
The objective of the Risk Classification with Loan Modeling accelerator is to predict how much loan amount will be approved by the SBA & their registered lenders when a business applies for a loan through the SBA.
The Small Business Administration (SBA) was founded in 1953 to assist small businesses and entrepreneurs in obtaining loans. Small businesses have been the primary source of employment in the United States-helping with job creation which reduces unemployment. Small business growth also promotes economic growth. One of the ways the SBA helps small businesses is by guaranteeing bank loans. This guarantee reduces the risk to banks and encourages them to lend to small businesses. If the loan defaults, the SBA covers the amount guaranteed, and the bank suffers a loss for the remaining balance.
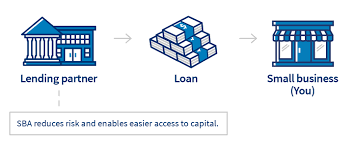
The SBA works with lenders to provide loans to small businesses. The agency doesn’t lend money directly to small business owners. Instead, it sets guidelines for loans made by its partnering lenders, community development organizations, and micro-lending institutions. The SBA reduces risk for lenders and makes it easier for them to access capital which makes it easier for small businesses to get loans. Loans guaranteed by the SBA range from small to large and can be used for most business purposes, including long-term fixed assets and operating capital.

Lenders and loan programs have unique eligibility requirements. In general, eligibility is based on what a business does to receive its income, the character of its ownership, and where the business operates. Normally, businesses must meet size standards, be able to repay, and have a sound business purpose. Even those with bad credit may qualify for startup funding.
Following are the baseline eligibility requirements:
- Be a for-profit business - the business is officially registered and operates legally.
- Do business in the United States - the business is physically located and operates in the U.S. or its territories.
- Have invested equity - the business owner has invested their own time or money into the business.
- Exhaust financing options - the business cannot get funds from any other financial lender.

Most U.S. banks view loans for exporters as risky. This can make it harder to get loans for things like day-to-day operations, advance orders with suppliers, and debt refinancing. This is why the SBA created programs to make it easier for U.S. small businesses to get export loans.
The Business Loan Data Set (reference : www.kaggle.com)
The original data set is from the U.S. SBA loan database, which includes historical data from 1987 through 2014 (899,164 observations) with 27 variables. The data set includes information on whether the loan was paid off in full or if the SBA had to charge off any amount and how much that amount was. The data set used is a subset of the original set. It contains loans about the Real Estate and Rental and Leasing industry in California. This file has 2,102 observations and 35 variables. The column default is an integer of 1 or zero (I had to change this column to a factor).
Variable Name Description
LoanNr_ChkDgt Identifier Primary key
Name Borrower name
City Borrower city
State Borrower state
Zip Borrower zip code
Bank Bank name
BankState Bank state
NAICS North American industry classification system code
ApprovalDate Date SBA commitment issued
ApprovalFY Fiscal year of commitment
Term Loan term in months
NoEmp Number of business employees
NewExist 1 = Existing business, 2 = New business
CreateJob Number of jobs created
RetainedJob Number of jobs retained
FranchiseCode Franchise code, (00000 or 00001) = No franchise
UrbanRural 1 = Urban, 2 = rural, 0 = undefined
RevLineCr Revolving line of credit: Y = Yes, N = No
LowDoc Loan Program Y = Yes, N = No
ChgOffDate The date when a loan is declared to be in default
DisbursementDate Disbursement date
DisbursementGross Amount disbursed
BalanceGross Gross amount outstanding
MIS_Status Loan status charged off = CHGOFF, Paid in full =PIF
ChgOffPrinGr Charged-off amount
GrAppv Gross amount of loan approved by bank
SBA_Appv SBA’s guaranteed amount of approved loan
The Business Loan Modeling project will use Azure Synapse Analytics, Azure DataLake Gen2, Azure Machine Learning and Power BI.



Goal is to train Machine Learning (ML) model on the SBA loan data and then build a Data engineering pipeline which can further process one or many new loan requests coming in as either API and/or Batch requests. Azure Synapse Pipe from Azure Synapse Workspace is used for consuming data from third party (same can be achieved by leveraging Azure Data Factory). Azure Synapse pipeline was used for multiple purposes:
- Data Ingestion (Third Party API to ADLS Gen2)
- Orchestration
Azure Machine Learning service was used for building and training ML model. Once a model was built, then Azure Synapse Pipeline was levaraged for orchestrating a call to Azure ML Batch pipeline to score on new SBI loan data requests.
Stages to accomplish goal: Stage 1: Build a ML model To build an ML model, we need to first cleanse the public data to a conformed state which we can feed to train a machine learning model.
-
Ingesting the SBA data from a Source (typically this would be a partner or data provider who provides a storage account\FTP site to access this data). Copy data activity in the below. Synapse pipeline will be able to copy the data from a remote partner to a local storage account. For this demo we are copying binary files from “sbasourcerawdata” to “sba” containers
-
Once we get the data (CSV file) in our scenario, we need to cleanse this data to shape it into a structure which is good enough to train a Machine Learning model. For that purpose, we are using a Dataflow activity within Synapse pipelines, where we can shape and structure the original raw data. Dataflow uses Synapse Spark clusters in the background to execute these transformations and your training data, even if it is in TB’s, can be quickly processed and cleansed. For this demo, the source of the Dataflows would be “sba” container and the sink of the dataflow would land it in “sbacurated” container.
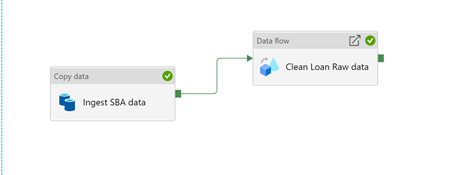
Dataflow activity looks like the below structure where we define datatypes and formats. Clean unnecessary characters like “$” values. Remove unnecessary columns etc which is not needed to train the model, etc. Finally, the output will be written in a Dataset which is cleansed and ready to be fed into Azure Machine Learning for training a model.

