The project aims to leverage machine learning and deep learning techniques to analyse the flux data and accurately classify stars as either exoplanet-stars or non-exoplanet-stars. By training a model on the provided dataset, we seek to uncover patterns and features indicative of exoplanet presence, enabling the model to make predictions on unseen data.
- What is Exoplanet?
- Methods for Detecting Exoplanets
- Transit Method used for Exoplanet Detection
- Literature Review
- Dataset Description
- Exploratory Data Analysis
- Data Preprocessing
- Modelling
- Results
- Conclusion
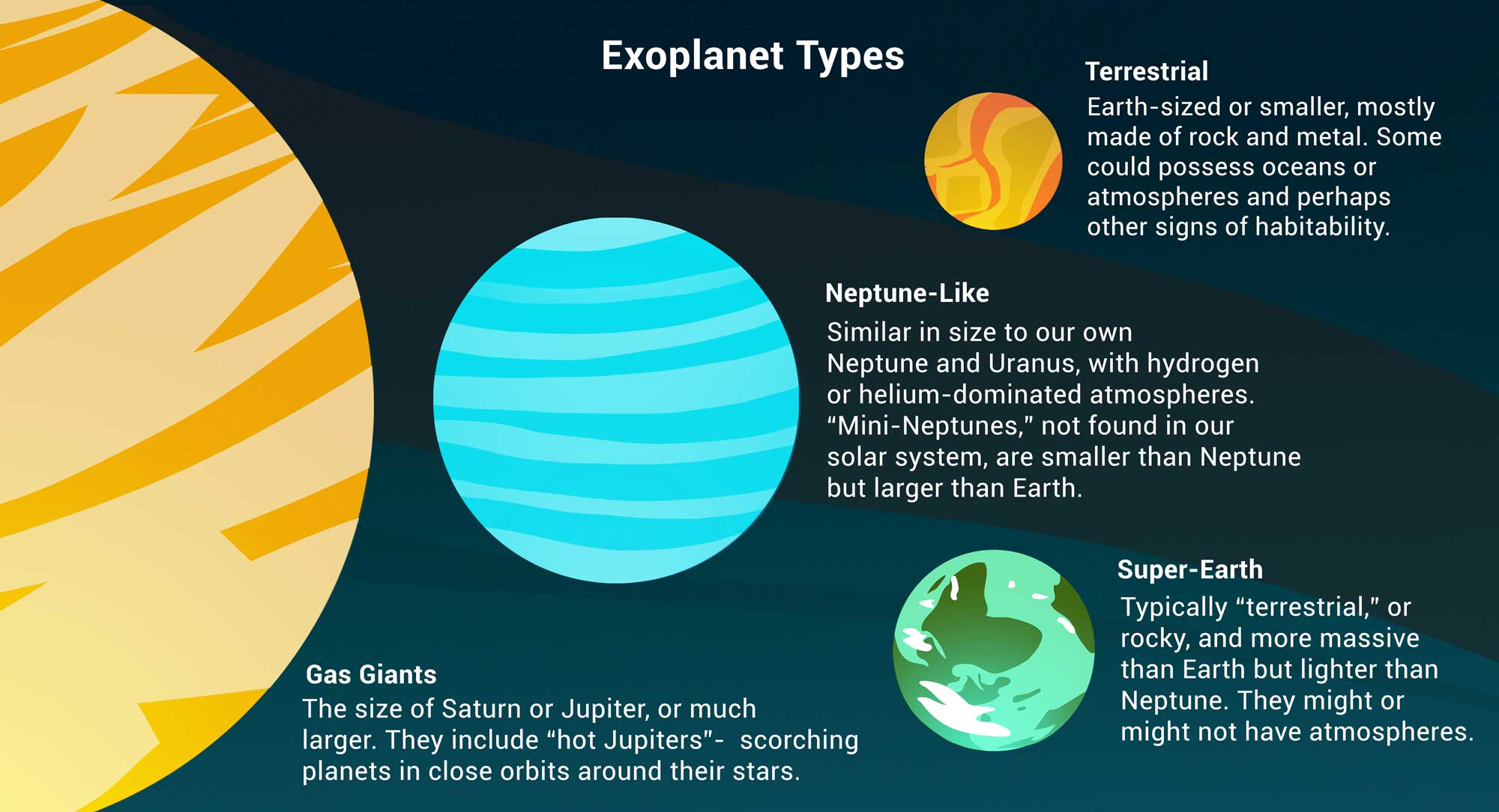
An exoplanet, or extrasolar planet, is a planet that orbits a star outside of our solar system. These celestial bodies are of great scientific interest as they provide valuable insights into the formation, composition, and diversity of planetary systems beyond our own. Exoplanets can vary in size, composition, and orbital characteristics, ranging from gas giants to rocky planets. Their detection is achieved through various indirect methods, such as observing the transit of a planet in front of its host star or measuring the gravitational influence on the star. The study of exoplanets plays a crucial role in advancing our understanding of planetary systems and the potential for extraterrestrial life.
- Indirect methods:
- Transit method: Observing periodic dimming of a star's light as a planet passes in front of it.
- Radial velocity method: Detecting the wobble of a star caused by the gravitational pull of an orbiting planet.
- Gravitational microlensing: Measuring the bending of light due to a planet's gravity.
- Astrometry: Detecting tiny changes in a star's position caused by an orbiting planet.
- Direct imaging: Capturing the actual light emitted or reflected by the exoplanet, although challenging due to the brightness of the host star.

