-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
2 changed files
with
136 additions
and
5 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,131 @@ | ||
| +++ | ||
| draft = false | ||
| date = 2024-11-28T12:02:09+08:00 | ||
| title = "AI 声音:数字音频、语音识别、TTS 简介与使用示例" | ||
| description = "AI 声音:数字音频、语音识别、TTS 简介与使用示例" | ||
| slug = "" | ||
| authors = [] | ||
| tags = ["AI"] | ||
| categories = ["AI"] | ||
| externalLink = "" | ||
| series = [] | ||
| disableComments = true | ||
| +++ | ||
|
|
||
| 在现代 AI 技术的推动下,声音处理领域取得了巨大进展。从语音识别(`ASR`)到文本转语音(`TTS`),再到个性化声音克隆,这些技术已经深入到我们的日常生活中:语音助手、自动字幕生成、语音导航等应用无处不在。 | ||
|
|
||
| ## 数字音频 | ||
|
|
||
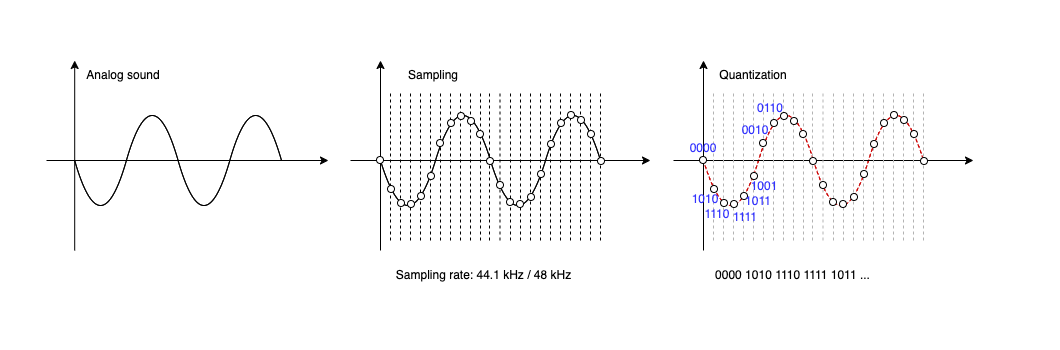
| 音频是声音的“数字化”。声音本质上是空气中振动的波,这些波的振动被麦克风捕捉后转化为电信号。接着,这些信号会通过采样和量化存储为数字数据。 | ||
|
|
||
|  | ||
|
|
||
| 如上图所示。声波最开始是一个连续的模拟信号,然后经过特定频率的采样得到采样点(比如采样频率 48kHz 就是将每秒切割为 48k 个采样点),再通过量化处理得到二进制数据(如果量化位数是 16 位,则表示每个采样点存储为 16 bit 即 2 个字节),最后将元数据(如采样率、量化位数、声道数量等)和采样点二进制数据组合起来就得到了音频文件(比如 WAV 或 MP3)。 | ||
|
|
||
|
|
||
| ## ASR 语音识别 | ||
|
|
||
| 语音识别(`Automatic Speech Recognition`,`ASR`)是将语言转化为文字的技术。 | ||
|
|
||
| #### 传统方法 | ||
|
|
||
| 早期的 `ASR` 系统主要依赖基于统计的模型,如: | ||
| - 声学模型(Acoustic Model):将音频信号转换为声学特征,如 MFCC(梅尔频率倒谱系数)。 | ||
| - 语言模型(Language Model):使用统计方法预测文字序列的概率。 | ||
| - 解码器(Decoder):结合声学和语言模型,将声学特征映射到最可能的文字序列。 | ||
|
|
||
| 这些方法需要大量手工设计的特征和规则,性能受限于数据量和语言模型的复杂度。 | ||
|
|
||
| #### 深度学习 | ||
|
|
||
| 现代 `ASR` 系统主要基于深度学习,使用端到端(End-to-End)方法,直接从音频输入到文本输出。 | ||
|
|
||
| 如果将 AI 模型看作一个黑盒,那么训练过程就是输入 <音频, 文本> 数据对,让模型自动学习输入和输出之间的映射关系。经过训练后,模型便可以对新的音频进行推理,生成对应文本。 | ||
|
|
||
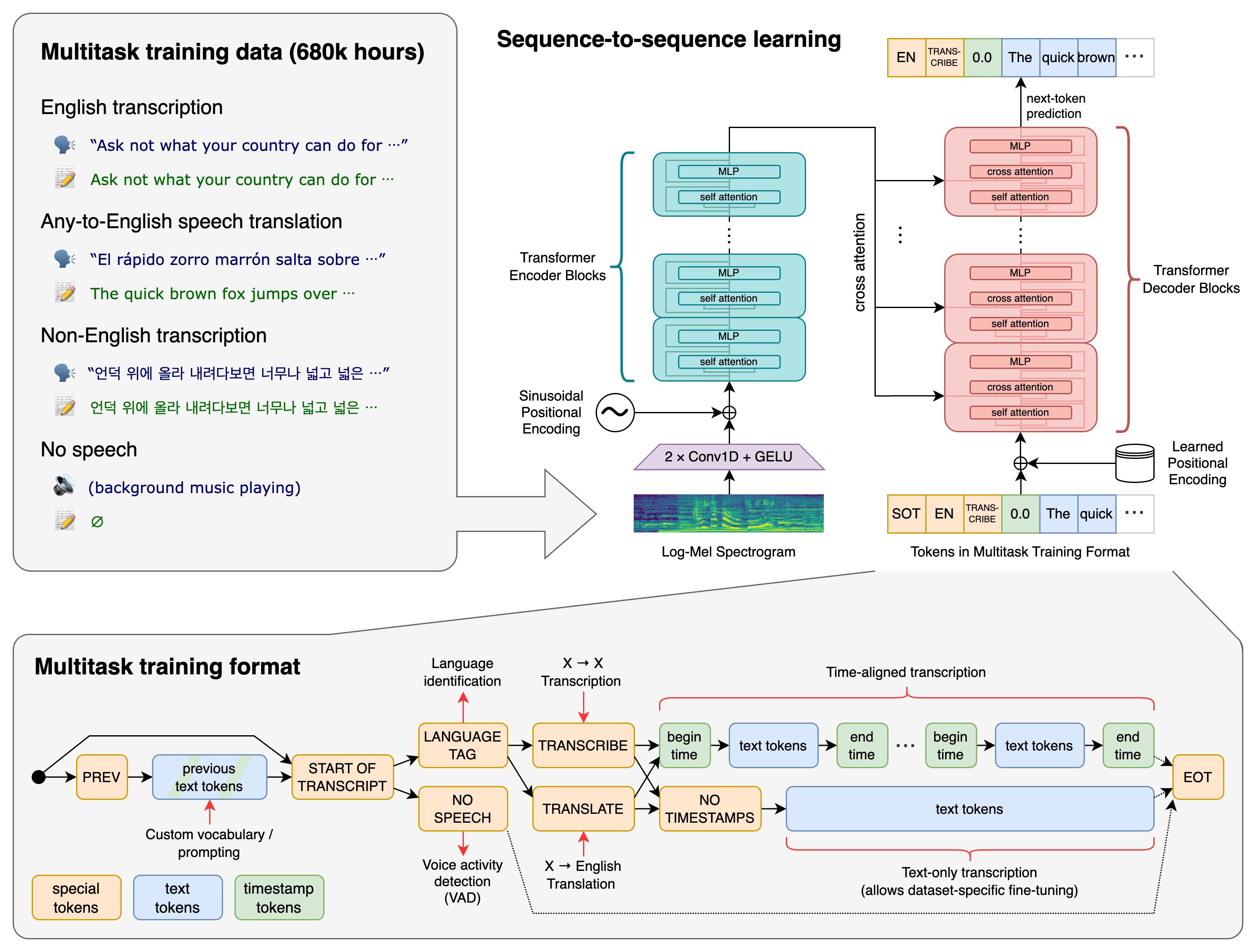
