-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
1 changed file
with
120 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,120 @@ | ||
| +++ | ||
| draft = false | ||
| date = 2024-10-25T20:06:12+08:00 | ||
| title = "如果自建 ChatGPT,我会如何从 Model、Inference runtime 构建整个系统" | ||
| description = "如果自建 ChatGPT,我会如何从 Model、Inference runtime 构建整个系统" | ||
| slug = "" | ||
| authors = [] | ||
| tags = ["AI", "LLM"] | ||
| categories = ["AI"] | ||
| externalLink = "" | ||
| series = [] | ||
| disableComments = true | ||
| +++ | ||
|
|
||
| ChatGPT 是一个基于 `LLM` 的对话系统。本文将介绍如何构建一个类似 ChatGPT 的系统,包括从模型、推理引擎到整体架构的构建过程。 | ||
|
|
||
| ## 系统概览 | ||
|
|
||
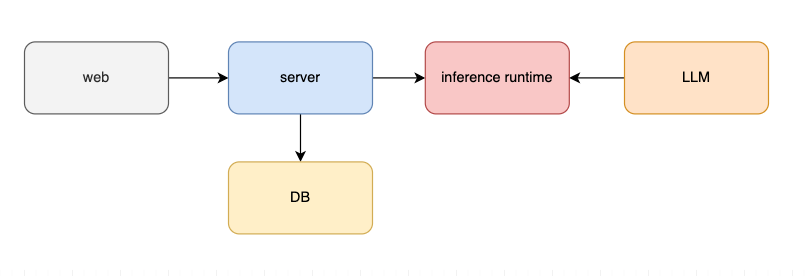
| 让我们关注最核心的对话部分。 | ||
|
|
||
|  | ||
|
|
||
| 如上图所示,web 负责与用户进行交互,`server` 接受用户的对话请求,并将消息传递给 `inference runtime`(推理运行时/推理引擎)。`inference runtime` 加载 `LLM` 进行推理(生成回复)并返回给用户。这是一个最基本的系统框架。 | ||
|
|
||
| ### 会话与历史消息管理 | ||
|
|
||
| 然而,上述系统存在一个致命缺陷:缺乏用户的会话与历史消息的管理。常见的 `inference runtime` 推理引擎本身是无状态的,不直接支持多轮对话的历史消息存储。这意味着在单个会话中会“遗忘”之前的上下文信息。 | ||
|
|
||
| 为此,我们需要对系统做一些必要的改进。 | ||
|
|
||
|  | ||
|
|
||
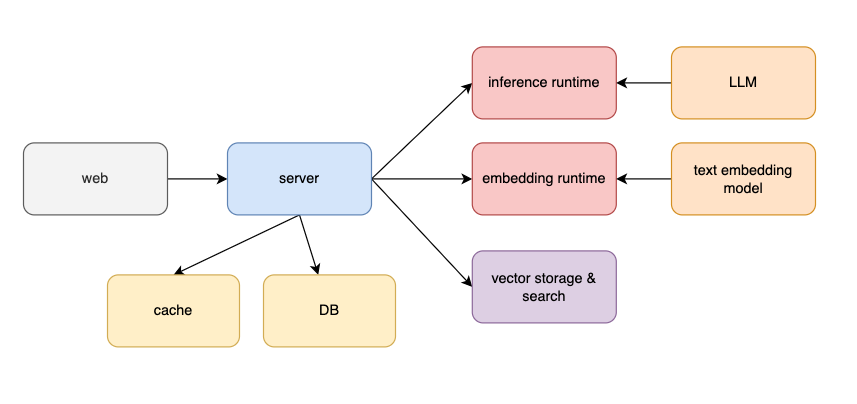
| 如上图所示,我们增加了数据库组件来存储用户的会话和历史消息。 | ||
|
|
||
| 在通信流程上,web 与 server 之间可使用 HTTP 协议,我们可以设计几个基本的 REST API: | ||
| - `POST /chat`:开启新的会话。 | ||
| - `POST /chat/:chatID/completion`:在已有的会话中继续对话。 | ||
| - `GET /chats`:获取会话列表。 | ||
| - `DELETE /chat/:chatID`:删除某个会话。 | ||
|
|
||
| 在数据存储上,server 将数据持久化到数据库中。对话消息的数据结构则应该包括 `userID`、`chatID`、`userMessage`、`assitantMessage` 等基本元素。 | ||
|
|
||
| server 向 `inference runtime` 发送数据时使用统一的 `prompt` 格式,例如: | ||
| ```json | ||
| [ | ||
| { | ||
| "role": "system", | ||
| "content": "You are a helpful assistant." | ||
| }, | ||
| { | ||
| "role": "user", | ||
| "content": "Hello!" | ||
| }, | ||
| { | ||
| "role": "assistant", | ||
| "content": "Hello there, how may I assist you today?" | ||
| }, | ||
| { | ||
| "role": "user", | ||
| "content": "How are you?" | ||
| } | ||
| ] | ||
