
Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch. Significance is further explained in Yannic Kilcher's video. There's really not much to code here, but may as well lay it out for everyone so we expedite the attention revolution.
For a Pytorch implementation with pretrained models, please see Ross Wightman's repository here.
The official Jax repository is here.
$ pip install vit-pytorchimport torch
from vit_pytorch import ViT
v = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(1, 3, 256, 256)
preds = v(img) # (1, 1000)image_size: int.
Image size. If you have rectangular images, make sure your image size is the maximum of the width and heightpatch_size: int.
Number of patches.image_sizemust be divisible bypatch_size.
The number of patches is:n = (image_size // patch_size) ** 2andnmust be greater than 16.num_classes: int.
Number of classes to classify.dim: int.
Last dimension of output tensor after linear transformationnn.Linear(..., dim).depth: int.
Number of Transformer blocks.heads: int.
Number of heads in Multi-head Attention layer.mlp_dim: int.
Dimension of the MLP (FeedForward) layer.channels: int, default3.
Number of image's channels.dropout: float between[0, 1], default0..
Dropout rate.emb_dropout: float between[0, 1], default0.
Embedding dropout rate.pool: string, eitherclstoken pooling ormeanpooling

A recent paper has shown that use of a distillation token for distilling knowledge from convolutional nets to vision transformer can yield small and efficient vision transformers. This repository offers the means to do distillation easily.
ex. distilling from Resnet50 (or any teacher) to a vision transformer
import torch
from torchvision.models import resnet50
from vit_pytorch.distill import DistillableViT, DistillWrapper
teacher = resnet50(pretrained = True)
v = DistillableViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 8,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
distiller = DistillWrapper(
student = v,
teacher = teacher,
temperature = 3, # temperature of distillation
alpha = 0.5, # trade between main loss and distillation loss
hard = False # whether to use soft or hard distillation
)
img = torch.randn(2, 3, 256, 256)
labels = torch.randint(0, 1000, (2,))
loss = distiller(img, labels)
loss.backward()
# after lots of training above ...
pred = v(img) # (2, 1000)The DistillableViT class is identical to ViT except for how the forward pass is handled, so you should be able to load the parameters back to ViT after you have completed distillation training.
You can also use the handy .to_vit method on the DistillableViT instance to get back a ViT instance.
v = v.to_vit()
type(v) # <class 'vit_pytorch.vit_pytorch.ViT'>This paper notes that ViT struggles to attend at greater depths (past 12 layers), and suggests mixing the attention of each head post-softmax as a solution, dubbed Re-attention. The results line up with the Talking Heads paper from NLP.
You can use it as follows
import torch
from vit_pytorch.deepvit import DeepViT
v = DeepViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(1, 3, 256, 256)
preds = v(img) # (1, 1000)This paper also notes difficulty in training vision transformers at greater depths and proposes two solutions. First it proposes to do per-channel multiplication of the output of the residual block. Second, it proposes to have the patches attend to one another, and only allow the CLS token to attend to the patches in the last few layers.
They also add Talking Heads, noting improvements
You can use this scheme as follows
import torch
from vit_pytorch.cait import CaiT
v = CaiT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 12, # depth of transformer for patch to patch attention only
cls_depth = 2, # depth of cross attention of CLS tokens to patch
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1,
layer_dropout = 0.05 # randomly dropout 5% of the layers
)
img = torch.randn(1, 3, 256, 256)
preds = v(img) # (1, 1000)
This paper proposes that the first couple layers should downsample the image sequence by unfolding, leading to overlapping image data in each token as shown in the figure above. You can use this variant of the ViT as follows.
