경북대학교 종합설계프로젝트2 - 3팀
AutoML 접근을 위한 gcp 접근용 json 파일은 보안상의 이유로 github에 공개하고 있지 않으며 필요시에 오픈소스 커뮤니티인 디스코드 채널을 통한 문의 부탁합니다.
- 깃허브 클론
아래의 명령어를 입력해 본 레포지토리를 git clone합니다.
git clone https://github.com/Geunboda/KNU_CapD2_3.git
- 서버 구동
Python3를 먼저 install한 후, google, google-cloud-automl, flask를 설치합니다.
pip3 install google
pip3 install google-cloud-automl
pip3 install flask
아래의 폴더로 이동하여 서버를 구동합니다. 서버를 구동하기 전 json 파일을 폴더 아래로 이동시켜주십시오.
cd KNU_CapD2_3/api/serving
python3 predict3.py
- 리액트 웹 서버 구동
호스팅한 웹 서버의 endpoint 주소를 변경하였는지 확인해주시고 React 웹을 실행하십시오.
cd ui/knu-capd2-ui
npm start
현재 우리가 살고 있는 4차산업혁명 시대엔 IT산업 전반에 인공지능이 곳곳에 포진해 있다고 해도 과언이 아닐 정도다. 인공지능과 머신러닝 기술은 산업을 넘어서 교육, 문화, 의료 등 우리 삶 속에서 인공지능의 적용을 볼 수 있다고 기대해도 좋기 때문이다.

▲<도표> Google Cloud Industries: Artificial Intelligence acceleration among manufacturers
덧붙여, 인터넷 사용자 수의 증가로 인해 로그 데이터 양이 증가하였다. 로그 데이터는 실제 현실에서 발생하는 사건을 데이터로 기록한 것으로, 로그 데이터를 분석하면 실제 현황에 대해서 자세히 확인할 수 있다.

▲<그래프> JetBrain 2020, Java 사용률 조사 결과
그 중 유용하게 사용되는 로그 데이터 중 하나는 바로 Java Thread Dump이다. Thread Dump는 정형화된 데이터이며 웹 서버에서는 많은 수의 동시 사용자를 처리하기 위해 수십~수백 개 정도의 Thread를 사용한다. 두 개 이상의 Thread가 같은 자원을 이용할 때는 필연적으로 Thread 간에 경합(Contention)이 발생하고 경우에 따라서는 데드락(Deadlock)이 발생할 수도 있다. 이러한 Thread의 정보를 담고 있는 로그 데이터인 Thread Dump를 분석하여 문제 발생 시에 그 문제를 해결할 수 있는 방법을 찾기 쉬우며 문제 발생 전에도 Thread Dump를 분석하여 Contention과 Deadlock 등 앞으로 발생할 문제를 사전에 예방할 수 있다. 때문에 서버 운영시 Thread Dump 분석이 필요하다.
하지만 운영시점에서는 시스템 특성에 따라 다양한 사용자들이 서비스를 동시에 사용하기 때문에 로그 추적이 어려우며, 로그 추적을 하지 못해 문제 원인 추적을 포기하는 경우도 자주 발생한다. 이 로그 데이터를 하나하나 인간이 구분하고 분석하는데에는 물리적인 한계가 있을 수 밖에 없다. 그리고 현재 사용되는 Thread Dump 분석 도구들은 단순하게 running, sleeping, blocked 정도로 간단한 덤프 분석만을 지원한다.

▲<그림> Thread Dump 분석을 지원하는 온라인 Dump 분석 사이트 FastThread
때문에 이러한 Thread Dump를 좀 더 체계적이고 효과적으로 분석할 수 있는 도구의 필요성이 대두되고 있다.

본 프로젝트에서는 Google Cloud Platform(이하, GCP)에서 제공하는 AutoML과 BERT를 활용하여 Thread Dump를 분석하는 자동화된 머신러닝 모델을 개발하고자 한다. 프로젝트의 전체적인 구조는 위 그림과 같다. 테스팅 환경을 통해 데이터를 직접 수집하고 분석한 후, 분석 모델을 통해 데이터를 분류하고 그 결과를 웹에 표시한다. OpenNaru의 OpenMaru APM인 Khan 서비스와 연계하여 현업에서도 쓰일 수 있도록 하고자 한다. Thread Dump 분석을 자동화하여 전문인력의 도움없이도 프로그램의 에러를 분석하고 이에 대응할 수 있도록 하는 것이 프로젝트의 최종 목적이다.
▼<그림> Java Thread Dump 3요소 분류


3-1-2의 1차 데이터 분석 내용을 토대로 Base/WAS코드와 Main Function을 기준으로 하여 레이블링 작업에 돌입했다. 구글 스프레드시트를 이용하여 각자 라벨을 붙이고, 해당 라벨에 해당하는 덤프 데이터가 몇 개인지 작성하는 것으로 진행하였다. 그 후 각 라벨의 샘플 데이터를 하나 첨부하여 라벨이 어떠한 형식(이하 패턴)을 갖추는지 파악하기 쉽게 하였다.