- Build an Azure ML training pipeline, there are multiple ways to achieve this like using Python notebooks, Designer and Auto ML, but the easiest would be to use the Azure ML designer where you get a canvas to drag and drop tasks to build a training pipeline.
We built the following pipeline to train a model using this training data which we have cleansed in the previous step. We add the “sbacurated” container in the previous stage as a dataset for Azure ML workspace. This dataset can now be used in various experiments.

The curated data which we processed in the previous steps using Dataflows is registered as a Dataset in Azure ML. That dataset which is shown as “sbacurated” acts as the training data. It goes through few steps like Splitting the data, filtering unnecessary columns etc and finally Train a model. We are using Boosted Decision Tree regression algorithm here but you can try different regression algorithms to compare the accuracy etc. Once you are satisfied with the model metrics like Accuracy, Spearman correlation, etc., the last step of the Model is to export out the Scored Data to a CSV file. This file is getting saved in the “amloutput” on the storage container and finally publishing this as a Batch pipeline. Here is a Batch pipeline which is shown after getting published. This is the Batch inference pipeline which comes with an endpoint. This will be executed as part of the Synapse pipeline for doing batch scoring on new SBA loan requests as part of a nightly schedule as explained in next stage.
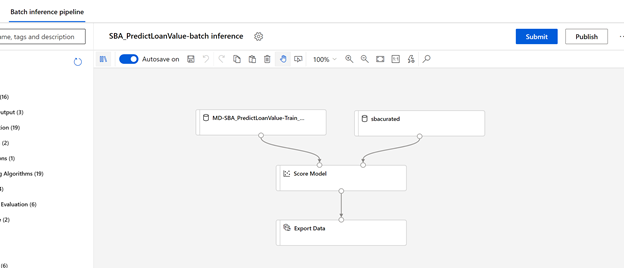
Stage 2: Build a Synapse pipeline to do daily Batch inferencing on new SBA loan requests As the ML model\Batch inference pipeline is already built in the previous step, now we need to execute a Synapse pipeline on a daily schedule, which will retrieve all the new data, cleanse it to make sure that there are no data consistency issues and finally call the Azure ML pipeline which we have built in the earlier stage. Step 1 and 2 in this stage are the same as the earlier stage and hence not repeating them for brevity purposes. You can reuse the same pipeline which you built earlier to add the last activity to execute a Machine Learning pipeline as shown below.

The last step of the Synapse pipeline, calls an Azure ML pipeline which we have built in the earlier stage. This step will trigger the Batch inference pipeline in Azure ML. From an Azure ML side, the Batch inference run would look something like the below image which confirms that all the stages have been completed successfully

The last step of the process would export the data out to “amloutput” storage account which contains the final CSV which is scored by the Azure ML batch inference pipeline. Here is a screenshot of all the containers in the storage account. Final CSV file gets stored in the amloutput container.

Best part of Azure Synapse is the new Synapse Serverless SQL which has an option to query this data natively from within the filesystem.

Finally, you can run a query to see all the scored amounts for different SBA requests.
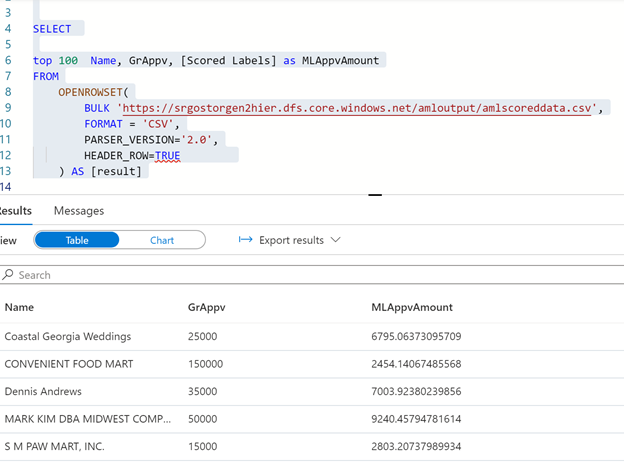
You can create a view on top of this query and any client which can talk to SQL can run this query to view all the Scored data as a simple SELECT query.
During Stage 1, we could have also deployed a Real-time Inference pipeline which would deploy the API to an existing Kubernetes clusters. Any application can pass parameters to this API with different values and in turn get a response with the Scored label value. This is ideal for interactive applications when a decision needs to be taken immediately.
synapse2_compressed.mp4
synapse3_compressed.mp4
Synapse4_compressed.mp4
synapse5_compressed.mp4
synapse6-compressed.mp4
synapse7_compressed.mp4

Copyright (c) Microsoft Corporation
All rights reserved.
MIT License
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the ""Software""), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED AS IS, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact [email protected] with any additional questions or comments.
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines. Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.