 +
+ +
+ +
+ -
- -
- +* * *
-* * *
+### [Export Tables](file:///Users/Zad/Desktop/GitHub/concurve/docs/reference/curve_table.html) Easily For Word, Powerpoint, & TeX documents
+
+* * *
-* * *
+### [Export Tables](file:///Users/Zad/Desktop/GitHub/concurve/docs/reference/curve_table.html) Easily For Word, Powerpoint, & TeX documents
+ -# Installation
+
-
+
+
+
+
-----
-# Installation
+### [Export Tables](file:///Users/Zad/Desktop/GitHub/concurve/docs/reference/curve_table.html) Easily For Word, Powerpoint, & TeX documents
-## For R:
+
-``` r
-install.packages("concurve")
-```
+
-# Installation
+
-
+
+
+
+
-----
-# Installation
+### [Export Tables](file:///Users/Zad/Desktop/GitHub/concurve/docs/reference/curve_table.html) Easily For Word, Powerpoint, & TeX documents
-## For R:
+
-``` r
-install.packages("concurve")
-```
+-
-
+
diff --git a/docs/CONTRIBUTING.html b/docs/CONTRIBUTING.html
new file mode 100644
index 0000000..bd0a829
--- /dev/null
+++ b/docs/CONTRIBUTING.html
@@ -0,0 +1,238 @@
+
+
+
+
+
+
+
+
+
Contributing to concurve • concurve + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + +++ + + + + + + + + + + diff --git a/docs/ISSUE_TEMPLATE.html b/docs/ISSUE_TEMPLATE.html new file mode 100644 index 0000000..3af6ae1 --- /dev/null +++ b/docs/ISSUE_TEMPLATE.html @@ -0,0 +1,199 @@ + + + + + + + + ++ + +++ + + ++++ ++ + + + concurve
+ 2.3.0
+
+ ++ + + + +++ +++ +
+ concurve
+ 2.3.0
+
+ ++ + + + +++ +++ +Contributing to concurve
++ ++ +This outlines how to propose a change to concurve. For more detailed info about contributing to this, and other tidyverse packages, please see the development contributing guide.
++++Fixing typos
+Small typos or grammatical errors in documentation may be edited directly using the GitHub web interface, so long as the changes are made in the source file.
+-
+
- YES: you edit a roxygen comment in a
.Rfile belowR/.
+ - NO: you edit an
.Rdfile belowman/.
+
+++Prerequisites
+Before you make a substantial pull request, you should always file an issue and make sure someone from the team agrees that it’s a problem. If you’ve found a bug, create an associated issue and illustrate the bug with a minimal reprex.
++++Pull request process
+-
+
- We recommend that you create a Git branch for each pull request (PR).
+
+ - Look at the Travis and AppVeyor build status before and after making changes. The
READMEshould contain badges for any continuous integration services used by the package.
+
+ - New code should follow the tidyverse style guide. You can use the styler package to apply these styles, but please don’t restyle code that has nothing to do with your PR.
+
+ - We use roxygen2, with Markdown syntax, for documentation.
+
+ - We use testthat. Contributions with test cases included are easier to accept.
+
+ - For user-facing changes, add a bullet to the top of
NEWS.mdbelow the current development version header describing the changes made followed by your GitHub username, and links to relevant issue(s)/PR(s).
+
+++Code of Conduct
+Please note that the concurve project is released with a Contributor Code of Conduct. By contributing to this project you agree to abide by its terms.
++++See tidyverse development contributing guide +
+for further details.
+NA • concurve + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + +++ + + + + + + + + + + diff --git a/docs/LICENSE-text.html b/docs/LICENSE-text.html index 9a55734..65cabe4 100644 --- a/docs/LICENSE-text.html +++ b/docs/LICENSE-text.html @@ -82,9 +82,9 @@ - ++ + +++ + + ++++ ++ + +
+ concurve
+ 2.3.0
+
+ ++ + + + +++ +++ + +NA
+Please briefly describe your problem and what output you expect. If you have a question, please don’t use this form. Instead, ask on https://stackoverflow.com/ or https://community.rstudio.com/.
+Please include a minimal reproducible example (AKA a reprex). If you’ve never heard of a reprex before, start by reading https://www.tidyverse.org/help/#reprex.
+
+Brief description of the problem
+ + + +
concurve
- 2.1.0
+ 2.3.0
@@ -120,7 +120,7 @@
- YES: you edit a roxygen comment in a
-
-
+
diff --git a/docs/SUPPORT.html b/docs/SUPPORT.html
new file mode 100644
index 0000000..ec46a06
--- /dev/null
+++ b/docs/SUPPORT.html
@@ -0,0 +1,208 @@
+
+
+
+
+
+
+
+
+
Getting help with concurve • concurve + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + +++ + + + + + + + + + + diff --git a/docs/articles/examples.html b/docs/articles/examples.html index c6b587d..b8cb1ab 100644 --- a/docs/articles/examples.html +++ b/docs/articles/examples.html @@ -39,9 +39,8 @@ - - concurve - 2.1.0 ++ + +++ + + ++++ ++ + +
+ concurve
+ 2.3.0
+
+ ++ + + + +++ +++ +Getting help with concurve
++ ++ +Thanks for using concurve. Before filing an issue, there are a few places to explore and pieces to put together to make the process as smooth as possible.
+Start by making a minimal reproducible example using the reprex package. If you haven’t heard of or used reprex before, you’re in for a treat! Seriously, reprex will make all of your R-question-asking endeavors easier (which is a pretty insane ROI for the five to ten minutes it’ll take you to learn what it’s all about). For additional reprex pointers, check out the Get help! section of the tidyverse site.
+Armed with your reprex, the next step is to figure out where to ask.
+-
+
- If it’s a question: start with community.rstudio.com, and/or StackOverflow. There are more people there to answer questions.
+
+ - If it’s a bug: you’re in the right place, file an issue.
+
+ - If you’re not sure: let the community help you figure it out! If your problem is a bug or a feature request, you can easily return here and report it. +
Before opening a new issue, be sure to search issues and pull requests to make sure the bug hasn’t been reported and/or already fixed in the development version. By default, the search will be pre-populated with
+is:issue is:open. You can edit the qualifiers (e.g.is:pr,is:closed) as needed. For example, you’d simply removeis:opento search all issues in the repo, open or closed.If you are in the right place, and need to file an issue, please review the “File issues” paragraph from the tidyverse contributing guidelines.
+Thanks for your help!
+concurve
+ 2.3.0
@@ -77,7 +76,7 @@
- If it’s a question: start with community.rstudio.com, and/or StackOverflow. There are more people there to answer questions.
-
-
+
@@ -98,181 +97,552 @@
- + +@@ -120,7 +120,7 @@diff --git a/docs/articles/examples_files/figure-html/unnamed-chunk-10-1.png b/docs/articles/examples_files/figure-html/unnamed-chunk-10-1.png new file mode 100644 index 0000000..2c840db Binary files /dev/null and b/docs/articles/examples_files/figure-html/unnamed-chunk-10-1.png differ diff --git a/docs/articles/examples_files/figure-html/unnamed-chunk-11-1.png b/docs/articles/examples_files/figure-html/unnamed-chunk-11-1.png new file mode 100644 index 0000000..86c6c9a Binary files /dev/null and b/docs/articles/examples_files/figure-html/unnamed-chunk-11-1.png differ diff --git a/docs/articles/examples_files/figure-html/unnamed-chunk-12-1.png b/docs/articles/examples_files/figure-html/unnamed-chunk-12-1.png new file mode 100644 index 0000000..249537a Binary files /dev/null and b/docs/articles/examples_files/figure-html/unnamed-chunk-12-1.png differ diff --git a/docs/articles/examples_files/figure-html/unnamed-chunk-12-2.png b/docs/articles/examples_files/figure-html/unnamed-chunk-12-2.png new file mode 100644 index 0000000..2708ff4 Binary files /dev/null and b/docs/articles/examples_files/figure-html/unnamed-chunk-12-2.png differ diff --git a/docs/articles/examples_files/figure-html/unnamed-chunk-13-1.png b/docs/articles/examples_files/figure-html/unnamed-chunk-13-1.png new file mode 100644 index 0000000..dd10750 Binary files /dev/null and b/docs/articles/examples_files/figure-html/unnamed-chunk-13-1.png differ diff --git a/docs/articles/examples_files/figure-html/unnamed-chunk-13-2.png b/docs/articles/examples_files/figure-html/unnamed-chunk-13-2.png new file mode 100644 index 0000000..44d938d Binary files /dev/null and b/docs/articles/examples_files/figure-html/unnamed-chunk-13-2.png differ diff --git a/docs/articles/examples_files/figure-html/unnamed-chunk-14-1.png b/docs/articles/examples_files/figure-html/unnamed-chunk-14-1.png new file mode 100644 index 0000000..74d7040 Binary files /dev/null and b/docs/articles/examples_files/figure-html/unnamed-chunk-14-1.png differ diff --git a/docs/articles/examples_files/figure-html/unnamed-chunk-15-1.png b/docs/articles/examples_files/figure-html/unnamed-chunk-15-1.png new file mode 100644 index 0000000..67264c8 Binary files /dev/null and b/docs/articles/examples_files/figure-html/unnamed-chunk-15-1.png differ diff --git a/docs/articles/examples_files/figure-html/unnamed-chunk-18-1.png b/docs/articles/examples_files/figure-html/unnamed-chunk-18-1.png new file mode 100644 index 0000000..f8cc906 Binary files /dev/null and b/docs/articles/examples_files/figure-html/unnamed-chunk-18-1.png differ diff --git a/docs/articles/examples_files/figure-html/unnamed-chunk-18-2.png b/docs/articles/examples_files/figure-html/unnamed-chunk-18-2.png new file mode 100644 index 0000000..ecef3ae Binary files /dev/null and b/docs/articles/examples_files/figure-html/unnamed-chunk-18-2.png differ diff --git a/docs/articles/examples_files/figure-html/unnamed-chunk-20-1.png b/docs/articles/examples_files/figure-html/unnamed-chunk-20-1.png new file mode 100644 index 0000000..8fcfd2c Binary files /dev/null and b/docs/articles/examples_files/figure-html/unnamed-chunk-20-1.png differ diff --git a/docs/articles/examples_files/figure-html/unnamed-chunk-22-1.png b/docs/articles/examples_files/figure-html/unnamed-chunk-22-1.png new file mode 100644 index 0000000..51401b4 Binary files /dev/null and b/docs/articles/examples_files/figure-html/unnamed-chunk-22-1.png differ diff --git a/docs/articles/examples_files/figure-html/unnamed-chunk-22-2.png b/docs/articles/examples_files/figure-html/unnamed-chunk-22-2.png new file mode 100644 index 0000000..3c1d335 Binary files /dev/null and b/docs/articles/examples_files/figure-html/unnamed-chunk-22-2.png differ diff --git a/docs/articles/examples_files/figure-html/unnamed-chunk-27-1.png b/docs/articles/examples_files/figure-html/unnamed-chunk-27-1.png new file mode 100644 index 0000000..1e7ec63 Binary files /dev/null and b/docs/articles/examples_files/figure-html/unnamed-chunk-27-1.png differ diff --git a/docs/articles/examples_files/figure-html/unnamed-chunk-27-2.png b/docs/articles/examples_files/figure-html/unnamed-chunk-27-2.png new file mode 100644 index 0000000..8af57eb Binary files /dev/null and b/docs/articles/examples_files/figure-html/unnamed-chunk-27-2.png differ diff --git a/docs/articles/examples_files/figure-html/unnamed-chunk-27-3.png b/docs/articles/examples_files/figure-html/unnamed-chunk-27-3.png new file mode 100644 index 0000000..cb0b637 Binary files /dev/null and b/docs/articles/examples_files/figure-html/unnamed-chunk-27-3.png differ diff --git a/docs/articles/examples_files/figure-html/unnamed-chunk-27-4.png b/docs/articles/examples_files/figure-html/unnamed-chunk-27-4.png new file mode 100644 index 0000000..5b194a6 Binary files /dev/null and b/docs/articles/examples_files/figure-html/unnamed-chunk-27-4.png differ diff --git a/docs/articles/examples_files/figure-html/unnamed-chunk-4-1.png b/docs/articles/examples_files/figure-html/unnamed-chunk-4-1.png new file mode 100644 index 0000000..aa45fa2 Binary files /dev/null and b/docs/articles/examples_files/figure-html/unnamed-chunk-4-1.png differ diff --git a/docs/articles/examples_files/figure-html/unnamed-chunk-5-1.png b/docs/articles/examples_files/figure-html/unnamed-chunk-5-1.png new file mode 100644 index 0000000..8a02eeb Binary files /dev/null and b/docs/articles/examples_files/figure-html/unnamed-chunk-5-1.png differ diff --git a/docs/articles/examples_files/figure-html/unnamed-chunk-6-1.png b/docs/articles/examples_files/figure-html/unnamed-chunk-6-1.png new file mode 100644 index 0000000..224650d Binary files /dev/null and b/docs/articles/examples_files/figure-html/unnamed-chunk-6-1.png differ diff --git a/docs/articles/examples_files/figure-html/unnamed-chunk-9-1.png b/docs/articles/examples_files/figure-html/unnamed-chunk-9-1.png new file mode 100644 index 0000000..9054067 Binary files /dev/null and b/docs/articles/examples_files/figure-html/unnamed-chunk-9-1.png differ diff --git a/docs/articles/examples_files/tabwid-1.0.0/tabwid.css b/docs/articles/examples_files/tabwid-1.0.0/tabwid.css new file mode 100644 index 0000000..42d1c96 --- /dev/null +++ b/docs/articles/examples_files/tabwid-1.0.0/tabwid.css @@ -0,0 +1,68 @@ +.tabwid table{ + border-collapse:collapse; + line-height:1; + margin-left:auto; + margin-right:auto; + border-width: 0; + display: table; + margin-top: 5px; + margin-bottom: 5px; + /*white-space:pre;*/ +} +.tabwid_left table{ + margin-left:0; +} +.tabwid_right table{ + margin-right:0; +} + +.tabwid th{ + padding:0; +} +.tabwid td { + line-height: 1em; + padding: 0; +} +.tabwid thead { + background-color: transparent; +} +.tabwid tfoot { + background-color: transparent; +} +.tabwid table tr { +background-color: transparent; +} + +.tabwid img { +background-color: transparent; +padding: 0; +border: 0; +border-radius: 0; +margin: 0; +} +.tabwid a { + text-decoration: none; +} + +.btlr { + /* FF3.5+ */ + -moz-transform: rotate(-90.0deg); + /* Opera 10.5 */ + -o-transform: rotate(-90.0deg); + /* Saf3.1+, Chrome */ + -webkit-transform: rotate(-90.0deg); + /* Standard */ + transform: rotate(-90.0deg); +} + +.tbrl { + /* FF3.5+ */ + -moz-transform: rotate(-270.0deg); + /* Opera 10.5 */ + -o-transform: rotate(-270.0deg); + /* Saf3.1+, Chrome */ + -webkit-transform: rotate(-270.0deg); + /* Standard */ + transform: rotate(-270.0deg); +} + diff --git a/docs/articles/examples_files/tabwid-1.0.0/tabwid.js b/docs/articles/examples_files/tabwid-1.0.0/tabwid.js new file mode 100644 index 0000000..d67f181 --- /dev/null +++ b/docs/articles/examples_files/tabwid-1.0.0/tabwid.js @@ -0,0 +1,6 @@ +if (window.jQuery){ + $(document).ready(function() { + $(".tabwid > .table").removeClass("table"); + }); +} + diff --git a/docs/articles/figures/densityfunction.png b/docs/articles/figures/densityfunction.png new file mode 100644 index 0000000..66d024c Binary files /dev/null and b/docs/articles/figures/densityfunction.png differ diff --git a/docs/articles/figures/function1.png b/docs/articles/figures/function1.png deleted file mode 100644 index 24d3ebe..0000000 Binary files a/docs/articles/figures/function1.png and /dev/null differ diff --git a/docs/articles/figures/function2.png b/docs/articles/figures/function2.png deleted file mode 100644 index e5b63e9..0000000 Binary files a/docs/articles/figures/function2.png and /dev/null differ diff --git a/docs/articles/figures/function3.png b/docs/articles/figures/function3.png deleted file mode 100644 index b4379b0..0000000 Binary files a/docs/articles/figures/function3.png and /dev/null differ diff --git a/docs/articles/figures/function4.png b/docs/articles/figures/function4.png deleted file mode 100644 index 5444297..0000000 Binary files a/docs/articles/figures/function4.png and /dev/null differ diff --git a/docs/articles/figures/function5.png b/docs/articles/figures/function5.png deleted file mode 100644 index ff6cdce..0000000 Binary files a/docs/articles/figures/function5.png and /dev/null differ diff --git a/docs/articles/figures/function6.png b/docs/articles/figures/function6.png deleted file mode 100644 index d596ca7..0000000 Binary files a/docs/articles/figures/function6.png and /dev/null differ diff --git a/docs/articles/figures/likelihood.png b/docs/articles/figures/likelihood.png deleted file mode 100644 index f2faf96..0000000 Binary files a/docs/articles/figures/likelihood.png and /dev/null differ diff --git a/docs/articles/index.html b/docs/articles/index.html index 736b1a9..ba67a6d 100644 --- a/docs/articles/index.html +++ b/docs/articles/index.html @@ -82,9 +82,9 @@ - +-+@@ -282,9 +652,15 @@-
-Using Mean Differences
-If we were to generate some random data from a normal distribution with the following code,
- -and compare the means of these two “groups” using a t-test,
- -we would likely see some differences, given that we have such a small sample in each group.
- -We can see our P-value for the statistical test along with the computed 95% interval with the command above (which is given to us by default by the program). Thus, effect sizes that range from the lower bound of this interval to the upper bound are compatible with the test model at this consonance level.
-However, as stated before, a 95% interval is only an artifact of the commonly used 5% alpha level for hypothesis testing and is nowhere near as informative as a function.
-If we were to take the information from this data and calculate a P-value function where every single consonance interval and its corresponding P-value were plotted, we would be able to see the full range of effect sizes compatible with the test model at various levels.
-It is relatively easy to produce such a function using the concurve package in R.
-Install the package directly from CRAN
- -or get a more slightly up-to-date version via GitHub.
- -We’ll use the same data from above to calculate a P-value function and since we are focusing on mean differences using a t-test, we will use the
-curve_meta()function to calculate our consonance intervals and store them in a dataframe.-library(concurve) -intervalsdf <- curve_mean(GroupA, GroupB, - data = RandomData, method = "default" -)Now thousands of consonance intervals at various levels have been stored in the dataframe “intervalsdf.” We can preview some of the entries via the
- -tibblepackage.There’s a quick look at the first few entries of our dataframe.
-We can plot this data using the
- -ggconcurve()function.- - -
-Now we can see every consonance interval and its corresponding P-value and consonance level plotted. As stated before, a single 95% consonance interval is simply a slice through this function, which provides far more information as to what is compatible with the test model and its assumptions.
-Furthermore, we can also produce a “surprisal” function by plotting every consonance interval and its corresponding S-value using the
- -ggconcurve()function with type being set as “surprisal”.- - -
-The graph from the code above provides us with consonance levels and the maximum amount of information against the effect sizes contained in the consonance interval.
----Simple Linear Models
-We can also try this with other simple linear models.
-Let’s simulate more normal data and fit a simple linear regression to it using ordinary least squares regression with the base R
-lm()function.-GroupA2 <- rnorm(500) -GroupB2 <- rnorm(500) - -RandomData2 <- data.frame(GroupA2, GroupB2) - -model <- lm(GroupA2 ~ GroupB2, data = RandomData2) - -summary(model)We can see some of the basic statistics of our model including the 95% interval for our predictor (GroupB). Perhaps we want more information. Well we can do that! Using the
- -curve_gen(), we can calculate several consonance intervals for the regression coefficient and then plot the consonance and surprisal functions.Now that we have our data frame, we can graph our function.
- -- - - -
-- - -
-We can also compare these functions to likelihood functions (also called support intervals), and we’ll see that we get very similar results. We’ll do this using the ProfileLikelihood package.
--xx <- profilelike.lm( - formula = GroupA2 ~ 1, data = RandomData2, - profile.theta = "GroupB2", - lo.theta = -0.3, hi.theta = 0.3, length = 500 -)Now we plot our likelihood function and we can see what the maximum likelihood estimation is. Notice that it’s practically similar to the interval in the S-value function with 0 bits of information against it and and the consonance interval in the P-value function with a P-value of 1.
--profilelike.plot( - theta = xx$theta, - profile.lik.norm = xx$profile.lik.norm, round = 3 -) -title(main = "Likelihood Function")- - -
-We’ve used a relatively easy example for this blog post, but the concurve package is also able to calculate consonance functions for multiple regressions, logistic regressions, ANOVAs, and meta-analyses (that have been produced by the metafor package).
-+Introduction ++Here I show how to produce P-value, S-value, likelihood, and deviance functions with the
+concurvepackage using fake data and data from real studies. Simply put, these functions are rich sources of information for scientific inference and the image below, taken from Xie & Singh, 20131 displays why.
+
For a more extensive discussion of these concepts, see the following references.1–13
+To get started, we could generate some normal data and combine two vectors in a dataframe
++library(concurve) +set.seed(1031) +GroupA <- rnorm(500) +GroupB <- rnorm(500) +RandomData <- data.frame(GroupA, GroupB)and look at the differences between the two vectors. We’ll plug these vectors and the dataframe they’re in inside of the
+ +curve_mean()function. Here, the default method involves calculating CIs using the Wald method.Each of the functions within
+concurvewill generally produce a list with three items, and the first will usually contain the function of interest.+tibble::tibble(intervalsdf[[1]]) +#> # A tibble: 10,000 x 1 +#> `intervalsdf[[1… $upper.limit $intrvl.width $intrvl.level $cdf $pvalue +#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> +#> 1 -0.113 -0.113 0 0 0.5 1 +#> 2 -0.113 -0.113 0.0000154 0.0001 0.500 1.000 +#> 3 -0.113 -0.113 0.0000309 0.0002 0.500 1.000 +#> 4 -0.113 -0.113 0.0000463 0.000300 0.500 1.000 +#> 5 -0.113 -0.113 0.0000617 0.0004 0.500 1.000 +#> 6 -0.113 -0.113 0.0000772 0.0005 0.500 1.000 +#> 7 -0.113 -0.113 0.0000926 0.000600 0.500 0.999 +#> 8 -0.113 -0.113 0.000108 0.0007 0.500 0.999 +#> 9 -0.113 -0.112 0.000123 0.0008 0.500 0.999 +#> 10 -0.113 -0.112 0.000139 0.0009 0.500 0.999 +#> # … with 9,990 more rows, and 1 more variable: $svalue <dbl>We can view the function using the
+ +ggcurve()function. The two basic arguments that must be provided are the data argument and the “type” argument. To plot a consonance function, we would write “c”.
+
We can see that the consonance “curve” is every interval estimate plotted, and provides the P-values, CIs, along with the median unbiased estimate It can be defined as such,
+\[C V_{n}(\theta)=1-2\left|H_{n}(\theta)-0.5\right|=2 \min \left\{H_{n}(\theta), 1-H_{n}(\theta)\right\}\]
+Its information counterpart, the surprisal function, can be constructed by taking the \(-log_{2}\) of the P-value.3,14,15
+To view the surprisal function, we simply change the type to “s”.
+ +
+
We can also view the consonance distribution by changing the type to “cdf”, which is a cumulative probability distribution. The point at which the curve reaches 50% is known as the “median unbiased estimate”. It is the same estimate that is typically at the peak of the P-value curve from above.
+ +
+
We can also get relevant statistics that show the range of values by using the
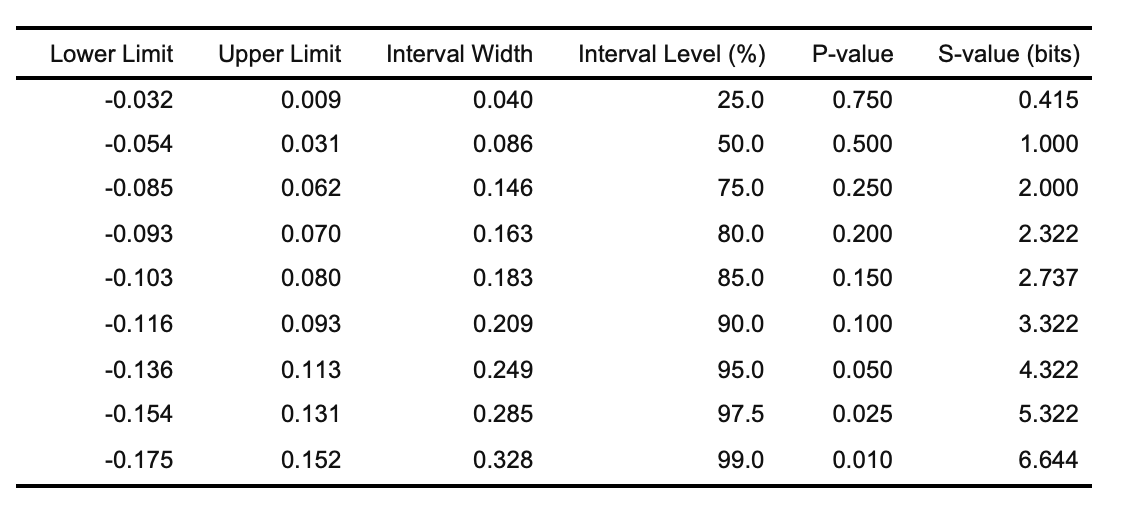
+ +curve_table()function. There are several formats that can be exported such as .docx, .ppt, and TeX.++
+ + +Lower Limit
Upper Limit
Interval Width
Interval Level (%)
CDF
P-value
S-value (bits)
+ +-0.132
-0.093
0.039
25.0
0.625
0.750
0.415
+ +-0.154
-0.071
0.083
50.0
0.750
0.500
1.000
+ +-0.183
-0.042
0.142
75.0
0.875
0.250
2.000
+ +-0.192
-0.034
0.158
80.0
0.900
0.200
2.322
+ +-0.201
-0.024
0.177
85.0
0.925
0.150
2.737
+ +-0.214
-0.011
0.203
90.0
0.950
0.100
3.322
+ +-0.233
0.008
0.242
95.0
0.975
0.050
4.322
+ +-0.251
0.026
0.276
97.5
0.988
0.025
5.322
+ + +-0.271
0.046
0.318
99.0
0.995
0.010
6.644
+++Comparing Functions
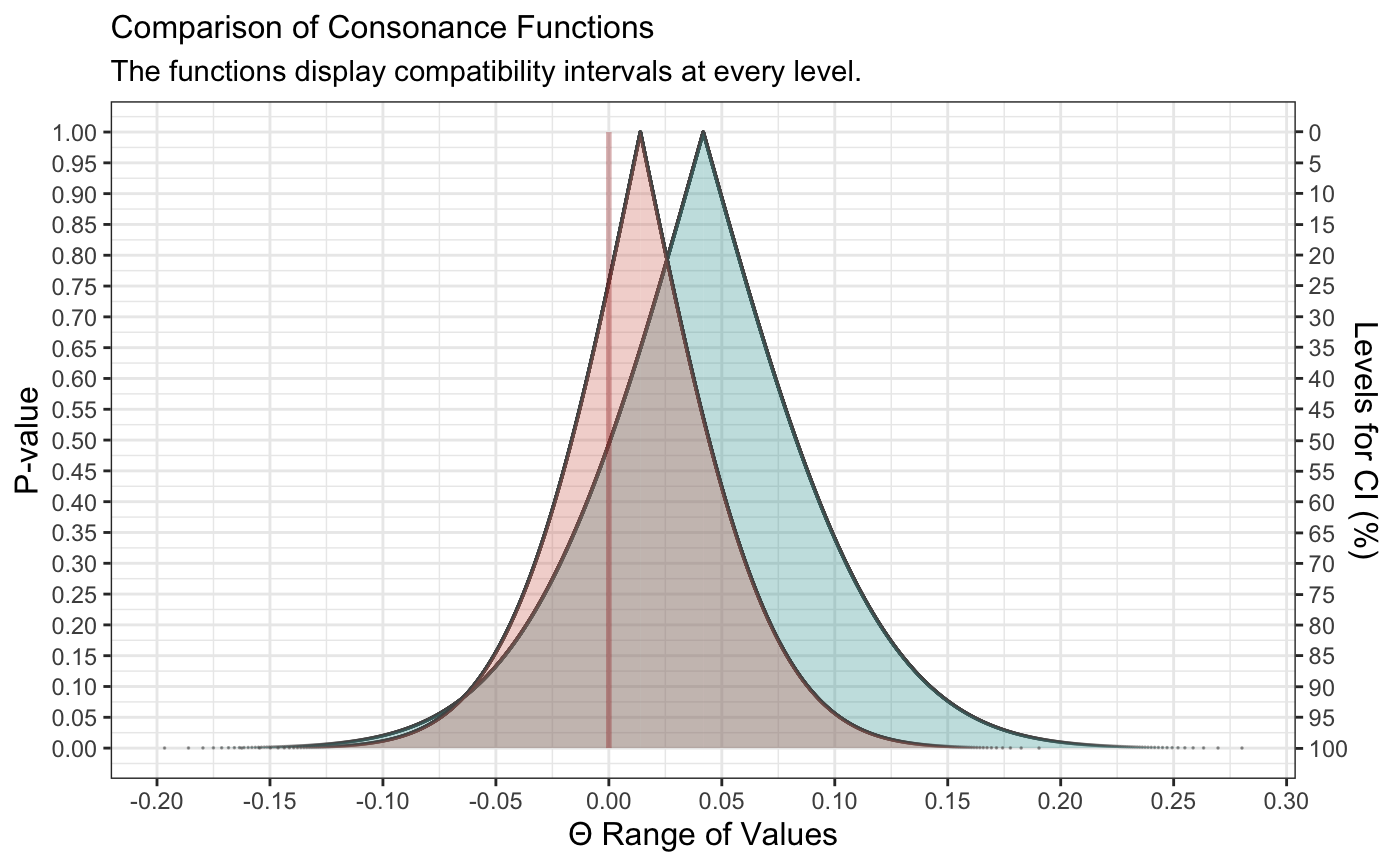
+If we wanted to compare two studies to see the amount of “consonance”, we could use the
+curve_compare()function to get a numerical output.First, we generate some more fake data
++GroupA2 <- rnorm(500) +GroupB2 <- rnorm(500) +RandomData2 <- data.frame(GroupA2, GroupB2) +model <- lm(GroupA2 ~ GroupB2, data = RandomData2) +randomframe <- curve_gen(model, "GroupB2")Once again, we’ll plot this data with
+ggcurve(). We can also indicate whether we want certain interval estimates to be plotted in the function with the “levels” argument. If we wanted to plot the 50%, 75%, and 95% intervals, we’d provide the argument this way:+(function2 <- ggcurve(type = "c", randomframe[[1]], levels = c(0.50, 0.75, 0.95), nullvalue = TRUE))
+
Now that we have two datasets and two functions, we can compare them using the
+curve_compare()function.+(curve_compare( + data1 = intervalsdf[[1]], data2 = randomframe[[1]], type = "c", + plot = TRUE, measure = "default", nullvalue = TRUE +)) +#> [1] "AUC = Area Under the Curve" +#> [[1]] +#> +#> +#> AUC 1 AUC 2 Shared AUC AUC Overlap (%) Overlap:Non-Overlap AUC Ratio +#> ------ ------ ----------- ---------------- ------------------------------ +#> 0.098 0.073 0.024 0.163 0.195 +#> +#> [[2]]
+
This function will provide us with the area that is shared between the curve, along with a ratio of overlap to non-overlap.
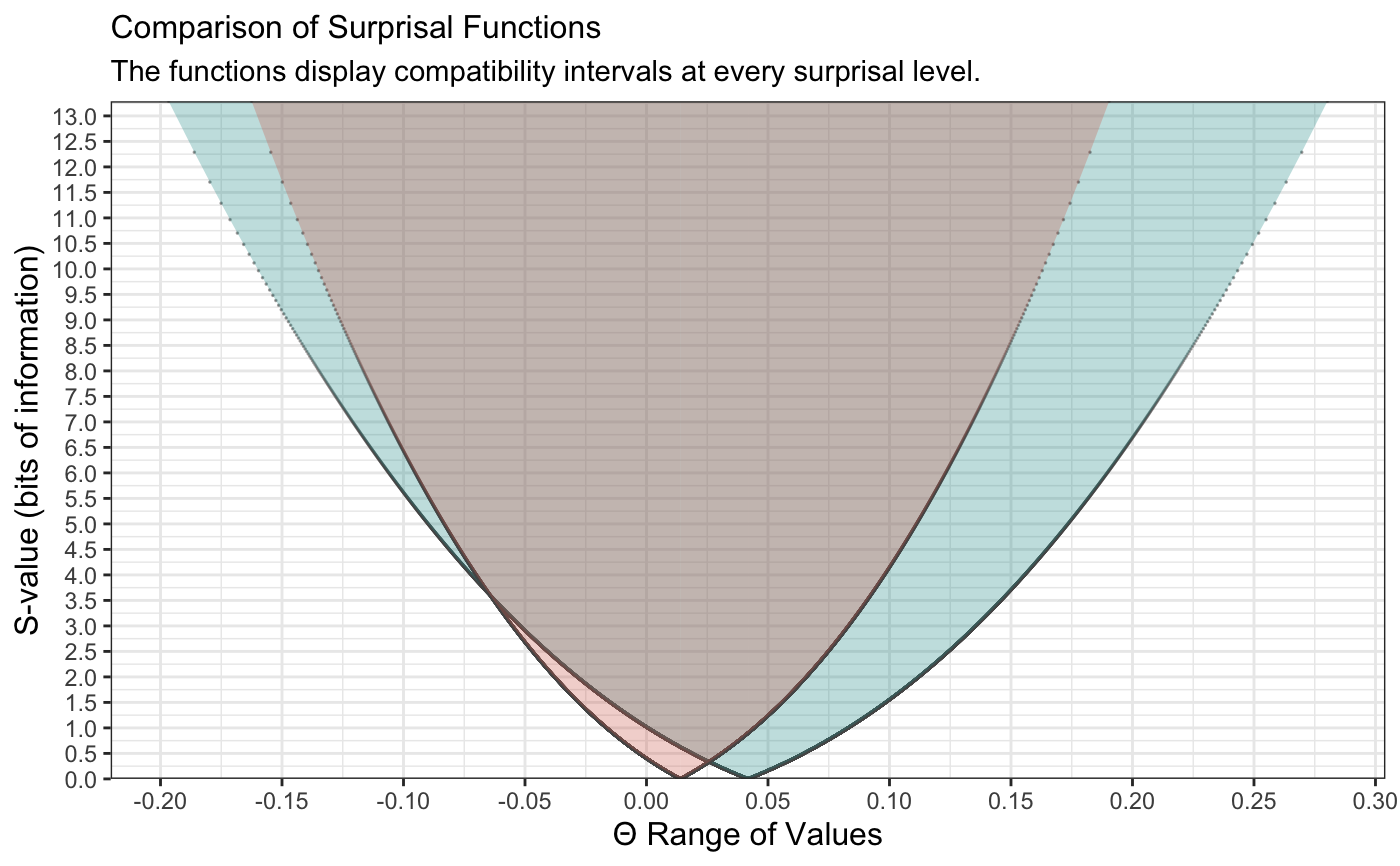
+We can also do this for the surprisal function simply by changing type to “s”.
++(curve_compare( + data1 = intervalsdf[[1]], data2 = randomframe[[1]], type = "s", + plot = TRUE, measure = "default", nullvalue = FALSE +)) +#> [1] "AUC = Area Under the Curve" +#> [[1]] +#> +#> +#> AUC 1 AUC 2 Shared AUC AUC Overlap (%) Overlap:Non-Overlap AUC Ratio +#> ------ ------ ----------- ---------------- ------------------------------ +#> 3.947 1.531 1.531 0.388 0.634 +#> +#> [[2]]
+
It’s clear that the outputs have changed and indicate far more overlap than before.
++++Constructing Functions From Single Intervals
+We can also take a set of confidence limits and use them to construct a consonance, surprisal, likelihood or deviance function using the
+curve_rev()function.Here, we’ll use two epidemiological studies16,17 that studied the impact of SSRI exposure in pregnant mothers, and the rate of autism in children.
+Both of these studies suggested a null effect of SSRI exposure on autism rates in children.
++curve1 <- curve_rev(point = 1.7, LL = 1.1, UL = 2.6, type = "c", measure = "ratio", steps = 10000) +(ggcurve(data = curve1[[1]], type = "c", measure = "ratio", nullvalue = TRUE))
+ +
+curve2 <- curve_rev(point = 1.61, LL = 0.997, UL = 2.59,type = "c", measure = "ratio", steps = 10000) +(ggcurve(data = curve2[[1]], type = "c", measure = "ratio", nullvalue = TRUE))
+
The null value is shown via the red line and it’s clear that a large mass of the function is away from it.
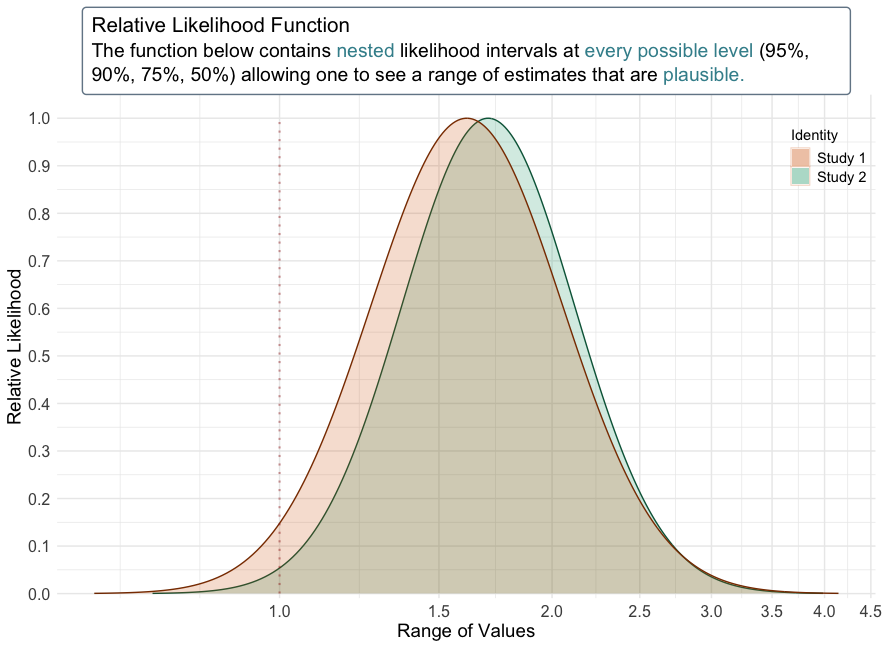
+We can also see this by plotting the likelihood functions via the
+curve_rev()function.+lik1 <- curve_rev(point = 1.7, LL = 1.1, UL = 2.6, type = "l", measure = "ratio", steps = 10000) +(ggcurve(data = lik1[[1]], type = "l1", measure = "ratio", nullvalue = TRUE))
+ +
+lik2 <- curve_rev(point = 1.61, LL = 0.997, UL = 2.59,type = "l", measure = "ratio", steps = 10000) +(ggcurve(data = lik2[[1]], type = "l1", measure = "ratio", nullvalue = TRUE))
+
We can also view the amount of agreement between the likelihood functions of these two studies.
++(plot_compare( + data1 = lik1[[1]], data2 = lik2[[1]], type = "l1", measure = "ratio", nullvalue = TRUE, title = "Brown et al. 2017. J Clin Psychiatry. vs. \nBrown et al. 2017. JAMA.", + subtitle = "J Clin Psychiatry: OR = 1.7, 1/6.83 LI: LL = 1.1, UL = 2.6 \nJAMA: HR = 1.61, 1/6.83 LI: LL = 0.997, UL = 2.59", xaxis = expression(Theta ~ "= Hazard Ratio / Odds Ratio") +))
+
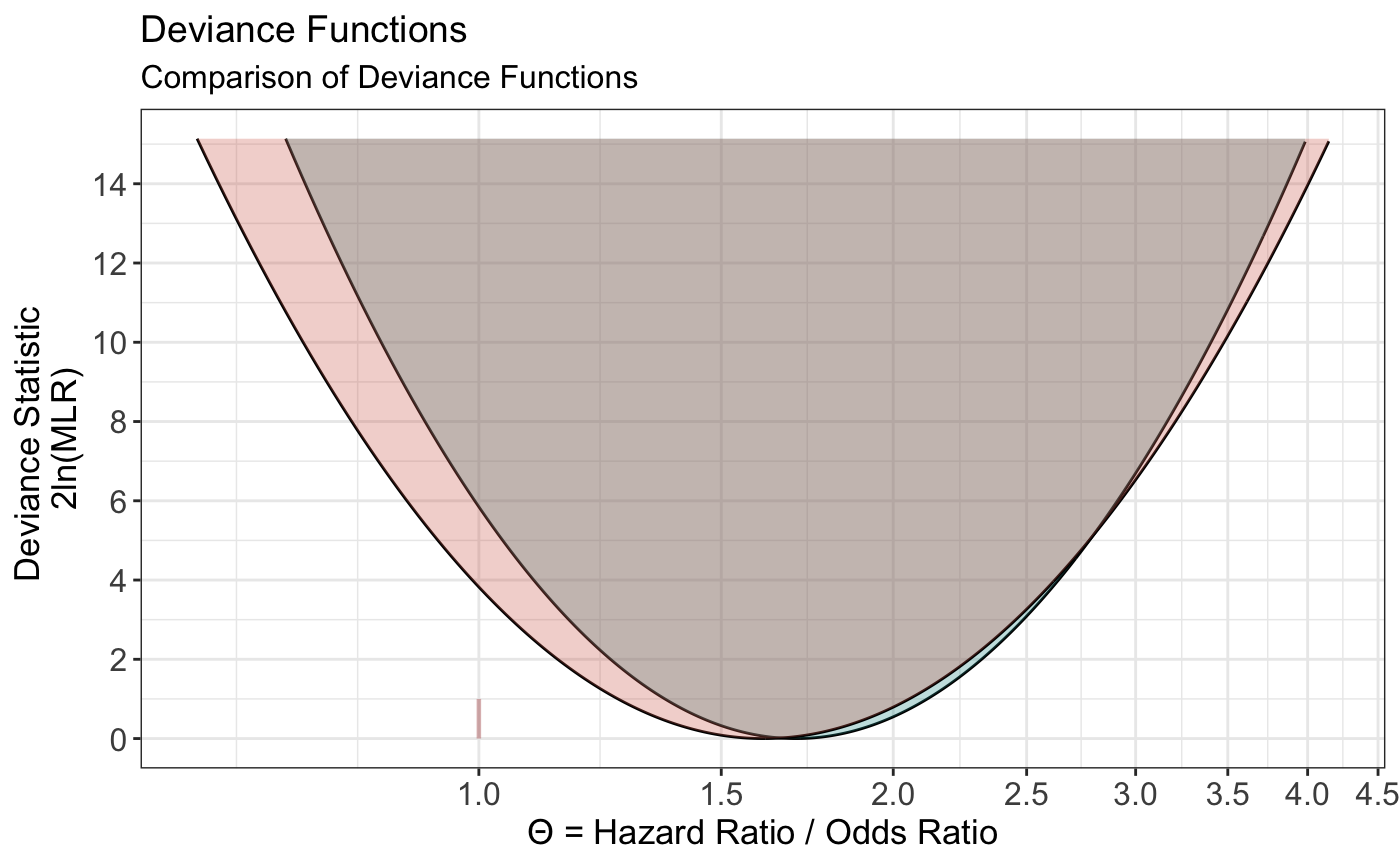
and the consonance functions
++(plot_compare( + data1 = curve1[[1]], data2 = curve2[[1]], type = "c", measure = "ratio", nullvalue = TRUE, title = "Brown et al. 2017. J Clin Psychiatry. vs. \nBrown et al. 2017. JAMA.", + subtitle = "J Clin Psychiatry: OR = 1.7, 1/6.83 LI: LL = 1.1, UL = 2.6 \nJAMA: HR = 1.61, 1/6.83 LI: LL = 0.997, UL = 2.59", xaxis = expression(Theta ~ "= Hazard Ratio / Odds Ratio") +))
+ ++
+++The Bootstrap and Consonance Functions
+Some authors have shown that the bootstrap distribution is equal to the confidence distribution because it meets the definition of a consonance distribution.1,18,19 The bootstrap distribution and the asymptotic consonance distribution would be defined as:
+\[H_{n}(\theta)=1-P\left(\hat{\theta}-\hat{\theta}^{*} \leq \hat{\theta}-\theta | \mathbf{x}\right)=P\left(\hat{\theta}^{*} \leq \theta | \mathbf{x}\right)\]
+Certain bootstrap methods such as the BCa method and t-bootstrap method also yield second order accuracy of consonance distributions.
+\[H_{n}(\theta)=1-P\left(\frac{\hat{\theta}^{*}-\hat{\theta}}{\widehat{S E}^{*}\left(\hat{\theta}^{*}\right)} \leq \frac{\hat{\theta}-\theta}{\widehat{S E}(\hat{\theta})} | \mathbf{x}\right)\]
+Here, I demonstrate how to use these particular bootstrap methods to arrive at consonance curves and densities.
+We’ll use the Iris dataset and construct a function that’ll yield a parameter of interest.
++iris <- datasets::iris +foo <- function(data, indices) { + dt <- data[indices, ] + c( + cor(dt[, 1], dt[, 2], method = "p") + ) +}We can now use the
+curve_boot()method to construct a function. The default method used for this function is the “BCa” method provided by thebcabootpackage.19I will suppress the output of the function because it is unnecessarily long. But we’ve placed all the estimates into a list object called y.
+The first item in the list will be the consonance distribution constructed by typical means, while the third item will be the bootstrap approximation to the consonance distribution.
+ +
+ +
+
We can also print out a table for TeX documents
+ +++
+ + +Lower Limit
Upper Limit
Interval Width
Interval Level (%)
CDF
P-value
S-value (bits)
+ +-0.142
-0.093
25
0.048
0.75
0.415
0.625
+ +-0.169
-0.067
50
0.102
0.50
1.000
0.750
+ +-0.205
-0.031
75
0.174
0.25
2.000
0.875
+ +-0.214
-0.021
80
0.194
0.20
2.322
0.900
+ +-0.266
0.031
95
0.296
0.05
4.322
0.975
+ + +-0.312
0.077
99
0.389
0.01
6.644
0.995
More bootstrap replications will lead to a smoother function. But for now, we can compare these two functions to see how similar they are.
+ +
+
The densities can also be calculated accurately using the t-bootstrap method. Here we use a different dataset to show this
++library(Lock5Data) +dataz <- data(CommuteAtlanta) +func = function(data, index) { + x <- as.numeric(unlist(data[1])) + y <- as.numeric(unlist(data[2])) + return(mean(x[index]) - mean(y[index])) +}Our function is a simple mean difference. This time, we’ll set the method to “t” for the t-bootstrap method
++z <- curve_boot(data = CommuteAtlanta, func = func, method = "t", replicates = 2000, steps = 1000) +#> Warning in norm.inter(t, alpha): extreme order statistics used as endpoints +ggcurve(data = z[[1]])
+ +
+
The consonance curve and density are nearly identical. With more bootstrap replications, they are very likely to converge.
+ +++
+ + +Lower Limit
Upper Limit
Interval Width
Interval Level (%)
CDF
P-value
S-value (bits)
+ +-39.400
-39.075
0.325
25.0
0.625
0.750
0.415
+ +-39.611
-38.876
0.735
50.0
0.750
0.500
1.000
+ +-39.873
-38.608
1.265
75.0
0.875
0.250
2.000
+ +-39.932
-38.530
1.402
80.0
0.900
0.200
2.322
+ +-40.026
-38.456
1.570
85.0
0.925
0.150
2.737
+ +-40.118
-38.354
1.763
90.0
0.950
0.100
3.322
+ +-40.294
-38.174
2.120
95.0
0.975
0.050
4.322
+ +-40.442
-38.026
2.416
97.5
0.988
0.025
5.322
+ + +-40.636
-37.806
2.830
99.0
0.995
0.010
6.644
+-Using Meta-Analysis Data
-Here we present another quick example with a meta-analysis of simulated data.
-First, we generate random data for two groups in two hypothetical studies
--GroupAData <- runif(20, min = 0, max = 100) -GroupAMean <- round(mean(GroupAData), digits = 2) -GroupASD <- round(sd(GroupAData), digits = 2) - -GroupBData <- runif(20, min = 0, max = 100) -GroupBMean <- round(mean(GroupBData), digits = 2) -GroupBSD <- round(sd(GroupBData), digits = 2) - -GroupCData <- runif(20, min = 0, max = 100) -GroupCMean <- round(mean(GroupCData), digits = 2) -GroupCSD <- round(sd(GroupCData), digits = 2) - -GroupDData <- runif(20, min = 0, max = 100) -GroupDMean <- round(mean(GroupDData), digits = 2) -GroupDSD <- round(sd(GroupDData), digits = 2)We can then quickly combine the data in a dataframe.
--StudyName <- c("Study1", "Study2") -MeanTreatment <- c(GroupAMean, GroupCMean) -MeanControl <- c(GroupBMean, GroupDMean) -SDTreatment <- c(GroupASD, GroupCSD) -SDControl <- c(GroupBSD, GroupDSD) -NTreatment <- c(20, 20) -NControl <- c(20, 20) - -metadf <- data.frame( - StudyName, MeanTreatment, MeanControl, - SDTreatment, SDControl, - NTreatment, NControl -)Then, we’ll use metafor to calculate the standardized mean difference.
--dat <- escalc( - measure = "SMD", - m1i = MeanTreatment, sd1i = SDTreatment, n1i = NTreatment, - m2i = MeanControl, sd2i = SDControl, n2i = NControl, - data = metadf -)Next, we’ll pool the data using a
-fixed-effectscommon-effects model-res <- rma(yi, vi, - data = dat, slab = paste(StudyName, sep = ", "), - method = "FE", digits = 2 -)Let’s look at our output.
- -
-Fixed-Effects Model (k = 2) - -Test for Heterogeneity: -Q(df = 1) = 0.61, p-val = 0.44 - -Model Results: - -estimate se zval pval ci.lb ci.ub - 0.16 0.22 0.73 0.47 -0.28 0.60 - ---- -Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Take a look at the pooled summary effect and its interval. Keep it in mind as we move onto constructing a consonance function.
-We can now take the object produced by the meta-analysis and calculate a P-value and S-value function with it to see the full spectrum of effect sizes compatible with the test model at every level. We’ll use the
- -curve_meta()function to do this.Now that we have our dataframe with every computed interval, we can plot the functions.
- -- - -
-And our S-value function
- -- - -
-Compare the span of these functions and the information they provide to the consonance interval provided by the forest plot. We are now no longer limited to interpreting an arbitrarily chosen interval by mindless analytic decisions often built into statistical packages by default.
+Using Profile Likelihoods +For this last example, we’ll explore the
+ +curve_lik()function, which can help generate profile likelihood functions, and deviance statistics with the help of theProfileLikelihoodpackage.We’ll use a simple example taken directly from the
+ProfileLikelihooddocumentation where we’ll calculate the likelihoods from a glm model+data(dataglm) +xx <- profilelike.glm(y ~ x1 + x2, data=dataglm, profile.theta="group", +family=binomial(link="logit"), length=500, round=2) +#> Warning message: provide lo.theta and hi.thetaThen, we’ll use
+curve_lik()on the object that theProfileLikelihoodpackage created.+lik <- curve_lik(xx, dataglm) +tibble::tibble(lik[[1]]) +#> # A tibble: 500 x 1 +#> `lik[[1]]`$values $likelihood $loglikelihood $support $deviancestat +#> <dbl> <dbl> <dbl> <dbl> <dbl> +#> 1 -1.41 9.26e-21 -9.79 0.0000560 9.79 +#> 2 -1.40 1.00e-20 -9.71 0.0000606 9.71 +#> 3 -1.39 1.08e-20 -9.63 0.0000655 9.63 +#> 4 -1.38 1.17e-20 -9.56 0.0000708 9.56 +#> 5 -1.37 1.26e-20 -9.48 0.0000765 9.48 +#> 6 -1.35 1.37e-20 -9.40 0.0000826 9.40 +#> 7 -1.34 1.47e-20 -9.32 0.0000892 9.32 +#> 8 -1.33 1.59e-20 -9.25 0.0000963 9.25 +#> 9 -1.32 1.72e-20 -9.17 0.000104 9.17 +#> 10 -1.31 1.85e-20 -9.10 0.000112 9.10 +#> # … with 490 more rowsNext, we’ll plot three functions, the relative likelihood, the log likelihood, the likelihoodm, and the deviance function.
+ +
+ +
+ +
+ +
+
The obvious advantage of using reduced likelihoods is that they are free of nuisance parameters
+\[L_{t_{n}}(\theta)=f_{n}\left(F_{n}^{-1}\left(H_{p i v}(\theta)\right)\right)\left|\frac{\partial}{\partial t} \psi\left(t_{n}, \theta\right)\right|=h_{p i v}(\theta)\left|\frac{\partial}{\partial t} \psi(t, \theta)\right| /\left.\left|\frac{\partial}{\partial \theta} \psi(t, \theta)\right|\right|_{t=t_{n}}\] thus, giving summaries of the data that can be incorporated into combined analyses.
+
+++References
+
++++1. Xie M-g, Singh K. Confidence Distribution, the Frequentist Distribution Estimator of a Parameter: A Review. International Statistical Review. 2013;81(1):3-39. doi:10.1111/insr.12000
+++2. Birnbaum A. A unified theory of estimation, I. The Annals of Mathematical Statistics. 1961;32(1):112-135. doi:10.1214/aoms/1177705145
+++3. Chow ZR, Greenland S. Semantic and Cognitive Tools to Aid Statistical Inference: Replace Confidence and Significance by Compatibility and Surprise. arXiv:190908579 [statME]. September 2019. http://arxiv.org/abs/1909.08579.
+++4. Fraser D. P-Values: The Insight to Modern Statistical Inference. Annual Review of Statistics and Its Application. 2017;4(1):1-14. doi:10.1146/annurev-statistics-060116-054139
+++5. Fraser DAS. The P-value function and statistical inference. The American Statistician. 2019;73(sup1):135-147. doi:10.1080/00031305.2018.1556735
+++6. Poole C. Beyond the confidence interval. American Journal of Public Health. 1987;77(2):195-199. doi:10.2105/AJPH.77.2.195
+++7. Poole C. Confidence intervals exclude nothing. American Journal of Public Health. 1987;77(4):492-493. doi:10.2105/ajph.77.4.492
+++8. Schweder T, Hjort NL. Confidence and Likelihood*. Scand J Stat. 2002;29(2):309-332. doi:10.1111/1467-9469.00285
+++9. Schweder T, Hjort NL. Confidence, Likelihood, Probability: Statistical Inference with Confidence Distributions. Cambridge University Press; 2016.
+++10. Singh K, Xie M, Strawderman WE. Confidence distribution (CD) – distribution estimator of a parameter. August 2007. http://arxiv.org/abs/0708.0976.
+++11. Sullivan KM, Foster DA. Use of the confidence interval function. Epidemiology. 1990;1(1):39-42. doi:10.1097/00001648-199001000-00009
+++12. Whitehead J. The case for frequentism in clinical trials. Statistics in Medicine. 1993;12(15-16):1405-1413. doi:10.1002/sim.4780121506
+++13. Rothman KJ, Greenland S, Lash TL. Precision and statistics in epidemiologic studies. In: Rothman KJ, Greenland S, Lash TL, eds. Modern Epidemiology. 3rd ed. Lippincott Williams & Wilkins; 2008:148-167.
+++14. Greenland S. Valid P-values behave exactly as they should: Some misleading criticisms of P-values and their resolution with S-values. The American Statistician. 2019;73(sup1):106-114. doi:10.1080/00031305.2018.1529625
+++15. Shannon CE. A mathematical theory of communication. The Bell System Technical Journal. 1948;27(3):379-423. doi:10.1002/j.1538-7305.1948.tb01338.x
+++16. Brown HK, Ray JG, Wilton AS, Lunsky Y, Gomes T, Vigod SN. Association between serotonergic antidepressant use during pregnancy and autism spectrum disorder in children. JAMA. 2017;317(15):1544-1552. doi:10.1001/jama.2017.3415
+++17. Brown HK, Hussain-Shamsy N, Lunsky Y, Dennis C-LE, Vigod SN. The association between antenatal exposure to selective serotonin reuptake inhibitors and autism: A systematic review and meta-analysis. The Journal of Clinical Psychiatry. 2017;78(1):e48-e58. doi:10.4088/JCP.15r10194
+++18. Efron B, Tibshirani RJ. An Introduction to the Bootstrap. CRC Press; 1994.
+++19. Efron B, Narasimhan B. The automatic construction of bootstrap confidence intervals. October 2018:17.
+Contents
concurve
- 2.1.0
+ 2.3.0
-
-
+
diff --git a/docs/articles/stata.html b/docs/articles/stata.html
index bb590ce..30ea1ab 100644
--- a/docs/articles/stata.html
+++ b/docs/articles/stata.html
@@ -39,9 +39,8 @@
-
- concurve
- 2.1.0
+ concurve
+ 2.3.0
@@ -77,7 +76,7 @@
-
-
+
@@ -104,7 +103,7 @@
Using Stata
- Source:vignettes/stata.Rmd+ Source:vignettes/stata.Rmddiff --git a/docs/authors.html b/docs/authors.html index 42246db..fb1aa38 100644 --- a/docs/authors.html +++ b/docs/authors.html @@ -82,9 +82,9 @@ - +stata.Rmd
concurve
- 2.1.0
+ 2.3.0
@@ -120,7 +120,7 @@
-
-
+
@@ -145,20 +145,18 @@
+
Chow Z, Vigotsky A (2019). -concurve: Computes and Plots Consonance (Confidence) Intervals, P-Values, and S-Values to Form Consonance and Surprisal Functions. -doi: 10.5281/zenodo.1308151, R package version 2.1.0, https://CRAN.R-project.org/package=concurve. +concurve: Computes and Plots Compatibility (Confidence) Intervals, P-Values, S-Values, & Likelihood Intervals to Form Consonance, Surprisal, & Likelihood Functions. +https://CRAN.R-project.org/package=concurve.
