




适用于 Windows7 x64 、Linux x64 ( 测试中 )
- 免费:本项目所有代码开源,完全免费。
- 方便:解压即用,离线运行,无需网络。
- 高效:自带高效率的离线OCR引擎,内置多种语言识别库。
- 灵活:支持命令行、HTTP接口等外部调用方式。
- 功能:截图OCR / 批量OCR / PDF识别 / 二维码 / 公式识别
- 截图识别
- 排版解析 - 识别不同排版,按正确顺序输出文字
- 批量识别
- 忽略区域 - 排除截图水印处的文字
- 二维码 支持扫码或生成二维码图片
- 文档识别 从PDF扫描件中提取文本,或转为双层可搜索PDF
- 全局设置
- 命令行调用
- HTTP接口
- 构建项目(Windows、Linux)
开发者请务必阅读 构建项目 。
以下发布链接均长期维护,提供最新软件版本。
- 蓝奏云 https://hiroi-sora.lanzoul.com/s/umi-ocr (国内推荐,免注册/无限速)
- GitHub https://github.com/hiroi-sora/Umi-OCR/releases/latest
- Source Forge https://sourceforge.net/projects/umi-ocr
• Scoop Installer(点击展开)
Scoop 是一款Windows下的命令行安装程序,可方便地管理多个应用。您可以先安装 Scoop ,再使用以下指令安装 Umi-OCR :
- 添加
extras桶:
scoop bucket add extras
- (可选1)安装 Umi-OCR(自带
Rapid-OCR引擎,兼容性好):
scoop install extras/umi-ocr
- (可选2)安装 Umi-OCR(自带
Paddle-OCR引擎,速度稍快):
scoop install extras/umi-ocr-paddle
- 不要同时安装二者,快捷方式可能会被覆盖。但您可以额外导入 插件 ,随时切换不同OCR引擎。
软件发布包下载为 .7z 压缩包或 .7z.exe 自解压包。自解压包可在没有安装压缩软件的电脑上,解压文件。
本软件无需安装。解压后,点击 Umi-OCR.exe 即可启动程序。
遇到任何问题,请提 Issue ,我会尽可能帮助你。
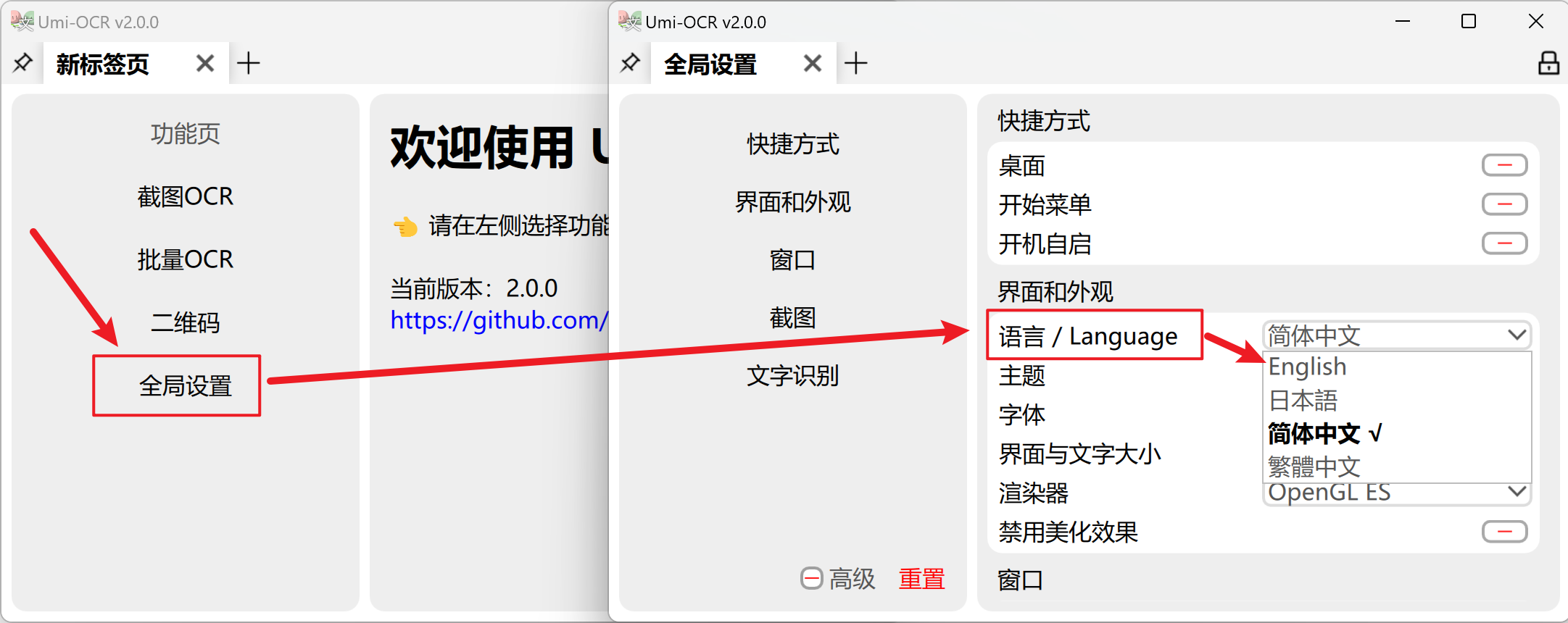
Umi-OCR 支持的界面多国语言。在第一次打开软件时,将会按照你的电脑的系统设置,自动切换语言。
如果需要手动切换语言,请参考下图,全局设置→语言/Language 。
