Architecture: Overview
Apache Kafka® was created in 2011, designed for traditional data centers. It leveraged the classic Shared Nothing architecture to address horizontal scalability issues and gradually evolved to the Tiered Storage architecture to benefit from the cost advantages of cloud storage. Today, AutoMQ introduces a more refined Shared Storage architecture that fully harnesses the benefits of cloud-native environments, offering ten times the cost advantage and a hundredfold increase in operational efficiency compared to Apache Kafka®.
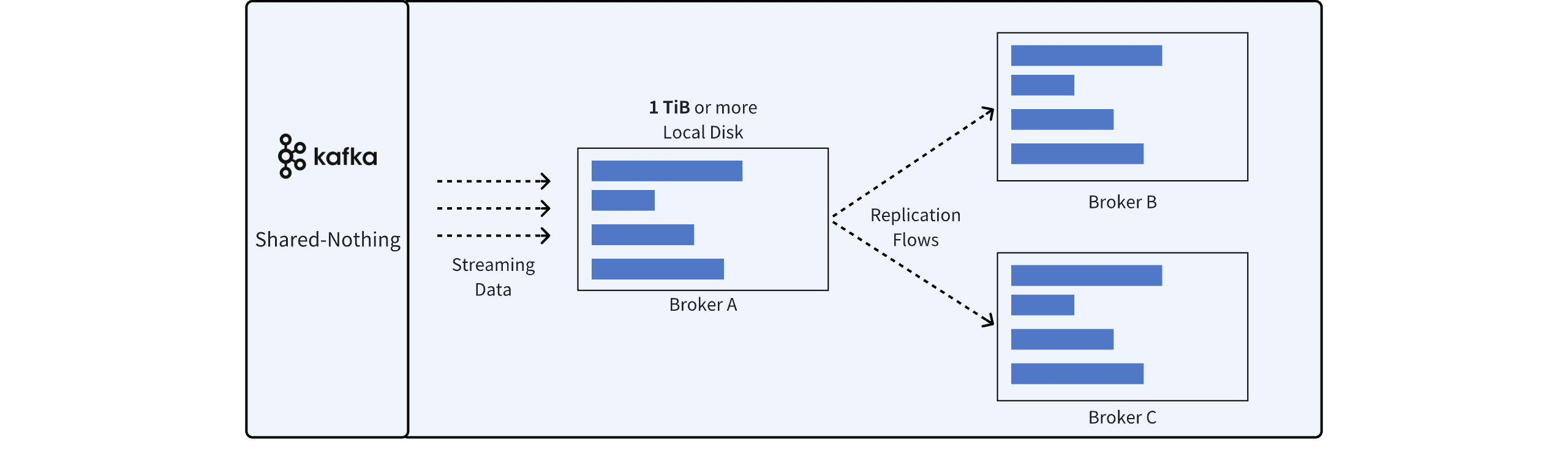
The Shared Nothing architecture, as the most classic design of Apache Kafka®, addresses scalability issues in distributed storage software within traditional data center environments by integrating storage and computation. Kafka employs a replication mechanism based on ISR[1] to ensure data durability and system availability.
With the maturation of cloud computing, the demand for elasticity has emerged. However, the classic Shared Nothing architecture cannot meet this requirement. When scaling up Apache Kafka® Broker nodes, a substantial amount of data replication is needed to complete partition reassignment, often taking several hours.
On the other hand, Apache Kafka® requires triple replication. When deploying on the cloud, users have two storage options:
-
Choosing cloud storage EBS as the storage medium for the Broker, although expensive. The three-replica mechanism of EBS combined with ISR replication leads to data being stored nine times, resulting in significant storage space wastage.
-
Choosing local disks as the storage medium for the Broker, which is relatively cost-effective. However, users face high operational costs, and the advantages of moving to the cloud are diminished.
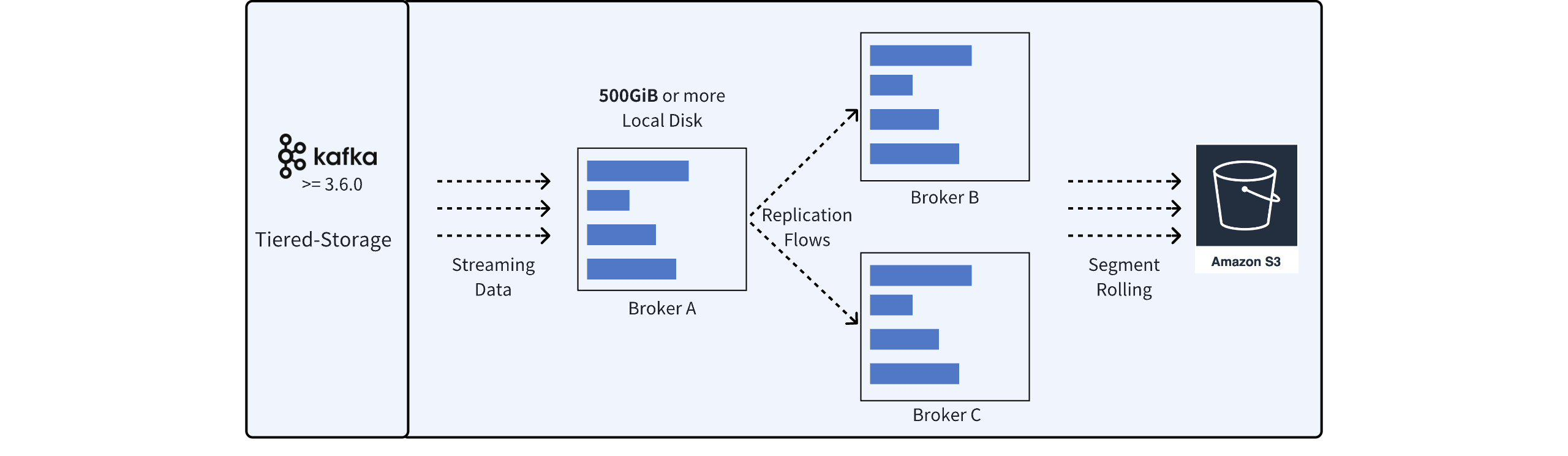
As cloud computing matures and scales up, the first to benefit is object storage. With its low storage costs and pay-as-you-go pricing model, object storage has driven a significant evolution of storage software towards a Tiered Storage architecture.