import torch
from vit_pytorch.t2t import T2TViT
v = T2TViT(
dim = 512,
image_size = 224,
depth = 5,
heads = 8,
mlp_dim = 512,
num_classes = 1000,
t2t_layers = ((7, 4), (3, 2), (3, 2)) # tuples of the kernel size and stride of each consecutive layers of the initial token to token module
)
img = torch.randn(1, 3, 224, 224)
preds = v(img) # (1, 1000)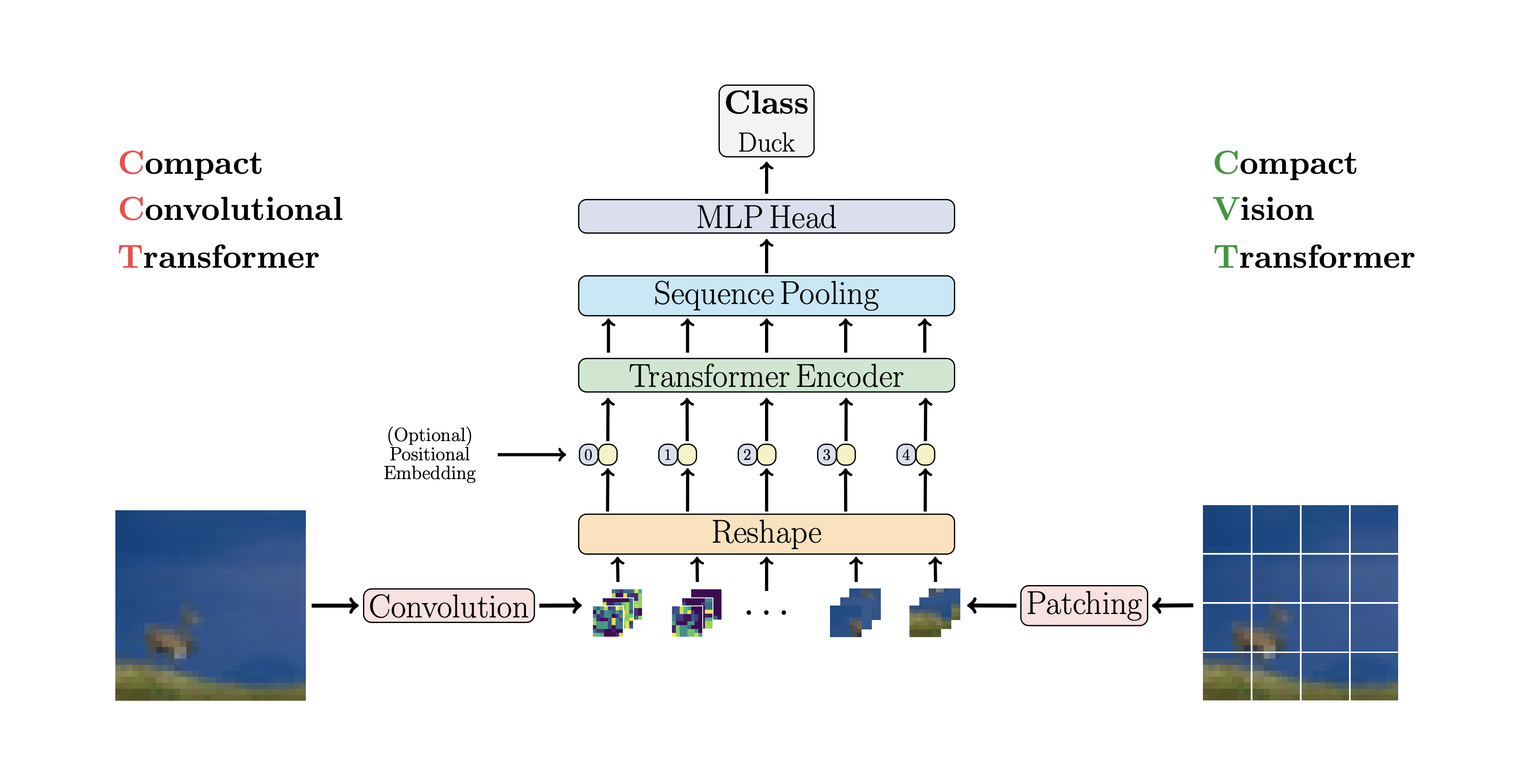
CCT proposes compact transformers by using convolutions instead of patching and performing sequence pooling. This allows for CCT to have high accuracy and a low number of parameters.
