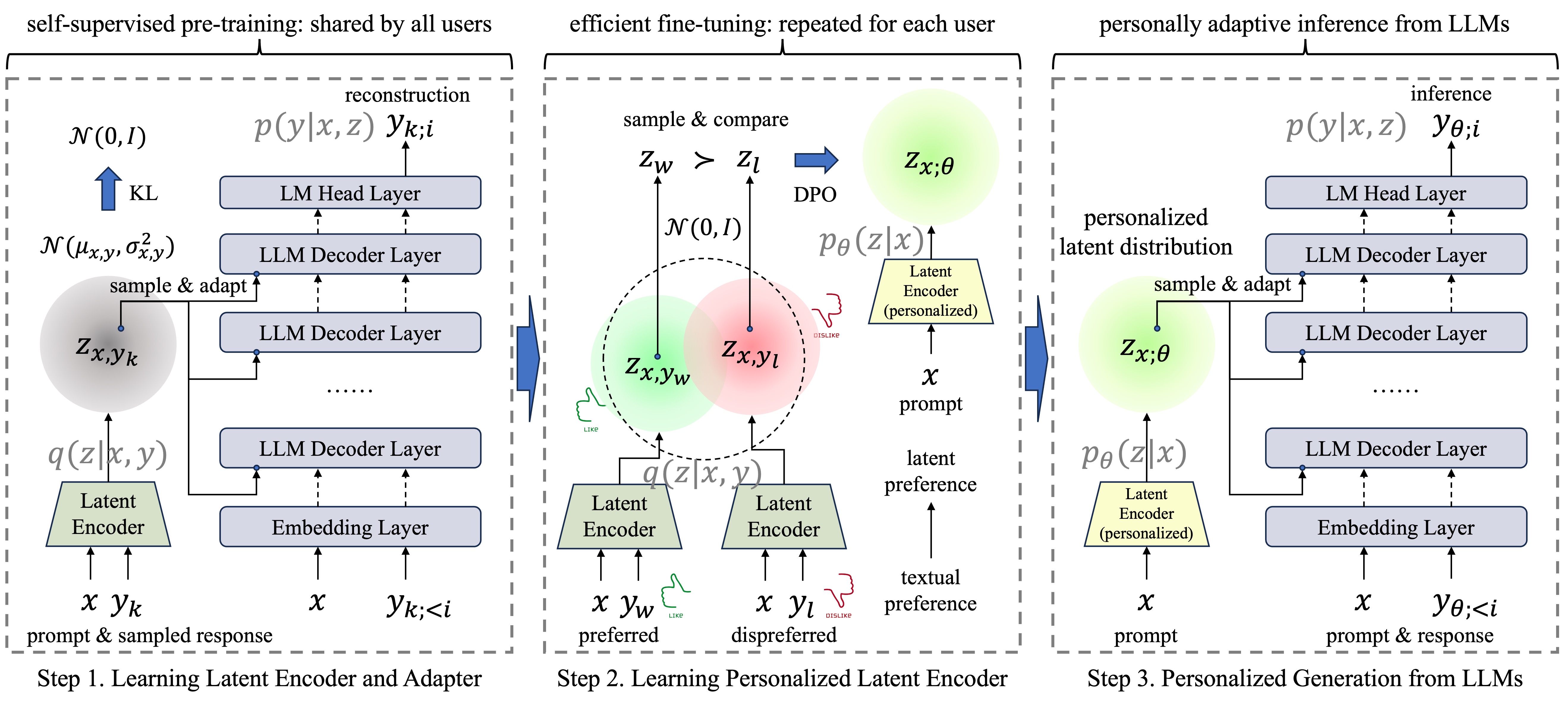
This repository contains the source code for Latent DPO (we also name it as LPO in our source code), an computation-efficient preference alignment method introduced in "Disentangling Preference Representation and Text Generation for Efficient Individual Preference Alignment (Coling 2025)", which reduces additional training time for each new preference to align by 80% to 90% in comparison with LoRA-based DPO or P-Tuning-based DPO.
We include all our code for model training in this repository, including DPO, LoRA-based DPO, P-Tuning-based DPO, and Latent DPO. Our experiment environment is mainly based on pyTorch + transformer + deepspeed. We include the main packages in requirements.txt.
The detailed introduction will be coming soon.