Tutorial_2022_04
Authors: Enrique Pérez-Montero, Borja Pérez-Díaz (Instituto de Astrofísica de Andalucía - CSIC. Apdo. 3004, 15080, granada, Spain)
PDF: download
Ionised gaseous nebulae are ubiquitous objects in the Universe that provide information about the galaxies where they are located by means of their bright emission lines. Among the different properties that we can derive from them are the relative chemical abundances of the observed ions, the excitation of the gas or the effective hardening of the ionising source. HII-CHI-Mistry (hereinafter, HCm) is a collection of Python scripts that help to analyse the observational the observational information from several bright emission lines observed in the ultraviolet, optical or infrared ranges of the spectrum, comparing them with predictions from large grids of photoionization models and providing estimates with their errors for some derived properties, adapting the accuracy of the solutions to the used input lines and their uncertainties.
HCm for the calculation of chemical abundances presents three main advantages in relation to other model-based solutions, including:
- The results are totally consistent with the so-called direct method, based on the previous determination of the electron temperature. This is true when the flux of an auroral line, such as [OIII] λ4363AA, is not used (see Pérez-Montero 2014).
- HCm provides consistent solutions independently of the set of input emission lines and their errors. This is especially useful when we want to compare results for different sets of objects observed with different spectral ranges or redshifts.
- As HCm provides independent solutions for N/O (in the optical and infrared) and C/O (in the ultraviolet), it allows the used from N or C emission lines for the derivation of O/H and N/O or C/O.
In this tutorial we explain the features of the different versions of the code and its instructions of use, along with its limitations and future expected improvements. There are four versions of HCm depending on the spectral range or its use for the determination of chemical abundances or the calculation of the hardening of the ionizing source. These are:
-
HII-CHI-Mistry (available here): The original HCm package described in Pérez-Montero (2014) fir the analysis of gaseous nebulae ionized by massive young star clusters and in Pérez-Montero et al. (2019a) for Narrow Line Regions (NLR) ionized by Active Galactic Nuclei (AGN), used to derive the total oxygen abundance (12+log(O/H), hereafter O/H), the nitrogen-to-oxygen abundance ratio (log(N/O), hereafter N/O) and the ionization parameter (log(U)), using optical emission lines from [OII] λ3727AA up to [SII] λλ6716+6731AA.
-
HII-CHI-Mistry-UV (available here): Described in Pérez-Montero & Amorín (2017), it calculates O/H, the carbon-to-oxygen abundance ratio (log(C/O), hereafter C/O) and log(U), using ultraviolet emission lines from Lyα λ1216AA up to CIII] λ1909AA.
-
HII-CHI-Mistry-IR (available here): Described in Fernández-Ontiveros et al. (2021), it calculates O/H, N/O and log(U), using infrared emission lines from Brα λ4.05μm up to [NII] λ205μm. The usage of this code for the IR emission from AGNs is described in Pérez-Díaz et al. (2022).
-
HII-CHI-Mistry-Teff (available here): It calculates the equivalent effective temperature (T*) and log(U) using optical emission lines and O/H, as described in Pérez-Montero et al. (2019b). It can also be used to derive the fraction of escaping photons for objects with HeII λ4686AA as described in Pérez-Montero et al. (2020).
All versions of HCm have been writing in Python and should work for both versions 2 and 3. All can be downloaded from this repository or the webpage of HCm. In this document I describe features for the public versions of HCm 5.2 and equivalents for other versions, which require the Python library NumPy. Each package contains the corresponding script (named with .py extension), an ascii file with instructions, an input text file example, different libraries containing the information from the models, and template files with information about constrained sub-grids used by the code in absence of certain emission lines.
If downloaded from the webpage, all files from a particular version are included in a compressed tar.gz file, which can be uncompressed using from a terminal prompt the command:
tar xvfz HCm_v5.22.tar.gzThe above command will generate a folder named HCm_v5.21 with all files and folders for the code. To uncompressed the file a particular directory, it can be done with the command:
tar xvfz HCm_v5.22.tar.gz -C /PATH-TO-DIRECTORY/If downloaded using GitHub, make sure you have installed on your computer Subversion package. Open a terminal prompt and move to the desired folder with the command:
cd /PATH-TO-DIRECTORYAnd then retrieved the desired version of the code by selecting its main folder (HCm-opt, HCm-uv, HCm-ir or HCm-teff) and the subversion:
svn checkout https://github.com/Borja-Perez-Diaz/HII-CHI-Mistry/trunk/HCm-opt/HCm_v5.22svn checkout https://github.com/Borja-Perez-Diaz/HII-CHI-Mistry/trunk/HCm-uv/HCm-UV_v4.22svn checkout https://github.com/Borja-Perez-Diaz/HII-CHI-Mistry/trunk/HCm-ir/HCm-IR_v3.01svn checkout https://github.com/Borja-Perez-Diaz/HII-CHI-Mistry/trunk/HCm-teff/HCm-Teff_v5.3All versions of HCm performs a bayesian-like approach to derive the chemical abundances, ionization parameter or effective temperature. In brief, for a given property X, the final result is:
where Xf is the result, XI are the input values in ach one of the models of the grid, and χ are the weights assigned to each one of the models caulated as the quadratic difference between the observed and the predicted values for some specific emission line ratios:
being Oj and Tji the observed and model-based values, respectively, for the considered emission-line dependent ratios. These are described in each one of the papers of the different versions of HCm (see section for more details) as a function of the input emission lines.
The errors assigned to each result are calculated as the quadratic sum between the dispersion off all the results obtained following a Monte-Carlo iteration through the nominal values perturbed with the nominal input observational errors, and the mean of all intrinsic uncertainties assigned to the bayesian process, calculated as:
For those versions of the code aimed at the calculation of chemical abundances, the first iteration is used to provide an estimation for the abundance ion (N for HCm-opt and HCm-ir, or C for HCm-UV), relative to oxygen, as these are based on emission line ratios very low sensitive to log(U). This also has the advantage that the grid can be constrained in a second iteration, once N/O or C/O are fixed, to calculate both O/H and log(U) using N or Clines without any a-priori assumption for the relation between O and the respective secondary element,
In the case of HCm-Teff this previous iteration is not performed, but the grid of models is interpolated to fix the value of O/H to the inout value in order to minimized the dependence of both T* and log(U) on the metallicity.