| 这种描述是一个高度抽象的视角,背后实际上是一个复杂的过程,比如 `OpenAI Whisper`: | ||
|
|
||
|  | ||
|
|
||
| 实践证明,基于深度学习方法训练出来的模型具有更好的鲁棒性、准确性和泛化能力。 | ||
|
|
||
| `OpenAI Whisper` 使用示例: | ||
| ```python | ||
| import whisper | ||
|
|
||
| # 加载模型,默认存储位置 ~/.cache/whisper,可以设置 download_root 改变路径 | ||
| model = whisper.load_model("base", download_root="root_dir") | ||
|
|
||
| # 将音频转换为文本 | ||
| result = model.transcribe("audio.mp3") | ||
| print(result["text"]) | ||
| ``` | ||
|
|
||
| 你也可以使用 `whisper.cpp`,一个使用 C/C++ 编写的 `OpenAI Whisper` 的高性能版本。 | ||
|
|
||
|
|
||
| ## TTS 文本转语言 | ||
|
|
||
| 文本转语音(`Text-to-Speech`,`TTS`)技术则是将输入文本转化为自然流畅的语音。 | ||
|
|
||
| 从某种抽象的角度来看,`TTS`(文本转语音)可以被视为语音识别(`ASR`)的“反过程”,两者都涉及将一种形式的数据(音频或文本)映射到另一种形式,并且现代都采用深度学习模型,通常基于 `Transformer` 或类似架构,但在某些技术实现(比如中间表示、损失函数、特征表示、目标优化等)和复杂度上并非完全对称。 | ||
|
|
||
| `TTS` 示例如下(使用的是 `HuggingFace` 上的 `OuteAI/OuteTTS-0.2-500M` 模型): | ||
|
|
||
| ```python | ||
| import outetts | ||
|
|
||
| model_config = outetts.HFModelConfig_v1( | ||
| model_path="OuteAI/OuteTTS-0.2-500M", | ||
| language="en", # Supported languages in v0.2: en, zh, ja, ko | ||
| ) | ||
|
|
||
| interface = outetts.InterfaceHF(model_version="0.2", cfg=model_config) | ||
|
|
||
| # Optional: Load speaker from default presets | ||
| interface.print_default_speakers() | ||
| speaker = interface.load_default_speaker(name="male_1") | ||
|
|
||
| output = interface.generate( | ||
| text="""Speech synthesis is the artificial production of human speech. | ||
| A computer system used for this purpose is called a speech synthesizer, | ||
| and it can be implemented in software or hardware products. | ||