Umi-OCR v2 由一系列灵活好用的标签页组成。您可按照自己的喜好,打开需要的标签页。
标签栏左上角可以切换窗口置顶。右上角能够锁定标签页,以防止日常使用中误触关闭标签页。
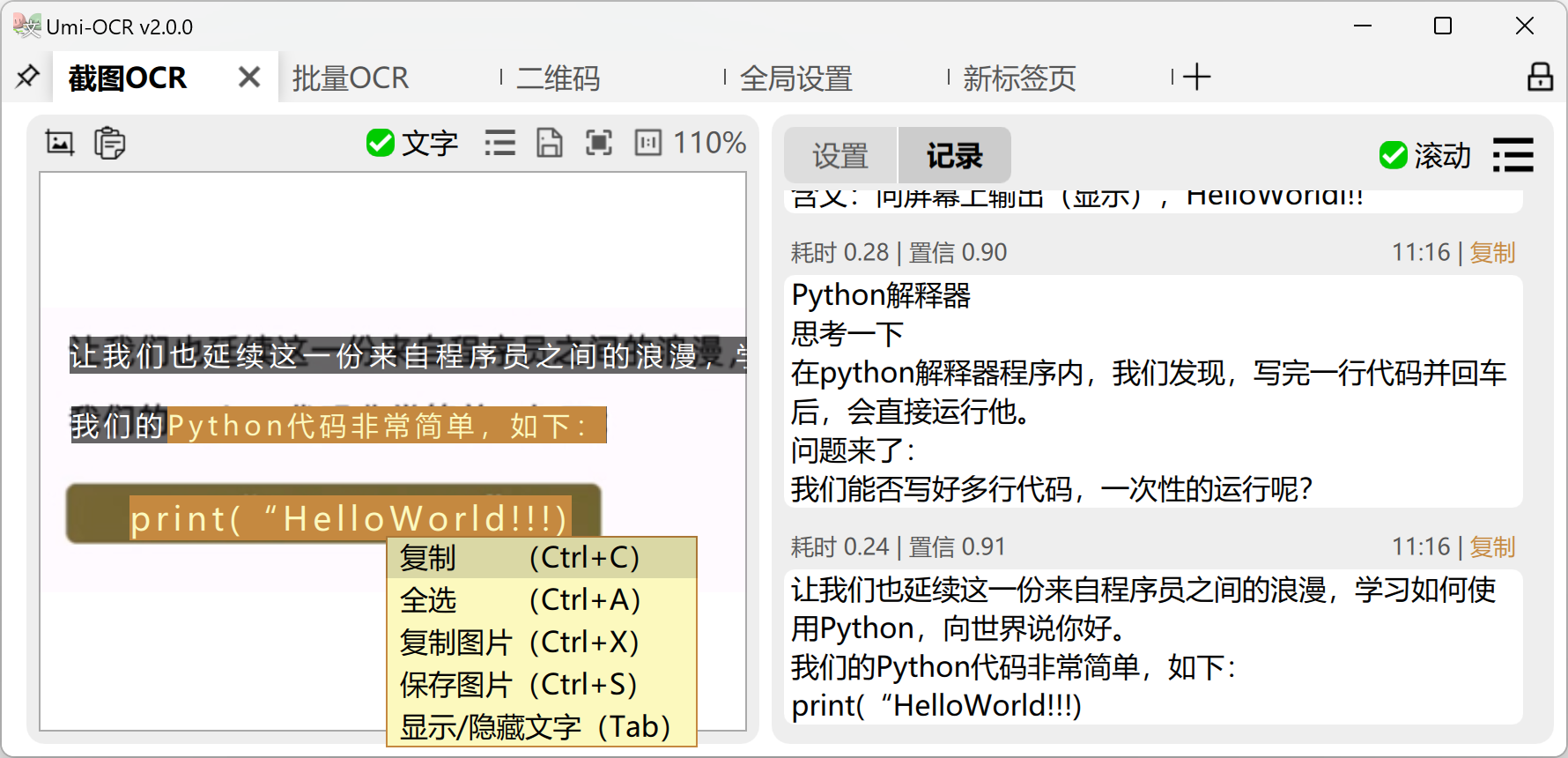
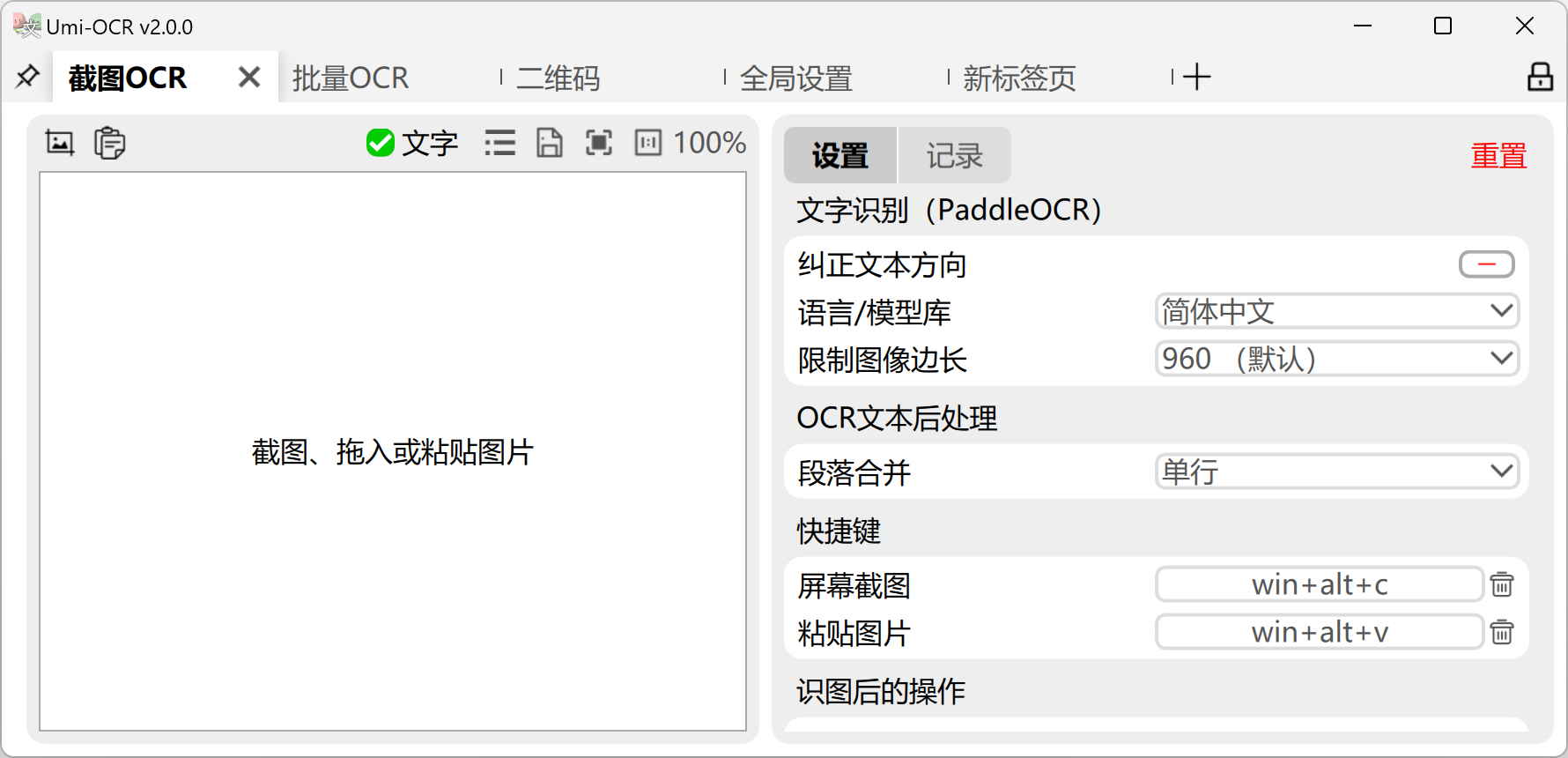
截图OCR:打开这一页后,就可以用快捷键唤起截图,识别图中的文字。
- 左侧的图片预览栏,可直接用鼠标划选复制。
- 右侧的识别记录栏,可以编辑文字,允许划选多个记录复制。
- 也支持在别处复制图片,粘贴到Umi-OCR进行识别。
- 关于 公式识别 功能
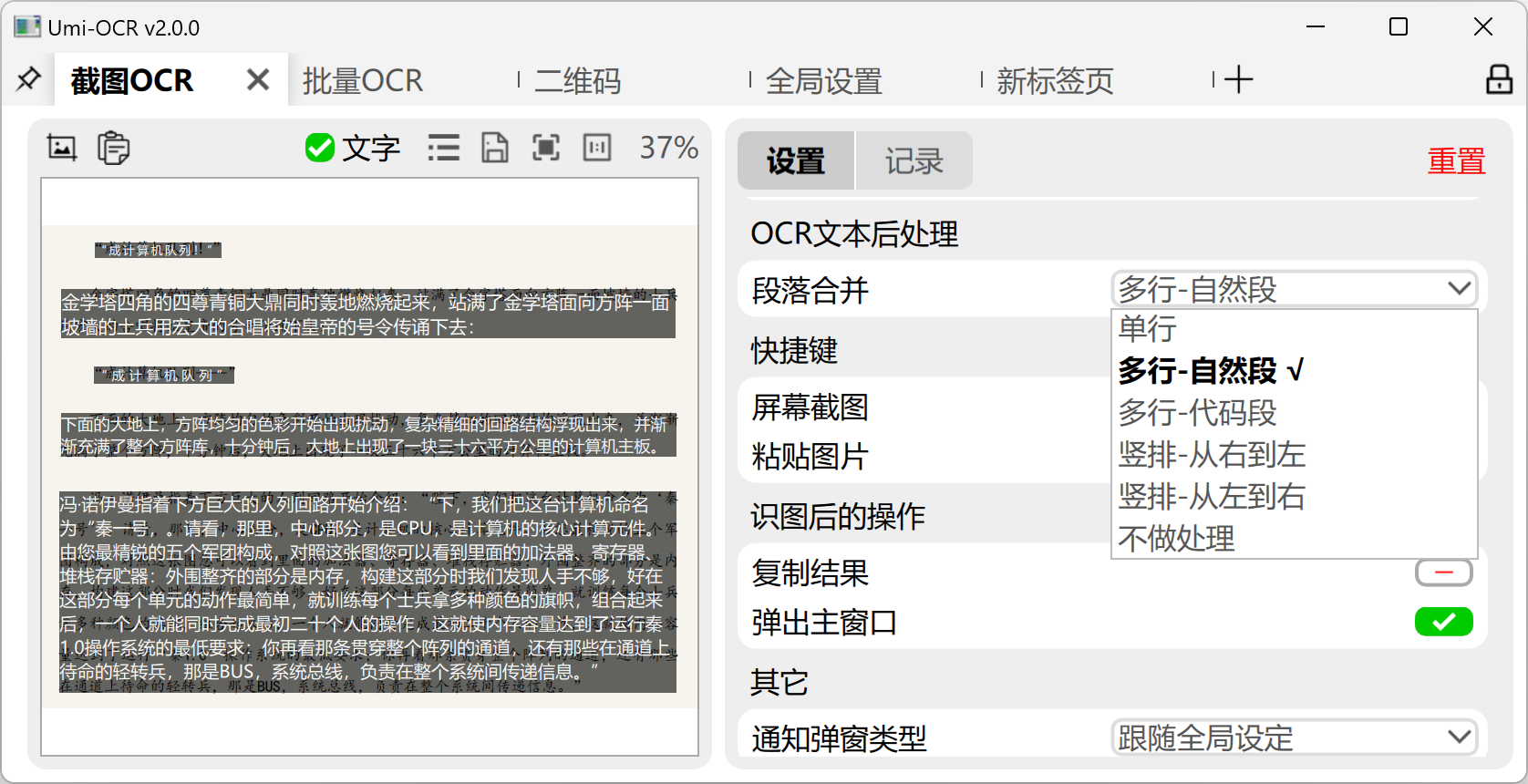
关于 OCR文本后处理 - 排版解析方案: 可以整理OCR结果的排版和顺序,使文本更适合阅读和使用。预设方案:
多栏-按自然段换行:适合大部分情景,自动识别多栏布局,按自然段规则进行换行。多栏-总是换行:每段语句都进行换行。多栏-无换行:强制将所有语句合并到同一行。单栏-按自然段换行/总是换行/无换行:与上述类似,不过 不区分多栏布局。单栏-保留缩进:适用于解析代码截图,保留行首缩进和行中空格。不做处理:OCR引擎的原始输出,默认每段语句都进行换行。
上述方案,均能自动处理横排和竖排(从右到左)的排版。(竖排文字还需要OCR引擎本身支持)
