The content of this chapter will be extended to official documents, opening the chapter of QuickStart in the form of annotations, codes and theories, the project structure of ShardingSphere-JDBC-examples is as follows (row and boot-mybatis have the same structure):
- ShardingJDBC implements Database read/write splitting (replica-query-example).
- ShardingJDBC Implementation of the database tables write (sharding-tables-example).
- ShardingJDBC Implement Database sharding-databases-example.
- ShardingJDBC Implement Database Sharding and table sharding (sharding-databases-tables-example) .
- ShardingJDBC Supports Database read/write splitting and sharding-replica-query.
ROW is a native JDBC operation and boot-mybatis is a framework operation.
Of course, there will be many extensions, such as database desensitization, one master and multiple slave transactions, and distributed transactions. No extensions will be made here. If necessary, they will be extended in the future.
spring-boot:1.5.20.RELEASE
mybatis:1.3.0
ShardingSphere:5.0.0 alpha
Note: different versions have different differences. Serious differences are shown in the configuration file/code. For more information, see the following articles.
See pom.xml
Official website link: https://shardingsphere.apache.org/
For more information, see: https://www.yuque.com/jieker/shardingsphere
Worth to be mention that each module in the project uses three configuration methods-properties, yaml, and Native API.
The theoretical analysis part involves many personal opinions of the author, which is not an official introduction. If there is any deviation, please correct it.
With the increase of data volume, the theory of database cluster and Database Sharding is derived naturally. Naturally, with the increase of data sources, configuration files gradually become large and tedious, and interface-oriented programming gradually becomes Ctrl C+Ctrl V (No) programming, in addition, it will bring complex logic to make O & M personnel dizzy. ShardingSphere is committed to solving such problems and optimizing, encapsulating, and even extending them.
Official website original sentence:
Apache ShardingSphere begin to focus on pluggable architecture from version 5.x, features can be embedded into project flexibility. Currently, the features such as data sharding, replica query, data encrypt, shadow test, and SQL dialects / database protocols such as MySQL, PostgreSQL, SQLServer, Oracle supported are all weaved by plugins. Developers can customize their own ShardingSphere just like building lego blocks. There are lots of SPI extensions for Apache ShardingSphere now and increase continuously.
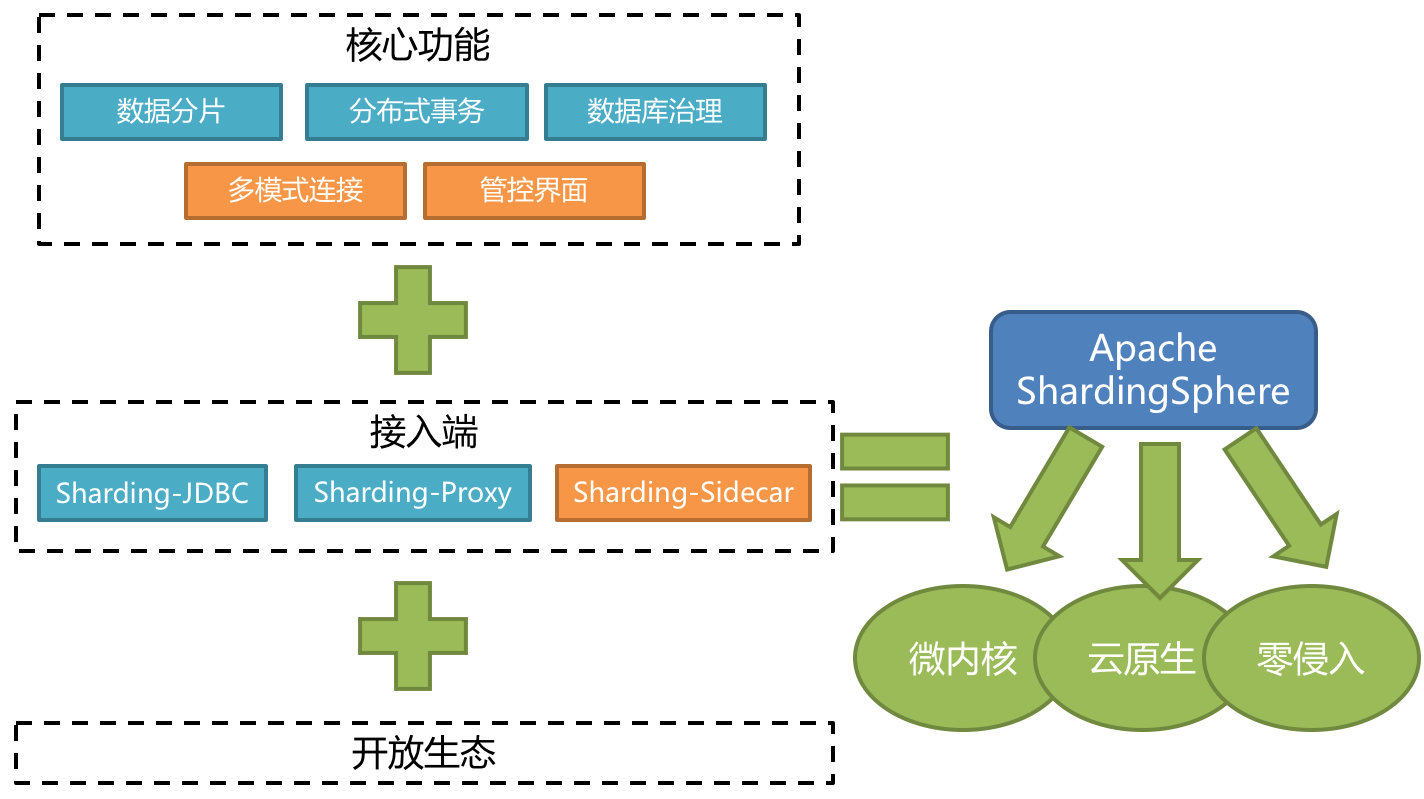
ShardingSphere JDBC is the focus of this Chapter. It is used in the way of integrating code. The core principle is to implement JDBC statements, each operation on the database is essentially ShardingSphere JDBC. The specific source code exploration will be extended in the following chapters, the original sentence on the official website:
ShardingSphere-JDBC defines itself as a lightweight Java framework that provides extra service at Java JDBC layer. With the client end connecting directly to the database, it provides service in the form of jar and requires no extra deployment and dependence. It can be considered as an enhanced JDBC driver, which is fully compatible with JDBC and all kinds of ORM frameworks.
- Applicable in any ORM framework based on JDBC, such as JPA, Hibernate, Mybatis, Spring JDBC Template or direct use of JDBC.
- Support any third-party database connection pool, such as DBCP, C3P0, BoneCP, Druid, HikariCP.
- Support any kind of JDBC standard database: MySQL, Oracle, SQLServer, PostgreSQL and any SQL92 followed databases.
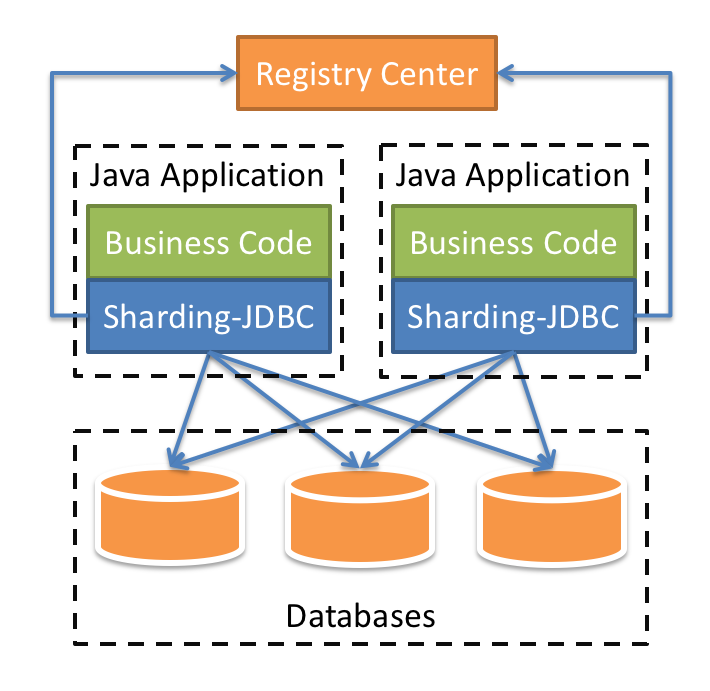
This chapter focuses on read/write splitting and data sharding. Before that, you need to understand what read/write splitting and data sharding are.
Introduction to the official website:
With increasing system TPS, database capacity has faced great bottleneck effect. For the application system with massive concurrence read operations but less write operations in the same time, we can divide the database into a primary database and a replica database. The primary database is responsible for the addition, deletion and modification of transactions, while the replica database is responsible for queries. It can significantly improve the query performance of the whole system by effectively avoiding line locks caused by data renewal.
