In this repo, our scripts can be divided to two parts: dataset preprocess and run fs.
You can also download the preprocessed dataset from Huggingface ERASE_Dataset
Please note that you need to run the following script from the root directory of the project.
- torch
- pandas
- numpy
- nni
- checkpoints
- checkpoints_for_retrain
- data
- avazu
- preprocessed_avazu.csv # your data should put here
- criteo
- preprocessed_criteo.csv # your data should put here
- movielens-1m
- aliccp
- preprocess.py # preprocess script
- nni
- search spaces
- fs
- specific-method.json # the hyperparameter search space for each methods in fs
config.json # some hyperparameters related to general training, e.g., number of selected fields, learning rate
- notebooks # some test notebooks
- utils
- datasets.py # read datasets
- fs_trainer.py # trainer for feature selection
- utils # some functions
- fs_run.py # main script to run feature selection
- nni_tune.py # run the nni tune
- requirements.text # python libraries needed for this repository
python data/preprocess.py --dataset=[avazu/criteo] --data_path=[default is data/]- dataset: (avazu/criteo)
- model: backbone model (mlp)
- fs: feature selection method (no_selecion/autofield/adafs/optfs/gbdt/lasso/gbr/pca)
- seed: random seed (specific number or 0(random))
- device: cuda or cpu
- data_path: your data path (default is
data/) - batch_size
- dataset_shuffle: (True or False)
- embedding_dim: embedding size (default is 8)
- train_or_search: need train_or_search (True/False)
- retrain: need retrain (True/False)
- k: number of selected fields (specific number)
- learning_rate
- epoch: training epoch (default 100)
- patience: patience of earlystopper (default 3)
- num_workers: num_workers in dataloader (default 32)
- nni: whether use nni to tune hyperparameters (default False)
- rank_path: if only want retrain, please specify the path of feature rank file
- read_feature_rank: whether to use pre-saved feature rank
python fs_run.py --model=[model_name] --fs=[feature_selection_method] --train_or_search=True --retrain=True-
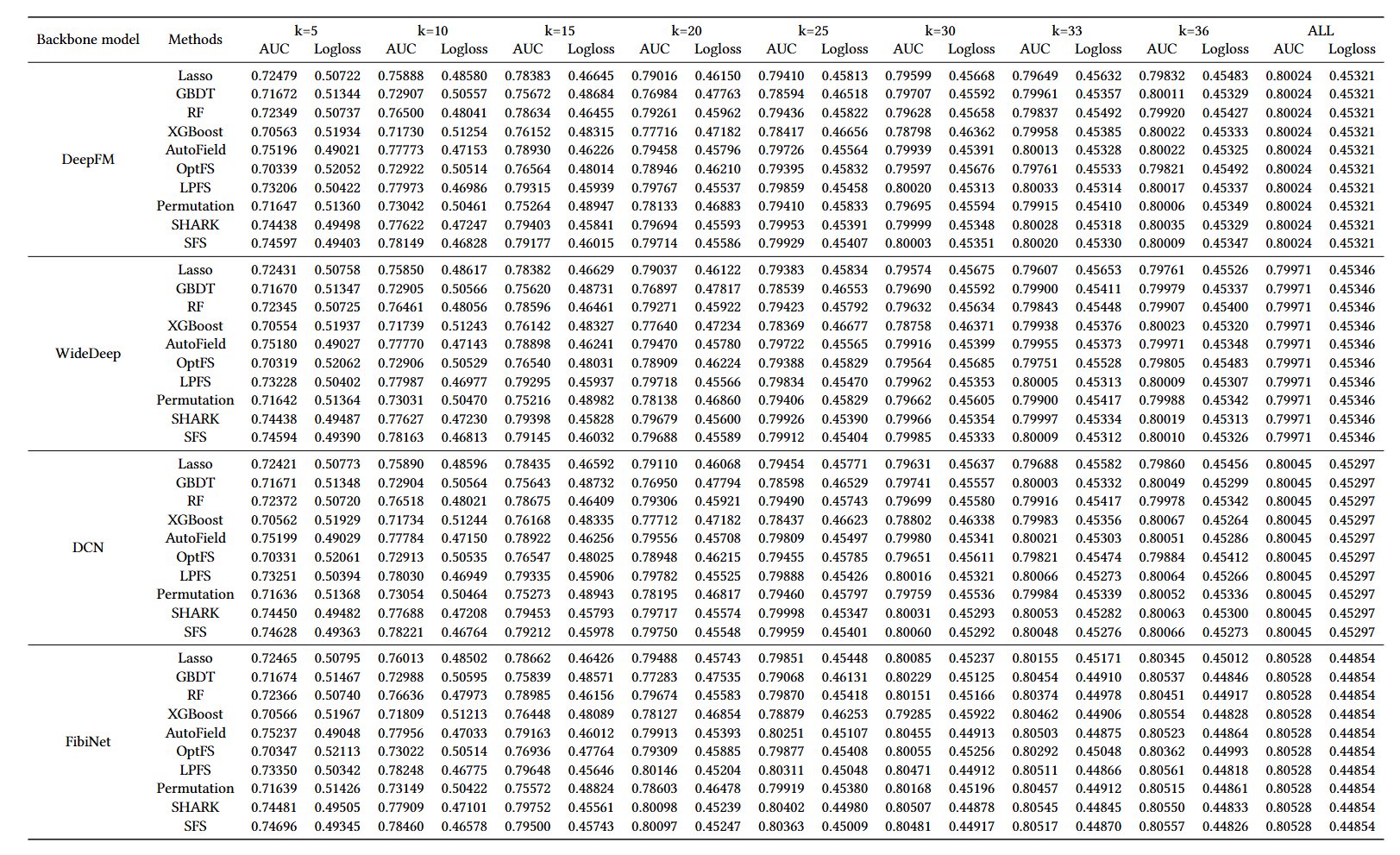
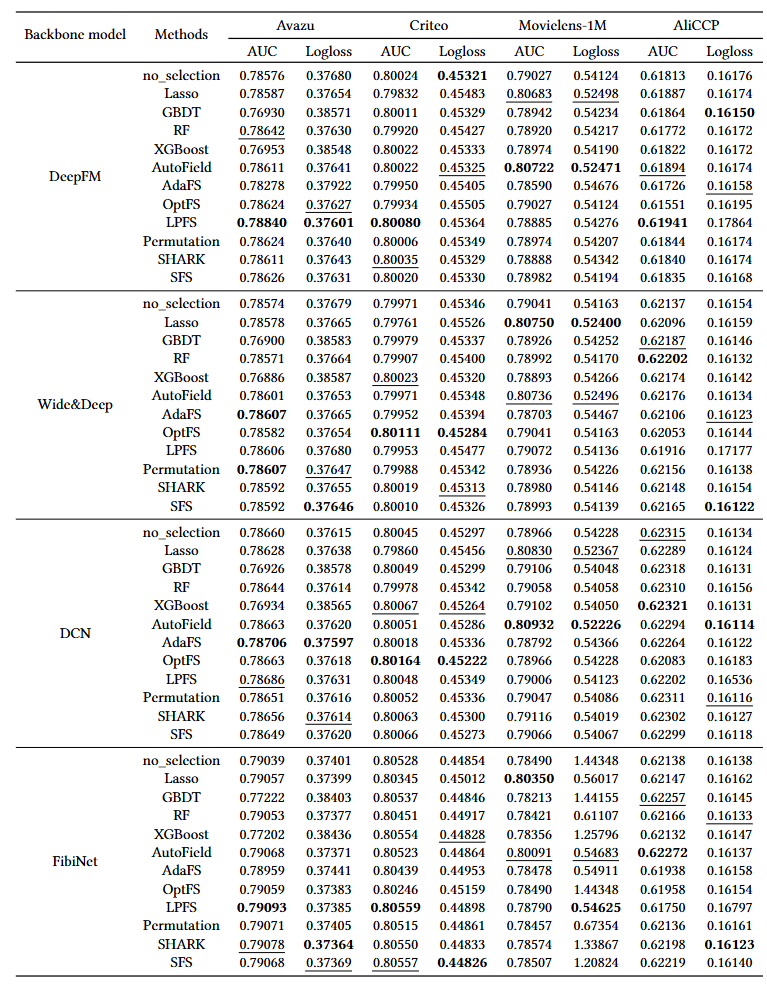
Overall experimental results of feature selection for deep recommender systems.
