# end of the function where we resolve if the status is ready and then set the spec.build.image to
# spec.image
@@ -441,7 +440,7 @@ def _handle_job_deploy_status(
log_file = log_path(project, f"build_{name}__{tag or 'latest'}")
if state in terminal_states and log_file.exists():
- if state == mlrun.api.schemas.FunctionState.ready:
+ if state == mlrun.common.schemas.FunctionState.ready:
# when the function has been built we set the created image into the `spec.image` for reference see at the
# end of the function where we resolve if the status is ready and then set the spec.build.image to
# spec.image
@@ -470,10 +469,10 @@ def _handle_job_deploy_status(
if state == "succeeded":
logger.info("build completed successfully")
- state = mlrun.api.schemas.FunctionState.ready
+ state = mlrun.common.schemas.FunctionState.ready
if state in ["failed", "error"]:
logger.error(f"build {state}, watch the build pod logs: {pod}")
- state = mlrun.api.schemas.FunctionState.error
+ state = mlrun.common.schemas.FunctionState.error
if (logs and state != "pending") or state in terminal_states:
resp = get_k8s().logs(pod)
@@ -487,11 +486,11 @@ def _handle_job_deploy_status(
out = resp[offset:].encode()
update_in(fn, "status.state", state)
- if state == mlrun.api.schemas.FunctionState.ready:
+ if state == mlrun.common.schemas.FunctionState.ready:
update_in(fn, "spec.image", image)
versioned = False
- if state == mlrun.api.schemas.FunctionState.ready:
+ if state == mlrun.common.schemas.FunctionState.ready:
versioned = True
mlrun.api.crud.Functions().store_function(
db_session,
@@ -596,7 +595,7 @@ def _handle_nuclio_deploy_status(
def _build_function(
db_session,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
function,
with_mlrun=True,
skip_deployed=False,
@@ -638,7 +637,7 @@ def _build_function(
model_monitoring_access_key = _process_model_monitoring_secret(
db_session,
fn.metadata.project,
- mlrun.model_monitoring.constants.ProjectSecretKeys.ACCESS_KEY,
+ mlrun.common.model_monitoring.ProjectSecretKeys.ACCESS_KEY,
)
if mlrun.utils.model_monitoring.get_stream_path(
project=fn.metadata.project
@@ -740,7 +739,7 @@ def _parse_start_function_body(db_session, data):
def _start_function(
function,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
client_version: str = None,
client_python_version: str = None,
):
@@ -778,7 +777,7 @@ def _start_function(
mlrun.api.db.session.close_session(db_session)
-async def _get_function_status(data, auth_info: mlrun.api.schemas.AuthInfo):
+async def _get_function_status(data, auth_info: mlrun.common.schemas.AuthInfo):
logger.info(f"function_status:\n{data}")
selector = data.get("selector")
kind = data.get("kind")
@@ -794,10 +793,10 @@ async def _get_function_status(data, auth_info: mlrun.api.schemas.AuthInfo):
project, name, _ = mlrun.runtimes.utils.parse_function_selector(selector)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.function,
+ mlrun.common.schemas.AuthorizationResourceTypes.function,
project,
name,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
@@ -886,8 +885,7 @@ def _process_model_monitoring_secret(db_session, project_name: str, secret_key:
logger.info(
"Getting project secret", project_name=project_name, namespace=config.namespace
)
-
- provider = SecretProviderName.kubernetes
+ provider = mlrun.common.schemas.SecretProviderName.kubernetes
secret_value = Secrets().get_project_secret(
project_name,
provider,
@@ -926,7 +924,9 @@ def _process_model_monitoring_secret(db_session, project_name: str, secret_key:
project_owner=project_owner.username,
)
- secrets = SecretsData(provider=provider, secrets={internal_key_name: secret_value})
+ secrets = mlrun.common.schemas.SecretsData(
+ provider=provider, secrets={internal_key_name: secret_value}
+ )
Secrets().store_project_secrets(project_name, secrets, allow_internal_secrets=True)
if user_provided_key:
logger.info(
diff --git a/mlrun/api/api/endpoints/grafana_proxy.py b/mlrun/api/api/endpoints/grafana_proxy.py
index eab4a5be6f9a..a17717830873 100644
--- a/mlrun/api/api/endpoints/grafana_proxy.py
+++ b/mlrun/api/api/endpoints/grafana_proxy.py
@@ -23,11 +23,10 @@
import mlrun.api.crud
import mlrun.api.crud.model_monitoring.grafana
-import mlrun.api.schemas
import mlrun.api.utils.auth.verifier
-import mlrun.model_monitoring
+import mlrun.common.model_monitoring
+import mlrun.common.schemas
from mlrun.api.api import deps
-from mlrun.api.schemas import GrafanaTable, GrafanaTimeSeriesTarget
router = APIRouter()
@@ -47,7 +46,7 @@
@router.get("/grafana-proxy/model-endpoints", status_code=HTTPStatus.OK.value)
def grafana_proxy_model_endpoints_check_connection(
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
):
"""
Root of grafana proxy for the model-endpoints API, used for validating the model-endpoints data source
@@ -61,7 +60,7 @@ def grafana_proxy_model_endpoints_check_connection(
@router.post("/grafana-proxy/model-endpoints/search", response_model=List[str])
async def grafana_proxy_model_endpoints_search(
request: Request,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
) -> List[str]:
"""
@@ -103,12 +102,21 @@ async def grafana_proxy_model_endpoints_search(
@router.post(
"/grafana-proxy/model-endpoints/query",
- response_model=List[Union[GrafanaTable, GrafanaTimeSeriesTarget]],
+ response_model=List[
+ Union[
+ mlrun.common.schemas.GrafanaTable,
+ mlrun.common.schemas.GrafanaTimeSeriesTarget,
+ ]
+ ],
)
async def grafana_proxy_model_endpoints_query(
request: Request,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
-) -> List[Union[GrafanaTable, GrafanaTimeSeriesTarget]]:
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
+) -> List[
+ Union[
+ mlrun.common.schemas.GrafanaTable, mlrun.common.schemas.GrafanaTimeSeriesTarget
+ ]
+]:
"""
Query route for model-endpoints grafana proxy API, used for creating an interface between grafana queries and
model-endpoints logic.
diff --git a/mlrun/api/api/endpoints/healthz.py b/mlrun/api/api/endpoints/healthz.py
index d17280ce8757..bc0924329d30 100644
--- a/mlrun/api/api/endpoints/healthz.py
+++ b/mlrun/api/api/endpoints/healthz.py
@@ -16,7 +16,7 @@
from fastapi import APIRouter
-import mlrun.api.schemas
+import mlrun.common.schemas
from mlrun.config import config as mlconfig
router = APIRouter()
@@ -31,8 +31,8 @@ def health():
# offline is the initial state
# waiting for chief is set for workers waiting for chief to be ready and then clusterize against it
if mlconfig.httpdb.state in [
- mlrun.api.schemas.APIStates.offline,
- mlrun.api.schemas.APIStates.waiting_for_chief,
+ mlrun.common.schemas.APIStates.offline,
+ mlrun.common.schemas.APIStates.waiting_for_chief,
]:
raise mlrun.errors.MLRunServiceUnavailableError()
diff --git a/mlrun/api/api/endpoints/hub.py b/mlrun/api/api/endpoints/hub.py
index b2ec74ddc11d..05ca5ae3a03e 100644
--- a/mlrun/api/api/endpoints/hub.py
+++ b/mlrun/api/api/endpoints/hub.py
@@ -25,9 +25,9 @@
import mlrun.api.api.deps
import mlrun.api.crud
import mlrun.api.utils.auth.verifier
-from mlrun.api.schemas import AuthorizationAction
-from mlrun.api.schemas.hub import HubCatalog, HubItem, IndexedHubSource
-from mlrun.api.utils.singletons.db import get_db
+import mlrun.api.utils.singletons.db
+import mlrun.common.schemas
+import mlrun.common.schemas.hub
router = APIRouter()
@@ -35,46 +35,52 @@
@router.post(
path="/hub/sources",
status_code=HTTPStatus.CREATED.value,
- response_model=IndexedHubSource,
+ response_model=mlrun.common.schemas.hub.IndexedHubSource,
)
async def create_source(
- source: IndexedHubSource,
+ source: mlrun.common.schemas.hub.IndexedHubSource,
db_session: Session = Depends(mlrun.api.api.deps.get_db_session),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(
mlrun.api.api.deps.authenticate_request
),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_global_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.hub_source,
- AuthorizationAction.create,
+ mlrun.common.schemas.AuthorizationResourceTypes.hub_source,
+ mlrun.common.schemas.AuthorizationAction.create,
auth_info,
)
- await run_in_threadpool(get_db().create_hub_source, db_session, source)
+ await run_in_threadpool(
+ mlrun.api.utils.singletons.db.get_db().create_hub_source, db_session, source
+ )
# Handle credentials if they exist
await run_in_threadpool(mlrun.api.crud.Hub().add_source, source.source)
return await run_in_threadpool(
- get_db().get_hub_source, db_session, source.source.metadata.name
+ mlrun.api.utils.singletons.db.get_db().get_hub_source,
+ db_session,
+ source.source.metadata.name,
)
@router.get(
path="/hub/sources",
- response_model=List[IndexedHubSource],
+ response_model=List[mlrun.common.schemas.hub.IndexedHubSource],
)
async def list_sources(
db_session: Session = Depends(mlrun.api.api.deps.get_db_session),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(
mlrun.api.api.deps.authenticate_request
),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_global_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.hub_source,
- AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationResourceTypes.hub_source,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
- return await run_in_threadpool(get_db().list_hub_sources, db_session)
+ return await run_in_threadpool(
+ mlrun.api.utils.singletons.db.get_db().list_hub_sources, db_session
+ )
@router.delete(
@@ -84,68 +90,82 @@ async def list_sources(
async def delete_source(
source_name: str,
db_session: Session = Depends(mlrun.api.api.deps.get_db_session),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(
mlrun.api.api.deps.authenticate_request
),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_global_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.hub_source,
- AuthorizationAction.delete,
+ mlrun.common.schemas.AuthorizationResourceTypes.hub_source,
+ mlrun.common.schemas.AuthorizationAction.delete,
auth_info,
)
- await run_in_threadpool(get_db().delete_hub_source, db_session, source_name)
+ await run_in_threadpool(
+ mlrun.api.utils.singletons.db.get_db().delete_hub_source,
+ db_session,
+ source_name,
+ )
await run_in_threadpool(mlrun.api.crud.Hub().remove_source, source_name)
@router.get(
path="/hub/sources/{source_name}",
- response_model=IndexedHubSource,
+ response_model=mlrun.common.schemas.hub.IndexedHubSource,
)
async def get_source(
source_name: str,
db_session: Session = Depends(mlrun.api.api.deps.get_db_session),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(
mlrun.api.api.deps.authenticate_request
),
):
hub_source = await run_in_threadpool(
- get_db().get_hub_source, db_session, source_name
+ mlrun.api.utils.singletons.db.get_db().get_hub_source, db_session, source_name
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_global_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.hub_source,
- AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationResourceTypes.hub_source,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
return hub_source
-@router.put(path="/hub/sources/{source_name}", response_model=IndexedHubSource)
+@router.put(
+ path="/hub/sources/{source_name}",
+ response_model=mlrun.common.schemas.hub.IndexedHubSource,
+)
async def store_source(
source_name: str,
- source: IndexedHubSource,
+ source: mlrun.common.schemas.hub.IndexedHubSource,
db_session: Session = Depends(mlrun.api.api.deps.get_db_session),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(
mlrun.api.api.deps.authenticate_request
),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_global_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.hub_source,
- AuthorizationAction.store,
+ mlrun.common.schemas.AuthorizationResourceTypes.hub_source,
+ mlrun.common.schemas.AuthorizationAction.store,
auth_info,
)
- await run_in_threadpool(get_db().store_hub_source, db_session, source_name, source)
+ await run_in_threadpool(
+ mlrun.api.utils.singletons.db.get_db().store_hub_source,
+ db_session,
+ source_name,
+ source,
+ )
# Handle credentials if they exist
await run_in_threadpool(mlrun.api.crud.Hub().add_source, source.source)
- return await run_in_threadpool(get_db().get_hub_source, db_session, source_name)
+ return await run_in_threadpool(
+ mlrun.api.utils.singletons.db.get_db().get_hub_source, db_session, source_name
+ )
@router.get(
path="/hub/sources/{source_name}/items",
- response_model=HubCatalog,
+ response_model=mlrun.common.schemas.hub.HubCatalog,
)
async def get_catalog(
source_name: str,
@@ -153,16 +173,16 @@ async def get_catalog(
tag: Optional[str] = Query(None),
force_refresh: Optional[bool] = Query(False, alias="force-refresh"),
db_session: Session = Depends(mlrun.api.api.deps.get_db_session),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(
mlrun.api.api.deps.authenticate_request
),
):
ordered_source = await run_in_threadpool(
- get_db().get_hub_source, db_session, source_name
+ mlrun.api.utils.singletons.db.get_db().get_hub_source, db_session, source_name
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_global_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.hub_source,
- AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationResourceTypes.hub_source,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
@@ -177,7 +197,7 @@ async def get_catalog(
@router.get(
"/hub/sources/{source_name}/items/{item_name}",
- response_model=HubItem,
+ response_model=mlrun.common.schemas.hub.HubItem,
)
async def get_item(
source_name: str,
@@ -186,16 +206,16 @@ async def get_item(
tag: Optional[str] = Query("latest"),
force_refresh: Optional[bool] = Query(False, alias="force-refresh"),
db_session: Session = Depends(mlrun.api.api.deps.get_db_session),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(
mlrun.api.api.deps.authenticate_request
),
):
ordered_source = await run_in_threadpool(
- get_db().get_hub_source, db_session, source_name
+ mlrun.api.utils.singletons.db.get_db().get_hub_source, db_session, source_name
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_global_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.hub_source,
- AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationResourceTypes.hub_source,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
@@ -216,12 +236,12 @@ async def get_object(
source_name: str,
url: str,
db_session: Session = Depends(mlrun.api.api.deps.get_db_session),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(
mlrun.api.api.deps.authenticate_request
),
):
ordered_source = await run_in_threadpool(
- get_db().get_hub_source, db_session, source_name
+ mlrun.api.utils.singletons.db.get_db().get_hub_source, db_session, source_name
)
object_data = await run_in_threadpool(
mlrun.api.crud.Hub().get_item_object_using_source_credentials,
@@ -229,8 +249,8 @@ async def get_object(
url,
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_global_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.hub_source,
- AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationResourceTypes.hub_source,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
@@ -251,7 +271,7 @@ async def get_asset(
tag: Optional[str] = Query("latest"),
version: Optional[str] = Query(None),
db_session: Session = Depends(mlrun.api.api.deps.get_db_session),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(
mlrun.api.api.deps.authenticate_request
),
):
@@ -268,11 +288,13 @@ async def get_asset(
:return: fastapi response with the asset in content
"""
- source = await run_in_threadpool(get_db().get_hub_source, db_session, source_name)
+ source = await run_in_threadpool(
+ mlrun.api.utils.singletons.db.get_db().get_hub_source, db_session, source_name
+ )
await mlrun.api.utils.auth.verifier.AuthVerifier().query_global_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.hub_source,
- AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationResourceTypes.hub_source,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
# Getting the relevant item which hold the asset information
diff --git a/mlrun/api/api/endpoints/internal/memory_reports.py b/mlrun/api/api/endpoints/internal/memory_reports.py
index fadc04a1e85d..0bd0df581bbb 100644
--- a/mlrun/api/api/endpoints/internal/memory_reports.py
+++ b/mlrun/api/api/endpoints/internal/memory_reports.py
@@ -14,26 +14,26 @@
#
import fastapi
-import mlrun.api.schemas
import mlrun.api.utils.memory_reports
+import mlrun.common.schemas
router = fastapi.APIRouter()
@router.get(
"/memory-reports/common-types",
- response_model=mlrun.api.schemas.MostCommonObjectTypesReport,
+ response_model=mlrun.common.schemas.MostCommonObjectTypesReport,
)
def get_most_common_objects_report():
report = (
mlrun.api.utils.memory_reports.MemoryUsageReport().create_most_common_objects_report()
)
- return mlrun.api.schemas.MostCommonObjectTypesReport(object_types=report)
+ return mlrun.common.schemas.MostCommonObjectTypesReport(object_types=report)
@router.get(
"/memory-reports/{object_type}",
- response_model=mlrun.api.schemas.ObjectTypeReport,
+ response_model=mlrun.common.schemas.ObjectTypeReport,
)
def get_memory_usage_report(
object_type: str,
@@ -47,7 +47,7 @@ def get_memory_usage_report(
object_type, sample_size, start_index, create_graph, max_depth
)
)
- return mlrun.api.schemas.ObjectTypeReport(
+ return mlrun.common.schemas.ObjectTypeReport(
object_type=object_type,
sample_size=sample_size,
start_index=start_index,
diff --git a/mlrun/api/api/endpoints/logs.py b/mlrun/api/api/endpoints/logs.py
index 24e45e0bedc8..8dc0b72dbd9c 100644
--- a/mlrun/api/api/endpoints/logs.py
+++ b/mlrun/api/api/endpoints/logs.py
@@ -18,8 +18,8 @@
import mlrun.api.api.deps
import mlrun.api.crud
-import mlrun.api.schemas
import mlrun.api.utils.auth.verifier
+import mlrun.common.schemas
router = fastapi.APIRouter()
@@ -30,15 +30,15 @@ async def store_log(
project: str,
uid: str,
append: bool = True,
- auth_info: mlrun.api.schemas.AuthInfo = fastapi.Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.log,
+ mlrun.common.schemas.AuthorizationResourceTypes.log,
project,
uid,
- mlrun.api.schemas.AuthorizationAction.store,
+ mlrun.common.schemas.AuthorizationAction.store,
auth_info,
)
body = await request.body()
@@ -58,7 +58,7 @@ async def get_log(
uid: str,
size: int = -1,
offset: int = 0,
- auth_info: mlrun.api.schemas.AuthInfo = fastapi.Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
db_session: sqlalchemy.orm.Session = fastapi.Depends(
@@ -66,10 +66,10 @@ async def get_log(
),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.log,
+ mlrun.common.schemas.AuthorizationResourceTypes.log,
project,
uid,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
run_state, log_stream = await mlrun.api.crud.Logs().get_logs(
diff --git a/mlrun/api/api/endpoints/model_endpoints.py b/mlrun/api/api/endpoints/model_endpoints.py
index 6d9282615de1..6359b1aaa2f9 100644
--- a/mlrun/api/api/endpoints/model_endpoints.py
+++ b/mlrun/api/api/endpoints/model_endpoints.py
@@ -24,8 +24,8 @@
import mlrun.api.api.deps
import mlrun.api.crud
-import mlrun.api.schemas
import mlrun.api.utils.auth.verifier
+import mlrun.common.schemas
from mlrun.errors import MLRunConflictError
router = APIRouter()
@@ -33,17 +33,17 @@
@router.put(
"/projects/{project}/model-endpoints/{endpoint_id}",
- response_model=mlrun.api.schemas.ModelEndpoint,
+ response_model=mlrun.common.schemas.ModelEndpoint,
)
async def create_or_patch(
project: str,
endpoint_id: str,
- model_endpoint: mlrun.api.schemas.ModelEndpoint,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(
+ model_endpoint: mlrun.common.schemas.ModelEndpoint,
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(
mlrun.api.api.deps.authenticate_request
),
db_session: Session = Depends(mlrun.api.api.deps.get_db_session),
-) -> mlrun.api.schemas.ModelEndpoint:
+) -> mlrun.common.schemas.ModelEndpoint:
"""
Either create or update the record of a given `ModelEndpoint` object.
Leaving here for backwards compatibility.
@@ -57,10 +57,10 @@ async def create_or_patch(
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.model_endpoint,
+ mlrun.common.schemas.AuthorizationResourceTypes.model_endpoint,
project,
endpoint_id,
- mlrun.api.schemas.AuthorizationAction.store,
+ mlrun.common.schemas.AuthorizationAction.store,
auth_info,
)
# get_access_key will validate the needed auth (which is used later) exists in the request
@@ -87,17 +87,17 @@ async def create_or_patch(
@router.post(
"/projects/{project}/model-endpoints/{endpoint_id}",
- response_model=mlrun.api.schemas.ModelEndpoint,
+ response_model=mlrun.common.schemas.ModelEndpoint,
)
async def create_model_endpoint(
project: str,
endpoint_id: str,
- model_endpoint: mlrun.api.schemas.ModelEndpoint,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(
+ model_endpoint: mlrun.common.schemas.ModelEndpoint,
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(
mlrun.api.api.deps.authenticate_request
),
db_session: Session = Depends(mlrun.api.api.deps.get_db_session),
-) -> mlrun.api.schemas.ModelEndpoint:
+) -> mlrun.common.schemas.ModelEndpoint:
"""
Create a DB record of a given `ModelEndpoint` object.
@@ -113,10 +113,10 @@ async def create_model_endpoint(
"""
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- resource_type=mlrun.api.schemas.AuthorizationResourceTypes.model_endpoint,
+ resource_type=mlrun.common.schemas.AuthorizationResourceTypes.model_endpoint,
project_name=project,
resource_name=endpoint_id,
- action=mlrun.api.schemas.AuthorizationAction.store,
+ action=mlrun.common.schemas.AuthorizationAction.store,
auth_info=auth_info,
)
@@ -139,16 +139,16 @@ async def create_model_endpoint(
@router.patch(
"/projects/{project}/model-endpoints/{endpoint_id}",
- response_model=mlrun.api.schemas.ModelEndpoint,
+ response_model=mlrun.common.schemas.ModelEndpoint,
)
async def patch_model_endpoint(
project: str,
endpoint_id: str,
attributes: str = None,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(
mlrun.api.api.deps.authenticate_request
),
-) -> mlrun.api.schemas.ModelEndpoint:
+) -> mlrun.common.schemas.ModelEndpoint:
"""
Update a DB record of a given `ModelEndpoint` object.
@@ -168,10 +168,10 @@ async def patch_model_endpoint(
"""
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- resource_type=mlrun.api.schemas.AuthorizationResourceTypes.model_endpoint,
+ resource_type=mlrun.common.schemas.AuthorizationResourceTypes.model_endpoint,
project_name=project,
resource_name=endpoint_id,
- action=mlrun.api.schemas.AuthorizationAction.update,
+ action=mlrun.common.schemas.AuthorizationAction.update,
auth_info=auth_info,
)
@@ -194,7 +194,7 @@ async def patch_model_endpoint(
async def delete_model_endpoint(
project: str,
endpoint_id: str,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(
mlrun.api.api.deps.authenticate_request
),
):
@@ -208,10 +208,10 @@ async def delete_model_endpoint(
"""
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- resource_type=mlrun.api.schemas.AuthorizationResourceTypes.model_endpoint,
+ resource_type=mlrun.common.schemas.AuthorizationResourceTypes.model_endpoint,
project_name=project,
resource_name=endpoint_id,
- action=mlrun.api.schemas.AuthorizationAction.delete,
+ action=mlrun.common.schemas.AuthorizationAction.delete,
auth_info=auth_info,
)
@@ -224,7 +224,7 @@ async def delete_model_endpoint(
@router.get(
"/projects/{project}/model-endpoints",
- response_model=mlrun.api.schemas.ModelEndpointList,
+ response_model=mlrun.common.schemas.ModelEndpointList,
)
async def list_model_endpoints(
project: str,
@@ -236,10 +236,10 @@ async def list_model_endpoints(
metrics: List[str] = Query([], alias="metric"),
top_level: bool = Query(False, alias="top-level"),
uids: List[str] = Query(None, alias="uid"),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(
mlrun.api.api.deps.authenticate_request
),
-) -> mlrun.api.schemas.ModelEndpointList:
+) -> mlrun.common.schemas.ModelEndpointList:
"""
Returns a list of endpoints of type 'ModelEndpoint', supports filtering by model, function, tag,
labels or top level. By default, when no filters are applied, all available endpoints for the given project will be
@@ -284,7 +284,7 @@ async def list_model_endpoints(
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_permissions(
project_name=project,
- action=mlrun.api.schemas.AuthorizationAction.read,
+ action=mlrun.common.schemas.AuthorizationAction.read,
auth_info=auth_info,
)
@@ -302,7 +302,7 @@ async def list_model_endpoints(
uids=uids,
)
allowed_endpoints = await mlrun.api.utils.auth.verifier.AuthVerifier().filter_project_resources_by_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.model_endpoint,
+ mlrun.common.schemas.AuthorizationResourceTypes.model_endpoint,
endpoints.endpoints,
lambda _endpoint: (
_endpoint.metadata.project,
@@ -317,7 +317,7 @@ async def list_model_endpoints(
@router.get(
"/projects/{project}/model-endpoints/{endpoint_id}",
- response_model=mlrun.api.schemas.ModelEndpoint,
+ response_model=mlrun.common.schemas.ModelEndpoint,
)
async def get_model_endpoint(
project: str,
@@ -326,10 +326,10 @@ async def get_model_endpoint(
end: str = Query(default="now"),
metrics: List[str] = Query([], alias="metric"),
feature_analysis: bool = Query(default=False),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(
mlrun.api.api.deps.authenticate_request
),
-) -> mlrun.api.schemas.ModelEndpoint:
+) -> mlrun.common.schemas.ModelEndpoint:
"""Get a single model endpoint object. You can apply different time series metrics that will be added to the
result.
@@ -356,10 +356,10 @@ async def get_model_endpoint(
:return: A `ModelEndpoint` object.
"""
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.model_endpoint,
+ mlrun.common.schemas.AuthorizationResourceTypes.model_endpoint,
project,
endpoint_id,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
diff --git a/mlrun/api/api/endpoints/operations.py b/mlrun/api/api/endpoints/operations.py
index 6751478cb485..527e99543a73 100644
--- a/mlrun/api/api/endpoints/operations.py
+++ b/mlrun/api/api/endpoints/operations.py
@@ -21,9 +21,9 @@
import mlrun.api.api.deps
import mlrun.api.crud
import mlrun.api.initial_data
-import mlrun.api.schemas
import mlrun.api.utils.background_tasks
import mlrun.api.utils.clients.chief
+import mlrun.common.schemas
from mlrun.utils import logger
router = fastapi.APIRouter()
@@ -36,7 +36,7 @@
"/operations/migrations",
responses={
http.HTTPStatus.OK.value: {},
- http.HTTPStatus.ACCEPTED.value: {"model": mlrun.api.schemas.BackgroundTask},
+ http.HTTPStatus.ACCEPTED.value: {"model": mlrun.common.schemas.BackgroundTask},
},
)
async def trigger_migrations(
@@ -47,7 +47,7 @@ async def trigger_migrations(
# only chief can execute migrations, redirecting request to chief
if (
mlrun.mlconf.httpdb.clusterization.role
- != mlrun.api.schemas.ClusterizationRole.chief
+ != mlrun.common.schemas.ClusterizationRole.chief
):
logger.info("Requesting to trigger migrations, re-routing to chief")
chief_client = mlrun.api.utils.clients.chief.Client()
@@ -72,18 +72,22 @@ async def trigger_migrations(
def _get_or_create_migration_background_task(
task_name: str, background_tasks
-) -> typing.Optional[mlrun.api.schemas.BackgroundTask]:
- if mlrun.mlconf.httpdb.state == mlrun.api.schemas.APIStates.migrations_in_progress:
+) -> typing.Optional[mlrun.common.schemas.BackgroundTask]:
+ if (
+ mlrun.mlconf.httpdb.state
+ == mlrun.common.schemas.APIStates.migrations_in_progress
+ ):
background_task = mlrun.api.utils.background_tasks.InternalBackgroundTasksHandler().get_background_task(
task_name
)
return background_task
- elif mlrun.mlconf.httpdb.state == mlrun.api.schemas.APIStates.migrations_failed:
+ elif mlrun.mlconf.httpdb.state == mlrun.common.schemas.APIStates.migrations_failed:
raise mlrun.errors.MLRunPreconditionFailedError(
"Migrations were already triggered and failed. Restart the API to retry"
)
elif (
- mlrun.mlconf.httpdb.state != mlrun.api.schemas.APIStates.waiting_for_migrations
+ mlrun.mlconf.httpdb.state
+ != mlrun.common.schemas.APIStates.waiting_for_migrations
):
return None
@@ -102,4 +106,4 @@ async def _perform_migration():
mlrun.api.initial_data.init_data, perform_migrations_if_needed=True
)
await mlrun.api.main.move_api_to_online()
- mlrun.mlconf.httpdb.state = mlrun.api.schemas.APIStates.online
+ mlrun.mlconf.httpdb.state = mlrun.common.schemas.APIStates.online
diff --git a/mlrun/api/api/endpoints/pipelines.py b/mlrun/api/api/endpoints/pipelines.py
index fbeefe3a946a..38fa53428851 100644
--- a/mlrun/api/api/endpoints/pipelines.py
+++ b/mlrun/api/api/endpoints/pipelines.py
@@ -23,8 +23,8 @@
from sqlalchemy.orm import Session
import mlrun.api.crud
-import mlrun.api.schemas
import mlrun.api.utils.auth.verifier
+import mlrun.common.schemas
import mlrun.errors
from mlrun.api.api import deps
from mlrun.api.api.utils import log_and_raise
@@ -36,7 +36,7 @@
@router.get(
- "/projects/{project}/pipelines", response_model=mlrun.api.schemas.PipelinesOutput
+ "/projects/{project}/pipelines", response_model=mlrun.common.schemas.PipelinesOutput
)
async def list_pipelines(
project: str,
@@ -44,11 +44,11 @@ async def list_pipelines(
sort_by: str = "",
page_token: str = "",
filter_: str = Query("", alias="filter"),
- format_: mlrun.api.schemas.PipelinesFormat = Query(
- mlrun.api.schemas.PipelinesFormat.metadata_only, alias="format"
+ format_: mlrun.common.schemas.PipelinesFormat = Query(
+ mlrun.common.schemas.PipelinesFormat.metadata_only, alias="format"
),
page_size: int = Query(None, gt=0, le=200),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(
mlrun.api.api.deps.authenticate_request
),
db_session: Session = Depends(deps.get_db_session),
@@ -58,7 +58,7 @@ async def list_pipelines(
if project != "*":
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_permissions(
project,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
total_size, next_page_token, runs = None, None, []
@@ -66,8 +66,8 @@ async def list_pipelines(
# we need to resolve the project from the returned run for the opa enforcement (project query param might be
# "*"), so we can't really get back only the names here
computed_format = (
- mlrun.api.schemas.PipelinesFormat.metadata_only
- if format_ == mlrun.api.schemas.PipelinesFormat.name_only
+ mlrun.common.schemas.PipelinesFormat.metadata_only
+ if format_ == mlrun.common.schemas.PipelinesFormat.name_only
else format_
)
total_size, next_page_token, runs = await run_in_threadpool(
@@ -82,7 +82,7 @@ async def list_pipelines(
page_size,
)
allowed_runs = await mlrun.api.utils.auth.verifier.AuthVerifier().filter_project_resources_by_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.pipeline,
+ mlrun.common.schemas.AuthorizationResourceTypes.pipeline,
runs,
lambda run: (
run["project"],
@@ -90,9 +90,9 @@ async def list_pipelines(
),
auth_info,
)
- if format_ == mlrun.api.schemas.PipelinesFormat.name_only:
+ if format_ == mlrun.common.schemas.PipelinesFormat.name_only:
allowed_runs = [run["name"] for run in allowed_runs]
- return mlrun.api.schemas.PipelinesOutput(
+ return mlrun.common.schemas.PipelinesOutput(
runs=allowed_runs,
total_size=total_size or 0,
next_page_token=next_page_token or None,
@@ -106,7 +106,7 @@ async def create_pipeline(
namespace: str = None,
experiment_name: str = Query("Default", alias="experiment"),
run_name: str = Query("", alias="run"),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(
mlrun.api.api.deps.authenticate_request
),
):
@@ -119,7 +119,7 @@ async def create_pipeline(
async def _create_pipeline(
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
request: Request,
namespace: str,
experiment_name: str,
@@ -129,10 +129,10 @@ async def _create_pipeline(
# If we have the project (new clients from 0.7.0 uses the new endpoint in which it's mandatory) - check auth now
if project:
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.pipeline,
+ mlrun.common.schemas.AuthorizationResourceTypes.pipeline,
project,
"",
- mlrun.api.schemas.AuthorizationAction.create,
+ mlrun.common.schemas.AuthorizationAction.create,
auth_info,
)
run_name = run_name or experiment_name + " " + datetime.now().strftime(
@@ -153,16 +153,16 @@ async def _create_pipeline(
)
else:
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.pipeline,
+ mlrun.common.schemas.AuthorizationResourceTypes.pipeline,
project,
"",
- mlrun.api.schemas.AuthorizationAction.create,
+ mlrun.common.schemas.AuthorizationAction.create,
auth_info,
)
arguments = {}
arguments_data = request.headers.get(
- mlrun.api.schemas.HeaderNames.pipeline_arguments
+ mlrun.common.schemas.HeaderNames.pipeline_arguments
)
if arguments_data:
arguments = ast.literal_eval(arguments_data)
@@ -203,10 +203,10 @@ async def get_pipeline(
run_id: str,
project: str,
namespace: str = Query(config.namespace),
- format_: mlrun.api.schemas.PipelinesFormat = Query(
- mlrun.api.schemas.PipelinesFormat.summary, alias="format"
+ format_: mlrun.common.schemas.PipelinesFormat = Query(
+ mlrun.common.schemas.PipelinesFormat.summary, alias="format"
),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(
mlrun.api.api.deps.authenticate_request
),
db_session: Session = Depends(deps.get_db_session),
@@ -223,10 +223,10 @@ async def get_pipeline(
await _get_pipeline_without_project(db_session, auth_info, run_id, namespace)
else:
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.pipeline,
+ mlrun.common.schemas.AuthorizationResourceTypes.pipeline,
project,
run_id,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
return pipeline
@@ -234,7 +234,7 @@ async def get_pipeline(
async def _get_pipeline_without_project(
db_session: Session,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
run_id: str,
namespace: str,
):
@@ -249,13 +249,13 @@ async def _get_pipeline_without_project(
run_id,
namespace=namespace,
# minimal format that includes the project
- format_=mlrun.api.schemas.PipelinesFormat.summary,
+ format_=mlrun.common.schemas.PipelinesFormat.summary,
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.pipeline,
+ mlrun.common.schemas.AuthorizationResourceTypes.pipeline,
run["run"]["project"],
run["run"]["id"],
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
return run
diff --git a/mlrun/api/api/endpoints/projects.py b/mlrun/api/api/endpoints/projects.py
index 2987bcba9251..e4a950a4100d 100644
--- a/mlrun/api/api/endpoints/projects.py
+++ b/mlrun/api/api/endpoints/projects.py
@@ -20,9 +20,9 @@
from fastapi.concurrency import run_in_threadpool
import mlrun.api.api.deps
-import mlrun.api.schemas
import mlrun.api.utils.auth.verifier
import mlrun.api.utils.clients.chief
+import mlrun.common.schemas
from mlrun.api.utils.singletons.project_member import get_project_member
from mlrun.utils import logger
@@ -32,17 +32,17 @@
@router.post(
"/projects",
responses={
- http.HTTPStatus.CREATED.value: {"model": mlrun.api.schemas.Project},
+ http.HTTPStatus.CREATED.value: {"model": mlrun.common.schemas.Project},
http.HTTPStatus.ACCEPTED.value: {},
},
)
def create_project(
- project: mlrun.api.schemas.Project,
+ project: mlrun.common.schemas.Project,
response: fastapi.Response,
# TODO: we're in a http request context here, therefore it doesn't make sense that by default it will hold the
# request until the process will be completed - after UI supports waiting - change default to False
wait_for_completion: bool = fastapi.Query(True, alias="wait-for-completion"),
- auth_info: mlrun.api.schemas.AuthInfo = fastapi.Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
db_session: sqlalchemy.orm.Session = fastapi.Depends(
@@ -65,17 +65,17 @@ def create_project(
@router.put(
"/projects/{name}",
responses={
- http.HTTPStatus.OK.value: {"model": mlrun.api.schemas.Project},
+ http.HTTPStatus.OK.value: {"model": mlrun.common.schemas.Project},
http.HTTPStatus.ACCEPTED.value: {},
},
)
def store_project(
- project: mlrun.api.schemas.Project,
+ project: mlrun.common.schemas.Project,
name: str,
# TODO: we're in a http request context here, therefore it doesn't make sense that by default it will hold the
# request until the process will be completed - after UI supports waiting - change default to False
wait_for_completion: bool = fastapi.Query(True, alias="wait-for-completion"),
- auth_info: mlrun.api.schemas.AuthInfo = fastapi.Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
db_session: sqlalchemy.orm.Session = fastapi.Depends(
@@ -98,21 +98,21 @@ def store_project(
@router.patch(
"/projects/{name}",
responses={
- http.HTTPStatus.OK.value: {"model": mlrun.api.schemas.Project},
+ http.HTTPStatus.OK.value: {"model": mlrun.common.schemas.Project},
http.HTTPStatus.ACCEPTED.value: {},
},
)
def patch_project(
project: dict,
name: str,
- patch_mode: mlrun.api.schemas.PatchMode = fastapi.Header(
- mlrun.api.schemas.PatchMode.replace,
- alias=mlrun.api.schemas.HeaderNames.patch_mode,
+ patch_mode: mlrun.common.schemas.PatchMode = fastapi.Header(
+ mlrun.common.schemas.PatchMode.replace,
+ alias=mlrun.common.schemas.HeaderNames.patch_mode,
),
# TODO: we're in a http request context here, therefore it doesn't make sense that by default it will hold the
# request until the process will be completed - after UI supports waiting - change default to False
wait_for_completion: bool = fastapi.Query(True, alias="wait-for-completion"),
- auth_info: mlrun.api.schemas.AuthInfo = fastapi.Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
db_session: sqlalchemy.orm.Session = fastapi.Depends(
@@ -133,13 +133,13 @@ def patch_project(
return project
-@router.get("/projects/{name}", response_model=mlrun.api.schemas.Project)
+@router.get("/projects/{name}", response_model=mlrun.common.schemas.Project)
async def get_project(
name: str,
db_session: sqlalchemy.orm.Session = fastapi.Depends(
mlrun.api.api.deps.get_db_session
),
- auth_info: mlrun.api.schemas.AuthInfo = fastapi.Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
):
@@ -150,7 +150,7 @@ async def get_project(
if not _is_request_from_leader(auth_info.projects_role):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_permissions(
name,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
return project
@@ -166,14 +166,14 @@ async def get_project(
async def delete_project(
name: str,
request: fastapi.Request,
- deletion_strategy: mlrun.api.schemas.DeletionStrategy = fastapi.Header(
- mlrun.api.schemas.DeletionStrategy.default(),
- alias=mlrun.api.schemas.HeaderNames.deletion_strategy,
+ deletion_strategy: mlrun.common.schemas.DeletionStrategy = fastapi.Header(
+ mlrun.common.schemas.DeletionStrategy.default(),
+ alias=mlrun.common.schemas.HeaderNames.deletion_strategy,
),
# TODO: we're in a http request context here, therefore it doesn't make sense that by default it will hold the
# request until the process will be completed - after UI supports waiting - change default to False
wait_for_completion: bool = fastapi.Query(True, alias="wait-for-completion"),
- auth_info: mlrun.api.schemas.AuthInfo = fastapi.Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
db_session: sqlalchemy.orm.Session = fastapi.Depends(
@@ -184,7 +184,7 @@ async def delete_project(
# that is why we re-route requests to chief
if (
mlrun.mlconf.httpdb.clusterization.role
- != mlrun.api.schemas.ClusterizationRole.chief
+ != mlrun.common.schemas.ClusterizationRole.chief
):
logger.info(
"Requesting to delete project, re-routing to chief",
@@ -209,15 +209,15 @@ async def delete_project(
return fastapi.Response(status_code=http.HTTPStatus.NO_CONTENT.value)
-@router.get("/projects", response_model=mlrun.api.schemas.ProjectsOutput)
+@router.get("/projects", response_model=mlrun.common.schemas.ProjectsOutput)
async def list_projects(
- format_: mlrun.api.schemas.ProjectsFormat = fastapi.Query(
- mlrun.api.schemas.ProjectsFormat.full, alias="format"
+ format_: mlrun.common.schemas.ProjectsFormat = fastapi.Query(
+ mlrun.common.schemas.ProjectsFormat.full, alias="format"
),
owner: str = None,
labels: typing.List[str] = fastapi.Query(None, alias="label"),
- state: mlrun.api.schemas.ProjectState = None,
- auth_info: mlrun.api.schemas.AuthInfo = fastapi.Depends(
+ state: mlrun.common.schemas.ProjectState = None,
+ auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
db_session: sqlalchemy.orm.Session = fastapi.Depends(
@@ -231,7 +231,7 @@ async def list_projects(
get_project_member().list_projects,
db_session,
owner,
- mlrun.api.schemas.ProjectsFormat.name_only,
+ mlrun.common.schemas.ProjectsFormat.name_only,
labels,
state,
auth_info.projects_role,
@@ -257,13 +257,13 @@ async def list_projects(
@router.get(
- "/project-summaries", response_model=mlrun.api.schemas.ProjectSummariesOutput
+ "/project-summaries", response_model=mlrun.common.schemas.ProjectSummariesOutput
)
async def list_project_summaries(
owner: str = None,
labels: typing.List[str] = fastapi.Query(None, alias="label"),
- state: mlrun.api.schemas.ProjectState = None,
- auth_info: mlrun.api.schemas.AuthInfo = fastapi.Depends(
+ state: mlrun.common.schemas.ProjectState = None,
+ auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
db_session: sqlalchemy.orm.Session = fastapi.Depends(
@@ -274,7 +274,7 @@ async def list_project_summaries(
get_project_member().list_projects,
db_session,
owner,
- mlrun.api.schemas.ProjectsFormat.name_only,
+ mlrun.common.schemas.ProjectsFormat.name_only,
labels,
state,
auth_info.projects_role,
@@ -299,14 +299,14 @@ async def list_project_summaries(
@router.get(
- "/project-summaries/{name}", response_model=mlrun.api.schemas.ProjectSummary
+ "/project-summaries/{name}", response_model=mlrun.common.schemas.ProjectSummary
)
async def get_project_summary(
name: str,
db_session: sqlalchemy.orm.Session = fastapi.Depends(
mlrun.api.api.deps.get_db_session
),
- auth_info: mlrun.api.schemas.AuthInfo = fastapi.Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
):
@@ -317,14 +317,14 @@ async def get_project_summary(
if not _is_request_from_leader(auth_info.projects_role):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_permissions(
name,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
return project_summary
def _is_request_from_leader(
- projects_role: typing.Optional[mlrun.api.schemas.ProjectsRole],
+ projects_role: typing.Optional[mlrun.common.schemas.ProjectsRole],
) -> bool:
if projects_role and projects_role.value == mlrun.mlconf.httpdb.projects.leader:
return True
diff --git a/mlrun/api/api/endpoints/runs.py b/mlrun/api/api/endpoints/runs.py
index e3f0c1111b99..ad1093d13c10 100644
--- a/mlrun/api/api/endpoints/runs.py
+++ b/mlrun/api/api/endpoints/runs.py
@@ -21,9 +21,9 @@
from sqlalchemy.orm import Session
import mlrun.api.crud
-import mlrun.api.schemas
import mlrun.api.utils.auth.verifier
import mlrun.api.utils.singletons.project_member
+import mlrun.common.schemas
from mlrun.api.api import deps
from mlrun.api.api.utils import log_and_raise
from mlrun.utils import logger
@@ -38,7 +38,7 @@ async def store_run(
project: str,
uid: str,
iter: int = 0,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await run_in_threadpool(
@@ -48,10 +48,10 @@ async def store_run(
auth_info=auth_info,
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.run,
+ mlrun.common.schemas.AuthorizationResourceTypes.run,
project,
uid,
- mlrun.api.schemas.AuthorizationAction.store,
+ mlrun.common.schemas.AuthorizationAction.store,
auth_info,
)
data = None
@@ -78,14 +78,14 @@ async def update_run(
project: str,
uid: str,
iter: int = 0,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.run,
+ mlrun.common.schemas.AuthorizationResourceTypes.run,
project,
uid,
- mlrun.api.schemas.AuthorizationAction.update,
+ mlrun.common.schemas.AuthorizationAction.update,
auth_info,
)
data = None
@@ -110,17 +110,17 @@ async def get_run(
project: str,
uid: str,
iter: int = 0,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
data = await run_in_threadpool(
mlrun.api.crud.Runs().get_run, db_session, uid, iter, project
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.run,
+ mlrun.common.schemas.AuthorizationResourceTypes.run,
project,
uid,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
return {
@@ -133,14 +133,14 @@ async def delete_run(
project: str,
uid: str,
iter: int = 0,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.run,
+ mlrun.common.schemas.AuthorizationResourceTypes.run,
project,
uid,
- mlrun.api.schemas.AuthorizationAction.delete,
+ mlrun.common.schemas.AuthorizationAction.delete,
auth_info,
)
await run_in_threadpool(
@@ -167,25 +167,25 @@ async def list_runs(
start_time_to: str = None,
last_update_time_from: str = None,
last_update_time_to: str = None,
- partition_by: mlrun.api.schemas.RunPartitionByField = Query(
+ partition_by: mlrun.common.schemas.RunPartitionByField = Query(
None, alias="partition-by"
),
rows_per_partition: int = Query(1, alias="rows-per-partition", gt=0),
- partition_sort_by: mlrun.api.schemas.SortField = Query(
+ partition_sort_by: mlrun.common.schemas.SortField = Query(
None, alias="partition-sort-by"
),
- partition_order: mlrun.api.schemas.OrderType = Query(
- mlrun.api.schemas.OrderType.desc, alias="partition-order"
+ partition_order: mlrun.common.schemas.OrderType = Query(
+ mlrun.common.schemas.OrderType.desc, alias="partition-order"
),
max_partitions: int = Query(0, alias="max-partitions", ge=0),
with_notifications: bool = Query(False, alias="with-notifications"),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
if project != "*":
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_permissions(
project,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
runs = await run_in_threadpool(
@@ -211,7 +211,7 @@ async def list_runs(
with_notifications=with_notifications,
)
filtered_runs = await mlrun.api.utils.auth.verifier.AuthVerifier().filter_project_resources_by_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.run,
+ mlrun.common.schemas.AuthorizationResourceTypes.run,
runs,
lambda run: (
run.get("metadata", {}).get("project", mlrun.mlconf.default_project),
@@ -231,7 +231,7 @@ async def delete_runs(
labels: List[str] = Query([], alias="label"),
state: str = None,
days_ago: int = None,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
if not project or project != "*":
@@ -239,10 +239,10 @@ async def delete_runs(
# Meaning there is no reason at the moment to query the permission for each run under the project
# TODO check for every run when we will manage permission per run inside a project
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.run,
+ mlrun.common.schemas.AuthorizationResourceTypes.run,
project or mlrun.mlconf.default_project,
"",
- mlrun.api.schemas.AuthorizationAction.delete,
+ mlrun.common.schemas.AuthorizationAction.delete,
auth_info,
)
else:
@@ -268,10 +268,10 @@ async def delete_runs(
# currently we fail if the user doesn't has permissions to delete runs to one of the projects in the system
# TODO Delete only runs from projects that user has permissions to
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.run,
+ mlrun.common.schemas.AuthorizationResourceTypes.run,
run_project,
"",
- mlrun.api.schemas.AuthorizationAction.delete,
+ mlrun.common.schemas.AuthorizationAction.delete,
auth_info,
)
diff --git a/mlrun/api/api/endpoints/runtime_resources.py b/mlrun/api/api/endpoints/runtime_resources.py
index d3ae6bde759a..91f41822d86f 100644
--- a/mlrun/api/api/endpoints/runtime_resources.py
+++ b/mlrun/api/api/endpoints/runtime_resources.py
@@ -23,8 +23,8 @@
import mlrun
import mlrun.api.api.deps
import mlrun.api.crud
-import mlrun.api.schemas
import mlrun.api.utils.auth.verifier
+import mlrun.common.schemas
router = fastapi.APIRouter()
@@ -32,9 +32,9 @@
@router.get(
"/projects/{project}/runtime-resources",
response_model=typing.Union[
- mlrun.api.schemas.RuntimeResourcesOutput,
- mlrun.api.schemas.GroupedByJobRuntimeResourcesOutput,
- mlrun.api.schemas.GroupedByProjectRuntimeResourcesOutput,
+ mlrun.common.schemas.RuntimeResourcesOutput,
+ mlrun.common.schemas.GroupedByJobRuntimeResourcesOutput,
+ mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput,
],
)
async def list_runtime_resources(
@@ -43,9 +43,9 @@ async def list_runtime_resources(
kind: typing.Optional[str] = None,
object_id: typing.Optional[str] = fastapi.Query(None, alias="object-id"),
group_by: typing.Optional[
- mlrun.api.schemas.ListRuntimeResourcesGroupByField
+ mlrun.common.schemas.ListRuntimeResourcesGroupByField
] = fastapi.Query(None, alias="group-by"),
- auth_info: mlrun.api.schemas.AuthInfo = fastapi.Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
):
@@ -56,7 +56,7 @@ async def list_runtime_resources(
@router.delete(
"/projects/{project}/runtime-resources",
- response_model=mlrun.api.schemas.GroupedByProjectRuntimeResourcesOutput,
+ response_model=mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput,
)
async def delete_runtime_resources(
project: str,
@@ -67,7 +67,7 @@ async def delete_runtime_resources(
grace_period: int = fastapi.Query(
mlrun.mlconf.runtime_resources_deletion_grace_period, alias="grace-period"
),
- auth_info: mlrun.api.schemas.AuthInfo = fastapi.Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
db_session: sqlalchemy.orm.Session = fastapi.Depends(
@@ -88,7 +88,7 @@ async def delete_runtime_resources(
async def _delete_runtime_resources(
db_session: sqlalchemy.orm.Session,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
project: str,
label_selector: typing.Optional[str] = None,
kind: typing.Optional[str] = None,
@@ -97,7 +97,7 @@ async def _delete_runtime_resources(
grace_period: int = mlrun.mlconf.runtime_resources_deletion_grace_period,
return_body: bool = True,
) -> typing.Union[
- mlrun.api.schemas.GroupedByProjectRuntimeResourcesOutput, fastapi.Response
+ mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput, fastapi.Response
]:
(
allowed_projects,
@@ -110,7 +110,7 @@ async def _delete_runtime_resources(
label_selector,
kind,
object_id,
- mlrun.api.schemas.AuthorizationAction.delete,
+ mlrun.common.schemas.AuthorizationAction.delete,
)
# TODO: once we have more granular permissions, we should check if the user is allowed to delete the specific
@@ -162,7 +162,7 @@ async def _delete_runtime_resources(
return mlrun.api.crud.RuntimeResources().filter_and_format_grouped_by_project_runtime_resources_output(
grouped_by_project_runtime_resources_output,
filtered_projects,
- mlrun.api.schemas.ListRuntimeResourcesGroupByField.project,
+ mlrun.common.schemas.ListRuntimeResourcesGroupByField.project,
)
else:
return fastapi.Response(status_code=http.HTTPStatus.NO_CONTENT.value)
@@ -170,17 +170,17 @@ async def _delete_runtime_resources(
async def _list_runtime_resources(
project: str,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
label_selector: typing.Optional[str] = None,
group_by: typing.Optional[
- mlrun.api.schemas.ListRuntimeResourcesGroupByField
+ mlrun.common.schemas.ListRuntimeResourcesGroupByField
] = None,
kind_filter: typing.Optional[str] = None,
object_id: typing.Optional[str] = None,
) -> typing.Union[
- mlrun.api.schemas.RuntimeResourcesOutput,
- mlrun.api.schemas.GroupedByJobRuntimeResourcesOutput,
- mlrun.api.schemas.GroupedByProjectRuntimeResourcesOutput,
+ mlrun.common.schemas.RuntimeResourcesOutput,
+ mlrun.common.schemas.GroupedByJobRuntimeResourcesOutput,
+ mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput,
]:
(
allowed_projects,
@@ -199,31 +199,31 @@ async def _list_runtime_resources(
async def _get_runtime_resources_allowed_projects(
project: str,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
label_selector: typing.Optional[str] = None,
kind: typing.Optional[str] = None,
object_id: typing.Optional[str] = None,
- action: mlrun.api.schemas.AuthorizationAction = mlrun.api.schemas.AuthorizationAction.read,
+ action: mlrun.common.schemas.AuthorizationAction = mlrun.common.schemas.AuthorizationAction.read,
) -> typing.Tuple[
typing.List[str],
- mlrun.api.schemas.GroupedByProjectRuntimeResourcesOutput,
+ mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput,
bool,
bool,
]:
if project != "*":
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_permissions(
project,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
- grouped_by_project_runtime_resources_output: mlrun.api.schemas.GroupedByProjectRuntimeResourcesOutput
+ grouped_by_project_runtime_resources_output: mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput
grouped_by_project_runtime_resources_output = await run_in_threadpool(
mlrun.api.crud.RuntimeResources().list_runtime_resources,
project,
kind,
object_id,
label_selector,
- mlrun.api.schemas.ListRuntimeResourcesGroupByField.project,
+ mlrun.common.schemas.ListRuntimeResourcesGroupByField.project,
)
projects = []
@@ -237,7 +237,7 @@ async def _get_runtime_resources_allowed_projects(
continue
projects.append(project)
allowed_projects = await mlrun.api.utils.auth.verifier.AuthVerifier().filter_project_resources_by_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.runtime_resource,
+ mlrun.common.schemas.AuthorizationResourceTypes.runtime_resource,
projects,
lambda project: (
project,
diff --git a/mlrun/api/api/endpoints/schedules.py b/mlrun/api/api/endpoints/schedules.py
index 94594c01d2c8..019585771cbc 100644
--- a/mlrun/api/api/endpoints/schedules.py
+++ b/mlrun/api/api/endpoints/schedules.py
@@ -23,7 +23,7 @@
import mlrun.api.utils.auth.verifier
import mlrun.api.utils.clients.chief
import mlrun.api.utils.singletons.project_member
-from mlrun.api import schemas
+import mlrun.common.schemas
from mlrun.api.api import deps
from mlrun.api.utils.singletons.scheduler import get_scheduler
from mlrun.utils import logger
@@ -34,9 +34,9 @@
@router.post("/projects/{project}/schedules")
async def create_schedule(
project: str,
- schedule: schemas.ScheduleInput,
+ schedule: mlrun.common.schemas.ScheduleInput,
request: fastapi.Request,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await run_in_threadpool(
@@ -46,16 +46,16 @@ async def create_schedule(
auth_info=auth_info,
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.schedule,
+ mlrun.common.schemas.AuthorizationResourceTypes.schedule,
project,
schedule.name,
- mlrun.api.schemas.AuthorizationAction.create,
+ mlrun.common.schemas.AuthorizationAction.create,
auth_info,
)
# to reduce redundant load on the chief, we re-route the request only if the user has permissions
if (
mlrun.mlconf.httpdb.clusterization.role
- != mlrun.api.schemas.ClusterizationRole.chief
+ != mlrun.common.schemas.ClusterizationRole.chief
):
logger.info(
"Requesting to create schedule, re-routing to chief",
@@ -90,22 +90,22 @@ async def create_schedule(
async def update_schedule(
project: str,
name: str,
- schedule: schemas.ScheduleUpdate,
+ schedule: mlrun.common.schemas.ScheduleUpdate,
request: fastapi.Request,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.schedule,
+ mlrun.common.schemas.AuthorizationResourceTypes.schedule,
project,
name,
- mlrun.api.schemas.AuthorizationAction.update,
+ mlrun.common.schemas.AuthorizationAction.update,
auth_info,
)
# to reduce redundant load on the chief, we re-route the request only if the user has permissions
if (
mlrun.mlconf.httpdb.clusterization.role
- != mlrun.api.schemas.ClusterizationRole.chief
+ != mlrun.common.schemas.ClusterizationRole.chief
):
logger.info(
"Requesting to update schedule, re-routing to chief",
@@ -136,20 +136,22 @@ async def update_schedule(
return Response(status_code=HTTPStatus.OK.value)
-@router.get("/projects/{project}/schedules", response_model=schemas.SchedulesOutput)
+@router.get(
+ "/projects/{project}/schedules", response_model=mlrun.common.schemas.SchedulesOutput
+)
async def list_schedules(
project: str,
name: str = None,
labels: str = None,
- kind: schemas.ScheduleKinds = None,
+ kind: mlrun.common.schemas.ScheduleKinds = None,
include_last_run: bool = False,
include_credentials: bool = fastapi.Query(False, alias="include-credentials"),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_permissions(
project,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
schedules = await run_in_threadpool(
@@ -163,7 +165,7 @@ async def list_schedules(
include_credentials,
)
filtered_schedules = await mlrun.api.utils.auth.verifier.AuthVerifier().filter_project_resources_by_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.schedule,
+ mlrun.common.schemas.AuthorizationResourceTypes.schedule,
schedules.schedules,
lambda schedule: (
schedule.project,
@@ -176,14 +178,15 @@ async def list_schedules(
@router.get(
- "/projects/{project}/schedules/{name}", response_model=schemas.ScheduleOutput
+ "/projects/{project}/schedules/{name}",
+ response_model=mlrun.common.schemas.ScheduleOutput,
)
async def get_schedule(
project: str,
name: str,
include_last_run: bool = False,
include_credentials: bool = fastapi.Query(False, alias="include-credentials"),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
schedule = await run_in_threadpool(
@@ -195,10 +198,10 @@ async def get_schedule(
include_credentials,
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.schedule,
+ mlrun.common.schemas.AuthorizationResourceTypes.schedule,
project,
name,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
return schedule
@@ -209,20 +212,20 @@ async def invoke_schedule(
project: str,
name: str,
request: fastapi.Request,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.schedule,
+ mlrun.common.schemas.AuthorizationResourceTypes.schedule,
project,
name,
- mlrun.api.schemas.AuthorizationAction.update,
+ mlrun.common.schemas.AuthorizationAction.update,
auth_info,
)
# to reduce redundant load on the chief, we re-route the request only if the user has permissions
if (
mlrun.mlconf.httpdb.clusterization.role
- != mlrun.api.schemas.ClusterizationRole.chief
+ != mlrun.common.schemas.ClusterizationRole.chief
):
logger.info(
"Requesting to invoke schedule, re-routing to chief",
@@ -244,20 +247,20 @@ async def delete_schedule(
project: str,
name: str,
request: fastapi.Request,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.schedule,
+ mlrun.common.schemas.AuthorizationResourceTypes.schedule,
project,
name,
- mlrun.api.schemas.AuthorizationAction.delete,
+ mlrun.common.schemas.AuthorizationAction.delete,
auth_info,
)
# to reduce redundant load on the chief, we re-route the request only if the user has permissions
if (
mlrun.mlconf.httpdb.clusterization.role
- != mlrun.api.schemas.ClusterizationRole.chief
+ != mlrun.common.schemas.ClusterizationRole.chief
):
logger.info(
"Requesting to delete schedule, re-routing to chief",
@@ -277,7 +280,7 @@ async def delete_schedule(
async def delete_schedules(
project: str,
request: fastapi.Request,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
schedules = await run_in_threadpool(
@@ -286,16 +289,16 @@ async def delete_schedules(
project,
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resources_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.schedule,
+ mlrun.common.schemas.AuthorizationResourceTypes.schedule,
schedules.schedules,
lambda schedule: (schedule.project, schedule.name),
- mlrun.api.schemas.AuthorizationAction.delete,
+ mlrun.common.schemas.AuthorizationAction.delete,
auth_info,
)
# to reduce redundant load on the chief, we re-route the request only if the user has permissions
if (
mlrun.mlconf.httpdb.clusterization.role
- != mlrun.api.schemas.ClusterizationRole.chief
+ != mlrun.common.schemas.ClusterizationRole.chief
):
logger.info(
"Requesting to delete all project schedules, re-routing to chief",
diff --git a/mlrun/api/api/endpoints/secrets.py b/mlrun/api/api/endpoints/secrets.py
index 138939ff6f35..0e6f2147ab57 100644
--- a/mlrun/api/api/endpoints/secrets.py
+++ b/mlrun/api/api/endpoints/secrets.py
@@ -23,8 +23,8 @@
import mlrun.api.crud
import mlrun.api.utils.auth.verifier
import mlrun.api.utils.singletons.project_member
+import mlrun.common.schemas
import mlrun.errors
-from mlrun.api import schemas
from mlrun.utils.vault import add_vault_user_secrets
router = fastapi.APIRouter()
@@ -33,8 +33,8 @@
@router.post("/projects/{project}/secrets", status_code=HTTPStatus.CREATED.value)
async def store_project_secrets(
project: str,
- secrets: schemas.SecretsData,
- auth_info: mlrun.api.schemas.AuthInfo = fastapi.Depends(
+ secrets: mlrun.common.schemas.SecretsData,
+ auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
db_session: Session = fastapi.Depends(mlrun.api.api.deps.get_db_session),
@@ -50,10 +50,10 @@ async def store_project_secrets(
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.secret,
+ mlrun.common.schemas.AuthorizationResourceTypes.secret,
project,
secrets.provider,
- mlrun.api.schemas.AuthorizationAction.create,
+ mlrun.common.schemas.AuthorizationAction.create,
auth_info,
)
await run_in_threadpool(
@@ -66,9 +66,9 @@ async def store_project_secrets(
@router.delete("/projects/{project}/secrets", status_code=HTTPStatus.NO_CONTENT.value)
async def delete_project_secrets(
project: str,
- provider: schemas.SecretProviderName = schemas.SecretProviderName.kubernetes,
+ provider: mlrun.common.schemas.SecretProviderName = mlrun.common.schemas.SecretProviderName.kubernetes,
secrets: List[str] = fastapi.Query(None, alias="secret"),
- auth_info: mlrun.api.schemas.AuthInfo = fastapi.Depends(
+ auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
db_session: Session = fastapi.Depends(mlrun.api.api.deps.get_db_session),
@@ -81,10 +81,10 @@ async def delete_project_secrets(
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.secret,
+ mlrun.common.schemas.AuthorizationResourceTypes.secret,
project,
provider,
- mlrun.api.schemas.AuthorizationAction.delete,
+ mlrun.common.schemas.AuthorizationAction.delete,
auth_info,
)
await run_in_threadpool(
@@ -94,12 +94,17 @@ async def delete_project_secrets(
return fastapi.Response(status_code=HTTPStatus.NO_CONTENT.value)
-@router.get("/projects/{project}/secret-keys", response_model=schemas.SecretKeysData)
+@router.get(
+ "/projects/{project}/secret-keys",
+ response_model=mlrun.common.schemas.SecretKeysData,
+)
async def list_project_secret_keys(
project: str,
- provider: schemas.SecretProviderName = schemas.SecretProviderName.kubernetes,
- token: str = fastapi.Header(None, alias=schemas.HeaderNames.secret_store_token),
- auth_info: mlrun.api.schemas.AuthInfo = fastapi.Depends(
+ provider: mlrun.common.schemas.SecretProviderName = mlrun.common.schemas.SecretProviderName.kubernetes,
+ token: str = fastapi.Header(
+ None, alias=mlrun.common.schemas.HeaderNames.secret_store_token
+ ),
+ auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
db_session: Session = fastapi.Depends(mlrun.api.api.deps.get_db_session),
@@ -111,10 +116,10 @@ async def list_project_secret_keys(
auth_info.session,
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.secret,
+ mlrun.common.schemas.AuthorizationResourceTypes.secret,
project,
provider,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
return await run_in_threadpool(
@@ -122,13 +127,17 @@ async def list_project_secret_keys(
)
-@router.get("/projects/{project}/secrets", response_model=schemas.SecretsData)
+@router.get(
+ "/projects/{project}/secrets", response_model=mlrun.common.schemas.SecretsData
+)
async def list_project_secrets(
project: str,
secrets: List[str] = fastapi.Query(None, alias="secret"),
- provider: schemas.SecretProviderName = schemas.SecretProviderName.kubernetes,
- token: str = fastapi.Header(None, alias=schemas.HeaderNames.secret_store_token),
- auth_info: mlrun.api.schemas.AuthInfo = fastapi.Depends(
+ provider: mlrun.common.schemas.SecretProviderName = mlrun.common.schemas.SecretProviderName.kubernetes,
+ token: str = fastapi.Header(
+ None, alias=mlrun.common.schemas.HeaderNames.secret_store_token
+ ),
+ auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
db_session: Session = fastapi.Depends(mlrun.api.api.deps.get_db_session),
@@ -140,10 +149,10 @@ async def list_project_secrets(
auth_info.session,
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.secret,
+ mlrun.common.schemas.AuthorizationResourceTypes.secret,
project,
provider,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
return await run_in_threadpool(
@@ -153,9 +162,9 @@ async def list_project_secrets(
@router.post("/user-secrets", status_code=HTTPStatus.CREATED.value)
def add_user_secrets(
- secrets: schemas.UserSecretCreationRequest,
+ secrets: mlrun.common.schemas.UserSecretCreationRequest,
):
- if secrets.provider != schemas.SecretProviderName.vault:
+ if secrets.provider != mlrun.common.schemas.SecretProviderName.vault:
return fastapi.Response(
status_code=HTTPStatus.BAD_REQUEST.vault,
content=f"Invalid secrets provider {secrets.provider}",
diff --git a/mlrun/api/api/endpoints/submit.py b/mlrun/api/api/endpoints/submit.py
index fce34fa7107f..f9eb9af19901 100644
--- a/mlrun/api/api/endpoints/submit.py
+++ b/mlrun/api/api/endpoints/submit.py
@@ -20,10 +20,10 @@
from sqlalchemy.orm import Session
import mlrun.api.api.utils
-import mlrun.api.schemas
import mlrun.api.utils.auth.verifier
import mlrun.api.utils.clients.chief
import mlrun.api.utils.singletons.project_member
+import mlrun.common.schemas
import mlrun.utils.helpers
from mlrun.api.api import deps
from mlrun.utils import logger
@@ -38,13 +38,13 @@
async def submit_job(
request: Request,
username: Optional[str] = Header(None, alias="x-remote-user"),
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
client_version: Optional[str] = Header(
- None, alias=mlrun.api.schemas.HeaderNames.client_version
+ None, alias=mlrun.common.schemas.HeaderNames.client_version
),
client_python_version: Optional[str] = Header(
- None, alias=mlrun.api.schemas.HeaderNames.python_version
+ None, alias=mlrun.common.schemas.HeaderNames.python_version
),
):
data = None
@@ -70,18 +70,18 @@ async def submit_job(
_,
) = mlrun.utils.helpers.parse_versioned_object_uri(function_url)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.function,
+ mlrun.common.schemas.AuthorizationResourceTypes.function,
function_project,
function_name,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
if data.get("schedule"):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.schedule,
+ mlrun.common.schemas.AuthorizationResourceTypes.schedule,
data["task"]["metadata"]["project"],
data["task"]["metadata"]["name"],
- mlrun.api.schemas.AuthorizationAction.create,
+ mlrun.common.schemas.AuthorizationAction.create,
auth_info,
)
# schedules are meant to be run solely by the chief, then if run is configured to run as scheduled
@@ -89,7 +89,7 @@ async def submit_job(
# to reduce redundant load on the chief, we re-route the request only if the user has permissions
if (
mlrun.mlconf.httpdb.clusterization.role
- != mlrun.api.schemas.ClusterizationRole.chief
+ != mlrun.common.schemas.ClusterizationRole.chief
):
logger.info(
"Requesting to submit job with schedules, re-routing to chief",
@@ -102,10 +102,10 @@ async def submit_job(
else:
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.run,
+ mlrun.common.schemas.AuthorizationResourceTypes.run,
data["task"]["metadata"]["project"],
"",
- mlrun.api.schemas.AuthorizationAction.create,
+ mlrun.common.schemas.AuthorizationAction.create,
auth_info,
)
diff --git a/mlrun/api/api/endpoints/tags.py b/mlrun/api/api/endpoints/tags.py
index b90b472024f4..342af3aa4cb7 100644
--- a/mlrun/api/api/endpoints/tags.py
+++ b/mlrun/api/api/endpoints/tags.py
@@ -20,20 +20,20 @@
import mlrun.api.api.deps
import mlrun.api.crud.tags
-import mlrun.api.schemas
import mlrun.api.utils.auth.verifier
import mlrun.api.utils.singletons.project_member
+import mlrun.common.schemas
from mlrun.utils.helpers import tag_name_regex_as_string
router = fastapi.APIRouter()
-@router.post("/projects/{project}/tags/{tag}", response_model=mlrun.api.schemas.Tag)
+@router.post("/projects/{project}/tags/{tag}", response_model=mlrun.common.schemas.Tag)
async def overwrite_object_tags_with_tag(
project: str,
tag: str = fastapi.Path(..., regex=tag_name_regex_as_string()),
- tag_objects: mlrun.api.schemas.TagObjects = fastapi.Body(...),
- auth_info: mlrun.api.schemas.AuthInfo = fastapi.Depends(
+ tag_objects: mlrun.common.schemas.TagObjects = fastapi.Body(...),
+ auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
db_session: sqlalchemy.orm.Session = fastapi.Depends(
@@ -49,11 +49,11 @@ async def overwrite_object_tags_with_tag(
# check permission per object type
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- getattr(mlrun.api.schemas.AuthorizationResourceTypes, tag_objects.kind),
+ getattr(mlrun.common.schemas.AuthorizationResourceTypes, tag_objects.kind),
project,
resource_name="",
# not actually overwriting objects, just overwriting the objects tags
- action=mlrun.api.schemas.AuthorizationAction.update,
+ action=mlrun.common.schemas.AuthorizationAction.update,
auth_info=auth_info,
)
@@ -64,15 +64,15 @@ async def overwrite_object_tags_with_tag(
tag,
tag_objects,
)
- return mlrun.api.schemas.Tag(name=tag, project=project)
+ return mlrun.common.schemas.Tag(name=tag, project=project)
-@router.put("/projects/{project}/tags/{tag}", response_model=mlrun.api.schemas.Tag)
+@router.put("/projects/{project}/tags/{tag}", response_model=mlrun.common.schemas.Tag)
async def append_tag_to_objects(
project: str,
tag: str = fastapi.Path(..., regex=tag_name_regex_as_string()),
- tag_objects: mlrun.api.schemas.TagObjects = fastapi.Body(...),
- auth_info: mlrun.api.schemas.AuthInfo = fastapi.Depends(
+ tag_objects: mlrun.common.schemas.TagObjects = fastapi.Body(...),
+ auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
db_session: sqlalchemy.orm.Session = fastapi.Depends(
@@ -87,10 +87,10 @@ async def append_tag_to_objects(
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- getattr(mlrun.api.schemas.AuthorizationResourceTypes, tag_objects.kind),
+ getattr(mlrun.common.schemas.AuthorizationResourceTypes, tag_objects.kind),
project,
resource_name="",
- action=mlrun.api.schemas.AuthorizationAction.update,
+ action=mlrun.common.schemas.AuthorizationAction.update,
auth_info=auth_info,
)
@@ -101,7 +101,7 @@ async def append_tag_to_objects(
tag,
tag_objects,
)
- return mlrun.api.schemas.Tag(name=tag, project=project)
+ return mlrun.common.schemas.Tag(name=tag, project=project)
@router.delete(
@@ -110,8 +110,8 @@ async def append_tag_to_objects(
async def delete_tag_from_objects(
project: str,
tag: str,
- tag_objects: mlrun.api.schemas.TagObjects,
- auth_info: mlrun.api.schemas.AuthInfo = fastapi.Depends(
+ tag_objects: mlrun.common.schemas.TagObjects,
+ auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
db_session: sqlalchemy.orm.Session = fastapi.Depends(
@@ -126,11 +126,11 @@ async def delete_tag_from_objects(
)
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- getattr(mlrun.api.schemas.AuthorizationResourceTypes, tag_objects.kind),
+ getattr(mlrun.common.schemas.AuthorizationResourceTypes, tag_objects.kind),
project,
resource_name="",
# not actually deleting objects, just deleting the objects tags
- action=mlrun.api.schemas.AuthorizationAction.update,
+ action=mlrun.common.schemas.AuthorizationAction.update,
auth_info=auth_info,
)
diff --git a/mlrun/api/api/utils.py b/mlrun/api/api/utils.py
index f937e6cfb35c..172a4dce251e 100644
--- a/mlrun/api/api/utils.py
+++ b/mlrun/api/api/utils.py
@@ -31,12 +31,11 @@
import mlrun.api.utils.auth.verifier
import mlrun.api.utils.clients.iguazio
import mlrun.api.utils.singletons.k8s
+import mlrun.common.schemas
import mlrun.errors
import mlrun.runtimes.pod
import mlrun.utils.helpers
-from mlrun.api import schemas
from mlrun.api.db.sqldb.db import SQLDB
-from mlrun.api.schemas import SecretProviderName, SecurityContextEnrichmentModes
from mlrun.api.utils.singletons.db import get_db
from mlrun.api.utils.singletons.logs_dir import get_logs_dir
from mlrun.api.utils.singletons.scheduler import get_scheduler
@@ -122,7 +121,11 @@ def get_allowed_path_prefixes_list() -> typing.List[str]:
return allowed_paths_list
-def get_secrets(auth_info: mlrun.api.schemas.AuthInfo):
+def get_secrets(
+ auth_info: typing.Union[
+ mlrun.common.schemas.AuthInfo,
+ ]
+):
return {
"V3IO_ACCESS_KEY": auth_info.data_session,
}
@@ -155,7 +158,7 @@ def parse_submit_run_body(data):
def _generate_function_and_task_from_submit_run_body(
- db_session: Session, auth_info: mlrun.api.schemas.AuthInfo, data
+ db_session: Session, auth_info: mlrun.common.schemas.AuthInfo, data
):
function_dict, function_url, task = parse_submit_run_body(data)
# TODO: block exec for function["kind"] in ["", "local] (must be a
@@ -192,7 +195,9 @@ def _generate_function_and_task_from_submit_run_body(
return function, task
-async def submit_run(db_session: Session, auth_info: mlrun.api.schemas.AuthInfo, data):
+async def submit_run(
+ db_session: Session, auth_info: mlrun.common.schemas.AuthInfo, data
+):
_, _, _, response = await run_in_threadpool(
submit_run_sync, db_session, auth_info, data
)
@@ -226,8 +231,8 @@ def mask_notification_params_with_secret(
)
mlrun.api.crud.Secrets().store_project_secrets(
project,
- mlrun.api.schemas.SecretsData(
- provider=mlrun.api.schemas.SecretProviderName.kubernetes,
+ mlrun.common.schemas.SecretsData(
+ provider=mlrun.common.schemas.SecretProviderName.kubernetes,
secrets={secret_key: json.dumps(notification_object.params)},
),
allow_internal_secrets=True,
@@ -265,7 +270,7 @@ def unmask_notification_params_secret(
notification_object.params = json.loads(
mlrun.api.crud.Secrets().get_project_secret(
project,
- mlrun.api.schemas.SecretProviderName.kubernetes,
+ mlrun.common.schemas.SecretProviderName.kubernetes,
secret_key=params_secret,
allow_internal_secrets=True,
allow_secrets_from_k8s=True,
@@ -291,7 +296,7 @@ def delete_notification_params_secret(
mlrun.api.crud.Secrets().delete_project_secret(
project,
- mlrun.api.schemas.SecretProviderName.kubernetes,
+ mlrun.common.schemas.SecretProviderName.kubernetes,
secret_key=params_secret,
allow_internal_secrets=True,
allow_secrets_from_k8s=True,
@@ -300,7 +305,7 @@ def delete_notification_params_secret(
def apply_enrichment_and_validation_on_function(
function,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
ensure_auth: bool = True,
perform_auto_mount: bool = True,
validate_service_account: bool = True,
@@ -340,14 +345,14 @@ def apply_enrichment_and_validation_on_function(
def ensure_function_auth_and_sensitive_data_is_masked(
function,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
allow_empty_access_key: bool = False,
):
ensure_function_has_auth_set(function, auth_info, allow_empty_access_key)
mask_function_sensitive_data(function, auth_info)
-def mask_function_sensitive_data(function, auth_info: mlrun.api.schemas.AuthInfo):
+def mask_function_sensitive_data(function, auth_info: mlrun.common.schemas.AuthInfo):
if not mlrun.runtimes.RuntimeKinds.is_local_runtime(function.kind):
_mask_v3io_access_key_env_var(function, auth_info)
_mask_v3io_volume_credentials(function)
@@ -431,8 +436,8 @@ def _mask_v3io_volume_credentials(function: mlrun.runtimes.pod.KubeResource):
if not username:
continue
secret_name = mlrun.api.crud.Secrets().store_auth_secret(
- mlrun.api.schemas.AuthSecretData(
- provider=mlrun.api.schemas.SecretProviderName.kubernetes,
+ mlrun.common.schemas.AuthSecretData(
+ provider=mlrun.common.schemas.SecretProviderName.kubernetes,
username=username,
access_key=access_key,
)
@@ -494,7 +499,7 @@ def _resolve_v3io_fuse_volume_access_key_matching_username(
def _mask_v3io_access_key_env_var(
- function: mlrun.runtimes.pod.KubeResource, auth_info: mlrun.api.schemas.AuthInfo
+ function: mlrun.runtimes.pod.KubeResource, auth_info: mlrun.common.schemas.AuthInfo
):
v3io_access_key = function.get_env("V3IO_ACCESS_KEY")
# if it's already a V1EnvVarSource or dict instance, it's already been masked
@@ -521,14 +526,14 @@ def _mask_v3io_access_key_env_var(
)
return
secret_name = mlrun.api.crud.Secrets().store_auth_secret(
- mlrun.api.schemas.AuthSecretData(
- provider=mlrun.api.schemas.SecretProviderName.kubernetes,
+ mlrun.common.schemas.AuthSecretData(
+ provider=mlrun.common.schemas.SecretProviderName.kubernetes,
username=username,
access_key=v3io_access_key,
)
)
- access_key_secret_key = mlrun.api.schemas.AuthSecretData.get_field_secret_key(
- "access_key"
+ access_key_secret_key = (
+ mlrun.common.schemas.AuthSecretData.get_field_secret_key("access_key")
)
function.set_env_from_secret(
"V3IO_ACCESS_KEY", secret_name, access_key_secret_key
@@ -537,7 +542,7 @@ def _mask_v3io_access_key_env_var(
def ensure_function_has_auth_set(
function: mlrun.runtimes.BaseRuntime,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
allow_empty_access_key: bool = False,
):
"""
@@ -584,8 +589,8 @@ def ensure_function_has_auth_set(
"Username is missing from auth info"
)
secret_name = mlrun.api.crud.Secrets().store_auth_secret(
- mlrun.api.schemas.AuthSecretData(
- provider=mlrun.api.schemas.SecretProviderName.kubernetes,
+ mlrun.common.schemas.AuthSecretData(
+ provider=mlrun.common.schemas.SecretProviderName.kubernetes,
username=auth_info.username,
access_key=function.metadata.credentials.access_key,
)
@@ -598,8 +603,8 @@ def ensure_function_has_auth_set(
mlrun.model.Credentials.secret_reference_prefix
)
- access_key_secret_key = mlrun.api.schemas.AuthSecretData.get_field_secret_key(
- "access_key"
+ access_key_secret_key = (
+ mlrun.common.schemas.AuthSecretData.get_field_secret_key("access_key")
)
auth_env_vars = {
mlrun.runtimes.constants.FunctionEnvironmentVariables.auth_session: (
@@ -611,7 +616,7 @@ def ensure_function_has_auth_set(
function.set_env_from_secret(env_key, secret_name, secret_key)
-def try_perform_auto_mount(function, auth_info: mlrun.api.schemas.AuthInfo):
+def try_perform_auto_mount(function, auth_info: mlrun.common.schemas.AuthInfo):
if (
mlrun.runtimes.RuntimeKinds.is_local_runtime(function.kind)
or function.spec.disable_auto_mount
@@ -645,7 +650,7 @@ def process_function_service_account(function):
def resolve_project_default_service_account(project_name: str):
allowed_service_accounts = mlrun.api.crud.secrets.Secrets().get_project_secret(
project_name,
- SecretProviderName.kubernetes,
+ mlrun.common.schemas.SecretProviderName.kubernetes,
mlrun.api.crud.secrets.Secrets().generate_client_project_secret_key(
mlrun.api.crud.secrets.SecretsClientType.service_accounts, "allowed"
),
@@ -660,7 +665,7 @@ def resolve_project_default_service_account(project_name: str):
default_service_account = mlrun.api.crud.secrets.Secrets().get_project_secret(
project_name,
- SecretProviderName.kubernetes,
+ mlrun.common.schemas.SecretProviderName.kubernetes,
mlrun.api.crud.secrets.Secrets().generate_client_project_secret_key(
mlrun.api.crud.secrets.SecretsClientType.service_accounts, "default"
),
@@ -687,7 +692,9 @@ def resolve_project_default_service_account(project_name: str):
return allowed_service_accounts, default_service_account
-def ensure_function_security_context(function, auth_info: mlrun.api.schemas.AuthInfo):
+def ensure_function_security_context(
+ function, auth_info: mlrun.common.schemas.AuthInfo
+):
"""
For iguazio we enforce that pods run with user id and group id depending on
mlrun.mlconf.function.spec.security_context.enrichment_mode
@@ -698,7 +705,7 @@ def ensure_function_security_context(function, auth_info: mlrun.api.schemas.Auth
# security context is not yet supported with spark runtime since it requires spark 3.2+
if (
mlrun.mlconf.function.spec.security_context.enrichment_mode
- == SecurityContextEnrichmentModes.disabled.value
+ == mlrun.common.schemas.SecurityContextEnrichmentModes.disabled.value
or mlrun.runtimes.RuntimeKinds.is_local_runtime(function.kind)
or function.kind == mlrun.runtimes.RuntimeKinds.spark
# remote spark image currently requires running with user 1000 or root
@@ -714,7 +721,7 @@ def ensure_function_security_context(function, auth_info: mlrun.api.schemas.Auth
# Enrichment with retain enrichment mode should occur on function creation only.
if (
mlrun.mlconf.function.spec.security_context.enrichment_mode
- == SecurityContextEnrichmentModes.retain.value
+ == mlrun.common.schemas.SecurityContextEnrichmentModes.retain.value
and function.spec.security_context is not None
and function.spec.security_context.run_as_user is not None
and function.spec.security_context.run_as_group is not None
@@ -727,8 +734,8 @@ def ensure_function_security_context(function, auth_info: mlrun.api.schemas.Auth
return
if mlrun.mlconf.function.spec.security_context.enrichment_mode in [
- SecurityContextEnrichmentModes.override.value,
- SecurityContextEnrichmentModes.retain.value,
+ mlrun.common.schemas.SecurityContextEnrichmentModes.override.value,
+ mlrun.common.schemas.SecurityContextEnrichmentModes.retain.value,
]:
# before iguazio 3.6 the user unix id is not passed in the session verification response headers
@@ -784,7 +791,7 @@ def ensure_function_security_context(function, auth_info: mlrun.api.schemas.Auth
def submit_run_sync(
- db_session: Session, auth_info: mlrun.api.schemas.AuthInfo, data
+ db_session: Session, auth_info: mlrun.common.schemas.AuthInfo, data
) -> typing.Tuple[str, str, str, typing.Dict]:
"""
:return: Tuple with:
@@ -814,7 +821,7 @@ def submit_run_sync(
if schedule:
cron_trigger = schedule
if isinstance(cron_trigger, dict):
- cron_trigger = schemas.ScheduleCronTrigger(**cron_trigger)
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(**cron_trigger)
schedule_labels = task["metadata"].get("labels")
created = False
@@ -835,7 +842,7 @@ def submit_run_sync(
auth_info,
task["metadata"]["project"],
task["metadata"]["name"],
- schemas.ScheduleKinds.job,
+ mlrun.common.schemas.ScheduleKinds.job,
data,
cron_trigger,
schedule_labels,
@@ -857,7 +864,7 @@ def submit_run_sync(
mlrun.api.crud.Secrets()
.list_project_secrets(
task["metadata"]["project"],
- mlrun.api.schemas.SecretProviderName.kubernetes,
+ mlrun.common.schemas.SecretProviderName.kubernetes,
allow_secrets_from_k8s=True,
)
.secrets
diff --git a/mlrun/api/crud/artifacts.py b/mlrun/api/crud/artifacts.py
index c95127331c5f..33ca4e4013fd 100644
--- a/mlrun/api/crud/artifacts.py
+++ b/mlrun/api/crud/artifacts.py
@@ -16,14 +16,14 @@
import sqlalchemy.orm
-import mlrun.api.schemas
import mlrun.api.utils.projects.remotes.follower
import mlrun.api.utils.singletons.db
import mlrun.api.utils.singletons.project_member
+import mlrun.common.schemas
+import mlrun.common.schemas.artifact
import mlrun.config
import mlrun.errors
import mlrun.utils.singleton
-from mlrun.api.schemas.artifact import ArtifactsFormat
class Artifacts(
@@ -66,7 +66,7 @@ def get_artifact(
tag: str = "latest",
iter: int = 0,
project: str = mlrun.mlconf.default_project,
- format_: ArtifactsFormat = ArtifactsFormat.full,
+ format_: mlrun.common.schemas.artifact.ArtifactsFormat = mlrun.common.schemas.artifact.ArtifactsFormat.full,
) -> dict:
project = project or mlrun.mlconf.default_project
artifact = mlrun.api.utils.singletons.db.get_db().read_artifact(
@@ -76,7 +76,7 @@ def get_artifact(
iter,
project,
)
- if format_ == ArtifactsFormat.legacy:
+ if format_ == mlrun.common.schemas.artifact.ArtifactsFormat.legacy:
return _transform_artifact_struct_to_legacy_format(artifact)
return artifact
@@ -90,10 +90,10 @@ def list_artifacts(
since=None,
until=None,
kind: typing.Optional[str] = None,
- category: typing.Optional[mlrun.api.schemas.ArtifactCategories] = None,
+ category: typing.Optional[mlrun.common.schemas.ArtifactCategories] = None,
iter: typing.Optional[int] = None,
best_iteration: bool = False,
- format_: ArtifactsFormat = ArtifactsFormat.full,
+ format_: mlrun.common.schemas.artifact.ArtifactsFormat = mlrun.common.schemas.artifact.ArtifactsFormat.full,
) -> typing.List:
project = project or mlrun.mlconf.default_project
if labels is None:
@@ -111,7 +111,7 @@ def list_artifacts(
iter,
best_iteration,
)
- if format_ != ArtifactsFormat.legacy:
+ if format_ != mlrun.common.schemas.artifact.ArtifactsFormat.legacy:
return artifacts
return [
_transform_artifact_struct_to_legacy_format(artifact)
@@ -122,7 +122,7 @@ def list_artifact_tags(
self,
db_session: sqlalchemy.orm.Session,
project: str = mlrun.mlconf.default_project,
- category: mlrun.api.schemas.ArtifactCategories = None,
+ category: mlrun.common.schemas.ArtifactCategories = None,
):
project = project or mlrun.mlconf.default_project
return mlrun.api.utils.singletons.db.get_db().list_artifact_tags(
@@ -148,7 +148,7 @@ def delete_artifacts(
name: str = "",
tag: str = "latest",
labels: typing.List[str] = None,
- auth_info: mlrun.api.schemas.AuthInfo = mlrun.api.schemas.AuthInfo(),
+ auth_info: mlrun.common.schemas.AuthInfo = mlrun.common.schemas.AuthInfo(),
):
project = project or mlrun.mlconf.default_project
mlrun.api.utils.singletons.db.get_db().del_artifacts(
diff --git a/mlrun/api/crud/client_spec.py b/mlrun/api/crud/client_spec.py
index 02e6567870d3..d19508242d47 100644
--- a/mlrun/api/crud/client_spec.py
+++ b/mlrun/api/crud/client_spec.py
@@ -12,7 +12,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
#
-import mlrun.api.schemas
+import mlrun.common.schemas
import mlrun.utils.singleton
from mlrun.config import Config, config, default_config
from mlrun.runtimes.utils import resolve_mpijob_crd_version, resolve_nuclio_version
@@ -25,7 +25,7 @@ def get_client_spec(
self, client_version: str = None, client_python_version: str = None
):
mpijob_crd_version = resolve_mpijob_crd_version(api_context=True)
- return mlrun.api.schemas.ClientSpec(
+ return mlrun.common.schemas.ClientSpec(
version=config.version,
namespace=config.namespace,
docker_registry=config.httpdb.builder.docker_registry,
diff --git a/mlrun/api/crud/clusterization_spec.py b/mlrun/api/crud/clusterization_spec.py
index 83b14659a814..ed1831ab770e 100644
--- a/mlrun/api/crud/clusterization_spec.py
+++ b/mlrun/api/crud/clusterization_spec.py
@@ -13,7 +13,7 @@
# limitations under the License.
#
import mlrun
-import mlrun.api.schemas
+import mlrun.common.schemas
import mlrun.utils.singleton
@@ -23,7 +23,7 @@ class ClusterizationSpec(
@staticmethod
def get_clusterization_spec():
is_chief = mlrun.mlconf.httpdb.clusterization.role == "chief"
- return mlrun.api.schemas.ClusterizationSpec(
+ return mlrun.common.schemas.ClusterizationSpec(
chief_api_state=mlrun.mlconf.httpdb.state if is_chief else None,
chief_version=mlrun.mlconf.version if is_chief else None,
)
diff --git a/mlrun/api/crud/feature_store.py b/mlrun/api/crud/feature_store.py
index 9e26c07be90b..3b0478263383 100644
--- a/mlrun/api/crud/feature_store.py
+++ b/mlrun/api/crud/feature_store.py
@@ -16,10 +16,10 @@
import sqlalchemy.orm
-import mlrun.api.schemas
import mlrun.api.utils.projects.remotes.follower
import mlrun.api.utils.singletons.db
import mlrun.api.utils.singletons.project_member
+import mlrun.common.schemas
import mlrun.config
import mlrun.errors
import mlrun.utils.singleton
@@ -32,7 +32,7 @@ def create_feature_set(
self,
db_session: sqlalchemy.orm.Session,
project: str,
- feature_set: mlrun.api.schemas.FeatureSet,
+ feature_set: mlrun.common.schemas.FeatureSet,
versioned: bool = True,
) -> str:
return self._create_object(
@@ -47,7 +47,7 @@ def store_feature_set(
db_session: sqlalchemy.orm.Session,
project: str,
name: str,
- feature_set: mlrun.api.schemas.FeatureSet,
+ feature_set: mlrun.common.schemas.FeatureSet,
tag: typing.Optional[str] = None,
uid: typing.Optional[str] = None,
versioned: bool = True,
@@ -70,11 +70,11 @@ def patch_feature_set(
feature_set_patch: dict,
tag: typing.Optional[str] = None,
uid: typing.Optional[str] = None,
- patch_mode: mlrun.api.schemas.PatchMode = mlrun.api.schemas.PatchMode.replace,
+ patch_mode: mlrun.common.schemas.PatchMode = mlrun.common.schemas.PatchMode.replace,
) -> str:
return self._patch_object(
db_session,
- mlrun.api.schemas.FeatureSet,
+ mlrun.common.schemas.FeatureSet,
project,
name,
feature_set_patch,
@@ -90,9 +90,9 @@ def get_feature_set(
name: str,
tag: typing.Optional[str] = None,
uid: typing.Optional[str] = None,
- ) -> mlrun.api.schemas.FeatureSet:
+ ) -> mlrun.common.schemas.FeatureSet:
return self._get_object(
- db_session, mlrun.api.schemas.FeatureSet, project, name, tag, uid
+ db_session, mlrun.common.schemas.FeatureSet, project, name, tag, uid
)
def list_feature_sets_tags(
@@ -104,7 +104,7 @@ def list_feature_sets_tags(
:return: a list of Tuple of (project, feature_set.name, tag)
"""
return self._list_object_type_tags(
- db_session, mlrun.api.schemas.FeatureSet, project
+ db_session, mlrun.common.schemas.FeatureSet, project
)
def list_feature_sets(
@@ -117,11 +117,11 @@ def list_feature_sets(
entities: typing.List[str] = None,
features: typing.List[str] = None,
labels: typing.List[str] = None,
- partition_by: mlrun.api.schemas.FeatureStorePartitionByField = None,
+ partition_by: mlrun.common.schemas.FeatureStorePartitionByField = None,
rows_per_partition: int = 1,
- partition_sort_by: mlrun.api.schemas.SortField = None,
- partition_order: mlrun.api.schemas.OrderType = mlrun.api.schemas.OrderType.desc,
- ) -> mlrun.api.schemas.FeatureSetsOutput:
+ partition_sort_by: mlrun.common.schemas.SortField = None,
+ partition_order: mlrun.common.schemas.OrderType = mlrun.common.schemas.OrderType.desc,
+ ) -> mlrun.common.schemas.FeatureSetsOutput:
project = project or mlrun.mlconf.default_project
return mlrun.api.utils.singletons.db.get_db().list_feature_sets(
db_session,
@@ -148,7 +148,7 @@ def delete_feature_set(
):
self._delete_object(
db_session,
- mlrun.api.schemas.FeatureSet,
+ mlrun.common.schemas.FeatureSet,
project,
name,
tag,
@@ -163,7 +163,7 @@ def list_features(
tag: typing.Optional[str] = None,
entities: typing.List[str] = None,
labels: typing.List[str] = None,
- ) -> mlrun.api.schemas.FeaturesOutput:
+ ) -> mlrun.common.schemas.FeaturesOutput:
project = project or mlrun.mlconf.default_project
return mlrun.api.utils.singletons.db.get_db().list_features(
db_session,
@@ -181,7 +181,7 @@ def list_entities(
name: str,
tag: typing.Optional[str] = None,
labels: typing.List[str] = None,
- ) -> mlrun.api.schemas.EntitiesOutput:
+ ) -> mlrun.common.schemas.EntitiesOutput:
project = project or mlrun.mlconf.default_project
return mlrun.api.utils.singletons.db.get_db().list_entities(
db_session,
@@ -195,7 +195,7 @@ def create_feature_vector(
self,
db_session: sqlalchemy.orm.Session,
project: str,
- feature_vector: mlrun.api.schemas.FeatureVector,
+ feature_vector: mlrun.common.schemas.FeatureVector,
versioned: bool = True,
) -> str:
return self._create_object(db_session, project, feature_vector, versioned)
@@ -205,7 +205,7 @@ def store_feature_vector(
db_session: sqlalchemy.orm.Session,
project: str,
name: str,
- feature_vector: mlrun.api.schemas.FeatureVector,
+ feature_vector: mlrun.common.schemas.FeatureVector,
tag: typing.Optional[str] = None,
uid: typing.Optional[str] = None,
versioned: bool = True,
@@ -228,11 +228,11 @@ def patch_feature_vector(
feature_vector_patch: dict,
tag: typing.Optional[str] = None,
uid: typing.Optional[str] = None,
- patch_mode: mlrun.api.schemas.PatchMode = mlrun.api.schemas.PatchMode.replace,
+ patch_mode: mlrun.common.schemas.PatchMode = mlrun.common.schemas.PatchMode.replace,
) -> str:
return self._patch_object(
db_session,
- mlrun.api.schemas.FeatureVector,
+ mlrun.common.schemas.FeatureVector,
project,
name,
feature_vector_patch,
@@ -248,10 +248,10 @@ def get_feature_vector(
name: str,
tag: typing.Optional[str] = None,
uid: typing.Optional[str] = None,
- ) -> mlrun.api.schemas.FeatureVector:
+ ) -> mlrun.common.schemas.FeatureVector:
return self._get_object(
db_session,
- mlrun.api.schemas.FeatureVector,
+ mlrun.common.schemas.FeatureVector,
project,
name,
tag,
@@ -267,7 +267,7 @@ def list_feature_vectors_tags(
:return: a list of Tuple of (project, feature_vector.name, tag)
"""
return self._list_object_type_tags(
- db_session, mlrun.api.schemas.FeatureVector, project
+ db_session, mlrun.common.schemas.FeatureVector, project
)
def list_feature_vectors(
@@ -278,11 +278,11 @@ def list_feature_vectors(
tag: typing.Optional[str] = None,
state: str = None,
labels: typing.List[str] = None,
- partition_by: mlrun.api.schemas.FeatureStorePartitionByField = None,
+ partition_by: mlrun.common.schemas.FeatureStorePartitionByField = None,
rows_per_partition: int = 1,
- partition_sort_by: mlrun.api.schemas.SortField = None,
- partition_order: mlrun.api.schemas.OrderType = mlrun.api.schemas.OrderType.desc,
- ) -> mlrun.api.schemas.FeatureVectorsOutput:
+ partition_sort_by: mlrun.common.schemas.SortField = None,
+ partition_order: mlrun.common.schemas.OrderType = mlrun.common.schemas.OrderType.desc,
+ ) -> mlrun.common.schemas.FeatureVectorsOutput:
project = project or mlrun.mlconf.default_project
return mlrun.api.utils.singletons.db.get_db().list_feature_vectors(
db_session,
@@ -307,7 +307,7 @@ def delete_feature_vector(
):
self._delete_object(
db_session,
- mlrun.api.schemas.FeatureVector,
+ mlrun.common.schemas.FeatureVector,
project,
name,
tag,
@@ -319,17 +319,17 @@ def _create_object(
db_session: sqlalchemy.orm.Session,
project: str,
object_: typing.Union[
- mlrun.api.schemas.FeatureSet, mlrun.api.schemas.FeatureVector
+ mlrun.common.schemas.FeatureSet, mlrun.common.schemas.FeatureVector
],
versioned: bool = True,
) -> str:
project = project or mlrun.mlconf.default_project
self._validate_and_enrich_identity_for_object_creation(project, object_)
- if isinstance(object_, mlrun.api.schemas.FeatureSet):
+ if isinstance(object_, mlrun.common.schemas.FeatureSet):
return mlrun.api.utils.singletons.db.get_db().create_feature_set(
db_session, project, object_, versioned
)
- elif isinstance(object_, mlrun.api.schemas.FeatureVector):
+ elif isinstance(object_, mlrun.common.schemas.FeatureVector):
return mlrun.api.utils.singletons.db.get_db().create_feature_vector(
db_session, project, object_, versioned
)
@@ -344,7 +344,7 @@ def _store_object(
project: str,
name: str,
object_: typing.Union[
- mlrun.api.schemas.FeatureSet, mlrun.api.schemas.FeatureVector
+ mlrun.common.schemas.FeatureSet, mlrun.common.schemas.FeatureVector
],
tag: typing.Optional[str] = None,
uid: typing.Optional[str] = None,
@@ -354,7 +354,7 @@ def _store_object(
self._validate_and_enrich_identity_for_object_store(
object_, project, name, tag, uid
)
- if isinstance(object_, mlrun.api.schemas.FeatureSet):
+ if isinstance(object_, mlrun.common.schemas.FeatureSet):
return mlrun.api.utils.singletons.db.get_db().store_feature_set(
db_session,
project,
@@ -364,7 +364,7 @@ def _store_object(
uid,
versioned,
)
- elif isinstance(object_, mlrun.api.schemas.FeatureVector):
+ elif isinstance(object_, mlrun.common.schemas.FeatureVector):
return mlrun.api.utils.singletons.db.get_db().store_feature_vector(
db_session,
project,
@@ -388,7 +388,7 @@ def _patch_object(
object_patch: dict,
tag: typing.Optional[str] = None,
uid: typing.Optional[str] = None,
- patch_mode: mlrun.api.schemas.PatchMode = mlrun.api.schemas.PatchMode.replace,
+ patch_mode: mlrun.common.schemas.PatchMode = mlrun.common.schemas.PatchMode.replace,
) -> str:
project = project or mlrun.mlconf.default_project
self._validate_identity_for_object_patch(
@@ -399,7 +399,7 @@ def _patch_object(
tag,
uid,
)
- if object_schema.__name__ == mlrun.api.schemas.FeatureSet.__name__:
+ if object_schema.__name__ == mlrun.common.schemas.FeatureSet.__name__:
return mlrun.api.utils.singletons.db.get_db().patch_feature_set(
db_session,
project,
@@ -409,7 +409,7 @@ def _patch_object(
uid,
patch_mode,
)
- elif object_schema.__name__ == mlrun.api.schemas.FeatureVector.__name__:
+ elif object_schema.__name__ == mlrun.common.schemas.FeatureVector.__name__:
return mlrun.api.utils.singletons.db.get_db().patch_feature_vector(
db_session,
project,
@@ -432,13 +432,15 @@ def _get_object(
name: str,
tag: typing.Optional[str] = None,
uid: typing.Optional[str] = None,
- ) -> typing.Union[mlrun.api.schemas.FeatureSet, mlrun.api.schemas.FeatureVector]:
+ ) -> typing.Union[
+ mlrun.common.schemas.FeatureSet, mlrun.common.schemas.FeatureVector
+ ]:
project = project or mlrun.mlconf.default_project
- if object_schema.__name__ == mlrun.api.schemas.FeatureSet.__name__:
+ if object_schema.__name__ == mlrun.common.schemas.FeatureSet.__name__:
return mlrun.api.utils.singletons.db.get_db().get_feature_set(
db_session, project, name, tag, uid
)
- elif object_schema.__name__ == mlrun.api.schemas.FeatureVector.__name__:
+ elif object_schema.__name__ == mlrun.common.schemas.FeatureVector.__name__:
return mlrun.api.utils.singletons.db.get_db().get_feature_vector(
db_session, project, name, tag, uid
)
@@ -454,11 +456,11 @@ def _list_object_type_tags(
project: str,
) -> typing.List[typing.Tuple[str, str, str]]:
project = project or mlrun.mlconf.default_project
- if object_schema.__name__ == mlrun.api.schemas.FeatureSet.__name__:
+ if object_schema.__name__ == mlrun.common.schemas.FeatureSet.__name__:
return mlrun.api.utils.singletons.db.get_db().list_feature_sets_tags(
db_session, project
)
- elif object_schema.__name__ == mlrun.api.schemas.FeatureVector.__name__:
+ elif object_schema.__name__ == mlrun.common.schemas.FeatureVector.__name__:
return mlrun.api.utils.singletons.db.get_db().list_feature_vectors_tags(
db_session, project
)
@@ -477,11 +479,11 @@ def _delete_object(
uid: typing.Optional[str] = None,
):
project = project or mlrun.mlconf.default_project
- if object_schema.__name__ == mlrun.api.schemas.FeatureSet.__name__:
+ if object_schema.__name__ == mlrun.common.schemas.FeatureSet.__name__:
mlrun.api.utils.singletons.db.get_db().delete_feature_set(
db_session, project, name, tag, uid
)
- elif object_schema.__name__ == mlrun.api.schemas.FeatureVector.__name__:
+ elif object_schema.__name__ == mlrun.common.schemas.FeatureVector.__name__:
mlrun.api.utils.singletons.db.get_db().delete_feature_vector(
db_session, project, name, tag, uid
)
@@ -519,7 +521,7 @@ def _validate_identity_for_object_patch(
@staticmethod
def _validate_and_enrich_identity_for_object_store(
object_: typing.Union[
- mlrun.api.schemas.FeatureSet, mlrun.api.schemas.FeatureVector
+ mlrun.common.schemas.FeatureSet, mlrun.common.schemas.FeatureVector
],
project: str,
name: str,
@@ -550,7 +552,7 @@ def _validate_and_enrich_identity_for_object_store(
def _validate_and_enrich_identity_for_object_creation(
project: str,
object_: typing.Union[
- mlrun.api.schemas.FeatureSet, mlrun.api.schemas.FeatureVector
+ mlrun.common.schemas.FeatureSet, mlrun.common.schemas.FeatureVector
],
):
object_type = object_.__class__.__name__
diff --git a/mlrun/api/crud/functions.py b/mlrun/api/crud/functions.py
index ef08a48e08fa..1583cdd0261a 100644
--- a/mlrun/api/crud/functions.py
+++ b/mlrun/api/crud/functions.py
@@ -17,10 +17,10 @@
import sqlalchemy.orm
import mlrun.api.api.utils
-import mlrun.api.schemas
import mlrun.api.utils.projects.remotes.follower
import mlrun.api.utils.singletons.db
import mlrun.api.utils.singletons.project_member
+import mlrun.common.schemas
import mlrun.config
import mlrun.errors
import mlrun.utils.singleton
@@ -37,7 +37,7 @@ def store_function(
project: str = mlrun.mlconf.default_project,
tag: str = "",
versioned: bool = False,
- auth_info: mlrun.api.schemas.AuthInfo = None,
+ auth_info: mlrun.common.schemas.AuthInfo = None,
) -> str:
project = project or mlrun.mlconf.default_project
if auth_info:
diff --git a/mlrun/api/crud/hub.py b/mlrun/api/crud/hub.py
index 0060a6c02f32..fe8cae6acfab 100644
--- a/mlrun/api/crud/hub.py
+++ b/mlrun/api/crud/hub.py
@@ -15,21 +15,14 @@
import json
from typing import Any, Dict, List, Optional, Tuple
+import mlrun.common.schemas
+import mlrun.common.schemas.hub
import mlrun.errors
import mlrun.utils.singleton
-from mlrun.api.schemas.hub import (
- HubCatalog,
- HubItem,
- HubItemMetadata,
- HubItemSpec,
- HubSource,
- ObjectStatus,
-)
from mlrun.api.utils.singletons.k8s import get_k8s
from mlrun.config import config
from mlrun.datastore import store_manager
-from ..schemas import SecretProviderName
from .secrets import Secrets, SecretsClientType
# Using a complex separator, as it's less likely someone will use it in a real secret name
@@ -55,7 +48,7 @@ def _generate_credentials_secret_key(source, key=""):
SecretsClientType.hub, full_key
)
- def add_source(self, source: HubSource):
+ def add_source(self, source: mlrun.common.schemas.hub.HubSource):
source_name = source.metadata.name
credentials = source.spec.credentials
if credentials:
@@ -75,7 +68,7 @@ def remove_source(self, source_name):
]
Secrets().delete_project_secrets(
self._internal_project_name,
- SecretProviderName.kubernetes,
+ mlrun.common.schemas.SecretProviderName.kubernetes,
secrets_to_delete,
allow_internal_secrets=True,
)
@@ -92,8 +85,9 @@ def _store_source_credentials(self, source_name, credentials: dict):
}
Secrets().store_project_secrets(
self._internal_project_name,
- mlrun.api.schemas.SecretsData(
- provider=SecretProviderName.kubernetes, secrets=adjusted_credentials
+ mlrun.common.schemas.SecretsData(
+ provider=mlrun.common.schemas.SecretProviderName.kubernetes,
+ secrets=adjusted_credentials,
),
allow_internal_secrets=True,
)
@@ -107,7 +101,7 @@ def _get_source_credentials(self, source_name):
Secrets()
.list_project_secrets(
self._internal_project_name,
- SecretProviderName.kubernetes,
+ mlrun.common.schemas.SecretProviderName.kubernetes,
allow_secrets_from_k8s=True,
allow_internal_secrets=True,
)
@@ -122,7 +116,11 @@ def _get_source_credentials(self, source_name):
return source_secrets
@staticmethod
- def _get_asset_full_path(source: HubSource, item: HubItem, asset: str):
+ def _get_asset_full_path(
+ source: mlrun.common.schemas.hub.HubSource,
+ item: mlrun.common.schemas.hub.HubItem,
+ asset: str,
+ ):
"""
Combining the item path with the asset path.
@@ -142,8 +140,8 @@ def _get_asset_full_path(source: HubSource, item: HubItem, asset: str):
@staticmethod
def _transform_catalog_dict_to_schema(
- source: HubSource, catalog_dict: Dict[str, Any]
- ) -> HubCatalog:
+ source: mlrun.common.schemas.hub.HubSource, catalog_dict: Dict[str, Any]
+ ) -> mlrun.common.schemas.hub.HubCatalog:
"""
Transforms catalog dictionary to HubCatalog schema
:param source: Hub source object.
@@ -152,20 +150,26 @@ def _transform_catalog_dict_to_schema(
bottom level keys include spec as a dict and all the rest is considered as metadata.
:return: catalog object
"""
- catalog = HubCatalog(catalog=[], channel=source.spec.channel)
+ catalog = mlrun.common.schemas.hub.HubCatalog(
+ catalog=[], channel=source.spec.channel
+ )
# Loop over objects, then over object versions.
for object_name, object_dict in catalog_dict.items():
for version_tag, version_dict in object_dict.items():
object_details_dict = version_dict.copy()
spec_dict = object_details_dict.pop("spec", {})
assets = object_details_dict.pop("assets", {})
- metadata = HubItemMetadata(tag=version_tag, **object_details_dict)
+ metadata = mlrun.common.schemas.hub.HubItemMetadata(
+ tag=version_tag, **object_details_dict
+ )
item_uri = source.get_full_uri(metadata.get_relative_path())
- spec = HubItemSpec(item_uri=item_uri, assets=assets, **spec_dict)
- item = HubItem(
+ spec = mlrun.common.schemas.hub.HubItemSpec(
+ item_uri=item_uri, assets=assets, **spec_dict
+ )
+ item = mlrun.common.schemas.hub.HubItem(
metadata=metadata,
spec=spec,
- status=ObjectStatus(),
+ status=mlrun.common.schemas.ObjectStatus(),
)
catalog.catalog.append(item)
@@ -173,11 +177,11 @@ def _transform_catalog_dict_to_schema(
def get_source_catalog(
self,
- source: HubSource,
+ source: mlrun.common.schemas.hub.HubSource,
version: Optional[str] = None,
tag: Optional[str] = None,
force_refresh: bool = False,
- ) -> HubCatalog:
+ ) -> mlrun.common.schemas.hub.HubCatalog:
"""
Getting the catalog object by source.
If version and/or tag are given, the catalog will be filtered accordingly.
@@ -200,7 +204,9 @@ def get_source_catalog(
else:
catalog = self._catalogs[source_name]
- result_catalog = HubCatalog(catalog=[], channel=source.spec.channel)
+ result_catalog = mlrun.common.schemas.hub.HubCatalog(
+ catalog=[], channel=source.spec.channel
+ )
for item in catalog.catalog:
# Because tag and version are optionals,
# we filter the catalog by one of them with priority to tag
@@ -213,12 +219,12 @@ def get_source_catalog(
def get_item(
self,
- source: HubSource,
+ source: mlrun.common.schemas.hub.HubSource,
item_name: str,
version: Optional[str] = None,
tag: Optional[str] = None,
force_refresh: bool = False,
- ) -> HubItem:
+ ) -> mlrun.common.schemas.hub.HubItem:
"""
Retrieve item from source. The item is filtered by tag and version.
@@ -250,9 +256,9 @@ def get_item(
@staticmethod
def _get_catalog_items_filtered_by_name(
- catalog: List[HubItem],
+ catalog: List[mlrun.common.schemas.hub.HubItem],
item_name: str,
- ) -> List[HubItem]:
+ ) -> List[mlrun.common.schemas.hub.HubItem]:
"""
Retrieve items from catalog filtered by name
@@ -263,7 +269,9 @@ def _get_catalog_items_filtered_by_name(
"""
return [item for item in catalog if item.metadata.name == item_name]
- def get_item_object_using_source_credentials(self, source: HubSource, url):
+ def get_item_object_using_source_credentials(
+ self, source: mlrun.common.schemas.hub.HubSource, url
+ ):
credentials = self._get_source_credentials(source.metadata.name)
if not url.startswith(source.spec.path):
@@ -283,8 +291,8 @@ def get_item_object_using_source_credentials(self, source: HubSource, url):
def get_asset(
self,
- source: HubSource,
- item: HubItem,
+ source: mlrun.common.schemas.hub.HubSource,
+ item: mlrun.common.schemas.hub.HubItem,
asset_name: str,
) -> Tuple[bytes, str]:
"""
diff --git a/mlrun/api/crud/logs.py b/mlrun/api/crud/logs.py
index aaaf2f07e31c..dd2f7c954e1f 100644
--- a/mlrun/api/crud/logs.py
+++ b/mlrun/api/crud/logs.py
@@ -21,8 +21,8 @@
from fastapi.concurrency import run_in_threadpool
from sqlalchemy.orm import Session
-import mlrun.api.schemas
import mlrun.api.utils.clients.log_collector as log_collector
+import mlrun.common.schemas
import mlrun.utils.singleton
from mlrun.api.api.utils import log_and_raise, log_path, project_logs_path
from mlrun.api.constants import LogSources
@@ -85,7 +85,7 @@ async def get_logs(
log_stream = None
if (
mlrun.mlconf.log_collector.mode
- == mlrun.api.schemas.LogsCollectorMode.best_effort
+ == mlrun.common.schemas.LogsCollectorMode.best_effort
and source == LogSources.AUTO
):
try:
@@ -112,7 +112,7 @@ async def get_logs(
)
elif (
mlrun.mlconf.log_collector.mode
- == mlrun.api.schemas.LogsCollectorMode.sidecar
+ == mlrun.common.schemas.LogsCollectorMode.sidecar
and source == LogSources.AUTO
):
log_stream = self._get_logs_from_logs_collector(
@@ -123,7 +123,7 @@ async def get_logs(
)
elif (
mlrun.mlconf.log_collector.mode
- == mlrun.api.schemas.LogsCollectorMode.legacy
+ == mlrun.common.schemas.LogsCollectorMode.legacy
or source != LogSources.AUTO
):
log_stream = self._get_logs_legacy_method_generator_wrapper(
diff --git a/mlrun/api/crud/model_monitoring/grafana.py b/mlrun/api/crud/model_monitoring/grafana.py
index 7bc527aec970..3ff8a586f3f5 100644
--- a/mlrun/api/crud/model_monitoring/grafana.py
+++ b/mlrun/api/crud/model_monitoring/grafana.py
@@ -21,17 +21,9 @@
from sqlalchemy.orm import Session
import mlrun.api.crud
-import mlrun.api.schemas
import mlrun.api.utils.auth.verifier
-import mlrun.model_monitoring
-from mlrun.api.schemas import (
- GrafanaColumn,
- GrafanaDataPoint,
- GrafanaNumberColumn,
- GrafanaTable,
- GrafanaTimeSeriesTarget,
- ProjectsFormat,
-)
+import mlrun.common.model_monitoring
+import mlrun.common.schemas
from mlrun.api.utils.singletons.project_member import get_project_member
from mlrun.errors import MLRunBadRequestError
from mlrun.utils import config, logger
@@ -41,7 +33,7 @@
def grafana_list_projects(
db_session: Session,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
query_parameters: Dict[str, str],
) -> List[str]:
"""
@@ -56,7 +48,9 @@ def grafana_list_projects(
"""
projects_output = get_project_member().list_projects(
- db_session, format_=ProjectsFormat.name_only, leader_session=auth_info.session
+ db_session,
+ format_=mlrun.common.schemas.ProjectsFormat.name_only,
+ leader_session=auth_info.session,
)
return projects_output.projects
@@ -68,8 +62,8 @@ def grafana_list_projects(
async def grafana_list_endpoints(
body: Dict[str, Any],
query_parameters: Dict[str, str],
- auth_info: mlrun.api.schemas.AuthInfo,
-) -> List[GrafanaTable]:
+ auth_info: mlrun.common.schemas.AuthInfo,
+) -> List[mlrun.common.schemas.GrafanaTable]:
project = query_parameters.get("project")
# Filters
@@ -89,7 +83,7 @@ async def grafana_list_endpoints(
if project:
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_permissions(
project,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
endpoint_list = await run_in_threadpool(
@@ -104,7 +98,7 @@ async def grafana_list_endpoints(
end=end,
)
allowed_endpoints = await mlrun.api.utils.auth.verifier.AuthVerifier().filter_project_resources_by_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.model_endpoint,
+ mlrun.common.schemas.AuthorizationResourceTypes.model_endpoint,
endpoint_list.endpoints,
lambda _endpoint: (
_endpoint.metadata.project,
@@ -115,20 +109,22 @@ async def grafana_list_endpoints(
endpoint_list.endpoints = allowed_endpoints
columns = [
- GrafanaColumn(text="endpoint_id", type="string"),
- GrafanaColumn(text="endpoint_function", type="string"),
- GrafanaColumn(text="endpoint_model", type="string"),
- GrafanaColumn(text="endpoint_model_class", type="string"),
- GrafanaColumn(text="first_request", type="time"),
- GrafanaColumn(text="last_request", type="time"),
- GrafanaColumn(text="accuracy", type="number"),
- GrafanaColumn(text="error_count", type="number"),
- GrafanaColumn(text="drift_status", type="number"),
- GrafanaColumn(text="predictions_per_second", type="number"),
- GrafanaColumn(text="latency_avg_1h", type="number"),
+ mlrun.common.schemas.GrafanaColumn(text="endpoint_id", type="string"),
+ mlrun.common.schemas.GrafanaColumn(text="endpoint_function", type="string"),
+ mlrun.common.schemas.GrafanaColumn(text="endpoint_model", type="string"),
+ mlrun.common.schemas.GrafanaColumn(text="endpoint_model_class", type="string"),
+ mlrun.common.schemas.GrafanaColumn(text="first_request", type="time"),
+ mlrun.common.schemas.GrafanaColumn(text="last_request", type="time"),
+ mlrun.common.schemas.GrafanaColumn(text="accuracy", type="number"),
+ mlrun.common.schemas.GrafanaColumn(text="error_count", type="number"),
+ mlrun.common.schemas.GrafanaColumn(text="drift_status", type="number"),
+ mlrun.common.schemas.GrafanaColumn(
+ text="predictions_per_second", type="number"
+ ),
+ mlrun.common.schemas.GrafanaColumn(text="latency_avg_1h", type="number"),
]
- table = GrafanaTable(columns=columns)
+ table = mlrun.common.schemas.GrafanaTable(columns=columns)
for endpoint in endpoint_list.endpoints:
row = [
endpoint.metadata.uid,
@@ -144,17 +140,19 @@ async def grafana_list_endpoints(
if (
endpoint.status.metrics
- and mlrun.model_monitoring.EventKeyMetrics.GENERIC
+ and mlrun.common.model_monitoring.EventKeyMetrics.GENERIC
in endpoint.status.metrics
):
row.extend(
[
endpoint.status.metrics[
- mlrun.model_monitoring.EventKeyMetrics.GENERIC
- ][mlrun.model_monitoring.EventLiveStats.PREDICTIONS_PER_SECOND],
+ mlrun.common.model_monitoring.EventKeyMetrics.GENERIC
+ ][
+ mlrun.common.model_monitoring.EventLiveStats.PREDICTIONS_PER_SECOND
+ ],
endpoint.status.metrics[
- mlrun.model_monitoring.EventKeyMetrics.GENERIC
- ][mlrun.model_monitoring.EventLiveStats.LATENCY_AVG_1H],
+ mlrun.common.model_monitoring.EventKeyMetrics.GENERIC
+ ][mlrun.common.model_monitoring.EventLiveStats.LATENCY_AVG_1H],
]
)
@@ -166,15 +164,15 @@ async def grafana_list_endpoints(
async def grafana_individual_feature_analysis(
body: Dict[str, Any],
query_parameters: Dict[str, str],
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
):
endpoint_id = query_parameters.get("endpoint_id")
project = query_parameters.get("project")
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.model_endpoint,
+ mlrun.common.schemas.AuthorizationResourceTypes.model_endpoint,
project,
endpoint_id,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
@@ -191,18 +189,18 @@ async def grafana_individual_feature_analysis(
current_stats = endpoint.status.current_stats or {}
drift_measures = endpoint.status.drift_measures or {}
- table = GrafanaTable(
+ table = mlrun.common.schemas.GrafanaTable(
columns=[
- GrafanaColumn(text="feature_name", type="string"),
- GrafanaColumn(text="actual_min", type="number"),
- GrafanaColumn(text="actual_mean", type="number"),
- GrafanaColumn(text="actual_max", type="number"),
- GrafanaColumn(text="expected_min", type="number"),
- GrafanaColumn(text="expected_mean", type="number"),
- GrafanaColumn(text="expected_max", type="number"),
- GrafanaColumn(text="tvd", type="number"),
- GrafanaColumn(text="hellinger", type="number"),
- GrafanaColumn(text="kld", type="number"),
+ mlrun.common.schemas.GrafanaColumn(text="feature_name", type="string"),
+ mlrun.common.schemas.GrafanaColumn(text="actual_min", type="number"),
+ mlrun.common.schemas.GrafanaColumn(text="actual_mean", type="number"),
+ mlrun.common.schemas.GrafanaColumn(text="actual_max", type="number"),
+ mlrun.common.schemas.GrafanaColumn(text="expected_min", type="number"),
+ mlrun.common.schemas.GrafanaColumn(text="expected_mean", type="number"),
+ mlrun.common.schemas.GrafanaColumn(text="expected_max", type="number"),
+ mlrun.common.schemas.GrafanaColumn(text="tvd", type="number"),
+ mlrun.common.schemas.GrafanaColumn(text="hellinger", type="number"),
+ mlrun.common.schemas.GrafanaColumn(text="kld", type="number"),
]
)
@@ -229,15 +227,15 @@ async def grafana_individual_feature_analysis(
async def grafana_overall_feature_analysis(
body: Dict[str, Any],
query_parameters: Dict[str, str],
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
):
endpoint_id = query_parameters.get("endpoint_id")
project = query_parameters.get("project")
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.model_endpoint,
+ mlrun.common.schemas.AuthorizationResourceTypes.model_endpoint,
project,
endpoint_id,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
endpoint = await run_in_threadpool(
@@ -248,14 +246,14 @@ async def grafana_overall_feature_analysis(
feature_analysis=True,
)
- table = GrafanaTable(
+ table = mlrun.common.schemas.GrafanaTable(
columns=[
- GrafanaNumberColumn(text="tvd_sum"),
- GrafanaNumberColumn(text="tvd_mean"),
- GrafanaNumberColumn(text="hellinger_sum"),
- GrafanaNumberColumn(text="hellinger_mean"),
- GrafanaNumberColumn(text="kld_sum"),
- GrafanaNumberColumn(text="kld_mean"),
+ mlrun.common.schemas.GrafanaNumberColumn(text="tvd_sum"),
+ mlrun.common.schemas.GrafanaNumberColumn(text="tvd_mean"),
+ mlrun.common.schemas.GrafanaNumberColumn(text="hellinger_sum"),
+ mlrun.common.schemas.GrafanaNumberColumn(text="hellinger_mean"),
+ mlrun.common.schemas.GrafanaNumberColumn(text="kld_sum"),
+ mlrun.common.schemas.GrafanaNumberColumn(text="kld_mean"),
]
)
@@ -275,7 +273,7 @@ async def grafana_overall_feature_analysis(
async def grafana_incoming_features(
body: Dict[str, Any],
query_parameters: Dict[str, str],
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
):
endpoint_id = query_parameters.get("endpoint_id")
project = query_parameters.get("project")
@@ -283,10 +281,10 @@ async def grafana_incoming_features(
end = body.get("rangeRaw", {}).get("to", "now")
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_resource_permissions(
- mlrun.api.schemas.AuthorizationResourceTypes.model_endpoint,
+ mlrun.common.schemas.AuthorizationResourceTypes.model_endpoint,
project,
endpoint_id,
- mlrun.api.schemas.AuthorizationAction.read,
+ mlrun.common.schemas.AuthorizationAction.read,
auth_info,
)
@@ -309,7 +307,7 @@ async def grafana_incoming_features(
return time_series
path = config.model_endpoint_monitoring.store_prefixes.default.format(
- project=project, kind=mlrun.api.schemas.ModelMonitoringStoreKinds.EVENTS
+ project=project, kind=mlrun.common.schemas.ModelMonitoringStoreKinds.EVENTS
)
_, container, path = parse_model_endpoint_store_prefix(path)
@@ -333,9 +331,11 @@ async def grafana_incoming_features(
data.index = data.index.astype(np.int64) // 10**6
for feature, indexed_values in data.to_dict().items():
- target = GrafanaTimeSeriesTarget(target=feature)
+ target = mlrun.common.schemas.GrafanaTimeSeriesTarget(target=feature)
for index, value in indexed_values.items():
- data_point = GrafanaDataPoint(value=float(value), timestamp=index)
+ data_point = mlrun.common.schemas.GrafanaDataPoint(
+ value=float(value), timestamp=index
+ )
target.add_data_point(data_point)
time_series.append(target)
diff --git a/mlrun/api/crud/model_monitoring/model_endpoints.py b/mlrun/api/crud/model_monitoring/model_endpoints.py
index e50d85954776..36c30d1a196c 100644
--- a/mlrun/api/crud/model_monitoring/model_endpoints.py
+++ b/mlrun/api/crud/model_monitoring/model_endpoints.py
@@ -21,15 +21,15 @@
import mlrun.api.api.endpoints.functions
import mlrun.api.api.utils
-import mlrun.api.schemas
-import mlrun.api.schemas.model_endpoints
import mlrun.api.utils.singletons.k8s
import mlrun.artifacts
+import mlrun.common.model_monitoring as model_monitoring_constants
+import mlrun.common.schemas
+import mlrun.common.schemas.model_endpoints
import mlrun.config
import mlrun.datastore.store_resources
import mlrun.errors
import mlrun.feature_store
-import mlrun.model_monitoring.constants as model_monitoring_constants
import mlrun.model_monitoring.helpers
import mlrun.runtimes.function
import mlrun.utils.helpers
@@ -46,9 +46,9 @@ def create_or_patch(
self,
db_session: sqlalchemy.orm.Session,
access_key: str,
- model_endpoint: mlrun.api.schemas.ModelEndpoint,
- auth_info: mlrun.api.schemas.AuthInfo = mlrun.api.schemas.AuthInfo(),
- ) -> mlrun.api.schemas.ModelEndpoint:
+ model_endpoint: mlrun.common.schemas.ModelEndpoint,
+ auth_info: mlrun.common.schemas.AuthInfo = mlrun.common.schemas.AuthInfo(),
+ ) -> mlrun.common.schemas.ModelEndpoint:
# TODO: deprecated in 1.3.0, remove in 1.5.0.
warnings.warn(
"This is deprecated in 1.3.0, and will be removed in 1.5.0."
@@ -74,8 +74,8 @@ def create_or_patch(
def create_model_endpoint(
self,
db_session: sqlalchemy.orm.Session,
- model_endpoint: mlrun.api.schemas.ModelEndpoint,
- ) -> mlrun.api.schemas.ModelEndpoint:
+ model_endpoint: mlrun.common.schemas.ModelEndpoint,
+ ) -> mlrun.common.schemas.ModelEndpoint:
"""
Creates model endpoint record in DB. The DB target type is defined under
`mlrun.config.model_endpoint_monitoring.store_type` (V3IO-NOSQL by default).
@@ -126,7 +126,7 @@ def create_model_endpoint(
# Create monitoring feature set if monitoring found in model endpoint object
if (
model_endpoint.spec.monitoring_mode
- == mlrun.model_monitoring.ModelMonitoringMode.enabled.value
+ == mlrun.common.model_monitoring.ModelMonitoringMode.enabled.value
):
monitoring_feature_set = self.create_monitoring_feature_set(
model_endpoint, model_obj, db_session, run_db
@@ -172,7 +172,7 @@ def create_model_endpoint(
def create_monitoring_feature_set(
self,
- model_endpoint: mlrun.api.schemas.ModelEndpoint,
+ model_endpoint: mlrun.common.schemas.ModelEndpoint,
model_obj: mlrun.artifacts.ModelArtifact,
db_session: sqlalchemy.orm.Session,
run_db: mlrun.db.sqldb.SQLDB,
@@ -355,7 +355,7 @@ def patch_model_endpoint(
project: str,
endpoint_id: str,
attributes: dict,
- ) -> mlrun.api.schemas.ModelEndpoint:
+ ) -> mlrun.common.schemas.ModelEndpoint:
"""
Update a model endpoint record with a given attributes.
@@ -364,7 +364,7 @@ def patch_model_endpoint(
:param attributes: Dictionary of attributes that will be used for update the model endpoint. Note that the keys
of the attributes dictionary should exist in the DB table. More details about the model
endpoint available attributes can be found under
- :py:class:`~mlrun.api.schemas.ModelEndpoint`.
+ :py:class:`~mlrun.common.schemas.ModelEndpoint`.
:return: A patched `ModelEndpoint` object.
"""
@@ -407,14 +407,14 @@ def delete_model_endpoint(
def get_model_endpoint(
self,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
project: str,
endpoint_id: str,
metrics: typing.List[str] = None,
start: str = "now-1h",
end: str = "now",
feature_analysis: bool = False,
- ) -> mlrun.api.schemas.ModelEndpoint:
+ ) -> mlrun.common.schemas.ModelEndpoint:
"""Get a single model endpoint object. You can apply different time series metrics that will be added to the
result.
@@ -473,7 +473,7 @@ def get_model_endpoint(
def list_model_endpoints(
self,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
project: str,
model: str = None,
function: str = None,
@@ -483,7 +483,7 @@ def list_model_endpoints(
end: str = "now",
top_level: bool = False,
uids: typing.List[str] = None,
- ) -> mlrun.api.schemas.ModelEndpointList:
+ ) -> mlrun.common.schemas.ModelEndpointList:
"""
Returns a list of `ModelEndpoint` objects, wrapped in `ModelEndpointList` object. Each `ModelEndpoint`
object represents the current state of a model endpoint. This functions supports filtering by the following
@@ -536,7 +536,7 @@ def list_model_endpoints(
)
# Initialize an empty model endpoints list
- endpoint_list = mlrun.api.schemas.model_endpoints.ModelEndpointList(
+ endpoint_list = mlrun.common.schemas.model_endpoints.ModelEndpointList(
endpoints=[]
)
@@ -578,11 +578,11 @@ def list_model_endpoints(
@staticmethod
def _add_real_time_metrics(
model_endpoint_store: mlrun.model_monitoring.stores.ModelEndpointStore,
- model_endpoint_object: mlrun.api.schemas.ModelEndpoint,
+ model_endpoint_object: mlrun.common.schemas.ModelEndpoint,
metrics: typing.List[str] = None,
start: str = "now-1h",
end: str = "now",
- ) -> mlrun.api.schemas.ModelEndpoint:
+ ) -> mlrun.common.schemas.ModelEndpoint:
"""Add real time metrics from the time series DB to a provided `ModelEndpoint` object. The real time metrics
will be stored under `ModelEndpoint.status.metrics.real_time`
@@ -622,7 +622,7 @@ def _add_real_time_metrics(
def _convert_into_model_endpoint_object(
self, endpoint: typing.Dict[str, typing.Any], feature_analysis: bool = False
- ) -> mlrun.api.schemas.ModelEndpoint:
+ ) -> mlrun.common.schemas.ModelEndpoint:
"""
Create a `ModelEndpoint` object according to a provided model endpoint dictionary.
@@ -635,7 +635,7 @@ def _convert_into_model_endpoint_object(
"""
# Convert into `ModelEndpoint` object
- endpoint_obj = mlrun.api.schemas.ModelEndpoint().from_flat_dict(endpoint)
+ endpoint_obj = mlrun.common.schemas.ModelEndpoint().from_flat_dict(endpoint)
# If feature analysis was applied, add feature stats and current stats to the model endpoint result
if feature_analysis and endpoint_obj.spec.feature_names:
@@ -662,7 +662,7 @@ def get_endpoint_features(
feature_names: typing.List[str],
feature_stats: dict = None,
current_stats: dict = None,
- ) -> typing.List[mlrun.api.schemas.Features]:
+ ) -> typing.List[mlrun.common.schemas.Features]:
"""
Getting a new list of features that exist in feature_names along with their expected (feature_stats) and
actual (current_stats) stats. The expected stats were calculated during the creation of the model endpoint,
@@ -676,7 +676,7 @@ def get_endpoint_features(
batch job.
return: List of feature objects. Each feature has a name, weight, expected values, and actual values. More info
- can be found under `mlrun.api.schemas.Features`.
+ can be found under `mlrun.common.schemas.Features`.
"""
# Initialize feature and current stats dictionaries
@@ -690,7 +690,7 @@ def get_endpoint_features(
logger.warn("Feature missing from 'feature_stats'", name=name)
if current_stats is not None and name not in current_stats:
logger.warn("Feature missing from 'current_stats'", name=name)
- f = mlrun.api.schemas.Features.new(
+ f = mlrun.common.schemas.Features.new(
name, safe_feature_stats.get(name), safe_current_stats.get(name)
)
features.append(f)
@@ -709,7 +709,7 @@ def deploy_monitoring_functions(
project: str,
model_monitoring_access_key: str,
db_session: sqlalchemy.orm.Session,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
tracking_policy: mlrun.utils.model_monitoring.TrackingPolicy,
):
"""
@@ -737,7 +737,7 @@ def deploy_monitoring_functions(
)
def verify_project_has_no_model_endpoints(self, project_name: str):
- auth_info = mlrun.api.schemas.AuthInfo(
+ auth_info = mlrun.common.schemas.AuthInfo(
data_session=os.getenv("V3IO_ACCESS_KEY")
)
@@ -757,7 +757,7 @@ def delete_model_endpoints_resources(project_name: str):
:param project_name: The name of the project.
"""
- auth_info = mlrun.api.schemas.AuthInfo(
+ auth_info = mlrun.common.schemas.AuthInfo(
data_session=os.getenv("V3IO_ACCESS_KEY")
)
@@ -780,7 +780,7 @@ def deploy_model_monitoring_stream_processing(
project: str,
model_monitoring_access_key: str,
db_session: sqlalchemy.orm.Session,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
tracking_policy: mlrun.utils.model_monitoring.TrackingPolicy,
):
"""
@@ -839,7 +839,7 @@ def deploy_model_monitoring_batch_processing(
project: str,
model_monitoring_access_key: str,
db_session: sqlalchemy.orm.Session,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
tracking_policy: mlrun.utils.model_monitoring.TrackingPolicy,
):
"""
@@ -923,7 +923,7 @@ def _clean_feature_name(feature_name):
return feature_name.replace(" ", "_").replace("(", "").replace(")", "")
@staticmethod
- def get_access_key(auth_info: mlrun.api.schemas.AuthInfo):
+ def get_access_key(auth_info: mlrun.common.schemas.AuthInfo):
"""
Getting access key from the current data session. This method is usually used to verify that the session
is valid and contains an access key.
@@ -962,7 +962,7 @@ def _get_batching_interval_param(intervals_list: typing.List):
@staticmethod
def _convert_to_cron_string(
- cron_trigger: mlrun.api.schemas.schedule.ScheduleCronTrigger,
+ cron_trigger: mlrun.common.schemas.schedule.ScheduleCronTrigger,
):
"""Converting the batch interval `ScheduleCronTrigger` into a cron trigger expression"""
return "{} {} {} * *".format(
diff --git a/mlrun/api/crud/pipelines.py b/mlrun/api/crud/pipelines.py
index f0b1c74e4ed1..26f5a5e34ece 100644
--- a/mlrun/api/crud/pipelines.py
+++ b/mlrun/api/crud/pipelines.py
@@ -24,7 +24,7 @@
import mlrun
import mlrun.api.api.utils
-import mlrun.api.schemas
+import mlrun.common.schemas
import mlrun.errors
import mlrun.kfpops
import mlrun.utils.helpers
@@ -44,14 +44,14 @@ def list_pipelines(
sort_by: str = "",
page_token: str = "",
filter_: str = "",
- format_: mlrun.api.schemas.PipelinesFormat = mlrun.api.schemas.PipelinesFormat.metadata_only,
+ format_: mlrun.common.schemas.PipelinesFormat = mlrun.common.schemas.PipelinesFormat.metadata_only,
page_size: typing.Optional[int] = None,
) -> typing.Tuple[int, typing.Optional[int], typing.List[dict]]:
if project != "*" and (page_token or page_size):
raise mlrun.errors.MLRunInvalidArgumentError(
"Filtering by project can not be used together with pagination"
)
- if format_ == mlrun.api.schemas.PipelinesFormat.summary:
+ if format_ == mlrun.common.schemas.PipelinesFormat.summary:
# we don't support summary format in list pipelines since the returned runs doesn't include the workflow
# manifest status that includes the nodes section we use to generate the DAG.
# (There is a workflow manifest under the run's pipeline_spec field, but it doesn't include the status)
@@ -72,7 +72,7 @@ def list_pipelines(
# the filter that was used to create it)
response = kfp_client._run_api.list_runs(
page_token=page_token,
- page_size=mlrun.api.schemas.PipelinesPagination.max_page_size,
+ page_size=mlrun.common.schemas.PipelinesPagination.max_page_size,
sort_by=sort_by,
filter=filter_ if page_token == "" else "",
)
@@ -90,7 +90,7 @@ def list_pipelines(
response = kfp_client._run_api.list_runs(
page_token=page_token,
page_size=page_size
- or mlrun.api.schemas.PipelinesPagination.default_page_size,
+ or mlrun.common.schemas.PipelinesPagination.default_page_size,
sort_by=sort_by,
filter=filter_,
)
@@ -107,7 +107,7 @@ def get_pipeline(
run_id: str,
project: typing.Optional[str] = None,
namespace: typing.Optional[str] = None,
- format_: mlrun.api.schemas.PipelinesFormat = mlrun.api.schemas.PipelinesFormat.summary,
+ format_: mlrun.common.schemas.PipelinesFormat = mlrun.common.schemas.PipelinesFormat.summary,
):
kfp_url = mlrun.mlconf.resolve_kfp_url(namespace)
if not kfp_url:
@@ -201,7 +201,7 @@ def _format_runs(
self,
db_session: sqlalchemy.orm.Session,
runs: typing.List[dict],
- format_: mlrun.api.schemas.PipelinesFormat = mlrun.api.schemas.PipelinesFormat.metadata_only,
+ format_: mlrun.common.schemas.PipelinesFormat = mlrun.common.schemas.PipelinesFormat.metadata_only,
) -> typing.List[dict]:
formatted_runs = []
for run in runs:
@@ -212,13 +212,13 @@ def _format_run(
self,
db_session: sqlalchemy.orm.Session,
run: dict,
- format_: mlrun.api.schemas.PipelinesFormat = mlrun.api.schemas.PipelinesFormat.metadata_only,
+ format_: mlrun.common.schemas.PipelinesFormat = mlrun.common.schemas.PipelinesFormat.metadata_only,
api_run_detail: typing.Optional[dict] = None,
) -> dict:
run["project"] = self.resolve_project_from_pipeline(run)
- if format_ == mlrun.api.schemas.PipelinesFormat.full:
+ if format_ == mlrun.common.schemas.PipelinesFormat.full:
return run
- elif format_ == mlrun.api.schemas.PipelinesFormat.metadata_only:
+ elif format_ == mlrun.common.schemas.PipelinesFormat.metadata_only:
return {
k: str(v)
for k, v in run.items()
@@ -235,9 +235,9 @@ def _format_run(
"description",
]
}
- elif format_ == mlrun.api.schemas.PipelinesFormat.name_only:
+ elif format_ == mlrun.common.schemas.PipelinesFormat.name_only:
return run.get("name")
- elif format_ == mlrun.api.schemas.PipelinesFormat.summary:
+ elif format_ == mlrun.common.schemas.PipelinesFormat.summary:
if not api_run_detail:
raise mlrun.errors.MLRunRuntimeError(
"The full kfp api_run_detail object is needed to generate the summary format"
diff --git a/mlrun/api/crud/projects.py b/mlrun/api/crud/projects.py
index 99dc1eeae2f9..b0363572fcd1 100644
--- a/mlrun/api/crud/projects.py
+++ b/mlrun/api/crud/projects.py
@@ -23,11 +23,11 @@
import mlrun.api.crud
import mlrun.api.db.session
-import mlrun.api.schemas
import mlrun.api.utils.projects.remotes.follower
import mlrun.api.utils.singletons.db
import mlrun.api.utils.singletons.k8s
import mlrun.api.utils.singletons.scheduler
+import mlrun.common.schemas
import mlrun.errors
import mlrun.utils.singleton
from mlrun.utils import logger
@@ -44,7 +44,7 @@ def __init__(self) -> None:
}
def create_project(
- self, session: sqlalchemy.orm.Session, project: mlrun.api.schemas.Project
+ self, session: sqlalchemy.orm.Session, project: mlrun.common.schemas.Project
):
logger.debug("Creating project", project=project)
mlrun.api.utils.singletons.db.get_db().create_project(session, project)
@@ -53,7 +53,7 @@ def store_project(
self,
session: sqlalchemy.orm.Session,
name: str,
- project: mlrun.api.schemas.Project,
+ project: mlrun.common.schemas.Project,
):
logger.debug("Storing project", name=name, project=project)
mlrun.api.utils.singletons.db.get_db().store_project(session, name, project)
@@ -63,7 +63,7 @@ def patch_project(
session: sqlalchemy.orm.Session,
name: str,
project: dict,
- patch_mode: mlrun.api.schemas.PatchMode = mlrun.api.schemas.PatchMode.replace,
+ patch_mode: mlrun.common.schemas.PatchMode = mlrun.common.schemas.PatchMode.replace,
):
logger.debug(
"Patching project", name=name, project=project, patch_mode=patch_mode
@@ -76,12 +76,12 @@ def delete_project(
self,
session: sqlalchemy.orm.Session,
name: str,
- deletion_strategy: mlrun.api.schemas.DeletionStrategy = mlrun.api.schemas.DeletionStrategy.default(),
+ deletion_strategy: mlrun.common.schemas.DeletionStrategy = mlrun.common.schemas.DeletionStrategy.default(),
):
logger.debug("Deleting project", name=name, deletion_strategy=deletion_strategy)
if (
deletion_strategy.is_restricted()
- or deletion_strategy == mlrun.api.schemas.DeletionStrategy.check
+ or deletion_strategy == mlrun.common.schemas.DeletionStrategy.check
):
if not mlrun.api.utils.singletons.db.get_db().is_project_exists(
session, name
@@ -91,7 +91,7 @@ def delete_project(
session, name
)
self._verify_project_has_no_external_resources(name)
- if deletion_strategy == mlrun.api.schemas.DeletionStrategy.check:
+ if deletion_strategy == mlrun.common.schemas.DeletionStrategy.check:
return
elif deletion_strategy.is_cascading():
self.delete_project_resources(session, name)
@@ -142,7 +142,7 @@ def delete_project_resources(
# log collector service will delete the logs, so we don't need to do it here
if (
mlrun.mlconf.log_collector.mode
- == mlrun.api.schemas.LogsCollectorMode.legacy
+ == mlrun.common.schemas.LogsCollectorMode.legacy
):
mlrun.api.crud.Logs().delete_logs(name)
@@ -160,18 +160,18 @@ def delete_project_resources(
def get_project(
self, session: sqlalchemy.orm.Session, name: str
- ) -> mlrun.api.schemas.Project:
+ ) -> mlrun.common.schemas.Project:
return mlrun.api.utils.singletons.db.get_db().get_project(session, name)
def list_projects(
self,
session: sqlalchemy.orm.Session,
owner: str = None,
- format_: mlrun.api.schemas.ProjectsFormat = mlrun.api.schemas.ProjectsFormat.full,
+ format_: mlrun.common.schemas.ProjectsFormat = mlrun.common.schemas.ProjectsFormat.full,
labels: typing.List[str] = None,
- state: mlrun.api.schemas.ProjectState = None,
+ state: mlrun.common.schemas.ProjectState = None,
names: typing.Optional[typing.List[str]] = None,
- ) -> mlrun.api.schemas.ProjectsOutput:
+ ) -> mlrun.common.schemas.ProjectsOutput:
return mlrun.api.utils.singletons.db.get_db().list_projects(
session, owner, format_, labels, state, names
)
@@ -181,14 +181,14 @@ async def list_project_summaries(
session: sqlalchemy.orm.Session,
owner: str = None,
labels: typing.List[str] = None,
- state: mlrun.api.schemas.ProjectState = None,
+ state: mlrun.common.schemas.ProjectState = None,
names: typing.Optional[typing.List[str]] = None,
- ) -> mlrun.api.schemas.ProjectSummariesOutput:
+ ) -> mlrun.common.schemas.ProjectSummariesOutput:
projects_output = await fastapi.concurrency.run_in_threadpool(
self.list_projects,
session,
owner,
- mlrun.api.schemas.ProjectsFormat.name_only,
+ mlrun.common.schemas.ProjectsFormat.name_only,
labels,
state,
names,
@@ -196,13 +196,13 @@ async def list_project_summaries(
project_summaries = await self.generate_projects_summaries(
projects_output.projects
)
- return mlrun.api.schemas.ProjectSummariesOutput(
+ return mlrun.common.schemas.ProjectSummariesOutput(
project_summaries=project_summaries
)
async def get_project_summary(
self, session: sqlalchemy.orm.Session, name: str
- ) -> mlrun.api.schemas.ProjectSummary:
+ ) -> mlrun.common.schemas.ProjectSummary:
# Call get project so we'll explode if project doesn't exists
await fastapi.concurrency.run_in_threadpool(self.get_project, session, name)
project_summaries = await self.generate_projects_summaries([name])
@@ -210,7 +210,7 @@ async def get_project_summary(
async def generate_projects_summaries(
self, projects: typing.List[str]
- ) -> typing.List[mlrun.api.schemas.ProjectSummary]:
+ ) -> typing.List[mlrun.common.schemas.ProjectSummary]:
(
project_to_files_count,
project_to_schedule_count,
@@ -223,7 +223,7 @@ async def generate_projects_summaries(
project_summaries = []
for project in projects:
project_summaries.append(
- mlrun.api.schemas.ProjectSummary(
+ mlrun.common.schemas.ProjectSummary(
name=project,
files_count=project_to_files_count.get(project, 0),
schedules_count=project_to_schedule_count.get(project, 0),
@@ -294,7 +294,7 @@ async def _get_project_resources_counters(
@staticmethod
def _list_pipelines(
session,
- format_: mlrun.api.schemas.PipelinesFormat = mlrun.api.schemas.PipelinesFormat.metadata_only,
+ format_: mlrun.common.schemas.PipelinesFormat = mlrun.common.schemas.PipelinesFormat.metadata_only,
):
return mlrun.api.crud.Pipelines().list_pipelines(session, "*", format_=format_)
diff --git a/mlrun/api/crud/runs.py b/mlrun/api/crud/runs.py
index e2b13972aba6..a03870edc826 100644
--- a/mlrun/api/crud/runs.py
+++ b/mlrun/api/crud/runs.py
@@ -16,10 +16,10 @@
import sqlalchemy.orm
-import mlrun.api.schemas
import mlrun.api.utils.projects.remotes.follower
import mlrun.api.utils.singletons.db
import mlrun.api.utils.singletons.project_member
+import mlrun.common.schemas
import mlrun.config
import mlrun.errors
import mlrun.lists
@@ -120,10 +120,10 @@ def list_runs(
start_time_to=None,
last_update_time_from=None,
last_update_time_to=None,
- partition_by: mlrun.api.schemas.RunPartitionByField = None,
+ partition_by: mlrun.common.schemas.RunPartitionByField = None,
rows_per_partition: int = 1,
- partition_sort_by: mlrun.api.schemas.SortField = None,
- partition_order: mlrun.api.schemas.OrderType = mlrun.api.schemas.OrderType.desc,
+ partition_sort_by: mlrun.common.schemas.SortField = None,
+ partition_order: mlrun.common.schemas.OrderType = mlrun.common.schemas.OrderType.desc,
max_partitions: int = 0,
requested_logs: bool = None,
return_as_run_structs: bool = True,
diff --git a/mlrun/api/crud/runtime_resources.py b/mlrun/api/crud/runtime_resources.py
index 33ac0556d6b2..fd92a5c3e8f0 100644
--- a/mlrun/api/crud/runtime_resources.py
+++ b/mlrun/api/crud/runtime_resources.py
@@ -18,9 +18,9 @@
import sqlalchemy.orm
import mlrun.api.api.utils
-import mlrun.api.schemas
import mlrun.api.utils.projects.remotes.follower
import mlrun.api.utils.singletons.db
+import mlrun.common.schemas
import mlrun.config
import mlrun.errors
import mlrun.runtimes
@@ -37,12 +37,12 @@ def list_runtime_resources(
object_id: typing.Optional[str] = None,
label_selector: typing.Optional[str] = None,
group_by: typing.Optional[
- mlrun.api.schemas.ListRuntimeResourcesGroupByField
+ mlrun.common.schemas.ListRuntimeResourcesGroupByField
] = None,
) -> typing.Union[
- mlrun.api.schemas.RuntimeResourcesOutput,
- mlrun.api.schemas.GroupedByJobRuntimeResourcesOutput,
- mlrun.api.schemas.GroupedByProjectRuntimeResourcesOutput,
+ mlrun.common.schemas.RuntimeResourcesOutput,
+ mlrun.common.schemas.GroupedByJobRuntimeResourcesOutput,
+ mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput,
]:
response = [] if group_by is None else {}
kinds = mlrun.runtimes.RuntimeKinds.runtime_with_handlers()
@@ -56,7 +56,7 @@ def list_runtime_resources(
)
if group_by is None:
response.append(
- mlrun.api.schemas.KindRuntimeResources(
+ mlrun.common.schemas.KindRuntimeResources(
kind=kind, resources=resources
)
)
@@ -66,15 +66,15 @@ def list_runtime_resources(
def filter_and_format_grouped_by_project_runtime_resources_output(
self,
- grouped_by_project_runtime_resources_output: mlrun.api.schemas.GroupedByProjectRuntimeResourcesOutput,
+ grouped_by_project_runtime_resources_output: mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput,
allowed_projects: typing.List[str],
group_by: typing.Optional[
- mlrun.api.schemas.ListRuntimeResourcesGroupByField
+ mlrun.common.schemas.ListRuntimeResourcesGroupByField
] = None,
) -> typing.Union[
- mlrun.api.schemas.RuntimeResourcesOutput,
- mlrun.api.schemas.GroupedByJobRuntimeResourcesOutput,
- mlrun.api.schemas.GroupedByProjectRuntimeResourcesOutput,
+ mlrun.common.schemas.RuntimeResourcesOutput,
+ mlrun.common.schemas.GroupedByJobRuntimeResourcesOutput,
+ mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput,
]:
runtime_resources_by_kind = {}
for (
@@ -94,7 +94,7 @@ def filter_and_format_grouped_by_project_runtime_resources_output(
)
if group_by is None:
runtimes_resources_output.append(
- mlrun.api.schemas.KindRuntimeResources(
+ mlrun.common.schemas.KindRuntimeResources(
kind=kind, resources=resources
)
)
diff --git a/mlrun/api/crud/secrets.py b/mlrun/api/crud/secrets.py
index 619fcfb67a47..97f3b8ac4aeb 100644
--- a/mlrun/api/crud/secrets.py
+++ b/mlrun/api/crud/secrets.py
@@ -17,8 +17,8 @@
import typing
import uuid
-import mlrun.api.schemas
import mlrun.api.utils.singletons.k8s
+import mlrun.common.schemas
import mlrun.errors
import mlrun.utils.helpers
import mlrun.utils.regex
@@ -74,7 +74,7 @@ def validate_internal_project_secret_key_allowed(
def store_project_secrets(
self,
project: str,
- secrets: mlrun.api.schemas.SecretsData,
+ secrets: mlrun.common.schemas.SecretsData,
allow_internal_secrets: bool = False,
key_map_secret_key: typing.Optional[str] = None,
allow_storing_key_maps: bool = False,
@@ -94,14 +94,14 @@ def store_project_secrets(
allow_storing_key_maps,
)
- if secrets.provider == mlrun.api.schemas.SecretProviderName.vault:
+ if secrets.provider == mlrun.common.schemas.SecretProviderName.vault:
# Init is idempotent and will do nothing if infra is already in place
mlrun.utils.vault.init_project_vault_configuration(project)
# If no secrets were passed, no need to touch the actual secrets.
if secrets_to_store:
mlrun.utils.vault.store_vault_project_secrets(project, secrets_to_store)
- elif secrets.provider == mlrun.api.schemas.SecretProviderName.kubernetes:
+ elif secrets.provider == mlrun.common.schemas.SecretProviderName.kubernetes:
if mlrun.api.utils.singletons.k8s.get_k8s():
mlrun.api.utils.singletons.k8s.get_k8s().store_project_secrets(
project, secrets_to_store
@@ -117,24 +117,24 @@ def store_project_secrets(
def read_auth_secret(
self, secret_name, raise_on_not_found=False
- ) -> mlrun.api.schemas.AuthSecretData:
+ ) -> mlrun.common.schemas.AuthSecretData:
(
username,
access_key,
) = mlrun.api.utils.singletons.k8s.get_k8s().read_auth_secret(
secret_name, raise_on_not_found=raise_on_not_found
)
- return mlrun.api.schemas.AuthSecretData(
- provider=mlrun.api.schemas.SecretProviderName.kubernetes,
+ return mlrun.common.schemas.AuthSecretData(
+ provider=mlrun.common.schemas.SecretProviderName.kubernetes,
username=username,
access_key=access_key,
)
def store_auth_secret(
self,
- secret: mlrun.api.schemas.AuthSecretData,
+ secret: mlrun.common.schemas.AuthSecretData,
) -> str:
- if secret.provider != mlrun.api.schemas.SecretProviderName.kubernetes:
+ if secret.provider != mlrun.common.schemas.SecretProviderName.kubernetes:
raise mlrun.errors.MLRunInvalidArgumentError(
f"Storing auth secret is not implemented for provider {secret.provider}"
)
@@ -148,10 +148,10 @@ def store_auth_secret(
def delete_auth_secret(
self,
- provider: mlrun.api.schemas.SecretProviderName,
+ provider: mlrun.common.schemas.SecretProviderName,
secret_name: str,
):
- if provider != mlrun.api.schemas.SecretProviderName.kubernetes:
+ if provider != mlrun.common.schemas.SecretProviderName.kubernetes:
raise mlrun.errors.MLRunInvalidArgumentError(
f"Storing auth secret is not implemented for provider {provider}"
)
@@ -164,7 +164,7 @@ def delete_auth_secret(
def delete_project_secrets(
self,
project: str,
- provider: mlrun.api.schemas.SecretProviderName,
+ provider: mlrun.common.schemas.SecretProviderName,
secrets: typing.Optional[typing.List[str]] = None,
allow_internal_secrets: bool = False,
):
@@ -186,11 +186,11 @@ def delete_project_secrets(
# nothing to remove - return
return
- if provider == mlrun.api.schemas.SecretProviderName.vault:
+ if provider == mlrun.common.schemas.SecretProviderName.vault:
raise mlrun.errors.MLRunInvalidArgumentError(
f"Delete secret is not implemented for provider {provider}"
)
- elif provider == mlrun.api.schemas.SecretProviderName.kubernetes:
+ elif provider == mlrun.common.schemas.SecretProviderName.kubernetes:
if mlrun.api.utils.singletons.k8s.get_k8s():
mlrun.api.utils.singletons.k8s.get_k8s().delete_project_secrets(
project, secrets
@@ -207,11 +207,11 @@ def delete_project_secrets(
def list_project_secret_keys(
self,
project: str,
- provider: mlrun.api.schemas.SecretProviderName,
+ provider: mlrun.common.schemas.SecretProviderName,
token: typing.Optional[str] = None,
allow_internal_secrets: bool = False,
- ) -> mlrun.api.schemas.SecretKeysData:
- if provider == mlrun.api.schemas.SecretProviderName.vault:
+ ) -> mlrun.common.schemas.SecretKeysData:
+ if provider == mlrun.common.schemas.SecretProviderName.vault:
if not token:
raise mlrun.errors.MLRunInvalidArgumentError(
"Vault list project secret keys request without providing token"
@@ -220,7 +220,7 @@ def list_project_secret_keys(
vault = mlrun.utils.vault.VaultStore(token)
secret_values = vault.get_secrets(None, project=project)
secret_keys = list(secret_values.keys())
- elif provider == mlrun.api.schemas.SecretProviderName.kubernetes:
+ elif provider == mlrun.common.schemas.SecretProviderName.kubernetes:
if token:
raise mlrun.errors.MLRunInvalidArgumentError(
"Cannot specify token when requesting k8s secret keys"
@@ -249,20 +249,20 @@ def list_project_secret_keys(
)
)
- return mlrun.api.schemas.SecretKeysData(
+ return mlrun.common.schemas.SecretKeysData(
provider=provider, secret_keys=secret_keys
)
def list_project_secrets(
self,
project: str,
- provider: mlrun.api.schemas.SecretProviderName,
+ provider: mlrun.common.schemas.SecretProviderName,
secrets: typing.Optional[typing.List[str]] = None,
token: typing.Optional[str] = None,
allow_secrets_from_k8s: bool = False,
allow_internal_secrets: bool = False,
- ) -> mlrun.api.schemas.SecretsData:
- if provider == mlrun.api.schemas.SecretProviderName.vault:
+ ) -> mlrun.common.schemas.SecretsData:
+ if provider == mlrun.common.schemas.SecretProviderName.vault:
if not token:
raise mlrun.errors.MLRunInvalidArgumentError(
"Vault list project secrets request without providing token"
@@ -270,7 +270,7 @@ def list_project_secrets(
vault = mlrun.utils.vault.VaultStore(token)
secrets_data = vault.get_secrets(secrets, project=project)
- elif provider == mlrun.api.schemas.SecretProviderName.kubernetes:
+ elif provider == mlrun.common.schemas.SecretProviderName.kubernetes:
if not allow_secrets_from_k8s:
raise mlrun.errors.MLRunAccessDeniedError(
"Not allowed to list secrets data from kubernetes provider"
@@ -291,12 +291,12 @@ def list_project_secrets(
for key, value in secrets_data.items()
if not self._is_internal_project_secret_key(key)
}
- return mlrun.api.schemas.SecretsData(provider=provider, secrets=secrets_data)
+ return mlrun.common.schemas.SecretsData(provider=provider, secrets=secrets_data)
def delete_project_secret(
self,
project: str,
- provider: mlrun.api.schemas.SecretProviderName,
+ provider: mlrun.common.schemas.SecretProviderName,
secret_key: str,
token: typing.Optional[str] = None,
allow_secrets_from_k8s: bool = False,
@@ -322,7 +322,7 @@ def delete_project_secret(
if key_map:
self.store_project_secrets(
project,
- mlrun.api.schemas.SecretsData(
+ mlrun.common.schemas.SecretsData(
provider=provider,
secrets={key_map_secret_key: json.dumps(key_map)},
),
@@ -337,7 +337,7 @@ def delete_project_secret(
def get_project_secret(
self,
project: str,
- provider: mlrun.api.schemas.SecretProviderName,
+ provider: mlrun.common.schemas.SecretProviderName,
secret_key: str,
token: typing.Optional[str] = None,
allow_secrets_from_k8s: bool = False,
@@ -366,7 +366,7 @@ def get_project_secret(
def _resolve_project_secret_key(
self,
project: str,
- provider: mlrun.api.schemas.SecretProviderName,
+ provider: mlrun.common.schemas.SecretProviderName,
secret_key: str,
token: typing.Optional[str] = None,
allow_secrets_from_k8s: bool = False,
@@ -374,7 +374,7 @@ def _resolve_project_secret_key(
key_map_secret_key: typing.Optional[str] = None,
) -> typing.Tuple[bool, str]:
if key_map_secret_key:
- if provider != mlrun.api.schemas.SecretProviderName.kubernetes:
+ if provider != mlrun.common.schemas.SecretProviderName.kubernetes:
raise mlrun.errors.MLRunInvalidArgumentError(
f"Secret using key map is not implemented for provider {provider}"
)
@@ -396,7 +396,7 @@ def _resolve_project_secret_key(
def _validate_and_enrich_project_secrets_to_store(
self,
project: str,
- secrets: mlrun.api.schemas.SecretsData,
+ secrets: mlrun.common.schemas.SecretsData,
allow_internal_secrets: bool = False,
key_map_secret_key: typing.Optional[str] = None,
allow_storing_key_maps: bool = False,
@@ -419,7 +419,10 @@ def _validate_and_enrich_project_secrets_to_store(
f"{self.key_map_secrets_key_prefix})"
)
if key_map_secret_key:
- if secrets.provider != mlrun.api.schemas.SecretProviderName.kubernetes:
+ if (
+ secrets.provider
+ != mlrun.common.schemas.SecretProviderName.kubernetes
+ ):
raise mlrun.errors.MLRunInvalidArgumentError(
f"Storing secret using key map is not implemented for provider {secrets.provider}"
)
@@ -467,7 +470,7 @@ def _get_project_secret_key_map(
) -> typing.Optional[dict]:
secrets_data = self.list_project_secrets(
project,
- mlrun.api.schemas.SecretProviderName.kubernetes,
+ mlrun.common.schemas.SecretProviderName.kubernetes,
[key_map_secret_key],
allow_secrets_from_k8s=True,
allow_internal_secrets=True,
diff --git a/mlrun/api/crud/tags.py b/mlrun/api/crud/tags.py
index 78d5ec270150..e10477d62b9f 100644
--- a/mlrun/api/crud/tags.py
+++ b/mlrun/api/crud/tags.py
@@ -15,10 +15,10 @@
import sqlalchemy.orm
import mlrun.api.db.sqldb.db
-import mlrun.api.schemas
import mlrun.api.utils.projects.remotes.follower
import mlrun.api.utils.singletons.db
import mlrun.api.utils.singletons.project_member
+import mlrun.common.schemas
import mlrun.config
import mlrun.errors
import mlrun.utils.singleton
@@ -40,7 +40,7 @@ def overwrite_object_tags_with_tag(
db_session: sqlalchemy.orm.Session,
project: str,
tag: str,
- tag_objects: mlrun.api.schemas.TagObjects,
+ tag_objects: mlrun.common.schemas.TagObjects,
):
overwrite_func = kind_to_function_names.get(tag_objects.kind, {}).get(
"overwrite"
@@ -61,7 +61,7 @@ def append_tag_to_objects(
db_session: sqlalchemy.orm.Session,
project: str,
tag: str,
- tag_objects: mlrun.api.schemas.TagObjects,
+ tag_objects: mlrun.common.schemas.TagObjects,
):
append_func = kind_to_function_names.get(tag_objects.kind, {}).get("append")
if not append_func:
@@ -80,7 +80,7 @@ def delete_tag_from_objects(
db_session: sqlalchemy.orm.Session,
project: str,
tag: str,
- tag_objects: mlrun.api.schemas.TagObjects,
+ tag_objects: mlrun.common.schemas.TagObjects,
):
delete_func = kind_to_function_names.get(tag_objects.kind, {}).get("delete")
if not delete_func:
diff --git a/mlrun/api/db/base.py b/mlrun/api/db/base.py
index 3d522e506bc7..fe72a36e7b02 100644
--- a/mlrun/api/db/base.py
+++ b/mlrun/api/db/base.py
@@ -17,8 +17,8 @@
from abc import ABC, abstractmethod
from typing import Any, Dict, List, Optional, Tuple, Union
+import mlrun.common.schemas
import mlrun.model
-from mlrun.api import schemas
class DBError(Exception):
@@ -98,10 +98,10 @@ def list_runs(
start_time_to=None,
last_update_time_from=None,
last_update_time_to=None,
- partition_by: schemas.RunPartitionByField = None,
+ partition_by: mlrun.common.schemas.RunPartitionByField = None,
rows_per_partition: int = 1,
- partition_sort_by: schemas.SortField = None,
- partition_order: schemas.OrderType = schemas.OrderType.desc,
+ partition_sort_by: mlrun.common.schemas.SortField = None,
+ partition_order: mlrun.common.schemas.OrderType = mlrun.common.schemas.OrderType.desc,
max_partitions: int = 0,
requested_logs: bool = None,
return_as_run_structs: bool = True,
@@ -122,7 +122,7 @@ def overwrite_artifacts_with_tag(
session,
project: str,
tag: str,
- identifiers: List[schemas.ArtifactIdentifier],
+ identifiers: List[mlrun.common.schemas.ArtifactIdentifier],
):
pass
@@ -131,7 +131,7 @@ def append_tag_to_artifacts(
session,
project: str,
tag: str,
- identifiers: List[schemas.ArtifactIdentifier],
+ identifiers: List[mlrun.common.schemas.ArtifactIdentifier],
):
pass
@@ -140,7 +140,7 @@ def delete_tag_from_artifacts(
session,
project: str,
tag: str,
- identifiers: List[schemas.ArtifactIdentifier],
+ identifiers: List[mlrun.common.schemas.ArtifactIdentifier],
):
pass
@@ -172,7 +172,7 @@ def list_artifacts(
since=None,
until=None,
kind=None,
- category: schemas.ArtifactCategories = None,
+ category: mlrun.common.schemas.ArtifactCategories = None,
iter: int = None,
best_iteration: bool = False,
as_records: bool = False,
@@ -235,9 +235,9 @@ def create_schedule(
session,
project: str,
name: str,
- kind: schemas.ScheduleKinds,
+ kind: mlrun.common.schemas.ScheduleKinds,
scheduled_object: Any,
- cron_trigger: schemas.ScheduleCronTrigger,
+ cron_trigger: mlrun.common.schemas.ScheduleCronTrigger,
concurrency_limit: int,
labels: Dict = None,
next_run_time: datetime.datetime = None,
@@ -251,7 +251,7 @@ def update_schedule(
project: str,
name: str,
scheduled_object: Any = None,
- cron_trigger: schemas.ScheduleCronTrigger = None,
+ cron_trigger: mlrun.common.schemas.ScheduleCronTrigger = None,
labels: Dict = None,
last_run_uri: str = None,
concurrency_limit: int = None,
@@ -266,12 +266,14 @@ def list_schedules(
project: str = None,
name: str = None,
labels: str = None,
- kind: schemas.ScheduleKinds = None,
- ) -> List[schemas.ScheduleRecord]:
+ kind: mlrun.common.schemas.ScheduleKinds = None,
+ ) -> List[mlrun.common.schemas.ScheduleRecord]:
pass
@abstractmethod
- def get_schedule(self, session, project: str, name: str) -> schemas.ScheduleRecord:
+ def get_schedule(
+ self, session, project: str, name: str
+ ) -> mlrun.common.schemas.ScheduleRecord:
pass
@abstractmethod
@@ -285,7 +287,7 @@ def delete_schedules(self, session, project: str):
@abstractmethod
def generate_projects_summaries(
self, session, projects: List[str]
- ) -> List[schemas.ProjectSummary]:
+ ) -> List[mlrun.common.schemas.ProjectSummary]:
pass
@abstractmethod
@@ -305,17 +307,17 @@ def list_projects(
self,
session,
owner: str = None,
- format_: schemas.ProjectsFormat = schemas.ProjectsFormat.full,
+ format_: mlrun.common.schemas.ProjectsFormat = mlrun.common.schemas.ProjectsFormat.full,
labels: List[str] = None,
- state: schemas.ProjectState = None,
+ state: mlrun.common.schemas.ProjectState = None,
names: Optional[List[str]] = None,
- ) -> schemas.ProjectsOutput:
+ ) -> mlrun.common.schemas.ProjectsOutput:
pass
@abstractmethod
def get_project(
self, session, name: str = None, project_id: int = None
- ) -> schemas.Project:
+ ) -> mlrun.common.schemas.Project:
pass
@abstractmethod
@@ -332,11 +334,11 @@ async def get_project_resources_counters(
pass
@abstractmethod
- def create_project(self, session, project: schemas.Project):
+ def create_project(self, session, project: mlrun.common.schemas.Project):
pass
@abstractmethod
- def store_project(self, session, name: str, project: schemas.Project):
+ def store_project(self, session, name: str, project: mlrun.common.schemas.Project):
pass
@abstractmethod
@@ -345,7 +347,7 @@ def patch_project(
session,
name: str,
project: dict,
- patch_mode: schemas.PatchMode = schemas.PatchMode.replace,
+ patch_mode: mlrun.common.schemas.PatchMode = mlrun.common.schemas.PatchMode.replace,
):
pass
@@ -354,7 +356,7 @@ def delete_project(
self,
session,
name: str,
- deletion_strategy: schemas.DeletionStrategy = schemas.DeletionStrategy.default(),
+ deletion_strategy: mlrun.common.schemas.DeletionStrategy = mlrun.common.schemas.DeletionStrategy.default(),
):
pass
@@ -363,7 +365,7 @@ def create_feature_set(
self,
session,
project,
- feature_set: schemas.FeatureSet,
+ feature_set: mlrun.common.schemas.FeatureSet,
versioned=True,
) -> str:
pass
@@ -374,7 +376,7 @@ def store_feature_set(
session,
project,
name,
- feature_set: schemas.FeatureSet,
+ feature_set: mlrun.common.schemas.FeatureSet,
tag=None,
uid=None,
versioned=True,
@@ -385,7 +387,7 @@ def store_feature_set(
@abstractmethod
def get_feature_set(
self, session, project: str, name: str, tag: str = None, uid: str = None
- ) -> schemas.FeatureSet:
+ ) -> mlrun.common.schemas.FeatureSet:
pass
@abstractmethod
@@ -397,7 +399,7 @@ def list_features(
tag: str = None,
entities: List[str] = None,
labels: List[str] = None,
- ) -> schemas.FeaturesOutput:
+ ) -> mlrun.common.schemas.FeaturesOutput:
pass
@abstractmethod
@@ -408,7 +410,7 @@ def list_entities(
name: str = None,
tag: str = None,
labels: List[str] = None,
- ) -> schemas.EntitiesOutput:
+ ) -> mlrun.common.schemas.EntitiesOutput:
pass
@abstractmethod
@@ -422,11 +424,11 @@ def list_feature_sets(
entities: List[str] = None,
features: List[str] = None,
labels: List[str] = None,
- partition_by: schemas.FeatureStorePartitionByField = None,
+ partition_by: mlrun.common.schemas.FeatureStorePartitionByField = None,
rows_per_partition: int = 1,
- partition_sort_by: schemas.SortField = None,
- partition_order: schemas.OrderType = schemas.OrderType.desc,
- ) -> schemas.FeatureSetsOutput:
+ partition_sort_by: mlrun.common.schemas.SortField = None,
+ partition_order: mlrun.common.schemas.OrderType = mlrun.common.schemas.OrderType.desc,
+ ) -> mlrun.common.schemas.FeatureSetsOutput:
pass
@abstractmethod
@@ -449,7 +451,7 @@ def patch_feature_set(
feature_set_patch: dict,
tag=None,
uid=None,
- patch_mode: schemas.PatchMode = schemas.PatchMode.replace,
+ patch_mode: mlrun.common.schemas.PatchMode = mlrun.common.schemas.PatchMode.replace,
) -> str:
pass
@@ -462,7 +464,7 @@ def create_feature_vector(
self,
session,
project,
- feature_vector: schemas.FeatureVector,
+ feature_vector: mlrun.common.schemas.FeatureVector,
versioned=True,
) -> str:
pass
@@ -470,7 +472,7 @@ def create_feature_vector(
@abstractmethod
def get_feature_vector(
self, session, project: str, name: str, tag: str = None, uid: str = None
- ) -> schemas.FeatureVector:
+ ) -> mlrun.common.schemas.FeatureVector:
pass
@abstractmethod
@@ -482,11 +484,11 @@ def list_feature_vectors(
tag: str = None,
state: str = None,
labels: List[str] = None,
- partition_by: schemas.FeatureStorePartitionByField = None,
+ partition_by: mlrun.common.schemas.FeatureStorePartitionByField = None,
rows_per_partition: int = 1,
- partition_sort_by: schemas.SortField = None,
- partition_order: schemas.OrderType = schemas.OrderType.desc,
- ) -> schemas.FeatureVectorsOutput:
+ partition_sort_by: mlrun.common.schemas.SortField = None,
+ partition_order: mlrun.common.schemas.OrderType = mlrun.common.schemas.OrderType.desc,
+ ) -> mlrun.common.schemas.FeatureVectorsOutput:
pass
@abstractmethod
@@ -506,7 +508,7 @@ def store_feature_vector(
session,
project,
name,
- feature_vector: schemas.FeatureVector,
+ feature_vector: mlrun.common.schemas.FeatureVector,
tag=None,
uid=None,
versioned=True,
@@ -523,7 +525,7 @@ def patch_feature_vector(
feature_vector_update: dict,
tag=None,
uid=None,
- patch_mode: schemas.PatchMode = schemas.PatchMode.replace,
+ patch_mode: mlrun.common.schemas.PatchMode = mlrun.common.schemas.PatchMode.replace,
) -> str:
pass
@@ -539,23 +541,33 @@ def delete_feature_vector(
pass
def list_artifact_tags(
- self, session, project, category: Union[str, schemas.ArtifactCategories] = None
+ self,
+ session,
+ project,
+ category: Union[str, mlrun.common.schemas.ArtifactCategories] = None,
):
return []
- def create_hub_source(self, session, ordered_source: schemas.IndexedHubSource):
+ def create_hub_source(
+ self, session, ordered_source: mlrun.common.schemas.IndexedHubSource
+ ):
pass
- def store_hub_source(self, session, name, ordered_source: schemas.IndexedHubSource):
+ def store_hub_source(
+ self,
+ session,
+ name,
+ ordered_source: mlrun.common.schemas.IndexedHubSource,
+ ):
pass
- def list_hub_sources(self, session) -> List[schemas.IndexedHubSource]:
+ def list_hub_sources(self, session) -> List[mlrun.common.schemas.IndexedHubSource]:
pass
def delete_hub_source(self, session, name):
pass
- def get_hub_source(self, session, name) -> schemas.IndexedHubSource:
+ def get_hub_source(self, session, name) -> mlrun.common.schemas.IndexedHubSource:
pass
def store_background_task(
@@ -563,14 +575,14 @@ def store_background_task(
session,
name: str,
project: str,
- state: str = schemas.BackgroundTaskState.running,
+ state: str = mlrun.common.schemas.BackgroundTaskState.running,
timeout: int = None,
):
pass
def get_background_task(
self, session, name: str, project: str
- ) -> schemas.BackgroundTask:
+ ) -> mlrun.common.schemas.BackgroundTask:
pass
@abstractmethod
diff --git a/mlrun/api/db/sqldb/db.py b/mlrun/api/db/sqldb/db.py
index 263eca4a1e19..0efdba750a36 100644
--- a/mlrun/api/db/sqldb/db.py
+++ b/mlrun/api/db/sqldb/db.py
@@ -32,9 +32,9 @@
import mlrun.api.db.session
import mlrun.api.utils.projects.remotes.follower
import mlrun.api.utils.singletons.k8s
+import mlrun.common.schemas
import mlrun.errors
import mlrun.model
-from mlrun.api import schemas
from mlrun.api.db.base import DBInterface
from mlrun.api.db.sqldb.helpers import (
generate_query_predicate_for_name,
@@ -321,10 +321,10 @@ def list_runs(
start_time_to=None,
last_update_time_from=None,
last_update_time_to=None,
- partition_by: schemas.RunPartitionByField = None,
+ partition_by: mlrun.common.schemas.RunPartitionByField = None,
rows_per_partition: int = 1,
- partition_sort_by: schemas.SortField = None,
- partition_order: schemas.OrderType = schemas.OrderType.desc,
+ partition_sort_by: mlrun.common.schemas.SortField = None,
+ partition_order: mlrun.common.schemas.OrderType = mlrun.common.schemas.OrderType.desc,
max_partitions: int = 0,
requested_logs: bool = None,
return_as_run_structs: bool = True,
@@ -358,7 +358,9 @@ def list_runs(
query = query.filter(Run.requested_logs == requested_logs)
if partition_by:
self._assert_partition_by_parameters(
- schemas.RunPartitionByField, partition_by, partition_sort_by
+ mlrun.common.schemas.RunPartitionByField,
+ partition_by,
+ partition_sort_by,
)
query = self._create_partitioned_query(
session,
@@ -456,7 +458,7 @@ def overwrite_artifacts_with_tag(
session: Session,
project: str,
tag: str,
- identifiers: typing.List[mlrun.api.schemas.ArtifactIdentifier],
+ identifiers: typing.List[mlrun.common.schemas.ArtifactIdentifier],
):
# query all artifacts which match the identifiers
artifacts = []
@@ -479,7 +481,7 @@ def append_tag_to_artifacts(
session: Session,
project: str,
tag: str,
- identifiers: typing.List[mlrun.api.schemas.ArtifactIdentifier],
+ identifiers: typing.List[mlrun.common.schemas.ArtifactIdentifier],
):
# query all artifacts which match the identifiers
artifacts = []
@@ -496,7 +498,7 @@ def delete_tag_from_artifacts(
session: Session,
project: str,
tag: str,
- identifiers: typing.List[mlrun.api.schemas.ArtifactIdentifier],
+ identifiers: typing.List[mlrun.common.schemas.ArtifactIdentifier],
):
# query all artifacts which match the identifiers
artifacts = []
@@ -512,7 +514,7 @@ def _list_artifacts_for_tagging(
self,
session: Session,
project_name: str,
- identifier: mlrun.api.schemas.ArtifactIdentifier,
+ identifier: mlrun.common.schemas.ArtifactIdentifier,
):
return self.list_artifacts(
session,
@@ -716,7 +718,7 @@ def list_artifacts(
since=None,
until=None,
kind=None,
- category: schemas.ArtifactCategories = None,
+ category: mlrun.common.schemas.ArtifactCategories = None,
iter: int = None,
best_iteration: bool = False,
as_records: bool = False,
@@ -1118,7 +1120,7 @@ def _list_function_tags(self, session, project, function_id):
return [row[0] for row in query]
def list_artifact_tags(
- self, session, project, category: schemas.ArtifactCategories = None
+ self, session, project, category: mlrun.common.schemas.ArtifactCategories = None
) -> typing.List[typing.Tuple[str, str, str]]:
"""
:return: a list of Tuple of (project, artifact.key, tag)
@@ -1149,9 +1151,9 @@ def create_schedule(
session: Session,
project: str,
name: str,
- kind: schemas.ScheduleKinds,
+ kind: mlrun.common.schemas.ScheduleKinds,
scheduled_object: Any,
- cron_trigger: schemas.ScheduleCronTrigger,
+ cron_trigger: mlrun.common.schemas.ScheduleCronTrigger,
concurrency_limit: int,
labels: Dict = None,
next_run_time: datetime = None,
@@ -1194,7 +1196,7 @@ def update_schedule(
project: str,
name: str,
scheduled_object: Any = None,
- cron_trigger: schemas.ScheduleCronTrigger = None,
+ cron_trigger: mlrun.common.schemas.ScheduleCronTrigger = None,
labels: Dict = None,
last_run_uri: str = None,
concurrency_limit: int = None,
@@ -1240,8 +1242,8 @@ def list_schedules(
project: str = None,
name: str = None,
labels: str = None,
- kind: schemas.ScheduleKinds = None,
- ) -> List[schemas.ScheduleRecord]:
+ kind: mlrun.common.schemas.ScheduleKinds = None,
+ ) -> List[mlrun.common.schemas.ScheduleRecord]:
logger.debug("Getting schedules from db", project=project, name=name, kind=kind)
query = self._query(session, Schedule, project=project, kind=kind)
if name is not None:
@@ -1257,7 +1259,7 @@ def list_schedules(
def get_schedule(
self, session: Session, project: str, name: str
- ) -> schemas.ScheduleRecord:
+ ) -> mlrun.common.schemas.ScheduleRecord:
logger.debug("Getting schedule from db", project=project, name=name)
schedule_record = self._get_schedule_record(session, project, name)
schedule = self._transform_schedule_record_to_scheme(schedule_record)
@@ -1265,7 +1267,7 @@ def get_schedule(
def _get_schedule_record(
self, session: Session, project: str, name: str
- ) -> schemas.ScheduleRecord:
+ ) -> mlrun.common.schemas.ScheduleRecord:
query = self._query(session, Schedule, project=project, name=name)
schedule_record = query.one_or_none()
if not schedule_record:
@@ -1358,7 +1360,7 @@ def tag_objects_v2(self, session, objs, project: str, name: str):
tags.append(tag)
self._upsert(session, tags)
- def create_project(self, session: Session, project: schemas.Project):
+ def create_project(self, session: Session, project: mlrun.common.schemas.Project):
logger.debug("Creating project in DB", project=project)
created = datetime.utcnow()
project.metadata.created = created
@@ -1377,7 +1379,9 @@ def create_project(self, session: Session, project: schemas.Project):
self._upsert(session, [project_record])
@retry_on_conflict
- def store_project(self, session: Session, name: str, project: schemas.Project):
+ def store_project(
+ self, session: Session, name: str, project: mlrun.common.schemas.Project
+ ):
logger.debug("Storing project in DB", name=name, project=project)
project_record = self._get_project_record(
session, name, raise_on_not_found=False
@@ -1392,7 +1396,7 @@ def patch_project(
session: Session,
name: str,
project: dict,
- patch_mode: schemas.PatchMode = schemas.PatchMode.replace,
+ patch_mode: mlrun.common.schemas.PatchMode = mlrun.common.schemas.PatchMode.replace,
):
logger.debug(
"Patching project in DB", name=name, project=project, patch_mode=patch_mode
@@ -1404,7 +1408,7 @@ def patch_project(
def get_project(
self, session: Session, name: str = None, project_id: int = None
- ) -> schemas.Project:
+ ) -> mlrun.common.schemas.Project:
project_record = self._get_project_record(session, name, project_id)
return self._transform_project_record_to_schema(session, project_record)
@@ -1413,7 +1417,7 @@ def delete_project(
self,
session: Session,
name: str,
- deletion_strategy: schemas.DeletionStrategy = schemas.DeletionStrategy.default(),
+ deletion_strategy: mlrun.common.schemas.DeletionStrategy = mlrun.common.schemas.DeletionStrategy.default(),
):
logger.debug(
"Deleting project from DB", name=name, deletion_strategy=deletion_strategy
@@ -1424,11 +1428,13 @@ def list_projects(
self,
session: Session,
owner: str = None,
- format_: mlrun.api.schemas.ProjectsFormat = mlrun.api.schemas.ProjectsFormat.full,
+ format_: typing.Union[
+ mlrun.common.schemas.ProjectsFormat, mlrun.common.schemas.ProjectsFormat
+ ] = mlrun.common.schemas.ProjectsFormat.full,
labels: List[str] = None,
- state: mlrun.api.schemas.ProjectState = None,
+ state: mlrun.common.schemas.ProjectState = None,
names: typing.Optional[typing.List[str]] = None,
- ) -> schemas.ProjectsOutput:
+ ) -> mlrun.common.schemas.ProjectsOutput:
query = self._query(session, Project, owner=owner, state=state)
if labels:
query = self._add_labels_filter(session, query, Project, labels)
@@ -1437,12 +1443,12 @@ def list_projects(
project_records = query.all()
projects = []
for project_record in project_records:
- if format_ == mlrun.api.schemas.ProjectsFormat.name_only:
+ if format_ == mlrun.common.schemas.ProjectsFormat.name_only:
projects = [project_record.name for project_record in project_records]
# leader format is only for follower mode which will format the projects returned from here
elif format_ in [
- mlrun.api.schemas.ProjectsFormat.full,
- mlrun.api.schemas.ProjectsFormat.leader,
+ mlrun.common.schemas.ProjectsFormat.full,
+ mlrun.common.schemas.ProjectsFormat.leader,
]:
projects.append(
self._transform_project_record_to_schema(session, project_record)
@@ -1451,7 +1457,7 @@ def list_projects(
raise NotImplementedError(
f"Provided format is not supported. format={format_}"
)
- return schemas.ProjectsOutput(projects=projects)
+ return mlrun.common.schemas.ProjectsOutput(projects=projects)
async def get_project_resources_counters(
self,
@@ -1560,7 +1566,10 @@ def _calculate_files_counters(self, session) -> Dict[str, int]:
# We're using the "latest" which gives us only one version of each artifact key, which is what we want to
# count (artifact count, not artifact versions count)
file_artifacts = self._find_artifacts(
- session, None, "latest", category=mlrun.api.schemas.ArtifactCategories.other
+ session,
+ None,
+ "latest",
+ category=mlrun.common.schemas.ArtifactCategories.other,
)
project_to_files_count = collections.defaultdict(int)
for file_artifact in file_artifacts:
@@ -1604,7 +1613,7 @@ def _calculate_runs_counters(
async def generate_projects_summaries(
self, session: Session, projects: List[str]
- ) -> List[mlrun.api.schemas.ProjectSummary]:
+ ) -> List[mlrun.common.schemas.ProjectSummary]:
(
project_to_function_count,
project_to_schedule_count,
@@ -1616,7 +1625,7 @@ async def generate_projects_summaries(
project_summaries = []
for project in projects:
project_summaries.append(
- mlrun.api.schemas.ProjectSummary(
+ mlrun.common.schemas.ProjectSummary(
name=project,
functions_count=project_to_function_count.get(project, 0),
schedules_count=project_to_schedule_count.get(project, 0),
@@ -1634,7 +1643,10 @@ async def generate_projects_summaries(
return project_summaries
def _update_project_record_from_project(
- self, session: Session, project_record: Project, project: schemas.Project
+ self,
+ session: Session,
+ project_record: Project,
+ project: mlrun.common.schemas.Project,
):
project.metadata.created = project_record.created
project_dict = project.dict()
@@ -1654,7 +1666,7 @@ def _patch_project_record_from_project(
name: str,
project_record: Project,
project: dict,
- patch_mode: schemas.PatchMode,
+ patch_mode: mlrun.common.schemas.PatchMode,
):
project.setdefault("metadata", {})["created"] = project_record.created
strategy = patch_mode.to_mergedeep_strategy()
@@ -1662,7 +1674,7 @@ def _patch_project_record_from_project(
mergedeep.merge(project_record_full_object, project, strategy=strategy)
# If a bad kind value was passed, it will fail here (return 422 to caller)
- project = schemas.Project(**project_record_full_object)
+ project = mlrun.common.schemas.Project(**project_record_full_object)
self.store_project(
session,
name,
@@ -1813,7 +1825,7 @@ def get_feature_set(
name: str,
tag: str = None,
uid: str = None,
- ) -> schemas.FeatureSet:
+ ) -> mlrun.common.schemas.FeatureSet:
feature_set = self._get_feature_set(session, project, name, tag, uid)
if not feature_set:
feature_set_uri = generate_object_uri(project, name, tag)
@@ -1861,10 +1873,10 @@ def _generate_records_with_tags_assigned(
return results
@staticmethod
- def _generate_feature_set_digest(feature_set: schemas.FeatureSet):
- return schemas.FeatureSetDigestOutput(
+ def _generate_feature_set_digest(feature_set: mlrun.common.schemas.FeatureSet):
+ return mlrun.common.schemas.FeatureSetDigestOutput(
metadata=feature_set.metadata,
- spec=schemas.FeatureSetDigestSpec(
+ spec=mlrun.common.schemas.FeatureSetDigestSpec(
entities=feature_set.spec.entities,
features=feature_set.spec.features,
),
@@ -1906,7 +1918,7 @@ def list_features(
tag: str = None,
entities: List[str] = None,
labels: List[str] = None,
- ) -> schemas.FeaturesOutput:
+ ) -> mlrun.common.schemas.FeaturesOutput:
# We don't filter by feature-set name here, as the name parameter refers to features
feature_set_id_tags = self._get_records_to_tags_map(
session, FeatureSet, project, tag, name=None
@@ -1921,7 +1933,7 @@ def list_features(
features_results = []
for row in query:
- feature_record = schemas.FeatureRecord.from_orm(row.Feature)
+ feature_record = mlrun.common.schemas.FeatureRecord.from_orm(row.Feature)
feature_name = feature_record.name
feature_sets = self._generate_records_with_tags_assigned(
@@ -1948,14 +1960,14 @@ def list_features(
)
features_results.append(
- schemas.FeatureListOutput(
+ mlrun.common.schemas.FeatureListOutput(
feature=feature,
feature_set_digest=self._generate_feature_set_digest(
feature_set
),
)
)
- return schemas.FeaturesOutput(features=features_results)
+ return mlrun.common.schemas.FeaturesOutput(features=features_results)
def list_entities(
self,
@@ -1964,7 +1976,7 @@ def list_entities(
name: str = None,
tag: str = None,
labels: List[str] = None,
- ) -> schemas.EntitiesOutput:
+ ) -> mlrun.common.schemas.EntitiesOutput:
feature_set_id_tags = self._get_records_to_tags_map(
session, FeatureSet, project, tag, name=None
)
@@ -1975,7 +1987,7 @@ def list_entities(
entities_results = []
for row in query:
- entity_record = schemas.FeatureRecord.from_orm(row.Entity)
+ entity_record = mlrun.common.schemas.FeatureRecord.from_orm(row.Entity)
entity_name = entity_record.name
feature_sets = self._generate_records_with_tags_assigned(
@@ -2002,14 +2014,14 @@ def list_entities(
)
entities_results.append(
- schemas.EntityListOutput(
+ mlrun.common.schemas.EntityListOutput(
entity=entity,
feature_set_digest=self._generate_feature_set_digest(
feature_set
),
)
)
- return schemas.EntitiesOutput(entities=entities_results)
+ return mlrun.common.schemas.EntitiesOutput(entities=entities_results)
@staticmethod
def _assert_partition_by_parameters(partition_by_enum_cls, partition_by, sort):
@@ -2032,11 +2044,12 @@ def _create_partitioned_query(
query,
cls,
partition_by: typing.Union[
- schemas.FeatureStorePartitionByField, schemas.RunPartitionByField
+ mlrun.common.schemas.FeatureStorePartitionByField,
+ mlrun.common.schemas.RunPartitionByField,
],
rows_per_partition: int,
- partition_sort_by: schemas.SortField,
- partition_order: schemas.OrderType,
+ partition_sort_by: mlrun.common.schemas.SortField,
+ partition_order: mlrun.common.schemas.OrderType,
max_partitions: int = 0,
):
@@ -2102,11 +2115,11 @@ def list_feature_sets(
entities: List[str] = None,
features: List[str] = None,
labels: List[str] = None,
- partition_by: schemas.FeatureStorePartitionByField = None,
+ partition_by: mlrun.common.schemas.FeatureStorePartitionByField = None,
rows_per_partition: int = 1,
- partition_sort_by: schemas.SortField = None,
- partition_order: schemas.OrderType = schemas.OrderType.desc,
- ) -> schemas.FeatureSetsOutput:
+ partition_sort_by: mlrun.common.schemas.SortField = None,
+ partition_order: mlrun.common.schemas.OrderType = mlrun.common.schemas.OrderType.desc,
+ ) -> mlrun.common.schemas.FeatureSetsOutput:
obj_id_tags = self._get_records_to_tags_map(
session, FeatureSet, project, tag, name
)
@@ -2129,7 +2142,9 @@ def list_feature_sets(
if partition_by:
self._assert_partition_by_parameters(
- schemas.FeatureStorePartitionByField, partition_by, partition_sort_by
+ mlrun.common.schemas.FeatureStorePartitionByField,
+ partition_by,
+ partition_sort_by,
)
query = self._create_partitioned_query(
session,
@@ -2151,7 +2166,7 @@ def list_feature_sets(
tag,
)
)
- return schemas.FeatureSetsOutput(feature_sets=feature_sets)
+ return mlrun.common.schemas.FeatureSetsOutput(feature_sets=feature_sets)
def list_feature_sets_tags(
self,
@@ -2282,7 +2297,7 @@ def store_feature_set(
session,
project,
name,
- feature_set: schemas.FeatureSet,
+ feature_set: mlrun.common.schemas.FeatureSet,
tag=None,
uid=None,
versioned=True,
@@ -2381,7 +2396,7 @@ def create_feature_set(
self,
session,
project,
- feature_set: schemas.FeatureSet,
+ feature_set: mlrun.common.schemas.FeatureSet,
versioned=True,
) -> str:
(uid, tag, feature_set_dict,) = self._validate_and_enrich_record_for_creation(
@@ -2406,7 +2421,7 @@ def patch_feature_set(
feature_set_patch: dict,
tag=None,
uid=None,
- patch_mode: schemas.PatchMode = schemas.PatchMode.replace,
+ patch_mode: mlrun.common.schemas.PatchMode = mlrun.common.schemas.PatchMode.replace,
) -> str:
feature_set_record = self._get_feature_set(session, project, name, tag, uid)
if not feature_set_record:
@@ -2423,7 +2438,7 @@ def patch_feature_set(
versioned = feature_set_record.metadata.uid is not None
# If a bad kind value was passed, it will fail here (return 422 to caller)
- feature_set = schemas.FeatureSet(**feature_set_struct)
+ feature_set = mlrun.common.schemas.FeatureSet(**feature_set_struct)
return self.store_feature_set(
session,
project,
@@ -2474,7 +2489,7 @@ def create_feature_vector(
self,
session,
project,
- feature_vector: schemas.FeatureVector,
+ feature_vector: mlrun.common.schemas.FeatureVector,
versioned=True,
) -> str:
(
@@ -2525,7 +2540,7 @@ def _get_feature_vector(
def get_feature_vector(
self, session, project: str, name: str, tag: str = None, uid: str = None
- ) -> schemas.FeatureVector:
+ ) -> mlrun.common.schemas.FeatureVector:
feature_vector = self._get_feature_vector(session, project, name, tag, uid)
if not feature_vector:
feature_vector_uri = generate_object_uri(project, name, tag)
@@ -2543,11 +2558,11 @@ def list_feature_vectors(
tag: str = None,
state: str = None,
labels: List[str] = None,
- partition_by: schemas.FeatureStorePartitionByField = None,
+ partition_by: mlrun.common.schemas.FeatureStorePartitionByField = None,
rows_per_partition: int = 1,
- partition_sort_by: schemas.SortField = None,
- partition_order: schemas.OrderType = schemas.OrderType.desc,
- ) -> schemas.FeatureVectorsOutput:
+ partition_sort_by: mlrun.common.schemas.SortField = None,
+ partition_order: mlrun.common.schemas.OrderType = mlrun.common.schemas.OrderType.desc,
+ ) -> mlrun.common.schemas.FeatureVectorsOutput:
obj_id_tags = self._get_records_to_tags_map(
session, FeatureVector, project, tag, name
)
@@ -2566,7 +2581,9 @@ def list_feature_vectors(
if partition_by:
self._assert_partition_by_parameters(
- schemas.FeatureStorePartitionByField, partition_by, partition_sort_by
+ mlrun.common.schemas.FeatureStorePartitionByField,
+ partition_by,
+ partition_sort_by,
)
query = self._create_partitioned_query(
session,
@@ -2588,7 +2605,9 @@ def list_feature_vectors(
tag,
)
)
- return schemas.FeatureVectorsOutput(feature_vectors=feature_vectors)
+ return mlrun.common.schemas.FeatureVectorsOutput(
+ feature_vectors=feature_vectors
+ )
def list_feature_vectors_tags(
self,
@@ -2609,7 +2628,7 @@ def store_feature_vector(
session,
project,
name,
- feature_vector: schemas.FeatureVector,
+ feature_vector: mlrun.common.schemas.FeatureVector,
tag=None,
uid=None,
versioned=True,
@@ -2672,7 +2691,7 @@ def patch_feature_vector(
feature_vector_update: dict,
tag=None,
uid=None,
- patch_mode: schemas.PatchMode = schemas.PatchMode.replace,
+ patch_mode: mlrun.common.schemas.PatchMode = mlrun.common.schemas.PatchMode.replace,
) -> str:
feature_vector_record = self._get_feature_vector(
session, project, name, tag, uid
@@ -2690,7 +2709,7 @@ def patch_feature_vector(
versioned = feature_vector_record.metadata.uid is not None
- feature_vector = schemas.FeatureVector(**feature_vector_struct)
+ feature_vector = mlrun.common.schemas.FeatureVector(**feature_vector_struct)
return self.store_feature_vector(
session,
project,
@@ -2942,7 +2961,7 @@ def _find_artifacts(
until=None,
name=None,
kind=None,
- category: schemas.ArtifactCategories = None,
+ category: mlrun.common.schemas.ArtifactCategories = None,
iter=None,
use_tag_as_uid: bool = None,
):
@@ -2993,7 +3012,7 @@ def _find_artifacts(
return query.all()
def _filter_artifacts_by_category(
- self, artifacts, category: schemas.ArtifactCategories
+ self, artifacts, category: mlrun.common.schemas.ArtifactCategories
):
kinds, exclude = category.to_kinds_filter()
return self._filter_artifacts_by_kinds(artifacts, kinds, exclude)
@@ -3140,8 +3159,8 @@ def _delete_class_labels(
def _transform_schedule_record_to_scheme(
self,
schedule_record: Schedule,
- ) -> schemas.ScheduleRecord:
- schedule = schemas.ScheduleRecord.from_orm(schedule_record)
+ ) -> mlrun.common.schemas.ScheduleRecord:
+ schedule = mlrun.common.schemas.ScheduleRecord.from_orm(schedule_record)
schedule.creation_time = self._add_utc_timezone(schedule.creation_time)
schedule.next_run_time = self._add_utc_timezone(schedule.next_run_time)
return schedule
@@ -3161,9 +3180,9 @@ def _add_utc_timezone(time_value: typing.Optional[datetime]):
def _transform_feature_set_model_to_schema(
feature_set_record: FeatureSet,
tag=None,
- ) -> schemas.FeatureSet:
+ ) -> mlrun.common.schemas.FeatureSet:
feature_set_full_dict = feature_set_record.full_object
- feature_set_resp = schemas.FeatureSet(**feature_set_full_dict)
+ feature_set_resp = mlrun.common.schemas.FeatureSet(**feature_set_full_dict)
feature_set_resp.metadata.tag = tag
return feature_set_resp
@@ -3172,9 +3191,11 @@ def _transform_feature_set_model_to_schema(
def _transform_feature_vector_model_to_schema(
feature_vector_record: FeatureVector,
tag=None,
- ) -> schemas.FeatureVector:
+ ) -> mlrun.common.schemas.FeatureVector:
feature_vector_full_dict = feature_vector_record.full_object
- feature_vector_resp = schemas.FeatureVector(**feature_vector_full_dict)
+ feature_vector_resp = mlrun.common.schemas.FeatureVector(
+ **feature_vector_full_dict
+ )
feature_vector_resp.metadata.tag = tag
feature_vector_resp.metadata.created = feature_vector_record.created
@@ -3182,26 +3203,26 @@ def _transform_feature_vector_model_to_schema(
def _transform_project_record_to_schema(
self, session: Session, project_record: Project
- ) -> schemas.Project:
+ ) -> mlrun.common.schemas.Project:
# in projects that was created before 0.6.0 the full object wasn't created properly - fix that, and return
if not project_record.full_object:
- project = schemas.Project(
- metadata=schemas.ProjectMetadata(
+ project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(
name=project_record.name,
created=project_record.created,
),
- spec=schemas.ProjectSpec(
+ spec=mlrun.common.schemas.ProjectSpec(
description=project_record.description,
source=project_record.source,
),
- status=schemas.ObjectStatus(
+ status=mlrun.common.schemas.ObjectStatus(
state=project_record.state,
),
)
self.store_project(session, project_record.name, project)
return project
# TODO: handle transforming the functions/workflows/artifacts references to real objects
- return schemas.Project(**project_record.full_object)
+ return mlrun.common.schemas.Project(**project_record.full_object)
def _transform_notification_record_to_spec_and_status(
self,
@@ -3277,16 +3298,16 @@ def _move_and_reorder_table_items(
@staticmethod
def _transform_hub_source_record_to_schema(
hub_source_record: HubSource,
- ) -> schemas.IndexedHubSource:
+ ) -> mlrun.common.schemas.IndexedHubSource:
source_full_dict = hub_source_record.full_object
- hub_source = schemas.HubSource(**source_full_dict)
- return schemas.IndexedHubSource(
+ hub_source = mlrun.common.schemas.HubSource(**source_full_dict)
+ return mlrun.common.schemas.IndexedHubSource(
index=hub_source_record.index, source=hub_source
)
@staticmethod
def _transform_hub_source_schema_to_record(
- hub_source_schema: schemas.IndexedHubSource,
+ hub_source_schema: mlrun.common.schemas.IndexedHubSource,
current_object: HubSource = None,
):
now = datetime.now(timezone.utc)
@@ -3322,7 +3343,7 @@ def _validate_and_adjust_hub_order(session, order):
if not max_order or max_order < 0:
max_order = 0
- if order == schemas.hub.last_source_index:
+ if order == mlrun.common.schemas.hub.last_source_index:
order = max_order + 1
if order > max_order + 1:
@@ -3332,11 +3353,13 @@ def _validate_and_adjust_hub_order(session, order):
if order < 1:
raise mlrun.errors.MLRunInvalidArgumentError(
"Order of inserted source must be greater than 0 or "
- + f"{schemas.hub.last_source_index} (for last). order = {order}"
+ + f"{mlrun.common.schemas.hub.last_source_index} (for last). order = {order}"
)
return order
- def create_hub_source(self, session, ordered_source: schemas.IndexedHubSource):
+ def create_hub_source(
+ self, session, ordered_source: mlrun.common.schemas.IndexedHubSource
+ ):
logger.debug(
"Creating hub source in DB",
index=ordered_source.index,
@@ -3361,7 +3384,7 @@ def store_hub_source(
self,
session,
name,
- ordered_source: schemas.IndexedHubSource,
+ ordered_source: mlrun.common.schemas.IndexedHubSource,
):
logger.debug("Storing hub source in DB", index=ordered_source.index, name=name)
@@ -3373,7 +3396,7 @@ def store_hub_source(
source_record = self._query(session, HubSource, name=name).one_or_none()
current_order = source_record.index if source_record else None
- if current_order == schemas.hub.last_source_index:
+ if current_order == mlrun.common.schemas.hub.last_source_index:
raise mlrun.errors.MLRunInvalidArgumentError(
"Attempting to modify the global hub source."
)
@@ -3385,13 +3408,13 @@ def store_hub_source(
session, source_record, move_to=order, move_from=current_order
)
- def list_hub_sources(self, session) -> List[schemas.IndexedHubSource]:
+ def list_hub_sources(self, session) -> List[mlrun.common.schemas.IndexedHubSource]:
results = []
query = self._query(session, HubSource).order_by(HubSource.index.desc())
for record in query:
ordered_source = self._transform_hub_source_record_to_schema(record)
# Need this to make the list return such that the default source is last in the response.
- if ordered_source.index != schemas.last_source_index:
+ if ordered_source.index != mlrun.common.schemas.last_source_index:
results.insert(0, ordered_source)
else:
results.append(ordered_source)
@@ -3405,7 +3428,7 @@ def delete_hub_source(self, session, name):
return
current_order = source_record.index
- if current_order == schemas.hub.last_source_index:
+ if current_order == mlrun.common.schemas.hub.last_source_index:
raise mlrun.errors.MLRunInvalidArgumentError(
"Attempting to delete the global hub source."
)
@@ -3414,7 +3437,7 @@ def delete_hub_source(self, session, name):
session, source_record, move_to=None, move_from=current_order
)
- def get_hub_source(self, session, name) -> schemas.IndexedHubSource:
+ def get_hub_source(self, session, name) -> mlrun.common.schemas.IndexedHubSource:
source_record = self._query(session, HubSource, name=name).one_or_none()
if not source_record:
raise mlrun.errors.MLRunNotFoundError(
@@ -3459,7 +3482,7 @@ def store_background_task(
session,
name: str,
project: str,
- state: str = mlrun.api.schemas.BackgroundTaskState.running,
+ state: str = mlrun.common.schemas.BackgroundTaskState.running,
timeout: int = None,
):
background_task_record = self._query(
@@ -3473,7 +3496,7 @@ def store_background_task(
# we don't want to be able to change state after it reached terminal state
if (
background_task_record.state
- in mlrun.api.schemas.BackgroundTaskState.terminal_states()
+ in mlrun.common.schemas.BackgroundTaskState.terminal_states()
and state != background_task_record.state
):
raise mlrun.errors.MLRunRuntimeError(
@@ -3500,7 +3523,7 @@ def store_background_task(
def get_background_task(
self, session, name: str, project: str
- ) -> schemas.BackgroundTask:
+ ) -> mlrun.common.schemas.BackgroundTask:
background_task_record = self._get_background_task_record(
session, name, project
)
@@ -3511,7 +3534,7 @@ def get_background_task(
session,
name,
project,
- mlrun.api.schemas.background_task.BackgroundTaskState.failed,
+ mlrun.common.schemas.background_task.BackgroundTaskState.failed,
)
background_task_record = self._get_background_task_record(
session, name, project
@@ -3522,17 +3545,17 @@ def get_background_task(
@staticmethod
def _transform_background_task_record_to_schema(
background_task_record: BackgroundTask,
- ) -> schemas.BackgroundTask:
- return schemas.BackgroundTask(
- metadata=schemas.BackgroundTaskMetadata(
+ ) -> mlrun.common.schemas.BackgroundTask:
+ return mlrun.common.schemas.BackgroundTask(
+ metadata=mlrun.common.schemas.BackgroundTaskMetadata(
name=background_task_record.name,
project=background_task_record.project,
created=background_task_record.created,
updated=background_task_record.updated,
timeout=background_task_record.timeout,
),
- spec=schemas.BackgroundTaskSpec(),
- status=schemas.BackgroundTaskStatus(
+ spec=mlrun.common.schemas.BackgroundTaskSpec(),
+ status=mlrun.common.schemas.BackgroundTaskStatus(
state=background_task_record.state,
),
)
@@ -3585,7 +3608,7 @@ def _is_background_task_timeout_exceeded(background_task_record) -> bool:
if (
timeout
and background_task_record.state
- not in mlrun.api.schemas.BackgroundTaskState.terminal_states()
+ not in mlrun.common.schemas.BackgroundTaskState.terminal_states()
and datetime.utcnow()
> timedelta(seconds=int(timeout)) + background_task_record.updated
):
@@ -3628,7 +3651,7 @@ def store_run_notifications(
notification.params = notification_model.params
notification.status = (
notification_model.status
- or mlrun.api.schemas.NotificationStatus.PENDING
+ or mlrun.common.schemas.NotificationStatus.PENDING
)
notification.sent_time = notification_model.sent_time
diff --git a/mlrun/api/db/sqldb/models/models_mysql.py b/mlrun/api/db/sqldb/models/models_mysql.py
index bc06b6b9c552..7c247550aca5 100644
--- a/mlrun/api/db/sqldb/models/models_mysql.py
+++ b/mlrun/api/db/sqldb/models/models_mysql.py
@@ -32,8 +32,8 @@
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship
+import mlrun.common.schemas
import mlrun.utils.db
-from mlrun.api import schemas
from mlrun.api.utils.db.sql_collation import SQLCollationUtil
Base = declarative_base()
@@ -107,7 +107,7 @@ class Artifact(Base, mlrun.utils.db.HasStruct):
project = Column(String(255, collation=SQLCollationUtil.collation()))
uid = Column(String(255, collation=SQLCollationUtil.collation()))
updated = Column(sqlalchemy.dialects.mysql.TIMESTAMP(fsp=3))
- # TODO: change to JSON, see mlrun/api/schemas/function.py::FunctionState for reasoning
+ # TODO: change to JSON, see mlrun/common/schemas/function.py::FunctionState for reasoning
body = Column(sqlalchemy.dialects.mysql.MEDIUMBLOB)
labels = relationship(Label, cascade="all, delete-orphan")
@@ -129,7 +129,7 @@ class Function(Base, mlrun.utils.db.HasStruct):
name = Column(String(255, collation=SQLCollationUtil.collation()))
project = Column(String(255, collation=SQLCollationUtil.collation()))
uid = Column(String(255, collation=SQLCollationUtil.collation()))
- # TODO: change to JSON, see mlrun/api/schemas/function.py::FunctionState for reasoning
+ # TODO: change to JSON, see mlrun/common/schemas/function.py::FunctionState for reasoning
body = Column(sqlalchemy.dialects.mysql.MEDIUMBLOB)
updated = Column(sqlalchemy.dialects.mysql.TIMESTAMP(fsp=3))
@@ -185,7 +185,7 @@ class Log(Base, mlrun.utils.db.BaseModel):
id = Column(Integer, primary_key=True)
uid = Column(String(255, collation=SQLCollationUtil.collation()))
project = Column(String(255, collation=SQLCollationUtil.collation()))
- # TODO: change to JSON, see mlrun/api/schemas/function.py::FunctionState for reasoning
+ # TODO: change to JSON, see mlrun/common/schemas/function.py::FunctionState for reasoning
body = Column(sqlalchemy.dialects.mysql.MEDIUMBLOB)
def get_identifier_string(self) -> str:
@@ -208,7 +208,7 @@ class Run(Base, mlrun.utils.db.HasStruct):
)
iteration = Column(Integer)
state = Column(String(255, collation=SQLCollationUtil.collation()))
- # TODO: change to JSON, see mlrun/api/schemas/function.py::FunctionState for reasoning
+ # TODO: change to JSON, see mlrun/common/schemas/function.py::FunctionState for reasoning
body = Column(sqlalchemy.dialects.mysql.MEDIUMBLOB)
start_time = Column(sqlalchemy.dialects.mysql.TIMESTAMP(fsp=3))
updated = Column(
@@ -270,7 +270,7 @@ class Schedule(Base, mlrun.utils.db.BaseModel):
creation_time = Column(sqlalchemy.dialects.mysql.TIMESTAMP(fsp=3))
cron_trigger_str = Column(String(255, collation=SQLCollationUtil.collation()))
last_run_uri = Column(String(255, collation=SQLCollationUtil.collation()))
- # TODO: change to JSON, see mlrun/api/schemas/function.py::FunctionState for reasoning
+ # TODO: change to JSON, see mlrun/common/schemas/function.py::FunctionState for reasoning
struct = Column(sqlalchemy.dialects.mysql.MEDIUMBLOB)
labels = relationship(Label, cascade="all, delete-orphan")
concurrency_limit = Column(Integer, nullable=False)
@@ -288,11 +288,11 @@ def scheduled_object(self, value):
self.struct = pickle.dumps(value)
@property
- def cron_trigger(self) -> schemas.ScheduleCronTrigger:
+ def cron_trigger(self) -> mlrun.common.schemas.ScheduleCronTrigger:
return orjson.loads(self.cron_trigger_str)
@cron_trigger.setter
- def cron_trigger(self, trigger: schemas.ScheduleCronTrigger):
+ def cron_trigger(self, trigger: mlrun.common.schemas.ScheduleCronTrigger):
self.cron_trigger_str = orjson.dumps(trigger.dict(exclude_unset=True))
# Define "many to many" users/projects
@@ -322,7 +322,7 @@ class Project(Base, mlrun.utils.db.BaseModel):
source = Column(String(255, collation=SQLCollationUtil.collation()))
# the attribute name used to be _spec which is just a wrong naming, the attribute was renamed to _full_object
# leaving the column as is to prevent redundant migration
- # TODO: change to JSON, see mlrun/api/schemas/function.py::FunctionState for reasoning
+ # TODO: change to JSON, see mlrun/common/schemas/function.py::FunctionState for reasoning
_full_object = Column("spec", sqlalchemy.dialects.mysql.MEDIUMBLOB)
created = Column(
sqlalchemy.dialects.mysql.TIMESTAMP(fsp=3), default=datetime.utcnow
diff --git a/mlrun/api/db/sqldb/models/models_sqlite.py b/mlrun/api/db/sqldb/models/models_sqlite.py
index ab7c576a89ae..e6218ab60a86 100644
--- a/mlrun/api/db/sqldb/models/models_sqlite.py
+++ b/mlrun/api/db/sqldb/models/models_sqlite.py
@@ -33,8 +33,8 @@
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship
+import mlrun.common.schemas
import mlrun.utils.db
-from mlrun.api import schemas
from mlrun.api.utils.db.sql_collation import SQLCollationUtil
Base = declarative_base()
@@ -111,7 +111,7 @@ class Artifact(Base, mlrun.utils.db.HasStruct):
project = Column(String(255, collation=SQLCollationUtil.collation()))
uid = Column(String(255, collation=SQLCollationUtil.collation()))
updated = Column(TIMESTAMP)
- # TODO: change to JSON, see mlrun/api/schemas/function.py::FunctionState for reasoning
+ # TODO: change to JSON, see mlrun/common/schemas/function.py::FunctionState for reasoning
body = Column(BLOB)
labels = relationship(Label)
@@ -131,7 +131,7 @@ class Function(Base, mlrun.utils.db.HasStruct):
name = Column(String(255, collation=SQLCollationUtil.collation()))
project = Column(String(255, collation=SQLCollationUtil.collation()))
uid = Column(String(255, collation=SQLCollationUtil.collation()))
- # TODO: change to JSON, see mlrun/api/schemas/function.py::FunctionState for reasoning
+ # TODO: change to JSON, see mlrun/common/schemas/function.py::FunctionState for reasoning
body = Column(BLOB)
updated = Column(TIMESTAMP)
labels = relationship(Label)
@@ -145,7 +145,7 @@ class Log(Base, mlrun.utils.db.BaseModel):
id = Column(Integer, primary_key=True)
uid = Column(String(255, collation=SQLCollationUtil.collation()))
project = Column(String(255, collation=SQLCollationUtil.collation()))
- # TODO: change to JSON, see mlrun/api/schemas/function.py::FunctionState for reasoning
+ # TODO: change to JSON, see mlrun/common/schemas/function.py::FunctionState for reasoning
body = Column(BLOB)
def get_identifier_string(self) -> str:
@@ -202,7 +202,7 @@ class Run(Base, mlrun.utils.db.HasStruct):
)
iteration = Column(Integer)
state = Column(String(255, collation=SQLCollationUtil.collation()))
- # TODO: change to JSON, see mlrun/api/schemas/function.py::FunctionState for reasoning
+ # TODO: change to JSON, see mlrun/common/schemas/function.py::FunctionState for reasoning
body = Column(BLOB)
start_time = Column(TIMESTAMP)
# requested logs column indicates whether logs were requested for this run
@@ -254,7 +254,7 @@ class Schedule(Base, mlrun.utils.db.BaseModel):
creation_time = Column(TIMESTAMP)
cron_trigger_str = Column(String(255, collation=SQLCollationUtil.collation()))
last_run_uri = Column(String(255, collation=SQLCollationUtil.collation()))
- # TODO: change to JSON, see mlrun/api/schemas/function.py::FunctionState for reasoning
+ # TODO: change to JSON, see mlrun/common/schemas/function.py::FunctionState for reasoning
struct = Column(BLOB)
labels = relationship(Label, cascade="all, delete-orphan")
concurrency_limit = Column(Integer, nullable=False)
@@ -272,11 +272,11 @@ def scheduled_object(self, value):
self.struct = pickle.dumps(value)
@property
- def cron_trigger(self) -> schemas.ScheduleCronTrigger:
+ def cron_trigger(self) -> mlrun.common.schemas.ScheduleCronTrigger:
return orjson.loads(self.cron_trigger_str)
@cron_trigger.setter
- def cron_trigger(self, trigger: schemas.ScheduleCronTrigger):
+ def cron_trigger(self, trigger: mlrun.common.schemas.ScheduleCronTrigger):
self.cron_trigger_str = orjson.dumps(trigger.dict(exclude_unset=True))
# Define "many to many" users/projects
@@ -306,7 +306,7 @@ class Project(Base, mlrun.utils.db.BaseModel):
source = Column(String(255, collation=SQLCollationUtil.collation()))
# the attribute name used to be _spec which is just a wrong naming, the attribute was renamed to _full_object
# leaving the column as is to prevent redundant migration
- # TODO: change to JSON, see mlrun/api/schemas/function.py::FunctionState for reasoning
+ # TODO: change to JSON, see mlrun/common/schemas/function.py::FunctionState for reasoning
_full_object = Column("spec", BLOB)
created = Column(TIMESTAMP, default=datetime.utcnow)
state = Column(String(255, collation=SQLCollationUtil.collation()))
diff --git a/mlrun/api/initial_data.py b/mlrun/api/initial_data.py
index 76c89e343edc..9bdb41a722a7 100644
--- a/mlrun/api/initial_data.py
+++ b/mlrun/api/initial_data.py
@@ -26,12 +26,12 @@
import mlrun.api.db.sqldb.db
import mlrun.api.db.sqldb.helpers
import mlrun.api.db.sqldb.models
-import mlrun.api.schemas
import mlrun.api.utils.db.alembic
import mlrun.api.utils.db.backup
import mlrun.api.utils.db.mysql
import mlrun.api.utils.db.sqlite_migration
import mlrun.artifacts
+import mlrun.common.schemas
from mlrun.api.db.init_db import init_db
from mlrun.api.db.session import close_session, create_session
from mlrun.config import config
@@ -62,7 +62,7 @@ def init_data(
and not perform_migrations_if_needed
and is_migration_needed
):
- state = mlrun.api.schemas.APIStates.waiting_for_migrations
+ state = mlrun.common.schemas.APIStates.waiting_for_migrations
logger.info("Migration is needed, changing API state", state=state)
config.httpdb.state = state
return
@@ -73,7 +73,7 @@ def init_data(
db_backup.backup_database()
logger.info("Creating initial data")
- config.httpdb.state = mlrun.api.schemas.APIStates.migrations_in_progress
+ config.httpdb.state = mlrun.common.schemas.APIStates.migrations_in_progress
if is_migration_from_scratch or is_migration_needed:
try:
@@ -89,7 +89,7 @@ def init_data(
finally:
close_session(db_session)
except Exception:
- state = mlrun.api.schemas.APIStates.migrations_failed
+ state = mlrun.common.schemas.APIStates.migrations_failed
logger.warning("Migrations failed, changing API state", state=state)
config.httpdb.state = state
raise
@@ -97,9 +97,9 @@ def init_data(
# should happen - we can't do it here because it requires an asyncio loop which can't be accessible here
# therefore moving to migration_completed state, and other component will take care of moving to online
if not is_migration_from_scratch and is_migration_needed:
- config.httpdb.state = mlrun.api.schemas.APIStates.migrations_completed
+ config.httpdb.state = mlrun.common.schemas.APIStates.migrations_completed
else:
- config.httpdb.state = mlrun.api.schemas.APIStates.online
+ config.httpdb.state = mlrun.common.schemas.APIStates.online
logger.info("Initial data created")
@@ -482,7 +482,7 @@ def _enrich_project_state(
changed = False
if not project.spec.desired_state:
changed = True
- project.spec.desired_state = mlrun.api.schemas.ProjectState.online
+ project.spec.desired_state = mlrun.common.schemas.ProjectState.online
if not project.status.state:
changed = True
project.status.state = project.spec.desired_state
@@ -505,14 +505,14 @@ def _add_default_hub_source_if_needed(
hub_marketplace_source = None
if not hub_marketplace_source:
- hub_source = mlrun.api.schemas.HubSource.generate_default_source()
+ hub_source = mlrun.common.schemas.HubSource.generate_default_source()
# hub_source will be None if the configuration has hub.default_source.create=False
if hub_source:
logger.info("Adding default hub source")
# Not using db.store_marketplace_source() since it doesn't allow changing the default hub source.
hub_record = db._transform_hub_source_schema_to_record(
- mlrun.api.schemas.IndexedHubSource(
- index=mlrun.api.schemas.hub.last_source_index,
+ mlrun.common.schemas.IndexedHubSource(
+ index=mlrun.common.schemas.hub.last_source_index,
source=hub_source,
)
)
diff --git a/mlrun/api/main.py b/mlrun/api/main.py
index 12805ae2b3ae..91ee1790e0e3 100644
--- a/mlrun/api/main.py
+++ b/mlrun/api/main.py
@@ -25,9 +25,9 @@
from fastapi.exception_handlers import http_exception_handler
import mlrun.api.db.base
-import mlrun.api.schemas
import mlrun.api.utils.clients.chief
import mlrun.api.utils.clients.log_collector
+import mlrun.common.schemas
import mlrun.errors
import mlrun.lists
import mlrun.utils
@@ -136,13 +136,13 @@ async def startup_event():
if (
config.httpdb.clusterization.worker.sync_with_chief.mode
- == mlrun.api.schemas.WaitForChiefToReachOnlineStateFeatureFlag.enabled
+ == mlrun.common.schemas.WaitForChiefToReachOnlineStateFeatureFlag.enabled
and config.httpdb.clusterization.role
- == mlrun.api.schemas.ClusterizationRole.worker
+ == mlrun.common.schemas.ClusterizationRole.worker
):
_start_chief_clusterization_spec_sync_loop()
- if config.httpdb.state == mlrun.api.schemas.APIStates.online:
+ if config.httpdb.state == mlrun.common.schemas.APIStates.online:
await move_api_to_online()
@@ -165,7 +165,10 @@ async def move_api_to_online():
initialize_project_member()
# maintenance periodic functions should only run on the chief instance
- if config.httpdb.clusterization.role == mlrun.api.schemas.ClusterizationRole.chief:
+ if (
+ config.httpdb.clusterization.role
+ == mlrun.common.schemas.ClusterizationRole.chief
+ ):
# runs cleanup/monitoring is not needed if we're not inside kubernetes cluster
if get_k8s_helper(silent=True).is_running_inside_kubernetes_cluster():
_start_periodic_cleanup()
@@ -175,7 +178,7 @@ async def move_api_to_online():
async def _start_logs_collection():
- if config.log_collector.mode == mlrun.api.schemas.LogsCollectorMode.legacy:
+ if config.log_collector.mode == mlrun.common.schemas.LogsCollectorMode.legacy:
logger.info(
"Using legacy logs collection method, skipping logs collection periodic function",
mode=config.log_collector.mode,
@@ -410,7 +413,7 @@ def _start_periodic_runs_monitoring():
async def _start_periodic_stop_logs():
- if config.log_collector.mode == mlrun.api.schemas.LogsCollectorMode.legacy:
+ if config.log_collector.mode == mlrun.common.schemas.LogsCollectorMode.legacy:
logger.info(
"Using legacy logs collection method, skipping stop logs periodic function",
mode=config.log_collector.mode,
@@ -469,7 +472,7 @@ def _start_chief_clusterization_spec_sync_loop():
async def _synchronize_with_chief_clusterization_spec():
# sanity
# if we are still in the periodic function and the worker has reached the terminal state, then cancel it
- if config.httpdb.state in mlrun.api.schemas.APIStates.terminal_states():
+ if config.httpdb.state in mlrun.common.schemas.APIStates.terminal_states():
cancel_periodic_function(_synchronize_with_chief_clusterization_spec.__name__)
try:
@@ -488,14 +491,14 @@ async def _synchronize_with_chief_clusterization_spec():
async def _align_worker_state_with_chief_state(
- clusterization_spec: mlrun.api.schemas.ClusterizationSpec,
+ clusterization_spec: mlrun.common.schemas.ClusterizationSpec,
):
chief_state = clusterization_spec.chief_api_state
if not chief_state:
logger.warning("Chief did not return any state")
return
- if chief_state not in mlrun.api.schemas.APIStates.terminal_states():
+ if chief_state not in mlrun.common.schemas.APIStates.terminal_states():
logger.debug(
"Chief did not reach online state yet, will retry after sync interval",
interval=config.httpdb.clusterization.worker.sync_with_chief.interval,
@@ -505,7 +508,7 @@ async def _align_worker_state_with_chief_state(
config.httpdb.state = chief_state
return
- if chief_state == mlrun.api.schemas.APIStates.online:
+ if chief_state == mlrun.common.schemas.APIStates.online:
logger.info("Chief reached online state! Switching worker state to online")
await move_api_to_online()
logger.info("Worker state reached online")
@@ -650,16 +653,19 @@ async def _stop_logs_for_runs(runs: list):
def main():
- if config.httpdb.clusterization.role == mlrun.api.schemas.ClusterizationRole.chief:
+ if (
+ config.httpdb.clusterization.role
+ == mlrun.common.schemas.ClusterizationRole.chief
+ ):
init_data()
elif (
config.httpdb.clusterization.worker.sync_with_chief.mode
- == mlrun.api.schemas.WaitForChiefToReachOnlineStateFeatureFlag.enabled
+ == mlrun.common.schemas.WaitForChiefToReachOnlineStateFeatureFlag.enabled
and config.httpdb.clusterization.role
- == mlrun.api.schemas.ClusterizationRole.worker
+ == mlrun.common.schemas.ClusterizationRole.worker
):
# we set this state to mark the phase between the startup of the instance until we able to pull the chief state
- config.httpdb.state = mlrun.api.schemas.APIStates.waiting_for_chief
+ config.httpdb.state = mlrun.common.schemas.APIStates.waiting_for_chief
logger.info(
"Starting API server",
diff --git a/mlrun/api/middlewares.py b/mlrun/api/middlewares.py
index 2f6a49a1b3db..64b581153ded 100644
--- a/mlrun/api/middlewares.py
+++ b/mlrun/api/middlewares.py
@@ -21,7 +21,7 @@
import uvicorn.protocols.utils
from starlette.middleware.base import BaseHTTPMiddleware
-import mlrun.api.schemas.constants
+import mlrun.common.schemas.constants
from mlrun.config import config
from mlrun.utils import logger
@@ -100,7 +100,7 @@ async def ui_clear_cache(request: fastapi.Request, call_next):
This middleware tells ui when to clear its cache based on backend version changes.
"""
ui_version = request.headers.get(
- mlrun.api.schemas.constants.HeaderNames.ui_version, ""
+ mlrun.common.schemas.constants.HeaderNames.ui_version, ""
)
response: fastapi.Response = await call_next(request)
development_version = config.version.startswith("0.0.0")
@@ -117,7 +117,7 @@ async def ui_clear_cache(request: fastapi.Request, call_next):
# tell ui to reload
response.headers[
- mlrun.api.schemas.constants.HeaderNames.ui_clear_cache
+ mlrun.common.schemas.constants.HeaderNames.ui_clear_cache
] = "true"
return response
@@ -128,7 +128,7 @@ async def ensure_be_version(request: fastapi.Request, call_next):
"""
response: fastapi.Response = await call_next(request)
response.headers[
- mlrun.api.schemas.constants.HeaderNames.backend_version
+ mlrun.common.schemas.constants.HeaderNames.backend_version
] = config.version
return response
diff --git a/mlrun/api/schemas/__init__.py b/mlrun/api/schemas/__init__.py
index dbe176f90db7..9c9384454ba0 100644
--- a/mlrun/api/schemas/__init__.py
+++ b/mlrun/api/schemas/__init__.py
@@ -14,139 +14,174 @@
#
# flake8: noqa - this is until we take care of the F401 violations with respect to __all__ & sphinx
-from .artifact import ArtifactCategories, ArtifactIdentifier, ArtifactsFormat
-from .auth import (
- AuthInfo,
- AuthorizationAction,
- AuthorizationResourceTypes,
- AuthorizationVerificationInput,
- Credentials,
- ProjectsRole,
-)
-from .background_task import (
- BackgroundTask,
- BackgroundTaskMetadata,
- BackgroundTaskSpec,
- BackgroundTaskState,
- BackgroundTaskStatus,
-)
-from .client_spec import ClientSpec
-from .clusterization_spec import (
- ClusterizationSpec,
- WaitForChiefToReachOnlineStateFeatureFlag,
-)
-from .constants import (
- APIStates,
- ClusterizationRole,
- DeletionStrategy,
- FeatureStorePartitionByField,
- HeaderNames,
- LogsCollectorMode,
- OrderType,
- PatchMode,
- RunPartitionByField,
- SortField,
-)
-from .feature_store import (
- EntitiesOutput,
- Entity,
- EntityListOutput,
- EntityRecord,
- Feature,
- FeatureListOutput,
- FeatureRecord,
- FeatureSet,
- FeatureSetDigestOutput,
- FeatureSetDigestSpec,
- FeatureSetIngestInput,
- FeatureSetIngestOutput,
- FeatureSetRecord,
- FeatureSetsOutput,
- FeatureSetSpec,
- FeatureSetsTagsOutput,
- FeaturesOutput,
- FeatureVector,
- FeatureVectorRecord,
- FeatureVectorsOutput,
- FeatureVectorsTagsOutput,
-)
-from .frontend_spec import (
- AuthenticationFeatureFlag,
- FeatureFlags,
- FrontendSpec,
- NuclioStreamsFeatureFlag,
- PreemptionNodesFeatureFlag,
- ProjectMembershipFeatureFlag,
-)
-from .function import FunctionState, PreemptionModes, SecurityContextEnrichmentModes
-from .http import HTTPSessionRetryMode
-from .hub import (
- HubCatalog,
- HubItem,
- HubObjectMetadata,
- HubSource,
- HubSourceSpec,
- IndexedHubSource,
- last_source_index,
-)
-from .k8s import NodeSelectorOperator, Resources, ResourceSpec
-from .memory_reports import MostCommonObjectTypesReport, ObjectTypeReport
-from .model_endpoints import (
- Features,
- FeatureValues,
- GrafanaColumn,
- GrafanaDataPoint,
- GrafanaNumberColumn,
- GrafanaStringColumn,
- GrafanaTable,
- GrafanaTimeSeriesTarget,
- ModelEndpoint,
- ModelEndpointList,
- ModelEndpointMetadata,
- ModelEndpointSpec,
- ModelEndpointStatus,
- ModelMonitoringStoreKinds,
-)
-from .notification import NotificationSeverity, NotificationStatus
-from .object import ObjectKind, ObjectMetadata, ObjectSpec, ObjectStatus
-from .pipeline import PipelinesFormat, PipelinesOutput, PipelinesPagination
-from .project import (
- IguazioProject,
- Project,
- ProjectDesiredState,
- ProjectMetadata,
- ProjectOwner,
- ProjectsFormat,
- ProjectsOutput,
- ProjectSpec,
- ProjectState,
- ProjectStatus,
- ProjectSummariesOutput,
- ProjectSummary,
-)
-from .runtime_resource import (
- GroupedByJobRuntimeResourcesOutput,
- GroupedByProjectRuntimeResourcesOutput,
- KindRuntimeResources,
- ListRuntimeResourcesGroupByField,
- RuntimeResource,
- RuntimeResources,
- RuntimeResourcesOutput,
-)
-from .schedule import (
- ScheduleCronTrigger,
- ScheduleInput,
- ScheduleKinds,
- ScheduleOutput,
- ScheduleRecord,
- SchedulesOutput,
- ScheduleUpdate,
-)
-from .secret import (
- AuthSecretData,
- SecretKeysData,
- SecretProviderName,
- SecretsData,
- UserSecretCreationRequest,
-)
-from .tag import Tag, TagObjects
+"""
+Schemas were moved to mlrun.common.schemas.
+For backwards compatibility with mlrun.api.schemas, we use this file to convert the old imports to the new ones.
+The DeprecationHelper class is used to print a deprecation warning when the old import is used, and return the new
+schema.