| """, | ||
| # Lower temperature values may result in a more stable tone, | ||
| # while higher values can introduce varied and expressive speech | ||
| temperature=0.1, | ||
| repetition_penalty=1.1, | ||
| max_length=4096, | ||
| speaker=speaker, | ||
| ) | ||
|
|
||
| output.save("output.wav") | ||
| ``` | ||
|
|
||
| #### 声音克隆 | ||
|
|
||
| 每个人的声音都有独特的特性,比如音调高低、响度、停顿、语气等等,声音克隆就是分析并提取一个人的声音特征,将这些特征参数化(通常表示为高维向量)。特征提取本身没有多大实际用途,为了让这些特征发挥作用,声音克隆通常与 `TTS`(文本转语音)技术结合,融合克隆的声音特征,将文本生成为与克隆声音相似的语音。 | ||
|
|
||
| 不少 `TTS` 模型也会直接支持声音克隆的功能,如何调用则取决于具体的模型。例如上例中的 `OuteAI/OuteTTS-0.2-500M` 模型可以输入一段音频创建具有该音频特征的 speaker: | ||
|
|
||
| ```python | ||
| # Optional: Create a speaker profile (use a 10-15 second audio clip) | ||
| speaker = interface.create_speaker( | ||
| audio_path="path/to/audio/file", | ||
| transcript="Transcription of the audio file." | ||
| ) | ||
| ``` | ||
|
|
||
| ## 总结 | ||
|
|
||
| 语音技术作为 `AI` 应用中的重要分支,正在改变人机交互的方式。从基础的数字音频处理到 `ASR` 和 `TTS` 技术的成熟,再到声音克隆赋予 `AI` 个性化表达能力,这些技术不仅满足了自动化需求,还为虚拟助手、娱乐、医疗、教育等领域带来了创新可能性。希望本文的介绍能为你打开探索 AI 声音领域的大门! | ||
|
|
||
| --- | ||
|
|
||
| (我是凌虚,关注我,无广告,专注技术,不煽动情绪,欢迎与我交流) | ||
|
|
||
| --- | ||
|
|
||
| 参考资料: | ||
|
|
||
| - *https://github.com/openai/whisper* | ||
| - *https://huggingface.co/OuteAI/OuteTTS-0.2-500M* |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -19,13 +19,14 @@ disableComments = true | |
| |:---- |:---- |:-------- |:------------ |:---------------- | | ||
| | 男 | 本科 | 1993年 | 187-7296-4832 | [email protected] | | ||
|
|
||
| 主导过的互联网 SaaS 项目处理**日均千万级** PV 流量、管理**数十亿**图片。 | ||
| 主导过的互联网 SaaS 项目处理**日均千万级** PV 流量、管理**数十亿**图片资源。 | ||