-
Experimental results on more backbone models with different number of selected features on Avazu.
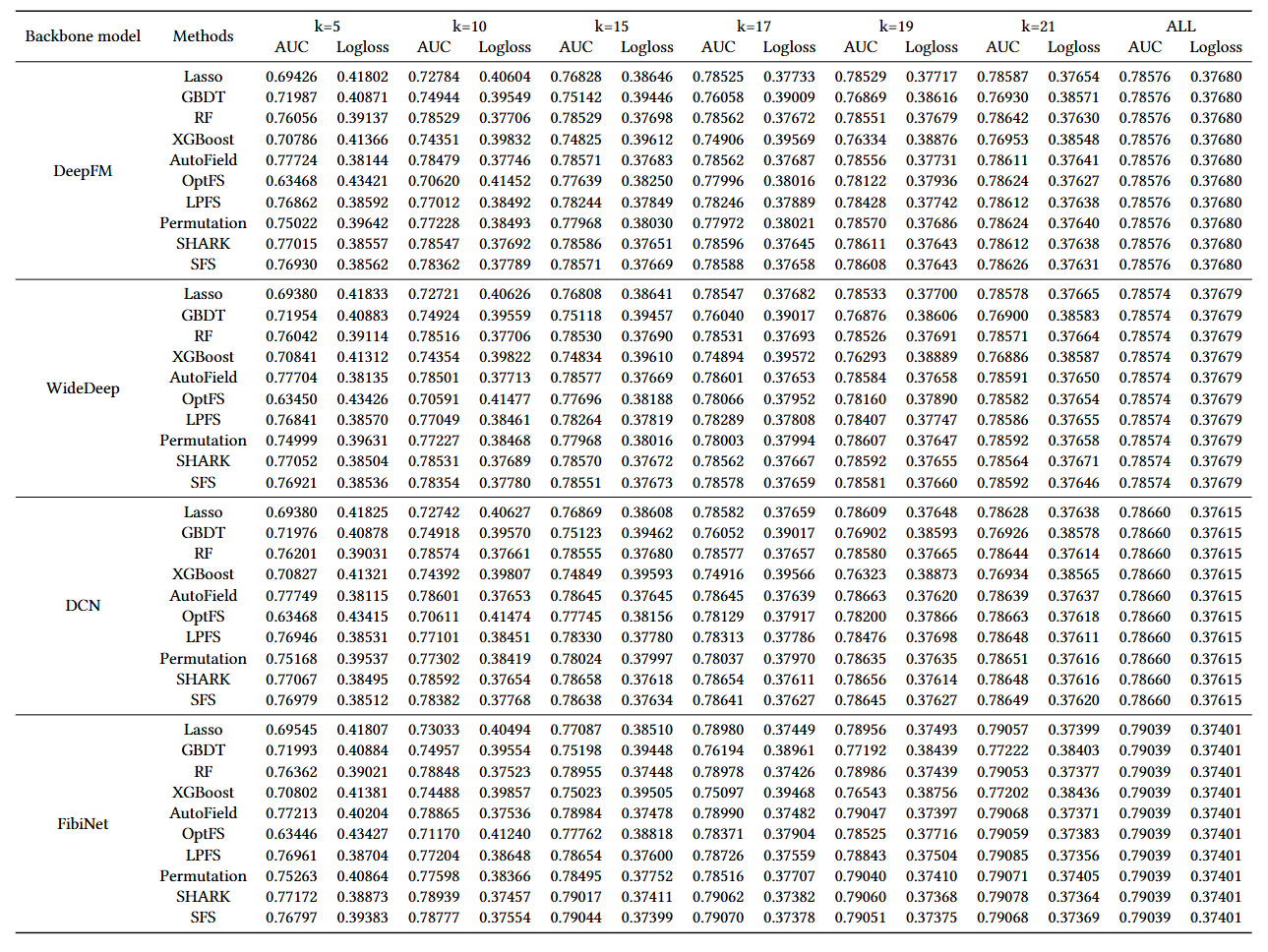
- Experimental results on more backbone models with different number of selected features on Criteo.