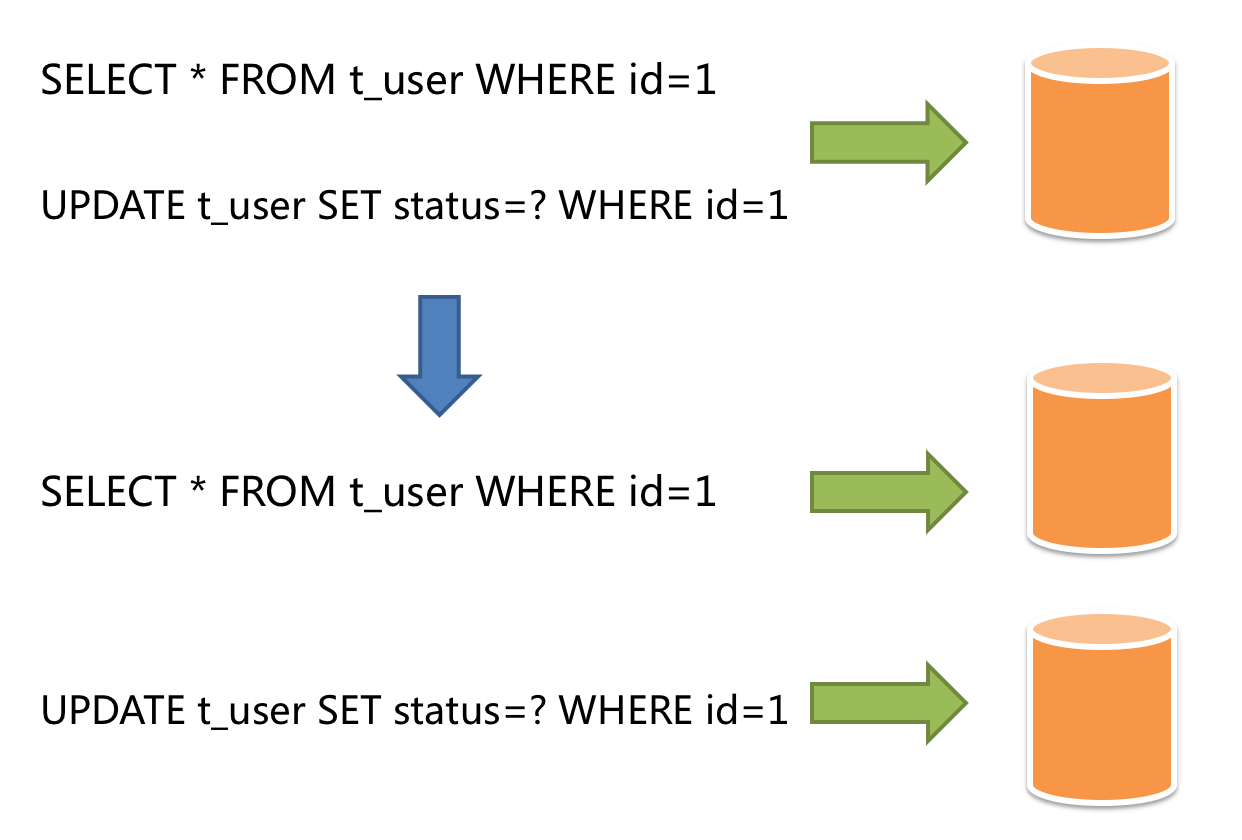
With the increase of concurrency, the characteristics of each database become more and more obvious. For example, there is a database that stores running water information. Obviously, the number of queries is far greater than the number of modifications. If these statements are put together, it is impossible to avoid the contention of X lock and S lock, and the speed will naturally decrease and the load will also increase.
Sharding refers to splitting the data in one database and storing them in multiple tables and databases according to some certain standard, so that the performance and availability can be improved. Both methods can effectively avoid the query limitation caused by data exceeding affordable threshold. What’s more, database sharding can also effectively disperse TPS. Table sharding, though cannot ease the database pressure, can provide possibilities to transfer distributed transactions to local transactions, since cross-database upgrades are once involved, distributed transactions can turn pretty tricky sometimes. The use of multiple replica query sharding method can effectively avoid the data concentrating on one node and increase the architecture availability. Splitting data through database sharding and table sharding is an effective method to deal with high TPS and mass amount data system, because it can keep the data amount lower than the threshold and evacuate the traffic. Sharding method can be divided into vertical sharding and horizontal sharding.
Data shards are divided into vertical shards and horizontal shards, that is, database shards and table shards.