+"""
+
+import mlrun.common.schemas
+from mlrun.utils.helpers import DeprecationHelper
+
+ArtifactCategories = DeprecationHelper(mlrun.common.schemas.ArtifactCategories)
+ArtifactIdentifier = DeprecationHelper(mlrun.common.schemas.ArtifactIdentifier)
+ArtifactsFormat = DeprecationHelper(mlrun.common.schemas.ArtifactsFormat)
+AuthInfo = DeprecationHelper(mlrun.common.schemas.AuthInfo)
+AuthorizationAction = DeprecationHelper(mlrun.common.schemas.AuthorizationAction)
+AuthorizationResourceTypes = DeprecationHelper(
+ mlrun.common.schemas.AuthorizationResourceTypes
+)
+AuthorizationVerificationInput = DeprecationHelper(
+ mlrun.common.schemas.AuthorizationVerificationInput
+)
+Credentials = DeprecationHelper(mlrun.common.schemas.Credentials)
+ProjectsRole = DeprecationHelper(mlrun.common.schemas.ProjectsRole)
+
+BackgroundTask = DeprecationHelper(mlrun.common.schemas.BackgroundTask)
+BackgroundTaskMetadata = DeprecationHelper(mlrun.common.schemas.BackgroundTaskMetadata)
+BackgroundTaskSpec = DeprecationHelper(mlrun.common.schemas.BackgroundTaskSpec)
+BackgroundTaskState = DeprecationHelper(mlrun.common.schemas.BackgroundTaskState)
+BackgroundTaskStatus = DeprecationHelper(mlrun.common.schemas.BackgroundTaskStatus)
+ClientSpe = DeprecationHelper(mlrun.common.schemas.ClientSpec)
+ClusterizationSpec = DeprecationHelper(mlrun.common.schemas.ClusterizationSpec)
+WaitForChiefToReachOnlineStateFeatureFlag = DeprecationHelper(
+ mlrun.common.schemas.WaitForChiefToReachOnlineStateFeatureFlag
+)
+APIStates = DeprecationHelper(mlrun.common.schemas.APIStates)
+ClusterizationRole = DeprecationHelper(mlrun.common.schemas.ClusterizationRole)
+DeletionStrategy = DeprecationHelper(mlrun.common.schemas.DeletionStrategy)
+FeatureStorePartitionByField = DeprecationHelper(
+ mlrun.common.schemas.FeatureStorePartitionByField
+)
+HeaderNames = DeprecationHelper(mlrun.common.schemas.HeaderNames)
+LogsCollectorMode = DeprecationHelper(mlrun.common.schemas.LogsCollectorMode)
+OrderType = DeprecationHelper(mlrun.common.schemas.OrderType)
+PatchMode = DeprecationHelper(mlrun.common.schemas.PatchMode)
+RunPartitionByField = DeprecationHelper(mlrun.common.schemas.RunPartitionByField)
+SortField = DeprecationHelper(mlrun.common.schemas.SortField)
+EntitiesOutput = DeprecationHelper(mlrun.common.schemas.EntitiesOutput)
+Entity = DeprecationHelper(mlrun.common.schemas.Entity)
+EntityListOutput = DeprecationHelper(mlrun.common.schemas.EntityListOutput)
+EntityRecord = DeprecationHelper(mlrun.common.schemas.EntityRecord)
+Feature = DeprecationHelper(mlrun.common.schemas.Feature)
+FeatureListOutput = DeprecationHelper(mlrun.common.schemas.FeatureListOutput)
+FeatureRecord = DeprecationHelper(mlrun.common.schemas.FeatureRecord)
+FeatureSet = DeprecationHelper(mlrun.common.schemas.FeatureSet)
+FeatureSetDigestOutput = DeprecationHelper(mlrun.common.schemas.FeatureSetDigestOutput)
+FeatureSetDigestSpec = DeprecationHelper(mlrun.common.schemas.FeatureSetDigestSpec)
+FeatureSetIngestInput = DeprecationHelper(mlrun.common.schemas.FeatureSetIngestInput)
+FeatureSetIngestOutput = DeprecationHelper(mlrun.common.schemas.FeatureSetIngestOutput)
+FeatureSetRecord = DeprecationHelper(mlrun.common.schemas.FeatureSetRecord)
+FeatureSetsOutput = DeprecationHelper(mlrun.common.schemas.FeatureSetsOutput)
+FeatureSetSpec = DeprecationHelper(mlrun.common.schemas.FeatureSetSpec)
+FeatureSetsTagsOutput = DeprecationHelper(mlrun.common.schemas.FeatureSetsTagsOutput)
+FeaturesOutput = DeprecationHelper(mlrun.common.schemas.FeaturesOutput)
+FeatureVector = DeprecationHelper(mlrun.common.schemas.FeatureVector)
+FeatureVectorRecord = DeprecationHelper(mlrun.common.schemas.FeatureVectorRecord)
+FeatureVectorsOutput = DeprecationHelper(mlrun.common.schemas.FeatureVectorsOutput)
+FeatureVectorsTagsOutput = DeprecationHelper(
+ mlrun.common.schemas.FeatureVectorsTagsOutput
+)
+AuthenticationFeatureFlag = DeprecationHelper(
+ mlrun.common.schemas.AuthenticationFeatureFlag
+)
+FeatureFlags = DeprecationHelper(mlrun.common.schemas.FeatureFlags)
+FrontendSpec = DeprecationHelper(mlrun.common.schemas.FrontendSpec)
+NuclioStreamsFeatureFlag = DeprecationHelper(
+ mlrun.common.schemas.NuclioStreamsFeatureFlag
+)
+PreemptionNodesFeatureFlag = DeprecationHelper(
+ mlrun.common.schemas.PreemptionNodesFeatureFlag
+)
+ProjectMembershipFeatureFlag = DeprecationHelper(
+ mlrun.common.schemas.ProjectMembershipFeatureFlag
+)
+FunctionState = DeprecationHelper(mlrun.common.schemas.FunctionState)
+PreemptionModes = DeprecationHelper(mlrun.common.schemas.PreemptionModes)
+SecurityContextEnrichmentModes = DeprecationHelper(
+ mlrun.common.schemas.SecurityContextEnrichmentModes
+)
+HTTPSessionRetryMode = DeprecationHelper(mlrun.common.schemas.HTTPSessionRetryMode)
+NodeSelectorOperator = DeprecationHelper(mlrun.common.schemas.NodeSelectorOperator)
+Resources = DeprecationHelper(mlrun.common.schemas.Resources)
+ResourceSpec = DeprecationHelper(mlrun.common.schemas.ResourceSpec)
+IndexedHubSource = DeprecationHelper(mlrun.common.schemas.IndexedHubSource)
+HubCatalog = DeprecationHelper(mlrun.common.schemas.HubCatalog)
+HubItem = DeprecationHelper(mlrun.common.schemas.HubItem)
+HubObjectMetadata = DeprecationHelper(mlrun.common.schemas.HubObjectMetadata)
+HubSource = DeprecationHelper(mlrun.common.schemas.HubSource)
+HubSourceSpec = DeprecationHelper(mlrun.common.schemas.HubSourceSpec)
+last_source_index = DeprecationHelper(mlrun.common.schemas.last_source_index)
+MostCommonObjectTypesReport = DeprecationHelper(
+ mlrun.common.schemas.MostCommonObjectTypesReport
+)
+ObjectTypeReport = DeprecationHelper(mlrun.common.schemas.ObjectTypeReport)
+Features = DeprecationHelper(mlrun.common.schemas.Features)
+FeatureValues = DeprecationHelper(mlrun.common.schemas.FeatureValues)
+GrafanaColumn = DeprecationHelper(mlrun.common.schemas.GrafanaColumn)
+GrafanaDataPoint = DeprecationHelper(mlrun.common.schemas.GrafanaDataPoint)
+GrafanaNumberColumn = DeprecationHelper(mlrun.common.schemas.GrafanaNumberColumn)
+GrafanaStringColumn = DeprecationHelper(mlrun.common.schemas.GrafanaStringColumn)
+GrafanaTable = DeprecationHelper(mlrun.common.schemas.GrafanaTable)
+GrafanaTimeSeriesTarget = DeprecationHelper(
+ mlrun.common.schemas.GrafanaTimeSeriesTarget
+)
+ModelEndpoint = DeprecationHelper(mlrun.common.schemas.ModelEndpoint)
+ModelEndpointList = DeprecationHelper(mlrun.common.schemas.ModelEndpointList)
+ModelEndpointMetadata = DeprecationHelper(mlrun.common.schemas.ModelEndpointMetadata)
+ModelEndpointSpec = DeprecationHelper(mlrun.common.schemas.ModelEndpointSpec)
+ModelEndpointStatus = DeprecationHelper(mlrun.common.schemas.ModelEndpointStatus)
+ModelMonitoringStoreKinds = DeprecationHelper(
+ mlrun.common.schemas.ModelMonitoringStoreKinds
+)
+NotificationSeverity = DeprecationHelper(mlrun.common.schemas.NotificationSeverity)
+NotificationStatus = DeprecationHelper(mlrun.common.schemas.NotificationStatus)
+ObjectKind = DeprecationHelper(mlrun.common.schemas.ObjectKind)
+ObjectMetadata = DeprecationHelper(mlrun.common.schemas.ObjectMetadata)
+ObjectSpec = DeprecationHelper(mlrun.common.schemas.ObjectSpec)
+ObjectStatus = DeprecationHelper(mlrun.common.schemas.ObjectStatus)
+PipelinesFormat = DeprecationHelper(mlrun.common.schemas.PipelinesFormat)
+PipelinesOutput = DeprecationHelper(mlrun.common.schemas.PipelinesOutput)
+PipelinesPagination = DeprecationHelper(mlrun.common.schemas.PipelinesPagination)
+IguazioProject = DeprecationHelper(mlrun.common.schemas.IguazioProject)
+Project = DeprecationHelper(mlrun.common.schemas.Project)
+ProjectDesiredState = DeprecationHelper(mlrun.common.schemas.ProjectDesiredState)
+ProjectMetadata = DeprecationHelper(mlrun.common.schemas.ProjectMetadata)
+ProjectOwner = DeprecationHelper(mlrun.common.schemas.ProjectOwner)
+ProjectsFormat = DeprecationHelper(mlrun.common.schemas.ProjectsFormat)
+ProjectsOutput = DeprecationHelper(mlrun.common.schemas.ProjectsOutput)
+ProjectSpec = DeprecationHelper(mlrun.common.schemas.ProjectSpec)
+ProjectState = DeprecationHelper(mlrun.common.schemas.ProjectState)
+ProjectStatus = DeprecationHelper(mlrun.common.schemas.ProjectStatus)
+ProjectSummariesOutput = DeprecationHelper(mlrun.common.schemas.ProjectSummariesOutput)
+ProjectSummary = DeprecationHelper(mlrun.common.schemas.ProjectSummary)
+GroupedByJobRuntimeResourcesOutput = DeprecationHelper(
+ mlrun.common.schemas.GroupedByJobRuntimeResourcesOutput
+)
+GroupedByProjectRuntimeResourcesOutput = DeprecationHelper(
+ mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput
+)
+KindRuntimeResources = DeprecationHelper(mlrun.common.schemas.KindRuntimeResources)
+ListRuntimeResourcesGroupByField = DeprecationHelper(
+ mlrun.common.schemas.ListRuntimeResourcesGroupByField
+)
+RuntimeResource = DeprecationHelper(mlrun.common.schemas.RuntimeResource)
+RuntimeResources = DeprecationHelper(mlrun.common.schemas.RuntimeResources)
+RuntimeResourcesOutput = DeprecationHelper(mlrun.common.schemas.RuntimeResourcesOutput)
+ScheduleCronTrigger = DeprecationHelper(mlrun.common.schemas.ScheduleCronTrigger)
+ScheduleInput = DeprecationHelper(mlrun.common.schemas.ScheduleInput)
+ScheduleKinds = DeprecationHelper(mlrun.common.schemas.ScheduleKinds)
+ScheduleOutput = DeprecationHelper(mlrun.common.schemas.ScheduleOutput)
+ScheduleRecord = DeprecationHelper(mlrun.common.schemas.ScheduleRecord)
+SchedulesOutput = DeprecationHelper(mlrun.common.schemas.SchedulesOutput)
+ScheduleUpdate = DeprecationHelper(mlrun.common.schemas.ScheduleUpdate)
+AuthSecretData = DeprecationHelper(mlrun.common.schemas.AuthSecretData)
+SecretKeysData = DeprecationHelper(mlrun.common.schemas.SecretKeysData)
+SecretProviderName = DeprecationHelper(mlrun.common.schemas.SecretProviderName)
+SecretsData = DeprecationHelper(mlrun.common.schemas.SecretsData)
+UserSecretCreationRequest = DeprecationHelper(
+ mlrun.common.schemas.UserSecretCreationRequest
+)
+Tag = DeprecationHelper(mlrun.common.schemas.Tag)
+TagObjects = DeprecationHelper(mlrun.common.schemas.TagObjects)
diff --git a/mlrun/api/utils/auth/providers/base.py b/mlrun/api/utils/auth/providers/base.py
index c5c2258139bf..e00cc77a0975 100644
--- a/mlrun/api/utils/auth/providers/base.py
+++ b/mlrun/api/utils/auth/providers/base.py
@@ -15,7 +15,7 @@
import abc
import typing
-import mlrun.api.schemas
+import mlrun.common.schemas
class Provider(abc.ABC):
@@ -23,8 +23,8 @@ class Provider(abc.ABC):
async def query_permissions(
self,
resource: str,
- action: mlrun.api.schemas.AuthorizationAction,
- auth_info: mlrun.api.schemas.AuthInfo,
+ action: mlrun.common.schemas.AuthorizationAction,
+ auth_info: mlrun.common.schemas.AuthInfo,
raise_on_forbidden: bool = True,
) -> bool:
pass
@@ -34,13 +34,13 @@ async def filter_by_permissions(
self,
resources: typing.List,
opa_resource_extractor: typing.Callable,
- action: mlrun.api.schemas.AuthorizationAction,
- auth_info: mlrun.api.schemas.AuthInfo,
+ action: mlrun.common.schemas.AuthorizationAction,
+ auth_info: mlrun.common.schemas.AuthInfo,
) -> typing.List:
pass
@abc.abstractmethod
def add_allowed_project_for_owner(
- self, project_name: str, auth_info: mlrun.api.schemas.AuthInfo
+ self, project_name: str, auth_info: mlrun.common.schemas.AuthInfo
):
pass
diff --git a/mlrun/api/utils/auth/providers/nop.py b/mlrun/api/utils/auth/providers/nop.py
index 4316585be2b1..987087081363 100644
--- a/mlrun/api/utils/auth/providers/nop.py
+++ b/mlrun/api/utils/auth/providers/nop.py
@@ -14,7 +14,6 @@
#
import typing
-import mlrun.api.schemas
import mlrun.api.utils.auth.providers.base
import mlrun.utils.singleton
@@ -26,8 +25,8 @@ class Provider(
async def query_permissions(
self,
resource: str,
- action: mlrun.api.schemas.AuthorizationAction,
- auth_info: mlrun.api.schemas.AuthInfo,
+ action: mlrun.common.schemas.AuthorizationAction,
+ auth_info: mlrun.common.schemas.AuthInfo,
raise_on_forbidden: bool = True,
) -> bool:
return True
@@ -36,12 +35,12 @@ async def filter_by_permissions(
self,
resources: typing.List,
opa_resource_extractor: typing.Callable,
- action: mlrun.api.schemas.AuthorizationAction,
- auth_info: mlrun.api.schemas.AuthInfo,
+ action: mlrun.common.schemas.AuthorizationAction,
+ auth_info: mlrun.common.schemas.AuthInfo,
) -> typing.List:
return resources
def add_allowed_project_for_owner(
- self, project_name: str, auth_info: mlrun.api.schemas.AuthInfo
+ self, project_name: str, auth_info: mlrun.common.schemas.AuthInfo
):
pass
diff --git a/mlrun/api/utils/auth/providers/opa.py b/mlrun/api/utils/auth/providers/opa.py
index d717c736e66e..d8da4b527239 100644
--- a/mlrun/api/utils/auth/providers/opa.py
+++ b/mlrun/api/utils/auth/providers/opa.py
@@ -21,9 +21,9 @@
import humanfriendly
-import mlrun.api.schemas
import mlrun.api.utils.auth.providers.base
import mlrun.api.utils.projects.remotes.leader
+import mlrun.common.schemas
import mlrun.errors
import mlrun.utils.helpers
import mlrun.utils.singleton
@@ -66,23 +66,23 @@ def __init__(self) -> None:
async def query_permissions(
self,
resource: str,
- action: mlrun.api.schemas.AuthorizationAction,
- auth_info: mlrun.api.schemas.AuthInfo,
+ action: mlrun.common.schemas.AuthorizationAction,
+ auth_info: mlrun.common.schemas.AuthInfo,
raise_on_forbidden: bool = True,
) -> bool:
# store is not really a verb in our OPA manifest, we map it to 2 query permissions requests (create & update)
- if action == mlrun.api.schemas.AuthorizationAction.store:
+ if action == mlrun.common.schemas.AuthorizationAction.store:
results = await asyncio.gather(
self.query_permissions(
resource,
- mlrun.api.schemas.AuthorizationAction.create,
+ mlrun.common.schemas.AuthorizationAction.create,
auth_info,
raise_on_forbidden,
),
self.query_permissions(
resource,
- mlrun.api.schemas.AuthorizationAction.update,
+ mlrun.common.schemas.AuthorizationAction.update,
auth_info,
raise_on_forbidden,
),
@@ -113,11 +113,11 @@ async def filter_by_permissions(
self,
resources: typing.List,
opa_resource_extractor: typing.Callable,
- action: mlrun.api.schemas.AuthorizationAction,
- auth_info: mlrun.api.schemas.AuthInfo,
+ action: mlrun.common.schemas.AuthorizationAction,
+ auth_info: mlrun.common.schemas.AuthInfo,
) -> typing.List:
# store is not really a verb in our OPA manifest, we map it to 2 query permissions requests (create & update)
- if action == mlrun.api.schemas.AuthorizationAction.store:
+ if action == mlrun.common.schemas.AuthorizationAction.store:
raise NotImplementedError("Store action is not supported in filtering")
if self._is_request_from_leader(auth_info.projects_role):
return resources
@@ -149,7 +149,7 @@ async def filter_by_permissions(
return allowed_resources
def add_allowed_project_for_owner(
- self, project_name: str, auth_info: mlrun.api.schemas.AuthInfo
+ self, project_name: str, auth_info: mlrun.common.schemas.AuthInfo
):
if (
not auth_info.user_id
@@ -168,7 +168,7 @@ def add_allowed_project_for_owner(
self._allowed_project_owners_cache[auth_info.user_id] = allowed_projects
def _check_allowed_project_owners_cache(
- self, resource: str, auth_info: mlrun.api.schemas.AuthInfo
+ self, resource: str, auth_info: mlrun.common.schemas.AuthInfo
):
# Cache shouldn't be big, simply clean it on get instead of scheduling it
self._clean_expired_records_from_cache()
@@ -199,7 +199,7 @@ def _clean_expired_records_from_cache(self):
del self._allowed_project_owners_cache[user_id]
def _is_request_from_leader(
- self, projects_role: typing.Optional[mlrun.api.schemas.ProjectsRole]
+ self, projects_role: typing.Optional[mlrun.common.schemas.ProjectsRole]
):
if projects_role and projects_role.value == self._leader_name:
return True
@@ -241,8 +241,8 @@ async def _on_request_api_failure(self, method, path, response, **kwargs):
@staticmethod
def _generate_permission_request_body(
resource: str,
- action: mlrun.api.schemas.AuthorizationAction,
- auth_info: mlrun.api.schemas.AuthInfo,
+ action: mlrun.common.schemas.AuthorizationAction,
+ auth_info: mlrun.common.schemas.AuthInfo,
) -> dict:
body = {
"input": {
@@ -256,8 +256,8 @@ def _generate_permission_request_body(
@staticmethod
def _generate_filter_request_body(
resources: typing.List[str],
- action: mlrun.api.schemas.AuthorizationAction,
- auth_info: mlrun.api.schemas.AuthInfo,
+ action: mlrun.common.schemas.AuthorizationAction,
+ auth_info: mlrun.common.schemas.AuthInfo,
) -> dict:
body = {
"input": {
diff --git a/mlrun/api/utils/auth/verifier.py b/mlrun/api/utils/auth/verifier.py
index c70bc10a5041..4ec5479545cc 100644
--- a/mlrun/api/utils/auth/verifier.py
+++ b/mlrun/api/utils/auth/verifier.py
@@ -19,10 +19,10 @@
import fastapi
import mlrun
-import mlrun.api.schemas
import mlrun.api.utils.auth.providers.nop
import mlrun.api.utils.auth.providers.opa
import mlrun.api.utils.clients.iguazio
+import mlrun.common.schemas
import mlrun.utils.singleton
@@ -41,11 +41,11 @@ def __init__(self) -> None:
async def filter_project_resources_by_permissions(
self,
- resource_type: mlrun.api.schemas.AuthorizationResourceTypes,
+ resource_type: mlrun.common.schemas.AuthorizationResourceTypes,
resources: typing.List,
project_and_resource_name_extractor: typing.Callable,
- auth_info: mlrun.api.schemas.AuthInfo,
- action: mlrun.api.schemas.AuthorizationAction = mlrun.api.schemas.AuthorizationAction.read,
+ auth_info: mlrun.common.schemas.AuthInfo,
+ action: mlrun.common.schemas.AuthorizationAction = mlrun.common.schemas.AuthorizationAction.read,
) -> typing.List:
def _generate_opa_resource(resource):
project_name, resource_name = project_and_resource_name_extractor(resource)
@@ -60,8 +60,8 @@ def _generate_opa_resource(resource):
async def filter_projects_by_permissions(
self,
project_names: typing.List[str],
- auth_info: mlrun.api.schemas.AuthInfo,
- action: mlrun.api.schemas.AuthorizationAction = mlrun.api.schemas.AuthorizationAction.read,
+ auth_info: mlrun.common.schemas.AuthInfo,
+ action: mlrun.common.schemas.AuthorizationAction = mlrun.common.schemas.AuthorizationAction.read,
) -> typing.List:
return await self.filter_by_permissions(
project_names,
@@ -72,11 +72,11 @@ async def filter_projects_by_permissions(
async def query_project_resources_permissions(
self,
- resource_type: mlrun.api.schemas.AuthorizationResourceTypes,
+ resource_type: mlrun.common.schemas.AuthorizationResourceTypes,
resources: typing.List,
project_and_resource_name_extractor: typing.Callable,
- action: mlrun.api.schemas.AuthorizationAction,
- auth_info: mlrun.api.schemas.AuthInfo,
+ action: mlrun.common.schemas.AuthorizationAction,
+ auth_info: mlrun.common.schemas.AuthInfo,
raise_on_forbidden: bool = True,
) -> bool:
project_resources = [
@@ -102,11 +102,11 @@ async def query_project_resources_permissions(
async def query_project_resource_permissions(
self,
- resource_type: mlrun.api.schemas.AuthorizationResourceTypes,
+ resource_type: mlrun.common.schemas.AuthorizationResourceTypes,
project_name: str,
resource_name: str,
- action: mlrun.api.schemas.AuthorizationAction,
- auth_info: mlrun.api.schemas.AuthInfo,
+ action: mlrun.common.schemas.AuthorizationAction,
+ auth_info: mlrun.common.schemas.AuthInfo,
raise_on_forbidden: bool = True,
) -> bool:
return await self.query_permissions(
@@ -121,8 +121,8 @@ async def query_project_resource_permissions(
async def query_project_permissions(
self,
project_name: str,
- action: mlrun.api.schemas.AuthorizationAction,
- auth_info: mlrun.api.schemas.AuthInfo,
+ action: mlrun.common.schemas.AuthorizationAction,
+ auth_info: mlrun.common.schemas.AuthInfo,
raise_on_forbidden: bool = True,
) -> bool:
return await self.query_permissions(
@@ -134,9 +134,9 @@ async def query_project_permissions(
async def query_global_resource_permissions(
self,
- resource_type: mlrun.api.schemas.AuthorizationResourceTypes,
- action: mlrun.api.schemas.AuthorizationAction,
- auth_info: mlrun.api.schemas.AuthInfo,
+ resource_type: mlrun.common.schemas.AuthorizationResourceTypes,
+ action: mlrun.common.schemas.AuthorizationAction,
+ auth_info: mlrun.common.schemas.AuthInfo,
raise_on_forbidden: bool = True,
) -> bool:
return await self.query_resource_permissions(
@@ -149,10 +149,10 @@ async def query_global_resource_permissions(
async def query_resource_permissions(
self,
- resource_type: mlrun.api.schemas.AuthorizationResourceTypes,
+ resource_type: mlrun.common.schemas.AuthorizationResourceTypes,
resource_name: str,
- action: mlrun.api.schemas.AuthorizationAction,
- auth_info: mlrun.api.schemas.AuthInfo,
+ action: mlrun.common.schemas.AuthorizationAction,
+ auth_info: mlrun.common.schemas.AuthInfo,
raise_on_forbidden: bool = True,
) -> bool:
return await self.query_permissions(
@@ -165,8 +165,8 @@ async def query_resource_permissions(
async def query_permissions(
self,
resource: str,
- action: mlrun.api.schemas.AuthorizationAction,
- auth_info: mlrun.api.schemas.AuthInfo,
+ action: mlrun.common.schemas.AuthorizationAction,
+ auth_info: mlrun.common.schemas.AuthInfo,
raise_on_forbidden: bool = True,
) -> bool:
return await self._auth_provider.query_permissions(
@@ -177,8 +177,8 @@ async def filter_by_permissions(
self,
resources: typing.List,
opa_resource_extractor: typing.Callable,
- action: mlrun.api.schemas.AuthorizationAction,
- auth_info: mlrun.api.schemas.AuthInfo,
+ action: mlrun.common.schemas.AuthorizationAction,
+ auth_info: mlrun.common.schemas.AuthInfo,
) -> typing.List:
return await self._auth_provider.filter_by_permissions(
resources,
@@ -188,14 +188,14 @@ async def filter_by_permissions(
)
def add_allowed_project_for_owner(
- self, project_name: str, auth_info: mlrun.api.schemas.AuthInfo
+ self, project_name: str, auth_info: mlrun.common.schemas.AuthInfo
):
self._auth_provider.add_allowed_project_for_owner(project_name, auth_info)
async def authenticate_request(
self, request: fastapi.Request
- ) -> mlrun.api.schemas.AuthInfo:
- auth_info = mlrun.api.schemas.AuthInfo()
+ ) -> mlrun.common.schemas.AuthInfo:
+ auth_info = mlrun.common.schemas.AuthInfo()
header = request.headers.get("Authorization", "")
if self._basic_auth_configured():
if not header.startswith(self._basic_prefix):
@@ -228,10 +228,10 @@ async def authenticate_request(
auth_info.username = request.headers["x-remote-user"]
projects_role_header = request.headers.get(
- mlrun.api.schemas.HeaderNames.projects_role
+ mlrun.common.schemas.HeaderNames.projects_role
)
auth_info.projects_role = (
- mlrun.api.schemas.ProjectsRole(projects_role_header)
+ mlrun.common.schemas.ProjectsRole(projects_role_header)
if projects_role_header
else None
)
@@ -248,7 +248,7 @@ async def authenticate_request(
async def generate_auth_info_from_session(
self, session: str
- ) -> mlrun.api.schemas.AuthInfo:
+ ) -> mlrun.common.schemas.AuthInfo:
if not self._iguazio_auth_configured():
raise NotImplementedError(
"Session is currently supported only for iguazio authentication mode"
@@ -273,13 +273,15 @@ def is_jobs_auth_required(self):
@staticmethod
def _generate_resource_string_from_project_name(project_name: str):
- return mlrun.api.schemas.AuthorizationResourceTypes.project.to_resource_string(
- project_name, ""
+ return (
+ mlrun.common.schemas.AuthorizationResourceTypes.project.to_resource_string(
+ project_name, ""
+ )
)
@staticmethod
def _generate_resource_string_from_project_resource(
- resource_type: mlrun.api.schemas.AuthorizationResourceTypes,
+ resource_type: mlrun.common.schemas.AuthorizationResourceTypes,
project_name: str,
resource_name: str,
):
diff --git a/mlrun/api/utils/background_tasks.py b/mlrun/api/utils/background_tasks.py
index 6372c136267d..29d40279dc87 100644
--- a/mlrun/api/utils/background_tasks.py
+++ b/mlrun/api/utils/background_tasks.py
@@ -22,10 +22,10 @@
import fastapi.concurrency
import sqlalchemy.orm
-import mlrun.api.schemas
import mlrun.api.utils.helpers
import mlrun.api.utils.singletons.db
import mlrun.api.utils.singletons.project_member
+import mlrun.common.schemas
import mlrun.errors
import mlrun.utils.singleton
from mlrun.utils import logger
@@ -41,13 +41,13 @@ def create_background_task(
timeout: int = None, # in seconds
*args,
**kwargs,
- ) -> mlrun.api.schemas.BackgroundTask:
+ ) -> mlrun.common.schemas.BackgroundTask:
name = str(uuid.uuid4())
mlrun.api.utils.singletons.db.get_db().store_background_task(
db_session,
name,
project,
- mlrun.api.schemas.BackgroundTaskState.running,
+ mlrun.common.schemas.BackgroundTaskState.running,
timeout,
)
background_tasks.add_task(
@@ -66,7 +66,7 @@ def get_background_task(
db_session: sqlalchemy.orm.Session,
name: str,
project: str,
- ) -> mlrun.api.schemas.BackgroundTask:
+ ) -> mlrun.common.schemas.BackgroundTask:
return mlrun.api.utils.singletons.db.get_db().get_background_task(
db_session, name, project
)
@@ -93,21 +93,21 @@ async def background_task_wrapper(
db_session,
name,
project=project,
- state=mlrun.api.schemas.BackgroundTaskState.failed,
+ state=mlrun.common.schemas.BackgroundTaskState.failed,
)
else:
mlrun.api.utils.singletons.db.get_db().store_background_task(
db_session,
name,
project=project,
- state=mlrun.api.schemas.BackgroundTaskState.succeeded,
+ state=mlrun.common.schemas.BackgroundTaskState.succeeded,
)
class InternalBackgroundTasksHandler(metaclass=mlrun.utils.singleton.Singleton):
def __init__(self):
self._internal_background_tasks: typing.Dict[
- str, mlrun.api.schemas.BackgroundTask
+ str, mlrun.common.schemas.BackgroundTask
] = {}
@mlrun.api.utils.helpers.ensure_running_on_chief
@@ -117,7 +117,7 @@ def create_background_task(
function,
*args,
**kwargs,
- ) -> mlrun.api.schemas.BackgroundTask:
+ ) -> mlrun.common.schemas.BackgroundTask:
name = str(uuid.uuid4())
# sanity
if name in self._internal_background_tasks:
@@ -138,7 +138,7 @@ def create_background_task(
def get_background_task(
self,
name: str,
- ) -> mlrun.api.schemas.BackgroundTask:
+ ) -> mlrun.common.schemas.BackgroundTask:
"""
:return: returns the background task object and bool whether exists
"""
@@ -160,17 +160,17 @@ async def background_task_wrapper(self, name: str, function, *args, **kwargs):
f"Failed during background task execution: {function.__name__}, exc: {traceback.format_exc()}"
)
self._update_background_task(
- name, mlrun.api.schemas.BackgroundTaskState.failed
+ name, mlrun.common.schemas.BackgroundTaskState.failed
)
else:
self._update_background_task(
- name, mlrun.api.schemas.BackgroundTaskState.succeeded
+ name, mlrun.common.schemas.BackgroundTaskState.succeeded
)
def _update_background_task(
self,
name: str,
- state: mlrun.api.schemas.BackgroundTaskState,
+ state: mlrun.common.schemas.BackgroundTaskState,
):
background_task = self._internal_background_tasks[name]
background_task.status.state = state
@@ -183,31 +183,31 @@ def _generate_background_task_not_found_response(
# in order to keep things simple we don't persist the internal background tasks to the DB
# If for some reason get is called and the background task doesn't exist, it means that probably we got
# restarted, therefore we want to return a failed background task so the client will retry (if needed)
- return mlrun.api.schemas.BackgroundTask(
- metadata=mlrun.api.schemas.BackgroundTaskMetadata(
+ return mlrun.common.schemas.BackgroundTask(
+ metadata=mlrun.common.schemas.BackgroundTaskMetadata(
name=name, project=project
),
- spec=mlrun.api.schemas.BackgroundTaskSpec(),
- status=mlrun.api.schemas.BackgroundTaskStatus(
- state=mlrun.api.schemas.BackgroundTaskState.failed
+ spec=mlrun.common.schemas.BackgroundTaskSpec(),
+ status=mlrun.common.schemas.BackgroundTaskStatus(
+ state=mlrun.common.schemas.BackgroundTaskState.failed
),
)
@staticmethod
def _generate_background_task(
name: str, project: typing.Optional[str] = None
- ) -> mlrun.api.schemas.BackgroundTask:
+ ) -> mlrun.common.schemas.BackgroundTask:
now = datetime.datetime.utcnow()
- metadata = mlrun.api.schemas.BackgroundTaskMetadata(
+ metadata = mlrun.common.schemas.BackgroundTaskMetadata(
name=name,
project=project,
created=now,
updated=now,
)
- spec = mlrun.api.schemas.BackgroundTaskSpec()
- status = mlrun.api.schemas.BackgroundTaskStatus(
- state=mlrun.api.schemas.BackgroundTaskState.running
+ spec = mlrun.common.schemas.BackgroundTaskSpec()
+ status = mlrun.common.schemas.BackgroundTaskStatus(
+ state=mlrun.common.schemas.BackgroundTaskState.running
)
- return mlrun.api.schemas.BackgroundTask(
+ return mlrun.common.schemas.BackgroundTask(
metadata=metadata, spec=spec, status=status
)
diff --git a/mlrun/api/utils/clients/chief.py b/mlrun/api/utils/clients/chief.py
index ece862c6bfe2..3575ed16c967 100644
--- a/mlrun/api/utils/clients/chief.py
+++ b/mlrun/api/utils/clients/chief.py
@@ -21,8 +21,8 @@
import aiohttp
import fastapi
-import mlrun.api.schemas
import mlrun.api.utils.projects.remotes.follower
+import mlrun.common.schemas
import mlrun.errors
import mlrun.utils.singleton
from mlrun.utils import logger
@@ -157,7 +157,7 @@ async def delete_project(self, name, request: fastapi.Request) -> fastapi.Respon
async def get_clusterization_spec(
self, return_fastapi_response: bool = True, raise_on_failure: bool = False
- ) -> typing.Union[fastapi.Response, mlrun.api.schemas.ClusterizationSpec]:
+ ) -> typing.Union[fastapi.Response, mlrun.common.schemas.ClusterizationSpec]:
"""
This method is used both for proxying requests from worker to chief and for aligning the worker state
with the clusterization spec brought from the chief
@@ -172,7 +172,9 @@ async def get_clusterization_spec(
chief_response
)
- return mlrun.api.schemas.ClusterizationSpec(**(await chief_response.json()))
+ return mlrun.common.schemas.ClusterizationSpec(
+ **(await chief_response.json())
+ )
async def _proxy_request_to_chief(
self,
diff --git a/mlrun/api/utils/clients/iguazio.py b/mlrun/api/utils/clients/iguazio.py
index 754d530bffa9..cb45f9923241 100644
--- a/mlrun/api/utils/clients/iguazio.py
+++ b/mlrun/api/utils/clients/iguazio.py
@@ -27,8 +27,8 @@
import requests.adapters
from fastapi.concurrency import run_in_threadpool
-import mlrun.api.schemas
import mlrun.api.utils.projects.remotes.leader
+import mlrun.common.schemas
import mlrun.errors
import mlrun.utils.helpers
import mlrun.utils.singleton
@@ -79,7 +79,7 @@ def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self._session = mlrun.utils.HTTPSessionWithRetry(
retry_on_exception=mlrun.mlconf.httpdb.projects.retry_leader_request_on_exception
- == mlrun.api.schemas.HTTPSessionRetryMode.enabled.value,
+ == mlrun.common.schemas.HTTPSessionRetryMode.enabled.value,
verbose=True,
)
self._api_url = mlrun.mlconf.iguazio_api_url
@@ -123,7 +123,7 @@ def try_get_grafana_service_url(self, session: str) -> typing.Optional[str]:
def verify_request_session(
self, request: fastapi.Request
- ) -> mlrun.api.schemas.AuthInfo:
+ ) -> mlrun.common.schemas.AuthInfo:
"""
Proxy the request to one of the session verification endpoints (which will verify the session of the request)
"""
@@ -140,7 +140,7 @@ def verify_request_session(
response.headers, response.json()
)
- def verify_session(self, session: str) -> mlrun.api.schemas.AuthInfo:
+ def verify_session(self, session: str) -> mlrun.common.schemas.AuthInfo:
response = self._send_request_to_api(
"POST",
mlrun.mlconf.httpdb.authentication.iguazio.session_verification_endpoint,
@@ -189,7 +189,7 @@ def get_or_create_access_key(
def create_project(
self,
session: str,
- project: mlrun.api.schemas.Project,
+ project: mlrun.common.schemas.Project,
wait_for_completion: bool = True,
) -> bool:
logger.debug("Creating project in Iguazio", project=project)
@@ -202,7 +202,7 @@ def update_project(
self,
session: str,
name: str,
- project: mlrun.api.schemas.Project,
+ project: mlrun.common.schemas.Project,
):
logger.debug("Updating project in Iguazio", name=name, project=project)
body = self._transform_mlrun_project_to_iguazio_project(project)
@@ -212,7 +212,7 @@ def delete_project(
self,
session: str,
name: str,
- deletion_strategy: mlrun.api.schemas.DeletionStrategy = mlrun.api.schemas.DeletionStrategy.default(),
+ deletion_strategy: mlrun.common.schemas.DeletionStrategy = mlrun.common.schemas.DeletionStrategy.default(),
wait_for_completion: bool = True,
) -> bool:
logger.debug(
@@ -221,8 +221,8 @@ def delete_project(
deletion_strategy=deletion_strategy,
)
body = self._transform_mlrun_project_to_iguazio_project(
- mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=name)
+ mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=name)
)
)
headers = {
@@ -266,7 +266,7 @@ def list_projects(
updated_after: typing.Optional[datetime.datetime] = None,
page_size: typing.Optional[int] = None,
) -> typing.Tuple[
- typing.List[mlrun.api.schemas.Project], typing.Optional[datetime.datetime]
+ typing.List[mlrun.common.schemas.Project], typing.Optional[datetime.datetime]
]:
params = {}
if updated_after is not None:
@@ -300,14 +300,14 @@ def get_project(
self,
session: str,
name: str,
- ) -> mlrun.api.schemas.Project:
+ ) -> mlrun.common.schemas.Project:
return self._get_project_from_iguazio(session, name)
def get_project_owner(
self,
session: str,
name: str,
- ) -> mlrun.api.schemas.ProjectOwner:
+ ) -> mlrun.common.schemas.ProjectOwner:
response = self._get_project_from_iguazio_without_parsing(
session, name, enrich_owner_access_key=True
)
@@ -323,15 +323,15 @@ def get_project_owner(
f"Unable to enrich project owner for project {name},"
f" because project has no owner configured"
)
- return mlrun.api.schemas.ProjectOwner(
+ return mlrun.common.schemas.ProjectOwner(
username=owner_username,
access_key=owner_access_key,
)
def format_as_leader_project(
- self, project: mlrun.api.schemas.Project
- ) -> mlrun.api.schemas.IguazioProject:
- return mlrun.api.schemas.IguazioProject(
+ self, project: mlrun.common.schemas.Project
+ ) -> mlrun.common.schemas.IguazioProject:
+ return mlrun.common.schemas.IguazioProject(
data=self._transform_mlrun_project_to_iguazio_project(project)["data"]
)
@@ -372,7 +372,7 @@ def _create_project_in_iguazio(
def _post_project_to_iguazio(
self, session: str, body: dict
- ) -> typing.Tuple[mlrun.api.schemas.Project, str]:
+ ) -> typing.Tuple[mlrun.common.schemas.Project, str]:
response = self._send_request_to_api(
"POST", "projects", "Failed creating project in Iguazio", session, json=body
)
@@ -384,7 +384,7 @@ def _post_project_to_iguazio(
def _put_project_to_iguazio(
self, session: str, name: str, body: dict
- ) -> mlrun.api.schemas.Project:
+ ) -> mlrun.common.schemas.Project:
response = self._send_request_to_api(
"PUT",
f"projects/__name__/{name}",
@@ -410,7 +410,7 @@ def _get_project_from_iguazio_without_parsing(
def _get_project_from_iguazio(
self, session: str, name: str, include_owner_session: bool = False
- ) -> mlrun.api.schemas.Project:
+ ) -> mlrun.common.schemas.Project:
response = self._get_project_from_iguazio_without_parsing(session, name)
return self._transform_iguazio_project_to_mlrun_project(response.json()["data"])
@@ -466,7 +466,7 @@ def _generate_auth_info_from_session_verification_response(
self,
response_headers: typing.Mapping[str, typing.Any],
response_body: typing.Mapping[typing.Any, typing.Any],
- ) -> mlrun.api.schemas.AuthInfo:
+ ) -> mlrun.common.schemas.AuthInfo:
(
username,
@@ -487,7 +487,7 @@ def _generate_auth_info_from_session_verification_response(
user_id = user_id_from_body or user_id
group_ids = group_ids_from_body or group_ids
- auth_info = mlrun.api.schemas.AuthInfo(
+ auth_info = mlrun.common.schemas.AuthInfo(
username=username,
session=session,
user_id=user_id,
@@ -546,7 +546,7 @@ def _resolve_params_from_response_body(
@staticmethod
def _transform_mlrun_project_to_iguazio_project(
- project: mlrun.api.schemas.Project,
+ project: mlrun.common.schemas.Project,
) -> dict:
body = {
"data": {
@@ -583,7 +583,7 @@ def _transform_mlrun_project_to_iguazio_project(
@staticmethod
def _transform_mlrun_project_to_iguazio_mlrun_project_attribute(
- project: mlrun.api.schemas.Project,
+ project: mlrun.common.schemas.Project,
):
project_dict = project.dict(
exclude_unset=True,
@@ -617,7 +617,7 @@ def _transform_iguazio_labels_to_mlrun_labels(
@staticmethod
def _transform_iguazio_project_to_mlrun_project(
iguazio_project,
- ) -> mlrun.api.schemas.Project:
+ ) -> mlrun.common.schemas.Project:
mlrun_project_without_common_fields = json.loads(
iguazio_project["attributes"].get("mlrun_project", "{}")
)
@@ -625,14 +625,16 @@ def _transform_iguazio_project_to_mlrun_project(
mlrun_project_without_common_fields.setdefault("metadata", {})[
"name"
] = iguazio_project["attributes"]["name"]
- mlrun_project = mlrun.api.schemas.Project(**mlrun_project_without_common_fields)
+ mlrun_project = mlrun.common.schemas.Project(
+ **mlrun_project_without_common_fields
+ )
mlrun_project.metadata.created = datetime.datetime.fromisoformat(
iguazio_project["attributes"]["created_at"]
)
- mlrun_project.spec.desired_state = mlrun.api.schemas.ProjectDesiredState(
+ mlrun_project.spec.desired_state = mlrun.common.schemas.ProjectDesiredState(
iguazio_project["attributes"]["admin_status"]
)
- mlrun_project.status.state = mlrun.api.schemas.ProjectState(
+ mlrun_project.status.state = mlrun.common.schemas.ProjectState(
iguazio_project["attributes"]["operational_status"]
)
if iguazio_project["attributes"].get("description"):
@@ -677,11 +679,11 @@ def _prepare_request_kwargs(self, session, path, *, kwargs):
if kwargs.get("timeout") is None:
kwargs["timeout"] = 20
if "projects" in path:
- if mlrun.api.schemas.HeaderNames.projects_role not in kwargs.get(
+ if mlrun.common.schemas.HeaderNames.projects_role not in kwargs.get(
"headers", {}
):
kwargs.setdefault("headers", {})[
- mlrun.api.schemas.HeaderNames.projects_role
+ mlrun.common.schemas.HeaderNames.projects_role
] = "mlrun"
# requests no longer supports header values to be enum (https://github.com/psf/requests/pull/6154)
@@ -755,7 +757,7 @@ def wrapper(*args, **kwargs):
async def verify_request_session(
self, request: fastapi.Request
- ) -> mlrun.api.schemas.AuthInfo:
+ ) -> mlrun.common.schemas.AuthInfo:
"""
Proxy the request to one of the session verification endpoints (which will verify the session of the request)
"""
@@ -772,7 +774,7 @@ async def verify_request_session(
response.headers, await response.json()
)
- async def verify_session(self, session: str) -> mlrun.api.schemas.AuthInfo:
+ async def verify_session(self, session: str) -> mlrun.common.schemas.AuthInfo:
async with self._send_request_to_api_async(
"POST",
mlrun.mlconf.httpdb.authentication.iguazio.session_verification_endpoint,
@@ -812,6 +814,6 @@ async def _ensure_async_session(self):
if not self._async_session:
self._async_session = mlrun.utils.AsyncClientWithRetry(
retry_on_exception=mlrun.mlconf.httpdb.projects.retry_leader_request_on_exception
- == mlrun.api.schemas.HTTPSessionRetryMode.enabled.value,
+ == mlrun.common.schemas.HTTPSessionRetryMode.enabled.value,
logger=logger,
)
diff --git a/mlrun/api/utils/clients/nuclio.py b/mlrun/api/utils/clients/nuclio.py
index f71f63821ee9..1e43ff14aebe 100644
--- a/mlrun/api/utils/clients/nuclio.py
+++ b/mlrun/api/utils/clients/nuclio.py
@@ -20,8 +20,8 @@
import requests.adapters
import sqlalchemy.orm
-import mlrun.api.schemas
import mlrun.api.utils.projects.remotes.follower
+import mlrun.common.schemas
import mlrun.errors
import mlrun.utils.singleton
from mlrun.utils import logger
@@ -37,7 +37,7 @@ def __init__(self) -> None:
self._api_url = mlrun.config.config.nuclio_dashboard_url
def create_project(
- self, session: sqlalchemy.orm.Session, project: mlrun.api.schemas.Project
+ self, session: sqlalchemy.orm.Session, project: mlrun.common.schemas.Project
):
logger.debug("Creating project in Nuclio", project=project)
body = self._generate_request_body(project)
@@ -47,7 +47,7 @@ def store_project(
self,
session: sqlalchemy.orm.Session,
name: str,
- project: mlrun.api.schemas.Project,
+ project: mlrun.common.schemas.Project,
):
logger.debug("Storing project in Nuclio", name=name, project=project)
body = self._generate_request_body(project)
@@ -65,7 +65,7 @@ def patch_project(
session: sqlalchemy.orm.Session,
name: str,
project: dict,
- patch_mode: mlrun.api.schemas.PatchMode = mlrun.api.schemas.PatchMode.replace,
+ patch_mode: mlrun.common.schemas.PatchMode = mlrun.common.schemas.PatchMode.replace,
):
logger.debug(
"Patching project in Nuclio",
@@ -93,14 +93,14 @@ def delete_project(
self,
session: sqlalchemy.orm.Session,
name: str,
- deletion_strategy: mlrun.api.schemas.DeletionStrategy = mlrun.api.schemas.DeletionStrategy.default(),
+ deletion_strategy: mlrun.common.schemas.DeletionStrategy = mlrun.common.schemas.DeletionStrategy.default(),
):
logger.debug(
"Deleting project in Nuclio", name=name, deletion_strategy=deletion_strategy
)
body = self._generate_request_body(
- mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=name)
+ mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=name)
)
)
headers = {
@@ -119,7 +119,7 @@ def delete_project(
def get_project(
self, session: sqlalchemy.orm.Session, name: str
- ) -> mlrun.api.schemas.Project:
+ ) -> mlrun.common.schemas.Project:
response = self._get_project_from_nuclio(name)
response_body = response.json()
return self._transform_nuclio_project_to_schema(response_body)
@@ -128,11 +128,11 @@ def list_projects(
self,
session: sqlalchemy.orm.Session,
owner: str = None,
- format_: mlrun.api.schemas.ProjectsFormat = mlrun.api.schemas.ProjectsFormat.full,
+ format_: mlrun.common.schemas.ProjectsFormat = mlrun.common.schemas.ProjectsFormat.full,
labels: typing.List[str] = None,
- state: mlrun.api.schemas.ProjectState = None,
+ state: mlrun.common.schemas.ProjectState = None,
names: typing.Optional[typing.List[str]] = None,
- ) -> mlrun.api.schemas.ProjectsOutput:
+ ) -> mlrun.common.schemas.ProjectsOutput:
if owner:
raise NotImplementedError(
"Listing nuclio projects by owner is currently not supported"
@@ -154,10 +154,10 @@ def list_projects(
projects = []
for nuclio_project in response_body.values():
projects.append(self._transform_nuclio_project_to_schema(nuclio_project))
- if format_ == mlrun.api.schemas.ProjectsFormat.full:
- return mlrun.api.schemas.ProjectsOutput(projects=projects)
- elif format_ == mlrun.api.schemas.ProjectsFormat.name_only:
- return mlrun.api.schemas.ProjectsOutput(
+ if format_ == mlrun.common.schemas.ProjectsFormat.full:
+ return mlrun.common.schemas.ProjectsOutput(projects=projects)
+ elif format_ == mlrun.common.schemas.ProjectsFormat.name_only:
+ return mlrun.common.schemas.ProjectsOutput(
projects=[project.metadata.name for project in projects]
)
else:
@@ -170,14 +170,14 @@ def list_project_summaries(
session: sqlalchemy.orm.Session,
owner: str = None,
labels: typing.List[str] = None,
- state: mlrun.api.schemas.ProjectState = None,
+ state: mlrun.common.schemas.ProjectState = None,
names: typing.Optional[typing.List[str]] = None,
- ) -> mlrun.api.schemas.ProjectSummariesOutput:
+ ) -> mlrun.common.schemas.ProjectSummariesOutput:
raise NotImplementedError("Listing project summaries is not supported")
def get_project_summary(
self, session: sqlalchemy.orm.Session, name: str
- ) -> mlrun.api.schemas.ProjectSummary:
+ ) -> mlrun.common.schemas.ProjectSummary:
raise NotImplementedError("Get project summary is not supported")
def get_dashboard_version(self) -> str:
@@ -226,7 +226,7 @@ def _send_request_to_api(self, method, path, **kwargs):
return response
@staticmethod
- def _generate_request_body(project: mlrun.api.schemas.Project):
+ def _generate_request_body(project: mlrun.common.schemas.Project):
body = {
"metadata": {"name": project.metadata.name},
}
@@ -240,13 +240,13 @@ def _generate_request_body(project: mlrun.api.schemas.Project):
@staticmethod
def _transform_nuclio_project_to_schema(nuclio_project):
- return mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(
+ return mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(
name=nuclio_project["metadata"]["name"],
labels=nuclio_project["metadata"].get("labels"),
annotations=nuclio_project["metadata"].get("annotations"),
),
- spec=mlrun.api.schemas.ProjectSpec(
+ spec=mlrun.common.schemas.ProjectSpec(
description=nuclio_project["spec"].get("description")
),
)
diff --git a/mlrun/api/utils/clients/protocols/grpc.py b/mlrun/api/utils/clients/protocols/grpc.py
index 311100475acc..5cd82e267b1e 100644
--- a/mlrun/api/utils/clients/protocols/grpc.py
+++ b/mlrun/api/utils/clients/protocols/grpc.py
@@ -15,7 +15,7 @@
import google.protobuf.reflection
import grpc
-import mlrun.api.schemas
+import mlrun.common.schemas
import mlrun.config
import mlrun.errors
diff --git a/mlrun/api/utils/helpers.py b/mlrun/api/utils/helpers.py
index 43dcdc0c8acd..7cc8499b9193 100644
--- a/mlrun/api/utils/helpers.py
+++ b/mlrun/api/utils/helpers.py
@@ -13,22 +13,12 @@
# limitations under the License.
#
import asyncio
-import enum
import mlrun
-import mlrun.api.schemas
+import mlrun.common.schemas
from mlrun.utils import logger
-# TODO: From python 3.11 StrEnum is built-in and this will not be needed
-class StrEnum(str, enum.Enum):
- def __str__(self):
- return self.value
-
- def __repr__(self):
- return self.value
-
-
def ensure_running_on_chief(function):
"""
The motivation of this function is to catch development bugs in which we are accidentally using functions / flows
@@ -41,7 +31,7 @@ def ensure_running_on_chief(function):
def _ensure_running_on_chief():
if (
mlrun.mlconf.httpdb.clusterization.role
- != mlrun.api.schemas.ClusterizationRole.chief
+ != mlrun.common.schemas.ClusterizationRole.chief
):
if (
mlrun.mlconf.httpdb.clusterization.ensure_function_running_on_chief_mode
diff --git a/mlrun/api/utils/projects/follower.py b/mlrun/api/utils/projects/follower.py
index b2c88f181b72..f2eef0b4ccc4 100644
--- a/mlrun/api/utils/projects/follower.py
+++ b/mlrun/api/utils/projects/follower.py
@@ -23,7 +23,6 @@
import mlrun.api.crud
import mlrun.api.db.session
-import mlrun.api.schemas
import mlrun.api.utils.auth.verifier
import mlrun.api.utils.clients.iguazio
import mlrun.api.utils.clients.nuclio
@@ -31,6 +30,7 @@
import mlrun.api.utils.projects.member
import mlrun.api.utils.projects.remotes.leader
import mlrun.api.utils.projects.remotes.nop_leader
+import mlrun.common.schemas
import mlrun.config
import mlrun.errors
import mlrun.utils
@@ -78,7 +78,7 @@ def initialize(self):
# we're doing a full_sync on every initialization
full_sync = (
mlrun.mlconf.httpdb.clusterization.role
- == mlrun.api.schemas.ClusterizationRole.chief
+ == mlrun.common.schemas.ClusterizationRole.chief
)
self._sync_projects(full_sync=full_sync)
except Exception as exc:
@@ -96,12 +96,12 @@ def shutdown(self):
def create_project(
self,
db_session: sqlalchemy.orm.Session,
- project: mlrun.api.schemas.Project,
- projects_role: typing.Optional[mlrun.api.schemas.ProjectsRole] = None,
+ project: mlrun.common.schemas.Project,
+ projects_role: typing.Optional[mlrun.common.schemas.ProjectsRole] = None,
leader_session: typing.Optional[str] = None,
wait_for_completion: bool = True,
commit_before_get: bool = False,
- ) -> typing.Tuple[typing.Optional[mlrun.api.schemas.Project], bool]:
+ ) -> typing.Tuple[typing.Optional[mlrun.common.schemas.Project], bool]:
if self._is_request_from_leader(projects_role):
mlrun.api.crud.Projects().create_project(db_session, project)
return project, False
@@ -137,11 +137,11 @@ def store_project(
self,
db_session: sqlalchemy.orm.Session,
name: str,
- project: mlrun.api.schemas.Project,
- projects_role: typing.Optional[mlrun.api.schemas.ProjectsRole] = None,
+ project: mlrun.common.schemas.Project,
+ projects_role: typing.Optional[mlrun.common.schemas.ProjectsRole] = None,
leader_session: typing.Optional[str] = None,
wait_for_completion: bool = True,
- ) -> typing.Tuple[typing.Optional[mlrun.api.schemas.Project], bool]:
+ ) -> typing.Tuple[typing.Optional[mlrun.common.schemas.Project], bool]:
if self._is_request_from_leader(projects_role):
mlrun.api.crud.Projects().store_project(db_session, name, project)
return project, False
@@ -166,11 +166,11 @@ def patch_project(
db_session: sqlalchemy.orm.Session,
name: str,
project: dict,
- patch_mode: mlrun.api.schemas.PatchMode = mlrun.api.schemas.PatchMode.replace,
- projects_role: typing.Optional[mlrun.api.schemas.ProjectsRole] = None,
+ patch_mode: mlrun.common.schemas.PatchMode = mlrun.common.schemas.PatchMode.replace,
+ projects_role: typing.Optional[mlrun.common.schemas.ProjectsRole] = None,
leader_session: typing.Optional[str] = None,
wait_for_completion: bool = True,
- ) -> typing.Tuple[typing.Optional[mlrun.api.schemas.Project], bool]:
+ ) -> typing.Tuple[typing.Optional[mlrun.common.schemas.Project], bool]:
if self._is_request_from_leader(projects_role):
# No real scenario for this to be useful currently - in iguazio patch is transformed to store request
raise NotImplementedError("Patch operation not supported from leader")
@@ -179,7 +179,7 @@ def patch_project(
strategy = patch_mode.to_mergedeep_strategy()
current_project_dict = current_project.dict(exclude_unset=True)
mergedeep.merge(current_project_dict, project, strategy=strategy)
- patched_project = mlrun.api.schemas.Project(**current_project_dict)
+ patched_project = mlrun.common.schemas.Project(**current_project_dict)
return self.store_project(
db_session,
name,
@@ -193,9 +193,9 @@ def delete_project(
self,
db_session: sqlalchemy.orm.Session,
name: str,
- deletion_strategy: mlrun.api.schemas.DeletionStrategy = mlrun.api.schemas.DeletionStrategy.default(),
- projects_role: typing.Optional[mlrun.api.schemas.ProjectsRole] = None,
- auth_info: mlrun.api.schemas.AuthInfo = mlrun.api.schemas.AuthInfo(),
+ deletion_strategy: mlrun.common.schemas.DeletionStrategy = mlrun.common.schemas.DeletionStrategy.default(),
+ projects_role: typing.Optional[mlrun.common.schemas.ProjectsRole] = None,
+ auth_info: mlrun.common.schemas.AuthInfo = mlrun.common.schemas.AuthInfo(),
wait_for_completion: bool = True,
) -> bool:
if self._is_request_from_leader(projects_role):
@@ -216,30 +216,30 @@ def get_project(
db_session: sqlalchemy.orm.Session,
name: str,
leader_session: typing.Optional[str] = None,
- ) -> mlrun.api.schemas.Project:
+ ) -> mlrun.common.schemas.Project:
return mlrun.api.crud.Projects().get_project(db_session, name)
def get_project_owner(
self,
db_session: sqlalchemy.orm.Session,
name: str,
- ) -> mlrun.api.schemas.ProjectOwner:
+ ) -> mlrun.common.schemas.ProjectOwner:
return self._leader_client.get_project_owner(self._sync_session, name)
def list_projects(
self,
db_session: sqlalchemy.orm.Session,
owner: str = None,
- format_: mlrun.api.schemas.ProjectsFormat = mlrun.api.schemas.ProjectsFormat.full,
+ format_: mlrun.common.schemas.ProjectsFormat = mlrun.common.schemas.ProjectsFormat.full,
labels: typing.List[str] = None,
- state: mlrun.api.schemas.ProjectState = None,
+ state: mlrun.common.schemas.ProjectState = None,
# needed only for external usage when requesting leader format
- projects_role: typing.Optional[mlrun.api.schemas.ProjectsRole] = None,
+ projects_role: typing.Optional[mlrun.common.schemas.ProjectsRole] = None,
leader_session: typing.Optional[str] = None,
names: typing.Optional[typing.List[str]] = None,
- ) -> mlrun.api.schemas.ProjectsOutput:
+ ) -> mlrun.common.schemas.ProjectsOutput:
if (
- format_ == mlrun.api.schemas.ProjectsFormat.leader
+ format_ == mlrun.common.schemas.ProjectsFormat.leader
and not self._is_request_from_leader(projects_role)
):
raise mlrun.errors.MLRunAccessDeniedError(
@@ -249,7 +249,7 @@ def list_projects(
projects_output = mlrun.api.crud.Projects().list_projects(
db_session, owner, format_, labels, state, names
)
- if format_ == mlrun.api.schemas.ProjectsFormat.leader:
+ if format_ == mlrun.common.schemas.ProjectsFormat.leader:
leader_projects = [
self._leader_client.format_as_leader_project(project)
for project in projects_output.projects
@@ -262,11 +262,11 @@ async def list_project_summaries(
db_session: sqlalchemy.orm.Session,
owner: str = None,
labels: typing.List[str] = None,
- state: mlrun.api.schemas.ProjectState = None,
- projects_role: typing.Optional[mlrun.api.schemas.ProjectsRole] = None,
+ state: mlrun.common.schemas.ProjectState = None,
+ projects_role: typing.Optional[mlrun.common.schemas.ProjectsRole] = None,
leader_session: typing.Optional[str] = None,
names: typing.Optional[typing.List[str]] = None,
- ) -> mlrun.api.schemas.ProjectSummariesOutput:
+ ) -> mlrun.common.schemas.ProjectSummariesOutput:
return await mlrun.api.crud.Projects().list_project_summaries(
db_session, owner, labels, state, names
)
@@ -276,7 +276,7 @@ async def get_project_summary(
db_session: sqlalchemy.orm.Session,
name: str,
leader_session: typing.Optional[str] = None,
- ) -> mlrun.api.schemas.ProjectSummary:
+ ) -> mlrun.common.schemas.ProjectSummary:
return await mlrun.api.crud.Projects().get_project_summary(db_session, name)
def _start_periodic_sync(self):
@@ -316,14 +316,14 @@ def _sync_projects(self, full_sync=False):
db_session = mlrun.api.db.session.create_session()
try:
db_projects = mlrun.api.crud.Projects().list_projects(
- db_session, format_=mlrun.api.schemas.ProjectsFormat.name_only
+ db_session, format_=mlrun.common.schemas.ProjectsFormat.name_only
)
# Don't add projects in non terminal state if they didn't exist before to prevent race conditions
filtered_projects = []
for leader_project in leader_projects:
if (
leader_project.status.state
- not in mlrun.api.schemas.ProjectState.terminal_states()
+ not in mlrun.common.schemas.ProjectState.terminal_states()
and leader_project.metadata.name not in db_projects.projects
):
continue
@@ -349,7 +349,7 @@ def _sync_projects(self, full_sync=False):
mlrun.api.crud.Projects().delete_project(
db_session,
project_to_remove,
- mlrun.api.schemas.DeletionStrategy.cascading,
+ mlrun.common.schemas.DeletionStrategy.cascading,
)
if latest_updated_at:
@@ -363,7 +363,7 @@ def _sync_projects(self, full_sync=False):
mlrun.api.db.session.close_session(db_session)
def _is_request_from_leader(
- self, projects_role: typing.Optional[mlrun.api.schemas.ProjectsRole]
+ self, projects_role: typing.Optional[mlrun.common.schemas.ProjectsRole]
) -> bool:
if projects_role and projects_role.value == self._leader_name:
return True
@@ -371,7 +371,7 @@ def _is_request_from_leader(
@staticmethod
def _is_project_matching_labels(
- labels: typing.List[str], project: mlrun.api.schemas.Project
+ labels: typing.List[str], project: mlrun.common.schemas.Project
):
if not project.metadata.labels:
return False
diff --git a/mlrun/api/utils/projects/leader.py b/mlrun/api/utils/projects/leader.py
index 30af77ee6676..d6470ae1d1d2 100644
--- a/mlrun/api/utils/projects/leader.py
+++ b/mlrun/api/utils/projects/leader.py
@@ -20,12 +20,12 @@
import sqlalchemy.orm
import mlrun.api.db.session
-import mlrun.api.schemas
import mlrun.api.utils.clients.nuclio
import mlrun.api.utils.periodic
import mlrun.api.utils.projects.member
import mlrun.api.utils.projects.remotes.follower
import mlrun.api.utils.projects.remotes.nop_follower
+import mlrun.common.schemas
import mlrun.config
import mlrun.errors
import mlrun.utils
@@ -58,12 +58,12 @@ def shutdown(self):
def create_project(
self,
db_session: sqlalchemy.orm.Session,
- project: mlrun.api.schemas.Project,
- projects_role: typing.Optional[mlrun.api.schemas.ProjectsRole] = None,
+ project: mlrun.common.schemas.Project,
+ projects_role: typing.Optional[mlrun.common.schemas.ProjectsRole] = None,
leader_session: typing.Optional[str] = None,
wait_for_completion: bool = True,
commit_before_get: bool = False,
- ) -> typing.Tuple[typing.Optional[mlrun.api.schemas.Project], bool]:
+ ) -> typing.Tuple[typing.Optional[mlrun.common.schemas.Project], bool]:
self._enrich_and_validate_before_creation(project)
self._run_on_all_followers(True, "create_project", db_session, project)
return self.get_project(db_session, project.metadata.name), False
@@ -72,11 +72,11 @@ def store_project(
self,
db_session: sqlalchemy.orm.Session,
name: str,
- project: mlrun.api.schemas.Project,
- projects_role: typing.Optional[mlrun.api.schemas.ProjectsRole] = None,
+ project: mlrun.common.schemas.Project,
+ projects_role: typing.Optional[mlrun.common.schemas.ProjectsRole] = None,
leader_session: typing.Optional[str] = None,
wait_for_completion: bool = True,
- ) -> typing.Tuple[typing.Optional[mlrun.api.schemas.Project], bool]:
+ ) -> typing.Tuple[typing.Optional[mlrun.common.schemas.Project], bool]:
self._enrich_project(project)
mlrun.projects.ProjectMetadata.validate_project_name(name)
self._validate_body_and_path_names_matches(name, project)
@@ -88,11 +88,11 @@ def patch_project(
db_session: sqlalchemy.orm.Session,
name: str,
project: dict,
- patch_mode: mlrun.api.schemas.PatchMode = mlrun.api.schemas.PatchMode.replace,
- projects_role: typing.Optional[mlrun.api.schemas.ProjectsRole] = None,
+ patch_mode: mlrun.common.schemas.PatchMode = mlrun.common.schemas.PatchMode.replace,
+ projects_role: typing.Optional[mlrun.common.schemas.ProjectsRole] = None,
leader_session: typing.Optional[str] = None,
wait_for_completion: bool = True,
- ) -> typing.Tuple[mlrun.api.schemas.Project, bool]:
+ ) -> typing.Tuple[mlrun.common.schemas.Project, bool]:
self._enrich_project_patch(project)
self._validate_body_and_path_names_matches(name, project)
self._run_on_all_followers(
@@ -104,9 +104,9 @@ def delete_project(
self,
db_session: sqlalchemy.orm.Session,
name: str,
- deletion_strategy: mlrun.api.schemas.DeletionStrategy = mlrun.api.schemas.DeletionStrategy.default(),
- projects_role: typing.Optional[mlrun.api.schemas.ProjectsRole] = None,
- auth_info: mlrun.api.schemas.AuthInfo = mlrun.api.schemas.AuthInfo(),
+ deletion_strategy: mlrun.common.schemas.DeletionStrategy = mlrun.common.schemas.DeletionStrategy.default(),
+ projects_role: typing.Optional[mlrun.common.schemas.ProjectsRole] = None,
+ auth_info: mlrun.common.schemas.AuthInfo = mlrun.common.schemas.AuthInfo(),
wait_for_completion: bool = True,
) -> bool:
self._projects_in_deletion.add(name)
@@ -123,20 +123,20 @@ def get_project(
db_session: sqlalchemy.orm.Session,
name: str,
leader_session: typing.Optional[str] = None,
- ) -> mlrun.api.schemas.Project:
+ ) -> mlrun.common.schemas.Project:
return self._leader_follower.get_project(db_session, name)
def list_projects(
self,
db_session: sqlalchemy.orm.Session,
owner: str = None,
- format_: mlrun.api.schemas.ProjectsFormat = mlrun.api.schemas.ProjectsFormat.full,
+ format_: mlrun.common.schemas.ProjectsFormat = mlrun.common.schemas.ProjectsFormat.full,
labels: typing.List[str] = None,
- state: mlrun.api.schemas.ProjectState = None,
- projects_role: typing.Optional[mlrun.api.schemas.ProjectsRole] = None,
+ state: mlrun.common.schemas.ProjectState = None,
+ projects_role: typing.Optional[mlrun.common.schemas.ProjectsRole] = None,
leader_session: typing.Optional[str] = None,
names: typing.Optional[typing.List[str]] = None,
- ) -> mlrun.api.schemas.ProjectsOutput:
+ ) -> mlrun.common.schemas.ProjectsOutput:
return self._leader_follower.list_projects(
db_session, owner, format_, labels, state, names
)
@@ -146,11 +146,11 @@ async def list_project_summaries(
db_session: sqlalchemy.orm.Session,
owner: str = None,
labels: typing.List[str] = None,
- state: mlrun.api.schemas.ProjectState = None,
- projects_role: typing.Optional[mlrun.api.schemas.ProjectsRole] = None,
+ state: mlrun.common.schemas.ProjectState = None,
+ projects_role: typing.Optional[mlrun.common.schemas.ProjectsRole] = None,
leader_session: typing.Optional[str] = None,
names: typing.Optional[typing.List[str]] = None,
- ) -> mlrun.api.schemas.ProjectSummariesOutput:
+ ) -> mlrun.common.schemas.ProjectSummariesOutput:
return await self._leader_follower.list_project_summaries(
db_session, owner, labels, state, names
)
@@ -160,14 +160,14 @@ async def get_project_summary(
db_session: sqlalchemy.orm.Session,
name: str,
leader_session: typing.Optional[str] = None,
- ) -> mlrun.api.schemas.ProjectSummary:
+ ) -> mlrun.common.schemas.ProjectSummary:
return await self._leader_follower.get_project_summary(db_session, name)
def get_project_owner(
self,
db_session: sqlalchemy.orm.Session,
name: str,
- ) -> mlrun.api.schemas.ProjectOwner:
+ ) -> mlrun.common.schemas.ProjectOwner:
raise NotImplementedError()
def _start_periodic_sync(self):
@@ -192,8 +192,8 @@ def _sync_projects(self):
db_session = mlrun.api.db.session.create_session()
try:
# re-generating all of the maps every time since _ensure_follower_projects_synced might cause changes
- leader_projects: mlrun.api.schemas.ProjectsOutput
- follower_projects_map: typing.Dict[str, mlrun.api.schemas.ProjectsOutput]
+ leader_projects: mlrun.common.schemas.ProjectsOutput
+ follower_projects_map: typing.Dict[str, mlrun.common.schemas.ProjectsOutput]
leader_projects, follower_projects_map = self._run_on_all_followers(
True, "list_projects", db_session
)
@@ -245,9 +245,9 @@ def _ensure_project_synced(
follower_names: typing.Set[str],
project_name: str,
followers_projects_map: typing.Dict[
- str, typing.Dict[str, mlrun.api.schemas.Project]
+ str, typing.Dict[str, mlrun.common.schemas.Project]
],
- leader_projects_map: typing.Dict[str, mlrun.api.schemas.Project],
+ leader_projects_map: typing.Dict[str, mlrun.common.schemas.Project],
):
# FIXME: This function only handles syncing project existence, i.e. if a user updates a project attribute
# through one of the followers this change won't be synced and the projects will be left with this discrepancy
@@ -308,7 +308,7 @@ def _store_project_in_followers(
db_session: sqlalchemy.orm.Session,
follower_names: typing.Set[str],
project_name: str,
- project: mlrun.api.schemas.Project,
+ project: mlrun.common.schemas.Project,
):
for follower_name in follower_names:
logger.debug(
@@ -341,7 +341,7 @@ def _create_project_in_missing_followers(
# the name of the follower which we took the missing project from
project_follower_name: str,
project_name: str,
- project: mlrun.api.schemas.Project,
+ project: mlrun.common.schemas.Project,
):
for missing_follower in missing_followers:
logger.debug(
@@ -428,12 +428,14 @@ def _initialize_follower(
raise ValueError(f"Unknown follower name: {name}")
return followers_classes_map[name]
- def _enrich_and_validate_before_creation(self, project: mlrun.api.schemas.Project):
+ def _enrich_and_validate_before_creation(
+ self, project: mlrun.common.schemas.Project
+ ):
self._enrich_project(project)
mlrun.projects.ProjectMetadata.validate_project_name(project.metadata.name)
@staticmethod
- def _enrich_project(project: mlrun.api.schemas.Project):
+ def _enrich_project(project: mlrun.common.schemas.Project):
project.status.state = project.spec.desired_state
@staticmethod
@@ -457,9 +459,9 @@ def validate_project_name(name: str, raise_on_failure: bool = True) -> bool:
@staticmethod
def _validate_body_and_path_names_matches(
- path_name: str, project: typing.Union[mlrun.api.schemas.Project, dict]
+ path_name: str, project: typing.Union[mlrun.common.schemas.Project, dict]
):
- if isinstance(project, mlrun.api.schemas.Project):
+ if isinstance(project, mlrun.common.schemas.Project):
body_name = project.metadata.name
elif isinstance(project, dict):
body_name = project.get("metadata", {}).get("name")
diff --git a/mlrun/api/utils/projects/member.py b/mlrun/api/utils/projects/member.py
index 9f71e80274cd..779cde48c162 100644
--- a/mlrun/api/utils/projects/member.py
+++ b/mlrun/api/utils/projects/member.py
@@ -19,8 +19,8 @@
import mlrun.api.crud
import mlrun.api.db.session
-import mlrun.api.schemas
import mlrun.api.utils.clients.log_collector
+import mlrun.common.schemas
import mlrun.utils.singleton
from mlrun.utils import logger
@@ -39,11 +39,11 @@ def ensure_project(
db_session: sqlalchemy.orm.Session,
name: str,
wait_for_completion: bool = True,
- auth_info: mlrun.api.schemas.AuthInfo = mlrun.api.schemas.AuthInfo(),
+ auth_info: mlrun.common.schemas.AuthInfo = mlrun.common.schemas.AuthInfo(),
):
project_names = self.list_projects(
db_session,
- format_=mlrun.api.schemas.ProjectsFormat.name_only,
+ format_=mlrun.common.schemas.ProjectsFormat.name_only,
leader_session=auth_info.session,
)
if name not in project_names.projects:
@@ -53,12 +53,12 @@ def ensure_project(
def create_project(
self,
db_session: sqlalchemy.orm.Session,
- project: mlrun.api.schemas.Project,
- projects_role: typing.Optional[mlrun.api.schemas.ProjectsRole] = None,
+ project: mlrun.common.schemas.Project,
+ projects_role: typing.Optional[mlrun.common.schemas.ProjectsRole] = None,
leader_session: typing.Optional[str] = None,
wait_for_completion: bool = True,
commit_before_get: bool = False,
- ) -> typing.Tuple[typing.Optional[mlrun.api.schemas.Project], bool]:
+ ) -> typing.Tuple[typing.Optional[mlrun.common.schemas.Project], bool]:
pass
@abc.abstractmethod
@@ -66,11 +66,11 @@ def store_project(
self,
db_session: sqlalchemy.orm.Session,
name: str,
- project: mlrun.api.schemas.Project,
- projects_role: typing.Optional[mlrun.api.schemas.ProjectsRole] = None,
+ project: mlrun.common.schemas.Project,
+ projects_role: typing.Optional[mlrun.common.schemas.ProjectsRole] = None,
leader_session: typing.Optional[str] = None,
wait_for_completion: bool = True,
- ) -> typing.Tuple[typing.Optional[mlrun.api.schemas.Project], bool]:
+ ) -> typing.Tuple[typing.Optional[mlrun.common.schemas.Project], bool]:
pass
@abc.abstractmethod
@@ -79,11 +79,11 @@ def patch_project(
db_session: sqlalchemy.orm.Session,
name: str,
project: dict,
- patch_mode: mlrun.api.schemas.PatchMode = mlrun.api.schemas.PatchMode.replace,
- projects_role: typing.Optional[mlrun.api.schemas.ProjectsRole] = None,
+ patch_mode: mlrun.common.schemas.PatchMode = mlrun.common.schemas.PatchMode.replace,
+ projects_role: typing.Optional[mlrun.common.schemas.ProjectsRole] = None,
leader_session: typing.Optional[str] = None,
wait_for_completion: bool = True,
- ) -> typing.Tuple[mlrun.api.schemas.Project, bool]:
+ ) -> typing.Tuple[mlrun.common.schemas.Project, bool]:
pass
@abc.abstractmethod
@@ -91,9 +91,9 @@ def delete_project(
self,
db_session: sqlalchemy.orm.Session,
name: str,
- deletion_strategy: mlrun.api.schemas.DeletionStrategy = mlrun.api.schemas.DeletionStrategy.default(),
- projects_role: typing.Optional[mlrun.api.schemas.ProjectsRole] = None,
- auth_info: mlrun.api.schemas.AuthInfo = mlrun.api.schemas.AuthInfo(),
+ deletion_strategy: mlrun.common.schemas.DeletionStrategy = mlrun.common.schemas.DeletionStrategy.default(),
+ projects_role: typing.Optional[mlrun.common.schemas.ProjectsRole] = None,
+ auth_info: mlrun.common.schemas.AuthInfo = mlrun.common.schemas.AuthInfo(),
wait_for_completion: bool = True,
) -> bool:
pass
@@ -104,7 +104,7 @@ def get_project(
db_session: sqlalchemy.orm.Session,
name: str,
leader_session: typing.Optional[str] = None,
- ) -> mlrun.api.schemas.Project:
+ ) -> mlrun.common.schemas.Project:
pass
@abc.abstractmethod
@@ -112,13 +112,13 @@ def list_projects(
self,
db_session: sqlalchemy.orm.Session,
owner: str = None,
- format_: mlrun.api.schemas.ProjectsFormat = mlrun.api.schemas.ProjectsFormat.full,
+ format_: mlrun.common.schemas.ProjectsFormat = mlrun.common.schemas.ProjectsFormat.full,
labels: typing.List[str] = None,
- state: mlrun.api.schemas.ProjectState = None,
- projects_role: typing.Optional[mlrun.api.schemas.ProjectsRole] = None,
+ state: mlrun.common.schemas.ProjectState = None,
+ projects_role: typing.Optional[mlrun.common.schemas.ProjectsRole] = None,
leader_session: typing.Optional[str] = None,
names: typing.Optional[typing.List[str]] = None,
- ) -> mlrun.api.schemas.ProjectsOutput:
+ ) -> mlrun.common.schemas.ProjectsOutput:
pass
@abc.abstractmethod
@@ -127,7 +127,7 @@ async def get_project_summary(
db_session: sqlalchemy.orm.Session,
name: str,
leader_session: typing.Optional[str] = None,
- ) -> mlrun.api.schemas.ProjectSummary:
+ ) -> mlrun.common.schemas.ProjectSummary:
pass
@abc.abstractmethod
@@ -136,11 +136,11 @@ async def list_project_summaries(
db_session: sqlalchemy.orm.Session,
owner: str = None,
labels: typing.List[str] = None,
- state: mlrun.api.schemas.ProjectState = None,
- projects_role: typing.Optional[mlrun.api.schemas.ProjectsRole] = None,
+ state: mlrun.common.schemas.ProjectState = None,
+ projects_role: typing.Optional[mlrun.common.schemas.ProjectsRole] = None,
leader_session: typing.Optional[str] = None,
names: typing.Optional[typing.List[str]] = None,
- ) -> mlrun.api.schemas.ProjectSummariesOutput:
+ ) -> mlrun.common.schemas.ProjectSummariesOutput:
pass
@abc.abstractmethod
@@ -148,7 +148,7 @@ def get_project_owner(
self,
db_session: sqlalchemy.orm.Session,
name: str,
- ) -> mlrun.api.schemas.ProjectOwner:
+ ) -> mlrun.common.schemas.ProjectOwner:
pass
async def post_delete_project(
@@ -157,7 +157,7 @@ async def post_delete_project(
):
if (
mlrun.mlconf.log_collector.mode
- != mlrun.api.schemas.LogsCollectorMode.legacy
+ != mlrun.common.schemas.LogsCollectorMode.legacy
):
await self._stop_logs_for_project(project_name)
await self._delete_project_logs(project_name)
diff --git a/mlrun/api/utils/projects/remotes/follower.py b/mlrun/api/utils/projects/remotes/follower.py
index 39777156043c..73c679a34d04 100644
--- a/mlrun/api/utils/projects/remotes/follower.py
+++ b/mlrun/api/utils/projects/remotes/follower.py
@@ -17,13 +17,13 @@
import sqlalchemy.orm
-import mlrun.api.schemas
+import mlrun.common.schemas
class Member(abc.ABC):
@abc.abstractmethod
def create_project(
- self, session: sqlalchemy.orm.Session, project: mlrun.api.schemas.Project
+ self, session: sqlalchemy.orm.Session, project: mlrun.common.schemas.Project
):
pass
@@ -32,7 +32,7 @@ def store_project(
self,
session: sqlalchemy.orm.Session,
name: str,
- project: mlrun.api.schemas.Project,
+ project: mlrun.common.schemas.Project,
):
pass
@@ -42,7 +42,7 @@ def patch_project(
session: sqlalchemy.orm.Session,
name: str,
project: dict,
- patch_mode: mlrun.api.schemas.PatchMode = mlrun.api.schemas.PatchMode.replace,
+ patch_mode: mlrun.common.schemas.PatchMode = mlrun.common.schemas.PatchMode.replace,
):
pass
@@ -51,14 +51,14 @@ def delete_project(
self,
session: sqlalchemy.orm.Session,
name: str,
- deletion_strategy: mlrun.api.schemas.DeletionStrategy = mlrun.api.schemas.DeletionStrategy.default(),
+ deletion_strategy: mlrun.common.schemas.DeletionStrategy = mlrun.common.schemas.DeletionStrategy.default(),
):
pass
@abc.abstractmethod
def get_project(
self, session: sqlalchemy.orm.Session, name: str
- ) -> mlrun.api.schemas.Project:
+ ) -> mlrun.common.schemas.Project:
pass
@abc.abstractmethod
@@ -66,11 +66,11 @@ def list_projects(
self,
session: sqlalchemy.orm.Session,
owner: str = None,
- format_: mlrun.api.schemas.ProjectsFormat = mlrun.api.schemas.ProjectsFormat.full,
+ format_: mlrun.common.schemas.ProjectsFormat = mlrun.common.schemas.ProjectsFormat.full,
labels: typing.List[str] = None,
- state: mlrun.api.schemas.ProjectState = None,
+ state: mlrun.common.schemas.ProjectState = None,
names: typing.Optional[typing.List[str]] = None,
- ) -> mlrun.api.schemas.ProjectsOutput:
+ ) -> mlrun.common.schemas.ProjectsOutput:
pass
@abc.abstractmethod
@@ -79,13 +79,13 @@ def list_project_summaries(
session: sqlalchemy.orm.Session,
owner: str = None,
labels: typing.List[str] = None,
- state: mlrun.api.schemas.ProjectState = None,
+ state: mlrun.common.schemas.ProjectState = None,
names: typing.Optional[typing.List[str]] = None,
- ) -> mlrun.api.schemas.ProjectSummariesOutput:
+ ) -> mlrun.common.schemas.ProjectSummariesOutput:
pass
@abc.abstractmethod
def get_project_summary(
self, session: sqlalchemy.orm.Session, name: str
- ) -> mlrun.api.schemas.ProjectSummary:
+ ) -> mlrun.common.schemas.ProjectSummary:
pass
diff --git a/mlrun/api/utils/projects/remotes/leader.py b/mlrun/api/utils/projects/remotes/leader.py
index 3b7522905438..3283f6d6614c 100644
--- a/mlrun/api/utils/projects/remotes/leader.py
+++ b/mlrun/api/utils/projects/remotes/leader.py
@@ -16,7 +16,7 @@
import datetime
import typing
-import mlrun.api.schemas
+import mlrun.common.schemas
class Member(abc.ABC):
@@ -24,7 +24,7 @@ class Member(abc.ABC):
def create_project(
self,
session: str,
- project: mlrun.api.schemas.Project,
+ project: mlrun.common.schemas.Project,
wait_for_completion: bool = True,
) -> bool:
pass
@@ -34,7 +34,7 @@ def update_project(
self,
session: str,
name: str,
- project: mlrun.api.schemas.Project,
+ project: mlrun.common.schemas.Project,
):
pass
@@ -43,7 +43,7 @@ def delete_project(
self,
session: str,
name: str,
- deletion_strategy: mlrun.api.schemas.DeletionStrategy = mlrun.api.schemas.DeletionStrategy.default(),
+ deletion_strategy: mlrun.common.schemas.DeletionStrategy = mlrun.common.schemas.DeletionStrategy.default(),
wait_for_completion: bool = True,
) -> bool:
pass
@@ -54,7 +54,7 @@ def list_projects(
session: str,
updated_after: typing.Optional[datetime.datetime] = None,
) -> typing.Tuple[
- typing.List[mlrun.api.schemas.Project], typing.Optional[datetime.datetime]
+ typing.List[mlrun.common.schemas.Project], typing.Optional[datetime.datetime]
]:
pass
@@ -63,13 +63,13 @@ def get_project(
self,
session: str,
name: str,
- ) -> mlrun.api.schemas.Project:
+ ) -> mlrun.common.schemas.Project:
pass
@abc.abstractmethod
def format_as_leader_project(
- self, project: mlrun.api.schemas.Project
- ) -> mlrun.api.schemas.IguazioProject:
+ self, project: mlrun.common.schemas.Project
+ ) -> mlrun.common.schemas.IguazioProject:
pass
@abc.abstractmethod
@@ -77,5 +77,5 @@ def get_project_owner(
self,
session: str,
name: str,
- ) -> mlrun.api.schemas.ProjectOwner:
+ ) -> mlrun.common.schemas.ProjectOwner:
pass
diff --git a/mlrun/api/utils/projects/remotes/nop_follower.py b/mlrun/api/utils/projects/remotes/nop_follower.py
index d29e6bb3420d..a2af0a42b20e 100644
--- a/mlrun/api/utils/projects/remotes/nop_follower.py
+++ b/mlrun/api/utils/projects/remotes/nop_follower.py
@@ -17,18 +17,18 @@
import mergedeep
import sqlalchemy.orm
-import mlrun.api.schemas
import mlrun.api.utils.projects.remotes.follower
+import mlrun.common.schemas
import mlrun.errors
class Member(mlrun.api.utils.projects.remotes.follower.Member):
def __init__(self) -> None:
super().__init__()
- self._projects: typing.Dict[str, mlrun.api.schemas.Project] = {}
+ self._projects: typing.Dict[str, mlrun.common.schemas.Project] = {}
def create_project(
- self, session: sqlalchemy.orm.Session, project: mlrun.api.schemas.Project
+ self, session: sqlalchemy.orm.Session, project: mlrun.common.schemas.Project
):
if project.metadata.name in self._projects:
raise mlrun.errors.MLRunConflictError("Project already exists")
@@ -39,7 +39,7 @@ def store_project(
self,
session: sqlalchemy.orm.Session,
name: str,
- project: mlrun.api.schemas.Project,
+ project: mlrun.common.schemas.Project,
):
# deep copy so we won't accidentally get changes from tests
self._projects[name] = project.copy(deep=True)
@@ -49,25 +49,25 @@ def patch_project(
session: sqlalchemy.orm.Session,
name: str,
project: dict,
- patch_mode: mlrun.api.schemas.PatchMode = mlrun.api.schemas.PatchMode.replace,
+ patch_mode: mlrun.common.schemas.PatchMode = mlrun.common.schemas.PatchMode.replace,
):
existing_project_dict = self._projects[name].dict()
strategy = patch_mode.to_mergedeep_strategy()
mergedeep.merge(existing_project_dict, project, strategy=strategy)
- self._projects[name] = mlrun.api.schemas.Project(**existing_project_dict)
+ self._projects[name] = mlrun.common.schemas.Project(**existing_project_dict)
def delete_project(
self,
session: sqlalchemy.orm.Session,
name: str,
- deletion_strategy: mlrun.api.schemas.DeletionStrategy = mlrun.api.schemas.DeletionStrategy.default(),
+ deletion_strategy: mlrun.common.schemas.DeletionStrategy = mlrun.common.schemas.DeletionStrategy.default(),
):
if name in self._projects:
del self._projects[name]
def get_project(
self, session: sqlalchemy.orm.Session, name: str
- ) -> mlrun.api.schemas.Project:
+ ) -> mlrun.common.schemas.Project:
# deep copy so we won't accidentally get changes from tests
return self._projects[name].copy(deep=True)
@@ -75,11 +75,11 @@ def list_projects(
self,
session: sqlalchemy.orm.Session,
owner: str = None,
- format_: mlrun.api.schemas.ProjectsFormat = mlrun.api.schemas.ProjectsFormat.full,
+ format_: mlrun.common.schemas.ProjectsFormat = mlrun.common.schemas.ProjectsFormat.full,
labels: typing.List[str] = None,
- state: mlrun.api.schemas.ProjectState = None,
+ state: mlrun.common.schemas.ProjectState = None,
names: typing.Optional[typing.List[str]] = None,
- ) -> mlrun.api.schemas.ProjectsOutput:
+ ) -> mlrun.common.schemas.ProjectsOutput:
if owner or labels or state:
raise NotImplementedError(
"Filtering by owner, labels or state is not supported"
@@ -93,11 +93,11 @@ def list_projects(
for project_name, project in self._projects.items()
if project_name in names
]
- if format_ == mlrun.api.schemas.ProjectsFormat.full:
- return mlrun.api.schemas.ProjectsOutput(projects=projects)
- elif format_ == mlrun.api.schemas.ProjectsFormat.name_only:
+ if format_ == mlrun.common.schemas.ProjectsFormat.full:
+ return mlrun.common.schemas.ProjectsOutput(projects=projects)
+ elif format_ == mlrun.common.schemas.ProjectsFormat.name_only:
project_names = [project.metadata.name for project in projects]
- return mlrun.api.schemas.ProjectsOutput(projects=project_names)
+ return mlrun.common.schemas.ProjectsOutput(projects=project_names)
else:
raise NotImplementedError(
f"Provided format is not supported. format={format_}"
@@ -108,12 +108,12 @@ def list_project_summaries(
session: sqlalchemy.orm.Session,
owner: str = None,
labels: typing.List[str] = None,
- state: mlrun.api.schemas.ProjectState = None,
+ state: mlrun.common.schemas.ProjectState = None,
names: typing.Optional[typing.List[str]] = None,
- ) -> mlrun.api.schemas.ProjectSummariesOutput:
+ ) -> mlrun.common.schemas.ProjectSummariesOutput:
raise NotImplementedError("Listing project summaries is not supported")
def get_project_summary(
self, session: sqlalchemy.orm.Session, name: str
- ) -> mlrun.api.schemas.ProjectSummary:
+ ) -> mlrun.common.schemas.ProjectSummary:
raise NotImplementedError("Get project summary is not supported")
diff --git a/mlrun/api/utils/projects/remotes/nop_leader.py b/mlrun/api/utils/projects/remotes/nop_leader.py
index 961d49148414..92bb717bc0a8 100644
--- a/mlrun/api/utils/projects/remotes/nop_leader.py
+++ b/mlrun/api/utils/projects/remotes/nop_leader.py
@@ -15,9 +15,9 @@
import datetime
import typing
-import mlrun.api.schemas
import mlrun.api.utils.projects.remotes.leader
import mlrun.api.utils.singletons.project_member
+import mlrun.common.schemas
import mlrun.errors
@@ -26,12 +26,12 @@ def __init__(self) -> None:
super().__init__()
self.db_session = None
self.project_owner_access_key = ""
- self._project_role = mlrun.api.schemas.ProjectsRole.nop
+ self._project_role = mlrun.common.schemas.ProjectsRole.nop
def create_project(
self,
session: str,
- project: mlrun.api.schemas.Project,
+ project: mlrun.common.schemas.Project,
wait_for_completion: bool = True,
) -> bool:
self._update_state(project)
@@ -47,7 +47,7 @@ def update_project(
self,
session: str,
name: str,
- project: mlrun.api.schemas.Project,
+ project: mlrun.common.schemas.Project,
):
self._update_state(project)
mlrun.api.utils.singletons.project_member.get_project_member().store_project(
@@ -55,12 +55,13 @@ def update_project(
)
@staticmethod
- def _update_state(project: mlrun.api.schemas.Project):
+ def _update_state(project: mlrun.common.schemas.Project):
if (
not project.status.state
- or project.status.state in mlrun.api.schemas.ProjectState.terminal_states()
+ or project.status.state
+ in mlrun.common.schemas.ProjectState.terminal_states()
):
- project.status.state = mlrun.api.schemas.ProjectState(
+ project.status.state = mlrun.common.schemas.ProjectState(
project.spec.desired_state
)
@@ -68,7 +69,7 @@ def delete_project(
self,
session: str,
name: str,
- deletion_strategy: mlrun.api.schemas.DeletionStrategy = mlrun.api.schemas.DeletionStrategy.default(),
+ deletion_strategy: mlrun.common.schemas.DeletionStrategy = mlrun.common.schemas.DeletionStrategy.default(),
wait_for_completion: bool = True,
) -> bool:
return mlrun.api.utils.singletons.project_member.get_project_member().delete_project(
@@ -80,7 +81,7 @@ def list_projects(
session: str,
updated_after: typing.Optional[datetime.datetime] = None,
) -> typing.Tuple[
- typing.List[mlrun.api.schemas.Project], typing.Optional[datetime.datetime]
+ typing.List[mlrun.common.schemas.Project], typing.Optional[datetime.datetime]
]:
return (
mlrun.api.utils.singletons.project_member.get_project_member()
@@ -93,7 +94,7 @@ def get_project(
self,
session: str,
name: str,
- ) -> mlrun.api.schemas.Project:
+ ) -> mlrun.common.schemas.Project:
return (
mlrun.api.utils.singletons.project_member.get_project_member().get_project(
self.db_session, name
@@ -101,16 +102,16 @@ def get_project(
)
def format_as_leader_project(
- self, project: mlrun.api.schemas.Project
- ) -> mlrun.api.schemas.IguazioProject:
- return mlrun.api.schemas.IguazioProject(data=project.dict())
+ self, project: mlrun.common.schemas.Project
+ ) -> mlrun.common.schemas.IguazioProject:
+ return mlrun.common.schemas.IguazioProject(data=project.dict())
def get_project_owner(
self,
session: str,
name: str,
- ) -> mlrun.api.schemas.ProjectOwner:
+ ) -> mlrun.common.schemas.ProjectOwner:
project = self.get_project(session, name)
- return mlrun.api.schemas.ProjectOwner(
+ return mlrun.common.schemas.ProjectOwner(
username=project.spec.owner, access_key=self.project_owner_access_key
)
diff --git a/mlrun/api/utils/scheduler.py b/mlrun/api/utils/scheduler.py
index 9c6e1f3edcd2..db0e3a370124 100644
--- a/mlrun/api/utils/scheduler.py
+++ b/mlrun/api/utils/scheduler.py
@@ -30,8 +30,8 @@
import mlrun.api.utils.auth.verifier
import mlrun.api.utils.clients.iguazio
import mlrun.api.utils.helpers
+import mlrun.common.schemas
import mlrun.errors
-from mlrun.api import schemas
from mlrun.api.db.session import close_session, create_session
from mlrun.api.utils.singletons.db import get_db
from mlrun.config import config
@@ -60,7 +60,7 @@ def __init__(self):
# we don't allow to schedule a job to run more than one time per X
# NOTE this cannot be less than one minute - see _validate_cron_trigger
self._min_allowed_interval = config.httpdb.scheduling.min_allowed_interval
- self._secrets_provider = schemas.SecretProviderName.kubernetes
+ self._secrets_provider = mlrun.common.schemas.SecretProviderName.kubernetes
async def start(self, db_session: Session):
logger.info("Starting scheduler")
@@ -73,7 +73,7 @@ async def start(self, db_session: Session):
try:
if (
mlrun.mlconf.httpdb.clusterization.role
- == mlrun.api.schemas.ClusterizationRole.chief
+ == mlrun.common.schemas.ClusterizationRole.chief
):
self._reload_schedules(db_session)
except Exception as exc:
@@ -93,7 +93,7 @@ def _append_access_key_secret_to_labels(self, labels, secret_name):
return labels
def _get_access_key_secret_name_from_db_record(
- self, db_schedule: schemas.ScheduleRecord
+ self, db_schedule: mlrun.common.schemas.ScheduleRecord
):
schedule_labels = db_schedule.dict()["labels"]
for label in schedule_labels:
@@ -104,19 +104,21 @@ def _get_access_key_secret_name_from_db_record(
def create_schedule(
self,
db_session: Session,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
project: str,
name: str,
- kind: schemas.ScheduleKinds,
+ kind: mlrun.common.schemas.ScheduleKinds,
scheduled_object: Union[Dict, Callable],
- cron_trigger: Union[str, schemas.ScheduleCronTrigger],
+ cron_trigger: Union[str, mlrun.common.schemas.ScheduleCronTrigger],
labels: Dict = None,
concurrency_limit: int = None,
):
if concurrency_limit is None:
concurrency_limit = config.httpdb.scheduling.default_concurrency_limit
if isinstance(cron_trigger, str):
- cron_trigger = schemas.ScheduleCronTrigger.from_crontab(cron_trigger)
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger.from_crontab(
+ cron_trigger
+ )
self._validate_cron_trigger(cron_trigger)
@@ -177,16 +179,18 @@ def update_schedule_next_run_time(
def update_schedule(
self,
db_session: Session,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
project: str,
name: str,
scheduled_object: Union[Dict, Callable] = None,
- cron_trigger: Union[str, schemas.ScheduleCronTrigger] = None,
+ cron_trigger: Union[str, mlrun.common.schemas.ScheduleCronTrigger] = None,
labels: Dict = None,
concurrency_limit: int = None,
):
if isinstance(cron_trigger, str):
- cron_trigger = schemas.ScheduleCronTrigger.from_crontab(cron_trigger)
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger.from_crontab(
+ cron_trigger
+ )
if cron_trigger is not None:
self._validate_cron_trigger(cron_trigger)
@@ -241,7 +245,7 @@ def list_schedules(
labels: str = None,
include_last_run: bool = False,
include_credentials: bool = False,
- ) -> schemas.SchedulesOutput:
+ ) -> mlrun.common.schemas.SchedulesOutput:
db_schedules = get_db().list_schedules(db_session, project, name, labels, kind)
schedules = []
for db_schedule in db_schedules:
@@ -249,7 +253,7 @@ def list_schedules(
db_session, db_schedule, include_last_run, include_credentials
)
schedules.append(schedule)
- return schemas.SchedulesOutput(schedules=schedules)
+ return mlrun.common.schemas.SchedulesOutput(schedules=schedules)
def get_schedule(
self,
@@ -258,7 +262,7 @@ def get_schedule(
name: str,
include_last_run: bool = False,
include_credentials: bool = False,
- ) -> schemas.ScheduleOutput:
+ ) -> mlrun.common.schemas.ScheduleOutput:
logger.debug("Getting schedule", project=project, name=name)
db_schedule = get_db().get_schedule(db_session, project, name)
return self._transform_and_enrich_db_schedule(
@@ -309,7 +313,7 @@ def _remove_schedule_from_scheduler(self, project, name):
async def invoke_schedule(
self,
db_session: Session,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
project: str,
name: str,
):
@@ -335,13 +339,13 @@ async def invoke_schedule(
def _ensure_auth_info_has_access_key(
self,
- auth_info: mlrun.api.schemas.AuthInfo,
- kind: schemas.ScheduleKinds,
+ auth_info: mlrun.common.schemas.AuthInfo,
+ kind: mlrun.common.schemas.ScheduleKinds,
):
import mlrun.api.crud
if (
- kind not in schemas.ScheduleKinds.local_kinds()
+ kind not in mlrun.common.schemas.ScheduleKinds.local_kinds()
and mlrun.api.utils.auth.verifier.AuthVerifier().is_jobs_auth_required()
):
if (
@@ -371,7 +375,7 @@ def _ensure_auth_info_has_access_key(
def _store_schedule_secrets_using_auth_secret(
self,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
) -> str:
# import here to avoid circular imports
import mlrun.api.crud
@@ -388,8 +392,8 @@ def _store_schedule_secrets_using_auth_secret(
auth_info.username = ""
secret_name = mlrun.api.crud.Secrets().store_auth_secret(
- mlrun.api.schemas.AuthSecretData(
- provider=mlrun.api.schemas.SecretProviderName.kubernetes,
+ mlrun.common.schemas.AuthSecretData(
+ provider=mlrun.common.schemas.SecretProviderName.kubernetes,
username=auth_info.username,
access_key=auth_info.access_key,
)
@@ -400,7 +404,7 @@ def _store_schedule_secrets_using_auth_secret(
# are sure we are far enough that it's no longer going to be used (or keep, and use for other things).
def _store_schedule_secrets(
self,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
project: str,
name: str,
):
@@ -441,7 +445,7 @@ def _store_schedule_secrets(
secrets[username_secret_key] = auth_info.username
mlrun.api.crud.Secrets().store_project_secrets(
project,
- schemas.SecretsData(
+ mlrun.common.schemas.SecretsData(
provider=self._secrets_provider,
secrets=secrets,
),
@@ -545,7 +549,7 @@ def _get_schedule_secrets(
def _validate_cron_trigger(
self,
- cron_trigger: schemas.ScheduleCronTrigger,
+ cron_trigger: mlrun.common.schemas.ScheduleCronTrigger,
# accepting now from outside for testing purposes
now: datetime = None,
):
@@ -598,11 +602,11 @@ def _create_schedule_in_scheduler(
self,
project: str,
name: str,
- kind: schemas.ScheduleKinds,
+ kind: mlrun.common.schemas.ScheduleKinds,
scheduled_object: Any,
- cron_trigger: schemas.ScheduleCronTrigger,
+ cron_trigger: mlrun.common.schemas.ScheduleCronTrigger,
concurrency_limit: int,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
):
job_id = self._resolve_job_id(project, name)
logger.debug("Adding schedule to scheduler", job_id=job_id)
@@ -628,11 +632,11 @@ def _update_schedule_in_scheduler(
self,
project: str,
name: str,
- kind: schemas.ScheduleKinds,
+ kind: mlrun.common.schemas.ScheduleKinds,
scheduled_object: Any,
- cron_trigger: schemas.ScheduleCronTrigger,
+ cron_trigger: mlrun.common.schemas.ScheduleCronTrigger,
concurrency_limit: int,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
):
job_id = self._resolve_job_id(project, name)
logger.debug("Updating schedule in scheduler", job_id=job_id)
@@ -706,7 +710,7 @@ def _reload_schedules(self, db_session: Session):
if access_key:
need_to_update_credentials = True
- auth_info = mlrun.api.schemas.AuthInfo(
+ auth_info = mlrun.common.schemas.AuthInfo(
username=username,
access_key=access_key,
# enriching with control plane tag because scheduling a function requires control plane
@@ -753,21 +757,21 @@ def _reload_schedules(self, db_session: Session):
def _transform_and_enrich_db_schedule(
self,
db_session: Session,
- schedule_record: schemas.ScheduleRecord,
+ schedule_record: mlrun.common.schemas.ScheduleRecord,
include_last_run: bool = False,
include_credentials: bool = False,
- ) -> schemas.ScheduleOutput:
+ ) -> mlrun.common.schemas.ScheduleOutput:
schedule_dict = schedule_record.dict()
schedule_dict["labels"] = {
label["name"]: label["value"] for label in schedule_dict["labels"]
}
- schedule = schemas.ScheduleOutput(**schedule_dict)
+ schedule = mlrun.common.schemas.ScheduleOutput(**schedule_dict)
# Schedules are running only on chief. Therefore, we query next_run_time from the scheduler only when
# running on chief.
if (
mlrun.mlconf.httpdb.clusterization.role
- == mlrun.api.schemas.ClusterizationRole.chief
+ == mlrun.common.schemas.ClusterizationRole.chief
):
job_id = self._resolve_job_id(schedule_record.project, schedule_record.name)
job = self._scheduler.get_job(job_id)
@@ -788,7 +792,7 @@ def _transform_and_enrich_db_schedule(
@staticmethod
def _enrich_schedule_with_last_run(
- db_session: Session, schedule_output: schemas.ScheduleOutput
+ db_session: Session, schedule_output: mlrun.common.schemas.ScheduleOutput
):
if schedule_output.last_run_uri:
run_project, run_uid, iteration, _ = RunObject.parse_uri(
@@ -798,7 +802,7 @@ def _enrich_schedule_with_last_run(
schedule_output.last_run = run_data
def _enrich_schedule_with_credentials(
- self, schedule_output: schemas.ScheduleOutput
+ self, schedule_output: mlrun.common.schemas.ScheduleOutput
):
secret_name = schedule_output.labels.get(self._db_record_auth_label)
if secret_name:
@@ -808,18 +812,18 @@ def _enrich_schedule_with_credentials(
def _resolve_job_function(
self,
- scheduled_kind: schemas.ScheduleKinds,
+ scheduled_kind: mlrun.common.schemas.ScheduleKinds,
scheduled_object: Any,
project_name: str,
schedule_name: str,
schedule_concurrency_limit: int,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
) -> Tuple[Callable, Optional[Union[List, Tuple]], Optional[Dict]]:
"""
:return: a tuple (function, args, kwargs) to be used with the APScheduler.add_job
"""
- if scheduled_kind == schemas.ScheduleKinds.job:
+ if scheduled_kind == mlrun.common.schemas.ScheduleKinds.job:
scheduled_object_copy = copy.deepcopy(scheduled_object)
return (
Scheduler.submit_run_wrapper,
@@ -833,7 +837,7 @@ def _resolve_job_function(
],
{},
)
- if scheduled_kind == schemas.ScheduleKinds.local_function:
+ if scheduled_kind == mlrun.common.schemas.ScheduleKinds.local_function:
return scheduled_object, [], {}
# sanity
@@ -858,7 +862,7 @@ async def submit_run_wrapper(
project_name,
schedule_name,
schedule_concurrency_limit,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
):
# removing the schedule from the body otherwise when the scheduler will submit this task it will go to an
@@ -872,7 +876,7 @@ async def submit_run_wrapper(
if "task" in scheduled_object and "metadata" in scheduled_object["task"]:
scheduled_object["task"]["metadata"].setdefault("labels", {})
scheduled_object["task"]["metadata"]["labels"][
- schemas.constants.LabelNames.schedule_name
+ mlrun.common.schemas.constants.LabelNames.schedule_name
] = schedule_name
return await fastapi.concurrency.run_in_threadpool(
@@ -887,7 +891,7 @@ async def submit_run_wrapper(
@staticmethod
def transform_schemas_cron_trigger_to_apscheduler_cron_trigger(
- cron_trigger: schemas.ScheduleCronTrigger,
+ cron_trigger: mlrun.common.schemas.ScheduleCronTrigger,
):
return APSchedulerCronTrigger(
cron_trigger.year,
@@ -927,7 +931,7 @@ def _submit_run_wrapper(
db_session,
states=RunStates.non_terminal_states(),
project=project_name,
- labels=f"{schemas.constants.LabelNames.schedule_name}={schedule_name}",
+ labels=f"{mlrun.common.schemas.constants.LabelNames.schedule_name}={schedule_name}",
)
if len(active_runs) >= schedule_concurrency_limit:
logger.warn(
@@ -965,7 +969,7 @@ def _submit_run_wrapper(
# Update the schedule with the new auth info so we won't need to do the above again in the next run
scheduler.update_schedule(
db_session,
- mlrun.api.schemas.AuthInfo(
+ mlrun.common.schemas.AuthInfo(
username=project_owner.username,
access_key=project_owner.access_key,
# enriching with control plane tag because scheduling a function requires control plane
diff --git a/mlrun/artifacts/dataset.py b/mlrun/artifacts/dataset.py
index b7b3d1743b37..8fdc5c090c48 100644
--- a/mlrun/artifacts/dataset.py
+++ b/mlrun/artifacts/dataset.py
@@ -22,6 +22,7 @@
from pandas.io.json import build_table_schema
import mlrun
+import mlrun.common.schemas
import mlrun.utils.helpers
from ..datastore import is_store_uri, store_manager
@@ -122,7 +123,7 @@ def __init__(self):
class DatasetArtifact(Artifact):
- kind = "dataset"
+ kind = mlrun.common.schemas.ArtifactCategories.dataset
# List of all the supported saving formats of a DataFrame:
SUPPORTED_FORMATS = ["csv", "parquet", "pq", "tsdb", "kv"]
diff --git a/mlrun/builder.py b/mlrun/builder.py
index 68370b7ffa1b..2b47b2473462 100644
--- a/mlrun/builder.py
+++ b/mlrun/builder.py
@@ -22,7 +22,7 @@
from kubernetes import client
-import mlrun.api.schemas
+import mlrun.common.schemas
import mlrun.errors
import mlrun.runtimes.utils
@@ -315,7 +315,7 @@ def upload_tarball(source_dir, target, secrets=None):
def build_image(
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
project: str,
image_target,
commands=None,
@@ -409,7 +409,7 @@ def build_image(
enriched_group_id = None
if (
mlrun.mlconf.function.spec.security_context.enrichment_mode
- != mlrun.api.schemas.SecurityContextEnrichmentModes.disabled.value
+ != mlrun.common.schemas.SecurityContextEnrichmentModes.disabled.value
):
from mlrun.api.api.utils import ensure_function_security_context
@@ -534,7 +534,7 @@ def resolve_upgrade_pip_command(commands=None):
def build_runtime(
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
runtime,
with_mlrun=True,
mlrun_version_specifier=None,
@@ -548,7 +548,7 @@ def build_runtime(
namespace = runtime.metadata.namespace
project = runtime.metadata.project
if skip_deployed and runtime.is_deployed():
- runtime.status.state = mlrun.api.schemas.FunctionState.ready
+ runtime.status.state = mlrun.common.schemas.FunctionState.ready
return True
if build.base_image:
mlrun_images = [
@@ -579,7 +579,7 @@ def build_runtime(
"The deployment was not successful because no image was specified or there are missing build parameters"
" (commands/source)"
)
- runtime.status.state = mlrun.api.schemas.FunctionState.ready
+ runtime.status.state = mlrun.common.schemas.FunctionState.ready
return True
build.image = mlrun.runtimes.utils.resolve_function_image_name(runtime, build.image)
@@ -629,11 +629,11 @@ def build_runtime(
# using enriched base image for the runtime spec image, because this will be the image that the function will
# run with
runtime.spec.image = enriched_base_image
- runtime.status.state = mlrun.api.schemas.FunctionState.ready
+ runtime.status.state = mlrun.common.schemas.FunctionState.ready
return True
if status.startswith("build:"):
- runtime.status.state = mlrun.api.schemas.FunctionState.deploying
+ runtime.status.state = mlrun.common.schemas.FunctionState.deploying
runtime.status.build_pod = status[6:]
# using the base_image, and not the enriched one so we won't have the client version in the image, useful for
# exports and other cases where we don't want to have the client version in the image, but rather enriched on
@@ -643,12 +643,12 @@ def build_runtime(
logger.info(f"build completed with {status}")
if status in ["failed", "error"]:
- runtime.status.state = mlrun.api.schemas.FunctionState.error
+ runtime.status.state = mlrun.common.schemas.FunctionState.error
return False
local = "" if build.secret or build.image.startswith(".") else "."
runtime.spec.image = local + build.image
- runtime.status.state = mlrun.api.schemas.FunctionState.ready
+ runtime.status.state = mlrun.common.schemas.FunctionState.ready
return True
diff --git a/mlrun/model_monitoring/constants.py b/mlrun/common/model_monitoring.py
similarity index 58%
rename from mlrun/model_monitoring/constants.py
rename to mlrun/common/model_monitoring.py
index ef201d78e13a..b4c17e87b6c6 100644
--- a/mlrun/model_monitoring/constants.py
+++ b/mlrun/common/model_monitoring.py
@@ -12,6 +12,15 @@
# See the License for the specific language governing permissions and
# limitations under the License.
#
+
+import enum
+import hashlib
+from dataclasses import dataclass
+from typing import Optional
+
+import mlrun.utils
+
+
class EventFieldType:
FUNCTION_URI = "function_uri"
FUNCTION = "function"
@@ -112,3 +121,94 @@ class FileTargetKind:
PARQUET = "parquet"
LOG_STREAM = "log_stream"
DEFAULT_HTTP_SINK = "default_http_sink"
+
+
+class ModelMonitoringMode(str, enum.Enum):
+ enabled = "enabled"
+ disabled = "disabled"
+
+
+class EndpointType(enum.IntEnum):
+ NODE_EP = 1 # end point that is not a child of a router
+ ROUTER = 2 # endpoint that is router
+ LEAF_EP = 3 # end point that is a child of a router
+
+
+def create_model_endpoint_uid(function_uri: str, versioned_model: str):
+ function_uri = FunctionURI.from_string(function_uri)
+ versioned_model = VersionedModel.from_string(versioned_model)
+
+ if (
+ not function_uri.project
+ or not function_uri.function
+ or not versioned_model.model
+ ):
+ raise ValueError("Both function_uri and versioned_model have to be initialized")
+
+ uid = EndpointUID(
+ function_uri.project,
+ function_uri.function,
+ function_uri.tag,
+ function_uri.hash_key,
+ versioned_model.model,
+ versioned_model.version,
+ )
+
+ return uid
+
+
+@dataclass
+class FunctionURI:
+ project: str
+ function: str
+ tag: Optional[str] = None
+ hash_key: Optional[str] = None
+
+ @classmethod
+ def from_string(cls, function_uri):
+ project, uri, tag, hash_key = mlrun.utils.parse_versioned_object_uri(
+ function_uri
+ )
+ return cls(
+ project=project,
+ function=uri,
+ tag=tag or None,
+ hash_key=hash_key or None,
+ )
+
+
+@dataclass
+class VersionedModel:
+ model: str
+ version: Optional[str]
+
+ @classmethod
+ def from_string(cls, model):
+ try:
+ model, version = model.split(":")
+ except ValueError:
+ model, version = model, None
+
+ return cls(model, version)
+
+
+@dataclass
+class EndpointUID:
+ project: str
+ function: str
+ function_tag: str
+ function_hash_key: str
+ model: str
+ model_version: str
+ uid: Optional[str] = None
+
+ def __post_init__(self):
+ function_ref = (
+ f"{self.function}_{self.function_tag or self.function_hash_key or 'N/A'}"
+ )
+ versioned_model = f"{self.model}_{self.model_version or 'N/A'}"
+ unique_string = f"{self.project}_{function_ref}_{versioned_model}"
+ self.uid = hashlib.sha1(unique_string.encode("utf-8")).hexdigest()
+
+ def __str__(self):
+ return self.uid
diff --git a/mlrun/common/schemas/__init__.py b/mlrun/common/schemas/__init__.py
new file mode 100644
index 000000000000..dbe176f90db7
--- /dev/null
+++ b/mlrun/common/schemas/__init__.py
@@ -0,0 +1,152 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+# flake8: noqa - this is until we take care of the F401 violations with respect to __all__ & sphinx
+
+from .artifact import ArtifactCategories, ArtifactIdentifier, ArtifactsFormat
+from .auth import (
+ AuthInfo,
+ AuthorizationAction,
+ AuthorizationResourceTypes,
+ AuthorizationVerificationInput,
+ Credentials,
+ ProjectsRole,
+)
+from .background_task import (
+ BackgroundTask,
+ BackgroundTaskMetadata,
+ BackgroundTaskSpec,
+ BackgroundTaskState,
+ BackgroundTaskStatus,
+)
+from .client_spec import ClientSpec
+from .clusterization_spec import (
+ ClusterizationSpec,
+ WaitForChiefToReachOnlineStateFeatureFlag,
+)
+from .constants import (
+ APIStates,
+ ClusterizationRole,
+ DeletionStrategy,
+ FeatureStorePartitionByField,
+ HeaderNames,
+ LogsCollectorMode,
+ OrderType,
+ PatchMode,
+ RunPartitionByField,
+ SortField,
+)
+from .feature_store import (
+ EntitiesOutput,
+ Entity,
+ EntityListOutput,
+ EntityRecord,
+ Feature,
+ FeatureListOutput,
+ FeatureRecord,
+ FeatureSet,
+ FeatureSetDigestOutput,
+ FeatureSetDigestSpec,
+ FeatureSetIngestInput,
+ FeatureSetIngestOutput,
+ FeatureSetRecord,
+ FeatureSetsOutput,
+ FeatureSetSpec,
+ FeatureSetsTagsOutput,
+ FeaturesOutput,
+ FeatureVector,
+ FeatureVectorRecord,
+ FeatureVectorsOutput,
+ FeatureVectorsTagsOutput,
+)
+from .frontend_spec import (
+ AuthenticationFeatureFlag,
+ FeatureFlags,
+ FrontendSpec,
+ NuclioStreamsFeatureFlag,
+ PreemptionNodesFeatureFlag,
+ ProjectMembershipFeatureFlag,
+)
+from .function import FunctionState, PreemptionModes, SecurityContextEnrichmentModes
+from .http import HTTPSessionRetryMode
+from .hub import (
+ HubCatalog,
+ HubItem,
+ HubObjectMetadata,
+ HubSource,
+ HubSourceSpec,
+ IndexedHubSource,
+ last_source_index,
+)
+from .k8s import NodeSelectorOperator, Resources, ResourceSpec
+from .memory_reports import MostCommonObjectTypesReport, ObjectTypeReport
+from .model_endpoints import (
+ Features,
+ FeatureValues,
+ GrafanaColumn,
+ GrafanaDataPoint,
+ GrafanaNumberColumn,
+ GrafanaStringColumn,
+ GrafanaTable,
+ GrafanaTimeSeriesTarget,
+ ModelEndpoint,
+ ModelEndpointList,
+ ModelEndpointMetadata,
+ ModelEndpointSpec,
+ ModelEndpointStatus,
+ ModelMonitoringStoreKinds,
+)
+from .notification import NotificationSeverity, NotificationStatus
+from .object import ObjectKind, ObjectMetadata, ObjectSpec, ObjectStatus
+from .pipeline import PipelinesFormat, PipelinesOutput, PipelinesPagination
+from .project import (
+ IguazioProject,
+ Project,
+ ProjectDesiredState,
+ ProjectMetadata,
+ ProjectOwner,
+ ProjectsFormat,
+ ProjectsOutput,
+ ProjectSpec,
+ ProjectState,
+ ProjectStatus,
+ ProjectSummariesOutput,
+ ProjectSummary,
+)
+from .runtime_resource import (
+ GroupedByJobRuntimeResourcesOutput,
+ GroupedByProjectRuntimeResourcesOutput,
+ KindRuntimeResources,
+ ListRuntimeResourcesGroupByField,
+ RuntimeResource,
+ RuntimeResources,
+ RuntimeResourcesOutput,
+)
+from .schedule import (
+ ScheduleCronTrigger,
+ ScheduleInput,
+ ScheduleKinds,
+ ScheduleOutput,
+ ScheduleRecord,
+ SchedulesOutput,
+ ScheduleUpdate,
+)
+from .secret import (
+ AuthSecretData,
+ SecretKeysData,
+ SecretProviderName,
+ SecretsData,
+ UserSecretCreationRequest,
+)
+from .tag import Tag, TagObjects
diff --git a/mlrun/api/schemas/artifact.py b/mlrun/common/schemas/artifact.py
similarity index 64%
rename from mlrun/api/schemas/artifact.py
rename to mlrun/common/schemas/artifact.py
index 1474ff567060..a61200661cc9 100644
--- a/mlrun/api/schemas/artifact.py
+++ b/mlrun/common/schemas/artifact.py
@@ -16,31 +16,30 @@
import pydantic
-import mlrun.api.utils.helpers
+import mlrun.common.types
-class ArtifactCategories(mlrun.api.utils.helpers.StrEnum):
+class ArtifactCategories(mlrun.common.types.StrEnum):
model = "model"
dataset = "dataset"
other = "other"
- def to_kinds_filter(self) -> typing.Tuple[typing.List[str], bool]:
- # FIXME: these artifact definitions (or at least the kinds enum) should sit in a dedicated module
- # import here to prevent import cycle
- import mlrun.artifacts.dataset
- import mlrun.artifacts.model
+ # we define the link as a category to prevent import cycles, but it's not a real category
+ # and should not be used as such
+ link = "link"
- link_kind = mlrun.artifacts.base.LinkArtifact.kind
+ def to_kinds_filter(self) -> typing.Tuple[typing.List[str], bool]:
+ link_kind = ArtifactCategories.link.value
if self.value == ArtifactCategories.model.value:
- return [mlrun.artifacts.model.ModelArtifact.kind, link_kind], False
+ return [ArtifactCategories.model.value, link_kind], False
if self.value == ArtifactCategories.dataset.value:
- return [mlrun.artifacts.dataset.DatasetArtifact.kind, link_kind], False
+ return [ArtifactCategories.dataset.value, link_kind], False
if self.value == ArtifactCategories.other.value:
return (
[
- mlrun.artifacts.model.ModelArtifact.kind,
- mlrun.artifacts.dataset.DatasetArtifact.kind,
+ ArtifactCategories.model.value,
+ ArtifactCategories.dataset.value,
],
True,
)
@@ -56,6 +55,6 @@ class ArtifactIdentifier(pydantic.BaseModel):
# hash: typing.Optional[str]
-class ArtifactsFormat(mlrun.api.utils.helpers.StrEnum):
+class ArtifactsFormat(mlrun.common.types.StrEnum):
full = "full"
legacy = "legacy"
diff --git a/mlrun/api/schemas/auth.py b/mlrun/common/schemas/auth.py
similarity index 95%
rename from mlrun/api/schemas/auth.py
rename to mlrun/common/schemas/auth.py
index 8e4bdde29e10..c27ef378c844 100644
--- a/mlrun/api/schemas/auth.py
+++ b/mlrun/common/schemas/auth.py
@@ -18,17 +18,17 @@
from nuclio.auth import AuthInfo as NuclioAuthInfo
from nuclio.auth import AuthKinds as NuclioAuthKinds
-import mlrun.api.utils.helpers
+import mlrun.common.types
-class ProjectsRole(mlrun.api.utils.helpers.StrEnum):
+class ProjectsRole(mlrun.common.types.StrEnum):
iguazio = "iguazio"
mlrun = "mlrun"
nuclio = "nuclio"
nop = "nop"
-class AuthorizationAction(mlrun.api.utils.helpers.StrEnum):
+class AuthorizationAction(mlrun.common.types.StrEnum):
read = "read"
create = "create"
update = "update"
@@ -39,7 +39,7 @@ class AuthorizationAction(mlrun.api.utils.helpers.StrEnum):
store = "store"
-class AuthorizationResourceTypes(mlrun.api.utils.helpers.StrEnum):
+class AuthorizationResourceTypes(mlrun.common.types.StrEnum):
project = "project"
log = "log"
runtime_resource = "runtime-resource"
diff --git a/mlrun/api/schemas/background_task.py b/mlrun/common/schemas/background_task.py
similarity index 94%
rename from mlrun/api/schemas/background_task.py
rename to mlrun/common/schemas/background_task.py
index 1a174cbb9459..a9fa1f25af2c 100644
--- a/mlrun/api/schemas/background_task.py
+++ b/mlrun/common/schemas/background_task.py
@@ -17,12 +17,12 @@
import pydantic
-import mlrun.api.utils.helpers
+import mlrun.common.types
from .object import ObjectKind
-class BackgroundTaskState(mlrun.api.utils.helpers.StrEnum):
+class BackgroundTaskState(mlrun.common.types.StrEnum):
succeeded = "succeeded"
failed = "failed"
running = "running"
diff --git a/mlrun/api/schemas/client_spec.py b/mlrun/common/schemas/client_spec.py
similarity index 100%
rename from mlrun/api/schemas/client_spec.py
rename to mlrun/common/schemas/client_spec.py
diff --git a/mlrun/api/schemas/clusterization_spec.py b/mlrun/common/schemas/clusterization_spec.py
similarity index 87%
rename from mlrun/api/schemas/clusterization_spec.py
rename to mlrun/common/schemas/clusterization_spec.py
index 9f77d90e953d..1d9ed1bc7bb8 100644
--- a/mlrun/api/schemas/clusterization_spec.py
+++ b/mlrun/common/schemas/clusterization_spec.py
@@ -16,7 +16,7 @@
import pydantic
-import mlrun.api.utils.helpers
+import mlrun.common.types
class ClusterizationSpec(pydantic.BaseModel):
@@ -24,6 +24,6 @@ class ClusterizationSpec(pydantic.BaseModel):
chief_version: typing.Optional[str]
-class WaitForChiefToReachOnlineStateFeatureFlag(mlrun.api.utils.helpers.StrEnum):
+class WaitForChiefToReachOnlineStateFeatureFlag(mlrun.common.types.StrEnum):
enabled = "enabled"
disabled = "disabled"
diff --git a/mlrun/api/schemas/constants.py b/mlrun/common/schemas/constants.py
similarity index 94%
rename from mlrun/api/schemas/constants.py
rename to mlrun/common/schemas/constants.py
index dafb4e7ed6af..2170af9453b7 100644
--- a/mlrun/api/schemas/constants.py
+++ b/mlrun/common/schemas/constants.py
@@ -14,11 +14,11 @@
#
import mergedeep
-import mlrun.api.utils.helpers
+import mlrun.common.types
import mlrun.errors
-class PatchMode(mlrun.api.utils.helpers.StrEnum):
+class PatchMode(mlrun.common.types.StrEnum):
replace = "replace"
additive = "additive"
@@ -33,7 +33,7 @@ def to_mergedeep_strategy(self) -> mergedeep.Strategy:
)
-class DeletionStrategy(mlrun.api.utils.helpers.StrEnum):
+class DeletionStrategy(mlrun.common.types.StrEnum):
restrict = "restrict"
restricted = "restricted"
cascade = "cascade"
@@ -97,7 +97,7 @@ class HeaderNames:
ui_clear_cache = f"{headers_prefix}ui-clear-cache"
-class FeatureStorePartitionByField(mlrun.api.utils.helpers.StrEnum):
+class FeatureStorePartitionByField(mlrun.common.types.StrEnum):
name = "name" # Supported for feature-store objects
def to_partition_by_db_field(self, db_cls):
@@ -109,7 +109,7 @@ def to_partition_by_db_field(self, db_cls):
)
-class RunPartitionByField(mlrun.api.utils.helpers.StrEnum):
+class RunPartitionByField(mlrun.common.types.StrEnum):
name = "name" # Supported for runs objects
def to_partition_by_db_field(self, db_cls):
@@ -121,7 +121,7 @@ def to_partition_by_db_field(self, db_cls):
)
-class SortField(mlrun.api.utils.helpers.StrEnum):
+class SortField(mlrun.common.types.StrEnum):
created = "created"
updated = "updated"
@@ -139,7 +139,7 @@ def to_db_field(self, db_cls):
)
-class OrderType(mlrun.api.utils.helpers.StrEnum):
+class OrderType(mlrun.common.types.StrEnum):
asc = "asc"
desc = "desc"
diff --git a/mlrun/api/schemas/feature_store.py b/mlrun/common/schemas/feature_store.py
similarity index 100%
rename from mlrun/api/schemas/feature_store.py
rename to mlrun/common/schemas/feature_store.py
diff --git a/mlrun/api/schemas/frontend_spec.py b/mlrun/common/schemas/frontend_spec.py
similarity index 88%
rename from mlrun/api/schemas/frontend_spec.py
rename to mlrun/common/schemas/frontend_spec.py
index 35ff1c2febfd..d8821292bbc0 100644
--- a/mlrun/api/schemas/frontend_spec.py
+++ b/mlrun/common/schemas/frontend_spec.py
@@ -16,29 +16,29 @@
import pydantic
-import mlrun.api.utils.helpers
+import mlrun.common.types
from .k8s import Resources
-class ProjectMembershipFeatureFlag(mlrun.api.utils.helpers.StrEnum):
+class ProjectMembershipFeatureFlag(mlrun.common.types.StrEnum):
enabled = "enabled"
disabled = "disabled"
-class PreemptionNodesFeatureFlag(mlrun.api.utils.helpers.StrEnum):
+class PreemptionNodesFeatureFlag(mlrun.common.types.StrEnum):
enabled = "enabled"
disabled = "disabled"
-class AuthenticationFeatureFlag(mlrun.api.utils.helpers.StrEnum):
+class AuthenticationFeatureFlag(mlrun.common.types.StrEnum):
none = "none"
basic = "basic"
bearer = "bearer"
iguazio = "iguazio"
-class NuclioStreamsFeatureFlag(mlrun.api.utils.helpers.StrEnum):
+class NuclioStreamsFeatureFlag(mlrun.common.types.StrEnum):
enabled = "enabled"
disabled = "disabled"
diff --git a/mlrun/api/schemas/function.py b/mlrun/common/schemas/function.py
similarity index 93%
rename from mlrun/api/schemas/function.py
rename to mlrun/common/schemas/function.py
index 078f53bafdf1..ca5fd24421a6 100644
--- a/mlrun/api/schemas/function.py
+++ b/mlrun/common/schemas/function.py
@@ -16,10 +16,10 @@
import pydantic
-import mlrun.api.utils.helpers
+import mlrun.common.types
-# Ideally we would want this to be class FunctionState(mlrun.api.utils.helpers.StrEnum) which is the
+# Ideally we would want this to be class FunctionState(mlrun.common.types.StrEnum) which is the
# "FastAPI-compatible" way of creating schemas
# But, when we save a function to the DB, we pickle the body, which saves the state as an instance of this class (and
# not just a string), then if for some reason we downgrade to 0.6.4, before we had this class, we fail reading (pickle
@@ -46,7 +46,7 @@ class FunctionState:
build = "build"
-class PreemptionModes(mlrun.api.utils.helpers.StrEnum):
+class PreemptionModes(mlrun.common.types.StrEnum):
# makes function pods be able to run on preemptible nodes
allow = "allow"
# makes the function pods run on preemptible nodes only
@@ -59,7 +59,7 @@ class PreemptionModes(mlrun.api.utils.helpers.StrEnum):
# used when running in Iguazio (otherwise use disabled mode)
# populates mlrun.mlconf.function.spec.security_context.enrichment_mode
-class SecurityContextEnrichmentModes(mlrun.api.utils.helpers.StrEnum):
+class SecurityContextEnrichmentModes(mlrun.common.types.StrEnum):
# always use the user id of the user that triggered the 1st run / created the function
# NOTE: this mode is incomplete and not fully supported yet
retain = "retain"
diff --git a/mlrun/api/schemas/http.py b/mlrun/common/schemas/http.py
similarity index 87%
rename from mlrun/api/schemas/http.py
rename to mlrun/common/schemas/http.py
index 640d75613df0..0b95a1e84f84 100644
--- a/mlrun/api/schemas/http.py
+++ b/mlrun/common/schemas/http.py
@@ -12,9 +12,9 @@
# See the License for the specific language governing permissions and
# limitations under the License.
#
-import mlrun.api.utils.helpers
+import mlrun.common.types
-class HTTPSessionRetryMode(mlrun.api.utils.helpers.StrEnum):
+class HTTPSessionRetryMode(mlrun.common.types.StrEnum):
enabled = "enabled"
disabled = "disabled"
diff --git a/mlrun/api/schemas/hub.py b/mlrun/common/schemas/hub.py
similarity index 96%
rename from mlrun/api/schemas/hub.py
rename to mlrun/common/schemas/hub.py
index b1ad7ba589be..49b7ab1e9b1b 100644
--- a/mlrun/api/schemas/hub.py
+++ b/mlrun/common/schemas/hub.py
@@ -17,9 +17,9 @@
from pydantic import BaseModel, Extra, Field
-import mlrun.api.utils.helpers
+import mlrun.common.types
import mlrun.errors
-from mlrun.api.schemas.object import ObjectKind, ObjectSpec, ObjectStatus
+from mlrun.common.schemas.object import ObjectKind, ObjectSpec, ObjectStatus
from mlrun.config import config
@@ -37,7 +37,7 @@ class Config:
# Currently only functions are supported. Will add more in the future.
-class HubSourceType(mlrun.api.utils.helpers.StrEnum):
+class HubSourceType(mlrun.common.types.StrEnum):
functions = "functions"
diff --git a/mlrun/api/schemas/k8s.py b/mlrun/common/schemas/k8s.py
similarity index 93%
rename from mlrun/api/schemas/k8s.py
rename to mlrun/common/schemas/k8s.py
index 3ab15cd3090b..ca93b16c340c 100644
--- a/mlrun/api/schemas/k8s.py
+++ b/mlrun/common/schemas/k8s.py
@@ -16,7 +16,7 @@
import pydantic
-import mlrun.api.utils.helpers
+import mlrun.common.types
class ResourceSpec(pydantic.BaseModel):
@@ -30,7 +30,7 @@ class Resources(pydantic.BaseModel):
limits: ResourceSpec = ResourceSpec()
-class NodeSelectorOperator(mlrun.api.utils.helpers.StrEnum):
+class NodeSelectorOperator(mlrun.common.types.StrEnum):
"""
A node selector operator is the set of operators that can be used in a node selector requirement
https://github.com/kubernetes/api/blob/b754a94214be15ffc8d648f9fe6481857f1fc2fe/core/v1/types.go#L2765
diff --git a/mlrun/api/schemas/memory_reports.py b/mlrun/common/schemas/memory_reports.py
similarity index 100%
rename from mlrun/api/schemas/memory_reports.py
rename to mlrun/common/schemas/memory_reports.py
diff --git a/mlrun/api/schemas/model_endpoints.py b/mlrun/common/schemas/model_endpoints.py
similarity index 83%
rename from mlrun/api/schemas/model_endpoints.py
rename to mlrun/common/schemas/model_endpoints.py
index 4cbe6aa00a61..319719316d3d 100644
--- a/mlrun/api/schemas/model_endpoints.py
+++ b/mlrun/common/schemas/model_endpoints.py
@@ -20,8 +20,8 @@
from pydantic import BaseModel, Field
from pydantic.main import Extra
-import mlrun.model_monitoring
-from mlrun.api.schemas.object import ObjectKind, ObjectSpec, ObjectStatus
+import mlrun.common.model_monitoring
+from mlrun.common.schemas.object import ObjectKind, ObjectSpec, ObjectStatus
class ModelMonitoringStoreKinds:
@@ -48,7 +48,7 @@ def from_flat_dict(cls, endpoint_dict: dict, json_parse_values: typing.List = No
"""
new_object = cls()
if json_parse_values is None:
- json_parse_values = [mlrun.model_monitoring.EventFieldType.LABELS]
+ json_parse_values = [mlrun.common.model_monitoring.EventFieldType.LABELS]
return _mapping_attributes(
base_model=new_object,
@@ -69,8 +69,8 @@ class ModelEndpointSpec(ObjectSpec):
monitor_configuration: Optional[dict] = {}
active: Optional[bool] = True
monitoring_mode: Optional[
- mlrun.model_monitoring.ModelMonitoringMode
- ] = mlrun.model_monitoring.ModelMonitoringMode.disabled.value
+ mlrun.common.model_monitoring.ModelMonitoringMode
+ ] = mlrun.common.model_monitoring.ModelMonitoringMode.disabled.value
@classmethod
def from_flat_dict(cls, endpoint_dict: dict, json_parse_values: typing.List = None):
@@ -83,9 +83,9 @@ def from_flat_dict(cls, endpoint_dict: dict, json_parse_values: typing.List = No
new_object = cls()
if json_parse_values is None:
json_parse_values = [
- mlrun.model_monitoring.EventFieldType.FEATURE_NAMES,
- mlrun.model_monitoring.EventFieldType.LABEL_NAMES,
- mlrun.model_monitoring.EventFieldType.MONITOR_CONFIGURATION,
+ mlrun.common.model_monitoring.EventFieldType.FEATURE_NAMES,
+ mlrun.common.model_monitoring.EventFieldType.LABEL_NAMES,
+ mlrun.common.model_monitoring.EventFieldType.MONITOR_CONFIGURATION,
]
return _mapping_attributes(
base_model=new_object,
@@ -148,17 +148,17 @@ class ModelEndpointStatus(ObjectStatus):
drift_status: Optional[str] = ""
drift_measures: Optional[dict] = {}
metrics: Optional[Dict[str, Dict[str, Any]]] = {
- mlrun.model_monitoring.EventKeyMetrics.GENERIC: {
- mlrun.model_monitoring.EventLiveStats.LATENCY_AVG_1H: 0,
- mlrun.model_monitoring.EventLiveStats.PREDICTIONS_PER_SECOND: 0,
+ mlrun.common.model_monitoring.EventKeyMetrics.GENERIC: {
+ mlrun.common.model_monitoring.EventLiveStats.LATENCY_AVG_1H: 0,
+ mlrun.common.model_monitoring.EventLiveStats.PREDICTIONS_PER_SECOND: 0,
}
}
features: Optional[List[Features]] = []
children: Optional[List[str]] = []
children_uids: Optional[List[str]] = []
endpoint_type: Optional[
- mlrun.model_monitoring.EndpointType
- ] = mlrun.model_monitoring.EndpointType.NODE_EP.value
+ mlrun.common.model_monitoring.EndpointType
+ ] = mlrun.common.model_monitoring.EndpointType.NODE_EP.value
monitoring_feature_set_uri: Optional[str] = ""
state: Optional[str] = ""
@@ -176,13 +176,13 @@ def from_flat_dict(cls, endpoint_dict: dict, json_parse_values: typing.List = No
new_object = cls()
if json_parse_values is None:
json_parse_values = [
- mlrun.model_monitoring.EventFieldType.FEATURE_STATS,
- mlrun.model_monitoring.EventFieldType.CURRENT_STATS,
- mlrun.model_monitoring.EventFieldType.DRIFT_MEASURES,
- mlrun.model_monitoring.EventFieldType.METRICS,
- mlrun.model_monitoring.EventFieldType.CHILDREN,
- mlrun.model_monitoring.EventFieldType.CHILDREN_UIDS,
- mlrun.model_monitoring.EventFieldType.ENDPOINT_TYPE,
+ mlrun.common.model_monitoring.EventFieldType.FEATURE_STATS,
+ mlrun.common.model_monitoring.EventFieldType.CURRENT_STATS,
+ mlrun.common.model_monitoring.EventFieldType.DRIFT_MEASURES,
+ mlrun.common.model_monitoring.EventFieldType.METRICS,
+ mlrun.common.model_monitoring.EventFieldType.CHILDREN,
+ mlrun.common.model_monitoring.EventFieldType.CHILDREN_UIDS,
+ mlrun.common.model_monitoring.EventFieldType.ENDPOINT_TYPE,
]
return _mapping_attributes(
base_model=new_object,
@@ -203,7 +203,7 @@ class Config:
def __init__(self, **data: Any):
super().__init__(**data)
if self.metadata.uid is None:
- uid = mlrun.model_monitoring.create_model_endpoint_uid(
+ uid = mlrun.common.model_monitoring.create_model_endpoint_uid(
function_uri=self.spec.function_uri,
versioned_model=self.spec.model,
)
@@ -234,16 +234,16 @@ def flat_dict(self):
else:
flatten_dict[key] = model_endpoint_dictionary[k_object][key]
- if mlrun.model_monitoring.EventFieldType.METRICS not in flatten_dict:
+ if mlrun.common.model_monitoring.EventFieldType.METRICS not in flatten_dict:
# Initialize metrics dictionary
- flatten_dict[mlrun.model_monitoring.EventFieldType.METRICS] = {
- mlrun.model_monitoring.EventKeyMetrics.GENERIC: {
- mlrun.model_monitoring.EventLiveStats.LATENCY_AVG_1H: 0,
- mlrun.model_monitoring.EventLiveStats.PREDICTIONS_PER_SECOND: 0,
+ flatten_dict[mlrun.common.model_monitoring.EventFieldType.METRICS] = {
+ mlrun.common.model_monitoring.EventKeyMetrics.GENERIC: {
+ mlrun.common.model_monitoring.EventLiveStats.LATENCY_AVG_1H: 0,
+ mlrun.common.model_monitoring.EventLiveStats.PREDICTIONS_PER_SECOND: 0,
}
}
# Remove the features from the dictionary as this field will be filled only within the feature analysis process
- flatten_dict.pop(mlrun.model_monitoring.EventFieldType.FEATURES, None)
+ flatten_dict.pop(mlrun.common.model_monitoring.EventFieldType.FEATURES, None)
return flatten_dict
@classmethod
diff --git a/mlrun/api/schemas/notification.py b/mlrun/common/schemas/notification.py
similarity index 83%
rename from mlrun/api/schemas/notification.py
rename to mlrun/common/schemas/notification.py
index ac5591c0addd..d406d66c813a 100644
--- a/mlrun/api/schemas/notification.py
+++ b/mlrun/common/schemas/notification.py
@@ -13,10 +13,10 @@
# limitations under the License.
-import mlrun.api.utils.helpers
+import mlrun.common.types
-class NotificationSeverity(mlrun.api.utils.helpers.StrEnum):
+class NotificationSeverity(mlrun.common.types.StrEnum):
INFO = "info"
DEBUG = "debug"
VERBOSE = "verbose"
@@ -24,7 +24,7 @@ class NotificationSeverity(mlrun.api.utils.helpers.StrEnum):
ERROR = "error"
-class NotificationStatus(mlrun.api.utils.helpers.StrEnum):
+class NotificationStatus(mlrun.common.types.StrEnum):
PENDING = "pending"
SENT = "sent"
ERROR = "error"
diff --git a/mlrun/api/schemas/object.py b/mlrun/common/schemas/object.py
similarity index 95%
rename from mlrun/api/schemas/object.py
rename to mlrun/common/schemas/object.py
index 8ec6a738efb1..f0cad67021a3 100644
--- a/mlrun/api/schemas/object.py
+++ b/mlrun/common/schemas/object.py
@@ -17,7 +17,7 @@
from pydantic import BaseModel, Extra
-import mlrun.api.utils.helpers
+import mlrun.common.types
class ObjectMetadata(BaseModel):
@@ -69,7 +69,7 @@ class Config:
orm_mode = True
-class ObjectKind(mlrun.api.utils.helpers.StrEnum):
+class ObjectKind(mlrun.common.types.StrEnum):
project = "project"
feature_set = "FeatureSet"
background_task = "BackgroundTask"
diff --git a/mlrun/api/schemas/pipeline.py b/mlrun/common/schemas/pipeline.py
similarity index 92%
rename from mlrun/api/schemas/pipeline.py
rename to mlrun/common/schemas/pipeline.py
index 30211c158c8c..e1e3815794dc 100644
--- a/mlrun/api/schemas/pipeline.py
+++ b/mlrun/common/schemas/pipeline.py
@@ -16,10 +16,10 @@
import pydantic
-import mlrun.api.utils.helpers
+import mlrun.common.types
-class PipelinesFormat(mlrun.api.utils.helpers.StrEnum):
+class PipelinesFormat(mlrun.common.types.StrEnum):
full = "full"
metadata_only = "metadata_only"
summary = "summary"
diff --git a/mlrun/api/schemas/project.py b/mlrun/common/schemas/project.py
similarity index 94%
rename from mlrun/api/schemas/project.py
rename to mlrun/common/schemas/project.py
index 6d81446d077b..5acaf35c1bf2 100644
--- a/mlrun/api/schemas/project.py
+++ b/mlrun/common/schemas/project.py
@@ -17,12 +17,12 @@
import pydantic
-import mlrun.api.utils.helpers
+import mlrun.common.types
from .object import ObjectKind, ObjectStatus
-class ProjectsFormat(mlrun.api.utils.helpers.StrEnum):
+class ProjectsFormat(mlrun.common.types.StrEnum):
full = "full"
name_only = "name_only"
# internal - allowed only in follower mode, only for the leader for upgrade purposes
@@ -39,13 +39,13 @@ class Config:
extra = pydantic.Extra.allow
-class ProjectDesiredState(mlrun.api.utils.helpers.StrEnum):
+class ProjectDesiredState(mlrun.common.types.StrEnum):
online = "online"
offline = "offline"
archived = "archived"
-class ProjectState(mlrun.api.utils.helpers.StrEnum):
+class ProjectState(mlrun.common.types.StrEnum):
unknown = "unknown"
creating = "creating"
deleting = "deleting"
diff --git a/mlrun/api/schemas/runtime_resource.py b/mlrun/common/schemas/runtime_resource.py
similarity index 93%
rename from mlrun/api/schemas/runtime_resource.py
rename to mlrun/common/schemas/runtime_resource.py
index 3fb9d204b279..332c27b67086 100644
--- a/mlrun/api/schemas/runtime_resource.py
+++ b/mlrun/common/schemas/runtime_resource.py
@@ -16,10 +16,10 @@
import pydantic
-import mlrun.api.utils.helpers
+import mlrun.common.types
-class ListRuntimeResourcesGroupByField(mlrun.api.utils.helpers.StrEnum):
+class ListRuntimeResourcesGroupByField(mlrun.common.types.StrEnum):
job = "job"
project = "project"
diff --git a/mlrun/api/schemas/schedule.py b/mlrun/common/schemas/schedule.py
similarity index 95%
rename from mlrun/api/schemas/schedule.py
rename to mlrun/common/schemas/schedule.py
index 08a6df5822d3..adadc2c31318 100644
--- a/mlrun/api/schemas/schedule.py
+++ b/mlrun/common/schemas/schedule.py
@@ -17,9 +17,9 @@
from pydantic import BaseModel
-import mlrun.api.utils.helpers
-from mlrun.api.schemas.auth import Credentials
-from mlrun.api.schemas.object import LabelRecord
+import mlrun.common.types
+from mlrun.common.schemas.auth import Credentials
+from mlrun.common.schemas.object import LabelRecord
class ScheduleCronTrigger(BaseModel):
@@ -78,7 +78,7 @@ def to_crontab(self) -> str:
return f"{self.minute} {self.hour} {self.day} {self.month} {self.day_of_week}"
-class ScheduleKinds(mlrun.api.utils.helpers.StrEnum):
+class ScheduleKinds(mlrun.common.types.StrEnum):
job = "job"
pipeline = "pipeline"
diff --git a/mlrun/api/schemas/secret.py b/mlrun/common/schemas/secret.py
similarity index 93%
rename from mlrun/api/schemas/secret.py
rename to mlrun/common/schemas/secret.py
index 5b842d5dadc9..27cac5d6a62d 100644
--- a/mlrun/api/schemas/secret.py
+++ b/mlrun/common/schemas/secret.py
@@ -16,10 +16,10 @@
from pydantic import BaseModel, Field
-import mlrun.api.utils.helpers
+import mlrun.common.types
-class SecretProviderName(mlrun.api.utils.helpers.StrEnum):
+class SecretProviderName(mlrun.common.types.StrEnum):
"""Enum containing names of valid providers for secrets."""
vault = "vault"
diff --git a/mlrun/api/schemas/tag.py b/mlrun/common/schemas/tag.py
similarity index 100%
rename from mlrun/api/schemas/tag.py
rename to mlrun/common/schemas/tag.py
diff --git a/mlrun/common/types.py b/mlrun/common/types.py
new file mode 100644
index 000000000000..92ce98e61e98
--- /dev/null
+++ b/mlrun/common/types.py
@@ -0,0 +1,25 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+import enum
+
+
+# TODO: From python 3.11 StrEnum is built-in and this will not be needed
+class StrEnum(str, enum.Enum):
+ def __str__(self):
+ return self.value
+
+ def __repr__(self):
+ return self.value
diff --git a/mlrun/config.py b/mlrun/config.py
index 9630b2f8e383..b2abebd84640 100644
--- a/mlrun/config.py
+++ b/mlrun/config.py
@@ -155,7 +155,7 @@
# default security context to be applied to all functions - json string base64 encoded format
# in camelCase format: {"runAsUser": 1000, "runAsGroup": 3000}
"default": "e30=", # encoded empty dict
- # see mlrun.api.schemas.function.SecurityContextEnrichmentModes for available options
+ # see mlrun.common.schemas.function.SecurityContextEnrichmentModes for available options
"enrichment_mode": "disabled",
# default 65534 (nogroup), set to -1 to use the user unix id or
# function.spec.security_context.pipelines.kfp_pod_user_unix_id for kfp pods
@@ -178,7 +178,7 @@
"mpijob": "mlrun/ml-models",
},
# see enrich_function_preemption_spec for more info,
- # and mlrun.api.schemas.function.PreemptionModes for available options
+ # and mlrun.common.schemas.function.PreemptionModes for available options
"preemption_mode": "prevent",
},
"httpdb": {
@@ -219,7 +219,7 @@
"allowed_file_paths": "s3://,gcs://,gs://,az://",
"db_type": "sqldb",
"max_workers": 64,
- # See mlrun.api.schemas.APIStates for options
+ # See mlrun.common.schemas.APIStates for options
"state": "online",
"retry_api_call_on_exception": "enabled",
"http_connection_timeout_keep_alive": 11,
@@ -400,7 +400,7 @@
"default_http_sink": "http://nuclio-{project}-model-monitoring-stream.mlrun.svc.cluster.local:8080",
"batch_processing_function_branch": "master",
"parquet_batching_max_events": 10000,
- # See mlrun.api.schemas.ModelEndpointStoreType for available options
+ # See mlrun.common.schemas.ModelEndpointStoreType for available options
"store_type": "v3io-nosql",
"endpoint_store_connection": "",
},
diff --git a/mlrun/datastore/store_resources.py b/mlrun/datastore/store_resources.py
index d6ffe47f5394..bee8811db97a 100644
--- a/mlrun/datastore/store_resources.py
+++ b/mlrun/datastore/store_resources.py
@@ -101,8 +101,8 @@ def get_table(self, uri):
if is_store_uri(uri):
resource = get_store_resource(uri)
if resource.kind in [
- mlrun.api.schemas.ObjectKind.feature_set.value,
- mlrun.api.schemas.ObjectKind.feature_vector.value,
+ mlrun.common.schemas.ObjectKind.feature_set.value,
+ mlrun.common.schemas.ObjectKind.feature_vector.value,
]:
target = get_online_target(resource)
if not target:
diff --git a/mlrun/datastore/targets.py b/mlrun/datastore/targets.py
index 95169487e1cc..d6d18a03ea94 100644
--- a/mlrun/datastore/targets.py
+++ b/mlrun/datastore/targets.py
@@ -1763,12 +1763,12 @@ def _get_target_path(driver, resource, run_id_mode=False):
if not suffix:
if (
kind == ParquetTarget.kind
- and resource.kind == mlrun.api.schemas.ObjectKind.feature_vector
+ and resource.kind == mlrun.common.schemas.ObjectKind.feature_vector
):
suffix = ".parquet"
kind_prefix = (
"sets"
- if resource.kind == mlrun.api.schemas.ObjectKind.feature_set
+ if resource.kind == mlrun.common.schemas.ObjectKind.feature_set
else "vectors"
)
name = resource.metadata.name
diff --git a/mlrun/db/base.py b/mlrun/db/base.py
index e794506e7aaf..807926716fd4 100644
--- a/mlrun/db/base.py
+++ b/mlrun/db/base.py
@@ -17,8 +17,8 @@
from abc import ABC, abstractmethod
from typing import List, Optional, Union
+import mlrun.common.schemas
import mlrun.model_monitoring.model_endpoint
-from mlrun.api import schemas
class RunDBError(Exception):
@@ -71,10 +71,12 @@ def list_runs(
start_time_to: datetime.datetime = None,
last_update_time_from: datetime.datetime = None,
last_update_time_to: datetime.datetime = None,
- partition_by: Union[schemas.RunPartitionByField, str] = None,
+ partition_by: Union[mlrun.common.schemas.RunPartitionByField, str] = None,
rows_per_partition: int = 1,
- partition_sort_by: Union[schemas.SortField, str] = None,
- partition_order: Union[schemas.OrderType, str] = schemas.OrderType.desc,
+ partition_sort_by: Union[mlrun.common.schemas.SortField, str] = None,
+ partition_order: Union[
+ mlrun.common.schemas.OrderType, str
+ ] = mlrun.common.schemas.OrderType.desc,
max_partitions: int = 0,
with_notifications: bool = False,
):
@@ -108,7 +110,7 @@ def list_artifacts(
iter: int = None,
best_iteration: bool = False,
kind: str = None,
- category: Union[str, schemas.ArtifactCategories] = None,
+ category: Union[str, mlrun.common.schemas.ArtifactCategories] = None,
):
pass
@@ -148,7 +150,7 @@ def tag_objects(
self,
project: str,
tag_name: str,
- tag_objects: schemas.TagObjects,
+ tag_objects: mlrun.common.schemas.TagObjects,
replace: bool = False,
):
pass
@@ -158,7 +160,7 @@ def delete_objects_tag(
self,
project: str,
tag_name: str,
- tag_objects: schemas.TagObjects,
+ tag_objects: mlrun.common.schemas.TagObjects,
):
pass
@@ -184,11 +186,11 @@ def delete_artifacts_tags(
@staticmethod
def _resolve_artifacts_to_tag_objects(
artifacts,
- ) -> schemas.TagObjects:
+ ) -> mlrun.common.schemas.TagObjects:
"""
:param artifacts: Can be a list of :py:class:`~mlrun.artifacts.Artifact` objects or
dictionaries, or a single object.
- :return: :py:class:`~mlrun.api.schemas.TagObjects`
+ :return: :py:class:`~mlrun.common.schemas.TagObjects`
"""
# to avoid circular imports we import here
import mlrun.artifacts.base
@@ -204,7 +206,7 @@ def _resolve_artifacts_to_tag_objects(
else artifact
)
artifact_identifiers.append(
- schemas.ArtifactIdentifier(
+ mlrun.common.schemas.ArtifactIdentifier(
key=mlrun.utils.get_in_artifact(artifact_obj, "key"),
# we are passing tree as uid when storing an artifact, so if uid is not defined,
# pass the tree as uid
@@ -214,13 +216,15 @@ def _resolve_artifacts_to_tag_objects(
iter=mlrun.utils.get_in_artifact(artifact_obj, "iter"),
)
)
- return schemas.TagObjects(kind="artifact", identifiers=artifact_identifiers)
+ return mlrun.common.schemas.TagObjects(
+ kind="artifact", identifiers=artifact_identifiers
+ )
@abstractmethod
def delete_project(
self,
name: str,
- deletion_strategy: schemas.DeletionStrategy = schemas.DeletionStrategy.default(),
+ deletion_strategy: mlrun.common.schemas.DeletionStrategy = mlrun.common.schemas.DeletionStrategy.default(),
):
pass
@@ -228,8 +232,8 @@ def delete_project(
def store_project(
self,
name: str,
- project: schemas.Project,
- ) -> schemas.Project:
+ project: mlrun.common.schemas.Project,
+ ) -> mlrun.common.schemas.Project:
pass
@abstractmethod
@@ -237,40 +241,45 @@ def patch_project(
self,
name: str,
project: dict,
- patch_mode: schemas.PatchMode = schemas.PatchMode.replace,
- ) -> schemas.Project:
+ patch_mode: mlrun.common.schemas.PatchMode = mlrun.common.schemas.PatchMode.replace,
+ ) -> mlrun.common.schemas.Project:
pass
@abstractmethod
def create_project(
self,
- project: schemas.Project,
- ) -> schemas.Project:
+ project: mlrun.common.schemas.Project,
+ ) -> mlrun.common.schemas.Project:
pass
@abstractmethod
def list_projects(
self,
owner: str = None,
- format_: schemas.ProjectsFormat = schemas.ProjectsFormat.full,
+ format_: mlrun.common.schemas.ProjectsFormat = mlrun.common.schemas.ProjectsFormat.full,
labels: List[str] = None,
- state: schemas.ProjectState = None,
- ) -> schemas.ProjectsOutput:
+ state: mlrun.common.schemas.ProjectState = None,
+ ) -> mlrun.common.schemas.ProjectsOutput:
pass
@abstractmethod
- def get_project(self, name: str) -> schemas.Project:
+ def get_project(self, name: str) -> mlrun.common.schemas.Project:
pass
@abstractmethod
def list_artifact_tags(
- self, project=None, category: Union[str, schemas.ArtifactCategories] = None
+ self,
+ project=None,
+ category: Union[str, mlrun.common.schemas.ArtifactCategories] = None,
):
pass
@abstractmethod
def create_feature_set(
- self, feature_set: Union[dict, schemas.FeatureSet], project="", versioned=True
+ self,
+ feature_set: Union[dict, mlrun.common.schemas.FeatureSet],
+ project="",
+ versioned=True,
) -> dict:
pass
@@ -288,7 +297,7 @@ def list_features(
tag: str = None,
entities: List[str] = None,
labels: List[str] = None,
- ) -> schemas.FeaturesOutput:
+ ) -> mlrun.common.schemas.FeaturesOutput:
pass
@abstractmethod
@@ -298,7 +307,7 @@ def list_entities(
name: str = None,
tag: str = None,
labels: List[str] = None,
- ) -> schemas.EntitiesOutput:
+ ) -> mlrun.common.schemas.EntitiesOutput:
pass
@abstractmethod
@@ -311,17 +320,21 @@ def list_feature_sets(
entities: List[str] = None,
features: List[str] = None,
labels: List[str] = None,
- partition_by: Union[schemas.FeatureStorePartitionByField, str] = None,
+ partition_by: Union[
+ mlrun.common.schemas.FeatureStorePartitionByField, str
+ ] = None,
rows_per_partition: int = 1,
- partition_sort_by: Union[schemas.SortField, str] = None,
- partition_order: Union[schemas.OrderType, str] = schemas.OrderType.desc,
+ partition_sort_by: Union[mlrun.common.schemas.SortField, str] = None,
+ partition_order: Union[
+ mlrun.common.schemas.OrderType, str
+ ] = mlrun.common.schemas.OrderType.desc,
) -> List[dict]:
pass
@abstractmethod
def store_feature_set(
self,
- feature_set: Union[dict, schemas.FeatureSet],
+ feature_set: Union[dict, mlrun.common.schemas.FeatureSet],
name=None,
project="",
tag=None,
@@ -338,7 +351,9 @@ def patch_feature_set(
project="",
tag=None,
uid=None,
- patch_mode: Union[str, schemas.PatchMode] = schemas.PatchMode.replace,
+ patch_mode: Union[
+ str, mlrun.common.schemas.PatchMode
+ ] = mlrun.common.schemas.PatchMode.replace,
):
pass
@@ -349,7 +364,7 @@ def delete_feature_set(self, name, project="", tag=None, uid=None):
@abstractmethod
def create_feature_vector(
self,
- feature_vector: Union[dict, schemas.FeatureVector],
+ feature_vector: Union[dict, mlrun.common.schemas.FeatureVector],
project="",
versioned=True,
) -> dict:
@@ -369,17 +384,21 @@ def list_feature_vectors(
tag: str = None,
state: str = None,
labels: List[str] = None,
- partition_by: Union[schemas.FeatureStorePartitionByField, str] = None,
+ partition_by: Union[
+ mlrun.common.schemas.FeatureStorePartitionByField, str
+ ] = None,
rows_per_partition: int = 1,
- partition_sort_by: Union[schemas.SortField, str] = None,
- partition_order: Union[schemas.OrderType, str] = schemas.OrderType.desc,
+ partition_sort_by: Union[mlrun.common.schemas.SortField, str] = None,
+ partition_order: Union[
+ mlrun.common.schemas.OrderType, str
+ ] = mlrun.common.schemas.OrderType.desc,
) -> List[dict]:
pass
@abstractmethod
def store_feature_vector(
self,
- feature_vector: Union[dict, schemas.FeatureVector],
+ feature_vector: Union[dict, mlrun.common.schemas.FeatureVector],
name=None,
project="",
tag=None,
@@ -396,7 +415,9 @@ def patch_feature_vector(
project="",
tag=None,
uid=None,
- patch_mode: Union[str, schemas.PatchMode] = schemas.PatchMode.replace,
+ patch_mode: Union[
+ str, mlrun.common.schemas.PatchMode
+ ] = mlrun.common.schemas.PatchMode.replace,
):
pass
@@ -413,10 +434,10 @@ def list_pipelines(
page_token: str = "",
filter_: str = "",
format_: Union[
- str, schemas.PipelinesFormat
- ] = schemas.PipelinesFormat.metadata_only,
+ str, mlrun.common.schemas.PipelinesFormat
+ ] = mlrun.common.schemas.PipelinesFormat.metadata_only,
page_size: int = None,
- ) -> schemas.PipelinesOutput:
+ ) -> mlrun.common.schemas.PipelinesOutput:
pass
@abstractmethod
@@ -424,8 +445,8 @@ def create_project_secrets(
self,
project: str,
provider: Union[
- str, schemas.SecretProviderName
- ] = schemas.SecretProviderName.kubernetes,
+ str, mlrun.common.schemas.SecretProviderName
+ ] = mlrun.common.schemas.SecretProviderName.kubernetes,
secrets: dict = None,
):
pass
@@ -436,10 +457,10 @@ def list_project_secrets(
project: str,
token: str,
provider: Union[
- str, schemas.SecretProviderName
- ] = schemas.SecretProviderName.kubernetes,
+ str, mlrun.common.schemas.SecretProviderName
+ ] = mlrun.common.schemas.SecretProviderName.kubernetes,
secrets: List[str] = None,
- ) -> schemas.SecretsData:
+ ) -> mlrun.common.schemas.SecretsData:
pass
@abstractmethod
@@ -447,10 +468,10 @@ def list_project_secret_keys(
self,
project: str,
provider: Union[
- str, schemas.SecretProviderName
- ] = schemas.SecretProviderName.kubernetes,
+ str, mlrun.common.schemas.SecretProviderName
+ ] = mlrun.common.schemas.SecretProviderName.kubernetes,
token: str = None,
- ) -> schemas.SecretKeysData:
+ ) -> mlrun.common.schemas.SecretKeysData:
pass
@abstractmethod
@@ -458,8 +479,8 @@ def delete_project_secrets(
self,
project: str,
provider: Union[
- str, schemas.SecretProviderName
- ] = schemas.SecretProviderName.kubernetes,
+ str, mlrun.common.schemas.SecretProviderName
+ ] = mlrun.common.schemas.SecretProviderName.kubernetes,
secrets: List[str] = None,
):
pass
@@ -469,8 +490,8 @@ def create_user_secrets(
self,
user: str,
provider: Union[
- str, schemas.SecretProviderName
- ] = schemas.SecretProviderName.vault,
+ str, mlrun.common.schemas.SecretProviderName
+ ] = mlrun.common.schemas.SecretProviderName.vault,
secrets: dict = None,
):
pass
@@ -529,12 +550,16 @@ def patch_model_endpoint(
pass
@abstractmethod
- def create_hub_source(self, source: Union[dict, schemas.IndexedHubSource]):
+ def create_hub_source(
+ self, source: Union[dict, mlrun.common.schemas.IndexedHubSource]
+ ):
pass
@abstractmethod
def store_hub_source(
- self, source_name: str, source: Union[dict, schemas.IndexedHubSource]
+ self,
+ source_name: str,
+ source: Union[dict, mlrun.common.schemas.IndexedHubSource],
):
pass
@@ -573,6 +598,7 @@ def get_hub_item(
@abstractmethod
def verify_authorization(
- self, authorization_verification_input: schemas.AuthorizationVerificationInput
+ self,
+ authorization_verification_input: mlrun.common.schemas.AuthorizationVerificationInput,
):
pass
diff --git a/mlrun/db/httpdb.py b/mlrun/db/httpdb.py
index c34b044a3d23..8589ec78f2dd 100644
--- a/mlrun/db/httpdb.py
+++ b/mlrun/db/httpdb.py
@@ -27,9 +27,9 @@
import semver
import mlrun
+import mlrun.common.schemas
import mlrun.model_monitoring.model_endpoint
import mlrun.projects
-from mlrun.api import schemas
from mlrun.errors import MLRunInvalidArgumentError, err_to_str
from ..artifacts import Artifact
@@ -192,13 +192,13 @@ def api_call(
if "Authorization" not in kw.setdefault("headers", {}):
kw["headers"].update({"Authorization": "Bearer " + self.token})
- if mlrun.api.schemas.HeaderNames.client_version not in kw.setdefault(
+ if mlrun.common.schemas.HeaderNames.client_version not in kw.setdefault(
"headers", {}
):
kw["headers"].update(
{
- mlrun.api.schemas.HeaderNames.client_version: self.client_version,
- mlrun.api.schemas.HeaderNames.python_version: self.python_version,
+ mlrun.common.schemas.HeaderNames.client_version: self.client_version,
+ mlrun.common.schemas.HeaderNames.python_version: self.python_version,
}
)
@@ -242,7 +242,7 @@ def api_call(
def _init_session(self):
return mlrun.utils.HTTPSessionWithRetry(
retry_on_exception=config.httpdb.retry_api_call_on_exception
- == mlrun.api.schemas.HTTPSessionRetryMode.enabled.value
+ == mlrun.common.schemas.HTTPSessionRetryMode.enabled.value
)
def _path_of(self, prefix, project, uid):
@@ -560,10 +560,12 @@ def list_runs(
start_time_to: datetime = None,
last_update_time_from: datetime = None,
last_update_time_to: datetime = None,
- partition_by: Union[schemas.RunPartitionByField, str] = None,
+ partition_by: Union[mlrun.common.schemas.RunPartitionByField, str] = None,
rows_per_partition: int = 1,
- partition_sort_by: Union[schemas.SortField, str] = None,
- partition_order: Union[schemas.OrderType, str] = schemas.OrderType.desc,
+ partition_sort_by: Union[mlrun.common.schemas.SortField, str] = None,
+ partition_order: Union[
+ mlrun.common.schemas.OrderType, str
+ ] = mlrun.common.schemas.OrderType.desc,
max_partitions: int = 0,
with_notifications: bool = False,
) -> RunList:
@@ -621,7 +623,7 @@ def list_runs(
if partition_by:
params.update(
self._generate_partition_by_params(
- schemas.RunPartitionByField,
+ mlrun.common.schemas.RunPartitionByField,
partition_by,
rows_per_partition,
partition_sort_by,
@@ -690,7 +692,7 @@ def read_artifact(self, key, tag=None, iter=None, project=""):
endpoint_path = f"projects/{project}/artifacts/{key}?tag={tag}"
error = f"read artifact {project}/{key}"
# explicitly set artifacts format to 'full' since old servers may default to 'legacy'
- params = {"format": schemas.ArtifactsFormat.full.value}
+ params = {"format": mlrun.common.schemas.ArtifactsFormat.full.value}
if iter:
params["iter"] = str(iter)
resp = self.api_call("GET", endpoint_path, error, params=params)
@@ -718,7 +720,7 @@ def list_artifacts(
iter: int = None,
best_iteration: bool = False,
kind: str = None,
- category: Union[str, schemas.ArtifactCategories] = None,
+ category: Union[str, mlrun.common.schemas.ArtifactCategories] = None,
) -> ArtifactList:
"""List artifacts filtered by various parameters.
@@ -762,7 +764,7 @@ def list_artifacts(
"best-iteration": best_iteration,
"kind": kind,
"category": category,
- "format": schemas.ArtifactsFormat.full.value,
+ "format": mlrun.common.schemas.ArtifactsFormat.full.value,
}
error = "list artifacts"
endpoint_path = f"projects/{project}/artifacts"
@@ -795,7 +797,7 @@ def del_artifacts(self, name=None, project=None, tag=None, labels=None, days_ago
def list_artifact_tags(
self,
project=None,
- category: Union[str, schemas.ArtifactCategories] = None,
+ category: Union[str, mlrun.common.schemas.ArtifactCategories] = None,
) -> List[str]:
"""Return a list of all the tags assigned to artifacts in the scope of the given project."""
@@ -877,11 +879,13 @@ def list_runtime_resources(
label_selector: Optional[str] = None,
kind: Optional[str] = None,
object_id: Optional[str] = None,
- group_by: Optional[mlrun.api.schemas.ListRuntimeResourcesGroupByField] = None,
+ group_by: Optional[
+ mlrun.common.schemas.ListRuntimeResourcesGroupByField
+ ] = None,
) -> Union[
- mlrun.api.schemas.RuntimeResourcesOutput,
- mlrun.api.schemas.GroupedByJobRuntimeResourcesOutput,
- mlrun.api.schemas.GroupedByProjectRuntimeResourcesOutput,
+ mlrun.common.schemas.RuntimeResourcesOutput,
+ mlrun.common.schemas.GroupedByJobRuntimeResourcesOutput,
+ mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput,
]:
"""List current runtime resources, which are usually (but not limited to) Kubernetes pods or CRDs.
Function applies for runs of type `['dask', 'job', 'spark', 'remote-spark', 'mpijob']`, and will return per
@@ -910,25 +914,25 @@ def list_runtime_resources(
)
if group_by is None:
structured_list = [
- mlrun.api.schemas.KindRuntimeResources(**kind_runtime_resources)
+ mlrun.common.schemas.KindRuntimeResources(**kind_runtime_resources)
for kind_runtime_resources in response.json()
]
return structured_list
- elif group_by == mlrun.api.schemas.ListRuntimeResourcesGroupByField.job:
+ elif group_by == mlrun.common.schemas.ListRuntimeResourcesGroupByField.job:
structured_dict = {}
for project, job_runtime_resources_map in response.json().items():
for job_id, runtime_resources in job_runtime_resources_map.items():
structured_dict.setdefault(project, {})[
job_id
- ] = mlrun.api.schemas.RuntimeResources(**runtime_resources)
+ ] = mlrun.common.schemas.RuntimeResources(**runtime_resources)
return structured_dict
- elif group_by == mlrun.api.schemas.ListRuntimeResourcesGroupByField.project:
+ elif group_by == mlrun.common.schemas.ListRuntimeResourcesGroupByField.project:
structured_dict = {}
for project, kind_runtime_resources_map in response.json().items():
for kind, runtime_resources in kind_runtime_resources_map.items():
structured_dict.setdefault(project, {})[
kind
- ] = mlrun.api.schemas.RuntimeResources(**runtime_resources)
+ ] = mlrun.common.schemas.RuntimeResources(**runtime_resources)
return structured_dict
else:
raise NotImplementedError(
@@ -943,7 +947,7 @@ def delete_runtime_resources(
object_id: Optional[str] = None,
force: bool = False,
grace_period: int = None,
- ) -> mlrun.api.schemas.GroupedByProjectRuntimeResourcesOutput:
+ ) -> mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput:
"""Delete all runtime resources which are in terminal state.
:param project: Delete only runtime resources of a specific project, by default None, which will delete only
@@ -958,7 +962,7 @@ def delete_runtime_resources(
:param grace_period: Grace period given to the runtime resource before they are actually removed, counted from
the moment they moved to terminal state (defaults to mlrun.mlconf.runtime_resources_deletion_grace_period).
- :returns: :py:class:`~mlrun.api.schemas.GroupedByProjectRuntimeResourcesOutput` listing the runtime resources
+ :returns: :py:class:`~mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput` listing the runtime resources
that were removed.
"""
if grace_period is None:
@@ -988,10 +992,12 @@ def delete_runtime_resources(
for kind, runtime_resources in kind_runtime_resources_map.items():
structured_dict.setdefault(project, {})[
kind
- ] = mlrun.api.schemas.RuntimeResources(**runtime_resources)
+ ] = mlrun.common.schemas.RuntimeResources(**runtime_resources)
return structured_dict
- def create_schedule(self, project: str, schedule: schemas.ScheduleInput):
+ def create_schedule(
+ self, project: str, schedule: mlrun.common.schemas.ScheduleInput
+ ):
"""Create a new schedule on the given project. The details on the actual object to schedule as well as the
schedule itself are within the schedule object provided.
The :py:class:`~ScheduleCronTrigger` follows the guidelines in
@@ -1003,7 +1009,7 @@ def create_schedule(self, project: str, schedule: schemas.ScheduleInput):
Example::
- from mlrun.api import schemas
+ from mlrun.common import schemas
# Execute the get_data_func function every Tuesday at 15:30
schedule = schemas.ScheduleInput(
@@ -1022,7 +1028,7 @@ def create_schedule(self, project: str, schedule: schemas.ScheduleInput):
self.api_call("POST", path, error_message, body=dict_to_json(schedule.dict()))
def update_schedule(
- self, project: str, name: str, schedule: schemas.ScheduleUpdate
+ self, project: str, name: str, schedule: mlrun.common.schemas.ScheduleUpdate
):
"""Update an existing schedule, replace it with the details contained in the schedule object."""
@@ -1034,7 +1040,7 @@ def update_schedule(
def get_schedule(
self, project: str, name: str, include_last_run: bool = False
- ) -> schemas.ScheduleOutput:
+ ) -> mlrun.common.schemas.ScheduleOutput:
"""Retrieve details of the schedule in question. Besides returning the details of the schedule object itself,
this function also returns the next scheduled run for this specific schedule, as well as potentially the
results of the last run executed through this schedule.
@@ -1050,15 +1056,15 @@ def get_schedule(
resp = self.api_call(
"GET", path, error_message, params={"include_last_run": include_last_run}
)
- return schemas.ScheduleOutput(**resp.json())
+ return mlrun.common.schemas.ScheduleOutput(**resp.json())
def list_schedules(
self,
project: str,
name: str = None,
- kind: schemas.ScheduleKinds = None,
+ kind: mlrun.common.schemas.ScheduleKinds = None,
include_last_run: bool = False,
- ) -> schemas.SchedulesOutput:
+ ) -> mlrun.common.schemas.SchedulesOutput:
"""Retrieve list of schedules of specific name or kind.
:param project: Project name.
@@ -1073,7 +1079,7 @@ def list_schedules(
path = f"projects/{project}/schedules"
error_message = f"Failed listing schedules for {project} ? {kind} {name}"
resp = self.api_call("GET", path, error_message, params=params)
- return schemas.SchedulesOutput(**resp.json())
+ return mlrun.common.schemas.SchedulesOutput(**resp.json())
def delete_schedule(self, project: str, name: str):
"""Delete a specific schedule by name."""
@@ -1202,7 +1208,7 @@ def get_builder_status(
text = resp.content.decode()
return text, last_log_timestamp
- def remote_start(self, func_url) -> schemas.BackgroundTask:
+ def remote_start(self, func_url) -> mlrun.common.schemas.BackgroundTask:
"""Execute a function remotely, Used for ``dask`` functions.
:param func_url: URL to the function to be executed.
@@ -1225,13 +1231,13 @@ def remote_start(self, func_url) -> schemas.BackgroundTask:
logger.error(f"bad resp!!\n{resp.text}")
raise ValueError("bad function start response")
- return schemas.BackgroundTask(**resp.json())
+ return mlrun.common.schemas.BackgroundTask(**resp.json())
def get_project_background_task(
self,
project: str,
name: str,
- ) -> schemas.BackgroundTask:
+ ) -> mlrun.common.schemas.BackgroundTask:
"""Retrieve updated information on a project background task being executed."""
project = project or config.default_project
@@ -1240,15 +1246,15 @@ def get_project_background_task(
f"Failed getting project background task. project={project}, name={name}"
)
response = self.api_call("GET", path, error_message)
- return schemas.BackgroundTask(**response.json())
+ return mlrun.common.schemas.BackgroundTask(**response.json())
- def get_background_task(self, name: str) -> schemas.BackgroundTask:
+ def get_background_task(self, name: str) -> mlrun.common.schemas.BackgroundTask:
"""Retrieve updated information on a background task being executed."""
path = f"background-tasks/{name}"
error_message = f"Failed getting background task. name={name}"
response = self.api_call("GET", path, error_message)
- return schemas.BackgroundTask(**response.json())
+ return mlrun.common.schemas.BackgroundTask(**response.json())
def remote_status(self, project, name, kind, selector):
"""Retrieve status of a function being executed remotely (relevant to ``dask`` functions).
@@ -1273,7 +1279,9 @@ def remote_status(self, project, name, kind, selector):
return resp.json()["data"]
def submit_job(
- self, runspec, schedule: Union[str, schemas.ScheduleCronTrigger] = None
+ self,
+ runspec,
+ schedule: Union[str, mlrun.common.schemas.ScheduleCronTrigger] = None,
):
"""Submit a job for remote execution.
@@ -1285,7 +1293,7 @@ def submit_job(
try:
req = {"task": runspec.to_dict()}
if schedule:
- if isinstance(schedule, schemas.ScheduleCronTrigger):
+ if isinstance(schedule, mlrun.common.schemas.ScheduleCronTrigger):
schedule = schedule.dict()
req["schedule"] = schedule
timeout = (int(config.submit_timeout) or 120) + 20
@@ -1367,7 +1375,9 @@ def submit_pipeline(
if arguments:
if not isinstance(arguments, dict):
raise ValueError("arguments must be dict type")
- headers[schemas.HeaderNames.pipeline_arguments] = str(arguments)
+ headers[mlrun.common.schemas.HeaderNames.pipeline_arguments] = str(
+ arguments
+ )
if not path.isfile(pipe_file):
raise OSError(f"file {pipe_file} doesnt exist")
@@ -1406,10 +1416,10 @@ def list_pipelines(
page_token: str = "",
filter_: str = "",
format_: Union[
- str, mlrun.api.schemas.PipelinesFormat
- ] = mlrun.api.schemas.PipelinesFormat.metadata_only,
+ str, mlrun.common.schemas.PipelinesFormat
+ ] = mlrun.common.schemas.PipelinesFormat.metadata_only,
page_size: int = None,
- ) -> mlrun.api.schemas.PipelinesOutput:
+ ) -> mlrun.common.schemas.PipelinesOutput:
"""Retrieve a list of KFP pipelines. This function can be invoked to get all pipelines from all projects,
by specifying ``project=*``, in which case pagination can be used and the various sorting and pagination
properties can be applied. If a specific project is requested, then the pagination options cannot be
@@ -1445,7 +1455,7 @@ def list_pipelines(
response = self.api_call(
"GET", f"projects/{project}/pipelines", error_message, params=params
)
- return mlrun.api.schemas.PipelinesOutput(**response.json())
+ return mlrun.common.schemas.PipelinesOutput(**response.json())
def get_pipeline(
self,
@@ -1453,8 +1463,8 @@ def get_pipeline(
namespace: str = None,
timeout: int = 10,
format_: Union[
- str, mlrun.api.schemas.PipelinesFormat
- ] = mlrun.api.schemas.PipelinesFormat.summary,
+ str, mlrun.common.schemas.PipelinesFormat
+ ] = mlrun.common.schemas.PipelinesFormat.summary,
project: str = None,
):
"""Retrieve details of a specific pipeline using its run ID (as provided when the pipeline was executed)."""
@@ -1489,7 +1499,7 @@ def _resolve_reference(tag, uid):
def create_feature_set(
self,
- feature_set: Union[dict, schemas.FeatureSet, FeatureSet],
+ feature_set: Union[dict, mlrun.common.schemas.FeatureSet, FeatureSet],
project="",
versioned=True,
) -> dict:
@@ -1502,7 +1512,7 @@ def create_feature_set(
will be kept in the DB and can be retrieved until explicitly deleted.
:returns: The :py:class:`~mlrun.feature_store.FeatureSet` object (as dict).
"""
- if isinstance(feature_set, schemas.FeatureSet):
+ if isinstance(feature_set, mlrun.common.schemas.FeatureSet):
feature_set = feature_set.dict()
elif isinstance(feature_set, FeatureSet):
feature_set = feature_set.to_dict()
@@ -1636,10 +1646,14 @@ def list_feature_sets(
entities: List[str] = None,
features: List[str] = None,
labels: List[str] = None,
- partition_by: Union[schemas.FeatureStorePartitionByField, str] = None,
+ partition_by: Union[
+ mlrun.common.schemas.FeatureStorePartitionByField, str
+ ] = None,
rows_per_partition: int = 1,
- partition_sort_by: Union[schemas.SortField, str] = None,
- partition_order: Union[schemas.OrderType, str] = schemas.OrderType.desc,
+ partition_sort_by: Union[mlrun.common.schemas.SortField, str] = None,
+ partition_order: Union[
+ mlrun.common.schemas.OrderType, str
+ ] = mlrun.common.schemas.OrderType.desc,
) -> List[FeatureSet]:
"""Retrieve a list of feature-sets matching the criteria provided.
@@ -1673,7 +1687,7 @@ def list_feature_sets(
if partition_by:
params.update(
self._generate_partition_by_params(
- schemas.FeatureStorePartitionByField,
+ mlrun.common.schemas.FeatureStorePartitionByField,
partition_by,
rows_per_partition,
partition_sort_by,
@@ -1693,7 +1707,7 @@ def list_feature_sets(
def store_feature_set(
self,
- feature_set: Union[dict, schemas.FeatureSet, FeatureSet],
+ feature_set: Union[dict, mlrun.common.schemas.FeatureSet, FeatureSet],
name=None,
project="",
tag=None,
@@ -1718,7 +1732,7 @@ def store_feature_set(
reference = self._resolve_reference(tag, uid)
params = {"versioned": versioned}
- if isinstance(feature_set, schemas.FeatureSet):
+ if isinstance(feature_set, mlrun.common.schemas.FeatureSet):
feature_set = feature_set.dict()
elif isinstance(feature_set, FeatureSet):
feature_set = feature_set.to_dict()
@@ -1741,7 +1755,9 @@ def patch_feature_set(
project="",
tag=None,
uid=None,
- patch_mode: Union[str, schemas.PatchMode] = schemas.PatchMode.replace,
+ patch_mode: Union[
+ str, mlrun.common.schemas.PatchMode
+ ] = mlrun.common.schemas.PatchMode.replace,
):
"""Modify (patch) an existing :py:class:`~mlrun.feature_store.FeatureSet` object.
The object is identified by its name (and project it belongs to), as well as optionally a ``tag`` or its
@@ -1764,7 +1780,7 @@ def patch_feature_set(
"""
project = project or config.default_project
reference = self._resolve_reference(tag, uid)
- headers = {schemas.HeaderNames.patch_mode: patch_mode}
+ headers = {mlrun.common.schemas.HeaderNames.patch_mode: patch_mode}
path = f"projects/{project}/feature-sets/{name}/references/{reference}"
error_message = f"Failed updating feature-set {project}/{name}"
self.api_call(
@@ -1793,7 +1809,7 @@ def delete_feature_set(self, name, project="", tag=None, uid=None):
def create_feature_vector(
self,
- feature_vector: Union[dict, schemas.FeatureVector, FeatureVector],
+ feature_vector: Union[dict, mlrun.common.schemas.FeatureVector, FeatureVector],
project="",
versioned=True,
) -> dict:
@@ -1805,7 +1821,7 @@ def create_feature_vector(
will be kept in the DB and can be retrieved until explicitly deleted.
:returns: The :py:class:`~mlrun.feature_store.FeatureVector` object (as dict).
"""
- if isinstance(feature_vector, schemas.FeatureVector):
+ if isinstance(feature_vector, mlrun.common.schemas.FeatureVector):
feature_vector = feature_vector.dict()
elif isinstance(feature_vector, FeatureVector):
feature_vector = feature_vector.to_dict()
@@ -1849,10 +1865,14 @@ def list_feature_vectors(
tag: str = None,
state: str = None,
labels: List[str] = None,
- partition_by: Union[schemas.FeatureStorePartitionByField, str] = None,
+ partition_by: Union[
+ mlrun.common.schemas.FeatureStorePartitionByField, str
+ ] = None,
rows_per_partition: int = 1,
- partition_sort_by: Union[schemas.SortField, str] = None,
- partition_order: Union[schemas.OrderType, str] = schemas.OrderType.desc,
+ partition_sort_by: Union[mlrun.common.schemas.SortField, str] = None,
+ partition_order: Union[
+ mlrun.common.schemas.OrderType, str
+ ] = mlrun.common.schemas.OrderType.desc,
) -> List[FeatureVector]:
"""Retrieve a list of feature-vectors matching the criteria provided.
@@ -1882,7 +1902,7 @@ def list_feature_vectors(
if partition_by:
params.update(
self._generate_partition_by_params(
- schemas.FeatureStorePartitionByField,
+ mlrun.common.schemas.FeatureStorePartitionByField,
partition_by,
rows_per_partition,
partition_sort_by,
@@ -1902,7 +1922,7 @@ def list_feature_vectors(
def store_feature_vector(
self,
- feature_vector: Union[dict, schemas.FeatureVector, FeatureVector],
+ feature_vector: Union[dict, mlrun.common.schemas.FeatureVector, FeatureVector],
name=None,
project="",
tag=None,
@@ -1927,7 +1947,7 @@ def store_feature_vector(
reference = self._resolve_reference(tag, uid)
params = {"versioned": versioned}
- if isinstance(feature_vector, schemas.FeatureVector):
+ if isinstance(feature_vector, mlrun.common.schemas.FeatureVector):
feature_vector = feature_vector.dict()
elif isinstance(feature_vector, FeatureVector):
feature_vector = feature_vector.to_dict()
@@ -1952,7 +1972,9 @@ def patch_feature_vector(
project="",
tag=None,
uid=None,
- patch_mode: Union[str, schemas.PatchMode] = schemas.PatchMode.replace,
+ patch_mode: Union[
+ str, mlrun.common.schemas.PatchMode
+ ] = mlrun.common.schemas.PatchMode.replace,
):
"""Modify (patch) an existing :py:class:`~mlrun.feature_store.FeatureVector` object.
The object is identified by its name (and project it belongs to), as well as optionally a ``tag`` or its
@@ -1970,7 +1992,7 @@ def patch_feature_vector(
"""
reference = self._resolve_reference(tag, uid)
project = project or config.default_project
- headers = {schemas.HeaderNames.patch_mode: patch_mode}
+ headers = {mlrun.common.schemas.HeaderNames.patch_mode: patch_mode}
path = f"projects/{project}/feature-vectors/{name}/references/{reference}"
error_message = f"Failed updating feature-vector {project}/{name}"
self.api_call(
@@ -2000,7 +2022,7 @@ def tag_objects(
self,
project: str,
tag_name: str,
- objects: Union[mlrun.api.schemas.TagObjects, dict],
+ objects: Union[mlrun.common.schemas.TagObjects, dict],
replace: bool = False,
):
"""Tag a list of objects.
@@ -2020,7 +2042,7 @@ def tag_objects(
error_message,
body=dict_to_json(
objects.dict()
- if isinstance(objects, mlrun.api.schemas.TagObjects)
+ if isinstance(objects, mlrun.common.schemas.TagObjects)
else objects
),
)
@@ -2029,7 +2051,7 @@ def delete_objects_tag(
self,
project: str,
tag_name: str,
- tag_objects: Union[mlrun.api.schemas.TagObjects, dict],
+ tag_objects: Union[mlrun.common.schemas.TagObjects, dict],
):
"""Delete a tag from a list of objects.
@@ -2046,7 +2068,7 @@ def delete_objects_tag(
error_message,
body=dict_to_json(
tag_objects.dict()
- if isinstance(tag_objects, mlrun.api.schemas.TagObjects)
+ if isinstance(tag_objects, mlrun.common.schemas.TagObjects)
else tag_objects
),
)
@@ -2089,10 +2111,10 @@ def list_projects(
self,
owner: str = None,
format_: Union[
- str, mlrun.api.schemas.ProjectsFormat
- ] = mlrun.api.schemas.ProjectsFormat.full,
+ str, mlrun.common.schemas.ProjectsFormat
+ ] = mlrun.common.schemas.ProjectsFormat.full,
labels: List[str] = None,
- state: Union[str, mlrun.api.schemas.ProjectState] = None,
+ state: Union[str, mlrun.common.schemas.ProjectState] = None,
) -> List[Union[mlrun.projects.MlrunProject, str]]:
"""Return a list of the existing projects, potentially filtered by specific criteria.
@@ -2115,9 +2137,9 @@ def list_projects(
error_message = f"Failed listing projects, query: {params}"
response = self.api_call("GET", "projects", error_message, params=params)
- if format_ == mlrun.api.schemas.ProjectsFormat.name_only:
+ if format_ == mlrun.common.schemas.ProjectsFormat.name_only:
return response.json()["projects"]
- elif format_ == mlrun.api.schemas.ProjectsFormat.full:
+ elif format_ == mlrun.common.schemas.ProjectsFormat.full:
return [
mlrun.projects.MlrunProject.from_dict(project_dict)
for project_dict in response.json()["projects"]
@@ -2142,8 +2164,8 @@ def delete_project(
self,
name: str,
deletion_strategy: Union[
- str, mlrun.api.schemas.DeletionStrategy
- ] = mlrun.api.schemas.DeletionStrategy.default(),
+ str, mlrun.common.schemas.DeletionStrategy
+ ] = mlrun.common.schemas.DeletionStrategy.default(),
):
"""Delete a project.
@@ -2156,7 +2178,9 @@ def delete_project(
"""
path = f"projects/{name}"
- headers = {schemas.HeaderNames.deletion_strategy: deletion_strategy}
+ headers = {
+ mlrun.common.schemas.HeaderNames.deletion_strategy: deletion_strategy
+ }
error_message = f"Failed deleting project {name}"
response = self.api_call("DELETE", path, error_message, headers=headers)
if response.status_code == http.HTTPStatus.ACCEPTED:
@@ -2165,13 +2189,13 @@ def delete_project(
def store_project(
self,
name: str,
- project: Union[dict, mlrun.projects.MlrunProject, mlrun.api.schemas.Project],
+ project: Union[dict, mlrun.projects.MlrunProject, mlrun.common.schemas.Project],
) -> mlrun.projects.MlrunProject:
"""Store a project in the DB. This operation will overwrite existing project of the same name if exists."""
path = f"projects/{name}"
error_message = f"Failed storing project {name}"
- if isinstance(project, mlrun.api.schemas.Project):
+ if isinstance(project, mlrun.common.schemas.Project):
project = project.dict()
elif isinstance(project, mlrun.projects.MlrunProject):
project = project.to_dict()
@@ -2189,7 +2213,9 @@ def patch_project(
self,
name: str,
project: dict,
- patch_mode: Union[str, schemas.PatchMode] = schemas.PatchMode.replace,
+ patch_mode: Union[
+ str, mlrun.common.schemas.PatchMode
+ ] = mlrun.common.schemas.PatchMode.replace,
) -> mlrun.projects.MlrunProject:
"""Patch an existing project object.
@@ -2200,7 +2226,7 @@ def patch_project(
"""
path = f"projects/{name}"
- headers = {schemas.HeaderNames.patch_mode: patch_mode}
+ headers = {mlrun.common.schemas.HeaderNames.patch_mode: patch_mode}
error_message = f"Failed patching project {name}"
response = self.api_call(
"PATCH", path, error_message, body=dict_to_json(project), headers=headers
@@ -2209,11 +2235,11 @@ def patch_project(
def create_project(
self,
- project: Union[dict, mlrun.projects.MlrunProject, mlrun.api.schemas.Project],
+ project: Union[dict, mlrun.projects.MlrunProject, mlrun.common.schemas.Project],
) -> mlrun.projects.MlrunProject:
"""Create a new project. A project with the same name must not exist prior to creation."""
- if isinstance(project, mlrun.api.schemas.Project):
+ if isinstance(project, mlrun.common.schemas.Project):
project = project.dict()
elif isinstance(project, mlrun.projects.MlrunProject):
project = project.to_dict()
@@ -2236,7 +2262,7 @@ def _verify_project_in_terminal_state():
project = self.get_project(project_name)
if (
project.status.state
- not in mlrun.api.schemas.ProjectState.terminal_states()
+ not in mlrun.common.schemas.ProjectState.terminal_states()
):
raise Exception(
f"Project not in terminal state. State: {project.status.state}"
@@ -2253,11 +2279,11 @@ def _verify_project_in_terminal_state():
def _wait_for_background_task_to_reach_terminal_state(
self, name: str
- ) -> schemas.BackgroundTask:
+ ) -> mlrun.common.schemas.BackgroundTask:
def _verify_background_task_in_terminal_state():
background_task = self.get_background_task(name)
state = background_task.status.state
- if state not in mlrun.api.schemas.BackgroundTaskState.terminal_states():
+ if state not in mlrun.common.schemas.BackgroundTaskState.terminal_states():
raise Exception(
f"Background task not in terminal state. name={name}, state={state}"
)
@@ -2274,7 +2300,7 @@ def _verify_background_task_in_terminal_state():
def _wait_for_project_to_be_deleted(self, project_name: str):
def _verify_project_deleted():
projects = self.list_projects(
- format_=mlrun.api.schemas.ProjectsFormat.name_only
+ format_=mlrun.common.schemas.ProjectsFormat.name_only
)
if project_name in projects:
raise Exception("Project still exists")
@@ -2291,8 +2317,8 @@ def create_project_secrets(
self,
project: str,
provider: Union[
- str, schemas.SecretProviderName
- ] = schemas.SecretProviderName.kubernetes,
+ str, mlrun.common.schemas.SecretProviderName
+ ] = mlrun.common.schemas.SecretProviderName.kubernetes,
secrets: dict = None,
):
"""Create project-context secrets using either ``vault`` or ``kubernetes`` provider.
@@ -2310,19 +2336,21 @@ def create_project_secrets(
:param project: The project context for which to generate the infra and store secrets.
:param provider: The name of the secrets-provider to work with. Accepts a
- :py:class:`~mlrun.api.schemas.secret.SecretProviderName` enum.
+ :py:class:`~mlrun.common.schemas.secret.SecretProviderName` enum.
:param secrets: A set of secret values to store.
Example::
secrets = {'password': 'myPassw0rd', 'aws_key': '111222333'}
db.create_project_secrets(
"project1",
- provider=mlrun.api.schemas.SecretProviderName.kubernetes,
+ provider=mlrun.common.schemas.SecretProviderName.kubernetes,
secrets=secrets
)
"""
path = f"projects/{project}/secrets"
- secrets_input = schemas.SecretsData(secrets=secrets, provider=provider)
+ secrets_input = mlrun.common.schemas.SecretsData(
+ secrets=secrets, provider=provider
+ )
body = secrets_input.dict()
error_message = f"Failed creating secret provider {project}/{provider}"
self.api_call(
@@ -2337,10 +2365,10 @@ def list_project_secrets(
project: str,
token: str = None,
provider: Union[
- str, schemas.SecretProviderName
- ] = schemas.SecretProviderName.kubernetes,
+ str, mlrun.common.schemas.SecretProviderName
+ ] = mlrun.common.schemas.SecretProviderName.kubernetes,
secrets: List[str] = None,
- ) -> schemas.SecretsData:
+ ) -> mlrun.common.schemas.SecretsData:
"""Retrieve project-context secrets from Vault.
Note:
@@ -2355,14 +2383,17 @@ def list_project_secrets(
to this specific project. ``kubernetes`` provider only supports an empty list.
"""
- if provider == schemas.SecretProviderName.vault.value and not token:
+ if (
+ provider == mlrun.common.schemas.SecretProviderName.vault.value
+ and not token
+ ):
raise MLRunInvalidArgumentError(
"A vault token must be provided when accessing vault secrets"
)
path = f"projects/{project}/secrets"
params = {"provider": provider, "secret": secrets}
- headers = {schemas.HeaderNames.secret_store_token: token}
+ headers = {mlrun.common.schemas.HeaderNames.secret_store_token: token}
error_message = f"Failed retrieving secrets {project}/{provider}"
result = self.api_call(
"GET",
@@ -2371,16 +2402,16 @@ def list_project_secrets(
params=params,
headers=headers,
)
- return schemas.SecretsData(**result.json())
+ return mlrun.common.schemas.SecretsData(**result.json())
def list_project_secret_keys(
self,
project: str,
provider: Union[
- str, schemas.SecretProviderName
- ] = schemas.SecretProviderName.kubernetes,
+ str, mlrun.common.schemas.SecretProviderName
+ ] = mlrun.common.schemas.SecretProviderName.kubernetes,
token: str = None,
- ) -> schemas.SecretKeysData:
+ ) -> mlrun.common.schemas.SecretKeysData:
"""Retrieve project-context secret keys from Vault or Kubernetes.
Note:
@@ -2389,12 +2420,15 @@ def list_project_secret_keys(
:param project: The project name.
:param provider: The name of the secrets-provider to work with. Accepts a
- :py:class:`~mlrun.api.schemas.secret.SecretProviderName` enum.
+ :py:class:`~mlrun.common.schemas.secret.SecretProviderName` enum.
:param token: Vault token to use for retrieving secrets. Only in use if ``provider`` is ``vault``.
Must be a valid Vault token, with permissions to retrieve secrets of the project in question.
"""
- if provider == schemas.SecretProviderName.vault.value and not token:
+ if (
+ provider == mlrun.common.schemas.SecretProviderName.vault.value
+ and not token
+ ):
raise MLRunInvalidArgumentError(
"A vault token must be provided when accessing vault secrets"
)
@@ -2402,8 +2436,8 @@ def list_project_secret_keys(
path = f"projects/{project}/secret-keys"
params = {"provider": provider}
headers = (
- {schemas.HeaderNames.secret_store_token: token}
- if provider == schemas.SecretProviderName.vault.value
+ {mlrun.common.schemas.HeaderNames.secret_store_token: token}
+ if provider == mlrun.common.schemas.SecretProviderName.vault.value
else None
)
error_message = f"Failed retrieving secret keys {project}/{provider}"
@@ -2414,14 +2448,14 @@ def list_project_secret_keys(
params=params,
headers=headers,
)
- return schemas.SecretKeysData(**result.json())
+ return mlrun.common.schemas.SecretKeysData(**result.json())
def delete_project_secrets(
self,
project: str,
provider: Union[
- str, schemas.SecretProviderName
- ] = schemas.SecretProviderName.kubernetes,
+ str, mlrun.common.schemas.SecretProviderName
+ ] = mlrun.common.schemas.SecretProviderName.kubernetes,
secrets: List[str] = None,
):
"""Delete project-context secrets from Kubernetes.
@@ -2446,8 +2480,8 @@ def create_user_secrets(
self,
user: str,
provider: Union[
- str, schemas.SecretProviderName
- ] = schemas.SecretProviderName.vault,
+ str, mlrun.common.schemas.SecretProviderName
+ ] = mlrun.common.schemas.SecretProviderName.vault,
secrets: dict = None,
):
"""Create user-context secret in Vault. Please refer to :py:func:`create_project_secrets` for more details
@@ -2462,7 +2496,7 @@ def create_user_secrets(
:param secrets: A set of secret values to store within the Vault.
"""
path = "user-secrets"
- secrets_creation_request = schemas.UserSecretCreationRequest(
+ secrets_creation_request = mlrun.common.schemas.UserSecretCreationRequest(
user=user,
provider=provider,
secrets=secrets,
@@ -2711,7 +2745,7 @@ def patch_model_endpoint(
of this dictionary should exist in the target table. Note that the values should be
from type string or from a valid numerical type such as int or float.
More details about the model endpoint available attributes can be found under
- :py:class:`~mlrun.api.schemas.ModelEndpoint`.
+ :py:class:`~mlrun.common.schemas.ModelEndpoint`.
Example::
@@ -2739,7 +2773,9 @@ def patch_model_endpoint(
params=attributes,
)
- def create_hub_source(self, source: Union[dict, schemas.IndexedHubSource]):
+ def create_hub_source(
+ self, source: Union[dict, mlrun.common.schemas.IndexedHubSource]
+ ):
"""
Add a new hub source.
@@ -2757,24 +2793,28 @@ def create_hub_source(self, source: Union[dict, schemas.IndexedHubSource]):
Example::
- import mlrun.api.schemas
+ import mlrun.common.schemas
# Add a private source as the last one (will be #1 in the list)
- private_source = mlrun.api.schemas.IndexedHubeSource(
+ private_source = mlrun.common.schemas.IndexedHubeSource(
order=-1,
- source=mlrun.api.schemas.HubSource(
- metadata=mlrun.api.schemas.HubObjectMetadata(name="priv", description="a private source"),
- spec=mlrun.api.schemas.HubSourceSpec(path="/local/path/to/source", channel="development")
+ source=mlrun.common.schemas.HubSource(
+ metadata=mlrun.common.schemas.HubObjectMetadata(
+ name="priv", description="a private source"
+ ),
+ spec=mlrun.common.schemas.HubSourceSpec(path="/local/path/to/source", channel="development")
)
)
db.create_hub_source(private_source)
# Add another source as 1st in the list - will push previous one to be #2
- another_source = mlrun.api.schemas.IndexedHubSource(
+ another_source = mlrun.common.schemas.IndexedHubSource(
order=1,
- source=mlrun.api.schemas.HubSource(
- metadata=mlrun.api.schemas.HubObjectMetadata(name="priv-2", description="another source"),
- spec=mlrun.api.schemas.HubSourceSpec(
+ source=mlrun.common.schemas.HubSource(
+ metadata=mlrun.common.schemas.HubObjectMetadata(
+ name="priv-2", description="another source"
+ ),
+ spec=mlrun.common.schemas.HubSourceSpec(
path="/local/path/to/source/2",
channel="development",
credentials={...}
@@ -2784,17 +2824,19 @@ def create_hub_source(self, source: Union[dict, schemas.IndexedHubSource]):
db.create_hub_source(another_source)
:param source: The source and its order, of type
- :py:class:`~mlrun.api.schemas.hub.IndexedHubSource`, or in dictionary form.
+ :py:class:`~mlrun.common.schemas.hub.IndexedHubSource`, or in dictionary form.
:returns: The source object as inserted into the database, with credentials stripped.
"""
path = "hub/sources"
- if isinstance(source, schemas.IndexedHubSource):
+ if isinstance(source, mlrun.common.schemas.IndexedHubSource):
source = source.dict()
response = self.api_call(method="POST", path=path, json=source)
- return schemas.IndexedHubSource(**response.json())
+ return mlrun.common.schemas.IndexedHubSource(**response.json())
def store_hub_source(
- self, source_name: str, source: Union[dict, schemas.IndexedHubSource]
+ self,
+ source_name: str,
+ source: Union[dict, mlrun.common.schemas.IndexedHubSource],
):
"""
Create or replace a hub source.
@@ -2808,11 +2850,11 @@ def store_hub_source(
:returns: The source object as stored in the DB.
"""
path = f"hub/sources/{source_name}"
- if isinstance(source, schemas.IndexedHubSource):
+ if isinstance(source, mlrun.common.schemas.IndexedHubSource):
source = source.dict()
response = self.api_call(method="PUT", path=path, json=source)
- return schemas.IndexedHubSource(**response.json())
+ return mlrun.common.schemas.IndexedHubSource(**response.json())
def list_hub_sources(self):
"""
@@ -2822,7 +2864,7 @@ def list_hub_sources(self):
response = self.api_call(method="GET", path=path).json()
results = []
for item in response:
- results.append(schemas.IndexedHubSource(**item))
+ results.append(mlrun.common.schemas.IndexedHubSource(**item))
return results
def get_hub_source(self, source_name: str):
@@ -2833,7 +2875,7 @@ def get_hub_source(self, source_name: str):
"""
path = f"hub/sources/{source_name}"
response = self.api_call(method="GET", path=path)
- return schemas.IndexedHubSource(**response.json())
+ return mlrun.common.schemas.IndexedHubSource(**response.json())
def delete_hub_source(self, source_name: str):
"""
@@ -2865,8 +2907,8 @@ def get_hub_catalog(
rather than rely on cached information which may exist from previous get requests. For example,
if the source was re-built,
this will make the server get the updated information. Default is ``False``.
- :returns: :py:class:`~mlrun.api.schemas.hub.HubCatalog` object, which is essentially a list
- of :py:class:`~mlrun.api.schemas.hub.HubItem` entries.
+ :returns: :py:class:`~mlrun.common.schemas.hub.HubCatalog` object, which is essentially a list
+ of :py:class:`~mlrun.common.schemas.hub.HubItem` entries.
"""
path = (f"hub/sources/{source_name}/items",)
params = {
@@ -2875,7 +2917,7 @@ def get_hub_catalog(
"force-refresh": force_refresh,
}
response = self.api_call(method="GET", path=path, params=params)
- return schemas.HubCatalog(**response.json())
+ return mlrun.common.schemas.HubCatalog(**response.json())
def get_hub_item(
self,
@@ -2895,7 +2937,7 @@ def get_hub_item(
:param force_refresh: Make the server fetch the information from the actual hub
source, rather than
rely on cached information. Default is ``False``.
- :returns: :py:class:`~mlrun.api.schemas.hub.HubItem`.
+ :returns: :py:class:`~mlrun.common.schemas.hub.HubItem`.
"""
path = (f"hub/sources/{source_name}/items/{item_name}",)
params = {
@@ -2904,7 +2946,7 @@ def get_hub_item(
"force-refresh": force_refresh,
}
response = self.api_call(method="GET", path=path, params=params)
- return schemas.HubItem(**response.json())
+ return mlrun.common.schemas.HubItem(**response.json())
def get_hub_asset(
self,
@@ -2934,12 +2976,13 @@ def get_hub_asset(
return response
def verify_authorization(
- self, authorization_verification_input: schemas.AuthorizationVerificationInput
+ self,
+ authorization_verification_input: mlrun.common.schemas.AuthorizationVerificationInput,
):
"""Verifies authorization for the provided action on the provided resource.
:param authorization_verification_input: Instance of
- :py:class:`~mlrun.api.schemas.AuthorizationVerificationInput` that includes all the needed parameters for
+ :py:class:`~mlrun.common.schemas.AuthorizationVerificationInput` that includes all the needed parameters for
the auth verification
"""
error_message = "Authorization check failed"
@@ -2950,10 +2993,10 @@ def verify_authorization(
body=dict_to_json(authorization_verification_input.dict()),
)
- def trigger_migrations(self) -> Optional[schemas.BackgroundTask]:
+ def trigger_migrations(self) -> Optional[mlrun.common.schemas.BackgroundTask]:
"""Trigger migrations (will do nothing if no migrations are needed) and wait for them to finish if actually
triggered
- :returns: :py:class:`~mlrun.api.schemas.BackgroundTask`.
+ :returns: :py:class:`~mlrun.common.schemas.BackgroundTask`.
"""
response = self.api_call(
"POST",
@@ -2961,7 +3004,7 @@ def trigger_migrations(self) -> Optional[schemas.BackgroundTask]:
"Failed triggering migrations",
)
if response.status_code == http.HTTPStatus.ACCEPTED:
- background_task = schemas.BackgroundTask(**response.json())
+ background_task = mlrun.common.schemas.BackgroundTask(**response.json())
return self._wait_for_background_task_to_reach_terminal_state(
background_task.metadata.name
)
diff --git a/mlrun/db/nopdb.py b/mlrun/db/nopdb.py
index 0f7a232086da..b629a37cd8e3 100644
--- a/mlrun/db/nopdb.py
+++ b/mlrun/db/nopdb.py
@@ -16,10 +16,9 @@
import datetime
from typing import List, Optional, Union
+import mlrun.common.schemas
import mlrun.errors
-from ..api import schemas
-from ..api.schemas import ModelEndpoint
from ..config import config
from ..utils import logger
from .base import RunDBInterface
@@ -87,10 +86,12 @@ def list_runs(
start_time_to: datetime.datetime = None,
last_update_time_from: datetime.datetime = None,
last_update_time_to: datetime.datetime = None,
- partition_by: Union[schemas.RunPartitionByField, str] = None,
+ partition_by: Union[mlrun.common.schemas.RunPartitionByField, str] = None,
rows_per_partition: int = 1,
- partition_sort_by: Union[schemas.SortField, str] = None,
- partition_order: Union[schemas.OrderType, str] = schemas.OrderType.desc,
+ partition_sort_by: Union[mlrun.common.schemas.SortField, str] = None,
+ partition_order: Union[
+ mlrun.common.schemas.OrderType, str
+ ] = mlrun.common.schemas.OrderType.desc,
max_partitions: int = 0,
):
pass
@@ -118,7 +119,7 @@ def list_artifacts(
iter: int = None,
best_iteration: bool = False,
kind: str = None,
- category: Union[str, schemas.ArtifactCategories] = None,
+ category: Union[str, mlrun.common.schemas.ArtifactCategories] = None,
):
pass
@@ -144,13 +145,13 @@ def tag_objects(
self,
project: str,
tag_name: str,
- tag_objects: schemas.TagObjects,
+ tag_objects: mlrun.common.schemas.TagObjects,
replace: bool = False,
):
pass
def delete_objects_tag(
- self, project: str, tag_name: str, tag_objects: schemas.TagObjects
+ self, project: str, tag_name: str, tag_objects: mlrun.common.schemas.TagObjects
):
pass
@@ -165,43 +166,52 @@ def delete_artifacts_tags(self, artifacts, project: str, tag_name: str):
def delete_project(
self,
name: str,
- deletion_strategy: schemas.DeletionStrategy = schemas.DeletionStrategy.default(),
+ deletion_strategy: mlrun.common.schemas.DeletionStrategy = mlrun.common.schemas.DeletionStrategy.default(),
):
pass
- def store_project(self, name: str, project: schemas.Project) -> schemas.Project:
+ def store_project(
+ self, name: str, project: mlrun.common.schemas.Project
+ ) -> mlrun.common.schemas.Project:
pass
def patch_project(
self,
name: str,
project: dict,
- patch_mode: schemas.PatchMode = schemas.PatchMode.replace,
- ) -> schemas.Project:
+ patch_mode: mlrun.common.schemas.PatchMode = mlrun.common.schemas.PatchMode.replace,
+ ) -> mlrun.common.schemas.Project:
pass
- def create_project(self, project: schemas.Project) -> schemas.Project:
+ def create_project(
+ self, project: mlrun.common.schemas.Project
+ ) -> mlrun.common.schemas.Project:
pass
def list_projects(
self,
owner: str = None,
- format_: schemas.ProjectsFormat = schemas.ProjectsFormat.full,
+ format_: mlrun.common.schemas.ProjectsFormat = mlrun.common.schemas.ProjectsFormat.full,
labels: List[str] = None,
- state: schemas.ProjectState = None,
- ) -> schemas.ProjectsOutput:
+ state: mlrun.common.schemas.ProjectState = None,
+ ) -> mlrun.common.schemas.ProjectsOutput:
pass
- def get_project(self, name: str) -> schemas.Project:
+ def get_project(self, name: str) -> mlrun.common.schemas.Project:
pass
def list_artifact_tags(
- self, project=None, category: Union[str, schemas.ArtifactCategories] = None
+ self,
+ project=None,
+ category: Union[str, mlrun.common.schemas.ArtifactCategories] = None,
):
pass
def create_feature_set(
- self, feature_set: Union[dict, schemas.FeatureSet], project="", versioned=True
+ self,
+ feature_set: Union[dict, mlrun.common.schemas.FeatureSet],
+ project="",
+ versioned=True,
) -> dict:
pass
@@ -217,12 +227,12 @@ def list_features(
tag: str = None,
entities: List[str] = None,
labels: List[str] = None,
- ) -> schemas.FeaturesOutput:
+ ) -> mlrun.common.schemas.FeaturesOutput:
pass
def list_entities(
self, project: str, name: str = None, tag: str = None, labels: List[str] = None
- ) -> schemas.EntitiesOutput:
+ ) -> mlrun.common.schemas.EntitiesOutput:
pass
def list_feature_sets(
@@ -234,16 +244,20 @@ def list_feature_sets(
entities: List[str] = None,
features: List[str] = None,
labels: List[str] = None,
- partition_by: Union[schemas.FeatureStorePartitionByField, str] = None,
+ partition_by: Union[
+ mlrun.common.schemas.FeatureStorePartitionByField, str
+ ] = None,
rows_per_partition: int = 1,
- partition_sort_by: Union[schemas.SortField, str] = None,
- partition_order: Union[schemas.OrderType, str] = schemas.OrderType.desc,
+ partition_sort_by: Union[mlrun.common.schemas.SortField, str] = None,
+ partition_order: Union[
+ mlrun.common.schemas.OrderType, str
+ ] = mlrun.common.schemas.OrderType.desc,
) -> List[dict]:
pass
def store_feature_set(
self,
- feature_set: Union[dict, schemas.FeatureSet],
+ feature_set: Union[dict, mlrun.common.schemas.FeatureSet],
name=None,
project="",
tag=None,
@@ -259,7 +273,9 @@ def patch_feature_set(
project="",
tag=None,
uid=None,
- patch_mode: Union[str, schemas.PatchMode] = schemas.PatchMode.replace,
+ patch_mode: Union[
+ str, mlrun.common.schemas.PatchMode
+ ] = mlrun.common.schemas.PatchMode.replace,
):
pass
@@ -268,7 +284,7 @@ def delete_feature_set(self, name, project="", tag=None, uid=None):
def create_feature_vector(
self,
- feature_vector: Union[dict, schemas.FeatureVector],
+ feature_vector: Union[dict, mlrun.common.schemas.FeatureVector],
project="",
versioned=True,
) -> dict:
@@ -286,16 +302,20 @@ def list_feature_vectors(
tag: str = None,
state: str = None,
labels: List[str] = None,
- partition_by: Union[schemas.FeatureStorePartitionByField, str] = None,
+ partition_by: Union[
+ mlrun.common.schemas.FeatureStorePartitionByField, str
+ ] = None,
rows_per_partition: int = 1,
- partition_sort_by: Union[schemas.SortField, str] = None,
- partition_order: Union[schemas.OrderType, str] = schemas.OrderType.desc,
+ partition_sort_by: Union[mlrun.common.schemas.SortField, str] = None,
+ partition_order: Union[
+ mlrun.common.schemas.OrderType, str
+ ] = mlrun.common.schemas.OrderType.desc,
) -> List[dict]:
pass
def store_feature_vector(
self,
- feature_vector: Union[dict, schemas.FeatureVector],
+ feature_vector: Union[dict, mlrun.common.schemas.FeatureVector],
name=None,
project="",
tag=None,
@@ -311,7 +331,9 @@ def patch_feature_vector(
project="",
tag=None,
uid=None,
- patch_mode: Union[str, schemas.PatchMode] = schemas.PatchMode.replace,
+ patch_mode: Union[
+ str, mlrun.common.schemas.PatchMode
+ ] = mlrun.common.schemas.PatchMode.replace,
):
pass
@@ -326,18 +348,18 @@ def list_pipelines(
page_token: str = "",
filter_: str = "",
format_: Union[
- str, schemas.PipelinesFormat
- ] = schemas.PipelinesFormat.metadata_only,
+ str, mlrun.common.schemas.PipelinesFormat
+ ] = mlrun.common.schemas.PipelinesFormat.metadata_only,
page_size: int = None,
- ) -> schemas.PipelinesOutput:
+ ) -> mlrun.common.schemas.PipelinesOutput:
pass
def create_project_secrets(
self,
project: str,
provider: Union[
- str, schemas.SecretProviderName
- ] = schemas.SecretProviderName.kubernetes,
+ str, mlrun.common.schemas.SecretProviderName
+ ] = mlrun.common.schemas.SecretProviderName.kubernetes,
secrets: dict = None,
):
pass
@@ -347,28 +369,28 @@ def list_project_secrets(
project: str,
token: str,
provider: Union[
- str, schemas.SecretProviderName
- ] = schemas.SecretProviderName.kubernetes,
+ str, mlrun.common.schemas.SecretProviderName
+ ] = mlrun.common.schemas.SecretProviderName.kubernetes,
secrets: List[str] = None,
- ) -> schemas.SecretsData:
+ ) -> mlrun.common.schemas.SecretsData:
pass
def list_project_secret_keys(
self,
project: str,
provider: Union[
- str, schemas.SecretProviderName
- ] = schemas.SecretProviderName.kubernetes,
+ str, mlrun.common.schemas.SecretProviderName
+ ] = mlrun.common.schemas.SecretProviderName.kubernetes,
token: str = None,
- ) -> schemas.SecretKeysData:
+ ) -> mlrun.common.schemas.SecretKeysData:
pass
def delete_project_secrets(
self,
project: str,
provider: Union[
- str, schemas.SecretProviderName
- ] = schemas.SecretProviderName.kubernetes,
+ str, mlrun.common.schemas.SecretProviderName
+ ] = mlrun.common.schemas.SecretProviderName.kubernetes,
secrets: List[str] = None,
):
pass
@@ -377,14 +399,17 @@ def create_user_secrets(
self,
user: str,
provider: Union[
- str, schemas.SecretProviderName
- ] = schemas.SecretProviderName.vault,
+ str, mlrun.common.schemas.SecretProviderName
+ ] = mlrun.common.schemas.SecretProviderName.vault,
secrets: dict = None,
):
pass
def create_model_endpoint(
- self, project: str, endpoint_id: str, model_endpoint: ModelEndpoint
+ self,
+ project: str,
+ endpoint_id: str,
+ model_endpoint: mlrun.common.schemas.ModelEndpoint,
):
pass
@@ -417,11 +442,15 @@ def get_model_endpoint(
def patch_model_endpoint(self, project: str, endpoint_id: str, attributes: dict):
pass
- def create_hub_source(self, source: Union[dict, schemas.IndexedHubSource]):
+ def create_hub_source(
+ self, source: Union[dict, mlrun.common.schemas.IndexedHubSource]
+ ):
pass
def store_hub_source(
- self, source_name: str, source: Union[dict, schemas.IndexedHubSource]
+ self,
+ source_name: str,
+ source: Union[dict, mlrun.common.schemas.IndexedHubSource],
):
pass
@@ -456,6 +485,7 @@ def get_hub_item(
pass
def verify_authorization(
- self, authorization_verification_input: schemas.AuthorizationVerificationInput
+ self,
+ authorization_verification_input: mlrun.common.schemas.AuthorizationVerificationInput,
):
pass
diff --git a/mlrun/db/sqldb.py b/mlrun/db/sqldb.py
index 2a5e97957b12..2682f27b3df9 100644
--- a/mlrun/db/sqldb.py
+++ b/mlrun/db/sqldb.py
@@ -15,7 +15,7 @@
import datetime
from typing import List, Optional, Union
-import mlrun.api.schemas
+import mlrun.common.schemas
import mlrun.model_monitoring.model_endpoint
from mlrun.api.db.base import DBError
from mlrun.api.db.sqldb.db import SQLDB as SQLAPIDB
@@ -29,7 +29,6 @@
# service, in order to prevent the api from calling itself several times for each submission request (since the runDB
# will be httpdb to that same api service) we have this class which is kind of a proxy between the RunDB interface to
# the api service's DB interface
-from ..api import schemas
from .base import RunDBError, RunDBInterface
@@ -123,10 +122,12 @@ def list_runs(
start_time_to: datetime.datetime = None,
last_update_time_from: datetime.datetime = None,
last_update_time_to: datetime.datetime = None,
- partition_by: Union[schemas.RunPartitionByField, str] = None,
+ partition_by: Union[mlrun.common.schemas.RunPartitionByField, str] = None,
rows_per_partition: int = 1,
- partition_sort_by: Union[schemas.SortField, str] = None,
- partition_order: Union[schemas.OrderType, str] = schemas.OrderType.desc,
+ partition_sort_by: Union[mlrun.common.schemas.SortField, str] = None,
+ partition_order: Union[
+ mlrun.common.schemas.OrderType, str
+ ] = mlrun.common.schemas.OrderType.desc,
max_partitions: int = 0,
with_notifications: bool = False,
):
@@ -216,12 +217,12 @@ def list_artifacts(
iter: int = None,
best_iteration: bool = False,
kind: str = None,
- category: Union[str, schemas.ArtifactCategories] = None,
+ category: Union[str, mlrun.common.schemas.ArtifactCategories] = None,
):
import mlrun.api.crud
if category and isinstance(category, str):
- category = schemas.ArtifactCategories(category)
+ category = mlrun.common.schemas.ArtifactCategories(category)
return self._transform_db_error(
mlrun.api.crud.Artifacts().list_artifacts,
@@ -309,7 +310,9 @@ def list_functions(self, name=None, project=None, tag=None, labels=None):
)
def list_artifact_tags(
- self, project=None, category: Union[str, schemas.ArtifactCategories] = None
+ self,
+ project=None,
+ category: Union[str, mlrun.common.schemas.ArtifactCategories] = None,
):
return self._transform_db_error(
self.db.list_artifact_tags, self.session, project
@@ -319,7 +322,9 @@ def tag_objects(
self,
project: str,
tag_name: str,
- tag_objects: mlrun.api.schemas.TagObjects,
+ tag_objects: Union[
+ mlrun.common.schemas.TagObjects, mlrun.common.schemas.TagObjects
+ ],
replace: bool = False,
):
import mlrun.api.crud
@@ -345,7 +350,9 @@ def delete_objects_tag(
self,
project: str,
tag_name: str,
- tag_objects: mlrun.api.schemas.TagObjects,
+ tag_objects: Union[
+ mlrun.common.schemas.TagObjects, mlrun.common.schemas.TagObjects
+ ],
):
import mlrun.api.crud
@@ -394,12 +401,12 @@ def list_schedules(self):
def store_project(
self,
name: str,
- project: mlrun.api.schemas.Project,
- ) -> mlrun.api.schemas.Project:
+ project: Union[mlrun.common.schemas.Project, mlrun.common.schemas.Project],
+ ) -> mlrun.common.schemas.Project:
import mlrun.api.crud
if isinstance(project, dict):
- project = mlrun.api.schemas.Project(**project)
+ project = mlrun.common.schemas.Project(**project)
return self._transform_db_error(
mlrun.api.crud.Projects().store_project,
@@ -412,8 +419,10 @@ def patch_project(
self,
name: str,
project: dict,
- patch_mode: mlrun.api.schemas.PatchMode = mlrun.api.schemas.PatchMode.replace,
- ) -> mlrun.api.schemas.Project:
+ patch_mode: Union[
+ mlrun.common.schemas.PatchMode, mlrun.common.schemas.PatchMode
+ ] = mlrun.common.schemas.PatchMode.replace,
+ ) -> mlrun.common.schemas.Project:
import mlrun.api.crud
return self._transform_db_error(
@@ -426,8 +435,8 @@ def patch_project(
def create_project(
self,
- project: mlrun.api.schemas.Project,
- ) -> mlrun.api.schemas.Project:
+ project: Union[mlrun.common.schemas.Project, mlrun.common.schemas.Project],
+ ) -> mlrun.common.schemas.Project:
import mlrun.api.crud
return self._transform_db_error(
@@ -439,7 +448,10 @@ def create_project(
def delete_project(
self,
name: str,
- deletion_strategy: mlrun.api.schemas.DeletionStrategy = mlrun.api.schemas.DeletionStrategy.default(),
+ deletion_strategy: Union[
+ mlrun.common.schemas.DeletionStrategy,
+ mlrun.common.schemas.DeletionStrategy,
+ ] = mlrun.common.schemas.DeletionStrategy.default(),
):
import mlrun.api.crud
@@ -452,7 +464,7 @@ def delete_project(
def get_project(
self, name: str = None, project_id: int = None
- ) -> mlrun.api.schemas.Project:
+ ) -> mlrun.common.schemas.Project:
import mlrun.api.crud
return self._transform_db_error(
@@ -464,10 +476,10 @@ def get_project(
def list_projects(
self,
owner: str = None,
- format_: mlrun.api.schemas.ProjectsFormat = mlrun.api.schemas.ProjectsFormat.full,
+ format_: mlrun.common.schemas.ProjectsFormat = mlrun.common.schemas.ProjectsFormat.full,
labels: List[str] = None,
- state: mlrun.api.schemas.ProjectState = None,
- ) -> mlrun.api.schemas.ProjectsOutput:
+ state: mlrun.common.schemas.ProjectState = None,
+ ) -> mlrun.common.schemas.ProjectsOutput:
import mlrun.api.crud
return self._transform_db_error(
@@ -559,10 +571,10 @@ def list_feature_sets(
entities: List[str] = None,
features: List[str] = None,
labels: List[str] = None,
- partition_by: mlrun.api.schemas.FeatureStorePartitionByField = None,
+ partition_by: mlrun.common.schemas.FeatureStorePartitionByField = None,
rows_per_partition: int = 1,
- partition_sort_by: mlrun.api.schemas.SortField = None,
- partition_order: mlrun.api.schemas.OrderType = mlrun.api.schemas.OrderType.desc,
+ partition_sort_by: mlrun.common.schemas.SortField = None,
+ partition_order: mlrun.common.schemas.OrderType = mlrun.common.schemas.OrderType.desc,
):
import mlrun.api.crud
@@ -584,7 +596,7 @@ def list_feature_sets(
def store_feature_set(
self,
- feature_set: Union[dict, mlrun.api.schemas.FeatureSet],
+ feature_set: Union[dict, mlrun.common.schemas.FeatureSet],
name=None,
project="",
tag=None,
@@ -594,7 +606,7 @@ def store_feature_set(
import mlrun.api.crud
if isinstance(feature_set, dict):
- feature_set = mlrun.api.schemas.FeatureSet(**feature_set)
+ feature_set = mlrun.common.schemas.FeatureSet(**feature_set)
name = name or feature_set.metadata.name
project = project or feature_set.metadata.project
@@ -669,10 +681,10 @@ def list_feature_vectors(
tag: str = None,
state: str = None,
labels: List[str] = None,
- partition_by: mlrun.api.schemas.FeatureStorePartitionByField = None,
+ partition_by: mlrun.common.schemas.FeatureStorePartitionByField = None,
rows_per_partition: int = 1,
- partition_sort_by: mlrun.api.schemas.SortField = None,
- partition_order: mlrun.api.schemas.OrderType = mlrun.api.schemas.OrderType.desc,
+ partition_sort_by: mlrun.common.schemas.SortField = None,
+ partition_order: mlrun.common.schemas.OrderType = mlrun.common.schemas.OrderType.desc,
):
import mlrun.api.crud
@@ -754,18 +766,18 @@ def list_pipelines(
page_token: str = "",
filter_: str = "",
format_: Union[
- str, mlrun.api.schemas.PipelinesFormat
- ] = mlrun.api.schemas.PipelinesFormat.metadata_only,
+ str, mlrun.common.schemas.PipelinesFormat
+ ] = mlrun.common.schemas.PipelinesFormat.metadata_only,
page_size: int = None,
- ) -> mlrun.api.schemas.PipelinesOutput:
+ ) -> mlrun.common.schemas.PipelinesOutput:
raise NotImplementedError()
def create_project_secrets(
self,
project: str,
provider: Union[
- str, mlrun.api.schemas.SecretProviderName
- ] = mlrun.api.schemas.SecretProviderName.kubernetes,
+ str, mlrun.common.schemas.SecretProviderName
+ ] = mlrun.common.schemas.SecretProviderName.kubernetes,
secrets: dict = None,
):
raise NotImplementedError()
@@ -775,28 +787,28 @@ def list_project_secrets(
project: str,
token: str,
provider: Union[
- str, mlrun.api.schemas.SecretProviderName
- ] = mlrun.api.schemas.SecretProviderName.kubernetes,
+ str, mlrun.common.schemas.SecretProviderName
+ ] = mlrun.common.schemas.SecretProviderName.kubernetes,
secrets: List[str] = None,
- ) -> mlrun.api.schemas.SecretsData:
+ ) -> mlrun.common.schemas.SecretsData:
raise NotImplementedError()
def list_project_secret_keys(
self,
project: str,
provider: Union[
- str, mlrun.api.schemas.SecretProviderName
- ] = mlrun.api.schemas.SecretProviderName.kubernetes,
+ str, mlrun.common.schemas.SecretProviderName
+ ] = mlrun.common.schemas.SecretProviderName.kubernetes,
token: str = None,
- ) -> mlrun.api.schemas.SecretKeysData:
+ ) -> mlrun.common.schemas.SecretKeysData:
raise NotImplementedError()
def delete_project_secrets(
self,
project: str,
provider: Union[
- str, mlrun.api.schemas.SecretProviderName
- ] = mlrun.api.schemas.SecretProviderName.kubernetes,
+ str, mlrun.common.schemas.SecretProviderName
+ ] = mlrun.common.schemas.SecretProviderName.kubernetes,
secrets: List[str] = None,
):
raise NotImplementedError()
@@ -805,8 +817,8 @@ def create_user_secrets(
self,
user: str,
provider: Union[
- str, mlrun.api.schemas.SecretProviderName
- ] = mlrun.api.schemas.SecretProviderName.vault,
+ str, mlrun.common.schemas.SecretProviderName
+ ] = mlrun.common.schemas.SecretProviderName.vault,
secrets: dict = None,
):
raise NotImplementedError()
@@ -859,11 +871,15 @@ def patch_model_endpoint(
):
raise NotImplementedError()
- def create_hub_source(self, source: Union[dict, schemas.IndexedHubSource]):
+ def create_hub_source(
+ self, source: Union[dict, mlrun.common.schemas.IndexedHubSource]
+ ):
raise NotImplementedError()
def store_hub_source(
- self, source_name: str, source: Union[dict, schemas.IndexedHubSource]
+ self,
+ source_name: str,
+ source: Union[dict, mlrun.common.schemas.IndexedHubSource],
):
raise NotImplementedError()
@@ -897,7 +913,7 @@ def get_hub_item(
def verify_authorization(
self,
- authorization_verification_input: mlrun.api.schemas.AuthorizationVerificationInput,
+ authorization_verification_input: mlrun.common.schemas.AuthorizationVerificationInput,
):
# on server side authorization is done in endpoint anyway, so for server side we can "pass" on check
# done from ingest()
diff --git a/mlrun/feature_store/api.py b/mlrun/feature_store/api.py
index 5f01b8c59f71..bf9ec12517d3 100644
--- a/mlrun/feature_store/api.py
+++ b/mlrun/feature_store/api.py
@@ -79,7 +79,7 @@ def _features_to_vector_and_check_permissions(features, update_stats):
"feature vector name must be specified"
)
verify_feature_vector_permissions(
- vector, mlrun.api.schemas.AuthorizationAction.update
+ vector, mlrun.common.schemas.AuthorizationAction.update
)
vector.save()
@@ -447,7 +447,7 @@ def ingest(
)
# remote job execution
verify_feature_set_permissions(
- featureset, mlrun.api.schemas.AuthorizationAction.update
+ featureset, mlrun.common.schemas.AuthorizationAction.update
)
run_config = run_config.copy() if run_config else RunConfig()
source, run_config.parameters = set_task_params(
@@ -479,7 +479,7 @@ def ingest(
featureset.validate_steps(namespace=namespace)
verify_feature_set_permissions(
- featureset, mlrun.api.schemas.AuthorizationAction.update
+ featureset, mlrun.common.schemas.AuthorizationAction.update
)
if not source:
raise mlrun.errors.MLRunInvalidArgumentError(
@@ -694,7 +694,7 @@ def preview(
source = mlrun.store_manager.object(url=source).as_df()
verify_feature_set_permissions(
- featureset, mlrun.api.schemas.AuthorizationAction.update
+ featureset, mlrun.common.schemas.AuthorizationAction.update
)
featureset.spec.validate_no_processing_for_passthrough()
@@ -790,7 +790,7 @@ def deploy_ingestion_service(
featureset = get_feature_set_by_uri(featureset)
verify_feature_set_permissions(
- featureset, mlrun.api.schemas.AuthorizationAction.update
+ featureset, mlrun.common.schemas.AuthorizationAction.update
)
verify_feature_set_exists(featureset)
diff --git a/mlrun/feature_store/common.py b/mlrun/feature_store/common.py
index a3b4bb886ac0..ea5e42237faa 100644
--- a/mlrun/feature_store/common.py
+++ b/mlrun/feature_store/common.py
@@ -16,7 +16,7 @@
import mlrun
import mlrun.errors
-from mlrun.api.schemas import AuthorizationVerificationInput
+from mlrun.common.schemas import AuthorizationVerificationInput
from mlrun.runtimes import BaseRuntime
from mlrun.runtimes.function_reference import FunctionReference
from mlrun.runtimes.utils import enrich_function_from_dict
@@ -86,13 +86,13 @@ def get_feature_set_by_uri(uri, project=None):
db = mlrun.get_run_db()
project, name, tag, uid = parse_feature_set_uri(uri, project)
resource = (
- mlrun.api.schemas.AuthorizationResourceTypes.feature_set.to_resource_string(
+ mlrun.common.schemas.AuthorizationResourceTypes.feature_set.to_resource_string(
project, "feature-set"
)
)
auth_input = AuthorizationVerificationInput(
- resource=resource, action=mlrun.api.schemas.AuthorizationAction.read
+ resource=resource, action=mlrun.common.schemas.AuthorizationAction.read
)
db.verify_authorization(auth_input)
@@ -115,19 +115,17 @@ def get_feature_vector_by_uri(uri, project=None, update=True):
project, name, tag, uid = parse_versioned_object_uri(uri, default_project)
- resource = (
- mlrun.api.schemas.AuthorizationResourceTypes.feature_vector.to_resource_string(
- project, "feature-vector"
- )
+ resource = mlrun.common.schemas.AuthorizationResourceTypes.feature_vector.to_resource_string(
+ project, "feature-vector"
)
if update:
auth_input = AuthorizationVerificationInput(
- resource=resource, action=mlrun.api.schemas.AuthorizationAction.update
+ resource=resource, action=mlrun.common.schemas.AuthorizationAction.update
)
else:
auth_input = AuthorizationVerificationInput(
- resource=resource, action=mlrun.api.schemas.AuthorizationAction.read
+ resource=resource, action=mlrun.common.schemas.AuthorizationAction.read
)
db.verify_authorization(auth_input)
@@ -136,12 +134,12 @@ def get_feature_vector_by_uri(uri, project=None, update=True):
def verify_feature_set_permissions(
- feature_set, action: mlrun.api.schemas.AuthorizationAction
+ feature_set, action: mlrun.common.schemas.AuthorizationAction
):
project, _, _, _ = parse_feature_set_uri(feature_set.uri)
resource = (
- mlrun.api.schemas.AuthorizationResourceTypes.feature_set.to_resource_string(
+ mlrun.common.schemas.AuthorizationResourceTypes.feature_set.to_resource_string(
project, "feature-set"
)
)
@@ -164,14 +162,12 @@ def verify_feature_set_exists(feature_set):
def verify_feature_vector_permissions(
- feature_vector, action: mlrun.api.schemas.AuthorizationAction
+ feature_vector, action: mlrun.common.schemas.AuthorizationAction
):
project = feature_vector._metadata.project or mlconf.default_project
- resource = (
- mlrun.api.schemas.AuthorizationResourceTypes.feature_vector.to_resource_string(
- project, "feature-vector"
- )
+ resource = mlrun.common.schemas.AuthorizationResourceTypes.feature_vector.to_resource_string(
+ project, "feature-vector"
)
db = mlrun.get_run_db()
diff --git a/mlrun/feature_store/feature_set.py b/mlrun/feature_store/feature_set.py
index eccc1848ef75..fdc718761095 100644
--- a/mlrun/feature_store/feature_set.py
+++ b/mlrun/feature_store/feature_set.py
@@ -19,7 +19,7 @@
from storey import EmitEveryEvent, EmitPolicy
import mlrun
-import mlrun.api.schemas
+import mlrun.common.schemas
from ..config import config as mlconf
from ..datastore import get_store_uri
@@ -317,7 +317,7 @@ def emit_policy_to_dict(policy: EmitPolicy):
class FeatureSet(ModelObj):
"""Feature set object, defines a set of features and their data pipeline"""
- kind = mlrun.api.schemas.ObjectKind.feature_set.value
+ kind = mlrun.common.schemas.ObjectKind.feature_set.value
_dict_fields = ["kind", "metadata", "spec", "status"]
def __init__(
@@ -529,7 +529,7 @@ def purge_targets(self, target_names: List[str] = None, silent: bool = False):
:param silent: Fail silently if target doesn't exist in featureset status"""
verify_feature_set_permissions(
- self, mlrun.api.schemas.AuthorizationAction.delete
+ self, mlrun.common.schemas.AuthorizationAction.delete
)
purge_targets = self._reload_and_get_status_targets(
diff --git a/mlrun/feature_store/feature_vector.py b/mlrun/feature_store/feature_vector.py
index bb4b84edda72..c219170d9448 100644
--- a/mlrun/feature_store/feature_vector.py
+++ b/mlrun/feature_store/feature_vector.py
@@ -154,7 +154,7 @@ def features(self, features: List[Feature]):
class FeatureVector(ModelObj):
"""Feature vector, specify selected features, their metadata and material views"""
- kind = mlrun.api.schemas.ObjectKind.feature_vector.value
+ kind = mlrun.common.schemas.ObjectKind.feature_vector.value
_dict_fields = ["kind", "metadata", "spec", "status"]
def __init__(
diff --git a/mlrun/k8s_utils.py b/mlrun/k8s_utils.py
index 19130716498e..3ed1b0ee0668 100644
--- a/mlrun/k8s_utils.py
+++ b/mlrun/k8s_utils.py
@@ -22,7 +22,7 @@
from kubernetes import client, config
from kubernetes.client.rest import ApiException
-import mlrun.api.schemas
+import mlrun.common.schemas
import mlrun.errors
from .config import config as mlconfig
@@ -452,10 +452,10 @@ def _get_secret_value(key):
return None
username = _get_secret_value(
- mlrun.api.schemas.AuthSecretData.get_field_secret_key("username")
+ mlrun.common.schemas.AuthSecretData.get_field_secret_key("username")
)
access_key = _get_secret_value(
- mlrun.api.schemas.AuthSecretData.get_field_secret_key("access_key")
+ mlrun.common.schemas.AuthSecretData.get_field_secret_key("access_key")
)
return username, access_key
@@ -463,8 +463,10 @@ def _get_secret_value(key):
def store_auth_secret(self, username: str, access_key: str, namespace="") -> str:
secret_name = self.get_auth_secret_name(access_key)
secret_data = {
- mlrun.api.schemas.AuthSecretData.get_field_secret_key("username"): username,
- mlrun.api.schemas.AuthSecretData.get_field_secret_key(
+ mlrun.common.schemas.AuthSecretData.get_field_secret_key(
+ "username"
+ ): username,
+ mlrun.common.schemas.AuthSecretData.get_field_secret_key(
"access_key"
): access_key,
}
@@ -795,7 +797,7 @@ def generate_preemptible_node_selector_requirements(
"""
Generate node selector requirements based on the pre-configured node selector of the preemptible nodes.
node selector operator represents a key's relationship to a set of values.
- Valid operators are listed in :py:class:`~mlrun.api.schemas.NodeSelectorOperator`
+ Valid operators are listed in :py:class:`~mlrun.common.schemas.NodeSelectorOperator`
:param node_selector_operator: The operator of V1NodeSelectorRequirement
:return: List[V1NodeSelectorRequirement]
"""
@@ -826,7 +828,7 @@ def generate_preemptible_nodes_anti_affinity_terms() -> typing.List[
:return: List contains one nodeSelectorTerm with multiple expressions.
"""
# import here to avoid circular imports
- from mlrun.api.schemas import NodeSelectorOperator
+ from mlrun.common.schemas import NodeSelectorOperator
# compile affinities with operator NotIn to make sure pods are not running on preemptible nodes.
node_selector_requirements = generate_preemptible_node_selector_requirements(
@@ -849,7 +851,7 @@ def generate_preemptible_nodes_affinity_terms() -> typing.List[
:return: List of nodeSelectorTerms associated with the preemptible nodes.
"""
# import here to avoid circular imports
- from mlrun.api.schemas import NodeSelectorOperator
+ from mlrun.common.schemas import NodeSelectorOperator
node_selector_terms = []
diff --git a/mlrun/model_monitoring/__init__.py b/mlrun/model_monitoring/__init__.py
index 80d3f7dacd3b..8a3c19723b7b 100644
--- a/mlrun/model_monitoring/__init__.py
+++ b/mlrun/model_monitoring/__init__.py
@@ -17,9 +17,6 @@
__all__ = [
"ModelEndpoint",
- "ModelMonitoringMode",
- "EndpointType",
- "create_model_endpoint_uid",
"EventFieldType",
"EventLiveStats",
"EventKeyMetrics",
@@ -30,8 +27,7 @@
"ModelMonitoringStoreKinds",
]
-from .common import EndpointType, ModelMonitoringMode, create_model_endpoint_uid
-from .constants import (
+from mlrun.common.model_monitoring import (
EventFieldType,
EventKeyMetrics,
EventLiveStats,
@@ -41,4 +37,5 @@
ProjectSecretKeys,
TimeSeriesTarget,
)
+
from .model_endpoint import ModelEndpoint
diff --git a/mlrun/model_monitoring/common.py b/mlrun/model_monitoring/common.py
deleted file mode 100644
index c20114473ee5..000000000000
--- a/mlrun/model_monitoring/common.py
+++ /dev/null
@@ -1,112 +0,0 @@
-# Copyright 2018 Iguazio
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-#
-
-import enum
-import hashlib
-from dataclasses import dataclass
-from typing import Optional
-
-import mlrun.utils
-
-
-class ModelMonitoringMode(str, enum.Enum):
- enabled = "enabled"
- disabled = "disabled"
-
-
-class EndpointType(enum.IntEnum):
- NODE_EP = 1 # end point that is not a child of a router
- ROUTER = 2 # endpoint that is router
- LEAF_EP = 3 # end point that is a child of a router
-
-
-def create_model_endpoint_uid(function_uri: str, versioned_model: str):
- function_uri = FunctionURI.from_string(function_uri)
- versioned_model = VersionedModel.from_string(versioned_model)
-
- if (
- not function_uri.project
- or not function_uri.function
- or not versioned_model.model
- ):
- raise ValueError("Both function_uri and versioned_model have to be initialized")
-
- uid = EndpointUID(
- function_uri.project,
- function_uri.function,
- function_uri.tag,
- function_uri.hash_key,
- versioned_model.model,
- versioned_model.version,
- )
-
- return uid
-
-
-@dataclass
-class FunctionURI:
- project: str
- function: str
- tag: Optional[str] = None
- hash_key: Optional[str] = None
-
- @classmethod
- def from_string(cls, function_uri):
- project, uri, tag, hash_key = mlrun.utils.parse_versioned_object_uri(
- function_uri
- )
- return cls(
- project=project,
- function=uri,
- tag=tag or None,
- hash_key=hash_key or None,
- )
-
-
-@dataclass
-class VersionedModel:
- model: str
- version: Optional[str]
-
- @classmethod
- def from_string(cls, model):
- try:
- model, version = model.split(":")
- except ValueError:
- model, version = model, None
-
- return cls(model, version)
-
-
-@dataclass
-class EndpointUID:
- project: str
- function: str
- function_tag: str
- function_hash_key: str
- model: str
- model_version: str
- uid: Optional[str] = None
-
- def __post_init__(self):
- function_ref = (
- f"{self.function}_{self.function_tag or self.function_hash_key or 'N/A'}"
- )
- versioned_model = f"{self.model}_{self.model_version or 'N/A'}"
- unique_string = f"{self.project}_{function_ref}_{versioned_model}"
- self.uid = hashlib.sha1(unique_string.encode("utf-8")).hexdigest()
-
- def __str__(self):
- return self.uid
diff --git a/mlrun/model_monitoring/helpers.py b/mlrun/model_monitoring/helpers.py
index 165d5d58ccf6..e9f8191b27f4 100644
--- a/mlrun/model_monitoring/helpers.py
+++ b/mlrun/model_monitoring/helpers.py
@@ -21,12 +21,12 @@
import mlrun
import mlrun.api.api.utils
import mlrun.api.crud.secrets
-import mlrun.api.schemas
import mlrun.api.utils.singletons.db
import mlrun.api.utils.singletons.k8s
+import mlrun.common.model_monitoring as model_monitoring_constants
+import mlrun.common.schemas
import mlrun.config
import mlrun.feature_store as fstore
-import mlrun.model_monitoring.constants as model_monitoring_constants
import mlrun.model_monitoring.stream_processing_fs
import mlrun.runtimes
import mlrun.utils.helpers
@@ -44,7 +44,7 @@ def initial_model_monitoring_stream_processing_function(
project: str,
model_monitoring_access_key: str,
tracking_policy: mlrun.utils.model_monitoring.TrackingPolicy,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
parquet_target: str,
):
"""
@@ -104,7 +104,7 @@ def get_model_monitoring_batch_function(
project: str,
model_monitoring_access_key: str,
db_session: sqlalchemy.orm.Session,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
tracking_policy: mlrun.utils.model_monitoring.TrackingPolicy,
):
"""
@@ -153,7 +153,7 @@ def _apply_stream_trigger(
project: str,
function: mlrun.runtimes.ServingRuntime,
model_monitoring_access_key: str = None,
- auth_info: mlrun.api.schemas.AuthInfo = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
) -> mlrun.runtimes.ServingRuntime:
"""Adding stream source for the nuclio serving function. By default, the function has HTTP stream trigger along
with another supported stream source that can be either Kafka or V3IO, depends on the stream path schema that is
@@ -208,7 +208,7 @@ def _apply_access_key_and_mount_function(
mlrun.runtimes.KubejobRuntime, mlrun.runtimes.ServingRuntime
],
model_monitoring_access_key: str,
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
) -> typing.Union[mlrun.runtimes.KubejobRuntime, mlrun.runtimes.ServingRuntime]:
"""Applying model monitoring access key on the provided function when using V3IO path. In addition, this method
mount the V3IO path for the provided function to configure the access to the system files.
diff --git a/mlrun/model_monitoring/model_endpoint.py b/mlrun/model_monitoring/model_endpoint.py
index 3ad8d094fa8d..991158e24d44 100644
--- a/mlrun/model_monitoring/model_endpoint.py
+++ b/mlrun/model_monitoring/model_endpoint.py
@@ -16,9 +16,12 @@
from typing import Any, Dict, List, Optional
import mlrun.model
-
-from .common import EndpointType, ModelMonitoringMode
-from .constants import EventKeyMetrics, EventLiveStats
+from mlrun.common.model_monitoring import (
+ EndpointType,
+ EventKeyMetrics,
+ EventLiveStats,
+ ModelMonitoringMode,
+)
class ModelEndpointSpec(mlrun.model.ModelObj):
diff --git a/mlrun/model_monitoring/model_monitoring_batch.py b/mlrun/model_monitoring/model_monitoring_batch.py
index ce07bab90f12..9179f05a6809 100644
--- a/mlrun/model_monitoring/model_monitoring_batch.py
+++ b/mlrun/model_monitoring/model_monitoring_batch.py
@@ -28,7 +28,8 @@
import v3io_frames
import mlrun
-import mlrun.api.schemas
+import mlrun.common.model_monitoring
+import mlrun.common.schemas
import mlrun.data_types.infer
import mlrun.feature_store as fstore
import mlrun.model_monitoring
@@ -538,7 +539,7 @@ def __init__(
# Get the batch interval range
self.batch_dict = context.parameters[
- mlrun.model_monitoring.EventFieldType.BATCH_INTERVALS_DICT
+ mlrun.common.model_monitoring.EventFieldType.BATCH_INTERVALS_DICT
]
# TODO: This will be removed in 1.5.0 once the job params can be parsed with different types
@@ -554,7 +555,8 @@ def _initialize_v3io_configurations(self):
# Define the required paths for the project objects
tsdb_path = mlrun.mlconf.get_model_monitoring_file_target_path(
- project=self.project, kind=mlrun.model_monitoring.FileTargetKind.EVENTS
+ project=self.project,
+ kind=mlrun.common.model_monitoring.FileTargetKind.EVENTS,
)
(
_,
@@ -564,7 +566,7 @@ def _initialize_v3io_configurations(self):
# stream_path = template.format(project=self.project, kind="log_stream")
stream_path = mlrun.mlconf.get_model_monitoring_file_target_path(
project=self.project,
- kind=mlrun.model_monitoring.FileTargetKind.LOG_STREAM,
+ kind=mlrun.common.model_monitoring.FileTargetKind.LOG_STREAM,
)
(
_,
@@ -617,18 +619,24 @@ def run(self):
for endpoint in endpoints:
if (
- endpoint[mlrun.model_monitoring.EventFieldType.ACTIVE]
- and endpoint[mlrun.model_monitoring.EventFieldType.MONITORING_MODE]
- == mlrun.model_monitoring.ModelMonitoringMode.enabled.value
+ endpoint[mlrun.common.model_monitoring.EventFieldType.ACTIVE]
+ and endpoint[
+ mlrun.common.model_monitoring.EventFieldType.MONITORING_MODE
+ ]
+ == mlrun.common.model_monitoring.ModelMonitoringMode.enabled.value
):
# Skip router endpoint:
if (
- int(endpoint[mlrun.model_monitoring.EventFieldType.ENDPOINT_TYPE])
- == mlrun.model_monitoring.EndpointType.ROUTER
+ int(
+ endpoint[
+ mlrun.common.model_monitoring.EventFieldType.ENDPOINT_TYPE
+ ]
+ )
+ == mlrun.common.model_monitoring.EndpointType.ROUTER
):
# Router endpoint has no feature stats
logger.info(
- f"{endpoint[mlrun.model_monitoring.EventFieldType.UID]} is router skipping"
+ f"{endpoint[mlrun.common.model_monitoring.EventFieldType.UID]} is router skipping"
)
continue
self.update_drift_metrics(endpoint=endpoint)
@@ -642,12 +650,12 @@ def update_drift_metrics(self, endpoint: dict):
_,
_,
) = mlrun.utils.helpers.parse_versioned_object_uri(
- endpoint[mlrun.model_monitoring.EventFieldType.FUNCTION_URI]
+ endpoint[mlrun.common.model_monitoring.EventFieldType.FUNCTION_URI]
)
- model_name = endpoint[mlrun.model_monitoring.EventFieldType.MODEL].replace(
- ":", "-"
- )
+ model_name = endpoint[
+ mlrun.common.model_monitoring.EventFieldType.MODEL
+ ].replace(":", "-")
m_fs = fstore.get_feature_set(
f"store://feature-sets/{self.project}/monitoring-{serving_function_name}-{model_name}"
@@ -660,14 +668,16 @@ def update_drift_metrics(self, endpoint: dict):
df = m_fs.to_dataframe(
start_time=start_time,
end_time=end_time,
- time_column=mlrun.model_monitoring.EventFieldType.TIMESTAMP,
+ time_column=mlrun.common.model_monitoring.EventFieldType.TIMESTAMP,
)
if len(df) == 0:
logger.warn(
"Not enough model events since the beginning of the batch interval",
parquet_target=m_fs.status.targets[0].path,
- endpoint=endpoint[mlrun.model_monitoring.EventFieldType.UID],
+ endpoint=endpoint[
+ mlrun.common.model_monitoring.EventFieldType.UID
+ ],
min_rqeuired_events=mlrun.mlconf.model_endpoint_monitoring.parquet_batching_max_events,
start_time=str(
datetime.datetime.now() - datetime.timedelta(hours=1)
@@ -684,7 +694,7 @@ def update_drift_metrics(self, endpoint: dict):
logger.warn(
"Parquet not found, probably due to not enough model events",
parquet_target=m_fs.status.targets[0].path,
- endpoint=endpoint[mlrun.model_monitoring.EventFieldType.UID],
+ endpoint=endpoint[mlrun.common.model_monitoring.EventFieldType.UID],
min_rqeuired_events=mlrun.mlconf.model_endpoint_monitoring.parquet_batching_max_events,
)
return
@@ -696,13 +706,15 @@ def update_drift_metrics(self, endpoint: dict):
# Create DataFrame based on the input features
stats_columns = [
- mlrun.model_monitoring.EventFieldType.TIMESTAMP,
+ mlrun.common.model_monitoring.EventFieldType.TIMESTAMP,
*feature_names,
]
# Add label names if provided
- if endpoint[mlrun.model_monitoring.EventFieldType.LABEL_NAMES]:
- labels = endpoint[mlrun.model_monitoring.EventFieldType.LABEL_NAMES]
+ if endpoint[mlrun.common.model_monitoring.EventFieldType.LABEL_NAMES]:
+ labels = endpoint[
+ mlrun.common.model_monitoring.EventFieldType.LABEL_NAMES
+ ]
if isinstance(labels, str):
labels = json.loads(labels)
stats_columns.extend(labels)
@@ -719,11 +731,13 @@ def update_drift_metrics(self, endpoint: dict):
m_fs.save()
# Get the timestamp of the latest request:
- timestamp = df[mlrun.model_monitoring.EventFieldType.TIMESTAMP].iloc[-1]
+ timestamp = df[mlrun.common.model_monitoring.EventFieldType.TIMESTAMP].iloc[
+ -1
+ ]
# Get the feature stats from the model endpoint for reference data
feature_stats = json.loads(
- endpoint[mlrun.model_monitoring.EventFieldType.FEATURE_STATS]
+ endpoint[mlrun.common.model_monitoring.EventFieldType.FEATURE_STATS]
)
# Get the current stats:
@@ -744,7 +758,7 @@ def update_drift_metrics(self, endpoint: dict):
monitor_configuration = (
json.loads(
endpoint[
- mlrun.model_monitoring.EventFieldType.MONITOR_CONFIGURATION
+ mlrun.common.model_monitoring.EventFieldType.MONITOR_CONFIGURATION
]
)
or {}
@@ -764,7 +778,7 @@ def update_drift_metrics(self, endpoint: dict):
)
logger.info(
"Drift status",
- endpoint_id=endpoint[mlrun.model_monitoring.EventFieldType.UID],
+ endpoint_id=endpoint[mlrun.common.model_monitoring.EventFieldType.UID],
drift_status=drift_status.value,
drift_measure=drift_measure,
)
@@ -776,14 +790,16 @@ def update_drift_metrics(self, endpoint: dict):
}
self.db.update_model_endpoint(
- endpoint_id=endpoint[mlrun.model_monitoring.EventFieldType.UID],
+ endpoint_id=endpoint[mlrun.common.model_monitoring.EventFieldType.UID],
attributes=attributes,
)
if not mlrun.mlconf.is_ce_mode():
# Update drift results in TSDB
self._update_drift_in_input_stream(
- endpoint_id=endpoint[mlrun.model_monitoring.EventFieldType.UID],
+ endpoint_id=endpoint[
+ mlrun.common.model_monitoring.EventFieldType.UID
+ ],
drift_status=drift_status,
drift_measure=drift_measure,
drift_result=drift_result,
@@ -791,21 +807,23 @@ def update_drift_metrics(self, endpoint: dict):
)
logger.info(
"Done updating drift measures",
- endpoint_id=endpoint[mlrun.model_monitoring.EventFieldType.UID],
+ endpoint_id=endpoint[
+ mlrun.common.model_monitoring.EventFieldType.UID
+ ],
)
except Exception as e:
logger.error(
- f"Exception for endpoint {endpoint[mlrun.model_monitoring.EventFieldType.UID]}"
+ f"Exception for endpoint {endpoint[mlrun.common.model_monitoring.EventFieldType.UID]}"
)
self.exception = e
def _get_interval_range(self) -> Tuple[datetime.datetime, datetime.datetime]:
"""Getting batch interval time range"""
minutes, hours, days = (
- self.batch_dict[mlrun.model_monitoring.EventFieldType.MINUTES],
- self.batch_dict[mlrun.model_monitoring.EventFieldType.HOURS],
- self.batch_dict[mlrun.model_monitoring.EventFieldType.DAYS],
+ self.batch_dict[mlrun.common.model_monitoring.EventFieldType.MINUTES],
+ self.batch_dict[mlrun.common.model_monitoring.EventFieldType.HOURS],
+ self.batch_dict[mlrun.common.model_monitoring.EventFieldType.DAYS],
)
start_time = datetime.datetime.now() - datetime.timedelta(
minutes=minutes, hours=hours, days=days
@@ -870,7 +888,7 @@ def _update_drift_in_input_stream(
"endpoint_id": endpoint_id,
"timestamp": pd.to_datetime(
timestamp,
- format=mlrun.model_monitoring.EventFieldType.TIME_FORMAT,
+ format=mlrun.common.model_monitoring.EventFieldType.TIME_FORMAT,
),
"record_type": "drift_measures",
"tvd_mean": drift_result["tvd_mean"],
diff --git a/mlrun/model_monitoring/stores/kv_model_endpoint_store.py b/mlrun/model_monitoring/stores/kv_model_endpoint_store.py
index 1d5bed5acbda..b84e21f16b86 100644
--- a/mlrun/model_monitoring/stores/kv_model_endpoint_store.py
+++ b/mlrun/model_monitoring/stores/kv_model_endpoint_store.py
@@ -20,7 +20,7 @@
import v3io_frames
import mlrun
-import mlrun.model_monitoring.constants as model_monitoring_constants
+import mlrun.common.model_monitoring as model_monitoring_constants
import mlrun.utils.model_monitoring
import mlrun.utils.v3io_clients
from mlrun.utils import logger
@@ -434,8 +434,8 @@ def _build_kv_cursor_filter_expression(
# Apply top_level filter (remove endpoints that considered a child of a router)
if top_level:
filter_expression.append(
- f"(endpoint_type=='{str(mlrun.model_monitoring.EndpointType.NODE_EP.value)}' "
- f"OR endpoint_type=='{str(mlrun.model_monitoring.EndpointType.ROUTER.value)}')"
+ f"(endpoint_type=='{str(model_monitoring_constants.EndpointType.NODE_EP.value)}' "
+ f"OR endpoint_type=='{str(model_monitoring_constants.EndpointType.ROUTER.value)}')"
)
return " AND ".join(filter_expression)
diff --git a/mlrun/model_monitoring/stores/models/mysql.py b/mlrun/model_monitoring/stores/models/mysql.py
index 69f3faf43b62..d9edc57583b1 100644
--- a/mlrun/model_monitoring/stores/models/mysql.py
+++ b/mlrun/model_monitoring/stores/models/mysql.py
@@ -17,7 +17,7 @@
import sqlalchemy.dialects
from sqlalchemy import Boolean, Column, Integer, String, Text
-import mlrun.model_monitoring.constants as model_monitoring_constants
+import mlrun.common.model_monitoring as model_monitoring_constants
from mlrun.utils.db import BaseModel
from .base import Base
diff --git a/mlrun/model_monitoring/stores/models/sqlite.py b/mlrun/model_monitoring/stores/models/sqlite.py
index 9e2ce9f05a23..e790b50d6925 100644
--- a/mlrun/model_monitoring/stores/models/sqlite.py
+++ b/mlrun/model_monitoring/stores/models/sqlite.py
@@ -16,7 +16,7 @@
from sqlalchemy import TIMESTAMP, Boolean, Column, Integer, String, Text
-import mlrun.model_monitoring.constants as model_monitoring_constants
+import mlrun.common.model_monitoring as model_monitoring_constants
from mlrun.utils.db import BaseModel
from .base import Base
diff --git a/mlrun/model_monitoring/stores/sql_model_endpoint_store.py b/mlrun/model_monitoring/stores/sql_model_endpoint_store.py
index 5fc5198791d7..3b720e3fbdeb 100644
--- a/mlrun/model_monitoring/stores/sql_model_endpoint_store.py
+++ b/mlrun/model_monitoring/stores/sql_model_endpoint_store.py
@@ -21,7 +21,7 @@
import sqlalchemy as db
import mlrun
-import mlrun.model_monitoring.constants as model_monitoring_constants
+import mlrun.common.model_monitoring as model_monitoring_constants
import mlrun.model_monitoring.model_endpoint
import mlrun.utils.model_monitoring
import mlrun.utils.v3io_clients
diff --git a/mlrun/model_monitoring/stream_processing_fs.py b/mlrun/model_monitoring/stream_processing_fs.py
index 9accb4a6c11b..98123b7a738b 100644
--- a/mlrun/model_monitoring/stream_processing_fs.py
+++ b/mlrun/model_monitoring/stream_processing_fs.py
@@ -22,13 +22,14 @@
import storey
import mlrun
+import mlrun.common.model_monitoring
import mlrun.config
import mlrun.datastore.targets
import mlrun.feature_store.steps
import mlrun.utils
import mlrun.utils.model_monitoring
import mlrun.utils.v3io_clients
-from mlrun.model_monitoring import (
+from mlrun.common.model_monitoring import (
EventFieldType,
EventKeyMetrics,
EventLiveStats,
@@ -607,7 +608,7 @@ def do(self, full_event):
version = event.get(EventFieldType.VERSION)
versioned_model = f"{model}:{version}" if version else f"{model}:latest"
- endpoint_id = mlrun.model_monitoring.create_model_endpoint_uid(
+ endpoint_id = mlrun.common.model_monitoring.create_model_endpoint_uid(
function_uri=function_uri,
versioned_model=versioned_model,
)
diff --git a/mlrun/projects/operations.py b/mlrun/projects/operations.py
index b9aeb9945319..a49ed905fa50 100644
--- a/mlrun/projects/operations.py
+++ b/mlrun/projects/operations.py
@@ -70,7 +70,7 @@ def run_function(
selector: str = None,
project_object=None,
auto_build: bool = None,
- schedule: Union[str, mlrun.api.schemas.ScheduleCronTrigger] = None,
+ schedule: Union[str, mlrun.common.schemas.ScheduleCronTrigger] = None,
artifact_path: str = None,
notifications: List[mlrun.model.Notification] = None,
returns: Optional[List[Union[str, Dict[str, str]]]] = None,
diff --git a/mlrun/projects/pipelines.py b/mlrun/projects/pipelines.py
index 76516ea024aa..a8394159c208 100644
--- a/mlrun/projects/pipelines.py
+++ b/mlrun/projects/pipelines.py
@@ -27,7 +27,7 @@
from kfp.compiler import compiler
import mlrun
-import mlrun.api.schemas
+import mlrun.common.schemas
import mlrun.utils.notifications
from mlrun.errors import err_to_str
from mlrun.utils import (
@@ -79,7 +79,7 @@ def __init__(
# TODO: deprecated, remove in 1.5.0
ttl=None,
args_schema: dict = None,
- schedule: typing.Union[str, mlrun.api.schemas.ScheduleCronTrigger] = None,
+ schedule: typing.Union[str, mlrun.common.schemas.ScheduleCronTrigger] = None,
cleanup_ttl: int = None,
):
if ttl:
@@ -285,7 +285,7 @@ def _enrich_kfp_pod_security_context(kfp_pod_template, function):
if (
mlrun.runtimes.RuntimeKinds.is_local_runtime(function.kind)
or mlrun.mlconf.function.spec.security_context.enrichment_mode
- == mlrun.api.schemas.SecurityContextEnrichmentModes.disabled.value
+ == mlrun.common.schemas.SecurityContextEnrichmentModes.disabled.value
):
return
@@ -978,7 +978,7 @@ def load_and_run(
ttl: int = None,
engine: str = None,
local: bool = None,
- schedule: typing.Union[str, mlrun.api.schemas.ScheduleCronTrigger] = None,
+ schedule: typing.Union[str, mlrun.common.schemas.ScheduleCronTrigger] = None,
cleanup_ttl: int = None,
):
"""
@@ -1044,7 +1044,7 @@ def load_and_run(
try:
notification_pusher.push(
message=message,
- severity=mlrun.api.schemas.NotificationSeverity.ERROR,
+ severity=mlrun.common.schemas.NotificationSeverity.ERROR,
)
except Exception as exc:
diff --git a/mlrun/projects/project.py b/mlrun/projects/project.py
index 95073d408c69..c881173254fc 100644
--- a/mlrun/projects/project.py
+++ b/mlrun/projects/project.py
@@ -33,10 +33,10 @@
import nuclio
import yaml
-import mlrun.api.schemas
+import mlrun.common.model_monitoring as model_monitoring_constants
+import mlrun.common.schemas
import mlrun.db
import mlrun.errors
-import mlrun.model_monitoring.constants as model_monitoring_constants
import mlrun.utils.regex
from mlrun.runtimes import RuntimeKinds
@@ -195,7 +195,7 @@ def new_project(
if overwrite:
logger.info(f"Deleting project {name} from MLRun DB due to overwrite")
_delete_project_from_db(
- name, secrets, mlrun.api.schemas.DeletionStrategy.cascade
+ name, secrets, mlrun.common.schemas.DeletionStrategy.cascade
)
try:
@@ -538,7 +538,7 @@ def __init__(
goals=None,
load_source_on_run=None,
default_requirements: typing.Union[str, typing.List[str]] = None,
- desired_state=mlrun.api.schemas.ProjectState.online.value,
+ desired_state=mlrun.common.schemas.ProjectState.online.value,
owner=None,
disable_auto_mount=None,
workdir=None,
@@ -1020,7 +1020,7 @@ def set_workflow(
engine=None,
args_schema: typing.List[EntrypointParam] = None,
handler=None,
- schedule: typing.Union[str, mlrun.api.schemas.ScheduleCronTrigger] = None,
+ schedule: typing.Union[str, mlrun.common.schemas.ScheduleCronTrigger] = None,
ttl=None,
**args,
):
@@ -1820,7 +1820,7 @@ def set_secrets(
self,
secrets: dict = None,
file_path: str = None,
- provider: typing.Union[str, mlrun.api.schemas.SecretProviderName] = None,
+ provider: typing.Union[str, mlrun.common.schemas.SecretProviderName] = None,
):
"""set project secrets from dict or secrets env file
when using a secrets file it should have lines in the form KEY=VALUE, comment line start with "#"
@@ -1858,7 +1858,7 @@ def set_secrets(
for key, val in secrets.items()
if key != "MLRUN_DBPATH" and not key.startswith("V3IO_")
}
- provider = provider or mlrun.api.schemas.SecretProviderName.kubernetes
+ provider = provider or mlrun.common.schemas.SecretProviderName.kubernetes
mlrun.db.get_run_db().create_project_secrets(
self.metadata.name, provider=provider, secrets=env_vars
)
@@ -1903,7 +1903,9 @@ def run(
ttl: int = None,
engine: str = None,
local: bool = None,
- schedule: typing.Union[str, mlrun.api.schemas.ScheduleCronTrigger, bool] = None,
+ schedule: typing.Union[
+ str, mlrun.common.schemas.ScheduleCronTrigger, bool
+ ] = None,
timeout: int = None,
overwrite: bool = False,
source: str = None,
@@ -2182,7 +2184,7 @@ def set_model_monitoring_credentials(
self.set_secrets(
secrets=secrets_dict,
- provider=mlrun.api.schemas.SecretProviderName.kubernetes,
+ provider=mlrun.common.schemas.SecretProviderName.kubernetes,
)
def run_function(
@@ -2203,7 +2205,7 @@ def run_function(
verbose: bool = None,
selector: str = None,
auto_build: bool = None,
- schedule: typing.Union[str, mlrun.api.schemas.ScheduleCronTrigger] = None,
+ schedule: typing.Union[str, mlrun.common.schemas.ScheduleCronTrigger] = None,
artifact_path: str = None,
notifications: typing.List[mlrun.model.Notification] = None,
returns: Optional[List[Union[str, Dict[str, str]]]] = None,
@@ -2387,7 +2389,7 @@ def list_artifacts(
iter: int = None,
best_iteration: bool = False,
kind: str = None,
- category: typing.Union[str, mlrun.api.schemas.ArtifactCategories] = None,
+ category: typing.Union[str, mlrun.common.schemas.ArtifactCategories] = None,
) -> mlrun.lists.ArtifactList:
"""List artifacts filtered by various parameters.
diff --git a/mlrun/run.py b/mlrun/run.py
index 8f4be7b79011..6489d779e2e8 100644
--- a/mlrun/run.py
+++ b/mlrun/run.py
@@ -36,7 +36,7 @@
from deprecated import deprecated
from kfp import Client
-import mlrun.api.schemas
+import mlrun.common.schemas
import mlrun.errors
import mlrun.utils.helpers
from mlrun.kfpops import format_summary_from_kfp_run, show_kfp_run
@@ -1195,8 +1195,8 @@ def get_pipeline(
run_id,
namespace=None,
format_: Union[
- str, mlrun.api.schemas.PipelinesFormat
- ] = mlrun.api.schemas.PipelinesFormat.summary,
+ str, mlrun.common.schemas.PipelinesFormat
+ ] = mlrun.common.schemas.PipelinesFormat.summary,
project: str = None,
remote: bool = True,
):
@@ -1232,7 +1232,7 @@ def get_pipeline(
resp = resp.to_dict()
if (
not format_
- or format_ == mlrun.api.schemas.PipelinesFormat.summary.value
+ or format_ == mlrun.common.schemas.PipelinesFormat.summary.value
):
resp = format_summary_from_kfp_run(resp)
@@ -1248,7 +1248,7 @@ def list_pipelines(
filter_="",
namespace=None,
project="*",
- format_: mlrun.api.schemas.PipelinesFormat = mlrun.api.schemas.PipelinesFormat.metadata_only,
+ format_: mlrun.common.schemas.PipelinesFormat = mlrun.common.schemas.PipelinesFormat.metadata_only,
) -> Tuple[int, Optional[int], List[dict]]:
"""List pipelines
@@ -1268,7 +1268,7 @@ def list_pipelines(
:param format_: Control what will be returned (full/metadata_only/name_only)
"""
if full:
- format_ = mlrun.api.schemas.PipelinesFormat.full
+ format_ = mlrun.common.schemas.PipelinesFormat.full
run_db = mlrun.db.get_run_db()
pipelines = run_db.list_pipelines(
project, namespace, sort_by, page_token, filter_, format_, page_size
diff --git a/mlrun/runtimes/base.py b/mlrun/runtimes/base.py
index bed99d0abf64..176ee5191e28 100644
--- a/mlrun/runtimes/base.py
+++ b/mlrun/runtimes/base.py
@@ -34,11 +34,11 @@
import mlrun.api.db.sqldb.session
import mlrun.api.utils.singletons.db
+import mlrun.common.schemas
import mlrun.errors
import mlrun.utils.helpers
import mlrun.utils.notifications
import mlrun.utils.regex
-from mlrun.api import schemas
from mlrun.api.constants import LogSources
from mlrun.api.db.base import DBInterface
from mlrun.utils.helpers import generate_object_uri, verify_field_regex
@@ -338,7 +338,7 @@ def run(
workdir: str = "",
artifact_path: str = "",
watch: bool = True,
- schedule: Union[str, schemas.ScheduleCronTrigger] = None,
+ schedule: Union[str, mlrun.common.schemas.ScheduleCronTrigger] = None,
hyperparams: Dict[str, list] = None,
hyper_param_options: HyperParamOptions = None,
verbose=None,
@@ -1551,11 +1551,13 @@ def list_resources(
project: str,
object_id: typing.Optional[str] = None,
label_selector: str = None,
- group_by: Optional[mlrun.api.schemas.ListRuntimeResourcesGroupByField] = None,
+ group_by: Optional[
+ mlrun.common.schemas.ListRuntimeResourcesGroupByField
+ ] = None,
) -> Union[
- mlrun.api.schemas.RuntimeResources,
- mlrun.api.schemas.GroupedByJobRuntimeResourcesOutput,
- mlrun.api.schemas.GroupedByProjectRuntimeResourcesOutput,
+ mlrun.common.schemas.RuntimeResources,
+ mlrun.common.schemas.GroupedByJobRuntimeResourcesOutput,
+ mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput,
]:
# We currently don't support removing runtime resources in non k8s env
if not mlrun.k8s_utils.get_k8s_helper(
@@ -1579,8 +1581,10 @@ def list_resources(
def build_output_from_runtime_resources(
self,
- runtime_resources_list: List[mlrun.api.schemas.RuntimeResources],
- group_by: Optional[mlrun.api.schemas.ListRuntimeResourcesGroupByField] = None,
+ runtime_resources_list: List[mlrun.common.schemas.RuntimeResources],
+ group_by: Optional[
+ mlrun.common.schemas.ListRuntimeResourcesGroupByField
+ ] = None,
):
pod_resources = []
crd_resources = []
@@ -1832,17 +1836,19 @@ def _get_main_runtime_resource_label_selector() -> str:
def _enrich_list_resources_response(
self,
response: Union[
- mlrun.api.schemas.RuntimeResources,
- mlrun.api.schemas.GroupedByJobRuntimeResourcesOutput,
- mlrun.api.schemas.GroupedByProjectRuntimeResourcesOutput,
+ mlrun.common.schemas.RuntimeResources,
+ mlrun.common.schemas.GroupedByJobRuntimeResourcesOutput,
+ mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput,
],
namespace: str,
label_selector: str = None,
- group_by: Optional[mlrun.api.schemas.ListRuntimeResourcesGroupByField] = None,
+ group_by: Optional[
+ mlrun.common.schemas.ListRuntimeResourcesGroupByField
+ ] = None,
) -> Union[
- mlrun.api.schemas.RuntimeResources,
- mlrun.api.schemas.GroupedByJobRuntimeResourcesOutput,
- mlrun.api.schemas.GroupedByProjectRuntimeResourcesOutput,
+ mlrun.common.schemas.RuntimeResources,
+ mlrun.common.schemas.GroupedByJobRuntimeResourcesOutput,
+ mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput,
]:
"""
Override this to list resources other then pods or CRDs (which are handled by the base class)
@@ -1852,12 +1858,14 @@ def _enrich_list_resources_response(
def _build_output_from_runtime_resources(
self,
response: Union[
- mlrun.api.schemas.RuntimeResources,
- mlrun.api.schemas.GroupedByJobRuntimeResourcesOutput,
- mlrun.api.schemas.GroupedByProjectRuntimeResourcesOutput,
+ mlrun.common.schemas.RuntimeResources,
+ mlrun.common.schemas.GroupedByJobRuntimeResourcesOutput,
+ mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput,
],
- runtime_resources_list: List[mlrun.api.schemas.RuntimeResources],
- group_by: Optional[mlrun.api.schemas.ListRuntimeResourcesGroupByField] = None,
+ runtime_resources_list: List[mlrun.common.schemas.RuntimeResources],
+ group_by: Optional[
+ mlrun.common.schemas.ListRuntimeResourcesGroupByField
+ ] = None,
):
"""
Override this to add runtime resources other than pods or CRDs (which are handled by the base class) to the
@@ -2124,10 +2132,10 @@ def _verify_crds_underlying_pods_removed():
"name"
]
still_in_deletion_crds_to_pod_names = {}
- jobs_runtime_resources: mlrun.api.schemas.GroupedByJobRuntimeResourcesOutput = self.list_resources(
+ jobs_runtime_resources: mlrun.common.schemas.GroupedByJobRuntimeResourcesOutput = self.list_resources(
"*",
label_selector=label_selector,
- group_by=mlrun.api.schemas.ListRuntimeResourcesGroupByField.job,
+ group_by=mlrun.common.schemas.ListRuntimeResourcesGroupByField.job,
)
for project, project_jobs in jobs_runtime_resources.items():
if project not in project_uid_crd_map:
@@ -2470,13 +2478,15 @@ def _monitor_runtime_resource(
def _build_list_resources_response(
self,
- pod_resources: List[mlrun.api.schemas.RuntimeResource] = None,
- crd_resources: List[mlrun.api.schemas.RuntimeResource] = None,
- group_by: Optional[mlrun.api.schemas.ListRuntimeResourcesGroupByField] = None,
+ pod_resources: List[mlrun.common.schemas.RuntimeResource] = None,
+ crd_resources: List[mlrun.common.schemas.RuntimeResource] = None,
+ group_by: Optional[
+ mlrun.common.schemas.ListRuntimeResourcesGroupByField
+ ] = None,
) -> Union[
- mlrun.api.schemas.RuntimeResources,
- mlrun.api.schemas.GroupedByJobRuntimeResourcesOutput,
- mlrun.api.schemas.GroupedByProjectRuntimeResourcesOutput,
+ mlrun.common.schemas.RuntimeResources,
+ mlrun.common.schemas.GroupedByJobRuntimeResourcesOutput,
+ mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput,
]:
if crd_resources is None:
crd_resources = []
@@ -2484,15 +2494,18 @@ def _build_list_resources_response(
pod_resources = []
if group_by is None:
- return mlrun.api.schemas.RuntimeResources(
+ return mlrun.common.schemas.RuntimeResources(
crd_resources=crd_resources, pod_resources=pod_resources
)
else:
- if group_by == mlrun.api.schemas.ListRuntimeResourcesGroupByField.job:
+ if group_by == mlrun.common.schemas.ListRuntimeResourcesGroupByField.job:
return self._build_grouped_by_job_list_resources_response(
pod_resources, crd_resources
)
- elif group_by == mlrun.api.schemas.ListRuntimeResourcesGroupByField.project:
+ elif (
+ group_by
+ == mlrun.common.schemas.ListRuntimeResourcesGroupByField.project
+ ):
return self._build_grouped_by_project_list_resources_response(
pod_resources, crd_resources
)
@@ -2503,9 +2516,9 @@ def _build_list_resources_response(
def _build_grouped_by_project_list_resources_response(
self,
- pod_resources: List[mlrun.api.schemas.RuntimeResource] = None,
- crd_resources: List[mlrun.api.schemas.RuntimeResource] = None,
- ) -> mlrun.api.schemas.GroupedByProjectRuntimeResourcesOutput:
+ pod_resources: List[mlrun.common.schemas.RuntimeResource] = None,
+ crd_resources: List[mlrun.common.schemas.RuntimeResource] = None,
+ ) -> mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput:
resources = {}
for pod_resource in pod_resources:
self._add_resource_to_grouped_by_project_resources_response(
@@ -2519,9 +2532,9 @@ def _build_grouped_by_project_list_resources_response(
def _build_grouped_by_job_list_resources_response(
self,
- pod_resources: List[mlrun.api.schemas.RuntimeResource] = None,
- crd_resources: List[mlrun.api.schemas.RuntimeResource] = None,
- ) -> mlrun.api.schemas.GroupedByJobRuntimeResourcesOutput:
+ pod_resources: List[mlrun.common.schemas.RuntimeResource] = None,
+ crd_resources: List[mlrun.common.schemas.RuntimeResource] = None,
+ ) -> mlrun.common.schemas.GroupedByJobRuntimeResourcesOutput:
resources = {}
for pod_resource in pod_resources:
self._add_resource_to_grouped_by_job_resources_response(
@@ -2535,9 +2548,9 @@ def _build_grouped_by_job_list_resources_response(
def _add_resource_to_grouped_by_project_resources_response(
self,
- resources: mlrun.api.schemas.GroupedByJobRuntimeResourcesOutput,
+ resources: mlrun.common.schemas.GroupedByJobRuntimeResourcesOutput,
resource_field_name: str,
- resource: mlrun.api.schemas.RuntimeResource,
+ resource: mlrun.common.schemas.RuntimeResource,
):
if "mlrun/class" in resource.labels:
project = resource.labels.get("mlrun/project", "")
@@ -2549,9 +2562,9 @@ def _add_resource_to_grouped_by_project_resources_response(
def _add_resource_to_grouped_by_job_resources_response(
self,
- resources: mlrun.api.schemas.GroupedByJobRuntimeResourcesOutput,
+ resources: mlrun.common.schemas.GroupedByJobRuntimeResourcesOutput,
resource_field_name: str,
- resource: mlrun.api.schemas.RuntimeResource,
+ resource: mlrun.common.schemas.RuntimeResource,
):
if "mlrun/uid" in resource.labels:
project = resource.labels.get("mlrun/project", config.default_project)
@@ -2564,16 +2577,18 @@ def _add_resource_to_grouped_by_job_resources_response(
def _add_resource_to_grouped_by_field_resources_response(
first_field_value: str,
second_field_value: str,
- resources: mlrun.api.schemas.GroupedByJobRuntimeResourcesOutput,
+ resources: mlrun.common.schemas.GroupedByJobRuntimeResourcesOutput,
resource_field_name: str,
- resource: mlrun.api.schemas.RuntimeResource,
+ resource: mlrun.common.schemas.RuntimeResource,
):
if first_field_value not in resources:
resources[first_field_value] = {}
if second_field_value not in resources[first_field_value]:
resources[first_field_value][
second_field_value
- ] = mlrun.api.schemas.RuntimeResources(pod_resources=[], crd_resources=[])
+ ] = mlrun.common.schemas.RuntimeResources(
+ pod_resources=[], crd_resources=[]
+ )
if not getattr(
resources[first_field_value][second_field_value], resource_field_name
):
@@ -2707,11 +2722,11 @@ def _resolve_runtime_resource_run(runtime_resource: Dict) -> Tuple[str, str, str
return project, uid, name
@staticmethod
- def _build_pod_resources(pods) -> List[mlrun.api.schemas.RuntimeResource]:
+ def _build_pod_resources(pods) -> List[mlrun.common.schemas.RuntimeResource]:
pod_resources = []
for pod in pods:
pod_resources.append(
- mlrun.api.schemas.RuntimeResource(
+ mlrun.common.schemas.RuntimeResource(
name=pod["metadata"]["name"],
labels=pod["metadata"]["labels"],
status=pod["status"],
@@ -2720,11 +2735,13 @@ def _build_pod_resources(pods) -> List[mlrun.api.schemas.RuntimeResource]:
return pod_resources
@staticmethod
- def _build_crd_resources(custom_objects) -> List[mlrun.api.schemas.RuntimeResource]:
+ def _build_crd_resources(
+ custom_objects,
+ ) -> List[mlrun.common.schemas.RuntimeResource]:
crd_resources = []
for custom_object in custom_objects:
crd_resources.append(
- mlrun.api.schemas.RuntimeResource(
+ mlrun.common.schemas.RuntimeResource(
name=custom_object["metadata"]["name"],
labels=custom_object["metadata"]["labels"],
status=custom_object.get("status", {}),
diff --git a/mlrun/runtimes/daskjob.py b/mlrun/runtimes/daskjob.py
index ed3fe30466d2..ebc68bfdefbc 100644
--- a/mlrun/runtimes/daskjob.py
+++ b/mlrun/runtimes/daskjob.py
@@ -23,7 +23,7 @@
from kubernetes.client.rest import ApiException
from sqlalchemy.orm import Session
-import mlrun.api.schemas
+import mlrun.common.schemas
import mlrun.errors
import mlrun.utils
import mlrun.utils.regex
@@ -273,11 +273,11 @@ def _start(self, watch=True):
)
if (
background_task.status.state
- in mlrun.api.schemas.BackgroundTaskState.terminal_states()
+ in mlrun.common.schemas.BackgroundTaskState.terminal_states()
):
if (
background_task.status.state
- == mlrun.api.schemas.BackgroundTaskState.failed
+ == mlrun.common.schemas.BackgroundTaskState.failed
):
raise mlrun.errors.MLRunRuntimeError(
"Failed bringing up dask cluster"
@@ -732,17 +732,19 @@ def resolve_object_id(
def _enrich_list_resources_response(
self,
response: Union[
- mlrun.api.schemas.RuntimeResources,
- mlrun.api.schemas.GroupedByJobRuntimeResourcesOutput,
- mlrun.api.schemas.GroupedByProjectRuntimeResourcesOutput,
+ mlrun.common.schemas.RuntimeResources,
+ mlrun.common.schemas.GroupedByJobRuntimeResourcesOutput,
+ mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput,
],
namespace: str,
label_selector: str = None,
- group_by: Optional[mlrun.api.schemas.ListRuntimeResourcesGroupByField] = None,
+ group_by: Optional[
+ mlrun.common.schemas.ListRuntimeResourcesGroupByField
+ ] = None,
) -> Union[
- mlrun.api.schemas.RuntimeResources,
- mlrun.api.schemas.GroupedByJobRuntimeResourcesOutput,
- mlrun.api.schemas.GroupedByProjectRuntimeResourcesOutput,
+ mlrun.common.schemas.RuntimeResources,
+ mlrun.common.schemas.GroupedByJobRuntimeResourcesOutput,
+ mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput,
]:
"""
Handling listing service resources
@@ -757,7 +759,7 @@ def _enrich_list_resources_response(
service_resources = []
for service in services.items:
service_resources.append(
- mlrun.api.schemas.RuntimeResource(
+ mlrun.common.schemas.RuntimeResource(
name=service.metadata.name, labels=service.metadata.labels
)
)
@@ -768,12 +770,14 @@ def _enrich_list_resources_response(
def _build_output_from_runtime_resources(
self,
response: Union[
- mlrun.api.schemas.RuntimeResources,
- mlrun.api.schemas.GroupedByJobRuntimeResourcesOutput,
- mlrun.api.schemas.GroupedByProjectRuntimeResourcesOutput,
+ mlrun.common.schemas.RuntimeResources,
+ mlrun.common.schemas.GroupedByJobRuntimeResourcesOutput,
+ mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput,
],
- runtime_resources_list: List[mlrun.api.schemas.RuntimeResources],
- group_by: Optional[mlrun.api.schemas.ListRuntimeResourcesGroupByField] = None,
+ runtime_resources_list: List[mlrun.common.schemas.RuntimeResources],
+ group_by: Optional[
+ mlrun.common.schemas.ListRuntimeResourcesGroupByField
+ ] = None,
):
enrich_needed = self._validate_if_enrich_is_needed_by_group_by(group_by)
if not enrich_needed:
@@ -788,13 +792,15 @@ def _build_output_from_runtime_resources(
def _validate_if_enrich_is_needed_by_group_by(
self,
- group_by: Optional[mlrun.api.schemas.ListRuntimeResourcesGroupByField] = None,
+ group_by: Optional[
+ mlrun.common.schemas.ListRuntimeResourcesGroupByField
+ ] = None,
) -> bool:
# Dask runtime resources are per function (and not per job) therefore, when grouping by job we're simply
# omitting the dask runtime resources
- if group_by == mlrun.api.schemas.ListRuntimeResourcesGroupByField.job:
+ if group_by == mlrun.common.schemas.ListRuntimeResourcesGroupByField.job:
return False
- elif group_by == mlrun.api.schemas.ListRuntimeResourcesGroupByField.project:
+ elif group_by == mlrun.common.schemas.ListRuntimeResourcesGroupByField.project:
return True
elif group_by is not None:
raise NotImplementedError(
@@ -805,14 +811,16 @@ def _validate_if_enrich_is_needed_by_group_by(
def _enrich_service_resources_in_response(
self,
response: Union[
- mlrun.api.schemas.RuntimeResources,
- mlrun.api.schemas.GroupedByJobRuntimeResourcesOutput,
- mlrun.api.schemas.GroupedByProjectRuntimeResourcesOutput,
+ mlrun.common.schemas.RuntimeResources,
+ mlrun.common.schemas.GroupedByJobRuntimeResourcesOutput,
+ mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput,
],
- service_resources: List[mlrun.api.schemas.RuntimeResource],
- group_by: Optional[mlrun.api.schemas.ListRuntimeResourcesGroupByField] = None,
+ service_resources: List[mlrun.common.schemas.RuntimeResource],
+ group_by: Optional[
+ mlrun.common.schemas.ListRuntimeResourcesGroupByField
+ ] = None,
):
- if group_by == mlrun.api.schemas.ListRuntimeResourcesGroupByField.project:
+ if group_by == mlrun.common.schemas.ListRuntimeResourcesGroupByField.project:
for service_resource in service_resources:
self._add_resource_to_grouped_by_project_resources_response(
response, "service_resources", service_resource
diff --git a/mlrun/runtimes/function.py b/mlrun/runtimes/function.py
index d3c7d8bfd4a6..bbe0b0fff163 100644
--- a/mlrun/runtimes/function.py
+++ b/mlrun/runtimes/function.py
@@ -33,10 +33,10 @@
import mlrun.errors
import mlrun.utils
+from mlrun.common.schemas import AuthInfo
from mlrun.datastore import parse_s3_bucket_and_key
from mlrun.db import RunDBError
-from ..api.schemas import AuthInfo
from ..config import config as mlconf
from ..config import is_running_as_api
from ..errors import err_to_str
@@ -667,7 +667,7 @@ def with_preemption_mode(self, mode):
The default preemption mode is configurable in mlrun.mlconf.function_defaults.preemption_mode,
by default it's set to **prevent**
- :param mode: allow | constrain | prevent | none defined in :py:class:`~mlrun.api.schemas.PreemptionModes`
+ :param mode: allow | constrain | prevent | none defined in :py:class:`~mlrun.common.schemas.PreemptionModes`
"""
super().with_preemption_mode(mode=mode)
diff --git a/mlrun/runtimes/kubejob.py b/mlrun/runtimes/kubejob.py
index 349c031ed0c5..6bb81dc1c427 100644
--- a/mlrun/runtimes/kubejob.py
+++ b/mlrun/runtimes/kubejob.py
@@ -18,7 +18,7 @@
from kubernetes import client
from kubernetes.client.rest import ApiException
-import mlrun.api.schemas
+import mlrun.common.schemas
import mlrun.errors
from mlrun.runtimes.base import BaseRuntimeHandler
@@ -243,7 +243,7 @@ def deploy(
else:
self.save(versioned=False)
ready = build_runtime(
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
self,
with_mlrun,
mlrun_version_specifier,
diff --git a/mlrun/runtimes/package/context_handler.py b/mlrun/runtimes/package/context_handler.py
index fe6a60277005..da1248b874eb 100644
--- a/mlrun/runtimes/package/context_handler.py
+++ b/mlrun/runtimes/package/context_handler.py
@@ -30,7 +30,7 @@
from mlrun.utils import logger
-# TODO: Move the `ArtifactType` to constants.py
+# TODO: Move the `ArtifactType` to common/constants/model_monitoring.py
class ArtifactType(Enum):
"""
Possible artifact types to log using the MLRun `context` decorator.
diff --git a/mlrun/runtimes/pod.py b/mlrun/runtimes/pod.py
index 0bc603646eec..d27c57d31058 100644
--- a/mlrun/runtimes/pod.py
+++ b/mlrun/runtimes/pod.py
@@ -24,12 +24,12 @@
import mlrun.errors
import mlrun.utils.regex
-
-from ..api.schemas import (
+from mlrun.common.schemas import (
NodeSelectorOperator,
PreemptionModes,
SecurityContextEnrichmentModes,
)
+
from ..config import config as mlconf
from ..k8s_utils import (
generate_preemptible_node_selector_requirements,
@@ -1115,7 +1115,7 @@ def with_preemption_mode(self, mode: typing.Union[PreemptionModes, str]):
The default preemption mode is configurable in mlrun.mlconf.function_defaults.preemption_mode,
by default it's set to **prevent**
- :param mode: allow | constrain | prevent | none defined in :py:class:`~mlrun.api.schemas.PreemptionModes`
+ :param mode: allow | constrain | prevent | none defined in :py:class:`~mlrun.common.schemas.PreemptionModes`
"""
preemptible_mode = PreemptionModes(mode)
self.spec.preemption_mode = preemptible_mode.value
@@ -1124,7 +1124,7 @@ def with_security_context(self, security_context: k8s_client.V1SecurityContext):
"""
Set security context for the pod.
