Pytorch implementation of Deepmind's WaveRNN model from Efficient Neural Audio Synthesis
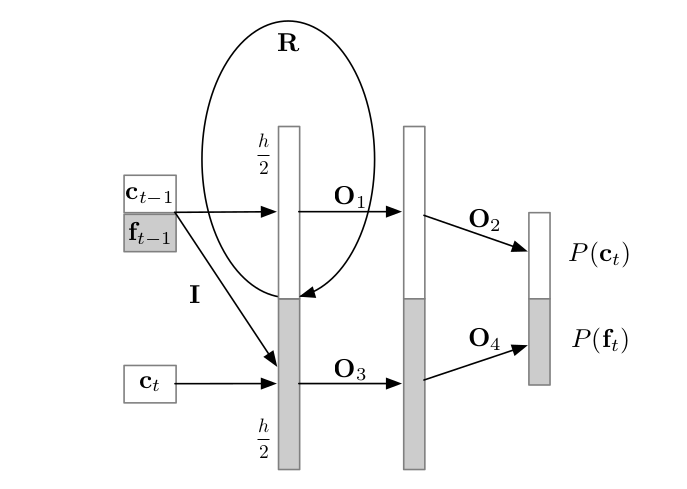
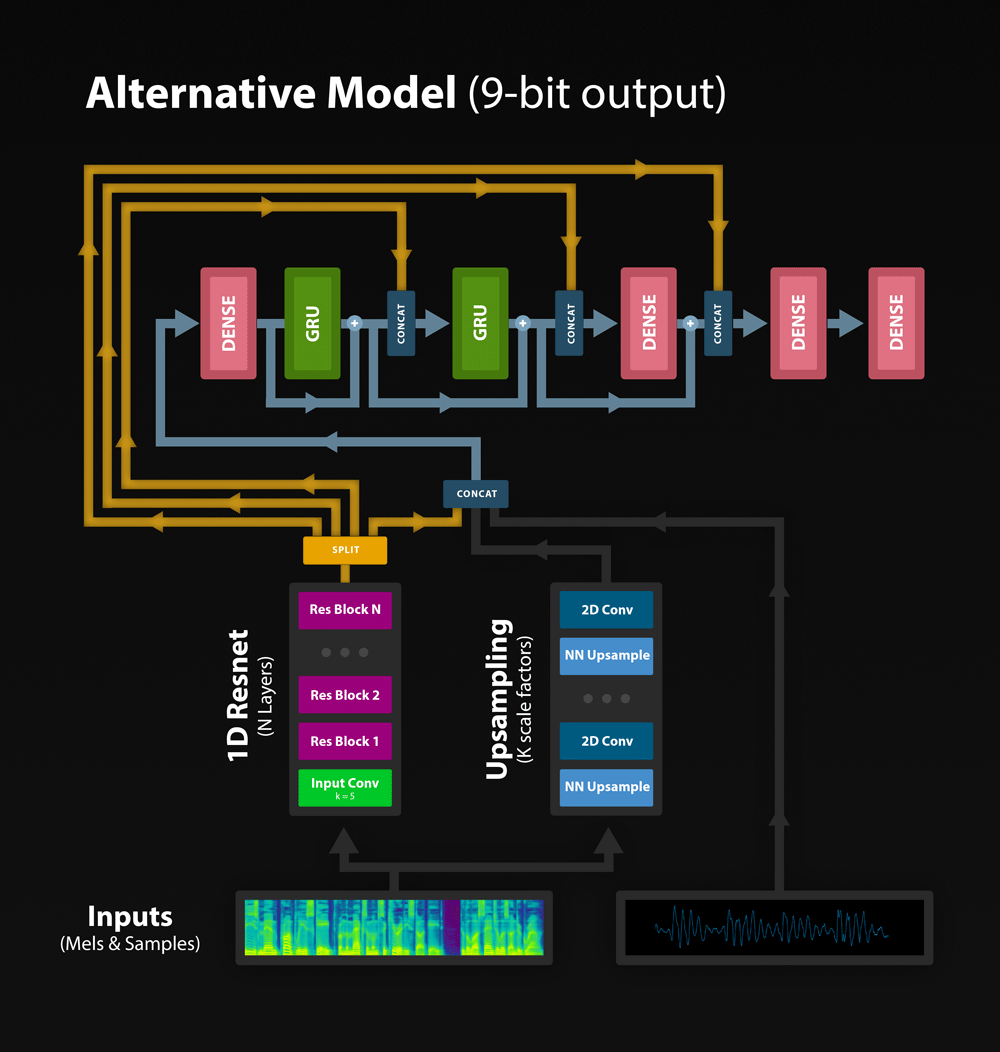
Currently, there are two models in this repo. The first is WaveRNN, however it is quite slow to train (~7 days).
The good news is that I came up with another model that trains much faster and can handle the noise in predicted features from Tacotron and similar models. The sound quality is not as good as Wavenet but it's not that far off. You can listen to the samples here and judge for yourself.
Notebooks 1 - 3 are self-contained however notebooks 4a and 4b need to be run sequentially. You can stop & close notebook 4b (training) whenever you like and it will pick up from where you left off.
- Python 3
- Pytorch v0.4
- Librosa
Disclaimer I do not represent or work for Deepmind/Google.