You can use this with two methods
import torch
from vit_pytorch.cct import CCT
model = CCT(
img_size=224,
embedding_dim=384,
n_conv_layers=2,
kernel_size=7,
stride=2,
padding=3,
pooling_kernel_size=3,
pooling_stride=2,
pooling_padding=1,
num_layers=14,
num_heads=6,
mlp_radio=3.,
num_classes=1000,
positional_embedding='learnable', # ['sine', 'learnable', 'none']
)Alternatively you can use one of several pre-defined models [2,4,6,7,8,14,16]
which pre-define the number of layers, number of attention heads, the mlp ratio,
and the embedding dimension.
import torch
from vit_pytorch.cct import cct_14
model = cct_14(
img_size=224,
n_conv_layers=1,
kernel_size=7,
stride=2,
padding=3,
pooling_kernel_size=3,
pooling_stride=2,
pooling_padding=1,
num_classes=1000,
positional_embedding='learnable', # ['sine', 'learnable', 'none']
)Official Repository includes links to pretrained model checkpoints.

This paper proposes to have two vision transformers processing the image at different scales, cross attending to one every so often. They show improvements on top of the base vision transformer.
import torch
from vit_pytorch.cross_vit import CrossViT
v = CrossViT(
image_size = 256,
num_classes = 1000,
depth = 4, # number of multi-scale encoding blocks
sm_dim = 192, # high res dimension
sm_patch_size = 16, # high res patch size (should be smaller than lg_patch_size)
sm_enc_depth = 2, # high res depth
sm_enc_heads = 8, # high res heads
sm_enc_mlp_dim = 2048, # high res feedforward dimension
lg_dim = 384, # low res dimension
lg_patch_size = 64, # low res patch size
lg_enc_depth = 3, # low res depth
lg_enc_heads = 8, # low res heads
lg_enc_mlp_dim = 2048, # low res feedforward dimensions
cross_attn_depth = 2, # cross attention rounds
cross_attn_heads = 8, # cross attention heads
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(1, 3, 256, 256)
pred = v(img) # (1, 1000)
This paper proposes to downsample the tokens through a pooling procedure using depth-wise convolutions.
import torch
from vit_pytorch.pit import PiT
v = PiT(
image_size = 224,
patch_size = 14,
dim = 256,
num_classes = 1000,
depth = (3, 3, 3), # list of depths, indicating the number of rounds of each stage before a downsample
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
# forward pass now returns predictions and the attention maps
img = torch.randn(1, 3, 224, 224)
preds = v(img) # (1, 1000)
This paper proposes a number of changes, including (1) convolutional embedding instead of patch-wise projection (2) downsampling in stages (3) extra non-linearity in attention (4) 2d relative positional biases instead of initial absolute positional bias (5) batchnorm in place of layernorm.
import torch
from vit_pytorch.levit import LeViT
levit = LeViT(
image_size = 224,
num_classes = 1000,
stages = 3, # number of stages
dim = (256, 384, 512), # dimensions at each stage
depth = 4, # transformer of depth 4 at each stage
heads = (4, 6, 8), # heads at each stage
mlp_mult = 2,
dropout = 0.1
)
img = torch.randn(1, 3, 224, 224)
levit(img) # (1, 1000)
This paper proposes mixing convolutions and attention. Specifically, convolutions are used to embed and downsample the image / feature map in three stages. Depthwise-convoltion is also used to project the queries, keys, and values for attention.
import torch
from vit_pytorch.cvt import CvT
v = CvT(
num_classes = 1000,
s1_emb_dim = 64, # stage 1 - dimension
s1_emb_kernel = 7, # stage 1 - conv kernel
s1_emb_stride = 4, # stage 1 - conv stride
s1_proj_kernel = 3, # stage 1 - attention ds-conv kernel size
s1_kv_proj_stride = 2, # stage 1 - attention key / value projection stride
s1_heads = 1, # stage 1 - heads
s1_depth = 1, # stage 1 - depth
s1_mlp_mult = 4, # stage 1 - feedforward expansion factor
s2_emb_dim = 192, # stage 2 - (same as above)
s2_emb_kernel = 3,
s2_emb_stride = 2,
s2_proj_kernel = 3,
s2_kv_proj_stride = 2,
s2_heads = 3,
s2_depth = 2,
s2_mlp_mult = 4,
s3_emb_dim = 384, # stage 3 - (same as above)
s3_emb_kernel = 3,
s3_emb_stride = 2,
s3_proj_kernel = 3,
s3_kv_proj_stride = 2,
s3_heads = 4,
s3_depth = 10,
s3_mlp_mult = 4,
dropout = 0.