For Iguazio we handle security context internally -
- see mlrun.api.schemas.function.SecurityContextEnrichmentModes
+ see mlrun.common.schemas.function.SecurityContextEnrichmentModes
Example:
diff --git a/mlrun/runtimes/serving.py b/mlrun/runtimes/serving.py
index 5e96cfbdec55..ddc76331fabe 100644
--- a/mlrun/runtimes/serving.py
+++ b/mlrun/runtimes/serving.py
@@ -21,7 +21,7 @@
from nuclio import KafkaTrigger
import mlrun
-import mlrun.api.schemas
+import mlrun.common.schemas
from ..datastore import parse_kafka_url
from ..model import ObjectList
@@ -585,7 +585,7 @@ def deploy(
project="",
tag="",
verbose=False,
- auth_info: mlrun.api.schemas.AuthInfo = None,
+ auth_info: mlrun.common.schemas.AuthInfo = None,
builder_env: dict = None,
):
"""deploy model serving function to a local/remote cluster
diff --git a/mlrun/runtimes/sparkjob/spark3job.py b/mlrun/runtimes/sparkjob/spark3job.py
index 9ddb538a6887..0500937e1244 100644
--- a/mlrun/runtimes/sparkjob/spark3job.py
+++ b/mlrun/runtimes/sparkjob/spark3job.py
@@ -16,7 +16,7 @@
import kubernetes.client
-import mlrun.api.schemas.function
+import mlrun.common.schemas.function
import mlrun.errors
import mlrun.runtimes.pod
@@ -520,7 +520,7 @@ def with_executor_node_selection(
self.spec.executor_tolerations = tolerations
def with_preemption_mode(
- self, mode: typing.Union[mlrun.api.schemas.function.PreemptionModes, str]
+ self, mode: typing.Union[mlrun.common.schemas.function.PreemptionModes, str]
):
"""
Use with_driver_preemption_mode / with_executor_preemption_mode to setup preemption_mode for spark operator
@@ -531,7 +531,7 @@ def with_preemption_mode(
)
def with_driver_preemption_mode(
- self, mode: typing.Union[mlrun.api.schemas.function.PreemptionModes, str]
+ self, mode: typing.Union[mlrun.common.schemas.function.PreemptionModes, str]
):
"""
Preemption mode controls whether the spark driver can be scheduled on preemptible nodes.
@@ -547,13 +547,13 @@ def with_driver_preemption_mode(
The default preemption mode is configurable in mlrun.mlconf.function_defaults.preemption_mode,
by default it's set to **prevent**
- :param mode: allow | constrain | prevent | none defined in :py:class:`~mlrun.api.schemas.PreemptionModes`
+ :param mode: allow | constrain | prevent | none defined in :py:class:`~mlrun.common.schemas.PreemptionModes`
"""
- preemption_mode = mlrun.api.schemas.function.PreemptionModes(mode)
+ preemption_mode = mlrun.common.schemas.function.PreemptionModes(mode)
self.spec.driver_preemption_mode = preemption_mode.value
def with_executor_preemption_mode(
- self, mode: typing.Union[mlrun.api.schemas.function.PreemptionModes, str]
+ self, mode: typing.Union[mlrun.common.schemas.function.PreemptionModes, str]
):
"""
Preemption mode controls whether the spark executor can be scheduled on preemptible nodes.
@@ -569,9 +569,9 @@ def with_executor_preemption_mode(
The default preemption mode is configurable in mlrun.mlconf.function_defaults.preemption_mode,
by default it's set to **prevent**
- :param mode: allow | constrain | prevent | none defined in :py:class:`~mlrun.api.schemas.PreemptionModes`
+ :param mode: allow | constrain | prevent | none defined in :py:class:`~mlrun.common.schemas.PreemptionModes`
"""
- preemption_mode = mlrun.api.schemas.function.PreemptionModes(mode)
+ preemption_mode = mlrun.common.schemas.function.PreemptionModes(mode)
self.spec.executor_preemption_mode = preemption_mode.value
def with_security_context(
diff --git a/mlrun/serving/routers.py b/mlrun/serving/routers.py
index 0b68ab019567..b870e4bda203 100644
--- a/mlrun/serving/routers.py
+++ b/mlrun/serving/routers.py
@@ -24,16 +24,11 @@
import numpy as np
import mlrun
-import mlrun.model_monitoring
+import mlrun.common.model_monitoring
+import mlrun.common.schemas
import mlrun.utils.model_monitoring
from mlrun.utils import logger, now_date, parse_versioned_object_uri
-from ..api.schemas import (
- ModelEndpoint,
- ModelEndpointMetadata,
- ModelEndpointSpec,
- ModelEndpointStatus,
-)
from ..config import config
from .server import GraphServer
from .utils import RouterToDict, _extract_input_data, _update_result_body
@@ -1041,7 +1036,7 @@ def _init_endpoint_record(
versioned_model_name = f"{voting_ensemble.name}:latest"
# Generating model endpoint ID based on function uri and model version
- endpoint_uid = mlrun.model_monitoring.create_model_endpoint_uid(
+ endpoint_uid = mlrun.common.model_monitoring.create_model_endpoint_uid(
function_uri=graph_server.function_uri, versioned_model=versioned_model_name
).uid
@@ -1059,9 +1054,11 @@ def _init_endpoint_record(
if hasattr(c, "endpoint_uid"):
children_uids.append(c.endpoint_uid)
- model_endpoint = ModelEndpoint(
- metadata=ModelEndpointMetadata(project=project, uid=endpoint_uid),
- spec=ModelEndpointSpec(
+ model_endpoint = mlrun.common.schemas.ModelEndpoint(
+ metadata=mlrun.common.schemas.ModelEndpointMetadata(
+ project=project, uid=endpoint_uid
+ ),
+ spec=mlrun.common.schemas.ModelEndpointSpec(
function_uri=graph_server.function_uri,
model=versioned_model_name,
model_class=voting_ensemble.__class__.__name__,
@@ -1069,13 +1066,13 @@ def _init_endpoint_record(
project=project, kind="stream"
),
active=True,
- monitoring_mode=mlrun.model_monitoring.ModelMonitoringMode.enabled
+ monitoring_mode=mlrun.common.model_monitoring.ModelMonitoringMode.enabled
if voting_ensemble.context.server.track_models
- else mlrun.model_monitoring.ModelMonitoringMode.disabled,
+ else mlrun.common.model_monitoring.ModelMonitoringMode.disabled,
),
- status=ModelEndpointStatus(
+ status=mlrun.common.schemas.ModelEndpointStatus(
children=list(voting_ensemble.routes.keys()),
- endpoint_type=mlrun.model_monitoring.EndpointType.ROUTER,
+ endpoint_type=mlrun.common.model_monitoring.EndpointType.ROUTER,
children_uids=children_uids,
),
)
@@ -1094,7 +1091,7 @@ def _init_endpoint_record(
project=project, endpoint_id=model_endpoint
)
current_endpoint.status.endpoint_type = (
- mlrun.model_monitoring.EndpointType.LEAF_EP
+ mlrun.common.model_monitoring.EndpointType.LEAF_EP
)
db.create_model_endpoint(
project=project,
diff --git a/mlrun/serving/server.py b/mlrun/serving/server.py
index 98d376eec195..0f76335cd741 100644
--- a/mlrun/serving/server.py
+++ b/mlrun/serving/server.py
@@ -24,9 +24,9 @@
import mlrun
import mlrun.utils.model_monitoring
+from mlrun.common.model_monitoring import FileTargetKind
from mlrun.config import config
from mlrun.errors import err_to_str
-from mlrun.model_monitoring import FileTargetKind
from mlrun.secrets import SecretsStore
from ..datastore import get_stream_pusher
diff --git a/mlrun/serving/v2_serving.py b/mlrun/serving/v2_serving.py
index 0b8675f794a3..d48529e0355b 100644
--- a/mlrun/serving/v2_serving.py
+++ b/mlrun/serving/v2_serving.py
@@ -17,13 +17,8 @@
from typing import Dict, Union
import mlrun
-import mlrun.model_monitoring
-from mlrun.api.schemas import (
- ModelEndpoint,
- ModelEndpointMetadata,
- ModelEndpointSpec,
- ModelEndpointStatus,
-)
+import mlrun.common.model_monitoring
+import mlrun.common.schemas
from mlrun.artifacts import ModelArtifact # noqa: F401
from mlrun.config import config
from mlrun.utils import logger, now_date, parse_versioned_object_uri
@@ -486,7 +481,7 @@ def _init_endpoint_record(
versioned_model_name = f"{model.name}:latest"
# Generating model endpoint ID based on function uri and model version
- uid = mlrun.model_monitoring.create_model_endpoint_uid(
+ uid = mlrun.common.model_monitoring.create_model_endpoint_uid(
function_uri=graph_server.function_uri, versioned_model=versioned_model_name
).uid
@@ -498,11 +493,11 @@ def _init_endpoint_record(
logger.info("Creating a new model endpoint record", endpoint_id=uid)
try:
- model_endpoint = ModelEndpoint(
- metadata=ModelEndpointMetadata(
+ model_endpoint = mlrun.common.schemas.ModelEndpoint(
+ metadata=mlrun.common.schemas.ModelEndpointMetadata(
project=project, labels=model.labels, uid=uid
),
- spec=ModelEndpointSpec(
+ spec=mlrun.common.schemas.ModelEndpointSpec(
function_uri=graph_server.function_uri,
model=versioned_model_name,
model_class=model.__class__.__name__,
@@ -511,12 +506,12 @@ def _init_endpoint_record(
project=project, kind="stream"
),
active=True,
- monitoring_mode=mlrun.model_monitoring.ModelMonitoringMode.enabled
+ monitoring_mode=mlrun.common.model_monitoring.ModelMonitoringMode.enabled
if model.context.server.track_models
- else mlrun.model_monitoring.ModelMonitoringMode.disabled,
+ else mlrun.common.model_monitoring.ModelMonitoringMode.disabled,
),
- status=ModelEndpointStatus(
- endpoint_type=mlrun.model_monitoring.EndpointType.NODE_EP
+ status=mlrun.common.schemas.ModelEndpointStatus(
+ endpoint_type=mlrun.common.model_monitoring.EndpointType.NODE_EP
),
)
diff --git a/mlrun/utils/helpers.py b/mlrun/utils/helpers.py
index 7b6aaa34401a..a587a356fed7 100644
--- a/mlrun/utils/helpers.py
+++ b/mlrun/utils/helpers.py
@@ -1295,3 +1295,26 @@ def ensure_git_branch(url: str, repo: git.Repo) -> str:
if not branch and not reference:
url = f"{url}#refs/heads/{repo.active_branch}"
return url
+
+
+class DeprecationHelper(object):
+ """A helper class to deprecate old schemas"""
+
+ def __init__(self, new_target, version="1.4.0"):
+ self._new_target = new_target
+ self._version = version
+
+ def _warn(self):
+ warnings.warn(
+ f"mlrun.api.schemas.{self._new_target.__name__} is deprecated in version {self._version}, "
+ f"Please use mlrun.common.schemas.{self._new_target.__name__} instead.",
+ FutureWarning,
+ )
+
+ def __call__(self, *args, **kwargs):
+ self._warn()
+ return self._new_target(*args, **kwargs)
+
+ def __getattr__(self, attr):
+ self._warn()
+ return getattr(self._new_target, attr)
diff --git a/mlrun/utils/model_monitoring.py b/mlrun/utils/model_monitoring.py
index 5b121d6dd721..226f2dd3c6ae 100644
--- a/mlrun/utils/model_monitoring.py
+++ b/mlrun/utils/model_monitoring.py
@@ -18,10 +18,10 @@
from typing import Union
import mlrun
+import mlrun.common.model_monitoring as model_monitoring_constants
import mlrun.model
-import mlrun.model_monitoring.constants as model_monitoring_constants
import mlrun.platforms.iguazio
-from mlrun.api.schemas.schedule import ScheduleCronTrigger
+from mlrun.common.schemas.schedule import ScheduleCronTrigger
from mlrun.config import is_running_as_api
@@ -44,7 +44,7 @@ def set_project_model_monitoring_credentials(access_key: str, project: str = Non
"""
mlrun.get_run_db().create_project_secrets(
project=project or mlrun.mlconf.default_project,
- provider=mlrun.api.schemas.SecretProviderName.kubernetes,
+ provider=mlrun.common.schemas.SecretProviderName.kubernetes,
secrets={model_monitoring_constants.ProjectSecretKeys.ACCESS_KEY: access_key},
)
@@ -133,12 +133,12 @@ def get_connection_string(project: str = None):
if is_running_as_api():
# Running on API server side
import mlrun.api.crud.secrets
- import mlrun.api.schemas
+ import mlrun.common.schemas
return (
mlrun.api.crud.secrets.Secrets().get_project_secret(
project=project,
- provider=mlrun.api.schemas.secret.SecretProviderName.kubernetes,
+ provider=mlrun.common.schemas.secret.SecretProviderName.kubernetes,
allow_secrets_from_k8s=True,
secret_key=model_monitoring_constants.ProjectSecretKeys.ENDPOINT_STORE_CONNECTION,
)
@@ -165,11 +165,11 @@ def get_stream_path(project: str = None):
# Running on API server side
import mlrun.api.crud.secrets
- import mlrun.api.schemas
+ import mlrun.common.schemas
stream_uri = mlrun.api.crud.secrets.Secrets().get_project_secret(
project=project,
- provider=mlrun.api.schemas.secret.SecretProviderName.kubernetes,
+ provider=mlrun.common.schemas.secret.SecretProviderName.kubernetes,
allow_secrets_from_k8s=True,
secret_key=model_monitoring_constants.ProjectSecretKeys.STREAM_PATH,
) or mlrun.mlconf.get_model_monitoring_file_target_path(
diff --git a/mlrun/utils/notifications/notification/base.py b/mlrun/utils/notifications/notification/base.py
index 4668f15c615c..4aaea3ef2c35 100644
--- a/mlrun/utils/notifications/notification/base.py
+++ b/mlrun/utils/notifications/notification/base.py
@@ -14,7 +14,7 @@
import typing
-import mlrun.api.schemas
+import mlrun.common.schemas
import mlrun.lists
@@ -35,8 +35,8 @@ def push(
self,
message: str,
severity: typing.Union[
- mlrun.api.schemas.NotificationSeverity, str
- ] = mlrun.api.schemas.NotificationSeverity.INFO,
+ mlrun.common.schemas.NotificationSeverity, str
+ ] = mlrun.common.schemas.NotificationSeverity.INFO,
runs: typing.Union[mlrun.lists.RunList, list] = None,
custom_html: str = None,
):
@@ -52,8 +52,8 @@ def _get_html(
self,
message: str,
severity: typing.Union[
- mlrun.api.schemas.NotificationSeverity, str
- ] = mlrun.api.schemas.NotificationSeverity.INFO,
+ mlrun.common.schemas.NotificationSeverity, str
+ ] = mlrun.common.schemas.NotificationSeverity.INFO,
runs: typing.Union[mlrun.lists.RunList, list] = None,
custom_html: str = None,
) -> str:
diff --git a/mlrun/utils/notifications/notification/console.py b/mlrun/utils/notifications/notification/console.py
index 4f56c34fa9ad..3b6aacbb8f1e 100644
--- a/mlrun/utils/notifications/notification/console.py
+++ b/mlrun/utils/notifications/notification/console.py
@@ -16,7 +16,7 @@
import tabulate
-import mlrun.api.schemas
+import mlrun.common.schemas
import mlrun.lists
import mlrun.utils.helpers
@@ -32,8 +32,8 @@ def push(
self,
message: str,
severity: typing.Union[
- mlrun.api.schemas.NotificationSeverity, str
- ] = mlrun.api.schemas.NotificationSeverity.INFO,
+ mlrun.common.schemas.NotificationSeverity, str
+ ] = mlrun.common.schemas.NotificationSeverity.INFO,
runs: typing.Union[mlrun.lists.RunList, list] = None,
custom_html: str = None,
):
diff --git a/mlrun/utils/notifications/notification/git.py b/mlrun/utils/notifications/notification/git.py
index 401a39f6dc75..4aad11c00499 100644
--- a/mlrun/utils/notifications/notification/git.py
+++ b/mlrun/utils/notifications/notification/git.py
@@ -18,7 +18,7 @@
import aiohttp
-import mlrun.api.schemas
+import mlrun.common.schemas
import mlrun.errors
import mlrun.lists
@@ -34,8 +34,8 @@ async def push(
self,
message: str,
severity: typing.Union[
- mlrun.api.schemas.NotificationSeverity, str
- ] = mlrun.api.schemas.NotificationSeverity.INFO,
+ mlrun.common.schemas.NotificationSeverity, str
+ ] = mlrun.common.schemas.NotificationSeverity.INFO,
runs: typing.Union[mlrun.lists.RunList, list] = None,
custom_html: str = None,
):
diff --git a/mlrun/utils/notifications/notification/ipython.py b/mlrun/utils/notifications/notification/ipython.py
index 7fc7f2fcc666..31157ab02df1 100644
--- a/mlrun/utils/notifications/notification/ipython.py
+++ b/mlrun/utils/notifications/notification/ipython.py
@@ -14,7 +14,7 @@
import typing
-import mlrun.api.schemas
+import mlrun.common.schemas
import mlrun.lists
import mlrun.utils.helpers
@@ -50,8 +50,8 @@ def push(
self,
message: str,
severity: typing.Union[
- mlrun.api.schemas.NotificationSeverity, str
- ] = mlrun.api.schemas.NotificationSeverity.INFO,
+ mlrun.common.schemas.NotificationSeverity, str
+ ] = mlrun.common.schemas.NotificationSeverity.INFO,
runs: typing.Union[mlrun.lists.RunList, list] = None,
custom_html: str = None,
):
diff --git a/mlrun/utils/notifications/notification/slack.py b/mlrun/utils/notifications/notification/slack.py
index 683b8c68857a..1edbaf90a97d 100644
--- a/mlrun/utils/notifications/notification/slack.py
+++ b/mlrun/utils/notifications/notification/slack.py
@@ -16,7 +16,7 @@
import aiohttp
-import mlrun.api.schemas
+import mlrun.common.schemas
import mlrun.lists
import mlrun.utils.helpers
@@ -38,8 +38,8 @@ async def push(
self,
message: str,
severity: typing.Union[
- mlrun.api.schemas.NotificationSeverity, str
- ] = mlrun.api.schemas.NotificationSeverity.INFO,
+ mlrun.common.schemas.NotificationSeverity, str
+ ] = mlrun.common.schemas.NotificationSeverity.INFO,
runs: typing.Union[mlrun.lists.RunList, list] = None,
custom_html: str = None,
):
@@ -63,8 +63,8 @@ def _generate_slack_data(
self,
message: str,
severity: typing.Union[
- mlrun.api.schemas.NotificationSeverity, str
- ] = mlrun.api.schemas.NotificationSeverity.INFO,
+ mlrun.common.schemas.NotificationSeverity, str
+ ] = mlrun.common.schemas.NotificationSeverity.INFO,
runs: typing.Union[mlrun.lists.RunList, list] = None,
) -> dict:
data = {
diff --git a/mlrun/utils/notifications/notification_pusher.py b/mlrun/utils/notifications/notification_pusher.py
index 36f1892ec225..9c70ebd60d1f 100644
--- a/mlrun/utils/notifications/notification_pusher.py
+++ b/mlrun/utils/notifications/notification_pusher.py
@@ -22,8 +22,8 @@
import mlrun.api.db.base
import mlrun.api.db.session
-import mlrun.api.schemas
import mlrun.api.utils.singletons.k8s
+import mlrun.common.schemas
import mlrun.config
import mlrun.lists
import mlrun.model
@@ -106,7 +106,7 @@ def _should_notify(
# if the notification isn't pending, don't push it
if (
notification.status
- and notification.status != mlrun.api.schemas.NotificationStatus.PENDING
+ and notification.status != mlrun.common.schemas.NotificationStatus.PENDING
):
return False
@@ -149,7 +149,8 @@ async def _push_notification(
):
message = self.messages.get(run.state(), "")
severity = (
- notification_object.severity or mlrun.api.schemas.NotificationSeverity.INFO
+ notification_object.severity
+ or mlrun.common.schemas.NotificationSeverity.INFO
)
logger.debug(
"Pushing notification",
@@ -168,7 +169,7 @@ async def _push_notification(
run.metadata.uid,
run.metadata.project,
notification_object,
- status=mlrun.api.schemas.NotificationStatus.SENT,
+ status=mlrun.common.schemas.NotificationStatus.SENT,
sent_time=datetime.datetime.now(tz=datetime.timezone.utc),
)
except Exception as exc:
@@ -178,7 +179,7 @@ async def _push_notification(
run.metadata.uid,
run.metadata.project,
notification_object,
- status=mlrun.api.schemas.NotificationStatus.ERROR,
+ status=mlrun.common.schemas.NotificationStatus.ERROR,
)
raise exc
@@ -216,8 +217,8 @@ def push(
self,
message: str,
severity: typing.Union[
- mlrun.api.schemas.NotificationSeverity, str
- ] = mlrun.api.schemas.NotificationSeverity.INFO,
+ mlrun.common.schemas.NotificationSeverity, str
+ ] = mlrun.common.schemas.NotificationSeverity.INFO,
runs: typing.Union[mlrun.lists.RunList, list] = None,
custom_html: str = None,
):
@@ -243,8 +244,8 @@ async def _push_notification(
notification: NotificationBase,
message: str,
severity: typing.Union[
- mlrun.api.schemas.NotificationSeverity, str
- ] = mlrun.api.schemas.NotificationSeverity.INFO,
+ mlrun.common.schemas.NotificationSeverity, str
+ ] = mlrun.common.schemas.NotificationSeverity.INFO,
runs: typing.Union[mlrun.lists.RunList, list] = None,
custom_html: str = None,
):
diff --git a/tests/api/api/feature_store/base.py b/tests/api/api/feature_store/base.py
index 840aa1323ce0..32008d6f94cd 100644
--- a/tests/api/api/feature_store/base.py
+++ b/tests/api/api/feature_store/base.py
@@ -17,7 +17,7 @@
from deepdiff import DeepDiff
from fastapi.testclient import TestClient
-import mlrun.api.schemas
+import mlrun.common.schemas
def _list_and_assert_objects(
@@ -68,7 +68,7 @@ def _patch_object(
patch_mode = "replace"
if additive:
patch_mode = "additive"
- headers = {mlrun.api.schemas.HeaderNames.patch_mode: patch_mode}
+ headers = {mlrun.common.schemas.HeaderNames.patch_mode: patch_mode}
response = client.patch(
f"projects/{project_name}/{object_url_path}/{name}/references/{reference}",
json=object_update,
diff --git a/tests/api/api/feature_store/test_feature_vectors.py b/tests/api/api/feature_store/test_feature_vectors.py
index 136e94d9e40f..1402a8602e1a 100644
--- a/tests/api/api/feature_store/test_feature_vectors.py
+++ b/tests/api/api/feature_store/test_feature_vectors.py
@@ -23,8 +23,8 @@
from sqlalchemy.orm import Session
import mlrun.api.api.endpoints.feature_store
-import mlrun.api.schemas
import mlrun.api.utils.auth.verifier
+import mlrun.common.schemas
import tests.api.api.utils
from .base import (
@@ -483,11 +483,11 @@ async def test_verify_feature_vector_features_permissions(
label_feature = "some-feature-set.some-feature"
def _verify_queried_resources(
- resource_type: mlrun.api.schemas.AuthorizationResourceTypes,
+ resource_type: mlrun.common.schemas.AuthorizationResourceTypes,
resources: typing.List,
project_and_resource_name_extractor: typing.Callable,
- action: mlrun.api.schemas.AuthorizationAction,
- auth_info: mlrun.api.schemas.AuthInfo,
+ action: mlrun.common.schemas.AuthorizationAction,
+ auth_info: mlrun.common.schemas.AuthInfo,
raise_on_forbidden: bool = True,
):
expected_resources = [
@@ -508,7 +508,7 @@ def _verify_queried_resources(
unittest.mock.AsyncMock(side_effect=_verify_queried_resources)
)
await mlrun.api.api.endpoints.feature_store._verify_feature_vector_features_permissions(
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
project,
{"spec": {"features": features, "label_feature": label_feature}},
)
diff --git a/tests/api/api/framework/test_middlewares.py b/tests/api/api/framework/test_middlewares.py
index 4fdcea3e75c9..2e98030df931 100644
--- a/tests/api/api/framework/test_middlewares.py
+++ b/tests/api/api/framework/test_middlewares.py
@@ -19,7 +19,7 @@
import pytest
import sqlalchemy.orm
-import mlrun.api.schemas.constants
+import mlrun.common.schemas.constants
import mlrun.utils.version
@@ -51,20 +51,20 @@ def test_ui_clear_cache_middleware(
response = client.get(
"client-spec",
headers={
- mlrun.api.schemas.constants.HeaderNames.ui_version: ui_version,
+ mlrun.common.schemas.constants.HeaderNames.ui_version: ui_version,
},
)
if clear_cache:
assert response.headers["Clear-Site-Data"] == '"cache"'
assert (
- response.headers[mlrun.api.schemas.constants.HeaderNames.ui_clear_cache]
+ response.headers[mlrun.common.schemas.constants.HeaderNames.ui_clear_cache]
== "true"
)
else:
assert "Clear-Site-Data" not in response.headers
assert (
- mlrun.api.schemas.constants.HeaderNames.ui_clear_cache
+ mlrun.common.schemas.constants.HeaderNames.ui_clear_cache
not in response.headers
)
@@ -77,6 +77,6 @@ def test_ensure_be_version_middleware(
) as mock_version_get:
response = client.get("client-spec")
assert (
- response.headers[mlrun.api.schemas.constants.HeaderNames.backend_version]
+ response.headers[mlrun.common.schemas.constants.HeaderNames.backend_version]
== mock_version_get.return_value["version"]
)
diff --git a/tests/api/api/hub/test_hub.py b/tests/api/api/hub/test_hub.py
index 46a7617ef8ab..7459d1e2aaa5 100644
--- a/tests/api/api/hub/test_hub.py
+++ b/tests/api/api/hub/test_hub.py
@@ -24,7 +24,7 @@
from sqlalchemy.orm import Session
import mlrun.api.crud
-import mlrun.api.schemas
+import mlrun.common.schemas
import tests.api.conftest
from mlrun.config import config
@@ -206,7 +206,7 @@ def test_hub_source_manager(
for key, value in credentials.items()
}
)
- source_object = mlrun.api.schemas.HubSource(**source_dict["source"])
+ source_object = mlrun.common.schemas.HubSource(**source_dict["source"])
manager.add_source(source_object)
k8s_secrets_mock.assert_project_secrets(
@@ -251,7 +251,7 @@ def test_hub_default_source(
) -> None:
# This test validates that the default source is valid is its catalog and objects can be retrieved.
manager = mlrun.api.crud.Hub()
- source_object = mlrun.api.schemas.HubSource.generate_default_source()
+ source_object = mlrun.common.schemas.HubSource.generate_default_source()
catalog = manager.get_source_catalog(source_object)
assert len(catalog.catalog) > 0
print(f"Retrieved function catalog. Has {len(catalog.catalog)} functions in it.")
@@ -337,7 +337,7 @@ def test_hub_get_asset(
"source", "secret"
): credentials["secret"]
}
- source_object = mlrun.api.schemas.HubSource(**source_dict["source"])
+ source_object = mlrun.common.schemas.HubSource(**source_dict["source"])
manager.add_source(source_object)
k8s_secrets_mock.assert_project_secrets(
config.hub.k8s_secrets_project_name, expected_credentials
diff --git a/tests/api/api/test_artifacts.py b/tests/api/api/test_artifacts.py
index e2172db10586..8c1121ace628 100644
--- a/tests/api/api/test_artifacts.py
+++ b/tests/api/api/test_artifacts.py
@@ -19,8 +19,8 @@
from fastapi.testclient import TestClient
from sqlalchemy.orm import Session
-import mlrun.api.schemas
import mlrun.artifacts
+import mlrun.common.schemas
from mlrun.utils.helpers import is_legacy_artifact
PROJECT = "prj"
@@ -45,9 +45,9 @@ def test_list_artifact_tags(db: Session, client: TestClient) -> None:
def _create_project(client: TestClient, project_name: str = PROJECT):
- project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=project_name),
- spec=mlrun.api.schemas.ProjectSpec(
+ project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=project_name),
+ spec=mlrun.common.schemas.ProjectSpec(
description="banana", source="source", goals="some goals"
),
)
@@ -134,7 +134,7 @@ def test_store_artifact_with_invalid_tag(db: Session, client: TestClient):
"projects/{project}/tags/{tag}".format(project=PROJECT, tag=tag),
json={
"kind": "artifact",
- "identifiers": [(mlrun.api.schemas.ArtifactIdentifier(key=KEY).dict())],
+ "identifiers": [(mlrun.common.schemas.ArtifactIdentifier(key=KEY).dict())],
},
)
@@ -145,7 +145,7 @@ def test_store_artifact_with_invalid_tag(db: Session, client: TestClient):
"projects/{project}/tags/{tag}".format(project=PROJECT, tag=tag),
json={
"kind": "artifact",
- "identifiers": [(mlrun.api.schemas.ArtifactIdentifier(key=KEY).dict())],
+ "identifiers": [(mlrun.common.schemas.ArtifactIdentifier(key=KEY).dict())],
},
)
assert resp.status_code == HTTPStatus.UNPROCESSABLE_ENTITY.value
@@ -368,7 +368,7 @@ def test_list_artifact_with_multiple_tags(db: Session, client: TestClient):
"projects/{project}/tags/{tag}".format(project=PROJECT, tag=new_tag),
json={
"kind": "artifact",
- "identifiers": [(mlrun.api.schemas.ArtifactIdentifier(key=KEY).dict())],
+ "identifiers": [(mlrun.common.schemas.ArtifactIdentifier(key=KEY).dict())],
},
)
diff --git a/tests/api/api/test_auth.py b/tests/api/api/test_auth.py
index 0c2c2625791f..3180c9133bd2 100644
--- a/tests/api/api/test_auth.py
+++ b/tests/api/api/test_auth.py
@@ -17,15 +17,18 @@
import fastapi.testclient
import sqlalchemy.orm
-import mlrun.api.schemas
import mlrun.api.utils.auth.verifier
+import mlrun.common.schemas
def test_verify_authorization(
db: sqlalchemy.orm.Session, client: fastapi.testclient.TestClient
) -> None:
- authorization_verification_input = mlrun.api.schemas.AuthorizationVerificationInput(
- resource="/some-resource", action=mlrun.api.schemas.AuthorizationAction.create
+ authorization_verification_input = (
+ mlrun.common.schemas.AuthorizationVerificationInput(
+ resource="/some-resource",
+ action=mlrun.common.schemas.AuthorizationAction.create,
+ )
)
async def _mock_successful_query_permissions(resource, action, *args):
diff --git a/tests/api/api/test_background_tasks.py b/tests/api/api/test_background_tasks.py
index 68ccd8b98a09..897104e708c1 100644
--- a/tests/api/api/test_background_tasks.py
+++ b/tests/api/api/test_background_tasks.py
@@ -25,10 +25,10 @@
import mlrun.api.api.deps
import mlrun.api.main
-import mlrun.api.schemas
import mlrun.api.utils.auth.verifier
import mlrun.api.utils.background_tasks
import mlrun.api.utils.clients.chief
+import mlrun.common.schemas
test_router = fastapi.APIRouter()
@@ -37,7 +37,7 @@
# and to get this class, we must trigger an endpoint
@test_router.post(
"/projects/{project}/background-tasks",
- response_model=mlrun.api.schemas.BackgroundTask,
+ response_model=mlrun.common.schemas.BackgroundTask,
)
def create_project_background_task(
project: str,
@@ -57,7 +57,7 @@ def create_project_background_task(
@test_router.post(
"/internal-background-tasks",
- response_model=mlrun.api.schemas.BackgroundTask,
+ response_model=mlrun.common.schemas.BackgroundTask,
)
def create_internal_background_task(
background_tasks: fastapi.BackgroundTasks,
@@ -174,9 +174,10 @@ def test_create_project_background_task_in_chief_success(
f"{ORIGINAL_VERSIONED_API_PREFIX}/projects/{project}/background-tasks/{background_task.metadata.name}"
)
assert response.status_code == http.HTTPStatus.OK.value
- background_task = mlrun.api.schemas.BackgroundTask(**response.json())
+ background_task = mlrun.common.schemas.BackgroundTask(**response.json())
assert (
- background_task.status.state == mlrun.api.schemas.BackgroundTaskState.succeeded
+ background_task.status.state
+ == mlrun.common.schemas.BackgroundTaskState.succeeded
)
assert background_task.metadata.updated is not None
assert call_counter == 1
@@ -194,8 +195,10 @@ def test_create_project_background_task_in_chief_failure(
f"{ORIGINAL_VERSIONED_API_PREFIX}/projects/{project}/background-tasks/{background_task.metadata.name}"
)
assert response.status_code == http.HTTPStatus.OK.value
- background_task = mlrun.api.schemas.BackgroundTask(**response.json())
- assert background_task.status.state == mlrun.api.schemas.BackgroundTaskState.failed
+ background_task = mlrun.common.schemas.BackgroundTask(**response.json())
+ assert (
+ background_task.status.state == mlrun.common.schemas.BackgroundTaskState.failed
+ )
assert background_task.metadata.updated is not None
@@ -219,7 +222,7 @@ def test_get_background_task_auth_skip(
mlrun.mlconf.igz_version = "3.2.0-b26.20210904121245"
response = client.post("/test/internal-background-tasks")
assert response.status_code == http.HTTPStatus.OK.value
- background_task = mlrun.api.schemas.BackgroundTask(**response.json())
+ background_task = mlrun.common.schemas.BackgroundTask(**response.json())
response = client.get(
f"{ORIGINAL_VERSIONED_API_PREFIX}/background-tasks/{background_task.metadata.name}"
)
@@ -257,7 +260,7 @@ def test_get_internal_background_task_redirect_from_worker_to_chief_exists(
)
response = client.get(f"{ORIGINAL_VERSIONED_API_PREFIX}/background-tasks/{name}")
assert response.status_code == http.HTTPStatus.OK.value
- background_task = mlrun.api.schemas.BackgroundTask(**response.json())
+ background_task = mlrun.common.schemas.BackgroundTask(**response.json())
assert background_task == expected_background_task
@@ -284,7 +287,7 @@ def test_get_internal_background_task_in_chief_exists(
):
response = client.post("/test/internal-background-tasks")
assert response.status_code == http.HTTPStatus.OK.value
- background_task = mlrun.api.schemas.BackgroundTask(**response.json())
+ background_task = mlrun.common.schemas.BackgroundTask(**response.json())
assert background_task.metadata.project is None
response = client.get(
@@ -340,26 +343,28 @@ def test_trigger_migrations_from_worker_returns_same_response_as_chief(
def _generate_background_task(
background_task_name,
- state: mlrun.api.schemas.BackgroundTaskState = mlrun.api.schemas.BackgroundTaskState.running,
-) -> mlrun.api.schemas.BackgroundTask:
+ state: mlrun.common.schemas.BackgroundTaskState = mlrun.common.schemas.BackgroundTaskState.running,
+) -> mlrun.common.schemas.BackgroundTask:
now = datetime.datetime.utcnow()
- return mlrun.api.schemas.BackgroundTask(
- metadata=mlrun.api.schemas.BackgroundTaskMetadata(
+ return mlrun.common.schemas.BackgroundTask(
+ metadata=mlrun.common.schemas.BackgroundTaskMetadata(
name=background_task_name,
created=now,
updated=now,
),
- status=mlrun.api.schemas.BackgroundTaskStatus(state=state.value),
- spec=mlrun.api.schemas.BackgroundTaskSpec(),
+ status=mlrun.common.schemas.BackgroundTaskStatus(state=state.value),
+ spec=mlrun.common.schemas.BackgroundTaskSpec(),
)
def _assert_background_task_creation(expected_project, response):
assert response.status_code == http.HTTPStatus.OK.value
- background_task = mlrun.api.schemas.BackgroundTask(**response.json())
- assert background_task.kind == mlrun.api.schemas.ObjectKind.background_task
+ background_task = mlrun.common.schemas.BackgroundTask(**response.json())
+ assert background_task.kind == mlrun.common.schemas.ObjectKind.background_task
assert background_task.metadata.project == expected_project
assert background_task.metadata.created is not None
assert background_task.metadata.updated is not None
- assert background_task.status.state == mlrun.api.schemas.BackgroundTaskState.running
+ assert (
+ background_task.status.state == mlrun.common.schemas.BackgroundTaskState.running
+ )
return background_task
diff --git a/tests/api/api/test_client_spec.py b/tests/api/api/test_client_spec.py
index 74eedfe814d6..b39d0edd8d39 100644
--- a/tests/api/api/test_client_spec.py
+++ b/tests/api/api/test_client_spec.py
@@ -23,8 +23,8 @@
import mlrun
import mlrun.api.crud
-import mlrun.api.schemas
import mlrun.api.utils.clients.iguazio
+import mlrun.common.schemas
import mlrun.errors
import mlrun.runtimes
import mlrun.utils.version
@@ -141,8 +141,8 @@ def test_client_spec_response_based_on_client_version(
response = client.get(
"client-spec",
headers={
- mlrun.api.schemas.HeaderNames.client_version: "",
- mlrun.api.schemas.HeaderNames.python_version: "",
+ mlrun.common.schemas.HeaderNames.client_version: "",
+ mlrun.common.schemas.HeaderNames.python_version: "",
},
)
assert response.status_code == http.HTTPStatus.OK.value
@@ -157,8 +157,8 @@ def test_client_spec_response_based_on_client_version(
response = client.get(
"client-spec",
headers={
- mlrun.api.schemas.HeaderNames.client_version: "",
- mlrun.api.schemas.HeaderNames.python_version: "",
+ mlrun.common.schemas.HeaderNames.client_version: "",
+ mlrun.common.schemas.HeaderNames.python_version: "",
},
)
assert response.status_code == http.HTTPStatus.OK.value
@@ -170,7 +170,7 @@ def test_client_spec_response_based_on_client_version(
response = client.get(
"client-spec",
headers={
- mlrun.api.schemas.HeaderNames.client_version: "1.2.0",
+ mlrun.common.schemas.HeaderNames.client_version: "1.2.0",
},
)
assert response.status_code == http.HTTPStatus.OK.value
@@ -182,8 +182,8 @@ def test_client_spec_response_based_on_client_version(
response = client.get(
"client-spec",
headers={
- mlrun.api.schemas.HeaderNames.client_version: "1.3.0-rc20",
- mlrun.api.schemas.HeaderNames.python_version: "3.7.13",
+ mlrun.common.schemas.HeaderNames.client_version: "1.3.0-rc20",
+ mlrun.common.schemas.HeaderNames.python_version: "3.7.13",
},
)
assert response.status_code == http.HTTPStatus.OK.value
@@ -194,8 +194,8 @@ def test_client_spec_response_based_on_client_version(
response = client.get(
"client-spec",
headers={
- mlrun.api.schemas.HeaderNames.client_version: "1.3.0-rc20",
- mlrun.api.schemas.HeaderNames.python_version: "3.9.13",
+ mlrun.common.schemas.HeaderNames.client_version: "1.3.0-rc20",
+ mlrun.common.schemas.HeaderNames.python_version: "3.9.13",
},
)
assert response.status_code == http.HTTPStatus.OK.value
@@ -207,8 +207,8 @@ def test_client_spec_response_based_on_client_version(
response = client.get(
"client-spec",
headers={
- mlrun.api.schemas.HeaderNames.client_version: "test-integration",
- mlrun.api.schemas.HeaderNames.python_version: "3.9.13",
+ mlrun.common.schemas.HeaderNames.client_version: "test-integration",
+ mlrun.common.schemas.HeaderNames.python_version: "3.9.13",
},
)
assert response.status_code == http.HTTPStatus.OK.value
diff --git a/tests/api/api/test_frontend_spec.py b/tests/api/api/test_frontend_spec.py
index 9aaded047d6b..0276e177ab0a 100644
--- a/tests/api/api/test_frontend_spec.py
+++ b/tests/api/api/test_frontend_spec.py
@@ -20,8 +20,8 @@
import sqlalchemy.orm
import mlrun.api.crud
-import mlrun.api.schemas
import mlrun.api.utils.clients.iguazio
+import mlrun.common.schemas
import mlrun.errors
import mlrun.runtimes
@@ -43,7 +43,7 @@ def test_get_frontend_spec(
response = client.get("frontend-spec")
assert response.status_code == http.HTTPStatus.OK.value
- frontend_spec = mlrun.api.schemas.FrontendSpec(**response.json())
+ frontend_spec = mlrun.common.schemas.FrontendSpec(**response.json())
assert (
deepdiff.DeepDiff(
frontend_spec.abortable_function_kinds,
@@ -53,19 +53,19 @@ def test_get_frontend_spec(
)
assert (
frontend_spec.feature_flags.project_membership
- == mlrun.api.schemas.ProjectMembershipFeatureFlag.disabled
+ == mlrun.common.schemas.ProjectMembershipFeatureFlag.disabled
)
assert (
frontend_spec.feature_flags.authentication
- == mlrun.api.schemas.AuthenticationFeatureFlag.none
+ == mlrun.common.schemas.AuthenticationFeatureFlag.none
)
assert (
frontend_spec.feature_flags.nuclio_streams
- == mlrun.api.schemas.NuclioStreamsFeatureFlag.disabled
+ == mlrun.common.schemas.NuclioStreamsFeatureFlag.disabled
)
assert (
frontend_spec.feature_flags.preemption_nodes
- == mlrun.api.schemas.PreemptionNodesFeatureFlag.disabled
+ == mlrun.common.schemas.PreemptionNodesFeatureFlag.disabled
)
assert frontend_spec.default_function_image_by_kind is not None
assert frontend_spec.function_deployment_mlrun_command is not None
@@ -79,7 +79,7 @@ def test_get_frontend_spec(
bla = f"{{{expected_template_field}}}"
assert bla in frontend_spec.function_deployment_target_image_template
- assert frontend_spec.default_function_pod_resources, mlrun.api.schemas.Resources(
+ assert frontend_spec.default_function_pod_resources, mlrun.common.schemas.Resources(
**default_function_pod_resources
)
assert (
@@ -93,7 +93,7 @@ def test_get_frontend_spec(
assert (
frontend_spec.default_function_preemption_mode
- == mlrun.api.schemas.PreemptionModes.prevent.value
+ == mlrun.common.schemas.PreemptionModes.prevent.value
)
assert (
frontend_spec.allowed_artifact_path_prefixes_list
@@ -110,7 +110,7 @@ def test_get_frontend_spec_jobs_dashboard_url_resolution(
# no cookie so no url
response = client.get("frontend-spec")
assert response.status_code == http.HTTPStatus.OK.value
- frontend_spec = mlrun.api.schemas.FrontendSpec(**response.json())
+ frontend_spec = mlrun.common.schemas.FrontendSpec(**response.json())
assert frontend_spec.jobs_dashboard_url is None
mlrun.api.utils.clients.iguazio.Client().try_get_grafana_service_url.assert_not_called()
@@ -119,7 +119,7 @@ def test_get_frontend_spec_jobs_dashboard_url_resolution(
mlrun.api.utils.clients.iguazio.AsyncClient().verify_request_session = (
unittest.mock.AsyncMock(
return_value=(
- mlrun.api.schemas.AuthInfo(
+ mlrun.common.schemas.AuthInfo(
username=None,
session="946b0749-5c40-4837-a4ac-341d295bfaf7",
user_id=None,
@@ -134,7 +134,7 @@ def test_get_frontend_spec_jobs_dashboard_url_resolution(
)
response = client.get("frontend-spec")
assert response.status_code == http.HTTPStatus.OK.value
- frontend_spec = mlrun.api.schemas.FrontendSpec(**response.json())
+ frontend_spec = mlrun.common.schemas.FrontendSpec(**response.json())
assert frontend_spec.jobs_dashboard_url is None
mlrun.api.utils.clients.iguazio.Client().try_get_grafana_service_url.assert_called_once()
@@ -146,7 +146,7 @@ def test_get_frontend_spec_jobs_dashboard_url_resolution(
response = client.get("frontend-spec")
assert response.status_code == http.HTTPStatus.OK.value
- frontend_spec = mlrun.api.schemas.FrontendSpec(**response.json())
+ frontend_spec = mlrun.common.schemas.FrontendSpec(**response.json())
assert (
frontend_spec.jobs_dashboard_url
== f"{grafana_url}/d/mlrun-jobs-monitoring/mlrun-jobs-monitoring?orgId=1"
@@ -162,7 +162,7 @@ def test_get_frontend_spec_jobs_dashboard_url_resolution(
cookies={"session": 'j:{"sid":"946b0749-5c40-4837-a4ac-341d295bfaf7"}'},
)
assert response.status_code == http.HTTPStatus.OK.value
- frontend_spec = mlrun.api.schemas.FrontendSpec(**response.json())
+ frontend_spec = mlrun.common.schemas.FrontendSpec(**response.json())
assert (
frontend_spec.jobs_dashboard_url
== f"{grafana_url}/d/mlrun-jobs-monitoring/mlrun-jobs-monitoring?orgId=1"
@@ -178,22 +178,22 @@ def test_get_frontend_spec_nuclio_streams(
{
"iguazio_version": "3.2.0",
"nuclio_version": "1.6.23",
- "expected_feature_flag": mlrun.api.schemas.NuclioStreamsFeatureFlag.disabled,
+ "expected_feature_flag": mlrun.common.schemas.NuclioStreamsFeatureFlag.disabled,
},
{
"iguazio_version": None,
"nuclio_version": "1.6.23",
- "expected_feature_flag": mlrun.api.schemas.NuclioStreamsFeatureFlag.disabled,
+ "expected_feature_flag": mlrun.common.schemas.NuclioStreamsFeatureFlag.disabled,
},
{
"iguazio_version": None,
"nuclio_version": "1.7.8",
- "expected_feature_flag": mlrun.api.schemas.NuclioStreamsFeatureFlag.disabled,
+ "expected_feature_flag": mlrun.common.schemas.NuclioStreamsFeatureFlag.disabled,
},
{
"iguazio_version": "3.4.0",
"nuclio_version": "1.7.8",
- "expected_feature_flag": mlrun.api.schemas.NuclioStreamsFeatureFlag.enabled,
+ "expected_feature_flag": mlrun.common.schemas.NuclioStreamsFeatureFlag.enabled,
},
]:
# init cached value to None in the beginning of each test case
@@ -202,7 +202,7 @@ def test_get_frontend_spec_nuclio_streams(
mlrun.mlconf.nuclio_version = test_case.get("nuclio_version")
response = client.get("frontend-spec")
- frontend_spec = mlrun.api.schemas.FrontendSpec(**response.json())
+ frontend_spec = mlrun.common.schemas.FrontendSpec(**response.json())
assert response.status_code == http.HTTPStatus.OK.value
assert frontend_spec.feature_flags.nuclio_streams == test_case.get(
"expected_feature_flag"
@@ -219,7 +219,7 @@ def test_get_frontend_spec_ce(
response = client.get("frontend-spec")
assert response.status_code == http.HTTPStatus.OK.value
- frontend_spec = mlrun.api.schemas.FrontendSpec(**response.json())
+ frontend_spec = mlrun.common.schemas.FrontendSpec(**response.json())
assert frontend_spec.ce["release"] == ce_release
assert frontend_spec.ce["mode"] == frontend_spec.ce_mode == ce_mode
@@ -238,7 +238,7 @@ def test_get_frontend_spec_feature_store_data_prefixes(
)
response = client.get("frontend-spec")
assert response.status_code == http.HTTPStatus.OK.value
- frontend_spec = mlrun.api.schemas.FrontendSpec(**response.json())
+ frontend_spec = mlrun.common.schemas.FrontendSpec(**response.json())
assert (
frontend_spec.feature_store_data_prefixes["default"]
== feature_store_data_prefix_default
diff --git a/tests/api/api/test_functions.py b/tests/api/api/test_functions.py
index 9cc0266b7c3a..4b88567ddec7 100644
--- a/tests/api/api/test_functions.py
+++ b/tests/api/api/test_functions.py
@@ -29,12 +29,12 @@
import mlrun.api.api.endpoints.functions
import mlrun.api.api.utils
import mlrun.api.crud
-import mlrun.api.schemas
import mlrun.api.utils.clients.chief
import mlrun.api.utils.singletons.db
import mlrun.api.utils.singletons.k8s
import mlrun.artifacts.dataset
import mlrun.artifacts.model
+import mlrun.common.schemas
import mlrun.errors
import mlrun.utils.model_monitoring
import tests.api.api.utils
@@ -400,16 +400,19 @@ def test_start_function_succeeded(
),
)
assert response.status_code == http.HTTPStatus.OK.value
- background_task = mlrun.api.schemas.BackgroundTask(**response.json())
- assert background_task.status.state == mlrun.api.schemas.BackgroundTaskState.running
+ background_task = mlrun.common.schemas.BackgroundTask(**response.json())
+ assert (
+ background_task.status.state == mlrun.common.schemas.BackgroundTaskState.running
+ )
response = client.get(
f"projects/{project}/background-tasks/{background_task.metadata.name}"
)
assert response.status_code == http.HTTPStatus.OK.value
- background_task = mlrun.api.schemas.BackgroundTask(**response.json())
+ background_task = mlrun.common.schemas.BackgroundTask(**response.json())
assert (
- background_task.status.state == mlrun.api.schemas.BackgroundTaskState.succeeded
+ background_task.status.state
+ == mlrun.common.schemas.BackgroundTaskState.succeeded
)
@@ -441,14 +444,18 @@ def failing_func():
),
)
assert response.status_code == http.HTTPStatus.OK
- background_task = mlrun.api.schemas.BackgroundTask(**response.json())
- assert background_task.status.state == mlrun.api.schemas.BackgroundTaskState.running
+ background_task = mlrun.common.schemas.BackgroundTask(**response.json())
+ assert (
+ background_task.status.state == mlrun.common.schemas.BackgroundTaskState.running
+ )
response = client.get(
f"projects/{project}/background-tasks/{background_task.metadata.name}"
)
assert response.status_code == http.HTTPStatus.OK.value
- background_task = mlrun.api.schemas.BackgroundTask(**response.json())
- assert background_task.status.state == mlrun.api.schemas.BackgroundTaskState.failed
+ background_task = mlrun.common.schemas.BackgroundTask(**response.json())
+ assert (
+ background_task.status.state == mlrun.common.schemas.BackgroundTaskState.failed
+ )
def test_start_function(
@@ -462,26 +469,26 @@ def failing_func():
for test_case in [
{
"_start_function_mock": unittest.mock.Mock,
- "expected_status_result": mlrun.api.schemas.BackgroundTaskState.succeeded,
+ "expected_status_result": mlrun.common.schemas.BackgroundTaskState.succeeded,
"background_timeout_mode": "enabled",
"dask_timeout": 100,
},
{
"_start_function_mock": failing_func,
- "expected_status_result": mlrun.api.schemas.BackgroundTaskState.failed,
+ "expected_status_result": mlrun.common.schemas.BackgroundTaskState.failed,
"background_timeout_mode": "enabled",
"dask_timeout": None,
},
{
"_start_function_mock": unittest.mock.Mock,
- "expected_status_result": mlrun.api.schemas.BackgroundTaskState.succeeded,
+ "expected_status_result": mlrun.common.schemas.BackgroundTaskState.succeeded,
"background_timeout_mode": "disabled",
"dask_timeout": 0,
},
]:
_start_function_mock = test_case.get("_start_function_mock", unittest.mock.Mock)
expected_status_result = test_case.get(
- "expected_status_result", mlrun.api.schemas.BackgroundTaskState.running
+ "expected_status_result", mlrun.common.schemas.BackgroundTaskState.running
)
background_timeout_mode = test_case.get("background_timeout_mode", "enabled")
dask_timeout = test_case.get("dask_timeout", None)
@@ -508,16 +515,16 @@ def failing_func():
),
)
assert response.status_code == http.HTTPStatus.OK
- background_task = mlrun.api.schemas.BackgroundTask(**response.json())
+ background_task = mlrun.common.schemas.BackgroundTask(**response.json())
assert (
background_task.status.state
- == mlrun.api.schemas.BackgroundTaskState.running
+ == mlrun.common.schemas.BackgroundTaskState.running
)
response = client.get(
f"projects/{project}/background-tasks/{background_task.metadata.name}"
)
assert response.status_code == http.HTTPStatus.OK.value
- background_task = mlrun.api.schemas.BackgroundTask(**response.json())
+ background_task = mlrun.common.schemas.BackgroundTask(**response.json())
assert background_task.status.state == expected_status_result
diff --git a/tests/api/api/test_grafana_proxy.py b/tests/api/api/test_grafana_proxy.py
index f1c6ed0621d7..81fa6323cec8 100644
--- a/tests/api/api/test_grafana_proxy.py
+++ b/tests/api/api/test_grafana_proxy.py
@@ -29,9 +29,9 @@
import mlrun
import mlrun.api.crud
-import mlrun.api.schemas
import mlrun.api.utils.clients.iguazio
-import mlrun.model_monitoring.constants as model_monitoring_constants
+import mlrun.common.model_monitoring as model_monitoring_constants
+import mlrun.common.schemas
import mlrun.model_monitoring.stores
from mlrun.api.crud.model_monitoring.grafana import (
parse_query_parameters,
@@ -62,7 +62,7 @@ def test_grafana_proxy_model_endpoints_check_connection(
mlrun.api.utils.clients.iguazio.AsyncClient().verify_request_session = (
unittest.mock.AsyncMock(
return_value=(
- mlrun.api.schemas.AuthInfo(
+ mlrun.common.schemas.AuthInfo(
username=None,
session="some-session",
data_session="some-session",
diff --git a/tests/api/api/test_healthz.py b/tests/api/api/test_healthz.py
index ce8f5eac72cb..c20dd11dae87 100644
--- a/tests/api/api/test_healthz.py
+++ b/tests/api/api/test_healthz.py
@@ -17,7 +17,7 @@
import fastapi.testclient
import sqlalchemy.orm
-import mlrun.api.schemas
+import mlrun.common.schemas
import mlrun.config
@@ -30,6 +30,6 @@ def test_health(
assert response.status_code == http.HTTPStatus.OK.value
# fail
- mlrun.config.config.httpdb.state = mlrun.api.schemas.APIStates.offline
+ mlrun.config.config.httpdb.state = mlrun.common.schemas.APIStates.offline
response = client.get("healthz")
assert response.status_code == http.HTTPStatus.SERVICE_UNAVAILABLE.value
diff --git a/tests/api/api/test_model_endpoints.py b/tests/api/api/test_model_endpoints.py
index a42206046c35..b771e28d0f39 100644
--- a/tests/api/api/test_model_endpoints.py
+++ b/tests/api/api/test_model_endpoints.py
@@ -22,7 +22,7 @@
import pytest
import mlrun.api.crud
-import mlrun.api.schemas
+import mlrun.common.schemas
from mlrun.errors import MLRunBadRequestError, MLRunInvalidArgumentError
from mlrun.model_monitoring import ModelMonitoringStoreKinds
from mlrun.model_monitoring.stores import ( # noqa: F401
@@ -84,12 +84,12 @@ def test_build_kv_cursor_filter_expression():
def test_get_access_key():
key = mlrun.api.crud.ModelEndpoints().get_access_key(
- mlrun.api.schemas.AuthInfo(data_session="asd")
+ mlrun.common.schemas.AuthInfo(data_session="asd")
)
assert key == "asd"
with pytest.raises(MLRunBadRequestError):
- mlrun.api.crud.ModelEndpoints().get_access_key(mlrun.api.schemas.AuthInfo())
+ mlrun.api.crud.ModelEndpoints().get_access_key(mlrun.common.schemas.AuthInfo())
def test_get_endpoint_features_function():
@@ -300,26 +300,26 @@ def test_generating_tsdb_paths():
assert filtered_path == full_path[-len(filtered_path) + 1 :] + "/"
-def _get_auth_info() -> mlrun.api.schemas.AuthInfo:
- return mlrun.api.schemas.AuthInfo(data_session=os.environ.get("V3IO_ACCESS_KEY"))
+def _get_auth_info() -> mlrun.common.schemas.AuthInfo:
+ return mlrun.common.schemas.AuthInfo(data_session=os.environ.get("V3IO_ACCESS_KEY"))
def _mock_random_endpoint(
state: Optional[str] = None,
-) -> mlrun.api.schemas.ModelEndpoint:
+) -> mlrun.common.schemas.ModelEndpoint:
def random_labels():
return {f"{choice(string.ascii_letters)}": randint(0, 100) for _ in range(1, 5)}
- return mlrun.api.schemas.ModelEndpoint(
- metadata=mlrun.api.schemas.ModelEndpointMetadata(
+ return mlrun.common.schemas.ModelEndpoint(
+ metadata=mlrun.common.schemas.ModelEndpointMetadata(
project=TEST_PROJECT, labels=random_labels(), uid=str(randint(1000, 5000))
),
- spec=mlrun.api.schemas.ModelEndpointSpec(
+ spec=mlrun.common.schemas.ModelEndpointSpec(
function_uri=f"test/function_{randint(0, 100)}:v{randint(0, 100)}",
model=f"model_{randint(0, 100)}:v{randint(0, 100)}",
model_class="classifier",
),
- status=mlrun.api.schemas.ModelEndpointStatus(state=state),
+ status=mlrun.common.schemas.ModelEndpointStatus(state=state),
)
@@ -426,7 +426,7 @@ def test_sql_target_patch_endpoint():
def test_validate_model_endpoints_schema():
# Validate that both model endpoint basemodel schema and model endpoint ModelObj schema have similar keys
- model_endpoint_basemodel = mlrun.api.schemas.ModelEndpoint()
+ model_endpoint_basemodel = mlrun.common.schemas.ModelEndpoint()
model_endpoint_modelobj = mlrun.model_monitoring.ModelEndpoint()
# Compare status
diff --git a/tests/api/api/test_operations.py b/tests/api/api/test_operations.py
index b6db68e8ff53..16b6c01b1bb2 100644
--- a/tests/api/api/test_operations.py
+++ b/tests/api/api/test_operations.py
@@ -24,10 +24,10 @@
import mlrun.api.api.endpoints.operations
import mlrun.api.crud
import mlrun.api.initial_data
-import mlrun.api.schemas
import mlrun.api.utils.background_tasks
import mlrun.api.utils.clients.iguazio
import mlrun.api.utils.singletons.scheduler
+import mlrun.common.schemas
import mlrun.errors
import mlrun.runtimes
from mlrun.utils import logger
@@ -49,10 +49,10 @@ def test_migrations_already_in_progress(
"InternalBackgroundTasksHandler",
lambda *args, **kwargs: handler_mock,
)
- mlrun.mlconf.httpdb.state = mlrun.api.schemas.APIStates.migrations_in_progress
+ mlrun.mlconf.httpdb.state = mlrun.common.schemas.APIStates.migrations_in_progress
response = client.post("operations/migrations")
assert response.status_code == http.HTTPStatus.ACCEPTED.value
- background_task = mlrun.api.schemas.BackgroundTask(**response.json())
+ background_task = mlrun.common.schemas.BackgroundTask(**response.json())
assert background_task_name == background_task.metadata.name
mlrun.api.api.endpoints.operations.current_migration_background_task_name = None
@@ -60,7 +60,7 @@ def test_migrations_already_in_progress(
def test_migrations_failed(
db: sqlalchemy.orm.Session, client: fastapi.testclient.TestClient
) -> None:
- mlrun.mlconf.httpdb.state = mlrun.api.schemas.APIStates.migrations_failed
+ mlrun.mlconf.httpdb.state = mlrun.common.schemas.APIStates.migrations_failed
response = client.post("operations/migrations")
assert response.status_code == http.HTTPStatus.PRECONDITION_FAILED.value
assert "Migrations were already triggered and failed" in response.text
@@ -69,19 +69,19 @@ def test_migrations_failed(
def test_migrations_not_needed(
db: sqlalchemy.orm.Session, client: fastapi.testclient.TestClient
) -> None:
- mlrun.mlconf.httpdb.state = mlrun.api.schemas.APIStates.online
+ mlrun.mlconf.httpdb.state = mlrun.common.schemas.APIStates.online
response = client.post("operations/migrations")
assert response.status_code == http.HTTPStatus.OK.value
def _mock_migration_process(*args, **kwargs):
logger.info("Mocking migration process")
- mlrun.mlconf.httpdb.state = mlrun.api.schemas.APIStates.migrations_completed
+ mlrun.mlconf.httpdb.state = mlrun.common.schemas.APIStates.migrations_completed
@pytest.fixture
def _mock_waiting_for_migration():
- mlrun.mlconf.httpdb.state = mlrun.api.schemas.APIStates.waiting_for_migrations
+ mlrun.mlconf.httpdb.state = mlrun.common.schemas.APIStates.waiting_for_migrations
def test_migrations_success(
@@ -103,15 +103,18 @@ def test_migrations_success(
# trigger migrations
response = client.post("operations/migrations")
assert response.status_code == http.HTTPStatus.ACCEPTED.value
- background_task = mlrun.api.schemas.BackgroundTask(**response.json())
- assert background_task.status.state == mlrun.api.schemas.BackgroundTaskState.running
+ background_task = mlrun.common.schemas.BackgroundTask(**response.json())
+ assert (
+ background_task.status.state == mlrun.common.schemas.BackgroundTaskState.running
+ )
response = client.get(f"background-tasks/{background_task.metadata.name}")
assert response.status_code == http.HTTPStatus.OK.value
- background_task = mlrun.api.schemas.BackgroundTask(**response.json())
+ background_task = mlrun.common.schemas.BackgroundTask(**response.json())
assert (
- background_task.status.state == mlrun.api.schemas.BackgroundTaskState.succeeded
+ background_task.status.state
+ == mlrun.common.schemas.BackgroundTaskState.succeeded
)
- assert mlrun.mlconf.httpdb.state == mlrun.api.schemas.APIStates.online
+ assert mlrun.mlconf.httpdb.state == mlrun.common.schemas.APIStates.online
# now we should be able to get projects
response = client.get("projects")
assert response.status_code == http.HTTPStatus.OK.value
@@ -124,15 +127,15 @@ def test_migrations_success(
def _generate_background_task_schema(
background_task_name,
-) -> mlrun.api.schemas.BackgroundTask:
- return mlrun.api.schemas.BackgroundTask(
- metadata=mlrun.api.schemas.BackgroundTaskMetadata(
+) -> mlrun.common.schemas.BackgroundTask:
+ return mlrun.common.schemas.BackgroundTask(
+ metadata=mlrun.common.schemas.BackgroundTaskMetadata(
name=background_task_name,
created=datetime.utcnow(),
updated=datetime.utcnow(),
),
- status=mlrun.api.schemas.BackgroundTaskStatus(
- state=mlrun.api.schemas.BackgroundTaskState.running
+ status=mlrun.common.schemas.BackgroundTaskStatus(
+ state=mlrun.common.schemas.BackgroundTaskState.running
),
- spec=mlrun.api.schemas.BackgroundTaskSpec(),
+ spec=mlrun.common.schemas.BackgroundTaskSpec(),
)
diff --git a/tests/api/api/test_pipelines.py b/tests/api/api/test_pipelines.py
index 7263f8ecd1ad..c77e23e7bdb5 100644
--- a/tests/api/api/test_pipelines.py
+++ b/tests/api/api/test_pipelines.py
@@ -24,8 +24,8 @@
import sqlalchemy.orm
import mlrun.api.crud
-import mlrun.api.schemas
import mlrun.api.utils.singletons.k8s
+import mlrun.common.schemas
import tests.conftest
@@ -33,7 +33,7 @@ def test_list_pipelines_not_exploding_on_no_k8s(
db: sqlalchemy.orm.Session, client: fastapi.testclient.TestClient
) -> None:
response = client.get("projects/*/pipelines")
- expected_response = mlrun.api.schemas.PipelinesOutput(
+ expected_response = mlrun.common.schemas.PipelinesOutput(
runs=[], total_size=0, next_page_token=None
)
_assert_list_pipelines_response(expected_response, response)
@@ -47,7 +47,7 @@ def test_list_pipelines_empty_list(
runs = []
_mock_list_runs(kfp_client_mock, runs)
response = client.get("projects/*/pipelines")
- expected_response = mlrun.api.schemas.PipelinesOutput(
+ expected_response = mlrun.common.schemas.PipelinesOutput(
runs=runs, total_size=len(runs), next_page_token=None
)
_assert_list_pipelines_response(expected_response, response)
@@ -59,9 +59,9 @@ def test_list_pipelines_formats(
kfp_client_mock: kfp.Client,
) -> None:
for format_ in [
- mlrun.api.schemas.PipelinesFormat.full,
- mlrun.api.schemas.PipelinesFormat.metadata_only,
- mlrun.api.schemas.PipelinesFormat.name_only,
+ mlrun.common.schemas.PipelinesFormat.full,
+ mlrun.common.schemas.PipelinesFormat.metadata_only,
+ mlrun.common.schemas.PipelinesFormat.name_only,
]:
runs = _generate_list_runs_mocks()
expected_runs = [run.to_dict() for run in runs]
@@ -73,7 +73,7 @@ def test_list_pipelines_formats(
"projects/*/pipelines",
params={"format": format_},
)
- expected_response = mlrun.api.schemas.PipelinesOutput(
+ expected_response = mlrun.common.schemas.PipelinesOutput(
runs=expected_runs, total_size=len(runs), next_page_token=None
)
_assert_list_pipelines_response(expected_response, response)
@@ -85,10 +85,10 @@ def test_get_pipeline_formats(
kfp_client_mock: kfp.Client,
) -> None:
for format_ in [
- mlrun.api.schemas.PipelinesFormat.full,
- mlrun.api.schemas.PipelinesFormat.metadata_only,
- mlrun.api.schemas.PipelinesFormat.summary,
- mlrun.api.schemas.PipelinesFormat.name_only,
+ mlrun.common.schemas.PipelinesFormat.full,
+ mlrun.common.schemas.PipelinesFormat.metadata_only,
+ mlrun.common.schemas.PipelinesFormat.summary,
+ mlrun.common.schemas.PipelinesFormat.name_only,
]:
api_run_detail = _generate_get_run_mock()
_mock_get_run(kfp_client_mock, api_run_detail)
@@ -107,7 +107,7 @@ def test_get_pipeline_no_project_opa_validation(
client: fastapi.testclient.TestClient,
kfp_client_mock: kfp.Client,
) -> None:
- format_ = (mlrun.api.schemas.PipelinesFormat.summary,)
+ format_ = (mlrun.common.schemas.PipelinesFormat.summary,)
project = "project-name"
mlrun.api.crud.Pipelines().resolve_project_from_pipeline = unittest.mock.Mock(
return_value=project
@@ -138,10 +138,10 @@ def test_get_pipeline_specific_project(
kfp_client_mock: kfp.Client,
) -> None:
for format_ in [
- mlrun.api.schemas.PipelinesFormat.full,
- mlrun.api.schemas.PipelinesFormat.metadata_only,
- mlrun.api.schemas.PipelinesFormat.summary,
- mlrun.api.schemas.PipelinesFormat.name_only,
+ mlrun.common.schemas.PipelinesFormat.full,
+ mlrun.common.schemas.PipelinesFormat.metadata_only,
+ mlrun.common.schemas.PipelinesFormat.summary,
+ mlrun.common.schemas.PipelinesFormat.name_only,
]:
project = "project-name"
api_run_detail = _generate_get_run_mock()
@@ -176,9 +176,9 @@ def test_list_pipelines_specific_project(
)
response = client.get(
f"projects/{project}/pipelines",
- params={"format": mlrun.api.schemas.PipelinesFormat.name_only},
+ params={"format": mlrun.common.schemas.PipelinesFormat.name_only},
)
- expected_response = mlrun.api.schemas.PipelinesOutput(
+ expected_response = mlrun.common.schemas.PipelinesOutput(
runs=expected_runs, total_size=len(expected_runs), next_page_token=None
)
_assert_list_pipelines_response(expected_response, response)
@@ -419,7 +419,7 @@ def _mock_list_runs_with_one_run_per_page(kfp_client_mock: kfp.Client, runs):
def list_runs_mock(*args, page_token=None, page_size=None, **kwargs):
assert expected_page_tokens.pop(0) == page_token
- assert mlrun.api.schemas.PipelinesPagination.max_page_size == page_size
+ assert mlrun.common.schemas.PipelinesPagination.max_page_size == page_size
return kfp_server_api.models.api_list_runs_response.ApiListRunsResponse(
[runs.pop(0)], 1, next_page_token=expected_page_tokens[0]
)
@@ -431,7 +431,7 @@ def _mock_list_runs(
kfp_client_mock: kfp.Client,
runs,
expected_page_token="",
- expected_page_size=mlrun.api.schemas.PipelinesPagination.default_page_size,
+ expected_page_size=mlrun.common.schemas.PipelinesPagination.default_page_size,
expected_sort_by="",
expected_filter="",
):
@@ -460,7 +460,7 @@ def get_run_mock(*args, **kwargs):
def _assert_list_pipelines_response(
- expected_response: mlrun.api.schemas.PipelinesOutput, response
+ expected_response: mlrun.common.schemas.PipelinesOutput, response
):
assert response.status_code == http.HTTPStatus.OK.value
assert (
diff --git a/tests/api/api/test_projects.py b/tests/api/api/test_projects.py
index 0959abf13533..b4df4a9f104a 100644
--- a/tests/api/api/test_projects.py
+++ b/tests/api/api/test_projects.py
@@ -33,7 +33,6 @@
import mlrun.api.api.utils
import mlrun.api.crud
import mlrun.api.main
-import mlrun.api.schemas
import mlrun.api.utils.background_tasks
import mlrun.api.utils.clients.log_collector
import mlrun.api.utils.singletons.db
@@ -43,6 +42,7 @@
import mlrun.api.utils.singletons.scheduler
import mlrun.artifacts.dataset
import mlrun.artifacts.model
+import mlrun.common.schemas
import mlrun.errors
import tests.api.conftest
import tests.api.utils.clients.test_log_collector
@@ -86,7 +86,7 @@ def test_redirection_from_worker_to_chief_delete_project(
mlrun.mlconf.httpdb.clusterization.role = "worker"
project = "test-project"
endpoint = f"{ORIGINAL_VERSIONED_API_PREFIX}/projects/{project}"
- for strategy in mlrun.api.schemas.DeletionStrategy:
+ for strategy in mlrun.common.schemas.DeletionStrategy:
headers = {"x-mlrun-deletion-strategy": strategy.value}
for test_case in [
# deleting schedule failed for unknown reason
@@ -134,8 +134,8 @@ def test_create_project_failure_already_exists(
db: Session, client: TestClient, project_member_mode: str
) -> None:
name1 = f"prj-{uuid4().hex}"
- project_1 = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=name1),
+ project_1 = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=name1),
)
# create
@@ -192,7 +192,7 @@ def test_delete_project_with_resources(
response = client.delete(
f"projects/{project_to_remove}",
headers={
- mlrun.api.schemas.HeaderNames.deletion_strategy: mlrun.api.schemas.DeletionStrategy.check.value
+ mlrun.common.schemas.HeaderNames.deletion_strategy: mlrun.common.schemas.DeletionStrategy.check.value
},
)
assert response.status_code == HTTPStatus.PRECONDITION_FAILED.value
@@ -201,7 +201,7 @@ def test_delete_project_with_resources(
response = client.delete(
f"projects/{project_to_remove}",
headers={
- mlrun.api.schemas.HeaderNames.deletion_strategy: mlrun.api.schemas.DeletionStrategy.restricted.value
+ mlrun.common.schemas.HeaderNames.deletion_strategy: mlrun.common.schemas.DeletionStrategy.restricted.value
},
)
assert response.status_code == HTTPStatus.PRECONDITION_FAILED.value
@@ -210,7 +210,7 @@ def test_delete_project_with_resources(
response = client.delete(
f"projects/{project_to_remove}",
headers={
- mlrun.api.schemas.HeaderNames.deletion_strategy: mlrun.api.schemas.DeletionStrategy.cascading.value
+ mlrun.common.schemas.HeaderNames.deletion_strategy: mlrun.common.schemas.DeletionStrategy.cascading.value
},
)
assert response.status_code == HTTPStatus.NO_CONTENT.value
@@ -249,7 +249,7 @@ def test_delete_project_with_resources(
response = client.delete(
f"projects/{project_to_remove}",
headers={
- mlrun.api.schemas.HeaderNames.deletion_strategy: mlrun.api.schemas.DeletionStrategy.check.value
+ mlrun.common.schemas.HeaderNames.deletion_strategy: mlrun.common.schemas.DeletionStrategy.check.value
},
)
assert response.status_code == HTTPStatus.NO_CONTENT.value
@@ -258,7 +258,7 @@ def test_delete_project_with_resources(
response = client.delete(
f"projects/{project_to_remove}",
headers={
- mlrun.api.schemas.HeaderNames.deletion_strategy: mlrun.api.schemas.DeletionStrategy.restricted.value
+ mlrun.common.schemas.HeaderNames.deletion_strategy: mlrun.common.schemas.DeletionStrategy.restricted.value
},
)
assert response.status_code == HTTPStatus.NO_CONTENT.value
@@ -269,16 +269,16 @@ def test_list_and_get_project_summaries(
) -> None:
# create empty project
empty_project_name = "empty-project"
- empty_project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=empty_project_name),
+ empty_project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=empty_project_name),
)
response = client.post("projects", json=empty_project.dict())
assert response.status_code == HTTPStatus.CREATED.value
# create project with resources
project_name = "project-with-resources"
- project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=project_name),
+ project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=project_name),
)
response = client.post("projects", json=project.dict())
assert response.status_code == HTTPStatus.CREATED.value
@@ -359,7 +359,7 @@ def test_list_and_get_project_summaries(
# list project summaries
response = client.get("project-summaries")
- project_summaries_output = mlrun.api.schemas.ProjectSummariesOutput(
+ project_summaries_output = mlrun.common.schemas.ProjectSummariesOutput(
**response.json()
)
for index, project_summary in enumerate(project_summaries_output.project_summaries):
@@ -381,7 +381,7 @@ def test_list_and_get_project_summaries(
# get project summary
response = client.get(f"project-summaries/{project_name}")
- project_summary = mlrun.api.schemas.ProjectSummary(**response.json())
+ project_summary = mlrun.common.schemas.ProjectSummary(**response.json())
_assert_project_summary(
project_summary,
files_count,
@@ -402,8 +402,8 @@ def test_list_project_summaries_different_installation_modes(
"""
# create empty project
empty_project_name = "empty-project"
- empty_project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=empty_project_name),
+ empty_project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=empty_project_name),
)
response = client.post("projects", json=empty_project.dict())
assert response.status_code == HTTPStatus.CREATED.value
@@ -418,7 +418,7 @@ def test_list_project_summaries_different_installation_modes(
response = client.get("project-summaries")
assert response.status_code == HTTPStatus.OK.value
- project_summaries_output = mlrun.api.schemas.ProjectSummariesOutput(
+ project_summaries_output = mlrun.common.schemas.ProjectSummariesOutput(
**response.json()
)
_assert_project_summary(
@@ -440,7 +440,7 @@ def test_list_project_summaries_different_installation_modes(
response = client.get("project-summaries")
assert response.status_code == HTTPStatus.OK.value
- project_summaries_output = mlrun.api.schemas.ProjectSummariesOutput(
+ project_summaries_output = mlrun.common.schemas.ProjectSummariesOutput(
**response.json()
)
_assert_project_summary(
@@ -462,7 +462,7 @@ def test_list_project_summaries_different_installation_modes(
response = client.get("project-summaries")
assert response.status_code == HTTPStatus.OK.value
- project_summaries_output = mlrun.api.schemas.ProjectSummariesOutput(
+ project_summaries_output = mlrun.common.schemas.ProjectSummariesOutput(
**response.json()
)
_assert_project_summary(
@@ -484,7 +484,7 @@ def test_list_project_summaries_different_installation_modes(
response = client.get("project-summaries")
assert response.status_code == HTTPStatus.OK.value
- project_summaries_output = mlrun.api.schemas.ProjectSummariesOutput(
+ project_summaries_output = mlrun.common.schemas.ProjectSummariesOutput(
**response.json()
)
_assert_project_summary(
@@ -506,9 +506,9 @@ def test_delete_project_deletion_strategy_check(
project_member_mode: str,
k8s_secrets_mock: tests.api.conftest.K8sSecretsMock,
) -> None:
- project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name="project-name"),
- spec=mlrun.api.schemas.ProjectSpec(),
+ project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name="project-name"),
+ spec=mlrun.common.schemas.ProjectSpec(),
)
# create
@@ -520,7 +520,7 @@ def test_delete_project_deletion_strategy_check(
response = client.delete(
f"projects/{project.metadata.name}",
headers={
- mlrun.api.schemas.HeaderNames.deletion_strategy: mlrun.api.schemas.DeletionStrategy.check.value
+ mlrun.common.schemas.HeaderNames.deletion_strategy: mlrun.common.schemas.DeletionStrategy.check.value
},
)
assert response.status_code == HTTPStatus.NO_CONTENT.value
@@ -542,7 +542,7 @@ def test_delete_project_deletion_strategy_check(
response = client.delete(
f"projects/{project.metadata.name}",
headers={
- mlrun.api.schemas.HeaderNames.deletion_strategy: mlrun.api.schemas.DeletionStrategy.check.value
+ mlrun.common.schemas.HeaderNames.deletion_strategy: mlrun.common.schemas.DeletionStrategy.check.value
},
)
assert response.status_code == HTTPStatus.PRECONDITION_FAILED.value
@@ -608,7 +608,7 @@ def test_delete_project_not_deleting_versioned_objects_multiple_times(
response = client.delete(
f"projects/{project_name}",
headers={
- mlrun.api.schemas.HeaderNames.deletion_strategy: mlrun.api.schemas.DeletionStrategy.cascading.value
+ mlrun.common.schemas.HeaderNames.deletion_strategy: mlrun.common.schemas.DeletionStrategy.cascading.value
},
)
assert response.status_code == HTTPStatus.NO_CONTENT.value
@@ -635,9 +635,9 @@ def test_delete_project_deletion_strategy_check_external_resource(
k8s_secrets_mock: tests.api.conftest.K8sSecretsMock,
) -> None:
mlrun.mlconf.namespace = "test-namespace"
- project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name="project-name"),
- spec=mlrun.api.schemas.ProjectSpec(),
+ project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name="project-name"),
+ spec=mlrun.common.schemas.ProjectSpec(),
)
# create
@@ -652,7 +652,7 @@ def test_delete_project_deletion_strategy_check_external_resource(
response = client.delete(
f"projects/{project.metadata.name}",
headers={
- mlrun.api.schemas.HeaderNames.deletion_strategy: mlrun.api.schemas.DeletionStrategy.restricted.value
+ mlrun.common.schemas.HeaderNames.deletion_strategy: mlrun.common.schemas.DeletionStrategy.restricted.value
},
)
assert response.status_code == HTTPStatus.PRECONDITION_FAILED.value
@@ -662,7 +662,7 @@ def test_delete_project_deletion_strategy_check_external_resource(
response = client.delete(
f"projects/{project.metadata.name}",
headers={
- mlrun.api.schemas.HeaderNames.deletion_strategy: mlrun.api.schemas.DeletionStrategy.restricted.value
+ mlrun.common.schemas.HeaderNames.deletion_strategy: mlrun.common.schemas.DeletionStrategy.restricted.value
},
)
assert response
@@ -674,14 +674,16 @@ def test_delete_project_with_stop_logs(
project_member_mode: str,
k8s_secrets_mock: tests.api.conftest.K8sSecretsMock,
):
- mlrun.config.config.log_collector.mode = mlrun.api.schemas.LogsCollectorMode.sidecar
+ mlrun.config.config.log_collector.mode = (
+ mlrun.common.schemas.LogsCollectorMode.sidecar
+ )
project_name = "project-name"
mlrun.mlconf.namespace = "test-namespace"
- project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=project_name),
- spec=mlrun.api.schemas.ProjectSpec(),
+ project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=project_name),
+ spec=mlrun.common.schemas.ProjectSpec(),
)
# create
@@ -720,8 +722,8 @@ def test_list_projects_leader_format(
project_names = []
for _ in range(5):
project_name = f"prj-{uuid4().hex}"
- project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=project_name),
+ project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=project_name),
)
mlrun.api.utils.singletons.db.get_db().create_project(db, project)
project_names.append(project_name)
@@ -729,9 +731,9 @@ def test_list_projects_leader_format(
# list in leader format
response = client.get(
"projects",
- params={"format": mlrun.api.schemas.ProjectsFormat.leader},
+ params={"format": mlrun.common.schemas.ProjectsFormat.leader},
headers={
- mlrun.api.schemas.HeaderNames.projects_role: mlrun.mlconf.httpdb.projects.leader
+ mlrun.common.schemas.HeaderNames.projects_role: mlrun.mlconf.httpdb.projects.leader
},
)
returned_project_names = [
@@ -758,9 +760,9 @@ def test_projects_crud(
k8s_secrets_mock.set_is_running_in_k8s_cluster(False)
name1 = f"prj-{uuid4().hex}"
- project_1 = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=name1),
- spec=mlrun.api.schemas.ProjectSpec(
+ project_1 = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=name1),
+ spec=mlrun.common.schemas.ProjectSpec(
description="banana", source="source", goals="some goals"
),
)
@@ -778,7 +780,7 @@ def test_projects_crud(
project_patch = {
"spec": {
"description": "lemon",
- "desired_state": mlrun.api.schemas.ProjectState.archived,
+ "desired_state": mlrun.common.schemas.ProjectState.archived,
}
}
response = client.patch(f"projects/{name1}", json=project_patch)
@@ -797,9 +799,9 @@ def test_projects_crud(
name2 = f"prj-{uuid4().hex}"
labels_2 = {"key": "value"}
- project_2 = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=name2, labels=labels_2),
- spec=mlrun.api.schemas.ProjectSpec(description="banana2", source="source2"),
+ project_2 = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=name2, labels=labels_2),
+ spec=mlrun.common.schemas.ProjectSpec(description="banana2", source="source2"),
)
# store
@@ -824,9 +826,9 @@ def test_projects_crud(
# list - full
response = client.get(
- "projects", params={"format": mlrun.api.schemas.ProjectsFormat.full}
+ "projects", params={"format": mlrun.common.schemas.ProjectsFormat.full}
)
- projects_output = mlrun.api.schemas.ProjectsOutput(**response.json())
+ projects_output = mlrun.common.schemas.ProjectsOutput(**response.json())
expected = [project_1, project_2]
for project in projects_output.projects:
for _project in expected:
@@ -874,7 +876,7 @@ def test_projects_crud(
# list - names only - filter by state
_list_project_names_and_assert(
- client, [name1], params={"state": mlrun.api.schemas.ProjectState.archived}
+ client, [name1], params={"state": mlrun.common.schemas.ProjectState.archived}
)
# add function to project 1
@@ -887,7 +889,7 @@ def test_projects_crud(
response = client.delete(
f"projects/{name1}",
headers={
- mlrun.api.schemas.HeaderNames.deletion_strategy: mlrun.api.schemas.DeletionStrategy.restricted.value
+ mlrun.common.schemas.HeaderNames.deletion_strategy: mlrun.common.schemas.DeletionStrategy.restricted.value
},
)
assert response.status_code == HTTPStatus.PRECONDITION_FAILED.value
@@ -896,7 +898,7 @@ def test_projects_crud(
response = client.delete(
f"projects/{name1}",
headers={
- mlrun.api.schemas.HeaderNames.deletion_strategy: mlrun.api.schemas.DeletionStrategy.cascading.value
+ mlrun.common.schemas.HeaderNames.deletion_strategy: mlrun.common.schemas.DeletionStrategy.cascading.value
},
)
assert response.status_code == HTTPStatus.NO_CONTENT.value
@@ -916,11 +918,11 @@ def _create_resources_of_all_kinds(
):
db = mlrun.api.utils.singletons.db.get_db()
# add labels to project
- project_schema = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(
+ project_schema = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(
name=project, labels={"key": "value"}
),
- spec=mlrun.api.schemas.ProjectSpec(description="some desc"),
+ spec=mlrun.common.schemas.ProjectSpec(description="some desc"),
)
mlrun.api.utils.singletons.project_member.get_project_member().store_project(
db_session, project, project_schema
@@ -1014,15 +1016,15 @@ def _create_resources_of_all_kinds(
"bla": "blabla",
"status": {"bla": "blabla"},
}
- schedule_cron_trigger = mlrun.api.schemas.ScheduleCronTrigger(year=1999)
+ schedule_cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(year=1999)
schedule_names = ["schedule_name_1", "schedule_name_2", "schedule_name_3"]
for schedule_name in schedule_names:
mlrun.api.utils.singletons.scheduler.get_scheduler().create_schedule(
db_session,
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
project,
schedule_name,
- mlrun.api.schemas.ScheduleKinds.job,
+ mlrun.common.schemas.ScheduleKinds.job,
schedule,
schedule_cron_trigger,
labels,
@@ -1032,18 +1034,18 @@ def _create_resources_of_all_kinds(
labels = {
"owner": "nobody",
}
- feature_set = mlrun.api.schemas.FeatureSet(
- metadata=mlrun.api.schemas.ObjectMetadata(
+ feature_set = mlrun.common.schemas.FeatureSet(
+ metadata=mlrun.common.schemas.ObjectMetadata(
name="dummy", tag="latest", labels=labels
),
- spec=mlrun.api.schemas.FeatureSetSpec(
+ spec=mlrun.common.schemas.FeatureSetSpec(
entities=[
- mlrun.api.schemas.Entity(
+ mlrun.common.schemas.Entity(
name="ent1", value_type="str", labels={"label": "1"}
)
],
features=[
- mlrun.api.schemas.Feature(
+ mlrun.common.schemas.Feature(
name="feat1", value_type="str", labels={"label": "1"}
)
],
@@ -1061,12 +1063,12 @@ def _create_resources_of_all_kinds(
feature_set.spec.index = index
db.store_feature_set(db_session, project, feature_set_name, feature_set)
- feature_vector = mlrun.api.schemas.FeatureVector(
- metadata=mlrun.api.schemas.ObjectMetadata(
+ feature_vector = mlrun.common.schemas.FeatureVector(
+ metadata=mlrun.common.schemas.ObjectMetadata(
name="dummy", tag="latest", labels=labels
),
- spec=mlrun.api.schemas.ObjectSpec(),
- status=mlrun.api.schemas.ObjectStatus(state="created"),
+ spec=mlrun.common.schemas.ObjectSpec(),
+ status=mlrun.common.schemas.ObjectStatus(state="created"),
)
feature_vector_names = ["feature_vector_1", "feature_vector_2", "feature_vector_3"]
feature_vector_tags = ["some_tag", "some_tag2", "some_tag3"]
@@ -1087,7 +1089,7 @@ def _create_resources_of_all_kinds(
db_session,
name="task",
project=project,
- state=mlrun.api.schemas.BackgroundTaskState.running,
+ state=mlrun.common.schemas.BackgroundTaskState.running,
)
@@ -1280,7 +1282,7 @@ def _list_project_names_and_assert(
client: TestClient, expected_names: typing.List[str], params: typing.Dict = None
):
params = params or {}
- params["format"] = mlrun.api.schemas.ProjectsFormat.name_only
+ params["format"] = mlrun.common.schemas.ProjectsFormat.name_only
# list - names only - filter by state
response = client.get(
"projects",
@@ -1297,14 +1299,14 @@ def _list_project_names_and_assert(
def _assert_project_response(
- expected_project: mlrun.api.schemas.Project, response, extra_exclude: dict = None
+ expected_project: mlrun.common.schemas.Project, response, extra_exclude: dict = None
):
- project = mlrun.api.schemas.Project(**response.json())
+ project = mlrun.common.schemas.Project(**response.json())
_assert_project(expected_project, project, extra_exclude)
def _assert_project_summary(
- project_summary: mlrun.api.schemas.ProjectSummary,
+ project_summary: mlrun.common.schemas.ProjectSummary,
files_count: int,
feature_sets_count: int,
models_count: int,
@@ -1323,8 +1325,8 @@ def _assert_project_summary(
def _assert_project(
- expected_project: mlrun.api.schemas.Project,
- project: mlrun.api.schemas.Project,
+ expected_project: mlrun.common.schemas.Project,
+ project: mlrun.common.schemas.Project,
extra_exclude: dict = None,
):
exclude = {"id": ..., "metadata": {"created"}, "status": {"state"}}
@@ -1422,11 +1424,11 @@ def _create_runs(
def _create_schedules(client: TestClient, project_name, schedules_count):
for index in range(schedules_count):
schedule_name = f"schedule-name-{str(uuid4())}"
- schedule = mlrun.api.schemas.ScheduleInput(
+ schedule = mlrun.common.schemas.ScheduleInput(
name=schedule_name,
- kind=mlrun.api.schemas.ScheduleKinds.job,
+ kind=mlrun.common.schemas.ScheduleKinds.job,
scheduled_object={"metadata": {"name": "something"}},
- cron_trigger=mlrun.api.schemas.ScheduleCronTrigger(year=1999),
+ cron_trigger=mlrun.common.schemas.ScheduleCronTrigger(year=1999),
)
response = client.post(
f"projects/{project_name}/schedules", json=schedule.dict()
diff --git a/tests/api/api/test_runs.py b/tests/api/api/test_runs.py
index 36ea17e6d8d9..368662061afe 100644
--- a/tests/api/api/test_runs.py
+++ b/tests/api/api/test_runs.py
@@ -22,8 +22,8 @@
from sqlalchemy.orm import Session
import mlrun.api.crud
-import mlrun.api.schemas
import mlrun.api.utils.auth.verifier
+import mlrun.common.schemas
import mlrun.errors
import mlrun.runtimes.constants
from mlrun.api.db.sqldb.models import Run
@@ -262,9 +262,9 @@ def test_list_runs_partition_by(db: Session, client: TestClient) -> None:
client,
{
"project": projects[0],
- "partition-by": mlrun.api.schemas.RunPartitionByField.name,
- "partition-sort-by": mlrun.api.schemas.SortField.created,
- "partition-order": mlrun.api.schemas.OrderType.asc,
+ "partition-by": mlrun.common.schemas.RunPartitionByField.name,
+ "partition-sort-by": mlrun.common.schemas.SortField.created,
+ "partition-order": mlrun.common.schemas.OrderType.asc,
},
3,
)
@@ -277,9 +277,9 @@ def test_list_runs_partition_by(db: Session, client: TestClient) -> None:
client,
{
"project": projects[0],
- "partition-by": mlrun.api.schemas.RunPartitionByField.name,
- "partition-sort-by": mlrun.api.schemas.SortField.updated,
- "partition-order": mlrun.api.schemas.OrderType.desc,
+ "partition-by": mlrun.common.schemas.RunPartitionByField.name,
+ "partition-sort-by": mlrun.common.schemas.SortField.updated,
+ "partition-order": mlrun.common.schemas.OrderType.desc,
},
3,
)
@@ -292,9 +292,9 @@ def test_list_runs_partition_by(db: Session, client: TestClient) -> None:
client,
{
"project": projects[0],
- "partition-by": mlrun.api.schemas.RunPartitionByField.name,
- "partition-sort-by": mlrun.api.schemas.SortField.updated,
- "partition-order": mlrun.api.schemas.OrderType.desc,
+ "partition-by": mlrun.common.schemas.RunPartitionByField.name,
+ "partition-sort-by": mlrun.common.schemas.SortField.updated,
+ "partition-order": mlrun.common.schemas.OrderType.desc,
"rows-per-partition": 5,
},
15,
@@ -305,9 +305,9 @@ def test_list_runs_partition_by(db: Session, client: TestClient) -> None:
client,
{
"project": projects[0],
- "partition-by": mlrun.api.schemas.RunPartitionByField.name,
- "partition-sort-by": mlrun.api.schemas.SortField.updated,
- "partition-order": mlrun.api.schemas.OrderType.desc,
+ "partition-by": mlrun.common.schemas.RunPartitionByField.name,
+ "partition-sort-by": mlrun.common.schemas.SortField.updated,
+ "partition-order": mlrun.common.schemas.OrderType.desc,
"rows-per-partition": 5,
"max-partitions": 2,
},
@@ -323,9 +323,9 @@ def test_list_runs_partition_by(db: Session, client: TestClient) -> None:
{
"project": projects[0],
"iter": False,
- "partition-by": mlrun.api.schemas.RunPartitionByField.name,
- "partition-sort-by": mlrun.api.schemas.SortField.updated,
- "partition-order": mlrun.api.schemas.OrderType.desc,
+ "partition-by": mlrun.common.schemas.RunPartitionByField.name,
+ "partition-sort-by": mlrun.common.schemas.SortField.updated,
+ "partition-order": mlrun.common.schemas.OrderType.desc,
"rows-per-partition": 2,
"max-partitions": 1,
},
diff --git a/tests/api/api/test_runtime_resources.py b/tests/api/api/test_runtime_resources.py
index 8e0fabc255df..ed88e9827fee 100644
--- a/tests/api/api/test_runtime_resources.py
+++ b/tests/api/api/test_runtime_resources.py
@@ -22,8 +22,8 @@
import mlrun.api.api.endpoints.runtime_resources
import mlrun.api.crud
-import mlrun.api.schemas
import mlrun.api.utils.singletons.k8s
+import mlrun.common.schemas
def test_list_runtimes_resources_opa_filtering(
@@ -83,7 +83,7 @@ def test_list_runtimes_resources_group_by_job(
)
response = client.get(
"projects/*/runtime-resources",
- params={"group-by": mlrun.api.schemas.ListRuntimeResourcesGroupByField.job},
+ params={"group-by": mlrun.common.schemas.ListRuntimeResourcesGroupByField.job},
)
body = response.json()
expected_body = {
@@ -140,9 +140,9 @@ def test_list_runtimes_resources_no_group_by(
)
body = response.json()
expected_body = [
- mlrun.api.schemas.KindRuntimeResources(
+ mlrun.common.schemas.KindRuntimeResources(
kind=mlrun.runtimes.RuntimeKinds.job,
- resources=mlrun.api.schemas.RuntimeResources(
+ resources=mlrun.common.schemas.RuntimeResources(
crd_resources=[],
pod_resources=grouped_by_project_runtime_resources_output[project_1][
mlrun.runtimes.RuntimeKinds.job
@@ -152,9 +152,9 @@ def test_list_runtimes_resources_no_group_by(
].pod_resources,
),
).dict(),
- mlrun.api.schemas.KindRuntimeResources(
+ mlrun.common.schemas.KindRuntimeResources(
kind=mlrun.runtimes.RuntimeKinds.dask,
- resources=mlrun.api.schemas.RuntimeResources(
+ resources=mlrun.common.schemas.RuntimeResources(
crd_resources=[],
pod_resources=grouped_by_project_runtime_resources_output[project_2][
mlrun.runtimes.RuntimeKinds.dask
@@ -164,9 +164,9 @@ def test_list_runtimes_resources_no_group_by(
][mlrun.runtimes.RuntimeKinds.dask].service_resources,
),
).dict(),
- mlrun.api.schemas.KindRuntimeResources(
+ mlrun.common.schemas.KindRuntimeResources(
kind=mlrun.runtimes.RuntimeKinds.mpijob,
- resources=mlrun.api.schemas.RuntimeResources(
+ resources=mlrun.common.schemas.RuntimeResources(
crd_resources=grouped_by_project_runtime_resources_output[project_3][
mlrun.runtimes.RuntimeKinds.mpijob
].crd_resources,
@@ -201,13 +201,15 @@ def test_list_runtime_resources_no_resources(
assert body == []
response = client.get(
"projects/*/runtime-resources",
- params={"group-by": mlrun.api.schemas.ListRuntimeResourcesGroupByField.job},
+ params={"group-by": mlrun.common.schemas.ListRuntimeResourcesGroupByField.job},
)
body = response.json()
assert body == {}
response = client.get(
"projects/*/runtime-resources",
- params={"group-by": mlrun.api.schemas.ListRuntimeResourcesGroupByField.project},
+ params={
+ "group-by": mlrun.common.schemas.ListRuntimeResourcesGroupByField.project
+ },
)
body = response.json()
assert body == {}
@@ -251,9 +253,9 @@ def test_list_runtime_resources_filter_by_kind(
params={"kind": mlrun.runtimes.RuntimeKinds.job},
)
body = response.json()
- expected_runtime_resources = mlrun.api.schemas.KindRuntimeResources(
+ expected_runtime_resources = mlrun.common.schemas.KindRuntimeResources(
kind=mlrun.runtimes.RuntimeKinds.job,
- resources=mlrun.api.schemas.RuntimeResources(
+ resources=mlrun.common.schemas.RuntimeResources(
crd_resources=[],
pod_resources=grouped_by_project_runtime_resources_output[project_1][
mlrun.runtimes.RuntimeKinds.job
@@ -523,9 +525,9 @@ def _generate_grouped_by_project_runtime_resources_with_legacy_builder_output():
no_project_builder_name = "builder-name"
grouped_by_project_runtime_resources_output = {
project_1: {
- mlrun.runtimes.RuntimeKinds.job: mlrun.api.schemas.RuntimeResources(
+ mlrun.runtimes.RuntimeKinds.job: mlrun.common.schemas.RuntimeResources(
pod_resources=[
- mlrun.api.schemas.RuntimeResource(
+ mlrun.common.schemas.RuntimeResource(
name=project_1_job_name,
labels={
"mlrun/project": project_1,
@@ -539,9 +541,9 @@ def _generate_grouped_by_project_runtime_resources_with_legacy_builder_output():
)
},
no_project: {
- mlrun.runtimes.RuntimeKinds.job: mlrun.api.schemas.RuntimeResources(
+ mlrun.runtimes.RuntimeKinds.job: mlrun.common.schemas.RuntimeResources(
pod_resources=[
- mlrun.api.schemas.RuntimeResource(
+ mlrun.common.schemas.RuntimeResource(
name=no_project_builder_name,
labels={
"mlrun/class": "build",
@@ -571,9 +573,9 @@ def _generate_grouped_by_project_runtime_resources_output():
project_3_mpijob_name = "project-3-mpijob-name"
grouped_by_project_runtime_resources_output = {
project_1: {
- mlrun.runtimes.RuntimeKinds.job: mlrun.api.schemas.RuntimeResources(
+ mlrun.runtimes.RuntimeKinds.job: mlrun.common.schemas.RuntimeResources(
pod_resources=[
- mlrun.api.schemas.RuntimeResource(
+ mlrun.common.schemas.RuntimeResource(
name=project_1_job_name,
labels={
"mlrun/project": project_1,
@@ -587,9 +589,9 @@ def _generate_grouped_by_project_runtime_resources_output():
)
},
project_2: {
- mlrun.runtimes.RuntimeKinds.dask: mlrun.api.schemas.RuntimeResources(
+ mlrun.runtimes.RuntimeKinds.dask: mlrun.common.schemas.RuntimeResources(
pod_resources=[
- mlrun.api.schemas.RuntimeResource(
+ mlrun.common.schemas.RuntimeResource(
name=project_2_dask_name,
labels={
"mlrun/project": project_2,
@@ -601,7 +603,7 @@ def _generate_grouped_by_project_runtime_resources_output():
],
crd_resources=[],
service_resources=[
- mlrun.api.schemas.RuntimeResource(
+ mlrun.common.schemas.RuntimeResource(
name=project_2_dask_name,
labels={
"mlrun/project": project_2,
@@ -612,9 +614,9 @@ def _generate_grouped_by_project_runtime_resources_output():
)
],
),
- mlrun.runtimes.RuntimeKinds.job: mlrun.api.schemas.RuntimeResources(
+ mlrun.runtimes.RuntimeKinds.job: mlrun.common.schemas.RuntimeResources(
pod_resources=[
- mlrun.api.schemas.RuntimeResource(
+ mlrun.common.schemas.RuntimeResource(
name=project_2_job_name,
labels={
"mlrun/project": project_2,
@@ -628,10 +630,10 @@ def _generate_grouped_by_project_runtime_resources_output():
),
},
project_3: {
- mlrun.runtimes.RuntimeKinds.mpijob: mlrun.api.schemas.RuntimeResources(
+ mlrun.runtimes.RuntimeKinds.mpijob: mlrun.common.schemas.RuntimeResources(
pod_resources=[],
crd_resources=[
- mlrun.api.schemas.RuntimeResource(
+ mlrun.common.schemas.RuntimeResource(
name=project_3_mpijob_name,
labels={
"mlrun/project": project_3,
@@ -658,7 +660,7 @@ def _generate_grouped_by_project_runtime_resources_output():
def _mock_opa_filter_and_assert_list_response(
client: fastapi.testclient.TestClient,
- grouped_by_project_runtime_resources_output: mlrun.api.schemas.GroupedByProjectRuntimeResourcesOutput,
+ grouped_by_project_runtime_resources_output: mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput,
opa_filter_response,
):
mlrun.api.utils.auth.verifier.AuthVerifier().filter_project_resources_by_permissions = unittest.mock.AsyncMock(
@@ -666,7 +668,9 @@ def _mock_opa_filter_and_assert_list_response(
)
response = client.get(
"projects/*/runtime-resources",
- params={"group-by": mlrun.api.schemas.ListRuntimeResourcesGroupByField.project},
+ params={
+ "group-by": mlrun.common.schemas.ListRuntimeResourcesGroupByField.project
+ },
)
body = response.json()
expected_body = (
@@ -687,7 +691,7 @@ def _mock_opa_filter_and_assert_list_response(
def _filter_allowed_projects_and_kind_from_grouped_by_project_runtime_resources_output(
allowed_projects: typing.List[str],
filter_kind: str,
- grouped_by_project_runtime_resources_output: mlrun.api.schemas.GroupedByProjectRuntimeResourcesOutput,
+ grouped_by_project_runtime_resources_output: mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput,
structured: bool = False,
):
filtered_output = (
@@ -702,7 +706,7 @@ def _filter_allowed_projects_and_kind_from_grouped_by_project_runtime_resources_
def _filter_kind_from_grouped_by_project_runtime_resources_output(
filter_kind: str,
- grouped_by_project_runtime_resources_output: mlrun.api.schemas.GroupedByProjectRuntimeResourcesOutput,
+ grouped_by_project_runtime_resources_output: mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput,
):
filtered_output = {}
for (
@@ -719,7 +723,7 @@ def _filter_kind_from_grouped_by_project_runtime_resources_output(
def _filter_allowed_projects_from_grouped_by_project_runtime_resources_output(
allowed_projects: typing.List[str],
- grouped_by_project_runtime_resources_output: mlrun.api.schemas.GroupedByProjectRuntimeResourcesOutput,
+ grouped_by_project_runtime_resources_output: mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput,
structured: bool = False,
):
filtered_output = {}
diff --git a/tests/api/api/test_schedules.py b/tests/api/api/test_schedules.py
index 4b0461cb5a80..e402880fd887 100644
--- a/tests/api/api/test_schedules.py
+++ b/tests/api/api/test_schedules.py
@@ -24,8 +24,8 @@
import mlrun.api.utils.auth.verifier
import mlrun.api.utils.singletons.project_member
import mlrun.api.utils.singletons.scheduler
+import mlrun.common.schemas
import tests.api.api.utils
-from mlrun.api import schemas
from mlrun.api.utils.singletons.db import get_db
from tests.common_fixtures import aioresponses_mock
@@ -46,14 +46,14 @@ def test_list_schedules(
labels_1 = {
"label1": "value1",
}
- cron_trigger = schemas.ScheduleCronTrigger(year="1999")
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(year="1999")
schedule_name = "schedule-name"
project = mlrun.mlconf.default_project
get_db().create_schedule(
db,
project,
schedule_name,
- schemas.ScheduleKinds.local_function,
+ mlrun.common.schemas.ScheduleKinds.local_function,
do_nothing,
cron_trigger,
mlrun.mlconf.httpdb.scheduling.default_concurrency_limit,
@@ -68,7 +68,7 @@ def test_list_schedules(
db,
project,
schedule_name_2,
- schemas.ScheduleKinds.local_function,
+ mlrun.common.schemas.ScheduleKinds.local_function,
do_nothing,
cron_trigger,
mlrun.mlconf.httpdb.scheduling.default_concurrency_limit,
diff --git a/tests/api/api/test_secrets.py b/tests/api/api/test_secrets.py
index 2f1fc7e3c71a..eb332ab50e71 100644
--- a/tests/api/api/test_secrets.py
+++ b/tests/api/api/test_secrets.py
@@ -19,8 +19,8 @@
from fastapi.testclient import TestClient
from sqlalchemy.orm import Session
+import mlrun.common.schemas
from mlrun import mlconf
-from mlrun.api import schemas
# Set a valid Vault token to run this test.
# For this test, you must also have a k8s cluster available (minikube is good enough).
@@ -45,8 +45,11 @@ def test_vault_create_project_secrets(db: Session, client: TestClient):
response = client.post(f"projects/{project_name}/secrets", json=data)
assert response.status_code == HTTPStatus.CREATED.value
- params = {"provider": schemas.SecretProviderName.vault.value, "secrets": None}
- headers = {schemas.HeaderNames.secret_store_token: user_token}
+ params = {
+ "provider": mlrun.common.schemas.SecretProviderName.vault.value,
+ "secrets": None,
+ }
+ headers = {mlrun.common.schemas.HeaderNames.secret_store_token: user_token}
response = client.get(
f"projects/{project_name}/secrets", headers=headers, params=params
diff --git a/tests/api/api/test_submit.py b/tests/api/api/test_submit.py
index d50bf04df208..92952f1d753f 100644
--- a/tests/api/api/test_submit.py
+++ b/tests/api/api/test_submit.py
@@ -32,8 +32,8 @@
import mlrun.api.utils.clients.chief
import mlrun.api.utils.clients.iguazio
import tests.api.api.utils
-from mlrun.api.schemas import AuthInfo
from mlrun.api.utils.singletons.k8s import get_k8s
+from mlrun.common.schemas import AuthInfo
from mlrun.config import config as mlconf
from tests.api.conftest import K8sSecretsMock
@@ -144,7 +144,7 @@ def test_submit_job_auto_mount(
"V3IO_USERNAME": username,
"V3IO_ACCESS_KEY": (
secret_name,
- mlrun.api.schemas.AuthSecretData.get_field_secret_key("access_key"),
+ mlrun.common.schemas.AuthSecretData.get_field_secret_key("access_key"),
),
}
_assert_pod_env_vars(pod_create_mock, expected_env_vars)
@@ -174,7 +174,7 @@ def test_submit_job_ensure_function_has_auth_set(
expected_env_vars = {
mlrun.runtimes.constants.FunctionEnvironmentVariables.auth_session: (
secret_name,
- mlrun.api.schemas.AuthSecretData.get_field_secret_key("access_key"),
+ mlrun.common.schemas.AuthSecretData.get_field_secret_key("access_key"),
),
}
_assert_pod_env_vars(pod_create_mock, expected_env_vars)
@@ -337,7 +337,7 @@ def test_submit_job_with_hyper_params_file(
)
async def auth_info_mock(*args, **kwargs):
- return mlrun.api.schemas.AuthInfo(username="user", data_session=access_key)
+ return mlrun.common.schemas.AuthInfo(username="user", data_session=access_key)
# Create test-specific mocks
monkeypatch.setattr(
@@ -526,7 +526,7 @@ def _create_submit_job_body(function, project, with_output_path=True):
def _create_submit_job_body_with_schedule(function, project):
job_body = _create_submit_job_body(function, project)
- job_body["schedule"] = mlrun.api.schemas.ScheduleCronTrigger(year=1999).dict()
+ job_body["schedule"] = mlrun.common.schemas.ScheduleCronTrigger(year=1999).dict()
return job_body
diff --git a/tests/api/api/test_tags.py b/tests/api/api/test_tags.py
index b9bcff56eef6..e89a93b415b3 100644
--- a/tests/api/api/test_tags.py
+++ b/tests/api/api/test_tags.py
@@ -21,7 +21,7 @@
import fastapi.testclient
import sqlalchemy.orm
-import mlrun.api.schemas
+import mlrun.common.schemas
API_PROJECTS_PATH = "projects"
API_ARTIFACTS_PATH = "projects/{project}/artifacts"
@@ -52,7 +52,7 @@ def test_overwrite_artifact_tags_by_key_identifier(
client=client,
tag=overwrite_tag,
identifiers=[
- mlrun.api.schemas.ArtifactIdentifier(key=artifact1_key),
+ mlrun.common.schemas.ArtifactIdentifier(key=artifact1_key),
],
)
assert response.status_code == http.HTTPStatus.OK.value
@@ -86,7 +86,7 @@ def test_overwrite_artifact_tags_by_uid_identifier(
client=client,
tag=overwrite_tag,
identifiers=[
- mlrun.api.schemas.ArtifactIdentifier(uid=artifact1_uid),
+ mlrun.common.schemas.ArtifactIdentifier(uid=artifact1_uid),
],
)
assert response.status_code == http.HTTPStatus.OK.value
@@ -120,8 +120,8 @@ def test_overwrite_artifact_tags_by_multiple_uid_identifiers(
client=client,
tag=overwrite_tag,
identifiers=[
- mlrun.api.schemas.ArtifactIdentifier(uid=artifact1_uid),
- mlrun.api.schemas.ArtifactIdentifier(uid=artifact2_uid),
+ mlrun.common.schemas.ArtifactIdentifier(uid=artifact1_uid),
+ mlrun.common.schemas.ArtifactIdentifier(uid=artifact2_uid),
],
)
assert response.status_code == http.HTTPStatus.OK.value
@@ -153,8 +153,8 @@ def test_overwrite_artifact_tags_by_multiple_key_identifiers(
client=client,
tag=overwrite_tag,
identifiers=[
- mlrun.api.schemas.ArtifactIdentifier(key=artifact1_key),
- mlrun.api.schemas.ArtifactIdentifier(key=artifact2_key),
+ mlrun.common.schemas.ArtifactIdentifier(key=artifact1_key),
+ mlrun.common.schemas.ArtifactIdentifier(key=artifact2_key),
],
)
assert response.status_code == http.HTTPStatus.OK.value
@@ -186,7 +186,7 @@ def test_append_artifact_tags_by_key_identifier(
client=client,
tag=new_tag,
identifiers=[
- mlrun.api.schemas.ArtifactIdentifier(key=artifact1_key),
+ mlrun.common.schemas.ArtifactIdentifier(key=artifact1_key),
],
)
assert response.status_code == http.HTTPStatus.OK.value
@@ -223,7 +223,7 @@ def test_append_artifact_tags_by_uid_identifier_latest(
client=client,
tag=new_tag,
identifiers=[
- mlrun.api.schemas.ArtifactIdentifier(
+ mlrun.common.schemas.ArtifactIdentifier(
key=artifact1_key, uid=artifact1_uid
),
],
@@ -269,7 +269,7 @@ def test_create_and_append_artifact_tags_with_invalid_characters(
client=client,
tag=invalid_tag_name,
identifiers=[
- mlrun.api.schemas.ArtifactIdentifier(
+ mlrun.common.schemas.ArtifactIdentifier(
key=artifact1_key, uid=artifact1_uid
),
],
@@ -299,7 +299,7 @@ def test_overwrite_artifact_tags_with_invalid_characters(
client=client,
tag=invalid_tag_name,
identifiers=[
- mlrun.api.schemas.ArtifactIdentifier(
+ mlrun.common.schemas.ArtifactIdentifier(
key=artifact_key, uid=artifact_uid
),
],
@@ -339,7 +339,7 @@ def test_delete_artifact_tags_with_invalid_characters(
client=client,
tag=invalid_tag_name,
identifiers=[
- mlrun.api.schemas.ArtifactIdentifier(
+ mlrun.common.schemas.ArtifactIdentifier(
key=artifact_key, uid=artifact_uid
),
],
@@ -369,7 +369,7 @@ def test_append_artifact_tags_by_uid_identifier(
client=client,
tag=new_tag,
identifiers=[
- mlrun.api.schemas.ArtifactIdentifier(uid=artifact1_uid),
+ mlrun.common.schemas.ArtifactIdentifier(uid=artifact1_uid),
],
)
assert response.status_code == http.HTTPStatus.OK.value
@@ -404,8 +404,8 @@ def test_append_artifact_tags_by_multiple_key_identifiers(
client=client,
tag=new_tag,
identifiers=[
- mlrun.api.schemas.ArtifactIdentifier(key=artifact1_key),
- mlrun.api.schemas.ArtifactIdentifier(key=artifact2_key),
+ mlrun.common.schemas.ArtifactIdentifier(key=artifact1_key),
+ mlrun.common.schemas.ArtifactIdentifier(key=artifact2_key),
],
)
assert response.status_code == http.HTTPStatus.OK.value
@@ -440,7 +440,7 @@ def test_append_artifact_existing_tag(
client=client,
tag=tag,
identifiers=[
- mlrun.api.schemas.ArtifactIdentifier(key=artifact1_key),
+ mlrun.common.schemas.ArtifactIdentifier(key=artifact1_key),
],
)
assert response.status_code == http.HTTPStatus.OK.value
@@ -470,7 +470,7 @@ def test_delete_artifact_tag_by_key_identifier(
client=client,
tag=tag,
identifiers=[
- mlrun.api.schemas.ArtifactIdentifier(key=artifact1_key),
+ mlrun.common.schemas.ArtifactIdentifier(key=artifact1_key),
],
)
assert response.status_code == http.HTTPStatus.NO_CONTENT.value
@@ -497,7 +497,7 @@ def test_delete_artifact_tag_by_uid_identifier(
client=client,
tag=tag,
identifiers=[
- mlrun.api.schemas.ArtifactIdentifier(uid=artifact1_uid),
+ mlrun.common.schemas.ArtifactIdentifier(uid=artifact1_uid),
],
)
assert response.status_code == http.HTTPStatus.NO_CONTENT.value
@@ -525,8 +525,8 @@ def test_delete_artifact_tag_by_multiple_key_identifiers(
client=client,
tag=tag,
identifiers=[
- mlrun.api.schemas.ArtifactIdentifier(key=artifact1_key),
- mlrun.api.schemas.ArtifactIdentifier(key=artifact2_key),
+ mlrun.common.schemas.ArtifactIdentifier(key=artifact1_key),
+ mlrun.common.schemas.ArtifactIdentifier(key=artifact2_key),
],
)
assert response.status_code == http.HTTPStatus.NO_CONTENT.value
@@ -553,8 +553,8 @@ def test_delete_artifact_tag_but_artifact_has_no_tag(
client=client,
tag=tag,
identifiers=[
- mlrun.api.schemas.ArtifactIdentifier(key=artifact1_key),
- mlrun.api.schemas.ArtifactIdentifier(key=artifact2_key),
+ mlrun.common.schemas.ArtifactIdentifier(key=artifact1_key),
+ mlrun.common.schemas.ArtifactIdentifier(key=artifact2_key),
],
)
assert response.status_code == http.HTTPStatus.NO_CONTENT.value
@@ -566,7 +566,7 @@ def _delete_artifact_tag(
client,
tag: str,
identifiers: typing.List[
- typing.Union[typing.Dict, mlrun.api.schemas.ArtifactIdentifier]
+ typing.Union[typing.Dict, mlrun.common.schemas.ArtifactIdentifier]
],
project: str = None,
):
@@ -583,7 +583,7 @@ def _append_artifact_tag(
client,
tag: str,
identifiers: typing.List[
- typing.Union[typing.Dict, mlrun.api.schemas.ArtifactIdentifier]
+ typing.Union[typing.Dict, mlrun.common.schemas.ArtifactIdentifier]
],
project: str = None,
):
@@ -597,7 +597,7 @@ def _overwrite_artifact_tags(
client,
tag: str,
identifiers: typing.List[
- typing.Union[typing.Dict, mlrun.api.schemas.ArtifactIdentifier]
+ typing.Union[typing.Dict, mlrun.common.schemas.ArtifactIdentifier]
],
project: str = None,
):
@@ -609,7 +609,7 @@ def _overwrite_artifact_tags(
@staticmethod
def _generate_tag_identifiers_json(
identifiers: typing.List[
- typing.Union[typing.Dict, mlrun.api.schemas.ArtifactIdentifier]
+ typing.Union[typing.Dict, mlrun.common.schemas.ArtifactIdentifier]
],
):
return {
@@ -617,7 +617,7 @@ def _generate_tag_identifiers_json(
"identifiers": [
(
identifier.dict()
- if isinstance(identifier, mlrun.api.schemas.ArtifactIdentifier)
+ if isinstance(identifier, mlrun.common.schemas.ArtifactIdentifier)
else identifier
)
for identifier in identifiers
@@ -649,11 +649,11 @@ def _assert_tag(artifacts, expected_tag):
def _create_project(
self, client: fastapi.testclient.TestClient, project_name: str = None
):
- project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(
+ project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(
name=project_name or self.project
),
- spec=mlrun.api.schemas.ProjectSpec(
+ spec=mlrun.common.schemas.ProjectSpec(
description="banana", source="source", goals="some goals"
),
)
diff --git a/tests/api/api/test_utils.py b/tests/api/api/test_utils.py
index 8eb1846bf4c5..847df6b2636c 100644
--- a/tests/api/api/test_utils.py
+++ b/tests/api/api/test_utils.py
@@ -25,9 +25,9 @@
import mlrun
import mlrun.api.crud
-import mlrun.api.schemas
import mlrun.api.utils.auth.verifier
import mlrun.api.utils.clients.iguazio
+import mlrun.common.schemas
import mlrun.k8s_utils
import mlrun.runtimes.pod
import tests.api.api.utils
@@ -40,7 +40,7 @@
ensure_function_security_context,
get_scheduler,
)
-from mlrun.api.schemas import SecurityContextEnrichmentModes
+from mlrun.common.schemas import SecurityContextEnrichmentModes
from mlrun.utils import logger
# Want to use k8s_secrets_mock for all tests in this module. It is needed since
@@ -50,7 +50,7 @@
def test_submit_run_sync(db: Session, client: TestClient):
- auth_info = mlrun.api.schemas.AuthInfo()
+ auth_info = mlrun.common.schemas.AuthInfo()
tests.api.api.utils.create_project(client, PROJECT)
project, function_name, function_tag, original_function = _mock_original_function(
client
@@ -242,7 +242,7 @@ def test_generate_function_and_task_from_submit_run_body_body_override_values(
},
}
parsed_function_object, task = _generate_function_and_task_from_submit_run_body(
- db, mlrun.api.schemas.AuthInfo(), submit_job_body
+ db, mlrun.common.schemas.AuthInfo(), submit_job_body
)
assert parsed_function_object.metadata.name == function_name
assert parsed_function_object.metadata.project == project
@@ -343,7 +343,7 @@ def test_generate_function_and_task_from_submit_run_with_preemptible_nodes_and_t
),
)
parsed_function_object, task = _generate_function_and_task_from_submit_run_body(
- db, mlrun.api.schemas.AuthInfo(), submit_job_body
+ db, mlrun.common.schemas.AuthInfo(), submit_job_body
)
assert (
parsed_function_object.spec.preemption_mode
@@ -372,7 +372,7 @@ def test_generate_function_and_task_from_submit_run_with_preemptible_nodes_and_t
"function": {"spec": {"preemption_mode": "constrain"}},
}
parsed_function_object, task = _generate_function_and_task_from_submit_run_body(
- db, mlrun.api.schemas.AuthInfo(), submit_job_body
+ db, mlrun.common.schemas.AuthInfo(), submit_job_body
)
expected_affinity = kubernetes.client.V1Affinity(
node_affinity=kubernetes.client.V1NodeAffinity(
@@ -407,7 +407,7 @@ def test_generate_function_and_task_from_submit_run_body_keep_resources(
"function": {"spec": {"resources": {"limits": {}, "requests": {}}}},
}
parsed_function_object, task = _generate_function_and_task_from_submit_run_body(
- db, mlrun.api.schemas.AuthInfo(), submit_job_body
+ db, mlrun.common.schemas.AuthInfo(), submit_job_body
)
assert parsed_function_object.metadata.name == function_name
assert parsed_function_object.metadata.project == PROJECT
@@ -448,7 +448,7 @@ def test_generate_function_and_task_from_submit_run_body_keep_credentials(
"function": {"metadata": {"credentials": None}},
}
parsed_function_object, task = _generate_function_and_task_from_submit_run_body(
- db, mlrun.api.schemas.AuthInfo(), submit_job_body
+ db, mlrun.common.schemas.AuthInfo(), submit_job_body
)
assert parsed_function_object.metadata.name == function_name
assert parsed_function_object.metadata.project == project
@@ -471,7 +471,7 @@ def test_ensure_function_has_auth_set(
)
original_function = mlrun.new_function(runtime=original_function_dict)
function = mlrun.new_function(runtime=original_function_dict)
- ensure_function_has_auth_set(function, mlrun.api.schemas.AuthInfo())
+ ensure_function_has_auth_set(function, mlrun.common.schemas.AuthInfo())
assert (
DeepDiff(
original_function.to_dict(),
@@ -494,7 +494,7 @@ def test_ensure_function_has_auth_set(
unittest.mock.Mock(return_value=access_key)
)
ensure_function_has_auth_set(
- function, mlrun.api.schemas.AuthInfo(username=username)
+ function, mlrun.common.schemas.AuthInfo(username=username)
)
assert (
DeepDiff(
@@ -519,7 +519,7 @@ def test_ensure_function_has_auth_set(
function,
mlrun.runtimes.constants.FunctionEnvironmentVariables.auth_session,
secret_name,
- mlrun.api.schemas.AuthSecretData.get_field_secret_key("access_key"),
+ mlrun.common.schemas.AuthSecretData.get_field_secret_key("access_key"),
)
logger.info("No access key - explode")
@@ -531,7 +531,7 @@ def test_ensure_function_has_auth_set(
mlrun.errors.MLRunInvalidArgumentError,
match=r"(.*)Function access key must be set(.*)",
):
- ensure_function_has_auth_set(function, mlrun.api.schemas.AuthInfo())
+ ensure_function_has_auth_set(function, mlrun.common.schemas.AuthInfo())
logger.info("Access key without username - explode")
_, _, _, original_function_dict = _generate_original_function(
@@ -541,7 +541,7 @@ def test_ensure_function_has_auth_set(
with pytest.raises(
mlrun.errors.MLRunInvalidArgumentError, match=r"(.*)Username is missing(.*)"
):
- ensure_function_has_auth_set(function, mlrun.api.schemas.AuthInfo())
+ ensure_function_has_auth_set(function, mlrun.common.schemas.AuthInfo())
logger.info("Access key ref provided - env should be set")
secret_name = "some-access-key-secret-name"
@@ -552,7 +552,7 @@ def test_ensure_function_has_auth_set(
)
original_function = mlrun.new_function(runtime=original_function_dict)
function = mlrun.new_function(runtime=original_function_dict)
- ensure_function_has_auth_set(function, mlrun.api.schemas.AuthInfo())
+ ensure_function_has_auth_set(function, mlrun.common.schemas.AuthInfo())
assert (
DeepDiff(
original_function.to_dict(),
@@ -567,7 +567,7 @@ def test_ensure_function_has_auth_set(
function,
mlrun.runtimes.constants.FunctionEnvironmentVariables.auth_session,
secret_name,
- mlrun.api.schemas.AuthSecretData.get_field_secret_key("access_key"),
+ mlrun.common.schemas.AuthSecretData.get_field_secret_key("access_key"),
)
logger.info(
@@ -582,7 +582,7 @@ def test_ensure_function_has_auth_set(
original_function = mlrun.new_function(runtime=original_function_dict)
function = mlrun.new_function(runtime=original_function_dict)
ensure_function_has_auth_set(
- function, mlrun.api.schemas.AuthInfo(username=username)
+ function, mlrun.common.schemas.AuthInfo(username=username)
)
secret_name = k8s_secrets_mock.get_auth_secret_name(username, access_key)
k8s_secrets_mock.assert_auth_secret(secret_name, username, access_key)
@@ -608,7 +608,7 @@ def test_ensure_function_has_auth_set(
function,
mlrun.runtimes.constants.FunctionEnvironmentVariables.auth_session,
secret_name,
- mlrun.api.schemas.AuthSecretData.get_field_secret_key("access_key"),
+ mlrun.common.schemas.AuthSecretData.get_field_secret_key("access_key"),
)
@@ -621,7 +621,7 @@ def test_mask_v3io_access_key_env_var(
_, _, _, original_function_dict = _generate_original_function()
original_function = mlrun.new_function(runtime=original_function_dict)
function = mlrun.new_function(runtime=original_function_dict)
- _mask_v3io_access_key_env_var(function, mlrun.api.schemas.AuthInfo())
+ _mask_v3io_access_key_env_var(function, mlrun.common.schemas.AuthInfo())
assert (
DeepDiff(
original_function.to_dict(),
@@ -646,7 +646,7 @@ def test_mask_v3io_access_key_env_var(
mlrun.errors.MLRunInvalidArgumentError,
match=r"(.*)Username is missing(.*)",
):
- _mask_v3io_access_key_env_var(function, mlrun.api.schemas.AuthInfo())
+ _mask_v3io_access_key_env_var(function, mlrun.common.schemas.AuthInfo())
logger.info(
"Mask function with access key without username when iguazio auth off - skip"
@@ -659,7 +659,7 @@ def test_mask_v3io_access_key_env_var(
)
original_function = mlrun.new_function(runtime=original_function_dict)
function = mlrun.new_function(runtime=original_function_dict)
- _mask_v3io_access_key_env_var(function, mlrun.api.schemas.AuthInfo())
+ _mask_v3io_access_key_env_var(function, mlrun.common.schemas.AuthInfo())
assert (
DeepDiff(
original_function.to_dict(),
@@ -681,7 +681,7 @@ def test_mask_v3io_access_key_env_var(
function: mlrun.runtimes.pod.KubeResource = mlrun.new_function(
runtime=original_function_dict
)
- _mask_v3io_access_key_env_var(function, mlrun.api.schemas.AuthInfo())
+ _mask_v3io_access_key_env_var(function, mlrun.common.schemas.AuthInfo())
assert (
DeepDiff(
original_function.to_dict(),
@@ -698,14 +698,14 @@ def test_mask_v3io_access_key_env_var(
function,
"V3IO_ACCESS_KEY",
secret_name,
- mlrun.api.schemas.AuthSecretData.get_field_secret_key("access_key"),
+ mlrun.common.schemas.AuthSecretData.get_field_secret_key("access_key"),
)
logger.info(
"mask same function again, access key is already a reference - nothing should change"
)
original_function = mlrun.new_function(runtime=function)
- _mask_v3io_access_key_env_var(function, mlrun.api.schemas.AuthInfo())
+ _mask_v3io_access_key_env_var(function, mlrun.common.schemas.AuthInfo())
mlrun.api.crud.Secrets().store_auth_secret = unittest.mock.Mock()
assert (
DeepDiff(
@@ -724,7 +724,7 @@ def test_mask_v3io_access_key_env_var(
function.spec.env.append(function.spec.env.pop().to_dict())
original_function = mlrun.new_function(runtime=function)
_mask_v3io_access_key_env_var(
- function, mlrun.api.schemas.AuthInfo(username=username)
+ function, mlrun.common.schemas.AuthInfo(username=username)
)
mlrun.api.crud.Secrets().store_auth_secret = unittest.mock.Mock()
assert (
@@ -904,7 +904,7 @@ def test_ensure_function_security_context_no_enrichment(
db: Session, client: TestClient
):
tests.api.api.utils.create_project(client, PROJECT)
- auth_info = mlrun.api.schemas.AuthInfo(user_unix_id=1000)
+ auth_info = mlrun.common.schemas.AuthInfo(user_unix_id=1000)
mlrun.mlconf.igz_version = "3.6"
logger.info("Enrichment mode is disabled, nothing should be changed")
@@ -955,7 +955,7 @@ def test_ensure_function_security_context_no_enrichment(
)
original_function = mlrun.new_function(runtime=original_function_dict_job_kind)
function = mlrun.new_function(runtime=original_function_dict_job_kind)
- ensure_function_security_context(function, mlrun.api.schemas.AuthInfo())
+ ensure_function_security_context(function, mlrun.common.schemas.AuthInfo())
assert (
DeepDiff(
original_function.to_dict(),
@@ -977,7 +977,7 @@ def test_ensure_function_security_context_override_enrichment_mode(
logger.info("Enrichment mode is override, security context should be enriched")
mlrun.api.utils.clients.iguazio.Client.get_user_unix_id = unittest.mock.Mock()
- auth_info = mlrun.api.schemas.AuthInfo(user_unix_id=1000)
+ auth_info = mlrun.common.schemas.AuthInfo(user_unix_id=1000)
_, _, _, original_function_dict = _generate_original_function(
kind=mlrun.runtimes.RuntimeKinds.job
)
@@ -1024,7 +1024,7 @@ def test_ensure_function_security_context_enrichment_group_id(
mlrun.mlconf.function.spec.security_context.enrichment_mode = (
SecurityContextEnrichmentModes.override.value
)
- auth_info = mlrun.api.schemas.AuthInfo(user_unix_id=1000)
+ auth_info = mlrun.common.schemas.AuthInfo(user_unix_id=1000)
_, _, _, original_function_dict = _generate_original_function(
kind=mlrun.runtimes.RuntimeKinds.job
)
@@ -1075,7 +1075,7 @@ def test_ensure_function_security_context_unknown_enrichment_mode(
tests.api.api.utils.create_project(client, PROJECT)
mlrun.mlconf.igz_version = "3.6"
mlrun.mlconf.function.spec.security_context.enrichment_mode = "not a real mode"
- auth_info = mlrun.api.schemas.AuthInfo(user_unix_id=1000)
+ auth_info = mlrun.common.schemas.AuthInfo(user_unix_id=1000)
_, _, _, original_function_dict = _generate_original_function(
kind=mlrun.runtimes.RuntimeKinds.job
)
@@ -1098,7 +1098,7 @@ def test_ensure_function_security_context_missing_control_plane_session_tag(
mlrun.mlconf.function.spec.security_context.enrichment_mode = (
SecurityContextEnrichmentModes.override
)
- auth_info = mlrun.api.schemas.AuthInfo(
+ auth_info = mlrun.common.schemas.AuthInfo(
planes=[mlrun.api.utils.clients.iguazio.SessionPlanes.data]
)
_, _, _, original_function_dict = _generate_original_function(
@@ -1121,7 +1121,7 @@ def test_ensure_function_security_context_missing_control_plane_session_tag(
mlrun.api.utils.clients.iguazio.Client.get_user_unix_id = unittest.mock.Mock(
return_value=user_unix_id
)
- auth_info = mlrun.api.schemas.AuthInfo(planes=[])
+ auth_info = mlrun.common.schemas.AuthInfo(planes=[])
logger.info(
"Session missing control plane, but actually just because it wasn't enriched, expected to succeed"
)
@@ -1142,7 +1142,7 @@ def test_ensure_function_security_context_get_user_unix_id(
)
# set auth info with control plane and without user unix id so that it will be fetched
- auth_info = mlrun.api.schemas.AuthInfo(
+ auth_info = mlrun.common.schemas.AuthInfo(
planes=[mlrun.api.utils.clients.iguazio.SessionPlanes.control]
)
mlrun.api.utils.clients.iguazio.Client.get_user_unix_id = unittest.mock.Mock(
@@ -1187,7 +1187,7 @@ def test_generate_function_and_task_from_submit_run_body_imported_function_proje
"function": {"spec": {"resources": {"limits": {}, "requests": {}}}},
}
parsed_function_object, task = _generate_function_and_task_from_submit_run_body(
- db, mlrun.api.schemas.AuthInfo(), submit_job_body
+ db, mlrun.common.schemas.AuthInfo(), submit_job_body
)
assert parsed_function_object.metadata.project == PROJECT
diff --git a/tests/api/api/utils.py b/tests/api/api/utils.py
index 1d2414c69a43..3fd608cd1be1 100644
--- a/tests/api/api/utils.py
+++ b/tests/api/api/utils.py
@@ -20,12 +20,12 @@
import mlrun.api.api.endpoints.functions
import mlrun.api.crud
-import mlrun.api.schemas
import mlrun.api.utils
import mlrun.api.utils.singletons.db
import mlrun.api.utils.singletons.k8s
import mlrun.artifacts.dataset
import mlrun.artifacts.model
+import mlrun.common.schemas
import mlrun.errors
PROJECT = "project-name"
@@ -41,11 +41,11 @@ def create_project(client: TestClient, project_name: str = PROJECT, artifact_pat
def compile_schedule(schedule_name: str = None, to_json: bool = True):
if not schedule_name:
schedule_name = f"schedule-name-{str(uuid.uuid4())}"
- schedule = mlrun.api.schemas.ScheduleInput(
+ schedule = mlrun.common.schemas.ScheduleInput(
name=schedule_name,
- kind=mlrun.api.schemas.ScheduleKinds.job,
+ kind=mlrun.common.schemas.ScheduleKinds.job,
scheduled_object={"metadata": {"name": "something"}},
- cron_trigger=mlrun.api.schemas.ScheduleCronTrigger(year=1999),
+ cron_trigger=mlrun.common.schemas.ScheduleCronTrigger(year=1999),
)
if not to_json:
return schedule
@@ -55,9 +55,9 @@ def compile_schedule(schedule_name: str = None, to_json: bool = True):
async def create_project_async(
async_client: httpx.AsyncClient, project_name: str = PROJECT
):
- project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=project_name),
- spec=mlrun.api.schemas.ProjectSpec(
+ project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=project_name),
+ spec=mlrun.common.schemas.ProjectSpec(
description="banana", source="source", goals="some goals"
),
)
@@ -69,10 +69,10 @@ async def create_project_async(
return resp
-def _create_project_obj(project_name, artifact_path) -> mlrun.api.schemas.Project:
- return mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=project_name),
- spec=mlrun.api.schemas.ProjectSpec(
+def _create_project_obj(project_name, artifact_path) -> mlrun.common.schemas.Project:
+ return mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=project_name),
+ spec=mlrun.common.schemas.ProjectSpec(
description="banana",
source="source",
goals="some goals",
diff --git a/tests/api/conftest.py b/tests/api/conftest.py
index a42cadbe1e3b..57cf75071313 100644
--- a/tests/api/conftest.py
+++ b/tests/api/conftest.py
@@ -23,8 +23,8 @@
import pytest
from fastapi.testclient import TestClient
-import mlrun.api.schemas
import mlrun.api.utils.singletons.k8s
+import mlrun.common.schemas
from mlrun import mlconf
from mlrun.api.db.sqldb.session import _init_engine, create_session
from mlrun.api.initial_data import init_data
@@ -134,8 +134,10 @@ def store_auth_secret(self, username: str, access_key: str, namespace="") -> str
@staticmethod
def _generate_auth_secret_data(username: str, access_key: str):
return {
- mlrun.api.schemas.AuthSecretData.get_field_secret_key("username"): username,
- mlrun.api.schemas.AuthSecretData.get_field_secret_key(
+ mlrun.common.schemas.AuthSecretData.get_field_secret_key(
+ "username"
+ ): username,
+ mlrun.common.schemas.AuthSecretData.get_field_secret_key(
"access_key"
): access_key,
}
@@ -153,10 +155,10 @@ def read_auth_secret(self, secret_name, namespace="", raise_on_not_found=False):
return None, None
username = secret[
- mlrun.api.schemas.AuthSecretData.get_field_secret_key("username")
+ mlrun.common.schemas.AuthSecretData.get_field_secret_key("username")
]
access_key = secret[
- mlrun.api.schemas.AuthSecretData.get_field_secret_key("access_key")
+ mlrun.common.schemas.AuthSecretData.get_field_secret_key("access_key")
]
return username, access_key
diff --git a/tests/api/crud/test_secrets.py b/tests/api/crud/test_secrets.py
index 438452319735..9d9d02d0b843 100644
--- a/tests/api/crud/test_secrets.py
+++ b/tests/api/crud/test_secrets.py
@@ -22,7 +22,7 @@
import sqlalchemy.orm
import mlrun.api.crud
-import mlrun.api.schemas
+import mlrun.common.schemas
import mlrun.errors
import tests.api.conftest
@@ -31,11 +31,11 @@ def test_store_project_secrets_verifications(
db: sqlalchemy.orm.Session, client: fastapi.testclient.TestClient
):
project = "project-name"
- provider = mlrun.api.schemas.SecretProviderName.kubernetes
+ provider = mlrun.common.schemas.SecretProviderName.kubernetes
with pytest.raises(mlrun.errors.MLRunInvalidArgumentError):
mlrun.api.crud.Secrets().store_project_secrets(
project,
- mlrun.api.schemas.SecretsData(
+ mlrun.common.schemas.SecretsData(
provider=provider, secrets={"invalid/key": "value"}
),
)
@@ -43,7 +43,7 @@ def test_store_project_secrets_verifications(
with pytest.raises(mlrun.errors.MLRunAccessDeniedError):
mlrun.api.crud.Secrets().store_project_secrets(
project,
- mlrun.api.schemas.SecretsData(
+ mlrun.common.schemas.SecretsData(
provider=provider, secrets={"mlrun.internal.key": "value"}
),
)
@@ -55,7 +55,7 @@ def test_store_project_secrets_with_key_map_verifications(
k8s_secrets_mock: tests.api.conftest.K8sSecretsMock,
):
project = "project-name"
- provider = mlrun.api.schemas.SecretProviderName.kubernetes
+ provider = mlrun.common.schemas.SecretProviderName.kubernetes
key_map_secret_key = (
mlrun.api.crud.Secrets().generate_client_key_map_project_secret_key(
mlrun.api.crud.SecretsClientType.schedules
@@ -65,7 +65,7 @@ def test_store_project_secrets_with_key_map_verifications(
with pytest.raises(mlrun.errors.MLRunAccessDeniedError):
mlrun.api.crud.Secrets().store_project_secrets(
project,
- mlrun.api.schemas.SecretsData(
+ mlrun.common.schemas.SecretsData(
provider=provider, secrets={key_map_secret_key: "value"}
),
)
@@ -74,8 +74,8 @@ def test_store_project_secrets_with_key_map_verifications(
with pytest.raises(mlrun.errors.MLRunInvalidArgumentError):
mlrun.api.crud.Secrets().store_project_secrets(
project,
- mlrun.api.schemas.SecretsData(
- provider=mlrun.api.schemas.SecretProviderName.vault,
+ mlrun.common.schemas.SecretsData(
+ provider=mlrun.common.schemas.SecretProviderName.vault,
secrets={"invalid/key": "value"},
),
)
@@ -84,7 +84,7 @@ def test_store_project_secrets_with_key_map_verifications(
with pytest.raises(mlrun.errors.MLRunInvalidArgumentError):
mlrun.api.crud.Secrets().store_project_secrets(
project,
- mlrun.api.schemas.SecretsData(
+ mlrun.common.schemas.SecretsData(
provider=provider, secrets={"invalid/key": "value"}
),
key_map_secret_key="invalid-key-map-secret-key",
@@ -94,7 +94,7 @@ def test_store_project_secrets_with_key_map_verifications(
with pytest.raises(mlrun.errors.MLRunInvalidArgumentError):
mlrun.api.crud.Secrets().store_project_secrets(
project,
- mlrun.api.schemas.SecretsData(
+ mlrun.common.schemas.SecretsData(
provider=provider, secrets={"invalid/key": "value"}
),
allow_internal_secrets=True,
@@ -105,7 +105,7 @@ def test_store_project_secrets_with_key_map_verifications(
with pytest.raises(mlrun.errors.MLRunAccessDeniedError):
mlrun.api.crud.Secrets().store_project_secrets(
project,
- mlrun.api.schemas.SecretsData(
+ mlrun.common.schemas.SecretsData(
provider=provider, secrets={"valid-key": "value"}
),
key_map_secret_key=key_map_secret_key,
@@ -118,7 +118,7 @@ def test_get_project_secret_verifications(
k8s_secrets_mock: tests.api.conftest.K8sSecretsMock,
):
project = "project-name"
- provider = mlrun.api.schemas.SecretProviderName.kubernetes
+ provider = mlrun.common.schemas.SecretProviderName.kubernetes
key_map_secret_key = (
mlrun.api.crud.Secrets().generate_client_key_map_project_secret_key(
mlrun.api.crud.SecretsClientType.schedules
@@ -136,7 +136,7 @@ def test_get_project_secret_verifications(
with pytest.raises(mlrun.errors.MLRunInvalidArgumentError):
mlrun.api.crud.Secrets().get_project_secret(
project,
- mlrun.api.schemas.SecretProviderName.vault,
+ mlrun.common.schemas.SecretProviderName.vault,
"does-not-exist-key",
key_map_secret_key=key_map_secret_key,
)
@@ -149,7 +149,7 @@ def test_get_project_secret(
):
_mock_secrets_crud_uuid_generation()
project = "project-name"
- provider = mlrun.api.schemas.SecretProviderName.kubernetes
+ provider = mlrun.common.schemas.SecretProviderName.kubernetes
key_map_secret_key = (
mlrun.api.crud.Secrets().generate_client_key_map_project_secret_key(
mlrun.api.crud.SecretsClientType.schedules
@@ -183,7 +183,7 @@ def test_get_project_secret(
mlrun.api.crud.Secrets().store_project_secrets(
project,
- mlrun.api.schemas.SecretsData(
+ mlrun.common.schemas.SecretsData(
provider=provider,
secrets={
valid_secret_key: valid_secret_value,
@@ -231,7 +231,7 @@ def test_delete_project_secret_verifications(
k8s_secrets_mock: tests.api.conftest.K8sSecretsMock,
):
project = "project-name"
- provider = mlrun.api.schemas.SecretProviderName.kubernetes
+ provider = mlrun.common.schemas.SecretProviderName.kubernetes
key_map_secret_key = (
mlrun.api.crud.Secrets().generate_client_key_map_project_secret_key(
mlrun.api.crud.SecretsClientType.schedules
@@ -249,14 +249,14 @@ def test_delete_project_secret_verifications(
# vault provider
with pytest.raises(mlrun.errors.MLRunInvalidArgumentError):
mlrun.api.crud.Secrets().delete_project_secret(
- project, mlrun.api.schemas.SecretProviderName.vault, "valid-key"
+ project, mlrun.common.schemas.SecretProviderName.vault, "valid-key"
)
# key map with provider other than k8s
with pytest.raises(mlrun.errors.MLRunInvalidArgumentError):
mlrun.api.crud.Secrets().delete_project_secret(
project,
- mlrun.api.schemas.SecretProviderName.vault,
+ mlrun.common.schemas.SecretProviderName.vault,
"invalid/key",
key_map_secret_key=key_map_secret_key,
)
@@ -275,7 +275,7 @@ def test_delete_project_secret(
):
_mock_secrets_crud_uuid_generation()
project = "project-name"
- provider = mlrun.api.schemas.SecretProviderName.kubernetes
+ provider = mlrun.common.schemas.SecretProviderName.kubernetes
key_map_secret_key = (
mlrun.api.crud.Secrets().generate_client_key_map_project_secret_key(
mlrun.api.crud.SecretsClientType.schedules
@@ -295,7 +295,7 @@ def test_delete_project_secret(
mlrun.api.crud.Secrets().store_project_secrets(
project,
- mlrun.api.schemas.SecretsData(
+ mlrun.common.schemas.SecretsData(
provider=provider,
secrets=collections.OrderedDict(
{
@@ -370,7 +370,7 @@ def test_store_project_secrets_with_key_map_success(
):
_mock_secrets_crud_uuid_generation()
project = "project-name"
- provider = mlrun.api.schemas.SecretProviderName.kubernetes
+ provider = mlrun.common.schemas.SecretProviderName.kubernetes
key_map_secret_key = (
mlrun.api.crud.Secrets().generate_client_key_map_project_secret_key(
mlrun.api.crud.SecretsClientType.schedules
@@ -389,7 +389,7 @@ def test_store_project_secrets_with_key_map_success(
# store secret with valid key - map shouldn't be used
mlrun.api.crud.Secrets().store_project_secrets(
project,
- mlrun.api.schemas.SecretsData(
+ mlrun.common.schemas.SecretsData(
provider=provider, secrets={valid_secret_key: valid_secret_value}
),
allow_internal_secrets=True,
@@ -402,7 +402,7 @@ def test_store_project_secrets_with_key_map_success(
# store secret with invalid key - map should be used
mlrun.api.crud.Secrets().store_project_secrets(
project,
- mlrun.api.schemas.SecretsData(
+ mlrun.common.schemas.SecretsData(
provider=provider, secrets={invalid_secret_key: invalid_secret_value}
),
allow_internal_secrets=True,
@@ -420,7 +420,7 @@ def test_store_project_secrets_with_key_map_success(
# store secret with the same invalid key and different value
mlrun.api.crud.Secrets().store_project_secrets(
project,
- mlrun.api.schemas.SecretsData(
+ mlrun.common.schemas.SecretsData(
provider=provider, secrets={invalid_secret_key: invalid_secret_value_2}
),
allow_internal_secrets=True,
@@ -439,7 +439,7 @@ def test_store_project_secrets_with_key_map_success(
for _ in range(2):
mlrun.api.crud.Secrets().store_project_secrets(
project,
- mlrun.api.schemas.SecretsData(
+ mlrun.common.schemas.SecretsData(
provider=provider,
secrets={invalid_secret_2_key: invalid_secret_2_value},
),
@@ -461,7 +461,7 @@ def test_store_project_secrets_with_key_map_success(
# change values to all secrets
mlrun.api.crud.Secrets().store_project_secrets(
project,
- mlrun.api.schemas.SecretsData(
+ mlrun.common.schemas.SecretsData(
provider=provider,
secrets={
valid_secret_key: valid_secret_value_2,
@@ -502,7 +502,7 @@ def test_secrets_crud_internal_project_secrets(
k8s_secrets_mock: tests.api.conftest.K8sSecretsMock,
):
project = "project-name"
- provider = mlrun.api.schemas.SecretProviderName.kubernetes
+ provider = mlrun.common.schemas.SecretProviderName.kubernetes
regular_secret_key = "key"
regular_secret_value = "value"
internal_secret_key = (
@@ -513,7 +513,7 @@ def test_secrets_crud_internal_project_secrets(
# store regular secret - pass
mlrun.api.crud.Secrets().store_project_secrets(
project,
- mlrun.api.schemas.SecretsData(
+ mlrun.common.schemas.SecretsData(
provider=provider, secrets={regular_secret_key: regular_secret_value}
),
)
@@ -522,7 +522,7 @@ def test_secrets_crud_internal_project_secrets(
with pytest.raises(mlrun.errors.MLRunAccessDeniedError):
mlrun.api.crud.Secrets().store_project_secrets(
project,
- mlrun.api.schemas.SecretsData(
+ mlrun.common.schemas.SecretsData(
provider=provider, secrets={internal_secret_key: internal_secret_value}
),
)
@@ -530,7 +530,7 @@ def test_secrets_crud_internal_project_secrets(
# store internal secret with allow - pass
mlrun.api.crud.Secrets().store_project_secrets(
project,
- mlrun.api.schemas.SecretsData(
+ mlrun.common.schemas.SecretsData(
provider=provider, secrets={internal_secret_key: internal_secret_value}
),
allow_internal_secrets=True,
@@ -634,7 +634,7 @@ def test_secrets_crud_internal_project_secrets(
# store internal secret again to verify deletion with empty list with allow - pass
mlrun.api.crud.Secrets().store_project_secrets(
project,
- mlrun.api.schemas.SecretsData(
+ mlrun.common.schemas.SecretsData(
provider=provider, secrets={internal_secret_key: internal_secret_value}
),
allow_internal_secrets=True,
@@ -666,8 +666,8 @@ def test_store_auth_secret_verifications(
# not allowed with provider other than k8s
with pytest.raises(mlrun.errors.MLRunInvalidArgumentError):
mlrun.api.crud.Secrets().store_auth_secret(
- mlrun.api.schemas.AuthSecretData(
- provider=mlrun.api.schemas.SecretProviderName.vault,
+ mlrun.common.schemas.AuthSecretData(
+ provider=mlrun.common.schemas.SecretProviderName.vault,
username="some-username",
access_key="some-access-key",
),
@@ -682,8 +682,8 @@ def test_store_auth_secret(
username = "some-username"
access_key = "some-access-key"
secret_name = mlrun.api.crud.Secrets().store_auth_secret(
- mlrun.api.schemas.AuthSecretData(
- provider=mlrun.api.schemas.SecretProviderName.kubernetes,
+ mlrun.common.schemas.AuthSecretData(
+ provider=mlrun.common.schemas.SecretProviderName.kubernetes,
username=username,
access_key=access_key,
),
diff --git a/tests/api/db/test_artifacts.py b/tests/api/db/test_artifacts.py
index 8d3b47f1847b..ebc04d25a57f 100644
--- a/tests/api/db/test_artifacts.py
+++ b/tests/api/db/test_artifacts.py
@@ -19,13 +19,13 @@
from sqlalchemy.orm import Session
import mlrun.api.initial_data
+import mlrun.common.schemas
import mlrun.errors
-from mlrun.api import schemas
from mlrun.api.db.base import DBInterface
-from mlrun.api.schemas.artifact import ArtifactCategories
from mlrun.artifacts.dataset import DatasetArtifact
from mlrun.artifacts.model import ModelArtifact
from mlrun.artifacts.plots import ChartArtifact, PlotArtifact
+from mlrun.common.schemas.artifact import ArtifactCategories
def test_list_artifact_name_filter(db: DBInterface, db_session: Session):
@@ -171,17 +171,21 @@ def test_list_artifact_category_filter(db: DBInterface, db_session: Session):
artifacts = db.list_artifacts(db_session)
assert len(artifacts) == 4
- artifacts = db.list_artifacts(db_session, category=schemas.ArtifactCategories.model)
+ artifacts = db.list_artifacts(
+ db_session, category=mlrun.common.schemas.ArtifactCategories.model
+ )
assert len(artifacts) == 1
assert artifacts[0]["metadata"]["name"] == artifact_name_3
artifacts = db.list_artifacts(
- db_session, category=schemas.ArtifactCategories.dataset
+ db_session, category=mlrun.common.schemas.ArtifactCategories.dataset
)
assert len(artifacts) == 1
assert artifacts[0]["metadata"]["name"] == artifact_name_4
- artifacts = db.list_artifacts(db_session, category=schemas.ArtifactCategories.other)
+ artifacts = db.list_artifacts(
+ db_session, category=mlrun.common.schemas.ArtifactCategories.other
+ )
assert len(artifacts) == 2
assert artifacts[0]["metadata"]["name"] == artifact_name_1
assert artifacts[1]["metadata"]["name"] == artifact_name_2
@@ -540,13 +544,13 @@ def test_list_artifacts_best_iter_with_tagged_iteration(
project=project,
)
- identifier_1 = schemas.ArtifactIdentifier(
+ identifier_1 = mlrun.common.schemas.ArtifactIdentifier(
kind=ArtifactCategories.model,
key=artifact_key_1,
uid=artifact_uid_1,
iter=best_iter,
)
- identifier_2 = schemas.ArtifactIdentifier(
+ identifier_2 = mlrun.common.schemas.ArtifactIdentifier(
kind=ArtifactCategories.model,
key=artifact_key_2,
uid=artifact_uid_2,
diff --git a/tests/api/db/test_background_tasks.py b/tests/api/db/test_background_tasks.py
index ea199b50b4fa..86ed054d79fe 100644
--- a/tests/api/db/test_background_tasks.py
+++ b/tests/api/db/test_background_tasks.py
@@ -18,8 +18,8 @@
from sqlalchemy.orm import Session
import mlrun.api.initial_data
+import mlrun.common.schemas
import mlrun.errors
-from mlrun.api import schemas
from mlrun.api.db.base import DBInterface
@@ -57,20 +57,27 @@ def test_store_project_background_task_after_status_updated(
project = "test-project"
db.store_background_task(db_session, "test", project=project)
background_task = db.get_background_task(db_session, "test", project=project)
- assert background_task.status.state == schemas.BackgroundTaskState.running
+ assert (
+ background_task.status.state == mlrun.common.schemas.BackgroundTaskState.running
+ )
db.store_background_task(
- db_session, "test", state=schemas.BackgroundTaskState.failed, project=project
+ db_session,
+ "test",
+ state=mlrun.common.schemas.BackgroundTaskState.failed,
+ project=project,
)
background_task = db.get_background_task(db_session, "test", project=project)
- assert background_task.status.state == schemas.BackgroundTaskState.failed
+ assert (
+ background_task.status.state == mlrun.common.schemas.BackgroundTaskState.failed
+ )
# Expecting to fail
with pytest.raises(mlrun.errors.MLRunRuntimeError):
db.store_background_task(
db_session,
"test",
- state=schemas.BackgroundTaskState.running,
+ state=mlrun.common.schemas.BackgroundTaskState.running,
project=project,
)
# expecting to fail, because terminal state is terminal which means it is not supposed to change
@@ -78,12 +85,15 @@ def test_store_project_background_task_after_status_updated(
db.store_background_task(
db_session,
"test",
- state=schemas.BackgroundTaskState.succeeded,
+ state=mlrun.common.schemas.BackgroundTaskState.succeeded,
project=project,
)
db.store_background_task(
- db_session, "test", state=schemas.BackgroundTaskState.failed, project=project
+ db_session,
+ "test",
+ state=mlrun.common.schemas.BackgroundTaskState.failed,
+ project=project,
)
@@ -102,25 +112,29 @@ def test_get_project_background_task_with_disabled_timeout(
assert background_task.metadata.timeout is None
# expecting created and updated time to be equal because mode disabled even if timeout exceeded
assert background_task.metadata.created == background_task.metadata.updated
- assert background_task.status.state == mlrun.api.schemas.BackgroundTaskState.running
+ assert (
+ background_task.status.state == mlrun.common.schemas.BackgroundTaskState.running
+ )
task_name = "test1"
db.store_background_task(db_session, name=task_name, project=project)
# because timeout default mode is disabled, expecting not to enrich the background task timeout
background_task = db.get_background_task(db_session, task_name, project)
assert background_task.metadata.timeout is None
assert background_task.metadata.created == background_task.metadata.updated
- assert background_task.status.state == mlrun.api.schemas.BackgroundTaskState.running
+ assert (
+ background_task.status.state == mlrun.common.schemas.BackgroundTaskState.running
+ )
db.store_background_task(
db_session,
name=task_name,
project=project,
- state=mlrun.api.schemas.BackgroundTaskState.succeeded,
+ state=mlrun.common.schemas.BackgroundTaskState.succeeded,
)
background_task_new = db.get_background_task(db_session, task_name, project)
assert (
background_task_new.status.state
- == mlrun.api.schemas.BackgroundTaskState.succeeded
+ == mlrun.common.schemas.BackgroundTaskState.succeeded
)
assert background_task_new.metadata.updated > background_task.metadata.updated
assert background_task_new.metadata.created == background_task.metadata.created
diff --git a/tests/api/db/test_feature_sets.py b/tests/api/db/test_feature_sets.py
index 5b595f0b52d6..3c62bbef209b 100644
--- a/tests/api/db/test_feature_sets.py
+++ b/tests/api/db/test_feature_sets.py
@@ -16,10 +16,10 @@
import pytest
from sqlalchemy.orm import Session
+import mlrun.common.schemas
import mlrun.feature_store as fstore
import mlrun.utils.helpers
from mlrun import errors
-from mlrun.api import schemas
from mlrun.api.db.base import DBInterface
@@ -64,7 +64,7 @@ def test_create_feature_set(db: DBInterface, db_session: Session):
project = "proj-test"
- feature_set = schemas.FeatureSet(**feature_set)
+ feature_set = mlrun.common.schemas.FeatureSet(**feature_set)
db.store_feature_set(
db_session, project, name, feature_set, tag="latest", versioned=True
)
@@ -86,7 +86,7 @@ def test_handle_feature_set_with_datetime_fields(db: DBInterface, db_session: Se
# This object will have datetime in the spec.source object fields
fs_object = fstore.FeatureSet.from_dict(feature_set)
# Convert it to DB schema object (will still have datetime fields)
- fs_server_object = schemas.FeatureSet(**fs_object.to_dict())
+ fs_server_object = mlrun.common.schemas.FeatureSet(**fs_object.to_dict())
mlrun.utils.helpers.fill_object_hash(fs_server_object.dict(), "uid")
@@ -96,7 +96,7 @@ def test_update_feature_set_labels(db: DBInterface, db_session: Session):
project = "proj-test"
- feature_set = schemas.FeatureSet(**feature_set)
+ feature_set = mlrun.common.schemas.FeatureSet(**feature_set)
db.store_feature_set(
db_session, project, name, feature_set, tag="latest", versioned=True
)
@@ -153,7 +153,7 @@ def test_update_feature_set_by_uid(db: DBInterface, db_session: Session):
project = "proj-test"
- feature_set = schemas.FeatureSet(**feature_set)
+ feature_set = mlrun.common.schemas.FeatureSet(**feature_set)
db.store_feature_set(
db_session, project, name, feature_set, tag="latest", versioned=True
)
diff --git a/tests/api/db/test_projects.py b/tests/api/db/test_projects.py
index cc05323450c5..211c8144cf7f 100644
--- a/tests/api/db/test_projects.py
+++ b/tests/api/db/test_projects.py
@@ -20,8 +20,8 @@
import sqlalchemy.orm
import mlrun.api.initial_data
-import mlrun.api.schemas
import mlrun.api.utils.singletons.db
+import mlrun.common.schemas
import mlrun.config
import mlrun.errors
from mlrun.api.db.base import DBInterface
@@ -39,11 +39,11 @@ def test_get_project(
}
db.create_project(
db_session,
- mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(
+ mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(
name=project_name, labels=project_labels
),
- spec=mlrun.api.schemas.ProjectSpec(description=project_description),
+ spec=mlrun.common.schemas.ProjectSpec(description=project_description),
),
)
@@ -92,12 +92,12 @@ def test_data_migration_enrich_project_state(
projects = db.list_projects(db_session)
for project in projects.projects:
# getting default value from the schema
- assert project.spec.desired_state == mlrun.api.schemas.ProjectState.online
+ assert project.spec.desired_state == mlrun.common.schemas.ProjectState.online
assert project.status.state is None
mlrun.api.initial_data._enrich_project_state(db, db_session)
projects = db.list_projects(db_session)
for project in projects.projects:
- assert project.spec.desired_state == mlrun.api.schemas.ProjectState.online
+ assert project.spec.desired_state == mlrun.common.schemas.ProjectState.online
assert project.status.state == project.spec.desired_state
# verify not storing for no reason
db.store_project = unittest.mock.Mock()
@@ -130,11 +130,11 @@ def test_list_project(
for project in expected_projects:
db.create_project(
db_session,
- mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(
+ mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(
name=project["name"], labels=project.get("labels")
),
- spec=mlrun.api.schemas.ProjectSpec(
+ spec=mlrun.common.schemas.ProjectSpec(
description=project.get("description")
),
),
@@ -162,14 +162,14 @@ def test_list_project_names_filter(
for project in project_names:
db.create_project(
db_session,
- mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=project),
+ mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=project),
),
)
filter_names = [project_names[0], project_names[3], project_names[4]]
projects_output = db.list_projects(
db_session,
- format_=mlrun.api.schemas.ProjectsFormat.name_only,
+ format_=mlrun.common.schemas.ProjectsFormat.name_only,
names=filter_names,
)
@@ -184,7 +184,7 @@ def test_list_project_names_filter(
projects_output = db.list_projects(
db_session,
- format_=mlrun.api.schemas.ProjectsFormat.name_only,
+ format_=mlrun.common.schemas.ProjectsFormat.name_only,
names=[],
)
@@ -229,8 +229,8 @@ def test_store_project_update(
db.store_project(
db_session,
project.metadata.name,
- mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=project.metadata.name),
+ mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=project.metadata.name),
),
)
project_output = db.get_project(db_session, project.metadata.name)
@@ -289,9 +289,9 @@ def test_delete_project(
project_description = "some description"
db.create_project(
db_session,
- mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=project_name),
- spec=mlrun.api.schemas.ProjectSpec(description=project_description),
+ mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=project_name),
+ spec=mlrun.common.schemas.ProjectSpec(description=project_description),
),
)
db.delete_project(db_session, project_name)
@@ -301,15 +301,15 @@ def test_delete_project(
def _generate_project():
- return mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(
+ return mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(
name="project-name",
created=datetime.datetime.utcnow() - datetime.timedelta(seconds=1),
labels={
"some-label": "some-label-value",
},
),
- spec=mlrun.api.schemas.ProjectSpec(
+ spec=mlrun.common.schemas.ProjectSpec(
description="some description", owner="owner-name"
),
)
@@ -318,7 +318,7 @@ def _generate_project():
def _assert_project(
db: DBInterface,
db_session: sqlalchemy.orm.Session,
- expected_project: mlrun.api.schemas.Project,
+ expected_project: mlrun.common.schemas.Project,
):
project_output = db.get_project(db_session, expected_project.metadata.name)
assert project_output.metadata.name == expected_project.metadata.name
diff --git a/tests/api/runtime_handlers/base.py b/tests/api/runtime_handlers/base.py
index 231d3c42e26e..468ff9674cb8 100644
--- a/tests/api/runtime_handlers/base.py
+++ b/tests/api/runtime_handlers/base.py
@@ -25,7 +25,7 @@
import mlrun
import mlrun.api.crud as crud
-import mlrun.api.schemas
+import mlrun.common.schemas
import mlrun.runtimes.constants
from mlrun.api.constants import LogSources
from mlrun.api.utils.singletons.db import get_db
@@ -150,14 +150,16 @@ def _assert_runtime_handler_list_resources(
expected_crds=None,
expected_pods=None,
expected_services=None,
- group_by: Optional[mlrun.api.schemas.ListRuntimeResourcesGroupByField] = None,
+ group_by: Optional[
+ mlrun.common.schemas.ListRuntimeResourcesGroupByField
+ ] = None,
):
runtime_handler = get_runtime_handler(runtime_kind)
if group_by is None:
project = "*"
label_selector = runtime_handler._get_default_label_selector()
assertion_func = TestRuntimeHandlerBase._assert_list_resources_response
- elif group_by == mlrun.api.schemas.ListRuntimeResourcesGroupByField.job:
+ elif group_by == mlrun.common.schemas.ListRuntimeResourcesGroupByField.job:
project = self.project
label_selector = ",".join(
[
@@ -168,7 +170,7 @@ def _assert_runtime_handler_list_resources(
assertion_func = (
TestRuntimeHandlerBase._assert_list_resources_grouped_by_job_response
)
- elif group_by == mlrun.api.schemas.ListRuntimeResourcesGroupByField.project:
+ elif group_by == mlrun.common.schemas.ListRuntimeResourcesGroupByField.project:
project = self.project
label_selector = ",".join(
[
@@ -213,7 +215,7 @@ def _assert_runtime_handler_list_resources(
def _assert_list_resources_grouped_by_job_response(
self,
- resources: mlrun.api.schemas.GroupedByJobRuntimeResourcesOutput,
+ resources: mlrun.common.schemas.GroupedByJobRuntimeResourcesOutput,
expected_crds=None,
expected_pods=None,
expected_services=None,
@@ -229,7 +231,7 @@ def _assert_list_resources_grouped_by_job_response(
def _assert_list_resources_grouped_by_project_response(
self,
- resources: mlrun.api.schemas.GroupedByJobRuntimeResourcesOutput,
+ resources: mlrun.common.schemas.GroupedByJobRuntimeResourcesOutput,
expected_crds=None,
expected_pods=None,
expected_services=None,
@@ -253,7 +255,7 @@ def _extract_project_and_kind_from_runtime_resources_labels(
def _assert_list_resources_grouped_by_response(
self,
- resources: mlrun.api.schemas.GroupedByJobRuntimeResourcesOutput,
+ resources: mlrun.common.schemas.GroupedByJobRuntimeResourcesOutput,
group_by_field_extractor,
expected_crds=None,
expected_pods=None,
@@ -285,7 +287,7 @@ def _assert_list_resources_grouped_by_response(
def _assert_resource_in_response_resources(
expected_resource_type: str,
expected_resource: dict,
- resources: mlrun.api.schemas.GroupedByJobRuntimeResourcesOutput,
+ resources: mlrun.common.schemas.GroupedByJobRuntimeResourcesOutput,
resources_field_name: str,
group_by_field_extractor,
):
@@ -323,7 +325,7 @@ def _assert_resource_in_response_resources(
def _assert_list_resources_response(
self,
- resources: mlrun.api.schemas.RuntimeResources,
+ resources: mlrun.common.schemas.RuntimeResources,
expected_crds=None,
expected_pods=None,
expected_services=None,
diff --git a/tests/api/runtime_handlers/test_daskjob.py b/tests/api/runtime_handlers/test_daskjob.py
index d62dad563814..ec3aa3b1d87d 100644
--- a/tests/api/runtime_handlers/test_daskjob.py
+++ b/tests/api/runtime_handlers/test_daskjob.py
@@ -16,7 +16,7 @@
from kubernetes import client
from sqlalchemy.orm import Session
-import mlrun.api.schemas
+import mlrun.common.schemas
from mlrun.api.utils.singletons.db import get_db
from mlrun.runtimes import RuntimeKinds, get_runtime_handler
from mlrun.runtimes.constants import PodPhases
@@ -104,7 +104,7 @@ def test_list_resources(self, db: Session, client: TestClient):
def test_list_resources_grouped_by(self, db: Session, client: TestClient):
for group_by in [
- mlrun.api.schemas.ListRuntimeResourcesGroupByField.project,
+ mlrun.common.schemas.ListRuntimeResourcesGroupByField.project,
]:
pods = self._mock_list_resources_pods()
services = self._mock_list_services([self.cluster_service])
@@ -127,7 +127,7 @@ def test_build_output_from_runtime_resources(self, db: Session, client: TestClie
runtime_handler = get_runtime_handler(RuntimeKinds.dask)
resources = runtime_handler.list_resources(
self.project,
- group_by=mlrun.api.schemas.ListRuntimeResourcesGroupByField.project,
+ group_by=mlrun.common.schemas.ListRuntimeResourcesGroupByField.project,
)
runtime_handler.build_output_from_runtime_resources(
[resources[self.project][RuntimeKinds.dask]]
diff --git a/tests/api/runtime_handlers/test_kubejob.py b/tests/api/runtime_handlers/test_kubejob.py
index 2124a7258878..a1cd686348a1 100644
--- a/tests/api/runtime_handlers/test_kubejob.py
+++ b/tests/api/runtime_handlers/test_kubejob.py
@@ -20,7 +20,7 @@
from sqlalchemy.orm import Session
import mlrun.api.crud
-import mlrun.api.schemas
+import mlrun.common.schemas
import tests.conftest
from mlrun.api.utils.singletons.db import get_db
from mlrun.config import config
@@ -81,8 +81,8 @@ def test_list_resources(self, db: Session, client: TestClient):
def test_list_resources_grouped_by(self, db: Session, client: TestClient):
for group_by in [
- mlrun.api.schemas.ListRuntimeResourcesGroupByField.job,
- mlrun.api.schemas.ListRuntimeResourcesGroupByField.project,
+ mlrun.common.schemas.ListRuntimeResourcesGroupByField.job,
+ mlrun.common.schemas.ListRuntimeResourcesGroupByField.project,
]:
pods = self._mock_list_resources_pods()
self._assert_runtime_handler_list_resources(
@@ -98,7 +98,7 @@ def test_list_resources_grouped_by_project_with_non_project_resources(
resources = self._assert_runtime_handler_list_resources(
RuntimeKinds.job,
expected_pods=pods,
- group_by=mlrun.api.schemas.ListRuntimeResourcesGroupByField.project,
+ group_by=mlrun.common.schemas.ListRuntimeResourcesGroupByField.project,
)
# the legacy builder pod does not have a project label, verify it is listed under the empty key
# so it will be removed on cleanup
diff --git a/tests/api/runtime_handlers/test_mpijob.py b/tests/api/runtime_handlers/test_mpijob.py
index 2269ab34666c..117d7c71d6bb 100644
--- a/tests/api/runtime_handlers/test_mpijob.py
+++ b/tests/api/runtime_handlers/test_mpijob.py
@@ -18,7 +18,7 @@
from fastapi.testclient import TestClient
from sqlalchemy.orm import Session
-import mlrun.api.schemas
+import mlrun.common.schemas
from mlrun.api.utils.singletons.db import get_db
from mlrun.api.utils.singletons.k8s import get_k8s
from mlrun.runtimes import RuntimeKinds, get_runtime_handler
@@ -123,8 +123,8 @@ def test_list_resources_with_crds_without_status(
def test_list_resources_grouped_by_job(self, db: Session, client: TestClient):
for group_by in [
- mlrun.api.schemas.ListRuntimeResourcesGroupByField.job,
- mlrun.api.schemas.ListRuntimeResourcesGroupByField.project,
+ mlrun.common.schemas.ListRuntimeResourcesGroupByField.job,
+ mlrun.common.schemas.ListRuntimeResourcesGroupByField.project,
]:
mocked_responses = self._mock_list_namespaced_crds(
[[self.succeeded_crd_dict]]
diff --git a/tests/api/runtime_handlers/test_sparkjob.py b/tests/api/runtime_handlers/test_sparkjob.py
index fae1b483c06a..f85bcc0f717d 100644
--- a/tests/api/runtime_handlers/test_sparkjob.py
+++ b/tests/api/runtime_handlers/test_sparkjob.py
@@ -18,7 +18,7 @@
from fastapi.testclient import TestClient
from sqlalchemy.orm import Session
-import mlrun.api.schemas
+import mlrun.common.schemas
from mlrun.api.utils.singletons.db import get_db
from mlrun.api.utils.singletons.k8s import get_k8s
from mlrun.runtimes import RuntimeKinds, get_runtime_handler
@@ -115,8 +115,8 @@ def test_list_resources(self, db: Session, client: TestClient):
def test_list_resources_grouped_by_job(self, db: Session, client: TestClient):
for group_by in [
- mlrun.api.schemas.ListRuntimeResourcesGroupByField.job,
- mlrun.api.schemas.ListRuntimeResourcesGroupByField.project,
+ mlrun.common.schemas.ListRuntimeResourcesGroupByField.job,
+ mlrun.common.schemas.ListRuntimeResourcesGroupByField.project,
]:
mocked_responses = self._mock_list_namespaced_crds(
[[self.completed_crd_dict]]
diff --git a/tests/api/runtimes/base.py b/tests/api/runtimes/base.py
index 1ae46684a4e7..63403d1e08a4 100644
--- a/tests/api/runtimes/base.py
+++ b/tests/api/runtimes/base.py
@@ -30,7 +30,7 @@
from kubernetes import client as k8s_client
from kubernetes.client import V1EnvVar
-import mlrun.api.schemas
+import mlrun.common.schemas
import mlrun.k8s_utils
import mlrun.runtimes.pod
from mlrun.api.utils.singletons.k8s import get_k8s
@@ -819,7 +819,7 @@ def assert_run_preemption_mode_with_preemptible_node_selector_and_tolerations(
json.dumps(preemptible_node_selector).encode("utf-8")
)
mlrun.mlconf.function_defaults.preemption_mode = (
- mlrun.api.schemas.PreemptionModes.prevent.value
+ mlrun.common.schemas.PreemptionModes.prevent.value
)
# set default preemptible tolerations
@@ -838,21 +838,25 @@ def assert_run_preemption_mode_with_preemptible_node_selector_and_tolerations(
preemptible_affinity = self._generate_preemptible_affinity()
preemptible_tolerations = self._generate_preemptible_tolerations()
logger.info("prevent -> constrain, expecting preemptible affinity")
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.constrain.value)
+ runtime.with_preemption_mode(
+ mlrun.common.schemas.PreemptionModes.constrain.value
+ )
self.execute_function(runtime)
self.assert_node_selection(
affinity=preemptible_affinity, tolerations=preemptible_tolerations
)
logger.info("constrain -> allow, expecting only preemption tolerations to stay")
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.allow.value)
+ runtime.with_preemption_mode(mlrun.common.schemas.PreemptionModes.allow.value)
self.execute_function(runtime)
self.assert_node_selection(tolerations=preemptible_tolerations)
logger.info(
"allow -> constrain, expecting preemptible affinity with tolerations"
)
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.constrain.value)
+ runtime.with_preemption_mode(
+ mlrun.common.schemas.PreemptionModes.constrain.value
+ )
self.execute_function(runtime)
self.assert_node_selection(
affinity=preemptible_affinity, tolerations=preemptible_tolerations
@@ -861,19 +865,19 @@ def assert_run_preemption_mode_with_preemptible_node_selector_and_tolerations(
logger.info(
"constrain -> prevent, expecting affinity and tolerations to be removed"
)
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.prevent.value)
+ runtime.with_preemption_mode(mlrun.common.schemas.PreemptionModes.prevent.value)
self.execute_function(runtime)
self.assert_node_selection()
logger.info("prevent -> allow, expecting preemptible tolerations")
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.allow.value)
+ runtime.with_preemption_mode(mlrun.common.schemas.PreemptionModes.allow.value)
self.execute_function(runtime)
self.assert_node_selection(tolerations=preemptible_tolerations)
logger.info(
"allow -> prevent, expecting affinity and tolerations to be removed"
)
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.prevent.value)
+ runtime.with_preemption_mode(mlrun.common.schemas.PreemptionModes.prevent.value)
self.execute_function(runtime)
self.assert_node_selection()
@@ -885,7 +889,7 @@ def assert_run_preemption_mode_with_preemptible_node_selector_and_tolerations_wi
json.dumps(preemptible_node_selector).encode("utf-8")
)
mlrun.mlconf.function_defaults.preemption_mode = (
- mlrun.api.schemas.PreemptionModes.prevent.value
+ mlrun.common.schemas.PreemptionModes.prevent.value
)
# set default preemptible tolerations
@@ -910,7 +914,9 @@ def assert_run_preemption_mode_with_preemptible_node_selector_and_tolerations_wi
"and preemptible anti-affinity to be removed and preemptible affinity to be added"
)
runtime.with_node_selection(node_selector=self._generate_node_selector())
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.constrain.value)
+ runtime.with_preemption_mode(
+ mlrun.common.schemas.PreemptionModes.constrain.value
+ )
self.execute_function(runtime)
self.assert_node_selection(
node_selector=preemptible_node_selector,
@@ -921,7 +927,7 @@ def assert_run_preemption_mode_with_preemptible_node_selector_and_tolerations_wi
"constrain -> allow, with preemptible node selector and affinity and tolerations,"
" expecting affinity and node selector to be removed and only preemptible tolerations to stay"
)
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.allow.value)
+ runtime.with_preemption_mode(mlrun.common.schemas.PreemptionModes.allow.value)
self.execute_function(runtime)
self.assert_node_selection(tolerations=preemptible_tolerations)
@@ -939,7 +945,7 @@ def assert_run_preemption_mode_with_preemptible_node_selector_and_tolerations_wi
logger.info(
"allow -> prevent, with not preemptible node selector, expecting to stay"
)
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.prevent.value)
+ runtime.with_preemption_mode(mlrun.common.schemas.PreemptionModes.prevent.value)
self.execute_function(runtime)
self.assert_node_selection(
node_selector=not_preemptible_node_selector,
@@ -949,7 +955,9 @@ def assert_run_preemption_mode_with_preemptible_node_selector_and_tolerations_wi
"prevent -> constrain, with not preemptible node selector, expecting to stay and"
" preemptible affinity and tolerations to be added"
)
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.constrain.value)
+ runtime.with_preemption_mode(
+ mlrun.common.schemas.PreemptionModes.constrain.value
+ )
self.execute_function(runtime)
self.assert_node_selection(
node_selector=not_preemptible_node_selector,
@@ -969,14 +977,18 @@ def assert_run_preemption_mode_with_preemptible_node_selector_and_tolerations_wi
"prevent -> constrain, with not preemptible affinity,"
" expecting to override affinity with preemptible affinity and add tolerations"
)
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.constrain.value)
+ runtime.with_preemption_mode(
+ mlrun.common.schemas.PreemptionModes.constrain.value
+ )
self.execute_function(runtime)
self.assert_node_selection(
affinity=preemptible_affinity, tolerations=preemptible_tolerations
)
logger.info("constrain > constrain, expecting to stay the same")
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.constrain.value)
+ runtime.with_preemption_mode(
+ mlrun.common.schemas.PreemptionModes.constrain.value
+ )
self.execute_function(runtime)
self.assert_node_selection(
affinity=preemptible_affinity, tolerations=preemptible_tolerations
@@ -988,7 +1000,7 @@ def assert_run_preemption_mode_with_preemptible_node_selector_and_tolerations_wi
)
runtime = self._generate_runtime()
runtime.with_node_selection(affinity=self._generate_not_preemptible_affinity())
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.allow.value)
+ runtime.with_preemption_mode(mlrun.common.schemas.PreemptionModes.allow.value)
self.execute_function(runtime)
self.assert_node_selection(
affinity=self._generate_not_preemptible_affinity(),
@@ -996,7 +1008,7 @@ def assert_run_preemption_mode_with_preemptible_node_selector_and_tolerations_wi
)
logger.info("allow -> allow, expecting to stay the same")
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.allow.value)
+ runtime.with_preemption_mode(mlrun.common.schemas.PreemptionModes.allow.value)
self.execute_function(runtime)
self.assert_node_selection(
affinity=self._generate_not_preemptible_affinity(),
@@ -1006,14 +1018,14 @@ def assert_run_preemption_mode_with_preemptible_node_selector_and_tolerations_wi
logger.info(
"allow -> prevent, with not preemptible affinity expecting tolerations to be removed"
)
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.prevent.value)
+ runtime.with_preemption_mode(mlrun.common.schemas.PreemptionModes.prevent.value)
self.execute_function(runtime)
self.assert_node_selection(affinity=self._generate_not_preemptible_affinity())
logger.info(
"prevent -> prevent, with not preemptible affinity expecting to stay the same"
)
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.prevent.value)
+ runtime.with_preemption_mode(mlrun.common.schemas.PreemptionModes.prevent.value)
self.execute_function(runtime)
self.assert_node_selection(affinity=self._generate_not_preemptible_affinity())
@@ -1025,7 +1037,9 @@ def assert_run_preemption_mode_with_preemptible_node_selector_and_tolerations_wi
)
runtime = self._generate_runtime()
runtime.with_node_selection(affinity=self._generate_affinity())
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.constrain.value)
+ runtime.with_preemption_mode(
+ mlrun.common.schemas.PreemptionModes.constrain.value
+ )
self.execute_function(runtime)
expected_affinity = self._generate_affinity()
expected_affinity.node_affinity.required_during_scheduling_ignored_during_execution = k8s_client.V1NodeSelector(
@@ -1060,7 +1074,7 @@ def assert_run_preemption_mode_with_preemptible_node_selector_and_tolerations_wi
+ self._generate_preemptible_tolerations()
)
runtime.with_preemption_mode(
- mode=mlrun.api.schemas.PreemptionModes.constrain.value
+ mode=mlrun.common.schemas.PreemptionModes.constrain.value
)
self.execute_function(runtime)
self.assert_node_selection(
@@ -1072,7 +1086,9 @@ def assert_run_preemption_mode_with_preemptible_node_selector_and_tolerations_wi
"constrain -> allow, with merged preemptible tolerations and preemptible affinity, "
"expecting only merged preemptible tolerations"
)
- runtime.with_preemption_mode(mode=mlrun.api.schemas.PreemptionModes.allow.value)
+ runtime.with_preemption_mode(
+ mode=mlrun.common.schemas.PreemptionModes.allow.value
+ )
self.execute_function(runtime)
self.assert_node_selection(
tolerations=merged_preemptible_tolerations,
@@ -1087,7 +1103,7 @@ def assert_run_preemption_mode_with_preemptible_node_selector_without_preemptibl
json.dumps(preemptible_node_selector).encode("utf-8")
)
mlrun.mlconf.function_defaults.preemption_mode = (
- mlrun.api.schemas.PreemptionModes.prevent.value
+ mlrun.common.schemas.PreemptionModes.prevent.value
)
logger.info(
"prevent, without setting any node selection expecting preemptible anti-affinity to be set"
@@ -1097,32 +1113,36 @@ def assert_run_preemption_mode_with_preemptible_node_selector_without_preemptibl
self.assert_node_selection(affinity=self._generate_preemptible_anti_affinity())
logger.info("prevent -> constrain, expecting preemptible affinity")
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.constrain.value)
+ runtime.with_preemption_mode(
+ mlrun.common.schemas.PreemptionModes.constrain.value
+ )
self.execute_function(runtime)
self.assert_node_selection(affinity=self._generate_preemptible_affinity())
logger.info("constrain -> allow, expecting no node selection to be set")
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.allow.value)
+ runtime.with_preemption_mode(mlrun.common.schemas.PreemptionModes.allow.value)
self.execute_function(runtime)
self.assert_node_selection()
logger.info("allow -> constrain, expecting preemptible affinity")
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.constrain.value)
+ runtime.with_preemption_mode(
+ mlrun.common.schemas.PreemptionModes.constrain.value
+ )
self.execute_function(runtime)
self.assert_node_selection(affinity=self._generate_preemptible_affinity())
logger.info("constrain -> prevent, expecting preemptible anti-affinity")
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.prevent.value)
+ runtime.with_preemption_mode(mlrun.common.schemas.PreemptionModes.prevent.value)
self.execute_function(runtime)
self.assert_node_selection(affinity=self._generate_preemptible_anti_affinity())
logger.info("prevent -> allow, expecting no node selection to be set")
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.allow.value)
+ runtime.with_preemption_mode(mlrun.common.schemas.PreemptionModes.allow.value)
self.execute_function(runtime)
self.assert_node_selection()
logger.info("allow -> prevent, expecting preemptible anti-affinity")
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.prevent.value)
+ runtime.with_preemption_mode(mlrun.common.schemas.PreemptionModes.prevent.value)
self.execute_function(runtime)
self.assert_node_selection(affinity=self._generate_preemptible_anti_affinity())
@@ -1135,7 +1155,7 @@ def assert_run_preemption_mode_with_preemptible_node_selector_without_preemptibl
json.dumps(preemptible_node_selector).encode("utf-8")
)
mlrun.mlconf.function_defaults.preemption_mode = (
- mlrun.api.schemas.PreemptionModes.prevent.value
+ mlrun.common.schemas.PreemptionModes.prevent.value
)
logger.info(
@@ -1151,7 +1171,9 @@ def assert_run_preemption_mode_with_preemptible_node_selector_without_preemptibl
"and preemptible anti-affinity to be removed and preemptible affinity to be added"
)
runtime.with_node_selection(node_selector=preemptible_node_selector)
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.constrain.value)
+ runtime.with_preemption_mode(
+ mlrun.common.schemas.PreemptionModes.constrain.value
+ )
self.execute_function(runtime)
self.assert_node_selection(
node_selector=preemptible_node_selector,
@@ -1160,7 +1182,7 @@ def assert_run_preemption_mode_with_preemptible_node_selector_without_preemptibl
logger.info(
"constrain -> allow with preemptible node selector and affinity, expecting both to be removed"
)
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.allow.value)
+ runtime.with_preemption_mode(mlrun.common.schemas.PreemptionModes.allow.value)
self.execute_function(runtime)
self.assert_node_selection()
@@ -1176,7 +1198,7 @@ def assert_run_preemption_mode_with_preemptible_node_selector_without_preemptibl
"allow -> prevent, with not preemptible node selector, expecting to stay and preemptible"
" anti-affinity"
)
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.prevent.value)
+ runtime.with_preemption_mode(mlrun.common.schemas.PreemptionModes.prevent.value)
self.execute_function(runtime)
self.assert_node_selection(
node_selector=not_preemptible_node_selector,
@@ -1186,7 +1208,9 @@ def assert_run_preemption_mode_with_preemptible_node_selector_without_preemptibl
"prevent -> constrain, with not preemptible node selector, expecting to stay and"
" preemptible affinity to be add and anti affinity to be remove"
)
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.constrain.value)
+ runtime.with_preemption_mode(
+ mlrun.common.schemas.PreemptionModes.constrain.value
+ )
self.execute_function(runtime)
self.assert_node_selection(
node_selector=not_preemptible_node_selector,
@@ -1206,12 +1230,16 @@ def assert_run_preemption_mode_with_preemptible_node_selector_without_preemptibl
"prevent -> constrain, with preemptible anti-affinity,"
" expecting to override anti-affinity with preemptible affinity"
)
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.constrain.value)
+ runtime.with_preemption_mode(
+ mlrun.common.schemas.PreemptionModes.constrain.value
+ )
self.execute_function(runtime)
self.assert_node_selection(affinity=self._generate_preemptible_affinity())
logger.info("constrain > constrain, expecting to stay the same")
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.constrain.value)
+ runtime.with_preemption_mode(
+ mlrun.common.schemas.PreemptionModes.constrain.value
+ )
self.execute_function(runtime)
self.assert_node_selection(affinity=self._generate_preemptible_affinity())
@@ -1220,26 +1248,26 @@ def assert_run_preemption_mode_with_preemptible_node_selector_without_preemptibl
logger.info("prevent -> allow, with not preemptible affinity expecting to stay")
runtime = self._generate_runtime()
runtime.with_node_selection(affinity=self._generate_not_preemptible_affinity())
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.allow.value)
+ runtime.with_preemption_mode(mlrun.common.schemas.PreemptionModes.allow.value)
self.execute_function(runtime)
self.assert_node_selection(affinity=self._generate_not_preemptible_affinity())
logger.info("allow -> allow, expecting to stay the same")
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.allow.value)
+ runtime.with_preemption_mode(mlrun.common.schemas.PreemptionModes.allow.value)
self.execute_function(runtime)
self.assert_node_selection(affinity=self._generate_not_preemptible_affinity())
logger.info(
"allow -> prevent, with not preemptible affinity expecting to be overridden with anti-affinity"
)
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.prevent.value)
+ runtime.with_preemption_mode(mlrun.common.schemas.PreemptionModes.prevent.value)
self.execute_function(runtime)
self.assert_node_selection(affinity=self._generate_preemptible_anti_affinity())
logger.info(
"prevent -> prevent, with anti-affinity, expecting to stay the same"
)
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.prevent.value)
+ runtime.with_preemption_mode(mlrun.common.schemas.PreemptionModes.prevent.value)
self.execute_function(runtime)
self.assert_node_selection(affinity=self._generate_preemptible_anti_affinity())
@@ -1250,7 +1278,9 @@ def assert_run_preemption_mode_with_preemptible_node_selector_without_preemptibl
)
runtime = self._generate_runtime()
runtime.with_node_selection(affinity=self._generate_affinity())
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.constrain.value)
+ runtime.with_preemption_mode(
+ mlrun.common.schemas.PreemptionModes.constrain.value
+ )
self.execute_function(runtime)
expected_affinity = self._generate_affinity()
expected_affinity.node_affinity.required_during_scheduling_ignored_during_execution = k8s_client.V1NodeSelector(
@@ -1280,7 +1310,7 @@ def assert_run_preemption_mode_with_preemptible_node_selector_without_preemptibl
)
runtime.with_preemption_mode(
- mode=mlrun.api.schemas.PreemptionModes.constrain.value
+ mode=mlrun.common.schemas.PreemptionModes.constrain.value
)
self.execute_function(runtime)
self.assert_node_selection(
@@ -1292,7 +1322,9 @@ def assert_run_preemption_mode_with_preemptible_node_selector_without_preemptibl
"constrain -> allow, with not preemptible tolerations and preemptible affinity, "
"expecting only not preemptible tolerations"
)
- runtime.with_preemption_mode(mode=mlrun.api.schemas.PreemptionModes.allow.value)
+ runtime.with_preemption_mode(
+ mode=mlrun.common.schemas.PreemptionModes.allow.value
+ )
self.execute_function(runtime)
self.assert_node_selection(
tolerations=self._generate_not_preemptible_tolerations(),
@@ -1305,7 +1337,7 @@ def assert_run_with_preemption_mode_none_transitions(self):
json.dumps(preemptible_node_selector).encode("utf-8")
)
mlrun.mlconf.function_defaults.preemption_mode = (
- mlrun.api.schemas.PreemptionModes.prevent.value
+ mlrun.common.schemas.PreemptionModes.prevent.value
)
logger.info("prevent, expecting anti affinity")
@@ -1315,7 +1347,7 @@ def assert_run_with_preemption_mode_none_transitions(self):
self.assert_node_selection(affinity=self._generate_preemptible_anti_affinity())
logger.info("prevent -> none, expecting to stay the same")
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.none.value)
+ runtime.with_preemption_mode(mlrun.common.schemas.PreemptionModes.none.value)
self.execute_function(runtime)
self.assert_node_selection(affinity=self._generate_preemptible_anti_affinity())
@@ -1332,7 +1364,9 @@ def assert_run_with_preemption_mode_none_transitions(self):
logger.info(
"none -> constrain, expecting preemptible affinity and user's tolerations"
)
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.constrain.value)
+ runtime.with_preemption_mode(
+ mlrun.common.schemas.PreemptionModes.constrain.value
+ )
self.execute_function(runtime)
self.assert_node_selection(
affinity=self._generate_preemptible_affinity(),
@@ -1342,7 +1376,7 @@ def assert_run_with_preemption_mode_none_transitions(self):
logger.info(
"constrain -> none, expecting preemptible affinity to stay and user's tolerations"
)
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.none.value)
+ runtime.with_preemption_mode(mlrun.common.schemas.PreemptionModes.none.value)
self.execute_function(runtime)
self.assert_node_selection(
affinity=self._generate_preemptible_affinity(),
@@ -1350,12 +1384,12 @@ def assert_run_with_preemption_mode_none_transitions(self):
)
logger.info("none -> allow, expecting user's tolerations to stay")
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.allow.value)
+ runtime.with_preemption_mode(mlrun.common.schemas.PreemptionModes.allow.value)
self.execute_function(runtime)
self.assert_node_selection(tolerations=self._generate_tolerations())
logger.info("allow -> none, expecting user's tolerations to stay")
- runtime.with_preemption_mode(mlrun.api.schemas.PreemptionModes.none.value)
+ runtime.with_preemption_mode(mlrun.common.schemas.PreemptionModes.none.value)
self.execute_function(runtime)
self.assert_node_selection(tolerations=self._generate_tolerations())
@@ -1404,7 +1438,7 @@ def assert_run_with_preemption_mode_without_preemptible_configuration(self):
if test_case.get("tolerations", False)
else None
)
- for preemption_mode in mlrun.api.schemas.PreemptionModes:
+ for preemption_mode in mlrun.common.schemas.PreemptionModes:
runtime = self._generate_runtime()
runtime.with_node_selection(
node_name=node_name,
diff --git a/tests/api/runtimes/test_dask.py b/tests/api/runtimes/test_dask.py
index 7489a7ac4cb2..32d99fcf6f4b 100644
--- a/tests/api/runtimes/test_dask.py
+++ b/tests/api/runtimes/test_dask.py
@@ -24,7 +24,7 @@
import mlrun
import mlrun.api.api.endpoints.functions
-import mlrun.api.schemas
+import mlrun.common.schemas
from mlrun import mlconf
from mlrun.platforms import auto_mount
from mlrun.runtimes.utils import generate_resources
@@ -437,10 +437,10 @@ def test_deploy_dask_function_with_enriched_security_context(
):
runtime = self._generate_runtime()
user_unix_id = 1000
- auth_info = mlrun.api.schemas.AuthInfo(user_unix_id=user_unix_id)
+ auth_info = mlrun.common.schemas.AuthInfo(user_unix_id=user_unix_id)
mlrun.mlconf.igz_version = "3.6"
mlrun.mlconf.function.spec.security_context.enrichment_mode = (
- mlrun.api.schemas.function.SecurityContextEnrichmentModes.disabled.value
+ mlrun.common.schemas.function.SecurityContextEnrichmentModes.disabled.value
)
_ = mlrun.api.api.endpoints.functions._start_function(runtime, auth_info)
pod = self._get_pod_creation_args()
@@ -448,7 +448,7 @@ def test_deploy_dask_function_with_enriched_security_context(
self.assert_security_context()
mlrun.mlconf.function.spec.security_context.enrichment_mode = (
- mlrun.api.schemas.function.SecurityContextEnrichmentModes.override.value
+ mlrun.common.schemas.function.SecurityContextEnrichmentModes.override.value
)
runtime = self._generate_runtime()
_ = mlrun.api.api.endpoints.functions._start_function(runtime, auth_info)
diff --git a/tests/api/runtimes/test_kubejob.py b/tests/api/runtimes/test_kubejob.py
index 0d72e054259a..3d2f8fb6e94f 100644
--- a/tests/api/runtimes/test_kubejob.py
+++ b/tests/api/runtimes/test_kubejob.py
@@ -23,11 +23,11 @@
from fastapi.testclient import TestClient
from sqlalchemy.orm import Session
-import mlrun.api.schemas
import mlrun.builder
+import mlrun.common.schemas
import mlrun.errors
import mlrun.k8s_utils
-from mlrun.api.schemas import SecurityContextEnrichmentModes
+from mlrun.common.schemas import SecurityContextEnrichmentModes
from mlrun.config import config as mlconf
from mlrun.platforms import auto_mount
from mlrun.runtimes.utils import generate_resources
diff --git a/tests/api/runtimes/test_nuclio.py b/tests/api/runtimes/test_nuclio.py
index acf2a872d05c..e084432a01ca 100644
--- a/tests/api/runtimes/test_nuclio.py
+++ b/tests/api/runtimes/test_nuclio.py
@@ -28,7 +28,7 @@
from fastapi.testclient import TestClient
from sqlalchemy.orm import Session
-import mlrun.api.schemas
+import mlrun.common.schemas
import mlrun.errors
import mlrun.runtimes.pod
from mlrun import code_to_function, mlconf
@@ -492,7 +492,7 @@ def test_deploy_with_project_service_accounts(
self, db: Session, k8s_secrets_mock: K8sSecretsMock
):
k8s_secrets_mock.set_service_account_keys(self.project, "sa1", ["sa1", "sa2"])
- auth_info = mlrun.api.schemas.AuthInfo()
+ auth_info = mlrun.common.schemas.AuthInfo()
function = self._generate_runtime(self.runtime_kind)
# Need to call _build_function, since service-account enrichment is happening only on server side, before the
# call to deploy_nuclio_function
@@ -519,17 +519,17 @@ def test_deploy_with_security_context_enrichment(
self, db: Session, k8s_secrets_mock: K8sSecretsMock
):
user_unix_id = 1000
- auth_info = mlrun.api.schemas.AuthInfo(user_unix_id=user_unix_id)
+ auth_info = mlrun.common.schemas.AuthInfo(user_unix_id=user_unix_id)
mlrun.mlconf.igz_version = "3.6"
mlrun.mlconf.function.spec.security_context.enrichment_mode = (
- mlrun.api.schemas.function.SecurityContextEnrichmentModes.disabled.value
+ mlrun.common.schemas.function.SecurityContextEnrichmentModes.disabled.value
)
function = self._generate_runtime(self.runtime_kind)
_build_function(db, auth_info, function)
self.assert_security_context({})
mlrun.mlconf.function.spec.security_context.enrichment_mode = (
- mlrun.api.schemas.function.SecurityContextEnrichmentModes.override.value
+ mlrun.common.schemas.function.SecurityContextEnrichmentModes.override.value
)
function = self._generate_runtime(self.runtime_kind)
_build_function(db, auth_info, function)
@@ -545,7 +545,7 @@ def test_deploy_with_global_service_account(
):
service_account_name = "default-sa"
mlconf.function.spec.service_account.default = service_account_name
- auth_info = mlrun.api.schemas.AuthInfo()
+ auth_info = mlrun.common.schemas.AuthInfo()
function = self._generate_runtime(self.runtime_kind)
# Need to call _build_function, since service-account enrichment is happening only on server side, before the
# call to deploy_nuclio_function
@@ -1302,20 +1302,20 @@ def test_deploy_function_with_image_pull_secret(
def test_nuclio_with_preemption_mode(self):
fn = self._generate_runtime(self.runtime_kind)
assert fn.spec.preemption_mode == "prevent"
- fn.with_preemption_mode(mlrun.api.schemas.PreemptionModes.allow.value)
+ fn.with_preemption_mode(mlrun.common.schemas.PreemptionModes.allow.value)
assert fn.spec.preemption_mode == "allow"
- fn.with_preemption_mode(mlrun.api.schemas.PreemptionModes.constrain.value)
+ fn.with_preemption_mode(mlrun.common.schemas.PreemptionModes.constrain.value)
assert fn.spec.preemption_mode == "constrain"
- fn.with_preemption_mode(mlrun.api.schemas.PreemptionModes.allow.value)
+ fn.with_preemption_mode(mlrun.common.schemas.PreemptionModes.allow.value)
assert fn.spec.preemption_mode == "allow"
mlconf.nuclio_version = "1.7.5"
with pytest.raises(mlrun.errors.MLRunIncompatibleVersionError):
- fn.with_preemption_mode(mlrun.api.schemas.PreemptionModes.allow.value)
+ fn.with_preemption_mode(mlrun.common.schemas.PreemptionModes.allow.value)
mlconf.nuclio_version = "1.8.6"
- fn.with_preemption_mode(mlrun.api.schemas.PreemptionModes.allow.value)
+ fn.with_preemption_mode(mlrun.common.schemas.PreemptionModes.allow.value)
assert fn.spec.preemption_mode == "allow"
def test_preemption_mode_without_preemptible_configuration(
diff --git a/tests/api/runtimes/test_spark.py b/tests/api/runtimes/test_spark.py
index 7d532abc7d80..7875d4ca1ed7 100644
--- a/tests/api/runtimes/test_spark.py
+++ b/tests/api/runtimes/test_spark.py
@@ -23,8 +23,8 @@
import pytest
import sqlalchemy.orm
-import mlrun.api.schemas
import mlrun.api.utils.singletons.k8s
+import mlrun.common.schemas
import mlrun.errors
import mlrun.runtimes.pod
import tests.api.runtimes.base
diff --git a/tests/api/test_api_states.py b/tests/api/test_api_states.py
index d1a75ed9d6cb..e7e8e9d01877 100644
--- a/tests/api/test_api_states.py
+++ b/tests/api/test_api_states.py
@@ -20,17 +20,17 @@
import sqlalchemy.orm
import mlrun.api.initial_data
-import mlrun.api.schemas
import mlrun.api.utils.auth.verifier
import mlrun.api.utils.db.alembic
import mlrun.api.utils.db.backup
import mlrun.api.utils.db.sqlite_migration
+import mlrun.common.schemas
def test_offline_state(
db: sqlalchemy.orm.Session, client: fastapi.testclient.TestClient
) -> None:
- mlrun.mlconf.httpdb.state = mlrun.api.schemas.APIStates.offline
+ mlrun.mlconf.httpdb.state = mlrun.common.schemas.APIStates.offline
response = client.get("healthz")
assert response.status_code == http.HTTPStatus.SERVICE_UNAVAILABLE.value
@@ -42,11 +42,17 @@ def test_offline_state(
@pytest.mark.parametrize(
"state, expected_healthz_status_code",
[
- (mlrun.api.schemas.APIStates.waiting_for_migrations, http.HTTPStatus.OK.value),
- (mlrun.api.schemas.APIStates.migrations_in_progress, http.HTTPStatus.OK.value),
- (mlrun.api.schemas.APIStates.migrations_failed, http.HTTPStatus.OK.value),
(
- mlrun.api.schemas.APIStates.waiting_for_chief,
+ mlrun.common.schemas.APIStates.waiting_for_migrations,
+ http.HTTPStatus.OK.value,
+ ),
+ (
+ mlrun.common.schemas.APIStates.migrations_in_progress,
+ http.HTTPStatus.OK.value,
+ ),
+ (mlrun.common.schemas.APIStates.migrations_failed, http.HTTPStatus.OK.value),
+ (
+ mlrun.common.schemas.APIStates.waiting_for_chief,
http.HTTPStatus.SERVICE_UNAVAILABLE.value,
),
],
@@ -68,7 +74,7 @@ def test_api_states(
assert response.status_code == http.HTTPStatus.OK.value
response = client.get("projects")
- expected_message = mlrun.api.schemas.APIStates.description(state)
+ expected_message = mlrun.common.schemas.APIStates.description(state)
assert response.status_code == http.HTTPStatus.PRECONDITION_FAILED.value
assert (
expected_message in response.text
@@ -189,12 +195,12 @@ def test_init_data_migration_required_recognition(monkeypatch) -> None:
)
is_latest_data_version_mock.return_value = not case.get("data_migration", False)
- mlrun.mlconf.httpdb.state = mlrun.api.schemas.APIStates.online
+ mlrun.mlconf.httpdb.state = mlrun.common.schemas.APIStates.online
mlrun.api.initial_data.init_data()
failure_message = f"Failed in case: {case}"
assert (
mlrun.mlconf.httpdb.state
- == mlrun.api.schemas.APIStates.waiting_for_migrations
+ == mlrun.common.schemas.APIStates.waiting_for_migrations
), failure_message
# assert the api just changed state and no operation was done
assert db_backup_util_mock.call_count == 0, failure_message
diff --git a/tests/api/test_initial_data.py b/tests/api/test_initial_data.py
index 5d8dd8ae9da1..80a1ea199a72 100644
--- a/tests/api/test_initial_data.py
+++ b/tests/api/test_initial_data.py
@@ -24,8 +24,8 @@
import mlrun.api.db.sqldb.db
import mlrun.api.db.sqldb.session
import mlrun.api.initial_data
-import mlrun.api.schemas
import mlrun.api.utils.singletons.db
+import mlrun.common.schemas
def test_add_data_version_empty_db():
@@ -54,8 +54,8 @@ def test_add_data_version_non_empty_db():
# fill db
db.create_project(
db_session,
- mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name="project-name"),
+ mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name="project-name"),
),
)
mlrun.api.initial_data._add_initial_data(db_session)
@@ -122,8 +122,8 @@ def test_resolve_current_data_version_before_and_after_projects(table_exists, db
# fill db
db.create_project(
db_session,
- mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name="project-name"),
+ mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name="project-name"),
),
)
assert mlrun.api.initial_data._resolve_current_data_version(db, db_session) == 1
diff --git a/tests/api/utils/auth/providers/test_opa.py b/tests/api/utils/auth/providers/test_opa.py
index 84087ad62688..185c86eeeae3 100644
--- a/tests/api/utils/auth/providers/test_opa.py
+++ b/tests/api/utils/auth/providers/test_opa.py
@@ -19,8 +19,8 @@
import deepdiff
import pytest
-import mlrun.api.schemas
import mlrun.api.utils.auth.providers.opa
+import mlrun.common.schemas
import mlrun.config
import mlrun.errors
@@ -74,8 +74,8 @@ async def test_query_permissions_success(
opa_provider: mlrun.api.utils.auth.providers.opa.Provider,
):
resource = "/projects/project-name/functions/function-name"
- action = mlrun.api.schemas.AuthorizationAction.create
- auth_info = mlrun.api.schemas.AuthInfo(
+ action = mlrun.common.schemas.AuthorizationAction.create
+ auth_info = mlrun.common.schemas.AuthInfo(
user_id="user-id", user_group_ids=["user-group-id-1", "user-group-id-2"]
)
@@ -128,8 +128,8 @@ async def test_filter_by_permission(
allowed_opa_resources = [
resource["opa_resource"] for resource in expected_allowed_resources
]
- action = mlrun.api.schemas.AuthorizationAction.create
- auth_info = mlrun.api.schemas.AuthInfo(
+ action = mlrun.common.schemas.AuthorizationAction.create
+ auth_info = mlrun.common.schemas.AuthInfo(
user_id="user-id", user_group_ids=["user-group-id-1", "user-group-id-2"]
)
@@ -174,8 +174,8 @@ async def test_query_permissions_failure(
requests_mock: aioresponses.aioresponses,
):
resource = "/projects/project-name/functions/function-name"
- action = mlrun.api.schemas.AuthorizationAction.create
- auth_info = mlrun.api.schemas.AuthInfo(
+ action = mlrun.common.schemas.AuthorizationAction.create
+ auth_info = mlrun.common.schemas.AuthInfo(
user_id="user-id", user_group_ids=["user-group-id-1", "user-group-id-2"]
)
@@ -211,7 +211,7 @@ async def test_query_permissions_use_cache(
permission_query_path: str,
opa_provider: mlrun.api.utils.auth.providers.opa.Provider,
):
- auth_info = mlrun.api.schemas.AuthInfo(user_id="user-id")
+ auth_info = mlrun.common.schemas.AuthInfo(user_id="user-id")
project_name = "project-name"
opa_provider.add_allowed_project_for_owner(project_name, auth_info)
@@ -219,7 +219,7 @@ async def test_query_permissions_use_cache(
assert (
await opa_provider.query_permissions(
f"/projects/{project_name}/resource",
- mlrun.api.schemas.AuthorizationAction.create,
+ mlrun.common.schemas.AuthorizationAction.create,
auth_info,
)
is True
@@ -232,7 +232,7 @@ def test_allowed_project_owners_cache(
permission_query_path: str,
opa_provider: mlrun.api.utils.auth.providers.opa.Provider,
):
- auth_info = mlrun.api.schemas.AuthInfo(user_id="user-id")
+ auth_info = mlrun.common.schemas.AuthInfo(user_id="user-id")
project_name = "project-name"
opa_provider.add_allowed_project_for_owner(project_name, auth_info)
# ensure nothing is wrong with adding the same project twice
@@ -252,7 +252,7 @@ def test_allowed_project_owners_cache(
assert (
opa_provider._check_allowed_project_owners_cache(
f"/projects/{project_name}/resource",
- mlrun.api.schemas.AuthInfo(user_id="other-user-id"),
+ mlrun.common.schemas.AuthInfo(user_id="other-user-id"),
)
is False
)
@@ -263,7 +263,7 @@ def test_allowed_project_owners_cache_ttl_refresh(
permission_query_path: str,
opa_provider: mlrun.api.utils.auth.providers.opa.Provider,
):
- auth_info = mlrun.api.schemas.AuthInfo(user_id="user-id")
+ auth_info = mlrun.common.schemas.AuthInfo(user_id="user-id")
opa_provider._allowed_project_owners_cache_ttl_seconds = 1
project_name = "project-name"
opa_provider.add_allowed_project_for_owner(project_name, auth_info)
@@ -291,8 +291,8 @@ def test_allowed_project_owners_cache_clean_expired(
permission_query_path: str,
opa_provider: mlrun.api.utils.auth.providers.opa.Provider,
):
- auth_info = mlrun.api.schemas.AuthInfo(user_id="user-id")
- auth_info_2 = mlrun.api.schemas.AuthInfo(user_id="user-id-2")
+ auth_info = mlrun.common.schemas.AuthInfo(user_id="user-id")
+ auth_info_2 = mlrun.common.schemas.AuthInfo(user_id="user-id-2")
opa_provider._allowed_project_owners_cache_ttl_seconds = 2
project_name = "project-name"
project_name_2 = "project-name-2"
diff --git a/tests/api/utils/clients/test_chief.py b/tests/api/utils/clients/test_chief.py
index 8e9d64171632..fba3c932fa5e 100644
--- a/tests/api/utils/clients/test_chief.py
+++ b/tests/api/utils/clients/test_chief.py
@@ -25,8 +25,8 @@
from aiohttp import ClientConnectorError
from aiohttp.test_utils import TestClient, TestServer
-import mlrun.api.schemas
import mlrun.api.utils.clients.chief
+import mlrun.common.schemas
import mlrun.config
import mlrun.errors
from tests.common_fixtures import aioresponses_mock
@@ -72,10 +72,12 @@ async def test_get_background_task_from_chief_success(
assert response.status_code == http.HTTPStatus.OK
background_task = _transform_response_to_background_task(response)
assert background_task.metadata.name == task_name
- assert background_task.status.state == mlrun.api.schemas.BackgroundTaskState.running
+ assert (
+ background_task.status.state == mlrun.common.schemas.BackgroundTaskState.running
+ )
assert background_task.metadata.created == background_schema.metadata.created
- background_schema.status.state = mlrun.api.schemas.BackgroundTaskState.succeeded
+ background_schema.status.state = mlrun.common.schemas.BackgroundTaskState.succeeded
background_schema.metadata.updated = datetime.datetime.utcnow()
response_body = fastapi.encoders.jsonable_encoder(background_schema)
aioresponses_mock.get(
@@ -86,7 +88,8 @@ async def test_get_background_task_from_chief_success(
background_task = _transform_response_to_background_task(response)
assert background_task.metadata.name == task_name
assert (
- background_task.status.state == mlrun.api.schemas.BackgroundTaskState.succeeded
+ background_task.status.state
+ == mlrun.common.schemas.BackgroundTaskState.succeeded
)
assert background_task.metadata.created == background_schema.metadata.created
assert background_task.metadata.updated == background_schema.metadata.updated
@@ -159,10 +162,12 @@ async def test_trigger_migration_succeeded(
assert response.status_code == http.HTTPStatus.ACCEPTED
background_task = _transform_response_to_background_task(response)
assert background_task.metadata.name == task_name
- assert background_task.status.state == mlrun.api.schemas.BackgroundTaskState.running
+ assert (
+ background_task.status.state == mlrun.common.schemas.BackgroundTaskState.running
+ )
assert background_task.metadata.created == background_schema.metadata.created
- background_schema.status.state = mlrun.api.schemas.BackgroundTaskState.succeeded
+ background_schema.status.state = mlrun.common.schemas.BackgroundTaskState.succeeded
background_schema.metadata.updated = datetime.datetime.utcnow()
response_body = fastapi.encoders.jsonable_encoder(background_schema)
aioresponses_mock.post(
@@ -175,7 +180,8 @@ async def test_trigger_migration_succeeded(
background_task = _transform_response_to_background_task(response)
assert background_task.metadata.name == task_name
assert (
- background_task.status.state == mlrun.api.schemas.BackgroundTaskState.succeeded
+ background_task.status.state
+ == mlrun.common.schemas.BackgroundTaskState.succeeded
)
assert background_task.metadata.created == background_schema.metadata.created
assert background_task.metadata.updated == background_schema.metadata.updated
@@ -229,12 +235,14 @@ async def test_trigger_migrations_chief_restarted_while_executing_migrations(
assert response.status_code == http.HTTPStatus.ACCEPTED
background_task = _transform_response_to_background_task(response)
assert background_task.metadata.name == task_name
- assert background_task.status.state == mlrun.api.schemas.BackgroundTaskState.running
+ assert (
+ background_task.status.state == mlrun.common.schemas.BackgroundTaskState.running
+ )
assert background_task.metadata.created == background_schema.metadata.created
# in internal background tasks, failed state is only when the background task doesn't exists in memory,
# which means the api was restarted
- background_schema.status.state = mlrun.api.schemas.BackgroundTaskState.failed
+ background_schema.status.state = mlrun.common.schemas.BackgroundTaskState.failed
response_body = fastapi.encoders.jsonable_encoder(background_schema)
aioresponses_mock.get(
f"{api_url}/api/v1/background-tasks/{task_name}", payload=response_body
@@ -243,29 +251,31 @@ async def test_trigger_migrations_chief_restarted_while_executing_migrations(
assert response.status_code == http.HTTPStatus.OK
background_task = _transform_response_to_background_task(response)
assert background_task.metadata.name == task_name
- assert background_task.status.state == mlrun.api.schemas.BackgroundTaskState.failed
+ assert (
+ background_task.status.state == mlrun.common.schemas.BackgroundTaskState.failed
+ )
assert background_task.metadata.created == background_schema.metadata.created
def _transform_response_to_background_task(response: fastapi.Response):
decoded_body = response.body.decode("utf-8")
body_dict = json.loads(decoded_body)
- return mlrun.api.schemas.BackgroundTask(**body_dict)
+ return mlrun.common.schemas.BackgroundTask(**body_dict)
def _generate_background_task(
background_task_name,
- state: mlrun.api.schemas.BackgroundTaskState = mlrun.api.schemas.BackgroundTaskState.running,
-) -> mlrun.api.schemas.BackgroundTask:
+ state: mlrun.common.schemas.BackgroundTaskState = mlrun.common.schemas.BackgroundTaskState.running,
+) -> mlrun.common.schemas.BackgroundTask:
now = datetime.datetime.utcnow()
- return mlrun.api.schemas.BackgroundTask(
- metadata=mlrun.api.schemas.BackgroundTaskMetadata(
+ return mlrun.common.schemas.BackgroundTask(
+ metadata=mlrun.common.schemas.BackgroundTaskMetadata(
name=background_task_name,
created=now,
updated=now,
),
- status=mlrun.api.schemas.BackgroundTaskStatus(state=state.value),
- spec=mlrun.api.schemas.BackgroundTaskSpec(),
+ status=mlrun.common.schemas.BackgroundTaskStatus(state=state.value),
+ spec=mlrun.common.schemas.BackgroundTaskSpec(),
)
diff --git a/tests/api/utils/clients/test_iguazio.py b/tests/api/utils/clients/test_iguazio.py
index 3fbe2d31ef17..458dd0460997 100644
--- a/tests/api/utils/clients/test_iguazio.py
+++ b/tests/api/utils/clients/test_iguazio.py
@@ -27,8 +27,8 @@
from aioresponses import CallbackResult
from requests.cookies import cookiejar_from_dict
-import mlrun.api.schemas
import mlrun.api.utils.clients.iguazio
+import mlrun.common.schemas
import mlrun.config
import mlrun.errors
from mlrun.api.utils.asyncio import maybe_coroutine
@@ -641,8 +641,8 @@ async def test_create_project_minimal_project(
iguazio_client: mlrun.api.utils.clients.iguazio.Client,
requests_mock: requests_mock_package.Mocker,
):
- project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(
+ project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(
name="some-name",
),
)
@@ -856,7 +856,7 @@ def _generate_session_verification_response_headers(
def _assert_auth_info_from_session_verification_mock_response_headers(
- auth_info: mlrun.api.schemas.AuthInfo, response_headers: dict
+ auth_info: mlrun.common.schemas.AuthInfo, response_headers: dict
):
_assert_auth_info(
auth_info,
@@ -869,7 +869,7 @@ def _assert_auth_info_from_session_verification_mock_response_headers(
def _assert_auth_info(
- auth_info: mlrun.api.schemas.AuthInfo,
+ auth_info: mlrun.common.schemas.AuthInfo,
username: str,
session: str,
data_session: str,
@@ -888,7 +888,7 @@ async def _create_project_and_assert(
api_url: str,
iguazio_client: mlrun.api.utils.clients.iguazio.Client,
requests_mock: requests_mock_package.Mocker,
- project: mlrun.api.schemas.Project,
+ project: mlrun.common.schemas.Project,
):
session = "1234"
job_id = "1d4c9d25-9c5c-4a34-b052-c1d3665fec5e"
@@ -920,7 +920,7 @@ def _verify_deletion(project_name, session, job_id, request, context):
assert request.json()["data"]["attributes"]["name"] == project_name
assert (
request.headers["igz-project-deletion-strategy"]
- == mlrun.api.schemas.DeletionStrategy.default().to_iguazio_deletion_strategy()
+ == mlrun.common.schemas.DeletionStrategy.default().to_iguazio_deletion_strategy()
)
_verify_project_request_headers(request.headers, session)
context.status_code = http.HTTPStatus.ACCEPTED.value
@@ -933,7 +933,7 @@ def _verify_creation(iguazio_client, project, session, job_id, request, context)
_verify_project_request_headers(request.headers, session)
return {
"data": _build_project_response(
- iguazio_client, project, job_id, mlrun.api.schemas.ProjectState.creating
+ iguazio_client, project, job_id, mlrun.common.schemas.ProjectState.creating
)
}
@@ -961,7 +961,7 @@ def _verify_request_cookie(headers: dict, session: str):
def _verify_project_request_headers(headers: dict, session: str):
_verify_request_cookie(headers, session)
- assert headers[mlrun.api.schemas.HeaderNames.projects_role] == "mlrun"
+ assert headers[mlrun.common.schemas.HeaderNames.projects_role] == "mlrun"
def _mock_job_progress(
@@ -1006,7 +1006,7 @@ def _generate_project(
annotations=None,
created=None,
owner="project-owner",
-) -> mlrun.api.schemas.Project:
+) -> mlrun.common.schemas.Project:
if labels is None:
labels = {
"some-label": "some-label-value",
@@ -1015,21 +1015,21 @@ def _generate_project(
annotations = {
"some-annotation": "some-annotation-value",
}
- return mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(
+ return mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(
name=name,
created=created or datetime.datetime.utcnow(),
labels=labels,
annotations=annotations,
some_extra_field="some value",
),
- spec=mlrun.api.schemas.ProjectSpec(
+ spec=mlrun.common.schemas.ProjectSpec(
description=description,
- desired_state=mlrun.api.schemas.ProjectState.online,
+ desired_state=mlrun.common.schemas.ProjectState.online,
owner=owner,
some_extra_field="some value",
),
- status=mlrun.api.schemas.ProjectStatus(
+ status=mlrun.common.schemas.ProjectStatus(
some_extra_field="some value",
),
)
@@ -1037,9 +1037,9 @@ def _generate_project(
def _build_project_response(
iguazio_client: mlrun.api.utils.clients.iguazio.Client,
- project: mlrun.api.schemas.Project,
+ project: mlrun.common.schemas.Project,
job_id: typing.Optional[str] = None,
- operational_status: typing.Optional[mlrun.api.schemas.ProjectState] = None,
+ operational_status: typing.Optional[mlrun.common.schemas.ProjectState] = None,
owner_access_key: typing.Optional[str] = None,
):
body = {
@@ -1051,7 +1051,7 @@ def _build_project_response(
else datetime.datetime.utcnow().isoformat(),
"updated_at": datetime.datetime.utcnow().isoformat(),
"admin_status": project.spec.desired_state
- or mlrun.api.schemas.ProjectState.online,
+ or mlrun.common.schemas.ProjectState.online,
"mlrun_project": iguazio_client._transform_mlrun_project_to_iguazio_mlrun_project_attribute(
project
),
@@ -1090,7 +1090,7 @@ def _build_project_response(
def _assert_project_creation(
iguazio_client: mlrun.api.utils.clients.iguazio.Client,
request_body: dict,
- project: mlrun.api.schemas.Project,
+ project: mlrun.common.schemas.Project,
):
assert request_body["data"]["attributes"]["name"] == project.metadata.name
assert request_body["data"]["attributes"]["description"] == project.spec.description
diff --git a/tests/api/utils/clients/test_log_collector.py b/tests/api/utils/clients/test_log_collector.py
index 772a0842d93a..d16d4a3967d3 100644
--- a/tests/api/utils/clients/test_log_collector.py
+++ b/tests/api/utils/clients/test_log_collector.py
@@ -21,8 +21,8 @@
import sqlalchemy.orm.session
import mlrun
-import mlrun.api.schemas
import mlrun.api.utils.clients.log_collector
+import mlrun.common.schemas
class BaseLogCollectorResponse:
@@ -67,7 +67,7 @@ def __init__(self, success, error, has_logs):
mlrun.mlconf.log_collector.address = "http://localhost:8080"
-mlrun.mlconf.log_collector.mode = mlrun.api.schemas.LogsCollectorMode.sidecar
+mlrun.mlconf.log_collector.mode = mlrun.common.schemas.LogsCollectorMode.sidecar
class TestLogCollector:
diff --git a/tests/api/utils/clients/test_nuclio.py b/tests/api/utils/clients/test_nuclio.py
index 0ab235d5242b..3dd763a8b289 100644
--- a/tests/api/utils/clients/test_nuclio.py
+++ b/tests/api/utils/clients/test_nuclio.py
@@ -18,8 +18,8 @@
import pytest
import requests_mock as requests_mock_package
-import mlrun.api.schemas
import mlrun.api.utils.clients.nuclio
+import mlrun.common.schemas
import mlrun.config
import mlrun.errors
@@ -179,13 +179,13 @@ def verify_creation(request, context):
requests_mock.post(f"{api_url}/api/projects", json=verify_creation)
nuclio_client.create_project(
None,
- mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(
+ mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(
name=project_name,
labels=project_labels,
annotations=project_annotations,
),
- spec=mlrun.api.schemas.ProjectSpec(description=project_description),
+ spec=mlrun.common.schemas.ProjectSpec(description=project_description),
),
)
@@ -230,13 +230,13 @@ def verify_store_creation(request, context):
nuclio_client.store_project(
None,
project_name,
- mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(
+ mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(
name=project_name,
labels=project_labels,
annotations=project_annotations,
),
- spec=mlrun.api.schemas.ProjectSpec(description=project_description),
+ spec=mlrun.common.schemas.ProjectSpec(description=project_description),
),
)
@@ -281,13 +281,13 @@ def verify_store_update(request, context):
nuclio_client.store_project(
None,
project_name,
- mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(
+ mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(
name=project_name,
labels=project_labels,
annotations=project_annotations,
),
- spec=mlrun.api.schemas.ProjectSpec(description=project_description),
+ spec=mlrun.common.schemas.ProjectSpec(description=project_description),
),
)
@@ -399,7 +399,7 @@ def verify_deletion(request, context):
)
assert (
request.headers["x-nuclio-delete-project-strategy"]
- == mlrun.api.schemas.DeletionStrategy.default().to_nuclio_deletion_strategy()
+ == mlrun.common.schemas.DeletionStrategy.default().to_nuclio_deletion_strategy()
)
context.status_code = http.HTTPStatus.NO_CONTENT.value
diff --git a/tests/api/utils/projects/test_follower_member.py b/tests/api/utils/projects/test_follower_member.py
index 26e13bd3cf15..a92a8cfa253c 100644
--- a/tests/api/utils/projects/test_follower_member.py
+++ b/tests/api/utils/projects/test_follower_member.py
@@ -22,11 +22,11 @@
import sqlalchemy.orm
import mlrun.api.crud
-import mlrun.api.schemas
import mlrun.api.utils.projects.follower
import mlrun.api.utils.projects.remotes.leader
import mlrun.api.utils.singletons.db
import mlrun.api.utils.singletons.project_member
+import mlrun.common.schemas
import mlrun.config
import mlrun.errors
import tests.api.conftest
@@ -63,25 +63,25 @@ def test_sync_projects(
):
project_nothing_changed = _generate_project(name="project-nothing-changed")
project_in_creation = _generate_project(
- name="project-in-creation", state=mlrun.api.schemas.ProjectState.creating
+ name="project-in-creation", state=mlrun.common.schemas.ProjectState.creating
)
project_in_deletion = _generate_project(
- name="project-in-deletion", state=mlrun.api.schemas.ProjectState.deleting
+ name="project-in-deletion", state=mlrun.common.schemas.ProjectState.deleting
)
project_will_be_in_deleting = _generate_project(
name="project-will-be-in-deleting",
- state=mlrun.api.schemas.ProjectState.creating,
+ state=mlrun.common.schemas.ProjectState.creating,
)
project_moved_to_deletion = _generate_project(
name=project_will_be_in_deleting.metadata.name,
- state=mlrun.api.schemas.ProjectState.deleting,
+ state=mlrun.common.schemas.ProjectState.deleting,
)
project_will_be_offline = _generate_project(
- name="project-will-be-offline", state=mlrun.api.schemas.ProjectState.online
+ name="project-will-be-offline", state=mlrun.common.schemas.ProjectState.online
)
project_offline = _generate_project(
name=project_will_be_offline.metadata.name,
- state=mlrun.api.schemas.ProjectState.offline,
+ state=mlrun.common.schemas.ProjectState.offline,
)
project_only_in_db = _generate_project(name="only-in-db")
for _project in [
@@ -197,7 +197,7 @@ def test_patch_project(
db, project.metadata.name, {"spec": {"description": patched_description}}
)
expected_patched_project = _generate_project(description=patched_description)
- expected_patched_project.status.state = mlrun.api.schemas.ProjectState.online
+ expected_patched_project.status.state = mlrun.common.schemas.ProjectState.online
_assert_projects_equal(expected_patched_project, patched_project)
_assert_project_in_follower(db, projects_follower, expected_patched_project)
@@ -274,8 +274,8 @@ def test_list_project(
project = _generate_project(name="name-1", owner=owner)
archived_project = _generate_project(
name="name-2",
- desired_state=mlrun.api.schemas.ProjectDesiredState.archived,
- state=mlrun.api.schemas.ProjectState.archived,
+ desired_state=mlrun.common.schemas.ProjectDesiredState.archived,
+ state=mlrun.common.schemas.ProjectState.archived,
owner=owner,
)
label_key = "key"
@@ -283,8 +283,8 @@ def test_list_project(
labeled_project = _generate_project(name="name-3", labels={label_key: label_value})
archived_and_labeled_project = _generate_project(
name="name-4",
- desired_state=mlrun.api.schemas.ProjectDesiredState.archived,
- state=mlrun.api.schemas.ProjectState.archived,
+ desired_state=mlrun.common.schemas.ProjectDesiredState.archived,
+ state=mlrun.common.schemas.ProjectState.archived,
labels={label_key: label_value},
)
all_projects = {
@@ -309,7 +309,7 @@ def test_list_project(
db,
projects_follower,
[archived_project, archived_and_labeled_project],
- state=mlrun.api.schemas.ProjectState.archived,
+ state=mlrun.common.schemas.ProjectState.archived,
)
# list by owner
@@ -373,7 +373,7 @@ def test_list_project(
db,
projects_follower,
[archived_and_labeled_project],
- state=mlrun.api.schemas.ProjectState.archived,
+ state=mlrun.common.schemas.ProjectState.archived,
labels=[f"{label_key}={label_value}", label_key],
)
@@ -385,7 +385,7 @@ async def test_list_project_summaries(
nop_leader: mlrun.api.utils.projects.remotes.leader.Member,
):
project = _generate_project(name="name-1")
- project_summary = mlrun.api.schemas.ProjectSummary(
+ project_summary = mlrun.common.schemas.ProjectSummary(
name=project.metadata.name,
files_count=4,
feature_sets_count=5,
@@ -423,7 +423,7 @@ async def test_list_project_summaries_fails_to_list_pipeline_runs(
project_name = "project-name"
_generate_project(name=project_name)
mlrun.api.utils.singletons.db.get_db().list_projects = unittest.mock.Mock(
- return_value=mlrun.api.schemas.ProjectsOutput(projects=[project_name])
+ return_value=mlrun.common.schemas.ProjectsOutput(projects=[project_name])
)
mlrun.api.crud.projects.Projects()._list_pipelines = unittest.mock.Mock(
side_effect=mlrun.errors.MLRunNotFoundError("not found")
@@ -446,12 +446,12 @@ def test_list_project_leader_format(
):
project = _generate_project(name="name-1")
mlrun.api.utils.singletons.db.get_db().list_projects = unittest.mock.Mock(
- return_value=mlrun.api.schemas.ProjectsOutput(projects=[project])
+ return_value=mlrun.common.schemas.ProjectsOutput(projects=[project])
)
projects = projects_follower.list_projects(
db,
- format_=mlrun.api.schemas.ProjectsFormat.leader,
- projects_role=mlrun.api.schemas.ProjectsRole.nop,
+ format_=mlrun.common.schemas.ProjectsFormat.leader,
+ projects_role=mlrun.common.schemas.ProjectsRole.nop,
)
assert (
deepdiff.DeepDiff(
@@ -466,7 +466,7 @@ def test_list_project_leader_format(
def _assert_list_projects(
db_session: sqlalchemy.orm.Session,
projects_follower: mlrun.api.utils.projects.follower.Member,
- expected_projects: typing.List[mlrun.api.schemas.Project],
+ expected_projects: typing.List[mlrun.common.schemas.Project],
**kwargs,
):
projects = projects_follower.list_projects(db_session, **kwargs)
@@ -479,7 +479,7 @@ def _assert_list_projects(
# assert again - with name only format
projects = projects_follower.list_projects(
- db_session, format_=mlrun.api.schemas.ProjectsFormat.name_only, **kwargs
+ db_session, format_=mlrun.common.schemas.ProjectsFormat.name_only, **kwargs
)
assert len(projects.projects) == len(expected_projects)
assert (
@@ -495,19 +495,19 @@ def _assert_list_projects(
def _generate_project(
name="project-name",
description="some description",
- desired_state=mlrun.api.schemas.ProjectDesiredState.online,
- state=mlrun.api.schemas.ProjectState.online,
+ desired_state=mlrun.common.schemas.ProjectDesiredState.online,
+ state=mlrun.common.schemas.ProjectState.online,
labels: typing.Optional[dict] = None,
owner="some-owner",
):
- return mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=name, labels=labels),
- spec=mlrun.api.schemas.ProjectSpec(
+ return mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=name, labels=labels),
+ spec=mlrun.common.schemas.ProjectSpec(
description=description,
desired_state=desired_state,
owner=owner,
),
- status=mlrun.api.schemas.ProjectStatus(
+ status=mlrun.common.schemas.ProjectStatus(
state=state,
),
)
@@ -523,9 +523,9 @@ def _assert_projects_equal(project_1, project_2):
)
== {}
)
- assert mlrun.api.schemas.ProjectState(
+ assert mlrun.common.schemas.ProjectState(
project_1.status.state
- ) == mlrun.api.schemas.ProjectState(project_2.status.state)
+ ) == mlrun.common.schemas.ProjectState(project_2.status.state)
def _assert_project_not_in_follower(
@@ -540,7 +540,7 @@ def _assert_project_not_in_follower(
def _assert_project_in_follower(
db_session: sqlalchemy.orm.Session,
projects_follower: mlrun.api.utils.projects.follower.Member,
- project: mlrun.api.schemas.Project,
+ project: mlrun.common.schemas.Project,
):
follower_project = projects_follower.get_project(db_session, project.metadata.name)
_assert_projects_equal(project, follower_project)
diff --git a/tests/api/utils/projects/test_leader_member.py b/tests/api/utils/projects/test_leader_member.py
index f26b3655fd02..1973ad2a7629 100644
--- a/tests/api/utils/projects/test_leader_member.py
+++ b/tests/api/utils/projects/test_leader_member.py
@@ -18,10 +18,10 @@
import pytest
import sqlalchemy.orm
-import mlrun.api.schemas
import mlrun.api.utils.projects.leader
import mlrun.api.utils.projects.remotes.follower
import mlrun.api.utils.singletons.project_member
+import mlrun.common.schemas
import mlrun.config
import mlrun.errors
from mlrun.utils import logger
@@ -72,9 +72,9 @@ def test_projects_sync_follower_project_adoption(
):
project_name = "project-name"
project_description = "some description"
- project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=project_name),
- spec=mlrun.api.schemas.ProjectSpec(description=project_description),
+ project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=project_name),
+ spec=mlrun.common.schemas.ProjectSpec(description=project_description),
)
nop_follower.create_project(
None,
@@ -105,9 +105,9 @@ def test_projects_sync_mid_deletion(
"""
project_name = "project-name"
project_description = "some description"
- project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=project_name),
- spec=mlrun.api.schemas.ProjectSpec(description=project_description),
+ project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=project_name),
+ spec=mlrun.common.schemas.ProjectSpec(description=project_description),
)
projects_leader.create_project(db, project)
_assert_project_in_followers(
@@ -141,17 +141,17 @@ def test_projects_sync_leader_project_syncing(
):
project_name = "project-name"
project_description = "some description"
- project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=project_name),
- spec=mlrun.api.schemas.ProjectSpec(description=project_description),
+ project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=project_name),
+ spec=mlrun.common.schemas.ProjectSpec(description=project_description),
)
enriched_project = project.copy(deep=True)
# simulate project enrichment
enriched_project.status.state = enriched_project.spec.desired_state
leader_follower.create_project(None, enriched_project)
invalid_project_name = "invalid_name"
- invalid_project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=invalid_project_name),
+ invalid_project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=invalid_project_name),
)
leader_follower.create_project(
None,
@@ -180,17 +180,19 @@ def test_projects_sync_multiple_follower_project_adoption(
):
second_follower_project_name = "project-name-2"
second_follower_project_description = "some description 2"
- second_follower_project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=second_follower_project_name),
- spec=mlrun.api.schemas.ProjectSpec(
+ second_follower_project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(
+ name=second_follower_project_name
+ ),
+ spec=mlrun.common.schemas.ProjectSpec(
description=second_follower_project_description
),
)
both_followers_project_name = "project-name"
both_followers_project_description = "some description"
- both_followers_project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=both_followers_project_name),
- spec=mlrun.api.schemas.ProjectSpec(
+ both_followers_project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=both_followers_project_name),
+ spec=mlrun.common.schemas.ProjectSpec(
description=both_followers_project_description
),
)
@@ -238,11 +240,11 @@ def test_create_project(
):
project_name = "project-name"
project_description = "some description"
- project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=project_name),
- spec=mlrun.api.schemas.ProjectSpec(
+ project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=project_name),
+ spec=mlrun.common.schemas.ProjectSpec(
description=project_description,
- desired_state=mlrun.api.schemas.ProjectState.archived,
+ desired_state=mlrun.common.schemas.ProjectState.archived,
),
)
projects_leader.create_project(
@@ -291,8 +293,8 @@ def test_create_and_store_project_failure_invalid_name(
]
for case in cases:
project_name = case["name"]
- project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=project_name),
+ project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=project_name),
)
if case["valid"]:
projects_leader.create_project(
@@ -334,8 +336,8 @@ def test_ensure_project(
project_name,
)
- project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=project_name),
+ project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=project_name),
)
projects_leader.create_project(
None,
@@ -362,9 +364,9 @@ def test_store_project_creation(
):
project_name = "project-name"
project_description = "some description"
- project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=project_name),
- spec=mlrun.api.schemas.ProjectSpec(description=project_description),
+ project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=project_name),
+ spec=mlrun.common.schemas.ProjectSpec(description=project_description),
)
_assert_no_projects_in_followers([leader_follower, nop_follower])
@@ -384,9 +386,9 @@ def test_store_project_update(
):
project_name = "project-name"
project_description = "some description"
- project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=project_name),
- spec=mlrun.api.schemas.ProjectSpec(description=project_description),
+ project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=project_name),
+ spec=mlrun.common.schemas.ProjectSpec(description=project_description),
)
projects_leader.create_project(
None,
@@ -395,10 +397,10 @@ def test_store_project_update(
_assert_project_in_followers([leader_follower, nop_follower], project)
# removing description from the projects and changing desired state
- updated_project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=project_name),
- spec=mlrun.api.schemas.ProjectSpec(
- desired_state=mlrun.api.schemas.ProjectState.archived
+ updated_project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=project_name),
+ spec=mlrun.common.schemas.ProjectSpec(
+ desired_state=mlrun.common.schemas.ProjectState.archived
),
)
@@ -417,8 +419,8 @@ def test_patch_project(
leader_follower: mlrun.api.utils.projects.remotes.follower.Member,
):
project_name = "project-name"
- project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=project_name),
+ project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=project_name),
)
projects_leader.create_project(
None,
@@ -430,7 +432,7 @@ def test_patch_project(
# Adding description to the project and changing state
project_description = "some description"
- project_desired_state = mlrun.api.schemas.ProjectState.archived
+ project_desired_state = mlrun.common.schemas.ProjectState.archived
projects_leader.patch_project(
None,
project_name,
@@ -453,8 +455,8 @@ def test_store_and_patch_project_failure_conflict_body_path_name(
leader_follower: mlrun.api.utils.projects.remotes.follower.Member,
):
project_name = "project-name"
- project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=project_name),
+ project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=project_name),
)
projects_leader.create_project(
None,
@@ -466,8 +468,8 @@ def test_store_and_patch_project_failure_conflict_body_path_name(
projects_leader.store_project(
None,
project_name,
- mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name="different-name"),
+ mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name="different-name"),
),
)
with pytest.raises(mlrun.errors.MLRunConflictError):
@@ -486,8 +488,8 @@ def test_delete_project(
leader_follower: mlrun.api.utils.projects.remotes.follower.Member,
):
project_name = "project-name"
- project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=project_name),
+ project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=project_name),
)
projects_leader.create_project(
None,
@@ -509,8 +511,8 @@ def mock_failed_delete(*args, **kwargs):
raise RuntimeError()
project_name = "project-name"
- project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=project_name),
+ project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=project_name),
)
projects_leader.create_project(
None,
@@ -534,8 +536,8 @@ def test_list_projects(
leader_follower: mlrun.api.utils.projects.remotes.follower.Member,
):
project_name = "project-name"
- project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=project_name),
+ project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=project_name),
)
projects_leader.create_project(
None,
@@ -546,8 +548,8 @@ def test_list_projects(
# add some project to follower
nop_follower.create_project(
None,
- mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name="some-other-project"),
+ mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name="some-other-project"),
),
)
@@ -565,9 +567,9 @@ def test_get_project(
):
project_name = "project-name"
project_description = "some description"
- project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=project_name),
- spec=mlrun.api.schemas.ProjectSpec(description=project_description),
+ project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=project_name),
+ spec=mlrun.common.schemas.ProjectSpec(description=project_description),
)
projects_leader.create_project(
None,
@@ -599,7 +601,7 @@ def _assert_no_projects_in_followers(followers):
def _assert_project_in_followers(
- followers, project: mlrun.api.schemas.Project, enriched=True
+ followers, project: mlrun.common.schemas.Project, enriched=True
):
for follower in followers:
assert (
diff --git a/tests/api/utils/test_scheduler.py b/tests/api/utils/test_scheduler.py
index fd9316d1d3a0..3ca5fad82f70 100644
--- a/tests/api/utils/test_scheduler.py
+++ b/tests/api/utils/test_scheduler.py
@@ -32,9 +32,9 @@
import mlrun.api.utils.auth.verifier
import mlrun.api.utils.singletons.k8s
import mlrun.api.utils.singletons.project_member
+import mlrun.common.schemas
import mlrun.errors
import tests.api.conftest
-from mlrun.api import schemas
from mlrun.api.utils.scheduler import Scheduler
from mlrun.api.utils.singletons.db import get_db
from mlrun.config import config
@@ -85,17 +85,17 @@ async def test_not_skipping_delayed_schedules(db: Session, scheduler: Scheduler)
number_of_jobs=expected_call_counter, seconds_interval=1
)
# this way we're leaving ourselves one second to create the schedule preventing transient test failure
- cron_trigger = schemas.ScheduleCronTrigger(
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(
second="*/1", start_date=start_date, end_date=end_date
)
schedule_name = "schedule-name"
project = config.default_project
scheduler.create_schedule(
db,
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
project,
schedule_name,
- schemas.ScheduleKinds.local_function,
+ mlrun.common.schemas.ScheduleKinds.local_function,
bump_counter,
cron_trigger,
)
@@ -116,17 +116,17 @@ async def test_create_schedule(db: Session, scheduler: Scheduler):
number_of_jobs=5, seconds_interval=1
)
# this way we're leaving ourselves one second to create the schedule preventing transient test failure
- cron_trigger = schemas.ScheduleCronTrigger(
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(
second="*/1", start_date=start_date, end_date=end_date
)
schedule_name = "schedule-name"
project = config.default_project
scheduler.create_schedule(
db,
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
project,
schedule_name,
- schemas.ScheduleKinds.local_function,
+ mlrun.common.schemas.ScheduleKinds.local_function,
bump_counter,
cron_trigger,
)
@@ -148,7 +148,7 @@ async def test_invoke_schedule(
scheduler: Scheduler,
k8s_secrets_mock: tests.api.conftest.K8sSecretsMock,
):
- cron_trigger = schemas.ScheduleCronTrigger(year=1999)
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(year=1999)
schedule_name = "schedule-name"
project_name = config.default_project
mlrun.new_project(project_name, save=False)
@@ -159,22 +159,22 @@ async def test_invoke_schedule(
assert len(runs) == 0
scheduler.create_schedule(
db,
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
project_name,
schedule_name,
- schemas.ScheduleKinds.job,
+ mlrun.common.schemas.ScheduleKinds.job,
scheduled_object,
cron_trigger,
)
runs = get_db().list_runs(db, project=project_name)
assert len(runs) == 0
response_1 = await scheduler.invoke_schedule(
- db, mlrun.api.schemas.AuthInfo(), project_name, schedule_name
+ db, mlrun.common.schemas.AuthInfo(), project_name, schedule_name
)
runs = get_db().list_runs(db, project=project_name)
assert len(runs) == 1
response_2 = await scheduler.invoke_schedule(
- db, mlrun.api.schemas.AuthInfo(), project_name, schedule_name
+ db, mlrun.common.schemas.AuthInfo(), project_name, schedule_name
)
runs = get_db().list_runs(db, project=project_name)
assert len(runs) == 2
@@ -213,7 +213,7 @@ async def test_create_schedule_mlrun_function(
number_of_jobs=expected_call_counter, seconds_interval=1
)
# this way we're leaving ourselves one second to create the schedule preventing transient test failure
- cron_trigger = schemas.ScheduleCronTrigger(
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(
second="*/1", start_date=start_date, end_date=end_date
)
schedule_name = "schedule-name"
@@ -227,10 +227,10 @@ async def test_create_schedule_mlrun_function(
assert len(runs) == 0
scheduler.create_schedule(
db,
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
project_name,
schedule_name,
- schemas.ScheduleKinds.job,
+ mlrun.common.schemas.ScheduleKinds.job,
scheduled_object,
cron_trigger,
)
@@ -267,13 +267,13 @@ async def test_create_schedule_success_cron_trigger_validation(
{"year": "2050"},
]
for index, case in enumerate(cases):
- cron_trigger = schemas.ScheduleCronTrigger(**case)
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(**case)
scheduler.create_schedule(
db,
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
"project",
f"schedule-name-{index}",
- schemas.ScheduleKinds.local_function,
+ mlrun.common.schemas.ScheduleKinds.local_function,
do_nothing,
cron_trigger,
)
@@ -297,16 +297,16 @@ async def test_schedule_upgrade_from_scheduler_without_credentials_store(
start_date, end_date = _get_start_and_end_time_for_scheduled_trigger(
number_of_jobs=expected_call_counter, seconds_interval=1
)
- cron_trigger = schemas.ScheduleCronTrigger(
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(
second="*/1", start_date=start_date, end_date=end_date
)
# we're before upgrade so create a schedule with empty auth info
scheduler.create_schedule(
db,
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
project_name,
name,
- schemas.ScheduleKinds.job,
+ mlrun.common.schemas.ScheduleKinds.job,
scheduled_object,
cron_trigger,
)
@@ -323,7 +323,7 @@ async def test_schedule_upgrade_from_scheduler_without_credentials_store(
access_key = "some-access_key"
mlrun.api.utils.singletons.project_member.get_project_member().get_project_owner = (
unittest.mock.Mock(
- return_value=mlrun.api.schemas.ProjectOwner(
+ return_value=mlrun.common.schemas.ProjectOwner(
username=username, access_key=access_key
)
)
@@ -361,14 +361,14 @@ async def test_create_schedule_failure_too_frequent_cron_trigger(
{"minute": "11,22,33,44,55,59"},
]
for case in cases:
- cron_trigger = schemas.ScheduleCronTrigger(**case)
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(**case)
with pytest.raises(ValueError) as excinfo:
scheduler.create_schedule(
db,
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
"project",
"schedule-name",
- schemas.ScheduleKinds.local_function,
+ mlrun.common.schemas.ScheduleKinds.local_function,
do_nothing,
cron_trigger,
)
@@ -379,15 +379,15 @@ async def test_create_schedule_failure_too_frequent_cron_trigger(
async def test_create_schedule_failure_already_exists(
db: Session, scheduler: Scheduler
):
- cron_trigger = schemas.ScheduleCronTrigger(year="1999")
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(year="1999")
schedule_name = "schedule-name"
project = config.default_project
scheduler.create_schedule(
db,
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
project,
schedule_name,
- schemas.ScheduleKinds.local_function,
+ mlrun.common.schemas.ScheduleKinds.local_function,
do_nothing,
cron_trigger,
)
@@ -398,10 +398,10 @@ async def test_create_schedule_failure_already_exists(
):
scheduler.create_schedule(
db,
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
project,
schedule_name,
- schemas.ScheduleKinds.local_function,
+ mlrun.common.schemas.ScheduleKinds.local_function,
do_nothing,
cron_trigger,
)
@@ -419,7 +419,7 @@ async def test_validate_cron_trigger_multi_checks(db: Session, scheduler: Schedu
every minute.
