
####ABOUT
The objective of this project is to see the ability of machine learning to make an Urban Landscape Quality Plan in a comparable way to the existing one for the city of Madrid, made by Prointec within the framework of the revision of the PGOUM of 2009.
The project is presented through a web data app in which filtering and popups are enabled.
What is landscape? "Any part of the territory, as perceived by the population, whose character is the result of the action and interaction of natural and/or human factors', as defined by the ELC (European Landscape Convention, 2008), founded with the purpose of establishing the management, planning and protection of European landscapes.
The urban landscape makes specific reference to the image of the city as a result of its environmental, natural and built elements as well as its social values. An image not only determined by the relationship of all these elements but also by the subjective value that we collectively extract from it. In the end, the ‘landscape culture’ helps us to understand cities as an aesthetic experience and a cultural construction that carries meaning.
The analysis of the quality of the city landscape allows us to rationalize this subjective value of the form of the city and transform it into a tool for its protection and management, ultimately affecting the development of plans and policies through which it is regulated.
There are already interventions and initiatives that have focused on collecting public opinion as a source for the development of databases, as well as promoting citizen participation in the dministration of cities and generating useful products through it.
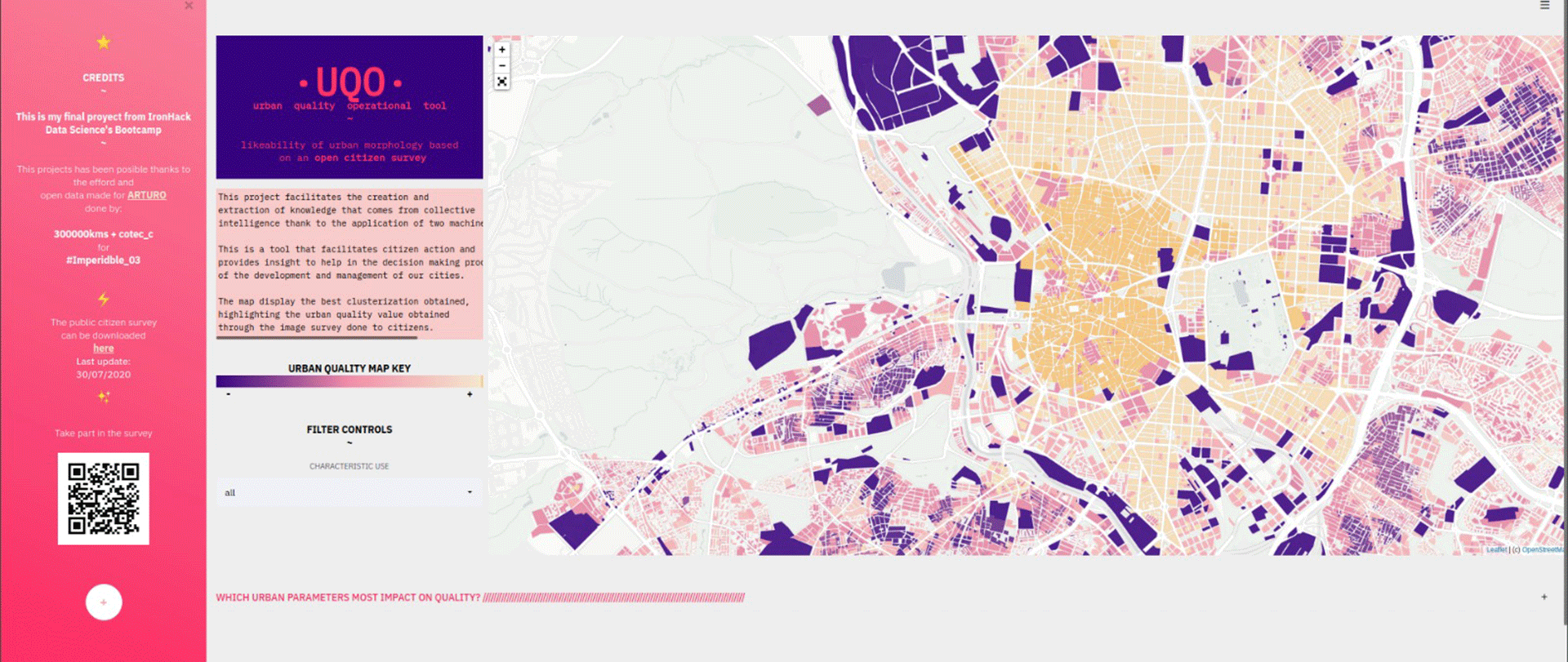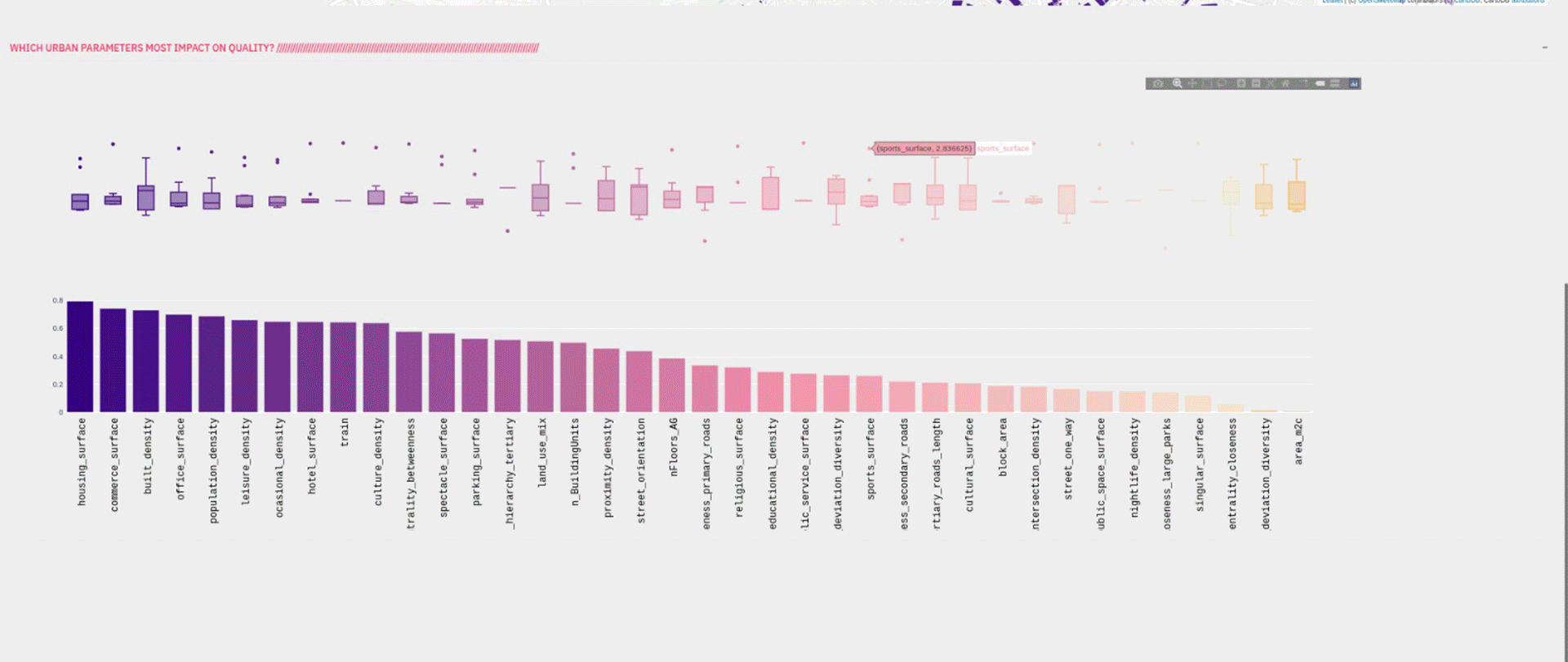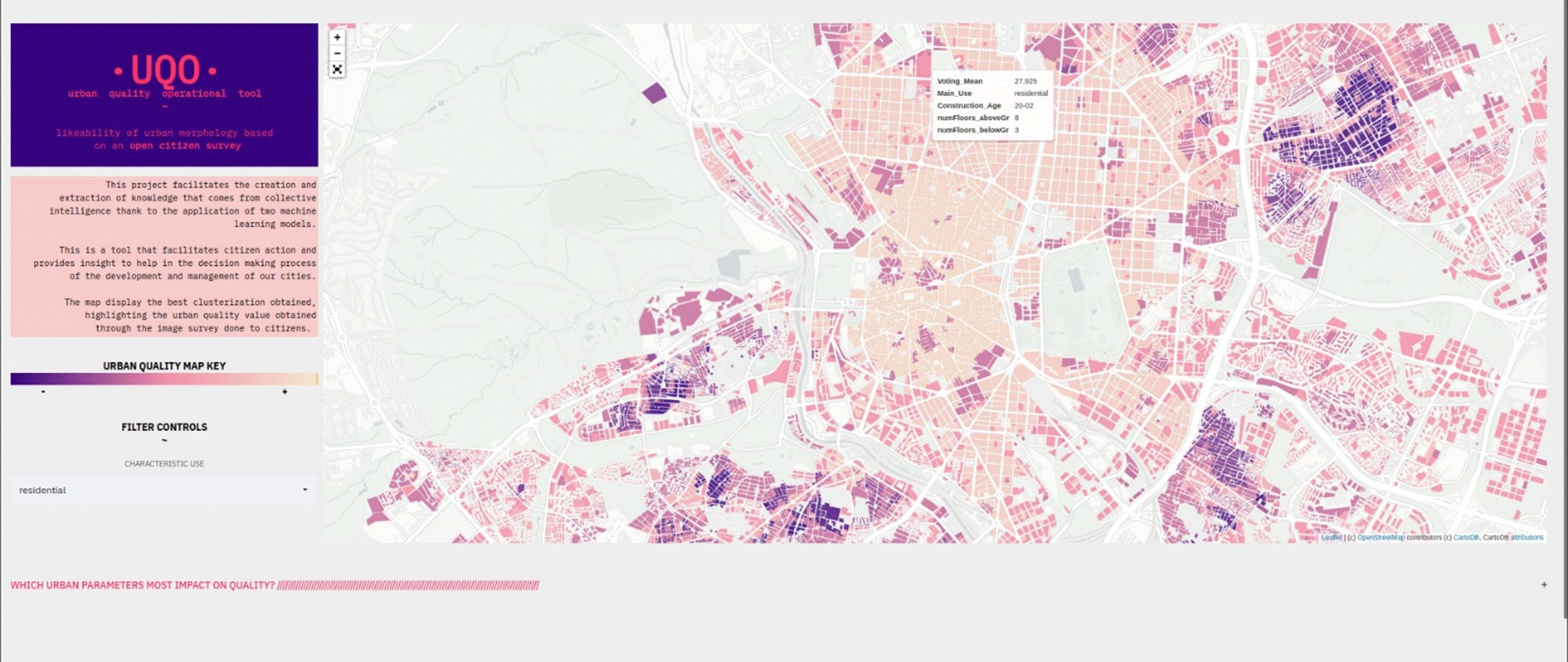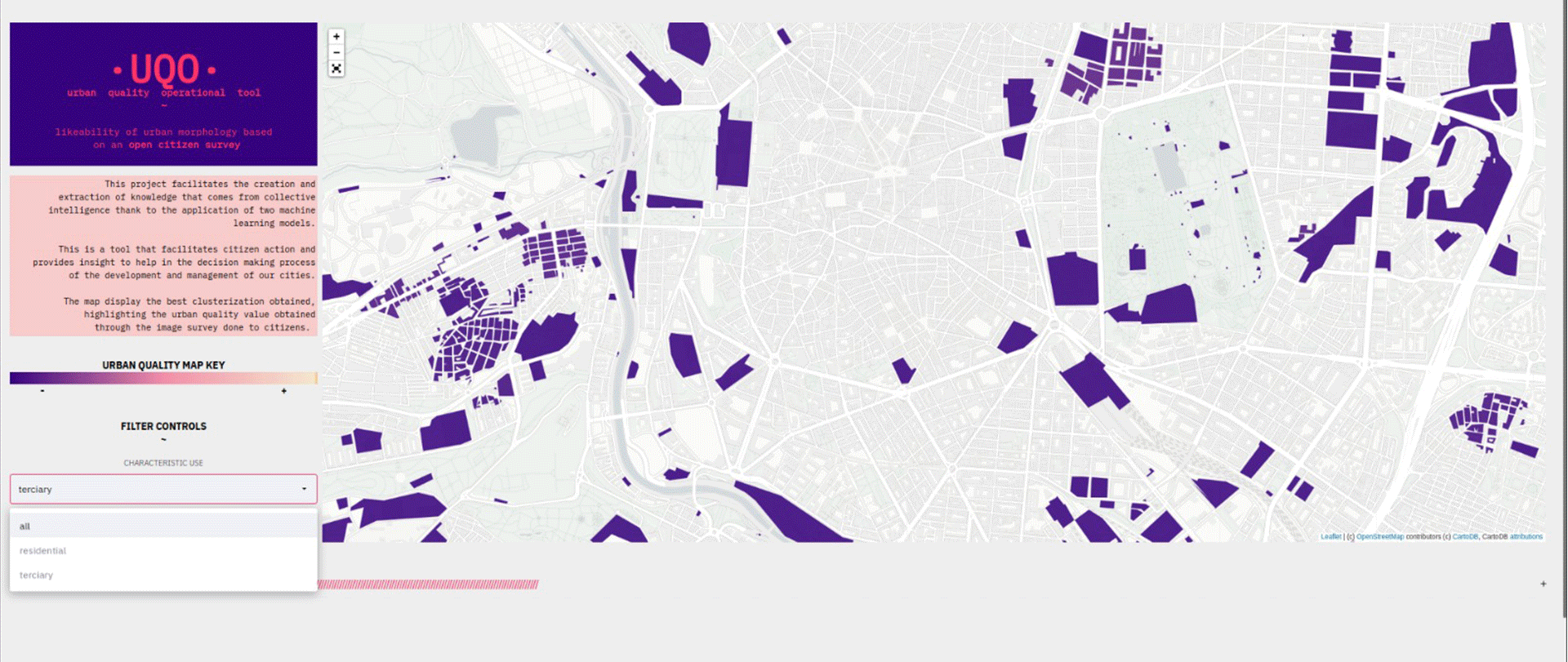
UQO starts from the data provided by the cadastre and previous projects and makes use of a regression model (Light