▲<그림> 전처리 하고자 하는 내용
전처리는 Stack을 기준으로 진행하였다. 우선 첫번째 네모는 Thread의 이름을 나타내며, 여기서 영어나 띄어쓰기를 제외한 숫자나 기호는 제거한다. 그리고 Thread 고유번호(#숫자)와 prio, os_prio와 같은 thread의 우선순위는 패턴과 관련없으므로 제거한다. 그 후 Tid(Java-Level Thread ID), nid(Native Thread ID), 포인터 저장위치([0x00…], <0x000…>), 자바파일 행번호, 포인터 주소값과 같이 각 Thread마다 실행할 때 마다 변화하는 의미없는 값들은 모두 제거한다. 그리고 남은 Javax, at, java, com, org 처럼 Thread 패턴을 분석하는 것에 유의미한 차이를 만들지 않는 공통되는 자주 등장하는 단어들을 제거한다.

▲ <그림> AutoML 1차 Label 정확도 및 정밀도
그러나 1차 데이터 분석에서 정확도와 재현율이 100%로 학습되는 나오는 이슈를 확인했다. 원인은 데이터의 레이블링 방식이라 생각하여 이를 바꿈으로써 이슈를 해결하고자 하였다. 기존에는 각 Thread Dump에 특정한 문장이 들어있으면 해당 패턴으로 분류하는 방식을 사용하였다. 한 문장만 보고 데이터를 레이블링 하다보니 모델 학습이 단조로워질 수 밖에 없었고, 이것이 원인이 되어 정밀도가 100%로 발생하였다고 결론지었다. 따라서 레이블링 방식에 수정이 필요하다고 보아, 각 패턴의 전체 구조를 파악하고 이에 맞게 라벨을 구성하여 레이블링을 진행하는 방식으로 변경하였다. Thread Dump를 각각 살펴보면서 어떠한 패턴이 나타나는지 확인하는 과정을 거치고 이를 바탕으로 레이블링을 진행하였다.

▲<그림> 최종 작업을 마친 라벨
2차 데이터 레이블링 방식은 1차와 같되, 패턴 전체의 흐름을 고려하여 레이블링을 진행하였다. 덤프의 State가 Waiting인 경우 프로그램에 문제를 발생시키지 않는 경우가 대다수이기에 무한 루프에 빠진 경우를 제외하고 Idle로 패턴을 명명하였다. 또한 라벨의 개수가 한 자리 수인 경우, 데이터가 충분하지 않아 학습 데이터에 악영향을 미칠 수 있는 노이즈 요소가 되므로 학습 데이터에서 제외하였다. 추후 레이블링을 쉽게 하기 위해, 패턴마다 샘플 링크를 추가하여 클릭시 해당 패턴의 코드로 이동하도록 하여 각 패턴에 해당하는 샘플 Dump 데이터를 쉽게 파악할 수 있도록 하였다.

▲<그림> 텍스트 레이블링 자동화 코드

▲<그림> AutoML 학습 후 정밀도와 재현율
AutoML 모델 개발은 Google Cloud Platform을 활용하여 진행하였다. 다중 텍스트 분류 기능을 사용하여 Thread Dump가 입력으로 주어지면 각 레이블에 해당하는 확률을 반환하는 모델을 개발하였다. 위 3-1의 결과물인 데이터 파일로 학습을 진행하였다. 165개의 레이블을 학습시켰으며, 정밀도는 99.02%로 높은 결과를 얻을 수 있었다. 예상보다 훨씬 높은 정밀도를 얻어서 이에 대한 이유를 파악하고자 하여 멘토님께 피드백을 요청한 결과, 2가지 원인을 생각해 볼 수 있게 되었다. 첫 번째로 데이터가 적은 점이다. 전체 데이터의 개수는 약 7500개 정도이다. 데이터의 다양성이 적다보니 예측이 좀 더 쉬웠다고 생각할 수 있다. 현업에서는 더 많은 데이터를 사용하므로 실제로 적용한다면 정상범위내의 정밀도와 재현율을 가질 것을 예측할 수 있다. 두 번째는 Thread Dump 데이터가 정형화 되어있다는 점이다. 일반적으로 자연어, 즉 대화 문장을 생각한다면 매우 다양하다는 점이 특징임을 알 수 있다. 그러나 Thread Dump 데이터는 형식이 정해져 있는 데이터로, 같은 레이블이라면 대부분이 동일한 내용을 가지고 있다. 이러한 점이 정밀도를 높이는 데에 크게 작용했을 것임을 알 수 있다. 추후에 이러한 점을 해결하기 위해서는 신규 학습을 자동으로 할 수 있는 환경을 구축하는 것이 필요할 것이다.

