- Introduction
- Preview
- Run
- Demo
- Inference
- Training
- Accuracy measures
- Dataset used
- Other Models Tried
- Documentation
- References
In this presentation, we will be demonstrating a Computer Vision demo using YOLOv5 on the American Sign Language Dataset including 26 classes.The model identifies signs in real time as well as with input image or audio and builds bounding boxes showing label with confidence value..The model is showcased using streamlit which can take input as an image.
Sign Language Detection Using YOLO Algorithm

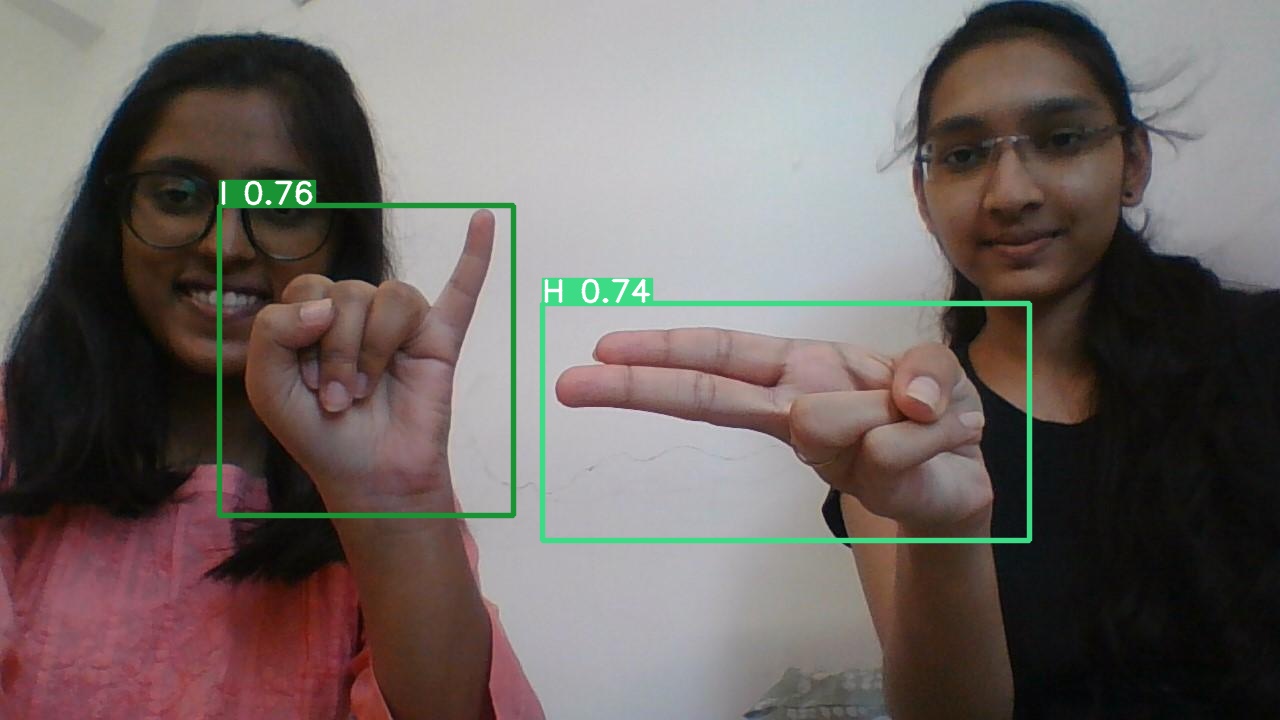
Yolo model: You Only Look Once (YOLO) family of detection frameworks aim to build a real time object detector, which what they lack in small differences of accuracy when compared to the two stage detectors, are able to provide faster inferences.It predicts over limited bounding boxes generated by splitting image into a grid of cells, with each cell being responsible for classification and generation of bounding boxes, which are then consolidated by NMS.
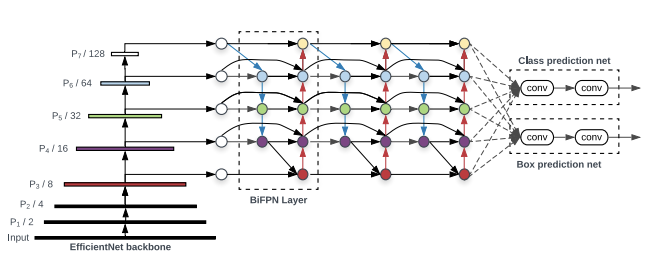
YOLOv5 architecture:
Clone the repo in virtual environment and open the website using the following command:
streamlit run app.pyhey2.mp4
hey3.mp4
Install
Clone repo and install requirements.txt in a Python>=3.7.0 environment, including PyTorch>=1.7.
