Manage Kafka with Terraform: Why & How
Terraform has become an essential tool for managing infrastructure as code, including Apache Kafka deployments. This blog explores why organizations are increasingly using Terraform to manage Kafka resources and how to implement this approach effectively.

Terraform allows you to define and manage your Kafka topics through code. This approach provides several key benefits:
-
Automation : Terraform automates the workflow for managing environments, Apache Kafka clusters, topics, and other resources, reducing manual intervention[1][5].
-
Consistency : Ensure the same configuration across different environments, preventing configuration drift[13].
-
Version Control : Infrastructure configurations can be versioned, making changes trackable and reversible[9].
-
Repeatability : Create predictable, repeatable deployments across development, testing, and production environments[11].
As organizations deploy Kafka clusters across multiple use cases, manual management of topic configurations becomes challenging, leading to inefficiency, human error, and scalability issues[5]. Terraform addresses these challenges by providing a declarative approach to infrastructure management.
Using Terraform for Kafka management offers particular benefits:
-
Simplified Topic Management : Automate topic provisioning with consistent configurations across all environments[5].
-
Multi-Cloud Support : Deploy Kafka seamlessly across different cloud providers with the same configuration approach[11].
-
Reduced Operational Burden : Focus on building applications instead of managing infrastructure, especially with managed services[1].
-
Standardized Deployments : Ensure all Kafka resources follow organizational standards and best practices[2].
Terraform relies on providers to interact with specific platforms. Several providers are available for managing Kafka:
|
Provider |
Purpose |
Key Features |
|---|---|---|
| Confluent Provider |
Manage Confluent Cloud resources |
Environments, clusters, topics, ACLs, RBAC |
| AutoMQ Provider |
Manage AutoMQ Kafka cluster |
Control Plane & Data plane ( clusters, topics, ACLs, RBAC) |
| AWS MSK Provider |
Manage Amazon MSK |
Clusters, configuration, security groups |
| Conduktor Provider |
Manage Conduktor products |
Console and Gateway resources |
| Mongey/Kafka Provider |
Manage self-hosted Apache Kafka |
Topics, ACLs, quotas |
Terraform defines various resource types for Kafka management:
-
Clusters : Define Kafka clusters with specific configurations, versions, and infrastructure requirements.
-
Topics : Manage topic properties, partitions, and replication factors.
-
Access Control : Configure ACLs, RBAC, and service accounts.
-
Connectors : Set up source and sink connectors for data integration.
For example, creating a Kafka topic with Terraform looks like this:
resource "confluent_kafka_topic" "orders" {
kafka_cluster {
id = confluent_kafka_cluster.inventory.id
}
topic_name = "orders"
rest_endpoint = confluent_kafka_cluster.inventory.rest_endpoint
credentials {
key = confluent_api_key.admin.id
secret = confluent_api_key.admin.secret
}
}
Terraform maintains state files to track the resources it manages. This is crucial for Kafka management, as it allows Terraform to know what resources exist and how they're configured[6]. Common state management issues include:
-
State File Conflicts : When multiple team members update the state simultaneously[6].
-
State Drift : When resources are modified outside of Terraform[6].
-
State File Loss : Accidental deletion or corruption of state files[6].
To address these challenges, use remote state backends with locking (such as AWS S3 with DynamoDB) to prevent concurrent updates and enable versioning to recover from state file loss[6].