As the name suggests, this architecture adds a secondary storage tier. After data is stored in the primary storage, it is asynchronously transferred to the secondary storage. This architecture can leverage the cost advantages of object storage to some extent while alleviating the elasticity issues of a Shared Nothing architecture.
However, the Tiered Storage architecture does not fundamentally solve the problems of Apache Kafka, for several reasons:
-
The space consumed by primary storage can be reduced, but the extent of reduction varies by scenario and still requires rigorous capacity evaluation. The high EBS costs incurred by ISR replication cannot be completely eliminated.
-
The issue of slow scaling remains; data in primary storage needs to be migrated and replicated during scaling operations, which can take hours instead of tens of hours with optimization.
Simply put, the primary storage in a Tiered Storage architecture does not fundamentally differ from a Shared Nothing architecture. Aside from reduced space, the partition storage layout in the file system and the ISR replication mechanism remain unchanged.
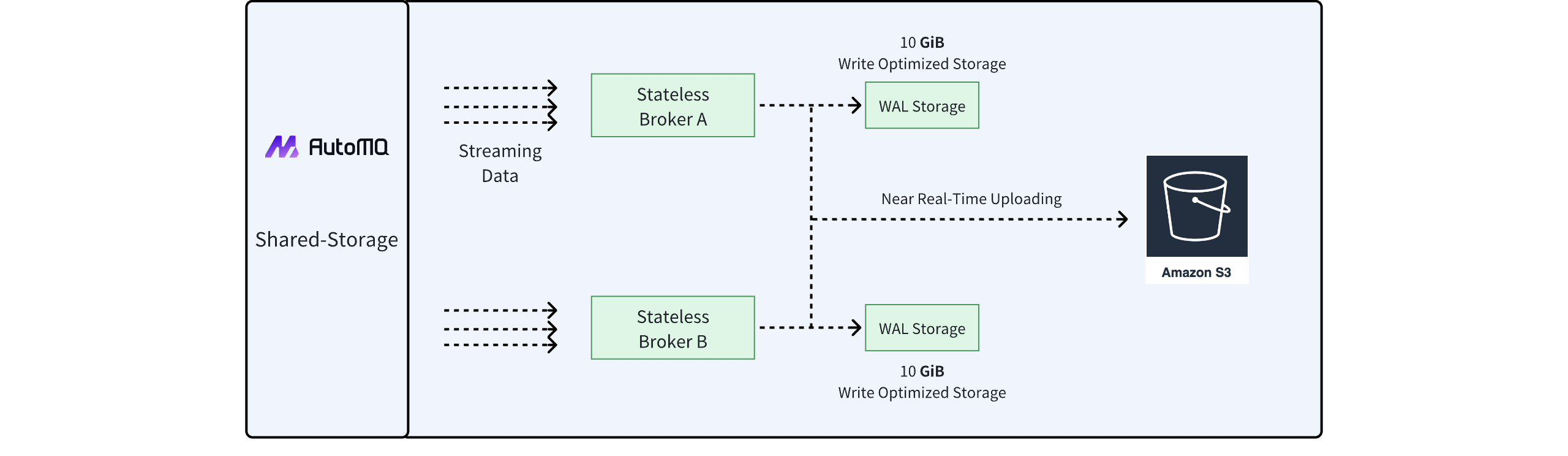
AutoMQ's Shared Storage architecture fully replaces Apache Kafka's storage layer, innovatively offloading data to cloud storage to make the Broker stateless. AutoMQ's Shared Storage architecture consists of WAL[2] storage and object storage. All data is stored in near real-time in object storage. In this architecture:
-
Object storage serves as the primary data storage, offering a flexible, pay-as-you-go, low-cost data storage solution.
-
Due to the high latency and low IOPS characteristics of Object storage, AutoMQ introduces a WAL storage layer to enhance data write efficiency and reduce IOPS consumption.
-
WAL storage can choose from various storage services on different Cloud providers' platforms. Options include Regional EBS services with multi-AZ disaster recovery, file storage services like AWS EFS and FSx, and even Object storage that can be used concurrently as WAL and primary data storage.
AutoMQ encapsulates these storage modules into a self-developed streaming repository called S3Stream, and then replaces the native Apache Kafka® Log storage with S3Stream, making the entire Broker node completely stateless. This greatly facilitates features like second-level partition reassignment, automatic scaling, and self-balancing of traffic. To achieve this, AutoMQ has built-in Controller components within its kernel, such as Auto Scaling and Auto Balancing components, which are responsible for cluster scaling operations and traffic rebalancing respectively.
[1]. Kafka ISR Replication Mechanism: https://kafka.apache.org/documentation/#replication
[2]. WAL Wiki:https://en.wikipedia.org/wiki/Write-ahead_logging