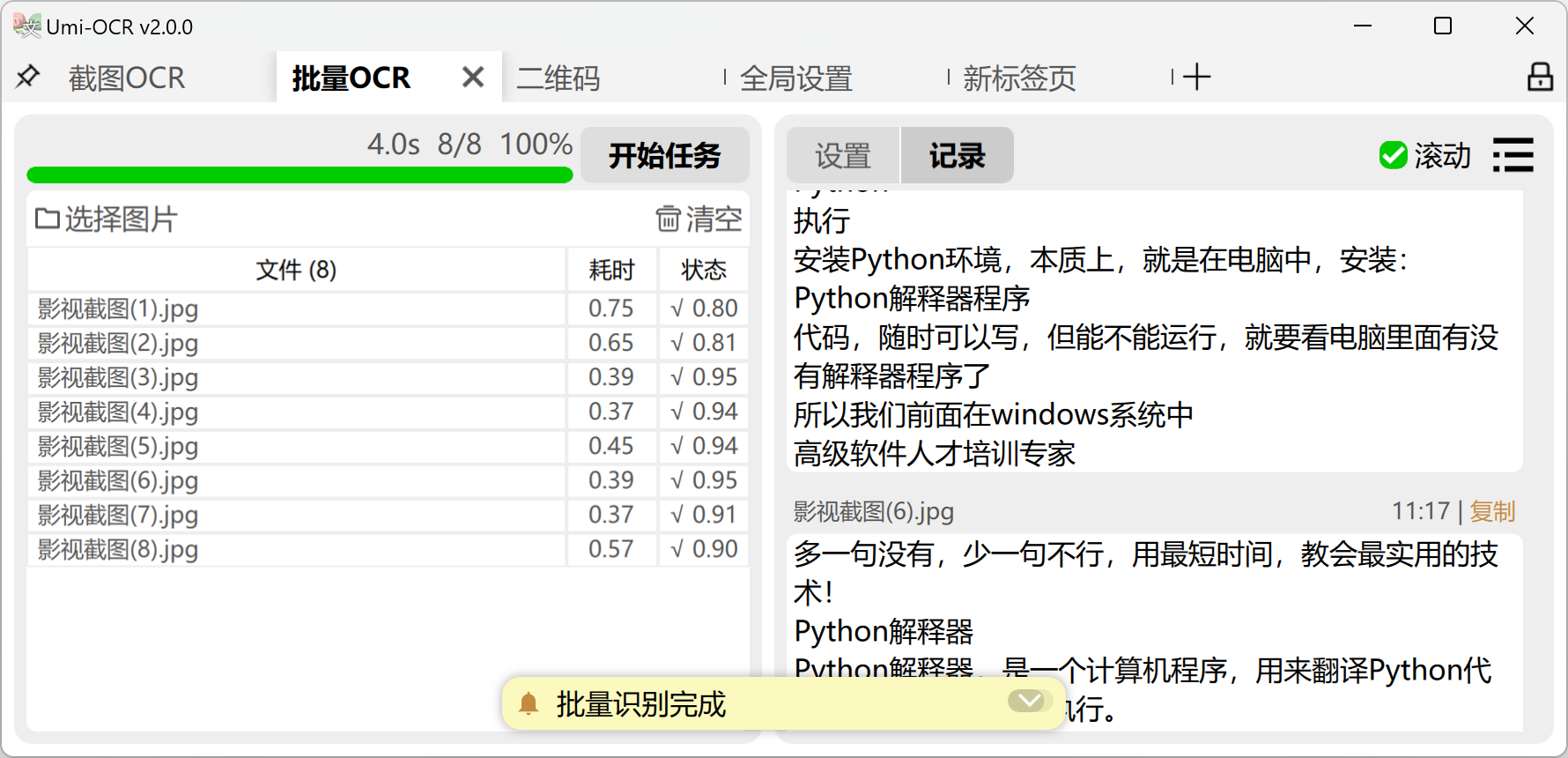
批量OCR:这一页用于批量导入本地图片进行识别。
- 支持格式:
jpg, jpe, jpeg, jfif, png, webp, bmp, tif, tiff。 - 保存识别结果的支持格式:
txt, jsonl, md, csv(Excel)。 - 与截图OCR一样,支持
文本后处理功能,整理OCR文本的排版和顺序。 - 没有数量上限,可一次性导入几百张图片进行任务。
- 支持任务完成后自动关机/待机。
- 如果要识别像素超大的长图或大图,请调整:页面的设置→文字识别→限制图像边长→【调高数值】。
- 拥有特殊功能
忽略区域。
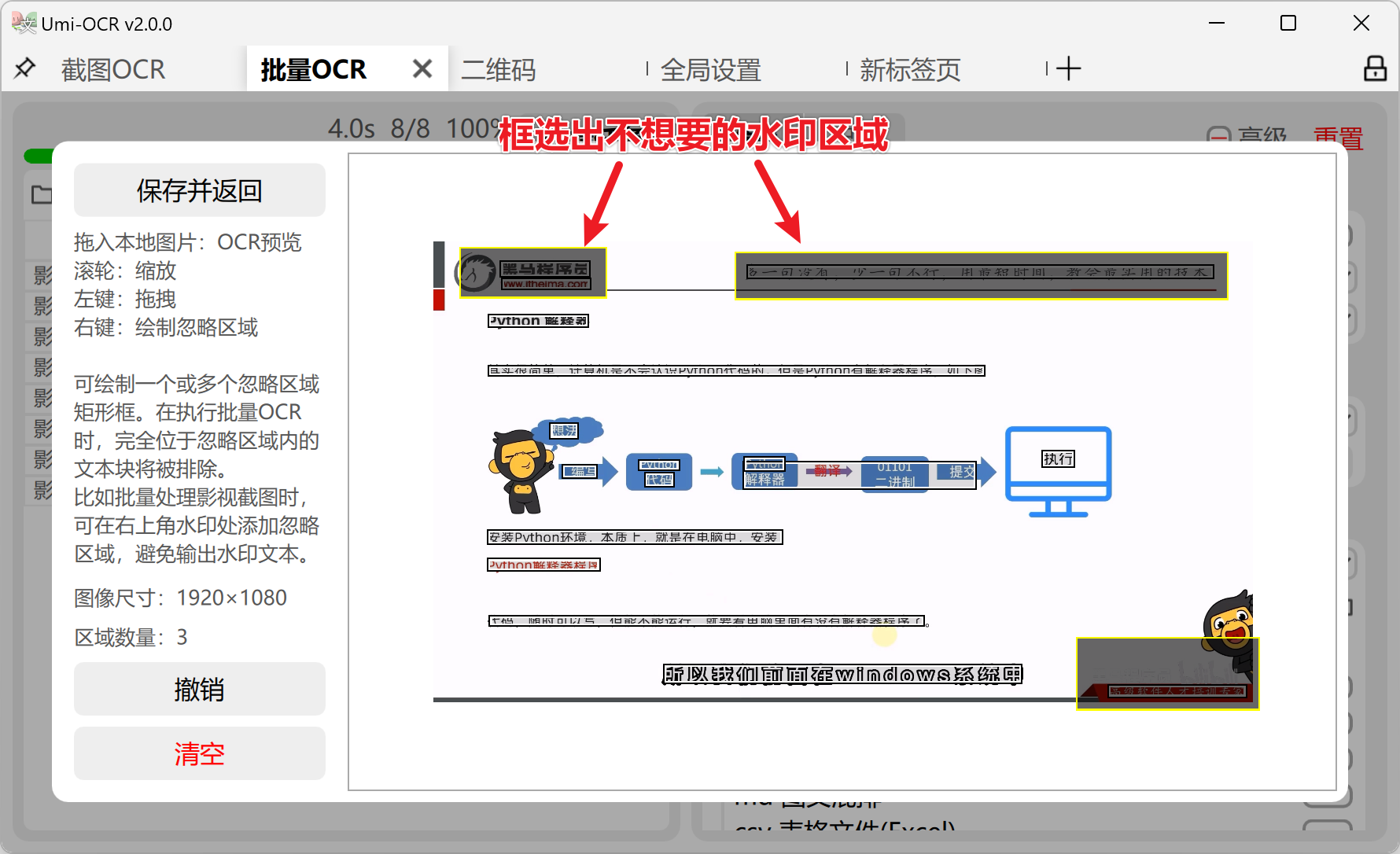
关于 OCR文本后处理 - 忽略区域: 批量OCR中的一种特殊功能,适用于排除图片中的不想要的文字。
- 在批量识别页的右栏设置中可进入忽略区域编辑器。
- 如上方样例,图片顶部和右下角存在多个水印 / LOGO。如果批量识别这类图片,水印会对识别结果造成干扰。
- 按住右键,绘制多个矩形框。这些区域内的文字将在任务中被忽略。
- 请尽量将矩形框画得大一些,完全包裹住水印所有可能出现的位置。