To run the HCm version 5.22 (analogous for other versions), we must typed in the terminal prompt:
python HCm_v5.22.pya text describing the code will appear on the screen and it will ask for the input containing the observational information:
-------------------------------------------------
This is HII-CHI-mistry v. 5.22
See Perez-Montero, E. (2014) and Perez-Montero et al. (2019, 2021) for details
Insert the name of your input text file with all or some of the following columns:
[OII] 3727
[NeIII] 3868
[OIII] 4363
[OIII] 4959 or [OIII] 5007
[NII] 6584
[SII] 6725 or [SII] 6716 and [SII]6731
with their corresponding labels and errors in adjacent columns
-------------------------------------------------
Insert input file name:
Alternative, the name of the inout file can be typed when the code is invoked, along with the desired number of iterations for the Monte-Carlo Simulation:
python HCm_v5.21.py input.txt 100although the number of iterations may not be specied, and the code sets 25 by default.
The input file must be an ascii file, with as many rows as the number of objects or points for which we want to perform the calculation, plus a mandatory first row indicating the labels of each column. Each introduced column represents the identification for each row and the reddening corrected relative to Hβ fluxes with their corresponding errors. Prior to version 5.0, all columns must be introduced, with their corresponding errors in adjacent columns. If information from a column is missing, this column value must be 0. From version 5.0, the first row of labels is mandatory, but the order is not essential and not all the columns need to be introduced. The columns assigned to the errors are neither mandatory. The labels for the emission line in this version are:
- ID: To identify each row with a name.1
- OII_3727 and eOII_3727: Emission line ratio [OII] λ3727AA/Hβ and its error. This is assumed to be the addition of [OII] λ3726AA/Hβ and [OII] λ3729AA/Hβ in resolved spectra.
- NeIII_3868 and eNeIII_3727: Emission line ratio [NeIII] λ3868AA/Hβ and its error.
- OIII_4959 and eOIII_4959: Emission line ratio [OIII] λ4959AA/Hβ and its error.
- OIII_5007 and eOIII_5007: Emission line ratio [OIII] λ5007AA/Hβ and its error.2
- NII_6584 and eNII_6584: Emission line ratio [NII] λ6584AA/Hβ and its error.
- SII_6716 and eSII_6716: Emission line ratio [SII] λ6716AA/Hβ and its error.
- SII_6731 and eSII_6731: Emission line ratio [SII] λ6731AA/Hβ and its error.3
Any comments in the input file must be preceded by # and written at the beginning of the file.
1 If missing, the code will assign a number to each row.
2 When only one of the two strong [OIII] lines is given, the code assumes the theoretical ratio between them into account.
3 Alternatively it can be given the addition of these two [SII] lines and its propagated error as SII_6725 and eSII_6725.
If the input file is correct, the code will ask for the grid of models to perform the calculation. The options are:
-------------------------------------------------
Default SEDs
------------
(1) POPSTAR with Chabrier IMF, age = 1 Myr
(2) BPASS v.2.1 a_IMF = 1.35, Mup = 300, age = 1Myr
(3) AGN, double component, a(UV) = -1.0
Other SED
---------
(4) Different library
-------------------------------------------------
Choose SED of the models:
Options (1)-(3) load default libraries downloaded with the code. These grids have been calculated with code CLOUDY v.17(Ferland et al. 2017) assuming a central ionizing source and a plane-parallel geometry.
- (1) This grid is described in Pérez-Montero (2014) and it has been calculated using
POPSTAR(Mollá et al. 2009) cluster model atmospheres with instantaneous burst at an age f 1 Myr, assumming Chabrier (2003) initial mass function (IMF) and a constant electron density of 100 cm-3. - (2) This grid is described in Pérez-Montero et al. (2021) and it has been calculated with cluster model atmospheres from
BPASS v.2.1(Eldridge et al. 2017) assuming an instantaneous burst at an age of 1 Myr, an IMF with slope x=-1.35 with an upper mass of 300 solar masses and with binaries, and a constant electron density of 100 cm-3. This grid is advisable for the case of Extreme Emission Line Galaxies (EELGs). - (3) This grid is used to derived chemical abundances in the NLR of AGN and include 4 different grids described in Pérez-Montero et al. (2019a). All models assume a doubled peak power law spectral energy distribution (SED) with a parameter αUV = - 1.0 and an electron density of 500 cm-3. If selected, the code will ask for ask for two values: the value for αOX (either -0.8 or -1.2) and the value for criterion used to stop models (at an outer radius when the fraction of free electrons is either 98% or 2%). This selection is done via interactive progress:
-------------------------------------------------
Choose SED of the models: 3
Choose value for alpha(OX) in the AGN models: [1] -0.8 [2] -1.2: 1
Choose stop criterion in the AGN models: [1] 2% free electrons [2] 98% free electrons: 1
- (4) From version 5.2, the user can introduced his/her personal grid of models. Those grids must be stored in an
asciifile in the folder "Libraries_opt", with the same format as the default libraries (although the code will automatically check the format of the loaded library and warn the user if some information is missing and which are those missing columns). Until version 5.21, the user should introduced the library sorted by O/H, N/O and U to perform the interpolation. This is no longer required. IMPORTANT: Do not delete default libraries since they are used to check format of any extra grid added to the folder.
Default grids cover an input O/H value in the range [6.9, 9.1] in bins of 0.1 dex and N/O in the range [-2.0, 0.0] in bins of 0.125 dex. Regarding log(U), is covered with a resolution of 0.25 dex in the range [-4.0, -1.5] for options (1) and (2) and in the range of [-4.0, -0.5] for AGN grids. Although not mandatory, we suggest that grids introduced by the user (option (4)) present a constant resolution.
Once the grid of models has been selected, the code will ask for the use of interpolation between the grid of models:
Choose models: [0] No interpolated [1] Interpolated:
which will increase the resolution by a factor 10 (0.01 dex for O/H, 0.0125 for N/O, 0.025 for log(U)). If the user introduces a grid, it must present the same resolution as the default libraries in order to use this option.
In a final step, the program will ask for the constraint laws that will be used to limit the grids. This is necessary when a limited set of emission lines is given and the models have to make assumptions on the relations between O/H and N/O (i.e. when N/O cannot be derived) or O/H and U (i.e. when no auroral line is given, so excitation is used to estimate metallicity). For AGN, as for the possible input lines there is a degeneracy of the O2O3 emission-line ratio (see Pérez-Montero et al. (2019a) for discussion details), the code will ask for the preferred log(U) range selected for the calculations: between high-ionization (log(U) ≥ -2.5) or low-ionization (log(U) ≤ -2.5). The prompt terminal will show the options as:
Select a file with the constraints to be used to limit the grid of models when the measurement of a quantity is impossible without any relation.