)
img = torch.randn(1, 3, 224, 224)
pred = v(img) # (1, 1000)
This paper proposes mixing local and global attention, along with position encoding generator (proposed in CPVT) and global average pooling, to achieve the same results as Swin, without the extra complexity of shifted windows, CLS tokens, nor positional embeddings.
import torch
from vit_pytorch.twins_svt import TwinsSVT
model = TwinsSVT(
num_classes = 1000, # number of output classes
s1_emb_dim = 64, # stage 1 - patch embedding projected dimension
s1_patch_size = 4, # stage 1 - patch size for patch embedding
s1_local_patch_size = 7, # stage 1 - patch size for local attention
s1_global_k = 7, # stage 1 - global attention key / value reduction factor, defaults to 7 as specified in paper
s1_depth = 1, # stage 1 - number of transformer blocks (local attn -> ff -> global attn -> ff)
s2_emb_dim = 128, # stage 2 (same as above)
s2_patch_size = 2,
s2_local_patch_size = 7,
s2_global_k = 7,
s2_depth = 1,
s3_emb_dim = 256, # stage 3 (same as above)
s3_patch_size = 2,
s3_local_patch_size = 7,
s3_global_k = 7,
s3_depth = 5,
s4_emb_dim = 512, # stage 4 (same as above)
s4_patch_size = 2,
s4_local_patch_size = 7,
s4_global_k = 7,
s4_depth = 4,
peg_kernel_size = 3, # positional encoding generator kernel size
dropout = 0. # dropout
)
img = torch.randn(1, 3, 224, 224)
pred = model(img) # (1, 1000)
This paper decided to process the image in hierarchical stages, with attention only within tokens of local blocks, which aggregate as it moves up the heirarchy. The aggregation is done in the image plane, and contains a convolution and subsequent maxpool to allow it to pass information across the boundary.
You can use it with the following code (ex. NesT-T)
import torch
from vit_pytorch.nest import NesT
nest = NesT(
image_size = 224,
patch_size = 4,
dim = 96,
heads = 3,
num_hierarchies = 3, # number of hierarchies
block_repeats = (8, 4, 1), # the number of transformer blocks at each heirarchy, starting from the bottom
num_classes = 1000
)
img = torch.randn(1, 3, 224, 224)
pred = nest(img) # (1, 1000)Thanks to Zach, you can train using the original masked patch prediction task presented in the paper, with the following code.
import torch
from vit_pytorch import ViT
from vit_pytorch.mpp import MPP
model = ViT(
image_size=256,
patch_size=32,
num_classes=1000,
dim=1024,
depth=6,
heads=8,
mlp_dim=2048,
dropout=0.1,
emb_dropout=0.1
)
mpp_trainer = MPP(
transformer=model,
patch_size=32,
dim=1024,
mask_prob=0.15, # probability of using token in masked prediction task
random_patch_prob=0.30, # probability of randomly replacing a token being used for mpp
replace_prob=0.50, # probability of replacing a token being used for mpp with the mask token
)
opt = torch.optim.Adam(mpp_trainer.parameters(), lr=3e-4)
def sample_unlabelled_images():
return torch.FloatTensor(20, 3, 256, 256).uniform_(0., 1.)
for _ in range(100):
images = sample_unlabelled_images()
loss = mpp_trainer(images)
opt.zero_grad()
loss.backward()
opt.step()
# save your improved network
torch.save(model.state_dict(), './pretrained-net.pt')
You can train ViT with the recent SOTA self-supervised learning technique, Dino, with the following code.
