The Acoustic-Net is designed to extract the features of amplitude change and phase difference by using raw sound data. Our proposed method is illustrated in this figure.
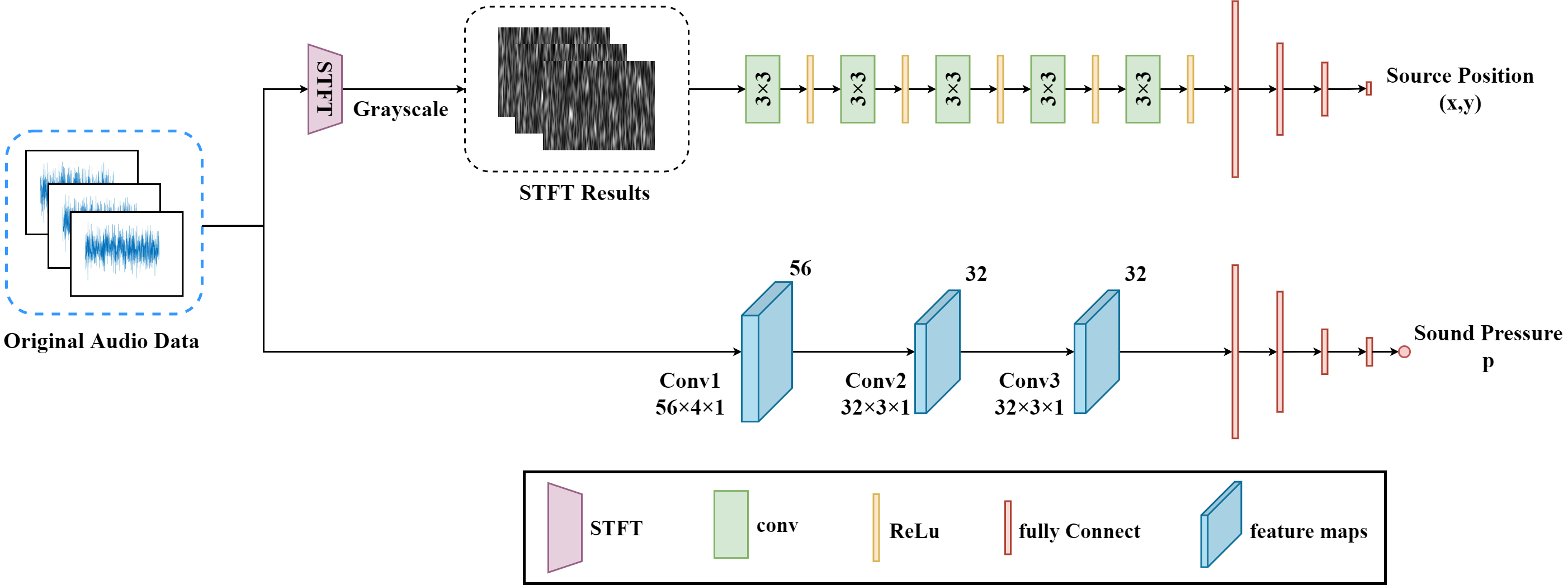
An Acoustic-Net is proposed to locate and quantify the acoustic source without reconstructing images and being restricted by CB map. The acoustic-Net, with RepVGG-B0 and shallow onedimensional convolution, is used to extract the amplitude and phase characteristics of original sound signals. The proposed method can be easily realized by the hardware devices with fast computing speed and limited memory utilization. The system is implemented in Pytorch.
- python = 3.6
- pytorch >= 1.1.0
- acoular
-
Beamforming Dataset
The Beamforming Dataset can be downloaded from the following link:
https://drive.google.com/file/d/1wPeOIcgcrq52-LQXwKE1-VQCMUrIBZuw/view?usp=sharing.
This dataset contains 4200 sound source samples with 2400 points for training, 800 points for validation and 1000 points for testing.
-
Data Prerprocessing
To run our tasks,
-
You need to add the train, val, test set (remove their folders) into a new folder named "
data_dir". Then, you can get 4200 h5 files about acoustic sound data collected by 56 microphones. -
Take the point
"x_0.00_y_-0.06_rms_0.69_sources.h5"for an example. You can run the./DET/stft.mto change the original sound data into the 56 grey images, and save the 56 images in the folder named"x_0.00_y_-0.06_rms_0.69_sources.h5". -
To be able to use our dataloader (
./dataset/dataset.py);- Each sample folder should contain 56 grey images and the original sound data as the Acoustic-Net input. For details please refer to
./dataset/dataset.py
- Each sample folder should contain 56 grey images and the original sound data as the Acoustic-Net input. For details please refer to
-
python repvgg_with_sound_pressure_and_location.py --data_dir data_path \
--train_image_dir train_stft_image_path \
--val_image_dir val_stft_image_path \
--model_dir save_model_pathThe parameters such as "epoch, batchsize and train_dir" you can add them in the shell command.
After training, you can convert the model by running:
cd utils
python convert_models.py --weights your_model_path convert_weights convert_model_pathWe provide pre-trained model for the Acoustic-Net architecture. You can download the model from ./Acousitc-Net/PretrainedModel/ to reproduce the results.
- Original Model
if you don't want to convert the training model, you can use the following codes to test your model.
python test_sound_source_pressure_and_location.py --data_dir data_path \
--test_image_dir your test_stft_image_path \
--result_dir save_visualization \
--weights your_model_path- Converted model
if you finish converting the model, you can use the following codes to test your model.
python test_sound_source_pressure_and_location.py --data_dir data_path \
--test_image_dir your test_stft_image_path \
--result_dir save_visualization \
--mode deploy \
--convert_weights your_convert_model_path