▲<그림> BERT 학습 코드 중 일부
좀 더 최적화된 분석 모델을 위해 BERT의 BertForSequenceClassification 모델로 학습을 진행하였다. BERT를 학습시키면서 신경쓴 부분은 Tokenizer로, Keras hub에서 제공하는 Default tokenizer를 사용하였다. 그 이유는 토크나이저의 최대 분석 토큰의 개수가 512개인데, Thread Dump 중에서 512개를 넘는 데이터가 다수 존재하였다. 보통 이는 자르는 방식(Default)이나 전체를 넣는 방식을 사용하는데, 프로젝트에서는 앞부분만 자르는 방식을 사용해서 진행하였다. 그리고 optimizer로는 Adam을 사용하였고, loss 계산은 cross entropy를 사용하였다. 그 결과, 95.08%의 정확도를 얻을 수 있었다. AutoML과 BERT 모델을 비교했을 때, 현 상황에서는 정밀도가 더 높게 나타난 AutoML 모델을 사용하는 것이 더욱 적절하다고 판단하였고, 이후 시각화를 위한 웹 서비스에서 AutoML 모델을 사용하였다.

▲<그림> BERT 학습 epoch에 따른 loss, accuracy, recall, precision, f1 그래프

▲<그림> 협력업체 OpenNaru의 서버 모니터링 및 관리 솔루션 OpenMaru APM
협력업체의 서비스인 OpenMaru APM(이하 Khan)과 연계하여 모델을 이용해 학습하고 결과 검증에 테스트할 Thread Dump를 추출하기로 하였다.

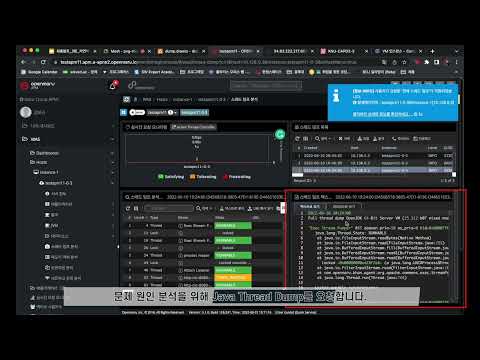
▲<그림> OpenMaru APM을 이용해 Thread Dump를 추출하는 모습
하지만 OpenNaru에서 고객의 동의없이 Thread Dump 데이터를 유출할 수 없고 아직 검증되지 않은 서비스의 결과를 고객에게 제공할 수 없어 초반에 제공받은 Thread Dump 데이터 외에 추가적인 데이터는 제공받기 어려웠다. 이러한 까닭으로 추후 추가 데이터 학습 및 결과 검증에는 직접 에러 상황을 재연해 필요한 Thread Dump를 생성해야 하였다. 따라서 직접 인위적인 에러를 발생시키는 웹 페이지를 개발하였다.

▲<그림> 인위적인 에러를 발생시키는 웹 페이지

▲<표> 로그 분석 서버 EndPoint
서버에서 로그 분석을 위해 Khan에서 로그 분석 서버로 Thread Dump를 전송받고 이를 AutoML을 이용해서 분석 후, 해당 분석 결과를 시각화 시키기 위한 웹 서비스에 결과 데이터를 전송해야하였다. AutoML에 Thread Dump 분석 요청을 하기 위해서는 Python을 이용한 서버 개발을 하는 것이 좀 더 용이했으며 이를 위해 Python Flask를 이용하여 서버를 개발하였다.

▲<그림> Khan Thread Dump 목록 요청 및 분석 탭
Khan에서 분석하고 싶은 상태의 웹 페이지의 Thread Dump를 요청한 후, 분석을 위해 퀵서비스 버튼을 눌러 Thread Dump 분석 버튼을 누르면 해당 Thread Dump가 로그 분석 서버의 Rest API를 통해 서버로 전송되게 된다.