Yannic Kilcher video
import torch
from vit_pytorch import ViT, Dino
model = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 8,
mlp_dim = 2048
)
learner = Dino(
model,
image_size = 256,
hidden_layer = 'to_latent', # hidden layer name or index, from which to extract the embedding
projection_hidden_size = 256, # projector network hidden dimension
projection_layers = 4, # number of layers in projection network
num_classes_K = 65336, # output logits dimensions (referenced as K in paper)
student_temp = 0.9, # student temperature
teacher_temp = 0.04, # teacher temperature, needs to be annealed from 0.04 to 0.07 over 30 epochs
local_upper_crop_scale = 0.4, # upper bound for local crop - 0.4 was recommended in the paper
global_lower_crop_scale = 0.5, # lower bound for global crop - 0.5 was recommended in the paper
moving_average_decay = 0.9, # moving average of encoder - paper showed anywhere from 0.9 to 0.999 was ok
center_moving_average_decay = 0.9, # moving average of teacher centers - paper showed anywhere from 0.9 to 0.999 was ok
)
opt = torch.optim.Adam(learner.parameters(), lr = 3e-4)
def sample_unlabelled_images():
return torch.randn(20, 3, 256, 256)
for _ in range(100):
images = sample_unlabelled_images()
loss = learner(images)
opt.zero_grad()
loss.backward()
opt.step()
learner.update_moving_average() # update moving average of teacher encoder and teacher centers
# save your improved network
torch.save(model.state_dict(), './pretrained-net.pt')If you would like to visualize the attention weights (post-softmax) for your research, just follow the procedure below
import torch
from vit_pytorch.vit import ViT
v = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
# import Recorder and wrap the ViT
from vit_pytorch.recorder import Recorder
v = Recorder(v)
# forward pass now returns predictions and the attention maps
img = torch.randn(1, 3, 256, 256)
preds, attns = v(img)
# there is one extra patch due to the CLS token
attns # (1, 6, 16, 65, 65) - (batch x layers x heads x patch x patch)to cleanup the class and the hooks once you have collected enough data
v = v.eject() # wrapper is discarded and original ViT instance is returnedThere may be some coming from computer vision who think attention still suffers from quadratic costs. Fortunately, we have a lot of new techniques that may help. This repository offers a way for you to plugin your own sparse attention transformer.
An example with Nystromformer
$ pip install nystrom-attentionimport torch
from vit_pytorch.efficient import ViT
from nystrom_attention import Nystromformer
efficient_transformer = Nystromformer(
dim = 512,
depth = 12,
heads = 8,
num_landmarks = 256
)
v = ViT(
dim = 512,
image_size = 2048,
patch_size = 32,
num_classes = 1000,
transformer = efficient_transformer
)
img = torch.randn(1, 3, 2048, 2048) # your high resolution picture
v(img) # (1, 1000)Other sparse attention frameworks I would highly recommend is Routing Transformer or Sinkhorn Transformer
This paper purposely used the most vanilla of attention networks to make a statement. If you would like to use some of the latest improvements for attention nets, please use the Encoder from this repository.
ex.
$ pip install x-transformersimport torch
from vit_pytorch.efficient import ViT
from x_transformers import Encoder
v = ViT(
dim = 512,
image_size = 224,
patch_size = 16,
num_classes = 1000,
transformer = Encoder(
dim = 512, # set to be the same as the wrapper
depth = 12,
heads = 8,
ff_glu = True, # ex. feed forward GLU variant https://arxiv.org/abs/2002.05202
residual_attn = True # ex. residual attention https://arxiv.org/abs/2012.11747
)
)
img = torch.randn(1, 3, 224, 224)
v(img) # (1, 1000)- How do I pass in non-square images?
You can already pass in non-square images - you just have to make sure your height and width is less than or equal to the image_size, and both divisible by the patch_size
ex.
import torch
from vit_pytorch import ViT
v = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(1, 3, 256, 128) # <-- not a square
preds = v(img) # (1, 1000)- How do I pass in non-square patches?
import torch
from vit_pytorch import ViT
v = ViT(
num_classes = 1000,
image_size = (256, 128), # image size is a tuple of (height, width)
patch_size = (32, 16), # patch size is a tuple of (height, width)
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(1, 3, 256, 128)
preds = v(img)Coming from computer vision and new to transformers? Here are some resources that greatly accelerated my learning.