-------------------------------------------------
Default constraints
-------------------
(1) Constraints for Star-Forming Galaxies
(2) Constraints for Extreme Emission Line Galaxies
(3) Constraints for AGNs (no restriction in the ionization parameter)
(4) Constraints for high ionization AGNs (log(U) > -2.5)
(5) Constraints for low ionization AGNs (log(U) < -2.5)
Other constraints
-----------------
(6) Different constraint file
-------------------------------------------------
Choose constraint for the grids:
Notice that the user can also introduce a particular file showing her/his own constraint assumption. As in the case of personal grids, the format must similar to the default files and should be located in the folder "Constraints". The code will automatically check the format of the input file and warn the user if the format is incorrect or there are missing columns. Important: The code will use as a template for the format the default files, so these files must not be removed.
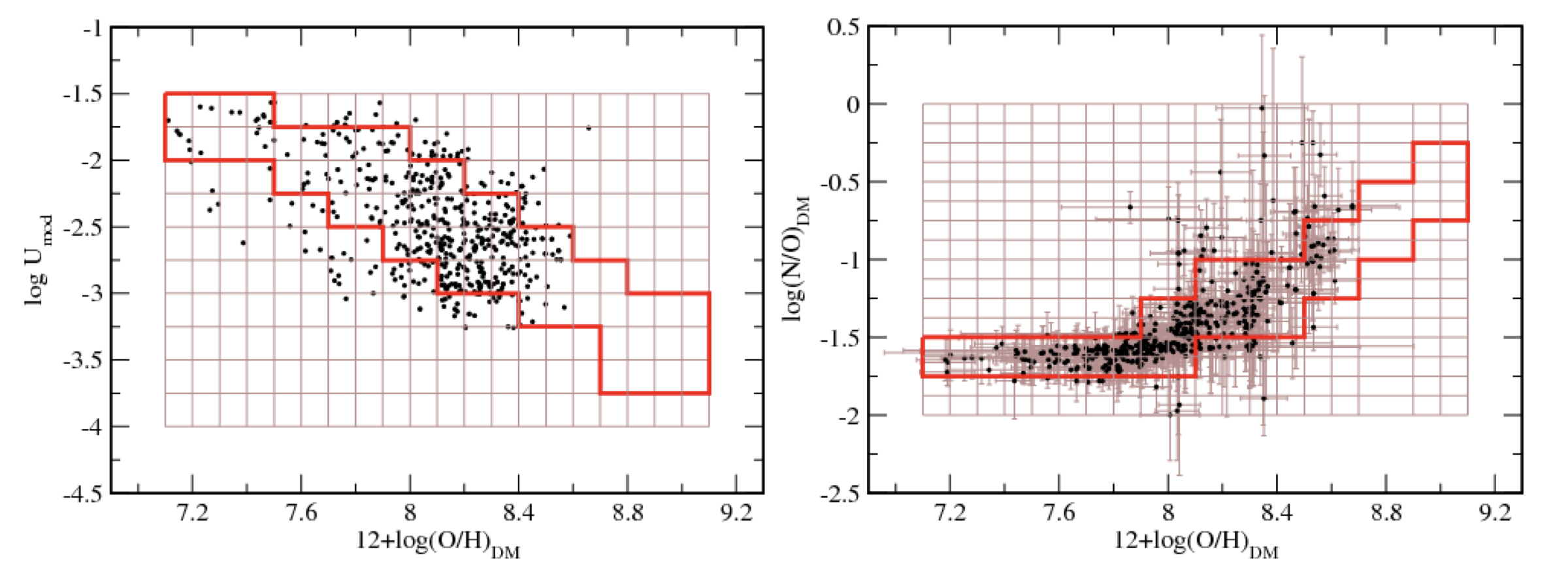 Fig. 1. At left, relation between total oxygen abundance and ionization parameter for the sample studied in Pérez-Montero (2014). The solid red line encompasses the most probable combination of parameters occupied by the objects. At right, empirical relation between O/H and N/O with the region occupied by the grid of models in case of no available observational information to constrain N/O.
Fig. 1. At left, relation between total oxygen abundance and ionization parameter for the sample studied in Pérez-Montero (2014). The solid red line encompasses the most probable combination of parameters occupied by the objects. At right, empirical relation between O/H and N/O with the region occupied by the grid of models in case of no available observational information to constrain N/O.
After this process, the program will summarise the different grids that are going to be used and the number of models for each grid:
-------------------------------------------------
Summary of the models
---------------------
Libraries generated with the constraint file: template_OH.dat. The following grids are going to be used:
- Full library (Grid#1): C17_AGN_alpha08_efrac02_CNfix.dat
Total number of models: 5865
- Library constrained by 12+log(O/H) - log(U) relation (Grid#2): C17_AGN_alpha08_efrac02_CNfix_OH_U_constrained.dat
Total number of models: 1208
- Library constrained by 12+log(O/H) - log(U) - log(N/O) relation (Grid#3): C17_AGN_alpha08_efrac02_CNfix_OH_U_NO_constrained.dat
Total number of models: 289
-------------------------------------------------The code will show on the screen the results for the calculations for each one of the rows, showing as well the ratio of completeness of the task:
Calculating...
----------------------------------------------------------------
(%) ID Grid 12+log(O/H) log(N/O) log(U)
----------------------------------------------------------------
0.0 % NGC435 1 7.89 0.27 -1.03 0.34 -1.92 0.01
1.5 % OBJECT2 1 8.32 0.12 -1.32 0.31 -2.34 0.08
At the end, it will create another ascii file with all results named in the same way as the input file (removing its extension) and adding "_hcm-output.dat". The first column lists the identification for each row. If this has been not been specified in the input file, a number is assigned. The next columns of this file contain the emission-line fluxes used as input, with their corresponding errors.
The next column is an index that indicates if the whole grid of models has been used or, in contrast, a constrained grid has been used instead. This depends mainly in each row on the introduced emission lines, as a limited observational set implies additional assumptions to calculate ionic abundances but, as described above, these constraints can be chosen as a function of the models or instead the user can use his/her own.
- An index 1 indicates that the whole grid of models has been used. This is done when a estimation of the electron temperature, similarly as in the direct method (see for instance Pérez-Montero 2017), can be made because both auroral and nebular [OIII] emission lines are present. If [OIII] λ4363AA is not given, what is a common situation in faint or metal-rich nebulae (Pérez-Montero & Díaz 2005), additional assumptions should be made.
- An index 2 represents the case when electron temperature cannot be estimated and the code assumes an empirical law between O/H and log(U) (see Fig. 1). This relation assumes that metal-poor objects present in average higher excitation and, on the contrary, metal-rich objects have lower excitation. This is the same assumption assumption behind the use of many high- to low-excitation emission-line flux ratios (e.g. O3O2, O3N2) to derive chemical abundances.
