本章内容将会以官方文档为延伸,以注解+代码+理论的形式开启QuickStart的篇章,ShardingSphere-JDBC-examples的项目结构如下(row与boot-mybatis结构相同):
- ShardingJDBC实现数据库的读写分离(replica-query-example)。
- ShardingJDBC实现数据库的分表读写(sharding-tables-example)。
- ShardingJDBC实现数据库的分库读写(sharding-databases-example)。
- ShardingJDBC实现数据库的分库分表(sharding-databases-tables-example)。
- ShardingJDBC实现数据库的读写分离+分库分表读写(sharding-replica-query)。
其中ROW为原生JDBC操作,boot-mybatis为框架结合操作。
当然,还会有很多扩展,类似于数据库脱敏、一主多从、分布式事务等等,这里暂不做延伸,如有必要,以后会加以扩展。
spring-boot:1.5.20.RELEASE
mybatis:1.3.0
ShardingSphere:5.0.0 alpha
注意:不同版本之间会有不同的差异,比较严重的差异在配置文件/代码中有所展示,其余的差异详见后续文章。
详见pom.xml
官网链接:https://shardingsphere.apache.org/
其他文章可见:https://www.yuque.com/jieker/shardingsphere
值得注意的是,项目中的每一个模块用到了三种配置方式——(properties、yaml、原生API)。
理论分析部分涉及了很多作者的个人观点,并非官方介绍,若有偏差还望指正。
随着数据量的增多,自然而然的衍生出了数据库集群、数据库分片的理论。自然,随着数据源的增多,配置文件逐渐变得庞大、冗杂,面向接口编程逐渐变成了面向Ctrl C+Ctrl V(不是)编程,此外还会带着庞杂的逻辑让运维人员头昏脑涨。ShardingSphere就致力于解决这类问题,并加以优化、封装甚至延伸。
官网原句:
Apache ShardingSphere 5.x 版本开始致力于可插拔架构,项目的功能组件能够灵活的以可插拔的方式进行扩展。 目前,数据分片、读写分离、数据加密、影子库压测等功能,以及对 MySQL、PostgreSQL、SQLServer、Oracle 等 SQL 与协议的支持,均通过插件的方式织入项目。 开发者能够像使用积木一样定制属于自己的独特系统。Apache ShardingSphere 目前已提供数十个 SPI 作为系统的扩展点,而且仍在不断增加中。
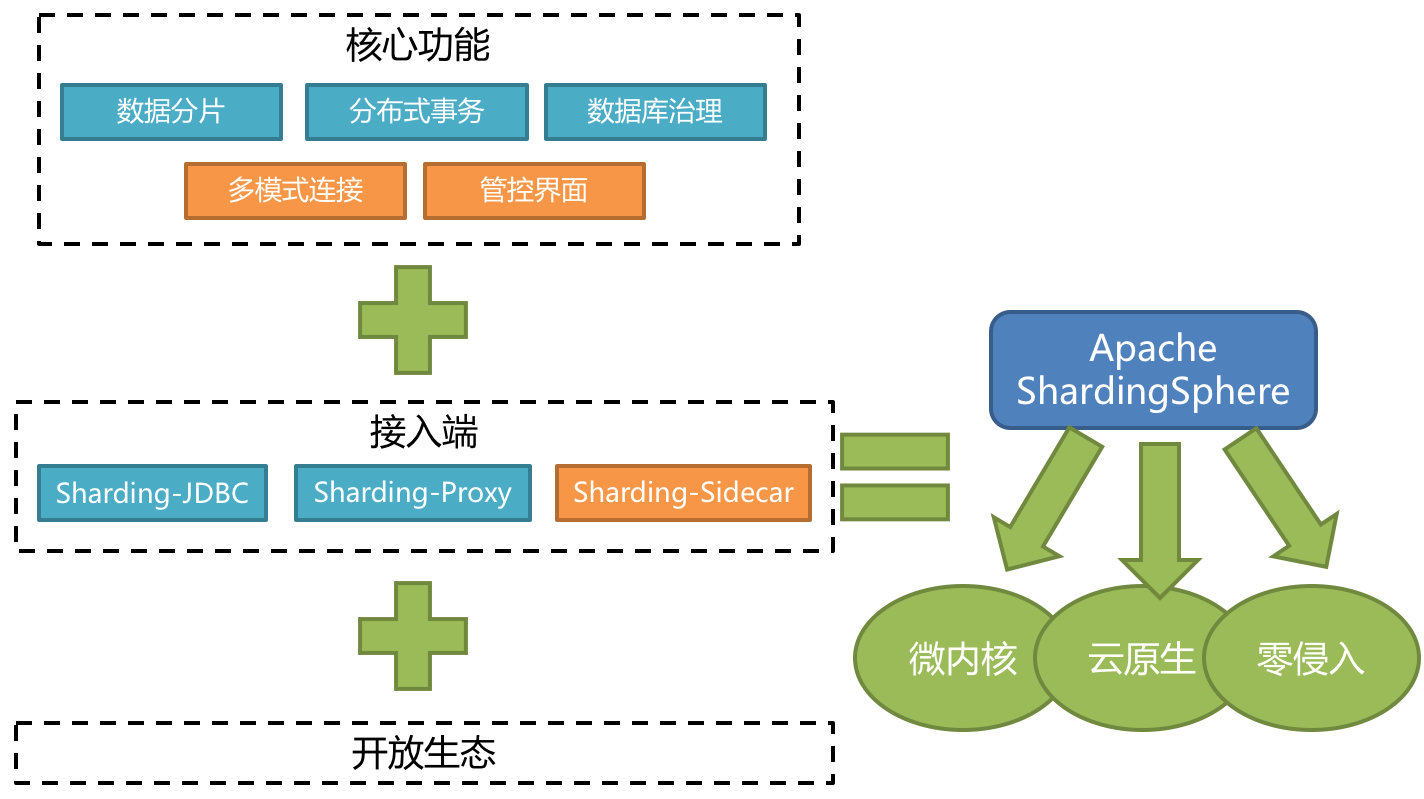
ShardingSphere JDBC是本章分析的重点,其使用方式是融入代码的方式进行使用,核心原理即实现了JDBC的语句,每次对数据库的操作本质上进行的是ShardingSphere JDBC的操作。具体的源码探究会在以后的篇章进行扩展,官网原句:
定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,Oracle,SQLServer,PostgreSQL 以及任何遵循 SQL92 标准的数据库。
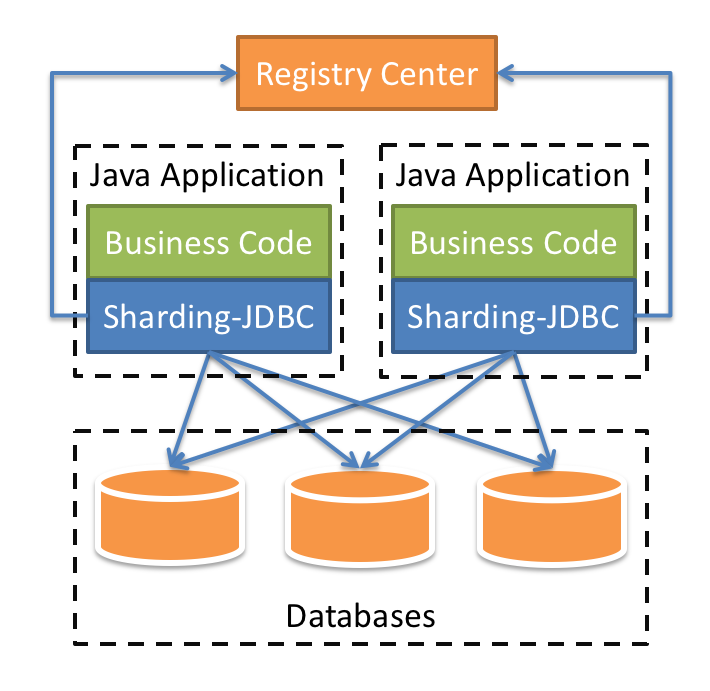
本章围绕读写分离、数据分片展开,再此之前,首先要了解一下什么是读写分离和数据分片。
官网介绍:
面对日益增加的系统访问量,数据库的吞吐量面临着巨大瓶颈。 对于同一时刻有大量并发读操作和较少写操作类型的应用系统来说,将数据库拆分为主库和从库,主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
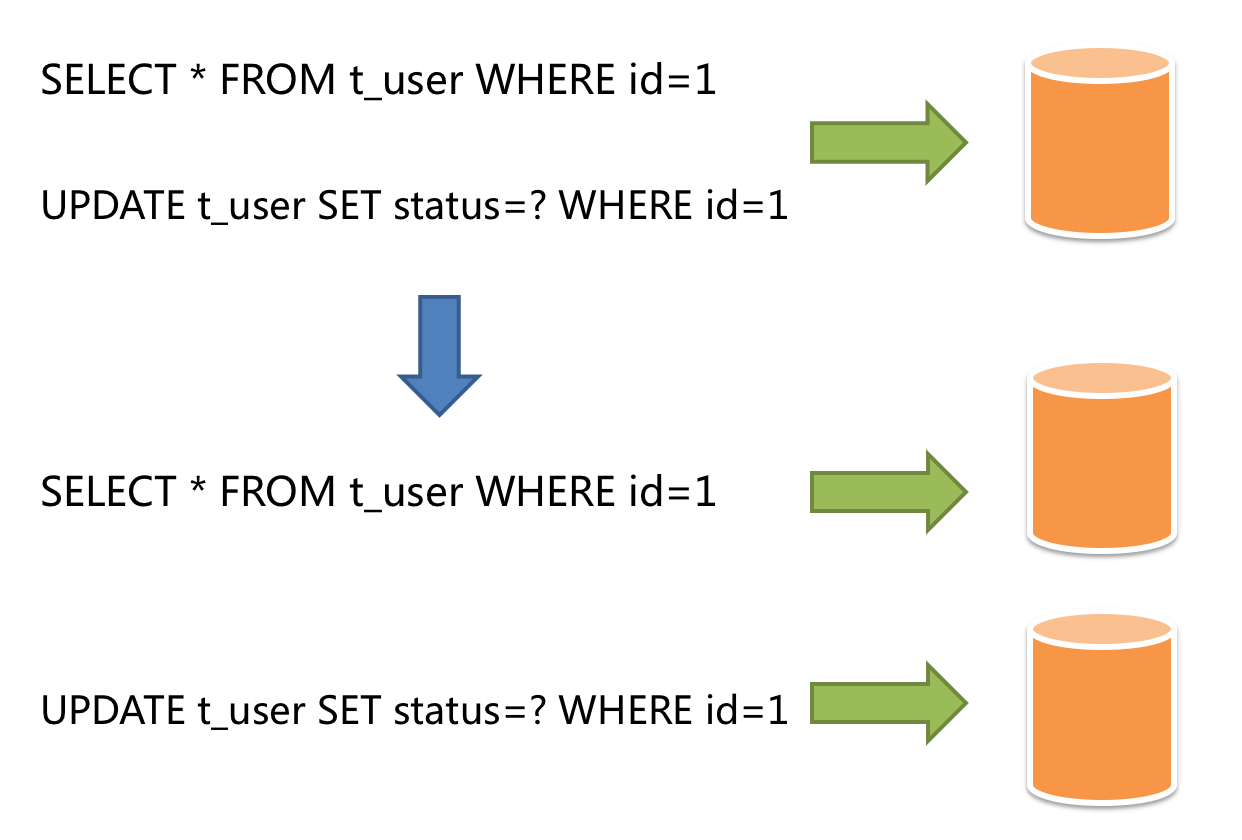
随着并发量的增多,每一个数据库的特点也愈发明显。譬如现在有一个存储流水信息的数据库,显然,它查询的次数会远远大于修改的次数。倘若把这些语句放在一起会无法避免X锁和S锁争用,速度自然而然的会降低,负荷也会提高。
数据分片指按照某个维度将存放在单一数据库中的数据分散地存放至多个数据库或表中以达到提升性能瓶颈以及可用性的效果。 数据分片的有效手段是对关系型数据库进行分库和分表。分库和分表均可以有效的避免由数据量超过可承受阈值而产生的查询瓶颈。 除此之外,分库还能够用于有效的分散对数据库单点的访问量;分表虽然无法缓解数据库压力,但却能够提供尽量将分布式事务转化为本地事务的可能,一旦涉及到跨库的更新操作,分布式事务往往会使问题变得复杂。 使用多主多从的分片方式,可以有效的避免数据单点,从而提升数据架构的可用性。 通过分库和分表进行数据的拆分来使得各个表的数据量保持在阈值以下,以及对流量进行疏导应对高访问量,是应对高并发和海量数据系统的有效手段。 数据分片的拆分方式又分为垂直分片和水平分片。