Flux is a crucial parameter used in the detection and characterization of exoplanets. Flux is a measure of the number of electric or magnetic field lines passing through a surface in a given amount time. By monitoring the flux, which represents the light intensity emitted by a star, astronomers can identify subtle changes that indicate the presence of an exoplanet. The transit method relies on observing periodic dips in flux as an exoplanet passes in front of its host star, causing a temporary decrease in the observed light. Additionally, the radial velocity method measures the small shifts in spectral lines caused by the gravitational tug of an exoplanet, resulting in periodic variations in flux. Analyzing these flux variations provides valuable information about the presence, size, and orbital characteristics of exoplanets.
In this section, we provide a brief review of the existing literature on exoplanet detection and related studies. The following key research papers and resources have been referenced to gain insights into the field:
- Priyadarshini, Ishaani & Puri, Vikram. (2021). A convolutional neural network (CNN) based ensemble model for exoplanet detection. Earth Science Informatics. 14. 1-13. 10.1007/s12145-021-00579-5:
- Using the same dataset used in our project, this study proposes Ensemble-CNN model with an accuracy of 99.62%. The performance of the models has been evaluated using parameters like Accuracy, Precision, Sensitivity, and Specificity. It uses Stacking method to build the final model. Stacking enables us to train multiple models to solve similar problems, and based on their combined output, it builds a new model with improved performance.
- Jin, Yucheng & Yang, Lanyi & Chiang, Chia-En. (2022). Identifying Exoplanets with Machine Learning Methods: A Preliminary Study.:
- In this study, machine learning methods were employed to identify exoplanets using the Kepler dataset. The researchers achieved high accuracies ranging from 88.50% to 99.79% in supervised learning tasks, where various algorithms were applied. Additionally, unsupervised learning using k-means clustering successfully formed distinct clusters for confirmed exoplanets.
- Mena, Francisco & Bugueño, Margarita & Araya, Mauricio. (2019). Classical Machine Learning Techniques in the Search of Extrasolar Planets. CLEI Electronic Journal. 22. 10.19153/cleiej.22.3.3. :
- This study explores automated methods for detecting transit planets in astronomical data. By leveraging supervised learning and advanced pattern recognition techniques, the study predicts and classifies unclassified light curves. The approach improves efficiency in transit planet detection, reducing the need for manual analysis by experts.
- Malik, Abhishek & Moster, Ben & Obermeier, Christian. (2020). Exoplanet Detection using Machine Learning. :
- This study presents a machine learning-based technique for exoplanet detection using the transit method. The proposed method achieves comparable results to state-of-the-art models while being computationally efficient. On Kepler data, it achieves an AUC of 0.948 and a Recall of 0.96. For TESS data, it demonstrates an accuracy of 98% and a Recall of 0.82, addressing challenges with shorter light curves. This method provides a reliable classification system for the increasing number of light curves received from TESS.
- Tiensuu, J., Linderholm, M., Dreborg, S., & Örn, F. (2019). Detecting exoplanets with machine learning : A comparative study between convolutional neural networks and support vector machines (Dissertation). :
- This project compares Support Vector Machine (SVM) and Convolutional Neural Networks (CNN) for classifying light intensity time series data of extrasolar stars. The imbalanced dataset is addressed through data augmentation. Preprocessing techniques such as feature extraction, Fourier transform, detrending, and smoothing are applied. Proposed CNN model achieves a recall of 1.000 and a precision of 0.769, outperforming SVM with a recall of 0.800 and a precision of 0.571.
- Singh, S. P., & Misra, D. K. (2020). Exoplanet Hunting in Deep Space with Machine Learning. International Journal of Research in Engineering, Science and Management, 3(9), 187–192. :
- This project uses machine learning on NASA's Kepler data to predict exoplanet habitability. Comparative analysis of algorithm performance is conducted to identify suitable models. The approach accelerates exoplanet detection, enhancing our understanding of habitability and exoplanet diversity. The proposed model can be optimized with new data from space telescopes and classifies exoplanet candidates as habitable or non-habitable from various observatories.
The dataset for the following project was collected by the NASA Kepler space telescope using the Transit method. By closely observing a star over extended periods, ranging from months to years, scientists can detect regular variations in the light intensity. These variations, known as "dimming," serve as evidence of the presence of an orbiting body around the star. Such stars exhibiting dimming can be considered potential exoplanet candidates. However, further study and investigation are required to confirm the existence of exoplanets. For example, employing satellites that capture light at different wavelengths can provide additional data to solidify the belief that a candidate system indeed harbors exoplanets.
The dataset provided is divided into Training and Testing data. The data describe the change in flux (light intensity) of several thousand stars. Each star has a binary label of 2 or 1. 2 indicated that that the star is confirmed to have at least one exoplanet in orbit; some observations are in fact multi-planet systems.
- Trainset:
- 5087 rows or observations.
- 37 confirmed exoplanet-stars and 5050 non-exoplanet-stars.
- Testset:
- 570 rows or observations.
- 5 confirmed exoplanet-stars and 565 non-exoplanet-stars.
Recall and precision are used as performance metrics for the above dataset in the context of exoplanet detection due to the nature of the problem and the importance of correctly identifying exoplanets. High recall ensures that we capture as many true exoplanets as possible, while high precision minimizes the number of false positives, reducing the resources required for further validation and confirmation processes. Balancing these metrics is crucial to achieving accurate and reliable exoplanet detection. Balancing these metrics is crucial to achieving accurate and reliable exoplanet detection.
Using the flux values, we plot the waves with respect to time for both exoplanet-stars and non-exoplanet-stars.

