This code is a Python implementation of the work described in:
3D Object Localisation from Multi-view Image Detections (TPAMI 2017).

Abstract
In this work we present a novel approach to recover objects 3D position and occupancy in a generic scene using only 2D
object detections from multiple view images. The method reformulates the problem as the estimation of a quadric
(ellipsoid) in 3D given a set of 2D ellipses fitted to the object detection bounding boxes in multiple views. We show
that a closed-form solution exists in the dual-space using a minimum of three views while a solution with two views is
possible through the use of non-linear optimisation and object constraints on the size of the object shape. In order to
make the solution robust toward inaccurate bounding boxes, a likely occurrence in object detection methods, we introduce
a data preconditioning technique and a non-linear refinement of the closed form solution based on implicit subspace
constraints. Results on synthetic tests and on different real datasets, involving challenging scenarios, demonstrate the
applicability and potential of our method in several realistic scenarios. DOI: 10.1109/TPAMI.2017.2701373
If you use this project for your research, please cite:
@inproceedings{rubino2017pami,
title={3D Object Localisation from Multi-view Image Detections},
author={Rubino, Cosimo and Crocco, Marco and Del Bue, Alessio},
booktitle={Pattern Analysis and Machine Intelligence (TPAMI), 2017 IEEE Transactions on},
year={2017},
organization={IEEE}
}
This version of the code was ported to Python by Matteo Taiana.
To install LfD inside a new Conda environment, please execute the following steps.
Installation was tested on Ubuntu 20.04, but should work on other OS's as well.
conda create --name LfD
conda activate LfD
conda install pip
pip install -r requirements.txt
The data is a reformatted version of the demo dataset which accompanies the paper:
A. Aldoma, T. Faulhammer, and M. Vincze, “Automation of
ground truth annotation for multi-view rgb-d object instance
recognition datasets,” in IROS. IEEE, 2014, pp. 5016–5023
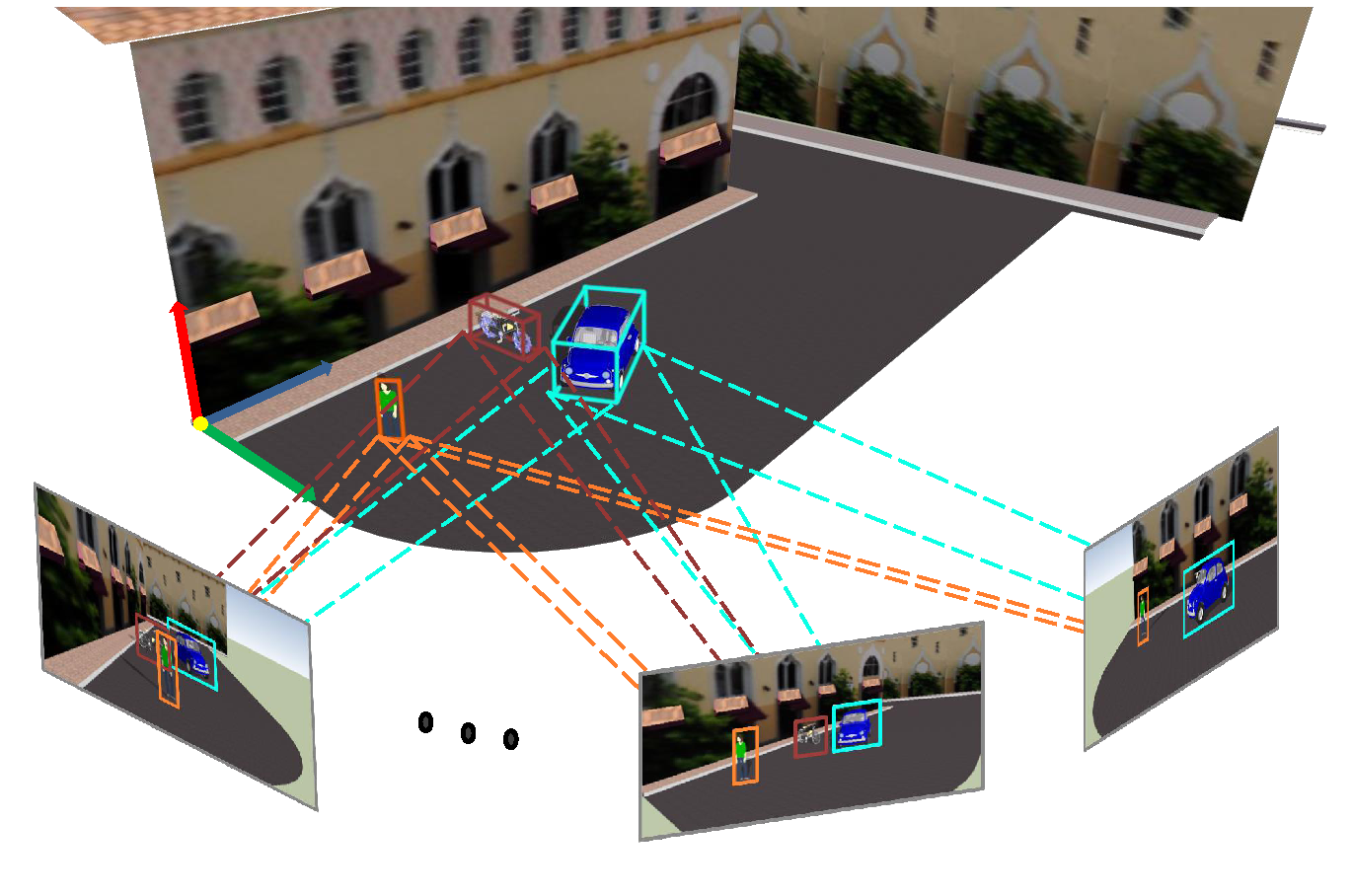
The dataset consists of eight images representing a scene in which six objects are visible. Objects are labelled with 2D bounding boxes. Data association is implicitly defined in the data structures, e.g., each column of the visibility matrix corresponds to one object. Camera parameters are provided, both the intrinsics and the extrinsics for each camera pose. The dataset provides Ground Truth ellipsoids for the objects, which can be used to assess the accuracy of the estimated ellipsoids.
You can run the demo by executing the following steps inside the LfD root directory.
The demo will plot Ground-Truth and estimated ellipses on the input images, as well as a 3D visualisation of the scene. The 3D visualisation includes camera poses and Ground-Truth and estimated ellipsoids. Plots will be both displayed and saved in the Output
directory.
conda activate LfD
python main.py
In order to run LfD on your data, you should create a new directory inside the Data directory, e.g.,
LfD/Data/MyTest.
You should populate the new directory with your data, replicating the structure used for the demo data. Then, you should
set the variable dataset in main.py to the name of the newly created directory.
When running LfD, the output data will be automatically stored in LfD/Output/MyTest.