"""
scheduler._min_allowed_interval = "10 minutes"
- cron_trigger = schemas.ScheduleCronTrigger(minute="0-45")
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(minute="0-45")
now = datetime(
year=2020,
month=2,
@@ -436,15 +436,15 @@ async def test_validate_cron_trigger_multi_checks(db: Session, scheduler: Schedu
@pytest.mark.asyncio
async def test_get_schedule_datetime_fields_timezone(db: Session, scheduler: Scheduler):
- cron_trigger = schemas.ScheduleCronTrigger(minute="*/10")
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(minute="*/10")
schedule_name = "schedule-name"
project = config.default_project
scheduler.create_schedule(
db,
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
project,
schedule_name,
- schemas.ScheduleKinds.local_function,
+ mlrun.common.schemas.ScheduleKinds.local_function,
do_nothing,
cron_trigger,
)
@@ -464,15 +464,15 @@ async def test_get_schedule(db: Session, scheduler: Scheduler):
"label1": "value1",
"label2": "value2",
}
- cron_trigger = schemas.ScheduleCronTrigger(year="1999")
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(year="1999")
schedule_name = "schedule-name"
project = config.default_project
scheduler.create_schedule(
db,
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
project,
schedule_name,
- schemas.ScheduleKinds.local_function,
+ mlrun.common.schemas.ScheduleKinds.local_function,
do_nothing,
cron_trigger,
labels_1,
@@ -484,7 +484,7 @@ async def test_get_schedule(db: Session, scheduler: Scheduler):
schedule,
project,
schedule_name,
- schemas.ScheduleKinds.local_function,
+ mlrun.common.schemas.ScheduleKinds.local_function,
cron_trigger,
None,
labels_1,
@@ -495,14 +495,14 @@ async def test_get_schedule(db: Session, scheduler: Scheduler):
"label4": "value4",
}
year = 2050
- cron_trigger_2 = schemas.ScheduleCronTrigger(year=year, timezone="utc")
+ cron_trigger_2 = mlrun.common.schemas.ScheduleCronTrigger(year=year, timezone="utc")
schedule_name_2 = "schedule-name-2"
scheduler.create_schedule(
db,
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
project,
schedule_name_2,
- schemas.ScheduleKinds.local_function,
+ mlrun.common.schemas.ScheduleKinds.local_function,
do_nothing,
cron_trigger_2,
labels_2,
@@ -513,7 +513,7 @@ async def test_get_schedule(db: Session, scheduler: Scheduler):
schedule_2,
project,
schedule_name_2,
- schemas.ScheduleKinds.local_function,
+ mlrun.common.schemas.ScheduleKinds.local_function,
cron_trigger_2,
year_datetime,
labels_2,
@@ -525,7 +525,7 @@ async def test_get_schedule(db: Session, scheduler: Scheduler):
schedules.schedules[0],
project,
schedule_name,
- schemas.ScheduleKinds.local_function,
+ mlrun.common.schemas.ScheduleKinds.local_function,
cron_trigger,
None,
labels_1,
@@ -534,7 +534,7 @@ async def test_get_schedule(db: Session, scheduler: Scheduler):
schedules.schedules[1],
project,
schedule_name_2,
- schemas.ScheduleKinds.local_function,
+ mlrun.common.schemas.ScheduleKinds.local_function,
cron_trigger_2,
year_datetime,
labels_2,
@@ -546,7 +546,7 @@ async def test_get_schedule(db: Session, scheduler: Scheduler):
schedules.schedules[0],
project,
schedule_name_2,
- schemas.ScheduleKinds.local_function,
+ mlrun.common.schemas.ScheduleKinds.local_function,
cron_trigger_2,
year_datetime,
labels_2,
@@ -555,15 +555,15 @@ async def test_get_schedule(db: Session, scheduler: Scheduler):
@pytest.mark.asyncio
async def test_get_schedule_next_run_time_from_db(db: Session, scheduler: Scheduler):
- cron_trigger = schemas.ScheduleCronTrigger(minute="*/10")
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(minute="*/10")
schedule_name = "schedule-name"
project = config.default_project
scheduler.create_schedule(
db,
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
project,
schedule_name,
- schemas.ScheduleKinds.local_function,
+ mlrun.common.schemas.ScheduleKinds.local_function,
do_nothing,
cron_trigger,
)
@@ -572,7 +572,7 @@ async def test_get_schedule_next_run_time_from_db(db: Session, scheduler: Schedu
# simulating when running in worker
mlrun.mlconf.httpdb.clusterization.role = (
- mlrun.api.schemas.ClusterizationRole.worker
+ mlrun.common.schemas.ClusterizationRole.worker
)
worker_schedule = scheduler.get_schedule(db, project, schedule_name)
assert worker_schedule.next_run_time is not None
@@ -602,7 +602,7 @@ async def test_list_schedules_name_filter(db: Session, scheduler: Scheduler):
{"name": "mluRn", "should_find": False},
]
- cron_trigger = schemas.ScheduleCronTrigger(minute="*/10")
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(minute="*/10")
project = config.default_project
expected_schedule_names = []
for case in cases:
@@ -610,10 +610,10 @@ async def test_list_schedules_name_filter(db: Session, scheduler: Scheduler):
should_find = case["should_find"]
scheduler.create_schedule(
db,
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
project,
name,
- schemas.ScheduleKinds.local_function,
+ mlrun.common.schemas.ScheduleKinds.local_function,
do_nothing,
cron_trigger,
)
@@ -651,15 +651,15 @@ async def test_list_schedules_from_scheduler(db: Session, scheduler: Scheduler):
@pytest.mark.asyncio
async def test_delete_schedule(db: Session, scheduler: Scheduler):
- cron_trigger = schemas.ScheduleCronTrigger(year="1999")
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(year="1999")
schedule_name = "schedule-name"
project = config.default_project
scheduler.create_schedule(
db,
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
project,
schedule_name,
- schemas.ScheduleKinds.local_function,
+ mlrun.common.schemas.ScheduleKinds.local_function,
do_nothing,
cron_trigger,
)
@@ -715,17 +715,17 @@ async def test_rescheduling(db: Session, scheduler: Scheduler):
start_date, end_date = _get_start_and_end_time_for_scheduled_trigger(
number_of_jobs=expected_call_counter, seconds_interval=1
)
- cron_trigger = schemas.ScheduleCronTrigger(
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(
second="*/1", start_date=start_date, end_date=end_date
)
schedule_name = "schedule-name"
project = config.default_project
scheduler.create_schedule(
db,
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
project,
schedule_name,
- schemas.ScheduleKinds.local_function,
+ mlrun.common.schemas.ScheduleKinds.local_function,
bump_counter,
cron_trigger,
)
@@ -758,13 +758,13 @@ async def test_rescheduling_secrets_storing(
scheduled_object = _create_mlrun_function_and_matching_scheduled_object(db, project)
username = "some-username"
access_key = "some-user-access-key"
- cron_trigger = schemas.ScheduleCronTrigger(year="1999")
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(year="1999")
scheduler.create_schedule(
db,
- mlrun.api.schemas.AuthInfo(username=username, access_key=access_key),
+ mlrun.common.schemas.AuthInfo(username=username, access_key=access_key),
project,
name,
- schemas.ScheduleKinds.job,
+ mlrun.common.schemas.ScheduleKinds.job,
scheduled_object,
cron_trigger,
)
@@ -805,13 +805,13 @@ async def test_schedule_crud_secrets_handling(
)
access_key = "some-user-access-key"
username = "some-username"
- cron_trigger = schemas.ScheduleCronTrigger(year="1999")
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(year="1999")
scheduler.create_schedule(
db,
- mlrun.api.schemas.AuthInfo(username=username, access_key=access_key),
+ mlrun.common.schemas.AuthInfo(username=username, access_key=access_key),
project,
schedule_name,
- schemas.ScheduleKinds.job,
+ mlrun.common.schemas.ScheduleKinds.job,
scheduled_object,
cron_trigger,
)
@@ -829,7 +829,7 @@ async def test_schedule_crud_secrets_handling(
# update labels
scheduler.update_schedule(
db,
- mlrun.api.schemas.AuthInfo(username=username, access_key=access_key),
+ mlrun.common.schemas.AuthInfo(username=username, access_key=access_key),
project,
schedule_name,
labels={"label-key": "label-value"},
@@ -864,17 +864,17 @@ async def test_schedule_access_key_generation(
project = config.default_project
schedule_name = "schedule-name"
scheduled_object = _create_mlrun_function_and_matching_scheduled_object(db, project)
- cron_trigger = schemas.ScheduleCronTrigger(year="1999")
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(year="1999")
access_key = "generated-access-key"
mlrun.api.utils.auth.verifier.AuthVerifier().get_or_create_access_key = (
unittest.mock.Mock(return_value=access_key)
)
scheduler.create_schedule(
db,
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
project,
schedule_name,
- schemas.ScheduleKinds.job,
+ mlrun.common.schemas.ScheduleKinds.job,
scheduled_object,
cron_trigger,
)
@@ -889,7 +889,7 @@ async def test_schedule_access_key_generation(
)
scheduler.update_schedule(
db,
- mlrun.api.schemas.AuthInfo(
+ mlrun.common.schemas.AuthInfo(
access_key=mlrun.model.Credentials.generate_access_key
),
project,
@@ -914,7 +914,7 @@ async def test_schedule_access_key_reference_handling(
project = config.default_project
schedule_name = "schedule-name"
scheduled_object = _create_mlrun_function_and_matching_scheduled_object(db, project)
- cron_trigger = schemas.ScheduleCronTrigger(year="1999")
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(year="1999")
username = "some-user-name"
access_key = "some-access-key"
@@ -922,7 +922,7 @@ async def test_schedule_access_key_reference_handling(
mlrun.model.Credentials.secret_reference_prefix
+ k8s_secrets_mock.store_auth_secret(username, access_key)
)
- auth_info = mlrun.api.schemas.AuthInfo()
+ auth_info = mlrun.common.schemas.AuthInfo()
auth_info.access_key = secret_ref
scheduler.create_schedule(
@@ -930,7 +930,7 @@ async def test_schedule_access_key_reference_handling(
auth_info,
project,
schedule_name,
- schemas.ScheduleKinds.job,
+ mlrun.common.schemas.ScheduleKinds.job,
scheduled_object,
cron_trigger,
labels={"label1": "value1", "label2": "value2"},
@@ -952,7 +952,7 @@ async def test_schedule_convert_from_old_credentials_to_new(
project = config.default_project
schedule_name = "schedule-name"
scheduled_object = _create_mlrun_function_and_matching_scheduled_object(db, project)
- cron_trigger = schemas.ScheduleCronTrigger(year="1999")
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(year="1999")
username = "some-user-name"
access_key = "some-access-key"
@@ -960,16 +960,16 @@ async def test_schedule_convert_from_old_credentials_to_new(
# to simulate an old schedule.
scheduler.create_schedule(
db,
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
project,
schedule_name,
- schemas.ScheduleKinds.job,
+ mlrun.common.schemas.ScheduleKinds.job,
scheduled_object,
cron_trigger,
labels={"label1": "value1", "label2": "value2"},
)
- auth_info = mlrun.api.schemas.AuthInfo(username=username, access_key=access_key)
+ auth_info = mlrun.common.schemas.AuthInfo(username=username, access_key=access_key)
mlrun.api.utils.auth.verifier.AuthVerifier().is_jobs_auth_required = (
unittest.mock.Mock(return_value=True)
)
@@ -1013,7 +1013,7 @@ async def test_update_schedule(
"label3": "value3",
"label4": "value4",
}
- inactive_cron_trigger = schemas.ScheduleCronTrigger(year="1999")
+ inactive_cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(year="1999")
schedule_name = "schedule-name"
project_name = config.default_project
mlrun.new_project(project_name, save=False)
@@ -1025,10 +1025,10 @@ async def test_update_schedule(
assert len(runs) == 0
scheduler.create_schedule(
db,
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
project_name,
schedule_name,
- schemas.ScheduleKinds.job,
+ mlrun.common.schemas.ScheduleKinds.job,
scheduled_object,
inactive_cron_trigger,
labels=labels_1,
@@ -1040,7 +1040,7 @@ async def test_update_schedule(
schedule,
project_name,
schedule_name,
- schemas.ScheduleKinds.job,
+ mlrun.common.schemas.ScheduleKinds.job,
inactive_cron_trigger,
None,
labels_1,
@@ -1049,7 +1049,7 @@ async def test_update_schedule(
# update labels
scheduler.update_schedule(
db,
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
project_name,
schedule_name,
labels=labels_2,
@@ -1060,7 +1060,7 @@ async def test_update_schedule(
schedule,
project_name,
schedule_name,
- schemas.ScheduleKinds.job,
+ mlrun.common.schemas.ScheduleKinds.job,
inactive_cron_trigger,
None,
labels_2,
@@ -1069,7 +1069,7 @@ async def test_update_schedule(
# update nothing
scheduler.update_schedule(
db,
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
project_name,
schedule_name,
)
@@ -1079,7 +1079,7 @@ async def test_update_schedule(
schedule,
project_name,
schedule_name,
- schemas.ScheduleKinds.job,
+ mlrun.common.schemas.ScheduleKinds.job,
inactive_cron_trigger,
None,
labels_2,
@@ -1088,7 +1088,7 @@ async def test_update_schedule(
# update labels to empty dict
scheduler.update_schedule(
db,
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
project_name,
schedule_name,
labels={},
@@ -1099,7 +1099,7 @@ async def test_update_schedule(
schedule,
project_name,
schedule_name,
- schemas.ScheduleKinds.job,
+ mlrun.common.schemas.ScheduleKinds.job,
inactive_cron_trigger,
None,
{},
@@ -1111,14 +1111,14 @@ async def test_update_schedule(
number_of_jobs=expected_call_counter, seconds_interval=1
)
# this way we're leaving ourselves one second to create the schedule preventing transient test failure
- cron_trigger = schemas.ScheduleCronTrigger(
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(
second="*/1",
start_date=start_date,
end_date=end_date,
)
scheduler.update_schedule(
db,
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
project_name,
schedule_name,
cron_trigger=cron_trigger,
@@ -1139,7 +1139,7 @@ async def test_update_schedule(
schedule,
project_name,
schedule_name,
- schemas.ScheduleKinds.job,
+ mlrun.common.schemas.ScheduleKinds.job,
cron_trigger,
next_run_time,
{},
@@ -1162,7 +1162,7 @@ async def test_update_schedule_failure_not_found_in_db(
project = config.default_project
with pytest.raises(mlrun.errors.MLRunNotFoundError) as excinfo:
scheduler.update_schedule(
- db, mlrun.api.schemas.AuthInfo(), project, schedule_name
+ db, mlrun.common.schemas.AuthInfo(), project, schedule_name
)
assert "Schedule not found" in str(excinfo.value)
@@ -1178,12 +1178,12 @@ async def test_update_schedule_failure_not_found_in_scheduler(
)
# create the schedule only in the db
- inactive_cron_trigger = schemas.ScheduleCronTrigger(year="1999")
+ inactive_cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(year="1999")
get_db().create_schedule(
db,
project_name,
schedule_name,
- schemas.ScheduleKinds.job,
+ mlrun.common.schemas.ScheduleKinds.job,
scheduled_object,
inactive_cron_trigger,
1,
@@ -1192,7 +1192,7 @@ async def test_update_schedule_failure_not_found_in_scheduler(
# update schedule should fail since the schedule job was not created in the scheduler
with pytest.raises(mlrun.errors.MLRunNotFoundError) as excinfo:
scheduler.update_schedule(
- db, mlrun.api.schemas.AuthInfo(), project_name, schedule_name
+ db, mlrun.common.schemas.AuthInfo(), project_name, schedule_name
)
job_id = scheduler._resolve_job_id(project_name, schedule_name)
assert (
@@ -1211,14 +1211,18 @@ async def test_update_schedule_failure_not_found_in_scheduler(
[(1, 2), (2, 3), (3, 4)],
)
@pytest.mark.parametrize(
- "schedule_kind", [schemas.ScheduleKinds.job, schemas.ScheduleKinds.local_function]
+ "schedule_kind",
+ [
+ mlrun.common.schemas.ScheduleKinds.job,
+ mlrun.common.schemas.ScheduleKinds.local_function,
+ ],
)
async def test_schedule_job_concurrency_limit(
db: Session,
scheduler: Scheduler,
concurrency_limit: int,
run_amount: int,
- schedule_kind: schemas.ScheduleKinds,
+ schedule_kind: mlrun.common.schemas.ScheduleKinds,
k8s_secrets_mock: tests.api.conftest.K8sSecretsMock,
):
global call_counter
@@ -1227,7 +1231,7 @@ async def test_schedule_job_concurrency_limit(
now = datetime.now(timezone.utc)
now_plus_1_seconds = now + timedelta(seconds=1)
now_plus_5_seconds = now + timedelta(seconds=5)
- cron_trigger = schemas.ScheduleCronTrigger(
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(
second="*/1", start_date=now_plus_1_seconds, end_date=now_plus_5_seconds
)
schedule_name = "schedule-name"
@@ -1238,7 +1242,7 @@ async def test_schedule_job_concurrency_limit(
_create_mlrun_function_and_matching_scheduled_object(
db, project_name, handler="sleep_two_seconds"
)
- if schedule_kind == schemas.ScheduleKinds.job
+ if schedule_kind == mlrun.common.schemas.ScheduleKinds.job
else bump_counter_and_wait
)
@@ -1247,7 +1251,7 @@ async def test_schedule_job_concurrency_limit(
scheduler.create_schedule(
db,
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
project_name,
schedule_name,
schedule_kind,
@@ -1276,7 +1280,7 @@ async def test_schedule_job_concurrency_limit(
# wait so all runs will complete
await asyncio.sleep(7 - random_sleep_time)
- if schedule_kind == schemas.ScheduleKinds.job:
+ if schedule_kind == mlrun.common.schemas.ScheduleKinds.job:
runs = get_db().list_runs(db, project=project_name)
assert len(runs) == run_amount
else:
@@ -1299,7 +1303,7 @@ async def test_schedule_job_next_run_time(
now = datetime.now(timezone.utc)
now_plus_1_seconds = now + timedelta(seconds=1)
now_plus_5_seconds = now + timedelta(seconds=5)
- cron_trigger = schemas.ScheduleCronTrigger(
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(
second="*/1", start_date=now_plus_1_seconds, end_date=now_plus_5_seconds
)
schedule_name = "schedule-name"
@@ -1315,10 +1319,10 @@ async def test_schedule_job_next_run_time(
scheduler.create_schedule(
db,
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
project_name,
schedule_name,
- schemas.ScheduleKinds.job,
+ mlrun.common.schemas.ScheduleKinds.job,
scheduled_object,
cron_trigger,
concurrency_limit=1,
@@ -1337,7 +1341,7 @@ async def test_schedule_job_next_run_time(
# the next run time should be updated to the next second after the invocation failure
schedule_invocation_timestamp = datetime.now(timezone.utc)
await scheduler.invoke_schedule(
- db, mlrun.api.schemas.AuthInfo(), project_name, schedule_name
+ db, mlrun.common.schemas.AuthInfo(), project_name, schedule_name
)
runs = get_db().list_runs(db, project=project_name)
@@ -1442,7 +1446,7 @@ def _assert_schedule_secrets(
def _assert_schedule(
- schedule: schemas.ScheduleOutput,
+ schedule: mlrun.common.schemas.ScheduleOutput,
project,
name,
kind,
@@ -1462,13 +1466,13 @@ def _assert_schedule(
def _create_do_nothing_schedule(
db: Session, scheduler: Scheduler, project: str, name: str
):
- cron_trigger = schemas.ScheduleCronTrigger(year="1999")
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(year="1999")
scheduler.create_schedule(
db,
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
project,
name,
- schemas.ScheduleKinds.local_function,
+ mlrun.common.schemas.ScheduleKinds.local_function,
do_nothing,
cron_trigger,
)
diff --git a/tests/common_fixtures.py b/tests/common_fixtures.py
index cf8e2495467f..2f1fc0925390 100644
--- a/tests/common_fixtures.py
+++ b/tests/common_fixtures.py
@@ -440,7 +440,7 @@ def assert_env_variables(self, expected_env_dict, function_name=None):
def verify_authorization(
self,
- authorization_verification_input: mlrun.api.schemas.AuthorizationVerificationInput,
+ authorization_verification_input: mlrun.common.schemas.AuthorizationVerificationInput,
):
pass
diff --git a/tests/integration/sdk_api/artifacts/test_artifacts.py b/tests/integration/sdk_api/artifacts/test_artifacts.py
index 3d83860e2016..6e9568a00f2b 100644
--- a/tests/integration/sdk_api/artifacts/test_artifacts.py
+++ b/tests/integration/sdk_api/artifacts/test_artifacts.py
@@ -76,7 +76,7 @@ def test_list_artifacts_filter_by_kind(self):
assert len(artifacts) == 1, "bad number of model artifacts"
artifacts = db.list_artifacts(
- project=prj, category=mlrun.api.schemas.ArtifactCategories.dataset
+ project=prj, category=mlrun.common.schemas.ArtifactCategories.dataset
)
assert len(artifacts) == 1, "bad number of dataset artifacts"
diff --git a/tests/integration/sdk_api/base.py b/tests/integration/sdk_api/base.py
index 4a826d6ea42a..891c649157c9 100644
--- a/tests/integration/sdk_api/base.py
+++ b/tests/integration/sdk_api/base.py
@@ -21,7 +21,7 @@
import pymysql
import mlrun
-import mlrun.api.schemas
+import mlrun.common.schemas
import tests.conftest
from mlrun.db.httpdb import HTTPRunDB
from mlrun.utils import create_logger, retry_until_successful
diff --git a/tests/integration/sdk_api/httpdb/runs/test_runs.py b/tests/integration/sdk_api/httpdb/runs/test_runs.py
index 75b985ef18b7..95a3e2c26ae1 100644
--- a/tests/integration/sdk_api/httpdb/runs/test_runs.py
+++ b/tests/integration/sdk_api/httpdb/runs/test_runs.py
@@ -18,7 +18,7 @@
import pytest
import mlrun
-import mlrun.api.schemas
+import mlrun.common.schemas
import tests.integration.sdk_api.base
from tests.conftest import examples_path
@@ -77,9 +77,9 @@ def test_list_runs(self):
runs = _list_and_assert_objects(
3,
project=projects[0],
- partition_by=mlrun.api.schemas.RunPartitionByField.name,
- partition_sort_by=mlrun.api.schemas.SortField.created,
- partition_order=mlrun.api.schemas.OrderType.asc,
+ partition_by=mlrun.common.schemas.RunPartitionByField.name,
+ partition_sort_by=mlrun.common.schemas.SortField.created,
+ partition_order=mlrun.common.schemas.OrderType.asc,
)
# sorted by ascending created so only the first ones created
for run in runs:
@@ -89,9 +89,9 @@ def test_list_runs(self):
runs = _list_and_assert_objects(
3,
project=projects[0],
- partition_by=mlrun.api.schemas.RunPartitionByField.name,
- partition_sort_by=mlrun.api.schemas.SortField.updated,
- partition_order=mlrun.api.schemas.OrderType.desc,
+ partition_by=mlrun.common.schemas.RunPartitionByField.name,
+ partition_sort_by=mlrun.common.schemas.SortField.updated,
+ partition_order=mlrun.common.schemas.OrderType.desc,
)
# sorted by descending updated so only the third ones created
for run in runs:
@@ -101,9 +101,9 @@ def test_list_runs(self):
runs = _list_and_assert_objects(
15,
project=projects[0],
- partition_by=mlrun.api.schemas.RunPartitionByField.name,
- partition_sort_by=mlrun.api.schemas.SortField.updated,
- partition_order=mlrun.api.schemas.OrderType.desc,
+ partition_by=mlrun.common.schemas.RunPartitionByField.name,
+ partition_sort_by=mlrun.common.schemas.SortField.updated,
+ partition_order=mlrun.common.schemas.OrderType.desc,
rows_per_partition=5,
iter=True,
)
@@ -112,9 +112,9 @@ def test_list_runs(self):
runs = _list_and_assert_objects(
10,
project=projects[0],
- partition_by=mlrun.api.schemas.RunPartitionByField.name,
- partition_sort_by=mlrun.api.schemas.SortField.updated,
- partition_order=mlrun.api.schemas.OrderType.desc,
+ partition_by=mlrun.common.schemas.RunPartitionByField.name,
+ partition_sort_by=mlrun.common.schemas.SortField.updated,
+ partition_order=mlrun.common.schemas.OrderType.desc,
rows_per_partition=5,
max_partitions=2,
iter=True,
@@ -125,9 +125,9 @@ def test_list_runs(self):
runs = _list_and_assert_objects(
6,
project=projects[0],
- partition_by=mlrun.api.schemas.RunPartitionByField.name,
- partition_sort_by=mlrun.api.schemas.SortField.updated,
- partition_order=mlrun.api.schemas.OrderType.desc,
+ partition_by=mlrun.common.schemas.RunPartitionByField.name,
+ partition_sort_by=mlrun.common.schemas.SortField.updated,
+ partition_order=mlrun.common.schemas.OrderType.desc,
rows_per_partition=4,
max_partitions=2,
iter=False,
@@ -138,7 +138,7 @@ def test_list_runs(self):
_list_and_assert_objects(
0,
project=projects[0],
- partition_by=mlrun.api.schemas.RunPartitionByField.name,
+ partition_by=mlrun.common.schemas.RunPartitionByField.name,
)
# An invalid partition-by field - will be failed by fastapi due to schema validation.
with pytest.raises(mlrun.errors.MLRunHTTPError) as excinfo:
@@ -146,7 +146,7 @@ def test_list_runs(self):
0,
project=projects[0],
partition_by="key",
- partition_sort_by=mlrun.api.schemas.SortField.updated,
+ partition_sort_by=mlrun.common.schemas.SortField.updated,
)
assert (
excinfo.value.response.status_code
diff --git a/tests/integration/sdk_api/httpdb/test_exception_handling.py b/tests/integration/sdk_api/httpdb/test_exception_handling.py
index e05d7104faf7..122b7e77655e 100644
--- a/tests/integration/sdk_api/httpdb/test_exception_handling.py
+++ b/tests/integration/sdk_api/httpdb/test_exception_handling.py
@@ -15,7 +15,7 @@
import pytest
import mlrun
-import mlrun.api.schemas
+import mlrun.common.schemas
import mlrun.errors
import tests.integration.sdk_api.base
@@ -47,8 +47,8 @@ def test_exception_handling(self):
# This is handled in the mlrun/api/main.py::http_status_error_handler
invalid_project_name = "some_project"
# Not using client class cause it does validation on client side and we want to fail on server side
- project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name=invalid_project_name)
+ project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name=invalid_project_name)
)
with pytest.raises(
mlrun.errors.MLRunBadRequestError,
diff --git a/tests/integration/sdk_api/hub/test_hub.py b/tests/integration/sdk_api/hub/test_hub.py
index cf2aa79b453d..bf75dc285a4b 100644
--- a/tests/integration/sdk_api/hub/test_hub.py
+++ b/tests/integration/sdk_api/hub/test_hub.py
@@ -40,18 +40,18 @@ def _assert_source_lists_match(expected_response):
def test_hub(self):
db = mlrun.get_run_db()
- default_source = mlrun.api.schemas.IndexedHubSource(
+ default_source = mlrun.common.schemas.IndexedHubSource(
index=-1,
- source=mlrun.api.schemas.HubSource.generate_default_source(),
+ source=mlrun.common.schemas.HubSource.generate_default_source(),
)
self._assert_source_lists_match([default_source])
- new_source = mlrun.api.schemas.IndexedHubSource(
- source=mlrun.api.schemas.HubSource(
- metadata=mlrun.api.schemas.HubObjectMetadata(
+ new_source = mlrun.common.schemas.IndexedHubSource(
+ source=mlrun.common.schemas.HubSource(
+ metadata=mlrun.common.schemas.HubObjectMetadata(
name="source-1", description="a private source"
),
- spec=mlrun.api.schemas.HubSourceSpec(
+ spec=mlrun.common.schemas.HubSourceSpec(
path="/local/path/to/source", channel="development"
),
)
@@ -60,13 +60,13 @@ def test_hub(self):
new_source.index = 1
self._assert_source_lists_match([new_source, default_source])
- new_source_2 = mlrun.api.schemas.IndexedHubSource(
+ new_source_2 = mlrun.common.schemas.IndexedHubSource(
index=1,
- source=mlrun.api.schemas.HubSource(
- metadata=mlrun.api.schemas.HubObjectMetadata(
+ source=mlrun.common.schemas.HubSource(
+ metadata=mlrun.common.schemas.HubObjectMetadata(
name="source-2", description="2nd private source"
),
- spec=mlrun.api.schemas.HubSourceSpec(
+ spec=mlrun.common.schemas.HubSourceSpec(
path="/local/path/to/source", channel="prod"
),
),
diff --git a/tests/integration/sdk_api/projects/test_project.py b/tests/integration/sdk_api/projects/test_project.py
index 93f962536a3f..3d7134c45630 100644
--- a/tests/integration/sdk_api/projects/test_project.py
+++ b/tests/integration/sdk_api/projects/test_project.py
@@ -18,7 +18,7 @@
import pytest
import mlrun
-import mlrun.api.schemas
+import mlrun.common.schemas
import tests.conftest
import tests.integration.sdk_api.base
diff --git a/tests/projects/test_remote_pipeline.py b/tests/projects/test_remote_pipeline.py
index 04ff486d6e45..3277b7b9a84a 100644
--- a/tests/projects/test_remote_pipeline.py
+++ b/tests/projects/test_remote_pipeline.py
@@ -26,7 +26,7 @@
import mlrun
import tests.projects.assets.remote_pipeline_with_overridden_resources
import tests.projects.base_pipeline
-from mlrun.api.schemas import SecurityContextEnrichmentModes
+from mlrun.common.schemas import SecurityContextEnrichmentModes
@pytest.fixture()
diff --git a/tests/rundb/test_httpdb.py b/tests/rundb/test_httpdb.py
index e2840d88e456..5d3bbf7611d2 100644
--- a/tests/rundb/test_httpdb.py
+++ b/tests/rundb/test_httpdb.py
@@ -30,10 +30,10 @@
import requests_mock
import mlrun.artifacts.base
+import mlrun.common.schemas
import mlrun.errors
import mlrun.projects.project
from mlrun import RunObject
-from mlrun.api import schemas
from mlrun.db.httpdb import HTTPRunDB
from tests.conftest import tests_root_directory, wait_for_server
@@ -633,7 +633,7 @@ def test_feature_vectors(create_server):
feature_vector_update,
project,
tag="latest",
- patch_mode=schemas.PatchMode.additive,
+ patch_mode=mlrun.common.schemas.PatchMode.additive,
)
feature_vectors = db.list_feature_vectors(project=project)
assert len(feature_vectors) == count, "bad list results - wrong number of members"
@@ -662,7 +662,10 @@ def test_feature_vectors(create_server):
# Perform a replace (vs. additive as done earlier) - now should only have 2 features
db.patch_feature_vector(
- name, feature_vector_update, project, patch_mode=schemas.PatchMode.replace
+ name,
+ feature_vector_update,
+ project,
+ patch_mode=mlrun.common.schemas.PatchMode.replace,
)
feature_vector = db.get_feature_vector(name, project)
assert (
@@ -677,7 +680,7 @@ def test_project_file_db_roundtrip(create_server):
project_name = "project-name"
description = "project description"
goals = "project goals"
- desired_state = mlrun.api.schemas.ProjectState.archived
+ desired_state = mlrun.common.schemas.ProjectState.archived
params = {"param_key": "param value"}
artifact_path = "/tmp"
conda = "conda"
diff --git a/tests/rundb/test_sqldb.py b/tests/rundb/test_sqldb.py
index 58a3b183cfcb..8535bcbee0ed 100644
--- a/tests/rundb/test_sqldb.py
+++ b/tests/rundb/test_sqldb.py
@@ -19,7 +19,7 @@
import deepdiff
from sqlalchemy.orm import Session
-import mlrun.api.schemas
+import mlrun.common.schemas
from mlrun.api.db.sqldb.db import SQLDB
from mlrun.api.db.sqldb.models import Artifact
from mlrun.lists import ArtifactList
@@ -59,12 +59,12 @@ def test_list_artifact_tags(db: SQLDB, db_session: Session):
# filter by category
model_tags = db.list_artifact_tags(
- db_session, "p1", mlrun.api.schemas.ArtifactCategories.model
+ db_session, "p1", mlrun.common.schemas.ArtifactCategories.model
)
assert [("p1", "k2", "t3"), ("p1", "k2", "latest")] == model_tags
model_tags = db.list_artifact_tags(
- db_session, "p2", mlrun.api.schemas.ArtifactCategories.dataset
+ db_session, "p2", mlrun.common.schemas.ArtifactCategories.dataset
)
assert [("p2", "k3", "t4"), ("p2", "k3", "latest")] == model_tags
@@ -200,10 +200,12 @@ def test_read_and_list_artifacts_with_tags(db: SQLDB, db_session: Session):
def test_projects_crud(db: SQLDB, db_session: Session):
- project = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name="p1"),
- spec=mlrun.api.schemas.ProjectSpec(description="banana", other_field="value"),
- status=mlrun.api.schemas.ObjectStatus(state="active"),
+ project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name="p1"),
+ spec=mlrun.common.schemas.ProjectSpec(
+ description="banana", other_field="value"
+ ),
+ status=mlrun.common.schemas.ObjectStatus(state="active"),
)
db.create_project(db_session, project)
project_output = db.get_project(db_session, name=project.metadata.name)
@@ -221,12 +223,12 @@ def test_projects_crud(db: SQLDB, db_session: Session):
project_output = db.get_project(db_session, name=project.metadata.name)
assert project_output.spec.description == project_patch["spec"]["description"]
- project_2 = mlrun.api.schemas.Project(
- metadata=mlrun.api.schemas.ProjectMetadata(name="p2"),
+ project_2 = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(name="p2"),
)
db.create_project(db_session, project_2)
projects_output = db.list_projects(
- db_session, format_=mlrun.api.schemas.ProjectsFormat.name_only
+ db_session, format_=mlrun.common.schemas.ProjectsFormat.name_only
)
assert [project.metadata.name, project_2.metadata.name] == projects_output.projects
diff --git a/tests/system/api/test_secrets.py b/tests/system/api/test_secrets.py
index 6220d821acbc..33f0a0fee026 100644
--- a/tests/system/api/test_secrets.py
+++ b/tests/system/api/test_secrets.py
@@ -18,7 +18,7 @@
import deepdiff
import pytest
-import mlrun.api.schemas
+import mlrun.common.schemas
import mlrun.errors
from tests.system.base import TestMLRunSystem
@@ -96,7 +96,7 @@ def test_k8s_project_secrets_using_api(self):
def test_k8s_project_secrets_using_httpdb(self):
secrets = {"secret1": "value1", "secret2": "value2"}
- expected_results = mlrun.api.schemas.SecretKeysData(
+ expected_results = mlrun.common.schemas.SecretKeysData(
provider="kubernetes", secret_keys=list(secrets.keys())
)
diff --git a/tests/system/base.py b/tests/system/base.py
index c371902966a0..aa9be58e40d2 100644
--- a/tests/system/base.py
+++ b/tests/system/base.py
@@ -21,7 +21,7 @@
import yaml
from deepdiff import DeepDiff
-import mlrun.api.schemas
+import mlrun.common.schemas
from mlrun import get_run_db, mlconf, set_environment
from mlrun.utils import create_logger
@@ -91,7 +91,7 @@ def _delete_test_project(self, name=None):
if self._should_clean_resources():
self._run_db.delete_project(
name or self.project_name,
- deletion_strategy=mlrun.api.schemas.DeletionStrategy.cascading,
+ deletion_strategy=mlrun.common.schemas.DeletionStrategy.cascading,
)
def teardown_method(self, method):
diff --git a/tests/system/model_monitoring/test_model_monitoring.py b/tests/system/model_monitoring/test_model_monitoring.py
index f2617e9f4a22..028457f864d8 100644
--- a/tests/system/model_monitoring/test_model_monitoring.py
+++ b/tests/system/model_monitoring/test_model_monitoring.py
@@ -28,12 +28,12 @@
import mlrun
import mlrun.api.crud
-import mlrun.api.schemas
import mlrun.artifacts.model
+import mlrun.common.model_monitoring as model_monitoring_constants
+import mlrun.common.schemas
import mlrun.feature_store
-import mlrun.model_monitoring.constants as model_monitoring_constants
import mlrun.utils
-from mlrun.api.schemas import (
+from mlrun.common.schemas import (
ModelEndpoint,
ModelEndpointMetadata,
ModelEndpointSpec,
diff --git a/tests/test_builder.py b/tests/test_builder.py
index 7c2bb0878077..2c3bd1b6802d 100644
--- a/tests/test_builder.py
+++ b/tests/test_builder.py
@@ -21,9 +21,9 @@
import pytest
import mlrun
-import mlrun.api.schemas
import mlrun.api.utils.singletons.k8s
import mlrun.builder
+import mlrun.common.schemas
import mlrun.k8s_utils
import mlrun.utils.version
from mlrun.config import config
@@ -35,7 +35,7 @@ def test_build_runtime_use_base_image_when_no_build():
fn.build_config(base_image=base_image)
assert fn.spec.image == ""
ready = mlrun.builder.build_runtime(
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
fn,
)
assert ready is True
@@ -49,7 +49,7 @@ def test_build_runtime_use_image_when_no_build():
)
assert fn.spec.image == image
ready = mlrun.builder.build_runtime(
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
fn,
with_mlrun=False,
)
@@ -113,7 +113,7 @@ def test_build_runtime_insecure_registries(
mlrun.mlconf.httpdb.builder.insecure_push_registry_mode = push_mode
mlrun.mlconf.httpdb.builder.docker_registry_secret = secret
mlrun.builder.build_runtime(
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
function,
)
assert (
@@ -151,7 +151,7 @@ def test_build_runtime_target_image(monkeypatch):
)
mlrun.builder.build_runtime(
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
function,
)
@@ -164,7 +164,7 @@ def test_build_runtime_target_image(monkeypatch):
f"{registry}/{image_name_prefix}-some-addition:{function.metadata.tag}"
)
mlrun.builder.build_runtime(
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
function,
)
target_image = _get_target_image_from_create_pod_mock()
@@ -177,7 +177,7 @@ def test_build_runtime_target_image(monkeypatch):
f"/{image_name_prefix}-some-addition:{function.metadata.tag}"
)
mlrun.builder.build_runtime(
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
function,
)
target_image = _get_target_image_from_create_pod_mock()
@@ -194,7 +194,7 @@ def test_build_runtime_target_image(monkeypatch):
function.spec.build.image = invalid_image
with pytest.raises(mlrun.errors.MLRunInvalidArgumentError):
mlrun.builder.build_runtime(
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
function,
)
@@ -204,7 +204,7 @@ def test_build_runtime_target_image(monkeypatch):
f":{function.metadata.tag}"
)
mlrun.builder.build_runtime(
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
function,
)
target_image = _get_target_image_from_create_pod_mock()
@@ -230,7 +230,7 @@ def test_build_runtime_use_default_node_selector(monkeypatch):
requirements=["some-package"],
)
mlrun.builder.build_runtime(
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
function,
)
assert (
@@ -263,7 +263,7 @@ def test_function_build_with_attributes_from_spec(monkeypatch):
function.spec.node_selector = node_selector
function.spec.priority_class_name = priority_class_name
mlrun.builder.build_runtime(
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
function,
)
assert (
@@ -300,7 +300,7 @@ def test_function_build_with_default_requests(monkeypatch):
requirements=["some-package"],
)
mlrun.builder.build_runtime(
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
function,
)
expected_resources = {"requests": {}}
@@ -321,7 +321,7 @@ def test_function_build_with_default_requests(monkeypatch):
expected_resources = {"requests": {"cpu": "25m", "memory": "1m"}}
mlrun.builder.build_runtime(
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
function,
)
assert (
@@ -348,7 +348,7 @@ def test_function_build_with_default_requests(monkeypatch):
expected_resources = {"requests": {"cpu": "25m", "memory": "1m"}}
mlrun.builder.build_runtime(
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
function,
)
assert (
@@ -460,7 +460,7 @@ def test_build_runtime_ecr_with_ec2_iam_policy(monkeypatch):
kind="job",
)
mlrun.builder.build_runtime(
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
function,
)
pod_spec = _create_pod_mock_pod_spec()
@@ -523,7 +523,7 @@ def test_build_runtime_resolve_ecr_registry(monkeypatch):
image += f":{case.get('tag')}"
function.spec.build.image = image
mlrun.builder.build_runtime(
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
function,
)
pod_spec = _create_pod_mock_pod_spec()
@@ -555,7 +555,7 @@ def test_build_runtime_ecr_with_aws_secret(monkeypatch):
requirements=["some-package"],
)
mlrun.builder.build_runtime(
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
function,
)
pod_spec = _create_pod_mock_pod_spec()
@@ -613,7 +613,7 @@ def test_build_runtime_ecr_with_repository(monkeypatch):
requirements=["some-package"],
)
mlrun.builder.build_runtime(
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
function,
)
pod_spec = _create_pod_mock_pod_spec()
@@ -771,7 +771,7 @@ def test_kaniko_pod_spec_default_service_account_enrichment(monkeypatch):
kind="job",
)
mlrun.builder.build_runtime(
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
function,
)
pod_spec = _create_pod_mock_pod_spec()
@@ -795,7 +795,7 @@ def test_kaniko_pod_spec_user_service_account_enrichment(monkeypatch):
service_account = "my-actual-sa"
function.spec.service_account = service_account
mlrun.builder.build_runtime(
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
function,
)
pod_spec = _create_pod_mock_pod_spec()
@@ -829,7 +829,7 @@ def test_builder_workdir(monkeypatch, clone_target_dir, expected_workdir):
function.spec.clone_target_dir = clone_target_dir
function.spec.build.source = "some-source.tgz"
mlrun.builder.build_runtime(
- mlrun.api.schemas.AuthInfo(),
+ mlrun.common.schemas.AuthInfo(),
function,
)
dockerfile = mlrun.builder.make_kaniko_pod.call_args[1]["dockertext"]
diff --git a/tests/test_config.py b/tests/test_config.py
index 8bc9288321e2..28e5bec41816 100644
--- a/tests/test_config.py
+++ b/tests/test_config.py
@@ -24,7 +24,7 @@
import mlrun.errors
from mlrun import config as mlconf
-from mlrun.api.schemas import SecurityContextEnrichmentModes
+from mlrun.common.schemas import SecurityContextEnrichmentModes
from mlrun.db.httpdb import HTTPRunDB
namespace_env_key = f"{mlconf.env_prefix}NAMESPACE"
diff --git a/tests/test_model.py b/tests/test_model.py
index 56429c4a097d..c9b56fa71c90 100644
--- a/tests/test_model.py
+++ b/tests/test_model.py
@@ -12,11 +12,11 @@
# See the License for the specific language governing permissions and
# limitations under the License.
#
-import mlrun.api.schemas
+import mlrun.common.schemas
import mlrun.runtimes
def test_enum_yaml_dump():
function = mlrun.new_function("function-name", kind="job")
- function.status.state = mlrun.api.schemas.FunctionState.ready
+ function.status.state = mlrun.common.schemas.FunctionState.ready
print(function.to_yaml())
diff --git a/tests/utils/test_deprecation.py b/tests/utils/test_deprecation.py
index 9f486b65bc5d..ccb1e97cb59d 100644
--- a/tests/utils/test_deprecation.py
+++ b/tests/utils/test_deprecation.py
@@ -64,3 +64,55 @@ def warn():
with pytest.raises(FutureWarning):
warn()
+
+
+def test_deprecation_helper():
+ """
+ This test validates that the deprecation warning is shown when using a deprecated class, and that the
+ object is created from the new class.
+ """
+ import mlrun.api.schemas
+ import mlrun.common.schemas
+
+ with warnings.catch_warnings(record=True) as w:
+ # create an object using the deprecated class
+ obj = mlrun.api.schemas.ObjectMetadata(name="name", project="project")
+
+ # validate that the object is created from the new class
+ assert type(obj) == mlrun.common.schemas.ObjectMetadata
+
+ # validate that the warning is shown
+ assert len(w) == 1
+ assert (
+ "mlrun.api.schemas.ObjectMetadata is deprecated in version 1.4.0, "
+ "Please use mlrun.common.schemas.ObjectMetadata instead."
+ in str(w[-1].message)
+ )
+
+
+def test_deprecated_schema_as_argument():
+ """
+ This test validates that the deprecation warning is shown when using a deprecated schema as an argument to a
+ function. And that the function still works, and the schema is converted to the new schema.
+ The test uses the get_secrets function as an example.
+ """
+ import mlrun.api.api.utils
+ import mlrun.api.schemas
+ import mlrun.common.schemas
+
+ data_session = "some-data-session"
+
+ with warnings.catch_warnings(record=True) as w:
+ secrets = mlrun.api.api.utils.get_secrets(
+ auth_info=mlrun.api.schemas.AuthInfo(data_session=data_session),
+ )
+
+ assert "V3IO_ACCESS_KEY" in secrets
+ assert secrets["V3IO_ACCESS_KEY"] == data_session
+
+ # validate that the warning is shown
+ assert len(w) == 1
+ assert (
+ "mlrun.api.schemas.AuthInfo is deprecated in version 1.4.0, "
+ "Please use mlrun.common.schemas.AuthInfo instead." in str(w[-1].message)
+ )
diff --git a/tests/utils/test_vault.py b/tests/utils/test_vault.py
index 39ce925edb76..9bc710aecb00 100644
--- a/tests/utils/test_vault.py
+++ b/tests/utils/test_vault.py
@@ -89,7 +89,7 @@ def test_vault_end_to_end():
# It executes on the API server
project.set_secrets(
{"aws_key": aws_key_value, "github_key": github_key_value},
- provider=mlrun.api.schemas.SecretProviderName.vault,
+ provider=mlrun.common.schemas.SecretProviderName.vault,
)
# This API executes on the client side
From fc8fc2b32a9aa15a16945ffcd349d55cf661fe05 Mon Sep 17 00:00:00 2001
From: Tom Tankilevitch <59158507+Tankilevitch@users.noreply.github.com>
Date: Sun, 7 May 2023 12:02:48 +0300
Subject: [PATCH 092/334] [CI] Add command to the `prepare.py` and
`deployer.py` (#3478)
---
automation/common/__init__.py | 13 -----
automation/common/helpers.py | 71 ----------------------
automation/deployment/deployer.py | 97 ++++++++++++++++++++++---------
automation/system_test/prepare.py | 59 ++++++++++++++++++-
4 files changed, 127 insertions(+), 113 deletions(-)
delete mode 100644 automation/common/__init__.py
delete mode 100644 automation/common/helpers.py
diff --git a/automation/common/__init__.py b/automation/common/__init__.py
deleted file mode 100644
index 7f557697af77..000000000000
--- a/automation/common/__init__.py
+++ /dev/null
@@ -1,13 +0,0 @@
-# Copyright 2023 MLRun Authors
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
diff --git a/automation/common/helpers.py b/automation/common/helpers.py
deleted file mode 100644
index 126272f245de..000000000000
--- a/automation/common/helpers.py
+++ /dev/null
@@ -1,71 +0,0 @@
-# Copyright 2023 MLRun Authors
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import subprocess
-import sys
-import typing
-
-
-def run_command(
- command: str,
- args: list = None,
- workdir: str = None,
- stdin: str = None,
- live: bool = True,
- log_file_handler: typing.IO[str] = None,
-) -> (str, str, int):
- if workdir:
- command = f"cd {workdir}; " + command
- if args:
- command += " " + " ".join(args)
-
- process = subprocess.Popen(
- command,
- stdout=subprocess.PIPE,
- stderr=subprocess.PIPE,
- stdin=subprocess.PIPE,
- shell=True,
- )
-
- if stdin:
- process.stdin.write(bytes(stdin, "ascii"))
- process.stdin.close()
-
- stdout = _handle_command_stdout(process.stdout, log_file_handler, live)
- stderr = process.stderr.read()
- exit_status = process.wait()
-
- return stdout, stderr, exit_status
-
-
-def _handle_command_stdout(
- stdout_stream: typing.IO[bytes],
- log_file_handler: typing.IO[str] = None,
- live: bool = True,
-) -> str:
- def _write_to_log_file(text: bytes):
- if log_file_handler:
- log_file_handler.write(text.decode(sys.stdout.encoding))
-
- stdout = ""
- if live:
- for line in iter(stdout_stream.readline, b""):
- stdout += str(line)
- sys.stdout.write(line.decode(sys.stdout.encoding))
- _write_to_log_file(line)
- else:
- stdout = stdout_stream.read()
- _write_to_log_file(stdout)
-
- return stdout
diff --git a/automation/deployment/deployer.py b/automation/deployment/deployer.py
index 62bfafaeac15..59a2113a314d 100644
--- a/automation/deployment/deployer.py
+++ b/automation/deployment/deployer.py
@@ -13,11 +13,12 @@
# limitations under the License.
import os.path
import platform
+import subprocess
+import sys
import typing
import requests
-import automation.common.helpers
import mlrun.utils
@@ -116,7 +117,7 @@ def deploy(
self._logger.info(
"Installing helm chart with arguments", helm_arguments=helm_arguments
)
- automation.common.helpers.run_command("helm", helm_arguments)
+ run_command("helm", helm_arguments)
self._teardown()
@@ -142,16 +143,14 @@ def delete(
self._logger.warning(
"Cleaning up entire namespace", namespace=self._namespace
)
- automation.common.helpers.run_command(
- "kubectl", ["delete", "namespace", self._namespace]
- )
+ run_command("kubectl", ["delete", "namespace", self._namespace])
return
if not skip_uninstall:
self._logger.info(
"Cleaning up helm release", release=Constants.helm_release_name
)
- automation.common.helpers.run_command(
+ run_command(
"helm",
[
"--namespace",
@@ -163,7 +162,7 @@ def delete(
if cleanup_volumes:
self._logger.warning("Cleaning up mlrun volumes")
- automation.common.helpers.run_command(
+ run_command(
"kubectl",
[
"--namespace",
@@ -180,7 +179,7 @@ def delete(
"Cleaning up registry secret",
secret_name=registry_secret_name,
)
- automation.common.helpers.run_command(
+ run_command(
"kubectl",
[
"--namespace",
@@ -210,7 +209,7 @@ def patch_minikube_images(
"""
for image in [mlrun_api_image, mlrun_ui_image, jupyter_image]:
if image:
- automation.common.helpers.run_command("minikube", ["load", image])
+ run_command("minikube", ["load", image])
self._teardown()
@@ -241,17 +240,15 @@ def _prepare_prerequisites(
self._validate_registry_url(registry_url)
self._logger.info("Creating namespace", namespace=self._namespace)
- automation.common.helpers.run_command(
- "kubectl", ["create", "namespace", self._namespace]
- )
+ run_command("kubectl", ["create", "namespace", self._namespace])
self._logger.debug("Adding helm repo")
- automation.common.helpers.run_command(
+ run_command(
"helm", ["repo", "add", Constants.helm_repo_name, Constants.helm_repo_url]
)
self._logger.debug("Updating helm repo")
- automation.common.helpers.run_command("helm", ["repo", "update"])
+ run_command("helm", ["repo", "update"])
if registry_username and registry_password:
self._create_registry_credentials_secret(
@@ -477,7 +474,7 @@ def _create_registry_credentials_secret(
"Creating registry credentials secret",
secret_name=registry_secret_name,
)
- automation.common.helpers.run_command(
+ run_command(
"kubectl",
[
"--namespace",
@@ -500,7 +497,7 @@ def _check_platform_architecture() -> str:
:return: Platform architecture
"""
if platform.system() == "Darwin":
- translated, _, exit_status = automation.common.helpers.run_command(
+ translated, _, exit_status = run_command(
"sysctl",
["-n", "sysctl.proc_translated"],
live=False,
@@ -518,15 +515,9 @@ def _get_host_ip(self) -> str:
:return: Host IP
"""
if platform.system() == "Darwin":
- return automation.common.helpers.run_command(
- "ipconfig", ["getifaddr", "en0"], live=False
- )[0].strip()
+ return run_command("ipconfig", ["getifaddr", "en0"], live=False)[0].strip()
elif platform.system() == "Linux":
- return (
- automation.common.helpers.run_command("hostname", ["-I"], live=False)[0]
- .split()[0]
- .strip()
- )
+ return run_command("hostname", ["-I"], live=False)[0].split()[0].strip()
else:
raise NotImplementedError(
f"Platform {platform.system()} is not supported for this action"
@@ -538,9 +529,7 @@ def _get_minikube_ip() -> str:
Get the minikube IP.
:return: Minikube IP
"""
- return automation.common.helpers.run_command("minikube", ["ip"], live=False)[
- 0
- ].strip()
+ return run_command("minikube", ["ip"], live=False)[0].strip()
def _validate_registry_url(self, registry_url):
"""
@@ -602,3 +591,57 @@ def _disable_deployment_in_helm_values(
"""
self._logger.warning("Disabling deployment", deployment=deployment)
helm_values[f"{deployment}.enabled"] = "false"
+
+
+def run_command(
+ command: str,
+ args: list = None,
+ workdir: str = None,
+ stdin: str = None,
+ live: bool = True,
+ log_file_handler: typing.IO[str] = None,
+) -> (str, str, int):
+ if workdir:
+ command = f"cd {workdir}; " + command
+ if args:
+ command += " " + " ".join(args)
+
+ process = subprocess.Popen(
+ command,
+ stdout=subprocess.PIPE,
+ stderr=subprocess.PIPE,
+ stdin=subprocess.PIPE,
+ shell=True,
+ )
+
+ if stdin:
+ process.stdin.write(bytes(stdin, "ascii"))
+ process.stdin.close()
+
+ stdout = _handle_command_stdout(process.stdout, log_file_handler, live)
+ stderr = process.stderr.read()
+ exit_status = process.wait()
+
+ return stdout, stderr, exit_status
+
+
+def _handle_command_stdout(
+ stdout_stream: typing.IO[bytes],
+ log_file_handler: typing.IO[str] = None,
+ live: bool = True,
+) -> str:
+ def _write_to_log_file(text: bytes):
+ if log_file_handler:
+ log_file_handler.write(text.decode(sys.stdout.encoding))
+
+ stdout = ""
+ if live:
+ for line in iter(stdout_stream.readline, b""):
+ stdout += str(line)
+ sys.stdout.write(line.decode(sys.stdout.encoding))
+ _write_to_log_file(line)
+ else:
+ stdout = stdout_stream.read()
+ _write_to_log_file(stdout)
+
+ return stdout
diff --git a/automation/system_test/prepare.py b/automation/system_test/prepare.py
index d579c65ae1d3..25b86e0f6179 100644
--- a/automation/system_test/prepare.py
+++ b/automation/system_test/prepare.py
@@ -16,8 +16,11 @@
import datetime
import logging
import pathlib
+import subprocess
+import sys
import tempfile
import time
+import typing
import urllib.parse
import boto3
@@ -27,8 +30,6 @@
import mlrun.utils
-from ..common.helpers import run_command
-
logger = mlrun.utils.create_logger(level="debug", name="automation")
logging.getLogger("paramiko").setLevel(logging.DEBUG)
@@ -727,5 +728,59 @@ def env(
raise
+def run_command(
+ command: str,
+ args: list = None,
+ workdir: str = None,
+ stdin: str = None,
+ live: bool = True,
+ log_file_handler: typing.IO[str] = None,
+) -> (str, str, int):
+ if workdir:
+ command = f"cd {workdir}; " + command
+ if args:
+ command += " " + " ".join(args)
+
+ process = subprocess.Popen(
+ command,
+ stdout=subprocess.PIPE,
+ stderr=subprocess.PIPE,
+ stdin=subprocess.PIPE,
+ shell=True,
+ )
+
+ if stdin:
+ process.stdin.write(bytes(stdin, "ascii"))
+ process.stdin.close()
+
+ stdout = _handle_command_stdout(process.stdout, log_file_handler, live)
+ stderr = process.stderr.read()
+ exit_status = process.wait()
+
+ return stdout, stderr, exit_status
+
+
+def _handle_command_stdout(
+ stdout_stream: typing.IO[bytes],
+ log_file_handler: typing.IO[str] = None,
+ live: bool = True,
+) -> str:
+ def _write_to_log_file(text: bytes):
+ if log_file_handler:
+ log_file_handler.write(text.decode(sys.stdout.encoding))
+
+ stdout = ""
+ if live:
+ for line in iter(stdout_stream.readline, b""):
+ stdout += str(line)
+ sys.stdout.write(line.decode(sys.stdout.encoding))
+ _write_to_log_file(line)
+ else:
+ stdout = stdout_stream.read()
+ _write_to_log_file(stdout)
+
+ return stdout
+
+
if __name__ == "__main__":
main()
From 77347c32c2b6999f14f86b63384d27d2b4dcbf52 Mon Sep 17 00:00:00 2001
From: Eyal Danieli
Date: Sun, 7 May 2023 23:27:05 +0300
Subject: [PATCH 093/334] [Model Monitoring] Fix EndpointType imports (#3486)
---
.../model_monitoring/stores/sql_model_endpoint_store.py | 9 ++-------
tests/system/model_monitoring/test_model_monitoring.py | 3 +--
2 files changed, 3 insertions(+), 9 deletions(-)
diff --git a/mlrun/model_monitoring/stores/sql_model_endpoint_store.py b/mlrun/model_monitoring/stores/sql_model_endpoint_store.py
index 3b720e3fbdeb..fc69c4ffffe7 100644
--- a/mlrun/model_monitoring/stores/sql_model_endpoint_store.py
+++ b/mlrun/model_monitoring/stores/sql_model_endpoint_store.py
@@ -82,7 +82,6 @@ def write_model_endpoint(self, endpoint: typing.Dict[str, typing.Any]):
"""
with self._engine.connect() as connection:
-
# Adjust timestamps fields
endpoint[
model_monitoring_constants.EventFieldType.FIRST_REQUEST
@@ -112,7 +111,6 @@ def update_model_endpoint(
# Update the model endpoint record using sqlalchemy ORM
with create_session(dsn=self.sql_connection_string) as session:
-
# Remove endpoint id (foreign key) from the update query
attributes.pop(model_monitoring_constants.EventFieldType.ENDPOINT_ID, None)
@@ -131,7 +129,6 @@ def delete_model_endpoint(self, endpoint_id: str):
# Delete the model endpoint record using sqlalchemy ORM
with create_session(dsn=self.sql_connection_string) as session:
-
# Generate and commit the delete query
session.query(self.ModelEndpointsTable).filter_by(uid=endpoint_id).delete()
session.commit()
@@ -152,7 +149,6 @@ def get_model_endpoint(
# Get the model endpoint record using sqlalchemy ORM
with create_session(dsn=self.sql_connection_string) as session:
-
# Generate the get query
endpoint_record = (
session.query(self.ModelEndpointsTable)
@@ -195,7 +191,6 @@ def list_model_endpoints(
# Get the model endpoints records using sqlalchemy ORM
with create_session(dsn=self.sql_connection_string) as session:
-
# Generate the list query
query = session.query(self.ModelEndpointsTable).filter_by(
project=self.project
@@ -225,8 +220,8 @@ def list_model_endpoints(
combined=False,
)
if top_level:
- node_ep = str(mlrun.model_monitoring.EndpointType.NODE_EP.value)
- router_ep = str(mlrun.model_monitoring.EndpointType.ROUTER.value)
+ node_ep = str(mlrun.common.model_monitoring.EndpointType.NODE_EP.value)
+ router_ep = str(mlrun.common.model_monitoring.EndpointType.ROUTER.value)
endpoint_types = [node_ep, router_ep]
query = self._filter_values(
query=query,
diff --git a/tests/system/model_monitoring/test_model_monitoring.py b/tests/system/model_monitoring/test_model_monitoring.py
index 028457f864d8..2fc302caac52 100644
--- a/tests/system/model_monitoring/test_model_monitoring.py
+++ b/tests/system/model_monitoring/test_model_monitoring.py
@@ -33,6 +33,7 @@
import mlrun.common.schemas
import mlrun.feature_store
import mlrun.utils
+from mlrun.common.model_monitoring import EndpointType, ModelMonitoringMode
from mlrun.common.schemas import (
ModelEndpoint,
ModelEndpointMetadata,
@@ -41,7 +42,6 @@
)
from mlrun.errors import MLRunNotFoundError
from mlrun.model import BaseMetadata
-from mlrun.model_monitoring import EndpointType, ModelMonitoringMode
from mlrun.runtimes import BaseRuntime
from mlrun.utils.v3io_clients import get_frames_client
from tests.system.base import TestMLRunSystem
@@ -547,7 +547,6 @@ def test_model_monitoring_voting_ensemble(self):
train = mlrun.import_function("hub://auto-trainer")
for name, pkg in model_names.items():
-
# Run the function and specify input dataset path and some parameters (algorithm and label column name)
train_run = train.run(
name=name,
From 6d3f8dc0d46f965f9a43d017e6f16700b9c25aa9 Mon Sep 17 00:00:00 2001
From: alxtkr77 <3098237+alxtkr77@users.noreply.github.com>
Date: Mon, 8 May 2023 14:11:12 +0300
Subject: [PATCH 094/334] [Spark] Fix treating single string entity as a list
when saving to Redis (#3490)
---
mlrun/datastore/spark_udf.py | 12 ++++++------
1 file changed, 6 insertions(+), 6 deletions(-)
diff --git a/mlrun/datastore/spark_udf.py b/mlrun/datastore/spark_udf.py
index c067b64fa8dc..09585496fae9 100644
--- a/mlrun/datastore/spark_udf.py
+++ b/mlrun/datastore/spark_udf.py
@@ -26,14 +26,14 @@ def _hash_list(*list_to_hash):
def _redis_stringify_key(key_list):
- try:
+ suffix = "}:static"
+ if isinstance(key_list, list):
if len(key_list) >= 2:
- return str(key_list[0]) + "." + _hash_list(key_list[1:]) + "}:static"
+ return str(key_list[0]) + "." + _hash_list(key_list[1:]) + suffix
if len(key_list) == 2:
- return str(key_list[0]) + "." + str(key_list[1]) + "}:static"
- return str(key_list[0]) + "}:static"
- except TypeError:
- return str(key_list) + "}:static"
+ return str(key_list[0]) + "." + str(key_list[1]) + suffix
+ return str(key_list[0]) + suffix
+ return str(key_list) + suffix
hash_and_concat_v3io_udf = udf(_hash_list, StringType())
From ef31a8ad8c8e689ff54f35c0c2e58f8dd0b6a152 Mon Sep 17 00:00:00 2001
From: Eyal Danieli
Date: Mon, 8 May 2023 15:14:32 +0300
Subject: [PATCH 095/334] [Model Monitoring] Fix BC issue when deleting a model
endpoint from KV (#3482)
---
mlrun/common/model_monitoring.py | 7 +------
.../stores/kv_model_endpoint_store.py | 13 ++++++++++---
2 files changed, 11 insertions(+), 9 deletions(-)
diff --git a/mlrun/common/model_monitoring.py b/mlrun/common/model_monitoring.py
index b4c17e87b6c6..4093cd6cab6b 100644
--- a/mlrun/common/model_monitoring.py
+++ b/mlrun/common/model_monitoring.py
@@ -30,6 +30,7 @@ class EventFieldType:
VERSIONED_MODEL = "versioned_model"
MODEL_CLASS = "model_class"
TIMESTAMP = "timestamp"
+ # `endpoint_id` is deprecated as a field in the model endpoint schema since 1.3.1, replaced by `uid`.
ENDPOINT_ID = "endpoint_id"
UID = "uid"
ENDPOINT_TYPE = "endpoint_type"
@@ -40,7 +41,6 @@ class EventFieldType:
NAMED_FEATURES = "named_features"
LABELS = "labels"
LATENCY = "latency"
- LABEL_COLUMNS = "label_columns"
LABEL_NAMES = "label_names"
PREDICTION = "prediction"
PREDICTIONS = "predictions"
@@ -50,12 +50,9 @@ class EventFieldType:
FIRST_REQUEST = "first_request"
LAST_REQUEST = "last_request"
METRICS = "metrics"
- BATCH_TIMESTAMP = "batch_timestamp"
TIME_FORMAT = "%Y-%m-%d %H:%M:%S.%f"
BATCH_INTERVALS_DICT = "batch_intervals_dict"
DEFAULT_BATCH_INTERVALS = "default_batch_intervals"
- DEFAULT_BATCH_IMAGE = "default_batch_image"
- STREAM_IMAGE = "stream_image"
MINUTES = "minutes"
HOURS = "hours"
DAYS = "days"
@@ -74,7 +71,6 @@ class EventFieldType:
MONITOR_CONFIGURATION = "monitor_configuration"
FEATURE_SET_URI = "monitoring_feature_set_uri"
ALGORITHM = "algorithm"
- ACCURACY = "accuracy"
class EventLiveStats:
@@ -120,7 +116,6 @@ class FileTargetKind:
STREAM = "stream"
PARQUET = "parquet"
LOG_STREAM = "log_stream"
- DEFAULT_HTTP_SINK = "default_http_sink"
class ModelMonitoringMode(str, enum.Enum):
diff --git a/mlrun/model_monitoring/stores/kv_model_endpoint_store.py b/mlrun/model_monitoring/stores/kv_model_endpoint_store.py
index b84e21f16b86..5a8222685093 100644
--- a/mlrun/model_monitoring/stores/kv_model_endpoint_store.py
+++ b/mlrun/model_monitoring/stores/kv_model_endpoint_store.py
@@ -168,7 +168,6 @@ def list_model_endpoints(
# Retrieve the raw data from the KV table and get the endpoint ids
try:
-
cursor = self.client.kv.new_cursor(
container=self.container,
table_path=self.path,
@@ -219,8 +218,17 @@ def delete_model_endpoints_resources(
# Delete model endpoint record from KV table
for endpoint_dict in endpoints:
+ if model_monitoring_constants.EventFieldType.UID not in endpoint_dict:
+ # This is kept for backwards compatibility - in old versions the key column named endpoint_id
+ endpoint_id = endpoint_dict[
+ model_monitoring_constants.EventFieldType.ENDPOINT_ID
+ ]
+ else:
+ endpoint_id = endpoint_dict[
+ model_monitoring_constants.EventFieldType.UID
+ ]
self.delete_model_endpoint(
- endpoint_dict[model_monitoring_constants.EventFieldType.UID],
+ endpoint_id,
)
# Delete remain records in the KV
@@ -420,7 +428,6 @@ def _build_kv_cursor_filter_expression(
# Add labels filters
if labels:
-
for label in labels:
if not label.startswith("_"):
label = f"_{label}"
From 018d56a10156a1b2c9c9a314e363913c162817fa Mon Sep 17 00:00:00 2001
From: Adam
Date: Mon, 8 May 2023 19:48:20 +0300
Subject: [PATCH 096/334] [CI] Use CE Deployer in Open Source System Tests CI
(#3491)
---
.github/workflows/system-tests-opensource.yml | 43 ++++-------
automation/deployment/ce.py | 11 ++-
automation/deployment/deployer.py | 72 ++++++++++++++-----
3 files changed, 74 insertions(+), 52 deletions(-)
diff --git a/.github/workflows/system-tests-opensource.yml b/.github/workflows/system-tests-opensource.yml
index 85f018739be1..d8e612df1d40 100644
--- a/.github/workflows/system-tests-opensource.yml
+++ b/.github/workflows/system-tests-opensource.yml
@@ -164,47 +164,28 @@ jobs:
# but this seems to work
start args: '--addons=registry --insecure-registry="192.168.49.2:5000"'
- - name: Get mlrun ce charts and create namespace
- run: |
- helm repo add mlrun-ce https://mlrun.github.io/ce
- helm repo update
- minikube kubectl -- create namespace ${NAMESPACE}
-
- name: Install MLRun CE helm chart
run: |
# TODO: There are a couple of modifications to the helm chart that we are doing right now:
# 1. The grafana prometheus stack is disabled as there are currently no system tests checking its
# functionality. Once the model monitoring feature is complete and we have system tests for it, we
- # can enable it. (flags: --set kube-prometheus-stack.enabled=false)
+ # can enable it.
# 2. The mlrun DB is set as the old SQLite db. There is a bug in github workers when trying to run a mysql
# server pod in minikube installed on the worker, the mysql pod crashes. There isn't much information
# about this issue online as this isn't how github expect you to use mysql in workflows - the worker
# has a mysql server installed directly on it and should be enabled and used as the DB. So we might
# want in the future to use that instead, unless the mysql will be able to come up without crashing.
- # (flags: --set mlrun.httpDB.dbType="sqlite" --set mlrun.httpDB.dirPath="/mlrun/db"
- # --set mlrun.httpDB.dsn="sqlite:////mlrun/db/mlrun.db?check_same_thread=false"
- # --set mlrun.httpDB.oldDsn="")
- helm --namespace ${NAMESPACE} \
- install mlrun-ce \
- --debug \
- --wait \
- --timeout 600s \
- --set kube-prometheus-stack.enabled=false \
- --set mlrun.httpDB.dbType="sqlite" \
- --set mlrun.httpDB.dirPath="/mlrun/db" \
- --set mlrun.httpDB.dsn="sqlite:////mlrun/db/mlrun.db?check_same_thread=false" \
- --set mlrun.httpDB.oldDsn="" \
- --set global.registry.url=$(minikube ip):5000 \
- --set global.registry.secretName="" \
- --set global.externalHostAddress=$(minikube ip) \
- --set nuclio.dashboard.externalIPAddresses[0]=$(minikube ip) \
- --set mlrun.api.image.repository=${{ steps.computed_params.outputs.mlrun_docker_registry }}${{ steps.computed_params.outputs.mlrun_docker_repo }}/mlrun-api \
- --set mlrun.api.image.tag=${{ steps.computed_params.outputs.mlrun_docker_tag }} \
- --set mlrun.ui.image.repository=ghcr.io/mlrun/mlrun-ui \
- --set mlrun.ui.image.tag=${{ steps.computed_params.outputs.mlrun_ui_version }} \
- --set mlrun.api.extraEnvKeyValue.MLRUN_HTTPDB__BUILDER__MLRUN_VERSION_SPECIFIER="mlrun[complete] @ git+https://github.com/mlrun/mlrun@${{ steps.computed_params.outputs.mlrun_hash }}" \
- --set mlrun.api.extraEnvKeyValue.MLRUN_IMAGES_REGISTRY="${{ steps.computed_params.outputs.mlrun_docker_registry }}" \
- mlrun-ce/mlrun-ce
+ python automation/deployment/ce.py deploy \
+ --verbose \
+ --minikube \
+ --namespace=${NAMESPACE} \
+ --registry-secret-name="" \
+ --disable-prometheus-stack \
+ --sqlite /mlrun/db/mlrun.db \
+ --override-mlrun-api-image="${{ steps.computed_params.outputs.mlrun_docker_registry }}${{ steps.computed_params.outputs.mlrun_docker_repo }}/mlrun-api:${{ steps.computed_params.outputs.mlrun_docker_tag }}" \
+ --override-mlrun-ui-image="ghcr.io/mlrun/mlrun-ui:${{ steps.computed_params.outputs.mlrun_ui_version }}" \
+ --set 'mlrun.api.extraEnvKeyValue.MLRUN_HTTPDB__BUILDER__MLRUN_VERSION_SPECIFIER="mlrun[complete] @ git+https://github.com/mlrun/mlrun@${{ steps.computed_params.outputs.mlrun_hash }}"' \
+ --set mlrun.api.extraEnvKeyValue.MLRUN_IMAGES_REGISTRY="${{ steps.computed_params.outputs.mlrun_docker_registry }}"
- name: Prepare system tests env
run: |
diff --git a/automation/deployment/ce.py b/automation/deployment/ce.py
index 0314d9ab06e0..b85501c8ddbb 100644
--- a/automation/deployment/ce.py
+++ b/automation/deployment/ce.py
@@ -16,8 +16,7 @@
import typing
import click
-
-from automation.deployment.deployer import CommunityEditionDeployer
+from deployer import CommunityEditionDeployer
common_options = [
click.option(
@@ -87,7 +86,6 @@ def cli():
@click.option(
"--registry-url",
help="URL of the container registry to use for storing images",
- required=True,
)
@click.option(
"--registry-username",
@@ -146,6 +144,11 @@ def cli():
is_flag=True,
help="Upgrade the existing mlrun installation",
)
+@click.option(
+ "--skip-registry-validation",
+ is_flag=True,
+ help="Skip validation of the registry URL",
+)
@add_options(common_options)
@add_options(common_deployment_options)
def deploy(
@@ -164,6 +167,7 @@ def deploy(
disable_pipelines: bool = False,
disable_prometheus_stack: bool = False,
disable_spark_operator: bool = False,
+ skip_registry_validation: bool = False,
sqlite: str = None,
devel: bool = False,
minikube: bool = False,
@@ -188,6 +192,7 @@ def deploy(
disable_pipelines=disable_pipelines,
disable_prometheus_stack=disable_prometheus_stack,
disable_spark_operator=disable_spark_operator,
+ skip_registry_validation=skip_registry_validation,
devel=devel,
minikube=minikube,
sqlite=sqlite,
diff --git a/automation/deployment/deployer.py b/automation/deployment/deployer.py
index 59a2113a314d..5c2a07713b56 100644
--- a/automation/deployment/deployer.py
+++ b/automation/deployment/deployer.py
@@ -30,6 +30,7 @@ class Constants:
default_registry_secret_name = "registry-credentials"
mlrun_image_values = ["mlrun.api", "mlrun.ui", "jupyterNotebook"]
disableable_deployments = ["pipelines", "kube-prometheus-stack", "spark-operator"]
+ minikube_registry_port = 5000
class CommunityEditionDeployer:
@@ -67,6 +68,7 @@ def deploy(
disable_pipelines: bool = False,
disable_prometheus_stack: bool = False,
disable_spark_operator: bool = False,
+ skip_registry_validation: bool = False,
devel: bool = False,
minikube: bool = False,
sqlite: str = None,
@@ -87,6 +89,7 @@ def deploy(
:param disable_pipelines: Disable the deployment of the pipelines component
:param disable_prometheus_stack: Disable the deployment of the Prometheus stack component
:param disable_spark_operator: Disable the deployment of the Spark operator component
+ :param skip_registry_validation: Skip the validation of the registry URL
:param devel: Deploy the development version of the helm chart
:param minikube: Deploy the helm chart with minikube configuration
:param sqlite: Path to sqlite file to use as the mlrun database. If not supplied, will use MySQL deployment
@@ -94,7 +97,12 @@ def deploy(
:param custom_values: List of custom values to pass to the helm chart
"""
self._prepare_prerequisites(
- registry_url, registry_username, registry_password, registry_secret_name
+ registry_url,
+ registry_username,
+ registry_password,
+ registry_secret_name,
+ skip_registry_validation,
+ minikube,
)
helm_arguments = self._generate_helm_install_arguments(
registry_url,
@@ -117,7 +125,14 @@ def deploy(
self._logger.info(
"Installing helm chart with arguments", helm_arguments=helm_arguments
)
- run_command("helm", helm_arguments)
+ stdout, stderr, exit_status = run_command("helm", helm_arguments)
+ if exit_status != 0:
+ self._logger.error(
+ "Failed to install helm chart",
+ stderr=stderr,
+ exit_status=exit_status,
+ )
+ raise RuntimeError("Failed to install helm chart")
self._teardown()
@@ -227,6 +242,8 @@ def _prepare_prerequisites(
registry_username: str = None,
registry_password: str = None,
registry_secret_name: str = None,
+ skip_registry_validation: bool = False,
+ minikube: bool = False,
) -> None:
"""
Prepare the prerequisites for the MLRun CE stack deployment.
@@ -235,9 +252,15 @@ def _prepare_prerequisites(
:param registry_username: Username of the registry to use (not required if registry_secret_name is provided)
:param registry_password: Password of the registry to use (not required if registry_secret_name is provided)
:param registry_secret_name: Name of the registry secret to use
+ :param skip_registry_validation: Skip the validation of the registry URL
+ :param minikube: Whether to deploy on minikube
"""
self._logger.info("Preparing prerequisites")
- self._validate_registry_url(registry_url)
+ skip_registry_validation = skip_registry_validation or (
+ registry_url is None and minikube
+ )
+ if not skip_registry_validation:
+ self._validate_registry_url(registry_url)
self._logger.info("Creating namespace", namespace=self._namespace)
run_command("kubectl", ["create", "namespace", self._namespace])
@@ -254,7 +277,7 @@ def _prepare_prerequisites(
self._create_registry_credentials_secret(
registry_url, registry_username, registry_password
)
- elif registry_secret_name:
+ elif registry_secret_name is not None:
self._logger.warning(
"Using existing registry secret", secret_name=registry_secret_name
)
@@ -304,8 +327,9 @@ def _generate_helm_install_arguments(
"--namespace",
self._namespace,
"upgrade",
- "--install",
Constants.helm_release_name,
+ Constants.helm_chart_name,
+ "--install",
"--wait",
"--timeout",
"960s",
@@ -345,8 +369,6 @@ def _generate_helm_install_arguments(
]
)
- helm_arguments.append(Constants.helm_chart_name)
-
if chart_version:
self._logger.warning(
"Installing specific chart version", chart_version=chart_version
@@ -393,14 +415,17 @@ def _generate_helm_values(
:param minikube: Use minikube
:return: Dictionary of helm values
"""
+ host_ip = self._get_minikube_ip() if minikube else self._get_host_ip()
+ if not registry_url and minikube:
+ registry_url = f"{host_ip}:{Constants.minikube_registry_port}"
helm_values = {
"global.registry.url": registry_url,
- "global.registry.secretName": registry_secret_name
- or Constants.default_registry_secret_name,
- "global.externalHostAddress": self._get_minikube_ip()
- if minikube
- else self._get_host_ip(),
+ "global.registry.secretName": f'"{registry_secret_name}"' # adding quotes in case of empty string
+ if registry_secret_name is not None
+ else Constants.default_registry_secret_name,
+ "global.externalHostAddress": host_ip,
+ "nuclio.dashboard.externalIPAddresses[0]": host_ip,
}
if mlrun_version:
@@ -433,9 +458,9 @@ def _generate_helm_values(
helm_values.update(
{
"mlrun.httpDB.dbType": "sqlite",
- "mlrun.httpDB.dirPath": {dir_path},
+ "mlrun.httpDB.dirPath": dir_path,
"mlrun.httpDB.dsn": f"sqlite:///{sqlite}?check_same_thread=false",
- "mlrun.httpDB.oldDsn": "",
+ "mlrun.httpDB.oldDsn": '""',
}
)
@@ -468,7 +493,9 @@ def _create_registry_credentials_secret(
:param registry_secret_name: Name of the registry secret to use
"""
registry_secret_name = (
- registry_secret_name or Constants.default_registry_secret_name
+ registry_secret_name
+ if registry_secret_name is not None
+ else Constants.default_registry_secret_name
)
self._logger.debug(
"Creating registry credentials secret",
@@ -515,9 +542,18 @@ def _get_host_ip(self) -> str:
:return: Host IP
"""
if platform.system() == "Darwin":
- return run_command("ipconfig", ["getifaddr", "en0"], live=False)[0].strip()
+ return (
+ run_command("ipconfig", ["getifaddr", "en0"], live=False)[0]
+ .strip()
+ .decode("utf-8")
+ )
elif platform.system() == "Linux":
- return run_command("hostname", ["-I"], live=False)[0].split()[0].strip()
+ return (
+ run_command("hostname", ["-I"], live=False)[0]
+ .split()[0]
+ .strip()
+ .decode("utf-8")
+ )
else:
raise NotImplementedError(
f"Platform {platform.system()} is not supported for this action"
@@ -529,7 +565,7 @@ def _get_minikube_ip() -> str:
Get the minikube IP.
:return: Minikube IP
"""
- return run_command("minikube", ["ip"], live=False)[0].strip()
+ return run_command("minikube", ["ip"], live=False)[0].strip().decode("utf-8")
def _validate_registry_url(self, registry_url):
"""
From 1ace8ddee7883b698e7646e788fef3f63cb3dd84 Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Tue, 9 May 2023 11:08:00 +0300
Subject: [PATCH 097/334] [Requirements] Blacklist orjson 3.8.12 (#3496)
---
requirements.txt | 3 ++-
tests/test_requirements.py | 1 +
2 files changed, 3 insertions(+), 1 deletion(-)
diff --git a/requirements.txt b/requirements.txt
index aa869b7653ac..f8f2f645c97e 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -38,7 +38,8 @@ sqlalchemy~=1.4
tabulate~=0.8.6
v3io~=0.5.20
pydantic~=1.5
-orjson~=3.3
+# blacklist 3.8.12 due to a bug not being able to collect traceback of exceptions
+orjson~=3.3, <3.8.12
alembic~=1.9
mergedeep~=1.3
v3io-frames~=0.10.4
diff --git a/tests/test_requirements.py b/tests/test_requirements.py
index 9eb3e7bc5570..814914cd8bd6 100644
--- a/tests/test_requirements.py
+++ b/tests/test_requirements.py
@@ -132,6 +132,7 @@ def test_requirement_specifiers_convention():
"ipython": {">=7.0, <9.0"},
"importlib_metadata": {">=3.6"},
"gitpython": {"~=3.1, >= 3.1.30"},
+ "orjson": {"~=3.3, <3.8.12"},
"pyopenssl": {">=23"},
"google-cloud-bigquery": {"[pandas, bqstorage]~=3.2"},
# plotly artifact body in 5.12.0 may contain chars that are not encodable in 'latin-1' encoding
From 2e2a711ef9c94ba553d9b366271b87168c8b21c1 Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Tue, 9 May 2023 12:04:40 +0300
Subject: [PATCH 098/334] [Requirements] Bump pytest to 7.x (#3499)
---
dev-requirements.txt | 2 +-
dockerfiles/base/requirements.txt | 2 +-
dockerfiles/test-system/requirements.txt | 2 +-
3 files changed, 3 insertions(+), 3 deletions(-)
diff --git a/dev-requirements.txt b/dev-requirements.txt
index b2a80acdff47..2f3c00bd1289 100644
--- a/dev-requirements.txt
+++ b/dev-requirements.txt
@@ -1,4 +1,4 @@
-pytest~=6.0
+pytest~=7.0
twine~=3.1
black~=22.0
flake8~=5.0
diff --git a/dockerfiles/base/requirements.txt b/dockerfiles/base/requirements.txt
index 34d6615c2931..f5ba8cd5bda6 100644
--- a/dockerfiles/base/requirements.txt
+++ b/dockerfiles/base/requirements.txt
@@ -10,7 +10,7 @@ lifelines~=0.25.0
# so, it cannot be logged as artifact (raised UnicodeEncode error - ML-3255)
plotly~=5.4, <5.12.0
pyod~=0.8.1
-pytest~=6.0
+pytest~=7.0
scikit-multiflow~=0.5.3
scikit-optimize~=0.8.1
scikit-image~=0.16.0
diff --git a/dockerfiles/test-system/requirements.txt b/dockerfiles/test-system/requirements.txt
index 4cf5c9bf2096..cd7bffd531a2 100644
--- a/dockerfiles/test-system/requirements.txt
+++ b/dockerfiles/test-system/requirements.txt
@@ -1,4 +1,4 @@
-pytest~=6.0
+pytest~=7.0
matplotlib~=3.5
graphviz~=0.20.0
scikit-learn~=1.0
From 521358102cbddbaf4d9f5fa6588d8d46ef4ce844 Mon Sep 17 00:00:00 2001
From: Tom Tankilevitch <59158507+Tankilevitch@users.noreply.github.com>
Date: Tue, 9 May 2023 12:37:59 +0300
Subject: [PATCH 099/334] [K8s] Move K8s Helper to API side (#3426)
---
mlrun/__main__.py | 15 -
mlrun/api/api/endpoints/functions.py | 14 +-
mlrun/api/api/endpoints/pipelines.py | 6 +-
mlrun/api/api/endpoints/secrets.py | 14 +-
mlrun/api/api/utils.py | 9 +-
mlrun/api/crud/client_spec.py | 2 +-
mlrun/api/crud/hub.py | 4 +-
mlrun/api/crud/logs.py | 10 +-
.../crud/model_monitoring/model_endpoints.py | 4 +-
mlrun/api/crud/projects.py | 6 +-
mlrun/api/crud/runtimes/__init__.py | 14 +
mlrun/api/crud/runtimes/nuclio/__init__.py | 14 +
mlrun/api/crud/runtimes/nuclio/function.py | 456 ++++++++++
mlrun/api/crud/runtimes/nuclio/helpers.py | 310 +++++++
mlrun/api/crud/secrets.py | 24 +-
mlrun/api/main.py | 2 +-
mlrun/api/utils/singletons/k8s.py | 636 +++++++++++++-
mlrun/builder.py | 8 +-
mlrun/config.py | 17 +-
mlrun/feature_store/common.py | 4 +-
mlrun/k8s_utils.py | 785 +-----------------
mlrun/model_monitoring/helpers.py | 4 +-
mlrun/runtimes/base.py | 42 +-
mlrun/runtimes/daskjob.py | 20 +-
mlrun/runtimes/function.py | 619 +-------------
mlrun/runtimes/kubejob.py | 48 +-
mlrun/runtimes/mpijob/abstract.py | 24 +-
mlrun/runtimes/pod.py | 11 +-
mlrun/runtimes/sparkjob/abstract.py | 32 +-
mlrun/runtimes/utils.py | 48 +-
mlrun/secrets.py | 32 +-
mlrun/utils/__init__.py | 1 -
mlrun/utils/vault.py | 537 ++++++------
tests/api/api/test_functions.py | 4 +-
tests/api/api/test_submit.py | 24 +-
tests/api/conftest.py | 12 +-
tests/api/crud/runtimes/__init__.py | 14 +
tests/api/crud/runtimes/nuclio/__init__.py | 14 +
.../api/crud/runtimes/nuclio/test_helpers.py | 104 +++
tests/api/runtime_handlers/base.py | 78 +-
tests/api/runtime_handlers/test_mpijob.py | 4 +-
tests/api/runtime_handlers/test_sparkjob.py | 4 +-
tests/api/runtimes/base.py | 53 +-
tests/api/runtimes/test_kubejob.py | 59 +-
tests/api/runtimes/test_mpijob.py | 6 +-
tests/api/runtimes/test_nuclio.py | 185 +++--
tests/api/runtimes/test_serving.py | 84 +-
tests/api/runtimes/test_spark.py | 2 +-
tests/api/utils/singletons/__init__.py | 14 +
.../utils/singletons}/test_k8s_utils.py | 4 +-
tests/common_fixtures.py | 1 -
tests/runtimes/test_function.py | 39 -
tests/test_builder.py | 16 +-
tests/test_code_to_func.py | 25 +-
tests/utils/test_vault.py | 241 +++---
55 files changed, 2458 insertions(+), 2301 deletions(-)
create mode 100644 mlrun/api/crud/runtimes/__init__.py
create mode 100644 mlrun/api/crud/runtimes/nuclio/__init__.py
create mode 100644 mlrun/api/crud/runtimes/nuclio/function.py
create mode 100644 mlrun/api/crud/runtimes/nuclio/helpers.py
create mode 100644 tests/api/crud/runtimes/__init__.py
create mode 100644 tests/api/crud/runtimes/nuclio/__init__.py
create mode 100644 tests/api/crud/runtimes/nuclio/test_helpers.py
create mode 100644 tests/api/utils/singletons/__init__.py
rename tests/{ => api/utils/singletons}/test_k8s_utils.py (92%)
diff --git a/mlrun/__main__.py b/mlrun/__main__.py
index 824c6629b178..9b5c336e1f7a 100644
--- a/mlrun/__main__.py
+++ b/mlrun/__main__.py
@@ -38,7 +38,6 @@
from .config import config as mlconf
from .db import get_run_db
from .errors import err_to_str
-from .k8s_utils import K8sHelper
from .model import RunTemplate
from .platforms import auto_mount as auto_mount_modifier
from .projects import load_project
@@ -700,20 +699,6 @@ def deploy(
fp.write(function.status.nuclio_name)
-@main.command(context_settings=dict(ignore_unknown_options=True))
-@click.argument("pod", type=str, callback=validate_base_argument)
-@click.option("--namespace", "-n", help="kubernetes namespace")
-@click.option(
- "--timeout", "-t", default=600, show_default=True, help="timeout in seconds"
-)
-def watch(pod, namespace, timeout):
- """Read current or previous task (pod) logs."""
- print("This command will be deprecated in future version !!!\n")
- k8s = K8sHelper(namespace)
- status = k8s.watch(pod, namespace, timeout)
- print(f"Pod {pod} last status is: {status}")
-
-
@main.command(context_settings=dict(ignore_unknown_options=True))
@click.argument("kind", type=str, callback=validate_base_argument)
@click.argument(
diff --git a/mlrun/api/api/endpoints/functions.py b/mlrun/api/api/endpoints/functions.py
index d2cf0cc5418f..7891ebdd0bf0 100644
--- a/mlrun/api/api/endpoints/functions.py
+++ b/mlrun/api/api/endpoints/functions.py
@@ -34,23 +34,23 @@
from sqlalchemy.orm import Session
import mlrun.api.crud
+import mlrun.api.crud.runtimes.nuclio.function
import mlrun.api.db.session
import mlrun.api.utils.auth.verifier
import mlrun.api.utils.background_tasks
import mlrun.api.utils.clients.chief
+import mlrun.api.utils.singletons.k8s
import mlrun.api.utils.singletons.project_member
import mlrun.common.model_monitoring
import mlrun.common.schemas
from mlrun.api.api import deps
from mlrun.api.api.utils import get_run_db_instance, log_and_raise, log_path
from mlrun.api.crud.secrets import Secrets, SecretsClientType
-from mlrun.api.utils.singletons.k8s import get_k8s
from mlrun.builder import build_runtime
from mlrun.config import config
from mlrun.errors import MLRunRuntimeError, err_to_str
from mlrun.run import new_function
from mlrun.runtimes import RuntimeKinds, ServingRuntime, runtime_resources_map
-from mlrun.runtimes.function import deploy_nuclio_function, get_nuclio_deploy_status
from mlrun.runtimes.utils import get_item_name
from mlrun.utils import get_in, logger, parse_versioned_object_uri, update_in
from mlrun.utils.model_monitoring import parse_model_endpoint_store_prefix
@@ -464,7 +464,9 @@ def _handle_job_deploy_status(
)
logger.info(f"get pod {pod} status")
- state = get_k8s().get_pod_status(pod)
+ state = mlrun.api.utils.singletons.k8s.get_k8s_helper(silent=False).get_pod_status(
+ pod
+ )
logger.info(f"pod state={state}")
if state == "succeeded":
@@ -475,7 +477,7 @@ def _handle_job_deploy_status(
state = mlrun.common.schemas.FunctionState.error
if (logs and state != "pending") or state in terminal_states:
- resp = get_k8s().logs(pod)
+ resp = mlrun.api.utils.singletons.k8s.get_k8s_helper(silent=False).logs(pod)
if state in terminal_states:
log_file.parent.mkdir(parents=True, exist_ok=True)
with log_file.open("wb") as fp:
@@ -523,7 +525,7 @@ def _handle_nuclio_deploy_status(
last_log_timestamp,
text,
status,
- ) = get_nuclio_deploy_status(
+ ) = mlrun.api.crud.runtimes.nuclio.function.get_nuclio_deploy_status(
name,
project,
tag,
@@ -677,7 +679,7 @@ def _build_function(
traceback=traceback.format_exc(),
)
- deploy_nuclio_function(
+ mlrun.api.crud.runtimes.nuclio.function.deploy_nuclio_function(
fn,
auth_info=auth_info,
client_version=client_version,
diff --git a/mlrun/api/api/endpoints/pipelines.py b/mlrun/api/api/endpoints/pipelines.py
index 38fa53428851..ada697101fab 100644
--- a/mlrun/api/api/endpoints/pipelines.py
+++ b/mlrun/api/api/endpoints/pipelines.py
@@ -24,12 +24,12 @@
import mlrun.api.crud
import mlrun.api.utils.auth.verifier
+import mlrun.api.utils.singletons.k8s
import mlrun.common.schemas
import mlrun.errors
from mlrun.api.api import deps
from mlrun.api.api.utils import log_and_raise
from mlrun.config import config
-from mlrun.k8s_utils import get_k8s_helper
from mlrun.utils import logger
router = APIRouter()
@@ -62,7 +62,9 @@ async def list_pipelines(
auth_info,
)
total_size, next_page_token, runs = None, None, []
- if get_k8s_helper(silent=True).is_running_inside_kubernetes_cluster():
+ if mlrun.api.utils.singletons.k8s.get_k8s_helper(
+ silent=True
+ ).is_running_inside_kubernetes_cluster():
# we need to resolve the project from the returned run for the opa enforcement (project query param might be
# "*"), so we can't really get back only the names here
computed_format = (
diff --git a/mlrun/api/api/endpoints/secrets.py b/mlrun/api/api/endpoints/secrets.py
index 0e6f2147ab57..3eaaf361ebd2 100644
--- a/mlrun/api/api/endpoints/secrets.py
+++ b/mlrun/api/api/endpoints/secrets.py
@@ -25,7 +25,6 @@
import mlrun.api.utils.singletons.project_member
import mlrun.common.schemas
import mlrun.errors
-from mlrun.utils.vault import add_vault_user_secrets
router = fastapi.APIRouter()
@@ -164,11 +163,8 @@ async def list_project_secrets(
def add_user_secrets(
secrets: mlrun.common.schemas.UserSecretCreationRequest,
):
- if secrets.provider != mlrun.common.schemas.SecretProviderName.vault:
- return fastapi.Response(
- status_code=HTTPStatus.BAD_REQUEST.vault,
- content=f"Invalid secrets provider {secrets.provider}",
- )
-
- add_vault_user_secrets(secrets.user, secrets.secrets)
- return fastapi.Response(status_code=HTTPStatus.CREATED.value)
+ # vault is not used
+ return fastapi.Response(
+ status_code=HTTPStatus.BAD_REQUEST.value,
+ content=f"Invalid secrets provider {secrets.provider}",
+ )
diff --git a/mlrun/api/api/utils.py b/mlrun/api/api/utils.py
index 172a4dce251e..b16a86c8f58a 100644
--- a/mlrun/api/api/utils.py
+++ b/mlrun/api/api/utils.py
@@ -42,7 +42,6 @@
from mlrun.config import config
from mlrun.db.sqldb import SQLDB as SQLRunDB
from mlrun.errors import err_to_str
-from mlrun.k8s_utils import get_k8s_helper
from mlrun.run import import_function, new_function
from mlrun.runtimes.utils import enrich_function_from_dict
from mlrun.utils import get_in, logger, parse_versioned_object_uri
@@ -261,7 +260,7 @@ def unmask_notification_params_secret(
if not params_secret:
return notification_object
- k8s = mlrun.api.utils.singletons.k8s.get_k8s()
+ k8s = mlrun.api.utils.singletons.k8s.get_k8s_helper()
if not k8s:
raise mlrun.errors.MLRunRuntimeError(
"Not running in k8s environment, cannot load notification params secret"
@@ -288,7 +287,7 @@ def delete_notification_params_secret(
if not params_secret:
return
- k8s = mlrun.api.utils.singletons.k8s.get_k8s()
+ k8s = mlrun.api.utils.singletons.k8s.get_k8s_helper()
if not k8s:
raise mlrun.errors.MLRunRuntimeError(
"Not running in k8s environment, cannot delete notification params secret"
@@ -634,7 +633,9 @@ def try_perform_auto_mount(function, auth_info: mlrun.common.schemas.AuthInfo):
def process_function_service_account(function):
# If we're not running inside k8s, skip this check as it's not relevant.
- if not get_k8s_helper(silent=True).is_running_inside_kubernetes_cluster():
+ if not mlrun.api.utils.singletons.k8s.get_k8s_helper(
+ silent=True
+ ).is_running_inside_kubernetes_cluster():
return
(
diff --git a/mlrun/api/crud/client_spec.py b/mlrun/api/crud/client_spec.py
index d19508242d47..10928eadab42 100644
--- a/mlrun/api/crud/client_spec.py
+++ b/mlrun/api/crud/client_spec.py
@@ -24,7 +24,7 @@ class ClientSpec(
def get_client_spec(
self, client_version: str = None, client_python_version: str = None
):
- mpijob_crd_version = resolve_mpijob_crd_version(api_context=True)
+ mpijob_crd_version = resolve_mpijob_crd_version()
return mlrun.common.schemas.ClientSpec(
version=config.version,
namespace=config.namespace,
diff --git a/mlrun/api/crud/hub.py b/mlrun/api/crud/hub.py
index fe8cae6acfab..042c30e7a8cb 100644
--- a/mlrun/api/crud/hub.py
+++ b/mlrun/api/crud/hub.py
@@ -15,11 +15,11 @@
import json
from typing import Any, Dict, List, Optional, Tuple
+import mlrun.api.utils.singletons.k8s
import mlrun.common.schemas
import mlrun.common.schemas.hub
import mlrun.errors
import mlrun.utils.singleton
-from mlrun.api.utils.singletons.k8s import get_k8s
from mlrun.config import config
from mlrun.datastore import store_manager
@@ -36,7 +36,7 @@ def __init__(self):
@staticmethod
def _in_k8s():
- k8s_helper = get_k8s()
+ k8s_helper = mlrun.api.utils.singletons.k8s.get_k8s_helper()
return (
k8s_helper is not None and k8s_helper.is_running_inside_kubernetes_cluster()
)
diff --git a/mlrun/api/crud/logs.py b/mlrun/api/crud/logs.py
index dd2f7c954e1f..ab3e639883d1 100644
--- a/mlrun/api/crud/logs.py
+++ b/mlrun/api/crud/logs.py
@@ -22,12 +22,12 @@
from sqlalchemy.orm import Session
import mlrun.api.utils.clients.log_collector as log_collector
+import mlrun.api.utils.singletons.k8s
import mlrun.common.schemas
import mlrun.utils.singleton
from mlrun.api.api.utils import log_and_raise, log_path, project_logs_path
from mlrun.api.constants import LogSources
from mlrun.api.utils.singletons.db import get_db
-from mlrun.api.utils.singletons.k8s import get_k8s
from mlrun.runtimes.constants import PodPhases
from mlrun.utils import logger
@@ -178,10 +178,12 @@ def _get_logs_legacy_method(
fp.seek(offset)
log_contents = fp.read(size)
elif source in [LogSources.AUTO, LogSources.K8S]:
- k8s = get_k8s()
+ k8s = mlrun.api.utils.singletons.k8s.get_k8s_helper()
if k8s and k8s.is_running_inside_kubernetes_cluster():
run_kind = run.get("metadata", {}).get("labels", {}).get("kind")
- pods = get_k8s().get_logger_pods(project, uid, run_kind)
+ pods = mlrun.api.utils.singletons.k8s.get_k8s_helper().get_logger_pods(
+ project, uid, run_kind
+ )
if pods:
if len(pods) > 1:
@@ -195,7 +197,7 @@ def _get_logs_legacy_method(
)
pod, pod_phase = list(pods.items())[0]
if pod_phase != PodPhases.pending:
- resp = get_k8s().logs(pod)
+ resp = mlrun.api.utils.singletons.k8s.get_k8s_helper().logs(pod)
if resp:
if size == -1:
log_contents = resp.encode()[offset:]
diff --git a/mlrun/api/crud/model_monitoring/model_endpoints.py b/mlrun/api/crud/model_monitoring/model_endpoints.py
index 36c30d1a196c..086e3253ec12 100644
--- a/mlrun/api/crud/model_monitoring/model_endpoints.py
+++ b/mlrun/api/crud/model_monitoring/model_endpoints.py
@@ -21,6 +21,7 @@
import mlrun.api.api.endpoints.functions
import mlrun.api.api.utils
+import mlrun.api.crud.runtimes.nuclio.function
import mlrun.api.utils.singletons.k8s
import mlrun.artifacts
import mlrun.common.model_monitoring as model_monitoring_constants
@@ -31,7 +32,6 @@
import mlrun.errors
import mlrun.feature_store
import mlrun.model_monitoring.helpers
-import mlrun.runtimes.function
import mlrun.utils.helpers
import mlrun.utils.model_monitoring
import mlrun.utils.v3io_clients
@@ -801,7 +801,7 @@ def deploy_model_monitoring_stream_processing(
)
try:
# validate that the model monitoring stream has not yet been deployed
- mlrun.runtimes.function.get_nuclio_deploy_status(
+ mlrun.api.crud.runtimes.nuclio.function.get_nuclio_deploy_status(
name="model-monitoring-stream",
project=project,
tag="",
diff --git a/mlrun/api/crud/projects.py b/mlrun/api/crud/projects.py
index b0363572fcd1..3098b0efc1b4 100644
--- a/mlrun/api/crud/projects.py
+++ b/mlrun/api/crud/projects.py
@@ -114,7 +114,7 @@ def _verify_project_has_no_external_resources(self, project: str):
# Therefore, this check should remain at the end of the verification flow.
if (
mlrun.mlconf.is_api_running_on_k8s()
- and mlrun.api.utils.singletons.k8s.get_k8s().get_project_secret_keys(
+ and mlrun.api.utils.singletons.k8s.get_k8s_helper().get_project_secret_keys(
project
)
):
@@ -156,7 +156,9 @@ def delete_project_resources(
# delete project secrets - passing None will delete all secrets
if mlrun.mlconf.is_api_running_on_k8s():
- mlrun.api.utils.singletons.k8s.get_k8s().delete_project_secrets(name, None)
+ mlrun.api.utils.singletons.k8s.get_k8s_helper().delete_project_secrets(
+ name, None
+ )
def get_project(
self, session: sqlalchemy.orm.Session, name: str
diff --git a/mlrun/api/crud/runtimes/__init__.py b/mlrun/api/crud/runtimes/__init__.py
new file mode 100644
index 000000000000..b3085be1eb56
--- /dev/null
+++ b/mlrun/api/crud/runtimes/__init__.py
@@ -0,0 +1,14 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
diff --git a/mlrun/api/crud/runtimes/nuclio/__init__.py b/mlrun/api/crud/runtimes/nuclio/__init__.py
new file mode 100644
index 000000000000..b3085be1eb56
--- /dev/null
+++ b/mlrun/api/crud/runtimes/nuclio/__init__.py
@@ -0,0 +1,14 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
diff --git a/mlrun/api/crud/runtimes/nuclio/function.py b/mlrun/api/crud/runtimes/nuclio/function.py
new file mode 100644
index 000000000000..409792516d7a
--- /dev/null
+++ b/mlrun/api/crud/runtimes/nuclio/function.py
@@ -0,0 +1,456 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+import base64
+import shlex
+
+import nuclio
+import nuclio.utils
+import requests
+
+import mlrun
+import mlrun.api.crud.runtimes.nuclio.helpers
+import mlrun.api.schemas
+import mlrun.api.utils.singletons.k8s
+import mlrun.datastore
+import mlrun.errors
+import mlrun.runtimes.function
+import mlrun.utils
+from mlrun.utils import logger
+
+
+def deploy_nuclio_function(
+ function: mlrun.runtimes.function.RemoteRuntime,
+ auth_info: mlrun.api.schemas.AuthInfo = None,
+ client_version: str = None,
+ builder_env: dict = None,
+ client_python_version: str = None,
+):
+ """Deploys a nuclio function.
+
+ :param function: nuclio function object
+ :param auth_info: service AuthInfo
+ :param client_version: mlrun client version
+ :param builder_env: mlrun builder environment (for config/credentials)
+ :param client_python_version: mlrun client python version
+ """
+ function_name, project_name, function_config = _compile_function_config(
+ function,
+ client_version=client_version,
+ client_python_version=client_python_version,
+ builder_env=builder_env or {},
+ auth_info=auth_info,
+ )
+
+ # if mode allows it, enrich function http trigger with an ingress
+ mlrun.api.crud.runtimes.nuclio.helpers.enrich_function_with_ingress(
+ function_config,
+ function.spec.add_templated_ingress_host_mode
+ or mlrun.mlconf.httpdb.nuclio.add_templated_ingress_host_mode,
+ function.spec.service_type or mlrun.mlconf.httpdb.nuclio.default_service_type,
+ )
+
+ try:
+ return nuclio.deploy.deploy_config(
+ function_config,
+ dashboard_url=mlrun.mlconf.nuclio_dashboard_url,
+ name=function_name,
+ project=project_name,
+ tag=function.metadata.tag,
+ verbose=function.verbose,
+ create_new=True,
+ watch=False,
+ return_address_mode=nuclio.deploy.ReturnAddressModes.all,
+ auth_info=auth_info.to_nuclio_auth_info() if auth_info else None,
+ )
+ except nuclio.utils.DeployError as exc:
+ if exc.err:
+ err_message = (
+ f"Failed to deploy nuclio function {project_name}/{function_name}"
+ )
+
+ try:
+
+ # the error might not be jsonable, so we'll try to parse it
+ # and extract the error message
+ json_err = exc.err.response.json()
+ if "error" in json_err:
+ err_message += f" {json_err['error']}"
+ if "errorStackTrace" in json_err:
+ logger.warning(
+ "Failed to deploy nuclio function",
+ nuclio_stacktrace=json_err["errorStackTrace"],
+ )
+ except Exception as parse_exc:
+ logger.warning(
+ "Failed to parse nuclio deploy error",
+ parse_exc=mlrun.errors.err_to_str(parse_exc),
+ )
+
+ mlrun.errors.raise_for_status(
+ exc.err.response,
+ err_message,
+ )
+ raise
+
+
+def get_nuclio_deploy_status(
+ name,
+ project,
+ tag,
+ last_log_timestamp=0,
+ verbose=False,
+ resolve_address=True,
+ auth_info: mlrun.api.schemas.AuthInfo = None,
+):
+ """
+ Get nuclio function deploy status
+
+ :param name: function name
+ :param project: project name
+ :param tag: function tag
+ :param last_log_timestamp: last log timestamp
+ :param verbose: print logs
+ :param resolve_address: whether to resolve function address
+ :param auth_info: authentication information
+ """
+ api_address = nuclio.deploy.find_dashboard_url(mlrun.mlconf.nuclio_dashboard_url)
+ name = mlrun.runtimes.function.get_fullname(name, project, tag)
+ get_err_message = f"Failed to get function {name} deploy status"
+
+ try:
+ (
+ state,
+ address,
+ last_log_timestamp,
+ outputs,
+ function_status,
+ ) = nuclio.deploy.get_deploy_status(
+ api_address,
+ name,
+ last_log_timestamp,
+ verbose,
+ resolve_address,
+ return_function_status=True,
+ auth_info=auth_info.to_nuclio_auth_info() if auth_info else None,
+ )
+ except requests.exceptions.ConnectionError as exc:
+ mlrun.errors.raise_for_status(
+ exc.response,
+ get_err_message,
+ )
+
+ except nuclio.utils.DeployError as exc:
+ if exc.err:
+ mlrun.errors.raise_for_status(
+ exc.err.response,
+ get_err_message,
+ )
+ raise exc
+ else:
+ text = "\n".join(outputs) if outputs else ""
+ return state, address, name, last_log_timestamp, text, function_status
+
+
+def _compile_function_config(
+ function: mlrun.runtimes.function.RemoteRuntime,
+ client_version: str = None,
+ client_python_version: str = None,
+ builder_env=None,
+ auth_info=None,
+):
+ labels = function.metadata.labels or {}
+ labels.update({"mlrun/class": function.kind})
+ for key, value in labels.items():
+ # Adding escaping to the key to prevent it from being split by dots if it contains any
+ function.set_config(f"metadata.labels.\\{key}\\", value)
+
+ # Add secret configurations to function's pod spec, if secret sources were added.
+ # Needs to be here, since it adds env params, which are handled in the next lines.
+ # This only needs to run if we're running within k8s context. If running in Docker, for example, skip.
+ if mlrun.api.utils.singletons.k8s.get_k8s_helper(
+ silent=True
+ ).is_running_inside_kubernetes_cluster():
+ function.add_secrets_config_to_spec()
+
+ env_dict, external_source_env_dict = function._get_nuclio_config_spec_env()
+
+ nuclio_runtime = (
+ function.spec.nuclio_runtime
+ or mlrun.api.crud.runtimes.nuclio.helpers.resolve_nuclio_runtime_python_image(
+ mlrun_client_version=client_version, python_version=client_python_version
+ )
+ )
+
+ if mlrun.api.crud.runtimes.nuclio.helpers.is_nuclio_version_in_range(
+ "0.0.0", "1.6.0"
+ ) and nuclio_runtime in [
+ "python:3.7",
+ "python:3.8",
+ ]:
+ nuclio_runtime_set_from_spec = nuclio_runtime == function.spec.nuclio_runtime
+ if nuclio_runtime_set_from_spec:
+ raise mlrun.errors.MLRunInvalidArgumentError(
+ f"Nuclio version does not support the configured runtime: {nuclio_runtime}"
+ )
+ else:
+ # our default is python:3.9, simply set it to python:3.6 to keep supporting envs with old Nuclio
+ nuclio_runtime = "python:3.6"
+
+ # In nuclio 1.6.0<=v<1.8.0, python runtimes default behavior was to not decode event strings
+ # Our code is counting on the strings to be decoded, so add the needed env var for those versions
+ if (
+ mlrun.api.crud.runtimes.nuclio.helpers.is_nuclio_version_in_range(
+ "1.6.0", "1.8.0"
+ )
+ and "NUCLIO_PYTHON_DECODE_EVENT_STRINGS" not in env_dict
+ ):
+ env_dict["NUCLIO_PYTHON_DECODE_EVENT_STRINGS"] = "true"
+
+ nuclio_spec = nuclio.ConfigSpec(
+ env=env_dict,
+ external_source_env=external_source_env_dict,
+ config=function.spec.config,
+ )
+ nuclio_spec.cmd = function.spec.build.commands or []
+
+ if function.spec.build.requirements:
+ resolved_requirements = []
+ # wrap in single quote to ensure that the requirement is treated as a single string
+ # quote the requirement to avoid issues with special characters, double quotes, etc.
+ for requirement in function.spec.build.requirements:
+ # -r / --requirement are flags and should not be escaped
+ # we allow such flags (could be passed within the requirements.txt file) and do not
+ # try to open the file and include its content since it might be a remote file
+ # given on the base image.
+ for req_flag in ["-r", "--requirement"]:
+ if requirement.startswith(req_flag):
+ requirement = requirement[len(req_flag) :].strip()
+ resolved_requirements.append(req_flag)
+ break
+
+ resolved_requirements.append(shlex.quote(requirement))
+
+ encoded_requirements = " ".join(resolved_requirements)
+ nuclio_spec.cmd.append(f"python -m pip install {encoded_requirements}")
+
+ project = function.metadata.project or "default"
+ tag = function.metadata.tag
+ handler = function.spec.function_handler
+
+ if function.spec.build.source:
+ mlrun.api.crud.runtimes.nuclio.helpers.compile_nuclio_archive_config(
+ nuclio_spec, function, builder_env, project, auth_info=auth_info
+ )
+
+ nuclio_spec.set_config("spec.runtime", nuclio_runtime)
+
+ # In Nuclio >= 1.6.x default serviceType has changed to "ClusterIP".
+ nuclio_spec.set_config(
+ "spec.serviceType",
+ function.spec.service_type or mlrun.mlconf.httpdb.nuclio.default_service_type,
+ )
+ if function.spec.readiness_timeout:
+ nuclio_spec.set_config(
+ "spec.readinessTimeoutSeconds", function.spec.readiness_timeout
+ )
+ if function.spec.resources:
+ nuclio_spec.set_config("spec.resources", function.spec.resources)
+ if function.spec.no_cache:
+ nuclio_spec.set_config("spec.build.noCache", True)
+ if function.spec.build.functionSourceCode:
+ nuclio_spec.set_config(
+ "spec.build.functionSourceCode", function.spec.build.functionSourceCode
+ )
+
+ image_pull_secret = (
+ mlrun.api.crud.runtimes.nuclio.helpers.resolve_function_image_pull_secret(
+ function
+ )
+ )
+ if image_pull_secret:
+ nuclio_spec.set_config("spec.imagePullSecrets", image_pull_secret)
+
+ if function.spec.base_image_pull:
+ nuclio_spec.set_config("spec.build.noBaseImagesPull", False)
+ # don't send node selections if nuclio is not compatible
+ if mlrun.runtimes.function.validate_nuclio_version_compatibility(
+ "1.5.20", "1.6.10"
+ ):
+ if function.spec.node_selector:
+ nuclio_spec.set_config("spec.nodeSelector", function.spec.node_selector)
+ if function.spec.node_name:
+ nuclio_spec.set_config("spec.nodeName", function.spec.node_name)
+ if function.spec.affinity:
+ nuclio_spec.set_config(
+ "spec.affinity",
+ mlrun.runtimes.pod.get_sanitized_attribute(function.spec, "affinity"),
+ )
+
+ # don't send tolerations if nuclio is not compatible
+ if mlrun.runtimes.function.validate_nuclio_version_compatibility("1.7.5"):
+ if function.spec.tolerations:
+ nuclio_spec.set_config(
+ "spec.tolerations",
+ mlrun.runtimes.pod.get_sanitized_attribute(
+ function.spec, "tolerations"
+ ),
+ )
+ # don't send preemption_mode if nuclio is not compatible
+ if mlrun.runtimes.function.validate_nuclio_version_compatibility("1.8.6"):
+ if function.spec.preemption_mode:
+ nuclio_spec.set_config(
+ "spec.PreemptionMode",
+ function.spec.preemption_mode,
+ )
+
+ # don't send default or any priority class name if nuclio is not compatible
+ if (
+ function.spec.priority_class_name
+ and mlrun.runtimes.function.validate_nuclio_version_compatibility("1.6.18")
+ and len(mlrun.mlconf.get_valid_function_priority_class_names())
+ ):
+ nuclio_spec.set_config(
+ "spec.priorityClassName", function.spec.priority_class_name
+ )
+
+ if function.spec.replicas:
+
+ nuclio_spec.set_config(
+ "spec.minReplicas",
+ mlrun.utils.as_number("spec.Replicas", function.spec.replicas),
+ )
+ nuclio_spec.set_config(
+ "spec.maxReplicas",
+ mlrun.utils.as_number("spec.Replicas", function.spec.replicas),
+ )
+
+ else:
+ nuclio_spec.set_config(
+ "spec.minReplicas",
+ mlrun.utils.as_number("spec.minReplicas", function.spec.min_replicas),
+ )
+ nuclio_spec.set_config(
+ "spec.maxReplicas",
+ mlrun.utils.as_number("spec.maxReplicas", function.spec.max_replicas),
+ )
+
+ if function.spec.service_account:
+ nuclio_spec.set_config("spec.serviceAccount", function.spec.service_account)
+
+ if function.spec.security_context:
+ nuclio_spec.set_config(
+ "spec.securityContext",
+ mlrun.runtimes.pod.get_sanitized_attribute(
+ function.spec, "security_context"
+ ),
+ )
+
+ if (
+ function.spec.base_spec
+ or function.spec.build.functionSourceCode
+ or function.spec.build.source
+ or function.kind == mlrun.runtimes.RuntimeKinds.serving # serving can be empty
+ ):
+ config = function.spec.base_spec
+ if not config:
+ # if base_spec was not set (when not using code_to_function) and we have base64 code
+ # we create the base spec with essential attributes
+ config = nuclio.config.new_config()
+ mlrun.utils.update_in(config, "spec.handler", handler or "main:handler")
+
+ config = nuclio.config.extend_config(
+ config, nuclio_spec, tag, function.spec.build.code_origin
+ )
+
+ mlrun.utils.update_in(config, "metadata.name", function.metadata.name)
+ mlrun.utils.update_in(
+ config, "spec.volumes", function.spec.generate_nuclio_volumes()
+ )
+ base_image = (
+ mlrun.utils.get_in(config, "spec.build.baseImage")
+ or function.spec.image
+ or function.spec.build.base_image
+ )
+ if base_image:
+ mlrun.utils.update_in(
+ config,
+ "spec.build.baseImage",
+ mlrun.utils.enrich_image_url(
+ base_image, client_version, client_python_version
+ ),
+ )
+
+ logger.info("deploy started")
+ name = mlrun.runtimes.function.get_fullname(
+ function.metadata.name, project, tag
+ )
+ function.status.nuclio_name = name
+ mlrun.utils.update_in(config, "metadata.name", name)
+
+ if (
+ function.kind == mlrun.runtimes.RuntimeKinds.serving
+ and not mlrun.utils.get_in(config, "spec.build.functionSourceCode")
+ ):
+ if not function.spec.build.source:
+ # set the source to the mlrun serving wrapper
+ body = nuclio.build.mlrun_footer.format(
+ mlrun.runtimes.serving.serving_subkind
+ )
+ mlrun.utils.update_in(
+ config,
+ "spec.build.functionSourceCode",
+ base64.b64encode(body.encode("utf-8")).decode("utf-8"),
+ )
+ elif not function.spec.function_handler:
+ # point the nuclio function handler to mlrun serving wrapper handlers
+ mlrun.utils.update_in(
+ config,
+ "spec.handler",
+ "mlrun.serving.serving_wrapper:handler",
+ )
+ else:
+ # this may also be called in case of using single file code_to_function(embed_code=False)
+ # this option need to be removed or be limited to using remote files (this code runs in server)
+ name, config, code = nuclio.build_file(
+ function.spec.source,
+ name=function.metadata.name,
+ project=project,
+ handler=handler,
+ tag=tag,
+ spec=nuclio_spec,
+ kind=function.spec.function_kind,
+ verbose=function.verbose,
+ )
+
+ mlrun.utils.update_in(
+ config, "spec.volumes", function.spec.generate_nuclio_volumes()
+ )
+ base_image = function.spec.image or function.spec.build.base_image
+ if base_image:
+ mlrun.utils.update_in(
+ config,
+ "spec.build.baseImage",
+ mlrun.utils.enrich_image_url(
+ base_image, client_version, client_python_version
+ ),
+ )
+
+ name = mlrun.runtimes.function.get_fullname(name, project, tag)
+ function.status.nuclio_name = name
+
+ mlrun.utils.update_in(config, "metadata.name", name)
+
+ return name, project, config
diff --git a/mlrun/api/crud/runtimes/nuclio/helpers.py b/mlrun/api/crud/runtimes/nuclio/helpers.py
new file mode 100644
index 000000000000..5fc746843444
--- /dev/null
+++ b/mlrun/api/crud/runtimes/nuclio/helpers.py
@@ -0,0 +1,310 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+import urllib.parse
+
+import semver
+
+import mlrun
+import mlrun.api.utils.singletons.k8s
+import mlrun.runtimes
+from mlrun.utils import logger
+
+
+def resolve_function_http_trigger(function_spec):
+ for trigger_name, trigger_config in function_spec.get("triggers", {}).items():
+ if trigger_config.get("kind") != "http":
+ continue
+ return trigger_config
+
+
+def resolve_nuclio_runtime_python_image(
+ mlrun_client_version: str = None, python_version: str = None
+):
+ # if no python version or mlrun version is passed it means we use mlrun client older than 1.3.0 therefore need
+ # to use the previoud default runtime which is python 3.7
+ if not python_version or not mlrun_client_version:
+ return "python:3.7"
+
+ # If the mlrun version is 0.0.0-, it is a dev version,
+ # so we can't check if it is higher than 1.3.0, but if the python version was passed,
+ # it means it is 1.3.0-rc or higher, so use the image according to the python version
+ if mlrun_client_version.startswith("0.0.0-") or "unstable" in mlrun_client_version:
+ if python_version.startswith("3.7"):
+ return "python:3.7"
+
+ return mlrun.mlconf.default_nuclio_runtime
+
+ # if mlrun version is older than 1.3.0 we need to use the previous default runtime which is python 3.7
+ if semver.VersionInfo.parse(mlrun_client_version) < semver.VersionInfo.parse(
+ "1.3.0-X"
+ ):
+ return "python:3.7"
+
+ # if mlrun version is 1.3.0 or newer and python version is 3.7 we need to use python 3.7 image
+ if semver.VersionInfo.parse(mlrun_client_version) >= semver.VersionInfo.parse(
+ "1.3.0-X"
+ ) and python_version.startswith("3.7"):
+ return "python:3.7"
+
+ # if none of the above conditions are met we use the default runtime which is python 3.9
+ return mlrun.mlconf.default_nuclio_runtime
+
+
+def resolve_function_ingresses(function_spec):
+ http_trigger = resolve_function_http_trigger(function_spec)
+ if not http_trigger:
+ return []
+
+ ingresses = []
+ for _, ingress_config in (
+ http_trigger.get("attributes", {}).get("ingresses", {}).items()
+ ):
+ ingresses.append(ingress_config)
+ return ingresses
+
+
+def enrich_function_with_ingress(config, mode, service_type):
+ # do not enrich with an ingress
+ if mode == mlrun.runtimes.constants.NuclioIngressAddTemplatedIngressModes.never:
+ return
+
+ ingresses = resolve_function_ingresses(config["spec"])
+
+ # function has ingresses already, nothing to add / enrich
+ if ingresses:
+ return
+
+ # if exists, get the http trigger the function has
+ # we would enrich it with an ingress
+ http_trigger = resolve_function_http_trigger(config["spec"])
+ if not http_trigger:
+ # function has an HTTP trigger without an ingress
+ # TODO: read from nuclio-api frontend-spec
+ http_trigger = {
+ "kind": "http",
+ "name": "http",
+ "maxWorkers": 1,
+ "workerAvailabilityTimeoutMilliseconds": 10000, # 10 seconds
+ "attributes": {},
+ }
+
+ def enrich():
+ http_trigger.setdefault("attributes", {}).setdefault("ingresses", {})["0"] = {
+ "paths": ["/"],
+ # this would tell Nuclio to use its default ingress host template
+ # and would auto assign a host for the ingress
+ "hostTemplate": "@nuclio.fromDefault",
+ }
+ http_trigger["attributes"]["serviceType"] = service_type
+ config["spec"].setdefault("triggers", {})[http_trigger["name"]] = http_trigger
+
+ if mode == mlrun.runtimes.constants.NuclioIngressAddTemplatedIngressModes.always:
+ enrich()
+ elif (
+ mode
+ == mlrun.runtimes.constants.NuclioIngressAddTemplatedIngressModes.on_cluster_ip
+ ):
+
+ # service type is not cluster ip, bail out
+ if service_type and service_type.lower() != "clusterip":
+ return
+
+ enrich()
+
+
+def resolve_function_image_pull_secret(function):
+ """
+ the corresponding attribute for 'build.secret' in nuclio is imagePullSecrets, attached link for reference
+ https://github.com/nuclio/nuclio/blob/e4af2a000dc52ee17337e75181ecb2652b9bf4e5/pkg/processor/build/builder.go#L1073
+ if only one of the secrets is set, use it.
+ if both are set, use the non default one and give precedence to image_pull_secret
+ """
+ # enrich only on server side
+ if not mlrun.config.is_running_as_api():
+ return function.spec.image_pull_secret or function.spec.build.secret
+
+ if function.spec.image_pull_secret is None:
+ function.spec.image_pull_secret = (
+ mlrun.mlconf.function.spec.image_pull_secret.default
+ )
+ elif (
+ function.spec.image_pull_secret
+ != mlrun.mlconf.function.spec.image_pull_secret.default
+ ):
+ return function.spec.image_pull_secret
+
+ if function.spec.build.secret is None:
+ function.spec.build.secret = mlrun.mlconf.httpdb.builder.docker_registry_secret
+ elif (
+ function.spec.build.secret != mlrun.mlconf.httpdb.builder.docker_registry_secret
+ ):
+ return function.spec.build.secret
+
+ return function.spec.image_pull_secret or function.spec.build.secret
+
+
+def resolve_work_dir_and_handler(handler):
+ """
+ Resolves a nuclio function working dir and handler inside an archive/git repo
+ :param handler: a path describing working dir and handler of a nuclio function
+ :return: (working_dir, handler) tuple, as nuclio expects to get it
+
+ Example: ("a/b/c#main:Handler") -> ("a/b/c", "main:Handler")
+ """
+
+ def extend_handler(base_handler):
+ # return default handler and module if not specified
+ if not base_handler:
+ return "main:handler"
+ if ":" not in base_handler:
+ base_handler = f"{base_handler}:handler"
+ return base_handler
+
+ if not handler:
+ return "", "main:handler"
+
+ split_handler = handler.split("#")
+ if len(split_handler) == 1:
+ return "", extend_handler(handler)
+
+ return split_handler[0], extend_handler(split_handler[1])
+
+
+def is_nuclio_version_in_range(min_version: str, max_version: str) -> bool:
+ """
+ Return whether the Nuclio version is in the range, inclusive for min, exclusive for max - [min, max)
+ """
+ resolved_nuclio_version = None
+ try:
+ parsed_min_version = semver.VersionInfo.parse(min_version)
+ parsed_max_version = semver.VersionInfo.parse(max_version)
+ resolved_nuclio_version = mlrun.runtimes.utils.resolve_nuclio_version()
+ parsed_current_version = semver.VersionInfo.parse(resolved_nuclio_version)
+ except ValueError:
+ logger.warning(
+ "Unable to parse nuclio version, assuming in range",
+ nuclio_version=resolved_nuclio_version,
+ min_version=min_version,
+ max_version=max_version,
+ )
+ return True
+ return parsed_min_version <= parsed_current_version < parsed_max_version
+
+
+def compile_nuclio_archive_config(
+ nuclio_spec,
+ function: mlrun.runtimes.function.RemoteRuntime,
+ builder_env,
+ project=None,
+ auth_info=None,
+):
+ secrets = {}
+ if (
+ project
+ and mlrun.api.utils.singletons.k8s.get_k8s_helper().is_running_inside_kubernetes_cluster()
+ ):
+ secrets = (
+ mlrun.api.utils.singletons.k8s.get_k8s_helper().get_project_secret_data(
+ project
+ )
+ )
+
+ def get_secret(key):
+ return builder_env.get(key) or secrets.get(key, "")
+
+ source = function.spec.build.source
+ parsed_url = urllib.parse.urlparse(source)
+ code_entry_type = ""
+ if source.startswith("s3://"):
+ code_entry_type = "s3"
+ if source.startswith("git://"):
+ code_entry_type = "git"
+ for archive_prefix in ["http://", "https://", "v3io://", "v3ios://"]:
+ if source.startswith(archive_prefix):
+ code_entry_type = "archive"
+
+ if code_entry_type == "":
+ raise mlrun.errors.MLRunInvalidArgumentError(
+ "Couldn't resolve code entry type from source"
+ )
+
+ code_entry_attributes = {}
+
+ # resolve work_dir and handler
+ work_dir, handler = resolve_work_dir_and_handler(function.spec.function_handler)
+ work_dir = function.spec.workdir or work_dir
+ if work_dir != "":
+ code_entry_attributes["workDir"] = work_dir
+
+ # archive
+ if code_entry_type == "archive":
+ v3io_access_key = builder_env.get("V3IO_ACCESS_KEY", "")
+ if source.startswith("v3io"):
+ if not parsed_url.netloc:
+ source = mlrun.mlconf.v3io_api + parsed_url.path
+ else:
+ source = f"http{source[len('v3io'):]}"
+ if auth_info and not v3io_access_key:
+ v3io_access_key = auth_info.data_session or auth_info.access_key
+
+ if v3io_access_key:
+ code_entry_attributes["headers"] = {"X-V3io-Session-Key": v3io_access_key}
+
+ # s3
+ if code_entry_type == "s3":
+ bucket, item_key = mlrun.datastore.parse_s3_bucket_and_key(source)
+
+ code_entry_attributes["s3Bucket"] = bucket
+ code_entry_attributes["s3ItemKey"] = item_key
+
+ code_entry_attributes["s3AccessKeyId"] = get_secret("AWS_ACCESS_KEY_ID")
+ code_entry_attributes["s3SecretAccessKey"] = get_secret("AWS_SECRET_ACCESS_KEY")
+ code_entry_attributes["s3SessionToken"] = get_secret("AWS_SESSION_TOKEN")
+
+ # git
+ if code_entry_type == "git":
+
+ # change git:// to https:// as nuclio expects it to be
+ if source.startswith("git://"):
+ source = source.replace("git://", "https://")
+
+ source, reference, branch = mlrun.utils.resolve_git_reference_from_source(
+ source
+ )
+ if not branch and not reference:
+ raise mlrun.errors.MLRunInvalidArgumentError(
+ "git branch or refs must be specified in the source e.g.: "
+ "'git:///org/repo.git#'"
+ )
+ if reference:
+ code_entry_attributes["reference"] = reference
+ if branch:
+ code_entry_attributes["branch"] = branch
+
+ password = get_secret("GIT_PASSWORD")
+ username = get_secret("GIT_USERNAME")
+
+ token = get_secret("GIT_TOKEN")
+ if token:
+ username, password = mlrun.utils.get_git_username_password_from_token(token)
+
+ code_entry_attributes["username"] = username
+ code_entry_attributes["password"] = password
+
+ # populate spec with relevant fields
+ nuclio_spec.set_config("spec.handler", handler)
+ nuclio_spec.set_config("spec.build.path", source)
+ nuclio_spec.set_config("spec.build.codeEntryType", code_entry_type)
+ nuclio_spec.set_config("spec.build.codeEntryAttributes", code_entry_attributes)
diff --git a/mlrun/api/crud/secrets.py b/mlrun/api/crud/secrets.py
index 97f3b8ac4aeb..644199e221cf 100644
--- a/mlrun/api/crud/secrets.py
+++ b/mlrun/api/crud/secrets.py
@@ -102,8 +102,8 @@ def store_project_secrets(
if secrets_to_store:
mlrun.utils.vault.store_vault_project_secrets(project, secrets_to_store)
elif secrets.provider == mlrun.common.schemas.SecretProviderName.kubernetes:
- if mlrun.api.utils.singletons.k8s.get_k8s():
- mlrun.api.utils.singletons.k8s.get_k8s().store_project_secrets(
+ if mlrun.api.utils.singletons.k8s.get_k8s_helper():
+ mlrun.api.utils.singletons.k8s.get_k8s_helper().store_project_secrets(
project, secrets_to_store
)
else:
@@ -121,7 +121,7 @@ def read_auth_secret(
(
username,
access_key,
- ) = mlrun.api.utils.singletons.k8s.get_k8s().read_auth_secret(
+ ) = mlrun.api.utils.singletons.k8s.get_k8s_helper().read_auth_secret(
secret_name, raise_on_not_found=raise_on_not_found
)
return mlrun.common.schemas.AuthSecretData(
@@ -138,11 +138,11 @@ def store_auth_secret(
raise mlrun.errors.MLRunInvalidArgumentError(
f"Storing auth secret is not implemented for provider {secret.provider}"
)
- if not mlrun.api.utils.singletons.k8s.get_k8s():
+ if not mlrun.api.utils.singletons.k8s.get_k8s_helper():
raise mlrun.errors.MLRunInternalServerError(
"K8s provider cannot be initialized"
)
- return mlrun.api.utils.singletons.k8s.get_k8s().store_auth_secret(
+ return mlrun.api.utils.singletons.k8s.get_k8s_helper().store_auth_secret(
secret.username, secret.access_key
)
@@ -155,11 +155,11 @@ def delete_auth_secret(
raise mlrun.errors.MLRunInvalidArgumentError(
f"Storing auth secret is not implemented for provider {provider}"
)
- if not mlrun.api.utils.singletons.k8s.get_k8s():
+ if not mlrun.api.utils.singletons.k8s.get_k8s_helper():
raise mlrun.errors.MLRunInternalServerError(
"K8s provider cannot be initialized"
)
- mlrun.api.utils.singletons.k8s.get_k8s().delete_auth_secret(secret_name)
+ mlrun.api.utils.singletons.k8s.get_k8s_helper().delete_auth_secret(secret_name)
def delete_project_secrets(
self,
@@ -191,8 +191,8 @@ def delete_project_secrets(
f"Delete secret is not implemented for provider {provider}"
)
elif provider == mlrun.common.schemas.SecretProviderName.kubernetes:
- if mlrun.api.utils.singletons.k8s.get_k8s():
- mlrun.api.utils.singletons.k8s.get_k8s().delete_project_secrets(
+ if mlrun.api.utils.singletons.k8s.get_k8s_helper():
+ mlrun.api.utils.singletons.k8s.get_k8s_helper().delete_project_secrets(
project, secrets
)
else:
@@ -226,9 +226,9 @@ def list_project_secret_keys(
"Cannot specify token when requesting k8s secret keys"
)
- if mlrun.api.utils.singletons.k8s.get_k8s():
+ if mlrun.api.utils.singletons.k8s.get_k8s_helper():
secret_keys = (
- mlrun.api.utils.singletons.k8s.get_k8s().get_project_secret_keys(
+ mlrun.api.utils.singletons.k8s.get_k8s_helper().get_project_secret_keys(
project
)
or []
@@ -276,7 +276,7 @@ def list_project_secrets(
"Not allowed to list secrets data from kubernetes provider"
)
secrets_data = (
- mlrun.api.utils.singletons.k8s.get_k8s().get_project_secret_data(
+ mlrun.api.utils.singletons.k8s.get_k8s_helper().get_project_secret_data(
project, secrets
)
)
diff --git a/mlrun/api/main.py b/mlrun/api/main.py
index 91ee1790e0e3..611585369dd2 100644
--- a/mlrun/api/main.py
+++ b/mlrun/api/main.py
@@ -43,6 +43,7 @@
run_function_periodically,
)
from mlrun.api.utils.singletons.db import get_db, initialize_db
+from mlrun.api.utils.singletons.k8s import get_k8s_helper
from mlrun.api.utils.singletons.logs_dir import initialize_logs_dir
from mlrun.api.utils.singletons.project_member import (
get_project_member,
@@ -51,7 +52,6 @@
from mlrun.api.utils.singletons.scheduler import get_scheduler, initialize_scheduler
from mlrun.config import config
from mlrun.errors import err_to_str
-from mlrun.k8s_utils import get_k8s_helper
from mlrun.runtimes import RuntimeClassMode, RuntimeKinds, get_runtime_handler
from mlrun.utils import logger
diff --git a/mlrun/api/utils/singletons/k8s.py b/mlrun/api/utils/singletons/k8s.py
index 184c3ce2b3e3..7fa3e8bb21c7 100644
--- a/mlrun/api/utils/singletons/k8s.py
+++ b/mlrun/api/utils/singletons/k8s.py
@@ -11,9 +11,637 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-#
-from mlrun.k8s_utils import K8sHelper, get_k8s_helper
+import base64
+import hashlib
+import time
+import typing
+
+from kubernetes import client, config
+from kubernetes.client.rest import ApiException
+
+import mlrun.api.schemas
+import mlrun.config as mlconfig
+import mlrun.errors
+import mlrun.platforms.iguazio
+from mlrun.utils import logger
+
+_k8s = None
+
+
+def get_k8s_helper(namespace=None, silent=True, log=False) -> "K8sHelper":
+ """
+ Get a k8s helper singleton object
+ :param namespace: the namespace to use, if not specified will use the namespace configured in mlrun config
+ :param silent: set to true if you're calling this function from a code that might run from remotely (outside of a
+ k8s cluster)
+ :param log: sometimes we want to avoid logging when executing init_k8s_config
+ """
+ global _k8s
+ if not _k8s:
+ _k8s = K8sHelper(namespace, silent=silent, log=log)
+ return _k8s
+
+
+class SecretTypes:
+ opaque = "Opaque"
+ v3io_fuse = "v3io/fuse"
+
+
+class K8sHelper:
+ def __init__(self, namespace=None, config_file=None, silent=False, log=True):
+ self.namespace = namespace or mlconfig.config.namespace
+ self.config_file = config_file
+ self.running_inside_kubernetes_cluster = False
+ try:
+ self._init_k8s_config(log)
+ self.v1api = client.CoreV1Api()
+ self.crdapi = client.CustomObjectsApi()
+ except Exception:
+ if not silent:
+ raise
+
+ def resolve_namespace(self, namespace=None):
+ return namespace or self.namespace
+
+ def _init_k8s_config(self, log=True):
+ try:
+ config.load_incluster_config()
+ self.running_inside_kubernetes_cluster = True
+ if log:
+ logger.info("using in-cluster config.")
+ except Exception:
+ try:
+ config.load_kube_config(self.config_file)
+ if log:
+ logger.info("using local kubernetes config.")
+ except Exception:
+ raise RuntimeError(
+ "cannot find local kubernetes config file,"
+ " place it in ~/.kube/config or specify it in "
+ "KUBECONFIG env var"
+ )
+
+ def is_running_inside_kubernetes_cluster(self):
+ return self.running_inside_kubernetes_cluster
+
+ def list_pods(self, namespace=None, selector="", states=None):
+ try:
+ resp = self.v1api.list_namespaced_pod(
+ self.resolve_namespace(namespace), label_selector=selector
+ )
+ except ApiException as exc:
+ logger.error(f"failed to list pods: {mlrun.errors.err_to_str(exc)}")
+ raise exc
+
+ items = []
+ for i in resp.items:
+ if not states or i.status.phase in states:
+ items.append(i)
+ return items
+
+ def create_pod(self, pod, max_retry=3, retry_interval=3):
+ if "pod" in dir(pod):
+ pod = pod.pod
+ pod.metadata.namespace = self.resolve_namespace(pod.metadata.namespace)
+
+ retry_count = 0
+ while True:
+ try:
+ resp = self.v1api.create_namespaced_pod(pod.metadata.namespace, pod)
+ except ApiException as exc:
+
+ if retry_count > max_retry:
+ logger.error(
+ "failed to create pod after max retries",
+ retry_count=retry_count,
+ exc=mlrun.errors.err_to_str(exc),
+ pod=pod,
+ )
+ raise exc
+
+ logger.error(
+ "failed to create pod", exc=mlrun.errors.err_to_str(exc), pod=pod
+ )
+
+ # known k8s issue, see https://github.com/kubernetes/kubernetes/issues/67761
+ if "gke-resource-quotas" in mlrun.errors.err_to_str(exc):
+ logger.warning(
+ "failed to create pod due to gke resource error, "
+ f"sleeping {retry_interval} seconds and retrying"
+ )
+ retry_count += 1
+ time.sleep(retry_interval)
+ continue
+
+ raise exc
+ else:
+ logger.info(f"Pod {resp.metadata.name} created")
+ return resp.metadata.name, resp.metadata.namespace
+
+ def delete_pod(self, name, namespace=None):
+ try:
+ api_response = self.v1api.delete_namespaced_pod(
+ name,
+ self.resolve_namespace(namespace),
+ grace_period_seconds=0,
+ propagation_policy="Background",
+ )
+ return api_response
+ except ApiException as exc:
+ # ignore error if pod is already removed
+ if exc.status != 404:
+ logger.error(
+ f"failed to delete pod: {mlrun.errors.err_to_str(exc)}",
+ pod_name=name,
+ )
+ raise exc
+
+ def get_pod(self, name, namespace=None, raise_on_not_found=False):
+ try:
+ api_response = self.v1api.read_namespaced_pod(
+ name=name, namespace=self.resolve_namespace(namespace)
+ )
+ return api_response
+ except ApiException as exc:
+ if exc.status != 404:
+ logger.error(f"failed to get pod: {mlrun.errors.err_to_str(exc)}")
+ raise exc
+ else:
+ if raise_on_not_found:
+ raise mlrun.errors.MLRunNotFoundError(f"Pod not found: {name}")
+ return None
+
+ def get_pod_status(self, name, namespace=None):
+ return self.get_pod(
+ name, namespace, raise_on_not_found=True
+ ).status.phase.lower()
+
+ def delete_crd(self, name, crd_group, crd_version, crd_plural, namespace=None):
+ try:
+ namespace = self.resolve_namespace(namespace)
+ self.crdapi.delete_namespaced_custom_object(
+ crd_group,
+ crd_version,
+ namespace,
+ crd_plural,
+ name,
+ )
+ logger.info(
+ "Deleted crd object",
+ crd_name=name,
+ namespace=namespace,
+ )
+ except ApiException as exc:
+
+ # ignore error if crd is already removed
+ if exc.status != 404:
+ logger.error(
+ f"failed to delete crd: {mlrun.errors.err_to_str(exc)}",
+ crd_name=name,
+ crd_group=crd_group,
+ crd_version=crd_version,
+ crd_plural=crd_plural,
+ )
+ raise exc
+
+ def logs(self, name, namespace=None):
+ try:
+ resp = self.v1api.read_namespaced_pod_log(
+ name=name, namespace=self.resolve_namespace(namespace)
+ )
+ except ApiException as exc:
+ logger.error(f"failed to get pod logs: {mlrun.errors.err_to_str(exc)}")
+ raise exc
+
+ return resp
+
+ def get_logger_pods(self, project, uid, run_kind, namespace=""):
+
+ # As this file is imported in mlrun.runtimes, we sadly cannot have this import in the top level imports
+ # as that will create an import loop.
+ # TODO: Fix the import loops already!
+ import mlrun.runtimes
+
+ namespace = self.resolve_namespace(namespace)
+ mpijob_crd_version = mlrun.runtimes.utils.resolve_mpijob_crd_version()
+ mpijob_role_label = (
+ mlrun.runtimes.constants.MPIJobCRDVersions.role_label_by_version(
+ mpijob_crd_version
+ )
+ )
+ extra_selectors = {
+ "spark": "spark-role=driver",
+ "mpijob": f"{mpijob_role_label}=launcher",
+ }
+
+ # TODO: all mlrun labels are sprinkled in a lot of places - they need to all be defined in a central,
+ # inclusive place.
+ selectors = [
+ "mlrun/class",
+ f"mlrun/project={project}",
+ f"mlrun/uid={uid}",
+ ]
+
+ # In order to make the `list_pods` request return a lighter and quicker result, we narrow the search for
+ # the relevant pods using the proper label selector according to the run kind
+ if run_kind in extra_selectors:
+ selectors.append(extra_selectors[run_kind])
+
+ selector = ",".join(selectors)
+ pods = self.list_pods(namespace, selector=selector)
+ if not pods:
+ logger.error("no pod matches that uid", uid=uid)
+ return
+
+ return {p.metadata.name: p.status.phase for p in pods}
+
+ def get_project_vault_secret_name(
+ self, project, service_account_name, namespace=""
+ ):
+ namespace = self.resolve_namespace(namespace)
+
+ try:
+ service_account = self.v1api.read_namespaced_service_account(
+ service_account_name, namespace
+ )
+ except ApiException as exc:
+ # It's valid for the service account to not exist. Simply return None
+ if exc.status != 404:
+ logger.error(
+ f"failed to retrieve service accounts: {mlrun.errors.err_to_str(exc)}"
+ )
+ raise exc
+ return None
+
+ if len(service_account.secrets) > 1:
+ raise ValueError(
+ f"Service account {service_account_name} has more than one secret"
+ )
+
+ return service_account.secrets[0].name
+
+ def get_project_secret_name(self, project) -> str:
+ return mlconfig.config.secret_stores.kubernetes.project_secret_name.format(
+ project=project
+ )
+
+ def get_auth_secret_name(self, access_key: str) -> str:
+ hashed_access_key = self._hash_access_key(access_key)
+ return mlconfig.config.secret_stores.kubernetes.auth_secret_name.format(
+ hashed_access_key=hashed_access_key
+ )
+
+ @staticmethod
+ def _hash_access_key(access_key: str):
+ return hashlib.sha224(access_key.encode()).hexdigest()
+
+ def store_project_secrets(self, project, secrets, namespace=""):
+ secret_name = self.get_project_secret_name(project)
+ self.store_secrets(secret_name, secrets, namespace)
+
+ def read_auth_secret(self, secret_name, namespace="", raise_on_not_found=False):
+ namespace = self.resolve_namespace(namespace)
+
+ try:
+ secret_data = self.v1api.read_namespaced_secret(secret_name, namespace).data
+ except ApiException as exc:
+ logger.error(
+ "Failed to read secret",
+ secret_name=secret_name,
+ namespace=namespace,
+ exc=mlrun.errors.err_to_str(exc),
+ )
+ if exc.status != 404:
+ raise exc
+ elif raise_on_not_found:
+ raise mlrun.errors.MLRunNotFoundError(
+ f"Secret '{secret_name}' was not found in namespace '{namespace}'"
+ ) from exc
+
+ return None, None
+
+ def _get_secret_value(key):
+ if secret_data.get(key):
+ return base64.b64decode(secret_data[key]).decode("utf-8")
+ else:
+ return None
+
+ username = _get_secret_value(
+ mlrun.api.schemas.AuthSecretData.get_field_secret_key("username")
+ )
+ access_key = _get_secret_value(
+ mlrun.api.schemas.AuthSecretData.get_field_secret_key("access_key")
+ )
+
+ return username, access_key
+
+ def store_auth_secret(self, username: str, access_key: str, namespace="") -> str:
+ secret_name = self.get_auth_secret_name(access_key)
+ secret_data = {
+ mlrun.api.schemas.AuthSecretData.get_field_secret_key("username"): username,
+ mlrun.api.schemas.AuthSecretData.get_field_secret_key(
+ "access_key"
+ ): access_key,
+ }
+ self.store_secrets(
+ secret_name,
+ secret_data,
+ namespace,
+ type_=SecretTypes.v3io_fuse,
+ labels={"mlrun/username": username},
+ )
+ return secret_name
+
+ def store_secrets(
+ self,
+ secret_name,
+ secrets,
+ namespace="",
+ type_=SecretTypes.opaque,
+ labels: typing.Optional[dict] = None,
+ ):
+ namespace = self.resolve_namespace(namespace)
+ try:
+ k8s_secret = self.v1api.read_namespaced_secret(secret_name, namespace)
+ except ApiException as exc:
+ # If secret doesn't exist, we'll simply create it
+ if exc.status != 404:
+ logger.error(
+ f"failed to retrieve k8s secret: {mlrun.errors.err_to_str(exc)}"
+ )
+ raise exc
+ k8s_secret = client.V1Secret(type=type_)
+ k8s_secret.metadata = client.V1ObjectMeta(
+ name=secret_name, namespace=namespace, labels=labels
+ )
+ k8s_secret.string_data = secrets
+ self.v1api.create_namespaced_secret(namespace, k8s_secret)
+ return
+
+ secret_data = k8s_secret.data.copy()
+ for key, value in secrets.items():
+ secret_data[key] = base64.b64encode(value.encode()).decode("utf-8")
+
+ k8s_secret.data = secret_data
+ self.v1api.replace_namespaced_secret(secret_name, namespace, k8s_secret)
+
+ def load_secret(self, secret_name, namespace=""):
+ namespace = namespace or self.resolve_namespace(namespace)
+
+ try:
+ k8s_secret = self.v1api.read_namespaced_secret(secret_name, namespace)
+ except ApiException:
+ return None
+
+ return k8s_secret.data
+
+ def delete_project_secrets(self, project, secrets, namespace=""):
+ secret_name = self.get_project_secret_name(project)
+ self.delete_secrets(secret_name, secrets, namespace)
+
+ def delete_auth_secret(self, secret_ref: str, namespace=""):
+ self.delete_secrets(secret_ref, {}, namespace)
+
+ def delete_secrets(self, secret_name, secrets, namespace=""):
+ namespace = self.resolve_namespace(namespace)
+
+ try:
+ k8s_secret = self.v1api.read_namespaced_secret(secret_name, namespace)
+ except ApiException as exc:
+ # If secret does not exist, return as if the deletion was successfully
+ if exc.status == 404:
+ return
+ else:
+ logger.error(
+ f"failed to retrieve k8s secret: {mlrun.errors.err_to_str(exc)}"
+ )
+ raise exc
+
+ if not secrets:
+ secret_data = {}
+ else:
+ secret_data = k8s_secret.data.copy()
+ for secret in secrets:
+ secret_data.pop(secret, None)
+
+ if not secret_data:
+ self.v1api.delete_namespaced_secret(secret_name, namespace)
+ else:
+ k8s_secret.data = secret_data
+ self.v1api.replace_namespaced_secret(secret_name, namespace, k8s_secret)
+
+ def _get_project_secrets_raw_data(self, project, namespace=""):
+ secret_name = self.get_project_secret_name(project)
+ return self._get_secret_raw_data(secret_name, namespace)
+
+ def _get_secret_raw_data(self, secret_name, namespace=""):
+ namespace = self.resolve_namespace(namespace)
+
+ try:
+ k8s_secret = self.v1api.read_namespaced_secret(secret_name, namespace)
+ except ApiException:
+ return None
+
+ return k8s_secret.data
+
+ def get_project_secret_keys(self, project, namespace="", filter_internal=False):
+ secrets_data = self._get_project_secrets_raw_data(project, namespace)
+ if not secrets_data:
+ return []
+
+ secret_keys = list(secrets_data.keys())
+ if filter_internal:
+ secret_keys = list(
+ filter(lambda key: not key.startswith("mlrun."), secret_keys)
+ )
+ return secret_keys
+
+ def get_project_secret_data(self, project, secret_keys=None, namespace=""):
+ secrets_data = self._get_project_secrets_raw_data(project, namespace)
+ return self._decode_secret_data(secrets_data, secret_keys)
+
+ def get_secret_data(self, secret_name, namespace=""):
+ secrets_data = self._get_secret_raw_data(secret_name, namespace)
+ return self._decode_secret_data(secrets_data)
+
+ def _decode_secret_data(self, secrets_data, secret_keys=None):
+ results = {}
+ if not secrets_data:
+ return results
+
+ # If not asking for specific keys, return all
+ secret_keys = secret_keys or secrets_data.keys()
+
+ for key in secret_keys:
+ encoded_value = secrets_data.get(key)
+ if encoded_value:
+ results[key] = base64.b64decode(secrets_data[key]).decode("utf-8")
+ return results
+
+
+class BasePod:
+ def __init__(
+ self,
+ task_name="",
+ image=None,
+ command=None,
+ args=None,
+ namespace="",
+ kind="job",
+ project=None,
+ default_pod_spec_attributes=None,
+ resources=None,
+ ):
+ self.namespace = namespace
+ self.name = ""
+ self.task_name = task_name
+ self.image = image
+ self.command = command
+ self.args = args
+ self._volumes = []
+ self._mounts = []
+ self.env = None
+ self.node_selector = None
+ self.project = project or mlrun.mlconf.default_project
+ self._labels = {
+ "mlrun/task-name": task_name,
+ "mlrun/class": kind,
+ "mlrun/project": self.project,
+ }
+ self._annotations = {}
+ self._init_containers = []
+ # will be applied on the pod spec only when calling .pod(), allows to override spec attributes
+ self.default_pod_spec_attributes = default_pod_spec_attributes
+ self.resources = resources
+
+ @property
+ def pod(self):
+ return self._get_spec()
+
+ @property
+ def init_containers(self):
+ return self._init_containers
+
+ @init_containers.setter
+ def init_containers(self, containers):
+ self._init_containers = containers
+
+ def append_init_container(
+ self,
+ image,
+ command=None,
+ args=None,
+ env=None,
+ image_pull_policy="IfNotPresent",
+ name="init",
+ ):
+ if isinstance(env, dict):
+ env = [client.V1EnvVar(name=k, value=v) for k, v in env.items()]
+ self._init_containers.append(
+ client.V1Container(
+ name=name,
+ image=image,
+ env=env,
+ command=command,
+ args=args,
+ image_pull_policy=image_pull_policy,
+ )
+ )
+
+ def add_label(self, key, value):
+ self._labels[key] = str(value)
+
+ def add_annotation(self, key, value):
+ self._annotations[key] = str(value)
+
+ def add_volume(self, volume: client.V1Volume, mount_path, name=None, sub_path=None):
+ self._mounts.append(
+ client.V1VolumeMount(
+ name=name or volume.name, mount_path=mount_path, sub_path=sub_path
+ )
+ )
+ self._volumes.append(volume)
+
+ def mount_empty(self, name="empty", mount_path="/empty"):
+ self.add_volume(
+ client.V1Volume(name=name, empty_dir=client.V1EmptyDirVolumeSource()),
+ mount_path=mount_path,
+ )
+
+ def mount_v3io(
+ self, name="v3io", remote="~/", mount_path="/User", access_key="", user=""
+ ):
+ self.add_volume(
+ mlrun.platforms.iguazio.v3io_to_vol(name, remote, access_key, user),
+ mount_path=mount_path,
+ name=name,
+ )
+
+ def mount_cfgmap(self, name, path="/config"):
+ self.add_volume(
+ client.V1Volume(
+ name=name, config_map=client.V1ConfigMapVolumeSource(name=name)
+ ),
+ mount_path=path,
+ )
+
+ def mount_secret(self, name, path="/secret", items=None, sub_path=None):
+ self.add_volume(
+ client.V1Volume(
+ name=name,
+ secret=client.V1SecretVolumeSource(
+ secret_name=name,
+ items=items,
+ ),
+ ),
+ mount_path=path,
+ sub_path=sub_path,
+ )
+
+ def set_node_selector(self, node_selector: typing.Optional[typing.Dict[str, str]]):
+ self.node_selector = node_selector
+
+ def _get_spec(self, template=False):
+
+ pod_obj = client.V1PodTemplate if template else client.V1Pod
+
+ if self.env and isinstance(self.env, dict):
+ env = [client.V1EnvVar(name=k, value=v) for k, v in self.env.items()]
+ else:
+ env = self.env
+ container = client.V1Container(
+ name="base",
+ image=self.image,
+ env=env,
+ command=self.command,
+ args=self.args,
+ volume_mounts=self._mounts,
+ resources=self.resources,
+ )
+
+ pod_spec = client.V1PodSpec(
+ containers=[container],
+ restart_policy="Never",
+ volumes=self._volumes,
+ node_selector=self.node_selector,
+ )
+
+ # if attribute isn't defined use default pod spec attributes
+ for key, val in self.default_pod_spec_attributes.items():
+ if not getattr(pod_spec, key, None):
+ setattr(pod_spec, key, val)
+ for init_containers in self._init_containers:
+ init_containers.volume_mounts = self._mounts
+ pod_spec.init_containers = self._init_containers
-def get_k8s() -> K8sHelper:
- return get_k8s_helper(silent=True)
+ pod = pod_obj(
+ metadata=client.V1ObjectMeta(
+ generate_name=f"{self.task_name}-",
+ namespace=self.namespace,
+ labels=self._labels,
+ annotations=self._annotations,
+ ),
+ spec=pod_spec,
+ )
+ return pod
diff --git a/mlrun/builder.py b/mlrun/builder.py
index 2b47b2473462..320b906f8ad2 100644
--- a/mlrun/builder.py
+++ b/mlrun/builder.py
@@ -22,13 +22,13 @@
from kubernetes import client
+import mlrun.api.utils.singletons.k8s
import mlrun.common.schemas
import mlrun.errors
import mlrun.runtimes.utils
from .config import config
from .datastore import store_manager
-from .k8s_utils import BasePod, get_k8s_helper
from .utils import enrich_image_url, get_parsed_docker_registry, logger, normalize_name
IMAGE_NAME_ENRICH_REGISTRY_PREFIX = "."
@@ -162,7 +162,7 @@ def make_kaniko_pod(
mem=default_requests.get("memory"), cpu=default_requests.get("cpu")
)
}
- kpod = BasePod(
+ kpod = mlrun.api.utils.singletons.k8s.BasePod(
name or "mlrun-build",
config.httpdb.builder.kaniko_image,
args=args,
@@ -467,7 +467,7 @@ def build_image(
user=username,
)
- k8s = get_k8s_helper()
+ k8s = mlrun.api.utils.singletons.k8s.get_k8s_helper(silent=False)
kpod.namespace = k8s.resolve_namespace(namespace)
if interactive:
@@ -653,7 +653,7 @@ def build_runtime(
def _generate_builder_env(project, builder_env):
- k8s = get_k8s_helper()
+ k8s = mlrun.api.utils.singletons.k8s.get_k8s_helper(silent=False)
secret_name = k8s.get_project_secret_name(project)
existing_secret_keys = k8s.get_project_secret_keys(project, filter_internal=True)
diff --git a/mlrun/config.py b/mlrun/config.py
index b2abebd84640..a2bb8a0f3138 100644
--- a/mlrun/config.py
+++ b/mlrun/config.py
@@ -1065,12 +1065,10 @@ def _do_populate(env=None, skip_errors=False):
def _validate_config(config):
- import mlrun.k8s_utils
-
try:
limits_gpu = config.default_function_pod_resources.limits.gpu
requests_gpu = config.default_function_pod_resources.requests.gpu
- mlrun.k8s_utils.verify_gpu_requests_and_limits(
+ _verify_gpu_requests_and_limits(
requests_gpu=requests_gpu,
limits_gpu=limits_gpu,
)
@@ -1080,6 +1078,19 @@ def _validate_config(config):
config.verify_security_context_enrichment_mode_is_allowed()
+def _verify_gpu_requests_and_limits(requests_gpu: str = None, limits_gpu: str = None):
+ # https://kubernetes.io/docs/tasks/manage-gpus/scheduling-gpus/
+ if requests_gpu and not limits_gpu:
+ raise mlrun.errors.MLRunConflictError(
+ "You cannot specify GPU requests without specifying limits"
+ )
+ if requests_gpu and limits_gpu and requests_gpu != limits_gpu:
+ raise mlrun.errors.MLRunConflictError(
+ f"When specifying both GPU requests and limits these two values must be equal, "
+ f"requests_gpu={requests_gpu}, limits_gpu={limits_gpu}"
+ )
+
+
def _convert_resources_to_str(config: dict = None):
resources_types = ["cpu", "memory", "gpu"]
resource_requirements = ["requests", "limits"]
diff --git a/mlrun/feature_store/common.py b/mlrun/feature_store/common.py
index ea5e42237faa..77c1e756a72a 100644
--- a/mlrun/feature_store/common.py
+++ b/mlrun/feature_store/common.py
@@ -20,7 +20,7 @@
from mlrun.runtimes import BaseRuntime
from mlrun.runtimes.function_reference import FunctionReference
from mlrun.runtimes.utils import enrich_function_from_dict
-from mlrun.utils import StorePrefix, logger, mlconf, parse_versioned_object_uri
+from mlrun.utils import StorePrefix, logger, parse_versioned_object_uri
from ..config import config
@@ -164,7 +164,7 @@ def verify_feature_set_exists(feature_set):
def verify_feature_vector_permissions(
feature_vector, action: mlrun.common.schemas.AuthorizationAction
):
- project = feature_vector._metadata.project or mlconf.default_project
+ project = feature_vector._metadata.project or config.default_project
resource = mlrun.common.schemas.AuthorizationResourceTypes.feature_vector.to_resource_string(
project, "feature-vector"
diff --git a/mlrun/k8s_utils.py b/mlrun/k8s_utils.py
index 3ed1b0ee0668..e0dbaeff8eda 100644
--- a/mlrun/k8s_utils.py
+++ b/mlrun/k8s_utils.py
@@ -11,784 +11,27 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-import base64
-import hashlib
-import time
import typing
-from datetime import datetime
-from sys import stdout
import kubernetes.client
-from kubernetes import client, config
-from kubernetes.client.rest import ApiException
import mlrun.common.schemas
import mlrun.errors
from .config import config as mlconfig
-from .errors import err_to_str
-from .platforms.iguazio import v3io_to_vol
-from .utils import logger
-_k8s = None
+_running_inside_kubernetes_cluster = None
-def get_k8s_helper(namespace=None, silent=False, log=False) -> "K8sHelper":
- """
- :param silent: set to true if you're calling this function from a code that might run from remotely (outside of a
- k8s cluster)
- :param log: sometimes we want to avoid logging when executing init_k8s_config
- """
- global _k8s
- if not _k8s:
- _k8s = K8sHelper(namespace, silent=silent, log=log)
- return _k8s
-
-
-class SecretTypes:
- opaque = "Opaque"
- v3io_fuse = "v3io/fuse"
-
-
-class K8sHelper:
- def __init__(self, namespace=None, config_file=None, silent=False, log=True):
- self.namespace = namespace or mlconfig.namespace
- self.config_file = config_file
- self.running_inside_kubernetes_cluster = False
- try:
- self._init_k8s_config(log)
- self.v1api = client.CoreV1Api()
- self.crdapi = client.CustomObjectsApi()
- except Exception:
- if not silent:
- raise
-
- def resolve_namespace(self, namespace=None):
- return namespace or self.namespace
-
- def _init_k8s_config(self, log=True):
- try:
- config.load_incluster_config()
- self.running_inside_kubernetes_cluster = True
- if log:
- logger.info("using in-cluster config.")
- except Exception:
- try:
- config.load_kube_config(self.config_file)
- if log:
- logger.info("using local kubernetes config.")
- except Exception:
- raise RuntimeError(
- "cannot find local kubernetes config file,"
- " place it in ~/.kube/config or specify it in "
- "KUBECONFIG env var"
- )
-
- def is_running_inside_kubernetes_cluster(self):
- return self.running_inside_kubernetes_cluster
-
- def list_pods(self, namespace=None, selector="", states=None):
- try:
- resp = self.v1api.list_namespaced_pod(
- self.resolve_namespace(namespace), label_selector=selector
- )
- except ApiException as exc:
- logger.error(f"failed to list pods: {err_to_str(exc)}")
- raise exc
-
- items = []
- for i in resp.items:
- if not states or i.status.phase in states:
- items.append(i)
- return items
-
- def clean_pods(self, namespace=None, selector="", states=None):
- if not selector and not states:
- raise ValueError("labels selector or states list must be specified")
- items = self.list_pods(namespace, selector, states)
- for item in items:
- self.delete_pod(item.metadata.name, item.metadata.namespace)
-
- def create_pod(self, pod, max_retry=3, retry_interval=3):
- if "pod" in dir(pod):
- pod = pod.pod
- pod.metadata.namespace = self.resolve_namespace(pod.metadata.namespace)
-
- retry_count = 0
- while True:
- try:
- resp = self.v1api.create_namespaced_pod(pod.metadata.namespace, pod)
- except ApiException as exc:
-
- if retry_count > max_retry:
- logger.error(
- "failed to create pod after max retries",
- retry_count=retry_count,
- exc=err_to_str(exc),
- pod=pod,
- )
- raise exc
-
- logger.error("failed to create pod", exc=err_to_str(exc), pod=pod)
-
- # known k8s issue, see https://github.com/kubernetes/kubernetes/issues/67761
- if "gke-resource-quotas" in err_to_str(exc):
- logger.warning(
- "failed to create pod due to gke resource error, "
- f"sleeping {retry_interval} seconds and retrying"
- )
- retry_count += 1
- time.sleep(retry_interval)
- continue
-
- raise exc
- else:
- logger.info(f"Pod {resp.metadata.name} created")
- return resp.metadata.name, resp.metadata.namespace
-
- def delete_pod(self, name, namespace=None):
- try:
- api_response = self.v1api.delete_namespaced_pod(
- name,
- self.resolve_namespace(namespace),
- grace_period_seconds=0,
- propagation_policy="Background",
- )
- return api_response
- except ApiException as exc:
- # ignore error if pod is already removed
- if exc.status != 404:
- logger.error(f"failed to delete pod: {err_to_str(exc)}", pod_name=name)
- raise exc
-
- def get_pod(self, name, namespace=None, raise_on_not_found=False):
- try:
- api_response = self.v1api.read_namespaced_pod(
- name=name, namespace=self.resolve_namespace(namespace)
- )
- return api_response
- except ApiException as exc:
- if exc.status != 404:
- logger.error(f"failed to get pod: {err_to_str(exc)}")
- raise exc
- else:
- if raise_on_not_found:
- raise mlrun.errors.MLRunNotFoundError(f"Pod not found: {name}")
- return None
-
- def get_pod_status(self, name, namespace=None):
- return self.get_pod(
- name, namespace, raise_on_not_found=True
- ).status.phase.lower()
-
- def delete_crd(self, name, crd_group, crd_version, crd_plural, namespace=None):
- try:
- namespace = self.resolve_namespace(namespace)
- self.crdapi.delete_namespaced_custom_object(
- crd_group,
- crd_version,
- namespace,
- crd_plural,
- name,
- )
- logger.info(
- "Deleted crd object",
- crd_name=name,
- namespace=namespace,
- )
- except ApiException as exc:
-
- # ignore error if crd is already removed
- if exc.status != 404:
- logger.error(
- f"failed to delete crd: {err_to_str(exc)}",
- crd_name=name,
- crd_group=crd_group,
- crd_version=crd_version,
- crd_plural=crd_plural,
- )
- raise exc
-
- def logs(self, name, namespace=None):
- try:
- resp = self.v1api.read_namespaced_pod_log(
- name=name, namespace=self.resolve_namespace(namespace)
- )
- except ApiException as exc:
- logger.error(f"failed to get pod logs: {err_to_str(exc)}")
- raise exc
-
- return resp
-
- def run_job(self, pod, timeout=600):
- pod_name, namespace = self.create_pod(pod)
- if not pod_name:
- logger.error("failed to create pod")
- return "error"
- return self.watch(pod_name, namespace, timeout)
-
- def watch(self, pod_name, namespace=None, timeout=600, writer=None):
- namespace = self.resolve_namespace(namespace)
- start_time = datetime.now()
- while True:
- try:
- pod = self.get_pod(pod_name, namespace)
- if not pod:
- return "error"
- status = pod.status.phase.lower()
- if status in ["running", "completed", "succeeded"]:
- print("")
- break
- if status == "failed":
- return "failed"
- elapsed_time = (datetime.now() - start_time).seconds
- if elapsed_time > timeout:
- return "timeout"
- time.sleep(2)
- stdout.write(".")
- if status != "pending":
- logger.warning(f"pod state in loop is {status}")
- except ApiException as exc:
- logger.error(f"failed waiting for pod: {err_to_str(exc)}\n")
- return "error"
- outputs = self.v1api.read_namespaced_pod_log(
- name=pod_name, namespace=namespace, follow=True, _preload_content=False
- )
- for out in outputs:
- print(out.decode("utf-8"), end="")
- if writer:
- writer.write(out)
-
- for i in range(5):
- pod_state = self.get_pod(pod_name, namespace).status.phase.lower()
- if pod_state != "running":
- break
- logger.warning("pod still running, waiting 2 sec")
- time.sleep(2)
-
- if pod_state == "failed":
- logger.error("pod exited with error")
- if writer:
- writer.flush()
- return pod_state
-
- def create_cfgmap(self, name, data, namespace="", labels=None):
- body = client.api_client.V1ConfigMap()
- namespace = self.resolve_namespace(namespace)
- body.data = data
- if name.endswith("*"):
- body.metadata = client.V1ObjectMeta(
- generate_name=name[:-1], namespace=namespace, labels=labels
- )
- else:
- body.metadata = client.V1ObjectMeta(
- name=name, namespace=namespace, labels=labels
- )
+def is_running_inside_kubernetes_cluster():
+ global _running_inside_kubernetes_cluster
+ if _running_inside_kubernetes_cluster is not None:
try:
- resp = self.v1api.create_namespaced_config_map(namespace, body)
- except ApiException as exc:
- logger.error(f"failed to create configmap: {err_to_str(exc)}")
- raise exc
-
- logger.info(f"ConfigMap {resp.metadata.name} created")
- return resp.metadata.name
-
- def del_cfgmap(self, name, namespace=None):
- try:
- api_response = self.v1api.delete_namespaced_config_map(
- name,
- self.resolve_namespace(namespace),
- grace_period_seconds=0,
- propagation_policy="Background",
- )
-
- return api_response
- except ApiException as exc:
- # ignore error if ConfigMap is already removed
- if exc.status != 404:
- logger.error(f"failed to delete ConfigMap: {err_to_str(exc)}")
- raise exc
-
- def list_cfgmap(self, namespace=None, selector=""):
- try:
- resp = self.v1api.list_namespaced_config_map(
- self.resolve_namespace(namespace), watch=False, label_selector=selector
- )
- except ApiException as exc:
- logger.error(f"failed to list ConfigMaps: {err_to_str(exc)}")
- raise exc
-
- items = []
- for i in resp.items:
- items.append(i)
- return items
-
- def get_logger_pods(self, project, uid, run_kind, namespace=""):
-
- # As this file is imported in mlrun.runtimes, we sadly cannot have this import in the top level imports
- # as that will create an import loop.
- # TODO: Fix the import loops already!
- import mlrun.runtimes
-
- namespace = self.resolve_namespace(namespace)
- mpijob_crd_version = mlrun.runtimes.utils.resolve_mpijob_crd_version(
- api_context=True
- )
- mpijob_role_label = (
- mlrun.runtimes.constants.MPIJobCRDVersions.role_label_by_version(
- mpijob_crd_version
- )
- )
- extra_selectors = {
- "spark": "spark-role=driver",
- "mpijob": f"{mpijob_role_label}=launcher",
- }
-
- # TODO: all mlrun labels are sprinkled in a lot of places - they need to all be defined in a central,
- # inclusive place.
- selectors = [
- "mlrun/class",
- f"mlrun/project={project}",
- f"mlrun/uid={uid}",
- ]
-
- # In order to make the `list_pods` request return a lighter and quicker result, we narrow the search for
- # the relevant pods using the proper label selector according to the run kind
- if run_kind in extra_selectors:
- selectors.append(extra_selectors[run_kind])
-
- selector = ",".join(selectors)
- pods = self.list_pods(namespace, selector=selector)
- if not pods:
- logger.error("no pod matches that uid", uid=uid)
- return
-
- return {p.metadata.name: p.status.phase for p in pods}
-
- def create_project_service_account(self, project, service_account, namespace=""):
- namespace = self.resolve_namespace(namespace)
- k8s_service_account = client.V1ServiceAccount()
- labels = {"mlrun/project": project}
- k8s_service_account.metadata = client.V1ObjectMeta(
- name=service_account, namespace=namespace, labels=labels
- )
- try:
- api_response = self.v1api.create_namespaced_service_account(
- namespace,
- k8s_service_account,
- )
- return api_response
- except ApiException as exc:
- logger.error(f"failed to create service account: {err_to_str(exc)}")
- raise exc
-
- def get_project_vault_secret_name(
- self, project, service_account_name, namespace=""
- ):
- namespace = self.resolve_namespace(namespace)
-
- try:
- service_account = self.v1api.read_namespaced_service_account(
- service_account_name, namespace
- )
- except ApiException as exc:
- # It's valid for the service account to not exist. Simply return None
- if exc.status != 404:
- logger.error(f"failed to retrieve service accounts: {err_to_str(exc)}")
- raise exc
- return None
-
- if len(service_account.secrets) > 1:
- raise ValueError(
- f"Service account {service_account_name} has more than one secret"
- )
-
- return service_account.secrets[0].name
-
- def get_project_secret_name(self, project) -> str:
- return mlconfig.secret_stores.kubernetes.project_secret_name.format(
- project=project
- )
-
- def get_auth_secret_name(self, access_key: str) -> str:
- hashed_access_key = self._hash_access_key(access_key)
- return mlconfig.secret_stores.kubernetes.auth_secret_name.format(
- hashed_access_key=hashed_access_key
- )
-
- @staticmethod
- def _hash_access_key(access_key: str):
- return hashlib.sha224(access_key.encode()).hexdigest()
-
- def store_project_secrets(self, project, secrets, namespace=""):
- secret_name = self.get_project_secret_name(project)
- self.store_secrets(secret_name, secrets, namespace)
-
- def read_auth_secret(self, secret_name, namespace="", raise_on_not_found=False):
- namespace = self.resolve_namespace(namespace)
-
- try:
- secret_data = self.v1api.read_namespaced_secret(secret_name, namespace).data
- except ApiException as exc:
- logger.error(
- "Failed to read secret",
- secret_name=secret_name,
- namespace=namespace,
- exc=err_to_str(exc),
- )
- if exc.status != 404:
- raise exc
- elif raise_on_not_found:
- raise mlrun.errors.MLRunNotFoundError(
- f"Secret '{secret_name}' was not found in namespace '{namespace}'"
- ) from exc
-
- return None, None
-
- def _get_secret_value(key):
- if secret_data.get(key):
- return base64.b64decode(secret_data[key]).decode("utf-8")
- else:
- return None
-
- username = _get_secret_value(
- mlrun.common.schemas.AuthSecretData.get_field_secret_key("username")
- )
- access_key = _get_secret_value(
- mlrun.common.schemas.AuthSecretData.get_field_secret_key("access_key")
- )
-
- return username, access_key
-
- def store_auth_secret(self, username: str, access_key: str, namespace="") -> str:
- secret_name = self.get_auth_secret_name(access_key)
- secret_data = {
- mlrun.common.schemas.AuthSecretData.get_field_secret_key(
- "username"
- ): username,
- mlrun.common.schemas.AuthSecretData.get_field_secret_key(
- "access_key"
- ): access_key,
- }
- self.store_secrets(
- secret_name,
- secret_data,
- namespace,
- type_=SecretTypes.v3io_fuse,
- labels={"mlrun/username": username},
- )
- return secret_name
-
- def store_secrets(
- self,
- secret_name,
- secrets,
- namespace="",
- type_=SecretTypes.opaque,
- labels: typing.Optional[dict] = None,
- ):
- namespace = self.resolve_namespace(namespace)
- try:
- k8s_secret = self.v1api.read_namespaced_secret(secret_name, namespace)
- except ApiException as exc:
- # If secret doesn't exist, we'll simply create it
- if exc.status != 404:
- logger.error(f"failed to retrieve k8s secret: {err_to_str(exc)}")
- raise exc
- k8s_secret = client.V1Secret(type=type_)
- k8s_secret.metadata = client.V1ObjectMeta(
- name=secret_name, namespace=namespace, labels=labels
- )
- k8s_secret.string_data = secrets
- self.v1api.create_namespaced_secret(namespace, k8s_secret)
- return
-
- secret_data = k8s_secret.data.copy()
- for key, value in secrets.items():
- secret_data[key] = base64.b64encode(value.encode()).decode("utf-8")
-
- k8s_secret.data = secret_data
- self.v1api.replace_namespaced_secret(secret_name, namespace, k8s_secret)
-
- def load_secret(self, secret_name, namespace=""):
- namespace = namespace or self.resolve_namespace(namespace)
-
- try:
- k8s_secret = self.v1api.read_namespaced_secret(secret_name, namespace)
- except ApiException:
- return None
-
- return k8s_secret.data
-
- def delete_project_secrets(self, project, secrets, namespace=""):
- secret_name = self.get_project_secret_name(project)
- self.delete_secrets(secret_name, secrets, namespace)
-
- def delete_auth_secret(self, secret_ref: str, namespace=""):
- self.delete_secrets(secret_ref, {}, namespace)
-
- def delete_secrets(self, secret_name, secrets, namespace=""):
- namespace = self.resolve_namespace(namespace)
-
- try:
- k8s_secret = self.v1api.read_namespaced_secret(secret_name, namespace)
- except ApiException as exc:
- # If secret does not exist, return as if the deletion was successfully
- if exc.status == 404:
- return
- else:
- logger.error(f"failed to retrieve k8s secret: {err_to_str(exc)}")
- raise exc
-
- if not secrets:
- secret_data = {}
- else:
- secret_data = k8s_secret.data.copy()
- for secret in secrets:
- secret_data.pop(secret, None)
-
- if not secret_data:
- self.v1api.delete_namespaced_secret(secret_name, namespace)
- else:
- k8s_secret.data = secret_data
- self.v1api.replace_namespaced_secret(secret_name, namespace, k8s_secret)
-
- def _get_project_secrets_raw_data(self, project, namespace=""):
- secret_name = self.get_project_secret_name(project)
- return self._get_secret_raw_data(secret_name, namespace)
-
- def _get_secret_raw_data(self, secret_name, namespace=""):
- namespace = self.resolve_namespace(namespace)
-
- try:
- k8s_secret = self.v1api.read_namespaced_secret(secret_name, namespace)
- except ApiException:
- return None
-
- return k8s_secret.data
-
- def get_project_secret_keys(self, project, namespace="", filter_internal=False):
- secrets_data = self._get_project_secrets_raw_data(project, namespace)
- if not secrets_data:
- return []
-
- secret_keys = list(secrets_data.keys())
- if filter_internal:
- secret_keys = list(
- filter(lambda key: not key.startswith("mlrun."), secret_keys)
- )
- return secret_keys
-
- def get_project_secret_data(self, project, secret_keys=None, namespace=""):
- secrets_data = self._get_project_secrets_raw_data(project, namespace)
- return self._decode_secret_data(secrets_data, secret_keys)
-
- def get_secret_data(self, secret_name, namespace=""):
- secrets_data = self._get_secret_raw_data(secret_name, namespace)
- return self._decode_secret_data(secrets_data)
-
- def _decode_secret_data(self, secrets_data, secret_keys=None):
- results = {}
- if not secrets_data:
- return results
-
- # If not asking for specific keys, return all
- secret_keys = secret_keys or secrets_data.keys()
-
- for key in secret_keys:
- encoded_value = secrets_data.get(key)
- if encoded_value:
- results[key] = base64.b64decode(secrets_data[key]).decode("utf-8")
- return results
-
-
-class BasePod:
- def __init__(
- self,
- task_name="",
- image=None,
- command=None,
- args=None,
- namespace="",
- kind="job",
- project=None,
- default_pod_spec_attributes=None,
- resources=None,
- ):
- self.namespace = namespace
- self.name = ""
- self.task_name = task_name
- self.image = image
- self.command = command
- self.args = args
- self._volumes = []
- self._mounts = []
- self.env = None
- self.node_selector = None
- self.project = project or mlrun.mlconf.default_project
- self._labels = {
- "mlrun/task-name": task_name,
- "mlrun/class": kind,
- "mlrun/project": self.project,
- }
- self._annotations = {}
- self._init_containers = []
- # will be applied on the pod spec only when calling .pod(), allows to override spec attributes
- self.default_pod_spec_attributes = default_pod_spec_attributes
- self.resources = resources
-
- @property
- def pod(self):
- return self._get_spec()
-
- @property
- def init_containers(self):
- return self._init_containers
-
- @init_containers.setter
- def init_containers(self, containers):
- self._init_containers = containers
-
- def append_init_container(
- self,
- image,
- command=None,
- args=None,
- env=None,
- image_pull_policy="IfNotPresent",
- name="init",
- ):
- if isinstance(env, dict):
- env = [client.V1EnvVar(name=k, value=v) for k, v in env.items()]
- self._init_containers.append(
- client.V1Container(
- name=name,
- image=image,
- env=env,
- command=command,
- args=args,
- image_pull_policy=image_pull_policy,
- )
- )
-
- def add_label(self, key, value):
- self._labels[key] = str(value)
-
- def add_annotation(self, key, value):
- self._annotations[key] = str(value)
-
- def add_volume(self, volume: client.V1Volume, mount_path, name=None, sub_path=None):
- self._mounts.append(
- client.V1VolumeMount(
- name=name or volume.name, mount_path=mount_path, sub_path=sub_path
- )
- )
- self._volumes.append(volume)
-
- def mount_empty(self, name="empty", mount_path="/empty"):
- self.add_volume(
- client.V1Volume(name=name, empty_dir=client.V1EmptyDirVolumeSource()),
- mount_path=mount_path,
- )
-
- def mount_v3io(
- self, name="v3io", remote="~/", mount_path="/User", access_key="", user=""
- ):
- self.add_volume(
- v3io_to_vol(name, remote, access_key, user),
- mount_path=mount_path,
- name=name,
- )
-
- def mount_cfgmap(self, name, path="/config"):
- self.add_volume(
- client.V1Volume(
- name=name, config_map=client.V1ConfigMapVolumeSource(name=name)
- ),
- mount_path=path,
- )
-
- def mount_secret(self, name, path="/secret", items=None, sub_path=None):
- self.add_volume(
- client.V1Volume(
- name=name,
- secret=client.V1SecretVolumeSource(
- secret_name=name,
- items=items,
- ),
- ),
- mount_path=path,
- sub_path=sub_path,
- )
-
- def set_node_selector(self, node_selector: typing.Optional[typing.Dict[str, str]]):
- self.node_selector = node_selector
-
- def _get_spec(self, template=False):
-
- pod_obj = client.V1PodTemplate if template else client.V1Pod
-
- if self.env and isinstance(self.env, dict):
- env = [client.V1EnvVar(name=k, value=v) for k, v in self.env.items()]
- else:
- env = self.env
- container = client.V1Container(
- name="base",
- image=self.image,
- env=env,
- command=self.command,
- args=self.args,
- volume_mounts=self._mounts,
- resources=self.resources,
- )
-
- pod_spec = client.V1PodSpec(
- containers=[container],
- restart_policy="Never",
- volumes=self._volumes,
- node_selector=self.node_selector,
- )
-
- # if attribute isn't defined use default pod spec attributes
- for key, val in self.default_pod_spec_attributes.items():
- if not getattr(pod_spec, key, None):
- setattr(pod_spec, key, val)
-
- for init_containers in self._init_containers:
- init_containers.volume_mounts = self._mounts
- pod_spec.init_containers = self._init_containers
-
- pod = pod_obj(
- metadata=client.V1ObjectMeta(
- generate_name=f"{self.task_name}-",
- namespace=self.namespace,
- labels=self._labels,
- annotations=self._annotations,
- ),
- spec=pod_spec,
- )
- return pod
-
-
-def format_labels(labels):
- """Convert a dictionary of labels into a comma separated string"""
- if labels:
- return ",".join([f"{k}={v}" for k, v in labels.items()])
- else:
- return ""
-
-
-def verify_gpu_requests_and_limits(requests_gpu: str = None, limits_gpu: str = None):
- # https://kubernetes.io/docs/tasks/manage-gpus/scheduling-gpus/
- if requests_gpu and not limits_gpu:
- raise mlrun.errors.MLRunConflictError(
- "You cannot specify GPU requests without specifying limits"
- )
- if requests_gpu and limits_gpu and requests_gpu != limits_gpu:
- raise mlrun.errors.MLRunConflictError(
- f"When specifying both GPU requests and limits these two values must be equal, "
- f"requests_gpu={requests_gpu}, limits_gpu={limits_gpu}"
- )
+ kubernetes.config.load_incluster_config()
+ _running_inside_kubernetes_cluster = True
+ except kubernetes.config.ConfigException:
+ _running_inside_kubernetes_cluster = False
+ return _running_inside_kubernetes_cluster
def generate_preemptible_node_selector_requirements(
@@ -827,12 +70,9 @@ def generate_preemptible_nodes_anti_affinity_terms() -> typing.List[
https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/#affinity-and-anti-affinity
:return: List contains one nodeSelectorTerm with multiple expressions.
"""
- # import here to avoid circular imports
- from mlrun.common.schemas import NodeSelectorOperator
-
# compile affinities with operator NotIn to make sure pods are not running on preemptible nodes.
node_selector_requirements = generate_preemptible_node_selector_requirements(
- NodeSelectorOperator.node_selector_op_not_in.value
+ mlrun.common.schemas.NodeSelectorOperator.node_selector_op_not_in.value
)
return [
kubernetes.client.V1NodeSelectorTerm(
@@ -850,14 +90,11 @@ def generate_preemptible_nodes_affinity_terms() -> typing.List[
then the pod can be scheduled onto a node if at least one of the nodeSelectorTerms can be satisfied.
:return: List of nodeSelectorTerms associated with the preemptible nodes.
"""
- # import here to avoid circular imports
- from mlrun.common.schemas import NodeSelectorOperator
-
node_selector_terms = []
# compile affinities with operator In so pods could schedule on at least one of the preemptible nodes.
node_selector_requirements = generate_preemptible_node_selector_requirements(
- NodeSelectorOperator.node_selector_op_in.value
+ mlrun.common.schemas.NodeSelectorOperator.node_selector_op_in.value
)
for expression in node_selector_requirements:
node_selector_terms.append(
diff --git a/mlrun/model_monitoring/helpers.py b/mlrun/model_monitoring/helpers.py
index e9f8191b27f4..2c1bde2235a7 100644
--- a/mlrun/model_monitoring/helpers.py
+++ b/mlrun/model_monitoring/helpers.py
@@ -226,7 +226,9 @@ def _apply_access_key_and_mount_function(
# Set model monitoring access key for managing permissions
function.set_env_from_secret(
model_monitoring_constants.ProjectSecretKeys.ACCESS_KEY,
- mlrun.api.utils.singletons.k8s.get_k8s().get_project_secret_name(project),
+ mlrun.api.utils.singletons.k8s.get_k8s_helper().get_project_secret_name(
+ project
+ ),
mlrun.api.crud.secrets.Secrets().generate_client_project_secret_key(
mlrun.api.crud.secrets.SecretsClientType.model_monitoring,
model_monitoring_constants.ProjectSecretKeys.ACCESS_KEY,
diff --git a/mlrun/runtimes/base.py b/mlrun/runtimes/base.py
index 176ee5191e28..307f34e1a8a5 100644
--- a/mlrun/runtimes/base.py
+++ b/mlrun/runtimes/base.py
@@ -48,7 +48,6 @@
from ..db import RunDBError, get_or_set_dburl, get_run_db
from ..errors import err_to_str
from ..execution import MLClientCtx
-from ..k8s_utils import get_k8s_helper
from ..kfpops import mlrun_op, write_kfpmeta
from ..lists import RunList
from ..model import (
@@ -76,7 +75,7 @@
from .constants import PodPhases, RunStates
from .funcdoc import update_function_entry_points
from .generators import get_generator
-from .utils import RunError, calc_hash, results_to_iter
+from .utils import RunError, calc_hash, get_k8s, results_to_iter
run_modes = ["pass"]
spec_fields = [
@@ -223,9 +222,6 @@ def status(self) -> FunctionStatus:
def status(self, status):
self._status = self._verify_dict(status, "status", FunctionStatus)
- def _get_k8s(self):
- return get_k8s_helper()
-
def set_label(self, key, value):
self.metadata.labels[key] = str(value)
return self
@@ -1560,12 +1556,9 @@ def list_resources(
mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput,
]:
# We currently don't support removing runtime resources in non k8s env
- if not mlrun.k8s_utils.get_k8s_helper(
- silent=True
- ).is_running_inside_kubernetes_cluster():
+ if not get_k8s().is_running_inside_kubernetes_cluster():
return {}
- k8s_helper = get_k8s_helper()
- namespace = k8s_helper.resolve_namespace()
+ namespace = get_k8s().resolve_namespace()
label_selector = self.resolve_label_selector(project, object_id, label_selector)
pods = self._list_pods(namespace, label_selector)
pod_resources = self._build_pod_resources(pods)
@@ -1610,12 +1603,9 @@ def delete_resources(
if grace_period is None:
grace_period = config.runtime_resources_deletion_grace_period
# We currently don't support removing runtime resources in non k8s env
- if not mlrun.k8s_utils.get_k8s_helper(
- silent=True
- ).is_running_inside_kubernetes_cluster():
+ if not get_k8s().is_running_inside_kubernetes_cluster():
return
- k8s_helper = get_k8s_helper()
- namespace = k8s_helper.resolve_namespace()
+ namespace = get_k8s().resolve_namespace()
label_selector = self.resolve_label_selector("*", label_selector=label_selector)
crd_group, crd_version, crd_plural = self._get_crd_info()
if crd_group and crd_version and crd_plural:
@@ -1663,8 +1653,7 @@ def delete_runtime_object_resources(
self.delete_resources(db, db_session, label_selector, force, grace_period)
def monitor_runs(self, db: DBInterface, db_session: Session):
- k8s_helper = get_k8s_helper()
- namespace = k8s_helper.resolve_namespace()
+ namespace = get_k8s().resolve_namespace()
label_selector = self._get_default_label_selector()
crd_group, crd_version, crd_plural = self._get_crd_info()
runtime_resource_is_crd = False
@@ -1996,20 +1985,18 @@ def _expect_pods_without_uid() -> bool:
return False
def _list_pods(self, namespace: str, label_selector: str = None) -> List:
- k8s_helper = get_k8s_helper()
- pods = k8s_helper.list_pods(namespace, selector=label_selector)
+ pods = get_k8s().list_pods(namespace, selector=label_selector)
# when we work with custom objects (list_namespaced_custom_object) it's always a dict, to be able to generalize
# code working on runtime resource (either a custom object or a pod) we're transforming to dicts
pods = [pod.to_dict() for pod in pods]
return pods
def _list_crd_objects(self, namespace: str, label_selector: str = None) -> List:
- k8s_helper = get_k8s_helper()
crd_group, crd_version, crd_plural = self._get_crd_info()
crd_objects = []
if crd_group and crd_version and crd_plural:
try:
- crd_objects = k8s_helper.crdapi.list_namespaced_custom_object(
+ crd_objects = get_k8s().crdapi.list_namespaced_custom_object(
crd_group,
crd_version,
namespace,
@@ -2075,11 +2062,10 @@ def _wait_for_pods_deletion(
deleted_pods: List[Dict],
label_selector: str = None,
):
- k8s_helper = get_k8s_helper()
deleted_pod_names = [pod_dict["metadata"]["name"] for pod_dict in deleted_pods]
def _verify_pods_removed():
- pods = k8s_helper.v1api.list_namespaced_pod(
+ pods = get_k8s().v1api.list_namespaced_pod(
namespace, label_selector=label_selector
)
existing_pod_names = [pod.metadata.name for pod in pods.items]
@@ -2183,8 +2169,7 @@ def _delete_pod_resources(
) -> List[Dict]:
if grace_period is None:
grace_period = config.runtime_resources_deletion_grace_period
- k8s_helper = get_k8s_helper()
- pods = k8s_helper.v1api.list_namespaced_pod(
+ pods = get_k8s().v1api.list_namespaced_pod(
namespace, label_selector=label_selector
)
deleted_pods = []
@@ -2225,7 +2210,7 @@ def _delete_pod_resources(
pod_name=pod.metadata.name,
)
- get_k8s_helper().delete_pod(pod.metadata.name, namespace)
+ get_k8s().delete_pod(pod.metadata.name, namespace)
deleted_pods.append(pod_dict)
except Exception as exc:
logger.warning(
@@ -2246,11 +2231,10 @@ def _delete_crd_resources(
) -> List[Dict]:
if grace_period is None:
grace_period = config.runtime_resources_deletion_grace_period
- k8s_helper = get_k8s_helper()
crd_group, crd_version, crd_plural = self._get_crd_info()
deleted_crds = []
try:
- crd_objects = k8s_helper.crdapi.list_namespaced_custom_object(
+ crd_objects = get_k8s().crdapi.list_namespaced_custom_object(
crd_group,
crd_version,
namespace,
@@ -2302,7 +2286,7 @@ def _delete_crd_resources(
crd_object_name=crd_object["metadata"]["name"],
)
- get_k8s_helper().delete_crd(
+ get_k8s().delete_crd(
crd_object["metadata"]["name"],
crd_group,
crd_version,
diff --git a/mlrun/runtimes/daskjob.py b/mlrun/runtimes/daskjob.py
index ebc68bfdefbc..79be2190c596 100644
--- a/mlrun/runtimes/daskjob.py
+++ b/mlrun/runtimes/daskjob.py
@@ -25,6 +25,7 @@
import mlrun.common.schemas
import mlrun.errors
+import mlrun.k8s_utils
import mlrun.utils
import mlrun.utils.regex
from mlrun.api.db.base import DBInterface
@@ -33,7 +34,6 @@
from ..config import config
from ..execution import MLClientCtx
-from ..k8s_utils import get_k8s_helper
from ..model import RunObject
from ..render import ipython_display
from ..utils import logger, normalize_name, update_in
@@ -41,7 +41,7 @@
from .kubejob import KubejobRuntime
from .local import exec_from_params, load_module
from .pod import KubeResourceSpec, kube_resource_spec_to_pod_spec
-from .utils import RunError, get_func_selector, get_resource_labels, log_std
+from .utils import RunError, get_func_selector, get_k8s, get_resource_labels, log_std
def get_dask_resource():
@@ -203,9 +203,7 @@ class DaskCluster(KubejobRuntime):
def __init__(self, spec=None, metadata=None):
super().__init__(spec, metadata)
self._cluster = None
- self.use_remote = not get_k8s_helper(
- silent=True
- ).is_running_inside_kubernetes_cluster()
+ self.use_remote = not mlrun.k8s_utils.is_running_inside_kubernetes_cluster()
self.spec.build.base_image = self.spec.build.base_image or "daskdev/dask:latest"
@property
@@ -673,7 +671,9 @@ def get_obj_status(selector=None, namespace=None):
if selector is None:
selector = []
- k8s = get_k8s_helper()
+ import mlrun.api.utils.singletons.k8s
+
+ k8s = mlrun.api.utils.singletons.k8s.get_k8s_helper()
namespace = namespace or config.namespace
selector = ",".join(["dask.org/component=scheduler"] + selector)
pods = k8s.list_pods(namespace, selector=selector)
@@ -752,8 +752,7 @@ def _enrich_list_resources_response(
enrich_needed = self._validate_if_enrich_is_needed_by_group_by(group_by)
if not enrich_needed:
return response
- k8s_helper = get_k8s_helper()
- services = k8s_helper.v1api.list_namespaced_service(
+ services = get_k8s().v1api.list_namespaced_service(
namespace, label_selector=label_selector
)
service_resources = []
@@ -855,14 +854,13 @@ def _delete_extra_resources(
if dask_component == "scheduler" and cluster_name:
service_names.append(cluster_name)
- k8s_helper = get_k8s_helper()
- services = k8s_helper.v1api.list_namespaced_service(
+ services = get_k8s().v1api.list_namespaced_service(
namespace, label_selector=label_selector
)
for service in services.items:
try:
if force or service.metadata.name in service_names:
- k8s_helper.v1api.delete_namespaced_service(
+ get_k8s().v1api.delete_namespaced_service(
service.metadata.name, namespace
)
logger.info(f"Deleted service: {service.metadata.name}")
diff --git a/mlrun/runtimes/function.py b/mlrun/runtimes/function.py
index bbe0b0fff163..40f7a2e6b990 100644
--- a/mlrun/runtimes/function.py
+++ b/mlrun/runtimes/function.py
@@ -14,13 +14,10 @@
import asyncio
import json
-import shlex
import typing
import warnings
-from base64 import b64encode
from datetime import datetime
from time import sleep
-from urllib.parse import urlparse
import nuclio
import nuclio.utils
@@ -32,15 +29,13 @@
from nuclio.triggers import V3IOStreamTrigger
import mlrun.errors
+import mlrun.k8s_utils
import mlrun.utils
from mlrun.common.schemas import AuthInfo
-from mlrun.datastore import parse_s3_bucket_and_key
from mlrun.db import RunDBError
from ..config import config as mlconf
-from ..config import is_running_as_api
from ..errors import err_to_str
-from ..k8s_utils import get_k8s_helper
from ..kfpops import deploy_op
from ..lists import RunList
from ..model import RunObject
@@ -51,9 +46,8 @@
split_path,
v3io_cred,
)
-from ..utils import as_number, enrich_image_url, get_in, logger, update_in
+from ..utils import get_in, logger, update_in
from .base import FunctionStatus, RunError
-from .constants import NuclioIngressAddTemplatedIngressModes
from .pod import KubeResource, KubeResourceSpec
from .utils import get_item_name, log_std
@@ -1056,9 +1050,7 @@ def _resolve_invocation_url(self, path, force_external_address):
if (
not force_external_address
and self.status.internal_invocation_urls
- and get_k8s_helper(
- silent=True, log=False
- ).is_running_inside_kubernetes_cluster()
+ and mlrun.k8s_utils.is_running_inside_kubernetes_cluster()
):
return f"http://{self.status.internal_invocation_urls[0]}{path}"
@@ -1177,451 +1169,6 @@ def get_fullname(name, project, tag):
return name
-def deploy_nuclio_function(
- function: RemoteRuntime,
- dashboard="",
- watch=False,
- auth_info: AuthInfo = None,
- client_version: str = None,
- builder_env: dict = None,
- client_python_version: str = None,
-):
- """Deploys a nuclio function.
-
- :param function: nuclio function object
- :param dashboard: DEPRECATED. Keep empty to allow auto-detection by MLRun API.
- :param watch: wait for function to be ready
- :param auth_info: service AuthInfo
- :param client_version: mlrun client version
- :param builder_env: mlrun builder environment (for config/credentials)
- :param client_python_version: mlrun client python version
- """
- dashboard = dashboard or mlconf.nuclio_dashboard_url
- function_name, project_name, function_config = compile_function_config(
- function,
- client_version=client_version,
- client_python_version=client_python_version,
- builder_env=builder_env or {},
- auth_info=auth_info,
- )
-
- # if mode allows it, enrich function http trigger with an ingress
- enrich_function_with_ingress(
- function_config,
- function.spec.add_templated_ingress_host_mode
- or mlconf.httpdb.nuclio.add_templated_ingress_host_mode,
- function.spec.service_type or mlconf.httpdb.nuclio.default_service_type,
- )
-
- try:
- return nuclio.deploy.deploy_config(
- function_config,
- dashboard_url=dashboard,
- name=function_name,
- project=project_name,
- tag=function.metadata.tag,
- verbose=function.verbose,
- create_new=True,
- watch=watch,
- return_address_mode=nuclio.deploy.ReturnAddressModes.all,
- auth_info=auth_info.to_nuclio_auth_info() if auth_info else None,
- )
- except nuclio.utils.DeployError as exc:
- if exc.err:
- err_message = (
- f"Failed to deploy nuclio function {project_name}/{function_name}"
- )
-
- try:
-
- # the error might not be jsonable, so we'll try to parse it
- # and extract the error message
- json_err = exc.err.response.json()
- if "error" in json_err:
- err_message += f" {json_err['error']}"
- if "errorStackTrace" in json_err:
- logger.warning(
- "Failed to deploy nuclio function",
- nuclio_stacktrace=json_err["errorStackTrace"],
- )
- except Exception as parse_exc:
- logger.warning(
- "Failed to parse nuclio deploy error",
- parse_exc=err_to_str(parse_exc),
- )
-
- mlrun.errors.raise_for_status(
- exc.err.response,
- err_message,
- )
- raise
-
-
-def resolve_function_ingresses(function_spec):
- http_trigger = resolve_function_http_trigger(function_spec)
- if not http_trigger:
- return []
-
- ingresses = []
- for _, ingress_config in (
- http_trigger.get("attributes", {}).get("ingresses", {}).items()
- ):
- ingresses.append(ingress_config)
- return ingresses
-
-
-def resolve_function_http_trigger(function_spec):
- for trigger_name, trigger_config in function_spec.get("triggers", {}).items():
- if trigger_config.get("kind") != "http":
- continue
- return trigger_config
-
-
-def _resolve_function_image_pull_secret(function):
- """
- the corresponding attribute for 'build.secret' in nuclio is imagePullSecrets, attached link for reference
- https://github.com/nuclio/nuclio/blob/e4af2a000dc52ee17337e75181ecb2652b9bf4e5/pkg/processor/build/builder.go#L1073
- if only one of the secrets is set, use it.
- if both are set, use the non default one and give precedence to image_pull_secret
- """
- # enrich only on server side
- if not is_running_as_api():
- return function.spec.image_pull_secret or function.spec.build.secret
-
- if function.spec.image_pull_secret is None:
- function.spec.image_pull_secret = (
- mlrun.mlconf.function.spec.image_pull_secret.default
- )
- elif (
- function.spec.image_pull_secret
- != mlrun.mlconf.function.spec.image_pull_secret.default
- ):
- return function.spec.image_pull_secret
-
- if function.spec.build.secret is None:
- function.spec.build.secret = mlrun.mlconf.httpdb.builder.docker_registry_secret
- elif (
- function.spec.build.secret != mlrun.mlconf.httpdb.builder.docker_registry_secret
- ):
- return function.spec.build.secret
-
- return function.spec.image_pull_secret or function.spec.build.secret
-
-
-def compile_function_config(
- function: RemoteRuntime,
- client_version: str = None,
- client_python_version: str = None,
- builder_env=None,
- auth_info=None,
-):
- labels = function.metadata.labels or {}
- labels.update({"mlrun/class": function.kind})
- for key, value in labels.items():
- # Adding escaping to the key to prevent it from being split by dots if it contains any
- function.set_config(f"metadata.labels.\\{key}\\", value)
-
- # Add secret configurations to function's pod spec, if secret sources were added.
- # Needs to be here, since it adds env params, which are handled in the next lines.
- # This only needs to run if we're running within k8s context. If running in Docker, for example, skip.
- if get_k8s_helper(silent=True).is_running_inside_kubernetes_cluster():
- function.add_secrets_config_to_spec()
-
- env_dict, external_source_env_dict = function._get_nuclio_config_spec_env()
-
- nuclio_runtime = (
- function.spec.nuclio_runtime
- or _resolve_nuclio_runtime_python_image(
- mlrun_client_version=client_version, python_version=client_python_version
- )
- )
-
- if is_nuclio_version_in_range("0.0.0", "1.6.0") and nuclio_runtime in [
- "python:3.7",
- "python:3.8",
- ]:
- nuclio_runtime_set_from_spec = nuclio_runtime == function.spec.nuclio_runtime
- if nuclio_runtime_set_from_spec:
- raise mlrun.errors.MLRunInvalidArgumentError(
- f"Nuclio version does not support the configured runtime: {nuclio_runtime}"
- )
- else:
- # our default is python:3.9, simply set it to python:3.6 to keep supporting envs with old Nuclio
- nuclio_runtime = "python:3.6"
-
- # In nuclio 1.6.0<=v<1.8.0, python runtimes default behavior was to not decode event strings
- # Our code is counting on the strings to be decoded, so add the needed env var for those versions
- if (
- is_nuclio_version_in_range("1.6.0", "1.8.0")
- and "NUCLIO_PYTHON_DECODE_EVENT_STRINGS" not in env_dict
- ):
- env_dict["NUCLIO_PYTHON_DECODE_EVENT_STRINGS"] = "true"
-
- nuclio_spec = nuclio.ConfigSpec(
- env=env_dict,
- external_source_env=external_source_env_dict,
- config=function.spec.config,
- )
- nuclio_spec.cmd = function.spec.build.commands or []
-
- if function.spec.build.requirements:
- resolved_requirements = []
- # wrap in single quote to ensure that the requirement is treated as a single string
- # quote the requirement to avoid issues with special characters, double quotes, etc.
- for requirement in function.spec.build.requirements:
- # -r / --requirement are flags and should not be escaped
- # we allow such flags (could be passed within the requirements.txt file) and do not
- # try to open the file and include its content since it might be a remote file
- # given on the base image.
- for req_flag in ["-r", "--requirement"]:
- if requirement.startswith(req_flag):
- requirement = requirement[len(req_flag) :].strip()
- resolved_requirements.append(req_flag)
- break
-
- resolved_requirements.append(shlex.quote(requirement))
-
- encoded_requirements = " ".join(resolved_requirements)
- nuclio_spec.cmd.append(f"python -m pip install {encoded_requirements}")
-
- project = function.metadata.project or "default"
- tag = function.metadata.tag
- handler = function.spec.function_handler
-
- if function.spec.build.source:
- _compile_nuclio_archive_config(
- nuclio_spec, function, builder_env, project, auth_info=auth_info
- )
-
- nuclio_spec.set_config("spec.runtime", nuclio_runtime)
-
- # In Nuclio >= 1.6.x default serviceType has changed to "ClusterIP".
- nuclio_spec.set_config(
- "spec.serviceType",
- function.spec.service_type or mlconf.httpdb.nuclio.default_service_type,
- )
- if function.spec.readiness_timeout:
- nuclio_spec.set_config(
- "spec.readinessTimeoutSeconds", function.spec.readiness_timeout
- )
- if function.spec.resources:
- nuclio_spec.set_config("spec.resources", function.spec.resources)
- if function.spec.no_cache:
- nuclio_spec.set_config("spec.build.noCache", True)
- if function.spec.build.functionSourceCode:
- nuclio_spec.set_config(
- "spec.build.functionSourceCode", function.spec.build.functionSourceCode
- )
-
- image_pull_secret = _resolve_function_image_pull_secret(function)
- if image_pull_secret:
- nuclio_spec.set_config("spec.imagePullSecrets", image_pull_secret)
-
- if function.spec.base_image_pull:
- nuclio_spec.set_config("spec.build.noBaseImagesPull", False)
- # don't send node selections if nuclio is not compatible
- if validate_nuclio_version_compatibility("1.5.20", "1.6.10"):
- if function.spec.node_selector:
- nuclio_spec.set_config("spec.nodeSelector", function.spec.node_selector)
- if function.spec.node_name:
- nuclio_spec.set_config("spec.nodeName", function.spec.node_name)
- if function.spec.affinity:
- nuclio_spec.set_config(
- "spec.affinity",
- mlrun.runtimes.pod.get_sanitized_attribute(function.spec, "affinity"),
- )
-
- # don't send tolerations if nuclio is not compatible
- if validate_nuclio_version_compatibility("1.7.5"):
- if function.spec.tolerations:
- nuclio_spec.set_config(
- "spec.tolerations",
- mlrun.runtimes.pod.get_sanitized_attribute(
- function.spec, "tolerations"
- ),
- )
- # don't send preemption_mode if nuclio is not compatible
- if validate_nuclio_version_compatibility("1.8.6"):
- if function.spec.preemption_mode:
- nuclio_spec.set_config(
- "spec.PreemptionMode",
- function.spec.preemption_mode,
- )
-
- # don't send default or any priority class name if nuclio is not compatible
- if (
- function.spec.priority_class_name
- and validate_nuclio_version_compatibility("1.6.18")
- and len(mlconf.get_valid_function_priority_class_names())
- ):
- nuclio_spec.set_config(
- "spec.priorityClassName", function.spec.priority_class_name
- )
-
- if function.spec.replicas:
-
- nuclio_spec.set_config(
- "spec.minReplicas", as_number("spec.Replicas", function.spec.replicas)
- )
- nuclio_spec.set_config(
- "spec.maxReplicas", as_number("spec.Replicas", function.spec.replicas)
- )
-
- else:
- nuclio_spec.set_config(
- "spec.minReplicas",
- as_number("spec.minReplicas", function.spec.min_replicas),
- )
- nuclio_spec.set_config(
- "spec.maxReplicas",
- as_number("spec.maxReplicas", function.spec.max_replicas),
- )
-
- if function.spec.service_account:
- nuclio_spec.set_config("spec.serviceAccount", function.spec.service_account)
-
- if function.spec.security_context:
- nuclio_spec.set_config(
- "spec.securityContext",
- mlrun.runtimes.pod.get_sanitized_attribute(
- function.spec, "security_context"
- ),
- )
-
- if (
- function.spec.base_spec
- or function.spec.build.functionSourceCode
- or function.spec.build.source
- or function.kind == mlrun.runtimes.RuntimeKinds.serving # serving can be empty
- ):
- config = function.spec.base_spec
- if not config:
- # if base_spec was not set (when not using code_to_function) and we have base64 code
- # we create the base spec with essential attributes
- config = nuclio.config.new_config()
- update_in(config, "spec.handler", handler or "main:handler")
-
- config = nuclio.config.extend_config(
- config, nuclio_spec, tag, function.spec.build.code_origin
- )
-
- update_in(config, "metadata.name", function.metadata.name)
- update_in(config, "spec.volumes", function.spec.generate_nuclio_volumes())
- base_image = (
- get_in(config, "spec.build.baseImage")
- or function.spec.image
- or function.spec.build.base_image
- )
- if base_image:
- update_in(
- config,
- "spec.build.baseImage",
- enrich_image_url(base_image, client_version, client_python_version),
- )
-
- logger.info("deploy started")
- name = get_fullname(function.metadata.name, project, tag)
- function.status.nuclio_name = name
- update_in(config, "metadata.name", name)
-
- if function.kind == mlrun.runtimes.RuntimeKinds.serving and not get_in(
- config, "spec.build.functionSourceCode"
- ):
- if not function.spec.build.source:
- # set the source to the mlrun serving wrapper
- body = nuclio.build.mlrun_footer.format(
- mlrun.runtimes.serving.serving_subkind
- )
- update_in(
- config,
- "spec.build.functionSourceCode",
- b64encode(body.encode("utf-8")).decode("utf-8"),
- )
- elif not function.spec.function_handler:
- # point the nuclio function handler to mlrun serving wrapper handlers
- update_in(
- config,
- "spec.handler",
- "mlrun.serving.serving_wrapper:handler",
- )
- else:
- # todo: should be deprecated (only work via MLRun service)
- # this may also be called in case of using single file code_to_function(embed_code=False)
- # this option need to be removed or be limited to using remote files (this code runs in server)
- name, config, code = nuclio.build_file(
- function.spec.source,
- name=function.metadata.name,
- project=project,
- handler=handler,
- tag=tag,
- spec=nuclio_spec,
- kind=function.spec.function_kind,
- verbose=function.verbose,
- )
-
- update_in(config, "spec.volumes", function.spec.generate_nuclio_volumes())
- base_image = function.spec.image or function.spec.build.base_image
- if base_image:
- update_in(
- config,
- "spec.build.baseImage",
- enrich_image_url(base_image, client_version, client_python_version),
- )
-
- name = get_fullname(name, project, tag)
- function.status.nuclio_name = name
-
- update_in(config, "metadata.name", name)
-
- return name, project, config
-
-
-def enrich_function_with_ingress(config, mode, service_type):
- # do not enrich with an ingress
- if mode == NuclioIngressAddTemplatedIngressModes.never:
- return
-
- ingresses = resolve_function_ingresses(config["spec"])
-
- # function has ingresses already, nothing to add / enrich
- if ingresses:
- return
-
- # if exists, get the http trigger the function has
- # we would enrich it with an ingress
- http_trigger = resolve_function_http_trigger(config["spec"])
- if not http_trigger:
- # function has an HTTP trigger without an ingress
- # TODO: read from nuclio-api frontend-spec
- http_trigger = {
- "kind": "http",
- "name": "http",
- "maxWorkers": 1,
- "workerAvailabilityTimeoutMilliseconds": 10000, # 10 seconds
- "attributes": {},
- }
-
- def enrich():
- http_trigger.setdefault("attributes", {}).setdefault("ingresses", {})["0"] = {
- "paths": ["/"],
- # this would tell Nuclio to use its default ingress host template
- # and would auto assign a host for the ingress
- "hostTemplate": "@nuclio.fromDefault",
- }
- http_trigger["attributes"]["serviceType"] = service_type
- config["spec"].setdefault("triggers", {})[http_trigger["name"]] = http_trigger
-
- if mode == NuclioIngressAddTemplatedIngressModes.always:
- enrich()
- elif mode == NuclioIngressAddTemplatedIngressModes.on_cluster_ip:
-
- # service type is not cluster ip, bail out
- if service_type and service_type.lower() != "clusterip":
- return
-
- enrich()
-
-
def get_nuclio_deploy_status(
name,
project,
@@ -1680,163 +1227,3 @@ def get_nuclio_deploy_status(
else:
text = "\n".join(outputs) if outputs else ""
return state, address, name, last_log_timestamp, text, function_status
-
-
-def _compile_nuclio_archive_config(
- nuclio_spec,
- function: RemoteRuntime,
- builder_env,
- project=None,
- auth_info=None,
-):
- secrets = {}
- if project and get_k8s_helper(silent=True).is_running_inside_kubernetes_cluster():
- secrets = get_k8s_helper().get_project_secret_data(project)
-
- def get_secret(key):
- return builder_env.get(key) or secrets.get(key, "")
-
- source = function.spec.build.source
- parsed_url = urlparse(source)
- code_entry_type = ""
- if source.startswith("s3://"):
- code_entry_type = "s3"
- if source.startswith("git://"):
- code_entry_type = "git"
- for archive_prefix in ["http://", "https://", "v3io://", "v3ios://"]:
- if source.startswith(archive_prefix):
- code_entry_type = "archive"
-
- if code_entry_type == "":
- raise mlrun.errors.MLRunInvalidArgumentError(
- "Couldn't resolve code entry type from source"
- )
-
- code_entry_attributes = {}
-
- # resolve work_dir and handler
- work_dir, handler = _resolve_work_dir_and_handler(function.spec.function_handler)
- work_dir = function.spec.workdir or work_dir
- if work_dir != "":
- code_entry_attributes["workDir"] = work_dir
-
- # archive
- if code_entry_type == "archive":
- v3io_access_key = builder_env.get("V3IO_ACCESS_KEY", "")
- if source.startswith("v3io"):
- if not parsed_url.netloc:
- source = mlrun.mlconf.v3io_api + parsed_url.path
- else:
- source = f"http{source[len('v3io'):]}"
- if auth_info and not v3io_access_key:
- v3io_access_key = auth_info.data_session or auth_info.access_key
-
- if v3io_access_key:
- code_entry_attributes["headers"] = {"X-V3io-Session-Key": v3io_access_key}
-
- # s3
- if code_entry_type == "s3":
- bucket, item_key = parse_s3_bucket_and_key(source)
-
- code_entry_attributes["s3Bucket"] = bucket
- code_entry_attributes["s3ItemKey"] = item_key
-
- code_entry_attributes["s3AccessKeyId"] = get_secret("AWS_ACCESS_KEY_ID")
- code_entry_attributes["s3SecretAccessKey"] = get_secret("AWS_SECRET_ACCESS_KEY")
- code_entry_attributes["s3SessionToken"] = get_secret("AWS_SESSION_TOKEN")
-
- # git
- if code_entry_type == "git":
-
- # change git:// to https:// as nuclio expects it to be
- if source.startswith("git://"):
- source = source.replace("git://", "https://")
-
- source, reference, branch = mlrun.utils.resolve_git_reference_from_source(
- source
- )
- if not branch and not reference:
- raise mlrun.errors.MLRunInvalidArgumentError(
- "git branch or refs must be specified in the source e.g.: "
- "'git:///org/repo.git#'"
- )
- if reference:
- code_entry_attributes["reference"] = reference
- if branch:
- code_entry_attributes["branch"] = branch
-
- password = get_secret("GIT_PASSWORD")
- username = get_secret("GIT_USERNAME")
-
- token = get_secret("GIT_TOKEN")
- if token:
- username, password = mlrun.utils.get_git_username_password_from_token(token)
-
- code_entry_attributes["username"] = username
- code_entry_attributes["password"] = password
-
- # populate spec with relevant fields
- nuclio_spec.set_config("spec.handler", handler)
- nuclio_spec.set_config("spec.build.path", source)
- nuclio_spec.set_config("spec.build.codeEntryType", code_entry_type)
- nuclio_spec.set_config("spec.build.codeEntryAttributes", code_entry_attributes)
-
-
-def _resolve_work_dir_and_handler(handler):
- """
- Resolves a nuclio function working dir and handler inside an archive/git repo
- :param handler: a path describing working dir and handler of a nuclio function
- :return: (working_dir, handler) tuple, as nuclio expects to get it
-
- Example: ("a/b/c#main:Handler") -> ("a/b/c", "main:Handler")
- """
-
- def extend_handler(base_handler):
- # return default handler and module if not specified
- if not base_handler:
- return "main:handler"
- if ":" not in base_handler:
- base_handler = f"{base_handler}:handler"
- return base_handler
-
- if not handler:
- return "", "main:handler"
-
- split_handler = handler.split("#")
- if len(split_handler) == 1:
- return "", extend_handler(handler)
-
- return split_handler[0], extend_handler(split_handler[1])
-
-
-def _resolve_nuclio_runtime_python_image(
- mlrun_client_version: str = None, python_version: str = None
-):
- # if no python version or mlrun version is passed it means we use mlrun client older than 1.3.0 therefore need
- # to use the previoud default runtime which is python 3.7
- if not python_version or not mlrun_client_version:
- return "python:3.7"
-
- # If the mlrun version is 0.0.0-, it is a dev version,
- # so we can't check if it is higher than 1.3.0, but if the python version was passed,
- # it means it is 1.3.0-rc or higher, so use the image according to the python version
- if mlrun_client_version.startswith("0.0.0-") or "unstable" in mlrun_client_version:
- if python_version.startswith("3.7"):
- return "python:3.7"
-
- return mlrun.mlconf.default_nuclio_runtime
-
- # if mlrun version is older than 1.3.0 we need to use the previous default runtime which is python 3.7
- if semver.VersionInfo.parse(mlrun_client_version) < semver.VersionInfo.parse(
- "1.3.0-X"
- ):
- return "python:3.7"
-
- # if mlrun version is 1.3.0 or newer and python version is 3.7 we need to use python 3.7 image
- if semver.VersionInfo.parse(mlrun_client_version) >= semver.VersionInfo.parse(
- "1.3.0-X"
- ) and python_version.startswith("3.7"):
- return "python:3.7"
-
- # if none of the above conditions are met we use the default runtime which is python 3.9
- return mlrun.mlconf.default_nuclio_runtime
diff --git a/mlrun/runtimes/kubejob.py b/mlrun/runtimes/kubejob.py
index 6bb81dc1c427..00a5c89a8699 100644
--- a/mlrun/runtimes/kubejob.py
+++ b/mlrun/runtimes/kubejob.py
@@ -30,7 +30,7 @@
from ..utils import get_in, logger
from .base import RunError, RuntimeClassMode
from .pod import KubeResource, kube_resource_spec_to_pod_spec
-from .utils import AsyncLogWriter
+from .utils import get_k8s
class KubejobRuntime(KubeResource):
@@ -287,36 +287,6 @@ def print_log(text):
print()
return self.status.state
- def builder_status(self, watch=True, logs=True):
- if self._is_remote_api():
- return self._build_watch(watch, logs)
-
- else:
- pod = self.status.build_pod
- if not self.status.state == "ready" and pod:
- k8s = self._get_k8s()
- status = k8s.get_pod_status(pod)
- if logs:
- if watch:
- status = k8s.watch(pod)
- else:
- resp = k8s.logs(pod)
- if resp:
- print(resp.encode())
-
- if status == "succeeded":
- self.status.build_pod = None
- self.status.state = "ready"
- logger.info("build completed successfully")
- return "ready"
- if status in ["failed", "error"]:
- self.status.state = status
- logger.error(f" build {status}, watch the build pod logs: {pod}")
- return status
-
- logger.info(f"builder status is: {status}, wait for it to complete")
- return None
-
def deploy_step(
self,
image=None,
@@ -348,7 +318,6 @@ def _run(self, runobj: RunObject, execution):
if runobj.metadata.iteration:
self.store_run(runobj)
- k8s = self._get_k8s()
new_meta = self._get_meta(runobj)
self._add_secrets_to_spec_before_running(runobj)
@@ -369,20 +338,13 @@ def _run(self, runobj: RunObject, execution):
)
pod = client.V1Pod(metadata=new_meta, spec=pod_spec)
try:
- pod_name, namespace = k8s.create_pod(pod)
+ pod_name, namespace = get_k8s().create_pod(pod)
except ApiException as exc:
raise RunError(err_to_str(exc))
- if pod_name and self.kfp:
- writer = AsyncLogWriter(self._db_conn, runobj)
- status = k8s.watch(pod_name, namespace, writer=writer)
-
- if status in ["failed", "error"]:
- raise RunError(f"pod exited with {status}, check logs")
- else:
- txt = f"Job is running in the background, pod: {pod_name}"
- logger.info(txt)
- runobj.status.status_text = txt
+ txt = f"Job is running in the background, pod: {pod_name}"
+ logger.info(txt)
+ runobj.status.status_text = txt
return None
diff --git a/mlrun/runtimes/mpijob/abstract.py b/mlrun/runtimes/mpijob/abstract.py
index d6ef2dc573d5..cde25bb948fd 100644
--- a/mlrun/runtimes/mpijob/abstract.py
+++ b/mlrun/runtimes/mpijob/abstract.py
@@ -24,7 +24,7 @@
from mlrun.model import RunObject
from mlrun.runtimes.kubejob import KubejobRuntime
from mlrun.runtimes.pod import KubeResourceSpec
-from mlrun.runtimes.utils import RunError
+from mlrun.runtimes.utils import RunError, get_k8s
from mlrun.utils import get_in, logger
@@ -191,10 +191,9 @@ def _run(self, runobj: RunObject, execution: MLClientCtx):
def _submit_mpijob(self, job, namespace=None):
mpi_group, mpi_version, mpi_plural = self._get_crd_info()
- k8s = self._get_k8s()
- namespace = k8s.resolve_namespace(namespace)
+ namespace = get_k8s().resolve_namespace(namespace)
try:
- resp = k8s.crdapi.create_namespaced_custom_object(
+ resp = get_k8s().crdapi.create_namespaced_custom_object(
mpi_group,
mpi_version,
namespace=namespace,
@@ -210,7 +209,7 @@ def _submit_mpijob(self, job, namespace=None):
def delete_job(self, name, namespace=None):
mpi_group, mpi_version, mpi_plural = self._get_crd_info()
- k8s = self._get_k8s()
+ k8s = get_k8s()
namespace = k8s.resolve_namespace(namespace)
try:
# delete the mpi job
@@ -225,11 +224,10 @@ def delete_job(self, name, namespace=None):
def list_jobs(self, namespace=None, selector="", show=True):
mpi_group, mpi_version, mpi_plural = self._get_crd_info()
- k8s = self._get_k8s()
- namespace = k8s.resolve_namespace(namespace)
+ namespace = get_k8s().resolve_namespace(namespace)
items = []
try:
- resp = k8s.crdapi.list_namespaced_custom_object(
+ resp = get_k8s().crdapi.list_namespaced_custom_object(
mpi_group,
mpi_version,
namespace,
@@ -249,10 +247,9 @@ def list_jobs(self, namespace=None, selector="", show=True):
def get_job(self, name, namespace=None):
mpi_group, mpi_version, mpi_plural = self._get_crd_info()
- k8s = self._get_k8s()
- namespace = k8s.resolve_namespace(namespace)
+ namespace = get_k8s().resolve_namespace(namespace)
try:
- resp = k8s.crdapi.get_namespaced_custom_object(
+ resp = get_k8s().crdapi.get_namespaced_custom_object(
mpi_group, mpi_version, namespace, mpi_plural, name
)
except client.exceptions.ApiException as exc:
@@ -261,12 +258,11 @@ def get_job(self, name, namespace=None):
return resp
def get_pods(self, name=None, namespace=None, launcher=False):
- k8s = self._get_k8s()
- namespace = k8s.resolve_namespace(namespace)
+ namespace = get_k8s().resolve_namespace(namespace)
selector = self._generate_pods_selector(name, launcher)
- pods = k8s.list_pods(selector=selector, namespace=namespace)
+ pods = get_k8s().list_pods(selector=selector, namespace=namespace)
if pods:
return {p.metadata.name: p.status.phase for p in pods}
diff --git a/mlrun/runtimes/pod.py b/mlrun/runtimes/pod.py
index d27c57d31058..667685151a45 100644
--- a/mlrun/runtimes/pod.py
+++ b/mlrun/runtimes/pod.py
@@ -44,6 +44,7 @@
apply_kfp,
get_gpu_from_resource_requirement,
get_item_name,
+ get_k8s,
get_resource_labels,
set_named_item,
verify_limits,
@@ -1157,7 +1158,7 @@ def get_default_priority_class_name(self):
return mlconf.default_function_priority_class_name
def _get_meta(self, runobj, unique=False):
- namespace = self._get_k8s().resolve_namespace()
+ namespace = get_k8s().resolve_namespace()
labels = get_resource_labels(self, runobj, runobj.spec.scrape_metrics)
new_meta = k8s_client.V1ObjectMeta(
@@ -1225,7 +1226,7 @@ def _add_k8s_secrets_to_spec(
mlconf.secret_stores.kubernetes.global_function_env_secret_name
)
if mlrun.config.is_running_as_api() and global_secret_name:
- global_secrets = self._get_k8s().get_secret_data(global_secret_name)
+ global_secrets = get_k8s().get_secret_data(global_secret_name)
for key, value in global_secrets.items():
env_var_name = (
SecretsStore.k8s_env_variable_name_for_secret(key)
@@ -1247,10 +1248,10 @@ def _add_k8s_secrets_to_spec(
logger.warning("No project provided. Cannot add k8s secrets")
return
- secret_name = self._get_k8s().get_project_secret_name(project_name)
+ secret_name = get_k8s().get_project_secret_name(project_name)
# Not utilizing the same functionality from the Secrets crud object because this code also runs client-side
# in the nuclio remote-dashboard flow, which causes dependency problems.
- existing_secret_keys = self._get_k8s().get_project_secret_keys(
+ existing_secret_keys = get_k8s().get_project_secret_keys(
project_name, filter_internal=True
)
@@ -1284,7 +1285,7 @@ def _add_vault_params_to_spec(self, runobj=None, project=None):
)
)
- project_vault_secret_name = self._get_k8s().get_project_vault_secret_name(
+ project_vault_secret_name = get_k8s().get_project_vault_secret_name(
project_name, service_account_name
)
if project_vault_secret_name is None:
diff --git a/mlrun/runtimes/sparkjob/abstract.py b/mlrun/runtimes/sparkjob/abstract.py
index fa6234e777ee..269915b7251c 100644
--- a/mlrun/runtimes/sparkjob/abstract.py
+++ b/mlrun/runtimes/sparkjob/abstract.py
@@ -31,7 +31,6 @@
from mlrun.runtimes.constants import RunStates, SparkApplicationStates
from ...execution import MLClientCtx
-from ...k8s_utils import get_k8s_helper
from ...model import RunObject
from ...platforms.iguazio import mount_v3io, mount_v3iod
from ...utils import (
@@ -45,7 +44,7 @@
from ..base import RunError, RuntimeClassMode
from ..kubejob import KubejobRuntime
from ..pod import KubeResourceSpec
-from ..utils import get_item_name
+from ..utils import get_item_name, get_k8s
_service_account = "sparkapp"
_sparkjob_template = {
@@ -592,7 +591,7 @@ def _submit_spark_job(
code=None,
):
namespace = meta.namespace
- k8s = self._get_k8s()
+ k8s = get_k8s()
namespace = k8s.resolve_namespace(namespace)
if code:
k8s_config_map = client.V1ConfigMap()
@@ -636,7 +635,7 @@ def _submit_spark_job(
raise RunError("Exception when creating SparkJob") from exc
def get_job(self, name, namespace=None):
- k8s = self._get_k8s()
+ k8s = get_k8s()
namespace = k8s.resolve_namespace(namespace)
try:
resp = k8s.crdapi.get_namespaced_custom_object(
@@ -826,26 +825,6 @@ def with_source_archive(
source, workdir, handler, pull_at_runtime, target_dir
)
- def get_pods(self, name=None, namespace=None, driver=False):
- k8s = self._get_k8s()
- namespace = k8s.resolve_namespace(namespace)
- selector = "mlrun/class=spark"
- if name:
- selector += f",sparkoperator.k8s.io/app-name={name}"
- if driver:
- selector += ",spark-role=driver"
- pods = k8s.list_pods(selector=selector, namespace=namespace)
- if pods:
- return {p.metadata.name: p.status.phase for p in pods}
-
- def _get_driver(self, name, namespace=None):
- pods = self.get_pods(name, namespace, driver=True)
- if not pods:
- logger.error("no pod matches that job name")
- return
- _ = self._get_k8s()
- return list(pods.items())[0]
-
def is_deployed(self):
if (
not self.spec.build.source
@@ -968,15 +947,14 @@ def _delete_extra_resources(
uid = crd_dict["metadata"].get("labels", {}).get("mlrun/uid", None)
uids.append(uid)
- k8s_helper = get_k8s_helper()
- config_maps = k8s_helper.v1api.list_namespaced_config_map(
+ config_maps = get_k8s().v1api.list_namespaced_config_map(
namespace, label_selector=label_selector
)
for config_map in config_maps.items:
try:
uid = config_map.metadata.labels.get("mlrun/uid", None)
if force or uid in uids:
- k8s_helper.v1api.delete_namespaced_config_map(
+ get_k8s().v1api.delete_namespaced_config_map(
config_map.metadata.name, namespace
)
logger.info(f"Deleted config map: {config_map.metadata.name}")
diff --git a/mlrun/runtimes/utils.py b/mlrun/runtimes/utils.py
index 2a02125b1372..880963518015 100644
--- a/mlrun/runtimes/utils.py
+++ b/mlrun/runtimes/utils.py
@@ -30,11 +30,11 @@
from mlrun.db import get_run_db
from mlrun.errors import err_to_str
from mlrun.frameworks.parallel_coordinates import gen_pcp_plot
-from mlrun.k8s_utils import get_k8s_helper
from mlrun.runtimes.constants import MPIJobCRDVersions
from ..artifacts import TableArtifact
-from ..config import config
+from ..config import config, is_running_as_api
+from ..k8s_utils import is_running_inside_kubernetes_cluster
from ..utils import get_in, helpers, logger, verify_field_regex
from .generators import selector
@@ -69,7 +69,7 @@ def set(self, context):
# if not specified, try resolving it according to the mpi-operator, otherwise set to default
# since this is a heavy operation (sending requests to k8s/API), and it's unlikely that the crd version
# will change in any context - cache it
-def resolve_mpijob_crd_version(api_context=False):
+def resolve_mpijob_crd_version():
global cached_mpijob_crd_version
if not cached_mpijob_crd_version:
@@ -77,11 +77,12 @@ def resolve_mpijob_crd_version(api_context=False):
mpijob_crd_version = config.mpijob_crd_version
if not mpijob_crd_version:
- in_k8s_cluster = get_k8s_helper(
- silent=True
- ).is_running_inside_kubernetes_cluster()
- if in_k8s_cluster:
- k8s_helper = get_k8s_helper()
+ in_k8s_cluster = is_running_inside_kubernetes_cluster()
+
+ if in_k8s_cluster and is_running_as_api():
+ import mlrun.api.utils.singletons.k8s
+
+ k8s_helper = mlrun.api.utils.singletons.k8s.get_k8s_helper()
namespace = k8s_helper.resolve_namespace()
# try resolving according to mpi-operator that's running
@@ -93,7 +94,7 @@ def resolve_mpijob_crd_version(api_context=False):
mpijob_crd_version = mpi_operator_pod.metadata.labels.get(
"crd-version"
)
- elif not in_k8s_cluster and not api_context:
+ elif not in_k8s_cluster:
# connect will populate the config from the server config
# TODO: something nicer
get_run_db()
@@ -182,22 +183,6 @@ def log_std(db, runobj, out, err="", skip=False, show=True, silent=False):
raise RunError(err)
-class AsyncLogWriter:
- def __init__(self, db, runobj):
- self.db = db
- self.uid = runobj.metadata.uid
- self.project = runobj.metadata.project or ""
- self.iter = runobj.metadata.iteration
-
- def write(self, data):
- if self.db:
- self.db.store_log(self.uid, self.project, data, append=True)
-
- def flush(self):
- # todo: verify writes are large enough, if not cache and use flush
- pass
-
-
def add_code_metadata(path=""):
if path:
if "://" in path:
@@ -232,6 +217,19 @@ def add_code_metadata(path=""):
return None
+def get_k8s():
+ """
+ Get the k8s helper object
+ :return: k8s helper object or None if not running as API
+ """
+ if is_running_as_api():
+ import mlrun.api.utils.singletons.k8s
+
+ return mlrun.api.utils.singletons.k8s.get_k8s_helper()
+
+ return None
+
+
def set_if_none(struct, key, value):
if not struct.get(key):
struct[key] = value
diff --git a/mlrun/secrets.py b/mlrun/secrets.py
index 89237010ad41..eff375ff0650 100644
--- a/mlrun/secrets.py
+++ b/mlrun/secrets.py
@@ -16,7 +16,7 @@
from os import environ, getenv
from typing import Callable, Dict, Optional, Union
-from .utils import AzureVaultStore, VaultStore, list2dict
+from .utils import AzureVaultStore, list2dict
class SecretsStore:
@@ -26,7 +26,6 @@ def __init__(self):
# for example from Vault, and when adding their source they will be retrieved from the external source.
self._hidden_sources = []
self._hidden_secrets = {}
- self.vault = VaultStore()
@classmethod
def from_list(cls, src_list: list):
@@ -60,21 +59,20 @@ def add_source(self, kind, source="", prefix=""):
for key in source.split(","):
k = key.strip()
self._secrets[prefix + k] = environ.get(k)
-
- elif kind == "vault":
- if isinstance(source, str):
- source = literal_eval(source)
- if not isinstance(source, dict):
- raise ValueError("vault secrets must be of type dict")
-
- for key, value in self.vault.get_secrets(
- source["secrets"],
- user=source.get("user"),
- project=source.get("project"),
- ).items():
- self._hidden_secrets[prefix + key] = value
- self._hidden_sources.append({"kind": kind, "source": source})
-
+ # TODO: Vault: uncomment when vault returns to be relevant
+ # elif kind == "vault":
+ # if isinstance(source, str):
+ # source = literal_eval(source)
+ # if not isinstance(source, dict):
+ # raise ValueError("vault secrets must be of type dict")
+ #
+ # for key, value in self.vault.get_secrets(
+ # source["secrets"],
+ # user=source.get("user"),
+ # project=source.get("project"),
+ # ).items():
+ # self._hidden_secrets[prefix + key] = value
+ # self._hidden_sources.append({"kind": kind, "source": source})
elif kind == "azure_vault":
if isinstance(source, str):
source = literal_eval(source)
diff --git a/mlrun/utils/__init__.py b/mlrun/utils/__init__.py
index ff2582c48454..854be7e0e41e 100644
--- a/mlrun/utils/__init__.py
+++ b/mlrun/utils/__init__.py
@@ -18,4 +18,3 @@
from .helpers import * # noqa
from .http import * # noqa
from .logger import * # noqa
-from .vault import * # noqa
diff --git a/mlrun/utils/vault.py b/mlrun/utils/vault.py
index 1a679466e5f3..5ca3e82230e8 100644
--- a/mlrun/utils/vault.py
+++ b/mlrun/utils/vault.py
@@ -11,271 +11,272 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-
-import json
-import os
-from os.path import expanduser
-
-import requests
-
-from mlrun.errors import MLRunInvalidArgumentError
-
-from ..config import config as mlconf
-from ..k8s_utils import get_k8s_helper
-from .helpers import logger
-
-vault_default_prefix = "v1/secret/data"
-
-
-class VaultStore:
- def __init__(self, token=None):
- self._token = token
- self.url = mlconf.secret_stores.vault.url
-
- @property
- def token(self):
- if not self._token:
- self._login()
-
- return self._token
-
- def _login(self):
- if self._token:
- return
-
- if mlconf.secret_stores.vault.user_token != "":
- logger.warning(
- "Using a user-token from configuration. This should only be done in test/debug!"