XG Boost / Gradient Boost) and two clustering models (partition and density). The resulting map provides direct knowledge and insight on which to draw useful conclusions that impact on decision making process of our cities.
The artificial intelligence allows us to extract useful perspectives and develop tools from the collective intelligence, in this case, for its application in the urban field.
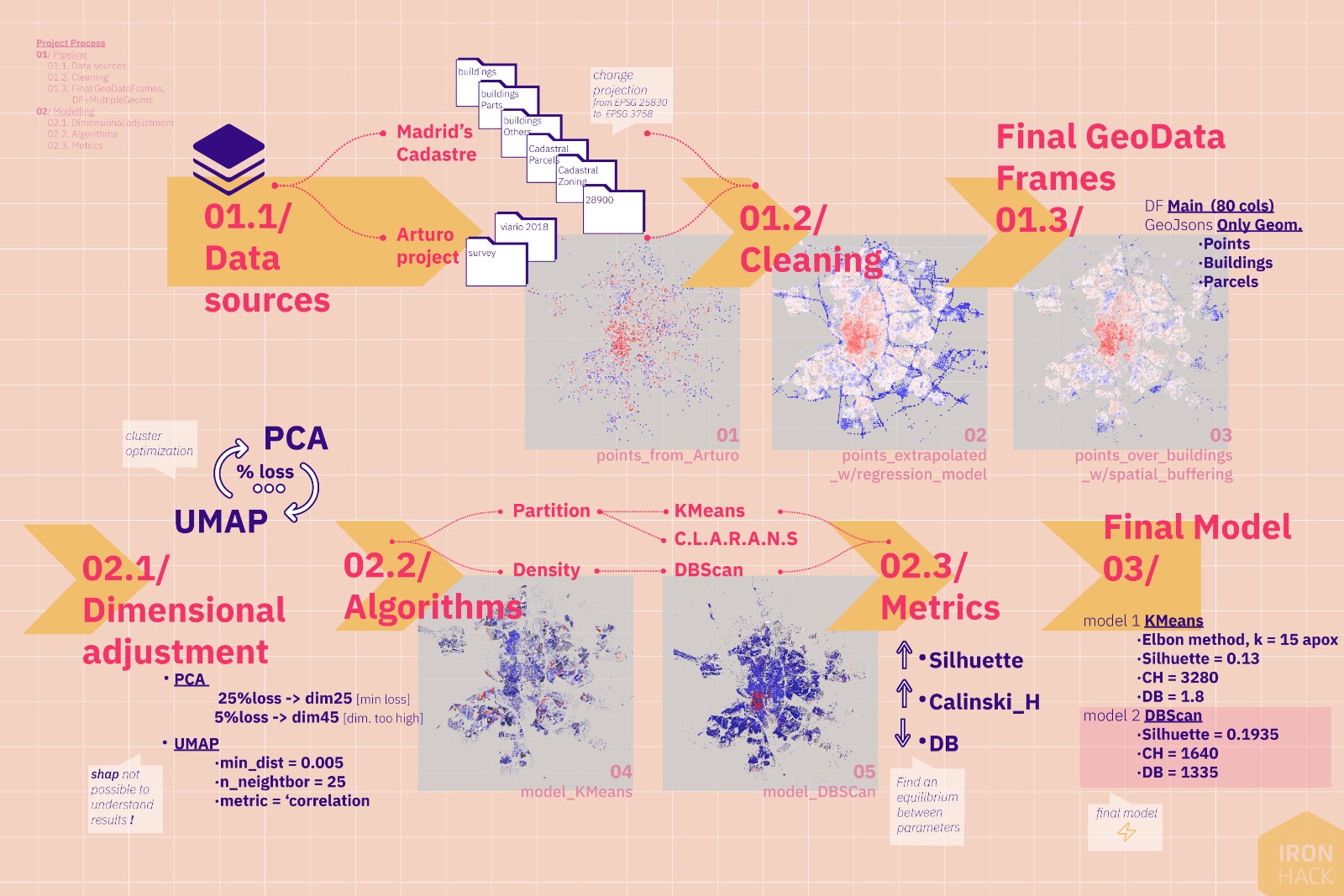
Conducted by the practice 300,000km/s, Arturo is a trained algorithm based on a citizen survey on comparative evaluation of streets in Madrid, which have been previously labeled with different urban parameters.
