


A multi-stage virtual try-on deep neural networks based on JPP-Net and CP-VTON. We provide SIMPLE and EASY-to-handle API on upper level, and combine some traditional image processing methods.
Feature:
- Fast Human_Image + Cloth_Image = Gen_Image, put on a specified upper clothes for specified people.
- Web and Backend response service on Flask
- Download 3 pretrained models to
/checkpoints. - install dependency packages
- Start Flask service
python main.py
Clients encode image in base64, and send them in Json format. Then server would return results in the same rule.
Model.py is the only file that needs attention. After install dependency and initialize model.init(path...), you can directly call model.predict(human_img, c_img, ...) to make prediction. All image are numpy arrays on RGB channels.
Template notebook would be a nice example to show you how to use it.
Model's core external function is "predict()". Just pay attention to 5 flag parameters in documentation comments.
def predict(self, human_img, c_img, need_pre=True, need_bright=False, keep_back=False, need_dilate=False, check_dirty=False):
'''
parameters:
human_img: human's image
c_img: cloth image with the shape of (256,192,3) RGB
need_pre: need preprocessing, including crop and zoom
need_bright: brightness enhancement
keep_back: keep image's background
need_dilate: if keep_back is True, and you need dilate the mask
check_dirty: check limb cross
return:
a (256, 192, 3) image with specified people wearing specified clothes
confidence of this image (a float)
'''
tensorflow==1.12.0
torch==1.2.0
torchvision==0.2.0
For now, GPU environment is essential. If you want to run it on CPU environment, delete all .cuda() calls in CPVTON.py and Networks.py.
CPU Mode: Model(.., use_cuda = False)
On Tesla P40, GPU memory usage is about 7.12Gb. Each prediction costs about 0.62s (JPPNet 0.6s, CPVTON 0.02s).
If you want Real-Time speed, try to change the method of human feature extraction, like CE2P.
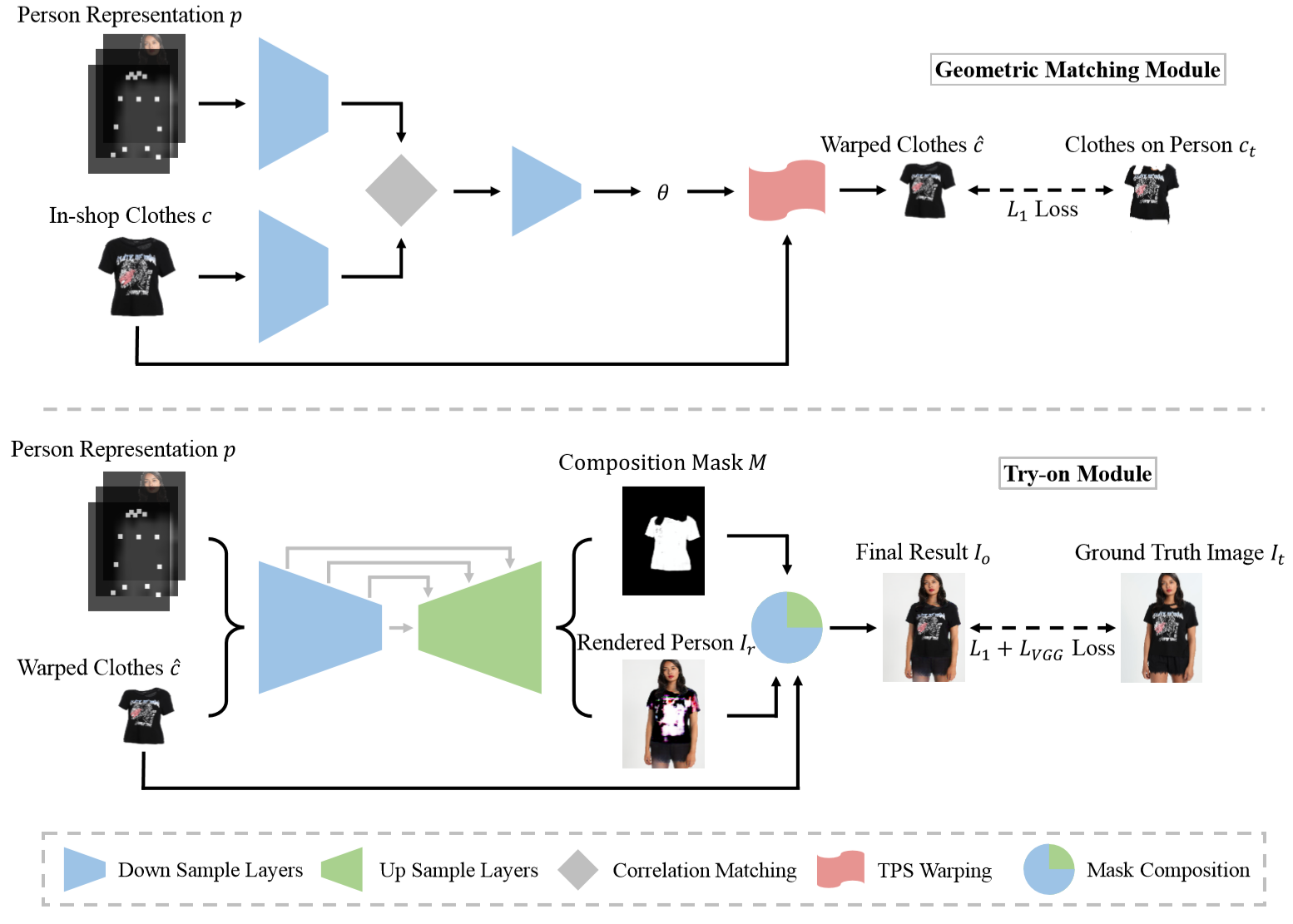
This multi-stage network consists of 3 parts:
- JPP-Net: Extract human features, make pose estimation & human parsing
- Geometric Matching Module: Input human features and clothes images, and twist clothes based on learned thin-plate-spline algorithm.
- Try-on Module: Input human feature and twisted clothes images, and generate try-on images.
| Fname | Usage |
|---|---|
| main.py | Flask service |
| get.py | clients post predict requests to Flask server |
| Model.py | Virtual Try-on Net |
| CPVTON.py | CPVTON model (GMM+TOM) |
| networks.py | CPVTON's basic network unit |
| JPPNet.py | JPP-Net model's init & predict |
| static/* | static resource |
| data/*, example/* | example test images |
| template/* | Flask's html file based on Jinjia |
| checkpoints/* | checkpoints dir |
coming soon..
download link on Google Drive and Baidu Pan
- Optimize model
- Web try-on service
- Basic documentation and comments
- Client post documentation
- Faster models download support
- CPU support
Model designs are based on JPP-Net & CPVTON, and their open-source repo on Github.
VITON: An Image-based Virtual Try-on Network,Xintong Han, Zuxuan Wu, Zhe Wu, Ruichi Yu, Larry S. Davis. CVPR 2018
(CP-VTON) Toward Characteristic-Preserving Image-based Virtual Try-On Networks, Bochao Wang, Huabin Zheng, Xiaodan Liang, Yimin Chen, Liang Lin, Meng Yang. ECCV 2018
(JPP-Net) Look into Person: Joint Body Parsing & Pose Estimation Network and A New Benchmark, Xiaodan Liang, Ke Gong, Xiaohui Shen, Liang Lin, T-PAMI 2018.
Powered By Imba, JD Digits