- )
- self._token = mlconf.secret_stores.vault.user_token
- return
-
- config_role = mlconf.secret_stores.vault.role
- if config_role != "":
- role_type, role_val = config_role.split(":", 1)
- vault_role = f"mlrun-role-{role_type}-{role_val}"
- self._safe_login_with_jwt_token(vault_role)
-
- if self._token is None:
- logger.warning(
- "Vault login: no vault token is available. No secrets will be accessible"
- )
-
- @staticmethod
- def _generate_path(
- prefix=vault_default_prefix,
- user=None,
- project=None,
- user_prefix="users",
- project_prefix="projects",
- ):
- if user and project:
- raise MLRunInvalidArgumentError(
- "Both user and project were provided for Vault operations"
- )
-
- if user:
- return prefix + f"/mlrun/{user_prefix}/{user}"
- elif project:
- return prefix + f"/mlrun/{project_prefix}/{project}"
- else:
- raise MLRunInvalidArgumentError(
- "To generate a vault secret path, either user or project must be specified"
- )
-
- @staticmethod
- def _read_jwt_token():
- # if for some reason the path to the token is not in conf, then attempt to get the SA token (works on k8s pods)
- token_path = "/var/run/secrets/kubernetes.io/serviceaccount/token"
- if mlconf.secret_stores.vault.token_path:
- # Override the default SA token in case a specific token is installed in the mlconf-specified path
- secret_token_path = expanduser(
- mlconf.secret_stores.vault.token_path + "/token"
- )
- if os.path.isfile(secret_token_path):
- token_path = secret_token_path
-
- with open(token_path, "r") as token_file:
- jwt_token = token_file.read()
-
- return jwt_token
-
- def _api_call(self, method, url, data=None):
- self._login()
-
- headers = {"X-Vault-Token": self._token}
- full_url = self.url + "/" + url
-
- response = requests.request(method, full_url, headers=headers, json=data)
-
- if not response:
- logger.error(
- "Vault failed the API call",
- status_code=response.status_code,
- reason=response.reason,
- url=url,
- )
- return response
-
- # This method logins to the vault, assuming the container has a JWT token mounted as part of its assigned service
- # account.
- def _safe_login_with_jwt_token(self, role):
-
- if role is None:
- logger.warning(
- "login_with_token: Role passed is None. Will not attempt login"
- )
- return
-
- jwt_token = self._read_jwt_token()
-
- login_url = f"{self.url}/v1/auth/kubernetes/login"
- data = {"jwt": jwt_token, "role": role}
-
- response = requests.post(login_url, data=json.dumps(data))
- if not response:
- logger.error(
- "login_with_token: Vault failed the login request",
- role=role,
- status_code=response.status_code,
- reason=response.reason,
- )
- return
- self._token = response.json()["auth"]["client_token"]
-
- def get_secrets(self, keys, user=None, project=None):
- secret_path = VaultStore._generate_path(user=user, project=project)
- secrets = {}
-
- # Since this method is called both on the client side (when constructing VaultStore before persisting to
- # pod configuration) and on server side and in execution pods, we let this method fail gracefully in this case.
- # Should replace with something that will explode on server-side, once we have a way to do that.
- if not self.url:
- return secrets
-
- response = self._api_call("GET", secret_path)
-
- if not response:
- return secrets
-
- values = response.json()["data"]["data"]
-
- # if no specific keys were asked for, return all the values available
- if not keys:
- return values
-
- for key in keys:
- if key in values:
- secrets[key] = values[key]
- return secrets
-
- def add_vault_secrets(self, items, project=None, user=None):
- data_object = {"data": items}
- url = VaultStore._generate_path(project=project, user=user)
-
- response = self._api_call("POST", url, data_object)
- if not response:
- raise MLRunInvalidArgumentError(
- f"Vault failed the API call to create secrets. project={project}/user={user}"
- )
-
- def delete_vault_secrets(self, project=None, user=None):
- self._login()
- # Using the API to delete all versions + metadata of the given secret.
- url = "v1/secret/metadata" + VaultStore._generate_path(
- prefix="", project=project, user=user
- )
-
- response = self._api_call("DELETE", url)
- if not response:
- raise MLRunInvalidArgumentError(
- f"Vault failed the API call to delete secrets. project={project}/user={user}"
- )
-
- def create_project_policy(self, project):
- policy_name = f"mlrun-project-{project}"
- # TODO - need to make sure name is escaped properly and invalid chars are stripped
- url = "v1/sys/policies/acl/" + policy_name
-
- policy_str = (
- f'path "secret/data/mlrun/projects/{project}" {{\n'
- + ' capabilities = ["read", "list", "create", "delete", "update"]\n'
- + "}\n"
- + f'path "secret/data/mlrun/projects/{project}/*" {{\n'
- + ' capabilities = ["read", "list", "create", "delete", "update"]\n'
- + "}"
- )
-
- data_object = {"policy": policy_str}
-
- response = self._api_call("PUT", url, data_object)
- if not response:
- raise MLRunInvalidArgumentError(
- f"Vault failed the API call to create a policy. "
- f"Response code: ({response.status_code}) - {response.reason}"
- )
- return policy_name
-
- def create_project_role(self, project, sa, policy, namespace="default-tenant"):
- role_name = f"mlrun-role-project-{project}"
- # TODO - need to make sure name is escaped properly and invalid chars are stripped
- url = "v1/auth/kubernetes/role/" + role_name
-
- role_object = {
- "bound_service_account_names": sa,
- "bound_service_account_namespaces": namespace,
- "policies": [policy],
- "token_ttl": mlconf.secret_stores.vault.token_ttl,
- }
-
- response = self._api_call("POST", url, role_object)
- if not response:
- raise MLRunInvalidArgumentError(
- f"Vault failed the API call to create a secret. "
- f"Response code: ({response.status_code}) - {response.reason}"
- )
- return role_name
-
-
-def store_vault_project_secrets(project, items):
- return VaultStore().add_vault_secrets(items, project=project)
-
-
-def add_vault_user_secrets(user, items):
- return VaultStore().add_vault_secrets(items, user=user)
-
-
-def init_project_vault_configuration(project):
- """Create needed configurations for this new project:
- - Create a k8s service account with the name sa_vault_{proj name}
- - Create a Vault policy with the name proj_{proj name}
- - Create a Vault k8s auth role with the name role_proj_{proj name}
- These constructs will enable any pod created as part of this project to access the project's secrets
- in Vault, assuming that the secret which is part of the SA created is mounted to the pod.
-
- :param project: Project name
- """
- logger.info("Initializing project vault configuration", project=project)
-
- namespace = mlconf.namespace
- k8s = get_k8s_helper(silent=True)
- service_account_name = (
- mlconf.secret_stores.vault.project_service_account_name.format(project=project)
- )
-
- secret_name = k8s.get_project_vault_secret_name(
- project, service_account_name, namespace=namespace
- )
-
- if not secret_name:
- k8s.create_project_service_account(
- project, service_account_name, namespace=namespace
- )
-
- vault = VaultStore()
- policy_name = vault.create_project_policy(project)
- role_name = vault.create_project_role(
- project, namespace=namespace, sa=service_account_name, policy=policy_name
- )
-
- logger.info("Created Vault policy. ", policy=policy_name, role=role_name)
+#
+# import json
+# import os
+# from os.path import expanduser
+#
+# import requests
+#
+# from mlrun.errors import MLRunInvalidArgumentError
+#
+# from ..config import config as mlconf
+# from ..k8s_utils import get_k8s_helper
+# from .helpers import logger
+#
+# vault_default_prefix = "v1/secret/data"
+#
+#
+# class VaultStore:
+# def __init__(self, token=None):
+# self._token = token
+# self.url = mlconf.secret_stores.vault.url
+#
+# @property
+# def token(self):
+# if not self._token:
+# self._login()
+#
+# return self._token
+#
+# def _login(self):
+# if self._token:
+# return
+#
+# if mlconf.secret_stores.vault.user_token != "":
+# logger.warning(
+# "Using a user-token from configuration. This should only be done in test/debug!"
+# )
+# self._token = mlconf.secret_stores.vault.user_token
+# return
+#
+# config_role = mlconf.secret_stores.vault.role
+# if config_role != "":
+# role_type, role_val = config_role.split(":", 1)
+# vault_role = f"mlrun-role-{role_type}-{role_val}"
+# self._safe_login_with_jwt_token(vault_role)
+#
+# if self._token is None:
+# logger.warning(
+# "Vault login: no vault token is available. No secrets will be accessible"
+# )
+#
+# @staticmethod
+# def _generate_path(
+# prefix=vault_default_prefix,
+# user=None,
+# project=None,
+# user_prefix="users",
+# project_prefix="projects",
+# ):
+# if user and project:
+# raise MLRunInvalidArgumentError(
+# "Both user and project were provided for Vault operations"
+# )
+#
+# if user:
+# return prefix + f"/mlrun/{user_prefix}/{user}"
+# elif project:
+# return prefix + f"/mlrun/{project_prefix}/{project}"
+# else:
+# raise MLRunInvalidArgumentError(
+# "To generate a vault secret path, either user or project must be specified"
+# )
+#
+# @staticmethod
+# def _read_jwt_token():
+# # if for some reason the path to the token is not in conf, then attempt to get the SA token
+# # (works on k8s pods)
+# token_path = "/var/run/secrets/kubernetes.io/serviceaccount/token"
+# if mlconf.secret_stores.vault.token_path:
+# # Override the default SA token in case a specific token is installed in the mlconf-specified path
+# secret_token_path = expanduser(
+# mlconf.secret_stores.vault.token_path + "/token"
+# )
+# if os.path.isfile(secret_token_path):
+# token_path = secret_token_path
+#
+# with open(token_path, "r") as token_file:
+# jwt_token = token_file.read()
+#
+# return jwt_token
+#
+# def _api_call(self, method, url, data=None):
+# self._login()
+#
+# headers = {"X-Vault-Token": self._token}
+# full_url = self.url + "/" + url
+#
+# response = requests.request(method, full_url, headers=headers, json=data)
+#
+# if not response:
+# logger.error(
+# "Vault failed the API call",
+# status_code=response.status_code,
+# reason=response.reason,
+# url=url,
+# )
+# return response
+#
+# # This method logins to the vault, assuming the container has a JWT token mounted as part of its assigned service
+# # account.
+# def _safe_login_with_jwt_token(self, role):
+#
+# if role is None:
+# logger.warning(
+# "login_with_token: Role passed is None. Will not attempt login"
+# )
+# return
+#
+# jwt_token = self._read_jwt_token()
+#
+# login_url = f"{self.url}/v1/auth/kubernetes/login"
+# data = {"jwt": jwt_token, "role": role}
+#
+# response = requests.post(login_url, data=json.dumps(data))
+# if not response:
+# logger.error(
+# "login_with_token: Vault failed the login request",
+# role=role,
+# status_code=response.status_code,
+# reason=response.reason,
+# )
+# return
+# self._token = response.json()["auth"]["client_token"]
+#
+# def get_secrets(self, keys, user=None, project=None):
+# secret_path = VaultStore._generate_path(user=user, project=project)
+# secrets = {}
+#
+# # Since this method is called both on the client side (when constructing VaultStore before persisting to
+# # pod configuration) and on server side and in execution pods, we let this method fail gracefully in this case
+# # Should replace with something that will explode on server-side, once we have a way to do that.
+# if not self.url:
+# return secrets
+#
+# response = self._api_call("GET", secret_path)
+#
+# if not response:
+# return secrets
+#
+# values = response.json()["data"]["data"]
+#
+# # if no specific keys were asked for, return all the values available
+# if not keys:
+# return values
+#
+# for key in keys:
+# if key in values:
+# secrets[key] = values[key]
+# return secrets
+#
+# def add_vault_secrets(self, items, project=None, user=None):
+# data_object = {"data": items}
+# url = VaultStore._generate_path(project=project, user=user)
+#
+# response = self._api_call("POST", url, data_object)
+# if not response:
+# raise MLRunInvalidArgumentError(
+# f"Vault failed the API call to create secrets. project={project}/user={user}"
+# )
+#
+# def delete_vault_secrets(self, project=None, user=None):
+# self._login()
+# # Using the API to delete all versions + metadata of the given secret.
+# url = "v1/secret/metadata" + VaultStore._generate_path(
+# prefix="", project=project, user=user
+# )
+#
+# response = self._api_call("DELETE", url)
+# if not response:
+# raise MLRunInvalidArgumentError(
+# f"Vault failed the API call to delete secrets. project={project}/user={user}"
+# )
+#
+# def create_project_policy(self, project):
+# policy_name = f"mlrun-project-{project}"
+# # TODO - need to make sure name is escaped properly and invalid chars are stripped
+# url = "v1/sys/policies/acl/" + policy_name
+#
+# policy_str = (
+# f'path "secret/data/mlrun/projects/{project}" {{\n'
+# + ' capabilities = ["read", "list", "create", "delete", "update"]\n'
+# + "}\n"
+# + f'path "secret/data/mlrun/projects/{project}/*" {{\n'
+# + ' capabilities = ["read", "list", "create", "delete", "update"]\n'
+# + "}"
+# )
+#
+# data_object = {"policy": policy_str}
+#
+# response = self._api_call("PUT", url, data_object)
+# if not response:
+# raise MLRunInvalidArgumentError(
+# f"Vault failed the API call to create a policy. "
+# f"Response code: ({response.status_code}) - {response.reason}"
+# )
+# return policy_name
+#
+# def create_project_role(self, project, sa, policy, namespace="default-tenant"):
+# role_name = f"mlrun-role-project-{project}"
+# # TODO - need to make sure name is escaped properly and invalid chars are stripped
+# url = "v1/auth/kubernetes/role/" + role_name
+#
+# role_object = {
+# "bound_service_account_names": sa,
+# "bound_service_account_namespaces": namespace,
+# "policies": [policy],
+# "token_ttl": mlconf.secret_stores.vault.token_ttl,
+# }
+#
+# response = self._api_call("POST", url, role_object)
+# if not response:
+# raise MLRunInvalidArgumentError(
+# f"Vault failed the API call to create a secret. "
+# f"Response code: ({response.status_code}) - {response.reason}"
+# )
+# return role_name
+#
+#
+# def store_vault_project_secrets(project, items):
+# return VaultStore().add_vault_secrets(items, project=project)
+#
+#
+# def add_vault_user_secrets(user, items):
+# return VaultStore().add_vault_secrets(items, user=user)
+#
+#
+# def init_project_vault_configuration(project):
+# """Create needed configurations for this new project:
+# - Create a k8s service account with the name sa_vault_{proj name}
+# - Create a Vault policy with the name proj_{proj name}
+# - Create a Vault k8s auth role with the name role_proj_{proj name}
+# These constructs will enable any pod created as part of this project to access the project's secrets
+# in Vault, assuming that the secret which is part of the SA created is mounted to the pod.
+#
+# :param project: Project name
+# """
+# logger.info("Initializing project vault configuration", project=project)
+#
+# namespace = mlconf.namespace
+# k8s = get_k8s_helper(silent=True)
+# service_account_name = (
+# mlconf.secret_stores.vault.project_service_account_name.format(project=project)
+# )
+#
+# secret_name = k8s.get_project_vault_secret_name(
+# project, service_account_name, namespace=namespace
+# )
+#
+# if not secret_name:
+# k8s.create_project_service_account(
+# project, service_account_name, namespace=namespace
+# )
+#
+# vault = VaultStore()
+# policy_name = vault.create_project_policy(project)
+# role_name = vault.create_project_role(
+# project, namespace=namespace, sa=service_account_name, policy=policy_name
+# )
+#
+# logger.info("Created Vault policy. ", policy=policy_name, role=role_name)
diff --git a/tests/api/api/test_functions.py b/tests/api/api/test_functions.py
index 4b88567ddec7..a20dcb274564 100644
--- a/tests/api/api/test_functions.py
+++ b/tests/api/api/test_functions.py
@@ -63,8 +63,8 @@ def test_build_status_pod_not_found(
)
assert response.status_code == HTTPStatus.OK.value
- mlrun.api.utils.singletons.k8s.get_k8s().v1api = unittest.mock.Mock()
- mlrun.api.utils.singletons.k8s.get_k8s().v1api.read_namespaced_pod = (
+ mlrun.api.utils.singletons.k8s.get_k8s_helper().v1api = unittest.mock.Mock()
+ mlrun.api.utils.singletons.k8s.get_k8s_helper().v1api.read_namespaced_pod = (
unittest.mock.Mock(
side_effect=kubernetes.client.rest.ApiException(
status=HTTPStatus.NOT_FOUND.value
diff --git a/tests/api/api/test_submit.py b/tests/api/api/test_submit.py
index 92952f1d753f..49dc6ddc922f 100644
--- a/tests/api/api/test_submit.py
+++ b/tests/api/api/test_submit.py
@@ -31,8 +31,8 @@
import mlrun.api.utils.auth.verifier
import mlrun.api.utils.clients.chief
import mlrun.api.utils.clients.iguazio
+import mlrun.api.utils.singletons.k8s
import tests.api.api.utils
-from mlrun.api.utils.singletons.k8s import get_k8s
from mlrun.common.schemas import AuthInfo
from mlrun.config import config as mlconf
from tests.api.conftest import K8sSecretsMock
@@ -65,12 +65,18 @@ def test_submit_job_failure_function_not_found(db: Session, client: TestClient)
@pytest.fixture()
def pod_create_mock():
- create_pod_orig_function = get_k8s().create_pod
+ create_pod_orig_function = (
+ mlrun.api.utils.singletons.k8s.get_k8s_helper().create_pod
+ )
_get_project_secrets_raw_data_orig_function = (
- get_k8s()._get_project_secrets_raw_data
+ mlrun.api.utils.singletons.k8s.get_k8s_helper()._get_project_secrets_raw_data
+ )
+ mlrun.api.utils.singletons.k8s.get_k8s_helper().create_pod = unittest.mock.Mock(
+ return_value=("pod-name", "namespace")
+ )
+ mlrun.api.utils.singletons.k8s.get_k8s_helper()._get_project_secrets_raw_data = (
+ unittest.mock.Mock(return_value={})
)
- get_k8s().create_pod = unittest.mock.Mock(return_value=("pod-name", "namespace"))
- get_k8s()._get_project_secrets_raw_data = unittest.mock.Mock(return_value={})
update_run_state_orig_function = (
mlrun.runtimes.kubejob.KubejobRuntime._update_run_state
@@ -97,11 +103,13 @@ def pod_create_mock():
unittest.mock.AsyncMock(return_value=auth_info_mock)
)
- yield get_k8s().create_pod
+ yield mlrun.api.utils.singletons.k8s.get_k8s_helper().create_pod
# Have to revert the mocks, otherwise other tests are failing
- get_k8s().create_pod = create_pod_orig_function
- get_k8s()._get_project_secrets_raw_data = (
+ mlrun.api.utils.singletons.k8s.get_k8s_helper().create_pod = (
+ create_pod_orig_function
+ )
+ mlrun.api.utils.singletons.k8s.get_k8s_helper()._get_project_secrets_raw_data = (
_get_project_secrets_raw_data_orig_function
)
mlrun.runtimes.kubejob.KubejobRuntime._update_run_state = (
diff --git a/tests/api/conftest.py b/tests/api/conftest.py
index 57cf75071313..ae94525c49b0 100644
--- a/tests/api/conftest.py
+++ b/tests/api/conftest.py
@@ -208,8 +208,10 @@ def get_expected_env_variables_from_secrets(
)
expected_env_from_secrets[env_variable_name] = {global_secret: key}
- secret_name = mlrun.api.utils.singletons.k8s.get_k8s().get_project_secret_name(
- project
+ secret_name = (
+ mlrun.api.utils.singletons.k8s.get_k8s_helper().get_project_secret_name(
+ project
+ )
)
for key in self.project_secrets_map.get(project, {}):
if key.startswith("mlrun.") and not include_internal:
@@ -283,7 +285,7 @@ def k8s_secrets_mock(monkeypatch, client: TestClient) -> K8sSecretsMock:
for mocked_function_name in mocked_function_names:
monkeypatch.setattr(
- mlrun.api.utils.singletons.k8s.get_k8s(),
+ mlrun.api.utils.singletons.k8s.get_k8s_helper(),
mocked_function_name,
getattr(k8s_secrets_mock, mocked_function_name),
)
@@ -293,8 +295,8 @@ def k8s_secrets_mock(monkeypatch, client: TestClient) -> K8sSecretsMock:
@pytest.fixture
def kfp_client_mock(monkeypatch) -> kfp.Client:
- mlrun.api.utils.singletons.k8s.get_k8s().is_running_inside_kubernetes_cluster = (
- unittest.mock.Mock(return_value=True)
+ mlrun.api.utils.singletons.k8s.get_k8s_helper().is_running_inside_kubernetes_cluster = unittest.mock.Mock(
+ return_value=True
)
kfp_client_mock = unittest.mock.Mock()
monkeypatch.setattr(kfp, "Client", lambda *args, **kwargs: kfp_client_mock)
diff --git a/tests/api/crud/runtimes/__init__.py b/tests/api/crud/runtimes/__init__.py
new file mode 100644
index 000000000000..b3085be1eb56
--- /dev/null
+++ b/tests/api/crud/runtimes/__init__.py
@@ -0,0 +1,14 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
diff --git a/tests/api/crud/runtimes/nuclio/__init__.py b/tests/api/crud/runtimes/nuclio/__init__.py
new file mode 100644
index 000000000000..b3085be1eb56
--- /dev/null
+++ b/tests/api/crud/runtimes/nuclio/__init__.py
@@ -0,0 +1,14 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
diff --git a/tests/api/crud/runtimes/nuclio/test_helpers.py b/tests/api/crud/runtimes/nuclio/test_helpers.py
new file mode 100644
index 000000000000..dcd5d805bea0
--- /dev/null
+++ b/tests/api/crud/runtimes/nuclio/test_helpers.py
@@ -0,0 +1,104 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+import pytest
+
+import mlrun
+import mlrun.api.crud.runtimes.nuclio.function
+import mlrun.api.crud.runtimes.nuclio.helpers
+from tests.conftest import examples_path
+
+
+def test_compiled_function_config_nuclio_golang():
+ name = f"{examples_path}/training.py"
+ fn = mlrun.code_to_function(
+ "nuclio", filename=name, kind="nuclio", handler="my_hand"
+ )
+ (
+ name,
+ project,
+ config,
+ ) = mlrun.api.crud.runtimes.nuclio.function._compile_function_config(fn)
+ assert fn.kind == "remote", "kind not set, test failed"
+ assert mlrun.utils.get_in(config, "spec.build.functionSourceCode"), "no source code"
+ assert mlrun.utils.get_in(config, "spec.runtime").startswith(
+ "py"
+ ), "runtime not set"
+ assert (
+ mlrun.utils.get_in(config, "spec.handler") == "training:my_hand"
+ ), "wrong handler"
+
+
+def test_compiled_function_config_nuclio_python():
+ name = f"{examples_path}/training.py"
+ fn = mlrun.code_to_function(
+ "nuclio", filename=name, kind="nuclio", handler="my_hand"
+ )
+ (
+ name,
+ project,
+ config,
+ ) = mlrun.api.crud.runtimes.nuclio.function._compile_function_config(fn)
+ assert fn.kind == "remote", "kind not set, test failed"
+ assert mlrun.utils.get_in(config, "spec.build.functionSourceCode"), "no source code"
+ assert mlrun.utils.get_in(config, "spec.runtime").startswith(
+ "py"
+ ), "runtime not set"
+ assert (
+ mlrun.utils.get_in(config, "spec.handler") == "training:my_hand"
+ ), "wrong handler"
+
+
+@pytest.mark.parametrize(
+ "handler, expected",
+ [
+ (None, ("", "main:handler")),
+ ("x", ("", "x:handler")),
+ ("x:y", ("", "x:y")),
+ ("dir#", ("dir", "main:handler")),
+ ("dir#x", ("dir", "x:handler")),
+ ("dir#x:y", ("dir", "x:y")),
+ ],
+)
+def test_resolve_work_dir_and_handler(handler, expected):
+ assert (
+ expected
+ == mlrun.api.crud.runtimes.nuclio.helpers.resolve_work_dir_and_handler(handler)
+ )
+
+
+@pytest.mark.parametrize(
+ "mlrun_client_version,python_version,expected_runtime",
+ [
+ ("1.3.0", "3.9.16", "python:3.9"),
+ ("1.3.0", "3.7.16", "python:3.7"),
+ (None, None, "python:3.7"),
+ (None, "3.9.16", "python:3.7"),
+ ("1.3.0", None, "python:3.7"),
+ ("0.0.0-unstable", "3.9.16", "python:3.9"),
+ ("0.0.0-unstable", "3.7.16", "python:3.7"),
+ ("1.2.0", "3.9.16", "python:3.7"),
+ ("1.2.0", "3.7.16", "python:3.7"),
+ ],
+)
+def test_resolve_nuclio_runtime_python_image(
+ mlrun_client_version, python_version, expected_runtime
+):
+ assert (
+ expected_runtime
+ == mlrun.api.crud.runtimes.nuclio.helpers.resolve_nuclio_runtime_python_image(
+ mlrun_client_version, python_version
+ )
+ )
diff --git a/tests/api/runtime_handlers/base.py b/tests/api/runtime_handlers/base.py
index 468ff9674cb8..a3584c3d8b1d 100644
--- a/tests/api/runtime_handlers/base.py
+++ b/tests/api/runtime_handlers/base.py
@@ -29,7 +29,7 @@
import mlrun.runtimes.constants
from mlrun.api.constants import LogSources
from mlrun.api.utils.singletons.db import get_db
-from mlrun.api.utils.singletons.k8s import get_k8s
+from mlrun.api.utils.singletons.k8s import get_k8s_helper
from mlrun.runtimes import get_runtime_handler
from mlrun.runtimes.constants import PodPhases, RunStates
from mlrun.utils import create_logger, now_date
@@ -80,9 +80,9 @@ def setup_method_fixture(self, db: Session, client: fastapi.testclient.TestClien
# We want this mock for every test, ideally we would have simply put it in the setup_method
# but it is happening before the fixtures initialization. We need the client fixture (which needs the db one)
# in order to be able to mock k8s stuff
- get_k8s().v1api = unittest.mock.Mock()
- get_k8s().crdapi = unittest.mock.Mock()
- get_k8s().is_running_inside_kubernetes_cluster = unittest.mock.Mock(
+ get_k8s_helper().v1api = unittest.mock.Mock()
+ get_k8s_helper().crdapi = unittest.mock.Mock()
+ get_k8s_helper().is_running_inside_kubernetes_cluster = unittest.mock.Mock(
return_value=True
)
# enable inheriting classes to do the same
@@ -124,7 +124,7 @@ def _generate_pod(name, labels, phase=PodPhases.succeeded):
)
status = client.V1PodStatus(phase=phase, container_statuses=[container_status])
metadata = client.V1ObjectMeta(
- name=name, labels=labels, namespace=get_k8s().resolve_namespace()
+ name=name, labels=labels, namespace=get_k8s_helper().resolve_namespace()
)
pod = client.V1Pod(metadata=metadata, status=status)
return pod
@@ -132,7 +132,7 @@ def _generate_pod(name, labels, phase=PodPhases.succeeded):
@staticmethod
def _generate_config_map(name, labels, data=None):
metadata = client.V1ObjectMeta(
- name=name, labels=labels, namespace=get_k8s().resolve_namespace()
+ name=name, labels=labels, namespace=get_k8s_helper().resolve_namespace()
)
if data is None:
data = {"key": "value"}
@@ -185,21 +185,21 @@ def _assert_runtime_handler_list_resources(
raise NotImplementedError("Unsupported group by value")
resources = runtime_handler.list_resources(project, group_by=group_by)
crd_group, crd_version, crd_plural = runtime_handler._get_crd_info()
- get_k8s().v1api.list_namespaced_pod.assert_called_once_with(
- get_k8s().resolve_namespace(),
+ get_k8s_helper().v1api.list_namespaced_pod.assert_called_once_with(
+ get_k8s_helper().resolve_namespace(),
label_selector=label_selector,
)
if expected_crds:
- get_k8s().crdapi.list_namespaced_custom_object.assert_called_once_with(
+ get_k8s_helper().crdapi.list_namespaced_custom_object.assert_called_once_with(
crd_group,
crd_version,
- get_k8s().resolve_namespace(),
+ get_k8s_helper().resolve_namespace(),
crd_plural,
label_selector=label_selector,
)
if expected_services:
- get_k8s().v1api.list_namespaced_service.assert_called_once_with(
- get_k8s().resolve_namespace(),
+ get_k8s_helper().v1api.list_namespaced_service.assert_called_once_with(
+ get_k8s_helper().resolve_namespace(),
label_selector=label_selector,
)
assertion_func(
@@ -361,7 +361,9 @@ def _mock_list_namespaced_pods(list_pods_call_responses: List[List[client.V1Pod]
for list_pods_call_response in list_pods_call_responses:
pods = client.V1PodList(items=list_pods_call_response)
calls.append(pods)
- get_k8s().v1api.list_namespaced_pod = unittest.mock.Mock(side_effect=calls)
+ get_k8s_helper().v1api.list_namespaced_pod = unittest.mock.Mock(
+ side_effect=calls
+ )
return calls
@staticmethod
@@ -378,9 +380,9 @@ def _assert_delete_namespaced_pods(
for expected_pod_name in expected_pod_names
]
if not expected_pod_names:
- assert get_k8s().v1api.delete_namespaced_pod.call_count == 0
+ assert get_k8s_helper().v1api.delete_namespaced_pod.call_count == 0
else:
- get_k8s().v1api.delete_namespaced_pod.assert_has_calls(calls)
+ get_k8s_helper().v1api.delete_namespaced_pod.assert_has_calls(calls)
@staticmethod
def _assert_delete_namespaced_services(
@@ -391,9 +393,9 @@ def _assert_delete_namespaced_services(
for expected_service_name in expected_service_names
]
if not expected_service_names:
- assert get_k8s().v1api.delete_namespaced_service.call_count == 0
+ assert get_k8s_helper().v1api.delete_namespaced_service.call_count == 0
else:
- get_k8s().v1api.delete_namespaced_service.assert_has_calls(calls)
+ get_k8s_helper().v1api.delete_namespaced_service.assert_has_calls(calls)
@staticmethod
def _assert_delete_namespaced_custom_objects(
@@ -413,26 +415,32 @@ def _assert_delete_namespaced_custom_objects(
for expected_custom_object_name in expected_custom_object_names
]
if not expected_custom_object_names:
- assert get_k8s().crdapi.delete_namespaced_custom_object.call_count == 0
+ assert (
+ get_k8s_helper().crdapi.delete_namespaced_custom_object.call_count == 0
+ )
else:
- get_k8s().crdapi.delete_namespaced_custom_object.assert_has_calls(calls)
+ get_k8s_helper().crdapi.delete_namespaced_custom_object.assert_has_calls(
+ calls
+ )
@staticmethod
def _mock_delete_namespaced_pods():
- get_k8s().v1api.delete_namespaced_pod = unittest.mock.Mock()
+ get_k8s_helper().v1api.delete_namespaced_pod = unittest.mock.Mock()
@staticmethod
def _mock_delete_namespaced_custom_objects():
- get_k8s().crdapi.delete_namespaced_custom_object = unittest.mock.Mock()
+ get_k8s_helper().crdapi.delete_namespaced_custom_object = unittest.mock.Mock()
@staticmethod
def _mock_delete_namespaced_services():
- get_k8s().v1api.delete_namespaced_service = unittest.mock.Mock()
+ get_k8s_helper().v1api.delete_namespaced_service = unittest.mock.Mock()
@staticmethod
def _mock_read_namespaced_pod_log():
log = "Some log string"
- get_k8s().v1api.read_namespaced_pod_log = unittest.mock.Mock(return_value=log)
+ get_k8s_helper().v1api.read_namespaced_pod_log = unittest.mock.Mock(
+ return_value=log
+ )
return log
@staticmethod
@@ -440,7 +448,7 @@ def _mock_list_namespaced_crds(crd_dicts_call_responses: List[List[Dict]]):
calls = []
for crd_dicts_call_response in crd_dicts_call_responses:
calls.append({"items": crd_dicts_call_response})
- get_k8s().crdapi.list_namespaced_custom_object = unittest.mock.Mock(
+ get_k8s_helper().crdapi.list_namespaced_custom_object = unittest.mock.Mock(
side_effect=calls
)
return calls
@@ -448,7 +456,7 @@ def _mock_list_namespaced_crds(crd_dicts_call_responses: List[List[Dict]]):
@staticmethod
def _mock_list_namespaced_config_map(config_maps):
config_maps_list = client.V1ConfigMapList(items=config_maps)
- get_k8s().v1api.list_namespaced_config_map = unittest.mock.Mock(
+ get_k8s_helper().v1api.list_namespaced_config_map = unittest.mock.Mock(
return_value=config_maps_list
)
return config_maps
@@ -456,7 +464,7 @@ def _mock_list_namespaced_config_map(config_maps):
@staticmethod
def _mock_list_services(services):
services_list = client.V1ServiceList(items=services)
- get_k8s().v1api.list_namespaced_service = unittest.mock.Mock(
+ get_k8s_helper().v1api.list_namespaced_service = unittest.mock.Mock(
return_value=services_list
)
return services
@@ -468,13 +476,15 @@ def _assert_list_namespaced_pods_calls(
expected_label_selector: str = None,
):
assert (
- get_k8s().v1api.list_namespaced_pod.call_count == expected_number_of_calls
+ get_k8s_helper().v1api.list_namespaced_pod.call_count
+ == expected_number_of_calls
)
expected_label_selector = (
expected_label_selector or runtime_handler._get_default_label_selector()
)
- get_k8s().v1api.list_namespaced_pod.assert_any_call(
- get_k8s().resolve_namespace(), label_selector=expected_label_selector
+ get_k8s_helper().v1api.list_namespaced_pod.assert_any_call(
+ get_k8s_helper().resolve_namespace(),
+ label_selector=expected_label_selector,
)
@staticmethod
@@ -483,13 +493,13 @@ def _assert_list_namespaced_crds_calls(
):
crd_group, crd_version, crd_plural = runtime_handler._get_crd_info()
assert (
- get_k8s().crdapi.list_namespaced_custom_object.call_count
+ get_k8s_helper().crdapi.list_namespaced_custom_object.call_count
== expected_number_of_calls
)
- get_k8s().crdapi.list_namespaced_custom_object.assert_any_call(
+ get_k8s_helper().crdapi.list_namespaced_custom_object.assert_any_call(
crd_group,
crd_version,
- get_k8s().resolve_namespace(),
+ get_k8s_helper().resolve_namespace(),
crd_plural,
label_selector=runtime_handler._get_default_label_selector(),
)
@@ -503,9 +513,9 @@ async def _assert_run_logs(
logger_pod_name: str = None,
):
if logger_pod_name is not None:
- get_k8s().v1api.read_namespaced_pod_log.assert_called_once_with(
+ get_k8s_helper().v1api.read_namespaced_pod_log.assert_called_once_with(
name=logger_pod_name,
- namespace=get_k8s().resolve_namespace(),
+ namespace=get_k8s_helper().resolve_namespace(),
)
_, logs = await crud.Logs().get_logs(
db, project, uid, source=LogSources.PERSISTENCY
diff --git a/tests/api/runtime_handlers/test_mpijob.py b/tests/api/runtime_handlers/test_mpijob.py
index 117d7c71d6bb..1758d95b36c4 100644
--- a/tests/api/runtime_handlers/test_mpijob.py
+++ b/tests/api/runtime_handlers/test_mpijob.py
@@ -20,7 +20,7 @@
import mlrun.common.schemas
from mlrun.api.utils.singletons.db import get_db
-from mlrun.api.utils.singletons.k8s import get_k8s
+from mlrun.api.utils.singletons.k8s import get_k8s_helper
from mlrun.runtimes import RuntimeKinds, get_runtime_handler
from mlrun.runtimes.constants import PodPhases, RunStates
from tests.api.runtime_handlers.base import TestRuntimeHandlerBase
@@ -362,7 +362,7 @@ def _generate_mpijob_crd(project, uid, status=None):
crd_dict = {
"metadata": {
"name": "train-eaf63df8",
- "namespace": get_k8s().resolve_namespace(),
+ "namespace": get_k8s_helper().resolve_namespace(),
"labels": {
"mlrun/class": "mpijob",
"mlrun/function": "trainer",
diff --git a/tests/api/runtime_handlers/test_sparkjob.py b/tests/api/runtime_handlers/test_sparkjob.py
index f85bcc0f717d..aca0a6a8e627 100644
--- a/tests/api/runtime_handlers/test_sparkjob.py
+++ b/tests/api/runtime_handlers/test_sparkjob.py
@@ -20,7 +20,7 @@
import mlrun.common.schemas
from mlrun.api.utils.singletons.db import get_db
-from mlrun.api.utils.singletons.k8s import get_k8s
+from mlrun.api.utils.singletons.k8s import get_k8s_helper
from mlrun.runtimes import RuntimeKinds, get_runtime_handler
from mlrun.runtimes.constants import PodPhases, RunStates
from tests.api.runtime_handlers.base import TestRuntimeHandlerBase
@@ -360,7 +360,7 @@ def _generate_sparkjob_crd(project, uid, status=None):
crd_dict = {
"metadata": {
"name": "my-spark-jdbc-2ea432f1",
- "namespace": get_k8s().resolve_namespace(),
+ "namespace": get_k8s_helper().resolve_namespace(),
"labels": {
"mlrun/class": "spark",
"mlrun/function": "my-spark-jdbc",
diff --git a/tests/api/runtimes/base.py b/tests/api/runtimes/base.py
index 63403d1e08a4..1b24289ce68a 100644
--- a/tests/api/runtimes/base.py
+++ b/tests/api/runtimes/base.py
@@ -33,13 +33,12 @@
import mlrun.common.schemas
import mlrun.k8s_utils
import mlrun.runtimes.pod
-from mlrun.api.utils.singletons.k8s import get_k8s
+from mlrun.api.utils.singletons.k8s import get_k8s_helper
from mlrun.config import config as mlconf
from mlrun.model import new_task
from mlrun.runtimes.constants import PodPhases
from mlrun.utils import create_logger
from mlrun.utils.azure_vault import AzureVaultStore
-from mlrun.utils.vault import VaultStore
logger = create_logger(level="debug", name="test-runtime")
@@ -47,7 +46,7 @@
class TestRuntimeBase:
def setup_method(self, method):
self.namespace = mlconf.namespace = "test-namespace"
- get_k8s().namespace = self.namespace
+ get_k8s_helper().namespace = self.namespace
# set auto-mount to work as if this is an Iguazio system (otherwise it may try to mount PVC)
mlconf.igz_version = "1.1.1"
@@ -65,8 +64,9 @@ def setup_method(self, method):
self.requirements_file = str(self.assets_path / "requirements.txt")
self.vault_secrets = ["secret1", "secret2", "AWS_KEY"]
- self.vault_secret_value = "secret123!@"
- self.vault_secret_name = "vault-secret"
+ # TODO: Vault: uncomment when vault returns to be relevant
+ # self.vault_secret_value = "secret123!@"
+ # self.vault_secret_name = "vault-secret"
self.azure_vault_secrets = ["azure_secret1", "azure_secret2"]
self.azure_secret_value = "azure-secret-123!@"
@@ -91,10 +91,10 @@ def setup_method_fixture(
# We want this mock for every test, ideally we would have simply put it in the setup_method
# but it is happening before the fixtures initialization. We need the client fixture (which needs the db one)
# in order to be able to mock k8s stuff
- get_k8s().get_project_secret_keys = unittest.mock.Mock(return_value=[])
- get_k8s().v1api = unittest.mock.Mock()
- get_k8s().crdapi = unittest.mock.Mock()
- get_k8s().is_running_inside_kubernetes_cluster = unittest.mock.Mock(
+ get_k8s_helper().get_project_secret_keys = unittest.mock.Mock(return_value=[])
+ get_k8s_helper().v1api = unittest.mock.Mock()
+ get_k8s_helper().crdapi = unittest.mock.Mock()
+ get_k8s_helper().is_running_inside_kubernetes_cluster = unittest.mock.Mock(
return_value=True
)
# enable inheriting classes to do the same
@@ -328,7 +328,7 @@ def _generate_pod(namespace, pod):
response_pod.metadata.namespace = namespace
return response_pod
- get_k8s().v1api.create_namespaced_pod = unittest.mock.Mock(
+ get_k8s_helper().v1api.create_namespaced_pod = unittest.mock.Mock(
side_effect=_generate_pod
)
@@ -336,10 +336,10 @@ def _generate_pod(namespace, pod):
def _mock_get_logger_pods(self):
# Our purpose is not to test the client watching on logs, mock empty list (used in get_logger_pods)
- get_k8s().v1api.list_namespaced_pod = unittest.mock.Mock(
+ get_k8s_helper().v1api.list_namespaced_pod = unittest.mock.Mock(
return_value=client.V1PodList(items=[])
)
- get_k8s().v1api.read_namespaced_pod_log = unittest.mock.Mock(
+ get_k8s_helper().v1api.read_namespaced_pod_log = unittest.mock.Mock(
return_value="Mocked pod logs"
)
@@ -354,15 +354,16 @@ def _generate_custom_object(
):
return deepcopy(body)
- get_k8s().crdapi.create_namespaced_custom_object = unittest.mock.Mock(
+ get_k8s_helper().crdapi.create_namespaced_custom_object = unittest.mock.Mock(
side_effect=_generate_custom_object
)
self._mock_get_logger_pods()
# Vault now supported in KubeJob and Serving, so moved to base.
def _mock_vault_functionality(self):
- secret_dict = {key: self.vault_secret_value for key in self.vault_secrets}
- VaultStore.get_secrets = unittest.mock.Mock(return_value=secret_dict)
+ # TODO: Vault: uncomment when vault returns to be relevant
+ # secret_dict = {key: self.vault_secret_value for key in self.vault_secrets}
+ # VaultStore.get_secrets = unittest.mock.Mock(return_value=secret_dict)
azure_secret_dict = {
key: self.azure_secret_value for key in self.azure_vault_secrets
@@ -378,7 +379,7 @@ def _mock_vault_functionality(self):
service_account = client.V1ServiceAccount(
metadata=object_meta, secrets=[secret]
)
- get_k8s().v1api.read_namespaced_service_account = unittest.mock.Mock(
+ get_k8s_helper().v1api.read_namespaced_service_account = unittest.mock.Mock(
return_value=service_account
)
@@ -390,13 +391,13 @@ def execute_function(self, runtime, **kwargs):
self._execute_run(runtime, **kwargs)
def _reset_mocks(self):
- get_k8s().v1api.create_namespaced_pod.reset_mock()
- get_k8s().v1api.list_namespaced_pod.reset_mock()
- get_k8s().v1api.read_namespaced_pod_log.reset_mock()
+ get_k8s_helper().v1api.create_namespaced_pod.reset_mock()
+ get_k8s_helper().v1api.list_namespaced_pod.reset_mock()
+ get_k8s_helper().v1api.read_namespaced_pod_log.reset_mock()
def _reset_custom_object_mocks(self):
- mlrun.api.utils.singletons.k8s.get_k8s().crdapi.create_namespaced_custom_object.reset_mock()
- get_k8s().v1api.list_namespaced_pod.reset_mock()
+ mlrun.api.utils.singletons.k8s.get_k8s_helper().crdapi.create_namespaced_custom_object.reset_mock()
+ get_k8s_helper().v1api.list_namespaced_pod.reset_mock()
def _execute_run(self, runtime, **kwargs):
# Reset the mock, so that when checking is create_pod was called, no leftovers are there (in case running
@@ -522,7 +523,7 @@ def _assert_pod_env_from_secrets(pod_env, expected_variables):
assert len(expected_variables) == 0
def _get_pod_creation_args(self):
- args, _ = get_k8s().v1api.create_namespaced_pod.call_args
+ args, _ = get_k8s_helper().v1api.create_namespaced_pod.call_args
return args[1]
def _get_custom_object_creation_body(self):
@@ -530,7 +531,7 @@ def _get_custom_object_creation_body(self):
_,
kwargs,
) = (
- mlrun.api.utils.singletons.k8s.get_k8s().crdapi.create_namespaced_custom_object.call_args
+ mlrun.api.utils.singletons.k8s.get_k8s_helper().crdapi.create_namespaced_custom_object.call_args
)
return kwargs["body"]
@@ -539,12 +540,12 @@ def _get_create_custom_object_namespace_arg(self):
_,
kwargs,
) = (
- mlrun.api.utils.singletons.k8s.get_k8s().crdapi.create_namespaced_custom_object.call_args
+ mlrun.api.utils.singletons.k8s.get_k8s_helper().crdapi.create_namespaced_custom_object.call_args
)
return kwargs["namespace"]
def _get_create_pod_namespace_arg(self):
- args, _ = get_k8s().v1api.create_namespaced_pod.call_args
+ args, _ = get_k8s_helper().v1api.create_namespaced_pod.call_args
return args[0]
def _assert_v3io_mount_or_creds_configured(
@@ -664,7 +665,7 @@ def _assert_pod_creation_config(
expected_args=None,
):
if assert_create_pod_called:
- create_pod_mock = get_k8s().v1api.create_namespaced_pod
+ create_pod_mock = get_k8s_helper().v1api.create_namespaced_pod
create_pod_mock.assert_called_once()
assert self._get_create_pod_namespace_arg() == self.namespace
diff --git a/tests/api/runtimes/test_kubejob.py b/tests/api/runtimes/test_kubejob.py
index 3d2f8fb6e94f..2a2443a4f790 100644
--- a/tests/api/runtimes/test_kubejob.py
+++ b/tests/api/runtimes/test_kubejob.py
@@ -414,35 +414,36 @@ def test_run_with_global_secrets(
expected_env_from_secrets=expected_env_from_secrets,
)
- def test_run_with_vault_secrets(self, db: Session, client: TestClient):
- self._mock_vault_functionality()
- runtime = self._generate_runtime()
-
- task = self._generate_task()
-
- task.metadata.project = self.project
- secret_source = {
- "kind": "vault",
- "source": {"project": self.project, "secrets": self.vault_secrets},
- }
- task.with_secrets(secret_source["kind"], self.vault_secrets)
- vault_url = "/url/for/vault"
- mlconf.secret_stores.vault.remote_url = vault_url
- mlconf.secret_stores.vault.token_path = vault_url
-
- self.execute_function(runtime, runspec=task)
-
- self._assert_pod_creation_config(
- expected_secrets=secret_source,
- expected_env={
- "MLRUN_SECRET_STORES__VAULT__ROLE": f"project:{self.project}",
- "MLRUN_SECRET_STORES__VAULT__URL": vault_url,
- },
- )
-
- self._assert_secret_mount(
- "vault-secret", self.vault_secret_name, 420, vault_url
- )
+ # TODO: Vault: uncomment when vault returns to be relevant
+ # def test_run_with_vault_secrets(self, db: Session, client: TestClient):
+ # self._mock_vault_functionality()
+ # runtime = self._generate_runtime()
+ #
+ # task = self._generate_task()
+ #
+ # task.metadata.project = self.project
+ # secret_source = {
+ # "kind": "vault",
+ # "source": {"project": self.project, "secrets": self.vault_secrets},
+ # }
+ # task.with_secrets(secret_source["kind"], self.vault_secrets)
+ # vault_url = "/url/for/vault"
+ # mlconf.secret_stores.vault.remote_url = vault_url
+ # mlconf.secret_stores.vault.token_path = vault_url
+ #
+ # self.execute_function(runtime, runspec=task)
+ #
+ # self._assert_pod_creation_config(
+ # expected_secrets=secret_source,
+ # expected_env={
+ # "MLRUN_SECRET_STORES__VAULT__ROLE": f"project:{self.project}",
+ # "MLRUN_SECRET_STORES__VAULT__URL": vault_url,
+ # },
+ # )
+ #
+ # self._assert_secret_mount(
+ # "vault-secret", self.vault_secret_name, 420, vault_url
+ # )
def test_run_with_code(self, db: Session, client: TestClient):
runtime = self._generate_runtime()
diff --git a/tests/api/runtimes/test_mpijob.py b/tests/api/runtimes/test_mpijob.py
index e220e70033b2..74988313120d 100644
--- a/tests/api/runtimes/test_mpijob.py
+++ b/tests/api/runtimes/test_mpijob.py
@@ -19,7 +19,7 @@
import mlrun.runtimes.pod
from mlrun import code_to_function, mlconf
-from mlrun.api.utils.singletons.k8s import get_k8s
+from mlrun.api.utils.singletons.k8s import get_k8s_helper
from mlrun.runtimes.constants import MPIJobCRDVersions
from tests.api.runtimes.base import TestRuntimeBase
@@ -45,7 +45,7 @@ def test_run_v1_sanity(self):
assert run.status.state == "running"
def _mock_get_namespaced_custom_object(self, workers=1):
- get_k8s().crdapi.get_namespaced_custom_object = unittest.mock.Mock(
+ get_k8s_helper().crdapi.get_namespaced_custom_object = unittest.mock.Mock(
return_value={
"status": {
"replicaStatuses": {
@@ -64,7 +64,7 @@ def _mock_list_pods(self, workers=1, pods=None, phase="Running"):
if pods is None:
pods = [self._get_worker_pod(phase=phase)] * workers
pods += [self._get_launcher_pod(phase=phase)]
- get_k8s().list_pods = unittest.mock.Mock(return_value=pods)
+ get_k8s_helper().list_pods = unittest.mock.Mock(return_value=pods)
def _get_worker_pod(self, phase="Running"):
return k8s_client.V1Pod(
diff --git a/tests/api/runtimes/test_nuclio.py b/tests/api/runtimes/test_nuclio.py
index e084432a01ca..bb6db1d3d7a1 100644
--- a/tests/api/runtimes/test_nuclio.py
+++ b/tests/api/runtimes/test_nuclio.py
@@ -28,23 +28,16 @@
from fastapi.testclient import TestClient
from sqlalchemy.orm import Session
+import mlrun.api.crud.runtimes.nuclio.function
+import mlrun.api.crud.runtimes.nuclio.helpers
import mlrun.common.schemas
import mlrun.errors
+import mlrun.runtimes.function
import mlrun.runtimes.pod
from mlrun import code_to_function, mlconf
from mlrun.api.api.endpoints.functions import _build_function
from mlrun.platforms.iguazio import split_path
from mlrun.runtimes.constants import NuclioIngressAddTemplatedIngressModes
-from mlrun.runtimes.function import (
- _compile_nuclio_archive_config,
- compile_function_config,
- deploy_nuclio_function,
- enrich_function_with_ingress,
- is_nuclio_version_in_range,
- min_nuclio_versions,
- resolve_function_ingresses,
- validate_nuclio_version_compatibility,
-)
from mlrun.utils import logger
from tests.api.conftest import K8sSecretsMock
from tests.api.runtimes.base import TestRuntimeBase
@@ -124,7 +117,11 @@ def _get_expected_struct_for_v3io_trigger(self, parameters):
}
def _execute_run(self, runtime, **kwargs):
- deploy_nuclio_function(runtime, **kwargs)
+ # deploy_nuclio_function doesn't accept watch, so we need to remove it
+ kwargs.pop("watch", None)
+ mlrun.api.crud.runtimes.nuclio.function.deploy_nuclio_function(
+ runtime, **kwargs
+ )
def _generate_runtime(
self, kind=None, labels=None
@@ -371,7 +368,9 @@ def test_compile_function_config_with_special_character_labels(
function = self._generate_runtime(self.runtime_kind)
key, val = "test.label.com/env", "test"
function.set_label(key, val)
- _, _, config = compile_function_config(function)
+ _, _, config = mlrun.api.crud.runtimes.nuclio.function._compile_function_config(
+ function
+ )
assert config["metadata"]["labels"].get(key) == val
def test_enrich_with_ingress_no_overriding(self, db: Session, client: TestClient):
@@ -384,12 +383,18 @@ def test_enrich_with_ingress_no_overriding(self, db: Session, client: TestClient
# both ingress and node port
ingress_host = "something.com"
function.with_http(host=ingress_host, paths=["/"], port=30030)
- function_name, project_name, config = compile_function_config(function)
+ (
+ function_name,
+ project_name,
+ config,
+ ) = mlrun.api.crud.runtimes.nuclio.function._compile_function_config(function)
service_type = "NodePort"
- enrich_function_with_ingress(
+ mlrun.api.crud.runtimes.nuclio.helpers.enrich_function_with_ingress(
config, NuclioIngressAddTemplatedIngressModes.always, service_type
)
- ingresses = resolve_function_ingresses(config["spec"])
+ ingresses = mlrun.api.crud.runtimes.nuclio.helpers.resolve_function_ingresses(
+ config["spec"]
+ )
assert len(ingresses) > 0, "Expected one ingress to be created"
for ingress in ingresses:
assert "hostTemplate" not in ingress, "No host template should be added"
@@ -400,12 +405,18 @@ def test_enrich_with_ingress_always(self, db: Session, client: TestClient):
Expect ingress template to be created as the configuration templated ingress mode is "always"
"""
function = self._generate_runtime(self.runtime_kind)
- function_name, project_name, config = compile_function_config(function)
+ (
+ function_name,
+ project_name,
+ config,
+ ) = mlrun.api.crud.runtimes.nuclio.function._compile_function_config(function)
service_type = "NodePort"
- enrich_function_with_ingress(
+ mlrun.api.crud.runtimes.nuclio.helpers.enrich_function_with_ingress(
config, NuclioIngressAddTemplatedIngressModes.always, service_type
)
- ingresses = resolve_function_ingresses(config["spec"])
+ ingresses = mlrun.api.crud.runtimes.nuclio.helpers.resolve_function_ingresses(
+ config["spec"]
+ )
assert ingresses[0]["hostTemplate"] != ""
def test_enrich_with_ingress_on_cluster_ip(self, db: Session, client: TestClient):
@@ -414,14 +425,20 @@ def test_enrich_with_ingress_on_cluster_ip(self, db: Session, client: TestClient
function service type is ClusterIP
"""
function = self._generate_runtime(self.runtime_kind)
- function_name, project_name, config = compile_function_config(function)
+ (
+ function_name,
+ project_name,
+ config,
+ ) = mlrun.api.crud.runtimes.nuclio.function._compile_function_config(function)
service_type = "ClusterIP"
- enrich_function_with_ingress(
+ mlrun.api.crud.runtimes.nuclio.helpers.enrich_function_with_ingress(
config,
NuclioIngressAddTemplatedIngressModes.on_cluster_ip,
service_type,
)
- ingresses = resolve_function_ingresses(config["spec"])
+ ingresses = mlrun.api.crud.runtimes.nuclio.helpers.resolve_function_ingresses(
+ config["spec"]
+ )
assert ingresses[0]["hostTemplate"] != ""
def test_enrich_with_ingress_never(self, db: Session, client: TestClient):
@@ -429,12 +446,18 @@ def test_enrich_with_ingress_never(self, db: Session, client: TestClient):
Expect no ingress to be created automatically as the configuration templated ingress mode is "never"
"""
function = self._generate_runtime(self.runtime_kind)
- function_name, project_name, config = compile_function_config(function)
+ (
+ function_name,
+ project_name,
+ config,
+ ) = mlrun.api.crud.runtimes.nuclio.function._compile_function_config(function)
service_type = "DoesNotMatter"
- enrich_function_with_ingress(
+ mlrun.api.crud.runtimes.nuclio.helpers.enrich_function_with_ingress(
config, NuclioIngressAddTemplatedIngressModes.never, service_type
)
- ingresses = resolve_function_ingresses(config["spec"])
+ ingresses = mlrun.api.crud.runtimes.nuclio.helpers.resolve_function_ingresses(
+ config["spec"]
+ )
assert ingresses == []
def test_nuclio_config_spec_env(self, db: Session, client: TestClient):
@@ -457,7 +480,11 @@ def test_nuclio_config_spec_env(self, db: Session, client: TestClient):
{"name": name2, "value": value2},
]
- function_name, project_name, config = compile_function_config(function)
+ (
+ function_name,
+ project_name,
+ config,
+ ) = mlrun.api.crud.runtimes.nuclio.function._compile_function_config(function)
for expected_env_var in expected_env_vars:
assert expected_env_var in config["spec"]["env"]
assert isinstance(function.spec.env[0], kubernetes.client.V1EnvVar)
@@ -465,7 +492,11 @@ def test_nuclio_config_spec_env(self, db: Session, client: TestClient):
# simulating sending to API - serialization through dict
function = function.from_dict(function.to_dict())
- function_name, project_name, config = compile_function_config(function)
+ (
+ function_name,
+ project_name,
+ config,
+ ) = mlrun.api.crud.runtimes.nuclio.function._compile_function_config(function)
for expected_env_var in expected_env_vars:
assert expected_env_var in config["spec"]["env"]
@@ -996,43 +1027,75 @@ def test_deploy_python_decode_string_env_var_enrichment(
def test_is_nuclio_version_in_range(self):
mlrun.runtimes.utils.cached_nuclio_version = "1.7.2"
- assert not is_nuclio_version_in_range("1.6.11", "1.7.2")
- assert not is_nuclio_version_in_range("1.7.0", "1.3.1")
- assert not is_nuclio_version_in_range("1.7.3", "1.8.5")
- assert not is_nuclio_version_in_range("1.7.2", "1.7.2")
- assert is_nuclio_version_in_range("1.7.2", "1.7.3")
- assert is_nuclio_version_in_range("1.7.0", "1.7.3")
- assert is_nuclio_version_in_range("1.5.5", "1.7.3")
- assert is_nuclio_version_in_range("1.5.5", "2.3.4")
+ assert not mlrun.api.crud.runtimes.nuclio.helpers.is_nuclio_version_in_range(
+ "1.6.11", "1.7.2"
+ )
+ assert not mlrun.api.crud.runtimes.nuclio.helpers.is_nuclio_version_in_range(
+ "1.7.0", "1.3.1"
+ )
+ assert not mlrun.api.crud.runtimes.nuclio.helpers.is_nuclio_version_in_range(
+ "1.7.3", "1.8.5"
+ )
+ assert not mlrun.api.crud.runtimes.nuclio.helpers.is_nuclio_version_in_range(
+ "1.7.2", "1.7.2"
+ )
+ assert mlrun.api.crud.runtimes.nuclio.helpers.is_nuclio_version_in_range(
+ "1.7.2", "1.7.3"
+ )
+ assert mlrun.api.crud.runtimes.nuclio.helpers.is_nuclio_version_in_range(
+ "1.7.0", "1.7.3"
+ )
+ assert mlrun.api.crud.runtimes.nuclio.helpers.is_nuclio_version_in_range(
+ "1.5.5", "1.7.3"
+ )
+ assert mlrun.api.crud.runtimes.nuclio.helpers.is_nuclio_version_in_range(
+ "1.5.5", "2.3.4"
+ )
# best effort - assumes compatibility
mlrun.runtimes.utils.cached_nuclio_version = ""
- assert is_nuclio_version_in_range("1.5.5", "2.3.4")
- assert is_nuclio_version_in_range("1.7.2", "1.7.2")
+ assert mlrun.api.crud.runtimes.nuclio.helpers.is_nuclio_version_in_range(
+ "1.5.5", "2.3.4"
+ )
+ assert mlrun.api.crud.runtimes.nuclio.helpers.is_nuclio_version_in_range(
+ "1.7.2", "1.7.2"
+ )
def test_validate_nuclio_version_compatibility(self):
# nuclio version we have
mlconf.nuclio_version = "1.6.10"
- # validate_nuclio_version_compatibility receives the min nuclio version required
- assert not validate_nuclio_version_compatibility("1.6.11")
- assert not validate_nuclio_version_compatibility("1.5.9", "1.6.11")
- assert not validate_nuclio_version_compatibility("1.6.11", "1.5.9")
- assert not validate_nuclio_version_compatibility("2.0.0")
- assert validate_nuclio_version_compatibility("1.6.9")
- assert validate_nuclio_version_compatibility("1.5.9")
+ # mlrun.runtimes.function.validate_nuclio_version_compatibility receives the min nuclio version required
+ assert not mlrun.runtimes.function.validate_nuclio_version_compatibility(
+ "1.6.11"
+ )
+ assert not mlrun.runtimes.function.validate_nuclio_version_compatibility(
+ "1.5.9", "1.6.11"
+ )
+ assert not mlrun.runtimes.function.validate_nuclio_version_compatibility(
+ "1.6.11", "1.5.9"
+ )
+ assert not mlrun.runtimes.function.validate_nuclio_version_compatibility(
+ "2.0.0"
+ )
+ assert mlrun.runtimes.function.validate_nuclio_version_compatibility("1.6.9")
+ assert mlrun.runtimes.function.validate_nuclio_version_compatibility("1.5.9")
mlconf.nuclio_version = "2.0.0"
- assert validate_nuclio_version_compatibility("1.6.11")
- assert validate_nuclio_version_compatibility("1.5.9", "1.6.11")
+ assert mlrun.runtimes.function.validate_nuclio_version_compatibility("1.6.11")
+ assert mlrun.runtimes.function.validate_nuclio_version_compatibility(
+ "1.5.9", "1.6.11"
+ )
# best effort - assumes compatibility
mlconf.nuclio_version = ""
- assert validate_nuclio_version_compatibility("1.6.11")
- assert validate_nuclio_version_compatibility("1.5.9", "1.6.11")
+ assert mlrun.runtimes.function.validate_nuclio_version_compatibility("1.6.11")
+ assert mlrun.runtimes.function.validate_nuclio_version_compatibility(
+ "1.5.9", "1.6.11"
+ )
with pytest.raises(ValueError):
- validate_nuclio_version_compatibility("")
+ mlrun.runtimes.function.validate_nuclio_version_compatibility("")
def test_min_nuclio_versions_decorator_failure(self):
mlconf.nuclio_version = "1.6.10"
@@ -1043,7 +1106,7 @@ def test_min_nuclio_versions_decorator_failure(self):
["1.5.9", "1.6.11"],
]:
- @min_nuclio_versions(*case)
+ @mlrun.runtimes.function.min_nuclio_versions(*case)
def fail():
pytest.fail("Should not enter this function")
@@ -1060,7 +1123,7 @@ def test_min_nuclio_versions_decorator_success(self):
["1.0.0", "0.9.81", "1.4.1"],
]:
- @min_nuclio_versions(*case)
+ @mlrun.runtimes.function.min_nuclio_versions(*case)
def success():
pass
@@ -1296,7 +1359,11 @@ def test_deploy_function_with_image_pull_secret(
if build_secret_name is not None:
fn.spec.build.secret = build_secret_name
- _, _, deployed_config = compile_function_config(fn)
+ (
+ _,
+ _,
+ deployed_config,
+ ) = mlrun.api.crud.runtimes.nuclio.function._compile_function_config(fn)
assert deployed_config["spec"].get("imagePullSecrets") == expected_secret_name
def test_nuclio_with_preemption_mode(self):
@@ -1476,11 +1543,19 @@ def test_deploy_with_service_type(
if expected_ingress_host_template is None:
# never
- ingresses = resolve_function_ingresses(deploy_spec)
+ ingresses = (
+ mlrun.api.crud.runtimes.nuclio.helpers.resolve_function_ingresses(
+ deploy_spec
+ )
+ )
assert ingresses == []
else:
- ingresses = resolve_function_ingresses(deploy_spec)
+ ingresses = (
+ mlrun.api.crud.runtimes.nuclio.helpers.resolve_function_ingresses(
+ deploy_spec
+ )
+ )
assert ingresses[0]["hostTemplate"] == expected_ingress_host_template
@@ -1495,6 +1570,8 @@ def runtime_kind(self):
def get_archive_spec(function, secrets):
spec = nuclio.ConfigSpec()
config = {}
- _compile_nuclio_archive_config(spec, function, secrets)
+ mlrun.api.crud.runtimes.nuclio.helpers.compile_nuclio_archive_config(
+ spec, function, secrets
+ )
spec.merge(config)
return config
diff --git a/tests/api/runtimes/test_serving.py b/tests/api/runtimes/test_serving.py
index ae6671eb3b29..55f01eb149cf 100644
--- a/tests/api/runtimes/test_serving.py
+++ b/tests/api/runtimes/test_serving.py
@@ -25,15 +25,12 @@
from sqlalchemy.orm import Session
import mlrun.api.api.utils
+import mlrun.api.crud.runtimes.nuclio.function
import tests.api.api.utils
from mlrun import mlconf, new_function
-from mlrun.api.utils.singletons.k8s import get_k8s
+from mlrun.api.utils.singletons.k8s import get_k8s_helper
from mlrun.db import SQLDB
-from mlrun.runtimes.function import (
- NuclioStatus,
- compile_function_config,
- deploy_nuclio_function,
-)
+from mlrun.runtimes.function import NuclioStatus
from .assets.serving_child_functions import * # noqa
@@ -55,7 +52,8 @@ def class_name(self):
def custom_setup_after_fixtures(self):
self._mock_nuclio_deploy_config()
- self._mock_vault_functionality()
+ # TODO: Vault: uncomment when vault returns to be relevant
+ # self._mock_vault_functionality()
# Since most of the Serving runtime handling is done client-side, we'll mock the calls to remote-build
# and instead just call the deploy_nuclio_function() API which actually performs the
# deployment in this case. This will keep the tests' code mostly client-side oriented, but validations
@@ -75,7 +73,7 @@ def custom_setup(self):
@staticmethod
def _mock_db_remote_deploy_functions():
def _remote_db_mock_function(func, with_mlrun, builder_env=None):
- deploy_nuclio_function(func)
+ mlrun.api.crud.runtimes.nuclio.function.deploy_nuclio_function(func)
return {
"data": {
"status": NuclioStatus(
@@ -121,21 +119,22 @@ def _assert_deploy_spec_has_secrets_config(self, expected_secret_sources):
args, _ = single_call_args
deploy_spec = args[0]["spec"]
- token_path = mlconf.secret_stores.vault.token_path.replace("~", "/root")
azure_secret_path = mlconf.secret_stores.azure_vault.secret_path.replace(
"~", "/root"
)
+ # TODO: Vault: uncomment when vault returns to be relevant
+ # token_path = mlconf.secret_stores.vault.token_path.replace("~", "/root")
expected_volumes = [
- {
- "volume": {
- "name": "vault-secret",
- "secret": {
- "defaultMode": 420,
- "secretName": self.vault_secret_name,
- },
- },
- "volumeMount": {"name": "vault-secret", "mountPath": token_path},
- },
+ # {
+ # "volume": {
+ # "name": "vault-secret",
+ # "secret": {
+ # "defaultMode": 420,
+ # "secretName": self.vault_secret_name,
+ # },
+ # },
+ # "volumeMount": {"name": "vault-secret", "mountPath": token_path},
+ # },
{
"volume": {
"name": "azure-vault-secret",
@@ -158,8 +157,9 @@ def _assert_deploy_spec_has_secrets_config(self, expected_secret_sources):
)
expected_env = {
- "MLRUN_SECRET_STORES__VAULT__ROLE": f"project:{self.project}",
- "MLRUN_SECRET_STORES__VAULT__URL": mlconf.secret_stores.vault.url,
+ # TODO: Vault: uncomment when vault returns to be relevant
+ # "MLRUN_SECRET_STORES__VAULT__ROLE": f"project:{self.project}",
+ # "MLRUN_SECRET_STORES__VAULT__URL": mlconf.secret_stores.vault.url,
# For now, just checking the variable exists, later we check specific contents
"SERVING_SPEC_ENV": None,
}
@@ -182,10 +182,11 @@ def _generate_expected_secret_sources(self):
full_inline_secrets["ENV_SECRET1"] = os.environ["ENV_SECRET1"]
expected_secret_sources = [
{"kind": "inline", "source": full_inline_secrets},
- {
- "kind": "vault",
- "source": {"project": self.project, "secrets": self.vault_secrets},
- },
+ # TODO: Vault: uncomment when vault returns to be relevant
+ # {
+ # "kind": "vault",
+ # "source": {"project": self.project, "secrets": self.vault_secrets},
+ # },
{
"kind": "azure_vault",
"source": {
@@ -212,9 +213,10 @@ def test_mock_server_secrets(self, db: Session, client: TestClient):
server = function.to_mock_server()
+ # TODO: Vault: uncomment when vault returns to be relevant
# Verify all secrets are in the context
- for secret_key in self.vault_secrets:
- assert server.context.get_secret(secret_key) == self.vault_secret_value
+ # for secret_key in self.vault_secrets:
+ # assert server.context.get_secret(secret_key) == self.vault_secret_value
for secret_key in self.inline_secrets:
assert (
server.context.get_secret(secret_key) == self.inline_secrets[secret_key]
@@ -226,7 +228,9 @@ def test_mock_server_secrets(self, db: Session, client: TestClient):
expected_response = [
{"inline_secret1": self.inline_secrets["inline_secret1"]},
{"ENV_SECRET1": os.environ["ENV_SECRET1"]},
- {"AWS_KEY": self.vault_secret_value},
+ # TODO: Vault: uncomment when vault returns to be relevant, and replace the AWS_KEY with the current key
+ # {"AWS_KEY": self.vault_secret_value},
+ {"AWS_KEY": None},
]
assert deepdiff.DeepDiff(resp, expected_response) == {}
@@ -244,8 +248,10 @@ def test_mock_bad_step(self, db: Session, client: TestClient):
server.test()
def test_serving_with_secrets_remote_build(self, db: Session, client: TestClient):
- orig_function = get_k8s()._get_project_secrets_raw_data
- get_k8s()._get_project_secrets_raw_data = unittest.mock.Mock(return_value={})
+ orig_function = get_k8s_helper()._get_project_secrets_raw_data
+ get_k8s_helper()._get_project_secrets_raw_data = unittest.mock.Mock(
+ return_value={}
+ )
mlrun.api.api.utils.mask_function_sensitive_data = unittest.mock.Mock()
function = self._create_serving_function()
@@ -263,7 +269,7 @@ def test_serving_with_secrets_remote_build(self, db: Session, client: TestClient
self._assert_deploy_called_basic_config(expected_class=self.class_name)
- get_k8s()._get_project_secrets_raw_data = orig_function
+ get_k8s_helper()._get_project_secrets_raw_data = orig_function
def test_child_functions_with_secrets(self, db: Session, client: TestClient):
function = self._create_serving_function()
@@ -315,7 +321,9 @@ def test_empty_function(self):
# test simple function (no source)
function = new_function("serving", kind="serving", image="mlrun/mlrun")
function.set_topology("flow")
- _, _, config = compile_function_config(function)
+ _, _, config = mlrun.api.crud.runtimes.nuclio.function._compile_function_config(
+ function
+ )
# verify the code is filled with the mlrun serving wrapper
assert config["spec"]["build"]["functionSourceCode"]
@@ -326,10 +334,14 @@ def test_empty_function(self):
function.set_topology("flow")
# mock secrets for the source (so it will not fail)
- orig_function = get_k8s()._get_project_secrets_raw_data
- get_k8s()._get_project_secrets_raw_data = unittest.mock.Mock(return_value={})
- _, _, config = compile_function_config(function, builder_env={})
- get_k8s()._get_project_secrets_raw_data = orig_function
+ orig_function = get_k8s_helper()._get_project_secrets_raw_data
+ get_k8s_helper()._get_project_secrets_raw_data = unittest.mock.Mock(
+ return_value={}
+ )
+ _, _, config = mlrun.api.crud.runtimes.nuclio.function._compile_function_config(
+ function, builder_env={}
+ )
+ get_k8s_helper()._get_project_secrets_raw_data = orig_function
# verify the handler points to mlrun serving wrapper handler
assert config["spec"]["handler"].startswith("mlrun.serving")
diff --git a/tests/api/runtimes/test_spark.py b/tests/api/runtimes/test_spark.py
index 7875d4ca1ed7..f6da95d0ad40 100644
--- a/tests/api/runtimes/test_spark.py
+++ b/tests/api/runtimes/test_spark.py
@@ -89,7 +89,7 @@ def _assert_custom_object_creation_config(
expected_code: typing.Optional[str] = None,
):
if assert_create_custom_object_called:
- mlrun.api.utils.singletons.k8s.get_k8s().crdapi.create_namespaced_custom_object.assert_called_once()
+ mlrun.api.utils.singletons.k8s.get_k8s_helper().crdapi.create_namespaced_custom_object.assert_called_once()
assert self._get_create_custom_object_namespace_arg() == self.namespace
diff --git a/tests/api/utils/singletons/__init__.py b/tests/api/utils/singletons/__init__.py
new file mode 100644
index 000000000000..b3085be1eb56
--- /dev/null
+++ b/tests/api/utils/singletons/__init__.py
@@ -0,0 +1,14 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
diff --git a/tests/test_k8s_utils.py b/tests/api/utils/singletons/test_k8s_utils.py
similarity index 92%
rename from tests/test_k8s_utils.py
rename to tests/api/utils/singletons/test_k8s_utils.py
index 0907de0f9513..364462ed3ede 100644
--- a/tests/test_k8s_utils.py
+++ b/tests/api/utils/singletons/test_k8s_utils.py
@@ -16,7 +16,7 @@
import pytest
-import mlrun.k8s_utils
+import mlrun.api.utils.singletons.k8s
import mlrun.runtimes
@@ -44,7 +44,7 @@ def test_get_logger_pods_label_selector(
if extra_selector:
selector += f",{extra_selector}"
- k8s_helper = mlrun.k8s_utils.K8sHelper(namespace, silent=True)
+ k8s_helper = mlrun.api.utils.singletons.k8s.K8sHelper(namespace, silent=True)
k8s_helper.list_pods = unittest.mock.MagicMock()
k8s_helper.get_logger_pods(project, uid, run_type)
diff --git a/tests/common_fixtures.py b/tests/common_fixtures.py
index 2f1fc0925390..801a4f19e2bb 100644
--- a/tests/common_fixtures.py
+++ b/tests/common_fixtures.py
@@ -96,7 +96,6 @@ def config_test_base():
mlrun.api.utils.singletons.k8s._k8s = None
mlrun.api.utils.singletons.logs_dir.logs_dir = None
- mlrun.k8s_utils._k8s = None
mlrun.runtimes.runtime_handler_instances_cache = {}
mlrun.runtimes.utils.cached_mpijob_crd_version = None
mlrun.runtimes.utils.cached_nuclio_version = None
diff --git a/tests/runtimes/test_function.py b/tests/runtimes/test_function.py
index f7a5829e947c..24c73659792b 100644
--- a/tests/runtimes/test_function.py
+++ b/tests/runtimes/test_function.py
@@ -20,10 +20,6 @@
import mlrun
from mlrun import code_to_function
-from mlrun.runtimes.function import (
- _resolve_nuclio_runtime_python_image,
- _resolve_work_dir_and_handler,
-)
from mlrun.utils.helpers import resolve_git_reference_from_source
from tests.runtimes.test_base import TestAutoMount
@@ -154,41 +150,6 @@ def test_v3io_stream_trigger():
assert trigger["attributes"]["ackWindowSize"] == 10
-def test_resolve_work_dir_and_handler():
- cases = [
- (None, ("", "main:handler")),
- ("x", ("", "x:handler")),
- ("x:y", ("", "x:y")),
- ("dir#", ("dir", "main:handler")),
- ("dir#x", ("dir", "x:handler")),
- ("dir#x:y", ("dir", "x:y")),
- ]
- for handler, expected in cases:
- assert expected == _resolve_work_dir_and_handler(handler)
-
-
-@pytest.mark.parametrize(
- "mlrun_client_version,python_version,expected_runtime",
- [
- ("1.3.0", "3.9.16", "python:3.9"),
- ("1.3.0", "3.7.16", "python:3.7"),
- (None, None, "python:3.7"),
- (None, "3.9.16", "python:3.7"),
- ("1.3.0", None, "python:3.7"),
- ("0.0.0-unstable", "3.9.16", "python:3.9"),
- ("0.0.0-unstable", "3.7.16", "python:3.7"),
- ("1.2.0", "3.9.16", "python:3.7"),
- ("1.2.0", "3.7.16", "python:3.7"),
- ],
-)
-def test_resolve_nuclio_runtime_python_image(
- mlrun_client_version, python_version, expected_runtime
-):
- assert expected_runtime == _resolve_nuclio_runtime_python_image(
- mlrun_client_version, python_version
- )
-
-
def test_resolve_git_reference_from_source():
cases = [
# source, (repo, refs, branch)
diff --git a/tests/test_builder.py b/tests/test_builder.py
index 2c3bd1b6802d..199e5973c4c2 100644
--- a/tests/test_builder.py
+++ b/tests/test_builder.py
@@ -119,7 +119,7 @@ def test_build_runtime_insecure_registries(
assert (
insecure_flags.issubset(
set(
- mlrun.builder.get_k8s_helper()
+ mlrun.api.utils.singletons.k8s.get_k8s_helper()
.create_pod.call_args[0][0]
.pod.spec.containers[0]
.args
@@ -843,7 +843,11 @@ def _get_target_image_from_create_pod_mock():
def _create_pod_mock_pod_spec():
- return mlrun.builder.get_k8s_helper().create_pod.call_args[0][0].pod.spec
+ return (
+ mlrun.api.utils.singletons.k8s.get_k8s_helper()
+ .create_pod.call_args[0][0]
+ .pod.spec
+ )
def _patch_k8s_helper(monkeypatch):
@@ -860,15 +864,9 @@ def _patch_k8s_helper(monkeypatch):
get_k8s_helper_mock.get_project_secret_data = unittest.mock.Mock(
side_effect=lambda project, keys: {"KEY": "val"}
)
- monkeypatch.setattr(
- mlrun.builder, "get_k8s_helper", lambda *args, **kwargs: get_k8s_helper_mock
- )
- monkeypatch.setattr(
- mlrun.k8s_utils, "get_k8s_helper", lambda *args, **kwargs: get_k8s_helper_mock
- )
monkeypatch.setattr(
mlrun.api.utils.singletons.k8s,
- "get_k8s",
+ "get_k8s_helper",
lambda *args, **kwargs: get_k8s_helper_mock,
)
diff --git a/tests/test_code_to_func.py b/tests/test_code_to_func.py
index 3cb3b7bbd6f6..5cc4c920ee34 100644
--- a/tests/test_code_to_func.py
+++ b/tests/test_code_to_func.py
@@ -15,9 +15,7 @@
from os import path
from mlrun import code_to_function, new_model_server
-from mlrun.runtimes.function import compile_function_config
-from mlrun.utils import get_in
-from tests.conftest import examples_path, results, tests_root_directory
+from tests.conftest import examples_path, results
def test_job_nb():
@@ -88,24 +86,3 @@ def test_local_file_codeout():
assert path.isfile(out), "output not generated"
fn.run(handler="training", params={"p1": 5})
-
-
-def test_nuclio_py():
- name = f"{examples_path}/training.py"
- fn = code_to_function("nuclio", filename=name, kind="nuclio", handler="my_hand")
- name, project, config = compile_function_config(fn)
- assert fn.kind == "remote", "kind not set, test failed"
- assert get_in(config, "spec.build.functionSourceCode"), "no source code"
- assert get_in(config, "spec.runtime").startswith("py"), "runtime not set"
- assert get_in(config, "spec.handler") == "training:my_hand", "wrong handler"
-
-
-def test_nuclio_golang():
- name = f"{tests_root_directory}/assets/hello.go"
- fn = code_to_function(
- "nuclio", filename=name, kind="nuclio", handler="main:Handler"
- )
- name, project, config = compile_function_config(fn)
- assert fn.kind == "remote", "kind not set, test failed"
- assert get_in(config, "spec.runtime") == "golang", "golang was not detected and set"
- assert get_in(config, "spec.handler") == "main:Handler", "wrong handler"
diff --git a/tests/utils/test_vault.py b/tests/utils/test_vault.py
index 9bc710aecb00..4c3035ef484b 100644
--- a/tests/utils/test_vault.py
+++ b/tests/utils/test_vault.py
@@ -12,123 +12,124 @@
# See the License for the specific language governing permissions and
# limitations under the License.
#
-import pytest
-
-import mlrun
-from mlrun import code_to_function, get_run_db, mlconf, new_project, new_task
-from mlrun.utils.vault import VaultStore
-from tests.conftest import examples_path, out_path, verify_state
-
-# Set a proper token value for Vault test
-user_token = ""
-
-
-# Set test secrets and configurations - you may need to modify these.
-def _set_vault_mlrun_configuration(api_server_port=None):
- if api_server_port:
- mlconf.dbpath = f"http://localhost:{api_server_port}"
- mlconf.secret_stores.vault.url = "http://localhost:8200"
- mlconf.secret_stores.vault.user_token = user_token
-
-
-# Verify that local activation of Vault functionality is successful. This does not
-# test the API-server implementation, which is verified in other tests
-@pytest.mark.skipif(user_token == "", reason="no vault configuration")
-def test_direct_vault_usage():
-
- _set_vault_mlrun_configuration()
- project_name = "the-blair-witch-project"
-
- vault = VaultStore()
- vault.delete_vault_secrets(project=project_name)
- secrets = vault.get_secrets(None, project=project_name)
- assert len(secrets) == 0, "Secrets were not deleted"
-
- expected_secrets = {"secret1": "123456", "secret2": "654321"}
- vault.add_vault_secrets(expected_secrets, project=project_name)
-
- secrets = vault.get_secrets(None, project=project_name)
- assert (
- secrets == expected_secrets
- ), "Vault contains different set of secrets than expected"
-
- secrets = vault.get_secrets(["secret1"], project=project_name)
- assert len(secrets) == 1 and secrets["secret1"] == expected_secrets["secret1"]
-
- # Test the same thing for user
- user_name = "pikachu"
- vault.delete_vault_secrets(user=user_name)
- secrets = vault.get_secrets(None, user=user_name)
- assert len(secrets) == 0, "Secrets were not deleted"
-
- vault.add_vault_secrets(expected_secrets, user=user_name)
- secrets = vault.get_secrets(None, user=user_name)
- assert (
- secrets == expected_secrets
- ), "Vault contains different set of secrets than expected"
-
- # Cleanup
- vault.delete_vault_secrets(project=project_name)
- vault.delete_vault_secrets(user=user_name)
-
-
-@pytest.mark.skipif(user_token == "", reason="no vault configuration")
-def test_vault_end_to_end():
- # This requires an MLRun API server to run and work with Vault. This port should
- # be configured to allow access to the server.
- api_server_port = 57764
-
- _set_vault_mlrun_configuration(api_server_port)
- project_name = "abc"
- func_name = "vault-function"
- aws_key_value = "1234567890"
- github_key_value = "proj1Key!!!"
-
- project = new_project(project_name)
- # This call will initialize Vault infrastructure and add the given secrets
- # It executes on the API server
- project.set_secrets(
- {"aws_key": aws_key_value, "github_key": github_key_value},
- provider=mlrun.common.schemas.SecretProviderName.vault,
- )
-
- # This API executes on the client side
- vault = VaultStore()
- project_secrets = vault.get_secrets(["aws_key", "github_key"], project=project_name)
- assert project_secrets == ["aws_key", "github_key"], "secrets not created"
-
- # Create function and set container configuration
- function = code_to_function(
- name=func_name,
- filename=f"{examples_path}/vault_function.py",
- handler="vault_func",
- project=project_name,
- kind="job",
- )
-
- function.spec.image = "saarcoiguazio/mlrun:unstable"
-
- # Create context for the execution
- spec = new_task(
- project=project_name,
- name="vault_test_run",
- handler="vault_func",
- out_path=out_path,
- params={"secrets": ["password", "path", "github_key", "aws_key"]},
- )
- spec.with_secrets("vault", [])
-
- result = function.run(spec)
- verify_state(result)
-
- db = get_run_db().connect()
- state, log = db.get_log(result.metadata.uid, project=project_name)
- log = str(log)
- print(state)
-
- assert (
- log.find(f"value: {aws_key_value}") != -1
- ), "secret value not detected in function output"
- assert (
- log.find(f"value: {github_key_value}") != -1
- ), "secret value not detected in function output"
+# TODO: Vault: uncomment when vault returns to be relevant
+# import pytest
+#
+# import mlrun
+# from mlrun import code_to_function, get_run_db, mlconf, new_project, new_task
+# from mlrun.utils.vault import VaultStore
+# from tests.conftest import examples_path, out_path, verify_state
+#
+# # Set a proper token value for Vault test
+# user_token = ""
+#
+#
+# # Set test secrets and configurations - you may need to modify these.
+# def _set_vault_mlrun_configuration(api_server_port=None):
+# if api_server_port:
+# mlconf.dbpath = f"http://localhost:{api_server_port}"
+# mlconf.secret_stores.vault.url = "http://localhost:8200"
+# mlconf.secret_stores.vault.user_token = user_token
+#
+#
+# # Verify that local activation of Vault functionality is successful. This does not
+# # test the API-server implementation, which is verified in other tests
+# @pytest.mark.skipif(user_token == "", reason="no vault configuration")
+# def test_direct_vault_usage():
+#
+# _set_vault_mlrun_configuration()
+# project_name = "the-blair-witch-project"
+#
+# vault = VaultStore()
+# vault.delete_vault_secrets(project=project_name)
+# secrets = vault.get_secrets(None, project=project_name)
+# assert len(secrets) == 0, "Secrets were not deleted"
+#
+# expected_secrets = {"secret1": "123456", "secret2": "654321"}
+# vault.add_vault_secrets(expected_secrets, project=project_name)
+#
+# secrets = vault.get_secrets(None, project=project_name)
+# assert (
+# secrets == expected_secrets
+# ), "Vault contains different set of secrets than expected"
+#
+# secrets = vault.get_secrets(["secret1"], project=project_name)
+# assert len(secrets) == 1 and secrets["secret1"] == expected_secrets["secret1"]
+#
+# # Test the same thing for user
+# user_name = "pikachu"
+# vault.delete_vault_secrets(user=user_name)
+# secrets = vault.get_secrets(None, user=user_name)
+# assert len(secrets) == 0, "Secrets were not deleted"
+#
+# vault.add_vault_secrets(expected_secrets, user=user_name)
+# secrets = vault.get_secrets(None, user=user_name)
+# assert (
+# secrets == expected_secrets
+# ), "Vault contains different set of secrets than expected"
+#
+# # Cleanup
+# vault.delete_vault_secrets(project=project_name)
+# vault.delete_vault_secrets(user=user_name)
+#
+#
+# @pytest.mark.skipif(user_token == "", reason="no vault configuration")
+# def test_vault_end_to_end():
+# # This requires an MLRun API server to run and work with Vault. This port should
+# # be configured to allow access to the server.
+# api_server_port = 57764
+#
+# _set_vault_mlrun_configuration(api_server_port)
+# project_name = "abc"
+# func_name = "vault-function"
+# aws_key_value = "1234567890"
+# github_key_value = "proj1Key!!!"
+#
+# project = new_project(project_name)
+# # This call will initialize Vault infrastructure and add the given secrets
+# # It executes on the API server
+# project.set_secrets(
+# {"aws_key": aws_key_value, "github_key": github_key_value},
+# provider=mlrun.api.schemas.SecretProviderName.vault,
+# )
+#
+# # This API executes on the client side
+# vault = VaultStore()
+# project_secrets = vault.get_secrets(["aws_key", "github_key"], project=project_name)
+# assert project_secrets == ["aws_key", "github_key"], "secrets not created"
+#
+# # Create function and set container configuration
+# function = code_to_function(
+# name=func_name,
+# filename=f"{examples_path}/vault_function.py",
+# handler="vault_func",
+# project=project_name,
+# kind="job",
+# )
+#
+# function.spec.image = "saarcoiguazio/mlrun:unstable"
+#
+# # Create context for the execution
+# spec = new_task(
+# project=project_name,
+# name="vault_test_run",
+# handler="vault_func",
+# out_path=out_path,
+# params={"secrets": ["password", "path", "github_key", "aws_key"]},
+# )
+# spec.with_secrets("vault", [])
+#
+# result = function.run(spec)
+# verify_state(result)
+#
+# db = get_run_db().connect()
+# state, log = db.get_log(result.metadata.uid, project=project_name)
+# log = str(log)
+# print(state)
+#
+# assert (
+# log.find(f"value: {aws_key_value}") != -1
+# ), "secret value not detected in function output"
+# assert (
+# log.find(f"value: {github_key_value}") != -1
+# ), "secret value not detected in function output"
From 5fab0cfff428fc8da7c8b36d015a8824b42159fc Mon Sep 17 00:00:00 2001
From: Adam
Date: Tue, 9 May 2023 16:25:14 +0300
Subject: [PATCH 100/334] [Projects] Minimal Project Response and Request
Iguazio Projects Separately During Sync (#3489)
---
mlrun/api/crud/projects.py | 24 ++++++-
mlrun/api/db/sqldb/db.py | 9 +++
mlrun/api/utils/clients/iguazio.py | 69 ++++++++++++-------
mlrun/api/utils/helpers.py | 9 +++
.../utils/projects/remotes/nop_follower.py | 8 +++
mlrun/common/schemas/project.py | 3 +
mlrun/db/httpdb.py | 7 +-
tests/api/db/test_projects.py | 37 ++++++++++
tests/api/utils/clients/test_iguazio.py | 51 ++++++++++----
9 files changed, 175 insertions(+), 42 deletions(-)
diff --git a/mlrun/api/crud/projects.py b/mlrun/api/crud/projects.py
index 3098b0efc1b4..fd6bff54dfb8 100644
--- a/mlrun/api/crud/projects.py
+++ b/mlrun/api/crud/projects.py
@@ -46,7 +46,17 @@ def __init__(self) -> None:
def create_project(
self, session: sqlalchemy.orm.Session, project: mlrun.common.schemas.Project
):
- logger.debug("Creating project", project=project)
+ logger.debug(
+ "Creating project",
+ name=project.metadata.name,
+ owner=project.spec.owner,
+ created_time=project.metadata.created,
+ desired_state=project.spec.desired_state,
+ state=project.status.state,
+ function_amount=len(project.spec.functions or []),
+ artifact_amount=len(project.spec.artifacts or []),
+ workflows_amount=len(project.spec.workflows or []),
+ )
mlrun.api.utils.singletons.db.get_db().create_project(session, project)
def store_project(
@@ -55,7 +65,17 @@ def store_project(
name: str,
project: mlrun.common.schemas.Project,
):
- logger.debug("Storing project", name=name, project=project)
+ logger.debug(
+ "Storing project",
+ name=project.metadata.name,
+ owner=project.spec.owner,
+ created_time=project.metadata.created,
+ desired_state=project.spec.desired_state,
+ state=project.status.state,
+ function_amount=len(project.spec.functions or []),
+ artifact_amount=len(project.spec.artifacts or []),
+ workflows_amount=len(project.spec.workflows or []),
+ )
mlrun.api.utils.singletons.db.get_db().store_project(session, name, project)
def patch_project(
diff --git a/mlrun/api/db/sqldb/db.py b/mlrun/api/db/sqldb/db.py
index 0efdba750a36..ec167bfff8b7 100644
--- a/mlrun/api/db/sqldb/db.py
+++ b/mlrun/api/db/sqldb/db.py
@@ -30,6 +30,7 @@
import mlrun
import mlrun.api.db.session
+import mlrun.api.utils.helpers
import mlrun.api.utils.projects.remotes.follower
import mlrun.api.utils.singletons.k8s
import mlrun.common.schemas
@@ -1446,6 +1447,14 @@ def list_projects(
if format_ == mlrun.common.schemas.ProjectsFormat.name_only:
projects = [project_record.name for project_record in project_records]
# leader format is only for follower mode which will format the projects returned from here
+ elif format_ == mlrun.common.schemas.ProjectsFormat.minimal:
+ projects.append(
+ mlrun.api.utils.helpers.minimize_project_schema(
+ self._transform_project_record_to_schema(
+ session, project_record
+ )
+ )
+ )
elif format_ in [
mlrun.common.schemas.ProjectsFormat.full,
mlrun.common.schemas.ProjectsFormat.leader,
diff --git a/mlrun/api/utils/clients/iguazio.py b/mlrun/api/utils/clients/iguazio.py
index cb45f9923241..38eb1df49e6b 100644
--- a/mlrun/api/utils/clients/iguazio.py
+++ b/mlrun/api/utils/clients/iguazio.py
@@ -268,33 +268,10 @@ def list_projects(
) -> typing.Tuple[
typing.List[mlrun.common.schemas.Project], typing.Optional[datetime.datetime]
]:
- params = {}
- if updated_after is not None:
- time_string = updated_after.isoformat().split("+")[0]
- params = {"filter[updated_at]": f"[$gt]{time_string}Z"}
- if page_size is None:
- page_size = (
- mlrun.mlconf.httpdb.projects.iguazio_list_projects_default_page_size
- )
- if page_size is not None:
- params["page[size]"] = int(page_size)
-
- params["include"] = "owner"
- response = self._send_request_to_api(
- "GET",
- "projects",
- "Failed listing projects from Iguazio",
- session,
- params=params,
+ project_names, latest_updated_at = self._list_project_names(
+ session, updated_after, page_size
)
- response_body = response.json()
- projects = []
- for iguazio_project in response_body["data"]:
- projects.append(
- self._transform_iguazio_project_to_mlrun_project(iguazio_project)
- )
- latest_updated_at = self._find_latest_updated_at(response_body)
- return projects, latest_updated_at
+ return self._list_projects_data(session, project_names), latest_updated_at
def get_project(
self,
@@ -342,6 +319,46 @@ def is_sync(self):
"""
return True
+ def _list_project_names(
+ self,
+ session: str,
+ updated_after: typing.Optional[datetime.datetime] = None,
+ page_size: typing.Optional[int] = None,
+ ) -> typing.Tuple[typing.List[str], typing.Optional[datetime.datetime]]:
+ params = {}
+ if updated_after is not None:
+ time_string = updated_after.isoformat().split("+")[0]
+ params = {"filter[updated_at]": f"[$gt]{time_string}Z"}
+ if page_size is None:
+ page_size = (
+ mlrun.mlconf.httpdb.projects.iguazio_list_projects_default_page_size
+ )
+ if page_size is not None:
+ params["page[size]"] = int(page_size)
+
+ response = self._send_request_to_api(
+ "GET",
+ "projects",
+ "Failed listing projects from Iguazio",
+ session,
+ params=params,
+ )
+ response_body = response.json()
+ project_names = [
+ iguazio_project["attributes"]["name"]
+ for iguazio_project in response_body["data"]
+ ]
+ latest_updated_at = self._find_latest_updated_at(response_body)
+ return project_names, latest_updated_at
+
+ def _list_projects_data(
+ self, session: str, project_names: typing.List[str]
+ ) -> typing.List[mlrun.common.schemas.Project]:
+ return [
+ self._get_project_from_iguazio(session, project_name)
+ for project_name in project_names
+ ]
+
def _find_latest_updated_at(
self, response_body: dict
) -> typing.Optional[datetime.datetime]:
diff --git a/mlrun/api/utils/helpers.py b/mlrun/api/utils/helpers.py
index 7cc8499b9193..035c471f8831 100644
--- a/mlrun/api/utils/helpers.py
+++ b/mlrun/api/utils/helpers.py
@@ -58,3 +58,12 @@ async def async_wrapper(*args, **kwargs):
if asyncio.iscoroutinefunction(function):
return async_wrapper
return wrapper
+
+
+def minimize_project_schema(
+ project: mlrun.common.schemas.Project,
+) -> mlrun.common.schemas.Project:
+ project.spec.functions = None
+ project.spec.workflows = None
+ project.spec.artifacts = None
+ return project
diff --git a/mlrun/api/utils/projects/remotes/nop_follower.py b/mlrun/api/utils/projects/remotes/nop_follower.py
index a2af0a42b20e..c5a7b4c12fe3 100644
--- a/mlrun/api/utils/projects/remotes/nop_follower.py
+++ b/mlrun/api/utils/projects/remotes/nop_follower.py
@@ -17,6 +17,7 @@
import mergedeep
import sqlalchemy.orm
+import mlrun.api.utils.helpers
import mlrun.api.utils.projects.remotes.follower
import mlrun.common.schemas
import mlrun.errors
@@ -95,6 +96,13 @@ def list_projects(
]
if format_ == mlrun.common.schemas.ProjectsFormat.full:
return mlrun.common.schemas.ProjectsOutput(projects=projects)
+ elif format_ == mlrun.common.schemas.ProjectsFormat.minimal:
+ return mlrun.common.schemas.ProjectsOutput(
+ projects=[
+ mlrun.api.utils.helpers.minimize_project_schema(project)
+ for project in projects
+ ]
+ )
elif format_ == mlrun.common.schemas.ProjectsFormat.name_only:
project_names = [project.metadata.name for project in projects]
return mlrun.common.schemas.ProjectsOutput(projects=project_names)
diff --git a/mlrun/common/schemas/project.py b/mlrun/common/schemas/project.py
index 5acaf35c1bf2..537884c1890f 100644
--- a/mlrun/common/schemas/project.py
+++ b/mlrun/common/schemas/project.py
@@ -25,6 +25,9 @@
class ProjectsFormat(mlrun.common.types.StrEnum):
full = "full"
name_only = "name_only"
+ # minimal format removes large fields from the response (e.g. functions, workflows, artifacts)
+ # and is used for faster response times (in the UI)
+ minimal = "minimal"
# internal - allowed only in follower mode, only for the leader for upgrade purposes
leader = "leader"
diff --git a/mlrun/db/httpdb.py b/mlrun/db/httpdb.py
index 8589ec78f2dd..d05aec302526 100644
--- a/mlrun/db/httpdb.py
+++ b/mlrun/db/httpdb.py
@@ -27,6 +27,7 @@
import semver
import mlrun
+import mlrun.api.utils.helpers
import mlrun.common.schemas
import mlrun.model_monitoring.model_endpoint
import mlrun.projects
@@ -2122,6 +2123,7 @@ def list_projects(
:param format_: Format of the results. Possible values are:
- ``full`` (default value) - Return full project objects.
+ - ``minimal`` - Return minimal project objects (minimization happens in the BE).
- ``name_only`` - Return just the names of the projects.
:param labels: Filter by labels attached to the project.
@@ -2139,7 +2141,10 @@ def list_projects(
response = self.api_call("GET", "projects", error_message, params=params)
if format_ == mlrun.common.schemas.ProjectsFormat.name_only:
return response.json()["projects"]
- elif format_ == mlrun.common.schemas.ProjectsFormat.full:
+ elif format_ in [
+ mlrun.common.schemas.ProjectsFormat.full,
+ mlrun.common.schemas.ProjectsFormat.minimal,
+ ]:
return [
mlrun.projects.MlrunProject.from_dict(project_dict)
for project_dict in response.json()["projects"]
diff --git a/tests/api/db/test_projects.py b/tests/api/db/test_projects.py
index 211c8144cf7f..27a443d5fced 100644
--- a/tests/api/db/test_projects.py
+++ b/tests/api/db/test_projects.py
@@ -153,6 +153,43 @@ def test_list_project(
)
+def test_list_project_minimal(
+ db: DBInterface,
+ db_session: sqlalchemy.orm.Session,
+):
+ expected_projects = ["project-name-1", "project-name-2", "project-name-3"]
+ for project in expected_projects:
+ db.create_project(
+ db_session,
+ mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(
+ name=project,
+ ),
+ spec=mlrun.common.schemas.ProjectSpec(
+ description="some-proj",
+ artifacts=[{"key": "value"}],
+ workflows=[{"key": "value"}],
+ functions=[{"key": "value"}],
+ ),
+ ),
+ )
+ projects_output = db.list_projects(
+ db_session, format_=mlrun.common.schemas.ProjectsFormat.minimal
+ )
+ for index, project in enumerate(projects_output.projects):
+ assert project.metadata.name == expected_projects[index]
+ assert project.spec.artifacts is None
+ assert project.spec.workflows is None
+ assert project.spec.functions is None
+
+ projects_output = db.list_projects(db_session)
+ for index, project in enumerate(projects_output.projects):
+ assert project.metadata.name == expected_projects[index]
+ assert project.spec.artifacts == [{"key": "value"}]
+ assert project.spec.workflows == [{"key": "value"}]
+ assert project.spec.functions == [{"key": "value"}]
+
+
def test_list_project_names_filter(
db: DBInterface,
db_session: sqlalchemy.orm.Session,
diff --git a/tests/api/utils/clients/test_iguazio.py b/tests/api/utils/clients/test_iguazio.py
index 458dd0460997..e9fd39573567 100644
--- a/tests/api/utils/clients/test_iguazio.py
+++ b/tests/api/utils/clients/test_iguazio.py
@@ -441,7 +441,6 @@ def verify_list(request, context):
"filter[updated_at]": [
f"[$gt]{updated_after.isoformat().split('+')[0]}Z".lower()
],
- "include": ["owner"],
"page[size]": [
str(
mlrun.mlconf.httpdb.projects.iguazio_list_projects_default_page_size
@@ -457,6 +456,15 @@ def verify_list(request, context):
f"{api_url}/api/projects",
json=verify_list,
)
+
+ requests_mock.get(
+ f"{api_url}/api/projects/__name__/{project.metadata.name}",
+ json={
+ "data": _build_project_response(
+ iguazio_client, project, with_mlrun_project=True
+ )
+ },
+ )
await maybe_coroutine(
iguazio_client.list_projects(
session,
@@ -489,22 +497,35 @@ async def test_list_project(
"annotations": {"annotation-key2": "annotation-value2"},
},
]
+ project_objects = [
+ _generate_project(
+ mock_project["name"],
+ mock_project.get("description", ""),
+ mock_project.get("labels", {}),
+ mock_project.get("annotations", {}),
+ owner=mock_project.get("owner", None),
+ )
+ for mock_project in mock_projects
+ ]
response_body = {
"data": [
_build_project_response(
iguazio_client,
- _generate_project(
- mock_project["name"],
- mock_project.get("description", ""),
- mock_project.get("labels", {}),
- mock_project.get("annotations", {}),
- owner=mock_project.get("owner", None),
- ),
+ mock_project,
)
- for mock_project in mock_projects
+ for mock_project in project_objects
]
}
requests_mock.get(f"{api_url}/api/projects", json=response_body)
+ for mock_project in project_objects:
+ requests_mock.get(
+ f"{api_url}/api/projects/__name__/{mock_project.metadata.name}",
+ json={
+ "data": _build_project_response(
+ iguazio_client, mock_project, with_mlrun_project=True
+ )
+ },
+ )
projects, latest_updated_at = await maybe_coroutine(
iguazio_client.list_projects(None)
)
@@ -827,7 +848,7 @@ async def test_format_as_leader_project(
)
assert (
deepdiff.DeepDiff(
- _build_project_response(iguazio_client, project),
+ _build_project_response(iguazio_client, project, with_mlrun_project=True),
iguazio_project.data,
ignore_order=True,
exclude_paths=[
@@ -1041,6 +1062,7 @@ def _build_project_response(
job_id: typing.Optional[str] = None,
operational_status: typing.Optional[mlrun.common.schemas.ProjectState] = None,
owner_access_key: typing.Optional[str] = None,
+ with_mlrun_project: bool = False,
):
body = {
"type": "project",
@@ -1052,11 +1074,14 @@ def _build_project_response(
"updated_at": datetime.datetime.utcnow().isoformat(),
"admin_status": project.spec.desired_state
or mlrun.common.schemas.ProjectState.online,
- "mlrun_project": iguazio_client._transform_mlrun_project_to_iguazio_mlrun_project_attribute(
- project
- ),
},
}
+ if with_mlrun_project:
+ body["attributes"][
+ "mlrun_project"
+ ] = iguazio_client._transform_mlrun_project_to_iguazio_mlrun_project_attribute(
+ project
+ )
if project.spec.description:
body["attributes"]["description"] = project.spec.description
if project.spec.owner:
From 588caa9a72be9c80269334e4de7846f66b211181 Mon Sep 17 00:00:00 2001
From: Adam
Date: Tue, 9 May 2023 16:33:16 +0300
Subject: [PATCH 101/334] [CI] Make Community Edition Deployer Self Contained
(#3501)
---
automation/deployment/deployer.py | 120 ++++++++++++++++++++----------
1 file changed, 80 insertions(+), 40 deletions(-)
diff --git a/automation/deployment/deployer.py b/automation/deployment/deployer.py
index 5c2a07713b56..03b256bb9e17 100644
--- a/automation/deployment/deployer.py
+++ b/automation/deployment/deployer.py
@@ -11,6 +11,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
+import logging
import os.path
import platform
import subprocess
@@ -19,7 +20,7 @@
import requests
-import mlrun.utils
+logging.basicConfig(format="> %(asctime)s [%(levelname)s] %(message)s")
class Constants:
@@ -46,12 +47,15 @@ def __init__(
) -> None:
self._debug = log_level == "debug"
self._log_file_handler = None
- self._logger = mlrun.utils.create_logger(level=log_level, name="automation")
+ self._logger = logging.getLogger("automation")
+ self._logger.setLevel(log_level.upper())
+
if log_file:
- self._log_file_handler = open(log_file, "w")
- self._logger.set_handler(
- "file", self._log_file_handler, mlrun.utils.HumanReadableFormatter()
- )
+ self._log_file_handler = open(log_file, "a")
+ # using StreamHandler instead of FileHandler (which opens a file descriptor) so the same file descriptor
+ # can be used for command stdout as well as the logs.
+ self._logger.addHandler(logging.StreamHandler(self._log_file_handler))
+
self._namespace = namespace
def deploy(
@@ -122,12 +126,17 @@ def deploy(
custom_values,
)
- self._logger.info(
- "Installing helm chart with arguments", helm_arguments=helm_arguments
+ self._log(
+ "info",
+ "Installing helm chart with arguments",
+ helm_arguments=helm_arguments,
+ )
+ stdout, stderr, exit_status = run_command(
+ "helm", helm_arguments, log_file_handler=self._log_file_handler
)
- stdout, stderr, exit_status = run_command("helm", helm_arguments)
if exit_status != 0:
- self._logger.error(
+ self._log(
+ "error",
"Failed to install helm chart",
stderr=stderr,
exit_status=exit_status,
@@ -155,15 +164,19 @@ def delete(
:param registry_secret_name: Name of the registry secret to delete
"""
if cleanup_namespace:
- self._logger.warning(
- "Cleaning up entire namespace", namespace=self._namespace
+ self._log(
+ "warning", "Cleaning up entire namespace", namespace=self._namespace
+ )
+ run_command(
+ "kubectl",
+ ["delete", "namespace", self._namespace],
+ log_file_handler=self._log_file_handler,
)
- run_command("kubectl", ["delete", "namespace", self._namespace])
return
if not skip_uninstall:
- self._logger.info(
- "Cleaning up helm release", release=Constants.helm_release_name
+ self._log(
+ "info", "Cleaning up helm release", release=Constants.helm_release_name
)
run_command(
"helm",
@@ -173,10 +186,11 @@ def delete(
"uninstall",
Constants.helm_release_name,
],
+ log_file_handler=self._log_file_handler,
)
if cleanup_volumes:
- self._logger.warning("Cleaning up mlrun volumes")
+ self._log("warning", "Cleaning up mlrun volumes")
run_command(
"kubectl",
[
@@ -187,10 +201,12 @@ def delete(
"-l",
f"app.kubernetes.io/name={Constants.helm_release_name}",
],
+ log_file_handler=self._log_file_handler,
)
if cleanup_registry_secret:
- self._logger.warning(
+ self._log(
+ "warning",
"Cleaning up registry secret",
secret_name=registry_secret_name,
)
@@ -203,6 +219,7 @@ def delete(
"secret",
registry_secret_name,
],
+ log_file_handler=self._log_file_handler,
)
if sqlite:
@@ -224,7 +241,9 @@ def patch_minikube_images(
"""
for image in [mlrun_api_image, mlrun_ui_image, jupyter_image]:
if image:
- run_command("minikube", ["load", image])
+ run_command(
+ "minikube", ["load", image], log_file_handler=self._log_file_handler
+ )
self._teardown()
@@ -255,31 +274,39 @@ def _prepare_prerequisites(
:param skip_registry_validation: Skip the validation of the registry URL
:param minikube: Whether to deploy on minikube
"""
- self._logger.info("Preparing prerequisites")
+ self._log("info", "Preparing prerequisites")
skip_registry_validation = skip_registry_validation or (
registry_url is None and minikube
)
if not skip_registry_validation:
self._validate_registry_url(registry_url)
- self._logger.info("Creating namespace", namespace=self._namespace)
- run_command("kubectl", ["create", "namespace", self._namespace])
+ self._log("info", "Creating namespace", namespace=self._namespace)
+ run_command(
+ "kubectl",
+ ["create", "namespace", self._namespace],
+ log_file_handler=self._log_file_handler,
+ )
- self._logger.debug("Adding helm repo")
+ self._log("debug", "Adding helm repo")
run_command(
- "helm", ["repo", "add", Constants.helm_repo_name, Constants.helm_repo_url]
+ "helm",
+ ["repo", "add", Constants.helm_repo_name, Constants.helm_repo_url],
+ log_file_handler=self._log_file_handler,
)
- self._logger.debug("Updating helm repo")
- run_command("helm", ["repo", "update"])
+ self._log("debug", "Updating helm repo")
+ run_command("helm", ["repo", "update"], log_file_handler=self._log_file_handler)
if registry_username and registry_password:
self._create_registry_credentials_secret(
registry_url, registry_username, registry_password
)
elif registry_secret_name is not None:
- self._logger.warning(
- "Using existing registry secret", secret_name=registry_secret_name
+ self._log(
+ "warning",
+ "Using existing registry secret",
+ secret_name=registry_secret_name,
)
else:
raise ValueError(
@@ -370,8 +397,10 @@ def _generate_helm_install_arguments(
)
if chart_version:
- self._logger.warning(
- "Installing specific chart version", chart_version=chart_version
+ self._log(
+ "warning",
+ "Installing specific chart version",
+ chart_version=chart_version,
)
helm_arguments.extend(
[
@@ -381,7 +410,7 @@ def _generate_helm_install_arguments(
)
if devel:
- self._logger.warning("Installing development chart version")
+ self._log("warning", "Installing development chart version")
helm_arguments.append("--devel")
return helm_arguments
@@ -466,12 +495,14 @@ def _generate_helm_values(
# TODO: We need to fix the pipelines metadata grpc server to work on arm
if self._check_platform_architecture() == "arm":
- self._logger.warning(
- "Kubeflow Pipelines is not supported on ARM architecture. Disabling KFP installation."
+ self._log(
+ "warning",
+ "Kubeflow Pipelines is not supported on ARM architecture. Disabling KFP installation.",
)
self._disable_deployment_in_helm_values(helm_values, "pipelines")
- self._logger.debug(
+ self._log(
+ "debug",
"Generated helm values",
helm_values=helm_values,
)
@@ -497,7 +528,8 @@ def _create_registry_credentials_secret(
if registry_secret_name is not None
else Constants.default_registry_secret_name
)
- self._logger.debug(
+ self._log(
+ "debug",
"Creating registry credentials secret",
secret_name=registry_secret_name,
)
@@ -514,6 +546,7 @@ def _create_registry_credentials_secret(
f"--docker-username={registry_username}",
f"--docker-password={registry_password}",
],
+ log_file_handler=self._log_file_handler,
)
@staticmethod
@@ -578,7 +611,7 @@ def _validate_registry_url(self, registry_url):
response = requests.get(registry_url)
response.raise_for_status()
except Exception as exc:
- self._logger.error("Failed to validate registry url", exc=exc)
+ self._log("error", "Failed to validate registry url", exc=exc)
raise exc
def _set_mlrun_version_in_helm_values(
@@ -589,8 +622,8 @@ def _set_mlrun_version_in_helm_values(
:param helm_values: Helm values to update
:param mlrun_version: MLRun version to use
"""
- self._logger.warning(
- "Installing specific mlrun version", mlrun_version=mlrun_version
+ self._log(
+ "warning", "Installing specific mlrun version", mlrun_version=mlrun_version
)
for image in Constants.mlrun_image_values:
helm_values[f"{image}.image.tag"] = mlrun_version
@@ -611,8 +644,11 @@ def _override_image_in_helm_values(
overriden_image_repo,
overriden_image_tag,
) = overriden_image.split(":")
- self._logger.warning(
- "Overriding image", image=image_helm_value, overriden_image=overriden_image
+ self._log(
+ "warning",
+ "Overriding image",
+ image=image_helm_value,
+ overriden_image=overriden_image,
)
helm_values[f"{image_helm_value}.image.repository"] = overriden_image_repo
helm_values[f"{image_helm_value}.image.tag"] = overriden_image_tag
@@ -625,9 +661,13 @@ def _disable_deployment_in_helm_values(
:param helm_values: Helm values to update
:param deployment: Deployment to disable
"""
- self._logger.warning("Disabling deployment", deployment=deployment)
+ self._log("warning", "Disabling deployment", deployment=deployment)
helm_values[f"{deployment}.enabled"] = "false"
+ def _log(self, level: str, message: str, **kwargs: typing.Any) -> None:
+ more = f": {kwargs}" if kwargs else ""
+ self._logger.log(logging.getLevelName(level.upper()), f"{message}{more}")
+
def run_command(
command: str,
From 00e8b478231f8a27a9eb572f5eaa2935afafdac6 Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Tue, 9 May 2023 17:00:38 +0300
Subject: [PATCH 102/334] [API] Add k8s util exception logging (#3504)
---
mlrun/api/utils/singletons/k8s.py | 5 ++++-
mlrun/utils/helpers.py | 2 +-
2 files changed, 5 insertions(+), 2 deletions(-)
diff --git a/mlrun/api/utils/singletons/k8s.py b/mlrun/api/utils/singletons/k8s.py
index 7fa3e8bb21c7..9cd901e91e22 100644
--- a/mlrun/api/utils/singletons/k8s.py
+++ b/mlrun/api/utils/singletons/k8s.py
@@ -56,7 +56,10 @@ def __init__(self, namespace=None, config_file=None, silent=False, log=True):
self._init_k8s_config(log)
self.v1api = client.CoreV1Api()
self.crdapi = client.CustomObjectsApi()
- except Exception:
+ except Exception as exc:
+ logger.warning(
+ "cannot initialize kubernetes client", exc=mlrun.errors.err_to_str(exc)
+ )
if not silent:
raise
diff --git a/mlrun/utils/helpers.py b/mlrun/utils/helpers.py
index a587a356fed7..5411cb676dd3 100644
--- a/mlrun/utils/helpers.py
+++ b/mlrun/utils/helpers.py
@@ -954,7 +954,7 @@ def retry_until_successful(
f" last_exception: {last_exception},"
f" function_name: {_function.__name__},"
f" timeout: {timeout}"
- )
+ ) from last_exception
def get_ui_url(project, uid=None):
From 7f4a51dc363da0824b4515e62746d90726e29bb7 Mon Sep 17 00:00:00 2001
From: Yael Genish <62285310+yaelgen@users.noreply.github.com>
Date: Tue, 9 May 2023 21:59:08 +0300
Subject: [PATCH 103/334] [System tests] Fix test run notifications (#3505)
---
mlrun/db/httpdb.py | 2 +-
tests/system/runtimes/test_notifications.py | 8 +++++---
2 files changed, 6 insertions(+), 4 deletions(-)
diff --git a/mlrun/db/httpdb.py b/mlrun/db/httpdb.py
index d05aec302526..a9d5accef49a 100644
--- a/mlrun/db/httpdb.py
+++ b/mlrun/db/httpdb.py
@@ -618,7 +618,7 @@ def list_runs(
"start_time_to": datetime_to_iso(start_time_to),
"last_update_time_from": datetime_to_iso(last_update_time_from),
"last_update_time_to": datetime_to_iso(last_update_time_to),
- "with_notifications": with_notifications,
+ "with-notifications": with_notifications,
}
if partition_by:
diff --git a/tests/system/runtimes/test_notifications.py b/tests/system/runtimes/test_notifications.py
index 9b2435ed4059..22910cd0d1cc 100644
--- a/tests/system/runtimes/test_notifications.py
+++ b/tests/system/runtimes/test_notifications.py
@@ -32,11 +32,13 @@ def _assert_notifications():
)
assert len(runs) == 1
assert len(runs[0]["status"]["notifications"]) == 2
- for notification in runs[0]["status"]["notifications"]:
+ for notification_name, notification in runs[0]["status"][
+ "notifications"
+ ].items():
if notification["name"] == error_notification.name:
- assert notification["status"] == "error"
+ assert notification_name["status"] == "error"
elif notification["name"] == success_notification.name:
- assert notification["status"] == "sent"
+ assert notification_name["status"] == "sent"
error_notification = self._create_notification(
name=error_notification_name,
From 67cd3040a051db5f71a2eaf305d4d70e429681e0 Mon Sep 17 00:00:00 2001
From: TomerShor <90552140+TomerShor@users.noreply.github.com>
Date: Wed, 10 May 2023 08:50:47 +0300
Subject: [PATCH 104/334] [Log Collector] Has logs - don't raise exception on
retryable errors (#3507)
---
mlrun/api/utils/clients/log_collector.py | 39 ++++++++++++++++++-
tests/api/utils/clients/test_log_collector.py | 37 ++++++++++++++++++
2 files changed, 75 insertions(+), 1 deletion(-)
diff --git a/mlrun/api/utils/clients/log_collector.py b/mlrun/api/utils/clients/log_collector.py
index 764376def26a..c6c90a310fbc 100644
--- a/mlrun/api/utils/clients/log_collector.py
+++ b/mlrun/api/utils/clients/log_collector.py
@@ -14,6 +14,7 @@
import asyncio
import enum
import http
+import re
import typing
import mlrun.api.utils.clients.protocols.grpc
@@ -52,6 +53,20 @@ def map_error_code_to_mlrun_error(
return mlrun_error_class(message)
+class LogCollectorErrorRegex:
+ # when multiple routines in the log collector service try to search the same directory,
+ # one of them can fail with this error
+ readdirent_resource_temporarily_unavailable = (
+ "readdirent.*resource temporarily unavailable"
+ )
+
+ @classmethod
+ def has_logs_retryable_errors(cls):
+ return [
+ cls.readdirent_resource_temporarily_unavailable,
+ ]
+
+
class LogCollectorClient(
mlrun.api.utils.clients.protocols.grpc.BaseGRPCClient,
metaclass=mlrun.utils.singleton.Singleton,
@@ -209,6 +224,18 @@ async def has_logs(
response = await self._call("HasLogs", request)
if not response.success:
+ if self._retryable_error(
+ response.errorMessage,
+ LogCollectorErrorRegex.has_logs_retryable_errors(),
+ ):
+ if verbose:
+ logger.warning(
+ "Failed to check if run has logs to collect, retrying",
+ run_uid=run_uid,
+ error=response.errorMessage,
+ )
+ return False
+
msg = f"Failed to check if run has logs to collect for {run_uid}"
if verbose:
logger.warning(msg, error=response.errorMessage)
@@ -233,7 +260,6 @@ async def stop_logs(
:param raise_on_error: Whether to raise an exception on error
:return: None
"""
-
request = self._log_collector_pb2.StopLogsRequest(
project=project, runUIDs=run_uids
)
@@ -277,3 +303,14 @@ async def delete_logs(
)
if verbose:
logger.warning(msg, error=response.errorMessage)
+
+ def _retryable_error(self, error_message, retryable_error_patterns) -> bool:
+ """
+ Check if the error is retryable
+ :param error_message: The error message
+ :param retryable_error_patterns: The retryable error regex patterns
+ :return: Whether the error is retryable
+ """
+ if any(re.match(regex, error_message) for regex in retryable_error_patterns):
+ return True
+ return False
diff --git a/tests/api/utils/clients/test_log_collector.py b/tests/api/utils/clients/test_log_collector.py
index d16d4a3967d3..db4ea4919dcd 100644
--- a/tests/api/utils/clients/test_log_collector.py
+++ b/tests/api/utils/clients/test_log_collector.py
@@ -150,6 +150,43 @@ async def test_get_logs(
async for log in log_stream:
assert log == b""
+ @pytest.mark.asyncio
+ async def test_get_log_with_retryable_error(
+ self, db: sqlalchemy.orm.session.Session, client: fastapi.testclient.TestClient
+ ):
+ run_uid = "123"
+ project_name = "some-project"
+ log_collector = mlrun.api.utils.clients.log_collector.LogCollectorClient()
+
+ # mock responses for HasLogs to return a retryable error
+ log_collector._call = unittest.mock.AsyncMock(
+ return_value=HasLogsResponse(
+ False,
+ "readdirent /var/mlrun/logs/blabla: resource temporarily unavailable",
+ True,
+ )
+ )
+
+ log_stream = log_collector.get_logs(
+ run_uid=run_uid, project=project_name, raise_on_error=False
+ )
+ async for log in log_stream:
+ assert log == b""
+
+ # mock responses for HasLogs to return a retryable error
+ log_collector._call = unittest.mock.AsyncMock(
+ return_value=HasLogsResponse(
+ False,
+ "I'm an error that should not be retried",
+ True,
+ )
+ )
+ with pytest.raises(mlrun.errors.MLRunInternalServerError):
+ async for log in log_collector.get_logs(
+ run_uid=run_uid, project=project_name
+ ):
+ assert log == b"" # should not get here
+
@pytest.mark.asyncio
async def test_stop_logs(
self, db: sqlalchemy.orm.session.Session, client: fastapi.testclient.TestClient
From 452dc4b02b11594f3ae90c014ee05b83886609c3 Mon Sep 17 00:00:00 2001
From: Yael Genish <62285310+yaelgen@users.noreply.github.com>
Date: Wed, 10 May 2023 09:59:51 +0300
Subject: [PATCH 105/334] [System Tests] Fix test run notifications (#3511)
---
tests/system/runtimes/test_notifications.py | 8 ++++----
1 file changed, 4 insertions(+), 4 deletions(-)
diff --git a/tests/system/runtimes/test_notifications.py b/tests/system/runtimes/test_notifications.py
index 22910cd0d1cc..fb50695f723c 100644
--- a/tests/system/runtimes/test_notifications.py
+++ b/tests/system/runtimes/test_notifications.py
@@ -35,10 +35,10 @@ def _assert_notifications():
for notification_name, notification in runs[0]["status"][
"notifications"
].items():
- if notification["name"] == error_notification.name:
- assert notification_name["status"] == "error"
- elif notification["name"] == success_notification.name:
- assert notification_name["status"] == "sent"
+ if notification_name == error_notification.name:
+ assert notification["status"] == "error"
+ elif notification_name == success_notification.name:
+ assert notification["status"] == "sent"
error_notification = self._create_notification(
name=error_notification_name,
From deda5e512069dbadd84e445005c3618c5939e674 Mon Sep 17 00:00:00 2001
From: Adam
Date: Wed, 10 May 2023 10:15:07 +0300
Subject: [PATCH 106/334] [CI] Enable Running Community Edition Deployer On
Remote Machine (#3508)
---
automation/deployment/ce.py | 32 ++++++
automation/deployment/deployer.py | 165 ++++++++++++++++++++++--------
2 files changed, 154 insertions(+), 43 deletions(-)
diff --git a/automation/deployment/ce.py b/automation/deployment/ce.py
index b85501c8ddbb..8d39597d72d1 100644
--- a/automation/deployment/ce.py
+++ b/automation/deployment/ce.py
@@ -30,6 +30,20 @@
"--log-file",
help="Path to log file. If not specified, will log only to stdout",
),
+ click.option(
+ "--remote",
+ help="Remote host to deploy to. If not specified, will deploy to the local host",
+ ),
+ click.option(
+ "--remote-ssh-username",
+ help="Username to use when connecting to the remote host via SSH. "
+ "If not specified, will use MLRUN_REMOTE_SSH_USERNAME environment variable",
+ ),
+ click.option(
+ "--remote-ssh-password",
+ help="Password to use when connecting to the remote host via SSH. "
+ "If not specified, will use MLRUN_REMOTE_SSH_PASSWORD environment variable",
+ ),
]
common_deployment_options = [
@@ -155,6 +169,9 @@ def deploy(
verbose: bool = False,
log_file: str = None,
namespace: str = "mlrun",
+ remote: str = None,
+ remote_ssh_username: str = None,
+ remote_ssh_password: str = None,
mlrun_version: str = None,
chart_version: str = None,
registry_url: str = None,
@@ -178,6 +195,9 @@ def deploy(
namespace=namespace,
log_level="debug" if verbose else "info",
log_file=log_file,
+ remote=remote,
+ remote_ssh_username=remote_ssh_username,
+ remote_ssh_password=remote_ssh_password,
)
deployer.deploy(
registry_url=registry_url,
@@ -230,6 +250,9 @@ def delete(
verbose: bool = False,
log_file: str = None,
namespace: str = "mlrun",
+ remote: str = None,
+ remote_ssh_username: str = None,
+ remote_ssh_password: str = None,
registry_secret_name: str = None,
skip_uninstall: bool = False,
skip_cleanup_registry_secret: bool = False,
@@ -241,6 +264,9 @@ def delete(
namespace=namespace,
log_level="debug" if verbose else "info",
log_file=log_file,
+ remote=remote,
+ remote_ssh_username=remote_ssh_username,
+ remote_ssh_password=remote_ssh_password,
)
deployer.delete(
skip_uninstall=skip_uninstall,
@@ -271,6 +297,9 @@ def delete(
)
@add_options(common_options)
def patch_minikube_images(
+ remote: str = None,
+ remote_ssh_username: str = None,
+ remote_ssh_password: str = None,
verbose: bool = False,
log_file: str = None,
mlrun_api_image: str = None,
@@ -281,6 +310,9 @@ def patch_minikube_images(
namespace="",
log_level="debug" if verbose else "info",
log_file=log_file,
+ remote=remote,
+ remote_ssh_username=remote_ssh_username,
+ remote_ssh_password=remote_ssh_password,
)
deployer.patch_minikube_images(
mlrun_api_image=mlrun_api_image,
diff --git a/automation/deployment/deployer.py b/automation/deployment/deployer.py
index 03b256bb9e17..73fd95e34c37 100644
--- a/automation/deployment/deployer.py
+++ b/automation/deployment/deployer.py
@@ -18,10 +18,9 @@
import sys
import typing
+import paramiko
import requests
-logging.basicConfig(format="> %(asctime)s [%(levelname)s] %(message)s")
-
class Constants:
helm_repo_name = "mlrun-ce"
@@ -32,6 +31,7 @@ class Constants:
mlrun_image_values = ["mlrun.api", "mlrun.ui", "jupyterNotebook"]
disableable_deployments = ["pipelines", "kube-prometheus-stack", "spark-operator"]
minikube_registry_port = 5000
+ log_format = "> %(asctime)s [%(levelname)s] %(message)s"
class CommunityEditionDeployer:
@@ -44,9 +44,13 @@ def __init__(
namespace: str,
log_level: str = "info",
log_file: str = None,
+ remote: str = None,
+ remote_ssh_username: str = None,
+ remote_ssh_password: str = None,
) -> None:
self._debug = log_level == "debug"
self._log_file_handler = None
+ logging.basicConfig(format="> %(asctime)s [%(levelname)s] %(message)s")
self._logger = logging.getLogger("automation")
self._logger.setLevel(log_level.upper())
@@ -54,9 +58,31 @@ def __init__(
self._log_file_handler = open(log_file, "a")
# using StreamHandler instead of FileHandler (which opens a file descriptor) so the same file descriptor
# can be used for command stdout as well as the logs.
- self._logger.addHandler(logging.StreamHandler(self._log_file_handler))
+ handler = logging.StreamHandler(self._log_file_handler)
+ handler.setFormatter(logging.Formatter(Constants.log_format))
+ self._logger.addHandler(handler)
self._namespace = namespace
+ self._remote = remote
+ self._remote_ssh_username = remote_ssh_username or os.environ.get(
+ "MLRUN_REMOTE_SSH_USERNAME"
+ )
+ self._remote_ssh_password = remote_ssh_password or os.environ.get(
+ "MLRUN_REMOTE_SSH_PASSWORD"
+ )
+ self._ssh_client = None
+ if self._remote:
+ self.connect_to_remote()
+
+ def connect_to_remote(self):
+ self._log("info", "Connecting to remote machine", remote=self._remote)
+ self._ssh_client = paramiko.SSHClient()
+ self._ssh_client.set_missing_host_key_policy(paramiko.WarningPolicy)
+ self._ssh_client.connect(
+ self._remote,
+ username=self._remote_ssh_username,
+ password=self._remote_ssh_password,
+ )
def deploy(
self,
@@ -131,9 +157,7 @@ def deploy(
"Installing helm chart with arguments",
helm_arguments=helm_arguments,
)
- stdout, stderr, exit_status = run_command(
- "helm", helm_arguments, log_file_handler=self._log_file_handler
- )
+ stdout, stderr, exit_status = self._run_command("helm", helm_arguments)
if exit_status != 0:
self._log(
"error",
@@ -167,18 +191,14 @@ def delete(
self._log(
"warning", "Cleaning up entire namespace", namespace=self._namespace
)
- run_command(
- "kubectl",
- ["delete", "namespace", self._namespace],
- log_file_handler=self._log_file_handler,
- )
+ self._run_command("kubectl", ["delete", "namespace", self._namespace])
return
if not skip_uninstall:
self._log(
"info", "Cleaning up helm release", release=Constants.helm_release_name
)
- run_command(
+ self._run_command(
"helm",
[
"--namespace",
@@ -186,12 +206,11 @@ def delete(
"uninstall",
Constants.helm_release_name,
],
- log_file_handler=self._log_file_handler,
)
if cleanup_volumes:
self._log("warning", "Cleaning up mlrun volumes")
- run_command(
+ self._run_command(
"kubectl",
[
"--namespace",
@@ -201,7 +220,6 @@ def delete(
"-l",
f"app.kubernetes.io/name={Constants.helm_release_name}",
],
- log_file_handler=self._log_file_handler,
)
if cleanup_registry_secret:
@@ -210,7 +228,7 @@ def delete(
"Cleaning up registry secret",
secret_name=registry_secret_name,
)
- run_command(
+ self._run_command(
"kubectl",
[
"--namespace",
@@ -219,7 +237,6 @@ def delete(
"secret",
registry_secret_name,
],
- log_file_handler=self._log_file_handler,
)
if sqlite:
@@ -241,9 +258,7 @@ def patch_minikube_images(
"""
for image in [mlrun_api_image, mlrun_ui_image, jupyter_image]:
if image:
- run_command(
- "minikube", ["load", image], log_file_handler=self._log_file_handler
- )
+ self._run_command("minikube", ["load", image])
self._teardown()
@@ -282,21 +297,15 @@ def _prepare_prerequisites(
self._validate_registry_url(registry_url)
self._log("info", "Creating namespace", namespace=self._namespace)
- run_command(
- "kubectl",
- ["create", "namespace", self._namespace],
- log_file_handler=self._log_file_handler,
- )
+ self._run_command("kubectl", ["create", "namespace", self._namespace])
self._log("debug", "Adding helm repo")
- run_command(
- "helm",
- ["repo", "add", Constants.helm_repo_name, Constants.helm_repo_url],
- log_file_handler=self._log_file_handler,
+ self._run_command(
+ "helm", ["repo", "add", Constants.helm_repo_name, Constants.helm_repo_url]
)
self._log("debug", "Updating helm repo")
- run_command("helm", ["repo", "update"], log_file_handler=self._log_file_handler)
+ self._run_command("helm", ["repo", "update"])
if registry_username and registry_password:
self._create_registry_credentials_secret(
@@ -533,7 +542,7 @@ def _create_registry_credentials_secret(
"Creating registry credentials secret",
secret_name=registry_secret_name,
)
- run_command(
+ self._run_command(
"kubectl",
[
"--namespace",
@@ -546,18 +555,23 @@ def _create_registry_credentials_secret(
f"--docker-username={registry_username}",
f"--docker-password={registry_password}",
],
- log_file_handler=self._log_file_handler,
)
- @staticmethod
- def _check_platform_architecture() -> str:
+ def _check_platform_architecture(self) -> str:
"""
Check the platform architecture. If running on macOS, check if Rosetta is enabled.
Used for kubeflow pipelines which is not supported on ARM architecture (specifically the metadata grpc server).
:return: Platform architecture
"""
+ if self._remote:
+ self._log(
+ "warning",
+ "Cannot check platform architecture on remote machine, assuming x86",
+ )
+ return "x86"
+
if platform.system() == "Darwin":
- translated, _, exit_status = run_command(
+ translated, _, exit_status = self._run_command(
"sysctl",
["-n", "sysctl.proc_translated"],
live=False,
@@ -576,13 +590,13 @@ def _get_host_ip(self) -> str:
"""
if platform.system() == "Darwin":
return (
- run_command("ipconfig", ["getifaddr", "en0"], live=False)[0]
+ self._run_command("ipconfig", ["getifaddr", "en0"], live=False)[0]
.strip()
.decode("utf-8")
)
elif platform.system() == "Linux":
return (
- run_command("hostname", ["-I"], live=False)[0]
+ self._run_command("hostname", ["-I"], live=False)[0]
.split()[0]
.strip()
.decode("utf-8")
@@ -592,13 +606,14 @@ def _get_host_ip(self) -> str:
f"Platform {platform.system()} is not supported for this action"
)
- @staticmethod
- def _get_minikube_ip() -> str:
+ def _get_minikube_ip(self) -> str:
"""
Get the minikube IP.
:return: Minikube IP
"""
- return run_command("minikube", ["ip"], live=False)[0].strip().decode("utf-8")
+ return (
+ self._run_command("minikube", ["ip"], live=False)[0].strip().decode("utf-8")
+ )
def _validate_registry_url(self, registry_url):
"""
@@ -664,6 +679,34 @@ def _disable_deployment_in_helm_values(
self._log("warning", "Disabling deployment", deployment=deployment)
helm_values[f"{deployment}.enabled"] = "false"
+ def _run_command(
+ self,
+ command: str,
+ args: list = None,
+ workdir: str = None,
+ stdin: str = None,
+ live: bool = True,
+ ) -> (str, str, int):
+ if self._remote:
+ return run_command_remotely(
+ self._ssh_client,
+ command=command,
+ args=args,
+ workdir=workdir,
+ stdin=stdin,
+ live=live,
+ log_file_handler=self._log_file_handler,
+ )
+ else:
+ return run_command(
+ command=command,
+ args=args,
+ workdir=workdir,
+ stdin=stdin,
+ live=live,
+ log_file_handler=self._log_file_handler,
+ )
+
def _log(self, level: str, message: str, **kwargs: typing.Any) -> None:
more = f": {kwargs}" if kwargs else ""
self._logger.log(logging.getLevelName(level.upper()), f"{message}{more}")
@@ -701,20 +744,56 @@ def run_command(
return stdout, stderr, exit_status
+def run_command_remotely(
+ ssh_client: paramiko.SSHClient,
+ command: str,
+ args: list = None,
+ workdir: str = None,
+ stdin: str = None,
+ live: bool = True,
+ log_file_handler: typing.IO[str] = None,
+) -> (str, str, int):
+ if workdir:
+ command = f"cd {workdir}; " + command
+ if args:
+ command += " " + " ".join(args)
+
+ stdin_stream, stdout_stream, stderr_stream = ssh_client.exec_command(command)
+
+ if stdin:
+ stdin_stream.write(stdin)
+ stdin_stream.close()
+
+ stdout = _handle_command_stdout(stdout_stream, log_file_handler, live, remote=True)
+ stderr = stderr_stream.read()
+ exit_status = stdout_stream.channel.recv_exit_status()
+
+ return stdout, stderr, exit_status
+
+
def _handle_command_stdout(
- stdout_stream: typing.IO[bytes],
+ stdout_stream: typing.Union[typing.IO[bytes], paramiko.channel.ChannelFile],
log_file_handler: typing.IO[str] = None,
live: bool = True,
+ remote: bool = False,
) -> str:
+ def _maybe_decode(text: typing.Union[str, bytes]) -> str:
+ if isinstance(text, bytes):
+ return text.decode(sys.stdout.encoding)
+ return text
+
def _write_to_log_file(text: bytes):
if log_file_handler:
- log_file_handler.write(text.decode(sys.stdout.encoding))
+ log_file_handler.write(_maybe_decode(text))
stdout = ""
if live:
for line in iter(stdout_stream.readline, b""):
+ # remote stream never ends, so we need to break when there's no more data
+ if remote and not line:
+ break
stdout += str(line)
- sys.stdout.write(line.decode(sys.stdout.encoding))
+ sys.stdout.write(_maybe_decode(line))
_write_to_log_file(line)
else:
stdout = stdout_stream.read()
From 60debd16bfe924fe28630c61d8ecdd359d6fdee3 Mon Sep 17 00:00:00 2001
From: Gal Topper
Date: Wed, 10 May 2023 16:46:58 +0800
Subject: [PATCH 107/334] [Tests] Fix `test_sync_pipeline_chunks` (#3517)
---
tests/system/feature_store/test_feature_store.py | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/tests/system/feature_store/test_feature_store.py b/tests/system/feature_store/test_feature_store.py
index af71566de6d8..5f4984548887 100644
--- a/tests/system/feature_store/test_feature_store.py
+++ b/tests/system/feature_store/test_feature_store.py
@@ -1853,7 +1853,7 @@ def test_sync_pipeline_chunks(self, with_graph):
self._logger.info(f"output df:\n{df}")
reference_df = pd.read_csv(csv_file)
- reference_df = reference_df[0:chunksize].set_index("patient_id")
+ reference_df = reference_df.set_index("patient_id")
# patient_id (index) and timestamp (timestamp_key) are not in features list
assert features + ["timestamp"] == list(reference_df.columns)
From 1605e16fcd4c9c45cab8aff8296519310a20a4a5 Mon Sep 17 00:00:00 2001
From: Yan Burman
Date: Wed, 10 May 2023 12:42:45 +0300
Subject: [PATCH 108/334] [Docs] Format ipynb files and add black[jupyter] to
packages (#3515)
---
dev-requirements.txt | 4 +-
docs/deployment/batch_inference.ipynb | 30 +--
docs/feature-store/basic-demo.ipynb | 77 ++++---
.../01-ingest-datasources.ipynb | 198 +++++++++++-------
.../02-create-training-model.ipynb | 155 +++++++-------
.../03-deploy-serving-model.ipynb | 71 ++++---
.../end-to-end-demo/04-pipeline.ipynb | 26 +--
docs/hyper-params.ipynb | 62 ++++--
.../initial-setup-configuration.ipynb | 27 ++-
docs/runtimes/dask-mlrun.ipynb | 50 ++---
docs/runtimes/dask-overview.ipynb | 30 +--
docs/runtimes/dask-pipeline.ipynb | 18 +-
docs/runtimes/mlrun_code_annotations.ipynb | 24 ++-
docs/runtimes/spark-operator.ipynb | 22 +-
docs/serving/distributed-graph.ipynb | 44 ++--
docs/serving/getting-started.ipynb | 21 +-
docs/serving/graph-example.ipynb | 42 ++--
docs/serving/model-serving-get-started.ipynb | 92 ++++----
docs/serving/realtime-pipelines.ipynb | 44 ++--
docs/serving/writing-custom-steps.ipynb | 6 +-
.../training/built-in-training-function.ipynb | 17 +-
.../create-a-basic-training-job.ipynb | 8 +-
docs/tutorial/01-mlrun-basics.ipynb | 79 +++++--
docs/tutorial/02-model-training.ipynb | 89 +++++---
docs/tutorial/03-model-serving.ipynb | 38 ++--
docs/tutorial/04-pipeline.ipynb | 57 ++++-
docs/tutorial/05-model-monitoring.ipynb | 25 ++-
docs/tutorial/06-add-mlops-to-code.ipynb | 14 +-
docs/tutorial/07-batch-infer.ipynb | 20 +-
examples/load-project.ipynb | 34 ++-
examples/mlrun_basics.ipynb | 90 ++++----
examples/mlrun_dask.ipynb | 60 +++---
examples/mlrun_db.ipynb | 14 +-
examples/mlrun_export_import.ipynb | 75 ++++---
examples/mlrun_jobs.ipynb | 163 +++++++-------
examples/mlrun_sparkk8s.ipynb | 117 ++++++-----
examples/mlrun_vault.ipynb | 44 ++--
examples/new-project.ipynb | 26 ++-
examples/remote-spark.ipynb | 32 +--
examples/v2_model_server.ipynb | 36 ++--
examples/xgb_serving.ipynb | 27 +--
41 files changed, 1253 insertions(+), 855 deletions(-)
diff --git a/dev-requirements.txt b/dev-requirements.txt
index 2f3c00bd1289..5f60e63bc9a0 100644
--- a/dev-requirements.txt
+++ b/dev-requirements.txt
@@ -1,6 +1,6 @@
pytest~=7.0
twine~=3.1
-black~=22.0
+black[jupyter]~=22.0
flake8~=5.0
pytest-asyncio~=0.15.0
pytest-alembic~=0.9.1
@@ -20,4 +20,4 @@ scikit-learn~=1.0
lightgbm~=3.0; platform_machine != 'arm64'
xgboost~=1.1
sqlalchemy_utils~=0.39.0
-import-linter~=1.8
\ No newline at end of file
+import-linter~=1.8
diff --git a/docs/deployment/batch_inference.ipynb b/docs/deployment/batch_inference.ipynb
index 9db49a64d85f..fcf6d4702f62 100644
--- a/docs/deployment/batch_inference.ipynb
+++ b/docs/deployment/batch_inference.ipynb
@@ -90,7 +90,10 @@
"outputs": [],
"source": [
"import mlrun\n",
- "project = mlrun.get_or_create_project('batch-inference', context=\"./\", user_project=True)\n",
+ "\n",
+ "project = mlrun.get_or_create_project(\n",
+ " \"batch-inference\", context=\"./\", user_project=True\n",
+ ")\n",
"batch_inference = mlrun.import_function(\"hub://batch_inference\")"
]
},
@@ -109,12 +112,10 @@
"metadata": {},
"outputs": [],
"source": [
- "model_path = mlrun.get_sample_path('models/batch-predict/model.pkl')\n",
+ "model_path = mlrun.get_sample_path(\"models/batch-predict/model.pkl\")\n",
"\n",
"model_artifact = project.log_model(\n",
- " key=\"model\",\n",
- " model_file=model_path,\n",
- " framework=\"sklearn\"\n",
+ " key=\"model\", model_file=model_path, framework=\"sklearn\"\n",
")"
]
},
@@ -133,7 +134,7 @@
"metadata": {},
"outputs": [],
"source": [
- "prediction_set_path = mlrun.get_sample_path('data/batch-predict/prediction_set.parquet')"
+ "prediction_set_path = mlrun.get_sample_path(\"data/batch-predict/prediction_set.parquet\")"
]
},
{
@@ -415,7 +416,7 @@
" batch_inference,\n",
" inputs={\"dataset\": prediction_set_path},\n",
" params={\"model\": model_artifact.uri},\n",
- " schedule='*/30 * * * *'\n",
+ " schedule=\"*/30 * * * *\",\n",
")"
]
},
@@ -442,18 +443,17 @@
"metadata": {},
"outputs": [],
"source": [
- "training_set_path = mlrun.get_sample_path('data/batch-predict/training_set.parquet')\n",
+ "training_set_path = mlrun.get_sample_path(\"data/batch-predict/training_set.parquet\")\n",
"\n",
"batch_run = project.run_function(\n",
" batch_inference,\n",
- " inputs={\n",
- " \"dataset\": prediction_set_path,\n",
- " \"sample_set\": training_set_path\n",
+ " inputs={\"dataset\": prediction_set_path, \"sample_set\": training_set_path},\n",
+ " params={\n",
+ " \"model\": model_artifact.uri,\n",
+ " \"label_columns\": \"label\",\n",
+ " \"perform_drift_analysis\": True,\n",
" },\n",
- " params={\"model\": model_artifact.uri,\n",
- " \"label_columns\": \"label\",\n",
- " \"perform_drift_analysis\" : True}\n",
- ")\n"
+ ")"
]
},
{
diff --git a/docs/feature-store/basic-demo.ipynb b/docs/feature-store/basic-demo.ipynb
index b4767501b4d8..a7af9a1d79a5 100644
--- a/docs/feature-store/basic-demo.ipynb
+++ b/docs/feature-store/basic-demo.ipynb
@@ -58,6 +58,7 @@
],
"source": [
"import mlrun\n",
+ "\n",
"mlrun.get_or_create_project(\"stocks\", \"./\")"
]
},
@@ -79,6 +80,7 @@
"outputs": [],
"source": [
"import pandas as pd\n",
+ "\n",
"quotes = pd.DataFrame(\n",
" {\n",
" \"time\": [\n",
@@ -89,55 +91,49 @@
" pd.Timestamp(\"2016-05-25 13:30:00.048\"),\n",
" pd.Timestamp(\"2016-05-25 13:30:00.049\"),\n",
" pd.Timestamp(\"2016-05-25 13:30:00.072\"),\n",
- " pd.Timestamp(\"2016-05-25 13:30:00.075\")\n",
+ " pd.Timestamp(\"2016-05-25 13:30:00.075\"),\n",
" ],\n",
- " \"ticker\": [\n",
- " \"GOOG\",\n",
- " \"MSFT\",\n",
- " \"MSFT\",\n",
- " \"MSFT\",\n",
- " \"GOOG\",\n",
- " \"AAPL\",\n",
- " \"GOOG\",\n",
- " \"MSFT\"\n",
- " ],\n",
- " \"bid\": [720.50, 51.95, 51.97, 51.99, 720.50, 97.99, 720.50, 52.01],\n",
- " \"ask\": [720.93, 51.96, 51.98, 52.00, 720.93, 98.01, 720.88, 52.03]\n",
+ " \"ticker\": [\"GOOG\", \"MSFT\", \"MSFT\", \"MSFT\", \"GOOG\", \"AAPL\", \"GOOG\", \"MSFT\"],\n",
+ " \"bid\": [720.50, 51.95, 51.97, 51.99, 720.50, 97.99, 720.50, 52.01],\n",
+ " \"ask\": [720.93, 51.96, 51.98, 52.00, 720.93, 98.01, 720.88, 52.03],\n",
" }\n",
")\n",
"\n",
"trades = pd.DataFrame(\n",
- " {\n",
- " \"time\": [\n",
- " pd.Timestamp(\"2016-05-25 13:30:00.023\"),\n",
- " pd.Timestamp(\"2016-05-25 13:30:00.038\"),\n",
- " pd.Timestamp(\"2016-05-25 13:30:00.048\"),\n",
- " pd.Timestamp(\"2016-05-25 13:30:00.048\"),\n",
- " pd.Timestamp(\"2016-05-25 13:30:00.048\")\n",
- " ],\n",
- " \"ticker\": [\"MSFT\", \"MSFT\", \"GOOG\", \"GOOG\", \"AAPL\"],\n",
- " \"price\": [51.95, 51.95, 720.77, 720.92, 98.0],\n",
- " \"quantity\": [75, 155, 100, 100, 100]\n",
- " }\n",
+ " {\n",
+ " \"time\": [\n",
+ " pd.Timestamp(\"2016-05-25 13:30:00.023\"),\n",
+ " pd.Timestamp(\"2016-05-25 13:30:00.038\"),\n",
+ " pd.Timestamp(\"2016-05-25 13:30:00.048\"),\n",
+ " pd.Timestamp(\"2016-05-25 13:30:00.048\"),\n",
+ " pd.Timestamp(\"2016-05-25 13:30:00.048\"),\n",
+ " ],\n",
+ " \"ticker\": [\"MSFT\", \"MSFT\", \"GOOG\", \"GOOG\", \"AAPL\"],\n",
+ " \"price\": [51.95, 51.95, 720.77, 720.92, 98.0],\n",
+ " \"quantity\": [75, 155, 100, 100, 100],\n",
+ " }\n",
")\n",
"\n",
"\n",
"stocks = pd.DataFrame(\n",
- " {\n",
- " \"ticker\": [\"MSFT\", \"GOOG\", \"AAPL\"],\n",
- " \"name\": [\"Microsoft Corporation\", \"Alphabet Inc\", \"Apple Inc\"],\n",
- " \"exchange\": [\"NASDAQ\", \"NASDAQ\", \"NASDAQ\"]\n",
- " }\n",
+ " {\n",
+ " \"ticker\": [\"MSFT\", \"GOOG\", \"AAPL\"],\n",
+ " \"name\": [\"Microsoft Corporation\", \"Alphabet Inc\", \"Apple Inc\"],\n",
+ " \"exchange\": [\"NASDAQ\", \"NASDAQ\", \"NASDAQ\"],\n",
+ " }\n",
")\n",
"\n",
"import datetime\n",
+ "\n",
+ "\n",
"def move_date(df, col):\n",
" max_date = df[col].max()\n",
" now_date = datetime.datetime.now()\n",
- " delta = now_date - max_date \n",
- " df[col] = df[col] + delta \n",
+ " delta = now_date - max_date\n",
+ " df[col] = df[col] + delta\n",
" return df\n",
"\n",
+ "\n",
"quotes = move_date(quotes, \"time\")\n",
"trades = move_date(trades, \"time\")"
]
@@ -529,7 +525,7 @@
}
],
"source": [
- "# add feature set without time column (stock ticker metadata) \n",
+ "# add feature set without time column (stock ticker metadata)\n",
"stocks_set = fstore.FeatureSet(\"stocks\", entities=[fstore.Entity(\"ticker\")])\n",
"fstore.ingest(stocks_set, stocks, infer_options=fstore.InferOptions.default())"
]
@@ -708,10 +704,9 @@
}
],
"source": [
- "quotes_set.graph.to(\"MyMap\", multiplier=3)\\\n",
- " .to(\"storey.Extend\", _fn=\"({'extra': event['bid'] * 77})\")\\\n",
- " .to(\"storey.Filter\", \"filter\", _fn=\"(event['bid'] > 51.92)\")\\\n",
- " .to(FeaturesetValidator())\n",
+ "quotes_set.graph.to(\"MyMap\", multiplier=3).to(\n",
+ " \"storey.Extend\", _fn=\"({'extra': event['bid'] * 77})\"\n",
+ ").to(\"storey.Filter\", \"filter\", _fn=\"(event['bid'] > 51.92)\").to(FeaturesetValidator())\n",
"\n",
"quotes_set.add_aggregation(\"ask\", [\"sum\", \"max\"], \"1h\", \"10m\", name=\"asks1\")\n",
"quotes_set.add_aggregation(\"ask\", [\"sum\", \"max\"], \"5h\", \"10m\", name=\"asks5\")\n",
@@ -1740,7 +1735,9 @@
" \"stocks.*\",\n",
"]\n",
"\n",
- "vector = fstore.FeatureVector(\"stocks-vec\", features, description=\"stocks demo feature vector\")\n",
+ "vector = fstore.FeatureVector(\n",
+ " \"stocks-vec\", features, description=\"stocks demo feature vector\"\n",
+ ")\n",
"vector.save()"
]
},
@@ -1862,7 +1859,9 @@
}
],
"source": [
- "resp = fstore.get_offline_features(vector, entity_rows=trades, entity_timestamp_column=\"time\")\n",
+ "resp = fstore.get_offline_features(\n",
+ " vector, entity_rows=trades, entity_timestamp_column=\"time\"\n",
+ ")\n",
"resp.to_dataframe()"
]
},
diff --git a/docs/feature-store/end-to-end-demo/01-ingest-datasources.ipynb b/docs/feature-store/end-to-end-demo/01-ingest-datasources.ipynb
index cf8cbc8c40aa..0143bb803b30 100644
--- a/docs/feature-store/end-to-end-demo/01-ingest-datasources.ipynb
+++ b/docs/feature-store/end-to-end-demo/01-ingest-datasources.ipynb
@@ -89,7 +89,7 @@
"metadata": {},
"outputs": [],
"source": [
- "project_name = 'fraud-demo'"
+ "project_name = \"fraud-demo\""
]
},
{
@@ -109,7 +109,7 @@
"import mlrun\n",
"\n",
"# Initialize the MLRun project object\n",
- "project = mlrun.get_or_create_project(project_name, context=\"./\", user_project=True) "
+ "project = mlrun.get_or_create_project(project_name, context=\"./\", user_project=True)"
]
},
{
@@ -147,33 +147,41 @@
"# while keeping the order of the selected events and\n",
"# the relative distance from one event to the other\n",
"\n",
+ "\n",
"def date_adjustment(sample, data_max, new_max, old_data_period, new_data_period):\n",
- " '''\n",
- " Adjust a specific sample's date according to the original and new time periods\n",
- " '''\n",
- " sample_dates_scale = ((data_max - sample) / old_data_period)\n",
+ " \"\"\"\n",
+ " Adjust a specific sample's date according to the original and new time periods\n",
+ " \"\"\"\n",
+ " sample_dates_scale = (data_max - sample) / old_data_period\n",
" sample_delta = new_data_period * sample_dates_scale\n",
" new_sample_ts = new_max - sample_delta\n",
" return new_sample_ts\n",
"\n",
- "def adjust_data_timespan(dataframe, timestamp_col='timestamp', new_period='2d', new_max_date_str='now'):\n",
- " '''\n",
- " Adjust the dataframe timestamps to the new time period\n",
- " '''\n",
+ "\n",
+ "def adjust_data_timespan(\n",
+ " dataframe, timestamp_col=\"timestamp\", new_period=\"2d\", new_max_date_str=\"now\"\n",
+ "):\n",
+ " \"\"\"\n",
+ " Adjust the dataframe timestamps to the new time period\n",
+ " \"\"\"\n",
" # Calculate old time period\n",
" data_min = dataframe.timestamp.min()\n",
" data_max = dataframe.timestamp.max()\n",
- " old_data_period = data_max-data_min\n",
- " \n",
+ " old_data_period = data_max - data_min\n",
+ "\n",
" # Set new time period\n",
" new_time_period = pd.Timedelta(new_period)\n",
" new_max = pd.Timestamp(new_max_date_str)\n",
- " new_min = new_max-new_time_period\n",
- " new_data_period = new_max-new_min\n",
- " \n",
+ " new_min = new_max - new_time_period\n",
+ " new_data_period = new_max - new_min\n",
+ "\n",
" # Apply the timestamp change\n",
" df = dataframe.copy()\n",
- " df[timestamp_col] = df[timestamp_col].apply(lambda x: date_adjustment(x, data_max, new_max, old_data_period, new_data_period))\n",
+ " df[timestamp_col] = df[timestamp_col].apply(\n",
+ " lambda x: date_adjustment(\n",
+ " x, data_max, new_max, old_data_period, new_data_period\n",
+ " )\n",
+ " )\n",
" return df"
]
},
@@ -293,16 +301,19 @@
"import pandas as pd\n",
"\n",
"# Fetch the transactions dataset from the server\n",
- "transactions_data = pd.read_csv('https://s3.wasabisys.com/iguazio/data/fraud-demo-mlrun-fs-docs/data.csv', parse_dates=['timestamp'])\n",
+ "transactions_data = pd.read_csv(\n",
+ " \"https://s3.wasabisys.com/iguazio/data/fraud-demo-mlrun-fs-docs/data.csv\",\n",
+ " parse_dates=[\"timestamp\"],\n",
+ ")\n",
"\n",
"# use only first 50k\n",
- "transactions_data = transactions_data.sort_values(by='source', axis=0)[:10000]\n",
+ "transactions_data = transactions_data.sort_values(by=\"source\", axis=0)[:10000]\n",
"\n",
"# Adjust the samples timestamp for the past 2 days\n",
- "transactions_data = adjust_data_timespan(transactions_data, new_period='2d')\n",
+ "transactions_data = adjust_data_timespan(transactions_data, new_period=\"2d\")\n",
"\n",
"# Sorting after adjusting timestamps\n",
- "transactions_data = transactions_data.sort_values(by='timestamp', axis=0)\n",
+ "transactions_data = transactions_data.sort_values(by=\"timestamp\", axis=0)\n",
"\n",
"# Preview\n",
"transactions_data.head(3)"
@@ -345,10 +356,12 @@
"outputs": [],
"source": [
"# Define the transactions FeatureSet\n",
- "transaction_set = fstore.FeatureSet(\"transactions\", \n",
- " entities=[fstore.Entity(\"source\")], \n",
- " timestamp_key='timestamp', \n",
- " description=\"transactions feature set\")"
+ "transaction_set = fstore.FeatureSet(\n",
+ " \"transactions\",\n",
+ " entities=[fstore.Entity(\"source\")],\n",
+ " timestamp_key=\"timestamp\",\n",
+ " description=\"transactions feature set\",\n",
+ ")"
]
},
{
@@ -464,35 +477,57 @@
],
"source": [
"# Define and add value mapping\n",
- "main_categories = [\"es_transportation\", \"es_health\", \"es_otherservices\",\n",
- " \"es_food\", \"es_hotelservices\", \"es_barsandrestaurants\",\n",
- " \"es_tech\", \"es_sportsandtoys\", \"es_wellnessandbeauty\",\n",
- " \"es_hyper\", \"es_fashion\", \"es_home\", \"es_contents\",\n",
- " \"es_travel\", \"es_leisure\"]\n",
+ "main_categories = [\n",
+ " \"es_transportation\",\n",
+ " \"es_health\",\n",
+ " \"es_otherservices\",\n",
+ " \"es_food\",\n",
+ " \"es_hotelservices\",\n",
+ " \"es_barsandrestaurants\",\n",
+ " \"es_tech\",\n",
+ " \"es_sportsandtoys\",\n",
+ " \"es_wellnessandbeauty\",\n",
+ " \"es_hyper\",\n",
+ " \"es_fashion\",\n",
+ " \"es_home\",\n",
+ " \"es_contents\",\n",
+ " \"es_travel\",\n",
+ " \"es_leisure\",\n",
+ "]\n",
"\n",
"# One Hot Encode the newly defined mappings\n",
- "one_hot_encoder_mapping = {'category': main_categories,\n",
- " 'gender': list(transactions_data.gender.unique())}\n",
+ "one_hot_encoder_mapping = {\n",
+ " \"category\": main_categories,\n",
+ " \"gender\": list(transactions_data.gender.unique()),\n",
+ "}\n",
"\n",
"# Define the graph steps\n",
- "transaction_set.graph\\\n",
- " .to(DateExtractor(parts = ['hour', 'day_of_week'], timestamp_col = 'timestamp'))\\\n",
- " .to(MapValues(mapping={'age': {'U': '0'}}, with_original_features=True))\\\n",
- " .to(OneHotEncoder(mapping=one_hot_encoder_mapping))\n",
+ "transaction_set.graph.to(\n",
+ " DateExtractor(parts=[\"hour\", \"day_of_week\"], timestamp_col=\"timestamp\")\n",
+ ").to(MapValues(mapping={\"age\": {\"U\": \"0\"}}, with_original_features=True)).to(\n",
+ " OneHotEncoder(mapping=one_hot_encoder_mapping)\n",
+ ")\n",
"\n",
"\n",
"# Add aggregations for 2, 12, and 24 hour time windows\n",
- "transaction_set.add_aggregation(name='amount',\n",
- " column='amount',\n",
- " operations=['avg','sum', 'count','max'],\n",
- " windows=['2h', '12h', '24h'],\n",
- " period='1h')\n",
+ "transaction_set.add_aggregation(\n",
+ " name=\"amount\",\n",
+ " column=\"amount\",\n",
+ " operations=[\"avg\", \"sum\", \"count\", \"max\"],\n",
+ " windows=[\"2h\", \"12h\", \"24h\"],\n",
+ " period=\"1h\",\n",
+ ")\n",
"\n",
"\n",
"# Add the category aggregations over a 14 day window\n",
"for category in main_categories:\n",
- " transaction_set.add_aggregation(name=category,column=f'category_{category}',\n",
- " operations=['sum'], windows=['14d'], period='1d')\n",
+ " transaction_set.add_aggregation(\n",
+ " name=category,\n",
+ " column=f\"category_{category}\",\n",
+ " operations=[\"sum\"],\n",
+ " windows=[\"14d\"],\n",
+ " period=\"1d\",\n",
+ " )\n",
"\n",
"# Add default (offline-parquet & online-nosql) targets\n",
"transaction_set.set_targets()\n",
@@ -712,8 +747,9 @@
],
"source": [
"# Ingest your transactions dataset through your defined pipeline\n",
- "transactions_df = fstore.ingest(transaction_set, transactions_data, \n",
- " infer_options=fstore.InferOptions.default())\n",
+ "transactions_df = fstore.ingest(\n",
+ " transaction_set, transactions_data, infer_options=fstore.InferOptions.default()\n",
+ ")\n",
"\n",
"transactions_df.head(3)"
]
@@ -825,11 +861,15 @@
],
"source": [
"# Fetch the user_events dataset from the server\n",
- "user_events_data = pd.read_csv('https://s3.wasabisys.com/iguazio/data/fraud-demo-mlrun-fs-docs/events.csv', \n",
- " index_col=0, quotechar=\"\\'\", parse_dates=['timestamp'])\n",
+ "user_events_data = pd.read_csv(\n",
+ " \"https://s3.wasabisys.com/iguazio/data/fraud-demo-mlrun-fs-docs/events.csv\",\n",
+ " index_col=0,\n",
+ " quotechar=\"'\",\n",
+ " parse_dates=[\"timestamp\"],\n",
+ ")\n",
"\n",
"# Adjust to the last 2 days to see the latest aggregations in the online feature vectors\n",
- "user_events_data = adjust_data_timespan(user_events_data, new_period='2d')\n",
+ "user_events_data = adjust_data_timespan(user_events_data, new_period=\"2d\")\n",
"\n",
"# Preview\n",
"user_events_data.head(3)"
@@ -851,10 +891,12 @@
"metadata": {},
"outputs": [],
"source": [
- "user_events_set = fstore.FeatureSet(\"events\",\n",
- " entities=[fstore.Entity(\"source\")],\n",
- " timestamp_key='timestamp', \n",
- " description=\"user events feature set\")"
+ "user_events_set = fstore.FeatureSet(\n",
+ " \"events\",\n",
+ " entities=[fstore.Entity(\"source\")],\n",
+ " timestamp_key=\"timestamp\",\n",
+ " description=\"user events feature set\",\n",
+ ")"
]
},
{
@@ -934,7 +976,7 @@
],
"source": [
"# Define and add value mapping\n",
- "events_mapping = {'event': list(user_events_data.event.unique())}\n",
+ "events_mapping = {\"event\": list(user_events_data.event.unique())}\n",
"\n",
"# One Hot Encode\n",
"user_events_set.graph.to(OneHotEncoder(mapping=events_mapping))\n",
@@ -1065,10 +1107,10 @@
"outputs": [],
"source": [
"def create_labels(df):\n",
- " labels = df[['fraud','timestamp']].copy()\n",
+ " labels = df[[\"fraud\", \"timestamp\"]].copy()\n",
" labels = labels.rename(columns={\"fraud\": \"label\"})\n",
- " labels['timestamp'] = labels['timestamp'].astype(\"datetime64[ms]\")\n",
- " labels['label'] = labels['label'].astype(int)\n",
+ " labels[\"timestamp\"] = labels[\"timestamp\"].astype(\"datetime64[ms]\")\n",
+ " labels[\"label\"] = labels[\"label\"].astype(int)\n",
" return labels"
]
},
@@ -1140,17 +1182,21 @@
"import os\n",
"\n",
"# Define the \"labels\" feature set\n",
- "labels_set = fstore.FeatureSet(\"labels\", \n",
- " entities=[fstore.Entity(\"source\")], \n",
- " timestamp_key='timestamp',\n",
- " description=\"training labels\",\n",
- " engine=\"pandas\")\n",
+ "labels_set = fstore.FeatureSet(\n",
+ " \"labels\",\n",
+ " entities=[fstore.Entity(\"source\")],\n",
+ " timestamp_key=\"timestamp\",\n",
+ " description=\"training labels\",\n",
+ " engine=\"pandas\",\n",
+ ")\n",
"\n",
"labels_set.graph.to(name=\"create_labels\", handler=create_labels)\n",
"\n",
"\n",
"# specify only Parquet (offline) target since its not used for real-time\n",
- "target = ParquetTarget(name='labels',path=f'v3io:///projects/{project.name}/target.parquet')\n",
+ "target = ParquetTarget(\n",
+ " name=\"labels\", path=f\"v3io:///projects/{project.name}/target.parquet\"\n",
+ ")\n",
"labels_set.set_targets([target], with_defaults=False)\n",
"labels_set.plot(with_targets=True)"
]
@@ -1273,7 +1319,7 @@
"outputs": [],
"source": [
"# Create iguazio v3io stream and transactions push API endpoint\n",
- "transaction_stream = f'v3io:///projects/{project.name}/streams/transaction'\n",
+ "transaction_stream = f\"v3io:///projects/{project.name}/streams/transaction\"\n",
"transaction_pusher = mlrun.datastore.get_stream_pusher(transaction_stream)"
]
},
@@ -1299,11 +1345,15 @@
"source": [
"# Define the source stream trigger (use v3io streams)\n",
"# define the `key` and `time` fields (extracted from the Json message).\n",
- "source = mlrun.datastore.sources.StreamSource(path=transaction_stream , key_field='source', time_field='timestamp')\n",
+ "source = mlrun.datastore.sources.StreamSource(\n",
+ " path=transaction_stream, key_field=\"source\", time_field=\"timestamp\"\n",
+ ")\n",
"\n",
"# Deploy the transactions feature set's ingestion service over a real-time (Nuclio) serverless function\n",
"# you can use the run_config parameter to pass function/service specific configuration\n",
- "transaction_set_endpoint = fstore.deploy_ingestion_service(featureset=transaction_set, source=source)"
+ "transaction_set_endpoint = fstore.deploy_ingestion_service(\n",
+ " featureset=transaction_set, source=source\n",
+ ")"
]
},
{
@@ -1355,8 +1405,10 @@
"import json\n",
"\n",
"# Select a sample from the dataset and serialize it to JSON\n",
- "transaction_sample = json.loads(transactions_data.sample(1).to_json(orient='records'))[0]\n",
- "transaction_sample['timestamp'] = str(pd.Timestamp.now())\n",
+ "transaction_sample = json.loads(transactions_data.sample(1).to_json(orient=\"records\"))[\n",
+ " 0\n",
+ "]\n",
+ "transaction_sample[\"timestamp\"] = str(pd.Timestamp.now())\n",
"transaction_sample"
]
},
@@ -1403,7 +1455,7 @@
"outputs": [],
"source": [
"# Create iguazio v3io stream and transactions push API endpoint\n",
- "events_stream = f'v3io:///projects/{project.name}/streams/events'\n",
+ "events_stream = f\"v3io:///projects/{project.name}/streams/events\"\n",
"events_pusher = mlrun.datastore.get_stream_pusher(events_stream)"
]
},
@@ -1427,11 +1479,15 @@
"source": [
"# Define the source stream trigger (use v3io streams)\n",
"# define the `key` and `time` fields (extracted from the Json message).\n",
- "source = mlrun.datastore.sources.StreamSource(path=events_stream , key_field='source', time_field='timestamp')\n",
+ "source = mlrun.datastore.sources.StreamSource(\n",
+ " path=events_stream, key_field=\"source\", time_field=\"timestamp\"\n",
+ ")\n",
"\n",
"# Deploy the transactions feature set's ingestion service over a real-time (Nuclio) serverless function\n",
"# you can use the run_config parameter to pass function/service specific configuration\n",
- "events_set_endpoint = fstore.deploy_ingestion_service(featureset=user_events_set, source=source)"
+ "events_set_endpoint = fstore.deploy_ingestion_service(\n",
+ " featureset=user_events_set, source=source\n",
+ ")"
]
},
{
@@ -1448,8 +1504,8 @@
"outputs": [],
"source": [
"# Select a sample from the events dataset and serialize it to JSON\n",
- "user_events_sample = json.loads(user_events_data.sample(1).to_json(orient='records'))[0]\n",
- "user_events_sample['timestamp'] = str(pd.Timestamp.now())\n",
+ "user_events_sample = json.loads(user_events_data.sample(1).to_json(orient=\"records\"))[0]\n",
+ "user_events_sample[\"timestamp\"] = str(pd.Timestamp.now())\n",
"user_events_sample"
]
},
diff --git a/docs/feature-store/end-to-end-demo/02-create-training-model.ipynb b/docs/feature-store/end-to-end-demo/02-create-training-model.ipynb
index b371f8f238f8..f5a56e748491 100644
--- a/docs/feature-store/end-to-end-demo/02-create-training-model.ipynb
+++ b/docs/feature-store/end-to-end-demo/02-create-training-model.ipynb
@@ -19,7 +19,7 @@
"metadata": {},
"outputs": [],
"source": [
- "project_name = 'fraud-demo'"
+ "project_name = \"fraud-demo\""
]
},
{
@@ -63,39 +63,41 @@
"outputs": [],
"source": [
"# Define the list of features to use\n",
- "features = ['events.*',\n",
- " 'transactions.amount_max_2h', \n",
- " 'transactions.amount_sum_2h', \n",
- " 'transactions.amount_count_2h',\n",
- " 'transactions.amount_avg_2h', \n",
- " 'transactions.amount_max_12h', \n",
- " 'transactions.amount_sum_12h',\n",
- " 'transactions.amount_count_12h', \n",
- " 'transactions.amount_avg_12h', \n",
- " 'transactions.amount_max_24h',\n",
- " 'transactions.amount_sum_24h', \n",
- " 'transactions.amount_count_24h', \n",
- " 'transactions.amount_avg_24h',\n",
- " 'transactions.es_transportation_sum_14d', \n",
- " 'transactions.es_health_sum_14d',\n",
- " 'transactions.es_otherservices_sum_14d', \n",
- " 'transactions.es_food_sum_14d',\n",
- " 'transactions.es_hotelservices_sum_14d', \n",
- " 'transactions.es_barsandrestaurants_sum_14d',\n",
- " 'transactions.es_tech_sum_14d', \n",
- " 'transactions.es_sportsandtoys_sum_14d',\n",
- " 'transactions.es_wellnessandbeauty_sum_14d', \n",
- " 'transactions.es_hyper_sum_14d',\n",
- " 'transactions.es_fashion_sum_14d', \n",
- " 'transactions.es_home_sum_14d', \n",
- " 'transactions.es_travel_sum_14d', \n",
- " 'transactions.es_leisure_sum_14d',\n",
- " 'transactions.gender_F',\n",
- " 'transactions.gender_M',\n",
- " 'transactions.step', \n",
- " 'transactions.amount', \n",
- " 'transactions.timestamp_hour',\n",
- " 'transactions.timestamp_day_of_week']"
+ "features = [\n",
+ " \"events.*\",\n",
+ " \"transactions.amount_max_2h\",\n",
+ " \"transactions.amount_sum_2h\",\n",
+ " \"transactions.amount_count_2h\",\n",
+ " \"transactions.amount_avg_2h\",\n",
+ " \"transactions.amount_max_12h\",\n",
+ " \"transactions.amount_sum_12h\",\n",
+ " \"transactions.amount_count_12h\",\n",
+ " \"transactions.amount_avg_12h\",\n",
+ " \"transactions.amount_max_24h\",\n",
+ " \"transactions.amount_sum_24h\",\n",
+ " \"transactions.amount_count_24h\",\n",
+ " \"transactions.amount_avg_24h\",\n",
+ " \"transactions.es_transportation_sum_14d\",\n",
+ " \"transactions.es_health_sum_14d\",\n",
+ " \"transactions.es_otherservices_sum_14d\",\n",
+ " \"transactions.es_food_sum_14d\",\n",
+ " \"transactions.es_hotelservices_sum_14d\",\n",
+ " \"transactions.es_barsandrestaurants_sum_14d\",\n",
+ " \"transactions.es_tech_sum_14d\",\n",
+ " \"transactions.es_sportsandtoys_sum_14d\",\n",
+ " \"transactions.es_wellnessandbeauty_sum_14d\",\n",
+ " \"transactions.es_hyper_sum_14d\",\n",
+ " \"transactions.es_fashion_sum_14d\",\n",
+ " \"transactions.es_home_sum_14d\",\n",
+ " \"transactions.es_travel_sum_14d\",\n",
+ " \"transactions.es_leisure_sum_14d\",\n",
+ " \"transactions.gender_F\",\n",
+ " \"transactions.gender_M\",\n",
+ " \"transactions.step\",\n",
+ " \"transactions.amount\",\n",
+ " \"transactions.timestamp_hour\",\n",
+ " \"transactions.timestamp_day_of_week\",\n",
+ "]"
]
},
{
@@ -108,13 +110,15 @@
"import mlrun.feature_store as fstore\n",
"\n",
"# Define the feature vector name for future reference\n",
- "fv_name = 'transactions-fraud'\n",
+ "fv_name = \"transactions-fraud\"\n",
"\n",
"# Define the feature vector using the feature store (fstore)\n",
- "transactions_fv = fstore.FeatureVector(fv_name, \n",
- " features, \n",
- " label_feature=\"labels.label\",\n",
- " description='Predicting a fraudulent transaction')\n",
+ "transactions_fv = fstore.FeatureVector(\n",
+ " fv_name,\n",
+ " features,\n",
+ " label_feature=\"labels.label\",\n",
+ " description=\"Predicting a fraudulent transaction\",\n",
+ ")\n",
"\n",
"# Save the feature vector in the feature store\n",
"transactions_fv.save()"
@@ -391,7 +395,7 @@
"outputs": [],
"source": [
"# Import the Sklearn classifier function from the functions hub\n",
- "classifier_fn = mlrun.import_function('hub://auto_trainer')"
+ "classifier_fn = mlrun.import_function(\"hub://auto_trainer\")"
]
},
{
@@ -677,24 +681,30 @@
"source": [
"# Prepare the parameters list for the training function\n",
"# you use 3 different models\n",
- "training_params = {\"model_name\": ['transaction_fraud_rf', \n",
- " 'transaction_fraud_xgboost', \n",
- " 'transaction_fraud_adaboost'],\n",
- " \n",
- " \"model_class\": ['sklearn.ensemble.RandomForestClassifier',\n",
- " 'sklearn.ensemble.GradientBoostingClassifier',\n",
- " 'sklearn.ensemble.AdaBoostClassifier']}\n",
+ "training_params = {\n",
+ " \"model_name\": [\n",
+ " \"transaction_fraud_rf\",\n",
+ " \"transaction_fraud_xgboost\",\n",
+ " \"transaction_fraud_adaboost\",\n",
+ " ],\n",
+ " \"model_class\": [\n",
+ " \"sklearn.ensemble.RandomForestClassifier\",\n",
+ " \"sklearn.ensemble.GradientBoostingClassifier\",\n",
+ " \"sklearn.ensemble.AdaBoostClassifier\",\n",
+ " ],\n",
+ "}\n",
"\n",
"# Define the training task, including your feature vector, label and hyperparams definitions\n",
- "train_task = mlrun.new_task('training', \n",
- " inputs={'dataset': transactions_fv.uri},\n",
- " params={'label_columns': 'label'}\n",
- " )\n",
+ "train_task = mlrun.new_task(\n",
+ " \"training\",\n",
+ " inputs={\"dataset\": transactions_fv.uri},\n",
+ " params={\"label_columns\": \"label\"},\n",
+ ")\n",
"\n",
- "train_task.with_hyper_params(training_params, strategy='list', selector='max.accuracy')\n",
+ "train_task.with_hyper_params(training_params, strategy=\"list\", selector=\"max.accuracy\")\n",
"\n",
"# Specify your cluster image\n",
- "classifier_fn.spec.image = 'mlrun/mlrun'\n",
+ "classifier_fn.spec.image = \"mlrun/mlrun\"\n",
"\n",
"# Run training\n",
"classifier_fn.run(train_task, local=False)"
@@ -954,19 +964,21 @@
}
],
"source": [
- "feature_selection_fn = mlrun.import_function('hub://feature_selection')\n",
+ "feature_selection_fn = mlrun.import_function(\"hub://feature_selection\")\n",
"\n",
"feature_selection_run = feature_selection_fn.run(\n",
- " params={\"k\": 18,\n",
- " \"min_votes\": 2,\n",
- " \"label_column\": 'label',\n",
- " 'output_vector_name':fv_name + \"-short\",\n",
- " 'ignore_type_errors': True},\n",
- " \n",
- " inputs={'df_artifact': transactions_fv.uri},\n",
- " name='feature_extraction',\n",
- " handler='feature_selection',\n",
- " local=False)"
+ " params={\n",
+ " \"k\": 18,\n",
+ " \"min_votes\": 2,\n",
+ " \"label_column\": \"label\",\n",
+ " \"output_vector_name\": fv_name + \"-short\",\n",
+ " \"ignore_type_errors\": True,\n",
+ " },\n",
+ " inputs={\"df_artifact\": transactions_fv.uri},\n",
+ " name=\"feature_extraction\",\n",
+ " handler=\"feature_selection\",\n",
+ " local=False,\n",
+ ")"
]
},
{
@@ -1156,7 +1168,7 @@
}
],
"source": [
- "mlrun.get_dataitem(feature_selection_run.outputs['top_features_vector']).as_df().tail(5)"
+ "mlrun.get_dataitem(feature_selection_run.outputs[\"top_features_vector\"]).as_df().tail(5)"
]
},
{
@@ -1452,11 +1464,14 @@
],
"source": [
"# Define your training task, including your feature vector, label and hyperparams definitions\n",
- "ensemble_train_task = mlrun.new_task('training', \n",
- " inputs={'dataset': feature_selection_run.outputs['top_features_vector']},\n",
- " params={'label_columns': 'label'}\n",
- " )\n",
- "ensemble_train_task.with_hyper_params(training_params, strategy='list', selector='max.accuracy')\n",
+ "ensemble_train_task = mlrun.new_task(\n",
+ " \"training\",\n",
+ " inputs={\"dataset\": feature_selection_run.outputs[\"top_features_vector\"]},\n",
+ " params={\"label_columns\": \"label\"},\n",
+ ")\n",
+ "ensemble_train_task.with_hyper_params(\n",
+ " training_params, strategy=\"list\", selector=\"max.accuracy\"\n",
+ ")\n",
"\n",
"classifier_fn.run(ensemble_train_task)"
]
diff --git a/docs/feature-store/end-to-end-demo/03-deploy-serving-model.ipynb b/docs/feature-store/end-to-end-demo/03-deploy-serving-model.ipynb
index 96a071749dac..8f3112b60810 100644
--- a/docs/feature-store/end-to-end-demo/03-deploy-serving-model.ipynb
+++ b/docs/feature-store/end-to-end-demo/03-deploy-serving-model.ipynb
@@ -71,7 +71,7 @@
"metadata": {},
"outputs": [],
"source": [
- "project_name = 'fraud-demo'"
+ "project_name = \"fraud-demo\""
]
},
{
@@ -122,17 +122,17 @@
"from cloudpickle import load\n",
"from mlrun.serving.v2_serving import V2ModelServer\n",
"\n",
+ "\n",
"class ClassifierModel(V2ModelServer):\n",
- " \n",
" def load(self):\n",
" \"\"\"load and initialize the model and/or other elements\"\"\"\n",
- " model_file, extra_data = self.get_model('.pkl')\n",
- " self.model = load(open(model_file, 'rb'))\n",
- " \n",
+ " model_file, extra_data = self.get_model(\".pkl\")\n",
+ " self.model = load(open(model_file, \"rb\"))\n",
+ "\n",
" def predict(self, body: dict) -> list:\n",
" \"\"\"Generate model predictions from sample\"\"\"\n",
" print(f\"Input -> {body['inputs']}\")\n",
- " feats = np.asarray(body['inputs'])\n",
+ " feats = np.asarray(body[\"inputs\"])\n",
" result: np.ndarray = self.model.predict(feats)\n",
" return result.tolist()"
]
@@ -257,19 +257,30 @@
],
"source": [
"# Create the serving function from your code above\n",
- "serving_fn = mlrun.code_to_function('transaction-fraud', kind='serving', image=\"mlrun/mlrun\").apply(mlrun.auto_mount())\n",
+ "serving_fn = mlrun.code_to_function(\n",
+ " \"transaction-fraud\", kind=\"serving\", image=\"mlrun/mlrun\"\n",
+ ").apply(mlrun.auto_mount())\n",
"\n",
- "serving_fn.set_topology('router', 'mlrun.serving.routers.EnrichmentVotingEnsemble', name='VotingEnsemble',\n",
- " feature_vector_uri=\"transactions-fraud-short\", impute_policy={\"*\": \"$mean\"})\n",
+ "serving_fn.set_topology(\n",
+ " \"router\",\n",
+ " \"mlrun.serving.routers.EnrichmentVotingEnsemble\",\n",
+ " name=\"VotingEnsemble\",\n",
+ " feature_vector_uri=\"transactions-fraud-short\",\n",
+ " impute_policy={\"*\": \"$mean\"},\n",
+ ")\n",
"\n",
"model_names = [\n",
- "'transaction_fraud_rf',\n",
- "'transaction_fraud_xgboost',\n",
- "'transaction_fraud_adaboost'\n",
+ " \"transaction_fraud_rf\",\n",
+ " \"transaction_fraud_xgboost\",\n",
+ " \"transaction_fraud_adaboost\",\n",
"]\n",
"\n",
"for i, name in enumerate(model_names, start=1):\n",
- " serving_fn.add_model(name, class_name=\"ClassifierModel\", model_path=project.get_artifact_uri(f\"{name}#{i}:latest\"))\n",
+ " serving_fn.add_model(\n",
+ " name,\n",
+ " class_name=\"ClassifierModel\",\n",
+ " model_path=project.get_artifact_uri(f\"{name}#{i}:latest\"),\n",
+ " )\n",
"\n",
"# Plot the ensemble configuration\n",
"serving_fn.spec.graph.plot()"
@@ -343,13 +354,12 @@
],
"source": [
"# Choose an id for your test\n",
- "sample_id = 'C1000148617'\n",
+ "sample_id = \"C1000148617\"\n",
"\n",
- "model_inference_path = '/v2/models/infer'\n",
+ "model_inference_path = \"/v2/models/infer\"\n",
"\n",
"# Send your sample ID for prediction\n",
- "local_server.test(path=model_inference_path,\n",
- " body={'inputs': [[sample_id]]})\n",
+ "local_server.test(path=model_inference_path, body={\"inputs\": [[sample_id]]})\n",
"\n",
"# notice the input vector is printed 3 times (once per child model) and is enriched with data from the feature store"
]
@@ -397,10 +407,12 @@
"import mlrun.feature_store as fstore\n",
"\n",
"# Create the online feature service\n",
- "svc = fstore.get_online_feature_service('transactions-fraud-short:latest', impute_policy={\"*\": \"$mean\"})\n",
+ "svc = fstore.get_online_feature_service(\n",
+ " \"transactions-fraud-short:latest\", impute_policy={\"*\": \"$mean\"}\n",
+ ")\n",
"\n",
"# Get sample feature vector\n",
- "sample_fv = svc.get([{'source': sample_id}])\n",
+ "sample_fv = svc.get([{\"source\": sample_id}])\n",
"sample_fv"
]
},
@@ -448,7 +460,7 @@
"\n",
"# Enable model monitoring\n",
"serving_fn.set_tracking()\n",
- "project.set_model_monitoring_credentials(os.getenv('V3IO_ACCESS_KEY'))\n",
+ "project.set_model_monitoring_credentials(os.getenv(\"V3IO_ACCESS_KEY\"))\n",
"\n",
"# Deploy the serving function\n",
"serving_fn.deploy()"
@@ -491,13 +503,12 @@
],
"source": [
"# Choose an id for your test\n",
- "sample_id = 'C1000148617'\n",
+ "sample_id = \"C1000148617\"\n",
"\n",
- "model_inference_path = '/v2/models/infer'\n",
+ "model_inference_path = \"/v2/models/infer\"\n",
"\n",
"# Send your sample ID for prediction\n",
- "serving_fn.invoke(path=model_inference_path,\n",
- " body={'inputs': [[sample_id]]})"
+ "serving_fn.invoke(path=model_inference_path, body={\"inputs\": [[sample_id]]})"
]
},
{
@@ -521,13 +532,15 @@
"outputs": [],
"source": [
"# Load the dataset\n",
- "data = mlrun.get_dataitem('https://s3.wasabisys.com/iguazio/data/fraud-demo-mlrun-fs-docs/data.csv').as_df()\n",
+ "data = mlrun.get_dataitem(\n",
+ " \"https://s3.wasabisys.com/iguazio/data/fraud-demo-mlrun-fs-docs/data.csv\"\n",
+ ").as_df()\n",
"\n",
"# use only first 10k\n",
- "data = data.sort_values(by='source', axis=0)[:10000]\n",
+ "data = data.sort_values(by=\"source\", axis=0)[:10000]\n",
"\n",
"# keys\n",
- "sample_ids = data['source'].to_list()"
+ "sample_ids = data[\"source\"].to_list()"
]
},
{
@@ -570,7 +583,9 @@
"for _ in range(10):\n",
" data_point = choice(sample_ids)\n",
" try:\n",
- " resp = serving_fn.invoke(path=model_inference_path, body={'inputs': [[data_point]]})\n",
+ " resp = serving_fn.invoke(\n",
+ " path=model_inference_path, body={\"inputs\": [[data_point]]}\n",
+ " )\n",
" print(resp)\n",
" sleep(uniform(0.2, 1.7))\n",
" except OSError:\n",
diff --git a/docs/feature-store/end-to-end-demo/04-pipeline.ipynb b/docs/feature-store/end-to-end-demo/04-pipeline.ipynb
index db3296b9aae1..415e6c8fab06 100644
--- a/docs/feature-store/end-to-end-demo/04-pipeline.ipynb
+++ b/docs/feature-store/end-to-end-demo/04-pipeline.ipynb
@@ -42,7 +42,7 @@
"outputs": [],
"source": [
"# Set the base project name\n",
- "project_name = 'fraud-demo'"
+ "project_name = \"fraud-demo\""
]
},
{
@@ -130,9 +130,9 @@
}
],
"source": [
- "project.set_function('hub://feature_selection', 'feature_selection')\n",
- "project.set_function('hub://auto_trainer','train')\n",
- "project.set_function('hub://v2_model_server', 'serving')"
+ "project.set_function(\"hub://feature_selection\", \"feature_selection\")\n",
+ "project.set_function(\"hub://auto_trainer\", \"train\")\n",
+ "project.set_function(\"hub://v2_model_server\", \"serving\")"
]
},
{
@@ -153,7 +153,7 @@
],
"source": [
"# set project level parameters and save\n",
- "project.spec.params = {'label_column': 'label'}\n",
+ "project.spec.params = {\"label_column\": \"label\"}\n",
"project.save()"
]
},
@@ -387,7 +387,7 @@
"outputs": [],
"source": [
"# Register the workflow file as \"main\"\n",
- "project.set_workflow('main', 'workflow.py')"
+ "project.set_workflow(\"main\", \"workflow.py\")"
]
},
{
@@ -572,10 +572,7 @@
}
],
"source": [
- "run_id = project.run(\n",
- " 'main',\n",
- " arguments={}, \n",
- " dirty=True, watch=True)"
+ "run_id = project.run(\"main\", arguments={}, dirty=True, watch=True)"
]
},
{
@@ -626,15 +623,14 @@
],
"source": [
"# Define your serving function\n",
- "serving_fn = project.get_function('serving')\n",
+ "serving_fn = project.get_function(\"serving\")\n",
"\n",
"# Choose an id for your test\n",
- "sample_id = 'C1000148617'\n",
- "model_inference_path = '/v2/models/fraud/infer'\n",
+ "sample_id = \"C1000148617\"\n",
+ "model_inference_path = \"/v2/models/fraud/infer\"\n",
"\n",
"# Send our sample ID for predcition\n",
- "serving_fn.invoke(path=model_inference_path,\n",
- " body={'inputs': [[sample_id]]})"
+ "serving_fn.invoke(path=model_inference_path, body={\"inputs\": [[sample_id]]})"
]
},
{
diff --git a/docs/hyper-params.ipynb b/docs/hyper-params.ipynb
index 5a947aa867f4..328f3c51f4e8 100644
--- a/docs/hyper-params.ipynb
+++ b/docs/hyper-params.ipynb
@@ -393,8 +393,10 @@
}
],
"source": [
- "grid_params = {\"p1\": [2,4,1], \"p2\": [10,20]}\n",
- "task = mlrun.new_task(\"grid-demo\").with_hyper_params(grid_params, selector=\"max.multiplier\")\n",
+ "grid_params = {\"p1\": [2, 4, 1], \"p2\": [10, 20]}\n",
+ "task = mlrun.new_task(\"grid-demo\").with_hyper_params(\n",
+ " grid_params, selector=\"max.multiplier\"\n",
+ ")\n",
"run = mlrun.new_function().run(task, handler=hyper_func)"
]
},
@@ -664,9 +666,11 @@
}
],
"source": [
- "grid_params = {\"p1\": [2,4,1,3], \"p2\": [10,20,30]}\n",
+ "grid_params = {\"p1\": [2, 4, 1, 3], \"p2\": [10, 20, 30]}\n",
"task = mlrun.new_task(\"random-demo\")\n",
- "task.with_hyper_params(grid_params, selector=\"max.multiplier\", strategy=\"random\", max_iterations=4)\n",
+ "task.with_hyper_params(\n",
+ " grid_params, selector=\"max.multiplier\", strategy=\"random\", max_iterations=4\n",
+ ")\n",
"run = mlrun.new_function().run(task, handler=hyper_func)"
]
},
@@ -925,9 +929,13 @@
}
],
"source": [
- "list_params = {\"p1\": [2,3,7,4,5], \"p2\": [15,10,10,20,30]}\n",
+ "list_params = {\"p1\": [2, 3, 7, 4, 5], \"p2\": [15, 10, 10, 20, 30]}\n",
"task = mlrun.new_task(\"list-demo\").with_hyper_params(\n",
- " list_params, selector=\"max.multiplier\", strategy=\"list\", stop_condition=\"multiplier>=70\")\n",
+ " list_params,\n",
+ " selector=\"max.multiplier\",\n",
+ " strategy=\"list\",\n",
+ " stop_condition=\"multiplier>=70\",\n",
+ ")\n",
"run = mlrun.new_function().run(task, handler=hyper_func)"
]
},
@@ -951,14 +959,14 @@
" for param in param_list:\n",
" with context.get_child_context(**param) as child:\n",
" hyper_func(child, **child.parameters)\n",
- " multiplier = child.results['multiplier']\n",
+ " multiplier = child.results[\"multiplier\"]\n",
" total += multiplier\n",
" if multiplier > best_multiplier:\n",
" child.mark_as_best()\n",
" best_multiplier = multiplier\n",
"\n",
" # log result at the parent\n",
- " context.log_result('avg_multiplier', total / len(param_list))"
+ " context.log_result(\"avg_multiplier\", total / len(param_list))"
]
},
{
@@ -1205,7 +1213,7 @@
}
],
"source": [
- "param_list = [{\"p1\":2, \"p2\":10}, {\"p1\":3, \"p2\":30}, {\"p1\":4, \"p2\":7}]\n",
+ "param_list = [{\"p1\": 2, \"p2\": 10}, {\"p1\": 3, \"p2\": 30}, {\"p1\": 4, \"p2\": 7}]\n",
"run = mlrun.new_function().run(handler=handler, params={\"param_list\": param_list})"
]
},
@@ -1252,6 +1260,8 @@
"source": [
"import socket\n",
"import pandas as pd\n",
+ "\n",
+ "\n",
"def hyper_func2(context, data, p1, p2, p3):\n",
" print(data.as_df().head())\n",
" context.logger.info(f\"p2={p2}, p3={p3}, r1={p2 * p3} at {socket.gethostname()}\")\n",
@@ -1307,10 +1317,10 @@
}
],
"source": [
- "dask_cluster = mlrun.new_function(\"dask-cluster\", kind='dask', image='mlrun/ml-models')\n",
- "dask_cluster.apply(mlrun.mount_v3io()) # add volume mounts\n",
- "dask_cluster.spec.service_type = \"NodePort\" # open interface to the dask UI dashboard\n",
- "dask_cluster.spec.replicas = 2 # define two containers\n",
+ "dask_cluster = mlrun.new_function(\"dask-cluster\", kind=\"dask\", image=\"mlrun/ml-models\")\n",
+ "dask_cluster.apply(mlrun.mount_v3io()) # add volume mounts\n",
+ "dask_cluster.spec.service_type = \"NodePort\" # open interface to the dask UI dashboard\n",
+ "dask_cluster.spec.replicas = 2 # define two containers\n",
"uri = dask_cluster.save()\n",
"uri"
]
@@ -1425,10 +1435,18 @@
}
],
"source": [
- "grid_params = {\"p2\": [2,1,4,1], \"p3\": [10,20]}\n",
- "task = mlrun.new_task(params={\"p1\": 8}, inputs={'data': 'https://s3.wasabisys.com/iguazio/data/iris/iris_dataset.csv'})\n",
+ "grid_params = {\"p2\": [2, 1, 4, 1], \"p3\": [10, 20]}\n",
+ "task = mlrun.new_task(\n",
+ " params={\"p1\": 8},\n",
+ " inputs={\"data\": \"https://s3.wasabisys.com/iguazio/data/iris/iris_dataset.csv\"},\n",
+ ")\n",
"task.with_hyper_params(\n",
- " grid_params, selector=\"r1\", strategy=\"grid\", parallel_runs=4, dask_cluster_uri=uri, teardown_dask=True\n",
+ " grid_params,\n",
+ " selector=\"r1\",\n",
+ " strategy=\"grid\",\n",
+ " parallel_runs=4,\n",
+ " dask_cluster_uri=uri,\n",
+ " teardown_dask=True,\n",
")"
]
},
@@ -1445,7 +1463,7 @@
"metadata": {},
"outputs": [],
"source": [
- "fn = mlrun.code_to_function(name='hyper-tst', kind='job', image='mlrun/ml-models')"
+ "fn = mlrun.code_to_function(name=\"hyper-tst\", kind=\"job\", image=\"mlrun/ml-models\")"
]
},
{
@@ -1844,7 +1862,7 @@
}
],
"source": [
- "fn = mlrun.code_to_function(name='hyper-tst2', kind='nuclio:mlrun', image='mlrun/mlrun')\n",
+ "fn = mlrun.code_to_function(name=\"hyper-tst2\", kind=\"nuclio:mlrun\", image=\"mlrun/mlrun\")\n",
"# replicas * workers need to match or exceed parallel_runs\n",
"fn.spec.replicas = 2\n",
"fn.with_http(workers=2)\n",
@@ -1867,6 +1885,7 @@
"# this is required to fix Jupyter issue with asyncio (not required outside of Jupyter)\n",
"# run it only once\n",
"import nest_asyncio\n",
+ "\n",
"nest_asyncio.apply()"
]
},
@@ -2144,8 +2163,11 @@
}
],
"source": [
- "grid_params = {\"p2\": [2,1,4,1], \"p3\": [10,20]}\n",
- "task = mlrun.new_task(params={\"p1\": 8}, inputs={'data': 'https://s3.wasabisys.com/iguazio/data/iris/iris_dataset.csv'})\n",
+ "grid_params = {\"p2\": [2, 1, 4, 1], \"p3\": [10, 20]}\n",
+ "task = mlrun.new_task(\n",
+ " params={\"p1\": 8},\n",
+ " inputs={\"data\": \"https://s3.wasabisys.com/iguazio/data/iris/iris_dataset.csv\"},\n",
+ ")\n",
"task.with_hyper_params(\n",
" grid_params, selector=\"r1\", strategy=\"grid\", parallel_runs=4, max_errors=3\n",
")\n",
diff --git a/docs/monitoring/initial-setup-configuration.ipynb b/docs/monitoring/initial-setup-configuration.ipynb
index b25fd9dcab6c..7a7e6f698fe7 100644
--- a/docs/monitoring/initial-setup-configuration.ipynb
+++ b/docs/monitoring/initial-setup-configuration.ipynb
@@ -90,15 +90,20 @@
"project.set_model_monitoring_credentials(os.environ.get(\"V3IO_ACCESS_KEY\"))\n",
"\n",
"# Download the pre-trained Iris model\n",
- "get_dataitem(\"https://s3.wasabisys.com/iguazio/models/iris/model.pkl\").download(\"model.pkl\")\n",
+ "get_dataitem(\"https://s3.wasabisys.com/iguazio/models/iris/model.pkl\").download(\n",
+ " \"model.pkl\"\n",
+ ")\n",
"\n",
"iris = load_iris()\n",
- "train_set = pd.DataFrame(iris['data'],\n",
- " columns=['sepal_length_cm', 'sepal_width_cm',\n",
- " 'petal_length_cm', 'petal_width_cm'])\n",
+ "train_set = pd.DataFrame(\n",
+ " iris[\"data\"],\n",
+ " columns=[\"sepal_length_cm\", \"sepal_width_cm\", \"petal_length_cm\", \"petal_width_cm\"],\n",
+ ")\n",
"\n",
"# Import the serving function from the Function Hub\n",
- "serving_fn = import_function('hub://v2_model_server', project=project_name).apply(auto_mount())\n",
+ "serving_fn = import_function(\"hub://v2_model_server\", project=project_name).apply(\n",
+ " auto_mount()\n",
+ ")\n",
"\n",
"model_name = \"RandomForestClassifier\"\n",
"\n",
@@ -106,7 +111,9 @@
"project.log_model(model_name, model_file=\"model.pkl\", training_set=train_set)\n",
"\n",
"# Add the model to the serving function's routing spec\n",
- "serving_fn.add_model(model_name, model_path=f\"store://models/{project_name}/{model_name}:latest\")\n",
+ "serving_fn.add_model(\n",
+ " model_name, model_path=f\"store://models/{project_name}/{model_name}:latest\"\n",
+ ")\n",
"\n",
"# Enable model monitoring\n",
"serving_fn.set_tracking()\n",
@@ -140,12 +147,14 @@
"from time import sleep\n",
"from random import choice, uniform\n",
"\n",
- "iris_data = iris['data'].tolist()\n",
+ "iris_data = iris[\"data\"].tolist()\n",
"\n",
"while True:\n",
" data_point = choice(iris_data)\n",
- " serving_fn.invoke(f'v2/models/{model_name}/infer', json.dumps({'inputs': [data_point]}))\n",
- " sleep(uniform(0.2, 1.7))\n"
+ " serving_fn.invoke(\n",
+ " f\"v2/models/{model_name}/infer\", json.dumps({\"inputs\": [data_point]})\n",
+ " )\n",
+ " sleep(uniform(0.2, 1.7))"
]
}
],
diff --git a/docs/runtimes/dask-mlrun.ipynb b/docs/runtimes/dask-mlrun.ipynb
index 5fd15e38318e..65951cd4a122 100644
--- a/docs/runtimes/dask-mlrun.ipynb
+++ b/docs/runtimes/dask-mlrun.ipynb
@@ -42,6 +42,7 @@
"source": [
"# set mlrun api path and artifact path for logging\n",
"import mlrun\n",
+ "\n",
"project = mlrun.get_or_create_project(\"dask-demo\", \"./\")"
]
},
@@ -89,7 +90,9 @@
"source": [
"# create an mlrun function that will init the dask cluster\n",
"dask_cluster_name = \"dask-cluster\"\n",
- "dask_cluster = mlrun.new_function(dask_cluster_name, kind='dask', image='mlrun/ml-models')\n",
+ "dask_cluster = mlrun.new_function(\n",
+ " dask_cluster_name, kind=\"dask\", image=\"mlrun/ml-models\"\n",
+ ")\n",
"dask_cluster.apply(mlrun.mount_v3io())"
]
},
@@ -103,12 +106,12 @@
"dask_cluster.spec.min_replicas = 1\n",
"dask_cluster.spec.max_replicas = 4\n",
"\n",
- "# set the use of dask remote cluster (distributed) \n",
+ "# set the use of dask remote cluster (distributed)\n",
"dask_cluster.spec.remote = True\n",
"dask_cluster.spec.service_type = \"NodePort\"\n",
"\n",
"# set dask memory and cpu limits\n",
- "dask_cluster.with_worker_requests(mem='2G', cpu='2')"
+ "dask_cluster.with_worker_requests(mem=\"2G\", cpu=\"2\")"
]
},
{
@@ -285,7 +288,7 @@
"metadata": {},
"outputs": [],
"source": [
- "import mlrun "
+ "import mlrun"
]
},
{
@@ -345,29 +348,26 @@
"metadata": {},
"outputs": [],
"source": [
- "def test_dask(context,\n",
- " dataset: mlrun.DataItem,\n",
- " client=None,\n",
- " dask_function: str=None) -> None:\n",
- " \n",
+ "def test_dask(\n",
+ " context, dataset: mlrun.DataItem, client=None, dask_function: str = None\n",
+ ") -> None:\n",
+ "\n",
" # setup dask client from the MLRun dask cluster function\n",
" if dask_function:\n",
" client = mlrun.import_function(dask_function).client\n",
" elif not client:\n",
" client = Client()\n",
- " \n",
+ "\n",
" # load the dataitem as dask dataframe (dd)\n",
" df = dataset.as_df(df_module=dd)\n",
- " \n",
+ "\n",
" # run describe (get statistics for the dataframe) with dask\n",
" df_describe = df.describe().compute()\n",
- " \n",
- " # run groupby and count using dask \n",
+ "\n",
+ " # run groupby and count using dask\n",
" df_grpby = df.groupby(\"VendorID\").count().compute()\n",
- " \n",
- " context.log_dataset(\"describe\", \n",
- " df=df_grpby,\n",
- " format='csv', index=True)\n",
+ "\n",
+ " context.log_dataset(\"describe\", df=df_grpby, format=\"csv\", index=True)\n",
" return"
]
},
@@ -400,7 +400,7 @@
"metadata": {},
"outputs": [],
"source": [
- "DATA_URL=\"/User/examples/ytrip.csv\""
+ "DATA_URL = \"/User/examples/ytrip.csv\""
]
},
{
@@ -444,9 +444,11 @@
"metadata": {},
"outputs": [],
"source": [
- "# mlrun transforms the code above (up to nuclio: end-code cell) into serverless function \n",
+ "# mlrun transforms the code above (up to nuclio: end-code cell) into serverless function\n",
"# which runs in k8s pods\n",
- "fn = mlrun.code_to_function(\"test_dask\", kind='job', handler=\"test_dask\").apply(mlrun.mount_v3io())"
+ "fn = mlrun.code_to_function(\"test_dask\", kind=\"job\", handler=\"test_dask\").apply(\n",
+ " mlrun.mount_v3io()\n",
+ ")"
]
},
{
@@ -470,7 +472,7 @@
"outputs": [],
"source": [
"# function URI is db:///\n",
- "dask_uri = f'db://{project.name}/{dask_cluster_name}'"
+ "dask_uri = f\"db://{project.name}/{dask_cluster_name}\""
]
},
{
@@ -723,9 +725,9 @@
}
],
"source": [
- "r = fn.run(handler = test_dask,\n",
- " inputs={\"dataset\": DATA_URL},\n",
- " params={\"dask_function\": dask_uri})"
+ "r = fn.run(\n",
+ " handler=test_dask, inputs={\"dataset\": DATA_URL}, params={\"dask_function\": dask_uri}\n",
+ ")"
]
},
{
diff --git a/docs/runtimes/dask-overview.ipynb b/docs/runtimes/dask-overview.ipynb
index 95b5b635ed56..913095625833 100644
--- a/docs/runtimes/dask-overview.ipynb
+++ b/docs/runtimes/dask-overview.ipynb
@@ -148,8 +148,9 @@
"from collections import Counter\n",
"from dask.distributed import Client\n",
"\n",
- "import warnings \n",
- "warnings.filterwarnings('ignore')"
+ "import warnings\n",
+ "\n",
+ "warnings.filterwarnings(\"ignore\")"
]
},
{
@@ -165,9 +166,9 @@
" :param size: the size in bytes\n",
" :return: void\n",
" \"\"\"\n",
- " chars = ''.join([random.choice(string.ascii_letters) for i in range(size)]) #1\n",
+ " chars = \"\".join([random.choice(string.ascii_letters) for i in range(size)]) # 1\n",
"\n",
- " with open(filename, 'w') as f:\n",
+ " with open(filename, \"w\") as f:\n",
" f.write(chars)\n",
" pass"
]
@@ -178,12 +179,11 @@
"metadata": {},
"outputs": [],
"source": [
- "PATH = '/User/howto/dask/random_files'\n",
+ "PATH = \"/User/howto/dask/random_files\"\n",
"SIZE = 10000000\n",
"\n",
"for i in range(100):\n",
- " generate_big_random_letters(filename = PATH + '/file_' + str(i) + '.txt', \n",
- " size = SIZE)"
+ " generate_big_random_letters(filename=PATH + \"/file_\" + str(i) + \".txt\", size=SIZE)"
]
},
{
@@ -212,10 +212,10 @@
"\n",
" # sort file\n",
" sorted_file = sorted(data)\n",
- " \n",
+ "\n",
" # count file\n",
" number_of_characters = len(sorted_file)\n",
- " \n",
+ "\n",
" return number_of_characters"
]
},
@@ -232,12 +232,12 @@
" \"\"\"\n",
" num_list = []\n",
" files = os.listdir(path)\n",
- " \n",
+ "\n",
" for file in files:\n",
" cnt = count_letters(os.path.join(path, file))\n",
" num_list.append(cnt)\n",
- " \n",
- " l = num_list \n",
+ "\n",
+ " l = num_list\n",
" return print(\"done!\")"
]
},
@@ -265,7 +265,7 @@
],
"source": [
"%%time\n",
- "PATH = '/User/howto/dask/random_files/'\n",
+ "PATH = \"/User/howto/dask/random_files/\"\n",
"process_files(PATH)"
]
},
@@ -282,7 +282,7 @@
"metadata": {},
"outputs": [],
"source": [
- "# get the dask client address \n",
+ "# get the dask client address\n",
"client = Client()"
]
},
@@ -332,7 +332,7 @@
],
"source": [
"%%time\n",
- "# gather results \n",
+ "# gather results\n",
"l = client.gather(a)"
]
},
diff --git a/docs/runtimes/dask-pipeline.ipynb b/docs/runtimes/dask-pipeline.ipynb
index 6ace6a67bd4a..8654ada46a83 100644
--- a/docs/runtimes/dask-pipeline.ipynb
+++ b/docs/runtimes/dask-pipeline.ipynb
@@ -47,11 +47,12 @@
"import os\n",
"import mlrun\n",
"import warnings\n",
+ "\n",
"warnings.filterwarnings(\"ignore\")\n",
"\n",
"# set project name and dir\n",
- "project_name = 'sk-project-dask'\n",
- "project_dir = './'\n",
+ "project_name = \"sk-project-dask\"\n",
+ "project_dir = \"./\"\n",
"\n",
"# specify artifacts target location\n",
"_, artifact_path = mlrun.set_environment(artifact_path=path)\n",
@@ -82,13 +83,14 @@
"outputs": [],
"source": [
"import mlrun\n",
+ "\n",
"# set up function from local file\n",
"dsf = mlrun.new_function(name=\"mydask\", kind=\"dask\", image=\"mlrun/ml-models\")\n",
"\n",
"# set up function specs for dask\n",
"dsf.spec.remote = True\n",
"dsf.spec.replicas = 5\n",
- "dsf.spec.service_type = 'NodePort'\n",
+ "dsf.spec.service_type = \"NodePort\"\n",
"dsf.with_limits(mem=\"6G\")\n",
"dsf.spec.nthreads = 5"
]
@@ -417,7 +419,7 @@
"outputs": [],
"source": [
"# register the workflow file as \"main\", embed the workflow code into the project YAML\n",
- "sk_dask_proj.set_workflow('main', 'workflow.py', embed=False)"
+ "sk_dask_proj.set_workflow(\"main\", \"workflow.py\", embed=False)"
]
},
{
@@ -581,13 +583,9 @@
}
],
"source": [
- "artifact_path = os.path.abspath('./pipe/{{workflow.uid}}')\n",
+ "artifact_path = os.path.abspath(\"./pipe/{{workflow.uid}}\")\n",
"run_id = sk_dask_proj.run(\n",
- " 'main',\n",
- " arguments={}, \n",
- " artifact_path=artifact_path, \n",
- " dirty=False, \n",
- " watch=True\n",
+ " \"main\", arguments={}, artifact_path=artifact_path, dirty=False, watch=True\n",
")"
]
},
diff --git a/docs/runtimes/mlrun_code_annotations.ipynb b/docs/runtimes/mlrun_code_annotations.ipynb
index 528ace5254bc..6fc751c80e58 100644
--- a/docs/runtimes/mlrun_code_annotations.ipynb
+++ b/docs/runtimes/mlrun_code_annotations.ipynb
@@ -28,6 +28,7 @@
"source": [
"# mlrun: start-code\n",
"\n",
+ "\n",
"def sub_handler():\n",
" return \"hello world\""
]
@@ -61,6 +62,7 @@
"def handler(context, event):\n",
" return sub_handler()\n",
"\n",
+ "\n",
"# mlrun: end-code"
]
},
@@ -333,8 +335,8 @@
"source": [
"from mlrun import code_to_function\n",
"\n",
- "some_function = code_to_function('some-function-name', kind='job', code_output='.')\n",
- "some_function.run(name='some-function-name', handler='handler', local=True)"
+ "some_function = code_to_function(\"some-function-name\", kind=\"job\", code_output=\".\")\n",
+ "some_function.run(name=\"some-function-name\", handler=\"handler\", local=True)"
]
},
{
@@ -365,9 +367,11 @@
"source": [
"# mlrun: start-code my-function-name\n",
"\n",
+ "\n",
"def handler(context, event):\n",
" return \"hello from my-function\"\n",
"\n",
+ "\n",
"# mlrun: end-code my-function-name"
]
},
@@ -629,8 +633,8 @@
}
],
"source": [
- "my_function = code_to_function('my-function-name', kind='job')\n",
- "my_function.run(name='my-function-name', handler='handler', local=True)"
+ "my_function = code_to_function(\"my-function-name\", kind=\"job\")\n",
+ "my_function.run(name=\"my-function-name\", handler=\"handler\", local=True)"
]
},
{
@@ -964,8 +968,10 @@
}
],
"source": [
- "my_multi_section_function = code_to_function('multi-section-function-name', kind='job')\n",
- "my_multi_section_function.run(name='multi-section-function-name', handler='handler', local=True)"
+ "my_multi_section_function = code_to_function(\"multi-section-function-name\", kind=\"job\")\n",
+ "my_multi_section_function.run(\n",
+ " name=\"multi-section-function-name\", handler=\"handler\", local=True\n",
+ ")"
]
},
{
@@ -985,9 +991,11 @@
"source": [
"# mlrun: start-code part-cell-function\n",
"\n",
+ "\n",
"def handler(context, event):\n",
" return f\"hello from {function_name}\"\n",
"\n",
+ "\n",
"function_name = \"part-cell-function\"\n",
"\n",
"# mlrun: end-code part-cell-function\n",
@@ -1246,8 +1254,8 @@
}
],
"source": [
- "my_multi_section_function = code_to_function('part-cell-function', kind='job')\n",
- "my_multi_section_function.run(name='part-cell-function', handler='handler', local=True)"
+ "my_multi_section_function = code_to_function(\"part-cell-function\", kind=\"job\")\n",
+ "my_multi_section_function.run(name=\"part-cell-function\", handler=\"handler\", local=True)"
]
},
{
diff --git a/docs/runtimes/spark-operator.ipynb b/docs/runtimes/spark-operator.ipynb
index 4bf99d0c4eb3..05596eb357cd 100644
--- a/docs/runtimes/spark-operator.ipynb
+++ b/docs/runtimes/spark-operator.ipynb
@@ -36,22 +36,22 @@
"# set up new spark function with spark operator\n",
"# command will use our spark code which needs to be located on our file system\n",
"# the name param can have only non capital letters (k8s convention)\n",
- "read_csv_filepath = os.path.join(os.path.abspath('.'), 'spark_read_csv.py')\n",
- "sj = mlrun.new_function(kind='spark', command=read_csv_filepath, name='sparkreadcsv') \n",
+ "read_csv_filepath = os.path.join(os.path.abspath(\".\"), \"spark_read_csv.py\")\n",
+ "sj = mlrun.new_function(kind=\"spark\", command=read_csv_filepath, name=\"sparkreadcsv\")\n",
"\n",
"# set spark driver config (gpu_type & gpus= supported too)\n",
"sj.with_driver_limits(cpu=\"1300m\")\n",
- "sj.with_driver_requests(cpu=1, mem=\"512m\") \n",
+ "sj.with_driver_requests(cpu=1, mem=\"512m\")\n",
"\n",
"# set spark executor config (gpu_type & gpus= are supported too)\n",
"sj.with_executor_limits(cpu=\"1400m\")\n",
"sj.with_executor_requests(cpu=1, mem=\"512m\")\n",
"\n",
"# adds fuse, daemon & iguazio's jars support\n",
- "sj.with_igz_spark() \n",
+ "sj.with_igz_spark()\n",
"\n",
- "# Alternately, move volume_mounts to driver and executor-specific fields and leave \n",
- "# v3io mounts out of executor mounts if mount_v3io_to_executor=False \n",
+ "# Alternately, move volume_mounts to driver and executor-specific fields and leave\n",
+ "# v3io mounts out of executor mounts if mount_v3io_to_executor=False\n",
"# sj.with_igz_spark(mount_v3io_to_executor=False)\n",
"\n",
"# set spark driver volume mount\n",
@@ -61,13 +61,13 @@
"# sj.function.with_executor_host_path_volume(\"/host/path\", \"/mount/path\")\n",
"\n",
"# confs are also supported\n",
- "sj.spec.spark_conf['spark.eventLog.enabled'] = True\n",
+ "sj.spec.spark_conf[\"spark.eventLog.enabled\"] = True\n",
"\n",
"# add python module\n",
- "sj.spec.build.commands = ['pip install matplotlib']\n",
+ "sj.spec.build.commands = [\"pip install matplotlib\"]\n",
"\n",
"# Number of executors\n",
- "sj.spec.replicas = 2 "
+ "sj.spec.replicas = 2"
]
},
{
@@ -77,7 +77,7 @@
"outputs": [],
"source": [
"# Rebuilds the image with MLRun - needed in order to support artifactlogging etc\n",
- "sj.deploy() "
+ "sj.deploy()"
]
},
{
@@ -87,7 +87,7 @@
"outputs": [],
"source": [
"# Run task while setting the artifact path on which our run artifact (in any) will be saved\n",
- "sj.run(artifact_path='/User')"
+ "sj.run(artifact_path=\"/User\")"
]
},
{
diff --git a/docs/serving/distributed-graph.ipynb b/docs/serving/distributed-graph.ipynb
index 5d2e09ffaf1b..09d602bafac7 100644
--- a/docs/serving/distributed-graph.ipynb
+++ b/docs/serving/distributed-graph.ipynb
@@ -83,6 +83,7 @@
"source": [
"# set up the environment\n",
"import mlrun\n",
+ "\n",
"project = mlrun.get_or_create_project(\"pipe\")"
]
},
@@ -260,20 +261,29 @@
],
"source": [
"# define a new real-time serving function (from code) with an async graph\n",
- "fn = mlrun.code_to_function(\"multi-func\", filename=\"./data_prep.py\", kind=\"serving\", image='mlrun/mlrun')\n",
+ "fn = mlrun.code_to_function(\n",
+ " \"multi-func\", filename=\"./data_prep.py\", kind=\"serving\", image=\"mlrun/mlrun\"\n",
+ ")\n",
"graph = fn.set_topology(\"flow\", engine=\"async\")\n",
"\n",
"# define the graph steps (DAG)\n",
- "graph.to(name=\"load_url\", handler=\"load_url\")\\\n",
- " .to(name=\"to_paragraphs\", handler=\"to_paragraphs\")\\\n",
- " .to(\"storey.FlatMap\", \"flatten_paragraphs\", _fn=\"(event)\")\\\n",
- " .to(\">>\", \"q1\", path=internal_stream)\\\n",
- " .to(name=\"nlp\", class_name=\"ApplyNLP\", function=\"enrich\")\\\n",
- " .to(name=\"extract_entities\", handler=\"extract_entities\", function=\"enrich\")\\\n",
- " .to(name=\"enrich_entities\", handler=\"enrich_entities\", function=\"enrich\")\\\n",
- " .to(\"storey.FlatMap\", \"flatten_entities\", _fn=\"(event)\", function=\"enrich\")\\\n",
- " .to(name=\"printer\", handler=\"myprint\", function=\"enrich\")\\\n",
- " .to(\">>\", \"output_stream\", path=out_stream)"
+ "graph.to(name=\"load_url\", handler=\"load_url\").to(\n",
+ " name=\"to_paragraphs\", handler=\"to_paragraphs\"\n",
+ ").to(\"storey.FlatMap\", \"flatten_paragraphs\", _fn=\"(event)\").to(\n",
+ " \">>\", \"q1\", path=internal_stream\n",
+ ").to(\n",
+ " name=\"nlp\", class_name=\"ApplyNLP\", function=\"enrich\"\n",
+ ").to(\n",
+ " name=\"extract_entities\", handler=\"extract_entities\", function=\"enrich\"\n",
+ ").to(\n",
+ " name=\"enrich_entities\", handler=\"enrich_entities\", function=\"enrich\"\n",
+ ").to(\n",
+ " \"storey.FlatMap\", \"flatten_entities\", _fn=\"(event)\", function=\"enrich\"\n",
+ ").to(\n",
+ " name=\"printer\", handler=\"myprint\", function=\"enrich\"\n",
+ ").to(\n",
+ " \">>\", \"output_stream\", path=out_stream\n",
+ ")"
]
},
{
@@ -435,10 +445,12 @@
],
"source": [
"# specify the \"enrich\" child function, add extra package requirements\n",
- "child = fn.add_child_function('enrich', './nlp.py', 'mlrun/mlrun')\n",
- "child.spec.build.commands = [\"python -m pip install spacy\",\n",
- " \"python -m spacy download en_core_web_sm\"]\n",
- "graph.plot(rankdir='LR')"
+ "child = fn.add_child_function(\"enrich\", \"./nlp.py\", \"mlrun/mlrun\")\n",
+ "child.spec.build.commands = [\n",
+ " \"python -m pip install spacy\",\n",
+ " \"python -m spacy download en_core_web_sm\",\n",
+ "]\n",
+ "graph.plot(rankdir=\"LR\")"
]
},
{
@@ -650,7 +662,7 @@
}
],
"source": [
- "fn.invoke('', body={\"url\": \"v3io:///users/admin/pipe/in.json\"})"
+ "fn.invoke(\"\", body={\"url\": \"v3io:///users/admin/pipe/in.json\"})"
]
},
{
diff --git a/docs/serving/getting-started.ipynb b/docs/serving/getting-started.ipynb
index 2298bb072b43..cd08dec0f7bc 100644
--- a/docs/serving/getting-started.ipynb
+++ b/docs/serving/getting-started.ipynb
@@ -39,12 +39,15 @@
"source": [
"# mlrun: start-code\n",
"\n",
+ "\n",
"def inc(x):\n",
" return x + 1\n",
"\n",
+ "\n",
"def mul(x):\n",
" return x * 2\n",
"\n",
+ "\n",
"class WithState:\n",
" def __init__(self, name, context, init_val=0):\n",
" self.name = name\n",
@@ -55,7 +58,8 @@
" self.counter += 1\n",
" print(f\"Echo: {self.name}, x: {x}, counter: {self.counter}\")\n",
" return x + self.counter\n",
- " \n",
+ "\n",
+ "\n",
"# mlrun: end-code"
]
},
@@ -75,6 +79,7 @@
"outputs": [],
"source": [
"import mlrun\n",
+ "\n",
"fn = mlrun.code_to_function(\"simple-graph\", kind=\"serving\", image=\"mlrun/mlrun\")\n",
"graph = fn.set_topology(\"flow\")"
]
@@ -113,9 +118,9 @@
}
],
"source": [
- "graph.to(name=\"+1\", handler='inc')\\\n",
- " .to(name=\"*2\", handler='mul')\\\n",
- " .to(name=\"(X+counter)\", class_name='WithState').respond()"
+ "graph.to(name=\"+1\", handler=\"inc\").to(name=\"*2\", handler=\"mul\").to(\n",
+ " name=\"(X+counter)\", class_name=\"WithState\"\n",
+ ").respond()"
]
},
{
@@ -201,7 +206,7 @@
}
],
"source": [
- "graph.plot(rankdir='LR')"
+ "graph.plot(rankdir=\"LR\")"
]
},
{
@@ -316,7 +321,7 @@
}
],
"source": [
- "fn.deploy(project='basic-graph-demo')"
+ "fn.deploy(project=\"basic-graph-demo\")"
]
},
{
@@ -352,7 +357,7 @@
}
],
"source": [
- "fn.invoke('', body=5)"
+ "fn.invoke(\"\", body=5)"
]
},
{
@@ -379,7 +384,7 @@
}
],
"source": [
- "fn.invoke('', body=5)"
+ "fn.invoke(\"\", body=5)"
]
}
],
diff --git a/docs/serving/graph-example.ipynb b/docs/serving/graph-example.ipynb
index 2ad39ac2f0c5..c152b35697ad 100644
--- a/docs/serving/graph-example.ipynb
+++ b/docs/serving/graph-example.ipynb
@@ -43,31 +43,33 @@
"class ClassifierModel(mlrun.serving.V2ModelServer):\n",
" def load(self):\n",
" \"\"\"load and initialize the model and/or other elements\"\"\"\n",
- " model_file, extra_data = self.get_model('.pkl')\n",
- " self.model = load(open(model_file, 'rb'))\n",
+ " model_file, extra_data = self.get_model(\".pkl\")\n",
+ " self.model = load(open(model_file, \"rb\"))\n",
"\n",
" def predict(self, body: dict) -> List:\n",
" \"\"\"Generate model predictions from sample.\"\"\"\n",
- " feats = np.asarray(body['inputs'])\n",
+ " feats = np.asarray(body[\"inputs\"])\n",
" result: np.ndarray = self.model.predict(feats)\n",
" return result.tolist()\n",
"\n",
+ "\n",
"# echo class, custom class example\n",
"class Echo:\n",
" def __init__(self, context, name=None, **kw):\n",
" self.context = context\n",
" self.name = name\n",
" self.kw = kw\n",
- " \n",
+ "\n",
" def do(self, x):\n",
" print(\"Echo:\", self.name, x)\n",
" return x\n",
"\n",
+ "\n",
"# error echo function, demo catching error and using custom function\n",
"def error_catcher(x):\n",
- " x.body = {\"body\": x.body, \"origin_state\": x.origin_state, \"error\": x.error}\n",
- " print(\"EchoError:\", x)\n",
- " return None"
+ " x.body = {\"body\": x.body, \"origin_state\": x.origin_state, \"error\": x.error}\n",
+ " print(\"EchoError:\", x)\n",
+ " return None"
]
},
{
@@ -94,11 +96,11 @@
"metadata": {},
"outputs": [],
"source": [
- "function = mlrun.code_to_function(\"advanced\", kind=\"serving\", \n",
- " image=\"mlrun/mlrun\",\n",
- " requirements=['storey'])\n",
+ "function = mlrun.code_to_function(\n",
+ " \"advanced\", kind=\"serving\", image=\"mlrun/mlrun\", requirements=[\"storey\"]\n",
+ ")\n",
"graph = function.set_topology(\"flow\", engine=\"async\")\n",
- "#function.verbose = True"
+ "# function.verbose = True"
]
},
{
@@ -119,7 +121,7 @@
"metadata": {},
"outputs": [],
"source": [
- "models_path = 'https://s3.wasabisys.com/iguazio/models/iris/model.pkl'\n",
+ "models_path = \"https://s3.wasabisys.com/iguazio/models/iris/model.pkl\"\n",
"path1 = models_path\n",
"path2 = models_path"
]
@@ -266,22 +268,25 @@
],
"source": [
"# use built-in storey class or our custom Echo class to create and link Task states\n",
- "graph.to(\"storey.Extend\", name=\"enrich\", _fn='({\"tag\": \"something\"})') \\\n",
- " .to(class_name=\"Echo\", name=\"pre-process\", some_arg='abc').error_handler(\"catcher\")\n",
+ "graph.to(\"storey.Extend\", name=\"enrich\", _fn='({\"tag\": \"something\"})').to(\n",
+ " class_name=\"Echo\", name=\"pre-process\", some_arg=\"abc\"\n",
+ ").error_handler(\"catcher\")\n",
"\n",
"# add an Ensemble router with two child models (routes). The \"*\" prefix mark it is a router class\n",
- "router = graph.add_step(\"*mlrun.serving.VotingEnsemble\", name=\"ensemble\", after=\"pre-process\")\n",
+ "router = graph.add_step(\n",
+ " \"*mlrun.serving.VotingEnsemble\", name=\"ensemble\", after=\"pre-process\"\n",
+ ")\n",
"router.add_route(\"m1\", class_name=\"ClassifierModel\", model_path=path1)\n",
"router.add_route(\"m2\", class_name=\"ClassifierModel\", model_path=path2)\n",
"\n",
"# add the final step (after the router) that handles post processing and responds to the client\n",
"graph.add_step(class_name=\"Echo\", name=\"final\", after=\"ensemble\").respond()\n",
"\n",
- "# add error handling state, run only when/if the \"pre-process\" state fails (keep after=\"\") \n",
+ "# add error handling state, run only when/if the \"pre-process\" state fails (keep after=\"\")\n",
"graph.add_step(handler=\"error_catcher\", name=\"catcher\", full_event=True, after=\"\")\n",
"\n",
"# plot the graph (using Graphviz) and run a test\n",
- "graph.plot(rankdir='LR')"
+ "graph.plot(rankdir=\"LR\")"
]
},
{
@@ -299,8 +304,9 @@
"outputs": [],
"source": [
"import random\n",
+ "\n",
"iris = load_iris()\n",
- "x = random.sample(iris['data'].tolist(), 5)"
+ "x = random.sample(iris[\"data\"].tolist(), 5)"
]
},
{
diff --git a/docs/serving/model-serving-get-started.ipynb b/docs/serving/model-serving-get-started.ipynb
index 02013318c1d5..4093fbf888ea 100644
--- a/docs/serving/model-serving-get-started.ipynb
+++ b/docs/serving/model-serving-get-started.ipynb
@@ -50,6 +50,7 @@
"\n",
"import mlrun\n",
"\n",
+ "\n",
"class ClassifierModel(mlrun.serving.V2ModelServer):\n",
" def load(self):\n",
" \"\"\"load and initialize the model and/or other elements\"\"\"\n",
@@ -85,9 +86,7 @@
"metadata": {},
"outputs": [],
"source": [
- "fn = mlrun.code_to_function(\"serving_example\",\n",
- " kind=\"serving\", \n",
- " image=\"mlrun/mlrun\")"
+ "fn = mlrun.code_to_function(\"serving_example\", kind=\"serving\", image=\"mlrun/mlrun\")"
]
},
{
@@ -128,14 +127,18 @@
"graph = fn.set_topology(\"router\")\n",
"\n",
"# Add the model\n",
- "fn.add_model(\"model1\", class_name=\"ClassifierModel\", model_path=\"https://s3.wasabisys.com/iguazio/models/iris/model.pkl\")\n",
+ "fn.add_model(\n",
+ " \"model1\",\n",
+ " class_name=\"ClassifierModel\",\n",
+ " model_path=\"https://s3.wasabisys.com/iguazio/models/iris/model.pkl\",\n",
+ ")\n",
"\n",
"# Add additional models\n",
- "#fn.add_model(\"model2\", class_name=\"ClassifierModel\", model_path=\"\")\n",
+ "# fn.add_model(\"model2\", class_name=\"ClassifierModel\", model_path=\"\")\n",
"\n",
"# create and use the graph simulator\n",
"server = fn.to_mock_server()\n",
- "x = load_iris()['data'].tolist()\n",
+ "x = load_iris()[\"data\"].tolist()\n",
"result = server.test(\"/v2/models/model1/infer\", {\"inputs\": x})\n",
"\n",
"print(result)"
@@ -247,24 +250,28 @@
}
],
"source": [
- "fn2 = mlrun.code_to_function(\"serving_example_flow\",\n",
- " kind=\"serving\", \n",
- " image=\"mlrun/mlrun\")\n",
+ "fn2 = mlrun.code_to_function(\n",
+ " \"serving_example_flow\", kind=\"serving\", image=\"mlrun/mlrun\"\n",
+ ")\n",
"\n",
- "graph2 = fn2.set_topology(\"flow\") \n",
+ "graph2 = fn2.set_topology(\"flow\")\n",
"\n",
"graph2_enrich = graph2.to(\"storey.Extend\", name=\"enrich\", _fn='({\"tag\": \"something\"})')\n",
"\n",
"# add an Ensemble router with two child models (routes)\n",
"router = graph2.add_step(mlrun.serving.ModelRouter(), name=\"router\", after=\"enrich\")\n",
- "router.add_route(\"m1\", class_name=\"ClassifierModel\", model_path='https://s3.wasabisys.com/iguazio/models/iris/model.pkl')\n",
+ "router.add_route(\n",
+ " \"m1\",\n",
+ " class_name=\"ClassifierModel\",\n",
+ " model_path=\"https://s3.wasabisys.com/iguazio/models/iris/model.pkl\",\n",
+ ")\n",
"router.respond()\n",
"\n",
"# Add additional models\n",
- "#router.add_route(\"m2\", class_name=\"ClassifierModel\", model_path=path2)\n",
+ "# router.add_route(\"m2\", class_name=\"ClassifierModel\", model_path=path2)\n",
"\n",
"# plot the graph (using Graphviz)\n",
- "graph2.plot(rankdir='LR')"
+ "graph2.plot(rankdir=\"LR\")"
]
},
{
@@ -336,12 +343,15 @@
"source": [
"remote_func_name = \"serving-example-flow\"\n",
"project_name = \"graph-basic-concepts\"\n",
- "fn_remote = mlrun.code_to_function(remote_func_name,\n",
- " project=project_name,\n",
- " kind=\"serving\", \n",
- " image=\"mlrun/mlrun\")\n",
+ "fn_remote = mlrun.code_to_function(\n",
+ " remote_func_name, project=project_name, kind=\"serving\", image=\"mlrun/mlrun\"\n",
+ ")\n",
"\n",
- "fn_remote.add_model(\"model1\", class_name=\"ClassifierModel\", model_path=\"https://s3.wasabisys.com/iguazio/models/iris/model.pkl\")\n",
+ "fn_remote.add_model(\n",
+ " \"model1\",\n",
+ " class_name=\"ClassifierModel\",\n",
+ " model_path=\"https://s3.wasabisys.com/iguazio/models/iris/model.pkl\",\n",
+ ")\n",
"\n",
"remote_addr = fn_remote.deploy()"
]
@@ -419,9 +429,10 @@
"graph_preprocessing = fn_preprocess.set_topology(\"flow\")\n",
"\n",
"graph_preprocessing.to(\"storey.Extend\", name=\"enrich\", _fn='({\"tag\": \"something\"})').to(\n",
- " \"$remote\", \"remote_func\", url=f'{remote_addr}v2/models/model1/infer', method='put').respond()\n",
+ " \"$remote\", \"remote_func\", url=f\"{remote_addr}v2/models/model1/infer\", method=\"put\"\n",
+ ").respond()\n",
"\n",
- "graph_preprocessing.plot(rankdir='LR')"
+ "graph_preprocessing.plot(rankdir=\"LR\")"
]
},
{
@@ -440,7 +451,7 @@
],
"source": [
"fn3_server = fn_preprocess.to_mock_server()\n",
- "my_data = '''{\"inputs\":[[5.1, 3.5, 1.4, 0.2],[7.7, 3.8, 6.7, 2.2]]}'''\n",
+ "my_data = \"\"\"{\"inputs\":[[5.1, 3.5, 1.4, 0.2],[7.7, 3.8, 6.7, 2.2]]}\"\"\"\n",
"result = fn3_server.test(\"/v2/models/my_model/infer\", body=my_data)\n",
"print(result)"
]
@@ -498,7 +509,10 @@
"outputs": [],
"source": [
"import os\n",
- "streams_prefix = f\"v3io:///users/{os.getenv('V3IO_USERNAME')}/examples/graph-basic-concepts\"\n",
+ "\n",
+ "streams_prefix = (\n",
+ " f\"v3io:///users/{os.getenv('V3IO_USERNAME')}/examples/graph-basic-concepts\"\n",
+ ")\n",
"\n",
"input_stream = streams_prefix + \"/in-stream\"\n",
"out_stream = streams_prefix + \"/out-stream\"\n",
@@ -618,16 +632,17 @@
],
"source": [
"fn_preprocess2 = mlrun.new_function(\"preprocess\", kind=\"serving\")\n",
- "fn_preprocess2.add_child_function('echo_func', './echo.py', 'mlrun/mlrun')\n",
+ "fn_preprocess2.add_child_function(\"echo_func\", \"./echo.py\", \"mlrun/mlrun\")\n",
"\n",
"graph_preprocess2 = fn_preprocess2.set_topology(\"flow\")\n",
"\n",
- "graph_preprocess2.to(\"storey.Extend\", name=\"enrich\", _fn='({\"tag\": \"something\"})')\\\n",
- " .to(\">>\", \"input_stream\", path=input_stream, group=\"mygroup\")\\\n",
- " .to(name=\"echo\", handler=\"echo_handler\", function=\"echo_func\")\\\n",
- " .to(\">>\", \"output_stream\", path=out_stream, sharding_func=\"partition\")\n",
+ "graph_preprocess2.to(\"storey.Extend\", name=\"enrich\", _fn='({\"tag\": \"something\"})').to(\n",
+ " \">>\", \"input_stream\", path=input_stream, group=\"mygroup\"\n",
+ ").to(name=\"echo\", handler=\"echo_handler\", function=\"echo_func\").to(\n",
+ " \">>\", \"output_stream\", path=out_stream, sharding_func=\"partition\"\n",
+ ")\n",
"\n",
- "graph_preprocess2.plot(rankdir='LR')"
+ "graph_preprocess2.plot(rankdir=\"LR\")"
]
},
{
@@ -650,7 +665,7 @@
"\n",
"fn4_server = fn_preprocess2.to_mock_server(current_function=\"*\")\n",
"\n",
- "my_data = '''{\"inputs\": [[5.1, 3.5, 1.4, 0.2], [7.7, 3.8, 6.7, 2.2]], \"partition\": 0}'''\n",
+ "my_data = \"\"\"{\"inputs\": [[5.1, 3.5, 1.4, 0.2], [7.7, 3.8, 6.7, 2.2]], \"partition\": 0}\"\"\"\n",
"\n",
"result = fn4_server.test(\"/v2/models/my_model/infer\", body=my_data)\n",
"\n",
@@ -724,16 +739,21 @@
"import mlrun\n",
"\n",
"fn_preprocess2 = mlrun.new_function(\"preprocess\", kind=\"serving\")\n",
- "fn_preprocess2.add_child_function('echo_func', './echo.py', 'mlrun/mlrun')\n",
+ "fn_preprocess2.add_child_function(\"echo_func\", \"./echo.py\", \"mlrun/mlrun\")\n",
"\n",
"graph_preprocess2 = fn_preprocess2.set_topology(\"flow\")\n",
"\n",
- "graph_preprocess2.to(\"storey.Extend\", name=\"enrich\", _fn='({\"tag\": \"something\"})')\\\n",
- " .to(\">>\", \"input_stream\", path=input_topic, group=\"mygroup\", kafka_bootstrap_servers=brokers)\\\n",
- " .to(name=\"echo\", handler=\"echo_handler\", function=\"echo_func\")\\\n",
- " .to(\">>\", \"output_stream\", path=out_topic, kafka_bootstrap_servers=brokers)\n",
+ "graph_preprocess2.to(\"storey.Extend\", name=\"enrich\", _fn='({\"tag\": \"something\"})').to(\n",
+ " \">>\",\n",
+ " \"input_stream\",\n",
+ " path=input_topic,\n",
+ " group=\"mygroup\",\n",
+ " kafka_bootstrap_servers=brokers,\n",
+ ").to(name=\"echo\", handler=\"echo_handler\", function=\"echo_func\").to(\n",
+ " \">>\", \"output_stream\", path=out_topic, kafka_bootstrap_servers=brokers\n",
+ ")\n",
"\n",
- "graph_preprocess2.plot(rankdir='LR')\n",
+ "graph_preprocess2.plot(rankdir=\"LR\")\n",
"\n",
"from echo import *\n",
"\n",
@@ -741,7 +761,7 @@
"\n",
"fn4_server.set_error_stream(f\"kafka://{brokers}/{err_topic}\")\n",
"\n",
- "my_data = '''{\"inputs\":[[5.1, 3.5, 1.4, 0.2],[7.7, 3.8, 6.7, 2.2]]}'''\n",
+ "my_data = \"\"\"{\"inputs\":[[5.1, 3.5, 1.4, 0.2],[7.7, 3.8, 6.7, 2.2]]}\"\"\"\n",
"\n",
"result = fn4_server.test(\"/v2/models/my_model/infer\", body=my_data)\n",
"\n",
diff --git a/docs/serving/realtime-pipelines.ipynb b/docs/serving/realtime-pipelines.ipynb
index c7e111e96411..bccbbac7e104 100644
--- a/docs/serving/realtime-pipelines.ipynb
+++ b/docs/serving/realtime-pipelines.ipynb
@@ -96,8 +96,8 @@
"outputs": [],
"source": [
"if self.context.verbose:\n",
- " self.context.logger.info('my message', some_arg='text')\n",
- " x = self.context.get_param('x', 0)"
+ " self.context.logger.info(\"my message\", some_arg=\"text\")\n",
+ " x = self.context.get_param(\"x\", 0)"
]
},
{
@@ -138,14 +138,18 @@
"graph = fn.set_topology(\"router\")\n",
"\n",
"# Add the model\n",
- "fn.add_model(\"model1\", class_name=\"ClassifierModel\", model_path=\"https://s3.wasabisys.com/iguazio/models/iris/model.pkl\")\n",
+ "fn.add_model(\n",
+ " \"model1\",\n",
+ " class_name=\"ClassifierModel\",\n",
+ " model_path=\"https://s3.wasabisys.com/iguazio/models/iris/model.pkl\",\n",
+ ")\n",
"\n",
"# Add additional models\n",
- "#fn.add_model(\"model2\", class_name=\"ClassifierModel\", model_path=\"\")\n",
+ "# fn.add_model(\"model2\", class_name=\"ClassifierModel\", model_path=\"\")\n",
"\n",
"# create and use the graph simulator\n",
"server = fn.to_mock_server()\n",
- "x = load_iris()['data'].tolist()\n",
+ "x = load_iris()[\"data\"].tolist()\n",
"result = server.test(\"/v2/models/model1/infer\", {\"inputs\": x})\n",
"\n",
"print(result)"
@@ -196,24 +200,28 @@
}
],
"source": [
- "fn2 = mlrun.code_to_function(\"serving_example_flow\",\n",
- " kind=\"serving\", \n",
- " image=\"mlrun/mlrun\")\n",
+ "fn2 = mlrun.code_to_function(\n",
+ " \"serving_example_flow\", kind=\"serving\", image=\"mlrun/mlrun\"\n",
+ ")\n",
"\n",
- "graph2 = fn2.set_topology(\"flow\") \n",
+ "graph2 = fn2.set_topology(\"flow\")\n",
"\n",
"graph2_enrich = graph2.to(\"storey.Extend\", name=\"enrich\", _fn='({\"tag\": \"something\"})')\n",
"\n",
"# add an Ensemble router with two child models (routes)\n",
"router = graph2.add_step(mlrun.serving.ModelRouter(), name=\"router\", after=\"enrich\")\n",
- "router.add_route(\"m1\", class_name=\"ClassifierModel\", model_path='https://s3.wasabisys.com/iguazio/models/iris/model.pkl')\n",
+ "router.add_route(\n",
+ " \"m1\",\n",
+ " class_name=\"ClassifierModel\",\n",
+ " model_path=\"https://s3.wasabisys.com/iguazio/models/iris/model.pkl\",\n",
+ ")\n",
"router.respond()\n",
"\n",
"# Add additional models\n",
- "#router.add_route(\"m2\", class_name=\"ClassifierModel\", model_path=path2)\n",
+ "# router.add_route(\"m2\", class_name=\"ClassifierModel\", model_path=path2)\n",
"\n",
"# plot the graph (using Graphviz)\n",
- "graph2.plot(rankdir='LR')"
+ "graph2.plot(rankdir=\"LR\")"
]
},
{
@@ -266,10 +274,12 @@
"metadata": {},
"outputs": [],
"source": [
- "fn.add_child_function('enrich', \n",
- " './entity_extraction.ipynb', \n",
- " image='mlrun/mlrun',\n",
- " requirements=[\"storey\", \"sklearn\"])"
+ "fn.add_child_function(\n",
+ " \"enrich\",\n",
+ " \"./entity_extraction.ipynb\",\n",
+ " image=\"mlrun/mlrun\",\n",
+ " requirements=[\"storey\", \"sklearn\"],\n",
+ ")"
]
},
{
@@ -347,7 +357,7 @@
"metadata": {},
"outputs": [],
"source": [
- "graph2.plot(rankdir='LR')"
+ "graph2.plot(rankdir=\"LR\")"
]
},
{
diff --git a/docs/serving/writing-custom-steps.ipynb b/docs/serving/writing-custom-steps.ipynb
index 1e736d86a929..05129323011d 100644
--- a/docs/serving/writing-custom-steps.ipynb
+++ b/docs/serving/writing-custom-steps.ipynb
@@ -53,7 +53,7 @@
" self.context = context\n",
" self.name = name\n",
" self.kw = kw\n",
- " \n",
+ "\n",
" def do(self, x):\n",
" print(\"Echo:\", self.name, x)\n",
" return x"
@@ -129,9 +129,9 @@
"\n",
"graph_echo = fn_echo.set_topology(\"flow\")\n",
"\n",
- "graph_echo.to(class_name=\"Echo\", name=\"pre-process\", some_arg='abc')\n",
+ "graph_echo.to(class_name=\"Echo\", name=\"pre-process\", some_arg=\"abc\")\n",
"\n",
- "graph_echo.plot(rankdir='LR')"
+ "graph_echo.plot(rankdir=\"LR\")"
]
},
{
diff --git a/docs/training/built-in-training-function.ipynb b/docs/training/built-in-training-function.ipynb
index 5e795fd4fa5e..7b61d24f86f5 100644
--- a/docs/training/built-in-training-function.ipynb
+++ b/docs/training/built-in-training-function.ipynb
@@ -58,11 +58,14 @@
"outputs": [],
"source": [
"import mlrun\n",
+ "\n",
"# Set the base project name\n",
- "project_name_base = 'training-test'\n",
+ "project_name_base = \"training-test\"\n",
"\n",
"# Initialize the MLRun project object\n",
- "project = mlrun.get_or_create_project(project_name_base, context=\"./\", user_project=True)"
+ "project = mlrun.get_or_create_project(\n",
+ " project_name_base, context=\"./\", user_project=True\n",
+ ")"
]
},
{
@@ -106,14 +109,16 @@
" params={\n",
" # Model parameters:\n",
" \"model_class\": \"sklearn.ensemble.RandomForestClassifier\",\n",
- " \"model_kwargs\": {\"max_depth\": 8}, # Could be also passed as \"MODEL_max_depth\": 8\n",
+ " \"model_kwargs\": {\n",
+ " \"max_depth\": 8\n",
+ " }, # Could be also passed as \"MODEL_max_depth\": 8\n",
" \"model_name\": \"MyModel\",\n",
" # Dataset parameters:\n",
" \"drop_columns\": [\"feat_0\", \"feat_2\"],\n",
" \"train_test_split_size\": 0.2,\n",
" \"random_state\": 42,\n",
" \"label_columns\": \"labels\",\n",
- " }\n",
+ " },\n",
")"
]
},
@@ -283,9 +288,9 @@
"source": [
"evaluate_run = auto_trainer.run(\n",
" handler=\"evaluate\",\n",
- " inputs={\"dataset\": train_run.outputs['test_set']},\n",
+ " inputs={\"dataset\": train_run.outputs[\"test_set\"]},\n",
" params={\n",
- " \"model\": train_run.outputs['model'],\n",
+ " \"model\": train_run.outputs[\"model\"],\n",
" \"label_columns\": \"labels\",\n",
" },\n",
")"
diff --git a/docs/training/create-a-basic-training-job.ipynb b/docs/training/create-a-basic-training-job.ipynb
index 961717127eac..80149d08129e 100644
--- a/docs/training/create-a-basic-training-job.ipynb
+++ b/docs/training/create-a-basic-training-job.ipynb
@@ -126,7 +126,7 @@
" filename=\"trainer.py\",\n",
" kind=\"job\",\n",
" image=\"mlrun/mlrun\",\n",
- " handler=\"train\"\n",
+ " handler=\"train\",\n",
")"
]
},
@@ -392,8 +392,10 @@
],
"source": [
"run = training_job.run(\n",
- " inputs={\"dataset\": \"https://igz-demo-datasets.s3.us-east-2.amazonaws.com/cancer-dataset.csv\"}, \n",
- " params = {\"n_estimators\": 100, \"learning_rate\": 1e-1, \"max_depth\": 3}\n",
+ " inputs={\n",
+ " \"dataset\": \"https://igz-demo-datasets.s3.us-east-2.amazonaws.com/cancer-dataset.csv\"\n",
+ " },\n",
+ " params={\"n_estimators\": 100, \"learning_rate\": 1e-1, \"max_depth\": 3},\n",
")"
]
},
diff --git a/docs/tutorial/01-mlrun-basics.ipynb b/docs/tutorial/01-mlrun-basics.ipynb
index deb74ae82220..b6b980fec59a 100644
--- a/docs/tutorial/01-mlrun-basics.ipynb
+++ b/docs/tutorial/01-mlrun-basics.ipynb
@@ -271,7 +271,13 @@
}
],
"source": [
- "data_gen_fn = project.set_function(\"data-prep.py\", name=\"data-prep\", kind=\"job\", image=\"mlrun/mlrun\", handler=\"breast_cancer_generator\")\n",
+ "data_gen_fn = project.set_function(\n",
+ " \"data-prep.py\",\n",
+ " name=\"data-prep\",\n",
+ " kind=\"job\",\n",
+ " image=\"mlrun/mlrun\",\n",