数据分片又分为了垂直和水平分片,即分库和分表。
官网介绍:
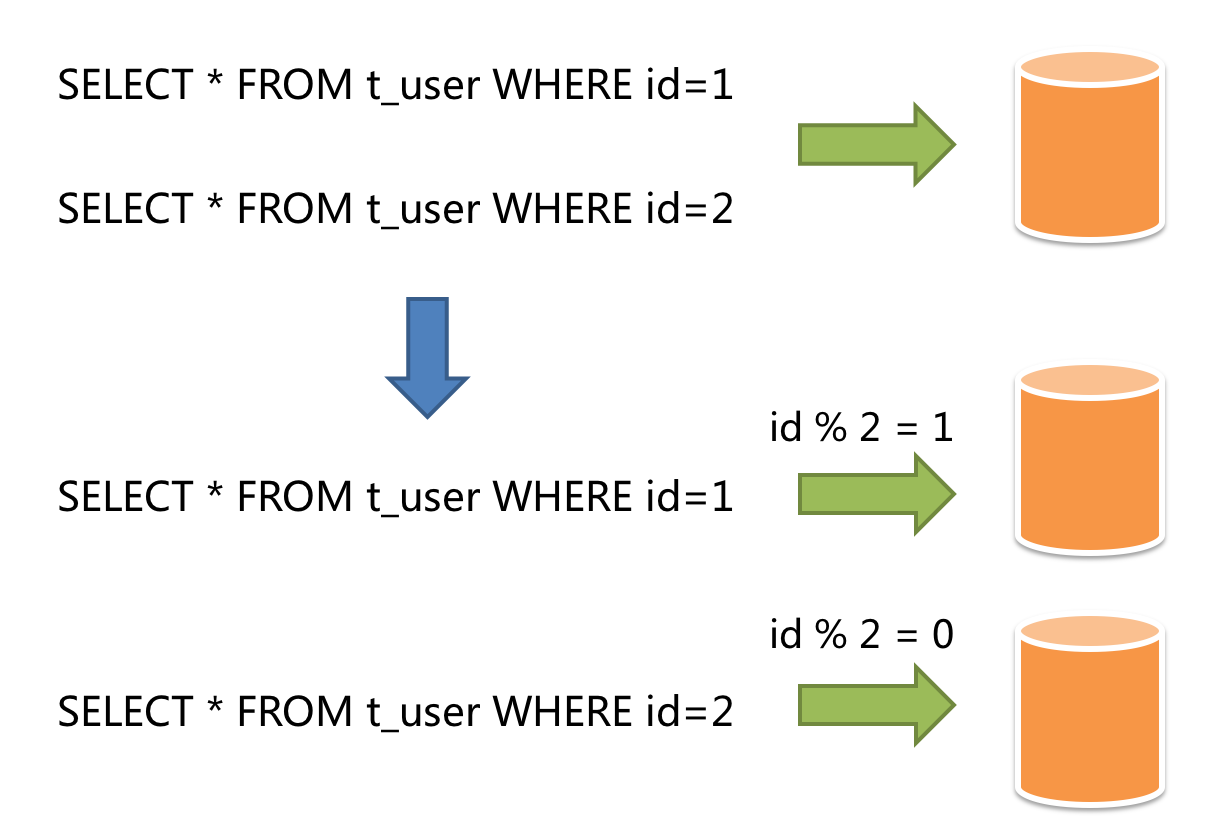
水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。 例如:根据主键分片,偶数主键的记录放入 0 库(或表),奇数主键的记录放入 1 库(或表),如下图所示。
官网介绍:
按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用。 在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库。 下图展示了根据业务需要,将用户表和订单表垂直分片到不同的数据库的方案。

以MySql为例,随着数据量的增多,库中的表会越来越多,表中的数据量也会越来越大,相应地,随着树的高度增加,B+Tree的问题也会越来越明显,即服务器的性能会直线下降,最终数据库所能承载的数据量、数据处理性能都会直线下降。
如果因为数据表的庞大,并且项目的各个表之间的关系明确,遵循三大范式,那么的垂直切分必是首选。而如果数据库中的表并不多,但单表的数据量很大、或数据热度很高,这种情况之下就应该选择水平切分。在现实项目中,往往是这两种情况兼而有之,这就需要做出权衡,甚至既需要垂直切分,又需要水平切分。