- An index 3 denotes the use of a constrained grid assuming an empirical relation between O/h and N/O as shown in Fig. 1. This is necessary in the case that N/O cannot be calculated independently in a first iteration using emission-line ratios such as N2O2 or N2S2. This assumption is behind all strong-line calibrators based on [NII] and implies a constant N/O value for low metallicities due to a mostly primary production of N, and an increasing N/O with O/H when a certain production of secondary N is assumed. This assumption can lead to non-negligible deviations from the real O/H if N/O does not lie in the expected regime, as discussed in Pérez-Montero & Contini (2009).
The final six columns of the output file give the results for O/H, N/O and log(U) with their corresponding errors. If no solution is found, O/H and U are denoted by 0 and N/O is denoted by -10.
Tab. 1. Mean offsets and standard deviation of the residuals of the resulting properties of the resulting properties derived by HCm when POPSTAR model for emission lines are used as input as a function of the used emission-line ratios. [OIII]a stands for the auroral line at λ4363AA and [OIII]n for the nebular lines at λ4959AA and λ5007AA.
| Used lines | Grid | ∆O/H | σO/H | ∆N/O | σN/O | ∆U | σU |
|---|---|---|---|---|---|---|---|
| All lines | 1 | +0.03 | 0.09 | -0.07 | 0.08 | +0.06 | 0.15 |
| [OIII]a, [OIII]n, [NII], [SII] | 1 | +0.02 | 0.09 | -0.01 | 0.07 | +0.06 | 0.15 |
| [OII], [OIII]n, [NII], [SII] | 2 | -0.04 | 0.08 | +0.00 | 0.03 | +0.05 | 0.10 |
| [OIII]n, [NII], [SII] | 2 | -0.03 | 0.07 | +0.00 | 0.04 | +0.05 | 0.10 |
| [OII], [OIII]n, [NII] | 2 | -0.04 | 0.24 | +0.00 | 0.23 | +0.03 | 0.09 |
| [NII], [SII] | 2 | +0.00 | 0.19 | +0.00 | 0.04 | 0.02 | 0.20 |
| [OIII]n, [NII] | 3 | -0.04 | 0.08 | +0.07 | 0.13 | ||
| [NII] | 3 | +0.01 | 0.15 | +0.03 | 0.21 | ||
| [OII], [OIII]n | 3 | +0.00 | 0.01 | +0.00 | 0.02 | ||
| [OII], [NeIII] | 3 | -0.01 | 0.02 | -0.01 | 0.03 |
The results and consistency for the abundances derived from HCm both for star-forming objects and for NLR of AGN are well discussed in their corresponding papers (see more details here). Nevertheless, in Tab. 1 we provide a list of the mean offsets and the standard deviation of the residuals of the resulting O/H, N/O and log(U) as compared with the input values from the models as a function of the used emission lines. These values illustrate how the code can recover the abundances from the values using only the emission lines as input, but cannot taken as true uncertainties.
The HII-CHI-Mistry-UV code (hereafter HCm-UV) is similar to the version in the optical but using a different set of emission lines in the ultraviolet regime and estimating in a first iteration C/O instead of N/O. It also admits two emission lines in the optical in order to provide an estimate of the abundance based on an emission-line ratio sensitive to the electron temperature (e.g. [OIII] λ5007AA/OIII] λ1665AA), although this can imply a larger inaccuracy due to reddening uncertainties. The code is described in Pérez-Montero & Amorín (2017).
Similar to the version in the optical, it can be executed from the terminal prompt with python and allows either just calling the script:
python HCm-UV_v4.22.py-------------------------------------------------
This is HII-CHI-mistry for UV version 4.22
See Perez-Montero, & Amorin (2017) for details
Insert the name of your input text file with some or all of the following columns:
Lya 1216
CIV 1549
HeII 1640
OIII 1665
CIII 1909
Hb 4861
OIII 5007
in arbitrary units and reddening corrected. Each column must be given with labels and followed by its corresponding flux error.
-------------------------------------------------
Insert input file name:
Or by premising the name of the input file and the number of iterations for the Monte Carlo simulations:
Python HCm-UV_v4.22 input.txt 100The input file is an ascii file whose first row must be the labels of the used columns, including:
- ID: To identify each row with a name.1
- Lya_1216 and eLya_1216: Emission line Lyα λ1665AA and its error.
- CIV_1549 and eCIV_1549: Emission line CIV] λ1549AA and its error.
- HeII_1640 and eHeII_1640: Emission line HeII λ1640AA and its error.
- OIII_1665 and eOIII_1665: Emission line OIII] λ1665AA and its error.4
- CIII_1909 and eCIII_1909: Emission line CIII] λ1909AA and its error.5
- Hb_4861 and eHb_4861: Emission line Hβ λ4861AA and its error.
- OIII_5007 and eOIII_5007: Emission line ratio [OIII] λ5007AA/Hβ and its error.
All emission lines can be introduced in arbitrary units, but must be the same for all of them. They must also be reddening corrected. Prior to version 4.0, all columns must be introduced, with their corresponding errors in adjacent columns. If information from a column is missing, this column value must be 0. From version 4.0, the first row of labels is mandatory, but the order is not essential and not all the columns need to be introduced. The columns assigned to the errors are neither mandatory. Any comments in the input file must be preceded by # and written at the beginning of the file.
4 This includes all lines of the OIII] multiplet between 1660AA and 1666AA.
5 This includes all lines of the CIII] multiplet.
If the input file is correct, the code will ask for the grids of models to perform the calculation. The options are:
-------------------------------------------------
Default SEDs
------------
(1) POPSTAR with Chabrier IMF, age = 1 Myr
(2) BPASS v.2.1 a_IMF = 1.35, Mup = 300, age = 1Myr
Other SED
---------
(3) Different library
-------------------------------------------------
Choose SED of the models:
Options (1) and (2) load default libraries downloaded with the code6. These libraries are the same ones used by the optical version, i.e., models calculated with POPSTAR (Mollá et al. 2009) or BPASS v.2.1 (Eldridge et al. 2017). Option (3), available from version 4.2, allows the user to load his/her personal grid of models. Those grids must be stored in an ascii file in the folder "Libraries_uv", with the proper format (i.e. the same one as the default libraries). The code will automatically check the format of the loaded file and warn the user if some information is missing and the columns required to fix the file). From version 4.21, it is no longer necessary to sort the grid of models by O/H, C/O and U, since this task is automatically performed by the code.
Default grids cover the range of [6.9, 9.1] for O/H in bins of 0.1 dex, the range [-1.4, 0.6] for C/O in bins of 0.125 dex and the range [-4.0, -1.75] for log(U) in bins of 0.25 dex. Although not mandatory, we suggest that grids introduced by the user (option (3)) present a constant resolution.