| ``` | ||
| 其中 `role` 代表不同的角色,`system` 设定对话的系统背景,`user` 代表用户输入,`assistant` 代表模型输出。 | ||
|
|
||
| 至于历史消息如何处理,往往有多种方式: | ||
| - 直接填充 `prompt`:把历史对话按照 `prompt` 的格式进行 user、assistant、user、assistant 不断填充。这种方式只适用于历史消息较少的情况。 | ||
| - 动态调整上下文:比如舍去较早的历史消息,由于 `LLM` 存在 token(上下文窗口)的限制,有时候不得不这么做。 | ||
| - 对历史消息进行总结:使用推理引擎生成对话总结,压缩信息后再填充 `prompt`。 | ||
|
|
||
| 至此,我们完成了会话管理与历史消息处理,实现了一个最基本的系统框架。 | ||
|
|
||
|
|
||
| ## 系统扩展 | ||
|
|
||
| 当用户数量较多时,上述系统需要进一步扩展。 | ||
|
|
||
| ### 增加 cache 缓存 | ||
|
|
||
| 我首先想到的是增加 `cache` 缓存,避免重复的推理过程。假设缓存的 key-value 分别是用户的提问和 AI 的回复,缓存命中则需要看用户提问的语义是否相似。例如,如果用户问了两个意思相同但表述不同的问题,系统可以返回相同的响应。 | ||
|
|
||
| 这种缓存设计不同于传统系统,如下图所示: | ||
|
|
||
|  | ||
|
|
||
| 除了 `cache` 模块,还需要引入 `embedding runtime` 和 `text embedding model`,用于将文本转换为 `vector` 向量。当两个向量相近,意味着文本语义相似。`vector storage & search` 模块则用于向量存储和检索。 | ||
|
|
||
| 在增加缓存时,还需考虑缓存的范围——是单个用户范围,还是全部用户范围。如果是单用户范围,缓存价值可能较小,因为同一个用户反反复复问同一个问题的概率很低;若是全用户范围,则可能涉及到信息泄露,我们不确定另一个用户的回复是否包含敏感信息。 | ||
|
|
||
| 综上所述,我个人更倾向于不优先考虑缓存,因为缓存的投资收益可能没有想象中的高。当然,这需要进一步数据验证。 | ||
|
|
||
| ### 弹性伸缩 | ||
|
|
||
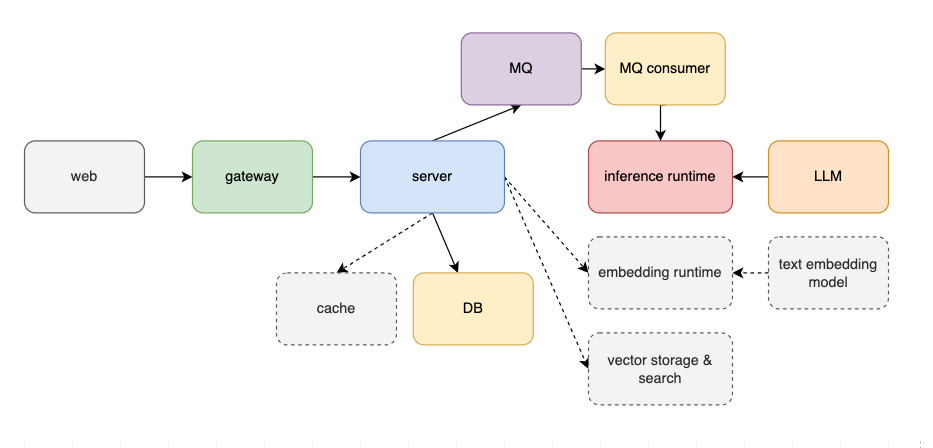
| 弹性伸缩也是应对高并发的重要手段。我们的 `server` 是无状态服务,可以很好地扩缩容。 | ||
|
|
||
|  | ||
|
|
||
| 在架构上增加 `gateway` 进行负载均衡。`inference runtime` 也是无状态的,因此也支持弹性扩展,但其硬件资源消耗更高,服务的响应能力通常低于 `server`。为应对流量高峰并保证推理服务稳定性,可增加 `MQ` 消息队列,同时将请求处理从同步变成异步,从而提升系统的抗压能力。 | ||
|
|
||
| ### 生产就绪 | ||
|
|
||
| 上述系统架构完成了逻辑设计,后续需完善以下方面,以实现生产就绪: | ||
| - 技术选型:选择数据库(如 PostgreSQL 或 MongoDB)、推理引擎(如 `llama.cpp`、`HuggingFace Transformers`、`vLLM` 等),将逻辑组件映射为实体组件。 | ||
| - 可观测性:增加 log、trace、metrics,以及监控和告警。 | ||
| - CI/CD 和部署环境:配置自动化部署和持续集成流程,选择合适的部署环境(如云平台、`Kubernetes` 等等)。 | ||
|
|
||
|
|
||
| ## 总结 | ||
|
|
||
| 本文介绍了自建 ChatGPT 系统的核心架构和扩展方式。从基础的对话流程入手,设计了包含会话管理和历史消息存储的系统框架,并讨论了系统的扩展策略。 | ||
|
|
||
|
|
||
| (关注我,无广告,专注技术,不煽动情绪,也欢迎与我交流) | ||
|
|
||
| --- | ||
|
|
||
| 参考资料: | ||
|
|
||
| - *https://github.com/ggerganov/llama.cpp* | ||
| - *https://platform.openai.com/docs/api-reference/chat/create* |