DescribeML is a VSCode language plugin to describe machine-learning datasets.
Precisely describe your data's provenance, composition, and social concerns in a structured format.
Make it easy to reproduce your experiments to others when you cannot share your data.
Check out the quick video presentating of the tool, and the tutorial presented in the MODELS '22 Conference
The easiest way to install the plugin is by using the Visual Studio Code Market. Just type "describeML" in the extension tab, and that's it!
Instead, you can install it manually using the packaged release of the plugin in this repository that can be found at the root of the project.
The file is DescribeML-1.2.1.vsix
Open your terminal (or the terminal inside the VSCode) and write this:
git clone https://github.com/SOM-Research/DescribeML.git datasets
cd datasets
code --install-extension DescribeML-1.2.1.vsix
Troubles: If you cannot see the syntax highlight in the examples files (p.e. Melanoma.descml) as the image below. Please, reload the VSCode editor and write the code --install command again
Great! That's it.
-
The first step is to create a .descml file
-
The easy way to start using our tool is to use the preloader data service, located at the top left of your editor, clicking at:

-
Select your dataset file (.csv), and the tool will generate a draft of your description file.
-
To help you, look to the Language Reference Guide and follow the examples in the examples/evaluation folders to get a sense of the tool's possibilities. Take a look at the Melanoma.descml file, for example.
-
During the documentation process, hitting CTRL + Space (equivalent in other OS) gives you auto-completion help. In addition, the part marked with the points below gives you hints to complete the documentation, and the outline in the right part shows you the document structure.

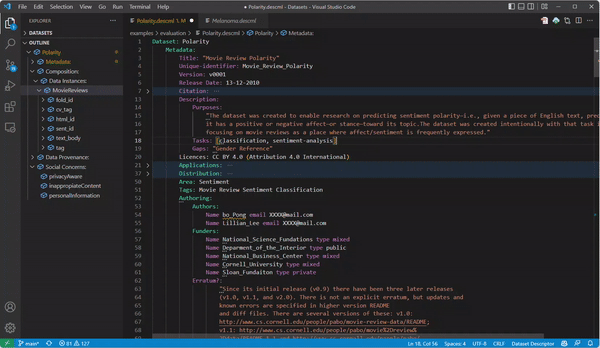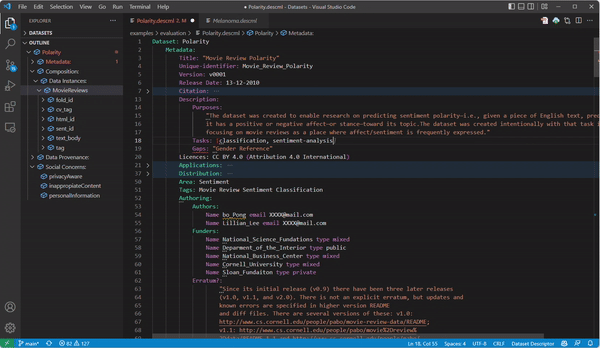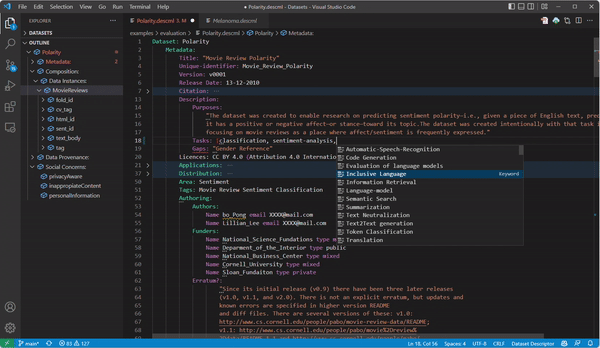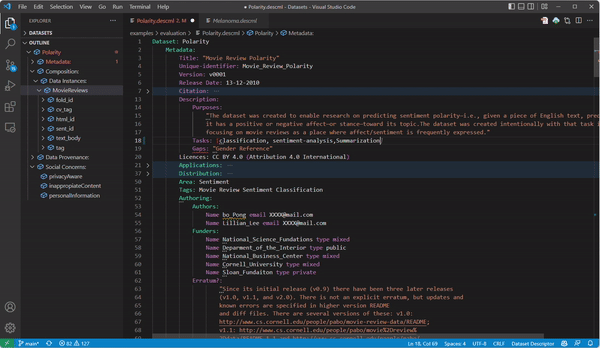
- Once you are happy with your documentation, you can generate HTML documentation by clicking the generator button next to the prealoder service:


For more information, check out the quick presentation video and the tutorial presented in the MODELS '22 Conference
This project is being development as part of a research line of the SOM Research Lab, but we are open to contributions from the community. If you are interested in contributing to this project, please first read the CONTRIBUTING.md guidelines file.
The following tree shows the list of the repository's relevant sections:
- The documentation and examples folders contains the mentioend examples and the language reference guide.
- The out folder contains the executable plugin in JS. You may not want to dive in as it is generated by the TypeScrpit compiler
- The src folder contains the project's source code
- The cli folder is the generated grammar and AST from Langium. You may not want to dive in it as it is a generated asset
- The generator-service folder contains all the code of the generation service. Could be a good place to start if you want to improve the generation of the tool.
- The uploader-service folder contains all the code of the uploader service. Could be a good place to contribute new statistical metrics, or ML techniques to do dataset reverse engineering
- The language-server folder contains all the language features, and the grammar declaration. If you want to improve the grammar, or some of the features the plugin offers here is the place you may want to start
- The dataset-description.langium file contains the main grammar declaration. This grammar is developed using the Langium Grammar Language. Please refer to the linked documentation to more insights on how to develop the grammar.
├── documentation
│ └── language-reference-guide.md // The language reference guide
├── examples
│ ├── evaluation
│ ├── Gender.descml // Gender dataset example
| ├── Melanoma.descml // Melanoma dataset example
| └── Polarity.descml // Polarity dataset example
├── out // The generated JS from the src folder
└── src // The source code of the project
├── cli // Langium framework utils
├── generator-service // The tool's HTML generator service
├── uploader-service // The tool's HTML uploader service
└── language-server // The tool's language features
├── generated // Generated grammar and AST from Langium
├── dataset-description-index.ts // Custom index feature
├── dataset-description-module.ts // Declaration of the custom language features
├── dataset-description-validator.ts // Custom language features
└── dataset-description.langium // The main grammar file of the tool
This repo comes with an already built-in config to debug. Just go to Debug in VSCode, and launch the Extension config. Please check your port 6009 is free.
For more information about how the framework works and how the language can be extended, please refer to https://github.com/langium/langium or the VSCode extension API documentation https://code.visualstudio.com/api
DescribeML is part of an ongoing research project to improve dataset documentation for machine learning. The core of our proposal is a domain-specific language published in the Journal of Computer Languages that allows data creators to describe relevant aspects of their data for the machine learning field and beyond. The Critical Dataset Studios of the Knowing Machines project have compiled an excellent list of current documentation practices.
To cite the domain-specific language:
Giner-Miguelez, J., Gómez, A., & Cabot, J. (2023). A domain-specific language for describing machine learning datasets. Journal of Computer Languages, 76, 101209.
The tool has been presented at the ACM/IEEE 25th International Conference on Model Driven Engineering Languages and Systems and published as an Original Software Publication in the Science of Computer Programming journal.
To cite the tool:
Giner-Miguelez, J., Gómez, A., & Cabot, J. (2023). DescribeML: A dataset description tool for machine learning. Science of Computer Programming, 2023, 103030, ISSN 0167-6423, https://doi.org/10.1016/j.scico.2023.103030.
At SOM Research Lab we are dedicated to creating and maintaining welcoming, inclusive, safe, and harassment-free development spaces. Anyone participating will be subject to and agrees to sign on to our Code of Conduct.
Shield:
The source code for the site is licensed under the MIT license, which you can find in the MIT-LICENSE file.
All graphical assets are licensed under the Creative Commons Attribution 3.0 Unported License.