By plotting the pairplot for first flux values, we can see that each one of them is highly correlated.

By observing the below distribution, we can conclude the same. Since the dataset is highly imbalanced, the distribution of exoplanet-stars is barely visible. Hence we have highlighted it using blue ink.

In the data pre-processing phase, several steps are taken to prepare the dataset for the exoplanet detection project.
- Firstly, to address the issue of data imbalance, outliers are removed from the dataset. As the data contains a high imbalance between the number of exoplanet and non-exoplanet instances, this step helps in creating a more balanced representation of the classes. The outlier removing technique is taken from here.
- Secondly, to further handle the data imbalance, a technique called Random Over Sampler is employed, which increases the number of minority class instances through random duplication. This helps in improving the learning process and the performance of the models.
- Lastly, the labels in the dataset are transformed from 1 and 2 to 0 and 1, respectively, to ensure a consistent binary representation.
The decision to not perform data scaling was taken while testing the models trained using scaled data. From the observations we found out that using the raw data produced better results compared to scaled data.
In this project, we explore various Machine Learning models to to accurately predict the presence or absence of exoplanets based on the flux variations of stars. The Machine Learning models are tuned using GridSearch Method. Additionally, we propose a Convolutional Neural Network (CNN) model to accurately predict the same. The CNN model is implemented using TensorFlow and Keras, taking advantage of their deep learning capabilities.
The CNN architecture consists of multiple convolutional layers, batch normalization, max pooling, dropout regularization, and dense layers. The model is trained using the training set and evaluated on the test set to assess its performance in detecting exoplanets.
The CNN Architecture is as follows:

The given CNN (Convolutional Neural Network) model is designed for a binary classification task. Let's break down each component and understand the model's architecture:
-
Sequential Model:
- The model is defined using the
keras.Sequential()class, which allows stacking multiple layers sequentially.
- The model is defined using the
-
Reshape Layer:
- The first layer reshapes the input data into a tensor with dimensions (3197, 1).
- The input shape is specified as (3197,) to indicate a 1D input of length 3197.
-
Normalization Layer:
- The normalization layer applies feature-wise normalization to the input data, bringing the mean to 0 and standard deviation to 1.
-
Conv1D Layer (First):
- This layer performs a 1D convolution operation on the input data.
- It has 11 filters, each of size 2, which means it applies 11 different convolutional filters of size 2 to the input.
- The activation function used is ReLU (Rectified Linear Unit), which introduces non-linearity to the output.
- The kernel_regularizer parameter is set to 'l2', indicating that L2 regularization is applied to the kernel weights of this layer.
-
Batch Normalization Layer (First):
- Batch normalization is applied after the first convolutional layer to normalize the outputs and improve the stability and performance of the model.
-
Conv1D Layer (Second):
- This layer is similar to the previous convolutional layer but has 7 filters instead of 11.
- Again, ReLU activation and L2 regularization are applied.
-
Batch Normalization Layer (Second):
- Batch normalization is applied after the second convolutional layer, following the same rationale as before.
-
MaxPooling1D Layer:
- This layer performs max pooling operation with a pool size of 2 and stride of 2.
- Max pooling reduces the spatial dimensions of the input, retaining the maximum value within each pool.
- This downsampling operation helps in capturing the most important features while reducing computational complexity.
-
Dropout Layer:
- Dropout is a regularization technique used to prevent overfitting.
- This layer randomly sets a fraction (0.4) of the input units to 0 at each update during training, which helps in reducing over-reliance on any particular feature.
-
Flatten Layer:
- The flatten layer flattens the tensor from the previous layer into a 1D vector.
- This prepares the data for the subsequent fully connected layers.
-
Dense Layers:
- Three dense (fully connected) layers follow the flatten layer.
- The first dense layer has 50 units and uses the ReLU activation function.
- The second and third dense layers have 30 and 12 units, respectively, both using the ReLU activation function.
-
Output Layer:
- The final dense layer has 1 unit, representing the output of the model.
- The activation function used is sigmoid, which squashes the output between 0 and 1, making it suitable for binary classification problems.
- The model predicts the probability of the positive class based on the input.
To summarize, this model applies a series of convolutional, pooling, normalization, dropout, and dense layers to process the input data and extract relevant features. The flattened output is then fed into a sequence of dense layers, progressively reducing the dimensionality and introducing non-linearities. The final layer produces a binary classification prediction using the sigmoid activation function. We use Adam optimizer for optimization purposes.
Additionally, we use EarlyStopping to stop training the model when it reaches a point of no further improvement and ExponentialDecay to improve deep learning model training even more.
The hyperparameters, including the learning rate, required to train the model can be found inside the Exoplanet_Detection notebook within the repository.
The results of the project are as follows:
-
The Proposed CNN Model:
- The proposed CNN model showed an exceptional performance, with 99.82% precision, 100% recall and 99.91% accuracy on the test set after multiple iterations and fine-tuning. Although such high accuracy is uncommon in real-world scenarios, it demonstrates the model's ability to effectively learn and capture the underlying patterns in exoplanet detection. The best-performing model has been saved and can be accessed in the GitHub repository.

-
Machine Learning Models:
- Traditional machine learning models did not perform as well as the CNN model in the exoplanet detection task. These models may have struggled to capture the complex relationships and patterns present in the dataset, resulting in low performance compared to the CNN model. However, they still provide valuable insights and serve as benchmarks for performance evaluation.
-
The Classifiers used are :
-
LightGBM
-
The fine-tuned model used:
-
Classification Report:
-
-
Random Forest
-
The fine-tuned model used:
-
Classification Report:
-
-
K Nearest Neighbors
-
The fine-tuned model used:
-
Classification Report:
-






-
Best Performing Machine Learning Model - Logistic Regression:
- Among the tested machine learning models, Logistic Regression emerged as the top performer. It exhibited comparatively better accuracy and predictive capabilities compared to other models. Logistic Regression offers a reliable and interpretable approach for predicting the target variable. Its performance highlights the significance of considering simpler models alongside more complex techniques in certain scenarios.
-
The fine-tuned model used:
-
Classification Report:


Overall, this project has shed light on the potential of machine learning in exoplanet detection and prediction. It has demonstrated the effectiveness of CNN models and the significance of selecting appropriate algorithms for specific tasks. While there is room for improvement in the performance of the machine learning models, this project serves as a valuable foundation for further research in the field of exoplanet exploration and offers insights into the application of machine learning techniques in the domain.
The project outcomes can guide future research efforts and inspire the development of more accurate and efficient models for exoplanet detection, ultimately advancing our knowledge of the universe and the existence of habitable planets beyond our solar system.