Introduction to the official website:
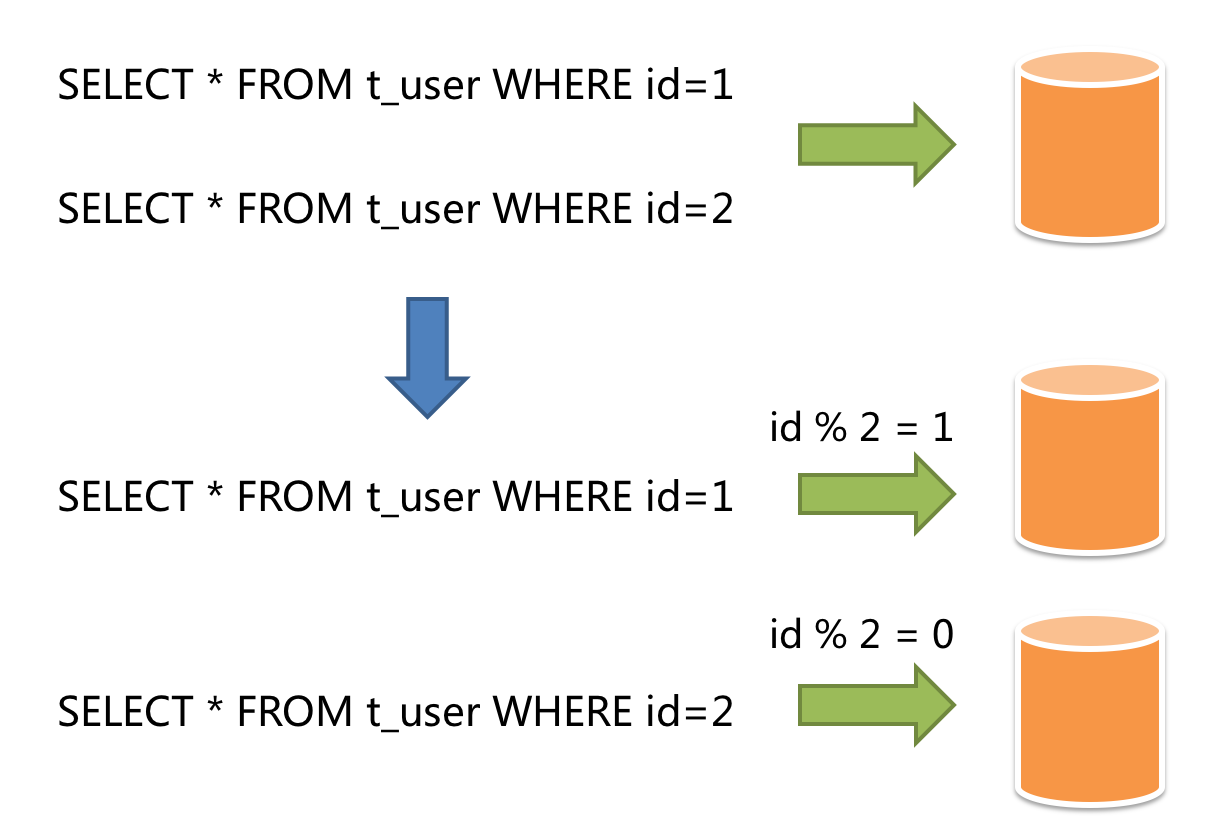
Horizontal sharding is also called transverse sharding. Compared with the categorization method according to business logic of vertical sharding, horizontal sharding categorizes data to multiple databases or tables according to some certain rules through certain fields, with each sharding containing only part of the data. For example, according to primary key sharding, even primary keys are put into the 0 database (or table) and odd primary keys are put into the 1 database (or table), which is illustrated as the following diagram.
Introduction to the official website:
According to business sharding method, it is called vertical sharding, or longitudinal sharding, the core concept of which is to specialize databases for different uses. Before sharding, a database consists of many tables corresponding to different businesses. But after sharding, tables are categorized into different databases according to business, and the pressure is also separated into different databases. The diagram below has presented the solution to assign user tables and order tables to different databases by vertical sharding according to business need.

Take MySql as an example. As the amount of data increases, the number of tables in the database increases and the amount of data in the tables increases. Accordingly, as the height of the tree increases, the problem of B + Tree will become more and more obvious, that is, the performance of the server will plummet, and eventually the data volume and data processing performance that the database can carry will plummet.
If the data table is huge and the relationship between each table of the project is clear, following the three paradigms, then vertical segmentation is the first choice. If there are not many tables in the database, but the data volume of a single table is large or the data popularity is high, horizontal segmentation should be selected. In real projects, these two situations are often combined, which requires weighing, even vertical segmentation and horizontal segmentation.