Once the grid of models has been selected, the code will ask for the use of interpolation between the grid of models:
Choose models: [0] No interpolated [1] Interpolated:
increasing the resolution by a factor of 10. This option can only be applied to a grid of models introduced by the user with the same steps as default libraries.
Finally, the program will ask for the constraint laws which will be used to limit the grids. This is necessary when a limited set of emission lines is given, so the models have to make assumptions on the relations between C/O and O/H (i.e when C/O cannot be directly derived) or O/H and U. The user can either select or load any file (providing the file is located in the folder "Constraints" and has the correct format). The options are:
Select a file with the constraint laws to be used to limit the grid of models when the measurement of a quantity is impossible without any relation.
-------------------------------------------------
Default constraints
-------------------
(1) Constraints for Star-Forming Galaxies
(2) Constraints for Extreme Emission Line Galaxies
Other constraints
-----------------
(3) Different constraint file
-------------------------------------------------
Choose constraint for the grids:
After this process, the program will summarise the different grids that are going to be used and the number of models for each grid:
-------------------------------------------------
Summary of the models
---------------------
Libraries generated with the constraint file: template_OH.dat. The following grids are going to be used:
- Full library (Grid#1): C17_POPSTAR_1myr.dat
Total number of models: 4301
- Library constrained by 12+log(O/H) - log(U) relation (Grid#2): C17_POPSTAR_1myr_OH_U_constrained.dat
Total number of models: 1208
- Library constrained by 12+log(O/H) - log(U) - log(C/O) relation (Grid#3): C17_POPSTAR_1myr_OH_U_CO_constrained.dat
Total number of models: 268
-------------------------------------------------
6 Models for AGN will be included and described in forthcoming papers.
The code will show on the prompt terminal the results for the calculations for each one of the rows in the input file, as well as the ratio of completeness:
Calculating...
----------------------------------------------------------------
(%) ID Grid 12+log(O/H) log(C/O) log(U)
----------------------------------------------------------------
0.0 % 1 3 0.0 0.0 -10.0 0.0 0.0 0.0
0.0 % 2 3 6.92 0.0 -10.0 0.0 -2.4 0.03
0.1 % 3 1 6.96 0.01 -0.55 0.3 -3.5 0.01
0.1 % 4 1 6.94 0.01 -0.61 0.32 -3.34 0.02
0.1 % 5 1 6.93 0.01 -0.64 0.34 -3.15 0.03
As in the optical version, the program will create another ascii file with all results named in the same way as the input file adding "_hcm-uv-output.dat". The first column shows the identification for each row while the following columns will show the emission-line fluxes and their fluxes introduced as input. The next column is an index that indicates if the whole grid of models has been used or, in contrast, a constrained was used. As in the optical version, this depends mainly in each row on the introduced emission line:
- An index 1 indicates that the whole grid of models has been used. This is only possible when OIII] λ1665AA and [OIII] λ5007AA are given, so the electron temperature can be estimated.
- An index 2 denotes a constrained grid with an implicit relation between O/H and log(U) as shown in Fig. 1.
- Ab index 3 denotes a grid constrained assuming a relation between C/O and O/H, similar to that shown in Fig. 1. For N/O and O/H, but considering a fixed C/N to the solar ratio. This is used when C/O cannot be calculated by means of the emission line ratio C3O3, depending on CIII] λ1909AA and OIII] λ1665AA, but an estimate for both O/H and log(U) can be given using C lines. In any case, as mentioned above, this relation can be changed by the user in the folder "Constraints". Another relation available is that derived by Pérez-Montero et al. (2021) for EELGs.
The six final columns give the results for O/H, C/O and log(U) with their corresponding uncertainties. As in the case for the optical, if no solution can be found for O/H and log(U) it is denoted as 0 in the file, and -10 for C/0.
Tab. 2. Mean offsets and standard deviation of the residuals of the resulting properties derived by HCm-UV when the model from POPSTAR is used as input as a function of the used emission-line ratios.
| Used lines | Grid | ∆O/H | σO/H | ∆C/O | σC/O | ∆U | σU |
|---|---|---|---|---|---|---|---|
| All lines | 1 | +0.02 | 0.28 | -0.05 | 0.08 | +0.04 | 0.25 |
| Lyα, CIV], HeII, OIII], CIII] | 2 | +0.02 | 0.27 | -0.06 | 0.19 | +0.05 | 0.10 |
| CIV], HeII, OIII], CIII] | 2 | +0.10 | 0.30 | -0.14 | 0.13 | -0.11 | 0.20 |
| Lyα, CIV], HeII, CIII] | 3 | +0.00 | 0.02 | +0.00 | 0.01 | ||
| CIV], HeII, CIII] | 3 | -0.01 | 0.03 | +0.00 | 0.02 |
In Tab. 2 we list the mean offsets and the standard deviation of the residuals when we use as input for the code the same predictions from the models of the grid, as a function of the different combination of emission lines that lead to a solution.
The program HII-CHI-Mistry-IR (hereafter HCm-IR) calculates O/H, N/O and log(U) from a set of observed emission-lines in the mid infrared. First versions of the code are described in [Fernández-Ontiveros et al. 2021), and the latest version 3.01, where AGN models are incorporated, is discussed in Pérez-Díaz et al. (Submitted).
Similarly to other versions, the code can be executed in an iterative process from a terminal prompt using python:
python HCm-IR_v3.01.py-------------------------------------------------
This is HII-CHI-mistry IR v. 3.01
See Fernandez-Ontiveros et al. (2021) and Perez-Diaz et al. (2022) for details
Insert the name of your input text file with all or some of the following columns:
HI 4.05m
HI 7.46m
[SIV] 10.5m
HI 12.4m
[NeII] 12.8m
[NeV] 14.3m
[NeIII] 15.5m
[SIII] 18.7m
[NeV] 24.2m
[OIV] 25.9m
[SIII] 33.7m
[OIII] 52m
[NIII] 57m
[OIII] 88m
[NII] 122m
[NII] 205m
with their corresponding labels and errors in adjacent columns
-------------------------------------------------
Insert input file name:
or by indicating in the same sentence the input file and the number of iterations:
python HCm-IR_v3.0.py input.txt 25The input file is an ascii file whose first row must be the labels of the used columns, including:
- ID: To identify each row with a name.1
- HI_4m and eHI_4m: Emission line Paα λ4.07μm and its error.
- HI_7m and eHI_7m: Emission line Brα λ7.46μm and its error.
- SIV_10m and eSIV_10m: Emission line [SIV] λ10.5μm and its error.
- HI_12m and eHI_12m: Emission line Huα λ12.46μm and its error.
