Our paper has been accepted to 2018 International Symposium on Advanced Intelligent Informatics (SAIN).
https://ieeexplore.ieee.org/document/8673354
https://arxiv.org/abs/1707.08254
https://www.researchgate.net/publication/318720999_Efficient_Yet_Deep_Convolutional_Neural_Networks_for_Semantic_Segmentation
Please cite our paper if you use our codes or material in your work:
@inproceedings{kamran2018efficient,
title={Efficient yet deep convolutional neural networks for semantic segmentation},
author={Kamran, Sharif Amit and Sabbir, Ali Shihab},
booktitle={2018 International Symposium on Advanced Intelligent Informatics (SAIN)},
pages={123--130},
year={2018},
organization={IEEE}
}
- FCN2s-Dilated-VGG16 Mean Iou score 67.6 percent FCN2s-Dilated-VGG16
- FCN2s-Dilated-VGG19 Mean Iou score 69 percent FCN2s-Dilated-VGG19
Make caffe with python wrapper. Detailed Instruction below
- FCN2s-Dilated-VGG16 download link - FCN2s-Dilated-VGG16
- FCN2s-Dilated-VGG19 download link - FCN2s-Dilated-VGG19
This models were only trained on SBD and VOC data and for 21 classes segmentation task for PASCAL VOC2012 Segmentation Challenge.
Will be uploading the net trained on NYUDv2 dataset and Pascal-Context later on. Keep an eye on the page.
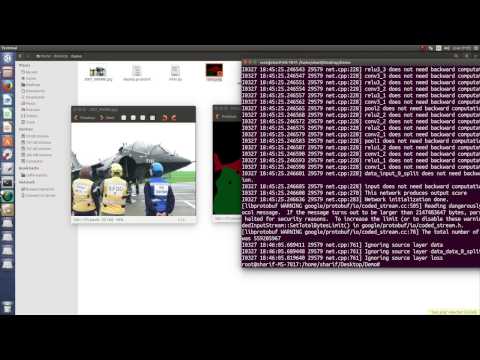
Open demo.py and change line 29 for running demo with different images. Run demo.py
A tutorial with elaborated instructions for running the inference is provided at ModelDepot.io
First read surgery-instructions.txt for details.
Then read training-instructions.txt for details.
To recreate our result you have to first train on VOC2012 dataset and then SBD dataset.
Read the training-sbd-instructions for details.
The code is released under the MIT License, you can read the license file included in the repository for details.

Caffe is a deep learning framework made with expression, speed, and modularity in mind. It is developed by Berkeley AI Research (BAIR)/The Berkeley Vision and Learning Center (BVLC) and community contributors.
Check out the project site for all the details like
- DIY Deep Learning for Vision with Caffe
- Tutorial Documentation
- BAIR reference models and the community model zoo
- Installation instructions
and step-by-step examples.
- Intel Caffe (Optimized for CPU and support for multi-node), in particular Xeon processors (HSW, BDW, Xeon Phi).
- OpenCL Caffe e.g. for AMD or Intel devices.
- Windows Caffe

Please join the caffe-users group or gitter chat to ask questions and talk about methods and models. Framework development discussions and thorough bug reports are collected on Issues.
Happy brewing!
Caffe is released under the BSD 2-Clause license. The BAIR/BVLC reference models are released for unrestricted use.
Please cite Caffe in your publications if it helps your research:
@article{jia2014caffe,
Author = {Jia, Yangqing and Shelhamer, Evan and Donahue, Jeff and Karayev, Sergey and Long, Jonathan and Girshick, Ross and Guadarrama, Sergio and Darrell, Trevor},
Journal = {arXiv preprint arXiv:1408.5093},
Title = {Caffe: Convolutional Architecture for Fast Feature Embedding},
Year = {2014}
}