| 负责研发的脑科学云平台及医疗器械项目服务于几十家头部医院、科研机构和诊所。 | ||
|
|
||
| 具备丰富的技术广度,涵盖 **后端**、**云原生**、**大数据** 等多项技术领域,拥有 **系统架构设计师**、**Kubernetes**、**ElasticSearch** 等官方技术认证。 | ||
| 丰富的技术广度,拥有 **系统架构设计师**、**Kubernetes**、**ElasticSearch** 等官方技术认证,涵盖 **后端**、**容器与云原生**、**搜索**、**大数据** 等多项技术领域。 | ||
|
|
||
| 职场表现卓越,每一段生涯都能做出优秀成绩,曾获:**年度优秀个人**、**年度创新团队** 等荣誉。 | ||
| 坚持运动、学习、写作 8 年,公众号:[系统架构师Go](https://raw.githubusercontent.com/RifeWang/images/master/qrcode.jpg),技术社区 Segmentfault 2022、2023 年度 Maintainer。 | ||
| 在掘金创作有:[Kubernetes 云原生](https://juejin.cn/column/7314642642869403682)、[AI 人工智能](https://juejin.cn/column/7425885062921928738)、[ELK 搜索与大数据](https://juejin.cn/column/7314860085930180623) 等多个专栏。 | ||
|
|
||
| ## 工作经历 | ||
|
|
||
|
|
@@ -41,12 +42,11 @@ disableComments = true | |
| 项目成绩:定制化的多模态阅片产品成功交付某部战区总医院;科研云平台支撑了多次大规模临床试验及日常科研;疗法云软件投入商业化运作并持续迭代。 | ||
|
|
||
| 个人职责: | ||
| - Team Leader,实施 Scrum 敏捷开发,协调团队成员工作,组织产品的上线发版。 | ||
| - 优化研发流程,组织 code review,关注团队成员的发展,结合公司发展方向组织对团队成员的技术培训。 | ||
| - Team Leader,实施 Scrum 敏捷开发,组织 code review,协调团队成员工作,安排产品的上线发版。 | ||
| - 架构设计和演化,包含技术选型、制定架构演进方案、组织技术评审、追踪并确保技术落地。 | ||
| - 日常编码实现业务需求,包括 RESTful API、MySQL 建模、Redis 缓存、MQ 消息队列、S3/Minio 对象存储、NAS/Ceph 文件存储、Serverless 集成、Puppeteer 无头浏览器截图,以及医学影像处理系统和算法集成。 | ||
| - 构建 Prometheus、Grafana 可观测性系统,采集日志、追踪、指标,搭建数据报表与可视化数据分析大屏。 | ||
| - 系统优化,深入整体架构、业务流、数据流、各组件等多角度优化系统,保障系统的高性能、可扩展、高质量。 | ||
| - 构建 Prometheus、Grafana 可观测性系统,采集日志、追踪、指标,搭建数据报表与可视化数据分析大屏。 | ||
| - 实施 DevOps 和云原生,负责 Kubernetes 基础设施、Argo-workflows 任务编排引擎、 Terraform IaC、以及等其它云原生工具。 | ||
|
|
||
| <h3 style="background-color: #87CEFA; padding: 10px;"> | ||
|
|
||