The aim of the project is to develop and implement neural networks algorithms (specifically LSTM, GRU and MLP) to predict tyre strategy during a Formula 1 race.
The data used for this project are taken from fastf1 library. If it is your first time with this library, you have to install the library with the following command in the prompt.
pip install fastf1Note that Python 3.8 or higher is required. (The live timing client does not support Python 3.10, therefore full functionality is only available with Python 3.8 and 3.9).
After that, to use the API functions, of course, you have to import the library into your project.
import fastf1 as ff1Since every weekend produce a huge amount of data, it takes time to load the data itself. The library gives us caching functionality that stores the data from a race weekend in a folder. You have to create a folder called 'cache' and enable the caching.
ff1.Cache.enable_cache('cache') # the argument is the name of the folder. Be careful at your folder path. Fastf1 has its documentation, where you can find all its functionality.
I conducted two experiments:
- In the first one, I trained a neural network to predict the compound used by drivers during a lap. It is actually a useless prediction since the target is already given in the last column of the dataset. It has been done only for learning reasons. I needed to undestand how to create a 3D dataset and how to train a neural network.
- The second experiment, instead, is the real purpose of the project. The aim is to predict the best tyre for each lap during the race. A metric (best lap time) has been used to decide what "best tyre" means.
The implementation has been splitted in the code. The datasets are different.
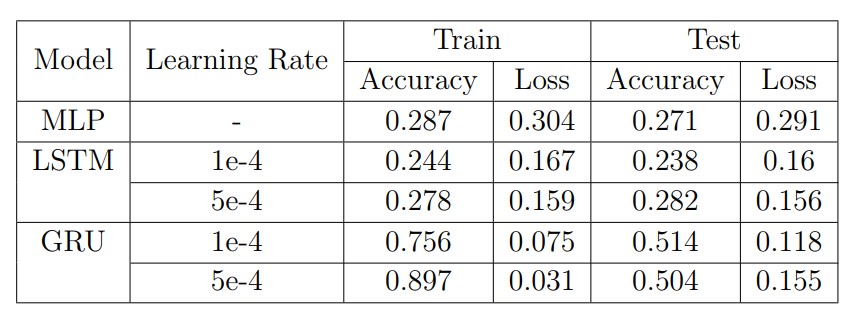
I observec that GRU consistenly outperformed the LSTM across the learning rates used. Specifically, with a learning rate of 1e−4, the GRU achieved an accuracy of 51.4% and a loss of 11.8%, while the LSTM only achieved an accuracy of 23.8% and a loss of 16%. Similarly, with a learning rate of 5e-4, the GRU achieved an accuracy of 50.4% and a loss of 15.5%, while the LSTM achieved an accuracy of 28.1% and a loss of 15.6%. These results suggest that the GRU is better suited for this particular task than the LSTM.
GRU model outperformed the MLP model as well, which get an accuracy of 27.1% and a loss of 29.1%. The superior performance of the GRU model can be attributed to its recurrent nature, which allows it to better capture the sequential nature of the data.
A blind classifier has been calculated to predict the class label of the test data based only on the prior probabilities of the classes in the training data. In my case, the blind classifier accuracy is 24.5%, which means that if you were to randomly guess the class label for each test sample, you would expect to get an accuracy of 24.5%.
The plot below shows the comparision between the blind classfier and the three model analyzed.

In conclusion, I have trained and compared the performance of three different models, to predict the best tyre strategy in Formula 1 races. GRU won the races between the other two models, achieving a 51.4% of accuracy, where, in this type of project, it is a great result.