Different Kafka distributions require specific provider configurations:
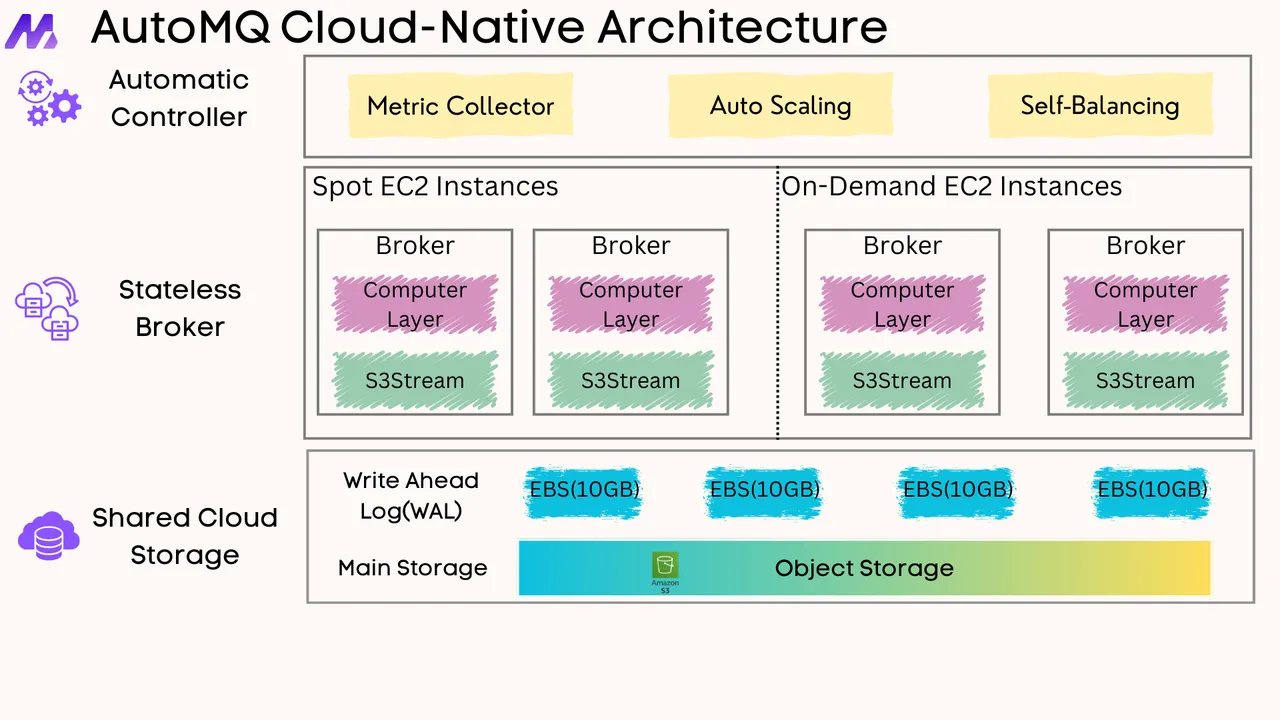
AutoMQ is 100% fully compatible with Apache Kafka. It also provides a provider that can manage all Kafka resources.
terraform {
required_providers {
automq = {
source = "automq/automq"
}
}
}
provider "automq" {
automq_byoc_endpoint = var.automq_byoc_endpoint # optionally use AUTOMQ_BYOC_ENDPOINT environment variable
automq_byoc_access_key_id = var.automq_byoc_access_key_id # optionally use AUTOMQ_BYOC_ACCESS_KEY_ID environment variable
automq_byoc_secret_key = var.automq_byoc_secret_key # optionally use AUTOMQ_BYOC_SECRET_KEY environment variable
}
variable "automq_byoc_endpoint" {
type = string
}
variable "automq_byoc_access_key_id" {
type = string
}
variable "automq_byoc_secret_key" {
type = string
}
variable "automq_environment_id" {
type = string
}
terraform {
required_providers {
confluent = {
source = "confluentinc/confluent"
version = "2.17.0"
}
}
}
provider "confluent" {
cloud_api_key = var.confluent_cloud_api_key
cloud_api_secret = var.confluent_cloud_api_secret
}
provider "kafka" {
bootstrap_servers = ["localhost:9092"]
ca_cert = file("../secrets/ca.crt")
client_cert = file("../secrets/terraform-cert.pem")
client_key = file("../secrets/terraform.pem")
tls_enabled = true
}
Creating a Kafka cluster depends on the platform you're using. For AutoMQ:
resource "confluent_kafka_cluster" "inventory" {
display_name = "inventory"
availability = "SINGLE_ZONE"
cloud = "AWS"
region = "us-east-2"
standard {}
environment {
id = confluent_environment.tutorial.id
}
}
For AutoMQ:
resource "automq_kafka_instance" "example" {
environment_id = "env-example"
name = "automq-example-1"
description = "example"
cloud_provider = "aws"
region = local.instance_deploy_region
networks = [
{
zone = var.instance_deploy_zone
subnets = [var.instance_deploy_subnet]
}
]
compute_specs = {
aku = "6"
}
acl = true
configs = {
"auto.create.topics.enable" = "false"
"log.retention.ms" = "3600000"
}
}
variable "instance_deploy_zone" {
type = string
}
variable "instance_deploy_subnet" {