+ " handler=\"breast_cancer_generator\",\n",
+ ")\n",
"project.save() # save the project with the latest config"
]
},
@@ -897,7 +903,7 @@
"outputs": [],
"source": [
"# Import the function\n",
- "trainer = mlrun.import_function('hub://auto_trainer')"
+ "trainer = mlrun.import_function(\"hub://auto_trainer\")"
]
},
{
@@ -1167,15 +1173,16 @@
}
],
"source": [
- "trainer_run = project.run_function(trainer,\n",
+ "trainer_run = project.run_function(\n",
+ " trainer,\n",
" inputs={\"dataset\": gen_data_run.outputs[\"dataset\"]},\n",
- " params = {\n",
+ " params={\n",
" \"model_class\": \"sklearn.ensemble.RandomForestClassifier\",\n",
" \"train_test_split_size\": 0.2,\n",
" \"label_columns\": \"label\",\n",
- " \"model_name\": 'cancer',\n",
- " }, \n",
- " handler='train',\n",
+ " \"model_name\": \"cancer\",\n",
+ " },\n",
+ " handler=\"train\",\n",
")"
]
},
@@ -1338,7 +1345,7 @@
],
"source": [
"# Display HTML output artifacts\n",
- "trainer_run.artifact('confusion-matrix').show()"
+ "trainer_run.artifact(\"confusion-matrix\").show()"
]
},
{
@@ -1365,7 +1372,12 @@
"metadata": {},
"outputs": [],
"source": [
- "serving_fn = mlrun.new_function(\"serving\", image=\"python:3.9\", kind=\"serving\", requirements=[\"mlrun[complete]\", \"scikit-learn~=1.2.0\"])"
+ "serving_fn = mlrun.new_function(\n",
+ " \"serving\",\n",
+ " image=\"python:3.9\",\n",
+ " kind=\"serving\",\n",
+ " requirements=[\"mlrun[complete]\", \"scikit-learn~=1.2.0\"],\n",
+ ")"
]
},
{
@@ -1405,7 +1417,11 @@
}
],
"source": [
- "serving_fn.add_model('cancer-classifier',model_path=trainer_run.outputs[\"model\"], class_name='mlrun.frameworks.sklearn.SklearnModelServer')"
+ "serving_fn.add_model(\n",
+ " \"cancer-classifier\",\n",
+ " model_path=trainer_run.outputs[\"model\"],\n",
+ " class_name=\"mlrun.frameworks.sklearn.SklearnModelServer\",\n",
+ ")"
]
},
{
@@ -1599,14 +1615,41 @@
}
],
"source": [
- "my_data = {\"inputs\"\n",
- " :[[\n",
- " 1.371e+01, 2.083e+01, 9.020e+01, 5.779e+02, 1.189e-01, 1.645e-01,\n",
- " 9.366e-02, 5.985e-02, 2.196e-01, 7.451e-02, 5.835e-01, 1.377e+00,\n",
- " 3.856e+00, 5.096e+01, 8.805e-03, 3.029e-02, 2.488e-02, 1.448e-02,\n",
- " 1.486e-02, 5.412e-03, 1.706e+01, 2.814e+01, 1.106e+02, 8.970e+02,\n",
- " 1.654e-01, 3.682e-01, 2.678e-01, 1.556e-01, 3.196e-01, 1.151e-01]\n",
- " ]\n",
+ "my_data = {\n",
+ " \"inputs\": [\n",
+ " [\n",
+ " 1.371e01,\n",
+ " 2.083e01,\n",
+ " 9.020e01,\n",
+ " 5.779e02,\n",
+ " 1.189e-01,\n",
+ " 1.645e-01,\n",
+ " 9.366e-02,\n",
+ " 5.985e-02,\n",
+ " 2.196e-01,\n",
+ " 7.451e-02,\n",
+ " 5.835e-01,\n",
+ " 1.377e00,\n",
+ " 3.856e00,\n",
+ " 5.096e01,\n",
+ " 8.805e-03,\n",
+ " 3.029e-02,\n",
+ " 2.488e-02,\n",
+ " 1.448e-02,\n",
+ " 1.486e-02,\n",
+ " 5.412e-03,\n",
+ " 1.706e01,\n",
+ " 2.814e01,\n",
+ " 1.106e02,\n",
+ " 8.970e02,\n",
+ " 1.654e-01,\n",
+ " 3.682e-01,\n",
+ " 2.678e-01,\n",
+ " 1.556e-01,\n",
+ " 3.196e-01,\n",
+ " 1.151e-01,\n",
+ " ]\n",
+ " ]\n",
"}\n",
"server.test(\"/v2/models/cancer-classifier/infer\", body=my_data)"
]
diff --git a/docs/tutorial/02-model-training.ipynb b/docs/tutorial/02-model-training.ipynb
index 86042167d28a..7f39ec2304c3 100644
--- a/docs/tutorial/02-model-training.ipynb
+++ b/docs/tutorial/02-model-training.ipynb
@@ -66,6 +66,7 @@
],
"source": [
"import mlrun\n",
+ "\n",
"project = mlrun.get_or_create_project(\"tutorial\", context=\"./\", user_project=True)"
]
},
@@ -167,7 +168,9 @@
"metadata": {},
"outputs": [],
"source": [
- "trainer = project.set_function(\"trainer.py\", name=\"trainer\", kind=\"job\", image=\"mlrun/mlrun\", handler=\"train\")"
+ "trainer = project.set_function(\n",
+ " \"trainer.py\", name=\"trainer\", kind=\"job\", image=\"mlrun/mlrun\", handler=\"train\"\n",
+ ")"
]
},
{
@@ -190,8 +193,11 @@
"source": [
"import pandas as pd\n",
"from sklearn.datasets import load_breast_cancer\n",
+ "\n",
"breast_cancer = load_breast_cancer()\n",
- "breast_cancer_dataset = pd.DataFrame(data=breast_cancer.data, columns=breast_cancer.feature_names)\n",
+ "breast_cancer_dataset = pd.DataFrame(\n",
+ " data=breast_cancer.data, columns=breast_cancer.feature_names\n",
+ ")\n",
"breast_cancer_labels = pd.DataFrame(data=breast_cancer.target, columns=[\"label\"])\n",
"breast_cancer_dataset = pd.concat([breast_cancer_dataset, breast_cancer_labels], axis=1)\n",
"\n",
@@ -449,10 +455,10 @@
],
"source": [
"trainer_run = project.run_function(\n",
- " \"trainer\", \n",
- " inputs={\"dataset\": \"cancer-dataset.csv\"}, \n",
- " params = {\"n_estimators\": 100, \"learning_rate\": 1e-1, \"max_depth\": 3},\n",
- " local=True\n",
+ " \"trainer\",\n",
+ " inputs={\"dataset\": \"cancer-dataset.csv\"},\n",
+ " params={\"n_estimators\": 100, \"learning_rate\": 1e-1, \"max_depth\": 3},\n",
+ " local=True,\n",
")"
]
},
@@ -586,7 +592,7 @@
}
],
"source": [
- "trainer_run.artifact('feature-importance').show()"
+ "trainer_run.artifact(\"feature-importance\").show()"
]
},
{
@@ -606,7 +612,7 @@
"metadata": {},
"outputs": [],
"source": [
- "trainer_run.artifact('model').meta.export(\"model.zip\")"
+ "trainer_run.artifact(\"model\").meta.export(\"model.zip\")"
]
},
{
@@ -638,7 +644,9 @@
"metadata": {},
"outputs": [],
"source": [
- "dataset_artifact = project.log_dataset(\"cancer-dataset\", df=breast_cancer_dataset, index=False)"
+ "dataset_artifact = project.log_dataset(\n",
+ " \"cancer-dataset\", df=breast_cancer_dataset, index=False\n",
+ ")"
]
},
{
@@ -897,14 +905,14 @@
],
"source": [
"hp_tuning_run = project.run_function(\n",
- " \"trainer\", \n",
- " inputs={\"dataset\": dataset_artifact.uri}, \n",
+ " \"trainer\",\n",
+ " inputs={\"dataset\": dataset_artifact.uri},\n",
" hyperparams={\n",
- " \"n_estimators\": [10, 100, 1000], \n",
- " \"learning_rate\": [1e-1, 1e-3], \n",
- " \"max_depth\": [2, 8]\n",
- " }, \n",
- " selector=\"max.accuracy\", \n",
+ " \"n_estimators\": [10, 100, 1000],\n",
+ " \"learning_rate\": [1e-1, 1e-3],\n",
+ " \"max_depth\": [2, 8],\n",
+ " },\n",
+ " selector=\"max.accuracy\",\n",
")"
]
},
@@ -1419,7 +1427,11 @@
],
"source": [
"serving_fn = mlrun.new_function(\"serving\", image=\"mlrun/mlrun\", kind=\"serving\")\n",
- "serving_fn.add_model('cancer-classifier',model_path=hp_tuning_run.outputs[\"model\"], class_name='mlrun.frameworks.sklearn.SklearnModelServer')"
+ "serving_fn.add_model(\n",
+ " \"cancer-classifier\",\n",
+ " model_path=hp_tuning_run.outputs[\"model\"],\n",
+ " class_name=\"mlrun.frameworks.sklearn.SklearnModelServer\",\n",
+ ")"
]
},
{
@@ -1464,14 +1476,41 @@
"# Create a mock (simulator of the real-time function)\n",
"server = serving_fn.to_mock_server()\n",
"\n",
- "my_data = {\"inputs\"\n",
- " :[[\n",
- " 1.371e+01, 2.083e+01, 9.020e+01, 5.779e+02, 1.189e-01, 1.645e-01,\n",
- " 9.366e-02, 5.985e-02, 2.196e-01, 7.451e-02, 5.835e-01, 1.377e+00,\n",
- " 3.856e+00, 5.096e+01, 8.805e-03, 3.029e-02, 2.488e-02, 1.448e-02,\n",
- " 1.486e-02, 5.412e-03, 1.706e+01, 2.814e+01, 1.106e+02, 8.970e+02,\n",
- " 1.654e-01, 3.682e-01, 2.678e-01, 1.556e-01, 3.196e-01, 1.151e-01]\n",
- " ]\n",
+ "my_data = {\n",
+ " \"inputs\": [\n",
+ " [\n",
+ " 1.371e01,\n",
+ " 2.083e01,\n",
+ " 9.020e01,\n",
+ " 5.779e02,\n",
+ " 1.189e-01,\n",
+ " 1.645e-01,\n",
+ " 9.366e-02,\n",
+ " 5.985e-02,\n",
+ " 2.196e-01,\n",
+ " 7.451e-02,\n",
+ " 5.835e-01,\n",
+ " 1.377e00,\n",
+ " 3.856e00,\n",
+ " 5.096e01,\n",
+ " 8.805e-03,\n",
+ " 3.029e-02,\n",
+ " 2.488e-02,\n",
+ " 1.448e-02,\n",
+ " 1.486e-02,\n",
+ " 5.412e-03,\n",
+ " 1.706e01,\n",
+ " 2.814e01,\n",
+ " 1.106e02,\n",
+ " 8.970e02,\n",
+ " 1.654e-01,\n",
+ " 3.682e-01,\n",
+ " 2.678e-01,\n",
+ " 1.556e-01,\n",
+ " 3.196e-01,\n",
+ " 1.151e-01,\n",
+ " ]\n",
+ " ]\n",
"}\n",
"server.test(\"/v2/models/cancer-classifier/infer\", body=my_data)"
]
diff --git a/docs/tutorial/03-model-serving.ipynb b/docs/tutorial/03-model-serving.ipynb
index b0b56875b227..483ef4778a70 100644
--- a/docs/tutorial/03-model-serving.ipynb
+++ b/docs/tutorial/03-model-serving.ipynb
@@ -59,6 +59,7 @@
"outputs": [],
"source": [
"import mlrun\n",
+ "\n",
"project = mlrun.get_or_create_project(\"tutorial\", context=\"./\", user_project=True)"
]
},
@@ -107,23 +108,28 @@
"metadata": {},
"outputs": [],
"source": [
- "models_dir = mlrun.get_sample_path('models/serving/')\n",
+ "models_dir = mlrun.get_sample_path(\"models/serving/\")\n",
"\n",
"# We choose the correct model to avoid pickle warnings\n",
"import sys\n",
- "suffix = mlrun.__version__.split(\"-\")[0].replace(\".\", \"_\") if sys.version_info[1] > 7 else \"3.7\"\n",
"\n",
- "framework = 'sklearn' # change to 'keras' to try the 2nd option \n",
+ "suffix = (\n",
+ " mlrun.__version__.split(\"-\")[0].replace(\".\", \"_\")\n",
+ " if sys.version_info[1] > 7\n",
+ " else \"3.7\"\n",
+ ")\n",
+ "\n",
+ "framework = \"sklearn\" # change to 'keras' to try the 2nd option\n",
"kwargs = {}\n",
"if framework == \"sklearn\":\n",
- " serving_class = 'mlrun.frameworks.sklearn.SklearnModelServer'\n",
- " model_path = models_dir + f'sklearn-{suffix}.pkl'\n",
- " image = 'mlrun/mlrun'\n",
+ " serving_class = \"mlrun.frameworks.sklearn.SklearnModelServer\"\n",
+ " model_path = models_dir + f\"sklearn-{suffix}.pkl\"\n",
+ " image = \"mlrun/mlrun\"\n",
"else:\n",
- " serving_class = 'mlrun.frameworks.tf_keras.TFKerasModelServer'\n",
- " model_path = models_dir + 'keras.h5'\n",
- " image = 'mlrun/ml-models' # or mlrun/ml-models-gpu when using GPUs\n",
- " kwargs['labels'] = {'model-format': 'h5'}"
+ " serving_class = \"mlrun.frameworks.tf_keras.TFKerasModelServer\"\n",
+ " model_path = models_dir + \"keras.h5\"\n",
+ " image = \"mlrun/ml-models\" # or mlrun/ml-models-gpu when using GPUs\n",
+ " kwargs[\"labels\"] = {\"model-format\": \"h5\"}"
]
},
{
@@ -141,7 +147,7 @@
"metadata": {},
"outputs": [],
"source": [
- "model_object = project.log_model(f'{framework}-model', model_file=model_path, **kwargs)"
+ "model_object = project.log_model(f\"{framework}-model\", model_file=model_path, **kwargs)"
]
},
{
@@ -224,7 +230,9 @@
],
"source": [
"serving_fn = mlrun.new_function(\"serving\", image=image, kind=\"serving\", requirements={})\n",
- "serving_fn.add_model(framework ,model_path=model_object.uri, class_name=serving_class, to_list=True)\n",
+ "serving_fn.add_model(\n",
+ " framework, model_path=model_object.uri, class_name=serving_class, to_list=True\n",
+ ")\n",
"\n",
"# Plot the serving topology input -> router -> model\n",
"serving_fn.plot(rankdir=\"LR\")"
@@ -311,8 +319,8 @@
}
],
"source": [
- "sample = {\"inputs\":[[5.1, 3.5, 1.4, 0.2],[7.7, 3.8, 6.7, 2.2]]}\n",
- "server.test(path=f'/v2/models/{framework}/infer',body=sample)"
+ "sample = {\"inputs\": [[5.1, 3.5, 1.4, 0.2], [7.7, 3.8, 6.7, 2.2]]}\n",
+ "server.test(path=f\"/v2/models/{framework}/infer\", body=sample)"
]
},
{
@@ -392,7 +400,7 @@
}
],
"source": [
- "serving_fn.invoke(path=f'/v2/models/{framework}/infer',body=sample)"
+ "serving_fn.invoke(path=f\"/v2/models/{framework}/infer\", body=sample)"
]
},
{
diff --git a/docs/tutorial/04-pipeline.ipynb b/docs/tutorial/04-pipeline.ipynb
index 7e81d39239cd..e8a8776a0f65 100644
--- a/docs/tutorial/04-pipeline.ipynb
+++ b/docs/tutorial/04-pipeline.ipynb
@@ -76,6 +76,7 @@
],
"source": [
"import mlrun\n",
+ "\n",
"project = mlrun.get_or_create_project(\"tutorial\", context=\"./\", user_project=True)"
]
},
@@ -184,7 +185,13 @@
}
],
"source": [
- "project.set_function(\"data-prep.py\", name=\"data-prep\", kind=\"job\", image=\"mlrun/mlrun\", handler=\"breast_cancer_generator\")"
+ "project.set_function(\n",
+ " \"data-prep.py\",\n",
+ " name=\"data-prep\",\n",
+ " kind=\"job\",\n",
+ " image=\"mlrun/mlrun\",\n",
+ " handler=\"breast_cancer_generator\",\n",
+ ")"
]
},
{
@@ -463,8 +470,9 @@
"# Run the workflow\n",
"run_id = project.run(\n",
" workflow_path=\"./workflow.py\",\n",
- " arguments={\"model_name\": \"cancer-classifier\"}, \n",
- " watch=True)"
+ " arguments={\"model_name\": \"cancer-classifier\"},\n",
+ " watch=True,\n",
+ ")"
]
},
{
@@ -535,14 +543,41 @@
],
"source": [
"# Create a mock (simulator of the real-time function)\n",
- "my_data = {\"inputs\"\n",
- " :[[\n",
- " 1.371e+01, 2.083e+01, 9.020e+01, 5.779e+02, 1.189e-01, 1.645e-01,\n",
- " 9.366e-02, 5.985e-02, 2.196e-01, 7.451e-02, 5.835e-01, 1.377e+00,\n",
- " 3.856e+00, 5.096e+01, 8.805e-03, 3.029e-02, 2.488e-02, 1.448e-02,\n",
- " 1.486e-02, 5.412e-03, 1.706e+01, 2.814e+01, 1.106e+02, 8.970e+02,\n",
- " 1.654e-01, 3.682e-01, 2.678e-01, 1.556e-01, 3.196e-01, 1.151e-01]\n",
- " ]\n",
+ "my_data = {\n",
+ " \"inputs\": [\n",
+ " [\n",
+ " 1.371e01,\n",
+ " 2.083e01,\n",
+ " 9.020e01,\n",
+ " 5.779e02,\n",
+ " 1.189e-01,\n",
+ " 1.645e-01,\n",
+ " 9.366e-02,\n",
+ " 5.985e-02,\n",
+ " 2.196e-01,\n",
+ " 7.451e-02,\n",
+ " 5.835e-01,\n",
+ " 1.377e00,\n",
+ " 3.856e00,\n",
+ " 5.096e01,\n",
+ " 8.805e-03,\n",
+ " 3.029e-02,\n",
+ " 2.488e-02,\n",
+ " 1.448e-02,\n",
+ " 1.486e-02,\n",
+ " 5.412e-03,\n",
+ " 1.706e01,\n",
+ " 2.814e01,\n",
+ " 1.106e02,\n",
+ " 8.970e02,\n",
+ " 1.654e-01,\n",
+ " 3.682e-01,\n",
+ " 2.678e-01,\n",
+ " 1.556e-01,\n",
+ " 3.196e-01,\n",
+ " 1.151e-01,\n",
+ " ]\n",
+ " ]\n",
"}\n",
"serving_fn.invoke(\"/v2/models/cancer-classifier/infer\", body=my_data)"
]
diff --git a/docs/tutorial/05-model-monitoring.ipynb b/docs/tutorial/05-model-monitoring.ipynb
index 1444506c4472..667aff5aa99f 100644
--- a/docs/tutorial/05-model-monitoring.ipynb
+++ b/docs/tutorial/05-model-monitoring.ipynb
@@ -103,10 +103,15 @@
"source": [
"# We choose the correct model to avoid pickle warnings\n",
"import sys\n",
- "suffix = mlrun.__version__.split(\"-\")[0].replace(\".\", \"_\") if sys.version_info[1] > 7 else \"3.7\"\n",
"\n",
- "model_path = mlrun.get_sample_path(f'models/model-monitoring/model-{suffix}.pkl')\n",
- "training_set_path = mlrun.get_sample_path('data/model-monitoring/iris_dataset.csv')"
+ "suffix = (\n",
+ " mlrun.__version__.split(\"-\")[0].replace(\".\", \"_\")\n",
+ " if sys.version_info[1] > 7\n",
+ " else \"3.7\"\n",
+ ")\n",
+ "\n",
+ "model_path = mlrun.get_sample_path(f\"models/model-monitoring/model-{suffix}.pkl\")\n",
+ "training_set_path = mlrun.get_sample_path(\"data/model-monitoring/iris_dataset.csv\")"
]
},
{
@@ -139,7 +144,7 @@
" model_file=model_path,\n",
" framework=\"sklearn\",\n",
" training_set=pd.read_csv(training_set_path),\n",
- " label_column=\"label\"\n",
+ " label_column=\"label\",\n",
")"
]
},
@@ -188,7 +193,7 @@
"outputs": [],
"source": [
"# Import the serving function from the Function Hub and mount filesystem\n",
- "serving_fn = mlrun.import_function('hub://v2_model_server', new_name=\"serving\")\n",
+ "serving_fn = mlrun.import_function(\"hub://v2_model_server\", new_name=\"serving\")\n",
"\n",
"# Add the model to the serving function's routing spec\n",
"serving_fn.add_model(model_name, model_path=model_artifact.uri)\n",
@@ -320,13 +325,17 @@
"logging.getLogger(name=\"mlrun\").setLevel(logging.WARNING)\n",
"\n",
"# Get training set as list\n",
- "iris_data = pd.read_csv(training_set_path).drop(\"label\", axis=1).to_dict(orient=\"split\")[\"data\"]\n",
+ "iris_data = (\n",
+ " pd.read_csv(training_set_path).drop(\"label\", axis=1).to_dict(orient=\"split\")[\"data\"]\n",
+ ")\n",
"\n",
"# Simulate traffic using random elements from training set\n",
"for i in tqdm(range(12_000)):\n",
" data_point = choice(iris_data)\n",
- " serving_fn.invoke(f'v2/models/{model_name}/infer', json.dumps({'inputs': [data_point]}))\n",
- " \n",
+ " serving_fn.invoke(\n",
+ " f\"v2/models/{model_name}/infer\", json.dumps({\"inputs\": [data_point]})\n",
+ " )\n",
+ "\n",
"# Resume normal logging\n",
"logging.getLogger(name=\"mlrun\").setLevel(logging.INFO)"
]
diff --git a/docs/tutorial/06-add-mlops-to-code.ipynb b/docs/tutorial/06-add-mlops-to-code.ipynb
index bd6ba752c232..f9d56d4f0484 100644
--- a/docs/tutorial/06-add-mlops-to-code.ipynb
+++ b/docs/tutorial/06-add-mlops-to-code.ipynb
@@ -244,7 +244,9 @@
}
],
"source": [
- "project = mlrun.get_or_create_project(name=\"apply-mlrun-tutorial\", context=\"./\", user_project=True)"
+ "project = mlrun.get_or_create_project(\n",
+ " name=\"apply-mlrun-tutorial\", context=\"./\", user_project=True\n",
+ ")"
]
},
{
@@ -285,7 +287,7 @@
" filename=\"./src/script.py\",\n",
" name=\"apply-mlrun-tutorial-function\",\n",
" kind=\"job\",\n",
- " image=\"mlrun/ml-models\"\n",
+ " image=\"mlrun/ml-models\",\n",
")"
]
},
@@ -558,7 +560,7 @@
"script_run = script_function.run(\n",
" inputs={\n",
" \"train_set\": \"https://s3.us-east-1.wasabisys.com/iguazio/data/nyc-taxi/train.csv\",\n",
- " \"test_set\": \"https://s3.us-east-1.wasabisys.com/iguazio/data/nyc-taxi/test.csv\"\n",
+ " \"test_set\": \"https://s3.us-east-1.wasabisys.com/iguazio/data/nyc-taxi/test.csv\",\n",
" },\n",
")"
]
@@ -712,7 +714,7 @@
}
],
"source": [
- "script_run.artifact('valid_0_rmse_plot').show()"
+ "script_run.artifact(\"valid_0_rmse_plot\").show()"
]
},
{
@@ -808,7 +810,7 @@
}
],
"source": [
- "script_run.artifact('valid_0-feature-importance').show()"
+ "script_run.artifact(\"valid_0-feature-importance\").show()"
]
},
{
@@ -939,7 +941,7 @@
}
],
"source": [
- "script_run.artifact('taxi_fare_submission').show()"
+ "script_run.artifact(\"taxi_fare_submission\").show()"
]
}
],
diff --git a/docs/tutorial/07-batch-infer.ipynb b/docs/tutorial/07-batch-infer.ipynb
index 44eb251327d0..95f60259e60c 100644
--- a/docs/tutorial/07-batch-infer.ipynb
+++ b/docs/tutorial/07-batch-infer.ipynb
@@ -108,11 +108,16 @@
"source": [
"# We choose the correct model to avoid pickle warnings\n",
"import sys\n",
- "suffix = mlrun.__version__.split(\"-\")[0].replace(\".\", \"_\") if sys.version_info[1] > 7 else \"3.7\"\n",
"\n",
- "model_path = mlrun.get_sample_path(f'models/batch-predict/model-{suffix}.pkl')\n",
- "training_set_path = mlrun.get_sample_path('data/batch-predict/training_set.parquet')\n",
- "prediction_set_path = mlrun.get_sample_path('data/batch-predict/prediction_set.parquet')"
+ "suffix = (\n",
+ " mlrun.__version__.split(\"-\")[0].replace(\".\", \"_\")\n",
+ " if sys.version_info[1] > 7\n",
+ " else \"3.7\"\n",
+ ")\n",
+ "\n",
+ "model_path = mlrun.get_sample_path(f\"models/batch-predict/model-{suffix}.pkl\")\n",
+ "training_set_path = mlrun.get_sample_path(\"data/batch-predict/training_set.parquet\")\n",
+ "prediction_set_path = mlrun.get_sample_path(\"data/batch-predict/prediction_set.parquet\")"
]
},
{
@@ -584,7 +589,7 @@
" model_file=model_path,\n",
" framework=\"sklearn\",\n",
" training_set=pd.read_parquet(training_set_path),\n",
- " label_column=\"label\"\n",
+ " label_column=\"label\",\n",
")"
]
},
@@ -879,11 +884,11 @@
" inputs={\n",
" \"dataset\": prediction_set_path,\n",
" # If you do not log a dataset with your model, you can pass it in here:\n",
- "# \"sample_set\" : training_set_path\n",
+ " # \"sample_set\" : training_set_path\n",
" },\n",
" params={\n",
" \"model\": model_artifact.uri,\n",
- " \"perform_drift_analysis\" : True,\n",
+ " \"perform_drift_analysis\": True,\n",
" },\n",
")"
]
@@ -1219,6 +1224,7 @@
"source": [
"# Data/concept drift per feature\n",
"import json\n",
+ "\n",
"json.loads(run.artifact(\"features_drift_results\").get())"
]
},
diff --git a/examples/load-project.ipynb b/examples/load-project.ipynb
index 213330eaea51..e568e7f37cb6 100644
--- a/examples/load-project.ipynb
+++ b/examples/load-project.ipynb
@@ -64,13 +64,13 @@
"\n",
"# source Git Repo\n",
"# YOU SHOULD fork this to your account and use the fork if you plan on modifying the code\n",
- "url = 'git://github.com/mlrun/demo-xgb-project.git' # refs/tags/v0.4.7'\n",
+ "url = \"git://github.com/mlrun/demo-xgb-project.git\" # refs/tags/v0.4.7'\n",
"\n",
"# alternatively can use tar files, e.g.\n",
- "#url = 'v3io:///users/admin/tars/src-project.tar.gz'\n",
+ "# url = 'v3io:///users/admin/tars/src-project.tar.gz'\n",
"\n",
"# change if you want to clone into a different dir, can use clone=True to override the dir content\n",
- "project_dir = path.join(str(Path.home()), 'my_proj')\n",
+ "project_dir = path.join(str(Path.home()), \"my_proj\")\n",
"proj = load_project(project_dir, url, clone=True)"
]
},
@@ -181,11 +181,16 @@
"source": [
"# You can update the function .py and .yaml from a notebook (code + spec)\n",
"# the \"code_output\" option will generate a .py file from our notebook which can be used for src control and local runs\n",
- "xgbfn = code_to_function('xgb', filename='notebooks/train-xgboost.ipynb' ,kind='job', code_output='src/iris.py')\n",
+ "xgbfn = code_to_function(\n",
+ " \"xgb\",\n",
+ " filename=\"notebooks/train-xgboost.ipynb\",\n",
+ " kind=\"job\",\n",
+ " code_output=\"src/iris.py\",\n",
+ ")\n",
"\n",
- "# tell the builder to clone this repo into the function container \n",
- "xgbfn.spec.build.source = './'\n",
- "xgbfn.export('src/iris.yaml')"
+ "# tell the builder to clone this repo into the function container\n",
+ "xgbfn.spec.build.source = \"./\"\n",
+ "xgbfn.export(\"src/iris.yaml\")"
]
},
{
@@ -268,7 +273,7 @@
],
"source": [
"# read specific function spec\n",
- "print(proj.func('xgb').to_yaml())"
+ "print(proj.func(\"xgb\").to_yaml())"
]
},
{
@@ -519,7 +524,8 @@
],
"source": [
"from mlrun import run_local, new_task\n",
- "run_local(new_task(handler='iris_generator'), proj.func('xgb'), workdir='./')"
+ "\n",
+ "run_local(new_task(handler=\"iris_generator\"), proj.func(\"xgb\"), workdir=\"./\")"
]
},
{
@@ -738,7 +744,13 @@
}
],
"source": [
- "proj.run('main', arguments={}, artifact_path='v3io:///users/admin/mlrun/kfp/{{workflow.uid}}/', dirty=True, watch=True)"
+ "proj.run(\n",
+ " \"main\",\n",
+ " arguments={},\n",
+ " artifact_path=\"v3io:///users/admin/mlrun/kfp/{{workflow.uid}}/\",\n",
+ " dirty=True,\n",
+ " watch=True,\n",
+ ")"
]
},
{
@@ -758,7 +770,7 @@
"metadata": {},
"outputs": [],
"source": [
- "proj.source = 'v3io:///users/admin/my-proj'"
+ "proj.source = \"v3io:///users/admin/my-proj\""
]
},
{
diff --git a/examples/mlrun_basics.ipynb b/examples/mlrun_basics.ipynb
index ae524fe4d4b9..b14d3bd66c9d 100644
--- a/examples/mlrun_basics.ipynb
+++ b/examples/mlrun_basics.ipynb
@@ -99,7 +99,8 @@
"source": [
"from mlrun import run_local, new_task, mlconf\n",
"from os import path\n",
- "mlconf.dbpath = mlconf.dbpath or './'"
+ "\n",
+ "mlconf.dbpath = mlconf.dbpath or \"./\""
]
},
{
@@ -158,9 +159,9 @@
"metadata": {},
"outputs": [],
"source": [
- "out = mlconf.artifact_path or path.abspath('./data')\n",
+ "out = mlconf.artifact_path or path.abspath(\"./data\")\n",
"# {{run.uid}} will be substituted with the run id, so output will be written to different directoried per run\n",
- "artifact_path = path.join(out, '{{run.uid}}')"
+ "artifact_path = path.join(out, \"{{run.uid}}\")"
]
},
{
@@ -177,7 +178,11 @@
"metadata": {},
"outputs": [],
"source": [
- "task = new_task(name='demo', params={'p1': 5}, artifact_path=artifact_path).with_secrets('file', 'secrets.txt').set_label('type', 'demo')"
+ "task = (\n",
+ " new_task(name=\"demo\", params={\"p1\": 5}, artifact_path=artifact_path)\n",
+ " .with_secrets(\"file\", \"secrets.txt\")\n",
+ " .set_label(\"type\", \"demo\")\n",
+ ")"
]
},
{
@@ -442,7 +447,7 @@
],
"source": [
"# run our task using our new function\n",
- "run_object = run_local(task, command='training.py')"
+ "run_object = run_local(task, command=\"training.py\")"
]
},
{
@@ -934,7 +939,7 @@
}
],
"source": [
- "run_object.artifact('dataset')"
+ "run_object.artifact(\"dataset\")"
]
},
{
@@ -1230,7 +1235,9 @@
}
],
"source": [
- "run = run_local(task.with_hyper_params({'p2': [5, 2, 3]}, 'min.loss'), command='training.py')"
+ "run = run_local(\n",
+ " task.with_hyper_params({\"p2\": [5, 2, 3]}, \"min.loss\"), command=\"training.py\"\n",
+ ")"
]
},
{
@@ -1424,46 +1431,53 @@
"\n",
"# define a function with spec as parameter\n",
"import time\n",
- "def handler(context, p1=1, p2='xx'):\n",
+ "\n",
+ "\n",
+ "def handler(context, p1=1, p2=\"xx\"):\n",
" \"\"\"this is a simple function\n",
- " \n",
+ "\n",
" :param p1: first param\n",
" :param p2: another param\n",
" \"\"\"\n",
" # access input metadata, values, and inputs\n",
- " print(f'Run: {context.name} (uid={context.uid})')\n",
- " print(f'Params: p1={p1}, p2={p2}')\n",
- " \n",
+ " print(f\"Run: {context.name} (uid={context.uid})\")\n",
+ " print(f\"Params: p1={p1}, p2={p2}\")\n",
+ "\n",
" time.sleep(1)\n",
- " \n",
+ "\n",
" # log the run results (scalar values)\n",
- " context.log_result('accuracy', p1 * 2)\n",
- " context.log_result('loss', p1 * 3)\n",
- " \n",
- " # add a lable/tag to this run \n",
- " context.set_label('category', 'tests')\n",
- " \n",
- " # create a matplot figure and store as artifact \n",
+ " context.log_result(\"accuracy\", p1 * 2)\n",
+ " context.log_result(\"loss\", p1 * 3)\n",
+ "\n",
+ " # add a lable/tag to this run\n",
+ " context.set_label(\"category\", \"tests\")\n",
+ "\n",
+ " # create a matplot figure and store as artifact\n",
" fig, ax = plt.subplots()\n",
" np.random.seed(0)\n",
" x, y = np.random.normal(size=(2, 200))\n",
" color, size = np.random.random((2, 200))\n",
" ax.scatter(x, y, c=color, s=500 * size, alpha=0.3)\n",
- " ax.grid(color='lightgray', alpha=0.7)\n",
- " \n",
- " context.log_artifact(PlotArtifact('myfig', body=fig, title='my plot'))\n",
- " \n",
- " # create a dataframe artifact \n",
- " df = pd.DataFrame([{'A':10, 'B':100}, {'A':11,'B':110}, {'A':12,'B':120}])\n",
- " context.log_dataset('mydf', df=df)\n",
- " \n",
- " # Log an ML Model artifact \n",
- " context.log_model('mymodel', body=b'abc is 123', \n",
- " model_file='model.txt', model_dir='data', \n",
- " metrics={'accuracy':0.85}, parameters={'xx':'abc'},\n",
- " labels={'framework': 'xgboost'})\n",
+ " ax.grid(color=\"lightgray\", alpha=0.7)\n",
+ "\n",
+ " context.log_artifact(PlotArtifact(\"myfig\", body=fig, title=\"my plot\"))\n",
+ "\n",
+ " # create a dataframe artifact\n",
+ " df = pd.DataFrame([{\"A\": 10, \"B\": 100}, {\"A\": 11, \"B\": 110}, {\"A\": 12, \"B\": 120}])\n",
+ " context.log_dataset(\"mydf\", df=df)\n",
+ "\n",
+ " # Log an ML Model artifact\n",
+ " context.log_model(\n",
+ " \"mymodel\",\n",
+ " body=b\"abc is 123\",\n",
+ " model_file=\"model.txt\",\n",
+ " model_dir=\"data\",\n",
+ " metrics={\"accuracy\": 0.85},\n",
+ " parameters={\"xx\": \"abc\"},\n",
+ " labels={\"framework\": \"xgboost\"},\n",
+ " )\n",
"\n",
- " return 'my resp'"
+ " return \"my resp\""
]
},
{
@@ -1723,7 +1737,9 @@
}
],
"source": [
- "task = new_task(name='demo2', handler=handler, artifact_path=artifact_path).with_params(p1=7)\n",
+ "task = new_task(name=\"demo2\", handler=handler, artifact_path=artifact_path).with_params(\n",
+ " p1=7\n",
+ ")\n",
"run = run_local(task)"
]
},
@@ -2025,7 +2041,9 @@
}
],
"source": [
- "task = new_task(name='demo2', handler=handler, artifact_path=artifact_path).with_param_file('params.csv', 'max.accuracy')\n",
+ "task = new_task(\n",
+ " name=\"demo2\", handler=handler, artifact_path=artifact_path\n",
+ ").with_param_file(\"params.csv\", \"max.accuracy\")\n",
"run = run_local(task)"
]
},
diff --git a/examples/mlrun_dask.ipynb b/examples/mlrun_dask.ipynb
index 316e8c8a8506..efe615968896 100644
--- a/examples/mlrun_dask.ipynb
+++ b/examples/mlrun_dask.ipynb
@@ -14,7 +14,7 @@
"outputs": [],
"source": [
"# recommended, installing the exact package versions as we use in the worker\n",
- "#!pip install dask==2.12.0 distributed==2.14.0 "
+ "#!pip install dask==2.12.0 distributed==2.14.0"
]
},
{
@@ -30,9 +30,9 @@
"metadata": {},
"outputs": [],
"source": [
- "# function that will be distributed \n",
+ "# function that will be distributed\n",
"def inc(x):\n",
- " return x+2"
+ " return x + 2"
]
},
{
@@ -50,13 +50,13 @@
"outputs": [],
"source": [
"# wrapper function, uses the dask client object\n",
- "def hndlr(context, x=1,y=2):\n",
- " context.logger.info('params: x={},y={}'.format(x,y))\n",
- " print('params: x={},y={}'.format(x,y))\n",
+ "def hndlr(context, x=1, y=2):\n",
+ " context.logger.info(\"params: x={},y={}\".format(x, y))\n",
+ " print(\"params: x={},y={}\".format(x, y))\n",
" x = context.dask_client.submit(inc, x)\n",
" print(x)\n",
" print(x.result())\n",
- " context.log_result('y', x.result())"
+ " context.log_result(\"y\", x.result())"
]
},
{
@@ -76,7 +76,8 @@
"outputs": [],
"source": [
"from mlrun import new_function, mlconf, code_to_function, mount_v3io, new_task\n",
- "#mlconf.dbpath = 'http://mlrun-api:8080'"
+ "\n",
+ "# mlconf.dbpath = 'http://mlrun-api:8080'"
]
},
{
@@ -107,7 +108,7 @@
"outputs": [],
"source": [
"# create the function from the notebook code + annotations, add volumes\n",
- "dsf = code_to_function('mydask', kind='dask').apply(mount_v3io())"
+ "dsf = code_to_function(\"mydask\", kind=\"dask\").apply(mount_v3io())"
]
},
{
@@ -116,10 +117,10 @@
"metadata": {},
"outputs": [],
"source": [
- "dsf.spec.image = 'mlrun/ml-models'\n",
+ "dsf.spec.image = \"mlrun/ml-models\"\n",
"dsf.spec.remote = True\n",
"dsf.spec.replicas = 1\n",
- "dsf.spec.service_type = 'NodePort'"
+ "dsf.spec.service_type = \"NodePort\""
]
},
{
@@ -399,7 +400,7 @@
}
],
"source": [
- "myrun = dsf.run(handler=hndlr, params={'x': 12})"
+ "myrun = dsf.run(handler=hndlr, params={\"x\": 12})"
]
},
{
@@ -520,8 +521,9 @@
],
"source": [
"from mlrun import import_function\n",
+ "\n",
"# Functions url: db:///[:tag]\n",
- "dsf_obj = import_function('db://default/mydask')\n",
+ "dsf_obj = import_function(\"db://default/mydask\")\n",
"c = dsf_obj.client"
]
},
@@ -550,12 +552,15 @@
"outputs": [],
"source": [
"@dsl.pipeline(name=\"dask_pipeline\")\n",
- "def dask_pipe(x=1,y=10):\n",
+ "def dask_pipe(x=1, y=10):\n",
" # use_db option will use a function (DB) pointer instead of adding the function spec to the YAML\n",
- " myrun = dsf.as_step(new_task(handler=hndlr, name=\"dask_pipeline\", params={'x': x, 'y': y}), use_db=True)\n",
- " \n",
+ " myrun = dsf.as_step(\n",
+ " new_task(handler=hndlr, name=\"dask_pipeline\", params={\"x\": x, \"y\": y}),\n",
+ " use_db=True,\n",
+ " )\n",
+ "\n",
" # if the step (dask client) need v3io access u should add: .apply(mount_v3io())\n",
- " \n",
+ "\n",
" # if its a new image we may want to tell Kubeflow to reload the image\n",
" # myrun.container.set_image_pull_policy('Always')"
]
@@ -578,7 +583,7 @@
],
"source": [
"# for pipeline debug\n",
- "kfp.compiler.Compiler().compile(dask_pipe, 'daskpipe.yaml', type_check=False)"
+ "kfp.compiler.Compiler().compile(dask_pipe, \"daskpipe.yaml\", type_check=False)"
]
},
{
@@ -631,13 +636,15 @@
}
],
"source": [
- "arguments={'x':4,'y':-5}\n",
- "artifact_path = '/User/test'\n",
- "run_id = run_pipeline(dask_pipe, \n",
- " arguments, \n",
- " artifact_path=artifact_path,\n",
- " run=\"DaskExamplePipeline\", \n",
- " experiment=\"dask pipe\")"
+ "arguments = {\"x\": 4, \"y\": -5}\n",
+ "artifact_path = \"/User/test\"\n",
+ "run_id = run_pipeline(\n",
+ " dask_pipe,\n",
+ " arguments,\n",
+ " artifact_path=artifact_path,\n",
+ " run=\"DaskExamplePipeline\",\n",
+ " experiment=\"dask pipe\",\n",
+ ")"
]
},
{
@@ -647,9 +654,10 @@
"outputs": [],
"source": [
"from mlrun import wait_for_pipeline_completion, get_run_db\n",
+ "\n",
"wait_for_pipeline_completion(run_id)\n",
"db = get_run_db().connect()\n",
- "db.list_runs(project='default', labels=f'workflow={run_id}').show()\n"
+ "db.list_runs(project=\"default\", labels=f\"workflow={run_id}\").show()"
]
}
],
diff --git a/examples/mlrun_db.ipynb b/examples/mlrun_db.ipynb
index b6bb0a365ba0..a11f215473b1 100644
--- a/examples/mlrun_db.ipynb
+++ b/examples/mlrun_db.ipynb
@@ -16,7 +16,7 @@
"outputs": [],
"source": [
"# specify the DB path (use 'http://mlrun-api:8080' for api service)\n",
- "mlconf.dbpath = mlconf.dbpath or 'http://mlrun-api:8080'\n",
+ "mlconf.dbpath = mlconf.dbpath or \"http://mlrun-api:8080\"\n",
"db = get_run_db().connect()"
]
},
@@ -251,7 +251,7 @@
],
"source": [
"# list all runs\n",
- "db.list_runs('download').show()"
+ "db.list_runs(\"download\").show()"
]
},
{
@@ -619,7 +619,7 @@
],
"source": [
"# list all artifact for version \"latest\"\n",
- "db.list_artifacts('', tag='latest', project='iris').show()"
+ "db.list_artifacts(\"\", tag=\"latest\", project=\"iris\").show()"
]
},
{
@@ -1182,8 +1182,8 @@
}
],
"source": [
- "# check different artifact versions \n",
- "db.list_artifacts('ch', tag='*').show()"
+ "# check different artifact versions\n",
+ "db.list_artifacts(\"ch\", tag=\"*\").show()"
]
},
{
@@ -1192,7 +1192,7 @@
"metadata": {},
"outputs": [],
"source": [
- "db.del_runs(state='completed')"
+ "db.del_runs(state=\"completed\")"
]
},
{
@@ -1201,7 +1201,7 @@
"metadata": {},
"outputs": [],
"source": [
- "db.del_artifacts(tag='*')"
+ "db.del_artifacts(tag=\"*\")"
]
},
{
diff --git a/examples/mlrun_export_import.ipynb b/examples/mlrun_export_import.ipynb
index 8f987c369952..f32636df7d14 100644
--- a/examples/mlrun_export_import.ipynb
+++ b/examples/mlrun_export_import.ipynb
@@ -24,31 +24,30 @@
"import zipfile\n",
"from mlrun import DataItem\n",
"\n",
- "def open_archive(context, \n",
- " target_dir: str,\n",
- " archive_url: DataItem = None):\n",
+ "\n",
+ "def open_archive(context, target_dir: str, archive_url: DataItem = None):\n",
" \"\"\"Open a file/object archive into a target directory\n",
- " \n",
+ "\n",
" :param target_dir: target directory\n",
" :param archive_url: source archive path/url (MLRun DataItem object)\n",
- " \n",
+ "\n",
" :returns: content dir\n",
" \"\"\"\n",
- " \n",
+ "\n",
" # Define locations\n",
" archive_file = archive_url.local()\n",
" os.makedirs(target_dir, exist_ok=True)\n",
- " context.logger.info('Verified directories')\n",
- " \n",
+ " context.logger.info(\"Verified directories\")\n",
+ "\n",
" # Extract dataset from zip\n",
- " context.logger.info('Extracting zip')\n",
- " zip_ref = zipfile.ZipFile(archive_file, 'r')\n",
+ " context.logger.info(\"Extracting zip\")\n",
+ " zip_ref = zipfile.ZipFile(archive_file, \"r\")\n",
" zip_ref.extractall(target_dir)\n",
" zip_ref.close()\n",
- " \n",
- " context.logger.info(f'extracted archive to {target_dir}')\n",
+ "\n",
+ " context.logger.info(f\"extracted archive to {target_dir}\")\n",
" # use target_path= to specify and absolute target path (vs artifact_path)\n",
- " context.log_artifact('content', target_path=target_dir)\n"
+ " context.log_artifact(\"content\", target_path=target_dir)"
]
},
{
@@ -75,11 +74,16 @@
"source": [
"# create job function object from notebook code and add doc/metadata\n",
"import mlrun\n",
- "fn = mlrun.code_to_function('file_utils', kind='job',\n",
- " handler='open_archive', image='mlrun/mlrun',\n",
- " description = \"this function opens a zip archive into a local/mounted folder\",\n",
- " categories = ['fileutils'],\n",
- " labels = {'author': 'me'})\n"
+ "\n",
+ "fn = mlrun.code_to_function(\n",
+ " \"file_utils\",\n",
+ " kind=\"job\",\n",
+ " handler=\"open_archive\",\n",
+ " image=\"mlrun/mlrun\",\n",
+ " description=\"this function opens a zip archive into a local/mounted folder\",\n",
+ " categories=[\"fileutils\"],\n",
+ " labels={\"author\": \"me\"},\n",
+ ")"
]
},
{
@@ -160,7 +164,7 @@
],
"source": [
"# save to a file (and can be pushed to a git)\n",
- "fn.export('function.yaml')"
+ "fn.export(\"function.yaml\")"
]
},
{
@@ -176,7 +180,7 @@
"metadata": {},
"outputs": [],
"source": [
- "mlrun.mlconf.dbpath = mlrun.mlconf.dbpath or 'http://mlrun-api:8080'"
+ "mlrun.mlconf.dbpath = mlrun.mlconf.dbpath or \"http://mlrun-api:8080\""
]
},
{
@@ -201,9 +205,9 @@
],
"source": [
"# load from local file\n",
- "xfn = mlrun.import_function('./function.yaml')\n",
+ "xfn = mlrun.import_function(\"./function.yaml\")\n",
"\n",
- "# load function from MLRun functions hub \n",
+ "# load function from MLRun functions hub\n",
"# xfn = mlrun.import_function('hub://open_archive')\n",
"\n",
"# get function doc\n",
@@ -218,15 +222,18 @@
"source": [
"from os import path\n",
"from mlrun.platforms import auto_mount\n",
+ "\n",
"# for auto choice between Iguazio platform and k8s PVC\n",
- "# should set the env var for PVC: MLRUN_PVC_MOUNT=:, or use mount_pvc() \n",
+ "# should set the env var for PVC: MLRUN_PVC_MOUNT=:, or use mount_pvc()\n",
"xfn.apply(auto_mount())\n",
"\n",
"# create and run the task\n",
- "images_path = path.abspath('images')\n",
- "open_archive_task = mlrun.new_task('download',\n",
- " params={'target_dir': images_path},\n",
- " inputs={'archive_url': 'http://iguazio-sample-data.s3.amazonaws.com/catsndogs.zip'})"
+ "images_path = path.abspath(\"images\")\n",
+ "open_archive_task = mlrun.new_task(\n",
+ " \"download\",\n",
+ " params={\"target_dir\": images_path},\n",
+ " inputs={\"archive_url\": \"http://iguazio-sample-data.s3.amazonaws.com/catsndogs.zip\"},\n",
+ ")"
]
},
{
@@ -485,8 +492,9 @@
"outputs": [],
"source": [
"from mlrun import mlconf\n",
- "mlconf.dbpath = mlconf.dbpath or './'\n",
- "artifact_path = mlconf.artifact_path or path.abspath('data')"
+ "\n",
+ "mlconf.dbpath = mlconf.dbpath or \"./\"\n",
+ "artifact_path = mlconf.artifact_path or path.abspath(\"data\")"
]
},
{
@@ -740,6 +748,7 @@
"outputs": [],
"source": [
"from mlrun import function_to_module, get_or_create_ctx\n",
+ "\n",
"mod = function_to_module(xfn)"
]
},
@@ -750,9 +759,11 @@
"outputs": [],
"source": [
"# create a context object and DataItem objects\n",
- "# you can also use existing context and data objects (e.g. from parant function) \n",
- "context = get_or_create_ctx('myfunc')\n",
- "data = mlrun.run.get_dataitem('http://iguazio-sample-data.s3.amazonaws.com/catsndogs.zip')"
+ "# you can also use existing context and data objects (e.g. from parant function)\n",
+ "context = get_or_create_ctx(\"myfunc\")\n",
+ "data = mlrun.run.get_dataitem(\n",
+ " \"http://iguazio-sample-data.s3.amazonaws.com/catsndogs.zip\"\n",
+ ")"
]
},
{
diff --git a/examples/mlrun_jobs.ipynb b/examples/mlrun_jobs.ipynb
index 4f473289c61a..32c3ee9653cb 100644
--- a/examples/mlrun_jobs.ipynb
+++ b/examples/mlrun_jobs.ipynb
@@ -82,8 +82,8 @@
"source": [
"# mlrun: ignore\n",
"# do not remove the comment above (it is a directive to nuclio, ignore that cell during build)\n",
- "# if the nuclio-jupyter package is not installed run !pip install nuclio-jupyter and restart the kernel \n",
- "import nuclio "
+ "# if the nuclio-jupyter package is not installed run !pip install nuclio-jupyter and restart the kernel\n",
+ "import nuclio"
]
},
{
@@ -138,11 +138,8 @@
"import time\n",
"import pandas as pd\n",
"\n",
- "def training(\n",
- " context: MLClientCtx,\n",
- " p1: int = 1,\n",
- " p2: int = 2\n",
- ") -> None:\n",
+ "\n",
+ "def training(context: MLClientCtx, p1: int = 1, p2: int = 2) -> None:\n",
" \"\"\"Train a model.\n",
"\n",
" :param context: The runtime context object.\n",
@@ -150,36 +147,38 @@
" :param p2: Another model parameter.\n",
" \"\"\"\n",
" # access input metadata, values, and inputs\n",
- " print(f'Run: {context.name} (uid={context.uid})')\n",
- " print(f'Params: p1={p1}, p2={p2}')\n",
- " context.logger.info('started training')\n",
- " \n",
+ " print(f\"Run: {context.name} (uid={context.uid})\")\n",
+ " print(f\"Params: p1={p1}, p2={p2}\")\n",
+ " context.logger.info(\"started training\")\n",
+ "\n",
" # \n",
- " \n",
+ "\n",
" # log the run results (scalar values)\n",
- " context.log_result('accuracy', p1 * 2)\n",
- " context.log_result('loss', p1 * 3)\n",
- " \n",
- " # add a lable/tag to this run \n",
- " context.set_label('category', 'tests')\n",
- " \n",
- " # log a simple artifact + label the artifact \n",
+ " context.log_result(\"accuracy\", p1 * 2)\n",
+ " context.log_result(\"loss\", p1 * 3)\n",
+ "\n",
+ " # add a lable/tag to this run\n",
+ " context.set_label(\"category\", \"tests\")\n",
+ "\n",
+ " # log a simple artifact + label the artifact\n",
" # If you want to upload a local file to the artifact repo add src_path=\n",
- " context.log_artifact('somefile', \n",
- " body=b'abc is 123', \n",
- " local_path='myfile.txt')\n",
- " \n",
- " # create a dataframe artifact \n",
- " df = pd.DataFrame([{'A':10, 'B':100}, {'A':11,'B':110}, {'A':12,'B':120}])\n",
- " context.log_dataset('mydf', df=df)\n",
- " \n",
+ " context.log_artifact(\"somefile\", body=b\"abc is 123\", local_path=\"myfile.txt\")\n",
+ "\n",
+ " # create a dataframe artifact\n",
+ " df = pd.DataFrame([{\"A\": 10, \"B\": 100}, {\"A\": 11, \"B\": 110}, {\"A\": 12, \"B\": 120}])\n",
+ " context.log_dataset(\"mydf\", df=df)\n",
+ "\n",
" # Log an ML Model artifact, add metrics, params, and labels to it\n",
- " # and place it in a subdir ('models') under artifacts path \n",
- " context.log_model('mymodel', body=b'abc is 123', \n",
- " model_file='model.txt', \n",
- " metrics={'accuracy':0.85}, parameters={'xx':'abc'},\n",
- " labels={'framework': 'xgboost'},\n",
- " artifact_path=context.artifact_subpath('models'))\n"
+ " # and place it in a subdir ('models') under artifacts path\n",
+ " context.log_model(\n",
+ " \"mymodel\",\n",
+ " body=b\"abc is 123\",\n",
+ " model_file=\"model.txt\",\n",
+ " metrics={\"accuracy\": 0.85},\n",
+ " parameters={\"xx\": \"abc\"},\n",
+ " labels={\"framework\": \"xgboost\"},\n",
+ " artifact_path=context.artifact_subpath(\"models\"),\n",
+ " )"
]
},
{
@@ -188,33 +187,28 @@
"metadata": {},
"outputs": [],
"source": [
- "def validation(\n",
- " context: MLClientCtx,\n",
- " model: DataItem\n",
- ") -> None:\n",
+ "def validation(context: MLClientCtx, model: DataItem) -> None:\n",
" \"\"\"Model validation.\n",
- " \n",
+ "\n",
" Dummy validation function.\n",
- " \n",
+ "\n",
" :param context: The runtime context object.\n",
" :param model: The extimated model object.\n",
" \"\"\"\n",
" # access input metadata, values, files, and secrets (passwords)\n",
- " print(f'Run: {context.name} (uid={context.uid})')\n",
- " context.logger.info('started validation')\n",
- " \n",
+ " print(f\"Run: {context.name} (uid={context.uid})\")\n",
+ " context.logger.info(\"started validation\")\n",
+ "\n",
" # get the model file, class (metadata), and extra_data (dict of key: DataItem)\n",
" model_file, model_obj, _ = get_model(model)\n",
"\n",
" # update model object elements and data\n",
- " update_model(model_obj, parameters={'one_more': 5})\n",
+ " update_model(model_obj, parameters={\"one_more\": 5})\n",
"\n",
- " print(f'path to local copy of model file - {model_file}')\n",
- " print('parameters:', model_obj.parameters)\n",
- " print('metrics:', model_obj.metrics)\n",
- " context.log_artifact('validation', \n",
- " body=b' validated ', \n",
- " format='html')"
+ " print(f\"path to local copy of model file - {model_file}\")\n",
+ " print(\"parameters:\", model_obj.parameters)\n",
+ " print(\"metrics:\", model_obj.metrics)\n",
+ " context.log_artifact(\"validation\", body=b\" validated \", format=\"html\")"
]
},
{
@@ -263,7 +257,8 @@
"source": [
"from mlrun import run_local, code_to_function, mlconf, new_task\n",
"from mlrun.platforms.other import auto_mount\n",
- "mlconf.dbpath = mlconf.dbpath or 'http://mlrun-api:8080'"
+ "\n",
+ "mlconf.dbpath = mlconf.dbpath or \"http://mlrun-api:8080\""
]
},
{
@@ -280,9 +275,10 @@
"outputs": [],
"source": [
"from os import path\n",
- "out = mlconf.artifact_path or path.abspath('./data')\n",
+ "\n",
+ "out = mlconf.artifact_path or path.abspath(\"./data\")\n",
"# {{run.uid}} will be substituted with the run id, so output will be written to different directoried per run\n",
- "artifact_path = path.join(out, '{{run.uid}}')"
+ "artifact_path = path.join(out, \"{{run.uid}}\")"
]
},
{
@@ -539,7 +535,7 @@
}
],
"source": [
- "train_run = run_local(new_task(handler=training, params={'p1': 5}, artifact_path=out))"
+ "train_run = run_local(new_task(handler=training, params={\"p1\": 5}, artifact_path=out))"
]
},
{
@@ -811,9 +807,11 @@
}
],
"source": [
- "model = train_run.outputs['mymodel']\n",
+ "model = train_run.outputs[\"mymodel\"]\n",
"\n",
- "validation_run = run_local(new_task(handler=validation, inputs={'model': model}, artifact_path=out))"
+ "validation_run = run_local(\n",
+ " new_task(handler=validation, inputs={\"model\": model}, artifact_path=out)\n",
+ ")"
]
},
{
@@ -842,7 +840,7 @@
"outputs": [],
"source": [
"# create an ML function from the notebook, attache it to iguazio data fabric (v3io)\n",
- "trainer = code_to_function(name='my-trainer', kind='job')"
+ "trainer = code_to_function(name=\"my-trainer\", kind=\"job\")"
]
},
{
@@ -913,7 +911,7 @@
],
"source": [
"# for auto choice between Iguazio platform and k8s PVC\n",
- "# should set the env var for PVC: MLRUN_PVC_MOUNT=:, or use mount_pvc() \n",
+ "# should set the env var for PVC: MLRUN_PVC_MOUNT=:, or use mount_pvc()\n",
"trainer.apply(auto_mount())"
]
},
@@ -1057,7 +1055,7 @@
"outputs": [],
"source": [
"# create the base task (common to both steps), and set the output path and experiment label\n",
- "base_task = new_task(artifact_path=out).set_label('stage', 'dev')"
+ "base_task = new_task(artifact_path=out).set_label(\"stage\", \"dev\")"
]
},
{
@@ -1296,7 +1294,9 @@
],
"source": [
"# run our training task, with hyper params, and select the one with max accuracy\n",
- "train_task = new_task(name='my-training', handler='training', params={'p1': 9}, base=base_task)\n",
+ "train_task = new_task(\n",
+ " name=\"my-training\", handler=\"training\", params={\"p1\": 9}, base=base_task\n",
+ ")\n",
"train_run = trainer.run(train_task)"
]
},
@@ -1545,9 +1545,9 @@
}
],
"source": [
- "# running validation, use the model result from the previous step \n",
- "model = train_run.outputs['mymodel']\n",
- "trainer.run(base_task, handler='validation', inputs={'model': model}, watch=True)"
+ "# running validation, use the model result from the previous step\n",
+ "model = train_run.outputs[\"mymodel\"]\n",
+ "trainer.run(base_task, handler=\"validation\", inputs={\"model\": model}, watch=True)"
]
},
{
@@ -1586,26 +1586,20 @@
"metadata": {},
"outputs": [],
"source": [
- "@dsl.pipeline(\n",
- " name = 'job test',\n",
- " description = 'demonstrating mlrun usage'\n",
- ")\n",
- "def job_pipeline(\n",
- " p1: int = 9\n",
- ") -> None:\n",
+ "@dsl.pipeline(name=\"job test\", description=\"demonstrating mlrun usage\")\n",
+ "def job_pipeline(p1: int = 9) -> None:\n",
" \"\"\"Define our pipeline.\n",
- " \n",
+ "\n",
" :param p1: A model parameter.\n",
" \"\"\"\n",
"\n",
- " train = trainer.as_step(handler='training',\n",
- " params={'p1': p1},\n",
- " outputs=['mymodel'])\n",
- " \n",
- " validate = trainer.as_step(handler='validation',\n",
- " inputs={'model': train.outputs['mymodel']},\n",
- " outputs=['validation'])\n",
- " "
+ " train = trainer.as_step(handler=\"training\", params={\"p1\": p1}, outputs=[\"mymodel\"])\n",
+ "\n",
+ " validate = trainer.as_step(\n",
+ " handler=\"validation\",\n",
+ " inputs={\"model\": train.outputs[\"mymodel\"]},\n",
+ " outputs=[\"validation\"],\n",
+ " )"
]
},
{
@@ -1621,7 +1615,7 @@
"metadata": {},
"outputs": [],
"source": [
- "kfp.compiler.Compiler().compile(job_pipeline, 'jobpipe.yaml')"
+ "kfp.compiler.Compiler().compile(job_pipeline, \"jobpipe.yaml\")"
]
},
{
@@ -1651,7 +1645,7 @@
"metadata": {},
"outputs": [],
"source": [
- "artifact_path = 'v3io:///users/admin/kfp/{{workflow.uid}}/'"
+ "artifact_path = \"v3io:///users/admin/kfp/{{workflow.uid}}/\""
]
},
{
@@ -1692,8 +1686,10 @@
}
],
"source": [
- "arguments = {'p1': 8}\n",
- "run_id = run_pipeline(job_pipeline, arguments, experiment='my-job', artifact_path=artifact_path)"
+ "arguments = {\"p1\": 8}\n",
+ "run_id = run_pipeline(\n",
+ " job_pipeline, arguments, experiment=\"my-job\", artifact_path=artifact_path\n",
+ ")"
]
},
{
@@ -1925,9 +1921,10 @@
],
"source": [
"from mlrun import wait_for_pipeline_completion, get_run_db\n",
+ "\n",
"wait_for_pipeline_completion(run_id)\n",
"db = get_run_db().connect()\n",
- "db.list_runs(project='default', labels=f'workflow={run_id}').show()"
+ "db.list_runs(project=\"default\", labels=f\"workflow={run_id}\").show()"
]
},
{
diff --git a/examples/mlrun_sparkk8s.ipynb b/examples/mlrun_sparkk8s.ipynb
index 095700541325..12de5596256f 100644
--- a/examples/mlrun_sparkk8s.ipynb
+++ b/examples/mlrun_sparkk8s.ipynb
@@ -31,12 +31,12 @@
"from os.path import isfile, join\n",
"from mlrun import new_function, new_task, mlconf\n",
"\n",
- "#Set the mlrun database/api\n",
- "mlconf.dbpath = 'http://mlrun-api:8080'\n",
+ "# Set the mlrun database/api\n",
+ "mlconf.dbpath = \"http://mlrun-api:8080\"\n",
"\n",
- "#Set the pyspark script path\n",
- "V3IO_WORKING_DIR = os.getcwd().replace('/User','/v3io/'+os.getenv('V3IO_HOME'))\n",
- "V3IO_SCRIPT_PATH = V3IO_WORKING_DIR+'/spark-function.py'"
+ "# Set the pyspark script path\n",
+ "V3IO_WORKING_DIR = os.getcwd().replace(\"/User\", \"/v3io/\" + os.getenv(\"V3IO_HOME\"))\n",
+ "V3IO_SCRIPT_PATH = V3IO_WORKING_DIR + \"/spark-function.py\""
]
},
{
@@ -52,36 +52,39 @@
"metadata": {},
"outputs": [],
"source": [
- "#Define a dict of input data sources\n",
- "DATA_SOURCES = {'family' :\n",
- " {'format': 'jdbc',\n",
- " 'url': 'jdbc:mysql://mysql-rfam-public.ebi.ac.uk:4497/Rfam',\n",
- " 'dbtable': 'Rfam.family',\n",
- " 'user': 'rfamro',\n",
- " 'password': '',\n",
- " 'driver': 'com.mysql.jdbc.Driver'},\n",
- " 'full_region':\n",
- " {'format': 'jdbc',\n",
- " 'url': 'jdbc:mysql://mysql-rfam-public.ebi.ac.uk:4497/Rfam',\n",
- " 'dbtable': 'Rfam.full_region',\n",
- " 'user': 'rfamro',\n",
- " 'password': '',\n",
- " 'driver': 'com.mysql.jdbc.Driver'}\n",
- " }\n",
- "\n",
- "#Define a query to execute on the input data sources\n",
- "QUERY = 'SELECT family.*, full_region.evalue_score from family INNER JOIN full_region ON family.rfam_acc = full_region.rfam_acc LIMIT 10'\n",
- "\n",
- "#Define the output destination\n",
- "WRITE_OPTIONS = {'format': 'io.iguaz.v3io.spark.sql.kv',\n",
- " 'mode': 'overwrite',\n",
- " 'key': 'rfam_id',\n",
- " 'path': 'v3io://users/admin/frommysql'}\n",
- "\n",
- "#Create a task execution with parameters\n",
- "PARAMS = {'data_sources': DATA_SOURCES,\n",
- " 'query': QUERY,\n",
- " 'write_options': WRITE_OPTIONS}\n",
+ "# Define a dict of input data sources\n",
+ "DATA_SOURCES = {\n",
+ " \"family\": {\n",
+ " \"format\": \"jdbc\",\n",
+ " \"url\": \"jdbc:mysql://mysql-rfam-public.ebi.ac.uk:4497/Rfam\",\n",
+ " \"dbtable\": \"Rfam.family\",\n",
+ " \"user\": \"rfamro\",\n",
+ " \"password\": \"\",\n",
+ " \"driver\": \"com.mysql.jdbc.Driver\",\n",
+ " },\n",
+ " \"full_region\": {\n",
+ " \"format\": \"jdbc\",\n",
+ " \"url\": \"jdbc:mysql://mysql-rfam-public.ebi.ac.uk:4497/Rfam\",\n",
+ " \"dbtable\": \"Rfam.full_region\",\n",
+ " \"user\": \"rfamro\",\n",
+ " \"password\": \"\",\n",
+ " \"driver\": \"com.mysql.jdbc.Driver\",\n",
+ " },\n",
+ "}\n",
+ "\n",
+ "# Define a query to execute on the input data sources\n",
+ "QUERY = \"SELECT family.*, full_region.evalue_score from family INNER JOIN full_region ON family.rfam_acc = full_region.rfam_acc LIMIT 10\"\n",
+ "\n",
+ "# Define the output destination\n",
+ "WRITE_OPTIONS = {\n",
+ " \"format\": \"io.iguaz.v3io.spark.sql.kv\",\n",
+ " \"mode\": \"overwrite\",\n",
+ " \"key\": \"rfam_id\",\n",
+ " \"path\": \"v3io://users/admin/frommysql\",\n",
+ "}\n",
+ "\n",
+ "# Create a task execution with parameters\n",
+ "PARAMS = {\"data_sources\": DATA_SOURCES, \"query\": QUERY, \"write_options\": WRITE_OPTIONS}\n",
"\n",
"SPARK_TASK = new_task(params=PARAMS)"
]
@@ -115,12 +118,15 @@
"metadata": {},
"outputs": [],
"source": [
- "#Get the list of the dpendency jars\n",
- "V3IO_JARS_PATH = '/igz/java/libs/'\n",
- "DEPS_JARS_LIST = [join(V3IO_JARS_PATH, f) for f in os.listdir(V3IO_JARS_PATH) \n",
- " if isfile(join(V3IO_JARS_PATH, f)) and f.startswith('v3io-') and f.endswith('.jar')]\n",
+ "# Get the list of the dpendency jars\n",
+ "V3IO_JARS_PATH = \"/igz/java/libs/\"\n",
+ "DEPS_JARS_LIST = [\n",
+ " join(V3IO_JARS_PATH, f)\n",
+ " for f in os.listdir(V3IO_JARS_PATH)\n",
+ " if isfile(join(V3IO_JARS_PATH, f)) and f.startswith(\"v3io-\") and f.endswith(\".jar\")\n",
+ "]\n",
"\n",
- "DEPS_JARS_LIST.append(V3IO_WORKING_DIR + '/mysql-connector-java-8.0.19.jar')"
+ "DEPS_JARS_LIST.append(V3IO_WORKING_DIR + \"/mysql-connector-java-8.0.19.jar\")"
]
},
{
@@ -129,11 +135,14 @@
"metadata": {},
"outputs": [],
"source": [
- "#Create MLRun function which runs locally in a passthrough mode (since we use spark-submit)\n",
- "local_spark_fn = new_function(kind='local', mode = 'pass',\n",
- " command= f\"spark-submit --jars {','.join(DEPS_JARS_LIST)} {V3IO_SCRIPT_PATH}\")\n",
- "\n",
- "#Run the function with a task\n",
+ "# Create MLRun function which runs locally in a passthrough mode (since we use spark-submit)\n",
+ "local_spark_fn = new_function(\n",
+ " kind=\"local\",\n",
+ " mode=\"pass\",\n",
+ " command=f\"spark-submit --jars {','.join(DEPS_JARS_LIST)} {V3IO_SCRIPT_PATH}\",\n",
+ ")\n",
+ "\n",
+ "# Run the function with a task\n",
"local_spark_fn.run(SPARK_TASK)"
]
},
@@ -150,13 +159,19 @@
"metadata": {},
"outputs": [],
"source": [
- "#Create MLRun function to run the spark-job on the kubernetes cluster\n",
- "serverless_spark_fn = new_function(kind='spark', command=V3IO_SCRIPT_PATH, name='my-spark-func')\n",
+ "# Create MLRun function to run the spark-job on the kubernetes cluster\n",
+ "serverless_spark_fn = new_function(\n",
+ " kind=\"spark\", command=V3IO_SCRIPT_PATH, name=\"my-spark-func\"\n",
+ ")\n",
"\n",
"serverless_spark_fn.with_driver_limits(cpu=\"1300m\")\n",
- "serverless_spark_fn.with_driver_requests(cpu=1, mem=\"4G\") # gpu_type & gpus= are supported too\n",
+ "serverless_spark_fn.with_driver_requests(\n",
+ " cpu=1, mem=\"4G\"\n",
+ ") # gpu_type & gpus= are supported too\n",
"serverless_spark_fn.with_executor_limits(cpu=\"1400m\")\n",
- "serverless_spark_fn.with_executor_requests(cpu=1, mem=\"4G\") # gpu_type & gpus= are supported too\n",
+ "serverless_spark_fn.with_executor_requests(\n",
+ " cpu=1, mem=\"4G\"\n",
+ ") # gpu_type & gpus= are supported too\n",
"\n",
"serverless_spark_fn.with_igz_spark()\n",
"\n",
@@ -166,10 +181,10 @@
" \"-O /spark/jars/mysql-connector-java-8.0.19.jar\"\n",
"]\n",
"\n",
- "#Set number of executors\n",
+ "# Set number of executors\n",
"serverless_spark_fn.spec.replicas = 2\n",
"\n",
- "#Deploy function and install MLRun in the spark image\n",
+ "# Deploy function and install MLRun in the spark image\n",
"serverless_spark_fn.deploy()\n",
"\n",
"run = serverless_spark_fn.run(SPARK_TASK, watch=False)"
diff --git a/examples/mlrun_vault.ipynb b/examples/mlrun_vault.ipynb
index 9bdad88e8b8d..4142731568e9 100644
--- a/examples/mlrun_vault.ipynb
+++ b/examples/mlrun_vault.ipynb
@@ -77,9 +77,7 @@
},
"outputs": [],
"source": [
- "func = mlrun.code_to_function(name='vault-func', \n",
- " kind='job',\n",
- " image='mlrun/mlrun')"
+ "func = mlrun.code_to_function(name=\"vault-func\", kind=\"job\", image=\"mlrun/mlrun\")"
]
},
{
@@ -113,11 +111,11 @@
"metadata": {},
"outputs": [],
"source": [
- "proj_name = 'vault-mlrun'\n",
+ "proj_name = \"vault-mlrun\"\n",
"\n",
"proj = mlrun.new_project(proj_name)\n",
"\n",
- "project_secrets = {'aws_key': '1234567890', 'github_key': 'proj1Key!!!'}\n",
+ "project_secrets = {\"aws_key\": \"1234567890\", \"github_key\": \"proj1Key!!!\"}\n",
"proj.create_vault_secrets(project_secrets)\n",
"\n",
"proj.get_vault_secrets()"
@@ -143,13 +141,15 @@
"metadata": {},
"outputs": [],
"source": [
- "task = mlrun.new_task(project=proj_name,\n",
- " name='vault_test_run',\n",
- " handler='vault_func',\n",
- " params={'secrets':['github_key', 'aws_key']})\n",
+ "task = mlrun.new_task(\n",
+ " project=proj_name,\n",
+ " name=\"vault_test_run\",\n",
+ " handler=\"vault_func\",\n",
+ " params={\"secrets\": [\"github_key\", \"aws_key\"]},\n",
+ ")\n",
"\n",
"# Add access to project-level secrets\n",
- "task.with_secrets('vault', [\"aws_key\"])"
+ "task.with_secrets(\"vault\", [\"aws_key\"])"
]
},
{
@@ -183,7 +183,7 @@
"outputs": [],
"source": [
"# Access to all project-level secrets can be obtained by passing an empty list of secret names\n",
- "task.with_secrets('vault', [])\n",
+ "task.with_secrets(\"vault\", [])\n",
"\n",
"result = func.run(task)"
]
@@ -207,9 +207,11 @@
"metadata": {},
"outputs": [],
"source": [
- "proj_name_2 = 'vault-mlrun-2'\n",
+ "proj_name_2 = \"vault-mlrun-2\"\n",
"proj2 = mlrun.new_project(proj_name_2)\n",
- "proj2.create_vault_secrets({'aws_key': '0987654321', 'github_key': 'proj2Key???', 'password': 'myPassword'})"
+ "proj2.create_vault_secrets(\n",
+ " {\"aws_key\": \"0987654321\", \"github_key\": \"proj2Key???\", \"password\": \"myPassword\"}\n",
+ ")"
]
},
{
@@ -218,11 +220,13 @@
"metadata": {},
"outputs": [],
"source": [
- "task2 = mlrun.new_task(project=proj_name_2,\n",
- " name='vault_test_run_2',\n",
- " handler='vault_func',\n",
- " params={'secrets':['password', 'github_key', 'aws_key']})\n",
- "task2.with_secrets('vault', [\"aws_key\", \"github_key\", \"password\"])\n",
+ "task2 = mlrun.new_task(\n",
+ " project=proj_name_2,\n",
+ " name=\"vault_test_run_2\",\n",
+ " handler=\"vault_func\",\n",
+ " params={\"secrets\": [\"password\", \"github_key\", \"aws_key\"]},\n",
+ ")\n",
+ "task2.with_secrets(\"vault\", [\"aws_key\", \"github_key\", \"password\"])\n",
"\n",
"result = func.run(task2)"
]
@@ -244,8 +248,8 @@
},
"outputs": [],
"source": [
- "proj.with_secrets('vault',['github_key'])\n",
- "proj.get_secret('github_key')"
+ "proj.with_secrets(\"vault\", [\"github_key\"])\n",
+ "proj.get_secret(\"github_key\")"
]
},
{
diff --git a/examples/new-project.ipynb b/examples/new-project.ipynb
index 0b9bf26be087..61a8127ed780 100644
--- a/examples/new-project.ipynb
+++ b/examples/new-project.ipynb
@@ -43,11 +43,11 @@
"metadata": {},
"outputs": [],
"source": [
- "# update the dir and repo to reflect real locations \n",
+ "# update the dir and repo to reflect real locations\n",
"# the remote git repo must be initialized in GitHub\n",
- "project_dir = '/User/new-proj'\n",
- "remote_git = 'https://github.com//.git'\n",
- "newproj = new_project('new-project', project_dir, init_git=True)"
+ "project_dir = \"/User/new-proj\"\n",
+ "remote_git = \"https://github.com//.git\"\n",
+ "newproj = new_project(\"new-project\", project_dir, init_git=True)"
]
},
{
@@ -129,7 +129,7 @@
}
],
"source": [
- "newproj.set_function('hub://load_dataset', 'ingest').doc()"
+ "newproj.set_function(\"hub://load_dataset\", \"ingest\").doc()"
]
},
{
@@ -192,10 +192,10 @@
],
"source": [
"# add function with build config (base image, run command)\n",
- "fn = code_to_function('tstfunc', filename='handler.py', kind='job')\n",
- "fn.build_config(base_image = 'mlrun/mlrun', commands=['pip install pandas'])\n",
+ "fn = code_to_function(\"tstfunc\", filename=\"handler.py\", kind=\"job\")\n",
+ "fn.build_config(base_image=\"mlrun/mlrun\", commands=[\"pip install pandas\"])\n",
"newproj.set_function(fn)\n",
- "print(newproj.func('tstfunc').to_yaml())"
+ "print(newproj.func(\"tstfunc\").to_yaml())"
]
},
{
@@ -250,7 +250,7 @@
"metadata": {},
"outputs": [],
"source": [
- "newproj.set_workflow('main', 'workflow.py')"
+ "newproj.set_workflow(\"main\", \"workflow.py\")"
]
},
{
@@ -311,7 +311,7 @@
"metadata": {},
"outputs": [],
"source": [
- "newproj.push('master', 'first push', add=['handler.py', 'workflow.py'])"
+ "newproj.push(\"master\", \"first push\", add=[\"handler.py\", \"workflow.py\"])"
]
},
{
@@ -394,7 +394,11 @@
}
],
"source": [
- "newproj.run('main', arguments={}, artifact_path='v3io:///users/admin/mlrun/kfp/{{workflow.uid}}/')"
+ "newproj.run(\n",
+ " \"main\",\n",
+ " arguments={},\n",
+ " artifact_path=\"v3io:///users/admin/mlrun/kfp/{{workflow.uid}}/\",\n",
+ ")"
]
},
{
diff --git a/examples/remote-spark.ipynb b/examples/remote-spark.ipynb
index c017f265cc45..b669c9ab6789 100644
--- a/examples/remote-spark.ipynb
+++ b/examples/remote-spark.ipynb
@@ -28,32 +28,34 @@
"\n",
"from pyspark.sql import SparkSession\n",
"\n",
- "def describe_spark(context: MLClientCtx, \n",
- " dataset: DataItem, \n",
- " artifact_path):\n",
+ "\n",
+ "def describe_spark(context: MLClientCtx, dataset: DataItem, artifact_path):\n",
"\n",
" # get file location\n",
" location = dataset.local()\n",
- " \n",
+ "\n",
" # build spark session\n",
" spark = SparkSession.builder.appName(\"Spark job\").getOrCreate()\n",
- " \n",
+ "\n",
" # read csv\n",
- " df = spark.read.csv(location, header=True, inferSchema= True)\n",
- " \n",
+ " df = spark.read.csv(location, header=True, inferSchema=True)\n",
+ "\n",
" # show\n",
" df.show(5)\n",
- " \n",
+ "\n",
" # sample for logging\n",
" df_to_log = df.sample(False, 0.1).toPandas()\n",
- " \n",
+ "\n",
" # log final report\n",
- " context.log_dataset(\"df_sample\", \n",
- " df=df_to_log,\n",
- " format=\"csv\", index=False,\n",
- " artifact_path=context.artifact_subpath('data'))\n",
- " \n",
- " spark.stop()\n"
+ " context.log_dataset(\n",
+ " \"df_sample\",\n",
+ " df=df_to_log,\n",
+ " format=\"csv\",\n",
+ " index=False,\n",
+ " artifact_path=context.artifact_subpath(\"data\"),\n",
+ " )\n",
+ "\n",
+ " spark.stop()"
]
},
{
diff --git a/examples/v2_model_server.ipynb b/examples/v2_model_server.ipynb
index 9fd040eda3be..1ccf8f589fba 100644
--- a/examples/v2_model_server.ipynb
+++ b/examples/v2_model_server.ipynb
@@ -87,12 +87,12 @@
"class ClassifierModel(mlrun.serving.V2ModelServer):\n",
" def load(self):\n",
" \"\"\"load and initialize the model and/or other elements\"\"\"\n",
- " model_file, extra_data = self.get_model('.pkl')\n",
- " self.model = load(open(model_file, 'rb'))\n",
+ " model_file, extra_data = self.get_model(\".pkl\")\n",
+ " self.model = load(open(model_file, \"rb\"))\n",
"\n",
" def predict(self, body: dict) -> List:\n",
" \"\"\"Generate model predictions from sample.\"\"\"\n",
- " feats = np.asarray(body['inputs'])\n",
+ " feats = np.asarray(body[\"inputs\"])\n",
" result: np.ndarray = self.model.predict(feats)\n",
" return result.tolist()"
]
@@ -126,7 +126,7 @@
"metadata": {},
"outputs": [],
"source": [
- "models_path = 'https://s3.wasabisys.com/iguazio/models/iris/model.pkl'"
+ "models_path = \"https://s3.wasabisys.com/iguazio/models/iris/model.pkl\""
]
},
{
@@ -160,12 +160,15 @@
}
],
"source": [
- "fn = mlrun.code_to_function('v2-model-server', description=\"generic sklearn model server\",\n",
- " categories=['serving', 'ml'],\n",
- " labels={'author': 'yaronh', 'framework': 'sklearn'},\n",
- " code_output='.')\n",
- "fn.spec.default_class = 'ClassifierModel'\n",
- "#print(fn.to_yaml())\n",
+ "fn = mlrun.code_to_function(\n",
+ " \"v2-model-server\",\n",
+ " description=\"generic sklearn model server\",\n",
+ " categories=[\"serving\", \"ml\"],\n",
+ " labels={\"author\": \"yaronh\", \"framework\": \"sklearn\"},\n",
+ " code_output=\".\",\n",
+ ")\n",
+ "fn.spec.default_class = \"ClassifierModel\"\n",
+ "# print(fn.to_yaml())\n",
"fn.export()"
]
},
@@ -182,8 +185,8 @@
"metadata": {},
"outputs": [],
"source": [
- "fn.add_model('mymodel', model_path=models_path)\n",
- "#fn.verbose = True"
+ "fn.add_model(\"mymodel\", model_path=models_path)\n",
+ "# fn.verbose = True"
]
},
{
@@ -217,8 +220,9 @@
"outputs": [],
"source": [
"from sklearn.datasets import load_iris\n",
+ "\n",
"iris = load_iris()\n",
- "x = iris['data'].tolist()"
+ "x = iris[\"data\"].tolist()"
]
},
{
@@ -285,7 +289,7 @@
],
"source": [
"fn.apply(mlrun.mount_v3io())\n",
- "fn.deploy(project='v2-srv')"
+ "fn.deploy(project=\"v2-srv\")"
]
},
{
@@ -314,8 +318,8 @@
}
],
"source": [
- "my_data = '''{\"inputs\":[[5.1, 3.5, 1.4, 0.2],[7.7, 3.8, 6.7, 2.2]]}'''\n",
- "fn.invoke('/v2/models/mymodel/infer', my_data)"
+ "my_data = \"\"\"{\"inputs\":[[5.1, 3.5, 1.4, 0.2],[7.7, 3.8, 6.7, 2.2]]}\"\"\"\n",
+ "fn.invoke(\"/v2/models/mymodel/infer\", my_data)"
]
},
{
diff --git a/examples/xgb_serving.ipynb b/examples/xgb_serving.ipynb
index 8316d6ff4d98..422269c795b1 100644
--- a/examples/xgb_serving.ipynb
+++ b/examples/xgb_serving.ipynb
@@ -35,7 +35,7 @@
"source": [
"# mlrun: ignore\n",
"# if the nuclio-jupyter package is not installed run !pip install nuclio-jupyter\n",
- "import nuclio "
+ "import nuclio"
]
},
{
@@ -128,18 +128,18 @@
" # this is called once to load the model\n",
" # get_model returns file path (copied to local) and extra data dict (of key: DataItem)\n",
" # model object can be accessed at self.model_spec (after running .get_model)\n",
- " model_file, _ = self.get_model('.bst')\n",
+ " model_file, _ = self.get_model(\".bst\")\n",
" self._booster = xgb.Booster(model_file=model_file)\n",
"\n",
" def predict(self, body):\n",
" try:\n",
" # Use of list as input is deprecated see https://github.com/dmlc/xgboost/pull/3970\n",
- " events = np.array(body['instances'])\n",
+ " events = np.array(body[\"instances\"])\n",
" dmatrix = xgb.DMatrix(events)\n",
" result: xgb.DMatrix = self._booster.predict(dmatrix)\n",
" return result.tolist()\n",
" except Exception as exc:\n",
- " raise Exception(f\"Failed to predict {exc}\")\n"
+ " raise Exception(f\"Failed to predict {exc}\")"
]
},
{
@@ -183,8 +183,8 @@
"outputs": [],
"source": [
"# a valist model.bst file MUST EXIST in the model dir\n",
- "#model_dir = os.path.abspath('./')\n",
- "model_dir = '/User/mlrun/kfp/032e6d59-6bfe-4ee7-bcf6-1fb26e5db550/1' #/model.bst'"
+ "# model_dir = os.path.abspath('./')\n",
+ "model_dir = \"/User/mlrun/kfp/032e6d59-6bfe-4ee7-bcf6-1fb26e5db550/1\" # /model.bst'"
]
},
{
@@ -193,7 +193,7 @@
"metadata": {},
"outputs": [],
"source": [
- "my_server = XGBoostModel('my-model', model_dir=model_dir)\n",
+ "my_server = XGBoostModel(\"my-model\", model_dir=model_dir)\n",
"my_server.load()"
]
},
@@ -291,12 +291,12 @@
}
],
"source": [
- "fn = new_model_server('iris-srv', \n",
- " models={'iris_v1': model_dir}, \n",
- " model_class='XGBoostModel')\n",
+ "fn = new_model_server(\n",
+ " \"iris-srv\", models={\"iris_v1\": model_dir}, model_class=\"XGBoostModel\"\n",
+ ")\n",
"\n",
"# use mount_v3io() for iguazio volumes or mount_pvc() for k8s PVC volumes\n",
- "fn.apply(mount_v3io()) "
+ "fn.apply(mount_v3io())"
]
},
{
@@ -339,7 +339,7 @@
"outputs": [],
"source": [
"# KFServing protocol event\n",
- "event_data = {\"instances\":[[5], [10]]}"
+ "event_data = {\"instances\": [[5], [10]]}"
]
},
{
@@ -349,7 +349,8 @@
"outputs": [],
"source": [
"import json\n",
- "resp = requests.put(addr + '/iris_v1/predict', json=json.dumps(event_data))\n",
+ "\n",
+ "resp = requests.put(addr + \"/iris_v1/predict\", json=json.dumps(event_data))\n",
"print(resp.text)"
]
},
From f8f68ba833f35f3e890bd65fa83e473563e40a4b Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Wed, 10 May 2023 12:43:30 +0300
Subject: [PATCH 109/334] [System Tests] Fix finding mlrun db pod name (#3516)
---
automation/system_test/prepare.py | 45 ++++++++++++++++++++++---------
1 file changed, 32 insertions(+), 13 deletions(-)
diff --git a/automation/system_test/prepare.py b/automation/system_test/prepare.py
index 25b86e0f6179..6e837a88f731 100644
--- a/automation/system_test/prepare.py
+++ b/automation/system_test/prepare.py
@@ -174,7 +174,7 @@ def _run_command(
local: bool = False,
detach: bool = False,
verbose: bool = True,
- ) -> str:
+ ) -> (bytes, bytes):
workdir = workdir or str(self.Constants.workdir)
stdout, stderr, exit_status = "", "", 0
@@ -189,7 +189,7 @@ def _run_command(
workdir=workdir,
)
if self._debug:
- return ""
+ return b"", b""
try:
if local:
stdout, stderr, exit_status = run_command(
@@ -227,7 +227,7 @@ def _run_command(
stderr=stderr,
exit_status=exit_status,
)
- return stdout
+ return stdout, stderr
def _run_command_remotely(
self,
@@ -478,13 +478,12 @@ def _resolve_iguazio_version(self):
# iguazio version is optional, if not provided, we will try to resolve it from the data node
if not self._iguazio_version:
self._logger.info("Resolving iguazio version")
- self._iguazio_version = self._run_command(
+ self._iguazio_version, _ = self._run_command(
f"cat {self.Constants.igz_version_file}",
verbose=False,
live=False,
- ).strip()
- if isinstance(self._iguazio_version, bytes):
- self._iguazio_version = self._iguazio_version.decode("utf-8")
+ )
+ self._iguazio_version = self._iguazio_version.strip().decode()
self._logger.info(
"Resolved iguazio version", iguazio_version=self._iguazio_version
)
@@ -509,6 +508,10 @@ def _delete_mlrun_db(self):
self._logger.info("No mlrun db pod found")
return
+ self._logger.info(
+ "Deleting mlrun db pod", mlrun_db_pod_name_cmd=mlrun_db_pod_name_cmd
+ )
+
password = ""
if self._mysql_password:
password = f"-p {self._mysql_password} "
@@ -520,19 +523,35 @@ def _delete_mlrun_db(self):
"-n",
self.Constants.namespace,
"-it",
- f"$({mlrun_db_pod_name_cmd})",
+ mlrun_db_pod_name_cmd,
"--",
drop_db_cmd,
],
verbose=False,
)
- def _get_pod_name_command(self, labels, namespace=None):
- namespace = namespace or self.Constants.namespace
+ def _get_pod_name_command(self, labels):
labels_selector = ",".join([f"{k}={v}" for k, v in labels.items()])
- return "kubectl get pods -n {namespace} -l {labels_selector} | tail -n 1 | awk '{{print $1}}'".format(
- namespace=namespace, labels_selector=labels_selector
+ pod_name, stderr = self._run_kubectl_command(
+ args=[
+ "get",
+ "pods",
+ "--namespace",
+ self.Constants.namespace,
+ "--selector",
+ labels_selector,
+ "|",
+ "tail",
+ "-n",
+ "1",
+ "|",
+ "awk",
+ "'{print $1}'",
+ ],
)
+ if b"No resources found" in stderr or not pod_name:
+ return None
+ return pod_name
def _scale_down_mlrun_deployments(self):
# scaling down to avoid automatically deployments restarts and failures
@@ -551,7 +570,7 @@ def _scale_down_mlrun_deployments(self):
)
def _run_kubectl_command(self, args, verbose=True):
- self._run_command(
+ return self._run_command(
command="kubectl",
args=args,
verbose=verbose,
From 1a2647b225e9fda05dee008466a58071c3e84166 Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Wed, 10 May 2023 13:00:03 +0300
Subject: [PATCH 110/334] [CI] Fix open source tests (#3512)
---
.github/workflows/system-tests-opensource.yml | 2 ++
1 file changed, 2 insertions(+)
diff --git a/.github/workflows/system-tests-opensource.yml b/.github/workflows/system-tests-opensource.yml
index d8e612df1d40..69c87f63f2e1 100644
--- a/.github/workflows/system-tests-opensource.yml
+++ b/.github/workflows/system-tests-opensource.yml
@@ -190,6 +190,8 @@ jobs:
- name: Prepare system tests env
run: |
echo "MLRUN_DBPATH: http://$(minikube ip):${MLRUN_API_NODE_PORT}" > tests/system/env.yml
+ echo "MLRUN_SYSTEM_TESTS_GIT_TOKEN: ${{ secrets.SYSTEM_TEST_GITHUB_ACCESS_TOKEN }}" >> tests/system/env.yml
+ # TODO: use `prepare.py` for open source system tests as well
- name: Run system tests
timeout-minutes: 180
From b51baf054ec0d493e60f92f6438374e2ab70a8f4 Mon Sep 17 00:00:00 2001
From: Gal Topper
Date: Wed, 10 May 2023 18:34:03 +0800
Subject: [PATCH 111/334] [Feature Store] Fix empty dataframe result from
`preview()` with pandas engine (#3519)
---
mlrun/feature_store/api.py | 4 +++-
1 file changed, 3 insertions(+), 1 deletion(-)
diff --git a/mlrun/feature_store/api.py b/mlrun/feature_store/api.py
index bf9ec12517d3..22c86b2145f0 100644
--- a/mlrun/feature_store/api.py
+++ b/mlrun/feature_store/api.py
@@ -719,7 +719,9 @@ def preview(
)
# reduce the size of the ingestion if we do not infer stats
rows_limit = (
- 0 if InferOptions.get_common_options(options, InferOptions.Stats) else 1000
+ None
+ if InferOptions.get_common_options(options, InferOptions.Stats)
+ else 1000
)
source = init_featureset_graph(
source,
From 207f6987e318c06f539ba3526acb03cc3323d2c1 Mon Sep 17 00:00:00 2001
From: TomerShor <90552140+TomerShor@users.noreply.github.com>
Date: Wed, 10 May 2023 18:57:48 +0300
Subject: [PATCH 112/334] [Schemas] Inject old imports to sys modules (#3526)
---
mlrun/api/schemas/__init__.py | 44 +++++++++++++++++++++++++++++++++++
1 file changed, 44 insertions(+)
diff --git a/mlrun/api/schemas/__init__.py b/mlrun/api/schemas/__init__.py
index 9c9384454ba0..13d30e387208 100644
--- a/mlrun/api/schemas/__init__.py
+++ b/mlrun/api/schemas/__init__.py
@@ -21,9 +21,53 @@
schema.
"""
+import sys
+
import mlrun.common.schemas
+import mlrun.common.schemas.artifact as old_artifact
+import mlrun.common.schemas.auth as old_auth
+import mlrun.common.schemas.background_task as old_background_task
+import mlrun.common.schemas.client_spec as old_client_spec
+import mlrun.common.schemas.clusterization_spec as old_clusterization_spec
+import mlrun.common.schemas.constants as old_constants
+import mlrun.common.schemas.feature_store as old_feature_store
+import mlrun.common.schemas.frontend_spec as old_frontend_spec
+import mlrun.common.schemas.function as old_function
+import mlrun.common.schemas.http as old_http
+import mlrun.common.schemas.k8s as old_k8s
+import mlrun.common.schemas.memory_reports as old_memory_reports
+import mlrun.common.schemas.object as old_object
+import mlrun.common.schemas.pipeline as old_pipeline
+import mlrun.common.schemas.project as old_project
+import mlrun.common.schemas.runtime_resource as old_runtime_resource
+import mlrun.common.schemas.schedule as old_schedule
+import mlrun.common.schemas.secret as old_secret
+import mlrun.common.schemas.tag as old_tag
from mlrun.utils.helpers import DeprecationHelper
+# for backwards compatibility, we need to inject the old import path to `sys.modules`
+sys.modules["mlrun.api.schemas.artifact"] = old_artifact
+sys.modules["mlrun.api.schemas.auth"] = old_auth
+sys.modules["mlrun.api.schemas.background_task"] = old_background_task
+sys.modules["mlrun.api.schemas.client_spec"] = old_client_spec
+sys.modules["mlrun.api.schemas.clusterization_spec"] = old_clusterization_spec
+sys.modules["mlrun.api.schemas.constants"] = old_constants
+sys.modules["mlrun.api.schemas.feature_store"] = old_feature_store
+sys.modules["mlrun.api.schemas.frontend_spec"] = old_frontend_spec
+sys.modules["mlrun.api.schemas.function"] = old_function
+sys.modules["mlrun.api.schemas.http"] = old_http
+sys.modules["mlrun.api.schemas.k8s"] = old_k8s
+sys.modules["mlrun.api.schemas.memory_reports"] = old_memory_reports
+sys.modules["mlrun.api.schemas.object"] = old_object
+sys.modules["mlrun.api.schemas.pipeline"] = old_pipeline
+sys.modules["mlrun.api.schemas.project"] = old_project
+sys.modules["mlrun.api.schemas.runtime_resource"] = old_runtime_resource
+sys.modules["mlrun.api.schemas.schedule"] = old_schedule
+sys.modules["mlrun.api.schemas.secret"] = old_secret
+sys.modules["mlrun.api.schemas.tag"] = old_tag
+
+# The DeprecationHelper class is used to print a deprecation warning when the old import is used,
+# and return the new schema. This is done for backwards compatibility with mlrun.api.schemas.
ArtifactCategories = DeprecationHelper(mlrun.common.schemas.ArtifactCategories)
ArtifactIdentifier = DeprecationHelper(mlrun.common.schemas.ArtifactIdentifier)
ArtifactsFormat = DeprecationHelper(mlrun.common.schemas.ArtifactsFormat)
From 79ace74e6d7d70860b96d799ad0cb83244385c3d Mon Sep 17 00:00:00 2001
From: Gal Topper
Date: Thu, 11 May 2023 15:14:00 +0800
Subject: [PATCH 113/334] [Feature Store] Fix `ingest()` local namespace
resolution (#3532)
---
mlrun/feature_store/api.py | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/mlrun/feature_store/api.py b/mlrun/feature_store/api.py
index 22c86b2145f0..ef02fc586b8c 100644
--- a/mlrun/feature_store/api.py
+++ b/mlrun/feature_store/api.py
@@ -341,7 +341,7 @@ def _get_namespace(run_config: RunConfig) -> Dict[str, Any]:
spec.loader.exec_module(module)
return vars(__import__(module_name))
else:
- return get_caller_globals()
+ return get_caller_globals(level=3)
def ingest(
From 6ec2c532a88ff42cf4b7eb0427df181dbac08583 Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Thu, 11 May 2023 10:16:44 +0300
Subject: [PATCH 114/334] [CI] Fix logging errors when verbose is set (#3530)
---
automation/system_test/prepare.py | 22 +++++++++++++---------
1 file changed, 13 insertions(+), 9 deletions(-)
diff --git a/automation/system_test/prepare.py b/automation/system_test/prepare.py
index 6e837a88f731..0916ae34186f 100644
--- a/automation/system_test/prepare.py
+++ b/automation/system_test/prepare.py
@@ -208,15 +208,19 @@ def _run_command(
if exit_status != 0 and not suppress_errors:
raise RuntimeError(f"Command failed with exit status: {exit_status}")
except (paramiko.SSHException, RuntimeError) as exc:
+ err_log_kwargs = {
+ "error": str(exc),
+ "stdout": stdout,
+ "stderr": stderr,
+ "exit_status": exit_status,
+ }
if verbose:
- self._logger.error(
- f"Failed running command {log_command_location}",
- command=command,
- error=exc,
- stdout=stdout,
- stderr=stderr,
- exit_status=exit_status,
- )
+ err_log_kwargs["command"] = command
+
+ self._logger.error(
+ f"Failed running command {log_command_location}",
+ **err_log_kwargs,
+ )
raise
else:
if verbose:
@@ -551,7 +555,7 @@ def _get_pod_name_command(self, labels):
)
if b"No resources found" in stderr or not pod_name:
return None
- return pod_name
+ return pod_name.strip()
def _scale_down_mlrun_deployments(self):
# scaling down to avoid automatically deployments restarts and failures
From 7d4cfbdd066f12d36eb4fe141c8affa928ffbebc Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Thu, 11 May 2023 11:47:39 +0300
Subject: [PATCH 115/334] [Test] Fix workflow file of system test (#3529)
---
tests/system/projects/test_project.py | 1 -
1 file changed, 1 deletion(-)
diff --git a/tests/system/projects/test_project.py b/tests/system/projects/test_project.py
index 4f9688ee88ce..399db6a339af 100644
--- a/tests/system/projects/test_project.py
+++ b/tests/system/projects/test_project.py
@@ -210,7 +210,6 @@ def test_run_git_build(self):
"main",
artifact_path=f"v3io:///projects/{name}",
arguments={"build": 1},
- workflow_path=str(self.assets_path / "kflow.py"),
)
run.wait_for_completion()
assert run.state == mlrun.run.RunStatuses.succeeded, "pipeline failed"
From c07ec53540889f991dac6b49665cdbdbb01e654e Mon Sep 17 00:00:00 2001
From: Gal Topper
Date: Thu, 11 May 2023 20:27:05 +0800
Subject: [PATCH 116/334] [Utils] Improve `get_caller_globals` to avoid future
bugs (#3534)
---
mlrun/feature_store/api.py | 2 +-
mlrun/utils/helpers.py | 11 +++++++++--
2 files changed, 10 insertions(+), 3 deletions(-)
diff --git a/mlrun/feature_store/api.py b/mlrun/feature_store/api.py
index ef02fc586b8c..22c86b2145f0 100644
--- a/mlrun/feature_store/api.py
+++ b/mlrun/feature_store/api.py
@@ -341,7 +341,7 @@ def _get_namespace(run_config: RunConfig) -> Dict[str, Any]:
spec.loader.exec_module(module)
return vars(__import__(module_name))
else:
- return get_caller_globals(level=3)
+ return get_caller_globals()
def ingest(
diff --git a/mlrun/utils/helpers.py b/mlrun/utils/helpers.py
index 5411cb676dd3..f94c8f98a676 100644
--- a/mlrun/utils/helpers.py
+++ b/mlrun/utils/helpers.py
@@ -1014,9 +1014,16 @@ def create_function(pkg_func: str):
return function_
-def get_caller_globals(level=2):
+def get_caller_globals():
+ """Returns a dictionary containing the first non-mlrun caller function's namespace."""
try:
- return inspect.stack()[level][0].f_globals
+ stack = inspect.stack()
+ # If an API function called this function directly, the first non-mlrun caller will be 2 levels up the stack.
+ # Otherwise, we keep going up the stack until we find it.
+ for level in range(2, len(stack)):
+ namespace = stack[level][0].f_globals
+ if not namespace["__name__"].startswith("mlrun."):
+ return namespace
except Exception:
return None
From 1d5e593602e0396fd73d08d63061be5eeb8ae55f Mon Sep 17 00:00:00 2001
From: TomerShor <90552140+TomerShor@users.noreply.github.com>
Date: Thu, 11 May 2023 15:40:20 +0300
Subject: [PATCH 117/334] [DB] Perform data migrations to rename 'Marketplace'
source type to 'Hub' (#3536)
---
mlrun/api/db/sqldb/db.py | 3 +++
mlrun/api/initial_data.py | 45 +++++++++++++++++++++++++++++++++-
tests/api/test_initial_data.py | 28 +++++++++++++++++----
3 files changed, 70 insertions(+), 6 deletions(-)
diff --git a/mlrun/api/db/sqldb/db.py b/mlrun/api/db/sqldb/db.py
index ec167bfff8b7..c7a6cda89d65 100644
--- a/mlrun/api/db/sqldb/db.py
+++ b/mlrun/api/db/sqldb/db.py
@@ -3429,6 +3429,9 @@ def list_hub_sources(self, session) -> List[mlrun.common.schemas.IndexedHubSourc
results.append(ordered_source)
return results
+ def _list_hub_sources_without_transform(self, session) -> List[HubSource]:
+ return self._query(session, HubSource).all()
+
def delete_hub_source(self, session, name):
logger.debug("Deleting hub source from DB", name=name)
diff --git a/mlrun/api/initial_data.py b/mlrun/api/initial_data.py
index 9bdb41a722a7..08ceb5462016 100644
--- a/mlrun/api/initial_data.py
+++ b/mlrun/api/initial_data.py
@@ -19,6 +19,7 @@
import typing
import dateutil.parser
+import pydantic.error_wrappers
import pymysql.err
import sqlalchemy.exc
import sqlalchemy.orm
@@ -107,7 +108,7 @@ def init_data(
# This is because data version 1 points to to a data migration which was added back in 0.6.0, and
# upgrading from a version earlier than 0.6.0 to v>=0.8.0 is not supported.
data_version_prior_to_table_addition = 1
-latest_data_version = 2
+latest_data_version = 3
def _resolve_needed_operations(
@@ -212,6 +213,9 @@ def _perform_data_migrations(db_session: sqlalchemy.orm.Session):
_perform_version_1_data_migrations(db, db_session)
if current_data_version < 2:
_perform_version_2_data_migrations(db, db_session)
+ if current_data_version < 3:
+ _perform_version_3_data_migrations(db, db_session)
+
db.create_data_version(db_session, str(latest_data_version))
@@ -465,6 +469,30 @@ def _align_runs_table(
db._upsert(db_session, [run], ignore=True)
+def _perform_version_3_data_migrations(
+ db: mlrun.api.db.sqldb.db.SQLDB, db_session: sqlalchemy.orm.Session
+):
+ _rename_marketplace_kind_to_hub(db, db_session)
+
+
+def _rename_marketplace_kind_to_hub(
+ db: mlrun.api.db.sqldb.db.SQLDB, db_session: sqlalchemy.orm.Session
+):
+ logger.info("Renaming 'Marketplace' kinds to 'Hub'")
+
+ hubs = db._list_hub_sources_without_transform(db_session)
+ for hub in hubs:
+ hub_dict = hub.full_object
+
+ # rename kind from "MarketplaceSource" to "HubSource"
+ if "Marketplace" in hub_dict.get("kind", ""):
+ hub_dict["kind"] = hub_dict["kind"].replace("Marketplace", "Hub")
+
+ # save the object back to the db
+ hub.full_object = hub_dict
+ db._upsert(db_session, [hub], ignore=True)
+
+
def _perform_version_1_data_migrations(
db: mlrun.api.db.sqldb.db.SQLDB, db_session: sqlalchemy.orm.Session
):
@@ -503,6 +531,21 @@ def _add_default_hub_source_if_needed(
)
except mlrun.errors.MLRunNotFoundError:
hub_marketplace_source = None
+ except pydantic.error_wrappers.ValidationError as exc:
+
+ # following the renaming of 'marketplace' to 'hub', validation errors can occur on the old 'marketplace'.
+ # this will be handled later in the data migrations, but for now - if a validation error occurs, we assume
+ # that a default hub source exists
+ if all(
+ [
+ "validation error for HubSource" in str(exc),
+ "value is not a valid enumeration member" in str(exc),
+ ]
+ ):
+ logger.info("Found existing default hub source, data migration needed")
+ hub_marketplace_source = True
+ else:
+ raise exc
if not hub_marketplace_source:
hub_source = mlrun.common.schemas.HubSource.generate_default_source()
diff --git a/tests/api/test_initial_data.py b/tests/api/test_initial_data.py
index 80a1ea199a72..8c0dee930cd8 100644
--- a/tests/api/test_initial_data.py
+++ b/tests/api/test_initial_data.py
@@ -69,25 +69,43 @@ def test_perform_data_migrations_from_zero_version():
# set version to 0
db.create_data_version(db_session, "0")
+ # keep a reference to the original functions, so we can restore them later
original_perform_version_1_data_migrations = (
mlrun.api.initial_data._perform_version_1_data_migrations
)
mlrun.api.initial_data._perform_version_1_data_migrations = unittest.mock.Mock()
+ original_perform_version_2_data_migrations = (
+ mlrun.api.initial_data._perform_version_2_data_migrations
+ )
+ mlrun.api.initial_data._perform_version_2_data_migrations = unittest.mock.Mock()
+ original_perform_version_3_data_migrations = (
+ mlrun.api.initial_data._perform_version_3_data_migrations
+ )
+ mlrun.api.initial_data._perform_version_3_data_migrations = unittest.mock.Mock()
+ # perform migrations
mlrun.api.initial_data._perform_data_migrations(db_session)
- mlrun.api.initial_data._perform_version_1_data_migrations.assert_called_once()
-
- # calling again should trigger migrations again
+ # calling again should not trigger migrations again, since we're already at the latest version
mlrun.api.initial_data._perform_data_migrations(db_session)
mlrun.api.initial_data._perform_version_1_data_migrations.assert_called_once()
+ mlrun.api.initial_data._perform_version_2_data_migrations.assert_called_once()
+ mlrun.api.initial_data._perform_version_3_data_migrations.assert_called_once()
+ assert db.get_current_data_version(db_session, raise_on_not_found=True) == str(
+ mlrun.api.initial_data.latest_data_version
+ )
+
+ # restore original functions
mlrun.api.initial_data._perform_version_1_data_migrations = (
original_perform_version_1_data_migrations
)
- assert db.get_current_data_version(db_session, raise_on_not_found=True) == str(
- mlrun.api.initial_data.latest_data_version
+ mlrun.api.initial_data._perform_version_2_data_migrations = (
+ original_perform_version_2_data_migrations
+ )
+ mlrun.api.initial_data._perform_version_3_data_migrations = (
+ original_perform_version_3_data_migrations
)
From afe1be2261cbe02ae1858bb9513845619fece7a6 Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Thu, 11 May 2023 15:46:43 +0300
Subject: [PATCH 118/334] [Builder] Do not copy relative path sources (#3500)
---
mlrun/builder.py | 16 +++++++++++-
tests/test_builder.py | 58 ++++++++++++++++++++++++++++++++++++++++++-
2 files changed, 72 insertions(+), 2 deletions(-)
diff --git a/mlrun/builder.py b/mlrun/builder.py
index 320b906f8ad2..2568d23fff5e 100644
--- a/mlrun/builder.py
+++ b/mlrun/builder.py
@@ -402,9 +402,23 @@ def build_image(
source = parsed_url.path
to_mount = True
source_dir_to_mount, source_to_copy = path.split(source)
- else:
+
+ # source is a path without a scheme, we allow to copy absolute paths assuming they are valid paths
+ # in the image, however, it is recommended to use `workdir` instead in such cases
+ # which is set during runtime (mlrun.runtimes.local.LocalRuntime._pre_run).
+ # relative paths are not supported at build time
+ # "." and "./" are considered as 'project context'
+ # TODO: enrich with project context if pulling on build time
+ elif path.isabs(source):
source_to_copy = source
+ else:
+ raise mlrun.errors.MLRunInvalidArgumentError(
+ f"Load of relative source ({source}) is not supported at build time"
+ "see 'mlrun.runtimes.kubejob.KubejobRuntime.with_source_archive' or "
+ "'mlrun.projects.project.MlrunProject.set_source' for more details"
+ )
+
user_unix_id = None
enriched_group_id = None
if (
diff --git a/tests/test_builder.py b/tests/test_builder.py
index 199e5973c4c2..530e19e91e33 100644
--- a/tests/test_builder.py
+++ b/tests/test_builder.py
@@ -14,8 +14,10 @@
#
import base64
import json
+import os
import re
import unittest.mock
+from contextlib import nullcontext as does_not_raise
import deepdiff
import pytest
@@ -827,7 +829,7 @@ def test_builder_workdir(monkeypatch, clone_target_dir, expected_workdir):
)
if clone_target_dir is not None:
function.spec.clone_target_dir = clone_target_dir
- function.spec.build.source = "some-source.tgz"
+ function.spec.build.source = "/path/some-source.tgz"
mlrun.builder.build_runtime(
mlrun.common.schemas.AuthInfo(),
function,
@@ -838,6 +840,60 @@ def test_builder_workdir(monkeypatch, clone_target_dir, expected_workdir):
assert expected_workdir_re.match(dockerfile_lines[1])
+@pytest.mark.parametrize(
+ "source,expectation",
+ [
+ ("v3io://path/some-source.tar.gz", does_not_raise()),
+ ("/path/some-source.tar.gz", does_not_raise()),
+ ("/path/some-source.zip", does_not_raise()),
+ (
+ "./relative/some-source",
+ pytest.raises(mlrun.errors.MLRunInvalidArgumentError),
+ ),
+ ("./", pytest.raises(mlrun.errors.MLRunInvalidArgumentError)),
+ ],
+)
+def test_builder_source(monkeypatch, source, expectation):
+ _patch_k8s_helper(monkeypatch)
+ mlrun.builder.make_kaniko_pod = unittest.mock.MagicMock()
+ docker_registry = "default.docker.registry/default-repository"
+ config.httpdb.builder.docker_registry = docker_registry
+
+ function = mlrun.new_function(
+ "some-function",
+ "some-project",
+ "some-tag",
+ image="mlrun/mlrun",
+ kind="job",
+ )
+
+ with expectation:
+ function.spec.build.source = source
+ mlrun.builder.build_runtime(
+ mlrun.common.schemas.AuthInfo(),
+ function,
+ )
+
+ dockerfile = mlrun.builder.make_kaniko_pod.call_args[1]["dockertext"]
+ dockerfile_lines = dockerfile.splitlines()
+
+ expected_source = source
+ if "://" in source:
+ _, expected_source = os.path.split(source)
+
+ if source.endswith(".zip"):
+ expected_output_re = re.compile(
+ rf"COPY {expected_source} .*/tmp.*/mlrun/source"
+ )
+ expected_line_index = 4
+
+ else:
+ expected_output_re = re.compile(rf"ADD {expected_source} .*/tmp.*/mlrun")
+ expected_line_index = 2
+
+ assert expected_output_re.match(dockerfile_lines[expected_line_index].strip())
+
+
def _get_target_image_from_create_pod_mock():
return _create_pod_mock_pod_spec().containers[0].args[5]
From eb4de9d5f3dd8eeec35021bcb264379e220fc500 Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Thu, 11 May 2023 16:19:50 +0300
Subject: [PATCH 119/334] [API] Reduce spammy logging (#3538)
---
mlrun/api/db/sqldb/db.py | 4 +---
mlrun/api/utils/clients/iguazio.py | 2 +-
mlrun/api/utils/projects/leader.py | 5 -----
3 files changed, 2 insertions(+), 9 deletions(-)
diff --git a/mlrun/api/db/sqldb/db.py b/mlrun/api/db/sqldb/db.py
index c7a6cda89d65..9eccb2aa2077 100644
--- a/mlrun/api/db/sqldb/db.py
+++ b/mlrun/api/db/sqldb/db.py
@@ -1399,9 +1399,7 @@ def patch_project(
project: dict,
patch_mode: mlrun.common.schemas.PatchMode = mlrun.common.schemas.PatchMode.replace,
):
- logger.debug(
- "Patching project in DB", name=name, project=project, patch_mode=patch_mode
- )
+ logger.debug("Patching project in DB", name=name, patch_mode=patch_mode)
project_record = self._get_project_record(session, name)
self._patch_project_record_from_project(
session, name, project_record, project, patch_mode
diff --git a/mlrun/api/utils/clients/iguazio.py b/mlrun/api/utils/clients/iguazio.py
index 38eb1df49e6b..aa3ca46b289b 100644
--- a/mlrun/api/utils/clients/iguazio.py
+++ b/mlrun/api/utils/clients/iguazio.py
@@ -204,7 +204,7 @@ def update_project(
name: str,
project: mlrun.common.schemas.Project,
):
- logger.debug("Updating project in Iguazio", name=name, project=project)
+ logger.debug("Updating project in Iguazio", name=name)
body = self._transform_mlrun_project_to_iguazio_project(project)
self._put_project_to_iguazio(session, name, body)
diff --git a/mlrun/api/utils/projects/leader.py b/mlrun/api/utils/projects/leader.py
index d6470ae1d1d2..e48c85265d23 100644
--- a/mlrun/api/utils/projects/leader.py
+++ b/mlrun/api/utils/projects/leader.py
@@ -272,7 +272,6 @@ def _ensure_project_synced(
logger.warning(
"Failed creating missing project in leader",
project_follower_name=project_follower_name,
- project=project,
project_name=project_name,
exc=err_to_str(exc),
traceback=traceback.format_exc(),
@@ -315,7 +314,6 @@ def _store_project_in_followers(
"Updating project in follower",
follower_name=follower_name,
project_name=project_name,
- project=project,
)
try:
self._enrich_and_validate_before_creation(project)
@@ -329,7 +327,6 @@ def _store_project_in_followers(
"Failed updating project in follower",
follower_name=follower_name,
project_name=project_name,
- project=project,
exc=err_to_str(exc),
traceback=traceback.format_exc(),
)
@@ -349,7 +346,6 @@ def _create_project_in_missing_followers(
missing_follower_name=missing_follower,
project_follower_name=project_follower_name,
project_name=project_name,
- project=project,
)
try:
self._enrich_and_validate_before_creation(project)
@@ -363,7 +359,6 @@ def _create_project_in_missing_followers(
missing_follower_name=missing_follower,
project_follower_name=project_follower_name,
project_name=project_name,
- project=project,
exc=err_to_str(exc),
traceback=traceback.format_exc(),
)
From cbf3ab19c01c8c57786690f1c5601482cc0e2422 Mon Sep 17 00:00:00 2001
From: Tom Tankilevitch <59158507+Tankilevitch@users.noreply.github.com>
Date: Thu, 11 May 2023 17:06:39 +0300
Subject: [PATCH 120/334] [Runtime] Add `has_args` and `has_kwargs` to function
doc (#3528)
---
mlrun/runtimes/funcdoc.py | 17 +++++++++-
tests/runtimes/info_cases.yml | 10 ++++++
tests/runtimes/test_funcdoc.py | 60 ++++++++++++++++++++++++++++++++--
3 files changed, 84 insertions(+), 3 deletions(-)
diff --git a/mlrun/runtimes/funcdoc.py b/mlrun/runtimes/funcdoc.py
index e53213a70059..5c87aa91f67e 100644
--- a/mlrun/runtimes/funcdoc.py
+++ b/mlrun/runtimes/funcdoc.py
@@ -49,13 +49,23 @@ def param_dict(name="", type="", doc="", default=""):
}
-def func_dict(name, doc, params, returns, lineno):
+def func_dict(
+ name,
+ doc,
+ params,
+ returns,
+ lineno,
+ has_varargs: bool = False,
+ has_kwargs: bool = False,
+):
return {
"name": name,
"doc": doc,
"params": params,
"return": returns,
"lineno": lineno,
+ "has_varargs": has_varargs,
+ "has_kwargs": has_kwargs,
}
@@ -165,6 +175,9 @@ def ast_func_info(func: ast.FunctionDef):
doc = ast.get_docstring(func) or ""
rtype = getattr(func.returns, "id", "")
params = [ast_param_dict(p) for p in func.args.args]
+ # adds info about *args and **kwargs to the function doc
+ has_varargs = func.args.vararg is not None
+ has_kwargs = func.args.kwarg is not None
defaults = func.args.defaults
if defaults:
for param, default in zip(params[-len(defaults) :], defaults):
@@ -176,6 +189,8 @@ def ast_func_info(func: ast.FunctionDef):
params=params,
returns=param_dict(type=rtype),
lineno=func.lineno,
+ has_varargs=has_varargs,
+ has_kwargs=has_kwargs,
)
if not doc.strip():
diff --git a/tests/runtimes/info_cases.yml b/tests/runtimes/info_cases.yml
index 04505b4191a6..e4e08b0822bb 100644
--- a/tests/runtimes/info_cases.yml
+++ b/tests/runtimes/info_cases.yml
@@ -30,6 +30,8 @@
doc: ""
default: ""
lineno: 1
+ has_varargs: false
+ has_kwargs: false
id: inc_ann
- code: |
def inc(n):
@@ -48,6 +50,8 @@
doc: ""
default: ""
lineno: 1
+ has_varargs: false
+ has_kwargs: false
id: inc_no_ann
- code: |
def inc(n: int) -> int:
@@ -72,6 +76,8 @@
doc: number to increment
default: ""
lineno: 1
+ has_varargs: false
+ has_kwargs: false
id: inc_ann_doc
- code: |
def inc(n: int, delta: int = 1) -> int:
@@ -95,6 +101,8 @@
doc: ""
default: "1"
lineno: 1
+ has_varargs: false
+ has_kwargs: false
id: inc_ann_default
- code: |
def open_archive(context,
@@ -129,4 +137,6 @@
doc: "source archive path/url"
default: "''"
lineno: 1
+ has_varargs: false
+ has_kwargs: false
id: undocumented param
diff --git a/tests/runtimes/test_funcdoc.py b/tests/runtimes/test_funcdoc.py
index 05b72facd26f..92244cd18c57 100644
--- a/tests/runtimes/test_funcdoc.py
+++ b/tests/runtimes/test_funcdoc.py
@@ -101,13 +101,15 @@ def inc(n):
"return": funcdoc.param_dict(),
"params": [funcdoc.param_dict("n")],
"lineno": 6,
+ "has_varargs": False,
+ "has_kwargs": False,
},
]
def test_find_handlers():
funcs = funcdoc.find_handlers(find_handlers_code)
- assert find_handlers_expected == funcs
+ assert funcs == find_handlers_expected
ast_code_cases = [
@@ -139,10 +141,64 @@ def test_ast_none():
def fn() -> None:
pass
"""
- fn = ast.parse(dedent(code)).body[0]
+ fn: ast.FunctionDef = ast.parse(dedent(code)).body[0]
funcdoc.ast_func_info(fn)
+@pytest.mark.parametrize(
+ "func_code,expected_has_varargs,expected_has_kwargs",
+ [
+ (
+ """
+ def fn(p1,p2,*args,**kwargs) -> None:
+ pass
+ """,
+ True,
+ True,
+ ),
+ (
+ """
+ def fn(p1,p2,*args) -> None:
+ pass
+ """,
+ True,
+ False,
+ ),
+ (
+ """
+ def fn(p1,p2,**kwargs) -> None:
+ pass
+ """,
+ False,
+ True,
+ ),
+ (
+ """
+ def fn(p1,p2) -> None:
+ pass
+ """,
+ False,
+ False,
+ ),
+ (
+ """
+ def fn(p1,p2,**something) -> None:
+ pass
+ """,
+ False,
+ True,
+ ),
+ ],
+)
+def test_ast_func_info_with_kwargs_and_args(
+ func_code, expected_has_varargs, expected_has_kwargs
+):
+ fn: ast.FunctionDef = ast.parse(dedent(func_code)).body[0]
+ func_info = funcdoc.ast_func_info(fn)
+ assert func_info["has_varargs"] == expected_has_varargs
+ assert func_info["has_kwargs"] == expected_has_kwargs
+
+
def test_ast_compound():
param_types = []
with open(f"{tests_root_directory}/runtimes/arc.txt") as fp:
From 39fde210f4945eb28b4f7769e6e34fa4859c6eb5 Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Thu, 11 May 2023 17:10:01 +0300
Subject: [PATCH 121/334] [Run] Introducing Run Launchers (#3524)
---
mlrun/api/launcher.py | 188 +++++++++++
mlrun/db/base.py | 10 +
mlrun/db/httpdb.py | 21 +-
mlrun/feature_store/retrieval/job.py | 2 +-
mlrun/launcher/__init__.py | 13 +
mlrun/launcher/base.py | 391 +++++++++++++++++++++++
mlrun/launcher/client.py | 123 ++++++++
mlrun/launcher/factory.py | 50 +++
mlrun/launcher/local.py | 267 ++++++++++++++++
mlrun/launcher/remote.py | 183 +++++++++++
mlrun/runtimes/base.py | 447 ++-------------------------
mlrun/runtimes/kubejob.py | 13 +-
tests/api/api/test_submit.py | 8 +-
tests/common_fixtures.py | 2 -
tests/run/test_run.py | 2 +-
15 files changed, 1280 insertions(+), 440 deletions(-)
create mode 100644 mlrun/api/launcher.py
create mode 100644 mlrun/launcher/__init__.py
create mode 100644 mlrun/launcher/base.py
create mode 100644 mlrun/launcher/client.py
create mode 100644 mlrun/launcher/factory.py
create mode 100644 mlrun/launcher/local.py
create mode 100644 mlrun/launcher/remote.py
diff --git a/mlrun/api/launcher.py b/mlrun/api/launcher.py
new file mode 100644
index 000000000000..ae1f2c6786af
--- /dev/null
+++ b/mlrun/api/launcher.py
@@ -0,0 +1,188 @@
+# Copyright 2023 MLRun Authors
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import Dict, List, Optional, Union
+
+import mlrun.api.crud
+import mlrun.api.db.sqldb.session
+import mlrun.common.schemas.schedule
+import mlrun.execution
+import mlrun.launcher.base
+import mlrun.runtimes
+import mlrun.runtimes.generators
+import mlrun.runtimes.utils
+import mlrun.utils
+import mlrun.utils.regex
+
+
+class ServerSideLauncher(mlrun.launcher.base.BaseLauncher):
+ def launch(
+ self,
+ runtime: mlrun.runtimes.BaseRuntime,
+ task: Optional[Union[mlrun.run.RunTemplate, mlrun.run.RunObject]] = None,
+ handler: Optional[str] = None,
+ name: Optional[str] = "",
+ project: Optional[str] = "",
+ params: Optional[dict] = None,
+ inputs: Optional[Dict[str, str]] = None,
+ out_path: Optional[str] = "",
+ workdir: Optional[str] = "",
+ artifact_path: Optional[str] = "",
+ watch: Optional[bool] = True,
+ schedule: Optional[
+ Union[str, mlrun.common.schemas.schedule.ScheduleCronTrigger]
+ ] = None,
+ hyperparams: Dict[str, list] = None,
+ hyper_param_options: Optional[mlrun.model.HyperParamOptions] = None,
+ verbose: Optional[bool] = None,
+ scrape_metrics: Optional[bool] = None,
+ local: Optional[bool] = False,
+ local_code_path: Optional[str] = None,
+ auto_build: Optional[bool] = None,
+ param_file_secrets: Optional[Dict[str, str]] = None,
+ notifications: Optional[List[mlrun.model.Notification]] = None,
+ returns: Optional[List[Union[str, Dict[str, str]]]] = None,
+ ) -> mlrun.run.RunObject:
+ self._enrich_runtime(runtime)
+
+ run = self._create_run_object(task)
+
+ run = self._enrich_run(
+ runtime,
+ run=run,
+ handler=handler,
+ project_name=project,
+ name=name,
+ params=params,
+ inputs=inputs,
+ returns=returns,
+ hyperparams=hyperparams,
+ hyper_param_options=hyper_param_options,
+ verbose=verbose,
+ scrape_metrics=scrape_metrics,
+ out_path=out_path,
+ artifact_path=artifact_path,
+ workdir=workdir,
+ notifications=notifications,
+ )
+ self._validate_runtime(runtime, run)
+
+ if runtime.verbose:
+ mlrun.utils.logger.info(f"Run:\n{run.to_yaml()}")
+
+ if not runtime.is_child:
+ mlrun.utils.logger.info(
+ "Storing function",
+ name=run.metadata.name,
+ uid=run.metadata.uid,
+ )
+ self._store_function(runtime, run)
+
+ execution = mlrun.execution.MLClientCtx.from_dict(
+ run.to_dict(),
+ self.db,
+ autocommit=False,
+ is_api=True,
+ store_run=False,
+ )
+
+ # create task generator (for child runs) from spec
+ task_generator = mlrun.runtimes.generators.get_generator(
+ run.spec, execution, param_file_secrets=param_file_secrets
+ )
+ if task_generator:
+ # verify valid task parameters
+ tasks = task_generator.generate(run)
+ for task in tasks:
+ self._validate_run_params(task.spec.parameters)
+
+ # post verifications, store execution in db and run pre run hooks
+ execution.store_run()
+ runtime._pre_run(run, execution) # hook for runtime specific prep
+
+ resp = None
+ last_err = None
+ # If the runtime is nested, it means the hyper-run will run within a single instance of the run.
+ # So while in the API, we consider the hyper-run as a single run, and then in the runtime itself when the
+ # runtime is now a local runtime and therefore `self._is_nested == False`, we run each task as a separate run by
+ # using the task generator
+ if task_generator and not runtime._is_nested:
+ # multiple runs (based on hyper params or params file)
+ runner = runtime._run_many
+ if hasattr(runtime, "_parallel_run_many") and task_generator.use_parallel():
+ runner = runtime._parallel_run_many
+ results = runner(task_generator, execution, run)
+ mlrun.runtimes.utils.results_to_iter(results, run, execution)
+ result = execution.to_dict()
+ result = runtime._update_run_state(result, task=run)
+
+ else:
+ # single run
+ try:
+ resp = runtime._run(run, execution)
+
+ except mlrun.runtimes.utils.RunError as err:
+ last_err = err
+
+ finally:
+ result = runtime._update_run_state(resp=resp, task=run, err=last_err)
+
+ self._save_or_push_notifications(run)
+
+ runtime._post_run(result, execution) # hook for runtime specific cleanup
+
+ return self._wrap_run_result(runtime, result, run, err=last_err)
+
+ @staticmethod
+ def verify_base_image(runtime):
+ pass
+
+ @staticmethod
+ def _enrich_runtime(runtime):
+ pass
+
+ def _save_or_push_notifications(self, runobj):
+ if not runobj.spec.notifications:
+ mlrun.utils.logger.debug(
+ "No notifications to push for run", run_uid=runobj.metadata.uid
+ )
+ return
+
+ # TODO: add support for other notifications per run iteration
+ if runobj.metadata.iteration and runobj.metadata.iteration > 0:
+ mlrun.utils.logger.debug(
+ "Notifications per iteration are not supported, skipping",
+ run_uid=runobj.metadata.uid,
+ )
+ return
+
+ # If in the api server, we can assume that watch=False, so we save notification
+ # configs to the DB, for the run monitor to later pick up and push.
+ session = mlrun.api.db.sqldb.session.create_session()
+ mlrun.api.crud.Notifications().store_run_notifications(
+ session,
+ runobj.spec.notifications,
+ runobj.metadata.uid,
+ runobj.metadata.project,
+ )
+
+ def _store_function(
+ self, runtime: mlrun.runtimes.base.BaseRuntime, run: mlrun.run.RunObject
+ ):
+ run.metadata.labels["kind"] = runtime.kind
+ if self.db and runtime.kind != "handler":
+ struct = runtime.to_dict()
+ hash_key = self.db.store_function(
+ struct, runtime.metadata.name, runtime.metadata.project, versioned=True
+ )
+ run.spec.function = runtime._function_uri(hash_key=hash_key)
diff --git a/mlrun/db/base.py b/mlrun/db/base.py
index 807926716fd4..ca46d3fa195e 100644
--- a/mlrun/db/base.py
+++ b/mlrun/db/base.py
@@ -602,3 +602,13 @@ def verify_authorization(
authorization_verification_input: mlrun.common.schemas.AuthorizationVerificationInput,
):
pass
+
+ def get_builder_status(
+ self,
+ func: "mlrun.runtimes.BaseRuntime",
+ offset: int = 0,
+ logs: bool = True,
+ last_log_timestamp: float = 0.0,
+ verbose: bool = False,
+ ):
+ pass
diff --git a/mlrun/db/httpdb.py b/mlrun/db/httpdb.py
index a9d5accef49a..bca7f9d46f37 100644
--- a/mlrun/db/httpdb.py
+++ b/mlrun/db/httpdb.py
@@ -1143,19 +1143,20 @@ def remote_builder(
def get_builder_status(
self,
func: BaseRuntime,
- offset=0,
- logs=True,
- last_log_timestamp=0,
- verbose=False,
+ offset: int = 0,
+ logs: bool = True,
+ last_log_timestamp: float = 0.0,
+ verbose: bool = False,
):
"""Retrieve the status of a build operation currently in progress.
- :param func: Function object that is being built.
- :param offset: Offset into the build logs to retrieve logs from.
- :param logs: Should build logs be retrieved.
- :param last_log_timestamp: Last timestamp of logs that were already retrieved. Function will return only logs
- later than this parameter.
- :param verbose: Add verbose logs into the output.
+ :param func: Function object that is being built.
+ :param offset: Offset into the build logs to retrieve logs from.
+ :param logs: Should build logs be retrieved.
+ :param last_log_timestamp: Last timestamp of logs that were already retrieved. Function will return only logs
+ later than this parameter.
+ :param verbose: Add verbose logs into the output.
+
:returns: The following parameters:
- Text of builder logs.
diff --git a/mlrun/feature_store/retrieval/job.py b/mlrun/feature_store/retrieval/job.py
index 63a48e14234c..a60fb911ea26 100644
--- a/mlrun/feature_store/retrieval/job.py
+++ b/mlrun/feature_store/retrieval/job.py
@@ -107,7 +107,7 @@ def set_default_resources(resources, setter_function):
"order_by": order_by,
"engine_args": engine_args,
},
- inputs={"entity_rows": entity_rows},
+ inputs={"entity_rows": entity_rows} if entity_rows is not None else {},
)
task.spec.secret_sources = run_config.secret_sources
task.set_label("job-type", "feature-merge").set_label("feature-vector", vector.uri)
diff --git a/mlrun/launcher/__init__.py b/mlrun/launcher/__init__.py
new file mode 100644
index 000000000000..7f557697af77
--- /dev/null
+++ b/mlrun/launcher/__init__.py
@@ -0,0 +1,13 @@
+# Copyright 2023 MLRun Authors
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
diff --git a/mlrun/launcher/base.py b/mlrun/launcher/base.py
new file mode 100644
index 000000000000..86fbb3cf023a
--- /dev/null
+++ b/mlrun/launcher/base.py
@@ -0,0 +1,391 @@
+# Copyright 2023 MLRun Authors
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import abc
+import ast
+import copy
+import os
+import uuid
+from typing import Any, Dict, List, Optional, Union
+
+import mlrun.common.schemas
+import mlrun.config
+import mlrun.errors
+import mlrun.kfpops
+import mlrun.lists
+import mlrun.model
+import mlrun.runtimes
+from mlrun.utils import logger
+
+run_modes = ["pass"]
+
+
+class BaseLauncher(abc.ABC):
+ """
+ Abstract class for managing and running functions in different contexts
+ This class is designed to encapsulate the logic of running a function in different contexts
+ i.e. running a function locally, remotely or in a server
+ Each context will have its own implementation of the abstract methods while the common logic resides in this class
+ """
+
+ def __init__(self):
+ self._db = None
+
+ @property
+ def db(self) -> mlrun.db.base.RunDBInterface:
+ if not self._db:
+ self._db = mlrun.db.get_run_db()
+ return self._db
+
+ def save_function(
+ self,
+ runtime: "mlrun.runtimes.BaseRuntime",
+ tag: str = "",
+ versioned: bool = False,
+ refresh: bool = False,
+ ) -> str:
+ """
+ store the function to the db
+ :param runtime: runtime object
+ :param tag: function tag to store
+ :param versioned: whether we want to version this function object so that it will queryable by its hash key
+ :param refresh: refresh function metadata
+
+ :return: function uri
+ """
+ if not self.db:
+ raise mlrun.errors.MLRunPreconditionFailedError(
+ "Database connection is not configured"
+ )
+
+ if refresh:
+ self._refresh_function_metadata(runtime)
+
+ tag = tag or runtime.metadata.tag
+
+ obj = runtime.to_dict()
+ logger.debug("Saving function", runtime_name=runtime.metadata.name, tag=tag)
+ hash_key = self.db.store_function(
+ obj, runtime.metadata.name, runtime.metadata.project, tag, versioned
+ )
+ hash_key = hash_key if versioned else None
+ return "db://" + runtime._function_uri(hash_key=hash_key, tag=tag)
+
+ def launch(
+ self,
+ runtime: "mlrun.runtimes.BaseRuntime",
+ task: Optional[Union["mlrun.run.RunTemplate", "mlrun.run.RunObject"]] = None,
+ handler: Optional[str] = None,
+ name: Optional[str] = "",
+ project: Optional[str] = "",
+ params: Optional[dict] = None,
+ inputs: Optional[Dict[str, str]] = None,
+ out_path: Optional[str] = "",
+ workdir: Optional[str] = "",
+ artifact_path: Optional[str] = "",
+ watch: Optional[bool] = True,
+ schedule: Optional[
+ Union[str, mlrun.common.schemas.schedule.ScheduleCronTrigger]
+ ] = None,
+ hyperparams: Dict[str, list] = None,
+ hyper_param_options: Optional[mlrun.model.HyperParamOptions] = None,
+ verbose: Optional[bool] = None,
+ scrape_metrics: Optional[bool] = None,
+ local: Optional[bool] = False,
+ local_code_path: Optional[str] = None,
+ auto_build: Optional[bool] = None,
+ param_file_secrets: Optional[Dict[str, str]] = None,
+ notifications: Optional[List[mlrun.model.Notification]] = None,
+ returns: Optional[List[Union[str, Dict[str, str]]]] = None,
+ ) -> "mlrun.run.RunObject":
+ """run the function from the server/client[local/remote]"""
+ pass
+
+ def _validate_runtime(
+ self,
+ runtime: "mlrun.runtimes.BaseRuntime",
+ run: "mlrun.run.RunObject",
+ ):
+ mlrun.utils.helpers.verify_dict_items_type(
+ "Inputs", run.spec.inputs, [str], [str]
+ )
+
+ if runtime.spec.mode and runtime.spec.mode not in run_modes:
+ raise ValueError(f'run mode can only be {",".join(run_modes)}')
+
+ self._validate_run_params(run.spec.parameters)
+ self._validate_output_path(runtime, run)
+
+ @staticmethod
+ def _validate_output_path(
+ runtime: "mlrun.runtimes.BaseRuntime",
+ run: "mlrun.run.RunObject",
+ ):
+ if not run.spec.output_path or "://" not in run.spec.output_path:
+ message = ""
+ if not os.path.isabs(run.spec.output_path):
+ message = (
+ "artifact/output path is not defined or is local and relative,"
+ " artifacts will not be visible in the UI"
+ )
+ if mlrun.runtimes.RuntimeKinds.requires_absolute_artifacts_path(
+ runtime.kind
+ ):
+ raise mlrun.errors.MLRunPreconditionFailedError(
+ "artifact path (`artifact_path`) must be absolute for remote tasks"
+ )
+ elif (
+ hasattr(runtime.spec, "volume_mounts")
+ and not runtime.spec.volume_mounts
+ ):
+ message = (
+ "artifact output path is local while no volume mount is specified. "
+ "artifacts would not be visible via UI."
+ )
+ if message:
+ logger.warning(message, output_path=run.spec.output_path)
+
+ def _validate_run_params(self, parameters: Dict[str, Any]):
+ for param_name, param_value in parameters.items():
+
+ if isinstance(param_value, dict):
+ # if the parameter is a dict, we might have some nested parameters,
+ # in this case we need to verify them as well recursively
+ self._validate_run_params(param_value)
+
+ # verify that integer parameters don't exceed a int64
+ if isinstance(param_value, int) and abs(param_value) >= 2**63:
+ raise mlrun.errors.MLRunInvalidArgumentError(
+ f"parameter {param_name} value {param_value} exceeds int64"
+ )
+
+ @staticmethod
+ def _create_run_object(task):
+ valid_task_types = (dict, mlrun.run.RunTemplate, mlrun.run.RunObject)
+
+ if not task:
+ # if task passed generate default RunObject
+ return mlrun.run.RunObject.from_dict(task)
+
+ # deepcopy user's task, so we don't modify / enrich the user's object
+ task = copy.deepcopy(task)
+
+ if isinstance(task, str):
+ task = ast.literal_eval(task)
+
+ if not isinstance(task, valid_task_types):
+ raise mlrun.errors.MLRunInvalidArgumentError(
+ f"Task is not a valid object, type={type(task)}, expected types={valid_task_types}"
+ )
+
+ if isinstance(task, mlrun.run.RunTemplate):
+ return mlrun.run.RunObject.from_template(task)
+ elif isinstance(task, dict):
+ return mlrun.run.RunObject.from_dict(task)
+
+ @staticmethod
+ def _enrich_run(
+ runtime,
+ run,
+ handler=None,
+ project_name=None,
+ name=None,
+ params=None,
+ inputs=None,
+ returns=None,
+ hyperparams=None,
+ hyper_param_options=None,
+ verbose=None,
+ scrape_metrics=None,
+ out_path=None,
+ artifact_path=None,
+ workdir=None,
+ notifications: List[mlrun.model.Notification] = None,
+ ):
+ run.spec.handler = (
+ handler or run.spec.handler or runtime.spec.default_handler or ""
+ )
+ if run.spec.handler and runtime.kind not in ["handler", "dask"]:
+ run.spec.handler = run.spec.handler_name
+
+ def_name = runtime.metadata.name
+ if run.spec.handler_name:
+ short_name = run.spec.handler_name
+ for separator in ["#", "::", "."]:
+ # drop paths, module or class name from short name
+ if separator in short_name:
+ short_name = short_name.split(separator)[-1]
+ def_name += "-" + short_name
+
+ run.metadata.name = mlrun.utils.normalize_name(
+ name=name or run.metadata.name or def_name,
+ # if name or runspec.metadata.name are set then it means that is user defined name and we want to warn the
+ # user that the passed name needs to be set without underscore, if its not user defined but rather enriched
+ # from the handler(function) name then we replace the underscore without warning the user.
+ # most of the time handlers will have `_` in the handler name (python convention is to separate function
+ # words with `_`), therefore we don't want to be noisy when normalizing the run name
+ verbose=bool(name or run.metadata.name),
+ )
+ mlrun.utils.verify_field_regex(
+ "run.metadata.name", run.metadata.name, mlrun.utils.regex.run_name
+ )
+ run.metadata.project = (
+ project_name
+ or run.metadata.project
+ or runtime.metadata.project
+ or mlrun.mlconf.default_project
+ )
+ run.spec.parameters = params or run.spec.parameters
+ run.spec.inputs = inputs or run.spec.inputs
+ run.spec.returns = returns or run.spec.returns
+ run.spec.hyperparams = hyperparams or run.spec.hyperparams
+ run.spec.hyper_param_options = (
+ hyper_param_options or run.spec.hyper_param_options
+ )
+ run.spec.verbose = verbose or run.spec.verbose
+ if scrape_metrics is None:
+ if run.spec.scrape_metrics is None:
+ scrape_metrics = mlrun.mlconf.scrape_metrics
+ else:
+ scrape_metrics = run.spec.scrape_metrics
+ run.spec.scrape_metrics = scrape_metrics
+ run.spec.input_path = workdir or run.spec.input_path or runtime.spec.workdir
+ if runtime.spec.allow_empty_resources:
+ run.spec.allow_empty_resources = runtime.spec.allow_empty_resources
+
+ spec = run.spec
+ if spec.secret_sources:
+ runtime._secrets = mlrun.secrets.SecretsStore.from_list(spec.secret_sources)
+
+ # update run metadata (uid, labels) and store in DB
+ meta = run.metadata
+ meta.uid = meta.uid or uuid.uuid4().hex
+
+ run.spec.output_path = out_path or artifact_path or run.spec.output_path
+
+ if not run.spec.output_path:
+ if run.metadata.project:
+ if (
+ mlrun.pipeline_context.project
+ and run.metadata.project
+ == mlrun.pipeline_context.project.metadata.name
+ ):
+ run.spec.output_path = (
+ mlrun.pipeline_context.project.spec.artifact_path
+ or mlrun.pipeline_context.workflow_artifact_path
+ )
+
+ if not run.spec.output_path and runtime._get_db():
+ try:
+ # not passing or loading the DB before the enrichment on purpose, because we want to enrich the
+ # spec first as get_db() depends on it
+ project = runtime._get_db().get_project(run.metadata.project)
+ # this is mainly for tests, so we won't need to mock get_project for so many tests
+ # in normal use cases if no project is found we will get an error
+ if project:
+ run.spec.output_path = project.spec.artifact_path
+ except mlrun.errors.MLRunNotFoundError:
+ logger.warning(
+ f"project {project_name} is not saved in DB yet, "
+ f"enriching output path with default artifact path: {mlrun.mlconf.artifact_path}"
+ )
+
+ if not run.spec.output_path:
+ run.spec.output_path = mlrun.mlconf.artifact_path
+
+ if run.spec.output_path:
+ run.spec.output_path = run.spec.output_path.replace("{{run.uid}}", meta.uid)
+ run.spec.output_path = mlrun.utils.helpers.fill_artifact_path_template(
+ run.spec.output_path, run.metadata.project
+ )
+
+ run.spec.notifications = notifications or run.spec.notifications or []
+ return run
+
+ @staticmethod
+ def _are_valid_notifications(runobj) -> bool:
+ if not runobj.spec.notifications:
+ logger.debug(
+ "No notifications to push for run", run_uid=runobj.metadata.uid
+ )
+ return False
+
+ # TODO: add support for other notifications per run iteration
+ if runobj.metadata.iteration and runobj.metadata.iteration > 0:
+ logger.debug(
+ "Notifications per iteration are not supported, skipping",
+ run_uid=runobj.metadata.uid,
+ )
+ return False
+
+ return True
+
+ def _wrap_run_result(
+ self,
+ runtime: "mlrun.runtimes.BaseRuntime",
+ result: dict,
+ run: "mlrun.run.RunObject",
+ schedule: Optional[mlrun.common.schemas.ScheduleCronTrigger] = None,
+ err: Optional[Exception] = None,
+ ):
+ # if the purpose was to schedule (and not to run) nothing to wrap
+ if schedule:
+ return
+
+ if result and runtime.kfp and err is None:
+ mlrun.kfpops.write_kfpmeta(result)
+
+ self._log_track_results(runtime, result, run)
+
+ if result:
+ run = mlrun.run.RunObject.from_dict(result)
+ logger.info(
+ f"run executed, status={run.status.state}", name=run.metadata.name
+ )
+ if run.status.state == "error":
+ if runtime._is_remote and not runtime.is_child:
+ logger.error(f"runtime error: {run.status.error}")
+ raise mlrun.runtimes.utils.RunError(run.status.error)
+ return run
+
+ return None
+
+ def _refresh_function_metadata(self, runtime: "mlrun.runtimes.BaseRuntime"):
+ pass
+
+ @staticmethod
+ @abc.abstractmethod
+ def verify_base_image(runtime):
+ """resolves and sets the build base image if build is needed"""
+ pass
+
+ @staticmethod
+ @abc.abstractmethod
+ def _enrich_runtime(runtime):
+ pass
+
+ @abc.abstractmethod
+ def _save_or_push_notifications(self, runobj):
+ pass
+
+ @abc.abstractmethod
+ def _store_function(
+ self, runtime: "mlrun.runtimes.BaseRuntime", run: "mlrun.run.RunObject"
+ ):
+ pass
+
+ @staticmethod
+ def _log_track_results(
+ runtime: "mlrun.runtimes.BaseRuntime", result: dict, run: "mlrun.run.RunObject"
+ ):
+ pass
diff --git a/mlrun/launcher/client.py b/mlrun/launcher/client.py
new file mode 100644
index 000000000000..77903fb56448
--- /dev/null
+++ b/mlrun/launcher/client.py
@@ -0,0 +1,123 @@
+# Copyright 2023 MLRun Authors
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import abc
+import getpass
+import os
+
+import IPython
+
+import mlrun.errors
+import mlrun.launcher.base
+import mlrun.lists
+import mlrun.model
+import mlrun.runtimes
+from mlrun.utils import logger
+
+
+class ClientBaseLauncher(mlrun.launcher.base.BaseLauncher, abc.ABC):
+ """
+ Abstract class for common code between client launchers
+ """
+
+ @staticmethod
+ def _enrich_runtime(runtime):
+ runtime.try_auto_mount_based_on_config()
+ runtime._fill_credentials()
+
+ def _store_function(
+ self, runtime: "mlrun.runtimes.BaseRuntime", run: "mlrun.run.RunObject"
+ ):
+ run.metadata.labels["kind"] = runtime.kind
+ if "owner" not in run.metadata.labels:
+ run.metadata.labels["owner"] = (
+ os.environ.get("V3IO_USERNAME") or getpass.getuser()
+ )
+ if run.spec.output_path:
+ run.spec.output_path = run.spec.output_path.replace(
+ "{{run.user}}", run.metadata.labels["owner"]
+ )
+
+ if self.db and runtime.kind != "handler":
+ struct = runtime.to_dict()
+ hash_key = self.db.store_function(
+ struct, runtime.metadata.name, runtime.metadata.project, versioned=True
+ )
+ run.spec.function = runtime._function_uri(hash_key=hash_key)
+
+ def _refresh_function_metadata(self, runtime: "mlrun.runtimes.BaseRuntime"):
+ try:
+ meta = runtime.metadata
+ db_func = self.db.get_function(meta.name, meta.project, meta.tag)
+ if db_func and "status" in db_func:
+ runtime.status = db_func["status"]
+ if (
+ runtime.status.state
+ and runtime.status.state == "ready"
+ and runtime.kind
+ # We don't want to override the nuclio image here because the build happens in nuclio
+ # TODO: have a better way to check if nuclio function deploy started
+ and not hasattr(runtime.status, "nuclio_name")
+ ):
+ runtime.spec.image = mlrun.utils.get_in(
+ db_func, "spec.image", runtime.spec.image
+ )
+ except mlrun.errors.MLRunNotFoundError:
+ pass
+
+ @staticmethod
+ def _log_track_results(
+ runtime: "mlrun.runtimes.BaseRuntime", result: dict, run: "mlrun.run.RunObject"
+ ):
+ """
+ log commands to track results
+ in jupyter, displays a table widget with the result
+ else, logs CLI commands to track results and a link to the results in UI
+
+ :param: runtime: runtime object
+ :param result: run result dict
+ :param run: run object
+ """
+ uid = run.metadata.uid
+ project = run.metadata.project
+
+ # show ipython/jupyter result table widget
+ results_tbl = mlrun.lists.RunList()
+ if result:
+ results_tbl.append(result)
+ else:
+ logger.info("no returned result (job may still be in progress)")
+ results_tbl.append(run.to_dict())
+
+ if mlrun.utils.is_ipython and mlrun.config.ipython_widget:
+ results_tbl.show()
+ print()
+ ui_url = mlrun.utils.get_ui_url(project, uid)
+ if ui_url:
+ ui_url = f' or click here to open in UI'
+ IPython.display.display(
+ IPython.display.HTML(
+ f" > to track results use the .show() or .logs() methods {ui_url}"
+ )
+ )
+ elif not runtime.is_child:
+ # TODO: Log sdk commands to track results instead of CLI commands
+ project_flag = f"-p {project}" if project else ""
+ info_cmd = f"mlrun get run {uid} {project_flag}"
+ logs_cmd = f"mlrun logs {uid} {project_flag}"
+ logger.info(
+ "To track results use the CLI", info_cmd=info_cmd, logs_cmd=logs_cmd
+ )
+ ui_url = mlrun.utils.get_ui_url(project, uid)
+ if ui_url:
+ logger.info("Or click for UI", ui_url=ui_url)
diff --git a/mlrun/launcher/factory.py b/mlrun/launcher/factory.py
new file mode 100644
index 000000000000..e434c34b1136
--- /dev/null
+++ b/mlrun/launcher/factory.py
@@ -0,0 +1,50 @@
+# Copyright 2023 MLRun Authors
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import mlrun.config
+import mlrun.errors
+import mlrun.launcher.base
+import mlrun.launcher.local
+import mlrun.launcher.remote
+
+
+class LauncherFactory(object):
+ @staticmethod
+ def create_launcher(
+ is_remote: bool, local: bool = False
+ ) -> mlrun.launcher.base.BaseLauncher:
+ """
+ Creates the appropriate launcher for the specified run.
+ ServerSideLauncher - if running as API.
+ ClientRemoteLauncher - if the run is remote and local was not specified.
+ ClientLocalLauncher - if the run is not remote or local was specified.
+
+ :param is_remote: Whether the runtime requires remote execution.
+ :param local: Run the function locally vs on the Runtime/Cluster
+
+ :return: The appropriate launcher for the specified run.
+ """
+ if mlrun.config.is_running_as_api():
+ if local:
+ raise mlrun.errors.MLRunInternalServerError(
+ "Launch of local run inside the server is not allowed"
+ )
+
+ from mlrun.api.launcher import ServerSideLauncher
+
+ return ServerSideLauncher()
+
+ if is_remote and not local:
+ return mlrun.launcher.remote.ClientRemoteLauncher()
+
+ return mlrun.launcher.local.ClientLocalLauncher(local)
diff --git a/mlrun/launcher/local.py b/mlrun/launcher/local.py
new file mode 100644
index 000000000000..98598d6199f9
--- /dev/null
+++ b/mlrun/launcher/local.py
@@ -0,0 +1,267 @@
+# Copyright 2023 MLRun Authors
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import os
+import pathlib
+from typing import Dict, List, Optional, Union
+
+import mlrun.common.schemas.schedule
+import mlrun.errors
+import mlrun.launcher.client
+import mlrun.run
+import mlrun.runtimes.generators
+import mlrun.utils.clones
+import mlrun.utils.notifications
+from mlrun.utils import logger
+
+
+class ClientLocalLauncher(mlrun.launcher.client.ClientBaseLauncher):
+ """
+ ClientLocalLauncher is a launcher that runs the job locally.
+ Either on the user's machine (_is_run_local is True) or on a remote machine (_is_run_local is False).
+ """
+
+ def __init__(self, local: bool):
+ """
+ Initialize a ClientLocalLauncher.
+ :param local: True if the job runs on the user's local machine,
+ False if it runs on a remote machine (e.g. a dedicated k8s pod).
+ """
+ super().__init__()
+ self._is_run_local = local
+
+ @staticmethod
+ def verify_base_image(runtime):
+ pass
+
+ def launch(
+ self,
+ runtime: "mlrun.runtimes.BaseRuntime",
+ task: Optional[Union["mlrun.run.RunTemplate", "mlrun.run.RunObject"]] = None,
+ handler: Optional[str] = None,
+ name: Optional[str] = "",
+ project: Optional[str] = "",
+ params: Optional[dict] = None,
+ inputs: Optional[Dict[str, str]] = None,
+ out_path: Optional[str] = "",
+ workdir: Optional[str] = "",
+ artifact_path: Optional[str] = "",
+ watch: Optional[bool] = True,
+ schedule: Optional[
+ Union[str, mlrun.common.schemas.schedule.ScheduleCronTrigger]
+ ] = None,
+ hyperparams: Dict[str, list] = None,
+ hyper_param_options: Optional[mlrun.model.HyperParamOptions] = None,
+ verbose: Optional[bool] = None,
+ scrape_metrics: Optional[bool] = None,
+ local: Optional[bool] = False,
+ local_code_path: Optional[str] = None,
+ auto_build: Optional[bool] = None,
+ param_file_secrets: Optional[Dict[str, str]] = None,
+ notifications: Optional[List[mlrun.model.Notification]] = None,
+ returns: Optional[List[Union[str, Dict[str, str]]]] = None,
+ ) -> "mlrun.run.RunObject":
+
+ # do not allow local function to be scheduled
+ if self._is_run_local and schedule is not None:
+ raise mlrun.errors.MLRunInvalidArgumentError(
+ "local and schedule cannot be used together"
+ )
+
+ self._enrich_runtime(runtime)
+ run = self._create_run_object(task)
+
+ if self._is_run_local:
+ runtime = self._create_local_function_for_execution(
+ runtime=runtime,
+ run=run,
+ local_code_path=local_code_path,
+ project=project,
+ name=name,
+ workdir=workdir,
+ handler=handler,
+ )
+
+ # sanity check
+ elif runtime._is_remote:
+ message = "Remote function cannot be executed locally"
+ logger.error(
+ message,
+ is_remote=runtime._is_remote,
+ local=self._is_run_local,
+ runtime=runtime.to_dict(),
+ )
+ raise mlrun.errors.MLRunRuntimeError(message)
+
+ run = self._enrich_run(
+ runtime=runtime,
+ run=run,
+ handler=handler,
+ project_name=project,
+ name=name,
+ params=params,
+ inputs=inputs,
+ returns=returns,
+ hyperparams=hyperparams,
+ hyper_param_options=hyper_param_options,
+ verbose=verbose,
+ scrape_metrics=scrape_metrics,
+ out_path=out_path,
+ artifact_path=artifact_path,
+ workdir=workdir,
+ notifications=notifications,
+ )
+ self._validate_runtime(runtime, run)
+ result = self.execute(
+ runtime=runtime,
+ run=run,
+ )
+
+ self._save_or_push_notifications(result)
+ return result
+
+ def execute(
+ self,
+ runtime: "mlrun.runtimes.BaseRuntime",
+ run: Optional[Union["mlrun.run.RunTemplate", "mlrun.run.RunObject"]] = None,
+ ):
+
+ if "V3IO_USERNAME" in os.environ and "v3io_user" not in run.metadata.labels:
+ run.metadata.labels["v3io_user"] = os.environ.get("V3IO_USERNAME")
+
+ logger.info(
+ "Storing function",
+ name=run.metadata.name,
+ uid=run.metadata.uid,
+ db=runtime.spec.rundb,
+ )
+ self._store_function(runtime, run)
+
+ execution = mlrun.run.MLClientCtx.from_dict(
+ run.to_dict(),
+ self.db,
+ autocommit=False,
+ is_api=False,
+ store_run=False,
+ )
+
+ # create task generator (for child runs) from spec
+ task_generator = mlrun.runtimes.generators.get_generator(run.spec, execution)
+ if task_generator:
+ # verify valid task parameters
+ tasks = task_generator.generate(run)
+ for task in tasks:
+ self._validate_run_params(task.spec.parameters)
+
+ # post verifications, store execution in db and run pre run hooks
+ execution.store_run()
+ runtime._pre_run(run, execution) # hook for runtime specific prep
+
+ last_err = None
+ # If the runtime is nested, it means the hyper-run will run within a single instance of the run.
+ # So while in the API, we consider the hyper-run as a single run, and then in the runtime itself when the
+ # runtime is now a local runtime and therefore `self._is_nested == False`, we run each task as a separate run by
+ # using the task generator
+ # TODO client-server separation might not need the not runtime._is_nested anymore as this executed local func
+ if task_generator and not runtime._is_nested:
+ # multiple runs (based on hyper params or params file)
+ runner = runtime._run_many
+ if hasattr(runtime, "_parallel_run_many") and task_generator.use_parallel():
+ runner = runtime._parallel_run_many
+ results = runner(task_generator, execution, run)
+ mlrun.runtimes.utils.results_to_iter(results, run, execution)
+ result = execution.to_dict()
+ result = runtime._update_run_state(result, task=run)
+
+ else:
+ # single run
+ try:
+ resp = runtime._run(run, execution)
+ result = runtime._update_run_state(resp, task=run)
+ except mlrun.runtimes.base.RunError as err:
+ last_err = err
+ result = runtime._update_run_state(task=run, err=err)
+
+ self._save_or_push_notifications(run)
+ # run post run hooks
+ runtime._post_run(result, execution) # hook for runtime specific cleanup
+
+ return self._wrap_run_result(runtime, result, run, err=last_err)
+
+ def _create_local_function_for_execution(
+ self,
+ runtime,
+ run,
+ local_code_path,
+ project,
+ name,
+ workdir,
+ handler,
+ ):
+
+ project = project or runtime.metadata.project
+ function_name = name or runtime.metadata.name
+ command, args = self._resolve_local_code_path(local_code_path)
+ if command:
+ function_name = name or pathlib.Path(command).stem
+
+ meta = mlrun.model.BaseMetadata(function_name, project=project)
+
+ command, runtime = mlrun.run.load_func_code(
+ command or runtime, workdir, name=name
+ )
+ if runtime:
+ if run:
+ handler = handler or run.spec.handler
+ handler = handler or runtime.spec.default_handler or ""
+ meta = runtime.metadata.copy()
+ meta.project = project or meta.project
+
+ # if the handler has module prefix force "local" (vs "handler") runtime
+ kind = "local" if isinstance(handler, str) and "." in handler else ""
+ fn = mlrun.new_function(meta.name, command=command, args=args, kind=kind)
+ fn.metadata = meta
+ setattr(fn, "_is_run_local", True)
+ if workdir:
+ fn.spec.workdir = str(workdir)
+ fn.spec.allow_empty_resources = runtime.spec.allow_empty_resources
+ if runtime:
+ # copy the code/base-spec to the local function (for the UI and code logging)
+ fn.spec.description = runtime.spec.description
+ fn.spec.build = runtime.spec.build
+
+ run.spec.handler = handler
+ return fn
+
+ @staticmethod
+ def _resolve_local_code_path(local_code_path: str) -> (str, List[str]):
+ command = None
+ args = []
+ if local_code_path:
+ command = local_code_path
+ if command:
+ sp = command.split()
+ # split command and args
+ command = sp[0]
+ if len(sp) > 1:
+ args = sp[1:]
+ return command, args
+
+ def _save_or_push_notifications(self, runobj):
+ if not self._are_valid_notifications(runobj):
+ return
+ # The run is local, so we can assume that watch=True, therefore this code runs
+ # once the run is completed, and we can just push the notifications.
+ # TODO: add store_notifications API endpoint so we can store notifications pushed from the
+ # SDK for documentation purposes.
+ mlrun.utils.notifications.NotificationPusher([runobj]).push()
diff --git a/mlrun/launcher/remote.py b/mlrun/launcher/remote.py
new file mode 100644
index 000000000000..03f1f94255b8
--- /dev/null
+++ b/mlrun/launcher/remote.py
@@ -0,0 +1,183 @@
+# Copyright 2023 MLRun Authors
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import os
+from typing import Dict, List, Optional, Union
+
+import requests
+
+import mlrun.common.schemas.schedule
+import mlrun.db
+import mlrun.errors
+import mlrun.launcher.client
+import mlrun.run
+import mlrun.runtimes
+import mlrun.runtimes.generators
+import mlrun.utils.clones
+import mlrun.utils.notifications
+from mlrun.utils import logger
+
+
+class ClientRemoteLauncher(mlrun.launcher.client.ClientBaseLauncher):
+ @staticmethod
+ def verify_base_image(runtime):
+ pass
+
+ def launch(
+ self,
+ runtime: "mlrun.runtimes.KubejobRuntime",
+ task: Optional[Union["mlrun.run.RunTemplate", "mlrun.run.RunObject"]] = None,
+ handler: Optional[str] = None,
+ name: Optional[str] = "",
+ project: Optional[str] = "",
+ params: Optional[dict] = None,
+ inputs: Optional[Dict[str, str]] = None,
+ out_path: Optional[str] = "",
+ workdir: Optional[str] = "",
+ artifact_path: Optional[str] = "",
+ watch: Optional[bool] = True,
+ schedule: Optional[
+ Union[str, mlrun.common.schemas.schedule.ScheduleCronTrigger]
+ ] = None,
+ hyperparams: Dict[str, list] = None,
+ hyper_param_options: Optional[mlrun.model.HyperParamOptions] = None,
+ verbose: Optional[bool] = None,
+ scrape_metrics: Optional[bool] = None,
+ local: Optional[bool] = False,
+ local_code_path: Optional[str] = None,
+ auto_build: Optional[bool] = None,
+ param_file_secrets: Optional[Dict[str, str]] = None,
+ notifications: Optional[List[mlrun.model.Notification]] = None,
+ returns: Optional[List[Union[str, Dict[str, str]]]] = None,
+ ) -> "mlrun.run.RunObject":
+ self._enrich_runtime(runtime)
+ run = self._create_run_object(task)
+
+ run = self._enrich_run(
+ runtime=runtime,
+ run=run,
+ handler=handler,
+ project_name=project,
+ name=name,
+ params=params,
+ inputs=inputs,
+ returns=returns,
+ hyperparams=hyperparams,
+ hyper_param_options=hyper_param_options,
+ verbose=verbose,
+ scrape_metrics=scrape_metrics,
+ out_path=out_path,
+ artifact_path=artifact_path,
+ workdir=workdir,
+ notifications=notifications,
+ )
+ self._validate_runtime(runtime, run)
+
+ if not runtime.is_deployed():
+ if runtime.spec.build.auto_build or auto_build:
+ logger.info(
+ "Function is not deployed and auto_build flag is set, starting deploy..."
+ )
+ runtime.deploy(skip_deployed=True, show_on_failure=True)
+
+ else:
+ raise mlrun.errors.MLRunRuntimeError(
+ "function image is not built/ready, set auto_build=True or use .deploy() method first"
+ )
+
+ if runtime.verbose:
+ logger.info(f"runspec:\n{run.to_yaml()}")
+
+ if "V3IO_USERNAME" in os.environ and "v3io_user" not in run.metadata.labels:
+ run.metadata.labels["v3io_user"] = os.environ.get("V3IO_USERNAME")
+
+ logger.info(
+ "Storing function",
+ name=run.metadata.name,
+ uid=run.metadata.uid,
+ db=runtime.spec.rundb,
+ )
+ self._store_function(runtime, run)
+
+ return self.submit_job(runtime, run, schedule, watch)
+
+ def submit_job(
+ self,
+ runtime: "mlrun.runtimes.KubejobRuntime",
+ run: "mlrun.run.RunObject",
+ schedule: Optional[mlrun.common.schemas.ScheduleCronTrigger] = None,
+ watch: Optional[bool] = None,
+ ):
+ if runtime._secrets:
+ run.spec.secret_sources = runtime._secrets.to_serial()
+ try:
+ resp = self.db.submit_job(run, schedule=schedule)
+ if schedule:
+ action = resp.pop("action", "created")
+ logger.info(f"task schedule {action}", **resp)
+ return
+
+ except (requests.HTTPError, Exception) as err:
+ logger.error(f"got remote run err, {mlrun.errors.err_to_str(err)}")
+
+ if isinstance(err, requests.HTTPError):
+ runtime._handle_submit_job_http_error(err)
+
+ result = None
+ # if we got a schedule no reason to do post_run stuff (it purposed to update the run status with error,
+ # but there's no run in case of schedule)
+ if not schedule:
+ result = runtime._update_run_state(
+ task=run, err=mlrun.errors.err_to_str(err)
+ )
+ return self._wrap_run_result(
+ runtime, result, run, schedule=schedule, err=err
+ )
+
+ if resp:
+ txt = mlrun.runtimes.utils.helpers.get_in(resp, "status.status_text")
+ if txt:
+ logger.info(txt)
+ # watch is None only in scenario where we run from pipeline step, in this case we don't want to watch the run
+ # logs too frequently but rather just pull the state of the run from the DB and pull the logs every x seconds
+ # which ideally greater than the pull state interval, this reduces unnecessary load on the API server, as
+ # running a pipeline is mostly not an interactive process which means the logs pulling doesn't need to be pulled
+ # in real time
+ if (
+ watch is None
+ and runtime.kfp
+ and mlrun.mlconf.httpdb.logs.pipelines.pull_state.mode == "enabled"
+ ):
+ state_interval = int(
+ mlrun.mlconf.httpdb.logs.pipelines.pull_state.pull_state_interval
+ )
+ logs_interval = int(
+ mlrun.mlconf.httpdb.logs.pipelines.pull_state.pull_logs_interval
+ )
+
+ run.wait_for_completion(
+ show_logs=True,
+ sleep=state_interval,
+ logs_interval=logs_interval,
+ raise_on_failure=False,
+ )
+ resp = runtime._get_db_run(run)
+
+ elif watch or runtime.kfp:
+ run.logs(True, self.db)
+ resp = runtime._get_db_run(run)
+
+ return self._wrap_run_result(runtime, resp, run, schedule=schedule)
+
+ def _save_or_push_notifications(self, runobj):
+ pass
diff --git a/mlrun/runtimes/base.py b/mlrun/runtimes/base.py
index 307f34e1a8a5..f8908a84b5fd 100644
--- a/mlrun/runtimes/base.py
+++ b/mlrun/runtimes/base.py
@@ -14,7 +14,6 @@
import enum
import getpass
import http
-import os.path
import traceback
import typing
import uuid
@@ -26,7 +25,6 @@
from os import environ
from typing import Dict, List, Optional, Tuple, Union
-import IPython
import requests.exceptions
from kubernetes.client.rest import ApiException
from nuclio.build import mlrun_footer
@@ -36,6 +34,7 @@
import mlrun.api.utils.singletons.db
import mlrun.common.schemas
import mlrun.errors
+import mlrun.launcher.factory
import mlrun.utils.helpers
import mlrun.utils.notifications
import mlrun.utils.regex
@@ -47,8 +46,7 @@
from ..datastore import store_manager
from ..db import RunDBError, get_or_set_dburl, get_run_db
from ..errors import err_to_str
-from ..execution import MLClientCtx
-from ..kfpops import mlrun_op, write_kfpmeta
+from ..kfpops import mlrun_op
from ..lists import RunList
from ..model import (
BaseMetadata,
@@ -65,8 +63,6 @@
enrich_image_url,
get_in,
get_parsed_docker_registry,
- get_ui_url,
- is_ipython,
logger,
normalize_name,
now_date,
@@ -74,10 +70,8 @@
)
from .constants import PodPhases, RunStates
from .funcdoc import update_function_entry_points
-from .generators import get_generator
-from .utils import RunError, calc_hash, get_k8s, results_to_iter
+from .utils import RunError, calc_hash, get_k8s
-run_modes = ["pass"]
spec_fields = [
"command",
"args",
@@ -189,14 +183,12 @@ def __init__(self, metadata=None, spec=None):
self.is_child = False
self._status = None
self.status = None
- self._is_api_server = False
self.verbose = False
self._enriched_image = False
def set_db_connection(self, conn):
if not self._db_conn:
self._db_conn = conn
- self._is_api_server = mlrun.config.is_running_as_api()
@property
def metadata(self) -> BaseMetadata:
@@ -239,39 +231,6 @@ def _is_remote_api(self):
return True
return False
- def _use_remote_api(self):
- if (
- self._is_remote
- and not self._is_api_server
- and self._get_db()
- and self._get_db().kind == "http"
- ):
- return True
- return False
-
- def _enrich_on_client_side(self):
- self.try_auto_mount_based_on_config()
- self._fill_credentials()
-
- def _enrich_on_server_side(self):
- pass
-
- def _enrich_on_server_and_client_sides(self):
- """
- enrich function also in client side and also on server side
- """
- pass
-
- def _enrich_function(self):
- """
- enriches the function based on the flow state we run in (sdk or server)
- """
- if self._use_remote_api():
- self._enrich_on_client_side()
- else:
- self._enrich_on_server_side()
- self._enrich_on_server_and_client_sides()
-
def _function_uri(self, tag=None, hash_key=None):
return generate_object_uri(
self.metadata.project,
@@ -288,7 +247,6 @@ def _get_db(self):
if not self._db_conn:
if self.spec.rundb:
self._db_conn = get_run_db(self.spec.rundb, secrets=self._secrets)
- self._is_api_server = mlrun.config.is_running_as_api()
return self._db_conn
# This function is different than the auto_mount function, as it mounts to runtimes based on the configuration.
@@ -392,210 +350,33 @@ def run(
:return: run context object (RunObject) with run metadata, results and status
"""
- mlrun.utils.helpers.verify_dict_items_type("Inputs", inputs, [str], [str])
-
- if self.spec.mode and self.spec.mode not in run_modes:
- raise ValueError(f'run mode can only be {",".join(run_modes)}')
-
- self._enrich_function()
-
- run = self._create_run_object(runspec)
-
- if local:
-
- # do not allow local function to be scheduled
- if schedule is not None:
- raise mlrun.errors.MLRunInvalidArgumentError(
- "local and schedule cannot be used together"
- )
- result = self._run_local(
- run,
- local_code_path,
- project,
- name,
- workdir,
- handler,
- params,
- inputs,
- returns,
- artifact_path,
- notifications=notifications,
- )
- self._save_or_push_notifications(result, local)
- return result
-
- run = self._enrich_run(
- run,
- handler,
- project,
- name,
- params,
- inputs,
- returns,
- hyperparams,
- hyper_param_options,
- verbose,
- scrape_metrics,
- out_path,
- artifact_path,
- workdir,
- notifications,
+ launcher = mlrun.launcher.factory.LauncherFactory.create_launcher(
+ self._is_remote, local
)
- self._validate_output_path(run)
- db = self._get_db()
-
- if not self.is_deployed():
- if self.spec.build.auto_build or auto_build:
- logger.info(
- "Function is not deployed and auto_build flag is set, starting deploy..."
- )
- self.deploy(skip_deployed=True, show_on_failure=True)
- else:
- raise RunError(
- "function image is not built/ready, set auto_build=True or use .deploy() method first"
- )
-
- if self.verbose:
- logger.info(f"runspec:\n{run.to_yaml()}")
-
- if "V3IO_USERNAME" in environ and "v3io_user" not in run.metadata.labels:
- run.metadata.labels["v3io_user"] = environ.get("V3IO_USERNAME")
-
- if not self.is_child:
- db_str = "self" if self._is_api_server else self.spec.rundb
- logger.info(
- "Storing function",
- name=run.metadata.name,
- uid=run.metadata.uid,
- db=db_str,
- )
- self._store_function(run, run.metadata, db)
-
- # execute the job remotely (to a k8s cluster via the API service)
- if self._use_remote_api():
- return self._submit_job(run, schedule, db, watch)
-
- elif self._is_remote and not self._is_api_server and not self.kfp:
- logger.warning(
- "warning!, Api url not set, " "trying to exec remote runtime locally"
- )
-
- execution = MLClientCtx.from_dict(
- run.to_dict(),
- db,
- autocommit=False,
- is_api=self._is_api_server,
- store_run=False,
- )
-
- self._verify_run_params(run.spec.parameters)
-
- # create task generator (for child runs) from spec
- task_generator = get_generator(
- run.spec, execution, param_file_secrets=param_file_secrets
+ return launcher.launch(
+ runtime=self,
+ task=runspec,
+ handler=handler,
+ name=name,
+ project=project,
+ params=params,
+ inputs=inputs,
+ out_path=out_path,
+ workdir=workdir,
+ artifact_path=artifact_path,
+ watch=watch,
+ schedule=schedule,
+ hyperparams=hyperparams,
+ hyper_param_options=hyper_param_options,
+ verbose=verbose,
+ scrape_metrics=scrape_metrics,
+ local=local,
+ local_code_path=local_code_path,
+ auto_build=auto_build,
+ param_file_secrets=param_file_secrets,
+ notifications=notifications,
+ returns=returns,
)
- if task_generator:
- # verify valid task parameters
- tasks = task_generator.generate(run)
- for task in tasks:
- self._verify_run_params(task.spec.parameters)
-
- # post verifications, store execution in db and run pre run hooks
- execution.store_run()
- self._pre_run(run, execution) # hook for runtime specific prep
-
- last_err = None
- # If the runtime is nested, it means the hyper-run will run within a single instance of the run.
- # So while in the API, we consider the hyper-run as a single run, and then in the runtime itself when the
- # runtime is now a local runtime and therefore `self._is_nested == False`, we run each task as a separate run by
- # using the task generator
- if task_generator and not self._is_nested:
- # multiple runs (based on hyper params or params file)
- runner = self._run_many
- if hasattr(self, "_parallel_run_many") and task_generator.use_parallel():
- runner = self._parallel_run_many
- results = runner(task_generator, execution, run)
- results_to_iter(results, run, execution)
- result = execution.to_dict()
- result = self._update_run_state(result, task=run)
-
- else:
- # single run
- try:
- resp = self._run(run, execution)
- if (
- watch
- and mlrun.runtimes.RuntimeKinds.is_watchable(self.kind)
- # API shouldn't watch logs, its the client job to query the run logs
- and not mlrun.config.is_running_as_api()
- ):
- state, _ = run.logs(True, self._get_db())
- if state not in ["succeeded", "completed"]:
- logger.warning(f"run ended with state {state}")
- result = self._update_run_state(resp, task=run)
- except RunError as err:
- last_err = err
- result = self._update_run_state(task=run, err=err)
-
- self._save_or_push_notifications(run)
-
- self._post_run(result, execution) # hook for runtime specific cleanup
-
- return self._wrap_run_result(result, run, schedule=schedule, err=last_err)
-
- def _wrap_run_result(
- self, result: dict, runspec: RunObject, schedule=None, err=None
- ):
- # if the purpose was to schedule (and not to run) nothing to wrap
- if schedule:
- return
-
- if result and self.kfp and err is None:
- write_kfpmeta(result)
-
- # show ipython/jupyter result table widget
- results_tbl = RunList()
- if result:
- results_tbl.append(result)
- else:
- logger.info("no returned result (job may still be in progress)")
- results_tbl.append(runspec.to_dict())
-
- uid = runspec.metadata.uid
- project = runspec.metadata.project
- if is_ipython and config.ipython_widget:
- results_tbl.show()
- print()
- ui_url = get_ui_url(project, uid)
- if ui_url:
- ui_url = f' or click here to open in UI'
- IPython.display.display(
- IPython.display.HTML(
- f" > to track results use the .show() or .logs() methods {ui_url}"
- )
- )
- elif not (self.is_child and is_running_as_api()):
- project_flag = f"-p {project}" if project else ""
- info_cmd = f"mlrun get run {uid} {project_flag}"
- logs_cmd = f"mlrun logs {uid} {project_flag}"
- logger.info(
- "To track results use the CLI", info_cmd=info_cmd, logs_cmd=logs_cmd
- )
- ui_url = get_ui_url(project, uid)
- if ui_url:
- logger.info("Or click for UI", ui_url=ui_url)
- if result:
- run = RunObject.from_dict(result)
- logger.info(
- f"run executed, status={run.status.state}", name=run.metadata.name
- )
- if run.status.state == "error":
- if self._is_remote and not self.is_child:
- logger.error(f"runtime error: {run.status.error}")
- raise RunError(run.status.error)
- return run
-
- return None
def _get_db_run(self, task: RunObject = None):
if self._get_db() and task:
@@ -624,43 +405,6 @@ def _generate_runtime_env(self, runobj: RunObject):
runtime_env["MLRUN_NAMESPACE"] = self.metadata.namespace or config.namespace
return runtime_env
- def _run_local(
- self,
- runspec,
- local_code_path,
- project,
- name,
- workdir,
- handler,
- params,
- inputs,
- returns,
- artifact_path,
- notifications: List[mlrun.model.Notification] = None,
- ):
- # allow local run simulation with a flip of a flag
- command = self
- if local_code_path:
- project = project or self.metadata.project
- name = name or self.metadata.name
- command = local_code_path
- return mlrun.run_local(
- runspec,
- command,
- name,
- self.spec.args,
- workdir=workdir,
- project=project,
- handler=handler,
- params=params,
- inputs=inputs,
- artifact_path=artifact_path,
- mode=self.spec.mode,
- allow_empty_resources=self.spec.allow_empty_resources,
- notifications=notifications,
- returns=returns,
- )
-
def _create_run_object(self, runspec):
# TODO: Once implemented the `Runtime` handlers configurations (doc strings, params type hints and returning
# log hints, possible parameter values, etc), the configured type hints and log hints should be set into
@@ -802,64 +546,6 @@ def _enrich_run(
runspec.spec.notifications = notifications or runspec.spec.notifications or []
return runspec
- def _submit_job(self, run: RunObject, schedule, db, watch):
- if self._secrets:
- run.spec.secret_sources = self._secrets.to_serial()
- try:
- resp = db.submit_job(run, schedule=schedule)
- if schedule:
- action = resp.pop("action", "created")
- logger.info(f"task schedule {action}", **resp)
- return
-
- except (requests.HTTPError, Exception) as err:
- logger.error(f"got remote run err, {err_to_str(err)}")
-
- if isinstance(err, requests.HTTPError):
- self._handle_submit_job_http_error(err)
-
- result = None
- # if we got a schedule no reason to do post_run stuff (it purposed to update the run status with error,
- # but there's no run in case of schedule)
- if not schedule:
- result = self._update_run_state(task=run, err=err_to_str(err))
- return self._wrap_run_result(result, run, schedule=schedule, err=err)
-
- if resp:
- txt = get_in(resp, "status.status_text")
- if txt:
- logger.info(txt)
- # watch is None only in scenario where we run from pipeline step, in this case we don't want to watch the run
- # logs too frequently but rather just pull the state of the run from the DB and pull the logs every x seconds
- # which ideally greater than the pull state interval, this reduces unnecessary load on the API server, as
- # running a pipeline is mostly not an interactive process which means the logs pulling doesn't need to be pulled
- # in real time
- if (
- watch is None
- and self.kfp
- and config.httpdb.logs.pipelines.pull_state.mode == "enabled"
- ):
- state_interval = int(
- config.httpdb.logs.pipelines.pull_state.pull_state_interval
- )
- logs_interval = int(
- config.httpdb.logs.pipelines.pull_state.pull_logs_interval
- )
-
- run.wait_for_completion(
- show_logs=True,
- sleep=state_interval,
- logs_interval=logs_interval,
- raise_on_failure=False,
- )
- resp = self._get_db_run(run)
-
- elif watch or self.kfp:
- run.logs(True, self._get_db())
- resp = self._get_db_run(run)
-
- return self._wrap_run_result(resp, run, schedule=schedule)
-
@staticmethod
def _handle_submit_job_http_error(error: requests.HTTPError):
# if we receive a 400 status code, this means the request was invalid and the run wasn't created in the DB.
@@ -1354,20 +1040,6 @@ def verify_base_image(self):
self.spec.build.base_image = image
self.spec.image = ""
- def _verify_run_params(self, parameters: typing.Dict[str, typing.Any]):
- for param_name, param_value in parameters.items():
-
- if isinstance(param_value, dict):
- # if the parameter is a dict, we might have some nested parameters,
- # in this case we need to verify them as well recursively
- self._verify_run_params(param_value)
-
- # verify that integer parameters don't exceed a int64
- if isinstance(param_value, int) and abs(param_value) >= 2**63:
- raise mlrun.errors.MLRunInvalidArgumentError(
- f"parameter {param_name} value {param_value} exceeds int64"
- )
-
def export(self, target="", format=".yaml", secrets=None, strip=True):
"""save function spec to a local/remote path (default to./function.yaml)
@@ -1397,35 +1069,12 @@ def export(self, target="", format=".yaml", secrets=None, strip=True):
return self
def save(self, tag="", versioned=False, refresh=False) -> str:
- db = self._get_db()
- if not db:
- logger.error("database connection is not configured")
- return ""
-
- if refresh and self._is_remote_api():
- try:
- meta = self.metadata
- db_func = db.get_function(meta.name, meta.project, meta.tag)
- if db_func and "status" in db_func:
- self.status = db_func["status"]
- if (
- self.status.state
- and self.status.state == "ready"
- and not hasattr(self.status, "nuclio_name")
- ):
- self.spec.image = get_in(db_func, "spec.image", self.spec.image)
- except mlrun.errors.MLRunNotFoundError:
- pass
-
- tag = tag or self.metadata.tag
-
- obj = self.to_dict()
- logger.debug(f"saving function: {self.metadata.name}, tag: {tag}")
- hash_key = db.store_function(
- obj, self.metadata.name, self.metadata.project, tag, versioned
+ launcher = mlrun.launcher.factory.LauncherFactory.create_launcher(
+ is_remote=self._is_remote
+ )
+ return launcher.save_function(
+ self, tag=tag, versioned=versioned, refresh=refresh
)
- hash_key = hash_key if versioned else None
- return "db://" + self._function_uri(hash_key=hash_key, tag=tag)
def to_dict(self, fields=None, exclude=None, strip=False):
struct = super().to_dict(fields, exclude=exclude)
@@ -1480,34 +1129,6 @@ def _resolve_requirements(requirements_to_resolve: typing.Union[str, list]) -> l
return requirements
- def _validate_output_path(self, run):
- if is_local(run.spec.output_path):
- message = ""
- if not os.path.isabs(run.spec.output_path):
- message = (
- "artifact/output path is not defined or is local and relative,"
- " artifacts will not be visible in the UI"
- )
- if mlrun.runtimes.RuntimeKinds.requires_absolute_artifacts_path(
- self.kind
- ):
- raise mlrun.errors.MLRunPreconditionFailedError(
- "artifact path (`artifact_path`) must be absolute for remote tasks"
- )
- elif hasattr(self.spec, "volume_mounts") and not self.spec.volume_mounts:
- message = (
- "artifact output path is local while no volume mount is specified. "
- "artifacts would not be visible via UI."
- )
- if message:
- logger.warning(message, output_path=run.spec.output_path)
-
-
-def is_local(url):
- if not url:
- return True
- return "://" not in url
-
class BaseRuntimeHandler(ABC):
# setting here to allow tests to override
@@ -1526,7 +1147,7 @@ def _get_object_label_selector(object_id: str) -> str:
def _should_collect_logs(self) -> bool:
"""
There are some runtimes which we don't collect logs for using the log collector
- :return: whether should collect log for it
+ :return: whether it should collect log for it
"""
return True
diff --git a/mlrun/runtimes/kubejob.py b/mlrun/runtimes/kubejob.py
index 00a5c89a8699..27b48582ff60 100644
--- a/mlrun/runtimes/kubejob.py
+++ b/mlrun/runtimes/kubejob.py
@@ -44,12 +44,13 @@ def is_deployed(self):
if self.spec.image:
return True
- if self._is_remote_api():
- db = self._get_db()
- try:
- db.get_builder_status(self, logs=False)
- except Exception:
- pass
+ db = self._get_db()
+ try:
+ # getting builder status enriches the runtime when it needs to be fetched from the API,
+ # otherwise it's a no-op
+ db.get_builder_status(self, logs=False)
+ except Exception:
+ pass
if self.spec.image:
return True
diff --git a/tests/api/api/test_submit.py b/tests/api/api/test_submit.py
index 49dc6ddc922f..60d08e1d5e6c 100644
--- a/tests/api/api/test_submit.py
+++ b/tests/api/api/test_submit.py
@@ -81,17 +81,12 @@ def pod_create_mock():
update_run_state_orig_function = (
mlrun.runtimes.kubejob.KubejobRuntime._update_run_state
)
- mlrun.runtimes.kubejob.KubejobRuntime._update_run_state = unittest.mock.Mock()
+ mlrun.runtimes.kubejob.KubejobRuntime._update_run_state = unittest.mock.MagicMock()
mock_run_object = mlrun.RunObject()
mock_run_object.metadata.uid = "1234567890"
mock_run_object.metadata.project = "project-name"
- wrap_run_result_orig_function = mlrun.runtimes.base.BaseRuntime._wrap_run_result
- mlrun.runtimes.base.BaseRuntime._wrap_run_result = unittest.mock.Mock(
- return_value=mock_run_object
- )
-
auth_info_mock = AuthInfo(
username=username, session="some-session", data_session=access_key
)
@@ -115,7 +110,6 @@ def pod_create_mock():
mlrun.runtimes.kubejob.KubejobRuntime._update_run_state = (
update_run_state_orig_function
)
- mlrun.runtimes.base.BaseRuntime._wrap_run_result = wrap_run_result_orig_function
mlrun.api.utils.auth.verifier.AuthVerifier().authenticate_request = (
authenticate_request_orig_function
)
diff --git a/tests/common_fixtures.py b/tests/common_fixtures.py
index 801a4f19e2bb..9c6c9286720a 100644
--- a/tests/common_fixtures.py
+++ b/tests/common_fixtures.py
@@ -458,7 +458,6 @@ def rundb_mock() -> RunDBMock:
mlrun.db.get_run_db = unittest.mock.Mock(return_value=mock_object)
mlrun.get_run_db = unittest.mock.Mock(return_value=mock_object)
- orig_use_remote_api = BaseRuntime._use_remote_api
orig_get_db = BaseRuntime._get_db
BaseRuntime._get_db = unittest.mock.Mock(return_value=mock_object)
@@ -469,6 +468,5 @@ def rundb_mock() -> RunDBMock:
# Have to revert the mocks, otherwise scheduling tests (and possibly others) are failing
mlrun.db.get_run_db = orig_get_run_db
mlrun.get_run_db = orig_get_run_db
- BaseRuntime._use_remote_api = orig_use_remote_api
BaseRuntime._get_db = orig_get_db
config.dbpath = orig_db_path
diff --git a/tests/run/test_run.py b/tests/run/test_run.py
index b38ae1b7a88e..79433cc0709f 100644
--- a/tests/run/test_run.py
+++ b/tests/run/test_run.py
@@ -74,7 +74,7 @@ def test_noparams(db):
def test_failed_schedule_not_creating_run():
function = new_function()
# mock we're with remote api (only there schedule is relevant)
- function._use_remote_api = Mock(return_value=True)
+ function._is_remote = True
# mock failure in submit job (failed schedule)
db = MagicMock()
function.set_db_connection(db)
From 3618d468853e804de8f3e4ad15d1420efd5e8aac Mon Sep 17 00:00:00 2001
From: Tom Tankilevitch <59158507+Tankilevitch@users.noreply.github.com>
Date: Thu, 11 May 2023 18:09:47 +0300
Subject: [PATCH 122/334] [Builder] Move `builder.py` to `api/utils/builder.py`
(#3527)
---
mlrun/__main__.py | 3 +-
mlrun/api/api/endpoints/frontend_spec.py | 4 +-
mlrun/api/api/endpoints/functions.py | 2 +-
mlrun/{ => api/utils}/builder.py | 34 +++----
mlrun/common/constants.py | 15 ++++
mlrun/datastore/utils.py | 15 ++++
mlrun/runtimes/kubejob.py | 13 +--
mlrun/runtimes/utils.py | 11 ++-
.../notifications/notification_pusher.py | 2 +-
tests/api/runtimes/base.py | 8 ++
tests/api/runtimes/test_kubejob.py | 48 +++++-----
tests/api/runtimes/test_mpijob.py | 29 +++---
tests/{ => api/utils}/test_builder.py | 90 +++++++------------
tests/runtimes/test_pod.py | 26 ++++++
14 files changed, 169 insertions(+), 131 deletions(-)
rename mlrun/{ => api/utils}/builder.py (97%)
create mode 100644 mlrun/common/constants.py
rename tests/{ => api/utils}/test_builder.py (92%)
diff --git a/mlrun/__main__.py b/mlrun/__main__.py
index 9b5c336e1f7a..7fc6ae7406fb 100644
--- a/mlrun/__main__.py
+++ b/mlrun/__main__.py
@@ -34,7 +34,6 @@
import mlrun
-from .builder import upload_tarball
from .config import config as mlconf
from .db import get_run_db
from .errors import err_to_str
@@ -544,7 +543,7 @@ def build(
logger.info(f"uploading data from {src} to {archive}")
target = archive if archive.endswith("/") else archive + "/"
target += f"src-{meta.project}-{meta.name}-{meta.tag or 'latest'}.tar.gz"
- upload_tarball(src, target)
+ mlrun.datastore.utils.upload_tarball(src, target)
# todo: replace function.yaml inside the tar
b.source = target
diff --git a/mlrun/api/api/endpoints/frontend_spec.py b/mlrun/api/api/endpoints/frontend_spec.py
index d2c7069cac85..eca8a07b300c 100644
--- a/mlrun/api/api/endpoints/frontend_spec.py
+++ b/mlrun/api/api/endpoints/frontend_spec.py
@@ -18,8 +18,8 @@
import semver
import mlrun.api.api.deps
+import mlrun.api.utils.builder
import mlrun.api.utils.clients.iguazio
-import mlrun.builder
import mlrun.common.schemas
import mlrun.runtimes
import mlrun.runtimes.utils
@@ -76,7 +76,7 @@ def get_frontend_spec(
function_deployment_target_image_template=function_deployment_target_image_template,
function_deployment_target_image_name_prefix_template=function_target_image_name_prefix_template,
function_deployment_target_image_registries_to_enforce_prefix=registries_to_enforce_prefix,
- function_deployment_mlrun_command=mlrun.builder.resolve_mlrun_install_command(),
+ function_deployment_mlrun_command=mlrun.api.utils.builder.resolve_mlrun_install_command(),
auto_mount_type=config.storage.auto_mount_type,
auto_mount_params=config.get_storage_auto_mount_params(),
default_artifact_path=config.artifact_path,
diff --git a/mlrun/api/api/endpoints/functions.py b/mlrun/api/api/endpoints/functions.py
index 7891ebdd0bf0..a909a0528873 100644
--- a/mlrun/api/api/endpoints/functions.py
+++ b/mlrun/api/api/endpoints/functions.py
@@ -46,7 +46,7 @@
from mlrun.api.api import deps
from mlrun.api.api.utils import get_run_db_instance, log_and_raise, log_path
from mlrun.api.crud.secrets import Secrets, SecretsClientType
-from mlrun.builder import build_runtime
+from mlrun.api.utils.builder import build_runtime
from mlrun.config import config
from mlrun.errors import MLRunRuntimeError, err_to_str
from mlrun.run import new_function
diff --git a/mlrun/builder.py b/mlrun/api/utils/builder.py
similarity index 97%
rename from mlrun/builder.py
rename to mlrun/api/utils/builder.py
index 2568d23fff5e..c6f74483f120 100644
--- a/mlrun/builder.py
+++ b/mlrun/api/utils/builder.py
@@ -14,7 +14,6 @@
import os.path
import pathlib
import re
-import tarfile
import tempfile
from base64 import b64decode, b64encode
from os import path
@@ -23,15 +22,17 @@
from kubernetes import client
import mlrun.api.utils.singletons.k8s
+import mlrun.common.constants
import mlrun.common.schemas
import mlrun.errors
import mlrun.runtimes.utils
-
-from .config import config
-from .datastore import store_manager
-from .utils import enrich_image_url, get_parsed_docker_registry, logger, normalize_name
-
-IMAGE_NAME_ENRICH_REGISTRY_PREFIX = "."
+from mlrun.config import config
+from mlrun.utils import (
+ enrich_image_url,
+ get_parsed_docker_registry,
+ logger,
+ normalize_name,
+)
def make_dockerfile(
@@ -303,17 +304,6 @@ def configure_kaniko_ecr_init_container(
)
-def upload_tarball(source_dir, target, secrets=None):
-
- # will delete the temp file
- with tempfile.NamedTemporaryFile(suffix=".tar.gz") as temp_fh:
- with tarfile.open(mode="w:gz", fileobj=temp_fh) as tar:
- tar.add(source_dir, arcname="")
- stores = store_manager.set(secrets)
- datastore, subpath = stores.get_or_create_store(target)
- datastore.upload(subpath, temp_fh.name)
-
-
def build_image(
auth_info: mlrun.common.schemas.AuthInfo,
project: str,
@@ -691,10 +681,14 @@ def _resolve_image_target_and_registry_secret(
return "/".join([registry, image_target]), secret_name
# if dest starts with a dot, we add the configured registry to the start of the dest
- if image_target.startswith(IMAGE_NAME_ENRICH_REGISTRY_PREFIX):
+ if image_target.startswith(
+ mlrun.common.constants.IMAGE_NAME_ENRICH_REGISTRY_PREFIX
+ ):
# remove prefix from image name
- image_target = image_target[len(IMAGE_NAME_ENRICH_REGISTRY_PREFIX) :]
+ image_target = image_target[
+ len(mlrun.common.constants.IMAGE_NAME_ENRICH_REGISTRY_PREFIX) :
+ ]
registry, repository = get_parsed_docker_registry()
secret_name = secret_name or config.httpdb.builder.docker_registry_secret
diff --git a/mlrun/common/constants.py b/mlrun/common/constants.py
new file mode 100644
index 000000000000..380ec1b97ab5
--- /dev/null
+++ b/mlrun/common/constants.py
@@ -0,0 +1,15 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+IMAGE_NAME_ENRICH_REGISTRY_PREFIX = "." # prefix for image name to enrich with registry
diff --git a/mlrun/datastore/utils.py b/mlrun/datastore/utils.py
index c1b0ed0f2bee..429f3826fa1d 100644
--- a/mlrun/datastore/utils.py
+++ b/mlrun/datastore/utils.py
@@ -12,9 +12,13 @@
# See the License for the specific language governing permissions and
# limitations under the License.
#
+import tarfile
+import tempfile
import typing
from urllib.parse import parse_qs, urlparse
+import mlrun.datastore
+
def store_path_to_spark(path):
if path.startswith("redis://") or path.startswith("rediss://"):
@@ -66,3 +70,14 @@ def parse_kafka_url(
topic = url.path
topic = topic.lstrip("/")
return topic, bootstrap_servers
+
+
+def upload_tarball(source_dir, target, secrets=None):
+
+ # will delete the temp file
+ with tempfile.NamedTemporaryFile(suffix=".tar.gz") as temp_fh:
+ with tarfile.open(mode="w:gz", fileobj=temp_fh) as tar:
+ tar.add(source_dir, arcname="")
+ stores = mlrun.datastore.store_manager.set(secrets)
+ datastore, subpath = stores.get_or_create_store(target)
+ datastore.upload(subpath, temp_fh.name)
diff --git a/mlrun/runtimes/kubejob.py b/mlrun/runtimes/kubejob.py
index 27b48582ff60..681749711d88 100644
--- a/mlrun/runtimes/kubejob.py
+++ b/mlrun/runtimes/kubejob.py
@@ -22,7 +22,6 @@
import mlrun.errors
from mlrun.runtimes.base import BaseRuntimeHandler
-from ..builder import build_runtime
from ..db import RunDBError
from ..errors import err_to_str
from ..kfpops import build_op
@@ -216,6 +215,7 @@ def deploy(
if is_kfp:
watch = True
+ ready = False
if self._is_remote_api():
db = self._get_db()
data = db.remote_builder(
@@ -241,17 +241,6 @@ def deploy(
state = self._build_watch(watch, show_on_failure=show_on_failure)
ready = state == "ready"
self.status.state = state
- else:
- self.save(versioned=False)
- ready = build_runtime(
- mlrun.common.schemas.AuthInfo(),
- self,
- with_mlrun,
- mlrun_version_specifier,
- skip_deployed,
- watch,
- )
- self.save(versioned=False)
if watch and not ready:
raise mlrun.errors.MLRunRuntimeError("Deploy failed")
diff --git a/mlrun/runtimes/utils.py b/mlrun/runtimes/utils.py
index 880963518015..77b932bfea81 100644
--- a/mlrun/runtimes/utils.py
+++ b/mlrun/runtimes/utils.py
@@ -24,7 +24,8 @@
from kubernetes import client
import mlrun
-import mlrun.builder
+import mlrun.api.utils.builder
+import mlrun.common.constants
import mlrun.utils.regex
from mlrun.api.utils.clients import nuclio
from mlrun.db import get_run_db
@@ -346,7 +347,11 @@ def generate_function_image_name(project: str, name: str, tag: str) -> str:
_, repository = helpers.get_parsed_docker_registry()
repository = helpers.get_docker_repository_or_default(repository)
return fill_function_image_name_template(
- mlrun.builder.IMAGE_NAME_ENRICH_REGISTRY_PREFIX, repository, project, name, tag
+ mlrun.common.constants.IMAGE_NAME_ENRICH_REGISTRY_PREFIX,
+ repository,
+ project,
+ name,
+ tag,
)
@@ -371,7 +376,7 @@ def resolve_function_target_image_registries_to_enforce_prefix():
registry, repository = helpers.get_parsed_docker_registry()
repository = helpers.get_docker_repository_or_default(repository)
return [
- f"{mlrun.builder.IMAGE_NAME_ENRICH_REGISTRY_PREFIX}{repository}/",
+ f"{mlrun.common.constants.IMAGE_NAME_ENRICH_REGISTRY_PREFIX}{repository}/",
f"{registry}/{repository}/",
]
diff --git a/mlrun/utils/notifications/notification_pusher.py b/mlrun/utils/notifications/notification_pusher.py
index 9c70ebd60d1f..e4f84bde8702 100644
--- a/mlrun/utils/notifications/notification_pusher.py
+++ b/mlrun/utils/notifications/notification_pusher.py
@@ -22,7 +22,6 @@
import mlrun.api.db.base
import mlrun.api.db.session
-import mlrun.api.utils.singletons.k8s
import mlrun.common.schemas
import mlrun.config
import mlrun.lists
@@ -192,6 +191,7 @@ async def _update_notification_status(
status: str = None,
sent_time: datetime.datetime = None,
):
+ # TODO: move to api side
db_session = mlrun.api.db.session.create_session()
notification.status = status or notification.status
notification.sent_time = sent_time or notification.sent_time
diff --git a/tests/api/runtimes/base.py b/tests/api/runtimes/base.py
index 1b24289ce68a..9cfa05088464 100644
--- a/tests/api/runtimes/base.py
+++ b/tests/api/runtimes/base.py
@@ -30,6 +30,7 @@
from kubernetes import client as k8s_client
from kubernetes.client import V1EnvVar
+import mlrun.api.api.endpoints.functions
import mlrun.common.schemas
import mlrun.k8s_utils
import mlrun.runtimes.pod
@@ -390,6 +391,13 @@ def execute_function(self, runtime, **kwargs):
kwargs.update({"watch": False})
self._execute_run(runtime, **kwargs)
+ @staticmethod
+ def deploy(db_session, runtime, with_mlrun=True):
+ auth_info = mlrun.common.schemas.AuthInfo()
+ mlrun.api.api.endpoints.functions._build_function(
+ db_session, auth_info, runtime, with_mlrun=with_mlrun
+ )
+
def _reset_mocks(self):
get_k8s_helper().v1api.create_namespaced_pod.reset_mock()
get_k8s_helper().v1api.list_namespaced_pod.reset_mock()
diff --git a/tests/api/runtimes/test_kubejob.py b/tests/api/runtimes/test_kubejob.py
index 2a2443a4f790..90737648f669 100644
--- a/tests/api/runtimes/test_kubejob.py
+++ b/tests/api/runtimes/test_kubejob.py
@@ -23,7 +23,8 @@
from fastapi.testclient import TestClient
from sqlalchemy.orm import Session
-import mlrun.builder
+import mlrun.api.api.endpoints.functions
+import mlrun.api.utils.builder
import mlrun.common.schemas
import mlrun.errors
import mlrun.k8s_utils
@@ -750,27 +751,30 @@ def test_deploy_upgrade_pip(
expected_to_upgrade,
):
mlrun.mlconf.httpdb.builder.docker_registry = "localhost:5000"
- mlrun.builder.make_kaniko_pod = unittest.mock.MagicMock()
-
- runtime = self._generate_runtime()
- runtime.spec.build.base_image = "some/image"
- runtime.spec.build.commands = copy.deepcopy(commands)
- runtime.deploy(with_mlrun=with_mlrun, watch=False)
- dockerfile = mlrun.builder.make_kaniko_pod.call_args[1]["dockertext"]
- if expected_to_upgrade:
- expected_str = ""
- if commands:
- expected_str += "\nRUN "
- expected_str += "\nRUN ".join(commands)
- expected_str += f"\nRUN python -m pip install --upgrade pip{mlrun.mlconf.httpdb.builder.pip_version}"
- if with_mlrun:
- expected_str += '\nRUN python -m pip install "mlrun[complete]'
- assert expected_str in dockerfile
- else:
- assert (
- f"pip install --upgrade pip{mlrun.mlconf.httpdb.builder.pip_version}"
- not in dockerfile
- )
+ with unittest.mock.patch(
+ "mlrun.api.utils.builder.make_kaniko_pod", unittest.mock.MagicMock()
+ ):
+ runtime = self._generate_runtime()
+ runtime.spec.build.base_image = "some/image"
+ runtime.spec.build.commands = copy.deepcopy(commands)
+ self.deploy(db, runtime, with_mlrun=with_mlrun)
+ dockerfile = mlrun.api.utils.builder.make_kaniko_pod.call_args[1][
+ "dockertext"
+ ]
+ if expected_to_upgrade:
+ expected_str = ""
+ if commands:
+ expected_str += "\nRUN "
+ expected_str += "\nRUN ".join(commands)
+ expected_str += f"\nRUN python -m pip install --upgrade pip{mlrun.mlconf.httpdb.builder.pip_version}"
+ if with_mlrun:
+ expected_str += '\nRUN python -m pip install "mlrun[complete]'
+ assert expected_str in dockerfile
+ else:
+ assert (
+ f"pip install --upgrade pip{mlrun.mlconf.httpdb.builder.pip_version}"
+ not in dockerfile
+ )
@pytest.mark.parametrize(
"workdir, source, pull_at_runtime, target_dir, expected_workdir",
diff --git a/tests/api/runtimes/test_mpijob.py b/tests/api/runtimes/test_mpijob.py
index 74988313120d..fbc164a88a96 100644
--- a/tests/api/runtimes/test_mpijob.py
+++ b/tests/api/runtimes/test_mpijob.py
@@ -15,8 +15,11 @@
import typing
import unittest.mock
+from fastapi.testclient import TestClient
from kubernetes import client as k8s_client
+from sqlalchemy.orm import Session
+import mlrun.api.utils.builder
import mlrun.runtimes.pod
from mlrun import code_to_function, mlconf
from mlrun.api.utils.singletons.k8s import get_k8s_helper
@@ -31,18 +34,22 @@ def custom_setup(self):
self.name = "test-mpi-v1"
mlconf.mpijob_crd_version = MPIJobCRDVersions.v1
- def test_run_v1_sanity(self):
- self._mock_list_pods()
- self._mock_create_namespaced_custom_object()
- self._mock_get_namespaced_custom_object()
- mpijob_function = self._generate_runtime(self.runtime_kind)
- mpijob_function.deploy()
- run = mpijob_function.run(
- artifact_path="v3io:///mypath",
- watch=False,
- )
+ def test_run_v1_sanity(self, db: Session, client: TestClient):
+ mlconf.httpdb.builder.docker_registry = "localhost:5000"
+ with unittest.mock.patch(
+ "mlrun.api.utils.builder.make_kaniko_pod", unittest.mock.MagicMock()
+ ):
+ self._mock_list_pods()
+ self._mock_create_namespaced_custom_object()
+ self._mock_get_namespaced_custom_object()
+ mpijob_function = self._generate_runtime(self.runtime_kind)
+ self.deploy(db, mpijob_function)
+ run = mpijob_function.run(
+ artifact_path="v3io:///mypath",
+ watch=False,
+ )
- assert run.status.state == "running"
+ assert run.status.state == "running"
def _mock_get_namespaced_custom_object(self, workers=1):
get_k8s_helper().crdapi.get_namespaced_custom_object = unittest.mock.Mock(
diff --git a/tests/test_builder.py b/tests/api/utils/test_builder.py
similarity index 92%
rename from tests/test_builder.py
rename to tests/api/utils/test_builder.py
index 530e19e91e33..d6881cbb505b 100644
--- a/tests/test_builder.py
+++ b/tests/api/utils/test_builder.py
@@ -23,8 +23,10 @@
import pytest
import mlrun
+import mlrun.api.api.utils
+import mlrun.api.utils.builder
import mlrun.api.utils.singletons.k8s
-import mlrun.builder
+import mlrun.common.constants
import mlrun.common.schemas
import mlrun.k8s_utils
import mlrun.utils.version
@@ -36,7 +38,7 @@ def test_build_runtime_use_base_image_when_no_build():
base_image = "mlrun/ml-models"
fn.build_config(base_image=base_image)
assert fn.spec.image == ""
- ready = mlrun.builder.build_runtime(
+ ready = mlrun.api.utils.builder.build_runtime(
mlrun.common.schemas.AuthInfo(),
fn,
)
@@ -50,7 +52,7 @@ def test_build_runtime_use_image_when_no_build():
"some-function", "some-project", "some-tag", image=image, kind="job"
)
assert fn.spec.image == image
- ready = mlrun.builder.build_runtime(
+ ready = mlrun.api.utils.builder.build_runtime(
mlrun.common.schemas.AuthInfo(),
fn,
with_mlrun=False,
@@ -59,32 +61,6 @@ def test_build_runtime_use_image_when_no_build():
assert fn.spec.image == image
-def test_build_config_with_multiple_commands():
- image = "mlrun/ml-models"
- fn = mlrun.new_function(
- "some-function", "some-project", "some-tag", image=image, kind="job"
- )
- fn.build_config(commands=["pip install pandas", "pip install numpy"])
- assert len(fn.spec.build.commands) == 2
-
- fn.build_config(commands=["pip install pandas"])
- assert len(fn.spec.build.commands) == 2
-
-
-def test_build_config_preserve_order():
- function = mlrun.new_function("some-function", kind="job")
- # run a lot of times as order change
- commands = []
- for index in range(10):
- commands.append(str(index))
- # when using un-stable (doesn't preserve order) methods to make a list unique (like list(set(x))) it's random
- # whether the order will be preserved, therefore run in a loop
- for _ in range(100):
- function.spec.build.commands = []
- function.build_config(commands=commands)
- assert function.spec.build.commands == commands
-
-
@pytest.mark.parametrize(
"pull_mode,push_mode,secret,flags_expected",
[
@@ -114,7 +90,7 @@ def test_build_runtime_insecure_registries(
mlrun.mlconf.httpdb.builder.insecure_pull_registry_mode = pull_mode
mlrun.mlconf.httpdb.builder.insecure_push_registry_mode = push_mode
mlrun.mlconf.httpdb.builder.docker_registry_secret = secret
- mlrun.builder.build_runtime(
+ mlrun.api.utils.builder.build_runtime(
mlrun.common.schemas.AuthInfo(),
function,
)
@@ -152,7 +128,7 @@ def test_build_runtime_target_image(monkeypatch):
)
)
- mlrun.builder.build_runtime(
+ mlrun.api.utils.builder.build_runtime(
mlrun.common.schemas.AuthInfo(),
function,
)
@@ -165,7 +141,7 @@ def test_build_runtime_target_image(monkeypatch):
function.spec.build.image = (
f"{registry}/{image_name_prefix}-some-addition:{function.metadata.tag}"
)
- mlrun.builder.build_runtime(
+ mlrun.api.utils.builder.build_runtime(
mlrun.common.schemas.AuthInfo(),
function,
)
@@ -175,10 +151,10 @@ def test_build_runtime_target_image(monkeypatch):
# assert the same with the registry enrich prefix
# assert we can override the target image as long as we stick to the prefix
function.spec.build.image = (
- f"{mlrun.builder.IMAGE_NAME_ENRICH_REGISTRY_PREFIX}username"
+ f"{mlrun.common.constants.IMAGE_NAME_ENRICH_REGISTRY_PREFIX}username"
f"/{image_name_prefix}-some-addition:{function.metadata.tag}"
)
- mlrun.builder.build_runtime(
+ mlrun.api.utils.builder.build_runtime(
mlrun.common.schemas.AuthInfo(),
function,
)
@@ -190,12 +166,12 @@ def test_build_runtime_target_image(monkeypatch):
# assert it raises if we don't stick to the prefix
for invalid_image in [
- f"{mlrun.builder.IMAGE_NAME_ENRICH_REGISTRY_PREFIX}username/without-prefix:{function.metadata.tag}",
+ f"{mlrun.common.constants.IMAGE_NAME_ENRICH_REGISTRY_PREFIX}username/without-prefix:{function.metadata.tag}",
f"{registry}/without-prefix:{function.metadata.tag}",
]:
function.spec.build.image = invalid_image
with pytest.raises(mlrun.errors.MLRunInvalidArgumentError):
- mlrun.builder.build_runtime(
+ mlrun.api.utils.builder.build_runtime(
mlrun.common.schemas.AuthInfo(),
function,
)
@@ -205,7 +181,7 @@ def test_build_runtime_target_image(monkeypatch):
f"registry.hub.docker.com/some-other-username/image-not-by-prefix"
f":{function.metadata.tag}"
)
- mlrun.builder.build_runtime(
+ mlrun.api.utils.builder.build_runtime(
mlrun.common.schemas.AuthInfo(),
function,
)
@@ -231,7 +207,7 @@ def test_build_runtime_use_default_node_selector(monkeypatch):
kind="job",
requirements=["some-package"],
)
- mlrun.builder.build_runtime(
+ mlrun.api.utils.builder.build_runtime(
mlrun.common.schemas.AuthInfo(),
function,
)
@@ -264,7 +240,7 @@ def test_function_build_with_attributes_from_spec(monkeypatch):
function.spec.node_name = node_name
function.spec.node_selector = node_selector
function.spec.priority_class_name = priority_class_name
- mlrun.builder.build_runtime(
+ mlrun.api.utils.builder.build_runtime(
mlrun.common.schemas.AuthInfo(),
function,
)
@@ -301,7 +277,7 @@ def test_function_build_with_default_requests(monkeypatch):
kind="job",
requirements=["some-package"],
)
- mlrun.builder.build_runtime(
+ mlrun.api.utils.builder.build_runtime(
mlrun.common.schemas.AuthInfo(),
function,
)
@@ -322,7 +298,7 @@ def test_function_build_with_default_requests(monkeypatch):
}
expected_resources = {"requests": {"cpu": "25m", "memory": "1m"}}
- mlrun.builder.build_runtime(
+ mlrun.api.utils.builder.build_runtime(
mlrun.common.schemas.AuthInfo(),
function,
)
@@ -349,7 +325,7 @@ def test_function_build_with_default_requests(monkeypatch):
}
expected_resources = {"requests": {"cpu": "25m", "memory": "1m"}}
- mlrun.builder.build_runtime(
+ mlrun.api.utils.builder.build_runtime(
mlrun.common.schemas.AuthInfo(),
function,
)
@@ -436,7 +412,7 @@ def test_resolve_mlrun_install_command():
client_version = case.get("client_version")
expected_result = case.get("expected_mlrun_install_command")
- result = mlrun.builder.resolve_mlrun_install_command(
+ result = mlrun.api.utils.builder.resolve_mlrun_install_command(
mlrun_version_specifier, client_version
)
assert (
@@ -461,7 +437,7 @@ def test_build_runtime_ecr_with_ec2_iam_policy(monkeypatch):
name="some-function",
kind="job",
)
- mlrun.builder.build_runtime(
+ mlrun.api.utils.builder.build_runtime(
mlrun.common.schemas.AuthInfo(),
function,
)
@@ -524,7 +500,7 @@ def test_build_runtime_resolve_ecr_registry(monkeypatch):
if case.get("tag"):
image += f":{case.get('tag')}"
function.spec.build.image = image
- mlrun.builder.build_runtime(
+ mlrun.api.utils.builder.build_runtime(
mlrun.common.schemas.AuthInfo(),
function,
)
@@ -556,7 +532,7 @@ def test_build_runtime_ecr_with_aws_secret(monkeypatch):
kind="job",
requirements=["some-package"],
)
- mlrun.builder.build_runtime(
+ mlrun.api.utils.builder.build_runtime(
mlrun.common.schemas.AuthInfo(),
function,
)
@@ -614,7 +590,7 @@ def test_build_runtime_ecr_with_repository(monkeypatch):
kind="job",
requirements=["some-package"],
)
- mlrun.builder.build_runtime(
+ mlrun.api.utils.builder.build_runtime(
mlrun.common.schemas.AuthInfo(),
function,
)
@@ -677,7 +653,7 @@ def test_resolve_image_dest(image_target, registry, default_repository, expected
config.httpdb.builder.docker_registry = default_repository
config.httpdb.builder.docker_registry_secret = docker_registry_secret
- image_target, _ = mlrun.builder._resolve_image_target_and_registry_secret(
+ image_target, _ = mlrun.api.utils.builder._resolve_image_target_and_registry_secret(
image_target, registry
)
assert image_target == expected_dest
@@ -751,7 +727,7 @@ def test_resolve_registry_secret(
config.httpdb.builder.docker_registry = docker_registry
config.httpdb.builder.docker_registry_secret = default_secret_name
- _, secret_name = mlrun.builder._resolve_image_target_and_registry_secret(
+ _, secret_name = mlrun.api.utils.builder._resolve_image_target_and_registry_secret(
image_target, registry, secret_name
)
assert secret_name == expected_secret_name
@@ -772,7 +748,7 @@ def test_kaniko_pod_spec_default_service_account_enrichment(monkeypatch):
image="mlrun/mlrun",
kind="job",
)
- mlrun.builder.build_runtime(
+ mlrun.api.utils.builder.build_runtime(
mlrun.common.schemas.AuthInfo(),
function,
)
@@ -796,7 +772,7 @@ def test_kaniko_pod_spec_user_service_account_enrichment(monkeypatch):
)
service_account = "my-actual-sa"
function.spec.service_account = service_account
- mlrun.builder.build_runtime(
+ mlrun.api.utils.builder.build_runtime(
mlrun.common.schemas.AuthInfo(),
function,
)
@@ -816,7 +792,7 @@ def test_kaniko_pod_spec_user_service_account_enrichment(monkeypatch):
)
def test_builder_workdir(monkeypatch, clone_target_dir, expected_workdir):
_patch_k8s_helper(monkeypatch)
- mlrun.builder.make_kaniko_pod = unittest.mock.MagicMock()
+ mlrun.api.utils.builder.make_kaniko_pod = unittest.mock.MagicMock()
docker_registry = "default.docker.registry/default-repository"
config.httpdb.builder.docker_registry = docker_registry
@@ -830,11 +806,11 @@ def test_builder_workdir(monkeypatch, clone_target_dir, expected_workdir):
if clone_target_dir is not None:
function.spec.clone_target_dir = clone_target_dir
function.spec.build.source = "/path/some-source.tgz"
- mlrun.builder.build_runtime(
+ mlrun.api.utils.builder.build_runtime(
mlrun.common.schemas.AuthInfo(),
function,
)
- dockerfile = mlrun.builder.make_kaniko_pod.call_args[1]["dockertext"]
+ dockerfile = mlrun.api.utils.builder.make_kaniko_pod.call_args[1]["dockertext"]
dockerfile_lines = dockerfile.splitlines()
expected_workdir_re = re.compile(expected_workdir)
assert expected_workdir_re.match(dockerfile_lines[1])
@@ -855,7 +831,7 @@ def test_builder_workdir(monkeypatch, clone_target_dir, expected_workdir):
)
def test_builder_source(monkeypatch, source, expectation):
_patch_k8s_helper(monkeypatch)
- mlrun.builder.make_kaniko_pod = unittest.mock.MagicMock()
+ mlrun.api.utils.builder.make_kaniko_pod = unittest.mock.MagicMock()
docker_registry = "default.docker.registry/default-repository"
config.httpdb.builder.docker_registry = docker_registry
@@ -869,12 +845,12 @@ def test_builder_source(monkeypatch, source, expectation):
with expectation:
function.spec.build.source = source
- mlrun.builder.build_runtime(
+ mlrun.api.utils.builder.build_runtime(
mlrun.common.schemas.AuthInfo(),
function,
)
- dockerfile = mlrun.builder.make_kaniko_pod.call_args[1]["dockertext"]
+ dockerfile = mlrun.api.utils.builder.make_kaniko_pod.call_args[1]["dockertext"]
dockerfile_lines = dockerfile.splitlines()
expected_source = source
diff --git a/tests/runtimes/test_pod.py b/tests/runtimes/test_pod.py
index 421089f9a93a..02016dd70047 100644
--- a/tests/runtimes/test_pod.py
+++ b/tests/runtimes/test_pod.py
@@ -205,3 +205,29 @@ def test_volume_mounts_addition():
sanitized_dict_volume_mount,
]
assert len(function.spec.volume_mounts) == 1
+
+
+def test_build_config_with_multiple_commands():
+ image = "mlrun/ml-models"
+ fn = mlrun.new_function(
+ "some-function", "some-project", "some-tag", image=image, kind="job"
+ )
+ fn.build_config(commands=["pip install pandas", "pip install numpy"])
+ assert len(fn.spec.build.commands) == 2
+
+ fn.build_config(commands=["pip install pandas"])
+ assert len(fn.spec.build.commands) == 2
+
+
+def test_build_config_preserve_order():
+ function = mlrun.new_function("some-function", kind="job")
+ # run a lot of times as order change
+ commands = []
+ for index in range(10):
+ commands.append(str(index))
+ # when using un-stable (doesn't preserve order) methods to make a list unique (like list(set(x))) it's random
+ # whether the order will be preserved, therefore run in a loop
+ for _ in range(100):
+ function.spec.build.commands = []
+ function.build_config(commands=commands)
+ assert function.spec.build.commands == commands
From 2d05dbe3c298a89a6de77f170d3f9e90104fbb58 Mon Sep 17 00:00:00 2001
From: TomerShor <90552140+TomerShor@users.noreply.github.com>
Date: Thu, 11 May 2023 19:21:54 +0300
Subject: [PATCH 123/334] [DB] Test HubSource kind migrations (#3540)
---
tests/api/db/test_hub.py | 55 ++++++++++++++++++++++++++++++++++++++++
1 file changed, 55 insertions(+)
create mode 100644 tests/api/db/test_hub.py
diff --git a/tests/api/db/test_hub.py b/tests/api/db/test_hub.py
new file mode 100644
index 000000000000..f03d2c426a74
--- /dev/null
+++ b/tests/api/db/test_hub.py
@@ -0,0 +1,55 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+from sqlalchemy.orm import Session
+
+import mlrun.api.db.sqldb.models
+import mlrun.api.initial_data
+from mlrun.api.db.base import DBInterface
+
+
+def test_data_migration_rename_marketplace_kind_to_hub(
+ db: DBInterface, db_session: Session
+):
+ # create hub sources
+ for i in range(3):
+ source_name = f"source-{i}"
+ source_dict = {
+ "metadata": {
+ "name": source_name,
+ },
+ "spec": {
+ "path": "/local/path/to/source",
+ },
+ "kind": "MarketplaceSource",
+ }
+ # id and index are multiplied by 2 to avoid sqlalchemy unique constraint error
+ source = mlrun.api.db.sqldb.models.HubSource(
+ id=i * 2,
+ name=source_name,
+ index=i * 2,
+ )
+ source.full_object = source_dict
+ db_session.add(source)
+ db_session.commit()
+
+ # run migration
+ mlrun.api.initial_data._rename_marketplace_kind_to_hub(db, db_session)
+
+ # check that all hub sources are now of kind 'HubSource'
+ hubs = db._list_hub_sources_without_transform(db_session)
+ for hub in hubs:
+ hub_dict = hub.full_object
+ assert "kind" in hub_dict
+ assert hub_dict["kind"] == "HubSource"
From 56936ac5782b55c3ace703048bb936a2ca104810 Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Sat, 13 May 2023 17:09:23 +0300
Subject: [PATCH 124/334] [Launcher] Remove unused local variable from `launch`
(#3543)
---
mlrun/api/launcher.py | 1 -
mlrun/launcher/base.py | 1 -
mlrun/launcher/local.py | 1 -
mlrun/launcher/remote.py | 1 -
mlrun/runtimes/base.py | 1 -
5 files changed, 5 deletions(-)
diff --git a/mlrun/api/launcher.py b/mlrun/api/launcher.py
index ae1f2c6786af..ae85bb898f22 100644
--- a/mlrun/api/launcher.py
+++ b/mlrun/api/launcher.py
@@ -46,7 +46,6 @@ def launch(
hyper_param_options: Optional[mlrun.model.HyperParamOptions] = None,
verbose: Optional[bool] = None,
scrape_metrics: Optional[bool] = None,
- local: Optional[bool] = False,
local_code_path: Optional[str] = None,
auto_build: Optional[bool] = None,
param_file_secrets: Optional[Dict[str, str]] = None,
diff --git a/mlrun/launcher/base.py b/mlrun/launcher/base.py
index 86fbb3cf023a..877576452a3a 100644
--- a/mlrun/launcher/base.py
+++ b/mlrun/launcher/base.py
@@ -101,7 +101,6 @@ def launch(
hyper_param_options: Optional[mlrun.model.HyperParamOptions] = None,
verbose: Optional[bool] = None,
scrape_metrics: Optional[bool] = None,
- local: Optional[bool] = False,
local_code_path: Optional[str] = None,
auto_build: Optional[bool] = None,
param_file_secrets: Optional[Dict[str, str]] = None,
diff --git a/mlrun/launcher/local.py b/mlrun/launcher/local.py
index 98598d6199f9..dc773a16d3f0 100644
--- a/mlrun/launcher/local.py
+++ b/mlrun/launcher/local.py
@@ -64,7 +64,6 @@ def launch(
hyper_param_options: Optional[mlrun.model.HyperParamOptions] = None,
verbose: Optional[bool] = None,
scrape_metrics: Optional[bool] = None,
- local: Optional[bool] = False,
local_code_path: Optional[str] = None,
auto_build: Optional[bool] = None,
param_file_secrets: Optional[Dict[str, str]] = None,
diff --git a/mlrun/launcher/remote.py b/mlrun/launcher/remote.py
index 03f1f94255b8..a9e0e2bdc54a 100644
--- a/mlrun/launcher/remote.py
+++ b/mlrun/launcher/remote.py
@@ -53,7 +53,6 @@ def launch(
hyper_param_options: Optional[mlrun.model.HyperParamOptions] = None,
verbose: Optional[bool] = None,
scrape_metrics: Optional[bool] = None,
- local: Optional[bool] = False,
local_code_path: Optional[str] = None,
auto_build: Optional[bool] = None,
param_file_secrets: Optional[Dict[str, str]] = None,
diff --git a/mlrun/runtimes/base.py b/mlrun/runtimes/base.py
index f8908a84b5fd..14ebe9dcc7f3 100644
--- a/mlrun/runtimes/base.py
+++ b/mlrun/runtimes/base.py
@@ -370,7 +370,6 @@ def run(
hyper_param_options=hyper_param_options,
verbose=verbose,
scrape_metrics=scrape_metrics,
- local=local,
local_code_path=local_code_path,
auto_build=auto_build,
param_file_secrets=param_file_secrets,
From 47bec480c93efe2e7c2339276236d3cfb780752d Mon Sep 17 00:00:00 2001
From: jillnogold <88145832+jillnogold@users.noreply.github.com>
Date: Sun, 14 May 2023 10:49:21 +0300
Subject: [PATCH 125/334] [Docs] Add CE version, minor edits to Kubernetes and
AWS install docs (#3539)
---
docs/conf.py | 7 +++-
docs/install/aws-install.md | 30 +++++++++-----
docs/install/kubernetes.md | 81 +++++++++++++++++++------------------
3 files changed, 68 insertions(+), 50 deletions(-)
diff --git a/docs/conf.py b/docs/conf.py
index c6825418c6da..4e7256d15e44 100644
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -141,7 +141,12 @@ def current_version():
myst_url_schemes = ("http", "https", "mailto")
myst_heading_anchors = 2
myst_all_links_external = True
-myst_substitutions = {"version": version}
+
+myst_substitutions = {
+ "version": "version",
+ "ceversion": "v1.2.1",
+ "releasedocumentation": "docs.mlrun.org/en/v1.2.1/index.html",
+}
# If true, `todo` and `todoList` produce output, else they produce nothing.
todo_include_todos = True
diff --git a/docs/install/aws-install.md b/docs/install/aws-install.md
index 58d2c7a73f52..57465fab695e 100644
--- a/docs/install/aws-install.md
+++ b/docs/install/aws-install.md
@@ -4,9 +4,19 @@
For AWS users, the easiest way to install MLRun is to use a native AWS deployment. This option deploys MLRun on an AWS EKS service using a CloudFormation stack.
```{admonition} Note
-These instructions install the community edition, which currently includes MLRun 1.2.1. See the [release documentation](https://docs.mlrun.org/en/v1.2.1/index.html).
+These instructions install the community edition, which currently includes MLRun {{ ceversion }}. See the {{ '[release documentation](https://{})'.format(releasedocumentation) }}.
```
+**In this section**
+- [Prerequisites](#prerequisites)
+- [Post deployment expectations](#post-deployment-expectations)
+- [Configuration settings](#configuration-settings)
+- [Getting started](#getting-started)
+- [Storage resources](#storage-resources)
+- [Configuring the online features store](#configuring-the-online-feature-store)
+- [Streaming support](#streaming-support)
+- [Cleanup](#cleanup)
+
## Prerequisites
1. An AWS account with permissions that include the ability to:
@@ -28,10 +38,10 @@ These instructions install the community edition, which currently includes MLRun
For more information, see [how to create a new AWS account](https://aws.amazon.com/premiumsupport/knowledge-center/create-and-activate-aws-account/) and [policies and permissions in IAM](https://docs.aws.amazon.com/IAM/latest/UserGuide/access_policies.html).
-2. You need to have a Route53 domain configured in the same AWS account and specify the full domain name in **Route 53 hosted DNS domain** configuration (See [Step 11](#route53_config) below). External domain registration is currently not supported. For more information see [What is Amazon Route 53?](https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/Welcome.html).
+2. A Route53 domain configured in the same AWS account, and with the full domain name specified in **Route 53 hosted DNS domain** configuration (See [Step 11](#route53_config) below). External domain registration is currently not supported. For more information see [What is Amazon Route 53?](https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/Welcome.html).
```{admonition} Notes
-The MLRun software is free of charge, however, there is a cost for the AWS infrastructure services such as EKS, EC2, S3 and ECR. The actual pricing depends on a large set of factors including, for example, the region, the number of EC2 instances, the amount of storage consumed, and the data transfer costs. Other factors include, for example, reserved instance configuration, saving plan, and AWS credits you have associated with your account. It is recommended to use the [AWS pricing calculator](https://calculator.aws) to calculate the expected cost, as well as the [AWS Cost Explorer](https://aws.amazon.com/aws-cost-management/aws-cost-explorer/) to manage the cost, monitor and set-up alerts.
+The MLRun software is free of charge, however, there is a cost for the AWS infrastructure services such as EKS, EC2, S3 and ECR. The actual pricing depends on a large set of factors including, for example, the region, the number of EC2 instances, the amount of storage consumed, and the data transfer costs. Other factors include, for example, reserved instance configuration, saving plan, and AWS credits you have associated with your account. It is recommended to use the [AWS pricing calculator](https://calculator.aws) to calculate the expected cost, as well as the [AWS Cost Explorer](https://aws.amazon.com/aws-cost-management/aws-cost-explorer/) to manage the cost, monitor, and set-up alerts.
```
## Post deployment expectations
@@ -69,9 +79,9 @@ You must fill in fields marked as mandatory (m) for the configuration to complet
**VPC network Configuration**
-3. **Number of Availability Zones** (m) — number of availability zones. The default is set to 3. Choose from the dropdown to change the number. The minimum is 2.
+3. **Number of Availability Zones** (m) — The default is set to 3. Choose from the dropdown to change the number. The minimum is 2.
4. **Availability zones** (m) — select a zone from the dropdown. The list is based on the region of the instance. The number of zones must match the number of zones Number of Availability Zones.
-5. **Allowed external access CIDR** (m) — range of IP address allowed to access the cluster. Addresses that are not in this range are not able to access the cluster. Contact your IT manager/network administrator if you are not sure what to fill here.
+5. **Allowed external access CIDR** (m) — range of IP addresses allowed to access the cluster. Addresses that are not in this range are not able to access the cluster. Contact your IT manager/network administrator if you are not sure what to fill in here.
**Amazon EKS configuration**
@@ -81,9 +91,9 @@ You must fill in fields marked as mandatory (m) for the configuration to complet
**Amazon EC2 configuration**
-9. **SSH key name** (o) — Users who wish to access the EC2 instance via SSH can enter an existing key. If left empty, it is possible to access the EC2 instance using the AWS Systems Manager Session Manager. For more information about SSH Keys see [Amazon EC2 key pairs and Linux instances](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-key-pairs.html).
+9. **SSH key name** (o) — To access the EC2 instance via SSH, enter an existing key. If left empty, it is possible to access the EC2 instance using the AWS Systems Manager Session Manager. For more information about SSH Keys see [Amazon EC2 key pairs and Linux instances](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-key-pairs.html).
-10. **Provision bastion host** (m) — create a bastion host for SSH access to the Kubernetes nodes. The default is enabled. This allows ssh access to your EKS EC2 instances through a public IP.
+10. **Provision bastion host** (m) — create a bastion host for SSH access to the Kubernetes nodes. The default is enabled. This allows SSH access to your EKS EC2 instances through a public IP.
**Iguazio MLRun configuration**
@@ -123,7 +133,7 @@ When installing the MLRun Community Edition via Cloud Formation, several storage
-## How to configure the online feature store
+## Configuring the online feature store
The feature store can store data on a fast key-value database table for quick serving. This online feature store capability requires an external key-value database.
@@ -131,13 +141,13 @@ Currently the MLRun feature store supports the following options:
- Redis
- Iguazio key-value database
-To use Redis, you must install Redis separately and provide the Redis URL when configuring the AWS CloudFormation stack. Refer to the [Redis getting-started page](https://redis.io/docs/getting-started/). for information about Redis installation.
+To use Redis, you must install Redis separately and provide the Redis URL when configuring the AWS CloudFormation stack. Refer to the [Redis getting-started page](https://redis.io/docs/getting-started/) for information about Redis installation.
## Streaming support
For online serving, it is often convenient to use MLRun graph with a streaming engine. This allows managing queues between steps and functions.
MLRun supports Kafka streams as well as Iguazio V3IO streams.
-See the examples on how to configure the MLRun serving graph with {ref}`kafka` and {ref}`V3IO`.
+See the examples on how to configure the MLRun serving graph with {ref}`Kafka` and {ref}`V3IO`.
## Cleanup
diff --git a/docs/install/kubernetes.md b/docs/install/kubernetes.md
index 3b06cebac62d..302a281c73e7 100644
--- a/docs/install/kubernetes.md
+++ b/docs/install/kubernetes.md
@@ -2,25 +2,25 @@
# Install MLRun on Kubernetes
```{admonition} Note
-These instructions install the community edition, which currently includes MLRun 1.2.1. See the [release documentation](https://docs.mlrun.org/en/v1.2.1/index.html).
+These instructions install the community edition, which currently includes MLRun {{ ceversion }}. See the {{ '[release documentation](https://{})'.format(releasedocumentation) }}.
```
**In this section**
- [Prerequisites](#prerequisites)
-- [Community Edition Flavors](#community-edition-flavors)
-- [Installing the Chart](#installing-the-chart)
-- [Configuring Online Feature Store](#configuring-online-feature-store)
+- [Community Edition flavors](#community-edition-flavors)
+- [Installing the chart](#installing-the-chart)
+- [Configuring the online features store](#configuring-the-online-feature-store)
- [Usage](#usage)
- [Start working](#start-working)
- [Configuring the remote environment](#configuring-the-remote-environment)
- [Advanced chart configuration](#advanced-chart-configuration)
-- [Storage Resources](#storage-resources)
+- [Storage resources](#storage-resources)
- [Uninstalling the chart](#uninstalling-the-chart)
- [Upgrading the chart](#upgrading-the-chart)
## Prerequisites
-- Access to a Kubernetes cluster. You must have administrator permissions in order to install MLRun on your cluster. MLRun fully supports k8s releases 1.22 and 1.23. For local installation
+- Access to a Kubernetes cluster. To install MLRun on your cluster, you must have administrator permissions. MLRun fully supports k8s releases 1.22 and 1.23. For local installation
on Windows or Mac, [Docker Desktop](https://www.docker.com/products/docker-desktop) is recommended.
- The Kubernetes command-line tool (kubectl) compatible with your Kubernetes cluster is installed. Refer to the [kubectl installation
instructions](https://kubernetes.io/docs/tasks/tools/install-kubectl/) for more information.
@@ -28,7 +28,7 @@ instructions](https://kubernetes.io/docs/tasks/tools/install-kubectl/) for more
- An accessible docker-registry (such as [Docker Hub](https://hub.docker.com)). The registry's URL and credentials are consumed by the applications via a pre-created secret.
- Storage:
- 8Gi
- - It is also required to set a default storage class for the kubernetes cluster in order for the pods to have persistent storage. Please see the [Kubernetes documentation](https://kubernetes.io/docs/concepts/storage/storage-classes/#the-storageclass-resource) for more information.
+ - Set a default storage class for the kubernetes cluster, in order for the pods to have persistent storage. See the [Kubernetes documentation](https://kubernetes.io/docs/concepts/storage/storage-classes/#the-storageclass-resource) for more information.
- RAM: A minimum of 8Gi is required for running all the initial MLRun components. The amount of RAM required for running MLRun jobs depends on the job's requirements.
``` {admonition} Note
@@ -54,7 +54,7 @@ The MLRun CE (Community Edition) includes the following components:
-## Installing the Chart
+## Installing the chart
```{admonition} Note
These instructions use `mlrun` as the namespace (`-n` parameter). You can choose a different namespace in your kubernetes cluster.
@@ -110,8 +110,8 @@ Where:
- `` is your Docker email.
```{admonition} Note
-First-time MLRun users will experience a relatively longer installation time because all required images
-are being pulled locally for the first time (it will take an average of 10-15 minutes mostly depends on
+First-time MLRun users experience a relatively longer installation time because all required images
+are pulled locally for the first time (it takes an average of 10-15 minutes, mostly depending on
your internet speed).
```
@@ -133,18 +133,18 @@ Where:
- `` is the registry URL that can be authenticated by the `registry-credentials` secret (e.g., `index.docker.io/` for Docker Hub).
- `` is the IP address of the host machine (or `$(minikube ip)` if using minikube).
-When the installation is complete, the helm command prints the URLs and Ports of all the MLRun CE services.
+When the installation is complete, the helm command prints the URLs and ports of all the MLRun CE services.
> **Note:**
> There is currently a known issue with installing the chart on Macs using Apple Silicon (M1). The current pipelines
> mysql database fails to start. The workaround for now is to opt out of pipelines by installing the chart with the
> `--set pipelines.mysql.enabled=false`.
-## Configuring Online Feature Store
-The MLRun Community Edition now supports the online feature store. To enable it, you need to first deploy a REDIS service that is accessible to your MLRun CE cluster.
-To deploy a REDIS service, refer to the following [link](https://redis.io/docs/getting-started/).
+## Configuring the online feature store
+The MLRun Community Edition now supports the online feature store. To enable it, you need to first deploy a Redis service that is accessible to your MLRun CE cluster.
+To deploy a Redis service, refer to the [Redis documentation](https://redis.io/docs/getting-started/).
-When you have a REDIS service deployed, you can configure MLRun CE to use it by adding the following helm value configuration to your helm install command:
+When you have a Redis service deployed, you can configure MLRun CE to use it by adding the following helm value configuration to your helm install command:
```bash
--set mlrun.api.extraEnvKeyValue.MLRUN_REDIS__URL=
```
@@ -152,34 +152,34 @@ When you have a REDIS service deployed, you can configure MLRun CE to use it by
## Usage
Your applications are now available in your local browser:
-- jupyter-notebook - `http://:30040`
-- nuclio - `http://:30050`
-- mlrun UI - `http://:30060`
-- mlrun API (external) - `http://:30070`
-- minio API - `http://:30080`
-- minio UI - `http://:30090`
-- pipeline UI - `http://:30100`
-- grafana UI - `http://:30110`
+- Jupyter Notebook - `http://:30040`
+- Nuclio - `http://:30050`
+- MLRun UI - `http://:30060`
+- MLRun API (external) - `http://:30070`
+- MinIO API - `http://:30080`
+- MinIO UI - `http://:30090`
+- Pipeline UI - `http://:30100`
+- Grafana UI - `http://:30110`
```{admonition} Check state
-You can check current state of installation via command `kubectl -n mlrun get pods`, where the main information
-is in columns `Ready` and `State`. If all images have already been pulled locally, typically it will take
+You can check the current state of the installation via the command `kubectl -n mlrun get pods`, where the main information
+is in columns `Ready` and `State`. If all images have already been pulled locally, typically it takes
a minute for all services to start.
```
```{admonition} Note
You can change the ports by providing values to the helm install command.
-You can add and configure a k8s ingress-controller for better security and control over external access.
+You can add and configure a Kubernetes ingress-controller for better security and control over external access.
```
-## Start Working
+## Start working
Open the Jupyter notebook on [**jupyter-notebook UI**](http://localhost:30040) and run the code in the
[**examples/mlrun_basics.ipynb**](https://github.com/mlrun/mlrun/blob/master/examples/mlrun_basics.ipynb) notebook.
```{admonition} Important
-Make sure to save your changes in the `data` folder within the Jupyter Lab. The root folder and any other folder do not retain the changes when you restart the Jupyter Lab.
+Make sure to save your changes in the `data` folder within the Jupyter Lab. The root folder and any other folders do not retain the changes when you restart the Jupyter Lab.
```
## Configuring the remote environment
@@ -191,8 +191,8 @@ You can use your code on a local machine while running your functions on a remot
Configurable values are documented in the `values.yaml`, and the `values.yaml` of all sub charts. Override those [in the normal methods](https://helm.sh/docs/chart_template_guide/values_files/).
### Opt out of components
-The chart installs many components. You might not need them all in your deployment depending on your use cases.
-In order to opt out of some of the components, you can use the following helm values:
+The chart installs many components. You may not need them all in your deployment depending on your use cases.
+To opt out of some of the components, use the following helm values:
```bash
...
--set pipelines.enabled=false \
@@ -213,11 +213,12 @@ Docker Desktop is available for Mac and Windows. For download information, syste
Docker Desktop includes a standalone Kubernetes server and client, as well as Docker CLI integration that runs on your machine. The
Kubernetes server runs locally within your Docker instance. To enable Kubernetes support and install a standalone instance of Kubernetes
-running as a Docker container, go to **Preferences** > **Kubernetes** and then click **Enable Kubernetes**. Click **Apply & Restart** to
-save the settings and then click **Install** to confirm. This instantiates the images that are required to run the Kubernetes server as
+running as a Docker container, go to **Preferences** > **Kubernetes** and then press **Enable Kubernetes**. Press **Apply & Restart** to
+save the settings and then press **Install** to confirm. This instantiates the images that are required to run the Kubernetes server as
containers, and installs the `/usr/local/bin/kubectl` command on your machine. For more information, see [the Kubernetes documentation](https://docs.docker.com/desktop/kubernetes/).
-It's recommended to limit the amount of memory allocated to Kubernetes. If you're using Windows and WSL 2, you can configure global WSL options by placing a `.wslconfig` file into the root directory of your users folder: `C:\Users\\.wslconfig`. Keep in mind that you might need to run `wsl --shutdown` to shut down the WSL 2 VM and then restart your WSL instance for these changes to take effect.
+It's recommended to limit the amount of memory allocated to Kubernetes. If you're using Windows and WSL 2, you can configure global WSL options by placing a `.wslconfig` file into the root directory of
+your users folder: `C:\Users\\.wslconfig`. Keep in mind that you might need to run `wsl --shutdown` to shut down the WSL 2 VM and then restart your WSL instance for these changes to take effect.
``` console
[wsl2]
@@ -233,10 +234,12 @@ To learn about the various UI options and their usage, see:
When installing the MLRun Community Edition, several storage resources are created:
-- **PVs via default configured storage class**: Used to hold the file system of the stacks pods, including the MySQL database of MLRun, Minio for artifacts and Pipelines Storage and more. These are not deleted when the stack is uninstalled to allow upgrades without losing data.
-- **Container Images in the configured docker-registry**: When building and deploying MLRun and Nuclio functions via the MLRun Community Edition, the function images are stored in the given configured docker registry. These images persist in the docker registry and are not deleted.
+- **PVs via default configured storage class**: Holds the file system of the stacks pods, including the MySQL database of MLRun, Minio for artifacts and Pipelines Storage and more.
+These are not deleted when the stack is uninstalled, which allows upgrading without losing data.
+- **Container Images in the configured docker-registry**: When building and deploying MLRun and Nuclio functions via the MLRun Community Edition, the function images are
+stored in the given configured docker registry. These images persist in the docker registry and are not deleted.
-## Uninstalling the Chart
+## Uninstalling the chart
The following command deletes the pods, deployments, config maps, services and roles+role bindings associated with the chart and release.
@@ -252,8 +255,8 @@ helm --namespace mlrun uninstall mlrun-ce
### Note on terminating pods and hanging resources
This chart generates several persistent volume claims that provide persistency (via PVC) out of the box.
-Upon uninstallation, any hanging / terminating pods will hold the PVCs and PVs respectively, as those prevent their safe removal.