git clone https://github.com/snarkyidiot/IITI_soc_ML.git # clone
cd yolov5
pip install -r requirements.txt # installInference
-
You can run inference inside YoloV5_main folder by using this command:
python detect.py --source 0 # webcam img.jpg # image vid.mp4 # video path/ # directory path/*.jpg # glob 'https://youtu.be/Zgi9g1ksQHc' # YouTube 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
-
The results are saved to
runs/detect
Tensorboard results:
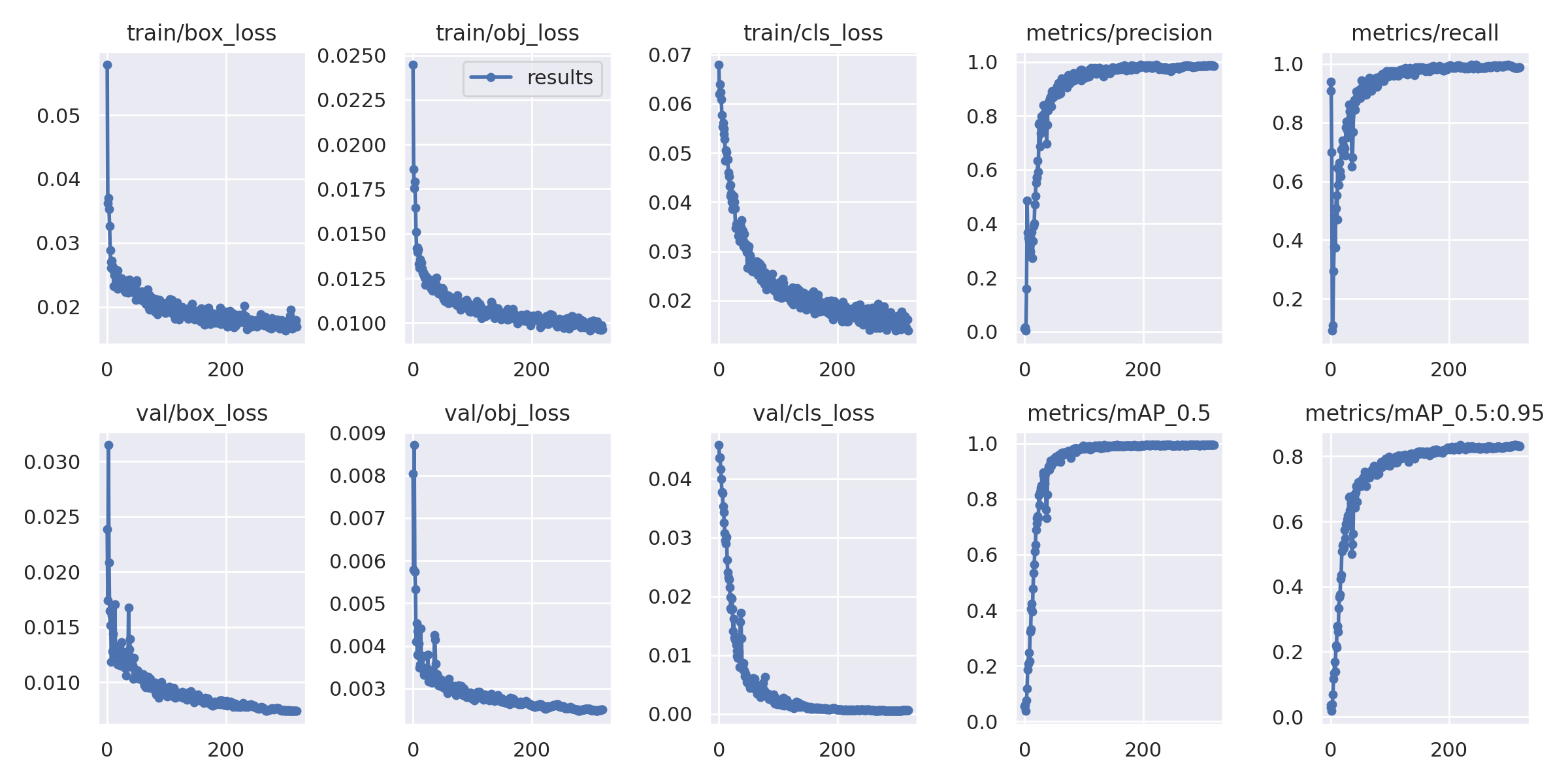 https://raw.githubusercontent.com/snarkyidiot/IITI_soc_ML/main/exp3/results.csv
for details on each epoch
https://raw.githubusercontent.com/snarkyidiot/IITI_soc_ML/main/exp3/results.csv
for details on each epoch
On testing our model on our testing dataset it returned the following metrics
- Precision:0.983
- recall:0.987
- F1Score:0.985
- [email protected]:0.993
- [email protected]:.95: 0.84
- Accuracy: 0.989
- for class wise detail refer this: https://docs.google.com/spreadsheets/d/1vNaIl_QhOzDW6Ybr08uVx-mlAI5BWqOOxjPJnY_aVR8/edit#gid=0
We have used an American Sign Language Dataset consisting of 3399 images having 26 American Sign language alphabets. This dataset was used because of the availability of annotations which were required for training our YOLO-v5s model.
-
(Model using CNN layers for real time sign language detection))
-
.png)
-
-

See the Sign language translator doc for full documentation on implementation of models and deployment.
- https://github.com/ultralytics/yolov5
- https://github.com/roboflow-ai
- https://zone.biblio.laurentian.ca/bitstream/10219/3843/1/Thesis%20FINAL%20-%20Devina%20Vaghasiya%20-%2025-Mar-2021.pdf
- https://docs.ovh.com/asia/en/publiccloud/ai/training/web-service-yolov5/
Thanks for Reading