@Manual{, - title = {{concurve}: Computes and Plots Consonance (Confidence) Intervals, P-Values, and S-Values to Form Consonance and Surprisal Functions}, + title = {{concurve}: Computes and Plots Compatibility (Confidence) Intervals, P-Values, S-Values, & Likelihood Intervals to Form Consonance, Surprisal, & Likelihood Functions}, author = {Zad R. Chow and Andrew D. Vigotsky}, year = {2019}, - note = {R package version 2.1.0}, url = {https://CRAN.R-project.org/package=concurve}, - doi = {10.5281/zenodo.1308151}, }diff --git a/docs/bootstrap.css b/docs/bootstrap.css new file mode 100644 index 0000000..fc8a203 --- /dev/null +++ b/docs/bootstrap.css @@ -0,0 +1,7331 @@ +@import url("https://fonts.googleapis.com/css?family=Roboto:300,400,500,700"); +/*! + * bootswatch v3.4.1 + * Homepage: http://bootswatch.com + * Copyright 2012-2019 Thomas Park + * Licensed under MIT + * Based on Bootstrap +*/ +/*! + * Bootstrap v3.4.1 (https://getbootstrap.com/) + * Copyright 2011-2019 Twitter, Inc. + * Licensed under MIT (https://github.com/twbs/bootstrap/blob/master/LICENSE) + */ +/*! normalize.css v3.0.3 | MIT License | github.com/necolas/normalize.css */ +html { + font-family: sans-serif; + -ms-text-size-adjust: 100%; + -webkit-text-size-adjust: 100%; +} +body { + margin: 0; +} +article, +aside, +details, +figcaption, +figure, +footer, +header, +hgroup, +main, +menu, +nav, +section, +summary { + display: block; +} +audio, +canvas, +progress, +video { + display: inline-block; + vertical-align: baseline; +} +audio:not([controls]) { + display: none; + height: 0; +} +[hidden], +template { + display: none; +} +a { + background-color: transparent; +} +a:active, +a:hover { + outline: 0; +} +abbr[title] { + border-bottom: none; + text-decoration: underline; + text-decoration: underline dotted; +} +b, +strong { + font-weight: bold; +} +dfn { + font-style: italic; +} +h1 { + font-size: 2em; + margin: 0.67em 0; +} +mark { + background: #ff0; + color: #000; +} +small { + font-size: 80%; +} +sub, +sup { + font-size: 75%; + line-height: 0; + position: relative; + vertical-align: baseline; +} +sup { + top: -0.5em; +} +sub { + bottom: -0.25em; +} +img { + border: 0; +} +svg:not(:root) { + overflow: hidden; +} +figure { + margin: 1em 40px; +} +hr { + box-sizing: content-box; + height: 0; +} +pre { + overflow: auto; +} +code, +kbd, +pre, +samp { + font-family: monospace, monospace; + font-size: 1em; +} +button, +input, +optgroup, +select, +textarea { + color: inherit; + font: inherit; + margin: 0; +} +button { + overflow: visible; +} +button, +select { + text-transform: none; +} +button, +html input[type="button"], +input[type="reset"], +input[type="submit"] { + -webkit-appearance: button; + cursor: pointer; +} +button[disabled], +html input[disabled] { + cursor: default; +} +button::-moz-focus-inner, +input::-moz-focus-inner { + border: 0; + padding: 0; +} +input { + line-height: normal; +} +input[type="checkbox"], +input[type="radio"] { + box-sizing: border-box; + padding: 0; +} +input[type="number"]::-webkit-inner-spin-button, +input[type="number"]::-webkit-outer-spin-button { + height: auto; +} +input[type="search"] { + -webkit-appearance: textfield; + box-sizing: content-box; +} +input[type="search"]::-webkit-search-cancel-button, +input[type="search"]::-webkit-search-decoration { + -webkit-appearance: none; +} +fieldset { + border: 1px solid #c0c0c0; + margin: 0 2px; + padding: 0.35em 0.625em 0.75em; +} +legend { + border: 0; + padding: 0; +} +textarea { + overflow: auto; +} +optgroup { + font-weight: bold; +} +table { + border-collapse: collapse; + border-spacing: 0; +} +td, +th { + padding: 0; +} +/*! Source: https://github.com/h5bp/html5-boilerplate/blob/master/src/css/main.css */ +@media print { + *, + *:before, + *:after { + color: #000 !important; + text-shadow: none !important; + background: transparent !important; + box-shadow: none !important; + } + a, + a:visited { + text-decoration: underline; + } + a[href]:after { + content: " (" attr(href) ")"; + } + abbr[title]:after { + content: " (" attr(title) ")"; + } + a[href^="#"]:after, + a[href^="javascript:"]:after { + content: ""; + } + pre, + blockquote { + border: 1px solid #999; + page-break-inside: avoid; + } + thead { + display: table-header-group; + } + tr, + img { + page-break-inside: avoid; + } + img { + max-width: 100% !important; + } + p, + h2, + h3 { + orphans: 3; + widows: 3; + } + h2, + h3 { + page-break-after: avoid; + } + .navbar { + display: none; + } + .btn > .caret, + .dropup > .btn > .caret { + border-top-color: #000 !important; + } + .label { + border: 1px solid #000; + } + .table { + border-collapse: collapse !important; + } + .table td, + .table th { + background-color: #fff !important; + } + .table-bordered th, + .table-bordered td { + border: 1px solid #ddd !important; + } +} +@font-face { + font-family: "Glyphicons Halflings"; + src: url("../fonts/glyphicons-halflings-regular.eot"); + src: url("../fonts/glyphicons-halflings-regular.eot?#iefix") format("embedded-opentype"), url("../fonts/glyphicons-halflings-regular.woff2") format("woff2"), url("../fonts/glyphicons-halflings-regular.woff") format("woff"), url("../fonts/glyphicons-halflings-regular.ttf") format("truetype"), url("../fonts/glyphicons-halflings-regular.svg#glyphicons_halflingsregular") format("svg"); +} +.glyphicon { + position: relative; + top: 1px; + display: inline-block; + font-family: "Glyphicons Halflings"; + font-style: normal; + font-weight: 400; + line-height: 1; + -webkit-font-smoothing: antialiased; + -moz-osx-font-smoothing: grayscale; +} +.glyphicon-asterisk:before { + content: "\002a"; +} +.glyphicon-plus:before { + content: "\002b"; +} +.glyphicon-euro:before, +.glyphicon-eur:before { + content: "\20ac"; +} +.glyphicon-minus:before { + content: "\2212"; +} +.glyphicon-cloud:before { + content: "\2601"; +} +.glyphicon-envelope:before { + content: "\2709"; +} +.glyphicon-pencil:before { + content: "\270f"; +} +.glyphicon-glass:before { + content: "\e001"; +} +.glyphicon-music:before { + content: "\e002"; +} +.glyphicon-search:before { + content: "\e003"; +} +.glyphicon-heart:before { + content: "\e005"; +} +.glyphicon-star:before { + content: "\e006"; +} +.glyphicon-star-empty:before { + content: "\e007"; +} +.glyphicon-user:before { + content: "\e008"; +} +.glyphicon-film:before { + content: "\e009"; +} +.glyphicon-th-large:before { + content: "\e010"; +} +.glyphicon-th:before { + content: "\e011"; +} +.glyphicon-th-list:before { + content: "\e012"; +} +.glyphicon-ok:before { + content: "\e013"; +} +.glyphicon-remove:before { + content: "\e014"; +} +.glyphicon-zoom-in:before { + content: "\e015"; +} +.glyphicon-zoom-out:before { + content: "\e016"; +} +.glyphicon-off:before { + content: "\e017"; +} +.glyphicon-signal:before { + content: "\e018"; +} +.glyphicon-cog:before { + content: "\e019"; +} +.glyphicon-trash:before { + content: "\e020"; +} +.glyphicon-home:before { + content: "\e021"; +} +.glyphicon-file:before { + content: "\e022"; +} +.glyphicon-time:before { + content: "\e023"; +} +.glyphicon-road:before { + content: "\e024"; +} +.glyphicon-download-alt:before { + content: "\e025"; +} +.glyphicon-download:before { + content: "\e026"; +} +.glyphicon-upload:before { + content: "\e027"; +} +.glyphicon-inbox:before { + content: "\e028"; +} +.glyphicon-play-circle:before { + content: "\e029"; +} +.glyphicon-repeat:before { + content: "\e030"; +} +.glyphicon-refresh:before { + content: "\e031"; +} +.glyphicon-list-alt:before { + content: "\e032"; +} +.glyphicon-lock:before { + content: "\e033"; +} +.glyphicon-flag:before { + content: "\e034"; +} +.glyphicon-headphones:before { + content: "\e035"; +} +.glyphicon-volume-off:before { + content: "\e036"; +} +.glyphicon-volume-down:before { + content: "\e037"; +} +.glyphicon-volume-up:before { + content: "\e038"; +} +.glyphicon-qrcode:before { + content: "\e039"; +} +.glyphicon-barcode:before { + content: "\e040"; +} +.glyphicon-tag:before { + content: "\e041"; +} +.glyphicon-tags:before { + content: "\e042"; +} +.glyphicon-book:before { + content: "\e043"; +} +.glyphicon-bookmark:before { + content: "\e044"; +} +.glyphicon-print:before { + content: "\e045"; +} +.glyphicon-camera:before { + content: "\e046"; +} +.glyphicon-font:before { + content: "\e047"; +} +.glyphicon-bold:before { + content: "\e048"; +} +.glyphicon-italic:before { + content: "\e049"; +} +.glyphicon-text-height:before { + content: "\e050"; +} +.glyphicon-text-width:before { + content: "\e051"; +} +.glyphicon-align-left:before { + content: "\e052"; +} +.glyphicon-align-center:before { + content: "\e053"; +} +.glyphicon-align-right:before { + content: "\e054"; +} +.glyphicon-align-justify:before { + content: "\e055"; +} +.glyphicon-list:before { + content: "\e056"; +} +.glyphicon-indent-left:before { + content: "\e057"; +} +.glyphicon-indent-right:before { + content: "\e058"; +} +.glyphicon-facetime-video:before { + content: "\e059"; +} +.glyphicon-picture:before { + content: "\e060"; +} +.glyphicon-map-marker:before { + content: "\e062"; +} +.glyphicon-adjust:before { + content: "\e063"; +} +.glyphicon-tint:before { + content: "\e064"; +} +.glyphicon-edit:before { + content: "\e065"; +} +.glyphicon-share:before { + content: "\e066"; +} +.glyphicon-check:before { + content: "\e067"; +} +.glyphicon-move:before { + content: "\e068"; +} +.glyphicon-step-backward:before { + content: "\e069"; +} +.glyphicon-fast-backward:before { + content: "\e070"; +} +.glyphicon-backward:before { + content: "\e071"; +} +.glyphicon-play:before { + content: "\e072"; +} +.glyphicon-pause:before { + content: "\e073"; +} +.glyphicon-stop:before { + content: "\e074"; +} +.glyphicon-forward:before { + content: "\e075"; +} +.glyphicon-fast-forward:before { + content: "\e076"; +} +.glyphicon-step-forward:before { + content: "\e077"; +} +.glyphicon-eject:before { + content: "\e078"; +} +.glyphicon-chevron-left:before { + content: "\e079"; +} +.glyphicon-chevron-right:before { + content: "\e080"; +} +.glyphicon-plus-sign:before { + content: "\e081"; +} +.glyphicon-minus-sign:before { + content: "\e082"; +} +.glyphicon-remove-sign:before { + content: "\e083"; +} +.glyphicon-ok-sign:before { + content: "\e084"; +} +.glyphicon-question-sign:before { + content: "\e085"; +} +.glyphicon-info-sign:before { + content: "\e086"; +} +.glyphicon-screenshot:before { + content: "\e087"; +} +.glyphicon-remove-circle:before { + content: "\e088"; +} +.glyphicon-ok-circle:before { + content: "\e089"; +} +.glyphicon-ban-circle:before { + content: "\e090"; +} +.glyphicon-arrow-left:before { + content: "\e091"; +} +.glyphicon-arrow-right:before { + content: "\e092"; +} +.glyphicon-arrow-up:before { + content: "\e093"; +} +.glyphicon-arrow-down:before { + content: "\e094"; +} +.glyphicon-share-alt:before { + content: "\e095"; +} +.glyphicon-resize-full:before { + content: "\e096"; +} +.glyphicon-resize-small:before { + content: "\e097"; +} +.glyphicon-exclamation-sign:before { + content: "\e101"; +} +.glyphicon-gift:before { + content: "\e102"; +} +.glyphicon-leaf:before { + content: "\e103"; +} +.glyphicon-fire:before { + content: "\e104"; +} +.glyphicon-eye-open:before { + content: "\e105"; +} +.glyphicon-eye-close:before { + content: "\e106"; +} +.glyphicon-warning-sign:before { + content: "\e107"; +} +.glyphicon-plane:before { + content: "\e108"; +} +.glyphicon-calendar:before { + content: "\e109"; +} +.glyphicon-random:before { + content: "\e110"; +} +.glyphicon-comment:before { + content: "\e111"; +} +.glyphicon-magnet:before { + content: "\e112"; +} +.glyphicon-chevron-up:before { + content: "\e113"; +} +.glyphicon-chevron-down:before { + content: "\e114"; +} +.glyphicon-retweet:before { + content: "\e115"; +} +.glyphicon-shopping-cart:before { + content: "\e116"; +} +.glyphicon-folder-close:before { + content: "\e117"; +} +.glyphicon-folder-open:before { + content: "\e118"; +} +.glyphicon-resize-vertical:before { + content: "\e119"; +} +.glyphicon-resize-horizontal:before { + content: "\e120"; +} +.glyphicon-hdd:before { + content: "\e121"; +} +.glyphicon-bullhorn:before { + content: "\e122"; +} +.glyphicon-bell:before { + content: "\e123"; +} +.glyphicon-certificate:before { + content: "\e124"; +} +.glyphicon-thumbs-up:before { + content: "\e125"; +} +.glyphicon-thumbs-down:before { + content: "\e126"; +} +.glyphicon-hand-right:before { + content: "\e127"; +} +.glyphicon-hand-left:before { + content: "\e128"; +} +.glyphicon-hand-up:before { + content: "\e129"; +} +.glyphicon-hand-down:before { + content: "\e130"; +} +.glyphicon-circle-arrow-right:before { + content: "\e131"; +} +.glyphicon-circle-arrow-left:before { + content: "\e132"; +} +.glyphicon-circle-arrow-up:before { + content: "\e133"; +} +.glyphicon-circle-arrow-down:before { + content: "\e134"; +} +.glyphicon-globe:before { + content: "\e135"; +} +.glyphicon-wrench:before { + content: "\e136"; +} +.glyphicon-tasks:before { + content: "\e137"; +} +.glyphicon-filter:before { + content: "\e138"; +} +.glyphicon-briefcase:before { + content: "\e139"; +} +.glyphicon-fullscreen:before { + content: "\e140"; +} +.glyphicon-dashboard:before { + content: "\e141"; +} +.glyphicon-paperclip:before { + content: "\e142"; +} +.glyphicon-heart-empty:before { + content: "\e143"; +} +.glyphicon-link:before { + content: "\e144"; +} +.glyphicon-phone:before { + content: "\e145"; +} +.glyphicon-pushpin:before { + content: "\e146"; +} +.glyphicon-usd:before { + content: "\e148"; +} +.glyphicon-gbp:before { + content: "\e149"; +} +.glyphicon-sort:before { + content: "\e150"; +} +.glyphicon-sort-by-alphabet:before { + content: "\e151"; +} +.glyphicon-sort-by-alphabet-alt:before { + content: "\e152"; +} +.glyphicon-sort-by-order:before { + content: "\e153"; +} +.glyphicon-sort-by-order-alt:before { + content: "\e154"; +} +.glyphicon-sort-by-attributes:before { + content: "\e155"; +} +.glyphicon-sort-by-attributes-alt:before { + content: "\e156"; +} +.glyphicon-unchecked:before { + content: "\e157"; +} +.glyphicon-expand:before { + content: "\e158"; +} +.glyphicon-collapse-down:before { + content: "\e159"; +} +.glyphicon-collapse-up:before { + content: "\e160"; +} +.glyphicon-log-in:before { + content: "\e161"; +} +.glyphicon-flash:before { + content: "\e162"; +} +.glyphicon-log-out:before { + content: "\e163"; +} +.glyphicon-new-window:before { + content: "\e164"; +} +.glyphicon-record:before { + content: "\e165"; +} +.glyphicon-save:before { + content: "\e166"; +} +.glyphicon-open:before { + content: "\e167"; +} +.glyphicon-saved:before { + content: "\e168"; +} +.glyphicon-import:before { + content: "\e169"; +} +.glyphicon-export:before { + content: "\e170"; +} +.glyphicon-send:before { + content: "\e171"; +} +.glyphicon-floppy-disk:before { + content: "\e172"; +} +.glyphicon-floppy-saved:before { + content: "\e173"; +} +.glyphicon-floppy-remove:before { + content: "\e174"; +} +.glyphicon-floppy-save:before { + content: "\e175"; +} +.glyphicon-floppy-open:before { + content: "\e176"; +} +.glyphicon-credit-card:before { + content: "\e177"; +} +.glyphicon-transfer:before { + content: "\e178"; +} +.glyphicon-cutlery:before { + content: "\e179"; +} +.glyphicon-header:before { + content: "\e180"; +} +.glyphicon-compressed:before { + content: "\e181"; +} +.glyphicon-earphone:before { + content: "\e182"; +} +.glyphicon-phone-alt:before { + content: "\e183"; +} +.glyphicon-tower:before { + content: "\e184"; +} +.glyphicon-stats:before { + content: "\e185"; +} +.glyphicon-sd-video:before { + content: "\e186"; +} +.glyphicon-hd-video:before { + content: "\e187"; +} +.glyphicon-subtitles:before { + content: "\e188"; +} +.glyphicon-sound-stereo:before { + content: "\e189"; +} +.glyphicon-sound-dolby:before { + content: "\e190"; +} +.glyphicon-sound-5-1:before { + content: "\e191"; +} +.glyphicon-sound-6-1:before { + content: "\e192"; +} +.glyphicon-sound-7-1:before { + content: "\e193"; +} +.glyphicon-copyright-mark:before { + content: "\e194"; +} +.glyphicon-registration-mark:before { + content: "\e195"; +} +.glyphicon-cloud-download:before { + content: "\e197"; +} +.glyphicon-cloud-upload:before { + content: "\e198"; +} +.glyphicon-tree-conifer:before { + content: "\e199"; +} +.glyphicon-tree-deciduous:before { + content: "\e200"; +} +.glyphicon-cd:before { + content: "\e201"; +} +.glyphicon-save-file:before { + content: "\e202"; +} +.glyphicon-open-file:before { + content: "\e203"; +} +.glyphicon-level-up:before { + content: "\e204"; +} +.glyphicon-copy:before { + content: "\e205"; +} +.glyphicon-paste:before { + content: "\e206"; +} +.glyphicon-alert:before { + content: "\e209"; +} +.glyphicon-equalizer:before { + content: "\e210"; +} +.glyphicon-king:before { + content: "\e211"; +} +.glyphicon-queen:before { + content: "\e212"; +} +.glyphicon-pawn:before { + content: "\e213"; +} +.glyphicon-bishop:before { + content: "\e214"; +} +.glyphicon-knight:before { + content: "\e215"; +} +.glyphicon-baby-formula:before { + content: "\e216"; +} +.glyphicon-tent:before { + content: "\26fa"; +} +.glyphicon-blackboard:before { + content: "\e218"; +} +.glyphicon-bed:before { + content: "\e219"; +} +.glyphicon-apple:before { + content: "\f8ff"; +} +.glyphicon-erase:before { + content: "\e221"; +} +.glyphicon-hourglass:before { + content: "\231b"; +} +.glyphicon-lamp:before { + content: "\e223"; +} +.glyphicon-duplicate:before { + content: "\e224"; +} +.glyphicon-piggy-bank:before { + content: "\e225"; +} +.glyphicon-scissors:before { + content: "\e226"; +} +.glyphicon-bitcoin:before { + content: "\e227"; +} +.glyphicon-btc:before { + content: "\e227"; +} +.glyphicon-xbt:before { + content: "\e227"; +} +.glyphicon-yen:before { + content: "\00a5"; +} +.glyphicon-jpy:before { + content: "\00a5"; +} +.glyphicon-ruble:before { + content: "\20bd"; +} +.glyphicon-rub:before { + content: "\20bd"; +} +.glyphicon-scale:before { + content: "\e230"; +} +.glyphicon-ice-lolly:before { + content: "\e231"; +} +.glyphicon-ice-lolly-tasted:before { + content: "\e232"; +} +.glyphicon-education:before { + content: "\e233"; +} +.glyphicon-option-horizontal:before { + content: "\e234"; +} +.glyphicon-option-vertical:before { + content: "\e235"; +} +.glyphicon-menu-hamburger:before { + content: "\e236"; +} +.glyphicon-modal-window:before { + content: "\e237"; +} +.glyphicon-oil:before { + content: "\e238"; +} +.glyphicon-grain:before { + content: "\e239"; +} +.glyphicon-sunglasses:before { + content: "\e240"; +} +.glyphicon-text-size:before { + content: "\e241"; +} +.glyphicon-text-color:before { + content: "\e242"; +} +.glyphicon-text-background:before { + content: "\e243"; +} +.glyphicon-object-align-top:before { + content: "\e244"; +} +.glyphicon-object-align-bottom:before { + content: "\e245"; +} +.glyphicon-object-align-horizontal:before { + content: "\e246"; +} +.glyphicon-object-align-left:before { + content: "\e247"; +} +.glyphicon-object-align-vertical:before { + content: "\e248"; +} +.glyphicon-object-align-right:before { + content: "\e249"; +} +.glyphicon-triangle-right:before { + content: "\e250"; +} +.glyphicon-triangle-left:before { + content: "\e251"; +} +.glyphicon-triangle-bottom:before { + content: "\e252"; +} +.glyphicon-triangle-top:before { + content: "\e253"; +} +.glyphicon-console:before { + content: "\e254"; +} +.glyphicon-superscript:before { + content: "\e255"; +} +.glyphicon-subscript:before { + content: "\e256"; +} +.glyphicon-menu-left:before { + content: "\e257"; +} +.glyphicon-menu-right:before { + content: "\e258"; +} +.glyphicon-menu-down:before { + content: "\e259"; +} +.glyphicon-menu-up:before { + content: "\e260"; +} +* { + box-sizing: border-box; +} +*:before, +*:after { + box-sizing: border-box; +} +html { + font-size: 10px; + -webkit-tap-highlight-color: rgba(0, 0, 0, 0); +} +body { + font-family: "Roboto", "Helvetica Neue", Helvetica, Arial, sans-serif; + font-size: 13px; + line-height: 1.846; + color: #666666; + background-color: #ffffff; +} +input, +button, +select, +textarea { + font-family: inherit; + font-size: inherit; + line-height: inherit; +} +a { + color: #2196f3; + text-decoration: none; +} +a:hover, +a:focus { + color: #0a6ebd; + text-decoration: underline; +} +a:focus { + outline: 5px auto -webkit-focus-ring-color; + outline-offset: -2px; +} +figure { + margin: 0; +} +img { + vertical-align: middle; +} +.img-responsive, +.thumbnail > img, +.thumbnail a > img, +.carousel-inner > .item > img, +.carousel-inner > .item > a > img { + display: block; + max-width: 100%; + height: auto; +} +.img-rounded { + border-radius: 3px; +} +.img-thumbnail { + padding: 4px; + line-height: 1.846; + background-color: #ffffff; + border: 1px solid #dddddd; + border-radius: 3px; + transition: all 0.2s ease-in-out; + display: inline-block; + max-width: 100%; + height: auto; +} +.img-circle { + border-radius: 50%; +} +hr { + margin-top: 23px; + margin-bottom: 23px; + border: 0; + border-top: 1px solid #eeeeee; +} +.sr-only { + position: absolute; + width: 1px; + height: 1px; + padding: 0; + margin: -1px; + overflow: hidden; + clip: rect(0, 0, 0, 0); + border: 0; +} +.sr-only-focusable:active, +.sr-only-focusable:focus { + position: static; + width: auto; + height: auto; + margin: 0; + overflow: visible; + clip: auto; +} +[role="button"] { + cursor: pointer; +} +h1, +h2, +h3, +h4, +h5, +h6, +.h1, +.h2, +.h3, +.h4, +.h5, +.h6 { + font-family: inherit; + font-weight: 400; + line-height: 1.1; + color: #444444; +} +h1 small, +h2 small, +h3 small, +h4 small, +h5 small, +h6 small, +.h1 small, +.h2 small, +.h3 small, +.h4 small, +.h5 small, +.h6 small, +h1 .small, +h2 .small, +h3 .small, +h4 .small, +h5 .small, +h6 .small, +.h1 .small, +.h2 .small, +.h3 .small, +.h4 .small, +.h5 .small, +.h6 .small { + font-weight: 400; + line-height: 1; + color: #bbbbbb; +} +h1, +.h1, +h2, +.h2, +h3, +.h3 { + margin-top: 23px; + margin-bottom: 11.5px; +} +h1 small, +.h1 small, +h2 small, +.h2 small, +h3 small, +.h3 small, +h1 .small, +.h1 .small, +h2 .small, +.h2 .small, +h3 .small, +.h3 .small { + font-size: 65%; +} +h4, +.h4, +h5, +.h5, +h6, +.h6 { + margin-top: 11.5px; + margin-bottom: 11.5px; +} +h4 small, +.h4 small, +h5 small, +.h5 small, +h6 small, +.h6 small, +h4 .small, +.h4 .small, +h5 .small, +.h5 .small, +h6 .small, +.h6 .small { + font-size: 75%; +} +h1, +.h1 { + font-size: 56px; +} +h2, +.h2 { + font-size: 45px; +} +h3, +.h3 { + font-size: 34px; +} +h4, +.h4 { + font-size: 24px; +} +h5, +.h5 { + font-size: 20px; +} +h6, +.h6 { + font-size: 14px; +} +p { + margin: 0 0 11.5px; +} +.lead { + margin-bottom: 23px; + font-size: 14px; + font-weight: 300; + line-height: 1.4; +} +@media (min-width: 768px) { + .lead { + font-size: 19.5px; + } +} +small, +.small { + font-size: 92%; +} +mark, +.mark { + padding: .2em; + background-color: #ffe0b2; +} +.text-left { + text-align: left; +} +.text-right { + text-align: right; +} +.text-center { + text-align: center; +} +.text-justify { + text-align: justify; +} +.text-nowrap { + white-space: nowrap; +} +.text-lowercase { + text-transform: lowercase; +} +.text-uppercase { + text-transform: uppercase; +} +.text-capitalize { + text-transform: capitalize; +} +.text-muted { + color: #bbbbbb; +} +.text-primary { + color: #2196f3; +} +a.text-primary:hover, +a.text-primary:focus { + color: #0c7cd5; +} +.text-success { + color: #4caf50; +} +a.text-success:hover, +a.text-success:focus { + color: #3d8b40; +} +.text-info { + color: #9c27b0; +} +a.text-info:hover, +a.text-info:focus { + color: #771e86; +} +.text-warning { + color: #ff9800; +} +a.text-warning:hover, +a.text-warning:focus { + color: #cc7a00; +} +.text-danger { + color: #e51c23; +} +a.text-danger:hover, +a.text-danger:focus { + color: #b9151b; +} +.bg-primary { + color: #fff; + background-color: #2196f3; +} +a.bg-primary:hover, +a.bg-primary:focus { + background-color: #0c7cd5; +} +.bg-success { + background-color: #dff0d8; +} +a.bg-success:hover, +a.bg-success:focus { + background-color: #c1e2b3; +} +.bg-info { + background-color: #e1bee7; +} +a.bg-info:hover, +a.bg-info:focus { + background-color: #d099d9; +} +.bg-warning { + background-color: #ffe0b2; +} +a.bg-warning:hover, +a.bg-warning:focus { + background-color: #ffcb7f; +} +.bg-danger { + background-color: #f9bdbb; +} +a.bg-danger:hover, +a.bg-danger:focus { + background-color: #f5908c; +} +.page-header { + padding-bottom: 10.5px; + margin: 46px 0 23px; + border-bottom: 1px solid #eeeeee; +} +ul, +ol { + margin-top: 0; + margin-bottom: 11.5px; +} +ul ul, +ol ul, +ul ol, +ol ol { + margin-bottom: 0; +} +.list-unstyled { + padding-left: 0; + list-style: none; +} +.list-inline { + padding-left: 0; + list-style: none; + margin-left: -5px; +} +.list-inline > li { + display: inline-block; + padding-right: 5px; + padding-left: 5px; +} +dl { + margin-top: 0; + margin-bottom: 23px; +} +dt, +dd { + line-height: 1.846; +} +dt { + font-weight: 700; +} +dd { + margin-left: 0; +} +@media (min-width: 768px) { + .dl-horizontal dt { + float: left; + width: 160px; + clear: left; + text-align: right; + overflow: hidden; + text-overflow: ellipsis; + white-space: nowrap; + } + .dl-horizontal dd { + margin-left: 180px; + } +} +abbr[title], +abbr[data-original-title] { + cursor: help; +} +.initialism { + font-size: 90%; + text-transform: uppercase; +} +blockquote { + padding: 11.5px 23px; + margin: 0 0 23px; + font-size: 16.25px; + border-left: 5px solid #eeeeee; +} +blockquote p:last-child, +blockquote ul:last-child, +blockquote ol:last-child { + margin-bottom: 0; +} +blockquote footer, +blockquote small, +blockquote .small { + display: block; + font-size: 80%; + line-height: 1.846; + color: #bbbbbb; +} +blockquote footer:before, +blockquote small:before, +blockquote .small:before { + content: "\2014 \00A0"; +} +.blockquote-reverse, +blockquote.pull-right { + padding-right: 15px; + padding-left: 0; + text-align: right; + border-right: 5px solid #eeeeee; + border-left: 0; +} +.blockquote-reverse footer:before, +blockquote.pull-right footer:before, +.blockquote-reverse small:before, +blockquote.pull-right small:before, +.blockquote-reverse .small:before, +blockquote.pull-right .small:before { + content: ""; +} +.blockquote-reverse footer:after, +blockquote.pull-right footer:after, +.blockquote-reverse small:after, +blockquote.pull-right small:after, +.blockquote-reverse .small:after, +blockquote.pull-right .small:after { + content: "\00A0 \2014"; +} +address { + margin-bottom: 23px; + font-style: normal; + line-height: 1.846; +} +code, +kbd, +pre, +samp { + font-family: Menlo, Monaco, Consolas, "Courier New", monospace; +} +code { + padding: 2px 4px; + font-size: 90%; + color: #c7254e; + background-color: #f9f2f4; + border-radius: 3px; +} +kbd { + padding: 2px 4px; + font-size: 90%; + color: #ffffff; + background-color: #333333; + border-radius: 3px; + box-shadow: inset 0 -1px 0 rgba(0, 0, 0, 0.25); +} +kbd kbd { + padding: 0; + font-size: 100%; + font-weight: 700; + box-shadow: none; +} +pre { + display: block; + padding: 11px; + margin: 0 0 11.5px; + font-size: 12px; + line-height: 1.846; + color: #212121; + word-break: break-all; + word-wrap: break-word; + background-color: #f5f5f5; + border: 1px solid #cccccc; + border-radius: 3px; +} +pre code { + padding: 0; + font-size: inherit; + color: inherit; + white-space: pre-wrap; + background-color: transparent; + border-radius: 0; +} +.pre-scrollable { + max-height: 340px; + overflow-y: scroll; +} +.container { + padding-right: 15px; + padding-left: 15px; + margin-right: auto; + margin-left: auto; +} +@media (min-width: 768px) { + .container { + width: 750px; + } +} +@media (min-width: 992px) { + .container { + width: 970px; + } +} +@media (min-width: 1200px) { + .container { + width: 1170px; + } +} +.container-fluid { + padding-right: 15px; + padding-left: 15px; + margin-right: auto; + margin-left: auto; +} +.row { + margin-right: -15px; + margin-left: -15px; +} +.row-no-gutters { + margin-right: 0; + margin-left: 0; +} +.row-no-gutters [class*="col-"] { + padding-right: 0; + padding-left: 0; +} +.col-xs-1, .col-sm-1, .col-md-1, .col-lg-1, .col-xs-2, .col-sm-2, .col-md-2, .col-lg-2, .col-xs-3, .col-sm-3, .col-md-3, .col-lg-3, .col-xs-4, .col-sm-4, .col-md-4, .col-lg-4, .col-xs-5, .col-sm-5, .col-md-5, .col-lg-5, .col-xs-6, .col-sm-6, .col-md-6, .col-lg-6, .col-xs-7, .col-sm-7, .col-md-7, .col-lg-7, .col-xs-8, .col-sm-8, .col-md-8, .col-lg-8, .col-xs-9, .col-sm-9, .col-md-9, .col-lg-9, .col-xs-10, .col-sm-10, .col-md-10, .col-lg-10, .col-xs-11, .col-sm-11, .col-md-11, .col-lg-11, .col-xs-12, .col-sm-12, .col-md-12, .col-lg-12 { + position: relative; + min-height: 1px; + padding-right: 15px; + padding-left: 15px; +} +.col-xs-1, .col-xs-2, .col-xs-3, .col-xs-4, .col-xs-5, .col-xs-6, .col-xs-7, .col-xs-8, .col-xs-9, .col-xs-10, .col-xs-11, .col-xs-12 { + float: left; +} +.col-xs-12 { + width: 100%; +} +.col-xs-11 { + width: 91.66666667%; +} +.col-xs-10 { + width: 83.33333333%; +} +.col-xs-9 { + width: 75%; +} +.col-xs-8 { + width: 66.66666667%; +} +.col-xs-7 { + width: 58.33333333%; +} +.col-xs-6 { + width: 50%; +} +.col-xs-5 { + width: 41.66666667%; +} +.col-xs-4 { + width: 33.33333333%; +} +.col-xs-3 { + width: 25%; +} +.col-xs-2 { + width: 16.66666667%; +} +.col-xs-1 { + width: 8.33333333%; +} +.col-xs-pull-12 { + right: 100%; +} +.col-xs-pull-11 { + right: 91.66666667%; +} +.col-xs-pull-10 { + right: 83.33333333%; +} +.col-xs-pull-9 { + right: 75%; +} +.col-xs-pull-8 { + right: 66.66666667%; +} +.col-xs-pull-7 { + right: 58.33333333%; +} +.col-xs-pull-6 { + right: 50%; +} +.col-xs-pull-5 { + right: 41.66666667%; +} +.col-xs-pull-4 { + right: 33.33333333%; +} +.col-xs-pull-3 { + right: 25%; +} +.col-xs-pull-2 { + right: 16.66666667%; +} +.col-xs-pull-1 { + right: 8.33333333%; +} +.col-xs-pull-0 { + right: auto; +} +.col-xs-push-12 { + left: 100%; +} +.col-xs-push-11 { + left: 91.66666667%; +} +.col-xs-push-10 { + left: 83.33333333%; +} +.col-xs-push-9 { + left: 75%; +} +.col-xs-push-8 { + left: 66.66666667%; +} +.col-xs-push-7 { + left: 58.33333333%; +} +.col-xs-push-6 { + left: 50%; +} +.col-xs-push-5 { + left: 41.66666667%; +} +.col-xs-push-4 { + left: 33.33333333%; +} +.col-xs-push-3 { + left: 25%; +} +.col-xs-push-2 { + left: 16.66666667%; +} +.col-xs-push-1 { + left: 8.33333333%; +} +.col-xs-push-0 { + left: auto; +} +.col-xs-offset-12 { + margin-left: 100%; +} +.col-xs-offset-11 { + margin-left: 91.66666667%; +} +.col-xs-offset-10 { + margin-left: 83.33333333%; +} +.col-xs-offset-9 { + margin-left: 75%; +} +.col-xs-offset-8 { + margin-left: 66.66666667%; +} +.col-xs-offset-7 { + margin-left: 58.33333333%; +} +.col-xs-offset-6 { + margin-left: 50%; +} +.col-xs-offset-5 { + margin-left: 41.66666667%; +} +.col-xs-offset-4 { + margin-left: 33.33333333%; +} +.col-xs-offset-3 { + margin-left: 25%; +} +.col-xs-offset-2 { + margin-left: 16.66666667%; +} +.col-xs-offset-1 { + margin-left: 8.33333333%; +} +.col-xs-offset-0 { + margin-left: 0%; +} +@media (min-width: 768px) { + .col-sm-1, .col-sm-2, .col-sm-3, .col-sm-4, .col-sm-5, .col-sm-6, .col-sm-7, .col-sm-8, .col-sm-9, .col-sm-10, .col-sm-11, .col-sm-12 { + float: left; + } + .col-sm-12 { + width: 100%; + } + .col-sm-11 { + width: 91.66666667%; + } + .col-sm-10 { + width: 83.33333333%; + } + .col-sm-9 { + width: 75%; + } + .col-sm-8 { + width: 66.66666667%; + } + .col-sm-7 { + width: 58.33333333%; + } + .col-sm-6 { + width: 50%; + } + .col-sm-5 { + width: 41.66666667%; + } + .col-sm-4 { + width: 33.33333333%; + } + .col-sm-3 { + width: 25%; + } + .col-sm-2 { + width: 16.66666667%; + } + .col-sm-1 { + width: 8.33333333%; + } + .col-sm-pull-12 { + right: 100%; + } + .col-sm-pull-11 { + right: 91.66666667%; + } + .col-sm-pull-10 { + right: 83.33333333%; + } + .col-sm-pull-9 { + right: 75%; + } + .col-sm-pull-8 { + right: 66.66666667%; + } + .col-sm-pull-7 { + right: 58.33333333%; + } + .col-sm-pull-6 { + right: 50%; + } + .col-sm-pull-5 { + right: 41.66666667%; + } + .col-sm-pull-4 { + right: 33.33333333%; + } + .col-sm-pull-3 { + right: 25%; + } + .col-sm-pull-2 { + right: 16.66666667%; + } + .col-sm-pull-1 { + right: 8.33333333%; + } + .col-sm-pull-0 { + right: auto; + } + .col-sm-push-12 { + left: 100%; + } + .col-sm-push-11 { + left: 91.66666667%; + } + .col-sm-push-10 { + left: 83.33333333%; + } + .col-sm-push-9 { + left: 75%; + } + .col-sm-push-8 { + left: 66.66666667%; + } + .col-sm-push-7 { + left: 58.33333333%; + } + .col-sm-push-6 { + left: 50%; + } + .col-sm-push-5 { + left: 41.66666667%; + } + .col-sm-push-4 { + left: 33.33333333%; + } + .col-sm-push-3 { + left: 25%; + } + .col-sm-push-2 { + left: 16.66666667%; + } + .col-sm-push-1 { + left: 8.33333333%; + } + .col-sm-push-0 { + left: auto; + } + .col-sm-offset-12 { + margin-left: 100%; + } + .col-sm-offset-11 { + margin-left: 91.66666667%; + } + .col-sm-offset-10 { + margin-left: 83.33333333%; + } + .col-sm-offset-9 { + margin-left: 75%; + } + .col-sm-offset-8 { + margin-left: 66.66666667%; + } + .col-sm-offset-7 { + margin-left: 58.33333333%; + } + .col-sm-offset-6 { + margin-left: 50%; + } + .col-sm-offset-5 { + margin-left: 41.66666667%; + } + .col-sm-offset-4 { + margin-left: 33.33333333%; + } + .col-sm-offset-3 { + margin-left: 25%; + } + .col-sm-offset-2 { + margin-left: 16.66666667%; + } + .col-sm-offset-1 { + margin-left: 8.33333333%; + } + .col-sm-offset-0 { + margin-left: 0%; + } +} +@media (min-width: 992px) { + .col-md-1, .col-md-2, .col-md-3, .col-md-4, .col-md-5, .col-md-6, .col-md-7, .col-md-8, .col-md-9, .col-md-10, .col-md-11, .col-md-12 { + float: left; + } + .col-md-12 { + width: 100%; + } + .col-md-11 { + width: 91.66666667%; + } + .col-md-10 { + width: 83.33333333%; + } + .col-md-9 { + width: 75%; + } + .col-md-8 { + width: 66.66666667%; + } + .col-md-7 { + width: 58.33333333%; + } + .col-md-6 { + width: 50%; + } + .col-md-5 { + width: 41.66666667%; + } + .col-md-4 { + width: 33.33333333%; + } + .col-md-3 { + width: 25%; + } + .col-md-2 { + width: 16.66666667%; + } + .col-md-1 { + width: 8.33333333%; + } + .col-md-pull-12 { + right: 100%; + } + .col-md-pull-11 { + right: 91.66666667%; + } + .col-md-pull-10 { + right: 83.33333333%; + } + .col-md-pull-9 { + right: 75%; + } + .col-md-pull-8 { + right: 66.66666667%; + } + .col-md-pull-7 { + right: 58.33333333%; + } + .col-md-pull-6 { + right: 50%; + } + .col-md-pull-5 { + right: 41.66666667%; + } + .col-md-pull-4 { + right: 33.33333333%; + } + .col-md-pull-3 { + right: 25%; + } + .col-md-pull-2 { + right: 16.66666667%; + } + .col-md-pull-1 { + right: 8.33333333%; + } + .col-md-pull-0 { + right: auto; + } + .col-md-push-12 { + left: 100%; + } + .col-md-push-11 { + left: 91.66666667%; + } + .col-md-push-10 { + left: 83.33333333%; + } + .col-md-push-9 { + left: 75%; + } + .col-md-push-8 { + left: 66.66666667%; + } + .col-md-push-7 { + left: 58.33333333%; + } + .col-md-push-6 { + left: 50%; + } + .col-md-push-5 { + left: 41.66666667%; + } + .col-md-push-4 { + left: 33.33333333%; + } + .col-md-push-3 { + left: 25%; + } + .col-md-push-2 { + left: 16.66666667%; + } + .col-md-push-1 { + left: 8.33333333%; + } + .col-md-push-0 { + left: auto; + } + .col-md-offset-12 { + margin-left: 100%; + } + .col-md-offset-11 { + margin-left: 91.66666667%; + } + .col-md-offset-10 { + margin-left: 83.33333333%; + } + .col-md-offset-9 { + margin-left: 75%; + } + .col-md-offset-8 { + margin-left: 66.66666667%; + } + .col-md-offset-7 { + margin-left: 58.33333333%; + } + .col-md-offset-6 { + margin-left: 50%; + } + .col-md-offset-5 { + margin-left: 41.66666667%; + } + .col-md-offset-4 { + margin-left: 33.33333333%; + } + .col-md-offset-3 { + margin-left: 25%; + } + .col-md-offset-2 { + margin-left: 16.66666667%; + } + .col-md-offset-1 { + margin-left: 8.33333333%; + } + .col-md-offset-0 { + margin-left: 0%; + } +} +@media (min-width: 1200px) { + .col-lg-1, .col-lg-2, .col-lg-3, .col-lg-4, .col-lg-5, .col-lg-6, .col-lg-7, .col-lg-8, .col-lg-9, .col-lg-10, .col-lg-11, .col-lg-12 { + float: left; + } + .col-lg-12 { + width: 100%; + } + .col-lg-11 { + width: 91.66666667%; + } + .col-lg-10 { + width: 83.33333333%; + } + .col-lg-9 { + width: 75%; + } + .col-lg-8 { + width: 66.66666667%; + } + .col-lg-7 { + width: 58.33333333%; + } + .col-lg-6 { + width: 50%; + } + .col-lg-5 { + width: 41.66666667%; + } + .col-lg-4 { + width: 33.33333333%; + } + .col-lg-3 { + width: 25%; + } + .col-lg-2 { + width: 16.66666667%; + } + .col-lg-1 { + width: 8.33333333%; + } + .col-lg-pull-12 { + right: 100%; + } + .col-lg-pull-11 { + right: 91.66666667%; + } + .col-lg-pull-10 { + right: 83.33333333%; + } + .col-lg-pull-9 { + right: 75%; + } + .col-lg-pull-8 { + right: 66.66666667%; + } + .col-lg-pull-7 { + right: 58.33333333%; + } + .col-lg-pull-6 { + right: 50%; + } + .col-lg-pull-5 { + right: 41.66666667%; + } + .col-lg-pull-4 { + right: 33.33333333%; + } + .col-lg-pull-3 { + right: 25%; + } + .col-lg-pull-2 { + right: 16.66666667%; + } + .col-lg-pull-1 { + right: 8.33333333%; + } + .col-lg-pull-0 { + right: auto; + } + .col-lg-push-12 { + left: 100%; + } + .col-lg-push-11 { + left: 91.66666667%; + } + .col-lg-push-10 { + left: 83.33333333%; + } + .col-lg-push-9 { + left: 75%; + } + .col-lg-push-8 { + left: 66.66666667%; + } + .col-lg-push-7 { + left: 58.33333333%; + } + .col-lg-push-6 { + left: 50%; + } + .col-lg-push-5 { + left: 41.66666667%; + } + .col-lg-push-4 { + left: 33.33333333%; + } + .col-lg-push-3 { + left: 25%; + } + .col-lg-push-2 { + left: 16.66666667%; + } + .col-lg-push-1 { + left: 8.33333333%; + } + .col-lg-push-0 { + left: auto; + } + .col-lg-offset-12 { + margin-left: 100%; + } + .col-lg-offset-11 { + margin-left: 91.66666667%; + } + .col-lg-offset-10 { + margin-left: 83.33333333%; + } + .col-lg-offset-9 { + margin-left: 75%; + } + .col-lg-offset-8 { + margin-left: 66.66666667%; + } + .col-lg-offset-7 { + margin-left: 58.33333333%; + } + .col-lg-offset-6 { + margin-left: 50%; + } + .col-lg-offset-5 { + margin-left: 41.66666667%; + } + .col-lg-offset-4 { + margin-left: 33.33333333%; + } + .col-lg-offset-3 { + margin-left: 25%; + } + .col-lg-offset-2 { + margin-left: 16.66666667%; + } + .col-lg-offset-1 { + margin-left: 8.33333333%; + } + .col-lg-offset-0 { + margin-left: 0%; + } +} +table { + background-color: transparent; +} +table col[class*="col-"] { + position: static; + display: table-column; + float: none; +} +table td[class*="col-"], +table th[class*="col-"] { + position: static; + display: table-cell; + float: none; +} +caption { + padding-top: 8px; + padding-bottom: 8px; + color: #bbbbbb; + text-align: left; +} +th { + text-align: left; +} +.table { + width: 100%; + max-width: 100%; + margin-bottom: 23px; +} +.table > thead > tr > th, +.table > tbody > tr > th, +.table > tfoot > tr > th, +.table > thead > tr > td, +.table > tbody > tr > td, +.table > tfoot > tr > td { + padding: 8px; + line-height: 1.846; + vertical-align: top; + border-top: 1px solid #dddddd; +} +.table > thead > tr > th { + vertical-align: bottom; + border-bottom: 2px solid #dddddd; +} +.table > caption + thead > tr:first-child > th, +.table > colgroup + thead > tr:first-child > th, +.table > thead:first-child > tr:first-child > th, +.table > caption + thead > tr:first-child > td, +.table > colgroup + thead > tr:first-child > td, +.table > thead:first-child > tr:first-child > td { + border-top: 0; +} +.table > tbody + tbody { + border-top: 2px solid #dddddd; +} +.table .table { + background-color: #ffffff; +} +.table-condensed > thead > tr > th, +.table-condensed > tbody > tr > th, +.table-condensed > tfoot > tr > th, +.table-condensed > thead > tr > td, +.table-condensed > tbody > tr > td, +.table-condensed > tfoot > tr > td { + padding: 5px; +} +.table-bordered { + border: 1px solid #dddddd; +} +.table-bordered > thead > tr > th, +.table-bordered > tbody > tr > th, +.table-bordered > tfoot > tr > th, +.table-bordered > thead > tr > td, +.table-bordered > tbody > tr > td, +.table-bordered > tfoot > tr > td { + border: 1px solid #dddddd; +} +.table-bordered > thead > tr > th, +.table-bordered > thead > tr > td { + border-bottom-width: 2px; +} +.table-striped > tbody > tr:nth-of-type(odd) { + background-color: #f9f9f9; +} +.table-hover > tbody > tr:hover { + background-color: #f5f5f5; +} +.table > thead > tr > td.active, +.table > tbody > tr > td.active, +.table > tfoot > tr > td.active, +.table > thead > tr > th.active, +.table > tbody > tr > th.active, +.table > tfoot > tr > th.active, +.table > thead > tr.active > td, +.table > tbody > tr.active > td, +.table > tfoot > tr.active > td, +.table > thead > tr.active > th, +.table > tbody > tr.active > th, +.table > tfoot > tr.active > th { + background-color: #f5f5f5; +} +.table-hover > tbody > tr > td.active:hover, +.table-hover > tbody > tr > th.active:hover, +.table-hover > tbody > tr.active:hover > td, +.table-hover > tbody > tr:hover > .active, +.table-hover > tbody > tr.active:hover > th { + background-color: #e8e8e8; +} +.table > thead > tr > td.success, +.table > tbody > tr > td.success, +.table > tfoot > tr > td.success, +.table > thead > tr > th.success, +.table > tbody > tr > th.success, +.table > tfoot > tr > th.success, +.table > thead > tr.success > td, +.table > tbody > tr.success > td, +.table > tfoot > tr.success > td, +.table > thead > tr.success > th, +.table > tbody > tr.success > th, +.table > tfoot > tr.success > th { + background-color: #dff0d8; +} +.table-hover > tbody > tr > td.success:hover, +.table-hover > tbody > tr > th.success:hover, +.table-hover > tbody > tr.success:hover > td, +.table-hover > tbody > tr:hover > .success, +.table-hover > tbody > tr.success:hover > th { + background-color: #d0e9c6; +} +.table > thead > tr > td.info, +.table > tbody > tr > td.info, +.table > tfoot > tr > td.info, +.table > thead > tr > th.info, +.table > tbody > tr > th.info, +.table > tfoot > tr > th.info, +.table > thead > tr.info > td, +.table > tbody > tr.info > td, +.table > tfoot > tr.info > td, +.table > thead > tr.info > th, +.table > tbody > tr.info > th, +.table > tfoot > tr.info > th { + background-color: #e1bee7; +} +.table-hover > tbody > tr > td.info:hover, +.table-hover > tbody > tr > th.info:hover, +.table-hover > tbody > tr.info:hover > td, +.table-hover > tbody > tr:hover > .info, +.table-hover > tbody > tr.info:hover > th { + background-color: #d8abe0; +} +.table > thead > tr > td.warning, +.table > tbody > tr > td.warning, +.table > tfoot > tr > td.warning, +.table > thead > tr > th.warning, +.table > tbody > tr > th.warning, +.table > tfoot > tr > th.warning, +.table > thead > tr.warning > td, +.table > tbody > tr.warning > td, +.table > tfoot > tr.warning > td, +.table > thead > tr.warning > th, +.table > tbody > tr.warning > th, +.table > tfoot > tr.warning > th { + background-color: #ffe0b2; +} +.table-hover > tbody > tr > td.warning:hover, +.table-hover > tbody > tr > th.warning:hover, +.table-hover > tbody > tr.warning:hover > td, +.table-hover > tbody > tr:hover > .warning, +.table-hover > tbody > tr.warning:hover > th { + background-color: #ffd699; +} +.table > thead > tr > td.danger, +.table > tbody > tr > td.danger, +.table > tfoot > tr > td.danger, +.table > thead > tr > th.danger, +.table > tbody > tr > th.danger, +.table > tfoot > tr > th.danger, +.table > thead > tr.danger > td, +.table > tbody > tr.danger > td, +.table > tfoot > tr.danger > td, +.table > thead > tr.danger > th, +.table > tbody > tr.danger > th, +.table > tfoot > tr.danger > th { + background-color: #f9bdbb; +} +.table-hover > tbody > tr > td.danger:hover, +.table-hover > tbody > tr > th.danger:hover, +.table-hover > tbody > tr.danger:hover > td, +.table-hover > tbody > tr:hover > .danger, +.table-hover > tbody > tr.danger:hover > th { + background-color: #f7a6a4; +} +.table-responsive { + min-height: .01%; + overflow-x: auto; +} +@media screen and (max-width: 767px) { + .table-responsive { + width: 100%; + margin-bottom: 17.25px; + overflow-y: hidden; + -ms-overflow-style: -ms-autohiding-scrollbar; + border: 1px solid #dddddd; + } + .table-responsive > .table { + margin-bottom: 0; + } + .table-responsive > .table > thead > tr > th, + .table-responsive > .table > tbody > tr > th, + .table-responsive > .table > tfoot > tr > th, + .table-responsive > .table > thead > tr > td, + .table-responsive > .table > tbody > tr > td, + .table-responsive > .table > tfoot > tr > td { + white-space: nowrap; + } + .table-responsive > .table-bordered { + border: 0; + } + .table-responsive > .table-bordered > thead > tr > th:first-child, + .table-responsive > .table-bordered > tbody > tr > th:first-child, + .table-responsive > .table-bordered > tfoot > tr > th:first-child, + .table-responsive > .table-bordered > thead > tr > td:first-child, + .table-responsive > .table-bordered > tbody > tr > td:first-child, + .table-responsive > .table-bordered > tfoot > tr > td:first-child { + border-left: 0; + } + .table-responsive > .table-bordered > thead > tr > th:last-child, + .table-responsive > .table-bordered > tbody > tr > th:last-child, + .table-responsive > .table-bordered > tfoot > tr > th:last-child, + .table-responsive > .table-bordered > thead > tr > td:last-child, + .table-responsive > .table-bordered > tbody > tr > td:last-child, + .table-responsive > .table-bordered > tfoot > tr > td:last-child { + border-right: 0; + } + .table-responsive > .table-bordered > tbody > tr:last-child > th, + .table-responsive > .table-bordered > tfoot > tr:last-child > th, + .table-responsive > .table-bordered > tbody > tr:last-child > td, + .table-responsive > .table-bordered > tfoot > tr:last-child > td { + border-bottom: 0; + } +} +fieldset { + min-width: 0; + padding: 0; + margin: 0; + border: 0; +} +legend { + display: block; + width: 100%; + padding: 0; + margin-bottom: 23px; + font-size: 19.5px; + line-height: inherit; + color: #212121; + border: 0; + border-bottom: 1px solid #e5e5e5; +} +label { + display: inline-block; + max-width: 100%; + margin-bottom: 5px; + font-weight: 700; +} +input[type="search"] { + box-sizing: border-box; + -webkit-appearance: none; + appearance: none; +} +input[type="radio"], +input[type="checkbox"] { + margin: 4px 0 0; + margin-top: 1px \9; + line-height: normal; +} +input[type="radio"][disabled], +input[type="checkbox"][disabled], +input[type="radio"].disabled, +input[type="checkbox"].disabled, +fieldset[disabled] input[type="radio"], +fieldset[disabled] input[type="checkbox"] { + cursor: not-allowed; +} +input[type="file"] { + display: block; +} +input[type="range"] { + display: block; + width: 100%; +} +select[multiple], +select[size] { + height: auto; +} +input[type="file"]:focus, +input[type="radio"]:focus, +input[type="checkbox"]:focus { + outline: 5px auto -webkit-focus-ring-color; + outline-offset: -2px; +} +output { + display: block; + padding-top: 7px; + font-size: 13px; + line-height: 1.846; + color: #666666; +} +.form-control { + display: block; + width: 100%; + height: 37px; + padding: 6px 16px; + font-size: 13px; + line-height: 1.846; + color: #666666; + background-color: transparent; + background-image: none; + border: 1px solid transparent; + border-radius: 3px; + box-shadow: inset 0 1px 1px rgba(0, 0, 0, 0.075); + transition: border-color ease-in-out .15s, box-shadow ease-in-out .15s; +} +.form-control:focus { + border-color: #66afe9; + outline: 0; + box-shadow: inset 0 1px 1px rgba(0, 0, 0, .075), 0 0 8px rgba(102, 175, 233, 0.6); +} +.form-control::-moz-placeholder { + color: #bbbbbb; + opacity: 1; +} +.form-control:-ms-input-placeholder { + color: #bbbbbb; +} +.form-control::-webkit-input-placeholder { + color: #bbbbbb; +} +.form-control::-ms-expand { + background-color: transparent; + border: 0; +} +.form-control[disabled], +.form-control[readonly], +fieldset[disabled] .form-control { + background-color: transparent; + opacity: 1; +} +.form-control[disabled], +fieldset[disabled] .form-control { + cursor: not-allowed; +} +textarea.form-control { + height: auto; +} +@media screen and (-webkit-min-device-pixel-ratio: 0) { + input[type="date"].form-control, + input[type="time"].form-control, + input[type="datetime-local"].form-control, + input[type="month"].form-control { + line-height: 37px; + } + input[type="date"].input-sm, + input[type="time"].input-sm, + input[type="datetime-local"].input-sm, + input[type="month"].input-sm, + .input-group-sm input[type="date"], + .input-group-sm input[type="time"], + .input-group-sm input[type="datetime-local"], + .input-group-sm input[type="month"] { + line-height: 30px; + } + input[type="date"].input-lg, + input[type="time"].input-lg, + input[type="datetime-local"].input-lg, + input[type="month"].input-lg, + .input-group-lg input[type="date"], + .input-group-lg input[type="time"], + .input-group-lg input[type="datetime-local"], + .input-group-lg input[type="month"] { + line-height: 45px; + } +} +.form-group { + margin-bottom: 15px; +} +.radio, +.checkbox { + position: relative; + display: block; + margin-top: 10px; + margin-bottom: 10px; +} +.radio.disabled label, +.checkbox.disabled label, +fieldset[disabled] .radio label, +fieldset[disabled] .checkbox label { + cursor: not-allowed; +} +.radio label, +.checkbox label { + min-height: 23px; + padding-left: 20px; + margin-bottom: 0; + font-weight: 400; + cursor: pointer; +} +.radio input[type="radio"], +.radio-inline input[type="radio"], +.checkbox input[type="checkbox"], +.checkbox-inline input[type="checkbox"] { + position: absolute; + margin-top: 4px \9; + margin-left: -20px; +} +.radio + .radio, +.checkbox + .checkbox { + margin-top: -5px; +} +.radio-inline, +.checkbox-inline { + position: relative; + display: inline-block; + padding-left: 20px; + margin-bottom: 0; + font-weight: 400; + vertical-align: middle; + cursor: pointer; +} +.radio-inline.disabled, +.checkbox-inline.disabled, +fieldset[disabled] .radio-inline, +fieldset[disabled] .checkbox-inline { + cursor: not-allowed; +} +.radio-inline + .radio-inline, +.checkbox-inline + .checkbox-inline { + margin-top: 0; + margin-left: 10px; +} +.form-control-static { + min-height: 36px; + padding-top: 7px; + padding-bottom: 7px; + margin-bottom: 0; +} +.form-control-static.input-lg, +.form-control-static.input-sm { + padding-right: 0; + padding-left: 0; +} +.input-sm { + height: 30px; + padding: 5px 10px; + font-size: 12px; + line-height: 1.5; + border-radius: 3px; +} +select.input-sm { + height: 30px; + line-height: 30px; +} +textarea.input-sm, +select[multiple].input-sm { + height: auto; +} +.form-group-sm .form-control { + height: 30px; + padding: 5px 10px; + font-size: 12px; + line-height: 1.5; + border-radius: 3px; +} +.form-group-sm select.form-control { + height: 30px; + line-height: 30px; +} +.form-group-sm textarea.form-control, +.form-group-sm select[multiple].form-control { + height: auto; +} +.form-group-sm .form-control-static { + height: 30px; + min-height: 35px; + padding: 6px 10px; + font-size: 12px; + line-height: 1.5; +} +.input-lg { + height: 45px; + padding: 10px 16px; + font-size: 17px; + line-height: 1.3333333; + border-radius: 3px; +} +select.input-lg { + height: 45px; + line-height: 45px; +} +textarea.input-lg, +select[multiple].input-lg { + height: auto; +} +.form-group-lg .form-control { + height: 45px; + padding: 10px 16px; + font-size: 17px; + line-height: 1.3333333; + border-radius: 3px; +} +.form-group-lg select.form-control { + height: 45px; + line-height: 45px; +} +.form-group-lg textarea.form-control, +.form-group-lg select[multiple].form-control { + height: auto; +} +.form-group-lg .form-control-static { + height: 45px; + min-height: 40px; + padding: 11px 16px; + font-size: 17px; + line-height: 1.3333333; +} +.has-feedback { + position: relative; +} +.has-feedback .form-control { + padding-right: 46.25px; +} +.form-control-feedback { + position: absolute; + top: 0; + right: 0; + z-index: 2; + display: block; + width: 37px; + height: 37px; + line-height: 37px; + text-align: center; + pointer-events: none; +} +.input-lg + .form-control-feedback, +.input-group-lg + .form-control-feedback, +.form-group-lg .form-control + .form-control-feedback { + width: 45px; + height: 45px; + line-height: 45px; +} +.input-sm + .form-control-feedback, +.input-group-sm + .form-control-feedback, +.form-group-sm .form-control + .form-control-feedback { + width: 30px; + height: 30px; + line-height: 30px; +} +.has-success .help-block, +.has-success .control-label, +.has-success .radio, +.has-success .checkbox, +.has-success .radio-inline, +.has-success .checkbox-inline, +.has-success.radio label, +.has-success.checkbox label, +.has-success.radio-inline label, +.has-success.checkbox-inline label { + color: #4caf50; +} +.has-success .form-control { + border-color: #4caf50; + box-shadow: inset 0 1px 1px rgba(0, 0, 0, 0.075); +} +.has-success .form-control:focus { + border-color: #3d8b40; + box-shadow: inset 0 1px 1px rgba(0, 0, 0, 0.075), 0 0 6px #92cf94; +} +.has-success .input-group-addon { + color: #4caf50; + background-color: #dff0d8; + border-color: #4caf50; +} +.has-success .form-control-feedback { + color: #4caf50; +} +.has-warning .help-block, +.has-warning .control-label, +.has-warning .radio, +.has-warning .checkbox, +.has-warning .radio-inline, +.has-warning .checkbox-inline, +.has-warning.radio label, +.has-warning.checkbox label, +.has-warning.radio-inline label, +.has-warning.checkbox-inline label { + color: #ff9800; +} +.has-warning .form-control { + border-color: #ff9800; + box-shadow: inset 0 1px 1px rgba(0, 0, 0, 0.075); +} +.has-warning .form-control:focus { + border-color: #cc7a00; + box-shadow: inset 0 1px 1px rgba(0, 0, 0, 0.075), 0 0 6px #ffc166; +} +.has-warning .input-group-addon { + color: #ff9800; + background-color: #ffe0b2; + border-color: #ff9800; +} +.has-warning .form-control-feedback { + color: #ff9800; +} +.has-error .help-block, +.has-error .control-label, +.has-error .radio, +.has-error .checkbox, +.has-error .radio-inline, +.has-error .checkbox-inline, +.has-error.radio label, +.has-error.checkbox label, +.has-error.radio-inline label, +.has-error.checkbox-inline label { + color: #e51c23; +} +.has-error .form-control { + border-color: #e51c23; + box-shadow: inset 0 1px 1px rgba(0, 0, 0, 0.075); +} +.has-error .form-control:focus { + border-color: #b9151b; + box-shadow: inset 0 1px 1px rgba(0, 0, 0, 0.075), 0 0 6px #ef787c; +} +.has-error .input-group-addon { + color: #e51c23; + background-color: #f9bdbb; + border-color: #e51c23; +} +.has-error .form-control-feedback { + color: #e51c23; +} +.has-feedback label ~ .form-control-feedback { + top: 28px; +} +.has-feedback label.sr-only ~ .form-control-feedback { + top: 0; +} +.help-block { + display: block; + margin-top: 5px; + margin-bottom: 10px; + color: #a6a6a6; +} +@media (min-width: 768px) { + .form-inline .form-group { + display: inline-block; + margin-bottom: 0; + vertical-align: middle; + } + .form-inline .form-control { + display: inline-block; + width: auto; + vertical-align: middle; + } + .form-inline .form-control-static { + display: inline-block; + } + .form-inline .input-group { + display: inline-table; + vertical-align: middle; + } + .form-inline .input-group .input-group-addon, + .form-inline .input-group .input-group-btn, + .form-inline .input-group .form-control { + width: auto; + } + .form-inline .input-group > .form-control { + width: 100%; + } + .form-inline .control-label { + margin-bottom: 0; + vertical-align: middle; + } + .form-inline .radio, + .form-inline .checkbox { + display: inline-block; + margin-top: 0; + margin-bottom: 0; + vertical-align: middle; + } + .form-inline .radio label, + .form-inline .checkbox label { + padding-left: 0; + } + .form-inline .radio input[type="radio"], + .form-inline .checkbox input[type="checkbox"] { + position: relative; + margin-left: 0; + } + .form-inline .has-feedback .form-control-feedback { + top: 0; + } +} +.form-horizontal .radio, +.form-horizontal .checkbox, +.form-horizontal .radio-inline, +.form-horizontal .checkbox-inline { + padding-top: 7px; + margin-top: 0; + margin-bottom: 0; +} +.form-horizontal .radio, +.form-horizontal .checkbox { + min-height: 30px; +} +.form-horizontal .form-group { + margin-right: -15px; + margin-left: -15px; +} +@media (min-width: 768px) { + .form-horizontal .control-label { + padding-top: 7px; + margin-bottom: 0; + text-align: right; + } +} +.form-horizontal .has-feedback .form-control-feedback { + right: 15px; +} +@media (min-width: 768px) { + .form-horizontal .form-group-lg .control-label { + padding-top: 11px; + font-size: 17px; + } +} +@media (min-width: 768px) { + .form-horizontal .form-group-sm .control-label { + padding-top: 6px; + font-size: 12px; + } +} +.btn { + display: inline-block; + margin-bottom: 0; + font-weight: normal; + text-align: center; + white-space: nowrap; + vertical-align: middle; + -ms-touch-action: manipulation; + touch-action: manipulation; + cursor: pointer; + background-image: none; + border: 1px solid transparent; + padding: 6px 16px; + font-size: 13px; + line-height: 1.846; + border-radius: 3px; + -webkit-user-select: none; + -moz-user-select: none; + -ms-user-select: none; + user-select: none; +} +.btn:focus, +.btn:active:focus, +.btn.active:focus, +.btn.focus, +.btn:active.focus, +.btn.active.focus { + outline: 5px auto -webkit-focus-ring-color; + outline-offset: -2px; +} +.btn:hover, +.btn:focus, +.btn.focus { + color: #444444; + text-decoration: none; +} +.btn:active, +.btn.active { + background-image: none; + outline: 0; + box-shadow: inset 0 3px 5px rgba(0, 0, 0, 0.125); +} +.btn.disabled, +.btn[disabled], +fieldset[disabled] .btn { + cursor: not-allowed; + filter: alpha(opacity=65); + opacity: 0.65; + box-shadow: none; +} +a.btn.disabled, +fieldset[disabled] a.btn { + pointer-events: none; +} +.btn-default { + color: #444444; + background-color: #ffffff; + border-color: transparent; +} +.btn-default:focus, +.btn-default.focus { + color: #444444; + background-color: #e6e6e6; + border-color: rgba(0, 0, 0, 0); +} +.btn-default:hover { + color: #444444; + background-color: #e6e6e6; + border-color: rgba(0, 0, 0, 0); +} +.btn-default:active, +.btn-default.active, +.open > .dropdown-toggle.btn-default { + color: #444444; + background-color: #e6e6e6; + background-image: none; + border-color: rgba(0, 0, 0, 0); +} +.btn-default:active:hover, +.btn-default.active:hover, +.open > .dropdown-toggle.btn-default:hover, +.btn-default:active:focus, +.btn-default.active:focus, +.open > .dropdown-toggle.btn-default:focus, +.btn-default:active.focus, +.btn-default.active.focus, +.open > .dropdown-toggle.btn-default.focus { + color: #444444; + background-color: #d4d4d4; + border-color: rgba(0, 0, 0, 0); +} +.btn-default.disabled:hover, +.btn-default[disabled]:hover, +fieldset[disabled] .btn-default:hover, +.btn-default.disabled:focus, +.btn-default[disabled]:focus, +fieldset[disabled] .btn-default:focus, +.btn-default.disabled.focus, +.btn-default[disabled].focus, +fieldset[disabled] .btn-default.focus { + background-color: #ffffff; + border-color: transparent; +} +.btn-default .badge { + color: #ffffff; + background-color: #444444; +} +.btn-primary { + color: #ffffff; + background-color: #2196f3; + border-color: transparent; +} +.btn-primary:focus, +.btn-primary.focus { + color: #ffffff; + background-color: #0c7cd5; + border-color: rgba(0, 0, 0, 0); +} +.btn-primary:hover { + color: #ffffff; + background-color: #0c7cd5; + border-color: rgba(0, 0, 0, 0); +} +.btn-primary:active, +.btn-primary.active, +.open > .dropdown-toggle.btn-primary { + color: #ffffff; + background-color: #0c7cd5; + background-image: none; + border-color: rgba(0, 0, 0, 0); +} +.btn-primary:active:hover, +.btn-primary.active:hover, +.open > .dropdown-toggle.btn-primary:hover, +.btn-primary:active:focus, +.btn-primary.active:focus, +.open > .dropdown-toggle.btn-primary:focus, +.btn-primary:active.focus, +.btn-primary.active.focus, +.open > .dropdown-toggle.btn-primary.focus { + color: #ffffff; + background-color: #0a68b4; + border-color: rgba(0, 0, 0, 0); +} +.btn-primary.disabled:hover, +.btn-primary[disabled]:hover, +fieldset[disabled] .btn-primary:hover, +.btn-primary.disabled:focus, +.btn-primary[disabled]:focus, +fieldset[disabled] .btn-primary:focus, +.btn-primary.disabled.focus, +.btn-primary[disabled].focus, +fieldset[disabled] .btn-primary.focus { + background-color: #2196f3; + border-color: transparent; +} +.btn-primary .badge { + color: #2196f3; + background-color: #ffffff; +} +.btn-success { + color: #ffffff; + background-color: #4caf50; + border-color: transparent; +} +.btn-success:focus, +.btn-success.focus { + color: #ffffff; + background-color: #3d8b40; + border-color: rgba(0, 0, 0, 0); +} +.btn-success:hover { + color: #ffffff; + background-color: #3d8b40; + border-color: rgba(0, 0, 0, 0); +} +.btn-success:active, +.btn-success.active, +.open > .dropdown-toggle.btn-success { + color: #ffffff; + background-color: #3d8b40; + background-image: none; + border-color: rgba(0, 0, 0, 0); +} +.btn-success:active:hover, +.btn-success.active:hover, +.open > .dropdown-toggle.btn-success:hover, +.btn-success:active:focus, +.btn-success.active:focus, +.open > .dropdown-toggle.btn-success:focus, +.btn-success:active.focus, +.btn-success.active.focus, +.open > .dropdown-toggle.btn-success.focus { + color: #ffffff; + background-color: #327334; + border-color: rgba(0, 0, 0, 0); +} +.btn-success.disabled:hover, +.btn-success[disabled]:hover, +fieldset[disabled] .btn-success:hover, +.btn-success.disabled:focus, +.btn-success[disabled]:focus, +fieldset[disabled] .btn-success:focus, +.btn-success.disabled.focus, +.btn-success[disabled].focus, +fieldset[disabled] .btn-success.focus { + background-color: #4caf50; + border-color: transparent; +} +.btn-success .badge { + color: #4caf50; + background-color: #ffffff; +} +.btn-info { + color: #ffffff; + background-color: #9c27b0; + border-color: transparent; +} +.btn-info:focus, +.btn-info.focus { + color: #ffffff; + background-color: #771e86; + border-color: rgba(0, 0, 0, 0); +} +.btn-info:hover { + color: #ffffff; + background-color: #771e86; + border-color: rgba(0, 0, 0, 0); +} +.btn-info:active, +.btn-info.active, +.open > .dropdown-toggle.btn-info { + color: #ffffff; + background-color: #771e86; + background-image: none; + border-color: rgba(0, 0, 0, 0); +} +.btn-info:active:hover, +.btn-info.active:hover, +.open > .dropdown-toggle.btn-info:hover, +.btn-info:active:focus, +.btn-info.active:focus, +.open > .dropdown-toggle.btn-info:focus, +.btn-info:active.focus, +.btn-info.active.focus, +.open > .dropdown-toggle.btn-info.focus { + color: #ffffff; + background-color: #5d1769; + border-color: rgba(0, 0, 0, 0); +} +.btn-info.disabled:hover, +.btn-info[disabled]:hover, +fieldset[disabled] .btn-info:hover, +.btn-info.disabled:focus, +.btn-info[disabled]:focus, +fieldset[disabled] .btn-info:focus, +.btn-info.disabled.focus, +.btn-info[disabled].focus, +fieldset[disabled] .btn-info.focus { + background-color: #9c27b0; + border-color: transparent; +} +.btn-info .badge { + color: #9c27b0; + background-color: #ffffff; +} +.btn-warning { + color: #ffffff; + background-color: #ff9800; + border-color: transparent; +} +.btn-warning:focus, +.btn-warning.focus { + color: #ffffff; + background-color: #cc7a00; + border-color: rgba(0, 0, 0, 0); +} +.btn-warning:hover { + color: #ffffff; + background-color: #cc7a00; + border-color: rgba(0, 0, 0, 0); +} +.btn-warning:active, +.btn-warning.active, +.open > .dropdown-toggle.btn-warning { + color: #ffffff; + background-color: #cc7a00; + background-image: none; + border-color: rgba(0, 0, 0, 0); +} +.btn-warning:active:hover, +.btn-warning.active:hover, +.open > .dropdown-toggle.btn-warning:hover, +.btn-warning:active:focus, +.btn-warning.active:focus, +.open > .dropdown-toggle.btn-warning:focus, +.btn-warning:active.focus, +.btn-warning.active.focus, +.open > .dropdown-toggle.btn-warning.focus { + color: #ffffff; + background-color: #a86400; + border-color: rgba(0, 0, 0, 0); +} +.btn-warning.disabled:hover, +.btn-warning[disabled]:hover, +fieldset[disabled] .btn-warning:hover, +.btn-warning.disabled:focus, +.btn-warning[disabled]:focus, +fieldset[disabled] .btn-warning:focus, +.btn-warning.disabled.focus, +.btn-warning[disabled].focus, +fieldset[disabled] .btn-warning.focus { + background-color: #ff9800; + border-color: transparent; +} +.btn-warning .badge { + color: #ff9800; + background-color: #ffffff; +} +.btn-danger { + color: #ffffff; + background-color: #e51c23; + border-color: transparent; +} +.btn-danger:focus, +.btn-danger.focus { + color: #ffffff; + background-color: #b9151b; + border-color: rgba(0, 0, 0, 0); +} +.btn-danger:hover { + color: #ffffff; + background-color: #b9151b; + border-color: rgba(0, 0, 0, 0); +} +.btn-danger:active, +.btn-danger.active, +.open > .dropdown-toggle.btn-danger { + color: #ffffff; + background-color: #b9151b; + background-image: none; + border-color: rgba(0, 0, 0, 0); +} +.btn-danger:active:hover, +.btn-danger.active:hover, +.open > .dropdown-toggle.btn-danger:hover, +.btn-danger:active:focus, +.btn-danger.active:focus, +.open > .dropdown-toggle.btn-danger:focus, +.btn-danger:active.focus, +.btn-danger.active.focus, +.open > .dropdown-toggle.btn-danger.focus { + color: #ffffff; + background-color: #991216; + border-color: rgba(0, 0, 0, 0); +} +.btn-danger.disabled:hover, +.btn-danger[disabled]:hover, +fieldset[disabled] .btn-danger:hover, +.btn-danger.disabled:focus, +.btn-danger[disabled]:focus, +fieldset[disabled] .btn-danger:focus, +.btn-danger.disabled.focus, +.btn-danger[disabled].focus, +fieldset[disabled] .btn-danger.focus { + background-color: #e51c23; + border-color: transparent; +} +.btn-danger .badge { + color: #e51c23; + background-color: #ffffff; +} +.btn-link { + font-weight: 400; + color: #2196f3; + border-radius: 0; +} +.btn-link, +.btn-link:active, +.btn-link.active, +.btn-link[disabled], +fieldset[disabled] .btn-link { + background-color: transparent; + box-shadow: none; +} +.btn-link, +.btn-link:hover, +.btn-link:focus, +.btn-link:active { + border-color: transparent; +} +.btn-link:hover, +.btn-link:focus { + color: #0a6ebd; + text-decoration: underline; + background-color: transparent; +} +.btn-link[disabled]:hover, +fieldset[disabled] .btn-link:hover, +.btn-link[disabled]:focus, +fieldset[disabled] .btn-link:focus { + color: #bbbbbb; + text-decoration: none; +} +.btn-lg, +.btn-group-lg > .btn { + padding: 10px 16px; + font-size: 17px; + line-height: 1.3333333; + border-radius: 3px; +} +.btn-sm, +.btn-group-sm > .btn { + padding: 5px 10px; + font-size: 12px; + line-height: 1.5; + border-radius: 3px; +} +.btn-xs, +.btn-group-xs > .btn { + padding: 1px 5px; + font-size: 12px; + line-height: 1.5; + border-radius: 3px; +} +.btn-block { + display: block; + width: 100%; +} +.btn-block + .btn-block { + margin-top: 5px; +} +input[type="submit"].btn-block, +input[type="reset"].btn-block, +input[type="button"].btn-block { + width: 100%; +} +.fade { + opacity: 0; + transition: opacity 0.15s linear; +} +.fade.in { + opacity: 1; +} +.collapse { + display: none; +} +.collapse.in { + display: block; +} +tr.collapse.in { + display: table-row; +} +tbody.collapse.in { + display: table-row-group; +} +.collapsing { + position: relative; + height: 0; + overflow: hidden; + transition-property: height, visibility; + transition-duration: 0.35s; + transition-timing-function: ease; +} +.caret { + display: inline-block; + width: 0; + height: 0; + margin-left: 2px; + vertical-align: middle; + border-top: 4px dashed; + border-top: 4px solid \9; + border-right: 4px solid transparent; + border-left: 4px solid transparent; +} +.dropup, +.dropdown { + position: relative; +} +.dropdown-toggle:focus { + outline: 0; +} +.dropdown-menu { + position: absolute; + top: 100%; + left: 0; + z-index: 1000; + display: none; + float: left; + min-width: 160px; + padding: 5px 0; + margin: 2px 0 0; + font-size: 13px; + text-align: left; + list-style: none; + background-color: #ffffff; + background-clip: padding-box; + border: 1px solid #cccccc; + border: 1px solid rgba(0, 0, 0, 0.15); + border-radius: 3px; + box-shadow: 0 6px 12px rgba(0, 0, 0, 0.175); +} +.dropdown-menu.pull-right { + right: 0; + left: auto; +} +.dropdown-menu .divider { + height: 1px; + margin: 10.5px 0; + overflow: hidden; + background-color: #e5e5e5; +} +.dropdown-menu > li > a { + display: block; + padding: 3px 20px; + clear: both; + font-weight: 400; + line-height: 1.846; + color: #666666; + white-space: nowrap; +} +.dropdown-menu > li > a:hover, +.dropdown-menu > li > a:focus { + color: #141414; + text-decoration: none; + background-color: #eeeeee; +} +.dropdown-menu > .active > a, +.dropdown-menu > .active > a:hover, +.dropdown-menu > .active > a:focus { + color: #ffffff; + text-decoration: none; + background-color: #2196f3; + outline: 0; +} +.dropdown-menu > .disabled > a, +.dropdown-menu > .disabled > a:hover, +.dropdown-menu > .disabled > a:focus { + color: #bbbbbb; +} +.dropdown-menu > .disabled > a:hover, +.dropdown-menu > .disabled > a:focus { + text-decoration: none; + cursor: not-allowed; + background-color: transparent; + background-image: none; + filter: progid:DXImageTransform.Microsoft.gradient(enabled = false); +} +.open > .dropdown-menu { + display: block; +} +.open > a { + outline: 0; +} +.dropdown-menu-right { + right: 0; + left: auto; +} +.dropdown-menu-left { + right: auto; + left: 0; +} +.dropdown-header { + display: block; + padding: 3px 20px; + font-size: 12px; + line-height: 1.846; + color: #bbbbbb; + white-space: nowrap; +} +.dropdown-backdrop { + position: fixed; + top: 0; + right: 0; + bottom: 0; + left: 0; + z-index: 990; +} +.pull-right > .dropdown-menu { + right: 0; + left: auto; +} +.dropup .caret, +.navbar-fixed-bottom .dropdown .caret { + content: ""; + border-top: 0; + border-bottom: 4px dashed; + border-bottom: 4px solid \9; +} +.dropup .dropdown-menu, +.navbar-fixed-bottom .dropdown .dropdown-menu { + top: auto; + bottom: 100%; + margin-bottom: 2px; +} +@media (min-width: 768px) { + .navbar-right .dropdown-menu { + right: 0; + left: auto; + } + .navbar-right .dropdown-menu-left { + right: auto; + left: 0; + } +} +.btn-group, +.btn-group-vertical { + position: relative; + display: inline-block; + vertical-align: middle; +} +.btn-group > .btn, +.btn-group-vertical > .btn { + position: relative; + float: left; +} +.btn-group > .btn:hover, +.btn-group-vertical > .btn:hover, +.btn-group > .btn:focus, +.btn-group-vertical > .btn:focus, +.btn-group > .btn:active, +.btn-group-vertical > .btn:active, +.btn-group > .btn.active, +.btn-group-vertical > .btn.active { + z-index: 2; +} +.btn-group .btn + .btn, +.btn-group .btn + .btn-group, +.btn-group .btn-group + .btn, +.btn-group .btn-group + .btn-group { + margin-left: -1px; +} +.btn-toolbar { + margin-left: -5px; +} +.btn-toolbar .btn, +.btn-toolbar .btn-group, +.btn-toolbar .input-group { + float: left; +} +.btn-toolbar > .btn, +.btn-toolbar > .btn-group, +.btn-toolbar > .input-group { + margin-left: 5px; +} +.btn-group > .btn:not(:first-child):not(:last-child):not(.dropdown-toggle) { + border-radius: 0; +} +.btn-group > .btn:first-child { + margin-left: 0; +} +.btn-group > .btn:first-child:not(:last-child):not(.dropdown-toggle) { + border-top-right-radius: 0; + border-bottom-right-radius: 0; +} +.btn-group > .btn:last-child:not(:first-child), +.btn-group > .dropdown-toggle:not(:first-child) { + border-top-left-radius: 0; + border-bottom-left-radius: 0; +} +.btn-group > .btn-group { + float: left; +} +.btn-group > .btn-group:not(:first-child):not(:last-child) > .btn { + border-radius: 0; +} +.btn-group > .btn-group:first-child:not(:last-child) > .btn:last-child, +.btn-group > .btn-group:first-child:not(:last-child) > .dropdown-toggle { + border-top-right-radius: 0; + border-bottom-right-radius: 0; +} +.btn-group > .btn-group:last-child:not(:first-child) > .btn:first-child { + border-top-left-radius: 0; + border-bottom-left-radius: 0; +} +.btn-group .dropdown-toggle:active, +.btn-group.open .dropdown-toggle { + outline: 0; +} +.btn-group > .btn + .dropdown-toggle { + padding-right: 8px; + padding-left: 8px; +} +.btn-group > .btn-lg + .dropdown-toggle { + padding-right: 12px; + padding-left: 12px; +} +.btn-group.open .dropdown-toggle { + box-shadow: inset 0 3px 5px rgba(0, 0, 0, 0.125); +} +.btn-group.open .dropdown-toggle.btn-link { + box-shadow: none; +} +.btn .caret { + margin-left: 0; +} +.btn-lg .caret { + border-width: 5px 5px 0; + border-bottom-width: 0; +} +.dropup .btn-lg .caret { + border-width: 0 5px 5px; +} +.btn-group-vertical > .btn, +.btn-group-vertical > .btn-group, +.btn-group-vertical > .btn-group > .btn { + display: block; + float: none; + width: 100%; + max-width: 100%; +} +.btn-group-vertical > .btn-group > .btn { + float: none; +} +.btn-group-vertical > .btn + .btn, +.btn-group-vertical > .btn + .btn-group, +.btn-group-vertical > .btn-group + .btn, +.btn-group-vertical > .btn-group + .btn-group { + margin-top: -1px; + margin-left: 0; +} +.btn-group-vertical > .btn:not(:first-child):not(:last-child) { + border-radius: 0; +} +.btn-group-vertical > .btn:first-child:not(:last-child) { + border-top-left-radius: 3px; + border-top-right-radius: 3px; + border-bottom-right-radius: 0; + border-bottom-left-radius: 0; +} +.btn-group-vertical > .btn:last-child:not(:first-child) { + border-top-left-radius: 0; + border-top-right-radius: 0; + border-bottom-right-radius: 3px; + border-bottom-left-radius: 3px; +} +.btn-group-vertical > .btn-group:not(:first-child):not(:last-child) > .btn { + border-radius: 0; +} +.btn-group-vertical > .btn-group:first-child:not(:last-child) > .btn:last-child, +.btn-group-vertical > .btn-group:first-child:not(:last-child) > .dropdown-toggle { + border-bottom-right-radius: 0; + border-bottom-left-radius: 0; +} +.btn-group-vertical > .btn-group:last-child:not(:first-child) > .btn:first-child { + border-top-left-radius: 0; + border-top-right-radius: 0; +} +.btn-group-justified { + display: table; + width: 100%; + table-layout: fixed; + border-collapse: separate; +} +.btn-group-justified > .btn, +.btn-group-justified > .btn-group { + display: table-cell; + float: none; + width: 1%; +} +.btn-group-justified > .btn-group .btn { + width: 100%; +} +.btn-group-justified > .btn-group .dropdown-menu { + left: auto; +} +[data-toggle="buttons"] > .btn input[type="radio"], +[data-toggle="buttons"] > .btn-group > .btn input[type="radio"], +[data-toggle="buttons"] > .btn input[type="checkbox"], +[data-toggle="buttons"] > .btn-group > .btn input[type="checkbox"] { + position: absolute; + clip: rect(0, 0, 0, 0); + pointer-events: none; +} +.input-group { + position: relative; + display: table; + border-collapse: separate; +} +.input-group[class*="col-"] { + float: none; + padding-right: 0; + padding-left: 0; +} +.input-group .form-control { + position: relative; + z-index: 2; + float: left; + width: 100%; + margin-bottom: 0; +} +.input-group .form-control:focus { + z-index: 3; +} +.input-group-lg > .form-control, +.input-group-lg > .input-group-addon, +.input-group-lg > .input-group-btn > .btn { + height: 45px; + padding: 10px 16px; + font-size: 17px; + line-height: 1.3333333; + border-radius: 3px; +} +select.input-group-lg > .form-control, +select.input-group-lg > .input-group-addon, +select.input-group-lg > .input-group-btn > .btn { + height: 45px; + line-height: 45px; +} +textarea.input-group-lg > .form-control, +textarea.input-group-lg > .input-group-addon, +textarea.input-group-lg > .input-group-btn > .btn, +select[multiple].input-group-lg > .form-control, +select[multiple].input-group-lg > .input-group-addon, +select[multiple].input-group-lg > .input-group-btn > .btn { + height: auto; +} +.input-group-sm > .form-control, +.input-group-sm > .input-group-addon, +.input-group-sm > .input-group-btn > .btn { + height: 30px; + padding: 5px 10px; + font-size: 12px; + line-height: 1.5; + border-radius: 3px; +} +select.input-group-sm > .form-control, +select.input-group-sm > .input-group-addon, +select.input-group-sm > .input-group-btn > .btn { + height: 30px; + line-height: 30px; +} +textarea.input-group-sm > .form-control, +textarea.input-group-sm > .input-group-addon, +textarea.input-group-sm > .input-group-btn > .btn, +select[multiple].input-group-sm > .form-control, +select[multiple].input-group-sm > .input-group-addon, +select[multiple].input-group-sm > .input-group-btn > .btn { + height: auto; +} +.input-group-addon, +.input-group-btn, +.input-group .form-control { + display: table-cell; +} +.input-group-addon:not(:first-child):not(:last-child), +.input-group-btn:not(:first-child):not(:last-child), +.input-group .form-control:not(:first-child):not(:last-child) { + border-radius: 0; +} +.input-group-addon, +.input-group-btn { + width: 1%; + white-space: nowrap; + vertical-align: middle; +} +.input-group-addon { + padding: 6px 16px; + font-size: 13px; + font-weight: 400; + line-height: 1; + color: #666666; + text-align: center; + background-color: transparent; + border: 1px solid transparent; + border-radius: 3px; +} +.input-group-addon.input-sm { + padding: 5px 10px; + font-size: 12px; + border-radius: 3px; +} +.input-group-addon.input-lg { + padding: 10px 16px; + font-size: 17px; + border-radius: 3px; +} +.input-group-addon input[type="radio"], +.input-group-addon input[type="checkbox"] { + margin-top: 0; +} +.input-group .form-control:first-child, +.input-group-addon:first-child, +.input-group-btn:first-child > .btn, +.input-group-btn:first-child > .btn-group > .btn, +.input-group-btn:first-child > .dropdown-toggle, +.input-group-btn:last-child > .btn:not(:last-child):not(.dropdown-toggle), +.input-group-btn:last-child > .btn-group:not(:last-child) > .btn { + border-top-right-radius: 0; + border-bottom-right-radius: 0; +} +.input-group-addon:first-child { + border-right: 0; +} +.input-group .form-control:last-child, +.input-group-addon:last-child, +.input-group-btn:last-child > .btn, +.input-group-btn:last-child > .btn-group > .btn, +.input-group-btn:last-child > .dropdown-toggle, +.input-group-btn:first-child > .btn:not(:first-child), +.input-group-btn:first-child > .btn-group:not(:first-child) > .btn { + border-top-left-radius: 0; + border-bottom-left-radius: 0; +} +.input-group-addon:last-child { + border-left: 0; +} +.input-group-btn { + position: relative; + font-size: 0; + white-space: nowrap; +} +.input-group-btn > .btn { + position: relative; +} +.input-group-btn > .btn + .btn { + margin-left: -1px; +} +.input-group-btn > .btn:hover, +.input-group-btn > .btn:focus, +.input-group-btn > .btn:active { + z-index: 2; +} +.input-group-btn:first-child > .btn, +.input-group-btn:first-child > .btn-group { + margin-right: -1px; +} +.input-group-btn:last-child > .btn, +.input-group-btn:last-child > .btn-group { + z-index: 2; + margin-left: -1px; +} +.nav { + padding-left: 0; + margin-bottom: 0; + list-style: none; +} +.nav > li { + position: relative; + display: block; +} +.nav > li > a { + position: relative; + display: block; + padding: 10px 15px; +} +.nav > li > a:hover, +.nav > li > a:focus { + text-decoration: none; + background-color: #eeeeee; +} +.nav > li.disabled > a { + color: #bbbbbb; +} +.nav > li.disabled > a:hover, +.nav > li.disabled > a:focus { + color: #bbbbbb; + text-decoration: none; + cursor: not-allowed; + background-color: transparent; +} +.nav .open > a, +.nav .open > a:hover, +.nav .open > a:focus { + background-color: #eeeeee; + border-color: #2196f3; +} +.nav .nav-divider { + height: 1px; + margin: 10.5px 0; + overflow: hidden; + background-color: #e5e5e5; +} +.nav > li > a > img { + max-width: none; +} +.nav-tabs { + border-bottom: 1px solid transparent; +} +.nav-tabs > li { + float: left; + margin-bottom: -1px; +} +.nav-tabs > li > a { + margin-right: 2px; + line-height: 1.846; + border: 1px solid transparent; + border-radius: 3px 3px 0 0; +} +.nav-tabs > li > a:hover { + border-color: #eeeeee #eeeeee transparent; +} +.nav-tabs > li.active > a, +.nav-tabs > li.active > a:hover, +.nav-tabs > li.active > a:focus { + color: #666666; + cursor: default; + background-color: transparent; + border: 1px solid transparent; + border-bottom-color: transparent; +} +.nav-tabs.nav-justified { + width: 100%; + border-bottom: 0; +} +.nav-tabs.nav-justified > li { + float: none; +} +.nav-tabs.nav-justified > li > a { + margin-bottom: 5px; + text-align: center; +} +.nav-tabs.nav-justified > .dropdown .dropdown-menu { + top: auto; + left: auto; +} +@media (min-width: 768px) { + .nav-tabs.nav-justified > li { + display: table-cell; + width: 1%; + } + .nav-tabs.nav-justified > li > a { + margin-bottom: 0; + } +} +.nav-tabs.nav-justified > li > a { + margin-right: 0; + border-radius: 3px; +} +.nav-tabs.nav-justified > .active > a, +.nav-tabs.nav-justified > .active > a:hover, +.nav-tabs.nav-justified > .active > a:focus { + border: 1px solid transparent; +} +@media (min-width: 768px) { + .nav-tabs.nav-justified > li > a { + border-bottom: 1px solid transparent; + border-radius: 3px 3px 0 0; + } + .nav-tabs.nav-justified > .active > a, + .nav-tabs.nav-justified > .active > a:hover, + .nav-tabs.nav-justified > .active > a:focus { + border-bottom-color: #ffffff; + } +} +.nav-pills > li { + float: left; +} +.nav-pills > li > a { + border-radius: 3px; +} +.nav-pills > li + li { + margin-left: 2px; +} +.nav-pills > li.active > a, +.nav-pills > li.active > a:hover, +.nav-pills > li.active > a:focus { + color: #ffffff; + background-color: #2196f3; +} +.nav-stacked > li { + float: none; +} +.nav-stacked > li + li { + margin-top: 2px; + margin-left: 0; +} +.nav-justified { + width: 100%; +} +.nav-justified > li { + float: none; +} +.nav-justified > li > a { + margin-bottom: 5px; + text-align: center; +} +.nav-justified > .dropdown .dropdown-menu { + top: auto; + left: auto; +} +@media (min-width: 768px) { + .nav-justified > li { + display: table-cell; + width: 1%; + } + .nav-justified > li > a { + margin-bottom: 0; + } +} +.nav-tabs-justified { + border-bottom: 0; +} +.nav-tabs-justified > li > a { + margin-right: 0; + border-radius: 3px; +} +.nav-tabs-justified > .active > a, +.nav-tabs-justified > .active > a:hover, +.nav-tabs-justified > .active > a:focus { + border: 1px solid transparent; +} +@media (min-width: 768px) { + .nav-tabs-justified > li > a { + border-bottom: 1px solid transparent; + border-radius: 3px 3px 0 0; + } + .nav-tabs-justified > .active > a, + .nav-tabs-justified > .active > a:hover, + .nav-tabs-justified > .active > a:focus { + border-bottom-color: #ffffff; + } +} +.tab-content > .tab-pane { + display: none; +} +.tab-content > .active { + display: block; +} +.nav-tabs .dropdown-menu { + margin-top: -1px; + border-top-left-radius: 0; + border-top-right-radius: 0; +} +.navbar { + position: relative; + min-height: 64px; + margin-bottom: 23px; + border: 1px solid transparent; +} +@media (min-width: 768px) { + .navbar { + border-radius: 3px; + } +} +@media (min-width: 768px) { + .navbar-header { + float: left; + } +} +.navbar-collapse { + padding-right: 15px; + padding-left: 15px; + overflow-x: visible; + border-top: 1px solid transparent; + box-shadow: inset 0 1px 0 rgba(255, 255, 255, 0.1); + -webkit-overflow-scrolling: touch; +} +.navbar-collapse.in { + overflow-y: auto; +} +@media (min-width: 768px) { + .navbar-collapse { + width: auto; + border-top: 0; + box-shadow: none; + } + .navbar-collapse.collapse { + display: block !important; + height: auto !important; + padding-bottom: 0; + overflow: visible !important; + } + .navbar-collapse.in { + overflow-y: visible; + } + .navbar-fixed-top .navbar-collapse, + .navbar-static-top .navbar-collapse, + .navbar-fixed-bottom .navbar-collapse { + padding-right: 0; + padding-left: 0; + } +} +.navbar-fixed-top, +.navbar-fixed-bottom { + position: fixed; + right: 0; + left: 0; + z-index: 1030; +} +.navbar-fixed-top .navbar-collapse, +.navbar-fixed-bottom .navbar-collapse { + max-height: 340px; +} +@media (max-device-width: 480px) and (orientation: landscape) { + .navbar-fixed-top .navbar-collapse, + .navbar-fixed-bottom .navbar-collapse { + max-height: 200px; + } +} +@media (min-width: 768px) { + .navbar-fixed-top, + .navbar-fixed-bottom { + border-radius: 0; + } +} +.navbar-fixed-top { + top: 0; + border-width: 0 0 1px; +} +.navbar-fixed-bottom { + bottom: 0; + margin-bottom: 0; + border-width: 1px 0 0; +} +.container > .navbar-header, +.container-fluid > .navbar-header, +.container > .navbar-collapse, +.container-fluid > .navbar-collapse { + margin-right: -15px; + margin-left: -15px; +} +@media (min-width: 768px) { + .container > .navbar-header, + .container-fluid > .navbar-header, + .container > .navbar-collapse, + .container-fluid > .navbar-collapse { + margin-right: 0; + margin-left: 0; + } +} +.navbar-static-top { + z-index: 1000; + border-width: 0 0 1px; +} +@media (min-width: 768px) { + .navbar-static-top { + border-radius: 0; + } +} +.navbar-brand { + float: left; + height: 64px; + padding: 10.5px 15px; + font-size: 17px; + line-height: 35px; +} +.navbar-brand:hover, +.navbar-brand:focus { + text-decoration: none; +} +.navbar-brand > img { + display: block; +} +@media (min-width: 768px) { + .navbar > .container .navbar-brand, + .navbar > .container-fluid .navbar-brand { + margin-left: -15px; + } +} +.navbar-toggle { + position: relative; + float: right; + padding: 9px 10px; + margin-right: 15px; + margin-top: 15px; + margin-bottom: 15px; + background-color: transparent; + background-image: none; + border: 1px solid transparent; + border-radius: 3px; +} +.navbar-toggle:focus { + outline: 0; +} +.navbar-toggle .icon-bar { + display: block; + width: 22px; + height: 2px; + border-radius: 1px; +} +.navbar-toggle .icon-bar + .icon-bar { + margin-top: 4px; +} +@media (min-width: 768px) { + .navbar-toggle { + display: none; + } +} +.navbar-nav { + margin: 10.25px -15px; +} +.navbar-nav > li > a { + padding-top: 10px; + padding-bottom: 10px; + line-height: 23px; +} +@media (max-width: 767px) { + .navbar-nav .open .dropdown-menu { + position: static; + float: none; + width: auto; + margin-top: 0; + background-color: transparent; + border: 0; + box-shadow: none; + } + .navbar-nav .open .dropdown-menu > li > a, + .navbar-nav .open .dropdown-menu .dropdown-header { + padding: 5px 15px 5px 25px; + } + .navbar-nav .open .dropdown-menu > li > a { + line-height: 23px; + } + .navbar-nav .open .dropdown-menu > li > a:hover, + .navbar-nav .open .dropdown-menu > li > a:focus { + background-image: none; + } +} +@media (min-width: 768px) { + .navbar-nav { + float: left; + margin: 0; + } + .navbar-nav > li { + float: left; + } + .navbar-nav > li > a { + padding-top: 20.5px; + padding-bottom: 20.5px; + } +} +.navbar-form { + padding: 10px 15px; + margin-right: -15px; + margin-left: -15px; + border-top: 1px solid transparent; + border-bottom: 1px solid transparent; + box-shadow: inset 0 1px 0 rgba(255, 255, 255, 0.1), 0 1px 0 rgba(255, 255, 255, 0.1); + margin-top: 13.5px; + margin-bottom: 13.5px; +} +@media (min-width: 768px) { + .navbar-form .form-group { + display: inline-block; + margin-bottom: 0; + vertical-align: middle; + } + .navbar-form .form-control { + display: inline-block; + width: auto; + vertical-align: middle; + } + .navbar-form .form-control-static { + display: inline-block; + } + .navbar-form .input-group { + display: inline-table; + vertical-align: middle; + } + .navbar-form .input-group .input-group-addon, + .navbar-form .input-group .input-group-btn, + .navbar-form .input-group .form-control { + width: auto; + } + .navbar-form .input-group > .form-control { + width: 100%; + } + .navbar-form .control-label { + margin-bottom: 0; + vertical-align: middle; + } + .navbar-form .radio, + .navbar-form .checkbox { + display: inline-block; + margin-top: 0; + margin-bottom: 0; + vertical-align: middle; + } + .navbar-form .radio label, + .navbar-form .checkbox label { + padding-left: 0; + } + .navbar-form .radio input[type="radio"], + .navbar-form .checkbox input[type="checkbox"] { + position: relative; + margin-left: 0; + } + .navbar-form .has-feedback .form-control-feedback { + top: 0; + } +} +@media (max-width: 767px) { + .navbar-form .form-group { + margin-bottom: 5px; + } + .navbar-form .form-group:last-child { + margin-bottom: 0; + } +} +@media (min-width: 768px) { + .navbar-form { + width: auto; + padding-top: 0; + padding-bottom: 0; + margin-right: 0; + margin-left: 0; + border: 0; + box-shadow: none; + } +} +.navbar-nav > li > .dropdown-menu { + margin-top: 0; + border-top-left-radius: 0; + border-top-right-radius: 0; +} +.navbar-fixed-bottom .navbar-nav > li > .dropdown-menu { + margin-bottom: 0; + border-top-left-radius: 3px; + border-top-right-radius: 3px; + border-bottom-right-radius: 0; + border-bottom-left-radius: 0; +} +.navbar-btn { + margin-top: 13.5px; + margin-bottom: 13.5px; +} +.navbar-btn.btn-sm { + margin-top: 17px; + margin-bottom: 17px; +} +.navbar-btn.btn-xs { + margin-top: 21px; + margin-bottom: 21px; +} +.navbar-text { + margin-top: 20.5px; + margin-bottom: 20.5px; +} +@media (min-width: 768px) { + .navbar-text { + float: left; + margin-right: 15px; + margin-left: 15px; + } +} +@media (min-width: 768px) { + .navbar-left { + float: left !important; + } + .navbar-right { + float: right !important; + margin-right: -15px; + } + .navbar-right ~ .navbar-right { + margin-right: 0; + } +} +.navbar-default { + background-color: #ffffff; + border-color: transparent; +} +.navbar-default .navbar-brand { + color: #666666; +} +.navbar-default .navbar-brand:hover, +.navbar-default .navbar-brand:focus { + color: #212121; + background-color: transparent; +} +.navbar-default .navbar-text { + color: #bbbbbb; +} +.navbar-default .navbar-nav > li > a { + color: #666666; +} +.navbar-default .navbar-nav > li > a:hover, +.navbar-default .navbar-nav > li > a:focus { + color: #212121; + background-color: transparent; +} +.navbar-default .navbar-nav > .active > a, +.navbar-default .navbar-nav > .active > a:hover, +.navbar-default .navbar-nav > .active > a:focus { + color: #212121; + background-color: #eeeeee; +} +.navbar-default .navbar-nav > .disabled > a, +.navbar-default .navbar-nav > .disabled > a:hover, +.navbar-default .navbar-nav > .disabled > a:focus { + color: #cccccc; + background-color: transparent; +} +.navbar-default .navbar-nav > .open > a, +.navbar-default .navbar-nav > .open > a:hover, +.navbar-default .navbar-nav > .open > a:focus { + color: #212121; + background-color: #eeeeee; +} +@media (max-width: 767px) { + .navbar-default .navbar-nav .open .dropdown-menu > li > a { + color: #666666; + } + .navbar-default .navbar-nav .open .dropdown-menu > li > a:hover, + .navbar-default .navbar-nav .open .dropdown-menu > li > a:focus { + color: #212121; + background-color: transparent; + } + .navbar-default .navbar-nav .open .dropdown-menu > .active > a, + .navbar-default .navbar-nav .open .dropdown-menu > .active > a:hover, + .navbar-default .navbar-nav .open .dropdown-menu > .active > a:focus { + color: #212121; + background-color: #eeeeee; + } + .navbar-default .navbar-nav .open .dropdown-menu > .disabled > a, + .navbar-default .navbar-nav .open .dropdown-menu > .disabled > a:hover, + .navbar-default .navbar-nav .open .dropdown-menu > .disabled > a:focus { + color: #cccccc; + background-color: transparent; + } +} +.navbar-default .navbar-toggle { + border-color: transparent; +} +.navbar-default .navbar-toggle:hover, +.navbar-default .navbar-toggle:focus { + background-color: transparent; +} +.navbar-default .navbar-toggle .icon-bar { + background-color: rgba(0, 0, 0, 0.5); +} +.navbar-default .navbar-collapse, +.navbar-default .navbar-form { + border-color: transparent; +} +.navbar-default .navbar-link { + color: #666666; +} +.navbar-default .navbar-link:hover { + color: #212121; +} +.navbar-default .btn-link { + color: #666666; +} +.navbar-default .btn-link:hover, +.navbar-default .btn-link:focus { + color: #212121; +} +.navbar-default .btn-link[disabled]:hover, +fieldset[disabled] .navbar-default .btn-link:hover, +.navbar-default .btn-link[disabled]:focus, +fieldset[disabled] .navbar-default .btn-link:focus { + color: #cccccc; +} +.navbar-inverse { + background-color: #2196f3; + border-color: transparent; +} +.navbar-inverse .navbar-brand { + color: #b2dbfb; +} +.navbar-inverse .navbar-brand:hover, +.navbar-inverse .navbar-brand:focus { + color: #ffffff; + background-color: transparent; +} +.navbar-inverse .navbar-text { + color: #bbbbbb; +} +.navbar-inverse .navbar-nav > li > a { + color: #b2dbfb; +} +.navbar-inverse .navbar-nav > li > a:hover, +.navbar-inverse .navbar-nav > li > a:focus { + color: #ffffff; + background-color: transparent; +} +.navbar-inverse .navbar-nav > .active > a, +.navbar-inverse .navbar-nav > .active > a:hover, +.navbar-inverse .navbar-nav > .active > a:focus { + color: #ffffff; + background-color: #0c7cd5; +} +.navbar-inverse .navbar-nav > .disabled > a, +.navbar-inverse .navbar-nav > .disabled > a:hover, +.navbar-inverse .navbar-nav > .disabled > a:focus { + color: #444444; + background-color: transparent; +} +.navbar-inverse .navbar-nav > .open > a, +.navbar-inverse .navbar-nav > .open > a:hover, +.navbar-inverse .navbar-nav > .open > a:focus { + color: #ffffff; + background-color: #0c7cd5; +} +@media (max-width: 767px) { + .navbar-inverse .navbar-nav .open .dropdown-menu > .dropdown-header { + border-color: transparent; + } + .navbar-inverse .navbar-nav .open .dropdown-menu .divider { + background-color: transparent; + } + .navbar-inverse .navbar-nav .open .dropdown-menu > li > a { + color: #b2dbfb; + } + .navbar-inverse .navbar-nav .open .dropdown-menu > li > a:hover, + .navbar-inverse .navbar-nav .open .dropdown-menu > li > a:focus { + color: #ffffff; + background-color: transparent; + } + .navbar-inverse .navbar-nav .open .dropdown-menu > .active > a, + .navbar-inverse .navbar-nav .open .dropdown-menu > .active > a:hover, + .navbar-inverse .navbar-nav .open .dropdown-menu > .active > a:focus { + color: #ffffff; + background-color: #0c7cd5; + } + .navbar-inverse .navbar-nav .open .dropdown-menu > .disabled > a, + .navbar-inverse .navbar-nav .open .dropdown-menu > .disabled > a:hover, + .navbar-inverse .navbar-nav .open .dropdown-menu > .disabled > a:focus { + color: #444444; + background-color: transparent; + } +} +.navbar-inverse .navbar-toggle { + border-color: transparent; +} +.navbar-inverse .navbar-toggle:hover, +.navbar-inverse .navbar-toggle:focus { + background-color: transparent; +} +.navbar-inverse .navbar-toggle .icon-bar { + background-color: rgba(0, 0, 0, 0.5); +} +.navbar-inverse .navbar-collapse, +.navbar-inverse .navbar-form { + border-color: #0c84e4; +} +.navbar-inverse .navbar-link { + color: #b2dbfb; +} +.navbar-inverse .navbar-link:hover { + color: #ffffff; +} +.navbar-inverse .btn-link { + color: #b2dbfb; +} +.navbar-inverse .btn-link:hover, +.navbar-inverse .btn-link:focus { + color: #ffffff; +} +.navbar-inverse .btn-link[disabled]:hover, +fieldset[disabled] .navbar-inverse .btn-link:hover, +.navbar-inverse .btn-link[disabled]:focus, +fieldset[disabled] .navbar-inverse .btn-link:focus { + color: #444444; +} +.breadcrumb { + padding: 8px 15px; + margin-bottom: 23px; + list-style: none; + background-color: #f5f5f5; + border-radius: 3px; +} +.breadcrumb > li { + display: inline-block; +} +.breadcrumb > li + li:before { + padding: 0 5px; + color: #cccccc; + content: "/\00a0"; +} +.breadcrumb > .active { + color: #bbbbbb; +} +.pagination { + display: inline-block; + padding-left: 0; + margin: 23px 0; + border-radius: 3px; +} +.pagination > li { + display: inline; +} +.pagination > li > a, +.pagination > li > span { + position: relative; + float: left; + padding: 6px 16px; + margin-left: -1px; + line-height: 1.846; + color: #2196f3; + text-decoration: none; + background-color: #ffffff; + border: 1px solid #dddddd; +} +.pagination > li > a:hover, +.pagination > li > span:hover, +.pagination > li > a:focus, +.pagination > li > span:focus { + z-index: 2; + color: #0a6ebd; + background-color: #eeeeee; + border-color: #dddddd; +} +.pagination > li:first-child > a, +.pagination > li:first-child > span { + margin-left: 0; + border-top-left-radius: 3px; + border-bottom-left-radius: 3px; +} +.pagination > li:last-child > a, +.pagination > li:last-child > span { + border-top-right-radius: 3px; + border-bottom-right-radius: 3px; +} +.pagination > .active > a, +.pagination > .active > span, +.pagination > .active > a:hover, +.pagination > .active > span:hover, +.pagination > .active > a:focus, +.pagination > .active > span:focus { + z-index: 3; + color: #ffffff; + cursor: default; + background-color: #2196f3; + border-color: #2196f3; +} +.pagination > .disabled > span, +.pagination > .disabled > span:hover, +.pagination > .disabled > span:focus, +.pagination > .disabled > a, +.pagination > .disabled > a:hover, +.pagination > .disabled > a:focus { + color: #bbbbbb; + cursor: not-allowed; + background-color: #ffffff; + border-color: #dddddd; +} +.pagination-lg > li > a, +.pagination-lg > li > span { + padding: 10px 16px; + font-size: 17px; + line-height: 1.3333333; +} +.pagination-lg > li:first-child > a, +.pagination-lg > li:first-child > span { + border-top-left-radius: 3px; + border-bottom-left-radius: 3px; +} +.pagination-lg > li:last-child > a, +.pagination-lg > li:last-child > span { + border-top-right-radius: 3px; + border-bottom-right-radius: 3px; +} +.pagination-sm > li > a, +.pagination-sm > li > span { + padding: 5px 10px; + font-size: 12px; + line-height: 1.5; +} +.pagination-sm > li:first-child > a, +.pagination-sm > li:first-child > span { + border-top-left-radius: 3px; + border-bottom-left-radius: 3px; +} +.pagination-sm > li:last-child > a, +.pagination-sm > li:last-child > span { + border-top-right-radius: 3px; + border-bottom-right-radius: 3px; +} +.pager { + padding-left: 0; + margin: 23px 0; + text-align: center; + list-style: none; +} +.pager li { + display: inline; +} +.pager li > a, +.pager li > span { + display: inline-block; + padding: 5px 14px; + background-color: #ffffff; + border: 1px solid #dddddd; + border-radius: 15px; +} +.pager li > a:hover, +.pager li > a:focus { + text-decoration: none; + background-color: #eeeeee; +} +.pager .next > a, +.pager .next > span { + float: right; +} +.pager .previous > a, +.pager .previous > span { + float: left; +} +.pager .disabled > a, +.pager .disabled > a:hover, +.pager .disabled > a:focus, +.pager .disabled > span { + color: #bbbbbb; + cursor: not-allowed; + background-color: #ffffff; +} +.label { + display: inline; + padding: .2em .6em .3em; + font-size: 75%; + font-weight: 700; + line-height: 1; + color: #ffffff; + text-align: center; + white-space: nowrap; + vertical-align: baseline; + border-radius: .25em; +} +a.label:hover, +a.label:focus { + color: #ffffff; + text-decoration: none; + cursor: pointer; +} +.label:empty { + display: none; +} +.btn .label { + position: relative; + top: -1px; +} +.label-default { + background-color: #bbbbbb; +} +.label-default[href]:hover, +.label-default[href]:focus { + background-color: #a2a2a2; +} +.label-primary { + background-color: #2196f3; +} +.label-primary[href]:hover, +.label-primary[href]:focus { + background-color: #0c7cd5; +} +.label-success { + background-color: #4caf50; +} +.label-success[href]:hover, +.label-success[href]:focus { + background-color: #3d8b40; +} +.label-info { + background-color: #9c27b0; +} +.label-info[href]:hover, +.label-info[href]:focus { + background-color: #771e86; +} +.label-warning { + background-color: #ff9800; +} +.label-warning[href]:hover, +.label-warning[href]:focus { + background-color: #cc7a00; +} +.label-danger { + background-color: #e51c23; +} +.label-danger[href]:hover, +.label-danger[href]:focus { + background-color: #b9151b; +} +.badge { + display: inline-block; + min-width: 10px; + padding: 3px 7px; + font-size: 12px; + font-weight: normal; + line-height: 1; + color: #ffffff; + text-align: center; + white-space: nowrap; + vertical-align: middle; + background-color: #bbbbbb; + border-radius: 10px; +} +.badge:empty { + display: none; +} +.btn .badge { + position: relative; + top: -1px; +} +.btn-xs .badge, +.btn-group-xs > .btn .badge { + top: 0; + padding: 1px 5px; +} +a.badge:hover, +a.badge:focus { + color: #ffffff; + text-decoration: none; + cursor: pointer; +} +.list-group-item.active > .badge, +.nav-pills > .active > a > .badge { + color: #2196f3; + background-color: #ffffff; +} +.list-group-item > .badge { + float: right; +} +.list-group-item > .badge + .badge { + margin-right: 5px; +} +.nav-pills > li > a > .badge { + margin-left: 3px; +} +.jumbotron { + padding-top: 30px; + padding-bottom: 30px; + margin-bottom: 30px; + color: inherit; + background-color: #f9f9f9; +} +.jumbotron h1, +.jumbotron .h1 { + color: #444444; +} +.jumbotron p { + margin-bottom: 15px; + font-size: 20px; + font-weight: 200; +} +.jumbotron > hr { + border-top-color: #e0e0e0; +} +.container .jumbotron, +.container-fluid .jumbotron { + padding-right: 15px; + padding-left: 15px; + border-radius: 3px; +} +.jumbotron .container { + max-width: 100%; +} +@media screen and (min-width: 768px) { + .jumbotron { + padding-top: 48px; + padding-bottom: 48px; + } + .container .jumbotron, + .container-fluid .jumbotron { + padding-right: 60px; + padding-left: 60px; + } + .jumbotron h1, + .jumbotron .h1 { + font-size: 59px; + } +} +.thumbnail { + display: block; + padding: 4px; + margin-bottom: 23px; + line-height: 1.846; + background-color: #ffffff; + border: 1px solid #dddddd; + border-radius: 3px; + transition: border 0.2s ease-in-out; +} +.thumbnail > img, +.thumbnail a > img { + margin-right: auto; + margin-left: auto; +} +a.thumbnail:hover, +a.thumbnail:focus, +a.thumbnail.active { + border-color: #2196f3; +} +.thumbnail .caption { + padding: 9px; + color: #666666; +} +.alert { + padding: 15px; + margin-bottom: 23px; + border: 1px solid transparent; + border-radius: 3px; +} +.alert h4 { + margin-top: 0; + color: inherit; +} +.alert .alert-link { + font-weight: bold; +} +.alert > p, +.alert > ul { + margin-bottom: 0; +} +.alert > p + p { + margin-top: 5px; +} +.alert-dismissable, +.alert-dismissible { + padding-right: 35px; +} +.alert-dismissable .close, +.alert-dismissible .close { + position: relative; + top: -2px; + right: -21px; + color: inherit; +} +.alert-success { + color: #4caf50; + background-color: #dff0d8; + border-color: #d6e9c6; +} +.alert-success hr { + border-top-color: #c9e2b3; +} +.alert-success .alert-link { + color: #3d8b40; +} +.alert-info { + color: #9c27b0; + background-color: #e1bee7; + border-color: #cba4dd; +} +.alert-info hr { + border-top-color: #c191d6; +} +.alert-info .alert-link { + color: #771e86; +} +.alert-warning { + color: #ff9800; + background-color: #ffe0b2; + border-color: #ffc599; +} +.alert-warning hr { + border-top-color: #ffb67f; +} +.alert-warning .alert-link { + color: #cc7a00; +} +.alert-danger { + color: #e51c23; + background-color: #f9bdbb; + border-color: #f7a4af; +} +.alert-danger hr { + border-top-color: #f58c9a; +} +.alert-danger .alert-link { + color: #b9151b; +} +@-webkit-keyframes progress-bar-stripes { + from { + background-position: 40px 0; + } + to { + background-position: 0 0; + } +} +@keyframes progress-bar-stripes { + from { + background-position: 40px 0; + } + to { + background-position: 0 0; + } +} +.progress { + height: 23px; + margin-bottom: 23px; + overflow: hidden; + background-color: #f5f5f5; + border-radius: 3px; + box-shadow: inset 0 1px 2px rgba(0, 0, 0, 0.1); +} +.progress-bar { + float: left; + width: 0%; + height: 100%; + font-size: 12px; + line-height: 23px; + color: #ffffff; + text-align: center; + background-color: #2196f3; + box-shadow: inset 0 -1px 0 rgba(0, 0, 0, 0.15); + transition: width 0.6s ease; +} +.progress-striped .progress-bar, +.progress-bar-striped { + background-image: linear-gradient(45deg, rgba(255, 255, 255, 0.15) 25%, transparent 25%, transparent 50%, rgba(255, 255, 255, 0.15) 50%, rgba(255, 255, 255, 0.15) 75%, transparent 75%, transparent); + background-size: 40px 40px; +} +.progress.active .progress-bar, +.progress-bar.active { + -webkit-animation: progress-bar-stripes 2s linear infinite; + animation: progress-bar-stripes 2s linear infinite; +} +.progress-bar-success { + background-color: #4caf50; +} +.progress-striped .progress-bar-success { + background-image: linear-gradient(45deg, rgba(255, 255, 255, 0.15) 25%, transparent 25%, transparent 50%, rgba(255, 255, 255, 0.15) 50%, rgba(255, 255, 255, 0.15) 75%, transparent 75%, transparent); +} +.progress-bar-info { + background-color: #9c27b0; +} +.progress-striped .progress-bar-info { + background-image: linear-gradient(45deg, rgba(255, 255, 255, 0.15) 25%, transparent 25%, transparent 50%, rgba(255, 255, 255, 0.15) 50%, rgba(255, 255, 255, 0.15) 75%, transparent 75%, transparent); +} +.progress-bar-warning { + background-color: #ff9800; +} +.progress-striped .progress-bar-warning { + background-image: linear-gradient(45deg, rgba(255, 255, 255, 0.15) 25%, transparent 25%, transparent 50%, rgba(255, 255, 255, 0.15) 50%, rgba(255, 255, 255, 0.15) 75%, transparent 75%, transparent); +} +.progress-bar-danger { + background-color: #e51c23; +} +.progress-striped .progress-bar-danger { + background-image: linear-gradient(45deg, rgba(255, 255, 255, 0.15) 25%, transparent 25%, transparent 50%, rgba(255, 255, 255, 0.15) 50%, rgba(255, 255, 255, 0.15) 75%, transparent 75%, transparent); +} +.media { + margin-top: 15px; +} +.media:first-child { + margin-top: 0; +} +.media, +.media-body { + overflow: hidden; + zoom: 1; +} +.media-body { + width: 10000px; +} +.media-object { + display: block; +} +.media-object.img-thumbnail { + max-width: none; +} +.media-right, +.media > .pull-right { + padding-left: 10px; +} +.media-left, +.media > .pull-left { + padding-right: 10px; +} +.media-left, +.media-right, +.media-body { + display: table-cell; + vertical-align: top; +} +.media-middle { + vertical-align: middle; +} +.media-bottom { + vertical-align: bottom; +} +.media-heading { + margin-top: 0; + margin-bottom: 5px; +} +.media-list { + padding-left: 0; + list-style: none; +} +.list-group { + padding-left: 0; + margin-bottom: 20px; +} +.list-group-item { + position: relative; + display: block; + padding: 10px 15px; + margin-bottom: -1px; + background-color: #ffffff; + border: 1px solid #dddddd; +} +.list-group-item:first-child { + border-top-left-radius: 3px; + border-top-right-radius: 3px; +} +.list-group-item:last-child { + margin-bottom: 0; + border-bottom-right-radius: 3px; + border-bottom-left-radius: 3px; +} +.list-group-item.disabled, +.list-group-item.disabled:hover, +.list-group-item.disabled:focus { + color: #bbbbbb; + cursor: not-allowed; + background-color: #eeeeee; +} +.list-group-item.disabled .list-group-item-heading, +.list-group-item.disabled:hover .list-group-item-heading, +.list-group-item.disabled:focus .list-group-item-heading { + color: inherit; +} +.list-group-item.disabled .list-group-item-text, +.list-group-item.disabled:hover .list-group-item-text, +.list-group-item.disabled:focus .list-group-item-text { + color: #bbbbbb; +} +.list-group-item.active, +.list-group-item.active:hover, +.list-group-item.active:focus { + z-index: 2; + color: #ffffff; + background-color: #2196f3; + border-color: #2196f3; +} +.list-group-item.active .list-group-item-heading, +.list-group-item.active:hover .list-group-item-heading, +.list-group-item.active:focus .list-group-item-heading, +.list-group-item.active .list-group-item-heading > small, +.list-group-item.active:hover .list-group-item-heading > small, +.list-group-item.active:focus .list-group-item-heading > small, +.list-group-item.active .list-group-item-heading > .small, +.list-group-item.active:hover .list-group-item-heading > .small, +.list-group-item.active:focus .list-group-item-heading > .small { + color: inherit; +} +.list-group-item.active .list-group-item-text, +.list-group-item.active:hover .list-group-item-text, +.list-group-item.active:focus .list-group-item-text { + color: #e3f2fd; +} +a.list-group-item, +button.list-group-item { + color: #555555; +} +a.list-group-item .list-group-item-heading, +button.list-group-item .list-group-item-heading { + color: #333333; +} +a.list-group-item:hover, +button.list-group-item:hover, +a.list-group-item:focus, +button.list-group-item:focus { + color: #555555; + text-decoration: none; + background-color: #f5f5f5; +} +button.list-group-item { + width: 100%; + text-align: left; +} +.list-group-item-success { + color: #4caf50; + background-color: #dff0d8; +} +a.list-group-item-success, +button.list-group-item-success { + color: #4caf50; +} +a.list-group-item-success .list-group-item-heading, +button.list-group-item-success .list-group-item-heading { + color: inherit; +} +a.list-group-item-success:hover, +button.list-group-item-success:hover, +a.list-group-item-success:focus, +button.list-group-item-success:focus { + color: #4caf50; + background-color: #d0e9c6; +} +a.list-group-item-success.active, +button.list-group-item-success.active, +a.list-group-item-success.active:hover, +button.list-group-item-success.active:hover, +a.list-group-item-success.active:focus, +button.list-group-item-success.active:focus { + color: #fff; + background-color: #4caf50; + border-color: #4caf50; +} +.list-group-item-info { + color: #9c27b0; + background-color: #e1bee7; +} +a.list-group-item-info, +button.list-group-item-info { + color: #9c27b0; +} +a.list-group-item-info .list-group-item-heading, +button.list-group-item-info .list-group-item-heading { + color: inherit; +} +a.list-group-item-info:hover, +button.list-group-item-info:hover, +a.list-group-item-info:focus, +button.list-group-item-info:focus { + color: #9c27b0; + background-color: #d8abe0; +} +a.list-group-item-info.active, +button.list-group-item-info.active, +a.list-group-item-info.active:hover, +button.list-group-item-info.active:hover, +a.list-group-item-info.active:focus, +button.list-group-item-info.active:focus { + color: #fff; + background-color: #9c27b0; + border-color: #9c27b0; +} +.list-group-item-warning { + color: #ff9800; + background-color: #ffe0b2; +} +a.list-group-item-warning, +button.list-group-item-warning { + color: #ff9800; +} +a.list-group-item-warning .list-group-item-heading, +button.list-group-item-warning .list-group-item-heading { + color: inherit; +} +a.list-group-item-warning:hover, +button.list-group-item-warning:hover, +a.list-group-item-warning:focus, +button.list-group-item-warning:focus { + color: #ff9800; + background-color: #ffd699; +} +a.list-group-item-warning.active, +button.list-group-item-warning.active, +a.list-group-item-warning.active:hover, +button.list-group-item-warning.active:hover, +a.list-group-item-warning.active:focus, +button.list-group-item-warning.active:focus { + color: #fff; + background-color: #ff9800; + border-color: #ff9800; +} +.list-group-item-danger { + color: #e51c23; + background-color: #f9bdbb; +} +a.list-group-item-danger, +button.list-group-item-danger { + color: #e51c23; +} +a.list-group-item-danger .list-group-item-heading, +button.list-group-item-danger .list-group-item-heading { + color: inherit; +} +a.list-group-item-danger:hover, +button.list-group-item-danger:hover, +a.list-group-item-danger:focus, +button.list-group-item-danger:focus { + color: #e51c23; + background-color: #f7a6a4; +} +a.list-group-item-danger.active, +button.list-group-item-danger.active, +a.list-group-item-danger.active:hover, +button.list-group-item-danger.active:hover, +a.list-group-item-danger.active:focus, +button.list-group-item-danger.active:focus { + color: #fff; + background-color: #e51c23; + border-color: #e51c23; +} +.list-group-item-heading { + margin-top: 0; + margin-bottom: 5px; +} +.list-group-item-text { + margin-bottom: 0; + line-height: 1.3; +} +.panel { + margin-bottom: 23px; + background-color: #ffffff; + border: 1px solid transparent; + border-radius: 3px; + box-shadow: 0 1px 1px rgba(0, 0, 0, 0.05); +} +.panel-body { + padding: 15px; +} +.panel-heading { + padding: 10px 15px; + border-bottom: 1px solid transparent; + border-top-left-radius: 2px; + border-top-right-radius: 2px; +} +.panel-heading > .dropdown .dropdown-toggle { + color: inherit; +} +.panel-title { + margin-top: 0; + margin-bottom: 0; + font-size: 15px; + color: inherit; +} +.panel-title > a, +.panel-title > small, +.panel-title > .small, +.panel-title > small > a, +.panel-title > .small > a { + color: inherit; +} +.panel-footer { + padding: 10px 15px; + background-color: #f5f5f5; + border-top: 1px solid #dddddd; + border-bottom-right-radius: 2px; + border-bottom-left-radius: 2px; +} +.panel > .list-group, +.panel > .panel-collapse > .list-group { + margin-bottom: 0; +} +.panel > .list-group .list-group-item, +.panel > .panel-collapse > .list-group .list-group-item { + border-width: 1px 0; + border-radius: 0; +} +.panel > .list-group:first-child .list-group-item:first-child, +.panel > .panel-collapse > .list-group:first-child .list-group-item:first-child { + border-top: 0; + border-top-left-radius: 2px; + border-top-right-radius: 2px; +} +.panel > .list-group:last-child .list-group-item:last-child, +.panel > .panel-collapse > .list-group:last-child .list-group-item:last-child { + border-bottom: 0; + border-bottom-right-radius: 2px; + border-bottom-left-radius: 2px; +} +.panel > .panel-heading + .panel-collapse > .list-group .list-group-item:first-child { + border-top-left-radius: 0; + border-top-right-radius: 0; +} +.panel-heading + .list-group .list-group-item:first-child { + border-top-width: 0; +} +.list-group + .panel-footer { + border-top-width: 0; +} +.panel > .table, +.panel > .table-responsive > .table, +.panel > .panel-collapse > .table { + margin-bottom: 0; +} +.panel > .table caption, +.panel > .table-responsive > .table caption, +.panel > .panel-collapse > .table caption { + padding-right: 15px; + padding-left: 15px; +} +.panel > .table:first-child, +.panel > .table-responsive:first-child > .table:first-child { + border-top-left-radius: 2px; + border-top-right-radius: 2px; +} +.panel > .table:first-child > thead:first-child > tr:first-child, +.panel > .table-responsive:first-child > .table:first-child > thead:first-child > tr:first-child, +.panel > .table:first-child > tbody:first-child > tr:first-child, +.panel > .table-responsive:first-child > .table:first-child > tbody:first-child > tr:first-child { + border-top-left-radius: 2px; + border-top-right-radius: 2px; +} +.panel > .table:first-child > thead:first-child > tr:first-child td:first-child, +.panel > .table-responsive:first-child > .table:first-child > thead:first-child > tr:first-child td:first-child, +.panel > .table:first-child > tbody:first-child > tr:first-child td:first-child, +.panel > .table-responsive:first-child > .table:first-child > tbody:first-child > tr:first-child td:first-child, +.panel > .table:first-child > thead:first-child > tr:first-child th:first-child, +.panel > .table-responsive:first-child > .table:first-child > thead:first-child > tr:first-child th:first-child, +.panel > .table:first-child > tbody:first-child > tr:first-child th:first-child, +.panel > .table-responsive:first-child > .table:first-child > tbody:first-child > tr:first-child th:first-child { + border-top-left-radius: 2px; +} +.panel > .table:first-child > thead:first-child > tr:first-child td:last-child, +.panel > .table-responsive:first-child > .table:first-child > thead:first-child > tr:first-child td:last-child, +.panel > .table:first-child > tbody:first-child > tr:first-child td:last-child, +.panel > .table-responsive:first-child > .table:first-child > tbody:first-child > tr:first-child td:last-child, +.panel > .table:first-child > thead:first-child > tr:first-child th:last-child, +.panel > .table-responsive:first-child > .table:first-child > thead:first-child > tr:first-child th:last-child, +.panel > .table:first-child > tbody:first-child > tr:first-child th:last-child, +.panel > .table-responsive:first-child > .table:first-child > tbody:first-child > tr:first-child th:last-child { + border-top-right-radius: 2px; +} +.panel > .table:last-child, +.panel > .table-responsive:last-child > .table:last-child { + border-bottom-right-radius: 2px; + border-bottom-left-radius: 2px; +} +.panel > .table:last-child > tbody:last-child > tr:last-child, +.panel > .table-responsive:last-child > .table:last-child > tbody:last-child > tr:last-child, +.panel > .table:last-child > tfoot:last-child > tr:last-child, +.panel > .table-responsive:last-child > .table:last-child > tfoot:last-child > tr:last-child { + border-bottom-right-radius: 2px; + border-bottom-left-radius: 2px; +} +.panel > .table:last-child > tbody:last-child > tr:last-child td:first-child, +.panel > .table-responsive:last-child > .table:last-child > tbody:last-child > tr:last-child td:first-child, +.panel > .table:last-child > tfoot:last-child > tr:last-child td:first-child, +.panel > .table-responsive:last-child > .table:last-child > tfoot:last-child > tr:last-child td:first-child, +.panel > .table:last-child > tbody:last-child > tr:last-child th:first-child, +.panel > .table-responsive:last-child > .table:last-child > tbody:last-child > tr:last-child th:first-child, +.panel > .table:last-child > tfoot:last-child > tr:last-child th:first-child, +.panel > .table-responsive:last-child > .table:last-child > tfoot:last-child > tr:last-child th:first-child { + border-bottom-left-radius: 2px; +} +.panel > .table:last-child > tbody:last-child > tr:last-child td:last-child, +.panel > .table-responsive:last-child > .table:last-child > tbody:last-child > tr:last-child td:last-child, +.panel > .table:last-child > tfoot:last-child > tr:last-child td:last-child, +.panel > .table-responsive:last-child > .table:last-child > tfoot:last-child > tr:last-child td:last-child, +.panel > .table:last-child > tbody:last-child > tr:last-child th:last-child, +.panel > .table-responsive:last-child > .table:last-child > tbody:last-child > tr:last-child th:last-child, +.panel > .table:last-child > tfoot:last-child > tr:last-child th:last-child, +.panel > .table-responsive:last-child > .table:last-child > tfoot:last-child > tr:last-child th:last-child { + border-bottom-right-radius: 2px; +} +.panel > .panel-body + .table, +.panel > .panel-body + .table-responsive, +.panel > .table + .panel-body, +.panel > .table-responsive + .panel-body { + border-top: 1px solid #dddddd; +} +.panel > .table > tbody:first-child > tr:first-child th, +.panel > .table > tbody:first-child > tr:first-child td { + border-top: 0; +} +.panel > .table-bordered, +.panel > .table-responsive > .table-bordered { + border: 0; +} +.panel > .table-bordered > thead > tr > th:first-child, +.panel > .table-responsive > .table-bordered > thead > tr > th:first-child, +.panel > .table-bordered > tbody > tr > th:first-child, +.panel > .table-responsive > .table-bordered > tbody > tr > th:first-child, +.panel > .table-bordered > tfoot > tr > th:first-child, +.panel > .table-responsive > .table-bordered > tfoot > tr > th:first-child, +.panel > .table-bordered > thead > tr > td:first-child, +.panel > .table-responsive > .table-bordered > thead > tr > td:first-child, +.panel > .table-bordered > tbody > tr > td:first-child, +.panel > .table-responsive > .table-bordered > tbody > tr > td:first-child, +.panel > .table-bordered > tfoot > tr > td:first-child, +.panel > .table-responsive > .table-bordered > tfoot > tr > td:first-child { + border-left: 0; +} +.panel > .table-bordered > thead > tr > th:last-child, +.panel > .table-responsive > .table-bordered > thead > tr > th:last-child, +.panel > .table-bordered > tbody > tr > th:last-child, +.panel > .table-responsive > .table-bordered > tbody > tr > th:last-child, +.panel > .table-bordered > tfoot > tr > th:last-child, +.panel > .table-responsive > .table-bordered > tfoot > tr > th:last-child, +.panel > .table-bordered > thead > tr > td:last-child, +.panel > .table-responsive > .table-bordered > thead > tr > td:last-child, +.panel > .table-bordered > tbody > tr > td:last-child, +.panel > .table-responsive > .table-bordered > tbody > tr > td:last-child, +.panel > .table-bordered > tfoot > tr > td:last-child, +.panel > .table-responsive > .table-bordered > tfoot > tr > td:last-child { + border-right: 0; +} +.panel > .table-bordered > thead > tr:first-child > td, +.panel > .table-responsive > .table-bordered > thead > tr:first-child > td, +.panel > .table-bordered > tbody > tr:first-child > td, +.panel > .table-responsive > .table-bordered > tbody > tr:first-child > td, +.panel > .table-bordered > thead > tr:first-child > th, +.panel > .table-responsive > .table-bordered > thead > tr:first-child > th, +.panel > .table-bordered > tbody > tr:first-child > th, +.panel > .table-responsive > .table-bordered > tbody > tr:first-child > th { + border-bottom: 0; +} +.panel > .table-bordered > tbody > tr:last-child > td, +.panel > .table-responsive > .table-bordered > tbody > tr:last-child > td, +.panel > .table-bordered > tfoot > tr:last-child > td, +.panel > .table-responsive > .table-bordered > tfoot > tr:last-child > td, +.panel > .table-bordered > tbody > tr:last-child > th, +.panel > .table-responsive > .table-bordered > tbody > tr:last-child > th, +.panel > .table-bordered > tfoot > tr:last-child > th, +.panel > .table-responsive > .table-bordered > tfoot > tr:last-child > th { + border-bottom: 0; +} +.panel > .table-responsive { + margin-bottom: 0; + border: 0; +} +.panel-group { + margin-bottom: 23px; +} +.panel-group .panel { + margin-bottom: 0; + border-radius: 3px; +} +.panel-group .panel + .panel { + margin-top: 5px; +} +.panel-group .panel-heading { + border-bottom: 0; +} +.panel-group .panel-heading + .panel-collapse > .panel-body, +.panel-group .panel-heading + .panel-collapse > .list-group { + border-top: 1px solid #dddddd; +} +.panel-group .panel-footer { + border-top: 0; +} +.panel-group .panel-footer + .panel-collapse .panel-body { + border-bottom: 1px solid #dddddd; +} +.panel-default { + border-color: #dddddd; +} +.panel-default > .panel-heading { + color: #212121; + background-color: #f5f5f5; + border-color: #dddddd; +} +.panel-default > .panel-heading + .panel-collapse > .panel-body { + border-top-color: #dddddd; +} +.panel-default > .panel-heading .badge { + color: #f5f5f5; + background-color: #212121; +} +.panel-default > .panel-footer + .panel-collapse > .panel-body { + border-bottom-color: #dddddd; +} +.panel-primary { + border-color: #2196f3; +} +.panel-primary > .panel-heading { + color: #ffffff; + background-color: #2196f3; + border-color: #2196f3; +} +.panel-primary > .panel-heading + .panel-collapse > .panel-body { + border-top-color: #2196f3; +} +.panel-primary > .panel-heading .badge { + color: #2196f3; + background-color: #ffffff; +} +.panel-primary > .panel-footer + .panel-collapse > .panel-body { + border-bottom-color: #2196f3; +} +.panel-success { + border-color: #d6e9c6; +} +.panel-success > .panel-heading { + color: #ffffff; + background-color: #4caf50; + border-color: #d6e9c6; +} +.panel-success > .panel-heading + .panel-collapse > .panel-body { + border-top-color: #d6e9c6; +} +.panel-success > .panel-heading .badge { + color: #4caf50; + background-color: #ffffff; +} +.panel-success > .panel-footer + .panel-collapse > .panel-body { + border-bottom-color: #d6e9c6; +} +.panel-info { + border-color: #cba4dd; +} +.panel-info > .panel-heading { + color: #ffffff; + background-color: #9c27b0; + border-color: #cba4dd; +} +.panel-info > .panel-heading + .panel-collapse > .panel-body { + border-top-color: #cba4dd; +} +.panel-info > .panel-heading .badge { + color: #9c27b0; + background-color: #ffffff; +} +.panel-info > .panel-footer + .panel-collapse > .panel-body { + border-bottom-color: #cba4dd; +} +.panel-warning { + border-color: #ffc599; +} +.panel-warning > .panel-heading { + color: #ffffff; + background-color: #ff9800; + border-color: #ffc599; +} +.panel-warning > .panel-heading + .panel-collapse > .panel-body { + border-top-color: #ffc599; +} +.panel-warning > .panel-heading .badge { + color: #ff9800; + background-color: #ffffff; +} +.panel-warning > .panel-footer + .panel-collapse > .panel-body { + border-bottom-color: #ffc599; +} +.panel-danger { + border-color: #f7a4af; +} +.panel-danger > .panel-heading { + color: #ffffff; + background-color: #e51c23; + border-color: #f7a4af; +} +.panel-danger > .panel-heading + .panel-collapse > .panel-body { + border-top-color: #f7a4af; +} +.panel-danger > .panel-heading .badge { + color: #e51c23; + background-color: #ffffff; +} +.panel-danger > .panel-footer + .panel-collapse > .panel-body { + border-bottom-color: #f7a4af; +} +.embed-responsive { + position: relative; + display: block; + height: 0; + padding: 0; + overflow: hidden; +} +.embed-responsive .embed-responsive-item, +.embed-responsive iframe, +.embed-responsive embed, +.embed-responsive object, +.embed-responsive video { + position: absolute; + top: 0; + bottom: 0; + left: 0; + width: 100%; + height: 100%; + border: 0; +} +.embed-responsive-16by9 { + padding-bottom: 56.25%; +} +.embed-responsive-4by3 { + padding-bottom: 75%; +} +.well { + min-height: 20px; + padding: 19px; + margin-bottom: 20px; + background-color: #f9f9f9; + border: 1px solid transparent; + border-radius: 3px; + box-shadow: inset 0 1px 1px rgba(0, 0, 0, 0.05); +} +.well blockquote { + border-color: #ddd; + border-color: rgba(0, 0, 0, 0.15); +} +.well-lg { + padding: 24px; + border-radius: 3px; +} +.well-sm { + padding: 9px; + border-radius: 3px; +} +.close { + float: right; + font-size: 19.5px; + font-weight: normal; + line-height: 1; + color: #000000; + text-shadow: none; + filter: alpha(opacity=20); + opacity: 0.2; +} +.close:hover, +.close:focus { + color: #000000; + text-decoration: none; + cursor: pointer; + filter: alpha(opacity=50); + opacity: 0.5; +} +button.close { + padding: 0; + cursor: pointer; + background: transparent; + border: 0; + -webkit-appearance: none; + appearance: none; +} +.modal-open { + overflow: hidden; +} +.modal { + position: fixed; + top: 0; + right: 0; + bottom: 0; + left: 0; + z-index: 1050; + display: none; + overflow: hidden; + -webkit-overflow-scrolling: touch; + outline: 0; +} +.modal.fade .modal-dialog { + -webkit-transform: translate(0, -25%); + transform: translate(0, -25%); + transition: -webkit-transform 0.3s ease-out; + transition: transform 0.3s ease-out; +} +.modal.in .modal-dialog { + -webkit-transform: translate(0, 0); + transform: translate(0, 0); +} +.modal-open .modal { + overflow-x: hidden; + overflow-y: auto; +} +.modal-dialog { + position: relative; + width: auto; + margin: 10px; +} +.modal-content { + position: relative; + background-color: #ffffff; + background-clip: padding-box; + border: 1px solid #999999; + border: 1px solid transparent; + border-radius: 3px; + box-shadow: 0 3px 9px rgba(0, 0, 0, 0.5); + outline: 0; +} +.modal-backdrop { + position: fixed; + top: 0; + right: 0; + bottom: 0; + left: 0; + z-index: 1040; + background-color: #000000; +} +.modal-backdrop.fade { + filter: alpha(opacity=0); + opacity: 0; +} +.modal-backdrop.in { + filter: alpha(opacity=50); + opacity: 0.5; +} +.modal-header { + padding: 15px; + border-bottom: 1px solid transparent; +} +.modal-header .close { + margin-top: -2px; +} +.modal-title { + margin: 0; + line-height: 1.846; +} +.modal-body { + position: relative; + padding: 15px; +} +.modal-footer { + padding: 15px; + text-align: right; + border-top: 1px solid transparent; +} +.modal-footer .btn + .btn { + margin-bottom: 0; + margin-left: 5px; +} +.modal-footer .btn-group .btn + .btn { + margin-left: -1px; +} +.modal-footer .btn-block + .btn-block { + margin-left: 0; +} +.modal-scrollbar-measure { + position: absolute; + top: -9999px; + width: 50px; + height: 50px; + overflow: scroll; +} +@media (min-width: 768px) { + .modal-dialog { + width: 600px; + margin: 30px auto; + } + .modal-content { + box-shadow: 0 5px 15px rgba(0, 0, 0, 0.5); + } + .modal-sm { + width: 300px; + } +} +@media (min-width: 992px) { + .modal-lg { + width: 900px; + } +} +.tooltip { + position: absolute; + z-index: 1070; + display: block; + font-family: "Roboto", "Helvetica Neue", Helvetica, Arial, sans-serif; + font-style: normal; + font-weight: 400; + line-height: 1.846; + line-break: auto; + text-align: left; + text-align: start; + text-decoration: none; + text-shadow: none; + text-transform: none; + letter-spacing: normal; + word-break: normal; + word-spacing: normal; + word-wrap: normal; + white-space: normal; + font-size: 12px; + filter: alpha(opacity=0); + opacity: 0; +} +.tooltip.in { + filter: alpha(opacity=90); + opacity: 0.9; +} +.tooltip.top { + padding: 5px 0; + margin-top: -3px; +} +.tooltip.right { + padding: 0 5px; + margin-left: 3px; +} +.tooltip.bottom { + padding: 5px 0; + margin-top: 3px; +} +.tooltip.left { + padding: 0 5px; + margin-left: -3px; +} +.tooltip.top .tooltip-arrow { + bottom: 0; + left: 50%; + margin-left: -5px; + border-width: 5px 5px 0; + border-top-color: #727272; +} +.tooltip.top-left .tooltip-arrow { + right: 5px; + bottom: 0; + margin-bottom: -5px; + border-width: 5px 5px 0; + border-top-color: #727272; +} +.tooltip.top-right .tooltip-arrow { + bottom: 0; + left: 5px; + margin-bottom: -5px; + border-width: 5px 5px 0; + border-top-color: #727272; +} +.tooltip.right .tooltip-arrow { + top: 50%; + left: 0; + margin-top: -5px; + border-width: 5px 5px 5px 0; + border-right-color: #727272; +} +.tooltip.left .tooltip-arrow { + top: 50%; + right: 0; + margin-top: -5px; + border-width: 5px 0 5px 5px; + border-left-color: #727272; +} +.tooltip.bottom .tooltip-arrow { + top: 0; + left: 50%; + margin-left: -5px; + border-width: 0 5px 5px; + border-bottom-color: #727272; +} +.tooltip.bottom-left .tooltip-arrow { + top: 0; + right: 5px; + margin-top: -5px; + border-width: 0 5px 5px; + border-bottom-color: #727272; +} +.tooltip.bottom-right .tooltip-arrow { + top: 0; + left: 5px; + margin-top: -5px; + border-width: 0 5px 5px; + border-bottom-color: #727272; +} +.tooltip-inner { + max-width: 200px; + padding: 3px 8px; + color: #ffffff; + text-align: center; + background-color: #727272; + border-radius: 3px; +} +.tooltip-arrow { + position: absolute; + width: 0; + height: 0; + border-color: transparent; + border-style: solid; +} +.popover { + position: absolute; + top: 0; + left: 0; + z-index: 1060; + display: none; + max-width: 276px; + padding: 1px; + font-family: "Roboto", "Helvetica Neue", Helvetica, Arial, sans-serif; + font-style: normal; + font-weight: 400; + line-height: 1.846; + line-break: auto; + text-align: left; + text-align: start; + text-decoration: none; + text-shadow: none; + text-transform: none; + letter-spacing: normal; + word-break: normal; + word-spacing: normal; + word-wrap: normal; + white-space: normal; + font-size: 13px; + background-color: #ffffff; + background-clip: padding-box; + border: 1px solid transparent; + border-radius: 3px; + box-shadow: 0 5px 10px rgba(0, 0, 0, 0.2); +} +.popover.top { + margin-top: -10px; +} +.popover.right { + margin-left: 10px; +} +.popover.bottom { + margin-top: 10px; +} +.popover.left { + margin-left: -10px; +} +.popover > .arrow { + border-width: 11px; +} +.popover > .arrow, +.popover > .arrow:after { + position: absolute; + display: block; + width: 0; + height: 0; + border-color: transparent; + border-style: solid; +} +.popover > .arrow:after { + content: ""; + border-width: 10px; +} +.popover.top > .arrow { + bottom: -11px; + left: 50%; + margin-left: -11px; + border-top-color: rgba(0, 0, 0, 0); + border-top-color: rgba(0, 0, 0, 0.075); + border-bottom-width: 0; +} +.popover.top > .arrow:after { + bottom: 1px; + margin-left: -10px; + content: " "; + border-top-color: #ffffff; + border-bottom-width: 0; +} +.popover.right > .arrow { + top: 50%; + left: -11px; + margin-top: -11px; + border-right-color: rgba(0, 0, 0, 0); + border-right-color: rgba(0, 0, 0, 0.075); + border-left-width: 0; +} +.popover.right > .arrow:after { + bottom: -10px; + left: 1px; + content: " "; + border-right-color: #ffffff; + border-left-width: 0; +} +.popover.bottom > .arrow { + top: -11px; + left: 50%; + margin-left: -11px; + border-top-width: 0; + border-bottom-color: rgba(0, 0, 0, 0); + border-bottom-color: rgba(0, 0, 0, 0.075); +} +.popover.bottom > .arrow:after { + top: 1px; + margin-left: -10px; + content: " "; + border-top-width: 0; + border-bottom-color: #ffffff; +} +.popover.left > .arrow { + top: 50%; + right: -11px; + margin-top: -11px; + border-right-width: 0; + border-left-color: rgba(0, 0, 0, 0); + border-left-color: rgba(0, 0, 0, 0.075); +} +.popover.left > .arrow:after { + right: 1px; + bottom: -10px; + content: " "; + border-right-width: 0; + border-left-color: #ffffff; +} +.popover-title { + padding: 8px 14px; + margin: 0; + font-size: 13px; + background-color: #f7f7f7; + border-bottom: 1px solid #ebebeb; + border-radius: 2px 2px 0 0; +} +.popover-content { + padding: 9px 14px; +} +.carousel { + position: relative; +} +.carousel-inner { + position: relative; + width: 100%; + overflow: hidden; +} +.carousel-inner > .item { + position: relative; + display: none; + transition: 0.6s ease-in-out left; +} +.carousel-inner > .item > img, +.carousel-inner > .item > a > img { + line-height: 1; +} +@media all and (transform-3d), (-webkit-transform-3d) { + .carousel-inner > .item { + transition: -webkit-transform 0.6s ease-in-out; + transition: transform 0.6s ease-in-out; + -webkit-backface-visibility: hidden; + backface-visibility: hidden; + -webkit-perspective: 1000px; + perspective: 1000px; + } + .carousel-inner > .item.next, + .carousel-inner > .item.active.right { + -webkit-transform: translate3d(100%, 0, 0); + transform: translate3d(100%, 0, 0); + left: 0; + } + .carousel-inner > .item.prev, + .carousel-inner > .item.active.left { + -webkit-transform: translate3d(-100%, 0, 0); + transform: translate3d(-100%, 0, 0); + left: 0; + } + .carousel-inner > .item.next.left, + .carousel-inner > .item.prev.right, + .carousel-inner > .item.active { + -webkit-transform: translate3d(0, 0, 0); + transform: translate3d(0, 0, 0); + left: 0; + } +} +.carousel-inner > .active, +.carousel-inner > .next, +.carousel-inner > .prev { + display: block; +} +.carousel-inner > .active { + left: 0; +} +.carousel-inner > .next, +.carousel-inner > .prev { + position: absolute; + top: 0; + width: 100%; +} +.carousel-inner > .next { + left: 100%; +} +.carousel-inner > .prev { + left: -100%; +} +.carousel-inner > .next.left, +.carousel-inner > .prev.right { + left: 0; +} +.carousel-inner > .active.left { + left: -100%; +} +.carousel-inner > .active.right { + left: 100%; +} +.carousel-control { + position: absolute; + top: 0; + bottom: 0; + left: 0; + width: 15%; + font-size: 20px; + color: #ffffff; + text-align: center; + text-shadow: 0 1px 2px rgba(0, 0, 0, 0.6); + background-color: rgba(0, 0, 0, 0); + filter: alpha(opacity=50); + opacity: 0.5; +} +.carousel-control.left { + background-image: linear-gradient(to right, rgba(0, 0, 0, 0.5) 0%, rgba(0, 0, 0, 0.0001) 100%); + filter: progid:DXImageTransform.Microsoft.gradient(startColorstr='#80000000', endColorstr='#00000000', GradientType=1); + background-repeat: repeat-x; +} +.carousel-control.right { + right: 0; + left: auto; + background-image: linear-gradient(to right, rgba(0, 0, 0, 0.0001) 0%, rgba(0, 0, 0, 0.5) 100%); + filter: progid:DXImageTransform.Microsoft.gradient(startColorstr='#00000000', endColorstr='#80000000', GradientType=1); + background-repeat: repeat-x; +} +.carousel-control:hover, +.carousel-control:focus { + color: #ffffff; + text-decoration: none; + outline: 0; + filter: alpha(opacity=90); + opacity: 0.9; +} +.carousel-control .icon-prev, +.carousel-control .icon-next, +.carousel-control .glyphicon-chevron-left, +.carousel-control .glyphicon-chevron-right { + position: absolute; + top: 50%; + z-index: 5; + display: inline-block; + margin-top: -10px; +} +.carousel-control .icon-prev, +.carousel-control .glyphicon-chevron-left { + left: 50%; + margin-left: -10px; +} +.carousel-control .icon-next, +.carousel-control .glyphicon-chevron-right { + right: 50%; + margin-right: -10px; +} +.carousel-control .icon-prev, +.carousel-control .icon-next { + width: 20px; + height: 20px; + font-family: serif; + line-height: 1; +} +.carousel-control .icon-prev:before { + content: "\2039"; +} +.carousel-control .icon-next:before { + content: "\203a"; +} +.carousel-indicators { + position: absolute; + bottom: 10px; + left: 50%; + z-index: 15; + width: 60%; + padding-left: 0; + margin-left: -30%; + text-align: center; + list-style: none; +} +.carousel-indicators li { + display: inline-block; + width: 10px; + height: 10px; + margin: 1px; + text-indent: -999px; + cursor: pointer; + background-color: #000 \9; + background-color: rgba(0, 0, 0, 0); + border: 1px solid #ffffff; + border-radius: 10px; +} +.carousel-indicators .active { + width: 12px; + height: 12px; + margin: 0; + background-color: #ffffff; +} +.carousel-caption { + position: absolute; + right: 15%; + bottom: 20px; + left: 15%; + z-index: 10; + padding-top: 20px; + padding-bottom: 20px; + color: #ffffff; + text-align: center; + text-shadow: 0 1px 2px rgba(0, 0, 0, 0.6); +} +.carousel-caption .btn { + text-shadow: none; +} +@media screen and (min-width: 768px) { + .carousel-control .glyphicon-chevron-left, + .carousel-control .glyphicon-chevron-right, + .carousel-control .icon-prev, + .carousel-control .icon-next { + width: 30px; + height: 30px; + margin-top: -10px; + font-size: 30px; + } + .carousel-control .glyphicon-chevron-left, + .carousel-control .icon-prev { + margin-left: -10px; + } + .carousel-control .glyphicon-chevron-right, + .carousel-control .icon-next { + margin-right: -10px; + } + .carousel-caption { + right: 20%; + left: 20%; + padding-bottom: 30px; + } + .carousel-indicators { + bottom: 20px; + } +} +.clearfix:before, +.clearfix:after, +.dl-horizontal dd:before, +.dl-horizontal dd:after, +.container:before, +.container:after, +.container-fluid:before, +.container-fluid:after, +.row:before, +.row:after, +.form-horizontal .form-group:before, +.form-horizontal .form-group:after, +.btn-toolbar:before, +.btn-toolbar:after, +.btn-group-vertical > .btn-group:before, +.btn-group-vertical > .btn-group:after, +.nav:before, +.nav:after, +.navbar:before, +.navbar:after, +.navbar-header:before, +.navbar-header:after, +.navbar-collapse:before, +.navbar-collapse:after, +.pager:before, +.pager:after, +.panel-body:before, +.panel-body:after, +.modal-header:before, +.modal-header:after, +.modal-footer:before, +.modal-footer:after { + display: table; + content: " "; +} +.clearfix:after, +.dl-horizontal dd:after, +.container:after, +.container-fluid:after, +.row:after, +.form-horizontal .form-group:after, +.btn-toolbar:after, +.btn-group-vertical > .btn-group:after, +.nav:after, +.navbar:after, +.navbar-header:after, +.navbar-collapse:after, +.pager:after, +.panel-body:after, +.modal-header:after, +.modal-footer:after { + clear: both; +} +.center-block { + display: block; + margin-right: auto; + margin-left: auto; +} +.pull-right { + float: right !important; +} +.pull-left { + float: left !important; +} +.hide { + display: none !important; +} +.show { + display: block !important; +} +.invisible { + visibility: hidden; +} +.text-hide { + font: 0/0 a; + color: transparent; + text-shadow: none; + background-color: transparent; + border: 0; +} +.hidden { + display: none !important; +} +.affix { + position: fixed; +} +@-ms-viewport { + width: device-width; +} +.visible-xs, +.visible-sm, +.visible-md, +.visible-lg { + display: none !important; +} +.visible-xs-block, +.visible-xs-inline, +.visible-xs-inline-block, +.visible-sm-block, +.visible-sm-inline, +.visible-sm-inline-block, +.visible-md-block, +.visible-md-inline, +.visible-md-inline-block, +.visible-lg-block, +.visible-lg-inline, +.visible-lg-inline-block { + display: none !important; +} +@media (max-width: 767px) { + .visible-xs { + display: block !important; + } + table.visible-xs { + display: table !important; + } + tr.visible-xs { + display: table-row !important; + } + th.visible-xs, + td.visible-xs { + display: table-cell !important; + } +} +@media (max-width: 767px) { + .visible-xs-block { + display: block !important; + } +} +@media (max-width: 767px) { + .visible-xs-inline { + display: inline !important; + } +} +@media (max-width: 767px) { + .visible-xs-inline-block { + display: inline-block !important; + } +} +@media (min-width: 768px) and (max-width: 991px) { + .visible-sm { + display: block !important; + } + table.visible-sm { + display: table !important; + } + tr.visible-sm { + display: table-row !important; + } + th.visible-sm, + td.visible-sm { + display: table-cell !important; + } +} +@media (min-width: 768px) and (max-width: 991px) { + .visible-sm-block { + display: block !important; + } +} +@media (min-width: 768px) and (max-width: 991px) { + .visible-sm-inline { + display: inline !important; + } +} +@media (min-width: 768px) and (max-width: 991px) { + .visible-sm-inline-block { + display: inline-block !important; + } +} +@media (min-width: 992px) and (max-width: 1199px) { + .visible-md { + display: block !important; + } + table.visible-md { + display: table !important; + } + tr.visible-md { + display: table-row !important; + } + th.visible-md, + td.visible-md { + display: table-cell !important; + } +} +@media (min-width: 992px) and (max-width: 1199px) { + .visible-md-block { + display: block !important; + } +} +@media (min-width: 992px) and (max-width: 1199px) { + .visible-md-inline { + display: inline !important; + } +} +@media (min-width: 992px) and (max-width: 1199px) { + .visible-md-inline-block { + display: inline-block !important; + } +} +@media (min-width: 1200px) { + .visible-lg { + display: block !important; + } + table.visible-lg { + display: table !important; + } + tr.visible-lg { + display: table-row !important; + } + th.visible-lg, + td.visible-lg { + display: table-cell !important; + } +} +@media (min-width: 1200px) { + .visible-lg-block { + display: block !important; + } +} +@media (min-width: 1200px) { + .visible-lg-inline { + display: inline !important; + } +} +@media (min-width: 1200px) { + .visible-lg-inline-block { + display: inline-block !important; + } +} +@media (max-width: 767px) { + .hidden-xs { + display: none !important; + } +} +@media (min-width: 768px) and (max-width: 991px) { + .hidden-sm { + display: none !important; + } +} +@media (min-width: 992px) and (max-width: 1199px) { + .hidden-md { + display: none !important; + } +} +@media (min-width: 1200px) { + .hidden-lg { + display: none !important; + } +} +.visible-print { + display: none !important; +} +@media print { + .visible-print { + display: block !important; + } + table.visible-print { + display: table !important; + } + tr.visible-print { + display: table-row !important; + } + th.visible-print, + td.visible-print { + display: table-cell !important; + } +} +.visible-print-block { + display: none !important; +} +@media print { + .visible-print-block { + display: block !important; + } +} +.visible-print-inline { + display: none !important; +} +@media print { + .visible-print-inline { + display: inline !important; + } +} +.visible-print-inline-block { + display: none !important; +} +@media print { + .visible-print-inline-block { + display: inline-block !important; + } +} +@media print { + .hidden-print { + display: none !important; + } +} +.navbar { + border: none; + box-shadow: 0 1px 2px rgba(0, 0, 0, 0.3); +} +.navbar-brand { + font-size: 24px; +} +.navbar-inverse .navbar-form input[type=text], +.navbar-inverse .navbar-form input[type=password] { + color: #fff; + box-shadow: inset 0 -1px 0 #b2dbfb; +} +.navbar-inverse .navbar-form input[type=text]::-moz-placeholder, +.navbar-inverse .navbar-form input[type=password]::-moz-placeholder { + color: #b2dbfb; + opacity: 1; +} +.navbar-inverse .navbar-form input[type=text]:-ms-input-placeholder, +.navbar-inverse .navbar-form input[type=password]:-ms-input-placeholder { + color: #b2dbfb; +} +.navbar-inverse .navbar-form input[type=text]::-webkit-input-placeholder, +.navbar-inverse .navbar-form input[type=password]::-webkit-input-placeholder { + color: #b2dbfb; +} +.navbar-inverse .navbar-form input[type=text]:focus, +.navbar-inverse .navbar-form input[type=password]:focus { + box-shadow: inset 0 -2px 0 #ffffff; +} +.btn-default { + background-size: 200% 200%; + background-position: 50%; +} +.btn-default:focus { + background-color: #ffffff; +} +.btn-default:hover, +.btn-default:active:hover { + background-color: #f0f0f0; +} +.btn-default:active { + background-color: #e0e0e0; + background-image: radial-gradient(circle, #e0e0e0 10%, #ffffff 11%); + background-repeat: no-repeat; + background-size: 1000% 1000%; + box-shadow: 2px 2px 4px rgba(0, 0, 0, 0.4); +} +.btn-primary { + background-size: 200% 200%; + background-position: 50%; +} +.btn-primary:focus { + background-color: #2196f3; +} +.btn-primary:hover, +.btn-primary:active:hover { + background-color: #0d87e9; +} +.btn-primary:active { + background-color: #0b76cc; + background-image: radial-gradient(circle, #0b76cc 10%, #2196f3 11%); + background-repeat: no-repeat; + background-size: 1000% 1000%; + box-shadow: 2px 2px 4px rgba(0, 0, 0, 0.4); +} +.btn-success { + background-size: 200% 200%; + background-position: 50%; +} +.btn-success:focus { + background-color: #4caf50; +} +.btn-success:hover, +.btn-success:active:hover { + background-color: #439a46; +} +.btn-success:active { + background-color: #39843c; + background-image: radial-gradient(circle, #39843c 10%, #4caf50 11%); + background-repeat: no-repeat; + background-size: 1000% 1000%; + box-shadow: 2px 2px 4px rgba(0, 0, 0, 0.4); +} +.btn-info { + background-size: 200% 200%; + background-position: 50%; +} +.btn-info:focus { + background-color: #9c27b0; +} +.btn-info:hover, +.btn-info:active:hover { + background-color: #862197; +} +.btn-info:active { + background-color: #701c7e; + background-image: radial-gradient(circle, #701c7e 10%, #9c27b0 11%); + background-repeat: no-repeat; + background-size: 1000% 1000%; + box-shadow: 2px 2px 4px rgba(0, 0, 0, 0.4); +} +.btn-warning { + background-size: 200% 200%; + background-position: 50%; +} +.btn-warning:focus { + background-color: #ff9800; +} +.btn-warning:hover, +.btn-warning:active:hover { + background-color: #e08600; +} +.btn-warning:active { + background-color: #c27400; + background-image: radial-gradient(circle, #c27400 10%, #ff9800 11%); + background-repeat: no-repeat; + background-size: 1000% 1000%; + box-shadow: 2px 2px 4px rgba(0, 0, 0, 0.4); +} +.btn-danger { + background-size: 200% 200%; + background-position: 50%; +} +.btn-danger:focus { + background-color: #e51c23; +} +.btn-danger:hover, +.btn-danger:active:hover { + background-color: #cb171e; +} +.btn-danger:active { + background-color: #b0141a; + background-image: radial-gradient(circle, #b0141a 10%, #e51c23 11%); + background-repeat: no-repeat; + background-size: 1000% 1000%; + box-shadow: 2px 2px 4px rgba(0, 0, 0, 0.4); +} +.btn-link { + background-size: 200% 200%; + background-position: 50%; +} +.btn-link:focus { + background-color: #ffffff; +} +.btn-link:hover, +.btn-link:active:hover { + background-color: #f0f0f0; +} +.btn-link:active { + background-color: #e0e0e0; + background-image: radial-gradient(circle, #e0e0e0 10%, #ffffff 11%); + background-repeat: no-repeat; + background-size: 1000% 1000%; + box-shadow: 2px 2px 4px rgba(0, 0, 0, 0.4); +} +.btn { + text-transform: uppercase; + border: none; + box-shadow: 1px 1px 4px rgba(0, 0, 0, 0.4); + transition: all 0.4s; +} +.btn-link { + border-radius: 3px; + box-shadow: none; + color: #444444; +} +.btn-link:hover, +.btn-link:focus { + box-shadow: none; + color: #444444; + text-decoration: none; +} +.btn-default.disabled { + background-color: rgba(0, 0, 0, 0.1); + color: rgba(0, 0, 0, 0.4); + opacity: 1; +} +.btn-group .btn + .btn, +.btn-group .btn + .btn-group, +.btn-group .btn-group + .btn, +.btn-group .btn-group + .btn-group { + margin-left: 0; +} +.btn-group-vertical > .btn + .btn, +.btn-group-vertical > .btn + .btn-group, +.btn-group-vertical > .btn-group + .btn, +.btn-group-vertical > .btn-group + .btn-group { + margin-top: 0; +} +body { + -webkit-font-smoothing: antialiased; + letter-spacing: .1px; +} +p { + margin: 0 0 1em; +} +input, +button { + -webkit-font-smoothing: antialiased; + letter-spacing: .1px; +} +a { + transition: all 0.2s; +} +.table-hover > tbody > tr, +.table-hover > tbody > tr > th, +.table-hover > tbody > tr > td { + transition: all 0.2s; +} +label { + font-weight: normal; +} +textarea, +textarea.form-control, +input.form-control, +input[type=text], +input[type=password], +input[type=email], +input[type=number], +[type=text].form-control, +[type=password].form-control, +[type=email].form-control, +[type=tel].form-control, +[contenteditable].form-control { + padding: 0; + border: none; + border-radius: 0; + -webkit-appearance: none; + box-shadow: inset 0 -1px 0 #dddddd; + font-size: 16px; +} +textarea:focus, +textarea.form-control:focus, +input.form-control:focus, +input[type=text]:focus, +input[type=password]:focus, +input[type=email]:focus, +input[type=number]:focus, +[type=text].form-control:focus, +[type=password].form-control:focus, +[type=email].form-control:focus, +[type=tel].form-control:focus, +[contenteditable].form-control:focus { + box-shadow: inset 0 -2px 0 #2196f3; +} +textarea[disabled], +textarea.form-control[disabled], +input.form-control[disabled], +input[type=text][disabled], +input[type=password][disabled], +input[type=email][disabled], +input[type=number][disabled], +[type=text].form-control[disabled], +[type=password].form-control[disabled], +[type=email].form-control[disabled], +[type=tel].form-control[disabled], +[contenteditable].form-control[disabled], +textarea[readonly], +textarea.form-control[readonly], +input.form-control[readonly], +input[type=text][readonly], +input[type=password][readonly], +input[type=email][readonly], +input[type=number][readonly], +[type=text].form-control[readonly], +[type=password].form-control[readonly], +[type=email].form-control[readonly], +[type=tel].form-control[readonly], +[contenteditable].form-control[readonly] { + box-shadow: none; + border-bottom: 1px dotted #ddd; +} +textarea.input-sm, +textarea.form-control.input-sm, +input.form-control.input-sm, +input[type=text].input-sm, +input[type=password].input-sm, +input[type=email].input-sm, +input[type=number].input-sm, +[type=text].form-control.input-sm, +[type=password].form-control.input-sm, +[type=email].form-control.input-sm, +[type=tel].form-control.input-sm, +[contenteditable].form-control.input-sm { + font-size: 12px; +} +textarea.input-lg, +textarea.form-control.input-lg, +input.form-control.input-lg, +input[type=text].input-lg, +input[type=password].input-lg, +input[type=email].input-lg, +input[type=number].input-lg, +[type=text].form-control.input-lg, +[type=password].form-control.input-lg, +[type=email].form-control.input-lg, +[type=tel].form-control.input-lg, +[contenteditable].form-control.input-lg { + font-size: 17px; +} +select, +select.form-control { + border: 0; + border-radius: 0; + -webkit-appearance: none; + -moz-appearance: none; + appearance: none; + padding-left: 0; + padding-right: 0\9; + background-image: url(data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABoAAAAaCAMAAACelLz8AAAAJ1BMVEVmZmZmZmZmZmZmZmZmZmZmZmZmZmZmZmZmZmZmZmZmZmZmZmZmZmaP/QSjAAAADHRSTlMAAgMJC0uWpKa6wMxMdjkoAAAANUlEQVR4AeXJyQEAERAAsNl7Hf3X6xt0QL6JpZWq30pdvdadme+0PMdzvHm8YThHcT1H7K0BtOMDniZhWOgAAAAASUVORK5CYII=); + background-size: 13px; + background-repeat: no-repeat; + background-position: right center; + box-shadow: inset 0 -1px 0 #dddddd; + font-size: 16px; + line-height: 1.5; +} +select::-ms-expand, +select.form-control::-ms-expand { + display: none; +} +select.input-sm, +select.form-control.input-sm { + font-size: 12px; +} +select.input-lg, +select.form-control.input-lg { + font-size: 17px; +} +select:focus, +select.form-control:focus { + box-shadow: inset 0 -2px 0 #2196f3; + background-image: url(data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABoAAAAaCAMAAACelLz8AAAAJ1BMVEUhISEhISEhISEhISEhISEhISEhISEhISEhISEhISEhISEhISEhISF8S9ewAAAADHRSTlMAAgMJC0uWpKa6wMxMdjkoAAAANUlEQVR4AeXJyQEAERAAsNl7Hf3X6xt0QL6JpZWq30pdvdadme+0PMdzvHm8YThHcT1H7K0BtOMDniZhWOgAAAAASUVORK5CYII=); +} +select[multiple], +select.form-control[multiple] { + background: none; +} +.radio label, +.radio-inline label, +.checkbox label, +.checkbox-inline label { + padding-left: 25px; +} +.radio input[type="radio"], +.radio-inline input[type="radio"], +.checkbox input[type="radio"], +.checkbox-inline input[type="radio"], +.radio input[type="checkbox"], +.radio-inline input[type="checkbox"], +.checkbox input[type="checkbox"], +.checkbox-inline input[type="checkbox"] { + margin-left: -25px; +} +input[type="radio"], +.radio input[type="radio"], +.radio-inline input[type="radio"] { + position: relative; + margin-top: 6px; + margin-right: 4px; + vertical-align: top; + border: none; + background-color: transparent; + -webkit-appearance: none; + appearance: none; + cursor: pointer; +} +input[type="radio"]:focus, +.radio input[type="radio"]:focus, +.radio-inline input[type="radio"]:focus { + outline: none; +} +input[type="radio"]:before, +.radio input[type="radio"]:before, +.radio-inline input[type="radio"]:before, +input[type="radio"]:after, +.radio input[type="radio"]:after, +.radio-inline input[type="radio"]:after { + content: ""; + display: block; + width: 18px; + height: 18px; + border-radius: 50%; + transition: 240ms; +} +input[type="radio"]:before, +.radio input[type="radio"]:before, +.radio-inline input[type="radio"]:before { + position: absolute; + left: 0; + top: -3px; + background-color: #2196f3; + -webkit-transform: scale(0); + transform: scale(0); +} +input[type="radio"]:after, +.radio input[type="radio"]:after, +.radio-inline input[type="radio"]:after { + position: relative; + top: -3px; + border: 2px solid #666666; +} +input[type="radio"]:checked:before, +.radio input[type="radio"]:checked:before, +.radio-inline input[type="radio"]:checked:before { + -webkit-transform: scale(0.5); + transform: scale(0.5); +} +input[type="radio"]:disabled:checked:before, +.radio input[type="radio"]:disabled:checked:before, +.radio-inline input[type="radio"]:disabled:checked:before { + background-color: #bbbbbb; +} +input[type="radio"]:checked:after, +.radio input[type="radio"]:checked:after, +.radio-inline input[type="radio"]:checked:after { + border-color: #2196f3; +} +input[type="radio"]:disabled:after, +.radio input[type="radio"]:disabled:after, +.radio-inline input[type="radio"]:disabled:after, +input[type="radio"]:disabled:checked:after, +.radio input[type="radio"]:disabled:checked:after, +.radio-inline input[type="radio"]:disabled:checked:after { + border-color: #bbbbbb; +} +input[type="checkbox"], +.checkbox input[type="checkbox"], +.checkbox-inline input[type="checkbox"] { + position: relative; + border: none; + margin-bottom: -4px; + -webkit-appearance: none; + appearance: none; + cursor: pointer; +} +input[type="checkbox"]:focus, +.checkbox input[type="checkbox"]:focus, +.checkbox-inline input[type="checkbox"]:focus { + outline: none; +} +input[type="checkbox"]:focus:after, +.checkbox input[type="checkbox"]:focus:after, +.checkbox-inline input[type="checkbox"]:focus:after { + border-color: #2196f3; +} +input[type="checkbox"]:after, +.checkbox input[type="checkbox"]:after, +.checkbox-inline input[type="checkbox"]:after { + content: ""; + display: block; + width: 18px; + height: 18px; + margin-top: -2px; + margin-right: 5px; + border: 2px solid #666666; + border-radius: 2px; + transition: 240ms; +} +input[type="checkbox"]:checked:before, +.checkbox input[type="checkbox"]:checked:before, +.checkbox-inline input[type="checkbox"]:checked:before { + content: ""; + position: absolute; + top: 0; + left: 6px; + display: table; + width: 6px; + height: 12px; + border: 2px solid #fff; + border-top-width: 0; + border-left-width: 0; + -webkit-transform: rotate(45deg); + transform: rotate(45deg); +} +input[type="checkbox"]:checked:after, +.checkbox input[type="checkbox"]:checked:after, +.checkbox-inline input[type="checkbox"]:checked:after { + background-color: #2196f3; + border-color: #2196f3; +} +input[type="checkbox"]:disabled:after, +.checkbox input[type="checkbox"]:disabled:after, +.checkbox-inline input[type="checkbox"]:disabled:after { + border-color: #bbbbbb; +} +input[type="checkbox"]:disabled:checked:after, +.checkbox input[type="checkbox"]:disabled:checked:after, +.checkbox-inline input[type="checkbox"]:disabled:checked:after { + background-color: #bbbbbb; + border-color: transparent; +} +.has-warning input:not([type=checkbox]), +.has-warning .form-control, +.has-warning input.form-control[readonly], +.has-warning input[type=text][readonly], +.has-warning [type=text].form-control[readonly], +.has-warning input:not([type=checkbox]):focus, +.has-warning .form-control:focus { + border-bottom: none; + box-shadow: inset 0 -2px 0 #ff9800; +} +.has-error input:not([type=checkbox]), +.has-error .form-control, +.has-error input.form-control[readonly], +.has-error input[type=text][readonly], +.has-error [type=text].form-control[readonly], +.has-error input:not([type=checkbox]):focus, +.has-error .form-control:focus { + border-bottom: none; + box-shadow: inset 0 -2px 0 #e51c23; +} +.has-success input:not([type=checkbox]), +.has-success .form-control, +.has-success input.form-control[readonly], +.has-success input[type=text][readonly], +.has-success [type=text].form-control[readonly], +.has-success input:not([type=checkbox]):focus, +.has-success .form-control:focus { + border-bottom: none; + box-shadow: inset 0 -2px 0 #4caf50; +} +.has-warning .input-group-addon, +.has-error .input-group-addon, +.has-success .input-group-addon { + color: #666666; + border-color: transparent; + background-color: transparent; +} +.form-group-lg select, +.form-group-lg select.form-control { + line-height: 1.5; +} +.nav-tabs > li > a, +.nav-tabs > li > a:focus { + margin-right: 0; + background-color: transparent; + border: none; + color: #666666; + box-shadow: inset 0 -1px 0 #dddddd; + transition: all 0.2s; +} +.nav-tabs > li > a:hover, +.nav-tabs > li > a:focus:hover { + background-color: transparent; + box-shadow: inset 0 -2px 0 #2196f3; + color: #2196f3; +} +.nav-tabs > li.active > a, +.nav-tabs > li.active > a:focus { + border: none; + box-shadow: inset 0 -2px 0 #2196f3; + color: #2196f3; +} +.nav-tabs > li.active > a:hover, +.nav-tabs > li.active > a:focus:hover { + border: none; + color: #2196f3; +} +.nav-tabs > li.disabled > a { + box-shadow: inset 0 -1px 0 #dddddd; +} +.nav-tabs.nav-justified > li > a, +.nav-tabs.nav-justified > li > a:hover, +.nav-tabs.nav-justified > li > a:focus, +.nav-tabs.nav-justified > .active > a, +.nav-tabs.nav-justified > .active > a:hover, +.nav-tabs.nav-justified > .active > a:focus { + border: none; +} +.nav-tabs .dropdown-menu { + margin-top: 0; +} +.dropdown-menu { + margin-top: 0; + border: none; + box-shadow: 0 1px 4px rgba(0, 0, 0, 0.3); +} +.alert { + border: none; + color: #fff; +} +.alert-success { + background-color: #4caf50; +} +.alert-info { + background-color: #9c27b0; +} +.alert-warning { + background-color: #ff9800; +} +.alert-danger { + background-color: #e51c23; +} +.alert a:not(.close):not(.btn), +.alert .alert-link { + color: #fff; + font-weight: bold; +} +.alert .close { + color: #fff; +} +.badge { + padding: 4px 6px 4px; +} +.progress { + position: relative; + z-index: 1; + height: 6px; + border-radius: 0; + box-shadow: none; +} +.progress-bar { + box-shadow: none; +} +.progress-bar:last-child { + border-radius: 0 3px 3px 0; +} +.progress-bar:last-child:before { + display: block; + content: ""; + position: absolute; + width: 100%; + height: 100%; + left: 0; + right: 0; + z-index: -1; + background-color: #cae6fc; +} +.progress-bar-success:last-child.progress-bar:before { + background-color: #c7e7c8; +} +.progress-bar-info:last-child.progress-bar:before { + background-color: #edc9f3; +} +.progress-bar-warning:last-child.progress-bar:before { + background-color: #ffe0b3; +} +.progress-bar-danger:last-child.progress-bar:before { + background-color: #f28e92; +} +.close { + font-size: 34px; + font-weight: 300; + line-height: 24px; + opacity: 0.6; + transition: all 0.2s; +} +.close:hover { + opacity: 1; +} +.list-group-item { + padding: 15px; +} +.list-group-item-text { + color: #bbbbbb; +} +.well { + border-radius: 0; + box-shadow: none; +} +.panel { + border: none; + border-radius: 2px; + box-shadow: 0 1px 4px rgba(0, 0, 0, 0.3); +} +.panel-heading { + border-bottom: none; +} +.panel-footer { + border-top: none; +} +.popover { + border: none; + box-shadow: 0 1px 4px rgba(0, 0, 0, 0.3); +} +.carousel-caption h1, +.carousel-caption h2, +.carousel-caption h3, +.carousel-caption h4, +.carousel-caption h5, +.carousel-caption h6 { + color: inherit; +} diff --git a/docs/docsearch.css b/docs/docsearch.css deleted file mode 100644 index e5f1fe1..0000000 --- a/docs/docsearch.css +++ /dev/null @@ -1,148 +0,0 @@ -/* Docsearch -------------------------------------------------------------- */ -/* - Source: https://github.com/algolia/docsearch/ - License: MIT -*/ - -.algolia-autocomplete { - display: block; - -webkit-box-flex: 1; - -ms-flex: 1; - flex: 1 -} - -.algolia-autocomplete .ds-dropdown-menu { - width: 100%; - min-width: none; - max-width: none; - padding: .75rem 0; - background-color: #fff; - background-clip: padding-box; - border: 1px solid rgba(0, 0, 0, .1); - box-shadow: 0 .5rem 1rem rgba(0, 0, 0, .175); -} - -@media (min-width:768px) { - .algolia-autocomplete .ds-dropdown-menu { - width: 175% - } -} - -.algolia-autocomplete .ds-dropdown-menu::before { - display: none -} - -.algolia-autocomplete .ds-dropdown-menu [class^=ds-dataset-] { - padding: 0; - background-color: rgb(255,255,255); - border: 0; - max-height: 80vh; -} - -.algolia-autocomplete .ds-dropdown-menu .ds-suggestions { - margin-top: 0 -} - -.algolia-autocomplete .algolia-docsearch-suggestion { - padding: 0; - overflow: visible -} - -.algolia-autocomplete .algolia-docsearch-suggestion--category-header { - padding: .125rem 1rem; - margin-top: 0; - font-size: 1.3em; - font-weight: 500; - color: #00008B; - border-bottom: 0 -} - -.algolia-autocomplete .algolia-docsearch-suggestion--wrapper { - float: none; - padding-top: 0 -} - -.algolia-autocomplete .algolia-docsearch-suggestion--subcategory-column { - float: none; - width: auto; - padding: 0; - text-align: left -} - -.algolia-autocomplete .algolia-docsearch-suggestion--content { - float: none; - width: auto; - padding: 0 -} - -.algolia-autocomplete .algolia-docsearch-suggestion--content::before { - display: none -} - -.algolia-autocomplete .ds-suggestion:not(:first-child) .algolia-docsearch-suggestion--category-header { - padding-top: .75rem; - margin-top: .75rem; - border-top: 1px solid rgba(0, 0, 0, .1) -} - -.algolia-autocomplete .ds-suggestion .algolia-docsearch-suggestion--subcategory-column { - display: block; - padding: .1rem 1rem; - margin-bottom: 0.1; - font-size: 1.0em; - font-weight: 400 - /* display: none */ -} - -.algolia-autocomplete .algolia-docsearch-suggestion--title { - display: block; - padding: .25rem 1rem; - margin-bottom: 0; - font-size: 0.9em; - font-weight: 400 -} - -.algolia-autocomplete .algolia-docsearch-suggestion--text { - padding: 0 1rem .5rem; - margin-top: -.25rem; - font-size: 0.8em; - font-weight: 400; - line-height: 1.25 -} - -.algolia-autocomplete .algolia-docsearch-footer { - width: 110px; - height: 20px; - z-index: 3; - margin-top: 10.66667px; - float: right; - font-size: 0; - line-height: 0; -} - -.algolia-autocomplete .algolia-docsearch-footer--logo { - background-image: url("data:image/svg+xml;utf8,"); - background-repeat: no-repeat; - background-position: 50%; - background-size: 100%; - overflow: hidden; - text-indent: -9000px; - width: 100%; - height: 100%; - display: block; - transform: translate(-8px); -} - -.algolia-autocomplete .algolia-docsearch-suggestion--highlight { - color: #FF8C00; - background: rgba(232, 189, 54, 0.1) -} - - -.algolia-autocomplete .algolia-docsearch-suggestion--text .algolia-docsearch-suggestion--highlight { - box-shadow: inset 0 -2px 0 0 rgba(105, 105, 105, .5) -} - -.algolia-autocomplete .ds-suggestion.ds-cursor .algolia-docsearch-suggestion--content { - background-color: rgba(192, 192, 192, .15) -} diff --git a/docs/docsearch.js b/docs/docsearch.js deleted file mode 100644 index b35504c..0000000 --- a/docs/docsearch.js +++ /dev/null @@ -1,85 +0,0 @@ -$(function() { - - // register a handler to move the focus to the search bar - // upon pressing shift + "/" (i.e. "?") - $(document).on('keydown', function(e) { - if (e.shiftKey && e.keyCode == 191) { - e.preventDefault(); - $("#search-input").focus(); - } - }); - - $(document).ready(function() { - // do keyword highlighting - /* modified from https://jsfiddle.net/julmot/bL6bb5oo/ */ - var mark = function() { - - var referrer = document.URL ; - var paramKey = "q" ; - - if (referrer.indexOf("?") !== -1) { - var qs = referrer.substr(referrer.indexOf('?') + 1); - var qs_noanchor = qs.split('#')[0]; - var qsa = qs_noanchor.split('&'); - var keyword = ""; - - for (var i = 0; i < qsa.length; i++) { - var currentParam = qsa[i].split('='); - - if (currentParam.length !== 2) { - continue; - } - - if (currentParam[0] == paramKey) { - keyword = decodeURIComponent(currentParam[1].replace(/\+/g, "%20")); - } - } - - if (keyword !== "") { - $(".contents").unmark({ - done: function() { - $(".contents").mark(keyword); - } - }); - } - } - }; - - mark(); - }); -}); - -/* Search term highlighting ------------------------------*/ - -function matchedWords(hit) { - var words = []; - - var hierarchy = hit._highlightResult.hierarchy; - // loop to fetch from lvl0, lvl1, etc. - for (var idx in hierarchy) { - words = words.concat(hierarchy[idx].matchedWords); - } - - var content = hit._highlightResult.content; - if (content) { - words = words.concat(content.matchedWords); - } - - // return unique words - var words_uniq = [...new Set(words)]; - return words_uniq; -} - -function updateHitURL(hit) { - - var words = matchedWords(hit); - var url = ""; - - if (hit.anchor) { - url = hit.url_without_anchor + '?q=' + escape(words.join(" ")) + '#' + hit.anchor; - } else { - url = hit.url + '?q=' + escape(words.join(" ")); - } - - return url; -} diff --git a/docs/extra.css b/docs/extra.css index 0f1be09..e02d945 100644 --- a/docs/extra.css +++ b/docs/extra.css @@ -7,8 +7,12 @@ html, body { .navbar-brand { font-size: 16px; font-weight: bold; + padding-bottom: 20px; + line-height: 32px; } + + .navbar-default .navbar-nav>li>a:hover, .navbar-default .navbar-nav>li>a:focus { background-color: #eee; @@ -42,7 +46,8 @@ a:focus { } h1, .h1 { - font-size: 32px; + font-size: 25px; + font-weight: 900; } h1 small, .h1 small { @@ -52,15 +57,15 @@ h1 small, .h1 small { } h2, .h2 { - font-size: 28px; + font-size: 25px; } h3, .h3 { - font-size: 20px; + font-size: 24px; } h4, .h4 { - font-size: 20px; + font-size: 23px; } .contents h1, .contents h2, .contents h3, .contents h4 { @@ -96,3 +101,5 @@ pre code { color: #eeeeee; background-color: #d46c5b; } + + diff --git a/docs/index.html b/docs/index.html index 8473efc..5e10a61 100644 --- a/docs/index.html +++ b/docs/index.html @@ -5,7 +5,9 @@ -@@ -213,6 +263,12 @@Computes and Plots Consonance (Confidence) Intervals, P-Values, and S-Values to Form Consonance and Surprisal Functions • concurve +Computes and Plots Compatibility (Confidence) Intervals, + P-Values, S-Values, & Likelihood Intervals to Form Consonance, + Surprisal, & Likelihood Functions • concurve @@ -19,8 +21,24 @@ - - + + + -+@@ -199,9 +249,9 @@--Install the Developer Version
- +Export Tables Easily For Word, Powerpoint, & TeX documents ++ + + +
+
+ --+---For Stata:
----Check out the Article on Using Stata for concurve.
+Check out the Article on Using Stata for concurve.
-+-Dependencies
++++Dependencies
- ggplot2
- metafor
- parallel +
- MASS +
- boot +
- bcaboot +
- compiler +
- ProfileLikelihood +
- pbmcapply +
- rlang +
- magrittr
- dplyr +
- tidyr +
- knitr +
- flextable +
- officer
- tibble
- survival
- survminer
- scales
++ +@@ -177,18 +206,39 @@+
+In particular, the usual 95% default forces the user’s focus onto parameter values that yield p > 0.05, without regard to the trivial difference between (say) p = 0.06 and p = 0.04 (a difference not even worth a coin toss). To address this problem, we first note that a 95% interval estimate is only one of a number of arbitrary dichotomization of possibilities of parameter values (into either inside or outside of an interval). A more accurate picture of uncertainty is then obtained by examining intervals using other percentiles, e.g., proportionally-spaced compatibility levels such as p 0.25, 0.05, 0.01, which correspond to 75%, 95%, 99% CIs and equally-spaced S-values of s < 2, 4.32, 6.64 bits. When a detailed picture is desired, a table or graph of all the P-values and S-values across a broad range of parameter values seems the clearest way to see how compatibility varies smoothly across the values.
+Graphs of P-values or their equivalent have been promoted for decades [34, 56–59], yet their adoption has been slight. Nonetheless, P-value and S-value graphing software is now available freely through several statistical packages [60–62]. A graph of the P-values p against possible parameter values allows one to see at a glance which parameter values are most compatible with the data under the background assumptions. This graph is known as the P-value function, or compatibility, consonance, or confidence curve [34, 57, 58, 63, 64]. Transforming the corresponding P-values in the graph to S-values produces an S-value (surprisal) function.
+Following the common (and important) warning that P-values are not hypothesis probabilities, we caution that the P-value graph is not a probability distribution: It shows compatibility of parameter values with the data, rather than plausibility or probability of those values given the data. This is not a subtle difference: compatibility is a much weaker condition than plausibility. Consider for example that complete fabrication of the data is always an explanation compatible with the data (and indeed has happened in some influential medical studies [65]), but in studies with many participants and authors involved in all aspects of data collection it becomes so implausible or improbable as to not even merit mention. We emphasize then that all the P-value ever addresses in a direct logical sense is compatibility; for hypothesis probabilities one must turn to Bayesian methods [25].
+ +
++
+In addition to the overt statistical position, the p-value function also provides easily and accurately many of the familiar types of summary information: a median estimate of the parameter; a one-sided test statistic for a scalar parameter value at any chosen level; the related power function; a lower confidence bound at any level; an upper confidence bound at any level; and confidence intervals with chosen upper and lower confidence limits. The p value reports all the common inference material, but with high accuracy, basic uniqueness, and wide generality.
+From a scientific perspective, the likelihood function and p-value function provide the basis for scientific judgments by an investigator, and by other investigators who might have interest. It thus replaces a blunt yes or no decision by an opportunity for appropriate informed judgment.” - Fraser, 2019
+
-
"Statistical software enables and promotes cargo-cult statistics. Marketing and adoption of statistical software are driven by ease of use and the range of statistical routines the software implements. Offering complex and “modern” methods provides a competitive advantage. And some disciplines have in effect standardised on particular statistical software, often proprietary software.
Statistical software does not help you know what to compute, nor how to interpret the result. It does not offer to explain the assumptions behind methods, nor does it flag delicate or dubious assumptions. It does not warn you about multiplicity or p-hacking. It does not check whether you picked the hypothesis or analysis after looking at the data, nor track the number of analyses you tried before arriving at the one you sought to publish – another form of multiplicity. The more “powerful” and “user-friendly” the software is, the more it invites cargo-cult statistics." - Stark & Saltelli, 2018
References
-
-
- Stark PB, Saltelli A. Cargo-cult statistics and scientific crisis. Significance. 2018;15(4):40-43. +
- Chow ZR, Greenland S. Semantic and Cognitive Tools to Aid Statistical Inference: Replace Confidence and Significance by Compatibility and Surprise. arXiv:1909.08579 [stat.ME]. 2019 +
- Greenland S, Chow ZR. To Aid Statistical Inference, Emphasize Unconditional Descriptions of Statistics. arXiv:1909.08583 [stat.ME]. 2019
- Poole C. Beyond the confidence interval. Am J Public Health. 1987;77(2):195-199. -
- Sullivan KM, Foster DA. Use of the confidence interval function. Epidemiology. 1990;1(1):39-42. +
- Sullivan KM, Foster DA. Use of the confidence interval function._Epidemiology._ 1990;1(1):39-42.
- Rothman KJ, Greenland S, Lash TL. Modern epidemiology. 2012.
- Singh K, Xie M, Strawderman WE. Confidence distribution (CD) – distribution estimator of a parameter. arXiv [mathST]. 2007.
- Schweder T, Hjort NL. Confidence and Likelihood*. Scand J Stat. 2002;29(2):309-332.
- Amrhein V, Trafimow D, Greenland S. Inferential Statistics as Descriptive Statistics: There is No Replication Crisis if We Don’t Expect Replication. Am Stat. 2019
- Greenland S. Valid P-values Behave Exactly As They Should. Some misleading criticisms of P-values and their resolution with S-values. Am Stat. 2019;18(136).
- Fraser DAS. The p-value Function and Statistical Inference. Am Stat. 2019 -
- Chow ZR, Greenland S. Semantic and Cognitive Tools to Aid Statistical Inference: Replace Confidence and Significance by Compatibility and Surprise. arXiv:1909.08579 [stat.ME]. 2019 -
- Greenland S, Chow ZR. To Aid Statistical Inference, Emphasize Unconditional Descriptions of Statistics. arXiv:1909.08583 [stat.ME]. 2019 +
- Stark PB, Saltelli A. Cargo-cult statistics and scientific crisis. Significance. 2018;15(4):40-43.
++Session info
+## R version 3.6.1 (2019-07-05) +## Platform: x86_64-apple-darwin15.6.0 (64-bit) +## Running under: macOS Catalina 10.15.1 +## +## Matrix products: default +## BLAS: /Library/Frameworks/R.framework/Versions/3.6/Resources/lib/libRblas.0.dylib +## LAPACK: /Library/Frameworks/R.framework/Versions/3.6/Resources/lib/libRlapack.dylib +## +## locale: +## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8 +## +## attached base packages: +## [1] stats graphics grDevices utils methods base +## +## loaded via a namespace (and not attached): +## [1] compiler_3.6.1 magrittr_1.5 tools_3.6.1 htmltools_0.4.0 yaml_2.2.0 Rcpp_1.0.3 stringi_1.4.3 +## [8] rmarkdown_1.18 knitr_1.26 stringr_1.4.0 xfun_0.11 digest_0.6.23 rlang_0.4.2 evaluate_0.14Links
- Download from CRAN at
https://cloud.r-project.org/package=concurve
- - Browse source code at
https://github.com/Zadchow/concurve + - Browse source code at
https://github.com/zadchow/concurve
- - Report a bug at
https://github.com/Zadchow/concurve/issues + - Report a bug at
https://github.com/zadchow/concurve/issues
License
+Community
+ +diff --git a/docs/link.svg b/docs/link.svg deleted file mode 100644 index 88ad827..0000000 --- a/docs/link.svg +++ /dev/null @@ -1,12 +0,0 @@ - - - diff --git a/docs/news/index.html b/docs/news/index.html index 8e666d7..563b32c 100644 --- a/docs/news/index.html +++ b/docs/news/index.html @@ -82,9 +82,9 @@ - +Citation
-
@@ -232,12 +288,12 @@
 -
- +
+-
+


Developers
Dev status
-
-
concurve
- 2.1.0
+ 2.3.0
@@ -120,7 +120,7 @@
-
-
+
@@ -145,34 +145,69 @@
-+
-concurve 2.1.0 Unreleased +concurve 2.3.0 Unreleased
+Major changes
-
-
ggconcurve()now plots both the P-values and CI level using both y-axes when the type = “consonance”. Previously, this was only possible viaplot_concurve()(which uses base R graphics) becauseggplot2had a bug in its last few versions, which inhibited proper transformations in the y-axis.
+ -
+
ggcurve()plots confidence (consonance) distributions, densities, likelihood, and deviance functions.
+ -
+
plot_curve()is now deprecated. Please useggcurve()instead.
+ -
+
curve_compare()compares two functions and calculates the area between the curve.
+ -
+
plot_compare()allows two separate functions to be plotted and compared simultaneously.
+ -
+
curve_table()produces publication-ready tables of relevant statistics.
+ -
+
curve_boot()uses bootstrapping to approximate the consonance functions via thebootandbcabootpackages.
+ -
+
curve_lik()produces likelihood functions by transforming the objects from theProfileLikelihoodpackage.
ggconcurve()is nowggcurve(). ++-+Minor changes
+-
+
- All functions now provide progress on how long it will take to complete the task. +
- Interval widths are now provided as measures of precision. +
+++-concurve 2.0.1 Unreleased +concurve 2.1.0 2019-09-19
+Major changes
-
-
plot_concurve()now has “measure” as an item which allows for ratio measures to be logarithmically scaled on the x axis. There are two options, “default”, which is set as the default option and is for mean differences, and “ratio”, which will result in the axis being logarithmically scaled.
+
ggconcurve()now plots both the P-values and CI level using both y-axes when the type = “consonance”. Previously, this was only possible viaplot_concurve()(which uses base R graphics) becauseggplot2had a bug in its last few versions, which inhibited proper transformations in the y-axis. ++@@ -180,15 +215,15 @@+concurve 2.0.1 Unreleased +
+++Major changes
+-
+
-
+
plot_concurve()now has “measure” as an item which allows for ratio measures to be logarithmically scaled on the x axis. There are two options, “default”, which is set as the default option and is for mean differences, and “ratio”, which will result in the axis being logarithmically scaled. -
-
plot_concurve()also now has a “fill” option which will allow users to choose the color of the plot.
+
plot_concurve()also now has a “fill” option which will allow users to choose the color of the plot.concurve 2.0 2019-07-10
-+-Major changes
+Major changes-
-
- The
plotpint()function which plotted consonance functions has been repackaged intoggconcurve().
- - The
plotsint()function which plotted surprisal functions has been repackaged intoggconcurve().
- - Functions can now also be plotted with base R via the
plot_concurve()function.
- - Consonance functions can be plotted as a pyramid (right side up) or inverted (upside down) via the “position” item in
ggconcurve().
- - Null values (for means & ratios) can be plotted via the
ggconcurve()function to show how much of the interval surrounds it.
+ - The
plotpint()function which plotted consonance functions has been repackaged intoggconcurve().
+ - The
plotsint()function which plotted surprisal functions has been repackaged intoggconcurve().
+ - Functions can now also be plotted with base R via the
plot_concurve()function.
+ - Consonance functions can be plotted as a pyramid (right side up) or inverted (upside down) via the “position” item in
ggconcurve().
+ - Null values (for means & ratios) can be plotted via the
ggconcurve()function to show how much of the interval surrounds it. - Log transformations included in all the plotting functions for ratio measures.
- Parallel programming has now been implemented into the computations via the
mclapply()function from the parallel package.
concurve 1.08 Unreleased
-+-Major changes
+Major changes- Can produce consonance and surprisal functions for correlations via the
corrintervals()function. - Now able to construct consonance and surprisal functions from the point estiate, and confidence limits via the
rev_eng()function.
@@ -212,9 +247,9 @@ - Can now produce consonance and surprisal functions for survival data produced with the
survivalpackage. - Default plots now contain grids, title, subtitle, and a caption.
- Updated figures in README and the ‘Examples in R’ vignette/article. @@ -246,6 +281,7 @@
- 2.3.0
- 2.1.0
- 2.0.1
- 2.0 diff --git a/docs/reference/concurve-package.html b/docs/reference/concurve-package.html new file mode 100644 index 0000000..f30c5b5 --- /dev/null +++ b/docs/reference/concurve-package.html @@ -0,0 +1,259 @@ + + + + + + + + +
-
-
+
@@ -146,100 +145,85 @@
@@ -122,7 +126,7 @@-
Plots the P- (Consonance) and S-Value (Surprisal) Functions using base R graphics.
- -+plot_concurve.RdCompares two functions and produces an AUC score to show the amount of consonance.
+ Source:R/curve_compare.R+curve_compare.Rd--Takes the dataframe produced by the interval functions and plots the p-values, s-values, consonance (confidence) -levels, and the interval estimates to produce p- and s-value functions using base R graphics.
+Compares the p-value/s-value, and likelihood functions and computes an AUC number.
plot_concurve(type, data, measure, intervals, title, xlab, ylab1, ylab2, fontsize, fill)
+curve_compare(data1, data2, type = "c", plot = TRUE, ...)
Arguments
-- -type -Choose whether to plot a "consonance" function or a "surprisal" function. The default option is set to "consonance". The type must be set in quotes, for example plot_concurve(type = "surprisal") or plot_concurve(type = "consonance").
- -data -Dataframe where the results from a curve_ function is stored.
- -measure -Indicates whether the object has a log transformation or is normal/default. The default setting is "default". If the measure is set to "ratio", it will take logarithmically transformed values and convert them back to normal values in the dataframe. This is typically a setting used for binary outcomes and their measures such as risk ratios, hazard ratios, and odds ratios.
- -intervals -Indicates whether the limits for different consonance levels should be plotted on the graph. By default, this is set to FALSE. When set to TRUE, it will plot 50%, 75%, 95%, and 99% intervals.
- -title -The title for the graph. By default, it is set to "Consonance Function". In order to set a title, it must be in quotes. For example, plot_concurve(type = "consonance", data = data, title = "Custom Title").
- xlab -The label for the x-axis. By default, it is set to "Theta.". In order to set a label, it must be in quotes. For example, plot_concurve(type = "consonance", data = data, xlab = "Custom Caption").
data1 +The first dataframe produced by one of the interval functions +in which the intervals are stored.
- ylab1 -A label for the y-axis on the left side of the graph. By default, it is set to "P-value." In order to set a custom y-axis label, it must be in quotes. For example, plot_concurve(type = "consonance", data = data, ylab1= "Custom y-axis title").
data2 +The second dataframe produced by one of the interval functions in +which the intervals are stored.
- ylab2 -A label for the y-axis on the right side of the graph. By default, it is set to "Confidence Level."" In order to set a custom y-axis label, it must be in quotes. For example, plot_concurve(type = "consonance", data = data, ylab2= "Custom y-axis title").
type +Choose whether to plot a "consonance" function, a "surprisal" function or +"likelihood". The default option is set to "c". The type must be set in quotes, +for example curve_compare (type = "s") or curve_compare(type = "c"). Other options +include "pd" for the consonance distribution function, and "cd" for the consonance +density function, "l1" for relative likelihood, "l2" for log-likelihood, "l3" +for likelihood and "d" for deviance function.
- fontsize -Controls the font size in the graphs. By default, it is set to size 12.).
plot +by default it is set to TRUE and will use the plot_compare() function +to plot the two functions.
- fill -Item that allows the user to choose the color of the ribbons in the graph. By default, it is set to color = "#239a98". The inputs must be in quotes.
... +Can be used to pass further arguments to plot_compare().
Value
- -Plot with intervals at every consonance level graphed with their corresponding p- and s-values.
-References
- -Amrhein V, Trafimow D, Greenland S. Inferential Statistics as Descriptive Statistics: -There Is No Replication Crisis If We Don’t Expect Replication. Am Stat; 2018.
-Greenland S. Valid P-values behave exactly as they should: Some misleading criticisms of P-values -and their resolution with S-values. Am Stat. 2018;18(136).
-Greenland S. The unconditional information in P-values, and its refutational interpretation -via S-values. 2018.
-Shannon CE. A Mathematical Theory of Communication. Bell System Technical Journal. -1948;27(3):379-423. doi:10.1002/j.1538-7305.1948.tb01338.x
-Poole C. Beyond the confidence interval. Am J Public Health. 1987;77(2):195-199.
-Sullivan KM, Foster DA. Use of the confidence interval function. Epidemiology. 1990;1(1):39-42.
-Rothman KJ, Greenland S, Lash TL, Others. Modern epidemiology. 2008.
Examples
-# Simulate random data - +@@ -123,7 +124,7 @@# \donttest{ +library(concurve) GroupA <- rnorm(50) GroupB <- rnorm(50) - RandomData <- data.frame(GroupA, GroupB) -RandomModel <- lm(GroupA ~ GroupB, data = RandomData) - -intervalsdf <- curve_gen(RandomModel, "GroupB") +intervalsdf <- curve_mean(GroupA, GroupB, data = RandomData) +GroupA2 <- rnorm(50) +GroupB2 <- rnorm(50) +RandomData2 <- data.frame(GroupA2, GroupB2) +model <- lm(GroupA2 ~ GroupB2, data = RandomData2) +randomframe <- curve_gen(model, "GroupB2") +(curve_compare(intervalsdf[[1]], randomframe[[1]]))#> [1] "AUC = Area Under the Curve"#> [[1]] +#> +#> +#> | AUC 1| AUC 2| Shared AUC| AUC Overlap (%)| Overlap:Non-Overlap AUC Ratio| +#> |-----:|-----:|----------:|---------------:|-----------------------------:| +#> | 0.317| 0.204| 0.043| 0.089| 0.098| +#> +#> [[2]] #>(curve_compare(intervalsdf[[1]], randomframe[[1]], type = "s"))#> [1] "AUC = Area Under the Curve"#> [[1]] +#> +#> +#> | AUC 1| AUC 2| Shared AUC| AUC Overlap (%)| Overlap:Non-Overlap AUC Ratio| +#> |------:|-----:|----------:|---------------:|-----------------------------:| +#> | 12.935| 4.309| 4.265| 0.329| 0.489| +#> +#> [[2]]
#>(curve_compare(intervalsdf[[1]], randomframe[[1]], type = "s"))#> [1] "AUC = Area Under the Curve"#> [[1]] +#> +#> +#> | AUC 1| AUC 2| Shared AUC| AUC Overlap (%)| Overlap:Non-Overlap AUC Ratio| +#> |------:|-----:|----------:|---------------:|-----------------------------:| +#> | 12.935| 4.309| 4.265| 0.329| 0.489| +#> +#> [[2]] #># } -plot_concurve(type = "consonance", data = intervalsdf)
#># } -plot_concurve(type = "consonance", data = intervalsdf)
-
-
+
@@ -147,80 +148,87 @@
@@ -123,7 +127,7 @@-
Computes consonance intervals for correlations
- +Computes Consonance Intervals for Correlations
+ Source:R/curve_corr.Rcurve_corr.Rd--Computes consonance intervals to produce P- and S-value functions for correlational analyses -using the cor.test function in base R and places the interval limits for each interval level -into a data frame along with the corresponding p-values and s-values.
+Computes consonance intervals to produce P- and S-value functions for +correlational analysesusing the cor.test function in base R and places the +interval limits for each interval levelinto a data frame along with the +corresponding p-values and s-values.
curve_corr(x, y, alternative, method, steps = 10000)
+curve_corr(x, y, alternative, method, steps = 10000, table = TRUE)
Arguments
-x -A vector that contains the data for one of the variables that will be analyzed for correlational analysis.
A vector that contains the data for one of the variables that will +be analyzed for correlational analysis.
y -A vector that contains the data for one of the variables that will be analyzed for correlational analysis.
A vector that contains the data for one of the variables that will +be analyzed for correlational analysis.
alternative -Indicates the alternative hypothesis and must be one of "two.sided", "greater" or "less". You can specify just the initial letter. "greater" corresponds to positive association, "less" to negative association.
Indicates the alternative hypothesis and must be one of "two.sided", +"greater" or "less". You can specify just the initial letter. "greater" corresponds to +positive association, "less" to negative association.
method -A character string indicating which correlation coefficient is to be used for the test. One of "pearson", "kendall", or "spearman", can be abbreviated.
A character string indicating which correlation coefficient is +to be used for the test. One of "pearson", "kendall", or "spearman", +can be abbreviated.
steps -Indicates how many consonance intervals are to be calculated at various levels. For example, setting -this to 100 will produce 100 consonance intervals from 0 to 100. Setting this to 10000 will produce more consonance levels. By default, it is set to 1000. Increasing the number substantially is not recommended as it will take longer to produce all the intervals and store them into a dataframe.
Indicates how many consonance intervals are to be calculated at +various levels. For example, setting this to 100 will produce 100 consonance +intervals from 0 to 100. Setting this to 10000 will produce more consonance +levels. By default, it is set to 1000. Increasing the number substantially +is not recommended as it will take longer to produce all the intervals and +store them into a dataframe.
+ table +Indicates whether or not a table output with some relevant +statistics should be generated. The default is TRUE and generates a table +which is included in the list object.
References
- -Poole C. Beyond the confidence interval. Am J Public Health. 1987;77(2):195-199.
-Sullivan KM, Foster DA. Use of the confidence interval function. Epidemiology. 1990;1(1):39-42.
-Rothman KJ, Greenland S, Lash TL, Others. Modern epidemiology. 2008.
Examples
+joe <- curve_corr(x = GroupA, y = GroupB, alternative = "two.sided", method = "pearson") +tibble::tibble(joe[[1]])GroupA <- rnorm(50) GroupB <- rnorm(50) - -joe <- curve_corr(x = GroupA, y = GroupB, - alternative = "two.sided", method = "pearson") - -tibble::tibble(joe)#> # A tibble: 10,000 x 1 -#> joe$lower.limit $upper.limit $intrvl.level $pvalue $svalue -#> <dbl> <dbl> <dbl> <dbl> <dbl> -#> 1 0.398 0.398 0 1 0 -#> 2 0.398 0.398 0.0001 1.000 0.000144 -#> 3 0.398 0.398 0.0002 1.000 0.000289 -#> 4 0.398 0.398 0.000300 1.000 0.000433 -#> 5 0.398 0.398 0.0004 1.000 0.000577 -#> 6 0.398 0.398 0.0005 1.000 0.000722 -#> 7 0.398 0.398 0.000600 0.999 0.000866 -#> 8 0.398 0.398 0.0007 0.999 0.00101 -#> 9 0.398 0.398 0.0008 0.999 0.00115 -#> 10 0.398 0.398 0.0009 0.999 0.00130 -#> # … with 9,990 more rows-#> # A tibble: 10,000 x 1 +#> `joe[[1]]`$lowe… $upper.limit $intrvl.width $intrvl.level $cdf $pvalue +#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> +#> 1 -0.0900 -0.0900 0 0 0.5 1 +#> 2 -0.0900 -0.0900 0.0000363 0.0001 0.500 1.000 +#> 3 -0.0900 -0.0900 0.0000725 0.0002 0.500 1.000 +#> 4 -0.0900 -0.0899 0.000109 0.000300 0.500 1.000 +#> 5 -0.0901 -0.0899 0.000145 0.0004 0.500 1.000 +#> 6 -0.0901 -0.0899 0.000181 0.0005 0.500 1.000 +#> 7 -0.0901 -0.0899 0.000218 0.000600 0.500 0.999 +#> 8 -0.0901 -0.0899 0.000254 0.0007 0.500 0.999 +#> 9 -0.0901 -0.0898 0.000290 0.0008 0.500 0.999 +#> 10 -0.0902 -0.0898 0.000326 0.0009 0.500 0.999 +#> # … with 9,990 more rows, and 1 more variable: $svalue <dbl>
-
-
+
@@ -147,89 +151,95 @@
@@ -121,7 +121,7 @@@@ -122,7 +124,7 @@-
Computes consonance intervals for linear models
- +General Consonance Functions Using Profile Likelihood, Wald, +or the bootstrap method for linear models.
+ Source:R/curve_gen.Rcurve_gen.Rd--Computes thousands of consonance (confidence) intervals for the chosen parameter in the -selected model(ANOVA, ANCOVA, regression, logistic regression) and places the interval limits -for each interval level into a data frame along with the corresponding p-values and s-values.
+Computes thousands of consonance (confidence) intervals for +the chosen parameter in the selected model +(ANOVA, ANCOVA, regression, logistic regression) and places +the interval limits for each interval level into a data frame along +with the corresponding p-values and s-values.
curve_gen(model, var, method = "default", replicates = 1000, steps = 10000)
+curve_gen(model, var, method = "wald", steps = 1000, table = TRUE)
Arguments
-model -The statistical model of interest(ANOVA, regression, logistic regression) is to be indicated here.
The statistical model of interest +(ANOVA, regression, logistic regression) is to be indicated here.
var -The variable of interest from the model (coefficients, intercept) for which the intervals are to be produced.
The variable of interest from the model (coefficients, intercept) +for which the intervals are to be produced.
method -Chooses the method to be used to calculate the consonance intervals. There are currently four -methods: "default", "wald", "lm", and "boot". The "default" method uses the profile likelihood method to -compute intervals and can be used for models created by the 'lm' function. The "wald" method is typically -what most people are familiar with when computing intervals based on the calculated standard error. -The "lm" method allows this function to be used for specific scenarios like logistic regression and -the 'glm' function. The "boot" method allows for bootstrapping at certain levels.
Chooses the method to be used to calculate the +consonance intervals. There are currently four methods: +"default", "wald", "lm", and "boot". The "default" method uses the profile +likelihood method to compute intervals and can be used for models created by +the 'lm' function. The "wald" method is typicallywhat most people are +familiar with when computing intervals based on the calculated standard error. +The "lm" method allows this function to be used for specific scenarios like +logistic regression and the 'glm' function. The "boot" method allows for +bootstrapping at certain levels.
- replicates -Indicates how many bootstrap replicates are to be performed if bootstrapping is enabled as a method.
steps +Indicates how many consonance intervals are to be calculated at +various levels. For example, setting this to 100 will produce 100 consonance +intervals from 0 to 100. Setting this to 10000 will produce more consonance +levels. By default, it is set to 1000. Increasing the number substantially +is not recommended as it will take longer to produce all the intervals and +store them into a dataframe.
- steps -Indicates how many consonance intervals are to be calculated at various levels. For example, setting -this to 100 will produce 100 compatibility intervals from 0 to 100. Setting this to 10000 will produce more consonance levels. By default, it is set to 1000. Increasing the number substantially is not recommended as it will take longer to produce all the intervals and store them into a dataframe.
table +Indicates whether or not a table output with some relevant +statistics should be generated. The default is TRUE and generates a table +which is included in the list object.
References
- -Poole C. Beyond the confidence interval. Am J Public Health. 1987;77(2):195-199.
-Sullivan KM, Foster DA. Use of the confidence interval function. Epidemiology. 1990;1(1):39-42.
-Rothman KJ, Greenland S, Lash TL, Others. Modern epidemiology. 2008.
Examples
+# \donttest{ # Simulate random data - GroupA <- rnorm(50) GroupB <- rnorm(50) - RandomData <- data.frame(GroupA, GroupB) +rob <- lm(GroupA ~ GroupB, data = RandomData) +bob <- curve_gen(rob, "GroupB") +tibble::tibble(bob[[1]])#> # A tibble: 998 x 1 +#> `bob[[1]]`$lowe… $upper.limit $intrvl.width $intrvl.level $cdf $pvalue +#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> +#> 1 0.0312 0.0315 0.000336 0.001 0.500 0.999 +#> 2 0.0310 0.0317 0.000672 0.002 0.501 0.998 +#> 3 0.0309 0.0319 0.00101 0.003 0.501 0.997 +#> 4 0.0307 0.0320 0.00134 0.004 0.502 0.996 +#> 5 0.0305 0.0322 0.00168 0.005 0.502 0.995 +#> 6 0.0304 0.0324 0.00202 0.006 0.503 0.994 +#> 7 0.0302 0.0325 0.00235 0.007 0.503 0.993 +#> 8 0.0300 0.0327 0.00269 0.008 0.504 0.992 +#> 9 0.0299 0.0329 0.00302 0.009 0.504 0.991 +#> 10 0.0297 0.0331 0.00336 0.01 0.505 0.99 +#> # … with 988 more rows, and 1 more variable: $svalue <dbl># } -rob <- glm(GroupA ~ GroupB, data = RandomData) -bob <- curve_gen(rob, "GroupB", method = "lm") - -tibble::tibble(bob)#> # A tibble: 10,000 x 1 -#> bob$lower.limit $upper.limit $intrvl.level $pvalue $svalue -#> <dbl> <dbl> <dbl> <dbl> <dbl> -#> 1 -0.0732 -0.0732 0 1 0 -#> 2 -0.0732 -0.0731 0.0001 1.000 0.000144 -#> 3 -0.0732 -0.0731 0.0002 1.000 0.000289 -#> 4 -0.0732 -0.0731 0.000300 1.000 0.000433 -#> 5 -0.0732 -0.0731 0.0004 1.000 0.000577 -#> 6 -0.0732 -0.0731 0.0005 1.000 0.000722 -#> 7 -0.0733 -0.0731 0.000600 0.999 0.000866 -#> 8 -0.0733 -0.0730 0.0007 0.999 0.00101 -#> 9 -0.0733 -0.0730 0.0008 0.999 0.00115 -#> 10 -0.0733 -0.0730 0.0009 0.999 0.00130 -#> # … with 9,990 more rows-
-
+
@@ -146,18 +148,28 @@
@@ -123,7 +124,7 @@-
Computes consonance intervals for mean differences
- +Mean Interval Consonance Function
+ Source:R/curve_mean.Rcurve_mean.Rd--Computes thousands of consonance (confidence) intervals for the chosen parameter in a statistical test -that compares means and places the interval limits for each interval level into a data frame along with the corresponding p-values and s-values.
+Computes thousands of consonance (confidence) intervals for the chosen +parameter in a statistical test that compares means and places the interval +limits for each interval level into a data frame along with the corresponding +p-values and s-values.
curve_mean(x, y, data, paired = F, method = "default", -replicates = 1000, steps = 10000)
+curve_mean( + x, + y, + data, + paired = F, + method = "default", + replicates = 1000, + steps = 10000, + table = TRUE +)
Arguments
References
- -Poole C. Beyond the confidence interval. Am J Public Health. 1987;77(2):195-199.
-Sullivan KM, Foster DA. Use of the confidence interval function. Epidemiology. 1990;1(1):39-42.
-Rothman KJ, Greenland S, Lash TL, Others. Modern epidemiology. 2008.
Examples
+tibble::tibble(bob[[1]])# Simulate random data - GroupA <- runif(100, min = 0, max = 100) GroupB <- runif(100, min = 0, max = 100) - RandomData <- data.frame(GroupA, GroupB) - bob <- curve_mean(GroupA, GroupB, RandomData) - -tibble::tibble(bob)#> # A tibble: 10,000 x 1 -#> bob$lower.limit $upper.limit $intrvl.level $pvalue $svalue -#> <dbl> <dbl> <dbl> <dbl> <dbl> -#> 1 -0.919 -0.919 0 1 0 -#> 2 -0.919 -0.918 0.0001 1.000 0.000144 -#> 3 -0.920 -0.917 0.0002 1.000 0.000289 -#> 4 -0.920 -0.917 0.000300 1.000 0.000433 -#> 5 -0.921 -0.916 0.0004 1.000 0.000577 -#> 6 -0.921 -0.916 0.0005 1.000 0.000722 -#> 7 -0.922 -0.915 0.000600 0.999 0.000866 -#> 8 -0.922 -0.915 0.0007 0.999 0.00101 -#> 9 -0.923 -0.914 0.0008 0.999 0.00115 -#> 10 -0.923 -0.914 0.0009 0.999 0.00130 -#> # … with 9,990 more rows-#> # A tibble: 10,000 x 1 +#> `bob[[1]]`$lowe… $upper.limit $intrvl.width $intrvl.level $cdf $pvalue +#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> +#> 1 5.15 5.15 0 0 0.5 1 +#> 2 5.15 5.15 0.00103 0.0001 0.500 1.000 +#> 3 5.15 5.15 0.00206 0.0002 0.500 1.000 +#> 4 5.15 5.15 0.00308 0.000300 0.500 1.000 +#> 5 5.15 5.15 0.00411 0.0004 0.500 1.000 +#> 6 5.15 5.15 0.00514 0.0005 0.500 1.000 +#> 7 5.15 5.15 0.00617 0.000600 0.500 0.999 +#> 8 5.15 5.15 0.00719 0.0007 0.500 0.999 +#> 9 5.15 5.15 0.00822 0.0008 0.500 0.999 +#> 10 5.15 5.15 0.00925 0.0009 0.500 0.999 +#> # … with 9,990 more rows, and 1 more variable: $svalue <dbl>
-
-
+
@@ -147,52 +148,57 @@
@@ -123,7 +125,7 @@-
Computes consonance intervals for meta-analysis data
- +Meta-analytic Consonance Function
+ Source:R/curve_meta.Rcurve_meta.Rd--Computes thousands of consonance (confidence) intervals for the chosen parameter in the -meta-analysis done by the metafor package and places the interval limits for each interval level -into a data frame along with the corresponding p-values and s-values.
+Computes thousands of consonance (confidence) intervals for the chosen +parameter in the meta-analysis done by the metafor package and places the +interval limits for each interval level into a data frame along with the +corresponding p-values and s-values.
curve_meta(x, measure = "default", steps = 10000)
+curve_meta(x, measure = "default", steps = 10000, table = TRUE)
Arguments
-x -Object where the meta-analysis parameters are stored, typically a list produced by 'metafor'
Object where the meta-analysis parameters are stored, typically a +list produced by 'metafor'
measure -Indicates whether the object has a log transformation or is normal/default. The default setting is "default. -If the measure is set to "ratio", it will take logarithmically transformed values and convert them back to normal values in the dataframe. This is typically a setting used for binary outcomes such as risk ratios, hazard ratios, and odds ratios.
Indicates whether the object has a log transformation or is normal/default. +The default setting is "default. If the measure is set to "ratio", it will take +logarithmically transformed values and convert them back to normal values in the dataframe. +This is typically a setting used for binary outcomes such as risk ratios, +hazard ratios, and odds ratios.
steps -Indicates how many consonance intervals are to be calculated at various levels. For example, setting -this to 100 will produce 100 consonance intervals from 0 to 100. Setting this to 10000 will produce more -consonance levels. By default, it is set to 1000. Increasing the number substantially is not recommended -as it will take longer to produce all the intervals and store them into a dataframe.
Indicates how many consonance intervals are to be calculated at +various levels. For example, setting this to 100 will produce 100 consonance +intervals from 0 to 100. Setting this to 10000 will produce more consonance +levels. By default, it is set to 1000. Increasing the number substantially +is not recommended as it will take longer to produce all the intervals and +store them into a dataframe.
+ table +Indicates whether or not a table output with some relevant +statistics should be generated. The default is TRUE and generates a table +which is included in the list object.
References
- -Viechtbauer W. Conducting meta-analyses in R with the metafor package. J Stat Softw. 2010;36(3). -https://www.jstatsoft.org/article/view/v036i03/v36i03.pdf.
-Poole C. Beyond the confidence interval. Am J Public Health. 1987;77(2):195-199.
-Sullivan KM, Foster DA. Use of the confidence interval function. Epidemiology. 1990;1(1):39-42.
-Rothman KJ, Greenland S, Lash TL, Others. Modern epidemiology. 2008.
Examples
+tibble::tibble(metaf[[1]])# Simulate random data for two groups in two studies - GroupAData <- runif(20, min = 0, max = 100) GroupAMean <- round(mean(GroupAData), digits = 2) GroupASD <- round(sd(GroupAData), digits = 2) @@ -229,38 +235,41 @@Examp library(metafor)
#>#> #>dat <- escalc( - measure = "SMD", m1i = MeanTreatment, sd1i = SDTreatment, n1i = NTreatment, - m2i = MeanControl, sd2i = SDControl, n2i = NControl, data = metadf + measure = "SMD", m1i = MeanTreatment, sd1i = SDTreatment, + n1i = NTreatment, m2i = MeanControl, sd2i = SDControl, + n2i = NControl, data = metadf ) # Pool the data using a particular method. Here "FE" is the fixed-effects model -res <- rma(yi, vi, data = dat, slab = paste(StudyName, sep = ", "), method = "FE", digits = 2) +res <- rma(yi, vi, + data = dat, slab = paste(StudyName, sep = ", "), + method = "FE", digits = 2 +) # Calculate the intervals using the metainterval function metaf <- curve_meta(res) -tibble::tibble(metaf)#> # A tibble: 10,000 x 1 -#> metaf$lower.limit $upper.limit $intrvl.level $pvalue $svalue -#> <dbl> <dbl> <dbl> <dbl> <dbl> -#> 1 0.120 0.120 0 1 0 -#> 2 0.120 0.121 0.0001 1.000 0.000144 -#> 3 0.120 0.121 0.0002 1.000 0.000289 -#> 4 0.120 0.121 0.000300 1.000 0.000433 -#> 5 0.120 0.121 0.0004 1.000 0.000577 -#> 6 0.120 0.121 0.0005 1.000 0.000722 -#> 7 0.120 0.121 0.000600 0.999 0.000866 -#> 8 0.120 0.121 0.0007 0.999 0.00101 -#> 9 0.120 0.121 0.0008 0.999 0.00115 -#> 10 0.120 0.121 0.0009 0.999 0.00130 -#> # … with 9,990 more rows#> # A tibble: 10,000 x 1 +#> `metaf[[1]]`$lo… $upper.limit $intrvl.level $pvalue $svalue $intrvl.width +#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> +#> 1 0.0617 0.0617 0 1 0. 0 +#> 2 0.0616 0.0617 0.0001 1.000 1.44e-4 0.0000562 +#> 3 0.0616 0.0617 0.0002 1.000 2.89e-4 0.000112 +#> 4 0.0616 0.0617 0.000300 1.000 4.33e-4 0.000169 +#> 5 0.0615 0.0618 0.0004 1.000 5.77e-4 0.000225 +#> 6 0.0615 0.0618 0.0005 1.000 7.22e-4 0.000281 +#> 7 0.0615 0.0618 0.000600 0.999 8.66e-4 0.000337 +#> 8 0.0615 0.0619 0.0007 0.999 1.01e-3 0.000394 +#> 9 0.0614 0.0619 0.0008 0.999 1.15e-3 0.000450 +#> 10 0.0614 0.0619 0.0009 0.999 1.30e-3 0.000506 +#> # … with 9,990 more rows, and 1 more variable: $cdf <dbl>
-
-
+
@@ -147,18 +149,27 @@
@@ -123,7 +124,7 @@-
Reverse engineer consonance and surprisal functions from confidence limits and point estimates
- +Reverse Engineer Consonance / Likelihood Functions Using the Point +Estimate and Confidence Limits
+ Source:R/curve_rev.Rcurve_rev.Rd--Using the confidence limits and point estimates from a dataset, one can use these estimates to -compute thousands of consonance intervals and graph the intervals to form a consonance and -surprisal function.
+Using the confidence limits and point estimates from a dataset, one can use +these estimates to compute thousands of consonance intervals and graph the +intervals to form a consonance and surprisal function.
curve_rev(point, LL, UL, measure = "default", steps = 10000)
+curve_rev( + point, + LL, + UL, + type = "c", + measure = "default", + steps = 10000, + table = TRUE +)
Arguments
References
- -Poole C. Beyond the confidence interval. Am J Public Health. 1987;77(2):195-199.
-Sullivan KM, Foster DA. Use of the confidence interval function. Epidemiology. 1990;1(1):39-42.
-Rothman KJ, Greenland S, Lash TL, Others. Modern epidemiology. 2008.
Examples
+tibble::tibble(df[[1]])# From a real published study. Point estimate of the result was hazard ratio of 1.61 and # lower bound of the interval is 0.997 while upper bound of the interval is 2.59. - +# df <- curve_rev(point = 1.61, LL = 0.997, UL = 2.59, measure = "ratio") -tibble::tibble(df)#> # A tibble: 9,999 x 1 -#> df$lower.limit $upper.limit $intrvl.level $pvalue $svalue -#> <dbl> <dbl> <dbl> <dbl> <dbl> -#> 1 0.624 4.15 1.000 0.0001000 13.3 -#> 2 0.651 3.98 1.000 0.000200 12.3 -#> 3 0.667 3.88 1.000 0.000300 11.7 -#> 4 0.680 3.81 1.000 0.000400 11.3 -#> 5 0.690 3.76 1.000 0.000500 11.0 -#> 6 0.698 3.71 0.999 0.0006 10.7 -#> 7 0.705 3.68 0.999 0.0007 10.5 -#> 8 0.712 3.64 0.999 0.0008 10.3 -#> 9 0.717 3.61 0.999 0.0009 10.1 -#> 10 0.722 3.59 0.999 0.001 9.97 -#> # … with 9,989 more rows-#> # A tibble: 9,999 x 1 +#> `df[[1]]`$lower… $upper.limit $intrvl.width $intrvl.level $cdf $pvalue +#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> +#> 1 0.624 4.15 3.53 1.000 1.000 10.00e-5 +#> 2 0.651 3.98 3.33 1.000 1.000 2.00e-4 +#> 3 0.667 3.88 3.22 1.000 1.000 3.00e-4 +#> 4 0.680 3.81 3.13 1.000 1.000 4.00e-4 +#> 5 0.690 3.76 3.07 1.000 1.000 5.00e-4 +#> 6 0.698 3.71 3.02 0.999 1.000 6.00e-4 +#> 7 0.705 3.68 2.97 0.999 1.000 7.00e-4 +#> 8 0.712 3.64 2.93 0.999 1.000 8.00e-4 +#> 9 0.717 3.61 2.90 0.999 1.000 9.00e-4 +#> 10 0.722 3.59 2.87 0.999 1.000 1.00e-3 +#> # … with 9,989 more rows, and 1 more variable: $svalue <dbl>
-
-
+
@@ -148,50 +149,55 @@
diff --git a/docs/reference/curve_table.html b/docs/reference/curve_table.html new file mode 100644 index 0000000..f295164 --- /dev/null +++ b/docs/reference/curve_table.html @@ -0,0 +1,290 @@ + + + + + + + + +--
Computes thousands of consonance (confidence) intervals for the chosen parameter in the -Cox model computed by the 'survival' package and places the interval limits for each interval level -into a data frame along with the corresponding p-value and s-value.
+Computes thousands of consonance (confidence) intervals for the chosen +parameter in the Cox model computed by the 'survival' package and places +the interval limits for each interval level into a data frame along +with the corresponding p-value and s-value.
curve_surv(data, x, steps = 10000)
+curve_surv(data, x, steps = 10000, table = TRUE)
Arguments
-data -Object where the Cox model is stored, typically a list produced by the 'survival' package.
Object where the Cox model is stored, typically a list produced by the +'survival' package.
x -Predictor of interest within the survival model for which the consonance intervals should be computed.
Predictor of interest within the survival model for which the +consonance intervals should be computed.
steps -Indicates how many consonance intervals are to be calculated at various levels. For example, setting -this to 100 will produce 100 consonance intervals from 0 to 100. Setting this to 10000 will produce more -consonance levels. By default, it is set to 1000. Increasing the number substantially is not recommended -as it will take longer to produce all the intervals and store them into a dataframe.
Indicates how many consonance intervals are to be calculated at +various levels. For example, setting this to 100 will produce 100 consonance +intervals from 0 to 100. Setting this to 10000 will produce more consonance +levels. By default, it is set to 1000. Increasing the number substantially +is not recommended as it will take longer to produce all the intervals and +store them into a dataframe.
+ table +Indicates whether or not a table output with some relevant +statistics should be generated. The default is TRUE and generates a table +which is included in the list object.
References
- -Poole C. Beyond the confidence interval. Am J Public Health. 1987;77(2):195-199.
-Sullivan KM, Foster DA. Use of the confidence interval function. Epidemiology. 1990;1(1):39-42.
-Rothman KJ, Greenland S, Lash TL, Others. Modern epidemiology. 2008.
Produce Tables For concurve Functions — curve_table • concurve + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + +++ + + + + + + + + + + diff --git a/docs/reference/defunct.html b/docs/reference/defunct.html index 3b6c20f..b83a676 100644 --- a/docs/reference/defunct.html +++ b/docs/reference/defunct.html @@ -83,9 +83,9 @@ - ++ + +++ + + ++++ ++ + +
+ concurve
+ 2.3.0
+
+ ++ + + ++ + ++ +++ +Produces publication-ready tables with relevant statistics of interest +for functions produced from the concurve package.
+curve_table(data, levels, type = "c", format = "data.frame")
+ +Arguments
++
+ + ++ +data +Dataframe from a concurve function to produce a table for
+ +levels +Levels of the consonance intervals or likelihood intervals that should be +included in the table.
+ +type +Indicates whether the table is for a consonance function or likelihood function. +The default is set to "c" for consonance and can be switched to "l" for likelihood.
+ +format +The format of the tables. The options include "data.frame" which is the +default, "tibble", "docx" (which creates a table for a word document), "pptx" (which +creates a table for powerpoint), "latex", (which creates a table for a TeX document), and +"image", which produces an image of the table.
Examples
+
++library(concurve) + +GroupA <- rnorm(500) +GroupB <- rnorm(500) + +RandomData <- data.frame(GroupA, GroupB) + +intervalsdf <- curve_mean(GroupA, GroupB, data = RandomData, method = "default") + +(z <- curve_table(intervalsdf[[1]], format = "data.frame"))#> Lower Limit Upper Limit Interval Width Interval Level (%) CDF P-value +#> 2501 0.131 0.172 0.041 25.0 0.625 0.750 +#> 5001 0.108 0.195 0.088 50.0 0.750 0.500 +#> 7501 0.077 0.226 0.149 75.0 0.875 0.250 +#> 8001 0.068 0.235 0.166 80.0 0.900 0.200 +#> 8501 0.058 0.245 0.187 85.0 0.925 0.150 +#> 9001 0.045 0.258 0.214 90.0 0.950 0.100 +#> 9501 0.024 0.279 0.255 95.0 0.975 0.050 +#> 9751 0.006 0.297 0.291 97.5 0.988 0.025 +#> 9901 -0.016 0.319 0.335 99.0 0.995 0.010 +#> S-value (bits) +#> 2501 0.415 +#> 5001 1.000 +#> 7501 2.000 +#> 8001 2.322 +#> 8501 2.737 +#> 9001 3.322 +#> 9501 4.322 +#> 9751 5.322 +#> 9901 6.644(z <- curve_table(intervalsdf[[1]], format = "tibble"))#> # A tibble: 9 x 1 +#> subdf$`Lower Li… $`Upper Limit` $`Interval Widt… $`Interval Leve… $CDF +#> <dbl> <dbl> <dbl> <dbl> <dbl> +#> 1 0.131 0.172 0.041 25 0.625 +#> 2 0.108 0.195 0.088 50 0.75 +#> 3 0.077 0.226 0.149 75 0.875 +#> 4 0.068 0.235 0.166 80 0.9 +#> 5 0.058 0.245 0.187 85 0.925 +#> 6 0.045 0.258 0.214 90 0.95 +#> 7 0.024 0.279 0.255 95 0.975 +#> 8 0.006 0.297 0.291 97.5 0.988 +#> 9 -0.016 0.319 0.335 99 0.995 +#> # … with 2 more variables: $`P-value` <dbl>, $`S-value (bits)` <dbl>(z <- curve_table(intervalsdf[[1]], format = "latex"))#> +#> +#> | | Lower Limit| Upper Limit| Interval Width| Interval Level (%)| CDF| P-value| S-value (bits)| +#> |:----|-----------:|-----------:|--------------:|------------------:|-----:|-------:|--------------:| +#> |2501 | 0.131| 0.172| 0.041| 25.0| 0.625| 0.750| 0.415| +#> |5001 | 0.108| 0.195| 0.088| 50.0| 0.750| 0.500| 1.000| +#> |7501 | 0.077| 0.226| 0.149| 75.0| 0.875| 0.250| 2.000| +#> |8001 | 0.068| 0.235| 0.166| 80.0| 0.900| 0.200| 2.322| +#> |8501 | 0.058| 0.245| 0.187| 85.0| 0.925| 0.150| 2.737| +#> |9001 | 0.045| 0.258| 0.214| 90.0| 0.950| 0.100| 3.322| +#> |9501 | 0.024| 0.279| 0.255| 95.0| 0.975| 0.050| 4.322| +#> |9751 | 0.006| 0.297| 0.291| 97.5| 0.988| 0.025| 5.322| +#> |9901 | -0.016| 0.319| 0.335| 99.0| 0.995| 0.010| 6.644|
concurve
- 2.1.0
+ 2.3.0
-
-
+
@@ -146,18 +148,28 @@
-
-
+
@@ -168,19 +168,33 @@
Deprecated functions in concurve.
survintervals(...) -rev_eng(...) +rev_eng(...) + +ggconcurve(...) + +plot_concurve(...)
-plotpintFor
+plotpint, useggconcurveorplot_concurve.For
plotpint, useggcurve.
-plotsintFor
+plotsint, useggconcurveorplot_concurve.For
+plotsint, useggcurve.
+ + + +plot_concurveFor
+plot_concurve, useggcurve.