-Since pods that are stuck in terminating state seem to be a never-ending plague in k8s, note this,
+Upon uninstallation, any hanging / terminating pods hold the PVCs and PVs respectively, as those prevent their safe removal.
+Since pods that are stuck in terminating state seem to be a never-ending plague in Kubernetes, note this,
and remember to clean the remaining PVs and PVCs.
### Handing stuck-at-terminating pods:
@@ -287,7 +290,7 @@ $ kubectl --namespace mlrun delete pvc
## Upgrading the chart
-In order to upgrade to the latest version of the chart, first make sure you have the latest helm repo
+To upgrade to the latest version of the chart, first make sure you have the latest helm repo
```bash
helm repo update
From 0bd70932839658db987497f3d6eaa14dc2b99875 Mon Sep 17 00:00:00 2001
From: Eyal Danieli
Date: Sun, 14 May 2023 13:16:45 +0300
Subject: [PATCH 126/334] [Model Monitoring] Fix error-count by converting it's
value to int before writing endpoint to DB (#3520)
---
mlrun/common/schemas/model_endpoints.py | 15 +++--
.../model_monitoring/test_model_monitoring.py | 62 ++++++++++++++-----
2 files changed, 56 insertions(+), 21 deletions(-)
diff --git a/mlrun/common/schemas/model_endpoints.py b/mlrun/common/schemas/model_endpoints.py
index 319719316d3d..ec36c738601c 100644
--- a/mlrun/common/schemas/model_endpoints.py
+++ b/mlrun/common/schemas/model_endpoints.py
@@ -13,6 +13,7 @@
# limitations under the License.
#
+import enum
import json
import typing
from typing import Any, Dict, List, Optional, Tuple, Union
@@ -223,16 +224,17 @@ def flat_dict(self):
flatten_dict = {}
for k_object in model_endpoint_dictionary:
for key in model_endpoint_dictionary[k_object]:
+ # Extract the value of the current field
+ current_value = model_endpoint_dictionary[k_object][key]
+
# If the value is not from type str or bool (e.g. dict), convert it into a JSON string
# for matching the database required format
- if not isinstance(
- model_endpoint_dictionary[k_object][key], (str, bool)
+ if not isinstance(current_value, (str, bool, int)) or isinstance(
+ current_value, enum.IntEnum
):
- flatten_dict[key] = json.dumps(
- model_endpoint_dictionary[k_object][key]
- )
+ flatten_dict[key] = json.dumps(current_value)
else:
- flatten_dict[key] = model_endpoint_dictionary[k_object][key]
+ flatten_dict[key] = current_value
if mlrun.common.model_monitoring.EventFieldType.METRICS not in flatten_dict:
# Initialize metrics dictionary
@@ -242,6 +244,7 @@ def flat_dict(self):
mlrun.common.model_monitoring.EventLiveStats.PREDICTIONS_PER_SECOND: 0,
}
}
+
# Remove the features from the dictionary as this field will be filled only within the feature analysis process
flatten_dict.pop(mlrun.common.model_monitoring.EventFieldType.FEATURES, None)
return flatten_dict
diff --git a/tests/system/model_monitoring/test_model_monitoring.py b/tests/system/model_monitoring/test_model_monitoring.py
index 2fc302caac52..ab1c8e56e55a 100644
--- a/tests/system/model_monitoring/test_model_monitoring.py
+++ b/tests/system/model_monitoring/test_model_monitoring.py
@@ -238,7 +238,6 @@ def test_basic_model_monitoring(self):
# Main validations:
# 1 - a single model endpoint is created
# 2 - stream metrics are recorded as expected under the model endpoint
- # 3 - invalid records are considered in the aggregated error count value
simulation_time = 90 # 90 seconds
# Deploy Model Servers
@@ -283,17 +282,6 @@ def test_basic_model_monitoring(self):
# Deploy the function
serving_fn.deploy()
- # Simulating invalid requests
- invalid_input = ["n", "s", "o", "-"]
- for _ in range(10):
- try:
- serving_fn.invoke(
- f"v2/models/{model_name}/infer",
- json.dumps({"inputs": [invalid_input]}),
- )
- except RuntimeError:
- pass
-
# Simulating valid requests
iris_data = iris["data"].tolist()
t_end = monotonic() + simulation_time
@@ -319,9 +307,6 @@ def test_basic_model_monitoring(self):
total = sum((m[1] for m in predictions_per_second))
assert total > 0
- # Validate error count value
- assert endpoint.status.error_count == 10
-
@TestMLRunSystem.skip_test_if_env_not_configured
@pytest.mark.enterprise
@@ -496,6 +481,8 @@ def test_model_monitoring_voting_ensemble(self):
# 2 - deployment status of monitoring stream nuclio function
# 3 - model endpoints types for both children and router
# 4 - metrics and drift status per model endpoint
+ # 5 - invalid records are considered in the aggregated error count value
+ # 6 - KV schema file is generated as expected
simulation_time = 120 # 120 seconds to allow tsdb batching
@@ -597,6 +584,15 @@ def test_model_monitoring_voting_ensemble(self):
# invoke the model before running the model monitoring batch job
iris_data = iris["data"].tolist()
+ # Simulating invalid request
+ invalid_input = ["n", "s", "o", "-"]
+ with pytest.raises(RuntimeError):
+ serving_fn.invoke(
+ "v2/models/VotingEnsemble/infer",
+ json.dumps({"inputs": [invalid_input]}),
+ )
+
+ # Simulating valid requests
t_end = monotonic() + simulation_time
start_time = datetime.now(timezone.utc)
data_sent = 0
@@ -615,6 +611,9 @@ def test_model_monitoring_voting_ensemble(self):
# it can take ~1 minute for the batch pod to finish running
sleep(60)
+ # Check that the KV schema has been generated as expected
+ self._check_kv_schema_file()
+
tsdb_path = f"/pipelines/{self.project_name}/model-endpoints/events/"
client = get_frames_client(
token=os.environ.get("V3IO_ACCESS_KEY"),
@@ -702,11 +701,44 @@ def test_model_monitoring_voting_ensemble(self):
assert measure in drift_measures
assert type(drift_measures[measure]) == float
+ # Validate error count value
+ assert endpoint.status.error_count == 1
+
def _check_monitoring_building_state(self, base_runtime):
# Check if model monitoring stream function is ready
stat = mlrun.get_run_db().get_builder_status(base_runtime)
assert base_runtime.status.state == "ready", stat
+ def _check_kv_schema_file(self):
+ """Check that the KV schema has been generated as expected"""
+
+ # Initialize V3IO client object that will be used to retrieve the KV schema
+ client = mlrun.utils.v3io_clients.get_v3io_client(
+ endpoint=mlrun.mlconf.v3io_api
+ )
+
+ # Get the schema raw object
+ schema_raw = client.object.get(
+ container="users",
+ path=f"pipelines/{self.project_name}/model-endpoints/endpoints/.#schema",
+ access_key=os.environ.get("V3IO_ACCESS_KEY"),
+ )
+
+ # Convert the content into a dict
+ schema = json.loads(schema_raw.body)
+
+ # Validate the schema key value
+ assert schema["key"] == model_monitoring_constants.EventFieldType.UID
+
+ # Create a new dictionary of field_name:field_type out of the schema dictionary
+ fields_dict = {item["name"]: item["type"] for item in schema["fields"]}
+
+ # Validate the type of several keys
+ assert fields_dict["error_count"] == "long"
+ assert fields_dict["function_uri"] == "string"
+ assert fields_dict["endpoint_type"] == "string"
+ assert fields_dict["active"] == "boolean"
+
@TestMLRunSystem.skip_test_if_env_not_configured
@pytest.mark.enterprise
From f2285eb223b01ee52555c240db58b1e817ad7818 Mon Sep 17 00:00:00 2001
From: Eyal Danieli
Date: Sun, 14 May 2023 18:22:24 +0300
Subject: [PATCH 127/334] [Model Monitoring] Fix
_process_model_monitoring_secret: remove internal unnecessary import (#3541)
---
mlrun/api/api/endpoints/functions.py | 5 -----
1 file changed, 5 deletions(-)
diff --git a/mlrun/api/api/endpoints/functions.py b/mlrun/api/api/endpoints/functions.py
index a909a0528873..ded6fe826090 100644
--- a/mlrun/api/api/endpoints/functions.py
+++ b/mlrun/api/api/endpoints/functions.py
@@ -439,7 +439,6 @@ def _handle_job_deploy_status(
terminal_states = ["failed", "error", "ready"]
log_file = log_path(project, f"build_{name}__{tag or 'latest'}")
if state in terminal_states and log_file.exists():
-
if state == mlrun.common.schemas.FunctionState.ready:
# when the function has been built we set the created image into the `spec.image` for reference see at the
# end of the function where we resolve if the status is ready and then set the spec.build.image to
@@ -621,7 +620,6 @@ def _build_function(
fn.set_db_connection(run_db)
fn.save(versioned=False)
if fn.kind in RuntimeKinds.nuclio_runtimes():
-
mlrun.api.api.utils.apply_enrichment_and_validation_on_function(
fn,
auth_info,
@@ -821,7 +819,6 @@ async def _get_function_status(data, auth_info: mlrun.common.schemas.AuthInfo):
def _create_model_monitoring_stream(project: str, function):
-
_init_serving_function_stream_args(fn=function)
stream_path = mlrun.mlconf.get_model_monitoring_file_target_path(
@@ -908,8 +905,6 @@ def _process_model_monitoring_secret(db_session, project_name: str, secret_key:
allow_internal_secrets=True,
)
if not secret_value:
- import mlrun.api.utils.singletons.project_member
-
project_owner = mlrun.api.utils.singletons.project_member.get_project_member().get_project_owner(
db_session, project_name
)
From 48447eac3d3a8173e45b1bc35b5de5ce282698db Mon Sep 17 00:00:00 2001
From: Tom Tankilevitch <59158507+Tankilevitch@users.noreply.github.com>
Date: Sun, 14 May 2023 21:31:58 +0300
Subject: [PATCH 128/334] [Runtime/Launcher] Use runtime db instead of launcher
db (#3551)
---
mlrun/api/launcher.py | 7 ++++---
mlrun/launcher/base.py | 20 +++++++-------------
mlrun/launcher/client.py | 15 +++++++++------
mlrun/launcher/local.py | 2 +-
mlrun/launcher/remote.py | 5 +++--
mlrun/runtimes/base.py | 1 +
6 files changed, 25 insertions(+), 25 deletions(-)
diff --git a/mlrun/api/launcher.py b/mlrun/api/launcher.py
index ae85bb898f22..42db4037ebf9 100644
--- a/mlrun/api/launcher.py
+++ b/mlrun/api/launcher.py
@@ -89,7 +89,7 @@ def launch(
execution = mlrun.execution.MLClientCtx.from_dict(
run.to_dict(),
- self.db,
+ runtime._get_db(),
autocommit=False,
is_api=True,
store_run=False,
@@ -179,9 +179,10 @@ def _store_function(
self, runtime: mlrun.runtimes.base.BaseRuntime, run: mlrun.run.RunObject
):
run.metadata.labels["kind"] = runtime.kind
- if self.db and runtime.kind != "handler":
+ db = runtime._get_db()
+ if db and runtime.kind != "handler":
struct = runtime.to_dict()
- hash_key = self.db.store_function(
+ hash_key = db.store_function(
struct, runtime.metadata.name, runtime.metadata.project, versioned=True
)
run.spec.function = runtime._function_uri(hash_key=hash_key)
diff --git a/mlrun/launcher/base.py b/mlrun/launcher/base.py
index 877576452a3a..f248c29f1978 100644
--- a/mlrun/launcher/base.py
+++ b/mlrun/launcher/base.py
@@ -38,15 +38,6 @@ class BaseLauncher(abc.ABC):
Each context will have its own implementation of the abstract methods while the common logic resides in this class
"""
- def __init__(self):
- self._db = None
-
- @property
- def db(self) -> mlrun.db.base.RunDBInterface:
- if not self._db:
- self._db = mlrun.db.get_run_db()
- return self._db
-
def save_function(
self,
runtime: "mlrun.runtimes.BaseRuntime",
@@ -63,7 +54,8 @@ def save_function(
:return: function uri
"""
- if not self.db:
+ db = runtime._get_db()
+ if not db:
raise mlrun.errors.MLRunPreconditionFailedError(
"Database connection is not configured"
)
@@ -75,7 +67,7 @@ def save_function(
obj = runtime.to_dict()
logger.debug("Saving function", runtime_name=runtime.metadata.name, tag=tag)
- hash_key = self.db.store_function(
+ hash_key = db.store_function(
obj, runtime.metadata.name, runtime.metadata.project, tag, versioned
)
hash_key = hash_key if versioned else None
@@ -359,7 +351,8 @@ def _wrap_run_result(
return None
- def _refresh_function_metadata(self, runtime: "mlrun.runtimes.BaseRuntime"):
+ @staticmethod
+ def _refresh_function_metadata(runtime: "mlrun.runtimes.BaseRuntime"):
pass
@staticmethod
@@ -377,9 +370,10 @@ def _enrich_runtime(runtime):
def _save_or_push_notifications(self, runobj):
pass
+ @staticmethod
@abc.abstractmethod
def _store_function(
- self, runtime: "mlrun.runtimes.BaseRuntime", run: "mlrun.run.RunObject"
+ runtime: "mlrun.runtimes.BaseRuntime", run: "mlrun.run.RunObject"
):
pass
diff --git a/mlrun/launcher/client.py b/mlrun/launcher/client.py
index 77903fb56448..5e64b0cf67fa 100644
--- a/mlrun/launcher/client.py
+++ b/mlrun/launcher/client.py
@@ -35,8 +35,9 @@ def _enrich_runtime(runtime):
runtime.try_auto_mount_based_on_config()
runtime._fill_credentials()
+ @staticmethod
def _store_function(
- self, runtime: "mlrun.runtimes.BaseRuntime", run: "mlrun.run.RunObject"
+ runtime: "mlrun.runtimes.BaseRuntime", run: "mlrun.run.RunObject"
):
run.metadata.labels["kind"] = runtime.kind
if "owner" not in run.metadata.labels:
@@ -47,18 +48,20 @@ def _store_function(
run.spec.output_path = run.spec.output_path.replace(
"{{run.user}}", run.metadata.labels["owner"]
)
-
- if self.db and runtime.kind != "handler":
+ db = runtime._get_db()
+ if db and runtime.kind != "handler":
struct = runtime.to_dict()
- hash_key = self.db.store_function(
+ hash_key = db.store_function(
struct, runtime.metadata.name, runtime.metadata.project, versioned=True
)
run.spec.function = runtime._function_uri(hash_key=hash_key)
- def _refresh_function_metadata(self, runtime: "mlrun.runtimes.BaseRuntime"):
+ @staticmethod
+ def _refresh_function_metadata(runtime: "mlrun.runtimes.BaseRuntime"):
try:
meta = runtime.metadata
- db_func = self.db.get_function(meta.name, meta.project, meta.tag)
+ db = runtime._get_db()
+ db_func = db.get_function(meta.name, meta.project, meta.tag)
if db_func and "status" in db_func:
runtime.status = db_func["status"]
if (
diff --git a/mlrun/launcher/local.py b/mlrun/launcher/local.py
index dc773a16d3f0..8ebcc48c4b51 100644
--- a/mlrun/launcher/local.py
+++ b/mlrun/launcher/local.py
@@ -148,7 +148,7 @@ def execute(
execution = mlrun.run.MLClientCtx.from_dict(
run.to_dict(),
- self.db,
+ runtime._get_db(),
autocommit=False,
is_api=False,
store_run=False,
diff --git a/mlrun/launcher/remote.py b/mlrun/launcher/remote.py
index a9e0e2bdc54a..8544436732e1 100644
--- a/mlrun/launcher/remote.py
+++ b/mlrun/launcher/remote.py
@@ -120,7 +120,8 @@ def submit_job(
if runtime._secrets:
run.spec.secret_sources = runtime._secrets.to_serial()
try:
- resp = self.db.submit_job(run, schedule=schedule)
+ db = runtime._get_db()
+ resp = db.submit_job(run, schedule=schedule)
if schedule:
action = resp.pop("action", "created")
logger.info(f"task schedule {action}", **resp)
@@ -173,7 +174,7 @@ def submit_job(
resp = runtime._get_db_run(run)
elif watch or runtime.kfp:
- run.logs(True, self.db)
+ run.logs(True, runtime._get_db())
resp = runtime._get_db_run(run)
return self._wrap_run_result(runtime, resp, run, schedule=schedule)
diff --git a/mlrun/runtimes/base.py b/mlrun/runtimes/base.py
index 14ebe9dcc7f3..08b164166122 100644
--- a/mlrun/runtimes/base.py
+++ b/mlrun/runtimes/base.py
@@ -243,6 +243,7 @@ def _ensure_run_db(self):
self.spec.rundb = self.spec.rundb or get_or_set_dburl()
def _get_db(self):
+ # TODO: remove this function and use the launcher db instead
self._ensure_run_db()
if not self._db_conn:
if self.spec.rundb:
From 70833dee1e3908025f19ad9cd61617b3b1a798cc Mon Sep 17 00:00:00 2001
From: TomerShor <90552140+TomerShor@users.noreply.github.com>
Date: Sun, 14 May 2023 21:36:52 +0300
Subject: [PATCH 129/334] [Schemas] Remove duplicates from typing hints (#3545)
---
mlrun/api/api/endpoints/feature_store.py | 9 ++-------
mlrun/api/api/utils.py | 4 +---
mlrun/api/db/sqldb/db.py | 4 +---
mlrun/common/schemas/tag.py | 2 +-
mlrun/db/sqldb.py | 21 ++++++---------------
5 files changed, 11 insertions(+), 29 deletions(-)
diff --git a/mlrun/api/api/endpoints/feature_store.py b/mlrun/api/api/endpoints/feature_store.py
index f274a0eea61b..dd3237cd1b8e 100644
--- a/mlrun/api/api/endpoints/feature_store.py
+++ b/mlrun/api/api/endpoints/feature_store.py
@@ -13,7 +13,6 @@
# limitations under the License.
#
import asyncio
-import typing
from http import HTTPStatus
from typing import List, Optional
@@ -506,9 +505,7 @@ async def list_entities(
name: str = None,
tag: str = None,
labels: List[str] = Query(None, alias="label"),
- auth_info: typing.Union[
- mlrun.common.schemas.AuthInfo, mlrun.common.schemas.AuthInfo
- ] = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await mlrun.api.utils.auth.verifier.AuthVerifier().query_project_permissions(
@@ -544,9 +541,7 @@ async def create_feature_vector(
project: str,
feature_vector: mlrun.common.schemas.FeatureVector,
versioned: bool = True,
- auth_info: typing.Union[
- mlrun.common.schemas.AuthInfo, mlrun.common.schemas.AuthInfo
- ] = Depends(deps.authenticate_request),
+ auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
db_session: Session = Depends(deps.get_db_session),
):
await run_in_threadpool(
diff --git a/mlrun/api/api/utils.py b/mlrun/api/api/utils.py
index b16a86c8f58a..1902c1a32f5c 100644
--- a/mlrun/api/api/utils.py
+++ b/mlrun/api/api/utils.py
@@ -121,9 +121,7 @@ def get_allowed_path_prefixes_list() -> typing.List[str]:
def get_secrets(
- auth_info: typing.Union[
- mlrun.common.schemas.AuthInfo,
- ]
+ auth_info: mlrun.common.schemas.AuthInfo,
):
return {
"V3IO_ACCESS_KEY": auth_info.data_session,
diff --git a/mlrun/api/db/sqldb/db.py b/mlrun/api/db/sqldb/db.py
index 9eccb2aa2077..bfca6a93e479 100644
--- a/mlrun/api/db/sqldb/db.py
+++ b/mlrun/api/db/sqldb/db.py
@@ -1427,9 +1427,7 @@ def list_projects(
self,
session: Session,
owner: str = None,
- format_: typing.Union[
- mlrun.common.schemas.ProjectsFormat, mlrun.common.schemas.ProjectsFormat
- ] = mlrun.common.schemas.ProjectsFormat.full,
+ format_: mlrun.common.schemas.ProjectsFormat = mlrun.common.schemas.ProjectsFormat.full,
labels: List[str] = None,
state: mlrun.common.schemas.ProjectState = None,
names: typing.Optional[typing.List[str]] = None,
diff --git a/mlrun/common/schemas/tag.py b/mlrun/common/schemas/tag.py
index 90d3bd3a2670..2bcab5ef7be6 100644
--- a/mlrun/common/schemas/tag.py
+++ b/mlrun/common/schemas/tag.py
@@ -29,4 +29,4 @@ class TagObjects(pydantic.BaseModel):
kind: str
# TODO: Add more types to the list for new supported tagged objects
- identifiers: typing.List[typing.Union[ArtifactIdentifier]]
+ identifiers: typing.List[ArtifactIdentifier]
diff --git a/mlrun/db/sqldb.py b/mlrun/db/sqldb.py
index 2682f27b3df9..69bc97751e4c 100644
--- a/mlrun/db/sqldb.py
+++ b/mlrun/db/sqldb.py
@@ -322,9 +322,7 @@ def tag_objects(
self,
project: str,
tag_name: str,
- tag_objects: Union[
- mlrun.common.schemas.TagObjects, mlrun.common.schemas.TagObjects
- ],
+ tag_objects: mlrun.common.schemas.TagObjects,
replace: bool = False,
):
import mlrun.api.crud
@@ -350,9 +348,7 @@ def delete_objects_tag(
self,
project: str,
tag_name: str,
- tag_objects: Union[
- mlrun.common.schemas.TagObjects, mlrun.common.schemas.TagObjects
- ],
+ tag_objects: mlrun.common.schemas.TagObjects,
):
import mlrun.api.crud
@@ -401,7 +397,7 @@ def list_schedules(self):
def store_project(
self,
name: str,
- project: Union[mlrun.common.schemas.Project, mlrun.common.schemas.Project],
+ project: mlrun.common.schemas.Project,
) -> mlrun.common.schemas.Project:
import mlrun.api.crud
@@ -419,9 +415,7 @@ def patch_project(
self,
name: str,
project: dict,
- patch_mode: Union[
- mlrun.common.schemas.PatchMode, mlrun.common.schemas.PatchMode
- ] = mlrun.common.schemas.PatchMode.replace,
+ patch_mode: mlrun.common.schemas.PatchMode = mlrun.common.schemas.PatchMode.replace,
) -> mlrun.common.schemas.Project:
import mlrun.api.crud
@@ -435,7 +429,7 @@ def patch_project(
def create_project(
self,
- project: Union[mlrun.common.schemas.Project, mlrun.common.schemas.Project],
+ project: mlrun.common.schemas.Project,
) -> mlrun.common.schemas.Project:
import mlrun.api.crud
@@ -448,10 +442,7 @@ def create_project(
def delete_project(
self,
name: str,
- deletion_strategy: Union[
- mlrun.common.schemas.DeletionStrategy,
- mlrun.common.schemas.DeletionStrategy,
- ] = mlrun.common.schemas.DeletionStrategy.default(),
+ deletion_strategy: mlrun.common.schemas.DeletionStrategy = mlrun.common.schemas.DeletionStrategy.default(),
):
import mlrun.api.crud
From 3e2135f6e25b3b8a5c1129b224a0fac46b87c3b7 Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Sun, 14 May 2023 22:46:08 +0300
Subject: [PATCH 130/334] [Launcher] Enrich run fixes (#3542)
---
mlrun/launcher/base.py | 3 +-
mlrun/runtimes/base.py | 125 -----------------------------------------
tests/run/test_run.py | 7 ++-
3 files changed, 8 insertions(+), 127 deletions(-)
diff --git a/mlrun/launcher/base.py b/mlrun/launcher/base.py
index f248c29f1978..9186e13709b4 100644
--- a/mlrun/launcher/base.py
+++ b/mlrun/launcher/base.py
@@ -184,8 +184,8 @@ def _create_run_object(task):
elif isinstance(task, dict):
return mlrun.run.RunObject.from_dict(task)
- @staticmethod
def _enrich_run(
+ self,
runtime,
run,
handler=None,
@@ -276,6 +276,7 @@ def _enrich_run(
or mlrun.pipeline_context.workflow_artifact_path
)
+ # get_db might be None when no rundb is set on runtime
if not run.spec.output_path and runtime._get_db():
try:
# not passing or loading the DB before the enrichment on purpose, because we want to enrich the
diff --git a/mlrun/runtimes/base.py b/mlrun/runtimes/base.py
index 08b164166122..1fcd8309fb47 100644
--- a/mlrun/runtimes/base.py
+++ b/mlrun/runtimes/base.py
@@ -16,7 +16,6 @@
import http
import traceback
import typing
-import uuid
from abc import ABC, abstractmethod
from ast import literal_eval
from base64 import b64encode
@@ -56,7 +55,6 @@
RunObject,
RunTemplate,
)
-from ..secrets import SecretsStore
from ..utils import (
dict_to_json,
dict_to_yaml,
@@ -64,7 +62,6 @@
get_in,
get_parsed_docker_registry,
logger,
- normalize_name,
now_date,
update_in,
)
@@ -424,128 +421,6 @@ def _create_run_object(self, runspec):
runspec = RunObject.from_dict(runspec)
return runspec
- def _enrich_run(
- self,
- runspec,
- handler,
- project_name,
- name,
- params,
- inputs,
- returns,
- hyperparams,
- hyper_param_options,
- verbose,
- scrape_metrics,
- out_path,
- artifact_path,
- workdir,
- notifications: List[mlrun.model.Notification] = None,
- ):
- runspec.spec.handler = (
- handler or runspec.spec.handler or self.spec.default_handler or ""
- )
- if runspec.spec.handler and self.kind not in ["handler", "dask"]:
- runspec.spec.handler = runspec.spec.handler_name
-
- def_name = self.metadata.name
- if runspec.spec.handler_name:
- short_name = runspec.spec.handler_name
- for separator in ["#", "::", "."]:
- # drop paths, module or class name from short name
- if separator in short_name:
- short_name = short_name.split(separator)[-1]
- def_name += "-" + short_name
-
- runspec.metadata.name = normalize_name(
- name=name or runspec.metadata.name or def_name,
- # if name or runspec.metadata.name are set then it means that is user defined name and we want to warn the
- # user that the passed name needs to be set without underscore, if its not user defined but rather enriched
- # from the handler(function) name then we replace the underscore without warning the user.
- # most of the time handlers will have `_` in the handler name (python convention is to separate function
- # words with `_`), therefore we don't want to be noisy when normalizing the run name
- verbose=bool(name or runspec.metadata.name),
- )
- verify_field_regex(
- "run.metadata.name", runspec.metadata.name, mlrun.utils.regex.run_name
- )
- runspec.metadata.project = (
- project_name
- or runspec.metadata.project
- or self.metadata.project
- or config.default_project
- )
- runspec.spec.parameters = params or runspec.spec.parameters
- runspec.spec.inputs = inputs or runspec.spec.inputs
- runspec.spec.returns = returns or runspec.spec.returns
- runspec.spec.hyperparams = hyperparams or runspec.spec.hyperparams
- runspec.spec.hyper_param_options = (
- hyper_param_options or runspec.spec.hyper_param_options
- )
- runspec.spec.verbose = verbose or runspec.spec.verbose
- if scrape_metrics is None:
- if runspec.spec.scrape_metrics is None:
- scrape_metrics = config.scrape_metrics
- else:
- scrape_metrics = runspec.spec.scrape_metrics
- runspec.spec.scrape_metrics = scrape_metrics
- runspec.spec.input_path = (
- workdir or runspec.spec.input_path or self.spec.workdir
- )
- if self.spec.allow_empty_resources:
- runspec.spec.allow_empty_resources = self.spec.allow_empty_resources
-
- spec = runspec.spec
- if spec.secret_sources:
- self._secrets = SecretsStore.from_list(spec.secret_sources)
-
- # update run metadata (uid, labels) and store in DB
- meta = runspec.metadata
- meta.uid = meta.uid or uuid.uuid4().hex
-
- runspec.spec.output_path = out_path or artifact_path or runspec.spec.output_path
-
- if not runspec.spec.output_path:
- if runspec.metadata.project:
- if (
- mlrun.pipeline_context.project
- and runspec.metadata.project
- == mlrun.pipeline_context.project.metadata.name
- ):
- runspec.spec.output_path = (
- mlrun.pipeline_context.project.spec.artifact_path
- or mlrun.pipeline_context.workflow_artifact_path
- )
-
- if not runspec.spec.output_path and self._get_db():
- try:
- # not passing or loading the DB before the enrichment on purpose, because we want to enrich the
- # spec first as get_db() depends on it
- project = self._get_db().get_project(runspec.metadata.project)
- # this is mainly for tests, so we won't need to mock get_project for so many tests
- # in normal use cases if no project is found we will get an error
- if project:
- runspec.spec.output_path = project.spec.artifact_path
- except mlrun.errors.MLRunNotFoundError:
- logger.warning(
- f"project {project_name} is not saved in DB yet, "
- f"enriching output path with default artifact path: {config.artifact_path}"
- )
-
- if not runspec.spec.output_path:
- runspec.spec.output_path = config.artifact_path
-
- if runspec.spec.output_path:
- runspec.spec.output_path = runspec.spec.output_path.replace(
- "{{run.uid}}", meta.uid
- )
- runspec.spec.output_path = mlrun.utils.helpers.fill_artifact_path_template(
- runspec.spec.output_path, runspec.metadata.project
- )
-
- runspec.spec.notifications = notifications or runspec.spec.notifications or []
- return runspec
-
@staticmethod
def _handle_submit_job_http_error(error: requests.HTTPError):
# if we receive a 400 status code, this means the request was invalid and the run wasn't created in the DB.
diff --git a/tests/run/test_run.py b/tests/run/test_run.py
index 79433cc0709f..4be35c4b1157 100644
--- a/tests/run/test_run.py
+++ b/tests/run/test_run.py
@@ -22,6 +22,7 @@
import mlrun
import mlrun.errors
+import mlrun.launcher.factory
from mlrun import MLClientCtx, new_function, new_task
from tests.conftest import (
examples_path,
@@ -295,7 +296,11 @@ def test_context_from_run_dict():
run = runtime._create_run_object(run_dict)
handler = "my_func"
out_path = "test_artifact_path"
- run = runtime._enrich_run(
+ launcher = mlrun.launcher.factory.LauncherFactory.create_launcher(
+ runtime._is_remote
+ )
+ run = launcher._enrich_run(
+ runtime,
run,
handler,
run_dict["metadata"]["project"],
From fbef19f75cb6f9a4f8a949cf5f93a9600c701083 Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Mon, 15 May 2023 09:56:30 +0300
Subject: [PATCH 131/334] [API] Remove more spammy log lines (#3554)
---
mlrun/api/api/endpoints/functions.py | 2 +-
mlrun/api/api/endpoints/runs.py | 2 --
mlrun/api/crud/runs.py | 3 +--
mlrun/api/db/sqldb/db.py | 6 +++++-
4 files changed, 7 insertions(+), 6 deletions(-)
diff --git a/mlrun/api/api/endpoints/functions.py b/mlrun/api/api/endpoints/functions.py
index ded6fe826090..cf25f03a6e1b 100644
--- a/mlrun/api/api/endpoints/functions.py
+++ b/mlrun/api/api/endpoints/functions.py
@@ -87,7 +87,7 @@ async def store_function(
except ValueError:
log_and_raise(HTTPStatus.BAD_REQUEST.value, reason="bad JSON body")
- logger.debug("Storing function", project=project, name=name, tag=tag, data=data)
+ logger.debug("Storing function", project=project, name=name, tag=tag)
hash_key = await run_in_threadpool(
mlrun.api.crud.Functions().store_function,
db_session,
diff --git a/mlrun/api/api/endpoints/runs.py b/mlrun/api/api/endpoints/runs.py
index ad1093d13c10..4186a9cb568c 100644
--- a/mlrun/api/api/endpoints/runs.py
+++ b/mlrun/api/api/endpoints/runs.py
@@ -26,7 +26,6 @@
import mlrun.common.schemas
from mlrun.api.api import deps
from mlrun.api.api.utils import log_and_raise
-from mlrun.utils import logger
from mlrun.utils.helpers import datetime_from_iso
router = APIRouter()
@@ -60,7 +59,6 @@ async def store_run(
except ValueError:
log_and_raise(HTTPStatus.BAD_REQUEST.value, reason="bad JSON body")
- logger.info("Storing run", data=data)
await run_in_threadpool(
mlrun.api.crud.Runs().store_run,
db_session,
diff --git a/mlrun/api/crud/runs.py b/mlrun/api/crud/runs.py
index a03870edc826..c99ce0f35023 100644
--- a/mlrun/api/crud/runs.py
+++ b/mlrun/api/crud/runs.py
@@ -41,7 +41,6 @@ def store_run(
project: str = mlrun.mlconf.default_project,
):
project = project or mlrun.mlconf.default_project
- logger.info("Storing run", data=data)
mlrun.api.utils.singletons.db.get_db().store_run(
db_session,
data,
@@ -59,7 +58,7 @@ def update_run(
data: dict,
):
project = project or mlrun.mlconf.default_project
- logger.debug("Updating run", project=project, uid=uid, iter=iter, data=data)
+ logger.debug("Updating run", project=project, uid=uid, iter=iter)
# TODO: do some desired state for run, it doesn't make sense that API user changes the status in order to
# trigger abortion
if (
diff --git a/mlrun/api/db/sqldb/db.py b/mlrun/api/db/sqldb/db.py
index bfca6a93e479..0ae58a85603b 100644
--- a/mlrun/api/db/sqldb/db.py
+++ b/mlrun/api/db/sqldb/db.py
@@ -185,7 +185,11 @@ def store_run(
iter=0,
):
logger.debug(
- "Storing run to db", project=project, uid=uid, iter=iter, run=run_data
+ "Storing run to db",
+ project=project,
+ uid=uid,
+ iter=iter,
+ run_name=run_data["metadata"]["name"],
)
run = self._get_run(session, uid, project, iter)
now = datetime.now(timezone.utc)
From 67d7fbcbca328c7f0ebe56f19e0470a8c6bc77a0 Mon Sep 17 00:00:00 2001
From: Yael Genish <62285310+yaelgen@users.noreply.github.com>
Date: Mon, 15 May 2023 12:22:44 +0300
Subject: [PATCH 132/334] [Artifact] Add a comment for allowing to create
artifacts with conflicting keys (#3544)
---
mlrun/artifacts/manager.py | 6 ++++++
1 file changed, 6 insertions(+)
diff --git a/mlrun/artifacts/manager.py b/mlrun/artifacts/manager.py
index 647ecba49cf0..fed8e36a55eb 100644
--- a/mlrun/artifacts/manager.py
+++ b/mlrun/artifacts/manager.py
@@ -191,6 +191,12 @@ def log_artifact(
if db_key is None:
# set the default artifact db key
if producer.kind == "run":
+ # When the producer's type is "run,"
+ # we generate a different db_key than the one we obtained in the request.
+ # As a result, a new artifact for the requested key will be created,
+ # which will contain the new db_key and will represent the current run.
+ # We implement this so that the user can query an artifact,
+ # and receive back all the runs that are associated with his search result.
db_key = producer.name + "_" + key
else:
db_key = key
From 8b07354166ac06dbf028b797706e61211347f0a9 Mon Sep 17 00:00:00 2001
From: tomerm-iguazio <125267619+tomerm-iguazio@users.noreply.github.com>
Date: Mon, 15 May 2023 15:55:35 +0300
Subject: [PATCH 133/334] [Feature Store] Change `test_read_csv` to use mlrun
CSVSource - ML-3820 (#3550)
---
.../feature_store/assets/testdata_short.csv | 4 ++
.../feature_store/test_feature_store.py | 42 +++++++++----------
2 files changed, 23 insertions(+), 23 deletions(-)
create mode 100644 tests/system/feature_store/assets/testdata_short.csv
diff --git a/tests/system/feature_store/assets/testdata_short.csv b/tests/system/feature_store/assets/testdata_short.csv
new file mode 100644
index 000000000000..0690a58d7e72
--- /dev/null
+++ b/tests/system/feature_store/assets/testdata_short.csv
@@ -0,0 +1,4 @@
+id,name,number,float_number,date_of_birth
+1,John,10,1.5,1990-01-01
+2,Jane,20,2.5,1995-05-10
+3,Bob,30,3.5,1985-12-15
diff --git a/tests/system/feature_store/test_feature_store.py b/tests/system/feature_store/test_feature_store.py
index 5f4984548887..439c22d24b63 100644
--- a/tests/system/feature_store/test_feature_store.py
+++ b/tests/system/feature_store/test_feature_store.py
@@ -1099,37 +1099,33 @@ def test_right_not_ordered_pandas_asof_merge(self):
assert res.shape[0] == left.shape[0]
def test_read_csv(self):
- from storey import CSVSource, ReduceToDataFrame, build_flow
-
- csv_path = str(self.results_path / _generate_random_name() / ".csv")
- targets = [CSVTarget("mycsv", path=csv_path)]
+ source = CSVSource(
+ "mycsv",
+ path=os.path.relpath(str(self.assets_path / "testdata_short.csv")),
+ parse_dates=["date_of_birth"],
+ )
stocks_set = fstore.FeatureSet(
- "tests", entities=[Entity("ticker", ValueType.STRING)]
+ "tests", entities=[Entity("id", ValueType.INT64)]
)
- fstore.ingest(
+ result = fstore.ingest(
stocks_set,
- stocks,
+ source=source,
infer_options=fstore.InferOptions.default(),
- targets=targets,
)
-
- # reading csv file
- final_path = stocks_set.get_target_path("mycsv")
- controller = build_flow([CSVSource(final_path), ReduceToDataFrame()]).run()
- termination_result = controller.await_termination()
-
expected = pd.DataFrame(
{
- 0: ["ticker", "MSFT", "GOOG", "AAPL"],
- 1: ["name", "Microsoft Corporation", "Alphabet Inc", "Apple Inc"],
- 2: ["exchange", "NASDAQ", "NASDAQ", "NASDAQ"],
- }
+ "name": ["John", "Jane", "Bob"],
+ "number": [10, 20, 30],
+ "float_number": [1.5, 2.5, 3.5],
+ "date_of_birth": [
+ datetime(1990, 1, 1),
+ datetime(1995, 5, 10),
+ datetime(1985, 12, 15),
+ ],
+ },
+ index=pd.Index([1, 2, 3], name="id"),
)
-
- assert termination_result.equals(
- expected
- ), f"{termination_result}\n!=\n{expected}"
- os.remove(final_path)
+ assert result.equals(expected)
def test_multiple_entities(self):
name = f"measurements_{uuid.uuid4()}"
From f988caac0940454ae04059bcad1b8cfca124f0f4 Mon Sep 17 00:00:00 2001
From: Eyal Danieli
Date: Mon, 15 May 2023 16:14:39 +0300
Subject: [PATCH 134/334] [Datastore] Fix HttpSource initialization (#3559)
---
mlrun/datastore/sources.py | 4 ----
1 file changed, 4 deletions(-)
diff --git a/mlrun/datastore/sources.py b/mlrun/datastore/sources.py
index 6b02907094f3..276745c4d2f4 100644
--- a/mlrun/datastore/sources.py
+++ b/mlrun/datastore/sources.py
@@ -251,7 +251,6 @@ def __init__(
start_time: Optional[Union[datetime, str]] = None,
end_time: Optional[Union[datetime, str]] = None,
):
-
super().__init__(
name,
path,
@@ -738,9 +737,6 @@ def add_nuclio_trigger(self, function):
class HttpSource(OnlineSource):
kind = "http"
- def __init__(self, path: str = None):
- super().__init__(path=path)
-
def add_nuclio_trigger(self, function):
trigger_args = self.attributes.get("trigger_args")
if trigger_args:
From 00d1719414086869e27a6c3669e07c5d7149dcd9 Mon Sep 17 00:00:00 2001
From: Tom Tankilevitch <59158507+Tankilevitch@users.noreply.github.com>
Date: Mon, 15 May 2023 16:15:58 +0300
Subject: [PATCH 135/334] [Local] Support passing more parameters to handler if
handler contains `**kwargs` keyword (#3533)
---
mlrun/runtimes/local.py | 31 ++++++++++++++++---
tests/run/assets/kwargs.py | 26 ++++++++++++++++
tests/run/test_run.py | 31 +++++++++++++++++++
.../runtimes/assets/function_with_kwargs.py | 20 ++++++++++++
tests/system/runtimes/test_kubejob.py | 17 ++++++++++
5 files changed, 120 insertions(+), 5 deletions(-)
create mode 100644 tests/run/assets/kwargs.py
create mode 100644 tests/system/runtimes/assets/function_with_kwargs.py
diff --git a/mlrun/runtimes/local.py b/mlrun/runtimes/local.py
index 18cc7982e74a..84aae0dc05f2 100644
--- a/mlrun/runtimes/local.py
+++ b/mlrun/runtimes/local.py
@@ -473,6 +473,13 @@ def get_func_arg(handler, runobj: RunObject, context: MLClientCtx, is_nuclio=Fal
kwargs = {}
args = inspect.signature(handler).parameters
+ def _get_input_value(input_key: str):
+ input_obj = context.get_input(input_key, inputs[input_key])
+ if type(args[input_key].default) is str or args[input_key].annotation == str:
+ return input_obj.local()
+ else:
+ return input_obj
+
for key in args.keys():
if key == "context":
kwargs[key] = context
@@ -481,9 +488,23 @@ def get_func_arg(handler, runobj: RunObject, context: MLClientCtx, is_nuclio=Fal
elif key in params:
kwargs[key] = copy(params[key])
elif key in inputs:
- obj = context.get_input(key, inputs[key])
- if type(args[key].default) is str or args[key].annotation == str:
- kwargs[key] = obj.local()
- else:
- kwargs[key] = context.get_input(key, inputs[key])
+ kwargs[key] = _get_input_value(key)
+
+ list_of_params = list(args.values())
+ if len(list_of_params) == 0:
+ return kwargs
+
+ # get the last parameter, as **kwargs can only be last in the function's parameters list
+ last_param = list_of_params[-1]
+ # VAR_KEYWORD meaning : A dict of keyword arguments that aren’t bound to any other parameter.
+ # This corresponds to a **kwargs parameter in a Python function definition.
+ if last_param.kind == last_param.VAR_KEYWORD:
+ # if handler has **kwargs, pass all parameters provided by the user to the handler which were not already set
+ # as part of the previous loop which handled all parameters which were explicitly defined in the handler
+ for key in params:
+ if key not in kwargs:
+ kwargs[key] = copy(params[key])
+ for key in inputs:
+ if key not in kwargs:
+ kwargs[key] = _get_input_value(key)
return kwargs
diff --git a/tests/run/assets/kwargs.py b/tests/run/assets/kwargs.py
new file mode 100644
index 000000000000..0753ea2d9a12
--- /dev/null
+++ b/tests/run/assets/kwargs.py
@@ -0,0 +1,26 @@
+# Copyright 2023 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+def func(context, x, **kwargs):
+ context.logger.info(x)
+ context.logger.info(kwargs)
+ return kwargs
+
+
+def func_with_default(context, x=4, **kwargs):
+ context.logger.info(x)
+ context.logger.info(kwargs)
+ if not kwargs:
+ raise Exception("kwargs is empty")
+ return kwargs
diff --git a/tests/run/test_run.py b/tests/run/test_run.py
index 4be35c4b1157..8a51c21690ed 100644
--- a/tests/run/test_run.py
+++ b/tests/run/test_run.py
@@ -143,6 +143,37 @@ def test_local_runtime_failure_before_executing_the_function_code(db):
assert "failed on pre-loading" in str(exc.value)
+@pytest.mark.parametrize(
+ "handler_name,params,kwargs,expected_kwargs",
+ [
+ ("func", {"x": 2}, {"y": 3, "z": 4}, {"y": 3, "z": 4}),
+ ("func", {"x": 2}, {}, {}),
+ ("func_with_default", {}, {"y": 3, "z": 4}, {"y": 3, "z": 4}),
+ ],
+)
+def test_local_runtime_with_kwargs(db, handler_name, params, kwargs, expected_kwargs):
+ params.update(kwargs)
+ function = new_function(command=f"{assets_path}/kwargs.py")
+ result = function.run(local=True, params=params, handler=handler_name)
+ verify_state(result)
+ assert result.outputs.get("return", {}) == expected_kwargs
+
+
+def test_local_runtime_with_kwargs_with_code_to_function(db):
+ function = mlrun.code_to_function(
+ "kwarg",
+ filename=f"{assets_path}/kwargs.py",
+ image="mlrun/mlrun",
+ kind="job",
+ handler="func",
+ )
+ kwargs = {"y": 3, "z": 4}
+ params = {"x": 2}
+ params.update(kwargs)
+ result = function.run(local=True, params=params)
+ assert result.outputs["return"] == kwargs
+
+
def test_local_runtime_hyper():
spec = tag_test(base_spec, "test_local_runtime_hyper")
spec.with_hyper_params({"p1": [1, 5, 3]}, selector="max.accuracy")
diff --git a/tests/system/runtimes/assets/function_with_kwargs.py b/tests/system/runtimes/assets/function_with_kwargs.py
new file mode 100644
index 000000000000..e41da76da4b0
--- /dev/null
+++ b/tests/system/runtimes/assets/function_with_kwargs.py
@@ -0,0 +1,20 @@
+# Copyright 2023 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+def func(context, x, **kwargs):
+ context.logger.info(x)
+ context.logger.info(kwargs)
+ if not kwargs:
+ raise Exception("kwargs is empty")
+ return kwargs
diff --git a/tests/system/runtimes/test_kubejob.py b/tests/system/runtimes/test_kubejob.py
index 76828dad2949..e115e2a68111 100644
--- a/tests/system/runtimes/test_kubejob.py
+++ b/tests/system/runtimes/test_kubejob.py
@@ -272,6 +272,23 @@ def test_new_function_with_args(self):
"val-with-artifact",
]
+ def test_function_with_kwargs(self):
+ code_path = str(self.assets_path / "function_with_kwargs.py")
+ mlrun.get_or_create_project(self.project_name, self.results_path)
+
+ function = mlrun.code_to_function(
+ name="function-with-kwargs",
+ kind="job",
+ project=self.project_name,
+ filename=code_path,
+ image="mlrun/mlrun",
+ )
+ kwargs = {"some_arg": "a-value-123", "another_arg": "another-value-456"}
+ params = {"x": "2"}
+ params.update(kwargs)
+ run = function.run(params=params, handler="func")
+ assert run.outputs["return"] == kwargs
+
def test_class_handler(self):
code_path = str(self.assets_path / "kubejob_function.py")
cases = [
From ac33f3d2eb0f877261b3f0135e3de8944b8280de Mon Sep 17 00:00:00 2001
From: Assaf Ben-Amitai
Date: Mon, 15 May 2023 16:20:35 +0300
Subject: [PATCH 136/334] [Requirements] Bump fsspec based dependancies to fix
gcsfs breakage after transformers==4.11.3 install (#3497)
---
automation/requirements.txt | 2 +-
dependencies.py | 19 +++++++++----------
extras-requirements.txt | 11 +++++------
requirements.txt | 2 +-
tests/test_requirements.py | 13 ++++++-------
5 files changed, 22 insertions(+), 25 deletions(-)
diff --git a/automation/requirements.txt b/automation/requirements.txt
index 1974693576bc..509738800659 100644
--- a/automation/requirements.txt
+++ b/automation/requirements.txt
@@ -2,4 +2,4 @@ click~=8.0.0
paramiko~=2.12
semver~=2.13
requests~=2.22
-boto3~=1.9, <1.17.107
+boto3~=1.24.59
diff --git a/dependencies.py b/dependencies.py
index e3d4e2f42714..ab7a8278234a 100644
--- a/dependencies.py
+++ b/dependencies.py
@@ -31,21 +31,20 @@ def extra_requirements() -> typing.Dict[str, typing.List[str]]:
# - We have a copy of these in extras-requirements.txt. If you modify these, make sure to change it
# there as well
extras_require = {
- # from 1.17.107 boto3 requires botocore>=1.20.107,<1.21.0 which
- # conflicts with s3fs 2021.8.1 that has aiobotocore~=1.4.0
- # which so far (1.4.1) has botocore>=1.20.106,<1.20.107
- # boto3 1.17.106 has botocore>=1.20.106,<1.21.0, so we must add botocore explicitly
+ # last version that supports python 3.7: fsspec: 2023.1.0, aiobotocore: 2.4.2, adlfs: 2022.2.0
+ # selecting ~=2023.1.0 for fsspec and its implementations s3fs and gcsfs (adlfs pinned per comment above)
+ # s3fs 2023.1.0 requires aiobotocore 2.4.2 which requires botocore 1.27.59
+ # requesting boto3 1.24.59, the only version that requires botocore 1.27.59
"s3": [
- "boto3~=1.9, <1.17.107",
- "botocore>=1.20.106,<1.20.107",
- "aiobotocore~=1.4.0",
- "s3fs~=2021.8.1",
+ "boto3~=1.24.59",
+ "aiobotocore~=2.4.2",
+ "s3fs~=2023.1.0",
],
"azure-blob-storage": [
"msrest~=0.6.21",
"azure-core~=1.24",
"azure-storage-blob~=12.13",
- "adlfs~=2021.8.1",
+ "adlfs~=2022.2.0",
"pyopenssl>=23",
],
"azure-key-vault": [
@@ -69,7 +68,7 @@ def extra_requirements() -> typing.Dict[str, typing.List[str]]:
"google-cloud-bigquery[pandas, bqstorage]~=3.2",
"google-cloud~=0.34",
],
- "google-cloud-storage": ["gcsfs~=2021.8.1"],
+ "google-cloud-storage": ["gcsfs~=2023.1.0"],
"google-cloud-bigquery": ["google-cloud-bigquery[pandas, bqstorage]~=3.2"],
"kafka": [
"kafka-python~=2.0",
diff --git a/extras-requirements.txt b/extras-requirements.txt
index b1ca7d9d6d20..08731198c752 100644
--- a/extras-requirements.txt
+++ b/extras-requirements.txt
@@ -8,22 +8,21 @@
# in setup.py so that we'll be able to copy and install this in the layer with all other requirements making the last
# layer (which is most commonly being re-built) as thin as possible
# we have a test test_extras_requirement_file_aligned to verify this file is aligned to setup.py
-boto3~=1.9, <1.17.107
-botocore>=1.20.106,<1.20.107
-aiobotocore~=1.4.0
-s3fs~=2021.8.1
+boto3~=1.24.59
+aiobotocore~=2.4.2
+s3fs~=2023.1.0
# https://github.com/Azure/azure-sdk-for-python/issues/24765#issuecomment-1150310498
msrest~=0.6.21
azure-core~=1.24
azure-storage-blob~=12.13
-adlfs~=2021.8.1
+adlfs~=2022.2.0
azure-identity~=1.5
azure-keyvault-secrets~=4.2
# cryptography>=39, which is required by azure, needs this, or else we get
# AttributeError: module 'lib' has no attribute 'OpenSSL_add_all_algorithms' (ML-3471)
pyopenssl>=23
bokeh~=2.4, >=2.4.2
-gcsfs~=2021.8.1
+gcsfs~=2023.1.0
# plotly artifact body in 5.12.0 may contain chars that are not encodable in 'latin-1' encoding
# so, it cannot be logged as artifact (raised UnicodeEncode error - ML-3255)
plotly~=5.4, <5.12.0
diff --git a/requirements.txt b/requirements.txt
index f8f2f645c97e..532d5341ff1e 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -52,7 +52,7 @@ kubernetes~=12.0
# separating the SDK and API code) (referring to humanfriendly and fastapi)
humanfriendly~=8.2
fastapi~=0.92.0
-fsspec~=2021.8.1
+fsspec~=2023.1.0
v3iofs~=0.1.15
storey~=1.3.19
deepdiff~=5.0
diff --git a/tests/test_requirements.py b/tests/test_requirements.py
index 814914cd8bd6..77518018d7c5 100644
--- a/tests/test_requirements.py
+++ b/tests/test_requirements.py
@@ -93,8 +93,7 @@ def test_requirement_specifiers_convention():
ignored_invalid_map = {
# See comment near requirement for why we're limiting to patch changes only for all of these
"kfp": {"~=1.8.0, <1.8.14"},
- "botocore": {">=1.20.106,<1.20.107"},
- "aiobotocore": {"~=1.4.0"},
+ "aiobotocore": {"~=2.4.2"},
"storey": {"~=1.3.19"},
"bokeh": {"~=2.4, >=2.4.2"},
"typing-extensions": {">=3.10.0,<5"},
@@ -111,10 +110,10 @@ def test_requirement_specifiers_convention():
"v3io-generator": {
" @ git+https://github.com/v3io/data-science.git#subdirectory=generator"
},
- "fsspec": {"~=2021.8.1"},
- "adlfs": {"~=2021.8.1"},
- "s3fs": {"~=2021.8.1"},
- "gcsfs": {"~=2021.8.1"},
+ "fsspec": {"~=2023.1.0"},
+ "adlfs": {"~=2022.2.0"},
+ "s3fs": {"~=2023.1.0"},
+ "gcsfs": {"~=2023.1.0"},
"distributed": {"~=2021.11.2"},
"dask": {"~=2021.11.2"},
# All of these are actually valid, they just don't use ~= so the test doesn't "understand" that
@@ -123,7 +122,7 @@ def test_requirement_specifiers_convention():
"chardet": {">=3.0.2, <4.0"},
"numpy": {">=1.16.5, <1.23.0"},
"alembic": {"~=1.4,<1.6.0"},
- "boto3": {"~=1.9, <1.17.107"},
+ "boto3": {"~=1.24.59"},
"dask-ml": {"~=1.4,<1.9.0"},
"pyarrow": {">=10.0, <12"},
"nbclassic": {">=0.2.8"},
From 3cfa675223bf41eb2b44f89a84fbfd6930d10c4d Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Mon, 15 May 2023 17:33:57 +0300
Subject: [PATCH 137/334] [Launcher] Unit tests and fixes (#3552)
---
mlrun/launcher/local.py | 23 +++--
tests/common_fixtures.py | 13 +++
tests/launcher/__init__.py | 14 +++
tests/launcher/assets/sample_function.py | 20 ++++
tests/launcher/test_factory.py | 91 +++++++++++++++++
tests/launcher/test_local.py | 118 +++++++++++++++++++++++
tests/launcher/test_remote.py | 75 ++++++++++++++
7 files changed, 345 insertions(+), 9 deletions(-)
create mode 100644 tests/launcher/__init__.py
create mode 100644 tests/launcher/assets/sample_function.py
create mode 100644 tests/launcher/test_factory.py
create mode 100644 tests/launcher/test_local.py
create mode 100644 tests/launcher/test_remote.py
diff --git a/mlrun/launcher/local.py b/mlrun/launcher/local.py
index 8ebcc48c4b51..3631bf0b7357 100644
--- a/mlrun/launcher/local.py
+++ b/mlrun/launcher/local.py
@@ -199,13 +199,13 @@ def execute(
def _create_local_function_for_execution(
self,
- runtime,
- run,
- local_code_path,
- project,
- name,
- workdir,
- handler,
+ runtime: "mlrun.runtimes.BaseRuntime",
+ run: "mlrun.run.RunObject",
+ local_code_path: Optional[str] = None,
+ project: Optional[str] = "",
+ name: Optional[str] = "",
+ workdir: Optional[str] = "",
+ handler: Optional[str] = None,
):
project = project or runtime.metadata.project
@@ -216,14 +216,18 @@ def _create_local_function_for_execution(
meta = mlrun.model.BaseMetadata(function_name, project=project)
- command, runtime = mlrun.run.load_func_code(
+ command, loaded_runtime = mlrun.run.load_func_code(
command or runtime, workdir, name=name
)
- if runtime:
+ # loaded_runtime is loaded from runtime or yaml file, if passed a command it should be None,
+ # so we keep the current runtime for enrichment
+ runtime = loaded_runtime or runtime
+ if loaded_runtime:
if run:
handler = handler or run.spec.handler
handler = handler or runtime.spec.default_handler or ""
meta = runtime.metadata.copy()
+ meta.name = function_name or meta.name
meta.project = project or meta.project
# if the handler has module prefix force "local" (vs "handler") runtime
@@ -233,6 +237,7 @@ def _create_local_function_for_execution(
setattr(fn, "_is_run_local", True)
if workdir:
fn.spec.workdir = str(workdir)
+
fn.spec.allow_empty_resources = runtime.spec.allow_empty_resources
if runtime:
# copy the code/base-spec to the local function (for the UI and code logging)
diff --git a/tests/common_fixtures.py b/tests/common_fixtures.py
index 9c6c9286720a..13058cefa338 100644
--- a/tests/common_fixtures.py
+++ b/tests/common_fixtures.py
@@ -152,6 +152,14 @@ def db_session() -> Generator:
db_session.close()
+@pytest.fixture()
+def running_as_api():
+ old_is_running_as_api = mlrun.config.is_running_as_api
+ mlrun.config.is_running_as_api = unittest.mock.Mock(return_value=True)
+ yield
+ mlrun.config.is_running_as_api = old_is_running_as_api
+
+
@pytest.fixture
def patch_file_forbidden(monkeypatch):
class MockV3ioClient:
@@ -265,6 +273,11 @@ def get_function(self, function, project, tag, hash_key=None):
def submit_job(self, runspec, schedule=None):
return {"status": {"status_text": "just a status"}}
+ def watch_log(self, uid, project="", watch=True, offset=0):
+ # mock API updated the run status to completed
+ self._runs[uid]["status"] = {"state": "completed"}
+ return "completed", 0
+
def submit_pipeline(
self,
project,
diff --git a/tests/launcher/__init__.py b/tests/launcher/__init__.py
new file mode 100644
index 000000000000..b3085be1eb56
--- /dev/null
+++ b/tests/launcher/__init__.py
@@ -0,0 +1,14 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
diff --git a/tests/launcher/assets/sample_function.py b/tests/launcher/assets/sample_function.py
new file mode 100644
index 000000000000..ede8b032dfd2
--- /dev/null
+++ b/tests/launcher/assets/sample_function.py
@@ -0,0 +1,20 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+def hello_word(context):
+ return "hello world"
+
+
+def handler_v2(context):
+ return "hello world v2"
diff --git a/tests/launcher/test_factory.py b/tests/launcher/test_factory.py
new file mode 100644
index 000000000000..b077aeb14ad0
--- /dev/null
+++ b/tests/launcher/test_factory.py
@@ -0,0 +1,91 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+import typing
+from contextlib import nullcontext as does_not_raise
+
+import pytest
+
+import mlrun.api.launcher
+import mlrun.launcher.base
+import mlrun.launcher.factory
+import mlrun.launcher.local
+import mlrun.launcher.remote
+
+
+@pytest.mark.parametrize(
+ "is_remote, local, expected_instance",
+ [
+ # runtime is remote and user didn't specify local - submit job flow
+ (
+ True,
+ False,
+ mlrun.launcher.remote.ClientRemoteLauncher,
+ ),
+ # runtime is remote but specify local - run local flow
+ (
+ True,
+ True,
+ mlrun.launcher.local.ClientLocalLauncher,
+ ),
+ # runtime is local and user specify local - run local flow
+ (
+ False,
+ True,
+ mlrun.launcher.local.ClientLocalLauncher,
+ ),
+ # runtime is local and user didn't specify local - run local flow
+ (
+ False,
+ False,
+ mlrun.launcher.local.ClientLocalLauncher,
+ ),
+ ],
+)
+def test_create_client_launcher(
+ is_remote: bool,
+ local: bool,
+ expected_instance: typing.Union[
+ mlrun.launcher.remote.ClientRemoteLauncher,
+ mlrun.launcher.local.ClientLocalLauncher,
+ ],
+):
+ launcher = mlrun.launcher.factory.LauncherFactory.create_launcher(is_remote, local)
+ assert isinstance(launcher, expected_instance)
+
+ if local:
+ assert launcher._is_run_local
+
+ elif not is_remote:
+ assert not launcher._is_run_local
+
+
+@pytest.mark.parametrize(
+ "is_remote, local, expectation",
+ [
+ (True, False, does_not_raise()),
+ (False, False, does_not_raise()),
+ # local run is not allowed when running as API
+ (True, True, pytest.raises(mlrun.errors.MLRunInternalServerError)),
+ (False, True, pytest.raises(mlrun.errors.MLRunInternalServerError)),
+ ],
+)
+def test_create_server_side_launcher(running_as_api, is_remote, local, expectation):
+ """Test that the server side launcher is created when we are running as API"""
+ with expectation:
+ launcher = mlrun.launcher.factory.LauncherFactory.create_launcher(
+ is_remote, local
+ )
+ assert isinstance(launcher, mlrun.api.launcher.ServerSideLauncher)
diff --git a/tests/launcher/test_local.py b/tests/launcher/test_local.py
new file mode 100644
index 000000000000..8b6ec761d32b
--- /dev/null
+++ b/tests/launcher/test_local.py
@@ -0,0 +1,118 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+import pathlib
+
+import pytest
+
+import mlrun.launcher.local
+
+assets_path = pathlib.Path(__file__).parent / "assets"
+func_path = assets_path / "sample_function.py"
+handler = "hello_word"
+
+
+def test_launch_local():
+ launcher = mlrun.launcher.local.ClientLocalLauncher(local=True)
+ runtime = mlrun.code_to_function(
+ name="test", kind="job", filename=str(func_path), handler=handler
+ )
+ result = launcher.launch(runtime)
+ assert result.status.state == "completed"
+ assert result.status.results.get("return") == "hello world"
+
+
+def test_override_handler():
+ launcher = mlrun.launcher.local.ClientLocalLauncher(local=True)
+ runtime = mlrun.code_to_function(
+ name="test", kind="job", filename=str(func_path), handler=handler
+ )
+ result = launcher.launch(runtime, handler="handler_v2")
+ assert result.status.state == "completed"
+ assert result.status.results.get("return") == "hello world v2"
+
+
+def test_launch_remote_job_locally():
+ launcher = mlrun.launcher.local.ClientLocalLauncher(local=False)
+ runtime = mlrun.code_to_function(
+ name="test", kind="job", filename=str(func_path), handler=handler
+ )
+ with pytest.raises(mlrun.errors.MLRunRuntimeError) as exc:
+ launcher.launch(runtime)
+ assert "Remote function cannot be executed locally" in str(exc.value)
+
+
+def test_create_local_function_for_execution():
+ launcher = mlrun.launcher.local.ClientLocalLauncher(local=False)
+ runtime = mlrun.code_to_function(
+ name="test", kind="job", filename=str(func_path), handler=handler
+ )
+ run = mlrun.run.RunObject()
+ runtime = launcher._create_local_function_for_execution(
+ runtime=runtime,
+ run=run,
+ )
+ assert runtime.metadata.project == "default"
+ assert runtime.metadata.name == "test"
+ assert run.spec.handler == handler
+ assert runtime.kind == ""
+ assert runtime._is_run_local
+
+
+def test_create_local_function_for_execution_with_enrichment():
+ launcher = mlrun.launcher.local.ClientLocalLauncher(local=False)
+ runtime = mlrun.code_to_function(
+ name="test", kind="job", filename=str(func_path), handler=handler
+ )
+ runtime.spec.allow_empty_resources = True
+ run = mlrun.run.RunObject()
+ runtime = launcher._create_local_function_for_execution(
+ runtime=runtime,
+ run=run,
+ local_code_path="some_path.py",
+ project="some_project",
+ name="other_name",
+ workdir="some_workdir",
+ handler="handler_v2",
+ )
+ assert runtime.spec.command == "some_path.py"
+ assert runtime.metadata.project == "some_project"
+ assert runtime.metadata.name == "other_name"
+ assert runtime.spec.workdir == "some_workdir"
+ assert run.spec.handler == "handler_v2"
+ assert runtime.kind == ""
+ assert runtime._is_run_local
+ assert runtime.spec.allow_empty_resources
+
+
+def test_validate_inputs():
+ launcher = mlrun.launcher.local.ClientLocalLauncher(local=False)
+ runtime = mlrun.code_to_function(
+ name="test", kind="job", filename=str(func_path), handler=handler
+ )
+ run = mlrun.run.RunObject(spec=mlrun.model.RunSpec(inputs={"input1": 1}))
+ with pytest.raises(mlrun.errors.MLRunInvalidArgumentTypeError) as exc:
+ launcher._validate_runtime(runtime, run)
+ assert "Inputs should be of type Dict[str,str]" in str(exc.value)
+
+
+def test_validate_runtime_success():
+ launcher = mlrun.launcher.local.ClientLocalLauncher(local=False)
+ runtime = mlrun.code_to_function(
+ name="test", kind="local", filename=str(func_path), handler=handler
+ )
+ run = mlrun.run.RunObject(
+ spec=mlrun.model.RunSpec(inputs={"input1": ""}, output_path="./some_path")
+ )
+ launcher._validate_runtime(runtime, run)
diff --git a/tests/launcher/test_remote.py b/tests/launcher/test_remote.py
new file mode 100644
index 000000000000..be251b47fa1f
--- /dev/null
+++ b/tests/launcher/test_remote.py
@@ -0,0 +1,75 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+import pathlib
+
+import pytest
+
+import mlrun.config
+import mlrun.launcher.remote
+
+assets_path = pathlib.Path(__file__).parent / "assets"
+func_path = assets_path / "sample_function.py"
+handler = "hello_word"
+
+
+def test_launch_remote_job(rundb_mock):
+ launcher = mlrun.launcher.remote.ClientRemoteLauncher()
+ mlrun.config.config.artifact_path = "v3io:///users/admin/mlrun"
+ runtime = mlrun.code_to_function(
+ name="test", kind="job", filename=str(func_path), handler=handler
+ )
+ runtime.spec.image = "mlrun/mlrun"
+
+ # store the run is done by the API so we need to mock it
+ uid = "123"
+ run = mlrun.run.RunObject(
+ metadata=mlrun.model.RunMetadata(uid=uid),
+ )
+ rundb_mock.store_run(run, uid)
+ result = launcher.launch(runtime, run)
+ assert result.status.state == "completed"
+
+
+def test_launch_remote_job_no_watch(rundb_mock):
+ launcher = mlrun.launcher.remote.ClientRemoteLauncher()
+ mlrun.config.config.artifact_path = "v3io:///users/admin/mlrun"
+ runtime = mlrun.code_to_function(
+ name="test", kind="job", filename=str(func_path), handler=handler
+ )
+ runtime.spec.image = "mlrun/mlrun"
+ result = launcher.launch(runtime, watch=False)
+ assert result.status.state == "created"
+
+
+def test_validate_inputs():
+ launcher = mlrun.launcher.remote.ClientRemoteLauncher()
+ runtime = mlrun.code_to_function(
+ name="test", kind="job", filename=str(func_path), handler=handler
+ )
+ run = mlrun.run.RunObject(spec=mlrun.model.RunSpec(inputs={"input1": 1}))
+ with pytest.raises(mlrun.errors.MLRunInvalidArgumentTypeError) as exc:
+ launcher._validate_runtime(runtime, run)
+ assert "Inputs should be of type Dict[str,str]" in str(exc.value)
+
+
+def test_validate_runtime_success():
+ launcher = mlrun.launcher.remote.ClientRemoteLauncher()
+ runtime = mlrun.code_to_function(
+ name="test", kind="local", filename=str(func_path), handler=handler
+ )
+ run = mlrun.run.RunObject(
+ spec=mlrun.model.RunSpec(inputs={"input1": ""}, output_path="./some_path")
+ )
+ launcher._validate_runtime(runtime, run)
From 22943a2fd5e41d3942f0469865388f792840a73d Mon Sep 17 00:00:00 2001
From: TomerShor <90552140+TomerShor@users.noreply.github.com>
Date: Mon, 15 May 2023 21:24:20 +0300
Subject: [PATCH 138/334] [Projects] Query db for name only when listing
projects with `name_only` format (#3560)
---
mlrun/api/db/sqldb/db.py | 16 ++++++++++++++--
1 file changed, 14 insertions(+), 2 deletions(-)
diff --git a/mlrun/api/db/sqldb/db.py b/mlrun/api/db/sqldb/db.py
index 0ae58a85603b..c48294480891 100644
--- a/mlrun/api/db/sqldb/db.py
+++ b/mlrun/api/db/sqldb/db.py
@@ -1437,16 +1437,26 @@ def list_projects(
names: typing.Optional[typing.List[str]] = None,
) -> mlrun.common.schemas.ProjectsOutput:
query = self._query(session, Project, owner=owner, state=state)
+
+ # if format is name_only, we don't need to query the full project object, we can just query the name
+ # and return it as a list of strings
+ if format_ == mlrun.common.schemas.ProjectsFormat.name_only:
+ query = self._query(session, Project.name, owner=owner, state=state)
+
+ # attach filters to the query
if labels:
query = self._add_labels_filter(session, query, Project, labels)
if names is not None:
query = query.filter(Project.name.in_(names))
+
project_records = query.all()
+
+ # format the projects according to the requested format
projects = []
for project_record in project_records:
if format_ == mlrun.common.schemas.ProjectsFormat.name_only:
- projects = [project_record.name for project_record in project_records]
- # leader format is only for follower mode which will format the projects returned from here
+ projects.append(project_record.name)
+
elif format_ == mlrun.common.schemas.ProjectsFormat.minimal:
projects.append(
mlrun.api.utils.helpers.minimize_project_schema(
@@ -1455,6 +1465,8 @@ def list_projects(
)
)
)
+
+ # leader format is only for follower mode which will format the projects returned from here
elif format_ in [
mlrun.common.schemas.ProjectsFormat.full,
mlrun.common.schemas.ProjectsFormat.leader,
From bce3000ba32c54a5fd676b566e784fa648998c83 Mon Sep 17 00:00:00 2001
From: Yael Genish <62285310+yaelgen@users.noreply.github.com>
Date: Tue, 16 May 2023 00:49:08 +0300
Subject: [PATCH 139/334] [Tests] Increase dockerized tests timeout (#3472)
---
tests/rundb/test_httpdb.py | 25 ++++++++++++++++++++++++-
1 file changed, 24 insertions(+), 1 deletion(-)
diff --git a/tests/rundb/test_httpdb.py b/tests/rundb/test_httpdb.py
index 5d3bbf7611d2..0ba78c6b54f6 100644
--- a/tests/rundb/test_httpdb.py
+++ b/tests/rundb/test_httpdb.py
@@ -14,6 +14,8 @@
import codecs
import io
+import sys
+import time
import unittest.mock
from collections import namedtuple
from os import environ
@@ -51,7 +53,7 @@ def free_port():
def check_server_up(url):
health_url = f"{url}/{HTTPRunDB.get_api_path_prefix()}/healthz"
- timeout = 30
+ timeout = 90
if not wait_for_server(health_url, timeout):
raise RuntimeError(f"server did not start after {timeout} sec")
@@ -201,6 +203,27 @@ def test_log(create_server):
assert data == body, "bad log data"
+@pytest.mark.skipif(
+ sys.platform == "darwin",
+ reason="We are developing on Apple Silicon Macs,"
+ " which will most likely fail this test due to the qemu being slow,"
+ " but should pass on native architecture",
+)
+def test_api_boot_speed(create_server):
+ run_times = 5
+ expected_time = 30
+ runs = []
+ for _ in range(run_times):
+ start_time = time.perf_counter()
+ create_server()
+ end_time = time.perf_counter()
+ runs.append(end_time - start_time)
+ avg_run_time = sum(runs) / run_times
+ assert (
+ avg_run_time <= expected_time
+ ), "Seems like a performance hit on creating api server"
+
+
def test_run(create_server):
server: Server = create_server()
db = server.conn
From 7169d42a03f209b22d87ffebd0ccbab02fc01eeb Mon Sep 17 00:00:00 2001
From: GiladShapira94 <100074049+GiladShapira94@users.noreply.github.com>
Date: Tue, 16 May 2023 00:50:53 +0300
Subject: [PATCH 140/334] [Projects] Fix file validation when set secrets or
set envs (#3549)
---
mlrun/projects/project.py | 13 ++++++++-----
mlrun/runtimes/pod.py | 14 ++++++++------
tests/projects/test_project.py | 10 ++++++++++
tests/runtimes/test_run.py | 21 +++++++++++++++++++++
4 files changed, 47 insertions(+), 11 deletions(-)
diff --git a/mlrun/projects/project.py b/mlrun/projects/project.py
index c881173254fc..d20c9122ddec 100644
--- a/mlrun/projects/project.py
+++ b/mlrun/projects/project.py
@@ -1847,11 +1847,14 @@ def set_secrets(
"must specify secrets OR file_path"
)
if file_path:
- secrets = dotenv.dotenv_values(file_path)
- if None in secrets.values():
- raise mlrun.errors.MLRunInvalidArgumentError(
- "env file lines must be in the form key=value"
- )
+ if path.isfile(file_path):
+ secrets = dotenv.dotenv_values(file_path)
+ if None in secrets.values():
+ raise mlrun.errors.MLRunInvalidArgumentError(
+ "env file lines must be in the form key=value"
+ )
+ else:
+ raise mlrun.errors.MLRunNotFoundError(f"{file_path} does not exist")
# drop V3IO paths/credentials and MLrun service API address
env_vars = {
key: val
diff --git a/mlrun/runtimes/pod.py b/mlrun/runtimes/pod.py
index 667685151a45..051586353eec 100644
--- a/mlrun/runtimes/pod.py
+++ b/mlrun/runtimes/pod.py
@@ -992,12 +992,14 @@ def set_envs(self, env_vars: dict = None, file_path: str = None):
"must specify env_vars OR file_path"
)
if file_path:
- env_vars = dotenv.dotenv_values(file_path)
- if None in env_vars.values():
- raise mlrun.errors.MLRunInvalidArgumentError(
- "env file lines must be in the form key=value"
- )
-
+ if os.path.isfile(file_path):
+ env_vars = dotenv.dotenv_values(file_path)
+ if None in env_vars.values():
+ raise mlrun.errors.MLRunInvalidArgumentError(
+ "env file lines must be in the form key=value"
+ )
+ else:
+ raise mlrun.errors.MLRunNotFoundError(f"{file_path} does not exist")
for name, value in env_vars.items():
self.set_env(name, value)
return self
diff --git a/tests/projects/test_project.py b/tests/projects/test_project.py
index ef70b65f38ae..a1bb17ddf00c 100644
--- a/tests/projects/test_project.py
+++ b/tests/projects/test_project.py
@@ -849,3 +849,13 @@ def test_remove_owner_name_in_load_project_from_yaml():
imported_project = mlrun.load_project("./", str(project_file_path), save=False)
assert project.spec.owner == "some_owner"
assert imported_project.spec.owner is None
+
+
+def test_set_secrets_file_not_found():
+ # Create project and generate owner name
+ project_name = "project-name"
+ file_name = ".env-test"
+ project = mlrun.new_project(project_name, save=False)
+ with pytest.raises(mlrun.errors.MLRunNotFoundError) as excinfo:
+ project.set_secrets(file_path=file_name)
+ assert f"{file_name} does not exist" in str(excinfo.value)
diff --git a/tests/runtimes/test_run.py b/tests/runtimes/test_run.py
index 91cd1a458b87..12b149950ed7 100644
--- a/tests/runtimes/test_run.py
+++ b/tests/runtimes/test_run.py
@@ -13,7 +13,9 @@
# limitations under the License.
#
import copy
+import pathlib
+import pytest
from deepdiff import DeepDiff
import mlrun
@@ -312,3 +314,22 @@ def test_new_function_invalid_characters():
invalid_function_name = "invalid_name with_spaces"
function = mlrun.new_function(name=invalid_function_name, runtime=runtime)
assert function.metadata.name == "invalid-name-with-spaces"
+
+
+def test_set_envs():
+ assets_path = pathlib.Path(__file__).parent.parent / "assets"
+ env_path = str(assets_path / "envfile")
+ runtime = _get_runtime()
+ function = mlrun.new_function(runtime=runtime)
+ function.set_envs(file_path=env_path)
+ assert function.get_env("ENV_ARG1") == "123"
+ assert function.get_env("ENV_ARG2") == "abc"
+
+
+def test_set_envs_file_not_find():
+ runtime = _get_runtime()
+ function = mlrun.new_function(runtime=runtime)
+ file_name = ".env-test"
+ with pytest.raises(mlrun.errors.MLRunNotFoundError) as excinfo:
+ function.set_envs(file_path=file_name)
+ assert f"{file_name} does not exist" in str(excinfo.value)
From e0f5b0f160cce4663aeea64e5e0aaae143b2f09b Mon Sep 17 00:00:00 2001
From: jillnogold <88145832+jillnogold@users.noreply.github.com>
Date: Tue, 16 May 2023 08:38:12 +0300
Subject: [PATCH 141/334] [Docs] Fix git error 3535, minor edits (#3558)
---
.gitignore | 2 +-
docs/CONTRIBUTING.md | 2 +-
docs/architecture.md | 2 +-
docs/feature-store/transformations.md | 9 ++++-----
docs/install/kubernetes.md | 4 ++--
docs/runtimes/load-from-hub.md | 10 +++++-----
6 files changed, 14 insertions(+), 15 deletions(-)
diff --git a/.gitignore b/.gitignore
index 580a9cd33ba3..0aa76c87fc68 100644
--- a/.gitignore
+++ b/.gitignore
@@ -31,7 +31,7 @@ tests/system/env.yml
# pyenv file for working with several python versions
.python-version
*.bak
-docs/CONTRIBUTING.md
+docs/contributing.md
mlrun/api/proto/*pb2*.py
docs/tutorial/colab/01-mlrun-basics-colab.ipynb
diff --git a/docs/CONTRIBUTING.md b/docs/CONTRIBUTING.md
index 5a6c03878999..c7f9f8d5724c 100644
--- a/docs/CONTRIBUTING.md
+++ b/docs/CONTRIBUTING.md
@@ -1,6 +1,6 @@
# Documenting mlrun
-This document describe how to write the external documentation for `mlrun`, the
+This document describes how to write the external documentation for `mlrun`, the
one you can view at https://mlrun.readthedocs.io
## Technology
diff --git a/docs/architecture.md b/docs/architecture.md
index 9840be4931fa..65d6677a872e 100644
--- a/docs/architecture.md
+++ b/docs/architecture.md
@@ -1,4 +1,4 @@
-(architecture)=
+(mlrun-architecture)=
# MLRun architecture
diff --git a/docs/feature-store/transformations.md b/docs/feature-store/transformations.md
index a3cbc0f9ad31..60851271dfd6 100644
--- a/docs/feature-store/transformations.md
+++ b/docs/feature-store/transformations.md
@@ -129,8 +129,8 @@ documentation.
## Built-in transformations
MLRun, and the associated `storey` package, have a built-in library of [transformation functions](../serving/available-steps.html) that can be
-applied as steps in the feature-set's internal execution graph. In order to add steps to the graph, it should be
-referenced from the {py:class}`~mlrun.feature_store.FeatureSet` object by using the
+applied as steps in the feature-set's internal execution graph. To add steps to the graph,
+reference them from the {py:class}`~mlrun.feature_store.FeatureSet` object by using the
{py:attr}`~mlrun.feature_store.FeatureSet.graph` property. Then, new steps can be added to the graph using the
functions in {py:mod}`storey.transformations` (follow the link to browse the documentation and the
list of existing functions). The transformations are also accessible directly from the `storey` module.
@@ -140,10 +140,9 @@ See the [built-in steps](../serving/available-steps.html).
```{admonition} Note
Internally, MLRun makes use of functions defined in the `storey` package for various purposes. When creating a
feature-set and configuring it with sources and targets, what MLRun does behind the scenes is to add steps to the
-execution graph that wraps methods and classes that perform the actions. When defining an async execution graph,
-
+execution graph that wraps methods and classes that perform the actions. When defining an async execution graph,
`storey` classes are used. For example, when defining a Parquet data-target in MLRun, a graph step is created that
-wraps storey's {py:func}`~storey.targets.ParquetTarget` function.
+wraps storey's [ParquetTarget function](https://storey.readthedocs.io/en/latest/api.html#storey.targets.ParquetTarget).
```
To use a function:
diff --git a/docs/install/kubernetes.md b/docs/install/kubernetes.md
index 302a281c73e7..26857672c7fd 100644
--- a/docs/install/kubernetes.md
+++ b/docs/install/kubernetes.md
@@ -69,7 +69,7 @@ kubectl create namespace mlrun
Add the Community Edition helm chart repo:
```bash
-helm repo add mlrun-ce https://mlrun.github.io/ce
+helm repo add mlrun-ce https://github.com/mlrun/ce
```
Run the following command to ensure that the repo is installed and available:
@@ -80,7 +80,7 @@ helm repo list
It should output something like:
```bash
NAME URL
-mlrun-ce https://mlrun.github.io/ce
+mlrun-ce https://github.com/mlrun/ce
```
Update the repo to make sure you're getting the latest chart:
diff --git a/docs/runtimes/load-from-hub.md b/docs/runtimes/load-from-hub.md
index 450493109770..11905638f1d6 100644
--- a/docs/runtimes/load-from-hub.md
+++ b/docs/runtimes/load-from-hub.md
@@ -59,7 +59,7 @@ print(f'Artifacts path: {artifact_path}\nMLRun DB path: {mlconf.dbpath}')
## Loading functions from the Hub
-Run `project.set_function` to load a functions.
+Run `project.set_function` to load a function.
`set_function` updates or adds a function object to the project.
`set_function(func, name='', kind='', image=None, with_repo=None)`
@@ -74,17 +74,17 @@ Parameters:
Returns: project object
-For more information see the {py:meth}`~mlrun.projects.MlrunProject.set_function`API documentation.
+For more information see the {py:meth}`~mlrun.projects.MlrunProject.set_function` API documentation.
### Load function example
-This example loads the describe function. This function analyzes a csv or parquet file for data analysis.
+This example loads the `describe` function. This function analyzes a csv or parquet file for data analysis.
```python
project.set_function('hub://describe', 'describe')
```
-Create a function object called my_describe:
+Create a function object called `my_describe`:
```python
my_describe = project.func('describe')
@@ -143,7 +143,7 @@ my_describe.run(name='describe',
### Viewing the jobs & the artifacts
-There are few options to view the outputs of the jobs we ran:
+There are few options to view the outputs of the jobs you ran:
- In Jupyter the result of the job is displayed in the Jupyter notebook. When you click on the artifacts it displays its content in Jupyter.
- In the MLRun UI, under the project name, you can view the job that was running as well as the artifacts it generated.
From 85960a2a97c2d959f540d5909bb7de1381978fda Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Tue, 16 May 2023 10:28:32 +0300
Subject: [PATCH 142/334] [HTTPDB] Do not enforce format (#3564)
---
mlrun/db/httpdb.py | 23 ++++++++++-------------
1 file changed, 10 insertions(+), 13 deletions(-)
diff --git a/mlrun/db/httpdb.py b/mlrun/db/httpdb.py
index bca7f9d46f37..786825d93361 100644
--- a/mlrun/db/httpdb.py
+++ b/mlrun/db/httpdb.py
@@ -2141,19 +2141,16 @@ def list_projects(
error_message = f"Failed listing projects, query: {params}"
response = self.api_call("GET", "projects", error_message, params=params)
if format_ == mlrun.common.schemas.ProjectsFormat.name_only:
+
+ # projects is just a list of strings
return response.json()["projects"]
- elif format_ in [
- mlrun.common.schemas.ProjectsFormat.full,
- mlrun.common.schemas.ProjectsFormat.minimal,
- ]:
- return [
- mlrun.projects.MlrunProject.from_dict(project_dict)
- for project_dict in response.json()["projects"]
- ]
- else:
- raise NotImplementedError(
- f"Provided format is not supported. format={format_}"
- )
+
+ # forwards compatibility - we want to be able to handle new formats that might be added in the future
+ # if format is not known to the api, it is up to the server to return either an error or a default format
+ return [
+ mlrun.projects.MlrunProject.from_dict(project_dict)
+ for project_dict in response.json()["projects"]
+ ]
def get_project(self, name: str) -> mlrun.projects.MlrunProject:
"""Get details for a specific project."""
@@ -2309,7 +2306,7 @@ def _verify_project_deleted():
format_=mlrun.common.schemas.ProjectsFormat.name_only
)
if project_name in projects:
- raise Exception("Project still exists")
+ raise Exception(f"Project {project_name} still exists")
return mlrun.utils.helpers.retry_until_successful(
self._wait_for_project_deletion_interval,
From 509501560d309d587041fc0ac8da4a247bd763ec Mon Sep 17 00:00:00 2001
From: eliyahu77 <40737397+eliyahu77@users.noreply.github.com>
Date: Tue, 16 May 2023 17:49:48 +0300
Subject: [PATCH 143/334] [CI] Add setup install fs required services script
(#3492)
---
.github/workflows/system-tests-enterprise.yml | 2 +
automation/system_test/prepare.py | 39 ++++++++++++++++---
2 files changed, 36 insertions(+), 5 deletions(-)
diff --git a/.github/workflows/system-tests-enterprise.yml b/.github/workflows/system-tests-enterprise.yml
index fec56b1b9124..81aa6915ae8f 100644
--- a/.github/workflows/system-tests-enterprise.yml
+++ b/.github/workflows/system-tests-enterprise.yml
@@ -309,6 +309,8 @@ jobs:
- name: Install curl and jq
run: sudo apt-get install curl jq
- name: Prepare System Test env.yaml and MLRun installation from current branch
+ env:
+ IP_ADDR_PREFIX: ${{ secrets.IP_ADDR_PREFIX }}
timeout-minutes: 5
run: |
python automation/system_test/prepare.py env \
diff --git a/automation/system_test/prepare.py b/automation/system_test/prepare.py
index 0916ae34186f..62d8f8333efe 100644
--- a/automation/system_test/prepare.py
+++ b/automation/system_test/prepare.py
@@ -15,6 +15,7 @@
import datetime
import logging
+import os
import pathlib
import subprocess
import sys
@@ -135,7 +136,10 @@ def connect_to_remote(self):
def run(self):
self.connect_to_remote()
-
+ try:
+ self._install_devutilities()
+ except Exception as exp:
+ self._logger.error("error on install devutilities", exception=str(exp))
# for sanity clean up before starting the run
self.clean_up_remote_workdir()
@@ -335,11 +339,39 @@ def _override_mlrun_api_env(self):
args=["apply", "-f", manifest_file_name],
)
+ def _install_devutilities(self):
+ urlscript = "https://gist.github.com/a51d75fe52e95df617b5dbb983c8e6e1.git"
+ ipaddr = "--ipaddr " + os.environ.get("IP_ADDR_PREFIX")
+ list_uninstall = [
+ "dev_utilities.py",
+ "uninstall",
+ "--redis",
+ "--mysql",
+ "--redisinsight",
+ "--kafka",
+ ]
+ list_install = [
+ "dev_utilities.py",
+ "install",
+ "--redis",
+ "--mysql",
+ "--redisinsight",
+ "--kafka",
+ ipaddr,
+ ]
+ self._run_command("rm", args=["-rf", "/home/iguazio/dev_utilities"])
+ self._run_command("git", args=["clone", urlscript, "dev_utilities"])
+ self._run_command(
+ "python3", args=list_uninstall, workdir="/home/iguazio/dev_utilities"
+ )
+ self._run_command(
+ "python3", args=list_install, workdir="/home/iguazio/dev_utilities"
+ )
+
def _download_provctl(self):
# extract bucket name, object name from s3 file path
# https://.s3.amazonaws.com/
# s3:///
-
parsed_url = urllib.parse.urlparse(self._provctl_download_url)
if self._provctl_download_url.startswith("s3://"):
object_name = parsed_url.path.lstrip("/")
@@ -347,7 +379,6 @@ def _download_provctl(self):
else:
object_name = parsed_url.path.lstrip("/")
bucket_name = parsed_url.netloc.split(".")[0]
-
# download provctl from s3
with tempfile.NamedTemporaryFile() as local_provctl_path:
self._logger.debug(
@@ -362,7 +393,6 @@ def _download_provctl(self):
aws_access_key_id=self._provctl_download_s3_key_id,
)
s3_client.download_file(bucket_name, object_name, local_provctl_path.name)
-
# upload provctl to data node
self._logger.debug(
"Uploading provctl to datanode",
@@ -372,7 +402,6 @@ def _download_provctl(self):
sftp_client = self._ssh_client.open_sftp()
sftp_client.put(local_provctl_path.name, str(self.Constants.provctl_path))
sftp_client.close()
-
# make provctl executable
self._run_command("chmod", args=["+x", str(self.Constants.provctl_path)])
From 19e2e8fd3244f162e1c585c90cdcc2984fe99b75 Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Tue, 16 May 2023 20:53:50 +0300
Subject: [PATCH 144/334] [SQLDB] Remove get function latest uid method (#3569)
---
mlrun/api/db/sqldb/db.py | 11 -----------
1 file changed, 11 deletions(-)
diff --git a/mlrun/api/db/sqldb/db.py b/mlrun/api/db/sqldb/db.py
index c48294480891..f944fea89553 100644
--- a/mlrun/api/db/sqldb/db.py
+++ b/mlrun/api/db/sqldb/db.py
@@ -2781,17 +2781,6 @@ def _query(self, session, cls, **kw):
kw = {k: v for k, v in kw.items() if v is not None}
return session.query(cls).filter_by(**kw)
- def _function_latest_uid(self, session, project, name):
- # FIXME
- query = (
- self._query(session, Function.uid)
- .filter(Function.project == project, Function.name == name)
- .order_by(Function.updated.desc())
- ).limit(1)
- out = query.one_or_none()
- if out:
- return out[0]
-
def _find_or_create_users(self, session, user_names):
users = list(self._query(session, User).filter(User.name.in_(user_names)))
new = set(user_names) - {user.name for user in users}
From 29160b9ed05ba97e42ec040136119c754ff8fccc Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Tue, 16 May 2023 22:18:42 +0300
Subject: [PATCH 145/334] [Dask] Remove commented out "is client" test (#3571)
---
mlrun/runtimes/daskjob.py | 4 ----
1 file changed, 4 deletions(-)
diff --git a/mlrun/runtimes/daskjob.py b/mlrun/runtimes/daskjob.py
index 79be2190c596..58f0d3080b19 100644
--- a/mlrun/runtimes/daskjob.py
+++ b/mlrun/runtimes/daskjob.py
@@ -352,10 +352,6 @@ def client(self):
f"remote scheduler at {addr} not ready, will try to restart {err_to_str(exc)}"
)
- # todo: figure out if test is needed
- # if self._is_remote_api():
- # raise Exception('no access to Kubernetes API')
-
status = self.get_status()
if status != "running":
self._start()
From 6417fa511ba42b925365df19913a795e8140d69f Mon Sep 17 00:00:00 2001
From: Tom Tankilevitch <59158507+Tankilevitch@users.noreply.github.com>
Date: Tue, 16 May 2023 23:34:09 +0300
Subject: [PATCH 146/334] [CI] Periodic rebuild of unstable images (#3562)
---
.github/workflows/periodic-rebuild.yaml | 51 +++++++++++++++++++++++++
1 file changed, 51 insertions(+)
create mode 100644 .github/workflows/periodic-rebuild.yaml
diff --git a/.github/workflows/periodic-rebuild.yaml b/.github/workflows/periodic-rebuild.yaml
new file mode 100644
index 000000000000..8ef39ea5ad1a
--- /dev/null
+++ b/.github/workflows/periodic-rebuild.yaml
@@ -0,0 +1,51 @@
+# Copyright 2023 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+name: Scheduled Re-Build Images
+
+on:
+ schedule:
+ # every night at 2am
+ - cron: "0 2 * * *"
+
+jobs:
+ re-build-images:
+ strategy:
+ fail-fast: false
+ matrix:
+ repo: ["mlrun","ui"]
+ branch: ["development","1.3.x"]
+ runs-on: ubuntu-latest
+ steps:
+ - name: Re-Build MLRun Image
+ if: matrix.repo == 'mlrun'
+ uses: convictional/trigger-workflow-and-wait@v1.6.5
+ with:
+ owner: mlrun
+ repo: mlrun
+ github_token: ${{ secrets.RELEASE_GITHUB_ACCESS_TOKEN }}
+ workflow_file_name: build.yaml
+ ref: ${{ matrix.branch }}
+ wait_interval: 60
+ client_payload: '{"skip_images": "models-gpu,models,base,tests", "build_from_cache": "false"}'
+ - name: Re-Build UI Image
+ if: matrix.repo == 'ui'
+ uses: convictional/trigger-workflow-and-wait@v1.6.5
+ with:
+ owner: mlrun
+ repo: ui
+ github_token: ${{ secrets.RELEASE_GITHUB_ACCESS_TOKEN }}
+ workflow_file_name: build.yaml
+ ref: ${{ matrix.branch }}
+ wait_interval: 60
From 4229670c859c2b5ae34752bee705e408e669889a Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Wed, 17 May 2023 10:04:52 +0300
Subject: [PATCH 147/334] [API] Prepare some configuration for local debugging
(#3578)
---
mlrun/api/main.py | 4 ++--
mlrun/api/utils/singletons/k8s.py | 2 +-
mlrun/config.py | 5 +++--
3 files changed, 6 insertions(+), 5 deletions(-)
diff --git a/mlrun/api/main.py b/mlrun/api/main.py
index 611585369dd2..037a50d305dc 100644
--- a/mlrun/api/main.py
+++ b/mlrun/api/main.py
@@ -120,8 +120,8 @@ async def http_status_error_handler(
@app.on_event("startup")
async def startup_event():
logger.info(
- "configuration dump",
- dumped_config=config.dump_yaml(),
+ "On startup event handler called",
+ config=config.dump_yaml(),
version=mlrun.utils.version.Version().get(),
)
loop = asyncio.get_running_loop()
diff --git a/mlrun/api/utils/singletons/k8s.py b/mlrun/api/utils/singletons/k8s.py
index 9cd901e91e22..a82a4b29a7b1 100644
--- a/mlrun/api/utils/singletons/k8s.py
+++ b/mlrun/api/utils/singletons/k8s.py
@@ -50,7 +50,7 @@ class SecretTypes:
class K8sHelper:
def __init__(self, namespace=None, config_file=None, silent=False, log=True):
self.namespace = namespace or mlconfig.config.namespace
- self.config_file = config_file
+ self.config_file = config_file or mlconfig.config.kubeconfig_path or None
self.running_inside_kubernetes_cluster = False
try:
self._init_k8s_config(log)
diff --git a/mlrun/config.py b/mlrun/config.py
index a2bb8a0f3138..286cf8253498 100644
--- a/mlrun/config.py
+++ b/mlrun/config.py
@@ -48,6 +48,7 @@
default_config = {
"namespace": "", # default kubernetes namespace
+ "kubeconfig_path": "", # path to kubeconfig file
"dbpath": "", # db/api url
# url to nuclio dashboard api (can be with user & token, e.g. https://username:password@dashboard-url.com)
"nuclio_dashboard_url": "",
@@ -538,7 +539,7 @@ def is_running_as_api():
if _is_running_as_api is None:
# os.getenv will load the env var as string, and json.loads will convert it to a bool
- _is_running_as_api = json.loads(os.getenv("MLRUN_IS_API_SERVER", "false"))
+ _is_running_as_api = os.getenv("MLRUN_IS_API_SERVER", "false").lower() == "true"
return _is_running_as_api
@@ -1028,7 +1029,7 @@ def _populate(skip_errors=False):
def _do_populate(env=None, skip_errors=False):
global config
- if not os.environ.get("MLRUN_IGNORE_ENV_FILE") and not is_running_as_api():
+ if not os.environ.get("MLRUN_IGNORE_ENV_FILE"):
if "MLRUN_ENV_FILE" in os.environ:
env_file = os.path.expanduser(os.environ["MLRUN_ENV_FILE"])
dotenv.load_dotenv(env_file, override=True)
From 2666afe02a8bf00c1a64ba587d8a4ae3004728d2 Mon Sep 17 00:00:00 2001
From: Tom Tankilevitch <59158507+Tankilevitch@users.noreply.github.com>
Date: Wed, 17 May 2023 11:11:44 +0300
Subject: [PATCH 148/334] [API] Align functions endpoints (#3576)
---
mlrun/api/api/endpoints/functions.py | 24 +++++++++++++++++++++---
mlrun/db/httpdb.py | 10 +++++-----
tests/api/api/test_functions.py | 8 ++++----
3 files changed, 30 insertions(+), 12 deletions(-)
diff --git a/mlrun/api/api/endpoints/functions.py b/mlrun/api/api/endpoints/functions.py
index cf25f03a6e1b..5765a96a76aa 100644
--- a/mlrun/api/api/endpoints/functions.py
+++ b/mlrun/api/api/endpoints/functions.py
@@ -58,7 +58,13 @@
router = APIRouter()
-@router.post("/func/{project}/{name}")
+@router.post(
+ "/func/{project}/{name}",
+ deprecated=True,
+ description="/func/{project}/{name} is deprecated in 1.4.0 and will be removed in 1.6.0, "
+ "use /projects/{project}/functions/{name} instead",
+)
+@router.post("/projects/{project}/functions/{name}")
async def store_function(
request: Request,
project: str,
@@ -103,7 +109,13 @@ async def store_function(
}
-@router.get("/func/{project}/{name}")
+@router.get(
+ "/func/{project}/{name}",
+ deprecated=True,
+ description="/func/{project}/{name} is deprecated in 1.4.0 and will be removed in 1.6.0, "
+ "use /projects/{project}/functions/{name} instead",
+)
+@router.get("/projects/{project}/functions/{name}")
async def get_function(
project: str,
name: str,
@@ -154,7 +166,13 @@ async def delete_function(
return Response(status_code=HTTPStatus.NO_CONTENT.value)
-@router.get("/funcs")
+@router.get(
+ "/funcs",
+ deprecated=True,
+ description="/funcs is deprecated in 1.4.0 and will be removed in 1.6.0, "
+ "use /projects/{project}/functions instead",
+)
+@router.get("/projects/{project}/functions")
async def list_functions(
project: str = None,
name: str = None,
diff --git a/mlrun/db/httpdb.py b/mlrun/db/httpdb.py
index 786825d93361..197c1ef17ac5 100644
--- a/mlrun/db/httpdb.py
+++ b/mlrun/db/httpdb.py
@@ -826,7 +826,7 @@ def store_function(
params = {"tag": tag, "versioned": versioned}
project = project or config.default_project
- path = self._path_of("func", project, name)
+ path = f"projects/{project}/functions/{name}"
error = f"store function {project}/{name}"
resp = self.api_call(
@@ -841,7 +841,7 @@ def get_function(self, name, project="", tag=None, hash_key=""):
params = {"tag": tag, "hash_key": hash_key}
project = project or config.default_project
- path = self._path_of("func", project, name)
+ path = f"projects/{project}/functions/{name}"
error = f"get function {project}/{name}"
resp = self.api_call("GET", path, error, params=params)
return resp.json()["func"]
@@ -863,15 +863,15 @@ def list_functions(self, name=None, project=None, tag=None, labels=None):
:param labels: Return functions that have specific labels assigned to them.
:returns: List of function objects (as dictionary).
"""
-
+ project = project or config.default_project
params = {
- "project": project or config.default_project,
"name": name,
"tag": tag,
"label": labels or [],
}
error = "list functions"
- resp = self.api_call("GET", "funcs", error, params=params)
+ path = f"projects/{project}/functions"
+ resp = self.api_call("GET", path, error, params=params)
return resp.json()["funcs"]
def list_runtime_resources(
diff --git a/tests/api/api/test_functions.py b/tests/api/api/test_functions.py
index a20dcb274564..5d7652dc8c87 100644
--- a/tests/api/api/test_functions.py
+++ b/tests/api/api/test_functions.py
@@ -29,6 +29,7 @@
import mlrun.api.api.endpoints.functions
import mlrun.api.api.utils
import mlrun.api.crud
+import mlrun.api.main
import mlrun.api.utils.clients.chief
import mlrun.api.utils.singletons.db
import mlrun.api.utils.singletons.k8s
@@ -113,8 +114,7 @@ async def test_list_functions_with_hash_key_versioned(
}
post_function1_response = await async_client.post(
- f"func/{function_project}/"
- f"{function_name}?tag={function_tag}&versioned={True}",
+ f"projects/{function_project}/functions/{function_name}?tag={function_tag}&versioned={True}",
json=function,
)
@@ -123,14 +123,14 @@ async def test_list_functions_with_hash_key_versioned(
# Store another function with the same project and name but different tag and hash key
post_function2_response = await async_client.post(
- f"func/{function_project}/"
+ f"projects/{function_project}/functions/"
f"{function_name}?tag={another_tag}&versioned={True}",
json=function2,
)
assert post_function2_response.status_code == HTTPStatus.OK.value
list_functions_by_hash_key_response = await async_client.get(
- f"funcs?project={function_project}&name={function_name}&hash_key={hash_key}"
+ f"projects/{function_project}/functions?name={function_name}&hash_key={hash_key}"
)
list_functions_results = list_functions_by_hash_key_response.json()["funcs"]
From 46b730edb3921247568531f81daacd6a0afce5c5 Mon Sep 17 00:00:00 2001
From: jillnogold <88145832+jillnogold@users.noreply.github.com>
Date: Wed, 17 May 2023 11:47:17 +0300
Subject: [PATCH 149/334] [Docs] Add Git best practices topic (#3573)
---
docs/projects/git-best-practices.ipynb | 344 +++++++++++++++++++++++++
docs/projects/project.md | 3 +-
docs/runtimes/spark-operator.ipynb | 2 +-
3 files changed, 347 insertions(+), 2 deletions(-)
create mode 100644 docs/projects/git-best-practices.ipynb
diff --git a/docs/projects/git-best-practices.ipynb b/docs/projects/git-best-practices.ipynb
new file mode 100644
index 000000000000..096c939fe21f
--- /dev/null
+++ b/docs/projects/git-best-practices.ipynb
@@ -0,0 +1,344 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "54d41da3",
+ "metadata": {},
+ "source": [
+ "# Git best practices"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "29a0e0da",
+ "metadata": {},
+ "source": [
+ "This section provides an overview of developing and deploying ML applications using MLRun and Git. It covers the following:\n",
+ "- [MLRun and Git Overview](#mlrun-and-git-overview)\n",
+ " - [Load Code from Container vs Load Code at Runtime](#load-code-from-container-vs-load-code-at-runtime)\n",
+ "- [Common Tasks](#common-tasks)\n",
+ " - [Setting Up New MLRun Project Repo](#setting-up-new-mlrun-project-repo)\n",
+ " - [Running Existing MLRun Project Repo](#running-existing-mlrun-project-repo)\n",
+ " - [Pushing Changes to MLRun Project Repo](#pushing-changes-to-mlrun-project-repo)\n",
+ " - [Utilizing Different Branches](#utilizing-different-branches)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e298490d-b0ce-4cc1-af66-2c4b00f09270",
+ "metadata": {},
+ "source": [
+ "```{admonition} Note\n",
+ "This section assumes basic familiarity with version control software such as GitHub, GitLab, etc. If you're new to Git and version control, see the [GitHub Hello World documentation](https://docs.github.com/en/get-started/quickstart/hello-world).\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6a3a0b29",
+ "metadata": {},
+ "source": [
+ "## MLRun and Git Overview"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "43164106",
+ "metadata": {},
+ "source": [
+ "As a best practice, your MLRun project **should be backed by a Git repo**. This allows you to keep track of your code in source control as well as utilize your entire code library within your MLRun functions."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d88ad2d5",
+ "metadata": {},
+ "source": [
+ "The typical lifecycle of a project is as follows:"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "60ca000e",
+ "metadata": {},
+ "source": [
+ "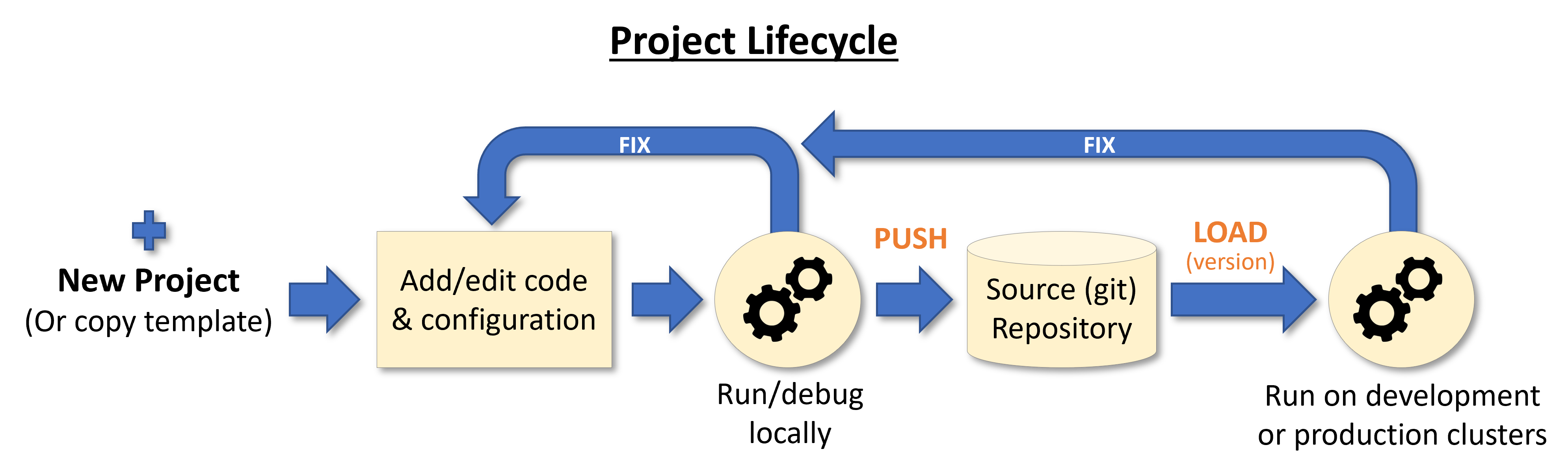"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bc981d84",
+ "metadata": {},
+ "source": [
+ "Many people like to develop locally on their laptops, Jupyter environments, or local IDE before submitting the code to Git and running on the larger cluster. See [Set up your client environment](https://docs.mlrun.org/en/latest/install/remote.html) for more details."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d4f36927-b688-406f-9555-1d6e90abcb50",
+ "metadata": {},
+ "source": [
+ "### Loading the code from container vs. loading the code at runtime"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dc5cd2ab-bd08-44a7-812e-47f252666ec7",
+ "metadata": {},
+ "source": [
+ "MLRun supports two approaches to loading the code from Git:\n",
+ "\n",
+ "- Loading the code from container (default behavior)
\n",
+ "The image for the MLRun function is built once, and consumes the code in the repo. **This is the preferred approach for production workloads**. For example:\n",
+ "\n",
+ "```python\n",
+ "project.set_source(source=\"git://github.com/mlrun/project-archive.git\")\n",
+ "\n",
+ "fn = project.set_function(\n",
+ " name=\"myjob\", handler=\"job_func.job_handler\",\n",
+ " image=\"mlrun/mlrun\", kind=\"job\", with_repo=True,\n",
+ ")\n",
+ "\n",
+ "project.build_function(fn)\n",
+ "```\n",
+ "\n",
+ "- Loading the code at runtime
\n",
+ "The MLRun function pulls the source code directly from Git at runtime. **This is a simpler approach during development that allows for making code changes without re-building the image each time.** For example:\n",
+ "\n",
+ "```python\n",
+ "project.set_source(source=\"git://github.com/mlrun/project-archive.git\", pull_at_runtime=True)\n",
+ "\n",
+ "fn = project.set_function(\n",
+ " name=\"nuclio\", handler=\"nuclio_func:nuclio_handler\",\n",
+ " image=\"mlrun/mlrun\", kind=\"nuclio\", with_repo=True,\n",
+ ")\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6cd96715-f85b-4ad1-82c1-1d063d45b3c9",
+ "metadata": {},
+ "source": [
+ "## Common tasks"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7641829b",
+ "metadata": {},
+ "source": [
+ "### Setting up a new MLRun project repo"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b994758b-6cf5-4c91-aa00-e4f1641471a1",
+ "metadata": {},
+ "source": [
+ "1. Initialize your repo using the command line as per [this guide](https://dev.to/bowmanjd/create-and-initialize-a-new-github-repository-from-the-command-line-85e) or using your version control software of choice (e.g. GitHub, GitLab, etc).\n",
+ "\n",
+ "```bash\n",
+ "git init ...\n",
+ "git add ...\n",
+ "git commit -m ...\n",
+ "git remote add origin ...\n",
+ "git branch -M \n",
+ "git push -u origin \n",
+ "\n",
+ "```\n",
+ "\n",
+ "2. Clone the repo to the local environment where the MLRun client is installed (e.g. Jupyter, VSCode, etc.) and navigate to the repo.\n",
+ "\n",
+ "```{admonition} Note\n",
+ "It is assumed that your local environment has the required access to pull a private repo.\n",
+ "```\n",
+ "```bash\n",
+ "git clone \n",
+ "cd \n",
+ "```\n",
+ "\n",
+ "3. Initialize a new MLRun project with the context pointing to your newly cloned repo.\n",
+ "\n",
+ "```python\n",
+ "import mlrun\n",
+ "\n",
+ "project = mlrun.get_or_create_project(name=\"my-super-cool-project\", context=\"./\")\n",
+ "```\n",
+ "\n",
+ "4. Set the MLRun project source with the desired `pull_at_runtime` behavior (see [Loading the code from container vs. loading the code at runtime](#load-code-from-container-vs-load-code-at-runtime) for more info). Also set `GIT_TOKEN` in MLRun project secrets for working with private repos.\n",
+ "\n",
+ "```python\n",
+ "# Notice the prefix has been changed to git://\n",
+ "project.set_source(source=\"git://github.com/mlrun/project-archive.git\", pull_at_runtime=True)\n",
+ "project.set_secrets(secrets={\"GIT_TOKEN\" : \"XXXXXXXXXXXXXXX\"}, provider=\"kubernetes\")\n",
+ "```\n",
+ "\n",
+ "5. Register any MLRun functions or workflows and save. Make sure `with_repo` is `True` in order to add source code to the function.\n",
+ "\n",
+ "```python\n",
+ "project.set_function(name='train_model', func='train_model.py', kind='job', image='mlrun/mlrun', with_repo=True)\n",
+ "project.set_workflow(name='training_pipeline', workflow_path='training_pipeline.py')\n",
+ "project.save()\n",
+ "```\n",
+ "\n",
+ "6. Push additions to Git.\n",
+ "\n",
+ "```bash\n",
+ "git add ...\n",
+ "git commit -m ...\n",
+ "git push ...\n",
+ "```\n",
+ "\n",
+ "7. Run the MLRun function/workflow. The source code is added to the function and is available via imports as expected.\n",
+ "\n",
+ "```python\n",
+ "project.run_function(function=\"train_model\")\n",
+ "project.run(name=\"training_pipeline\")\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "547733d0",
+ "metadata": {},
+ "source": [
+ "### Running an existing MLRun project repo"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8bbf162a-7348-424b-a72d-d64c90dd4db2",
+ "metadata": {},
+ "source": [
+ "1. Clone an existing MLRun project repo to your local environment where the MLRun client is installed (e.g. Jupyter, VSCode, etc.) and navigate to the repo.\n",
+ "\n",
+ "```bash\n",
+ "git clone \n",
+ "cd \n",
+ "```\n",
+ "\n",
+ "2. Load the MLRun project with the context pointing to your newly cloned repo. **MLRun is looking for a `project.yaml` file in the root of the repo**.\n",
+ "\n",
+ "```python\n",
+ "project = mlrun.load_project(context=\"./\")\n",
+ "```\n",
+ "\n",
+ "3. Optionally enable `pull_at_runtime` for easier development. Also set `GIT_TOKEN` in the MLRun Project secrets for working with private repos.\n",
+ "\n",
+ "```python\n",
+ "# source=None will use current Git source\n",
+ "project.set_source(source=None, pull_at_runtime=True)\n",
+ "project.set_secrets(secrets={\"GIT_TOKEN\" : \"XXXXXXXXXXXXXXX\"}, provider=\"kubernetes\")\n",
+ "```\n",
+ "\n",
+ "4. Run the MLRun function/workflow. The source code is added to the function and is available via imports as expected.\n",
+ "\n",
+ "```python\n",
+ "project.run_function(function=\"train_model\")\n",
+ "project.run(name=\"training_pipeline\")\n",
+ "```\n",
+ "\n",
+ "```{admonition} Note\n",
+ "If another user previously ran the project in your MLRun environment, ensure that your user has project permissions (otherwise you may not be able to view or run the project).\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "aea0970c",
+ "metadata": {},
+ "source": [
+ "### Pushing changes to the MLRun project repo"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ef0d8e9a-f5b0-4675-99e1-7764b054c0ba",
+ "metadata": {},
+ "source": [
+ "1. Edit the source code/functions/workflows in some way.\n",
+ "2. Check-in changes to Git.\n",
+ "\n",
+ "```bash\n",
+ "git add ...\n",
+ "git commit -m ...\n",
+ "git push ...\n",
+ "```\n",
+ "\n",
+ "3. If `pull_at_runtime=False`, re-build the Docker image. If `pull_at_runtime=True`, skip this step.\n",
+ "\n",
+ "```python\n",
+ "import mlrun\n",
+ "\n",
+ "project = mlrun.load_project(context=\"./\")\n",
+ "project.build_function(\"my_updated_function\")\n",
+ "```\n",
+ "\n",
+ "4. Run the MLRun function/workflow. The source code with changes is added to the function and is available via imports as expected.\n",
+ "\n",
+ "```python\n",
+ "project.run_function(function=\"train_model\")\n",
+ "project.run(name=\"training_pipeline\")\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7d0a5e97",
+ "metadata": {},
+ "source": [
+ "### Utilizing different branches"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c5a1878c-a565-478d-a9b6-96a876a7f3ff",
+ "metadata": {},
+ "source": [
+ "1. Check out the desired branch in the local environment.\n",
+ "\n",
+ "```bash\n",
+ "git checkout \n",
+ "```\n",
+ "\n",
+ "2. Update the desired branch in MLRun project. Optionally, save if the branch should be used for future runs.\n",
+ "\n",
+ "```python\n",
+ "project.set_source(\n",
+ " source=\"git://github.com/igz-us-sales/mlrun-git-example.git#spanish\",\n",
+ " pull_at_runtime=True\n",
+ ")\n",
+ "project.save()\n",
+ "```\n",
+ "\n",
+ "3. Run the MLRun function/workflow. The source code from desired branch is added to the function and is available via imports as expected.\n",
+ "\n",
+ "```python\n",
+ "project.run_function(\"greetings\")\n",
+ "```"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.7"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/docs/projects/project.md b/docs/projects/project.md
index 7481422458f8..16ab5c20c983 100644
--- a/docs/projects/project.md
+++ b/docs/projects/project.md
@@ -9,7 +9,7 @@ MLRun **Project** is a container for all your work on a particular ML applicatio
Projects are stored in a GIT or archive and map to IDE projects (in PyCharm, VSCode, etc.), which enables versioning, collaboration, and [CI/CD](../projects/ci-integration.html).
Projects simplify how you process data, [submit jobs](../concepts/submitting-tasks-jobs-to-functions.html), run [multi-stage workflows](../concepts/workflow-overview.html), and deploy [real-time pipelines](../serving/serving-graph.html) in continuous development or production environments.
-
+
**In this section**
@@ -17,6 +17,7 @@ Projects simplify how you process data, [submit jobs](../concepts/submitting-tas
:maxdepth: 1
create-project
+git-best-practices
load-project
run-build-deploy
build-run-workflows-pipelines
diff --git a/docs/runtimes/spark-operator.ipynb b/docs/runtimes/spark-operator.ipynb
index 05596eb357cd..440fa6b9f9c6 100644
--- a/docs/runtimes/spark-operator.ipynb
+++ b/docs/runtimes/spark-operator.ipynb
@@ -64,7 +64,7 @@
"sj.spec.spark_conf[\"spark.eventLog.enabled\"] = True\n",
"\n",
"# add python module\n",
- "sj.spec.build.commands = [\"pip install matplotlib\"]\n",
+ "sj.with_requiremants([`matplotlib`])\n",
"\n",
"# Number of executors\n",
"sj.spec.replicas = 2"
From 84a1d7f352d388ae90d645edab213be27f649633 Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Wed, 17 May 2023 12:59:00 +0300
Subject: [PATCH 150/334] [API] Deprecate artifacts endpoints (#3574)
---
mlrun/api/api/endpoints/artifacts.py | 45 +++++++++++++++++++++-------
1 file changed, 35 insertions(+), 10 deletions(-)
diff --git a/mlrun/api/api/endpoints/artifacts.py b/mlrun/api/api/endpoints/artifacts.py
index ee43f16f8b15..169e75ef665b 100644
--- a/mlrun/api/api/endpoints/artifacts.py
+++ b/mlrun/api/api/endpoints/artifacts.py
@@ -32,8 +32,13 @@
router = APIRouter()
-# TODO /artifact/{project}/{uid}/{key:path} should be deprecated in 1.4
-@router.post("/artifact/{project}/{uid}/{key:path}")
+# TODO: remove /artifact/{project}/{uid}/{key:path} in 1.6.0
+@router.post(
+ "/artifact/{project}/{uid}/{key:path}",
+ deprecated=True,
+ description="/artifact/{project}/{uid}/{key:path} is deprecated in 1.4.0 and will be removed in 1.6.0, "
+ "use /projects/{project}/artifacts/{uid}/{key:path} instead",
+)
@router.post("/projects/{project}/artifacts/{uid}/{key:path}")
async def store_artifact(
request: Request,
@@ -116,8 +121,13 @@ async def list_artifact_tags(
}
-# TODO /projects/{project}/artifact/{key:path} should be deprecated in 1.4
-@router.get("/projects/{project}/artifact/{key:path}")
+# TODO: remove /projects/{project}/artifact/{key:path} in 1.6.0
+@router.get(
+ "/projects/{project}/artifact/{key:path}",
+ deprecated=True,
+ description="/projects/{project}/artifact/{key:path} is deprecated in 1.4.0 and will be removed in 1.6.0, "
+ "use /projects/{project}/artifacts/{key:path} instead",
+)
@router.get("/projects/{project}/artifacts/{key:path}")
async def get_artifact(
project: str,
@@ -149,8 +159,13 @@ async def get_artifact(
}
-# TODO /artifact/{project}/{uid} should be deprecated in 1.4
-@router.delete("/artifact/{project}/{uid}")
+# TODO: remove /artifact/{project}/{uid} in 1.6.0
+@router.delete(
+ "/artifact/{project}/{uid}",
+ deprecated=True,
+ description="/artifact/{project}/{uid} is deprecated in 1.4.0 and will be removed in 1.6.0, "
+ "use /projects/{project}/artifacts/{uid} instead",
+)
@router.delete("/projects/{project}/artifacts/{uid}")
async def delete_artifact(
project: str,
@@ -173,8 +188,13 @@ async def delete_artifact(
return {}
-# TODO /artifacts should be deprecated in 1.4
-@router.get("/artifacts")
+# TODO: remove /artifacts in 1.6.0
+@router.get(
+ "/artifacts",
+ deprecated=True,
+ description="/artifacts is deprecated in 1.4.0 and will be removed in 1.6.0, "
+ "use /projects/{project}/artifacts instead",
+)
@router.get("/projects/{project}/artifacts")
async def list_artifacts(
project: str = None,
@@ -222,8 +242,13 @@ async def list_artifacts(
}
-# TODO /artifacts should be deprecated in 1.4
-@router.delete("/artifacts")
+# TODO: remove /artifacts in 1.6.0
+@router.delete(
+ "/artifacts",
+ deprecated=True,
+ description="/artifacts is deprecated in 1.4.0 and will be removed in 1.6.0, "
+ "use /projects/{project}/artifacts instead",
+)
async def delete_artifacts_legacy(
project: str = mlrun.mlconf.default_project,
name: str = "",
From c68868080e5f53386530ce6df778cf6ccc19cf77 Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Wed, 17 May 2023 13:00:04 +0300
Subject: [PATCH 151/334] [API] Update comment on /api router prefix (#3575)
---
mlrun/api/main.py | 5 +++--
1 file changed, 3 insertions(+), 2 deletions(-)
diff --git a/mlrun/api/main.py b/mlrun/api/main.py
index 037a50d305dc..80e00d196017 100644
--- a/mlrun/api/main.py
+++ b/mlrun/api/main.py
@@ -80,8 +80,9 @@
)
app.include_router(api_router, prefix=BASE_VERSIONED_API_PREFIX)
# This is for backward compatibility, that is why we still leave it here but not include it in the schema
-# so new users won't use the old un-versioned api
-# TODO: remove in 1.4.0
+# so new users won't use the old un-versioned api.
+# /api points to /api/v1 since it is used externally, and we don't want to break it.
+# TODO: make sure UI and all relevant Iguazio versions uses /api/v1 and deprecate this
app.include_router(api_router, prefix=API_PREFIX, include_in_schema=False)
init_middlewares(app)
From 746ae26a1530009ca2edac1c29868a89745ef654 Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Wed, 17 May 2023 13:19:52 +0300
Subject: [PATCH 152/334] [API] Prepare some configuration for local debugging
follow up (#3580)
---
mlrun/api/utils/singletons/k8s.py | 4 ++--
mlrun/config.py | 6 ++++--
2 files changed, 6 insertions(+), 4 deletions(-)
diff --git a/mlrun/api/utils/singletons/k8s.py b/mlrun/api/utils/singletons/k8s.py
index a82a4b29a7b1..420765a9dcc8 100644
--- a/mlrun/api/utils/singletons/k8s.py
+++ b/mlrun/api/utils/singletons/k8s.py
@@ -48,9 +48,9 @@ class SecretTypes:
class K8sHelper:
- def __init__(self, namespace=None, config_file=None, silent=False, log=True):
+ def __init__(self, namespace=None, silent=False, log=True):
self.namespace = namespace or mlconfig.config.namespace
- self.config_file = config_file or mlconfig.config.kubeconfig_path or None
+ self.config_file = mlconfig.config.kubernetes.kubeconfig_path or None
self.running_inside_kubernetes_cluster = False
try:
self._init_k8s_config(log)
diff --git a/mlrun/config.py b/mlrun/config.py
index 286cf8253498..5b2c352f7b56 100644
--- a/mlrun/config.py
+++ b/mlrun/config.py
@@ -48,7 +48,10 @@
default_config = {
"namespace": "", # default kubernetes namespace
- "kubeconfig_path": "", # path to kubeconfig file
+ "kubernetes": {
+ "kubeconfig_path": "", # local path to kubeconfig file (for development purposes),
+ # empty by default as the API already running inside k8s cluster
+ },
"dbpath": "", # db/api url
# url to nuclio dashboard api (can be with user & token, e.g. https://username:password@dashboard-url.com)
"nuclio_dashboard_url": "",
@@ -538,7 +541,6 @@ def is_running_as_api():
global _is_running_as_api
if _is_running_as_api is None:
- # os.getenv will load the env var as string, and json.loads will convert it to a bool
_is_running_as_api = os.getenv("MLRUN_IS_API_SERVER", "false").lower() == "true"
return _is_running_as_api
From d6df3a7f02737e0344ec88defd3de224b7836043 Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Wed, 17 May 2023 14:34:39 +0300
Subject: [PATCH 153/334] [Launcher] Prepare image for deploy (#3563)
---
mlrun/api/launcher.py | 4 --
mlrun/launcher/base.py | 5 +-
mlrun/launcher/client.py | 30 +++++++++++
mlrun/launcher/local.py | 4 --
mlrun/launcher/remote.py | 4 --
mlrun/projects/pipelines.py | 2 +-
mlrun/run.py | 7 +--
mlrun/runtimes/base.py | 94 ++++++++++++++++++++---------------
mlrun/runtimes/kubejob.py | 26 +++++++---
tests/launcher/test_remote.py | 26 ++++++++++
10 files changed, 137 insertions(+), 65 deletions(-)
diff --git a/mlrun/api/launcher.py b/mlrun/api/launcher.py
index 42db4037ebf9..870dc09749fd 100644
--- a/mlrun/api/launcher.py
+++ b/mlrun/api/launcher.py
@@ -142,10 +142,6 @@ def launch(
return self._wrap_run_result(runtime, result, run, err=last_err)
- @staticmethod
- def verify_base_image(runtime):
- pass
-
@staticmethod
def _enrich_runtime(runtime):
pass
diff --git a/mlrun/launcher/base.py b/mlrun/launcher/base.py
index 9186e13709b4..97e8551679e2 100644
--- a/mlrun/launcher/base.py
+++ b/mlrun/launcher/base.py
@@ -357,9 +357,8 @@ def _refresh_function_metadata(runtime: "mlrun.runtimes.BaseRuntime"):
pass
@staticmethod
- @abc.abstractmethod
- def verify_base_image(runtime):
- """resolves and sets the build base image if build is needed"""
+ def prepare_image_for_deploy(runtime: "mlrun.runtimes.BaseRuntime"):
+ """Check if the runtime requires to build the image and updates the spec accordingly"""
pass
@staticmethod
diff --git a/mlrun/launcher/client.py b/mlrun/launcher/client.py
index 5e64b0cf67fa..3b6531d96ef2 100644
--- a/mlrun/launcher/client.py
+++ b/mlrun/launcher/client.py
@@ -35,6 +35,36 @@ def _enrich_runtime(runtime):
runtime.try_auto_mount_based_on_config()
runtime._fill_credentials()
+ @staticmethod
+ def prepare_image_for_deploy(runtime: "mlrun.runtimes.BaseRuntime"):
+ """
+ Check if the runtime requires to build the image.
+ If build is needed, set the image as the base_image for the build.
+ If image is not given set the default one.
+ """
+ if runtime.kind in mlrun.runtimes.RuntimeKinds.nuclio_runtimes():
+ return
+
+ build = runtime.spec.build
+ require_build = (
+ build.commands
+ or build.requirements
+ or (build.source and not build.load_source_on_run)
+ )
+ image = runtime.spec.image
+ # we allow users to not set an image, in that case we'll use the default
+ if (
+ not image
+ and runtime.kind in mlrun.mlconf.function_defaults.image_by_kind.to_dict()
+ ):
+ image = mlrun.mlconf.function_defaults.image_by_kind.to_dict()[runtime.kind]
+
+ # TODO: need a better way to decide whether a function requires a build
+ if require_build and image and not runtime.spec.build.base_image:
+ # when the function require build use the image as the base_image for the build
+ runtime.spec.build.base_image = image
+ runtime.spec.image = ""
+
@staticmethod
def _store_function(
runtime: "mlrun.runtimes.BaseRuntime", run: "mlrun.run.RunObject"
diff --git a/mlrun/launcher/local.py b/mlrun/launcher/local.py
index 3631bf0b7357..fb6e3e9756a0 100644
--- a/mlrun/launcher/local.py
+++ b/mlrun/launcher/local.py
@@ -40,10 +40,6 @@ def __init__(self, local: bool):
super().__init__()
self._is_run_local = local
- @staticmethod
- def verify_base_image(runtime):
- pass
-
def launch(
self,
runtime: "mlrun.runtimes.BaseRuntime",
diff --git a/mlrun/launcher/remote.py b/mlrun/launcher/remote.py
index 8544436732e1..ddb630496b01 100644
--- a/mlrun/launcher/remote.py
+++ b/mlrun/launcher/remote.py
@@ -29,10 +29,6 @@
class ClientRemoteLauncher(mlrun.launcher.client.ClientBaseLauncher):
- @staticmethod
- def verify_base_image(runtime):
- pass
-
def launch(
self,
runtime: "mlrun.runtimes.KubejobRuntime",
diff --git a/mlrun/projects/pipelines.py b/mlrun/projects/pipelines.py
index a8394159c208..bbd3efdd5929 100644
--- a/mlrun/projects/pipelines.py
+++ b/mlrun/projects/pipelines.py
@@ -411,7 +411,7 @@ def enrich_function_object(
f.spec.build.source = project.spec.source
f.spec.build.load_source_on_run = project.spec.load_source_on_run
f.spec.workdir = project.spec.workdir or project.spec.subpath
- f.verify_base_image()
+ f.prepare_image_for_deploy()
if project.spec.default_requirements:
f.with_requirements(project.spec.default_requirements)
diff --git a/mlrun/run.py b/mlrun/run.py
index 6489d779e2e8..e63da50ff523 100644
--- a/mlrun/run.py
+++ b/mlrun/run.py
@@ -652,8 +652,9 @@ def new_function(
runner.spec.default_handler = handler
if requirements:
- runner.with_requirements(requirements)
- runner.verify_base_image()
+ runner.with_requirements(requirements, prepare_image_for_deploy=False)
+
+ runner.prepare_image_for_deploy()
return runner
@@ -921,7 +922,7 @@ def resolve_nuclio_subkind(kind):
build.image = get_in(spec, "spec.build.image")
update_common(r, spec)
- r.verify_base_image()
+ r.prepare_image_for_deploy()
if with_doc:
update_function_entry_points(r, code)
diff --git a/mlrun/runtimes/base.py b/mlrun/runtimes/base.py
index 1fcd8309fb47..dad9590ecf48 100644
--- a/mlrun/runtimes/base.py
+++ b/mlrun/runtimes/base.py
@@ -16,6 +16,7 @@
import http
import traceback
import typing
+import warnings
from abc import ABC, abstractmethod
from ast import literal_eval
from base64 import b64encode
@@ -25,6 +26,7 @@
from typing import Dict, List, Optional, Tuple, Union
import requests.exceptions
+from deprecated import deprecated
from kubernetes.client.rest import ApiException
from nuclio.build import mlrun_footer
from sqlalchemy.orm import Session
@@ -824,13 +826,16 @@ def with_requirements(
self,
requirements: Union[str, List[str]],
overwrite: bool = False,
- verify_base_image: bool = True,
+ verify_base_image: bool = False,
+ prepare_image_for_deploy: bool = True,
):
"""add package requirements from file or list to build spec.
- :param requirements: python requirements file path or list of packages
- :param overwrite: overwrite existing requirements
- :param verify_base_image: verify that the base image is configured
+ :param requirements: python requirements file path or list of packages
+ :param overwrite: overwrite existing requirements
+ :param verify_base_image: verify that the base image is configured
+ (deprecated, use prepare_image_for_deploy)
+ :param prepare_image_for_deploy: prepare the image/base_image spec for deployment
:return: function object
"""
resolved_requirements = self._resolve_requirements(requirements)
@@ -843,8 +848,15 @@ def with_requirements(
self.spec.build.requirements = requirements
- if verify_base_image:
- self.verify_base_image()
+ if verify_base_image or prepare_image_for_deploy:
+ # TODO: remove verify_base_image in 1.6.0
+ if verify_base_image:
+ warnings.warn(
+ "verify_base_image is deprecated in 1.4.0 and will be removed in 1.6.0, "
+ "use prepare_image_for_deploy",
+ category=FutureWarning,
+ )
+ self.prepare_image_for_deploy()
return self
@@ -852,11 +864,16 @@ def with_commands(
self,
commands: List[str],
overwrite: bool = False,
- verify_base_image: bool = True,
+ verify_base_image: bool = False,
+ prepare_image_for_deploy: bool = True,
):
"""add commands to build spec.
- :param commands: list of commands to run during build
+ :param commands: list of commands to run during build
+ :param overwrite: overwrite existing commands
+ :param verify_base_image: verify that the base image is configured
+ (deprecated, use prepare_image_for_deploy)
+ :param prepare_image_for_deploy: prepare the image/base_image spec for deployment
:return: function object
"""
@@ -872,48 +889,47 @@ def with_commands(
# using list(set(x)) won't retain order,
# solution inspired from https://stackoverflow.com/a/17016257/8116661
self.spec.build.commands = list(dict.fromkeys(self.spec.build.commands))
- if verify_base_image:
- self.verify_base_image()
+
+ if verify_base_image or prepare_image_for_deploy:
+ # TODO: remove verify_base_image in 1.6.0
+ if verify_base_image:
+ warnings.warn(
+ "verify_base_image is deprecated in 1.4.0 and will be removed in 1.6.0, "
+ "use prepare_image_for_deploy",
+ category=FutureWarning,
+ )
+
+ self.prepare_image_for_deploy()
return self
def clean_build_params(self):
- # when using `with_requirements` we also execute `verify_base_image` which adds the base image and cleans the
- # spec.image, so we need to restore the image back
+ # when using `with_requirements` we also execute `prepare_image_for_deploy` which adds the base image
+ # and cleans the spec.image, so we need to restore the image back
if self.spec.build.base_image and not self.spec.image:
self.spec.image = self.spec.build.base_image
self.spec.build = {}
return self
+ # TODO: remove in 1.6.0
+ @deprecated(
+ version="1.4.0",
+ reason="'verify_base_image' will be removed in 1.6.0, use 'prepare_image_for_deploy' instead",
+ category=FutureWarning,
+ )
def verify_base_image(self):
- build = self.spec.build
- require_build = (
- build.commands
- or build.requirements
- or (build.source and not build.load_source_on_run)
+ self.prepare_image_for_deploy()
+
+ def prepare_image_for_deploy(self):
+ """
+ if a function has a 'spec.image' it is considered to be deployed,
+ but because we allow the user to set 'spec.image' for usability purposes,
+ we need to check whether this is a built image or it requires to be built on top.
+ """
+ launcher = mlrun.launcher.factory.LauncherFactory.create_launcher(
+ is_remote=self._is_remote
)
- image = self.spec.image
- # we allow users to not set an image, in that case we'll use the default
- if (
- not image
- and self.kind in mlrun.mlconf.function_defaults.image_by_kind.to_dict()
- ):
- image = mlrun.mlconf.function_defaults.image_by_kind.to_dict()[self.kind]
-
- if (
- self.kind not in mlrun.runtimes.RuntimeKinds.nuclio_runtimes()
- # TODO: need a better way to decide whether a function requires a build
- and require_build
- and image
- and not self.spec.build.base_image
- # when submitting a run we are loading the function from the db, and using new_function for it,
- # this results reaching here, but we are already after deploy of the image, meaning we don't need to prepare
- # the base image for deployment
- and self._is_remote_api()
- ):
- # when the function require build use the image as the base_image for the build
- self.spec.build.base_image = image
- self.spec.image = ""
+ launcher.prepare_image_for_deploy(self)
def export(self, target="", format=".yaml", secrets=None, strip=True):
"""save function spec to a local/remote path (default to./function.yaml)
diff --git a/mlrun/runtimes/kubejob.py b/mlrun/runtimes/kubejob.py
index 681749711d88..964559b0aec1 100644
--- a/mlrun/runtimes/kubejob.py
+++ b/mlrun/runtimes/kubejob.py
@@ -14,6 +14,7 @@
import os
import time
+import warnings
from kubernetes import client
from kubernetes.client.rest import ApiException
@@ -110,7 +111,8 @@ def build_config(
auto_build=None,
requirements=None,
overwrite=False,
- verify_base_image=True,
+ verify_base_image=False,
+ prepare_image_for_deploy=True,
):
"""specify builder configuration for the deploy operation
@@ -131,17 +133,20 @@ def build_config(
* False: the new params are merged with the existing (currently merge is applied to requirements and
commands)
* True: the existing params are replaced by the new ones
- :param verify_base_image: verify the base image is set
- """
+ :param verify_base_image: verify that the base image is configured
+ (deprecated, use prepare_image_for_deploy)
+ :param prepare_image_for_deploy: prepare the image/base_image spec for deployment"""
if image:
self.spec.build.image = image
if base_image:
self.spec.build.base_image = base_image
if commands:
- self.with_commands(commands, overwrite=overwrite, verify_base_image=False)
+ self.with_commands(
+ commands, overwrite=overwrite, prepare_image_for_deploy=False
+ )
if requirements:
self.with_requirements(
- requirements, overwrite=overwrite, verify_base_image=False
+ requirements, overwrite=overwrite, prepare_image_for_deploy=False
)
if extra:
self.spec.build.extra = extra
@@ -156,8 +161,15 @@ def build_config(
if auto_build:
self.spec.build.auto_build = auto_build
- if verify_base_image:
- self.verify_base_image()
+ if verify_base_image or prepare_image_for_deploy:
+ if verify_base_image:
+ # TODO: remove verify_base_image in 1.6.0
+ warnings.warn(
+ "verify_base_image is deprecated in 1.4.0 and will be removed in 1.6.0, "
+ "use prepare_image_for_deploy",
+ category=FutureWarning,
+ )
+ self.prepare_image_for_deploy()
def deploy(
self,
diff --git a/tests/launcher/test_remote.py b/tests/launcher/test_remote.py
index be251b47fa1f..3e7246d1c5a1 100644
--- a/tests/launcher/test_remote.py
+++ b/tests/launcher/test_remote.py
@@ -73,3 +73,29 @@ def test_validate_runtime_success():
spec=mlrun.model.RunSpec(inputs={"input1": ""}, output_path="./some_path")
)
launcher._validate_runtime(runtime, run)
+
+
+@pytest.mark.parametrize(
+ "kind, requirements, expected_base_image, expected_image",
+ [
+ ("job", [], None, "mlrun/mlrun"),
+ ("job", ["pandas"], "mlrun/mlrun", ""),
+ ("nuclio", ["pandas"], None, "mlrun/mlrun"),
+ ("serving", ["pandas"], None, "mlrun/mlrun"),
+ ],
+)
+def test_prepare_image_for_deploy(
+ kind, requirements, expected_base_image, expected_image
+):
+ launcher = mlrun.launcher.remote.ClientRemoteLauncher()
+ runtime = mlrun.code_to_function(
+ name="test",
+ kind=kind,
+ filename=str(func_path),
+ handler=handler,
+ image="mlrun/mlrun",
+ requirements=requirements,
+ )
+ launcher.prepare_image_for_deploy(runtime)
+ assert runtime.spec.build.base_image == expected_base_image
+ assert runtime.spec.image == expected_image
From 338b93d195f4e6f5071b99c142fe0bea77c1a424 Mon Sep 17 00:00:00 2001
From: Tom Tankilevitch <59158507+Tankilevitch@users.noreply.github.com>
Date: Wed, 17 May 2023 15:14:45 +0300
Subject: [PATCH 154/334] [CI] Move `IP_ADDR_PREFIX` to prepare run (#3584)
---
.github/workflows/system-tests-enterprise.yml | 6 +++---
1 file changed, 3 insertions(+), 3 deletions(-)
diff --git a/.github/workflows/system-tests-enterprise.yml b/.github/workflows/system-tests-enterprise.yml
index 81aa6915ae8f..c8558451b011 100644
--- a/.github/workflows/system-tests-enterprise.yml
+++ b/.github/workflows/system-tests-enterprise.yml
@@ -241,7 +241,9 @@ jobs:
INPUT_OVERRIDE_IGUAZIO_VERSION: ${{ github.event.inputs.override_iguazio_version }}
INPUT_CLEAN_RESOURCES_IN_TEARDOWN: ${{ github.event.inputs.clean_resources_in_teardown }}
- - name: Prepare System Test env.yaml and MLRun installation from current branch
+ - name: Prepare System Test Environment and Install MLRun
+ env:
+ IP_ADDR_PREFIX: ${{ secrets.IP_ADDR_PREFIX }}
timeout-minutes: 50
run: |
python automation/system_test/prepare.py run \
@@ -309,8 +311,6 @@ jobs:
- name: Install curl and jq
run: sudo apt-get install curl jq
- name: Prepare System Test env.yaml and MLRun installation from current branch
- env:
- IP_ADDR_PREFIX: ${{ secrets.IP_ADDR_PREFIX }}
timeout-minutes: 5
run: |
python automation/system_test/prepare.py env \
From 2a920e6cfffc4332f26673b6970bbca07cd5ecd9 Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Wed, 17 May 2023 15:15:07 +0300
Subject: [PATCH 155/334] [Utils] Add named logger (#3579)
---
mlrun/utils/logger.py | 54 +++++++++++++++++++++++++++----
tests/utils/logger/test_logger.py | 18 +++++++++++
2 files changed, 65 insertions(+), 7 deletions(-)
diff --git a/mlrun/utils/logger.py b/mlrun/utils/logger.py
index b5606b8c6e1c..87a76f81fef5 100644
--- a/mlrun/utils/logger.py
+++ b/mlrun/utils/logger.py
@@ -17,7 +17,7 @@
from enum import Enum
from sys import stdout
from traceback import format_exception
-from typing import IO, Union
+from typing import IO, Optional, Union
from mlrun.config import config
@@ -42,20 +42,39 @@ def format(self, record):
class HumanReadableFormatter(logging.Formatter):
- def __init__(self):
- super(HumanReadableFormatter, self).__init__()
-
def format(self, record):
+ record_with = self._record_with(record)
+ more = f": {record_with}" if record_with else ""
+ return f"> {self.formatTime(record, self.datefmt)} [{record.levelname.lower()}] {record.getMessage()}{more}"
+
+ def _record_with(self, record):
record_with = getattr(record, "with", {})
if record.exc_info:
record_with.update(exc_info=format_exception(*record.exc_info))
+ return record_with
+
+
+class HumanReadableExtendedFormatter(HumanReadableFormatter):
+ def format(self, record):
+ record_with = self._record_with(record)
more = f": {record_with}" if record_with else ""
- return f"> {self.formatTime(record, self.datefmt)} [{record.levelname.lower()}] {record.getMessage()}{more}"
+ return (
+ "> "
+ f"{self.formatTime(record, self.datefmt)} "
+ f"[{record.name}:{record.levelname.lower()}] "
+ f"{record.getMessage()}{more}"
+ )
class Logger(object):
- def __init__(self, level, name="mlrun", propagate=True):
- self._logger = logging.getLogger(name)
+ def __init__(
+ self,
+ level,
+ name="mlrun",
+ propagate=True,
+ logger: Optional[logging.Logger] = None,
+ ):
+ self._logger = logger or logging.getLogger(name)
self._logger.propagate = propagate
self._logger.setLevel(level)
self._bound_variables = {}
@@ -90,6 +109,25 @@ def set_handler(
# add the handler to the logger
self._logger.addHandler(stream_handler)
+ def get_child(self, suffix):
+ """
+ Get a child logger with the given suffix.
+ This is useful for when you want to have a logger for a specific component.
+ Once the formatter will support logger name, it will be easier to understand
+ which component logged the message.
+
+ :param suffix: The suffix to add to the logger name.
+ """
+ return Logger(
+ self.level,
+ # name is not set as it is provided by the "getChild"
+ name="",
+ # allowing child to delegate events logged to ancestor logger
+ # not doing so, will leave log lines not being handled
+ propagate=True,
+ logger=self._logger.getChild(suffix),
+ )
+
@property
def level(self):
return self._logger.level
@@ -143,12 +181,14 @@ def _update_bound_vars_and_log(
class FormatterKinds(Enum):
HUMAN = "human"
+ HUMAN_EXTENDED = "human_extended"
JSON = "json"
def _create_formatter_instance(formatter_kind: FormatterKinds) -> logging.Formatter:
return {
FormatterKinds.HUMAN: HumanReadableFormatter(),
+ FormatterKinds.HUMAN_EXTENDED: HumanReadableExtendedFormatter(),
FormatterKinds.JSON: JSONFormatter(),
}[formatter_kind]
diff --git a/tests/utils/logger/test_logger.py b/tests/utils/logger/test_logger.py
index 33a935662e47..692df88a3b5d 100644
--- a/tests/utils/logger/test_logger.py
+++ b/tests/utils/logger/test_logger.py
@@ -106,3 +106,21 @@ def test_redundant_logger_creation():
assert stream.getvalue().count("[info] 2\n") == 1
logger3.info("3")
assert stream.getvalue().count("[info] 3\n") == 1
+
+
+def test_child_logger():
+ stream = StringIO()
+ logger = create_logger(
+ "debug",
+ name="test-logger",
+ stream=stream,
+ formatter_kind=FormatterKinds.HUMAN_EXTENDED.name,
+ )
+ child_logger = logger.get_child("child")
+ logger.debug("")
+ child_logger.debug("")
+ log_lines = stream.getvalue().strip().splitlines()
+
+ # validate parent and child log lines
+ assert "test-logger:debug" in log_lines[0]
+ assert "test-logger.child:debug" in log_lines[1]
From 927bebdcd623ebdfe8b2a31b56d1279f3c6ea277 Mon Sep 17 00:00:00 2001
From: jillnogold <88145832+jillnogold@users.noreply.github.com>
Date: Wed, 17 May 2023 16:08:36 +0300
Subject: [PATCH 156/334] [Docs] Add example of Nuclio function (#3567)
---
.../concepts/nuclio-real-time-functions.ipynb | 118 ++++++++++++++++++
docs/concepts/nuclio-real-time-functions.md | 32 -----
2 files changed, 118 insertions(+), 32 deletions(-)
create mode 100644 docs/concepts/nuclio-real-time-functions.ipynb
delete mode 100644 docs/concepts/nuclio-real-time-functions.md
diff --git a/docs/concepts/nuclio-real-time-functions.ipynb b/docs/concepts/nuclio-real-time-functions.ipynb
new file mode 100644
index 000000000000..de9c63e5e2fb
--- /dev/null
+++ b/docs/concepts/nuclio-real-time-functions.ipynb
@@ -0,0 +1,118 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "887ae6fb",
+ "metadata": {},
+ "source": [
+ "(nuclio-real-time-functions)=\n",
+ "# Nuclio real-time functions\n",
+ "\n",
+ "Nuclio is a high-performance \"serverless\" framework focused on data, I/O, and compute intensive workloads. It is well integrated with popular \n",
+ "data science tools, such as Jupyter and Kubeflow; supports a variety of data and streaming sources; and supports execution over CPUs and GPUs. \n",
+ "\n",
+ "You can use Nuclio through a fully managed application service (in the cloud or on-prem) in the Iguazio MLOps Platform. MLRun serving \n",
+ "utilizes serverless Nuclio functions to create multi-stage real-time pipelines. \n",
+ "\n",
+ "The underlying Nuclio serverless engine uses a high-performance parallel processing engine that maximizes the utilization of CPUs and GPUs, \n",
+ "supports 13 protocols and invocation methods (for example, HTTP, Cron, Kafka, Kinesis), and includes dynamic auto-scaling for HTTP and \n",
+ "streaming. Nuclio and MLRun support the full life cycle, including auto-generation of micro-services, APIs, load-balancing, logging, \n",
+ "monitoring, and configuration management—such that developers can focus on code, and deploy to production faster with minimal work.\n",
+ "\n",
+ "Nuclio is extremely fast: a single function instance can process hundreds of thousands of HTTP requests or data records per second. To learn \n",
+ "more about how Nuclio works, see the Nuclio architecture [documentation](https://nuclio.io/docs/latest/concepts/architecture/). \n",
+ "\n",
+ "Nuclio is secure: Nuclio is integrated with Kaniko to allow a secure and production-ready way of building Docker images at run time.\n",
+ "\n",
+ "Read more in the [Nuclio documentation](https://nuclio.io/docs/latest/) and the open-source [MLRun library](https://github.com/mlrun/mlrun).\n",
+ "\n",
+ "## Example of Nuclio function\n",
+ "\n",
+ "You can create your own Nuclio function, for example a data processing function. The following code illustrates an example of an MLRun function, of kind 'nuclio', that can be deployed to the cluster."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3c9b59b3",
+ "metadata": {},
+ "source": [
+ "Create a file `func.py` with the code of the function: \n",
+ "```\n",
+ "def handler(context, event):\n",
+ " return \"Hello\"\n",
+ "``` "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b2dcd26e",
+ "metadata": {},
+ "source": [
+ "Create the project and the Nuclio function:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "105fb38e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import mlrun"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "dc620518",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Create the project\n",
+ "project = mlrun.get_or_create_project(\"nuclio-project\", \"./\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5dda40ef",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Create a Nuclio function\n",
+ "project.set_function(\n",
+ " func=\"func.py\",\n",
+ " image=\"mlrun/mlrun\",\n",
+ " kind=\"nuclio\",\n",
+ " name=\"nuclio-func\",\n",
+ " handler=\"handler\",\n",
+ ")\n",
+ "# Save the function within the project\n",
+ "project.save()\n",
+ "# Deploy the function in the cluster\n",
+ "project.deploy_function(\"nuclio-func\")"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.7"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/docs/concepts/nuclio-real-time-functions.md b/docs/concepts/nuclio-real-time-functions.md
deleted file mode 100644
index b6d0acf227bf..000000000000
--- a/docs/concepts/nuclio-real-time-functions.md
+++ /dev/null
@@ -1,32 +0,0 @@
-(nuclio-real-time-functions)=
-# Nuclio real-time functions
-
-Nuclio is a high-performance "serverless" framework focused on data, I/O, and compute intensive workloads. It is well integrated with popular
-data science tools, such as Jupyter and Kubeflow; supports a variety of data and streaming sources; and supports execution over CPUs and GPUs.
-
-You can use Nuclio through a fully managed application service (in the cloud or on-prem) in the Iguazio MLOps Platform. MLRun serving
-utilizes serverless Nuclio functions to create multi-stage real-time pipelines.
-
-The underlying Nuclio serverless engine uses a high-performance parallel processing engine that maximizes the utilization of CPUs and GPUs,
-supports 13 protocols and invocation methods (for example, HTTP, Cron, Kafka, Kinesis), and includes dynamic auto-scaling for HTTP and
-streaming. Nuclio and MLRun support the full life cycle, including auto-generation of micro-services, APIs, load-balancing, logging,
-monitoring, and configuration management—such that developers can focus on code, and deploy to production faster with minimal work.
-
-Nuclio is extremely fast: a single function instance can process hundreds of thousands of HTTP requests or data records per second. To learn
-more about how Nuclio works, see the Nuclio architecture [documentation](https://nuclio.io/docs/latest/concepts/architecture/).
-
-Nuclio is secure: Nuclio is integrated with Kaniko to allow a secure and production-ready way of building Docker images at run time.
-
-Read more in the [Nuclio documentation](https://nuclio.io/docs/latest/) and the open-source [MLRun library](https://github.com/mlrun/mlrun).
-
-## Why another "serverless" project?
-None of the existing cloud and open-source serverless solutions addressed all the desired capabilities of a serverless framework:
-
-- Real-time processing with minimal CPU/GPU and I/O overhead and maximum parallelism
-- Native integration with a large variety of data sources, triggers, processing models, and ML frameworks
-- Stateful functions with data-path acceleration
-- Simple debugging, regression testing, and multi-versioned CI/CD pipelines
-- Portability across low-power devices, laptops, edge and on-prem clusters, and public clouds
-- Open-source but designed for the enterprise (including logging, monitoring, security, and usability)
-
-Nuclio was created to fulfill these requirements. It was intentionally designed as an extendable open-source framework, using a modular and layered approach that supports constant addition of triggers and data sources, with the hope that many will join the effort of developing new modules, developer tools, and platforms for Nuclio.
\ No newline at end of file
From 501ab66960659b856969c54b499d58cf6083fbe2 Mon Sep 17 00:00:00 2001
From: TomerShor <90552140+TomerShor@users.noreply.github.com>
Date: Thu, 18 May 2023 08:34:44 +0300
Subject: [PATCH 157/334] [Requirements] Bump nuclio-jupyter to 0.9.10 (#3588)
---
dockerfiles/jupyter/requirements.txt | 2 +-
requirements.txt | 2 +-
2 files changed, 2 insertions(+), 2 deletions(-)
diff --git a/dockerfiles/jupyter/requirements.txt b/dockerfiles/jupyter/requirements.txt
index 32934bf13df7..5747a632c67c 100644
--- a/dockerfiles/jupyter/requirements.txt
+++ b/dockerfiles/jupyter/requirements.txt
@@ -6,7 +6,7 @@ scikit-plot~=0.3.7
xgboost~=1.1
graphviz~=0.20.0
python-dotenv~=0.17.0
-nuclio-jupyter[jupyter-server]~=0.9.9
+nuclio-jupyter[jupyter-server]~=0.9.10
nbclassic>=0.2.8
# added to tackle security vulnerabilities
notebook~=6.4
diff --git a/requirements.txt b/requirements.txt
index 532d5341ff1e..2c62b925cd41 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -21,7 +21,7 @@ nest-asyncio~=1.0
# ipython 8.0 + only supports python3.8 +, so to keep backwards compatibility with python 3.7 we support 7.x
# we rely on pip and nuclio-jupyter requirements to install the right package per python version
ipython>=7.0, <9.0
-nuclio-jupyter~=0.9.9
+nuclio-jupyter~=0.9.10
# >=1.16.5 from pandas 1.2.1 and <1.23.0 from storey
numpy>=1.16.5, <1.23.0
# limiting pandas to <1.5.0 since 1.5.0 causes exception in storey on casting from ns to us
From a1b8087915f06451dbf6537beeed7420a0b3ee23 Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Thu, 18 May 2023 08:35:30 +0300
Subject: [PATCH 158/334] [Test] Fix transient scheduler unit test failure
(#3587)
---
tests/api/utils/test_scheduler.py | 32 ++++++++++++++++---------------
1 file changed, 17 insertions(+), 15 deletions(-)
diff --git a/tests/api/utils/test_scheduler.py b/tests/api/utils/test_scheduler.py
index 3ca5fad82f70..e445cdbd3760 100644
--- a/tests/api/utils/test_scheduler.py
+++ b/tests/api/utils/test_scheduler.py
@@ -208,6 +208,15 @@ async def test_create_schedule_mlrun_function(
k8s_secrets_mock: tests.api.conftest.K8sSecretsMock,
):
+ project_name = config.default_project
+ mlrun.new_project(project_name, save=False)
+
+ scheduled_object = _create_mlrun_function_and_matching_scheduled_object(
+ db, project_name
+ )
+ runs = get_db().list_runs(db, project=project_name)
+ assert len(runs) == 0
+
expected_call_counter = 1
start_date, end_date = _get_start_and_end_time_for_scheduled_trigger(
number_of_jobs=expected_call_counter, seconds_interval=1
@@ -217,14 +226,6 @@ async def test_create_schedule_mlrun_function(
second="*/1", start_date=start_date, end_date=end_date
)
schedule_name = "schedule-name"
- project_name = config.default_project
- mlrun.new_project(project_name, save=False)
-
- scheduled_object = _create_mlrun_function_and_matching_scheduled_object(
- db, project_name
- )
- runs = get_db().list_runs(db, project=project_name)
- assert len(runs) == 0
scheduler.create_schedule(
db,
mlrun.common.schemas.AuthInfo(),
@@ -1228,13 +1229,6 @@ async def test_schedule_job_concurrency_limit(
global call_counter
call_counter = 0
- now = datetime.now(timezone.utc)
- now_plus_1_seconds = now + timedelta(seconds=1)
- now_plus_5_seconds = now + timedelta(seconds=5)
- cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(
- second="*/1", start_date=now_plus_1_seconds, end_date=now_plus_5_seconds
- )
- schedule_name = "schedule-name"
project_name = config.default_project
mlrun.new_project(project_name, save=False)
@@ -1249,6 +1243,14 @@ async def test_schedule_job_concurrency_limit(
runs = get_db().list_runs(db, project=project_name)
assert len(runs) == 0
+ now = datetime.now(timezone.utc)
+ now_plus_1_seconds = now + timedelta(seconds=1)
+ now_plus_5_seconds = now + timedelta(seconds=5)
+ cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(
+ second="*/1", start_date=now_plus_1_seconds, end_date=now_plus_5_seconds
+ )
+ schedule_name = "schedule-name"
+
scheduler.create_schedule(
db,
mlrun.common.schemas.AuthInfo(),
From 85073c971b5d6f1723082d3873e2b90c15dd7332 Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Thu, 18 May 2023 10:03:15 +0300
Subject: [PATCH 159/334] [DB] Runtime configurable sql mode (#3577)
---
mlrun/api/db/init_db.py | 3 +-
mlrun/api/initial_data.py | 21 +++++++--
mlrun/api/utils/db/mysql.py | 47 ++++++++++----------
mlrun/api/utils/db/sqlite_migration.py | 2 +-
mlrun/config.py | 12 +++++-
tests/api/test_initial_data.py | 2 +-
tests/system/api/assets/function.py | 18 +++++++-
tests/system/api/test_artifacts.py | 59 ++++++++++++++++++++++++++
8 files changed, 130 insertions(+), 34 deletions(-)
create mode 100644 tests/system/api/test_artifacts.py
diff --git a/mlrun/api/db/init_db.py b/mlrun/api/db/init_db.py
index 21b6966cb757..fe58fbdfad72 100644
--- a/mlrun/api/db/init_db.py
+++ b/mlrun/api/db/init_db.py
@@ -12,13 +12,12 @@
# See the License for the specific language governing permissions and
# limitations under the License.
#
-from sqlalchemy.orm import Session
from mlrun.api.db.sqldb.models import Base
from mlrun.api.db.sqldb.session import get_engine
from mlrun.config import config
-def init_db(db_session: Session) -> None:
+def init_db() -> None:
if config.httpdb.db_type != "filedb":
Base.metadata.create_all(bind=get_engine())
diff --git a/mlrun/api/initial_data.py b/mlrun/api/initial_data.py
index 08ceb5462016..cc02b4d77c63 100644
--- a/mlrun/api/initial_data.py
+++ b/mlrun/api/initial_data.py
@@ -44,7 +44,20 @@ def init_data(
from_scratch: bool = False, perform_migrations_if_needed: bool = False
) -> None:
logger.info("Initializing DB data")
- mlrun.api.utils.db.mysql.MySQLUtil.wait_for_db_liveness(logger)
+
+ # create mysql util, and if mlrun is configured to use mysql, wait for it to be live and set its db modes
+ mysql_util = mlrun.api.utils.db.mysql.MySQLUtil(logger)
+ if mysql_util.get_mysql_dsn_data():
+ mysql_util.wait_for_db_liveness()
+ mysql_util.set_modes(mlrun.mlconf.httpdb.db.mysql.modes)
+ else:
+ dsn = mysql_util.get_dsn()
+ if "sqlite" in dsn:
+ logger.debug("SQLite DB is used, liveness check not needed")
+ else:
+ logger.warn(
+ f"Invalid mysql dsn: {dsn}, assuming live and skipping liveness verification"
+ )
sqlite_migration_util = None
if not from_scratch and config.httpdb.db.database_migration_mode == "enabled":
@@ -82,9 +95,9 @@ def init_data(
_perform_database_migration(sqlite_migration_util)
+ init_db()
db_session = create_session()
try:
- init_db(db_session)
_add_initial_data(db_session)
_perform_data_migrations(db_session)
finally:
@@ -105,9 +118,11 @@ def init_data(
# If the data_table version doesn't exist, we can assume the data version is 1.
-# This is because data version 1 points to to a data migration which was added back in 0.6.0, and
+# This is because data version 1 points to a data migration which was added back in 0.6.0, and
# upgrading from a version earlier than 0.6.0 to v>=0.8.0 is not supported.
data_version_prior_to_table_addition = 1
+
+# NOTE: Bump this number when adding a new data migration
latest_data_version = 3
diff --git a/mlrun/api/utils/db/mysql.py b/mlrun/api/utils/db/mysql.py
index c4c80961174d..31a69b53e621 100644
--- a/mlrun/api/utils/db/mysql.py
+++ b/mlrun/api/utils/db/mysql.py
@@ -32,29 +32,16 @@ class MySQLUtil(object):
"functions",
]
- def __init__(self):
- mysql_dsn_data = self.get_mysql_dsn_data()
- if not mysql_dsn_data:
- raise RuntimeError(f"Invalid mysql dsn: {self.get_dsn()}")
-
- @staticmethod
- def wait_for_db_liveness(logger, retry_interval=3, timeout=2 * 60):
- logger.debug("Waiting for database liveness")
- mysql_dsn_data = MySQLUtil.get_mysql_dsn_data()
- if not mysql_dsn_data:
- dsn = MySQLUtil.get_dsn()
- if "sqlite" in dsn:
- logger.debug("SQLite DB is used, liveness check not needed")
- else:
- logger.warn(
- f"Invalid mysql dsn: {MySQLUtil.get_dsn()}, assuming live and skipping liveness verification"
- )
- return
+ def __init__(self, logger: mlrun.utils.Logger):
+ self._logger = logger
+ def wait_for_db_liveness(self, retry_interval=3, timeout=2 * 60):
+ self._logger.debug("Waiting for database liveness")
+ mysql_dsn_data = self.get_mysql_dsn_data()
tmp_connection = mlrun.utils.retry_until_successful(
retry_interval,
timeout,
- logger,
+ self._logger,
True,
pymysql.connect,
host=mysql_dsn_data["host"],
@@ -62,7 +49,7 @@ def wait_for_db_liveness(logger, retry_interval=3, timeout=2 * 60):
port=int(mysql_dsn_data["port"]),
database=mysql_dsn_data["database"],
)
- logger.debug("Database ready for connection")
+ self._logger.debug("Database ready for connection")
tmp_connection.close()
def check_db_has_tables(self):
@@ -78,6 +65,18 @@ def check_db_has_tables(self):
finally:
connection.close()
+ def set_modes(self, modes):
+ if not modes or modes in ["nil", "none"]:
+ self._logger.debug("No sql modes were given, bailing", modes=modes)
+ return
+ connection = self._create_connection()
+ try:
+ self._logger.debug("Setting sql modes", modes=modes)
+ with connection.cursor() as cursor:
+ cursor.execute("SET GLOBAL sql_mode=%s;", (modes,))
+ finally:
+ connection.close()
+
def check_db_has_data(self):
connection = self._create_connection()
try:
@@ -101,10 +100,6 @@ def _create_connection(self):
database=mysql_dsn_data["database"],
)
- @staticmethod
- def get_dsn() -> str:
- return os.environ.get(MySQLUtil.dsn_env_var, "")
-
@staticmethod
def get_mysql_dsn_data() -> typing.Optional[dict]:
match = re.match(MySQLUtil.dsn_regex, MySQLUtil.get_dsn())
@@ -112,3 +107,7 @@ def get_mysql_dsn_data() -> typing.Optional[dict]:
return None
return match.groupdict()
+
+ @staticmethod
+ def get_dsn() -> str:
+ return os.environ.get(MySQLUtil.dsn_env_var, "")
diff --git a/mlrun/api/utils/db/sqlite_migration.py b/mlrun/api/utils/db/sqlite_migration.py
index c5030798e84d..16492ff635f4 100644
--- a/mlrun/api/utils/db/sqlite_migration.py
+++ b/mlrun/api/utils/db/sqlite_migration.py
@@ -64,7 +64,7 @@ def __init__(self):
self._migrator = self._create_migrator()
self._mysql_util = None
if self._mysql_dsn_data:
- self._mysql_util = MySQLUtil()
+ self._mysql_util = MySQLUtil(logger)
def is_database_migration_needed(self) -> bool:
# if some data is missing, don't transfer the data
diff --git a/mlrun/config.py b/mlrun/config.py
index 5b2c352f7b56..41c5e3869203 100644
--- a/mlrun/config.py
+++ b/mlrun/config.py
@@ -234,10 +234,10 @@
"conflict_retry_interval": None,
# Whether to perform data migrations on initialization. enabled or disabled
"data_migrations_mode": "enabled",
- # Whether or not to perform database migration from sqlite to mysql on initialization
+ # Whether to perform database migration from sqlite to mysql on initialization
"database_migration_mode": "enabled",
"backup": {
- # Whether or not to use db backups on initialization
+ # Whether to use db backups on initialization
"mode": "enabled",
"file_format": "db_backup_%Y%m%d%H%M.db",
"use_rotation": True,
@@ -248,6 +248,14 @@
# None will set this to be equal to the httpdb.max_workers
"connections_pool_size": None,
"connections_pool_max_overflow": None,
+ # below is a db-specific configuration
+ "mysql": {
+ # comma separated mysql modes (globally) to set on runtime
+ # optional values (as per https://dev.mysql.com/doc/refman/8.0/en/sql-mode.html#sql-mode-full):
+ #
+ # if set to "nil" or "none", nothing would be set
+ "modes": "STRICT_TRANS_TABLES",
+ },
},
"jobs": {
# whether to allow to run local runtimes in the API - configurable to allow the scheduler testing to work
diff --git a/tests/api/test_initial_data.py b/tests/api/test_initial_data.py
index 8c0dee930cd8..74f332df8846 100644
--- a/tests/api/test_initial_data.py
+++ b/tests/api/test_initial_data.py
@@ -158,5 +158,5 @@ def _initialize_db_without_migrations() -> typing.Tuple[
db_session = mlrun.api.db.sqldb.session.create_session(dsn=dsn)
db = mlrun.api.db.sqldb.db.SQLDB(dsn)
db.initialize(db_session)
- mlrun.api.db.init_db.init_db(db_session)
+ mlrun.api.db.init_db.init_db()
return db, db_session
diff --git a/tests/system/api/assets/function.py b/tests/system/api/assets/function.py
index ede3e5d724dd..c56fa92f8062 100644
--- a/tests/system/api/assets/function.py
+++ b/tests/system/api/assets/function.py
@@ -12,15 +12,31 @@
# See the License for the specific language governing permissions and
# limitations under the License.
#
-def secret_test_function(context, secrets: list = []):
+
+
+def secret_test_function(context, secrets: list = None):
"""Validate that given secrets exists
:param context: the MLRun context
:param secrets: name of the secrets that we want to look at
"""
context.logger.info("running function")
+ secrets = secrets or []
for sec_name in secrets:
sec_value = context.get_secret(sec_name)
context.logger.info("Secret: {} ==> {}".format(sec_name, sec_value))
context.log_result(sec_name, sec_value)
return True
+
+
+def log_artifact_test_function(context, body_size: int = 1000, inline: bool = True):
+ """Logs artifact given its event body
+ :param context: the MLRun context
+ :param body_size: size of the artifact body
+ :param inline: whether to log the artifact body inline or not
+ """
+ context.logger.info("running function")
+ body = b"a" * body_size
+ context.log_artifact("test", body=body, is_inline=inline)
+ context.logger.info("run complete!", body_len=len(body))
+ return True
diff --git a/tests/system/api/test_artifacts.py b/tests/system/api/test_artifacts.py
new file mode 100644
index 000000000000..f1549283d7b0
--- /dev/null
+++ b/tests/system/api/test_artifacts.py
@@ -0,0 +1,59 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+import pathlib
+
+import pytest
+
+import mlrun.common.schemas
+import mlrun.errors
+from tests.system.base import TestMLRunSystem
+
+
+@TestMLRunSystem.skip_test_if_env_not_configured
+class TestAPIArtifacts(TestMLRunSystem):
+ project_name = "db-system-test-project"
+
+ def test_fail_overflowing_artifact(self):
+ """
+ Test that we fail when trying to (inline) log an artifact that is too big
+ This is done to ensure that we don't corrupt the DB while truncating the data
+ """
+ filename = str(pathlib.Path(__file__).parent / "assets" / "function.py")
+ function = mlrun.code_to_function(
+ name="test-func",
+ project=self.project_name,
+ filename=filename,
+ handler="log_artifact_test_function",
+ kind="job",
+ image="mlrun/mlrun",
+ )
+ task = mlrun.new_task()
+
+ # run artifact field is MEDIUMBLOB which is limited to 16MB by mysql
+ # overflow and expect it to fail execution and not allow db to truncate the data
+ # to avoid data corruption
+ with pytest.raises(mlrun.runtimes.utils.RunError):
+ function.run(
+ task, params={"body_size": 16 * 1024 * 1024 + 1, "inline": True}
+ )
+
+ runs = mlrun.get_run_db().list_runs()
+ assert len(runs) == 1, "run should not be created"
+ run = runs[0]
+ assert run["status"]["state"] == "error", "run should fail"
+ assert (
+ "Failed committing changes to DB" in run["status"]["error"]
+ ), "run should fail with a reason"
From 8b226ed4a1fea32b35af958c84857ff80953fa5b Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Thu, 18 May 2023 12:53:49 +0300
Subject: [PATCH 160/334] [Launcher] Fix duplicate push notification call for
local runs (#3593)
---
mlrun/kfpops.py | 2 +-
mlrun/launcher/local.py | 2 +-
mlrun/runtimes/base.py | 43 +----------------------------------------
3 files changed, 3 insertions(+), 44 deletions(-)
diff --git a/mlrun/kfpops.py b/mlrun/kfpops.py
index 2139316fee79..408c14734098 100644
--- a/mlrun/kfpops.py
+++ b/mlrun/kfpops.py
@@ -226,7 +226,7 @@ def mlrun_op(
:param labels: labels to tag the job/run with ({key:val, ..})
:param inputs: dictionary of input objects + optional paths (if path is
omitted the path will be the in_path/key.
- :param outputs: dictionary of input objects + optional paths (if path is
+ :param outputs: dictionary of output objects + optional paths (if path is
omitted the path will be the out_path/key.
:param in_path: default input path/url (prefix) for inputs
:param out_path: default output path/url (prefix) for artifacts
diff --git a/mlrun/launcher/local.py b/mlrun/launcher/local.py
index fb6e3e9756a0..e4e8880a3715 100644
--- a/mlrun/launcher/local.py
+++ b/mlrun/launcher/local.py
@@ -122,7 +122,6 @@ def launch(
run=run,
)
- self._save_or_push_notifications(result)
return result
def execute(
@@ -188,6 +187,7 @@ def execute(
result = runtime._update_run_state(task=run, err=err)
self._save_or_push_notifications(run)
+
# run post run hooks
runtime._post_run(result, execution) # hook for runtime specific cleanup
diff --git a/mlrun/runtimes/base.py b/mlrun/runtimes/base.py
index dad9590ecf48..f9b47dcc51bd 100644
--- a/mlrun/runtimes/base.py
+++ b/mlrun/runtimes/base.py
@@ -43,7 +43,7 @@
from mlrun.api.db.base import DBInterface
from mlrun.utils.helpers import generate_object_uri, verify_field_regex
-from ..config import config, is_running_as_api
+from ..config import config
from ..datastore import store_manager
from ..db import RunDBError, get_or_set_dburl, get_run_db
from ..errors import err_to_str
@@ -623,47 +623,6 @@ def _update_run_state(
return resp
- def _save_or_push_notifications(self, runobj: RunObject, local: bool = False):
-
- if not runobj.spec.notifications:
- logger.debug(
- "No notifications to push for run", run_uid=runobj.metadata.uid
- )
- return
-
- # TODO: add support for other notifications per run iteration
- if runobj.metadata.iteration and runobj.metadata.iteration > 0:
- logger.debug(
- "Notifications per iteration are not supported, skipping",
- run_uid=runobj.metadata.uid,
- )
- return
-
- # If the run is remote, and we are in the SDK, we let the api deal with the notifications
- # so there's nothing to do here.
- # Otherwise, we continue on.
- if is_running_as_api():
-
- # import here to avoid circular imports and to avoid importing api requirements
- from mlrun.api.crud import Notifications
-
- # If in the api server, we can assume that watch=False, so we save notification
- # configs to the DB, for the run monitor to later pick up and push.
- session = mlrun.api.db.sqldb.session.create_session()
- Notifications().store_run_notifications(
- session,
- runobj.spec.notifications,
- runobj.metadata.uid,
- runobj.metadata.project,
- )
-
- elif local:
- # If the run is local, we can assume that watch=True, therefore this code runs
- # once the run is completed, and we can just push the notifications.
- # TODO: add store_notifications API endpoint so we can store notifications pushed from the
- # SDK for documentation purposes.
- mlrun.utils.notifications.NotificationPusher([runobj]).push()
-
def _force_handler(self, handler):
if not handler:
raise RunError(f"handler must be provided for {self.kind} runtime")
From 1eab2db9292172d1406986975501b9dda9092dcb Mon Sep 17 00:00:00 2001
From: Yael Genish <62285310+yaelgen@users.noreply.github.com>
Date: Thu, 18 May 2023 13:01:49 +0300
Subject: [PATCH 161/334] [System tests] Fix for test run notifications (#3591)
---
tests/system/runtimes/test_notifications.py | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/tests/system/runtimes/test_notifications.py b/tests/system/runtimes/test_notifications.py
index fb50695f723c..e8343c421476 100644
--- a/tests/system/runtimes/test_notifications.py
+++ b/tests/system/runtimes/test_notifications.py
@@ -69,7 +69,7 @@ def _assert_notifications():
# the notifications are sent asynchronously, so we need to wait for them
mlrun.utils.retry_until_successful(
1,
- 20,
+ 40,
self._logger,
True,
_assert_notifications,
From 308702aa72dfbbc390bb7da04dd1d28cc042cfbe Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Thu, 18 May 2023 13:02:01 +0300
Subject: [PATCH 162/334] [CI] Refined tag description for security scan
(#3590)
---
.github/workflows/security_scan.yaml | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/.github/workflows/security_scan.yaml b/.github/workflows/security_scan.yaml
index 642a1bdc4ca8..e2fc70a12521 100644
--- a/.github/workflows/security_scan.yaml
+++ b/.github/workflows/security_scan.yaml
@@ -20,7 +20,7 @@ on:
workflow_dispatch:
inputs:
tag:
- description: 'MLRun image tag to scan (unstable, 1.3.0 or any other tag)'
+ description: 'MLRun image tag to scan (unstable-cache, unstable-cache-13x, 1.3.0-wwwwwwww, 1.3.0 or any other tag)'
required: false
default: 'unstable'
registry:
From 94496af500a0dc0b9de361ff0819e2b045f5b229 Mon Sep 17 00:00:00 2001
From: davesh0812 <85231462+davesh0812@users.noreply.github.com>
Date: Thu, 18 May 2023 13:11:51 +0300
Subject: [PATCH 163/334] [Feature Set] Fix set_targets to overwrite the
existing targets and allow no-target ingest if running locally (#3583)
---
mlrun/feature_store/api.py | 9 ++++-----
mlrun/feature_store/feature_set.py | 17 ++++++++++++++---
.../system/feature_store/test_feature_store.py | 6 +++---
3 files changed, 21 insertions(+), 11 deletions(-)
diff --git a/mlrun/feature_store/api.py b/mlrun/feature_store/api.py
index 22c86b2145f0..4333c262b7a1 100644
--- a/mlrun/feature_store/api.py
+++ b/mlrun/feature_store/api.py
@@ -30,7 +30,6 @@
from ..datastore.targets import (
BaseStoreTarget,
get_default_prefix_for_source,
- get_default_targets,
get_target_driver,
kind_to_driver,
validate_target_list,
@@ -431,10 +430,10 @@ def ingest(
not mlrun_context
and not targets
and not (featureset.spec.targets or featureset.spec.with_default_targets)
+ and (run_config is not None and not run_config.local)
):
raise mlrun.errors.MLRunInvalidArgumentError(
- f"No targets provided to feature set {featureset.metadata.name} ingest, aborting.\n"
- "(preview can be used as an alternative to local ingest when targets are not needed)"
+ f"Feature set {featureset.metadata.name} is remote ingested with no targets defined, aborting"
)
if featureset is not None:
@@ -522,7 +521,7 @@ def ingest(
if not namespace:
namespace = _get_namespace(run_config)
- targets_to_ingest = targets or featureset.spec.targets or get_default_targets()
+ targets_to_ingest = targets or featureset.spec.targets
targets_to_ingest = copy.deepcopy(targets_to_ingest)
validate_target_paths_for_engine(targets_to_ingest, featureset.spec.engine, source)
@@ -805,7 +804,7 @@ def deploy_ingestion_service(
name=featureset.metadata.name,
)
- targets_to_ingest = targets or featureset.spec.targets or get_default_targets()
+ targets_to_ingest = targets or featureset.spec.targets
targets_to_ingest = copy.deepcopy(targets_to_ingest)
featureset.update_targets_for_ingest(targets_to_ingest)
diff --git a/mlrun/feature_store/feature_set.py b/mlrun/feature_store/feature_set.py
index fdc718761095..a9b7e1b9a21a 100644
--- a/mlrun/feature_store/feature_set.py
+++ b/mlrun/feature_store/feature_set.py
@@ -376,6 +376,7 @@ def __init__(
self.status = None
self._last_state = ""
self._aggregations = {}
+ self.set_targets()
@property
def spec(self) -> FeatureSetSpec:
@@ -479,8 +480,20 @@ def set_targets(
else:
self.spec.with_default_targets = False
- validate_target_list(targets=targets)
+ self.spec.targets = []
+ self.__set_targets_add_targets_helper(targets)
+
+ if default_final_step:
+ self.spec.graph.final_step = default_final_step
+
+ def __set_targets_add_targets_helper(self, targets):
+ """
+ Add the desired target list
+ :param targets: list of target type names ('csv', 'nosql', ..) or target objects
+ CSVTarget(), ParquetTarget(), NoSqlTarget(), StreamTarget(), ..
+ """
+ validate_target_list(targets=targets)
for target in targets:
kind = target.kind if hasattr(target, "kind") else target
if kind not in TargetTypes.all():
@@ -492,8 +505,6 @@ def set_targets(
target, name=str(target), partitioned=(target == "parquet")
)
self.spec.targets.update(target)
- if default_final_step:
- self.spec.graph.final_step = default_final_step
def validate_steps(self, namespace):
if not self.spec:
diff --git a/tests/system/feature_store/test_feature_store.py b/tests/system/feature_store/test_feature_store.py
index 439c22d24b63..8276b3ab107e 100644
--- a/tests/system/feature_store/test_feature_store.py
+++ b/tests/system/feature_store/test_feature_store.py
@@ -2380,7 +2380,7 @@ def test_join_with_table(self):
attributes=["aug"],
inner_join=True,
)
- df = fstore.preview(
+ df = fstore.ingest(
fset,
df,
)
@@ -2425,7 +2425,7 @@ def test_directional_graph(self):
attributes=["aug"],
inner_join=True,
)
- df = fstore.preview(fset, df)
+ df = fstore.ingest(fset, df)
assert df.to_dict() == {
"foreignkey1": {
"mykey1_1": "AB",
@@ -2745,7 +2745,7 @@ def test_map_with_state_with_table(self):
group_by_key=True,
_fn="map_with_state_test_function",
)
- df = fstore.preview(fset, df)
+ df = fstore.ingest(fset, df)
assert df.to_dict() == {
"name": {"a": "a", "b": "b"},
"sum": {"a": 16, "b": 26},
From f7d79b822cd9e277aafab0a6535b5fe7dbf3e1db Mon Sep 17 00:00:00 2001
From: davesh0812 <85231462+davesh0812@users.noreply.github.com>
Date: Thu, 18 May 2023 15:16:22 +0300
Subject: [PATCH 164/334] [Servnig] Fix plot when before param exists. (#3585)
---
mlrun/serving/states.py | 23 ++++++++++++++---------
1 file changed, 14 insertions(+), 9 deletions(-)
diff --git a/mlrun/serving/states.py b/mlrun/serving/states.py
index 28b765802c48..46fd01a84816 100644
--- a/mlrun/serving/states.py
+++ b/mlrun/serving/states.py
@@ -1282,15 +1282,8 @@ def _add_graphviz_flow(
_add_graphviz_router(sg, child)
else:
graph.node(child.fullname, label=child.name, shape=child.get_shape())
- after = child.after or []
- for item in after:
- previous_object = step[item]
- kw = (
- {"ltail": "cluster_" + previous_object.fullname}
- if previous_object.kind == StepKinds.router
- else {}
- )
- graph.edge(previous_object.fullname, child.fullname, **kw)
+ _add_edges(child.after or [], step, graph, child)
+ _add_edges(getattr(child, "before", []), step, graph, child, after=False)
if child.on_error:
graph.edge(child.fullname, child.on_error, style="dashed")
@@ -1310,6 +1303,18 @@ def _add_graphviz_flow(
graph.edge(last_step, target.fullname)
+def _add_edges(items, step, graph, child, after=True):
+ for item in items:
+ next_or_prev_object = step[item]
+ kw = {}
+ if next_or_prev_object.kind == StepKinds.router:
+ kw["ltail"] = f"cluster_{next_or_prev_object.fullname}"
+ if after:
+ graph.edge(next_or_prev_object.fullname, child.fullname, **kw)
+ else:
+ graph.edge(child.fullname, next_or_prev_object.fullname, **kw)
+
+
def _generate_graphviz(
step,
renderer,
From 5b2bc3d47f3f871287e7e4bcaa962238c487c339 Mon Sep 17 00:00:00 2001
From: tomer-mamia <125267619+tomerm-iguazio@users.noreply.github.com>
Date: Thu, 18 May 2023 15:46:48 +0300
Subject: [PATCH 165/334] [Requirements] bump storey to 1.4.0 (#3592)
---
mlrun/datastore/sources.py | 1 -
requirements.txt | 2 +-
tests/test_requirements.py | 2 +-
3 files changed, 2 insertions(+), 3 deletions(-)
diff --git a/mlrun/datastore/sources.py b/mlrun/datastore/sources.py
index 276745c4d2f4..13b02001978d 100644
--- a/mlrun/datastore/sources.py
+++ b/mlrun/datastore/sources.py
@@ -171,7 +171,6 @@ def to_step(self, key_field=None, time_field=None, context=None):
return storey.CSVSource(
paths=self.path,
- header=True,
build_dict=True,
key_field=self.key_field or key_field,
storage_options=self._get_store().get_storage_options(),
diff --git a/requirements.txt b/requirements.txt
index 2c62b925cd41..b7ea9199a2a4 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -54,7 +54,7 @@ humanfriendly~=8.2
fastapi~=0.92.0
fsspec~=2023.1.0
v3iofs~=0.1.15
-storey~=1.3.19
+storey~=1.4.0
deepdiff~=5.0
pymysql~=1.0
inflection~=0.5.0
diff --git a/tests/test_requirements.py b/tests/test_requirements.py
index 77518018d7c5..c439c517523b 100644
--- a/tests/test_requirements.py
+++ b/tests/test_requirements.py
@@ -94,7 +94,7 @@ def test_requirement_specifiers_convention():
# See comment near requirement for why we're limiting to patch changes only for all of these
"kfp": {"~=1.8.0, <1.8.14"},
"aiobotocore": {"~=2.4.2"},
- "storey": {"~=1.3.19"},
+ "storey": {"~=1.4.0"},
"bokeh": {"~=2.4, >=2.4.2"},
"typing-extensions": {">=3.10.0,<5"},
"sphinx": {"~=4.3.0"},
From 007f604a8f653dd6b42e630f094789e54f5e964e Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Fri, 19 May 2023 23:00:43 +0300
Subject: [PATCH 166/334] [CI] Fix removing stale mlrun docker images (#3604)
---
automation/system_test/cleanup.py | 51 ++++++++++++++++++++++---------
1 file changed, 36 insertions(+), 15 deletions(-)
diff --git a/automation/system_test/cleanup.py b/automation/system_test/cleanup.py
index bbcda2be2389..252a28f2d724 100644
--- a/automation/system_test/cleanup.py
+++ b/automation/system_test/cleanup.py
@@ -45,6 +45,15 @@ def docker_images(registry_url: str, registry_container_name: str, images: str):
click.echo(
f"Unable to remove images from datanode docker: {exc}, continuing anyway"
)
+
+ try:
+ click.echo("Removing dangling images from datanode docker")
+ _remove_dangling_images_from_datanode_docker()
+ except Exception as exc:
+ click.echo(
+ f"Unable to remove dangling images from datanode docker: {exc}, continuing anyway"
+ )
+
try:
_run_registry_garbage_collection(registry_container_name)
except Exception as exc:
@@ -90,23 +99,35 @@ async def _collect_image_tags(
def _remove_image_from_datanode_docker():
"""Remove image from datanode docker"""
+ formatted_docker_images = subprocess.Popen(
+ ["docker", "images", "--format", "'{{.Repository }}:{{.Tag}}'"],
+ stdout=subprocess.PIPE,
+ )
+ grep = subprocess.Popen(
+ ["grep", "mlrun"],
+ stdin=formatted_docker_images.stdout,
+ stdout=subprocess.PIPE,
+ )
subprocess.run(
- [
- "docker",
- "images",
- "--format",
- "'{{.Repository }}:{{.Tag}}'",
- "|",
- "grep",
- "mlrun",
- "|",
- "xargs",
- "--no-run-if-empty",
- "docker",
- "rmi",
- "-f",
- ]
+ ["xargs", "--no-run-if-empty", "docker", "rmi", "-f"],
+ stdin=grep.stdout,
+ )
+ formatted_docker_images.stdout.close()
+ grep.stdout.close()
+
+
+def _remove_dangling_images_from_datanode_docker():
+ """Remove dangling images from datanode docker"""
+
+ dangling_docker_images = subprocess.Popen(
+ ["docker", "images", "--quiet", "--filter", "dangling=true"],
+ stdout=subprocess.PIPE,
+ )
+ subprocess.run(
+ ["xargs", "--no-run-if-empty", "docker", "rmi", "-f"],
+ stdin=dangling_docker_images.stdout,
)
+ dangling_docker_images.stdout.close()
async def _delete_image_tags(
From 95a0caff603a902ea3cbc206145c09c2bacdeddb Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Sun, 21 May 2023 13:15:14 +0300
Subject: [PATCH 167/334] [CI] Fix dev utilities working directory (#3605)
---
automation/system_test/prepare.py | 20 ++++++++++++--------
1 file changed, 12 insertions(+), 8 deletions(-)
diff --git a/automation/system_test/prepare.py b/automation/system_test/prepare.py
index 62d8f8333efe..e323dd3cecc5 100644
--- a/automation/system_test/prepare.py
+++ b/automation/system_test/prepare.py
@@ -136,10 +136,12 @@ def connect_to_remote(self):
def run(self):
self.connect_to_remote()
- try:
- self._install_devutilities()
- except Exception as exp:
- self._logger.error("error on install devutilities", exception=str(exp))
+
+ # try:
+ # self._install_dev_utilities()
+ # except Exception as exp:
+ # self._logger.error("error on install dev utilities", exception=str(exp))
+
# for sanity clean up before starting the run
self.clean_up_remote_workdir()
@@ -339,9 +341,8 @@ def _override_mlrun_api_env(self):
args=["apply", "-f", manifest_file_name],
)
- def _install_devutilities(self):
+ def _install_dev_utilities(self):
urlscript = "https://gist.github.com/a51d75fe52e95df617b5dbb983c8e6e1.git"
- ipaddr = "--ipaddr " + os.environ.get("IP_ADDR_PREFIX")
list_uninstall = [
"dev_utilities.py",
"uninstall",
@@ -357,10 +358,13 @@ def _install_devutilities(self):
"--mysql",
"--redisinsight",
"--kafka",
- ipaddr,
+ "--ipadd",
+ os.environ.get("IP_ADDR_PREFIX", "localhost"),
]
self._run_command("rm", args=["-rf", "/home/iguazio/dev_utilities"])
- self._run_command("git", args=["clone", urlscript, "dev_utilities"])
+ self._run_command(
+ "git", args=["clone", urlscript, "dev_utilities"], workdir="/home/iguazio"
+ )
self._run_command(
"python3", args=list_uninstall, workdir="/home/iguazio/dev_utilities"
)
From a1d04bbbf7004921f62d21c6506066d77c1add7e Mon Sep 17 00:00:00 2001
From: Saar Cohen <66667568+theSaarco@users.noreply.github.com>
Date: Sun, 21 May 2023 14:37:54 +0300
Subject: [PATCH 168/334] [Projects] Add `project.build_image()` enabling build
of images directly from the project (#3594)
---
mlrun/config.py | 2 +
mlrun/model.py | 110 ++++++++++++++++++++
mlrun/projects/project.py | 144 ++++++++++++++++++++++++--
mlrun/runtimes/base.py | 49 +--------
mlrun/runtimes/kubejob.py | 42 +++-----
tests/runtimes/test_base.py | 4 +-
tests/system/projects/test_project.py | 70 +++++++++++++
7 files changed, 341 insertions(+), 80 deletions(-)
diff --git a/mlrun/config.py b/mlrun/config.py
index 41c5e3869203..897cd9fead85 100644
--- a/mlrun/config.py
+++ b/mlrun/config.py
@@ -81,6 +81,8 @@
"builder_alpine_image": "alpine:3.13.1", # builder alpine image (as kaniko's initContainer)
"package_path": "mlrun", # mlrun pip package
"default_base_image": "mlrun/mlrun", # default base image when doing .deploy()
+ # template for project default image name. Parameter {name} will be replaced with project name
+ "default_project_image_name": ".mlrun-project-image-{name}",
"default_project": "default", # default project name
"default_archive": "", # default remote archive URL (for build tar.gz)
"mpijob_crd_version": "", # mpijob crd version (e.g: "v1alpha1". must be in: mlrun.runtime.MPIJobCRDVersions)
diff --git a/mlrun/model.py b/mlrun/model.py
index 98ce4379b84e..2439c8b1212f 100644
--- a/mlrun/model.py
+++ b/mlrun/model.py
@@ -16,6 +16,7 @@
import pathlib
import re
import time
+import typing
from collections import OrderedDict
from copy import deepcopy
from datetime import datetime
@@ -377,6 +378,115 @@ def source(self, source):
self._source = source
+ def build_config(
+ self,
+ image="",
+ base_image=None,
+ commands: list = None,
+ secret=None,
+ source=None,
+ extra=None,
+ load_source_on_run=None,
+ with_mlrun=None,
+ auto_build=None,
+ requirements=None,
+ overwrite=False,
+ ):
+ if image:
+ self.image = image
+ if base_image:
+ self.base_image = base_image
+ if commands:
+ self.with_commands(commands, overwrite=overwrite)
+ if requirements:
+ self.with_requirements(requirements, overwrite=overwrite)
+ if extra:
+ self.extra = extra
+ if secret is not None:
+ self.secret = secret
+ if source:
+ self.source = source
+ if load_source_on_run:
+ self.load_source_on_run = load_source_on_run
+ if with_mlrun is not None:
+ self.with_mlrun = with_mlrun
+ if auto_build:
+ self.auto_build = auto_build
+
+ def with_commands(
+ self,
+ commands: List[str],
+ overwrite: bool = False,
+ ):
+ """add commands to build spec.
+
+ :param commands: list of commands to run during build
+ :param overwrite: whether to overwrite the existing commands or add to them (the default)
+
+ :return: function object
+ """
+ if not isinstance(commands, list) or not all(
+ isinstance(item, str) for item in commands
+ ):
+ raise ValueError("commands must be a string list")
+ if not self.commands or overwrite:
+ self.commands = commands
+ else:
+ # add commands to existing build commands
+ for command in commands:
+ if command not in self.commands:
+ self.commands.append(command)
+ # using list(set(x)) won't retain order,
+ # solution inspired from https://stackoverflow.com/a/17016257/8116661
+ self.commands = list(dict.fromkeys(self.commands))
+
+ def with_requirements(
+ self,
+ requirements: Union[str, List[str]],
+ overwrite: bool = False,
+ ):
+ """add package requirements from file or list to build spec.
+
+ :param requirements: python requirements file path or list of packages
+ :param overwrite: overwrite existing requirements
+ :return: function object
+ """
+ resolved_requirements = self._resolve_requirements(requirements)
+ requirements = self.requirements or [] if not overwrite else []
+
+ # make sure we don't append the same line twice
+ for requirement in resolved_requirements:
+ if requirement not in requirements:
+ requirements.append(requirement)
+
+ self.requirements = requirements
+
+ @staticmethod
+ def _resolve_requirements(requirements_to_resolve: typing.Union[str, list]) -> list:
+ # if a string, read the file then encode
+ if isinstance(requirements_to_resolve, str):
+ with open(requirements_to_resolve, "r") as fp:
+ requirements_to_resolve = fp.read().splitlines()
+
+ requirements = []
+ for requirement in requirements_to_resolve:
+ # clean redundant leading and trailing whitespaces
+ requirement = requirement.strip()
+
+ # ignore empty lines
+ # ignore comments
+ if not requirement or requirement.startswith("#"):
+ continue
+
+ # ignore inline comments as well
+ inline_comment = requirement.split(" #")
+ if len(inline_comment) > 1:
+ requirement = inline_comment[0].strip()
+
+ requirements.append(requirement)
+
+ return requirements
+
class Notification(ModelObj):
"""Notification specification"""
diff --git a/mlrun/projects/project.py b/mlrun/projects/project.py
index d20c9122ddec..a092a7e8d3a6 100644
--- a/mlrun/projects/project.py
+++ b/mlrun/projects/project.py
@@ -44,7 +44,7 @@
from ..artifacts.manager import ArtifactManager, dict_to_artifact, extend_artifact_path
from ..datastore import store_manager
from ..features import Feature
-from ..model import EntrypointParam, ModelObj
+from ..model import EntrypointParam, ImageBuilder, ModelObj
from ..run import code_to_function, get_object, import_function, new_function
from ..runtimes.utils import add_code_metadata
from ..secrets import SecretsStore
@@ -543,6 +543,7 @@ def __init__(
disable_auto_mount=None,
workdir=None,
default_image=None,
+ build=None,
):
self.repo = None
@@ -576,6 +577,8 @@ def __init__(
self.disable_auto_mount = disable_auto_mount
self.default_image = default_image
+ self.build = build
+
@property
def source(self) -> str:
"""source url or git repo"""
@@ -752,6 +755,14 @@ def _need_repo(self):
return True
return False
+ @property
+ def build(self) -> ImageBuilder:
+ return self._build
+
+ @build.setter
+ def build(self, build):
+ self._build = self._verify_dict(build, "build", ImageBuilder)
+
def get_code_path(self):
"""Get the path to the code root/workdir"""
return path.join(self.context, self.workdir or self.subpath or "")
@@ -910,7 +921,6 @@ def set_source(self, source, pull_at_runtime=False, workdir=None):
self.spec.source = source or self.spec.source
if self.spec.source.startswith("git://"):
-
source, reference, branch = resolve_git_reference_from_source(source)
if not branch and not reference:
logger.warn(
@@ -2296,12 +2306,12 @@ def build_function(
function: typing.Union[str, mlrun.runtimes.BaseRuntime],
with_mlrun: bool = None,
skip_deployed: bool = False,
- image=None,
- base_image=None,
+ image: str = None,
+ base_image: str = None,
commands: list = None,
- secret_name=None,
+ secret_name: str = None,
requirements: typing.Union[str, typing.List[str]] = None,
- mlrun_version_specifier=None,
+ mlrun_version_specifier: str = None,
builder_env: dict = None,
overwrite_build_params: bool = False,
) -> typing.Union[BuildStatus, kfp.dsl.ContainerOp]:
@@ -2336,6 +2346,128 @@ def build_function(
overwrite_build_params=overwrite_build_params,
)
+ def build_config(
+ self,
+ image: str = None,
+ set_as_default: bool = False,
+ with_mlrun: bool = None,
+ base_image: str = None,
+ commands: list = None,
+ secret_name: str = None,
+ requirements: typing.Union[str, typing.List[str]] = None,
+ overwrite_build_params: bool = False,
+ ):
+ """specify builder configuration for the project
+
+ :param image: target image name/path. If not specified the project's existing `default_image` name will be
+ used. If not set, the `mlconf.default_project_image_name` value will be used
+ :param set_as_default: set `image` to be the project's default image (default False)
+ :param with_mlrun: add the current mlrun package to the container build
+ :param base_image: base image name/path
+ :param commands: list of docker build (RUN) commands e.g. ['pip install pandas']
+ :param secret_name: k8s secret for accessing the docker registry
+ :param requirements: requirements.txt file to install or list of packages to install on the built image
+ :param overwrite_build_params: overwrite existing build configuration (default False)
+
+ * False: the new params are merged with the existing (currently merge is applied to requirements and
+ commands)
+ * True: the existing params are replaced by the new ones
+ """
+ default_image_name = mlrun.mlconf.default_project_image_name.format(
+ name=self.name
+ )
+ image = image or self.default_image or default_image_name
+
+ self.spec.build.build_config(
+ image=image,
+ base_image=base_image,
+ commands=commands,
+ secret=secret_name,
+ with_mlrun=with_mlrun,
+ requirements=requirements,
+ overwrite=overwrite_build_params,
+ )
+
+ if set_as_default and image != self.default_image:
+ self.set_default_image(image)
+
+ def build_image(
+ self,
+ image: str = None,
+ set_as_default: bool = True,
+ with_mlrun: bool = None,
+ skip_deployed: bool = False,
+ base_image: str = None,
+ commands: list = None,
+ secret_name: str = None,
+ requirements: typing.Union[str, typing.List[str]] = None,
+ mlrun_version_specifier: str = None,
+ builder_env: dict = None,
+ overwrite_build_params: bool = False,
+ ) -> typing.Union[BuildStatus, kfp.dsl.ContainerOp]:
+ """Builder docker image for the project, based on the project's build config. Parameters allow to override
+ the build config.
+
+ :param image: target image name/path. If not specified the project's existing `default_image` name will be
+ used. If not set, the `mlconf.default_project_image_name` value will be used
+ :param set_as_default: set `image` to be the project's default image (default False)
+ :param with_mlrun: add the current mlrun package to the container build
+ :param skip_deployed: skip the build if we already have the image specified built
+ :param base_image: base image name/path (commands and source code will be added to it)
+ :param commands: list of docker build (RUN) commands e.g. ['pip install pandas']
+ :param secret_name: k8s secret for accessing the docker registry
+ :param requirements: list of python packages or pip requirements file path, defaults to None
+ :param mlrun_version_specifier: which mlrun package version to include (if not current)
+ :param builder_env: Kaniko builder pod env vars dict (for config/credentials)
+ e.g. builder_env={"GIT_TOKEN": token}, does not work yet in KFP
+ :param overwrite_build_params: overwrite existing build configuration (default False)
+
+ * False: the new params are merged with the existing (currently merge is applied to requirements and
+ commands)
+ * True: the existing params are replaced by the new ones
+ """
+
+ self.build_config(
+ image=image,
+ set_as_default=set_as_default,
+ base_image=base_image,
+ commands=commands,
+ secret_name=secret_name,
+ with_mlrun=with_mlrun,
+ requirements=requirements,
+ overwrite_build_params=overwrite_build_params,
+ )
+
+ function = mlrun.new_function("mlrun--project--image--builder", kind="job")
+
+ build = self.spec.build
+ result = self.build_function(
+ function=function,
+ with_mlrun=build.with_mlrun,
+ image=build.image,
+ base_image=build.base_image,
+ commands=build.commands,
+ secret_name=build.secret,
+ requirements=build.requirements,
+ skip_deployed=skip_deployed,
+ overwrite_build_params=overwrite_build_params,
+ mlrun_version_specifier=mlrun_version_specifier,
+ builder_env=builder_env,
+ )
+
+ try:
+ mlrun.db.get_run_db(secrets=self._secrets).delete_function(
+ name=function.metadata.name
+ )
+ except Exception as exc:
+ logger.warning(
+ f"Image was successfully built, but failed to delete temporary function {function.metadata.name}."
+ " To remove the function, attempt to manually delete it.",
+ exc=repr(exc),
+ )
+
+ return result
+
def deploy_function(
self,
function: typing.Union[str, mlrun.runtimes.BaseRuntime],
diff --git a/mlrun/runtimes/base.py b/mlrun/runtimes/base.py
index f9b47dcc51bd..0f5d366cec1b 100644
--- a/mlrun/runtimes/base.py
+++ b/mlrun/runtimes/base.py
@@ -797,15 +797,7 @@ def with_requirements(
:param prepare_image_for_deploy: prepare the image/base_image spec for deployment
:return: function object
"""
- resolved_requirements = self._resolve_requirements(requirements)
- requirements = self.spec.build.requirements or [] if not overwrite else []
-
- # make sure we don't append the same line twice
- for requirement in resolved_requirements:
- if requirement not in requirements:
- requirements.append(requirement)
-
- self.spec.build.requirements = requirements
+ self.spec.build.with_requirements(requirements, overwrite)
if verify_base_image or prepare_image_for_deploy:
# TODO: remove verify_base_image in 1.6.0
@@ -836,18 +828,7 @@ def with_commands(
:return: function object
"""
- if not isinstance(commands, list):
- raise ValueError("commands must be a string list")
- if not self.spec.build.commands or overwrite:
- self.spec.build.commands = commands
- else:
- # add commands to existing build commands
- for command in commands:
- if command not in self.spec.build.commands:
- self.spec.build.commands.append(command)
- # using list(set(x)) won't retain order,
- # solution inspired from https://stackoverflow.com/a/17016257/8116661
- self.spec.build.commands = list(dict.fromkeys(self.spec.build.commands))
+ self.spec.build.with_commands(commands, overwrite)
if verify_base_image or prepare_image_for_deploy:
# TODO: remove verify_base_image in 1.6.0
@@ -953,32 +934,6 @@ def doc(self):
line += f", default={p['default']}"
print(" " + line)
- @staticmethod
- def _resolve_requirements(requirements_to_resolve: typing.Union[str, list]) -> list:
- # if a string, read the file then encode
- if isinstance(requirements_to_resolve, str):
- with open(requirements_to_resolve, "r") as fp:
- requirements_to_resolve = fp.read().splitlines()
-
- requirements = []
- for requirement in requirements_to_resolve:
- # clean redundant leading and trailing whitespaces
- requirement = requirement.strip()
-
- # ignore empty lines
- # ignore comments
- if not requirement or requirement.startswith("#"):
- continue
-
- # ignore inline comments as well
- inline_comment = requirement.split(" #")
- if len(inline_comment) > 1:
- requirement = inline_comment[0].strip()
-
- requirements.append(requirement)
-
- return requirements
-
class BaseRuntimeHandler(ABC):
# setting here to allow tests to override
diff --git a/mlrun/runtimes/kubejob.py b/mlrun/runtimes/kubejob.py
index 964559b0aec1..dea0d890005c 100644
--- a/mlrun/runtimes/kubejob.py
+++ b/mlrun/runtimes/kubejob.py
@@ -135,31 +135,22 @@ def build_config(
* True: the existing params are replaced by the new ones
:param verify_base_image: verify that the base image is configured
(deprecated, use prepare_image_for_deploy)
- :param prepare_image_for_deploy: prepare the image/base_image spec for deployment"""
- if image:
- self.spec.build.image = image
- if base_image:
- self.spec.build.base_image = base_image
- if commands:
- self.with_commands(
- commands, overwrite=overwrite, prepare_image_for_deploy=False
- )
- if requirements:
- self.with_requirements(
- requirements, overwrite=overwrite, prepare_image_for_deploy=False
- )
- if extra:
- self.spec.build.extra = extra
- if secret is not None:
- self.spec.build.secret = secret
- if source:
- self.spec.build.source = source
- if load_source_on_run:
- self.spec.build.load_source_on_run = load_source_on_run
- if with_mlrun is not None:
- self.spec.build.with_mlrun = with_mlrun
- if auto_build:
- self.spec.build.auto_build = auto_build
+ :param prepare_image_for_deploy: prepare the image/base_image spec for deployment
+ """
+
+ self.spec.build.build_config(
+ image,
+ base_image,
+ commands,
+ secret,
+ source,
+ extra,
+ load_source_on_run,
+ with_mlrun,
+ auto_build,
+ requirements,
+ overwrite,
+ )
if verify_base_image or prepare_image_for_deploy:
if verify_base_image:
@@ -315,7 +306,6 @@ def deploy_step(
)
def _run(self, runobj: RunObject, execution):
-
command, args, extra_env = self._get_cmd_args(runobj)
if runobj.metadata.iteration:
diff --git a/tests/runtimes/test_base.py b/tests/runtimes/test_base.py
index 1042c1d4f5b5..703e977be068 100644
--- a/tests/runtimes/test_base.py
+++ b/tests/runtimes/test_base.py
@@ -135,7 +135,9 @@ def test_resolve_requirements(self, requirements, encoded_requirements):
f.write(requirement + "\n")
requirements = temp_file.name
- encoded = self._generate_runtime()._resolve_requirements(requirements)
+ encoded = self._generate_runtime().spec.build._resolve_requirements(
+ requirements
+ )
assert (
encoded == encoded_requirements
), f"Failed to encode {requirements} as file {requirements_as_file}"
diff --git a/tests/system/projects/test_project.py b/tests/system/projects/test_project.py
index 399db6a339af..8fd4dcc6874f 100644
--- a/tests/system/projects/test_project.py
+++ b/tests/system/projects/test_project.py
@@ -857,3 +857,73 @@ def test_remote_workflow_source_with_subpath(self):
name=project_name,
)
project.run("main", arguments={"x": 1}, engine="remote:kfp", watch=True)
+
+ def test_project_build_image(self):
+ name = "test-build-image"
+ self.custom_project_names_to_delete.append(name)
+ project = mlrun.new_project(name, context=str(self.assets_path))
+
+ image_name = ".test-custom-image"
+ project.build_image(
+ image=image_name,
+ set_as_default=True,
+ with_mlrun=False,
+ base_image="mlrun/mlrun",
+ requirements=["vaderSentiment"],
+ commands=["echo 1"],
+ )
+
+ assert project.default_image == image_name
+
+ # test with user provided function object
+ project.set_function(
+ str(self.assets_path / "sentiment.py"),
+ name="scores",
+ kind="job",
+ handler="handler",
+ )
+
+ run_result = project.run_function("scores", params={"text": "good morning"})
+ assert run_result.output("score")
+
+ def test_project_build_config_export_import(self):
+ # Verify that the build config is exported properly by the project, and a new project loaded from it
+ # can build default image directly without needing additional details.
+
+ name_export = "test-build-image-export"
+ name_import = "test-build-image-import"
+ self.custom_project_names_to_delete.extend([name_export, name_import])
+
+ project = mlrun.new_project(name_export, context=str(self.assets_path))
+ image_name = ".test-export-custom-image"
+
+ project.build_config(
+ image=image_name,
+ set_as_default=True,
+ with_mlrun=False,
+ base_image="mlrun/mlrun",
+ requirements=["vaderSentiment"],
+ commands=["echo 1"],
+ )
+ assert project.default_image == image_name
+
+ project_dir = f"{projects_dir}/{name_export}"
+ proj_file_path = project_dir + "/project.yaml"
+ project.export(proj_file_path)
+
+ new_project = mlrun.load_project(project_dir, name=name_import)
+ new_project.build_image()
+
+ new_project.set_function(
+ str(self.assets_path / "sentiment.py"),
+ name="scores",
+ kind="job",
+ handler="handler",
+ )
+
+ run_result = new_project.run_function(
+ "scores", params={"text": "terrible evening"}
+ )
+ assert run_result.output("score")
+
+ shutil.rmtree(project_dir, ignore_errors=True)
From 4aeebcc3e2b91cbc831bbcfab83888cae498ce38 Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Sun, 21 May 2023 15:31:03 +0300
Subject: [PATCH 169/334] [API] Remove session param from GET /frontend-spec
(#3570)
---
mlrun/api/api/endpoints/frontend_spec.py | 6 +-----
tests/api/api/test_frontend_spec.py | 16 ----------------
2 files changed, 1 insertion(+), 21 deletions(-)
diff --git a/mlrun/api/api/endpoints/frontend_spec.py b/mlrun/api/api/endpoints/frontend_spec.py
index eca8a07b300c..7cd21d2d8d10 100644
--- a/mlrun/api/api/endpoints/frontend_spec.py
+++ b/mlrun/api/api/endpoints/frontend_spec.py
@@ -39,13 +39,9 @@ def get_frontend_spec(
auth_info: mlrun.common.schemas.AuthInfo = fastapi.Depends(
mlrun.api.api.deps.authenticate_request
),
- # In Iguazio 3.0 auth is turned off, but for this endpoint specifically the session is a must, so getting it from
- # the cookie like it was before
- # TODO: remove when Iguazio 3.0 is no longer relevant
- session: typing.Optional[str] = fastapi.Cookie(None),
):
jobs_dashboard_url = None
- session = auth_info.session or session
+ session = auth_info.session
if session and is_iguazio_session_cookie(session):
jobs_dashboard_url = _resolve_jobs_dashboard_url(session)
feature_flags = _resolve_feature_flags()
diff --git a/tests/api/api/test_frontend_spec.py b/tests/api/api/test_frontend_spec.py
index 0276e177ab0a..f68a7e160330 100644
--- a/tests/api/api/test_frontend_spec.py
+++ b/tests/api/api/test_frontend_spec.py
@@ -154,22 +154,6 @@ def test_get_frontend_spec_jobs_dashboard_url_resolution(
)
mlrun.api.utils.clients.iguazio.Client().try_get_grafana_service_url.assert_called_once()
- # now one time with the 3.0 iguazio auth way
- mlrun.mlconf.httpdb.authentication.mode = "none"
- mlrun.api.utils.clients.iguazio.Client().try_get_grafana_service_url.reset_mock()
- response = client.get(
- "frontend-spec",
- cookies={"session": 'j:{"sid":"946b0749-5c40-4837-a4ac-341d295bfaf7"}'},
- )
- assert response.status_code == http.HTTPStatus.OK.value
- frontend_spec = mlrun.common.schemas.FrontendSpec(**response.json())
- assert (
- frontend_spec.jobs_dashboard_url
- == f"{grafana_url}/d/mlrun-jobs-monitoring/mlrun-jobs-monitoring?orgId=1"
- f"&var-groupBy={{filter_name}}&var-filter={{filter_value}}"
- )
- mlrun.api.utils.clients.iguazio.Client().try_get_grafana_service_url.assert_called_once()
-
def test_get_frontend_spec_nuclio_streams(
db: sqlalchemy.orm.Session, client: fastapi.testclient.TestClient
From 182623c0e5fc750bf3583dd33f4b37ea0ab8149a Mon Sep 17 00:00:00 2001
From: Tom Tankilevitch <59158507+Tankilevitch@users.noreply.github.com>
Date: Sun, 21 May 2023 22:58:40 +0300
Subject: [PATCH 170/334] [Config] Fix overriding API SQL DB with nopDB (#3608)
---
mlrun/k8s_utils.py | 2 +-
mlrun/runtimes/utils.py | 9 ++-------
2 files changed, 3 insertions(+), 8 deletions(-)
diff --git a/mlrun/k8s_utils.py b/mlrun/k8s_utils.py
index e0dbaeff8eda..78966a5f8aef 100644
--- a/mlrun/k8s_utils.py
+++ b/mlrun/k8s_utils.py
@@ -25,7 +25,7 @@
def is_running_inside_kubernetes_cluster():
global _running_inside_kubernetes_cluster
- if _running_inside_kubernetes_cluster is not None:
+ if _running_inside_kubernetes_cluster is None:
try:
kubernetes.config.load_incluster_config()
_running_inside_kubernetes_cluster = True
diff --git a/mlrun/runtimes/utils.py b/mlrun/runtimes/utils.py
index 77b932bfea81..372d7a365c8e 100644
--- a/mlrun/runtimes/utils.py
+++ b/mlrun/runtimes/utils.py
@@ -28,7 +28,6 @@
import mlrun.common.constants
import mlrun.utils.regex
from mlrun.api.utils.clients import nuclio
-from mlrun.db import get_run_db
from mlrun.errors import err_to_str
from mlrun.frameworks.parallel_coordinates import gen_pcp_plot
from mlrun.runtimes.constants import MPIJobCRDVersions
@@ -75,6 +74,7 @@ def resolve_mpijob_crd_version():
if not cached_mpijob_crd_version:
# config override everything
+ # on client side, expecting it to get enriched from the API through the client-spec
mpijob_crd_version = config.mpijob_crd_version
if not mpijob_crd_version:
@@ -95,13 +95,8 @@ def resolve_mpijob_crd_version():
mpijob_crd_version = mpi_operator_pod.metadata.labels.get(
"crd-version"
)
- elif not in_k8s_cluster:
- # connect will populate the config from the server config
- # TODO: something nicer
- get_run_db()
- mpijob_crd_version = config.mpijob_crd_version
- # If resolution failed simply use default
+ # backoff to use default if wasn't resolved in API
if not mpijob_crd_version:
mpijob_crd_version = MPIJobCRDVersions.default()
From 06284af1e268eaa999f8034368aab30804b042ea Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Mon, 22 May 2023 08:47:14 +0300
Subject: [PATCH 171/334] [Builder] Loading source with local path fixes
(#3276)
---
mlrun/api/launcher.py | 25 ++++++++++++++++++++---
mlrun/api/utils/builder.py | 15 +++++++-------
mlrun/launcher/base.py | 5 ++++-
mlrun/launcher/client.py | 5 ++++-
mlrun/platforms/iguazio.py | 1 -
mlrun/projects/project.py | 32 +++++++++++++++++++++---------
mlrun/run.py | 5 ++++-
mlrun/runtimes/kubejob.py | 9 ++++-----
mlrun/runtimes/local.py | 2 ++
mlrun/utils/helpers.py | 28 ++++++++++++++++++++++++++
tests/api/runtimes/base.py | 8 ++++++++
tests/api/runtimes/test_kubejob.py | 12 +++++++++++
tests/api/runtimes/test_serving.py | 2 --
tests/api/runtimes/test_spark.py | 7 +++++--
tests/api/utils/test_scheduler.py | 25 +++++++++++++++++------
tests/common_fixtures.py | 10 ++++++++--
16 files changed, 151 insertions(+), 40 deletions(-)
diff --git a/mlrun/api/launcher.py b/mlrun/api/launcher.py
index 870dc09749fd..31ba05ed0477 100644
--- a/mlrun/api/launcher.py
+++ b/mlrun/api/launcher.py
@@ -16,6 +16,7 @@
import mlrun.api.crud
import mlrun.api.db.sqldb.session
import mlrun.common.schemas.schedule
+import mlrun.config
import mlrun.execution
import mlrun.launcher.base
import mlrun.runtimes
@@ -52,7 +53,7 @@ def launch(
notifications: Optional[List[mlrun.model.Notification]] = None,
returns: Optional[List[Union[str, Dict[str, str]]]] = None,
) -> mlrun.run.RunObject:
- self._enrich_runtime(runtime)
+ self._enrich_runtime(runtime, project)
run = self._create_run_object(task)
@@ -143,8 +144,26 @@ def launch(
return self._wrap_run_result(runtime, result, run, err=last_err)
@staticmethod
- def _enrich_runtime(runtime):
- pass
+ def _enrich_runtime(
+ runtime: "mlrun.runtimes.base.BaseRuntime", project: Optional[str] = ""
+ ):
+ """
+ Enrich the runtime object with the project spec and metadata.
+ This is done only on the server side, since it's the source of truth for the project, and we want to keep the
+ client side enrichment as minimal as possible.
+ """
+ # ensure the runtime has a project before we enrich it with the project's spec
+ runtime.metadata.project = (
+ project or runtime.metadata.project or mlrun.config.config.default_project
+ )
+ project = runtime._get_db().get_project(runtime.metadata.project)
+ # this is mainly for tests with nop db
+ # in normal use cases if no project is found we will get an error
+ if project:
+ project = mlrun.projects.project.MlrunProject.from_dict(project.dict())
+ mlrun.projects.pipelines.enrich_function_object(
+ project, runtime, copy_function=False
+ )
def _save_or_push_notifications(self, runobj):
if not runobj.spec.notifications:
diff --git a/mlrun/api/utils/builder.py b/mlrun/api/utils/builder.py
index c6f74483f120..6476dd548601 100644
--- a/mlrun/api/utils/builder.py
+++ b/mlrun/api/utils/builder.py
@@ -358,11 +358,10 @@ def build_image(
context = "/context"
to_mount = False
- v3io = (
- source.startswith("v3io://") or source.startswith("v3ios://")
- if source
- else None
- )
+ is_v3io_source = False
+ if source:
+ is_v3io_source = source.startswith("v3io://") or source.startswith("v3ios://")
+
access_key = builder_env.get(
"V3IO_ACCESS_KEY", auth_info.data_session or auth_info.access_key
)
@@ -376,7 +375,8 @@ def build_image(
if inline_code or runtime_spec.build.load_source_on_run or not source:
context = "/empty"
- elif source and "://" in source and not v3io:
+ # source is remote
+ elif source and "://" in source and not is_v3io_source:
if source.startswith("git://"):
# if the user provided branch (w/o refs/..) we add the "refs/.."
fragment = parsed_url.fragment or ""
@@ -387,8 +387,9 @@ def build_image(
context = source
source_to_copy = "."
+ # source is local / v3io
else:
- if v3io:
+ if is_v3io_source:
source = parsed_url.path
to_mount = True
source_dir_to_mount, source_to_copy = path.split(source)
diff --git a/mlrun/launcher/base.py b/mlrun/launcher/base.py
index 97e8551679e2..8a0abb31b30e 100644
--- a/mlrun/launcher/base.py
+++ b/mlrun/launcher/base.py
@@ -363,7 +363,10 @@ def prepare_image_for_deploy(runtime: "mlrun.runtimes.BaseRuntime"):
@staticmethod
@abc.abstractmethod
- def _enrich_runtime(runtime):
+ def _enrich_runtime(
+ runtime: "mlrun.runtimes.base.BaseRuntime",
+ project: Optional[str] = "",
+ ):
pass
@abc.abstractmethod
diff --git a/mlrun/launcher/client.py b/mlrun/launcher/client.py
index 3b6531d96ef2..5af3596f4161 100644
--- a/mlrun/launcher/client.py
+++ b/mlrun/launcher/client.py
@@ -14,6 +14,7 @@
import abc
import getpass
import os
+from typing import Optional
import IPython
@@ -31,7 +32,9 @@ class ClientBaseLauncher(mlrun.launcher.base.BaseLauncher, abc.ABC):
"""
@staticmethod
- def _enrich_runtime(runtime):
+ def _enrich_runtime(
+ runtime: "mlrun.runtimes.base.BaseRuntime", project: Optional[str] = ""
+ ):
runtime.try_auto_mount_based_on_config()
runtime._fill_credentials()
diff --git a/mlrun/platforms/iguazio.py b/mlrun/platforms/iguazio.py
index 2194819fe66f..062122f9afa7 100644
--- a/mlrun/platforms/iguazio.py
+++ b/mlrun/platforms/iguazio.py
@@ -326,7 +326,6 @@ def v3io_to_vol(name, remote="~/", access_key="", user="", secret=None):
if secret:
secret = {"name": secret}
- # vol = client.V1Volume(name=name, flex_volume=client.V1FlexVolumeSource('v3io/fuse', options=opts))
vol = {
"flexVolume": client.V1FlexVolumeSource(
"v3io/fuse", options=opts, secret_ref=secret
diff --git a/mlrun/projects/project.py b/mlrun/projects/project.py
index a092a7e8d3a6..11d8b8100ab4 100644
--- a/mlrun/projects/project.py
+++ b/mlrun/projects/project.py
@@ -37,8 +37,10 @@
import mlrun.common.schemas
import mlrun.db
import mlrun.errors
+import mlrun.runtimes
+import mlrun.runtimes.pod
+import mlrun.runtimes.utils
import mlrun.utils.regex
-from mlrun.runtimes import RuntimeKinds
from ..artifacts import Artifact, ArtifactProducer, DatasetArtifact, ModelArtifact
from ..artifacts.manager import ArtifactManager, dict_to_artifact, extend_artifact_path
@@ -46,7 +48,6 @@
from ..features import Feature
from ..model import EntrypointParam, ImageBuilder, ModelObj
from ..run import code_to_function, get_object, import_function, new_function
-from ..runtimes.utils import add_code_metadata
from ..secrets import SecretsStore
from ..utils import (
is_ipython,
@@ -908,15 +909,24 @@ def source(self) -> str:
def source(self, source):
self.spec.source = source
- def set_source(self, source, pull_at_runtime=False, workdir=None):
+ def set_source(
+ self,
+ source: str = "",
+ pull_at_runtime: bool = False,
+ workdir: Optional[str] = None,
+ ):
"""set the project source code path(can be git/tar/zip archive)
- :param source: valid path to git, zip, or tar file, (or None for current) e.g.
- git://github.com/mlrun/something.git
- http://some/url/file.zip
+ :param source: valid absolute path or URL to git, zip, or tar file, (or None for current) e.g.
+ git://github.com/mlrun/something.git
+ http://some/url/file.zip
+ note path source must exist on the image or exist locally when run is local
+ (it is recommended to use 'workdir' when source is a filepath instead)
:param pull_at_runtime: load the archive into the container at job runtime vs on build/deploy
- :param workdir: the relative workdir path (under the context dir)
+ :param workdir: workdir path relative to the context dir or absolute
"""
+ mlrun.utils.helpers.validate_builder_source(source, pull_at_runtime, workdir)
+
self.spec.load_source_on_run = pull_at_runtime
self.spec.source = source or self.spec.source
@@ -1613,6 +1623,7 @@ def set_function(
if image:
function_object.spec.image = image
if with_repo:
+ # mark source to be enriched before run with project source (enrich_function_object)
function_object.spec.build.source = "./"
if requirements:
function_object.with_requirements(requirements)
@@ -1763,7 +1774,7 @@ def sync_functions(self, names: list = None, always=True, save=False):
if not names:
names = self.spec._function_definitions.keys()
funcs = {}
- origin = add_code_metadata(self.spec.context)
+ origin = mlrun.runtimes.utils.add_code_metadata(self.spec.context)
for name in names:
f = self.spec._function_definitions.get(name)
if not f:
@@ -2765,6 +2776,7 @@ def _init_function_from_dict(f, project, name=None):
raise ValueError(f"unsupported function url:handler {url}:{handler} or no spec")
if with_repo:
+ # mark source to be enriched before run with project source (enrich_function_object)
func.spec.build.source = "./"
if requirements:
func.with_requirements(requirements)
@@ -2792,7 +2804,9 @@ def _init_function_from_obj(func, project, name=None):
def _has_module(handler, kind):
if not handler:
return False
- return (kind in RuntimeKinds.nuclio_runtimes() and ":" in handler) or "." in handler
+ return (
+ kind in mlrun.runtimes.RuntimeKinds.nuclio_runtimes() and ":" in handler
+ ) or "." in handler
def _is_imported_artifact(artifact):
diff --git a/mlrun/run.py b/mlrun/run.py
index e63da50ff523..d0a711456ffb 100644
--- a/mlrun/run.py
+++ b/mlrun/run.py
@@ -585,8 +585,11 @@ def new_function(
(job, mpijob, ..) the handler can also be specified in the `.run()` command, when not specified
the entire file will be executed (as main).
for nuclio functions the handler is in the form of module:function, defaults to "main:handler"
- :param source: valid path to git, zip, or tar file, e.g. `git://github.com/mlrun/something.git`,
+ :param source: valid absolute path or URL to git, zip, or tar file, e.g.
+ `git://github.com/mlrun/something.git`,
`http://some/url/file.zip`
+ note path source must exist on the image or exist locally when run is local
+ (it is recommended to use 'function.spec.workdir' when source is a filepath instead)
:param requirements: list of python packages or pip requirements file path, defaults to None
:param kfp: reserved, flag indicating running within kubeflow pipeline
diff --git a/mlrun/runtimes/kubejob.py b/mlrun/runtimes/kubejob.py
index dea0d890005c..b2c3124a6429 100644
--- a/mlrun/runtimes/kubejob.py
+++ b/mlrun/runtimes/kubejob.py
@@ -63,18 +63,17 @@ def with_source_archive(
):
"""load the code from git/tar/zip archive at runtime or build
- :param source: valid path to git, zip, or tar file, e.g.
+ :param source: valid absolute path or URL to git, zip, or tar file, e.g.
git://github.com/mlrun/something.git
http://some/url/file.zip
+ note path source must exist on the image or exist locally when run is local
+ (it is recommended to use 'workdir' when source is a filepath instead)
:param handler: default function handler
:param workdir: working dir relative to the archive root (e.g. './subdir') or absolute to the image root
:param pull_at_runtime: load the archive into the container at job runtime vs on build/deploy
:param target_dir: target dir on runtime pod or repo clone / archive extraction
"""
- if source.endswith(".zip") and not pull_at_runtime:
- logger.warn(
- "zip files are not natively extracted by docker, use tar.gz for faster loading during build"
- )
+ mlrun.utils.helpers.validate_builder_source(source, pull_at_runtime, workdir)
self.spec.build.source = source
if handler:
diff --git a/mlrun/runtimes/local.py b/mlrun/runtimes/local.py
index 84aae0dc05f2..fbcf16566b56 100644
--- a/mlrun/runtimes/local.py
+++ b/mlrun/runtimes/local.py
@@ -217,6 +217,8 @@ def _pre_run(self, runobj: RunObject, execution: MLClientCtx):
execution._current_workdir = workdir
execution._old_workdir = None
+ # _is_run_local is set when the user specifies local=True in run()
+ # in this case we don't want to extract the source code and contaminate the user's local dir
if self.spec.build.source and not hasattr(self, "_is_run_local"):
target_dir = extract_source(
self.spec.build.source,
diff --git a/mlrun/utils/helpers.py b/mlrun/utils/helpers.py
index f94c8f98a676..5a860d180f4b 100644
--- a/mlrun/utils/helpers.py
+++ b/mlrun/utils/helpers.py
@@ -163,6 +163,34 @@ def verify_field_regex(
return True
+def validate_builder_source(
+ source: str, pull_at_runtime: bool = False, workdir: str = None
+):
+ if pull_at_runtime or not source:
+ return
+
+ if "://" not in source:
+ if not path.isabs(source):
+ raise mlrun.errors.MLRunInvalidArgumentError(
+ f"Source '{source}' must be a valid URL or absolute path when 'pull_at_runtime' is False"
+ "set 'source' to a remote URL to clone/copy the source to the base image, "
+ "or set 'pull_at_runtime' to True to pull the source at runtime."
+ )
+ else:
+ logger.warn(
+ "Loading local source at build time requires the source to be on the base image, "
+ "in which case it is recommended to use 'workdir' instead",
+ source=source,
+ workdir=workdir,
+ )
+
+ if source.endswith(".zip"):
+ logger.warn(
+ "zip files are not natively extracted by docker, use tar.gz for faster loading during build",
+ source=source,
+ )
+
+
def validate_tag_name(
tag_name: str, field_name: str, raise_on_failure: bool = True
) -> bool:
diff --git a/tests/api/runtimes/base.py b/tests/api/runtimes/base.py
index 9cfa05088464..715e30149e2c 100644
--- a/tests/api/runtimes/base.py
+++ b/tests/api/runtimes/base.py
@@ -31,9 +31,11 @@
from kubernetes.client import V1EnvVar
import mlrun.api.api.endpoints.functions
+import mlrun.api.crud
import mlrun.common.schemas
import mlrun.k8s_utils
import mlrun.runtimes.pod
+import tests.api.api.utils
from mlrun.api.utils.singletons.k8s import get_k8s_helper
from mlrun.config import config as mlconf
from mlrun.model import new_task
@@ -98,6 +100,7 @@ def setup_method_fixture(
get_k8s_helper().is_running_inside_kubernetes_cluster = unittest.mock.Mock(
return_value=True
)
+ self._create_project(client)
# enable inheriting classes to do the same
self.custom_setup_after_fixtures()
@@ -143,6 +146,11 @@ def custom_setup_after_fixtures(self):
def custom_teardown(self):
pass
+ def _create_project(
+ self, client: fastapi.testclient.TestClient, project_name: str = None
+ ):
+ tests.api.api.utils.create_project(client, project_name or self.project)
+
def _generate_task(self):
return new_task(
name=self.name, project=self.project, artifact_path=self.artifact_path
diff --git a/tests/api/runtimes/test_kubejob.py b/tests/api/runtimes/test_kubejob.py
index 90737648f669..ef086a1800fe 100644
--- a/tests/api/runtimes/test_kubejob.py
+++ b/tests/api/runtimes/test_kubejob.py
@@ -803,6 +803,18 @@ def test_resolve_workdir(
pod = self._get_pod_creation_args()
assert pod.spec.containers[0].working_dir == expected_workdir
+ def test_with_source_archive_validation(self):
+ runtime = self._generate_runtime()
+ source = "./some/relative/path"
+ with pytest.raises(mlrun.errors.MLRunInvalidArgumentError) as e:
+ runtime.with_source_archive(source, pull_at_runtime=False)
+ assert (
+ f"Source '{source}' must be a valid URL or absolute path when 'pull_at_runtime' is False"
+ "set 'source' to a remote URL to clone/copy the source to the base image, "
+ "or set 'pull_at_runtime' to True to pull the source at runtime."
+ in str(e.value)
+ )
+
@staticmethod
def _assert_build_commands(expected_commands, runtime):
assert (
diff --git a/tests/api/runtimes/test_serving.py b/tests/api/runtimes/test_serving.py
index 55f01eb149cf..c71023177b79 100644
--- a/tests/api/runtimes/test_serving.py
+++ b/tests/api/runtimes/test_serving.py
@@ -26,7 +26,6 @@
import mlrun.api.api.utils
import mlrun.api.crud.runtimes.nuclio.function
-import tests.api.api.utils
from mlrun import mlconf, new_function
from mlrun.api.utils.singletons.k8s import get_k8s_helper
from mlrun.db import SQLDB
@@ -255,7 +254,6 @@ def test_serving_with_secrets_remote_build(self, db: Session, client: TestClient
mlrun.api.api.utils.mask_function_sensitive_data = unittest.mock.Mock()
function = self._create_serving_function()
- tests.api.api.utils.create_project(client, self.project)
# Simulate a remote build by issuing client's API. Code below is taken from httpdb.
req = {
diff --git a/tests/api/runtimes/test_spark.py b/tests/api/runtimes/test_spark.py
index f6da95d0ad40..cfa50f3884c4 100644
--- a/tests/api/runtimes/test_spark.py
+++ b/tests/api/runtimes/test_spark.py
@@ -620,6 +620,9 @@ def test_get_offline_features(
target=ParquetTarget(),
)
+ self.project = "default"
+ self._create_project(client)
+
resp = fstore.get_offline_features(
fv,
with_indexes=True,
@@ -661,13 +664,12 @@ def test_get_offline_features(
expected_runspec,
# excluding function attribute as it contains hash of the object, excluding this path because any change
# in the structure of the run will require to update the function hash
- exclude_paths="function",
+ exclude_paths=["root['function']"],
)
== {}
)
self.name = "my-vector-merger"
- self.project = "default"
expected_code = _default_merger_handler.replace(
"{{{engine}}}", "SparkFeatureMerger"
@@ -707,6 +709,7 @@ def test_run_with_load_source_on_run(
# generate runtime and set source code to load on run
runtime: mlrun.runtimes.Spark3Runtime = self._generate_runtime()
runtime.metadata.name = "test-spark-runtime"
+ runtime.metadata.project = self.project
runtime.spec.build.source = "git://github.com/mock/repo"
runtime.spec.build.load_source_on_run = True
# expect pre-condition error, not supported
diff --git a/tests/api/utils/test_scheduler.py b/tests/api/utils/test_scheduler.py
index e445cdbd3760..1d377f411905 100644
--- a/tests/api/utils/test_scheduler.py
+++ b/tests/api/utils/test_scheduler.py
@@ -75,6 +75,19 @@ async def do_nothing():
pass
+def create_project(
+ db: Session, project_name: str = None
+) -> mlrun.common.schemas.Project:
+ """API tests use sql db, so we need to create the project with its schema"""
+ project = mlrun.common.schemas.Project(
+ metadata=mlrun.common.schemas.ProjectMetadata(
+ name=project_name or config.default_project
+ )
+ )
+ mlrun.api.crud.Projects().create_project(db, project)
+ return project
+
+
@pytest.mark.asyncio
async def test_not_skipping_delayed_schedules(db: Session, scheduler: Scheduler):
global call_counter
@@ -151,7 +164,7 @@ async def test_invoke_schedule(
cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(year=1999)
schedule_name = "schedule-name"
project_name = config.default_project
- mlrun.new_project(project_name, save=False)
+ create_project(db, project_name)
scheduled_object = _create_mlrun_function_and_matching_scheduled_object(
db, project_name
)
@@ -209,7 +222,7 @@ async def test_create_schedule_mlrun_function(
):
project_name = config.default_project
- mlrun.new_project(project_name, save=False)
+ create_project(db, project_name)
scheduled_object = _create_mlrun_function_and_matching_scheduled_object(
db, project_name
@@ -288,7 +301,7 @@ async def test_schedule_upgrade_from_scheduler_without_credentials_store(
):
name = "schedule-name"
project_name = config.default_project
- mlrun.new_project(project_name, save=False)
+ create_project(db, project_name)
scheduled_object = _create_mlrun_function_and_matching_scheduled_object(
db, project_name
@@ -1017,7 +1030,7 @@ async def test_update_schedule(
inactive_cron_trigger = mlrun.common.schemas.ScheduleCronTrigger(year="1999")
schedule_name = "schedule-name"
project_name = config.default_project
- mlrun.new_project(project_name, save=False)
+ create_project(db, project_name)
scheduled_object = _create_mlrun_function_and_matching_scheduled_object(
db, project_name
@@ -1230,7 +1243,7 @@ async def test_schedule_job_concurrency_limit(
call_counter = 0
project_name = config.default_project
- mlrun.new_project(project_name, save=False)
+ create_project(db, project_name)
scheduled_object = (
_create_mlrun_function_and_matching_scheduled_object(
@@ -1310,7 +1323,7 @@ async def test_schedule_job_next_run_time(
)
schedule_name = "schedule-name"
project_name = config.default_project
- mlrun.new_project(project_name, save=False)
+ create_project(db, project_name)
scheduled_object = _create_mlrun_function_and_matching_scheduled_object(
db, project_name, handler="sleep_two_seconds"
diff --git a/tests/common_fixtures.py b/tests/common_fixtures.py
index 13058cefa338..258b8a2ec424 100644
--- a/tests/common_fixtures.py
+++ b/tests/common_fixtures.py
@@ -212,6 +212,7 @@ def __init__(self):
self._functions = {}
self._artifacts = {}
self._project_name = None
+ self._project = None
self._runs = {}
def reset(self):
@@ -299,8 +300,13 @@ def store_project(self, name, project):
def get_project(self, name):
if self._project_name and name == self._project_name:
return self._project
- else:
- raise mlrun.errors.MLRunNotFoundError("Project not found")
+
+ elif name == config.default_project and not self._project:
+ project = mlrun.projects.MlrunProject(name)
+ self.store_project(name, project)
+ return project
+
+ raise mlrun.errors.MLRunNotFoundError(f"Project '{name}' not found")
def remote_builder(
self,
From e15e35cc54ebd3b07a1dcbb967828395a13dc1a7 Mon Sep 17 00:00:00 2001
From: TomerShor <90552140+TomerShor@users.noreply.github.com>
Date: Mon, 22 May 2023 09:22:25 +0300
Subject: [PATCH 172/334] [System Tests] Change `test_run` project name (#3606)
---
tests/system/projects/test_project.py | 6 +++++-
1 file changed, 5 insertions(+), 1 deletion(-)
diff --git a/tests/system/projects/test_project.py b/tests/system/projects/test_project.py
index 8fd4dcc6874f..86021beceb67 100644
--- a/tests/system/projects/test_project.py
+++ b/tests/system/projects/test_project.py
@@ -64,6 +64,10 @@ def custom_setup(self):
pass
def custom_teardown(self):
+ self._logger.debug(
+ "Deleting custom projects",
+ num_projects_to_delete=len(self.custom_project_names_to_delete),
+ )
for name in self.custom_project_names_to_delete:
self._delete_test_project(name)
@@ -123,7 +127,7 @@ def test_project_persists_function_changes(self):
)
def test_run(self):
- name = "pipe1"
+ name = "pipe0"
self.custom_project_names_to_delete.append(name)
# create project in context
self._create_project(name)
From 7472234fbc929a7cae56d98e39bec484d26523c5 Mon Sep 17 00:00:00 2001
From: Adam
Date: Mon, 22 May 2023 11:20:27 +0300
Subject: [PATCH 173/334] [Notifications] Fix raising exception when git
notification gets a Bad Request (#3611)
fix exception
Co-authored-by: quaark
---
mlrun/utils/notifications/notification/git.py | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/mlrun/utils/notifications/notification/git.py b/mlrun/utils/notifications/notification/git.py
index 4aad11c00499..cffed15ae049 100644
--- a/mlrun/utils/notifications/notification/git.py
+++ b/mlrun/utils/notifications/notification/git.py
@@ -120,7 +120,7 @@ async def _pr_comment(
if not resp.ok:
resp_text = await resp.text()
raise mlrun.errors.MLRunBadRequestError(
- f"Failed commenting on PR: {resp_text}", status=resp.status
+ f"Failed commenting on PR: {resp_text}"
)
data = await resp.json()
return data.get("id")
From b4558d0fa6f922647043d94a38b6bd9c011877f2 Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Mon, 22 May 2023 13:07:28 +0300
Subject: [PATCH 174/334] [CI] Fix allowing tmate for OSS tests (#3610)
---
.github/workflows/system-tests-opensource.yml | 16 +++++++++++-----
1 file changed, 11 insertions(+), 5 deletions(-)
diff --git a/.github/workflows/system-tests-opensource.yml b/.github/workflows/system-tests-opensource.yml
index 69c87f63f2e1..0f03c470dc9c 100644
--- a/.github/workflows/system-tests-opensource.yml
+++ b/.github/workflows/system-tests-opensource.yml
@@ -193,6 +193,17 @@ jobs:
echo "MLRUN_SYSTEM_TESTS_GIT_TOKEN: ${{ secrets.SYSTEM_TEST_GITHUB_ACCESS_TOKEN }}" >> tests/system/env.yml
# TODO: use `prepare.py` for open source system tests as well
+ # Enable tmate debugging of manually-triggered workflows if the input option was provided
+ - name: Setup tmate session
+ uses: mxschmitt/action-tmate@v3
+ if: ${{ github.event_name == 'workflow_dispatch' && github.event.inputs.debug_enabled == 'true' }}
+ with:
+
+ # run in detach mode to allow the workflow to continue running while session is active
+ # this will wait up to 10 minutes AFTER the entire job is done. Once user connects to the session,
+ # it will wait until the user disconnects before finishing up the job.
+ detached: true
+
- name: Run system tests
timeout-minutes: 180
run: |
@@ -218,8 +229,3 @@ jobs:
minikube kubectl -- --namespace ${NAMESPACE} get pvc
minikube kubectl -- --namespace ${NAMESPACE} get pv
set +x
-
- # Enable tmate debugging of manually-triggered workflows if the input option was provided
- - name: Setup tmate session
- uses: mxschmitt/action-tmate@v3
- if: ${{ github.event_name == 'workflow_dispatch' && github.event.inputs.debug_enabled == 'true' }}
From 3bf2d375218529a8834f5228b6a8b672af519999 Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Mon, 22 May 2023 17:36:24 +0300
Subject: [PATCH 175/334] [Launcher] Fix `mlrun.config` read (#3618)
---
mlrun/launcher/client.py | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/mlrun/launcher/client.py b/mlrun/launcher/client.py
index 5af3596f4161..45d9ab9d22c8 100644
--- a/mlrun/launcher/client.py
+++ b/mlrun/launcher/client.py
@@ -135,7 +135,7 @@ def _log_track_results(
logger.info("no returned result (job may still be in progress)")
results_tbl.append(run.to_dict())
- if mlrun.utils.is_ipython and mlrun.config.ipython_widget:
+ if mlrun.utils.is_ipython and mlrun.config.config.ipython_widget:
results_tbl.show()
print()
ui_url = mlrun.utils.get_ui_url(project, uid)
From 3025dbe96fbed13e664ec63be08af5060afbb180 Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Mon, 22 May 2023 19:52:53 +0300
Subject: [PATCH 176/334] [CI] Fix generating env for OSS tests (#3616)
---
.github/workflows/system-tests-opensource.yml | 6 +--
automation/system_test/prepare.py | 48 +++++++++++++------
2 files changed, 37 insertions(+), 17 deletions(-)
diff --git a/.github/workflows/system-tests-opensource.yml b/.github/workflows/system-tests-opensource.yml
index 0f03c470dc9c..c77aebbaac94 100644
--- a/.github/workflows/system-tests-opensource.yml
+++ b/.github/workflows/system-tests-opensource.yml
@@ -189,9 +189,9 @@ jobs:
- name: Prepare system tests env
run: |
- echo "MLRUN_DBPATH: http://$(minikube ip):${MLRUN_API_NODE_PORT}" > tests/system/env.yml
- echo "MLRUN_SYSTEM_TESTS_GIT_TOKEN: ${{ secrets.SYSTEM_TEST_GITHUB_ACCESS_TOKEN }}" >> tests/system/env.yml
- # TODO: use `prepare.py` for open source system tests as well
+ python automation/system_test/prepare.py env \
+ "http://$(minikube ip):${MLRUN_API_NODE_PORT}" \
+ "${{ secrets.SYSTEM_TEST_GITHUB_ACCESS_TOKEN }}"
# Enable tmate debugging of manually-triggered workflows if the input option was provided
- name: Setup tmate session
diff --git a/automation/system_test/prepare.py b/automation/system_test/prepare.py
index e323dd3cecc5..9ab9f072307e 100644
--- a/automation/system_test/prepare.py
+++ b/automation/system_test/prepare.py
@@ -17,6 +17,7 @@
import logging
import os
import pathlib
+import shutil
import subprocess
import sys
import tempfile
@@ -29,8 +30,10 @@
import paramiko
import yaml
+# TODO: remove and use local logger
import mlrun.utils
+project_dir = pathlib.Path(__file__).resolve().parent.parent.parent
logger = mlrun.utils.create_logger(level="debug", name="automation")
logging.getLogger("paramiko").setLevel(logging.DEBUG)
@@ -43,7 +46,9 @@ class Constants:
igz_version_file = homedir / "igz" / "version.txt"
mlrun_code_path = workdir / "mlrun"
provctl_path = workdir / "provctl"
- system_tests_env_yaml = pathlib.Path("tests") / "system" / "env.yml"
+ system_tests_env_yaml = (
+ project_dir / pathlib.Path("tests") / "system" / "env.yml"
+ )
namespace = "default-tenant"
git_url = "https://github.com/mlrun/mlrun.git"
@@ -293,16 +298,20 @@ def _prepare_env_remote(self):
)
def _prepare_env_local(self):
- contents = yaml.safe_dump(self._env_config)
filepath = str(self.Constants.system_tests_env_yaml)
+ backup_filepath = str(self.Constants.system_tests_env_yaml) + ".bak"
self._logger.debug("Populating system tests env.yml", filepath=filepath)
- self._run_command(
- "cat > ",
- workdir=".",
- args=[filepath],
- stdin=contents,
- local=True,
- )
+
+ # if filepath exists, backup the file first (to avoid overriding it)
+ if os.path.isfile(filepath) and not os.path.isfile(backup_filepath):
+ self._logger.debug(
+ "Backing up existing env.yml", destination=backup_filepath
+ )
+ shutil.copy(filepath, backup_filepath)
+
+ serialized_env_config = self._serialize_env_config()
+ with open(filepath, "w") as f:
+ f.write(serialized_env_config)
def _override_mlrun_api_env(self):
version_specifier = (
@@ -613,6 +622,17 @@ def _run_kubectl_command(self, args, verbose=True):
verbose=verbose,
)
+ def _serialize_env_config(self, allow_none_values: bool = False):
+ env_config = self._env_config.copy()
+
+ # we sanitize None values from config to avoid "null" values in yaml
+ if not allow_none_values:
+ for key in list(env_config):
+ if env_config[key] is None:
+ del env_config[key]
+
+ return yaml.safe_dump(env_config)
+
@click.group()
def main():
@@ -736,11 +756,11 @@ def run(
@main.command(context_settings=dict(ignore_unknown_options=True))
@click.argument("mlrun-dbpath", type=str, required=True)
-@click.argument("webapi-direct-url", type=str, required=True)
-@click.argument("framesd-url", type=str, required=True)
-@click.argument("username", type=str, required=True)
-@click.argument("access-key", type=str, required=True)
-@click.argument("spark-service", type=str, required=True)
+@click.argument("webapi-direct-url", type=str, required=False)
+@click.argument("framesd-url", type=str, required=False)
+@click.argument("username", type=str, required=False)
+@click.argument("access-key", type=str, required=False)
+@click.argument("spark-service", type=str, required=False)
@click.argument("password", type=str, default=None, required=False)
@click.argument("slack-webhook-url", type=str, default=None, required=False)
@click.option(
From 2c360eb7b38584cd202dbb1b882c47f289a779ff Mon Sep 17 00:00:00 2001
From: Adam
Date: Mon, 22 May 2023 20:49:02 +0300
Subject: [PATCH 177/334] [Notifications] Fix notifications being resent when
api restarts (#3614)
---
mlrun/model.py | 2 ++
mlrun/utils/notifications/notification_pusher.py | 3 +++
2 files changed, 5 insertions(+)
diff --git a/mlrun/model.py b/mlrun/model.py
index 2439c8b1212f..4f824272464c 100644
--- a/mlrun/model.py
+++ b/mlrun/model.py
@@ -943,6 +943,7 @@ def __init__(
iterations=None,
ui_url=None,
reason: str = None,
+ notifications: Dict[str, Notification] = None,
):
self.state = state or "created"
self.status_text = status_text
@@ -956,6 +957,7 @@ def __init__(
self.iterations = iterations
self.ui_url = ui_url
self.reason = reason
+ self.notifications = notifications or {}
class RunTemplate(ModelObj):
diff --git a/mlrun/utils/notifications/notification_pusher.py b/mlrun/utils/notifications/notification_pusher.py
index e4f84bde8702..8bc2fb85d7e3 100644
--- a/mlrun/utils/notifications/notification_pusher.py
+++ b/mlrun/utils/notifications/notification_pusher.py
@@ -49,6 +49,9 @@ def __init__(self, runs: typing.Union[mlrun.lists.RunList, list]):
run = mlrun.model.RunObject.from_dict(run)
for notification in run.spec.notifications:
+ notification.status = run.status.notifications.get(
+ notification.name
+ ).status
if self._should_notify(run, notification):
self._notification_data.append((run, notification))
From 1b5fc7231758d1343e152ab06cde575d9b3f7028 Mon Sep 17 00:00:00 2001
From: Adam
Date: Mon, 22 May 2023 20:51:56 +0300
Subject: [PATCH 178/334] [Notifications] Fix sending duplicate notifications
(#3612)
---
mlrun/api/launcher.py | 17 +++--------------
mlrun/launcher/base.py | 6 +-----
mlrun/launcher/local.py | 14 ++++++++------
mlrun/launcher/remote.py | 3 ---
4 files changed, 12 insertions(+), 28 deletions(-)
diff --git a/mlrun/api/launcher.py b/mlrun/api/launcher.py
index 31ba05ed0477..2d1fd462447a 100644
--- a/mlrun/api/launcher.py
+++ b/mlrun/api/launcher.py
@@ -137,7 +137,7 @@ def launch(
finally:
result = runtime._update_run_state(resp=resp, task=run, err=last_err)
- self._save_or_push_notifications(run)
+ self._save_notifications(run)
runtime._post_run(result, execution) # hook for runtime specific cleanup
@@ -165,19 +165,8 @@ def _enrich_runtime(
project, runtime, copy_function=False
)
- def _save_or_push_notifications(self, runobj):
- if not runobj.spec.notifications:
- mlrun.utils.logger.debug(
- "No notifications to push for run", run_uid=runobj.metadata.uid
- )
- return
-
- # TODO: add support for other notifications per run iteration
- if runobj.metadata.iteration and runobj.metadata.iteration > 0:
- mlrun.utils.logger.debug(
- "Notifications per iteration are not supported, skipping",
- run_uid=runobj.metadata.uid,
- )
+ def _save_notifications(self, runobj):
+ if not self._run_has_valid_notifications(runobj):
return
# If in the api server, we can assume that watch=False, so we save notification
diff --git a/mlrun/launcher/base.py b/mlrun/launcher/base.py
index 8a0abb31b30e..380d4980339a 100644
--- a/mlrun/launcher/base.py
+++ b/mlrun/launcher/base.py
@@ -305,7 +305,7 @@ def _enrich_run(
return run
@staticmethod
- def _are_valid_notifications(runobj) -> bool:
+ def _run_has_valid_notifications(runobj) -> bool:
if not runobj.spec.notifications:
logger.debug(
"No notifications to push for run", run_uid=runobj.metadata.uid
@@ -369,10 +369,6 @@ def _enrich_runtime(
):
pass
- @abc.abstractmethod
- def _save_or_push_notifications(self, runobj):
- pass
-
@staticmethod
@abc.abstractmethod
def _store_function(
diff --git a/mlrun/launcher/local.py b/mlrun/launcher/local.py
index e4e8880a3715..cf9e28f0bb3a 100644
--- a/mlrun/launcher/local.py
+++ b/mlrun/launcher/local.py
@@ -186,7 +186,7 @@ def execute(
last_err = err
result = runtime._update_run_state(task=run, err=err)
- self._save_or_push_notifications(run)
+ self._push_notifications(run)
# run post run hooks
runtime._post_run(result, execution) # hook for runtime specific cleanup
@@ -257,11 +257,13 @@ def _resolve_local_code_path(local_code_path: str) -> (str, List[str]):
args = sp[1:]
return command, args
- def _save_or_push_notifications(self, runobj):
- if not self._are_valid_notifications(runobj):
+ def _push_notifications(self, runobj):
+ if not self._run_has_valid_notifications(runobj):
return
- # The run is local, so we can assume that watch=True, therefore this code runs
- # once the run is completed, and we can just push the notifications.