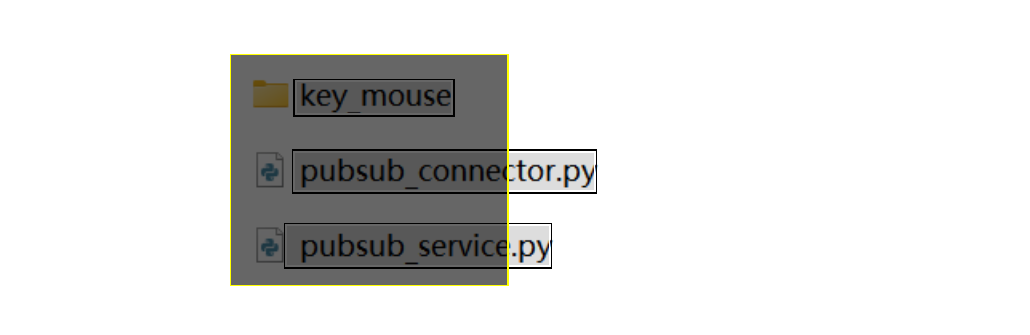
- 注意,只有处于忽略区域框内部的整个文本块(而不是单个字符)会被忽略。如下图所示,黄色边框的深色矩形是一个忽略区域。那么只有
key_mouse才会被忽略。pubsub_connector.py、pubsub_service.py这两个文本块得以保留。

文档识别:
- 支持格式:
pdf, xps, epub, mobi, fb2, cbz。 - 对扫描件进行OCR,或提取原有文本。可输出为 双层可搜索PDF 。
- 支持设定 忽略区域 ,可用于排除页眉页脚的文字。
- 可设置任务完成后 自动关机/休眠 。
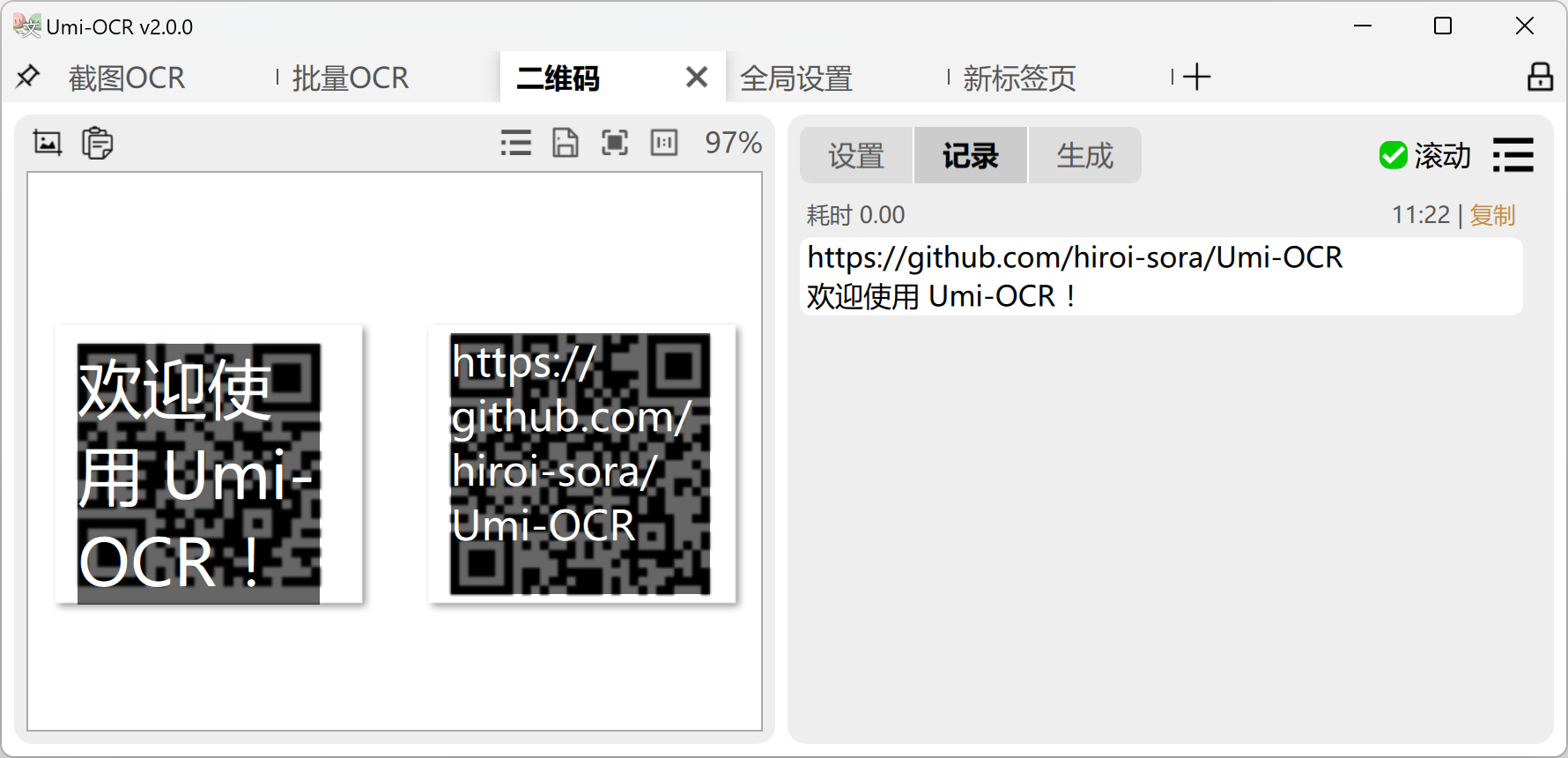
扫码:
- 截图/粘贴/拖入本地图片,读取其中的二维码、条形码。
- 支持一图多码。
- 支持19种协议,如下:
Aztec,Codabar,Code128,Code39,Code93,DataBar,DataBarExpanded,DataMatrix,EAN13,EAN8,ITF,LinearCodes,MatrixCodes,MaxiCode,MicroQRCode,PDF417,QRCode,UPCA,UPCE
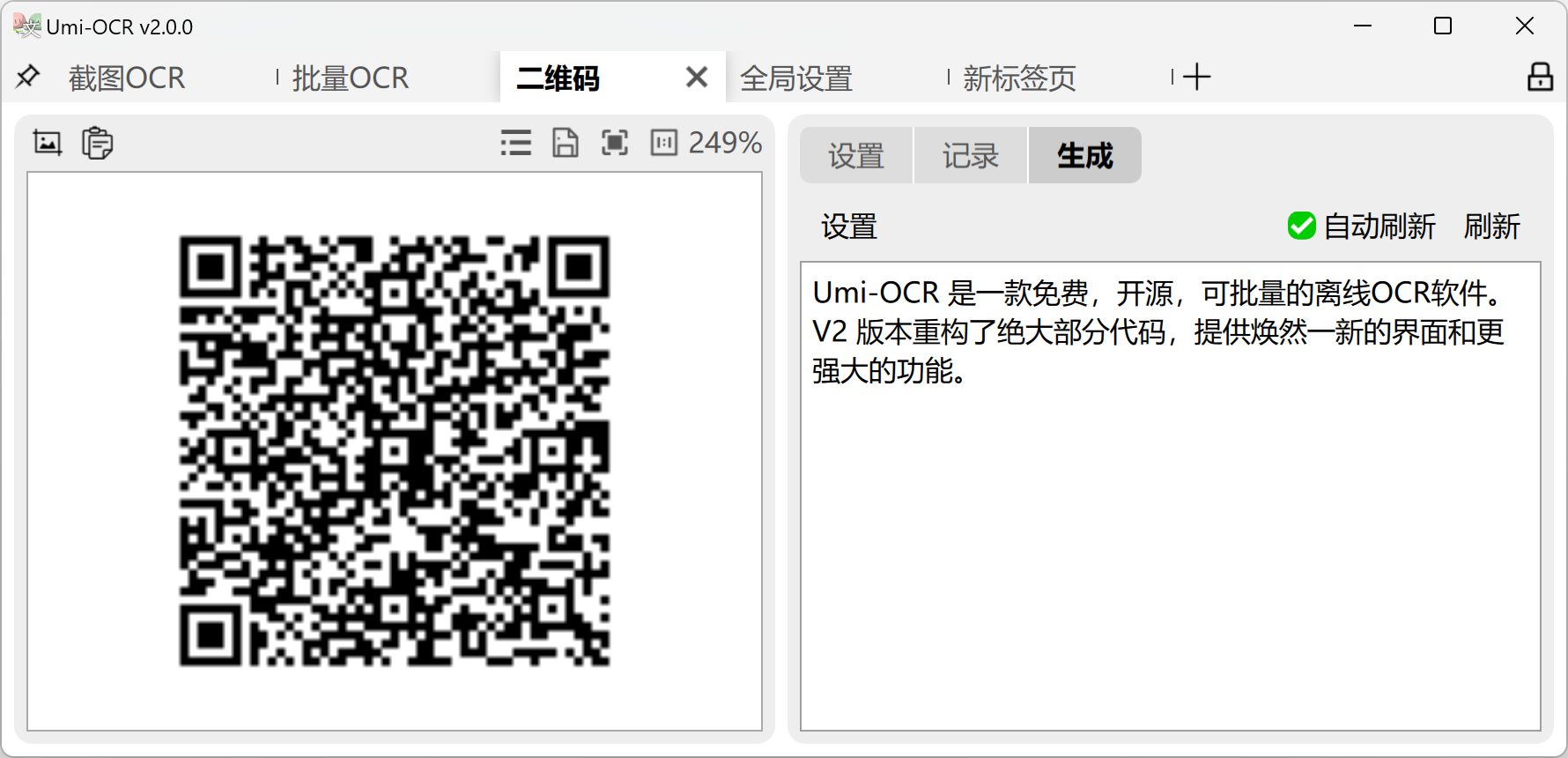