type = string
}
Topics can be created and managed with specific configurations:
resource "automq_kafka_topic" "example" {
environment_id = "env-example"
kafka_instance_id = "kf-gm4q8xxxxxxvkg2"
name = "example"
partition = 16
configs = {
"delete.retention.ms" = "86400"
}
}
Access control can be managed through service accounts and role bindings:
resource "automq_kafka_acl" "example" {
environment_id = "env-example"
kafka_instance_id = "kf-gm4xxxxxxxxg2"
resource_type = "TOPIC"
resource_name = "example-"
pattern_type = "PREFIXED"
principal = "User:automq_xxxx_user"
operation_group = "ALL"
permission = "ALLOW"
}
Structure your Terraform code effectively:
-
Environment Separation : Use separate configurations or workspaces for different environments[16].
-
Module Usage : Create reusable modules for common Kafka patterns[16].
-
Consistent Naming : Adopt a consistent naming convention throughout your code[2].
When managing Kafka with Terraform, security is paramount:
-
Secrets Management : Never store API keys or secrets in plaintext within Terraform files[2].
-
API Key Rotation : Implement secure rotation of API keys and secrets[2].
-
Encrypted State : Use encrypted remote backends for state storage[2].
-
Use Remote State : Store state remotely rather than locally to enhance collaboration and reliability[2].
-
Implement Locking : Prevent concurrent state modifications that can cause conflicts[6].
-
Regular State Refresh : Keep the state in sync with the actual infrastructure using
terraform refresh[2].
-
Avoid Hard-Coding : Use variables instead of hard-coded values for flexibility[2].
-
Leverage Lifecycle Blocks : Protect critical resources with
prevent_destroy=true[2]. -
Implement Validation : Use validation blocks to enforce standards and prevent misconfiguration[2].
Testing your Terraform configurations is crucial:
-
Use Terratest : A Go library for testing Terraform code[13].
-
Implement CI/CD : Automate testing and deployment of your Terraform configurations[13].
-
Plan Verification : Review execution plans before applying changes[12].