# TODO: add store_notifications API endpoint so we can store notifications pushed from the
# SDK for documentation purposes.
- mlrun.utils.notifications.NotificationPusher([runobj]).push()
+ # The run is local, so we can assume that watch=True, therefore this code runs
+ # once the run is completed, and we can just push the notifications.
+ # Only push from jupyter, not from the CLI.
+ if self._is_run_local:
+ mlrun.utils.notifications.NotificationPusher([runobj]).push()
diff --git a/mlrun/launcher/remote.py b/mlrun/launcher/remote.py
index ddb630496b01..49865818226b 100644
--- a/mlrun/launcher/remote.py
+++ b/mlrun/launcher/remote.py
@@ -174,6 +174,3 @@ def submit_job(
resp = runtime._get_db_run(run)
return self._wrap_run_result(runtime, resp, run, schedule=schedule)
-
- def _save_or_push_notifications(self, runobj):
- pass
From 04c1b07463fdd6b7a8567973962421cc1a095ab9 Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Tue, 23 May 2023 09:31:56 +0300
Subject: [PATCH 179/334] [CI] Fix calling prepare.py script (#3621)
---
.github/workflows/system-tests-enterprise.yml | 60 +++++++++----------
.github/workflows/system-tests-opensource.yml | 4 +-
2 files changed, 32 insertions(+), 32 deletions(-)
diff --git a/.github/workflows/system-tests-enterprise.yml b/.github/workflows/system-tests-enterprise.yml
index c8558451b011..2ef1dde4a633 100644
--- a/.github/workflows/system-tests-enterprise.yml
+++ b/.github/workflows/system-tests-enterprise.yml
@@ -247,26 +247,26 @@ jobs:
timeout-minutes: 50
run: |
python automation/system_test/prepare.py run \
- "${{ steps.computed_params.outputs.mlrun_version }}" \
- "${{ secrets.LATEST_SYSTEM_TEST_DATA_CLUSTER_IP }}" \
- "${{ secrets.LATEST_SYSTEM_TEST_DATA_CLUSTER_SSH_USERNAME }}" \
- "${{ secrets.LATEST_SYSTEM_TEST_DATA_CLUSTER_SSH_PASSWORD }}" \
- "${{ secrets.LATEST_SYSTEM_TEST_APP_CLUSTER_SSH_PASSWORD }}" \
- "${{ secrets.SYSTEM_TEST_GITHUB_ACCESS_TOKEN }}" \
- "${{ secrets.LATEST_SYSTEM_TEST_PROVCTL_DOWNLOAD_PATH }}" \
- "${{ secrets.LATEST_SYSTEM_TEST_PROVCTL_DOWNLOAD_URL_S3_ACCESS_KEY }}" \
- "${{ secrets.LATEST_SYSTEM_TEST_PROVCTL_DOWNLOAD_URL_S3_KEY_ID }}" \
- "${{ secrets.LATEST_SYSTEM_TEST_MLRUN_DB_PATH }}" \
- "${{ secrets.LATEST_SYSTEM_TEST_WEBAPI_DIRECT_URL }}" \
- "${{ secrets.LATEST_SYSTEM_TEST_FRAMESD_URL }}" \
- "${{ secrets.LATEST_SYSTEM_TEST_USERNAME }}" \
- "${{ secrets.LATEST_SYSTEM_TEST_ACCESS_KEY }}" \
- "${{ steps.computed_params.outputs.iguazio_version }}" \
- "${{ secrets.LATEST_SYSTEM_TEST_SPARK_SERVICE }}" \
- "${{ secrets.LATEST_SYSTEM_TEST_PASSWORD }}" \
- "${{ secrets.LATEST_SYSTEM_TEST_SLACK_WEBHOOK_URL }}" \
- "${{ secrets.LATEST_SYSTEM_TEST_MYSQL_USER }}" \
- "${{ secrets.LATEST_SYSTEM_TEST_MYSQL_PASSWORD }}" \
+ --mlrun-version "${{ steps.computed_params.outputs.mlrun_version }}" \
+ --data-cluster-ip "${{ secrets.LATEST_SYSTEM_TEST_DATA_CLUSTER_IP }}" \
+ --data-cluster-ssh-username "${{ secrets.LATEST_SYSTEM_TEST_DATA_CLUSTER_SSH_USERNAME }}" \
+ --data-cluster-ssh-password "${{ secrets.LATEST_SYSTEM_TEST_DATA_CLUSTER_SSH_PASSWORD }}" \
+ --app-cluster-ssh-password "${{ secrets.LATEST_SYSTEM_TEST_APP_CLUSTER_SSH_PASSWORD }}" \
+ --github-access-token "${{ secrets.SYSTEM_TEST_GITHUB_ACCESS_TOKEN }}" \
+ --provctl-download-url "${{ secrets.LATEST_SYSTEM_TEST_PROVCTL_DOWNLOAD_PATH }}" \
+ --provctl-download-s3-access-key "${{ secrets.LATEST_SYSTEM_TEST_PROVCTL_DOWNLOAD_URL_S3_ACCESS_KEY }}" \
+ --provctl-download-s3-key-id "${{ secrets.LATEST_SYSTEM_TEST_PROVCTL_DOWNLOAD_URL_S3_KEY_ID }}" \
+ --mlrun-dbpath "${{ secrets.LATEST_SYSTEM_TEST_MLRUN_DB_PATH }}" \
+ --webapi-direct-url "${{ secrets.LATEST_SYSTEM_TEST_WEBAPI_DIRECT_URL }}" \
+ --framesd-url "${{ secrets.LATEST_SYSTEM_TEST_FRAMESD_URL }}" \
+ --username "${{ secrets.LATEST_SYSTEM_TEST_USERNAME }}" \
+ --access-key "${{ secrets.LATEST_SYSTEM_TEST_ACCESS_KEY }}" \
+ --iguazio-version "${{ steps.computed_params.outputs.iguazio_version }}" \
+ --spark-service "${{ secrets.LATEST_SYSTEM_TEST_SPARK_SERVICE }}" \
+ --password "${{ secrets.LATEST_SYSTEM_TEST_PASSWORD }}" \
+ --slack-webhook-url "${{ secrets.LATEST_SYSTEM_TEST_SLACK_WEBHOOK_URL }}" \
+ --mysql-user "${{ secrets.LATEST_SYSTEM_TEST_MYSQL_USER }}" \
+ --mysql-password "${{ secrets.LATEST_SYSTEM_TEST_MYSQL_PASSWORD }}" \
--purge-db \
--mlrun-commit "${{ steps.computed_params.outputs.mlrun_hash }}" \
--override-image-registry "${{ steps.computed_params.outputs.mlrun_docker_registry }}" \
@@ -314,16 +314,16 @@ jobs:
timeout-minutes: 5
run: |
python automation/system_test/prepare.py env \
- "${{ secrets.LATEST_SYSTEM_TEST_MLRUN_DB_PATH }}" \
- "${{ secrets.LATEST_SYSTEM_TEST_WEBAPI_DIRECT_URL }}" \
- "${{ secrets.LATEST_SYSTEM_TEST_FRAMESD_URL }}" \
- "${{ secrets.LATEST_SYSTEM_TEST_USERNAME }}" \
- "${{ secrets.LATEST_SYSTEM_TEST_ACCESS_KEY }}" \
- "${{ secrets.LATEST_SYSTEM_TEST_SPARK_SERVICE }}" \
- "${{ secrets.LATEST_SYSTEM_TEST_PASSWORD }}" \
- "${{ secrets.LATEST_SYSTEM_TEST_SLACK_WEBHOOK_URL }}" \
- "${{ needs.prepare-system-tests-enterprise-ci.outputs.mlrunBranch }}" \
- "${{ secrets.SYSTEM_TEST_GITHUB_ACCESS_TOKEN }}"
+ --mlrun-dbpath "${{ secrets.LATEST_SYSTEM_TEST_MLRUN_DB_PATH }}" \
+ --webapi-direct-url "${{ secrets.LATEST_SYSTEM_TEST_WEBAPI_DIRECT_URL }}" \
+ --framesd-url "${{ secrets.LATEST_SYSTEM_TEST_FRAMESD_URL }}" \
+ --username "${{ secrets.LATEST_SYSTEM_TEST_USERNAME }}" \
+ --access-key "${{ secrets.LATEST_SYSTEM_TEST_ACCESS_KEY }}" \
+ --spark-service "${{ secrets.LATEST_SYSTEM_TEST_SPARK_SERVICE }}" \
+ --password "${{ secrets.LATEST_SYSTEM_TEST_PASSWORD }}" \
+ --slack-webhook-url "${{ secrets.LATEST_SYSTEM_TEST_SLACK_WEBHOOK_URL }}" \
+ --branch "${{ needs.prepare-system-tests-enterprise-ci.outputs.mlrunBranch }}" \
+ --github-access-token "${{ secrets.SYSTEM_TEST_GITHUB_ACCESS_TOKEN }}"
- name: Run System Tests
run: |
MLRUN_SYSTEM_TESTS_CLEAN_RESOURCES="${{ needs.prepare-system-tests-enterprise-ci.outputs.mlrunSystemTestsCleanResources }}" \
diff --git a/.github/workflows/system-tests-opensource.yml b/.github/workflows/system-tests-opensource.yml
index c77aebbaac94..4b9b20abcc83 100644
--- a/.github/workflows/system-tests-opensource.yml
+++ b/.github/workflows/system-tests-opensource.yml
@@ -190,8 +190,8 @@ jobs:
- name: Prepare system tests env
run: |
python automation/system_test/prepare.py env \
- "http://$(minikube ip):${MLRUN_API_NODE_PORT}" \
- "${{ secrets.SYSTEM_TEST_GITHUB_ACCESS_TOKEN }}"
+ --mlrun-dbpath "http://$(minikube ip):${MLRUN_API_NODE_PORT}" \
+ --github-access-token "${{ secrets.SYSTEM_TEST_GITHUB_ACCESS_TOKEN }}"
# Enable tmate debugging of manually-triggered workflows if the input option was provided
- name: Setup tmate session
From f3c3b566cad1599b6302d30c85384879dfc42cc2 Mon Sep 17 00:00:00 2001
From: Adam
Date: Tue, 23 May 2023 10:02:37 +0300
Subject: [PATCH 180/334] [Notifications] Fix notification param masking on run
object (#3613)
* fix masking
* add ut
---------
Co-authored-by: quaark
---
mlrun/api/api/utils.py | 8 +++++++-
tests/utils/test_notifications.py | 27 +++++++++++++++++++++++++++
2 files changed, 34 insertions(+), 1 deletion(-)
diff --git a/mlrun/api/api/utils.py b/mlrun/api/api/utils.py
index 1902c1a32f5c..2c136ccbe7b4 100644
--- a/mlrun/api/api/utils.py
+++ b/mlrun/api/api/utils.py
@@ -211,10 +211,16 @@ def mask_notification_params_on_task(task):
run_uid = get_in(task, "metadata.uid")
project = get_in(task, "metadata.project")
notifications = task.get("spec", {}).get("notifications", [])
+ masked_notifications = []
if notifications:
for notification in notifications:
notification_object = mlrun.model.Notification.from_dict(notification)
- mask_notification_params_with_secret(project, run_uid, notification_object)
+ masked_notifications.append(
+ mask_notification_params_with_secret(
+ project, run_uid, notification_object
+ ).to_dict()
+ )
+ task.setdefault("spec", {})["notifications"] = masked_notifications
def mask_notification_params_with_secret(
diff --git a/tests/utils/test_notifications.py b/tests/utils/test_notifications.py
index f223c478bf8f..1d1e25d14418 100644
--- a/tests/utils/test_notifications.py
+++ b/tests/utils/test_notifications.py
@@ -20,6 +20,8 @@
import pytest
import tabulate
+import mlrun.api.api.utils
+import mlrun.api.crud
import mlrun.utils.notifications
@@ -289,3 +291,28 @@ def test_inverse_dependencies(
custom_notification_pusher.push("test-message", "info", [])
assert mock_console_push.call_count == expected_console_call_amount
assert mock_ipython_push.call_count == expected_ipython_call_amount
+
+
+def test_notification_params_masking_on_run(monkeypatch):
+ def _store_project_secrets(*args, **kwargs):
+ pass
+
+ monkeypatch.setattr(
+ mlrun.api.crud.Secrets, "store_project_secrets", _store_project_secrets
+ )
+ run_uid = "test-run-uid"
+ run = {
+ "metadata": {"uid": run_uid, "project": "test-project"},
+ "spec": {
+ "notifications": [
+ {"when": "completed", "params": {"sensitive": "sensitive-value"}}
+ ]
+ },
+ }
+ mlrun.api.api.utils.mask_notification_params_on_task(run)
+ assert "sensitive" not in run["spec"]["notifications"][0]["params"]
+ assert "secret" in run["spec"]["notifications"][0]["params"]
+ assert (
+ run["spec"]["notifications"][0]["params"]["secret"]
+ == f"mlrun.notifications.{run_uid}"
+ )
From 7d8fe06896dff023fa8b20c286957a0a73cbc903 Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Tue, 23 May 2023 11:59:50 +0300
Subject: [PATCH 181/334] [Runtime] Fix `run` type hints (#3620)
---
mlrun/api/launcher.py | 4 +-
mlrun/launcher/base.py | 13 +++-
mlrun/launcher/local.py | 8 ++-
mlrun/launcher/remote.py | 4 +-
mlrun/runtimes/base.py | 140 ++++++++++++++++-----------------------
tests/run/test_run.py | 2 +-
6 files changed, 78 insertions(+), 93 deletions(-)
diff --git a/mlrun/api/launcher.py b/mlrun/api/launcher.py
index 2d1fd462447a..9eca3c7606a3 100644
--- a/mlrun/api/launcher.py
+++ b/mlrun/api/launcher.py
@@ -30,7 +30,9 @@ class ServerSideLauncher(mlrun.launcher.base.BaseLauncher):
def launch(
self,
runtime: mlrun.runtimes.BaseRuntime,
- task: Optional[Union[mlrun.run.RunTemplate, mlrun.run.RunObject]] = None,
+ task: Optional[
+ Union["mlrun.run.RunTemplate", "mlrun.run.RunObject", dict]
+ ] = None,
handler: Optional[str] = None,
name: Optional[str] = "",
project: Optional[str] = "",
diff --git a/mlrun/launcher/base.py b/mlrun/launcher/base.py
index 380d4980339a..8c6405d19213 100644
--- a/mlrun/launcher/base.py
+++ b/mlrun/launcher/base.py
@@ -16,7 +16,7 @@
import copy
import os
import uuid
-from typing import Any, Dict, List, Optional, Union
+from typing import Any, Callable, Dict, List, Optional, Union
import mlrun.common.schemas
import mlrun.config
@@ -76,8 +76,10 @@ def save_function(
def launch(
self,
runtime: "mlrun.runtimes.BaseRuntime",
- task: Optional[Union["mlrun.run.RunTemplate", "mlrun.run.RunObject"]] = None,
- handler: Optional[str] = None,
+ task: Optional[
+ Union["mlrun.run.RunTemplate", "mlrun.run.RunObject", dict]
+ ] = None,
+ handler: Optional[Union[str, Callable]] = None,
name: Optional[str] = "",
project: Optional[str] = "",
params: Optional[dict] = None,
@@ -184,6 +186,9 @@ def _create_run_object(task):
elif isinstance(task, dict):
return mlrun.run.RunObject.from_dict(task)
+ # task is already a RunObject
+ return task
+
def _enrich_run(
self,
runtime,
@@ -206,6 +211,8 @@ def _enrich_run(
run.spec.handler = (
handler or run.spec.handler or runtime.spec.default_handler or ""
)
+ # callable handlers are valid for handler and dask runtimes,
+ # for other runtimes we need to convert the handler to a string
if run.spec.handler and runtime.kind not in ["handler", "dask"]:
run.spec.handler = run.spec.handler_name
diff --git a/mlrun/launcher/local.py b/mlrun/launcher/local.py
index cf9e28f0bb3a..87be8beb9c0f 100644
--- a/mlrun/launcher/local.py
+++ b/mlrun/launcher/local.py
@@ -13,7 +13,7 @@
# limitations under the License.
import os
import pathlib
-from typing import Dict, List, Optional, Union
+from typing import Callable, Dict, List, Optional, Union
import mlrun.common.schemas.schedule
import mlrun.errors
@@ -43,8 +43,10 @@ def __init__(self, local: bool):
def launch(
self,
runtime: "mlrun.runtimes.BaseRuntime",
- task: Optional[Union["mlrun.run.RunTemplate", "mlrun.run.RunObject"]] = None,
- handler: Optional[str] = None,
+ task: Optional[
+ Union["mlrun.run.RunTemplate", "mlrun.run.RunObject", dict]
+ ] = None,
+ handler: Optional[Union[str, Callable]] = None,
name: Optional[str] = "",
project: Optional[str] = "",
params: Optional[dict] = None,
diff --git a/mlrun/launcher/remote.py b/mlrun/launcher/remote.py
index 49865818226b..30853dd5a5d8 100644
--- a/mlrun/launcher/remote.py
+++ b/mlrun/launcher/remote.py
@@ -32,7 +32,9 @@ class ClientRemoteLauncher(mlrun.launcher.client.ClientBaseLauncher):
def launch(
self,
runtime: "mlrun.runtimes.KubejobRuntime",
- task: Optional[Union["mlrun.run.RunTemplate", "mlrun.run.RunObject"]] = None,
+ task: Optional[
+ Union["mlrun.run.RunTemplate", "mlrun.run.RunObject", dict]
+ ] = None,
handler: Optional[str] = None,
name: Optional[str] = "",
project: Optional[str] = "",
diff --git a/mlrun/runtimes/base.py b/mlrun/runtimes/base.py
index 0f5d366cec1b..f6e10ec798b1 100644
--- a/mlrun/runtimes/base.py
+++ b/mlrun/runtimes/base.py
@@ -15,15 +15,12 @@
import getpass
import http
import traceback
-import typing
import warnings
from abc import ABC, abstractmethod
-from ast import literal_eval
from base64 import b64encode
-from copy import deepcopy
from datetime import datetime, timedelta, timezone
from os import environ
-from typing import Dict, List, Optional, Tuple, Union
+from typing import Callable, Dict, List, Optional, Tuple, Union
import requests.exceptions
from deprecated import deprecated
@@ -49,14 +46,7 @@
from ..errors import err_to_str
from ..kfpops import mlrun_op
from ..lists import RunList
-from ..model import (
- BaseMetadata,
- HyperParamOptions,
- ImageBuilder,
- ModelObj,
- RunObject,
- RunTemplate,
-)
+from ..model import BaseMetadata, HyperParamOptions, ImageBuilder, ModelObj, RunObject
from ..utils import (
dict_to_json,
dict_to_yaml,
@@ -282,61 +272,62 @@ def _fill_credentials(self):
def run(
self,
- runspec: RunObject = None,
- handler=None,
- name: str = "",
- project: str = "",
- params: dict = None,
- inputs: Dict[str, str] = None,
- out_path: str = "",
- workdir: str = "",
- artifact_path: str = "",
- watch: bool = True,
- schedule: Union[str, mlrun.common.schemas.ScheduleCronTrigger] = None,
- hyperparams: Dict[str, list] = None,
- hyper_param_options: HyperParamOptions = None,
- verbose=None,
- scrape_metrics: bool = None,
- local=False,
- local_code_path=None,
- auto_build=None,
- param_file_secrets: Dict[str, str] = None,
- notifications: List[mlrun.model.Notification] = None,
+ runspec: Optional[
+ Union["mlrun.run.RunTemplate", "mlrun.run.RunObject", dict]
+ ] = None,
+ handler: Optional[Union[str, Callable]] = None,
+ name: Optional[str] = "",
+ project: Optional[str] = "",
+ params: Optional[dict] = None,
+ inputs: Optional[Dict[str, str]] = None,
+ out_path: Optional[str] = "",
+ workdir: Optional[str] = "",
+ artifact_path: Optional[str] = "",
+ watch: Optional[bool] = True,
+ schedule: Optional[Union[str, mlrun.common.schemas.ScheduleCronTrigger]] = None,
+ hyperparams: Optional[Dict[str, list]] = None,
+ hyper_param_options: Optional[HyperParamOptions] = None,
+ verbose: Optional[bool] = None,
+ scrape_metrics: Optional[bool] = None,
+ local: Optional[bool] = False,
+ local_code_path: Optional[str] = None,
+ auto_build: Optional[bool] = None,
+ param_file_secrets: Optional[Dict[str, str]] = None,
+ notifications: Optional[List[mlrun.model.Notification]] = None,
returns: Optional[List[Union[str, Dict[str, str]]]] = None,
) -> RunObject:
"""
Run a local or remote task.
- :param runspec: run template object or dict (see RunTemplate)
- :param handler: pointer or name of a function handler
- :param name: execution name
- :param project: project name
- :param params: input parameters (dict)
+ :param runspec: The run spec to generate the RunObject from. Can be RunTemplate | RunObject | dict.
+ :param handler: Pointer or name of a function handler.
+ :param name: Execution name.
+ :param project: Project name.
+ :param params: Input parameters (dict).
:param inputs: Input objects to pass to the handler. Type hints can be given so the input will be parsed
during runtime from `mlrun.DataItem` to the given type hint. The type hint can be given
in the key field of the dictionary after a colon, e.g: " : ".
- :param out_path: default artifact output path
- :param artifact_path: default artifact output path (will replace out_path)
- :param workdir: default input artifacts path
- :param watch: watch/follow run log
+ :param out_path: Default artifact output path.
+ :param artifact_path: Default artifact output path (will replace out_path).
+ :param workdir: Default input artifacts path.
+ :param watch: Watch/follow run log.
:param schedule: ScheduleCronTrigger class instance or a standard crontab expression string
(which will be converted to the class using its `from_crontab` constructor),
see this link for help:
https://apscheduler.readthedocs.io/en/3.x/modules/triggers/cron.html#module-apscheduler.triggers.cron
- :param hyperparams: dict of param name and list of values to be enumerated e.g. {"p1": [1,2,3]}
+ :param hyperparams: Dict of param name and list of values to be enumerated e.g. {"p1": [1,2,3]}
the default strategy is grid search, can specify strategy (grid, list, random)
- and other options in the hyper_param_options parameter
- :param hyper_param_options: dict or :py:class:`~mlrun.model.HyperParamOptions` struct of
- hyper parameter options
- :param verbose: add verbose prints/logs
- :param scrape_metrics: whether to add the `mlrun/scrape-metrics` label to this run's resources
- :param local: run the function locally vs on the runtime/cluster
- :param local_code_path: path of the code for local runs & debug
- :param auto_build: when set to True and the function require build it will be built on the first
- function run, use only if you dont plan on changing the build config between runs
- :param param_file_secrets: dictionary of secrets to be used only for accessing the hyper-param parameter file.
- These secrets are only used locally and will not be stored anywhere
- :param notifications: list of notifications to push when the run is completed
+ and other options in the hyper_param_options parameter.
+ :param hyper_param_options: Dict or :py:class:`~mlrun.model.HyperParamOptions` struct of hyperparameter options.
+ :param verbose: Add verbose prints/logs.
+ :param scrape_metrics: Whether to add the `mlrun/scrape-metrics` label to this run's resources.
+ :param local: Run the function locally vs on the runtime/cluster.
+ :param local_code_path: Path of the code for local runs & debug.
+ :param auto_build: When set to True and the function require build it will be built on the first
+ function run, use only if you don't plan on changing the build config between runs.
+ :param param_file_secrets: Dictionary of secrets to be used only for accessing the hyper-param parameter file.
+ These secrets are only used locally and will not be stored anywhere
+ :param notifications: List of notifications to push when the run is completed
:param returns: List of log hints - configurations for how to log the returning values from the handler's run
(as artifacts or results). The list's length must be equal to the amount of returning objects. A
log hint may be given as:
@@ -348,7 +339,7 @@ def run(
* A dictionary of configurations to use when logging. Further info per object type and artifact
type can be given there. The artifact key must appear in the dictionary as "key": "the_key".
- :return: run context object (RunObject) with run metadata, results and status
+ :return: Run context object (RunObject) with run metadata, results and status
"""
launcher = mlrun.launcher.factory.LauncherFactory.create_launcher(
self._is_remote, local
@@ -404,25 +395,6 @@ def _generate_runtime_env(self, runobj: RunObject):
runtime_env["MLRUN_NAMESPACE"] = self.metadata.namespace or config.namespace
return runtime_env
- def _create_run_object(self, runspec):
- # TODO: Once implemented the `Runtime` handlers configurations (doc strings, params type hints and returning
- # log hints, possible parameter values, etc), the configured type hints and log hints should be set into
- # the `RunObject` from the `Runtime`.
- if runspec:
- runspec = deepcopy(runspec)
- if isinstance(runspec, str):
- runspec = literal_eval(runspec)
- if not isinstance(runspec, (dict, RunTemplate, RunObject)):
- raise ValueError(
- "task/runspec is not a valid task object," f" type={type(runspec)}"
- )
-
- if isinstance(runspec, RunTemplate):
- runspec = RunObject.from_template(runspec)
- if isinstance(runspec, dict) or runspec is None:
- runspec = RunObject.from_dict(runspec)
- return runspec
-
@staticmethod
def _handle_submit_job_http_error(error: requests.HTTPError):
# if we receive a 400 status code, this means the request was invalid and the run wasn't created in the DB.
@@ -938,7 +910,7 @@ def doc(self):
class BaseRuntimeHandler(ABC):
# setting here to allow tests to override
kind = "base"
- class_modes: typing.Dict[RuntimeClassMode, str] = {}
+ class_modes: Dict[RuntimeClassMode, str] = {}
wait_for_deletion_interval = 10
@staticmethod
@@ -957,7 +929,7 @@ def _should_collect_logs(self) -> bool:
return True
def _get_possible_mlrun_class_label_values(
- self, class_mode: typing.Union[RuntimeClassMode, str] = None
+ self, class_mode: Union[RuntimeClassMode, str] = None
) -> List[str]:
"""
Should return the possible values of the mlrun/class label for runtime resources that are of this runtime
@@ -971,7 +943,7 @@ def _get_possible_mlrun_class_label_values(
def list_resources(
self,
project: str,
- object_id: typing.Optional[str] = None,
+ object_id: Optional[str] = None,
label_selector: str = None,
group_by: Optional[
mlrun.common.schemas.ListRuntimeResourcesGroupByField
@@ -1228,8 +1200,8 @@ def _ensure_run_not_stuck_on_non_terminal_state(
def _add_object_label_selector_if_needed(
self,
- object_id: typing.Optional[str] = None,
- label_selector: typing.Optional[str] = None,
+ object_id: Optional[str] = None,
+ label_selector: Optional[str] = None,
):
if object_id:
object_label_selector = self._get_object_label_selector(object_id)
@@ -1362,7 +1334,7 @@ def _resolve_pod_status_info(
return in_terminal_state, last_container_completion_time, run_state
def _get_default_label_selector(
- self, class_mode: typing.Union[RuntimeClassMode, str] = None
+ self, class_mode: Union[RuntimeClassMode, str] = None
) -> str:
"""
Override this to add a default label selector
@@ -1440,9 +1412,9 @@ def _list_crd_objects(self, namespace: str, label_selector: str = None) -> List:
def resolve_label_selector(
self,
project: str,
- object_id: typing.Optional[str] = None,
- label_selector: typing.Optional[str] = None,
- class_mode: typing.Union[RuntimeClassMode, str] = None,
+ object_id: Optional[str] = None,
+ label_selector: Optional[str] = None,
+ class_mode: Union[RuntimeClassMode, str] = None,
with_main_runtime_resource_label_selector: bool = False,
) -> str:
default_label_selector = self._get_default_label_selector(class_mode=class_mode)
@@ -1473,7 +1445,7 @@ def resolve_label_selector(
@staticmethod
def resolve_object_id(
run: dict,
- ) -> typing.Optional[str]:
+ ) -> Optional[str]:
"""
Get the object id from the run object
Override this if the object id is not the run uid
diff --git a/tests/run/test_run.py b/tests/run/test_run.py
index 8a51c21690ed..67d84a3c34f9 100644
--- a/tests/run/test_run.py
+++ b/tests/run/test_run.py
@@ -324,12 +324,12 @@ def test_context_from_run_dict():
},
}
runtime = mlrun.runtimes.base.BaseRuntime.from_dict(run_dict)
- run = runtime._create_run_object(run_dict)
handler = "my_func"
out_path = "test_artifact_path"
launcher = mlrun.launcher.factory.LauncherFactory.create_launcher(
runtime._is_remote
)
+ run = launcher._create_run_object(run_dict)
run = launcher._enrich_run(
runtime,
run,
From 08704a0c8771d498edf2bdc5b33324b840ffb05f Mon Sep 17 00:00:00 2001
From: TomerShor <90552140+TomerShor@users.noreply.github.com>
Date: Tue, 23 May 2023 16:44:11 +0300
Subject: [PATCH 182/334] [Nuclio] Resolve full image names if enrichment
prefix is given (#3623)
---
mlrun/api/crud/runtimes/nuclio/function.py | 294 ++++++++++++---------
mlrun/api/utils/builder.py | 65 +++--
tests/api/runtimes/test_nuclio.py | 14 +
tests/api/utils/test_builder.py | 4 +-
4 files changed, 214 insertions(+), 163 deletions(-)
diff --git a/mlrun/api/crud/runtimes/nuclio/function.py b/mlrun/api/crud/runtimes/nuclio/function.py
index 409792516d7a..72a1a51d9a3f 100644
--- a/mlrun/api/crud/runtimes/nuclio/function.py
+++ b/mlrun/api/crud/runtimes/nuclio/function.py
@@ -23,10 +23,12 @@
import mlrun
import mlrun.api.crud.runtimes.nuclio.helpers
import mlrun.api.schemas
+import mlrun.api.utils.builder
import mlrun.api.utils.singletons.k8s
import mlrun.datastore
import mlrun.errors
import mlrun.runtimes.function
+import mlrun.runtimes.pod
import mlrun.utils
from mlrun.utils import logger
@@ -63,6 +65,7 @@ def deploy_nuclio_function(
)
try:
+ logger.info("Starting Nuclio function deployment")
return nuclio.deploy.deploy_config(
function_config,
dashboard_url=mlrun.mlconf.nuclio_dashboard_url,
@@ -171,12 +174,88 @@ def _compile_function_config(
builder_env=None,
auth_info=None,
):
+ _set_function_labels(function)
+
+ # resolve env vars before compiling the nuclio spec, as we need to set them in the spec
+ env_dict, external_source_env_dict = _resolve_env_vars(function)
+
+ nuclio_spec = nuclio.ConfigSpec(
+ env=env_dict,
+ external_source_env=external_source_env_dict,
+ config=function.spec.config,
+ )
+ nuclio_spec.cmd = function.spec.build.commands or []
+
+ _resolve_and_set_build_requirements(function, nuclio_spec)
+ _resolve_and_set_nuclio_runtime(
+ function, nuclio_spec, client_version, client_python_version
+ )
+
+ project = function.metadata.project or "default"
+ tag = function.metadata.tag
+ handler = function.spec.function_handler
+
+ _set_build_params(function, nuclio_spec, builder_env, project, auth_info)
+ _set_function_scheduling_params(function, nuclio_spec)
+ _set_function_replicas(function, nuclio_spec)
+ _set_misc_specs(function, nuclio_spec)
+
+ # if the user code is given explicitly or from a source, we need to set the handler and relevant attributes
+ if (
+ function.spec.base_spec
+ or function.spec.build.functionSourceCode
+ or function.spec.build.source
+ or function.kind == mlrun.runtimes.RuntimeKinds.serving # serving can be empty
+ ):
+ config = function.spec.base_spec
+ if not config:
+ # if base_spec was not set (when not using code_to_function) and we have base64 code
+ # we create the base spec with essential attributes
+ config = nuclio.config.new_config()
+ mlrun.utils.update_in(config, "spec.handler", handler or "main:handler")
+
+ config = nuclio.config.extend_config(
+ config, nuclio_spec, tag, function.spec.build.code_origin
+ )
+
+ if (
+ function.kind == mlrun.runtimes.RuntimeKinds.serving
+ and not mlrun.utils.get_in(config, "spec.build.functionSourceCode")
+ ):
+ _set_source_code_and_handler(function, config)
+ else:
+ # this may also be called in case of using single file code_to_function(embed_code=False)
+ # this option need to be removed or be limited to using remote files (this code runs in server)
+ function_name, config, code = nuclio.build_file(
+ function.spec.source,
+ name=function.metadata.name,
+ project=project,
+ handler=handler,
+ tag=tag,
+ spec=nuclio_spec,
+ kind=function.spec.function_kind,
+ verbose=function.verbose,
+ )
+
+ mlrun.utils.update_in(
+ config, "spec.volumes", function.spec.generate_nuclio_volumes()
+ )
+
+ _resolve_and_set_base_image(function, config, client_version, client_python_version)
+ function_name = _set_function_name(function, config, project, tag)
+
+ return function_name, project, config
+
+
+def _set_function_labels(function):
labels = function.metadata.labels or {}
labels.update({"mlrun/class": function.kind})
for key, value in labels.items():
# Adding escaping to the key to prevent it from being split by dots if it contains any
function.set_config(f"metadata.labels.\\{key}\\", value)
+
+def _resolve_env_vars(function):
# Add secret configurations to function's pod spec, if secret sources were added.
# Needs to be here, since it adds env params, which are handled in the next lines.
# This only needs to run if we're running within k8s context. If running in Docker, for example, skip.
@@ -187,6 +266,22 @@ def _compile_function_config(
env_dict, external_source_env_dict = function._get_nuclio_config_spec_env()
+ # In nuclio 1.6.0<=v<1.8.0, python runtimes default behavior was to not decode event strings
+ # Our code is counting on the strings to be decoded, so add the needed env var for those versions
+ if (
+ mlrun.api.crud.runtimes.nuclio.helpers.is_nuclio_version_in_range(
+ "1.6.0", "1.8.0"
+ )
+ and "NUCLIO_PYTHON_DECODE_EVENT_STRINGS" not in env_dict
+ ):
+ env_dict["NUCLIO_PYTHON_DECODE_EVENT_STRINGS"] = "true"
+
+ return env_dict, external_source_env_dict
+
+
+def _resolve_and_set_nuclio_runtime(
+ function, nuclio_spec, client_version, client_python_version
+):
nuclio_runtime = (
function.spec.nuclio_runtime
or mlrun.api.crud.runtimes.nuclio.helpers.resolve_nuclio_runtime_python_image(
@@ -194,6 +289,7 @@ def _compile_function_config(
)
)
+ # For backwards compatibility, we need to adjust the runtime for old Nuclio versions
if mlrun.api.crud.runtimes.nuclio.helpers.is_nuclio_version_in_range(
"0.0.0", "1.6.0"
) and nuclio_runtime in [
@@ -209,23 +305,10 @@ def _compile_function_config(
# our default is python:3.9, simply set it to python:3.6 to keep supporting envs with old Nuclio
nuclio_runtime = "python:3.6"
- # In nuclio 1.6.0<=v<1.8.0, python runtimes default behavior was to not decode event strings
- # Our code is counting on the strings to be decoded, so add the needed env var for those versions
- if (
- mlrun.api.crud.runtimes.nuclio.helpers.is_nuclio_version_in_range(
- "1.6.0", "1.8.0"
- )
- and "NUCLIO_PYTHON_DECODE_EVENT_STRINGS" not in env_dict
- ):
- env_dict["NUCLIO_PYTHON_DECODE_EVENT_STRINGS"] = "true"
+ nuclio_spec.set_config("spec.runtime", nuclio_runtime)
- nuclio_spec = nuclio.ConfigSpec(
- env=env_dict,
- external_source_env=external_source_env_dict,
- config=function.spec.config,
- )
- nuclio_spec.cmd = function.spec.build.commands or []
+def _resolve_and_set_build_requirements(function, nuclio_spec):
if function.spec.build.requirements:
resolved_requirements = []
# wrap in single quote to ensure that the requirement is treated as a single string
@@ -246,28 +329,14 @@ def _compile_function_config(
encoded_requirements = " ".join(resolved_requirements)
nuclio_spec.cmd.append(f"python -m pip install {encoded_requirements}")
- project = function.metadata.project or "default"
- tag = function.metadata.tag
- handler = function.spec.function_handler
+def _set_build_params(function, nuclio_spec, builder_env, project, auth_info=None):
+ # handle archive build params
if function.spec.build.source:
mlrun.api.crud.runtimes.nuclio.helpers.compile_nuclio_archive_config(
nuclio_spec, function, builder_env, project, auth_info=auth_info
)
- nuclio_spec.set_config("spec.runtime", nuclio_runtime)
-
- # In Nuclio >= 1.6.x default serviceType has changed to "ClusterIP".
- nuclio_spec.set_config(
- "spec.serviceType",
- function.spec.service_type or mlrun.mlconf.httpdb.nuclio.default_service_type,
- )
- if function.spec.readiness_timeout:
- nuclio_spec.set_config(
- "spec.readinessTimeoutSeconds", function.spec.readiness_timeout
- )
- if function.spec.resources:
- nuclio_spec.set_config("spec.resources", function.spec.resources)
if function.spec.no_cache:
nuclio_spec.set_config("spec.build.noCache", True)
if function.spec.build.functionSourceCode:
@@ -285,6 +354,9 @@ def _compile_function_config(
if function.spec.base_image_pull:
nuclio_spec.set_config("spec.build.noBaseImagesPull", False)
+
+
+def _set_function_scheduling_params(function, nuclio_spec):
# don't send node selections if nuclio is not compatible
if mlrun.runtimes.function.validate_nuclio_version_compatibility(
"1.5.20", "1.6.10"
@@ -316,18 +388,9 @@ def _compile_function_config(
function.spec.preemption_mode,
)
- # don't send default or any priority class name if nuclio is not compatible
- if (
- function.spec.priority_class_name
- and mlrun.runtimes.function.validate_nuclio_version_compatibility("1.6.18")
- and len(mlrun.mlconf.get_valid_function_priority_class_names())
- ):
- nuclio_spec.set_config(
- "spec.priorityClassName", function.spec.priority_class_name
- )
+def _set_function_replicas(function, nuclio_spec):
if function.spec.replicas:
-
nuclio_spec.set_config(
"spec.minReplicas",
mlrun.utils.as_number("spec.Replicas", function.spec.replicas),
@@ -336,7 +399,6 @@ def _compile_function_config(
"spec.maxReplicas",
mlrun.utils.as_number("spec.Replicas", function.spec.replicas),
)
-
else:
nuclio_spec.set_config(
"spec.minReplicas",
@@ -347,6 +409,30 @@ def _compile_function_config(
mlrun.utils.as_number("spec.maxReplicas", function.spec.max_replicas),
)
+
+def _set_misc_specs(function, nuclio_spec):
+ # in Nuclio >= 1.6.x default serviceType has changed to "ClusterIP".
+ nuclio_spec.set_config(
+ "spec.serviceType",
+ function.spec.service_type or mlrun.mlconf.httpdb.nuclio.default_service_type,
+ )
+ if function.spec.readiness_timeout:
+ nuclio_spec.set_config(
+ "spec.readinessTimeoutSeconds", function.spec.readiness_timeout
+ )
+ if function.spec.resources:
+ nuclio_spec.set_config("spec.resources", function.spec.resources)
+
+ # don't send default or any priority class name if nuclio is not compatible
+ if (
+ function.spec.priority_class_name
+ and mlrun.runtimes.function.validate_nuclio_version_compatibility("1.6.18")
+ and len(mlrun.mlconf.get_valid_function_priority_class_names())
+ ):
+ nuclio_spec.set_config(
+ "spec.priorityClassName", function.spec.priority_class_name
+ )
+
if function.spec.service_account:
nuclio_spec.set_config("spec.serviceAccount", function.spec.service_account)
@@ -358,99 +444,53 @@ def _compile_function_config(
),
)
- if (
- function.spec.base_spec
- or function.spec.build.functionSourceCode
- or function.spec.build.source
- or function.kind == mlrun.runtimes.RuntimeKinds.serving # serving can be empty
- ):
- config = function.spec.base_spec
- if not config:
- # if base_spec was not set (when not using code_to_function) and we have base64 code
- # we create the base spec with essential attributes
- config = nuclio.config.new_config()
- mlrun.utils.update_in(config, "spec.handler", handler or "main:handler")
-
- config = nuclio.config.extend_config(
- config, nuclio_spec, tag, function.spec.build.code_origin
- )
- mlrun.utils.update_in(config, "metadata.name", function.metadata.name)
+def _set_source_code_and_handler(function, config):
+ if not function.spec.build.source:
+ # set the source to the mlrun serving wrapper
+ body = nuclio.build.mlrun_footer.format(mlrun.runtimes.serving.serving_subkind)
mlrun.utils.update_in(
- config, "spec.volumes", function.spec.generate_nuclio_volumes()
+ config,
+ "spec.build.functionSourceCode",
+ base64.b64encode(body.encode("utf-8")).decode("utf-8"),
)
- base_image = (
- mlrun.utils.get_in(config, "spec.build.baseImage")
- or function.spec.image
- or function.spec.build.base_image
+ elif not function.spec.function_handler:
+ # point the nuclio function handler to mlrun serving wrapper handlers
+ mlrun.utils.update_in(
+ config,
+ "spec.handler",
+ "mlrun.serving.serving_wrapper:handler",
)
- if base_image:
- mlrun.utils.update_in(
- config,
- "spec.build.baseImage",
- mlrun.utils.enrich_image_url(
- base_image, client_version, client_python_version
- ),
- )
- logger.info("deploy started")
- name = mlrun.runtimes.function.get_fullname(
- function.metadata.name, project, tag
- )
- function.status.nuclio_name = name
- mlrun.utils.update_in(config, "metadata.name", name)
- if (
- function.kind == mlrun.runtimes.RuntimeKinds.serving
- and not mlrun.utils.get_in(config, "spec.build.functionSourceCode")
- ):
- if not function.spec.build.source:
- # set the source to the mlrun serving wrapper
- body = nuclio.build.mlrun_footer.format(
- mlrun.runtimes.serving.serving_subkind
- )
- mlrun.utils.update_in(
- config,
- "spec.build.functionSourceCode",
- base64.b64encode(body.encode("utf-8")).decode("utf-8"),
- )
- elif not function.spec.function_handler:
- # point the nuclio function handler to mlrun serving wrapper handlers
- mlrun.utils.update_in(
- config,
- "spec.handler",
- "mlrun.serving.serving_wrapper:handler",
- )
- else:
- # this may also be called in case of using single file code_to_function(embed_code=False)
- # this option need to be removed or be limited to using remote files (this code runs in server)
- name, config, code = nuclio.build_file(
- function.spec.source,
- name=function.metadata.name,
- project=project,
- handler=handler,
- tag=tag,
- spec=nuclio_spec,
- kind=function.spec.function_kind,
- verbose=function.verbose,
+def _resolve_and_set_base_image(
+ function, config, client_version, client_python_version
+):
+ base_image = (
+ mlrun.utils.get_in(config, "spec.build.baseImage")
+ or function.spec.image
+ or function.spec.build.base_image
+ )
+ if base_image:
+ # we ignore the returned registry secret as nuclio uses the image pull secret, which is resolved in the
+ # build params
+ (
+ base_image,
+ _,
+ ) = mlrun.api.utils.builder.resolve_image_target_and_registry_secret(
+ base_image, secret_name=function.spec.build.secret
)
-
mlrun.utils.update_in(
- config, "spec.volumes", function.spec.generate_nuclio_volumes()
+ config,
+ "spec.build.baseImage",
+ mlrun.utils.enrich_image_url(
+ base_image, client_version, client_python_version
+ ),
)
- base_image = function.spec.image or function.spec.build.base_image
- if base_image:
- mlrun.utils.update_in(
- config,
- "spec.build.baseImage",
- mlrun.utils.enrich_image_url(
- base_image, client_version, client_python_version
- ),
- )
-
- name = mlrun.runtimes.function.get_fullname(name, project, tag)
- function.status.nuclio_name = name
- mlrun.utils.update_in(config, "metadata.name", name)
- return name, project, config
+def _set_function_name(function, config, project, tag):
+ name = mlrun.runtimes.function.get_fullname(function.metadata.name, project, tag)
+ function.status.nuclio_name = name
+ mlrun.utils.update_in(config, "metadata.name", name)
+ return name
diff --git a/mlrun/api/utils/builder.py b/mlrun/api/utils/builder.py
index 6476dd548601..f11fb0be88e3 100644
--- a/mlrun/api/utils/builder.py
+++ b/mlrun/api/utils/builder.py
@@ -26,13 +26,8 @@
import mlrun.common.schemas
import mlrun.errors
import mlrun.runtimes.utils
+import mlrun.utils
from mlrun.config import config
-from mlrun.utils import (
- enrich_image_url,
- get_parsed_docker_registry,
- logger,
- normalize_name,
-)
def make_dockerfile(
@@ -86,7 +81,7 @@ def make_dockerfile(
dock += f"RUN python -m pip install -r {requirements_path}\n"
if extra:
dock += extra
- logger.debug("Resolved dockerfile", dockfile_contents=dock)
+ mlrun.utils.logger.debug("Resolved dockerfile", dockfile_contents=dock)
return dock
@@ -329,7 +324,7 @@ def build_image(
):
runtime_spec = runtime.spec if runtime else None
builder_env = builder_env or {}
- image_target, secret_name = _resolve_image_target_and_registry_secret(
+ image_target, secret_name = resolve_image_target_and_registry_secret(
image_target, registry, secret_name
)
if requirements and isinstance(requirements, list):
@@ -353,7 +348,7 @@ def build_image(
commands.append(mlrun_command)
if not inline_code and not source and not commands and not requirements:
- logger.info("skipping build, nothing to add")
+ mlrun.utils.logger.info("skipping build, nothing to add")
return "skipped"
context = "/context"
@@ -479,7 +474,9 @@ def build_image(
return k8s.run_job(kpod)
else:
pod, ns = k8s.create_pod(kpod)
- logger.info(f'started build, to watch build logs use "mlrun watch {pod} {ns}"')
+ mlrun.utils.logger.info(
+ f'started build, to watch build logs use "mlrun watch {pod} {ns}"'
+ )
return f"build:{pod}"
@@ -597,13 +594,13 @@ def build_runtime(
raise mlrun.errors.MLRunInvalidArgumentError(
"build spec must have a target image, set build.image = "
)
- logger.info(f"building image ({build.image})")
+ mlrun.utils.logger.info(f"building image ({build.image})")
- name = normalize_name(f"mlrun-build-{runtime.metadata.name}")
+ name = mlrun.utils.normalize_name(f"mlrun-build-{runtime.metadata.name}")
base_image: str = (
build.base_image or runtime.spec.image or config.default_base_image
)
- enriched_base_image = enrich_image_url(
+ enriched_base_image = mlrun.utils.enrich_image_url(
base_image,
client_version,
client_python_version,
@@ -646,7 +643,7 @@ def build_runtime(
runtime.spec.build.base_image = base_image
return False
- logger.info(f"build completed with {status}")
+ mlrun.utils.logger.info(f"build completed with {status}")
if status in ["failed", "error"]:
runtime.status.state = mlrun.common.schemas.FunctionState.error
return False
@@ -657,25 +654,7 @@ def build_runtime(
return True
-def _generate_builder_env(project, builder_env):
- k8s = mlrun.api.utils.singletons.k8s.get_k8s_helper(silent=False)
- secret_name = k8s.get_project_secret_name(project)
- existing_secret_keys = k8s.get_project_secret_keys(project, filter_internal=True)
-
- # generate env list from builder env and project secrets
- env = []
- for key in existing_secret_keys:
- if key not in builder_env:
- value_from = client.V1EnvVarSource(
- secret_key_ref=client.V1SecretKeySelector(name=secret_name, key=key)
- )
- env.append(client.V1EnvVar(name=key, value_from=value_from))
- for key, value in builder_env.items():
- env.append(client.V1EnvVar(name=key, value=value))
- return env
-
-
-def _resolve_image_target_and_registry_secret(
+def resolve_image_target_and_registry_secret(
image_target: str, registry: str = None, secret_name: str = None
) -> (str, str):
if registry:
@@ -691,7 +670,7 @@ def _resolve_image_target_and_registry_secret(
len(mlrun.common.constants.IMAGE_NAME_ENRICH_REGISTRY_PREFIX) :
]
- registry, repository = get_parsed_docker_registry()
+ registry, repository = mlrun.utils.get_parsed_docker_registry()
secret_name = secret_name or config.httpdb.builder.docker_registry_secret
if not registry:
raise ValueError(
@@ -705,3 +684,21 @@ def _resolve_image_target_and_registry_secret(
return "/".join(image_target_components), secret_name
return image_target, secret_name
+
+
+def _generate_builder_env(project, builder_env):
+ k8s = mlrun.api.utils.singletons.k8s.get_k8s_helper(silent=False)
+ secret_name = k8s.get_project_secret_name(project)
+ existing_secret_keys = k8s.get_project_secret_keys(project, filter_internal=True)
+
+ # generate env list from builder env and project secrets
+ env = []
+ for key in existing_secret_keys:
+ if key not in builder_env:
+ value_from = client.V1EnvVarSource(
+ secret_key_ref=client.V1SecretKeySelector(name=secret_name, key=key)
+ )
+ env.append(client.V1EnvVar(name=key, value_from=value_from))
+ for key, value in builder_env.items():
+ env.append(client.V1EnvVar(name=key, value=value))
+ return env
diff --git a/tests/api/runtimes/test_nuclio.py b/tests/api/runtimes/test_nuclio.py
index bb6db1d3d7a1..31937b7860cc 100644
--- a/tests/api/runtimes/test_nuclio.py
+++ b/tests/api/runtimes/test_nuclio.py
@@ -650,6 +650,20 @@ def test_deploy_without_image_and_build_base_image(
self._assert_deploy_called_basic_config(expected_class=self.class_name)
+ def test_deploy_image_with_enrich_registry_prefix(self):
+ function = self._generate_runtime(self.runtime_kind)
+ function.spec.image = ".my/image:latest"
+
+ with unittest.mock.patch(
+ "mlrun.utils.get_parsed_docker_registry",
+ return_value=["some.registry", "some-repository"],
+ ):
+ self.execute_function(function)
+ self._assert_deploy_called_basic_config(
+ expected_class=self.class_name,
+ expected_build_base_image="some.registry/some-repository/my/image:latest",
+ )
+
@pytest.mark.parametrize(
"requirements,expected_commands",
[
diff --git a/tests/api/utils/test_builder.py b/tests/api/utils/test_builder.py
index d6881cbb505b..ff391a70e924 100644
--- a/tests/api/utils/test_builder.py
+++ b/tests/api/utils/test_builder.py
@@ -653,7 +653,7 @@ def test_resolve_image_dest(image_target, registry, default_repository, expected
config.httpdb.builder.docker_registry = default_repository
config.httpdb.builder.docker_registry_secret = docker_registry_secret
- image_target, _ = mlrun.api.utils.builder._resolve_image_target_and_registry_secret(
+ image_target, _ = mlrun.api.utils.builder.resolve_image_target_and_registry_secret(
image_target, registry
)
assert image_target == expected_dest
@@ -727,7 +727,7 @@ def test_resolve_registry_secret(
config.httpdb.builder.docker_registry = docker_registry
config.httpdb.builder.docker_registry_secret = default_secret_name
- _, secret_name = mlrun.api.utils.builder._resolve_image_target_and_registry_secret(
+ _, secret_name = mlrun.api.utils.builder.resolve_image_target_and_registry_secret(
image_target, registry, secret_name
)
assert secret_name == expected_secret_name
From 78141b508478412d0ce1def366ac0ac45c1aeb59 Mon Sep 17 00:00:00 2001
From: Adam
Date: Tue, 23 May 2023 18:55:39 +0300
Subject: [PATCH 183/334] [Launcher] Fix pipeline steps being saved as
functions to the DB (#3627)
---
mlrun/launcher/local.py | 16 +++++++++-------
1 file changed, 9 insertions(+), 7 deletions(-)
diff --git a/mlrun/launcher/local.py b/mlrun/launcher/local.py
index 87be8beb9c0f..c47560a23016 100644
--- a/mlrun/launcher/local.py
+++ b/mlrun/launcher/local.py
@@ -135,13 +135,15 @@ def execute(
if "V3IO_USERNAME" in os.environ and "v3io_user" not in run.metadata.labels:
run.metadata.labels["v3io_user"] = os.environ.get("V3IO_USERNAME")
- logger.info(
- "Storing function",
- name=run.metadata.name,
- uid=run.metadata.uid,
- db=runtime.spec.rundb,
- )
- self._store_function(runtime, run)
+ # store function object in db unless running from within a run pod
+ if not runtime.is_child:
+ logger.info(
+ "Storing function",
+ name=run.metadata.name,
+ uid=run.metadata.uid,
+ db=runtime.spec.rundb,
+ )
+ self._store_function(runtime, run)
execution = mlrun.run.MLClientCtx.from_dict(
run.to_dict(),
From 5796e80f8c53fe6c246b79cb80ebc899927f0876 Mon Sep 17 00:00:00 2001
From: Yael Genish <62285310+yaelgen@users.noreply.github.com>
Date: Tue, 23 May 2023 20:39:56 +0300
Subject: [PATCH 184/334] [Projects] Fix BC for GET requests of non-normalized
function names (#3568)
---
mlrun/api/db/sqldb/db.py | 26 +++++++++++++++-
mlrun/projects/project.py | 45 +++++++++++++++++++++++-----
tests/api/db/test_functions.py | 30 +++++++++++++++++++
tests/projects/test_project.py | 54 ++++++++++++++++++++++++++++++----
4 files changed, 140 insertions(+), 15 deletions(-)
diff --git a/mlrun/api/db/sqldb/db.py b/mlrun/api/db/sqldb/db.py
index f944fea89553..264766427a08 100644
--- a/mlrun/api/db/sqldb/db.py
+++ b/mlrun/api/db/sqldb/db.py
@@ -988,7 +988,31 @@ def store_function(
self.tag_objects_v2(session, [fn], project, tag)
return hash_key
- def get_function(self, session, name, project="", tag="", hash_key=""):
+ def get_function(self, session, name, project="", tag="", hash_key="") -> dict:
+ """
+ In version 1.4.0 we added a normalization to the function name before storing.
+ To be backwards compatible and allow users to query old non-normalized functions,
+ we're providing a fallback to get_function:
+ normalize the requested name and try to retrieve it from the database.
+ If no answer is received, we will check to see if the original name contained underscores,
+ if so, the retrieval will be repeated and the result (if it exists) returned.
+ """
+ normalized_function_name = mlrun.utils.normalize_name(name)
+ try:
+ return self._get_function(
+ session, normalized_function_name, project, tag, hash_key
+ )
+ except mlrun.errors.MLRunNotFoundError as exc:
+ if "_" in name:
+ logger.warning(
+ "Failed to get underscore-named function, trying without normalization",
+ function_name=name,
+ )
+ return self._get_function(session, name, project, tag, hash_key)
+ else:
+ raise exc
+
+ def _get_function(self, session, name, project="", tag="", hash_key=""):
project = project or config.default_project
query = self._query(session, Function, name=name, project=project)
computed_tag = tag or "latest"
diff --git a/mlrun/projects/project.py b/mlrun/projects/project.py
index 11d8b8100ab4..2772ea9b9aa5 100644
--- a/mlrun/projects/project.py
+++ b/mlrun/projects/project.py
@@ -14,6 +14,7 @@
import datetime
import getpass
import glob
+import http
import json
import pathlib
import shutil
@@ -31,6 +32,7 @@
import inflection
import kfp
import nuclio
+import requests
import yaml
import mlrun.common.model_monitoring as model_monitoring_constants
@@ -1660,21 +1662,48 @@ def get_function(
:returns: function object
"""
- if key in self.spec._function_objects and not sync and not ignore_cache:
- function = self.spec._function_objects[key]
- elif key in self.spec._function_definitions and not ignore_cache:
- self.sync_functions([key])
- function = self.spec._function_objects[key]
- else:
- function = get_db_function(self, key)
- self.spec._function_objects[key] = function
+ function, err = self._get_function(
+ mlrun.utils.normalize_name(key), sync, ignore_cache
+ )
+ if not function and "_" in key:
+ function, err = self._get_function(key, sync, ignore_cache)
+
+ if not function:
+ raise err
+
if enrich:
function = enrich_function_object(
self, function, copy_function=copy_function
)
self.spec._function_objects[key] = function
+
return function
+ def _get_function(self, key, sync, ignore_cache):
+ """
+ Function can be retrieved from the project spec (cache) or from the database.
+ In sync mode, we first perform a sync of the function_objects from the function_definitions,
+ and then returning it from the function_objects (if exists).
+ When not in sync mode, we verify and return from the function objects directly.
+ In ignore_cache mode, we query the function from the database rather than from the project spec.
+ """
+ if key in self.spec._function_objects and not sync and not ignore_cache:
+ function = self.spec._function_objects[key]
+
+ elif key in self.spec._function_definitions and not ignore_cache:
+ self.sync_functions([key])
+ function = self.spec._function_objects[key]
+ else:
+ try:
+ function = get_db_function(self, key)
+ self.spec._function_objects[key] = function
+ except requests.HTTPError as exc:
+ if exc.response.status_code != http.HTTPStatus.NOT_FOUND.value:
+ raise exc
+ return None, exc
+
+ return function, None
+
def get_function_objects(self) -> typing.Dict[str, mlrun.runtimes.BaseRuntime]:
""" "get a virtual dict with all the project functions ready for use in a pipeline"""
self.sync_functions()
diff --git a/tests/api/db/test_functions.py b/tests/api/db/test_functions.py
index 235b796bff1f..1f1e8bb15466 100644
--- a/tests/api/db/test_functions.py
+++ b/tests/api/db/test_functions.py
@@ -121,6 +121,36 @@ def test_get_function_by_hash_key(db: DBInterface, db_session: Session):
assert function_queried_with_hash_key["metadata"]["tag"] == ""
+def test_get_function_when_using_not_normalize_name(
+ db: DBInterface, db_session: Session
+):
+ # add a function with a non-normalized name to the database
+ function_name = "function_name"
+ project_name = "project"
+ _generate_and_insert_function_record(db_session, function_name, project_name)
+
+ # getting the function using the non-normalized name, and ensure that it works
+ response = db.get_function(db_session, function_name, project_name)
+ assert response["metadata"]["name"] == function_name
+
+
+def _generate_and_insert_function_record(
+ db_session: Session, function_name: str, project_name: str
+):
+ function = {
+ "metadata": {"name": function_name, "project": project_name},
+ "spec": {"asd": "test"},
+ }
+ fn = Function(
+ name=function_name, project=project_name, struct=function, uid="1", id="1"
+ )
+ tag = Function.Tag(project=project_name, name="latest", obj_name=fn.name)
+ tag.obj_id, tag.uid = fn.id, fn.uid
+ db_session.add(fn)
+ db_session.add(tag)
+ db_session.commit()
+
+
def test_get_function_by_tag(db: DBInterface, db_session: Session):
function_1 = _generate_function()
function_hash_key = db.store_function(
diff --git a/tests/projects/test_project.py b/tests/projects/test_project.py
index a1bb17ddf00c..3e9aac77c4b6 100644
--- a/tests/projects/test_project.py
+++ b/tests/projects/test_project.py
@@ -406,13 +406,55 @@ def test_set_function_requirements():
]
+def test_backwards_compatibility_get_non_normalized_function_name(rundb_mock):
+ project = mlrun.projects.MlrunProject(
+ "project", default_requirements=["pandas>1, <3"]
+ )
+ func_name = "name_with_underscores"
+ func_path = str(pathlib.Path(__file__).parent / "assets" / "handler.py")
+
+ func = mlrun.code_to_function(
+ name=func_name,
+ kind="job",
+ image="mlrun/mlrun",
+ handler="myhandler",
+ filename=func_path,
+ )
+ # nuclio also normalizes the name, so we de-normalize the function name before storing it
+ func.metadata.name = func_name
+
+ # mock the normalize function response in order to insert a non-normalized function name to the db
+ with unittest.mock.patch("mlrun.utils.normalize_name", return_value=func_name):
+ project.set_function(name=func_name, func=func)
+
+ # getting the function using the original non-normalized name, and ensure that querying it works
+ enriched_function = project.get_function(key=func_name)
+ assert enriched_function.metadata.name == func_name
+
+ enriched_function = project.get_function(key=func_name, sync=True)
+ assert enriched_function.metadata.name == func_name
+
+ # override the function by sending an update request,
+ # a new function is created, and the old one is no longer accessible
+ normalized_function_name = mlrun.utils.normalize_name(func_name)
+ func.metadata.name = normalized_function_name
+ project.set_function(name=func_name, func=func)
+
+ # using both normalized and non-normalized names to query the function
+ enriched_function = project.get_function(key=normalized_function_name)
+ assert enriched_function.metadata.name == normalized_function_name
+
+ resp = project.get_function(key=func_name)
+ assert resp.metadata.name == normalized_function_name
+
+
def test_set_function_underscore_name(rundb_mock):
project = mlrun.projects.MlrunProject(
"project", default_requirements=["pandas>1, <3"]
)
func_name = "name_with_underscores"
- # Create a function with a name that includes underscores
+ # create a function with a name that includes underscores
func_path = str(pathlib.Path(__file__).parent / "assets" / "handler.py")
func = mlrun.code_to_function(
name=func_name,
@@ -423,12 +465,12 @@ def test_set_function_underscore_name(rundb_mock):
)
project.set_function(name=func_name, func=func)
- # Attempt to get the function using the original name (with underscores) and ensure that it fails
- with pytest.raises(mlrun.errors.MLRunNotFoundError):
- project.get_function(key=func_name)
-
- # Get the function using a normalized name and make sure it works
+ # get the function using the original name (with underscores) and ensure that it works and returns normalized name
normalized_name = mlrun.utils.normalize_name(func_name)
+ enriched_function = project.get_function(key=func_name)
+ assert enriched_function.metadata.name == normalized_name
+
+ # get the function using a normalized name and make sure it works
enriched_function = project.get_function(key=normalized_name)
assert enriched_function.metadata.name == normalized_name
From e5ea97f23be0bc821e355bfefdb2921ff826a45f Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Tue, 23 May 2023 21:35:06 +0300
Subject: [PATCH 185/334] [CI] Use click option instead of positional arguement
(#3629)
---
automation/system_test/prepare.py | 70 +++++++++++++++----------------
1 file changed, 33 insertions(+), 37 deletions(-)
diff --git a/automation/system_test/prepare.py b/automation/system_test/prepare.py
index 9ab9f072307e..47073d6aedc8 100644
--- a/automation/system_test/prepare.py
+++ b/automation/system_test/prepare.py
@@ -75,7 +75,6 @@ def __init__(
access_key: str = None,
iguazio_version: str = None,
spark_service: str = None,
- password: str = None,
slack_webhook_url: str = None,
mysql_user: str = None,
mysql_password: str = None,
@@ -120,8 +119,6 @@ def __init__(
# (e.g. tests which use public repos, therefor doesn't need that access token)
"MLRUN_SYSTEM_TESTS_GIT_TOKEN": github_access_token,
}
- if password:
- self._env_config["V3IO_PASSWORD"] = password
def prepare_local_env(self):
self._prepare_env_local()
@@ -640,7 +637,7 @@ def main():
@main.command(context_settings=dict(ignore_unknown_options=True))
-@click.argument("mlrun-version", type=str, required=True)
+@click.option("--mlrun-version")
@click.option(
"--override-image-registry",
"-oireg",
@@ -665,25 +662,24 @@ def main():
default=None,
help="The commit (in mlrun/mlrun) of the tested mlrun version.",
)
-@click.argument("data-cluster-ip", type=str, required=True)
-@click.argument("data-cluster-ssh-username", type=str, required=True)
-@click.argument("data-cluster-ssh-password", type=str, required=True)
-@click.argument("app-cluster-ssh-password", type=str, required=True)
-@click.argument("github-access-token", type=str, required=True)
-@click.argument("provctl-download-url", type=str, required=True)
-@click.argument("provctl-download-s3-access-key", type=str, required=True)
-@click.argument("provctl-download-s3-key-id", type=str, required=True)
-@click.argument("mlrun-dbpath", type=str, required=True)
-@click.argument("webapi-direct-url", type=str, required=True)
-@click.argument("framesd-url", type=str, required=True)
-@click.argument("username", type=str, required=True)
-@click.argument("access-key", type=str, required=True)
-@click.argument("iguazio-version", type=str, default=None, required=True)
-@click.argument("spark-service", type=str, required=True)
-@click.argument("password", type=str, default=None, required=False)
-@click.argument("slack-webhook-url", type=str, default=None, required=False)
-@click.argument("mysql-user", type=str, default=None, required=False)
-@click.argument("mysql-password", type=str, default=None, required=False)
+@click.option("--data-cluster-ip", required=True)
+@click.option("--data-cluster-ssh-username", required=True)
+@click.option("--data-cluster-ssh-password", required=True)
+@click.option("--app-cluster-ssh-password", required=True)
+@click.option("--github-access-token", required=True)
+@click.option("--provctl-download-url", required=True)
+@click.option("--provctl-download-s3-access-key", required=True)
+@click.option("--provctl-download-s3-key-id", required=True)
+@click.option("--mlrun-dbpath", required=True)
+@click.option("--webapi-direct-url", required=True)
+@click.option("--framesd-url", required=True)
+@click.option("--username", required=True)
+@click.option("--access-key", required=True)
+@click.option("--iguazio-version", default=None)
+@click.option("--spark-service", required=True)
+@click.option("--slack-webhook-url")
+@click.option("--mysql-user")
+@click.option("--mysql-password")
@click.option("--purge-db", "-pdb", is_flag=True, help="Purge mlrun db")
@click.option(
"--debug",
@@ -712,7 +708,6 @@ def run(
access_key: str,
iguazio_version: str,
spark_service: str,
- password: str,
slack_webhook_url: str,
mysql_user: str,
mysql_password: str,
@@ -740,7 +735,6 @@ def run(
access_key,
iguazio_version,
spark_service,
- password,
slack_webhook_url,
mysql_user,
mysql_password,
@@ -755,22 +749,26 @@ def run(
@main.command(context_settings=dict(ignore_unknown_options=True))
-@click.argument("mlrun-dbpath", type=str, required=True)
-@click.argument("webapi-direct-url", type=str, required=False)
-@click.argument("framesd-url", type=str, required=False)
-@click.argument("username", type=str, required=False)
-@click.argument("access-key", type=str, required=False)
-@click.argument("spark-service", type=str, required=False)
-@click.argument("password", type=str, default=None, required=False)
-@click.argument("slack-webhook-url", type=str, default=None, required=False)
+@click.option("--mlrun-dbpath", help="The mlrun api address", required=True)
+@click.option("--webapi-direct-url", help="Iguazio webapi direct url")
+@click.option("--framesd-url", help="Iguazio framesd url")
+@click.option("--username", help="Iguazio running username")
+@click.option("--access-key", help="Iguazio running user access key")
+@click.option("--spark-service", help="Iguazio kubernetes spark service name")
+@click.option(
+ "--slack-webhook-url", help="Slack webhook url to send tests notifications to"
+)
@click.option(
"--debug",
"-d",
is_flag=True,
help="Don't run the ci only show the commands that will be run",
)
-@click.argument("branch", type=str, default=None, required=False)
-@click.argument("github-access-token", type=str, default=None, required=False)
+@click.option("--branch", help="The mlrun branch to run the tests against")
+@click.option(
+ "--github-access-token",
+ help="Github access token to use for fetching private functions",
+)
def env(
mlrun_dbpath: str,
webapi_direct_url: str,
@@ -778,7 +776,6 @@ def env(
username: str,
access_key: str,
spark_service: str,
- password: str,
slack_webhook_url: str,
debug: bool,
branch: str,
@@ -791,7 +788,6 @@ def env(
username=username,
access_key=access_key,
spark_service=spark_service,
- password=password,
debug=debug,
slack_webhook_url=slack_webhook_url,
branch=branch,
From 1e5a9a644a554b3f34c2eebbb85d5dcc1c7d6c28 Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Tue, 23 May 2023 22:15:59 +0300
Subject: [PATCH 186/334] [Logging] Remove spammy storing artifact log line
(#3630)
---
mlrun/api/api/endpoints/artifacts.py | 4 +++-
1 file changed, 3 insertions(+), 1 deletion(-)
diff --git a/mlrun/api/api/endpoints/artifacts.py b/mlrun/api/api/endpoints/artifacts.py
index 169e75ef665b..028ac924446a 100644
--- a/mlrun/api/api/endpoints/artifacts.py
+++ b/mlrun/api/api/endpoints/artifacts.py
@@ -70,7 +70,9 @@ async def store_artifact(
except ValueError:
log_and_raise(HTTPStatus.BAD_REQUEST.value, reason="bad JSON body")
- logger.debug("Storing artifact", data=data)
+ logger.debug(
+ "Storing artifact", project=project, uid=uid, key=key, tag=tag, iter=iter
+ )
await run_in_threadpool(
mlrun.api.crud.Artifacts().store_artifact,
db_session,
From 81c963b065a068e744f4ad82a176a89fccb9db05 Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Wed, 24 May 2023 09:04:17 +0300
Subject: [PATCH 187/334] [CI] Remove deprecated field (#3635)
---
.github/workflows/system-tests-enterprise.yml | 1 -
1 file changed, 1 deletion(-)
diff --git a/.github/workflows/system-tests-enterprise.yml b/.github/workflows/system-tests-enterprise.yml
index 2ef1dde4a633..a3e657187242 100644
--- a/.github/workflows/system-tests-enterprise.yml
+++ b/.github/workflows/system-tests-enterprise.yml
@@ -263,7 +263,6 @@ jobs:
--access-key "${{ secrets.LATEST_SYSTEM_TEST_ACCESS_KEY }}" \
--iguazio-version "${{ steps.computed_params.outputs.iguazio_version }}" \
--spark-service "${{ secrets.LATEST_SYSTEM_TEST_SPARK_SERVICE }}" \
- --password "${{ secrets.LATEST_SYSTEM_TEST_PASSWORD }}" \
--slack-webhook-url "${{ secrets.LATEST_SYSTEM_TEST_SLACK_WEBHOOK_URL }}" \
--mysql-user "${{ secrets.LATEST_SYSTEM_TEST_MYSQL_USER }}" \
--mysql-password "${{ secrets.LATEST_SYSTEM_TEST_MYSQL_PASSWORD }}" \
From 8a4a85d7803765da7f887a487e81d7390119b498 Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Wed, 24 May 2023 09:10:27 +0300
Subject: [PATCH 188/334] [LogCollector] Update deps (#3632)
---
go/cmd/logcollector/docker/Dockerfile | 2 +-
go/go.mod | 24 +++++++--------
go/go.sum | 44 +++++++++++++++------------
3 files changed, 37 insertions(+), 33 deletions(-)
diff --git a/go/cmd/logcollector/docker/Dockerfile b/go/cmd/logcollector/docker/Dockerfile
index a09d205430a8..73e09cdfb5b9 100644
--- a/go/cmd/logcollector/docker/Dockerfile
+++ b/go/cmd/logcollector/docker/Dockerfile
@@ -35,7 +35,7 @@ RUN GOOS=linux \
FROM alpine:latest as install-health-probe
-ARG GRPC_HEALTH_PROBE_VERSION=v0.4.14
+ARG GRPC_HEALTH_PROBE_VERSION=v0.4.18
RUN mkdir /app
WORKDIR /app
diff --git a/go/go.mod b/go/go.mod
index ebca7a271b04..7658af2c90b6 100644
--- a/go/go.mod
+++ b/go/go.mod
@@ -3,7 +3,6 @@ module github.com/mlrun/mlrun
go 1.19
require (
- github.com/golang/protobuf v1.5.2
github.com/google/uuid v1.3.0
github.com/grpc-ecosystem/go-grpc-middleware v1.3.0
github.com/nuclio/errors v0.0.4
@@ -11,8 +10,9 @@ require (
github.com/nuclio/loggerus v0.0.6
github.com/sirupsen/logrus v1.8.0
github.com/stretchr/testify v1.8.1
- golang.org/x/sync v0.1.0
- google.golang.org/grpc v1.51.0
+ golang.org/x/sync v0.2.0
+ google.golang.org/grpc v1.55.0
+ google.golang.org/protobuf v1.30.0
k8s.io/api v0.23.15
k8s.io/apimachinery v0.23.15
k8s.io/client-go v0.23.15
@@ -23,7 +23,8 @@ require (
github.com/evanphx/json-patch v4.12.0+incompatible // indirect
github.com/go-logr/logr v1.2.0 // indirect
github.com/gogo/protobuf v1.3.2 // indirect
- github.com/google/go-cmp v0.5.6 // indirect
+ github.com/golang/protobuf v1.5.3 // indirect
+ github.com/google/go-cmp v0.5.9 // indirect
github.com/google/gofuzz v1.1.0 // indirect
github.com/googleapis/gnostic v0.5.5 // indirect
github.com/imdario/mergo v0.3.5 // indirect
@@ -35,15 +36,14 @@ require (
github.com/pkg/errors v0.9.1 // indirect
github.com/pmezard/go-difflib v1.0.0 // indirect
github.com/spf13/pflag v1.0.5 // indirect
- golang.org/x/net v0.7.0 // indirect
- golang.org/x/oauth2 v0.0.0-20210819190943-2bc19b11175f // indirect
- golang.org/x/sys v0.5.0 // indirect
- golang.org/x/term v0.5.0 // indirect
- golang.org/x/text v0.7.0 // indirect
- golang.org/x/time v0.0.0-20210723032227-1f47c861a9ac // indirect
+ golang.org/x/net v0.8.0 // indirect
+ golang.org/x/oauth2 v0.6.0 // indirect
+ golang.org/x/sys v0.6.0 // indirect
+ golang.org/x/term v0.6.0 // indirect
+ golang.org/x/text v0.8.0 // indirect
+ golang.org/x/time v0.3.0 // indirect
google.golang.org/appengine v1.6.7 // indirect
- google.golang.org/genproto v0.0.0-20210402141018-6c239bbf2bb1 // indirect
- google.golang.org/protobuf v1.28.1 // indirect
+ google.golang.org/genproto v0.0.0-20230306155012-7f2fa6fef1f4 // indirect
gopkg.in/inf.v0 v0.9.1 // indirect
gopkg.in/yaml.v2 v2.4.0 // indirect
gopkg.in/yaml.v3 v3.0.1 // indirect
diff --git a/go/go.sum b/go/go.sum
index d6b28c4cdba6..a2601027c8c1 100644
--- a/go/go.sum
+++ b/go/go.sum
@@ -124,8 +124,9 @@ github.com/golang/protobuf v1.4.2/go.mod h1:oDoupMAO8OvCJWAcko0GGGIgR6R6ocIYbsSw
github.com/golang/protobuf v1.4.3/go.mod h1:oDoupMAO8OvCJWAcko0GGGIgR6R6ocIYbsSw735rRwI=
github.com/golang/protobuf v1.5.0/go.mod h1:FsONVRAS9T7sI+LIUmWTfcYkHO4aIWwzhcaSAoJOfIk=
github.com/golang/protobuf v1.5.1/go.mod h1:DopwsBzvsk0Fs44TXzsVbJyPhcCPeIwnvohx4u74HPM=
-github.com/golang/protobuf v1.5.2 h1:ROPKBNFfQgOUMifHyP+KYbvpjbdoFNs+aK7DXlji0Tw=
github.com/golang/protobuf v1.5.2/go.mod h1:XVQd3VNwM+JqD3oG2Ue2ip4fOMUkwXdXDdiuN0vRsmY=
+github.com/golang/protobuf v1.5.3 h1:KhyjKVUg7Usr/dYsdSqoFveMYd5ko72D+zANwlG1mmg=
+github.com/golang/protobuf v1.5.3/go.mod h1:XVQd3VNwM+JqD3oG2Ue2ip4fOMUkwXdXDdiuN0vRsmY=
github.com/google/btree v0.0.0-20180813153112-4030bb1f1f0c/go.mod h1:lNA+9X1NB3Zf8V7Ke586lFgjr2dZNuvo3lPJSGZ5JPQ=
github.com/google/btree v1.0.0/go.mod h1:lNA+9X1NB3Zf8V7Ke586lFgjr2dZNuvo3lPJSGZ5JPQ=
github.com/google/btree v1.0.1/go.mod h1:xXMiIv4Fb/0kKde4SpL7qlzvu5cMJDRkFDxJfI9uaxA=
@@ -140,8 +141,8 @@ github.com/google/go-cmp v0.5.2/go.mod h1:v8dTdLbMG2kIc/vJvl+f65V22dbkXbowE6jgT/
github.com/google/go-cmp v0.5.3/go.mod h1:v8dTdLbMG2kIc/vJvl+f65V22dbkXbowE6jgT/gNBxE=
github.com/google/go-cmp v0.5.4/go.mod h1:v8dTdLbMG2kIc/vJvl+f65V22dbkXbowE6jgT/gNBxE=
github.com/google/go-cmp v0.5.5/go.mod h1:v8dTdLbMG2kIc/vJvl+f65V22dbkXbowE6jgT/gNBxE=
-github.com/google/go-cmp v0.5.6 h1:BKbKCqvP6I+rmFHt06ZmyQtvB8xAkWdhFyr0ZUNZcxQ=
-github.com/google/go-cmp v0.5.6/go.mod h1:v8dTdLbMG2kIc/vJvl+f65V22dbkXbowE6jgT/gNBxE=
+github.com/google/go-cmp v0.5.9 h1:O2Tfq5qg4qc4AmwVlvv0oLiVAGB7enBSJ2x2DqQFi38=
+github.com/google/go-cmp v0.5.9/go.mod h1:17dUlkBOakJ0+DkrSSNjCkIjxS6bF9zb3elmeNGIjoY=
github.com/google/gofuzz v1.0.0/go.mod h1:dBl0BpW6vV/+mYPU4Po3pmUjxk6FQPldtuIdl/M65Eg=
github.com/google/gofuzz v1.1.0 h1:Hsa8mG0dQ46ij8Sl2AYJDUv1oA9/d6Vk+3LG99Oe02g=
github.com/google/gofuzz v1.1.0/go.mod h1:dBl0BpW6vV/+mYPU4Po3pmUjxk6FQPldtuIdl/M65Eg=
@@ -354,8 +355,8 @@ golang.org/x/net v0.0.0-20210226172049-e18ecbb05110/go.mod h1:m0MpNAwzfU5UDzcl9v
golang.org/x/net v0.0.0-20210316092652-d523dce5a7f4/go.mod h1:RBQZq4jEuRlivfhVLdyRGr576XBO4/greRjx4P4O3yc=
golang.org/x/net v0.0.0-20210405180319-a5a99cb37ef4/go.mod h1:p54w0d4576C0XHj96bSt6lcn1PtDYWL6XObtHCRCNQM=
golang.org/x/net v0.0.0-20211209124913-491a49abca63/go.mod h1:9nx3DQGgdP8bBQD5qxJ1jj9UTztislL4KSBs9R2vV5Y=
-golang.org/x/net v0.7.0 h1:rJrUqqhjsgNp7KqAIc25s9pZnjU7TUcSY7HcVZjdn1g=
-golang.org/x/net v0.7.0/go.mod h1:2Tu9+aMcznHK/AK1HMvgo6xiTLG5rD5rZLDS+rp2Bjs=
+golang.org/x/net v0.8.0 h1:Zrh2ngAOFYneWTAIAPethzeaQLuHwhuBkuV6ZiRnUaQ=
+golang.org/x/net v0.8.0/go.mod h1:QVkue5JL9kW//ek3r6jTKnTFis1tRmNAW2P1shuFdJc=
golang.org/x/oauth2 v0.0.0-20180821212333-d2e6202438be/go.mod h1:N/0e6XlmueqKjAGxoOufVs8QHGRruUQn6yWY3a++T0U=
golang.org/x/oauth2 v0.0.0-20190226205417-e64efc72b421/go.mod h1:gOpvHmFTYa4IltrdGE7lF6nIHvwfUNPOp7c8zoXwtLw=
golang.org/x/oauth2 v0.0.0-20190604053449-0f29369cfe45/go.mod h1:gOpvHmFTYa4IltrdGE7lF6nIHvwfUNPOp7c8zoXwtLw=
@@ -367,8 +368,9 @@ golang.org/x/oauth2 v0.0.0-20201208152858-08078c50e5b5/go.mod h1:KelEdhl1UZF7XfJ
golang.org/x/oauth2 v0.0.0-20210218202405-ba52d332ba99/go.mod h1:KelEdhl1UZF7XfJ4dDtk6s++YSgaE7mD/BuKKDLBl4A=
golang.org/x/oauth2 v0.0.0-20210220000619-9bb904979d93/go.mod h1:KelEdhl1UZF7XfJ4dDtk6s++YSgaE7mD/BuKKDLBl4A=
golang.org/x/oauth2 v0.0.0-20210313182246-cd4f82c27b84/go.mod h1:KelEdhl1UZF7XfJ4dDtk6s++YSgaE7mD/BuKKDLBl4A=
-golang.org/x/oauth2 v0.0.0-20210819190943-2bc19b11175f h1:Qmd2pbz05z7z6lm0DrgQVVPuBm92jqujBKMHMOlOQEw=
golang.org/x/oauth2 v0.0.0-20210819190943-2bc19b11175f/go.mod h1:KelEdhl1UZF7XfJ4dDtk6s++YSgaE7mD/BuKKDLBl4A=
+golang.org/x/oauth2 v0.6.0 h1:Lh8GPgSKBfWSwFvtuWOfeI3aAAnbXTSutYxJiOJFgIw=
+golang.org/x/oauth2 v0.6.0/go.mod h1:ycmewcwgD4Rpr3eZJLSB4Kyyljb3qDh40vJ8STE5HKw=
golang.org/x/sync v0.0.0-20180314180146-1d60e4601c6f/go.mod h1:RxMgew5VJxzue5/jJTE5uejpjVlOe/izrB70Jof72aM=
golang.org/x/sync v0.0.0-20181108010431-42b317875d0f/go.mod h1:RxMgew5VJxzue5/jJTE5uejpjVlOe/izrB70Jof72aM=
golang.org/x/sync v0.0.0-20181221193216-37e7f081c4d4/go.mod h1:RxMgew5VJxzue5/jJTE5uejpjVlOe/izrB70Jof72aM=
@@ -380,8 +382,8 @@ golang.org/x/sync v0.0.0-20200625203802-6e8e738ad208/go.mod h1:RxMgew5VJxzue5/jJ
golang.org/x/sync v0.0.0-20201020160332-67f06af15bc9/go.mod h1:RxMgew5VJxzue5/jJTE5uejpjVlOe/izrB70Jof72aM=
golang.org/x/sync v0.0.0-20201207232520-09787c993a3a/go.mod h1:RxMgew5VJxzue5/jJTE5uejpjVlOe/izrB70Jof72aM=
golang.org/x/sync v0.0.0-20210220032951-036812b2e83c/go.mod h1:RxMgew5VJxzue5/jJTE5uejpjVlOe/izrB70Jof72aM=
-golang.org/x/sync v0.1.0 h1:wsuoTGHzEhffawBOhz5CYhcrV4IdKZbEyZjBMuTp12o=
-golang.org/x/sync v0.1.0/go.mod h1:RxMgew5VJxzue5/jJTE5uejpjVlOe/izrB70Jof72aM=
+golang.org/x/sync v0.2.0 h1:PUR+T4wwASmuSTYdKjYHI5TD22Wy5ogLU5qZCOLxBrI=
+golang.org/x/sync v0.2.0/go.mod h1:RxMgew5VJxzue5/jJTE5uejpjVlOe/izrB70Jof72aM=
golang.org/x/sys v0.0.0-20180830151530-49385e6e1522/go.mod h1:STP8DvDyc/dI5b8T5hshtkjS+E42TnysNCUPdjciGhY=
golang.org/x/sys v0.0.0-20180909124046-d0be0721c37e/go.mod h1:STP8DvDyc/dI5b8T5hshtkjS+E42TnysNCUPdjciGhY=
golang.org/x/sys v0.0.0-20190215142949-d0b11bdaac8a/go.mod h1:STP8DvDyc/dI5b8T5hshtkjS+E42TnysNCUPdjciGhY=
@@ -429,12 +431,12 @@ golang.org/x/sys v0.0.0-20210423082822-04245dca01da/go.mod h1:h1NjWce9XRLGQEsW7w
golang.org/x/sys v0.0.0-20210510120138-977fb7262007/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
golang.org/x/sys v0.0.0-20210615035016-665e8c7367d1/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
golang.org/x/sys v0.0.0-20210831042530-f4d43177bf5e/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
-golang.org/x/sys v0.5.0 h1:MUK/U/4lj1t1oPg0HfuXDN/Z1wv31ZJ/YcPiGccS4DU=
-golang.org/x/sys v0.5.0/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
+golang.org/x/sys v0.6.0 h1:MVltZSvRTcU2ljQOhs94SXPftV6DCNnZViHeQps87pQ=
+golang.org/x/sys v0.6.0/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
golang.org/x/term v0.0.0-20201126162022-7de9c90e9dd1/go.mod h1:bj7SfCRtBDWHUb9snDiAeCFNEtKQo2Wmx5Cou7ajbmo=
golang.org/x/term v0.0.0-20210615171337-6886f2dfbf5b/go.mod h1:jbD1KX2456YbFQfuXm/mYQcufACuNUgVhRMnK/tPxf8=
-golang.org/x/term v0.5.0 h1:n2a8QNdAb0sZNpU9R1ALUXBbY+w51fCQDN+7EdxNBsY=
-golang.org/x/term v0.5.0/go.mod h1:jMB1sMXY+tzblOD4FWmEbocvup2/aLOaQEp7JmGp78k=
+golang.org/x/term v0.6.0 h1:clScbb1cHjoCkyRbWwBEUZ5H/tIFu5TAXIqaZD0Gcjw=
+golang.org/x/term v0.6.0/go.mod h1:m6U89DPEgQRMq3DNkDClhWw02AUbt2daBVO4cn4Hv9U=
golang.org/x/text v0.0.0-20170915032832-14c0d48ead0c/go.mod h1:NqM8EUOU14njkJ3fqMW+pc6Ldnwhi/IjpwHt7yyuwOQ=
golang.org/x/text v0.3.0/go.mod h1:NqM8EUOU14njkJ3fqMW+pc6Ldnwhi/IjpwHt7yyuwOQ=
golang.org/x/text v0.3.1-0.20180807135948-17ff2d5776d2/go.mod h1:NqM8EUOU14njkJ3fqMW+pc6Ldnwhi/IjpwHt7yyuwOQ=
@@ -444,13 +446,14 @@ golang.org/x/text v0.3.4/go.mod h1:5Zoc/QRtKVWzQhOtBMvqHzDpF6irO9z98xDceosuGiQ=
golang.org/x/text v0.3.5/go.mod h1:5Zoc/QRtKVWzQhOtBMvqHzDpF6irO9z98xDceosuGiQ=
golang.org/x/text v0.3.6/go.mod h1:5Zoc/QRtKVWzQhOtBMvqHzDpF6irO9z98xDceosuGiQ=
golang.org/x/text v0.3.7/go.mod h1:u+2+/6zg+i71rQMx5EYifcz6MCKuco9NR6JIITiCfzQ=
-golang.org/x/text v0.7.0 h1:4BRB4x83lYWy72KwLD/qYDuTu7q9PjSagHvijDw7cLo=
-golang.org/x/text v0.7.0/go.mod h1:mrYo+phRRbMaCq/xk9113O4dZlRixOauAjOtrjsXDZ8=
+golang.org/x/text v0.8.0 h1:57P1ETyNKtuIjB4SRd15iJxuhj8Gc416Y78H3qgMh68=
+golang.org/x/text v0.8.0/go.mod h1:e1OnstbJyHTd6l/uOt8jFFHp6TRDWZR/bV3emEE/zU8=
golang.org/x/time v0.0.0-20181108054448-85acf8d2951c/go.mod h1:tRJNPiyCQ0inRvYxbN9jk5I+vvW/OXSQhTDSoE431IQ=
golang.org/x/time v0.0.0-20190308202827-9d24e82272b4/go.mod h1:tRJNPiyCQ0inRvYxbN9jk5I+vvW/OXSQhTDSoE431IQ=
golang.org/x/time v0.0.0-20191024005414-555d28b269f0/go.mod h1:tRJNPiyCQ0inRvYxbN9jk5I+vvW/OXSQhTDSoE431IQ=
-golang.org/x/time v0.0.0-20210723032227-1f47c861a9ac h1:7zkz7BUtwNFFqcowJ+RIgu2MaV/MapERkDIy+mwPyjs=
golang.org/x/time v0.0.0-20210723032227-1f47c861a9ac/go.mod h1:tRJNPiyCQ0inRvYxbN9jk5I+vvW/OXSQhTDSoE431IQ=
+golang.org/x/time v0.3.0 h1:rg5rLMjNzMS1RkNLzCG38eapWhnYLFYXDXj2gOlr8j4=
+golang.org/x/time v0.3.0/go.mod h1:tRJNPiyCQ0inRvYxbN9jk5I+vvW/OXSQhTDSoE431IQ=
golang.org/x/tools v0.0.0-20180917221912-90fa682c2a6e/go.mod h1:n7NCudcB/nEzxVGmLbDWY5pfWTLqBcC2KZ6jyYvM4mQ=
golang.org/x/tools v0.0.0-20190114222345-bf090417da8b/go.mod h1:n7NCudcB/nEzxVGmLbDWY5pfWTLqBcC2KZ6jyYvM4mQ=
golang.org/x/tools v0.0.0-20190226205152-f727befe758c/go.mod h1:9Yl7xja0Znq3iFh3HoIrodX9oNMXvdceNzlUR8zjMvY=
@@ -575,8 +578,9 @@ google.golang.org/genproto v0.0.0-20210222152913-aa3ee6e6a81c/go.mod h1:FWY/as6D
google.golang.org/genproto v0.0.0-20210303154014-9728d6b83eeb/go.mod h1:FWY/as6DDZQgahTzZj3fqbO1CbirC29ZNUFHwi0/+no=
google.golang.org/genproto v0.0.0-20210310155132-4ce2db91004e/go.mod h1:FWY/as6DDZQgahTzZj3fqbO1CbirC29ZNUFHwi0/+no=
google.golang.org/genproto v0.0.0-20210319143718-93e7006c17a6/go.mod h1:FWY/as6DDZQgahTzZj3fqbO1CbirC29ZNUFHwi0/+no=
-google.golang.org/genproto v0.0.0-20210402141018-6c239bbf2bb1 h1:E7wSQBXkH3T3diucK+9Z1kjn4+/9tNG7lZLr75oOhh8=
google.golang.org/genproto v0.0.0-20210402141018-6c239bbf2bb1/go.mod h1:9lPAdzaEmUacj36I+k7YKbEc5CXzPIeORRgDAUOu28A=
+google.golang.org/genproto v0.0.0-20230306155012-7f2fa6fef1f4 h1:DdoeryqhaXp1LtT/emMP1BRJPHHKFi5akj/nbx/zNTA=
+google.golang.org/genproto v0.0.0-20230306155012-7f2fa6fef1f4/go.mod h1:NWraEVixdDnqcqQ30jipen1STv2r/n24Wb7twVTGR4s=
google.golang.org/grpc v1.19.0/go.mod h1:mqu4LbDTu4XGKhr4mRzUsmM4RtVoemTSY81AxZiDr8c=
google.golang.org/grpc v1.20.1/go.mod h1:10oTOabMzJvdu6/UiuZezV6QK5dSlG84ov/aaiqXj38=
google.golang.org/grpc v1.21.1/go.mod h1:oYelfM1adQP15Ek0mdvEgi9Df8B9CZIaU1084ijfRaM=
@@ -595,8 +599,8 @@ google.golang.org/grpc v1.34.0/go.mod h1:WotjhfgOW/POjDeRt8vscBtXq+2VjORFy659qA5
google.golang.org/grpc v1.35.0/go.mod h1:qjiiYl8FncCW8feJPdyg3v6XW24KsRHe+dy9BAGRRjU=
google.golang.org/grpc v1.36.0/go.mod h1:qjiiYl8FncCW8feJPdyg3v6XW24KsRHe+dy9BAGRRjU=
google.golang.org/grpc v1.36.1/go.mod h1:qjiiYl8FncCW8feJPdyg3v6XW24KsRHe+dy9BAGRRjU=
-google.golang.org/grpc v1.51.0 h1:E1eGv1FTqoLIdnBCZufiSHgKjlqG6fKFf6pPWtMTh8U=
-google.golang.org/grpc v1.51.0/go.mod h1:wgNDFcnuBGmxLKI/qn4T+m5BtEBYXJPvibbUPsAIPww=
+google.golang.org/grpc v1.55.0 h1:3Oj82/tFSCeUrRTg/5E/7d/W5A1tj6Ky1ABAuZuv5ag=
+google.golang.org/grpc v1.55.0/go.mod h1:iYEXKGkEBhg1PjZQvoYEVPTDkHo1/bjTnfwTeGONTY8=
google.golang.org/protobuf v0.0.0-20200109180630-ec00e32a8dfd/go.mod h1:DFci5gLYBciE7Vtevhsrf46CRTquxDuWsQurQQe4oz8=
google.golang.org/protobuf v0.0.0-20200221191635-4d8936d0db64/go.mod h1:kwYJMbMJ01Woi6D6+Kah6886xMZcty6N08ah7+eCXa0=
google.golang.org/protobuf v0.0.0-20200228230310-ab0ca4ff8a60/go.mod h1:cfTl7dwQJ+fmap5saPgwCLgHXTUD7jkjRqWcaiX5VyM=
@@ -610,8 +614,8 @@ google.golang.org/protobuf v1.25.0/go.mod h1:9JNX74DMeImyA3h4bdi1ymwjUzf21/xIlba
google.golang.org/protobuf v1.26.0-rc.1/go.mod h1:jlhhOSvTdKEhbULTjvd4ARK9grFBp09yW+WbY/TyQbw=
google.golang.org/protobuf v1.26.0/go.mod h1:9q0QmTI4eRPtz6boOQmLYwt+qCgq0jsYwAQnmE0givc=
google.golang.org/protobuf v1.27.1/go.mod h1:9q0QmTI4eRPtz6boOQmLYwt+qCgq0jsYwAQnmE0givc=
-google.golang.org/protobuf v1.28.1 h1:d0NfwRgPtno5B1Wa6L2DAG+KivqkdutMf1UhdNx175w=
-google.golang.org/protobuf v1.28.1/go.mod h1:HV8QOd/L58Z+nl8r43ehVNZIU/HEI6OcFqwMG9pJV4I=
+google.golang.org/protobuf v1.30.0 h1:kPPoIgf3TsEvrm0PFe15JQ+570QVxYzEvvHqChK+cng=
+google.golang.org/protobuf v1.30.0/go.mod h1:HV8QOd/L58Z+nl8r43ehVNZIU/HEI6OcFqwMG9pJV4I=
gopkg.in/check.v1 v0.0.0-20161208181325-20d25e280405/go.mod h1:Co6ibVJAznAaIkqp8huTwlJQCZ016jof/cbN4VW5Yz0=
gopkg.in/check.v1 v1.0.0-20180628173108-788fd7840127/go.mod h1:Co6ibVJAznAaIkqp8huTwlJQCZ016jof/cbN4VW5Yz0=
gopkg.in/check.v1 v1.0.0-20190902080502-41f04d3bba15/go.mod h1:Co6ibVJAznAaIkqp8huTwlJQCZ016jof/cbN4VW5Yz0=
From 2efa69845448b475da2ad9dfb7852daaf585d6d9 Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Wed, 24 May 2023 10:05:40 +0300
Subject: [PATCH 189/334] [CI] Skip test for OSS (#3634)
---
tests/system/api/test_artifacts.py | 1 +
1 file changed, 1 insertion(+)
diff --git a/tests/system/api/test_artifacts.py b/tests/system/api/test_artifacts.py
index f1549283d7b0..09ccac7b686f 100644
--- a/tests/system/api/test_artifacts.py
+++ b/tests/system/api/test_artifacts.py
@@ -26,6 +26,7 @@
class TestAPIArtifacts(TestMLRunSystem):
project_name = "db-system-test-project"
+ @pytest.mark.enterprise
def test_fail_overflowing_artifact(self):
"""
Test that we fail when trying to (inline) log an artifact that is too big
From 9771d0653c1cf01cf1d2be887089b1a0e5f883a5 Mon Sep 17 00:00:00 2001
From: Yael Genish <62285310+yaelgen@users.noreply.github.com>
Date: Wed, 24 May 2023 10:07:39 +0300
Subject: [PATCH 190/334] [Notifications] Fix missed notifications in
notifications pusher (#3607)
---
mlrun/api/main.py | 5 +++--
tests/api/utils/test_scheduler.py | 5 ++++-
2 files changed, 7 insertions(+), 3 deletions(-)
diff --git a/mlrun/api/main.py b/mlrun/api/main.py
index 80e00d196017..b2b4cc1fec11 100644
--- a/mlrun/api/main.py
+++ b/mlrun/api/main.py
@@ -566,7 +566,6 @@ def _push_terminal_run_notifications(db: mlrun.api.db.base.DBInterface, db_sessi
Get all runs with notification configs which became terminal since the last call to the function
and push their notifications if they haven't been pushed yet.
"""
-
# Import here to avoid circular import
import mlrun.api.api.utils
@@ -576,6 +575,8 @@ def _push_terminal_run_notifications(db: mlrun.api.db.base.DBInterface, db_sessi
# and their notifications haven't been sent yet.
global _last_notification_push_time
+ now = datetime.datetime.now(datetime.timezone.utc)
+
runs = db.list_runs(
db_session,
project="*",
@@ -599,7 +600,7 @@ def _push_terminal_run_notifications(db: mlrun.api.db.base.DBInterface, db_sessi
)
mlrun.utils.notifications.NotificationPusher(unmasked_runs).push(db)
- _last_notification_push_time = datetime.datetime.now(datetime.timezone.utc)
+ _last_notification_push_time = now
async def _stop_logs():
diff --git a/tests/api/utils/test_scheduler.py b/tests/api/utils/test_scheduler.py
index 1d377f411905..1c5f25faf751 100644
--- a/tests/api/utils/test_scheduler.py
+++ b/tests/api/utils/test_scheduler.py
@@ -56,7 +56,10 @@ async def scheduler(db: Session) -> typing.Generator:
call_counter: int = 0
-schedule_end_time_margin = 0.5
+
+# TODO: The margin will need to rise for each additional CPU-consuming operation added along the flow,
+# we need to consider how to decouple in the future
+schedule_end_time_margin = 0.7
async def bump_counter():
From 008a22ac6556a644d4598a89d8cae20ea8b43eba Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Wed, 24 May 2023 10:09:33 +0300
Subject: [PATCH 191/334] [Logs] Update some log lines to be better structured
(#3633)
---
mlrun/api/api/endpoints/functions.py | 18 +++++++-----------
mlrun/api/utils/builder.py | 12 +++++++++---
2 files changed, 16 insertions(+), 14 deletions(-)
diff --git a/mlrun/api/api/endpoints/functions.py b/mlrun/api/api/endpoints/functions.py
index 5765a96a76aa..97ed1cd665c3 100644
--- a/mlrun/api/api/endpoints/functions.py
+++ b/mlrun/api/api/endpoints/functions.py
@@ -405,13 +405,10 @@ async def build_status(
return await run_in_threadpool(
_handle_job_deploy_status,
db_session,
- auth_info,
fn,
name,
project,
tag,
- last_log_timestamp,
- verbose,
offset,
logs,
)
@@ -419,13 +416,10 @@ async def build_status(
def _handle_job_deploy_status(
db_session,
- auth_info,
fn,
name,
project,
tag,
- last_log_timestamp,
- verbose,
offset,
logs,
):
@@ -480,22 +474,24 @@ def _handle_job_deploy_status(
},
)
- logger.info(f"get pod {pod} status")
+ # TODO: change state to pod_status
state = mlrun.api.utils.singletons.k8s.get_k8s_helper(silent=False).get_pod_status(
pod
)
- logger.info(f"pod state={state}")
+ logger.info("Resolved pod status", pod_status=state, pod_name=pod)
if state == "succeeded":
- logger.info("build completed successfully")
+ logger.info("Build completed successfully")
state = mlrun.common.schemas.FunctionState.ready
if state in ["failed", "error"]:
- logger.error(f"build {state}, watch the build pod logs: {pod}")
+ logger.error("Build failed", pod_name=pod, pod_status=state)
state = mlrun.common.schemas.FunctionState.error
if (logs and state != "pending") or state in terminal_states:
resp = mlrun.api.utils.singletons.k8s.get_k8s_helper(silent=False).logs(pod)
if state in terminal_states:
+
+ # TODO: move to log collector
log_file.parent.mkdir(parents=True, exist_ok=True)
with log_file.open("wb") as fp:
fp.write(resp.encode())
@@ -724,7 +720,7 @@ def _build_function(
client_python_version=client_python_version,
)
fn.save(versioned=True)
- logger.info("Fn:\n %s", fn.to_yaml())
+ logger.info("Resolved function", fn=fn.to_yaml())
except Exception as err:
logger.error(traceback.format_exc())
log_and_raise(
diff --git a/mlrun/api/utils/builder.py b/mlrun/api/utils/builder.py
index f11fb0be88e3..1fdeaf905504 100644
--- a/mlrun/api/utils/builder.py
+++ b/mlrun/api/utils/builder.py
@@ -475,7 +475,7 @@ def build_image(
else:
pod, ns = k8s.create_pod(kpod)
mlrun.utils.logger.info(
- f'started build, to watch build logs use "mlrun watch {pod} {ns}"'
+ "Build started", pod=pod, namespace=ns, project=project, image=image_target
)
return f"build:{pod}"
@@ -594,9 +594,8 @@ def build_runtime(
raise mlrun.errors.MLRunInvalidArgumentError(
"build spec must have a target image, set build.image = "
)
- mlrun.utils.logger.info(f"building image ({build.image})")
-
name = mlrun.utils.normalize_name(f"mlrun-build-{runtime.metadata.name}")
+
base_image: str = (
build.base_image or runtime.spec.image or config.default_base_image
)
@@ -605,6 +604,13 @@ def build_runtime(
client_version,
client_python_version,
)
+ mlrun.utils.logger.info(
+ "Building runtime image",
+ base_image=enriched_base_image,
+ image=build.image,
+ project=project,
+ name=name,
+ )
status = build_image(
auth_info,
From 6bd07176bfb8640a338cdc34ac78ece3e404b56a Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Wed, 24 May 2023 11:13:00 +0300
Subject: [PATCH 192/334] [Requirements] Remove protobuf requirement (#3617)
---
conda-arm64-requirements.txt | 1 -
requirements.txt | 5 -----
tests/test_requirements.py | 1 -
3 files changed, 7 deletions(-)
diff --git a/conda-arm64-requirements.txt b/conda-arm64-requirements.txt
index 00aeb2548f5f..f984aba006d9 100644
--- a/conda-arm64-requirements.txt
+++ b/conda-arm64-requirements.txt
@@ -1,4 +1,3 @@
# with moving to arm64 for the new M1/M2 macs some packages are not yet compatible via pip and require
# conda which supports different architecture environments on the same machine
-protobuf>=3.13, <3.20
lightgbm>=3.0
diff --git a/requirements.txt b/requirements.txt
index b7ea9199a2a4..f8826e7bc382 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -7,11 +7,6 @@ aiohttp~=3.8
aiohttp-retry~=2.8
# 8.1.0+ breaks dask/distributed versions older than 2022.04.0, see here - https://github.com/dask/distributed/pull/6018
click~=8.0.0
-# when installing google-cloud-storage which required >=3.20.1, <5 it was upgrading the protobuf version to the latest
-# version and because kfp 1.8.13 requires protobuf>=3.13, <4 it resulted incompatibility between kfp and protobuf
-# this can be removed once kfp will support protobuf > 4
-# since google-cloud blacklisted 3.20.0 and 3.20.1 we start from 3.20.2
-protobuf>=3.13, <3.20
# 3.0/3.2 iguazio system uses 1.0.1, but we needed >=1.6.0 to be compatible with k8s>=12.0 to fix scurity issue
# since the sdk is still mark as beta (and not stable) I'm limiting to only patch changes
# 1.8.14 introduced new features related to ParallelFor, while our actual kfp server is 1.8.1, which isn't compatible
diff --git a/tests/test_requirements.py b/tests/test_requirements.py
index c439c517523b..d8899b149592 100644
--- a/tests/test_requirements.py
+++ b/tests/test_requirements.py
@@ -126,7 +126,6 @@ def test_requirement_specifiers_convention():
"dask-ml": {"~=1.4,<1.9.0"},
"pyarrow": {">=10.0, <12"},
"nbclassic": {">=0.2.8"},
- "protobuf": {">=3.13, <3.20"},
"pandas": {"~=1.2, <1.5.0"},
"ipython": {">=7.0, <9.0"},
"importlib_metadata": {">=3.6"},
From f62d0ba73621aaaa3e733f5d2fad3f0c3e4e4c1c Mon Sep 17 00:00:00 2001
From: TomerShor <90552140+TomerShor@users.noreply.github.com>
Date: Wed, 24 May 2023 14:38:55 +0300
Subject: [PATCH 193/334] [Runtime] Deprecate `requirements` as string and add
`requirements_file` argument (#3628)
---
mlrun/api/crud/runtimes/nuclio/function.py | 6 +-
mlrun/model.py | 51 ++++++++++++++---
mlrun/projects/operations.py | 6 +-
mlrun/projects/project.py | 33 +++++++----
mlrun/runtimes/base.py | 6 +-
mlrun/runtimes/kubejob.py | 5 +-
mlrun/utils/helpers.py | 6 ++
tests/runtimes/test_base.py | 64 +++++++++++++++++++---
8 files changed, 143 insertions(+), 34 deletions(-)
diff --git a/mlrun/api/crud/runtimes/nuclio/function.py b/mlrun/api/crud/runtimes/nuclio/function.py
index 72a1a51d9a3f..0588960f388d 100644
--- a/mlrun/api/crud/runtimes/nuclio/function.py
+++ b/mlrun/api/crud/runtimes/nuclio/function.py
@@ -65,7 +65,11 @@ def deploy_nuclio_function(
)
try:
- logger.info("Starting Nuclio function deployment")
+ logger.info(
+ "Starting Nuclio function deployment",
+ function_name=function_name,
+ project_name=project_name,
+ )
return nuclio.deploy.deploy_config(
function_config,
dashboard_url=mlrun.mlconf.nuclio_dashboard_url,
diff --git a/mlrun/model.py b/mlrun/model.py
index 4f824272464c..0faba796a824 100644
--- a/mlrun/model.py
+++ b/mlrun/model.py
@@ -17,6 +17,7 @@
import re
import time
import typing
+import warnings
from collections import OrderedDict
from copy import deepcopy
from datetime import datetime
@@ -390,6 +391,7 @@ def build_config(
with_mlrun=None,
auto_build=None,
requirements=None,
+ requirements_file=None,
overwrite=False,
):
if image:
@@ -399,7 +401,7 @@ def build_config(
if commands:
self.with_commands(commands, overwrite=overwrite)
if requirements:
- self.with_requirements(requirements, overwrite=overwrite)
+ self.with_requirements(requirements, requirements_file, overwrite=overwrite)
if extra:
self.extra = extra
if secret is not None:
@@ -443,15 +445,28 @@ def with_commands(
def with_requirements(
self,
requirements: Union[str, List[str]],
+ requirements_file: str = "",
overwrite: bool = False,
):
"""add package requirements from file or list to build spec.
- :param requirements: python requirements file path or list of packages
- :param overwrite: overwrite existing requirements
+ :param requirements: a list of python packages
+ :param requirements_file: path to a python requirements file
+ :param overwrite: overwrite existing requirements,
+ when False (default) will append to existing requirements
:return: function object
"""
- resolved_requirements = self._resolve_requirements(requirements)
+ if isinstance(requirements, str) and mlrun.utils.is_file_path(requirements):
+ # TODO: remove in 1.6.0
+ warnings.warn(
+ "Passing a requirements file path as a string in the 'requirements' argument is deprecated "
+ "and will be removed in 1.6.0, use 'requirements_file' instead",
+ FutureWarning,
+ )
+
+ resolved_requirements = self._resolve_requirements(
+ requirements, requirements_file
+ )
requirements = self.requirements or [] if not overwrite else []
# make sure we don't append the same line twice
@@ -462,11 +477,29 @@ def with_requirements(
self.requirements = requirements
@staticmethod
- def _resolve_requirements(requirements_to_resolve: typing.Union[str, list]) -> list:
- # if a string, read the file then encode
- if isinstance(requirements_to_resolve, str):
- with open(requirements_to_resolve, "r") as fp:
- requirements_to_resolve = fp.read().splitlines()
+ def _resolve_requirements(
+ requirements: typing.Union[str, list], requirements_file: str = ""
+ ) -> list:
+ requirements_to_resolve = []
+
+ # handle the requirements_file argument
+ if requirements_file:
+ with open(requirements_file, "r") as fp:
+ requirements_to_resolve.extend(fp.read().splitlines())
+
+ # handle the requirements argument
+ # TODO: remove in 1.6.0, when requirements can only be a list
+ if isinstance(requirements, str):
+ # if it's a file path, read the file and add its content to the list
+ if mlrun.utils.is_file_path(requirements):
+ with open(requirements, "r") as fp:
+ requirements_to_resolve.extend(fp.read().splitlines())
+ else:
+ # it's a string but not a file path, split it by lines and add it to the list
+ requirements_to_resolve.append(requirements)
+ else:
+ # it's a list, add it to the list
+ requirements_to_resolve.extend(requirements)
requirements = []
for requirement in requirements_to_resolve:
diff --git a/mlrun/projects/operations.py b/mlrun/projects/operations.py
index a49ed905fa50..e518bbd52053 100644
--- a/mlrun/projects/operations.py
+++ b/mlrun/projects/operations.py
@@ -236,6 +236,7 @@ def build_function(
commands: list = None,
secret_name=None,
requirements: Union[str, List[str]] = None,
+ requirements_file: str = None,
mlrun_version_specifier=None,
builder_env: dict = None,
project_object=None,
@@ -250,7 +251,8 @@ def build_function(
:param base_image: base image name/path (commands and source code will be added to it)
:param commands: list of docker build (RUN) commands e.g. ['pip install pandas']
:param secret_name: k8s secret for accessing the docker registry
- :param requirements: list of python packages or pip requirements file path, defaults to None
+ :param requirements: list of python packages, defaults to None
+ :param requirements_file: pip requirements file path, defaults to None
:param mlrun_version_specifier: which mlrun package version to include (if not current)
:param builder_env: Kaniko builder pod env vars dict (for config/credentials)
e.g. builder_env={"GIT_TOKEN": token}, does not work yet in KFP
@@ -269,7 +271,7 @@ def build_function(
if overwrite_build_params:
function.spec.build.commands = None
if requirements:
- function.with_requirements(requirements)
+ function.with_requirements(requirements, requirements_file)
if commands:
function.with_commands(commands)
return function.deploy_step(
diff --git a/mlrun/projects/project.py b/mlrun/projects/project.py
index 2772ea9b9aa5..7c891f910504 100644
--- a/mlrun/projects/project.py
+++ b/mlrun/projects/project.py
@@ -2354,20 +2354,22 @@ def build_function(
mlrun_version_specifier: str = None,
builder_env: dict = None,
overwrite_build_params: bool = False,
+ requirements_file: str = None,
) -> typing.Union[BuildStatus, kfp.dsl.ContainerOp]:
"""deploy ML function, build container with its dependencies
- :param function: name of the function (in the project) or function object
- :param with_mlrun: add the current mlrun package to the container build
- :param skip_deployed: skip the build if we already have an image for the function
- :param image: target image name/path
- :param base_image: base image name/path (commands and source code will be added to it)
- :param commands: list of docker build (RUN) commands e.g. ['pip install pandas']
- :param secret_name: k8s secret for accessing the docker registry
- :param requirements: list of python packages or pip requirements file path, defaults to None
+ :param function: name of the function (in the project) or function object
+ :param with_mlrun: add the current mlrun package to the container build
+ :param skip_deployed: skip the build if we already have an image for the function
+ :param image: target image name/path
+ :param base_image: base image name/path (commands and source code will be added to it)
+ :param commands: list of docker build (RUN) commands e.g. ['pip install pandas']
+ :param secret_name: k8s secret for accessing the docker registry
+ :param requirements: list of python packages, defaults to None
+ :param requirements_file: pip requirements file path, defaults to None
:param mlrun_version_specifier: which mlrun package version to include (if not current)
- :param builder_env: Kaniko builder pod env vars dict (for config/credentials)
- e.g. builder_env={"GIT_TOKEN": token}, does not work yet in KFP
+ :param builder_env: Kaniko builder pod env vars dict (for config/credentials)
+ e.g. builder_env={"GIT_TOKEN": token}, does not work yet in KFP
:param overwrite_build_params: overwrite the function build parameters with the provided ones, or attempt to
add to existing parameters
"""
@@ -2380,6 +2382,7 @@ def build_function(
commands=commands,
secret_name=secret_name,
requirements=requirements,
+ requirements_file=requirements_file,
mlrun_version_specifier=mlrun_version_specifier,
builder_env=builder_env,
project_object=self,
@@ -2396,6 +2399,7 @@ def build_config(
secret_name: str = None,
requirements: typing.Union[str, typing.List[str]] = None,
overwrite_build_params: bool = False,
+ requirements_file: str = None,
):
"""specify builder configuration for the project
@@ -2406,7 +2410,8 @@ def build_config(
:param base_image: base image name/path
:param commands: list of docker build (RUN) commands e.g. ['pip install pandas']
:param secret_name: k8s secret for accessing the docker registry
- :param requirements: requirements.txt file to install or list of packages to install on the built image
+ :param requirements: a list of packages to install on the built image
+ :param requirements_file: requirements file to install on the built image
:param overwrite_build_params: overwrite existing build configuration (default False)
* False: the new params are merged with the existing (currently merge is applied to requirements and
@@ -2425,6 +2430,7 @@ def build_config(
secret=secret_name,
with_mlrun=with_mlrun,
requirements=requirements,
+ requirements_file=requirements_file,
overwrite=overwrite_build_params,
)
@@ -2444,6 +2450,7 @@ def build_image(
mlrun_version_specifier: str = None,
builder_env: dict = None,
overwrite_build_params: bool = False,
+ requirements_file: str = None,
) -> typing.Union[BuildStatus, kfp.dsl.ContainerOp]:
"""Builder docker image for the project, based on the project's build config. Parameters allow to override
the build config.
@@ -2456,7 +2463,8 @@ def build_image(
:param base_image: base image name/path (commands and source code will be added to it)
:param commands: list of docker build (RUN) commands e.g. ['pip install pandas']
:param secret_name: k8s secret for accessing the docker registry
- :param requirements: list of python packages or pip requirements file path, defaults to None
+ :param requirements: list of python packages, defaults to None
+ :param requirements_file: pip requirements file path, defaults to None
:param mlrun_version_specifier: which mlrun package version to include (if not current)
:param builder_env: Kaniko builder pod env vars dict (for config/credentials)
e.g. builder_env={"GIT_TOKEN": token}, does not work yet in KFP
@@ -2475,6 +2483,7 @@ def build_image(
secret_name=secret_name,
with_mlrun=with_mlrun,
requirements=requirements,
+ requirements_file=requirements_file,
overwrite_build_params=overwrite_build_params,
)
diff --git a/mlrun/runtimes/base.py b/mlrun/runtimes/base.py
index f6e10ec798b1..72adafe98ec3 100644
--- a/mlrun/runtimes/base.py
+++ b/mlrun/runtimes/base.py
@@ -759,17 +759,19 @@ def with_requirements(
overwrite: bool = False,
verify_base_image: bool = False,
prepare_image_for_deploy: bool = True,
+ requirements_file: str = "",
):
"""add package requirements from file or list to build spec.
- :param requirements: python requirements file path or list of packages
+ :param requirements: a list of python packages
+ :param requirements_file: a local python requirements file path
:param overwrite: overwrite existing requirements
:param verify_base_image: verify that the base image is configured
(deprecated, use prepare_image_for_deploy)
:param prepare_image_for_deploy: prepare the image/base_image spec for deployment
:return: function object
"""
- self.spec.build.with_requirements(requirements, overwrite)
+ self.spec.build.with_requirements(requirements, requirements_file, overwrite)
if verify_base_image or prepare_image_for_deploy:
# TODO: remove verify_base_image in 1.6.0
diff --git a/mlrun/runtimes/kubejob.py b/mlrun/runtimes/kubejob.py
index b2c3124a6429..9b06beebca7b 100644
--- a/mlrun/runtimes/kubejob.py
+++ b/mlrun/runtimes/kubejob.py
@@ -112,6 +112,7 @@ def build_config(
overwrite=False,
verify_base_image=False,
prepare_image_for_deploy=True,
+ requirements_file=None,
):
"""specify builder configuration for the deploy operation
@@ -126,7 +127,8 @@ def build_config(
:param with_mlrun: add the current mlrun package to the container build
:param auto_build: when set to True and the function require build it will be built on the first
function run, use only if you dont plan on changing the build config between runs
- :param requirements: requirements.txt file to install or list of packages to install
+ :param requirements: a list of packages to install
+ :param requirements_file: requirements file to install
:param overwrite: overwrite existing build configuration
* False: the new params are merged with the existing (currently merge is applied to requirements and
@@ -148,6 +150,7 @@ def build_config(
with_mlrun,
auto_build,
requirements,
+ requirements_file,
overwrite,
)
diff --git a/mlrun/utils/helpers.py b/mlrun/utils/helpers.py
index 5a860d180f4b..62f714683f43 100644
--- a/mlrun/utils/helpers.py
+++ b/mlrun/utils/helpers.py
@@ -16,6 +16,7 @@
import hashlib
import inspect
import json
+import os
import re
import sys
import time
@@ -1332,6 +1333,11 @@ def ensure_git_branch(url: str, repo: git.Repo) -> str:
return url
+def is_file_path(filepath):
+ root, ext = os.path.splitext(filepath)
+ return os.path.isfile(filepath) and ext
+
+
class DeprecationHelper(object):
"""A helper class to deprecate old schemas"""
diff --git a/tests/runtimes/test_base.py b/tests/runtimes/test_base.py
index 703e977be068..ee8ff07c2bc9 100644
--- a/tests/runtimes/test_base.py
+++ b/tests/runtimes/test_base.py
@@ -127,13 +127,7 @@ def test_resolve_requirements(self, requirements, encoded_requirements):
if requirements_as_file:
# create a temporary file with the requirements
- with tempfile.NamedTemporaryFile(
- delete=False, dir=self._temp_dir
- ) as temp_file:
- with open(temp_file.name, "w") as f:
- for requirement in requirements:
- f.write(requirement + "\n")
- requirements = temp_file.name
+ requirements = self._create_temp_requirements_file(requirements)
encoded = self._generate_runtime().spec.build._resolve_requirements(
requirements
@@ -142,6 +136,53 @@ def test_resolve_requirements(self, requirements, encoded_requirements):
encoded == encoded_requirements
), f"Failed to encode {requirements} as file {requirements_as_file}"
+ @pytest.mark.parametrize(
+ "requirements,requirements_in_file,encoded_requirements,requirements_as_file",
+ [
+ (
+ ["pandas==1.0.0", "numpy==1.0.0"],
+ ["something==1.0.0", "otherthing==1.0.0"],
+ [
+ "something==1.0.0",
+ "otherthing==1.0.0",
+ "pandas==1.0.0",
+ "numpy==1.0.0",
+ ],
+ False,
+ ),
+ (
+ ["pandas==1.0.0", "numpy==1.0.0"],
+ ["something==1.0.0", "otherthing==1.0.0"],
+ [
+ "something==1.0.0",
+ "otherthing==1.0.0",
+ "pandas==1.0.0",
+ "numpy==1.0.0",
+ ],
+ True,
+ ),
+ ],
+ )
+ def test_resolve_requirements_file(
+ self,
+ requirements,
+ requirements_in_file,
+ encoded_requirements,
+ requirements_as_file,
+ ):
+ # create requirements file
+ requirements_file = self._create_temp_requirements_file(requirements_in_file)
+
+ if requirements_as_file:
+ requirements = self._create_temp_requirements_file(requirements)
+
+ encoded = self._generate_runtime().spec.build._resolve_requirements(
+ requirements, requirements_file
+ )
+ assert (
+ encoded == encoded_requirements
+ ), f"Failed to encode {requirements.extend(requirements_in_file)} as file {requirements_file}"
+
def test_fill_credentials(self, rundb_mock):
"""
expects to set the generate access key so that the API will enrich with the auth session that is being passed
@@ -292,3 +333,12 @@ def test_auto_mount_env(self, rundb_mock):
rundb_mock.reset()
self._execute_run(runtime)
rundb_mock.assert_env_variables(expected_env)
+
+ def _create_temp_requirements_file(self, requirements):
+ with tempfile.NamedTemporaryFile(
+ delete=False, dir=self._temp_dir, suffix=".txt"
+ ) as temp_file:
+ with open(temp_file.name, "w") as f:
+ for requirement in requirements:
+ f.write(requirement + "\n")
+ return temp_file.name
From d6b31e7e83311a882902757140ff104432278dcb Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Thu, 25 May 2023 09:09:35 +0300
Subject: [PATCH 194/334] [CI] Remove obsoleted flag (#3644)
---
.github/workflows/system-tests-enterprise.yml | 1 -
1 file changed, 1 deletion(-)
diff --git a/.github/workflows/system-tests-enterprise.yml b/.github/workflows/system-tests-enterprise.yml
index a3e657187242..13989d14448e 100644
--- a/.github/workflows/system-tests-enterprise.yml
+++ b/.github/workflows/system-tests-enterprise.yml
@@ -319,7 +319,6 @@ jobs:
--username "${{ secrets.LATEST_SYSTEM_TEST_USERNAME }}" \
--access-key "${{ secrets.LATEST_SYSTEM_TEST_ACCESS_KEY }}" \
--spark-service "${{ secrets.LATEST_SYSTEM_TEST_SPARK_SERVICE }}" \
- --password "${{ secrets.LATEST_SYSTEM_TEST_PASSWORD }}" \
--slack-webhook-url "${{ secrets.LATEST_SYSTEM_TEST_SLACK_WEBHOOK_URL }}" \
--branch "${{ needs.prepare-system-tests-enterprise-ci.outputs.mlrunBranch }}" \
--github-access-token "${{ secrets.SYSTEM_TEST_GITHUB_ACCESS_TOKEN }}"
From 5fe0a2e9ab0ae48b5814f02d1fac866d6b497fcf Mon Sep 17 00:00:00 2001
From: jillnogold <88145832+jillnogold@users.noreply.github.com>
Date: Thu, 25 May 2023 09:12:18 +0300
Subject: [PATCH 195/334] [Docs] Add change log for v1.3.1 and v1.2.3 (#3502)
---
docs/change-log/index.md | 42 ++++++++++++++++++++++++++++++++++++++--
docs/conf.py | 3 ---
2 files changed, 40 insertions(+), 5 deletions(-)
diff --git a/docs/change-log/index.md b/docs/change-log/index.md
index 6844a6606531..c1099e34ef32 100644
--- a/docs/change-log/index.md
+++ b/docs/change-log/index.md
@@ -1,6 +1,9 @@
(change-log)=
# Change log
+- [v1.3.1](#v1-3-1)
- [v1.3.0](#v1-3-0)
+- [v1.2.3](#v1-2-3)
+- [v1.2.2](#v1-2-2)
- [v1.2.1](#v1-2-1)
- [v1.2.0](#v1-2-0)
- [v1.1.3](#1-1-3)
@@ -14,6 +17,22 @@
- [Limitations](#limitations)
- [Deprecations](#deprecations)
+## v1.3.1
+
+### Closed issues
+
+| ID | Description |
+| --- | ----------------------------------------------------------------- |
+| ML-3764 | Fixed the scikit-learn to 1.2 in the tutorial 02-model-training. (Previously pointed to 1.0.) [View in Git](https://github.com/mlrun/mlrun/pull/3437). |
+| ML-3794 | Fixed a Mask detection demo notebook (3-automatic-pipeline.ipynb). [View in Git](https://github.com/mlrun/demos/releases/tag/v1.3.1-rc6). |
+| ML-3819 | Reduce overly-verbose logs on the backend side. [View in Git](https://github.com/mlrun/mlrun/pull/3531). [View in Git](https://github.com/mlrun/mlrun/pull/3553). |
+| ML-3823 | Optimized `/projects` endpoint to work faster. [View in Git](https://github.com/mlrun/mlrun/pull/3560). |
+
+
+### Documentation
+New sections describing [Git best practices](../projects/git-best-practices.html) and an example [Nuclio function](../concepts/nuclio-real-time-functions.html#example-of-nuclio-function).
+
+
## v1.3.0
### Client/server matrix, prerequisites, and installing
@@ -32,8 +51,8 @@ To install on a **Python 3.9** environment, run:
To install on a **Python 3.7** environment (and optionally upgrade to python 3.9), run:
-1. Configure the Jupyter service with the env variable`JUPYTER_PREFER_ENV_PATH=false`.
-2. Within the Jupyter service, open a terminal and update conda and pip to have an up to date pip resolver.
+1. Configure the Jupyter service with the env variable `JUPYTER_PREFER_ENV_PATH=false`.
+2. Within the Jupyter service, open a terminal and update conda and pip to have an up-to-date pip resolver.
```
$CONDA_HOME/bin/conda install -y conda=23.1.0
@@ -202,6 +221,24 @@ The `--ensure-project` flag of the `mlrun project` CLI command is deprecated and
| ML-3446 | Fix: Failed MLRun Nuclio deploy needs better error messages. [View in Git](https://github.com/mlrun/mlrun/pull/3241). |
| ML-3482 | Fixed model-monitoring incompatibility issue with mlrun client running v1.1.x and a server running v1.2.x. [View in Git](https://github.com/mlrun/mlrun/pull/3180). |
+## v1.2.3
+
+### Closed issues
+
+| ID | Description |
+| --- | ----------------------------------------------------------------- |
+| ML-3287 | UI now resets the cache upon MLRun upgrades, and the Projects page displays correctly. [View in Git](https://github.com/mlrun/ui/pull/1612). |
+| ML-3801 | Optimized `/projects` endpoint to work faster [View in Git](https://github.com/mlrun/ui/pull/1715). |
+| ML-3819 | Reduce overly-verbose logs on the backend side. [View in Git](https://github.com/mlrun/mlrun/pull/3531). |
+
+## v1.2.2
+
+### Closed issues
+
+| ID | Description |
+| --- | ----------------------------------------------------------------- |
+| ML-3797, ML-3798 | Fixed presenting and serving large-sized projects. [View in Git](https://github.com/mlrun/mlrun/pull/3477). |
+
## v1.2.1
@@ -528,6 +565,7 @@ with a drill-down to view the steps and their details. [Tech Preview]
| ML-2014 | Model deployment returns ResourceNotFoundException (Nuclio error that Service is invalid.) | Verify that all `metadata.labels` values are 63 characters or less. See the [Kubernetes limitation](https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/#syntax-and-character-set). | v1.0.0 |
| ML-3315 | The feature store does not support an aggregation of aggregations | NA | v1.2.1 |
| ML-3381 | Private repo is not supported as a marketplace hub | NA | v1.2.1 |
+| ML-3824 | MLRun supports TensorFlow up to 2.11. | NA | v1.3.1 |
## Deprecations
diff --git a/docs/conf.py b/docs/conf.py
index 4e7256d15e44..272cd41eb630 100644
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -63,9 +63,6 @@ def current_version():
"sphinx_reredirects",
]
-# redirect paths due to filename changes
-redirects = {"runtimes/load-from-hub": "load-from-hub.html"}
-
# Add any paths that contain templates here, relative to this directory.
templates_path = [
"_templates",
From f6e96edbe87fa43423fe68d87330e32198f540be Mon Sep 17 00:00:00 2001
From: TomerShor <90552140+TomerShor@users.noreply.github.com>
Date: Thu, 25 May 2023 12:26:55 +0300
Subject: [PATCH 196/334] [Log Collector] Change log file names to old format
(#3647)
---
.../logcollector/logcollector_test.go | 17 ++--
go/pkg/services/logcollector/server.go | 78 +++++++------------
mlrun/api/crud/logs.py | 12 ++-
mlrun/api/utils/clients/log_collector.py | 5 ++
4 files changed, 45 insertions(+), 67 deletions(-)
diff --git a/go/pkg/services/logcollector/logcollector_test.go b/go/pkg/services/logcollector/logcollector_test.go
index 5e8f03aa5557..cebd8f8702c4 100644
--- a/go/pkg/services/logcollector/logcollector_test.go
+++ b/go/pkg/services/logcollector/logcollector_test.go
@@ -211,7 +211,7 @@ func (suite *LogCollectorTestSuite) TestStreamPodLogs() {
suite.Require().True(started, "Log streaming didn't start")
// resolve log file path
- logFilePath := suite.logCollectorServer.resolvePodLogFilePath(suite.projectName, runId, pod.Name)
+ logFilePath := suite.logCollectorServer.resolveRunLogFilePath(suite.projectName, runId)
// read log file until it has content, or timeout
timeout := time.After(30 * time.Second)
@@ -259,10 +259,9 @@ func (suite *LogCollectorTestSuite) TestStartLogBestEffort() {
func (suite *LogCollectorTestSuite) TestGetLogsSuccessful() {
runUID := uuid.New().String()
- podName := "my-pod"
// creat log file for runUID and pod
- logFilePath := suite.logCollectorServer.resolvePodLogFilePath(suite.projectName, runUID, podName)
+ logFilePath := suite.logCollectorServer.resolveRunLogFilePath(suite.projectName, runUID)
// write log file
logText := "Some fake pod logs\n"
@@ -397,8 +396,6 @@ func (suite *LogCollectorTestSuite) TestReadLogsFromFileWhileWriting() {
func (suite *LogCollectorTestSuite) TestHasLogs() {
runUID := uuid.New().String()
- podName := "my-pod"
-
request := &log_collector.HasLogsRequest{
RunUID: runUID,
ProjectName: suite.projectName,
@@ -411,7 +408,7 @@ func (suite *LogCollectorTestSuite) TestHasLogs() {
suite.Require().False(hasLogsResponse.HasLogs, "Expected run to not have logs")
// create log file for runUID and pod
- logFilePath := suite.logCollectorServer.resolvePodLogFilePath(suite.projectName, runUID, podName)
+ logFilePath := suite.logCollectorServer.resolveRunLogFilePath(suite.projectName, runUID)
// write log file
logText := "Some fake pod logs\n"
@@ -521,7 +518,7 @@ func (suite *LogCollectorTestSuite) TestDeleteLogs() {
for i := 0; i < testCase.logsNumToCreate; i++ {
runUID := uuid.New().String()
runUIDs = append(runUIDs, runUID)
- logFilePath := suite.logCollectorServer.resolvePodLogFilePath(projectName, runUID, "pod")
+ logFilePath := suite.logCollectorServer.resolveRunLogFilePath(projectName, runUID)
err := common.WriteToFile(logFilePath, []byte("some log"), false)
suite.Require().NoError(err, "Failed to write to file")
}
@@ -558,7 +555,7 @@ func (suite *LogCollectorTestSuite) TestDeleteProjectLogs() {
for i := 0; i < logsNum; i++ {
runUID := uuid.New().String()
runUIDs = append(runUIDs, runUID)
- logFilePath := suite.logCollectorServer.resolvePodLogFilePath(projectName, runUID, "pod")
+ logFilePath := suite.logCollectorServer.resolveRunLogFilePath(projectName, runUID)
err := common.WriteToFile(logFilePath, []byte("some log"), false)
suite.Require().NoError(err, "Failed to write to file")
}
@@ -596,7 +593,7 @@ func (suite *LogCollectorTestSuite) TestGetLogFilePath() {
suite.Require().NoError(err)
// make the run file
- runFilePath := suite.logCollectorServer.resolvePodLogFilePath(projectName, runUID, "pod")
+ runFilePath := suite.logCollectorServer.resolveRunLogFilePath(projectName, runUID)
err = common.WriteToFile(runFilePath, []byte("some log"), false)
suite.Require().NoError(err, "Failed to write to file")
@@ -627,7 +624,7 @@ func (suite *LogCollectorTestSuite) TestGetLogFilePathConcurrently() {
suite.Require().NoError(err)
// make the run file
- runFilePath := suite.logCollectorServer.resolvePodLogFilePath(projectName, runUID, "pod")
+ runFilePath := suite.logCollectorServer.resolveRunLogFilePath(projectName, runUID)
err = common.WriteToFile(runFilePath, []byte("some log"), false)
suite.Require().NoError(err, "Failed to write to file")
diff --git a/go/pkg/services/logcollector/server.go b/go/pkg/services/logcollector/server.go
index 20f0623e37b4..cf4fd6281207 100644
--- a/go/pkg/services/logcollector/server.go
+++ b/go/pkg/services/logcollector/server.go
@@ -18,7 +18,6 @@ import (
"context"
"fmt"
"io"
- "io/fs"
"math"
"os"
"path"
@@ -433,6 +432,10 @@ func (s *Server) GetLogs(request *protologcollector.GetLogsRequest, responseStre
// HasLogs returns true if the log file exists for a given run id
func (s *Server) HasLogs(ctx context.Context, request *protologcollector.HasLogsRequest) (*protologcollector.HasLogsResponse, error) {
+ s.Logger.DebugWithCtx(ctx,
+ "Received has log request",
+ "runUID", request.RunUID,
+ "project", request.ProjectName)
// get log file path
if _, err := s.getLogFilePath(ctx, request.RunUID, request.ProjectName); err != nil {
@@ -656,7 +659,7 @@ func (s *Server) startLogStreaming(ctx context.Context,
startedStreamingGoroutine <- true
// create a log file to the pod
- logFilePath := s.resolvePodLogFilePath(projectName, runUID, podName)
+ logFilePath := s.resolveRunLogFilePath(projectName, runUID)
if err := common.EnsureFileExists(logFilePath); err != nil {
s.Logger.ErrorWithCtx(ctx,
"Failed to ensure log file",
@@ -785,9 +788,9 @@ func (s *Server) streamPodLogs(ctx context.Context,
return true, nil
}
-// resolvePodLogFilePath returns the path to the pod log file
-func (s *Server) resolvePodLogFilePath(projectName, runUID, podName string) string {
- return path.Join(s.baseDir, projectName, fmt.Sprintf("%s_%s", runUID, podName))
+// resolveRunLogFilePath returns the path to the pod log file
+func (s *Server) resolveRunLogFilePath(projectName, runUID string) string {
+ return path.Join(s.baseDir, projectName, runUID)
}
// getLogFilePath returns the path to the run's latest log file
@@ -808,8 +811,6 @@ func (s *Server) getLogFilePath(ctx context.Context, runUID, projectName string)
defer projectMutex.(*sync.Mutex).Unlock()
var logFilePath string
- var latestModTime time.Time
-
var retryCount int
if err := common.RetryUntilSuccessful(5*time.Second, 1*time.Second, func() (bool, error) {
defer func() {
@@ -836,52 +837,29 @@ func (s *Server) getLogFilePath(ctx context.Context, runUID, projectName string)
return false, errors.Wrap(err, "Failed to get project directory")
}
- // list all files in project directory
- if err := filepath.WalkDir(filepath.Join(s.baseDir, projectName),
- func(path string, dirEntry fs.DirEntry, err error) error {
- if err != nil {
- s.Logger.WarnWithCtx(ctx,
- "Failed to walk path",
- "retryCount", retryCount,
- "path", path,
- "err", errors.GetErrorStackString(err, 10))
- return errors.Wrapf(err, "Failed to walk path %s", path)
- }
-
- // skip directories
- if dirEntry.IsDir() {
- return nil
- }
-
- // if file name starts with run id, it's a log file
- if strings.HasPrefix(dirEntry.Name(), runUID) {
- info, err := dirEntry.Info()
- if err != nil {
- return errors.Wrapf(err, "Failed to get file info for %s", path)
- }
-
- // if it's the first file, set it as the log file path
- // otherwise, check if it's the latest modified file
- if logFilePath == "" || info.ModTime().After(latestModTime) {
- logFilePath = path
- latestModTime = info.ModTime()
- }
- }
-
- return nil
- }); err != nil {
+ // get run log file path
+ runLogFilePath := s.resolveRunLogFilePath(projectName, runUID)
- // retry
- return true, errors.Wrap(err, "Failed to list files in base directory")
- }
-
- if logFilePath == "" {
- return true, errors.Errorf("Log file not found for run %s", runUID)
+ if exists, err := common.FileExists(runLogFilePath); err != nil {
+ s.Logger.WarnWithCtx(ctx,
+ "Failed to get run log file path",
+ "retryCount", retryCount,
+ "runUID", runUID,
+ "projectName", projectName,
+ "err", err.Error())
+ return false, errors.Wrap(err, "Failed to get project directory")
+ } else if !exists {
+ s.Logger.WarnWithCtx(ctx,
+ "Run log file not found",
+ "retryCount", retryCount,
+ "runUID", runUID,
+ "projectName", projectName)
+ return true, errors.New("Run log file not found")
}
- // found log file
+ // found it
+ logFilePath = runLogFilePath
return false, nil
-
}); err != nil {
return "", errors.Wrap(err, "Exhausted getting log file path")
}
@@ -1108,7 +1086,7 @@ func (s *Server) successfulBaseResponse() *protologcollector.BaseResponse {
func (s *Server) deleteRunLogFiles(ctx context.Context, runUID, project string) error {
// get all files that have the runUID as a prefix
- pattern := path.Join(s.baseDir, project, fmt.Sprintf("%s_*", runUID))
+ pattern := path.Join(s.baseDir, project, runUID)
files, err := filepath.Glob(pattern)
if err != nil {
return errors.Wrap(err, "Failed to get log files")
diff --git a/mlrun/api/crud/logs.py b/mlrun/api/crud/logs.py
index ab3e639883d1..20a9a3e19359 100644
--- a/mlrun/api/crud/logs.py
+++ b/mlrun/api/crud/logs.py
@@ -244,10 +244,7 @@ def get_log_mtime(self, project: str, uid: str) -> int:
def log_file_exists_for_run_uid(project: str, uid: str) -> (bool, pathlib.Path):
"""
Checks if the log file exists for the given project and uid
- There could be two types of log files:
- 1. Log file which was created by the legacy logger with the following file format - project/)
- 2. Log file which was created by the new logger with the following file format- /project/-
- Therefore, we check if the log file exists for both formats
+ A Run's log file path is: /mlrun/logs/{project}/{uid}
:param project: project name
:param uid: run uid
:return: True if the log file exists, False otherwise, and the log file path
@@ -255,9 +252,10 @@ def log_file_exists_for_run_uid(project: str, uid: str) -> (bool, pathlib.Path):
project_logs_dir = project_logs_path(project)
if not project_logs_dir.exists():
return False, None
- for file in os.listdir(str(project_logs_dir)):
- if file.startswith(uid):
- return True, project_logs_dir / file
+
+ log_file = log_path(project, uid)
+ if log_file.exists():
+ return True, log_file
return False, None
diff --git a/mlrun/api/utils/clients/log_collector.py b/mlrun/api/utils/clients/log_collector.py
index c6c90a310fbc..8c6576c19f9d 100644
--- a/mlrun/api/utils/clients/log_collector.py
+++ b/mlrun/api/utils/clients/log_collector.py
@@ -152,6 +152,11 @@ async def get_logs(
try:
has_logs = await self.has_logs(run_uid, project, verbose, raise_on_error)
if not has_logs:
+ logger.debug(
+ "Run has no logs to collect",
+ run_uid=run_uid,
+ project=project,
+ )
# run has no logs - return empty logs and exit so caller won't wait for logs or retry
yield b""
From 1b0c54a0ef8a0f28ca71bdd8fd58f5ea73340c33 Mon Sep 17 00:00:00 2001
From: Yael Genish <62285310+yaelgen@users.noreply.github.com>
Date: Thu, 25 May 2023 22:31:24 +0300
Subject: [PATCH 197/334] [Function] Fix deleting a function with schedule
(#3642)
---
mlrun/api/db/sqldb/db.py | 11 +++++++++++
tests/api/db/test_functions.py | 30 ++++++++++++++++++++++++++++++
2 files changed, 41 insertions(+)
diff --git a/mlrun/api/db/sqldb/db.py b/mlrun/api/db/sqldb/db.py
index 264766427a08..40d844d368e3 100644
--- a/mlrun/api/db/sqldb/db.py
+++ b/mlrun/api/db/sqldb/db.py
@@ -1056,6 +1056,7 @@ def delete_function(self, session: Session, project: str, name: str):
# deleting tags and labels, because in sqlite the relationships aren't necessarily cascading
self._delete_function_tags(session, project, name, commit=False)
+ self._delete_function_schedules(session, project, name)
self._delete_class_labels(
session, Function, project=project, name=name, commit=False
)
@@ -1140,6 +1141,16 @@ def _delete_function_tags(self, session, project, function_name, commit=True):
if commit:
session.commit()
+ def _delete_function_schedules(self, session, project, function_name, commit=True):
+ try:
+ self.delete_schedule(session=session, project=project, name=function_name)
+ except mlrun.errors.MLRunNotFoundError:
+ logger.info(
+ "No schedules were found for function",
+ project=project,
+ function=function_name,
+ )
+
def _list_function_tags(self, session, project, function_id):
query = (
session.query(Function.Tag.name)
diff --git a/tests/api/db/test_functions.py b/tests/api/db/test_functions.py
index 1f1e8bb15466..adce32a47449 100644
--- a/tests/api/db/test_functions.py
+++ b/tests/api/db/test_functions.py
@@ -100,6 +100,36 @@ def test_store_function_not_versioned(db: DBInterface, db_session: Session):
assert len(functions) == 1
+def test_delete_schedule_when_deleting_function(db: DBInterface, db_session: Session):
+ project_name, func_name = "project", "function"
+ func = _generate_function()
+
+ db.store_function(db_session, func.to_dict(), func.metadata.name, versioned=True)
+
+ # creating a schedule for the created function
+ db.create_schedule(
+ db_session,
+ project=project_name,
+ name=func_name,
+ kind=mlrun.common.schemas.ScheduleKinds.local_function,
+ scheduled_object="*/15 * * * *",
+ cron_trigger=mlrun.common.schemas.ScheduleCronTrigger(minute="*/15"),
+ concurrency_limit=15,
+ )
+
+ # get the schedule and make sure it was created
+ schedule = db.get_schedule(session=db_session, project=project_name, name=func_name)
+ assert schedule.name == func_name
+
+ db.delete_function(session=db_session, project=project_name, name=func_name)
+
+ # ensure that both the function and the schedule have been removed
+ with pytest.raises(mlrun.errors.MLRunNotFoundError):
+ db.get_function(session=db_session, project=project_name, name=func_name)
+ with pytest.raises(mlrun.errors.MLRunNotFoundError):
+ db.get_schedule(session=db_session, project=project_name, name=func_name)
+
+
def test_get_function_by_hash_key(db: DBInterface, db_session: Session):
function_1 = _generate_function()
function_hash_key = db.store_function(
From a20bd5fe287fc59e5178cf745d25ea50f0006972 Mon Sep 17 00:00:00 2001
From: Eyal Danieli
Date: Fri, 26 May 2023 11:37:42 +0300
Subject: [PATCH 198/334] [Model Monitoring] Fix deployment of monitoring V3IO
stream (#3641)
---
mlrun/api/api/endpoints/functions.py | 15 +++++++--------
1 file changed, 7 insertions(+), 8 deletions(-)
diff --git a/mlrun/api/api/endpoints/functions.py b/mlrun/api/api/endpoints/functions.py
index 97ed1cd665c3..d4e1bab49617 100644
--- a/mlrun/api/api/endpoints/functions.py
+++ b/mlrun/api/api/endpoints/functions.py
@@ -490,7 +490,6 @@ def _handle_job_deploy_status(
if (logs and state != "pending") or state in terminal_states:
resp = mlrun.api.utils.singletons.k8s.get_k8s_helper(silent=False).logs(pod)
if state in terminal_states:
-
# TODO: move to log collector
log_file.parent.mkdir(parents=True, exist_ok=True)
with log_file.open("wb") as fp:
@@ -653,13 +652,17 @@ def _build_function(
fn.metadata.project,
mlrun.common.model_monitoring.ProjectSecretKeys.ACCESS_KEY,
)
- if mlrun.utils.model_monitoring.get_stream_path(
+
+ stream_path = mlrun.utils.model_monitoring.get_stream_path(
project=fn.metadata.project
- ).startswith("v3io://"):
+ )
+
+ if stream_path.startswith("v3io://"):
# Initialize model monitoring V3IO stream
_create_model_monitoring_stream(
project=fn.metadata.project,
function=fn,
+ stream_path=stream_path,
)
if fn.spec.tracking_policy:
@@ -832,13 +835,9 @@ async def _get_function_status(data, auth_info: mlrun.common.schemas.AuthInfo):
)
-def _create_model_monitoring_stream(project: str, function):
+def _create_model_monitoring_stream(project: str, function, stream_path):
_init_serving_function_stream_args(fn=function)
- stream_path = mlrun.mlconf.get_model_monitoring_file_target_path(
- project=project, kind="events"
- )
-
_, container, stream_path = parse_model_endpoint_store_prefix(stream_path)
# TODO: How should we configure sharding here?
From 9f86d76b8932f88384ca0a9efb9e4b0b9fe29575 Mon Sep 17 00:00:00 2001
From: Tom Tankilevitch <59158507+Tankilevitch@users.noreply.github.com>
Date: Sun, 28 May 2023 16:16:35 +0300
Subject: [PATCH 199/334] [CI] Add condition to run periodic re-build only on
`mlrun/mlrun` repo (#3651)
---
.github/workflows/periodic-rebuild.yaml | 2 ++
1 file changed, 2 insertions(+)
diff --git a/.github/workflows/periodic-rebuild.yaml b/.github/workflows/periodic-rebuild.yaml
index 8ef39ea5ad1a..300bf1d2f726 100644
--- a/.github/workflows/periodic-rebuild.yaml
+++ b/.github/workflows/periodic-rebuild.yaml
@@ -21,6 +21,8 @@ on:
jobs:
re-build-images:
+ # let's not run this on every fork, change to your fork when developing
+ if: github.repository == 'mlrun/mlrun' || github.event_name == 'workflow_dispatch'
strategy:
fail-fast: false
matrix:
From 50d2733992a7a05f14d10defecd376dcf04876d3 Mon Sep 17 00:00:00 2001
From: TomerShor <90552140+TomerShor@users.noreply.github.com>
Date: Sun, 28 May 2023 17:04:59 +0300
Subject: [PATCH 200/334] [Build] Install requirements using `pip --upgrade`
(#3652)
---
mlrun/api/crud/runtimes/nuclio/function.py | 4 +++-
mlrun/api/utils/builder.py | 2 +-
tests/api/runtimes/test_nuclio.py | 21 ++++++++++++++-------
3 files changed, 18 insertions(+), 9 deletions(-)
diff --git a/mlrun/api/crud/runtimes/nuclio/function.py b/mlrun/api/crud/runtimes/nuclio/function.py
index 0588960f388d..1d1b103ac928 100644
--- a/mlrun/api/crud/runtimes/nuclio/function.py
+++ b/mlrun/api/crud/runtimes/nuclio/function.py
@@ -331,7 +331,9 @@ def _resolve_and_set_build_requirements(function, nuclio_spec):
resolved_requirements.append(shlex.quote(requirement))
encoded_requirements = " ".join(resolved_requirements)
- nuclio_spec.cmd.append(f"python -m pip install {encoded_requirements}")
+ nuclio_spec.cmd.append(
+ f"python -m pip install --upgrade {encoded_requirements}"
+ )
def _set_build_params(function, nuclio_spec, builder_env, project, auth_info=None):
diff --git a/mlrun/api/utils/builder.py b/mlrun/api/utils/builder.py
index 1fdeaf905504..641d945c270f 100644
--- a/mlrun/api/utils/builder.py
+++ b/mlrun/api/utils/builder.py
@@ -78,7 +78,7 @@ def make_dockerfile(
dock += (
f"RUN echo 'Installing {requirements_path}...'; cat {requirements_path}\n"
)
- dock += f"RUN python -m pip install -r {requirements_path}\n"
+ dock += f"RUN python -m pip install --upgrade -r {requirements_path}\n"
if extra:
dock += extra
mlrun.utils.logger.debug("Resolved dockerfile", dockfile_contents=dock)
diff --git a/tests/api/runtimes/test_nuclio.py b/tests/api/runtimes/test_nuclio.py
index 31937b7860cc..24617e361dca 100644
--- a/tests/api/runtimes/test_nuclio.py
+++ b/tests/api/runtimes/test_nuclio.py
@@ -667,21 +667,28 @@ def test_deploy_image_with_enrich_registry_prefix(self):
@pytest.mark.parametrize(
"requirements,expected_commands",
[
- (["pandas", "numpy"], ["python -m pip install pandas numpy"]),
+ (["pandas", "numpy"], ["python -m pip install --upgrade pandas numpy"]),
(
["-r requirements.txt", "numpy"],
- ["python -m pip install -r requirements.txt numpy"],
+ ["python -m pip install --upgrade -r requirements.txt numpy"],
+ ),
+ (
+ ["pandas>=1.0.0, <2"],
+ ["python -m pip install --upgrade 'pandas>=1.0.0, <2'"],
+ ),
+ (
+ ["pandas>=1.0.0,<2"],
+ ["python -m pip install --upgrade 'pandas>=1.0.0,<2'"],
),
- (["pandas>=1.0.0, <2"], ["python -m pip install 'pandas>=1.0.0, <2'"]),
- (["pandas>=1.0.0,<2"], ["python -m pip install 'pandas>=1.0.0,<2'"]),
(
["-r somewhere/requirements.txt"],
- ["python -m pip install -r somewhere/requirements.txt"],
+ ["python -m pip install --upgrade -r somewhere/requirements.txt"],
),
(
["something @ git+https://somewhere.com/a/b.git@v0.0.0#egg=something"],
[
- "python -m pip install 'something @ git+https://somewhere.com/a/b.git@v0.0.0#egg=something'"
+ "python -m pip install --upgrade "
+ "'something @ git+https://somewhere.com/a/b.git@v0.0.0#egg=something'"
],
),
],
@@ -709,7 +716,7 @@ def test_deploy_function_with_commands_and_requirements(
self.execute_function(function)
expected_commands = [
"python -m pip install scikit-learn",
- "python -m pip install pandas numpy",
+ "python -m pip install --upgrade pandas numpy",
]
self._assert_deploy_called_basic_config(
expected_class=self.class_name, expected_build_commands=expected_commands
From bfd8b9705b59e75355ed7c106899660a1c9f4706 Mon Sep 17 00:00:00 2001
From: Gal Topper
Date: Sun, 28 May 2023 23:22:18 +0800
Subject: [PATCH 201/334] [Tests] Fix spark merger tests (#3646)
---
.../system/feature_store/test_spark_engine.py | 18 +++++++++---------
1 file changed, 9 insertions(+), 9 deletions(-)
diff --git a/tests/system/feature_store/test_spark_engine.py b/tests/system/feature_store/test_spark_engine.py
index 6c992ec9d6d1..1955d2019ef9 100644
--- a/tests/system/feature_store/test_spark_engine.py
+++ b/tests/system/feature_store/test_spark_engine.py
@@ -1362,7 +1362,7 @@ def test_get_offline_features_with_filter_and_indexes(self, timestamp_key):
target=target,
query="bad>6 and bad<8",
engine="spark",
- run_config=fstore.RunConfig(local=self.run_local),
+ run_config=fstore.RunConfig(local=self.run_local, kind="remote-spark"),
spark_service=self.spark_service,
)
resp_df = resp.to_dataframe()
@@ -1432,7 +1432,7 @@ def test_get_offline_features_with_spark_engine(self, passthrough, target_type):
fv_name,
target=target,
query="bad>6 and bad<8",
- run_config=fstore.RunConfig(local=self.run_local),
+ run_config=fstore.RunConfig(local=self.run_local, kind="remote-spark"),
engine="spark",
spark_service=self.spark_service,
)
@@ -1929,7 +1929,7 @@ def test_relation_join(self, join_type, with_indexes):
vector,
target=target,
with_indexes=with_indexes,
- run_config=fstore.RunConfig(local=self.run_local),
+ run_config=fstore.RunConfig(local=self.run_local, kind="remote-spark"),
engine="spark",
spark_service=self.spark_service,
join_type=join_type,
@@ -1959,7 +1959,7 @@ def test_relation_join(self, join_type, with_indexes):
vector,
target=target,
with_indexes=with_indexes,
- run_config=fstore.RunConfig(local=self.run_local),
+ run_config=fstore.RunConfig(local=self.run_local, kind="remote-spark"),
engine="spark",
spark_service=self.spark_service,
join_type=join_type,
@@ -1985,7 +1985,7 @@ def test_relation_join(self, join_type, with_indexes):
vector,
target=target,
with_indexes=with_indexes,
- run_config=fstore.RunConfig(local=self.run_local),
+ run_config=fstore.RunConfig(local=self.run_local, kind="remote-spark"),
engine="spark",
spark_service=self.spark_service,
join_type=join_type,
@@ -2007,7 +2007,7 @@ def test_relation_join(self, join_type, with_indexes):
vector,
target=target,
with_indexes=with_indexes,
- run_config=fstore.RunConfig(local=self.run_local),
+ run_config=fstore.RunConfig(local=self.run_local, kind="remote-spark"),
engine="spark",
spark_service=self.spark_service,
join_type=join_type,
@@ -2034,7 +2034,7 @@ def test_relation_join(self, join_type, with_indexes):
vector,
target=target,
with_indexes=with_indexes,
- run_config=fstore.RunConfig(local=self.run_local),
+ run_config=fstore.RunConfig(local=self.run_local, kind="remote-spark"),
engine="spark",
spark_service=self.spark_service,
join_type=join_type,
@@ -2117,7 +2117,7 @@ def test_relation_asof_join(self, with_indexes):
vector,
target=target,
with_indexes=with_indexes,
- run_config=fstore.RunConfig(local=self.run_local),
+ run_config=fstore.RunConfig(local=self.run_local, kind="remote-spark"),
engine="spark",
spark_service=self.spark_service,
order_by=["n"],
@@ -2202,7 +2202,7 @@ def test_as_of_join_result(self):
resp = fstore.get_offline_features(
vec_for_spark,
engine="spark",
- run_config=fstore.RunConfig(local=self.run_local),
+ run_config=fstore.RunConfig(local=self.run_local, kind="remote-spark"),
spark_service=self.spark_service,
target=target,
)
From 5e6d70938fbae76af105f5057440ca009f516463 Mon Sep 17 00:00:00 2001
From: Adam
Date: Mon, 29 May 2023 10:20:54 +0300
Subject: [PATCH 202/334] [Notifications] Fix notifications pusher failing to
initialize (#3654)
fix
Co-authored-by: quaark
---
mlrun/utils/notifications/notification_pusher.py | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/mlrun/utils/notifications/notification_pusher.py b/mlrun/utils/notifications/notification_pusher.py
index 8bc2fb85d7e3..06807cecd215 100644
--- a/mlrun/utils/notifications/notification_pusher.py
+++ b/mlrun/utils/notifications/notification_pusher.py
@@ -51,7 +51,7 @@ def __init__(self, runs: typing.Union[mlrun.lists.RunList, list]):
for notification in run.spec.notifications:
notification.status = run.status.notifications.get(
notification.name
- ).status
+ ).get("status", mlrun.common.schemas.NotificationStatus.PENDING)
if self._should_notify(run, notification):
self._notification_data.append((run, notification))
From c4916254c9dd71989a558fcabf3a051055eb5cd1 Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Mon, 29 May 2023 10:22:20 +0300
Subject: [PATCH 203/334] [Run] Write meaningful logs when waiting for pipeline
to finish (#3631)
---
mlrun/run.py | 26 ++++++++++++++------------
1 file changed, 14 insertions(+), 12 deletions(-)
diff --git a/mlrun/run.py b/mlrun/run.py
index d0a711456ffb..569151a294dd 100644
--- a/mlrun/run.py
+++ b/mlrun/run.py
@@ -1141,22 +1141,24 @@ def wait_for_pipeline_completion(
if remote:
mldb = mlrun.db.get_run_db()
- def get_pipeline_if_completed(run_id, namespace=namespace):
- resp = mldb.get_pipeline(run_id, namespace=namespace, project=project)
- status = resp["run"]["status"]
- show_kfp_run(resp, clear_output=True)
- if status not in RunStatuses.stable_statuses():
- # TODO: think of nicer liveness indication and make it re-usable
- # log '.' each retry as a liveness indication
- logger.debug(".")
+ def _wait_for_pipeline_completion():
+ pipeline = mldb.get_pipeline(run_id, namespace=namespace, project=project)
+ pipeline_status = pipeline["run"]["status"]
+ show_kfp_run(pipeline, clear_output=True)
+ if pipeline_status not in RunStatuses.stable_statuses():
+ logger.debug(
+ "Waiting for pipeline completion",
+ run_id=run_id,
+ status=pipeline_status,
+ )
raise RuntimeError("pipeline run has not completed yet")
- return resp
+ return pipeline
if mldb.kind != "http":
raise ValueError(
- "get pipeline require access to remote api-service"
- ", please set the dbpath url"
+ "get pipeline requires access to remote api-service"
+ ", set the dbpath url"
)
resp = retry_until_successful(
@@ -1164,7 +1166,7 @@ def get_pipeline_if_completed(run_id, namespace=namespace):
timeout,
logger,
False,
- get_pipeline_if_completed,
+ _wait_for_pipeline_completion,
run_id,
namespace=namespace,
)
From 1afcb83dee94da5ac513a0dc5aaa8e87843f6d3a Mon Sep 17 00:00:00 2001
From: Eyal Danieli
Date: Mon, 29 May 2023 10:36:23 +0300
Subject: [PATCH 204/334] [Model Monitoring] Fix event error message in
monitoring stream graph (#3639)
---
.../model_monitoring/stream_processing_fs.py | 24 +++++--------------
1 file changed, 6 insertions(+), 18 deletions(-)
diff --git a/mlrun/model_monitoring/stream_processing_fs.py b/mlrun/model_monitoring/stream_processing_fs.py
index 98123b7a738b..fa5ff0d4a253 100644
--- a/mlrun/model_monitoring/stream_processing_fs.py
+++ b/mlrun/model_monitoring/stream_processing_fs.py
@@ -407,7 +407,6 @@ def __init__(self, **kwargs):
super().__init__(**kwargs)
def do(self, event):
-
# Compute prediction per second
event[EventLiveStats.PREDICTIONS_PER_SECOND] = (
float(event[EventLiveStats.PREDICTIONS_COUNT_5M]) / 300
@@ -465,7 +464,6 @@ def __init__(self, **kwargs):
super().__init__(**kwargs)
def do(self, event):
-
# Compute prediction per second
event[EventLiveStats.PREDICTIONS_PER_SECOND] = (
float(event[EventLiveStats.PREDICTIONS_COUNT_5M]) / 300
@@ -535,7 +533,6 @@ def __init__(self, **kwargs):
super().__init__(**kwargs)
def do(self, event):
-
logger.info("ProcessBeforeParquet1", event=event)
# Remove the following keys from the event
for key in [
@@ -621,10 +618,12 @@ def do(self, full_event):
# In case this process fails, resume state from existing record
self.resume_state(endpoint_id)
- # Handle errors coming from stream
- found_errors = self.handle_errors(endpoint_id, event)
- if found_errors:
- return None
+ # If error key has been found in the current event,
+ # increase the error counter by 1 and raise the error description
+ error = event.get("error")
+ if error:
+ self.error_count[endpoint_id] += 1
+ raise mlrun.errors.MLRunInvalidArgumentError(str(error))
# Validate event fields
model_class = event.get("model_class") or event.get("class")
@@ -745,7 +744,6 @@ def _validate_last_request_timestamp(self, endpoint_id: str, timestamp: str):
endpoint_id in self.last_request
and self.last_request[endpoint_id] > timestamp
):
-
logger.error(
f"current event request time {timestamp} is earlier than the last request time "
f"{self.last_request[endpoint_id]} - write to TSDB will be rejected"
@@ -767,7 +765,6 @@ def resume_state(self, endpoint_id):
# Make sure process is resumable, if process fails for any reason, be able to pick things up close to where we
# left them
if endpoint_id not in self.endpoints:
-
logger.info("Trying to resume state", endpoint_id=endpoint_id)
endpoint_record = get_endpoint_record(
project=self.project,
@@ -783,7 +780,6 @@ def resume_state(self, endpoint_id):
last_request = endpoint_record.get(EventFieldType.LAST_REQUEST)
if last_request:
-
self.last_request[endpoint_id] = last_request
error_count = endpoint_record.get(EventFieldType.ERROR_COUNT)
@@ -806,13 +802,6 @@ def is_valid(
self.error_count[endpoint_id] += 1
return False
- def handle_errors(self, endpoint_id, event) -> bool:
- if "error" in event:
- self.error_count[endpoint_id] += 1
- return True
-
- return False
-
def is_not_none(field: typing.Any, dict_path: typing.List[str]):
if field is not None:
@@ -1065,7 +1054,6 @@ def __init__(
self.keys = set()
def do(self, event: typing.Dict):
-
key_set = set(event.keys())
if not key_set.issubset(self.keys):
self.keys.update(key_set)
From bdba955656082211a1b80f25bedb47159fde563a Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Mon, 29 May 2023 13:44:36 +0300
Subject: [PATCH 205/334] [System test] Fix access to relative path (#3655)
---
tests/system/projects/test_project.py | 6 ++++++
1 file changed, 6 insertions(+)
diff --git a/tests/system/projects/test_project.py b/tests/system/projects/test_project.py
index 86021beceb67..704de3548a7d 100644
--- a/tests/system/projects/test_project.py
+++ b/tests/system/projects/test_project.py
@@ -517,6 +517,12 @@ def test_remote_from_archive(self):
def test_kfp_from_local_code(self):
name = "kfp-from-local-code"
self.custom_project_names_to_delete.append(name)
+
+ # change cwd to the current file's dir to make sure the handler file is found
+ current_file_abspath = os.path.abspath(__file__)
+ current_dirname = os.path.dirname(current_file_abspath)
+ os.chdir(current_dirname)
+
project = mlrun.get_or_create_project(name, user_project=True, context="./")
handler_fn = project.set_function(
From a1151c2971561e2ced139213d20ccda8710ca102 Mon Sep 17 00:00:00 2001
From: Yan Burman
Date: Mon, 29 May 2023 13:52:09 +0300
Subject: [PATCH 206/334] [API] Use APIRouter prefix where possible (#3615)
---
mlrun/api/api/endpoints/feature_store.py | 46 ++++++++-----------
mlrun/api/api/endpoints/grafana_proxy.py | 8 ++--
mlrun/api/api/endpoints/hub.py | 20 ++++----
.../api/endpoints/internal/memory_reports.py | 6 +--
mlrun/api/api/endpoints/logs.py | 6 +--
mlrun/api/api/endpoints/model_endpoints.py | 14 +++---
mlrun/api/api/endpoints/pipelines.py | 10 ++--
mlrun/api/api/endpoints/runtime_resources.py | 6 +--
mlrun/api/api/endpoints/schedules.py | 20 ++++----
mlrun/api/api/endpoints/tags.py | 10 ++--
10 files changed, 66 insertions(+), 80 deletions(-)
diff --git a/mlrun/api/api/endpoints/feature_store.py b/mlrun/api/api/endpoints/feature_store.py
index dd3237cd1b8e..1c5c3f3849b9 100644
--- a/mlrun/api/api/endpoints/feature_store.py
+++ b/mlrun/api/api/endpoints/feature_store.py
@@ -34,12 +34,10 @@
from mlrun.feature_store.api import RunConfig, ingest
from mlrun.model import DataSource, DataTargetBase
-router = APIRouter()
+router = APIRouter(prefix="/projects/{project}")
-@router.post(
- "/projects/{project}/feature-sets", response_model=mlrun.common.schemas.FeatureSet
-)
+@router.post("/feature-sets", response_model=mlrun.common.schemas.FeatureSet)
async def create_feature_set(
project: str,
feature_set: mlrun.common.schemas.FeatureSet,
@@ -79,7 +77,7 @@ async def create_feature_set(
@router.put(
- "/projects/{project}/feature-sets/{name}/references/{reference}",
+ "/feature-sets/{name}/references/{reference}",
response_model=mlrun.common.schemas.FeatureSet,
)
async def store_feature_set(
@@ -125,7 +123,7 @@ async def store_feature_set(
)
-@router.patch("/projects/{project}/feature-sets/{name}/references/{reference}")
+@router.patch("/feature-sets/{name}/references/{reference}")
async def patch_feature_set(
project: str,
name: str,
@@ -160,7 +158,7 @@ async def patch_feature_set(
@router.get(
- "/projects/{project}/feature-sets/{name}/references/{reference}",
+ "/feature-sets/{name}/references/{reference}",
response_model=mlrun.common.schemas.FeatureSet,
)
async def get_feature_set(
@@ -189,8 +187,8 @@ async def get_feature_set(
return feature_set
-@router.delete("/projects/{project}/feature-sets/{name}")
-@router.delete("/projects/{project}/feature-sets/{name}/references/{reference}")
+@router.delete("/feature-sets/{name}")
+@router.delete("/feature-sets/{name}/references/{reference}")
async def delete_feature_set(
project: str,
name: str,
@@ -220,7 +218,7 @@ async def delete_feature_set(
@router.get(
- "/projects/{project}/feature-sets",
+ "/feature-sets",
response_model=mlrun.common.schemas.FeatureSetsOutput,
)
async def list_feature_sets(
@@ -277,7 +275,7 @@ async def list_feature_sets(
@router.get(
- "/projects/{project}/feature-sets/{name}/tags",
+ "/feature-sets/{name}/tags",
response_model=mlrun.common.schemas.FeatureSetsTagsOutput,
)
async def list_feature_sets_tags(
@@ -347,7 +345,7 @@ def _has_v3io_path(data_source, data_targets, feature_set):
@router.post(
- "/projects/{project}/feature-sets/{name}/references/{reference}/ingest",
+ "/feature-sets/{name}/references/{reference}/ingest",
response_model=mlrun.common.schemas.FeatureSetIngestOutput,
status_code=HTTPStatus.ACCEPTED.value,
)
@@ -459,9 +457,7 @@ async def ingest_feature_set(
)
-@router.get(
- "/projects/{project}/features", response_model=mlrun.common.schemas.FeaturesOutput
-)
+@router.get("/features", response_model=mlrun.common.schemas.FeaturesOutput)
async def list_features(
project: str,
name: str = None,
@@ -497,9 +493,7 @@ async def list_features(
return mlrun.common.schemas.FeaturesOutput(features=features)
-@router.get(
- "/projects/{project}/entities", response_model=mlrun.common.schemas.EntitiesOutput
-)
+@router.get("/entities", response_model=mlrun.common.schemas.EntitiesOutput)
async def list_entities(
project: str,
name: str = None,
@@ -534,7 +528,7 @@ async def list_entities(
@router.post(
- "/projects/{project}/feature-vectors",
+ "/feature-vectors",
response_model=mlrun.common.schemas.FeatureVector,
)
async def create_feature_vector(
@@ -579,7 +573,7 @@ async def create_feature_vector(
@router.get(
- "/projects/{project}/feature-vectors/{name}/references/{reference}",
+ "/feature-vectors/{name}/references/{reference}",
response_model=mlrun.common.schemas.FeatureVector,
)
async def get_feature_vector(
@@ -612,7 +606,7 @@ async def get_feature_vector(
@router.get(
- "/projects/{project}/feature-vectors",
+ "/feature-vectors",
response_model=mlrun.common.schemas.FeatureVectorsOutput,
)
async def list_feature_vectors(
@@ -671,7 +665,7 @@ async def list_feature_vectors(
@router.get(
- "/projects/{project}/feature-vectors/{name}/tags",
+ "/feature-vectors/{name}/tags",
response_model=mlrun.common.schemas.FeatureVectorsTagsOutput,
)
async def list_feature_vectors_tags(
@@ -718,7 +712,7 @@ async def list_feature_vectors_tags(
@router.put(
- "/projects/{project}/feature-vectors/{name}/references/{reference}",
+ "/feature-vectors/{name}/references/{reference}",
response_model=mlrun.common.schemas.FeatureVector,
)
async def store_feature_vector(
@@ -768,7 +762,7 @@ async def store_feature_vector(
)
-@router.patch("/projects/{project}/feature-vectors/{name}/references/{reference}")
+@router.patch("/feature-vectors/{name}/references/{reference}")
async def patch_feature_vector(
project: str,
name: str,
@@ -805,8 +799,8 @@ async def patch_feature_vector(
return Response(status_code=HTTPStatus.OK.value)
-@router.delete("/projects/{project}/feature-vectors/{name}")
-@router.delete("/projects/{project}/feature-vectors/{name}/references/{reference}")
+@router.delete("/feature-vectors/{name}")
+@router.delete("/feature-vectors/{name}/references/{reference}")
async def delete_feature_vector(
project: str,
name: str,
diff --git a/mlrun/api/api/endpoints/grafana_proxy.py b/mlrun/api/api/endpoints/grafana_proxy.py
index a17717830873..bc6bd44e0142 100644
--- a/mlrun/api/api/endpoints/grafana_proxy.py
+++ b/mlrun/api/api/endpoints/grafana_proxy.py
@@ -28,7 +28,7 @@
import mlrun.common.schemas
from mlrun.api.api import deps
-router = APIRouter()
+router = APIRouter(prefix="/grafana-proxy/model-endpoints")
NAME_TO_SEARCH_FUNCTION_DICTIONARY = {
"list_projects": mlrun.api.crud.model_monitoring.grafana.grafana_list_projects,
@@ -44,7 +44,7 @@
SUPPORTED_SEARCH_FUNCTIONS = set(NAME_TO_SEARCH_FUNCTION_DICTIONARY)
-@router.get("/grafana-proxy/model-endpoints", status_code=HTTPStatus.OK.value)
+@router.get("", status_code=HTTPStatus.OK.value)
def grafana_proxy_model_endpoints_check_connection(
auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
):
@@ -57,7 +57,7 @@ def grafana_proxy_model_endpoints_check_connection(
return Response(status_code=HTTPStatus.OK.value)
-@router.post("/grafana-proxy/model-endpoints/search", response_model=List[str])
+@router.post("/search", response_model=List[str])
async def grafana_proxy_model_endpoints_search(
request: Request,
auth_info: mlrun.common.schemas.AuthInfo = Depends(deps.authenticate_request),
@@ -101,7 +101,7 @@ async def grafana_proxy_model_endpoints_search(
@router.post(
- "/grafana-proxy/model-endpoints/query",
+ "/query",
response_model=List[
Union[
mlrun.common.schemas.GrafanaTable,
diff --git a/mlrun/api/api/endpoints/hub.py b/mlrun/api/api/endpoints/hub.py
index 05ca5ae3a03e..91e5bbc80456 100644
--- a/mlrun/api/api/endpoints/hub.py
+++ b/mlrun/api/api/endpoints/hub.py
@@ -29,11 +29,11 @@
import mlrun.common.schemas
import mlrun.common.schemas.hub
-router = APIRouter()
+router = APIRouter(prefix="/hub/sources")
@router.post(
- path="/hub/sources",
+ path="",
status_code=HTTPStatus.CREATED.value,
response_model=mlrun.common.schemas.hub.IndexedHubSource,
)
@@ -63,7 +63,7 @@ async def create_source(
@router.get(
- path="/hub/sources",
+ path="",
response_model=List[mlrun.common.schemas.hub.IndexedHubSource],
)
async def list_sources(
@@ -84,7 +84,7 @@ async def list_sources(
@router.delete(
- path="/hub/sources/{source_name}",
+ path="/{source_name}",
status_code=HTTPStatus.NO_CONTENT.value,
)
async def delete_source(
@@ -109,7 +109,7 @@ async def delete_source(
@router.get(
- path="/hub/sources/{source_name}",
+ path="/{source_name}",
response_model=mlrun.common.schemas.hub.IndexedHubSource,
)
async def get_source(
@@ -132,7 +132,7 @@ async def get_source(
@router.put(
- path="/hub/sources/{source_name}",
+ path="/{source_name}",
response_model=mlrun.common.schemas.hub.IndexedHubSource,
)
async def store_source(
@@ -164,7 +164,7 @@ async def store_source(
@router.get(
- path="/hub/sources/{source_name}/items",
+ path="/{source_name}/items",
response_model=mlrun.common.schemas.hub.HubCatalog,
)
async def get_catalog(
@@ -196,7 +196,7 @@ async def get_catalog(
@router.get(
- "/hub/sources/{source_name}/items/{item_name}",
+ "/{source_name}/items/{item_name}",
response_model=mlrun.common.schemas.hub.HubItem,
)
async def get_item(
@@ -230,7 +230,7 @@ async def get_item(
@router.get(
- "/hub/sources/{source_name}/item-object",
+ "/{source_name}/item-object",
)
async def get_object(
source_name: str,
@@ -263,7 +263,7 @@ async def get_object(
return Response(content=object_data, media_type=ctype)
-@router.get("/hub/sources/{source_name}/items/{item_name}/assets/{asset_name}")
+@router.get("/{source_name}/items/{item_name}/assets/{asset_name}")
async def get_asset(
source_name: str,
item_name: str,
diff --git a/mlrun/api/api/endpoints/internal/memory_reports.py b/mlrun/api/api/endpoints/internal/memory_reports.py
index 0bd0df581bbb..9ba58c71f8b5 100644
--- a/mlrun/api/api/endpoints/internal/memory_reports.py
+++ b/mlrun/api/api/endpoints/internal/memory_reports.py
@@ -17,11 +17,11 @@
import mlrun.api.utils.memory_reports
import mlrun.common.schemas
-router = fastapi.APIRouter()
+router = fastapi.APIRouter(prefix="/memory-reports")
@router.get(
- "/memory-reports/common-types",
+ "/common-types",
response_model=mlrun.common.schemas.MostCommonObjectTypesReport,
)
def get_most_common_objects_report():
@@ -32,7 +32,7 @@ def get_most_common_objects_report():
@router.get(
- "/memory-reports/{object_type}",
+ "/{object_type}",
response_model=mlrun.common.schemas.ObjectTypeReport,
)
def get_memory_usage_report(
diff --git a/mlrun/api/api/endpoints/logs.py b/mlrun/api/api/endpoints/logs.py
index 8dc0b72dbd9c..3a0df343ac80 100644
--- a/mlrun/api/api/endpoints/logs.py
+++ b/mlrun/api/api/endpoints/logs.py
@@ -21,10 +21,10 @@
import mlrun.api.utils.auth.verifier
import mlrun.common.schemas
-router = fastapi.APIRouter()
+router = fastapi.APIRouter(prefix="/log/{project}")
-@router.post("/log/{project}/{uid}")
+@router.post("/{uid}")
async def store_log(
request: fastapi.Request,
project: str,
@@ -52,7 +52,7 @@ async def store_log(
return {}
-@router.get("/log/{project}/{uid}")
+@router.get("/{uid}")
async def get_log(
project: str,
uid: str,
diff --git a/mlrun/api/api/endpoints/model_endpoints.py b/mlrun/api/api/endpoints/model_endpoints.py
index 6359b1aaa2f9..567c17815cc1 100644
--- a/mlrun/api/api/endpoints/model_endpoints.py
+++ b/mlrun/api/api/endpoints/model_endpoints.py
@@ -28,11 +28,11 @@
import mlrun.common.schemas
from mlrun.errors import MLRunConflictError
-router = APIRouter()
+router = APIRouter(prefix="/projects/{project}/model-endpoints")
@router.put(
- "/projects/{project}/model-endpoints/{endpoint_id}",
+ "/{endpoint_id}",
response_model=mlrun.common.schemas.ModelEndpoint,
)
async def create_or_patch(
@@ -86,7 +86,7 @@ async def create_or_patch(
@router.post(
- "/projects/{project}/model-endpoints/{endpoint_id}",
+ "/{endpoint_id}",
response_model=mlrun.common.schemas.ModelEndpoint,
)
async def create_model_endpoint(
@@ -138,7 +138,7 @@ async def create_model_endpoint(
@router.patch(
- "/projects/{project}/model-endpoints/{endpoint_id}",
+ "/{endpoint_id}",
response_model=mlrun.common.schemas.ModelEndpoint,
)
async def patch_model_endpoint(
@@ -188,7 +188,7 @@ async def patch_model_endpoint(
@router.delete(
- "/projects/{project}/model-endpoints/{endpoint_id}",
+ "/{endpoint_id}",
status_code=HTTPStatus.NO_CONTENT.value,
)
async def delete_model_endpoint(
@@ -223,7 +223,7 @@ async def delete_model_endpoint(
@router.get(
- "/projects/{project}/model-endpoints",
+ "",
response_model=mlrun.common.schemas.ModelEndpointList,
)
async def list_model_endpoints(
@@ -316,7 +316,7 @@ async def list_model_endpoints(
@router.get(
- "/projects/{project}/model-endpoints/{endpoint_id}",
+ "/{endpoint_id}",
response_model=mlrun.common.schemas.ModelEndpoint,
)
async def get_model_endpoint(
diff --git a/mlrun/api/api/endpoints/pipelines.py b/mlrun/api/api/endpoints/pipelines.py
index ada697101fab..d9d44a0e0d86 100644
--- a/mlrun/api/api/endpoints/pipelines.py
+++ b/mlrun/api/api/endpoints/pipelines.py
@@ -32,12 +32,10 @@
from mlrun.config import config
from mlrun.utils import logger
-router = APIRouter()
+router = APIRouter(prefix="/projects/{project}/pipelines")
-@router.get(
- "/projects/{project}/pipelines", response_model=mlrun.common.schemas.PipelinesOutput
-)
+@router.get("", response_model=mlrun.common.schemas.PipelinesOutput)
async def list_pipelines(
project: str,
namespace: str = None,
@@ -101,7 +99,7 @@ async def list_pipelines(
)
-@router.post("/projects/{project}/pipelines")
+@router.post("")
async def create_pipeline(
project: str,
request: Request,
@@ -200,7 +198,7 @@ def _try_resolve_project_from_body(
)
-@router.get("/projects/{project}/pipelines/{run_id}")
+@router.get("/{run_id}")
async def get_pipeline(
run_id: str,
project: str,
diff --git a/mlrun/api/api/endpoints/runtime_resources.py b/mlrun/api/api/endpoints/runtime_resources.py
index 91f41822d86f..3586e9ee406f 100644
--- a/mlrun/api/api/endpoints/runtime_resources.py
+++ b/mlrun/api/api/endpoints/runtime_resources.py
@@ -26,11 +26,11 @@
import mlrun.api.utils.auth.verifier
import mlrun.common.schemas
-router = fastapi.APIRouter()
+router = fastapi.APIRouter(prefix="/projects/{project}/runtime-resources")
@router.get(
- "/projects/{project}/runtime-resources",
+ "",
response_model=typing.Union[
mlrun.common.schemas.RuntimeResourcesOutput,
mlrun.common.schemas.GroupedByJobRuntimeResourcesOutput,
@@ -55,7 +55,7 @@ async def list_runtime_resources(
@router.delete(
- "/projects/{project}/runtime-resources",
+ "",
response_model=mlrun.common.schemas.GroupedByProjectRuntimeResourcesOutput,
)
async def delete_runtime_resources(
diff --git a/mlrun/api/api/endpoints/schedules.py b/mlrun/api/api/endpoints/schedules.py
index 019585771cbc..61c30d1467a5 100644
--- a/mlrun/api/api/endpoints/schedules.py
+++ b/mlrun/api/api/endpoints/schedules.py
@@ -28,10 +28,10 @@
from mlrun.api.utils.singletons.scheduler import get_scheduler
from mlrun.utils import logger
-router = APIRouter()
+router = APIRouter(prefix="/projects/{project}/schedules")
-@router.post("/projects/{project}/schedules")
+@router.post("")
async def create_schedule(
project: str,
schedule: mlrun.common.schemas.ScheduleInput,
@@ -86,7 +86,7 @@ async def create_schedule(
return Response(status_code=HTTPStatus.CREATED.value)
-@router.put("/projects/{project}/schedules/{name}")
+@router.put("/{name}")
async def update_schedule(
project: str,
name: str,
@@ -136,9 +136,7 @@ async def update_schedule(
return Response(status_code=HTTPStatus.OK.value)
-@router.get(
- "/projects/{project}/schedules", response_model=mlrun.common.schemas.SchedulesOutput
-)
+@router.get("", response_model=mlrun.common.schemas.SchedulesOutput)
async def list_schedules(
project: str,
name: str = None,
@@ -178,7 +176,7 @@ async def list_schedules(
@router.get(
- "/projects/{project}/schedules/{name}",
+ "/{name}",
response_model=mlrun.common.schemas.ScheduleOutput,
)
async def get_schedule(
@@ -207,7 +205,7 @@ async def get_schedule(
return schedule
-@router.post("/projects/{project}/schedules/{name}/invoke")
+@router.post("/{name}/invoke")
async def invoke_schedule(
project: str,
name: str,
@@ -240,9 +238,7 @@ async def invoke_schedule(
return await get_scheduler().invoke_schedule(db_session, auth_info, project, name)
-@router.delete(
- "/projects/{project}/schedules/{name}", status_code=HTTPStatus.NO_CONTENT.value
-)
+@router.delete("/{name}", status_code=HTTPStatus.NO_CONTENT.value)
async def delete_schedule(
project: str,
name: str,
@@ -276,7 +272,7 @@ async def delete_schedule(
return Response(status_code=HTTPStatus.NO_CONTENT.value)
-@router.delete("/projects/{project}/schedules", status_code=HTTPStatus.NO_CONTENT.value)
+@router.delete("", status_code=HTTPStatus.NO_CONTENT.value)
async def delete_schedules(
project: str,
request: fastapi.Request,
diff --git a/mlrun/api/api/endpoints/tags.py b/mlrun/api/api/endpoints/tags.py
index 342af3aa4cb7..a625955954ac 100644
--- a/mlrun/api/api/endpoints/tags.py
+++ b/mlrun/api/api/endpoints/tags.py
@@ -25,10 +25,10 @@
import mlrun.common.schemas
from mlrun.utils.helpers import tag_name_regex_as_string
-router = fastapi.APIRouter()
+router = fastapi.APIRouter(prefix="/projects/{project}/tags")
-@router.post("/projects/{project}/tags/{tag}", response_model=mlrun.common.schemas.Tag)
+@router.post("/{tag}", response_model=mlrun.common.schemas.Tag)
async def overwrite_object_tags_with_tag(
project: str,
tag: str = fastapi.Path(..., regex=tag_name_regex_as_string()),
@@ -67,7 +67,7 @@ async def overwrite_object_tags_with_tag(
return mlrun.common.schemas.Tag(name=tag, project=project)
-@router.put("/projects/{project}/tags/{tag}", response_model=mlrun.common.schemas.Tag)
+@router.put("/{tag}", response_model=mlrun.common.schemas.Tag)
async def append_tag_to_objects(
project: str,
tag: str = fastapi.Path(..., regex=tag_name_regex_as_string()),
@@ -104,9 +104,7 @@ async def append_tag_to_objects(
return mlrun.common.schemas.Tag(name=tag, project=project)
-@router.delete(
- "/projects/{project}/tags/{tag}", status_code=http.HTTPStatus.NO_CONTENT.value
-)
+@router.delete("/{tag}", status_code=http.HTTPStatus.NO_CONTENT.value)
async def delete_tag_from_objects(
project: str,
tag: str,
From 83022b572e6ab12717f9447e57fd680374be3dde Mon Sep 17 00:00:00 2001
From: Yan Burman
Date: Mon, 29 May 2023 13:52:54 +0300
Subject: [PATCH 207/334] [API] Fix get pipelines return code in case of
nonexistent project (#3625)
---
mlrun/api/crud/pipelines.py | 5 +++--
tests/api/api/test_pipelines.py | 16 ++++++++++++++++
2 files changed, 19 insertions(+), 2 deletions(-)
diff --git a/mlrun/api/crud/pipelines.py b/mlrun/api/crud/pipelines.py
index 26f5a5e34ece..b5f39b2fefd8 100644
--- a/mlrun/api/crud/pipelines.py
+++ b/mlrun/api/crud/pipelines.py
@@ -123,13 +123,14 @@ def get_pipeline(
if project and project != "*":
run_project = self.resolve_project_from_pipeline(run)
if run_project != project:
- raise mlrun.errors.MLRunInvalidArgumentError(
+ raise mlrun.errors.MLRunNotFoundError(
f"Pipeline run with id {run_id} is not of project {project}"
)
run = self._format_run(
db_session, run, format_, api_run_detail.to_dict()
)
-
+ except mlrun.errors.MLRunHTTPStatusError:
+ raise
except Exception as exc:
raise mlrun.errors.MLRunRuntimeError(
f"Failed getting kfp run: {err_to_str(exc)}"
diff --git a/tests/api/api/test_pipelines.py b/tests/api/api/test_pipelines.py
index c77e23e7bdb5..1b634ffe49a2 100644
--- a/tests/api/api/test_pipelines.py
+++ b/tests/api/api/test_pipelines.py
@@ -231,6 +231,22 @@ def _generate_get_run_mock() -> kfp_server_api.models.api_run_detail.ApiRunDetai
)
+def test_get_pipeline_nonexistent_project(
+ db: sqlalchemy.orm.Session,
+ client: fastapi.testclient.TestClient,
+ kfp_client_mock: kfp.Client,
+) -> None:
+ format_ = (mlrun.common.schemas.PipelinesFormat.summary,)
+ project = "n0_pr0ject"
+ api_run_detail = _generate_get_run_mock()
+ _mock_get_run(kfp_client_mock, api_run_detail)
+ response = client.get(
+ f"projects/{project}/pipelines/{api_run_detail.run.id}",
+ params={"format": format_},
+ )
+ assert response.status_code == http.HTTPStatus.NOT_FOUND.value
+
+
def _generate_list_runs_mocks():
workflow_manifest = _generate_workflow_manifest()
return [
From 729b30200c9c7e156527a2a9a2a6ebf92d6fc454 Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Mon, 29 May 2023 22:50:54 +0300
Subject: [PATCH 208/334] [CI] Show run names (#3658)
---
.github/workflows/build.yaml | 2 ++
.github/workflows/release.yaml | 2 ++
.github/workflows/security_scan.yaml | 1 +
.github/workflows/system-tests-enterprise.yml | 2 +-
4 files changed, 6 insertions(+), 1 deletion(-)
diff --git a/.github/workflows/build.yaml b/.github/workflows/build.yaml
index a127c7e89d73..695d495858b8 100644
--- a/.github/workflows/build.yaml
+++ b/.github/workflows/build.yaml
@@ -14,6 +14,7 @@
#
# This name is referenced in the release.yaml workflow, if you're changing here - change there
name: Build
+run-name: Building ${{ inputs.version }} ${{ github.ref_name }}
on:
push:
@@ -43,6 +44,7 @@ on:
description: 'Whether to build images from cache or not. Default: true, set to false only if required because that will cause a significant increase in build time'
required: true
default: 'true'
+
jobs:
matrix_prep:
runs-on: ubuntu-latest
diff --git a/.github/workflows/release.yaml b/.github/workflows/release.yaml
index b644a9e389d7..5b84b1b04507 100644
--- a/.github/workflows/release.yaml
+++ b/.github/workflows/release.yaml
@@ -12,7 +12,9 @@
# See the License for the specific language governing permissions and
# limitations under the License.
#
+
name: Release
+run-name: Releasing ${{ inputs.version }}
on:
workflow_dispatch:
diff --git a/.github/workflows/security_scan.yaml b/.github/workflows/security_scan.yaml
index e2fc70a12521..25a65cd5844e 100644
--- a/.github/workflows/security_scan.yaml
+++ b/.github/workflows/security_scan.yaml
@@ -15,6 +15,7 @@
# Currently supported running against prebuilt images
name: Security Scan
+run-name: Scanning ${{ inputs.tag }}
on:
workflow_dispatch:
diff --git a/.github/workflows/system-tests-enterprise.yml b/.github/workflows/system-tests-enterprise.yml
index 13989d14448e..0b7e36beb1d6 100644
--- a/.github/workflows/system-tests-enterprise.yml
+++ b/.github/workflows/system-tests-enterprise.yml
@@ -282,7 +282,7 @@ jobs:
run-system-tests-enterprise-ci:
# When increasing the timeout make sure it's not larger than the schedule cron interval
timeout-minutes: 360
- name: Run System Tests Enterprise
+ name: Test [${{ needs.prepare-system-tests-enterprise-ci.outputs.mlrunBranch }}]
# requires prepare to finish before starting
needs: [prepare-system-tests-enterprise-ci]
runs-on: ubuntu-latest
From 71812b782a671114cb0ec2a2eb32b78f1971d047 Mon Sep 17 00:00:00 2001
From: Saar Cohen <66667568+theSaarco@users.noreply.github.com>
Date: Tue, 30 May 2023 10:40:55 +0300
Subject: [PATCH 209/334] [Docs] Add documentation for project `build_image`
and `build_config` (#3622)
---
docs/projects/run-build-deploy.md | 198 +++++++++++++++++++++---------
1 file changed, 142 insertions(+), 56 deletions(-)
diff --git a/docs/projects/run-build-deploy.md b/docs/projects/run-build-deploy.md
index 52bf1b88b311..9585646c59c4 100644
--- a/docs/projects/run-build-deploy.md
+++ b/docs/projects/run-build-deploy.md
@@ -7,6 +7,8 @@
- [build_function](#build)
- [deploy_function](#deploy)
- [Default image](#default_image)
+- [Image build configuration](#build_config)
+- [build_image](#build_image)
## Overview
@@ -20,29 +22,34 @@ When used inside a pipeline, each method is automatically mapped to the relevant
You can use those methods as `project` methods, or as global (`mlrun.`) methods. For example:
- # run the "train" function in myproject
- run = myproject.run_function("train", inputs={"data": data_url})
-
- # run the "train" function in the current/active project (or in a pipeline)
- run = mlrun.run_function("train", inputs={"data": data_url})
+```python
+# run the "train" function in myproject
+run = myproject.run_function("train", inputs={"data": data_url})
+
+# run the "train" function in the current/active project (or in a pipeline)
+run = mlrun.run_function("train", inputs={"data": data_url})
+```
The first parameter in all three methods is either the function name (in the project), or a function object, used if you want to
specify functions that you imported/created ad hoc, or to modify a function spec. For example:
- # import a serving function from the Function Hub and deploy a trained model over it
- serving = import_function("hub://v2_model_server", new_name="serving")
- serving.spec.replicas = 2
- deploy = deploy_function(
- serving,
- models=[{"key": "mymodel", "model_path": train.outputs["model"]}],
- )
+```python
+# import a serving function from the Function Hub and deploy a trained model over it
+serving = import_function("hub://v2_model_server", new_name="serving")
+serving.spec.replicas = 2
+deploy = deploy_function(
+ serving,
+ models=[{"key": "mymodel", "model_path": train.outputs["model"]}],
+)
+```
You can use the {py:meth}`~mlrun.projects.MlrunProject.get_function` method to get the function object and manipulate it, for example:
- trainer = project.get_function("train")
- trainer.with_limits(mem="2G", cpu=2, gpus=1)
- run = project.run_function("train", inputs={"data": data_url})
-
+```python
+trainer = project.get_function("train")
+trainer.with_limits(mem="2G", cpu=2, gpus=1)
+run = project.run_function("train", inputs={"data": data_url})
+```
## run_function
@@ -65,16 +72,17 @@ Read further details on [**running tasks and getting their results**](../concept
Usage examples:
- # create a project with two functions (local and from Function Hub)
- project = mlrun.new_project(project_name, "./proj")
- project.set_function("mycode.py", "prep", image="mlrun/mlrun")
- project.set_function("hub://auto_trainer", "train")
-
- # run functions (refer to them by name)
- run1 = project.run_function("prep", params={"x": 7}, inputs={'data': data_url})
- run2 = project.run_function("train", inputs={"dataset": run1.outputs["data"]})
- run2.artifact('confusion-matrix').show()
+```python
+# create a project with two functions (local and from Function Hub)
+project = mlrun.new_project(project_name, "./proj")
+project.set_function("mycode.py", "prep", image="mlrun/mlrun")
+project.set_function("hub://auto_trainer", "train")
+# run functions (refer to them by name)
+run1 = project.run_function("prep", params={"x": 7}, inputs={'data': data_url})
+run2 = project.run_function("train", inputs={"dataset": run1.outputs["data"]})
+run2.artifact('confusion-matrix').show()
+```
```{admonition} Run/simulate functions locally:
Functions can also run and be debugged locally by using the `local` runtime or by setting the `local=True`
@@ -88,8 +96,10 @@ The {py:meth}`~mlrun.projects.build_function` method is used to deploy an ML fun
Example:
- # build the "trainer" function image (based on the specified requirements and code repo)
- project.build_function("trainer")
+```python
+# build the "trainer" function image (based on the specified requirements and code repo)
+project.build_function("trainer")
+```
The {py:meth}`~mlrun.projects.build_function` method accepts different parameters that can add to, or override, the function build spec.
You can specify the target or base `image` extra docker `commands`, builder environment, and source credentials (`builder_env`), etc.
@@ -105,29 +115,33 @@ Read more about [**Real-time serving pipelines**](../serving/serving-graph.html)
Basic example:
- # Deploy a real-time nuclio function ("myapi")
- deployment = project.deploy_function("myapi")
-
- # invoke the deployed function (using HTTP request)
- resp = deployment.function.invoke("/do")
+```python
+# Deploy a real-time nuclio function ("myapi")
+deployment = project.deploy_function("myapi")
+
+# invoke the deployed function (using HTTP request)
+resp = deployment.function.invoke("/do")
+```
You can provide the `env` dict with: extra environment variables; `models` list to specify specific models and their attributes
(in the case of serving functions); builder environment; and source credentials (`builder_env`).
Example of using `deploy_function` inside a pipeline, after the `train` step, to generate a model:
- # Deploy the trained model (from the "train" step) as a serverless serving function
- serving_fn = mlrun.new_function("serving", image="mlrun/mlrun", kind="serving")
- mlrun.deploy_function(
- serving_fn,
- models=[
- {
- "key": model_name,
- "model_path": train.outputs["model"],
- "class_name": 'mlrun.frameworks.sklearn.SklearnModelServer',
- }
- ],
- )
+```python
+# Deploy the trained model (from the "train" step) as a serverless serving function
+serving_fn = mlrun.new_function("serving", image="mlrun/mlrun", kind="serving")
+mlrun.deploy_function(
+ serving_fn,
+ models=[
+ {
+ "key": model_name,
+ "model_path": train.outputs["model"],
+ "class_name": 'mlrun.frameworks.sklearn.SklearnModelServer',
+ }
+ ],
+)
+```
```{admonition} Note
@@ -147,20 +161,92 @@ image that was set when the function was added to the project.
For example:
- project = mlrun.new_project(project_name, "./proj")
- # use v1 of a pre-built image as default
- project.set_default_image("myrepo/my-prebuilt-image:v1")
- # set function without an image, will use the project's default image
- project.set_function("mycode.py", "prep")
+```python
+ project = mlrun.new_project(project_name, "./proj")
+ # use v1 of a pre-built image as default
+ project.set_default_image("myrepo/my-prebuilt-image:v1")
+ # set function without an image, will use the project's default image
+ project.set_function("mycode.py", "prep")
+
+ # function will run with the "myrepo/my-prebuilt-image:v1" image
+ run1 = project.run_function("prep", params={"x": 7}, inputs={'data': data_url})
+
+ ...
+
+ # replace the default image with a newer v2
+ project.set_default_image("myrepo/my-prebuilt-image:v2")
+ # function will now run using the v2 version of the image
+ run2 = project.run_function("prep", params={"x": 7}, inputs={'data': data_url})
+```
- # function will run with the "myrepo/my-prebuilt-image:v1" image
- run1 = project.run_function("prep", params={"x": 7}, inputs={'data': data_url})
+
+## Image build configuration
- ...
+Use the {py:meth}`~mlrun.projects.MlrunProject.set_default_image` function to configure a project to use an existing
+image. The configuration for building this default image can be contained within the project, by using the
+{py:meth}`~mlrun.projects.MlrunProject.build_config` and {py:meth}`~mlrun.projects.MlrunProject.build_image`
+functions.
- # replace the default image with a newer v2
- project.set_default_image("myrepo/my-prebuilt-image:v2")
- # function will now run using the v2 version of the image
- run2 = project.run_function("prep", params={"x": 7}, inputs={'data': data_url})
+The project build configuration is maintained in the project object. When saving, exporting and importing the project
+these configurations are carried over with it. This makes it simple to transport a project between systems while
+ensuring that the needed runtime images are built and are ready for execution.
+When using {py:meth}`~mlrun.projects.MlrunProject.build_config`, build configurations can be passed along with the
+resulting image name, and these are used to build the image. The image name is assigned following these rules,
+based on the project configuration and provided parameters:
+1. If provided, the name passed in the `image` parameter of {py:meth}`~mlrun.projects.MlrunProject.build_config`.
+2. The project's default image name, if configured using {py:meth}`~mlrun.projects.MlrunProject.set_default_image`.
+3. The value set in MLRun's `default_project_image_name` config parameter - by default this value is
+ `.mlrun-project-image-{name}` with the project name as template parameter.
+
+For example:
+
+```python
+ # Set image config for current project object, using base mlrun image with additional requirements.
+ image_name = ".my-project-image"
+ project.build_config(
+ image=image_name,
+ set_as_default=True,
+ with_mlrun=False,
+ base_image="mlrun/mlrun",
+ requirements=["vaderSentiment"],
+ )
+
+ # Export the project configuration. The yaml file will contain the build configuration
+ proj_file_path = "~/mlrun/my-project/project.yaml"
+ project.export(proj_file_path)
+```
+
+This project can then be imported and the default image can be built:
+
+```python
+ # Import the project as a new project with a different name
+ new_project = mlrun.load_project("~/mlrun/my-project", name="my-other-project")
+ # Build the default image for the project, based on project build config
+ new_project.build_image()
+
+ # Set a new function and run it (new function uses the my-project-image image built previously)
+ new_project.set_function("sentiment.py", name="scores", kind="job", handler="handler")
+ new_project.run_function("scores")
+```
+
+
+## build_image
+
+The {py:meth}`~mlrun.projects.MlrunProject.build_image` function builds an image using the existing build configuration.
+This method can also be used to set the build configuration and build the image based on it - in a single step.
+
+When using `set_as_default=False` any build config provided is still kept in the project object but the generated
+image name is not set as the default image for this project.
+
+For example:
+
+```python
+image_name = ".temporary-image"
+project.build_image(image=image_name, set_as_default=False)
+
+# Create a function using the temp image name
+project.set_function("sentiment.py", name="scores", kind="job", handler="handler", image=image_name)
+```
+
\ No newline at end of file
From affcd95ff9adfdcc45349e9f00d0d38f6304a5f5 Mon Sep 17 00:00:00 2001
From: Saar Cohen <66667568+theSaarco@users.noreply.github.com>
Date: Tue, 30 May 2023 10:41:05 +0300
Subject: [PATCH 210/334] [Docs] Document building custom transformations for
multiple engines (#3653)
---
docs/api/mlrun.feature_store.rst | 7 +++
docs/api/mlrun.serving.rst | 3 +
docs/feature-store/transformations.md | 81 ++++++++++++++++++++++++++-
mlrun/feature_store/steps.py | 22 +++++++-
4 files changed, 111 insertions(+), 2 deletions(-)
diff --git a/docs/api/mlrun.feature_store.rst b/docs/api/mlrun.feature_store.rst
index 8a7776e60d5f..a1328bc40a4d 100644
--- a/docs/api/mlrun.feature_store.rst
+++ b/docs/api/mlrun.feature_store.rst
@@ -9,6 +9,13 @@ mlrun.feature_store
.. autoclass:: mlrun.feature_store.feature_set.FeatureSetSpec
.. autoclass:: mlrun.feature_store.feature_set.FeatureSetStatus
+.. autoclass:: mlrun.feature_store.steps.MLRunStep
+ :members:
+ :private-members: _do_pandas, _do_storey, _do_spark
+
.. automodule:: mlrun.feature_store.steps
+ :exclude-members: MLRunStep
:members:
:special-members: __init__
+
+
diff --git a/docs/api/mlrun.serving.rst b/docs/api/mlrun.serving.rst
index aa36f96465de..6efd3dcdb17e 100644
--- a/docs/api/mlrun.serving.rst
+++ b/docs/api/mlrun.serving.rst
@@ -9,3 +9,6 @@ mlrun.serving
.. automodule:: mlrun.serving.remote
:members:
:special-members: __init__
+
+.. autoclass:: mlrun.serving.utils.StepToDict
+ :members:
diff --git a/docs/feature-store/transformations.md b/docs/feature-store/transformations.md
index 60851271dfd6..2743a2b325d7 100644
--- a/docs/feature-store/transformations.md
+++ b/docs/feature-store/transformations.md
@@ -189,4 +189,83 @@ quotes_set.graph.add_step("MyMap", "multi", after="filter", multiplier=3)
```
This uses the `add_step` function of the graph to add a step called `multi` utilizing `MyMap` after the `filter` step
-that was added previously. The class is initialized with a multiplier of 3.
\ No newline at end of file
+that was added previously. The class is initialized with a multiplier of 3.
+
+## Supporting multiple engines
+
+MLRun supports multiple processing engines for executing graphs. These engines differ in the way they invoke graph
+steps. When implementing custom transformations, the code has to support all engines that are expected to run it.
+
+```{admonition} Note
+The vast majority of MLRun's built-in transformations support all engines. The support matrix is available
+[here](../serving/available-steps.html#data-transformations).
+```
+
+The following are the main differences between transformation steps executing on different engines:
+
+* `storey` - the step receives a single event (either as a dictionary or as an Event object, depending on whether
+ `full_event` is configured for the step). The step is expected to process the event and return the modified event.
+* `spark` - the step receives a Spark dataframe object. Steps are expected to add their processing and calculations to
+ the dataframe (either in-place or not) and return the resulting dataframe without materializing the data.
+* `pandas` - the step receives a Pandas dataframe, processes it, and returns the dataframe.
+
+To support multiple engines, extend the {py:class}`~mlrun.feature_store.steps.MLRunStep` class with a custom
+transformation. This class allows implementing engine-specific code by overriding the following methods:
+{py:func}`~mlrun.feature_store.steps.MLRunStep._do_storey`, {py:func}`~mlrun.feature_store.steps.MLRunStep._do_pandas`
+and {py:func}`~mlrun.feature_store.steps.MLRunStep._do_spark`. To add support for a given engine, the relevant `do`
+method needs to be implemented.
+
+When a graph is executed, each step is a single instance of the relevant class that gets invoked as events flow through
+the graph. For `spark` and `pandas` engines, this only happens once per ingestion, since the entire data-frame is fed to
+the graph. For the `storey` engine the same instance's {py:func}`~mlrun.feature_store.steps.MLRunStep._do_storey`
+function will be invoked per input row. As the graph is initialized, this class instance can receive global parameters
+in its `__init__` method that determines its behavior.
+
+The following example class multiplies a feature by a value and adds it to the event. (For simplicity, data type
+checks and validations were omitted as well as needed imports.) Note that the class also extends
+{py:class}`~mlrun.serving.utils.StepToDict` - this class implements generic serialization of graph steps to
+a python dictionary. This functionality allows passing instances of this class to `graph.to()` and `graph.add_step()`:
+
+```python
+class MultiplyFeature(StepToDict, MLRunStep):
+ def __init__(self, feature: str, value: int, **kwargs):
+ super().__init__(**kwargs)
+ self._feature = feature
+ self._value = value
+ self._new_feature = f"{feature}_times_{value}"
+
+ def _do_storey(self, event):
+ # event is a single row represented by a dictionary
+ event[self._new_feature] = event[self._feature] * self._value
+ return event
+
+ def _do_pandas(self, event):
+ # event is a pandas.DataFrame
+ event[self._new_feature] = event[self._feature].multiply(self._value)
+ return event
+
+ def _do_spark(self, event):
+ # event is a pyspark.sql.DataFrame
+ return event.withColumn(self._new_feature,
+ col(self._feature) * lit(self._value)
+ )
+```
+
+The following example uses this step in a feature-set graph with the `pandas` engine. This example adds a feature called
+`number1_times_4` with the value of the `number1` feature multiplied by 4. Note how the global parameters are passed
+when creating the graph step:
+
+```python
+import mlrun.feature_store as fstore
+
+feature_set = fstore.FeatureSet("fs-new",
+ entities=[fstore.Entity("id")],
+ engine="pandas",
+ )
+# Adding multiply step, with specific parameters
+feature_set.graph.to(MultiplyFeature(feature="number1", value=4))
+df_pandas = fstore.ingest(feature_set, data)
+```
+
+
+
diff --git a/mlrun/feature_store/steps.py b/mlrun/feature_store/steps.py
index 3d9a47c84c1b..140a84229fd1 100644
--- a/mlrun/feature_store/steps.py
+++ b/mlrun/feature_store/steps.py
@@ -41,7 +41,9 @@ def get_engine(first_event):
class MLRunStep(MapClass):
def __init__(self, **kwargs):
"""Abstract class for mlrun step.
- Can be used in pandas/storey/spark feature set ingestion"""
+ Can be used in pandas/storey/spark feature set ingestion. Extend this class and implement the relevant
+ `_do_XXX` methods to support the required execution engines.
+ """
super().__init__(**kwargs)
self._engine_to_do_method = {
"pandas": self._do_pandas,
@@ -52,6 +54,9 @@ def __init__(self, **kwargs):
def do(self, event):
"""
This method defines the do method of this class according to the first event type.
+
+ .. warning::
+ When extending this class, do not override this method; only override the `_do_XXX` methods.
"""
engine = get_engine(event)
self.do = self._engine_to_do_method.get(engine, None)
@@ -63,12 +68,27 @@ def do(self, event):
return self.do(event)
def _do_pandas(self, event):
+ """
+ The execution method for pandas engine.
+
+ :param event: Incoming event, a `pandas.DataFrame` object.
+ """
raise NotImplementedError
def _do_storey(self, event):
+ """
+ The execution method for storey engine.
+
+ :param event: Incoming event, a dictionary or `storey.Event` object, depending on the `full_event` value.
+ """
raise NotImplementedError
def _do_spark(self, event):
+ """
+ The execution method for spark engine.
+
+ :param event: Incoming event, a `pyspark.sql.DataFrame` object.
+ """
raise NotImplementedError
From 29e0d840931eb7a8e5e5022ff831384462e2676c Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Tue, 30 May 2023 12:28:17 +0300
Subject: [PATCH 211/334] [Execution] Fix missing run inputs on submit job from
UI (#3596)
---
mlrun/execution.py | 45 ++++++----
mlrun/launcher/base.py | 1 +
tests/run/test_run.py | 144 +-----------------------------
tests/test_execution.py | 190 ++++++++++++++++++++++++++++++++++++++++
4 files changed, 218 insertions(+), 162 deletions(-)
create mode 100644 tests/test_execution.py
diff --git a/mlrun/execution.py b/mlrun/execution.py
index 98eaf6722edd..95744817b44d 100644
--- a/mlrun/execution.py
+++ b/mlrun/execution.py
@@ -304,8 +304,8 @@ def from_dict(
self._init_dbs(rundb)
- if spec and not is_api:
- # init data related objects (require DB & Secrets to be set first), skip when running in the api service
+ if spec:
+ # init data related objects (require DB & Secrets to be set first)
self._data_stores.from_dict(spec)
if inputs and isinstance(inputs, dict):
for k, v in inputs.items():
@@ -380,7 +380,7 @@ def parameters(self):
@property
def inputs(self):
- """dictionary of input data items (read-only)"""
+ """dictionary of input data item urls (read-only)"""
return self._inputs
@property
@@ -497,27 +497,34 @@ def _set_input(self, key, url=""):
url = key
if self.in_path and is_relative_path(url):
url = os.path.join(self._in_path, url)
- obj = self._data_stores.object(
- url,
- key,
- project=self._project,
- allow_empty_resources=self._allow_empty_resources,
- )
- self._inputs[key] = obj
- return obj
+ self._inputs[key] = url
def get_input(self, key: str, url: str = ""):
- """get an input :py:class:`~mlrun.DataItem` object, data objects have methods such as
- .get(), .download(), .url, .. to access the actual data
+ """
+ Get an input :py:class:`~mlrun.DataItem` object,
+ data objects have methods such as .get(), .download(), .url, .. to access the actual data.
+ Requires access to the data store secrets if configured.
- example::
+ Example::
data = context.get_input("my_data").get()
+
+ :param key: The key name for the input url entry.
+ :param url: The url of the input data (file, stream, ..) - optional, saved in the inputs dictionary
+ if the key is not already present.
+
+ :return: :py:class:`~mlrun.datastore.base.DataItem` object
"""
if key not in self._inputs:
- return self._set_input(key, url)
- else:
- return self._inputs[key]
+ self._set_input(key, url)
+
+ url = self._inputs[key]
+ return self._data_stores.object(
+ url,
+ key,
+ project=self._project,
+ allow_empty_resources=self._allow_empty_resources,
+ )
def log_result(self, key: str, value, commit=False):
"""log a scalar result value
@@ -945,7 +952,7 @@ def set_if_not_none(_struct, key, val):
"handler": self._handler,
"outputs": self._outputs,
run_keys.output_path: self.artifact_path,
- run_keys.inputs: {k: v.artifact_url for k, v in self._inputs.items()},
+ run_keys.inputs: self._inputs,
"notifications": self._notifications,
},
"status": {
@@ -982,7 +989,7 @@ def set_if_not_none(_struct, key, val):
"metadata.annotations": self._annotations,
"spec.parameters": self._parameters,
"spec.outputs": self._outputs,
- "spec.inputs": {k: v.artifact_url for k, v in self._inputs.items()},
+ "spec.inputs": self._inputs,
"status.results": self._results,
"status.start_time": to_date_str(self._start_time),
"status.last_update": to_date_str(self._last_update),
diff --git a/mlrun/launcher/base.py b/mlrun/launcher/base.py
index 8c6405d19213..4412cfe78ad6 100644
--- a/mlrun/launcher/base.py
+++ b/mlrun/launcher/base.py
@@ -73,6 +73,7 @@ def save_function(
hash_key = hash_key if versioned else None
return "db://" + runtime._function_uri(hash_key=hash_key, tag=tag)
+ @abc.abstractmethod
def launch(
self,
runtime: "mlrun.runtimes.BaseRuntime",
diff --git a/tests/run/test_run.py b/tests/run/test_run.py
index 67d84a3c34f9..cd3f6ff303b7 100644
--- a/tests/run/test_run.py
+++ b/tests/run/test_run.py
@@ -12,7 +12,6 @@
# See the License for the specific language governing permissions and
# limitations under the License.
import contextlib
-import datetime
import io
import pathlib
import sys
@@ -23,7 +22,7 @@
import mlrun
import mlrun.errors
import mlrun.launcher.factory
-from mlrun import MLClientCtx, new_function, new_task
+from mlrun import new_function, new_task
from tests.conftest import (
examples_path,
has_secrets,
@@ -250,147 +249,6 @@ async def test_local_args(db, db_session):
assert output.find(", --xyz, 789") != -1, "params not detected in argv"
-def test_local_context(rundb_mock):
- project_name = "xtst"
- mlrun.mlconf.artifact_path = out_path
- context = mlrun.get_or_create_ctx("xx", project=project_name, upload_artifacts=True)
- db = mlrun.get_run_db()
- run = db.read_run(context._uid, project=project_name)
- assert run["struct"]["status"]["state"] == "running", "run status not updated in db"
-
- with context:
- context.log_artifact("xx", body="123", local_path="a.txt")
- context.log_model("mdl", body="456", model_file="mdl.pkl", artifact_path="+/mm")
- context.get_param("p1", 1)
- context.get_param("p2", "a string")
- context.log_result("accuracy", 16)
- context.set_label("label-key", "label-value")
- context.set_annotation("annotation-key", "annotation-value")
- context._set_input("input-key", "input-url")
-
- artifact = context.get_cached_artifact("xx")
- artifact.format = "z"
- context.update_artifact(artifact)
-
- assert context._state == "completed", "task did not complete"
-
- run = db.read_run(context._uid, project=project_name)
- run = run["struct"]
-
- # run state should not be updated by the context
- assert run["status"]["state"] == "running", "run status was updated in db"
- assert (
- run["status"]["artifacts"][0]["metadata"]["key"] == "xx"
- ), "artifact not updated in db"
- assert (
- run["status"]["artifacts"][0]["spec"]["format"] == "z"
- ), "run/artifact attribute not updated in db"
- assert run["status"]["artifacts"][1]["spec"]["target_path"].startswith(
- out_path
- ), "artifact not uploaded to subpath"
-
- db_artifact = db.read_artifact(artifact.db_key, project=project_name)
- assert db_artifact["spec"]["format"] == "z", "artifact attribute not updated in db"
-
- assert run["spec"]["parameters"]["p1"] == 1, "param not updated in db"
- assert run["spec"]["parameters"]["p2"] == "a string", "param not updated in db"
- assert run["status"]["results"]["accuracy"] == 16, "result not updated in db"
- assert run["metadata"]["labels"]["label-key"] == "label-value", "label not updated"
- assert (
- run["metadata"]["annotations"]["annotation-key"] == "annotation-value"
- ), "annotation not updated"
-
- assert run["spec"]["inputs"]["input-key"] == "input-url", "input not updated"
-
-
-def test_context_from_dict_when_start_time_is_string():
- context = mlrun.get_or_create_ctx("ctx")
- context_dict = context.to_dict()
- context = mlrun.MLClientCtx.from_dict(context_dict)
- assert isinstance(context._start_time, datetime.datetime)
-
-
-def test_context_from_run_dict():
- run_dict = {
- "metadata": {
- "name": "test-context-from-run-dict",
- "project": "default",
- "labels": {"label-key": "label-value"},
- "annotations": {"annotation-key": "annotation-value"},
- },
- "spec": {
- "parameters": {"p1": 1, "p2": "a string"},
- "inputs": {"input-key": "input-url"},
- },
- }
- runtime = mlrun.runtimes.base.BaseRuntime.from_dict(run_dict)
- handler = "my_func"
- out_path = "test_artifact_path"
- launcher = mlrun.launcher.factory.LauncherFactory.create_launcher(
- runtime._is_remote
- )
- run = launcher._create_run_object(run_dict)
- run = launcher._enrich_run(
- runtime,
- run,
- handler,
- run_dict["metadata"]["project"],
- run_dict["metadata"]["name"],
- run_dict["spec"]["parameters"],
- run_dict["spec"]["inputs"],
- returns="",
- hyperparams=None,
- hyper_param_options=None,
- verbose=False,
- scrape_metrics=None,
- out_path=out_path,
- artifact_path="",
- workdir="",
- )
- context = MLClientCtx.from_dict(run.to_dict())
- assert context.name == run_dict["metadata"]["name"]
- assert context._project == run_dict["metadata"]["project"]
- assert context._labels == run_dict["metadata"]["labels"]
- assert context._annotations == run_dict["metadata"]["annotations"]
- assert context.get_param("p1") == run_dict["spec"]["parameters"]["p1"]
- assert context.get_param("p2") == run_dict["spec"]["parameters"]["p2"]
- assert (
- context.get_input("input-key").artifact_url
- == run_dict["spec"]["inputs"]["input-key"]
- )
- assert context.labels["label-key"] == run_dict["metadata"]["labels"]["label-key"]
- assert (
- context.annotations["annotation-key"]
- == run_dict["metadata"]["annotations"]["annotation-key"]
- )
- assert context.artifact_path == out_path
-
-
-@pytest.mark.parametrize(
- "state, error, expected_state",
- [
- ("running", None, "completed"),
- ("completed", None, "completed"),
- (None, "error message", "error"),
- (None, "", "error"),
- ],
-)
-def test_context_set_state(rundb_mock, state, error, expected_state):
- project_name = "test_context_error"
- mlrun.mlconf.artifact_path = out_path
- context = mlrun.get_or_create_ctx("xx", project=project_name, upload_artifacts=True)
- db = mlrun.get_run_db()
- run = db.read_run(context._uid, project=project_name)
- assert run["struct"]["status"]["state"] == "running", "run status not updated in db"
-
- with context:
- context.set_state(execution_state=state, error=error, commit=False)
- context.commit(completed=True)
-
- assert context._state == expected_state, "task state was not set correctly"
- assert context._error == error, "task error was not set"
-
-
def test_run_class_code():
cases = [
({"y": 3}, {"rx": 0, "ry": 3, "ra1": 1}),
diff --git a/tests/test_execution.py b/tests/test_execution.py
new file mode 100644
index 000000000000..c71c50640f72
--- /dev/null
+++ b/tests/test_execution.py
@@ -0,0 +1,190 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import datetime
+import unittest.mock
+
+import pytest
+
+import mlrun
+import mlrun.artifacts
+import mlrun.errors
+from tests.conftest import out_path
+
+
+def test_local_context(rundb_mock):
+ project_name = "xtst"
+ mlrun.mlconf.artifact_path = out_path
+ context = mlrun.get_or_create_ctx("xx", project=project_name, upload_artifacts=True)
+ db = mlrun.get_run_db()
+ run = db.read_run(context._uid, project=project_name)
+ assert run["struct"]["status"]["state"] == "running", "run status not updated in db"
+
+ # calls __exit__ and commits the context
+ with context:
+ context.log_artifact("xx", body="123", local_path="a.txt")
+ context.log_model("mdl", body="456", model_file="mdl.pkl", artifact_path="+/mm")
+ context.get_param("p1", 1)
+ context.get_param("p2", "a string")
+ context.log_result("accuracy", 16)
+ context.set_label("label-key", "label-value")
+ context.set_annotation("annotation-key", "annotation-value")
+ context._set_input("input-key", "input-url")
+
+ artifact = context.get_cached_artifact("xx")
+ artifact.format = "z"
+ context.update_artifact(artifact)
+
+ assert context._state == "completed", "task did not complete"
+
+ run = db.read_run(context._uid, project=project_name)
+ run = run["struct"]
+
+ # run state should not be updated by the context
+ assert run["status"]["state"] == "running", "run status was updated in db"
+ assert (
+ run["status"]["artifacts"][0]["metadata"]["key"] == "xx"
+ ), "artifact not updated in db"
+ assert (
+ run["status"]["artifacts"][0]["spec"]["format"] == "z"
+ ), "run/artifact attribute not updated in db"
+ assert run["status"]["artifacts"][1]["spec"]["target_path"].startswith(
+ out_path
+ ), "artifact not uploaded to subpath"
+
+ db_artifact = db.read_artifact(artifact.db_key, project=project_name)
+ assert db_artifact["spec"]["format"] == "z", "artifact attribute not updated in db"
+
+ assert run["spec"]["parameters"]["p1"] == 1, "param not updated in db"
+ assert run["spec"]["parameters"]["p2"] == "a string", "param not updated in db"
+ assert run["status"]["results"]["accuracy"] == 16, "result not updated in db"
+ assert run["metadata"]["labels"]["label-key"] == "label-value", "label not updated"
+ assert (
+ run["metadata"]["annotations"]["annotation-key"] == "annotation-value"
+ ), "annotation not updated"
+
+ assert run["spec"]["inputs"]["input-key"] == "input-url", "input not updated"
+
+
+def test_context_from_dict_when_start_time_is_string():
+ context = mlrun.get_or_create_ctx("ctx")
+ context_dict = context.to_dict()
+ context = mlrun.MLClientCtx.from_dict(context_dict)
+ assert isinstance(context._start_time, datetime.datetime)
+
+
+@pytest.mark.parametrize(
+ "is_api",
+ [True, False],
+)
+def test_context_from_run_dict(is_api):
+ with unittest.mock.patch("mlrun.config.is_running_as_api", return_value=is_api):
+ run_dict = _generate_run_dict()
+
+ # create run object from dict and dict again to mock the run serialization
+ run = mlrun.run.RunObject.from_dict(run_dict)
+ context = mlrun.MLClientCtx.from_dict(run.to_dict(), is_api=is_api)
+
+ assert context.name == run_dict["metadata"]["name"]
+ assert context._project == run_dict["metadata"]["project"]
+ assert context._labels == run_dict["metadata"]["labels"]
+ assert context._annotations == run_dict["metadata"]["annotations"]
+ assert context.get_param("p1") == run_dict["spec"]["parameters"]["p1"]
+ assert context.get_param("p2") == run_dict["spec"]["parameters"]["p2"]
+ assert (
+ context.labels["label-key"] == run_dict["metadata"]["labels"]["label-key"]
+ )
+ assert (
+ context.annotations["annotation-key"]
+ == run_dict["metadata"]["annotations"]["annotation-key"]
+ )
+ assert context.artifact_path == run_dict["spec"]["output_path"]
+
+
+@pytest.mark.parametrize(
+ "state, error, expected_state",
+ [
+ ("running", None, "completed"),
+ ("completed", None, "completed"),
+ (None, "error message", "error"),
+ (None, "", "error"),
+ ],
+)
+def test_context_set_state(rundb_mock, state, error, expected_state):
+ project_name = "test_context_error"
+ mlrun.mlconf.artifact_path = out_path
+ context = mlrun.get_or_create_ctx("xx", project=project_name, upload_artifacts=True)
+ db = mlrun.get_run_db()
+ run = db.read_run(context._uid, project=project_name)
+ assert run["struct"]["status"]["state"] == "running", "run status not updated in db"
+
+ # calls __exit__ and commits the context
+ with context:
+ context.set_state(execution_state=state, error=error, commit=False)
+
+ assert context._state == expected_state, "task state was not set correctly"
+ assert context._error == error, "task error was not set"
+
+
+@pytest.mark.parametrize(
+ "is_api",
+ [True, False],
+)
+def test_context_inputs(rundb_mock, is_api):
+ with unittest.mock.patch("mlrun.config.is_running_as_api", return_value=is_api):
+ run_dict = _generate_run_dict()
+
+ # create run object from dict and dict again to mock the run serialization
+ run = mlrun.run.RunObject.from_dict(run_dict)
+ context = mlrun.MLClientCtx.from_dict(run.to_dict(), is_api=is_api)
+ assert (
+ context.get_input("input-key").artifact_url
+ == run_dict["spec"]["inputs"]["input-key"]
+ )
+ assert context._inputs["input-key"] == run_dict["spec"]["inputs"]["input-key"]
+
+ key = "store-input"
+ url = run_dict["spec"]["inputs"][key]
+ assert context._inputs[key] == run_dict["spec"]["inputs"][key]
+
+ # 'store-input' is a store artifact, store it in the db before getting it
+ artifact = mlrun.artifacts.Artifact(key, b"123")
+ rundb_mock.store_artifact(key, artifact.to_dict(), uid="123")
+ mlrun.datastore.store_manager.object(
+ url,
+ key,
+ project=run_dict["metadata"]["project"],
+ allow_empty_resources=True,
+ )
+ context._allow_empty_resources = True
+ assert context.get_input(key).artifact_url == run_dict["spec"]["inputs"][key]
+
+
+def _generate_run_dict():
+ return {
+ "metadata": {
+ "name": "test-context-from-run-dict",
+ "project": "default",
+ "labels": {"label-key": "label-value"},
+ "annotations": {"annotation-key": "annotation-value"},
+ },
+ "spec": {
+ "parameters": {"p1": 1, "p2": "a string"},
+ "output_path": "test_artifact_path",
+ "inputs": {
+ "input-key": "input-url",
+ "store-input": "store://store-input",
+ },
+ "allow_empty_resources": True,
+ },
+ }
From 8eed891c74202d2553b3bee7534b805c13f4f20a Mon Sep 17 00:00:00 2001
From: Liran BG
Date: Tue, 30 May 2023 14:14:42 +0300
Subject: [PATCH 212/334] [CI] Fix system test step name missing matrix item
(#3661)
---
.github/workflows/system-tests-enterprise.yml | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/.github/workflows/system-tests-enterprise.yml b/.github/workflows/system-tests-enterprise.yml
index 0b7e36beb1d6..7a9e44d327d7 100644
--- a/.github/workflows/system-tests-enterprise.yml
+++ b/.github/workflows/system-tests-enterprise.yml
@@ -282,7 +282,7 @@ jobs:
run-system-tests-enterprise-ci:
# When increasing the timeout make sure it's not larger than the schedule cron interval
timeout-minutes: 360
- name: Test [${{ needs.prepare-system-tests-enterprise-ci.outputs.mlrunBranch }}]
+ name: Test ${{ matrix.test_component }} [${{ needs.prepare-system-tests-enterprise-ci.outputs.mlrunBranch }}]
# requires prepare to finish before starting
needs: [prepare-system-tests-enterprise-ci]
runs-on: ubuntu-latest
From aad5b69c1c2fed419afe604e8d2a21df84f8c1e8 Mon Sep 17 00:00:00 2001
From: Adam
Date: Tue, 30 May 2023 14:37:04 +0300
Subject: [PATCH 213/334] [Logs] Fix `/build/status` returning 500 when failing
`kubectl logs` (#3660)
---
mlrun/api/api/endpoints/functions.py | 14 +++++++++++++-
1 file changed, 13 insertions(+), 1 deletion(-)
diff --git a/mlrun/api/api/endpoints/functions.py b/mlrun/api/api/endpoints/functions.py
index d4e1bab49617..0dcbe5c19055 100644
--- a/mlrun/api/api/endpoints/functions.py
+++ b/mlrun/api/api/endpoints/functions.py
@@ -31,6 +31,7 @@
Response,
)
from fastapi.concurrency import run_in_threadpool
+from kubernetes.client.rest import ApiException
from sqlalchemy.orm import Session
import mlrun.api.crud
@@ -488,7 +489,18 @@ def _handle_job_deploy_status(
state = mlrun.common.schemas.FunctionState.error
if (logs and state != "pending") or state in terminal_states:
- resp = mlrun.api.utils.singletons.k8s.get_k8s_helper(silent=False).logs(pod)
+ try:
+ resp = mlrun.api.utils.singletons.k8s.get_k8s_helper(silent=False).logs(pod)
+ except ApiException as exc:
+ logger.warning(
+ "Failed to get build logs",
+ function_name=name,
+ function_state=state,
+ pod=pod,
+ exc_info=exc,
+ )
+ resp = ""
+
if state in terminal_states:
# TODO: move to log collector
log_file.parent.mkdir(parents=True, exist_ok=True)
From 123d88cfbfa2008b5ea65c56d14e0e228ee77d65 Mon Sep 17 00:00:00 2001
From: Alon Maor <48641682+alonmr@users.noreply.github.com>
Date: Tue, 30 May 2023 15:23:33 +0300
Subject: [PATCH 214/334] [API] Fix access of deprecated schema (#3664)
---
mlrun/api/crud/runtimes/nuclio/function.py | 6 +++---
1 file changed, 3 insertions(+), 3 deletions(-)
diff --git a/mlrun/api/crud/runtimes/nuclio/function.py b/mlrun/api/crud/runtimes/nuclio/function.py
index 1d1b103ac928..953ff1b23dfd 100644
--- a/mlrun/api/crud/runtimes/nuclio/function.py
+++ b/mlrun/api/crud/runtimes/nuclio/function.py
@@ -22,9 +22,9 @@
import mlrun
import mlrun.api.crud.runtimes.nuclio.helpers
-import mlrun.api.schemas
import mlrun.api.utils.builder
import mlrun.api.utils.singletons.k8s
+import mlrun.common.schemas
import mlrun.datastore
import mlrun.errors
import mlrun.runtimes.function
@@ -35,7 +35,7 @@
def deploy_nuclio_function(
function: mlrun.runtimes.function.RemoteRuntime,
- auth_info: mlrun.api.schemas.AuthInfo = None,
+ auth_info: mlrun.common.schemas.AuthInfo = None,
client_version: str = None,
builder_env: dict = None,
client_python_version: str = None,
@@ -120,7 +120,7 @@ def get_nuclio_deploy_status(
last_log_timestamp=0,
verbose=False,
resolve_address=True,
- auth_info: mlrun.api.schemas.AuthInfo = None,
+ auth_info: mlrun.common.schemas.AuthInfo = None,
):
"""
Get nuclio function deploy status
From 7859866aca7951025529e698b3cc94f6627a5fef Mon Sep 17 00:00:00 2001
From: eliyahu77 <40737397+eliyahu77@users.noreply.github.com>
Date: Tue, 30 May 2023 17:25:06 +0300
Subject: [PATCH 215/334] [CI] Add devutils (#3624)
---
.github/workflows/system-tests-enterprise.yml | 6 +
automation/system_test/dev_utilities.py | 369 ++++++++++++++++++
automation/system_test/prepare.py | 13 +-
3 files changed, 377 insertions(+), 11 deletions(-)
create mode 100644 automation/system_test/dev_utilities.py
diff --git a/.github/workflows/system-tests-enterprise.yml b/.github/workflows/system-tests-enterprise.yml
index 7a9e44d327d7..dcda2e33d543 100644
--- a/.github/workflows/system-tests-enterprise.yml
+++ b/.github/workflows/system-tests-enterprise.yml
@@ -81,6 +81,12 @@ jobs:
automation/system_test/cleanup.py \
${{ secrets.LATEST_SYSTEM_TEST_DATA_CLUSTER_SSH_USERNAME }}@${{ secrets.LATEST_SYSTEM_TEST_DATA_CLUSTER_IP }}:/home/iguazio/cleanup.py
+ sshpass \
+ -p "${{ secrets.LATEST_SYSTEM_TEST_DATA_CLUSTER_SSH_PASSWORD }}" \
+ scp \
+ automation/system_test/dev_utilities.py \
+ ${{ secrets.LATEST_SYSTEM_TEST_DATA_CLUSTER_SSH_USERNAME }}@${{ secrets.LATEST_SYSTEM_TEST_DATA_CLUSTER_IP }}:/home/iguazio/dev_utilities.py
+
sshpass \
-p "${{ secrets.LATEST_SYSTEM_TEST_DATA_CLUSTER_SSH_PASSWORD }}" \
ssh \
diff --git a/automation/system_test/dev_utilities.py b/automation/system_test/dev_utilities.py
new file mode 100644
index 000000000000..452bf46fee7c
--- /dev/null
+++ b/automation/system_test/dev_utilities.py
@@ -0,0 +1,369 @@
+# Copyright 2018 Iguazio
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+import base64
+import subprocess
+
+import click
+
+
+def run_click_command(command, **kwargs):
+ """
+ Runs a click command with the specified arguments.
+ :param command: The click command to run.
+ :param kwargs: Keyword arguments to pass to the click command.
+ """
+ # create a Click context object
+ ctx = click.Context(command)
+ # invoke the Click command with the desired arguments
+ ctx.invoke(command, **kwargs)
+
+
+def get_installed_releases(namespace):
+ cmd = ["helm", "ls", "-n", namespace, "--deployed", "--short"]
+ output = subprocess.check_output(cmd).decode("utf-8")
+ release_names = output.strip().split("\n")
+ return release_names
+
+
+def run_command(cmd):
+ """
+ Runs a shell command and returns its output and exit status.
+ """
+ result = subprocess.run(
+ cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE, shell=True
+ )
+ return result.stdout.decode("utf-8"), result.returncode
+
+
+def create_ingress_resource(domain_name, ipadd):
+ # Replace the placeholder string with the actual domain name
+ yaml_manifest = """
+ apiVersion: networking.k8s.io/v1
+ kind: Ingress
+ metadata:
+ annotations:
+ nginx.ingress.kubernetes.io/auth-cache-duration: 200 202 5m, 401 30s
+ nginx.ingress.kubernetes.io/auth-cache-key: $host$http_x_remote_user$http_cookie$http_authorization
+ nginx.ingress.kubernetes.io/proxy-body-size: "0"
+ nginx.ingress.kubernetes.io/whitelist-source-range: "{}"
+ nginx.ingress.kubernetes.io/service-upstream: "true"
+ nginx.ingress.kubernetes.io/ssl-redirect: "false"
+ labels:
+ release: redisinsight
+ name: redisinsight
+ namespace: devtools
+ spec:
+ ingressClassName: nginx
+ rules:
+ - host: {}
+ http:
+ paths:
+ - backend:
+ service:
+ name: redisinsight
+ port:
+ number: 80
+ path: /
+ pathType: ImplementationSpecific
+ tls:
+ - hosts:
+ - {}
+ secretName: ingress-tls
+ """.format(
+ ipadd, domain_name, domain_name
+ )
+ subprocess.run(
+ ["kubectl", "apply", "-f", "-"], input=yaml_manifest.encode(), check=True
+ )
+
+
+def get_ingress_controller_version():
+ # Run the kubectl command and capture its output
+ kubectl_cmd = "kubectl"
+ namespace = "default-tenant"
+ grep_cmd = "grep shell.default-tenant"
+ awk_cmd1 = "awk '{print $3}'"
+ awk_cmd2 = "awk -F shell.default-tenant '{print $2}'"
+ cmd = f"{kubectl_cmd} get ingress -n {namespace} | {grep_cmd} | {awk_cmd1} | {awk_cmd2}"
+ result = subprocess.run(
+ cmd, shell=True, check=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE
+ )
+ return result.stdout.decode("utf-8").strip()
+
+
+def get_svc_password(namespace, service_name, key):
+ cmd = f'kubectl get secret --namespace {namespace} {service_name} -o jsonpath="{{.data.{key}}}" | base64 --decode'
+ result = subprocess.run(
+ cmd, shell=True, check=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE
+ )
+ return result.stdout.decode("utf-8").strip()
+
+
+def print_svc_info(svc_host, svc_port, svc_username, svc_password, nodeport):
+ print(f"Service is running at {svc_host}:{svc_port}")
+ print(f"Service username: {svc_username}")
+ print(f"Service password: {svc_password}")
+ print(f"service nodeport: {nodeport}")
+
+
+def check_redis_installation():
+ cmd = "helm ls -A | grep -w redis | awk '{print $1}' | wc -l"
+ result = subprocess.check_output(cmd, shell=True)
+ return result.decode("utf-8").strip()
+
+
+def add_repos():
+ repos = {"bitnami": "https://charts.bitnami.com/bitnami"}
+ for repo, url in repos.items():
+ cmd = f"helm repo add {repo} {url}"
+ subprocess.run(cmd.split(), check=True)
+
+
+def install_redisinsight(ipadd):
+ print(check_redis_installation)
+ if check_redis_installation() == "1":
+ subprocess.run(["rm", "-rf", "redisinsight-chart-0.1.0.tgz*"])
+ chart_url = "https://docs.redis.com/latest/pkgs/redisinsight-chart-0.1.0.tgz"
+ chart_file = "redisinsight-chart-0.1.0.tgz"
+ subprocess.run(["wget", chart_url])
+ # get redis password
+ redis_password = subprocess.check_output(
+ [
+ "kubectl",
+ "get",
+ "secret",
+ "--namespace",
+ "devtools",
+ "redis",
+ "-o",
+ 'jsonpath="{.data.redis-password}"',
+ ],
+ encoding="utf-8",
+ ).strip('"\n')
+ redis_password = base64.b64decode(redis_password).decode("utf-8")
+ cmd = [
+ "helm",
+ "install",
+ "redisinsight",
+ chart_file,
+ "--set",
+ "redis.url=redis-master",
+ "--set",
+ "master.service.nodePort=6379",
+ "--set",
+ f"auth.password={redis_password}",
+ "--set",
+ "fullnameOverride=redisinsight",
+ "--namespace",
+ "devtools",
+ ]
+ subprocess.run(cmd.split(), check=True)
+ # run patch cmd
+ fqdn = get_ingress_controller_version()
+ full_domain = "redisinsight" + fqdn
+ create_ingress_resource(full_domain, ipadd)
+ deployment_name = "redisinsight"
+ container_name = "redisinsight-chart"
+ env_name = "RITRUSTEDORIGINS"
+ full_domain = full_domain
+ pfull_domain = "https://" + full_domain
+ patch_command = (
+ f'kubectl patch deployment -n devtools {deployment_name} -p \'{{"spec":{{"template":{{"spec":{{'
+ f'"containers":[{{"name":"{container_name}","env":[{{"name":"{env_name}","value":"'
+ f"{pfull_domain}\"}}]}}]}}}}}}}}'"
+ )
+ subprocess.run(patch_command, shell=True)
+ clean_command = "rm -rf redisinsight-chart-0.1.0.tgz*"
+ subprocess.run(clean_command, shell=True)
+ else:
+ print("redis is not install, please install redis first")
+ exit()
+
+
+@click.command()
+@click.option("--redis", is_flag=True, help="Install Redis")
+@click.option("--kafka", is_flag=True, help="Install Kafka")
+@click.option("--mysql", is_flag=True, help="Install MySQL")
+@click.option("--redisinsight", is_flag=True, help="Install Redis GUI")
+@click.option("--ipadd", default="localhost", help="IP address as string")
+def install(redis, kafka, mysql, redisinsight, ipadd):
+ # Check if the local-path storage class exists
+ output, exit_code = run_command(
+ "kubectl get storageclass local-path >/dev/null 2>&1"
+ )
+ if exit_code != 0:
+ # Install the local-path provisioner
+ cmd = (
+ "kubectl apply -f https://raw.githubusercontent.com/rancher/local-path-provisioner/v0.0.24/deploy/local"
+ "-path-storage.yaml"
+ )
+ output, exit_code = run_command(cmd)
+ if exit_code == 0:
+ # Set the local-path storage class as the default
+ cmd = (
+ 'kubectl patch storageclass local-path -p \'{"metadata": {"annotations":{'
+ '"storageclass.kubernetes.io/is-default-class":"true"}}}\''
+ )
+ output, exit_code = run_command(cmd)
+ if exit_code == 0:
+ print(
+ "local-path storage class has been installed and set as the default."
+ )
+ else:
+ print(f"Error setting local-path storage class as default: {output}")
+ else:
+ print(f"Error installing local-path storage class: {output}")
+ else:
+ print("local-path storage class already exists.")
+ services = {
+ "redis": {
+ "chart": "bitnami/redis",
+ "set_values": "--set master.service.nodePorts.redis=31001",
+ },
+ "kafka": {
+ "chart": "bitnami/kafka",
+ "set_values": "--set service.nodePorts.client=31002",
+ },
+ "mysql": {
+ "chart": "bitnami/mysql",
+ "set_values": "--set primary.service.nodePorts.mysql=31003",
+ },
+ }
+ namespace = "devtools"
+ # Add Helm repos
+ add_repos()
+ # Check if the namespace exists, if not create it
+ check_namespace_cmd = f"kubectl get namespace {namespace}"
+ try:
+ subprocess.run(check_namespace_cmd.split(), check=True)
+ except subprocess.CalledProcessError:
+ create_namespace_cmd = f"kubectl create namespace {namespace}"
+ subprocess.run(create_namespace_cmd.split(), check=True)
+ for service, data in services.items():
+ if locals().get(service):
+ chart = data["chart"]
+ set_values = data["set_values"]
+ cmd = f"helm install {service} {chart} {set_values} --namespace {namespace}"
+ print(cmd)
+ subprocess.run(cmd.split(), check=True)
+ if redisinsight:
+ install_redisinsight(ipadd)
+
+
+@click.command()
+@click.option("--redis", is_flag=True, help="Uninstall Redis")
+@click.option("--kafka", is_flag=True, help="Uninstall Kafka")
+@click.option("--mysql", is_flag=True, help="Uninstall MySQL")
+@click.option("--redisinsight", is_flag=True, help="Uninstall Redis GUI")
+def uninstall(redis, kafka, mysql, redisinsight):
+ services = ["redis", "kafka", "mysql", "redisinsight"]
+ namespace = "devtools"
+ try:
+ if redisinsight:
+ cmd = "kubectl delete ingress -n devtools redisinsight"
+ subprocess.run(cmd.split(), check=True)
+ for service in services:
+ if locals().get(service):
+ cmd = f"helm uninstall {service} --namespace {namespace}"
+ subprocess.run(cmd.split(), check=True)
+ print("namespace deleteted")
+ delns = "kubectl delete namespace devtools"
+ subprocess.run(cmd.split(), check=True)
+ except Exception as e: # !!!
+ print(e)
+ pass
+ # code to handle any exception
+
+
+@click.command()
+def list_services():
+ namespace = "devtools"
+ # for service in services:
+ cmd = f"helm ls --namespace {namespace} "
+ subprocess.run(cmd.split(), check=True)
+
+
+def list_services_h():
+ namespace = "devtools"
+ return get_installed_releases(namespace)
+
+
+@click.command()
+@click.option("--redis", is_flag=True, help="Install Redis")
+@click.option("--kafka", is_flag=True, help="Install Kafka")
+@click.option("--mysql", is_flag=True, help="Install MySQL")
+@click.option("--redisinsight", is_flag=True, help="Install Redis GUI")
+def status(redis, kafka, mysql, redisinsight):
+ namespace = "devtools"
+ if redis:
+ svc_password = get_svc_password(namespace, "redis", "redis-password")
+ print_svc_info(
+ "redis-master-0.redis-headless.devtools.svc.cluster.local",
+ 6379,
+ "default",
+ svc_password,
+ "-------",
+ )
+ if kafka:
+ print_svc_info("kafka", 9092, "-------", "-------", "-------")
+ if mysql:
+ svc_password = get_svc_password(namespace, "mysql", "mysql-root-password")
+ print_svc_info("mysql", 3306, "root", svc_password, "-------")
+ if redisinsight:
+ fqdn = get_ingress_controller_version()
+ full_domain = "https://redisinsight" + fqdn
+ print_svc_info("", " " + full_domain, "-------", "-------", "-------")
+
+
+def status_h(svc):
+ namespace = "devtools"
+ if svc == "redis":
+ svc_password = get_svc_password(namespace, "redis", "redis-password")
+ dict = {
+ "app_url": "redis-master-0.redis-headless.devtools.svc.cluster.local:6379",
+ "username": "default",
+ "password": svc_password,
+ }
+ return dict
+ if svc == "kafka":
+ dict = {"app_url": "kafka-0.kafka-headless.devtools.svc.cluster.local:9092"}
+ return dict
+ if svc == "mysql":
+ svc_password = get_svc_password(namespace, "mysql", "mysql-root-password")
+ dict = {
+ "app_url": "mysql-0.mysql.devtools.svc.cluster.local:3306",
+ "username": "root",
+ "password": svc_password,
+ }
+ return dict
+ if svc == "redisinsight":
+ fqdn = get_ingress_controller_version()
+ full_domain = "https://redisinsight" + fqdn
+ dict = {"app_url": full_domain}
+ return dict
+
+
+@click.group()
+def cli():
+ pass
+
+
+cli.add_command(install)
+cli.add_command(uninstall)
+cli.add_command(list_services)
+cli.add_command(status)
+
+if __name__ == "__main__":
+ cli()
diff --git a/automation/system_test/prepare.py b/automation/system_test/prepare.py
index 47073d6aedc8..a6941421fe66 100644
--- a/automation/system_test/prepare.py
+++ b/automation/system_test/prepare.py
@@ -348,7 +348,6 @@ def _override_mlrun_api_env(self):
)
def _install_dev_utilities(self):
- urlscript = "https://gist.github.com/a51d75fe52e95df617b5dbb983c8e6e1.git"
list_uninstall = [
"dev_utilities.py",
"uninstall",
@@ -368,15 +367,8 @@ def _install_dev_utilities(self):
os.environ.get("IP_ADDR_PREFIX", "localhost"),
]
self._run_command("rm", args=["-rf", "/home/iguazio/dev_utilities"])
- self._run_command(
- "git", args=["clone", urlscript, "dev_utilities"], workdir="/home/iguazio"
- )
- self._run_command(
- "python3", args=list_uninstall, workdir="/home/iguazio/dev_utilities"
- )
- self._run_command(
- "python3", args=list_install, workdir="/home/iguazio/dev_utilities"
- )
+ self._run_command("python3", args=list_uninstall, workdir="/home/iguazio/")
+ self._run_command("python3", args=list_install, workdir="/home/iguazio/")
def _download_provctl(self):
# extract bucket name, object name from s3 file path
@@ -517,7 +509,6 @@ def _patch_mlrun(self):
self._run_command(f"cat {provctl_patch_mlrun_log}")
def _resolve_iguazio_version(self):
-
# iguazio version is optional, if not provided, we will try to resolve it from the data node
if not self._iguazio_version:
self._logger.info("Resolving iguazio version")
From 0123ed74bcf908749a44e18363b0bc574d57b1d0 Mon Sep 17 00:00:00 2001
From: jillnogold <88145832+jillnogold@users.noreply.github.com>
Date: Tue, 30 May 2023 17:25:43 +0300
Subject: [PATCH 216/334] [Docs] Add simple descriptions of function types: job
and serving (#3586)
---
docs/concepts/functions-overview.md | 6 ++--
docs/projects/git-best-practices.ipynb | 2 +-
docs/projects/project.md | 2 +-
docs/runtimes/job-function.md | 38 ++++++++++++++++++++++++++
docs/runtimes/serving-function.md | 21 ++++++++++++++
docs/tutorial/03-model-serving.ipynb | 1 +
mlrun/run.py | 3 +-
7 files changed, 67 insertions(+), 6 deletions(-)
create mode 100644 docs/runtimes/job-function.md
create mode 100644 docs/runtimes/serving-function.md
diff --git a/docs/concepts/functions-overview.md b/docs/concepts/functions-overview.md
index 638a7b2b484c..d9c5aa5b8249 100644
--- a/docs/concepts/functions-overview.md
+++ b/docs/concepts/functions-overview.md
@@ -8,12 +8,12 @@ MLRun supports real-time and batch runtimes.
Real-time runtimes:
* **{ref}`nuclio `** - real-time serverless functions over Nuclio
-* **{ref}`serving `** - higher level real-time Graph (DAG) over one or more Nuclio functions
+* **{ref}`serving `** - deploy models and higher-level real-time Graph (DAG) over one or more Nuclio functions
Batch runtimes:
* **handler** - execute python handler (used automatically in notebooks or for debug)
* **local** - execute a Python or shell program
-* **job** - run the code in a Kubernetes Pod
+* **{ref}`job `** - run the code in a Kubernetes Pod
* **{ref}`dask `** - run the code as a Dask Distributed job (over Kubernetes)
* **{ref}`mpijob `** - run distributed jobs and Horovod over the MPI job operator, used mainly for deep learning jobs
* **{ref}`spark