-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
1 changed file
with
124 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,124 @@ | ||
| +++ | ||
| draft = false | ||
| date = 2024-11-19T16:22:09+08:00 | ||
| title = "RAG 示例:使用 langchain、Redis、llama.cpp 构建一个 kubernetes 知识库问答" | ||
| description = "RAG 示例:使用 langchain、Redis、llama.cpp 构建一个 kubernetes 知识库问答" | ||
| slug = "" | ||
| authors = [] | ||
| tags = ["AI", "LLM", "Redis", "Kubernetes"] | ||
| categories = ["AI"] | ||
| externalLink = "" | ||
| series = [] | ||
| disableComments = true | ||
| +++ | ||
|
|
||
| `RAG`(`Retrieval Augmented Generation` 检索增强生成)是目前业界中的一种主流方法,通过增加额外知识的方式来减少大语言模型(`LLM`)的幻觉问题(一本正经的胡说八道)。 | ||
|
|
||
| ## RAG 系统概览 | ||
|
|
||
| 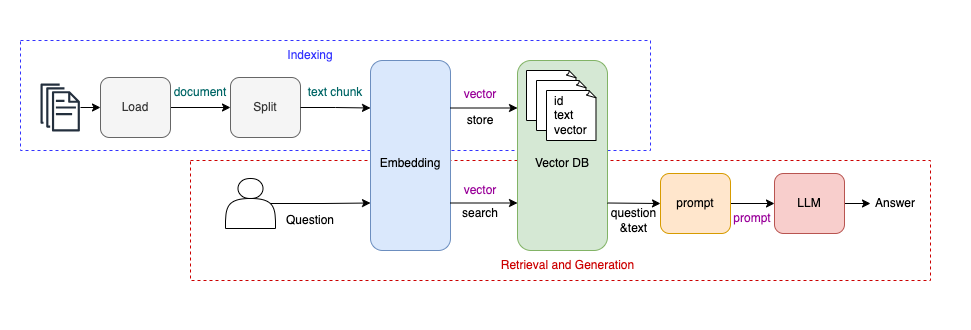 | ||
|
|
||
| 如上图所示,`RAG` 系统可以分为两个部分: | ||
| - `Indexing`:构建知识库。 | ||
| - `Retrieval & Generation`:从知识库中获取相关信息,然后生成结果。 | ||
|
|
||
| `Indexing` 构建知识库的过程可以分为四步: | ||
| 1. `Load`:加载 PDF、doc、markdown、web 等等形式的知识数据。 | ||
| 2. `Split`:由于 `LLM` 上下文大小的限制,需要将文档进行切割。 | ||
| 3. `Embedding`:将文本转换为向量。 | ||
| 4. `store to VectorDB`:将文本内容和向量存储至向量数据库,即知识库。 | ||
|
|
||
| `Retrieval & Generation` 的过程也是四步: | ||
| 1. `Embedding`:将用户提出的问题转换为向量。 | ||
| 2. `search VectorDB`:从知识库中查询与问题语义相近的文本段落。 | ||
| 3. `prompt`:将检索出来的文本段落与用户问题合并,生成 prompt。 | ||
| 4. `LLM`:将 prompt 提交给大语言模型,得到最终答案。 | ||
|
|
||
| 从上述过程中可以看到,相较于直接把问题提交给 `LLM` 得到答案,`RAG` 系统额外构建了一个知识库,并且会把问题跟已有知识相结合,生成新的 `prompt` 后再提交给 `LLM` 得到答案。 | ||
| 换句话说,`RAG` 系统就是在用户提出的问题之外,额外增加了一些上下文/背景信息,这些信息可以是实时信息、也可以是专业领域信息,以此从 `LLM` 得到更好的回答。 | ||
|
|
||
| ## RAG 系统示例 | ||
|
|
||
| 在本示例中,我将使用 `langchain`、`Redis`、`llama.cpp` 构建一个 `kubernetes` 知识库问答。 | ||
|
|
||
| `langchain` 是一个工具包,`Redis` 被我用作向量数据库,`llama.cpp` 是一个开源的加载大语言模型的运行时程序。 | ||
|
|
||
| 我在本地使用了 Docker 容器环境进行开发,通过以下 docker-compose 文件拉取依赖的服务: | ||
| ```yaml | ||
| version: "3.9" | ||
|
|
||
| services: | ||
| redis: | ||
| image: redis/redis-stack:7.4.0-v1 | ||
| container_name: redis | ||
| ports: | ||
| - "6379:6379" # 映射 Redis 默认端口 | ||
| - "8001:8001" # 映射 RedisInsight 默认端口 | ||
|
|
||
| llama_cpp_server: | ||
| image: ghcr.io/ggerganov/llama.cpp:server | ||