生成码:
- 输入文本,生成二维码图片。
- 支持19种协议和纠错等级等参数。
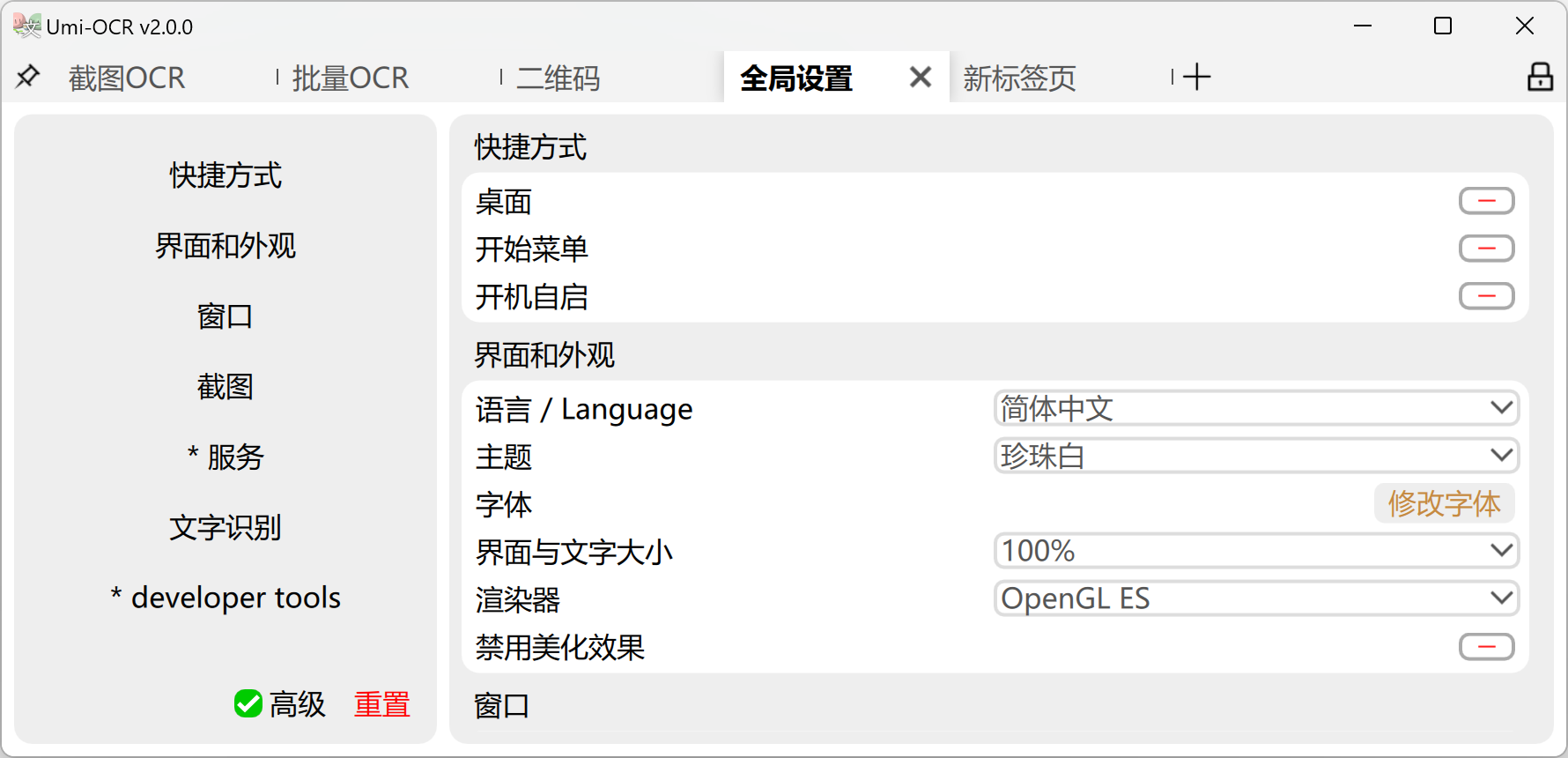
全局设置:在这里可以调整软件的全局参数。常用功能如下:
- 一键添加快捷方式或设置开机自启。
- 更改界面语言。Umi支持繁中、英语、日语等语言。
- 切换界面主题。Umi拥有多个亮/暗主题。
- 调整界面文字的大小和字体。
- 切换OCR插件。
- 渲染器:软件界面默认支持显卡加速渲染。如果在你的机器上出现截屏闪烁、UI错位的情况,请调整
界面和外观→渲染器,尝试切换到不同渲染方案,或关闭硬件加速。
感谢以下译者,为 Umi-OCR 贡献了本地化翻译工作:(排名不分先后)
| 译者 | 贡献语言 |
|---|---|
| bob | English, 繁體中文, 日本語 |
| Qingzheng Gao | English, 繁體中文 |
| Weng, Chia-Ling | English, 繁體中文 |
| linzow | English, 繁體中文 |
| Eric Guo | English |
| steven0081 | English |
| plum7x | 繁體中文 |
| hugoalh | 繁體中文 |
