Memory is one of the biggest challenge in area of deep learning. There are several challenges in Java to manage the memory. Firstly, GC(Garbage Collector) doesn't have the control over the native memory. Secondly, to close every AutoClosable manually makes the code boilerplate and not practical. Thirdly, the system lacks in support of releasing a group of native resources. As a result, we create the NDManager to help us release the native memory.
We design the NDManager in tree structure. It provides fine-grained control of native resource and manage the resource scope in more effectively way.
NDManager can make any kind of tree. However, using the Predictor/Trainer classes will automatically create a certain kind of tree.
The structure of the NDManager for the classic inference case is like 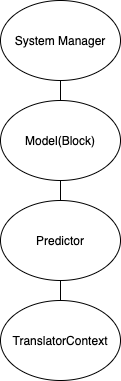 .
The structure of the NDManager for the classic training case is like
.
The structure of the NDManager for the classic training case is like 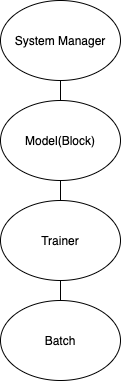 .
The topmost is System NDManager. The model, which is one layer below, contains the weight and bias of the Neural Network.
The bottommost NDManager takes care of the intermediate NDArrays we would like to close as soon as the program exit the scope of the functions that use them.
.
The topmost is System NDManager. The model, which is one layer below, contains the weight and bias of the Neural Network.
The bottommost NDManager takes care of the intermediate NDArrays we would like to close as soon as the program exit the scope of the functions that use them.
If the native resources is no longer used, we allow GC collect it's native memory before NDManager close them. However, there are still some limitations. For example, it may cause OOM(Out of memory) if preprocessing and postprocessing create a large amount of NDArrays in the training loop before GC kicks in.
Here are the rule of thumb:
- The output of the NDArray operation should be attached to the same manager as the input one. The order matters as we use first NDArray's manager on the NDArray operation by default.
- If intermediate NDArray get into upper level NDManager, e.g from Trainer -> Model, the memory leak will happen.
- You can use
NDManager.debugDump()to see if any of NDManager's resource count is keep increasing. - If a large amount of intermediate NDArrays are needed, it is recommended to create your own subNDManager or close them manually.
For the majority of the inference cases, you would be working on the ProcessInput and ProcessOutput. Make sure all temporary NDArrays are attached to the NDManager in TranslatorContext. Note that if you don't specify NDManager in a NDArray operation, it uses the NDManger from the input NDArray.
The intermediate NDArrays involving in training case are usually
- a batch of the dataset
- custom operation you write
In general, all the parameters in the model should be associated with Model level NDManager. All of the input and output NDArrays should be associated with one NDManager which is one level down to the model NDManager. Please check if you call batch.close() to release one batch of the dataset at the end of each batch. If you still see the memory grows as the training process goes, it is most likely that intermediate NDArrays are attached to the Model(Block) parameter level. As a result, those NDArrays would not closed until the training is finished. On the other hand, if you implement your own block, be aware of not attaching the parameter to batch level NDManager.