Confluent Cloud is well-supported by Terraform, allowing you to manage environments, clusters, topics, and access controls:
resource "confluent_environment" "tutorial" {
display_name = "Tutorial Environment"
}
resource "confluent_kafka_cluster" "inventory" {
display_name = "inventory"
availability = "SINGLE_ZONE"
cloud = "AWS"
region = "us-east-2"
standard {}
environment {
id = confluent_environment.tutorial.id
}
}
resource "confluent_service_account" "admin" {
display_name = "admin"
description = "Service account for Kafka cluster administration"
}
For AWS MSK, you can manage clusters, configurations, and security:
resource "aws_msk_cluster" "kafka_cluster" {
cluster_name = "my-kafka-cluster"
kafka_version = "2.8.1"
number_of_broker_nodes = 3
encryption_info {
encryption_at_rest_kms_key_arn = aws_kms_key.kafka_kms_key.arn
}
logging_info {
broker_logs {
cloudwatch_logs {
enabled = true
log_group = aws_cloudwatch_log_group.kafka_log_group.name
}
}
}
}
terraform {
required_providers {
automq = {
source = "automq/automq"
}
aws = {
source = "hashicorp/aws"
}
}
}
locals {
vpc_id = "vpc-0xxxxxxxxxxxf"
region = "us-east-1"
az = "us-east-1b"
}
provider "automq" {
automq_byoc_endpoint = var.automq_byoc_endpoint
automq_byoc_access_key_id = var.automq_byoc_access_key_id
automq_byoc_secret_key = var.automq_byoc_secret_key
}
data "aws_subnets" "aws_subnets_example" {
provider = aws
filter {
name = "vpc-id"
values = [local.vpc_id]
}
filter {
name = "availability-zone"
values = [local.az]
}
}
resource "automq_kafka_instance" "example" {
environment_id = var.automq_environment_id
name = "automq-example-1"
description = "example"
cloud_provider = "aws"
region = local.region
networks = [
{
zone = local.az
subnets = [data.aws_subnets.aws_subnets_example.ids[0]]
}
]
compute_specs = {
aku = "12"
}
acl = true
configs = {
"auto.create.topics.enable" = "false"
"log.retention.ms" = "3600000"
}
}
resource "automq_kafka_topic" "example" {
environment_id = var.automq_environment_id
kafka_instance_id = automq_kafka_instance.example.id
name = "topic-example"
partition = 16
configs = {
"delete.retention.ms" = "86400"
"retention.ms" = "3600000"
"max.message.bytes" = "1024"
}
}
resource "automq_kafka_user" "example" {
environment_id = var.automq_environment_id
kafka_instance_id = automq_kafka_instance.example.id
username = "kafka_user-example"
password = "user_password-example"
}
resource "automq_kafka_acl" "example" {
environment_id = var.automq_environment_id
kafka_instance_id = automq_kafka_instance.example.id
resource_type = "TOPIC"
resource_name = automq_kafka_topic.example.name
pattern_type = "LITERAL"
principal = "User:${automq_kafka_user.example.username}"
operation_group = "ALL"
permission = "ALLOW"
}
variable "automq_byoc_endpoint" {
type = string
}
variable "automq_byoc_access_key_id" {
type = string
}
variable "automq_byoc_secret_key" {
type = string
}
variable "automq_environment_id" {
type = string
}
For managing multiple topics with similar configurations:
locals {
topics = {
orders = { partitions = 6, retention_ms = 604800000 },
users = { partitions = 3, retention_ms = 259200000 },
events = { partitions = 12, retention_ms = 86400000 }
}
}
resource "confluent_kafka_topic" "topics" {
for_each = local.topics
kafka_cluster {
id = confluent_kafka_cluster.inventory.id
}
topic_name = each.key
partitions_count = each.value.partitions
config = {
"retention.ms" = each.value.retention_ms
}
}
Managing Kafka with Terraform offers significant benefits through automation, consistency, and version control. By adopting infrastructure as code for your Kafka resources, you can streamline deployments, reduce human error, and improve scalability.
The ecosystem of Terraform providers for Kafka continues to evolve, with options for managing Confluent Cloud, AWS MSK, self-hosted Kafka, and specialty tools like Conduktor. By following best practices for state management, code organization, and security, you can build a robust infrastructure management approach.
As event-driven architectures become increasingly important, the combination of Terraform and Kafka provides a powerful foundation for building scalable, reliable, and maintainable streaming applications.
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
-
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
-
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
-
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
-
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
-
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
-
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
-
JD.com x AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging
-
Automate Topic Provisioning and Configuration Using Terraform with Amazon MSK
-
Reddit Discussion: Creating Kafka Topics in Homelab Using Terraform
-
Event-Driven Architecture with Kafka: Implementing MSK with Terraform and Python
-
Google Cloud Managed Service for Apache Kafka: Terraform Guide
-
Creating Kafka Topics Using Terraform and Testing with Terratest
-
Managing Kafka Consumer Groups with Terraform on Alibaba Cloud
-
Deploying Kafka: Streamlining Data Streaming Infrastructure with Terraform