Omega_h Usage
o:: precedes symbols from the Omega_h namespace
The majority of code will be either directly inside, or is designed to be
called from, an OMEGA_H_LAMBDA or SCS_LAMBDA.
o::Write and o::Read array objects support random access on
the device/GPU via the bracket ([ ]) operator.
As the name suggests, o::HostWrite and o::HostRead support
random access on the host.
File read/write is done on the host. File read/write uses o::HostWrite, which is similar to C-style dynamic-array taking run-time size for creation, but easier when conversion to/from device data is done.
OMEGA_H_LAMBDA or SCS_LAMBDA can be used for accessing device data. If particle data (SCS) is to be used, then SCS_LAMBDA is the correct way. Note that the 'pid' is not particle sequential index or id, which is stored specifically in SCS. When storing particle specific stuff for intermediate use, there are 2 ways: 1) use scs-capacity as array size, or 2) use total number of particles as array size. If option (1) is used , then the array filled is valid only in the current iteration, specifically until SCS is re-built. If option (2) is used, the the index should be permanent particle id retrieved from the SCS data member. The option (1) has disadvantage that the array-size should be too large to accommodate the 'pid', which potentially has not limit. Or, the array would have to be generated in each iteration, which seems to be not efficient in summit. The option (2) has disadvantage that the array is fixed size, causing carrying around many unused elements towards the end of simulation.
OMEGA_H_LAMBDA is the right way to process device data when particle data is not used. When both particle and array device data are used, SCS_LAMBDA is to be used.
//in class hpp file
o::Reals data;
// in cpp file
data = o::Reals(o::HostWrite<o::Real>dataIn);
OMEGA_H_DEVICE void subFunc(o::Reals& data) {
//to print first element
printf("%g ", data[i]); //OK
}
//somewhere in the class definition
inline void func(o::Reals& data) {
//to print first element
printf("%g ", data[i]); //Error
//Use
o::parallel_for(1, OMEGA_H_LAMBDA(const int& i){
printf("%g ", data[i]);
});
auto lambda = OMEGA_H_LAMBDA(const int& i){
subFunc(data);
}
o::parallel_for(n, lambda);
}
int main() {
...create object, obj
func(obj.data); //OK, calling kernel
subFunc(obj.data); //ERROR, not a kernel
}
GDB is the recommended way to get a stack trace when there is a failure in GPU kernel code. Note, the stack will not provide the line number in the kernel. Print statements are currently the best way to determine the location.
Core dumps can also be used: https://jvns.ca/blog/2018/04/28/debugging-a-segfault-on-linux/
OMEGA_H_DEVICE myFunction(o::Write<o::Real> &data) {
//do something, uninitialized memory error is swallowed
}
void kernel(o::Write<o::Real> &data) {
auto lambda = SCS_LAMBDA(const int &elem, const int &pid, const int &mask) {
// pass unitialized data
myFunction(data);
};
scs->parallel_for(lambda);
}
The solution is to use assert or OMEGA_H_CHECK() before accessing arrays.
Device data pointers to Omega_h array objects can be stored in classes or structs.
Class functions which need to be called from GPU kernels need to be public;
private functions cannot be called from kernels [REFERENCE NEEDED].
Current kernels are done as inline functions in hpp files. The keyword 'inline' is also required if definition and declaration are not separate in files, when there is no class or namespace. [EXAMPLE?]
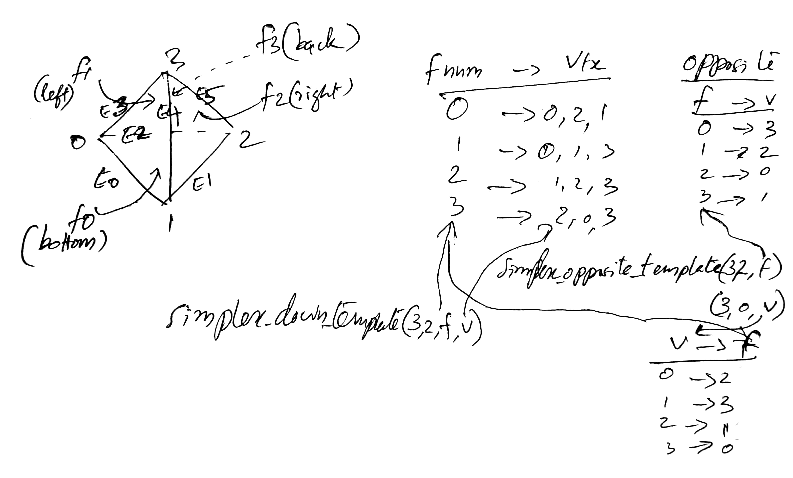
see description: Omega_h_simplex.hpp, Omega_h_refine_topology.hpp line 26
face_vert:0,2,1; 0,1,3; 1,2,3; 2,0,3.
corresp. opp. vertexes: 3,2,0,1, by simplex_opposite_template(3, 2, iface, i) ?
Side note: r3d.cpp line 528: 3,2,1; 0,2,3; 0,3,1; 0,1,2 .Vertexes opp.:0,1,2,3
3
/ | \
/ | \
0----|----2
\ | /
\ | /
1
Omega_h_refine_topology.hpp says
The triangle-of-tet-to-vertices template specifies all triangles curling outward (such that implicit face
derivation orients all surface aces outward), while the tet-to-vertices convention as the bottom face
curling inward for consistency ith Gmsh, PUMI, Simmetrix, etc. rather than break either of those two
compatibilities, we will remember to flip the triangle here to get the right orientation for new tets.
But all the faces in pumi have counter-clockwise vertex ordering when viewed from outside the tet, means outward orientation !
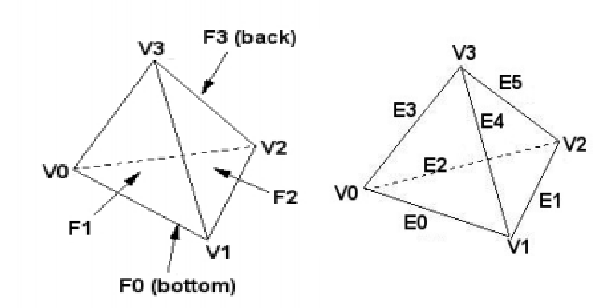
The above figure is god for Omega_h. Not sure if the opposite_template use is right.
Face vertices are in counter-clockwise order.
It seems the ordering is different. The face ordering is clockwise.
http://gmsh.info/doc/texinfo/gmsh.html#Node-ordering
Tetrahedron: Tetrahedron10:
v
.
,/
/
2 2
,/|`\ ,/|`\
,/ | `\ ,/ | `\
,/ '. `\ ,6 '. `5
,/ | `\ ,/ 8 `\
,/ | `\ ,/ | `\
0-----------'.--------1 --> u 0--------4--'.--------1
`\. | ,/ `\. | ,/
`\. | ,/ `\. | ,9
`\. '. ,/ `7. '. ,/
`\. |/ `\. |/
`3 `3
`\.
` w