-
Illustrated Transformer - Jay Alammar
-
Transformers from Scratch - Peter Bloem
-
The Annotated Transformer - Harvard NLP
@article{hassani2021escaping,
title = {Escaping the Big Data Paradigm with Compact Transformers},
author = {Ali Hassani and Steven Walton and Nikhil Shah and Abulikemu Abuduweili and Jiachen Li and Humphrey Shi},
year = 2021,
url = {https://arxiv.org/abs/2104.05704},
eprint = {2104.05704},
archiveprefix = {arXiv},
primaryclass = {cs.CV}
}@misc{dosovitskiy2020image,
title = {An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author = {Alexey Dosovitskiy and Lucas Beyer and Alexander Kolesnikov and Dirk Weissenborn and Xiaohua Zhai and Thomas Unterthiner and Mostafa Dehghani and Matthias Minderer and Georg Heigold and Sylvain Gelly and Jakob Uszkoreit and Neil Houlsby},
year = {2020},
eprint = {2010.11929},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}@misc{touvron2020training,
title = {Training data-efficient image transformers & distillation through attention},
author = {Hugo Touvron and Matthieu Cord and Matthijs Douze and Francisco Massa and Alexandre Sablayrolles and Hervé Jégou},
year = {2020},
eprint = {2012.12877},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}@misc{yuan2021tokenstotoken,
title = {Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet},
author = {Li Yuan and Yunpeng Chen and Tao Wang and Weihao Yu and Yujun Shi and Francis EH Tay and Jiashi Feng and Shuicheng Yan},
year = {2021},
eprint = {2101.11986},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}@misc{zhou2021deepvit,
title = {DeepViT: Towards Deeper Vision Transformer},
author = {Daquan Zhou and Bingyi Kang and Xiaojie Jin and Linjie Yang and Xiaochen Lian and Qibin Hou and Jiashi Feng},
year = {2021},
eprint = {2103.11886},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}@misc{touvron2021going,
title = {Going deeper with Image Transformers},
author = {Hugo Touvron and Matthieu Cord and Alexandre Sablayrolles and Gabriel Synnaeve and Hervé Jégou},
year = {2021},
eprint = {2103.17239},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}@misc{chen2021crossvit,
title = {CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification},
author = {Chun-Fu Chen and Quanfu Fan and Rameswar Panda},
year = {2021},
eprint = {2103.14899},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}@misc{wu2021cvt,
title = {CvT: Introducing Convolutions to Vision Transformers},
author = {Haiping Wu and Bin Xiao and Noel Codella and Mengchen Liu and Xiyang Dai and Lu Yuan and Lei Zhang},
year = {2021},
eprint = {2103.15808},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}@misc{heo2021rethinking,
title = {Rethinking Spatial Dimensions of Vision Transformers},
author = {Byeongho Heo and Sangdoo Yun and Dongyoon Han and Sanghyuk Chun and Junsuk Choe and Seong Joon Oh},
year = {2021},
eprint = {2103.16302},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}@misc{graham2021levit,
title = {LeViT: a Vision Transformer in ConvNet's Clothing for Faster Inference},
author = {Ben Graham and Alaaeldin El-Nouby and Hugo Touvron and Pierre Stock and Armand Joulin and Hervé Jégou and Matthijs Douze},
year = {2021},
eprint = {2104.01136},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}@misc{li2021localvit,
title = {LocalViT: Bringing Locality to Vision Transformers},
author = {Yawei Li and Kai Zhang and Jiezhang Cao and Radu Timofte and Luc Van Gool},
year = {2021},
eprint = {2104.05707},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}@misc{chu2021twins,
title = {Twins: Revisiting Spatial Attention Design in Vision Transformers},
author = {Xiangxiang Chu and Zhi Tian and Yuqing Wang and Bo Zhang and Haibing Ren and Xiaolin Wei and Huaxia Xia and Chunhua Shen},
year = {2021},
eprint = {2104.13840},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}@misc{su2021roformer,
title = {RoFormer: Enhanced Transformer with Rotary Position Embedding},
author = {Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu},
year = {2021},
eprint = {2104.09864},
archivePrefix = {arXiv},
primaryClass = {cs.CL}
}@misc{zhang2021aggregating,
title = {Aggregating Nested Transformers},
author = {Zizhao Zhang and Han Zhang and Long Zhao and Ting Chen and Tomas Pfister},
year = {2021},
eprint = {2105.12723},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}@misc{caron2021emerging,
title = {Emerging Properties in Self-Supervised Vision Transformers},
author = {Mathilde Caron and Hugo Touvron and Ishan Misra and Hervé Jégou and Julien Mairal and Piotr Bojanowski and Armand Joulin},
year = {2021},
eprint = {2104.14294},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}@misc{vaswani2017attention,
title = {Attention Is All You Need},
author = {Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin},
year = {2017},
eprint = {1706.03762},
archivePrefix = {arXiv},
primaryClass = {cs.CL}
}I visualise a time when we will be to robots what dogs are to humans, and I’m rooting for the machines. — Claude Shannon