+ + + +ggconcurveFor
ggconcurve, useggcurve.
@@ -218,6 +232,8 @@meanintervalsContents
plotpintplotsint
+ plot_concurve
+ ggconcurvemeanintervalsmetaintervalsgenintervals
diff --git a/docs/reference/ggconcurve-1.png b/docs/reference/ggconcurve-1.png
deleted file mode 100644
index 0e3ceea..0000000
Binary files a/docs/reference/ggconcurve-1.png and /dev/null differ
diff --git a/docs/reference/ggconcurve-2.png b/docs/reference/ggconcurve-2.png
deleted file mode 100644
index 2729fb7..0000000
Binary files a/docs/reference/ggconcurve-2.png and /dev/null differ
diff --git a/docs/reference/ggcurve-1.png b/docs/reference/ggcurve-1.png
new file mode 100644
index 0000000..e61d22e
Binary files /dev/null and b/docs/reference/ggcurve-1.png differ
diff --git a/docs/reference/ggconcurve.html b/docs/reference/ggcurve.html
similarity index 57%
rename from docs/reference/ggconcurve.html
rename to docs/reference/ggcurve.html
index 6140f81..13aa8b9 100644
--- a/docs/reference/ggconcurve.html
+++ b/docs/reference/ggcurve.html
@@ -6,7 +6,8 @@
-
Plots the P-Value (Consonance) and S-value (Surprisal) Function via ggplot2 — ggconcurve • concurve +Plots the P-Value (Consonance), S-value (Surprisal), +and Likelihood Function via ggplot2 — ggcurve • concurve @@ -50,9 +51,12 @@ - - + + @@ -84,9 +88,9 @@ - +
concurve
- 2.1.0
+ 2.3.0
-
-
+
@@ -146,98 +150,154 @@
@@ -120,7 +120,7 @@-
Plots the P-Value (Consonance) and S-value (Surprisal) Function via ggplot2
- -+ggconcurve.RdPlots the P-Value (Consonance), S-value (Surprisal), +and Likelihood Function via ggplot2
+ Source:R/ggcurve.R+ggcurve.Rd--Takes the dataframe produced by the interval functions and plots the p-values/s-values, consonance (confidence) -levels, and the interval estimates to produce a p-value/s-value function using ggplot2 graphics.
+Takes the dataframe produced by the interval functions and +plots the p-values/s-values, consonance (confidence) levels, and +the interval estimates to produce a p-value/s-value function +using ggplot2 graphics.
ggconcurve(type, data, measure, nullvalue, position, - title, subtitle, xaxis, yaxis, color, fill)
+ggcurve( + data, + type = "c", + measure = "default", + levels = 0.95, + nullvalue = FALSE, + position = "pyramid", + title = "Interval Function", + subtitle = "The function displays intervals at every level.", + xaxis = expression(Theta ~ "Range of Values"), + yaxis = "P-value", + color = "#000000", + fill = "#239a98" +)
Arguments
- type -Choose whether to plot a "consonance" function or a "surprisal" function. The default option is set to "consonance". The type must be set in quotes, for example ggconcurve(type = "surprisal") or ggconcurve(type = "consonance").
data +The dataframe produced by one of the interval functions +in which the intervals are stored.
- data -The dataframe produced by one of the interval functions in which the intervals are stored.
type +Choose whether to plot a "consonance" function, a +"surprisal" function or "likelihood". The default option is set to "c". +The type must be set in quotes, for example ggcurve (type = "s") or +ggcurve(type = "c"). Other options include "pd" for the consonance +distribution function, and "cd" for the consonance density function, +"l1" for relative likelihood, "l2" for log-likelihood, "l3" for likelihood +and "d" for deviance function.
measure -Indicates whether the object has a log transformation or is normal/default. The default setting is "default". If the measure is set to "ratio", it will take logarithmically transformed values and convert them back to normal values in the dataframe. This is typically a setting used for binary outcomes and their measures such as risk ratios, hazard ratios, and odds ratios.
Indicates whether the object has a log transformation +or is normal/default. The default setting is "default". If the measure +is set to "ratio", it will take logarithmically transformed values and +convert them back to normal values in the dataframe. This is typically a +setting used for binary outcomes and their measures such as risk ratios, +hazard ratios, and odds ratios.
+ levels +Indicates which interval levels should be plotted on the function. +By default it is set to 0.95 to plot the 95% interval on the consonance function, +but more levels can be plotted by using the c() function for example, +levels = c(0.50, 0.75, 0.95).
nullvalue -Indicates whether the null value for the measure should be plotted. By default, it is set to "absent", meaning it will not be plotted as a vertical line. Changing this to "present", will plot a vertical line at 0 when the measure is set to "default" and a vertical line at 1 when the measure is set to "ratio". For example, ggconcurve(type = "consonance", data = df, measure = "ratio", nullvalue = "present"). This feature is not yet available for surprisal functions.
Indicates whether the null value for the measure +should be plotted. By default, it is set to FALSE, meaning it will not be +plotted as a vertical line. Changing this to TRUE, will plot a vertical +line at 0 when the measure is set to " default" and a vertical line at +1 when the measure is set to "ratio". For example, +ggcurve(type = "c", data = df, measure = "ratio", nullvalue = "present"). +This feature is not yet available for surprisal functions.
position -Determines the orientation of the P-value (consonance) function By default, it is set to "pyramid", meaning the p-value function will stand right side up, like a pyramid. However, it can also be inverted via the option "inverted". This will also change the sequence of the y-axes to match the orientation. This can be set as such, ggconcurve(type = "consonance", data = df, position = "inverted")
Determines the orientation of the P-value (consonance) function. +By default, it is set to "pyramid", meaning the p-value function will +stand right side up, like a pyramid. However, it can also be inverted +via the option "inverted". This will also change the sequence of the +y-axes to match the orientation.This can be set as such, +ggcurve(type = "c", data = df, position = "inverted").
title -A custom title for the graph. By default, it is set to "Consonance Function". In order to set a title, it must be in quotes. For example, ggconcurve(type = "consonance", data = x, title = "Custom Title").
A custom title for the graph. By default, it is +set to "Consonance Function". In order to set a title, it must +be in quotes. For example, ggcurve(type = "c", +data = x, title = "Custom Title").
subtitle -A custom subtitle for the graph. By default, it is set to "The function contains consonance/confidence intervals at every level and the P-values." In order to set a subtitle, it must be in quotes. For example, ggconcurve(type = "consonance", data = x, subtitle = "Custom Subtitle").
A custom subtitle for the graph. By default, it is set +to "The function contains consonance/confidence intervals at every level +and the P-values." In order to set a subtitle, it must be in quotes. +For example, ggcurve(type = "c", data = x, subtitle = "Custom Subtitle").
xaxis -A custom x-axis title for the graph. By default, it is set to "Range of Values. In order to set a x-axis title, it must be in quotes. For example, ggconcurve(type = "consonance", data = x, xaxis = "Hazard Ratio").
A custom x-axis title for the graph. By default, +it is set to "Range of Values. +In order to set a x-axis title, it must be in quotes. For example, +ggcurve(type = "c", data = x, xaxis = "Hazard Ratio").
yaxis -A custom y-axis title for the graph. By default, it is set to "Consonance Level". In order to set a y-axis title, it must be in quotes. For example, ggconcurve(type = "consonance", data = x, yxis = "Confidence Level").
A custom y-axis title for the graph. By default, +it is set to "Consonance Level". +In order to set a y-axis title, it must be in quotes. For example, +ggcurve(type = "c", data = x, yxis = "Confidence Level").
color -Item that allows the user to choose the color of the points and the ribbons in the graph. By default, it is set to color = "#555555". The inputs must be in quotes. For example, ggconcurve(type = "consonance", data = x, color = "#333333").
Item that allows the user to choose the color of the points +and the ribbons in the graph. By default, it is set to color = "#555555". +The inputs must be in quotes. +For example, ggcurve(type = "c", data = x, color = "#333333").
fill -Item that allows the user to choose the color of the ribbons in the graph. By default, it is set to color = "#239a98". The inputs must be in quotes. For example, ggconcurve(type = "consonance", data = x, fill = "#333333").
Item that allows the user to choose the color of the ribbons in the graph. +By default, it is set to fill = "#239a98". The inputs must be in quotes. For example, +ggcurve(type = "c", data = x, fill = "#333333").
Value
-Plot with intervals at every consonance level graphed with their corresponding p-values and compatibility levels.
-References
- -Poole C. Beyond the confidence interval. Am J Public Health. 1987;77(2):195-199.
-Sullivan KM, Foster DA. Use of the confidence interval function. Epidemiology. 1990;1(1):39-42.
-Rothman KJ, Greenland S, Lash TL, Others. Modern epidemiology. 2008.
+Plot with intervals at every consonance level graphed with their corresponding +p-values and compatibility levels.
Examples
-# Simulate random data +
+intervalsdf <- curve_mean(GroupA, GroupB, data = RandomData, method = "default") +(function1 <- ggcurve(type = "c", intervalsdf[[1]]))+# Simulate random data -GroupA <- rnorm(50) -GroupB <- rnorm(50) +library(concurve) -RandomData <- data.frame(GroupA, GroupB) -RandomModel <- lm(GroupA ~ GroupB, data = RandomData) +GroupA <- rnorm(500) +GroupB <- rnorm(500) -intervalsdf <- curve_gen(RandomModel, "GroupB") +RandomData <- data.frame(GroupA, GroupB) -ggconcurve(type = "consonance", data = intervalsdf, nullvalue = "present") -ggconcurve(type = "surprisal", data = intervalsdf)
-ggconcurve(type = "surprisal", data = intervalsdf) -
-
-
-
+
@@ -164,34 +164,54 @@
curve_boot() + +
Generate Consonance Functions via Bootstrapping
+ + + + +Compares two functions and produces an AUC score to show the amount of consonance.
+ Computes consonance intervals for correlations
Computes Consonance Intervals for Correlations
Computes consonance intervals for linear models
General Consonance Functions Using Profile Likelihood, Wald, +or the bootstrap method for linear models.
+ + + + +Compute the Profile Likelihood Functions
Computes consonance intervals for mean differences
Mean Interval Consonance Function
Computes consonance intervals for meta-analysis data
Meta-analytic Consonance Function
Reverse engineer consonance and surprisal functions from confidence limits and point estimates
Reverse Engineer Consonance / Likelihood Functions Using the Point +Estimate and Confidence Limits
@@ -201,15 +221,22 @@ +ggconcurve() +
+Produce Tables For concurve Functions
+ + + -Plots the P-Value (Consonance) and S-value (Surprisal) Function via ggplot2
Plots the P-Value (Consonance), S-value (Surprisal), +and Likelihood Function via ggplot2
- + -Plots the P- (Consonance) and S-Value (Surprisal) Functions using base R graphics.
Compares the P-Value (Consonance), S-value (Surprisal), and Likelihood Function via ggplot2
Compares the P-Value (Consonance), S-value (Surprisal), and Likelihood Function via ggplot2 — plot_compare • concurve + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + +++ + + + + + + + + + + diff --git a/docs/reference/plot_concurve-1.png b/docs/reference/plot_concurve-1.png deleted file mode 100644 index e699976..0000000 Binary files a/docs/reference/plot_concurve-1.png and /dev/null differ diff --git a/docs/reference/tidyeval.html b/docs/reference/tidyeval.html new file mode 100644 index 0000000..941bdd1 --- /dev/null +++ b/docs/reference/tidyeval.html @@ -0,0 +1,269 @@ + + + + + + + + ++ + +++ + + ++++ ++ + +
+ concurve
+ 2.3.0
+
+ ++ + + +++ +++ +Compares the P-Value (Consonance), S-value (Surprisal), and Likelihood Function via ggplot2
+ Source:R/plot_compare.R++plot_compare.Rd++ +Compares the p-value/s-value, and likelihood functions using ggplot2 graphics.
+plot_compare( + data1, + data2, + type = "c", + measure = "default", + nullvalue = FALSE, + position = "pyramid", + title = "Interval Functions", + subtitle = "The function displays intervals at every level.", + xaxis = expression(Theta ~ "Range of Values"), + yaxis = "P-value", + color = "#000000", + fill1 = "#239a98", + fill2 = "#d46c5b" +)
+ +Arguments
++
+ ++ +data1 +The first dataframe produced by one of the interval functions in which the +intervals are stored.
+ +data2 +The second dataframe produced by one of the interval functions in which the +intervals are stored.
+ +type +Choose whether to plot a "consonance" function, a +"surprisal" function or "likelihood". The default option is set to "c". +The type must be set in quotes, for example plot_compare(type = "s") or +plot_compare(type = "c"). Other options include "pd" for the consonance +distribution function, and "cd" for the consonance density function, +"l1" for relative likelihood, "l2" for log-likelihood, "l3" for likelihood +and "d" for deviance function.
+ +measure +Indicates whether the object has a log transformation +or is normal/default. The default setting is "default". If the measure +is set to "ratio", it will take logarithmically transformed values and +convert them back to normal values in the dataframe. This is typically a +setting used for binary outcomes and their measures such as risk ratios, +hazard ratios, and odds ratios.
+ +nullvalue +Indicates whether the null value for the measure +should be plotted. By default, it is set to FALSE, meaning it will not be +plotted as a vertical line. Changing this to TRUE, will plot a vertical +line at 0 when the measure is set to " default" and a vertical line at +1 when the measure is set to "ratio". For example, +plot_compare(type = "c", data = df, measure = "ratio", nullvalue = "present"). +This feature is not yet available for surprisal functions.
+ +position +Determines the orientation of the P-value (consonance) function. +By default, it is set to "pyramid", meaning the p-value function will +stand right side up, like a pyramid. However, it can also be inverted +via the option "inverted". This will also change the sequence of the +y-axes to match the orientation.This can be set as such, +plot_compare(type = "c", data = df, position = "inverted").
+ +title +A custom title for the graph. By default, it is +set to "Consonance Function". In order to set a title, it must +be in quotes. For example, plot_compare(type = "c", +data = x, title = "Custom Title").
+ +subtitle +A custom subtitle for the graph. By default, it is set +to "The function contains consonance/confidence intervals at every level +and the P-values." In order to set a subtitle, it must be in quotes. +For example, plot_compare(type = "c", data = x, subtitle = "Custom Subtitle").
+ +xaxis +A custom x-axis title for the graph. By default, +it is set to "Range of Values. +In order to set a x-axis title, it must be in quotes. For example, +plot_compare(type = "c", data = x, xaxis = "Hazard Ratio").
+ +yaxis +A custom y-axis title for the graph. By default, +it is set to "Consonance Level". +In order to set a y-axis title, it must be in quotes. For example, +plot_compare(type = "c", data = x, yxis = "Confidence Level").
+ +color +Item that allows the user to choose the color of the points +and the ribbons in the graph. By default, it is set to color = "#555555". +The inputs must be in quotes. +For example, plot_compare(type = "c", data = x, color = "#333333").
+ +fill1 +Item that allows the user to choose the color of the ribbons in the graph +for data1. By default, it is set to fill1 = "#239a98". The inputs must be in quotes. +For example, plot_compare(type = "c", data = x, fill1 = "#333333").
+ +fill2 +Item that allows the user to choose the color of the ribbons in the graph +for data1. By default, it is set to fill2 = "#d46c5b". The inputs must be in quotes. +For example, plot_compare(type = "c", data = x, fill2 = "#333333").
Value
+ +A plot that compares two functions.
+ +Examples
+
+# \donttest{ +library(concurve) + +GroupA <- rnorm(50) +GroupB <- rnorm(50) +RandomData <- data.frame(GroupA, GroupB) +intervalsdf <- curve_mean(GroupA, GroupB, data = RandomData) +GroupA2 <- rnorm(50) +GroupB2 <- rnorm(50) +RandomData2 <- data.frame(GroupA2, GroupB2) +model <- lm(GroupA2 ~ GroupB2, data = RandomData2) + +randomframe <- curve_gen(model, "GroupB2") + +(plot_compare(intervalsdf[[1]], randomframe[[1]], type = "s")) # } + +
# } + +Tidy eval helpers — tidyeval • concurve + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + +++ + + + + + + + + + + diff --git a/docs/sitemap.xml b/docs/sitemap.xml index 79e4879..9c86710 100644 --- a/docs/sitemap.xml +++ b/docs/sitemap.xml @@ -3,12 +3,24 @@+ + +++ + + ++++ ++ + +
+ concurve
+ 2.3.0
+
+ ++ + + ++ + ++ ++ ++ + + + +-
+
sym()creates a symbol from a string and +syms()creates a list of symbols from a +character vector.
+enquo()and +enquos()delay the execution of one or +several function arguments.enquo()returns a single quoted +expression, which is like a blueprint for the delayed computation. +enquos()returns a list of such quoted expressions.
+expr()quotes a new expression locally. It +is mostly useful to build new expressions around arguments +captured withenquo()orenquos(): +expr(mean(!!enquo(arg), na.rm = TRUE)).
+
+as_name()transforms a quoted variable name +into a string. Supplying something else than a quoted variable +name is an error.That's unlike
+as_label()which also returns +a single string but supports any kind of R object as input, +including quoted function calls and vectors. Its purpose is to +summarise that object into a single label. That label is often +suitable as a default name.If you don't know what a quoted expression contains (for instance +expressions captured with
enquo()could be a variable +name, a call to a function, or an unquoted constant), then use +as_label(). If you know you have quoted a simple variable +name, or would like to enforce this, useas_name().
+
To learn more about tidy eval and how to use these tools, visit +https://tidyeval.tidyverse.org and the +Metaprogramming +section of Advanced R.
+https://data.lesslikely.com/concurve//index.html + +https://data.lesslikely.com/concurve//reference/concurve-package.html ++ +https://data.lesslikely.com/concurve//reference/curve_boot.html ++ https://data.lesslikely.com/concurve//reference/curve_compare.html +https://data.lesslikely.com/concurve//reference/curve_corr.html https://data.lesslikely.com/concurve//reference/curve_gen.html + https://data.lesslikely.com/concurve//reference/curve_lik.html +https://data.lesslikely.com/concurve//reference/curve_mean.html https://data.lesslikely.com/concurve//reference/curve_surv.html + https://data.lesslikely.com/concurve//reference/curve_table.html +https://data.lesslikely.com/concurve//reference/defunct.html - +https://data.lesslikely.com/concurve//reference/ggconcurve.html +https://data.lesslikely.com/concurve//reference/ggcurve.html ++ https://data.lesslikely.com/concurve//reference/plot_compare.html - https://data.lesslikely.com/concurve//reference/plot_concurve.html +https://data.lesslikely.com/concurve//reference/tidyeval.html https://data.lesslikely.com/concurve//articles/examples.html diff --git a/examples/Untitled.R b/examples/Untitled.R new file mode 100644 index 0000000..8667220 --- /dev/null +++ b/examples/Untitled.R @@ -0,0 +1,209 @@ + +library(concurve) +library(rstan) +library(rstanarm) + +GroupA2<-rnorm(1000) +GroupB2<-rnorm(1000) + +RandomData2<-data.frame(GroupA2, GroupB2) + +model<-lm(GroupA2 ~ GroupB2, data=RandomData2) +model2 <- stan_glm(GroupA2 ~ GroupB2, data = RandomData2) + +z<- bayes_R2(model2) +install.packages("tidybayes") + +median(z) + +summary(model) +summary(model2) +model2 +library(tidybayes) +install.packages("broom") +library(broom) +tidymodel<- tidy(model2) + +model_intercept <- tidymodel$estimate[1] +model_slope <- tidymodel$estimate[2] +draws <- spread_draws(model2, `(Intercept)`, GroupB2) + +library(ggplot2) +ggplot() + + geom_point(data = RandomData2, mapping = aes(x = GroupB2, y = GroupA2)) + + geom_abline(data = draws, aes(intercept = `(Intercept)`, slope = GroupB2), color = "skyblue", alpha = 0.2, size = 0.2) + + geom_abline(slope = model_slope, intercept = model_intercept) + + +ggplot(data = RandomData2, mapping = aes(x = GroupB2, y = GroupA2)) + + geom_point() + + geom_smooth(se = TRUE) + +posterior_interval(model2) + +system.time(randomframe<-genintervals(model, "GroupB2")) + + + +par(mar = c(5, 5, 4, 5), font.main = 1, cex.main = 1.3, cex.lab = 1.15, las = 1) +with(randomframe, + plot(lower.limit, pvalue, + xlim = c(min(lower.limit), max(upper.limit)), + panel.first = grid(nx = 10, ny = 0), + type = "l", + xlab = "Theta", + ylab = "P-value", + main = "P-value Function", + yaxt = "n", + las = 1)) +with(randomframe, lines(upper.limit, pvalue)) +polygon(c(max(randomframe$lower.limit), randomframe$lower.limit), + c(min(randomframe$pvalue), randomframe$pvalue), col = "#239a9880", border = NA) +polygon(c(min(randomframe$upper.limit), randomframe$upper.limit), + c(min(randomframe$pvalue), randomframe$pvalue), col = "#239a9880", border = NA) +axis(side = 2, at = c(seq(from = 0, to = 1, by = .10)), lty = 2, col = "grey", las = 1) +abline(v = 0, lty = 2, lwd = 1.2, col = "black") +par(new = T) +axis(side = 2, at = c(seq(from = 0, to = 1, by = .10)), + tck = -0.025, lty = 2, col = "grey", labels = NA) +par(new = T) +with(randomframe, + plot(1, type = "n", + ylim = rev(range(intrvl.level * 100)), + axes = F, + xlab = NA, + ylab = NA)) +axis(side = 4, at = c(seq(from = 0, to = 100, by = 10)), + tck = 1, lty = 2, col = "grey", las = 1) +text(par("usr") + 0.95, 28, srt=-90, adj = 0, labels = "Consonance Level (%)", cex = 1.05, + xpd = TRUE) +par(new = T) +axis(side = 4, at = c(seq(from = 0, to = 100, by = 10)), + tck = -0.025, lty = 2, col = "grey", labels = NA) +text(x = 1.25, y = 10, paste("MLE:", + round(((max(randomframe$lower.limit) + min(randomframe$upper.limit)) / 2), 3)), + cex = 0.8, col = "black") +text(x = 1.25, y = 15, paste("50% CI:", + round(unname((quantile(randomframe$lower.limit, prob = 0.50))), 3), "-", + round(unname((quantile(randomframe$upper.limit, prob = 0.50))), 3), sep=" ", collapse=", "), + cex = 0.8, col = "black") +text(x = 1.25, y = 20, paste("75% CI:", + round(unname((quantile(randomframe$lower.limit, prob = 0.25))), 3), "-", + round(unname((quantile(randomframe$upper.limit, prob = 0.75))), 3), sep=" ", collapse=", "), + cex = 0.8, col = "black") +text(x = 1.25, y = 25, paste("95% CI:", + round(unname((quantile(randomframe$lower.limit, prob = 0.05))), 3), "-", + round(unname((quantile(randomframe$upper.limit, prob = 0.95))), 3), sep=" ", collapse=", "), + cex = 0.8, col = "black") +text(x = 1.25, y = 30, paste("99% CI:", + round(unname((quantile(randomframe$lower.limit, prob = 0.01))), 3), "-", + round(unname((quantile(randomframe$upper.limit, prob = 0.99))), 3), sep=" ", collapse=", "), + cex = 0.8, col = "black") + + + + + +par(mar = c(5, 5, 4, 5), font.main = 1, cex.main = 1.3, cex.lab = 1.15, las = 1) +with(randomframe, + plot(lower.limit, svalue, + xlim = c(min(lower.limit), max(upper.limit)), + panel.first = grid(), + type = "l", + xlab = "Theta", + ylab = "S-value", + main = "Surpisal Function", + yaxt = "n", + las = 1)) +with(randomframe, lines(upper.limit, svalue)) +polygon(c(max(randomframe$lower.limit), randomframe$lower.limit), + c(max(randomframe$svalue), randomframe$svalue), col = "#239a9880", border = NA) +polygon(c(min(randomframe$upper.limit), randomframe$upper.limit), + c(max(randomframe$svalue), randomframe$svalue), col = "#239a9880", border = NA) +axis(side = 2, lty = 2, col = "grey", las = 1) +par(new = T) +axis(side = 2, tck = -0.025, lty = 2, col = "grey", labels = NA) +par(new = T) +with(randomframe, + plot(1, type = "n", + ylim = rev(range(intrvl.level * 100)), + axes = F, + xlab = NA, + ylab = NA)) +axis(side = 4, at = c(seq(from = 0, to = 100, by = 10)), + tck = 1, lty = 2, col = "grey", las = 1) +text(par("usr") + 0.95, 28, srt=-90, adj = 0, labels = "Consonance Level (%)", cex = 1.05, + xpd = TRUE) +par(new = T) +axis(side = 4, at = c(seq(from = 0, to = 100, by = 10)), + tck = -0.025, lty = 2, col = "grey", labels = NA) +text(x = 1.25, y = 10, paste("MLE:", + round(((max(randomframe$lower.limit) + min(randomframe$upper.limit)) / 2), 3)), + cex = 0.8, col = "black") +text(x = 1.25, y = 15, paste("50% CI:", + round(unname((quantile(randomframe$lower.limit, prob = 0.50))), 3), "-", + round(unname((quantile(randomframe$upper.limit, prob = 0.50))), 3), sep=" ", collapse=", "), + cex = 0.8, col = "black") +text(x = 1.25, y = 20, paste("75% CI:", + round(unname((quantile(randomframe$lower.limit, prob = 0.25))), 3), "-", + round(unname((quantile(randomframe$upper.limit, prob = 0.75))), 3), sep=" ", collapse=", "), + cex = 0.8, col = "black") +text(x = 1.25, y = 25, paste("95% CI:", + round(unname((quantile(randomframe$lower.limit, prob = 0.05))), 3), "-", + round(unname((quantile(randomframe$upper.limit, prob = 0.95))), 3), sep=" ", collapse=", "), + cex = 0.8, col = "black") +text(x = 1.25, y = 30, paste("99% CI:", + round(unname((quantile(randomframe$lower.limit, prob = 0.01))), 3), "-", + round(unname((quantile(randomframe$upper.limit, prob = 0.99))), 3), sep=" ", collapse=", "), + cex = 0.8, col = "black") + + + + + +ggcurve("consonance", randomframe, position = "pyramid", nullvalue = "present") +plot.concurve(type = "consonance", data = randomframe) + +library(microbenchmark) +library(ggplot2) +library(concurve) + +microbenchmark( + base_R = plot_concurve(randomframe), + ggplot_R = gg_consonance(randomframe) +) + +library(benchplot) + +benchplot(gg_consonance(randomframe)) + + +install.packages("benchplot") + +gg_surprisal(randomframe) + + + + + + +library(ProfileLikelihood) + +profilelike.lm + +dffer<- curve_lik(formula = GroupA2 ~ 1, data = RandomData2, + profile.theta= "GroupB2", lo.theta = -.3, hi.theta = .3, length = 500) + +(plotlikely <- gglikely(dffer, x = dffer$theta, y = dffer$log.norm.lik)) + +library(benchmarkme) +ram <- get_ram() +ram +cpu <- get_cpu() +cpu + +# Run the io benchmark +res <- benchmark_io(runs = 1, size = 5) + +# Plot the results +plot(res) diff --git a/examples/boot.R b/examples/boot.R new file mode 100644 index 0000000..defa202 --- /dev/null +++ b/examples/boot.R @@ -0,0 +1,73 @@ +library(boot) +library(boot) +library(Lock5Data) +dataz <- data(CommuteAtlanta) + +func = function(data, index) { + x <- as.numeric(unlist(data[1])) + y <- as.numeric(unlist(data[2])) + return(mean(x[index]) - mean(y[index])) +} + +library(parallel) +detectCores() + +intervals <- 1:1000/1000 + +set.seed(1031) + +GroupA <- runif(100, min = 0, max = 100) +GroupB <- runif(100, min = 0, max = 100) + +RandomData <- data.frame(GroupA, GroupB) + +replicates <- 20000 + + +t.boot = boot(data = CommuteAtlanta, func, replicates, parallel = "multicore", ncpus = (detectCores())) + +intrvls <- 1:1000/1000 + +library(parallel) +library(pbapply) +library(microbenchmark) +library(boot) +library(concurve) + +microbenchmark( +t = mclapply(intrvls, FUN = function(i) boot.ci(t.boot, conf = i, type = "perc")$perc[4:5], + mc.cores = detectCores()), +a = pblapply(intrvls, FUN = function(i) boot.ci(t.boot, conf = i, type = "perc")$perc[4:5], + cl = detectCores())) + +df <- data.frame(do.call(rbind, t)) +intrvl.limit <- c("lower.limit", "upper.limit") +colnames(df) <- intrvl.limit +df$intrvl.width <- (abs((df$upper.limit) - (df$lower.limit))) +df$intrvl.level <- intrvls +df$cdf <- (abs(df$intrvl.level / 2)) + 0.5 +df$pvalue <- 1 - intrvls +df$svalue <- -log2(df$pvalue) +df <- head(df, -1) +class(df) <- c("data.frame","concurve") + + +densdf <- data.frame(c(df$lower.limit, df$upper.limit)) +colnames(densdf) <- "x" +densdf <- head(densdf, -1) +class(densdf) <- c("data.frame","concurve") +plot(density(densdf$x)) + +if (table == TRUE) { + levels <- c(0.25, 0.50, 0.75, 0.80, 0.85, 0.90, 0.95, 0.975, 0.99) + (df_subintervals <- (curve_table(df, levels, type = "data.frame"))) + class(df_subintervals) <- c("data.frame","concurve") + dataframes <- list(df, densdf, df_subintervals) + names(dataframes) <- c("Intervals Dataframe", "Intervals Density", "Intervals Table") + class(dataframes) <- "concurve" + return(dataframes) + +} else if (table == FALSE) { + return(list(df, densdf)) +} + diff --git a/examples/examples.R b/examples/examples.R new file mode 100644 index 0000000..7b7aa36 --- /dev/null +++ b/examples/examples.R @@ -0,0 +1,266 @@ +library(concurve) + +GroupA <- rnorm(500) +GroupB <- rnorm(500) + +RandomData <- data.frame(GroupA, GroupB) + +(intervalsdf <- curve_mean(GroupA, GroupB, + data = RandomData, method = "default" +)) + +tibble::tibble(intervalsdf[[1]]) + + +(z <- curve_table(intervalsdf[[1]], format = "data.frame")) +(z <- curve_table(intervalsdf[[1]], format = "tibble")) +# (z <- curve_table(intervalsdf, format = "docx")) +# (z <- curve_table(intervalsdf, format = "pptx")) +(z <- curve_table(intervalsdf[[1]], format = "latex")) +(z <- curve_table(intervalsdf[[1]], format = "image")) + +(function1 <- ggcurve(data = intervalsdf[[1]], type = "c")) +(function1 <- ggcurve(data = intervalsdf[[1]], type = "s")) +(function1s <- ggcurve(data = intervalsdf[[2]], type = "cdf")) + + +options(mc.cores = 8L) +getOption("mc.cores", 2L) + +GroupA2 <- rnorm(500) +GroupB2 <- rnorm(500) + +RandomData2 <- data.frame(GroupA2, GroupB2) + +model <- glm(GroupA2 ~ GroupB2, data = RandomData2) + +system.time(randomframe <- curve_gen(model, "GroupB2", method = "glm", steps = 10000)) + +options(mc.cores = 2L) + +GroupA2 <- rnorm(500) +GroupB2 <- rnorm(500) + +RandomData2 <- data.frame(GroupA2, GroupB2) + +model <- glm(GroupA2 ~ GroupB2, data = RandomData2) + +system.time(randomframe <- curve_gen(model, "GroupB2", method = "glm", steps = 10000)) + + +(function2 <- ggcurve(type = "c", randomframe[[1]], levels = c(0.50, 0.75, 0.95), nullvalue = TRUE)) + +(curve_compare( + data1 = intervalsdf[[1]], data2 = randomframe[[1]], type = "c", + plot = TRUE, measure = "default", nullvalue = TRUE +)) + +(curve_compare( + data1 = intervalsdf[[1]], data2 = randomframe[[1]], type = "s", + plot = TRUE, measure = "default", nullvalue = FALSE +)) + +(plot_compare(data1 = intervalsdf[[1]], data2 = randomframe[[1]], type = "s", measure = "default", nullvalue = TRUE)) + + +(df1 <- curve_rev(point = 1.61, LL = 0.997, UL = 2.59, measure = "ratio", steps = 10000)) ## may take some time +(df2 <- curve_rev(point = 1.7, LL = 1.1, UL = 2.6, measure = "ratio", steps = 10000)) ## may take some time + + +(r <- (curve_compare( + data1 = df1[[1]], data2 = df2[[1]], type = "c", + plot = TRUE, measure = "ratio", nullvalue = TRUE +))) + +(curve_compare( + data1 = df1[[1]], data2 = df2[[1]], type = "s", + plot = TRUE, measure = "ratio", nullvalue = FALSE +)) + +(plot_compare( + data1 = df1[[1]], data2 = df2[[1]], type = "c", measure = "ratio", nullvalue = TRUE, title = "Brown et al. 2017. J Clin Psychiatry. vs. Brown et al. 2017. JAMA.", + subtitle = "J Clin Psychiatry: OR = 1.7, 95% CL: LL = 1.1, UL = 2.6 \nJAMA: HR = 1.61, 95% CL: LL = 0.997, UL = 2.59", xaxis = expression(Theta ~ "= Hazard Ratio / Odds Ratio") +)) +(plot_compare( + data1 = df1[[1]], data2 = df2[[1]], type = "s", measure = "ratio", nullvalue = FALSE, title = "Brown et al. 2017. J Clin Psychiatry. vs. Brown et al. 2017. JAMA.", + subtitle = "J Clin Psychiatry: OR = 1.7, 95% CL: LL = 1.1, UL = 2.6 \nJAMA: HR = 1.61, 95% CL: LL = 0.997, UL = 2.59", xaxis = expression(Theta ~ "= Hazard Ratio / Odds Ratio") +)) + + +lik1 <- curve_rev(point = 1.7, LL = 1.1, UL = 2.6, type = "l", measure = "ratio", steps = 10000) +(ggcurve(data = lik1[[1]], type = "l1", measure = "ratio", nullvalue = FALSE)) + + +lik2 <- curve_rev(point = 1.61, LL = 0.997, UL = 2.59,type = "l", measure = "ratio", steps = 10000) +(ggcurve(data = lik2[[1]], type = "l1", measure = "ratio", nullvalue = FALSE)) + + +(plot_compare( + data1 = lik1[[1]], data2 = lik2[[1]], type = "l1", measure = "ratio", nullvalue = TRUE, title = "Brown et al. 2017. J Clin Psychiatry. vs. \nBrown et al. 2017. JAMA.", + subtitle = "J Clin Psychiatry: OR = 1.7, 1/6.83 LI: LL = 1.1, UL = 2.6 \nJAMA: HR = 1.61, 1/6.83 LI: LL = 0.997, UL = 2.59", xaxis = expression(Theta ~ "= Hazard Ratio / Odds Ratio") +)) +(plot_compare( + data1 = lik1[[1]], data2 = lik2[[1]], type = "d", measure = "ratio", nullvalue = TRUE, title = "Brown et al. 2017. J Clin Psychiatry. vs. \nBrown et al. 2017. JAMA.", + subtitle = "J Clin Psychiatry: OR = 1.7, 1/6.83 LI: LL = 1.1, UL = 2.6 \nJAMA: HR = 1.61, 1/6.83 LI: LL = 0.997, UL = 2.59", xaxis = expression(Theta ~ "= Hazard Ratio / Odds Ratio") +)) + + + +(plot_compare(data1 = intervalsdf[[1]], data2 = randomframe[[1]], type = "c", measure = "default", nullvalue = TRUE)) + +plot_compare(data1 = lik1[[1]], data2 = lik2[[1]], type = "d", measure = "ratio", nullvalue = FALSE) + +(function4 <- ggcurve(randomframe[[1]], type = "s", title = "Surprisal Function", subtitle = "Interval estimates are plotted to their corresponding S-values") +) + + +# Bootstrapping ----------------------------------------------------------- + +options(mc.cores = 8L) +getOption("mc.cores", 2L) + +data(diabetes, package = "bcaboot") +Xy <- cbind(diabetes$x, diabetes$y) +rfun <- function(Xy) { + y <- Xy[, 11] + X <- Xy[, 1:10] + return(summary(lm(y ~ X))$adj.r.squared) +} + +system.time(x <- curve_boot(data = Xy, func = rfun, method = "bca", replicates = 20000, steps = 1000)) + + +options(mc.cores = 2L) +getOption("mc.cores", 2L) + +data(diabetes, package = "bcaboot") +Xy <- cbind(diabetes$x, diabetes$y) +rfun <- function(Xy) { + y <- Xy[, 11] + X <- Xy[, 1:10] + return(summary(lm(y ~ X))$adj.r.squared) +} + +system.time(x <- curve_boot(data = Xy, func = rfun, method = "bca", replicates = 20000, steps = 1000)) + + +ggcurve(data = x[[1]]) +ggcurve(data = x[[3]]) + +plot_compare(x[[1]], x[[3]]) + + +iris <- datasets::iris +foo <- function(data, indices) { + dt <- data[indices, ] + c( + cor(dt[, 1], dt[, 2], method = "p") + ) +} + +y <- curve_boot(data = iris, func = foo, method = "bca", replicates = 200, steps = 1000) + + +ggcurve(data = y[[1]]) +ggcurve(data = y[[3]]) + +plot_compare(y[[1]], y[[3]]) + + + +library(Lock5Data) +dataz <- data(CommuteAtlanta) + +func = function(data, index) { + x <- as.numeric(unlist(data[1])) + y <- as.numeric(unlist(data[2])) + return(mean(x[index]) - mean(y[index])) +} + +z <- curve_boot(data = CommuteAtlanta, func = func, method = "t", replicates = 200, steps = 1000) +ggcurve(data = z[[1]]) +ggcurve(data = z[[2]], type = "cd") + +# Meta-Analysis ----------------------------------------------------------- + +GroupAData <- runif(20, min = 0, max = 100) +GroupAMean <- round(mean(GroupAData), digits = 2) +GroupASD <- round(sd(GroupAData), digits = 2) + +GroupBData <- runif(20, min = 0, max = 100) +GroupBMean <- round(mean(GroupBData), digits = 2) +GroupBSD <- round(sd(GroupBData), digits = 2) + +GroupCData <- runif(20, min = 0, max = 100) +GroupCMean <- round(mean(GroupCData), digits = 2) +GroupCSD <- round(sd(GroupCData), digits = 2) + +GroupDData <- runif(20, min = 0, max = 100) +GroupDMean <- round(mean(GroupDData), digits = 2) +GroupDSD <- round(sd(GroupDData), digits = 2) + + +StudyName <- c("Study1", "Study2") +MeanTreatment <- c(GroupAMean, GroupCMean) +MeanControl <- c(GroupBMean, GroupDMean) +SDTreatment <- c(GroupASD, GroupCSD) +SDControl <- c(GroupBSD, GroupDSD) +NTreatment <- c(20, 20) +NControl <- c(20, 20) + +metadf <- data.frame( + StudyName, MeanTreatment, MeanControl, + SDTreatment, SDControl, + NTreatment, NControl +) + +library(metafor) + +dat <- escalc( + measure = "SMD", + m1i = MeanTreatment, sd1i = SDTreatment, n1i = NTreatment, + m2i = MeanControl, sd2i = SDControl, n2i = NControl, + data = metadf +) + + +res <- rma(yi, vi, + data = dat, slab = paste(StudyName, sep = ", "), + method = "FE", digits = 2 +) + +res + + +metaf <- curve_meta(res) +tibble::tibble(metaf[[1]]) + +res2 <- rma(yi, vi, + data = dat, slab = paste(StudyName, sep = ", "), + method = "REML", digits = 2 +) + +res2 + + +metaf2 <- curve_meta(res2) +tibble::tibble(metaf2[[1]]) + + +(function5 <- ggcurve(metaf[[1]], type = "c")) + + +(function6 <- ggcurve(metaf[[1]], type = "s", title = "Surprisal Function", subtitle = "Interval estimates are plotted to their corresponding S-values") +) + +(function7 <- ggcurve(metaf2[[1]], type = "c")) + + +(function8 <- ggcurve(metaf2[[1]], type = "s", title = "Surprisal Function", subtitle = "Interval estimates are plotted to their corresponding S-values") +) + +(curve_compare(data1 = metaf[[1]], data2 = metaf2[[1]], type = "c", plot = TRUE, measure = "default") +) +(curve_compare(data1 = metaf[[1]], data2 = metaf2[[1]], type = "s", plot = TRUE, measure = "default") +) + diff --git a/R/plot_concurve.R b/examples/plot_concurve.R similarity index 70% rename from R/plot_concurve.R rename to examples/plot_concurve.R index c5ada9d..bff8da9 100644 --- a/R/plot_concurve.R +++ b/examples/plot_concurve.R @@ -1,9 +1,9 @@ -plot_concurve <- function(type = "consonance", - data, +plot_concurve <- function(data, + type = "c", measure = "default", intervals = FALSE, title = "Consonance Function", - xlab = "Theta", + xlab = expression(Theta ~ "Range of Values"), ylab1 = "P-value", ylab2 = "Confidence Level (%)", fontsize = 12, @@ -104,50 +104,50 @@ plot_concurve <- function(type = "consonance", # Labels for interval estimates and maximum likelihood if (intervals == TRUE) { - text( - x = 1.27, y = 3, - paste( - "Point Estimate:", - round(((max(data$lower.limit) + min(data$upper.limit)) / 2), 3) - ), - cex = 0.93, col = "black" - ) - text( - x = 1.27, y = 10, - paste("50% CI:", - round(unname((quantile(data$lower.limit, prob = 0.50))), 3), "-", - round(unname((quantile(data$upper.limit, prob = 0.50))), 3), - sep = " ", collapse = ", " - ), - cex = 0.93, col = "black" - ) - text( - x = 1.27, y = 17, - paste("75% CI:", - round(unname((quantile(data$lower.limit, prob = 0.25))), 3), "-", - round(unname((quantile(data$upper.limit, prob = 0.75))), 3), - sep = " ", collapse = ", " - ), - cex = 0.93, col = "black" - ) - text( - x = 1.27, y = 24, - paste("95% CI:", - round(unname((quantile(data$lower.limit, prob = 0.05))), 3), "-", - round(unname((quantile(data$upper.limit, prob = 0.95))), 3), - sep = " ", collapse = ", " - ), - cex = 0.93, col = "black" - ) - text( - x = 1.27, y = 31, - paste("99% CI:", - round(unname((quantile(data$lower.limit, prob = 0.01))), 3), "-", - round(unname((quantile(data$upper.limit, prob = 0.99))), 3), - sep = " ", collapse = ", " - ), - cex = 0.93, col = "black" - ) + text( + x = 1.27, y = 3, + paste( + "Point Estimate:", + round(((max(data$lower.limit) + min(data$upper.limit)) / 2), 3) + ), + cex = 0.93, col = "black" + ) + text( + x = 1.27, y = 10, + paste("50% CI:", + round(unname((quantile(data$lower.limit, prob = 0.50))), 3), "-", + round(unname((quantile(data$upper.limit, prob = 0.50))), 3), + sep = " ", collapse = ", " + ), + cex = 0.93, col = "black" + ) + text( + x = 1.27, y = 17, + paste("75% CI:", + round(unname((quantile(data$lower.limit, prob = 0.25))), 3), "-", + round(unname((quantile(data$upper.limit, prob = 0.75))), 3), + sep = " ", collapse = ", " + ), + cex = 0.93, col = "black" + ) + text( + x = 1.27, y = 24, + paste("95% CI:", + round(unname((quantile(data$lower.limit, prob = 0.05))), 3), "-", + round(unname((quantile(data$upper.limit, prob = 0.95))), 3), + sep = " ", collapse = ", " + ), + cex = 0.93, col = "black" + ) + text( + x = 1.27, y = 31, + paste("99% CI:", + round(unname((quantile(data$lower.limit, prob = 0.01))), 3), "-", + round(unname((quantile(data$upper.limit, prob = 0.99))), 3), + sep = " ", collapse = ", " + ), + cex = 0.93, col = "black" + ) } } @@ -201,4 +201,4 @@ plot_concurve <- function(type = "consonance", # RMD Check -utils::globalVariables(c("df", "lower.limit", "upper.limit", "intrvl.level", "pvalue", "svalue")) +utils::globalVariables(c("df", "lower.limit", "upper.limit", "intrvl.width", "intrvl.level", "cdf", "pvalue", "svalue")) diff --git a/inst/CITATION b/inst/CITATION index a6e1bd1..949e0ff 100644 --- a/inst/CITATION +++ b/inst/CITATION @@ -1,12 +1,11 @@ -year <- sub("-.*", "", meta$Date) -note <- sprintf("R package version %s", meta$Version) +citHeader("To cite concurve in publications use:") -bibentry( - bibtype = "Manual", - title = paste("{concurve}: Computes and Plots Consonance (Confidence) Intervals, P-Values, and S-Values to Form Consonance and Surprisal Functions"), - author = c(person("Zad R.", "Chow"), person("Andrew D.", "Vigotsky")), - year = year, - note = note, - url = "https://CRAN.R-project.org/package=concurve", - doi = "10.5281/zenodo.1308151" +citEntry( + entry = "Manual", + title = paste("{concurve}: Computes and Plots Compatibility (Confidence) Intervals, P-Values, S-Values, & Likelihood Intervals to Form Consonance, Surprisal, & Likelihood Functions"), + author = c(person("Zad R.", "Chow"), person("Andrew D.", "Vigotsky")), + year = 2019, + url = "https://CRAN.R-project.org/package=concurve", + textVersion = paste( + ) ) diff --git a/inst/WORDLIST b/inst/WORDLIST new file mode 100644 index 0000000..fee2d03 --- /dev/null +++ b/inst/WORDLIST @@ -0,0 +1,91 @@ +AJPH +Amrhein +analysesusing +ANCOVA +arXiv +bca +BCa +bcaboot +boostrap +cd +cdf +DAS +databrowser +defaultis +df +dichotomization +distrbutions +docx +doi +dplyr +estiate +eval +flextable +forvalues +frac +functons +ggcurve +ggplot +glm +Hjort +insertedinto +kendall +KJ +knitr +leq +levelinto +Lifecycle +likelihoodm +lm +logarithmically +lointerval +magrittr +mathbf +mathST +metafor +Metaprogramming +NL +nullvalue +ORCID +paranthesis +pbmcapply +pearson +postfile +powerpoint +Powerpoint +ppt +pptx +ProfileLikelihood +pvalue +Pvalue +Rdoc +README +relace +rlang +Rothman +Saltelli +Scand +Schweder +spearman +SSRI +Stata +Strawderman +summarise +surprisal +Surprisal +survminer +svalue +Svalue +tibble +tidyr +topost +Trafimow +Twoway +typicallywhat +upinterval +wald +widehat +xaxis +Xie +yxis +Zad diff --git a/inst/assets/bootstrap.css b/inst/assets/bootstrap.css new file mode 100644 index 0000000..fc8a203 --- /dev/null +++ b/inst/assets/bootstrap.css @@ -0,0 +1,7331 @@ +@import url("https://fonts.googleapis.com/css?family=Roboto:300,400,500,700"); +/*! + * bootswatch v3.4.1 + * Homepage: http://bootswatch.com + * Copyright 2012-2019 Thomas Park + * Licensed under MIT + * Based on Bootstrap +*/ +/*! + * Bootstrap v3.4.1 (https://getbootstrap.com/) + * Copyright 2011-2019 Twitter, Inc. + * Licensed under MIT (https://github.com/twbs/bootstrap/blob/master/LICENSE) + */ +/*! normalize.css v3.0.3 | MIT License | github.com/necolas/normalize.css */ +html { + font-family: sans-serif; + -ms-text-size-adjust: 100%; + -webkit-text-size-adjust: 100%; +} +body { + margin: 0; +} +article, +aside, +details, +figcaption, +figure, +footer, +header, +hgroup, +main, +menu, +nav, +section, +summary { + display: block; +} +audio, +canvas, +progress, +video { + display: inline-block; + vertical-align: baseline; +} +audio:not([controls]) { + display: none; + height: 0; +} +[hidden], +template { + display: none; +} +a { + background-color: transparent; +} +a:active, +a:hover { + outline: 0; +} +abbr[title] { + border-bottom: none; + text-decoration: underline; + text-decoration: underline dotted; +} +b, +strong { + font-weight: bold; +} +dfn { + font-style: italic; +} +h1 { + font-size: 2em; + margin: 0.67em 0; +} +mark { + background: #ff0; + color: #000; +} +small { + font-size: 80%; +} +sub, +sup { + font-size: 75%; + line-height: 0; + position: relative; + vertical-align: baseline; +} +sup { + top: -0.5em; +} +sub { + bottom: -0.25em; +} +img { + border: 0; +} +svg:not(:root) { + overflow: hidden; +} +figure { + margin: 1em 40px; +} +hr { + box-sizing: content-box; + height: 0; +} +pre { + overflow: auto; +} +code, +kbd, +pre, +samp { + font-family: monospace, monospace; + font-size: 1em; +} +button, +input, +optgroup, +select, +textarea { + color: inherit; + font: inherit; + margin: 0; +} +button { + overflow: visible; +} +button, +select { + text-transform: none; +} +button, +html input[type="button"], +input[type="reset"], +input[type="submit"] { + -webkit-appearance: button; + cursor: pointer; +} +button[disabled], +html input[disabled] { + cursor: default; +} +button::-moz-focus-inner, +input::-moz-focus-inner { + border: 0; + padding: 0; +} +input { + line-height: normal; +} +input[type="checkbox"], +input[type="radio"] { + box-sizing: border-box; + padding: 0; +} +input[type="number"]::-webkit-inner-spin-button, +input[type="number"]::-webkit-outer-spin-button { + height: auto; +} +input[type="search"] { + -webkit-appearance: textfield; + box-sizing: content-box; +} +input[type="search"]::-webkit-search-cancel-button, +input[type="search"]::-webkit-search-decoration { + -webkit-appearance: none; +} +fieldset { + border: 1px solid #c0c0c0; + margin: 0 2px; + padding: 0.35em 0.625em 0.75em; +} +legend { + border: 0; + padding: 0; +} +textarea { + overflow: auto; +} +optgroup { + font-weight: bold; +} +table { + border-collapse: collapse; + border-spacing: 0; +} +td, +th { + padding: 0; +} +/*! Source: https://github.com/h5bp/html5-boilerplate/blob/master/src/css/main.css */ +@media print { + *, + *:before, + *:after { + color: #000 !important; + text-shadow: none !important; + background: transparent !important; + box-shadow: none !important; + } + a, + a:visited { + text-decoration: underline; + } + a[href]:after { + content: " (" attr(href) ")"; + } + abbr[title]:after { + content: " (" attr(title) ")"; + } + a[href^="#"]:after, + a[href^="javascript:"]:after { + content: ""; + } + pre, + blockquote { + border: 1px solid #999; + page-break-inside: avoid; + } + thead { + display: table-header-group; + } + tr, + img { + page-break-inside: avoid; + } + img { + max-width: 100% !important; + } + p, + h2, + h3 { + orphans: 3; + widows: 3; + } + h2, + h3 { + page-break-after: avoid; + } + .navbar { + display: none; + } + .btn > .caret, + .dropup > .btn > .caret { + border-top-color: #000 !important; + } + .label { + border: 1px solid #000; + } + .table { + border-collapse: collapse !important; + } + .table td, + .table th { + background-color: #fff !important; + } + .table-bordered th, + .table-bordered td { + border: 1px solid #ddd !important; + } +} +@font-face { + font-family: "Glyphicons Halflings"; + src: url("../fonts/glyphicons-halflings-regular.eot"); + src: url("../fonts/glyphicons-halflings-regular.eot?#iefix") format("embedded-opentype"), url("../fonts/glyphicons-halflings-regular.woff2") format("woff2"), url("../fonts/glyphicons-halflings-regular.woff") format("woff"), url("../fonts/glyphicons-halflings-regular.ttf") format("truetype"), url("../fonts/glyphicons-halflings-regular.svg#glyphicons_halflingsregular") format("svg"); +} +.glyphicon { + position: relative; + top: 1px; + display: inline-block; + font-family: "Glyphicons Halflings"; + font-style: normal; + font-weight: 400; + line-height: 1; + -webkit-font-smoothing: antialiased; + -moz-osx-font-smoothing: grayscale; +} +.glyphicon-asterisk:before { + content: "\002a"; +} +.glyphicon-plus:before { + content: "\002b"; +} +.glyphicon-euro:before, +.glyphicon-eur:before { + content: "\20ac"; +} +.glyphicon-minus:before { + content: "\2212"; +} +.glyphicon-cloud:before { + content: "\2601"; +} +.glyphicon-envelope:before { + content: "\2709"; +} +.glyphicon-pencil:before { + content: "\270f"; +} +.glyphicon-glass:before { + content: "\e001"; +} +.glyphicon-music:before { + content: "\e002"; +} +.glyphicon-search:before { + content: "\e003"; +} +.glyphicon-heart:before { + content: "\e005"; +} +.glyphicon-star:before { + content: "\e006"; +} +.glyphicon-star-empty:before { + content: "\e007"; +} +.glyphicon-user:before { + content: "\e008"; +} +.glyphicon-film:before { + content: "\e009"; +} +.glyphicon-th-large:before { + content: "\e010"; +} +.glyphicon-th:before { + content: "\e011"; +} +.glyphicon-th-list:before { + content: "\e012"; +} +.glyphicon-ok:before { + content: "\e013"; +} +.glyphicon-remove:before { + content: "\e014"; +} +.glyphicon-zoom-in:before { + content: "\e015"; +} +.glyphicon-zoom-out:before { + content: "\e016"; +} +.glyphicon-off:before { + content: "\e017"; +} +.glyphicon-signal:before { + content: "\e018"; +} +.glyphicon-cog:before { + content: "\e019"; +} +.glyphicon-trash:before { + content: "\e020"; +} +.glyphicon-home:before { + content: "\e021"; +} +.glyphicon-file:before { + content: "\e022"; +} +.glyphicon-time:before { + content: "\e023"; +} +.glyphicon-road:before { + content: "\e024"; +} +.glyphicon-download-alt:before { + content: "\e025"; +} +.glyphicon-download:before { + content: "\e026"; +} +.glyphicon-upload:before { + content: "\e027"; +} +.glyphicon-inbox:before { + content: "\e028"; +} +.glyphicon-play-circle:before { + content: "\e029"; +} +.glyphicon-repeat:before { + content: "\e030"; +} +.glyphicon-refresh:before { + content: "\e031"; +} +.glyphicon-list-alt:before { + content: "\e032"; +} +.glyphicon-lock:before { + content: "\e033"; +} +.glyphicon-flag:before { + content: "\e034"; +} +.glyphicon-headphones:before { + content: "\e035"; +} +.glyphicon-volume-off:before { + content: "\e036"; +} +.glyphicon-volume-down:before { + content: "\e037"; +} +.glyphicon-volume-up:before { + content: "\e038"; +} +.glyphicon-qrcode:before { + content: "\e039"; +} +.glyphicon-barcode:before { + content: "\e040"; +} +.glyphicon-tag:before { + content: "\e041"; +} +.glyphicon-tags:before { + content: "\e042"; +} +.glyphicon-book:before { + content: "\e043"; +} +.glyphicon-bookmark:before { + content: "\e044"; +} +.glyphicon-print:before { + content: "\e045"; +} +.glyphicon-camera:before { + content: "\e046"; +} +.glyphicon-font:before { + content: "\e047"; +} +.glyphicon-bold:before { + content: "\e048"; +} +.glyphicon-italic:before { + content: "\e049"; +} +.glyphicon-text-height:before { + content: "\e050"; +} +.glyphicon-text-width:before { + content: "\e051"; +} +.glyphicon-align-left:before { + content: "\e052"; +} +.glyphicon-align-center:before { + content: "\e053"; +} +.glyphicon-align-right:before { + content: "\e054"; +} +.glyphicon-align-justify:before { + content: "\e055"; +} +.glyphicon-list:before { + content: "\e056"; +} +.glyphicon-indent-left:before { + content: "\e057"; +} +.glyphicon-indent-right:before { + content: "\e058"; +} +.glyphicon-facetime-video:before { + content: "\e059"; +} +.glyphicon-picture:before { + content: "\e060"; +} +.glyphicon-map-marker:before { + content: "\e062"; +} +.glyphicon-adjust:before { + content: "\e063"; +} +.glyphicon-tint:before { + content: "\e064"; +} +.glyphicon-edit:before { + content: "\e065"; +} +.glyphicon-share:before { + content: "\e066"; +} +.glyphicon-check:before { + content: "\e067"; +} +.glyphicon-move:before { + content: "\e068"; +} +.glyphicon-step-backward:before { + content: "\e069"; +} +.glyphicon-fast-backward:before { + content: "\e070"; +} +.glyphicon-backward:before { + content: "\e071"; +} +.glyphicon-play:before { + content: "\e072"; +} +.glyphicon-pause:before { + content: "\e073"; +} +.glyphicon-stop:before { + content: "\e074"; +} +.glyphicon-forward:before { + content: "\e075"; +} +.glyphicon-fast-forward:before { + content: "\e076"; +} +.glyphicon-step-forward:before { + content: "\e077"; +} +.glyphicon-eject:before { + content: "\e078"; +} +.glyphicon-chevron-left:before { + content: "\e079"; +} +.glyphicon-chevron-right:before { + content: "\e080"; +} +.glyphicon-plus-sign:before { + content: "\e081"; +} +.glyphicon-minus-sign:before { + content: "\e082"; +} +.glyphicon-remove-sign:before { + content: "\e083"; +} +.glyphicon-ok-sign:before { + content: "\e084"; +} +.glyphicon-question-sign:before { + content: "\e085"; +} +.glyphicon-info-sign:before { + content: "\e086"; +} +.glyphicon-screenshot:before { + content: "\e087"; +} +.glyphicon-remove-circle:before { + content: "\e088"; +} +.glyphicon-ok-circle:before { + content: "\e089"; +} +.glyphicon-ban-circle:before { + content: "\e090"; +} +.glyphicon-arrow-left:before { + content: "\e091"; +} +.glyphicon-arrow-right:before { + content: "\e092"; +} +.glyphicon-arrow-up:before { + content: "\e093"; +} +.glyphicon-arrow-down:before { + content: "\e094"; +} +.glyphicon-share-alt:before { + content: "\e095"; +} +.glyphicon-resize-full:before { + content: "\e096"; +} +.glyphicon-resize-small:before { + content: "\e097"; +} +.glyphicon-exclamation-sign:before { + content: "\e101"; +} +.glyphicon-gift:before { + content: "\e102"; +} +.glyphicon-leaf:before { + content: "\e103"; +} +.glyphicon-fire:before { + content: "\e104"; +} +.glyphicon-eye-open:before { + content: "\e105"; +} +.glyphicon-eye-close:before { + content: "\e106"; +} +.glyphicon-warning-sign:before { + content: "\e107"; +} +.glyphicon-plane:before { + content: "\e108"; +} +.glyphicon-calendar:before { + content: "\e109"; +} +.glyphicon-random:before { + content: "\e110"; +} +.glyphicon-comment:before { + content: "\e111"; +} +.glyphicon-magnet:before { + content: "\e112"; +} +.glyphicon-chevron-up:before { + content: "\e113"; +} +.glyphicon-chevron-down:before { + content: "\e114"; +} +.glyphicon-retweet:before { + content: "\e115"; +} +.glyphicon-shopping-cart:before { + content: "\e116"; +} +.glyphicon-folder-close:before { + content: "\e117"; +} +.glyphicon-folder-open:before { + content: "\e118"; +} +.glyphicon-resize-vertical:before { + content: "\e119"; +} +.glyphicon-resize-horizontal:before { + content: "\e120"; +} +.glyphicon-hdd:before { + content: "\e121"; +} +.glyphicon-bullhorn:before { + content: "\e122"; +} +.glyphicon-bell:before { + content: "\e123"; +} +.glyphicon-certificate:before { + content: "\e124"; +} +.glyphicon-thumbs-up:before { + content: "\e125"; +} +.glyphicon-thumbs-down:before { + content: "\e126"; +} +.glyphicon-hand-right:before { + content: "\e127"; +} +.glyphicon-hand-left:before { + content: "\e128"; +} +.glyphicon-hand-up:before { + content: "\e129"; +} +.glyphicon-hand-down:before { + content: "\e130"; +} +.glyphicon-circle-arrow-right:before { + content: "\e131"; +} +.glyphicon-circle-arrow-left:before { + content: "\e132"; +} +.glyphicon-circle-arrow-up:before { + content: "\e133"; +} +.glyphicon-circle-arrow-down:before { + content: "\e134"; +} +.glyphicon-globe:before { + content: "\e135"; +} +.glyphicon-wrench:before { + content: "\e136"; +} +.glyphicon-tasks:before { + content: "\e137"; +} +.glyphicon-filter:before { + content: "\e138"; +} +.glyphicon-briefcase:before { + content: "\e139"; +} +.glyphicon-fullscreen:before { + content: "\e140"; +} +.glyphicon-dashboard:before { + content: "\e141"; +} +.glyphicon-paperclip:before { + content: "\e142"; +} +.glyphicon-heart-empty:before { + content: "\e143"; +} +.glyphicon-link:before { + content: "\e144"; +} +.glyphicon-phone:before { + content: "\e145"; +} +.glyphicon-pushpin:before { + content: "\e146"; +} +.glyphicon-usd:before { + content: "\e148"; +} +.glyphicon-gbp:before { + content: "\e149"; +} +.glyphicon-sort:before { + content: "\e150"; +} +.glyphicon-sort-by-alphabet:before { + content: "\e151"; +} +.glyphicon-sort-by-alphabet-alt:before { + content: "\e152"; +} +.glyphicon-sort-by-order:before { + content: "\e153"; +} +.glyphicon-sort-by-order-alt:before { + content: "\e154"; +} +.glyphicon-sort-by-attributes:before { + content: "\e155"; +} +.glyphicon-sort-by-attributes-alt:before { + content: "\e156"; +} +.glyphicon-unchecked:before { + content: "\e157"; +} +.glyphicon-expand:before { + content: "\e158"; +} +.glyphicon-collapse-down:before { + content: "\e159"; +} +.glyphicon-collapse-up:before { + content: "\e160"; +} +.glyphicon-log-in:before { + content: "\e161"; +} +.glyphicon-flash:before { + content: "\e162"; +} +.glyphicon-log-out:before { + content: "\e163"; +} +.glyphicon-new-window:before { + content: "\e164"; +} +.glyphicon-record:before { + content: "\e165"; +} +.glyphicon-save:before { + content: "\e166"; +} +.glyphicon-open:before { + content: "\e167"; +} +.glyphicon-saved:before { + content: "\e168"; +} +.glyphicon-import:before { + content: "\e169"; +} +.glyphicon-export:before { + content: "\e170"; +} +.glyphicon-send:before { + content: "\e171"; +} +.glyphicon-floppy-disk:before { + content: "\e172"; +} +.glyphicon-floppy-saved:before { + content: "\e173"; +} +.glyphicon-floppy-remove:before { + content: "\e174"; +} +.glyphicon-floppy-save:before { + content: "\e175"; +} +.glyphicon-floppy-open:before { + content: "\e176"; +} +.glyphicon-credit-card:before { + content: "\e177"; +} +.glyphicon-transfer:before { + content: "\e178"; +} +.glyphicon-cutlery:before { + content: "\e179"; +} +.glyphicon-header:before { + content: "\e180"; +} +.glyphicon-compressed:before { + content: "\e181"; +} +.glyphicon-earphone:before { + content: "\e182"; +} +.glyphicon-phone-alt:before { + content: "\e183"; +} +.glyphicon-tower:before { + content: "\e184"; +} +.glyphicon-stats:before { + content: "\e185"; +} +.glyphicon-sd-video:before { + content: "\e186"; +} +.glyphicon-hd-video:before { + content: "\e187"; +} +.glyphicon-subtitles:before { + content: "\e188"; +} +.glyphicon-sound-stereo:before { + content: "\e189"; +} +.glyphicon-sound-dolby:before { + content: "\e190"; +} +.glyphicon-sound-5-1:before { + content: "\e191"; +} +.glyphicon-sound-6-1:before { + content: "\e192"; +} +.glyphicon-sound-7-1:before { + content: "\e193"; +} +.glyphicon-copyright-mark:before { + content: "\e194"; +} +.glyphicon-registration-mark:before { + content: "\e195"; +} +.glyphicon-cloud-download:before { + content: "\e197"; +} +.glyphicon-cloud-upload:before { + content: "\e198"; +} +.glyphicon-tree-conifer:before { + content: "\e199"; +} +.glyphicon-tree-deciduous:before { + content: "\e200"; +} +.glyphicon-cd:before { + content: "\e201"; +} +.glyphicon-save-file:before { + content: "\e202"; +} +.glyphicon-open-file:before { + content: "\e203"; +} +.glyphicon-level-up:before { + content: "\e204"; +} +.glyphicon-copy:before { + content: "\e205"; +} +.glyphicon-paste:before { + content: "\e206"; +} +.glyphicon-alert:before { + content: "\e209"; +} +.glyphicon-equalizer:before { + content: "\e210"; +} +.glyphicon-king:before { + content: "\e211"; +} +.glyphicon-queen:before { + content: "\e212"; +} +.glyphicon-pawn:before { + content: "\e213"; +} +.glyphicon-bishop:before { + content: "\e214"; +} +.glyphicon-knight:before { + content: "\e215"; +} +.glyphicon-baby-formula:before { + content: "\e216"; +} +.glyphicon-tent:before { + content: "\26fa"; +} +.glyphicon-blackboard:before { + content: "\e218"; +} +.glyphicon-bed:before { + content: "\e219"; +} +.glyphicon-apple:before { + content: "\f8ff"; +} +.glyphicon-erase:before { + content: "\e221"; +} +.glyphicon-hourglass:before { + content: "\231b"; +} +.glyphicon-lamp:before { + content: "\e223"; +} +.glyphicon-duplicate:before { + content: "\e224"; +} +.glyphicon-piggy-bank:before { + content: "\e225"; +} +.glyphicon-scissors:before { + content: "\e226"; +} +.glyphicon-bitcoin:before { + content: "\e227"; +} +.glyphicon-btc:before { + content: "\e227"; +} +.glyphicon-xbt:before { + content: "\e227"; +} +.glyphicon-yen:before { + content: "\00a5"; +} +.glyphicon-jpy:before { + content: "\00a5"; +} +.glyphicon-ruble:before { + content: "\20bd"; +} +.glyphicon-rub:before { + content: "\20bd"; +} +.glyphicon-scale:before { + content: "\e230"; +} +.glyphicon-ice-lolly:before { + content: "\e231"; +} +.glyphicon-ice-lolly-tasted:before { + content: "\e232"; +} +.glyphicon-education:before { + content: "\e233"; +} +.glyphicon-option-horizontal:before { + content: "\e234"; +} +.glyphicon-option-vertical:before { + content: "\e235"; +} +.glyphicon-menu-hamburger:before { + content: "\e236"; +} +.glyphicon-modal-window:before { + content: "\e237"; +} +.glyphicon-oil:before { + content: "\e238"; +} +.glyphicon-grain:before { + content: "\e239"; +} +.glyphicon-sunglasses:before { + content: "\e240"; +} +.glyphicon-text-size:before { + content: "\e241"; +} +.glyphicon-text-color:before { + content: "\e242"; +} +.glyphicon-text-background:before { + content: "\e243"; +} +.glyphicon-object-align-top:before { + content: "\e244"; +} +.glyphicon-object-align-bottom:before { + content: "\e245"; +} +.glyphicon-object-align-horizontal:before { + content: "\e246"; +} +.glyphicon-object-align-left:before { + content: "\e247"; +} +.glyphicon-object-align-vertical:before { + content: "\e248"; +} +.glyphicon-object-align-right:before { + content: "\e249"; +} +.glyphicon-triangle-right:before { + content: "\e250"; +} +.glyphicon-triangle-left:before { + content: "\e251"; +} +.glyphicon-triangle-bottom:before { + content: "\e252"; +} +.glyphicon-triangle-top:before { + content: "\e253"; +} +.glyphicon-console:before { + content: "\e254"; +} +.glyphicon-superscript:before { + content: "\e255"; +} +.glyphicon-subscript:before { + content: "\e256"; +} +.glyphicon-menu-left:before { + content: "\e257"; +} +.glyphicon-menu-right:before { + content: "\e258"; +} +.glyphicon-menu-down:before { + content: "\e259"; +} +.glyphicon-menu-up:before { + content: "\e260"; +} +* { + box-sizing: border-box; +} +*:before, +*:after { + box-sizing: border-box; +} +html { + font-size: 10px; + -webkit-tap-highlight-color: rgba(0, 0, 0, 0); +} +body { + font-family: "Roboto", "Helvetica Neue", Helvetica, Arial, sans-serif; + font-size: 13px; + line-height: 1.846; + color: #666666; + background-color: #ffffff; +} +input, +button, +select, +textarea { + font-family: inherit; + font-size: inherit; + line-height: inherit; +} +a { + color: #2196f3; + text-decoration: none; +} +a:hover, +a:focus { + color: #0a6ebd; + text-decoration: underline; +} +a:focus { + outline: 5px auto -webkit-focus-ring-color; + outline-offset: -2px; +} +figure { + margin: 0; +} +img { + vertical-align: middle; +} +.img-responsive, +.thumbnail > img, +.thumbnail a > img, +.carousel-inner > .item > img, +.carousel-inner > .item > a > img { + display: block; + max-width: 100%; + height: auto; +} +.img-rounded { + border-radius: 3px; +} +.img-thumbnail { + padding: 4px; + line-height: 1.846; + background-color: #ffffff; + border: 1px solid #dddddd; + border-radius: 3px; + transition: all 0.2s ease-in-out; + display: inline-block; + max-width: 100%; + height: auto; +} +.img-circle { + border-radius: 50%; +} +hr { + margin-top: 23px; + margin-bottom: 23px; + border: 0; + border-top: 1px solid #eeeeee; +} +.sr-only { + position: absolute; + width: 1px; + height: 1px; + padding: 0; + margin: -1px; + overflow: hidden; + clip: rect(0, 0, 0, 0); + border: 0; +} +.sr-only-focusable:active, +.sr-only-focusable:focus { + position: static; + width: auto; + height: auto; + margin: 0; + overflow: visible; + clip: auto; +} +[role="button"] { + cursor: pointer; +} +h1, +h2, +h3, +h4, +h5, +h6, +.h1, +.h2, +.h3, +.h4, +.h5, +.h6 { + font-family: inherit; + font-weight: 400; + line-height: 1.1; + color: #444444; +} +h1 small, +h2 small, +h3 small, +h4 small, +h5 small, +h6 small, +.h1 small, +.h2 small, +.h3 small, +.h4 small, +.h5 small, +.h6 small, +h1 .small, +h2 .small, +h3 .small, +h4 .small, +h5 .small, +h6 .small, +.h1 .small, +.h2 .small, +.h3 .small, +.h4 .small, +.h5 .small, +.h6 .small { + font-weight: 400; + line-height: 1; + color: #bbbbbb; +} +h1, +.h1, +h2, +.h2, +h3, +.h3 { + margin-top: 23px; + margin-bottom: 11.5px; +} +h1 small, +.h1 small, +h2 small, +.h2 small, +h3 small, +.h3 small, +h1 .small, +.h1 .small, +h2 .small, +.h2 .small, +h3 .small, +.h3 .small { + font-size: 65%; +} +h4, +.h4, +h5, +.h5, +h6, +.h6 { + margin-top: 11.5px; + margin-bottom: 11.5px; +} +h4 small, +.h4 small, +h5 small, +.h5 small, +h6 small, +.h6 small, +h4 .small, +.h4 .small, +h5 .small, +.h5 .small, +h6 .small, +.h6 .small { + font-size: 75%; +} +h1, +.h1 { + font-size: 56px; +} +h2, +.h2 { + font-size: 45px; +} +h3, +.h3 { + font-size: 34px; +} +h4, +.h4 { + font-size: 24px; +} +h5, +.h5 { + font-size: 20px; +} +h6, +.h6 { + font-size: 14px; +} +p { + margin: 0 0 11.5px; +} +.lead { + margin-bottom: 23px; + font-size: 14px; + font-weight: 300; + line-height: 1.4; +} +@media (min-width: 768px) { + .lead { + font-size: 19.5px; + } +} +small, +.small { + font-size: 92%; +} +mark, +.mark { + padding: .2em; + background-color: #ffe0b2; +} +.text-left { + text-align: left; +} +.text-right { + text-align: right; +} +.text-center { + text-align: center; +} +.text-justify { + text-align: justify; +} +.text-nowrap { + white-space: nowrap; +} +.text-lowercase { + text-transform: lowercase; +} +.text-uppercase { + text-transform: uppercase; +} +.text-capitalize { + text-transform: capitalize; +} +.text-muted { + color: #bbbbbb; +} +.text-primary { + color: #2196f3; +} +a.text-primary:hover, +a.text-primary:focus { + color: #0c7cd5; +} +.text-success { + color: #4caf50; +} +a.text-success:hover, +a.text-success:focus { + color: #3d8b40; +} +.text-info { + color: #9c27b0; +} +a.text-info:hover, +a.text-info:focus { + color: #771e86; +} +.text-warning { + color: #ff9800; +} +a.text-warning:hover, +a.text-warning:focus { + color: #cc7a00; +} +.text-danger { + color: #e51c23; +} +a.text-danger:hover, +a.text-danger:focus { + color: #b9151b; +} +.bg-primary { + color: #fff; + background-color: #2196f3; +} +a.bg-primary:hover, +a.bg-primary:focus { + background-color: #0c7cd5; +} +.bg-success { + background-color: #dff0d8; +} +a.bg-success:hover, +a.bg-success:focus { + background-color: #c1e2b3; +} +.bg-info { + background-color: #e1bee7; +} +a.bg-info:hover, +a.bg-info:focus { + background-color: #d099d9; +} +.bg-warning { + background-color: #ffe0b2; +} +a.bg-warning:hover, +a.bg-warning:focus { + background-color: #ffcb7f; +} +.bg-danger { + background-color: #f9bdbb; +} +a.bg-danger:hover, +a.bg-danger:focus { + background-color: #f5908c; +} +.page-header { + padding-bottom: 10.5px; + margin: 46px 0 23px; + border-bottom: 1px solid #eeeeee; +} +ul, +ol { + margin-top: 0; + margin-bottom: 11.5px; +} +ul ul, +ol ul, +ul ol, +ol ol { + margin-bottom: 0; +} +.list-unstyled { + padding-left: 0; + list-style: none; +} +.list-inline { + padding-left: 0; + list-style: none; + margin-left: -5px; +} +.list-inline > li { + display: inline-block; + padding-right: 5px; + padding-left: 5px; +} +dl { + margin-top: 0; + margin-bottom: 23px; +} +dt, +dd { + line-height: 1.846; +} +dt { + font-weight: 700; +} +dd { + margin-left: 0; +} +@media (min-width: 768px) { + .dl-horizontal dt { + float: left; + width: 160px; + clear: left; + text-align: right; + overflow: hidden; + text-overflow: ellipsis; + white-space: nowrap; + } + .dl-horizontal dd { + margin-left: 180px; + } +} +abbr[title], +abbr[data-original-title] { + cursor: help; +} +.initialism { + font-size: 90%; + text-transform: uppercase; +} +blockquote { + padding: 11.5px 23px; + margin: 0 0 23px; + font-size: 16.25px; + border-left: 5px solid #eeeeee; +} +blockquote p:last-child, +blockquote ul:last-child, +blockquote ol:last-child { + margin-bottom: 0; +} +blockquote footer, +blockquote small, +blockquote .small { + display: block; + font-size: 80%; + line-height: 1.846; + color: #bbbbbb; +} +blockquote footer:before, +blockquote small:before, +blockquote .small:before { + content: "\2014 \00A0"; +} +.blockquote-reverse, +blockquote.pull-right { + padding-right: 15px; + padding-left: 0; + text-align: right; + border-right: 5px solid #eeeeee; + border-left: 0; +} +.blockquote-reverse footer:before, +blockquote.pull-right footer:before, +.blockquote-reverse small:before, +blockquote.pull-right small:before, +.blockquote-reverse .small:before, +blockquote.pull-right .small:before { + content: ""; +} +.blockquote-reverse footer:after, +blockquote.pull-right footer:after, +.blockquote-reverse small:after, +blockquote.pull-right small:after, +.blockquote-reverse .small:after, +blockquote.pull-right .small:after { + content: "\00A0 \2014"; +} +address { + margin-bottom: 23px; + font-style: normal; + line-height: 1.846; +} +code, +kbd, +pre, +samp { + font-family: Menlo, Monaco, Consolas, "Courier New", monospace; +} +code { + padding: 2px 4px; + font-size: 90%; + color: #c7254e; + background-color: #f9f2f4; + border-radius: 3px; +} +kbd { + padding: 2px 4px; + font-size: 90%; + color: #ffffff; + background-color: #333333; + border-radius: 3px; + box-shadow: inset 0 -1px 0 rgba(0, 0, 0, 0.25); +} +kbd kbd { + padding: 0; + font-size: 100%; + font-weight: 700; + box-shadow: none; +} +pre { + display: block; + padding: 11px; + margin: 0 0 11.5px; + font-size: 12px; + line-height: 1.846; + color: #212121; + word-break: break-all; + word-wrap: break-word; + background-color: #f5f5f5; + border: 1px solid #cccccc; + border-radius: 3px; +} +pre code { + padding: 0; + font-size: inherit; + color: inherit; + white-space: pre-wrap; + background-color: transparent; + border-radius: 0; +} +.pre-scrollable { + max-height: 340px; + overflow-y: scroll; +} +.container { + padding-right: 15px; + padding-left: 15px; + margin-right: auto; + margin-left: auto; +} +@media (min-width: 768px) { + .container { + width: 750px; + } +} +@media (min-width: 992px) { + .container { + width: 970px; + } +} +@media (min-width: 1200px) { + .container { + width: 1170px; + } +} +.container-fluid { + padding-right: 15px; + padding-left: 15px; + margin-right: auto; + margin-left: auto; +} +.row { + margin-right: -15px; + margin-left: -15px; +} +.row-no-gutters { + margin-right: 0; + margin-left: 0; +} +.row-no-gutters [class*="col-"] { + padding-right: 0; + padding-left: 0; +} +.col-xs-1, .col-sm-1, .col-md-1, .col-lg-1, .col-xs-2, .col-sm-2, .col-md-2, .col-lg-2, .col-xs-3, .col-sm-3, .col-md-3, .col-lg-3, .col-xs-4, .col-sm-4, .col-md-4, .col-lg-4, .col-xs-5, .col-sm-5, .col-md-5, .col-lg-5, .col-xs-6, .col-sm-6, .col-md-6, .col-lg-6, .col-xs-7, .col-sm-7, .col-md-7, .col-lg-7, .col-xs-8, .col-sm-8, .col-md-8, .col-lg-8, .col-xs-9, .col-sm-9, .col-md-9, .col-lg-9, .col-xs-10, .col-sm-10, .col-md-10, .col-lg-10, .col-xs-11, .col-sm-11, .col-md-11, .col-lg-11, .col-xs-12, .col-sm-12, .col-md-12, .col-lg-12 { + position: relative; + min-height: 1px; + padding-right: 15px; + padding-left: 15px; +} +.col-xs-1, .col-xs-2, .col-xs-3, .col-xs-4, .col-xs-5, .col-xs-6, .col-xs-7, .col-xs-8, .col-xs-9, .col-xs-10, .col-xs-11, .col-xs-12 { + float: left; +} +.col-xs-12 { + width: 100%; +} +.col-xs-11 { + width: 91.66666667%; +} +.col-xs-10 { + width: 83.33333333%; +} +.col-xs-9 { + width: 75%; +} +.col-xs-8 { + width: 66.66666667%; +} +.col-xs-7 { + width: 58.33333333%; +} +.col-xs-6 { + width: 50%; +} +.col-xs-5 { + width: 41.66666667%; +} +.col-xs-4 { + width: 33.33333333%; +} +.col-xs-3 { + width: 25%; +} +.col-xs-2 { + width: 16.66666667%; +} +.col-xs-1 { + width: 8.33333333%; +} +.col-xs-pull-12 { + right: 100%; +} +.col-xs-pull-11 { + right: 91.66666667%; +} +.col-xs-pull-10 { + right: 83.33333333%; +} +.col-xs-pull-9 { + right: 75%; +} +.col-xs-pull-8 { + right: 66.66666667%; +} +.col-xs-pull-7 { + right: 58.33333333%; +} +.col-xs-pull-6 { + right: 50%; +} +.col-xs-pull-5 { + right: 41.66666667%; +} +.col-xs-pull-4 { + right: 33.33333333%; +} +.col-xs-pull-3 { + right: 25%; +} +.col-xs-pull-2 { + right: 16.66666667%; +} +.col-xs-pull-1 { + right: 8.33333333%; +} +.col-xs-pull-0 { + right: auto; +} +.col-xs-push-12 { + left: 100%; +} +.col-xs-push-11 { + left: 91.66666667%; +} +.col-xs-push-10 { + left: 83.33333333%; +} +.col-xs-push-9 { + left: 75%; +} +.col-xs-push-8 { + left: 66.66666667%; +} +.col-xs-push-7 { + left: 58.33333333%; +} +.col-xs-push-6 { + left: 50%; +} +.col-xs-push-5 { + left: 41.66666667%; +} +.col-xs-push-4 { + left: 33.33333333%; +} +.col-xs-push-3 { + left: 25%; +} +.col-xs-push-2 { + left: 16.66666667%; +} +.col-xs-push-1 { + left: 8.33333333%; +} +.col-xs-push-0 { + left: auto; +} +.col-xs-offset-12 { + margin-left: 100%; +} +.col-xs-offset-11 { + margin-left: 91.66666667%; +} +.col-xs-offset-10 { + margin-left: 83.33333333%; +} +.col-xs-offset-9 { + margin-left: 75%; +} +.col-xs-offset-8 { + margin-left: 66.66666667%; +} +.col-xs-offset-7 { + margin-left: 58.33333333%; +} +.col-xs-offset-6 { + margin-left: 50%; +} +.col-xs-offset-5 { + margin-left: 41.66666667%; +} +.col-xs-offset-4 { + margin-left: 33.33333333%; +} +.col-xs-offset-3 { + margin-left: 25%; +} +.col-xs-offset-2 { + margin-left: 16.66666667%; +} +.col-xs-offset-1 { + margin-left: 8.33333333%; +} +.col-xs-offset-0 { + margin-left: 0%; +} +@media (min-width: 768px) { + .col-sm-1, .col-sm-2, .col-sm-3, .col-sm-4, .col-sm-5, .col-sm-6, .col-sm-7, .col-sm-8, .col-sm-9, .col-sm-10, .col-sm-11, .col-sm-12 { + float: left; + } + .col-sm-12 { + width: 100%; + } + .col-sm-11 { + width: 91.66666667%; + } + .col-sm-10 { + width: 83.33333333%; + } + .col-sm-9 { + width: 75%; + } + .col-sm-8 { + width: 66.66666667%; + } + .col-sm-7 { + width: 58.33333333%; + } + .col-sm-6 { + width: 50%; + } + .col-sm-5 { + width: 41.66666667%; + } + .col-sm-4 { + width: 33.33333333%; + } + .col-sm-3 { + width: 25%; + } + .col-sm-2 { + width: 16.66666667%; + } + .col-sm-1 { + width: 8.33333333%; + } + .col-sm-pull-12 { + right: 100%; + } + .col-sm-pull-11 { + right: 91.66666667%; + } + .col-sm-pull-10 { + right: 83.33333333%; + } + .col-sm-pull-9 { + right: 75%; + } + .col-sm-pull-8 { + right: 66.66666667%; + } + .col-sm-pull-7 { + right: 58.33333333%; + } + .col-sm-pull-6 { + right: 50%; + } + .col-sm-pull-5 { + right: 41.66666667%; + } + .col-sm-pull-4 { + right: 33.33333333%; + } + .col-sm-pull-3 { + right: 25%; + } + .col-sm-pull-2 { + right: 16.66666667%; + } + .col-sm-pull-1 { + right: 8.33333333%; + } + .col-sm-pull-0 { + right: auto; + } + .col-sm-push-12 { + left: 100%; + } + .col-sm-push-11 { + left: 91.66666667%; + } + .col-sm-push-10 { + left: 83.33333333%; + } + .col-sm-push-9 { + left: 75%; + } + .col-sm-push-8 { + left: 66.66666667%; + } + .col-sm-push-7 { + left: 58.33333333%; + } + .col-sm-push-6 { + left: 50%; + } + .col-sm-push-5 { + left: 41.66666667%; + } + .col-sm-push-4 { + left: 33.33333333%; + } + .col-sm-push-3 { + left: 25%; + } + .col-sm-push-2 { + left: 16.66666667%; + } + .col-sm-push-1 { + left: 8.33333333%; + } + .col-sm-push-0 { + left: auto; + } + .col-sm-offset-12 { + margin-left: 100%; + } + .col-sm-offset-11 { + margin-left: 91.66666667%; + } + .col-sm-offset-10 { + margin-left: 83.33333333%; + } + .col-sm-offset-9 { + margin-left: 75%; + } + .col-sm-offset-8 { + margin-left: 66.66666667%; + } + .col-sm-offset-7 { + margin-left: 58.33333333%; + } + .col-sm-offset-6 { + margin-left: 50%; + } + .col-sm-offset-5 { + margin-left: 41.66666667%; + } + .col-sm-offset-4 { + margin-left: 33.33333333%; + } + .col-sm-offset-3 { + margin-left: 25%; + } + .col-sm-offset-2 { + margin-left: 16.66666667%; + } + .col-sm-offset-1 { + margin-left: 8.33333333%; + } + .col-sm-offset-0 { + margin-left: 0%; + } +} +@media (min-width: 992px) { + .col-md-1, .col-md-2, .col-md-3, .col-md-4, .col-md-5, .col-md-6, .col-md-7, .col-md-8, .col-md-9, .col-md-10, .col-md-11, .col-md-12 { + float: left; + } + .col-md-12 { + width: 100%; + } + .col-md-11 { + width: 91.66666667%; + } + .col-md-10 { + width: 83.33333333%; + } + .col-md-9 { + width: 75%; + } + .col-md-8 { + width: 66.66666667%; + } + .col-md-7 { + width: 58.33333333%; + } + .col-md-6 { + width: 50%; + } + .col-md-5 { + width: 41.66666667%; + } + .col-md-4 { + width: 33.33333333%; + } + .col-md-3 { + width: 25%; + } + .col-md-2 { + width: 16.66666667%; + } + .col-md-1 { + width: 8.33333333%; + } + .col-md-pull-12 { + right: 100%; + } + .col-md-pull-11 { + right: 91.66666667%; + } + .col-md-pull-10 { + right: 83.33333333%; + } + .col-md-pull-9 { + right: 75%; + } + .col-md-pull-8 { + right: 66.66666667%; + } + .col-md-pull-7 { + right: 58.33333333%; + } + .col-md-pull-6 { + right: 50%; + } + .col-md-pull-5 { + right: 41.66666667%; + } + .col-md-pull-4 { + right: 33.33333333%; + } + .col-md-pull-3 { + right: 25%; + } + .col-md-pull-2 { + right: 16.66666667%; + } + .col-md-pull-1 { + right: 8.33333333%; + } + .col-md-pull-0 { + right: auto; + } + .col-md-push-12 { + left: 100%; + } + .col-md-push-11 { + left: 91.66666667%; + } + .col-md-push-10 { + left: 83.33333333%; + } + .col-md-push-9 { + left: 75%; + } + .col-md-push-8 { + left: 66.66666667%; + } + .col-md-push-7 { + left: 58.33333333%; + } + .col-md-push-6 { + left: 50%; + } + .col-md-push-5 { + left: 41.66666667%; + } + .col-md-push-4 { + left: 33.33333333%; + } + .col-md-push-3 { + left: 25%; + } + .col-md-push-2 { + left: 16.66666667%; + } + .col-md-push-1 { + left: 8.33333333%; + } + .col-md-push-0 { + left: auto; + } + .col-md-offset-12 { + margin-left: 100%; + } + .col-md-offset-11 { + margin-left: 91.66666667%; + } + .col-md-offset-10 { + margin-left: 83.33333333%; + } + .col-md-offset-9 { + margin-left: 75%; + } + .col-md-offset-8 { + margin-left: 66.66666667%; + } + .col-md-offset-7 { + margin-left: 58.33333333%; + } + .col-md-offset-6 { + margin-left: 50%; + } + .col-md-offset-5 { + margin-left: 41.66666667%; + } + .col-md-offset-4 { + margin-left: 33.33333333%; + } + .col-md-offset-3 { + margin-left: 25%; + } + .col-md-offset-2 { + margin-left: 16.66666667%; + } + .col-md-offset-1 { + margin-left: 8.33333333%; + } + .col-md-offset-0 { + margin-left: 0%; + } +} +@media (min-width: 1200px) { + .col-lg-1, .col-lg-2, .col-lg-3, .col-lg-4, .col-lg-5, .col-lg-6, .col-lg-7, .col-lg-8, .col-lg-9, .col-lg-10, .col-lg-11, .col-lg-12 { + float: left; + } + .col-lg-12 { + width: 100%; + } + .col-lg-11 { + width: 91.66666667%; + } + .col-lg-10 { + width: 83.33333333%; + } + .col-lg-9 { + width: 75%; + } + .col-lg-8 { + width: 66.66666667%; + } + .col-lg-7 { + width: 58.33333333%; + } + .col-lg-6 { + width: 50%; + } + .col-lg-5 { + width: 41.66666667%; + } + .col-lg-4 { + width: 33.33333333%; + } + .col-lg-3 { + width: 25%; + } + .col-lg-2 { + width: 16.66666667%; + } + .col-lg-1 { + width: 8.33333333%; + } + .col-lg-pull-12 { + right: 100%; + } + .col-lg-pull-11 { + right: 91.66666667%; + } + .col-lg-pull-10 { + right: 83.33333333%; + } + .col-lg-pull-9 { + right: 75%; + } + .col-lg-pull-8 { + right: 66.66666667%; + } + .col-lg-pull-7 { + right: 58.33333333%; + } + .col-lg-pull-6 { + right: 50%; + } + .col-lg-pull-5 { + right: 41.66666667%; + } + .col-lg-pull-4 { + right: 33.33333333%; + } + .col-lg-pull-3 { + right: 25%; + } + .col-lg-pull-2 { + right: 16.66666667%; + } + .col-lg-pull-1 { + right: 8.33333333%; + } + .col-lg-pull-0 { + right: auto; + } + .col-lg-push-12 { + left: 100%; + } + .col-lg-push-11 { + left: 91.66666667%; + } + .col-lg-push-10 { + left: 83.33333333%; + } + .col-lg-push-9 { + left: 75%; + } + .col-lg-push-8 { + left: 66.66666667%; + } + .col-lg-push-7 { + left: 58.33333333%; + } + .col-lg-push-6 { + left: 50%; + } + .col-lg-push-5 { + left: 41.66666667%; + } + .col-lg-push-4 { + left: 33.33333333%; + } + .col-lg-push-3 { + left: 25%; + } + .col-lg-push-2 { + left: 16.66666667%; + } + .col-lg-push-1 { + left: 8.33333333%; + } + .col-lg-push-0 { + left: auto; + } + .col-lg-offset-12 { + margin-left: 100%; + } + .col-lg-offset-11 { + margin-left: 91.66666667%; + } + .col-lg-offset-10 { + margin-left: 83.33333333%; + } + .col-lg-offset-9 { + margin-left: 75%; + } + .col-lg-offset-8 { + margin-left: 66.66666667%; + } + .col-lg-offset-7 { + margin-left: 58.33333333%; + } + .col-lg-offset-6 { + margin-left: 50%; + } + .col-lg-offset-5 { + margin-left: 41.66666667%; + } + .col-lg-offset-4 { + margin-left: 33.33333333%; + } + .col-lg-offset-3 { + margin-left: 25%; + } + .col-lg-offset-2 { + margin-left: 16.66666667%; + } + .col-lg-offset-1 { + margin-left: 8.33333333%; + } + .col-lg-offset-0 { + margin-left: 0%; + } +} +table { + background-color: transparent; +} +table col[class*="col-"] { + position: static; + display: table-column; + float: none; +} +table td[class*="col-"], +table th[class*="col-"] { + position: static; + display: table-cell; + float: none; +} +caption { + padding-top: 8px; + padding-bottom: 8px; + color: #bbbbbb; + text-align: left; +} +th { + text-align: left; +} +.table { + width: 100%; + max-width: 100%; + margin-bottom: 23px; +} +.table > thead > tr > th, +.table > tbody > tr > th, +.table > tfoot > tr > th, +.table > thead > tr > td, +.table > tbody > tr > td, +.table > tfoot > tr > td { + padding: 8px; + line-height: 1.846; + vertical-align: top; + border-top: 1px solid #dddddd; +} +.table > thead > tr > th { + vertical-align: bottom; + border-bottom: 2px solid #dddddd; +} +.table > caption + thead > tr:first-child > th, +.table > colgroup + thead > tr:first-child > th, +.table > thead:first-child > tr:first-child > th, +.table > caption + thead > tr:first-child > td, +.table > colgroup + thead > tr:first-child > td, +.table > thead:first-child > tr:first-child > td { + border-top: 0; +} +.table > tbody + tbody { + border-top: 2px solid #dddddd; +} +.table .table { + background-color: #ffffff; +} +.table-condensed > thead > tr > th, +.table-condensed > tbody > tr > th, +.table-condensed > tfoot > tr > th, +.table-condensed > thead > tr > td, +.table-condensed > tbody > tr > td, +.table-condensed > tfoot > tr > td { + padding: 5px; +} +.table-bordered { + border: 1px solid #dddddd; +} +.table-bordered > thead > tr > th, +.table-bordered > tbody > tr > th, +.table-bordered > tfoot > tr > th, +.table-bordered > thead > tr > td, +.table-bordered > tbody > tr > td, +.table-bordered > tfoot > tr > td { + border: 1px solid #dddddd; +} +.table-bordered > thead > tr > th, +.table-bordered > thead > tr > td { + border-bottom-width: 2px; +} +.table-striped > tbody > tr:nth-of-type(odd) { + background-color: #f9f9f9; +} +.table-hover > tbody > tr:hover { + background-color: #f5f5f5; +} +.table > thead > tr > td.active, +.table > tbody > tr > td.active, +.table > tfoot > tr > td.active, +.table > thead > tr > th.active, +.table > tbody > tr > th.active, +.table > tfoot > tr > th.active, +.table > thead > tr.active > td, +.table > tbody > tr.active > td, +.table > tfoot > tr.active > td, +.table > thead > tr.active > th, +.table > tbody > tr.active > th, +.table > tfoot > tr.active > th { + background-color: #f5f5f5; +} +.table-hover > tbody > tr > td.active:hover, +.table-hover > tbody > tr > th.active:hover, +.table-hover > tbody > tr.active:hover > td, +.table-hover > tbody > tr:hover > .active, +.table-hover > tbody > tr.active:hover > th { + background-color: #e8e8e8; +} +.table > thead > tr > td.success, +.table > tbody > tr > td.success, +.table > tfoot > tr > td.success, +.table > thead > tr > th.success, +.table > tbody > tr > th.success, +.table > tfoot > tr > th.success, +.table > thead > tr.success > td, +.table > tbody > tr.success > td, +.table > tfoot > tr.success > td, +.table > thead > tr.success > th, +.table > tbody > tr.success > th, +.table > tfoot > tr.success > th { + background-color: #dff0d8; +} +.table-hover > tbody > tr > td.success:hover, +.table-hover > tbody > tr > th.success:hover, +.table-hover > tbody > tr.success:hover > td, +.table-hover > tbody > tr:hover > .success, +.table-hover > tbody > tr.success:hover > th { + background-color: #d0e9c6; +} +.table > thead > tr > td.info, +.table > tbody > tr > td.info, +.table > tfoot > tr > td.info, +.table > thead > tr > th.info, +.table > tbody > tr > th.info, +.table > tfoot > tr > th.info, +.table > thead > tr.info > td, +.table > tbody > tr.info > td, +.table > tfoot > tr.info > td, +.table > thead > tr.info > th, +.table > tbody > tr.info > th, +.table > tfoot > tr.info > th { + background-color: #e1bee7; +} +.table-hover > tbody > tr > td.info:hover, +.table-hover > tbody > tr > th.info:hover, +.table-hover > tbody > tr.info:hover > td, +.table-hover > tbody > tr:hover > .info, +.table-hover > tbody > tr.info:hover > th { + background-color: #d8abe0; +} +.table > thead > tr > td.warning, +.table > tbody > tr > td.warning, +.table > tfoot > tr > td.warning, +.table > thead > tr > th.warning, +.table > tbody > tr > th.warning, +.table > tfoot > tr > th.warning, +.table > thead > tr.warning > td, +.table > tbody > tr.warning > td, +.table > tfoot > tr.warning > td, +.table > thead > tr.warning > th, +.table > tbody > tr.warning > th, +.table > tfoot > tr.warning > th { + background-color: #ffe0b2; +} +.table-hover > tbody > tr > td.warning:hover, +.table-hover > tbody > tr > th.warning:hover, +.table-hover > tbody > tr.warning:hover > td, +.table-hover > tbody > tr:hover > .warning, +.table-hover > tbody > tr.warning:hover > th { + background-color: #ffd699; +} +.table > thead > tr > td.danger, +.table > tbody > tr > td.danger, +.table > tfoot > tr > td.danger, +.table > thead > tr > th.danger, +.table > tbody > tr > th.danger, +.table > tfoot > tr > th.danger, +.table > thead > tr.danger > td, +.table > tbody > tr.danger > td, +.table > tfoot > tr.danger > td, +.table > thead > tr.danger > th, +.table > tbody > tr.danger > th, +.table > tfoot > tr.danger > th { + background-color: #f9bdbb; +} +.table-hover > tbody > tr > td.danger:hover, +.table-hover > tbody > tr > th.danger:hover, +.table-hover > tbody > tr.danger:hover > td, +.table-hover > tbody > tr:hover > .danger, +.table-hover > tbody > tr.danger:hover > th { + background-color: #f7a6a4; +} +.table-responsive { + min-height: .01%; + overflow-x: auto; +} +@media screen and (max-width: 767px) { + .table-responsive { + width: 100%; + margin-bottom: 17.25px; + overflow-y: hidden; + -ms-overflow-style: -ms-autohiding-scrollbar; + border: 1px solid #dddddd; + } + .table-responsive > .table { + margin-bottom: 0; + } + .table-responsive > .table > thead > tr > th, + .table-responsive > .table > tbody > tr > th, + .table-responsive > .table > tfoot > tr > th, + .table-responsive > .table > thead > tr > td, + .table-responsive > .table > tbody > tr > td, + .table-responsive > .table > tfoot > tr > td { + white-space: nowrap; + } + .table-responsive > .table-bordered { + border: 0; + } + .table-responsive > .table-bordered > thead > tr > th:first-child, + .table-responsive > .table-bordered > tbody > tr > th:first-child, + .table-responsive > .table-bordered > tfoot > tr > th:first-child, + .table-responsive > .table-bordered > thead > tr > td:first-child, + .table-responsive > .table-bordered > tbody > tr > td:first-child, + .table-responsive > .table-bordered > tfoot > tr > td:first-child { + border-left: 0; + } + .table-responsive > .table-bordered > thead > tr > th:last-child, + .table-responsive > .table-bordered > tbody > tr > th:last-child, + .table-responsive > .table-bordered > tfoot > tr > th:last-child, + .table-responsive > .table-bordered > thead > tr > td:last-child, + .table-responsive > .table-bordered > tbody > tr > td:last-child, + .table-responsive > .table-bordered > tfoot > tr > td:last-child { + border-right: 0; + } + .table-responsive > .table-bordered > tbody > tr:last-child > th, + .table-responsive > .table-bordered > tfoot > tr:last-child > th, + .table-responsive > .table-bordered > tbody > tr:last-child > td, + .table-responsive > .table-bordered > tfoot > tr:last-child > td { + border-bottom: 0; + } +} +fieldset { + min-width: 0; + padding: 0; + margin: 0; + border: 0; +} +legend { + display: block; + width: 100%; + padding: 0; + margin-bottom: 23px; + font-size: 19.5px; + line-height: inherit; + color: #212121; + border: 0; + border-bottom: 1px solid #e5e5e5; +} +label { + display: inline-block; + max-width: 100%; + margin-bottom: 5px; + font-weight: 700; +} +input[type="search"] { + box-sizing: border-box; + -webkit-appearance: none; + appearance: none; +} +input[type="radio"], +input[type="checkbox"] { + margin: 4px 0 0; + margin-top: 1px \9; + line-height: normal; +} +input[type="radio"][disabled], +input[type="checkbox"][disabled], +input[type="radio"].disabled, +input[type="checkbox"].disabled, +fieldset[disabled] input[type="radio"], +fieldset[disabled] input[type="checkbox"] { + cursor: not-allowed; +} +input[type="file"] { + display: block; +} +input[type="range"] { + display: block; + width: 100%; +} +select[multiple], +select[size] { + height: auto; +} +input[type="file"]:focus, +input[type="radio"]:focus, +input[type="checkbox"]:focus { + outline: 5px auto -webkit-focus-ring-color; + outline-offset: -2px; +} +output { + display: block; + padding-top: 7px; + font-size: 13px; + line-height: 1.846; + color: #666666; +} +.form-control { + display: block; + width: 100%; + height: 37px; + padding: 6px 16px; + font-size: 13px; + line-height: 1.846; + color: #666666; + background-color: transparent; + background-image: none; + border: 1px solid transparent; + border-radius: 3px; + box-shadow: inset 0 1px 1px rgba(0, 0, 0, 0.075); + transition: border-color ease-in-out .15s, box-shadow ease-in-out .15s; +} +.form-control:focus { + border-color: #66afe9; + outline: 0; + box-shadow: inset 0 1px 1px rgba(0, 0, 0, .075), 0 0 8px rgba(102, 175, 233, 0.6); +} +.form-control::-moz-placeholder { + color: #bbbbbb; + opacity: 1; +} +.form-control:-ms-input-placeholder { + color: #bbbbbb; +} +.form-control::-webkit-input-placeholder { + color: #bbbbbb; +} +.form-control::-ms-expand { + background-color: transparent; + border: 0; +} +.form-control[disabled], +.form-control[readonly], +fieldset[disabled] .form-control { + background-color: transparent; + opacity: 1; +} +.form-control[disabled], +fieldset[disabled] .form-control { + cursor: not-allowed; +} +textarea.form-control { + height: auto; +} +@media screen and (-webkit-min-device-pixel-ratio: 0) { + input[type="date"].form-control, + input[type="time"].form-control, + input[type="datetime-local"].form-control, + input[type="month"].form-control { + line-height: 37px; + } + input[type="date"].input-sm, + input[type="time"].input-sm, + input[type="datetime-local"].input-sm, + input[type="month"].input-sm, + .input-group-sm input[type="date"], + .input-group-sm input[type="time"], + .input-group-sm input[type="datetime-local"], + .input-group-sm input[type="month"] { + line-height: 30px; + } + input[type="date"].input-lg, + input[type="time"].input-lg, + input[type="datetime-local"].input-lg, + input[type="month"].input-lg, + .input-group-lg input[type="date"], + .input-group-lg input[type="time"], + .input-group-lg input[type="datetime-local"], + .input-group-lg input[type="month"] { + line-height: 45px; + } +} +.form-group { + margin-bottom: 15px; +} +.radio, +.checkbox { + position: relative; + display: block; + margin-top: 10px; + margin-bottom: 10px; +} +.radio.disabled label, +.checkbox.disabled label, +fieldset[disabled] .radio label, +fieldset[disabled] .checkbox label { + cursor: not-allowed; +} +.radio label, +.checkbox label { + min-height: 23px; + padding-left: 20px; + margin-bottom: 0; + font-weight: 400; + cursor: pointer; +} +.radio input[type="radio"], +.radio-inline input[type="radio"], +.checkbox input[type="checkbox"], +.checkbox-inline input[type="checkbox"] { + position: absolute; + margin-top: 4px \9; + margin-left: -20px; +} +.radio + .radio, +.checkbox + .checkbox { + margin-top: -5px; +} +.radio-inline, +.checkbox-inline { + position: relative; + display: inline-block; + padding-left: 20px; + margin-bottom: 0; + font-weight: 400; + vertical-align: middle; + cursor: pointer; +} +.radio-inline.disabled, +.checkbox-inline.disabled, +fieldset[disabled] .radio-inline, +fieldset[disabled] .checkbox-inline { + cursor: not-allowed; +} +.radio-inline + .radio-inline, +.checkbox-inline + .checkbox-inline { + margin-top: 0; + margin-left: 10px; +} +.form-control-static { + min-height: 36px; + padding-top: 7px; + padding-bottom: 7px; + margin-bottom: 0; +} +.form-control-static.input-lg, +.form-control-static.input-sm { + padding-right: 0; + padding-left: 0; +} +.input-sm { + height: 30px; + padding: 5px 10px; + font-size: 12px; + line-height: 1.5; + border-radius: 3px; +} +select.input-sm { + height: 30px; + line-height: 30px; +} +textarea.input-sm, +select[multiple].input-sm { + height: auto; +} +.form-group-sm .form-control { + height: 30px; + padding: 5px 10px; + font-size: 12px; + line-height: 1.5; + border-radius: 3px; +} +.form-group-sm select.form-control { + height: 30px; + line-height: 30px; +} +.form-group-sm textarea.form-control, +.form-group-sm select[multiple].form-control { + height: auto; +} +.form-group-sm .form-control-static { + height: 30px; + min-height: 35px; + padding: 6px 10px; + font-size: 12px; + line-height: 1.5; +} +.input-lg { + height: 45px; + padding: 10px 16px; + font-size: 17px; + line-height: 1.3333333; + border-radius: 3px; +} +select.input-lg { + height: 45px; + line-height: 45px; +} +textarea.input-lg, +select[multiple].input-lg { + height: auto; +} +.form-group-lg .form-control { + height: 45px; + padding: 10px 16px; + font-size: 17px; + line-height: 1.3333333; + border-radius: 3px; +} +.form-group-lg select.form-control { + height: 45px; + line-height: 45px; +} +.form-group-lg textarea.form-control, +.form-group-lg select[multiple].form-control { + height: auto; +} +.form-group-lg .form-control-static { + height: 45px; + min-height: 40px; + padding: 11px 16px; + font-size: 17px; + line-height: 1.3333333; +} +.has-feedback { + position: relative; +} +.has-feedback .form-control { + padding-right: 46.25px; +} +.form-control-feedback { + position: absolute; + top: 0; + right: 0; + z-index: 2; + display: block; + width: 37px; + height: 37px; + line-height: 37px; + text-align: center; + pointer-events: none; +} +.input-lg + .form-control-feedback, +.input-group-lg + .form-control-feedback, +.form-group-lg .form-control + .form-control-feedback { + width: 45px; + height: 45px; + line-height: 45px; +} +.input-sm + .form-control-feedback, +.input-group-sm + .form-control-feedback, +.form-group-sm .form-control + .form-control-feedback { + width: 30px; + height: 30px; + line-height: 30px; +} +.has-success .help-block, +.has-success .control-label, +.has-success .radio, +.has-success .checkbox, +.has-success .radio-inline, +.has-success .checkbox-inline, +.has-success.radio label, +.has-success.checkbox label, +.has-success.radio-inline label, +.has-success.checkbox-inline label { + color: #4caf50; +} +.has-success .form-control { + border-color: #4caf50; + box-shadow: inset 0 1px 1px rgba(0, 0, 0, 0.075); +} +.has-success .form-control:focus { + border-color: #3d8b40; + box-shadow: inset 0 1px 1px rgba(0, 0, 0, 0.075), 0 0 6px #92cf94; +} +.has-success .input-group-addon { + color: #4caf50; + background-color: #dff0d8; + border-color: #4caf50; +} +.has-success .form-control-feedback { + color: #4caf50; +} +.has-warning .help-block, +.has-warning .control-label, +.has-warning .radio, +.has-warning .checkbox, +.has-warning .radio-inline, +.has-warning .checkbox-inline, +.has-warning.radio label, +.has-warning.checkbox label, +.has-warning.radio-inline label, +.has-warning.checkbox-inline label { + color: #ff9800; +} +.has-warning .form-control { + border-color: #ff9800; + box-shadow: inset 0 1px 1px rgba(0, 0, 0, 0.075); +} +.has-warning .form-control:focus { + border-color: #cc7a00; + box-shadow: inset 0 1px 1px rgba(0, 0, 0, 0.075), 0 0 6px #ffc166; +} +.has-warning .input-group-addon { + color: #ff9800; + background-color: #ffe0b2; + border-color: #ff9800; +} +.has-warning .form-control-feedback { + color: #ff9800; +} +.has-error .help-block, +.has-error .control-label, +.has-error .radio, +.has-error .checkbox, +.has-error .radio-inline, +.has-error .checkbox-inline, +.has-error.radio label, +.has-error.checkbox label, +.has-error.radio-inline label, +.has-error.checkbox-inline label { + color: #e51c23; +} +.has-error .form-control { + border-color: #e51c23; + box-shadow: inset 0 1px 1px rgba(0, 0, 0, 0.075); +} +.has-error .form-control:focus { + border-color: #b9151b; + box-shadow: inset 0 1px 1px rgba(0, 0, 0, 0.075), 0 0 6px #ef787c; +} +.has-error .input-group-addon { + color: #e51c23; + background-color: #f9bdbb; + border-color: #e51c23; +} +.has-error .form-control-feedback { + color: #e51c23; +} +.has-feedback label ~ .form-control-feedback { + top: 28px; +} +.has-feedback label.sr-only ~ .form-control-feedback { + top: 0; +} +.help-block { + display: block; + margin-top: 5px; + margin-bottom: 10px; + color: #a6a6a6; +} +@media (min-width: 768px) { + .form-inline .form-group { + display: inline-block; + margin-bottom: 0; + vertical-align: middle; + } + .form-inline .form-control { + display: inline-block; + width: auto; + vertical-align: middle; + } + .form-inline .form-control-static { + display: inline-block; + } + .form-inline .input-group { + display: inline-table; + vertical-align: middle; + } + .form-inline .input-group .input-group-addon, + .form-inline .input-group .input-group-btn, + .form-inline .input-group .form-control { + width: auto; + } + .form-inline .input-group > .form-control { + width: 100%; + } + .form-inline .control-label { + margin-bottom: 0; + vertical-align: middle; + } + .form-inline .radio, + .form-inline .checkbox { + display: inline-block; + margin-top: 0; + margin-bottom: 0; + vertical-align: middle; + } + .form-inline .radio label, + .form-inline .checkbox label { + padding-left: 0; + } + .form-inline .radio input[type="radio"], + .form-inline .checkbox input[type="checkbox"] { + position: relative; + margin-left: 0; + } + .form-inline .has-feedback .form-control-feedback { + top: 0; + } +} +.form-horizontal .radio, +.form-horizontal .checkbox, +.form-horizontal .radio-inline, +.form-horizontal .checkbox-inline { + padding-top: 7px; + margin-top: 0; + margin-bottom: 0; +} +.form-horizontal .radio, +.form-horizontal .checkbox { + min-height: 30px; +} +.form-horizontal .form-group { + margin-right: -15px; + margin-left: -15px; +} +@media (min-width: 768px) { + .form-horizontal .control-label { + padding-top: 7px; + margin-bottom: 0; + text-align: right; + } +} +.form-horizontal .has-feedback .form-control-feedback { + right: 15px; +} +@media (min-width: 768px) { + .form-horizontal .form-group-lg .control-label { + padding-top: 11px; + font-size: 17px; + } +} +@media (min-width: 768px) { + .form-horizontal .form-group-sm .control-label { + padding-top: 6px; + font-size: 12px; + } +} +.btn { + display: inline-block; + margin-bottom: 0; + font-weight: normal; + text-align: center; + white-space: nowrap; + vertical-align: middle; + -ms-touch-action: manipulation; + touch-action: manipulation; + cursor: pointer; + background-image: none; + border: 1px solid transparent; + padding: 6px 16px; + font-size: 13px; + line-height: 1.846; + border-radius: 3px; + -webkit-user-select: none; + -moz-user-select: none; + -ms-user-select: none; + user-select: none; +} +.btn:focus, +.btn:active:focus, +.btn.active:focus, +.btn.focus, +.btn:active.focus, +.btn.active.focus { + outline: 5px auto -webkit-focus-ring-color; + outline-offset: -2px; +} +.btn:hover, +.btn:focus, +.btn.focus { + color: #444444; + text-decoration: none; +} +.btn:active, +.btn.active { + background-image: none; + outline: 0; + box-shadow: inset 0 3px 5px rgba(0, 0, 0, 0.125); +} +.btn.disabled, +.btn[disabled], +fieldset[disabled] .btn { + cursor: not-allowed; + filter: alpha(opacity=65); + opacity: 0.65; + box-shadow: none; +} +a.btn.disabled, +fieldset[disabled] a.btn { + pointer-events: none; +} +.btn-default { + color: #444444; + background-color: #ffffff; + border-color: transparent; +} +.btn-default:focus, +.btn-default.focus { + color: #444444; + background-color: #e6e6e6; + border-color: rgba(0, 0, 0, 0); +} +.btn-default:hover { + color: #444444; + background-color: #e6e6e6; + border-color: rgba(0, 0, 0, 0); +} +.btn-default:active, +.btn-default.active, +.open > .dropdown-toggle.btn-default { + color: #444444; + background-color: #e6e6e6; + background-image: none; + border-color: rgba(0, 0, 0, 0); +} +.btn-default:active:hover, +.btn-default.active:hover, +.open > .dropdown-toggle.btn-default:hover, +.btn-default:active:focus, +.btn-default.active:focus, +.open > .dropdown-toggle.btn-default:focus, +.btn-default:active.focus, +.btn-default.active.focus, +.open > .dropdown-toggle.btn-default.focus { + color: #444444; + background-color: #d4d4d4; + border-color: rgba(0, 0, 0, 0); +} +.btn-default.disabled:hover, +.btn-default[disabled]:hover, +fieldset[disabled] .btn-default:hover, +.btn-default.disabled:focus, +.btn-default[disabled]:focus, +fieldset[disabled] .btn-default:focus, +.btn-default.disabled.focus, +.btn-default[disabled].focus, +fieldset[disabled] .btn-default.focus { + background-color: #ffffff; + border-color: transparent; +} +.btn-default .badge { + color: #ffffff; + background-color: #444444; +} +.btn-primary { + color: #ffffff; + background-color: #2196f3; + border-color: transparent; +} +.btn-primary:focus, +.btn-primary.focus { + color: #ffffff; + background-color: #0c7cd5; + border-color: rgba(0, 0, 0, 0); +} +.btn-primary:hover { + color: #ffffff; + background-color: #0c7cd5; + border-color: rgba(0, 0, 0, 0); +} +.btn-primary:active, +.btn-primary.active, +.open > .dropdown-toggle.btn-primary { + color: #ffffff; + background-color: #0c7cd5; + background-image: none; + border-color: rgba(0, 0, 0, 0); +} +.btn-primary:active:hover, +.btn-primary.active:hover, +.open > .dropdown-toggle.btn-primary:hover, +.btn-primary:active:focus, +.btn-primary.active:focus, +.open > .dropdown-toggle.btn-primary:focus, +.btn-primary:active.focus, +.btn-primary.active.focus, +.open > .dropdown-toggle.btn-primary.focus { + color: #ffffff; + background-color: #0a68b4; + border-color: rgba(0, 0, 0, 0); +} +.btn-primary.disabled:hover, +.btn-primary[disabled]:hover, +fieldset[disabled] .btn-primary:hover, +.btn-primary.disabled:focus, +.btn-primary[disabled]:focus, +fieldset[disabled] .btn-primary:focus, +.btn-primary.disabled.focus, +.btn-primary[disabled].focus, +fieldset[disabled] .btn-primary.focus { + background-color: #2196f3; + border-color: transparent; +} +.btn-primary .badge { + color: #2196f3; + background-color: #ffffff; +} +.btn-success { + color: #ffffff; + background-color: #4caf50; + border-color: transparent; +} +.btn-success:focus, +.btn-success.focus { + color: #ffffff; + background-color: #3d8b40; + border-color: rgba(0, 0, 0, 0); +} +.btn-success:hover { + color: #ffffff; + background-color: #3d8b40; + border-color: rgba(0, 0, 0, 0); +} +.btn-success:active, +.btn-success.active, +.open > .dropdown-toggle.btn-success { + color: #ffffff; + background-color: #3d8b40; + background-image: none; + border-color: rgba(0, 0, 0, 0); +} +.btn-success:active:hover, +.btn-success.active:hover, +.open > .dropdown-toggle.btn-success:hover, +.btn-success:active:focus, +.btn-success.active:focus, +.open > .dropdown-toggle.btn-success:focus, +.btn-success:active.focus, +.btn-success.active.focus, +.open > .dropdown-toggle.btn-success.focus { + color: #ffffff; + background-color: #327334; + border-color: rgba(0, 0, 0, 0); +} +.btn-success.disabled:hover, +.btn-success[disabled]:hover, +fieldset[disabled] .btn-success:hover, +.btn-success.disabled:focus, +.btn-success[disabled]:focus, +fieldset[disabled] .btn-success:focus, +.btn-success.disabled.focus, +.btn-success[disabled].focus, +fieldset[disabled] .btn-success.focus { + background-color: #4caf50; + border-color: transparent; +} +.btn-success .badge { + color: #4caf50; + background-color: #ffffff; +} +.btn-info { + color: #ffffff; + background-color: #9c27b0; + border-color: transparent; +} +.btn-info:focus, +.btn-info.focus { + color: #ffffff; + background-color: #771e86; + border-color: rgba(0, 0, 0, 0); +} +.btn-info:hover { + color: #ffffff; + background-color: #771e86; + border-color: rgba(0, 0, 0, 0); +} +.btn-info:active, +.btn-info.active, +.open > .dropdown-toggle.btn-info { + color: #ffffff; + background-color: #771e86; + background-image: none; + border-color: rgba(0, 0, 0, 0); +} +.btn-info:active:hover, +.btn-info.active:hover, +.open > .dropdown-toggle.btn-info:hover, +.btn-info:active:focus, +.btn-info.active:focus, +.open > .dropdown-toggle.btn-info:focus, +.btn-info:active.focus, +.btn-info.active.focus, +.open > .dropdown-toggle.btn-info.focus { + color: #ffffff; + background-color: #5d1769; + border-color: rgba(0, 0, 0, 0); +} +.btn-info.disabled:hover, +.btn-info[disabled]:hover, +fieldset[disabled] .btn-info:hover, +.btn-info.disabled:focus, +.btn-info[disabled]:focus, +fieldset[disabled] .btn-info:focus, +.btn-info.disabled.focus, +.btn-info[disabled].focus, +fieldset[disabled] .btn-info.focus { + background-color: #9c27b0; + border-color: transparent; +} +.btn-info .badge { + color: #9c27b0; + background-color: #ffffff; +} +.btn-warning { + color: #ffffff; + background-color: #ff9800; + border-color: transparent; +} +.btn-warning:focus, +.btn-warning.focus { + color: #ffffff; + background-color: #cc7a00; + border-color: rgba(0, 0, 0, 0); +} +.btn-warning:hover { + color: #ffffff; + background-color: #cc7a00; + border-color: rgba(0, 0, 0, 0); +} +.btn-warning:active, +.btn-warning.active, +.open > .dropdown-toggle.btn-warning { + color: #ffffff; + background-color: #cc7a00; + background-image: none; + border-color: rgba(0, 0, 0, 0); +} +.btn-warning:active:hover, +.btn-warning.active:hover, +.open > .dropdown-toggle.btn-warning:hover, +.btn-warning:active:focus, +.btn-warning.active:focus, +.open > .dropdown-toggle.btn-warning:focus, +.btn-warning:active.focus, +.btn-warning.active.focus, +.open > .dropdown-toggle.btn-warning.focus { + color: #ffffff; + background-color: #a86400; + border-color: rgba(0, 0, 0, 0); +} +.btn-warning.disabled:hover, +.btn-warning[disabled]:hover, +fieldset[disabled] .btn-warning:hover, +.btn-warning.disabled:focus, +.btn-warning[disabled]:focus, +fieldset[disabled] .btn-warning:focus, +.btn-warning.disabled.focus, +.btn-warning[disabled].focus, +fieldset[disabled] .btn-warning.focus { + background-color: #ff9800; + border-color: transparent; +} +.btn-warning .badge { + color: #ff9800; + background-color: #ffffff; +} +.btn-danger { + color: #ffffff; + background-color: #e51c23; + border-color: transparent; +} +.btn-danger:focus, +.btn-danger.focus { + color: #ffffff; + background-color: #b9151b; + border-color: rgba(0, 0, 0, 0); +} +.btn-danger:hover { + color: #ffffff; + background-color: #b9151b; + border-color: rgba(0, 0, 0, 0); +} +.btn-danger:active, +.btn-danger.active, +.open > .dropdown-toggle.btn-danger { + color: #ffffff; + background-color: #b9151b; + background-image: none; + border-color: rgba(0, 0, 0, 0); +} +.btn-danger:active:hover, +.btn-danger.active:hover, +.open > .dropdown-toggle.btn-danger:hover, +.btn-danger:active:focus, +.btn-danger.active:focus, +.open > .dropdown-toggle.btn-danger:focus, +.btn-danger:active.focus, +.btn-danger.active.focus, +.open > .dropdown-toggle.btn-danger.focus { + color: #ffffff; + background-color: #991216; + border-color: rgba(0, 0, 0, 0); +} +.btn-danger.disabled:hover, +.btn-danger[disabled]:hover, +fieldset[disabled] .btn-danger:hover, +.btn-danger.disabled:focus, +.btn-danger[disabled]:focus, +fieldset[disabled] .btn-danger:focus, +.btn-danger.disabled.focus, +.btn-danger[disabled].focus, +fieldset[disabled] .btn-danger.focus { + background-color: #e51c23; + border-color: transparent; +} +.btn-danger .badge { + color: #e51c23; + background-color: #ffffff; +} +.btn-link { + font-weight: 400; + color: #2196f3; + border-radius: 0; +} +.btn-link, +.btn-link:active, +.btn-link.active, +.btn-link[disabled], +fieldset[disabled] .btn-link { + background-color: transparent; + box-shadow: none; +} +.btn-link, +.btn-link:hover, +.btn-link:focus, +.btn-link:active { + border-color: transparent; +} +.btn-link:hover, +.btn-link:focus { + color: #0a6ebd; + text-decoration: underline; + background-color: transparent; +} +.btn-link[disabled]:hover, +fieldset[disabled] .btn-link:hover, +.btn-link[disabled]:focus, +fieldset[disabled] .btn-link:focus { + color: #bbbbbb; + text-decoration: none; +} +.btn-lg, +.btn-group-lg > .btn { + padding: 10px 16px; + font-size: 17px; + line-height: 1.3333333; + border-radius: 3px; +} +.btn-sm, +.btn-group-sm > .btn { + padding: 5px 10px; + font-size: 12px; + line-height: 1.5; + border-radius: 3px; +} +.btn-xs, +.btn-group-xs > .btn { + padding: 1px 5px; + font-size: 12px; + line-height: 1.5; + border-radius: 3px; +} +.btn-block { + display: block; + width: 100%; +} +.btn-block + .btn-block { + margin-top: 5px; +} +input[type="submit"].btn-block, +input[type="reset"].btn-block, +input[type="button"].btn-block { + width: 100%; +} +.fade { + opacity: 0; + transition: opacity 0.15s linear; +} +.fade.in { + opacity: 1; +} +.collapse { + display: none; +} +.collapse.in { + display: block; +} +tr.collapse.in { + display: table-row; +} +tbody.collapse.in { + display: table-row-group; +} +.collapsing { + position: relative; + height: 0; + overflow: hidden; + transition-property: height, visibility; + transition-duration: 0.35s; + transition-timing-function: ease; +} +.caret { + display: inline-block; + width: 0; + height: 0; + margin-left: 2px; + vertical-align: middle; + border-top: 4px dashed; + border-top: 4px solid \9; + border-right: 4px solid transparent; + border-left: 4px solid transparent; +} +.dropup, +.dropdown { + position: relative; +} +.dropdown-toggle:focus { + outline: 0; +} +.dropdown-menu { + position: absolute; + top: 100%; + left: 0; + z-index: 1000; + display: none; + float: left; + min-width: 160px; + padding: 5px 0; + margin: 2px 0 0; + font-size: 13px; + text-align: left; + list-style: none; + background-color: #ffffff; + background-clip: padding-box; + border: 1px solid #cccccc; + border: 1px solid rgba(0, 0, 0, 0.15); + border-radius: 3px; + box-shadow: 0 6px 12px rgba(0, 0, 0, 0.175); +} +.dropdown-menu.pull-right { + right: 0; + left: auto; +} +.dropdown-menu .divider { + height: 1px; + margin: 10.5px 0; + overflow: hidden; + background-color: #e5e5e5; +} +.dropdown-menu > li > a { + display: block; + padding: 3px 20px; + clear: both; + font-weight: 400; + line-height: 1.846; + color: #666666; + white-space: nowrap; +} +.dropdown-menu > li > a:hover, +.dropdown-menu > li > a:focus { + color: #141414; + text-decoration: none; + background-color: #eeeeee; +} +.dropdown-menu > .active > a, +.dropdown-menu > .active > a:hover, +.dropdown-menu > .active > a:focus { + color: #ffffff; + text-decoration: none; + background-color: #2196f3; + outline: 0; +} +.dropdown-menu > .disabled > a, +.dropdown-menu > .disabled > a:hover, +.dropdown-menu > .disabled > a:focus { + color: #bbbbbb; +} +.dropdown-menu > .disabled > a:hover, +.dropdown-menu > .disabled > a:focus { + text-decoration: none; + cursor: not-allowed; + background-color: transparent; + background-image: none; + filter: progid:DXImageTransform.Microsoft.gradient(enabled = false); +} +.open > .dropdown-menu { + display: block; +} +.open > a { + outline: 0; +} +.dropdown-menu-right { + right: 0; + left: auto; +} +.dropdown-menu-left { + right: auto; + left: 0; +} +.dropdown-header { + display: block; + padding: 3px 20px; + font-size: 12px; + line-height: 1.846; + color: #bbbbbb; + white-space: nowrap; +} +.dropdown-backdrop { + position: fixed; + top: 0; + right: 0; + bottom: 0; + left: 0; + z-index: 990; +} +.pull-right > .dropdown-menu { + right: 0; + left: auto; +} +.dropup .caret, +.navbar-fixed-bottom .dropdown .caret { + content: ""; + border-top: 0; + border-bottom: 4px dashed; + border-bottom: 4px solid \9; +} +.dropup .dropdown-menu, +.navbar-fixed-bottom .dropdown .dropdown-menu { + top: auto; + bottom: 100%; + margin-bottom: 2px; +} +@media (min-width: 768px) { + .navbar-right .dropdown-menu { + right: 0; + left: auto; + } + .navbar-right .dropdown-menu-left { + right: auto; + left: 0; + } +} +.btn-group, +.btn-group-vertical { + position: relative; + display: inline-block; + vertical-align: middle; +} +.btn-group > .btn, +.btn-group-vertical > .btn { + position: relative; + float: left; +} +.btn-group > .btn:hover, +.btn-group-vertical > .btn:hover, +.btn-group > .btn:focus, +.btn-group-vertical > .btn:focus, +.btn-group > .btn:active, +.btn-group-vertical > .btn:active, +.btn-group > .btn.active, +.btn-group-vertical > .btn.active { + z-index: 2; +} +.btn-group .btn + .btn, +.btn-group .btn + .btn-group, +.btn-group .btn-group + .btn, +.btn-group .btn-group + .btn-group { + margin-left: -1px; +} +.btn-toolbar { + margin-left: -5px; +} +.btn-toolbar .btn, +.btn-toolbar .btn-group, +.btn-toolbar .input-group { + float: left; +} +.btn-toolbar > .btn, +.btn-toolbar > .btn-group, +.btn-toolbar > .input-group { + margin-left: 5px; +} +.btn-group > .btn:not(:first-child):not(:last-child):not(.dropdown-toggle) { + border-radius: 0; +} +.btn-group > .btn:first-child { + margin-left: 0; +} +.btn-group > .btn:first-child:not(:last-child):not(.dropdown-toggle) { + border-top-right-radius: 0; + border-bottom-right-radius: 0; +} +.btn-group > .btn:last-child:not(:first-child), +.btn-group > .dropdown-toggle:not(:first-child) { + border-top-left-radius: 0; + border-bottom-left-radius: 0; +} +.btn-group > .btn-group { + float: left; +} +.btn-group > .btn-group:not(:first-child):not(:last-child) > .btn { + border-radius: 0; +} +.btn-group > .btn-group:first-child:not(:last-child) > .btn:last-child, +.btn-group > .btn-group:first-child:not(:last-child) > .dropdown-toggle { + border-top-right-radius: 0; + border-bottom-right-radius: 0; +} +.btn-group > .btn-group:last-child:not(:first-child) > .btn:first-child { + border-top-left-radius: 0; + border-bottom-left-radius: 0; +} +.btn-group .dropdown-toggle:active, +.btn-group.open .dropdown-toggle { + outline: 0; +} +.btn-group > .btn + .dropdown-toggle { + padding-right: 8px; + padding-left: 8px; +} +.btn-group > .btn-lg + .dropdown-toggle { + padding-right: 12px; + padding-left: 12px; +} +.btn-group.open .dropdown-toggle { + box-shadow: inset 0 3px 5px rgba(0, 0, 0, 0.125); +} +.btn-group.open .dropdown-toggle.btn-link { + box-shadow: none; +} +.btn .caret { + margin-left: 0; +} +.btn-lg .caret { + border-width: 5px 5px 0; + border-bottom-width: 0; +} +.dropup .btn-lg .caret { + border-width: 0 5px 5px; +} +.btn-group-vertical > .btn, +.btn-group-vertical > .btn-group, +.btn-group-vertical > .btn-group > .btn { + display: block; + float: none; + width: 100%; + max-width: 100%; +} +.btn-group-vertical > .btn-group > .btn { + float: none; +} +.btn-group-vertical > .btn + .btn, +.btn-group-vertical > .btn + .btn-group, +.btn-group-vertical > .btn-group + .btn, +.btn-group-vertical > .btn-group + .btn-group { + margin-top: -1px; + margin-left: 0; +} +.btn-group-vertical > .btn:not(:first-child):not(:last-child) { + border-radius: 0; +} +.btn-group-vertical > .btn:first-child:not(:last-child) { + border-top-left-radius: 3px; + border-top-right-radius: 3px; + border-bottom-right-radius: 0; + border-bottom-left-radius: 0; +} +.btn-group-vertical > .btn:last-child:not(:first-child) { + border-top-left-radius: 0; + border-top-right-radius: 0; + border-bottom-right-radius: 3px; + border-bottom-left-radius: 3px; +} +.btn-group-vertical > .btn-group:not(:first-child):not(:last-child) > .btn { + border-radius: 0; +} +.btn-group-vertical > .btn-group:first-child:not(:last-child) > .btn:last-child, +.btn-group-vertical > .btn-group:first-child:not(:last-child) > .dropdown-toggle { + border-bottom-right-radius: 0; + border-bottom-left-radius: 0; +} +.btn-group-vertical > .btn-group:last-child:not(:first-child) > .btn:first-child { + border-top-left-radius: 0; + border-top-right-radius: 0; +} +.btn-group-justified { + display: table; + width: 100%; + table-layout: fixed; + border-collapse: separate; +} +.btn-group-justified > .btn, +.btn-group-justified > .btn-group { + display: table-cell; + float: none; + width: 1%; +} +.btn-group-justified > .btn-group .btn { + width: 100%; +} +.btn-group-justified > .btn-group .dropdown-menu { + left: auto; +} +[data-toggle="buttons"] > .btn input[type="radio"], +[data-toggle="buttons"] > .btn-group > .btn input[type="radio"], +[data-toggle="buttons"] > .btn input[type="checkbox"], +[data-toggle="buttons"] > .btn-group > .btn input[type="checkbox"] { + position: absolute; + clip: rect(0, 0, 0, 0); + pointer-events: none; +} +.input-group { + position: relative; + display: table; + border-collapse: separate; +} +.input-group[class*="col-"] { + float: none; + padding-right: 0; + padding-left: 0; +} +.input-group .form-control { + position: relative; + z-index: 2; + float: left; + width: 100%; + margin-bottom: 0; +} +.input-group .form-control:focus { + z-index: 3; +} +.input-group-lg > .form-control, +.input-group-lg > .input-group-addon, +.input-group-lg > .input-group-btn > .btn { + height: 45px; + padding: 10px 16px; + font-size: 17px; + line-height: 1.3333333; + border-radius: 3px; +} +select.input-group-lg > .form-control, +select.input-group-lg > .input-group-addon, +select.input-group-lg > .input-group-btn > .btn { + height: 45px; + line-height: 45px; +} +textarea.input-group-lg > .form-control, +textarea.input-group-lg > .input-group-addon, +textarea.input-group-lg > .input-group-btn > .btn, +select[multiple].input-group-lg > .form-control, +select[multiple].input-group-lg > .input-group-addon, +select[multiple].input-group-lg > .input-group-btn > .btn { + height: auto; +} +.input-group-sm > .form-control, +.input-group-sm > .input-group-addon, +.input-group-sm > .input-group-btn > .btn { + height: 30px; + padding: 5px 10px; + font-size: 12px; + line-height: 1.5; + border-radius: 3px; +} +select.input-group-sm > .form-control, +select.input-group-sm > .input-group-addon, +select.input-group-sm > .input-group-btn > .btn { + height: 30px; + line-height: 30px; +} +textarea.input-group-sm > .form-control, +textarea.input-group-sm > .input-group-addon, +textarea.input-group-sm > .input-group-btn > .btn, +select[multiple].input-group-sm > .form-control, +select[multiple].input-group-sm > .input-group-addon, +select[multiple].input-group-sm > .input-group-btn > .btn { + height: auto; +} +.input-group-addon, +.input-group-btn, +.input-group .form-control { + display: table-cell; +} +.input-group-addon:not(:first-child):not(:last-child), +.input-group-btn:not(:first-child):not(:last-child), +.input-group .form-control:not(:first-child):not(:last-child) { + border-radius: 0; +} +.input-group-addon, +.input-group-btn { + width: 1%; + white-space: nowrap; + vertical-align: middle; +} +.input-group-addon { + padding: 6px 16px; + font-size: 13px; + font-weight: 400; + line-height: 1; + color: #666666; + text-align: center; + background-color: transparent; + border: 1px solid transparent; + border-radius: 3px; +} +.input-group-addon.input-sm { + padding: 5px 10px; + font-size: 12px; + border-radius: 3px; +} +.input-group-addon.input-lg { + padding: 10px 16px; + font-size: 17px; + border-radius: 3px; +} +.input-group-addon input[type="radio"], +.input-group-addon input[type="checkbox"] { + margin-top: 0; +} +.input-group .form-control:first-child, +.input-group-addon:first-child, +.input-group-btn:first-child > .btn, +.input-group-btn:first-child > .btn-group > .btn, +.input-group-btn:first-child > .dropdown-toggle, +.input-group-btn:last-child > .btn:not(:last-child):not(.dropdown-toggle), +.input-group-btn:last-child > .btn-group:not(:last-child) > .btn { + border-top-right-radius: 0; + border-bottom-right-radius: 0; +} +.input-group-addon:first-child { + border-right: 0; +} +.input-group .form-control:last-child, +.input-group-addon:last-child, +.input-group-btn:last-child > .btn, +.input-group-btn:last-child > .btn-group > .btn, +.input-group-btn:last-child > .dropdown-toggle, +.input-group-btn:first-child > .btn:not(:first-child), +.input-group-btn:first-child > .btn-group:not(:first-child) > .btn { + border-top-left-radius: 0; + border-bottom-left-radius: 0; +} +.input-group-addon:last-child { + border-left: 0; +} +.input-group-btn { + position: relative; + font-size: 0; + white-space: nowrap; +} +.input-group-btn > .btn { + position: relative; +} +.input-group-btn > .btn + .btn { + margin-left: -1px; +} +.input-group-btn > .btn:hover, +.input-group-btn > .btn:focus, +.input-group-btn > .btn:active { + z-index: 2; +} +.input-group-btn:first-child > .btn, +.input-group-btn:first-child > .btn-group { + margin-right: -1px; +} +.input-group-btn:last-child > .btn, +.input-group-btn:last-child > .btn-group { + z-index: 2; + margin-left: -1px; +} +.nav { + padding-left: 0; + margin-bottom: 0; + list-style: none; +} +.nav > li { + position: relative; + display: block; +} +.nav > li > a { + position: relative; + display: block; + padding: 10px 15px; +} +.nav > li > a:hover, +.nav > li > a:focus { + text-decoration: none; + background-color: #eeeeee; +} +.nav > li.disabled > a { + color: #bbbbbb; +} +.nav > li.disabled > a:hover, +.nav > li.disabled > a:focus { + color: #bbbbbb; + text-decoration: none; + cursor: not-allowed; + background-color: transparent; +} +.nav .open > a, +.nav .open > a:hover, +.nav .open > a:focus { + background-color: #eeeeee; + border-color: #2196f3; +} +.nav .nav-divider { + height: 1px; + margin: 10.5px 0; + overflow: hidden; + background-color: #e5e5e5; +} +.nav > li > a > img { + max-width: none; +} +.nav-tabs { + border-bottom: 1px solid transparent; +} +.nav-tabs > li { + float: left; + margin-bottom: -1px; +} +.nav-tabs > li > a { + margin-right: 2px; + line-height: 1.846; + border: 1px solid transparent; + border-radius: 3px 3px 0 0; +} +.nav-tabs > li > a:hover { + border-color: #eeeeee #eeeeee transparent; +} +.nav-tabs > li.active > a, +.nav-tabs > li.active > a:hover, +.nav-tabs > li.active > a:focus { + color: #666666; + cursor: default; + background-color: transparent; + border: 1px solid transparent; + border-bottom-color: transparent; +} +.nav-tabs.nav-justified { + width: 100%; + border-bottom: 0; +} +.nav-tabs.nav-justified > li { + float: none; +} +.nav-tabs.nav-justified > li > a { + margin-bottom: 5px; + text-align: center; +} +.nav-tabs.nav-justified > .dropdown .dropdown-menu { + top: auto; + left: auto; +} +@media (min-width: 768px) { + .nav-tabs.nav-justified > li { + display: table-cell; + width: 1%; + } + .nav-tabs.nav-justified > li > a { + margin-bottom: 0; + } +} +.nav-tabs.nav-justified > li > a { + margin-right: 0; + border-radius: 3px; +} +.nav-tabs.nav-justified > .active > a, +.nav-tabs.nav-justified > .active > a:hover, +.nav-tabs.nav-justified > .active > a:focus { + border: 1px solid transparent; +} +@media (min-width: 768px) { + .nav-tabs.nav-justified > li > a { + border-bottom: 1px solid transparent; + border-radius: 3px 3px 0 0; + } + .nav-tabs.nav-justified > .active > a, + .nav-tabs.nav-justified > .active > a:hover, + .nav-tabs.nav-justified > .active > a:focus { + border-bottom-color: #ffffff; + } +} +.nav-pills > li { + float: left; +} +.nav-pills > li > a { + border-radius: 3px; +} +.nav-pills > li + li { + margin-left: 2px; +} +.nav-pills > li.active > a, +.nav-pills > li.active > a:hover, +.nav-pills > li.active > a:focus { + color: #ffffff; + background-color: #2196f3; +} +.nav-stacked > li { + float: none; +} +.nav-stacked > li + li { + margin-top: 2px; + margin-left: 0; +} +.nav-justified { + width: 100%; +} +.nav-justified > li { + float: none; +} +.nav-justified > li > a { + margin-bottom: 5px; + text-align: center; +} +.nav-justified > .dropdown .dropdown-menu { + top: auto; + left: auto; +} +@media (min-width: 768px) { + .nav-justified > li { + display: table-cell; + width: 1%; + } + .nav-justified > li > a { + margin-bottom: 0; + } +} +.nav-tabs-justified { + border-bottom: 0; +} +.nav-tabs-justified > li > a { + margin-right: 0; + border-radius: 3px; +} +.nav-tabs-justified > .active > a, +.nav-tabs-justified > .active > a:hover, +.nav-tabs-justified > .active > a:focus { + border: 1px solid transparent; +} +@media (min-width: 768px) { + .nav-tabs-justified > li > a { + border-bottom: 1px solid transparent; + border-radius: 3px 3px 0 0; + } + .nav-tabs-justified > .active > a, + .nav-tabs-justified > .active > a:hover, + .nav-tabs-justified > .active > a:focus { + border-bottom-color: #ffffff; + } +} +.tab-content > .tab-pane { + display: none; +} +.tab-content > .active { + display: block; +} +.nav-tabs .dropdown-menu { + margin-top: -1px; + border-top-left-radius: 0; + border-top-right-radius: 0; +} +.navbar { + position: relative; + min-height: 64px; + margin-bottom: 23px; + border: 1px solid transparent; +} +@media (min-width: 768px) { + .navbar { + border-radius: 3px; + } +} +@media (min-width: 768px) { + .navbar-header { + float: left; + } +} +.navbar-collapse { + padding-right: 15px; + padding-left: 15px; + overflow-x: visible; + border-top: 1px solid transparent; + box-shadow: inset 0 1px 0 rgba(255, 255, 255, 0.1); + -webkit-overflow-scrolling: touch; +} +.navbar-collapse.in { + overflow-y: auto; +} +@media (min-width: 768px) { + .navbar-collapse { + width: auto; + border-top: 0; + box-shadow: none; + } + .navbar-collapse.collapse { + display: block !important; + height: auto !important; + padding-bottom: 0; + overflow: visible !important; + } + .navbar-collapse.in { + overflow-y: visible; + } + .navbar-fixed-top .navbar-collapse, + .navbar-static-top .navbar-collapse, + .navbar-fixed-bottom .navbar-collapse { + padding-right: 0; + padding-left: 0; + } +} +.navbar-fixed-top, +.navbar-fixed-bottom { + position: fixed; + right: 0; + left: 0; + z-index: 1030; +} +.navbar-fixed-top .navbar-collapse, +.navbar-fixed-bottom .navbar-collapse { + max-height: 340px; +} +@media (max-device-width: 480px) and (orientation: landscape) { + .navbar-fixed-top .navbar-collapse, + .navbar-fixed-bottom .navbar-collapse { + max-height: 200px; + } +} +@media (min-width: 768px) { + .navbar-fixed-top, + .navbar-fixed-bottom { + border-radius: 0; + } +} +.navbar-fixed-top { + top: 0; + border-width: 0 0 1px; +} +.navbar-fixed-bottom { + bottom: 0; + margin-bottom: 0; + border-width: 1px 0 0; +} +.container > .navbar-header, +.container-fluid > .navbar-header, +.container > .navbar-collapse, +.container-fluid > .navbar-collapse { + margin-right: -15px; + margin-left: -15px; +} +@media (min-width: 768px) { + .container > .navbar-header, + .container-fluid > .navbar-header, + .container > .navbar-collapse, + .container-fluid > .navbar-collapse { + margin-right: 0; + margin-left: 0; + } +} +.navbar-static-top { + z-index: 1000; + border-width: 0 0 1px; +} +@media (min-width: 768px) { + .navbar-static-top { + border-radius: 0; + } +} +.navbar-brand { + float: left; + height: 64px; + padding: 10.5px 15px; + font-size: 17px; + line-height: 35px; +} +.navbar-brand:hover, +.navbar-brand:focus { + text-decoration: none; +} +.navbar-brand > img { + display: block; +} +@media (min-width: 768px) { + .navbar > .container .navbar-brand, + .navbar > .container-fluid .navbar-brand { + margin-left: -15px; + } +} +.navbar-toggle { + position: relative; + float: right; + padding: 9px 10px; + margin-right: 15px; + margin-top: 15px; + margin-bottom: 15px; + background-color: transparent; + background-image: none; + border: 1px solid transparent; + border-radius: 3px; +} +.navbar-toggle:focus { + outline: 0; +} +.navbar-toggle .icon-bar { + display: block; + width: 22px; + height: 2px; + border-radius: 1px; +} +.navbar-toggle .icon-bar + .icon-bar { + margin-top: 4px; +} +@media (min-width: 768px) { + .navbar-toggle { + display: none; + } +} +.navbar-nav { + margin: 10.25px -15px; +} +.navbar-nav > li > a { + padding-top: 10px; + padding-bottom: 10px; + line-height: 23px; +} +@media (max-width: 767px) { + .navbar-nav .open .dropdown-menu { + position: static; + float: none; + width: auto; + margin-top: 0; + background-color: transparent; + border: 0; + box-shadow: none; + } + .navbar-nav .open .dropdown-menu > li > a, + .navbar-nav .open .dropdown-menu .dropdown-header { + padding: 5px 15px 5px 25px; + } + .navbar-nav .open .dropdown-menu > li > a { + line-height: 23px; + } + .navbar-nav .open .dropdown-menu > li > a:hover, + .navbar-nav .open .dropdown-menu > li > a:focus { + background-image: none; + } +} +@media (min-width: 768px) { + .navbar-nav { + float: left; + margin: 0; + } + .navbar-nav > li { + float: left; + } + .navbar-nav > li > a { + padding-top: 20.5px; + padding-bottom: 20.5px; + } +} +.navbar-form { + padding: 10px 15px; + margin-right: -15px; + margin-left: -15px; + border-top: 1px solid transparent; + border-bottom: 1px solid transparent; + box-shadow: inset 0 1px 0 rgba(255, 255, 255, 0.1), 0 1px 0 rgba(255, 255, 255, 0.1); + margin-top: 13.5px; + margin-bottom: 13.5px; +} +@media (min-width: 768px) { + .navbar-form .form-group { + display: inline-block; + margin-bottom: 0; + vertical-align: middle; + } + .navbar-form .form-control { + display: inline-block; + width: auto; + vertical-align: middle; + } + .navbar-form .form-control-static { + display: inline-block; + } + .navbar-form .input-group { + display: inline-table; + vertical-align: middle; + } + .navbar-form .input-group .input-group-addon, + .navbar-form .input-group .input-group-btn, + .navbar-form .input-group .form-control { + width: auto; + } + .navbar-form .input-group > .form-control { + width: 100%; + } + .navbar-form .control-label { + margin-bottom: 0; + vertical-align: middle; + } + .navbar-form .radio, + .navbar-form .checkbox { + display: inline-block; + margin-top: 0; + margin-bottom: 0; + vertical-align: middle; + } + .navbar-form .radio label, + .navbar-form .checkbox label { + padding-left: 0; + } + .navbar-form .radio input[type="radio"], + .navbar-form .checkbox input[type="checkbox"] { + position: relative; + margin-left: 0; + } + .navbar-form .has-feedback .form-control-feedback { + top: 0; + } +} +@media (max-width: 767px) { + .navbar-form .form-group { + margin-bottom: 5px; + } + .navbar-form .form-group:last-child { + margin-bottom: 0; + } +} +@media (min-width: 768px) { + .navbar-form { + width: auto; + padding-top: 0; + padding-bottom: 0; + margin-right: 0; + margin-left: 0; + border: 0; + box-shadow: none; + } +} +.navbar-nav > li > .dropdown-menu { + margin-top: 0; + border-top-left-radius: 0; + border-top-right-radius: 0; +} +.navbar-fixed-bottom .navbar-nav > li > .dropdown-menu { + margin-bottom: 0; + border-top-left-radius: 3px; + border-top-right-radius: 3px; + border-bottom-right-radius: 0; + border-bottom-left-radius: 0; +} +.navbar-btn { + margin-top: 13.5px; + margin-bottom: 13.5px; +} +.navbar-btn.btn-sm { + margin-top: 17px; + margin-bottom: 17px; +} +.navbar-btn.btn-xs { + margin-top: 21px; + margin-bottom: 21px; +} +.navbar-text { + margin-top: 20.5px; + margin-bottom: 20.5px; +} +@media (min-width: 768px) { + .navbar-text { + float: left; + margin-right: 15px; + margin-left: 15px; + } +} +@media (min-width: 768px) { + .navbar-left { + float: left !important; + } + .navbar-right { + float: right !important; + margin-right: -15px; + } + .navbar-right ~ .navbar-right { + margin-right: 0; + } +} +.navbar-default { + background-color: #ffffff; + border-color: transparent; +} +.navbar-default .navbar-brand { + color: #666666; +} +.navbar-default .navbar-brand:hover, +.navbar-default .navbar-brand:focus { + color: #212121; + background-color: transparent; +} +.navbar-default .navbar-text { + color: #bbbbbb; +} +.navbar-default .navbar-nav > li > a { + color: #666666; +} +.navbar-default .navbar-nav > li > a:hover, +.navbar-default .navbar-nav > li > a:focus { + color: #212121; + background-color: transparent; +} +.navbar-default .navbar-nav > .active > a, +.navbar-default .navbar-nav > .active > a:hover, +.navbar-default .navbar-nav > .active > a:focus { + color: #212121; + background-color: #eeeeee; +} +.navbar-default .navbar-nav > .disabled > a, +.navbar-default .navbar-nav > .disabled > a:hover, +.navbar-default .navbar-nav > .disabled > a:focus { + color: #cccccc; + background-color: transparent; +} +.navbar-default .navbar-nav > .open > a, +.navbar-default .navbar-nav > .open > a:hover, +.navbar-default .navbar-nav > .open > a:focus { + color: #212121; + background-color: #eeeeee; +} +@media (max-width: 767px) { + .navbar-default .navbar-nav .open .dropdown-menu > li > a { + color: #666666; + } + .navbar-default .navbar-nav .open .dropdown-menu > li > a:hover, + .navbar-default .navbar-nav .open .dropdown-menu > li > a:focus { + color: #212121; + background-color: transparent; + } + .navbar-default .navbar-nav .open .dropdown-menu > .active > a, + .navbar-default .navbar-nav .open .dropdown-menu > .active > a:hover, + .navbar-default .navbar-nav .open .dropdown-menu > .active > a:focus { + color: #212121; + background-color: #eeeeee; + } + .navbar-default .navbar-nav .open .dropdown-menu > .disabled > a, + .navbar-default .navbar-nav .open .dropdown-menu > .disabled > a:hover, + .navbar-default .navbar-nav .open .dropdown-menu > .disabled > a:focus { + color: #cccccc; + background-color: transparent; + } +} +.navbar-default .navbar-toggle { + border-color: transparent; +} +.navbar-default .navbar-toggle:hover, +.navbar-default .navbar-toggle:focus { + background-color: transparent; +} +.navbar-default .navbar-toggle .icon-bar { + background-color: rgba(0, 0, 0, 0.5); +} +.navbar-default .navbar-collapse, +.navbar-default .navbar-form { + border-color: transparent; +} +.navbar-default .navbar-link { + color: #666666; +} +.navbar-default .navbar-link:hover { + color: #212121; +} +.navbar-default .btn-link { + color: #666666; +} +.navbar-default .btn-link:hover, +.navbar-default .btn-link:focus { + color: #212121; +} +.navbar-default .btn-link[disabled]:hover, +fieldset[disabled] .navbar-default .btn-link:hover, +.navbar-default .btn-link[disabled]:focus, +fieldset[disabled] .navbar-default .btn-link:focus { + color: #cccccc; +} +.navbar-inverse { + background-color: #2196f3; + border-color: transparent; +} +.navbar-inverse .navbar-brand { + color: #b2dbfb; +} +.navbar-inverse .navbar-brand:hover, +.navbar-inverse .navbar-brand:focus { + color: #ffffff; + background-color: transparent; +} +.navbar-inverse .navbar-text { + color: #bbbbbb; +} +.navbar-inverse .navbar-nav > li > a { + color: #b2dbfb; +} +.navbar-inverse .navbar-nav > li > a:hover, +.navbar-inverse .navbar-nav > li > a:focus { + color: #ffffff; + background-color: transparent; +} +.navbar-inverse .navbar-nav > .active > a, +.navbar-inverse .navbar-nav > .active > a:hover, +.navbar-inverse .navbar-nav > .active > a:focus { + color: #ffffff; + background-color: #0c7cd5; +} +.navbar-inverse .navbar-nav > .disabled > a, +.navbar-inverse .navbar-nav > .disabled > a:hover, +.navbar-inverse .navbar-nav > .disabled > a:focus { + color: #444444; + background-color: transparent; +} +.navbar-inverse .navbar-nav > .open > a, +.navbar-inverse .navbar-nav > .open > a:hover, +.navbar-inverse .navbar-nav > .open > a:focus { + color: #ffffff; + background-color: #0c7cd5; +} +@media (max-width: 767px) { + .navbar-inverse .navbar-nav .open .dropdown-menu > .dropdown-header { + border-color: transparent; + } + .navbar-inverse .navbar-nav .open .dropdown-menu .divider { + background-color: transparent; + } + .navbar-inverse .navbar-nav .open .dropdown-menu > li > a { + color: #b2dbfb; + } + .navbar-inverse .navbar-nav .open .dropdown-menu > li > a:hover, + .navbar-inverse .navbar-nav .open .dropdown-menu > li > a:focus { + color: #ffffff; + background-color: transparent; + } + .navbar-inverse .navbar-nav .open .dropdown-menu > .active > a, + .navbar-inverse .navbar-nav .open .dropdown-menu > .active > a:hover, + .navbar-inverse .navbar-nav .open .dropdown-menu > .active > a:focus { + color: #ffffff; + background-color: #0c7cd5; + } + .navbar-inverse .navbar-nav .open .dropdown-menu > .disabled > a, + .navbar-inverse .navbar-nav .open .dropdown-menu > .disabled > a:hover, + .navbar-inverse .navbar-nav .open .dropdown-menu > .disabled > a:focus { + color: #444444; + background-color: transparent; + } +} +.navbar-inverse .navbar-toggle { + border-color: transparent; +} +.navbar-inverse .navbar-toggle:hover, +.navbar-inverse .navbar-toggle:focus { + background-color: transparent; +} +.navbar-inverse .navbar-toggle .icon-bar { + background-color: rgba(0, 0, 0, 0.5); +} +.navbar-inverse .navbar-collapse, +.navbar-inverse .navbar-form { + border-color: #0c84e4; +} +.navbar-inverse .navbar-link { + color: #b2dbfb; +} +.navbar-inverse .navbar-link:hover { + color: #ffffff; +} +.navbar-inverse .btn-link { + color: #b2dbfb; +} +.navbar-inverse .btn-link:hover, +.navbar-inverse .btn-link:focus { + color: #ffffff; +} +.navbar-inverse .btn-link[disabled]:hover, +fieldset[disabled] .navbar-inverse .btn-link:hover, +.navbar-inverse .btn-link[disabled]:focus, +fieldset[disabled] .navbar-inverse .btn-link:focus { + color: #444444; +} +.breadcrumb { + padding: 8px 15px; + margin-bottom: 23px; + list-style: none; + background-color: #f5f5f5; + border-radius: 3px; +} +.breadcrumb > li { + display: inline-block; +} +.breadcrumb > li + li:before { + padding: 0 5px; + color: #cccccc; + content: "/\00a0"; +} +.breadcrumb > .active { + color: #bbbbbb; +} +.pagination { + display: inline-block; + padding-left: 0; + margin: 23px 0; + border-radius: 3px; +} +.pagination > li { + display: inline; +} +.pagination > li > a, +.pagination > li > span { + position: relative; + float: left; + padding: 6px 16px; + margin-left: -1px; + line-height: 1.846; + color: #2196f3; + text-decoration: none; + background-color: #ffffff; + border: 1px solid #dddddd; +} +.pagination > li > a:hover, +.pagination > li > span:hover, +.pagination > li > a:focus, +.pagination > li > span:focus { + z-index: 2; + color: #0a6ebd; + background-color: #eeeeee; + border-color: #dddddd; +} +.pagination > li:first-child > a, +.pagination > li:first-child > span { + margin-left: 0; + border-top-left-radius: 3px; + border-bottom-left-radius: 3px; +} +.pagination > li:last-child > a, +.pagination > li:last-child > span { + border-top-right-radius: 3px; + border-bottom-right-radius: 3px; +} +.pagination > .active > a, +.pagination > .active > span, +.pagination > .active > a:hover, +.pagination > .active > span:hover, +.pagination > .active > a:focus, +.pagination > .active > span:focus { + z-index: 3; + color: #ffffff; + cursor: default; + background-color: #2196f3; + border-color: #2196f3; +} +.pagination > .disabled > span, +.pagination > .disabled > span:hover, +.pagination > .disabled > span:focus, +.pagination > .disabled > a, +.pagination > .disabled > a:hover, +.pagination > .disabled > a:focus { + color: #bbbbbb; + cursor: not-allowed; + background-color: #ffffff; + border-color: #dddddd; +} +.pagination-lg > li > a, +.pagination-lg > li > span { + padding: 10px 16px; + font-size: 17px; + line-height: 1.3333333; +} +.pagination-lg > li:first-child > a, +.pagination-lg > li:first-child > span { + border-top-left-radius: 3px; + border-bottom-left-radius: 3px; +} +.pagination-lg > li:last-child > a, +.pagination-lg > li:last-child > span { + border-top-right-radius: 3px; + border-bottom-right-radius: 3px; +} +.pagination-sm > li > a, +.pagination-sm > li > span { + padding: 5px 10px; + font-size: 12px; + line-height: 1.5; +} +.pagination-sm > li:first-child > a, +.pagination-sm > li:first-child > span { + border-top-left-radius: 3px; + border-bottom-left-radius: 3px; +} +.pagination-sm > li:last-child > a, +.pagination-sm > li:last-child > span { + border-top-right-radius: 3px; + border-bottom-right-radius: 3px; +} +.pager { + padding-left: 0; + margin: 23px 0; + text-align: center; + list-style: none; +} +.pager li { + display: inline; +} +.pager li > a, +.pager li > span { + display: inline-block; + padding: 5px 14px; + background-color: #ffffff; + border: 1px solid #dddddd; + border-radius: 15px; +} +.pager li > a:hover, +.pager li > a:focus { + text-decoration: none; + background-color: #eeeeee; +} +.pager .next > a, +.pager .next > span { + float: right; +} +.pager .previous > a, +.pager .previous > span { + float: left; +} +.pager .disabled > a, +.pager .disabled > a:hover, +.pager .disabled > a:focus, +.pager .disabled > span { + color: #bbbbbb; + cursor: not-allowed; + background-color: #ffffff; +} +.label { + display: inline; + padding: .2em .6em .3em; + font-size: 75%; + font-weight: 700; + line-height: 1; + color: #ffffff; + text-align: center; + white-space: nowrap; + vertical-align: baseline; + border-radius: .25em; +} +a.label:hover, +a.label:focus { + color: #ffffff; + text-decoration: none; + cursor: pointer; +} +.label:empty { + display: none; +} +.btn .label { + position: relative; + top: -1px; +} +.label-default { + background-color: #bbbbbb; +} +.label-default[href]:hover, +.label-default[href]:focus { + background-color: #a2a2a2; +} +.label-primary { + background-color: #2196f3; +} +.label-primary[href]:hover, +.label-primary[href]:focus { + background-color: #0c7cd5; +} +.label-success { + background-color: #4caf50; +} +.label-success[href]:hover, +.label-success[href]:focus { + background-color: #3d8b40; +} +.label-info { + background-color: #9c27b0; +} +.label-info[href]:hover, +.label-info[href]:focus { + background-color: #771e86; +} +.label-warning { + background-color: #ff9800; +} +.label-warning[href]:hover, +.label-warning[href]:focus { + background-color: #cc7a00; +} +.label-danger { + background-color: #e51c23; +} +.label-danger[href]:hover, +.label-danger[href]:focus { + background-color: #b9151b; +} +.badge { + display: inline-block; + min-width: 10px; + padding: 3px 7px; + font-size: 12px; + font-weight: normal; + line-height: 1; + color: #ffffff; + text-align: center; + white-space: nowrap; + vertical-align: middle; + background-color: #bbbbbb; + border-radius: 10px; +} +.badge:empty { + display: none; +} +.btn .badge { + position: relative; + top: -1px; +} +.btn-xs .badge, +.btn-group-xs > .btn .badge { + top: 0; + padding: 1px 5px; +} +a.badge:hover, +a.badge:focus { + color: #ffffff; + text-decoration: none; + cursor: pointer; +} +.list-group-item.active > .badge, +.nav-pills > .active > a > .badge { + color: #2196f3; + background-color: #ffffff; +} +.list-group-item > .badge { + float: right; +} +.list-group-item > .badge + .badge { + margin-right: 5px; +} +.nav-pills > li > a > .badge { + margin-left: 3px; +} +.jumbotron { + padding-top: 30px; + padding-bottom: 30px; + margin-bottom: 30px; + color: inherit; + background-color: #f9f9f9; +} +.jumbotron h1, +.jumbotron .h1 { + color: #444444; +} +.jumbotron p { + margin-bottom: 15px; + font-size: 20px; + font-weight: 200; +} +.jumbotron > hr { + border-top-color: #e0e0e0; +} +.container .jumbotron, +.container-fluid .jumbotron { + padding-right: 15px; + padding-left: 15px; + border-radius: 3px; +} +.jumbotron .container { + max-width: 100%; +} +@media screen and (min-width: 768px) { + .jumbotron { + padding-top: 48px; + padding-bottom: 48px; + } + .container .jumbotron, + .container-fluid .jumbotron { + padding-right: 60px; + padding-left: 60px; + } + .jumbotron h1, + .jumbotron .h1 { + font-size: 59px; + } +} +.thumbnail { + display: block; + padding: 4px; + margin-bottom: 23px; + line-height: 1.846; + background-color: #ffffff; + border: 1px solid #dddddd; + border-radius: 3px; + transition: border 0.2s ease-in-out; +} +.thumbnail > img, +.thumbnail a > img { + margin-right: auto; + margin-left: auto; +} +a.thumbnail:hover, +a.thumbnail:focus, +a.thumbnail.active { + border-color: #2196f3; +} +.thumbnail .caption { + padding: 9px; + color: #666666; +} +.alert { + padding: 15px; + margin-bottom: 23px; + border: 1px solid transparent; + border-radius: 3px; +} +.alert h4 { + margin-top: 0; + color: inherit; +} +.alert .alert-link { + font-weight: bold; +} +.alert > p, +.alert > ul { + margin-bottom: 0; +} +.alert > p + p { + margin-top: 5px; +} +.alert-dismissable, +.alert-dismissible { + padding-right: 35px; +} +.alert-dismissable .close, +.alert-dismissible .close { + position: relative; + top: -2px; + right: -21px; + color: inherit; +} +.alert-success { + color: #4caf50; + background-color: #dff0d8; + border-color: #d6e9c6; +} +.alert-success hr { + border-top-color: #c9e2b3; +} +.alert-success .alert-link { + color: #3d8b40; +} +.alert-info { + color: #9c27b0; + background-color: #e1bee7; + border-color: #cba4dd; +} +.alert-info hr { + border-top-color: #c191d6; +} +.alert-info .alert-link { + color: #771e86; +} +.alert-warning { + color: #ff9800; + background-color: #ffe0b2; + border-color: #ffc599; +} +.alert-warning hr { + border-top-color: #ffb67f; +} +.alert-warning .alert-link { + color: #cc7a00; +} +.alert-danger { + color: #e51c23; + background-color: #f9bdbb; + border-color: #f7a4af; +} +.alert-danger hr { + border-top-color: #f58c9a; +} +.alert-danger .alert-link { + color: #b9151b; +} +@-webkit-keyframes progress-bar-stripes { + from { + background-position: 40px 0; + } + to { + background-position: 0 0; + } +} +@keyframes progress-bar-stripes { + from { + background-position: 40px 0; + } + to { + background-position: 0 0; + } +} +.progress { + height: 23px; + margin-bottom: 23px; + overflow: hidden; + background-color: #f5f5f5; + border-radius: 3px; + box-shadow: inset 0 1px 2px rgba(0, 0, 0, 0.1); +} +.progress-bar { + float: left; + width: 0%; + height: 100%; + font-size: 12px; + line-height: 23px; + color: #ffffff; + text-align: center; + background-color: #2196f3; + box-shadow: inset 0 -1px 0 rgba(0, 0, 0, 0.15); + transition: width 0.6s ease; +} +.progress-striped .progress-bar, +.progress-bar-striped { + background-image: linear-gradient(45deg, rgba(255, 255, 255, 0.15) 25%, transparent 25%, transparent 50%, rgba(255, 255, 255, 0.15) 50%, rgba(255, 255, 255, 0.15) 75%, transparent 75%, transparent); + background-size: 40px 40px; +} +.progress.active .progress-bar, +.progress-bar.active { + -webkit-animation: progress-bar-stripes 2s linear infinite; + animation: progress-bar-stripes 2s linear infinite; +} +.progress-bar-success { + background-color: #4caf50; +} +.progress-striped .progress-bar-success { + background-image: linear-gradient(45deg, rgba(255, 255, 255, 0.15) 25%, transparent 25%, transparent 50%, rgba(255, 255, 255, 0.15) 50%, rgba(255, 255, 255, 0.15) 75%, transparent 75%, transparent); +} +.progress-bar-info { + background-color: #9c27b0; +} +.progress-striped .progress-bar-info { + background-image: linear-gradient(45deg, rgba(255, 255, 255, 0.15) 25%, transparent 25%, transparent 50%, rgba(255, 255, 255, 0.15) 50%, rgba(255, 255, 255, 0.15) 75%, transparent 75%, transparent); +} +.progress-bar-warning { + background-color: #ff9800; +} +.progress-striped .progress-bar-warning { + background-image: linear-gradient(45deg, rgba(255, 255, 255, 0.15) 25%, transparent 25%, transparent 50%, rgba(255, 255, 255, 0.15) 50%, rgba(255, 255, 255, 0.15) 75%, transparent 75%, transparent); +} +.progress-bar-danger { + background-color: #e51c23; +} +.progress-striped .progress-bar-danger { + background-image: linear-gradient(45deg, rgba(255, 255, 255, 0.15) 25%, transparent 25%, transparent 50%, rgba(255, 255, 255, 0.15) 50%, rgba(255, 255, 255, 0.15) 75%, transparent 75%, transparent); +} +.media { + margin-top: 15px; +} +.media:first-child { + margin-top: 0; +} +.media, +.media-body { + overflow: hidden; + zoom: 1; +} +.media-body { + width: 10000px; +} +.media-object { + display: block; +} +.media-object.img-thumbnail { + max-width: none; +} +.media-right, +.media > .pull-right { + padding-left: 10px; +} +.media-left, +.media > .pull-left { + padding-right: 10px; +} +.media-left, +.media-right, +.media-body { + display: table-cell; + vertical-align: top; +} +.media-middle { + vertical-align: middle; +} +.media-bottom { + vertical-align: bottom; +} +.media-heading { + margin-top: 0; + margin-bottom: 5px; +} +.media-list { + padding-left: 0; + list-style: none; +} +.list-group { + padding-left: 0; + margin-bottom: 20px; +} +.list-group-item { + position: relative; + display: block; + padding: 10px 15px; + margin-bottom: -1px; + background-color: #ffffff; + border: 1px solid #dddddd; +} +.list-group-item:first-child { + border-top-left-radius: 3px; + border-top-right-radius: 3px; +} +.list-group-item:last-child { + margin-bottom: 0; + border-bottom-right-radius: 3px; + border-bottom-left-radius: 3px; +} +.list-group-item.disabled, +.list-group-item.disabled:hover, +.list-group-item.disabled:focus { + color: #bbbbbb; + cursor: not-allowed; + background-color: #eeeeee; +} +.list-group-item.disabled .list-group-item-heading, +.list-group-item.disabled:hover .list-group-item-heading, +.list-group-item.disabled:focus .list-group-item-heading { + color: inherit; +} +.list-group-item.disabled .list-group-item-text, +.list-group-item.disabled:hover .list-group-item-text, +.list-group-item.disabled:focus .list-group-item-text { + color: #bbbbbb; +} +.list-group-item.active, +.list-group-item.active:hover, +.list-group-item.active:focus { + z-index: 2; + color: #ffffff; + background-color: #2196f3; + border-color: #2196f3; +} +.list-group-item.active .list-group-item-heading, +.list-group-item.active:hover .list-group-item-heading, +.list-group-item.active:focus .list-group-item-heading, +.list-group-item.active .list-group-item-heading > small, +.list-group-item.active:hover .list-group-item-heading > small, +.list-group-item.active:focus .list-group-item-heading > small, +.list-group-item.active .list-group-item-heading > .small, +.list-group-item.active:hover .list-group-item-heading > .small, +.list-group-item.active:focus .list-group-item-heading > .small { + color: inherit; +} +.list-group-item.active .list-group-item-text, +.list-group-item.active:hover .list-group-item-text, +.list-group-item.active:focus .list-group-item-text { + color: #e3f2fd; +} +a.list-group-item, +button.list-group-item { + color: #555555; +} +a.list-group-item .list-group-item-heading, +button.list-group-item .list-group-item-heading { + color: #333333; +} +a.list-group-item:hover, +button.list-group-item:hover, +a.list-group-item:focus, +button.list-group-item:focus { + color: #555555; + text-decoration: none; + background-color: #f5f5f5; +} +button.list-group-item { + width: 100%; + text-align: left; +} +.list-group-item-success { + color: #4caf50; + background-color: #dff0d8; +} +a.list-group-item-success, +button.list-group-item-success { + color: #4caf50; +} +a.list-group-item-success .list-group-item-heading, +button.list-group-item-success .list-group-item-heading { + color: inherit; +} +a.list-group-item-success:hover, +button.list-group-item-success:hover, +a.list-group-item-success:focus, +button.list-group-item-success:focus { + color: #4caf50; + background-color: #d0e9c6; +} +a.list-group-item-success.active, +button.list-group-item-success.active, +a.list-group-item-success.active:hover, +button.list-group-item-success.active:hover, +a.list-group-item-success.active:focus, +button.list-group-item-success.active:focus { + color: #fff; + background-color: #4caf50; + border-color: #4caf50; +} +.list-group-item-info { + color: #9c27b0; + background-color: #e1bee7; +} +a.list-group-item-info, +button.list-group-item-info { + color: #9c27b0; +} +a.list-group-item-info .list-group-item-heading, +button.list-group-item-info .list-group-item-heading { + color: inherit; +} +a.list-group-item-info:hover, +button.list-group-item-info:hover, +a.list-group-item-info:focus, +button.list-group-item-info:focus { + color: #9c27b0; + background-color: #d8abe0; +} +a.list-group-item-info.active, +button.list-group-item-info.active, +a.list-group-item-info.active:hover, +button.list-group-item-info.active:hover, +a.list-group-item-info.active:focus, +button.list-group-item-info.active:focus { + color: #fff; + background-color: #9c27b0; + border-color: #9c27b0; +} +.list-group-item-warning { + color: #ff9800; + background-color: #ffe0b2; +} +a.list-group-item-warning, +button.list-group-item-warning { + color: #ff9800; +} +a.list-group-item-warning .list-group-item-heading, +button.list-group-item-warning .list-group-item-heading { + color: inherit; +} +a.list-group-item-warning:hover, +button.list-group-item-warning:hover, +a.list-group-item-warning:focus, +button.list-group-item-warning:focus { + color: #ff9800; + background-color: #ffd699; +} +a.list-group-item-warning.active, +button.list-group-item-warning.active, +a.list-group-item-warning.active:hover, +button.list-group-item-warning.active:hover, +a.list-group-item-warning.active:focus, +button.list-group-item-warning.active:focus { + color: #fff; + background-color: #ff9800; + border-color: #ff9800; +} +.list-group-item-danger { + color: #e51c23; + background-color: #f9bdbb; +} +a.list-group-item-danger, +button.list-group-item-danger { + color: #e51c23; +} +a.list-group-item-danger .list-group-item-heading, +button.list-group-item-danger .list-group-item-heading { + color: inherit; +} +a.list-group-item-danger:hover, +button.list-group-item-danger:hover, +a.list-group-item-danger:focus, +button.list-group-item-danger:focus { + color: #e51c23; + background-color: #f7a6a4; +} +a.list-group-item-danger.active, +button.list-group-item-danger.active, +a.list-group-item-danger.active:hover, +button.list-group-item-danger.active:hover, +a.list-group-item-danger.active:focus, +button.list-group-item-danger.active:focus { + color: #fff; + background-color: #e51c23; + border-color: #e51c23; +} +.list-group-item-heading { + margin-top: 0; + margin-bottom: 5px; +} +.list-group-item-text { + margin-bottom: 0; + line-height: 1.3; +} +.panel { + margin-bottom: 23px; + background-color: #ffffff; + border: 1px solid transparent; + border-radius: 3px; + box-shadow: 0 1px 1px rgba(0, 0, 0, 0.05); +} +.panel-body { + padding: 15px; +} +.panel-heading { + padding: 10px 15px; + border-bottom: 1px solid transparent; + border-top-left-radius: 2px; + border-top-right-radius: 2px; +} +.panel-heading > .dropdown .dropdown-toggle { + color: inherit; +} +.panel-title { + margin-top: 0; + margin-bottom: 0; + font-size: 15px; + color: inherit; +} +.panel-title > a, +.panel-title > small, +.panel-title > .small, +.panel-title > small > a, +.panel-title > .small > a { + color: inherit; +} +.panel-footer { + padding: 10px 15px; + background-color: #f5f5f5; + border-top: 1px solid #dddddd; + border-bottom-right-radius: 2px; + border-bottom-left-radius: 2px; +} +.panel > .list-group, +.panel > .panel-collapse > .list-group { + margin-bottom: 0; +} +.panel > .list-group .list-group-item, +.panel > .panel-collapse > .list-group .list-group-item { + border-width: 1px 0; + border-radius: 0; +} +.panel > .list-group:first-child .list-group-item:first-child, +.panel > .panel-collapse > .list-group:first-child .list-group-item:first-child { + border-top: 0; + border-top-left-radius: 2px; + border-top-right-radius: 2px; +} +.panel > .list-group:last-child .list-group-item:last-child, +.panel > .panel-collapse > .list-group:last-child .list-group-item:last-child { + border-bottom: 0; + border-bottom-right-radius: 2px; + border-bottom-left-radius: 2px; +} +.panel > .panel-heading + .panel-collapse > .list-group .list-group-item:first-child { + border-top-left-radius: 0; + border-top-right-radius: 0; +} +.panel-heading + .list-group .list-group-item:first-child { + border-top-width: 0; +} +.list-group + .panel-footer { + border-top-width: 0; +} +.panel > .table, +.panel > .table-responsive > .table, +.panel > .panel-collapse > .table { + margin-bottom: 0; +} +.panel > .table caption, +.panel > .table-responsive > .table caption, +.panel > .panel-collapse > .table caption { + padding-right: 15px; + padding-left: 15px; +} +.panel > .table:first-child, +.panel > .table-responsive:first-child > .table:first-child { + border-top-left-radius: 2px; + border-top-right-radius: 2px; +} +.panel > .table:first-child > thead:first-child > tr:first-child, +.panel > .table-responsive:first-child > .table:first-child > thead:first-child > tr:first-child, +.panel > .table:first-child > tbody:first-child > tr:first-child, +.panel > .table-responsive:first-child > .table:first-child > tbody:first-child > tr:first-child { + border-top-left-radius: 2px; + border-top-right-radius: 2px; +} +.panel > .table:first-child > thead:first-child > tr:first-child td:first-child, +.panel > .table-responsive:first-child > .table:first-child > thead:first-child > tr:first-child td:first-child, +.panel > .table:first-child > tbody:first-child > tr:first-child td:first-child, +.panel > .table-responsive:first-child > .table:first-child > tbody:first-child > tr:first-child td:first-child, +.panel > .table:first-child > thead:first-child > tr:first-child th:first-child, +.panel > .table-responsive:first-child > .table:first-child > thead:first-child > tr:first-child th:first-child, +.panel > .table:first-child > tbody:first-child > tr:first-child th:first-child, +.panel > .table-responsive:first-child > .table:first-child > tbody:first-child > tr:first-child th:first-child { + border-top-left-radius: 2px; +} +.panel > .table:first-child > thead:first-child > tr:first-child td:last-child, +.panel > .table-responsive:first-child > .table:first-child > thead:first-child > tr:first-child td:last-child, +.panel > .table:first-child > tbody:first-child > tr:first-child td:last-child, +.panel > .table-responsive:first-child > .table:first-child > tbody:first-child > tr:first-child td:last-child, +.panel > .table:first-child > thead:first-child > tr:first-child th:last-child, +.panel > .table-responsive:first-child > .table:first-child > thead:first-child > tr:first-child th:last-child, +.panel > .table:first-child > tbody:first-child > tr:first-child th:last-child, +.panel > .table-responsive:first-child > .table:first-child > tbody:first-child > tr:first-child th:last-child { + border-top-right-radius: 2px; +} +.panel > .table:last-child, +.panel > .table-responsive:last-child > .table:last-child { + border-bottom-right-radius: 2px; + border-bottom-left-radius: 2px; +} +.panel > .table:last-child > tbody:last-child > tr:last-child, +.panel > .table-responsive:last-child > .table:last-child > tbody:last-child > tr:last-child, +.panel > .table:last-child > tfoot:last-child > tr:last-child, +.panel > .table-responsive:last-child > .table:last-child > tfoot:last-child > tr:last-child { + border-bottom-right-radius: 2px; + border-bottom-left-radius: 2px; +} +.panel > .table:last-child > tbody:last-child > tr:last-child td:first-child, +.panel > .table-responsive:last-child > .table:last-child > tbody:last-child > tr:last-child td:first-child, +.panel > .table:last-child > tfoot:last-child > tr:last-child td:first-child, +.panel > .table-responsive:last-child > .table:last-child > tfoot:last-child > tr:last-child td:first-child, +.panel > .table:last-child > tbody:last-child > tr:last-child th:first-child, +.panel > .table-responsive:last-child > .table:last-child > tbody:last-child > tr:last-child th:first-child, +.panel > .table:last-child > tfoot:last-child > tr:last-child th:first-child, +.panel > .table-responsive:last-child > .table:last-child > tfoot:last-child > tr:last-child th:first-child { + border-bottom-left-radius: 2px; +} +.panel > .table:last-child > tbody:last-child > tr:last-child td:last-child, +.panel > .table-responsive:last-child > .table:last-child > tbody:last-child > tr:last-child td:last-child, +.panel > .table:last-child > tfoot:last-child > tr:last-child td:last-child, +.panel > .table-responsive:last-child > .table:last-child > tfoot:last-child > tr:last-child td:last-child, +.panel > .table:last-child > tbody:last-child > tr:last-child th:last-child, +.panel > .table-responsive:last-child > .table:last-child > tbody:last-child > tr:last-child th:last-child, +.panel > .table:last-child > tfoot:last-child > tr:last-child th:last-child, +.panel > .table-responsive:last-child > .table:last-child > tfoot:last-child > tr:last-child th:last-child { + border-bottom-right-radius: 2px; +} +.panel > .panel-body + .table, +.panel > .panel-body + .table-responsive, +.panel > .table + .panel-body, +.panel > .table-responsive + .panel-body { + border-top: 1px solid #dddddd; +} +.panel > .table > tbody:first-child > tr:first-child th, +.panel > .table > tbody:first-child > tr:first-child td { + border-top: 0; +} +.panel > .table-bordered, +.panel > .table-responsive > .table-bordered { + border: 0; +} +.panel > .table-bordered > thead > tr > th:first-child, +.panel > .table-responsive > .table-bordered > thead > tr > th:first-child, +.panel > .table-bordered > tbody > tr > th:first-child, +.panel > .table-responsive > .table-bordered > tbody > tr > th:first-child, +.panel > .table-bordered > tfoot > tr > th:first-child, +.panel > .table-responsive > .table-bordered > tfoot > tr > th:first-child, +.panel > .table-bordered > thead > tr > td:first-child, +.panel > .table-responsive > .table-bordered > thead > tr > td:first-child, +.panel > .table-bordered > tbody > tr > td:first-child, +.panel > .table-responsive > .table-bordered > tbody > tr > td:first-child, +.panel > .table-bordered > tfoot > tr > td:first-child, +.panel > .table-responsive > .table-bordered > tfoot > tr > td:first-child { + border-left: 0; +} +.panel > .table-bordered > thead > tr > th:last-child, +.panel > .table-responsive > .table-bordered > thead > tr > th:last-child, +.panel > .table-bordered > tbody > tr > th:last-child, +.panel > .table-responsive > .table-bordered > tbody > tr > th:last-child, +.panel > .table-bordered > tfoot > tr > th:last-child, +.panel > .table-responsive > .table-bordered > tfoot > tr > th:last-child, +.panel > .table-bordered > thead > tr > td:last-child, +.panel > .table-responsive > .table-bordered > thead > tr > td:last-child, +.panel > .table-bordered > tbody > tr > td:last-child, +.panel > .table-responsive > .table-bordered > tbody > tr > td:last-child, +.panel > .table-bordered > tfoot > tr > td:last-child, +.panel > .table-responsive > .table-bordered > tfoot > tr > td:last-child { + border-right: 0; +} +.panel > .table-bordered > thead > tr:first-child > td, +.panel > .table-responsive > .table-bordered > thead > tr:first-child > td, +.panel > .table-bordered > tbody > tr:first-child > td, +.panel > .table-responsive > .table-bordered > tbody > tr:first-child > td, +.panel > .table-bordered > thead > tr:first-child > th, +.panel > .table-responsive > .table-bordered > thead > tr:first-child > th, +.panel > .table-bordered > tbody > tr:first-child > th, +.panel > .table-responsive > .table-bordered > tbody > tr:first-child > th { + border-bottom: 0; +} +.panel > .table-bordered > tbody > tr:last-child > td, +.panel > .table-responsive > .table-bordered > tbody > tr:last-child > td, +.panel > .table-bordered > tfoot > tr:last-child > td, +.panel > .table-responsive > .table-bordered > tfoot > tr:last-child > td, +.panel > .table-bordered > tbody > tr:last-child > th, +.panel > .table-responsive > .table-bordered > tbody > tr:last-child > th, +.panel > .table-bordered > tfoot > tr:last-child > th, +.panel > .table-responsive > .table-bordered > tfoot > tr:last-child > th { + border-bottom: 0; +} +.panel > .table-responsive { + margin-bottom: 0; + border: 0; +} +.panel-group { + margin-bottom: 23px; +} +.panel-group .panel { + margin-bottom: 0; + border-radius: 3px; +} +.panel-group .panel + .panel { + margin-top: 5px; +} +.panel-group .panel-heading { + border-bottom: 0; +} +.panel-group .panel-heading + .panel-collapse > .panel-body, +.panel-group .panel-heading + .panel-collapse > .list-group { + border-top: 1px solid #dddddd; +} +.panel-group .panel-footer { + border-top: 0; +} +.panel-group .panel-footer + .panel-collapse .panel-body { + border-bottom: 1px solid #dddddd; +} +.panel-default { + border-color: #dddddd; +} +.panel-default > .panel-heading { + color: #212121; + background-color: #f5f5f5; + border-color: #dddddd; +} +.panel-default > .panel-heading + .panel-collapse > .panel-body { + border-top-color: #dddddd; +} +.panel-default > .panel-heading .badge { + color: #f5f5f5; + background-color: #212121; +} +.panel-default > .panel-footer + .panel-collapse > .panel-body { + border-bottom-color: #dddddd; +} +.panel-primary { + border-color: #2196f3; +} +.panel-primary > .panel-heading { + color: #ffffff; + background-color: #2196f3; + border-color: #2196f3; +} +.panel-primary > .panel-heading + .panel-collapse > .panel-body { + border-top-color: #2196f3; +} +.panel-primary > .panel-heading .badge { + color: #2196f3; + background-color: #ffffff; +} +.panel-primary > .panel-footer + .panel-collapse > .panel-body { + border-bottom-color: #2196f3; +} +.panel-success { + border-color: #d6e9c6; +} +.panel-success > .panel-heading { + color: #ffffff; + background-color: #4caf50; + border-color: #d6e9c6; +} +.panel-success > .panel-heading + .panel-collapse > .panel-body { + border-top-color: #d6e9c6; +} +.panel-success > .panel-heading .badge { + color: #4caf50; + background-color: #ffffff; +} +.panel-success > .panel-footer + .panel-collapse > .panel-body { + border-bottom-color: #d6e9c6; +} +.panel-info { + border-color: #cba4dd; +} +.panel-info > .panel-heading { + color: #ffffff; + background-color: #9c27b0; + border-color: #cba4dd; +} +.panel-info > .panel-heading + .panel-collapse > .panel-body { + border-top-color: #cba4dd; +} +.panel-info > .panel-heading .badge { + color: #9c27b0; + background-color: #ffffff; +} +.panel-info > .panel-footer + .panel-collapse > .panel-body { + border-bottom-color: #cba4dd; +} +.panel-warning { + border-color: #ffc599; +} +.panel-warning > .panel-heading { + color: #ffffff; + background-color: #ff9800; + border-color: #ffc599; +} +.panel-warning > .panel-heading + .panel-collapse > .panel-body { + border-top-color: #ffc599; +} +.panel-warning > .panel-heading .badge { + color: #ff9800; + background-color: #ffffff; +} +.panel-warning > .panel-footer + .panel-collapse > .panel-body { + border-bottom-color: #ffc599; +} +.panel-danger { + border-color: #f7a4af; +} +.panel-danger > .panel-heading { + color: #ffffff; + background-color: #e51c23; + border-color: #f7a4af; +} +.panel-danger > .panel-heading + .panel-collapse > .panel-body { + border-top-color: #f7a4af; +} +.panel-danger > .panel-heading .badge { + color: #e51c23; + background-color: #ffffff; +} +.panel-danger > .panel-footer + .panel-collapse > .panel-body { + border-bottom-color: #f7a4af; +} +.embed-responsive { + position: relative; + display: block; + height: 0; + padding: 0; + overflow: hidden; +} +.embed-responsive .embed-responsive-item, +.embed-responsive iframe, +.embed-responsive embed, +.embed-responsive object, +.embed-responsive video { + position: absolute; + top: 0; + bottom: 0; + left: 0; + width: 100%; + height: 100%; + border: 0; +} +.embed-responsive-16by9 { + padding-bottom: 56.25%; +} +.embed-responsive-4by3 { + padding-bottom: 75%; +} +.well { + min-height: 20px; + padding: 19px; + margin-bottom: 20px; + background-color: #f9f9f9; + border: 1px solid transparent; + border-radius: 3px; + box-shadow: inset 0 1px 1px rgba(0, 0, 0, 0.05); +} +.well blockquote { + border-color: #ddd; + border-color: rgba(0, 0, 0, 0.15); +} +.well-lg { + padding: 24px; + border-radius: 3px; +} +.well-sm { + padding: 9px; + border-radius: 3px; +} +.close { + float: right; + font-size: 19.5px; + font-weight: normal; + line-height: 1; + color: #000000; + text-shadow: none; + filter: alpha(opacity=20); + opacity: 0.2; +} +.close:hover, +.close:focus { + color: #000000; + text-decoration: none; + cursor: pointer; + filter: alpha(opacity=50); + opacity: 0.5; +} +button.close { + padding: 0; + cursor: pointer; + background: transparent; + border: 0; + -webkit-appearance: none; + appearance: none; +} +.modal-open { + overflow: hidden; +} +.modal { + position: fixed; + top: 0; + right: 0; + bottom: 0; + left: 0; + z-index: 1050; + display: none; + overflow: hidden; + -webkit-overflow-scrolling: touch; + outline: 0; +} +.modal.fade .modal-dialog { + -webkit-transform: translate(0, -25%); + transform: translate(0, -25%); + transition: -webkit-transform 0.3s ease-out; + transition: transform 0.3s ease-out; +} +.modal.in .modal-dialog { + -webkit-transform: translate(0, 0); + transform: translate(0, 0); +} +.modal-open .modal { + overflow-x: hidden; + overflow-y: auto; +} +.modal-dialog { + position: relative; + width: auto; + margin: 10px; +} +.modal-content { + position: relative; + background-color: #ffffff; + background-clip: padding-box; + border: 1px solid #999999; + border: 1px solid transparent; + border-radius: 3px; + box-shadow: 0 3px 9px rgba(0, 0, 0, 0.5); + outline: 0; +} +.modal-backdrop { + position: fixed; + top: 0; + right: 0; + bottom: 0; + left: 0; + z-index: 1040; + background-color: #000000; +} +.modal-backdrop.fade { + filter: alpha(opacity=0); + opacity: 0; +} +.modal-backdrop.in { + filter: alpha(opacity=50); + opacity: 0.5; +} +.modal-header { + padding: 15px; + border-bottom: 1px solid transparent; +} +.modal-header .close { + margin-top: -2px; +} +.modal-title { + margin: 0; + line-height: 1.846; +} +.modal-body { + position: relative; + padding: 15px; +} +.modal-footer { + padding: 15px; + text-align: right; + border-top: 1px solid transparent; +} +.modal-footer .btn + .btn { + margin-bottom: 0; + margin-left: 5px; +} +.modal-footer .btn-group .btn + .btn { + margin-left: -1px; +} +.modal-footer .btn-block + .btn-block { + margin-left: 0; +} +.modal-scrollbar-measure { + position: absolute; + top: -9999px; + width: 50px; + height: 50px; + overflow: scroll; +} +@media (min-width: 768px) { + .modal-dialog { + width: 600px; + margin: 30px auto; + } + .modal-content { + box-shadow: 0 5px 15px rgba(0, 0, 0, 0.5); + } + .modal-sm { + width: 300px; + } +} +@media (min-width: 992px) { + .modal-lg { + width: 900px; + } +} +.tooltip { + position: absolute; + z-index: 1070; + display: block; + font-family: "Roboto", "Helvetica Neue", Helvetica, Arial, sans-serif; + font-style: normal; + font-weight: 400; + line-height: 1.846; + line-break: auto; + text-align: left; + text-align: start; + text-decoration: none; + text-shadow: none; + text-transform: none; + letter-spacing: normal; + word-break: normal; + word-spacing: normal; + word-wrap: normal; + white-space: normal; + font-size: 12px; + filter: alpha(opacity=0); + opacity: 0; +} +.tooltip.in { + filter: alpha(opacity=90); + opacity: 0.9; +} +.tooltip.top { + padding: 5px 0; + margin-top: -3px; +} +.tooltip.right { + padding: 0 5px; + margin-left: 3px; +} +.tooltip.bottom { + padding: 5px 0; + margin-top: 3px; +} +.tooltip.left { + padding: 0 5px; + margin-left: -3px; +} +.tooltip.top .tooltip-arrow { + bottom: 0; + left: 50%; + margin-left: -5px; + border-width: 5px 5px 0; + border-top-color: #727272; +} +.tooltip.top-left .tooltip-arrow { + right: 5px; + bottom: 0; + margin-bottom: -5px; + border-width: 5px 5px 0; + border-top-color: #727272; +} +.tooltip.top-right .tooltip-arrow { + bottom: 0; + left: 5px; + margin-bottom: -5px; + border-width: 5px 5px 0; + border-top-color: #727272; +} +.tooltip.right .tooltip-arrow { + top: 50%; + left: 0; + margin-top: -5px; + border-width: 5px 5px 5px 0; + border-right-color: #727272; +} +.tooltip.left .tooltip-arrow { + top: 50%; + right: 0; + margin-top: -5px; + border-width: 5px 0 5px 5px; + border-left-color: #727272; +} +.tooltip.bottom .tooltip-arrow { + top: 0; + left: 50%; + margin-left: -5px; + border-width: 0 5px 5px; + border-bottom-color: #727272; +} +.tooltip.bottom-left .tooltip-arrow { + top: 0; + right: 5px; + margin-top: -5px; + border-width: 0 5px 5px; + border-bottom-color: #727272; +} +.tooltip.bottom-right .tooltip-arrow { + top: 0; + left: 5px; + margin-top: -5px; + border-width: 0 5px 5px; + border-bottom-color: #727272; +} +.tooltip-inner { + max-width: 200px; + padding: 3px 8px; + color: #ffffff; + text-align: center; + background-color: #727272; + border-radius: 3px; +} +.tooltip-arrow { + position: absolute; + width: 0; + height: 0; + border-color: transparent; + border-style: solid; +} +.popover { + position: absolute; + top: 0; + left: 0; + z-index: 1060; + display: none; + max-width: 276px; + padding: 1px; + font-family: "Roboto", "Helvetica Neue", Helvetica, Arial, sans-serif; + font-style: normal; + font-weight: 400; + line-height: 1.846; + line-break: auto; + text-align: left; + text-align: start; + text-decoration: none; + text-shadow: none; + text-transform: none; + letter-spacing: normal; + word-break: normal; + word-spacing: normal; + word-wrap: normal; + white-space: normal; + font-size: 13px; + background-color: #ffffff; + background-clip: padding-box; + border: 1px solid transparent; + border-radius: 3px; + box-shadow: 0 5px 10px rgba(0, 0, 0, 0.2); +} +.popover.top { + margin-top: -10px; +} +.popover.right { + margin-left: 10px; +} +.popover.bottom { + margin-top: 10px; +} +.popover.left { + margin-left: -10px; +} +.popover > .arrow { + border-width: 11px; +} +.popover > .arrow, +.popover > .arrow:after { + position: absolute; + display: block; + width: 0; + height: 0; + border-color: transparent; + border-style: solid; +} +.popover > .arrow:after { + content: ""; + border-width: 10px; +} +.popover.top > .arrow { + bottom: -11px; + left: 50%; + margin-left: -11px; + border-top-color: rgba(0, 0, 0, 0); + border-top-color: rgba(0, 0, 0, 0.075); + border-bottom-width: 0; +} +.popover.top > .arrow:after { + bottom: 1px; + margin-left: -10px; + content: " "; + border-top-color: #ffffff; + border-bottom-width: 0; +} +.popover.right > .arrow { + top: 50%; + left: -11px; + margin-top: -11px; + border-right-color: rgba(0, 0, 0, 0); + border-right-color: rgba(0, 0, 0, 0.075); + border-left-width: 0; +} +.popover.right > .arrow:after { + bottom: -10px; + left: 1px; + content: " "; + border-right-color: #ffffff; + border-left-width: 0; +} +.popover.bottom > .arrow { + top: -11px; + left: 50%; + margin-left: -11px; + border-top-width: 0; + border-bottom-color: rgba(0, 0, 0, 0); + border-bottom-color: rgba(0, 0, 0, 0.075); +} +.popover.bottom > .arrow:after { + top: 1px; + margin-left: -10px; + content: " "; + border-top-width: 0; + border-bottom-color: #ffffff; +} +.popover.left > .arrow { + top: 50%; + right: -11px; + margin-top: -11px; + border-right-width: 0; + border-left-color: rgba(0, 0, 0, 0); + border-left-color: rgba(0, 0, 0, 0.075); +} +.popover.left > .arrow:after { + right: 1px; + bottom: -10px; + content: " "; + border-right-width: 0; + border-left-color: #ffffff; +} +.popover-title { + padding: 8px 14px; + margin: 0; + font-size: 13px; + background-color: #f7f7f7; + border-bottom: 1px solid #ebebeb; + border-radius: 2px 2px 0 0; +} +.popover-content { + padding: 9px 14px; +} +.carousel { + position: relative; +} +.carousel-inner { + position: relative; + width: 100%; + overflow: hidden; +} +.carousel-inner > .item { + position: relative; + display: none; + transition: 0.6s ease-in-out left; +} +.carousel-inner > .item > img, +.carousel-inner > .item > a > img { + line-height: 1; +} +@media all and (transform-3d), (-webkit-transform-3d) { + .carousel-inner > .item { + transition: -webkit-transform 0.6s ease-in-out; + transition: transform 0.6s ease-in-out; + -webkit-backface-visibility: hidden; + backface-visibility: hidden; + -webkit-perspective: 1000px; + perspective: 1000px; + } + .carousel-inner > .item.next, + .carousel-inner > .item.active.right { + -webkit-transform: translate3d(100%, 0, 0); + transform: translate3d(100%, 0, 0); + left: 0; + } + .carousel-inner > .item.prev, + .carousel-inner > .item.active.left { + -webkit-transform: translate3d(-100%, 0, 0); + transform: translate3d(-100%, 0, 0); + left: 0; + } + .carousel-inner > .item.next.left, + .carousel-inner > .item.prev.right, + .carousel-inner > .item.active { + -webkit-transform: translate3d(0, 0, 0); + transform: translate3d(0, 0, 0); + left: 0; + } +} +.carousel-inner > .active, +.carousel-inner > .next, +.carousel-inner > .prev { + display: block; +} +.carousel-inner > .active { + left: 0; +} +.carousel-inner > .next, +.carousel-inner > .prev { + position: absolute; + top: 0; + width: 100%; +} +.carousel-inner > .next { + left: 100%; +} +.carousel-inner > .prev { + left: -100%; +} +.carousel-inner > .next.left, +.carousel-inner > .prev.right { + left: 0; +} +.carousel-inner > .active.left { + left: -100%; +} +.carousel-inner > .active.right { + left: 100%; +} +.carousel-control { + position: absolute; + top: 0; + bottom: 0; + left: 0; + width: 15%; + font-size: 20px; + color: #ffffff; + text-align: center; + text-shadow: 0 1px 2px rgba(0, 0, 0, 0.6); + background-color: rgba(0, 0, 0, 0); + filter: alpha(opacity=50); + opacity: 0.5; +} +.carousel-control.left { + background-image: linear-gradient(to right, rgba(0, 0, 0, 0.5) 0%, rgba(0, 0, 0, 0.0001) 100%); + filter: progid:DXImageTransform.Microsoft.gradient(startColorstr='#80000000', endColorstr='#00000000', GradientType=1); + background-repeat: repeat-x; +} +.carousel-control.right { + right: 0; + left: auto; + background-image: linear-gradient(to right, rgba(0, 0, 0, 0.0001) 0%, rgba(0, 0, 0, 0.5) 100%); + filter: progid:DXImageTransform.Microsoft.gradient(startColorstr='#00000000', endColorstr='#80000000', GradientType=1); + background-repeat: repeat-x; +} +.carousel-control:hover, +.carousel-control:focus { + color: #ffffff; + text-decoration: none; + outline: 0; + filter: alpha(opacity=90); + opacity: 0.9; +} +.carousel-control .icon-prev, +.carousel-control .icon-next, +.carousel-control .glyphicon-chevron-left, +.carousel-control .glyphicon-chevron-right { + position: absolute; + top: 50%; + z-index: 5; + display: inline-block; + margin-top: -10px; +} +.carousel-control .icon-prev, +.carousel-control .glyphicon-chevron-left { + left: 50%; + margin-left: -10px; +} +.carousel-control .icon-next, +.carousel-control .glyphicon-chevron-right { + right: 50%; + margin-right: -10px; +} +.carousel-control .icon-prev, +.carousel-control .icon-next { + width: 20px; + height: 20px; + font-family: serif; + line-height: 1; +} +.carousel-control .icon-prev:before { + content: "\2039"; +} +.carousel-control .icon-next:before { + content: "\203a"; +} +.carousel-indicators { + position: absolute; + bottom: 10px; + left: 50%; + z-index: 15; + width: 60%; + padding-left: 0; + margin-left: -30%; + text-align: center; + list-style: none; +} +.carousel-indicators li { + display: inline-block; + width: 10px; + height: 10px; + margin: 1px; + text-indent: -999px; + cursor: pointer; + background-color: #000 \9; + background-color: rgba(0, 0, 0, 0); + border: 1px solid #ffffff; + border-radius: 10px; +} +.carousel-indicators .active { + width: 12px; + height: 12px; + margin: 0; + background-color: #ffffff; +} +.carousel-caption { + position: absolute; + right: 15%; + bottom: 20px; + left: 15%; + z-index: 10; + padding-top: 20px; + padding-bottom: 20px; + color: #ffffff; + text-align: center; + text-shadow: 0 1px 2px rgba(0, 0, 0, 0.6); +} +.carousel-caption .btn { + text-shadow: none; +} +@media screen and (min-width: 768px) { + .carousel-control .glyphicon-chevron-left, + .carousel-control .glyphicon-chevron-right, + .carousel-control .icon-prev, + .carousel-control .icon-next { + width: 30px; + height: 30px; + margin-top: -10px; + font-size: 30px; + } + .carousel-control .glyphicon-chevron-left, + .carousel-control .icon-prev { + margin-left: -10px; + } + .carousel-control .glyphicon-chevron-right, + .carousel-control .icon-next { + margin-right: -10px; + } + .carousel-caption { + right: 20%; + left: 20%; + padding-bottom: 30px; + } + .carousel-indicators { + bottom: 20px; + } +} +.clearfix:before, +.clearfix:after, +.dl-horizontal dd:before, +.dl-horizontal dd:after, +.container:before, +.container:after, +.container-fluid:before, +.container-fluid:after, +.row:before, +.row:after, +.form-horizontal .form-group:before, +.form-horizontal .form-group:after, +.btn-toolbar:before, +.btn-toolbar:after, +.btn-group-vertical > .btn-group:before, +.btn-group-vertical > .btn-group:after, +.nav:before, +.nav:after, +.navbar:before, +.navbar:after, +.navbar-header:before, +.navbar-header:after, +.navbar-collapse:before, +.navbar-collapse:after, +.pager:before, +.pager:after, +.panel-body:before, +.panel-body:after, +.modal-header:before, +.modal-header:after, +.modal-footer:before, +.modal-footer:after { + display: table; + content: " "; +} +.clearfix:after, +.dl-horizontal dd:after, +.container:after, +.container-fluid:after, +.row:after, +.form-horizontal .form-group:after, +.btn-toolbar:after, +.btn-group-vertical > .btn-group:after, +.nav:after, +.navbar:after, +.navbar-header:after, +.navbar-collapse:after, +.pager:after, +.panel-body:after, +.modal-header:after, +.modal-footer:after { + clear: both; +} +.center-block { + display: block; + margin-right: auto; + margin-left: auto; +} +.pull-right { + float: right !important; +} +.pull-left { + float: left !important; +} +.hide { + display: none !important; +} +.show { + display: block !important; +} +.invisible { + visibility: hidden; +} +.text-hide { + font: 0/0 a; + color: transparent; + text-shadow: none; + background-color: transparent; + border: 0; +} +.hidden { + display: none !important; +} +.affix { + position: fixed; +} +@-ms-viewport { + width: device-width; +} +.visible-xs, +.visible-sm, +.visible-md, +.visible-lg { + display: none !important; +} +.visible-xs-block, +.visible-xs-inline, +.visible-xs-inline-block, +.visible-sm-block, +.visible-sm-inline, +.visible-sm-inline-block, +.visible-md-block, +.visible-md-inline, +.visible-md-inline-block, +.visible-lg-block, +.visible-lg-inline, +.visible-lg-inline-block { + display: none !important; +} +@media (max-width: 767px) { + .visible-xs { + display: block !important; + } + table.visible-xs { + display: table !important; + } + tr.visible-xs { + display: table-row !important; + } + th.visible-xs, + td.visible-xs { + display: table-cell !important; + } +} +@media (max-width: 767px) { + .visible-xs-block { + display: block !important; + } +} +@media (max-width: 767px) { + .visible-xs-inline { + display: inline !important; + } +} +@media (max-width: 767px) { + .visible-xs-inline-block { + display: inline-block !important; + } +} +@media (min-width: 768px) and (max-width: 991px) { + .visible-sm { + display: block !important; + } + table.visible-sm { + display: table !important; + } + tr.visible-sm { + display: table-row !important; + } + th.visible-sm, + td.visible-sm { + display: table-cell !important; + } +} +@media (min-width: 768px) and (max-width: 991px) { + .visible-sm-block { + display: block !important; + } +} +@media (min-width: 768px) and (max-width: 991px) { + .visible-sm-inline { + display: inline !important; + } +} +@media (min-width: 768px) and (max-width: 991px) { + .visible-sm-inline-block { + display: inline-block !important; + } +} +@media (min-width: 992px) and (max-width: 1199px) { + .visible-md { + display: block !important; + } + table.visible-md { + display: table !important; + } + tr.visible-md { + display: table-row !important; + } + th.visible-md, + td.visible-md { + display: table-cell !important; + } +} +@media (min-width: 992px) and (max-width: 1199px) { + .visible-md-block { + display: block !important; + } +} +@media (min-width: 992px) and (max-width: 1199px) { + .visible-md-inline { + display: inline !important; + } +} +@media (min-width: 992px) and (max-width: 1199px) { + .visible-md-inline-block { + display: inline-block !important; + } +} +@media (min-width: 1200px) { + .visible-lg { + display: block !important; + } + table.visible-lg { + display: table !important; + } + tr.visible-lg { + display: table-row !important; + } + th.visible-lg, + td.visible-lg { + display: table-cell !important; + } +} +@media (min-width: 1200px) { + .visible-lg-block { + display: block !important; + } +} +@media (min-width: 1200px) { + .visible-lg-inline { + display: inline !important; + } +} +@media (min-width: 1200px) { + .visible-lg-inline-block { + display: inline-block !important; + } +} +@media (max-width: 767px) { + .hidden-xs { + display: none !important; + } +} +@media (min-width: 768px) and (max-width: 991px) { + .hidden-sm { + display: none !important; + } +} +@media (min-width: 992px) and (max-width: 1199px) { + .hidden-md { + display: none !important; + } +} +@media (min-width: 1200px) { + .hidden-lg { + display: none !important; + } +} +.visible-print { + display: none !important; +} +@media print { + .visible-print { + display: block !important; + } + table.visible-print { + display: table !important; + } + tr.visible-print { + display: table-row !important; + } + th.visible-print, + td.visible-print { + display: table-cell !important; + } +} +.visible-print-block { + display: none !important; +} +@media print { + .visible-print-block { + display: block !important; + } +} +.visible-print-inline { + display: none !important; +} +@media print { + .visible-print-inline { + display: inline !important; + } +} +.visible-print-inline-block { + display: none !important; +} +@media print { + .visible-print-inline-block { + display: inline-block !important; + } +} +@media print { + .hidden-print { + display: none !important; + } +} +.navbar { + border: none; + box-shadow: 0 1px 2px rgba(0, 0, 0, 0.3); +} +.navbar-brand { + font-size: 24px; +} +.navbar-inverse .navbar-form input[type=text], +.navbar-inverse .navbar-form input[type=password] { + color: #fff; + box-shadow: inset 0 -1px 0 #b2dbfb; +} +.navbar-inverse .navbar-form input[type=text]::-moz-placeholder, +.navbar-inverse .navbar-form input[type=password]::-moz-placeholder { + color: #b2dbfb; + opacity: 1; +} +.navbar-inverse .navbar-form input[type=text]:-ms-input-placeholder, +.navbar-inverse .navbar-form input[type=password]:-ms-input-placeholder { + color: #b2dbfb; +} +.navbar-inverse .navbar-form input[type=text]::-webkit-input-placeholder, +.navbar-inverse .navbar-form input[type=password]::-webkit-input-placeholder { + color: #b2dbfb; +} +.navbar-inverse .navbar-form input[type=text]:focus, +.navbar-inverse .navbar-form input[type=password]:focus { + box-shadow: inset 0 -2px 0 #ffffff; +} +.btn-default { + background-size: 200% 200%; + background-position: 50%; +} +.btn-default:focus { + background-color: #ffffff; +} +.btn-default:hover, +.btn-default:active:hover { + background-color: #f0f0f0; +} +.btn-default:active { + background-color: #e0e0e0; + background-image: radial-gradient(circle, #e0e0e0 10%, #ffffff 11%); + background-repeat: no-repeat; + background-size: 1000% 1000%; + box-shadow: 2px 2px 4px rgba(0, 0, 0, 0.4); +} +.btn-primary { + background-size: 200% 200%; + background-position: 50%; +} +.btn-primary:focus { + background-color: #2196f3; +} +.btn-primary:hover, +.btn-primary:active:hover { + background-color: #0d87e9; +} +.btn-primary:active { + background-color: #0b76cc; + background-image: radial-gradient(circle, #0b76cc 10%, #2196f3 11%); + background-repeat: no-repeat; + background-size: 1000% 1000%; + box-shadow: 2px 2px 4px rgba(0, 0, 0, 0.4); +} +.btn-success { + background-size: 200% 200%; + background-position: 50%; +} +.btn-success:focus { + background-color: #4caf50; +} +.btn-success:hover, +.btn-success:active:hover { + background-color: #439a46; +} +.btn-success:active { + background-color: #39843c; + background-image: radial-gradient(circle, #39843c 10%, #4caf50 11%); + background-repeat: no-repeat; + background-size: 1000% 1000%; + box-shadow: 2px 2px 4px rgba(0, 0, 0, 0.4); +} +.btn-info { + background-size: 200% 200%; + background-position: 50%; +} +.btn-info:focus { + background-color: #9c27b0; +} +.btn-info:hover, +.btn-info:active:hover { + background-color: #862197; +} +.btn-info:active { + background-color: #701c7e; + background-image: radial-gradient(circle, #701c7e 10%, #9c27b0 11%); + background-repeat: no-repeat; + background-size: 1000% 1000%; + box-shadow: 2px 2px 4px rgba(0, 0, 0, 0.4); +} +.btn-warning { + background-size: 200% 200%; + background-position: 50%; +} +.btn-warning:focus { + background-color: #ff9800; +} +.btn-warning:hover, +.btn-warning:active:hover { + background-color: #e08600; +} +.btn-warning:active { + background-color: #c27400; + background-image: radial-gradient(circle, #c27400 10%, #ff9800 11%); + background-repeat: no-repeat; + background-size: 1000% 1000%; + box-shadow: 2px 2px 4px rgba(0, 0, 0, 0.4); +} +.btn-danger { + background-size: 200% 200%; + background-position: 50%; +} +.btn-danger:focus { + background-color: #e51c23; +} +.btn-danger:hover, +.btn-danger:active:hover { + background-color: #cb171e; +} +.btn-danger:active { + background-color: #b0141a; + background-image: radial-gradient(circle, #b0141a 10%, #e51c23 11%); + background-repeat: no-repeat; + background-size: 1000% 1000%; + box-shadow: 2px 2px 4px rgba(0, 0, 0, 0.4); +} +.btn-link { + background-size: 200% 200%; + background-position: 50%; +} +.btn-link:focus { + background-color: #ffffff; +} +.btn-link:hover, +.btn-link:active:hover { + background-color: #f0f0f0; +} +.btn-link:active { + background-color: #e0e0e0; + background-image: radial-gradient(circle, #e0e0e0 10%, #ffffff 11%); + background-repeat: no-repeat; + background-size: 1000% 1000%; + box-shadow: 2px 2px 4px rgba(0, 0, 0, 0.4); +} +.btn { + text-transform: uppercase; + border: none; + box-shadow: 1px 1px 4px rgba(0, 0, 0, 0.4); + transition: all 0.4s; +} +.btn-link { + border-radius: 3px; + box-shadow: none; + color: #444444; +} +.btn-link:hover, +.btn-link:focus { + box-shadow: none; + color: #444444; + text-decoration: none; +} +.btn-default.disabled { + background-color: rgba(0, 0, 0, 0.1); + color: rgba(0, 0, 0, 0.4); + opacity: 1; +} +.btn-group .btn + .btn, +.btn-group .btn + .btn-group, +.btn-group .btn-group + .btn, +.btn-group .btn-group + .btn-group { + margin-left: 0; +} +.btn-group-vertical > .btn + .btn, +.btn-group-vertical > .btn + .btn-group, +.btn-group-vertical > .btn-group + .btn, +.btn-group-vertical > .btn-group + .btn-group { + margin-top: 0; +} +body { + -webkit-font-smoothing: antialiased; + letter-spacing: .1px; +} +p { + margin: 0 0 1em; +} +input, +button { + -webkit-font-smoothing: antialiased; + letter-spacing: .1px; +} +a { + transition: all 0.2s; +} +.table-hover > tbody > tr, +.table-hover > tbody > tr > th, +.table-hover > tbody > tr > td { + transition: all 0.2s; +} +label { + font-weight: normal; +} +textarea, +textarea.form-control, +input.form-control, +input[type=text], +input[type=password], +input[type=email], +input[type=number], +[type=text].form-control, +[type=password].form-control, +[type=email].form-control, +[type=tel].form-control, +[contenteditable].form-control { + padding: 0; + border: none; + border-radius: 0; + -webkit-appearance: none; + box-shadow: inset 0 -1px 0 #dddddd; + font-size: 16px; +} +textarea:focus, +textarea.form-control:focus, +input.form-control:focus, +input[type=text]:focus, +input[type=password]:focus, +input[type=email]:focus, +input[type=number]:focus, +[type=text].form-control:focus, +[type=password].form-control:focus, +[type=email].form-control:focus, +[type=tel].form-control:focus, +[contenteditable].form-control:focus { + box-shadow: inset 0 -2px 0 #2196f3; +} +textarea[disabled], +textarea.form-control[disabled], +input.form-control[disabled], +input[type=text][disabled], +input[type=password][disabled], +input[type=email][disabled], +input[type=number][disabled], +[type=text].form-control[disabled], +[type=password].form-control[disabled], +[type=email].form-control[disabled], +[type=tel].form-control[disabled], +[contenteditable].form-control[disabled], +textarea[readonly], +textarea.form-control[readonly], +input.form-control[readonly], +input[type=text][readonly], +input[type=password][readonly], +input[type=email][readonly], +input[type=number][readonly], +[type=text].form-control[readonly], +[type=password].form-control[readonly], +[type=email].form-control[readonly], +[type=tel].form-control[readonly], +[contenteditable].form-control[readonly] { + box-shadow: none; + border-bottom: 1px dotted #ddd; +} +textarea.input-sm, +textarea.form-control.input-sm, +input.form-control.input-sm, +input[type=text].input-sm, +input[type=password].input-sm, +input[type=email].input-sm, +input[type=number].input-sm, +[type=text].form-control.input-sm, +[type=password].form-control.input-sm, +[type=email].form-control.input-sm, +[type=tel].form-control.input-sm, +[contenteditable].form-control.input-sm { + font-size: 12px; +} +textarea.input-lg, +textarea.form-control.input-lg, +input.form-control.input-lg, +input[type=text].input-lg, +input[type=password].input-lg, +input[type=email].input-lg, +input[type=number].input-lg, +[type=text].form-control.input-lg, +[type=password].form-control.input-lg, +[type=email].form-control.input-lg, +[type=tel].form-control.input-lg, +[contenteditable].form-control.input-lg { + font-size: 17px; +} +select, +select.form-control { + border: 0; + border-radius: 0; + -webkit-appearance: none; + -moz-appearance: none; + appearance: none; + padding-left: 0; + padding-right: 0\9; + background-image: url(data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABoAAAAaCAMAAACelLz8AAAAJ1BMVEVmZmZmZmZmZmZmZmZmZmZmZmZmZmZmZmZmZmZmZmZmZmZmZmZmZmaP/QSjAAAADHRSTlMAAgMJC0uWpKa6wMxMdjkoAAAANUlEQVR4AeXJyQEAERAAsNl7Hf3X6xt0QL6JpZWq30pdvdadme+0PMdzvHm8YThHcT1H7K0BtOMDniZhWOgAAAAASUVORK5CYII=); + background-size: 13px; + background-repeat: no-repeat; + background-position: right center; + box-shadow: inset 0 -1px 0 #dddddd; + font-size: 16px; + line-height: 1.5; +} +select::-ms-expand, +select.form-control::-ms-expand { + display: none; +} +select.input-sm, +select.form-control.input-sm { + font-size: 12px; +} +select.input-lg, +select.form-control.input-lg { + font-size: 17px; +} +select:focus, +select.form-control:focus { + box-shadow: inset 0 -2px 0 #2196f3; + background-image: url(data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABoAAAAaCAMAAACelLz8AAAAJ1BMVEUhISEhISEhISEhISEhISEhISEhISEhISEhISEhISEhISEhISEhISF8S9ewAAAADHRSTlMAAgMJC0uWpKa6wMxMdjkoAAAANUlEQVR4AeXJyQEAERAAsNl7Hf3X6xt0QL6JpZWq30pdvdadme+0PMdzvHm8YThHcT1H7K0BtOMDniZhWOgAAAAASUVORK5CYII=); +} +select[multiple], +select.form-control[multiple] { + background: none; +} +.radio label, +.radio-inline label, +.checkbox label, +.checkbox-inline label { + padding-left: 25px; +} +.radio input[type="radio"], +.radio-inline input[type="radio"], +.checkbox input[type="radio"], +.checkbox-inline input[type="radio"], +.radio input[type="checkbox"], +.radio-inline input[type="checkbox"], +.checkbox input[type="checkbox"], +.checkbox-inline input[type="checkbox"] { + margin-left: -25px; +} +input[type="radio"], +.radio input[type="radio"], +.radio-inline input[type="radio"] { + position: relative; + margin-top: 6px; + margin-right: 4px; + vertical-align: top; + border: none; + background-color: transparent; + -webkit-appearance: none; + appearance: none; + cursor: pointer; +} +input[type="radio"]:focus, +.radio input[type="radio"]:focus, +.radio-inline input[type="radio"]:focus { + outline: none; +} +input[type="radio"]:before, +.radio input[type="radio"]:before, +.radio-inline input[type="radio"]:before, +input[type="radio"]:after, +.radio input[type="radio"]:after, +.radio-inline input[type="radio"]:after { + content: ""; + display: block; + width: 18px; + height: 18px; + border-radius: 50%; + transition: 240ms; +} +input[type="radio"]:before, +.radio input[type="radio"]:before, +.radio-inline input[type="radio"]:before { + position: absolute; + left: 0; + top: -3px; + background-color: #2196f3; + -webkit-transform: scale(0); + transform: scale(0); +} +input[type="radio"]:after, +.radio input[type="radio"]:after, +.radio-inline input[type="radio"]:after { + position: relative; + top: -3px; + border: 2px solid #666666; +} +input[type="radio"]:checked:before, +.radio input[type="radio"]:checked:before, +.radio-inline input[type="radio"]:checked:before { + -webkit-transform: scale(0.5); + transform: scale(0.5); +} +input[type="radio"]:disabled:checked:before, +.radio input[type="radio"]:disabled:checked:before, +.radio-inline input[type="radio"]:disabled:checked:before { + background-color: #bbbbbb; +} +input[type="radio"]:checked:after, +.radio input[type="radio"]:checked:after, +.radio-inline input[type="radio"]:checked:after { + border-color: #2196f3; +} +input[type="radio"]:disabled:after, +.radio input[type="radio"]:disabled:after, +.radio-inline input[type="radio"]:disabled:after, +input[type="radio"]:disabled:checked:after, +.radio input[type="radio"]:disabled:checked:after, +.radio-inline input[type="radio"]:disabled:checked:after { + border-color: #bbbbbb; +} +input[type="checkbox"], +.checkbox input[type="checkbox"], +.checkbox-inline input[type="checkbox"] { + position: relative; + border: none; + margin-bottom: -4px; + -webkit-appearance: none; + appearance: none; + cursor: pointer; +} +input[type="checkbox"]:focus, +.checkbox input[type="checkbox"]:focus, +.checkbox-inline input[type="checkbox"]:focus { + outline: none; +} +input[type="checkbox"]:focus:after, +.checkbox input[type="checkbox"]:focus:after, +.checkbox-inline input[type="checkbox"]:focus:after { + border-color: #2196f3; +} +input[type="checkbox"]:after, +.checkbox input[type="checkbox"]:after, +.checkbox-inline input[type="checkbox"]:after { + content: ""; + display: block; + width: 18px; + height: 18px; + margin-top: -2px; + margin-right: 5px; + border: 2px solid #666666; + border-radius: 2px; + transition: 240ms; +} +input[type="checkbox"]:checked:before, +.checkbox input[type="checkbox"]:checked:before, +.checkbox-inline input[type="checkbox"]:checked:before { + content: ""; + position: absolute; + top: 0; + left: 6px; + display: table; + width: 6px; + height: 12px; + border: 2px solid #fff; + border-top-width: 0; + border-left-width: 0; + -webkit-transform: rotate(45deg); + transform: rotate(45deg); +} +input[type="checkbox"]:checked:after, +.checkbox input[type="checkbox"]:checked:after, +.checkbox-inline input[type="checkbox"]:checked:after { + background-color: #2196f3; + border-color: #2196f3; +} +input[type="checkbox"]:disabled:after, +.checkbox input[type="checkbox"]:disabled:after, +.checkbox-inline input[type="checkbox"]:disabled:after { + border-color: #bbbbbb; +} +input[type="checkbox"]:disabled:checked:after, +.checkbox input[type="checkbox"]:disabled:checked:after, +.checkbox-inline input[type="checkbox"]:disabled:checked:after { + background-color: #bbbbbb; + border-color: transparent; +} +.has-warning input:not([type=checkbox]), +.has-warning .form-control, +.has-warning input.form-control[readonly], +.has-warning input[type=text][readonly], +.has-warning [type=text].form-control[readonly], +.has-warning input:not([type=checkbox]):focus, +.has-warning .form-control:focus { + border-bottom: none; + box-shadow: inset 0 -2px 0 #ff9800; +} +.has-error input:not([type=checkbox]), +.has-error .form-control, +.has-error input.form-control[readonly], +.has-error input[type=text][readonly], +.has-error [type=text].form-control[readonly], +.has-error input:not([type=checkbox]):focus, +.has-error .form-control:focus { + border-bottom: none; + box-shadow: inset 0 -2px 0 #e51c23; +} +.has-success input:not([type=checkbox]), +.has-success .form-control, +.has-success input.form-control[readonly], +.has-success input[type=text][readonly], +.has-success [type=text].form-control[readonly], +.has-success input:not([type=checkbox]):focus, +.has-success .form-control:focus { + border-bottom: none; + box-shadow: inset 0 -2px 0 #4caf50; +} +.has-warning .input-group-addon, +.has-error .input-group-addon, +.has-success .input-group-addon { + color: #666666; + border-color: transparent; + background-color: transparent; +} +.form-group-lg select, +.form-group-lg select.form-control { + line-height: 1.5; +} +.nav-tabs > li > a, +.nav-tabs > li > a:focus { + margin-right: 0; + background-color: transparent; + border: none; + color: #666666; + box-shadow: inset 0 -1px 0 #dddddd; + transition: all 0.2s; +} +.nav-tabs > li > a:hover, +.nav-tabs > li > a:focus:hover { + background-color: transparent; + box-shadow: inset 0 -2px 0 #2196f3; + color: #2196f3; +} +.nav-tabs > li.active > a, +.nav-tabs > li.active > a:focus { + border: none; + box-shadow: inset 0 -2px 0 #2196f3; + color: #2196f3; +} +.nav-tabs > li.active > a:hover, +.nav-tabs > li.active > a:focus:hover { + border: none; + color: #2196f3; +} +.nav-tabs > li.disabled > a { + box-shadow: inset 0 -1px 0 #dddddd; +} +.nav-tabs.nav-justified > li > a, +.nav-tabs.nav-justified > li > a:hover, +.nav-tabs.nav-justified > li > a:focus, +.nav-tabs.nav-justified > .active > a, +.nav-tabs.nav-justified > .active > a:hover, +.nav-tabs.nav-justified > .active > a:focus { + border: none; +} +.nav-tabs .dropdown-menu { + margin-top: 0; +} +.dropdown-menu { + margin-top: 0; + border: none; + box-shadow: 0 1px 4px rgba(0, 0, 0, 0.3); +} +.alert { + border: none; + color: #fff; +} +.alert-success { + background-color: #4caf50; +} +.alert-info { + background-color: #9c27b0; +} +.alert-warning { + background-color: #ff9800; +} +.alert-danger { + background-color: #e51c23; +} +.alert a:not(.close):not(.btn), +.alert .alert-link { + color: #fff; + font-weight: bold; +} +.alert .close { + color: #fff; +} +.badge { + padding: 4px 6px 4px; +} +.progress { + position: relative; + z-index: 1; + height: 6px; + border-radius: 0; + box-shadow: none; +} +.progress-bar { + box-shadow: none; +} +.progress-bar:last-child { + border-radius: 0 3px 3px 0; +} +.progress-bar:last-child:before { + display: block; + content: ""; + position: absolute; + width: 100%; + height: 100%; + left: 0; + right: 0; + z-index: -1; + background-color: #cae6fc; +} +.progress-bar-success:last-child.progress-bar:before { + background-color: #c7e7c8; +} +.progress-bar-info:last-child.progress-bar:before { + background-color: #edc9f3; +} +.progress-bar-warning:last-child.progress-bar:before { + background-color: #ffe0b3; +} +.progress-bar-danger:last-child.progress-bar:before { + background-color: #f28e92; +} +.close { + font-size: 34px; + font-weight: 300; + line-height: 24px; + opacity: 0.6; + transition: all 0.2s; +} +.close:hover { + opacity: 1; +} +.list-group-item { + padding: 15px; +} +.list-group-item-text { + color: #bbbbbb; +} +.well { + border-radius: 0; + box-shadow: none; +} +.panel { + border: none; + border-radius: 2px; + box-shadow: 0 1px 4px rgba(0, 0, 0, 0.3); +} +.panel-heading { + border-bottom: none; +} +.panel-footer { + border-top: none; +} +.popover { + border: none; + box-shadow: 0 1px 4px rgba(0, 0, 0, 0.3); +} +.carousel-caption h1, +.carousel-caption h2, +.carousel-caption h3, +.carousel-caption h4, +.carousel-caption h5, +.carousel-caption h6 { + color: inherit; +} diff --git a/inst/assets/pkgdown.css b/inst/assets/pkgdown.css new file mode 100644 index 0000000..9145958 --- /dev/null +++ b/inst/assets/pkgdown.css @@ -0,0 +1,256 @@ +/* Sticky footer */ + +/** + * Basic idea: https://philipwalton.github.io/solved-by-flexbox/demos/sticky-footer/ + * Details: https://github.com/philipwalton/solved-by-flexbox/blob/master/assets/css/components/site.css + * + * .Site -> body > .container + * .Site-content -> body > .container .row + * .footer -> footer + * + * Key idea seems to be to ensure that .container and __all its parents__ + * have height set to 100% + * + */ + +html, body { + height: 100%; +} + +body > .container { + display: flex; + height: 100%; + flex-direction: column; +} + +body > .container .row { + flex: 1 0 auto; +} + +footer { + margin-top: 45px; + padding: 35px 0 36px; + border-top: 1px solid #e5e5e5; + color: #666; + display: flex; + flex-shrink: 0; +} +footer p { + margin-bottom: 0; +} +footer div { + flex: 1; +} +footer .pkgdown { + text-align: right; +} +footer p { + margin-bottom: 0; +} + +img.icon { + float: right; +} + +img { + max-width: 100%; +} + +/* Fix bug in bootstrap (only seen in firefox) */ +summary { + display: list-item; +} + +/* Typographic tweaking ---------------------------------*/ + +.contents .page-header { + margin-top: calc(-60px + 1em); +} + +/* Section anchors ---------------------------------*/ + +a.anchor { + margin-left: -30px; + display:inline-block; + width: 30px; + height: 30px; + visibility: hidden; + + background-image: url(./link.svg); + background-repeat: no-repeat; + background-size: 20px 20px; + background-position: center center; +} + +.hasAnchor:hover a.anchor { + visibility: visible; +} + +@media (max-width: 767px) { + .hasAnchor:hover a.anchor { + visibility: hidden; + } +} + + +/* Fixes for fixed navbar --------------------------*/ + +.contents h1, .contents h2, .contents h3, .contents h4 { + padding-top: 60px; + margin-top: -40px; +} + +/* Sidebar --------------------------*/ + +#sidebar { + margin-top: 30px; + position: -webkit-sticky; + position: sticky; + top: 70px; +} +#sidebar h2 { + font-size: 1.5em; + margin-top: 1em; +} + +#sidebar h2:first-child { + margin-top: 0; +} + +#sidebar .list-unstyled li { + margin-bottom: 0.5em; +} + +.orcid { + height: 16px; + /* margins are required by official ORCID trademark and display guidelines */ + margin-left:4px; + margin-right:4px; + vertical-align: middle; +} + +/* Reference index & topics ----------------------------------------------- */ + +.ref-index th {font-weight: normal;} + +.ref-index td {vertical-align: top;} +.ref-index .icon {width: 40px;} +.ref-index .alias {width: 40%;} +.ref-index-icons .alias {width: calc(40% - 40px);} +.ref-index .title {width: 60%;} + +.ref-arguments th {text-align: right; padding-right: 10px;} +.ref-arguments th, .ref-arguments td {vertical-align: top;} +.ref-arguments .name {width: 20%;} +.ref-arguments .desc {width: 80%;} + +/* Nice scrolling for wide elements --------------------------------------- */ + +table { + display: block; + overflow: auto; +} + +/* Syntax highlighting ---------------------------------------------------- */ + +pre { + word-wrap: normal; + word-break: normal; + border: 1px solid #eee; +} + +pre, code { + background-color: #f8f8f8; + color: #333; +} + +pre code { + overflow: auto; + word-wrap: normal; + white-space: pre; +} + +pre .img { + margin: 5px 0; +} + +pre .img img { + background-color: #fff; + display: block; + height: auto; +} + +code a, pre a { + color: #375f84; +} + +a.sourceLine:hover { + text-decoration: none; +} + +.fl {color: #1514b5;} +.fu {color: #000000;} /* function */ +.ch,.st {color: #036a07;} /* string */ +.kw {color: #264D66;} /* keyword */ +.co {color: #888888;} /* comment */ + +.message { color: black; font-weight: bolder;} +.error { color: orange; font-weight: bolder;} +.warning { color: #6A0366; font-weight: bolder;} + +/* Clipboard --------------------------*/ + +.hasCopyButton { + position: relative; +} + +.btn-copy-ex { + position: absolute; + right: 0; + top: 0; + visibility: hidden; +} + +.hasCopyButton:hover button.btn-copy-ex { + visibility: visible; +} + +/* headroom.js ------------------------ */ + +.headroom { + will-change: transform; + transition: transform 200ms linear; +} +.headroom--pinned { + transform: translateY(0%); +} +.headroom--unpinned { + transform: translateY(-100%); +} + +/* mark.js ----------------------------*/ + +mark { + background-color: rgba(255, 255, 51, 0.5); + border-bottom: 2px solid rgba(255, 153, 51, 0.3); + padding: 1px; +} + +/* vertical spacing after htmlwidgets */ +.html-widget { + margin-bottom: 10px; +} + +/* fontawesome ------------------------ */ + +.fab { + font-family: "Font Awesome 5 Brands" !important; +} + +/* don't display links in code chunks when printing */ +/* source: https://stackoverflow.com/a/10781533 */ +@media print { + code a:link:after, code a:visited:after { + content: ""; + } +} diff --git a/inst/assets/pkgdown.js b/inst/assets/pkgdown.js new file mode 100644 index 0000000..087a762 --- /dev/null +++ b/inst/assets/pkgdown.js @@ -0,0 +1,113 @@ +/* http://gregfranko.com/blog/jquery-best-practices/ */ +(function($) { + $(function() { + + $('.navbar-fixed-top').headroom(); + + $('body').css('padding-top', $('.navbar').height() + 10); + $(window).resize(function(){ + $('body').css('padding-top', $('.navbar').height() + 10); + }); + + $('body').scrollspy({ + target: '#sidebar', + offset: 60 + }); + + $('[data-toggle="tooltip"]').tooltip(); + + var cur_path = paths(location.pathname); + var links = $("#navbar ul li a"); + var max_length = -1; + var pos = -1; + for (var i = 0; i < links.length; i++) { + if (links[i].getAttribute("href") === "#") + continue; + // Ignore external links + if (links[i].host !== location.host) + continue; + + var nav_path = paths(links[i].pathname); + + var length = prefix_length(nav_path, cur_path); + if (length > max_length) { + max_length = length; + pos = i; + } + } + + // Add class to parent- , and enclosing
- if in dropdown + if (pos >= 0) { + var menu_anchor = $(links[pos]); + menu_anchor.parent().addClass("active"); + menu_anchor.closest("li.dropdown").addClass("active"); + } + }); + + function paths(pathname) { + var pieces = pathname.split("/"); + pieces.shift(); // always starts with / + + var end = pieces[pieces.length - 1]; + if (end === "index.html" || end === "") + pieces.pop(); + return(pieces); + } + + // Returns -1 if not found + function prefix_length(needle, haystack) { + if (needle.length > haystack.length) + return(-1); + + // Special case for length-0 haystack, since for loop won't run + if (haystack.length === 0) { + return(needle.length === 0 ? 0 : -1); + } + + for (var i = 0; i < haystack.length; i++) { + if (needle[i] != haystack[i]) + return(i); + } + + return(haystack.length); + } + + /* Clipboard --------------------------*/ + + function changeTooltipMessage(element, msg) { + var tooltipOriginalTitle=element.getAttribute('data-original-title'); + element.setAttribute('data-original-title', msg); + $(element).tooltip('show'); + element.setAttribute('data-original-title', tooltipOriginalTitle); + } + + if(ClipboardJS.isSupported()) { + $(document).ready(function() { + var copyButton = ""; + + $(".examples, div.sourceCode").addClass("hasCopyButton"); + + // Insert copy buttons: + $(copyButton).prependTo(".hasCopyButton"); + + // Initialize tooltips: + $('.btn-copy-ex').tooltip({container: 'body'}); + + // Initialize clipboard: + var clipboardBtnCopies = new ClipboardJS('[data-clipboard-copy]', { + text: function(trigger) { + return trigger.parentNode.textContent; + } + }); + + clipboardBtnCopies.on('success', function(e) { + changeTooltipMessage(e.trigger, 'Copied!'); + e.clearSelection(); + }); + + clipboardBtnCopies.on('error', function() { + changeTooltipMessage(e.trigger,'Press Ctrl+C or Command+C to copy'); + }); + }); + } +})(window.jQuery || window.$) diff --git a/inst/templates/navbar.html b/inst/templates/navbar.html new file mode 100644 index 0000000..6dec913 --- /dev/null +++ b/inst/templates/navbar.html @@ -0,0 +1,38 @@ +{{#navbar}} +
++{{/navbar}} diff --git a/man/.DS_Store b/man/.DS_Store index 562a934..dba8243 100644 Binary files a/man/.DS_Store and b/man/.DS_Store differ diff --git a/man/concurve-package.Rd b/man/concurve-package.Rd new file mode 100644 index 0000000..e883c24 --- /dev/null +++ b/man/concurve-package.Rd @@ -0,0 +1,48 @@ +% Generated by roxygen2: do not edit by hand +% Please edit documentation in R/concurve-package.R +\docType{package} +\name{concurve-package} +\alias{concurve} +\alias{concurve-package} +\title{concurve: Computes and Plots Compatibility (Confidence) Intervals, + P-Values, S-Values, & Likelihood Intervals to Form Consonance, + Surprisal, & Likelihood Functions} +\description{ +\if{html}{\figure{logo.png}{options: align='right' alt='logo' width='120'}} + +Allows one to compute consonance (confidence) + intervals for various statistical tests along with their corresponding + P-values, S-values, and likelihoods. The intervals can be plotted to + create consonance, surprisal, and likelihood functions allowing one to + see what effect sizes are compatible with the test model at various + consonance levels rather than being limited to one interval estimate + such as 95%. These methods are discussed by Poole C. (1987) ++++ ++ + +
+ {{#site}}{{title}}{{/site}}
+ {{#package}}{{version}}{{/package}}
+
+
+For a more extensive discussion of these concepts, see the following references. [@birnbaum1961ams; @chow2019asb; @fraser2017arsa; @fraser2019as; @Poole1987-nb; @poole1987ajph; @Schweder2002-vh; @schweder2016; @Singh2007-zr; @Sullivan1990-ha; @whitehead1993sm; @xie2013isr; @rothman2008me]
+
+To get started, we could generate some normal data and combine two vectors in a dataframe
+
+```{r echo=TRUE, fig.height=4.5, fig.width=6}
+library(concurve)
+set.seed(1031)
+GroupA <- rnorm(500)
+GroupB <- rnorm(500)
RandomData <- data.frame(GroupA, GroupB)
```
-and compare the means of these two "groups" using a t-test,
+and look at the differences between the two vectors. We'll plug these vectors and the dataframe they're in inside of the `curve_mean()` function. Here, the default method involves calculating CIs using the Wald method.