| container_name: llama_cpp_server | ||
| ports: | ||
| - "8080:8080" | ||
| volumes: | ||
| - ~/ai-models:/models # 映射主机路径到容器 | ||
| environment: | ||
| LLAMA_ARG_MODEL: /models/llama3.2-1B.gguf | ||
| LLAMA_ARG_CTX_SIZE: 4096 | ||
| LLAMA_ARG_HOST: "0.0.0.0" | ||
| LLAMA_ARG_PORT: 8080 | ||
| ``` | ||
| 代码示例如下: | ||
| 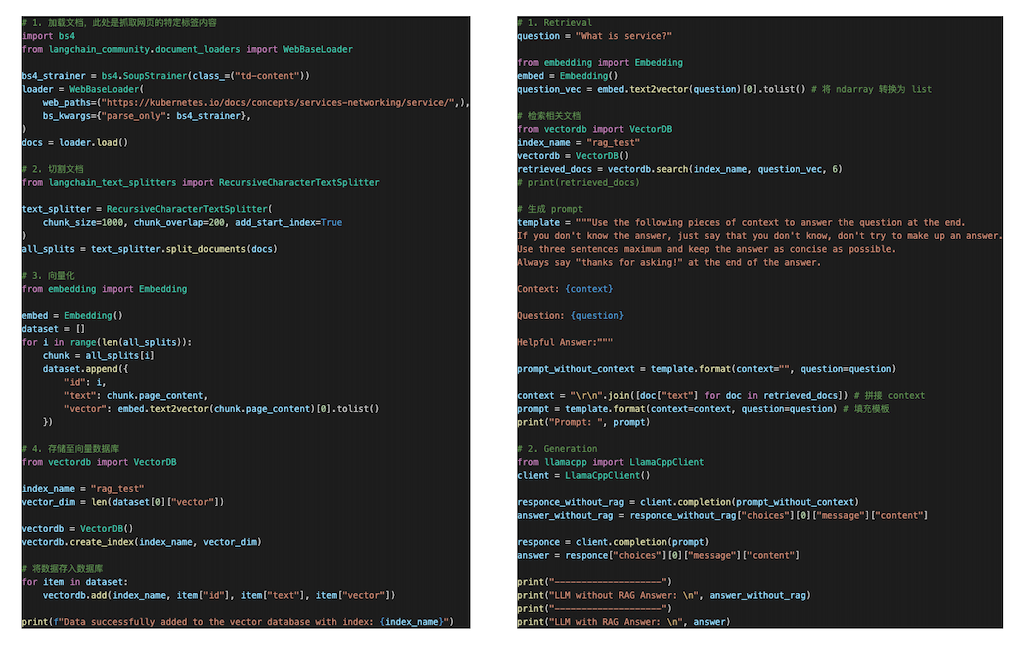 | ||
| 代码释义: | ||
| - 加载文档:使用 `langchain` 抓取 `kubernetes` 官方文档页面内容。 | ||
| - 切割文档:使用 `langchain` 切割文档。 | ||
| - 向量化:使用 [`sentence_transformers`](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) 将文本转换为向量: | ||
| ```Python | ||
| from sentence_transformers import SentenceTransformer | ||
| sentences = ["This is an example sentence"] | ||
| model = SentenceTransformer('sentence-transformers/all-mpnet-base-v2') | ||
| embeddings = model.encode(sentences) | ||
| print(embeddings) | ||
| ``` | ||
| - 存储至向量数据库:将文本和向量存储至 `Redis`,你也可以使用其它向量数据库。 | ||
| - 用户提问向量化:使用同样的模型将用户提出的问题转换为向量。 | ||
| - 向量相似性检索:从向量数据库中检索出与提问相似的文本段落。 | ||
| - 组合生成 `prompt`:将检索出来的信息与用户提问一起合并生成新的 `prompt`。 | ||
| - 将 `prompt` 提交给 `LLM` 得到答案。 | ||
|
|
||
| 最终的测试结果如下: | ||
|
|
||
|  | ||
|
|
||
| 可以看到,加了上下文之后,`LLM` 给出的答案更好了。 | ||
|
|
||
| ## RAG 面临的挑战 | ||
|
|
||
| `RAG` 的每一步几乎都面临挑战: | ||
| - 如何加载不同形式的文档数据?这一步问题倒不大。 | ||
| - 如何切割文档?切割的效果影响了 `prompt` 的上下文信息,因此也会影响 `LLM` 生成的结果。 | ||
| - 如何做 `embedding`,选择哪种模型? | ||
| - 选择哪个向量数据库?常见的技术选型问题。 | ||
| - 如何将检索出来的信息与用户提问一起合并成新的 `prompt`?`prompt` 本来就可以五花八门。 | ||
| - 选择哪个 `LLM` 以及运行时?就模型而言,`Llama` 系列算是最火的开源模型了;而运行时则有 `llama.cpp`(或者在其之上封装的 `Ollama`)、`HuggingFace/transformers`、`vLLM` 等等。 | ||
|
|
||
| ## 总结 | ||
|
|
||
| `RAG` 系统通过引入知识库,扩展了 `LLM` 对专业领域和实时信息的支持能力,使其在回答专业问题时更加准确高效。 | ||
|
|
||
|
|
||
| (我是凌虚,关注我,无广告,专注技术,不煽动情绪,欢迎与我交流) | ||
|
|
||
| --- | ||
|
|
||
| 参考资料: | ||
|
|
||
| - *https://python.langchain.com/docs/tutorials/rag/* | ||
| - *https://huggingface.co/sentence-transformers/all-mpnet-base-v2* | ||
| - *https://github.com/ggerganov/llama.cpp/blob/master/examples/server/README.md* | ||
| - *https://redis.io/docs/latest/develop/interact/search-and-query/query/vector-search/* |