- NeII_12m and eNeII_12n: Emission line [NeII] λ12.8μm and its error.
- NeV_14m and eNeV_14m: Emission line [NeV] λ14.9μm and its error.
- NeIII_15m and eNeIII_15m: Emission line [NeIII] λ15.5μm and its error.
- SIII_18m and eSIII_18m: Emission line [SIII] λ18.8μm and its error.
- NeV_24m and eNeV_24m: Emission line [NeV] λ24.3μm and its error.
- OIV_26m and eOIV_26m: Emission line [OIV] λ25.9μm and its error.
- SIII_33m and eSIII_33m: Emission line [SIII] λ33.7μm and its error.7
- OIII_52m and eOIII_52m: Emission line [OIII] λ52μm and its error.
- NII_57m and eNIII_57m: Emission line [NII] λ57μm and its error.
- OIII_88m and eOIII_88m: Emission line [OIII] λ88μm and its error.8
- NII_122m and eNII_122m: Emission line [NII] λ122μm and its error.9
- NII_205m and eNII_205m: Emission line [NII] λ205μm and its error.9
All emission lines can be introduced in arbitrary units as long as they are the same for all input lines. Emission-line fluxes do not need necessarily to be reddening corrected. The order is not essential and not all the columns need to be introduced. Any comments in the input file must be preceded by # and written at the beginning of the file.
7 When models for AGN are considered, this emission line will only be used if the other [SIII] λ18.8μm emission line is missing.
8 When models for AGN are considered, this emission line will only be used if the other [OIII] λ52μm emission line is missing.
9 These two [NII] emission lines are only considered For SFG models due to its critical density.
Once the code has checked the correct format of the input file, the code will ask for the grid of models to perform the calculation:
-------------------------------------------------
Default SEDs
------------
(1) POPSTAR with Chabrier IMF, age = 1 Myr
(2) BPASS v.2.1 a_IMF = 1.35, Mup = 300, age = 1Myr
(3) AGN, double component, a(UV) = -1.0
Other SED
---------
(4) Different library
-------------------------------------------------
Choose SED of the models:
Options (1)-(3) load default libraries downloaded with the code. These libraries are the same ones as those employed by the optical version (see that section for more details on these libraries). Option (4), available from version 2.2, allows the user to load her/his personal grid of models. The library must be stored in an ascii file located in the folder "Libraries_ir". The code will automatically check the format of the loaded library and warn the user about missing columns with necessary information. Until version 3.0, the grid of models introduced by the user must be sorted in O/H, N/O and U to perform interpolation. IMPORTANT: DO not delete default libraries since they are used to check format of any extra grid added to the folder.
As for the optical and ultraviolet version, interpolation is also available for HCm-IR, increasing the resolution of the default grids by a factor 10:
Choose models [0] No interpolated [1] Interpolated:
Finally, the program will ask for the constraint laws that will be used to limit the grids. This is necessary when a limited set of emission lines and the models need to make assumptions. The options are:
Select a file with the constraints to be used to limit the grid of models when the measurement of a quantity is impossible without any relation.
-------------------------------------------------
Default constraints
-------------------
(1) Constraints for Star-Forming Galaxies
(2) Constraints for Extreme Emission Line Galaxies
(3) Constraints for AGNs (no restriction in the ionization parameter)
(4) Constraints for high ionization AGNs (log(U) > -2.5)
(5) Constraints for low ionization AGNs (log(U) < -2.5)
Other constraints
-----------------
(6) Different constraint file
-------------------------------------------------
Choose constraint for the grids:
which are the same options as those offered for the optical version. After this process, the code will summarise the models used with their constraints:
-------------------------------------------------
Summary of the models
---------------------
Libraries generated with the constraint file: template_OH.dat. The following grids are going to be used:
- Full library (Grid#1): C17_POPSTAR_1myr.dat
Total number of models: 4301
- Library constrained by 12+log(O/H) - log(U) relation (Grid#2): C17_POPSTAR_1myr_OH_U_constrained.dat
Total number of models: 1208
- Library constrained by 12+log(O/H) - log(U) - log(N/O) relation (Grid#3): C17_POPSTAR_1myr_OH_U_NO_constrained.dat
Total number of models: 289
-------------------------------------------------
The code will show on the screen the results for the calculations for each rows towards the ratio of completeness of the task:
Calculating...
----------------------------------------------------------------
(%) ID Grid 12+log(O/H) log(N/O) log(U)
----------------------------------------------------------------
16.7 % 1 2 7.78 0.28 -0.51 0.24 -2.43 0.15
33.3 % 2 2 8.04 0.37 -1.36 0.15 -2.68 0.2
50.0 % 3 2 7.93 0.13 -1.67 0.06 -2.56 0.11
66.7 % 4 2 8.12 0.35 -1.31 0.05 -2.71 0.23
83.3 % 5 2 8.22 0.07 -0.6 0.37 -2.61 0.07
100.0 % 6 2 8.25 0.09 -0.74 0.41 -2.66 0.08
At the end, it will create another ascii file with all results named in the same way as the input file with the extension "_hcm-ir-output.dat". The first columns lists the identification for each column. Then, all columns introduced as inputs are also displayed. After these columns, another column will indicate an index as a reference to the grid employed:
- An index 1 indicates that the whole grid of models has been used. As no auroral lines are available in this spectral range, this is not used in any case.
- An index 2 corresponds to the grid constrained following an empirical relation between O/H and log(U) (e.g. relation shown in Fig. 1).
- An index 3 corresponds to a grid of models constrained by a relation between O/H and N/O, due to the lack of previous estimations of N/O.
Tab. 3. Mean offsets and standard deviation of the residuals of the resulting properties derived by HCm-IR when the model from POPSTAR is used as input as a function of the used emission-line ratios.
| Used lines | Grid | ∆O/H | σO/H | ∆C/O | σC/O | ∆U | σU |
|---|---|---|---|---|---|---|---|
| All lines | 2 | +0.04 | 0.09 | -0.00 | 0.01 | +0.02 | 0.07 |
| [NeII], [NeIII], [SIII], [SIV], [OIII], [NIII], [NII] | 2 | +0.03 | 0.13 | +0.00 | 0.01 | +0.02 | 0.07 |
| [OIII], [NIII], [NII] | 2 | -0.01 | 0.18 | +0.00 | 0.01 | +0.02 | 0.15 |
| HI, [SIII], [SIV], [NeII], [NeIII] | 3 | +0.04 | 0.04 | -0.01 | 0.01 | ||
| [SIII], [SIV], [NeII], [NeIII] | 3 | +0.04 | 0.04 | +0.00 | 0.01 | ||
| [SIII], [SIV] | 3 | +0.02 | 0.02 | +0.00 | 0.01 | ||
| [NeII], [NeIII] | 3 | +0.03 | 0.09 | +0.00 | 0.06 | ||
| [NII], [NIII] | 3 | +0.00 | 0.11 | +0.00 | 0.06 |
HII-CHI-Mistry-Teff (hereafter HCm-Teff) is different to the previously described versions of HCm, as its aim is not the derivation of chemical abundances, but the calculation of the equivalent effective temperature of the ionizing source or the fraction of escaping photons. This code makes use of the so-called softness parameter (Vílchez & Pagel 1988, Pérez-Montero & Vílchez 2009) and it is well described in Pérez-Montero et al. (2019b) and Pérez-Montero et al. (2020).