-```r
-testresults <- t.test(GroupA, GroupB, data = RandomData, paired = FALSE)
+``` {r}
+intervalsdf <- curve_mean(GroupA, GroupB,
+ data = RandomData, method = "default"
+)
```
-we would likely see some differences, given that we have such a small
-sample in each group.
-```r
-summary(testresults)
+Each of the functions within `concurve` will generally produce a list with three items, and the first will usually contain the function of interest.
+
+```{r echo=TRUE, fig.height=4.5, fig.width=6}
+tibble::tibble(intervalsdf[[1]])
```
-We can see our P-value for the statistical test along with the computed
-95% interval with the command above (which is given to us by default by the program). Thus,
-effect sizes that range from the lower bound of this interval to the
-upper bound are compatible with the test model at this consonance
-level.
+We can view the function using the `ggcurve()` function. The two basic arguments that must be provided are the data argument and the "type" argument. To plot a consonance function, we would write "c".
-However, as stated before, a 95% interval is only an artifact of the
-commonly used 5% alpha level for hypothesis testing and is nowhere near
-as informative as a function.
+```{r echo=TRUE, fig.height=4.5, fig.width=6}
+(function1 <- ggcurve(data = intervalsdf[[1]], type = "c"))
+```
-If we were to take the information from this data and calculate a
-P-value function where every single consonance interval and its
-corresponding P-value were plotted, we would be able to see the full
-range of effect sizes compatible with the test model at various levels.
+We can see that the consonance "curve" is every interval estimate plotted, and provides the _P_-values, CIs, along with the median unbiased estimate It can be defined as such,
-It is relatively easy to produce such a function using the
-[**concurve**](https://github.com/Zadchow/concurve)
-package in R.
+$$C V_{n}(\theta)=1-2\left|H_{n}(\theta)-0.5\right|=2 \min \left\{H_{n}(\theta), 1-H_{n}(\theta)\right\}$$
-Install the package directly from [CRAN](https://cran.r-project.org/package=concurve)
+Its information counterpart, the surprisal function, can be constructed by taking the $-log_{2}$ of the _P_-value.[@chow2019asb; @greenland2019as; @Shannon1948-uq]
-``` r
-install.packages("concurve")
-```
-or get a more slightly up-to-date version via GitHub.
+To view the surprisal function, we simply change the type to "s".
-``` r
-library(devtools)
-install_github("zadchow/concurve")
+```{r echo=TRUE, fig.height=4.5, fig.width=6}
+(function1 <- ggcurve(data = intervalsdf[[1]], type = "s"))
```
-We’ll use the same data from above to calculate a P-value function and
-since we are focusing on mean differences using a t-test, we will use
-the `curve_meta()` function to calculate our consonance
-intervals and store them in a dataframe.
-``` r
-library(concurve)
-intervalsdf <- curve_mean(GroupA, GroupB,
- data = RandomData, method = "default"
-)
-```
+We can also view the consonance distribution by changing the type to "cdf", which is a cumulative probability distribution. The point at which the curve reaches 50% is known as the "median unbiased estimate". It is the same estimate that is typically at the peak of the _P_-value curve from above.
-Now thousands of consonance intervals at various levels have been
-stored in the dataframe “intervalsdf.” We can preview some of the entries
-via the `tibble` package.
-```r
-tibble::tibble(intervalsdf)
+```{r echo=TRUE, fig.height=4.5, fig.width=6}
+(function1s <- ggcurve(data = intervalsdf[[2]], type = "cdf"))
```
-There's a quick look at the first few entries of our dataframe.
-
-We can plot this data using the `ggconcurve()` function.
+We can also get relevant statistics that show the range of values by using the `curve_table()` function. There are several formats that can be exported such as .docx, .ppt, and TeX.
-``` r
-pfunction <- ggconcurve(type = "consonance", intervalsdf)
-pfunction
+```{r echo=TRUE, fig.height=2, fig.width=4}
+(x <- curve_table(data = intervalsdf[[1]], format = "image"))
```
-- - -Now we can see every consonance interval and its corresponding -P-value and consonance level plotted. As stated before, a single 95% -consonance interval is simply a slice through this function, which -provides far more information as to what is compatible with the test -model and its assumptions. - -Furthermore, we can also produce a "surprisal" function by plotting every consonance interval and its corresponding -[***S-value***](https://lesslikely.com/statistics/s-values/) -using the `ggconcurve()` function with type being set as "surprisal". - -``` r -sfunction <- ggconcurve(type = "surprisal", intervalsdf) -sfunction -``` - -
-- - -The graph from the code above provides us with consonance levels and the maximum -amount of information against the effect sizes contained in the -consonance interval. -## Simple Linear Models +# Comparing Functions -We can also try this with other simple linear models. +If we wanted to compare two studies to see the amount of "consonance", we could use the `curve_compare()` function to get a numerical output. -Let’s simulate more normal data and fit a simple linear regression to it -using ordinary least squares regression with the base R `lm()` function. +First, we generate some more fake data -``` r +```{r echo=TRUE, fig.height=4.5, fig.width=6} GroupA2 <- rnorm(500) GroupB2 <- rnorm(500) - RandomData2 <- data.frame(GroupA2, GroupB2) - model <- lm(GroupA2 ~ GroupB2, data = RandomData2) +randomframe <- curve_gen(model, "GroupB2") +``` + +Once again, we'll plot this data with `ggcurve()`. We can also indicate whether we want certain interval estimates to be plotted in the function with the "levels" argument. If we wanted to plot the 50%, 75%, and 95% intervals, we'd provide the argument this way: -summary(model) +```{r echo=TRUE, fig.height=4.5, fig.width=6} +(function2 <- ggcurve(type = "c", randomframe[[1]], levels = c(0.50, 0.75, 0.95), nullvalue = TRUE)) ``` -We can see some of the basic statistics of our model including the 95% -interval for our predictor (GroupB). Perhaps we want more information. -Well we can do that! Using the `curve_gen()`, we can calculate several -consonance intervals for the regression coefficient and then plot the -consonance and surprisal functions. +Now that we have two datasets and two functions, we can compare them using the `curve_compare()` function. -``` r -randomframe <- curve_gen(model, "GroupB2") -tibble::tibble(randomframe) +```{r echo=TRUE, fig.height=4.5, fig.width=6} +(curve_compare( + data1 = intervalsdf[[1]], data2 = randomframe[[1]], type = "c", + plot = TRUE, measure = "default", nullvalue = TRUE +)) ``` -Now that we have our data frame, we can graph our function. +This function will provide us with the area that is shared between the curve, along with a ratio of overlap to non-overlap. -``` r -ggconcurve(type = "consonance", randomframe) +We can also do this for the surprisal function simply by changing type to "s". + +```{r echo=TRUE, fig.height=4.5, fig.width=6} +(curve_compare( + data1 = intervalsdf[[1]], data2 = randomframe[[1]], type = "s", + plot = TRUE, measure = "default", nullvalue = FALSE +)) ``` -
-- +It's clear that the outputs have changed and indicate far more overlap than before. + +# Constructing Functions From Single Intervals + +We can also take a set of confidence limits and use them to construct a consonance, surprisal, likelihood or deviance function using the `curve_rev()` function. -``` r -s <- ggconcurve(type = "surprisal", randomframe) -s +Here, we'll use two epidemiological studies[@brown2017j; @brown2017jcp] that studied the impact of SSRI exposure in pregnant mothers, and the rate of autism in children. + +Both of these studies suggested a null effect of SSRI exposure on autism rates in children. + +```{r echo=TRUE, fig.height=4.5, fig.width=6} +curve1 <- curve_rev(point = 1.7, LL = 1.1, UL = 2.6, type = "c", measure = "ratio", steps = 10000) +(ggcurve(data = curve1[[1]], type = "c", measure = "ratio", nullvalue = TRUE)) +curve2 <- curve_rev(point = 1.61, LL = 0.997, UL = 2.59,type = "c", measure = "ratio", steps = 10000) +(ggcurve(data = curve2[[1]], type = "c", measure = "ratio", nullvalue = TRUE)) ``` -
-- +The null value is shown via the red line and it's clear that a large mass of the function is away from it. -We can also compare these functions to likelihood functions (also called -support intervals), and we’ll see that we get very similar results. -We’ll do this using the ***ProfileLikelihood*** package. +We can also see this by plotting the likelihood functions via the `curve_rev()` function. -``` r -xx <- profilelike.lm( - formula = GroupA2 ~ 1, data = RandomData2, - profile.theta = "GroupB2", - lo.theta = -0.3, hi.theta = 0.3, length = 500 -) +```{r echo=TRUE, fig.height=4.5, fig.width=6} +lik1 <- curve_rev(point = 1.7, LL = 1.1, UL = 2.6, type = "l", measure = "ratio", steps = 10000) +(ggcurve(data = lik1[[1]], type = "l1", measure = "ratio", nullvalue = TRUE)) +lik2 <- curve_rev(point = 1.61, LL = 0.997, UL = 2.59,type = "l", measure = "ratio", steps = 10000) +(ggcurve(data = lik2[[1]], type = "l1", measure = "ratio", nullvalue = TRUE)) ``` -Now we plot our likelihood function and we can see what the maximum -likelihood estimation is. Notice that it’s practically similar to the -interval in the S-value function with 0 bits of information against it -and and the consonance interval in the P-value function with a -P-value of 1. +We can also view the amount of agreement between the likelihood functions of these two studies. -``` r -profilelike.plot( - theta = xx$theta, - profile.lik.norm = xx$profile.lik.norm, round = 3 -) -title(main = "Likelihood Function") +```{r echo=TRUE, fig.height=4.5, fig.width=6} +(plot_compare( + data1 = lik1[[1]], data2 = lik2[[1]], type = "l1", measure = "ratio", nullvalue = TRUE, title = "Brown et al. 2017. J Clin Psychiatry. vs. \nBrown et al. 2017. JAMA.", + subtitle = "J Clin Psychiatry: OR = 1.7, 1/6.83 LI: LL = 1.1, UL = 2.6 \nJAMA: HR = 1.61, 1/6.83 LI: LL = 0.997, UL = 2.59", xaxis = expression(Theta ~ "= Hazard Ratio / Odds Ratio") +)) ``` -
-- +and the consonance functions + +```{r echo=TRUE, fig.height=4.5, fig.width=6} +(plot_compare( + data1 = curve1[[1]], data2 = curve2[[1]], type = "c", measure = "ratio", nullvalue = TRUE, title = "Brown et al. 2017. J Clin Psychiatry. vs. \nBrown et al. 2017. JAMA.", + subtitle = "J Clin Psychiatry: OR = 1.7, 1/6.83 LI: LL = 1.1, UL = 2.6 \nJAMA: HR = 1.61, 1/6.83 LI: LL = 0.997, UL = 2.59", xaxis = expression(Theta ~ "= Hazard Ratio / Odds Ratio") +)) +``` -We’ve used a relatively easy example for this blog post, but the -[**concurve**](https://github.com/Zadchow/concurve) -package is also able to calculate consonance functions for multiple -regressions, logistic regressions, ANOVAs, and meta-analyses (that have -been produced by the ***metafor*** package). +# The Bootstrap and Consonance Functions -## Using Meta-Analysis Data +Some authors have shown that the bootstrap distribution is equal to the confidence distribution because it meets the definition of a consonance distribution.[@efron1994; @efron2018; @xie2013isr] The bootstrap distribution and the asymptotic consonance distribution would be defined as: -Here we present another quick example with a meta-analysis of simulated -data. +$$H_{n}(\theta)=1-P\left(\hat{\theta}-\hat{\theta}^{*} \leq \hat{\theta}-\theta | \mathbf{x}\right)=P\left(\hat{\theta}^{*} \leq \theta | \mathbf{x}\right)$$ -First, we generate random data for two groups in two hypothetical -studies +Certain bootstrap methods such as the BCa method and _t_-bootstrap method also yield second order accuracy of consonance distributions. -``` r -GroupAData <- runif(20, min = 0, max = 100) -GroupAMean <- round(mean(GroupAData), digits = 2) -GroupASD <- round(sd(GroupAData), digits = 2) +$$H_{n}(\theta)=1-P\left(\frac{\hat{\theta}^{*}-\hat{\theta}}{\widehat{S E}^{*}\left(\hat{\theta}^{*}\right)} \leq \frac{\hat{\theta}-\theta}{\widehat{S E}(\hat{\theta})} | \mathbf{x}\right)$$ -GroupBData <- runif(20, min = 0, max = 100) -GroupBMean <- round(mean(GroupBData), digits = 2) -GroupBSD <- round(sd(GroupBData), digits = 2) +Here, I demonstrate how to use these particular bootstrap methods to arrive at consonance curves and densities. -GroupCData <- runif(20, min = 0, max = 100) -GroupCMean <- round(mean(GroupCData), digits = 2) -GroupCSD <- round(sd(GroupCData), digits = 2) +We'll use the Iris dataset and construct a function that'll yield a parameter of interest. -GroupDData <- runif(20, min = 0, max = 100) -GroupDMean <- round(mean(GroupDData), digits = 2) -GroupDSD <- round(sd(GroupDData), digits = 2) +```{r echo=TRUE, fig.height=4.5, fig.width=6} +iris <- datasets::iris +foo <- function(data, indices) { + dt <- data[indices, ] + c( + cor(dt[, 1], dt[, 2], method = "p") + ) +} ``` -We can then quickly combine the data in a dataframe. - -``` r -StudyName <- c("Study1", "Study2") -MeanTreatment <- c(GroupAMean, GroupCMean) -MeanControl <- c(GroupBMean, GroupDMean) -SDTreatment <- c(GroupASD, GroupCSD) -SDControl <- c(GroupBSD, GroupDSD) -NTreatment <- c(20, 20) -NControl <- c(20, 20) - -metadf <- data.frame( - StudyName, MeanTreatment, MeanControl, - SDTreatment, SDControl, - NTreatment, NControl -) +We can now use the `curve_boot()` method to construct a function. The default method used for this function is the "BCa" method provided by the [`bcaboot`](https://cran.r-project.org/package=bcaboot) package.[@efron2018] + +```{r include=FALSE} +y <- curve_boot(data = iris, func = foo, method = "bca", replicates = 2000, steps = 1000) ``` -Then, we’ll use ***metafor*** to calculate the standardized mean -difference. +I will suppress the output of the function because it is unnecessarily long. But we've placed all the estimates into a list object called y. -``` r -dat <- escalc( - measure = "SMD", - m1i = MeanTreatment, sd1i = SDTreatment, n1i = NTreatment, - m2i = MeanControl, sd2i = SDControl, n2i = NControl, - data = metadf -) +The first item in the list will be the consonance distribution constructed by typical means, while the third item will be the bootstrap approximation to the consonance distribution. + +```{r echo=TRUE, fig.height=4.5, fig.width=6} +ggcurve(data = y[[1]]) +ggcurve(data = y[[3]]) ``` -Next, we’ll pool the data using a ~~fixed-effects~~ common-effects model +We can also print out a table for TeX documents -``` r -res <- rma(yi, vi, - data = dat, slab = paste(StudyName, sep = ", "), - method = "FE", digits = 2 -) +```{r echo=TRUE, fig.height=2, fig.width=4} +(gg <- curve_table(data = y[[1]], format = "image")) ``` -Let’s look at our output. +More bootstrap replications will lead to a smoother function. But for now, we can compare these two functions to see how similar they are. -```r -res +```{r echo=TRUE, fig.height=4.5, fig.width=6} +plot_compare(y[[1]], y[[3]]) ``` +The densities can also be calculated accurately using the _t_-bootstrap method. Here we use a different dataset to show this + +```{r echo=TRUE, fig.height=4.5, fig.width=6} +library(Lock5Data) +dataz <- data(CommuteAtlanta) +func = function(data, index) { + x <- as.numeric(unlist(data[1])) + y <- as.numeric(unlist(data[2])) + return(mean(x[index]) - mean(y[index])) +} ``` -Fixed-Effects Model (k = 2) -Test for Heterogeneity: -Q(df = 1) = 0.61, p-val = 0.44 +Our function is a simple mean difference. This time, we'll set the method to "t" for the _t_-bootstrap method -Model Results: +```{r echo=TRUE, fig.height=4.5, fig.width=6} +z <- curve_boot(data = CommuteAtlanta, func = func, method = "t", replicates = 2000, steps = 1000) +ggcurve(data = z[[1]]) +ggcurve(data = z[[2]], type = "cd") +``` -estimate se zval pval ci.lb ci.ub - 0.16 0.22 0.73 0.47 -0.28 0.60 +The consonance curve and density are nearly identical. With more bootstrap replications, they are very likely to converge. ---- -Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 +```{r echo=TRUE, fig.height=2, fig.width=4} +(zz <- curve_table(data = z[[1]], format = "image")) ``` -Take a look at the pooled summary effect and its interval. Keep it in -mind as we move onto constructing a consonance function. +## Using Profile Likelihoods -We can now take the object produced by the meta-analysis and calculate a -P-value and S-value function with it to see the full spectrum of effect -sizes compatible with the test model at every level. We’ll use the -`curve_meta()` function to do this. +For this last example, we'll explore the `curve_lik()` function, which can help generate profile likelihood functions, and deviance statistics with the help of the [`ProfileLikelihood`](https://cran.r-project.org/package=ProfileLikelihood) package. -``` r -metaf <- curve_meta(res) -tibble::tibble(metaf) +```{r echo=TRUE, fig.height=4.5, fig.width=6} +library(ProfileLikelihood) ``` -Now that we have our dataframe with every computed interval, we can plot -the functions. +We'll use a simple example taken directly from the [`ProfileLikelihood`](https://cran.r-project.org/package=ProfileLikelihood) documentation where we'll calculate the likelihoods from a glm model -``` r -ggconcurve(type = "consonance", metaf) +```{r echo=TRUE, fig.height=4.5, fig.width=6} +data(dataglm) +xx <- profilelike.glm(y ~ x1 + x2, data=dataglm, profile.theta="group", +family=binomial(link="logit"), length=500, round=2) ``` -
-- +Then, we’ll use `curve_lik()` on the object that the [`ProfileLikelihood`](https://cran.r-project.org/package=ProfileLikelihood) package created. + +```{r echo=TRUE, fig.height=4.5, fig.width=6} +lik <- curve_lik(xx, dataglm) +tibble::tibble(lik[[1]]) +``` -And our S-value function +Next, we’ll plot three functions, the relative likelihood, the log likelihood, the likelihoodm, and the deviance function. -``` r -ggconcurve(type = "surprisal", metaf) +```{r echo=TRUE, fig.height=4.5, fig.width=6} +ggcurve(lik[[1]], type = "l1") +ggcurve(lik[[1]], type = "l2") +ggcurve(lik[[1]], type = "l3") +ggcurve(lik[[1]], type = "d") ``` -
-- - -Compare the span of these functions and the information they provide to -the consonance interval provided by the forest plot. We are now no -longer limited to interpreting an arbitrarily chosen interval by -mindless analytic decisions often built into statistical packages by -default. + +The obvious advantage of using reduced likelihoods is that they are free of nuisance parameters + +$$L_{t_{n}}(\theta)=f_{n}\left(F_{n}^{-1}\left(H_{p i v}(\theta)\right)\right)\left|\frac{\partial}{\partial t} \psi\left(t_{n}, \theta\right)\right|=h_{p i v}(\theta)\left|\frac{\partial}{\partial t} \psi(t, \theta)\right| /\left.\left|\frac{\partial}{\partial \theta} \psi(t, \theta)\right|\right|_{t=t_{n}}$$ +thus, giving summaries of the data that can be incorporated into combined analyses. + +* * * + +# References + +* * * diff --git a/vignettes/examples.html b/vignettes/examples.html deleted file mode 100644 index a792cdb..0000000 --- a/vignettes/examples.html +++ /dev/null @@ -1,484 +0,0 @@ - - - - - - - - - - - - - - - -
-Examples in R - - - - - - - - - - - - - - - - - - - - - -Examples in R
- - - ---Using Mean Differences
-If we were to generate some random data from a normal distribution with the following code,
- -and compare the means of these two “groups” using a t-test,
- -we would likely see some differences, given that we have such a small sample in each group.
- -We can see our P-value for the statistical test along with the computed 95% interval with the command above (which is given to us by default by the program). Thus, effect sizes that range from the lower bound of this interval to the upper bound are compatible with the test model at this consonance level.
-However, as stated before, a 95% interval is only an artifact of the commonly used 5% alpha level for hypothesis testing and is nowhere near as informative as a function.
-If we were to take the information from this data and calculate a P-value function where every single consonance interval and its corresponding P-value were plotted, we would be able to see the full range of effect sizes compatible with the test model at various levels.
-It is relatively easy to produce such a function using the concurve package in R.
-Install the package directly from CRAN
- -or get a more slightly up-to-date version via GitHub.
- -We’ll use the same data from above to calculate a P-value function and since we are focusing on mean differences using a t-test, we will use the
-curve_meta()function to calculate our consonance intervals and store them in a dataframe.-library(concurve) -intervalsdf <- curve_mean(GroupA, GroupB, - data = RandomData, method = "default" -)Now thousands of consonance intervals at various levels have been stored in the dataframe “intervalsdf.” We can preview some of the entries via the
- -tibblepackage.There’s a quick look at the first few entries of our dataframe.
-We can plot this data using the
- -ggconcurve()function.- - -
-Now we can see every consonance interval and its corresponding P-value and consonance level plotted. As stated before, a single 95% consonance interval is simply a slice through this function, which provides far more information as to what is compatible with the test model and its assumptions.
-Furthermore, we can also produce a “surprisal” function by plotting every consonance interval and its corresponding S-value using the
- -ggconcurve()function with type being set as “surprisal”.- - -
-The graph from the code above provides us with consonance levels and the maximum amount of information against the effect sizes contained in the consonance interval.
---Simple Linear Models
-We can also try this with other simple linear models.
-Let’s simulate more normal data and fit a simple linear regression to it using ordinary least squares regression with the base R
-lm()function.-GroupA2 <- rnorm(500) -GroupB2 <- rnorm(500) - -RandomData2 <- data.frame(GroupA2, GroupB2) - -model <- lm(GroupA2 ~ GroupB2, data = RandomData2) - -summary(model)We can see some of the basic statistics of our model including the 95% interval for our predictor (GroupB). Perhaps we want more information. Well we can do that! Using the
- -curve_gen(), we can calculate several consonance intervals for the regression coefficient and then plot the consonance and surprisal functions.Now that we have our data frame, we can graph our function.
- -- - - -
-- - -
-We can also compare these functions to likelihood functions (also called support intervals), and we’ll see that we get very similar results. We’ll do this using the ProfileLikelihood package.
--xx <- profilelike.lm( - formula = GroupA2 ~ 1, data = RandomData2, - profile.theta = "GroupB2", - lo.theta = -0.3, hi.theta = 0.3, length = 500 -)Now we plot our likelihood function and we can see what the maximum likelihood estimation is. Notice that it’s practically similar to the interval in the S-value function with 0 bits of information against it and and the consonance interval in the P-value function with a P-value of 1.
--profilelike.plot( - theta = xx$theta, - profile.lik.norm = xx$profile.lik.norm, round = 3 -) -title(main = "Likelihood Function")- - -
-We’ve used a relatively easy example for this blog post, but the concurve package is also able to calculate consonance functions for multiple regressions, logistic regressions, ANOVAs, and meta-analyses (that have been produced by the metafor package).
--- - - - - - - - - - - diff --git a/vignettes/figures/densityfunction.png b/vignettes/figures/densityfunction.png new file mode 100644 index 0000000..66d024c Binary files /dev/null and b/vignettes/figures/densityfunction.png differ diff --git a/vignettes/references.bib b/vignettes/references.bib new file mode 100644 index 0000000..09d0ea6 --- /dev/null +++ b/vignettes/references.bib @@ -0,0 +1,296 @@ +@Article{Singh2007-zr, + archiveprefix = {arXiv}, + eprinttype = {arxiv}, + eprint = {0708.0976}, + primaryclass = {math.ST}, + title = {Confidence Distribution ({{CD}}) -- Distribution Estimator of a Parameter}, + note = {\url{http://arxiv.org/abs/0708.0976}}, + author = {Kesar Singh and Minge Xie and William E Strawderman}, + month = {aug}, + year = {2007}, + keywords = {⛔ No DOI found}, + file = {/Users/Zad/Desktop/Google Drive/Research/Zotero/undefined/2007/Singh et al_2007_Confidence distribution (CD) -- distribution estimator of a parameter.pdf}, + arxivid = {0708.0976}, +} + +@Article{Schweder2002-vh, + title = {Confidence and {{Likelihood}}*}, + volume = {29}, + issn = {0303-6898, 1467-9469}, + number = {2}, + journal = {Scand J Stat}, + note = {\url{http://doi.wiley.com/10.1111/1467-9469.00285}}, + doi = {10.1111/1467-9469.00285}, + author = {Tore Schweder and Nils Lid Hjort}, + month = {jun}, + year = {2002}, + pages = {309-332}, + file = {/Users/Zad/Desktop/Google Drive/Research/Zotero/Scand J Stat/2002/Schweder_Hjort_2002_Confidence and Likelihood.pdf}, +} + +@Article{Sullivan1990-ha, + title = {Use of the Confidence Interval Function}, + volume = {1}, + issn = {1044-3983}, + language = {English}, + number = {1}, + journal = {Epidemiology}, + note = {\url{https://doi.org/10.1097/00001648-199001000-00009}}, + doi = {10.1097/00001648-199001000-00009}, + author = {K M Sullivan and D A Foster}, + month = {jan}, + year = {1990}, + pages = {39-42}, + affiliation = {Division of Nutrition, Centers for Disease Control, Atlanta, GA 30333.}, + pmid = {2150497}, +} + +@Article{Poole1987-nb, + title = {Beyond the Confidence Interval}, + volume = {77}, + issn = {0090-0036}, + language = {English}, + number = {2}, + journal = {American Journal of Public Health}, + note = {\url{https://doi.org/10.2105/AJPH.77.2.195}}, + doi = {10.2105/AJPH.77.2.195}, + author = {Charles Poole}, + month = {feb}, + year = {1987}, + pages = {195-199}, + file = {/Users/Zad/Desktop/Google Drive/Research/Zotero/American Journal of Public Health/1987/Poole_1987_Beyond the confidence interval.pdf}, + pmc = {PMC1646825}, + pmid = {3799860}, +} + +@Article{fraser2019as, + title = {The {{P}}-Value Function and Statistical Inference}, + volume = {73}, + issn = {0003-1305}, + number = {sup1}, + journal = {The American Statistician}, + note = {\url{https://doi.org/10.1080/00031305.2018.1556735}}, + doi = {10.1080/00031305.2018.1556735}, + author = {D. A. S. Fraser}, + month = {mar}, + year = {2019}, + keywords = {Accept–Reject,Ancillarity,Box–Cox,Conditioning,Decision or judgment,Discrete data,Extreme value model,Fieller–Creasy,Gamma mean,Percentile position,Power function,Statistical position}, + pages = {135-147}, + file = {/Users/Zad/Desktop/Google Drive/Research/Zotero/The American Statistician/2019/Fraser_2019_The p-value Function and Statistical Inference.pdf}, +} + +@Article{whitehead1993sm, + title = {The Case for Frequentism in Clinical Trials}, + volume = {12}, + copyright = {Copyright \textcopyright{} 1993 John Wiley \& Sons, Ltd.}, + issn = {1097-0258}, + language = {en}, + number = {15-16}, + journal = {Statistics in Medicine}, + note = {\url{https://doi.org/10.1002/sim.4780121506}}, + doi = {10.1002/sim.4780121506}, + author = {John Whitehead}, + year = {1993}, + pages = {1405-1413}, + file = {/Users/Zad/Desktop/Google Drive/Research/Zotero/Statistics in Medicine/1993/Whitehead_1993_The case for frequentism in clinical trials.pdf}, +} + +@Article{poole1987ajph, + title = {Confidence Intervals Exclude Nothing.}, + volume = {77}, + issn = {0090-0036}, + number = {4}, + journal = {American Journal of Public Health}, + note = {\url{https://doi.org/10.2105/ajph.77.4.492}}, + doi = {10.2105/ajph.77.4.492}, + author = {Charles Poole}, + month = {apr}, + year = {1987}, + pages = {492-493}, + file = {/Users/Zad/Desktop/Google Drive/Research/Zotero/American Journal of Public Health/1987/Poole_1987_Confidence intervals exclude nothing.pdf}, + pmid = {2950780}, + pmcid = {PMC1646956}, +} + +@Article{birnbaum1961ams, + title = {A Unified Theory of Estimation, {{I}}}, + volume = {32}, + issn = {0003-4851}, + number = {1}, + journal = {The Annals of Mathematical Statistics}, + note = {\url{https://doi.org/10.1214/aoms/1177705145}}, + doi = {10.1214/aoms/1177705145}, + author = {Allan Birnbaum}, + year = {1961}, + pages = {112-135}, + file = {/Users/Zad/Desktop/Google Drive/Research/Zotero/The Annals of Mathematical Statistics/1961/Birnbaum_1961_A unified theory of estimation, I.pdf}, +} + +@Article{chow2019asb, + archiveprefix = {arXiv}, + eprinttype = {arxiv}, + eprint = {1909.08579}, + primaryclass = {stat.ME}, + title = {Semantic and {{Cognitive Tools}} to {{Aid Statistical Inference}}: {{Replace Confidence}} and {{Significance}} by {{Compatibility}} and {{Surprise}}}, + copyright = {All rights reserved}, + shorttitle = {Semantic and {{Cognitive Tools}} to {{Aid Statistical Inference}}}, + journal = {arXiv:1909.08579 [stat.ME]}, + note = {\url{https://arxiv.org/abs/1909.08579}}, + author = {Zad R. Chow and Sander Greenland}, + month = {sep}, + year = {2019}, + keywords = {⛔ No DOI found}, + file = {/Users/Zad/Desktop/Google Drive/Research/Zotero/arXiv1909.08579 [stat]/2019/Chow_Greenland_2019_Semantic and cognitive tools to aid statistical inference.pdf}, + arxivid = {1909.08579}, +} + +@Book{schweder2016, + title = {Confidence, {{Likelihood}}, {{Probability}}: {{Statistical Inference}} with {{Confidence Distributions}}}, + isbn = {978-1-316-44505-1}, + shorttitle = {Confidence, {{Likelihood}}, {{Probability}}}, + language = {en}, + publisher = {{Cambridge University Press}}, + author = {Tore Schweder and Nils Lid Hjort}, + month = {feb}, + year = {2016}, + keywords = {Mathematics / Probability \& Statistics / General,Business \& Economics / Economics / General,Business \& Economics / Econometrics}, + googlebooks = {t7KzCwAAQBAJ}, +} + +@Article{xie2013isr, + title = {Confidence {{Distribution}}, the {{Frequentist Distribution Estimator}} of a {{Parameter}}: {{A Review}}}, + volume = {81}, + issn = {0306-7734}, + number = {1}, + journal = {International Statistical Review}, + note = {\url{https://doi.org/10.1111/insr.12000}}, + doi = {10.1111/insr.12000}, + author = {Min-ge Xie and Kesar Singh}, + month = {apr}, + year = {2013}, + keywords = {Bayesian method,Confidence distribution,estimation theory,fiducial distribution,likelihood function,statistical inference}, + pages = {3-39}, +} + +@Article{fraser2017arsa, + title = {P-{{Values}}: {{The Insight}} to {{Modern Statistical Inference}}}, + volume = {4}, + issn = {2326-8298}, + number = {1}, + journal = {Annual Review of Statistics and Its Application}, + note = {\url{https://doi.org/10.1146/annurev-statistics-060116-054139}}, + doi = {10.1146/annurev-statistics-060116-054139}, + author = {D.A.S. Fraser}, + month = {mar}, + year = {2017}, + pages = {1-14}, + file = {/Users/Zad/Desktop/Google Drive/Research/Zotero/Annual Review of Statistics and Its Application/2017/Fraser_2017_p-Values.pdf}, +} +@InCollection{rothman2008me, + edition = {3rd}, + title = {Precision and Statistics in Epidemiologic Studies}, + isbn = {978-0-7817-5564-1}, + language = {en}, + booktitle = {Modern {{Epidemiology}}}, + publisher = {{Lippincott Williams \& Wilkins}}, + author = {Kenneth J. Rothman and Sander Greenland and Timothy L. Lash}, + editor = {Kenneth J. Rothman and Sander Greenland and Timothy L. Lash}, + year = {2008}, + keywords = {Medical / Education \& Training,Medical / Epidemiology,Medical / Public Health,Medical / Infectious Diseases,Medical / Occupational \& Industrial Medicine,Medical / Test Preparation \& Review}, + pages = {148-167}, + googlebooks = {Z3vjT9ALxHUC}, +} +@Article{Shannon1948-uq, + title = {A Mathematical Theory of Communication}, + volume = {27}, + issn = {0005-8580}, + number = {3}, + journal = {The Bell System Technical Journal}, + note = {\url{https://doi.org/10.1002/j.1538-7305.1948.tb01338.x}}, + doi = {10.1002/j.1538-7305.1948.tb01338.x}, + author = {C E Shannon}, + month = {jul}, + year = {1948}, + pages = {379-423}, + file = {/Users/Zad/Desktop/Google Drive/Research/Zotero/The Bell System Technical Journal/1948/Shannon_1948_A mathematical theory of communication.pdf}, +} + +@Article{greenland2019as, + title = {Valid {{P}}-Values Behave Exactly as They Should: {{Some}} Misleading Criticisms of {{P}}-Values and Their Resolution with {{S}}-Values}, + volume = {73}, + issn = {0003-1305}, + shorttitle = {Valid {{P}}-{{Values Behave Exactly}} as {{They Should}}}, + number = {sup1}, + journal = {The American Statistician}, + note = {\url{https://doi.org/10.1080/00031305.2018.1529625}}, + doi = {10.1080/00031305.2018.1529625}, + author = {Sander Greenland}, + month = {mar}, + year = {2019}, + keywords = {Evidence,Compatibility,Dichotomania,Information,Logworth,Nullism,P-values,S-values,Significance testing,Surprisal}, + pages = {106-114}, + file = {/Users/Zad/Desktop/Google Drive/Research/Zotero/The American Statistician/2019/Greenland_2019_Valid P-Values Behave Exactly as They Should.pdf}, +} +@Article{brown2017j, + title = {Association between Serotonergic Antidepressant Use during Pregnancy and Autism Spectrum Disorder in Children}, + volume = {317}, + issn = {0098-7484}, + language = {en}, + number = {15}, + journal = {JAMA}, + note = {\url{https://doi.org/10.1001/jama.2017.3415}}, + doi = {10.1001/jama.2017.3415}, + author = {Hilary K. Brown and Joel G. Ray and Andrew S. Wilton and Yona Lunsky and Tara Gomes and Simone N. Vigod}, + month = {apr}, + year = {2017}, + pages = {1544-1552}, + file = {/Users/Zad/Desktop/Google Drive/Research/Zotero/JAMA/2017/Brown et al_2017_Association Between Serotonergic Antidepressant Use During Pregnancy and Autism.pdf}, +} + +@Article{brown2017jcp, + title = {The Association between Antenatal Exposure to Selective Serotonin Reuptake Inhibitors and Autism: {{A}} Systematic Review and Meta-Analysis}, + volume = {78}, + issn = {1555-2101}, + shorttitle = {The Association between Antenatal Exposure to Selective Serotonin Reuptake Inhibitors and Autism: {{A}} Systematic Review and Meta-Analysis}, + language = {eng}, + number = {1}, + journal = {The Journal of Clinical Psychiatry}, + note = {\url{https://doi.org/10.4088/JCP.15r10194}}, + doi = {10.4088/JCP.15r10194}, + author = {Hilary K. Brown and Neesha Hussain-Shamsy and Yona Lunsky and Cindy-Lee E. Dennis and Simone N. Vigod}, + month = {jan}, + year = {2017}, + keywords = {Female,Humans,Pregnancy,Child,Cohort Studies,Child; Preschool,Observational Studies as Topic,Odds Ratio,Infant,Infant; Newborn,Pregnancy Complications,Autism Spectrum Disorder,Case-Control Studies,Depressive Disorder,Pregnancy Trimester; First,Prenatal Exposure Delayed Effects,Serotonin Uptake Inhibitors}, + pages = {e48-e58}, + pmid = {28129495}, +} +@Article{efron, + title = {The Automatic Construction of Bootstrap Confidence Intervals}, + language = {en}, + author = {Bradley Efron and Balasubramanian Narasimhan}, + keywords = {⛔ No DOI found}, + pages = {17}, + file = {/Users/Zad/Documents/Zotero/storage/AI2JYX3Y/Efron and Narasimhan - The automatic construction of bootstrap confidence .pdf}, +} + +@Book{efron1994, + title = {An {{Introduction}} to the {{Bootstrap}}}, + isbn = {978-0-412-04231-7}, + language = {en}, + publisher = {{CRC Press}}, + author = {Bradley Efron and R. J. Tibshirani}, + month = {may}, + year = {1994}, + keywords = {Computers / Mathematical \& Statistical Software,Mathematics / General,Mathematics / Probability \& Statistics / General}, + googlebooks = {gLlpIUxRntoC}, +} +@Article{efron2018, + title = {The Automatic Construction of Bootstrap Confidence Intervals}, + language = {en}, + author = {Bradley Efron and Balasubramanian Narasimhan}, + month = {oct}, + year = {2018}, + keywords = {⛔ No DOI found}, + pages = {17}, + file = {/Users/Zad/Documents/Zotero/storage/AI2JYX3Y/Efron and Narasimhan - The automatic construction of bootstrap confidence .pdf}, +} diff --git a/vignettes/stata.html b/vignettes/stata.html deleted file mode 100644 index e6985b2..0000000 --- a/vignettes/stata.html +++ /dev/null @@ -1,478 +0,0 @@ - - - - - - - - - - - - - - -Using Meta-Analysis Data
-Here we present another quick example with a meta-analysis of simulated data.
-First, we generate random data for two groups in two hypothetical studies
--GroupAData <- runif(20, min = 0, max = 100) -GroupAMean <- round(mean(GroupAData), digits = 2) -GroupASD <- round(sd(GroupAData), digits = 2) - -GroupBData <- runif(20, min = 0, max = 100) -GroupBMean <- round(mean(GroupBData), digits = 2) -GroupBSD <- round(sd(GroupBData), digits = 2) - -GroupCData <- runif(20, min = 0, max = 100) -GroupCMean <- round(mean(GroupCData), digits = 2) -GroupCSD <- round(sd(GroupCData), digits = 2) - -GroupDData <- runif(20, min = 0, max = 100) -GroupDMean <- round(mean(GroupDData), digits = 2) -GroupDSD <- round(sd(GroupDData), digits = 2)We can then quickly combine the data in a dataframe.
--StudyName <- c("Study1", "Study2") -MeanTreatment <- c(GroupAMean, GroupCMean) -MeanControl <- c(GroupBMean, GroupDMean) -SDTreatment <- c(GroupASD, GroupCSD) -SDControl <- c(GroupBSD, GroupDSD) -NTreatment <- c(20, 20) -NControl <- c(20, 20) - -metadf <- data.frame( - StudyName, MeanTreatment, MeanControl, - SDTreatment, SDControl, - NTreatment, NControl -)Then, we’ll use metafor to calculate the standardized mean difference.
--dat <- escalc( - measure = "SMD", - m1i = MeanTreatment, sd1i = SDTreatment, n1i = NTreatment, - m2i = MeanControl, sd2i = SDControl, n2i = NControl, - data = metadf -)Next, we’ll pool the data using a
-fixed-effectscommon-effects model-res <- rma(yi, vi, - data = dat, slab = paste(StudyName, sep = ", "), - method = "FE", digits = 2 -)Let’s look at our output.
- -
-Fixed-Effects Model (k = 2) - -Test for Heterogeneity: -Q(df = 1) = 0.61, p-val = 0.44 - -Model Results: - -estimate se zval pval ci.lb ci.ub - 0.16 0.22 0.73 0.47 -0.28 0.60 - ---- -Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Take a look at the pooled summary effect and its interval. Keep it in mind as we move onto constructing a consonance function.
-We can now take the object produced by the meta-analysis and calculate a P-value and S-value function with it to see the full spectrum of effect sizes compatible with the test model at every level. We’ll use the
- -curve_meta()function to do this.Now that we have our dataframe with every computed interval, we can plot the functions.
- -- - -
-And our S-value function
- -- - -
-Compare the span of these functions and the information they provide to the consonance interval provided by the forest plot. We are now no longer limited to interpreting an arbitrarily chosen interval by mindless analytic decisions often built into statistical packages by default.
-Using Stata - - - - - - - - - - - - - - - - - - - - - -Using Stata
- - - -Although
-concurvewas originally designed to be used inR, it is possible to achieve very similar results inStata. We can use some datasets that are built intoStatato show how to achieve this.First, let’s load the auto2 dataset which contains data about cars and their characteristics.
- -Browse the dataset in your databrowser to get more familiar with some of the variables. Let’s say we’re interested in the relationship between miles per gallon and price. We could fit a very simple linear model to assess that relationship.
-First, let’s visualize the data with a scatterplot.
- -
-- - -
-
-
That’s what our data looks like. Clearly there seems to be an inverse relationship between miles per gallon and price.Now we could fit a very simple linear model with miles per gallon being the predictor and price being the outcome and get some estimates of the relationship.
- -
-- - -
-
-
That’s what our output looks like.Our output also gives us 95% consonance (confidence) intervals by default. The interval includes values as low as -344 and as high as -133. Here’s what our model looks graphed.
-
-- - -
-
-Unfortunately, the program only gives us one interval at 95% and we’re interested in seeing every single interval at every level, and plotting it to form a function.
-Here’s the code that we’ll be using to achieve that.
---postfile topost level pvalue svalue lointerval upinterval using my_new_data, replace - -forvalues i = 10/99.9 { - quietly regress price mpg, level(`i') - matrix E = r(table) - matrix list E - post topost (`i') (1-`i'/100) ( ln(1-`i'/100)/ln(2) * -1) (E[5,1]) (E[6,1]) - } - -postclose topost -use my_new_data, clear -list - -twoway (pcscatter level lointerval level upinterval), -ytitle(Consonance Level (%)) xtitle(Consonance Limits) /// -title(Consonance Curve) -subtitle(A function comprised of several consonance intervals at various levels.)That’s a lot and may seem intimidating at first, but I’ll explain it line by line.
- -“postfile” is the command that will be responsible for pasting the data from our overall loop into a new dataset. Here, we are telling
-Statathat the internalStatamemory used to hold these results (the post) will be named “topost” and that it will have five variables, “level”, “pvalue”, “svalue”, “lointerval”, and “upinterval.”-
-
“level” will contain the consonance level that corresponds to the limits of the interval, with “lointerval” being the lower bound of the interval and “upinterval” being the upper bound.
-“pvalue”is computed by taking 1 - “level”, which is alpha.
-“svalue”is computed by taking the \(-log_{2}\) of the computed P-value, and this column will be used to plot the surprisal function.
-“my_new_data” is the filename that we’ve assigned to our new dataset.
-“replace” indicates that if there is an existing filename that already exists, we’re willing to relace it.
-
Here are the next few major lines
--forvalues i = 10/99.9 { - quietly regress price mpg, level(`i') - matrix E = r(table) - matrix list E - post topost (`i') (1-`i'/100) ( ln(1-`i'/100)/ln(2) * -1) (E[5,1]) (E[6,1]) - }The command “forvalues” is responsible for taking a set of numbers that we provide it, and running the contents within the braces through those numbers. So here, we’ve set the local macro “i” to contain numbers between 10 and 99.99 for our consonance levels. Why 10?
-Statacannot compute consonance intervals lower than 10%.Our next line contains the actual contents of what we want to do. Here, it says that we will run a simple linear regression where mpg is the predictor and where price is the outcome, and that the outputs for each loop will be suppressed, hence the “quiet.”
-Then, we have the command “level” with the local macro “i” inside of it. As you may already know, “level” dictates the consonance level that
-Stataprovides us. By default, this is set to 95%, but here, we’ve set it “i”, which we established via “forvalues” as being set to numbers between 10 and 99.The next line two lines
- -indicate that we will take variables of a certain class r(), (this class contains the interval bounds we need) and place them within a matrix called E. Then we will list the contents of this matrix.
- -From the contents of this matrix list, we will take the estimates from the fifth and sixth rows (look at the last two paranthesis of this line of code above and then the image below) in the first column which contain our consonance limits, with the fifth row containing the lower bound of the interval and the sixth containing the upper bound.
-
-- - -
-
-We will place the contents from the fifth row into the second variable we set originally for our new dataset, which was “lointerval.” The contents of the sixth row will be placed into “upinterval.”
-All potential values of “i” (10-99) will be placed into the first variable that we set, “level”. From this first variable, we can compute the second variable we set up, which was “Pvalue” and we’ve done that here by subtracting “level” from 1 and then dividing the whole equation by 100, so that our P-value can be on the proper scale. Our third variable, which is the longest, computes the “Svalue” by using the previous variable, the “Pvalue” and taking the \(-log_{2}\) of it.
-The relationships between the variables on this line and the variables we set up in the very first line are dictated by the order of the commands we have set, and therefore they correspond to the same order.
-“post topost” is writing the results from each loop as new observations in this data structure.
-With that, our loop has concluded, and we can now tell
- -Statathat “post” is no longer neededWe then tell
- -Statato clear its memory to make room for the new dataset we just created and we can list the contents of this new dataset.Now we have an actual dataset with all the consonance intervals at all the levels we wanted, ranging from 10% all the way up to 99%.
-In order to get a function, we’ll need to be able to graph these results, and that can be tricky since for each observation we have one y value (the consonance level), and two x values, the lower bound of the interval and the upper bound of the interval.
-So a typical scatterplot will not work, since
-Statawill only accept one x value. To bypass this, we’ll have to use a paired-coordinate scatterplot which will allow us to plot two different y variables and two different x variables.Of course, we don’t need two y variables, so we can set both options to the variable “level”, and then we can set our first x variable to “lointerval” and the second x variable to “upinterval.”
-This can all be done with the following commands, which will also allow us to set the title and subtitle of the graph, along with the titles of the axes.
--twoway (pcscatter level lointerval level upinterval), -ytitle(Consonance Level (%)) xtitle(Consonance Limits) /// -title(Consonance Curve) -subtitle(A function comprised of several consonance intervals at various levels.)However, I would recommend using the menu to customize the plots as much as possible. Simply go to the Graphics menu and select Twoway Graphs. Then create a new plot definition, and select the Advanced plots and choose a paired coordinate scatterplot and fill in the y variables, both of which will be “levels” and the x variables, which will be “lointerval” and “upinterval”.
-
-- - -
-
-So now, here’s what our consonance function looks like.
-
-- - -
-
-
And here’s what our surprisal function looks like.
-- - -
-
-
It looks slighly better when the y-axis is transformed logarithmically…
-- - -
-
-
…but then we lose our ability to differentiate between the effects contained in intervals with higher bits of information and S-values are already logarithmically scaled.It’s clear that in both plots, we’re missing values of intervals with a consonance level of less than 10%, but unfortunately, this is the best
-Statacan do, and what we’ll have to work with. It may not look as pretty as an output fromR, but it’s far more useful than blankly staring at a 95% interval and thinking that it is the only piece of information we have regarding compatibility of different effect estimates.The code that I have pasted above can be used for most commands in
-Statathat have an option to calculate a consonance level. Thus, if there’s an option for “level”, then the commands above will work to produce a dataset of several consonance intervals.For example, if we wished to fit a generalized linear model, here’s what our code would look like.
--postfile topost level pvalue svalue lointerval upinterval using my_new_data, replace - -forvalues i = 10/99.9 { - quietly glm price mpg, level(`i') - matrix E = r(table) - matrix list E - post topost (`i') (1-`i'/100) ( ln(1-`i'/100)/ln(2) * -1) (E[5,1]) (E[6,1]) - } - -postclose topost -use my_new_data, clear -list - -twoway (pcscatter level lointerval level upinterval), -ytitle(Confidence Level (%)) xtitle(Confidence Limits) /// -title(Consonance Curve) -subtitle(A function comprised of several consonance intervals at various levels.)We simply replace the first line within the loop with our intended command, just as I’ve replaced
- -with
- -If we wanted fit something more complex, like a multilevel mixed model that used restricted maximum likelihood, here’s what our code would look like
--postfile topost level pvalue svalue lointerval upinterval using my_new_data, replace - -forvalues i = 10/99.9 { - quietly mixed outcome predictor, reml level(`i') - matrix E = r(table) - matrix list E - post topost (`i') (1-`i'/100) ( ln(1-`i'/100)/ln(2) * -1) (E[5,1]) (E[6,1]) - } - -postclose topost -use my_new_data, clear -list - -twoway (pcscatter level lointerval level upinterval), -ytitle(Confidence Level (%)) xtitle(Confidence Limits) /// -title(Consonance Curve) -subtitle(A function comprised of several consonance intervals at various levels.)Basically, our code doesn’t really change that much and with only a few lines of it, we are able to produce graphical tools that can better help us interpret the wide range of effect sizes that are compatible with the model and its assumptions.
- - - - - - - -
-
-
+
@@ -164,34 +164,54 @@
-
-
+
@@ -147,80 +148,87 @@
concurve 1.07 Unreleased
-+-Major changes
+Major changesconcurve 1.06 Unreleased
-+ -+-Minor changes
+Minor changes@@ -122,7 +121,7 @@Contents
-
+
concurve: Computes and Plots Compatibility (Confidence) Intervals, + P-Values, S-Values, & Likelihood Intervals to Form Consonance, + Surprisal, & Likelihood Functions — concurve-package • concurve + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + +++ + + + + + + + + + + diff --git a/docs/reference/curve_boot-1.png b/docs/reference/curve_boot-1.png new file mode 100644 index 0000000..80865c1 Binary files /dev/null and b/docs/reference/curve_boot-1.png differ diff --git a/docs/reference/curve_boot-2.png b/docs/reference/curve_boot-2.png new file mode 100644 index 0000000..6aec793 Binary files /dev/null and b/docs/reference/curve_boot-2.png differ diff --git a/docs/reference/curve_boot-3.png b/docs/reference/curve_boot-3.png new file mode 100644 index 0000000..620acfd Binary files /dev/null and b/docs/reference/curve_boot-3.png differ diff --git a/docs/reference/curve_boot.html b/docs/reference/curve_boot.html new file mode 100644 index 0000000..77f0564 --- /dev/null +++ b/docs/reference/curve_boot.html @@ -0,0 +1,277 @@ + + + + + + + + ++ + +++ + + ++++ ++ + +
+ concurve
+ 2.3.0
+
+ ++ + + +++ +++ +concurve: Computes and Plots Compatibility (Confidence) Intervals, + P-Values, S-Values, & Likelihood Intervals to Form Consonance, + Surprisal, & Likelihood Functions
+ Source:R/concurve-package.R++concurve-package.Rd++ + + +
+
Allows one to compute consonance (confidence) + intervals for various statistical tests along with their corresponding + P-values, S-values, and likelihoods. The intervals can be plotted to + create consonance, surprisal, and likelihood functions allowing one to + see what effect sizes are compatible with the test model at various + consonance levels rather than being limited to one interval estimate + such as 95 + <doi:10.2105/AJPH.77.2.195>, Schweder T, Hjort NL. (2002) + <doi:10.1111/1467-9469.00285>, Singh K, Xie M, Strawderman WE. (2007) + <arXiv:0708.0976>, Rothman KJ, Greenland S, Lash TL. (2008, + ISBN:9781451190052), Amrhein V, Trafimow D, Greenland S. (2019) + <doi:10.1080/00031305.2018.1543137>, Greenland S. (2019) + <doi:10.1080/00031305.2018.1529625>, Chow ZR, Greenland S. (2019) + <arXiv:1909.08579>, and Greenland S, Chow ZR. (2019) + <arXiv:1909.08583>.
+See also
+ ++ +Useful links:
+ +Generate Consonance Functions via Bootstrapping — curve_boot • concurve + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + +++ + + + + + + + + + + diff --git a/docs/reference/curve_compare-1.png b/docs/reference/curve_compare-1.png new file mode 100644 index 0000000..7c080af Binary files /dev/null and b/docs/reference/curve_compare-1.png differ diff --git a/docs/reference/curve_compare-2.png b/docs/reference/curve_compare-2.png new file mode 100644 index 0000000..cbb33f8 Binary files /dev/null and b/docs/reference/curve_compare-2.png differ diff --git a/docs/reference/plot_concurve.html b/docs/reference/curve_compare.html similarity index 58% rename from docs/reference/plot_concurve.html rename to docs/reference/curve_compare.html index 71bf165..375bb2f 100644 --- a/docs/reference/plot_concurve.html +++ b/docs/reference/curve_compare.html @@ -6,7 +6,7 @@ -+ + +++ + + ++++ ++ + +
+ concurve
+ 2.3.0
+
+ ++ + + ++ + ++ +++ +Use the BCa bootstrap method and the t boostrap method from the bcaboot and boot packages +to generate consonance distrbutions.
+curve_boot( + data = data, + func = func, + method = "bca", + replicates = 2000, + steps = 1000, + table = TRUE +)
+ +Arguments
++
+ ++ +data +Dataset that is being used to create a consonance function.
+ +func +Custom function that is used to create parameters of interest that +will be bootstrapped.
+ +method +The boostrap method that will be used to generate the functions. +Methods include "bca" which is the default and "t".
+ +replicates +Indicates how many bootstrap replicates are to be performed. +The defaultis currently 20000 but more may be desirable, especially to make +the functions more smooth.
+ +steps +Indicates how many consonance intervals are to be calculated at +various levels. For example, setting this to 100 will produce 100 consonance +intervals from 0 to 100. Setting this to 10000 will produce more consonance +levels. By default, it is set to 1000. Increasing the number substantially +is not recommended as it will take longer to produce all the intervals and +store them into a dataframe.
+ +table +Indicates whether or not a table output with some relevant +statistics should be generated. The default is TRUE and generates a table +which is included in the list object.
Value
+ +A list with the dataframe of values in the first list and the table +in the second if table = TRUE.
+ +Examples
+
++# \donttest{ +data(diabetes, package = "bcaboot") +Xy <- cbind(diabetes$x, diabetes$y) +rfun <- function(Xy) { + y <- Xy[, 11] + X <- Xy[, 1:10] + return(summary(lm(y ~ X))$adj.r.squared) +} + +x <- curve_boot(data = Xy, func = rfun, method = "bca", replicates = 200, steps = 1000)#> | | | 0% | |= | 1% | |= | 2% | |== | 2% | |== | 3% | |== | 4% | |=== | 4% | |==== | 5% | |==== | 6% | |===== | 6% | |===== | 7% | |===== | 8% | |====== | 8% | |====== | 9% | |======= | 10% | |======== | 11% | |======== | 12% | |========= | 12% | |========= | 13% | |========= | 14% | |========== | 14% | |========== | 15% | |=========== | 16% | |============ | 16% | |============ | 17% | |============ | 18% | |============= | 18% | |============= | 19% | |============== | 20% | |=============== | 21% | |=============== | 22% | |================ | 22% | |================ | 23% | |================ | 24% | |================= | 24% | |================== | 25% | |================== | 26% | |=================== | 26% | |=================== | 27% | |=================== | 28% | |==================== | 28% | |==================== | 29% | |===================== | 30% | |====================== | 31% | |====================== | 32% | |======================= | 32% | |======================= | 33% | |======================= | 34% | |======================== | 34% | |======================== | 35% | |========================= | 36% | |========================== | 36% | |========================== | 37% | |========================== | 38% | |=========================== | 38% | |=========================== | 39% | |============================ | 40% | |============================= | 41% | |============================= | 42% | |============================== | 42% | |============================== | 43% | |============================== | 44% | |=============================== | 44% | |================================ | 45% | |================================ | 46% | |================================= | 46% | |================================= | 47% | |================================= | 48% | |================================== | 48% | |================================== | 49% | |=================================== | 50% | |==================================== | 51% | |==================================== | 52% | |===================================== | 52% | |===================================== | 53% | |===================================== | 54% | |====================================== | 54% | |====================================== | 55% | |======================================= | 56% | |======================================== | 56% | |======================================== | 57% | |======================================== | 58% | |========================================= | 58% | |========================================= | 59% | |========================================== | 60% | |=========================================== | 61% | |=========================================== | 62% | |============================================ | 62% | |============================================ | 63% | |============================================ | 64% | |============================================= | 64% | |============================================== | 65% | |============================================== | 66% | |=============================================== | 66% | |=============================================== | 67% | |=============================================== | 68% | |================================================ | 68% | |================================================ | 69% | |================================================= | 70% | |================================================== | 71% | |================================================== | 72% | |=================================================== | 72% | |=================================================== | 73% | |=================================================== | 74% | |==================================================== | 74% | |==================================================== | 75% | |===================================================== | 76% | |====================================================== | 76% | |====================================================== | 77% | |====================================================== | 78% | |======================================================= | 78% | |======================================================= | 79% | |======================================================== | 80% | |========================================================= | 81% | |========================================================= | 82% | |========================================================== | 82% | |========================================================== | 83% | |========================================================== | 84% | |=========================================================== | 84% | |============================================================ | 85% | |============================================================ | 86% | |============================================================= | 86% | |============================================================= | 87% | |============================================================= | 88% | |============================================================== | 88% | |============================================================== | 89% | |=============================================================== | 90% | |================================================================ | 91% | |================================================================ | 92% | |================================================================= | 92% | |================================================================= | 93% | |================================================================= | 94% | |================================================================== | 94% | |================================================================== | 95% | |=================================================================== | 96% | |==================================================================== | 96% | |==================================================================== | 97% | |==================================================================== | 98% | |===================================================================== | 98% | |===================================================================== | 99% | |======================================================================| 100%

 # } + +
# } + +Plots the P- (Consonance) and S-Value (Surprisal) Functions using base R graphics. — plot_concurve • concurve +Compares two functions and produces an AUC score to show the amount of consonance. — curve_compare • concurve @@ -50,9 +50,8 @@ - - + + @@ -84,9 +83,9 @@ - +
concurve
- 2.1.0
+ 2.3.0
-
-