| ドコモ光 | 日本語 |
如果有信息错误或人员缺漏,请在 这个讨论 中回复。
本项目使用在线平台 Weblate: Umi-OCR 进行本地化翻译协作。我们欢迎任何用户参与翻译工作,您可校对、补充现有语言,或添加新语言。
** 后缀表示本仓库(主仓库)包含的内容。
Umi-OCR
├─ Umi-OCR.exe
├─ umi-ocr.sh
└─ UmiOCR-data
├─ main.py **
├─ version.py **
├─ qt_res **
│ └─ 项目qt资源,包括图标和qml源码
├─ py_src **
│ └─ 项目python源码
├─ plugins
│ └─ 插件
└─ i18n **
└─ 翻译文件
支持的离线OCR引擎:
运行环境框架:
- PyStand 定制版
请参考 更新日志 开头的说明。
请跳转下述仓库,完成对应平台的开发/运行环境部署。
Umi-OCR 项目主要由作者 hiroi-sora 用业余时间在开发和维护。如果您喜欢这款软件,欢迎赞助。
- 国内用户可通过 爱发电 赞助作者。
已完成的工作
- 标签页框架。
- OCR API控制器。
- OCR 任务控制器。
- 主题管理器,支持切换浅色/深色主题主题。
- 实现 批量OCR。
- 实现 截图OCR。
- 快捷键机制。