The options to run the program are similar to those offered for other versions. The first option is through a complete iterative process:
python HCm-Teff_v5.3.py---------------------------------------------------------------------
This is HII-CHI-mistry-Teff v. 5.2
See Perez-Montero et al (2019) for details
Insert the name of your input text file with all or some of the following columns:
12+log(O/H)
3727 [OII]
4471 HeI
4686 HeII
4740 [ArIV]
4959,5007 [OIII]
5876 HeI
6584 [NII]
6678 HeI
6717+31 [SII]
7135 [ArIII]
9069, 9532 [SIII]
with their corresponding labels and errors in adjacent columns
---------------------------------------------------------------------
Insert input file name:
Or by indicating in the same sentence the input file and the number of iterations:
python HCm-Teff_v5.3.py input.txt 72 The input file is an ascii file whose first row must be the labels of the used columns, including:
- ID: To identify each row with a name.1
- 12logOH and e12logOH: Oxygen abundance 12+log(O/H) and its error.10
- OII_3727 and eOII_3727: Emission line [OII] λ3727AA and its error.11
- HeI_4471 and eHeI_4471: Emission line HeI λ4471AA and its error.
- HeII_4686 and eHeII_4686: Emission line HeII λ4686AA and its error.
- ArIV_4740 and eArIV_4740: Emission line [ArIV] λ4740AA and its error.
- OIII_4959 and eOIII_4959: Emission line [OIII] λ4959AA and its error.
- OIII_5007 and eOIII_5007: Emission line [OIII] λ5007AA and its error.12
- 'NII_6584' and 'eNII_6584': Emission line [NII] 6584 and its error.13
- HeI_5876 and eHeI_5876: Emission line HeI λ5876AA and its error.
- SII_6716 and eSII_6716: Emission line [SII] λ6716AA and its error.
- SII_6731 and eSII_6731: Emission line [SII] λ6731AA and its error.14
- ArIII_7135 and eArIII_7135: Emission line [ArIII] λ7135AA and its error.
- SIII_9069 and eSIII_9069: Emission line [SIII] λ9069AA and its error.
- SIII_9532 and eSIII_9532: Emission line [SIII] λ9532AA and its error.15
All lines must be introduced in the same units, not necessarily referred to Hβ but they must be reddening corrected. As in other versions, any comments in the input file must placed at the beginning preceded by #.
10 This can be done using HCm in a previous iteration.
11 As in the case of HCm in the optical, this value corresponds to the addition of the two doublet lines of [OII] if there is good spectral resolution.
12 As in the case of its optical version, if only one [OIII] strong nebular line is introduced, the code will assume the theoretical ratio between them.
13 [NII] emission line can replace [SII] emission lines, which are more affected by background diffuse ionized gas.
14 Alternatively it can be given the addition of these two [SII] lines and its propagated error as SII_6725 and eSII_6725.
15 If only one [SIII] nebular line is introduced, the code will assume the theoretical ratio between them.
Contrary to other versions of the code, HCm-Teff allows the determination of two sets of parameters: either the effective temperature T* and the ionization log(U) or either the photon absorption fraction fabs and log(U). The user must choose between these two options once the code has checked the correct format of the input file:
-------------------------------------------------
------------
(1) Effective temperature and ionization parameter
(2) Photon absorption fraction and ionization parameter
-------------------------------------------------
Choose derived parameters:
Depending on this initial selection, the user will choose between different grid of models for the calculations. Contrary to the other versions, only default libraries can be used for this code. These default libraries have computed with CLOUDY v.17 (Ferland et al. (2017)).
When selected option (1) (estimation of effective temperature and ionization parameter), the user must select one of the following grids:
---------------------------------------------------------------------
(1) WM-Basic (30-60 kK)
(2) WM-Basic (30-60 kK) and Rauch (80-120 kK) stellar atmospheres
(3) Black body (30-90 kK)
---------------------------------------------------------------------
Choose and models:
- (1) This option loads models computed using
WM_Basicsingle star atmospheres from Pauldrach et al. (2001) from 30 to 60 kK. - (2) This option extends the range of the previous option range up to 120 kK using post-AGB stellar atmospheres from Rauch (2003).
- (3) This option uses black-body spectral energy distributions in the range 30-90 kK.
As the geometry assumed in the models can affect its position on the softness diagrams, the code will also ask for the desired geometry:
(1) Plane-parallel geometry
(2) Spherical geometry
---------------------------------------------------------------------
And, finally, the code will provide the possibility of performing an interpolation for the results:
Choose models [0] No interpolated [1] Interpolated:
On the other hand, if we want to calculate the photon absorption factor fabs, defined as the ratio of ionizing hydrogen photons that do not escape from the nebula, along with log(U), the user must load BPASS v.2.1 (Eldridge et al. 2017) models. Particularly, the options are:
---------------------------------------------------------------------
(1) BPASS cluster atmospheres, age = 4 Myr, Mup = 300, x = 1.35, w/binaries, Z* = Zg
(2) BPASS cluster atmospheres, age = 4 Myr, Mup = 300, x = 1.35, w/binaries, Z* = 1e-5
---------------------------------------------------------------------
Both options are calculated assuming an instantaneous burst at 4 Myur, with binaries and an IMF with slope x=-1.35 and an upper Nass limit of 300 solar masses. The difference between these two grids is located in the stellar metallicity: (1) assumes the metallicity of stars is identical to that of the gas; and (2) assumes nearly-free metal stars.