▲<그림> 전송된 Thread Dump Data를 받은 GCP에 배포된 로그 분석 서버
이렇게 받은 Thread Dump값을 서버에 저장시킨다. DB를 이용해서 받은 데이터를 저장하려고 하였지만, Thread Dump의 특성상 실행되는 Thread의 history를 Stack처럼 쌓아 보여주는 것이기 때문에 어려움이 있었다. 제공받은 Thread Dump Sample Data 만해도 char 크기가 200에서 25000까지 굉장히 차이가 크므로 DB에 저장하기에 적합하지 않았다. 또한 서버의 특성에 따라 Thread Dump 의 Stack 크기는 무궁무진하게 커질 수 있기 때문에 DB를 이용하여 저장시킬 때 Lossless하게 저장하기는 어려웠다. 때문에 local에 txt로 저장시킴으로서 데이터의 크기에 구애받지 않고 모델 분석에 필요한 데이터를 손상없이 모델로 전송할 수 있게 하였다.
이렇게 전송되어 저장된 Thread Dump는 시각화 웹 서비스에서 api를 통해 분석 요청이 들어오면 저장된 파일을 열어 저장된 데이터를 레이블링에 도입한 전처리와 똑같이 데이터 전처리를 해준 후, 전처리 완료된 데이터를 AutoML 모델로 전송한다.

▲<그림> Thread Dump 전처리 코드
전처리 완료된 Dump 데이터를 학습시킨 Google AutoML 모델로 전송하고 반환받은 모델의 결과값을 웹으로 전송한다. 시각화 웹 서비스는 전송받은 값을 가공해 그래프를 그릴 수 있다.

▲<그림> AutoML Thread Dump 분석 결과값

▲<그림> Thread Dump 분석 결과값을 확인할 수 있는 웹 서비스
React와 Typescript를 이용해서 AutoML 예측값을 각 라벨과 확률로 출력하는 UI를 개발했다. 웹의 최초 렌더링 시, API 호출을 통해 예측값을 요청하고, 그 반환 값을 텍스트 형식과 그래프 형식으로 출력한다. 여기서 그래프는 차트 라이브러리인 amcharts4를 사용했다.

▲<표> 이경전, 황보유정. (2020). 인공지능과 생산성. 정보과학회지, 38(11), 8-16
-
기업 관점에서의 기대 효과
-
업무 프로세스 간소화
-
로그 데이터 분석을 위한 시간 및 인건비 절감
-
개발자 관점에서의 기대 효과
-
NLP 기반의 로그 데이터 분석 방향성 제시 및 활용성 극대화
-
시스템 유지 및 보수 방향성 제시
-
소비자 관점에서의 기대효과
-
쾌적하고 편리한 서비스 제공받음
-
니즈에 최적화된 서비스 제공받음
-
로그 데이터 분석 웹 애플리케이션
-
로그 분석 모델 개발 후, 모델 활용에는 전문 인력의 도입이 필수적이지 않다. 그러한 장점을 극대화 시키기 위해 모델을 활용할 수 있는 서비스를 통해 접근성을 높이는 것이 중요하다. 따라서 Khan과 연계하여 분석 결과를 가시화하는 웹 애플리케이션을 통해 비개발자도 빠르고 쉽게 분석이 가능하도록 하였다.
-
REST API를 활용한 분석 결과 통신
-
타 사에서 요청받은 데이터 분석을 개발된 모델을 통해 진행 한 후 분석 결과를 REST API로 넘겨주는 기능을 개발했다. 이를 통해 타 기업의 소프트웨어에 모델을 이식하여 사용할 수 있어 활용도가 높아질 것이다.
| Name | 김보근 | 김나형 | 김다혜 | 옥명주 | 이현지 |
|---|---|---|---|---|---|
| Profile |  |
 |
 |
 |
 |
| role | Team Leader 1,2차 데이터 분석 1, 2차 레이블링 AutoML 개발 BERT 개발 |
1차 데이터 분석 AutoML 개발 Test Web Application Model Serving Server 개발 |
1, 2차 데이터 분석 1, 2차 레이블링 AutoML 개발 학습용 데이터 파일 구축 |
데이터 전처리 1, 2차 데이터 분석 및 1, 2차 레이블링 AutoML 개발 BERT 개발 |
1차 데이터 분석 AutoML 개발 Serving Web Service UI/UX 디자인 및 FrontEnd 개발 |
| Github | @Geunboda | @lamknh | @Loreha0223 | @dhraudwn | @hyunji-lee99 |