- 系统托盘菜单。
- 文本块后处理(排版优化)。
- 引擎内存清理。
- 软件界面多国语言。
- 命令行模式。
- Win7兼容。
- Excel(csv)输出格式。
Esc中断截图操作- 外置主题文件
- 字体切换
- 加载动画
- 忽略区域。
- 二维码识别。
- 批量识别页面的图片预览窗口。
- PDF识别。
- 调用本地图片浏览器打开图片。 #335
- 重复上一次截图。 #357
- 修Bug:文档识别在Windows7系统的兼容性问题。
- HTTP/命令行接口添加二维码识别/生成功能。 (#423)
- 二维码接口的文档。
- 重构底层插件机制。
- 在线 OCR API 插件。
- 独立的数学公式识别插件。
展开
这些是预想中的功能,在开发初期已预留好接口,将在远期慢慢实现。
但开发途中受限于实际情况,可能更改功能设计、新增及取消功能。
-
“数学公式”标签页,提供独立的数学公式识别/Latex渲染。
-
检查更新机制。
-
排版解析之外的文本后处理模块(如保留数字、半全角字符转换、文本纠错)。
-
关键接口函数添加事件触发方式。
-
基于GPU的离线OCR。
-
图片翻译
-
离线翻译。
-
固定区域识别。
-
识别表格图片,输出为Excel。
-
历史记录系统。
-
兼容 MacOS / Ubuntu 等平台。