When calculating fabs, only spherical geometry is considered. However, the user still has the option of interpolating the grid of models selected:
Choose models [0] No interpolated [1] Interpolated:
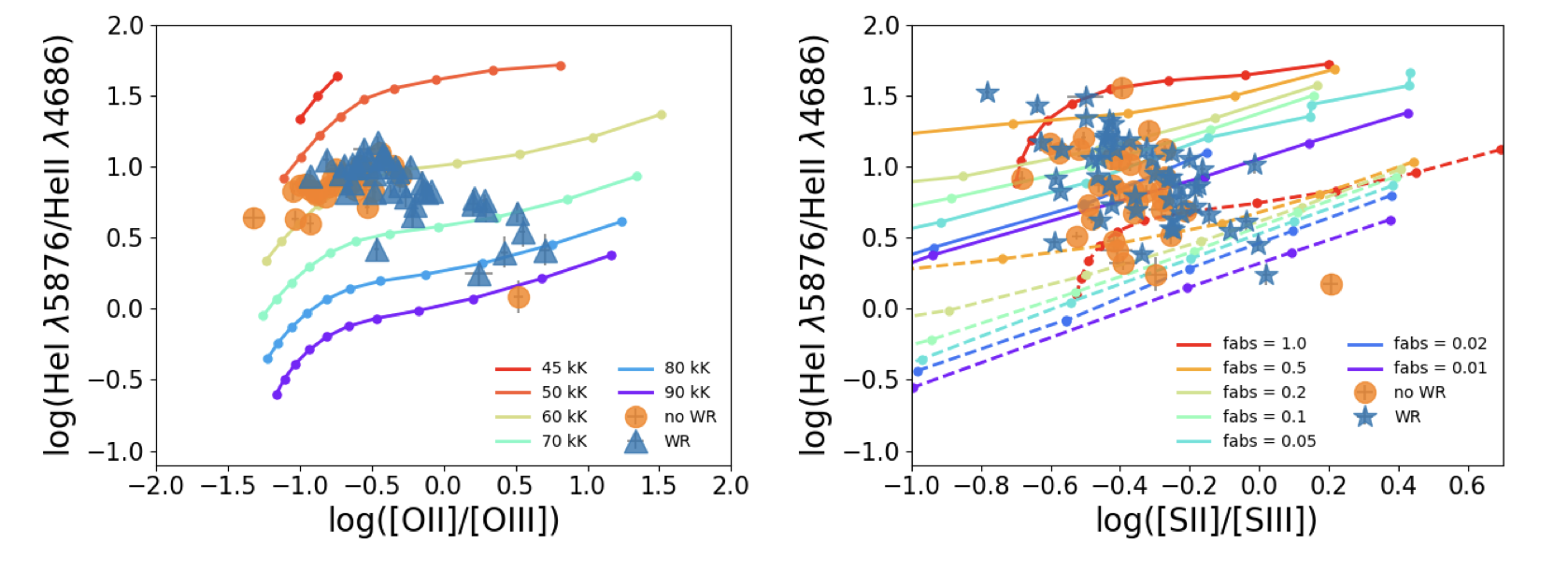 Fig. 2. Examples of two softness diagrams for the sample of HeII-emitters in Pérez-Montero et al. (2020). At left [OII]/[OIII] vs HeI/HeII with models at a fixed metallicity and different values for T*. At right [SII]/[SIII] vs HeI/HeII using
Fig. 2. Examples of two softness diagrams for the sample of HeII-emitters in Pérez-Montero et al. (2020). At left [OII]/[OIII] vs HeI/HeII with models at a fixed metallicity and different values for T*. At right [SII]/[SIII] vs HeI/HeII using BPASS models for different values of fabs. In all sequences values in the lower left part correspond to higher values for log(U).
In Fig. 2 it can been two examples of the behaviour of the grids of models in one of the softness diagrams as shown in Pérez-Montero et al. (2020) and how the grids of models cover the space of the emission line ratios.
As in other versions, the code will display in the prompt terminal the results and the completeness ratio. Depending on the type of calculations, the code will show:
---------------------------------------
(%) ID. 12+log(O/H) T_eff(K) log(U)
---------------------------------------
12.5 % 1 6.9 0.0 74000 5100 -1.5 0.0
25.0 % 2 7.1 0.0 37100 10400 -1.82 0.43
37.5 % 3 7.4 0.0 69500 1000 -1.99 0.02
50.0 % 4 7.4 0.0 69900 0 -2.25 0.0
62.5 % 5 7.9 0.0 40000 0 -1.75 0.0
75.0 % 6 8.5 0.0 47300 7100 -3.76 0.19
87.5 % 7 8.7 0.0 89900 0 -2.25 0.0
100.0 % 8 9.0 0.0 32700 400 -1.68 0.16
________________________________
or:
---------------------------------------
(%) ID 12+log(O/H) f_abs log(U)
---------------------------------------
25.0 % 2 7.1 0.0 0.58 0.33 -3.19 0.07
50.0 % 4 7.4 0.0 0.2 0.85 -2.74 0.0
75.0 % 6 8.5 0.0 0.75 0.44 -3.99 0.01
100.0 % 8 9.0 0.0 0.52 0.28 -3.38 0.01
________________________________
At the end, it will create another ascii file with all the results named in the same way as the input file (removing its extension) and adding "_hcm-teff-output.dat". The first column will show the identification for each row. The following columns contain the emission-line fluxes used as input with their corresponding errors. The next two columns correspond to the assumed O/H and its error (if no value is introduced it will displayed 0 for both). The following columns show either T* (options (1)) or fabs (option (2)) and their corresponding errors as well as log(U) and its error. Again, if no solution is found or the input information is not enough, a value 0 will be displayed.
Tab. 4. Mean offsets and standard deviation of the residuals of the resulting properties derived by HCm-Teff when the model from POPSTAR is used as input as a function of the used emission-line ratios.
| Used ratios | ∆T* | σT* | ∆U/sub> | σU/sub> | ∆fabs | σfabs | ∆U/sub> | σU/sub> |
|---|---|---|---|---|---|---|---|---|
| [OII]/[OIII], [SII]/[SIII], HeI/HeII | +0.8 | 2.1 | +0.01 | 0.10 | +0.11 | 0.34 | -0.10 | 0.53 |
| [OII]/[OIII], HeI/HeII | +0.8 | 2.1 | +0.01 | 0.10 | -0.12 | 0.27 | +0.14 | 0.47 |
| [SII]/[SIII], HeI/HeII | +0.6 | 2.0 | +0.03 | 0.13 | -0.19 | 0.35 | +0.10 | 0.62 |
| [SII]/[OIII], HeI/HeII | -0.3 | 5.1 | +0.04 | 0.51 | -0.07 | 0.27 | -0.10 | 0.59 |
| HeI/HeII | -0.5 | 6.8 | +0.04 | 0.72 | -0.12 | 0.35 | -0.25 | 0.63 |
In Tab. 4 we list the mean offsets and standard deviation of the residuals for the obtained results as a function of the input emission lines when compared with the input information from the code. The first four columns are obtained for option (1) while the other four columns for option (2).