The survey collects 10% of the streets of Madrid, and through the use of Gradient Boost the common patterns in the rest of the streets of the city are searched; in this way an interactive map of the quality of public space is obtained as well as determining which indexes are more important to determine such quality.
The General Directorate of Cadastre offers different sets of data regarding the data it manages on built heritage within the Inspire European framework. The link specifies what resources it offers; for this project, we work with the 6 available layers, obtained from qGIS:
- Buildings,
- Building Parts,
- Cadastral Zoning,
- Cadastral Parcels,
- 28900
Previous experiences based in NYC:
- Street Score: by Camera Culture and Macro Connections from the Media Lab, it measures the degree of safety or danger of the streets.
- Urbanopticon: Collective mental map of NYC.
Urban Landscape Quality Study conducted as part of the 2009 PGOUM review:
As a prerequisite, the programming lenguage of this repository is Python 3.7.9, therefore must have Python 3 installed. The native packages in use are:
Furthermore, it is need to be installed in the proper environment the following libraries:
- Pandas (v.0.24.2)
- Numpy (v.1.18.1)
- Geopandas
- GeoJson
- Matplotlib (v.3.1.2)
- Seaborn
- Plotly (v.3.1.2)
- Branca
- Scikit-learn (v.0.23.1)
- UMAP
- LightGBM
- Folium
- Streamlit (v.3.1.2)
Version 1.0 [04.07.2020] > First version done for class presentation
ISSUES
----------------
+ Spider Plot finally dropped of Web
+ To do: Deploy with Hedoku
+ To do: Map has performance issues regarding making filtering better
+ Data: raw/ clean data to large for repo
+ Streamlit front need of review
+ At least, upload final GDF
linkedin.com/in/lauramielgo for inqueries.
Big thanks to TAs and teachers for the help and support in the development of this project:
@github/potacho
@github/TheGurus
The project's structure is as follows:
└── project
├── __trash__
├── .gitignore
├── .env
├── requeriments.txt
├── README.md
├── str_app.py
├── notebooks
│ ├── 01_Catastro pt1.ipynb
│ ├── 02_Catastro pt2.ipynb
│ ├── 03_Arturo Model - Gradient Boosting.ipynb
│ ├── 04_Merging DataSets.ipynb
│ ├── 05_Clustering Results - Viz.ipynb
│ └── 06_Final Map.ipynb
├── models
│ ├── 011_Partitioning Algos.ipynb
│ ├── 012_Density Algos - UMAP 10.py
│ ├── 022_Density Algos - UMAP 25.py
│ ├── 122_Density Algos - Catastro.py
│ ├── model_dbscan_silh167.sav
│ ├── model_dbscan_silh193.sav
│ └── mmdel_dbscan_silh261.sav
├── catastro_inspire_etl
│ ├── m_acquisition.py
│ ├── m_cleaning.py
│ └── __init__.py
├── streamlit_back
│ ├── m_opening_final.py
│ └── __init__.py
├── streamlit_front
│ ├── load_css.py
│ ├── style.css.py
│ └── __init__.py
├── streamlit_graphics
│ ├── main_map.py
│ ├── ranking_fig.py
│ ├── spider_plot.py
│ ├── map_to_render.html
│ ├── ranking_fig.html
│ └── __init__.py
└── data
├── raw
├── labelled
├── final_streamlit
└── clean